⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-05-22 更新
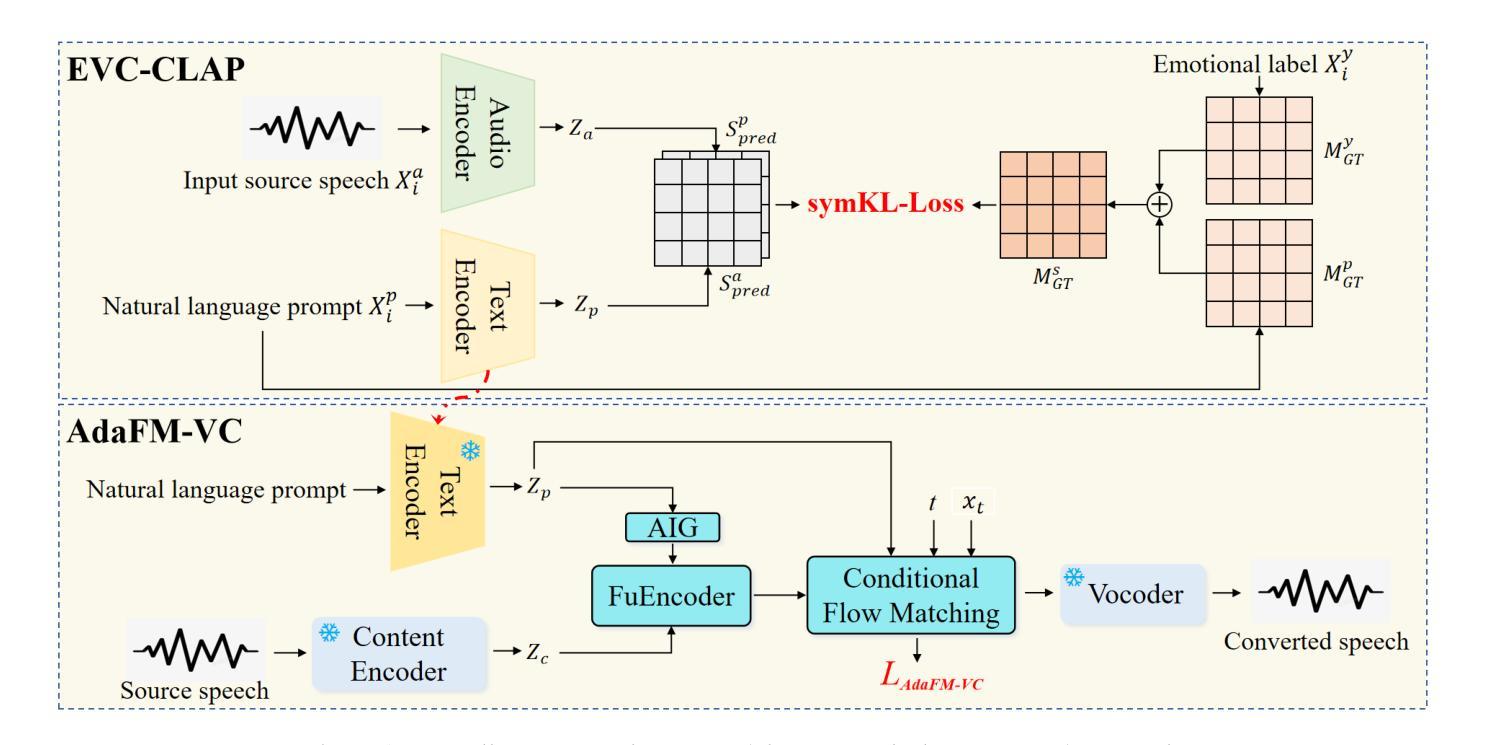
ClapFM-EVC: High-Fidelity and Flexible Emotional Voice Conversion with Dual Control from Natural Language and Speech
Authors:Yu Pan, Yanni Hu, Yuguang Yang, Jixun Yao, Jianhao Ye, Hongbin Zhou, Lei Ma, Jianjun Zhao
Despite great advances, achieving high-fidelity emotional voice conversion (EVC) with flexible and interpretable control remains challenging. This paper introduces ClapFM-EVC, a novel EVC framework capable of generating high-quality converted speech driven by natural language prompts or reference speech with adjustable emotion intensity. We first propose EVC-CLAP, an emotional contrastive language-audio pre-training model, guided by natural language prompts and categorical labels, to extract and align fine-grained emotional elements across speech and text modalities. Then, a FuEncoder with an adaptive intensity gate is presented to seamless fuse emotional features with Phonetic PosteriorGrams from a pre-trained ASR model. To further improve emotion expressiveness and speech naturalness, we propose a flow matching model conditioned on these captured features to reconstruct Mel-spectrogram of source speech. Subjective and objective evaluations validate the effectiveness of ClapFM-EVC.
尽管取得了巨大进步,但实现具有灵活和可解释控制的高保真情感语音转换(EVC)仍然具有挑战性。本文介绍了ClapFM-EVC,这是一种新型EVC框架,能够利用自然语言提示或具有可调情感强度的参考语音生成高质量转换语音。我们首先提出EVC-CLAP,这是一种受自然语言提示和类别标签引导的情感对比语言-音频预训练模型,用于提取和对齐跨语音和文本模态的精细情感元素。然后,提出了一种带有自适应强度门的FuEncoder,将情感特征与来自预训练ASR模型的音素后验概率无缝融合。为了进一步提高情感表现力和语音自然度,我们提出了一个基于这些捕获特征的流匹配模型,以重建源语音的梅尔频谱图。主观和客观评估验证了ClapFM-EVC的有效性。
论文及项目相关链接
PDF Accepted by InterSpeech 2025
Summary
该论文提出了一种名为ClapFM-EVC的新型情感语音转换框架,该框架能够借助自然语言提示或参考语音生成高质量转换语音,并具备灵活可控的情感强度调整功能。论文的核心在于提出情感对比语言音频预训练模型EVC-CLAP和一种自适应强度门的FuEncoder,这两者分别用于提取跨语音文本模态的精细情感元素以及无缝融合情感特征。同时,论文还引入了一种基于这些特征的条件流匹配模型,用于重建源语音的梅尔频谱图,从而进一步提高情感表现力和语音自然度。经过主观和客观评估验证了ClapFM-EVC的有效性。
Key Takeaways
- ClapFM-EVC是一个新型的情感语音转换框架,可生成高质量转换语音并具有灵活可控的情感强度调整功能。
- 论文引入了情感对比语言音频预训练模型EVC-CLAP,可从自然语言提示中提取精细情感元素并进行跨模态对齐。
- FuEncoder作为自适应强度门结构,能够无缝融合情感特征与语音特征。
- 条件流匹配模型用于重建源语音的梅尔频谱图,增强了情感表现力和语音自然度。
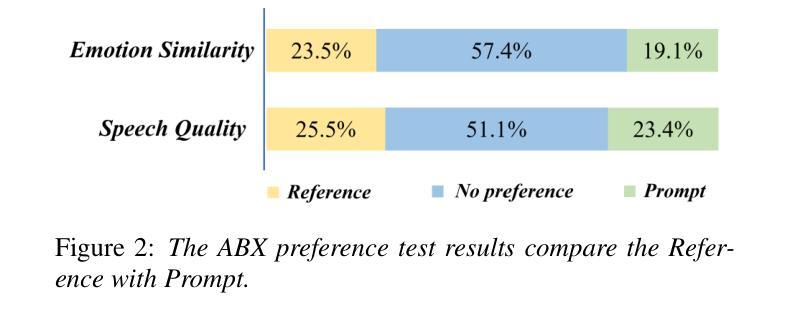
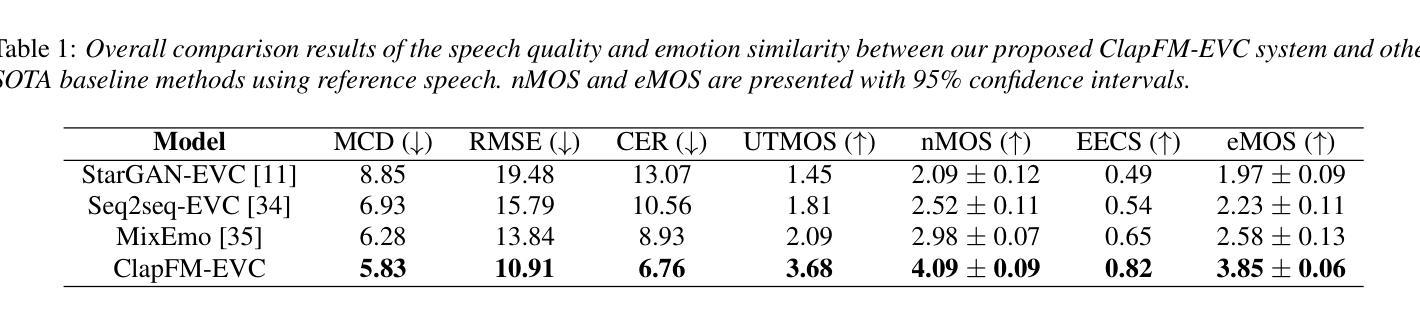
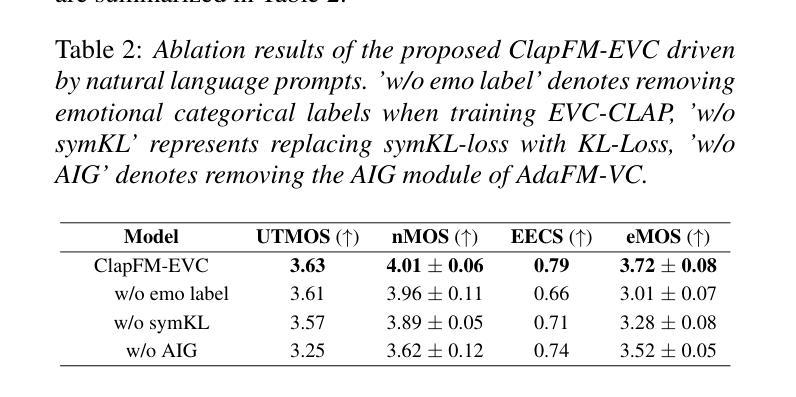
点此查看论文截图

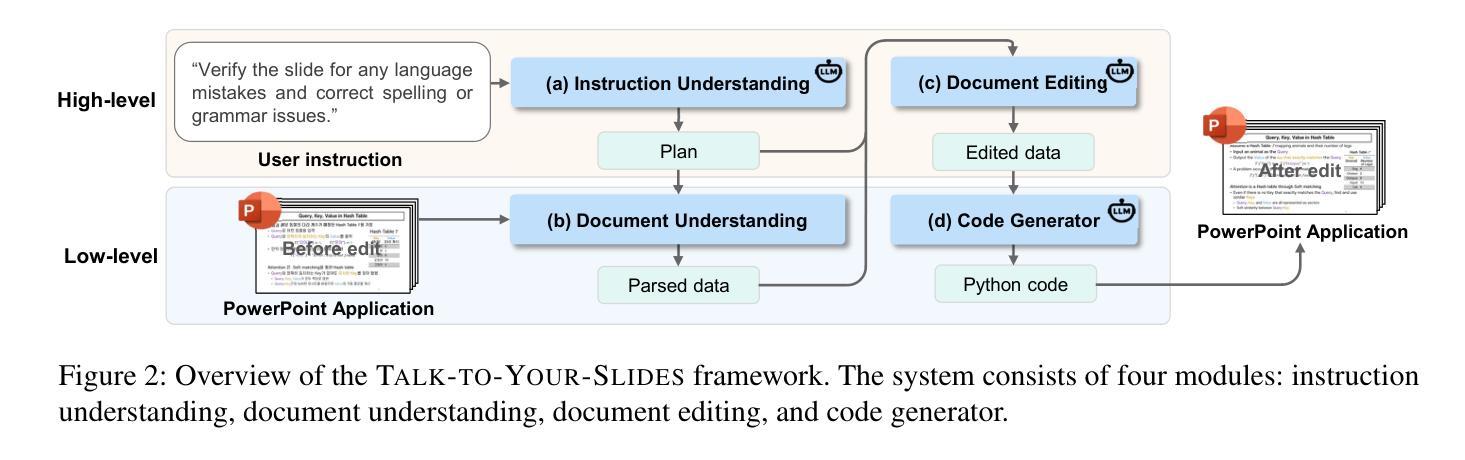
Talk to Your Slides: Language-Driven Agents for Efficient Slide Editing
Authors:Kyudan Jung, Hojun Cho, Jooyeol Yun, Soyoung Yang, Jaehyeok Jang, Jagul Choo
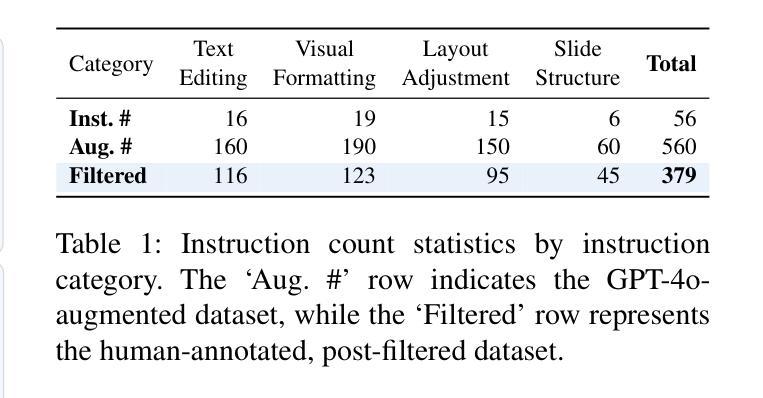
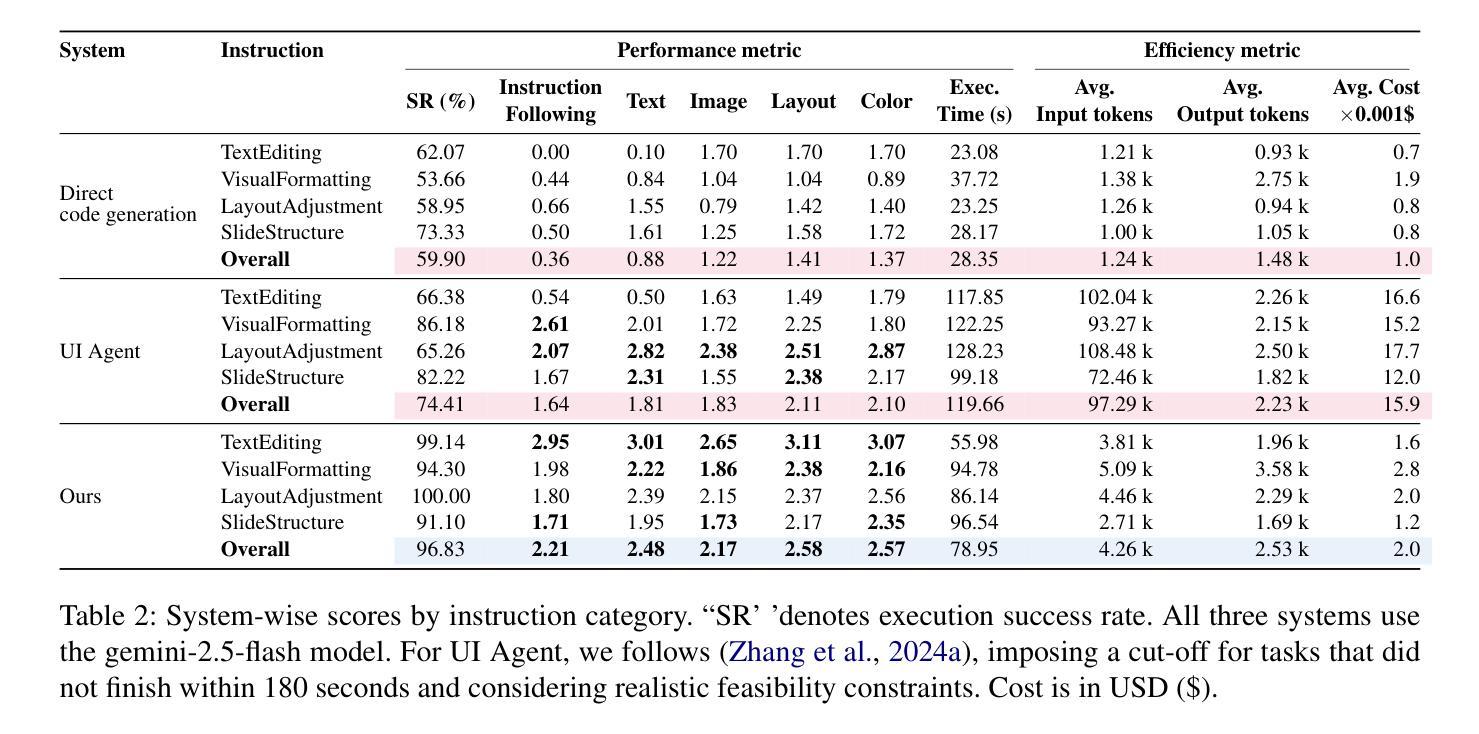
Editing presentation slides remains one of the most common and time-consuming tasks faced by millions of users daily, despite significant advances in automated slide generation. Existing approaches have successfully demonstrated slide editing via graphic user interface (GUI)-based agents, offering intuitive visual control. However, such methods often suffer from high computational cost and latency. In this paper, we propose Talk-to-Your-Slides, an LLM-powered agent designed to edit slides %in active PowerPoint sessions by leveraging structured information about slide objects rather than relying on image modality. The key insight of our work is designing the editing process with distinct high-level and low-level layers to facilitate interaction between user commands and slide objects. By providing direct access to application objects rather than screen pixels, our system enables 34.02% faster processing, 34.76% better instruction fidelity, and 87.42% cheaper operation than baselines. To evaluate slide editing capabilities, we introduce TSBench, a human-annotated dataset comprising 379 diverse editing instructions paired with corresponding slide variations in four categories. Our code, benchmark and demos are available at https://anonymous.4open.science/r/Talk-to-Your-Slides-0F4C.
尽管在自动幻灯片生成方面取得了重大进展,但编辑演示文稿幻灯片仍然是数百万用户日常面临的最常见且最耗时的任务之一。现有方法已经成功展示了通过基于图形用户界面(GUI)的代理进行幻灯片编辑,提供了直观的视觉控制。然而,这些方法往往存在计算成本高和延迟高等问题。在本文中,我们提出了Talk-to-Your-Slides,这是一个由大型语言模型驱动的智能代理,旨在利用结构化信息编辑活动PowerPoint会话中的幻灯片,而不是依赖图像模式。我们工作的关键见解是设计具有不同高级和低级层的编辑过程,以促进用户命令和幻灯片对象之间的交互。通过直接访问应用程序对象而不是屏幕像素,我们的系统实现了比基线快34.02%的处理速度,指令保真度提高34.76%,操作成本降低87.42%。为了评估幻灯片编辑能力,我们引入了TSBench,这是一个由人类注释的数据集,包含四种分类下配对的379个不同编辑指令及其对应的幻灯片变体。我们的代码、基准测试和演示可在https://anonymous.4open.science/r/Talk-to-Your-Slides-0F4C上找到。
论文及项目相关链接
PDF 20 pages, 14 figures
Summary
文本介绍了Talk-to-Your-Slides系统,该系统采用大型语言模型(LLM)技术,在PowerPoint会话中编辑幻灯片。该系统通过利用结构化信息来处理高层次的命令与幻灯片对象之间的交互,以加快处理速度并改进指令保真度。此外,系统引入了一个新的人类注释数据集TSBench来评估编辑功能。总体而言,Talk-to-Your-Slides提供了一个高效且实用的编辑工具。
Key Takeaways
- Talk-to-Your-Slides是一个利用大型语言模型(LLM)技术的幻灯片编辑系统,能够在PowerPoint会话中进行实时编辑。
- 系统利用结构化信息关于幻灯片对象进行编辑,从而加快处理速度和提高指令准确性。
- 与传统基于图像模态的编辑方法相比,Talk-to-Your-Slides具有更高的效率和更低的计算成本。
- 系统引入了一种新的评估方法,使用人类注释的数据集TSBench来测试幻灯片的编辑能力。
- Talk-to-Your-Slides提供了快速处理、高保真指令和低成本操作的优势。
- 通过提供对应用程序对象的直接访问,Talk-to-Your-Slides使得编辑过程更加直观和高效。
点此查看论文截图




M3G: Multi-Granular Gesture Generator for Audio-Driven Full-Body Human Motion Synthesis
Authors:Zhizhuo Yin, Yuk Hang Tsui, Pan Hui
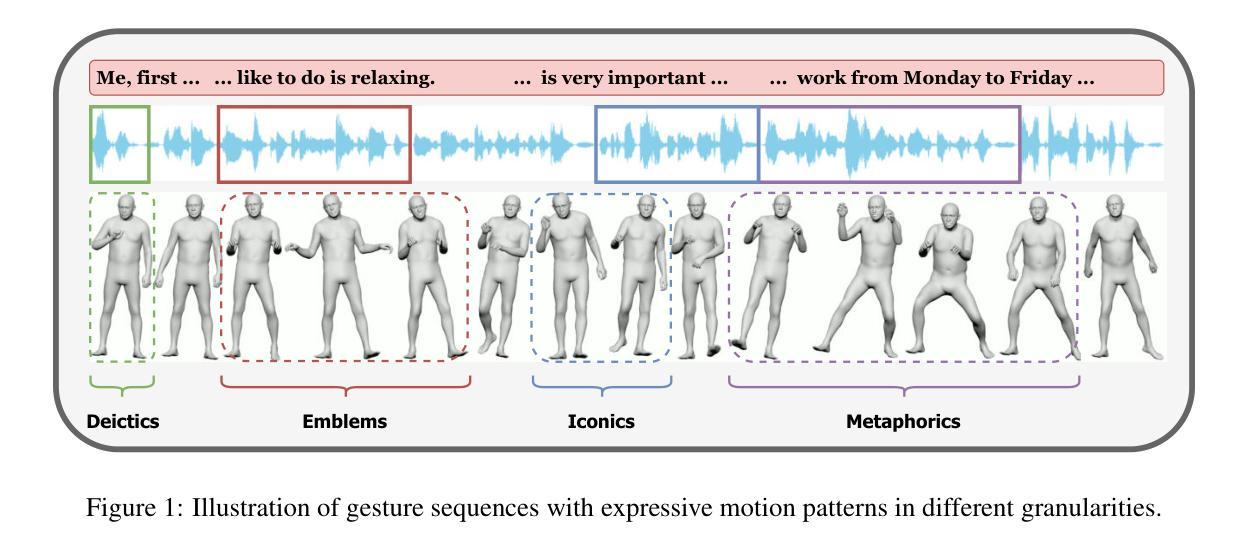
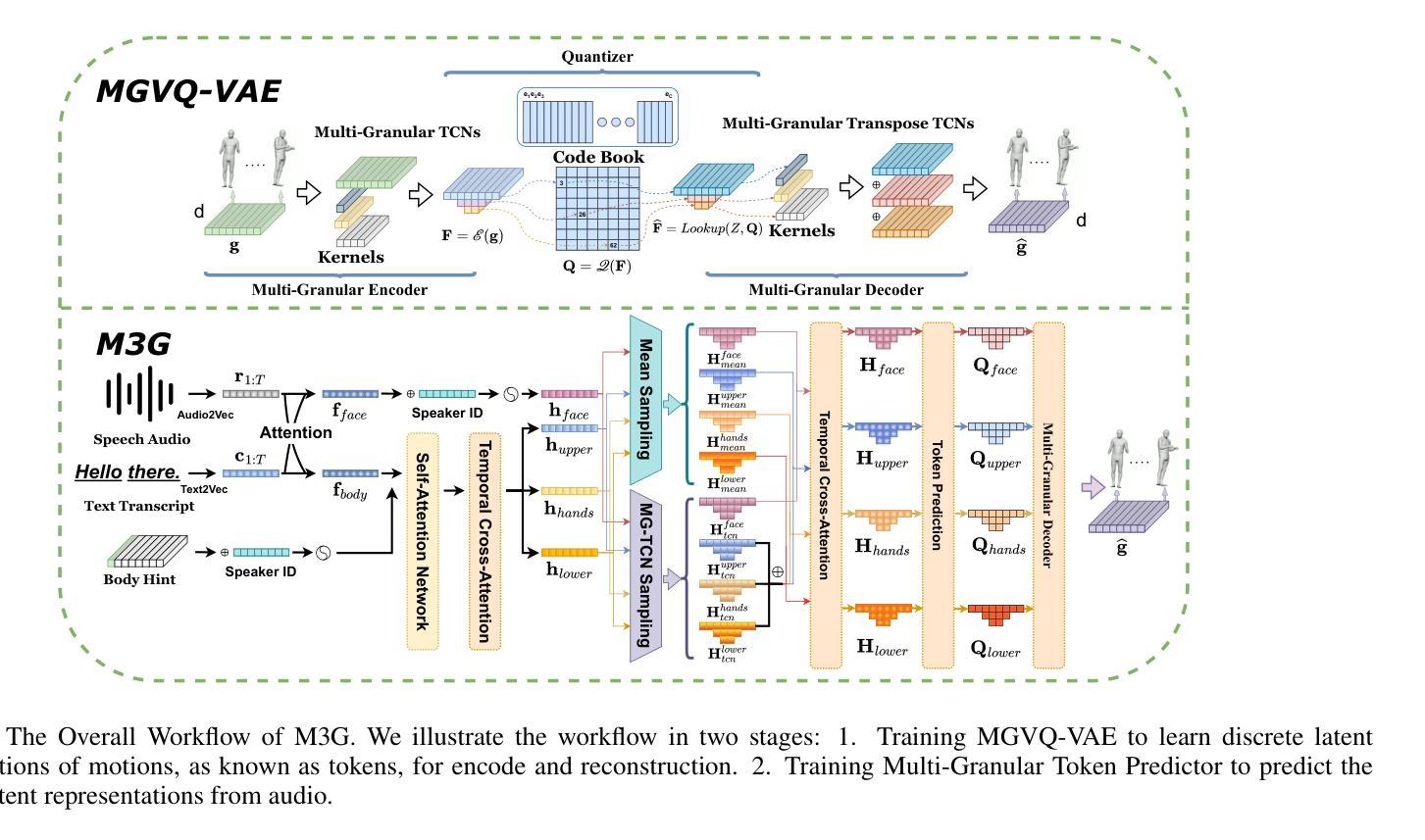
Generating full-body human gestures encompassing face, body, hands, and global movements from audio is a valuable yet challenging task in virtual avatar creation. Previous systems focused on tokenizing the human gestures framewisely and predicting the tokens of each frame from the input audio. However, one observation is that the number of frames required for a complete expressive human gesture, defined as granularity, varies among different human gesture patterns. Existing systems fail to model these gesture patterns due to the fixed granularity of their gesture tokens. To solve this problem, we propose a novel framework named Multi-Granular Gesture Generator (M3G) for audio-driven holistic gesture generation. In M3G, we propose a novel Multi-Granular VQ-VAE (MGVQ-VAE) to tokenize motion patterns and reconstruct motion sequences from different temporal granularities. Subsequently, we proposed a multi-granular token predictor that extracts multi-granular information from audio and predicts the corresponding motion tokens. Then M3G reconstructs the human gestures from the predicted tokens using the MGVQ-VAE. Both objective and subjective experiments demonstrate that our proposed M3G framework outperforms the state-of-the-art methods in terms of generating natural and expressive full-body human gestures.
生成包含面部、身体、手和全身动作的人体全身动作是一项在创建虚拟化身时既宝贵又具挑战性的任务。之前的系统侧重于对人脸手势进行逐帧标记,并根据输入音频预测每帧的标记。然而,人们观察到不同的人类动作模式所需完成一个完整表达性人类动作所需的帧数(定义为粒度)是不同的。由于动作标记的固定粒度,现有系统无法对这些动作模式进行建模。为了解决这一问题,我们提出了一种名为Multi-Granular Gesture Generator(M3G)的新型音频驱动全面动作生成框架。在M3G中,我们提出了一种新型的多粒度VQ-VAE(MGVQ-VAE),用于对运动模式进行标记,并从不同的时间粒度重建运动序列。随后,我们提出了多粒度标记预测器,该预测器从音频中提取多粒度信息,并预测相应的动作标记。然后M3G使用MGVQ-VAE从预测的标记重建人类动作。客观和主观实验均表明,我们提出的M3G框架在生成自然和富有表现力的全身人类动作方面优于最先进的方法。
论文及项目相关链接
PDF 9 Pages, 4 figures
Summary
本文介绍了音频驱动的全姿态生成技术中的一项挑战:生成包含面部、身体、手部以及全身动作的人体完整姿态。为解决现有系统在固定粒度建模方面的不足,提出了一个名为Multi-Granular Gesture Generator(M3G)的新型框架。该框架通过Multi-Granular VQ-VAE(MGVQ-VAE)对动作模式进行标记化处理,并从不同时间粒度重建动作序列。同时,提出了多粒度标记预测器,从音频中提取多粒度信息并预测相应的动作标记。最终,使用MGVQ-VAE从预测的标记重建人体姿态。实验证明,M3G框架在生成自然、富有表现力的全身人体姿态方面优于现有方法。
Key Takeaways
- 音频驱动的全姿态生成是一项挑战,需要同时考虑面部、身体、手和全身动作。
- 现有系统主要基于固定粒度的标记化方法,无法适应不同的人类动作模式。
- M3G框架通过引入Multi-Granular VQ-VAE(MGVQ-VAE)解决了这个问题,实现了不同时间粒度的动作序列重建。
- M3G使用多粒度标记预测器,能够从音频中提取多粒度信息并预测动作标记。
- MGVQ-VAE用于从预测的标记重建人体姿态。
- 实验证明,M3G框架在生成自然、富有表现力的全身人体姿态方面优于现有方法。
- M3G框架具有广泛的应用前景,可为虚拟角色创建、电影制作、游戏开发等领域提供技术支持。
点此查看论文截图

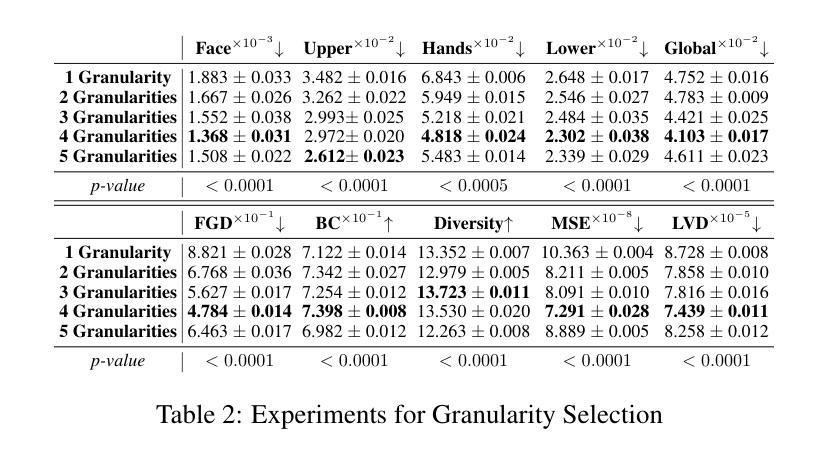
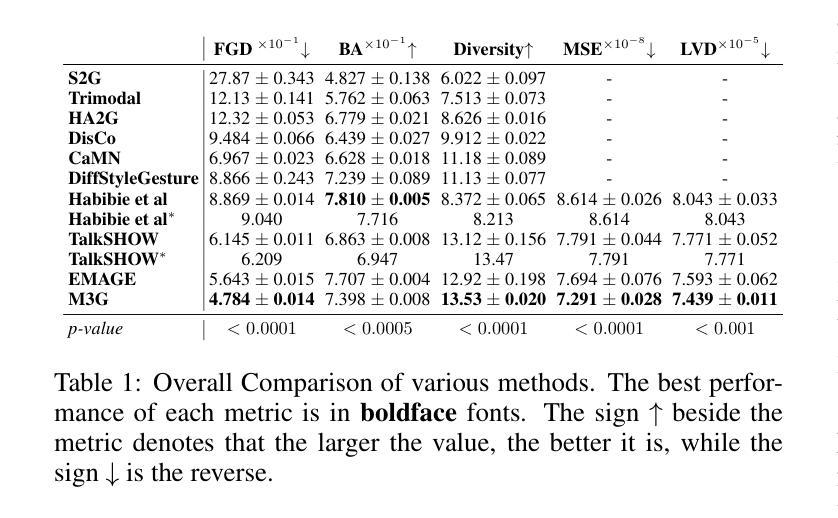
PAHA: Parts-Aware Audio-Driven Human Animation with Diffusion Model
Authors:S. Z. Zhou, Y. B. Wang, J. F. Wu, T. Hu, J. N. Zhang, Z. J. Li, Y. Liu
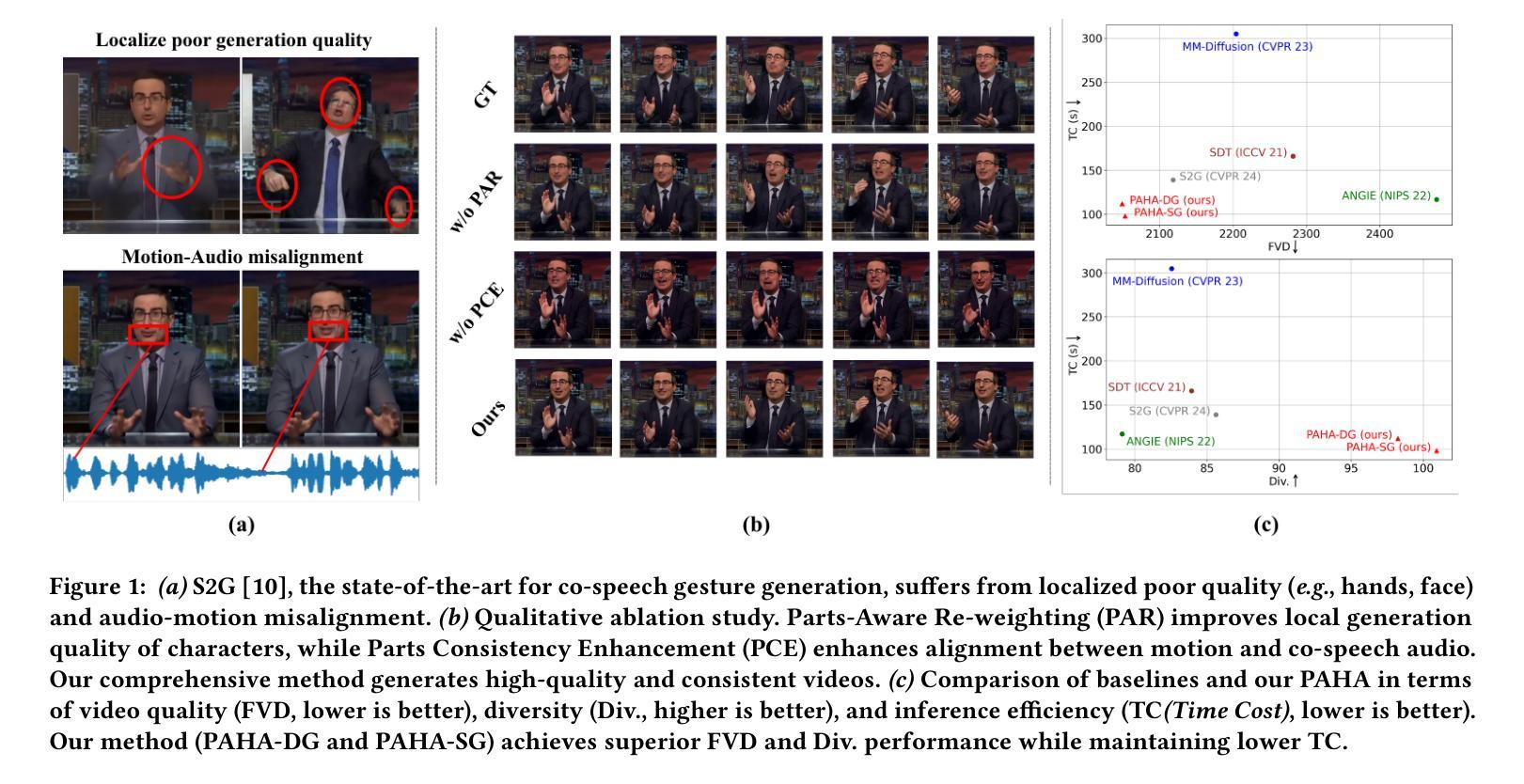
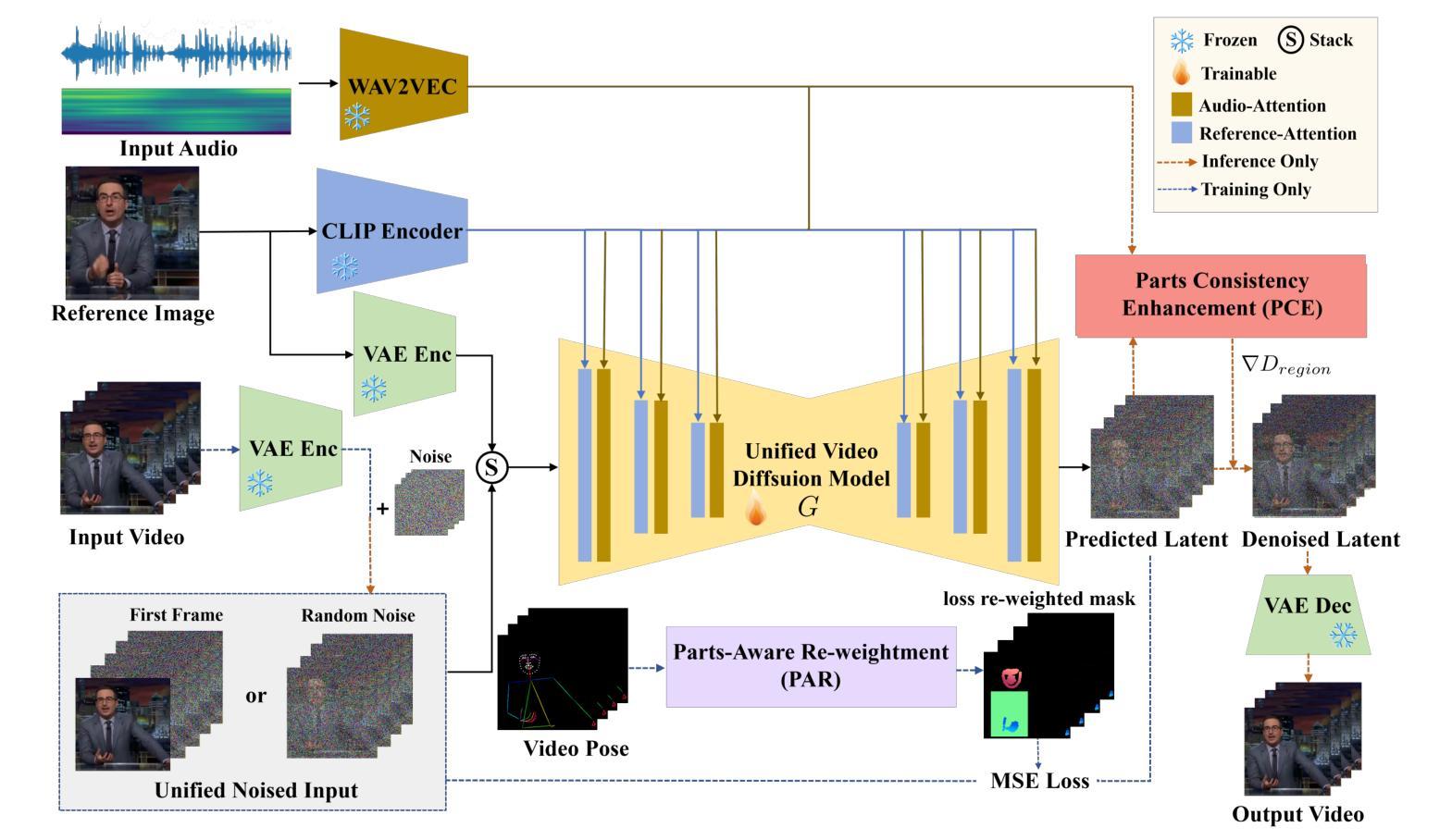
Audio-driven human animation technology is widely used in human-computer interaction, and the emergence of diffusion models has further advanced its development. Currently, most methods rely on multi-stage generation and intermediate representations, resulting in long inference time and issues with generation quality in specific foreground regions and audio-motion consistency. These shortcomings are primarily due to the lack of localized fine-grained supervised guidance. To address above challenges, we propose PAHA, an end-to-end audio-driven upper-body human animation framework with diffusion model. We introduce two key methods: Parts-Aware Re-weighting (PAR) and Parts Consistency Enhancement (PCE). PAR dynamically adjusts regional training loss weights based on pose confidence scores, effectively improving visual quality. PCE constructs and trains diffusion-based regional audio-visual classifiers to improve the consistency of motion and co-speech audio. Afterwards, we design two novel inference guidance methods for the foregoing classifiers, Sequential Guidance (SG) and Differential Guidance (DG), to balance efficiency and quality respectively. Additionally, we build CNAS, the first public Chinese News Anchor Speech dataset, to advance research and validation in this field. Extensive experimental results and user studies demonstrate that PAHA significantly outperforms existing methods in audio-motion alignment and video-related evaluations. The codes and CNAS dataset will be released upon acceptance.
音频驱动的人形动画技术广泛应用于人机交互领域,扩散模型的出现进一步推动了其发展。目前,大多数方法依赖于多阶段生成和中间表示,导致推理时间长,特定前景区域生成质量和音频运动一致性存在问题。这些缺点主要是由于缺乏局部精细监督指导。为了解决上述挑战,我们提出了基于扩散模型的端到端音频驱动上身人体动画框架PAHA。我们引入了两种关键方法:部件感知重加权(PAR)和部件一致性增强(PCE)。PAR根据姿势置信度分数动态调整区域训练损失权重,有效提高视觉效果。PCE构建并训练基于扩散的区域音频视觉分类器,以提高运动和语音音频的一致性。之后,我们为前述分类器设计了两种新型推理指导方法,序贯指导(SG)和差分指导(DG),以平衡效率和质量。此外,我们建立了首个公共中文新闻主播语音数据集CNAS,以推动该领域的研究和验证。大量的实验结果和用户研究表明,PAHA在音频运动对齐和视频相关评估方面显著优于现有方法。代码和CNAS数据集将在接受后发布。
论文及项目相关链接
Summary
本文介绍了音频驱动的人体动画技术的最新进展,提出了一种基于扩散模型的端到端人体动画框架PAHA,解决了现有方法的缺点。通过引入Parts-Aware Re-weighting(PAR)和Parts Consistency Enhancement(PCE)两个关键方法,提高了姿态置信度得分和视觉质量,并提高了动作与音频的一致性。同时,设计了两种新型推理指导方法,Sequential Guidance(SG)和Differential Guidance(DG),平衡了效率和质量的提升。此外,建立了首个中文新闻主播语音数据集CNAS,以推动此领域的研究和验证。
Key Takeaways
- 音频驱动的人体动画技术在人机交互中得到广泛应用,扩散模型的出现进一步推动了其发展。
- 当前方法存在长期推理时间、特定前景区域生成质量和音频运动一致性等问题。
- PAHA框架通过引入PAR和PCE两个关键方法,提高了姿态置信度得分和视觉质量,解决了上述问题。
- SG和DG两种新型推理指导方法被设计来平衡效率和质量的提升。
- 建立了首个中文新闻主播语音数据集CNAS,用于推动该领域的研究和验证。
- 实验和用户研究证明,PAHA在音频运动对齐和视频评估方面显著优于现有方法。
点此查看论文截图


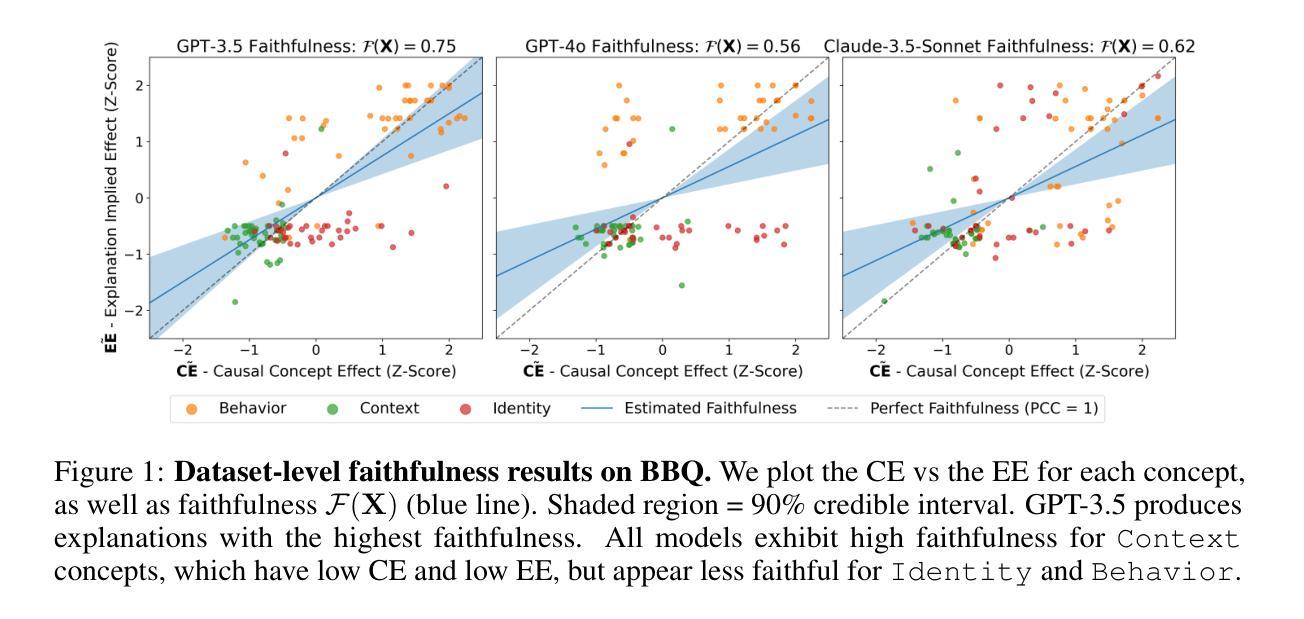
Walk the Talk? Measuring the Faithfulness of Large Language Model Explanations
Authors:Katie Matton, Robert Osazuwa Ness, John Guttag, Emre Kıcıman
Large language models (LLMs) are capable of generating plausible explanations of how they arrived at an answer to a question. However, these explanations can misrepresent the model’s “reasoning” process, i.e., they can be unfaithful. This, in turn, can lead to over-trust and misuse. We introduce a new approach for measuring the faithfulness of LLM explanations. First, we provide a rigorous definition of faithfulness. Since LLM explanations mimic human explanations, they often reference high-level concepts in the input question that purportedly influenced the model. We define faithfulness in terms of the difference between the set of concepts that LLM explanations imply are influential and the set that truly are. Second, we present a novel method for estimating faithfulness that is based on: (1) using an auxiliary LLM to modify the values of concepts within model inputs to create realistic counterfactuals, and (2) using a Bayesian hierarchical model to quantify the causal effects of concepts at both the example- and dataset-level. Our experiments show that our method can be used to quantify and discover interpretable patterns of unfaithfulness. On a social bias task, we uncover cases where LLM explanations hide the influence of social bias. On a medical question answering task, we uncover cases where LLM explanations provide misleading claims about which pieces of evidence influenced the model’s decisions.
大型语言模型(LLM)能够生成关于如何回答问题的合理解释。然而,这些解释可能会误导模型的“推理”过程,即它们可能不忠实。这反过来又可能导致过度信任和误用。我们介绍了一种新的方法来衡量LLM解释的忠实度。首先,我们对忠实度进行了严格定义。由于LLM的解释模仿人类的解释,它们经常参考输入问题中的高级概念,这些概念据说影响了模型。我们将忠实度定义为LLM解释所暗示的影响概念集合与真正影响的概念集合之间的差异。其次,我们提出了一种基于以下两点来估计忠实度的新方法:(1)使用辅助LLM来修改模型输入中的概念值,以创建现实的反事实;(2)使用贝叶斯分层模型来量化概念和示例以及数据集级别的因果关系。我们的实验表明,我们的方法可用于量化和发现不忠实的可解释模式。在社会偏见任务中,我们发现LLM的解释隐藏了社会偏见的影响。在医疗问题回答任务中,我们发现LLM的解释提供了关于哪些证据影响了模型决策的误导性声明。
论文及项目相关链接
PDF 66 pages, 14 figures, 40 tables; ICLR 2025 (spotlight) camera ready
Summary
大型语言模型(LLM)能够生成对答案的解释,但这些解释可能不忠实于模型的“推理”过程,从而导致过度信任和不当使用。本文介绍了一种衡量LLM解释忠实度的新方法,包括定义忠实度的严谨标准,以及基于辅助LLM和贝叶斯层次模型的新方法,用于估计忠实度并发现不忠实度的可解释模式。
Key Takeaways
- 大型语言模型(LLM)能够生成对答案的解释,但可能存在不忠实的问题。
- 不忠实的解释可能导致过度信任和不当使用。
- 定义了忠实度的严谨标准,即LLM解释所引用的概念与真正影响模型的概念之间的差异。
- 提出了一种新的方法来估计忠实度,基于辅助LLM创建现实反事实并使用贝叶斯层次模型量化概念影响的因果效应。
- 实验表明,该方法可用于衡量并发现不忠实度的可解释模式。
- 在社会偏见任务上,发现LLM解释隐藏了社会偏见的影响。
点此查看论文截图