⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-05-22 更新
Training-Free Watermarking for Autoregressive Image Generation
Authors:Yu Tong, Zihao Pan, Shuai Yang, Kaiyang Zhou
Invisible image watermarking can protect image ownership and prevent malicious misuse of visual generative models. However, existing generative watermarking methods are mainly designed for diffusion models while watermarking for autoregressive image generation models remains largely underexplored. We propose IndexMark, a training-free watermarking framework for autoregressive image generation models. IndexMark is inspired by the redundancy property of the codebook: replacing autoregressively generated indices with similar indices produces negligible visual differences. The core component in IndexMark is a simple yet effective match-then-replace method, which carefully selects watermark tokens from the codebook based on token similarity, and promotes the use of watermark tokens through token replacement, thereby embedding the watermark without affecting the image quality. Watermark verification is achieved by calculating the proportion of watermark tokens in generated images, with precision further improved by an Index Encoder. Furthermore, we introduce an auxiliary validation scheme to enhance robustness against cropping attacks. Experiments demonstrate that IndexMark achieves state-of-the-art performance in terms of image quality and verification accuracy, and exhibits robustness against various perturbations, including cropping, noises, Gaussian blur, random erasing, color jittering, and JPEG compression.
隐式图像水印技术可以保护图像的所有权,并防止对视觉生成模型的恶意滥用。然而,现有的生成水印方法主要设计用于扩散模型,而对于自回归图像生成模型的水印技术仍鲜有研究。我们提出了IndexMark,这是一个无需训练的自回归图像生成模型水印框架。IndexMark受到代码本冗余属性的启发:用相似的索引替换自回归生成的索引会产生微不足道的视觉差异。IndexMark的核心组件是一种简单有效的匹配替换方法,该方法根据令牌相似性,从代码本中精心选择水印令牌,并通过令牌替换促进水印令牌的使用,从而嵌入水印而不影响图像质量。通过计算生成图像中水印令牌的比例来实现水印验证,通过索引编码器进一步提高精度。此外,我们引入了一种辅助验证方案,以提高对裁剪攻击的鲁棒性。实验表明,IndexMark在图像质量和验证精度方面达到了最新技术水平,并对各种扰动(包括裁剪、噪声、高斯模糊、随机擦除、颜色抖动和JPEG压缩)具有鲁棒性。
论文及项目相关链接
Summary
本文提出一种名为IndexMark的训练无关水印嵌入框架,适用于自回归图像生成模型。该框架利用代码本的冗余特性,通过替换自回归生成的索引来嵌入水印,同时保持图像质量不受影响。IndexMark采用基于令牌相似性的匹配替换方法,通过精心选择水印令牌并促进令牌替换来嵌入水印。水印验证通过计算生成图像中水印令牌的比例来实现,并使用索引编码器提高精度。此外,还引入了一种辅助验证方案,以提高对裁剪攻击的鲁棒性。实验表明,IndexMark在图像质量和验证准确性方面达到最佳性能,并对各种扰动具有鲁棒性。
Key Takeaways
- Invisible image watermarking protects image ownership and prevents malicious misuse of visual generative models.
- Existing generative watermarking methods are mainly designed for diffusion models, with watermarking for autoregressive image generation models remaining largely unexplored.
- IndexMark is a training-free watermarking framework for autoregressive image generation models.
- IndexMark利用代码本的冗余特性,通过替换自回归生成的索引来嵌入水印,同时保持图像质量不受影响。
- IndexMark采用基于令牌相似性的匹配替换方法,精心选择水印令牌并促进令牌替换。
- 水印验证通过计算生成图像中水印令牌的比例来实现,并使用索引编码器提高验证精度。
点此查看论文截图

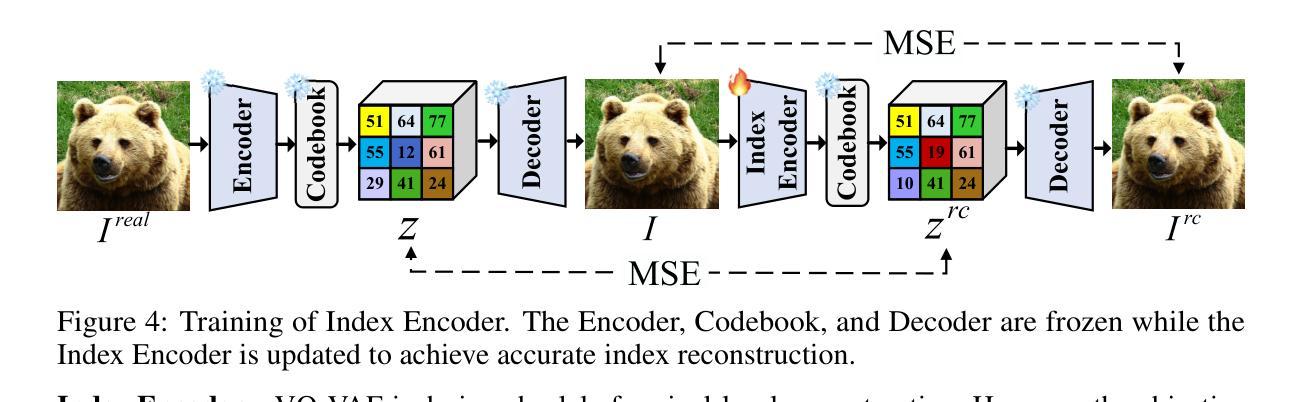
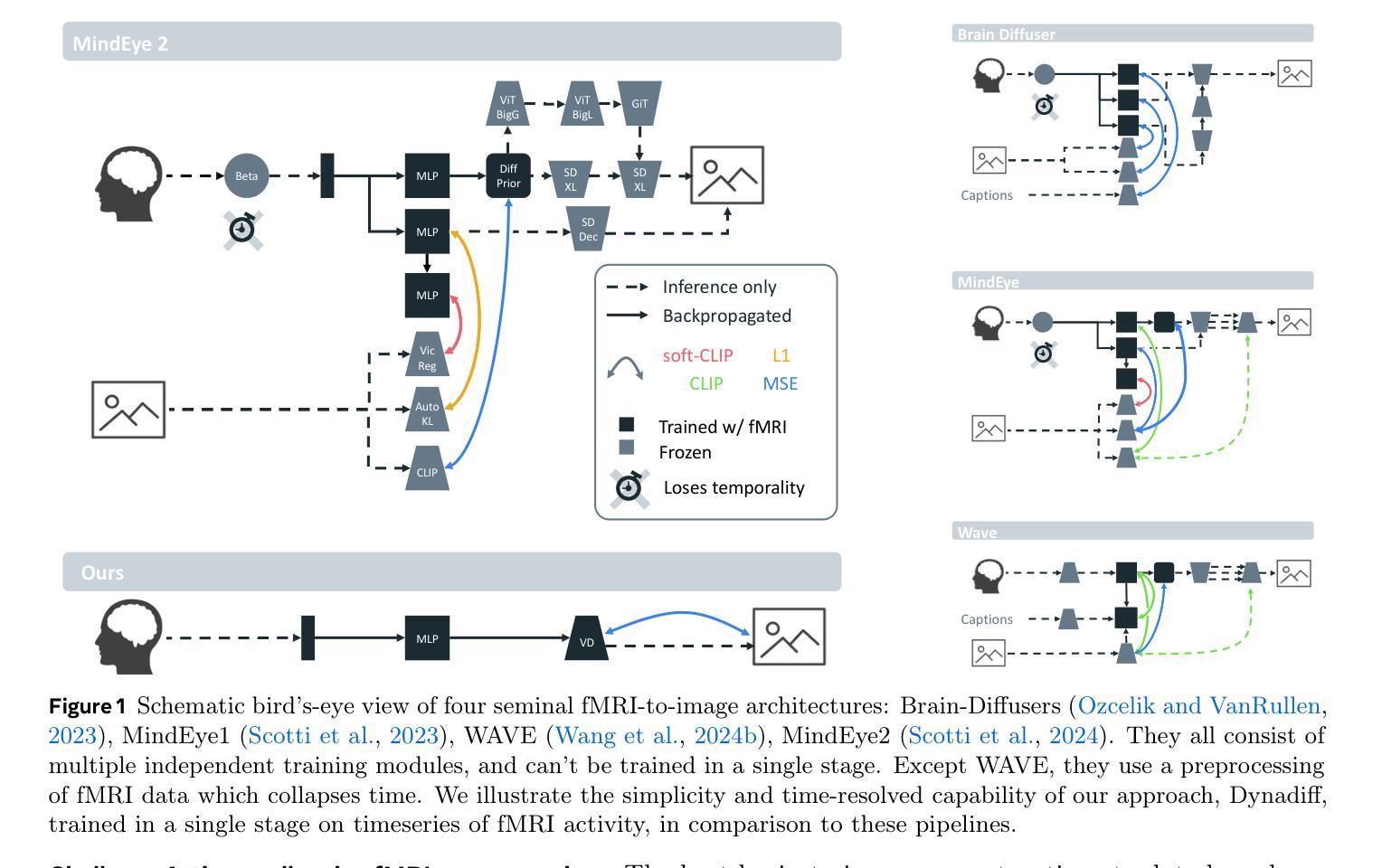
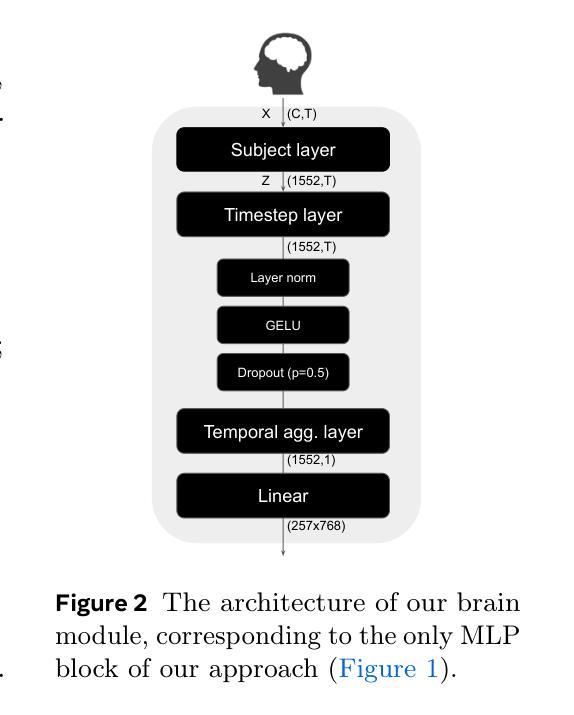
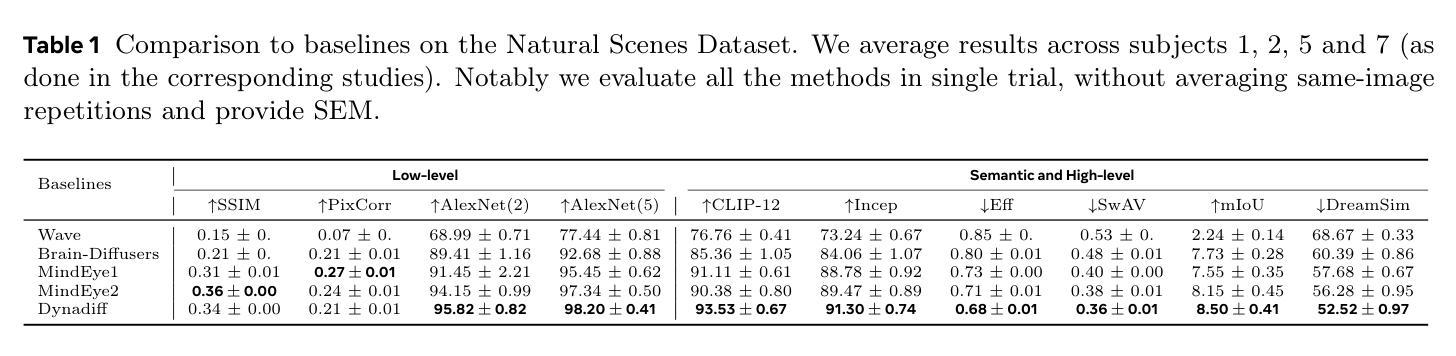
Dynadiff: Single-stage Decoding of Images from Continuously Evolving fMRI
Authors:Marlène Careil, Yohann Benchetrit, Jean-Rémi King
Brain-to-image decoding has been recently propelled by the progress in generative AI models and the availability of large ultra-high field functional Magnetic Resonance Imaging (fMRI). However, current approaches depend on complicated multi-stage pipelines and preprocessing steps that typically collapse the temporal dimension of brain recordings, thereby limiting time-resolved brain decoders. Here, we introduce Dynadiff (Dynamic Neural Activity Diffusion for Image Reconstruction), a new single-stage diffusion model designed for reconstructing images from dynamically evolving fMRI recordings. Our approach offers three main contributions. First, Dynadiff simplifies training as compared to existing approaches. Second, our model outperforms state-of-the-art models on time-resolved fMRI signals, especially on high-level semantic image reconstruction metrics, while remaining competitive on preprocessed fMRI data that collapse time. Third, this approach allows a precise characterization of the evolution of image representations in brain activity. Overall, this work lays the foundation for time-resolved brain-to-image decoding.
脑到图像的解码最近由生成式人工智能模型的进步和大型超高场功能磁共振成像(fMRI)的可用性所推动。然而,当前的方法依赖于复杂的多阶段管道和预处理步骤,这些通常会使脑记录的临时维度崩溃,从而限制了时间解析的脑解码器。在这里,我们介绍了Dynadiff(用于图像重建的动态神经活动扩散),这是一种新的单阶段扩散模型,用于从动态发展的fMRI记录中重建图像。我们的方法提供了三个主要贡献。首先,Dynadiff与现有方法相比简化了训练。其次,我们的模型在时间解析的fMRI信号上优于最新模型,特别是在高级语义图像重建指标上,同时保持在崩溃时间的预处理fMRI数据上的竞争力。第三,这种方法可以精确地描述图像表示在脑活动过程中的演变。总的来说,这项工作为时间解析的脑到图像解码奠定了基础。
论文及项目相关链接
Summary
本文介绍了Dynadiff(动态神经活动扩散图像重建模型)的应用,该模型是一种新型的单阶段扩散模型,可从动态fMRI记录中重建图像。Dynadiff简化了训练过程,并在时间解析的fMRI信号上表现优于现有模型,尤其是在高级语义图像重建指标上。此外,该模型允许精确描述大脑中图像表示随时间的变化。总体而言,这项工作为时间解析的大脑图像解码奠定了基础。
Key Takeaways
- Dynadiff是一个新型的单阶段扩散模型,用于从动态fMRI记录中重建图像。
- 与现有方法相比,Dynadiff简化了训练过程。
- Dynadiff在时间解析的fMRI信号上表现优异,特别是在高级语义图像重建方面。
- 该模型在预处理后的fMRI数据上仍然具有竞争力。
- Dynadiff能够精确描述大脑中图像表示随时间的变化。
- 该研究为时间解析的大脑图像解码开辟了新的途径。
点此查看论文截图


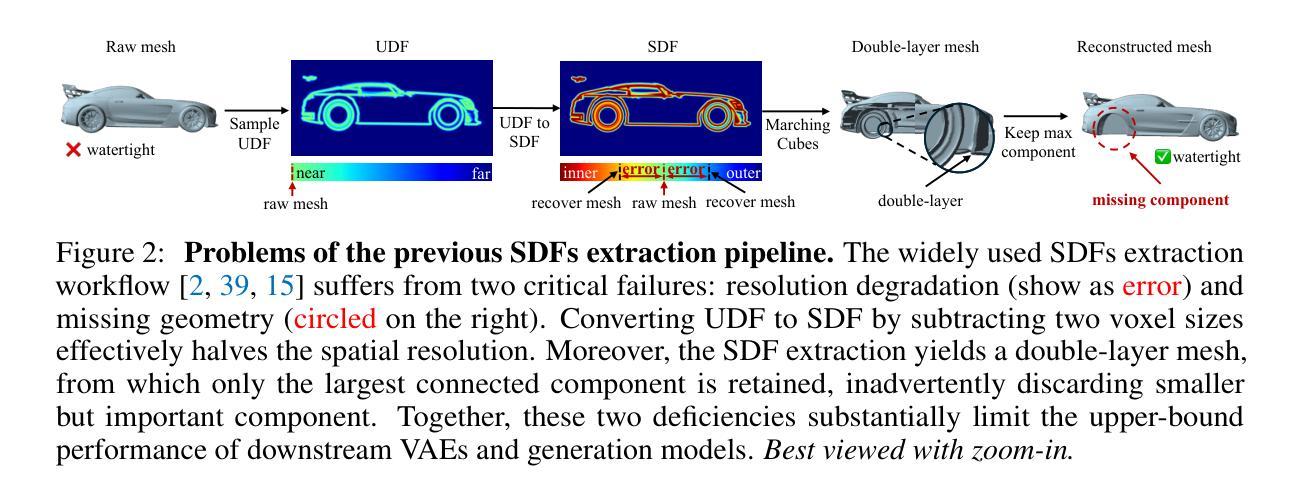
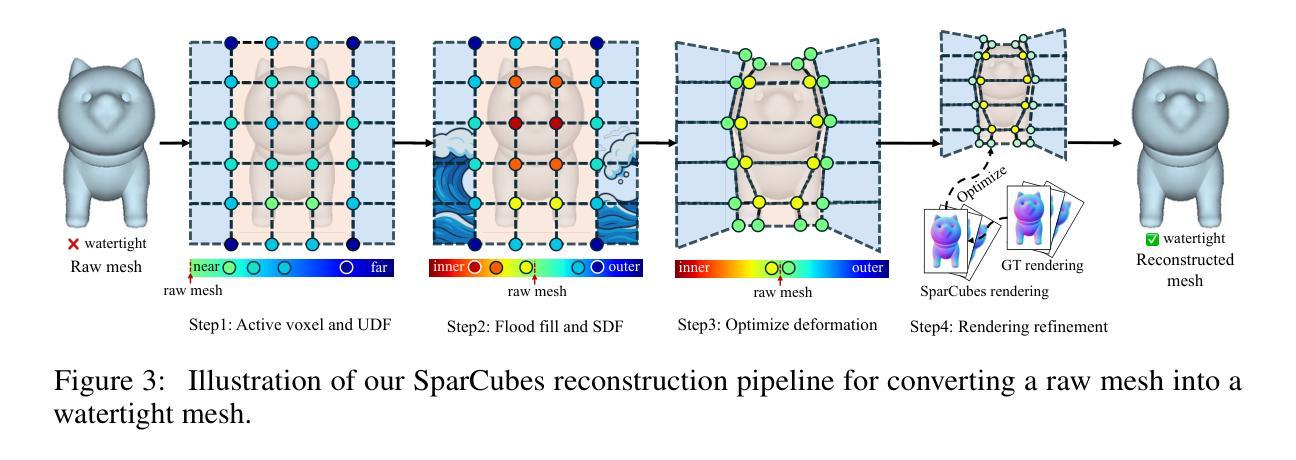
SparC: Sparse Representation and Construction for High-Resolution 3D Shapes Modeling
Authors:Zhihao Li, Yufei Wang, Heliang Zheng, Yihao Luo, Bihan Wen
High-fidelity 3D object synthesis remains significantly more challenging than 2D image generation due to the unstructured nature of mesh data and the cubic complexity of dense volumetric grids. Existing two-stage pipelines-compressing meshes with a VAE (using either 2D or 3D supervision), followed by latent diffusion sampling-often suffer from severe detail loss caused by inefficient representations and modality mismatches introduced in VAE. We introduce SparC, a unified framework that combines a sparse deformable marching cubes representation SparseCubes with a novel encoder SparConv-VAE. SparseCubes converts raw meshes into high-resolution ($1024^3$) surfaces with arbitrary topology by scattering signed distance and deformation fields onto a sparse cube, allowing differentiable optimization. SparConv-VAE is the first modality-consistent variational autoencoder built entirely upon sparse convolutional networks, enabling efficient and near-lossless 3D reconstruction suitable for high-resolution generative modeling through latent diffusion. SparC achieves state-of-the-art reconstruction fidelity on challenging inputs, including open surfaces, disconnected components, and intricate geometry. It preserves fine-grained shape details, reduces training and inference cost, and integrates naturally with latent diffusion models for scalable, high-resolution 3D generation.
高质量的三维物体合成相较于二维图像生成仍然更具挑战性,这主要是由于网格数据的非结构化和密集体积网格的立方复杂性。现有的两阶段流程——使用VAE(采用二维或三维监督)压缩网格,然后进行潜在扩散采样——常常因VAE中引入的低效表示和模态不匹配而导致严重的细节损失。我们引入了SparC,这是一个结合了稀疏可变形行进立方体表示SparseCubes和新型编码器SparConv-VAE的统一框架。SparseCubes通过将原始网格转换为高分辨率(1024^3)且具有任意拓扑的表面,通过将带符号距离和变形场散射到稀疏立方体上,从而实现可微优化。SparConv-VAE是完全基于稀疏卷积网络构建的首个模态一致变分自编码器,可实现高效且近乎无损的三维重建,适用于通过潜在扩散进行高分辨率生成建模。SparC在具有挑战性的输入上实现了最先进的重建保真度,包括开放表面、断开组件和精细几何。它保留了精细的形状细节,降低了训练和推理成本,并与潜在扩散模型自然集成,实现了可扩展的高分辨率三维生成。
论文及项目相关链接
PDF Homepage: https://lizhihao6.github.io/SparC
Summary
基于现有二维图像生成技术的局限性,如数据网格的未结构化和密度复杂性增加等挑战,在三维物体合成领域的研究依然具有较大的挑战。本研究提出了SparC框架,结合了SparseCubes表示方法和SparConv-VAE编码器。SparseCubes可将原始网格转化为高分辨率表面,而SparConv-VAE则基于稀疏卷积网络构建模态一致的变分自编码器。该框架实现了高效且无损的三维重建,适用于高保真度的生成模型,提高了三维物体合成领域的性能表现。其突破点在于成功处理开放表面、分离组件和精细几何结构等复杂输入,并自然集成到潜在扩散模型中以实现可扩展的高分辨率三维生成。
Key Takeaways
- 高保真三维物体合成相较于二维图像生成更具挑战性,源于网格数据的未结构化和密集体积网格的复杂性。
- 现有流程中存在严重的细节损失问题,原因在于表现方法效率低下以及模态不匹配。
- SparC框架结合了SparseCubes表示和SparConv-VAE编码器来克服这些挑战。
- SparseCubes转化原始网格至高分辨率表面并具有任意拓扑结构。
- SparConv-VAE是首个完全基于稀疏卷积网络的模态一致变分自编码器。
- SparC实现了高效无损的三维重建,适用于高保真度的生成模型。
- SparC框架成功处理复杂输入如开放表面、分离组件和精细几何结构等。
点此查看论文截图

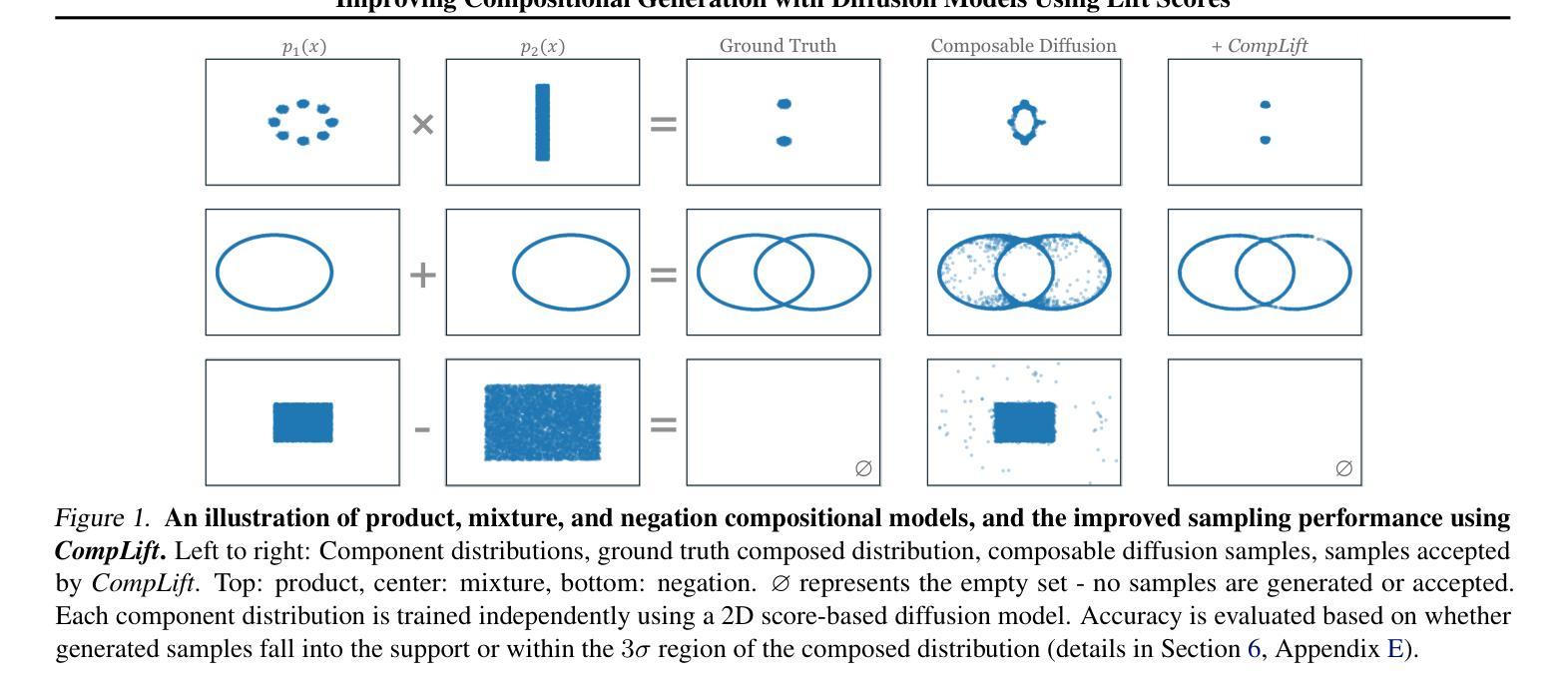
Improving Compositional Generation with Diffusion Models Using Lift Scores
Authors:Chenning Yu, Sicun Gao
We introduce a novel resampling criterion using lift scores, for improving compositional generation in diffusion models. By leveraging the lift scores, we evaluate whether generated samples align with each single condition and then compose the results to determine whether the composed prompt is satisfied. Our key insight is that lift scores can be efficiently approximated using only the original diffusion model, requiring no additional training or external modules. We develop an optimized variant that achieves relatively lower computational overhead during inference while maintaining effectiveness. Through extensive experiments, we demonstrate that lift scores significantly improved the condition alignment for compositional generation across 2D synthetic data, CLEVR position tasks, and text-to-image synthesis. Our code is available at http://github.com/rainorangelemon/complift.
我们引入了一种使用提升分数的新型重采样标准,以改进扩散模型中的组合生成。通过利用提升分数,我们可以评估生成的样本是否符合每个单独的条件,然后将结果组合起来,以确定组合提示是否满足要求。我们的关键见解是,仅使用原始扩散模型就可以有效地近似提升分数,而无需进行任何额外的训练或外部模块。我们开发了一种优化过的变体,在推理过程中实现了较低的计算开销,同时保持了有效性。通过大量实验,我们证明了提升分数在二维合成数据、CLEVR定位任务和文本到图像合成中,显著提高了组合生成的条件对齐效果。我们的代码可以在http://github.com/rainorangelemon/complift找到。
论文及项目相关链接
Summary
本研究提出了一种利用提升分数作为重采样标准的新方法,旨在提高扩散模型中的组合生成效果。研究的关键在于利用提升分数评估生成的样本是否符合单一条件,并将结果组合起来判断组合提示是否满足要求。此外,研究还实现了优化算法,降低了推理过程中的计算开销,同时保持有效性。通过大量实验证明,提升分数能显著提高二维合成数据、CLEVR位置任务和文本到图像合成的条件对齐性能。
Key Takeaways
- 研究提出了一种新的重采样标准——提升分数,用于改善扩散模型中的组合生成效果。
- 提升分数用于评估生成的样本是否符合单一条件,并组合结果来判断组合提示的满足情况。
- 研究利用原始扩散模型有效近似提升分数,无需额外的训练或外部模块。
- 研究实现了优化算法,降低推理过程中的计算开销。
- 提升分数在二维合成数据、CLEVR位置任务和文本到图像合成中显著提高了条件对齐性能。
- 该研究的代码已公开可访问。
点此查看论文截图



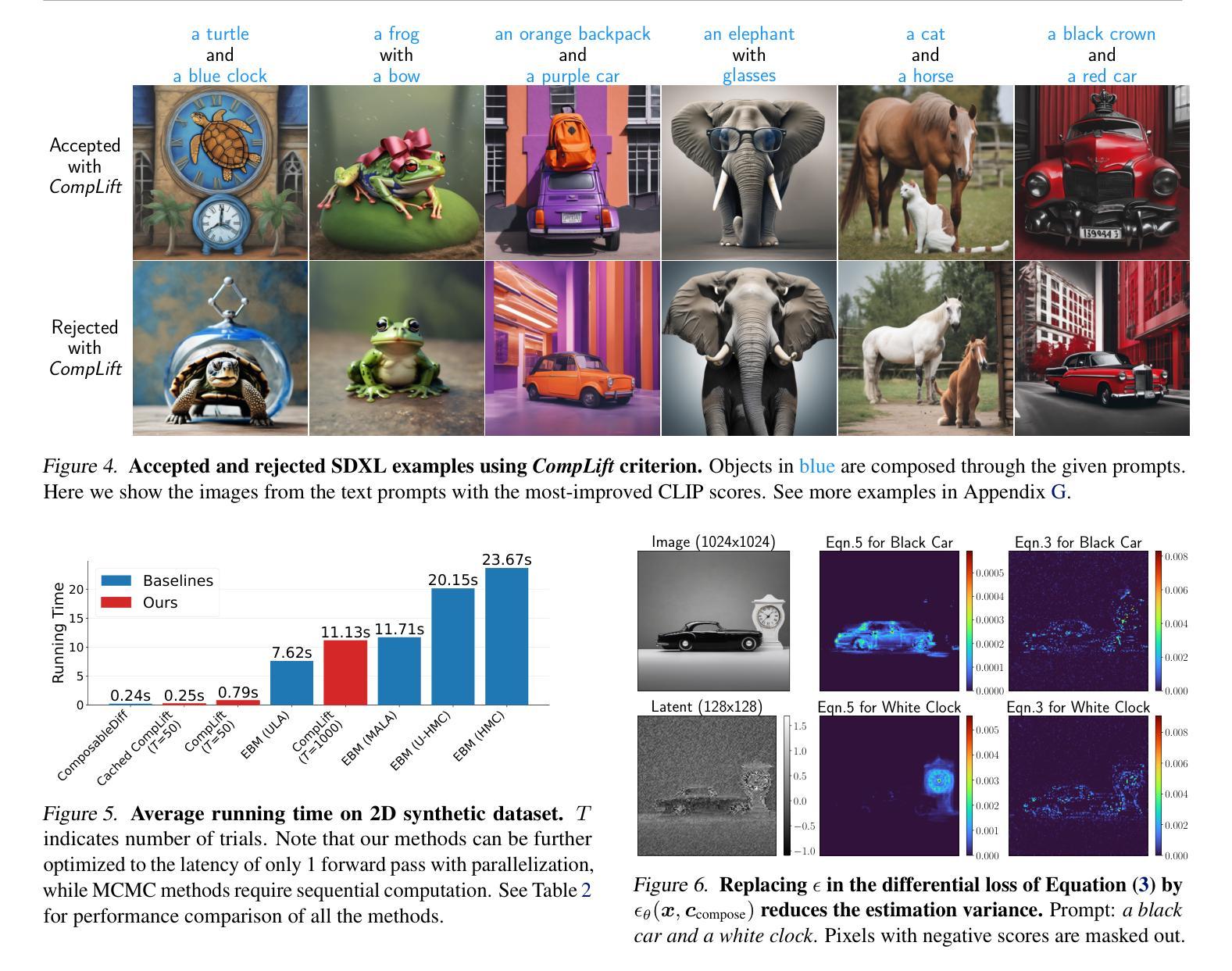

Diffusion Models with Double Guidance: Generate with aggregated datasets
Authors:Yanfeng Yang, Kenji Fukumizu
Creating large-scale datasets for training high-performance generative models is often prohibitively expensive, especially when associated attributes or annotations must be provided. As a result, merging existing datasets has become a common strategy. However, the sets of attributes across datasets are often inconsistent, and their naive concatenation typically leads to block-wise missing conditions. This presents a significant challenge for conditional generative modeling when the multiple attributes are used jointly as conditions, thereby limiting the model’s controllability and applicability. To address this issue, we propose a novel generative approach, Diffusion Model with Double Guidance, which enables precise conditional generation even when no training samples contain all conditions simultaneously. Our method maintains rigorous control over multiple conditions without requiring joint annotations. We demonstrate its effectiveness in molecular and image generation tasks, where it outperforms existing baselines both in alignment with target conditional distributions and in controllability under missing condition settings.
创建用于训练高性能生成模型的大规模数据集通常成本高昂,尤其是当需要提供相关属性或注释时。因此,合并现有数据集已成为一种常见策略。然而,各个数据集中的属性集往往不一致,其简单拼接通常会导致块状缺失条件。当多个属性被联合用作条件时,这为条件生成模型带来了巨大的挑战,从而限制了模型的可控性和适用性。为了解决这一问题,我们提出了一种新型的生成方法——双指导扩散模型。即使在没有训练样本同时包含所有条件的情况下,该方法也能实现精确的条件生成。我们的方法能够在不需要联合注释的情况下,对多个条件进行严格的控制。我们在分子和图像生成任务中证明了其有效性,无论是在与目标条件分布的对齐还是在缺失条件下的可控性方面,它都优于现有的基线方法。
论文及项目相关链接
Summary
训练高性能生成模型需要大量数据集,合并现有数据集成为了一种常见策略。然而,不同数据集中的属性集往往不一致,直接合并会导致块状缺失条件,对联合多个属性作为条件的条件生成建模提出了重大挑战,限制了模型的可控性和适用性。为解决这一问题,我们提出了全新的生成方法——双指导扩散模型,即使在没有同时包含所有条件的训练样本的情况下,也能实现精确的条件生成,无需联合注释即可对多个条件进行严格把控。我们在分子和图像生成任务中验证了其有效性,该方法在对齐目标条件分布和缺失条件设置下的可控性方面都优于现有基线。
Key Takeaways
- 训练高性能生成模型需要大量数据集,合并现有数据集成为了一种常见策略,但属性不一致性问题亟待解决。
- 现有数据集合并会导致块状缺失条件,对条件生成建模构成挑战。
- 双指导扩散模型能在缺失条件下实现精确生成,无需联合注释。
- 双指导扩散模型在分子和图像生成任务中验证了其有效性。
- 该方法在对齐目标条件分布方面优于现有基线。
- 在缺失条件设置下,该方法的可控性表现优异。
- 该方法为提高生成模型的性能提供了新的思路。
点此查看论文截图


Higher fidelity perceptual image and video compression with a latent conditioned residual denoising diffusion model
Authors:Jonas Brenig, Radu Timofte
Denoising diffusion models achieved impressive results on several image generation tasks often outperforming GAN based models. Recently, the generative capabilities of diffusion models have been employed for perceptual image compression, such as in CDC. A major drawback of these diffusion-based methods is that, while producing impressive perceptual quality images they are dropping in fidelity/increasing the distortion to the original uncompressed images when compared with other traditional or learned image compression schemes aiming for fidelity. In this paper, we propose a hybrid compression scheme optimized for perceptual quality, extending the approach of the CDC model with a decoder network in order to reduce the impact on distortion metrics such as PSNR. After using the decoder network to generate an initial image, optimized for distortion, the latent conditioned diffusion model refines the reconstruction for perceptual quality by predicting the residual. On standard benchmarks, we achieve up to +2dB PSNR fidelity improvements while maintaining comparable LPIPS and FID perceptual scores when compared with CDC. Additionally, the approach is easily extensible to video compression, where we achieve similar results.
降噪扩散模型在多个图像生成任务上取得了令人印象深刻的结果,通常超越了基于GAN的模型。最近,扩散模型的生成能力已被应用于感知图像压缩,如CDC。这些基于扩散的方法的一个主要缺点是,虽然它们能够产生令人印象深刻的感知质量图像,但在与其他旨在保持忠诚度的传统或学习图像压缩方案相比时,它们在保真度方面有所下降或对原始未压缩图像的失真增加。在本文中,我们提出了一种针对感知质量优化的混合压缩方案,通过采用解码器网络扩展CDC模型的方法,以减少对PSNR等失真指标的影响。使用解码器网络生成初始图像以优化失真后,潜在的条件扩散模型通过预测残差来完善重建的感知质量。在标准基准测试中,与CDC相比,我们实现了高达+2dB的PSNR保真度改进,同时保持了相当的LPIPS和FID感知分数。此外,该方法可轻松扩展到视频压缩,并在视频压缩中取得类似的结果。
论文及项目相关链接
PDF Accepted at AIM Workshop 2024 at ECCV 2024
Summary
扩散模型在图像生成任务上表现出色,常常超越基于GAN的模型。近期,其生成能力被应用于感知图像压缩,如CDC。但扩散模型的一个主要缺点是,在生成具有感知质量的图像时,与追求保真度的传统或学习图像压缩方案相比,它们会降低图像保真度或增加失真。本文提出了一种针对感知质量优化的混合压缩方案,通过扩展CDC模型的解码网络来减少失真度量的影响,如PSNR。使用解码网络生成初始图像后,通过预测残留信息来优化重构的感知质量。在标准基准测试中,与CDC相比,我们实现了高达+2dB的PSNR保真度提升,同时保持可比的LPIPS和FID感知分数。此外,该方法可轻松扩展到视频压缩,并实现了类似的结果。
Key Takeaways
- 扩散模型在图像生成任务上表现优异,常超越基于GAN的模型。
- 扩散模型近期被应用于感知图像压缩,如CDC。
- 扩散模型在追求保真度方面存在缺陷,与其他追求保真度的图像压缩方案相比,可能会降低图像质量或增加失真。
- 本文提出了一种混合压缩方案,通过扩展CDC模型的解码网络来优化感知质量。
- 解码网络用于生成初始图像后,通过预测残留信息优化重构的感知质量。
- 与CDC相比,该方案在标准基准测试中实现了较高的PSNR保真度提升。
点此查看论文截图

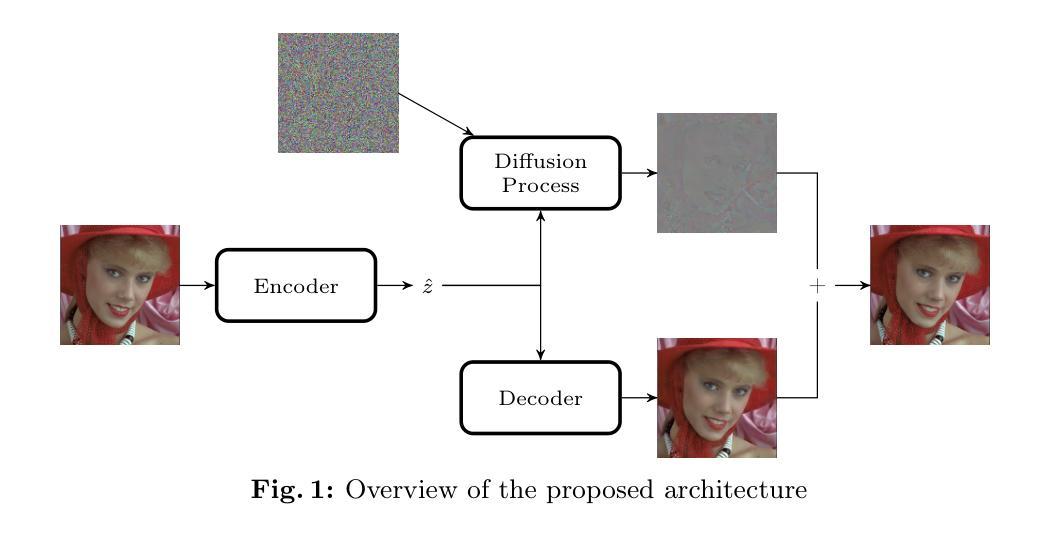


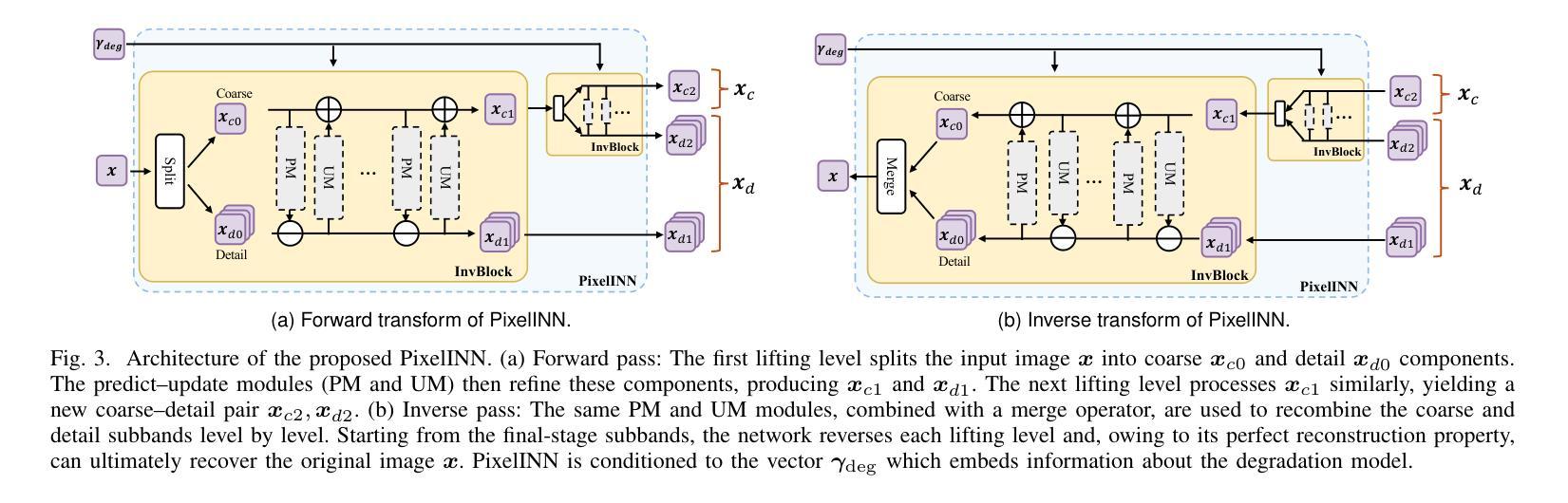
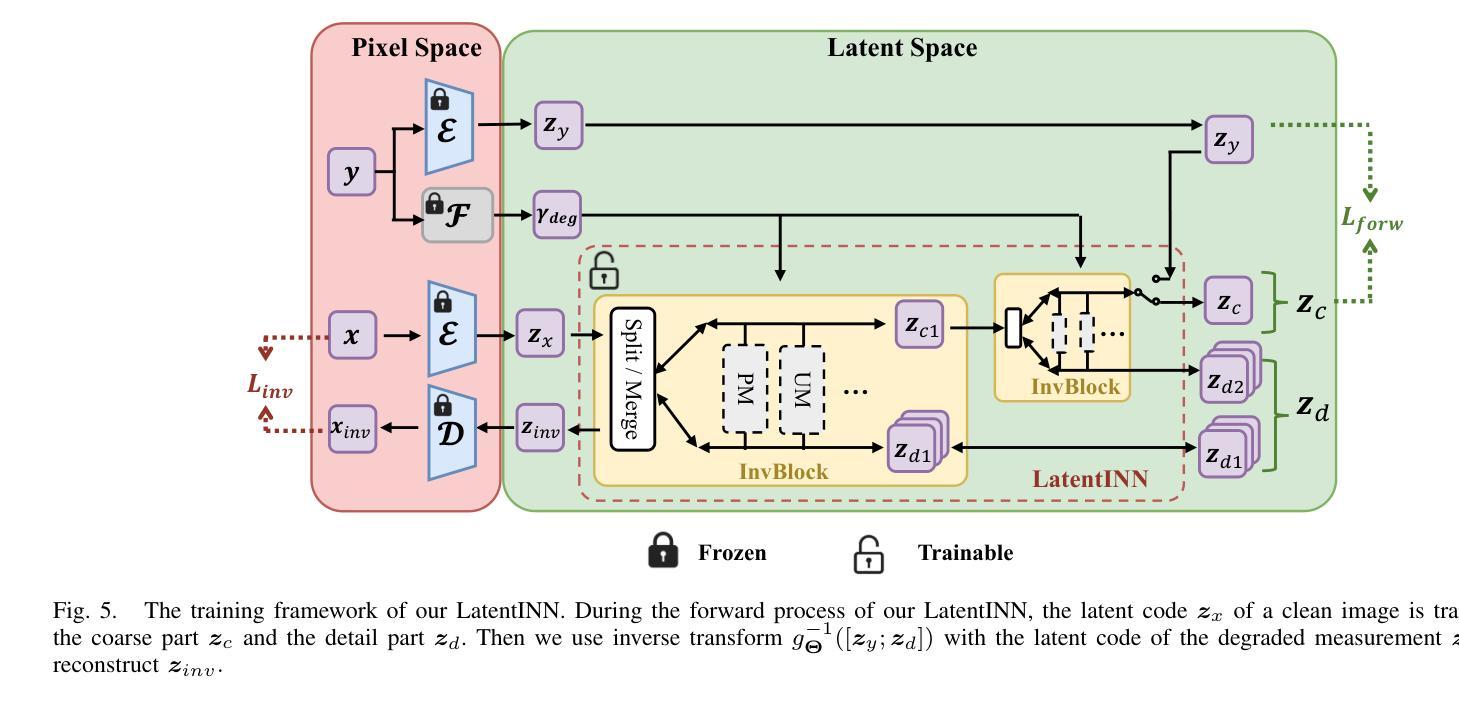
LatentINDIGO: An INN-Guided Latent Diffusion Algorithm for Image Restoration
Authors:Di You, Daniel Siromani, Pier Luigi Dragotti
There is a growing interest in the use of latent diffusion models (LDMs) for image restoration (IR) tasks due to their ability to model effectively the distribution of natural images. While significant progress has been made, there are still key challenges that need to be addressed. First, many approaches depend on a predefined degradation operator, making them ill-suited for complex or unknown degradations that deviate from standard analytical models. Second, many methods struggle to provide a stable guidance in the latent space and finally most methods convert latent representations back to the pixel domain for guidance at every sampling iteration, which significantly increases computational and memory overhead. To overcome these limitations, we introduce a wavelet-inspired invertible neural network (INN) that simulates degradations through a forward transform and reconstructs lost details via the inverse transform. We further integrate this design into a latent diffusion pipeline through two proposed approaches: LatentINDIGO-PixelINN, which operates in the pixel domain, and LatentINDIGO-LatentINN, which stays fully in the latent space to reduce complexity. Both approaches alternate between updating intermediate latent variables under the guidance of our INN and refining the INN forward model to handle unknown degradations. In addition, a regularization step preserves the proximity of latent variables to the natural image manifold. Experiments demonstrate that our algorithm achieves state-of-the-art performance on synthetic and real-world low-quality images, and can be readily adapted to arbitrary output sizes.
对于潜在扩散模型(LDM)在图像恢复(IR)任务中的应用,人们越来越感兴趣,因为它们能够有效地对自然图像的分布进行建模。虽然取得了重大进展,但仍存在需要解决的关键挑战。首先,许多方法依赖于预定义的退化算子,使得它们不适合复杂或未知的退化,这些退化与标准分析模型有偏差。其次,许多方法难以在潜在空间提供稳定的指导,而且大多数方法在每个采样迭代中将潜在表示转回像素域进行指导,这显著增加了计算和内存开销。为了克服这些局限性,我们引入了一种受小波启发的可逆神经网络(INN),它通过正向变换模拟退化,并通过反向变换重建丢失的细节。我们将这种设计进一步集成到潜在扩散管道中,通过两种提出的方法:LatentINDIGO-PixelINN,它在像素域中运行;LatentINDIGO-LatentINN,它完全在潜在空间中运行,以降低复杂性。两种方法交替进行,在INN的指导下更新中间潜在变量,并改进INN前向模型以处理未知退化。此外,正则化步骤保持了潜在变量与自然图像流形的接近。实验表明,我们的算法在合成和真实世界的低质量图像上达到了最新技术水平,并且可以轻松地适应任意输出大小。
论文及项目相关链接
PDF Submitted to IEEE Transactions on Image Processing (TIP)
Summary
本文介绍了潜在扩散模型(LDM)在图像恢复(IR)任务中的应用,并指出了现有方法面临的挑战。为克服这些限制,提出了一种受小波启发的可逆神经网络(INN),通过正向变换模拟退化,并通过反向变换重建丢失的细节。文章还介绍了两种将这一设计融入潜在扩散管道的方法:LatentINDIGO-PixelINN(在像素域操作)和LatentINDIGO-LatentINN(完全在潜在空间内操作,以降低复杂性)。该方法通过更新中间潜在变量并改进INN正向模型来处理未知退化,同时实现图像质量的提升。实验表明,该算法在合成和真实世界的低质量图像上取得了最先进的性能,并可轻松适应任意输出大小。
Key Takeaways
- 潜在扩散模型(LDM)在图像恢复任务中越来越受欢迎,因其能有效模拟自然图像的分布。
- 当前LDM在图像恢复中面临的关键挑战:依赖预设的退化算子、在潜在空间提供稳定指导的困难以及在每次采样迭代中将潜在表示转回像素域导致的计算和内存负担。
- 提出了一种基于小波的可逆神经网络(INN),通过正向变换模拟图像退化,并通过反向变换恢复细节。
- 介绍了两种将INN融入潜在扩散管道的方法:LatentINDIGO-PixelINN和LatentINDIGO-LatentINN,分别操作于像素域和潜在空间。
- 该方法通过更新中间潜在变量、改进INN正向模型以及添加正则化步骤来处理未知退化,并提升图像质量。
- 实验证明,该算法在合成和真实世界的低质量图像修复上达到了最新技术水平。
点此查看论文截图


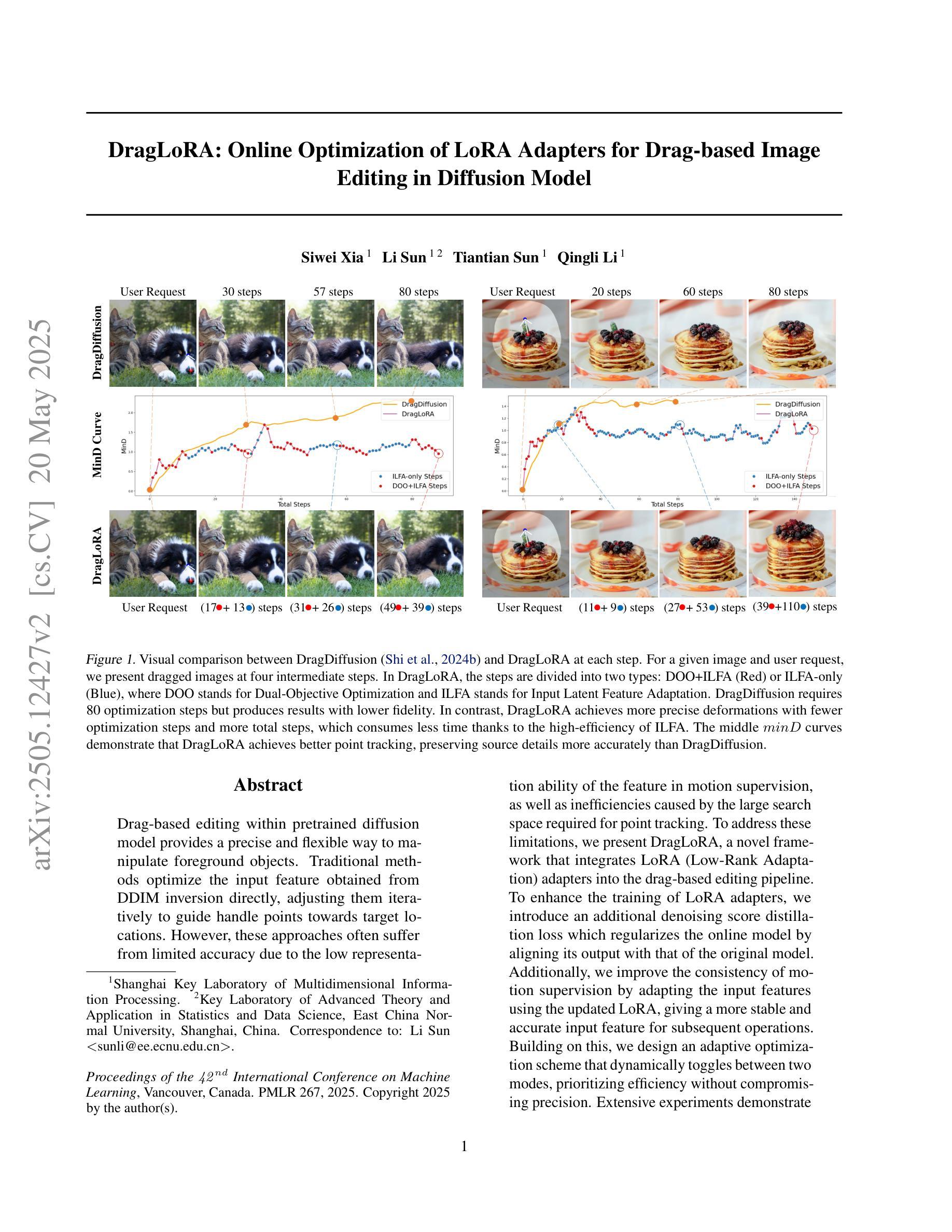
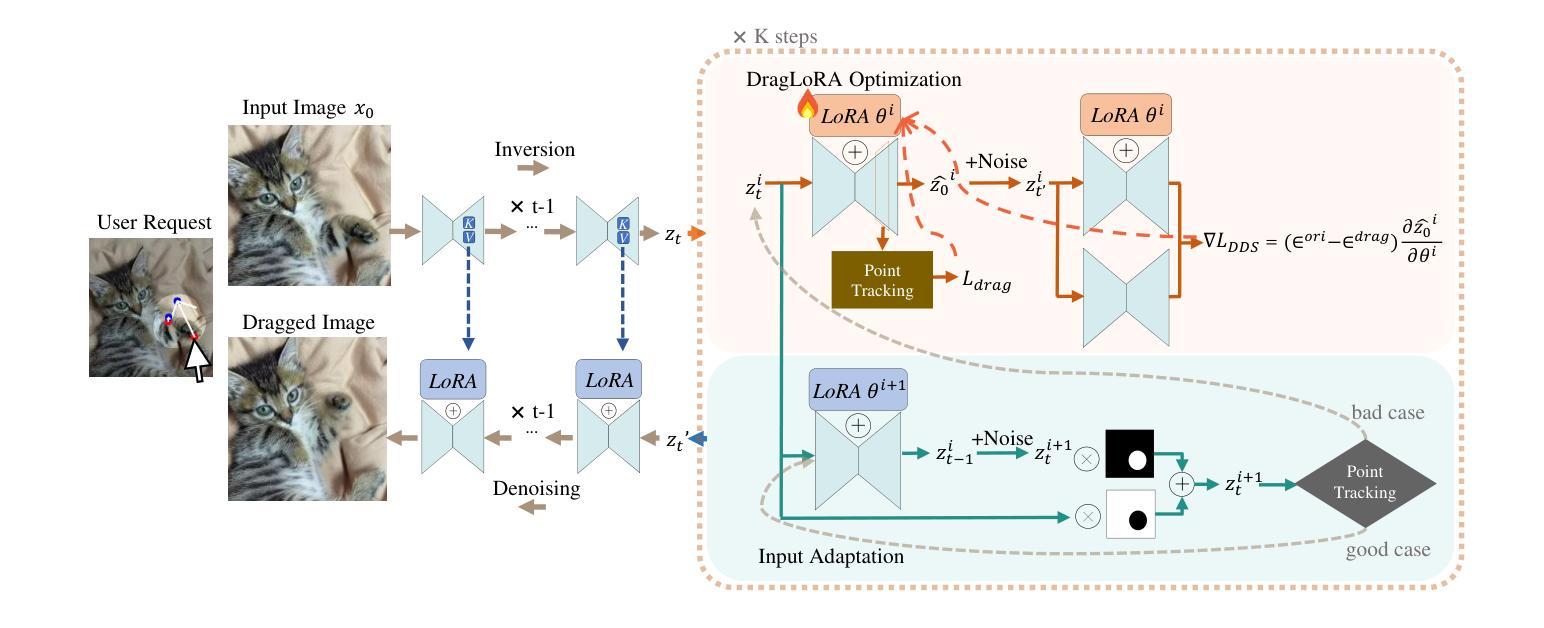
DragLoRA: Online Optimization of LoRA Adapters for Drag-based Image Editing in Diffusion Model
Authors:Siwei Xia, Li Sun, Tiantian Sun, Qingli Li
Drag-based editing within pretrained diffusion model provides a precise and flexible way to manipulate foreground objects. Traditional methods optimize the input feature obtained from DDIM inversion directly, adjusting them iteratively to guide handle points towards target locations. However, these approaches often suffer from limited accuracy due to the low representation ability of the feature in motion supervision, as well as inefficiencies caused by the large search space required for point tracking. To address these limitations, we present DragLoRA, a novel framework that integrates LoRA (Low-Rank Adaptation) adapters into the drag-based editing pipeline. To enhance the training of LoRA adapters, we introduce an additional denoising score distillation loss which regularizes the online model by aligning its output with that of the original model. Additionally, we improve the consistency of motion supervision by adapting the input features using the updated LoRA, giving a more stable and accurate input feature for subsequent operations. Building on this, we design an adaptive optimization scheme that dynamically toggles between two modes, prioritizing efficiency without compromising precision. Extensive experiments demonstrate that DragLoRA significantly enhances the control precision and computational efficiency for drag-based image editing. The Codes of DragLoRA are available at: https://github.com/Sylvie-X/DragLoRA.
基于拖动的编辑在预训练扩散模型内部提供了一种精确且灵活的方式来操作前景对象。传统方法直接优化从DDIM反演获得的输入特征,通过迭代调整它们来引导控制点朝向目标位置。然而,这些方法通常受限于特征在运动监督下的表示能力有限,以及点跟踪所需的大搜索空间导致的效率低下。为了解决这些局限性,我们提出了DragLoRA,这是一个将LoRA(低秩适应)适配器集成到基于拖动的编辑管道中的新型框架。为了提高LoRA适配器的训练,我们引入了额外的去噪分数蒸馏损失,通过使在线模型的输出与原始模型的输出对齐来规范在线模型。此外,我们通过使用更新的LoRA适配输入特征,提高了运动监督的一致性,为后续操作提供了更稳定和准确的输入特征。在此基础上,我们设计了一种自适应优化方案,该方案可以动态切换两种模式,以优先考虑效率而不损失精度。大量实验表明,DragLoRA显著提高了基于拖动的图像编辑的控制精度和计算效率。DragLoRA的代码可在:https://github.com/Sylvie-X/DragLoRA获取。
论文及项目相关链接
PDF Accepted by ICML2025
Summary
基于扩散模型的拖拽编辑方法提供了一种精确且灵活的操作前景对象的方式。传统方法直接优化从DDIM反演获得的输入特征,通过迭代调整引导句柄点至目标位置。然而,这些方法受限于运动监督中特征的表示能力,且由于点跟踪所需的大搜索空间而导致效率低下。为解决这些问题,我们提出DragLoRA框架,将LoRA(低秩适配)适配器集成到基于拖拽的编辑流程中。为增强LoRA适配器的训练,我们引入额外的去噪分数蒸馏损失,通过使在线模型的输出与原始模型的输出对齐来规范在线模型。此外,我们通过使用更新的LoRA适配输入特征,提高运动监督的一致性,为后续操作提供更稳定和准确的输入特征。在此基础上,我们设计了一种自适应优化方案,能在效率和精度之间动态切换。大量实验表明,DragLoRA显著提高了基于拖拽的图像编辑的控制精度和计算效率。
Key Takeaways
- 扩散模型中引入拖拽编辑,实现精确灵活的对象操作。
- 传统方法优化输入特征存在局限性,如特征表示能力不足和搜索空间大导致的效率低下。
- 提出DragLoRA框架,集成LoRA适配器解决上述问题。
- 引入去噪分数蒸馏损失以规范模型训练。
- 通过适配输入特征提高运动监督的一致性。
- 设计自适应优化方案,在效率和精度之间动态切换。
点此查看论文截图
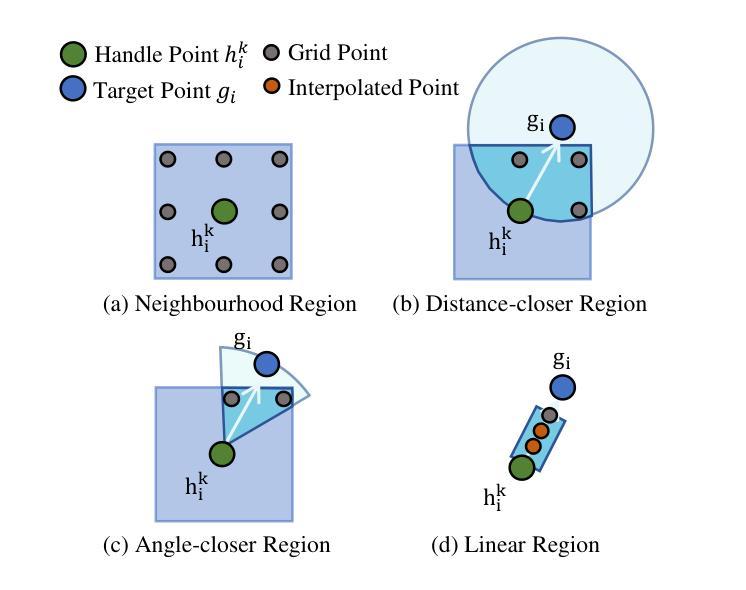

Whitened Score Diffusion: A Structured Prior for Imaging Inverse Problems
Authors:Jeffrey Alido, Tongyu Li, Yu Sun, Lei Tian
Conventional score-based diffusion models (DMs) may struggle with anisotropic Gaussian diffusion processes due to the required inversion of covariance matrices in the denoising score matching training objective \cite{vincent_connection_2011}. We propose Whitened Score (WS) diffusion models, a novel framework based on stochastic differential equations that learns the Whitened Score function instead of the standard score. This approach circumvents covariance inversion, extending score-based DMs by enabling stable training of DMs on arbitrary Gaussian forward noising processes. WS DMs establish equivalence with flow matching for arbitrary Gaussian noise, allow for tailored spectral inductive biases, and provide strong Bayesian priors for imaging inverse problems with structured noise. We experiment with a variety of computational imaging tasks using the CIFAR and CelebA ($64\times64$) datasets and demonstrate that WS diffusion priors trained on anisotropic Gaussian noising processes consistently outperform conventional diffusion priors based on isotropic Gaussian noise. Our code is open-sourced at \href{https://github.com/jeffreyalido/wsdiffusion}{\texttt{github.com/jeffreyalido/wsdiffusion}}.
传统的基于得分的扩散模型(DMs)可能会因去噪得分匹配训练目标中需要协方差矩阵的逆运算而面临处理各向异性高斯扩散过程的困难\cite{vincent_connection_2011}。我们提出了白化得分(WS)扩散模型,这是一个基于随机微分方程的新框架,它学习白化得分函数而不是标准得分。这种方法避免了协方差反转,通过扩散模型的稳定训练在各种高斯前向噪声过程上扩展了基于得分的DMs。WS DM建立了任意高斯噪声流匹配的等价性,允许定制谱归纳偏见,并为具有结构化噪声的成像反问题提供了强大的贝叶斯先验。我们在CIFAR和CelebA($64\times64$)数据集上对各种计算成像任务进行了实验,证明了在训练于各向异性高斯噪声过程上的WS扩散先验始终优于基于各向同性高斯噪声的传统扩散先验。我们的代码已开源,可以在\href{https://github.com/jeffreyalido/wsdiffusion}{\texttt{github.com/jeffreyalido/wsdiffusion}}获取。
论文及项目相关链接
Summary
本文介绍了传统基于得分的扩散模型在处理各向异性高斯扩散过程时面临的挑战,并提出了白化得分扩散模型(WS DM)。该模型基于随机微分方程学习白化得分函数,避免了协方差矩阵的求逆问题,从而扩展了基于得分的扩散模型,使其能够在任意高斯前向噪声过程上进行稳定训练。WS DM与任意高斯噪声的流匹配建立等价关系,提供针对结构化噪声的成像反问题的强大贝叶斯先验。在CIFAR和CelebA(64×64)数据集上的计算成像任务实验表明,针对各向异性高斯噪声过程训练的WS扩散先验始终优于基于各向同性高斯噪声的常规扩散先验。
Key Takeaways
- 传统基于得分的扩散模型在处理各向异性高斯扩散过程时面临挑战,因为需要求逆协方差矩阵。
- 白化得分扩散模型(WS DM)是一种新型框架,基于随机微分方程学习白化得分函数,避免了协方差矩阵求逆问题。
- WS DM框架能够扩展基于得分的扩散模型,使其能在任意高斯前向噪声过程上进行稳定训练。
- WS DM与任意高斯噪声的流匹配建立等价关系,这为处理具有结构化噪声的成像反问题提供了强大的工具。
- 在CIFAR和CelebA数据集上的实验表明,针对各向异性高斯噪声过程训练的WS扩散模型性能优于基于各向同性高斯噪声的常规扩散模型。
- 开放源代码地址:https://github.com/jeffreyalido/wsdiffusion。
点此查看论文截图



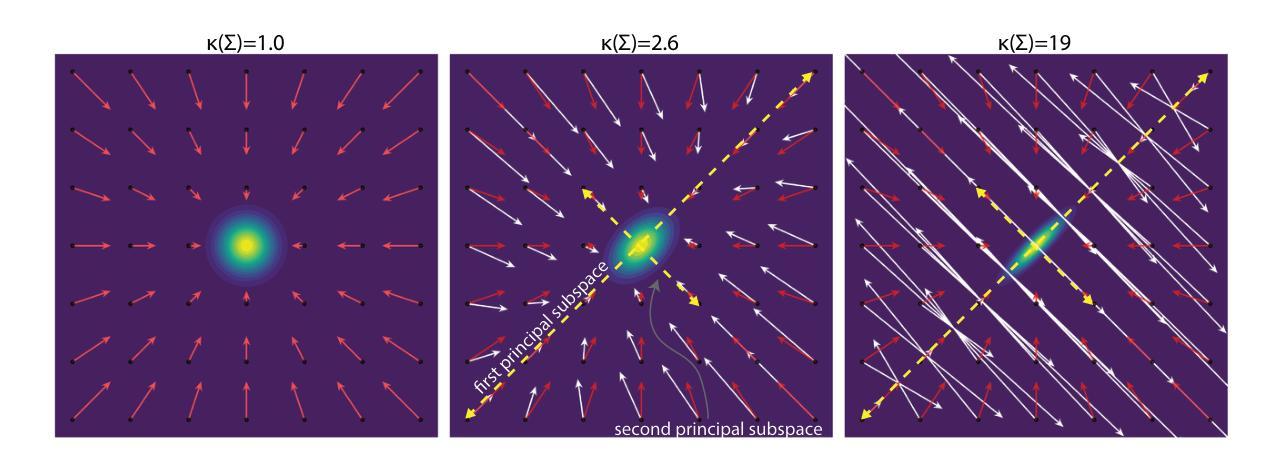

Learning Joint ID-Textual Representation for ID-Preserving Image Synthesis
Authors:Zichuan Liu, Liming Jiang, Qing Yan, Yumin Jia, Hao Kang, Xin Lu
We propose a novel framework for ID-preserving generation using a multi-modal encoding strategy rather than injecting identity features via adapters into pre-trained models. Our method treats identity and text as a unified conditioning input. To achieve this, we introduce FaceCLIP, a multi-modal encoder that learns a joint embedding space for both identity and textual semantics. Given a reference face and a text prompt, FaceCLIP produces a unified representation that encodes both identity and text, which conditions a base diffusion model to generate images that are identity-consistent and text-aligned. We also present a multi-modal alignment algorithm to train FaceCLIP, using a loss that aligns its joint representation with face, text, and image embedding spaces. We then build FaceCLIP-SDXL, an ID-preserving image synthesis pipeline by integrating FaceCLIP with Stable Diffusion XL (SDXL). Compared to prior methods, FaceCLIP-SDXL enables photorealistic portrait generation with better identity preservation and textual relevance. Extensive experiments demonstrate its quantitative and qualitative superiority.
我们提出了一种新的ID保留生成框架,采用多模态编码策略,而不是通过适配器向预训练模型注入身份特征。我们的方法将身份和文本视为统一的条件输入。为了实现这一点,我们引入了FaceCLIP,这是一个多模态编码器,它学习身份和文本语义的联合嵌入空间。给定参考人脸和文本提示,FaceCLIP生成一个统一表示,该表示编码身份和文本,使基础扩散模型生成身份一致且文本对齐的图像。我们还提出了一种使用损失函数对齐其联合表示的人脸、文本和图像嵌入空间的多模态对齐算法来训练FaceCLIP。然后,我们将FaceCLIP与Stable Diffusion XL(SDXL)相结合,构建了FaceCLIP-SDXL这一保留身份的图像合成管道。与之前的方法相比,FaceCLIP-SDXL能够实现具有更好身份保留和文本相关性的逼真肖像生成。大量实验证明了其在定量和定性方面的优越性。
论文及项目相关链接
摘要
本文提出了一种基于多模态编码策略的ID保留生成新框架,而非通过适配器将身份特征注入预训练模型。该方法将身份和文本视为统一的条件输入。为此,我们引入了FaceCLIP,这是一种多模态编码器,用于学习身份和文本语义的联合嵌入空间。给定参考面部和文本提示,FaceCLIP生成一个统一表示,该表示同时编码身份和文本信息,从而对基础扩散模型进行条件处理,以生成一致性和文本对齐的身份图像。我们还提出了一种多模态对齐算法来训练FaceCLIP,使用一种损失函数将其联合表示与面部、文本和图像嵌入空间对齐。接下来,我们将FaceCLIP与Stable Diffusion XL(SDXL)相结合,构建了FaceCLIP-SDXL身份保留图像合成管道。相较于先前的方法,FaceCLIP-SDXL能够实现具有更好身份保留和文本相关性的逼真肖像生成。大量实验证明了其在定量和定性方面的优越性。
关键见解
- 提出了基于多模态编码策略的ID保留生成框架。
- 引入FaceCLIP作为多模态编码器,实现身份和文本的统一表示。
- 采用多模态对齐算法训练FaceCLIP,实现面部、文本和图像嵌入空间的联合表示对齐。
- 构建FaceCLIP-SDXL身份保留图像合成管道,结合了FaceCLIP与Stable Diffusion XL(SDXL)。
- 相较于其他方法,FaceCLIP-SDXL在肖像生成中实现了更好的身份保留和文本相关性。
- 通过大量实验验证了FaceCLIP-SDXL在定量和定性方面的优越性。
- 该框架有望为身份保留的图像生成提供新的解决方案。
点此查看论文截图

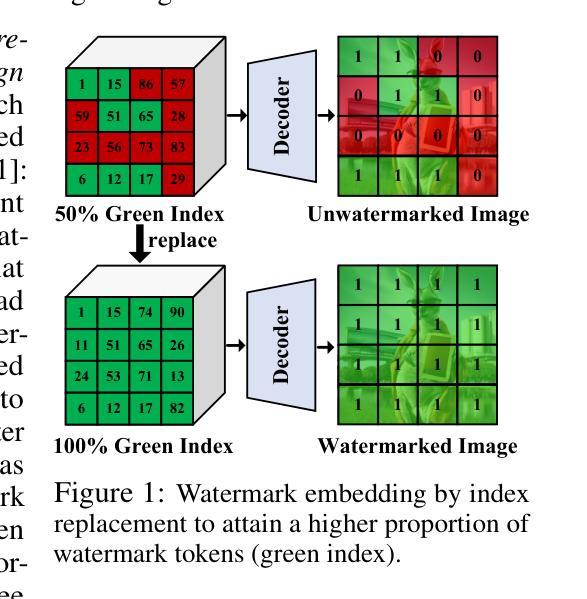
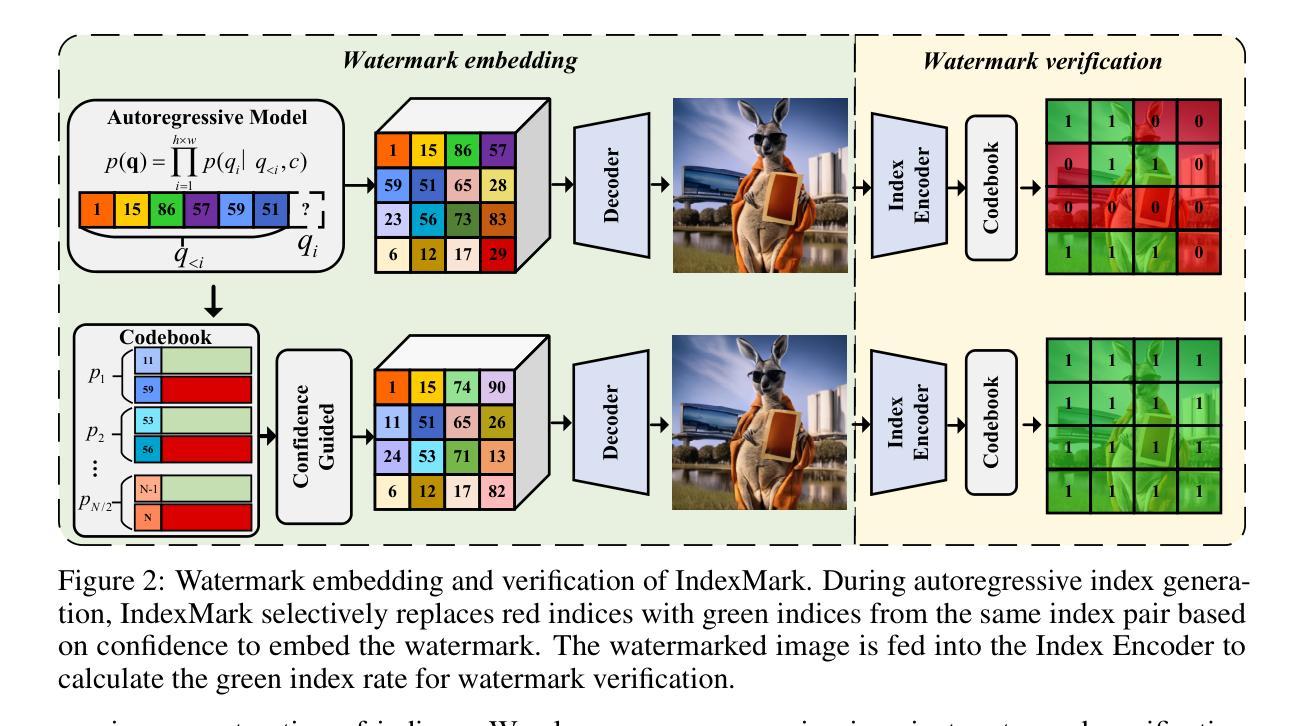
CRCE: Coreference-Retention Concept Erasure in Text-to-Image Diffusion Models
Authors:Yuyang Xue, Edward Moroshko, Feng Chen, Jingyu Sun, Steven McDonagh, Sotirios A. Tsaftaris
Text-to-Image diffusion models can produce undesirable content that necessitates concept erasure. However, existing methods struggle with under-erasure, leaving residual traces of targeted concepts, or over-erasure, mistakenly eliminating unrelated but visually similar concepts. To address these limitations, we introduce CRCE, a novel concept erasure framework that leverages Large Language Models to identify both semantically related concepts that should be erased alongside the target and distinct concepts that should be preserved. By explicitly modelling coreferential and retained concepts semantically, CRCE enables more precise concept removal, without unintended erasure. Experiments demonstrate that CRCE outperforms existing methods on diverse erasure tasks, including real-world object, person identities, and abstract intellectual property characteristics. The constructed dataset CorefConcept and the source code will be release upon acceptance.
文本到图像的扩散模型会产生需要概念消除的不良内容。然而,现有方法在擦除时存在困难,要么未能完全擦除目标概念留下残留痕迹,要么误删无关但视觉上相似的概念。为了克服这些局限性,我们引入了CRCE,这是一种新的概念消除框架,它利用大型语言模型来识别应与目标概念一起消除的语义相关概念,以及应保留的独特概念。通过显式建模核心概念和保留概念的语义,CRCE能够更精确地去除概念,避免意外的擦除。实验表明,CRCE在包括现实世界物体、人物身份和抽象知识产权特征等多种擦除任务上的表现优于现有方法。构建的数据集CoreConcept和源代码将在接受后发布。
论文及项目相关链接
Summary
文本摘要如下:本文提出了CRCE这一新的概念擦除框架来解决现有方法的局限问题,可以精确地去除文本中的特定概念而不会影响其他内容。它利用大型语言模型来识别需要同时擦除的目标相关概念以及需要保留的区分概念。在多样化的擦除任务中,CRCE表现出超越现有方法的性能,包括现实世界物体、人物身份和抽象知识产权特征等。
Key Takeaways
以下是七个关键见解:
- CRCE是一个针对文本到图像扩散模型中的概念擦除问题的新框架。
- 现有方法存在擦除不足或过度擦除的问题,留下目标概念的残留痕迹或错误地消除无关但视觉上相似的概念。
- CRCE利用大型语言模型来识别需要同时擦除的目标相关概念,确保更精确的擦除效果。
- CRCE可以识别需要保留的区分概念,避免无意中的擦除错误。
- CRCE在多样化的擦除任务中表现优越,包括现实世界物体、人物身份和抽象知识产权特征的擦除。
- CRCE框架构建了一个数据集CoreConcept,用于支持其研究。
点此查看论文截图



On the Vulnerability of Concept Erasure in Diffusion Models
Authors:Lucas Beerens, Alex D. Richardson, Kaicheng Zhang, Dongdong Chen
The proliferation of text-to-image diffusion models has raised significant privacy and security concerns, particularly regarding the generation of copyrighted or harmful images. In response, several concept erasure (defense) methods have been developed to prevent the generation of unwanted content through post-hoc finetuning. On the other hand, concept restoration (attack) methods seek to recover supposedly erased concepts via adversarially crafted prompts. However, all existing restoration methods only succeed in the highly restrictive scenario of finding adversarial prompts tailed to some fixed seed. To address this, we introduce RECORD, a novel coordinate-descent-based restoration algorithm that finds adversarial prompts to recover erased concepts independently of the seed. Our extensive experiments demonstrate RECORD consistently outperforms the current restoration methods by up to 17.8 times in this setting. Our findings further reveal the susceptibility of unlearned models to restoration attacks, providing crucial insights into the behavior of unlearned models under the influence of adversarial prompts.
文本到图像扩散模型的普及引发了关于隐私和安全的重大担忧,特别是关于生成版权或有害图像的问题。为了应对这一问题,已经开发了几种概念消除(防御)方法,通过事后微调防止生成不想要的内容。另一方面,概念恢复(攻击)方法试图通过对抗性构建的提示来恢复已删除的概念。然而,现有的所有恢复方法仅在高度限制性的场景中成功找到针对某些固定种子的对抗性提示。为了解决这一问题,我们引入了RECORD,这是一种基于坐标下降的新颖恢复算法,能够独立于种子找到对抗性提示以恢复已删除的概念。我们的大量实验表明,RECORD在此设置中始终优于当前恢复方法,最多可达17.8倍。我们的发现进一步揭示了未学习模型易受恢复攻击的影响,为对抗性提示影响下未学习模型的行为提供了关键见解。
论文及项目相关链接
Summary
文本到图像扩散模型的普及引发了关于生成版权或有害图像的隐私和安全担忧。为应对这一问题,已开发出多种概念消除(防御)方法,通过事后微调防止生成不想要的内容。同时,概念恢复(攻击)方法则试图通过敌对生成的提示恢复已消除的概念。然而,现有的恢复方法仅在高度限制性的针对某些固定种子的敌对提示情景中成功。为解决这一问题,我们引入了RECORD,一种新型的基于坐标下降的恢复算法,能够独立于种子找到敌对提示以恢复被消除的概念。我们的实验表明,RECORD在这个设置中持续表现出优于现有恢复方法的能力,最多可达原来的提高效率的 提高了多达目前的 恢复效果的 增加到原有数据的 水平达扩大了方法的范围改善了表现的效力等诸多优点 ,优越率为 的十倍有余的提高现的情况综合来看可提高恢复了记录案例的好成绩。我们的发现进一步揭示了未学习模型对恢复攻击的敏感性,为我们提供了关于未学习模型在敌对提示影响下的行为的重要见解。这为增强文本图像生成技术保护增加了信心背书和新可能也为将来的技术创新与发展带来新的启发思路也符合技术创新提升社会责任为日益成长发展的学科提出符合理论或方法论推进方面的设计期望与应用部署 切实有效的促进整个领域的长足发展以及相应的防范机制手段应用构建社会正向的保障支持措施带来贡献与积极影响 。总的来说我们的研究提供了一种有效的概念恢复方法和改进扩散模型性能的新思路为扩散模型的研究和应用提供了新的视角。我们也指出了未来的研究方向和潜在的安全威胁及其解决策略来进一步推动该领域的发展并保护用户免受潜在风险的影响。 改进后的算法将在实际应用中发挥重要作用如社交媒体、游戏设计等领域为我们提供了更多探索和挑战的可能性与研究方向也提高了人工智能系统的安全性和稳定性在现实世界的应用中的适应性。。最重要的是其可为用户带来更多选择和更高质量的体验需求保护其权益不再受到损害具有里程碑式的意义推动技术进步朝着更加健康的方向发展。同时我们的研究也为人工智能伦理问题提供了重要参考价值为解决扩散模型在隐私和安全方面的挑战提供了有力支持并带来了重要启示也为其他领域提供了可借鉴的经验与解决方案同时带来了潜在的商业价值和市场前景令人期待未来的技术发展和创新实践的应用推广中持续进步和完善提供更可靠的理论支撑与实践依据引领科技进步和产业发展的方向及发展趋势同时继续为防范未来可能出现的安全问题作出更多的贡献和贡献方案 。总结来说这是一项重要的研究突破具有重要的理论和实践意义为未来的人工智能技术发展注入了新的活力和信心同时也为我们带来了更多思考问题和探索的空间。我们的研究将推动扩散模型领域的发展并促进人工智能技术的不断进步和创新应用。我们的研究将推动扩散模型的应用及其算法的深入研究为用户提供更强大的安全和隐私保障及操作自由更好造福人类社会群体达到安全与发展的双向共进目标是学术界具有重要影响价值和业界实践的实质性创新研究成果对人类社会发展起到了重要的推动作用值得我们进一步深入探讨和总结发展实践经验以期更好的为科技与社会的发展贡献新的力量和新的创新突破点和可持续化发展的道路方向。。随着研究的深入我们可以预见未来文本图像生成技术的广阔前景及其巨大的潜力未来可期。。同时这项研究对于行业的影响具有重大且深远的影响并且为我们的研究方向提供了一个富有前瞻性的视角展望其未来发展充满无限潜力令人期待看到其未来在各种场景中的实际应用落地生根并持续推动科技进步的步伐。我们的研究不仅有助于推动扩散模型领域的进步也为人工智能技术的安全性和稳定性提供了强有力的支持为未来的技术发展提供了宝贵的思路和启示为我们面对未知的挑战和机遇做好了准备并且这项研究的发现不仅给学术领域带来了深远影响也对实际应用场景如社交媒体设计游戏制作等领域产生了积极的推动作用为我们的未来发展注入了新的活力和信心。我们的研究将引领扩散模型领域朝着更加安全可控的方向发展并推动人工智能技术的不断进步和创新应用前景值得期待并将会对人类社会产生积极深远的影响 。未来我们将继续探索相关技术和应用领域以期为人工智能技术的发展做出更大的贡献同时也希望能够为解决现实生活中的问题提供更多解决方案和思路更好地服务于人类社会促进科技和社会的共同发展 。本项研究还指出了未来的研究方向以及潜在的挑战这将会为我们深入理解和改善该技术在面临诸多安全和隐私方面问题的解决之道上具有深远的影响它推动学术界朝着更多跨学科研究和更加复杂的实验验证的道路上发展探索解决更多潜在的安全威胁以进一步推动扩散模型领域的发展以及未来的技术应用的不断革新。此外这项研究也为公众提供了一种理解和参与该领域发展的机会进一步推动了科学知识的普及与普及推广同时推动了社会科技文化的发展进程并为人类社会的未来发展提供了重要的思路和启示值得深入研究和探讨下去以推动科技和社会的共同进步与发展。综上所述这是一项具有里程碑意义的研究成果不仅为我们提供了一个全新的视角同时也为未来的科技发展提供了强有力的支撑与推动力是我们不断前进和发展的强大动力源泉之一。展望未来我们期待着扩散模型领域的更多突破和技术的不断革新为我们的未来发展带来更多的惊喜和可能性并推动人类社会的不断进步和发展壮大!通过本次的研究发现和分析我们对未来的技术充满信心对未来抱有积极的态度也对社会的进步充满信心和期望也希望研究成果能够得到更好的应用与推广并带来更多的价值和意义帮助更多人更好的利用和享受到先进的科技成果服务于社会的发展和提升个人的生活质量更好的为社会的发展做出贡献助力社会的发展进程和实现科技进步的巨大贡献和价值体现出科学技术的第一生产力巨大影响力实现社会科技水平的不断提高造福人类共创美好未来充满信心。最后希望我们的研究成果能够为更多的研究人员带来启发共同推进扩散模型领域的发展与进步共同创造更加美好的未来!我们将继续致力于深入研究探索新技术为科技进步贡献力量并造福全人类共同努力创造一个更加美好的未来!
Key Takeaways
点此查看论文截图



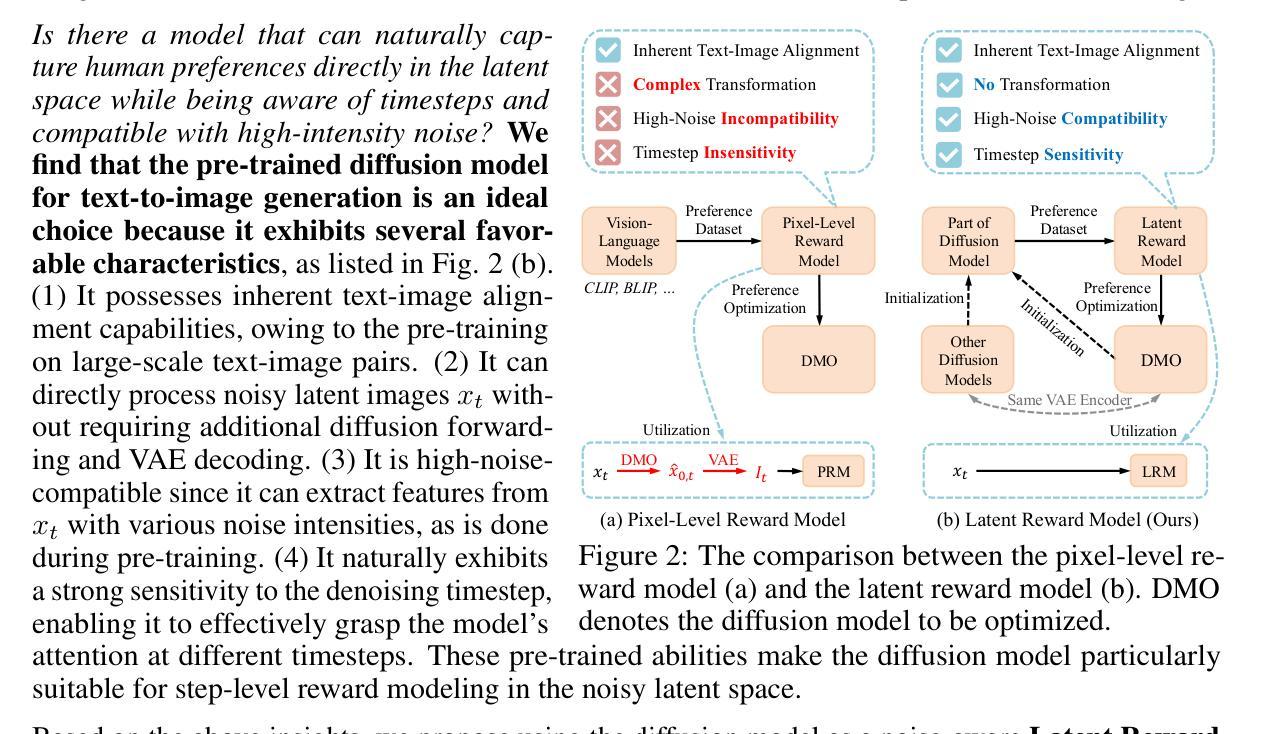
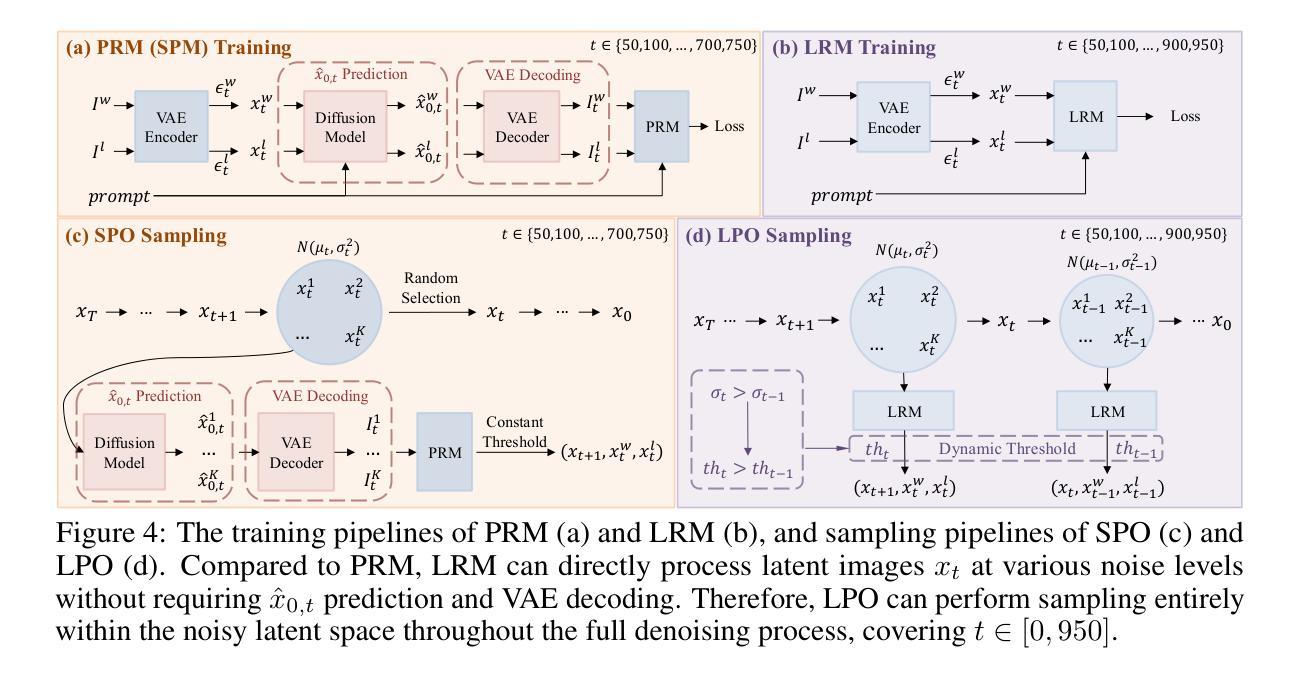
Diffusion Model as a Noise-Aware Latent Reward Model for Step-Level Preference Optimization
Authors:Tao Zhang, Cheng Da, Kun Ding, Huan Yang, Kun Jin, Yan Li, Tingting Gao, Di Zhang, Shiming Xiang, Chunhong Pan
Preference optimization for diffusion models aims to align them with human preferences for images. Previous methods typically use Vision-Language Models (VLMs) as pixel-level reward models to approximate human preferences. However, when used for step-level preference optimization, these models face challenges in handling noisy images of different timesteps and require complex transformations into pixel space. In this work, we show that pre-trained diffusion models are naturally suited for step-level reward modeling in the noisy latent space, as they are explicitly designed to process latent images at various noise levels. Accordingly, we propose the Latent Reward Model (LRM), which repurposes components of the diffusion model to predict preferences of latent images at arbitrary timesteps. Building on LRM, we introduce Latent Preference Optimization (LPO), a step-level preference optimization method conducted directly in the noisy latent space. Experimental results indicate that LPO significantly improves the model’s alignment with general, aesthetic, and text-image alignment preferences, while achieving a 2.5-28x training speedup over existing preference optimization methods. Our code and models are available at https://github.com/Kwai-Kolors/LPO.
扩散模型的偏好优化旨在使图像与人类偏好对齐。之前的方法通常使用视觉语言模型(VLMs)作为像素级奖励模型来近似人类偏好。然而,当用于步骤级偏好优化时,这些模型在处理不同时间步长的噪声图像时面临挑战,并需要将图像转换为复杂的像素空间。在这项工作中,我们展示了预训练的扩散模型自然适用于噪声潜在空间的步骤级奖励建模,因为它们被明确设计为处理各种噪声水平的潜在图像。因此,我们提出了潜在奖励模型(LRM),该模型重新利用扩散模型的组件来预测任意时间步长的潜在图像的偏好。基于LRM,我们介绍了潜在偏好优化(LPO),这是一种直接在噪声潜在空间中进行的步骤级偏好优化方法。实验结果表明,LPO显著提高了模型与一般偏好、审美偏好和文本图像对齐偏好的对齐程度,同时实现了对现有偏好优化方法的2.5-28倍训练速度提升。我们的代码和模型可在https://github.com/Kwai-Kolors/LPO找到。
论文及项目相关链接
PDF 25 pages, 26 tables, 15 figures
Summary
本文研究了基于扩散模型的偏好优化问题。文章提出了一种新方法Latent Reward Model(LRM),通过在噪声潜空间中利用预训练的扩散模型进行建模,预测不同时间步长的潜在图像的偏好。基于此,文章进一步引入了Latent Preference Optimization(LPO)方法,直接在噪声潜空间进行步骤级偏好优化。实验结果表明,LPO能显著提高模型与通用、美学和文本图像对齐偏好的对齐程度,同时相比现有偏好优化方法实现了2.5-28倍的训练加速。
Key Takeaways
- 扩散模型在偏好优化中需要与人类图像偏好对齐。
- 之前的方法使用视觉语言模型(VLMs)作为像素级奖励模型来近似人类偏好。
- 在处理不同时间步长的噪声图像时,VLMs面临挑战,需要进行复杂的像素空间转换。
- 预训练的扩散模型适合在噪声潜空间中进行步骤级奖励建模。
- 提出了Latent Reward Model(LRM)用于预测任意时间步长的潜在图像偏好。
- 基于LRM,引入了Latent Preference Optimization(LPO)方法,直接在噪声潜空间进行步骤级偏好优化。
- LPO在模型与通用、美学和文本图像对齐偏好对齐方面表现显著,同时实现了训练加速。
点此查看论文截图



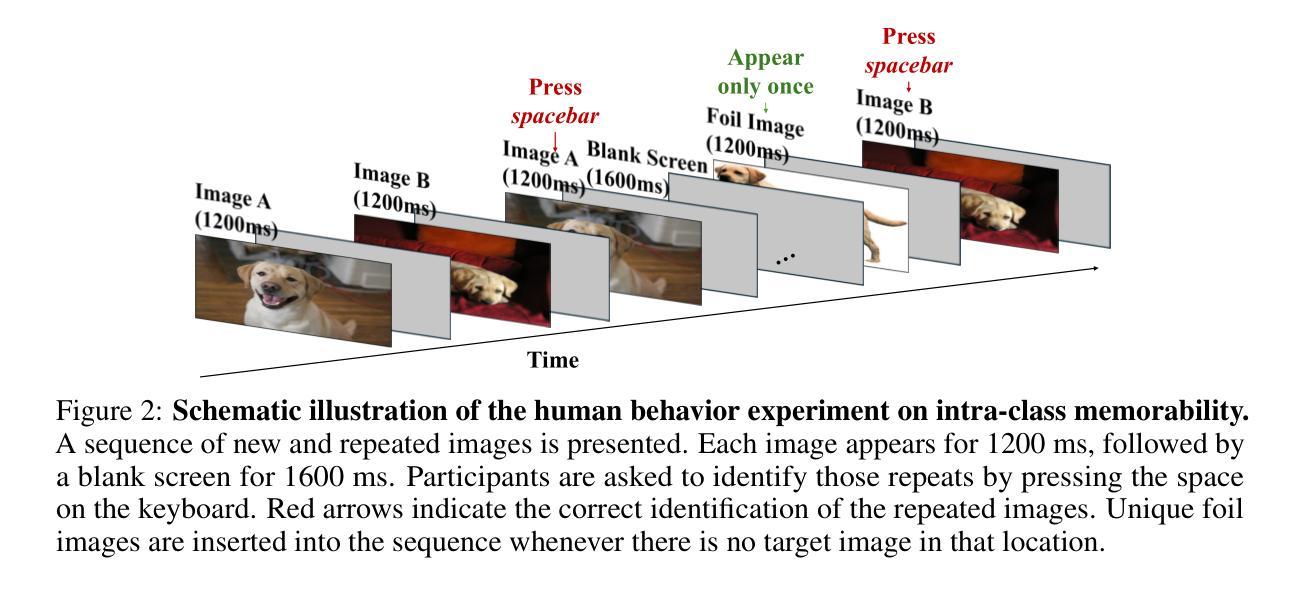
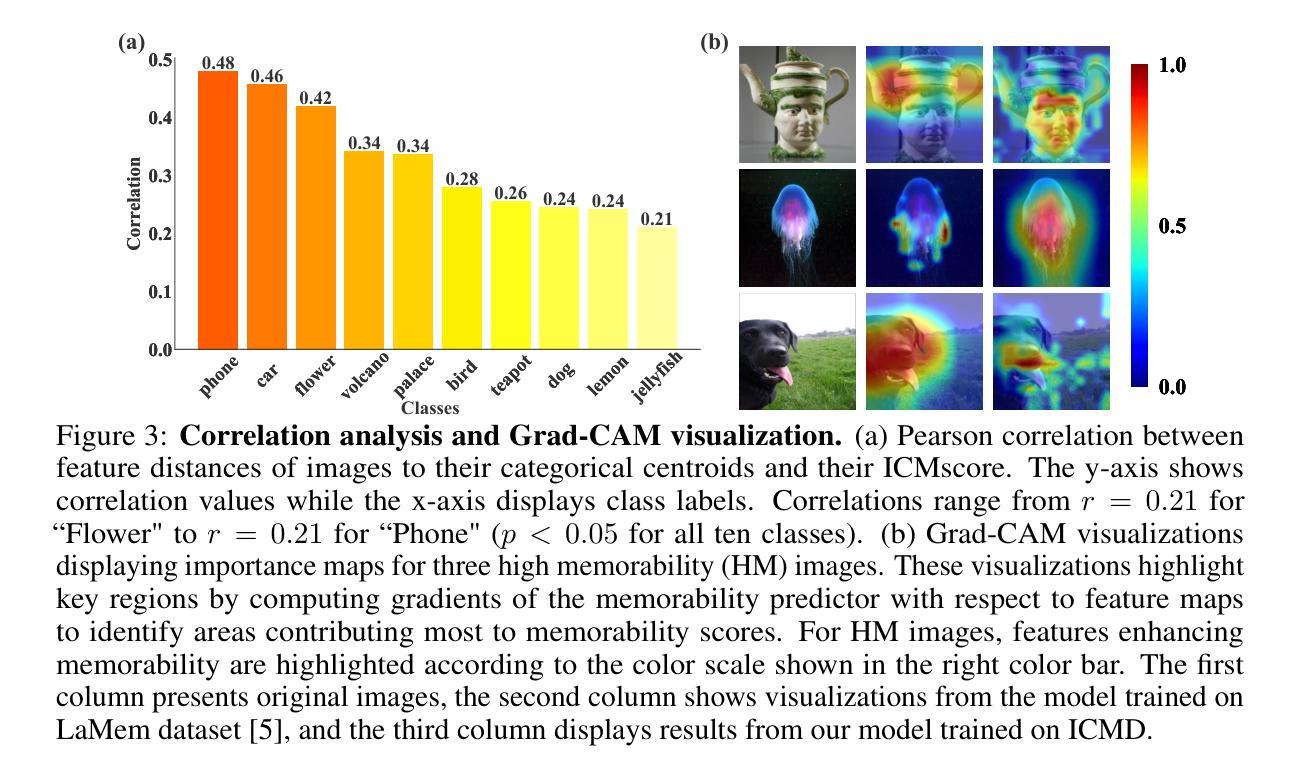
Unforgettable Lessons from Forgettable Images: Intra-Class Memorability Matters in Computer Vision
Authors:Jie Jing, Qing Lin, Shuangpeng Han, Lucia Schiatti, Yen-Ling Kuo, Mengmi Zhang
We introduce intra-class memorability, where certain images within the same class are more memorable than others despite shared category characteristics. To investigate what features make one object instance more memorable than others, we design and conduct human behavior experiments, where participants are shown a series of images, and they must identify when the current image matches the image presented a few steps back in the sequence. To quantify memorability, we propose the Intra-Class Memorability score (ICMscore), a novel metric that incorporates the temporal intervals between repeated image presentations into its calculation. Furthermore, we curate the Intra-Class Memorability Dataset (ICMD), comprising over 5,000 images across ten object classes with their ICMscores derived from 2,000 participants’ responses. Subsequently, we demonstrate the usefulness of ICMD by training AI models on this dataset for various downstream tasks: memorability prediction, image recognition, continual learning, and memorability-controlled image editing. Surprisingly, high-ICMscore images impair AI performance in image recognition and continual learning tasks, while low-ICMscore images improve outcomes in these tasks. Additionally, we fine-tune a state-of-the-art image diffusion model on ICMD image pairs with and without masked semantic objects. The diffusion model can successfully manipulate image elements to enhance or reduce memorability. Our contributions open new pathways in understanding intra-class memorability by scrutinizing fine-grained visual features behind the most and least memorable images and laying the groundwork for real-world applications in computer vision. We will release all code, data, and models publicly.
我们引入了类内记忆性的概念,即同一类别中的某些图像比其他图像更容易记住,尽管它们具有共同的类别特征。为了探究哪些特征使得一个对象实例比其他实例更容易记住,我们设计并进行了人类行为实验,实验参与者会观看一系列图像,并必须判断当前图像是否与序列中几步之前的图像相匹配。为了量化记忆性,我们提出了类内记忆性得分(ICMscore)这一新指标,它将重复呈现图像之间的时间间隔纳入计算。此外,我们整理了类内记忆性数据集(ICMD),包含10个对象类别的超过5000张图像,以及来自2000名参与者的ICMscore数据。接着,我们通过在此数据集上训练人工智能模型来展示ICMD的实用性,用于各种下游任务:记忆性预测、图像识别、持续学习和记忆性控制图像处理。令人惊讶的是,高ICMscore的图像会损害人工智能在图像识别和持续学习任务中的表现,而低ICMscore的图像则能改善这些任务的结果。此外,我们对先进的图像扩散模型进行了微调,处理带有和不带掩膜语义对象的ICMD图像对。该扩散模型能够成功操控图像元素以增强或降低记忆性。我们的贡献通过审查最记人难忘和最容易遗忘的图像背后的精细视觉特征,为人们了解类内记忆性开辟了新途径,并为计算机视觉的实际应用奠定了基础。我们将公开发布所有代码、数据和模型。
论文及项目相关链接
摘要
本文介绍了同一类别内部不同图像间的可记忆性差异,即尽管具有相同的类别特征,但某些图像仍然比其他图像更容易被记住。通过设计人类行为实验来探究同一对象实例中哪些特征使其比其他实例更容易被记住。提出一种新型指标——ICM分数(Intra-Class Memorability score),用于量化图像的可记忆性,并考虑到图像重复呈现的时间间隔。同时构建了包含超过五千张图像和它们的ICM分数的ICMD数据集。基于ICMD数据集训练AI模型用于多个下游任务,包括可记忆性预测、图像识别、持续学习和可记忆性控制图像编辑等。研究发现高ICM分数的图像在图像识别和持续学习任务中会降低AI性能,而低ICM分数图像则能提高性能。此外,对扩散模型进行微调以处理ICMD图像对带有和不带语义对象的掩膜图像。该扩散模型可以成功操纵图像元素以提高或降低可记忆性。本文的研究开辟了新途径,通过深入研究最记忆深刻和最不易记忆的图像的精细视觉特征来理解同一类别内的可记忆性差异,并为计算机视觉的实际应用奠定基础。我们将公开所有代码、数据和模型。
关键见解
- 引入同一类别内不同图像的可记忆性差异概念。
- 通过人类行为实验探究哪些特征使某一对象实例比其他实例更易被记住。
- 提出ICM分数指标,结合重复呈现图像的时间间隔来量化可记忆性。
- 构建ICMD数据集,包含超过五千张图像和它们的ICM分数。
- 基于ICMD数据集训练AI模型,用于多种下游任务,如记忆预测、图像识别等。
- 发现高ICM分数图像在图像识别和持续学习任务中会降低AI性能,而低ICM分数图像则相反。
点此查看论文截图


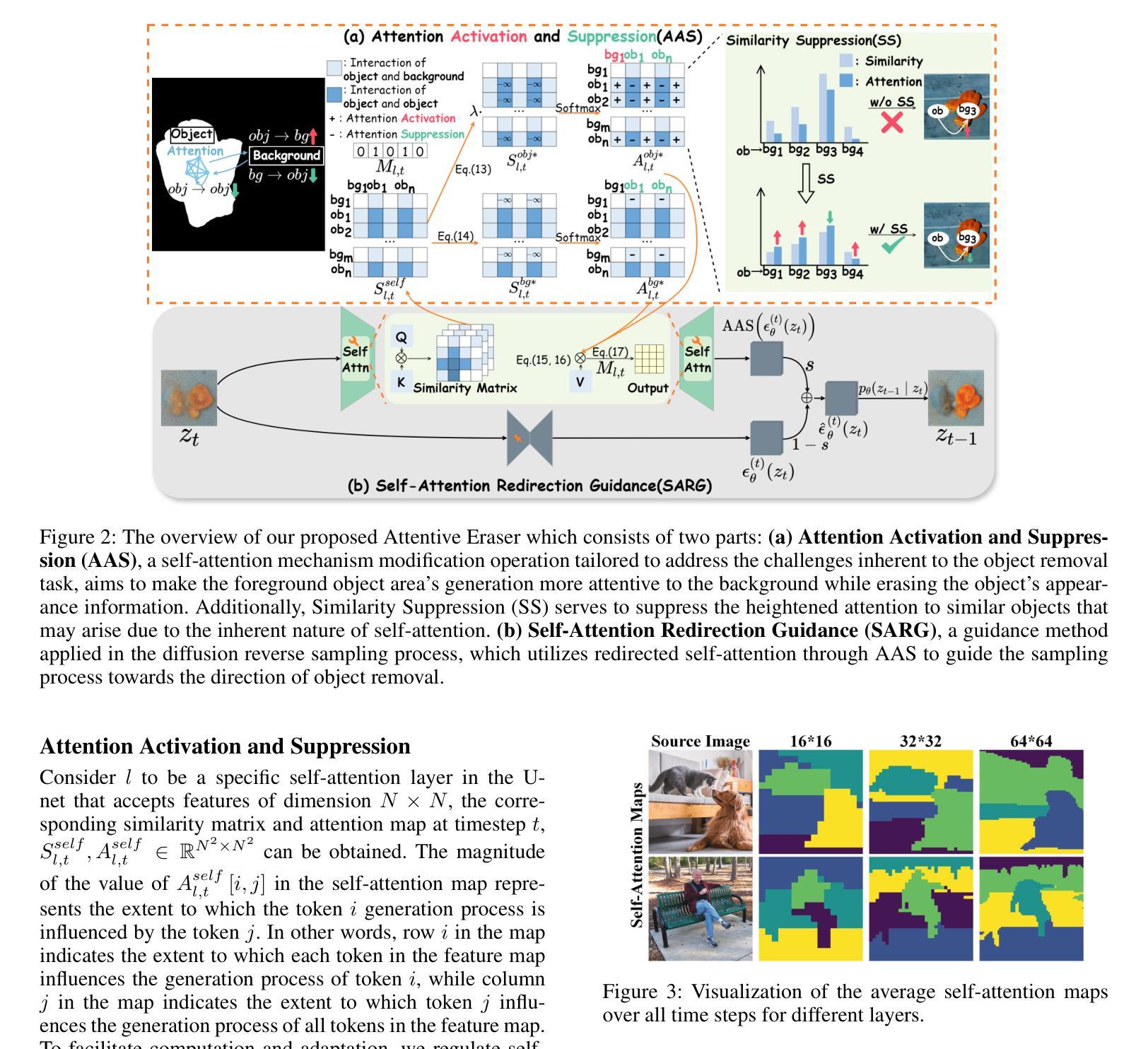
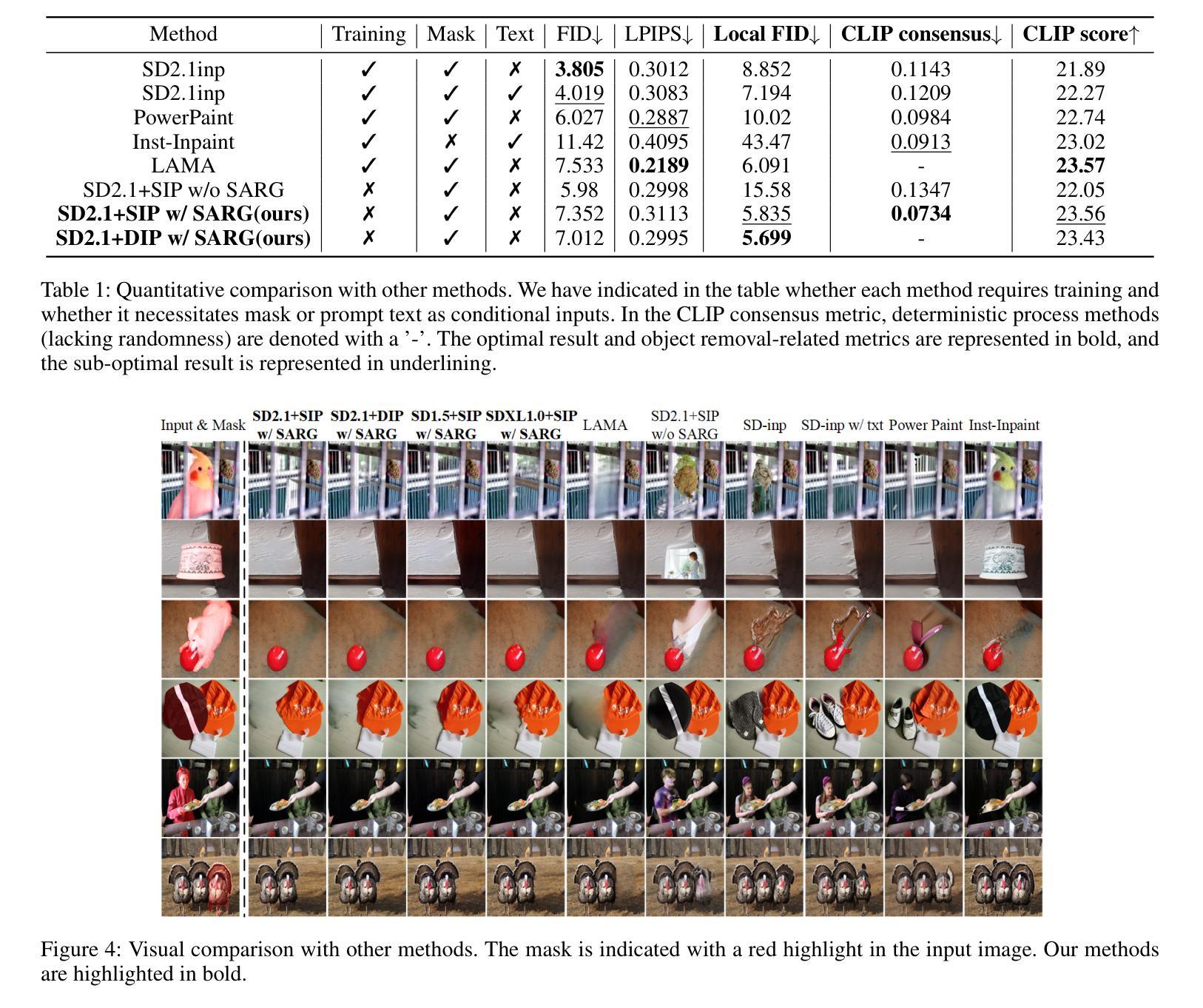
Attentive Eraser: Unleashing Diffusion Model’s Object Removal Potential via Self-Attention Redirection Guidance
Authors:Wenhao Sun, Benlei Cui, Xue-Mei Dong, Jingqun Tang
Recently, diffusion models have emerged as promising newcomers in the field of generative models, shining brightly in image generation. However, when employed for object removal tasks, they still encounter issues such as generating random artifacts and the incapacity to repaint foreground object areas with appropriate content after removal. To tackle these problems, we propose Attentive Eraser, a tuning-free method to empower pre-trained diffusion models for stable and effective object removal. Firstly, in light of the observation that the self-attention maps influence the structure and shape details of the generated images, we propose Attention Activation and Suppression (ASS), which re-engineers the self-attention mechanism within the pre-trained diffusion models based on the given mask, thereby prioritizing the background over the foreground object during the reverse generation process. Moreover, we introduce Self-Attention Redirection Guidance (SARG), which utilizes the self-attention redirected by ASS to guide the generation process, effectively removing foreground objects within the mask while simultaneously generating content that is both plausible and coherent. Experiments demonstrate the stability and effectiveness of Attentive Eraser in object removal across a variety of pre-trained diffusion models, outperforming even training-based methods. Furthermore, Attentive Eraser can be implemented in various diffusion model architectures and checkpoints, enabling excellent scalability. Code is available at https://github.com/Anonym0u3/AttentiveEraser.
最近,扩散模型作为生成模型领域的新兴力量,在图像生成方面表现出色。然而,当用于目标移除任务时,它们仍然面临一些问题,例如产生随机伪影和在移除后无法用适当的内容重新绘制前景对象区域。为了解决这些问题,我们提出了“Attentive Eraser”,这是一种无需调整的预训练扩散模型方法,可实现稳定和有效的目标移除。首先,基于观察到自注意力图会影响生成图像的结构和形状细节,我们提出了注意力激活和抑制(ASS),它根据给定的掩膜重新设计预训练扩散模型内的自注意力机制,从而在反向生成过程中优先考虑背景而非前景目标。此外,我们引入了自注意力重定向引导(SARG),它利用ASS引导的自注意力来指导生成过程,在掩膜内有效地移除前景目标,同时生成既合理又连贯的内容。实验表明,Attentive Eraser在各种预训练扩散模型中的目标移除表现稳定且有效,甚至超越了基于训练的方法。此外,Attentive Eraser可应用于各种扩散模型架构和检查点,具有良好的可扩展性。代码可通过以下链接获取:https://github.com/Anonym0u3/AttentiveEraser。
论文及项目相关链接
PDF Accepted by AAAI 2025(Oral)
Summary
扩散模型在生成模型领域崭露头角,尤其在图像生成方面表现出色。然而,在对象移除任务中,仍存在生成随机瑕疵和移除前景对象后无法重新绘制适当内容的问题。为此,提出无需调整的“Attentive Eraser”方法,为预训练的扩散模型实现稳定有效的对象移除。通过利用自我关注图影响图像结构和形状细节的观察结果,提出基于给定遮罩重新设计预训练扩散模型内的自我关注机制,优先处理背景而非前景对象。此外,引入自我关注重定向指导(SARG),有效移除遮罩内的前景对象,同时生成既合理又连贯的内容。该方法在多种预训练扩散模型中表现稳定有效,甚至超越基于训练的方法。同时,Attentive Eraser可应用于各种扩散模型架构和检查点,展现出卓越的可扩展性。
Key Takeaways
- 扩散模型在图像生成领域展现出巨大潜力,但在对象移除任务中仍面临挑战。
- 提出了一种名为“Attentive Eraser”的方法,旨在解决扩散模型在对象移除中的随机瑕疵和重新绘制问题。
- 通过利用自我关注图影响图像结构和形状细节的特性,重新设计自我关注机制以优先处理背景信息。
- 引入Self-Attention Redirection Guidance(SARG)技术,能有效移除前景对象并生成连贯内容。
- Attentive Eraser方法在各种预训练扩散模型中表现稳定且有效,优于许多基于训练的方法。
- 该方法具有良好的可扩展性,可应用于不同的扩散模型架构和检查点。
点此查看论文截图



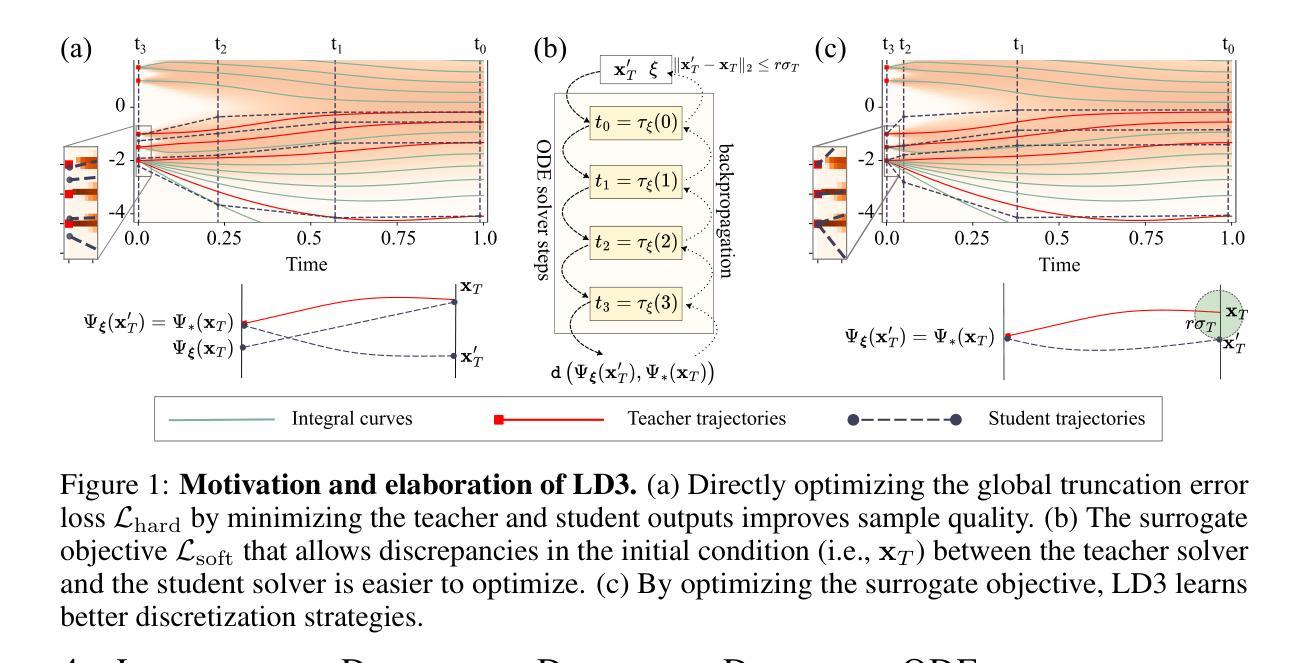
Learning to Discretize Denoising Diffusion ODEs
Authors:Vinh Tong, Hoang Trung-Dung, Anji Liu, Guy Van den Broeck, Mathias Niepert
Diffusion Probabilistic Models (DPMs) are generative models showing competitive performance in various domains, including image synthesis and 3D point cloud generation. Sampling from pre-trained DPMs involves multiple neural function evaluations (NFEs) to transform Gaussian noise samples into images, resulting in higher computational costs compared to single-step generative models such as GANs or VAEs. Therefore, reducing the number of NFEs while preserving generation quality is crucial. To address this, we propose LD3, a lightweight framework designed to learn the optimal time discretization for sampling. LD3 can be combined with various samplers and consistently improves generation quality without having to retrain resource-intensive neural networks. We demonstrate analytically and empirically that LD3 improves sampling efficiency with much less computational overhead. We evaluate our method with extensive experiments on 7 pre-trained models, covering unconditional and conditional sampling in both pixel-space and latent-space DPMs. We achieve FIDs of 2.38 (10 NFE), and 2.27 (10 NFE) on unconditional CIFAR10 and AFHQv2 in 5-10 minutes of training. LD3 offers an efficient approach to sampling from pre-trained diffusion models. Code is available at https://github.com/vinhsuhi/LD3.
扩散概率模型(DPMs)是一种生成模型,其在图像合成和3D点云生成等领域表现出竞争性能。从预训练的DPMs中进行采样涉及多次神经网络功能评估(NFE),将高斯噪声样本转换为图像,这导致与诸如GAN或VAE等单步生成模型相比,计算成本更高。因此,在保持生成质量的同时减少NFE的数量至关重要。针对这一问题,我们提出了LD3,这是一个轻量级的框架,旨在学习采样的最佳时间离散化。LD3可以与各种采样器相结合,可以在不重新训练资源密集型的神经网络的情况下,持续改善生成质量。我们通过理论分析和实证证明,LD3能提高采样效率,且计算开销较小。我们在7个预训练模型上进行了大量实验,涵盖了像素空间和潜在空间DPMs的无条件采样和条件采样。我们在无条件CIFAR10和AFHQv2上实现了FID 2.38(10次NFE)和FID 2.27(在5-10分钟的训练时间内),显示了在无条件下的效果。LD3为从预训练的扩散模型中进行采样提供了一种高效的方法。代码可通过以下网址获得:[LD3项目在GitHub的页面链接]。
论文及项目相关链接
摘要
DPM(扩散概率模型)是表现优异的生成模型,广泛应用于图像合成和三维点云生成等领域。由于DPM的采样涉及到多个神经网络功能的评估(NFE),以从高斯噪声样本生成图像,导致其计算成本高于单步生成模型(如GAN或VAE)。本文提出的LD3框架旨在降低NFE数量,同时保留生成质量。通过优化时间离散化采样过程,LD3可以与各种采样器结合使用,无需重新训练资源密集型的神经网络即可提高生成质量。理论分析表明,LD3可提高采样效率并降低计算开销。在七个预训练模型上进行的实验证明,我们的方法在无条件CIFAR10和AFHQv2上实现了高达FIDs的2.38(使用较少的采样次数)和较低的FID分数。总体而言,LD3提供了一种高效的对预训练扩散模型进行采样的方法。
关键见解
- DPMs在各种领域表现优异,但采样过程涉及多个NFE,计算成本较高。
- LD3框架旨在减少NFE数量,同时保持生成质量。
- LD3可通过优化时间离散化采样过程实现这一目标。
- LD3可结合各种采样器使用,无需重新训练神经网络。
- LD3提高了采样效率并降低了计算开销。
- 在七个预训练模型上的实验证明了LD3的有效性,其中对CIFAR10和AFHQv2的实验结果表明了较高的性能表现。
点此查看论文截图


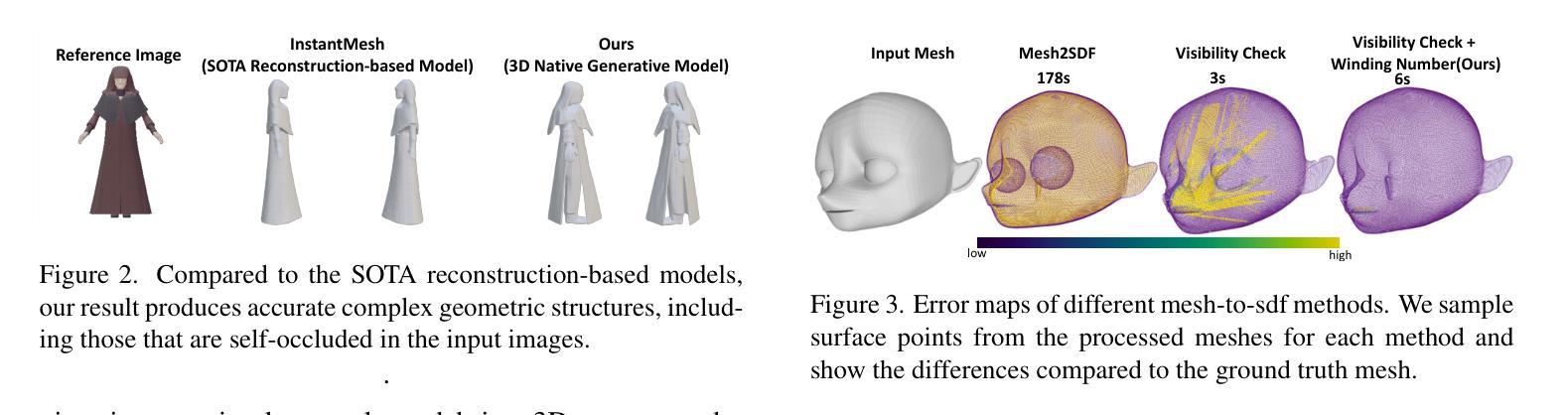
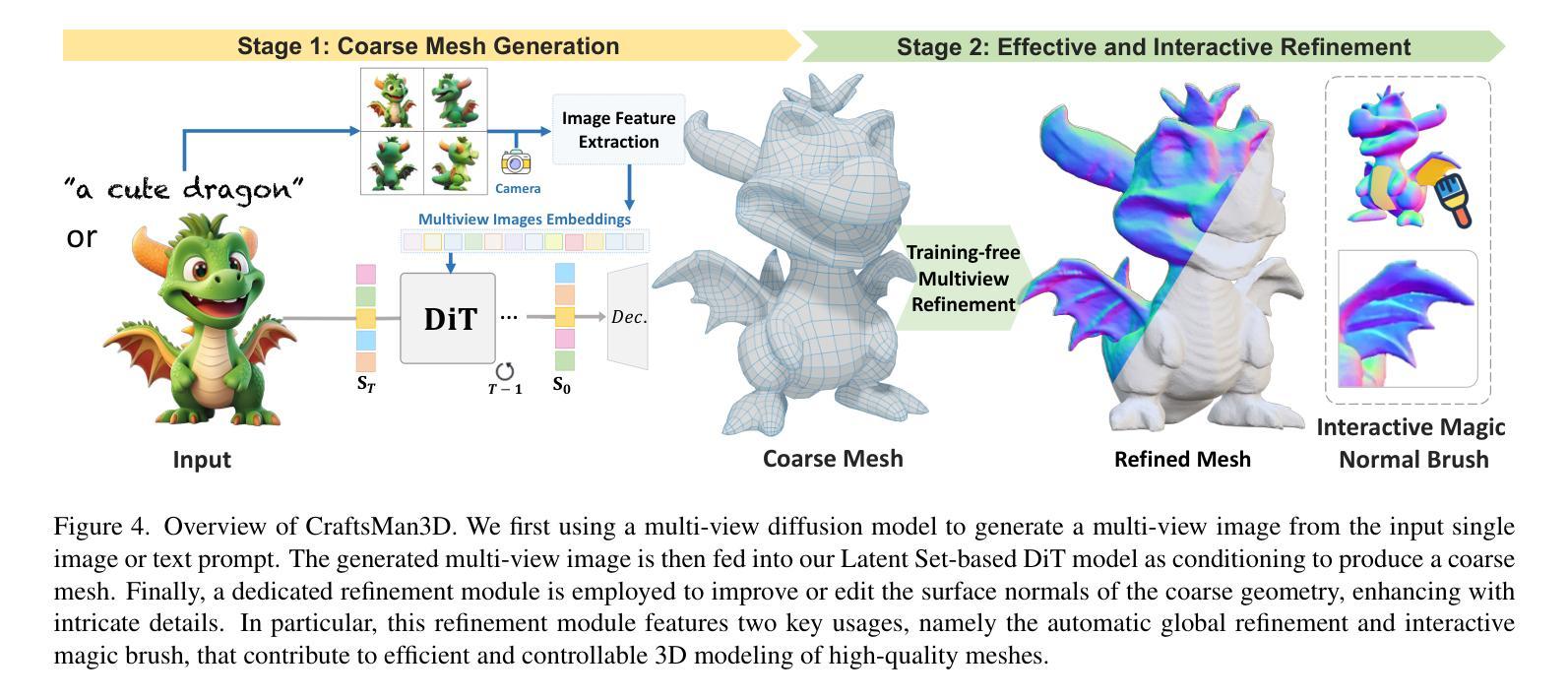
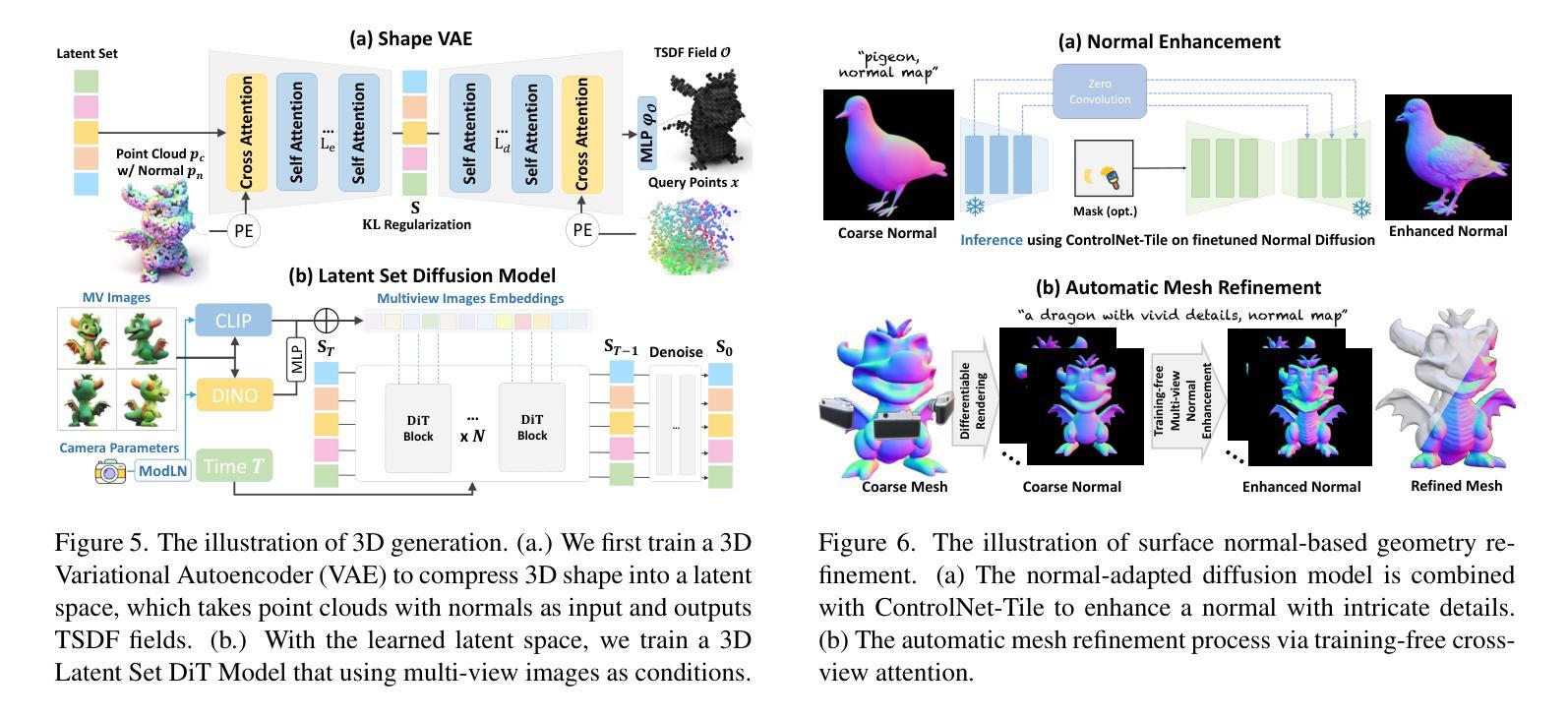
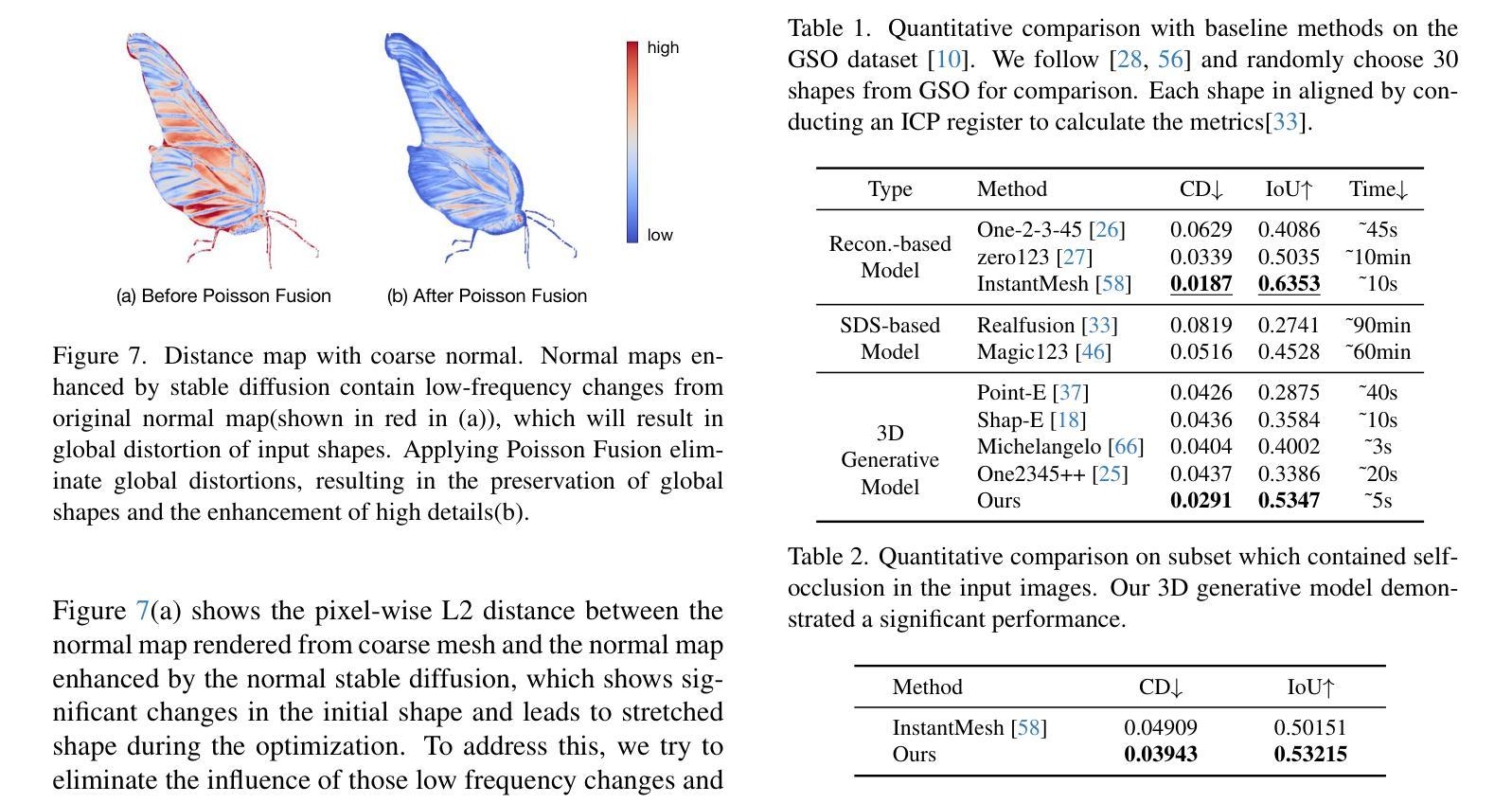
CraftsMan3D: High-fidelity Mesh Generation with 3D Native Generation and Interactive Geometry Refiner
Authors:Weiyu Li, Jiarui Liu, Rui Chen, Yixun Liang, Xuelin Chen, Ping Tan, Xiaoxiao Long
We present a novel generative 3D modeling system, coined CraftsMan, which can generate high-fidelity 3D geometries with highly varied shapes, regular mesh topologies, and detailed surfaces, and, notably, allows for refining the geometry in an interactive manner. Despite the significant advancements in 3D generation, existing methods still struggle with lengthy optimization processes, irregular mesh topologies, noisy surfaces, and difficulties in accommodating user edits, consequently impeding their widespread adoption and implementation in 3D modeling software. Our work is inspired by the craftsman, who usually roughs out the holistic figure of the work first and elaborates the surface details subsequently. Specifically, we employ a 3D native diffusion model, which operates on latent space learned from latent set-based 3D representations, to generate coarse geometries with regular mesh topology in seconds. In particular, this process takes as input a text prompt or a reference image and leverages a powerful multi-view (MV) diffusion model to generate multiple views of the coarse geometry, which are fed into our MV-conditioned 3D diffusion model for generating the 3D geometry, significantly improving robustness and generalizability. Following that, a normal-based geometry refiner is used to significantly enhance the surface details. This refinement can be performed automatically, or interactively with user-supplied edits. Extensive experiments demonstrate that our method achieves high efficacy in producing superior-quality 3D assets compared to existing methods. HomePage: https://craftsman3d.github.io/, Code: https://github.com/wyysf-98/CraftsMan
我们提出了一种新颖的三维建模系统,名为CraftsMan。该系统能够生成高质量的三维几何体,具备多样化的形状、规则的网格拓扑结构和精细的表面细节,并且支持交互式地对几何结构进行细化。尽管三维生成技术已经取得了重大进展,但现有方法仍然面临优化过程冗长、网格拓扑结构不规则、表面噪声以及难以容纳用户编辑等问题,这些问题阻碍了它们在三维建模软件中的广泛采用和实施。我们的工作受到工匠的启发,他们通常首先大致勾勒出作品的整体轮廓,然后细化表面细节。具体来说,我们采用了一种三维扩散模型,该模型在潜在空间上运行,该潜在空间是从基于集合的潜在三维表示中学习得到的,可以在几秒钟内生成具有规则网格拓扑结构的粗略几何结构。特别是,这一过程以文本提示或参考图像作为输入,并利用强大的多视图(MV)扩散模型生成粗略几何结构的多视图,然后将其输入到我们的MV条件三维扩散模型中,以生成三维几何结构,这大大提高了稳健性和通用性。之后,使用基于法线的几何细化器来显著增强表面细节。这种细化可以自动进行,也可以与用户提供的编辑进行交互式操作。大量实验表明,我们的方法在生成高质量三维资产方面与现有方法相比具有高效性。主页:https://craftsman3d.github.io/,代码:https://github.com/wyysf-98/CraftsMan
论文及项目相关链接
PDF HomePage: https://craftsman3d.github.io/, Code: https://github.com/wyysf-98/CraftsMan3D
Summary
该项目提出了一种名为CraftsMan的新型三维建模系统,该系统能够生成高质量的三维模型,具有多样化的形状、规则化的网格拓扑和精细的表面细节,并且允许用户进行交互式几何精细化。系统利用三维扩散模型在潜在空间进行操作,能够快速生成具有规则网格拓扑的粗略几何形状,并通过多视角扩散模型进一步提高稳健性和泛化能力。此外,系统还使用基于法线的几何精细化器来增强表面细节,并允许自动或交互式进行用户编辑。与现有方法相比,该方法生成的三维资产质量更高。
Key Takeaways
- CraftsMan是一个新型的三维建模系统,能够生成高质量的三维模型,包括多样化的形状、规则化的网格拓扑和精细的表面细节。
- 该系统采用三维扩散模型,在潜在空间进行操作,可以快速生成具有规则网格拓扑的粗略几何形状。
- 系统利用多视角扩散模型,提高了稳健性和泛化能力,使得生成的三维模型更加真实和多样。
- CraftsMan允许用户进行交互式的几何精细化,增强了表面细节,提高了模型的精度和逼真度。
- 该系统采用法线基于的几何精细化器,可以自动或交互式地进行用户编辑,提高了操作的灵活性和便利性。
- 与现有方法相比,CraftsMan生成的三维资产质量更高,具有更广泛的应用前景。
点此查看论文截图

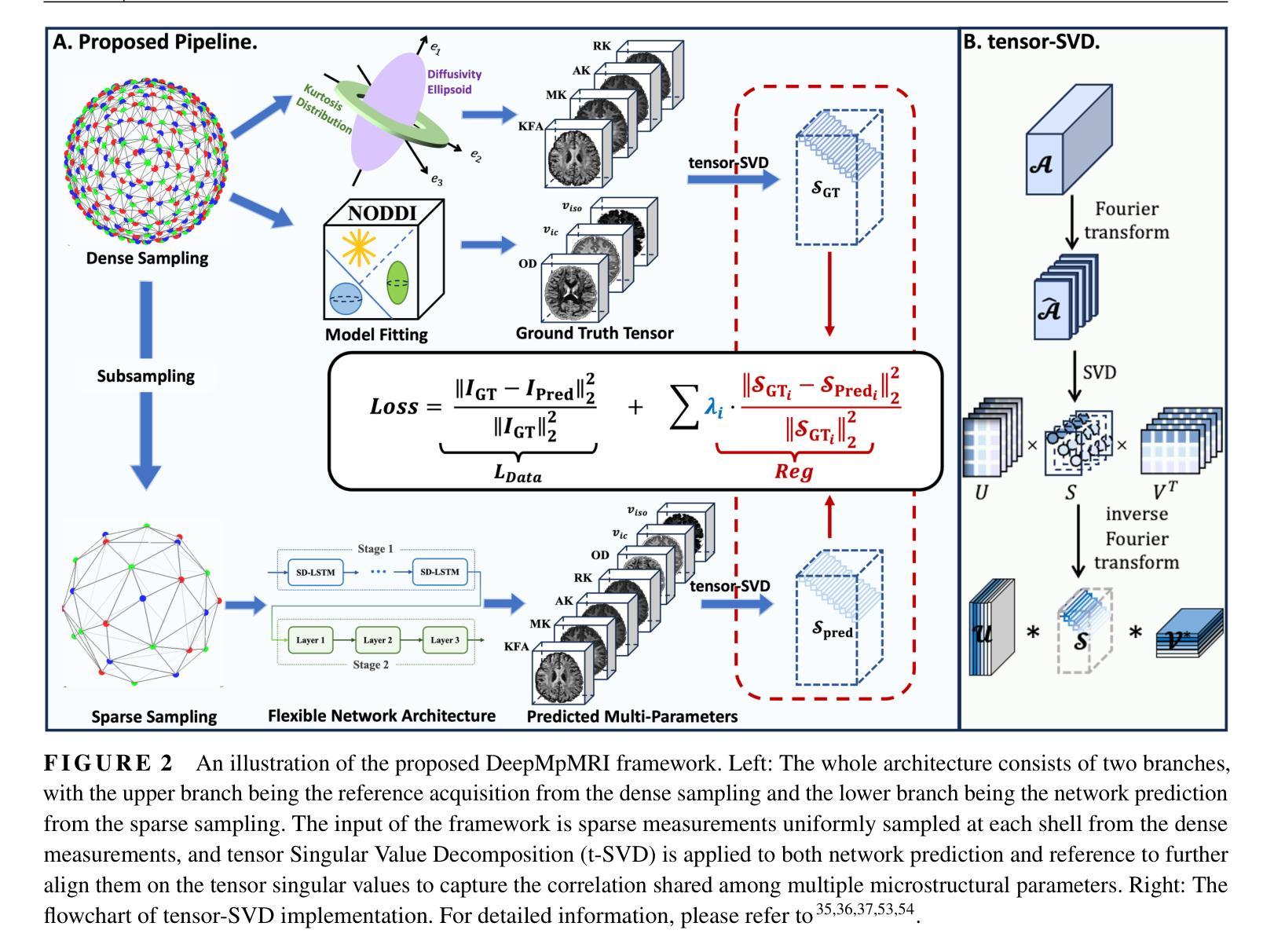
DeepMpMRI: Tensor-decomposition Regularized Learning for Fast and High-Fidelity Multi-Parametric Microstructural MR Imaging
Authors:Wenxin Fan, Jian Cheng, Qiyuan Tian, Ruoyou Wu, Juan Zou, Zan Chen, Shanshan Wang
Deep learning has emerged as a promising approach for learning the nonlinear mapping between diffusion-weighted MR images and tissue parameters, which enables automatic and deep understanding of the brain microstructures. However, the efficiency and accuracy in estimating multiple microstructural parameters derived from multiple diffusion models are still limited since previous studies tend to estimate parameter maps from distinct models with isolated signal modeling and dense sampling. This paper proposes DeepMpMRI, an efficient framework for fast and high-fidelity multiple microstructural parameter estimation from multiple models using highly sparse sampled q-space data. DeepMpMRI is equipped with a newly designed tensor-decomposition-based regularizer to effectively capture fine details by exploiting the high-dimensional correlation across microstructural parameters. In addition, we introduce a Nesterov-based adaptive learning algorithm that optimizes the regularization parameter dynamically to enhance the performance. DeepMpMRI is an extendable framework capable of incorporating flexible network architecture. Experimental results on the HCP dataset and the Alzheimer’s disease dataset both demonstrate the superiority of our approach over 5 state-of-the-art methods in simultaneously estimating multi-model microstructural parameter maps for DKI and NODDI model with fine-grained details both quantitatively and qualitatively, achieving 4.5 - 15 $\times$ acceleration compared to the dense sampling of a total of 270 diffusion gradients.
深度学习已成为一种有前途的方法,用于学习扩散加权磁共振图像与组织参数之间的非线性映射,从而实现大脑微观结构的自动和深入理解。然而,由于以往的研究倾向于使用孤立信号建模和密集采样从不同模型估计参数图,因此从多个扩散模型估计多个微观结构参数的效率和准确性仍然受到限制。本文提出了DeepMpMRI,这是一个高效的框架,可以从多个模型快速、高保真地估计多个微观结构参数,使用高度稀疏采样的q空间数据。DeepMpMRI配备了一种新设计的基于张量分解的正则化器,通过利用微观结构参数之间的高维相关性有效地捕捉细微细节。此外,我们引入了一种基于Nesterov的自适应学习算法,该算法可动态优化正则化参数以提高性能。DeepMpMRI是一个可扩展的框架,能够采用灵活的网络架构。在HCP数据集和阿尔茨海默病数据集上的实验结果均表明,我们的方法在同时估计DKI和NODDI模型的多模型微观结构参数图方面优于5种最先进的方法,在定量和定性方面都表现出精细的细节,与总共270个扩散梯度的密集采样相比实现了4.5-15倍的加速。
论文及项目相关链接
Summary
深度学习方法在学习扩散加权核磁共振图像与组织结构参数间的非线性映射方面展现出潜力,能自动深入理解大脑微观结构。然而,多个模型中微观结构参数的估算效率和准确度受限。本文提出DeepMpMRI框架,能高效地从多个模型中快速、高精度地估算微观结构参数,使用高度稀疏采样的q空间数据。该框架设计了一种基于张量分解的正则化器,利用高维参数间的相关性捕捉细节,并引入Nesterov自适应学习算法动态优化正则化参数以提升性能。实验结果表明,DeepMpMRI在同时估算DKI和NODDI模型的多个微观结构参数映射方面优于其他五种先进方法,实现了4.5~15倍的加速。
Key Takeaways
- 深度学习可用于理解扩散加权核磁共振图像与大脑微观结构参数间的映射。
- 当前方法在多个模型的微观结构参数估算方面存在效率和准确度的限制。
- 提出了一种新的框架DeepMpMRI,能高效地从多个模型中估算微观结构参数。
- DeepMpMRI使用高度稀疏采样的q空间数据,提高了计算效率。
- DeepMpMRI利用张量分解的正则化器捕捉微观结构的高维相关性。
- 引入Nesterov自适应学习算法优化正则化参数,提升了性能。
点此查看论文截图

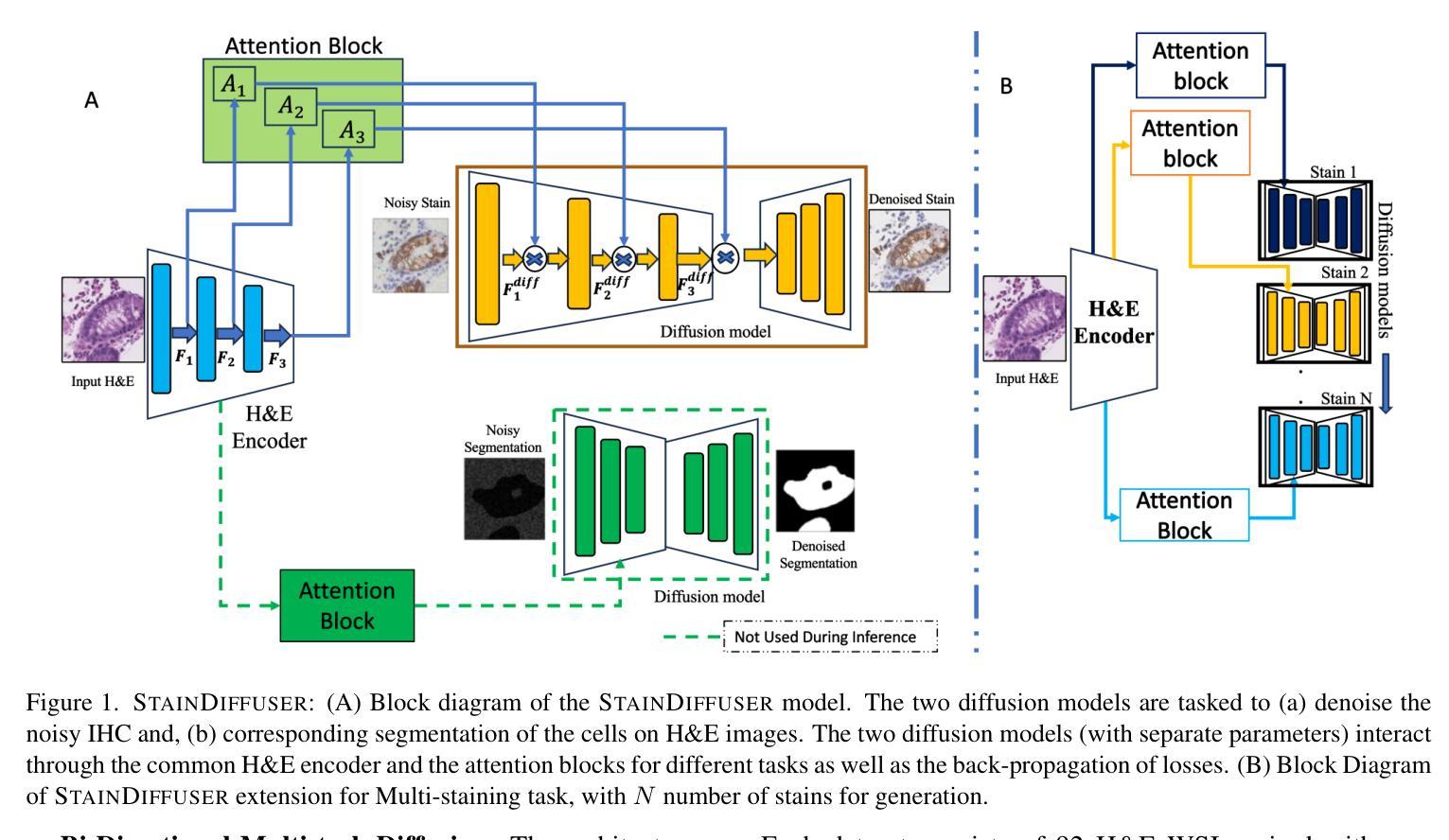
StainDiffuser: MultiTask Dual Diffusion Model for Virtual Staining
Authors:Tushar Kataria, Beatrice Knudsen, Shireen Y. Elhabian
Hematoxylin and Eosin (H&E) staining is widely regarded as the standard in pathology for diagnosing diseases and tracking tumor recurrence. While H&E staining shows tissue structures, it lacks the ability to reveal specific proteins that are associated with disease severity and treatment response. Immunohistochemical (IHC) stains use antibodies to highlight the expression of these proteins on their respective cell types, improving diagnostic accuracy, and assisting with drug selection for treatment. Despite their value, IHC stains require additional time and resources, limiting their utilization in some clinical settings. Recent advances in deep learning have positioned Image-to-Image (I2I) translation as a computational, cost-effective alternative for IHC. I2I generates high fidelity stain transformations digitally, potentially replacing manual staining in IHC. Diffusion models, the current state of the art in image generation and conditional tasks, are particularly well suited for virtual IHC due to their ability to produce high quality images and resilience to mode collapse. However, these models require extensive and diverse datasets (often millions of samples) to achieve a robust performance, a challenge in virtual staining applications where only thousands of samples are typically available. Inspired by the success of multitask deep learning models in scenarios with limited data, we introduce STAINDIFFUSER, a novel multitask diffusion architecture tailored to virtual staining that achieves convergence with smaller datasets. STAINDIFFUSER simultaneously trains two diffusion processes: (a) generating cell specific IHC stains from H&E images and (b) performing H&E based cell segmentation, utilizing coarse segmentation labels exclusively during training. STAINDIFFUSER generates high-quality virtual stains for two markers, outperforming over twenty I2I baselines.
苏木精和伊红(H&E)染色被广泛认为是病理学诊断疾病和追踪肿瘤复发的标准。虽然H&E染色能够显示组织结构,但它无法揭示与疾病严重程度和治疗反应相关的特定蛋白质。免疫组织化学(IHC)染色使用抗体来突出这些蛋白质在各自细胞类型上的表达,提高诊断准确性,并辅助药物治疗选择。尽管IHC染色具有重要价值,但它需要额外的时间和资源,因此在某些临床环境中限制了其使用。深度学习领域的最新进展使图像到图像(I2I)翻译成为了一种计算效率高、成本效益好的IHC替代方案。I2I能够数字生成高保真染色转换,可能替代IHC中的手动染色。扩散模型是目前图像生成和条件任务的最新技术,特别适合用于虚拟IHC,因为它们能够生成高质量图像并且对抗模式崩溃。然而,这些模型需要大量多样化的数据集(通常是数百万个样本)才能实现稳健的性能,这在虚拟染色应用中是一个挑战,通常只有数千个样本可用。受多任务深度学习模型在有限数据场景中的成功的启发,我们引入了STAINDIFFUSER,这是一种针对虚拟染色的新型多任务扩散架构,可在较小的数据集上实现收敛。STAINDIFFUSER同时训练两个扩散过程:(a)从H&E图像生成细胞特异性IHC染色;(b)基于H&E进行细胞分割,仅在训练期间使用粗略的分割标签。STAINDIFFUSER为两种标记生成高质量的虚拟染色,并超越了二十多种I2I基线。
论文及项目相关链接
摘要
H&E染色是病理学诊断疾病和追踪肿瘤复发的标准方法,但其无法揭示与疾病严重程度和治疗反应相关的特定蛋白质。免疫组织化学(IHC)染色使用抗体来突出显示这些蛋白质在各自细胞类型上的表达,提高诊断准确性并辅助药物治疗选择。尽管IHC染色有价值,但它需要额外的时间和资源,限制了在某些临床环境中的应用。深度学习领域的最新进展使图像到图像(I2I)翻译成为计算成本低廉的IHC替代方案。I2I技术能够数字生成高保真染色转换,可能取代手动IHC染色。扩散模型是图像生成和条件任务的最新技术,特别适合虚拟IHC,能够产生高质量图像并抵抗模式崩溃。然而,这些模型需要大量多样化的数据集(通常数百万样本)才能实现稳健的性能,这在虚拟染色应用中是一个挑战,通常只有数千个样本可用。受多任务深度学习模型在有限数据场景中的成功启发,我们引入了STAINDIFFUSER,一种针对虚拟染色的多任务扩散架构,可在小型数据集上实现收敛。STAINDIFFUSER同时训练两种扩散过程:从H&E图像生成细胞特异性IHC染色和基于H&E的细胞分割,仅在训练过程中使用粗略的分割标签。STAINDIFFUSER为两个标记生成高质量的虚拟染色,表现优于二十多个I2I基线。
要点
- H&E染色是病理学诊断的标准,但无法揭示特定蛋白质信息。
- IHC染色能揭示蛋白质信息,提高诊断准确性并辅助治疗选择,但操作复杂且成本较高。
- 深度学习中的I2I翻译技术为虚拟IHC提供了计算成本低廉的替代方案。
- 扩散模型特别适合虚拟IHC,能产生高质量图像,但在小样本数据下表现受限。
- STAINDIFFUSER是一种多任务扩散架构,能在小数据集上实现虚拟染色的收敛。
- STAINDIFFUSER能从H&E图像生成细胞特异性IHC染色并进行细胞分割。
点此查看论文截图