⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-05-24 更新
Visual Perturbation and Adaptive Hard Negative Contrastive Learning for Compositional Reasoning in Vision-Language Models
Authors:Xin Huang, Ruibin Li, Tong Jia, Wei Zheng, Ya Wang
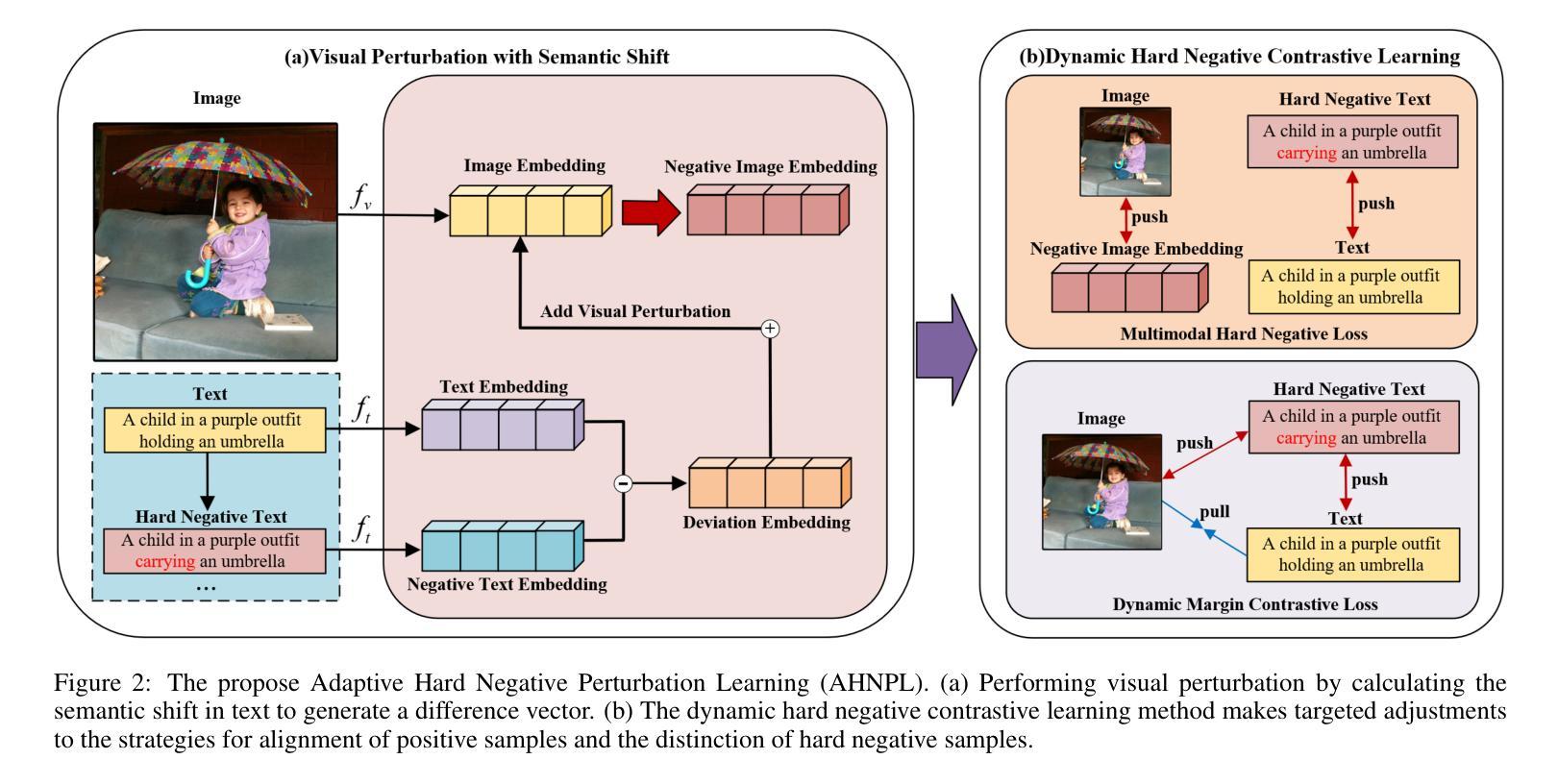
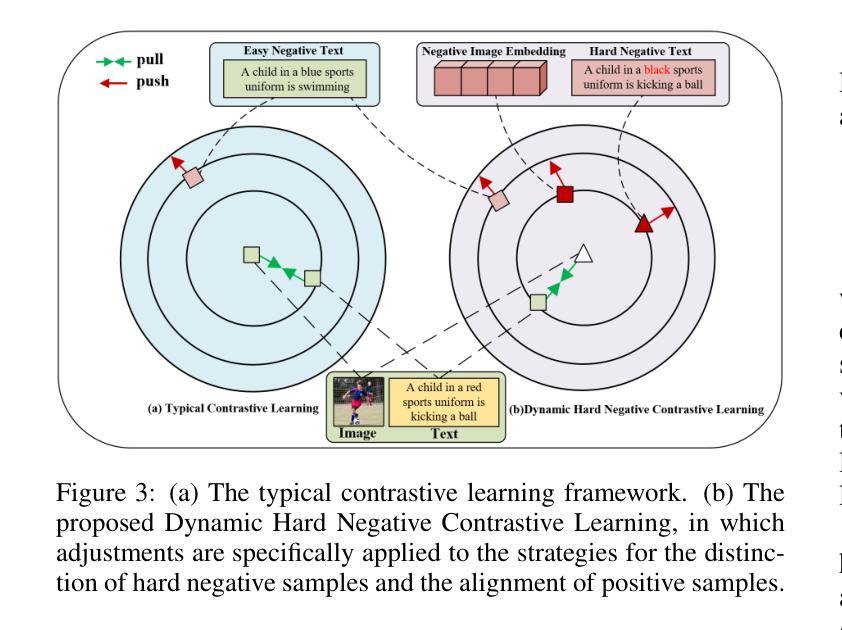
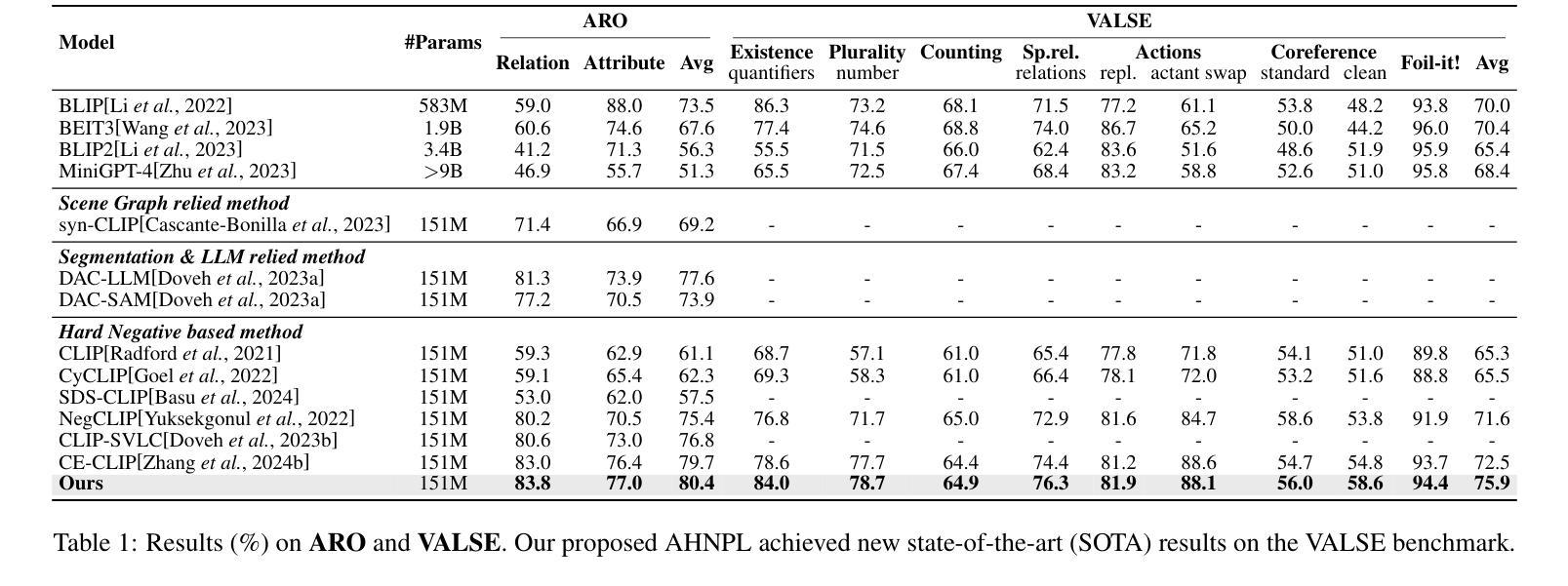
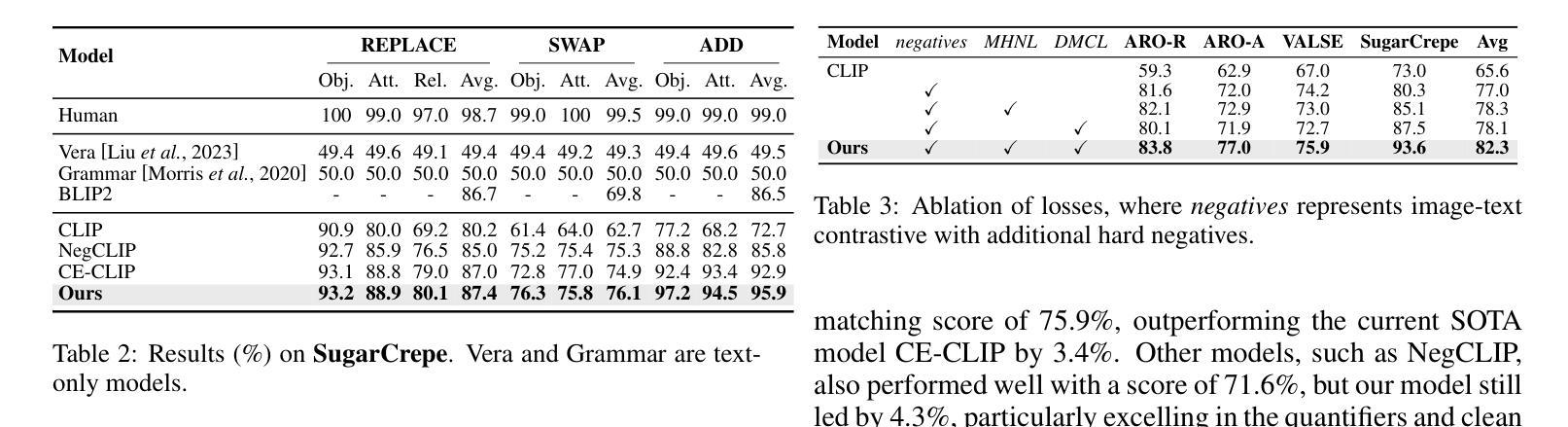
Vision-Language Models (VLMs) are essential for multimodal tasks, especially compositional reasoning (CR) tasks, which require distinguishing fine-grained semantic differences between visual and textual embeddings. However, existing methods primarily fine-tune the model by generating text-based hard negative samples, neglecting the importance of image-based negative samples, which results in insufficient training of the visual encoder and ultimately impacts the overall performance of the model. Moreover, negative samples are typically treated uniformly, without considering their difficulty levels, and the alignment of positive samples is insufficient, which leads to challenges in aligning difficult sample pairs. To address these issues, we propose Adaptive Hard Negative Perturbation Learning (AHNPL). AHNPL translates text-based hard negatives into the visual domain to generate semantically disturbed image-based negatives for training the model, thereby enhancing its overall performance. AHNPL also introduces a contrastive learning approach using a multimodal hard negative loss to improve the model’s discrimination of hard negatives within each modality and a dynamic margin loss that adjusts the contrastive margin according to sample difficulty to enhance the distinction of challenging sample pairs. Experiments on three public datasets demonstrate that our method effectively boosts VLMs’ performance on complex CR tasks. The source code is available at https://github.com/nynu-BDAI/AHNPL.
视觉语言模型(VLMs)对于多模态任务至关重要,特别是需要区分视觉和文本嵌入之间细微语义差异的组合推理(CR)任务。然而,现有方法主要通过生成基于文本的硬负样本来微调模型,忽略了基于图像的负样本的重要性,这导致视觉编码器的训练不足,并最终影响模型的总体性能。此外,负样本通常被一视同仁,没有考虑其难度水平,正样本的对齐也不足,这导致难以对齐样本对。为了解决这些问题,我们提出了自适应硬负扰动学习(AHNPL)。AHNPL将基于文本的硬负样本转换到视觉领域,生成语义干扰的基于图像的负样本,以训练模型,从而提高其总体性能。AHNPL还引入了一种对比学习方法,使用多模态硬负损失来提高模型在每个模态内对硬负样本的辨别能力,以及一种动态边距损失,根据样本难度调整对比边距,以提高具有挑战性的样本对的区分度。在三个公共数据集上的实验表明,我们的方法有效地提高了VLMs在复杂的CR任务上的性能。源代码可在https://github.com/nynu-BDAI/AHNPL找到。
论文及项目相关链接
PDF Accepted at the International Joint Conference on Artificial Intelligence (IJCAI 2025)
Summary
本文指出在视觉语言模型(VLMs)中处理多模态任务时面临的挑战,特别是组合推理(CR)任务。现有方法主要侧重于基于文本生成硬负样本进行微调,忽略了基于图像的负样本的重要性,导致视觉编码器训练不足,影响模型整体性能。为解决这些问题,本文提出自适应硬负扰动学习(AHNPL)方法,通过生成语义干扰的图像负样本进行训练,提高模型性能。同时引入跨模态对比学习方法和动态边界损失来调整对比边界和应对困难样本。实验表明,该方法有效提升了VLMs在复杂CR任务上的性能。
Key Takeaways
- VLMs在处理多模态任务时面临挑战,特别是在组合推理(CR)任务中需要区分视觉和文本嵌入的细微语义差异。
- 现有方法主要依赖基于文本生成硬负样本进行微调,忽略了基于图像的负样本的重要性。
- AHNPL通过生成语义干扰的图像负样本进行训练,提高了模型的整体性能。
- AHNPL引入跨模态对比学习方法,通过提高模型对不同模态内困难样本的区分能力来改善性能。
- 动态边界损失用于调整对比边界以适应样本的难度差异,从而提高对困难样本对的区分能力。
- 实验表明AHNPL方法能显著提高VLMs在复杂CR任务上的性能。
点此查看论文截图

Infinite hierarchical contrastive clustering for personal digital envirotyping
Authors:Ya-Yun Huang, Joseph McClernon, Jason A. Oliver, Matthew M. Engelhard
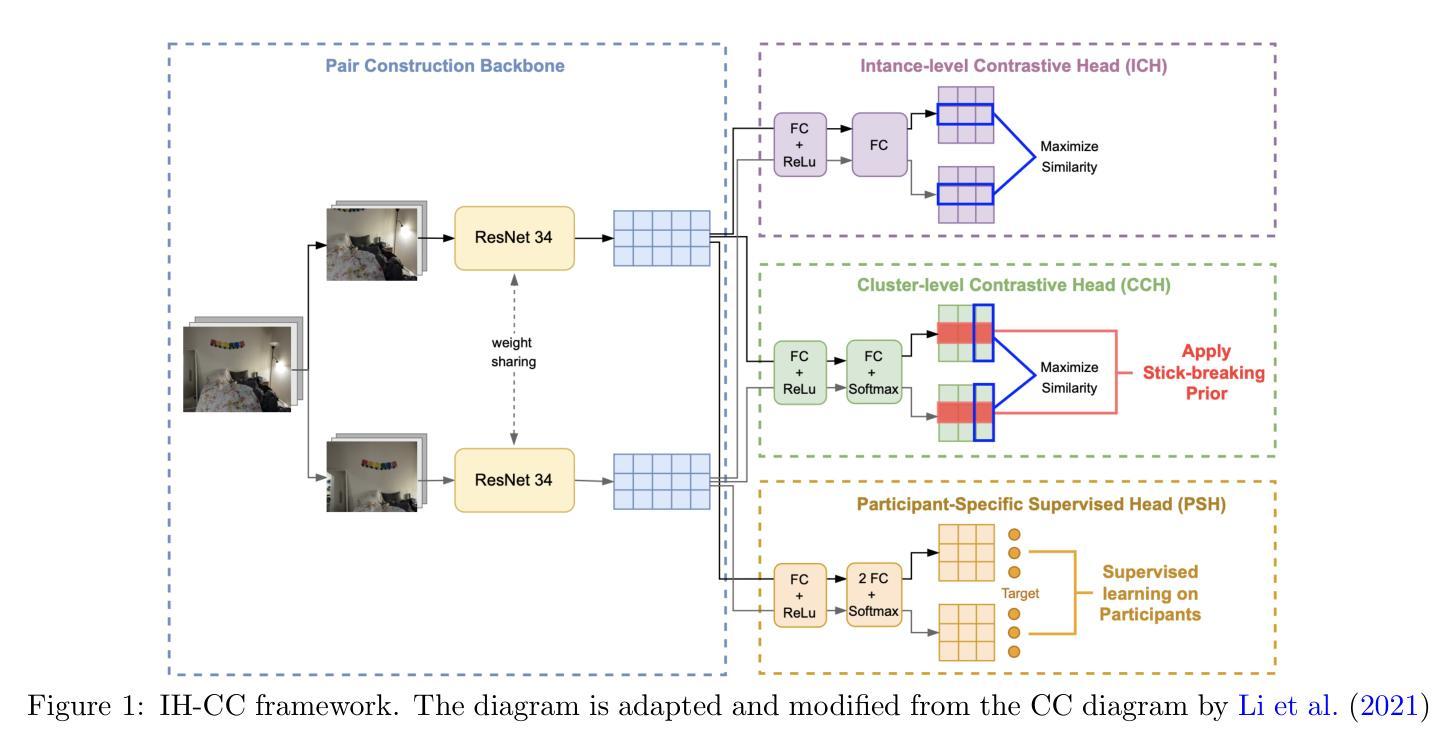
Daily environments have profound influence on our health and behavior. Recent work has shown that digital envirotyping, where computer vision is applied to images of daily environments taken during ecological momentary assessment (EMA), can be used to identify meaningful relationships between environmental features and health outcomes of interest. To systematically study such effects on an individual level, it is helpful to group images into distinct environments encountered in an individual’s daily life; these may then be analyzed, further grouped into related environments with similar features, and linked to health outcomes. Here we introduce infinite hierarchical contrastive clustering to address this challenge. Building on the established contrastive clustering framework, our method a) allows an arbitrary number of clusters without requiring the full Dirichlet Process machinery by placing a stick-breaking prior on predicted cluster probabilities; and b) encourages distinct environments to form well-defined sub-clusters within each cluster of related environments by incorporating a participant-specific prediction loss. Our experiments show that our model effectively identifies distinct personal environments and groups these environments into meaningful environment types. We then illustrate how the resulting clusters can be linked to various health outcomes, highlighting the potential of our approach to advance the envirotyping paradigm.
日常环境对我们的健康和行为有着深远的影响。近期的研究表明,数字环境塑造(将计算机视觉应用于生态即时评估过程中拍摄的日常环境图像)可以用来识别环境特征与所关注的健康结果之间的有意义的关系。为了系统地研究这种个体层面的影响,将图像分组为个体日常生活中遇到的不同环境是非常有帮助的;之后可以进一步分析这些图像,将它们分组为具有相似特征的相关环境,并与健康结果相联系。在这里,我们引入无限层次对比聚类来解决这一挑战。我们的方法在已建立的对比聚类框架的基础上,a)通过对预测的聚类概率放置棒状断裂先验值,允许任意数量的聚类而无需使用完整的狄利克雷过程机器;b)通过结合参与者特定的预测损失,鼓励不同的环境在相关环境的每个聚类中形成定义明确的子聚类。我们的实验表明,该模型有效地识别了不同的个人环境,并将这些环境分组为有意义的环境类型。然后,我们说明了如何将所得的聚类与各种健康结果联系起来,突出了我们的方法在推进环境塑造范式方面的潜力。
论文及项目相关链接
PDF 10pages, 5 figures, Machine Learning four Health(ML4H 2024)
Summary
本文介绍了数字环境分型技术在健康研究领域的应用,通过计算机视觉技术识别日常环境图像,并研究环境与个体健康结果之间的关系。为解决在个人层面上研究环境对健康的系统影响,引入了无限层次对比聚类方法。该方法建立在对比聚类框架上,通过采用棒状断裂先验预测聚类概率,不需要完整的Dirichlet Process装置,即可形成任意数量的聚类;同时通过融入参与者特定预测损失,鼓励在相关环境聚类的内部形成明确的子聚类。实验证明,该模型能有效识别出个人的不同环境,并将这些环境分组为有意义的环境类型。然后展示了如何将所得聚类与各种健康结果联系起来,突显了此方法在推进环境分型范式方面的潜力。
Key Takeaways
- 数字环境分型技术可通过计算机视觉识别日常环境图像,研究环境与个体健康之间的关系。
- 无限层次对比聚类方法用于解决个人层面上的环境对健康影响的系统研究。
- 该方法允许形成任意数量的聚类,不需要完整的Dirichlet Process装置。
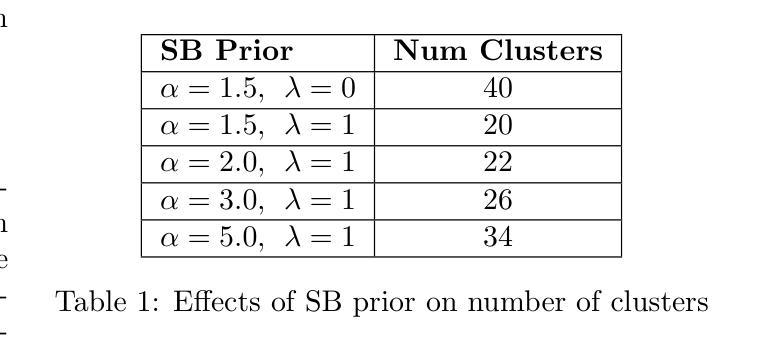
- 引入棒状断裂先验和参与者特定预测损失,以鼓励形成明确的子聚类。
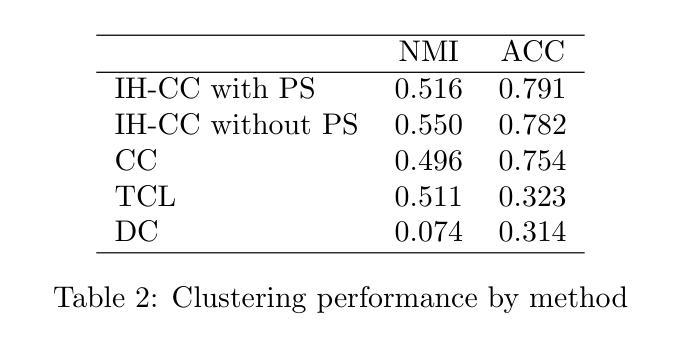
- 实验证明模型能有效识别个人不同环境并分组为有意义的环境类型。
- 所得聚类可与各种健康结果相联系。
点此查看论文截图


SpikeCLIP: A Contrastive Language-Image Pretrained Spiking Neural Network
Authors:Changze Lv, Tianlong Li, Wenhao Liu, Yufei Gu, Jianhan Xu, Cenyuan Zhang, Muling Wu, Xiaoqing Zheng, Xuanjing Huang
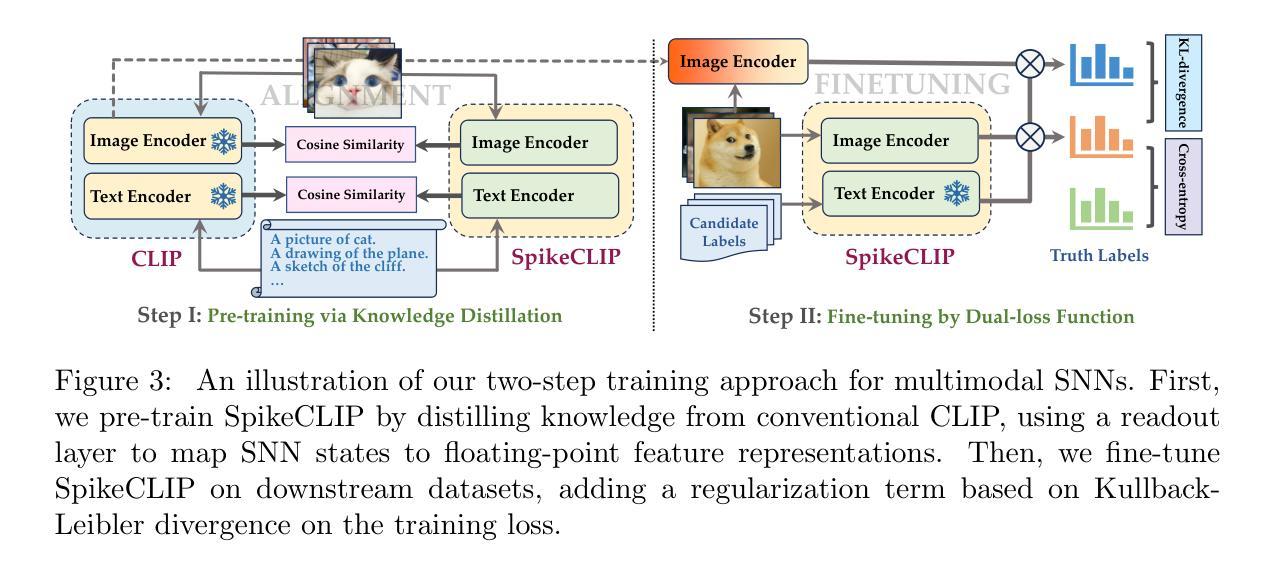
Spiking Neural Networks (SNNs) have emerged as a promising alternative to conventional Artificial Neural Networks (ANNs), demonstrating comparable performance in both visual and linguistic tasks while offering the advantage of improved energy efficiency. Despite these advancements, the integration of linguistic and visual features into a unified representation through spike trains poses a significant challenge, and the application of SNNs to multimodal scenarios remains largely unexplored. This paper presents SpikeCLIP, a novel framework designed to bridge the modality gap in spike-based computation. Our approach employs a two-step recipe: an alignment pre-training'' to align features across modalities, followed by a dual-loss fine-tuning’’ to refine the model’s performance. Extensive experiments reveal that SNNs achieve results on par with ANNs while substantially reducing energy consumption across various datasets commonly used for multimodal model evaluation. Furthermore, SpikeCLIP maintains robust image classification capabilities, even when dealing with classes that fall outside predefined categories. This study marks a significant advancement in the development of energy-efficient and biologically plausible multimodal learning systems. Our code is available at https://github.com/Lvchangze/SpikeCLIP.
脉冲神经网络(Spiking Neural Networks,SNNs)作为传统人工神经网络(Artificial Neural Networks,ANNs)的一种有前途的替代品已经出现,它在视觉和语言任务中表现出相当的性能,同时提供改进的能量效率优势。尽管有这些进展,但通过脉冲串将语言和视觉特征融合到统一表示中仍然存在重大挑战,脉冲神经网络在多模式场景的应用仍然很少被探索。本文提出了SpikeCLIP,这是一个旨在填补脉冲计算中的模式鸿沟的新颖框架。我们的方法采用两步法:先进行“对齐预训练”,以对齐跨模式特征,然后进行“双损失微调”,以优化模型性能。大量实验表明,SNNs的结果与ANNs相当,同时在常用的多模式模型评估数据集上大大降低能耗。此外,SpikeCLIP在处理超出预定类别的类别时,仍能保持稳健的图像分类能力。这项研究标志着在开发节能和生物上合理的多模式学习系统方面取得了重大进展。我们的代码可在https://github.com/Lvchangze/SpikeCLIP上找到。
论文及项目相关链接
Summary
Spiking Neural Networks (SNNs)因其在视觉和语言学任务中的优异表现及更高的能源效率而受到关注。然而,将语言学和视觉特征通过脉冲序列整合到统一表征中是一大挑战,SNNs在多模态场景的应用也尚未得到充分探索。本文提出SpikeCLIP框架,旨在填补脉冲计算中的模态差距。该研究采用两步法:先进行“对齐预训练”,以跨模态对齐特征,然后进行“双损失微调”,以提高模型性能。实验证明,SNNs的结果与人工神经网络相当,同时大大降低了跨多个数据集的多模态模型评估的能耗。SpikeCLIP在应对超出预设类别的图像分类时,仍保持了稳健性。标志着能源高效且符合生物实际的多模态学习系统的重要进步。
Key Takeaways
- Spiking Neural Networks (SNNs)在视觉和语言学任务中展现出与传统人工神经网络(ANNs)相当的性能,并具备更高的能源效率优势。
- 整合语言学和视觉特征到统一表征中是一大挑战,尤其是在脉冲序列表示中。
- SpikeCLIP框架旨在解决模态差距问题,通过两步法实现跨模态特征对齐和模型性能优化。
- 实验证明SNNs的结果与ANNs相当,且显著降低多模态场景下的能耗。
- SpikeCLIP框架在图像分类方面表现出稳健性,即使面对超出预设类别的图像也能有效处理。
- 该研究为能源高效、符合生物实际的多模态学习系统的发展做出了重要贡献。
点此查看论文截图