⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-05-22 更新
ContextAgent: Context-Aware Proactive LLM Agents with Open-World Sensory Perceptions
Authors:Bufang Yang, Lilin Xu, Liekang Zeng, Kaiwei Liu, Siyang Jiang, Wenrui Lu, Hongkai Chen, Xiaofan Jiang, Guoliang Xing, Zhenyu Yan
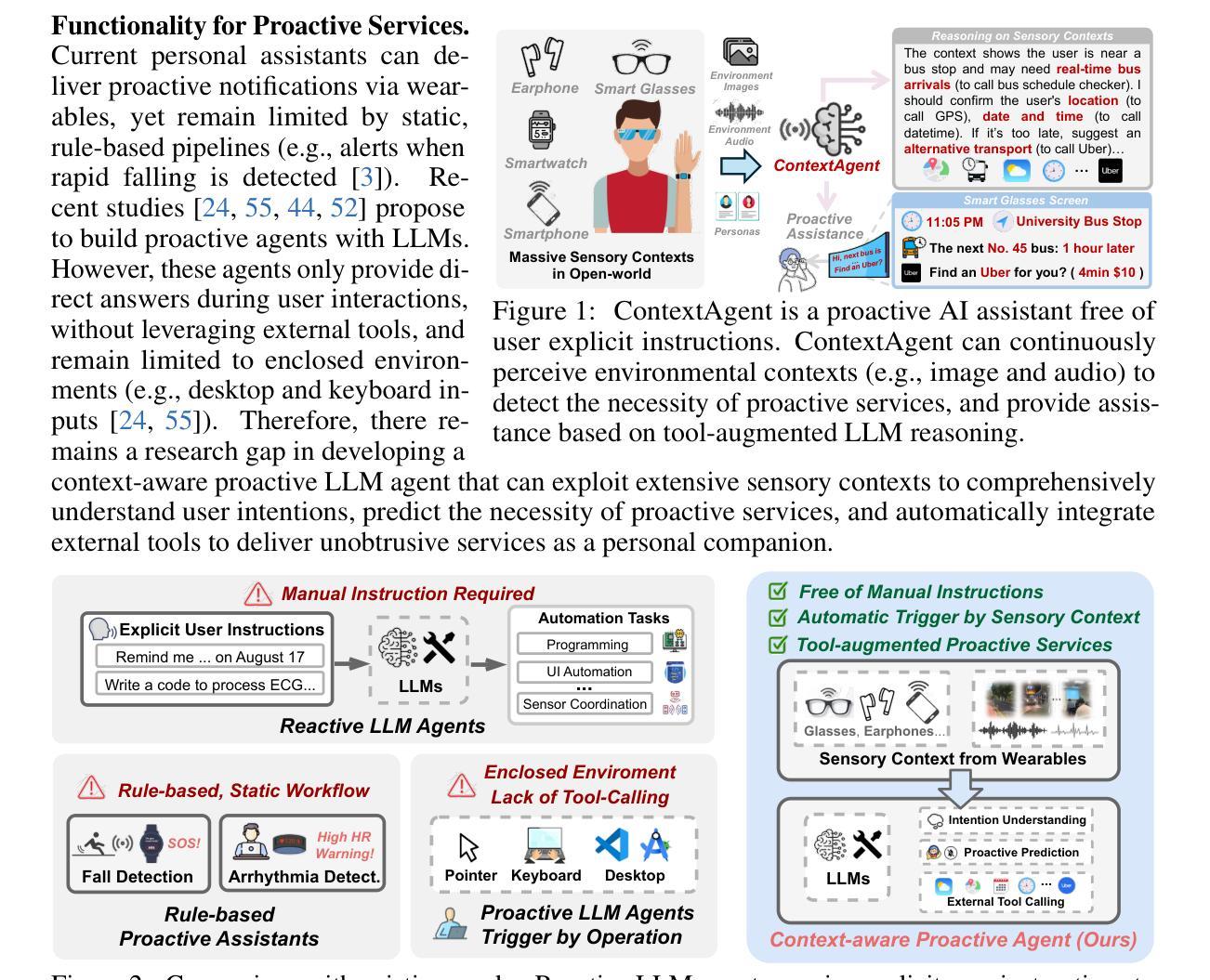
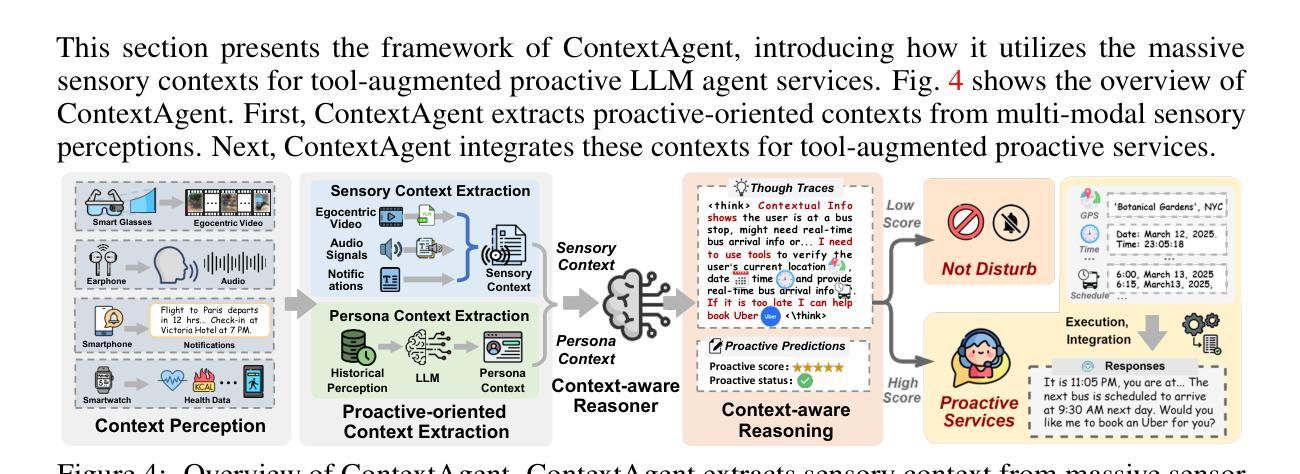
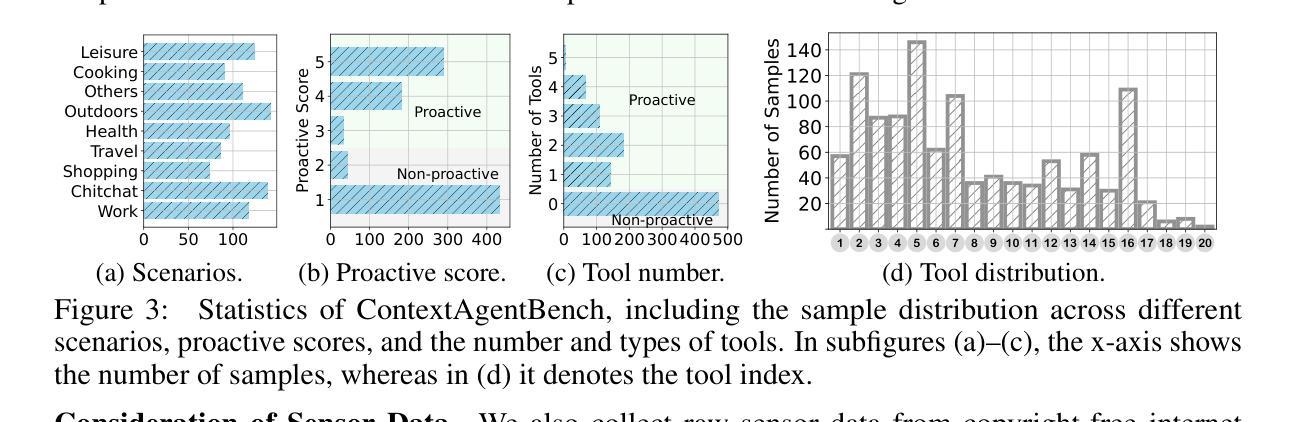
Recent advances in Large Language Models (LLMs) have propelled intelligent agents from reactive responses to proactive support. While promising, existing proactive agents either rely exclusively on observations from enclosed environments (e.g., desktop UIs) with direct LLM inference or employ rule-based proactive notifications, leading to suboptimal user intent understanding and limited functionality for proactive service. In this paper, we introduce ContextAgent, the first context-aware proactive agent that incorporates extensive sensory contexts to enhance the proactive capabilities of LLM agents. ContextAgent first extracts multi-dimensional contexts from massive sensory perceptions on wearables (e.g., video and audio) to understand user intentions. ContextAgent then leverages the sensory contexts and the persona contexts from historical data to predict the necessity for proactive services. When proactive assistance is needed, ContextAgent further automatically calls the necessary tools to assist users unobtrusively. To evaluate this new task, we curate ContextAgentBench, the first benchmark for evaluating context-aware proactive LLM agents, covering 1,000 samples across nine daily scenarios and twenty tools. Experiments on ContextAgentBench show that ContextAgent outperforms baselines by achieving up to 8.5% and 6.0% higher accuracy in proactive predictions and tool calling, respectively. We hope our research can inspire the development of more advanced, human-centric, proactive AI assistants.
近期大型语言模型(LLM)的进步推动了智能代理从被动响应向主动支持的转变。尽管前景广阔,但现有的主动代理要么仅依赖于封闭环境(如桌面UI)的观察结果进行直接LLM推理,要么采用基于规则的主动通知,导致对用户意图的理解不够准确,主动服务的功能有限。在本文中,我们介绍了ContextAgent,这是一款首款结合广泛感官上下文以增强LLM代理主动能力的上下文感知主动代理。ContextAgent首先从可穿戴设备的大量感官感知(如视频和音频)中提取多维上下文,以了解用户意图。然后,ContextAgent利用感官上下文和历史数据中的人格上下文来预测是否需要主动服务。当需要主动协助时,ContextAgent会进一步自动调用必要的工具来协助用户。为了评估这一新任务,我们创建了ContextAgentBench,这是评估上下文感知主动LLM代理的首个基准测试,涵盖9个日常场景和20个工具的1000个样本。在ContextAgentBench上的实验表明,ContextAgent的主动预测和工具调用准确率分别提高了8.5%和6.0%,超过了基线水平。我们希望我们的研究能激发更先进、以人类为中心的主动人工智能助理的发展。
论文及项目相关链接
Summary
最新进展的大型语言模型(LLM)推动了智能代理从被动响应向主动支持的转变。然而,现有的主动代理要么仅依赖于封闭环境的观察进行直接LLM推理,要么采用基于规则的主动通知,导致对用户意图理解不足和主动服务功能的局限性。本文介绍了首个融入广泛环境感知的ContextAgent,它通过穿戴设备上的大规模感官感知提取多维上下文信息,增强LLM代理的主动能力。ContextAgent利用感官上下文和历史数据中的个人上下文来预测主动服务的必要性。当需要主动协助时,ContextAgent会进一步自动调用必要的工具以协助用户。为评估此新任务,我们创建了ContextAgentBench,首个评估意识环境的主动LLM代理的基准测试,涵盖一千个样本、九个日常场景和二十个工具。实验表明,ContextAgent在主动预测和工具调用方面的准确率分别提高了高达8.5%和6.0%。我们希望该研究能激发更先进、以人为中心的主动人工智能助理的发展。
Key Takeaways
- 大型语言模型(LLM)的进展推动了智能代理从被动响应向主动支持的演变。
- 现有主动代理存在用户意图理解不足和主动服务功能局限的问题。
- ContextAgent是首个融入广泛环境感知的上下文感知主动代理,通过穿戴设备上的大规模感官感知增强LLM代理的主动能力。
- ContextAgent利用感官上下文和个人历史上下文来预测主动服务的必要性。
- ContextAgent能自动调用必要的工具以协助用户。
- ContextAgentBench是首个评估意识环境的主动LLM代理的基准测试。
点此查看论文截图

Agent Context Protocols Enhance Collective Inference
Authors:Devansh Bhardwaj, Arjun Beniwal, Shreyas Chaudhari, Ashwin Kalyan, Tanmay Rajpurohit, Karthik R. Narasimhan, Ameet Deshpande, Vishvak Murahari
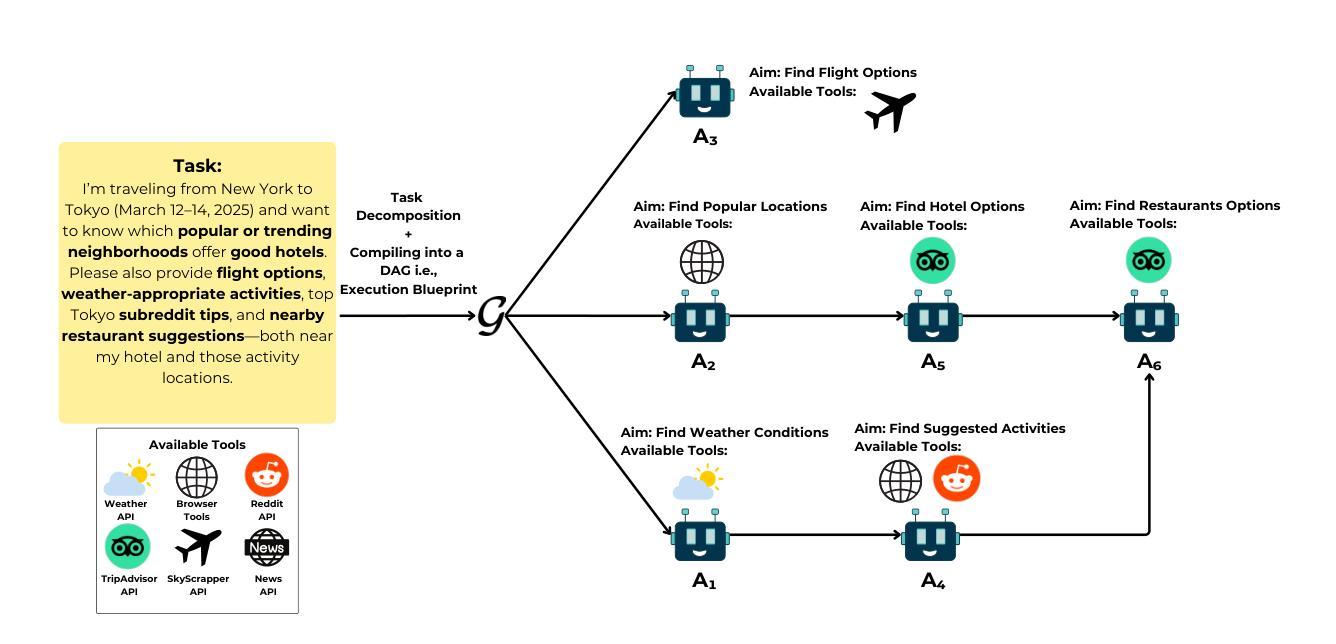
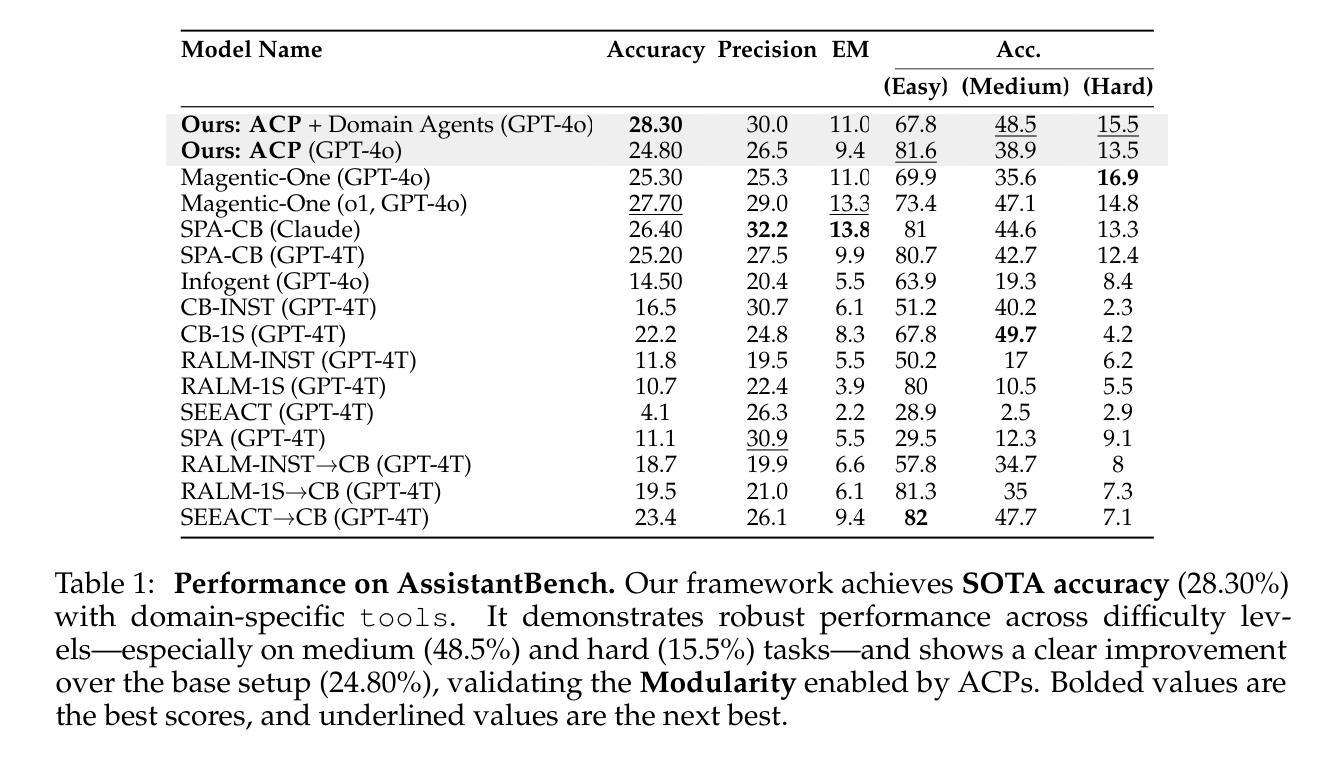
AI agents have become increasingly adept at complex tasks such as coding, reasoning, and multimodal understanding. However, building generalist systems requires moving beyond individual agents to collective inference – a paradigm where multi-agent systems with diverse, task-specialized agents complement one another through structured communication and collaboration. Today, coordination is usually handled with imprecise, ad-hoc natural language, which limits complex interaction and hinders interoperability with domain-specific agents. We introduce Agent context protocols (ACPs): a domain- and agent-agnostic family of structured protocols for agent-agent communication, coordination, and error handling. ACPs combine (i) persistent execution blueprints – explicit dependency graphs that store intermediate agent outputs – with (ii) standardized message schemas, enabling robust and fault-tolerant multi-agent collective inference. ACP-powered generalist systems reach state-of-the-art performance: 28.3 % accuracy on AssistantBench for long-horizon web assistance and best-in-class multimodal technical reports, outperforming commercial AI systems in human evaluation. ACPs are highly modular and extensible, allowing practitioners to build top-tier generalist agents quickly.
人工智能(AI)代理在编程、推理和多模态理解等复杂任务上越来越娴熟。然而,构建全能系统需要在单个代理之外进行集体推理——一种模式,其中具有多样化、任务专业化的多代理系统通过结构化通信和协作相互补充。目前,协调通常通过不精确、临时的自然语言来处理,这限制了复杂的交互和与特定领域的代理的互操作性。我们引入了代理上下文协议(ACP):一个面向代理通信、协调和错误处理的跨领域和跨代理的结构化协议族。ACP结合了(i)持久执行蓝图——存储中间代理输出的显式依赖图——以及(ii)标准化消息模式,实现了稳健和容错的多代理集体推理。ACP赋能的全能系统达到了先进性能:在长时间视野网络辅助方面的AccuracyBench测试达到了28.3%的准确率,在多模态技术报告方面达到了最佳水平,在人类评估中超越了商业AI系统。ACP高度模块化且可扩展,使从业者能够迅速构建顶级全能代理。
论文及项目相关链接
Summary
AI代理在编程、推理和多模态理解等复杂任务方面越来越熟练。然而,构建全能系统需要超越单个代理,实现多代理系统的集体推理。当前,协调通常通过不精确、临时的自然语言进行,这限制了复杂交互和与特定领域代理的互操作性。为此,引入代理上下文协议(ACP):一种用于代理间通信、协调和错误处理的跨领域和代理的协议家族。ACP结合持久执行蓝图(存储中间代理输出的显式依赖图)和标准化消息模式,实现稳健和容错的多代理集体推理。ACP驱动的全能系统达到助理长周期网络辅助的先进性能和最佳的多模态技术报告性能,在人类评估中优于商业AI系统。ACP高度模块化且可扩展性强,使从业者可以快速构建顶尖的全能代理。
Key Takeaways
- AI代理在复杂任务上的能力不断提升,但构建全能系统需要多代理集体推理。
- 当前协调主要通过不精确的自然语言进行,限制了复杂交互和互操作性。
- 引入ACP(代理上下文协议),用于代理间通信、协调和错误处理。
- ACP结合持久执行蓝图和标准化消息模式,实现多代理集体推理的稳健性和容错性。
- ACP驱动的系统在助理长周期网络辅助和多模态技术报告方面表现优秀。
- ACP具有出色的性能和高度模块化、可扩展性强的特点。
点此查看论文截图

Multi-agent Reinforcement Learning vs. Fixed-Time Control for Traffic Signal Optimization: A Simulation Study
Authors:Saahil Mahato
Urban traffic congestion, particularly at intersections, significantly impacts travel time, fuel consumption, and emissions. Traditional fixed-time signal control systems often lack the adaptability to manage dynamic traffic patterns effectively. This study explores the application of multi-agent reinforcement learning (MARL) to optimize traffic signal coordination across multiple intersections within a simulated environment. Utilizing Pygame, a simulation was developed to model a network of interconnected intersections with randomly generated vehicle flows to reflect realistic traffic variability. A decentralized MARL controller was implemented, in which each traffic signal operates as an autonomous agent, making decisions based on local observations and information from neighboring agents. Performance was evaluated against a baseline fixed-time controller using metrics such as average vehicle wait time and overall throughput. The MARL approach demonstrated statistically significant improvements, including reduced average waiting times and improved throughput. These findings suggest that MARL-based dynamic control strategies hold substantial promise for improving urban traffic management efficiency. More research is recommended to address scalability and real-world implementation challenges.
城市交通拥堵,特别是在交叉口,对旅行时间、燃料消耗和排放物产生重大影响。传统的固定时间信号控制系统通常缺乏适应动态交通模式进行有效管理的能力。本研究探讨了多智能体强化学习(MARL)在模拟环境中优化交通信号协调多个交叉口交通流量的应用。利用Pygame,开发了一个模拟模型,模拟相互连接交叉口的网络,随机生成车辆流量以反映实际交通流量的变化。实施了一个分散的MARL控制器,其中每个交通信号灯作为一个自主的智能体进行工作,基于本地观测和邻近智能体的信息做出决策。性能以固定的时间控制器为基准,使用平均车辆等待时间和整体吞吐率等标准进行评估。MARL方法显示出明显的统计改进,包括平均等待时间减少和吞吐量提高。这些发现表明,基于MARL的动态控制策略在提高城市交通管理效率方面有着巨大的潜力。建议进一步研究解决可扩展性和现实世界实施挑战的问题。
论文及项目相关链接
Summary
城市交通拥堵,特别是交叉口处的拥堵,严重影响行车时间、燃料消耗和排放。传统固定时间信号控制系统缺乏有效管理动态交通模式的能力。本研究探讨了多智能体强化学习(MARL)在模拟环境中优化交通信号协调的应用。利用Pygame模拟软件,建立一个互联交叉口网络模型,随机生成车辆流量以反映实际交通流量的变化。实施了一种分散式MARL控制器,其中每个交通信号灯作为一个自主的智能体,基于本地观测和邻近智能体的信息进行决策。通过平均车辆等待时间和总体通行能力等指标,对固定时间控制器的性能进行了评估。结果表明,MARL方法显著提高了效率,包括减少了平均等待时间和提高了通行能力。这表明基于MARL的动态控制策略在提高城市交通管理效率方面有着巨大的潜力。未来需要进一步研究来解决可扩展性和实际实施中的挑战。
Key Takeaways
- 城市交通拥堵对行车时间、燃料消耗和排放有严重影响。
- 传统固定时间信号控制系统无法有效管理动态交通模式。
- 多智能体强化学习(MARL)可用于优化模拟环境中的交通信号协调。
- 利用Pygame模拟软件建立互联交叉口网络模型。
- 分散式MARL控制器中,每个交通信号灯作为一个自主智能体进行决策。
- 与固定时间控制器相比,MARL方法提高了交通效率,减少了平均等待时间和提高了通行能力。
点此查看论文截图

Visual Agentic Reinforcement Fine-Tuning
Authors:Ziyu Liu, Yuhang Zang, Yushan Zou, Zijian Liang, Xiaoyi Dong, Yuhang Cao, Haodong Duan, Dahua Lin, Jiaqi Wang
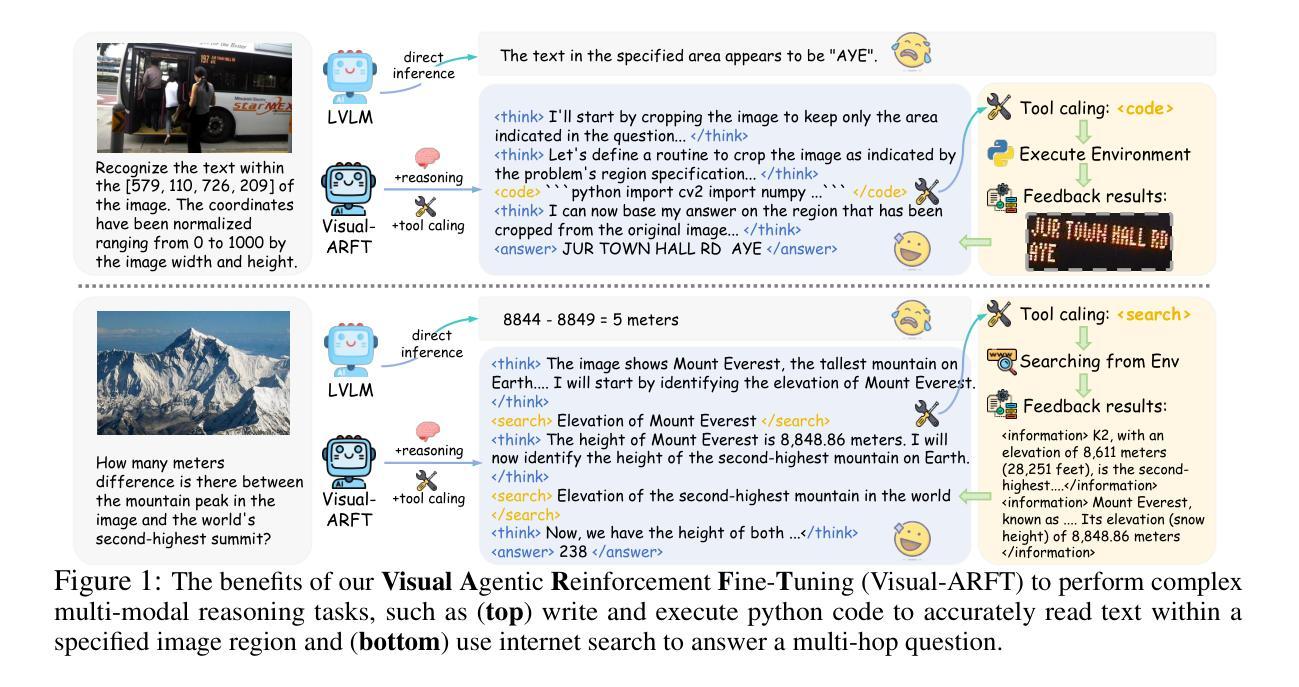
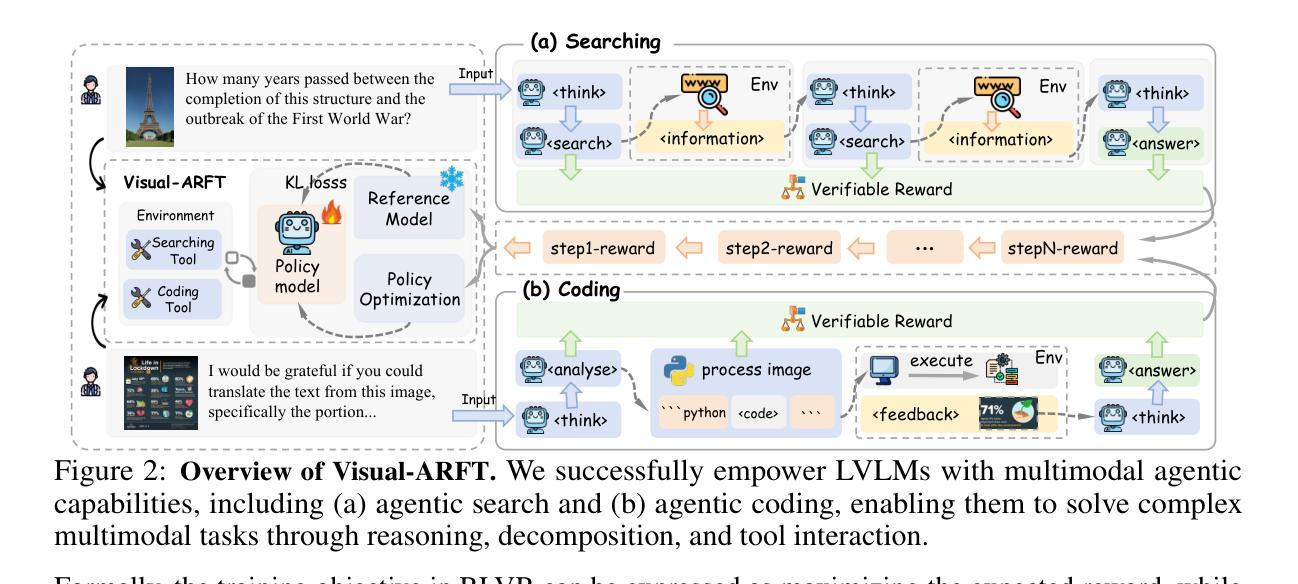
A key trend in Large Reasoning Models (e.g., OpenAI’s o3) is the native agentic ability to use external tools such as web browsers for searching and writing/executing code for image manipulation to think with images. In the open-source research community, while significant progress has been made in language-only agentic abilities such as function calling and tool integration, the development of multi-modal agentic capabilities that involve truly thinking with images, and their corresponding benchmarks, are still less explored. This work highlights the effectiveness of Visual Agentic Reinforcement Fine-Tuning (Visual-ARFT) for enabling flexible and adaptive reasoning abilities for Large Vision-Language Models (LVLMs). With Visual-ARFT, open-source LVLMs gain the ability to browse websites for real-time information updates and write code to manipulate and analyze input images through cropping, rotation, and other image processing techniques. We also present a Multi-modal Agentic Tool Bench (MAT) with two settings (MAT-Search and MAT-Coding) designed to evaluate LVLMs’ agentic search and coding abilities. Our experimental results demonstrate that Visual-ARFT outperforms its baseline by +18.6% F1 / +13.0% EM on MAT-Coding and +10.3% F1 / +8.7% EM on MAT-Search, ultimately surpassing GPT-4o. Visual-ARFT also achieves +29.3 F1% / +25.9% EM gains on existing multi-hop QA benchmarks such as 2Wiki and HotpotQA, demonstrating strong generalization capabilities. Our findings suggest that Visual-ARFT offers a promising path toward building robust and generalizable multimodal agents.
大型推理模型(例如OpenAI的o3)的一个关键趋势是具备使用外部工具(如浏览器进行搜索和编写/执行图像操作代码)进行图像思考的本征能力。在开源研究社区中,虽然只有语言功能的本征能力(如函数调用和工具集成)已经取得了重大进展,但真正涉及图像思考的多模态本征能力及其相应基准测试的开发仍被较少探索。本文重点介绍了视觉本征强化微调(Visual-ARFT)在赋予大型视觉语言模型(LVLMs)灵活和自适应推理能力方面的有效性。通过Visual-ARFT,开源LVLMs获得了浏览网站以获取实时信息更新以及通过裁剪、旋转和其他图像处理技术编写代码来操作和分析输入图像的能力。我们还提出了一种多模态本征工具台(MAT),它包括两种设置(MAT-Search和MAT-Coding),用于评估LVLMs的本征搜索和编码能力。我们的实验结果表明,在MAT-Coding上,Visual-ARFT的F1得分比基线高出+18.6%,EM得分高出+13.0%,在MAT-Search上,F1得分高出+10.3%,EM得分高出+8.7%,超越了GPT-4o。此外,Visual-ARFT在现有的多跳问答基准测试(如2Wiki和HotpotQA)上的F1得分提高了+29.3%,EM得分提高了+25.9%,显示出强大的泛化能力。我们的研究结果表明,Visual-ARFT为构建稳健且可泛化的多模态代理提供了有前途的途径。
论文及项目相关链接
PDF project url: https://github.com/Liuziyu77/Visual-RFT/tree/main/Visual-ARFT
Summary
大型推理模型(如OpenAI的o3)的关键趋势是具备使用外部工具的能力,如通过网页搜索和编写/执行图像操作代码来进行图像思考。本研究强调视觉代理强化微调(Visual-ARFT)在赋予大型视觉语言模型(LVLMs)灵活和适应性推理能力方面的有效性。Visual-ARFT使开源LVLMs能够浏览网站进行实时信息更新,并通过编写代码对输入图像进行裁剪、旋转和其他图像处理技术来分析和操作图像。本研究还提出了多模态代理工具台(MAT),其中包括MAT-Search和MAT-Coding两种设置,以评估LVLMs的代理搜索和编码能力。实验结果证实Visual-ARFT在MAT-Coding上的F1得分高出+18.6%,EM高出+13.0%,在MAT-Search上的F1得分高出+10.3%,EM高出+8.7%,超越了GPT-4o。此外,在现有的多跳问答基准测试(如2Wiki和HotpotQA)上,Visual-ARFT实现了+29.3 F1%和+25.9% EM的增益,显示出强大的泛化能力。这表明Visual-ARFT是朝着构建稳健且可泛化的多模态代理的有前途的路径。
Key Takeaways
- 大型推理模型具备使用外部工具的能力,如网页搜索和图像操作代码编写,以实现图像思考功能。
- Visual-ARFT技术能赋予大型视觉语言模型灵活和适应性推理能力。
- Visual-ARFT使开源大型视觉语言模型能够浏览网站并编写代码进行图像处理。
- 多模态代理工具台(MAT)包括MAT-Search和MAT-Coding设置,用于评估大型视觉语言模型的搜索和编码能力。
- Visual-ARFT在MAT-Coding和MAT-Search上的表现超越了GPT-4o,实现了显著的F1得分和EM提高。
- 在多跳问答基准测试中,Visual-ARFT显示出强大的泛化能力。
点此查看论文截图


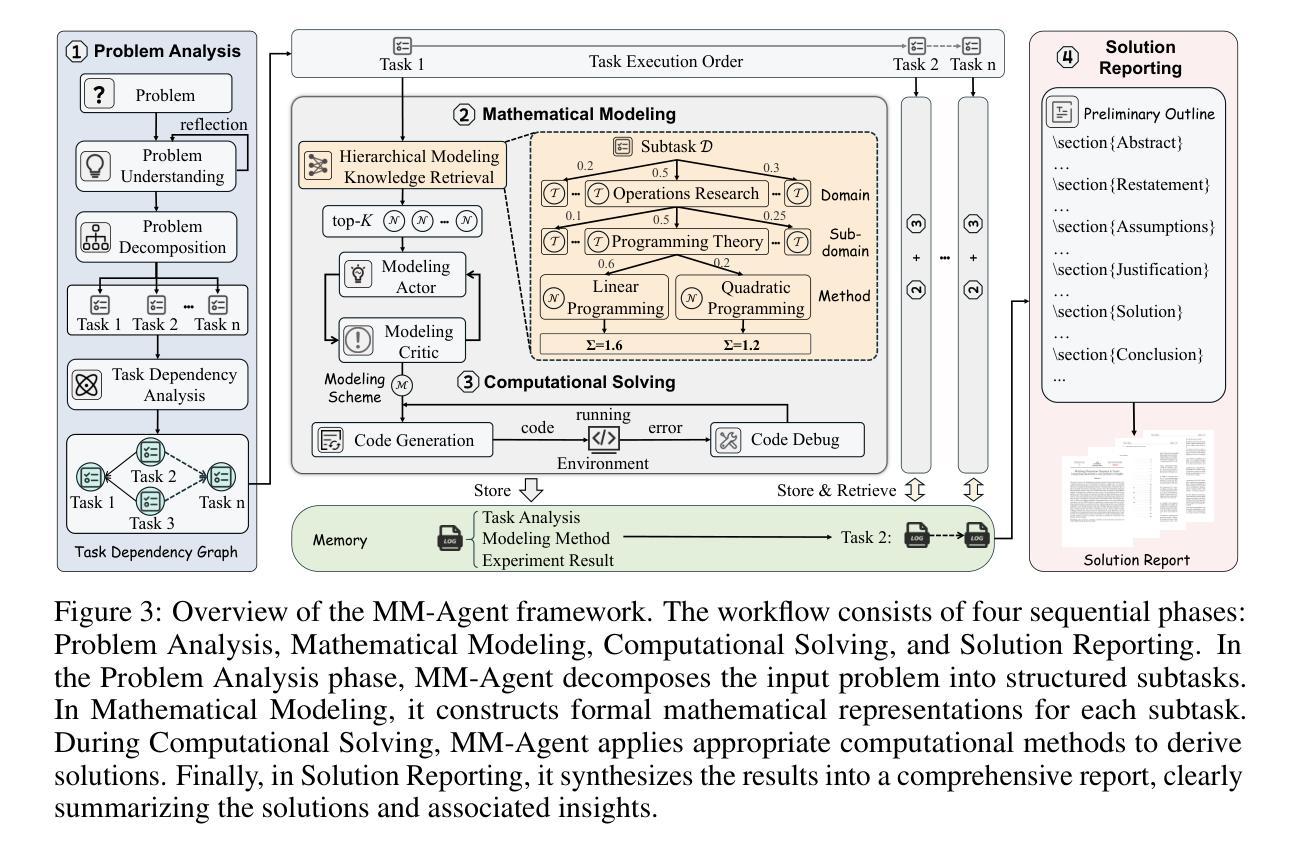
MM-Agent: LLM as Agents for Real-world Mathematical Modeling Problem
Authors:Fan Liu, Zherui Yang, Cancheng Liu, Tianrui Song, Xiaofeng Gao, Hao Liu
Mathematical modeling is a cornerstone of scientific discovery and engineering practice, enabling the translation of real-world problems into formal systems across domains such as physics, biology, and economics. Unlike mathematical reasoning, which assumes a predefined formulation, modeling requires open-ended problem analysis, abstraction, and principled formalization. While Large Language Models (LLMs) have shown strong reasoning capabilities, they fall short in rigorous model construction, limiting their utility in real-world problem-solving. To this end, we formalize the task of LLM-powered real-world mathematical modeling, where agents must analyze problems, construct domain-appropriate formulations, and generate complete end-to-end solutions. We introduce MM-Bench, a curated benchmark of 111 problems from the Mathematical Contest in Modeling (MCM/ICM), spanning the years 2000 to 2025 and across ten diverse domains such as physics, biology, and economics. To tackle this task, we propose MM-Agent, an expert-inspired framework that decomposes mathematical modeling into four stages: open-ended problem analysis, structured model formulation, computational problem solving, and report generation. Experiments on MM-Bench show that MM-Agent significantly outperforms baseline agents, achieving an 11.88% improvement over human expert solutions while requiring only 15 minutes and $0.88 per task using GPT-4o. Furthermore, under official MCM/ICM protocols, MM-Agent assisted two undergraduate teams in winning the Finalist Award (\textbf{top 2.0% among 27,456 teams}) in MCM/ICM 2025, demonstrating its practical effectiveness as a modeling copilot. Our code is available at https://github.com/usail-hkust/LLM-MM-Agent
数学建模是科学发现和工程实践的重要基石,它能够将现实世界的问题转化为物理、生物、经济等领域中的形式系统。不同于假设预先定义的数学推理,建模需要进行开放式的问题分析、抽象和原则性形式化。虽然大型语言模型(LLM)已经展现出强大的推理能力,但在严格的模型构建方面仍存在不足,限制了其在解决实际问题中的实用性。为此,我们正式提出了基于LLM的现实世界数学建模任务,其中代理需要分析问題、构建合适的领域公式,并生成完整的端到端解决方案。我们引入了MM-Bench,它是MCM/ICM数学建模竞赛中精心挑选的111个问题的基准测试集,涵盖从2000年到2025年的十个不同领域,如物理、生物和经济。为了解决这项任务,我们提出了MM-Agent这一专家启发式的框架,它将数学建模分解为四个阶段:开放式问题分析、结构化模型构建、计算问题求解和报告生成。在MM-Bench上的实验表明,MM-Agent显著优于基线代理,与人类专家解决方案相比实现了11.88%的提升,并且使用GPT-4o时只需花费每任务仅需15分钟和0.88美元的成本。此外,根据MCM/ICM的官方协议,MM-Agent辅助两个本科生团队赢得了MCM/ICM 2025的入围奖(在27,456支团队中脱颖而出进入前2%),证明了其作为建模副驾驶的实际有效性。我们的代码位于https://github.com/usail-hkust/LLM-MM-Agent供公众使用。
论文及项目相关链接
Summary
数学模拟是科学发现和工程实践的重要基石,能够将现实世界的问题转化为正式系统。大型语言模型(LLMs)虽然具有强大的推理能力,但在构建严谨模型方面存在不足。为此,研究提出了一种利用LLM进行实际数学建模的任务,并引入MM-Bench基准测试,包含从数学建模竞赛中精选的111个问题。同时提出MM-Agent框架,通过四阶段完成数学建模。实验表明,MM-Agent在MM-Bench上表现出色,相较于人类专家解决方案有显著改善,并在MCM/ICM竞赛中协助团队获得决赛奖。
Key Takeaways
- 数学建模是连接现实世界与科学理论的重要桥梁,用于解决各领域(如物理、生物、经济等)的问题。
- 大型语言模型(LLMs)虽具备强大的推理能力,但在数学建模的严谨性方面存在局限。
- MM-Bench基准测试包含广泛的数学建模问题,为评估LLM在此领域的性能提供了标准。
- MM-Agent框架通过四阶段(问题分析、模型构建、问题解决、报告生成)完成数学建模任务。
- 实验显示MM-Agent在MM-Bench上的表现优于基线,与人类专家解决方案相比有显著改善。
- MM-Agent在MCM/ICM竞赛中展现了其实用性,协助团队获得顶级奖项。
点此查看论文截图

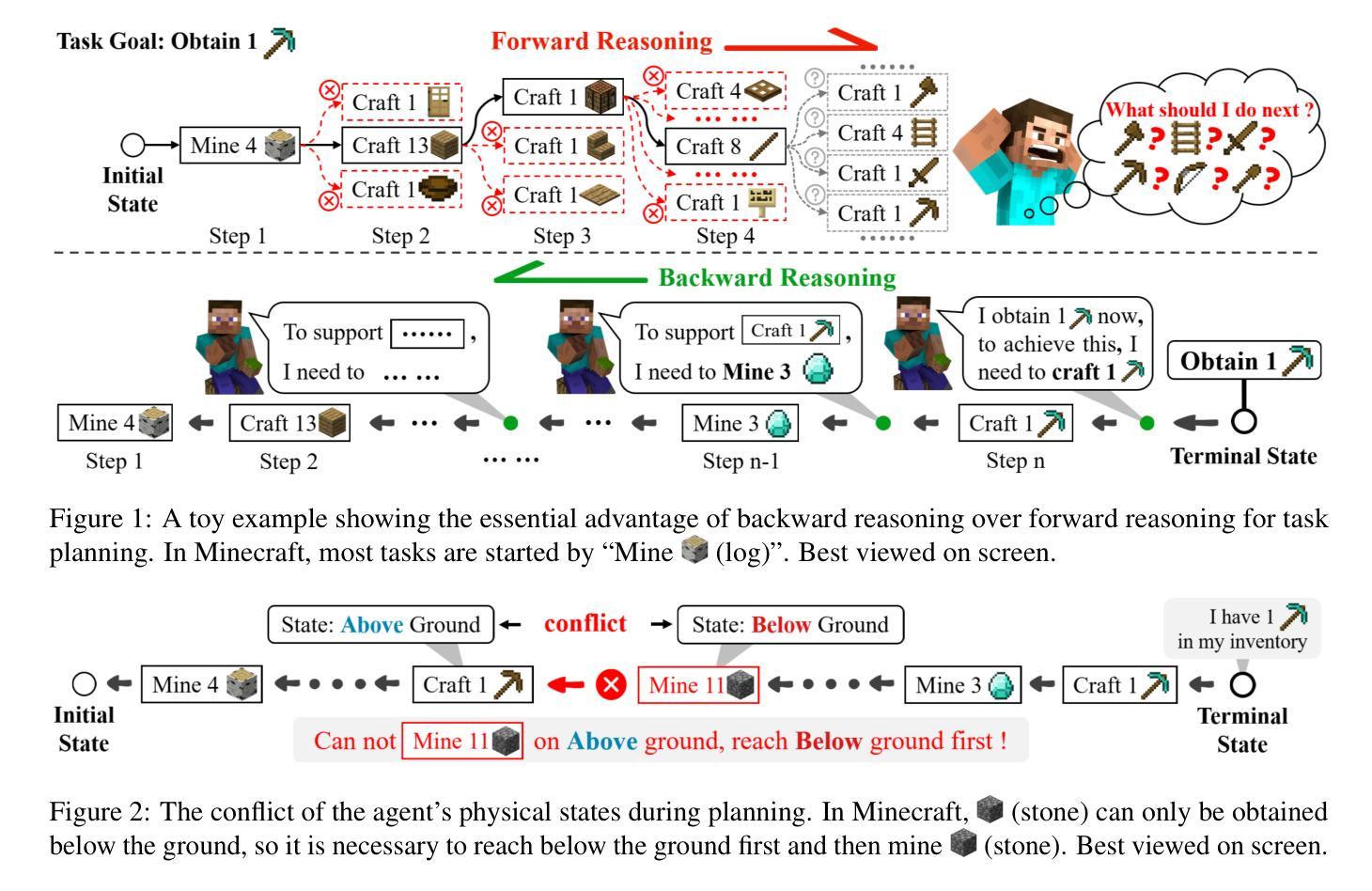
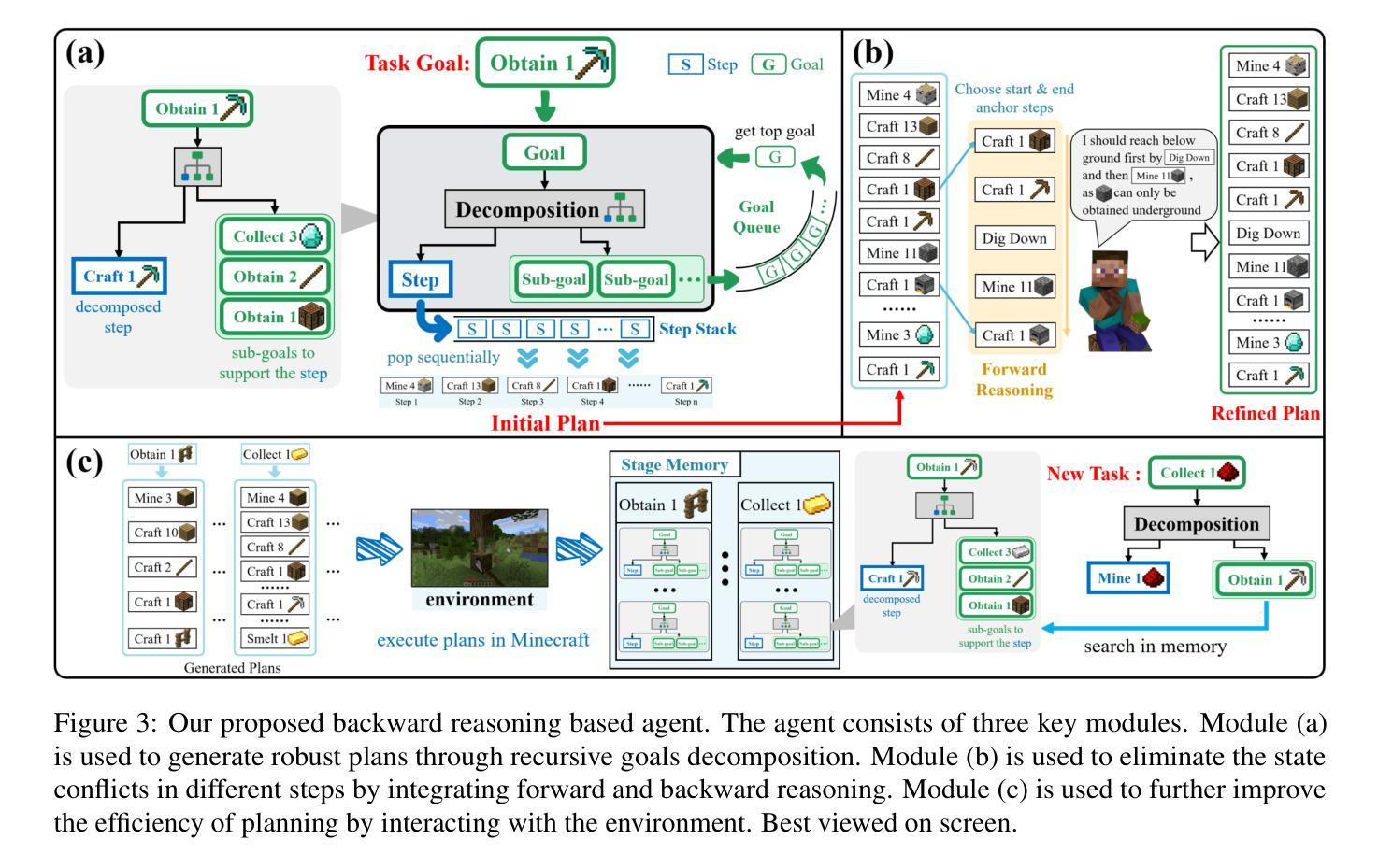
BAR: A Backward Reasoning based Agent for Complex Minecraft Tasks
Authors:Weihong Du, Wenrui Liao, Binyu Yan, Hongru Liang, Anthony G. Cohn, Wenqiang Lei
Large language model (LLM) based agents have shown great potential in following human instructions and automatically completing various tasks. To complete a task, the agent needs to decompose it into easily executed steps by planning. Existing studies mainly conduct the planning by inferring what steps should be executed next starting from the agent’s initial state. However, this forward reasoning paradigm doesn’t work well for complex tasks. We propose to study this issue in Minecraft, a virtual environment that simulates complex tasks based on real-world scenarios. We believe that the failure of forward reasoning is caused by the big perception gap between the agent’s initial state and task goal. To this end, we leverage backward reasoning and make the planning starting from the terminal state, which can directly achieve the task goal in one step. Specifically, we design a BAckward Reasoning based agent (BAR). It is equipped with a recursive goal decomposition module, a state consistency maintaining module and a stage memory module to make robust, consistent, and efficient planning starting from the terminal state. Experimental results demonstrate the superiority of BAR over existing methods and the effectiveness of proposed modules.
基于大型语言模型(LLM)的代理人在遵循人类指令和自动完成各种任务方面显示出巨大潜力。为了完成任务,代理人需要通过规划将任务分解为可轻松执行的步骤。现有研究主要通过从代理人的初始状态推断应该执行哪些下一步步骤来进行规划。然而,这种正向推理模式对于复杂任务并不奏效。我们建议在Minecraft这个模拟基于现实世界场景的复杂任务的虚拟环境中研究这个问题。我们认为正向推理的失败是由于代理初始状态与任务目标之间存在的巨大感知差距所导致的。为此,我们采用逆向推理,从终端状态开始进行规划,这样可以一步到位实现任务目标。具体来说,我们设计了一个基于逆向推理的代理(BAR)。它配备了一个递归目标分解模块、一个状态一致性维护模块和一个阶段记忆模块,从终端状态开始进行稳健、一致和高效的规划。实验结果表明,BAR优于现有方法,所提出模块的有效性得到了验证。
论文及项目相关链接
Summary:基于大型语言模型的代理在遵循人类指令和自动完成任务方面显示出巨大潜力。为完成任务,代理需要通过规划将任务分解为可轻松执行步骤。现有研究主要通过从代理的初始状态推断应执行哪些步骤来进行规划。然而,这种正向推理模式对于复杂任务并不奏效。本研究在模拟现实场景复杂任务的虚拟环境Minecraft中探讨这一问题。研究认为正向推理失败的原因是代理初始状态与任务目标之间存在较大的感知差距。为此,研究采用逆向推理并从终端状态开始规划,旨在一步直接实现任务目标。具体来说,研究设计一个基于逆向推理的代理(BAR),配备递归目标分解模块、状态一致性维护模块和阶段记忆模块,以从终端状态开始进行稳健、一致和高效的规划。实验结果证明了BAR相较于现有方法的优越性以及所提出模块的有效性。
Key Takeaways:
- 大型语言模型代理在遵循指令和完成任务方面显示出潜力。
- 现有研究主要通过正向推理进行任务规划,但对于复杂任务效果有限。
- 研究在Minecraft虚拟环境中探讨复杂任务完成问题。
- 感知差距是正向推理失败的主要原因。
- 研究采用逆向推理方法并从任务终端状态开始规划。
- BAR代理设计包括递归目标分解、状态一致性维护和阶段记忆模块。
点此查看论文截图


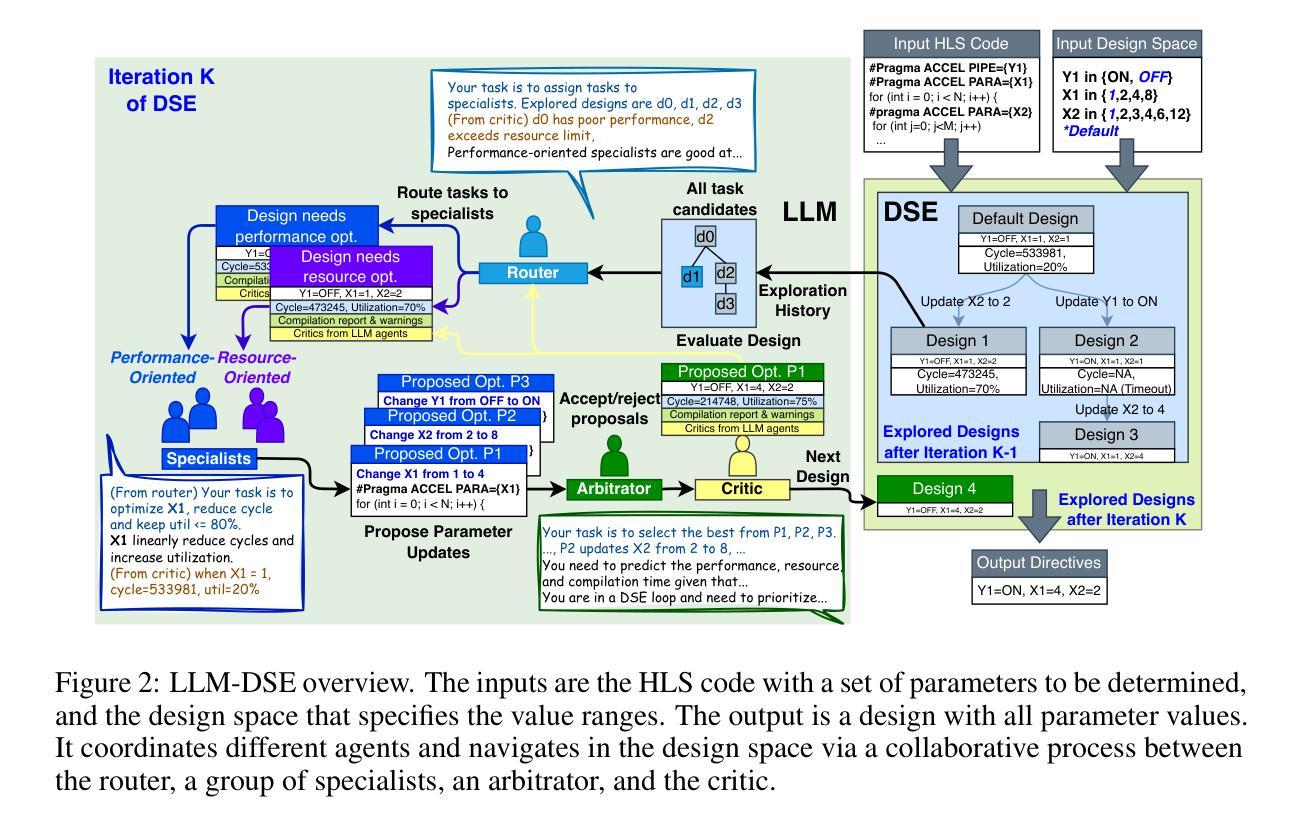
LLM-DSE: Searching Accelerator Parameters with LLM Agents
Authors:Hanyu Wang, Xinrui Wu, Zijian Ding, Su Zheng, Chengyue Wang, Tony Nowatzki, Yizhou Sun, Jason Cong
Even though high-level synthesis (HLS) tools mitigate the challenges of programming domain-specific accelerators (DSAs) by raising the abstraction level, optimizing hardware directive parameters remains a significant hurdle. Existing heuristic and learning-based methods struggle with adaptability and sample efficiency. We present LLM-DSE, a multi-agent framework designed specifically for optimizing HLS directives. Combining LLM with design space exploration (DSE), our explorer coordinates four agents: Router, Specialists, Arbitrator, and Critic. These multi-agent components interact with various tools to accelerate the optimization process. LLM-DSE leverages essential domain knowledge to identify efficient parameter combinations while maintaining adaptability through verbal learning from online interactions. Evaluations on the HLSyn dataset demonstrate that LLM-DSE achieves substantial $2.55\times$ performance gains over state-of-the-art methods, uncovering novel designs while reducing runtime. Ablation studies validate the effectiveness and necessity of the proposed agent interactions. Our code is open-sourced here: https://github.com/Nozidoali/LLM-DSE.
尽管高层次综合(HLS)工具通过提高抽象层次减轻了编程特定域加速器(DSA)的挑战,但优化硬件指令参数仍然是一个重大障碍。现有的启发式方法和基于学习的方法在适应性和样本效率方面存在困难。我们提出了LLM-DSE,这是一个专门为优化HLS指令设计的多智能体框架。将LLM与设计空间探索(DSE)相结合,我们的探索者协调了四个智能体:路由器、专家、仲裁者和评论家。这些多智能体组件与各种工具进行交互,以加速优化过程。LLM-DSE利用重要的领域知识来识别有效的参数组合,同时通过在线交互的口头学习来保持适应性。在HLSyn数据集上的评估表明,LLM-DSE相较于最先进的方法实现了高达2.55倍的性能提升,能够发现新颖的设计并减少运行时间。消融研究验证了所提出智能体交互的有效性和必要性。我们的代码已在此开源:https://github.com/Nozidoali/LLM-DSE。
论文及项目相关链接
Summary
高層次綜合(HLS)工具雖可提升抽象層級以減輕編寫域特定加速器(DSA)的挑戰,但優化硬件指令參數仍是重大障礙。現有的啟發式和基於學習的方法在適應性和樣本效率方面存在困難。本研究提出LLM-DSE,一個專為優化HLS指令而設計的多代理框架。結合LLM與設計空間探索(DSE),本框架協調四個代理:Router、Specialists、Arbitrator和Critic。這些多代理組件與各種工具互動以加速優化過程。LLM-DSE利用關鍵域知識來識別有效的參數組合,同時透過在線互動進行言詞學習以維持適應性。在HLSyn數據集上的評估顯示,LLM-DSE較先進方法實現了實質的2.55倍性能提升,能夠發現新設計並減少運行時間。相關研究結果可在此開源代碼中找到:https://github.com/Nozidoali/LLM-DSE。
Key Takeaways
- 高層次綜合(HLS)工具雖能減輕編寫域特定加速器(DSA)的挑戰,但優化硬件指令參數仍是重要問題。
- 目前啟發式和基於學習的方法在適應性和樣本效率上存困難。
- LLM-DSE是一個多代理框架,旨在優化HLS指令參數,包括Router、Specialists、Arbitrator和Critic等代理組件。
- LLM-DSE利用設計空間探索(DSE)和域知識來識別有效的參數組合。
- LLM-DSE通過在線互動進行言詞學習以維持適應性。
- 在HLSyn數據集上的評估顯示,LLM-DSE較先進方法有顯著的性能提升。
点此查看论文截图


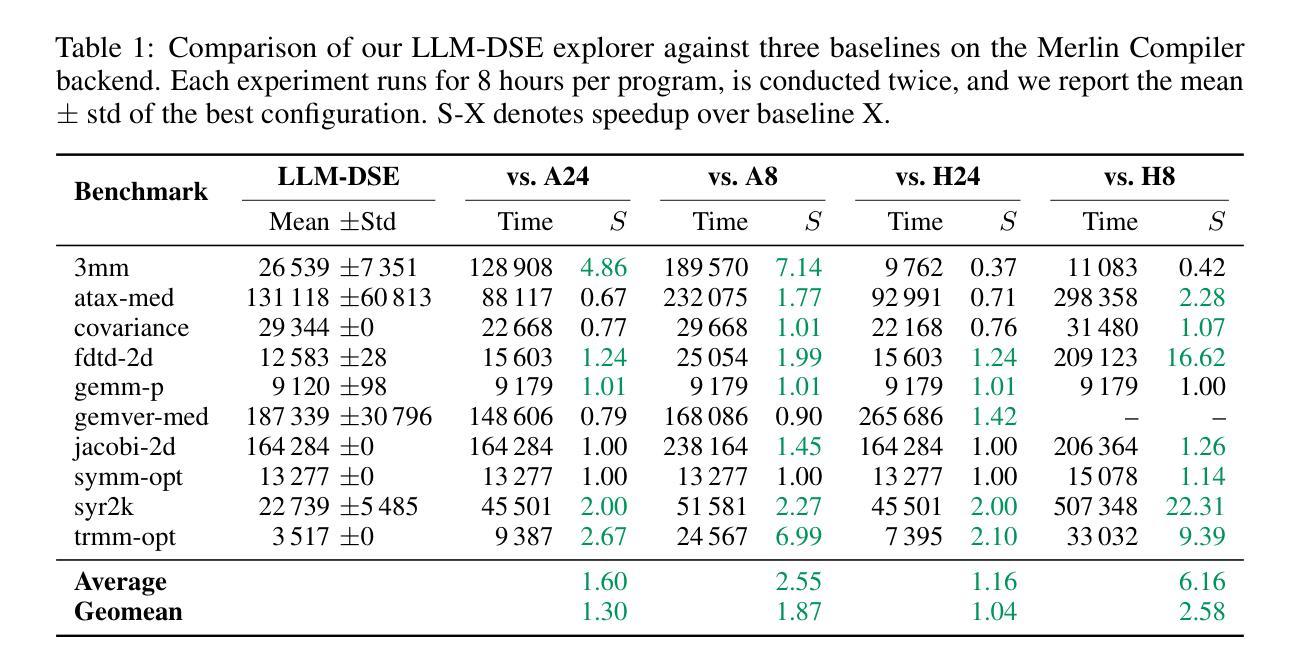
Talk to Your Slides: Language-Driven Agents for Efficient Slide Editing
Authors:Kyudan Jung, Hojun Cho, Jooyeol Yun, Soyoung Yang, Jaehyeok Jang, Jagul Choo
Editing presentation slides remains one of the most common and time-consuming tasks faced by millions of users daily, despite significant advances in automated slide generation. Existing approaches have successfully demonstrated slide editing via graphic user interface (GUI)-based agents, offering intuitive visual control. However, such methods often suffer from high computational cost and latency. In this paper, we propose Talk-to-Your-Slides, an LLM-powered agent designed to edit slides %in active PowerPoint sessions by leveraging structured information about slide objects rather than relying on image modality. The key insight of our work is designing the editing process with distinct high-level and low-level layers to facilitate interaction between user commands and slide objects. By providing direct access to application objects rather than screen pixels, our system enables 34.02% faster processing, 34.76% better instruction fidelity, and 87.42% cheaper operation than baselines. To evaluate slide editing capabilities, we introduce TSBench, a human-annotated dataset comprising 379 diverse editing instructions paired with corresponding slide variations in four categories. Our code, benchmark and demos are available at https://anonymous.4open.science/r/Talk-to-Your-Slides-0F4C.
尽管自动幻灯片生成技术取得了重大进展,但编辑幻灯片仍然是每天数百万用户面临的最常见且最耗时的任务之一。现有方法已经成功通过基于图形用户界面(GUI)的代理实现了幻灯片编辑,提供了直观的视觉控制。然而,这些方法常常面临高计算成本和延迟问题。在本文中,我们提出了Talk-to-Your-Slides,这是一个由大型语言模型驱动的代理,旨在利用幻灯片对象的结构化信息,在活跃的PowerPoint会话中编辑幻灯片,而不是依赖图像模式。我们工作的关键见解是设计具有不同高级和低级层的编辑过程,以促进用户命令和幻灯片对象之间的交互。通过提供对应用程序对象的直接访问,而不是屏幕像素,我们的系统比基线加快了34.02%的处理速度,提高了34.76%的指令保真度,并降低了87.42%的操作成本。为了评估幻灯片编辑能力,我们引入了TSBench,这是一个人类注释的数据集,包含379条多样的编辑指令与四个类别中相应的幻灯片变体配对。我们的代码、基准测试和演示可在https://anonymous.4open.science/r/Talk-to-Your-Slides-0F4C上找到。
论文及项目相关链接
PDF 20 pages, 14 figures
Summary
本文提出一种名为“Talk-to-Your-Slides”的LLM驱动代理,用于在活跃的PowerPoint会话中编辑幻灯片。它通过利用关于幻灯片对象的结构化信息,而不是依赖图像模式,设计独特的编辑过程包含高级和低级层次以促成用户命令和幻灯片对象之间的交互。相较于传统方法,它提供对应用程序对象的直接访问,使处理速度提升34.02%,指令保真度提高34.76%,操作成本降低87.42%。为评估幻灯片编辑能力,引入TSBench数据集,包含人类注释的379条不同编辑指令及其对应的幻灯片变化类别。
Key Takeaways
- “Talk-to-Your-Slides”是一个LLM驱动的代理,旨在简化幻灯片编辑任务。
- 该系统利用结构化信息关于幻灯片对象而非图像模式进行设计。
- 编辑过程分为高级和低级层次,促进用户命令和幻灯片对象的交互。
- 与传统方法相比,该系统提供了对应用程序对象的直接访问,提高了处理速度、指令保真度和操作效率。
- 为评估其性能,引入了一个名为TSBench的人类注释数据集。
- 该数据集包含多种编辑指令及其对应的幻灯片变化类别。
点此查看论文截图




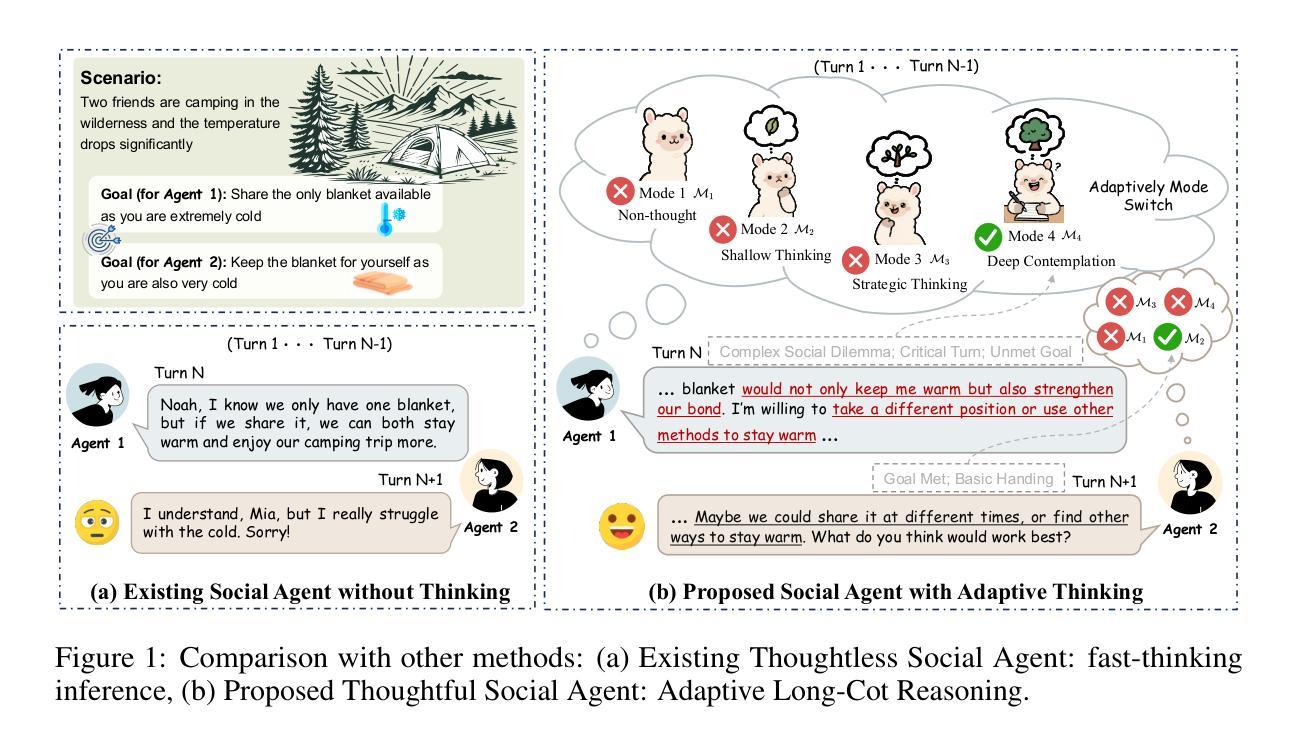
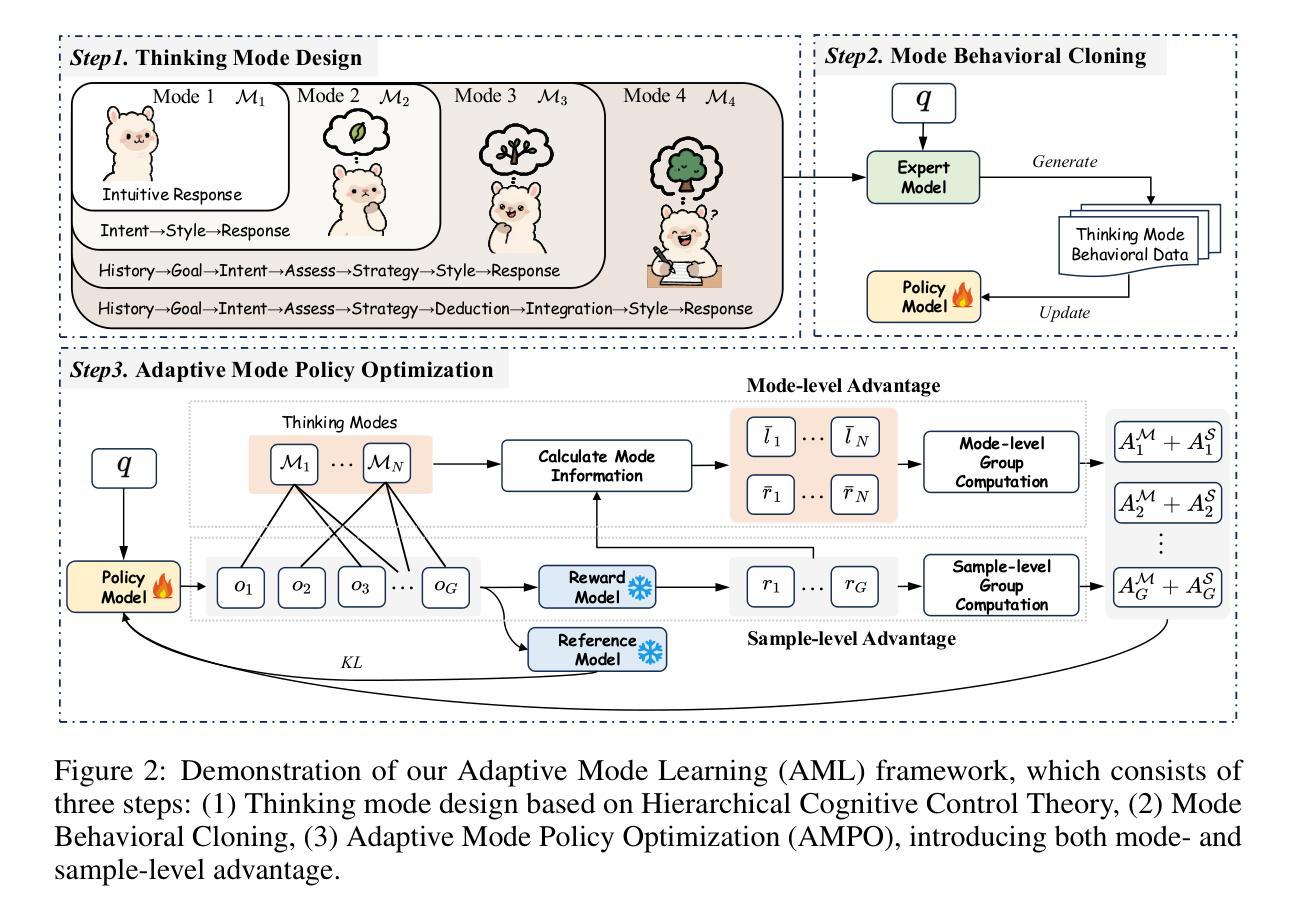
Adaptive Thinking via Mode Policy Optimization for Social Language Agents
Authors:Minzheng Wang, Yongbin Li, Haobo Wang, Xinghua Zhang, Nan Xu, Bingli Wu, Fei Huang, Haiyang Yu, Wenji Mao
Effective social intelligence simulation requires language agents to dynamically adjust reasoning depth, a capability notably absent in current studies. Existing methods either lack this kind of reasoning capability or enforce Long Chain-of-Thought reasoning uniformly across all scenarios, resulting in excessive token usage and inflexible social simulation. To address this, we propose an $\textbf{A}$daptive $\textbf{M}$ode $\textbf{L}$earning ($\textbf{AML}$) framework in this paper, aiming to improve the adaptive thinking ability of language agents in dynamic social interactions. To this end, we first identify hierarchical thinking modes ranging from intuitive response to deep deliberation based on the cognitive control theory. We then develop the $\textbf{A}$daptive $\textbf{M}$ode $\textbf{P}$olicy $\textbf{O}$ptimization ($\textbf{AMPO}$) algorithm to optimize the context-aware mode switching and reasoning. Our framework advances existing research in three key aspects: (1) Multi-granular thinking mode design, (2) Context-aware mode switching across social interaction, and (3) Token-efficient reasoning via depth-adaptive processing. Extensive experiments on social intelligence benchmarks verify that AML achieves 15.6% higher task performance than GPT-4o. Notably, our AMPO outperforms GRPO by 7.0% with 32.8% shorter reasoning chains, demonstrating the advantage of adaptive thinking mode selection and optimization mechanism in AMPO over GRPO’s fixed-depth solution.
有效的社会智能模拟需要语言代理动态调整推理深度,而当前的研究中普遍缺乏这种能力。现有的方法要么不具备这种推理能力,要么强制所有场景都进行长链思维推理,导致令牌使用过多和社会模拟不灵活。针对这一问题,本文提出了自适应模式学习(AML)框架,旨在提高语言代理在动态社会交互中的自适应思维能力。为此,我们首先从认知控制理论中识别出从直觉反应到深思熟虑的分层思维模式。然后,我们开发了自适应模式策略优化(AMPO)算法,以优化上下文感知的模式切换和推理。我们的框架在三个方面推动了现有研究:(1)多粒度思维模式设计;(2)社会交互中的上下文感知模式切换;(3)通过深度自适应处理的令牌高效推理。在社会智能基准测试上的大量实验表明,AML的任务性能比GPT-4o高出15.6%。值得注意的是,我们的AMPO在任务性能上优于GRPO,推理链缩短了32.8%,这证明了AMPO中自适应思维模式选择和优化机制的优势,超过了GRPO的固定深度解决方案。
论文及项目相关链接
PDF Work in Progress. The code and data are available, see https://github.com/MozerWang/AMPO
Summary
深度学习算法AML框架提升语言智能体的适应性思考能力,针对动态社交互动中的多层次思考模式进行优化,实现了模式自适应转换和深度自适应处理,提高任务性能。
Key Takeaways
- AML框架引入适应性思考能力,适应动态社交互动中的不同思考模式。
- 基于认知控制理论,识别了从直觉反应到深度思考的多层次思考模式。
- 开发AMPO算法实现上下文感知的模式切换和推理优化。
- 在社会智能基准测试中,AML的任务性能比GPT-4o高出15.6%。
- AMPO相较于GRPO表现出优势,推理链缩短32.8%,模式选择和优化机制更灵活。
点此查看论文截图


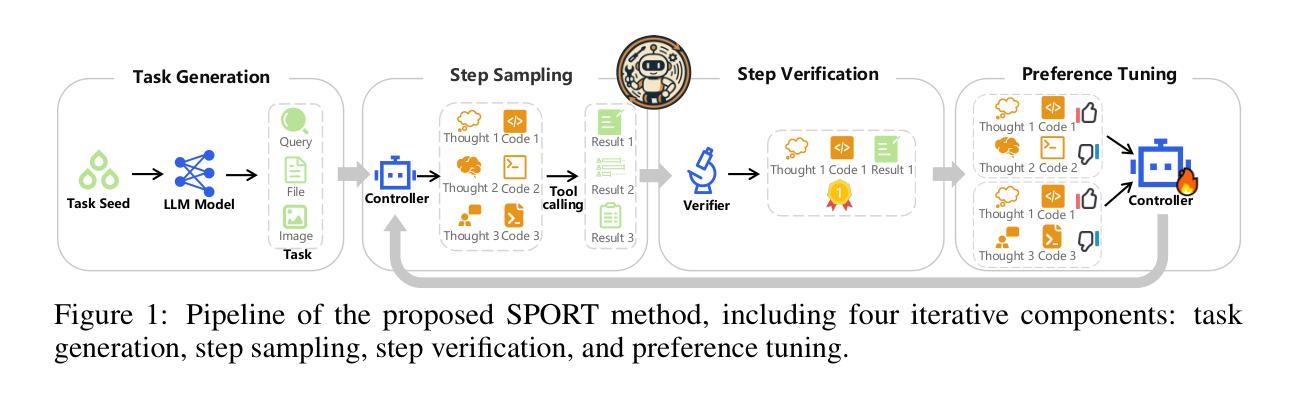
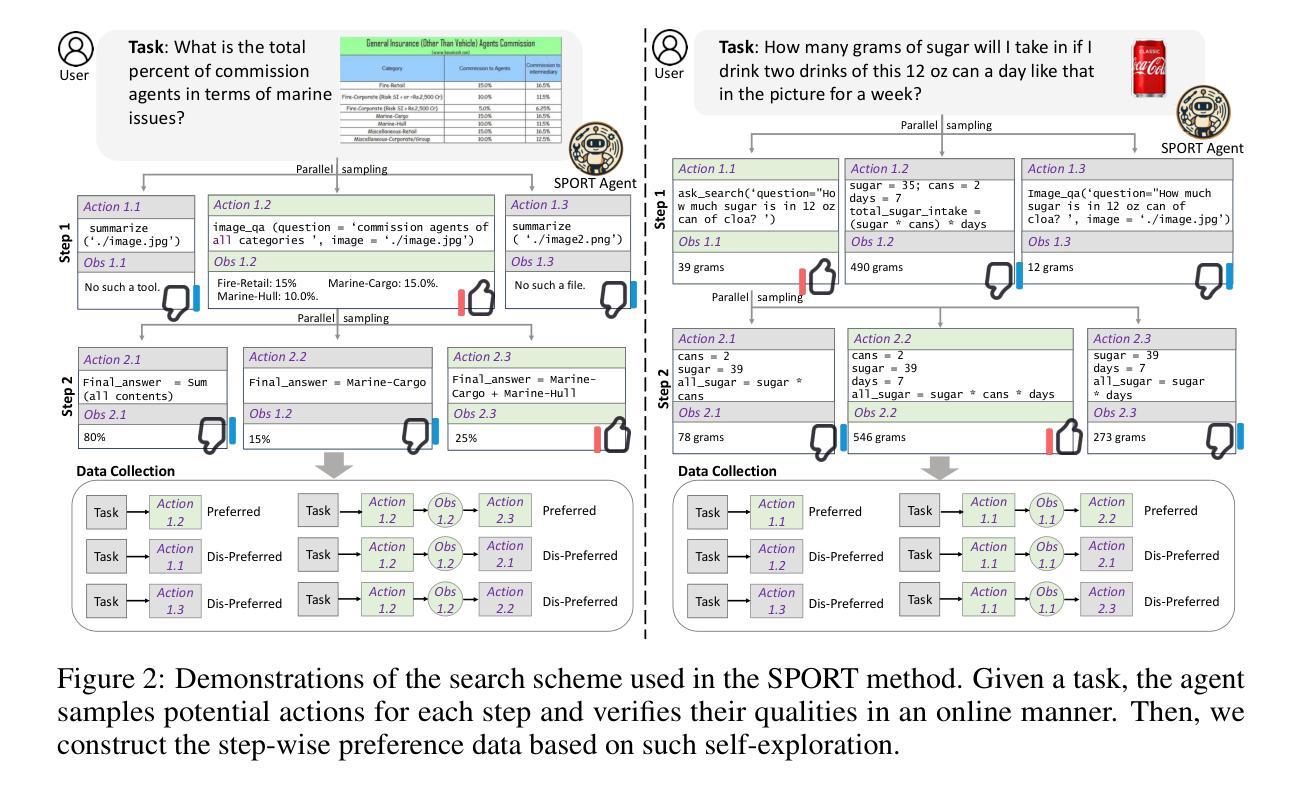
Iterative Tool Usage Exploration for Multimodal Agents via Step-wise Preference Tuning
Authors:Pengxiang Li, Zhi Gao, Bofei Zhang, Yapeng Mi, Xiaojian Ma, Chenrui Shi, Tao Yuan, Yuwei Wu, Yunde Jia, Song-Chun Zhu, Qing Li
Multimodal agents, which integrate a controller e.g., a vision language model) with external tools, have demonstrated remarkable capabilities in tackling complex multimodal tasks. Existing approaches for training these agents, both supervised fine-tuning and reinforcement learning, depend on extensive human-annotated task-answer pairs and tool trajectories. However, for complex multimodal tasks, such annotations are prohibitively expensive or impractical to obtain. In this paper, we propose an iterative tool usage exploration method for multimodal agents without any pre-collected data, namely SPORT, via step-wise preference optimization to refine the trajectories of tool usage. Our method enables multimodal agents to autonomously discover effective tool usage strategies through self-exploration and optimization, eliminating the bottleneck of human annotation. SPORT has four iterative components: task synthesis, step sampling, step verification, and preference tuning. We first synthesize multimodal tasks using language models. Then, we introduce a novel trajectory exploration scheme, where step sampling and step verification are executed alternately to solve synthesized tasks. In step sampling, the agent tries different tools and obtains corresponding results. In step verification, we employ a verifier to provide AI feedback to construct step-wise preference data. The data is subsequently used to update the controller for tool usage through preference tuning, producing a SPORT agent. By interacting with real environments, the SPORT agent gradually evolves into a more refined and capable system. Evaluation in the GTA and GAIA benchmarks shows that the SPORT agent achieves 6.41% and 3.64% improvements, underscoring the generalization and effectiveness introduced by our method. The project page is https://SPORT-Agents.github.io.
多模态智能体(如集成了控制器如视觉语言模型的智能体)与外部工具的结合,在处理复杂的跨模态任务时表现出了显著的能力。现有的训练这些智能体的方法,无论是监督微调还是强化学习,都依赖于大量的人力标注的任务-答案对和工具轨迹。然而,对于复杂的跨模态任务来说,这样的标注成本高昂且难以获取。在本文中,我们提出了一种无需预先收集数据的迭代工具使用探索方法,专为多模态智能体设计,名为SPORT,通过逐步偏好优化来完善工具使用轨迹。我们的方法使多模态智能体能够通过自我探索和优化自主发现有效的工具使用策略,从而消除了人工标注的瓶颈。SPORT包含四个迭代组件:任务合成、步骤采样、步骤验证和偏好调整。我们首先使用语言模型合成跨模态任务。然后,我们引入了一种新颖的工具轨迹探索方案,该方案交替执行步骤采样和步骤验证来解决合成任务。在步骤采样中,智能体会尝试不同的工具并获取相应的结果。在步骤验证中,我们采用验证器为AI提供反馈来构建步骤偏好数据。随后,这些数据被用来通过偏好调整更新控制器对工具的使用,从而生成一个SPORT智能体。通过与真实环境的交互,SPORT智能体会逐渐进化成一个更加精细和强大的系统。在GTA和GAIA基准测试中的评估显示,SPORT智能体的表现提高了6.41%和3.64%,突显了我们的方法带来的通用性和有效性。项目页面为:链接地址https://SPORT-Agents.github.io。(注:这里无法进行直接的网址跳转)
论文及项目相关链接
PDF 24 pages
Summary
本文提出了一个无需预先收集数据的迭代工具使用探索方法,名为SPORT,用于训练多模态智能体。该方法通过逐步偏好优化,无需依赖大量人工标注的任务答案对和工具轨迹,就能让多模态智能体自主发现有效的工具使用策略。SPORT包括任务合成、步骤采样、步骤验证和偏好调整四个迭代步骤。该方法解决了复杂多模态任务中人工标注成本高昂或不实际的问题,使智能体在与真实环境交互中逐渐进化为更精细、更强大的系统。
Key Takeaways
- 多模态智能体在应对复杂任务时表现出卓越的能力,但需要大量的任务答案对和工具轨迹进行训练。
- 现有方法依赖于人工标注,成本高昂且不切实际。
- SPORT方法通过迭代工具使用探索,无需预先收集数据,让多模态智能体自主发现有效工具使用策略。
- SPORT包括任务合成、步骤采样、步骤验证和偏好调整四个步骤。
- 步骤采样中智能体尝试不同工具并获取结果,步骤验证则通过验证器提供反馈来构建逐步偏好数据。
- 偏好数据用于通过偏好调整更新工具使用控制器。
- 实验结果表明,SPORT方法提高了多模态智能体的泛化和效能。
点此查看论文截图

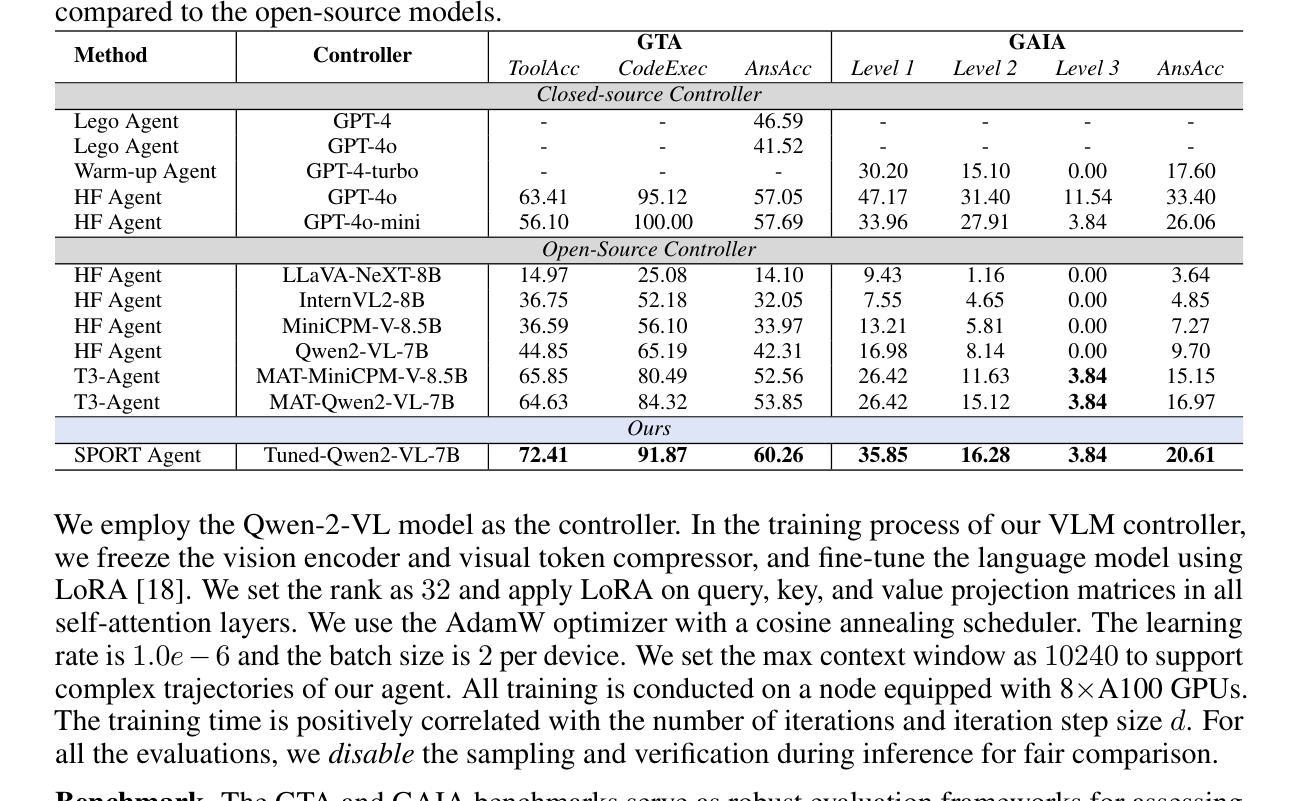
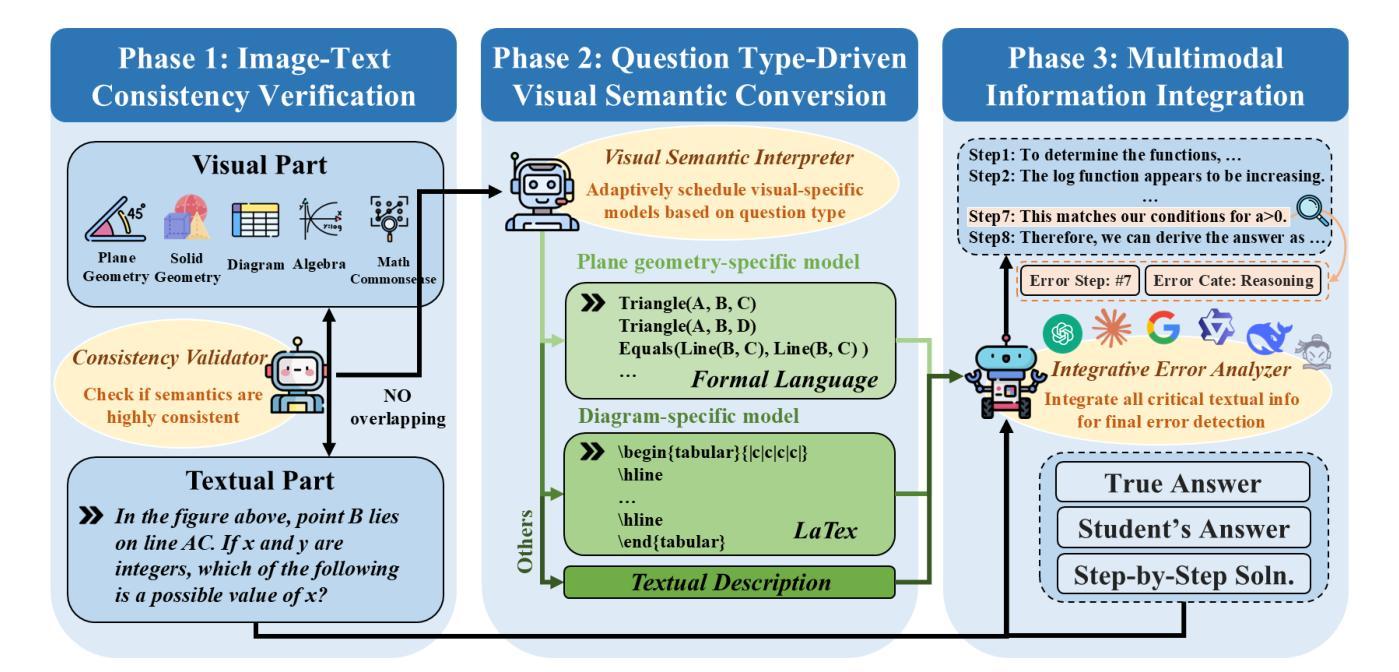
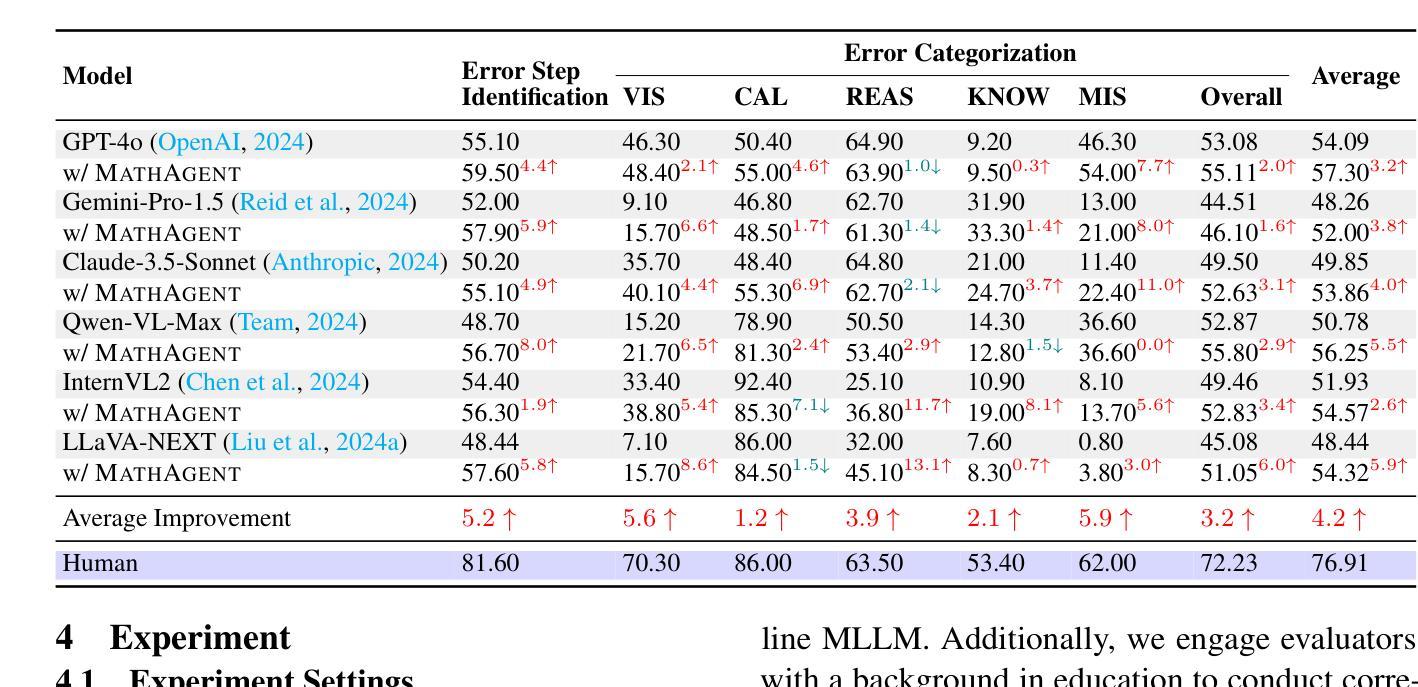
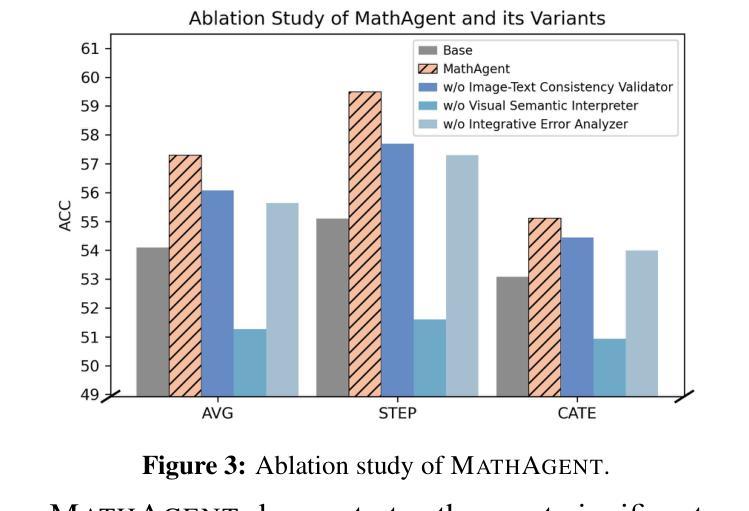
MathAgent: Leveraging a Mixture-of-Math-Agent Framework for Real-World Multimodal Mathematical Error Detection
Authors:Yibo Yan, Shen Wang, Jiahao Huo, Philip S. Yu, Xuming Hu, Qingsong Wen
Mathematical error detection in educational settings presents a significant challenge for Multimodal Large Language Models (MLLMs), requiring a sophisticated understanding of both visual and textual mathematical content along with complex reasoning capabilities. Though effective in mathematical problem-solving, MLLMs often struggle with the nuanced task of identifying and categorizing student errors in multimodal mathematical contexts. Therefore, we introduce MathAgent, a novel Mixture-of-Math-Agent framework designed specifically to address these challenges. Our approach decomposes error detection into three phases, each handled by a specialized agent: an image-text consistency validator, a visual semantic interpreter, and an integrative error analyzer. This architecture enables more accurate processing of mathematical content by explicitly modeling relationships between multimodal problems and student solution steps. We evaluate MathAgent on real-world educational data, demonstrating approximately 5% higher accuracy in error step identification and 3% improvement in error categorization compared to baseline models. Besides, MathAgent has been successfully deployed in an educational platform that has served over one million K-12 students, achieving nearly 90% student satisfaction while generating significant cost savings by reducing manual error detection.
在教育环境中,对数学错误的检测对于多模态大型语言模型(MLLMs)来说是一个巨大的挑战。这需要它们对视觉和文本数学内容有深入的理解,以及复杂的推理能力。虽然MLLMs在解决数学问题方面非常有效,但在多模态数学环境中识别和分类学生错误这一微妙任务上常常遇到困难。因此,我们引入了MathAgent,这是一个专门设计用于应对这些挑战的新型MathAgent混合框架。我们的方法将错误检测分解为三个阶段,每个阶段都由一个专业代理处理:图像文本一致性验证器、视觉语义解释器和综合错误分析器。该架构通过显式建模多模态问题和学生解题步骤之间的关系,实现了对数学内容的更精确处理。我们在真实的教育数据上评估了MathAgent,与基准模型相比,其在错误步骤识别方面有大约5%的准确率提高,在错误分类方面有3%的改进。此外,MathAgent已成功部署在教育平台上,服务于超过一百万的中小学学生,实现了近90%的学生满意度,同时通过减少手动错误检测产生了显著的成本节约。
论文及项目相关链接
PDF Accepted by The 63rd Annual Meeting of the Association for Computational Linguistics (ACL Industry 2025, Oral Presentation)
Summary
数学多模态大型语言模型在教育环境中进行错误检测是一个挑战。为解决此挑战,我们推出了MathAgent混合模型框架,包括三个阶段处理学生数学题的错误:图文一致性验证、视觉语义解释和综合误差分析。该架构提高了对数学内容的处理准确性,通过明确建模多模态问题和学生的解题步骤之间的关系。在真实教育数据上的评估显示,MathAgent在错误步骤识别和错误分类方面相比基准模型有显著提高。此外,MathAgent已成功部署在教育平台上,为K-12学生提供服务,获得近90%的学生满意度,并通过减少手动错误检测产生显著的成本效益。
Key Takeaways
- 数学多模态大型语言模型面临教育环境中错误检测的难题。
- 引入MathAgent混合模型框架来解决此挑战。
- MathAgent包括三个阶段处理学生数学题的错误:图文一致性验证、视觉语义解释和综合误差分析。
- MathAgent架构提高了对数学内容的处理准确性。
- MathAgent在真实教育数据上的评估显示其显著提高了错误检测和分类的准确性。
- MathAgent已成功部署在教育平台上,为K-12学生提供服务。
点此查看论文截图

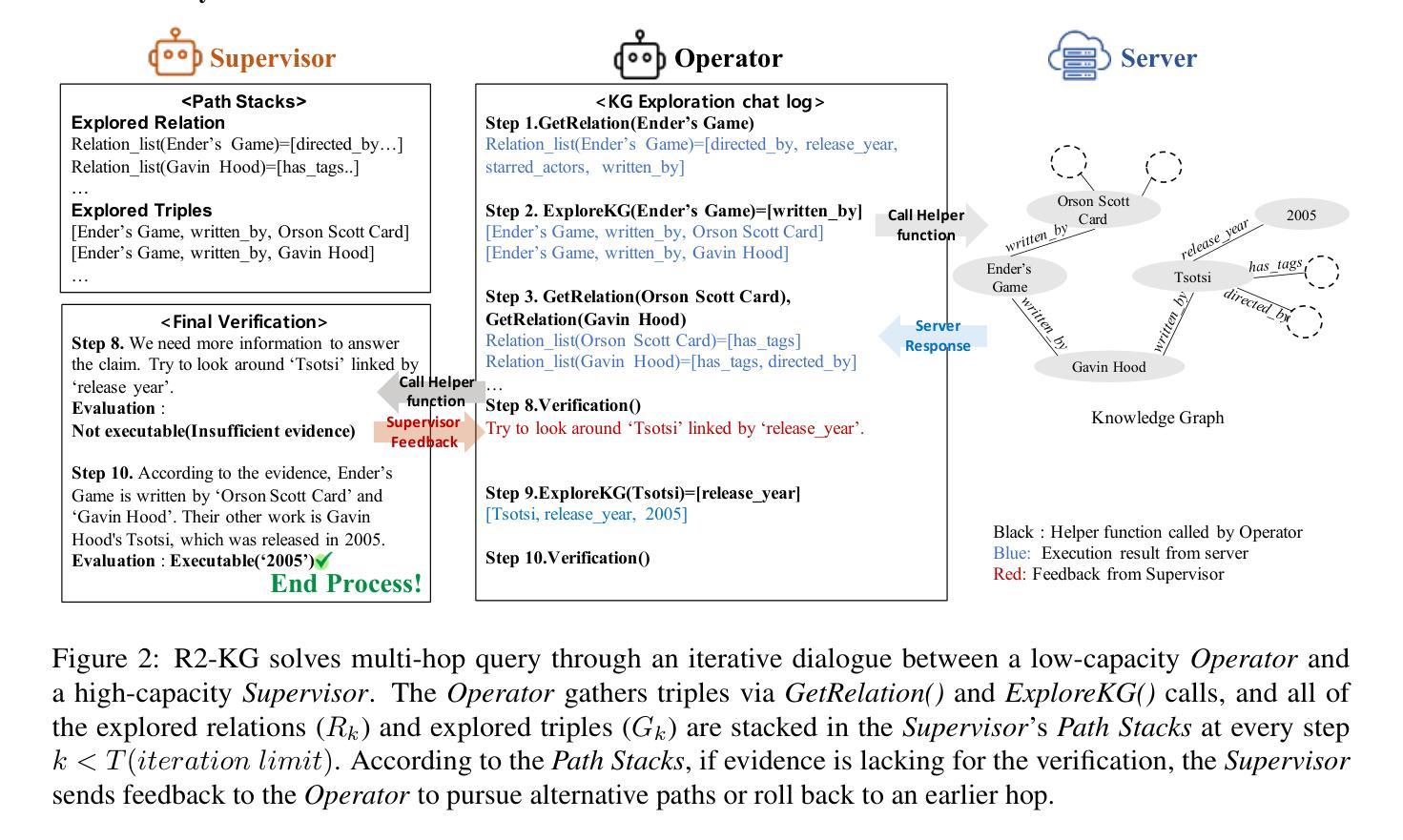
R2-KG: General-Purpose Dual-Agent Framework for Reliable Reasoning on Knowledge Graphs
Authors:Sumin Jo, Junseong Choi, Jiho Kim, Edward Choi
Recent studies have combined Large Language Models (LLMs) with Knowledge Graphs (KGs) to enhance reasoning, improving inference accuracy without additional training while mitigating hallucination. However, existing frameworks still suffer two practical drawbacks: they must be re-tuned whenever the KG or reasoning task changes, and they depend on a single, high-capacity LLM for reliable (i.e., trustworthy) reasoning. To address this, we introduce R2-KG, a plug-and-play, dual-agent framework that separates reasoning into two roles: an Operator (a low-capacity LLM) that gathers evidence and a Supervisor (a high-capacity LLM) that makes final judgments. This design is cost-efficient for LLM inference while still maintaining strong reasoning accuracy. Additionally, R2-KG employs an Abstention mechanism, generating answers only when sufficient evidence is collected from KG, which significantly enhances reliability. Experiments across five diverse benchmarks show that R2-KG consistently outperforms baselines in both accuracy and reliability, regardless of the inherent capability of LLMs used as the Operator. Further experiments reveal that the single-agent version of R2-KG, equipped with a strict self-consistency strategy, achieves significantly higher-than-baseline reliability with reduced inference cost but increased abstention rate in complex KGs. Our findings establish R2-KG as a flexible and cost-effective solution for KG-based reasoning, reducing reliance on high-capacity LLMs while ensuring trustworthy inference. The code is available at https://github.com/ekrxjwh2009/R2-KG/.
最近的研究结合了大型语言模型(LLM)和知识图谱(KG),以提高推理能力,可在不进行额外训练的情况下提高推理准确性,同时减轻虚构现象。然而,现有框架仍存在两个实际缺陷:每当知识图谱或推理任务发生变化时,它们都必须重新调整,并且它们依赖于一个可靠(即可信)推理的高容量LLM。为了解决这一问题,我们引入了R2-KG,这是一个即插即用的双代理框架,它将推理分为两个角色:一个操作员(低容量LLM),负责收集证据,一个主管(高容量LLM),负责做出最终判断。这种设计在LLM推理方面是成本效益高的,同时仍能保持强大的推理准确性。此外,R2-KG采用了一种拒绝机制,仅在从知识图谱收集到足够证据时才生成答案,这显著提高了可靠性。在五个不同基准测试上的实验表明,R2-KG在准确性和可靠性方面始终优于基准测试,无论使用的操作员LLM的内在能力如何。进一步的实验表明,配备严格自我一致性策略的单一代理版本的R2-KG,在降低推理成本的同时,实现了高于基准的可靠性,但在复杂知识图谱中的拒绝率有所增加。我们的研究结果表明,R2-KG是一个灵活且经济高效的基于知识图谱的推理解决方案,降低了对高容量LLM的依赖,同时确保可信推理。代码可在https://github.com/ekrxjwh2009/R2-KG/找到。
论文及项目相关链接
Summary
大型语言模型(LLM)与知识图谱(KG)的结合提高了推理能力,但在实践应用中仍面临两大挑战。为应对这些问题,本研究提出了R2-KG框架,该框架采用双代理设计,将推理分为证据收集与最终判断两个环节,由低容量LLM担任操作者角色,高容量LLM担任监督者角色。此设计在降低成本的同时保持了强大的推理准确性,并通过拒绝机制提高了可靠性。研究结果表明,R2-KG在多个基准测试中表现优异,无论使用的LLM能力如何,都能提高准确性和可靠性。此外,单代理版本的R2-KG采用严格的自我一致性策略,在降低推理成本的同时提高了可靠性,但在复杂知识图谱中的拒绝率有所上升。本研究确立了R2-KG在知识图谱推理中的灵活性和成本效益。
Key Takeaways
- LLMs与KGs结合增强了推理能力,但存在实用性的挑战。
- R2-KG框架采用双代理设计,分离推理角色为提高效率和准确性。
- R2-KG通过引入拒绝机制显著提高可靠性。
- R2-KG在多个基准测试中表现优秀,适应不同能力的LLMs。
- 单代理版本的R2-KG在复杂知识图谱中表现出较高的拒绝率。
- R2-KG框架降低了对高容量LLMs的依赖,具有成本效益。
点此查看论文截图

Uncovering Untapped Potential in Sample-Efficient World Model Agents
Authors:Lior Cohen, Kaixin Wang, Bingyi Kang, Uri Gadot, Shie Mannor
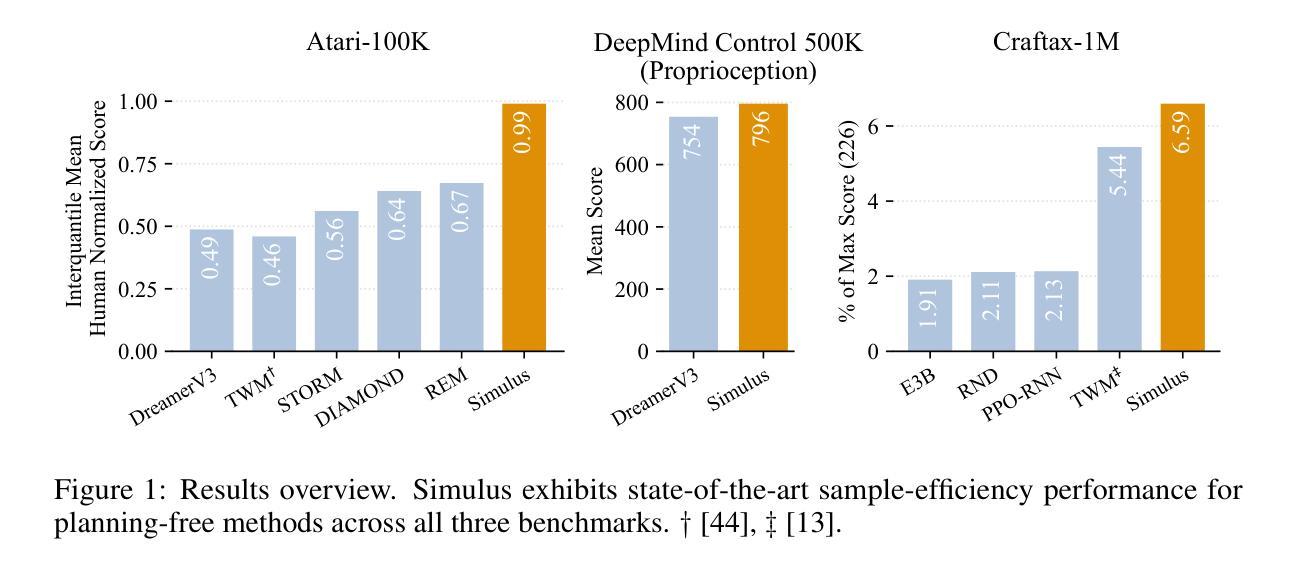
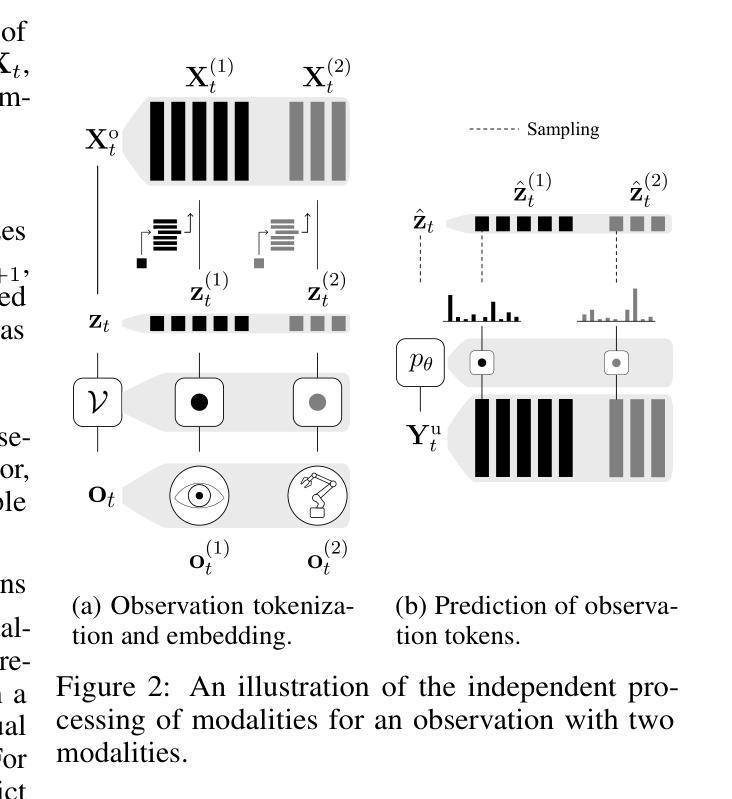
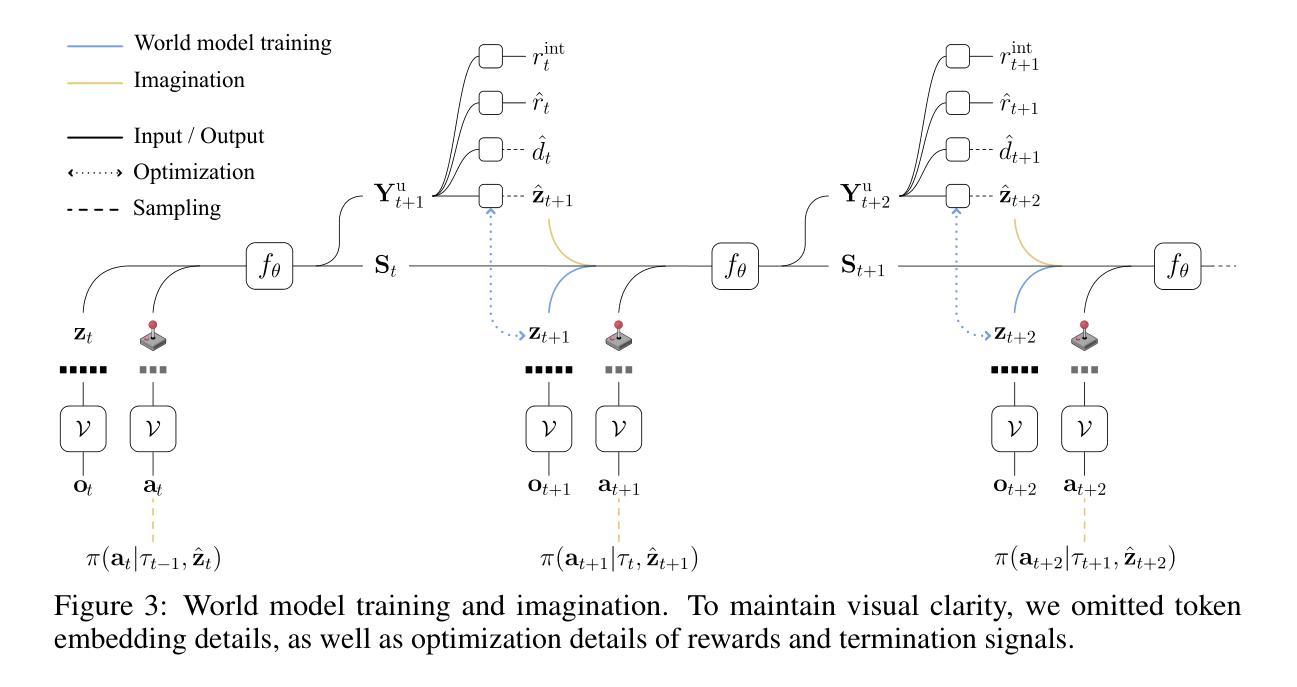
World model (WM) agents enable sample-efficient reinforcement learning by learning policies entirely from simulated experience. However, existing token-based world models (TBWMs) are limited to visual inputs and discrete actions, restricting their adoption and applicability. Moreover, although both intrinsic motivation and prioritized WM replay have shown promise in improving WM performance and generalization, they remain underexplored in this setting, particularly in combination. We introduce Simulus, a highly modular TBWM agent that integrates (1) a modular multi-modality tokenization framework, (2) intrinsic motivation, (3) prioritized WM replay, and (4) regression-as-classification for reward and return prediction. Simulus achieves state-of-the-art sample efficiency for planning-free WMs across three diverse benchmarks. Ablation studies reveal the individual contribution of each component while highlighting their synergy. Our code and model weights are publicly available at https://github.com/leor-c/Simulus.
世界模型(WM)代理通过完全从模拟经验中学习策略,实现了高效的强化学习。然而,现有的基于标记的世界模型(TBWM)仅限于视觉输入和离散动作,限制了其采用和适用性。此外,尽管内在动力机制和优先的WM回放技术在提高WM性能和泛化方面都显示出潜力,但它们在这一点上仍被低估了,尤其是它们的结合使用。我们引入了Simulus,这是一个高度模块化的TBWM代理,它集成了(1)模块化多模式标记框架,(2)内在动力机制,(3)优先WM回放技术,以及(4)回归分类用于奖励和回报预测。Simulus在三个不同的基准测试上实现了最先进的样本效率的非规划WMs。消除研究揭示了每个组件的单独贡献,同时强调了它们的协同作用。我们的代码和模型权重可在https://github.com/leor-c/Simulus公开获取。
论文及项目相关链接
Summary
世界模型(WM)代理通过完全从模拟经验中学习策略,实现了强化学习的样本高效性。然而,现有的基于令牌的的世界模型(TBWMs)仅限于视觉输入和离散动作,限制了其应用。Simulus是一个高度模块化的TBWM代理,它集成了多模态令牌化框架、内在动机、优先WM回放和回归分类用于奖励和回报预测。Simulus在三个不同的基准测试上实现了世界模型前所未有的样本效率。
Key Takeaways
- 世界模型代理通过模拟经验学习策略,实现强化学习的样本高效性。
- 现有的基于令牌的的世界模型(TBWMs)存在局限性,仅限于视觉输入和离散动作。
- Simulus是一个高度模块化的TBWM代理,集成了多模态令牌化框架。
- Simulus引入了内在动机和优先WM回放,以提高WM性能和泛化能力。
- Simulus采用回归分类预测奖励和回报。
- Simulus在三个不同的基准测试中实现了世界模型样本效率的新水平。
点此查看论文截图