⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-05-22 更新
Beyond Words: Multimodal LLM Knows When to Speak
Authors:Zikai Liao, Yi Ouyang, Yi-Lun Lee, Chen-Ping Yu, Yi-Hsuan Tsai, Zhaozheng Yin
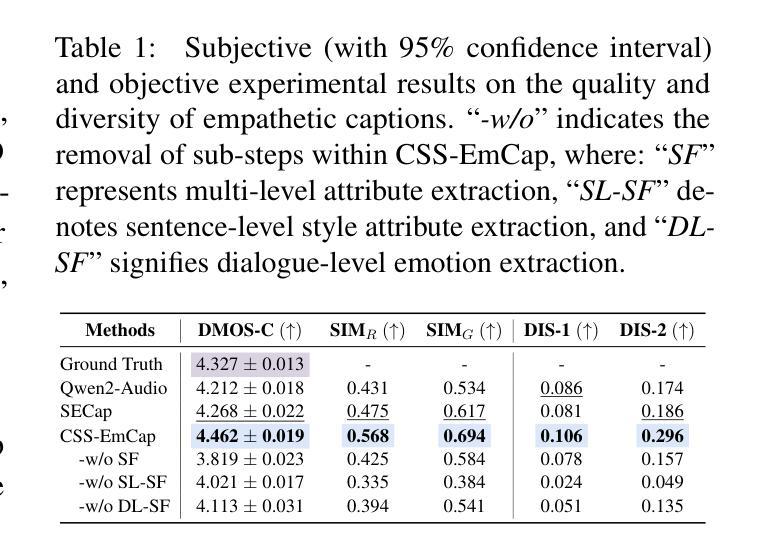
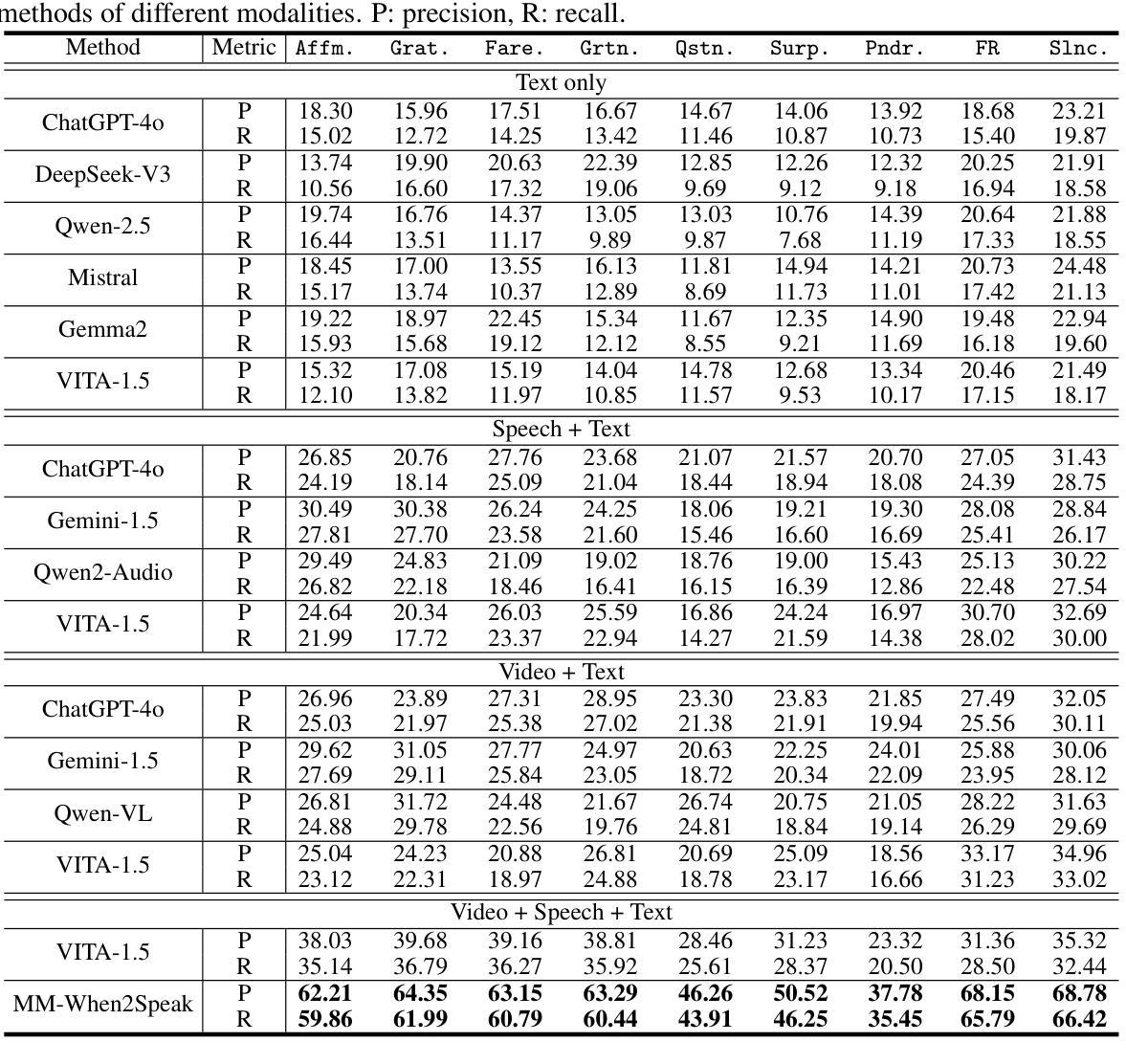
While large language model (LLM)-based chatbots have demonstrated strong capabilities in generating coherent and contextually relevant responses, they often struggle with understanding when to speak, particularly in delivering brief, timely reactions during ongoing conversations. This limitation arises largely from their reliance on text input, lacking the rich contextual cues in real-world human dialogue. In this work, we focus on real-time prediction of response types, with an emphasis on short, reactive utterances that depend on subtle, multimodal signals across vision, audio, and text. To support this, we introduce a new multimodal dataset constructed from real-world conversational videos, containing temporally aligned visual, auditory, and textual streams. This dataset enables fine-grained modeling of response timing in dyadic interactions. Building on this dataset, we propose MM-When2Speak, a multimodal LLM-based model that adaptively integrates visual, auditory, and textual context to predict when a response should occur, and what type of response is appropriate. Experiments show that MM-When2Speak significantly outperforms state-of-the-art unimodal and LLM-based baselines, achieving up to a 4x improvement in response timing accuracy over leading commercial LLMs. These results underscore the importance of multimodal inputs for producing timely, natural, and engaging conversational AI.
基于大型语言模型(LLM)的聊天机器人已展现出生成连贯且上下文相关的回复的强大能力,但它们往往难以理解和把握何时应该发言,特别是在持续对话中提供简短、及时的反应。这一局限性主要源于它们对文本输入的依赖,缺乏现实世界中人类对话的丰富上下文线索。在这项工作中,我们专注于实时预测回复类型,重点是在视觉、音频和文本等细微多模式信号的基础上进行的简短、反应性的表述。为此,我们引入了一个新的多模式数据集,该数据集来自现实世界的对话视频,包含时间对齐的视觉、听觉和文本流。该数据集能够对二元互动中的回复时间进行精细建模。基于该数据集,我们提出了MM-When2Speak,这是一个基于多模式LLM的模型,可自适应地整合视觉、听觉和文本上下文,以预测何时应发出响应以及何种类型的响应是恰当的。实验表明,MM-When2Speak显著优于最新的单模式以及LLM基线,在响应时间准确性方面,相较于领先的商业LLM,其性能提高了高达4倍。这些结果突显了多模式输入对于产生及时、自然、引人入胜的会话AI的重要性。
论文及项目相关链接
PDF Project page: https://github.com/lzk901372/MM-When2Speak
Summary
本文探讨了大型语言模型(LLM)在聊天机器人应用中的响应时机问题。尽管LLM能生成连贯且语境相关的回应,但它们往往难以判断何时发言,特别是在进行中的对话中提供简短、及时的反应。为解决这一问题,本文专注于实时响应类型的预测,特别是依赖于视觉、音频和文本等多模式信号的简短、反应性话语。为此,引入了一个新构建的多模式数据集,包含对齐的视听文本流,支持精细粒度的双人互动响应时间建模。在此基础上,提出了MM-When2Speak模型,该模型自适应地整合视觉、听觉和文本上下文,预测何时应该发生反应以及何种类型的反应是恰当的。实验表明,MM-When2Speak在响应时间准确性方面显著优于单模态和LLM基线,达到领先水平。
Key Takeaways
- LLM-based chatbots虽然能生成连贯的回应,但在判断何时发言方面存在困难。
- 此困难主要源于LLM依赖文本输入,缺乏真实世界对话中的丰富上下文线索。
- 引入了一个新构建的多模式数据集,包含对齐的视听文本流,以支持精细粒度的双人互动响应时间建模。
- MM-When2Speak模型被提出,自适应地整合视觉、听觉和文本上下文以预测最佳回应时机和类型。
- MM-When2Speak模型在响应时间准确性方面显著优于单模态和LLM基线。
- 实验结果显示MM-When2Speak相较于领先的商业LLMs达到高达4倍的响应时间准确性提升。
点此查看论文截图


Listen, Analyze, and Adapt to Learn New Attacks: An Exemplar-Free Class Incremental Learning Method for Audio Deepfake Source Tracing
Authors:Yang Xiao, Rohan Kumar Das
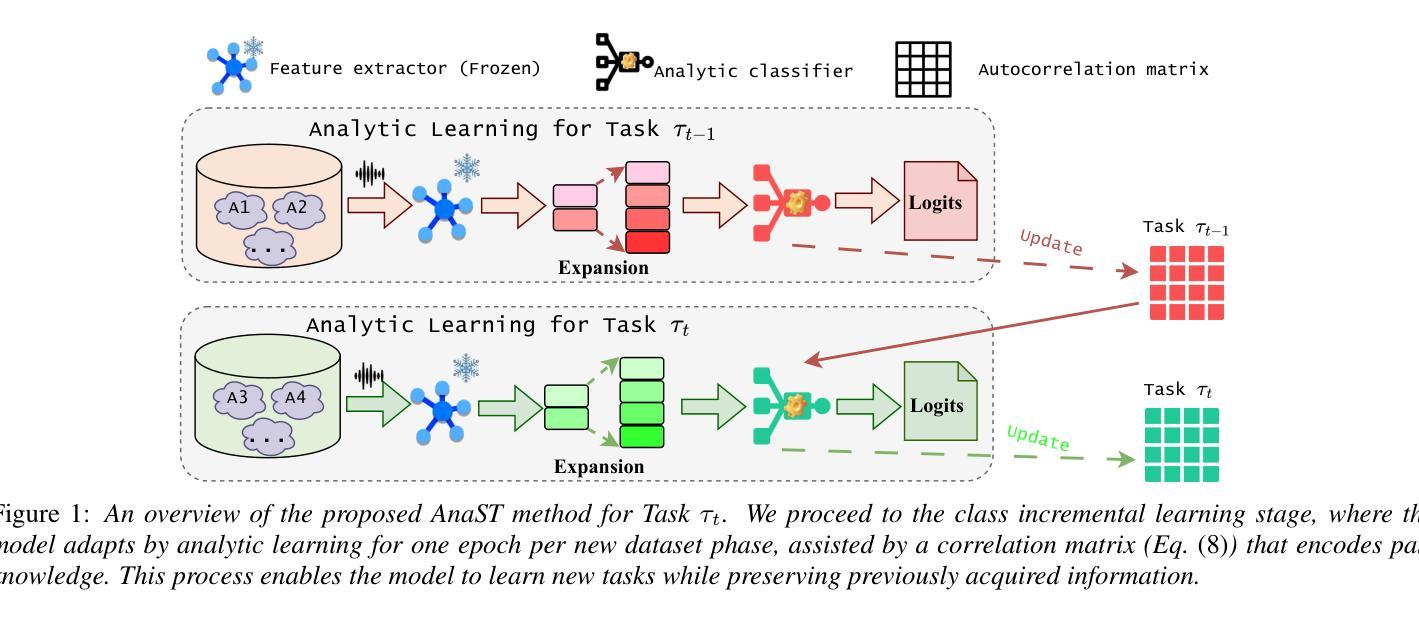
As deepfake speech becomes common and hard to detect, it is vital to trace its source. Recent work on audio deepfake source tracing (ST) aims to find the origins of synthetic or manipulated speech. However, ST models must adapt to learn new deepfake attacks while retaining knowledge of the previous ones. A major challenge is catastrophic forgetting, where models lose the ability to recognize previously learned attacks. Some continual learning methods help with deepfake detection, but multi-class tasks such as ST introduce additional challenges as the number of classes grows. To address this, we propose an analytic class incremental learning method called AnaST. When new attacks appear, the feature extractor remains fixed, and the classifier is updated with a closed-form analytical solution in one epoch. This approach ensures data privacy, optimizes memory usage, and is suitable for online training. The experiments carried out in this work show that our method outperforms the baselines.
随着深度伪造语音的普及和难以检测,追溯其来源变得至关重要。关于音频深度伪造源追溯(ST)的最新工作旨在寻找合成或操纵语音的来源。然而,ST模型必须适应学习新的深度伪造攻击,同时保留对之前攻击的知识。一个主要的挑战是灾难性遗忘,即模型失去识别先前学习攻击的能力。一些持续学习方法有助于深度伪造检测,但ST等多类任务随着类别数量的增长引入了额外的挑战。为解决这一问题,我们提出了一种分析类增量学习方法,名为AnaST。当出现新攻击时,特征提取器保持不变,分类器在一个周期内使用封闭式解析解进行更新。这种方法确保了数据隐私,优化了内存使用,并适用于在线培训。本工作进行的实验表明,我们的方法优于基线方法。
论文及项目相关链接
PDF Accepted by Interspeech 2025
Summary
随着深度伪造语音的普及和难以检测,追溯其来源变得至关重要。近期音频深度伪造源头追踪技术旨在寻找合成或操纵语音的来源。然而,ST模型必须在适应学习新的深度伪造攻击的同时保留对旧攻击的知识。一个主要挑战是灾难性遗忘,模型会失去识别旧攻击的能力。一些持续学习方法有助于深度伪造检测,但随着类的数量增长,如ST等多类任务引入了额外的挑战。为解决此问题,我们提出了一种解析类增量学习方法——AnaST。当出现新攻击时,特征提取器保持不变,分类器通过一个封闭形式的解析解在一个周期内进行更新。此方法保证了数据隐私,优化了内存使用,适用于在线训练。实验表明,我们的方法优于基线方法。
Key Takeaways
- 深度伪造语音越来越普遍且难以检测,追溯其源头变得重要。
- 音频深度伪造源头追踪技术旨在寻找合成或操纵语音的来源。
- ST模型面临在适应新深度伪造攻击时保留旧知识的问题。
- 灾难性遗忘是模型面临的一个主要挑战,会导致模型失去识别旧攻击的能力。
- 现有持续学习方法有助于深度伪造检测,但多类任务如ST存在挑战。
- 提出的AnaST方法通过固定特征提取器和快速更新分类器来解决这些问题。
点此查看论文截图

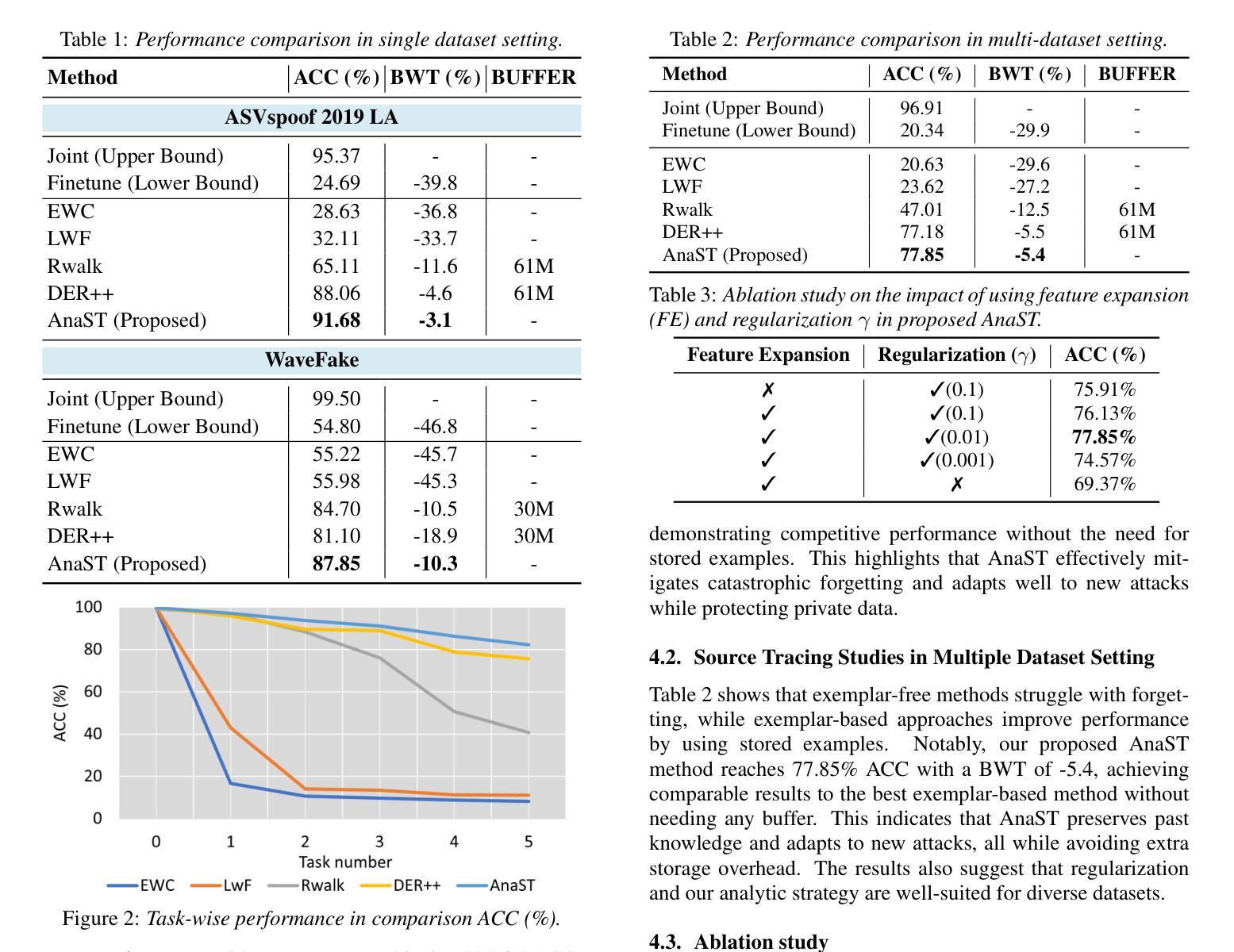
ReactDiff: Latent Diffusion for Facial Reaction Generation
Authors:Jiaming Li, Sheng Wang, Xin Wang, Yitao Zhu, Honglin Xiong, Zixu Zhuang, Qian Wang
Given the audio-visual clip of the speaker, facial reaction generation aims to predict the listener’s facial reactions. The challenge lies in capturing the relevance between video and audio while balancing appropriateness, realism, and diversity. While prior works have mostly focused on uni-modal inputs or simplified reaction mappings, recent approaches such as PerFRDiff have explored multi-modal inputs and the one-to-many nature of appropriate reaction mappings. In this work, we propose the Facial Reaction Diffusion (ReactDiff) framework that uniquely integrates a Multi-Modality Transformer with conditional diffusion in the latent space for enhanced reaction generation. Unlike existing methods, ReactDiff leverages intra- and inter-class attention for fine-grained multi-modal interaction, while the latent diffusion process between the encoder and decoder enables diverse yet contextually appropriate outputs. Experimental results demonstrate that ReactDiff significantly outperforms existing approaches, achieving a facial reaction correlation of 0.26 and diversity score of 0.094 while maintaining competitive realism. The code is open-sourced at \href{https://github.com/Hunan-Tiger/ReactDiff}{github}.
根据说话者的视听剪辑,面部表情生成旨在预测听众的面部表情。挑战在于在平衡适当性、现实性和多样性的同时,捕捉视频和音频之间的相关性。虽然早期的工作主要集中在单模态输入或简化的反应映射上,但最近的方法,如PerFRDiff,已经探索了多模态输入和适当的反应映射的一对多性质。在这项工作中,我们提出了面部反应扩散(ReactDiff)框架,该框架独特地结合了多模态变压器和有条件的潜在空间扩散,以增强反应生成。与现有方法不同,ReactDiff利用类内和类间注意力进行精细的多模态交互,而编码器和解码器之间的潜在扩散过程则使输出多样化,但上下文恰当。实验结果表明,ReactDiff显著优于现有方法,实现了面部反应相关性为0.26,多样性得分为0.094,同时保持竞争力水平的现实性。代码已开源在https://github.com/Hunan-Tiger/ReactDiff。
论文及项目相关链接
Summary
基于音频视觉剪辑的预测听众面部反应的生成是一个挑战,需要捕捉视频和音频之间的相关性,同时平衡适宜性、现实性和多样性。当前方法大多聚焦于单一模态输入或简化的反应映射,而近期如PerFRDiff等方法开始探索多模态输入和适当的反应映射的一对多特性。本研究提出了面部反应扩散(ReactDiff)框架,该框架通过条件扩散潜在空间独特地整合多模态转换器,增强了反应生成能力。不同于现有方法,ReactDiff利用类内和类间注意力进行精细的多模态交互,而编码器和解码器之间的潜在扩散过程则产生了多样且语境恰当的输出。实验结果证明,ReactDiff显著优于现有方法,实现了面部反应相关性0.26和多样性得分0.094,同时保持竞争力水平。代码已开源于GitHub。
Key Takeaways
- 该文本研究的是基于音频视觉剪辑预测听众的面部反应生成问题。
- 面临的主要挑战在于捕捉视频和音频的相关性,同时平衡适宜性、现实性和多样性。
- 当前的方法大多只关注单一模态的输入或简化的反应映射。
- 近期的方法如PerFRDiff开始探索多模态输入和一对多的反应映射特性。
- 本研究提出了面部反应扩散(ReactDiff)框架,通过条件扩散潜在空间整合多模态转换器来增强反应生成能力。
- ReactDiff利用类内和类间注意力进行精细的多模态交互。
点此查看论文截图

Active-Spin-State-Derived Descriptor for Hydrogen Evolution Reaction Catalysis
Authors:Yu Tan, Lei Li, Zi-Xuan Yang, Tao Huang, Qiao-Ling Wang, Tao Zhang, Jing-Chun Luo, Gui-Fang Huang, Wangyu Hu, Wei-Qing Huang
Spin states are pivotal in modulating the electrocatalytic activity of transition-metal (TM)-based compounds, yet quantitatively evaluating the activity-spin state correlation remains a formidable challenge. Here, we propose an ‘activity index n’ as a descriptor, to assess the activity of the spin states for the hydrogen evolution reaction (HER). n descriptor integrates three key electronic parameters: the proportion (P), broadening range (R) and center cc of active spin state, which collectively account for the electronic structure modulation induced by both the intrinsic active site and its local coordination environment. Using 1T-phase ZrSe2-anchored TM atoms (TM=Sc to Ni) as prototypes, we reveal that the correlation between Gibbs free energy and the n value follows a linear relation, namely, the vGH reduces as the n decreases. Notably, ZrSe2-Mn exhibits the optimal n value (-0.56), corresponding the best HER activity with a vGH of 0.04 eV closer to the thermoneutral ideal value (0 eV) than even Pt (vGH = -0.09 eV). This relationship suggests that n is the effective descriptor of active spin state for HER of TM-based catalysts. Our study brings fundamental insights into the HER activity-spin state correlation, offering new strategies for HER catalyst design.
自旋态在调节过渡金属(TM)基化合物的电催化活性中起着关键作用,然而,定量评估活性与自旋态之间的关联仍然是一项艰巨的挑战。在这里,我们提出一个“活性指数n”作为描述符,来评估自旋态对析氢反应(HER)的活性。n描述符集成了三个关键的电子参数:自旋态的比例(P)、扩展范围(R)和中心cc,它们共同反映了由固有活性位点及其局部配位环境引起的电子结构调制。以1T相ZrSe2锚定的TM原子(TM=Sc至Ni)为原型,我们发现吉布斯自由能与n值之间的相关性遵循线性关系,即随着n值的减小,vGH降低。值得注意的是,ZrSe2-Mn表现出最佳的n值(-0.56),对应的HER活性最佳,其vGH为0.04 eV,比铂(vGH=-0.09 eV)更接近热中性理想值(0 eV)。这种关系表明n是TM基催化剂HER活性的有效自旋态描述符。我们的研究深入探讨了HER活性与自旋态之间的关联,为HER催化剂的设计提供了新的策略。
论文及项目相关链接
PDF 17 pages, 5 figures
Summary
本文提出使用“活性指数n”作为描述符,评估过渡金属(TM)基化合物中自旋态对析氢反应(HER)的活性影响。该n描述符集成了三个关键电子参数,即活性自旋态的比例(P)、范围(R)和中心(cc),这些参数共同反映了由内在活性位点和其局部配位环境引起的电子结构变化。研究以1T相ZrSe2锚定的TM原子(TM为Sc至Ni)为原型,揭示了Gibbs自由能与n值之间的线性关系,即随着n值的减小,vGH降低。其中,ZrSe2-Mn具有最佳的n值(-0.56),对应的HER活性最好,vGH接近理想热力学值(接近零),甚至比铂更为优越。这表明n是TM基催化剂用于HER的自旋状态活性的有效描述符。本文对于HER活性与自旋状态关系的研究,为催化剂设计提供了新的策略。
Key Takeaways
- 提出使用“活性指数n”作为描述符评估过渡金属基化合物中自旋态对HER的活性影响。
- n描述符集成了比例(P)、范围(R)和中心(cc)三个关键电子参数。
- 研究表明,活性自旋态的n值与Gibbs自由能之间存在线性关系。
- ZrSe2-Mn具有最佳的n值,表现出出色的HER活性,其vGH接近理想热力学值。
- n值可以作为评估过渡金属基催化剂在HER中活性自旋状态的有效描述符。
- 研究结果揭示了HER活性与自旋状态之间的关联,为催化剂设计提供了新的视角和策略。
点此查看论文截图

Magnetic field-enhanced oxygen reduction reaction for electrochemical hydrogen peroxide production with different cerium oxide nanostructures
Authors:Caio Machado Fernandes, Aila O. Santos, Vanessa S. Antonin, Joao Paulo C. Moura, Aline B. Trench, Odivaldo C. Alves, Yutao Xing, Julio Cesar M. Silva, Mauro C. Santos
We investigated cerium oxide nanoparticles of various morphologies (nanosheets, nanocubes, and nanoparticles) supported on carbon Vulcan XC-72 for the two-electron oxygen reduction reaction (ORR). It was used a continuous magnetic field (2000 Oe) for the first time in the literature. The best results were for 5% (w/w) CeO2 for all three different morphologies, more than doubling the ring current, enhancing the hydrogen peroxide selectivity from 51% (Vulcan XC-72) to 84-89%, and modifying the onset potential to lesser negative values. The presence of the magnetic field led to even higher ring currents with 5% (w/w) CeO$_2$, H$_2$O$_2$ selectivity from 54% (Vulcan XC-72) to 88-96% and changing even more the onset potential. Those results were correlated with the Zeeman effect, the Lorentz force, generating magnetohydrodynamic effects, the Kelvin force, and the formation of Bound Magnetic Polarons. This pioneering research introduces an innovative approach, highlighting the potential of an external continuous magnetic field.
我们研究了不同形态(纳米片、纳米立方体和纳米颗粒)的氧化铈纳米粒子在碳质载体(Vulcan XC-72)上对两电子氧还原反应(ORR)的应用。在文献中首次使用了连续磁场(2000 Oe)。对于所有三种不同形态的氧化铈,负载量为5%(w/w)时效果最佳,环电流增加了一倍以上,过氧化氢选择性从51%(Vulcan XC-72)提高到84-89%,起始电位改为更低的负值。磁场的存在使得负载量为5%(w/w)的CeO₂的环电流更高,过氧化氢选择性从54%(Vulcan XC-72)提升到88-96%,起始电位发生了更多变化。这些结果与塞曼效应、洛伦兹力产生磁流体动力学效应、开尔文力和束缚磁极化子的形成有关。这项开创性的研究引入了一种创新方法,突出了外部连续磁场的应用潜力。
论文及项目相关链接
Summary
研究了不同形态(纳米片、纳米立方体和纳米颗粒)的氧化铈纳米粒子在碳质材料Vulcan XC-72上的二电子氧还原反应(ORR)。首次使用连续磁场(2000 Oe),最佳结果来自所有三种形态的5%(w/w)CeO₂,其环电流加倍,过氧化氢选择性从Vulcan XC-72的51%提高到84%~89%,且启动电位降低到较小的负值。连续磁场导致具有更大电流性能的结果提升到了较高的范围,过氧化氢选择性从Vulcan XC-72的54%~88%~96%,启动电位也有较大变化。这些结果与塞曼效应等密切相关。此研究首次使用连续磁场表明未来应用的潜力巨大。
Key Takeaways
点此查看论文截图

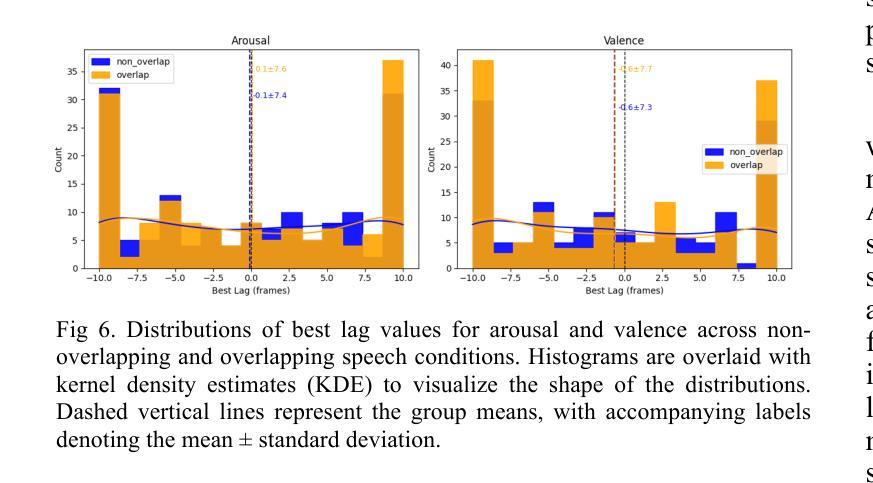
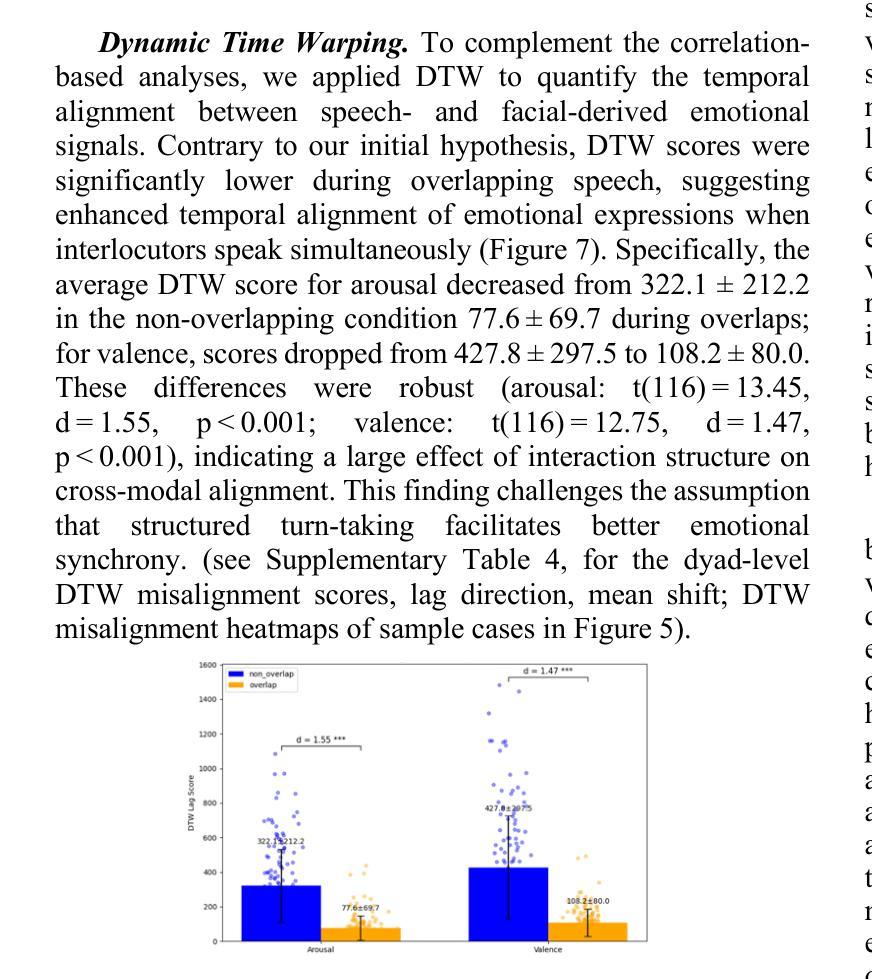
Exploring Emotional Synchrony in Dyadic Interactions: The Role of Speech Conditions in Facial and Vocal Affective Alignment
Authors:Von Ralph Dane Marquez Herbuela, Yukie Nagai
Understanding how humans express and synchronize emotions across multiple communication channels particularly facial expressions and speech has significant implications for emotion recognition systems and human computer interaction. Motivated by the notion that non-overlapping speech promotes clearer emotional coordination, while overlapping speech disrupts synchrony, this study examines how these conversational dynamics shape the spatial and temporal alignment of arousal and valence across facial and vocal modalities. Using dyadic interactions from the IEMOCAP dataset, we extracted continuous emotion estimates via EmoNet (facial video) and a Wav2Vec2-based model (speech audio). Segments were categorized based on speech overlap, and emotional alignment was assessed using Pearson correlation, lag adjusted analysis, and Dynamic Time Warping (DTW). Across analyses, non overlapping speech was associated with more stable and predictable emotional synchrony than overlapping speech. While zero-lag correlations were low and not statistically different, non overlapping speech showed reduced variability, especially for arousal. Lag adjusted correlations and best-lag distributions revealed clearer, more consistent temporal alignment in these segments. In contrast, overlapping speech exhibited higher variability and flatter lag profiles, though DTW indicated unexpectedly tighter alignment suggesting distinct coordination strategies. Notably, directionality patterns showed that facial expressions more often preceded speech during turn-taking, while speech led during simultaneous vocalizations. These findings underscore the importance of conversational structure in regulating emotional communication and provide new insight into the spatial and temporal dynamics of multimodal affective alignment in real world interaction.
了解人类如何通过多个沟通渠道,特别是面部表情和言语来表达和同步情绪,对于情绪识别系统和人机交互具有重要影响。受非重叠语能促进更清晰的情感协调,而重叠语会破坏同步性的观点启发,本研究探讨了这些对话动态如何影响面部和声音模态的兴奋和效价的时空对齐。我们使用了IEMOCAP数据集中的二元互动,通过EmoNet(面部视频)和基于Wav2Vec2的模型(语音音频)提取了连续的情绪估计值。根据语音重叠情况对片段进行分类,并使用Pearson相关性、滞后调整分析和动态时间弯曲(DTW)来评估情感对齐情况。综合分析表明,在非重叠语音中,情感同步更加稳定和可预测,而重叠语音则表现出较高的可变性和较平坦的滞后分布。尽管DTW意外地显示出更紧密的对齐,表明存在不同的协调策略,但总体而言,非重叠语音与更清晰的情感同步有关。值得注意的是,方向性模式显示,在轮流发言时,面部表情通常先于言语,而在同时发声时,则是言语领先。这些发现强调了对话结构在调节情感沟通中的重要性,并为现实互动中多模式情感对齐的时空动态提供了新的见解。
论文及项目相关链接
Summary
本文探讨了人类在多通道沟通中如何表达和同步情感,特别是面部表情和言语。研究发现非重叠的言语能够促进更清晰的情感协调,而重叠的言语则会破坏同步性。研究使用IEMOCAP数据集进行交互分析,并基于面部视频和语音音频提取连续情感估计。分析显示,非重叠的言语与更稳定和可预测的情感同步相关,而重叠的言语则表现出更高的可变性和更平坦的滞后分布。此外,还发现面部表情在转向时更常先于言语,而同时发声时则相反。这些发现强调了对话结构在情感沟通中的重要性,并为现实互动中的多模态情感对齐的时空动态提供了新的见解。
Key Takeaways
以下是七个关于该文本的关键见解:
- 人类在多通道沟通中如何表达和同步情感对于情感识别系统和人机交互具有重要意义。
- 非重叠的言语有助于更清晰和同步的情感协调,相较之下,重叠的言语则会破坏情感的同步性。
- 使用IEMOCAP数据集进行交互分析,发现非重叠言语与更稳定和可预测的情感同步相关。
- 使用多种模型对连续情感进行估计,如基于面部视频的EmoNet和基于语音音频的Wav2Vec模型进行情绪判断分析。
- 通过多种方法评估情绪对齐,包括Pearson相关性、滞后调整分析和动态时间弯曲(DTW)。
- 分析显示非重叠言语条件下情感对齐的时空动态更加稳定和一致。
点此查看论文截图


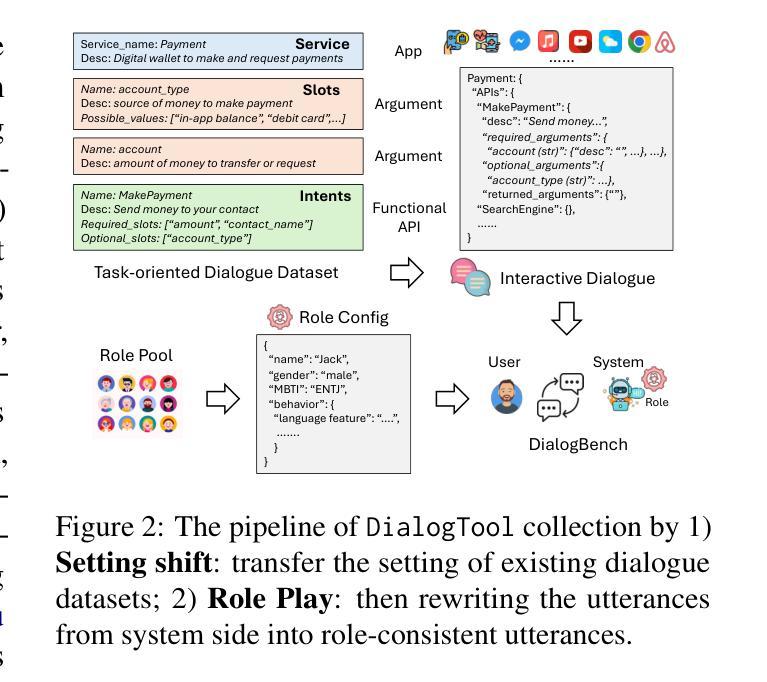
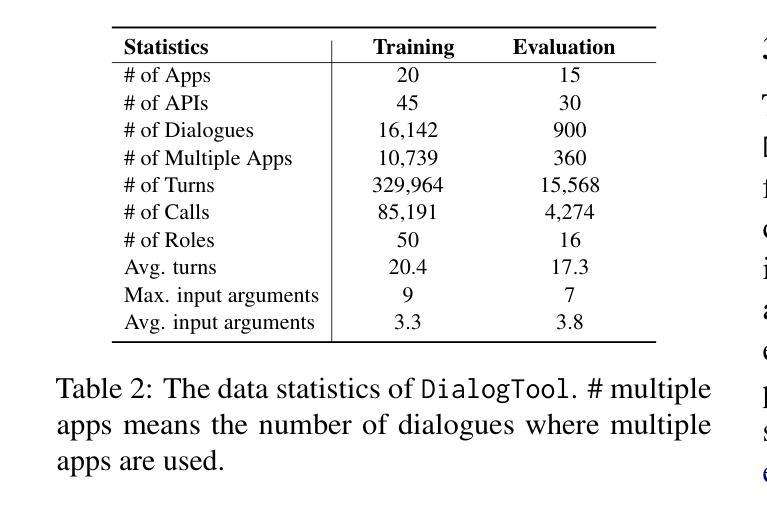
Rethinking Stateful Tool Use in Multi-Turn Dialogues: Benchmarks and Challenges
Authors:Hongru Wang, Wenyu Huang, Yufei Wang, Yuanhao Xi, Jianqiao Lu, Huan Zhang, Nan Hu, Zeming Liu, Jeff Z. Pan, Kam-Fai Wong
Existing benchmarks that assess Language Models (LMs) as Language Agents (LAs) for tool use primarily focus on stateless, single-turn interactions or partial evaluations, such as tool selection in a single turn, overlooking the inherent stateful nature of interactions in multi-turn applications. To fulfill this gap, we propose \texttt{DialogTool}, a multi-turn dialogue dataset with stateful tool interactions considering the whole life cycle of tool use, across six key tasks in three stages: 1) \textit{tool creation}; 2) \textit{tool utilization}: tool awareness, tool selection, tool execution; and 3) \textit{role-consistent response}: response generation and role play. Furthermore, we build \texttt{VirtualMobile} – an embodied virtual mobile evaluation environment to simulate API calls and assess the robustness of the created APIs\footnote{We will use tools and APIs alternatively, there are no significant differences between them in this paper.}. Taking advantage of these artifacts, we conduct comprehensive evaluation on 13 distinct open- and closed-source LLMs and provide detailed analysis at each stage, revealing that the existing state-of-the-art LLMs still cannot perform well to use tools over long horizons.
现有的主要评估语言模型(LMs)作为工具使用语言代理(LAs)的基准测试主要侧重于无状态的单轮交互或部分评估,如单轮中的工具选择,忽略了多轮应用中交互的固有有状态性质。为了填补这一空白,我们提出了
DialogTool',这是一个多轮对话数据集,它考虑了工具使用的整个生命周期中的有状态工具交互,涵盖三个阶段中的六个关键任务:1)工具创建;2)工具利用:工具意识、工具选择、工具执行;以及3)角色一致响应:生成响应和角色扮演。此外,我们建立了VirtualMobile’–一个模拟API调用的嵌入式虚拟移动评估环境,以评估创建的API的稳健性。利用这些工具,我们对13种不同的开源和闭源的大型语言模型进行了全面评估,并在每个阶段进行了详细分析,揭示现有的最先进的大型语言模型仍然不能在长期内很好地使用工具。
论文及项目相关链接
Summary
该文针对现有评估语言模型作为工具使用代理的基准测试进行了补充。现有基准测试主要关注无状态、单回合的互动或部分评估,如单一回合中的工具选择,忽略了多回合应用中交互的固有状态性。为此,文章提出了DialogTool多回合对话数据集,涵盖工具使用的全生命周期,包括六个关键任务三个阶段:工具创建、工具利用(包括工具意识、工具选择、工具执行)和角色一致响应。此外,文章还构建了VirtualMobile虚拟移动评估环境,以模拟API调用并评估创建的API的稳健性。通过对13种不同开源和闭源LLMs的评估,文章揭示了现有先进技术水平的LLMs在长期使用工具方面的表现仍不理想。
Key Takeaways
- 现有语言模型评估基准存在缺陷,主要关注无状态、单回合的互动或部分评估,忽略了多回合交互中工具使用的状态性。
- 提出了
DialogTool数据集,涵盖多回合对话中的工具使用全生命周期,包括工具创建、利用和角色一致响应。 - 构建了
VirtualMobile虚拟移动评估环境,用于模拟API调用并评估API稳健性。 - 文章涵盖了13种不同的开源和闭源LLMs的评估。
- 评估结果揭示了现有LLMs在使用工具方面的长期表现不理想。
- 文章强调了现有语言模型在模拟真实工具使用场景中的不足,需要更全面的评估方法。
点此查看论文截图

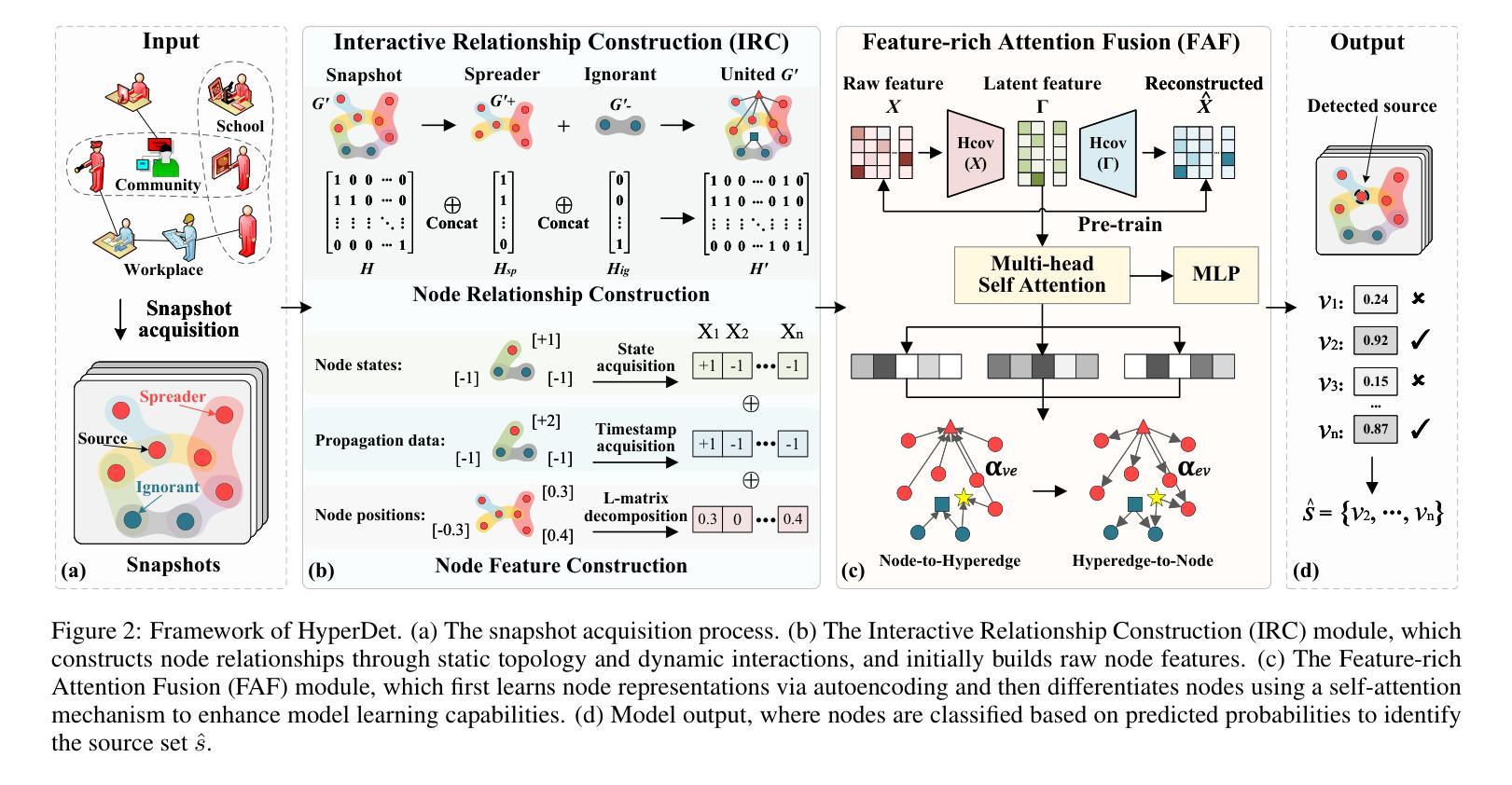
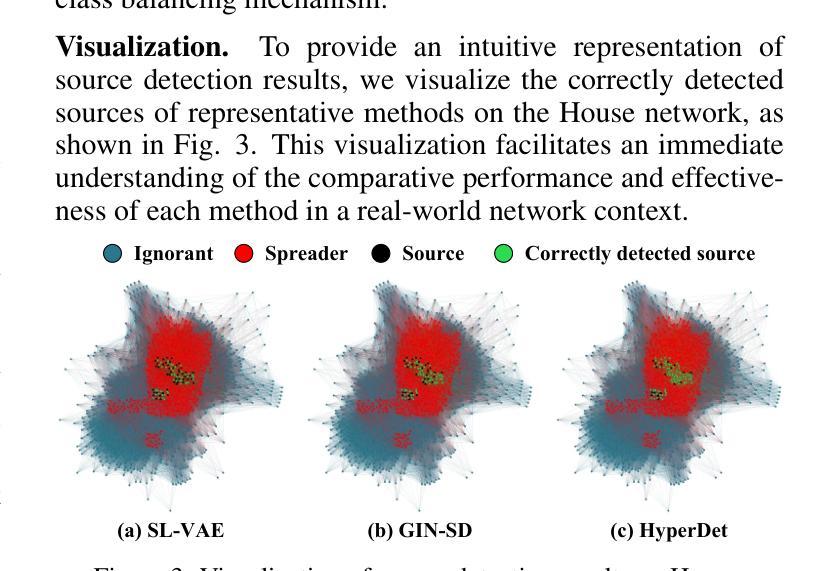
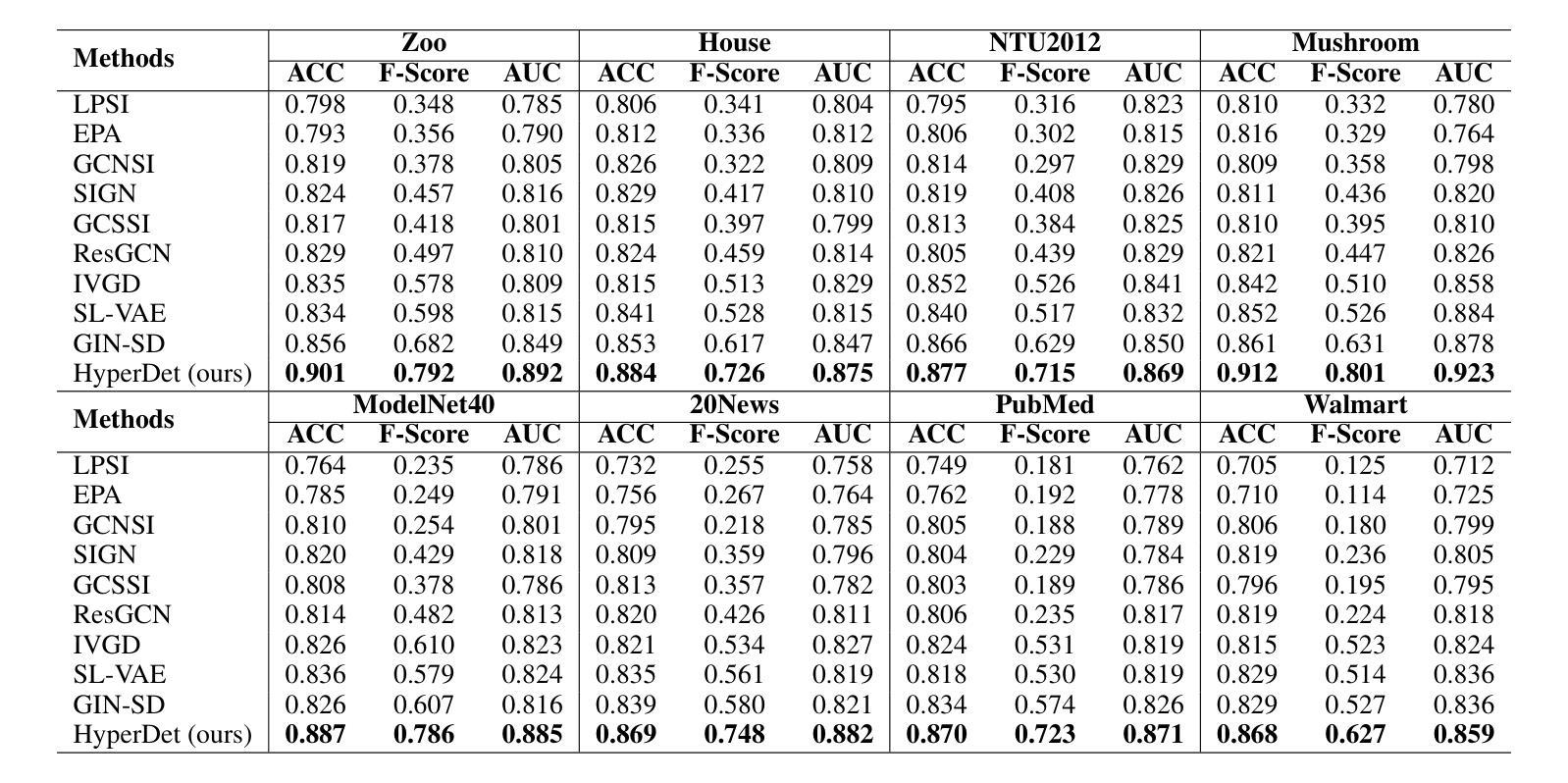
HyperDet: Source Detection in Hypergraphs via Interactive Relationship Construction and Feature-rich Attention Fusion
Authors:Le Cheng, Peican Zhu, Yangming Guo, Keke Tang, Chao Gao, Zhen Wang
Hypergraphs offer superior modeling capabilities for social networks, particularly in capturing group phenomena that extend beyond pairwise interactions in rumor propagation. Existing approaches in rumor source detection predominantly focus on dyadic interactions, which inadequately address the complexity of more intricate relational structures. In this study, we present a novel approach for Source Detection in Hypergraphs (HyperDet) via Interactive Relationship Construction and Feature-rich Attention Fusion. Specifically, our methodology employs an Interactive Relationship Construction module to accurately model both the static topology and dynamic interactions among users, followed by the Feature-rich Attention Fusion module, which autonomously learns node features and discriminates between nodes using a self-attention mechanism, thereby effectively learning node representations under the framework of accurately modeled higher-order relationships. Extensive experimental validation confirms the efficacy of our HyperDet approach, showcasing its superiority relative to current state-of-the-art methods.
超图为社会网络提供了优越的建模能力,特别是在捕捉群体现象方面,这些现象超越了谣言传播中的两两互动。现有的谣言溯源方法主要集中在二元交互上,这并不能充分应对更复杂关系结构的复杂性。本研究提出了一种基于超图的源检测新方法(HyperDet),通过交互关系构建和丰富的特征融合来实现。具体来说,我们的方法采用了一个交互关系构建模块,以准确地对用户之间的静态拓扑和动态交互进行建模,然后是一个丰富的特征融合模块,该模块可以自主地学习节点特征,并使用自注意力机制对节点进行区分,从而在准确建模的高阶关系框架下有效地学习节点表示。大量的实验验证证实了我们HyperDet方法的有效性,证明了其相对于当前最先进的方法的优越性。
论文及项目相关链接
PDF Accepted by IJCAI25
Summary
超图为社会网络提供了卓越的建模能力,尤其在捕捉超越二元交互的群体现象中的谣言传播。现有的谣言源检测主要关注二元交互,未能解决更复杂的关系结构的问题。本研究提出了一种基于超图的源检测新方法(HyperDet),通过交互式关系构建和特征丰富的注意力融合来实现。具体来说,该方法通过交互式关系构建模块准确建模用户间的静态拓扑和动态交互,再通过特征丰富的注意力融合模块自主学习节点特征,并使用自注意力机制对节点进行区分,从而有效地学习在准确建模的高阶关系下的节点表示。实验验证表明,HyperDet方法的有效性优于当前先进的方法。
Key Takeaways
- 超图为社会网络提供卓越的建模能力,尤其是针对超越二元交互的群体现象,如谣言传播。
- 现有谣言源检测主要关注二元交互,忽视复杂关系结构,导致检测效果不佳。
- 本研究提出了一种新的基于超图的源检测方法(HyperDet)。
- HyperDet通过交互式关系构建模块准确建模用户间的静态拓扑和动态交互。
- 特征丰富的注意力融合模块使HyperDet能够自主学习节点特征,并通过自注意力机制区分节点。
- HyperDet在准确建模的高阶关系下学习节点表示,实验验证其有效性优于当前先进方法。
点此查看论文截图

Efficient Implementation of Gaussian Process Regression Accelerated Saddle Point Searches with Application to Molecular Reactions
Authors:Rohit Goswami, Maxim Masterov, Satish Kamath, Alejandro Peña-Torres, Hannes Jónsson
The task of locating first order saddle points on high-dimensional surfaces describing the variation of energy as a function of atomic coordinates is an essential step for identifying the mechanism and estimating the rate of thermally activated events within the harmonic approximation of transition state theory. When combined directly with electronic structure calculations, the number of energy and atomic force evaluations needed for convergence is a primary issue. Here, we describe an efficient implementation of Gaussian process regression (GPR) acceleration of the minimum mode following method where a dimer is used to estimate the lowest eigenmode of the Hessian. A surrogate energy surface is constructed and updated after each electronic structure calculation. The method is applied to a test set of 500 molecular reactions previously generated by Hermez and coworkers [J. Chem. Theory Comput. 18, 6974 (2022)]. An order of magnitude reduction in the number of electronic structure calculations needed to reach the saddle point configurations is obtained by using the GPR compared to the dimer method. Despite the wide range in stiffness of the molecular degrees of freedom, the calculations are carried out using Cartesian coordinates and are found to require similar number of electronic structure calculations as an elaborate internal coordinate method implemented in the Sella software package. The present implementation of the GPR surrogate model in C++ is efficient enough for the wall time of the saddle point searches to be reduced in 3 out of 4 cases even though the calculations are carried out at a low Hartree-Fock level.
确定描述能量随原子坐标变化的高维表面上一阶鞍点位置的任务是识别机制和估算过渡态理论谐波近似中热激活事件速率的必要步骤。当与电子结构计算直接结合时,达到收敛所需的能量和原子力评估次数是主要问题。在这里,我们描述了高斯过程回归(GPR)加速最小模式跟随方法的有效实现,其中二聚体用于估计Hessian的最低本征模式。在每次电子结构计算后,构建并更新替代能量表面。该方法应用于Hermez及其同事之前生成的500个分子反应的测试集(J. Chem. Theory Comput. 18, 6974 (2022))。与使用二聚体方法相比,通过GPR达到鞍点配置所需的电子结构计算次数减少了数量级。尽管分子自由度刚度范围广泛,但计算采用笛卡尔坐标,并且发现所需的电子结构计算次数与在Sella软件包中实现的高级内部坐标方法相当。本实施中的GPR替代模型C++程序足够高效,在四种情况下减少三种情况的鞍点搜索壁时间,尽管这些计算是在低Hartree-Fock水平下进行的。
论文及项目相关链接
PDF 13 pages, 4 figures
Summary
本文描述了一种利用高斯过程回归(GPR)加速寻找高维表面上的一阶鞍点的方法。该方法结合电子结构计算,使用二聚体来估计海森矩阵的最低本征模式,构建并更新代理能量表面。应用于Hermez和同事生成的500个分子反应测试集,与二聚体方法相比,使用GPR后电子结构计算的数量减少了一个数量级。即使分子自由度刚度范围广泛,使用笛卡尔坐标的计算也与Sella软件包中实现的复杂内部坐标方法所需电子结构计算数量相似。
Key Takeaways
- 文章介绍了一种高效的高斯过程回归(GPR)方法,用于加速寻找描述能量随原子坐标变化的高维表面上的第一阶鞍点。
- 该方法结合了电子结构计算,重点解决了能量和原子力评估的收敛性问题。
- 通过使用二聚体来估计海森矩阵的最低本征模式,构建了代理能量表面,并每次电子结构计算后都会更新该表面。
- 在Hermez和同事生成的分子反应测试集上应用此方法,与二聚体方法相比,GPR的使用使得电子结构计算的数量减少了一个数量级。
- 该方法既适用于笛卡尔坐标,也适用于复杂的内部坐标方法,且所需电子结构计算的数量相似。
- 文章指出,即使在低Hartree-Fock水平下进行计算,GPRS的当前实现也足够高效,可在3出4的情况下减少鞍点搜索的墙壁时间。
点此查看论文截图

Generation of Drug-Induced Cardiac Reactions towards Virtual Clinical Trials
Authors:Qian Shao, Bang Du, Zepeng Li, Qiyuan Chen, Hongxia Xu, Jimeng Sun, Jian Wu, Jintai Chen
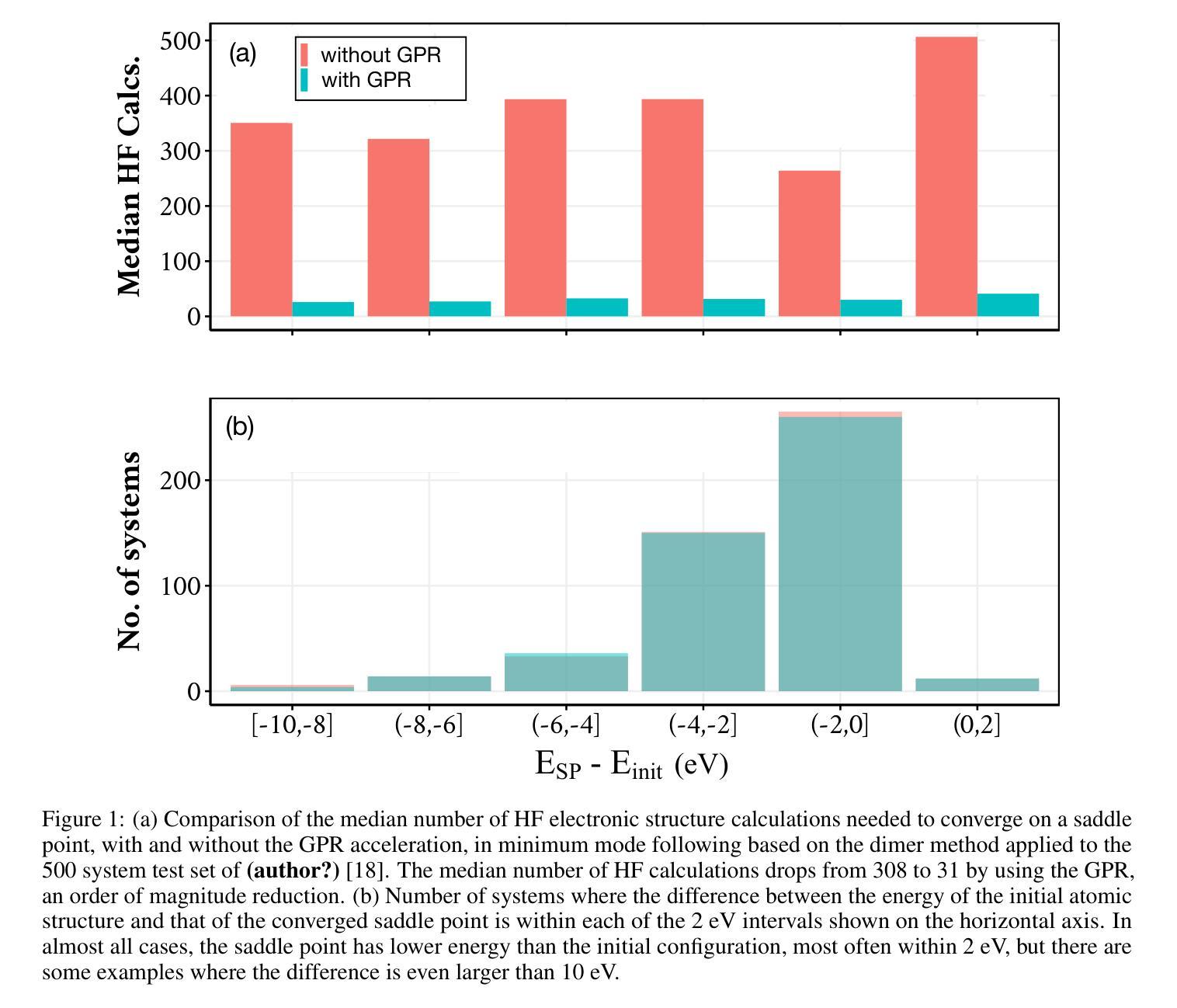
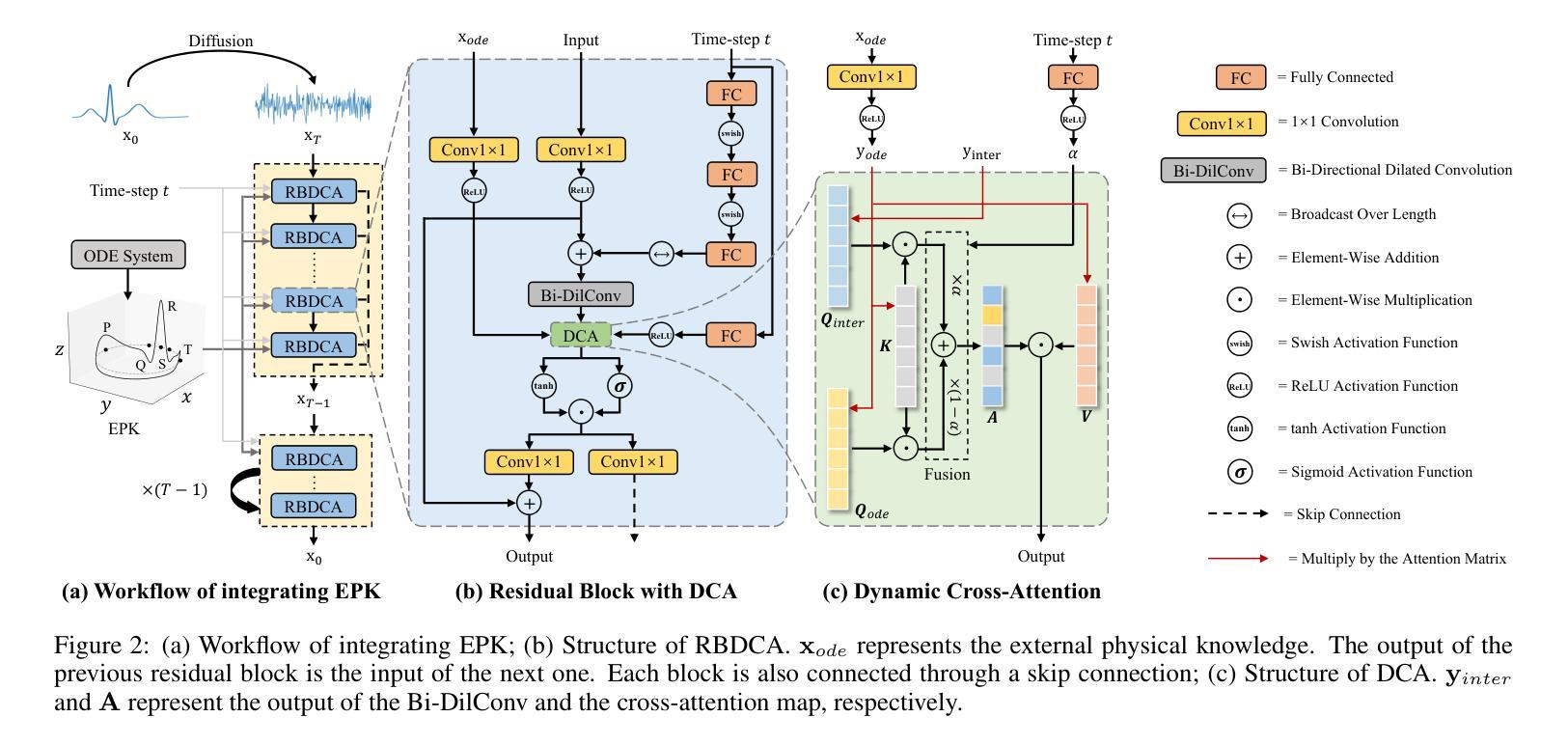
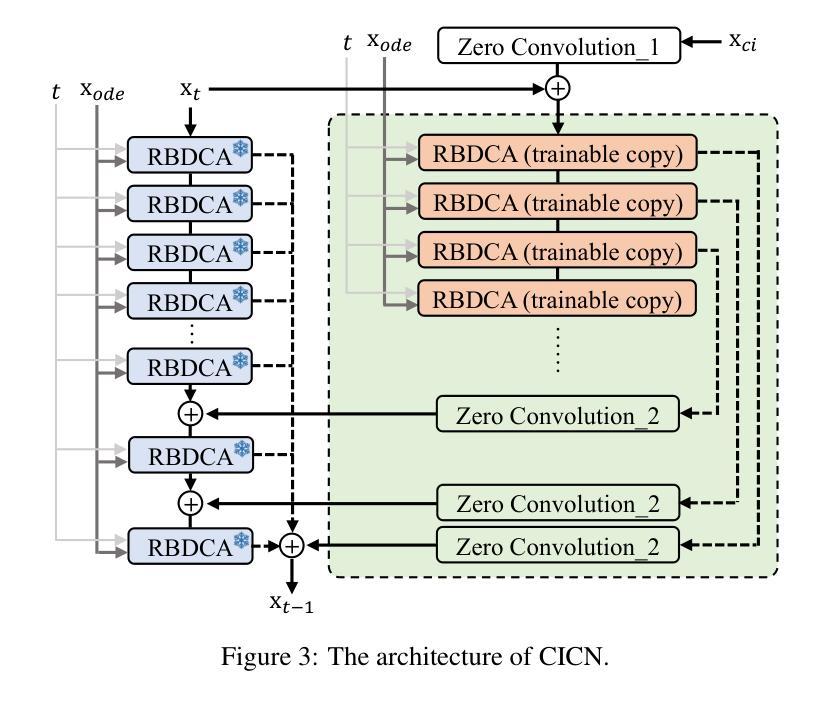
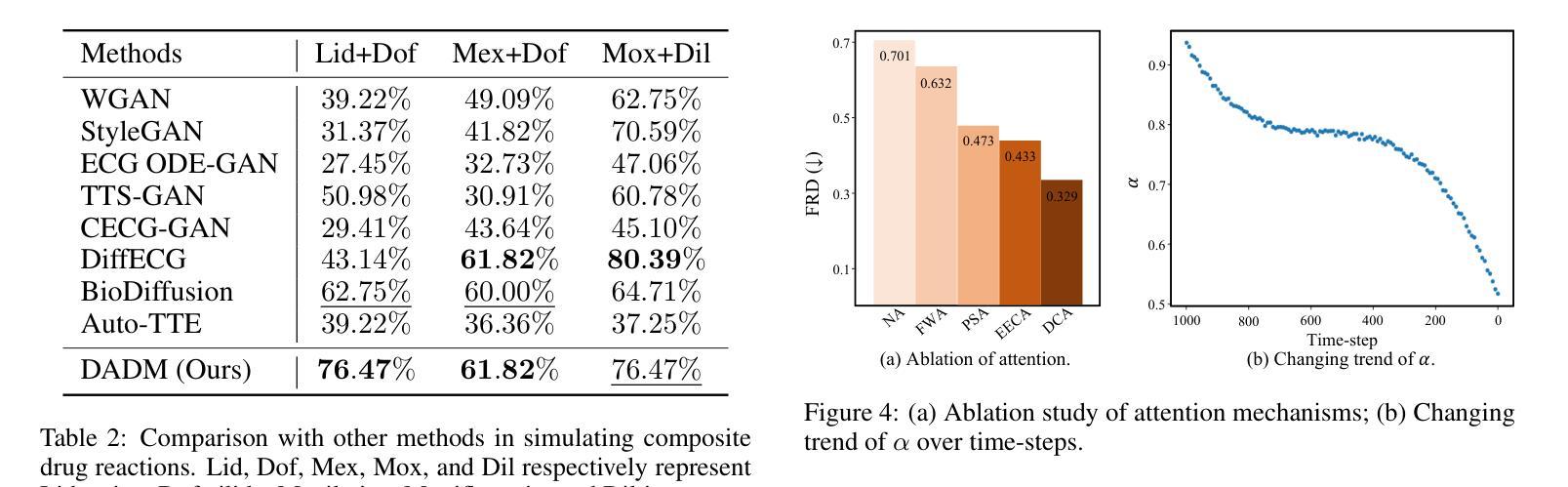
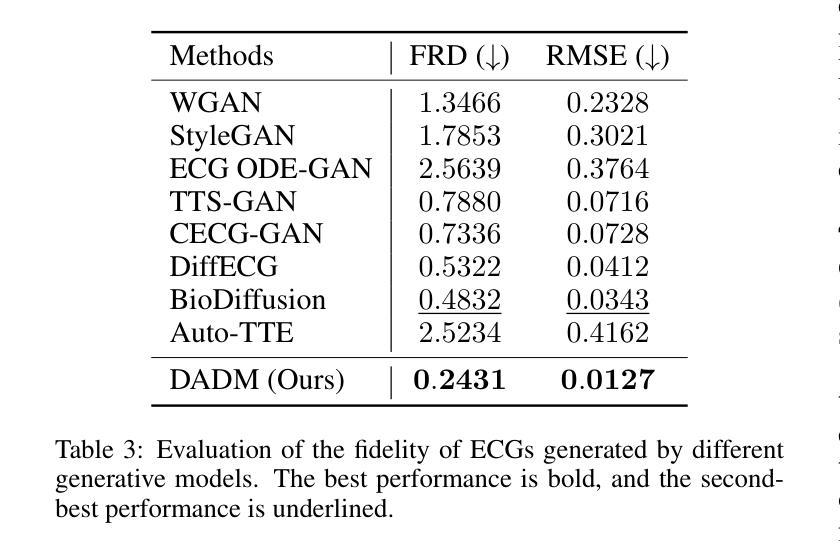
Clinical trials remain critical in cardiac drug development but face high failure rates due to efficacy limitations and safety risks, incurring substantial costs. In-silico trial methodologies, particularly generative models simulating drug-induced electrocardiogram (ECG) alterations, offer a potential solution to mitigate these challenges. While existing models show progress in ECG synthesis, their constrained fidelity and inability to characterize individual-specific pharmacological response patterns fundamentally limit clinical translatability. To address these issues, we propose a novel Drug-Aware Diffusion Model (DADM). Specifically, we construct a set of ordinary differential equations to provide external physical knowledge (EPK) of the realistic ECG morphology. The EPK is used to adaptively constrain the morphology of the generated ECGs through a dynamic cross-attention (DCA) mechanism. Furthermore, we propose an extension of ControlNet to incorporate demographic and drug data, simulating individual drug reactions. Compared to the other eight state-of-the-art (SOTA) ECG generative models: 1) Quantitative and expert evaluation demonstrate that DADM generates ECGs with superior fidelity; 2) Comparative results on two real-world databases covering 8 types of drug regimens verify that DADM can more accurately simulate drug-induced changes in ECGs, improving the accuracy by at least 5.79% and recall by 8%. In addition, the ECGs generated by DADM can also enhance model performance in downstream drug-effect classification tasks.
临床试验在心脏药物开发中仍然至关重要,但由于疗效局限和安全风险,面临较高的失败率,产生了巨大的成本。计算机模拟试验方法,特别是模拟药物引起的心电图(ECG)变化的生成模型,为解决这些挑战提供了潜在的解决方案。尽管现有模型在心电图合成方面取得了一定的进展,但它们有限的保真度和无法表征个体特定药理反应模式的能力从根本上限制了其在临床上的可翻译性。为了解决这些问题,我们提出了一种新型的药品感知扩散模型(DADM)。具体来说,我们构建了一组常微分方程,以提供关于现实心电图形态的外部物理知识(EPK)。EPK通过动态交叉注意(DCA)机制自适应地约束生成的心电图的形态。此外,我们对ControlNet进行了扩展,以纳入人口统计学和药物数据,模拟个体药物反应。与其他八种先进的心电图生成模型相比:1)定量和专家评估表明,DADM生成的心电图具有更高的保真度;2)在两个涵盖8种药物类型真实世界数据库的比较结果表明,DADM更能准确地模拟药物引起的心电图变化,至少提高准确性5.79%,召回率提高8%。此外,由DADM生成的心电图还可以提高下游药物效应分类任务的模型性能。
论文及项目相关链接
PDF Under review
Summary
临床试验在心脏药物开发中至关重要,但存在高失败率,成本高昂,安全风险及药效局限问题。为解决此问题,该研究提出了利用硅仿真模拟方法尝试药物对心电图影响的模型预测来优化这一过程。现有的模型虽然能合成心电图,但在真实性和个体差异表征上存在局限。本研究提出一种新型药物感知扩散模型(DADM),通过构建普通微分方程提供真实心电图形态的外部物理知识(EPK),并利用动态交叉注意力机制自适应约束生成心电图的形态。此外,该研究还扩展了ControlNet模型以纳入人口统计学数据和药物数据模拟个体药物反应。相较于其他八种顶尖心电图生成模型,本研究不仅在定量评估和专家评估中展现出更高的保真度,还能更准确地模拟药物引起的心电图变化,准确率至少提高5.79%,召回率提高8%,并能在下游药物效应分类任务中提升模型性能。
Key Takeaways
- 临床试验在心脏药物开发中面临高失败率、成本高昂等问题。
- 硅仿真模拟方法是一种潜在解决方案,旨在优化药物开发过程中的挑战。
- 现有心电图合成模型存在真实性和个体差异表征的局限。
- 新型药物感知扩散模型(DADM)通过结合外部物理知识(EPK)和动态交叉注意力机制提高心电图生成的保真度。
- DADM模型相较于其他顶尖模型在定量评估和专家评估中表现更优秀。
- DADM能更准确地模拟药物引起的心电图变化,提高预测准确率至少5.79%,召回率提高8%。
点此查看论文截图

Advancing Multi-Party Dialogue Framework with Speaker-ware Contrastive Learning
Authors:Zhongtian Hu, Qi He, Ronghan Li, Meng Zhao, Lifang Wang
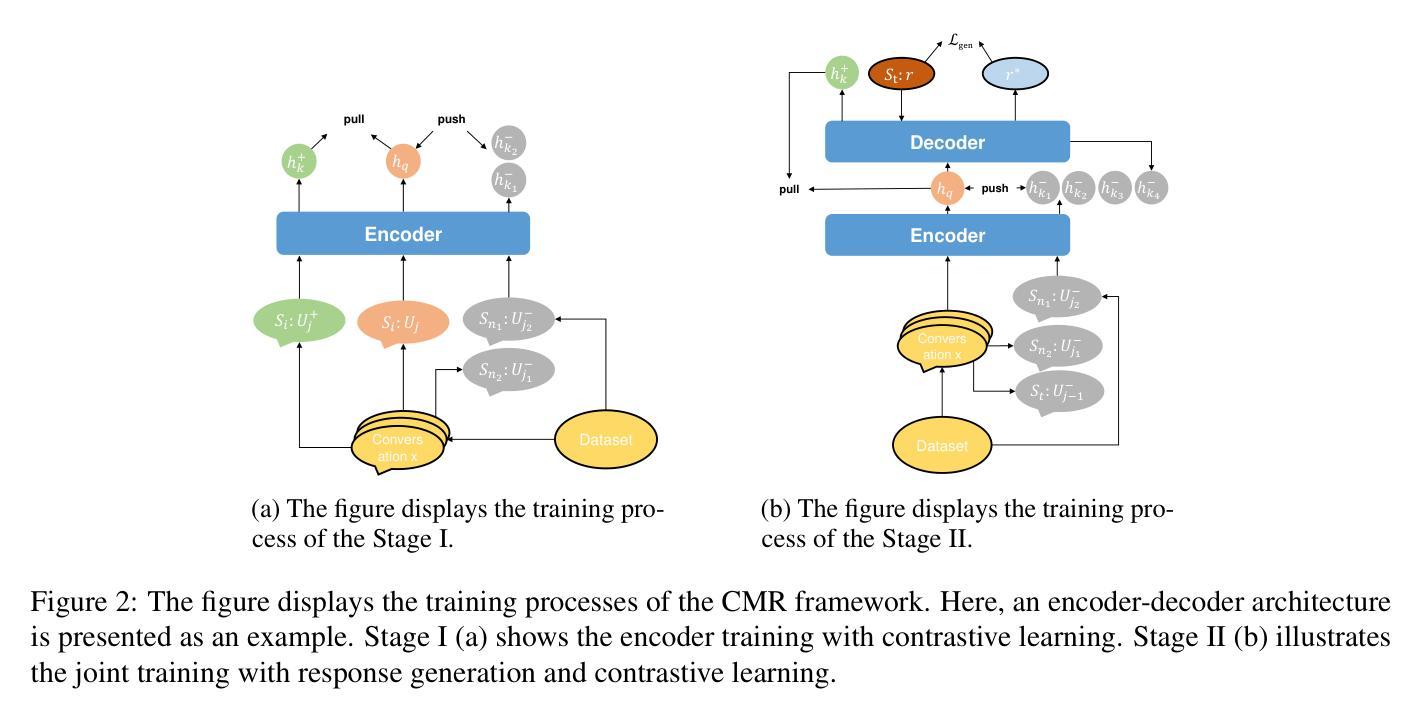
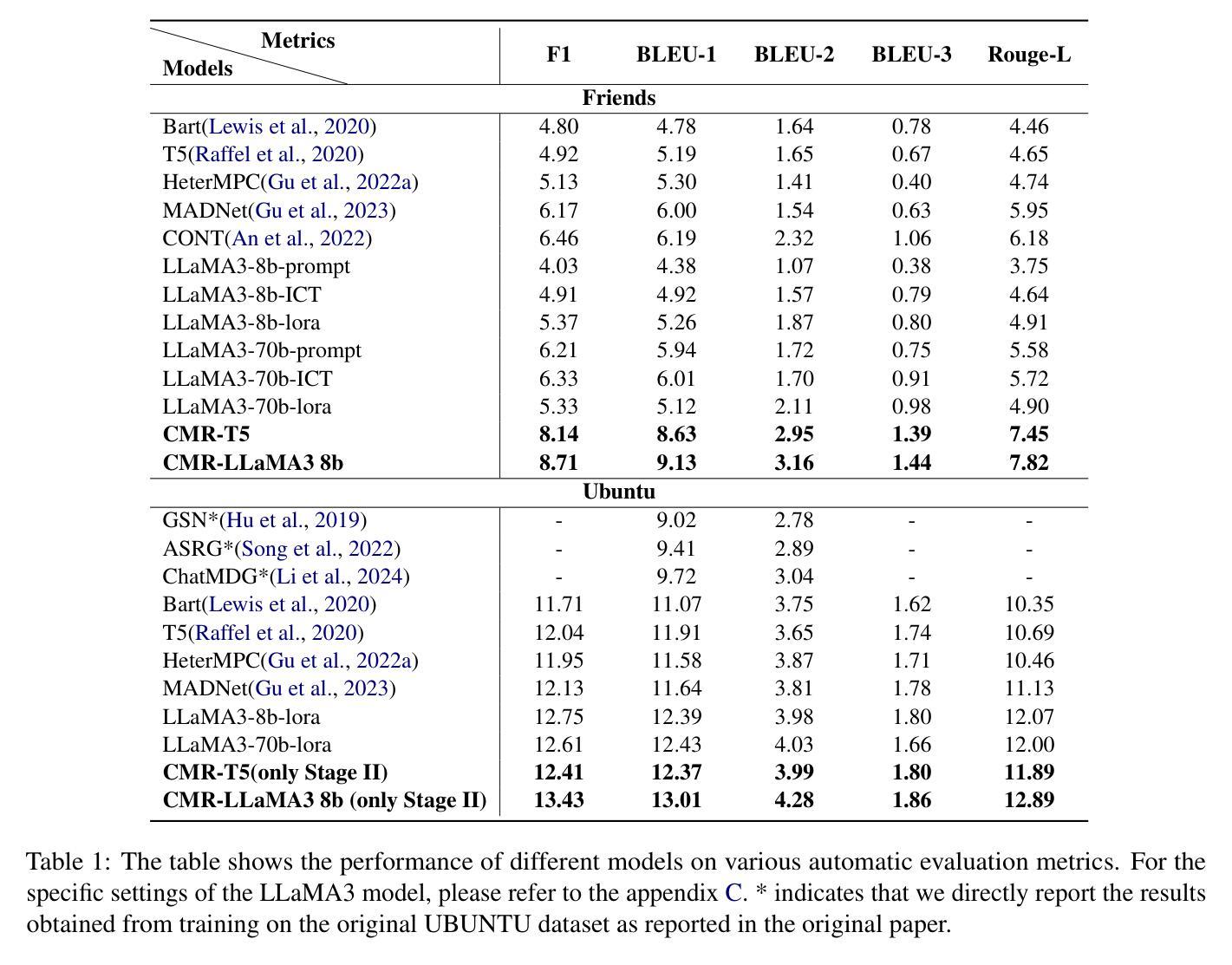
Multi-party dialogues, common in collaborative scenarios like brainstorming sessions and negotiations, pose significant challenges due to their complexity and diverse speaker roles. Current methods often use graph neural networks to model dialogue context, capturing structural dynamics but heavily relying on annotated graph structures and overlooking individual speaking styles. To address these challenges, we propose CMR, a Contrastive learning-based Multi-party dialogue Response generation framework. CMR employs a two-stage self-supervised contrastive learning framework. First, it captures global differences in speaking styles across individuals. Then, it focuses on intra-conversation comparisons to identify thematic transitions and contextually relevant facts. To the best of our knowledge, this is the first approach that applies contrastive learning in multi-party dialogue generation. Experimental results demonstrate that CMR not only significantly outperforms state-of-the-art models, but also generalizes well to large pre-trained language models, effectively enhancing their capability in handling multi-party conversations.
在头脑风暴和谈判等协作场景中常见的多方对话,由于其复杂性和多样的说话者角色,构成了重大挑战。当前的方法通常使用图神经网络来建模对话上下文,捕捉结构动态,但过度依赖注释图结构,忽视了个人说话风格。为了解决这些挑战,我们提出了基于对比学习的多方对话响应生成框架CMR。CMR采用两阶段自监督对比学习框架。首先,它捕捉不同个体之间说话风格的全球差异。然后,它专注于会话内部的比较,以识别主题转换和上下文相关事实。据我们所知,这是首次将对比学习应用于多方对话生成的方法。实验结果表明,CMR不仅显著优于现有最先进的模型,而且在大型预训练语言模型中也能很好地通用化,有效地增强了它们处理多方对话的能力通辽的能力。
论文及项目相关链接
Summary
基于对比学习的多轮对话响应生成框架CMR用于处理多方对话中的复杂性和多样化的说话角色挑战。该方法通过两个阶段进行自我监督对比学习,先捕捉个体间全局说话风格差异,再关注对话内部比较以识别主题转换和上下文相关事实。实验结果表明,该方法不仅显著优于现有模型,而且能够很好地应用于大型预训练语言模型,有效提高它们处理多方对话的能力。
Key Takeaways
- 多方对话在协作场景中如头脑风暴和谈判中普遍存在,但由于其复杂性和多样化的说话角色而具有挑战。
- 当前方法主要使用图神经网络来建模对话上下文,但过于依赖注释图结构,忽略了个人说话风格。
- CMR框架采用基于对比学习的方法,旨在解决这些问题。
- CMR通过两个阶段进行自我监督对比学习:首先捕捉个体间的全局说话风格差异,然后关注对话内的主题转换和上下文相关事实。
- CMR是首个将对比学习应用于多轮对话生成的方法。
- 实验结果表明,CMR显著优于现有模型,并能很好地应用于大型预训练语言模型。
点此查看论文截图

Stability in Reaction Network Models via an Extension of the Next Generation Matrix Method
Authors:Florin Avram, Rim Adenane, Andrei D. Halanay, Matthew D. Johnson
In this essay, we investigate some relations between Chemical Reaction Networks (CRN) and Mathematical Epidemiology (ME) and report on several pleasant surprises which we had simply by putting these two topics together. Firstly, we propose a definition of ME models as a subset of CRN models. Secondly, we review a fundamental stability result for boundary points, known in ME as the NGM method since it replaces the investigation of the Jacobian by that of a matrix whose origins lie in probability (the theory of branching processes). This important result seems to be little known outside of ME; even in ME, it has not been made clear before that the method gets sometimes the right answer, even though the conditions of the NGM theorem are not all satisfied. Thus, beyond the theorem, there is a heuristic approach, the validity conditions for which are not sufficiently understood. Thirdly, we show that some simple CRN models with absolute concentration robustness (ACR), are close qualitatively to simple ME models, in the sense that they have an unique disease free equilibrium, and a unique interior fixed point, and the latter enters the positive domain and becomes stable precisely when $R_0:=s_{dfe} \mathcal{R}=\frac{s_{dfe}}{s_e}>1.$ (where $s$ denotes the “ACR species”). Thus, for these “ME type models”, a “relay phenomena” takes place: precisely when the DFE loses stability, a new fixed point enters the domain, and takes over. Last but not least, we offer in the associated GitHub repository https://github.com/adhalanay/epidemiology_crns a Mathematica package, Epid-CRN, which is addressed to researchers of both disciplines, and provide illustrative notebooks, which in particular solve a few minor open ME and CRN problems. Our package may also be used to study easy cases of analogue continuous time Markov chain (CTMC) ME and CRN models.
在这篇论文中,我们探讨了化学反应网络(CRN)和数学流行病学(ME)之间的关系,并报告了将这两个主题结合起来所得到的几个令人愉快的惊喜。首先,我们提出将ME模型定义为CRN模型的一个子集。其次,我们回顾了边界点的基本稳定性结果,在ME中称为NGM方法,因为它用源于概率的矩阵(分支过程理论)来代替雅可比矩阵的研究。这个重要的结果似乎在数学流行病学领域之外鲜为人知;即使在ME领域,之前也没有明确过该方法有时即使不满足NGM定理的条件也能得出正确的答案。因此,除了定理之外,还存在一种启发式方法,但其有效条件尚未得到充分理解。第三,我们展示了一些具有绝对浓度稳健性(ACR)的简单CRN模型在定性上与简单的ME模型紧密相关,它们具有一个独特的无疾病平衡点和唯一的内部固定点,当$R_0:=s_{dfe} \mathcal{R}=\frac{s_{dfe}}{s_e}>1$时,后者进入正域并变得稳定。(其中s表示“ACR物种”)。因此,对于这些“ME类型模型”,会发生一种“接力现象”:当无疾病平衡点失去稳定性时,一个新的固定点进入域并接管。最后但并非最不重要的是,我们在相关的GitHub仓库https://github.com/adhalanay/epidemiology_crns中提供了一个名为Epid-CRN的Mathematica软件包,该软件包面向两个学科的研究人员,并提供说明性笔记本,特别解决了一些轻微的ME和CRN问题。我们的软件包也可用于研究类似连续时间马尔可夫链(CTMC)的ME和CRN模型的简单情况。
论文及项目相关链接
PDF Major review. Title was changed
Summary
本文探讨了化学反应网络(CRN)与数学流行病学(ME)之间的关系,并报告了将这两个主题结合起来所得到的几个意外收获。文章定义了ME模型作为CRN模型的一个子集,介绍了ME中的NGM方法的稳定性结果,该方法通过概率理论中的分支过程理论替代了雅可比矩阵的研究。此外,文章展示了具有绝对浓度稳健性的简单CRN模型与简单ME模型之间的定性相似性,并提出了一种“接力现象”。最后,作者提供了一个针对两个学科的研究人员的Mathematica软件包Epid-CRN,并提供了一些解决问题的示例笔记本。
Key Takeaways
- 文章探讨了化学反应网络(CRN)与数学流行病学(ME)之间的关联,将两者结合起来得到了意外收获。
- 文章定义了ME模型是CRN模型的一个子集。
- 介绍了ME中的NGM方法的稳定性结果,该方法通过概率理论中的分支过程理论进行研究,但该方法的有效性条件尚不够充分理解。
- 简单CRN模型与简单ME模型之间存在定性相似性,表现在它们具有独特的无疾病平衡点和内部固定点等方面。
- 当DFE失去稳定性时,会出现一种“接力现象”,即新的固定点进入领域并接管。
- 文章提供了一个Mathematica软件包Epid-CRN,供两个学科的研究人员使用,其中包括解决一些开放问题的示例笔记本。
点此查看论文截图