⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-05-22 更新
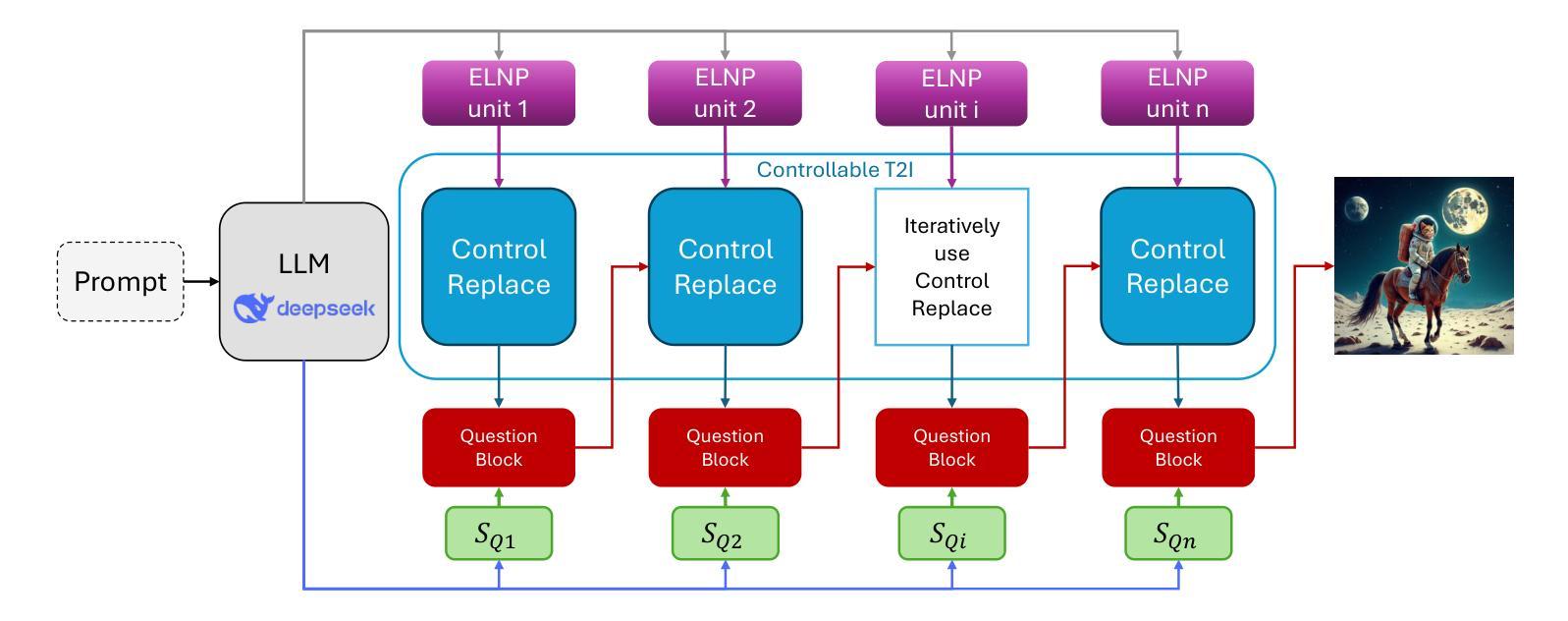
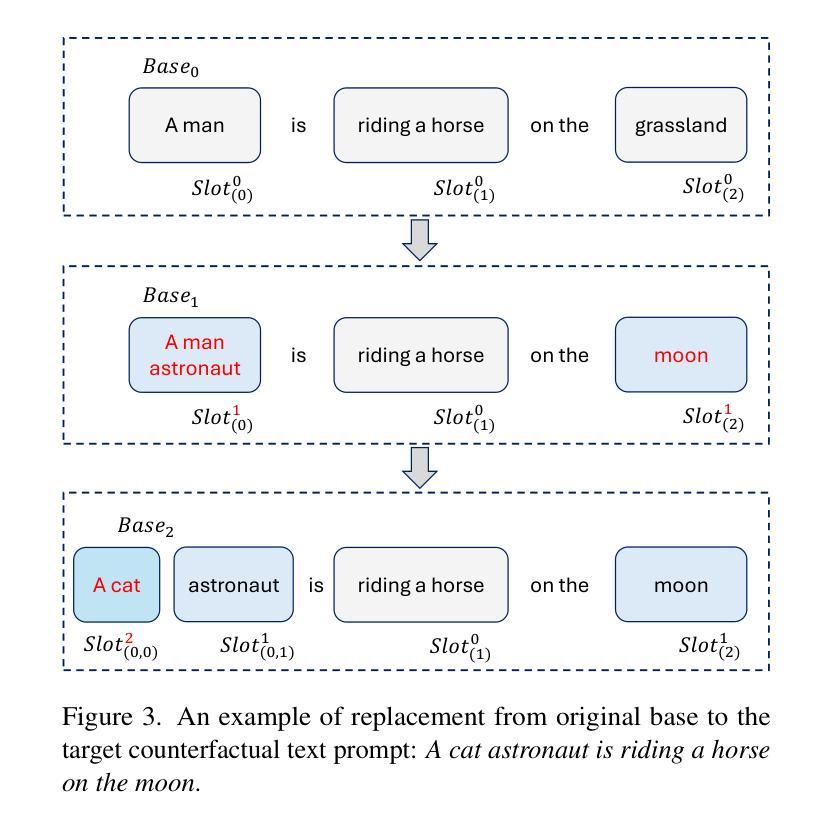
Replace in Translation: Boost Concept Alignment in Counterfactual Text-to-Image
Authors:Sifan Li, Ming Tao, Hao Zhao, Ling Shao, Hao Tang
Text-to-Image (T2I) has been prevalent in recent years, with most common condition tasks having been optimized nicely. Besides, counterfactual Text-to-Image is obstructing us from a more versatile AIGC experience. For those scenes that are impossible to happen in real world and anti-physics, we should spare no efforts in increasing the factual feel, which means synthesizing images that people think very likely to be happening, and concept alignment, which means all the required objects should be in the same frame. In this paper, we focus on concept alignment. As controllable T2I models have achieved satisfactory performance for real applications, we utilize this technology to replace the objects in a synthesized image in latent space step-by-step to change the image from a common scene to a counterfactual scene to meet the prompt. We propose a strategy to instruct this replacing process, which is called as Explicit Logical Narrative Prompt (ELNP), by using the newly SoTA language model DeepSeek to generate the instructions. Furthermore, to evaluate models’ performance in counterfactual T2I, we design a metric to calculate how many required concepts in the prompt can be covered averagely in the synthesized images. The extensive experiments and qualitative comparisons demonstrate that our strategy can boost the concept alignment in counterfactual T2I.
文本转图像(T2I)近年来备受关注,大多数常规任务都已得到很好的优化。此外,反事实文本转图像阻碍了我们获得更加通用的AIGC体验。对于那些不可能在现实中发生并且反物理的场景,我们应该不遗余力地增强事实感,这意味着合成人们认为很可能发生的图像,以及概念对齐,这意味着所有所需的对象都应在同一帧中。本文中,我们重点关注概念对齐。由于可控的T2I模型在真实应用方面已取得了令人满意的效果,我们利用这项技术在潜在空间内逐步替换合成图像中的对象,从而将图像从常见场景转变为符合提示的反事实场景。我们提出了一种指导此替换过程的策略,称为明确逻辑叙事提示(ELNP),并使用最新的SoTA语言模型DeepSeek来生成指令。此外,为了评估模型在反事实T2I中的性能,我们设计了一个指标,来计算合成图像中平均能覆盖提示中多少必要概念。大量的实验和定性比较表明,我们的策略可以提高反事实T2I中的概念对齐。
论文及项目相关链接
Summary
文本到图像(T2I)近年盛行,常规任务优化良好。针对反事实T2I,需提高真实感和概念对齐。本文利用可控T2I模型,在潜在空间逐步替换图像中的对象,从常见场景转变为符合提示的反场景。提出名为Explicit Logical Narrative Prompt(ELNP)的策略来指导替换过程,并使用最新的SoTA语言模型DeepSeek生成指令。设计评估指标来衡量合成图像对提示中所需概念的覆盖程度。实验和定性对比证明,此策略能提高反事实T2I的概念对齐能力。
Key Takeaways
- T2I技术近年得到广泛应用和优化,尤其在常规任务上。
- 反事实T2I是一个挑战,需要提高合成图像的真实感和概念对齐。
- 本文利用可控T2I模型在潜在空间逐步替换图像对象,创造符合提示的反场景。
- 提出ELNP策略来指导替换过程,使用DeepSeek语言模型生成指令。
- 设计了评估指标来衡量合成图像对提示中概念的覆盖程度。
- 实验和对比证明,该策略能提高反事实T2I在概念对齐方面的性能。
点此查看论文截图



Towards Generating Realistic Underwater Images
Authors:Abdul-Kazeem Shamba
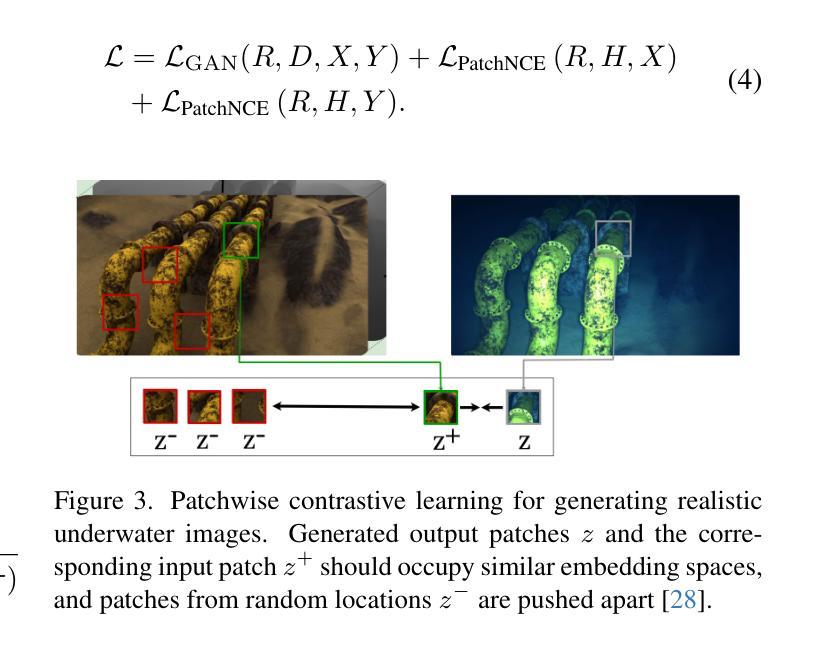
This paper explores the use of contrastive learning and generative adversarial networks for generating realistic underwater images from synthetic images with uniform lighting. We investigate the performance of image translation models for generating realistic underwater images using the VAROS dataset. Two key evaluation metrics, Fr'echet Inception Distance (FID) and Structural Similarity Index Measure (SSIM), provide insights into the trade-offs between perceptual quality and structural preservation. For paired image translation, pix2pix achieves the best FID scores due to its paired supervision and PatchGAN discriminator, while the autoencoder model attains the highest SSIM, suggesting better structural fidelity despite producing blurrier outputs. Among unpaired methods, CycleGAN achieves a competitive FID score by leveraging cycle-consistency loss, whereas CUT, which replaces cycle-consistency with contrastive learning, attains higher SSIM, indicating improved spatial similarity retention. Notably, incorporating depth information into CUT results in the lowest overall FID score, demonstrating that depth cues enhance realism. However, the slight decrease in SSIM suggests that depth-aware learning may introduce structural variations.
本文探讨了使用对比学习和生成对抗网络从均匀光照的合成图像生成逼真水下图像的方法。我们使用VAROS数据集研究图像翻译模型在生成水下图像方面的性能。Fréchet Inception Distance(FID)和结构相似性指数度量(SSIM)两个关键评价指标提供了感知质量和结构保持之间权衡的见解。对于配对图像翻译,pix2pix由于其配对监督和PatchGAN鉴别器而获得了最佳FID分数,而自编码器模型获得了最高的SSIM,这表明尽管输出略显模糊,但其结构保真度更高。在无配对方法中,CycleGAN通过利用循环一致性损失实现了具有竞争力的FID分数,而CUT则通过舍弃循环一致性并引入对比学习来实现更高的SSIM,表明其在空间相似性保持方面有所改进。值得注意的是,将深度信息融入CUT中取得了最低的总体FID分数,这表明深度线索增强了逼真度。然而,SSIM的轻微下降表明深度感知学习可能会引入结构变化。
论文及项目相关链接
Summary
本文探讨了使用对比学习和生成对抗网络(GAN)技术,从合成图像生成具有均匀光照的真实水下图像的方法。研究使用VAROS数据集评估图像翻译模型性能,通过Fréchet Inception Distance(FID)和Structural Similarity Index Measure(SSIM)两个关键评价指标,分析了模型在感知质量和结构保持方面的优劣。结果显示,对于配对图像翻译,pix2pix因配对监督和PatchGAN鉴别器获得最佳FID分数;而在结构相似性方面,自编码器模型表现最佳,尽管其输出略显模糊。对于非配对方法,CycleGAN利用循环一致性损失实现了具有竞争力的FID分数,而采用对比学习替代循环一致性的CUT方法提高了空间相似性保持能力,显示出更高的SSIM。尤其值得关注的是,将深度信息融入CUT后获得了最低FID分数,证明深度线索能增强真实感;但SSIM略有下降,表明深度感知学习可能引入结构变化。
Key Takeaways
- 使用对比学习和生成对抗网络(GAN)技术生成真实水下图像。
- 研究使用VAROS数据集评估图像翻译模型性能。
- 通过FID和SSIM两个关键评价指标分析模型性能。
- 对于配对图像翻译,pix2pix因配对监督和PatchGAN鉴别器获得最佳FID分数。
- 自编码器模型在结构相似性方面表现最佳,但输出略显模糊。
- 非配对方法中的CycleGAN利用循环一致性损失实现了具有竞争力的FID分数。
点此查看论文截图




RoboFAC: A Comprehensive Framework for Robotic Failure Analysis and Correction
Authors:Weifeng Lu, Minghao Ye, Zewei Ye, Ruihan Tao, Shuo Yang, Bo Zhao
Vision-Language-Action (VLA) models have recently advanced robotic manipulation by translating natural-language instructions and image information into sequential control actions. However, these models often underperform in open-world scenarios, as they are predominantly trained on successful expert demonstrations and exhibit a limited capacity for failure recovery. In this work, we present a Robotic Failure Analysis and Correction (RoboFAC) framework to address this issue. Firstly, we construct RoboFAC dataset comprising 9,440 erroneous manipulation trajectories and 78,623 QA pairs across 16 diverse tasks and 53 scenes in both simulation and real-world environments. Leveraging our dataset, we develop RoboFAC model, which is capable of Task Understanding, Failure Analysis and Failure Correction. Experimental results demonstrate that the RoboFAC model outperforms GPT-4o by 34.1% on our evaluation benchmark. Furthermore, we integrate the RoboFAC model into a real-world VLA control pipeline as an external supervision providing correction instructions, yielding a 29.1% relative improvement on average on four real-world tasks. The results show that our RoboFAC framework effectively handles robotic failures and assists the VLA model in recovering from failures.
视觉语言动作(VLA)模型最近通过将自然语言指令和图像信息翻译成连续的控制动作,促进了机器人操作技术的发展。然而,这些模型在开放世界场景下往往表现不佳,因为它们主要基于成功的专家演示进行训练,并且在故障恢复方面能力有限。针对这一问题,我们在工作中提出了机器人故障分析与纠正(RoboFAC)框架。首先,我们构建了RoboFAC数据集,其中包含9440个错误的操作轨迹和78623个问答对,涉及仿真和真实环境中的16个不同任务和53个场景。利用我们的数据集,我们开发了RoboFAC模型,具备任务理解、故障分析和故障纠正能力。实验结果表明,RoboFAC模型在我们的评估基准测试上比GPT-4o高出34.1%。此外,我们将RoboFAC模型集成到真实的VLA控制管道中,作为外部监督提供纠正指令,在四个真实任务上平均相对提高了29.1%。结果表明,我们的RoboFAC框架有效地处理了机器人故障,并帮助VLA模型从故障中恢复。
论文及项目相关链接
Summary
本文介绍了一种名为RoboFAC的机器人故障分析与纠正框架,用于解决Vision-Language-Action(VLA)模型在开放世界场景下性能不足的问题。该框架构建了包含错误操作轨迹和问答对的RoboFAC数据集,并开发了具备任务理解、故障分析和故障纠正能力的RoboFAC模型。实验结果表明,RoboFAC模型在评估指标上优于GPT-4o,且在真实世界VLA控制管道中的集成应用,为机器人操作提供了有效的故障处理与纠正能力。
Key Takeaways
- VLA模型能够将自然语言指令和图像信息转化为连续的控制动作,从而促进机器人的操作。
- 在开放世界场景下,VLA模型存在性能不足的问题,主要因为其主要基于成功的专家演示进行训练,对失败恢复的能力有限。
- 提出了RoboFAC框架来解决这一问题,构建了包含错误操作轨迹和问答对的RoboFAC数据集。
- RoboFAC模型具备任务理解、故障分析和故障纠正的能力。
- 实验结果表明,RoboFAC模型在评估指标上显著优于GPT-4o。
- RoboFAC模型被集成到真实世界的VLA控制管道中,为机器人操作提供了外部监督与纠正指令。
点此查看论文截图




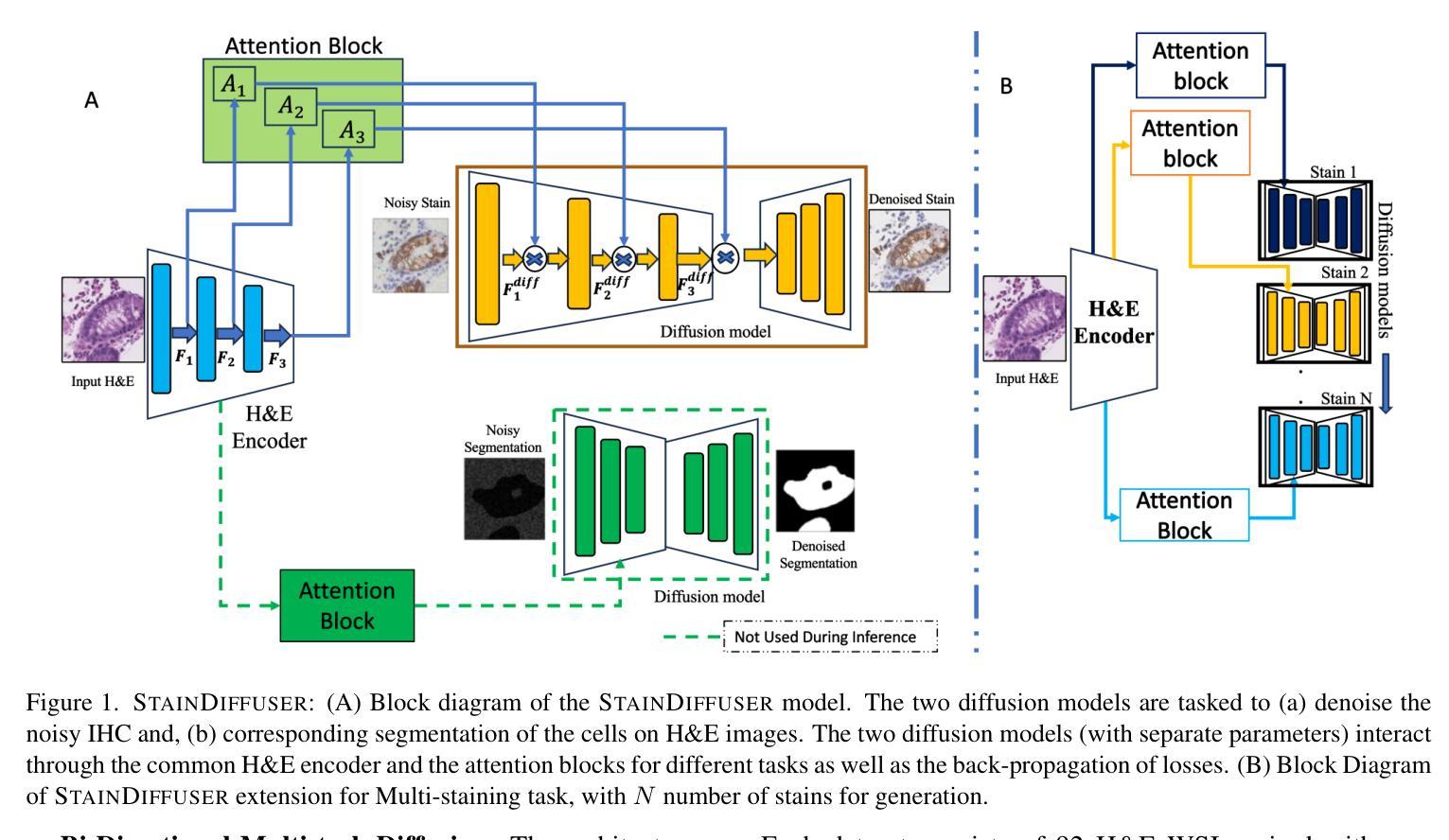
StainDiffuser: MultiTask Dual Diffusion Model for Virtual Staining
Authors:Tushar Kataria, Beatrice Knudsen, Shireen Y. Elhabian
Hematoxylin and Eosin (H&E) staining is widely regarded as the standard in pathology for diagnosing diseases and tracking tumor recurrence. While H&E staining shows tissue structures, it lacks the ability to reveal specific proteins that are associated with disease severity and treatment response. Immunohistochemical (IHC) stains use antibodies to highlight the expression of these proteins on their respective cell types, improving diagnostic accuracy, and assisting with drug selection for treatment. Despite their value, IHC stains require additional time and resources, limiting their utilization in some clinical settings. Recent advances in deep learning have positioned Image-to-Image (I2I) translation as a computational, cost-effective alternative for IHC. I2I generates high fidelity stain transformations digitally, potentially replacing manual staining in IHC. Diffusion models, the current state of the art in image generation and conditional tasks, are particularly well suited for virtual IHC due to their ability to produce high quality images and resilience to mode collapse. However, these models require extensive and diverse datasets (often millions of samples) to achieve a robust performance, a challenge in virtual staining applications where only thousands of samples are typically available. Inspired by the success of multitask deep learning models in scenarios with limited data, we introduce STAINDIFFUSER, a novel multitask diffusion architecture tailored to virtual staining that achieves convergence with smaller datasets. STAINDIFFUSER simultaneously trains two diffusion processes: (a) generating cell specific IHC stains from H&E images and (b) performing H&E based cell segmentation, utilizing coarse segmentation labels exclusively during training. STAINDIFFUSER generates high-quality virtual stains for two markers, outperforming over twenty I2I baselines.
哈氏苏木素和伊红染色(H&E染色)被广泛认为是病理学诊断疾病和追踪肿瘤复发的标准。虽然H&E染色可以显示组织结构,但它无法揭示与疾病严重程度和治疗反应相关的特定蛋白质。免疫组织化学(IHC)染色使用抗体来突出这些蛋白质在各自细胞类型上的表达,提高诊断准确性,并辅助药物治疗选择。尽管其价值很高,但IHC染色需要额外的时间和资源,这在某些临床环境中限制了其使用。深度学习领域的最新进展使图像到图像(I2I)翻译成为了一种计算成本效益高的IHC替代方案。I2I能够以数字方式生成高保真染色转换,可能会替代IHC中的手动染色。扩散模型是图像生成和条件任务的最新技术,特别适合用于虚拟IHC,因为它们能够产生高质量图像并抵抗模式崩溃。然而,这些模型需要广泛且多样的数据集(通常是数百万个样本)才能达到稳健的性能,这在虚拟染色应用中是一个挑战,通常只有数千个样本可用。受多任务深度学习模型在有限数据场景中的成功的启发,我们引入了STAINDIFFUSER,这是一种针对虚拟染色定制的新型多任务扩散架构,可在小型数据集上实现收敛。STAINDIFFUSER同时训练两个扩散过程:(a)从H&E图像生成细胞特异性IHC染色;(b)基于H&E进行细胞分割,仅在训练期间使用粗略的分割标签。STAINDIFFUSER为两个标记生成高质量的虚拟染色,并超越了二十多个I2I基线。
论文及项目相关链接
Summary
在病理学诊断疾病和追踪肿瘤复发方面,H&E染色是广泛应用的标准方法,但其无法揭示与疾病严重程度和治疗反应相关的特定蛋白质。免疫组织化学(IHC)染色使用抗体来突出显示这些蛋白质在各自细胞类型中的表达,提高诊断准确性并辅助药物治疗选择。然而,IHC染色需要额外的时间和资源,这在某些临床环境中限制了其应用。最近深度学习的进步使图像到图像(I2I)翻译成为一种计算效率高、成本效益好的IHC替代方案。I2I能够数字生成高保真染色转化,可能取代手动IHC染色。受多任务深度学习模型在有限数据场景中的成功的启发,我们引入了STAINDIFFUSER,这是一种针对虚拟染色的新型多任务扩散架构,可在较小的数据集上实现收敛。STAINDIFFUSER同时训练两个扩散过程:从H&E图像生成细胞特异性IHC染色和基于H&E的细胞分割,在训练过程中仅使用粗略的分割标签。STAINDIFFUSER为两个标记生成高质量的虚拟染色,并超越了二十多个I2I基线。
Key Takeaways
- H&E染色是病理学诊断的常用方法,但无法揭示特定蛋白质的表达信息。
- 免疫组织化学(IHC)染色能提高诊断准确性并辅助治疗选择,但需要额外的时间和资源。
- 深度学习中的图像到图像(I2I)翻译技术为虚拟染色提供了计算高效、成本效益高的替代方案。
- 扩散模型是图像生成和条件任务的最新技术,特别适合用于虚拟IHC染色。
- 虚拟染色应用中的数据挑战可通过多任务深度学习模型解决,例如STAINDIFFUSER,它能够在较小的数据集上实现收敛并生成高质量的虚拟染色。
- STAINDIFFUSER同时执行从H&E图像生成细胞特异性IHC染色和基于H&E的细胞分割任务。
点此查看论文截图