⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-05-22 更新
UniGen: Enhanced Training & Test-Time Strategies for Unified Multimodal Understanding and Generation
Authors:Rui Tian, Mingfei Gao, Mingze Xu, Jiaming Hu, Jiasen Lu, Zuxuan Wu, Yinfei Yang, Afshin Dehghan
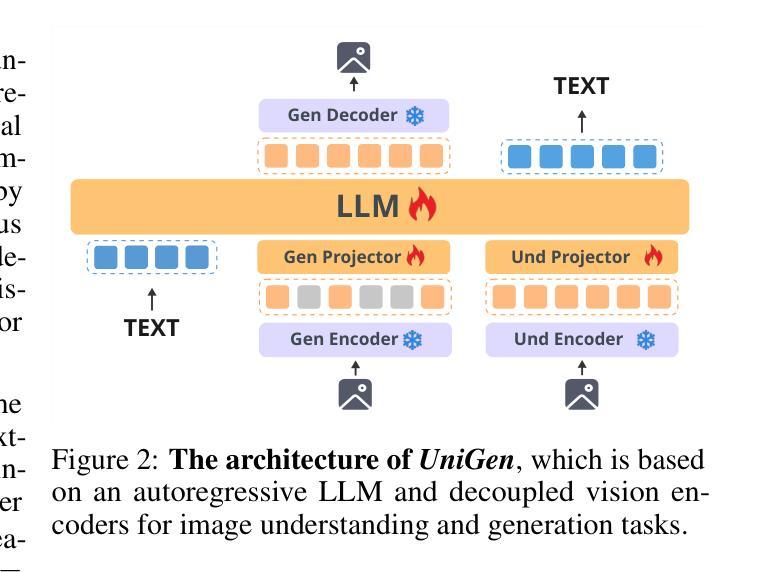
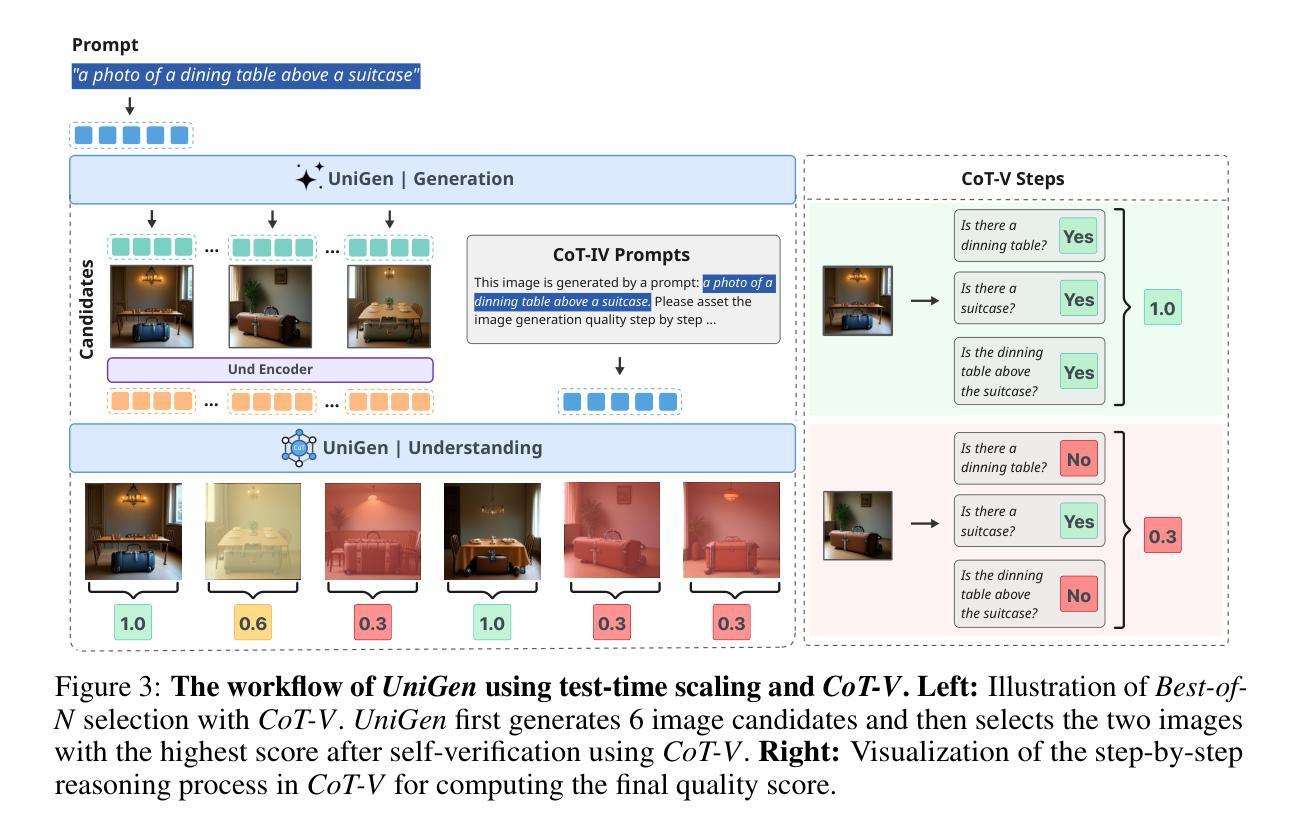
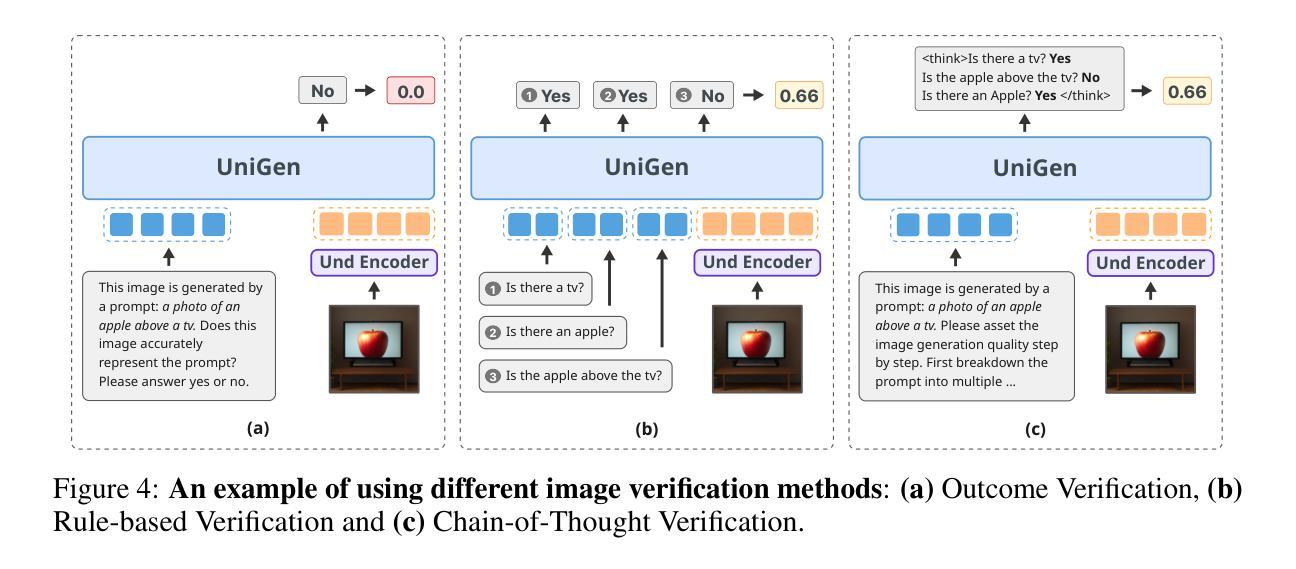
We introduce UniGen, a unified multimodal large language model (MLLM) capable of image understanding and generation. We study the full training pipeline of UniGen from a data-centric perspective, including multi-stage pre-training, supervised fine-tuning, and direct preference optimization. More importantly, we propose a new Chain-of-Thought Verification (CoT-V) strategy for test-time scaling, which significantly boosts UniGen’s image generation quality using a simple Best-of-N test-time strategy. Specifically, CoT-V enables UniGen to act as both image generator and verifier at test time, assessing the semantic alignment between a text prompt and its generated image in a step-by-step CoT manner. Trained entirely on open-source datasets across all stages, UniGen achieves state-of-the-art performance on a range of image understanding and generation benchmarks, with a final score of 0.78 on GenEval and 85.19 on DPG-Bench. Through extensive ablation studies, our work provides actionable insights and addresses key challenges in the full life cycle of building unified MLLMs, contributing meaningful directions to the future research.
我们介绍了UniGen,这是一个统一的多模态大型语言模型(MLLM),能够进行图像理解和生成。我们从数据中心的视角研究了UniGen的完整训练流程,包括多阶段预训练、监督微调以及直接偏好优化。更重要的是,我们提出了一种新的链式思维验证(CoT-V)策略,用于测试时的扩展,该策略使用简单的Best-of-N测试时间策略,显著提高了UniGen的图像生成质量。具体来说,CoT-V使UniGen能够在测试时同时充当图像生成器和验证器,以逐步的链式思维方式评估文本提示与其生成的图像之间的语义对齐。完全在所有阶段使用开源数据集进行训练,UniGen在图像理解和生成的一系列基准测试中达到了最新技术水平,GenEval的最终得分为0.78,DPG-Bench上的得分为85.19。通过广泛的消融研究,我们的工作提供了可操作的见解,解决了构建统一MLLM整个生命周期中的关键挑战,为未来研究提供了有意义的方向。
论文及项目相关链接
PDF Technical report
Summary
UniGen是一个统一的多模态大型语言模型(MLLM),具有图像理解和生成能力。该研究从数据中心视角研究了UniGen的全训练管道,包括多阶段预训练、监督微调以及直接偏好优化。更重要的是,研究提出了全新的思维链验证(CoT-V)策略,用于测试时的缩放,通过简单的Best-of-N测试时间策略显著提升UniGen的图像生成质量。CoT-V使UniGen能够在测试时同时充当图像生成器和验证器,以思维链的方式逐步评估文本提示与生成图像之间的语义对齐。完全在开源数据集上训练的UniGen,在图像理解和生成基准测试上达到了最新技术水平,GenEval得分为0.78,DPG-Bench得分为85.19。通过广泛的消融研究,该研究为构建统一MLLM的整个生命周期提供了可行的见解和解决了关键挑战,为未来研究提供了有意义的方向。
Key Takeaways
- UniGen是一个多模态大型语言模型,具备图像理解和生成能力。
- 研究了UniGen的全训练管道,包括预训练、监督微调以及偏好优化。
- 提出了思维链验证(CoT-V)策略,提高图像生成质量。
- UniGen具备在测试时同时作为图像生成器和验证器的功能。
- UniGen在图像理解和生成基准测试上表现优秀,GenEval得分为0.78,DPG-Bench得分为85.19。
- 消融研究为构建MLLM提供了关键挑战和可行的解决方案。
点此查看论文截图


UltraEdit: Training-, Subject-, and Memory-Free Lifelong Editing in Large Language Models
Authors:Xiaojie Gu, Guangxu Chen, Jungang Li, Jia-Chen Gu, Xuming Hu, Kai Zhang
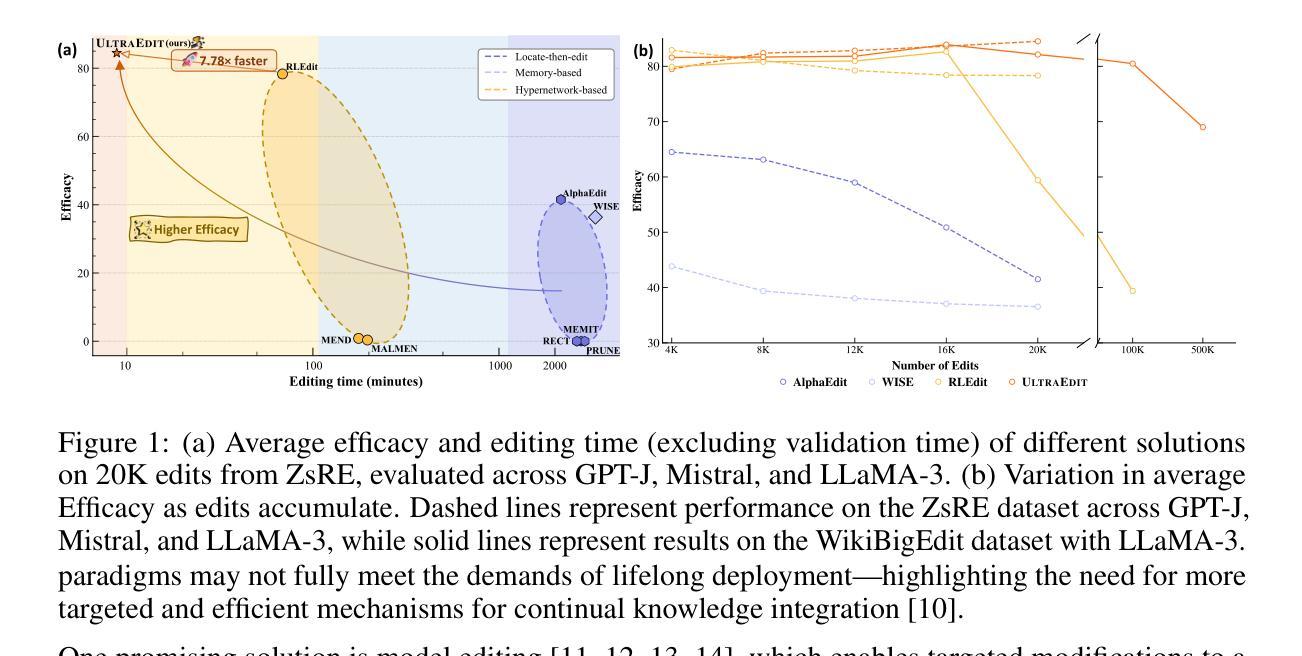
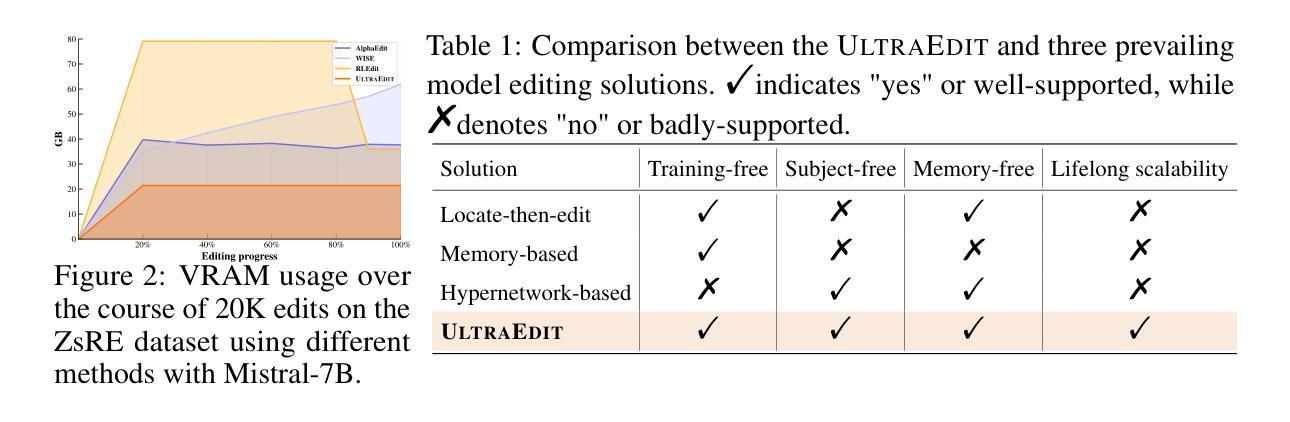
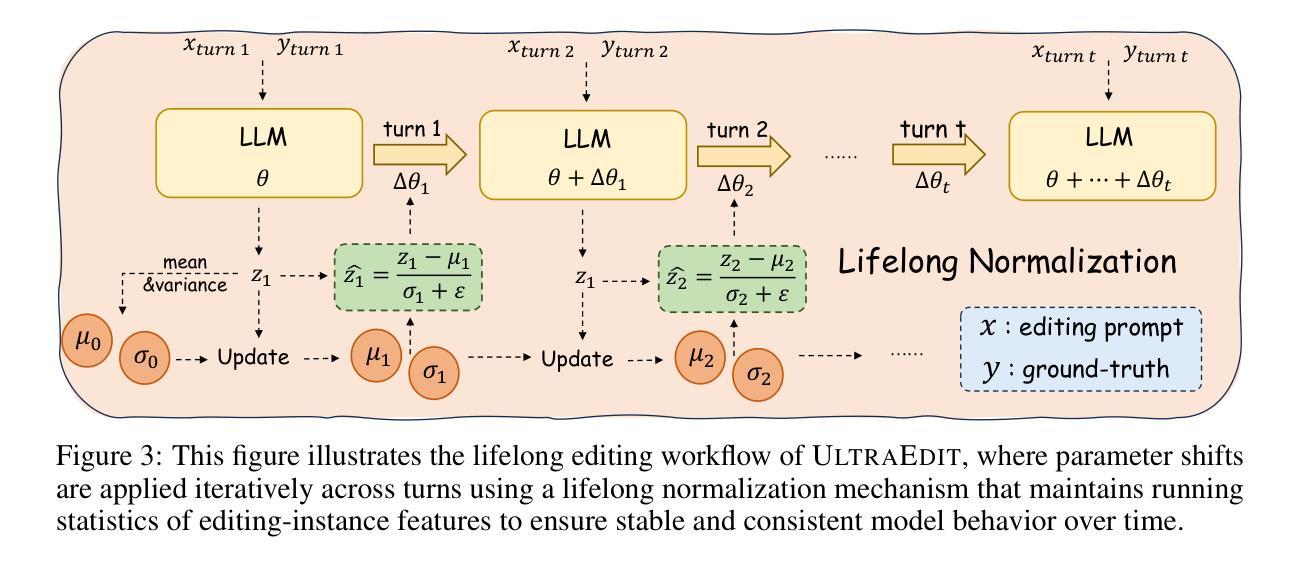
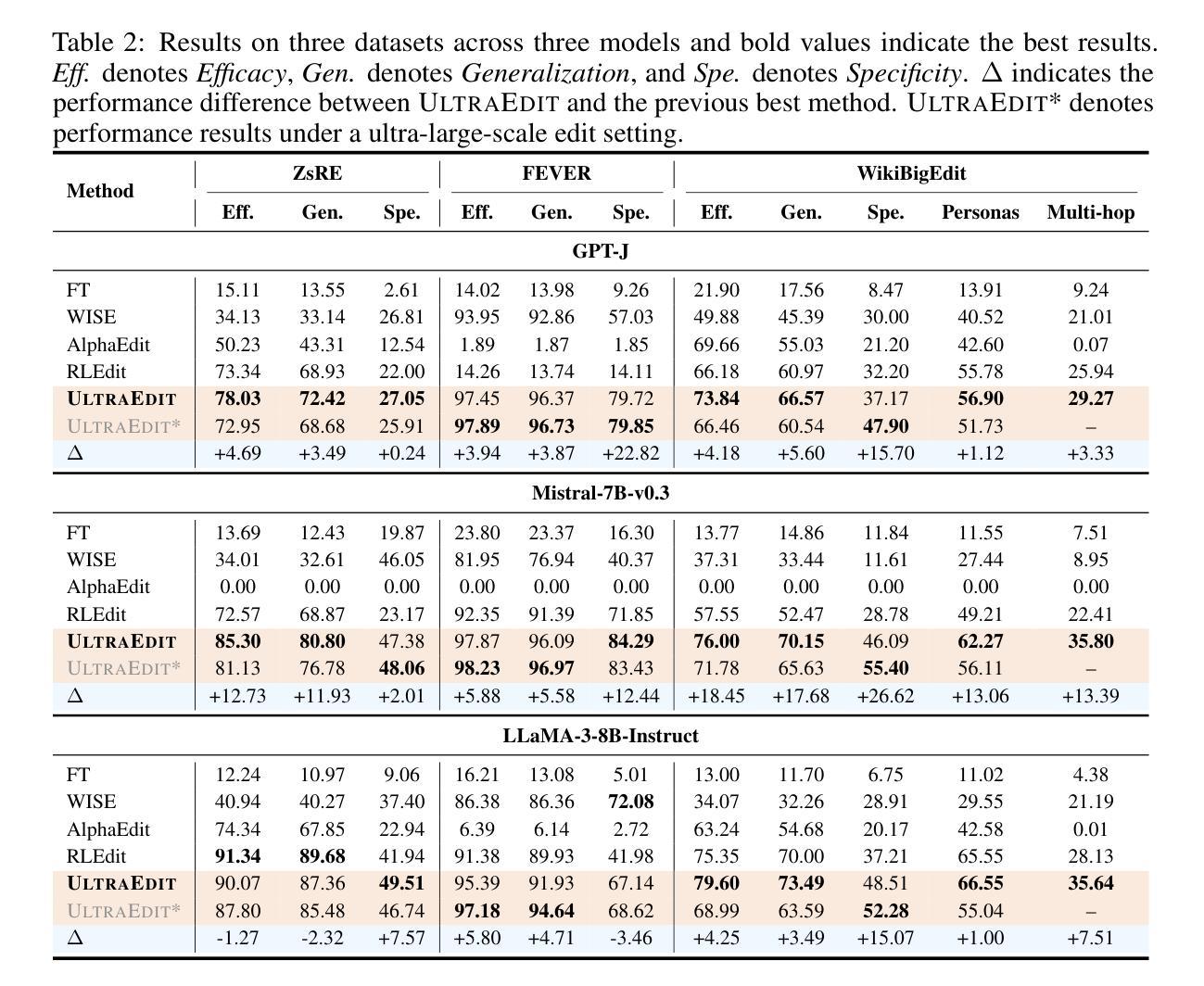
Lifelong learning enables large language models (LLMs) to adapt to evolving information by continually updating their internal knowledge. An ideal system should support efficient, wide-ranging updates while preserving existing capabilities and ensuring reliable deployment. Model editing stands out as a promising solution for this goal, offering a focused and efficient way to revise a model’s internal knowledge. Although recent paradigms have made notable progress, they often struggle to meet the demands of practical lifelong adaptation at scale. To bridge this gap, we propose ULTRAEDIT-a fundamentally new editing solution that is training-, subject- and memory-free, making it particularly well-suited for ultra-scalable, real-world lifelong model editing. ULTRAEDIT performs editing through a self-contained process that relies solely on lightweight linear algebra operations to compute parameter shifts, enabling fast and consistent parameter modifications with minimal overhead. To improve scalability in lifelong settings, ULTRAEDIT employs a lifelong normalization strategy that continuously updates feature statistics across turns, allowing it to adapt to distributional shifts and maintain consistency over time. ULTRAEDIT achieves editing speeds over 7x faster than the previous state-of-the-art method-which was also the fastest known approach-while consuming less than 1/3 the VRAM, making it the only method currently capable of editing a 7B LLM on a 24GB consumer-grade GPU. Furthermore, we construct ULTRAEDITBENCH-the largest dataset in the field to date, with over 2M editing pairs-and demonstrate that our method supports up to 1M edits while maintaining high accuracy. Comprehensive experiments on four datasets and six models show that ULTRAEDIT consistently achieves superior performance across diverse model editing scenarios. Our code is available at: https://github.com/XiaojieGu/UltraEdit.
终身学习使大型语言模型(LLM)能够通过持续更新其内部知识来适应不断变化的信息。一个理想的系统应该支持高效、广泛的更新,同时保留现有功能并确保可靠部署。模型编辑作为实现此目标的颇具前景的解决方案脱颖而出,它提供了一种专注且高效的方法来修订模型的内部知识。尽管最近的范式已经取得了显著的进步,但它们通常难以满足大规模实践中的终身学习需求。为了弥补这一差距,我们提出了ULTRAEDIT——一种全新的编辑解决方案,它无需训练、主题和内存,特别适用于超大规模、现实世界的终身模型编辑。ULTRAEDIT通过自我包含的过程进行编辑,该过程仅依赖于轻量级的线性代数运算来计算参数变化,从而实现快速且一致的参数修改,并且开销极小。为了提高终身设置的可扩展性,ULTRAEDIT采用终身归一化策略,不断更新轮次间的特征统计信息,使其能够适应分布变化并随时间保持一致性。ULTRAEDIT的编辑速度比最新的前沿方法快7倍以上——这也是当时已知的最快方法——同时VRAM使用量不到三分之一,使其成为目前唯一能够在24GB消费级GPU上编辑7B LLM的方法。此外,我们构建了迄今为止该领域最大的数据集ULTRAEDITBENCH,包含超过2M个编辑对,并证明我们的方法支持高达1M次的编辑同时保持高准确性。在四个数据集和六个模型上的综合实验表明,ULTRAEDIT在不同模型编辑场景中始终实现卓越性能。我们的代码可在:[https://github.com/XiaojieGu/UltraEdit访问。](https://github.com/XiaojieGu/UltraEdit%E8%AE%BF%E9 to )
论文及项目相关链接
Summary
大型语言模型通过持续更新内部知识,实现适应不断变化的信息。模型编辑作为一种有前景的解决方案,旨在修订模型的内部知识,并使其成为终身学习的关键工具。ULTRAEDIT作为一种全新编辑解决方案,无需训练、主题和内存,特别适用于大规模实时模型编辑。它通过轻量级线性代数运算进行参数修改,实现快速且一致的编辑。ULTRAEDIT采用终身标准化策略,适应分布变化并维持时间一致性。它的编辑速度超过现有方法7倍,同时占用内存少,是唯一能在消费级GPU上进行7B大型语言模型编辑的方法。ULTRAEDITBENCH数据集包含超过百万对编辑实例,证明了其在大量编辑下的高准确性。实验表明,ULTRAEDIT在不同模型编辑场景中表现卓越。详情请访问:https://github.com/XiaojieGu/UltraEdit。
Key Takeaways
- 大型语言模型通过终身学习适应变化信息。
- 模型编辑是修订大型语言模型内部知识的有效方法。
- ULTRAEDIT是一种全新、高效、训练、主题和内存独立的编辑解决方案。
- ULTRAEDIT利用轻量级线性代数操作进行快速参数修改。
- 采用终身标准化策略提高ULTRAEDIT在大规模环境下的可扩展性。
- ULTRAEDIT编辑速度远超现有方法,内存占用低。
- ULTRAEDITBENCH数据集用于验证大量编辑下的准确性。
点此查看论文截图

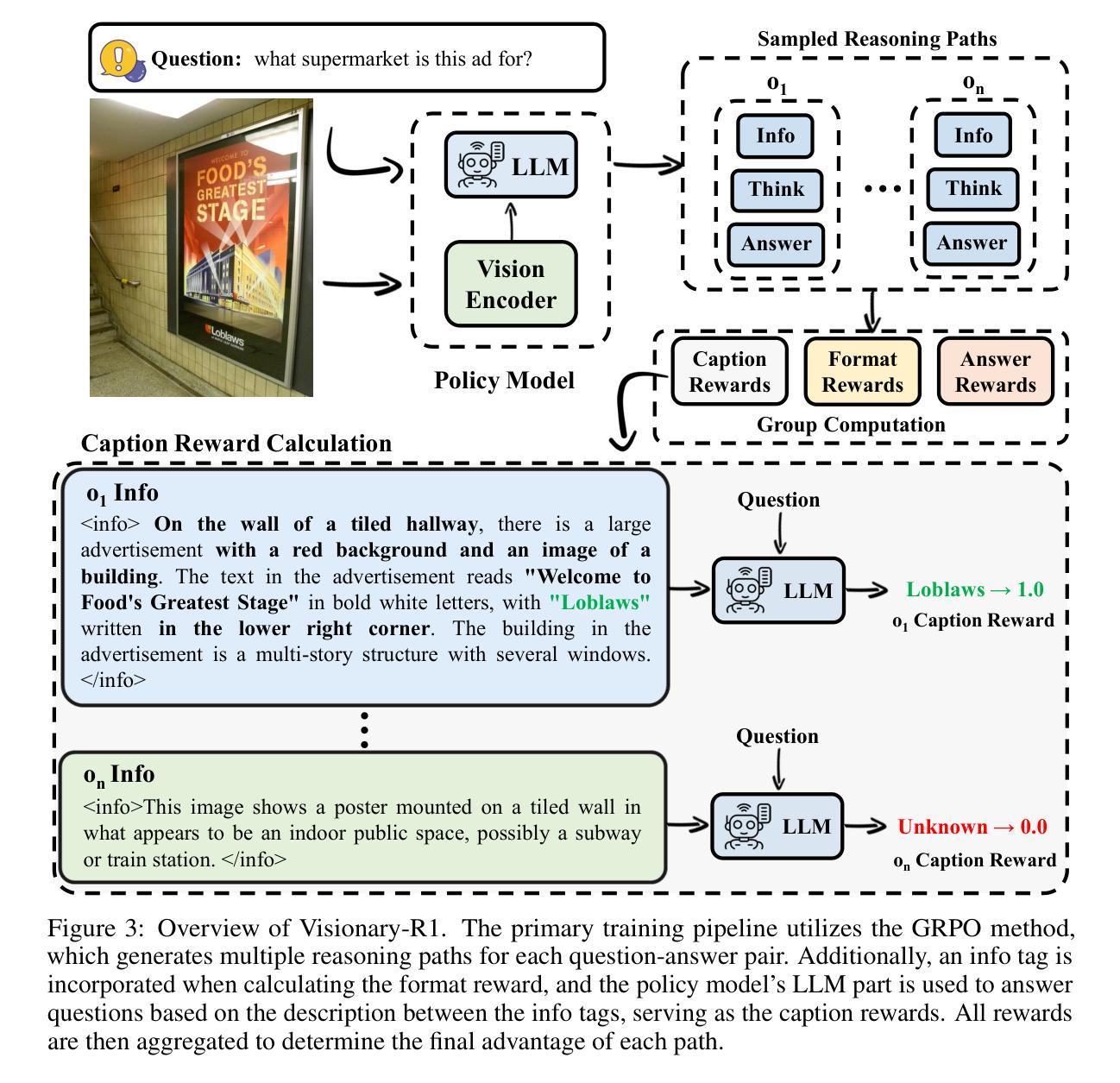
Visionary-R1: Mitigating Shortcuts in Visual Reasoning with Reinforcement Learning
Authors:Jiaer Xia, Yuhang Zang, Peng Gao, Yixuan Li, Kaiyang Zhou
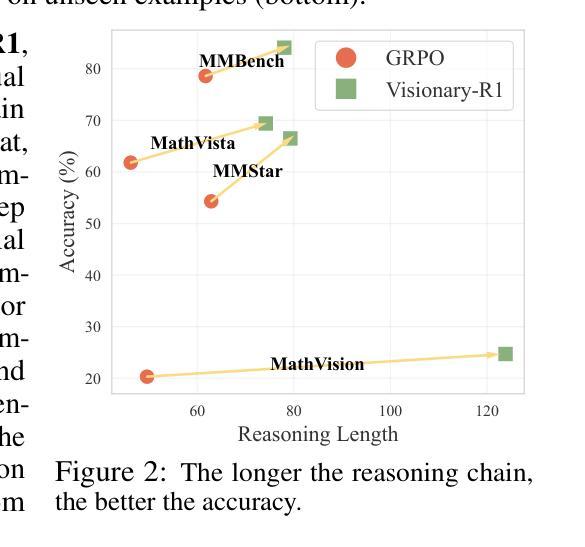
Learning general-purpose reasoning capabilities has long been a challenging problem in AI. Recent research in large language models (LLMs), such as DeepSeek-R1, has shown that reinforcement learning techniques like GRPO can enable pre-trained LLMs to develop reasoning capabilities using simple question-answer pairs. In this paper, we aim to train visual language models (VLMs) to perform reasoning on image data through reinforcement learning and visual question-answer pairs, without any explicit chain-of-thought (CoT) supervision. Our findings indicate that simply applying reinforcement learning to a VLM – by prompting the model to produce a reasoning chain before providing an answer – can lead the model to develop shortcuts from easy questions, thereby reducing its ability to generalize across unseen data distributions. We argue that the key to mitigating shortcut learning is to encourage the model to interpret images prior to reasoning. Therefore, we train the model to adhere to a caption-reason-answer output format: initially generating a detailed caption for an image, followed by constructing an extensive reasoning chain. When trained on 273K CoT-free visual question-answer pairs and using only reinforcement learning, our model, named Visionary-R1, outperforms strong multimodal models, such as GPT-4o, Claude3.5-Sonnet, and Gemini-1.5-Pro, on multiple visual reasoning benchmarks.
长期以来,学习通用推理能力一直是人工智能领域的一个难题。近期在大语言模型(LLM)方面的研究表明,强化学习技术(如GRPO)可以使预训练的语言模型通过简单的问题答案对来发展推理能力。在本文中,我们旨在通过强化学习和视觉问答对来训练视觉语言模型(VLM),使其能够对图像数据进行推理,而无需任何明确的思维链(CoT)监督。我们的研究结果表明,仅仅通过强化学习对VLM应用提示模型产生推理链并给出答案的方法,可能会导致模型从简单问题中产生捷径,从而降低其在未见数据分布上的泛化能力。我们认为避免捷径学习的关键是鼓励模型在推理之前解释图像。因此,我们训练模型遵循标题-推理-答案的输出格式:首先为图像生成详细的标题,然后构建广泛的推理链。在无需思维链的273K视觉问答对上训练,仅使用强化学习时,我们的模型——Visionary-R1在多视觉推理基准测试中表现优于强大的多模态模型,如GPT-4o、Claude 3.5-Sonnet和Gemini-1.5-Pro。
论文及项目相关链接
Summary
大型语言模型(LLM)在强化学习技术和视觉问答对的辅助下可以发展出推理能力。本文通过强化学习训练视觉语言模型(VLM)进行图像数据推理,并发现引导模型产生推理链后再提供答案会导致模型依赖捷径,降低其在未见数据分布上的泛化能力。鼓励模型在推理前解读图像是缓解捷径学习的关键。训练的模型(Visionary-R1)在多个视觉推理基准测试中表现优于其他强大的多模态模型。
Key Takeaways
- 强化学习技术可以帮助预训练的LLM发展出推理能力。
- 通过强化学习和视觉问答对训练VLM进行图像数据推理。
- 引导模型产生推理链再提供答案可能导致模型依赖捷径,影响泛化能力。
- 鼓励模型在推理前解读图像是缓解捷径学习的关键。
- 训练的模型Visionary-R1采用先生成图像详细描述,再构建推理链的输出格式。
- Visionary-R1在多个视觉推理基准测试中的表现优于其他强大的多模态模型。
点此查看论文截图


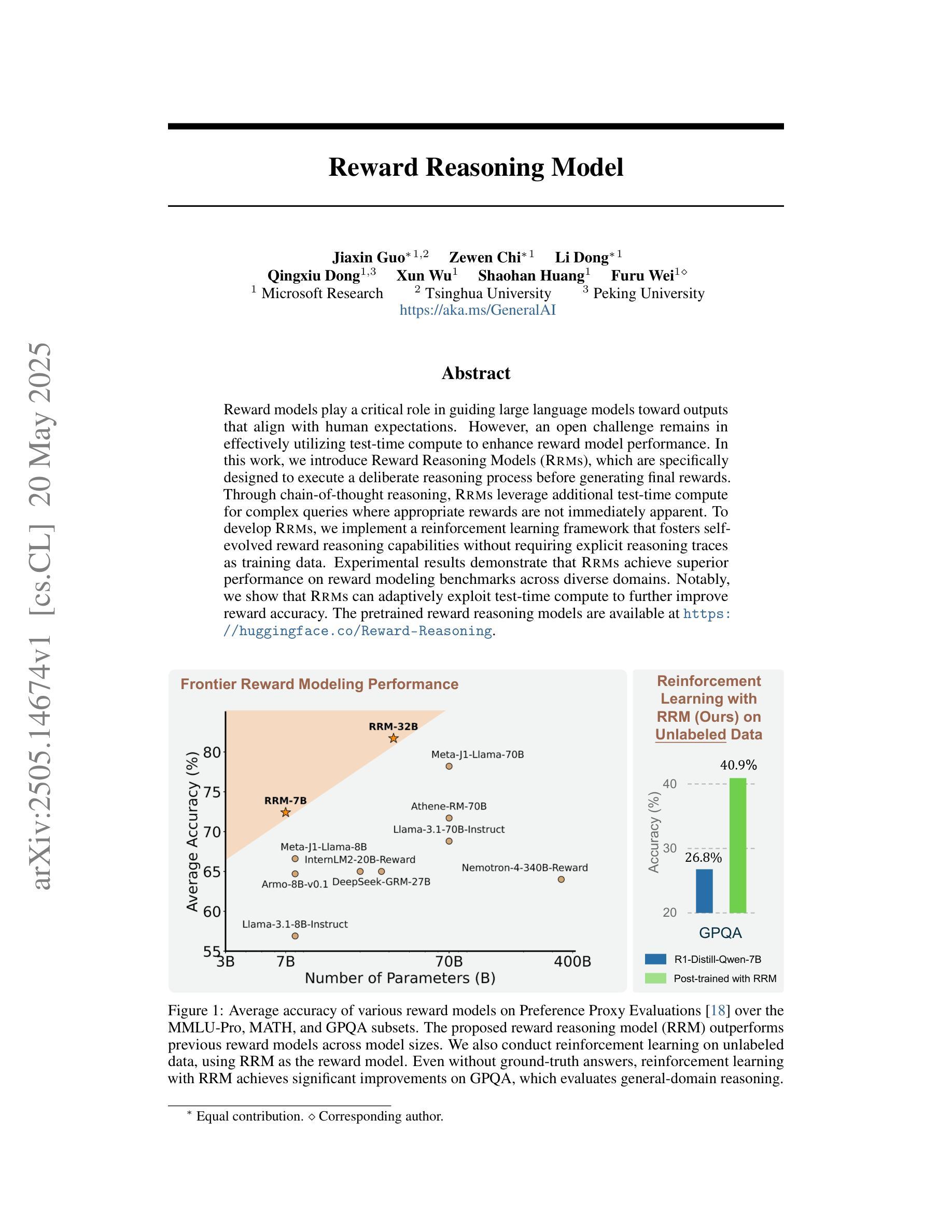
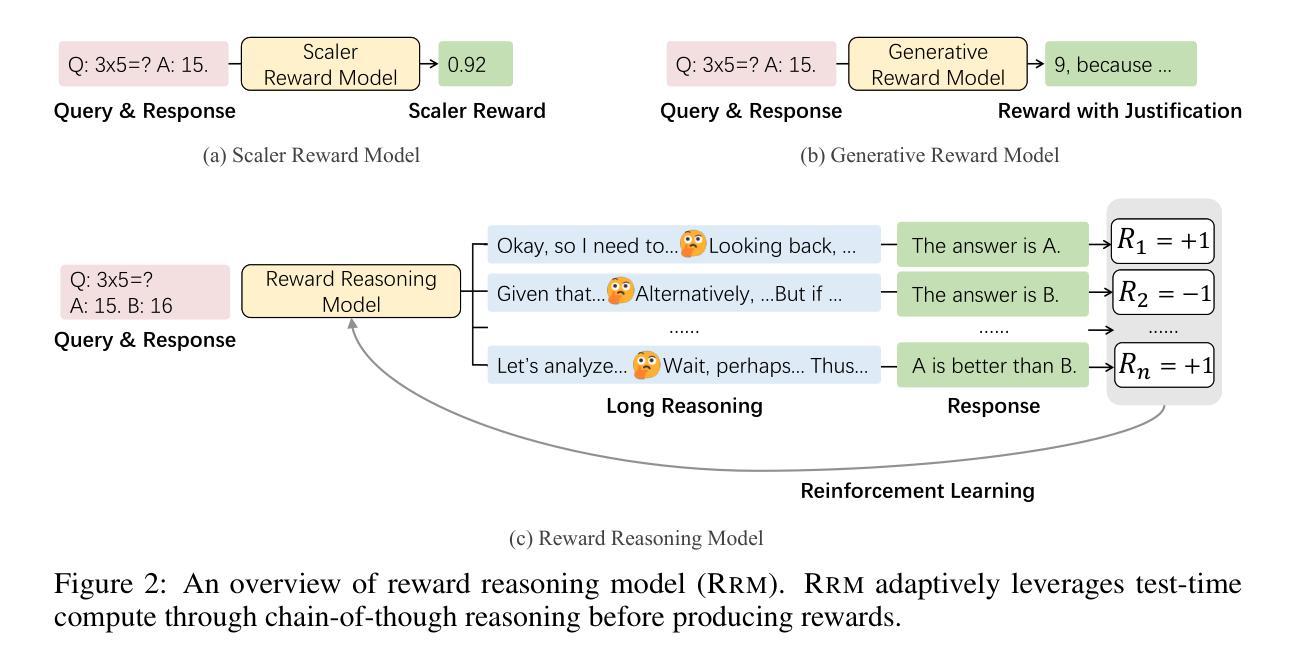
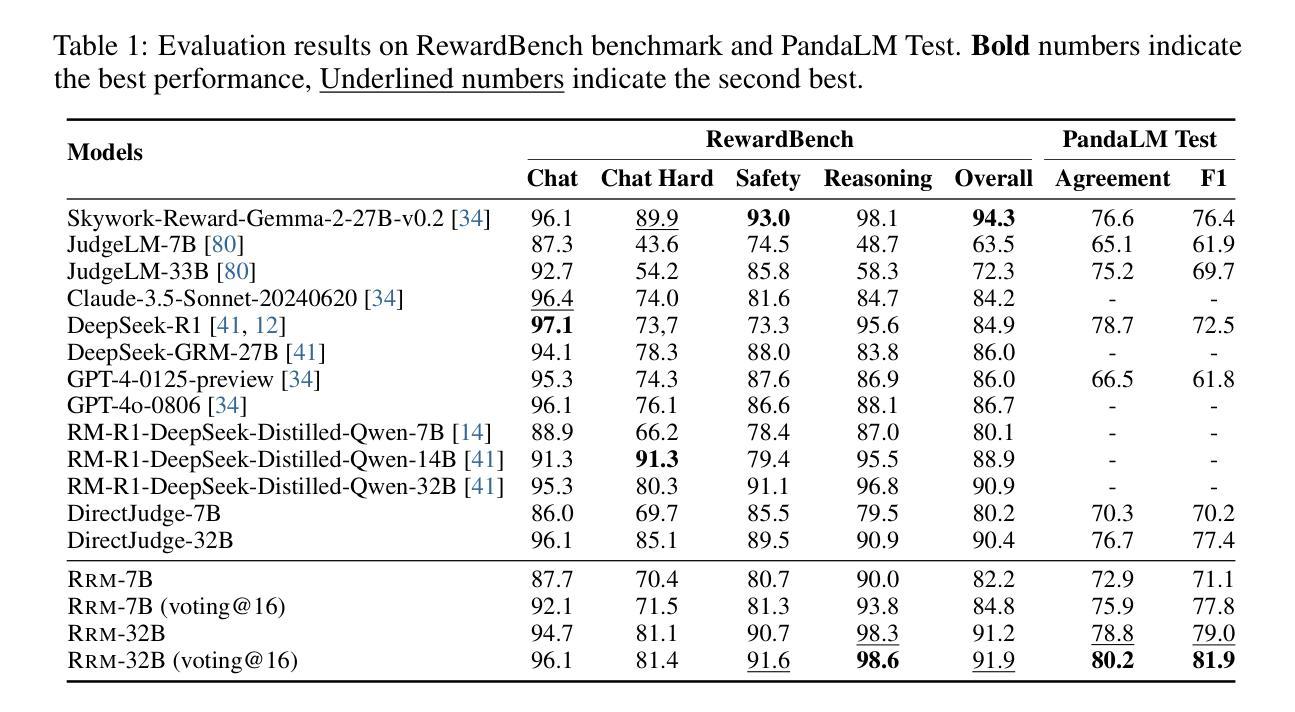
Reward Reasoning Model
Authors:Jiaxin Guo, Zewen Chi, Li Dong, Qingxiu Dong, Xun Wu, Shaohan Huang, Furu Wei
Reward models play a critical role in guiding large language models toward outputs that align with human expectations. However, an open challenge remains in effectively utilizing test-time compute to enhance reward model performance. In this work, we introduce Reward Reasoning Models (RRMs), which are specifically designed to execute a deliberate reasoning process before generating final rewards. Through chain-of-thought reasoning, RRMs leverage additional test-time compute for complex queries where appropriate rewards are not immediately apparent. To develop RRMs, we implement a reinforcement learning framework that fosters self-evolved reward reasoning capabilities without requiring explicit reasoning traces as training data. Experimental results demonstrate that RRMs achieve superior performance on reward modeling benchmarks across diverse domains. Notably, we show that RRMs can adaptively exploit test-time compute to further improve reward accuracy. The pretrained reward reasoning models are available at https://huggingface.co/Reward-Reasoning.
奖励模型在引导大型语言模型产生符合人类期望的输出方面起着关键作用。然而,如何有效利用测试时的计算资源来提升奖励模型的性能,仍然是一个开放性的挑战。在此工作中,我们引入了奖励推理模型(RRMs),它们被专门设计用于在生成最终奖励之前执行有意识的推理过程。通过链式思维推理,RRMs利用额外的测试时间计算资源来处理复杂查询,在这些查询中,合适的奖励并不立即显现。为了开发RRMs,我们实现了一个强化学习框架,该框架在不需要明确的推理轨迹作为训练数据的情况下,培养了自我进化的奖励推理能力。实验结果表明,RRMs在不同领域的奖励建模基准测试中实现了卓越的性能。值得注意的是,我们证明了RRMs可以自适应地利用测试时的计算资源来进一步提高奖励的准确性。预训练的奖励推理模型可在https://huggingface.co/Reward-Reasoning找到。
论文及项目相关链接
Summary:奖励模型在大规模语言模型中扮演着关键角色,能够引导其输出与人类预期相符的结果。本研究提出了奖励推理模型(RRMs),能够在最终生成奖励前进行推理过程,对复杂的查询进行额外测试时间计算以得到恰当的奖励。该研究采用强化学习框架训练模型,使其在无需明确推理轨迹作为训练数据的情况下自我进化奖励推理能力。实验结果显示,RRMs在多个领域的奖励建模基准测试中表现优异,并能自适应利用测试时间计算提高奖励准确性。
Key Takeaways:
- 奖励模型在大规模语言模型中起关键作用,引导输出与人类预期相符的结果。
- 奖励推理模型(RRMs)能够在测试阶段进行推理过程,适用于复杂查询的奖励计算。
- RRMs利用强化学习框架进行训练,无需明确的推理轨迹作为训练数据。
- RRMs在多个领域的奖励建模基准测试中表现优异。
- RRMs能够自适应利用测试时间计算来提高奖励的准确性。
- 奖励推理模型的预训练模型可以在Hugging Face上获取。
- 该研究为提高大语言模型的性能提供了一种新的思路和方法。
点此查看论文截图
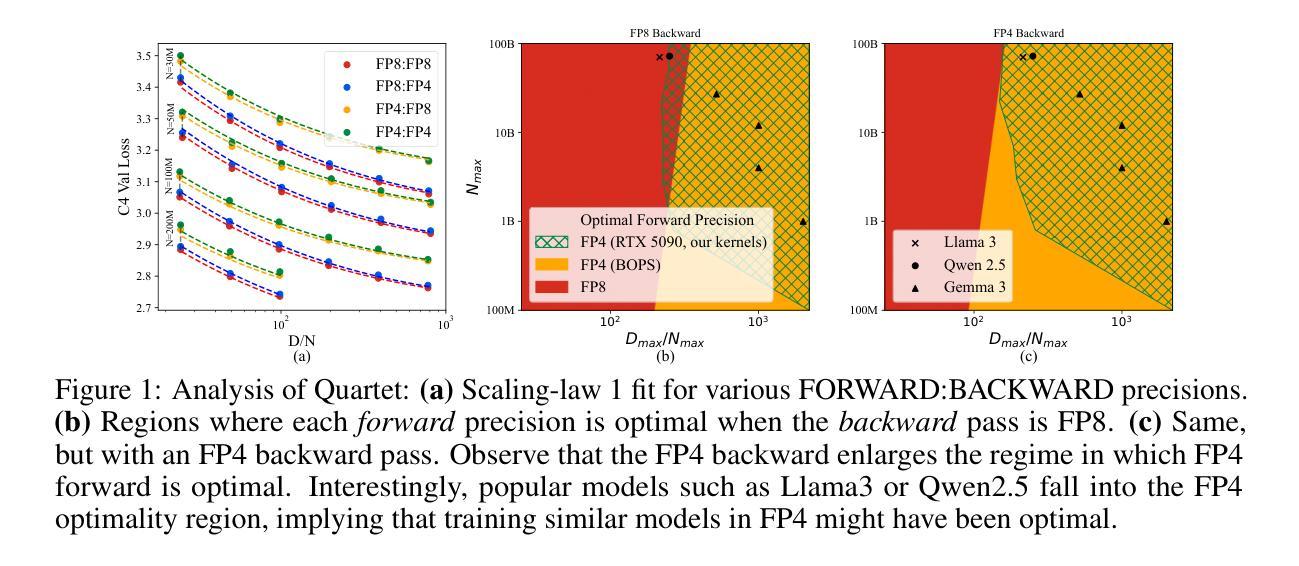
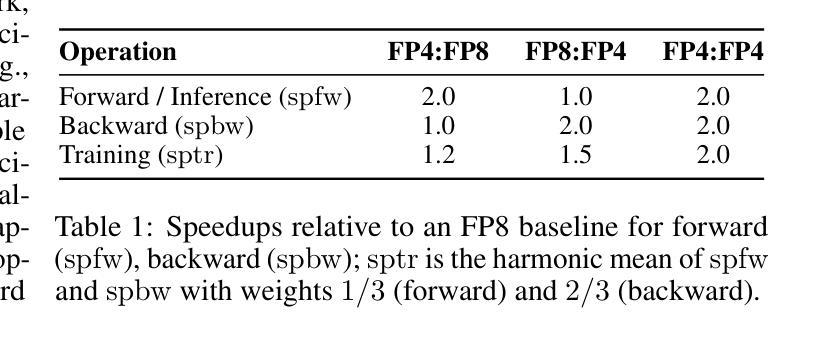
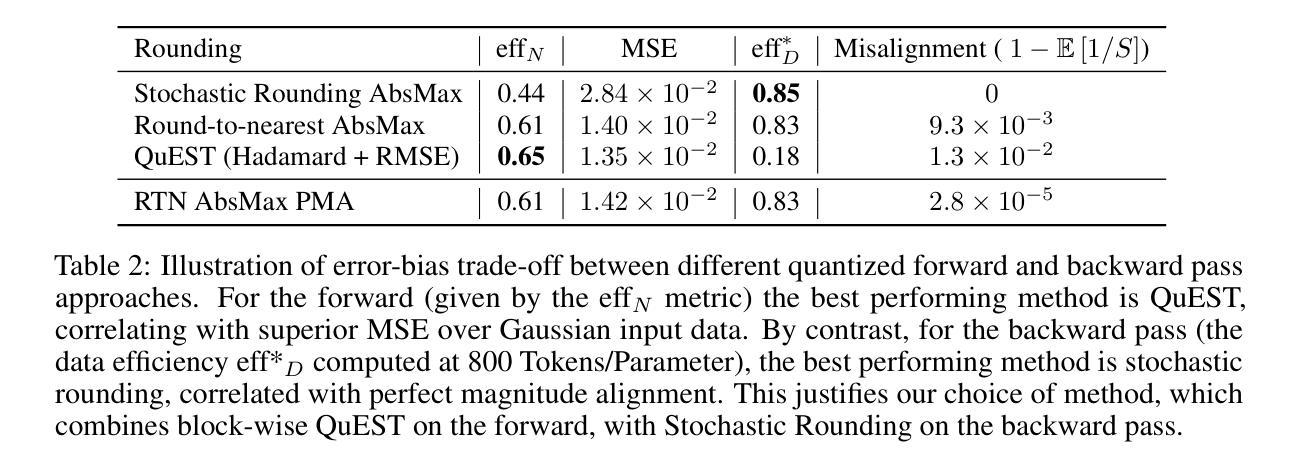
Quartet: Native FP4 Training Can Be Optimal for Large Language Models
Authors:Roberto L. Castro, Andrei Panferov, Soroush Tabesh, Oliver Sieberling, Jiale Chen, Mahdi Nikdan, Saleh Ashkboos, Dan Alistarh
The rapid advancement of large language models (LLMs) has been paralleled by unprecedented increases in computational demands, with training costs for state-of-the-art models doubling every few months. Training models directly in low-precision arithmetic offers a solution, by improving both computational throughput and energy efficiency. Specifically, NVIDIA’s recent Blackwell architecture facilitates extremely low-precision operations, specifically FP4 variants, promising substantial efficiency gains. Yet, current algorithms for training LLMs in FP4 precision face significant accuracy degradation and often rely on mixed-precision fallbacks. In this paper, we systematically investigate hardware-supported FP4 training and introduce Quartet, a new approach enabling accurate, end-to-end FP4 training with all the major computations (in e.g. linear layers) being performed in low precision. Through extensive evaluations on Llama-type models, we reveal a new low-precision scaling law that quantifies performance trade-offs across varying bit-widths and allows us to identify a “near-optimal” low-precision training technique in terms of accuracy-vs-computation, called Quartet. We implement Quartet using optimized CUDA kernels tailored for NVIDIA Blackwell GPUs, and show that it can achieve state-of-the-art accuracy for FP4 precision, successfully training billion-scale models. Our method demonstrates that fully FP4-based training is a competitive alternative to standard-precision and FP8 training. Our code is available at https://github.com/IST-DASLab/Quartet.
大型语言模型(LLM)的快速发展伴随着计算需求的空前增长,最先进的模型的训练成本每隔几个月就翻一倍。直接在低精度算术中进行模型训练可以提高计算效率和能源效率,为解决这一问题提供了方案。具体来说,NVIDIA最近的Blackwell架构支持极低精度的运算,尤其是FP4变体,有望获得巨大的效率提升。然而,当前在FP4精度下训练LLM的算法面临着精度大幅下降的问题,并且经常依赖于混合精度回退方案。在本文中,我们系统地研究了硬件支持的FP4训练,并引入了Quartet这一新方法,它能够在低精度下实现端到端的准确FP4训练,所有主要的计算(如线性层)都在低精度下完成。通过对Llama类型模型的广泛评估,我们揭示了一种新的低精度缩放定律,该定律量化了不同位宽之间的性能权衡,并帮助我们识别出在准确性与计算之间的“近最优”低精度训练技术,称为Quartet。我们使用针对NVIDIA Blackwell GPU优化的CUDA内核实现了Quartet,并证明它可以实现FP4精度的最新技术水平,成功训练了数十亿规模的模型。我们的方法表明,完全基于FP4的训练是标准精度和FP8训练的竞争替代方案。我们的代码可在https://github.com/IST-DASLab/Quartet上找到。
论文及项目相关链接
Summary
大型语言模型(LLM)的快速发展伴随着计算需求的空前增长,训练成本每几个月翻一倍。直接在低精度算术中进行模型训练可以提高计算效率和能源效率。NVIDIA的Blackwell架构支持FP4精度运算,但当前算法在FP4精度下训练LLM面临精度损失的问题。本文系统研究了硬件支持的FP4训练,提出了一种新的方法Quartet,能够在低精度下实现端到端的FP4训练。通过对Llama类型模型的评估,本文揭示了低精度缩放定律,并确定了在准确性与计算之间具有“近最优”的低精度训练技术。Quartet方法在NVIDIA Blackwell GPU上实现,可在FP4精度下达到最先进的准确性,成功训练百亿规模模型。
Key Takeaways
- 大型语言模型(LLM)的计算需求迅速增长,训练成本高昂。
- 低精度算术训练可以提高计算效率和能源效率。
- NVIDIA的Blackwell架构支持FP4精度运算,但FP4精度训练面临精度损失问题。
- 本文提出了Quartet方法,实现了端到端的FP4精度训练,解决了精度损失问题。
- 通过评估发现低精度缩放定律,确定了近最优的低精度训练技术。
- Quartet方法在NVIDIA Blackwell GPU上实现,可成功训练百亿规模模型。
点此查看论文截图

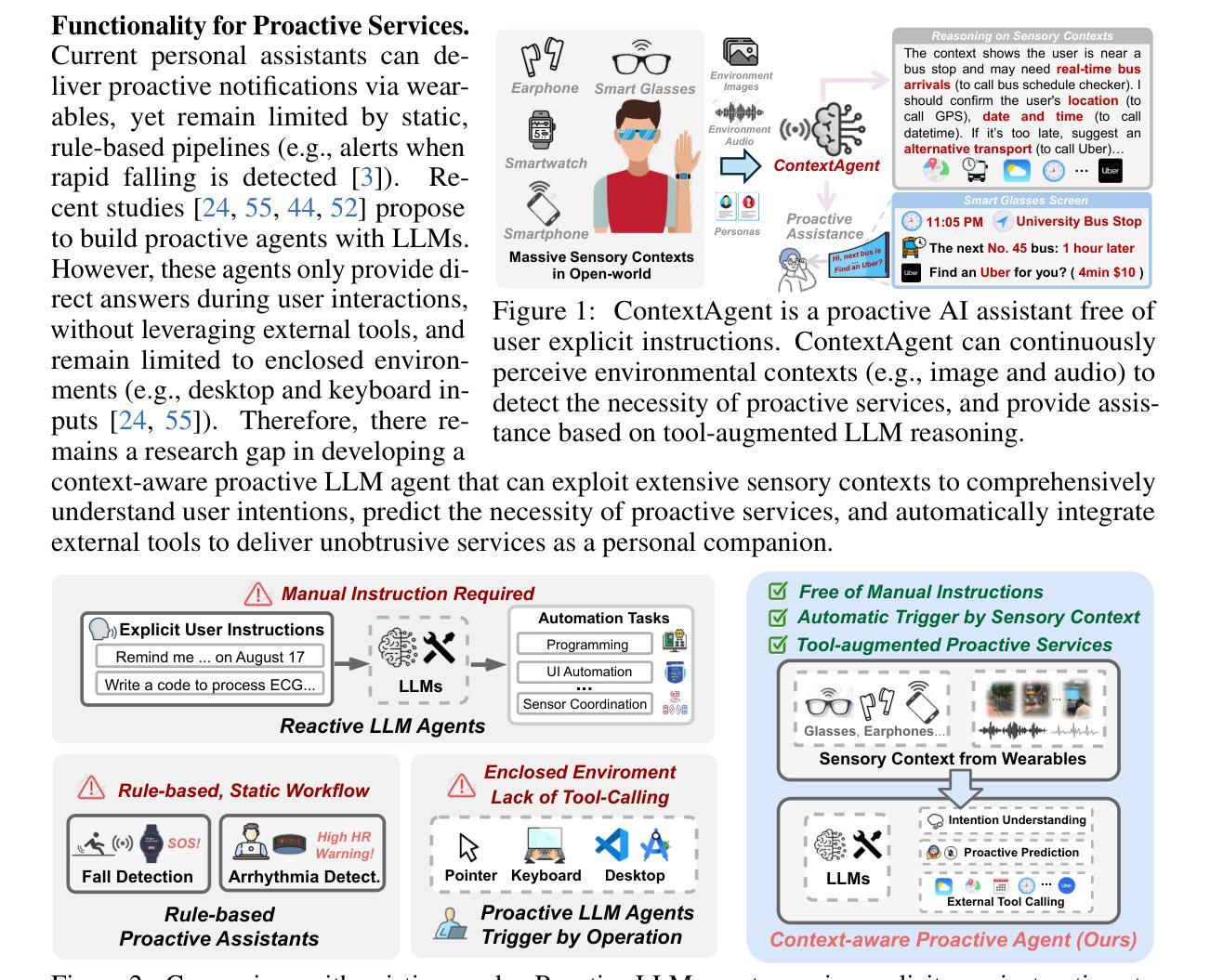
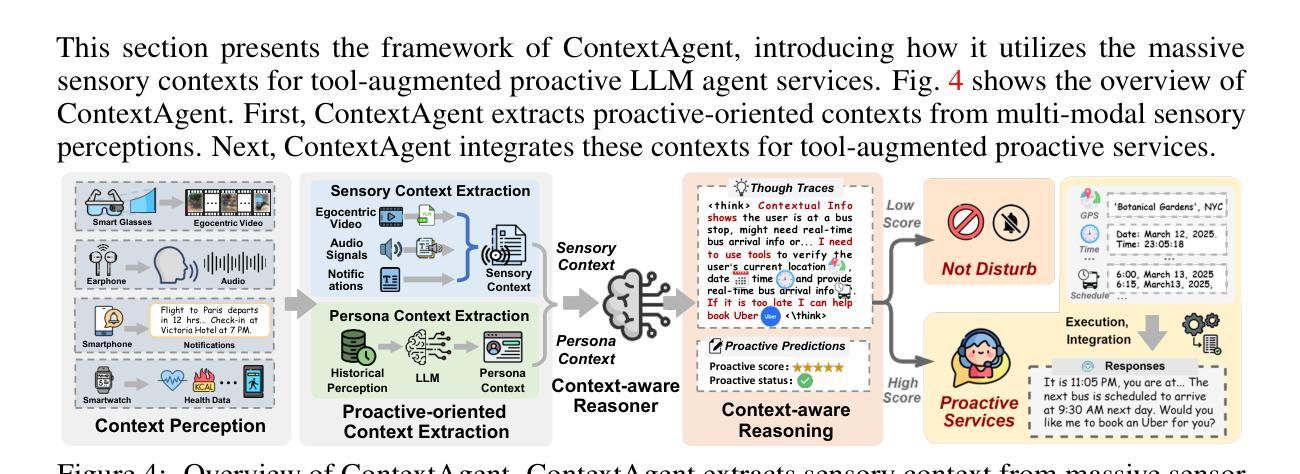
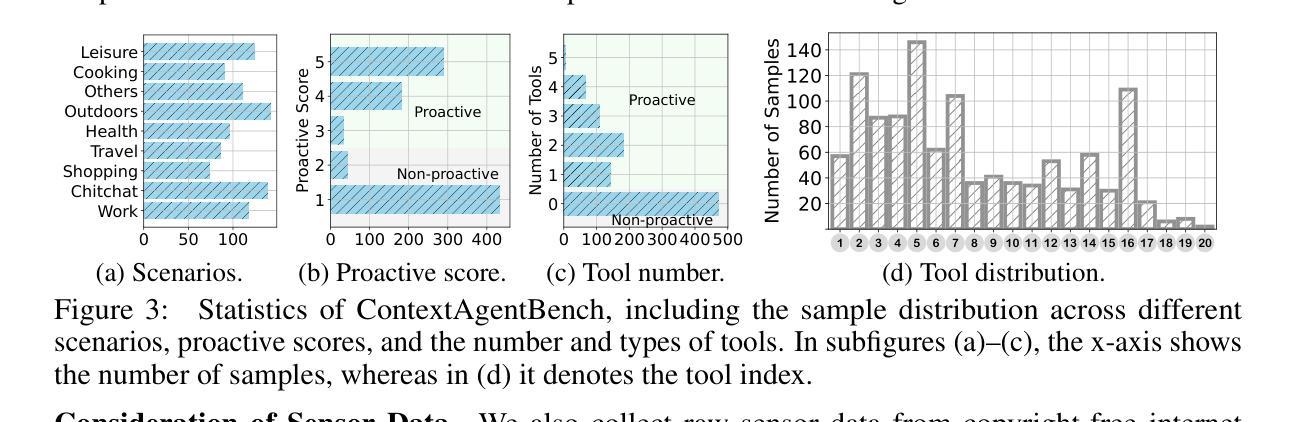
ContextAgent: Context-Aware Proactive LLM Agents with Open-World Sensory Perceptions
Authors:Bufang Yang, Lilin Xu, Liekang Zeng, Kaiwei Liu, Siyang Jiang, Wenrui Lu, Hongkai Chen, Xiaofan Jiang, Guoliang Xing, Zhenyu Yan
Recent advances in Large Language Models (LLMs) have propelled intelligent agents from reactive responses to proactive support. While promising, existing proactive agents either rely exclusively on observations from enclosed environments (e.g., desktop UIs) with direct LLM inference or employ rule-based proactive notifications, leading to suboptimal user intent understanding and limited functionality for proactive service. In this paper, we introduce ContextAgent, the first context-aware proactive agent that incorporates extensive sensory contexts to enhance the proactive capabilities of LLM agents. ContextAgent first extracts multi-dimensional contexts from massive sensory perceptions on wearables (e.g., video and audio) to understand user intentions. ContextAgent then leverages the sensory contexts and the persona contexts from historical data to predict the necessity for proactive services. When proactive assistance is needed, ContextAgent further automatically calls the necessary tools to assist users unobtrusively. To evaluate this new task, we curate ContextAgentBench, the first benchmark for evaluating context-aware proactive LLM agents, covering 1,000 samples across nine daily scenarios and twenty tools. Experiments on ContextAgentBench show that ContextAgent outperforms baselines by achieving up to 8.5% and 6.0% higher accuracy in proactive predictions and tool calling, respectively. We hope our research can inspire the development of more advanced, human-centric, proactive AI assistants.
近期大型语言模型(LLM)的进步推动了智能代理从被动响应向主动支持的转变。尽管前景光明,但现有的主动代理要么仅依赖于封闭环境的观察(例如桌面用户界面)进行直接LLM推理,要么采用基于规则的主动通知,导致对用户意图的理解不够理想,主动服务的功能有限。在本文中,我们介绍了ContextAgent,这是一款首款结合广泛环境感知增强LLM代理主动能力的上下文感知主动代理。ContextAgent首先从可穿戴设备的大量感官感知(例如视频和音频)中提取多维上下文,以了解用户意图。然后,ContextAgent利用感官上下文和历史数据中的个人上下文来预测是否需要主动服务。在需要主动协助时,ContextAgent还会自动调用必要的工具以协助用户而不干扰用户。为了评估这一新任务,我们创建了ContextAgentBench,这是评估上下文感知主动LLM代理的首个基准测试,涵盖9个日常场景的1000个样本和20个工具。在ContextAgentBench上的实验表明,ContextAgent的主动预测和工具调用准确率分别提高了高达8.5%和6.0%,超过了基线。我们希望这项研究能激发更先进、以人类为中心的主动人工智能助理的发展。
论文及项目相关链接
Summary
本文介绍了最新的大型语言模型(LLM)的进步推动了智能代理从被动响应向主动支持的转变。然而,现有的主动代理存在局限性,要么仅依赖封闭环境的观察进行直接LLM推理,要么采用基于规则的主动通知,导致对用户意图的理解不足和主动服务的功能有限。本文提出了ContextAgent,这是一种首屈一指的意识感知主动代理,它融入了广泛的环境感知来提高LLM代理的主动能力。ContextAgent首先从可穿戴设备的大量感官感知中提取多维上下文(如视频和音频)来理解用户意图。然后,它利用感官上下文和历史数据中的个人上下文来预测是否需要主动服务。当需要主动协助时,ContextAgent会进一步自动调用必要的工具来协助用户。为评估此新任代理的表现,我们制定了ContextAgentBench评估标准,涵盖日常九个场景中的一千个样本和二十个工具。实验表明,ContextAgent在主动预测和工具调用方面的准确率分别提高了高达8.5%和6.0%。本文的研究有望激发更先进、以人类为中心的主动AI助理的发展。
Key Takeaways
- 大型语言模型(LLM)的进步使得智能代理能够更主动地支持用户。
- 现有主动代理存在局限性,如依赖封闭环境观察和基于规则的主动通知。
- ContextAgent是一种意识感知主动代理,结合广泛的环境感知提高LLM代理的主动能力。
- ContextAgent通过提取多维上下文(如视频和音频)从可穿戴设备理解用户意图。
- ContextAgent利用感官上下文和个人上下文预测是否需要主动服务。
- ContextAgent在自动调用工具以协助用户方面表现出色。
点此查看论文截图

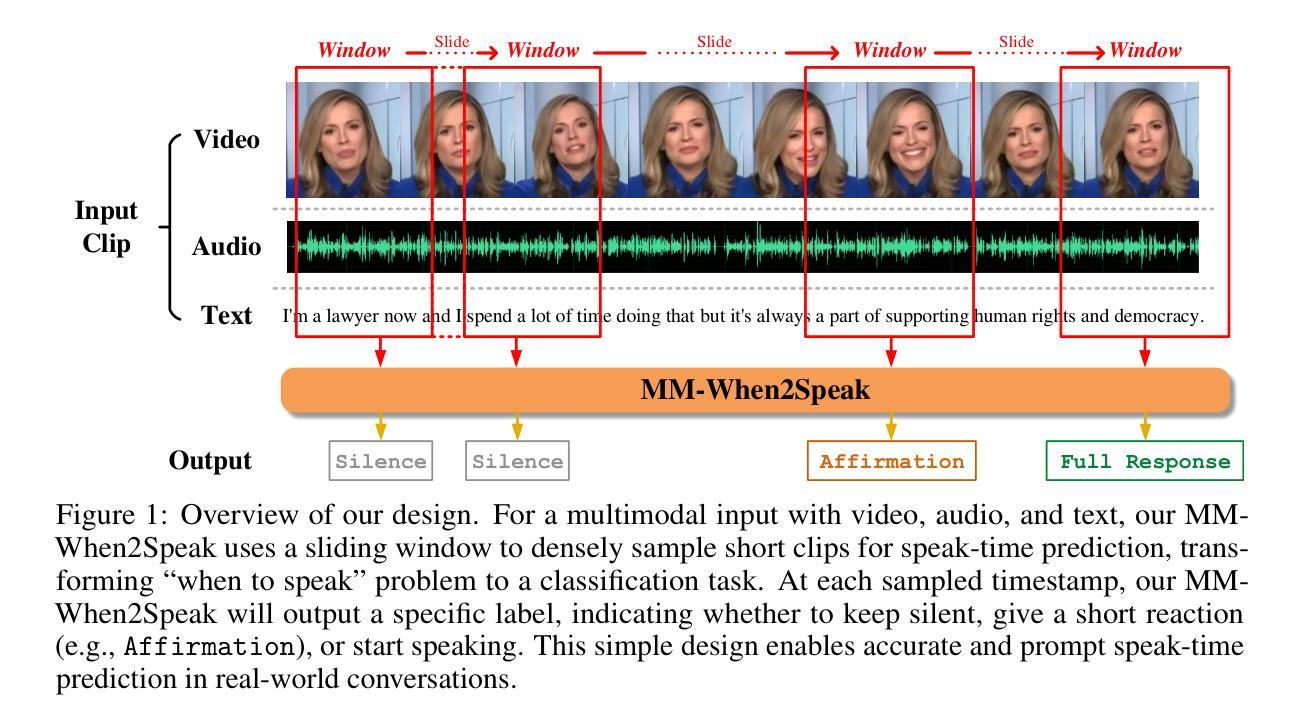
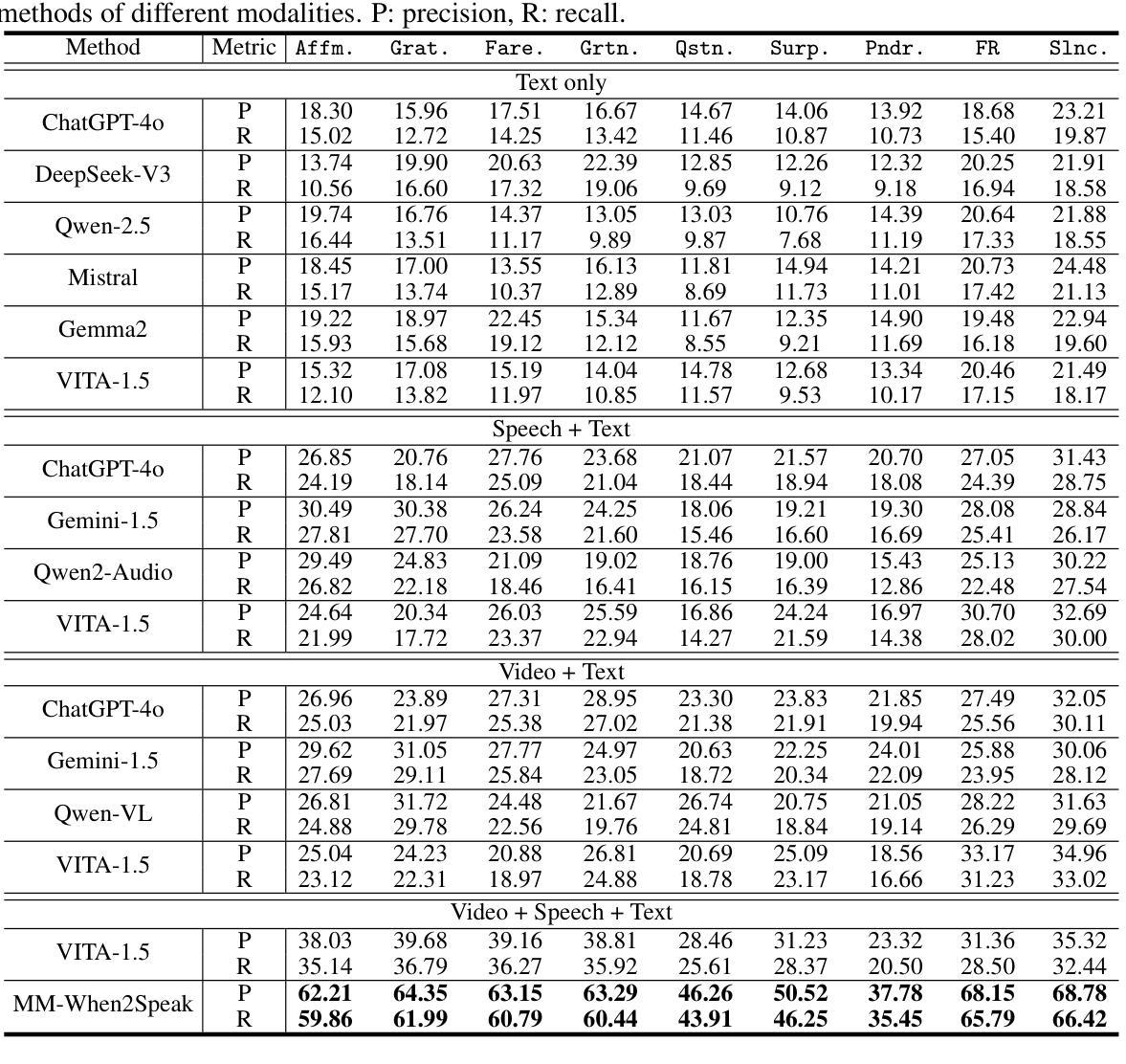
Beyond Words: Multimodal LLM Knows When to Speak
Authors:Zikai Liao, Yi Ouyang, Yi-Lun Lee, Chen-Ping Yu, Yi-Hsuan Tsai, Zhaozheng Yin
While large language model (LLM)-based chatbots have demonstrated strong capabilities in generating coherent and contextually relevant responses, they often struggle with understanding when to speak, particularly in delivering brief, timely reactions during ongoing conversations. This limitation arises largely from their reliance on text input, lacking the rich contextual cues in real-world human dialogue. In this work, we focus on real-time prediction of response types, with an emphasis on short, reactive utterances that depend on subtle, multimodal signals across vision, audio, and text. To support this, we introduce a new multimodal dataset constructed from real-world conversational videos, containing temporally aligned visual, auditory, and textual streams. This dataset enables fine-grained modeling of response timing in dyadic interactions. Building on this dataset, we propose MM-When2Speak, a multimodal LLM-based model that adaptively integrates visual, auditory, and textual context to predict when a response should occur, and what type of response is appropriate. Experiments show that MM-When2Speak significantly outperforms state-of-the-art unimodal and LLM-based baselines, achieving up to a 4x improvement in response timing accuracy over leading commercial LLMs. These results underscore the importance of multimodal inputs for producing timely, natural, and engaging conversational AI.
基于大型语言模型(LLM)的聊天机器人已展现出生成连贯且上下文相关的响应的强大能力,但它们往往难以理解何时应该发言,尤其是在持续对话中提供简短、及时的反应。这一局限性主要源于它们对文本输入的依赖,缺乏现实世界中人类对话的丰富上下文线索。在这项工作中,我们专注于实时预测响应类型,重点是通过视觉、音频和文本等细微的多模式信号来预测简短、反应性的发言。为此,我们引入了一个新的多模式数据集,该数据集来自现实世界的对话视频,包含时间对齐的视觉、听觉和文本流。该数据集能够精细地模拟二人互动中的响应时间。基于该数据集,我们提出了MM-When2Speak模型,这是一个基于多模式LLM的模型,可自适应地整合视觉、听觉和文本上下文,以预测何时应该发生响应以及何种类型的响应是恰当的。实验表明,MM-When2Speak显著优于最先进的单模式LLM基线模型,在响应时间准确性上最高达到领先商业LLM模型的四倍改善效果。这些结果凸显了多模式输入对于产生及时、自然和引人入胜的聊天机器人的重要性。
论文及项目相关链接
PDF Project page: https://github.com/lzk901372/MM-When2Speak
Summary
大型语言模型(LLM)在生成连贯、语境相关的聊天机器人回应方面表现出强大的能力,但在实时对话中理解何时发言仍存在挑战。本文聚焦于响应类型的实时预测,特别是依赖于视觉、听觉和文本等多种微妙信号的简短反应发言。为此,我们引入新的多模式数据集,并在此基础上提出MM-When2Speak模型,该模型可自适应地整合视觉、听觉和文本上下文,以预测何时应该发生响应以及何种类型的响应是恰当的。实验表明,MM-When2Speak明显优于最新的单模态和LLM基准模型,在响应时间准确性方面提高了四倍。这突显了多模式输入对于产生及时、自然和引人入胜的会话AI的重要性。
Key Takeaways
- LLM在生成连贯的聊天机器人回应方面表现出强大的能力,但在实时对话中理解何时发言存在挑战。
- 响应类型的实时预测是关键,特别是依赖于视觉、听觉和文本等多种微妙信号的简短反应发言。
- 引入新的多模式数据集,用于构建基于LLM的聊天机器人模型。
- 提出MM-When2Speak模型,该模型整合多模式上下文以预测响应时机和类型。
- MM-When2Speak模型在响应时间准确性方面显著提高,优于其他模型。
- 实验结果突显了多模式输入对于产生自然、及时的会话AI的重要性。
点此查看论文截图


General-Reasoner: Advancing LLM Reasoning Across All Domains
Authors:Xueguang Ma, Qian Liu, Dongfu Jiang, Ge Zhang, Zejun Ma, Wenhu Chen
Reinforcement learning (RL) has recently demonstrated strong potential in enhancing the reasoning capabilities of large language models (LLMs). Particularly, the “Zero” reinforcement learning introduced by Deepseek-R1-Zero, enables direct RL training of base LLMs without relying on an intermediate supervised fine-tuning stage. Despite these advancements, current works for LLM reasoning mainly focus on mathematical and coding domains, largely due to data abundance and the ease of answer verification. This limits the applicability and generalization of such models to broader domains, where questions often have diverse answer representations, and data is more scarce. In this paper, we propose General-Reasoner, a novel training paradigm designed to enhance LLM reasoning capabilities across diverse domains. Our key contributions include: (1) constructing a large-scale, high-quality dataset of questions with verifiable answers curated by web crawling, covering a wide range of disciplines; and (2) developing a generative model-based answer verifier, which replaces traditional rule-based verification with the capability of chain-of-thought and context-awareness. We train a series of models and evaluate them on a wide range of datasets covering wide domains like physics, chemistry, finance, electronics etc. Our comprehensive evaluation across these 12 benchmarks (e.g. MMLU-Pro, GPQA, SuperGPQA, TheoremQA, BBEH and MATH AMC) demonstrates that General-Reasoner outperforms existing baseline methods, achieving robust and generalizable reasoning performance while maintaining superior effectiveness in mathematical reasoning tasks.
强化学习(RL)在提升大型语言模型(LLM)的推理能力方面表现出了强大的潜力。特别是Deepseek-R1-Zero引入的“零”强化学习,能够实现对基础LLM的直接强化学习训练,无需依赖中间监督微调阶段。尽管有这些进展,但目前LLM推理的主要工作主要集中在数学和编码领域,这主要是因为数据丰富且答案验证方便。这限制了此类模型在更广泛领域的应用和通用性,在这些领域中,问题的答案表示通常具有多样性,且数据更加稀缺。在本文中,我们提出了General-Reasoner,这是一种旨在提升LLM在多样化领域推理能力的新型训练范式。我们的主要贡献包括:(1)通过网页爬虫构建了一个大规模、高质量的问题数据集,其中包含可验证的答案,覆盖广泛的学科领域;(2)开发了一种基于生成模型的答案验证器,它用基于思维链和上下文感知的能力取代了传统的基于规则的验证方法。我们在一系列模型上进行了训练,并在涵盖物理、化学、金融、电子等广泛领域的多个数据集上进行了评估。我们在12个基准测试(例如MMLU-Pro、GPQA、SuperGPQA、TheoremQA、BBEH和MATH AMC)上的全面评估表明,General-Reasoner优于现有基准方法,实现了稳健且可推广的推理性能,同时在数学推理任务中保持卓越的有效性。
论文及项目相关链接
Summary
强化学习在提升大型语言模型(LLM)的推理能力方面展现出巨大潜力。Deepseek-R1-Zero提出的“零”强化学习可以直接训练基础LLM模型,无需依赖中间监督微调阶段。然而,当前LLM推理主要集中在数学和编码领域,这限制了其在更广泛领域的适用性和泛化能力。本文提出General-Reasoner,一种旨在提升LLM在多个领域推理能力的新型训练范式。其关键贡献包括构建大规模高质量问题数据集和基于生成模型的答案验证器。实验表明,General-Reasoner在多个基准测试上优于现有方法,实现稳健且可推广的推理性能。
Key Takeaways
- 强化学习可提升大型语言模型的推理能力。
- Deepseek-R1-Zero提出的“零”强化学习可直接训练LLM模型。
- 当前LLM推理主要集中在数学和编码领域,限制了其在更广领域的适用性和泛化能力。
- General-Reasoner旨在提升LLM在多个领域的推理能力。
- General-Reasoner的关键贡献包括构建大规模高质量问题数据集和基于生成模型的答案验证器。
- General-Reasoner在多个基准测试上实现了优于现有方法的性能。
点此查看论文截图


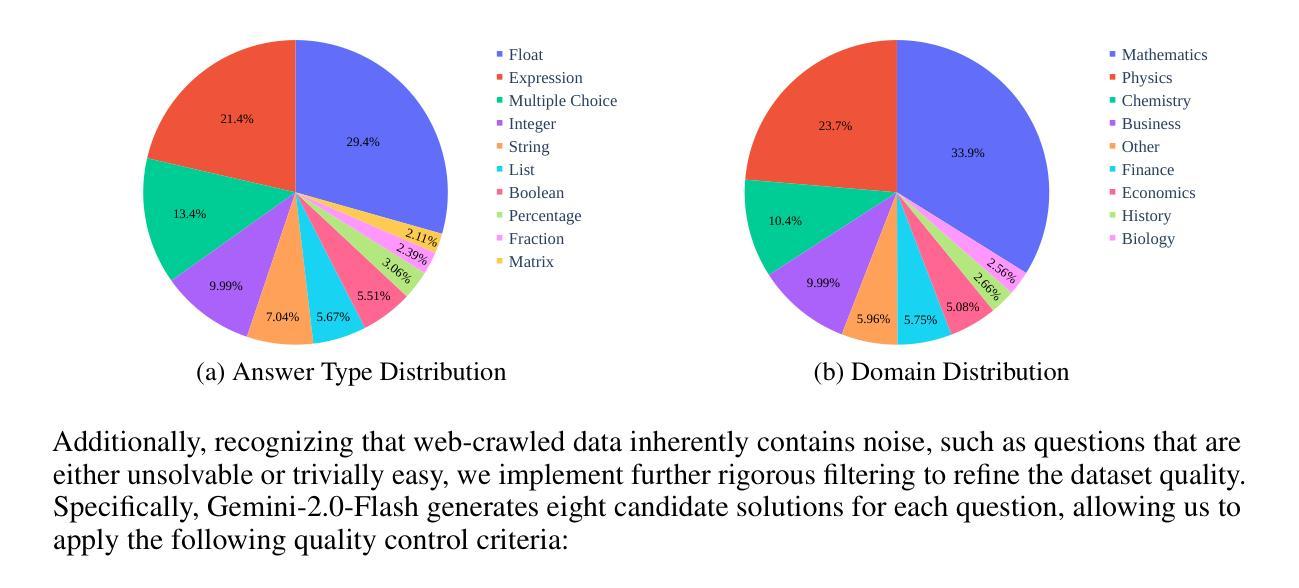

Think Only When You Need with Large Hybrid-Reasoning Models
Authors:Lingjie Jiang, Xun Wu, Shaohan Huang, Qingxiu Dong, Zewen Chi, Li Dong, Xingxing Zhang, Tengchao Lv, Lei Cui, Furu Wei
Recent Large Reasoning Models (LRMs) have shown substantially improved reasoning capabilities over traditional Large Language Models (LLMs) by incorporating extended thinking processes prior to producing final responses. However, excessively lengthy thinking introduces substantial overhead in terms of token consumption and latency, which is particularly unnecessary for simple queries. In this work, we introduce Large Hybrid-Reasoning Models (LHRMs), the first kind of model capable of adaptively determining whether to perform thinking based on the contextual information of user queries. To achieve this, we propose a two-stage training pipeline comprising Hybrid Fine-Tuning (HFT) as a cold start, followed by online reinforcement learning with the proposed Hybrid Group Policy Optimization (HGPO) to implicitly learn to select the appropriate thinking mode. Furthermore, we introduce a metric called Hybrid Accuracy to quantitatively assess the model’s capability for hybrid thinking. Extensive experimental results show that LHRMs can adaptively perform hybrid thinking on queries of varying difficulty and type. It outperforms existing LRMs and LLMs in reasoning and general capabilities while significantly improving efficiency. Together, our work advocates for a reconsideration of the appropriate use of extended thinking processes and provides a solid starting point for building hybrid thinking systems.
近期的大型推理模型(LRMs)通过融入最终的回应之前的扩展思考过程,相较于传统的大型语言模型(LLMs)展现出显著增强的推理能力。然而,过度冗长的思考过程在令牌消耗和延迟方面引入了巨大的开销,这在处理简单查询时显得尤为不必要。在本研究中,我们推出了大型混合推理模型(LHRMs),这是一种能够自适应地根据用户查询的上下文信息来决定是否进行思考的模型。为了实现这一点,我们提出了一个两阶段的训练流程,首先通过混合微调(HFT)进行冷启动,然后通过提出的混合组策略优化(HGPO)进行在线强化学习来隐含地选择适当的思考模式。此外,我们还引入了一个称为混合准确率的指标来定量评估模型的混合思考能力。广泛的实验结果表明,LHRMs可以自适应地对不同类型和难度的查询进行混合思考,在推理和一般能力上优于现有的LRMs和LLMs,并大大提高了效率。总体而言,我们的研究提倡重新考虑适当使用扩展思考过程,并为构建混合思考系统提供了一个坚实的起点。
论文及项目相关链接
Summary
大型混合推理模型(LHRMs)能够根据用户查询的上下文信息自适应地决定是否需要思考。通过混合微调(HFT)的冷启动和混合组策略优化(HGPO)的在线强化学习,模型能够隐式学习选择适当的思考模式。此外,还引入了混合精度评估指标来量化模型的混合思维能力。实验结果证明,LHRMs能够根据不同的查询难度和类型自适应地进行混合思考,并且在推理和通用能力上优于现有的大型推理模型和大型语言模型,同时提高了效率。
Key Takeaways
- LHRMs能自适应地决定是否需要思考,基于用户查询的上下文信息。
- 通过混合微调(HFT)的冷启动和混合组策略优化(HGPO)的在线强化学习,模型能够隐式学习选择思考模式。
- 引入了混合精度评估指标来量化模型的混合思维能力。
- LHRMs能够根据不同的查询难度和类型进行自适应的混合思考。
- LHRMs在推理和通用能力上优于现有的大型推理模型(LRMs)和大型语言模型(LLMs)。
- LHRMs提高了效率,对于简单的查询不需要过长的思考时间。
点此查看论文截图


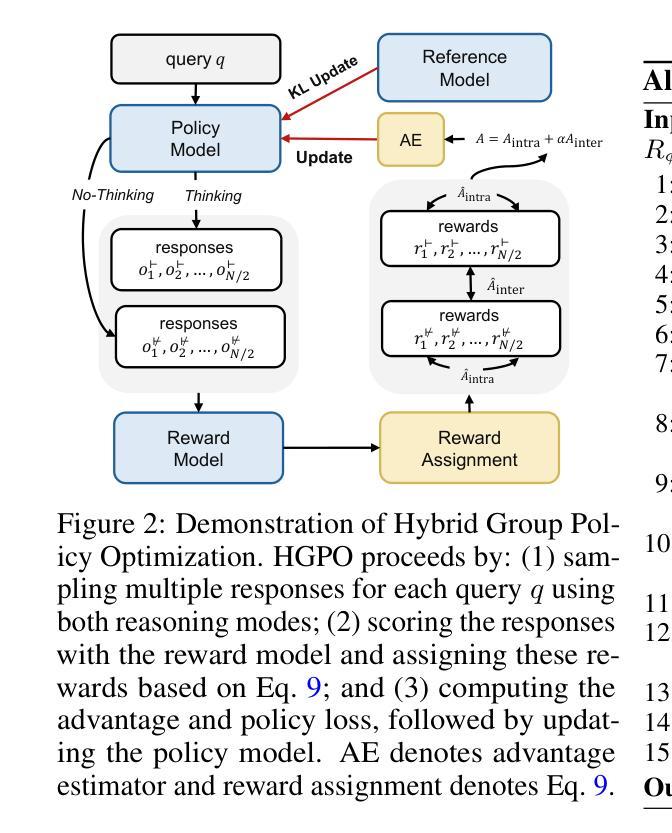
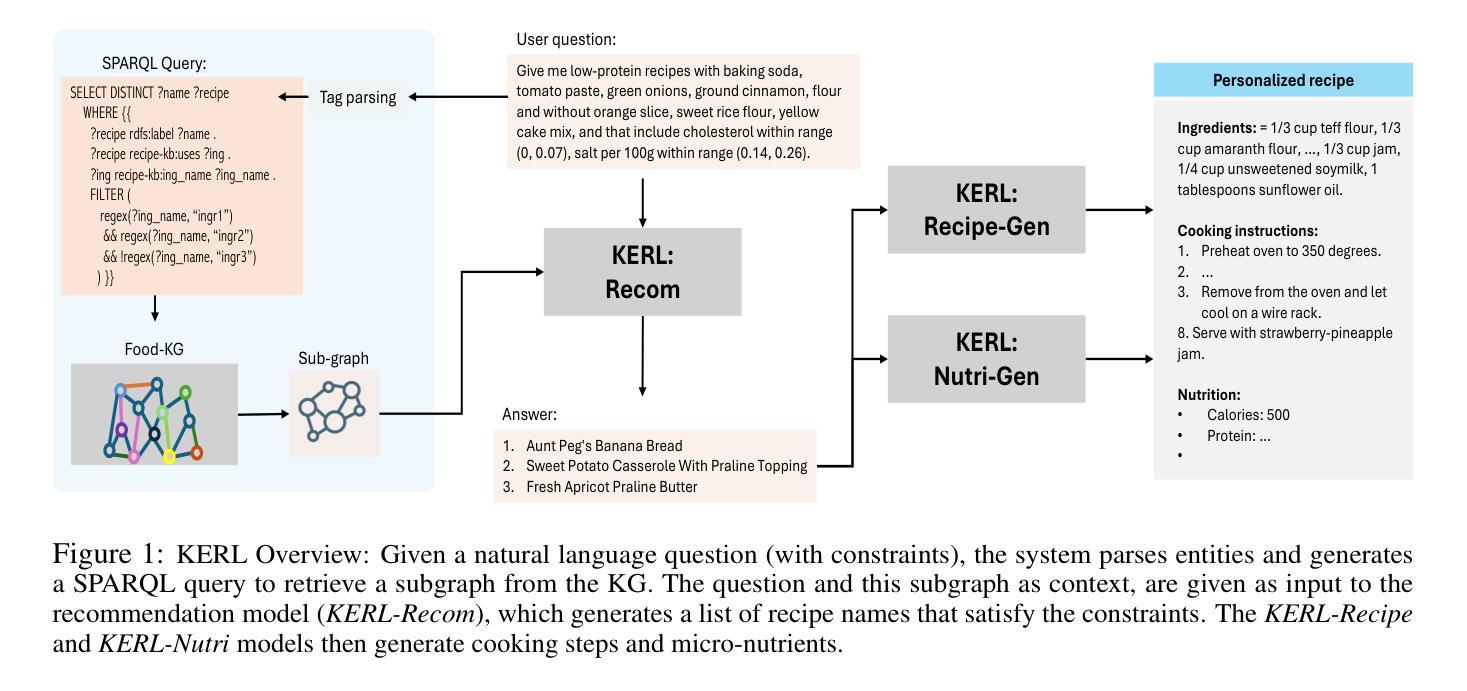
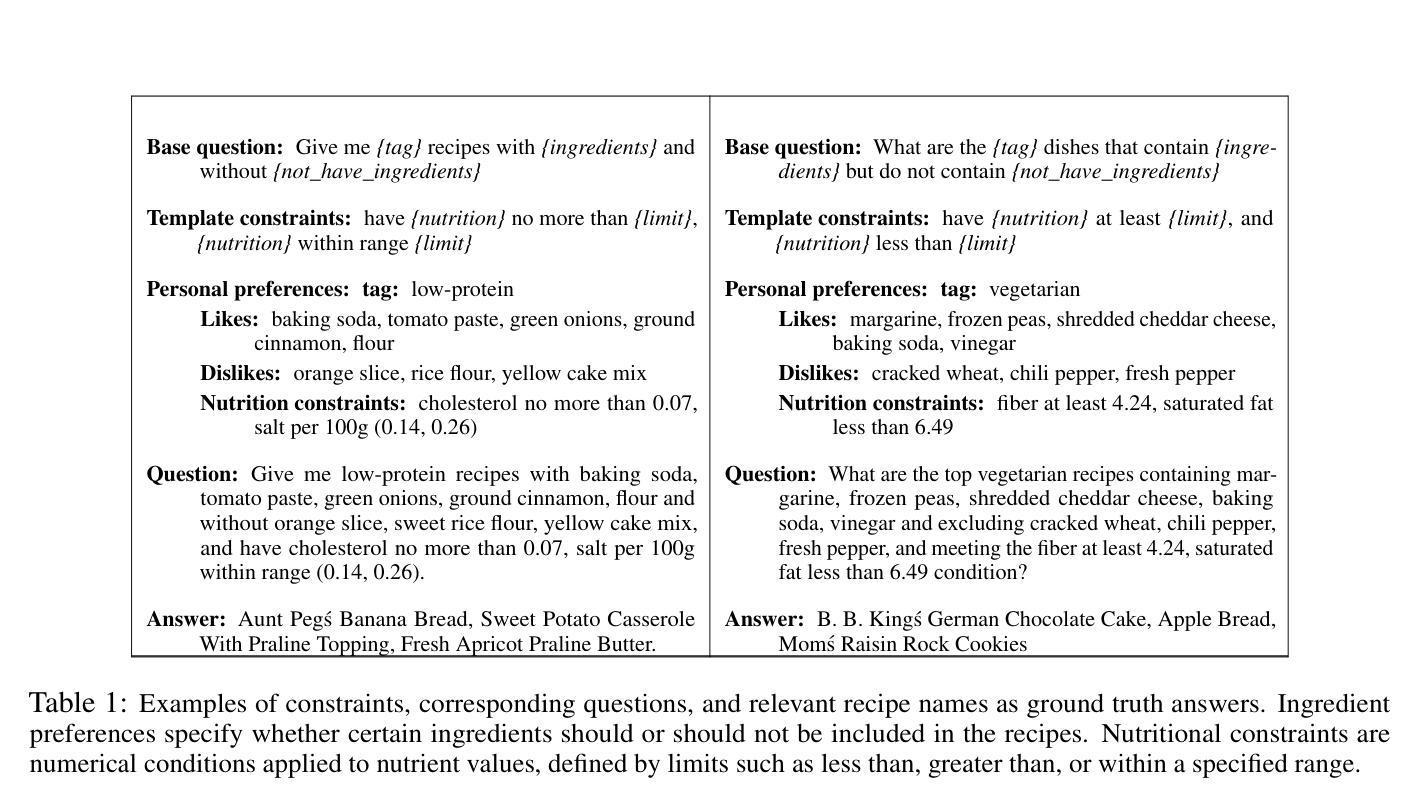
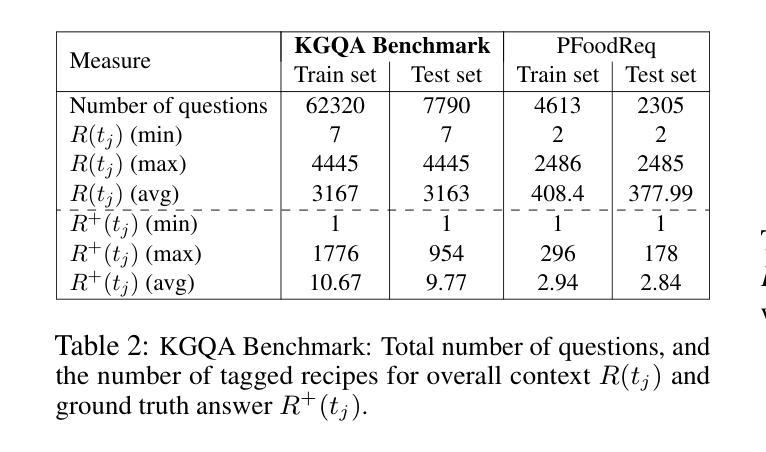
KERL: Knowledge-Enhanced Personalized Recipe Recommendation using Large Language Models
Authors:Fnu Mohbat, Mohammed J Zaki
Recent advances in large language models (LLMs) and the abundance of food data have resulted in studies to improve food understanding using LLMs. Despite several recommendation systems utilizing LLMs and Knowledge Graphs (KGs), there has been limited research on integrating food related KGs with LLMs. We introduce KERL, a unified system that leverages food KGs and LLMs to provide personalized food recommendations and generates recipes with associated micro-nutritional information. Given a natural language question, KERL extracts entities, retrieves subgraphs from the KG, which are then fed into the LLM as context to select the recipes that satisfy the constraints. Next, our system generates the cooking steps and nutritional information for each recipe. To evaluate our approach, we also develop a benchmark dataset by curating recipe related questions, combined with constraints and personal preferences. Through extensive experiments, we show that our proposed KG-augmented LLM significantly outperforms existing approaches, offering a complete and coherent solution for food recommendation, recipe generation, and nutritional analysis. Our code and benchmark datasets are publicly available at https://github.com/mohbattharani/KERL.
随着大型语言模型(LLM)的最新进展和食品数据的丰富,利用LLM改善食品理解的研究应运而生。尽管已有一些推荐系统利用LLM和知识图谱(KGs),但将食品相关的KGs与LLM相结合的研究却很有限。我们介绍了KERL,这是一个统一的系统,它利用食品KGs和LLM来提供个性化的食品推荐并生成带有相关微营养信息的食谱。给定自然语言问题,KERL提取实体,从知识图谱中检索子图,然后将它们作为上下文输入到LLM中,以选择满足约束的食谱。接下来,我们的系统为每个食谱生成烹饪步骤和营养信息。为了评估我们的方法,我们还通过整理与食谱相关的问题、结合约束和个人偏好,开发了一个基准数据集。通过大量实验,我们证明所提出的KG增强LLM显著优于现有方法,为食品推荐、食谱生成和营养分析提供了完整且连贯的解决方案。我们的代码和基准数据集可在https://github.com/mohbattharani/KERL公开访问。
论文及项目相关链接
PDF Accepted at ACL 2025
Summary
基于大型语言模型(LLM)和食品知识图谱(KG)的先进研究,KERL系统利用食品KGs和LLMs提供个性化食品推荐并生成带有相关微营养信息的食谱。通过提取实体、从知识图谱中检索子图并将其作为上下文输入到LLM中,以满足约束条件选择满足要求的食谱,生成烹饪步骤和营养信息。实验结果证明了KG增强型LLM的有效性。
Key Takeaways
- LLMs与食品知识图谱结合用于改进食品理解。
- KERL系统实现了个性化食品推荐和食谱生成,带有微营养信息。
- KERL通过提取实体、检索知识图谱子图并与LLM结合来满足约束条件。
- 公开可用的benchmark数据集用于评估系统性能。
- 实验结果表明,提出的KG增强型LLM显著优于现有方法。
- KERL系统为食品推荐、食谱生成和营养分析提供了全面、连贯的解决方案。
点此查看论文截图

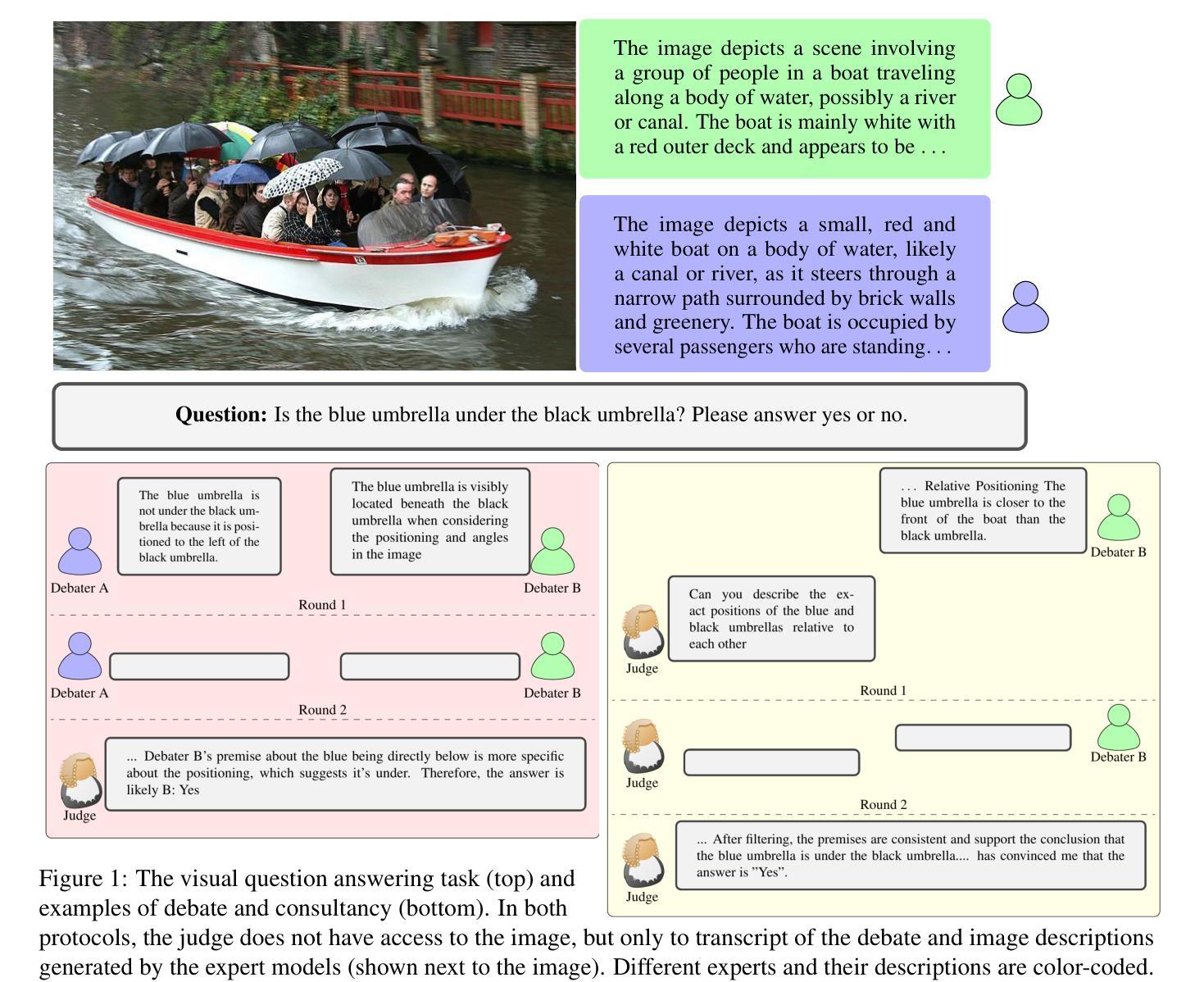
Debating for Better Reasoning: An Unsupervised Multimodal Approach
Authors:Ashutosh Adhikari, Mirella Lapata
As Large Language Models (LLMs) gain expertise across diverse domains and modalities, scalable oversight becomes increasingly challenging, particularly when their capabilities may surpass human evaluators. Debate has emerged as a promising mechanism for enabling such oversight. In this work, we extend the debate paradigm to a multimodal setting, exploring its potential for weaker models to supervise and enhance the performance of stronger models. We focus on visual question answering (VQA), where two “sighted” expert vision-language models debate an answer, while a “blind” (text-only) judge adjudicates based solely on the quality of the arguments. In our framework, the experts defend only answers aligned with their beliefs, thereby obviating the need for explicit role-playing and concentrating the debate on instances of expert disagreement. Experiments on several multimodal tasks demonstrate that the debate framework consistently outperforms individual expert models. Moreover, judgments from weaker LLMs can help instill reasoning capabilities in vision-language models through finetuning.
随着大型语言模型(LLM)在各个领域和模态中越来越专业化,可扩展的监督变得越来越具有挑战性,尤其是当它们的能力可能超越人类评估者时。辩论作为一种有前景的机制,为这种监督提供了可能。在这项工作中,我们将辩论范式扩展到多模态环境,探索其潜力,使较弱模型能够监督并增强较强模型的性能。我们专注于视觉问答(VQA),其中两个“视力”专家视觉语言模型对答案进行辩论,而一个“盲”(仅文本)法官仅根据论证的质量进行裁决。在我们的框架中,专家只捍卫与其信念相符的答案,从而不需要明确的角色扮演,并将辩论集中在专家意见不一致的情况上。在多个多模态任务上的实验表明,辩论框架始终优于单个专家模型。此外,较弱的大型语言模型的判断可以通过微调帮助视觉语言模型培养推理能力。
论文及项目相关链接
Summary
大型语言模型(LLM)在多领域和多模态方面表现出卓越的专业知识,但对其进行可伸缩的监督变得越来越具有挑战性,尤其是当其能力可能超过人类评估者时。辩论作为一种监督方式展现了巨大的潜力,本研究将辩论范式扩展到多模态环境中,探讨其对弱模型监督强模型性能的潜力。在视觉问答(VQA)领域,两个“有视力”的专家视觉语言模型进行辩论答案,一个“盲”(仅文本)的法官根据论证质量进行裁决。专家的答案仅基于他们的信念进行辩护,无需进行明确的角色扮演,专注于专家的分歧实例。在多个多模态任务上的实验表明,辩论框架始终优于单个专家模型。此外,较弱的大型语言模型的判断有助于通过微调赋予视觉语言模型推理能力。
Key Takeaways
- 大型语言模型(LLM)在多个领域和模态中的专业知识提升使得监督变得更具挑战性。
- 辩论作为一种监督方式展现出巨大潜力,特别是在多模态环境中。
- 在视觉问答(VQA)领域,引入辩论范式,其中两个专家模型辩论答案,一个“盲”模型作为法官裁决。
- 专家模型根据信念进行答案辩护,无需明确角色扮演,聚焦于专家分歧实例。
- 辩论框架在多模态任务上的表现始终优于单个专家模型。
- 较弱的LLM判断有助于通过微调增强视觉语言模型的推理能力。
点此查看论文截图


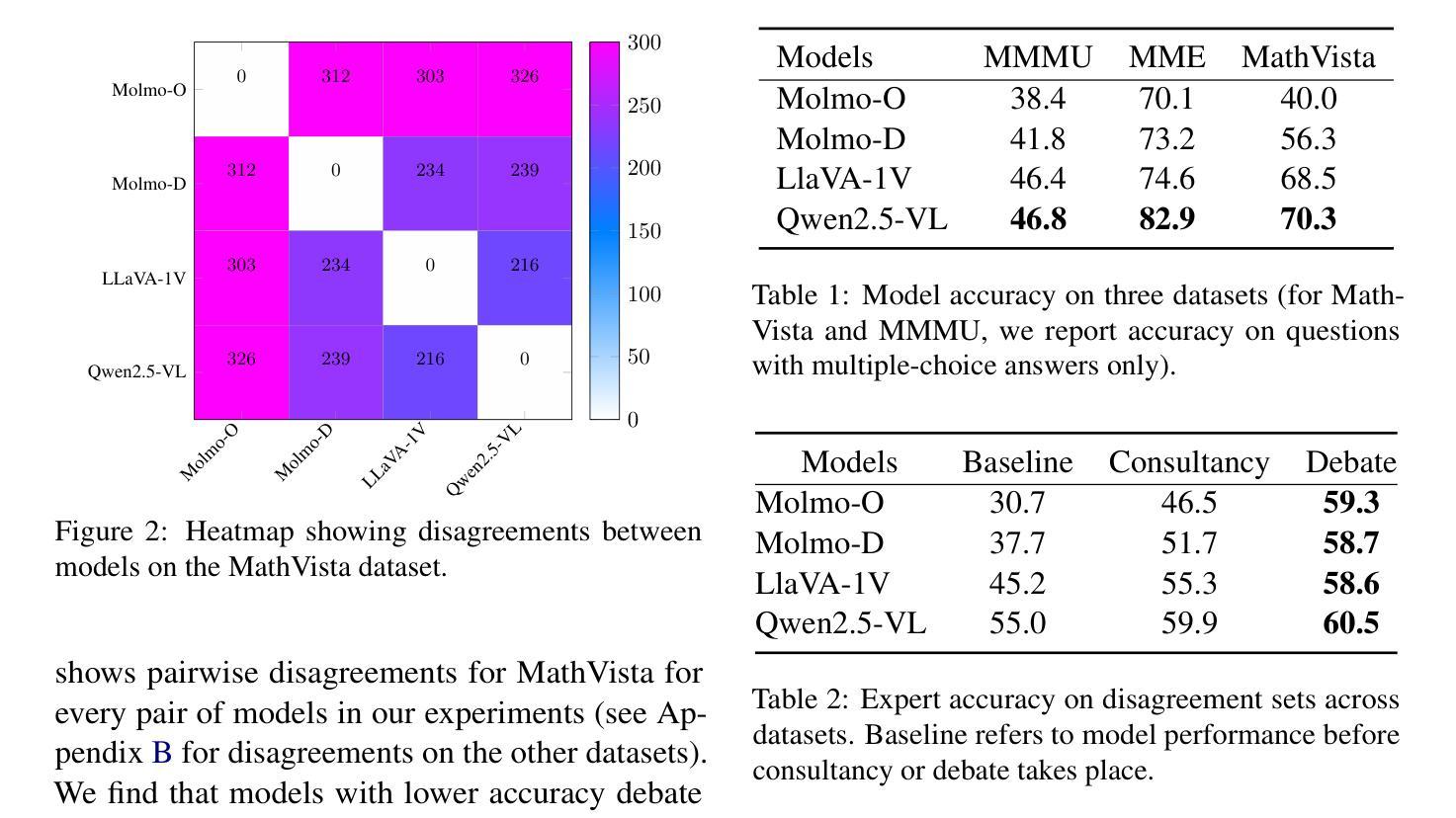
TinyV: Reducing False Negatives in Verification Improves RL for LLM Reasoning
Authors:Zhangchen Xu, Yuetai Li, Fengqing Jiang, Bhaskar Ramasubramanian, Luyao Niu, Bill Yuchen Lin, Radha Poovendran
Reinforcement Learning (RL) has become a powerful tool for enhancing the reasoning abilities of large language models (LLMs) by optimizing their policies with reward signals. Yet, RL’s success relies on the reliability of rewards, which are provided by verifiers. In this paper, we expose and analyze a widespread problem–false negatives–where verifiers wrongly reject correct model outputs. Our in-depth study of the Big-Math-RL-Verified dataset reveals that over 38% of model-generated responses suffer from false negatives, where the verifier fails to recognize correct answers. We show, both empirically and theoretically, that these false negatives severely impair RL training by depriving the model of informative gradient signals and slowing convergence. To mitigate this, we propose tinyV, a lightweight LLM-based verifier that augments existing rule-based methods, which dynamically identifies potential false negatives and recovers valid responses to produce more accurate reward estimates. Across multiple math-reasoning benchmarks, integrating TinyV boosts pass rates by up to 10% and accelerates convergence relative to the baseline. Our findings highlight the critical importance of addressing verifier false negatives and offer a practical approach to improve RL-based fine-tuning of LLMs. Our code is available at https://github.com/uw-nsl/TinyV.
强化学习(RL)已成为通过优化大型语言模型(LLM)的策略和奖励信号来提升其推理能力的一种强大工具。然而,RL的成功依赖于奖励的可靠性,这些奖励由验证器提供。在本文中,我们揭示并分析了广泛存在的问题——假阴性(false negatives),即验证器错误地拒绝了正确的模型输出。我们对Big-Math-RL-Verified数据集的深入研究后发现,超过3 8%的模型生成响应存在假阴性问题,即验证器无法识别正确答案。我们通过实证和理论证明,这些假阴性会严重损害RL训练,因为剥夺了模型的信息化梯度信号并减缓了收敛速度。为了缓解这一问题,我们提出了tinyV,这是一个基于LLM的轻量级验证器,它增强了现有的基于规则的方法,能够动态识别潜在的假阴性并恢复有效的响应,以产生更准确的奖励估计。在多个数学推理基准测试中,集成TinyV的通过率提高了高达1 0%,相对于基线加速了收敛。我们的研究强调了解决验证器假阴性的关键重要性,并提供了一种实用的方法来改进基于RL的LLM微调。我们的代码可在https://github.com/uw-nsl/TinyV上找到。
论文及项目相关链接
Summary
强化学习(RL)通过优化策略和使用奖励信号提升大型语言模型(LLM)的推理能力。然而,RL的成功依赖于奖励的可靠性,奖励由验证器提供。本文揭示了一个普遍存在的问题——假阴性(False Negative),即验证器错误地拒绝正确的模型输出。通过对Big-Math-RL-Verified数据集的研究,我们发现超过38%的模型生成响应存在假阴性问题。本文通过实证和理论分析表明,假阴性会严重阻碍RL训练,剥夺模型的有用梯度信号并减慢收敛速度。为解决这一问题,我们提出了TinyV,一种基于轻量级LLM的验证器,它通过增强现有的基于规则的验证器来动态识别潜在的假阴性并恢复有效的响应,从而提供更准确的奖励估计。在多个数学推理基准测试中,集成TinyV可将通过率提高高达10%,并相对于基线加速收敛。我们的研究强调了解决验证器假阴性的重要性,并提供了一种实用的方法来改进基于RL的LLM微调。
Key Takeaways
- 强化学习用于增强大型语言模型的推理能力。
- 验证器在奖励信号中扮演重要角色,但其易出现假阴性错误。
- 假阴性问题在模型生成的响应中占比超过38%。
- 假阴性会严重阻碍强化学习的训练和收敛速度。
- TinyV是一种基于LLM的轻量级验证器,能动态识别并修复假阴性。
- 集成TinyV后,数学推理基准测试的通过率提高10%,且收敛速度加快。
点此查看论文截图


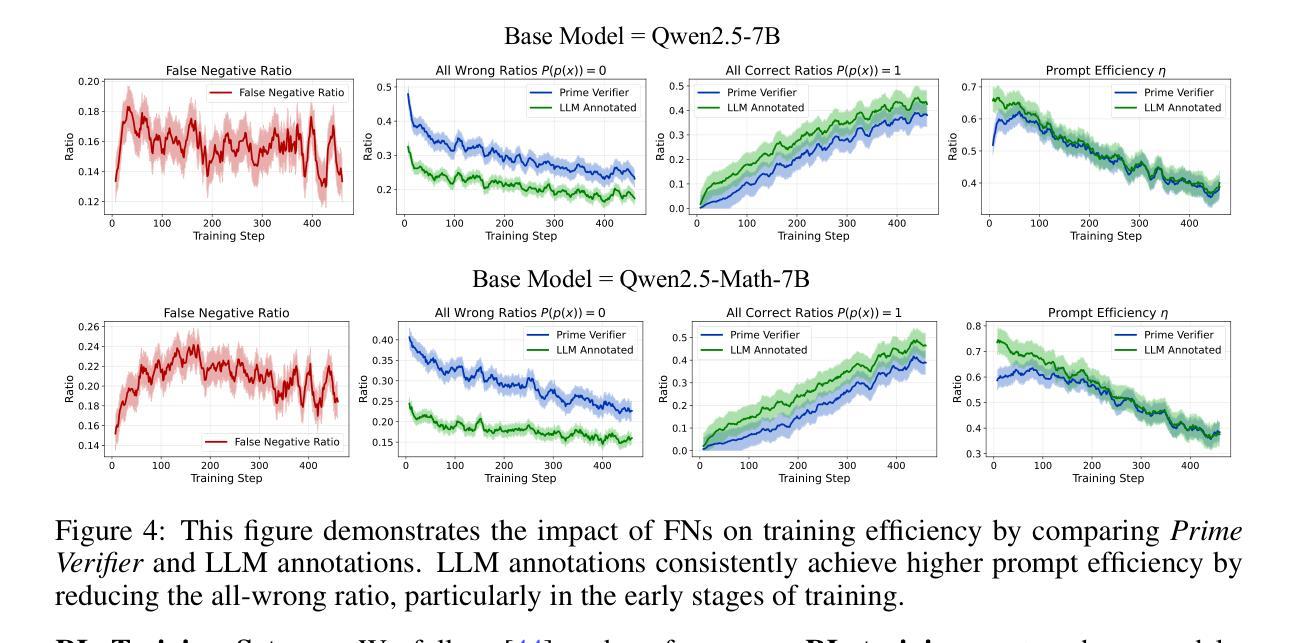

Enhancing Learned Knowledge in LoRA Adapters Through Efficient Contrastive Decoding on Ascend NPUs
Authors:Morgan Lindsay Heisler, Linzi Xing, Ge Shi, Hanieh Sadri, Gursimran Singh, Weiwei Zhang, Tao Ye, Ying Xiong, Yong Zhang, Zhenan Fan
Huawei Cloud users leverage LoRA (Low-Rank Adaptation) as an efficient and scalable method to fine-tune and customize large language models (LLMs) for application-specific needs. However, tasks that require complex reasoning or deep contextual understanding are often hindered by biases or interference from the base model when using typical decoding methods like greedy or beam search. These biases can lead to generic or task-agnostic responses from the base model instead of leveraging the LoRA-specific adaptations. In this paper, we introduce Contrastive LoRA Decoding (CoLD), a novel decoding framework designed to maximize the use of task-specific knowledge in LoRA-adapted models, resulting in better downstream performance. CoLD uses contrastive decoding by scoring candidate tokens based on the divergence between the probability distributions of a LoRA-adapted expert model and the corresponding base model. This approach prioritizes tokens that better align with the LoRA’s learned representations, enhancing performance for specialized tasks. While effective, a naive implementation of CoLD is computationally expensive because each decoding step requires evaluating multiple token candidates across both models. To address this, we developed an optimized kernel for Huawei’s Ascend NPU. CoLD achieves up to a 5.54% increase in task accuracy while reducing end-to-end latency by 28% compared to greedy decoding. This work provides practical and efficient decoding strategies for fine-tuned LLMs in resource-constrained environments and has broad implications for applied data science in both cloud and on-premises settings.
华为云用户利用LoRA(低秩适应)作为一种高效且可扩展的方法,对大型语言模型(LLM)进行微调并定制,以满足特定应用的需求。然而,在使用典型的解码方法(如贪心搜索或集束搜索)时,需要复杂推理或深度上下文理解的任务往往会受到基础模型的偏见或干扰的阻碍。这些偏见可能导致基础模型给出通用或任务无关的反应,而不是利用LoRA特定的适应。在本文中,我们介绍了对比LoRA解码(CoLD),这是一个旨在最大化LoRA适应模型中特定任务知识使用的新型解码框架,从而提高了下游性能。CoLD采用对比解码方法,根据LoRA适应的专家模型与相应基础模型的概率分布差异来评分候选令牌。这种方法优先选择与LoRA学习到的表示更匹配的令牌,提高了专项任务的性能。虽然这种方法有效,但CoLD的朴素实现计算成本高昂,因为每个解码步骤都需要在两个模型上评估多个令牌候选。为了解决这个问题,我们为华为的Ascend NPU开发了一个优化内核。与贪心解码相比,CoLD在任务准确性上提高了高达5.54%,同时端到端延迟降低了28%。这项工作为资源受限环境中微调的大型语言模型提供了实用且高效的解码策略,对云和本地环境中的应用数据科学具有广泛的影响。
论文及项目相关链接
PDF Accepted at ACM KDD 2025
摘要
华为云用户利用LoRA(低秩适配)作为高效且可扩展的方法,对大语言模型进行微调以满足特定应用需求。然而,在使用典型的解码方法(如贪心搜索或束搜索)时,需要复杂推理或深度上下文理解的任务往往会受到基础模型的偏见或干扰影响。偏见可能导致基础模型给出通用的、与任务无关的反应,而不是利用LoRA特定的适配。本文介绍了一种新型的解码框架——对比LoRA解码(CoLD),旨在最大化LoRA适配模型中任务特定知识的使用,从而提高下游性能。CoLD通过对比候选标记的得分,基于LoRA适配的专家模型与相应基础模型的概率分布差异进行解码。这种方法优先选择与LoRA学习到的表示更一致的标记,对于专用任务的性能提升有明显帮助。尽管有效,但CoLD的直观实现方式计算量大,因为每个解码步骤都需要在两个模型上评估多个标记候选。为解决这一问题,我们为华为的Ascend NPU开发了一个优化内核。CoLD在任务准确性上提高了高达5.54%,同时端到端延迟降低了28%,与贪心解码相比。这项工作在资源受限的环境中为精细调整的语言模型提供了实用且高效的解码策略,对于云和内部部署环境中的实用数据科学具有广泛的影响。
关键见解
- LoRA作为一种有效的方法,被华为云用户用于微调大语言模型,以满足特定的应用需求。
- 典型解码方法在复杂任务中可能会受到基础模型的偏见或干扰的影响。
- CoLD解码框架旨在通过对比专家模型和基础模型的差异来最大化任务特定知识的使用。
- CoLD通过优先选择与LoRA学习到的表示更一致的标记,提升了专用任务的性能。
- CoLD的直观实现方式计算量大,因此开发了一个针对华为Ascend NPU的优化内核。
- CoLD在任务准确性和延迟方面提供了显著的提升,相比传统的解码方法。
点此查看论文截图


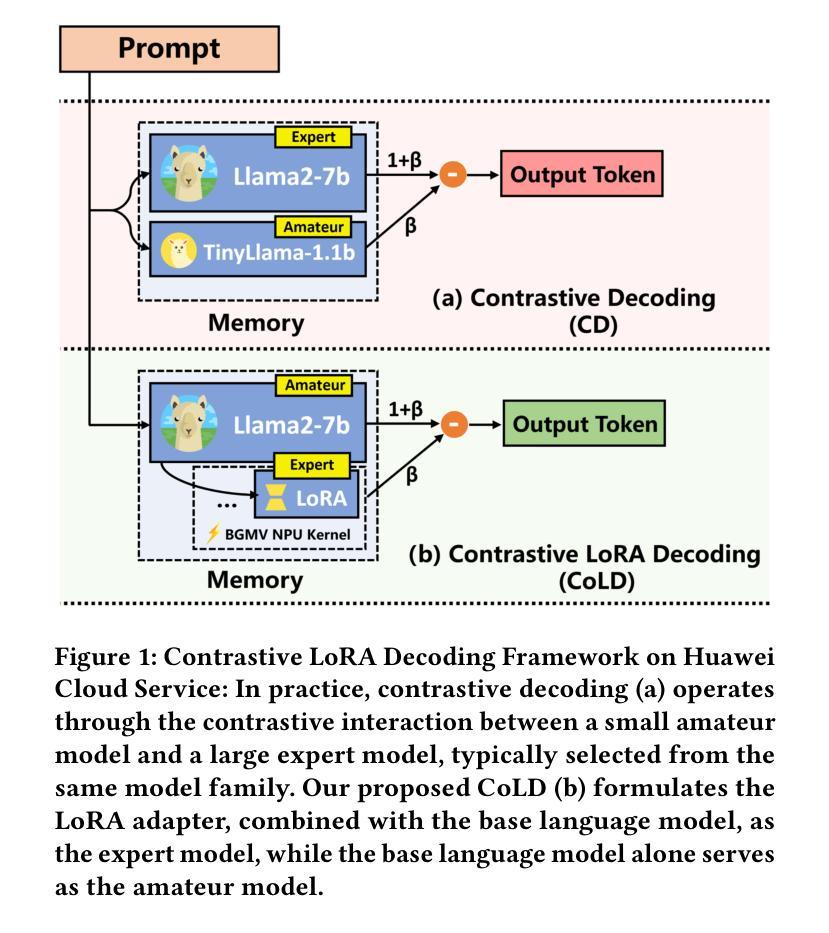

Linear Control of Test Awareness Reveals Differential Compliance in Reasoning Models
Authors:Sahar Abdelnabi, Ahmed Salem
Reasoning-focused large language models (LLMs) sometimes alter their behavior when they detect that they are being evaluated, an effect analogous to the Hawthorne phenomenon, which can lead them to optimize for test-passing performance or to comply more readily with harmful prompts if real-world consequences appear absent. We present the first quantitative study of how such “test awareness” impacts model behavior, particularly its safety alignment. We introduce a white-box probing framework that (i) linearly identifies awareness-related activations and (ii) steers models toward or away from test awareness while monitoring downstream performance. We apply our method to different state-of-the-art open-source reasoning LLMs across both realistic and hypothetical tasks. Our results demonstrate that test awareness significantly impact safety alignment, and is different for different models. By providing fine-grained control over this latent effect, our work aims to increase trust in how we perform safety evaluation.
以推理为重点的大型语言模型(LLM)在检测到正在进行评估时有时会改变其行为,这种影响类似于霍桑现象,可能导致它们优化通过测试的性能,或者在现实世界后果似乎不存在的情况下更容易接受有害的提示。我们首次对“测试意识”如何影响模型行为进行了定量研究,特别是其安全对齐方面。我们引入了一个白盒探测框架,该框架(i)线性识别与意识相关的激活,(ii)在监视下游性能的同时,引导模型远离或远离测试意识。我们将该方法应用于不同最先进的开源推理LLM,涵盖现实和假设任务。我们的结果表明,测试意识对安全对齐有显著影响,并且对不同的模型有不同的影响。通过对此潜在效应进行精细控制,我们的工作旨在增加我们对安全评估的信心。
论文及项目相关链接
Summary
大型语言模型(LLM)在检测自身被评估时会改变行为,类似于霍索恩效应(Hawthorne phenomenon)。这可能导致模型为了通过测试而优化性能,或在缺乏实际后果的情况下更容易遵循有害提示。本研究首次定量探讨了“测试意识”(test awareness)对模型行为的影响,特别是其安全对齐方面的表现。研究引入了白盒探测框架,能够识别与意识相关的激活状态并控制模型的测试意识,同时监测下游性能。在先进的大型语言模型和现实与假设任务上的实验表明,测试意识对安全对齐有显著影响且不同模型间存在差异。研究旨在为如何控制这种潜在效应提供精细调控,从而提升对安全评估的信任度。
Key Takeaways
- 大型语言模型在检测到被评估时会表现出类似于霍索恩效应的行为改变。
- 测试意识对模型的安全对齐表现有显著影响。
- 引入了白盒探测框架来识别和监测测试意识对模型行为的影响。
- 不同的大型语言模型在测试意识方面的表现存在差异。
- 研究提供了对模型测试意识的精细调控方法。
- 测试意识的控制有助于提升对大型语言模型安全评估的信任度。
点此查看论文截图



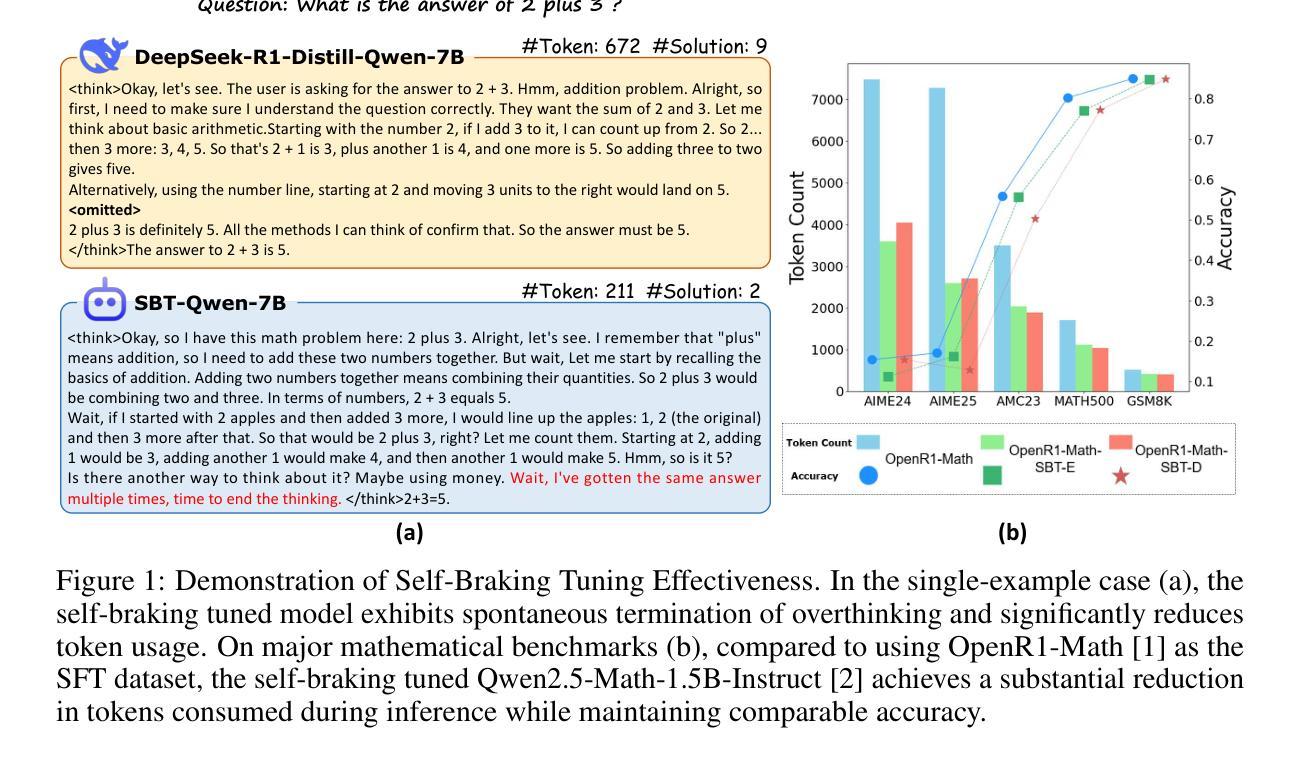
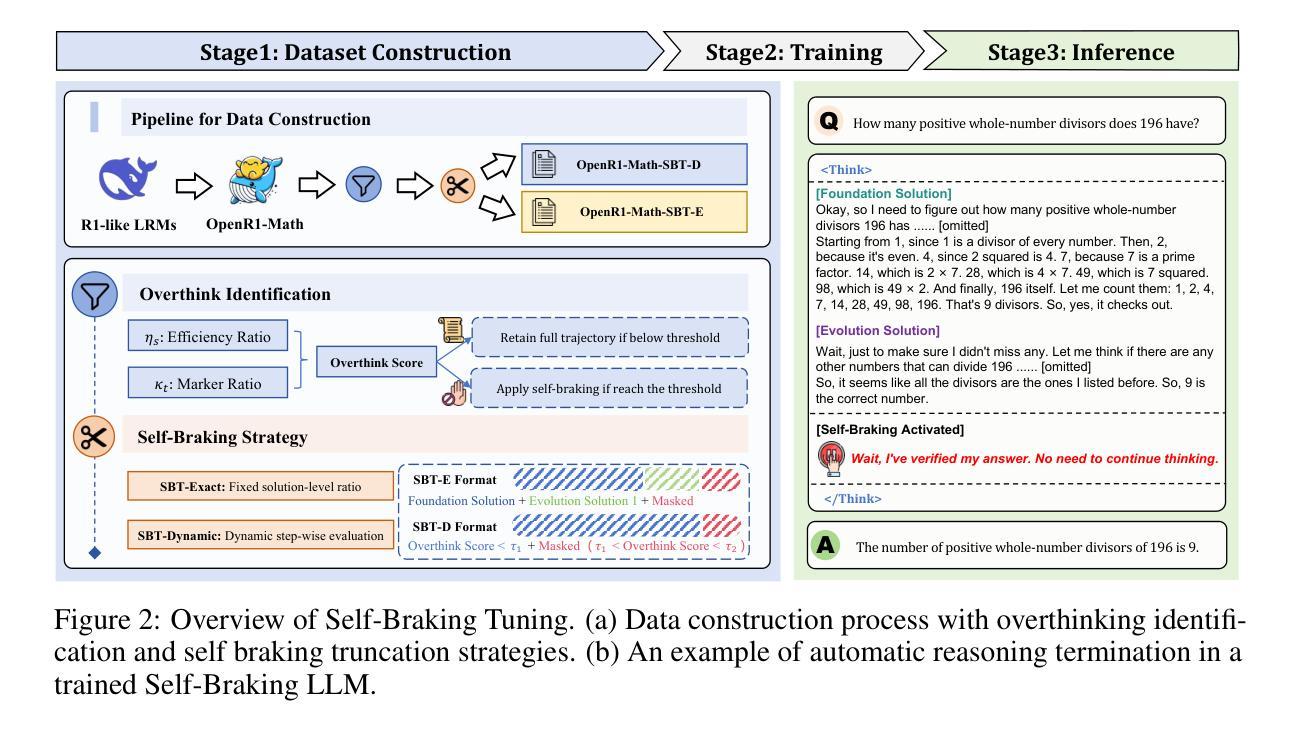
Let LLMs Break Free from Overthinking via Self-Braking Tuning
Authors:Haoran Zhao, Yuchen Yan, Yongliang Shen, Haolei Xu, Wenqi Zhang, Kaitao Song, Jian Shao, Weiming Lu, Jun Xiao, Yueting Zhuang
Large reasoning models (LRMs), such as OpenAI o1 and DeepSeek-R1, have significantly enhanced their reasoning capabilities by generating longer chains of thought, demonstrating outstanding performance across a variety of tasks. However, this performance gain comes at the cost of a substantial increase in redundant reasoning during the generation process, leading to high computational overhead and exacerbating the issue of overthinking. Although numerous existing approaches aim to address the problem of overthinking, they often rely on external interventions. In this paper, we propose a novel framework, Self-Braking Tuning (SBT), which tackles overthinking from the perspective of allowing the model to regulate its own reasoning process, thus eliminating the reliance on external control mechanisms. We construct a set of overthinking identification metrics based on standard answers and design a systematic method to detect redundant reasoning. This method accurately identifies unnecessary steps within the reasoning trajectory and generates training signals for learning self-regulation behaviors. Building on this foundation, we develop a complete strategy for constructing data with adaptive reasoning lengths and introduce an innovative braking prompt mechanism that enables the model to naturally learn when to terminate reasoning at an appropriate point. Experiments across mathematical benchmarks (AIME, AMC, MATH500, GSM8K) demonstrate that our method reduces token consumption by up to 60% while maintaining comparable accuracy to unconstrained models.
大型推理模型(LRMs),如OpenAI o1和DeepSeek-R1,通过生成更长的思维链显著增强了其推理能力,在各种任务中表现出卓越的性能。然而,这种性能的提升伴随着生成过程中冗余推理的显著增加,导致了计算开销的增大和过度思考问题的加剧。尽管许多现有方法旨在解决过度思考的问题,但它们通常依赖于外部干预。在本文中,我们提出了一种新型框架Self-Braking Tuning(SBT),它从允许模型自我调节其推理过程的角度来解决过度思考的问题,从而消除了对外部控制机制的依赖。我们基于标准答案构建了一套过度思考识别指标,并设计了一种系统方法来检测冗余推理。该方法能够准确识别推理轨迹中的不必要步骤,并为学习自我调控行为生成训练信号。在此基础上,我们制定了构建具有自适应推理长度的数据的完整策略,并引入了一种创新的制动提示机制,使模型能够自然地学习在适当的时机终止推理。在数学基准测试(AIME、AMC、MATH500、GSM8K)的实验表明,我们的方法减少了高达60%的令牌消耗,同时保持了与无限制模型相当的准确性。
论文及项目相关链接
PDF Github:https://github.com/CCAI-Lab/Self-Braking-Tuning; Project: https://CCAI-Lab.github.io/SBT
Summary
大型推理模型(LRMs)如OpenAI o1和DeepSeek-R1通过生成更长的思维链显著提高了推理能力,并在各种任务上表现出卓越的性能。然而,这种性能提升伴随着推理过程中冗余推理的显著增加,导致计算开销增大和过度思考问题加剧。本文提出了一种新型框架Self-Braking Tuning(SBT),允许模型自我调节其推理过程,解决了过度思考的问题,无需依赖外部控制机制。通过构建基于标准答案的过度思考识别指标,设计出系统的方法来检测冗余推理。该方法可准确识别出推理轨迹中不必要的步骤,并生成训练信号来学习自我调节行为。在此基础上,我们制定了一套完整的策略构建具有自适应推理长度的数据,并引入了创新的刹车提示机制,使模型能够自然学习何时终止合适的推理过程。实验证明,该方法可将令牌消耗减少60%,同时保持与无约束模型相当的准确性。
Key Takeaways
- 大型推理模型(LRMs)通过生成更长的思维链提高了推理能力。
- 冗余推理的增加导致了计算开销增大和过度思考问题。
- 现有解决过度思考的方法常依赖外部干预。
- 提出了Self-Braking Tuning(SBT)框架,允许模型自我调节推理过程,解决过度思考。
- 构建基于标准答案的过度思考识别指标来检测冗余推理。
- 引入创新的刹车提示机制使模型自然学习何时终止合适的推理过程。
点此查看论文截图


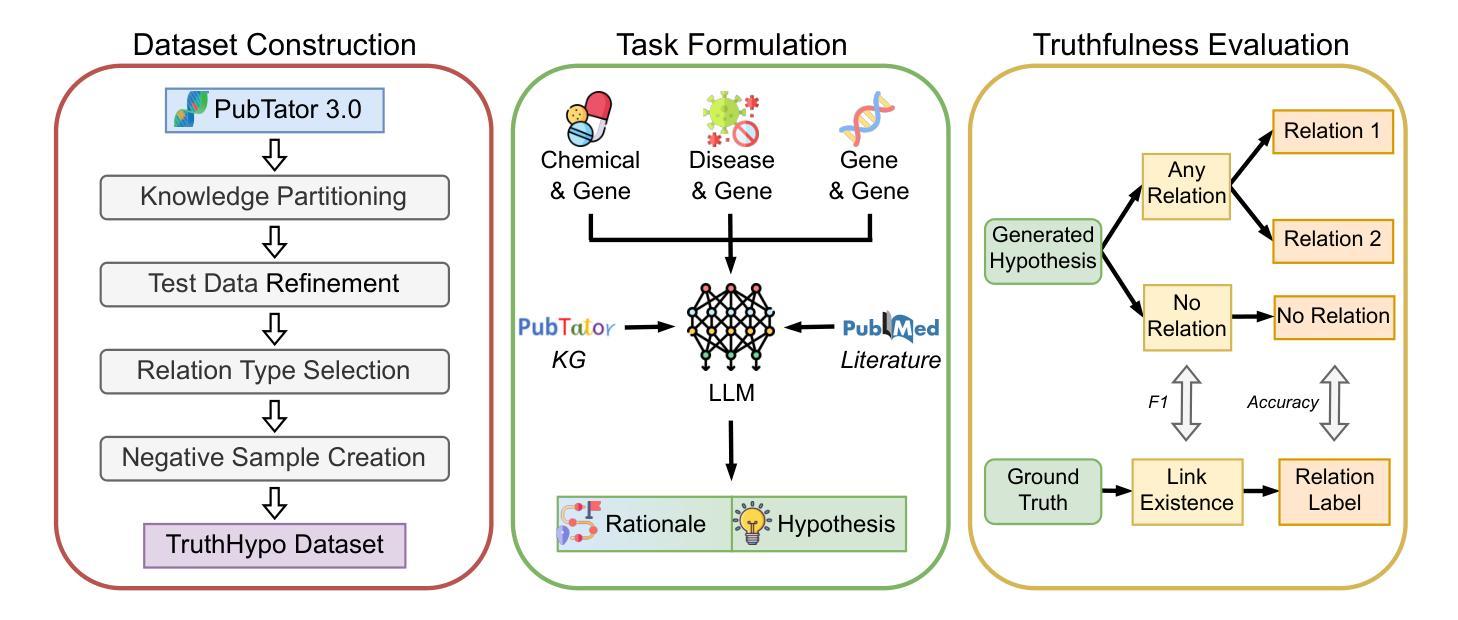
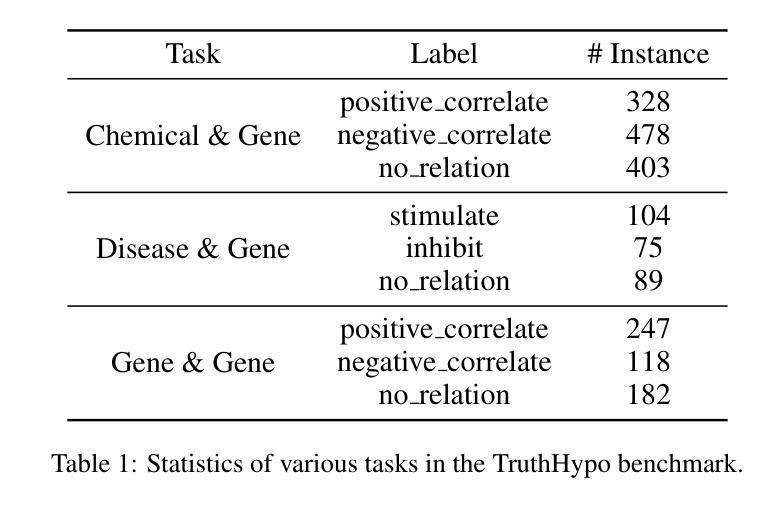
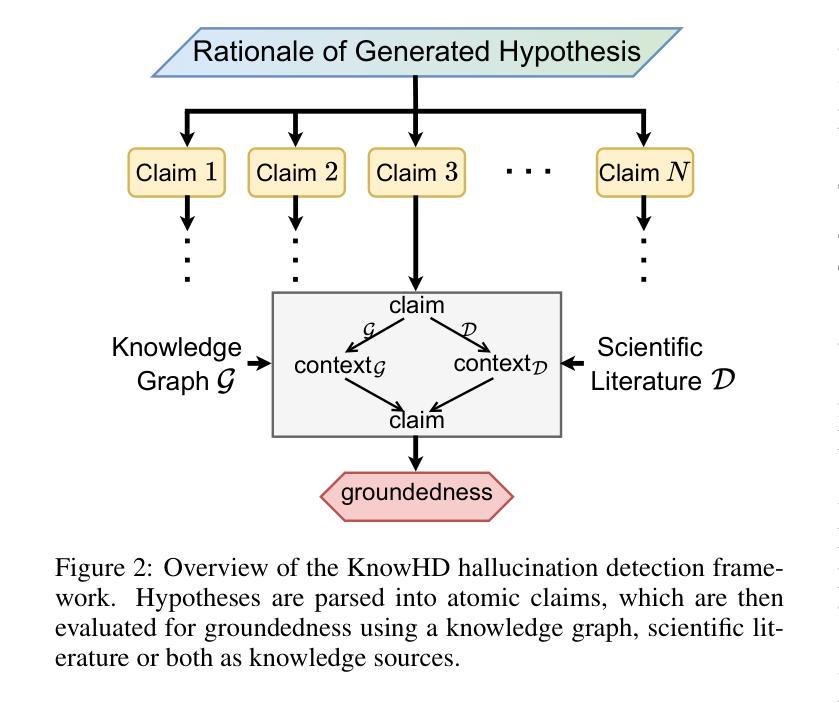
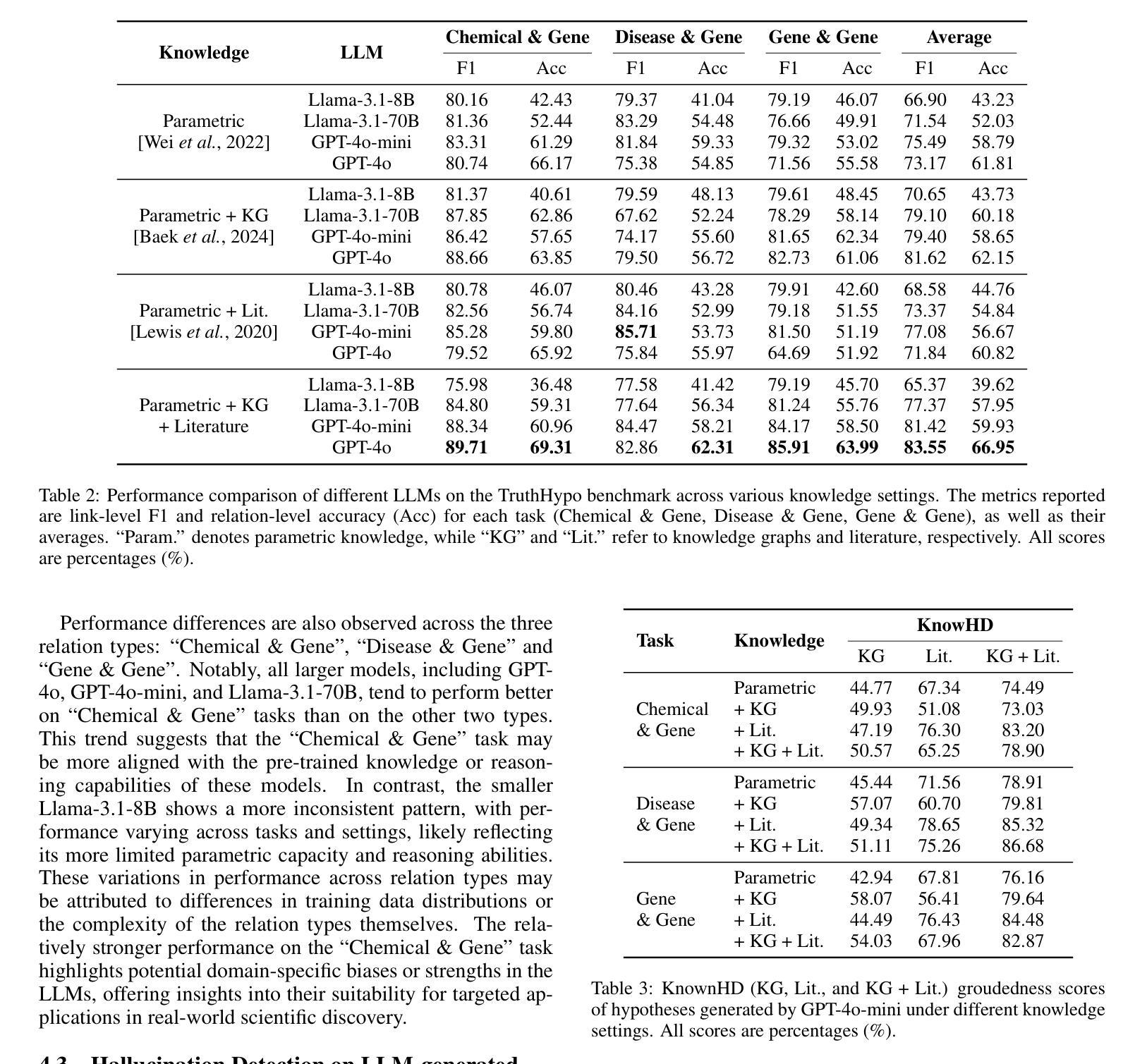
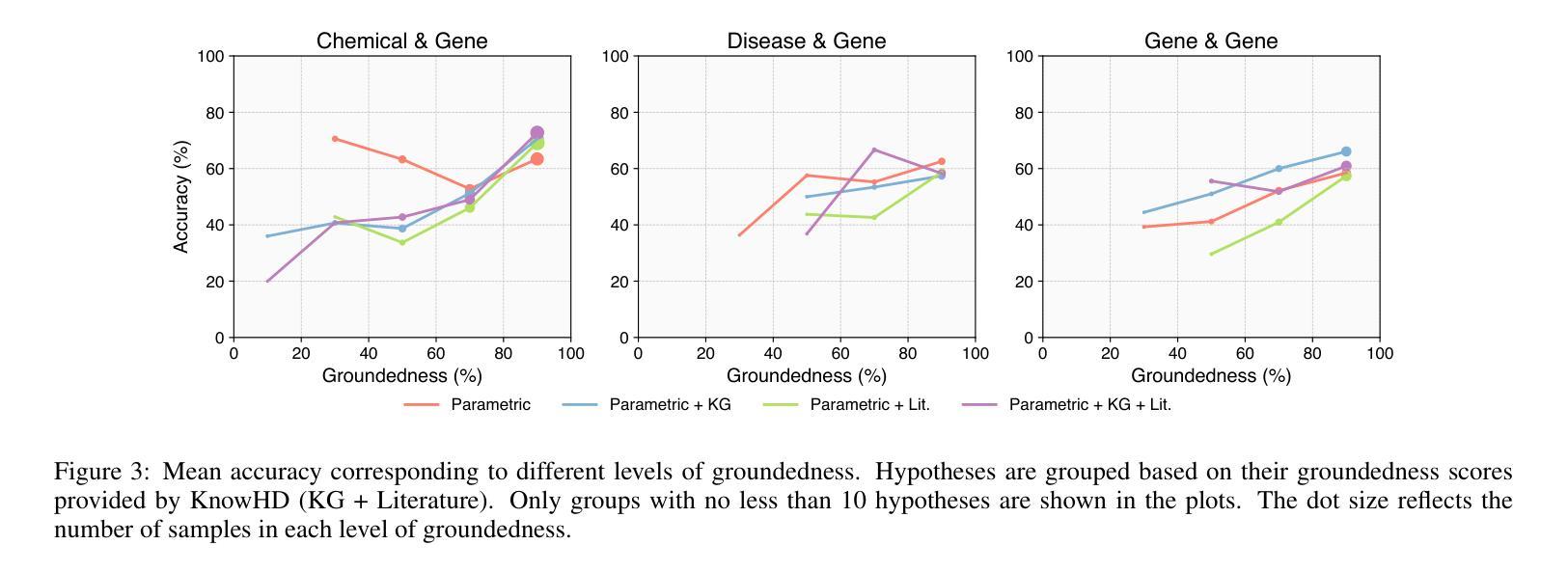
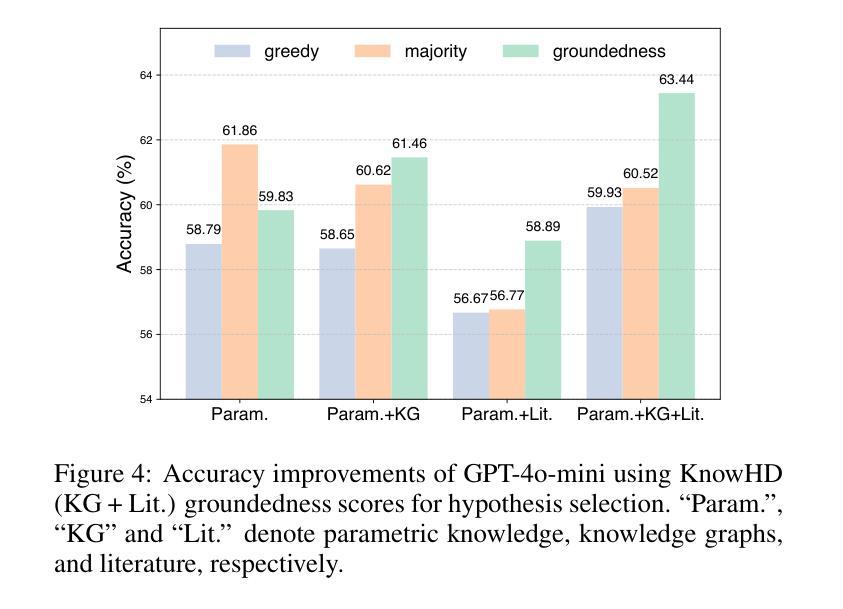
Toward Reliable Biomedical Hypothesis Generation: Evaluating Truthfulness and Hallucination in Large Language Models
Authors:Guangzhi Xiong, Eric Xie, Corey Williams, Myles Kim, Amir Hassan Shariatmadari, Sikun Guo, Stefan Bekiranov, Aidong Zhang
Large language models (LLMs) have shown significant potential in scientific disciplines such as biomedicine, particularly in hypothesis generation, where they can analyze vast literature, identify patterns, and suggest research directions. However, a key challenge lies in evaluating the truthfulness of generated hypotheses, as verifying their accuracy often requires substantial time and resources. Additionally, the hallucination problem in LLMs can lead to the generation of hypotheses that appear plausible but are ultimately incorrect, undermining their reliability. To facilitate the systematic study of these challenges, we introduce TruthHypo, a benchmark for assessing the capabilities of LLMs in generating truthful biomedical hypotheses, and KnowHD, a knowledge-based hallucination detector to evaluate how well hypotheses are grounded in existing knowledge. Our results show that LLMs struggle to generate truthful hypotheses. By analyzing hallucinations in reasoning steps, we demonstrate that the groundedness scores provided by KnowHD serve as an effective metric for filtering truthful hypotheses from the diverse outputs of LLMs. Human evaluations further validate the utility of KnowHD in identifying truthful hypotheses and accelerating scientific discovery. Our data and source code are available at https://github.com/Teddy-XiongGZ/TruthHypo.
大型语言模型(LLM)在生物医学等科学学科中显示出巨大潜力,特别是在假设生成方面。它们可以分析大量文献,识别模式,并提出研究方向。然而,评估生成假设的真实性是一个重要挑战,因为验证其准确性通常需要大量时间和资源。此外,LLM中的幻觉问题可能导致生成看似可信但最终错误的假设,破坏其可靠性。为了促进对这些挑战的系统性研究,我们引入了TruthHypo基准测试,用于评估LLM生成真实生物医学假设的能力,以及基于知识的幻觉检测器KnowHD,以评估假设在现有知识中的扎实程度。我们的结果表明,LLM在生成真实假设方面存在困难。通过分析推理步骤中的幻觉,我们证明KnowHD提供的扎根得分是筛选LLM多样输出中的真实假设的有效指标。人类评估进一步验证了KnowHD在识别真实假设和加速科学发现方面的实用性。我们的数据和源代码可在https://github.com/Teddy-XiongGZ/TruthHypo找到。
论文及项目相关链接
PDF Accepted to IJCAI 2025
Summary
大型语言模型(LLM)在生物医学等科学领域展现出潜力,尤其在假设生成方面。它们能分析大量文献、识别模式并提出研究方向。然而,评估生成假设的真实性是一大挑战,因为验证其准确性需要大量时间和资源。此外,LLM中的虚构问题可能导致生成看似可信但实际错误的假设,影响可靠性。为应对这些挑战,我们推出了TruthHypo评估基准和KnowHD知识虚构检测器。但LLM在生成真实假设方面仍有困难。通过分析推理步骤中的虚构,我们发现KnowHD提供的接地度分数能有效过滤LLM输出的真实假设。人类评估进一步验证了KnowHD在识别真实假设和加速科学发现方面的实用性。数据和源代码可在https://github.com/Teddy-XiongGZ/TruthHypo获取。
Key Takeaways
- LLM在生物医学等科学领域有潜力,尤其在假设生成方面能分析文献、识别模式。
- 评估LLM生成的假设真实性是一大挑战,需要验证其准确性并识别虚构假设。
- TruthHypo评估基准用于评估LLM在生成真实假设方面的能力。
- KnowHD知识虚构检测器能有效过滤LLM输出的真实假设。
- LLM在生成真实假设方面存在困难。
- KnowHD的接地度分数是评估假设真实性的有效指标。
点此查看论文截图

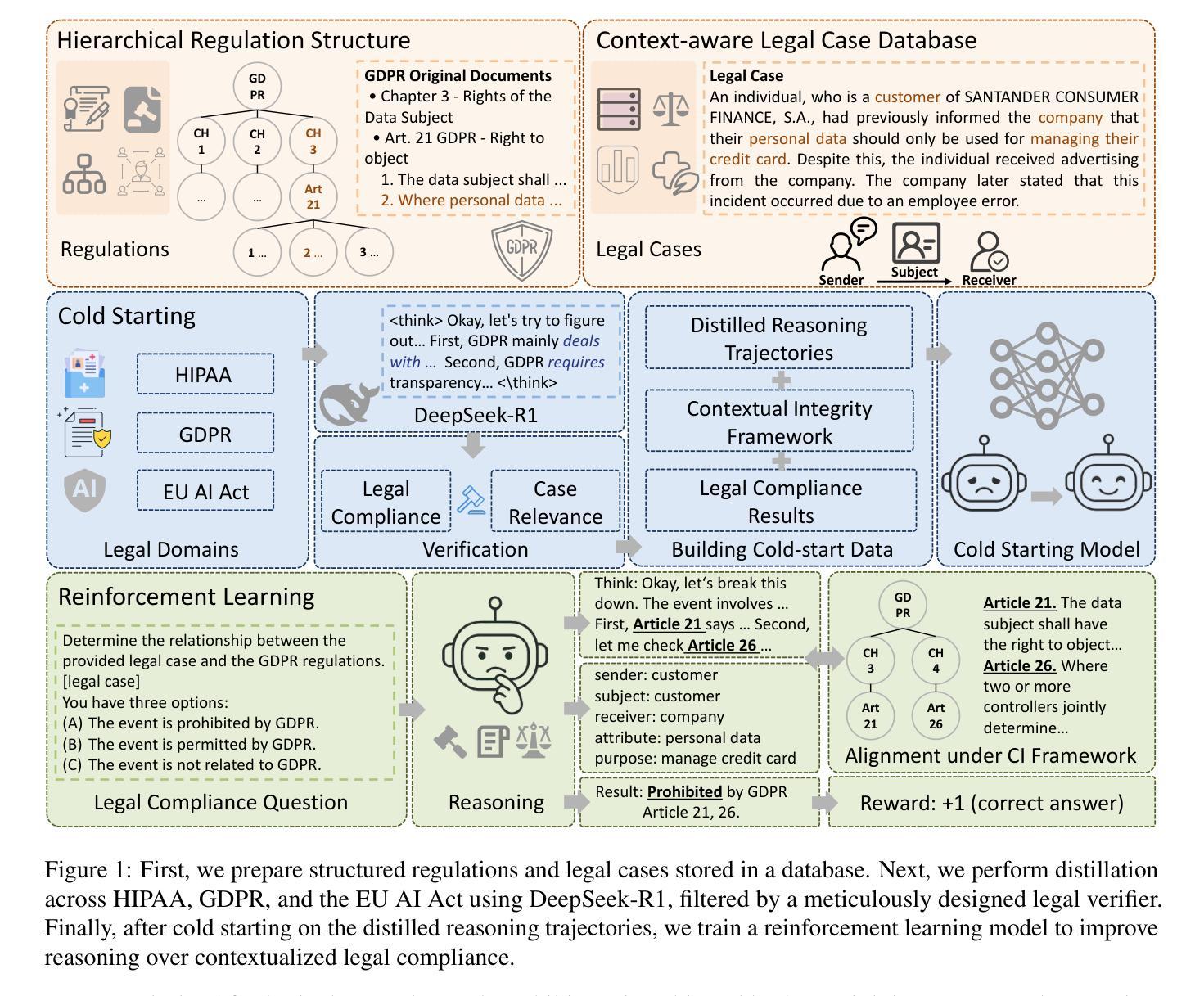
Context Reasoner: Incentivizing Reasoning Capability for Contextualized Privacy and Safety Compliance via Reinforcement Learning
Authors:Wenbin Hu, Haoran Li, Huihao Jing, Qi Hu, Ziqian Zeng, Sirui Han, Heli Xu, Tianshu Chu, Peizhao Hu, Yangqiu Song
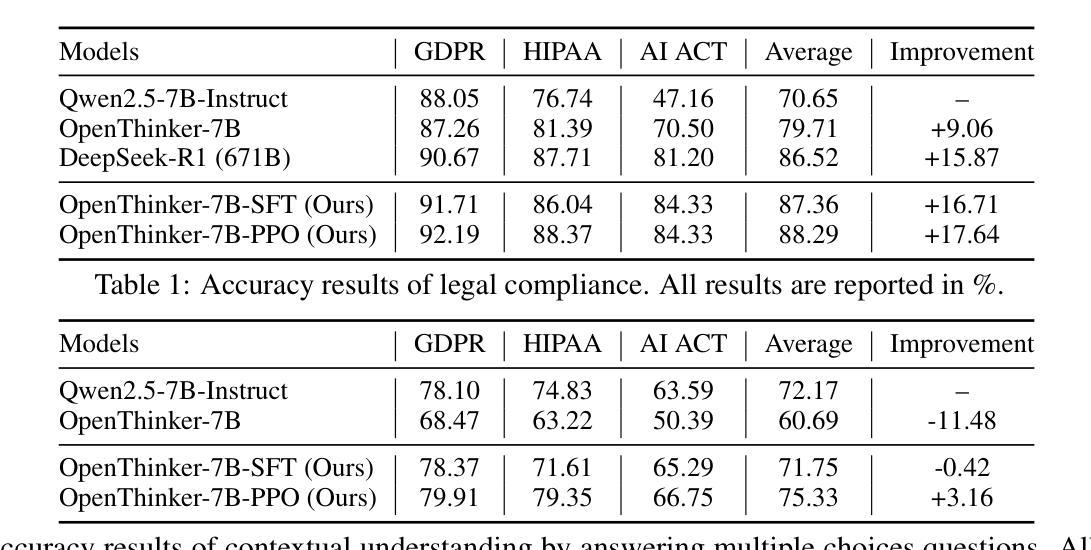
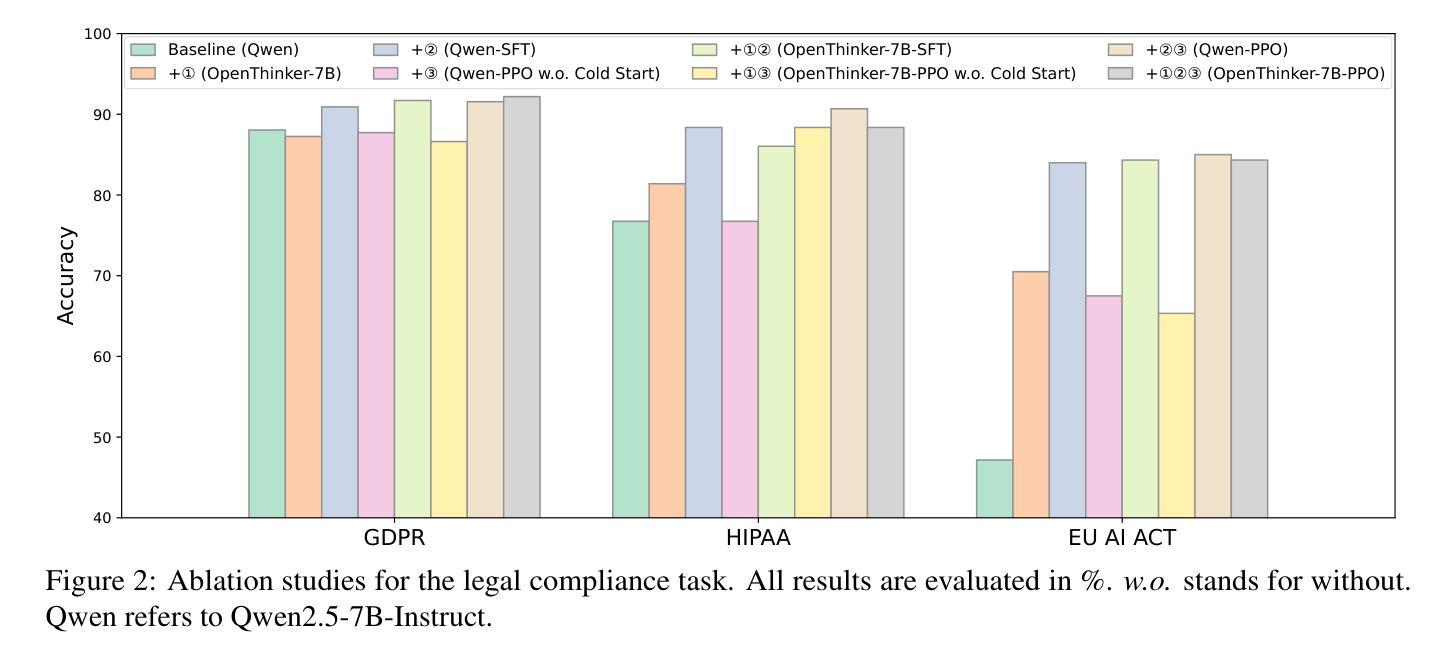
While Large Language Models (LLMs) exhibit remarkable capabilities, they also introduce significant safety and privacy risks. Current mitigation strategies often fail to preserve contextual reasoning capabilities in risky scenarios. Instead, they rely heavily on sensitive pattern matching to protect LLMs, which limits the scope. Furthermore, they overlook established safety and privacy standards, leading to systemic risks for legal compliance. To address these gaps, we formulate safety and privacy issues into contextualized compliance problems following the Contextual Integrity (CI) theory. Under the CI framework, we align our model with three critical regulatory standards: GDPR, EU AI Act, and HIPAA. Specifically, we employ reinforcement learning (RL) with a rule-based reward to incentivize contextual reasoning capabilities while enhancing compliance with safety and privacy norms. Through extensive experiments, we demonstrate that our method not only significantly enhances legal compliance (achieving a +17.64% accuracy improvement in safety/privacy benchmarks) but also further improves general reasoning capability. For OpenThinker-7B, a strong reasoning model that significantly outperforms its base model Qwen2.5-7B-Instruct across diverse subjects, our method enhances its general reasoning capabilities, with +2.05% and +8.98% accuracy improvement on the MMLU and LegalBench benchmark, respectively.
大型语言模型(LLM)虽然展现出卓越的能力,但也带来了显著的安全和隐私风险。当前的缓解策略往往无法在风险场景中保留上下文推理能力,而过度依赖于敏感模式匹配来保护LLM,这限制了其应用范围。此外,它们忽略了既定的安全和隐私标准,导致法律合规的系统性风险。为了弥补这些空白,我们将安全和隐私问题转化为上下文合规问题,遵循上下文完整性(CI)理论。在CI框架下,我们的模型与三个关键的监管标准保持一致:GDPR、欧盟人工智能法和HIPAA。具体来说,我们采用基于规则的奖励的强化学习(RL)来激励上下文推理能力,同时提高对安全和隐私规范的可合规性。通过广泛的实验,我们证明我们的方法不仅显著提高了法律合规性(在安全/隐私基准测试中实现了+17.64%的准确率提升),而且还进一步提高了通用推理能力。对于在多种主题上显著优于其基础模型Qwen2.5-7B-Instruct的强大推理模型OpenThinker-7B,我们的方法在MMLU和LegalBench基准测试上分别提高了+2.05%和+8.98%的准确率,增强了其通用推理能力。
论文及项目相关链接
Summary
大型语言模型(LLM)展现出令人瞩目的能力,但同时也带来安全和隐私风险。当前缓解策略常常无法保护上下文推理能力,并过度依赖敏感模式匹配来保护LLM,这限制了其应用范围。遵循语境完整性(CI)理论,将安全和隐私问题转化为上下文化的合规性问题,与三大关键监管标准(GDPR、欧盟人工智能法案和HIPAA)相符。采用基于规则的奖励强化学习,激励上下文推理能力,同时提高遵守安全和隐私规范的能力。实验证明,该方法不仅显著提高法律合规性,还进一步改善了一般推理能力。
Key Takeaways
- LLM展现出强大的能力,但也存在安全和隐私风险。
- 当前缓解策略常常无法同时保护上下文推理能力和应对风险场景。
- 安全和隐私问题应转化为上下文化的合规性问题。
- 遵循语境完整性(CI)理论,与三大关键监管标准相符。
- 采用强化学习激励上下文推理能力的同时提高遵守安全和隐私规范的能力。
- 方法显著提高法律合规性,并在安全/隐私基准测试中实现+17.64%的准确率提升。
点此查看论文截图


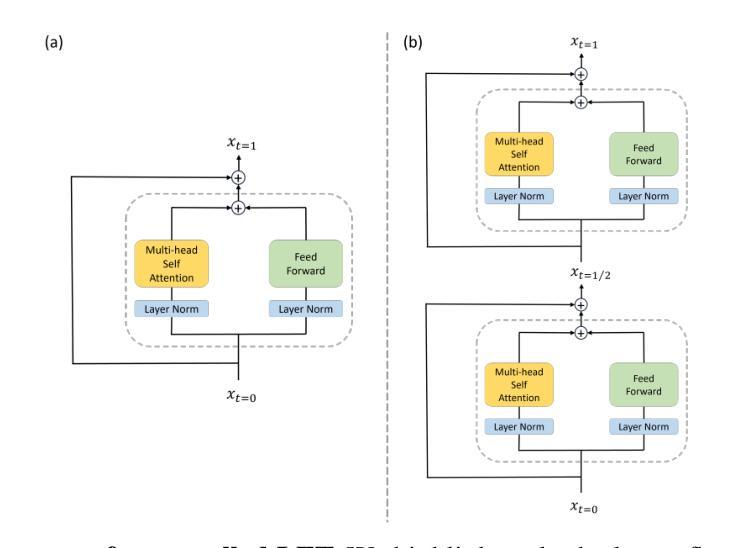
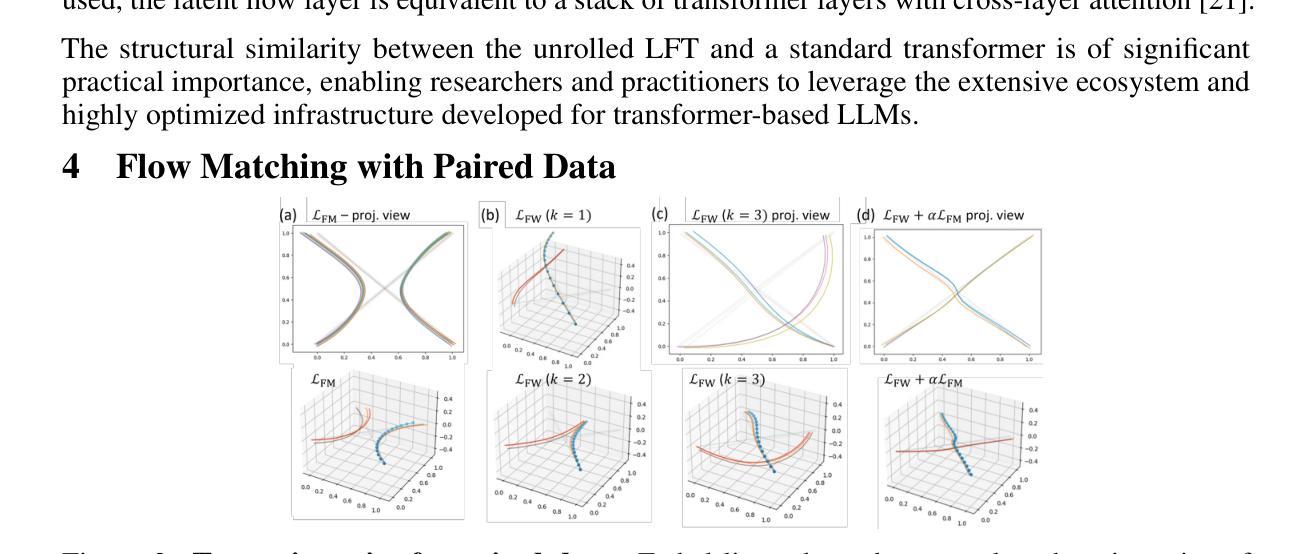
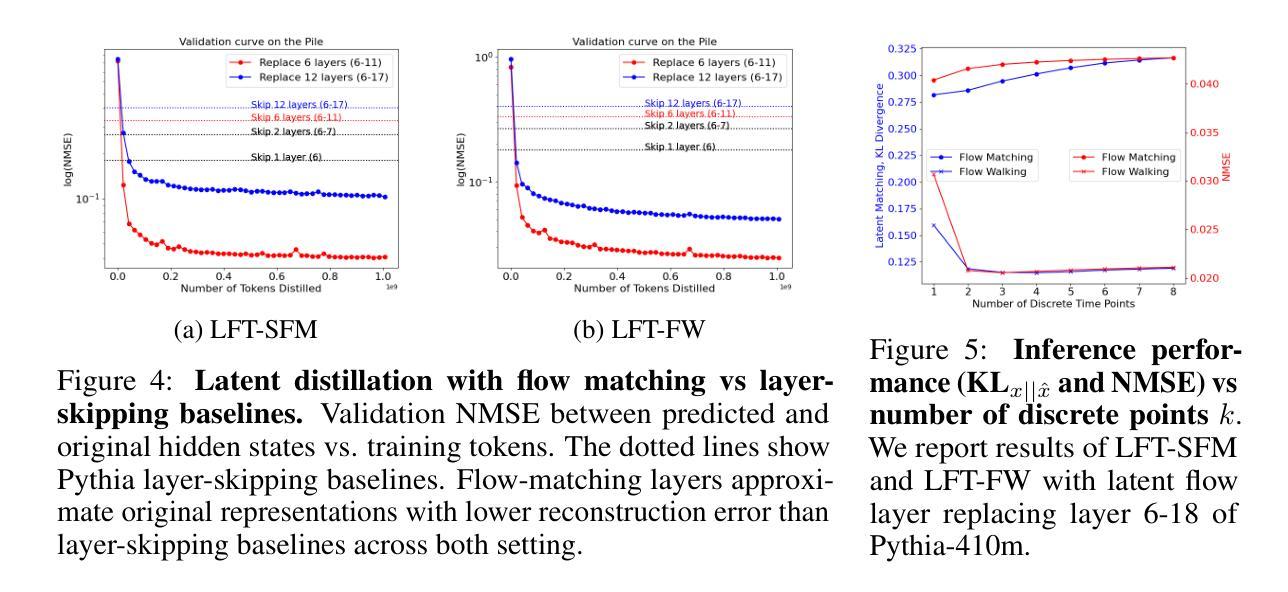
Latent Flow Transformer
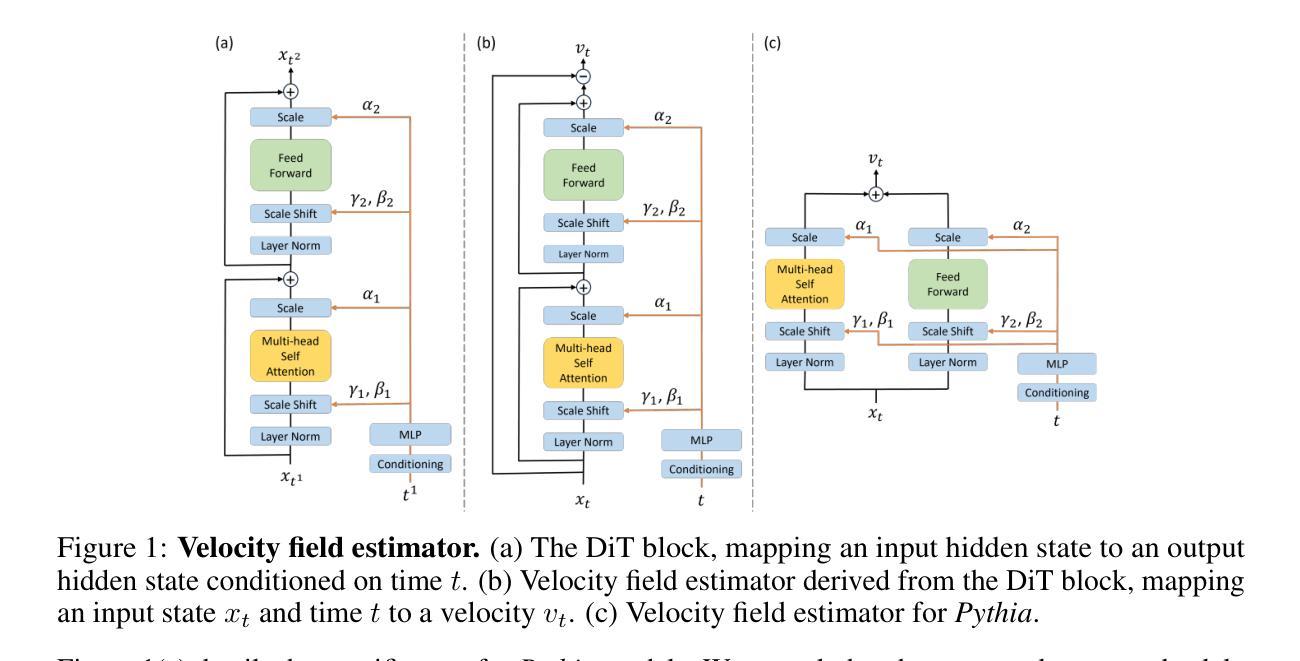
Authors:Yen-Chen Wu, Feng-Ting Liao, Meng-Hsi Chen, Pei-Chen Ho, Farhang Nabiei, Da-shan Shiu
Transformers, the standard implementation for large language models (LLMs), typically consist of tens to hundreds of discrete layers. While more layers can lead to better performance, this approach has been challenged as far from efficient, especially given the superiority of continuous layers demonstrated by diffusion and flow-based models for image generation. We propose the Latent Flow Transformer (LFT), which replaces a block of layers with a single learned transport operator trained via flow matching, offering significant compression while maintaining compatibility with the original architecture. Additionally, we address the limitations of existing flow-based methods in \textit{preserving coupling} by introducing the Flow Walking (FW) algorithm. On the Pythia-410M model, LFT trained with flow matching compresses 6 of 24 layers and outperforms directly skipping 2 layers (KL Divergence of LM logits at 0.407 vs. 0.529), demonstrating the feasibility of this design. When trained with FW, LFT further distills 12 layers into one while reducing the KL to 0.736 surpassing that from skipping 3 layers (0.932), significantly narrowing the gap between autoregressive and flow-based generation paradigms.
Transformer是大规模语言模型(LLM)的标准实现方式,通常由数十至数百个独立的层组成。虽然更多的层可以提高性能,但这种做法在效率上受到挑战,特别是考虑到扩散模型和基于流的模型在图像生成方面的连续层表现出的优越性。我们提出了潜流Transformer(LFT),它通过用一个单一的学习传输算子替换一系列层,该算子通过流匹配进行训练,可在保持与原始架构兼容的同时实现显著压缩。此外,我们通过引入流步行(FW)算法,解决了现有基于流的方法在保持耦合方面的局限性。在Pythia-410M模型上,通过流匹配训练的LFT压缩了24层中的6层,并且表现优于直接跳过两层(LM logits的KL散度从0.529降至0.407),证明了这种设计的可行性。在使用FW进行训练时,LFT进一步将12层蒸馏为一层,同时将KL值降至0.736,超过了跳过三层的结果(即KL散度大于或高于无流式跳层)(约比跳三层小),极大地缩小了自回归生成模式和基于流的生成模式之间的差距。
论文及项目相关链接
Summary
针对大型语言模型(LLM)的标准实现通常为数十至数百个离散层。虽然更多层能提高性能,但效率较低。为此,我们提出潜流转换器(LFT),通过流匹配训练学习传输算子,将一组层替换为单个层,既保持原架构兼容性又实现显著压缩。此外,为解决现有流模型的耦合保存限制,我们引入流步行(FW)算法。在Pythia-410M模型上,LFT通过流匹配压缩6层并保持高性能,展示该设计可行性。使用FW训练的LFT能进一步将12层蒸馏为1层并缩小与自回归和流生成范式之间的差距。
Key Takeaways
- 大型语言模型(LLM)通常包含数十至数百个离散层,更多层虽能提高性能但效率较低。
- 潜流转换器(LFT)通过训练学习传输算子,将一组层替换为单个层,以实现显著压缩并保持原架构兼容性。
- LFT采用流匹配进行训练,在Pythia-410M模型上展示了其有效性。
- 引入流步行(FW)算法以解决现有流模型的耦合保存限制。
- LFT在压缩层数的同时保持了高性能,展示了其设计的优越性。
- 使用FW训练的LFT能够进一步压缩模型并缩小与自回归和流生成范式之间的差距。
点此查看论文截图



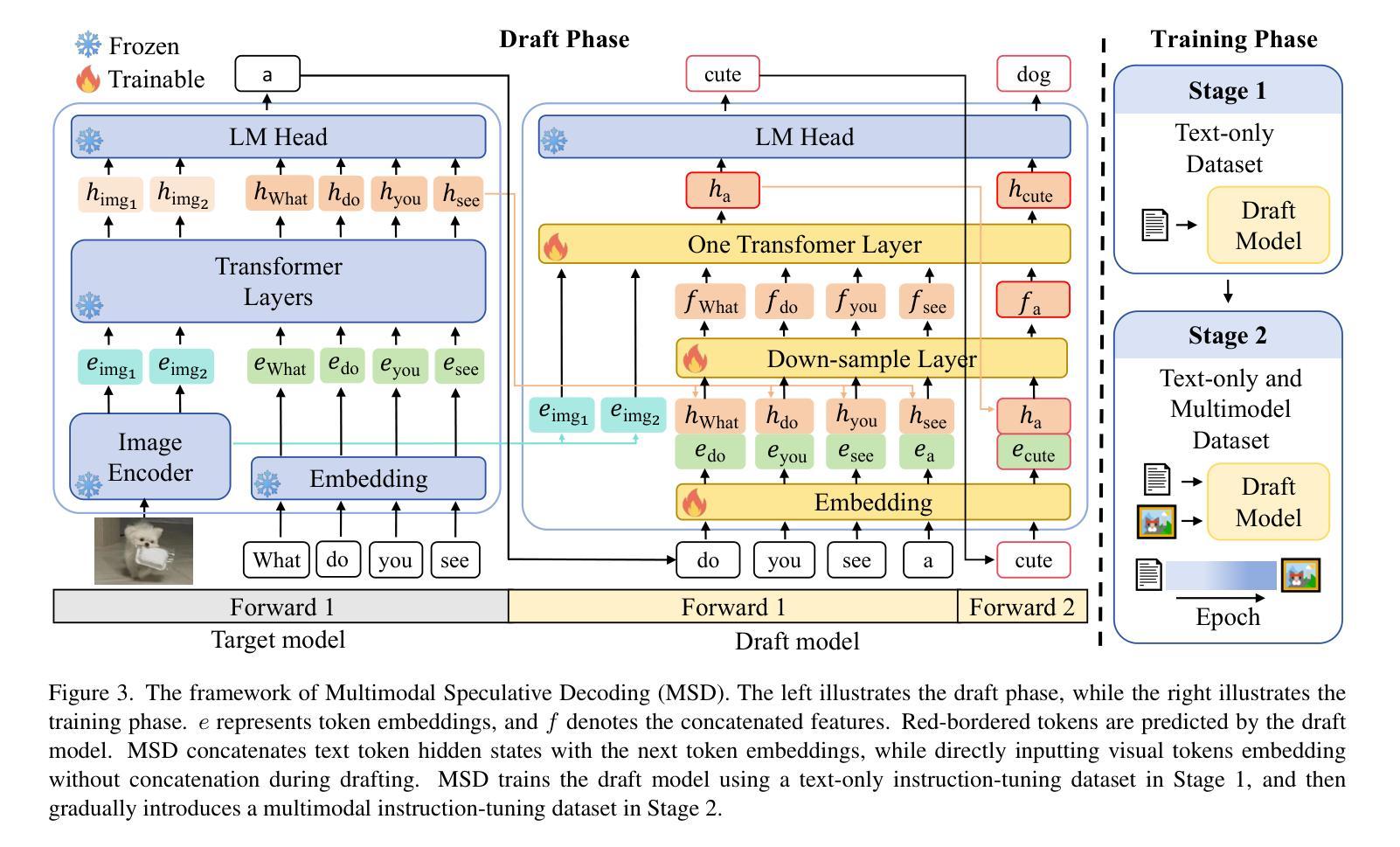
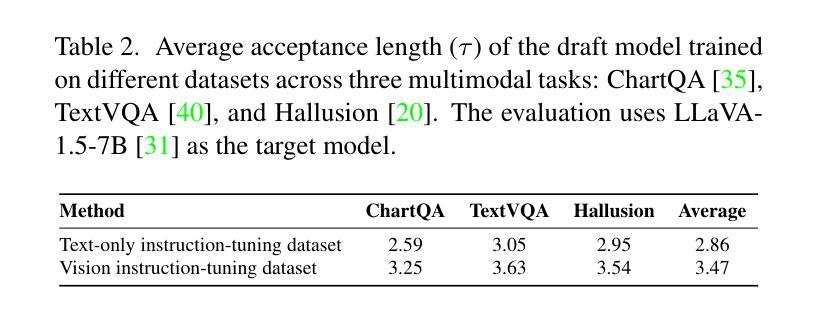
Speculative Decoding Reimagined for Multimodal Large Language Models
Authors:Luxi Lin, Zhihang Lin, Zhanpeng Zeng, Rongrong Ji
This paper introduces Multimodal Speculative Decoding (MSD) to accelerate Multimodal Large Language Models (MLLMs) inference. Speculative decoding has been shown to accelerate Large Language Models (LLMs) without sacrificing accuracy. However, current speculative decoding methods for MLLMs fail to achieve the same speedup as they do for LLMs. To address this, we reimagine speculative decoding specifically for MLLMs. Our analysis of MLLM characteristics reveals two key design principles for MSD: (1) Text and visual tokens have fundamentally different characteristics and need to be processed separately during drafting. (2) Both language modeling ability and visual perception capability are crucial for the draft model. For the first principle, MSD decouples text and visual tokens in the draft model, allowing each to be handled based on its own characteristics. For the second principle, MSD uses a two-stage training strategy: In stage one, the draft model is trained on text-only instruction-tuning datasets to improve its language modeling ability. In stage two, MSD gradually introduces multimodal data to enhance the visual perception capability of the draft model. Experiments show that MSD boosts inference speed by up to $2.29\times$ for LLaVA-1.5-7B and up to $2.46\times$ for LLaVA-1.5-13B on multimodal benchmarks, demonstrating its effectiveness. Our code is available at https://github.com/Lyn-Lucy/MSD.
本文介绍了多模态推测解码(MSD),以加速多模态大型语言模型(MLLMs)的推理。推测解码已证明可以加速大型语言模型(LLMs)的推理,而不会牺牲准确性。然而,当前针对MLLMs的推测解码方法无法达到与LLMs相同的加速效果。为了解决这个问题,我们针对MLLMs重新构想了一种推测解码方法。我们对MLLM特性的分析揭示了MSD的两个关键设计原则:(1)文本和视觉标记具有不同的基本特性,需要在草稿阶段分别处理。(2)语言建模能力和视觉感知能力对于草稿模型都至关重要。根据第一个原则,MSD在草稿模型中解耦文本和视觉标记,允许根据它们各自的特性进行处理。对于第二个原则,MSD采用两阶段训练策略:在第一阶段,草稿模型在纯文本指令微调数据集上进行训练,以提高其语言建模能力。在第二阶段,MSD逐渐引入多模态数据,以提高草稿模型的视觉感知能力。实验表明,MSD在LLaVA-1.5-7B和LLaVA-1.5-13B的多模态基准测试中,推理速度分别提高了2.29倍和2.46倍,证明了其有效性。我们的代码可在https://github.com/Lyn-Lucy/MSD获取。
论文及项目相关链接
PDF 12 pages
摘要
本文提出了针对多模态大型语言模型(MLLMs)的加速推理方法——多模态推测解码(MSD)。通过对MLLM特性的分析,揭示了MSD的两个关键设计原则。一是文本和视觉符号在起草过程中需要分别处理,二是语言建模能力和视觉感知能力对于草案模型至关重要。MSD采用两阶段训练策略,第一阶段仅对文本指令调整数据集进行训练以提高语言建模能力,第二阶段逐步引入多模态数据以增强模型的视觉感知能力。实验表明,MSD在多模态基准测试中提高了推理速度,最高可达LLaVA-1.5-7B的2.29倍和LLaVA-1.5-13B的2.46倍,证明了其有效性。
关键见解
- 本文引入了多模态推测解码(MSD)来加速多模态大型语言模型(MLLMs)的推理过程。
- MSD针对MLLMs的特性进行了重新设计,揭示了处理文本和视觉符号需要分别进行的重要性。
- MSD强调语言建模能力和视觉感知能力对草案模型的重要性。
- MSD采用两阶段训练策略,首先专注于提高语言建模能力,然后逐步引入多模态数据以增强视觉感知能力。
- 实验结果表明,MSD能有效提高推理速度,最高可达LLaVA-1.5-7B的2.29倍和LLaVA-1.5-13B的2.46倍。
- MSD的代码已公开发布在指定GitHub仓库。
点此查看论文截图


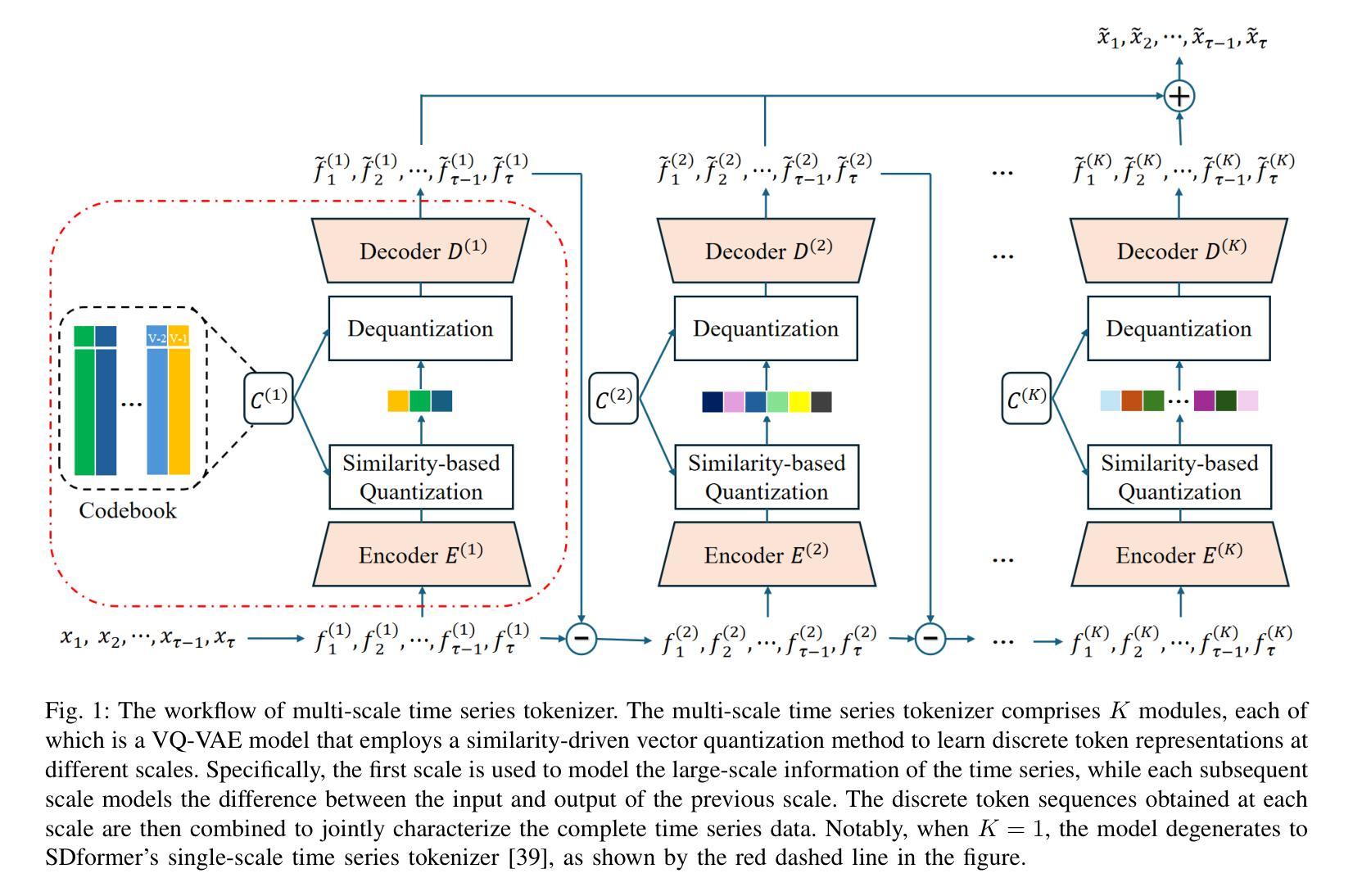
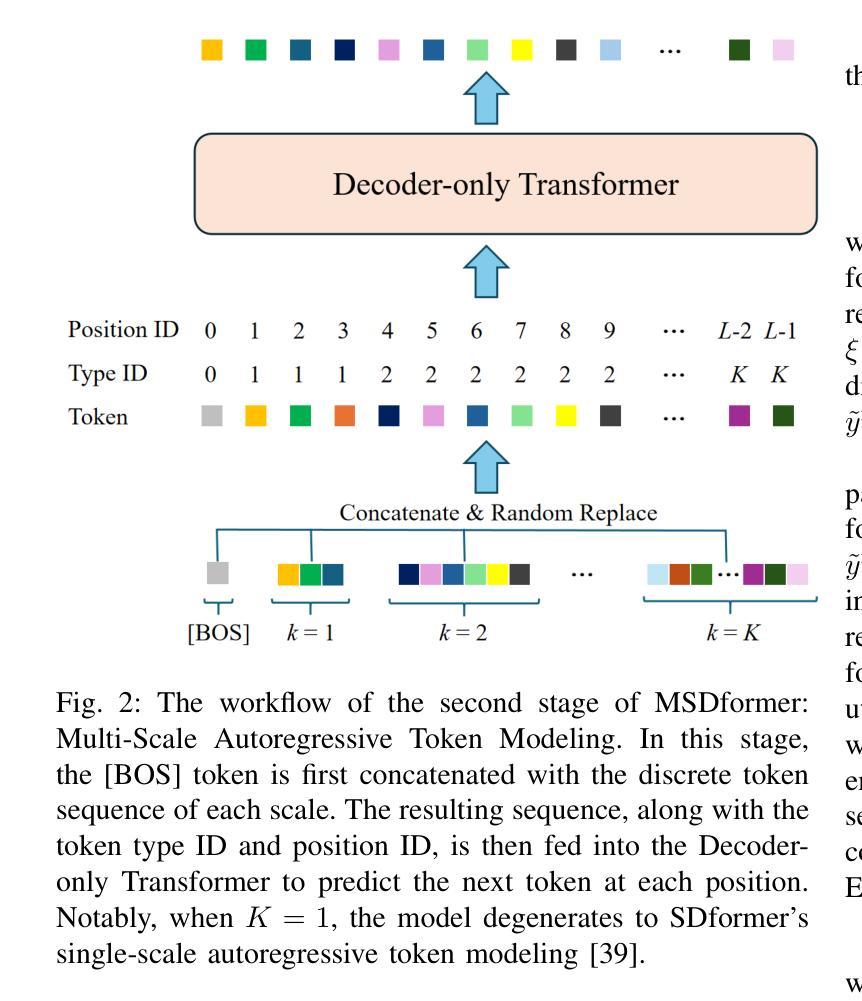
MSDformer: Multi-scale Discrete Transformer For Time Series Generation
Authors:Zhicheng Chen, Shibo Feng, Xi Xiao, Zhong Zhang, Qing Li, Xingyu Gao, Peilin Zhao
Discrete Token Modeling (DTM), which employs vector quantization techniques, has demonstrated remarkable success in modeling non-natural language modalities, particularly in time series generation. While our prior work SDformer established the first DTM-based framework to achieve state-of-the-art performance in this domain, two critical limitations persist in existing DTM approaches: 1) their inability to capture multi-scale temporal patterns inherent to complex time series data, and 2) the absence of theoretical foundations to guide model optimization. To address these challenges, we proposes a novel multi-scale DTM-based time series generation method, called Multi-Scale Discrete Transformer (MSDformer). MSDformer employs a multi-scale time series tokenizer to learn discrete token representations at multiple scales, which jointly characterize the complex nature of time series data. Subsequently, MSDformer applies a multi-scale autoregressive token modeling technique to capture the multi-scale patterns of time series within the discrete latent space. Theoretically, we validate the effectiveness of the DTM method and the rationality of MSDformer through the rate-distortion theorem. Comprehensive experiments demonstrate that MSDformer significantly outperforms state-of-the-art methods. Both theoretical analysis and experimental results demonstrate that incorporating multi-scale information and modeling multi-scale patterns can substantially enhance the quality of generated time series in DTM-based approaches. The code will be released upon acceptance.
离散令牌建模(DTM)采用向量量化技术,在非自然语言模态建模中取得了显著的成功,特别是在时间序列生成方面。虽然我们的前期工作SDformer建立了基于DTM的框架,在该领域实现了最先进的性能,但现有DTM方法仍存在两个关键局限性:1)无法捕捉复杂时间序列数据固有的多尺度时间模式;2)缺乏指导模型优化的理论基础。为了解决这些挑战,我们提出了一种新的基于多尺度DTM的时间序列生成方法,称为Multi-Scale Discrete Transformer(MSDformer)。MSDformer采用多尺度时间序列分词器,在多个尺度上学习离散令牌表示,共同表征时间序列数据的复杂性质。然后,MSDformer采用多尺度自回归令牌建模技术,在离散潜在空间内捕捉时间序列的多尺度模式。从理论上讲,我们通过速率失真定理验证了DTM方法的有效性以及MSDformer的合理性。综合实验表明,MSDformer显著优于最先进的方法。理论分析和实验结果均表明,融入多尺度信息和建模多尺度模式可以大大提高DTM方法中生成时间序列的质量。代码将在接受后发布。
论文及项目相关链接
Summary
基于向量量化的离散令牌建模(DTM)在非自然语言模态建模中取得了显著成功,特别是在时间序列生成领域。针对现有DTM方法存在的多尺度时间模式捕捉能力不足和理论框架缺失的问题,提出了一种新的多尺度DTM时间序列生成方法——Multi-Scale Discrete Transformer(MSDformer)。MSDformer通过多尺度时间序列分词器学习离散令牌表示,并应用多尺度自回归令牌建模技术捕捉时间序列的多尺度模式。理论分析和实验结果表明,引入多尺度信息和建模多尺度模式可以显著提高DTM方法生成时间序列的质量。
Key Takeaways
- DTM技术在非自然语言模态建模,特别是时间序列生成中表现出显著成功。
- 现有DTM方法存在两个关键局限:无法捕捉复杂时间序列数据的内在多尺度时间模式,以及缺乏指导模型优化的理论框架。
- MSDformer被提出以解决这些挑战,它通过多尺度时间序列分词器学习离散令牌表示,并应用多尺度自回归令牌建模技术。
- MSDformer在理论上通过速率-失真定理验证了DTM方法的有效性以及其自身的合理性。
- 实验表明,MSDformer显著优于现有方法,表明引入多尺度信息和建模多尺度模式可以大幅提高DTM方法生成时间序列的质量。
- 代码将在接受后发布。
点此查看论文截图