⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-05-22 更新
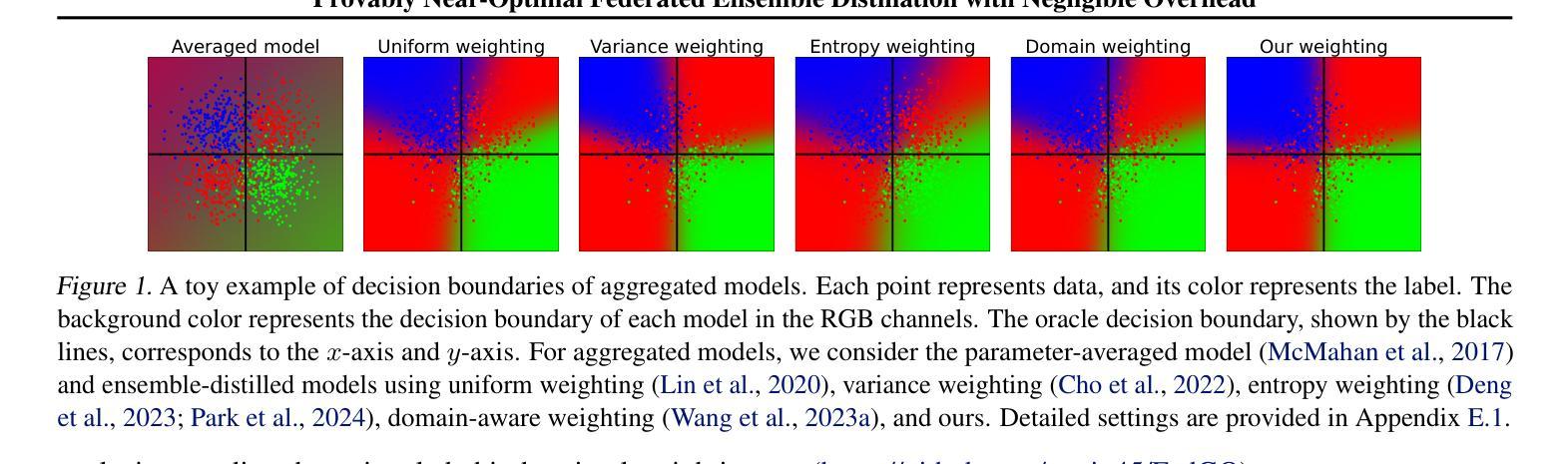
Provably Near-Optimal Federated Ensemble Distillation with Negligible Overhead
Authors:Won-Jun Jang, Hyeon-Seo Park, Si-Hyeon Lee
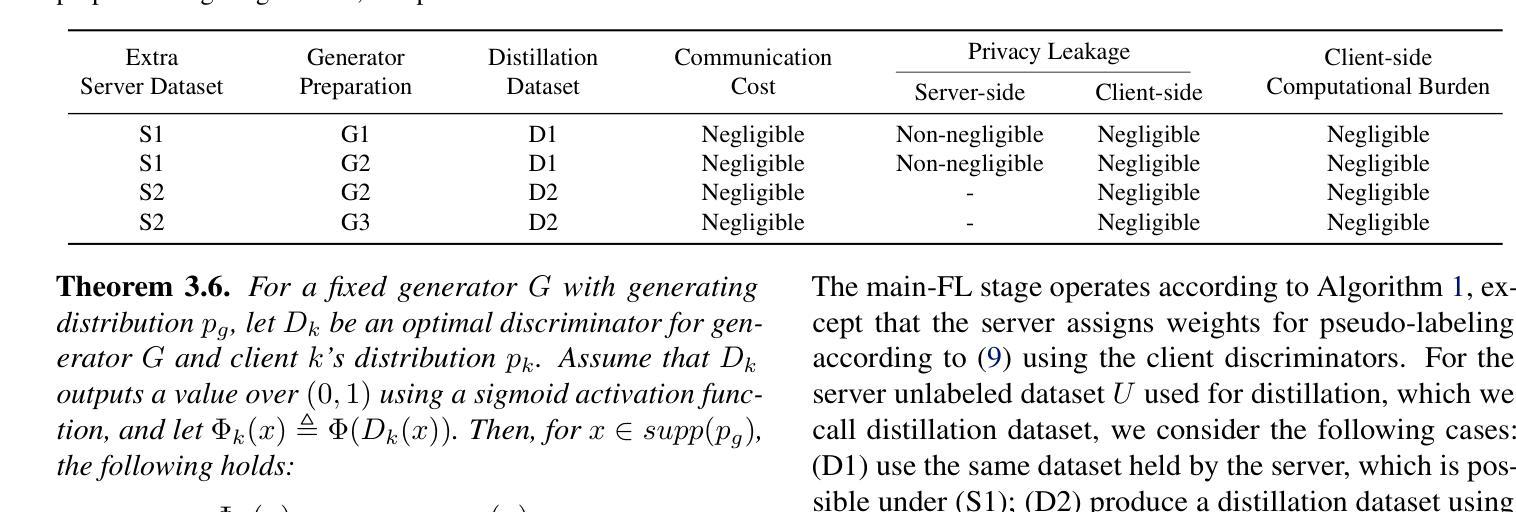
Federated ensemble distillation addresses client heterogeneity by generating pseudo-labels for an unlabeled server dataset based on client predictions and training the server model using the pseudo-labeled dataset. The unlabeled server dataset can either be pre-existing or generated through a data-free approach. The effectiveness of this approach critically depends on the method of assigning weights to client predictions when creating pseudo-labels, especially in highly heterogeneous settings. Inspired by theoretical results from GANs, we propose a provably near-optimal weighting method that leverages client discriminators trained with a server-distributed generator and local datasets. Our experiments on various image classification tasks demonstrate that the proposed method significantly outperforms baselines. Furthermore, we show that the additional communication cost, client-side privacy leakage, and client-side computational overhead introduced by our method are negligible, both in scenarios with and without a pre-existing server dataset.
联邦集成蒸馏技术通过为未标记的服务器数据集生成伪标签来解决客户端异构性问题。这些伪标签是基于客户端预测生成的,并使用伪标记数据集训练服务器模型。未标记的服务器数据集可以是预先存在的,也可以通过无数据方法生成。该方法的有效性在生成伪标签时为客户端预测分配权重的方法上严重依赖,特别是在高度异构的环境中。受生成对抗网络(GANs)理论结果的启发,我们提出了一种可证明近似最优的加权方法,该方法利用与服务器分布式生成器和本地数据集一起训练的客户端鉴别器。我们在各种图像分类任务上的实验表明,该方法显著优于基线。此外,我们证明,无论是否存在预先存在的服务器数据集,该方法引入的额外通信成本、客户端隐私泄露和客户端计算开销都是微不足道的。
论文及项目相关链接
PDF Accepted (Poster) at ICML 2025
Summary
联邦集成蒸馏通过基于客户端预测为无标签的服务器端数据集生成伪标签,并使用伪标签数据集训练服务器端模型,从而解决客户端异构性问题。该方法的有效性关键在于在创建伪标签时为客户端预测分配权重的方法,特别是在高度异构的环境中。受生成对抗网络(GANs)的理论结果的启发,我们提出了一种利用服务器分布式生成器和本地数据集训练的客户端鉴别器进行近优权重分配的方案。实验表明,在各种图像分类任务上,该方法显著优于基线方法。此外,我们的方法在有无预存的服务器端数据集的情况下,额外通信成本、客户端隐私泄露和客户端计算开销均可忽略不计。
Key Takeaways
- 联邦集成蒸馏通过生成伪标签解决客户端异构性问题。
- 伪标签是基于客户端预测生成的,用于训练服务器模型。
- 分配客户端预测权重的方法在创建伪标签时至关重要,特别是在高度异构的环境中。
- 受GANs理论结果的启发,提出了一种近优的权重分配方案。
- 实验证明该方法在各种图像分类任务上显著优于基线。
- 该方法的额外通信成本、客户端隐私泄露和计算开销较小。
点此查看论文截图



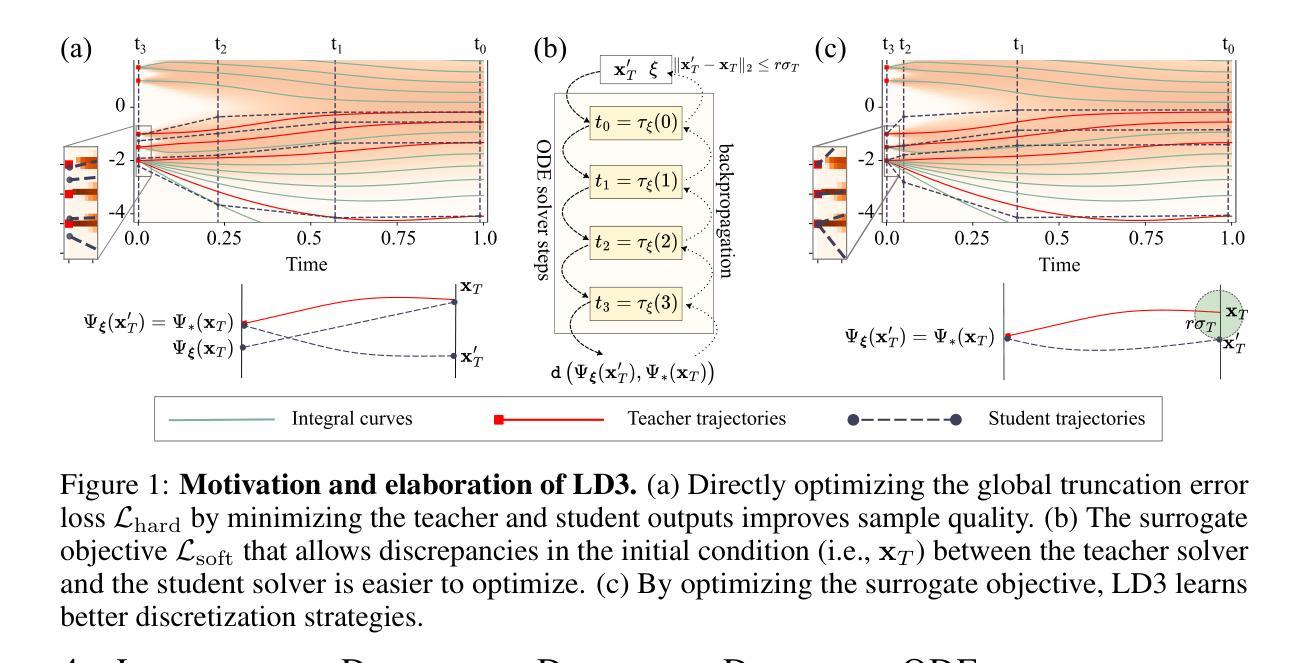
Learning to Discretize Denoising Diffusion ODEs
Authors:Vinh Tong, Hoang Trung-Dung, Anji Liu, Guy Van den Broeck, Mathias Niepert
Diffusion Probabilistic Models (DPMs) are generative models showing competitive performance in various domains, including image synthesis and 3D point cloud generation. Sampling from pre-trained DPMs involves multiple neural function evaluations (NFEs) to transform Gaussian noise samples into images, resulting in higher computational costs compared to single-step generative models such as GANs or VAEs. Therefore, reducing the number of NFEs while preserving generation quality is crucial. To address this, we propose LD3, a lightweight framework designed to learn the optimal time discretization for sampling. LD3 can be combined with various samplers and consistently improves generation quality without having to retrain resource-intensive neural networks. We demonstrate analytically and empirically that LD3 improves sampling efficiency with much less computational overhead. We evaluate our method with extensive experiments on 7 pre-trained models, covering unconditional and conditional sampling in both pixel-space and latent-space DPMs. We achieve FIDs of 2.38 (10 NFE), and 2.27 (10 NFE) on unconditional CIFAR10 and AFHQv2 in 5-10 minutes of training. LD3 offers an efficient approach to sampling from pre-trained diffusion models. Code is available at https://github.com/vinhsuhi/LD3.
扩散概率模型(DPMs)是一类在各种领域表现出竞争力的生成模型,包括图像合成和3D点云生成。从预训练的DPMs中进行采样,需要通过多次神经网络功能评估(NFEs)将高斯噪声样本转换为图像,这导致与一次性生成模型(如GANs或VAEs)相比,计算成本更高。因此,在保持生成质量的同时减少NFE的数量是至关重要的。为了解决这个问题,我们提出了LD3,这是一个轻量级的框架,旨在学习采样的最佳时间离散化。LD 可以用在各种采样器上,可以在不重新训练资源密集型的神经网络的情况下一致地提高生成质量。我们通过分析和实证证明,LD3可以提高采样效率,并且计算开销较小。我们在七个预训练模型上进行了大量实验,涵盖了像素空间和潜在空间DPMs的无条件采样和条件采样。我们在无条件CIFAR10和AFHQv2上实现了FID 2.38(使用有限的10个NFE),并且训练时间仅为五分钟至十分钟。LD3提供了一种从预训练的扩散模型中进行高效采样的方法。代码可在 https://github.com/vinhsuhi/LD3 获得。
论文及项目相关链接
Summary
DPM(扩散概率模型)在各领域表现出优秀的生成性能,包括图像合成和3D点云生成。但采样过程涉及多次神经网络功能评估(NFE),计算成本较高。为此,提出LD3这一轻量级框架,旨在学习采样最优时间离散化。LD3可结合各种采样器,在不重新训练资源密集型神经网络的情况下提高生成质量。分析表明,LD3能提高采样效率且计算开销较小。在7个预训练模型上进行实验验证,无条件与条件采样的像素空间和潜在空间DPM均取得良好效果。
Key Takeaways
1. DPMs展现出色的生成性能,但采样过程的计算成本较高。
2. LD3框架旨在减少DPM采样的NFE次数,同时保持生成质量。
3. LD3可结合各种采样器使用,无需重新训练神经网络。
4. LD3通过学习和优化时间离散化来提高采样效率。
5. LD3在多种预训练模型上验证有效,包括无条件与条件采样的像素空间和潜在空间DPM。
6. LD3方法在CIFAR10和AFHQv2上的无条件采样取得了良好效果,实验结果显示FID值为2.38(10 NFE)和2.27(10 NFE)。
点此查看论文截图