⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-05-22 更新
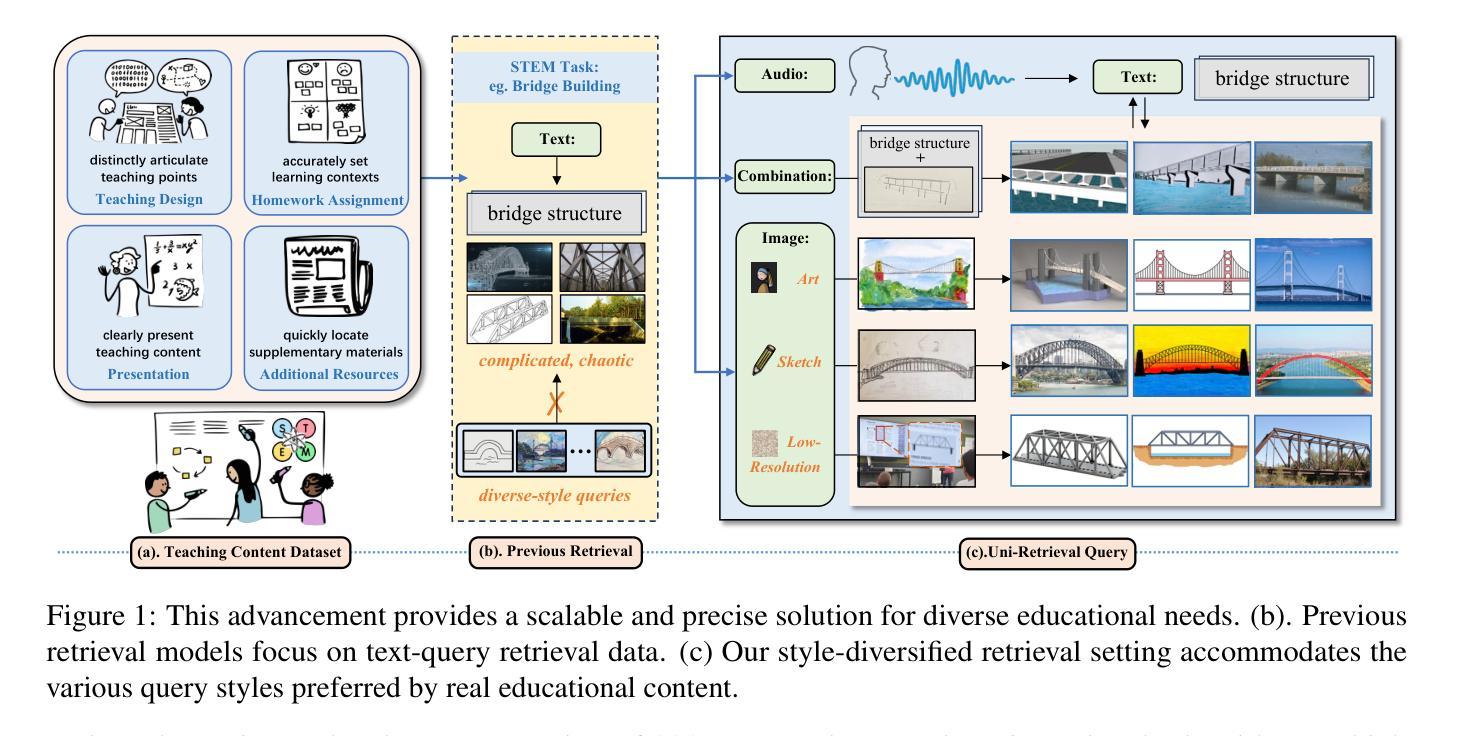
Uni-Retrieval: A Multi-Style Retrieval Framework for STEM’s Education
Authors:Yanhao Jia, Xinyi Wu, Hao Li, Qinglin Zhang, Yuxiao Hu, Shuai Zhao, Wenqi Fan
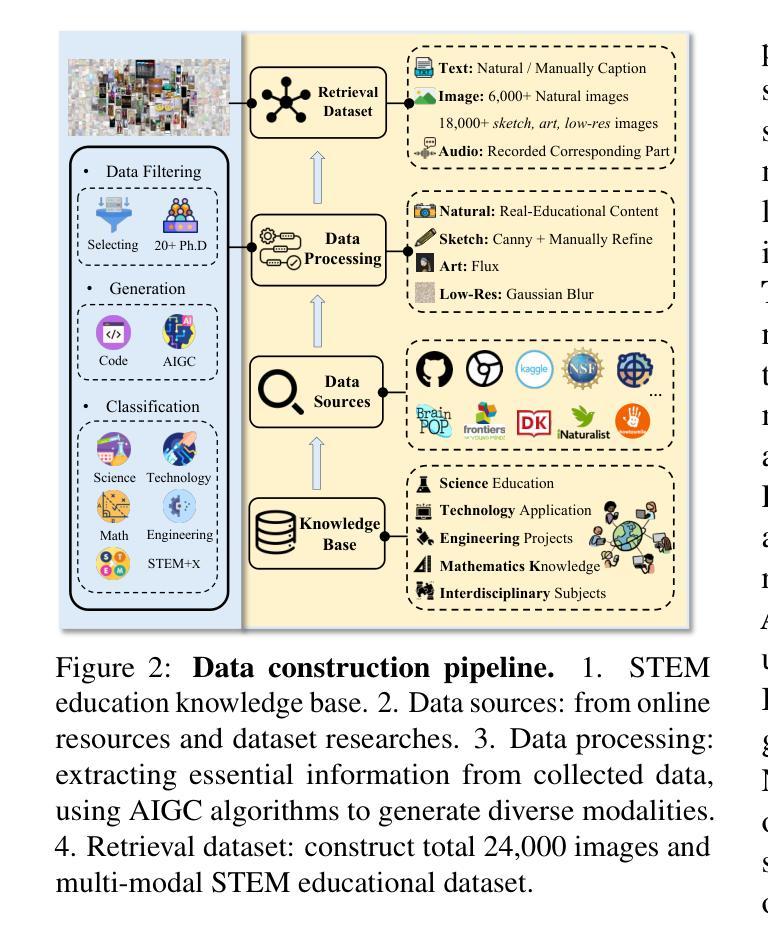
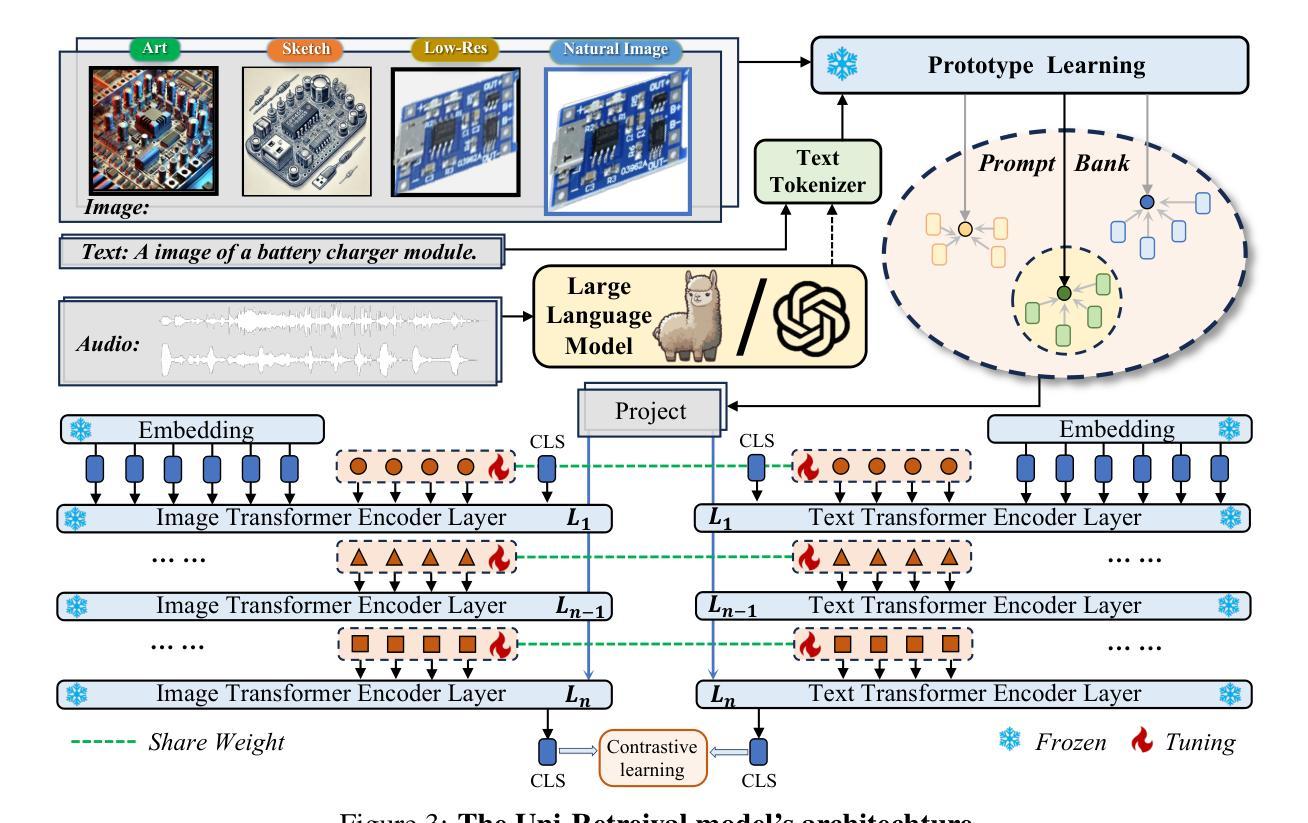
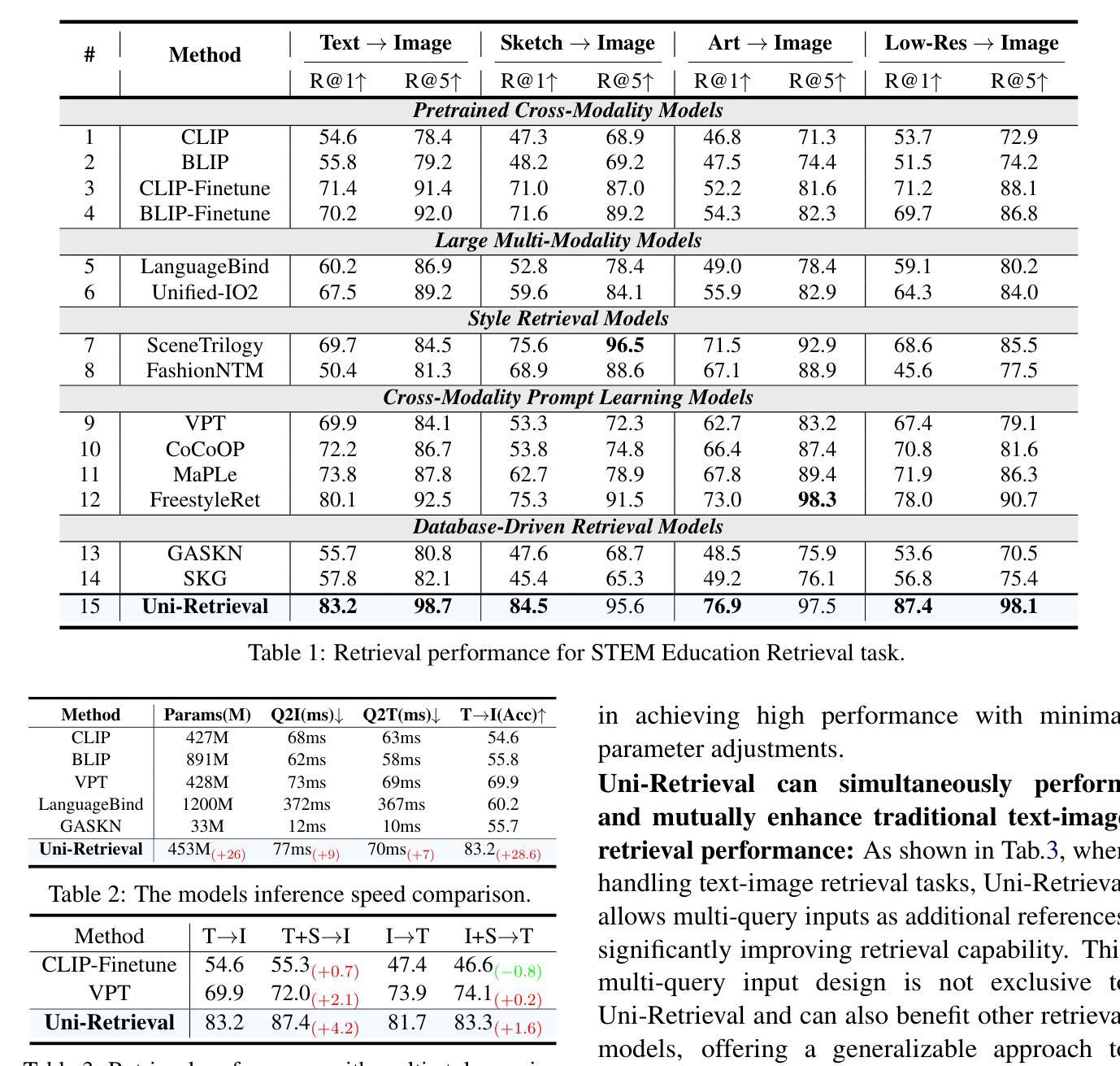
In AI-facilitated teaching, leveraging various query styles to interpret abstract text descriptions is crucial for ensuring high-quality teaching. However, current retrieval models primarily focus on natural text-image retrieval, making them insufficiently tailored to educational scenarios due to the ambiguities in the retrieval process. In this paper, we propose a diverse expression retrieval task tailored to educational scenarios, supporting retrieval based on multiple query styles and expressions. We introduce the STEM Education Retrieval Dataset (SER), which contains over 24,000 query pairs of different styles, and the Uni-Retrieval, an efficient and style-diversified retrieval vision-language model based on prompt tuning. Uni-Retrieval extracts query style features as prototypes and builds a continuously updated Prompt Bank containing prompt tokens for diverse queries. This bank can updated during test time to represent domain-specific knowledge for different subject retrieval scenarios. Our framework demonstrates scalability and robustness by dynamically retrieving prompt tokens based on prototype similarity, effectively facilitating learning for unknown queries. Experimental results indicate that Uni-Retrieval outperforms existing retrieval models in most retrieval tasks. This advancement provides a scalable and precise solution for diverse educational needs.
在人工智能辅助教学中,利用多种查询风格来解读抽象文本描述对于确保高质量教学至关重要。然而,当前的检索模型主要关注自然文本图像检索,由于检索过程中的模糊性,它们对教育场景的适应性不足。在本文中,我们针对教育场景提出了一项多样化的表达检索任务,支持基于多种查询风格和表达方式的检索。我们介绍了STEM教育检索数据集(SER),其中包含超过24,000种不同风格的查询对,以及基于提示调整的Uni-Retrieval高效、多样化的检索视觉语言模型。Uni-Retrieval提取查询风格特征作为原型,并建立一个不断更新的提示库,其中包含用于不同查询的提示令牌。此库可在测试期间进行更新,以代表不同主题检索场景的专业领域知识。我们的框架通过基于原型相似度动态检索提示令牌来展示可扩展性和稳健性,有效地促进了未知查询的学习。实验结果表明,Uni-Retrieval在大多数检索任务中优于现有检索模型。这一进展为多样化的教育需求提供了可扩展和精确的解决方案。
论文及项目相关链接
Summary
教育场景下利用多样的查询风格解读抽象文本描述至关重要。当前检索模型主要关注自然语言文本图像检索,但由于检索过程中的歧义性,难以满足教育需求。本文提出针对教育场景的多样表达检索任务,支持基于多种查询风格和表达方式的检索。引入STEM教育检索数据集(SER),包含超过24,000种不同风格的查询对,以及基于提示调整的高效、风格多样的视觉语言模型Uni-Retrieval。Uni-Retrieval提取查询风格特征作为原型,建立一个不断更新的提示库,包含不同查询的提示标记。该库可在测试期间更新,以表示不同主题检索场景的领域特定知识。通过基于原型相似度的动态检索提示标记,框架展现出可扩展性和稳健性,有效支持未知查询的学习。实验结果证明,Uni-Retrieval在大多数检索任务中优于现有检索模型。此进展为多样化的教育需求提供了可扩展和精确的解决方案。
Key Takeaways
- 当前教育场景下的检索模型需要改进,以支持多样的查询风格和表达方式。
- STEM教育检索数据集(SER)包含大量的查询对,有助于满足教育场景下的检索需求。
- Uni-Retrieval模型通过提取查询风格特征作为原型,支持基于多种查询风格的检索。
- Uni-Retrieval建立了一个可更新的提示库,以适应不同主题和场景的领域特定知识。
- 该框架通过动态检索提示标记展现出可扩展性和稳健性。
- Uni-Retrieval在大多数检索任务中的性能优于现有模型。
点此查看论文截图

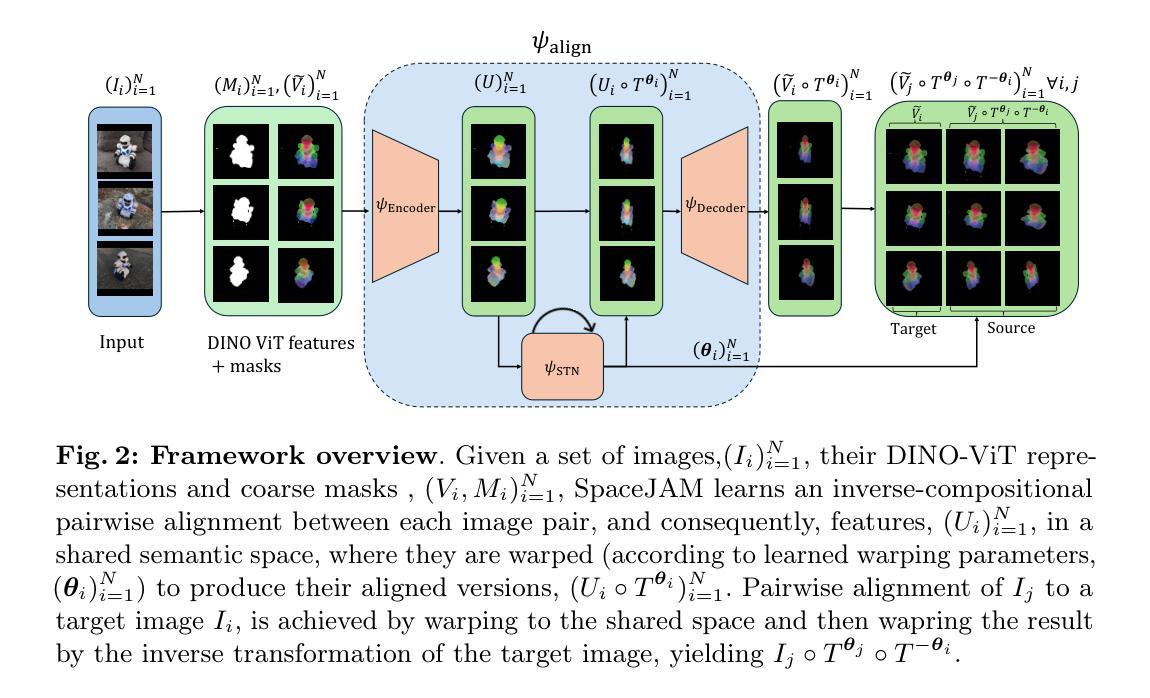
SpaceJAM: a Lightweight and Regularization-free Method for Fast Joint Alignment of Images
Authors:Nir Barel, Ron Shapira Weber, Nir Mualem, Shahaf E. Finder, Oren Freifeld
The unsupervised task of Joint Alignment (JA) of images is beset by challenges such as high complexity, geometric distortions, and convergence to poor local or even global optima. Although Vision Transformers (ViT) have recently provided valuable features for JA, they fall short of fully addressing these issues. Consequently, researchers frequently depend on expensive models and numerous regularization terms, resulting in long training times and challenging hyperparameter tuning. We introduce the Spatial Joint Alignment Model (SpaceJAM), a novel approach that addresses the JA task with efficiency and simplicity. SpaceJAM leverages a compact architecture with only 16K trainable parameters and uniquely operates without the need for regularization or atlas maintenance. Evaluations on SPair-71K and CUB datasets demonstrate that SpaceJAM matches the alignment capabilities of existing methods while significantly reducing computational demands and achieving at least a 10x speedup. SpaceJAM sets a new standard for rapid and effective image alignment, making the process more accessible and efficient. Our code is available at: https://bgu-cs-vil.github.io/SpaceJAM/.
图像联合对齐(JA)的无监督任务面临着高复杂性、几何失真以及收敛到局部甚至全局不佳的问题。尽管视觉变压器(ViT)最近为JA提供了有价值的特征,但它们尚未完全解决这些问题。因此,研究人员经常依赖昂贵的模型和大量的正则化术语,导致训练时间长和参数调试具有挑战性。我们引入了空间联合对齐模型(SpaceJAM),这是一种针对JA任务的高效简洁的新方法。SpaceJAM利用了一种紧凑的架构,仅有16K个可训练参数,并且独特地无需正则化或图谱维护即可运行。在SPair-71K和CUB数据集上的评估表明,SpaceJAM在实现对齐能力时与现有方法相匹配,同时显著降低了计算需求并实现了至少10倍的速度提升。SpaceJAM为快速有效的图像对齐设定了一个新的标准,使过程更加易于访问和高效。我们的代码位于:[https://bgu-cs-vil.github.io/SpaceJAM/]上。
论文及项目相关链接
PDF Accepted to ECCV 2024
Summary
基于Vision Transformer的图像联合对齐任务面临高复杂度、几何失真及易陷入局部甚至全局最优等问题。我们提出一种新型的Spatial Joint Alignment Model(SpaceJAM),该模型具有高效简洁的特点,仅需少量训练参数即可实现图像对齐任务,无需使用正则化或维护图谱,大大缩短了训练时间和调整了超参数的需求。通过SPair-71K和CUB数据集上的评估,SpaceJAM与现有方法的对齐能力相当,同时显著降低了计算需求,实现了至少10倍的加速。SpaceJAM为快速有效的图像对齐设定了新的标准,使该过程更加便捷高效。
Key Takeaways
- Vision Transformer在图像联合对齐任务中面临挑战,如高复杂度、几何失真和易陷入局部/全局最优解。
- SpaceJAM是一种新型的图像联合对齐模型,旨在解决这些问题。
- SpaceJAM具有高效简洁的特点,仅需少量训练参数。
- SpaceJAM无需使用正则化或维护图谱,简化了训练过程。
- SpaceJAM在SPair-71K和CUB数据集上的性能与现有方法相当,但计算需求更低,实现了显著的加速。
- SpaceJAM为图像对齐任务设定了新的标准,使其更加便捷高效。
点此查看论文截图