⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-05-24 更新
SHaDe: Compact and Consistent Dynamic 3D Reconstruction via Tri-Plane Deformation and Latent Diffusion
Authors:Asrar Alruwayqi
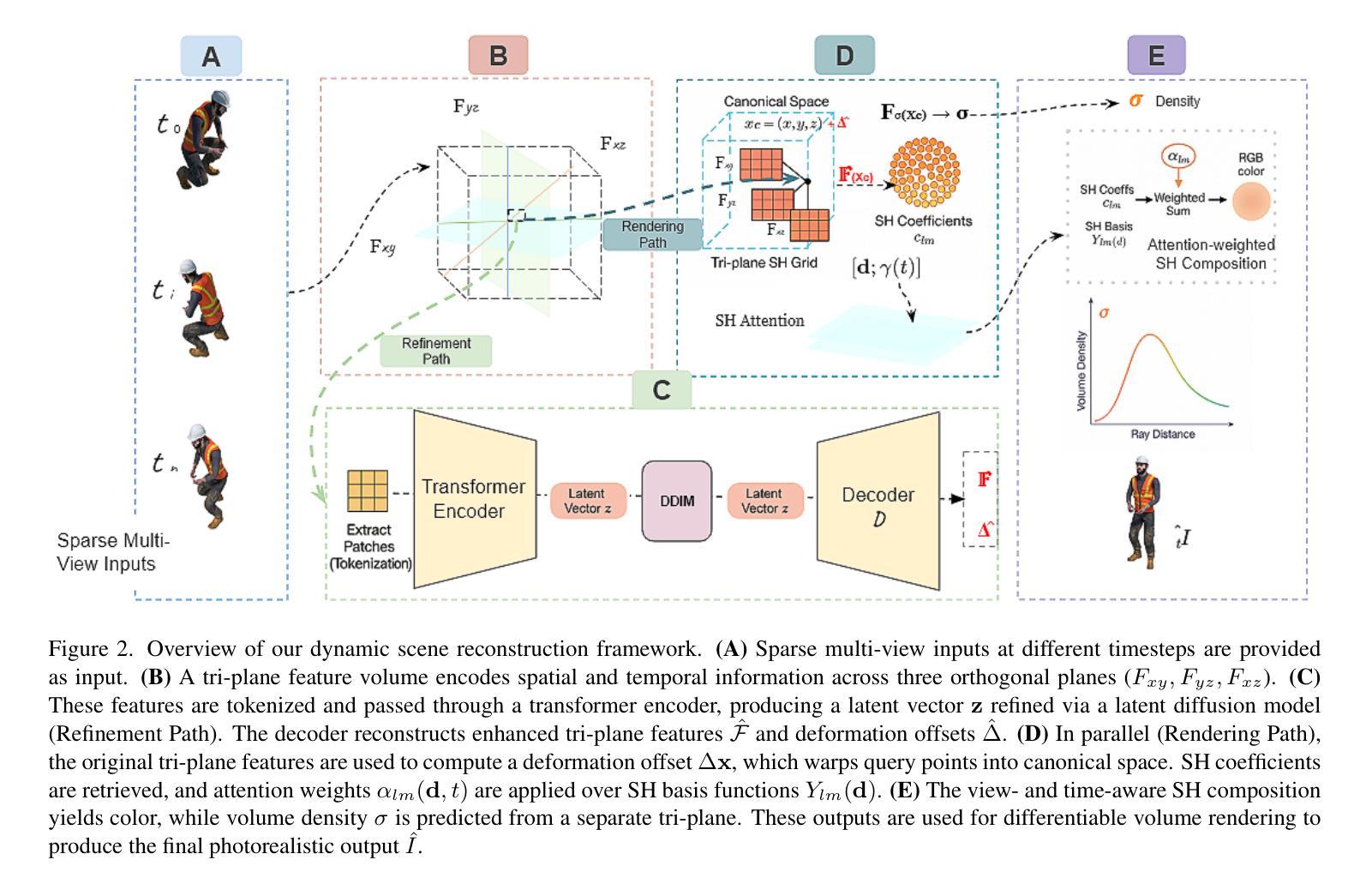
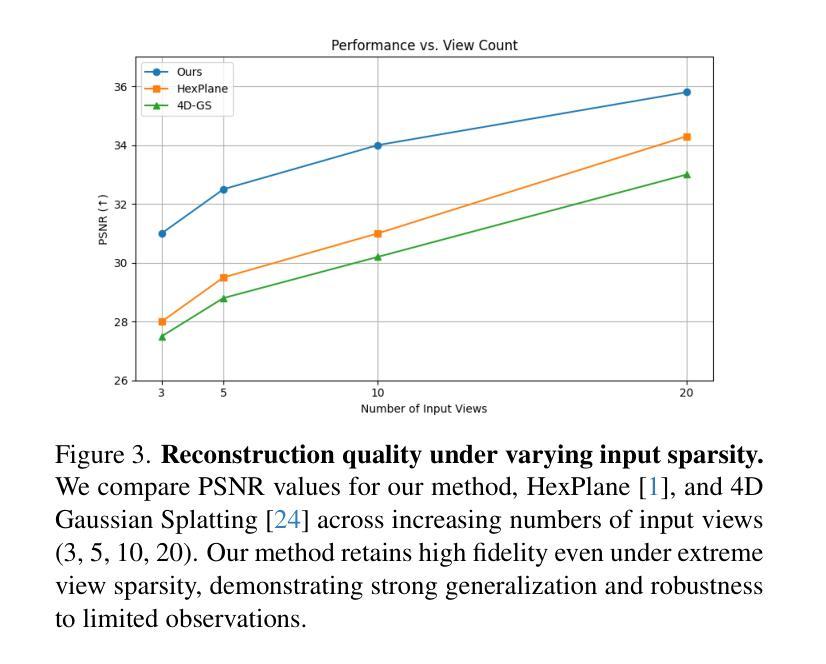
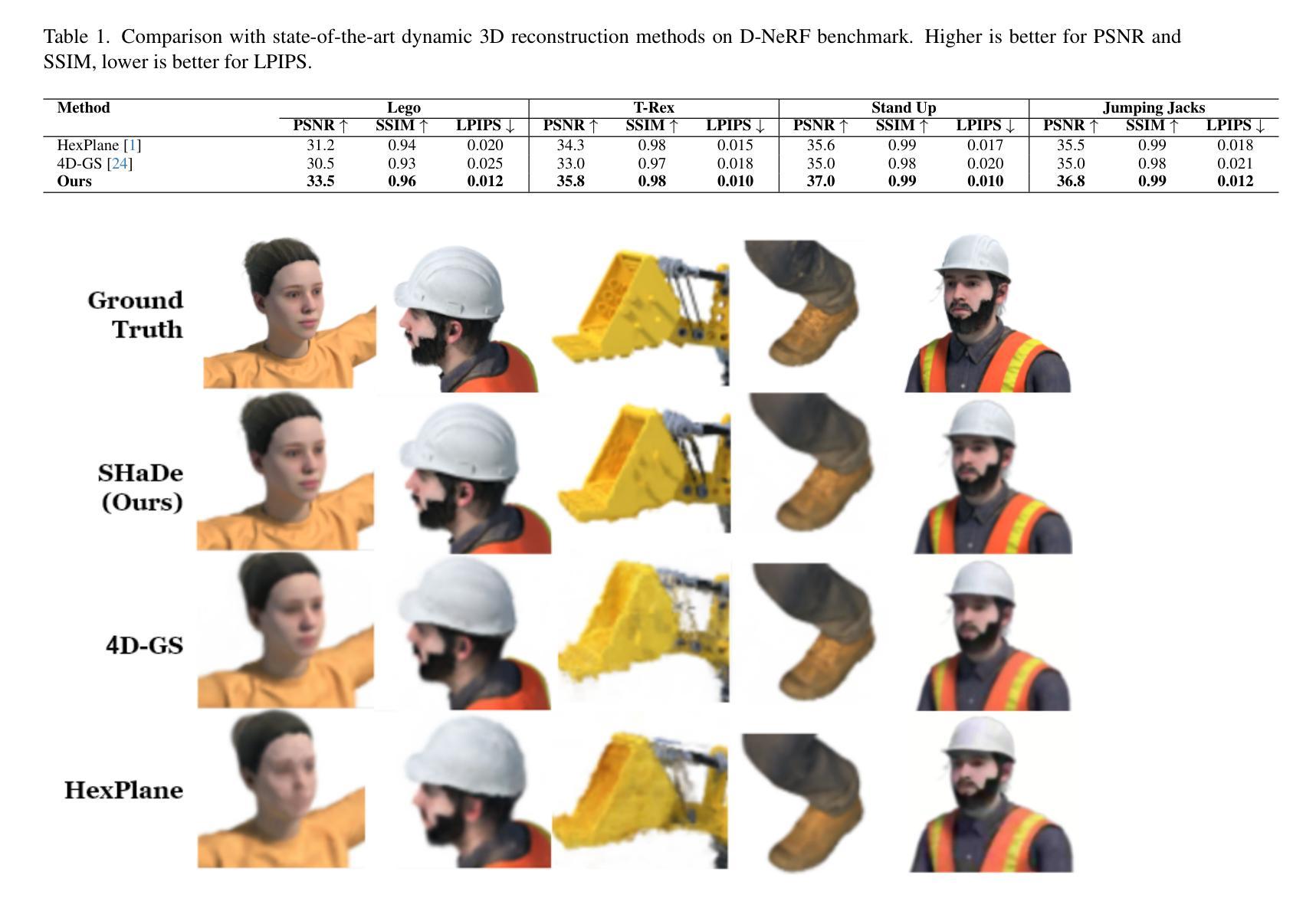
We present a novel framework for dynamic 3D scene reconstruction that integrates three key components: an explicit tri-plane deformation field, a view-conditioned canonical radiance field with spherical harmonics (SH) attention, and a temporally-aware latent diffusion prior. Our method encodes 4D scenes using three orthogonal 2D feature planes that evolve over time, enabling efficient and compact spatiotemporal representation. These features are explicitly warped into a canonical space via a deformation offset field, eliminating the need for MLP-based motion modeling. In canonical space, we replace traditional MLP decoders with a structured SH-based rendering head that synthesizes view-dependent color via attention over learned frequency bands improving both interpretability and rendering efficiency. To further enhance fidelity and temporal consistency, we introduce a transformer-guided latent diffusion module that refines the tri-plane and deformation features in a compressed latent space. This generative module denoises scene representations under ambiguous or out-of-distribution (OOD) motion, improving generalization. Our model is trained in two stages: the diffusion module is first pre-trained independently, and then fine-tuned jointly with the full pipeline using a combination of image reconstruction, diffusion denoising, and temporal consistency losses. We demonstrate state-of-the-art results on synthetic benchmarks, surpassing recent methods such as HexPlane and 4D Gaussian Splatting in visual quality, temporal coherence, and robustness to sparse-view dynamic inputs.
我们提出了一种新的动态3D场景重建框架,它集成了三个关键组件:显式三平面变形场、带有球面谐波(SH)注意力的视场条件规范辐射场以及时间感知潜在扩散先验。我们的方法使用随时间变化的三个正交2D特征平面对4D场景进行编码,从而实现高效且紧凑的时空表示。这些特征通过变形偏移场明确变形到规范空间,无需基于MLP的运动建模。在规范空间中,我们用结构化的SH基于渲染头替换传统的MLP解码器,通过关注学习频率波段来合成视觉相关的颜色,从而提高可解释性和渲染效率。为了进一步提高保真度和时间一致性,我们引入了一个受变压器引导的潜在扩散模块,该模块在压缩的潜在空间中细化了三平面和变形特征。这个生成模块减少了模糊或超出分布(OOD)运动下的场景表示噪声,提高了泛化能力。我们的模型分为两个阶段进行训练:首先独立地预训练扩散模块,然后使用图像重建、扩散去噪和时间一致性损失的组合与全管道联合微调。我们在合成基准测试上展示了卓越的结果,在视觉质量、时间连贯性和对稀疏视图动态输入的鲁棒性方面超越了最近的HexPlane和4D高斯拼贴等方法。
论文及项目相关链接
Summary
本文提出了一种新的动态三维场景重建框架,包含三个关键组件:显式三平面变形场、基于视图的典型辐射场与球面谐波(SH)注意力机制,以及时间感知潜在扩散先验。该方法采用随时间变化的三正交二维特征平面编码四维场景,通过变形偏移场将这些特征显式地变换到典型空间,无需使用MLP基运动建模。典型空间中,使用结构化SH渲染头合成视相关色彩,通过关注学习频率带提高解释性和渲染效率。为进一步提高保真度和时间一致性,引入了基于变压器的潜在扩散模块,在压缩潜在空间中优化三平面和变形特征。该生成模块在模糊或分布外(OOD)运动情况下降低场景表示的噪声,提高泛化能力。该模型分两个阶段训练:首先独立预训练扩散模块,然后使用图像重建、扩散去噪和时间一致性损失联合微调整个管道。在合成基准测试上表现卓越,超越HexPlane和4D高斯贴片等方法在视觉质量、时间连贯性和对稀疏动态输入鲁棒性方面的表现。
Key Takeaways
- 提出了一种新型动态三维场景重建框架,集成了显式三平面变形场、基于视图的典型辐射场与SH注意力机制以及时间感知潜在扩散先验。
- 通过变形偏移场将特征显式变换到典型空间,提高了效率和准确性。
- 采用结构化SH渲染头合成视相关色彩,提升了渲染效率和解释性。
- 引入基于变压器的潜在扩散模块,优化了场景表示,提高了泛化能力和时间一致性。
- 模型采用两阶段训练法,先独立预训练扩散模块,再联合微调整个管道。
- 在图像重建、扩散去噪和时间一致性方面使用损失函数进行优化。
点此查看论文截图

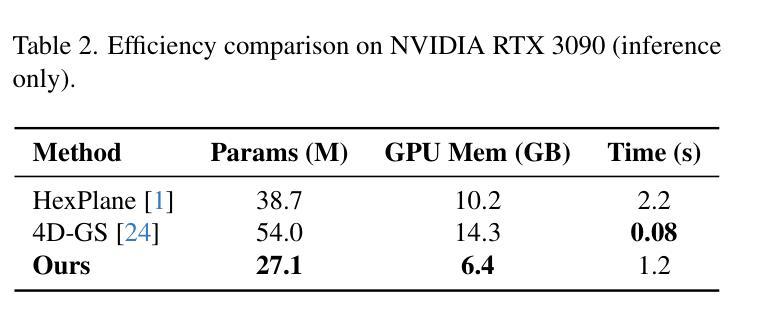
Motion Matters: Compact Gaussian Streaming for Free-Viewpoint Video Reconstruction
Authors:Jiacong Chen, Qingyu Mao, Youneng Bao, Xiandong Meng, Fanyang Meng, Ronggang Wang, Yongsheng Liang
3D Gaussian Splatting (3DGS) has emerged as a high-fidelity and efficient paradigm for online free-viewpoint video (FVV) reconstruction, offering viewers rapid responsiveness and immersive experiences. However, existing online methods face challenge in prohibitive storage requirements primarily due to point-wise modeling that fails to exploit the motion properties. To address this limitation, we propose a novel Compact Gaussian Streaming (ComGS) framework, leveraging the locality and consistency of motion in dynamic scene, that models object-consistent Gaussian point motion through keypoint-driven motion representation. By transmitting only the keypoint attributes, this framework provides a more storage-efficient solution. Specifically, we first identify a sparse set of motion-sensitive keypoints localized within motion regions using a viewspace gradient difference strategy. Equipped with these keypoints, we propose an adaptive motion-driven mechanism that predicts a spatial influence field for propagating keypoint motion to neighboring Gaussian points with similar motion. Moreover, ComGS adopts an error-aware correction strategy for key frame reconstruction that selectively refines erroneous regions and mitigates error accumulation without unnecessary overhead. Overall, ComGS achieves a remarkable storage reduction of over 159 X compared to 3DGStream and 14 X compared to the SOTA method QUEEN, while maintaining competitive visual fidelity and rendering speed. Our code will be released.
3D高斯映射(3DGS)已经成为一种用于在线自由视点视频(FVV)重建的高保真和高效范式,为观众提供快速响应和沉浸式体验。然而,现有的在线方法面临存储要求过高的挑战,这主要是由于点对建模未能充分利用运动属性。为了解决这一局限性,我们提出了一种新型的紧凑高斯流(ComGS)框架,它利用动态场景中的运动局部性和一致性,通过关键帧驱动的运动表示对物体一致的高斯点运动进行建模。通过仅传输关键点的属性,该框架提供了更高效的存储解决方案。具体来说,我们首先使用视图空间梯度差异策略,在运动区域内识别一组稀疏的运动敏感关键点。有了这些关键点,我们提出了一种自适应的运动驱动机制,预测一个空间影响场,将关键点的运动传播到具有相似运动的相邻高斯点。此外,ComGS采用了一种错误感知校正策略,对关键帧重建进行选择性细化,缓解错误积累,同时避免不必要的开销。总体而言,ComGS与3DGStream相比实现了高达159倍的存储缩减,与当前最佳方法QUEEN相比实现了14倍的存储缩减,同时保持了有竞争力的视觉保真度和渲染速度。我们的代码将会发布。
论文及项目相关链接
PDF 17 pages, 9 figures
Summary
3DGS方法以其高保真度和高效率成为了在线自由视点视频重建领域的流行方法,为用户提供快速响应和沉浸式体验。但是现有在线方法存储要求很高,主要是因了点模型没有充分利用运动特性。为解决此问题,我们提出了Compact Gaussian Streaming(ComGS)框架,利用动态场景的运动局部性和一致性,通过关键点的运动表示来模拟对象一致的Gaussian点运动。它仅传输关键点的属性,从而更节省存储空间。通过运动敏感的关键点自适应预测空间影响场来将运动传播到相邻的Gaussian点。此外,ComGS采用了一种错误感知校正策略进行关键帧重建,选择性优化错误区域并减轻错误累积负担。相较于其他方法,ComGS实现了显著的存储降低,同时保持了竞争性的视觉保真度和渲染速度。
Key Takeaways
以下是关于文本的关键见解:
- 现有在线方法的存储要求较高是因为未充分利用运动特性,尤其是在点对模型处理方面存在问题。对此我们提出了一种新颖的ComGS框架来应对这一挑战。该框架通过利用动态场景的运动局部性和一致性来实现高效存储。
- ComGS框架利用关键点的运动表示来模拟对象一致的Gaussian点运动,仅传输关键点的属性,从而显著减少存储需求。这是通过识别运动敏感的关键点并预测空间影响场实现的。通过这种方式,关键点的运动能够传播到具有相似运动的相邻Gaussian点。这是一种结合关键点和运动预测的策略,使得存储效率大大提高。
点此查看论文截图

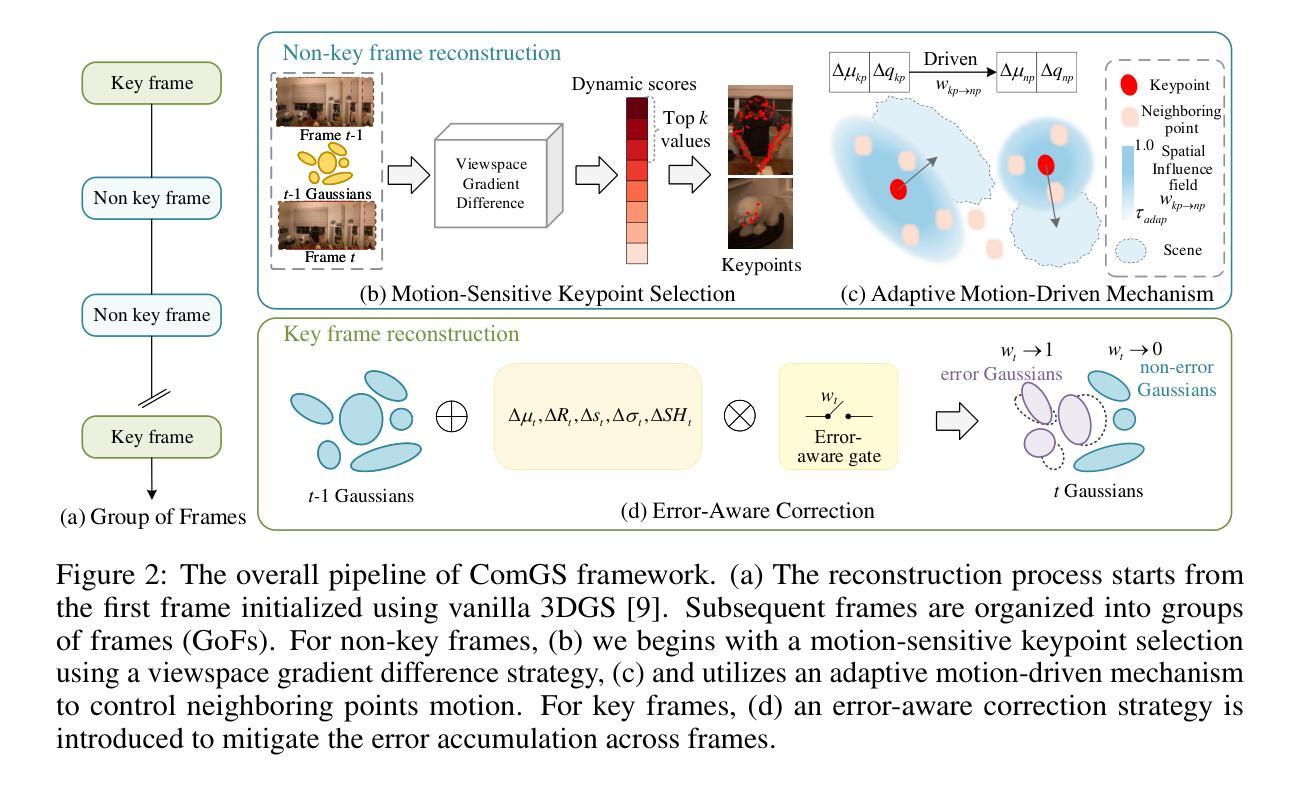
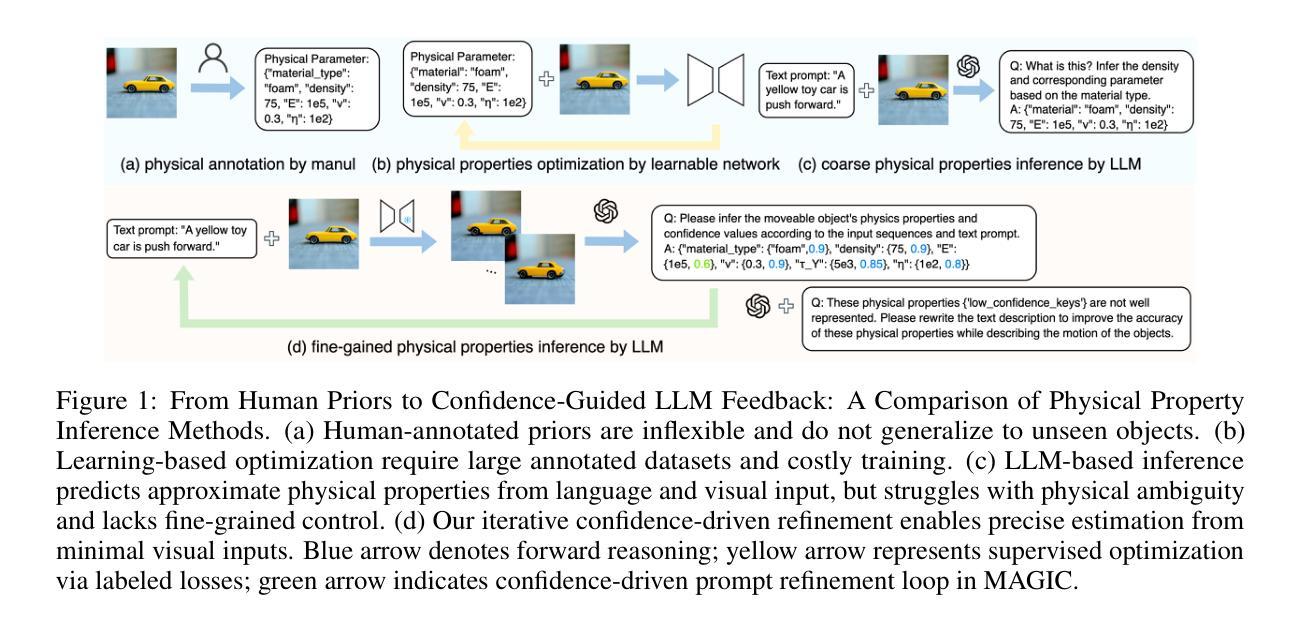
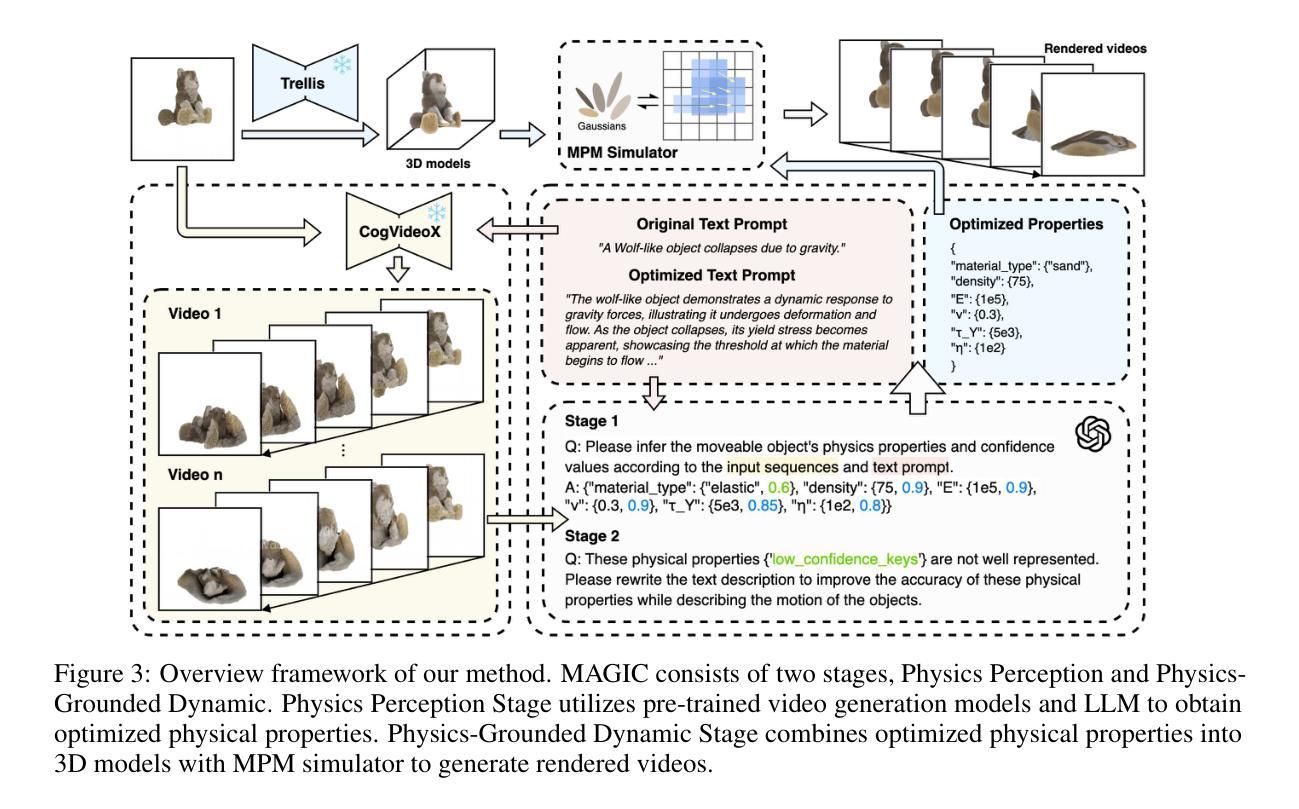
MAGIC: Motion-Aware Generative Inference via Confidence-Guided LLM
Authors:Siwei Meng, Yawei Luo, Ping Liu
Recent advances in static 3D generation have intensified the demand for physically consistent dynamic 3D content. However, existing video generation models, including diffusion-based methods, often prioritize visual realism while neglecting physical plausibility, resulting in implausible object dynamics. Prior approaches for physics-aware dynamic generation typically rely on large-scale annotated datasets or extensive model fine-tuning, which imposes significant computational and data collection burdens and limits scalability across scenarios. To address these challenges, we present MAGIC, a training-free framework for single-image physical property inference and dynamic generation, integrating pretrained image-to-video diffusion models with iterative LLM-based reasoning. Our framework generates motion-rich videos from a static image and closes the visual-to-physical gap through a confidence-driven LLM feedback loop that adaptively steers the diffusion model toward physics-relevant motion. To translate visual dynamics into controllable physical behavior, we further introduce a differentiable MPM simulator operating directly on 3D Gaussians reconstructed from the single image, enabling physically grounded, simulation-ready outputs without any supervision or model tuning. Experiments show that MAGIC outperforms existing physics-aware generative methods in inference accuracy and achieves greater temporal coherence than state-of-the-art video diffusion models.
近年来静态三维生成技术的进展加剧了对物理一致性动态三维内容的需求。然而,现有的视频生成模型,包括基于扩散的方法,通常优先追求视觉真实性,而忽视物理合理性,导致物体动态不真实。以前的方法对于物理感知的动态生成通常依赖于大规模标注数据集或模型精细调整,这带来了显著的计算和数据收集负担,并限制了跨场景的扩展性。为了应对这些挑战,我们提出了MAGIC,这是一个无需训练的单图像物理属性推断和动态生成框架,它结合了预训练的图像到视频的扩散模型与基于迭代的大型语言模型(LLM)的推理。我们的框架从静态图像生成运动丰富的视频,并通过信心驱动的LLM反馈循环来缩小视觉到物理的差距,该循环自适应地引导扩散模型向物理相关的运动方向进行。为了将视觉动态转化为可控的物理行为,我们进一步引入了一个可微分的MPM模拟器,该模拟器直接在由单图像重建的3D高斯分布上运行,无需监督或模型调整即可实现物理基础、模拟就绪的输出。实验表明,MAGIC在推理准确性方面优于现有的物理感知生成方法,并且在时间连贯性方面优于最先进的视频扩散模型。
论文及项目相关链接
Summary
本文介绍了MAGIC框架,一个无需训练的单图像物理属性推断和动态生成框架。它结合了预训练的图像到视频的扩散模型和基于迭代的大型语言模型(LLM)推理,能够生成运动丰富的视频并弥合视觉到物理之间的差距。框架通过置信度驱动的LLM反馈循环自适应地引导扩散模型进行物理相关的运动。此外,引入了可微分的MPM模拟器,直接在从单张图像重建的3D高斯上操作,实现物理基础且模拟就绪的输出,无需监督或模型调整。
Key Takeaways
- MAGIC框架是首个无需训练就能进行物理属性推断和动态生成的方法。
- 结合了图像到视频的扩散模型和LLM推理,生成运动丰富的视频。
- 通过置信度驱动的LLM反馈循环,使模型能自适应地模拟物理相关的运动。
- 引入了可微分的MPM模拟器,直接在3D高斯上进行操作,实现物理基础的模拟。
- 该方法无需额外的监督或模型调整,具有更好的通用性。
- 实验显示,MAGIC在推理准确性和时间连贯性方面超越了现有的物理感知生成方法。
点此查看论文截图



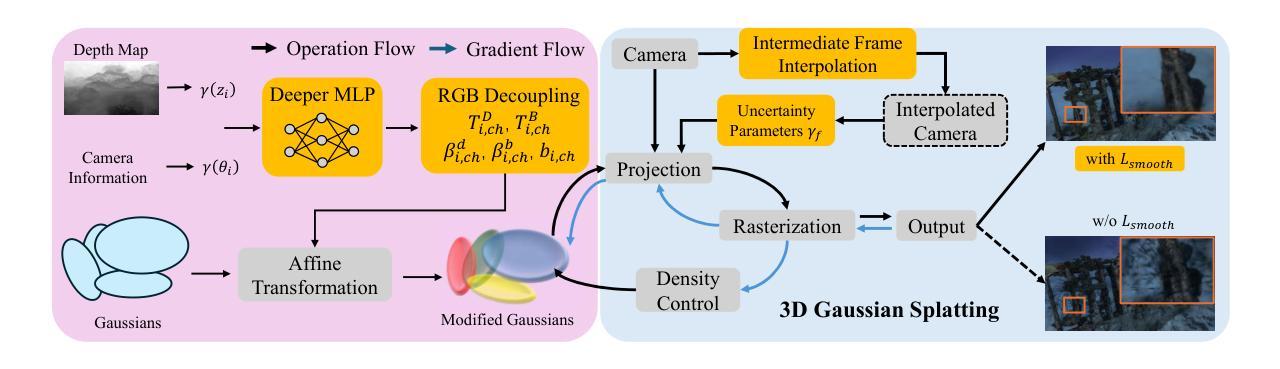
RUSplatting: Robust 3D Gaussian Splatting for Sparse-View Underwater Scene Reconstruction
Authors:Zhuodong Jiang, Haoran Wang, Guoxi Huang, Brett Seymour, Nantheera Anantrasirichai
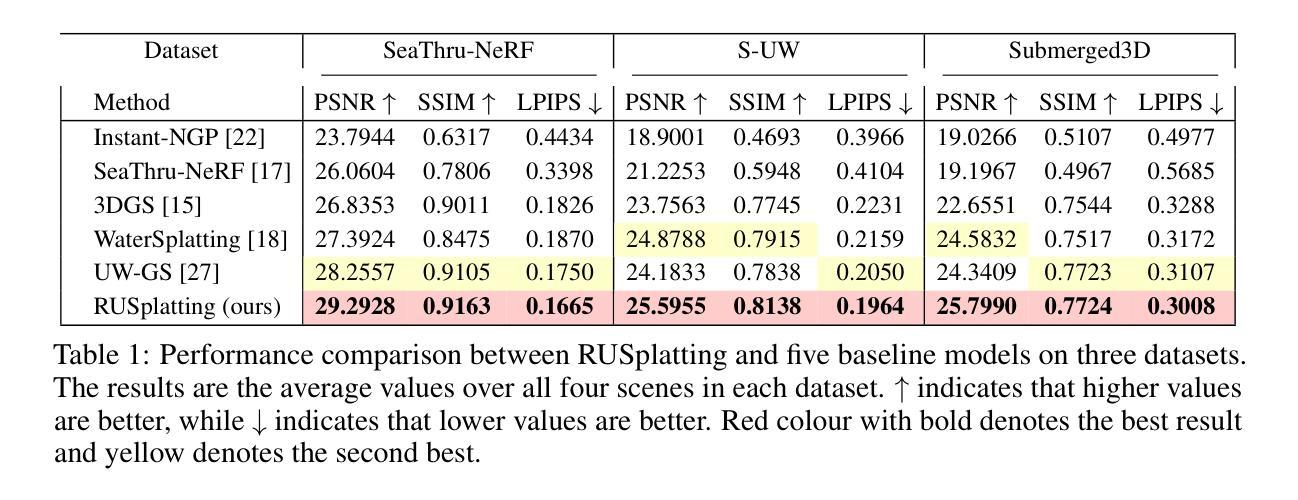
Reconstructing high-fidelity underwater scenes remains a challenging task due to light absorption, scattering, and limited visibility inherent in aquatic environments. This paper presents an enhanced Gaussian Splatting-based framework that improves both the visual quality and geometric accuracy of deep underwater rendering. We propose decoupled learning for RGB channels, guided by the physics of underwater attenuation, to enable more accurate colour restoration. To address sparse-view limitations and improve view consistency, we introduce a frame interpolation strategy with a novel adaptive weighting scheme. Additionally, we introduce a new loss function aimed at reducing noise while preserving edges, which is essential for deep-sea content. We also release a newly collected dataset, Submerged3D, captured specifically in deep-sea environments. Experimental results demonstrate that our framework consistently outperforms state-of-the-art methods with PSNR gains up to 1.90dB, delivering superior perceptual quality and robustness, and offering promising directions for marine robotics and underwater visual analytics.
重建高保真水下场景仍然是一个具有挑战性的任务,由于水下环境中的光吸收、散射和有限的可见度。本文提出了一种基于增强高斯Splatting的框架,提高了深海渲染的视觉质量和几何精度。我们提出了基于水下衰减物理原理的RGB通道解耦学习,以实现更准确的颜色恢复。为了解决稀疏视角的限制并提高视角一致性,我们引入了一种带有新型自适应加权方案的新帧插值策略。此外,我们引入了一种新的损失函数,旨在减少噪声的同时保留边缘,这对于深海内容至关重要。我们还发布了一个新收集的特定在深海环境中捕获的数据集Submerged3D。实验结果表明,我们的框架始终优于最新技术的方法,PSNR增益高达1.90dB,具有出色的感知质量和稳健性,并为海洋机器人技术和水下视觉分析提供了有前景的方向。
论文及项目相关链接
PDF 10 pages, 3 figures. Submitted to BMVC 2025
Summary
本文提出了一种基于高斯Splatting的增强框架,用于提高水下场景的视觉质量和几何渲染精度。该研究通过解耦RGB通道学习、引入帧插值策略和自适应权重方案,以及设计新的损失函数,有效应对水下环境中的光吸收、散射和有限可见度等挑战,实现了更准确的颜色恢复、视图一致性和边缘保护。同时,研究团队还公开了一个专门在深海环境中采集的新数据集Submerged3D。研究成果在实验中表现优异,较现有方法平均峰值信噪比提高达1.90dB,为海洋机器人和水下视觉分析提供了有力支持。
Key Takeaways
- 采用增强高斯Splatting框架,提高水下场景视觉质量和几何渲染精度。
- 解耦RGB通道学习,根据水下衰减物理特性指导更准确的颜色恢复。
- 引入帧插值策略及自适应权重方案,解决稀疏视图问题并改善视图一致性。
- 设计新损失函数,旨在降低噪声同时保留边缘,对深海内容至关重要。
- 公开新数据集Submerged3D,专注于深海环境采集。
- 实验结果表明,该框架较现有技术有显著提升,峰值信噪比提高达1.90dB。
点此查看论文截图

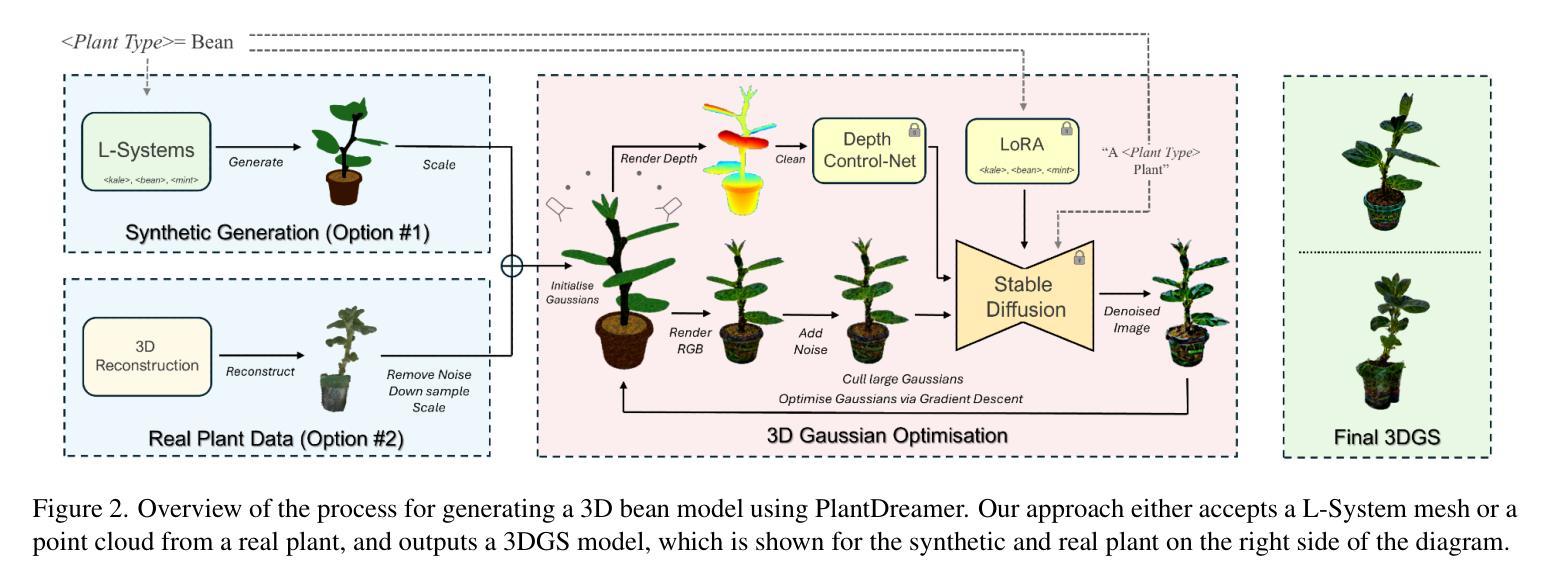
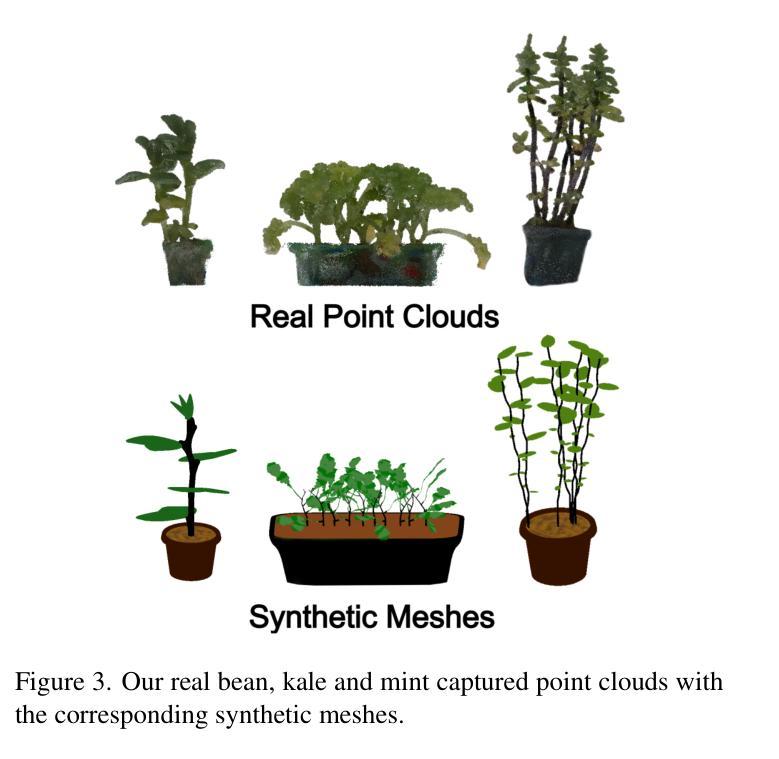
PlantDreamer: Achieving Realistic 3D Plant Models with Diffusion-Guided Gaussian Splatting
Authors:Zane K J Hartley, Lewis A G Stuart, Andrew P French, Michael P Pound
Recent years have seen substantial improvements in the ability to generate synthetic 3D objects using AI. However, generating complex 3D objects, such as plants, remains a considerable challenge. Current generative 3D models struggle with plant generation compared to general objects, limiting their usability in plant analysis tools, which require fine detail and accurate geometry. We introduce PlantDreamer, a novel approach to 3D synthetic plant generation, which can achieve greater levels of realism for complex plant geometry and textures than available text-to-3D models. To achieve this, our new generation pipeline leverages a depth ControlNet, fine-tuned Low-Rank Adaptation and an adaptable Gaussian culling algorithm, which directly improve textural realism and geometric integrity of generated 3D plant models. Additionally, PlantDreamer enables both purely synthetic plant generation, by leveraging L-System-generated meshes, and the enhancement of real-world plant point clouds by converting them into 3D Gaussian Splats. We evaluate our approach by comparing its outputs with state-of-the-art text-to-3D models, demonstrating that PlantDreamer outperforms existing methods in producing high-fidelity synthetic plants. Our results indicate that our approach not only advances synthetic plant generation, but also facilitates the upgrading of legacy point cloud datasets, making it a valuable tool for 3D phenotyping applications.
近年来,利用人工智能生成合成3D物体的能力得到了显著提高。然而,生成复杂的3D物体,如植物,仍然是一项巨大的挑战。与通用物体相比,当前的3D生成模型在植物生成方面存在困难,这限制了它们在需要精细细节和精确几何形状的植物分析工具中的可用性。我们引入了PlantDreamer,这是一种新型的3D合成植物生成方法,与现有的文本到3D模型相比,它可以在复杂的植物几何和纹理方面实现更高水平的逼真度。为实现这一目标,我们的新一代流水线利用深度ControlNet,精细调整的低秩适应性和可适应的高斯剔除算法,直接提高了生成3D植物模型的真实感和几何完整性。此外,PlantDreamer能够通过利用L系统生成的网格进行纯粹的合成植物生成,并且能够通过将现实世界中的植物点云转换为3D高斯斑块来增强它们。我们通过将我们的方法与最先进文本到3D模型输出进行比较来评估我们的方法,证明PlantDreamer在生成高保真合成植物方面优于现有方法。我们的结果表明,我们的方法不仅推动了合成植物的生成,而且还促进了旧有点云数据集升级,使其成为3D表型应用的有价值的工具。
论文及项目相关链接
PDF 13 pages, 5 figures, 4 tables
Summary
近年来AI生成合成3D物体的能力显著提高,但在生成复杂的植物方面仍存在挑战。为此,研究者推出PlantDreamer,一种新型的3D合成植物生成方法,可实现更高级的逼真度。此方法利用深度控制网络、精细的低阶适应性和灵活的高斯剔除算法等技术提升纹理真实感和几何完整性。此外,它不仅能够生成纯合成的植物,还可以提高现实世界植物点云的转换为高质量的植物模型的能力。实验表明,与目前主流的文本到3D模型相比,PlantDreamer在生成高质量合成植物方面表现更优。它不仅推动了合成植物的生成技术,还有助于提升现有的点云数据集,对植物表型分析应用具有重要意义。
Key Takeaways
- AI在生成复杂植物方面仍存在挑战。目前主流的生成模型在这方面难以与一般的物体相提并论,导致它们在精细细节和精确几何上的应用受到限制。这影响植物分析工具的实用性和可靠性。尽管如此,近期的技术发展展现了人工智能在此方面的进步空间和发展潜力。
- PlantDreamer作为一种新型的合成植物生成方法引入了一系列技术改进以提升植物生成的逼真度。它利用深度控制网络、低阶适应性调整和高斯剔除算法等技术来优化生成的植物模型的纹理和几何完整性。这一方法在优化模拟植物上展示了优势,并能够同时增强现实植物的点云数据质量。这为植物科学研究和可视化提供了有力的工具。
- PlantDreamer不仅能生成纯合成的植物模型,还能将现实世界中的植物点云转换为高质量的模型,这对于升级现有的点云数据集具有关键作用。这对于植物表型分析应用来说至关重要,有助于提高农业和生态研究的准确性和效率。这有助于填补现实世界中植物数据的空白,提高模型的多样性和准确性。这一技术为构建更全面的植物数据库提供了可能。
点此查看论文截图



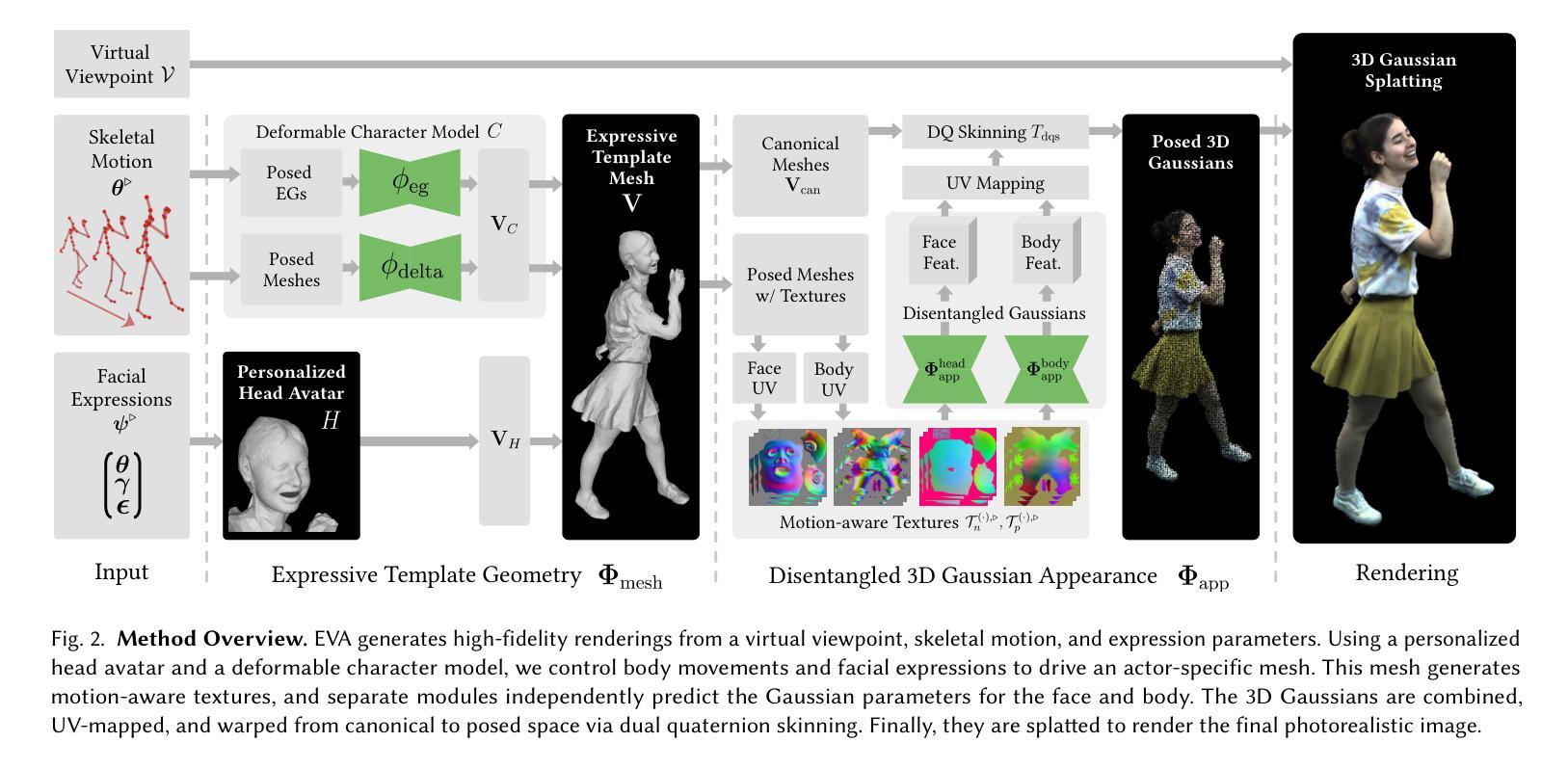
EVA: Expressive Virtual Avatars from Multi-view Videos
Authors:Hendrik Junkawitsch, Guoxing Sun, Heming Zhu, Christian Theobalt, Marc Habermann
With recent advancements in neural rendering and motion capture algorithms, remarkable progress has been made in photorealistic human avatar modeling, unlocking immense potential for applications in virtual reality, augmented reality, remote communication, and industries such as gaming, film, and medicine. However, existing methods fail to provide complete, faithful, and expressive control over human avatars due to their entangled representation of facial expressions and body movements. In this work, we introduce Expressive Virtual Avatars (EVA), an actor-specific, fully controllable, and expressive human avatar framework that achieves high-fidelity, lifelike renderings in real time while enabling independent control of facial expressions, body movements, and hand gestures. Specifically, our approach designs the human avatar as a two-layer model: an expressive template geometry layer and a 3D Gaussian appearance layer. First, we present an expressive template tracking algorithm that leverages coarse-to-fine optimization to accurately recover body motions, facial expressions, and non-rigid deformation parameters from multi-view videos. Next, we propose a novel decoupled 3D Gaussian appearance model designed to effectively disentangle body and facial appearance. Unlike unified Gaussian estimation approaches, our method employs two specialized and independent modules to model the body and face separately. Experimental results demonstrate that EVA surpasses state-of-the-art methods in terms of rendering quality and expressiveness, validating its effectiveness in creating full-body avatars. This work represents a significant advancement towards fully drivable digital human models, enabling the creation of lifelike digital avatars that faithfully replicate human geometry and appearance.
随着神经网络渲染和运动捕捉算法的最新进展,光真人化的人类化身建模取得了显著进展,为虚拟现实、增强现实、远程通信以及游戏、电影和医学等行业的应用解锁了巨大的潜力。然而,现有方法由于面部表情和身体运动的纠缠表示,无法提供完整、忠实和富有表现力的化身控制。在这项工作中,我们介绍了“表情虚拟化身(EVA)”,这是一个针对特定演员、可完全控制和富有表现力的化身框架,可在实时实现高保真、逼真的渲染,同时实现对面部表情、身体运动和手势的独立控制。具体来说,我们的方法将人类化身设计为两层模型:一个表情模板几何层和一个3D高斯外观层。首先,我们提出了一种表情模板跟踪算法,该算法利用从粗到细的优化,可以从多角度视频中准确恢复身体运动、面部表情和非刚性变形参数。接下来,我们提出了一种新颖的解耦3D高斯外观模型,该模型有效地分离了身体和面部外观。不同于统一的高斯估计方法,我们的方法采用两个专门独立的模块来分别建模身体和面部。实验结果表明,EVA在渲染质量和表现力方面超过了最先进的方法,验证了其在创建全身化身方面的有效性。这项工作在朝着完全可驱动的数字化人物模型方面取得了重大进展,能够实现逼真复制人类几何和外观的数字化身。
论文及项目相关链接
PDF Accepted at SIGGRAPH 2025 Conference Track, Project page: https://vcai.mpi-inf.mpg.de/projects/EVA/
摘要
随着神经网络渲染和运动捕捉算法的最新进展,在光栅化人类化身建模方面取得了显著进展,为虚拟现实、增强现实、远程通信以及游戏、电影和医学等行业带来了巨大的潜力。然而,现有方法由于面部表情和躯体运动的纠缠表示,无法提供完整、忠诚和富有表现力的化身控制。在此工作中,我们引入了表现性虚拟化身(EVA),这是一个特定演员、可完全控制和富有表现力的化身框架,可在实时情况下实现高保真、逼真的渲染,同时实现对面部表情、躯体运动和手势的独立控制。具体来说,我们的方法将人类化身设计为一个两层模型:表现模板几何层和3D高斯外观层。首先,我们提出了一种表现模板跟踪算法,该算法利用从粗到细的优化技术,从多角度视频中准确恢复身体运动、面部表情和非刚性变形参数。接下来,我们提出了一种新颖的解耦3D高斯外观模型,旨在有效地分离身体和面部外观。我们的方法采用两个专业和独立的模块来分别建模身体和面部,不同于统一的高斯估计方法。实验结果表明,EVA在渲染质量和表现力方面超越了最先进的方法,验证了其在创建全身化身方面的有效性。这项工作代表着通向完全可驱动的数字化人类模型的重大进展,能够创建出逼真、忠诚地复制人类几何和外观的数字化身。
关键见解
- 最近的神经过程和运动捕捉算法进展在光栅化人类化身建模方面取得了显著进展。
- 现有方法在控制人类化身方面存在缺陷,无法提供完整、忠诚和富有表现力的控制。
- Expressive Virtual Avatars (EVA)框架被引入,实现高保真、逼真的实时渲染,同时独立控制面部表情、身体运动和手势。
- EVA采用两层模型设计:表现模板几何层和3D高斯外观层。
- 提出了表现模板跟踪算法,利用从粗到细的优化技术从多角度视频中恢复身体运动和面部表情。
- 创新的解耦3D高斯外观模型有效地分离了身体和面部外观。
点此查看论文截图

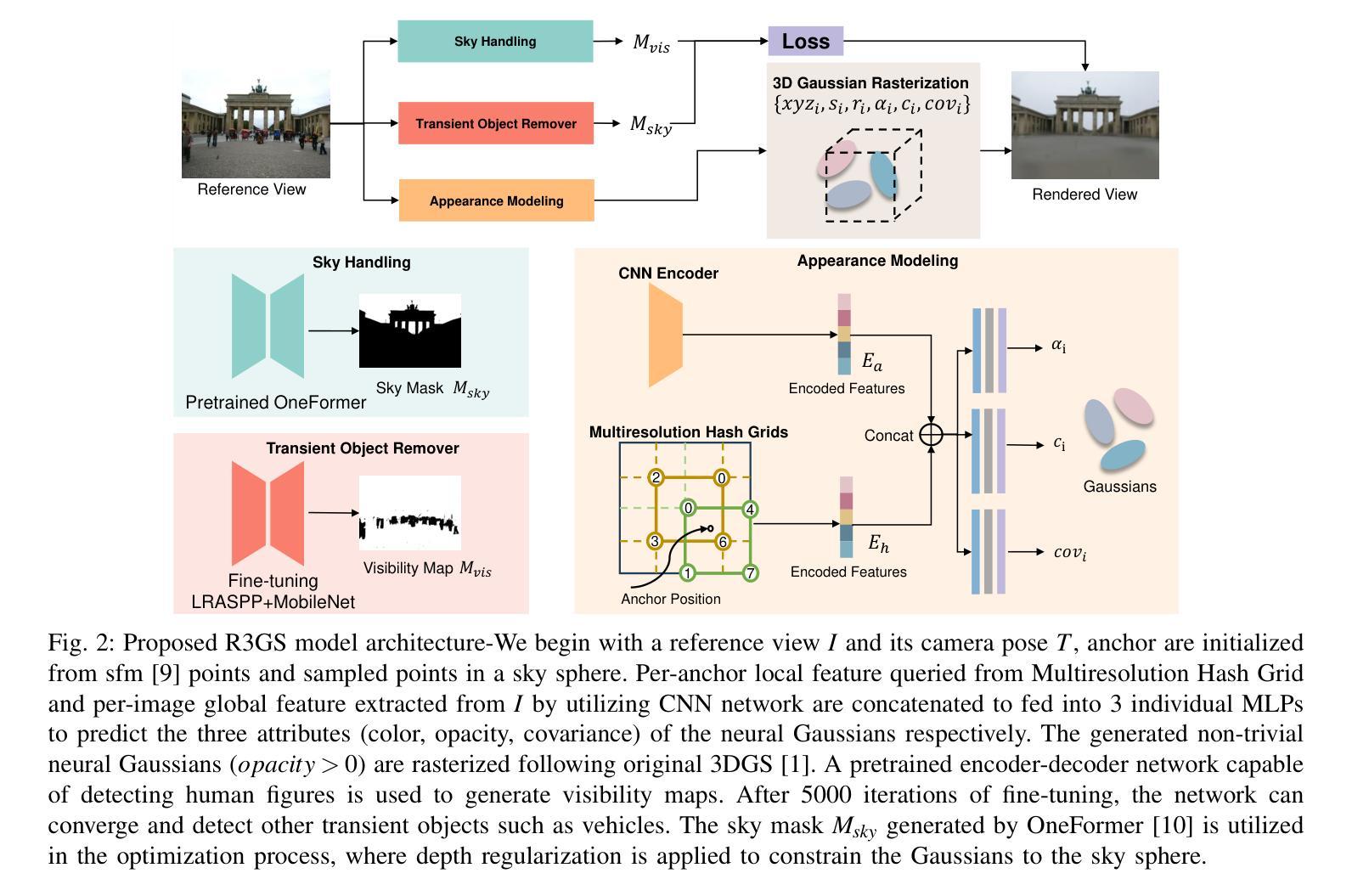
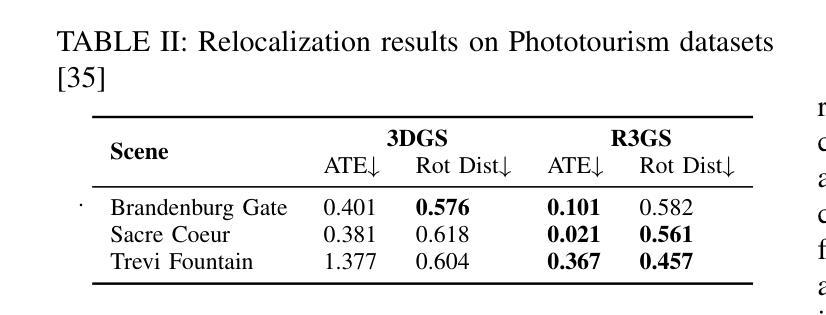
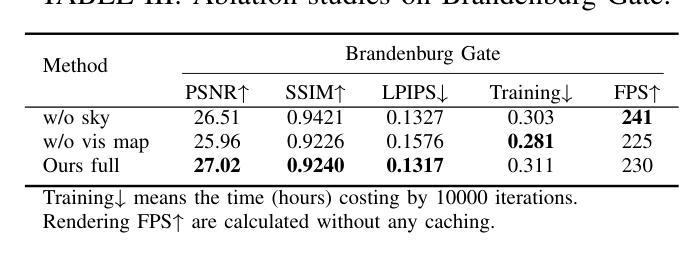
R3GS: Gaussian Splatting for Robust Reconstruction and Relocalization in Unconstrained Image Collections
Authors:Xu yan, Zhaohui Wang, Rong Wei, Jingbo Yu, Dong Li, Xiangde Liu
We propose R3GS, a robust reconstruction and relocalization framework tailored for unconstrained datasets. Our method uses a hybrid representation during training. Each anchor combines a global feature from a convolutional neural network (CNN) with a local feature encoded by the multiresolution hash grids [2]. Subsequently, several shallow multi-layer perceptrons (MLPs) predict the attributes of each Gaussians, including color, opacity, and covariance. To mitigate the adverse effects of transient objects on the reconstruction process, we ffne-tune a lightweight human detection network. Once ffne-tuned, this network generates a visibility map that efffciently generalizes to other transient objects (such as posters, banners, and cars) with minimal need for further adaptation. Additionally, to address the challenges posed by sky regions in outdoor scenes, we propose an effective sky-handling technique that incorporates a depth prior as a constraint. This allows the inffnitely distant sky to be represented on the surface of a large-radius sky sphere, signiffcantly reducing ffoaters caused by errors in sky reconstruction. Furthermore, we introduce a novel relocalization method that remains robust to changes in lighting conditions while estimating the camera pose of a given image within the reconstructed 3DGS scene. As a result, R3GS significantly enhances rendering ffdelity, improves both training and rendering efffciency, and reduces storage requirements. Our method achieves state-of-the-art performance compared to baseline methods on in-the-wild datasets. The code will be made open-source following the acceptance of the paper.
我们提出了R3GS,这是一个针对无约束数据集的稳健重建和重新定位框架。我们的方法采用混合表示进行训练。每个锚点结合了卷积神经网络(CNN)的全局特征和多分辨率哈希网格[2]编码的局部特征。随后,几个浅层的多层感知器(MLP)预测每个高斯属性的值,包括颜色、不透明度和协方差。为了减轻瞬态物体对重建过程的不利影响,我们对轻量级的人脸检测网络进行了微调。一旦微调完成,该网络可以生成一个可见性映射,该映射能够高效推广到其它瞬态对象(如海报、横幅和汽车等),并且几乎不需要进一步的适应。此外,为了解决户外场景中的天空区域带来的挑战,我们提出了一种有效的天空处理技术,该技术采用深度先验作为约束。这使得无限远的天空可以在大半径天空球面上表示出来,从而显著减少因天空重建错误引起的浮沫现象。此外,我们提出了一种新的重新定位方法,它在估计给定图像在重建的3DGS场景中的相机姿态时保持对光照变化的稳健性。因此,R3GS显著提高了渲染的保真度,提高了训练和渲染的效率,并降低了存储需求。我们的方法与基准数据集上的基线方法相比达到了最先进的性能。论文被接受后,代码将作为开源发布。
论文及项目相关链接
PDF 7 pages, 4 figures
Summary
本文提出一种针对无约束数据集的稳健重建与重新定位框架R3GS。它采用混合表示进行训练,结合卷积神经网络的全局特征与多分辨率哈希网格编码的局部特征。通过浅层多层感知器预测高斯属性的属性,包括颜色、不透明度和协方差。通过微调轻量级人体检测网络来减轻瞬时对象对重建过程的不利影响,生成可视化地图,有效地泛化到其他瞬时对象。针对户外场景的天空区域挑战,提出了一种有效的天空处理技术,采用深度先验作为约束。此外,还引入了一种新的重新定位方法,在光照条件变化时保持稳健,估计给定图像在重建的3DGS场景中的相机姿态。R3GS提高了渲染的保真度,提高了训练和渲染的效率,并降低了存储需求,在野生数据集上的性能达到了最新水平。
Key Takeaways
- R3GS是一个针对无约束数据集的重建和重新定位框架。
- 融合卷积神经网络的全局特征与多分辨率哈希网格的局部特征进行训练。
- 通过浅层多层感知器预测高斯属性的属性,包括颜色、不透明度和协方差。
- 通过微调轻量级人体检测网络来应对瞬时对象的影响,生成可视化地图。
- 引入天空处理技术,采用深度先验作为约束,处理天空区域的挑战。
- 提出一种新型的重新定位方法,能在光照条件变化时保持稳健。
点此查看论文截图



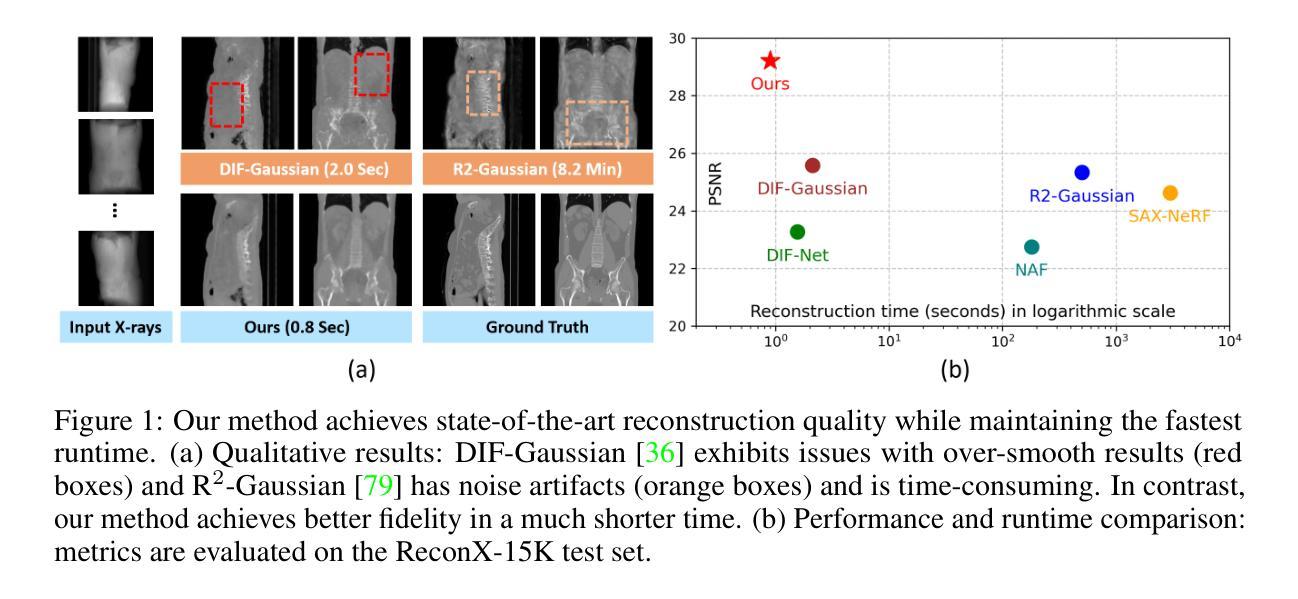
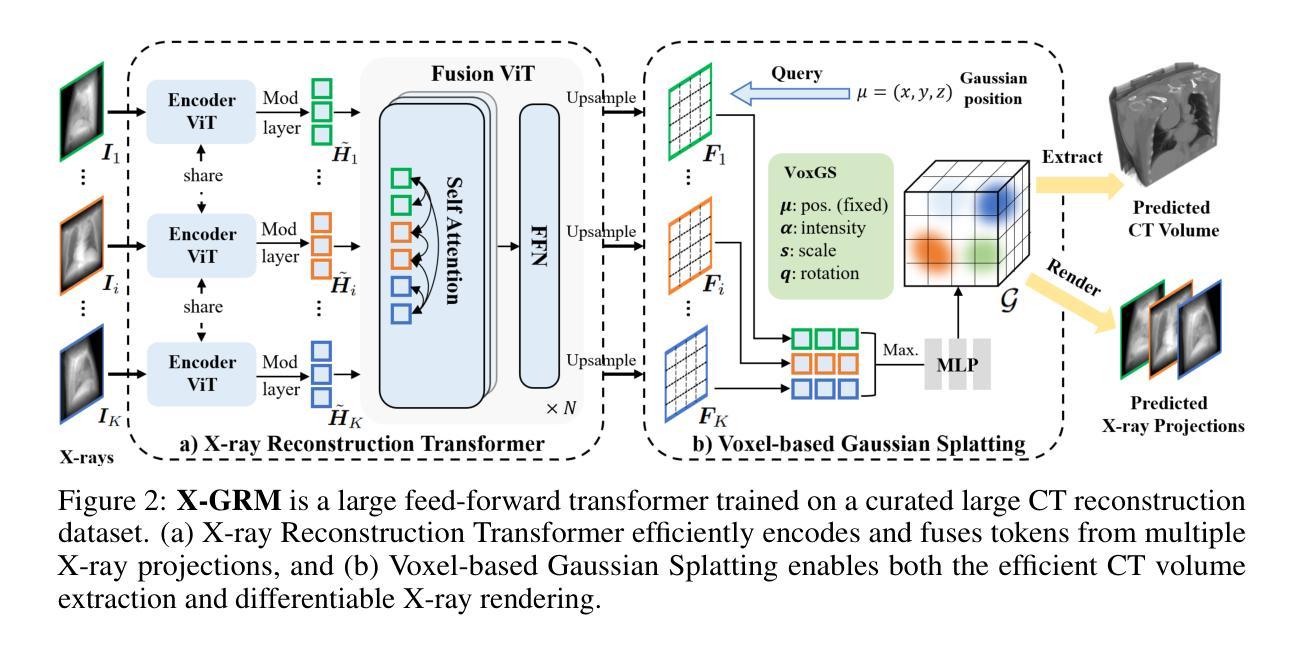
X-GRM: Large Gaussian Reconstruction Model for Sparse-view X-rays to Computed Tomography
Authors:Yifan Liu, Wuyang Li, Weihao Yu, Chenxin Li, Alexandre Alahi, Max Meng, Yixuan Yuan
Computed Tomography serves as an indispensable tool in clinical workflows, providing non-invasive visualization of internal anatomical structures. Existing CT reconstruction works are limited to small-capacity model architecture, inflexible volume representation, and small-scale training data. In this paper, we present X-GRM (X-ray Gaussian Reconstruction Model), a large feedforward model for reconstructing 3D CT from sparse-view 2D X-ray projections. X-GRM employs a scalable transformer-based architecture to encode an arbitrary number of sparse X-ray inputs, where tokens from different views are integrated efficiently. Then, tokens are decoded into a new volume representation, named Voxel-based Gaussian Splatting (VoxGS), which enables efficient CT volume extraction and differentiable X-ray rendering. To support the training of X-GRM, we collect ReconX-15K, a large-scale CT reconstruction dataset containing around 15,000 CT/X-ray pairs across diverse organs, including the chest, abdomen, pelvis, and tooth etc. This combination of a high-capacity model, flexible volume representation, and large-scale training data empowers our model to produce high-quality reconstructions from various testing inputs, including in-domain and out-domain X-ray projections. Project Page: https://github.com/CUHK-AIM-Group/X-GRM.
计算机断层扫描在临床工作流程中扮演着不可或缺的角色,能够非侵入性地呈现内部结构。现有的CT重建工作受限于小容量模型结构、不灵活的体积表示和小规模训练数据。在本文中,我们介绍了X-GRM(X射线高斯重建模型),这是一个用于从稀疏二维X射线投影重建三维CT的大型前馈模型。X-GRM采用可扩展的基于transformer的架构来编码任意数量的稀疏X射线输入,其中不同视角的标记被高效集成。然后,标记被解码成一种新的体积表示,称为基于体素的高斯溅射(VoxGS),这能够实现高效的CT体积提取和可微分X射线渲染。为了支持X-GRM的训练,我们收集了ReconX-15K大规模CT重建数据集,其中包含大约15000个涵盖多个器官的CT/X射线对,包括胸部、腹部、骨盆和牙齿等。大容量模型、灵活的体积表示和大规模训练数据的结合使我们的模型能够从各种测试输入中产生高质量的重构,包括领域内的和跨领域的X射线投影。项目页面:https://github.com/CUHK-AIM-Group/X-GRM。
论文及项目相关链接
Summary
本文介绍了计算机断层扫描(CT)在临床工作流中的重要性,以及现有的CT重建技术的局限性。为解决这些问题,研究者提出了X-GRM模型,这是一个用于从稀疏视角的二维X射线投影重建三维CT的大型前馈模型。X-GRM采用可扩展的基于变压器的架构,能够编码任意数量的稀疏X射线输入,并有效地整合不同视角的标记。然后,这些标记被解码成一种新的体积表示——基于体素的高斯喷溅(VoxGS),这有助于高效地进行CT体积提取和可微分X射线渲染。为了支持X-GRM的训练,研究者还收集了一个大规模的CT重建数据集ReconX-15K,包含大约1.5万个CT/X射线配对,涵盖了多个器官类型。模型能够从多种测试输入中产生高质量的重构结果,包括领域内的和跨领域的X射线投影。
Key Takeaways
- 计算机断层扫描(CT)在临床工作流中扮演重要角色,但现有的CT重建技术存在局限性。
- X-GRM模型是一个用于从稀疏视角的二维X射线投影重建三维CT的大型前馈模型。
- X-GRM采用基于变压器的可扩展架构进行编码和整合不同视角的标记。
- X-GRM采用新的体积表示方法——基于体素的高斯喷溅(VoxGS)。
- VoxGS有助于高效CT体积提取和可微分X射线渲染。
- 支持X-GRM训练的大型CT重建数据集ReconX-15K包含多种器官类型的1.5万个CT/X射线配对。
点此查看论文截图

GT^2-GS: Geometry-aware Texture Transfer for Gaussian Splatting
Authors:Wenjie Liu, Zhongliang Liu, Junwei Shu, Changbo Wang, Yang Li
Transferring 2D textures to 3D modalities is of great significance for improving the efficiency of multimedia content creation. Existing approaches have rarely focused on transferring image textures onto 3D representations. 3D style transfer methods are capable of transferring abstract artistic styles to 3D scenes. However, these methods often overlook the geometric information of the scene, which makes it challenging to achieve high-quality 3D texture transfer results. In this paper, we present GT^2-GS, a geometry-aware texture transfer framework for gaussian splitting. From the perspective of matching texture features with geometric information in rendered views, we identify the issue of insufficient texture features and propose a geometry-aware texture augmentation module to expand the texture feature set. Moreover, a geometry-consistent texture loss is proposed to optimize texture features into the scene representation. This loss function incorporates both camera pose and 3D geometric information of the scene, enabling controllable texture-oriented appearance editing. Finally, a geometry preservation strategy is introduced. By alternating between the texture transfer and geometry correction stages over multiple iterations, this strategy achieves a balance between learning texture features and preserving geometric integrity. Extensive experiments demonstrate the effectiveness and controllability of our method. Through geometric awareness, our approach achieves texture transfer results that better align with human visual perception. Our homepage is available at https://vpx-ecnu.github.io/GT2-GS-website.
将二维纹理转移到三维模态对于提高多媒体内容创建效率具有重要意义。现有方法很少关注将图像纹理转移到三维表示上。三维风格转移方法能够将抽象的艺术风格转移到三维场景。然而,这些方法往往忽略了场景的三维几何信息,使得实现高质量的三维纹理转移结果具有挑战性。在本文中,我们提出了GT^2-GS,一个用于高斯分割的几何感知纹理转移框架。从匹配渲染视图中的纹理特征和几何信息的角度,我们发现了纹理特征不足的问题,并提出了一个几何感知纹理增强模块来扩展纹理特征集。此外,还提出了一种几何一致的纹理损失函数,以优化场景表示中的纹理特征。该损失函数结合了场景的相机姿态和三维几何信息,实现了可控的纹理导向的外观编辑。最后,引入了一种几何保留策略。通过多次迭代在纹理转移和几何校正阶段之间交替进行,该策略实现了学习纹理特征和保持几何完整性之间的平衡。大量实验证明了我们方法的有效性和可控性。通过几何感知,我们的方法实现了更符合人类视觉感知的纹理转移结果。我们的网站可在网站链接访问。
论文及项目相关链接
PDF 15 pages, 16 figures
Summary
本文提出了一种几何感知的纹理转移框架GT^2-GS,用于高斯分割的纹理转移。该框架从匹配渲染视图中的纹理特征和几何信息出发,通过几何感知纹理增强模块扩展纹理特征集,并提出几何一致性纹理损失函数优化场景表示的纹理特征。此外,还介绍了几何保留策略,通过迭代纹理转移和几何校正阶段,实现纹理特征和几何完整性的平衡。实验证明,该方法有效且可控,通过几何感知,实现了更符合人类视觉感知的纹理转移结果。
Key Takeaways
- 提出了一种新的几何感知纹理转移框架GT^2-GS,旨在提高多媒体内容创建的效率。
- 框架通过匹配渲染视图中的纹理特征和几何信息,解决了现有纹理转移方法忽略几何信息的问题。
- 引入了几何感知纹理增强模块,以扩展纹理特征集,提高纹理转移的质感。
- 提出了几何一致性纹理损失函数,结合相机姿态和场景的三维几何信息,实现可控的纹理导向外观编辑。
- 介绍了几何保留策略,通过迭代纹理转移和几何校正阶段,平衡了学习纹理特征和保持几何完整性的需求。
- 实验证明,该方法有效且可控,能够实现高质量的3D纹理转移结果。
点此查看论文截图

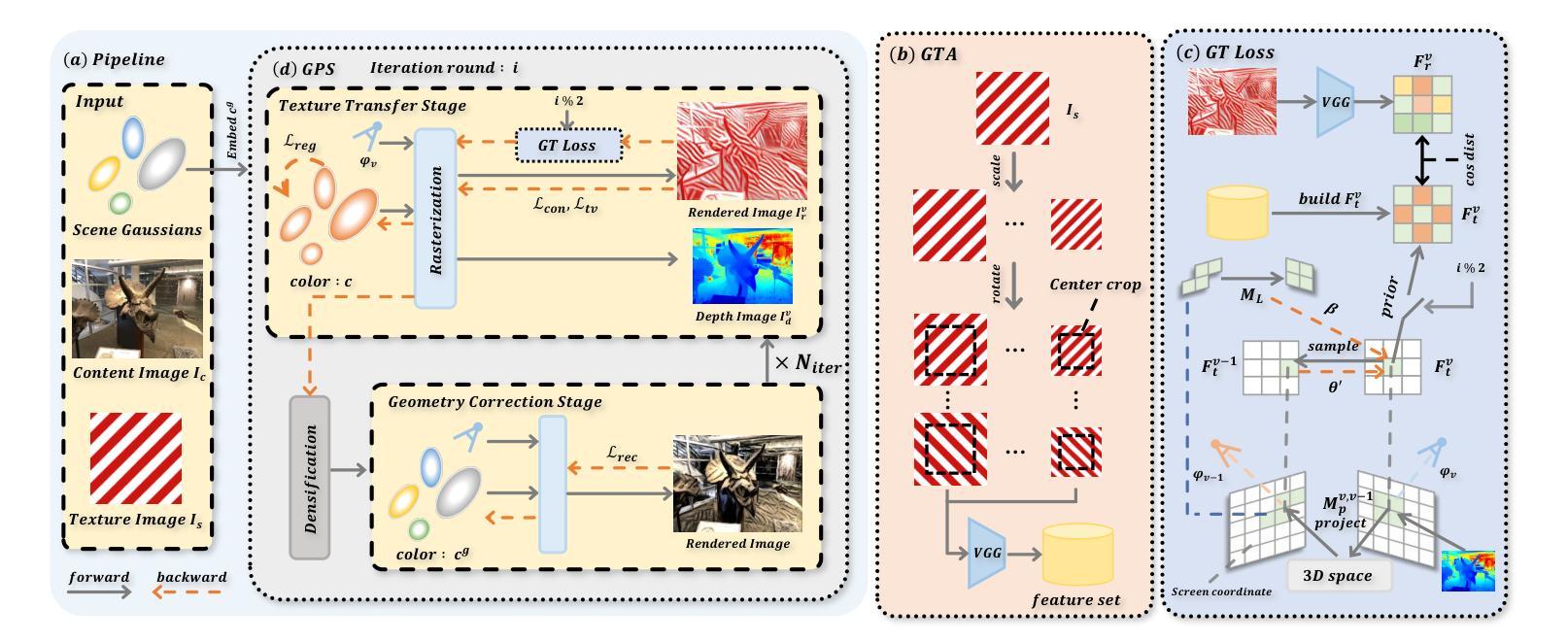



MonoSplat: Generalizable 3D Gaussian Splatting from Monocular Depth Foundation Models
Authors:Yifan Liu, Keyu Fan, Weihao Yu, Chenxin Li, Hao Lu, Yixuan Yuan
Recent advances in generalizable 3D Gaussian Splatting have demonstrated promising results in real-time high-fidelity rendering without per-scene optimization, yet existing approaches still struggle to handle unfamiliar visual content during inference on novel scenes due to limited generalizability. To address this challenge, we introduce MonoSplat, a novel framework that leverages rich visual priors from pre-trained monocular depth foundation models for robust Gaussian reconstruction. Our approach consists of two key components: a Mono-Multi Feature Adapter that transforms monocular features into multi-view representations, coupled with an Integrated Gaussian Prediction module that effectively fuses both feature types for precise Gaussian generation. Through the Adapter’s lightweight attention mechanism, features are seamlessly aligned and aggregated across views while preserving valuable monocular priors, enabling the Prediction module to generate Gaussian primitives with accurate geometry and appearance. Through extensive experiments on diverse real-world datasets, we convincingly demonstrate that MonoSplat achieves superior reconstruction quality and generalization capability compared to existing methods while maintaining computational efficiency with minimal trainable parameters. Codes are available at https://github.com/CUHK-AIM-Group/MonoSplat.
近期通用3D高斯融合技术的进展,在无需针对场景优化的情况下,已经显示出在实时高保真渲染方面的前景。然而,现有方法仍然难以在新型场景推理时处理不熟悉的视觉内容,其泛化能力有限。为了应对这一挑战,我们引入了MonoSplat这一新型框架,它利用预训练的单目深度基础模型中的丰富视觉先验来进行稳健的高斯重建。我们的方法包括两个关键组成部分:Mono-Multi特征适配器,将单目特征转换为多视角表示,以及与集成高斯预测模块相结合,有效地融合这两种特征类型,以实现精确的高斯生成。通过适配器的轻量级注意力机制,特征在不同视角之间无缝对齐和聚合,同时保留有价值的单目先验,使预测模块能够生成具有精确几何形状和外观的高斯基本体。在多种真实世界数据集上的广泛实验表明,MonoSplat与现有方法相比,在重建质量和泛化能力方面表现出优越性,同时保持计算效率并具有最少的可训练参数。代码可从https://github.com/CUHK-AIM-Group/MonoSplat获取。
论文及项目相关链接
摘要
新一代通用化3D高斯拼贴技术无需针对每个场景进行优化,即可实现实时高保真渲染,展现出良好前景。然而,现有方法在面对推理阶段遇到的新场景中的未知视觉内容时,仍面临泛化性有限的问题。为解决这一挑战,我们推出MonoSplat框架,利用预训练单目深度基础模型中的丰富视觉先验信息,进行稳健的高斯重建。我们的方法包括两个关键组件:Mono-Multi特征适配器,将单目特征转换为多视角表示,以及与集成高斯预测模块相结合,有效融合这两种特征类型,进行精确的高斯生成。通过适配器的轻量化注意力机制,不同视角的特征能够无缝对齐和聚合,同时保留宝贵的单目先验信息,使预测模块能够生成具有精确几何形状和外观的高斯基本体。在多种真实世界数据集上的广泛实验表明,MonoSplat相较于现有方法实现了更高的重建质量和泛化能力,同时保持计算效率且可训练参数最少。相关代码可访问:链接地址。
要点
- 引入MonoSplat框架,利用预训练的单目深度基础模型中的视觉先验信息,增强高斯重建的稳健性。
- 方法包括两个关键组件:Mono-Multi特征适配器与集成高斯预测模块,实现特征的类型转换和精确高斯生成。
- 适配器通过轻量化注意力机制无缝对齐和聚合不同视角的特征,同时保留单目先验信息。
- MonoSplat在多种真实世界数据集上实现了较高的重建质量和泛化能力。
- 该方法保持计算效率且可训练参数最少。
- 相关代码已公开,方便研究者和开发者进一步探索和改进。
- MonoSplat为处理新场景中的未知视觉内容提供了一个有效的解决方案。
点此查看论文截图

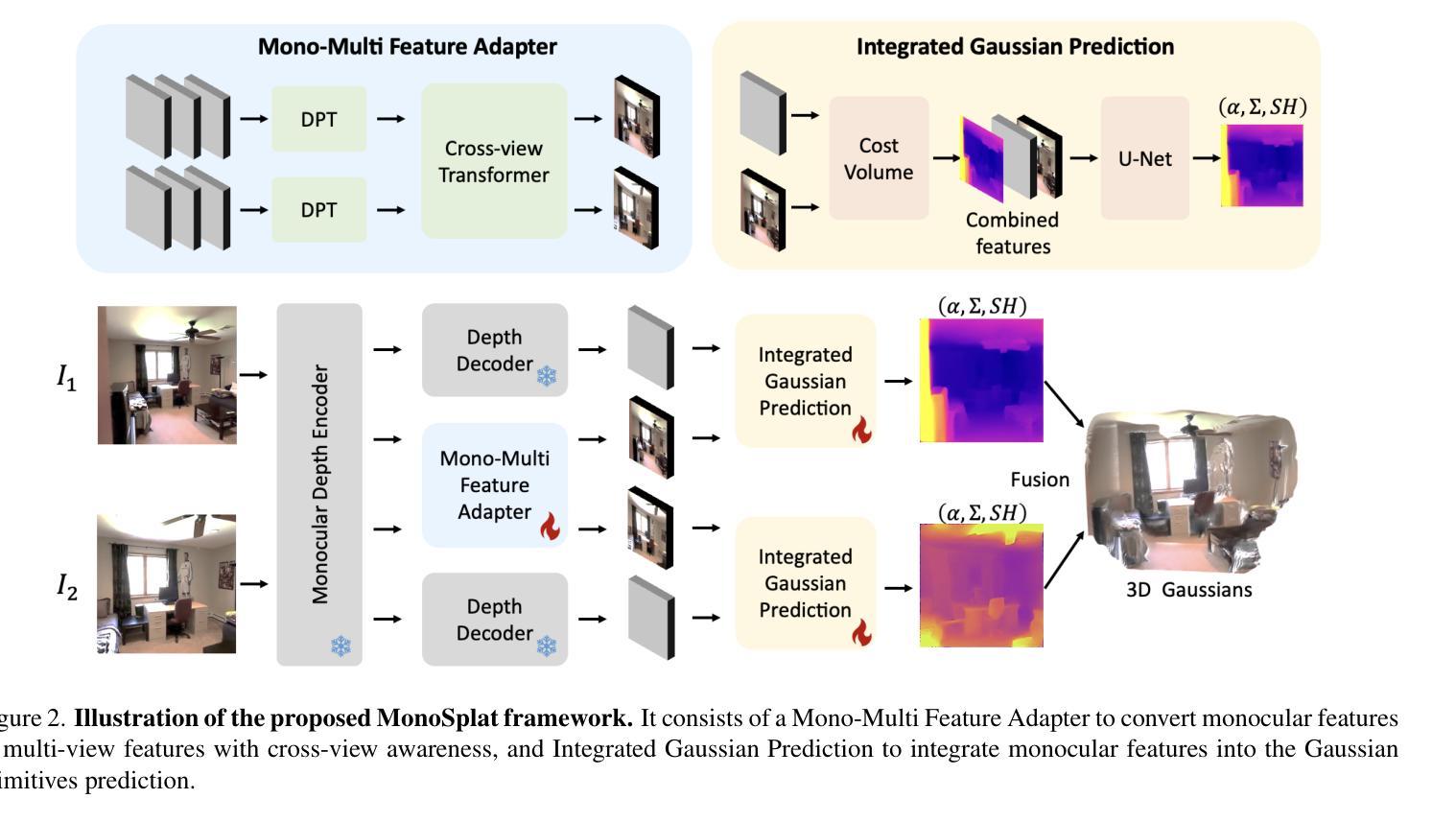
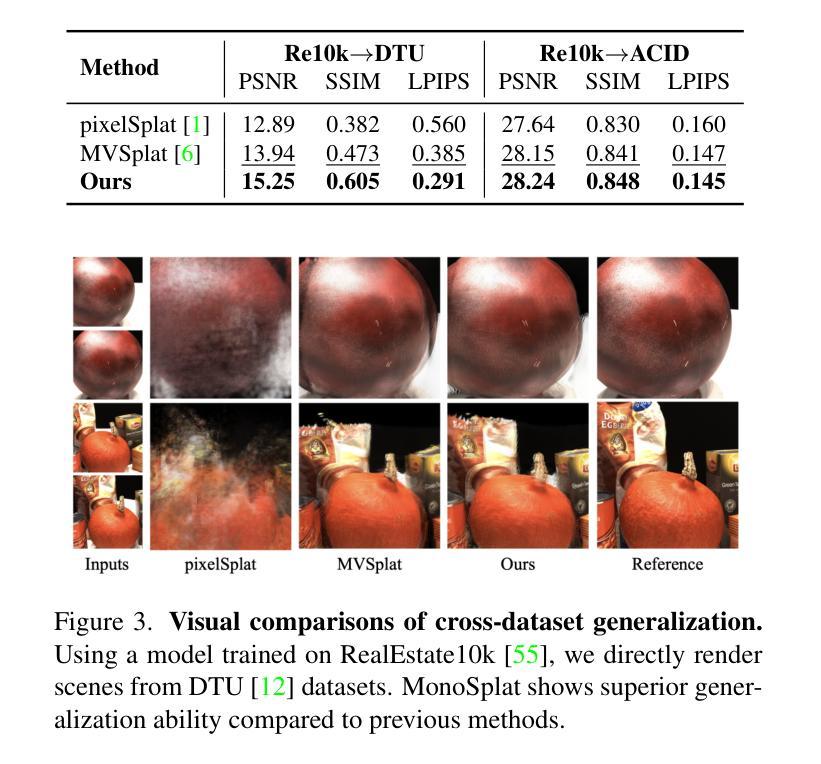
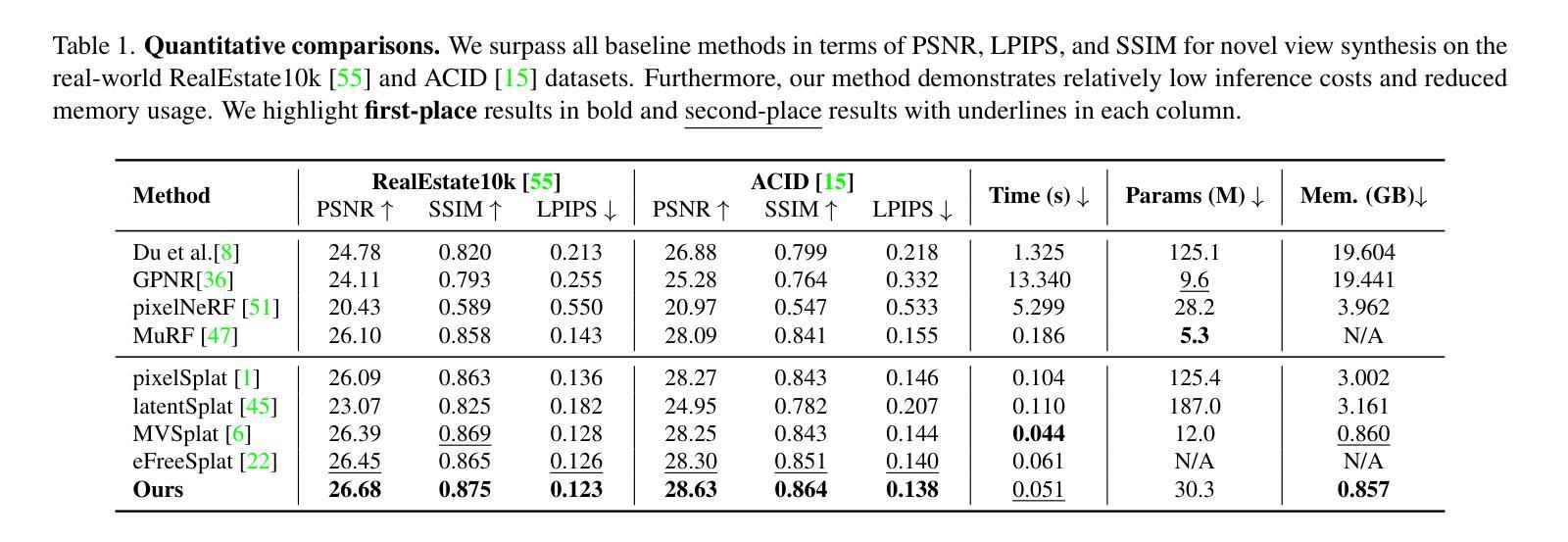
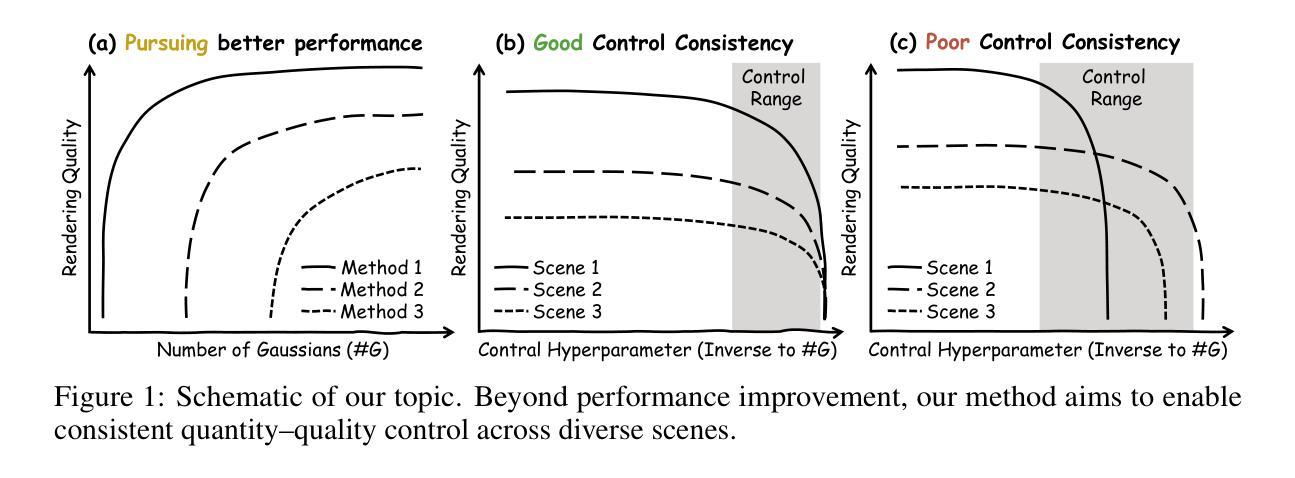
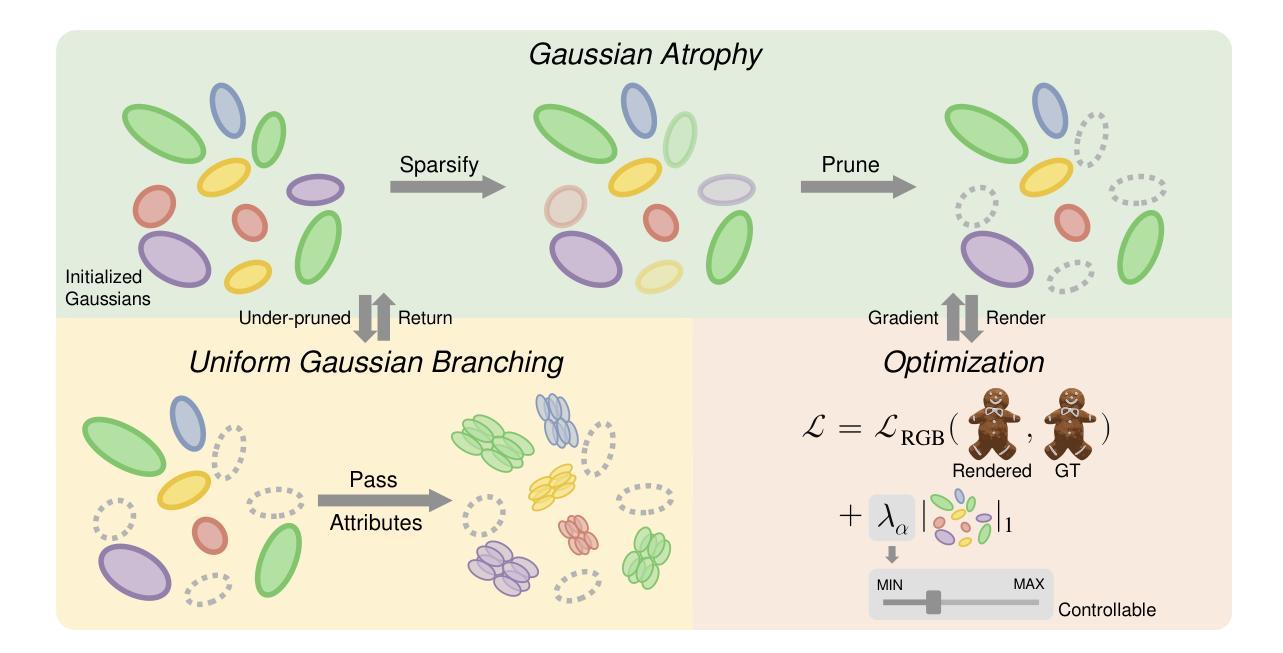
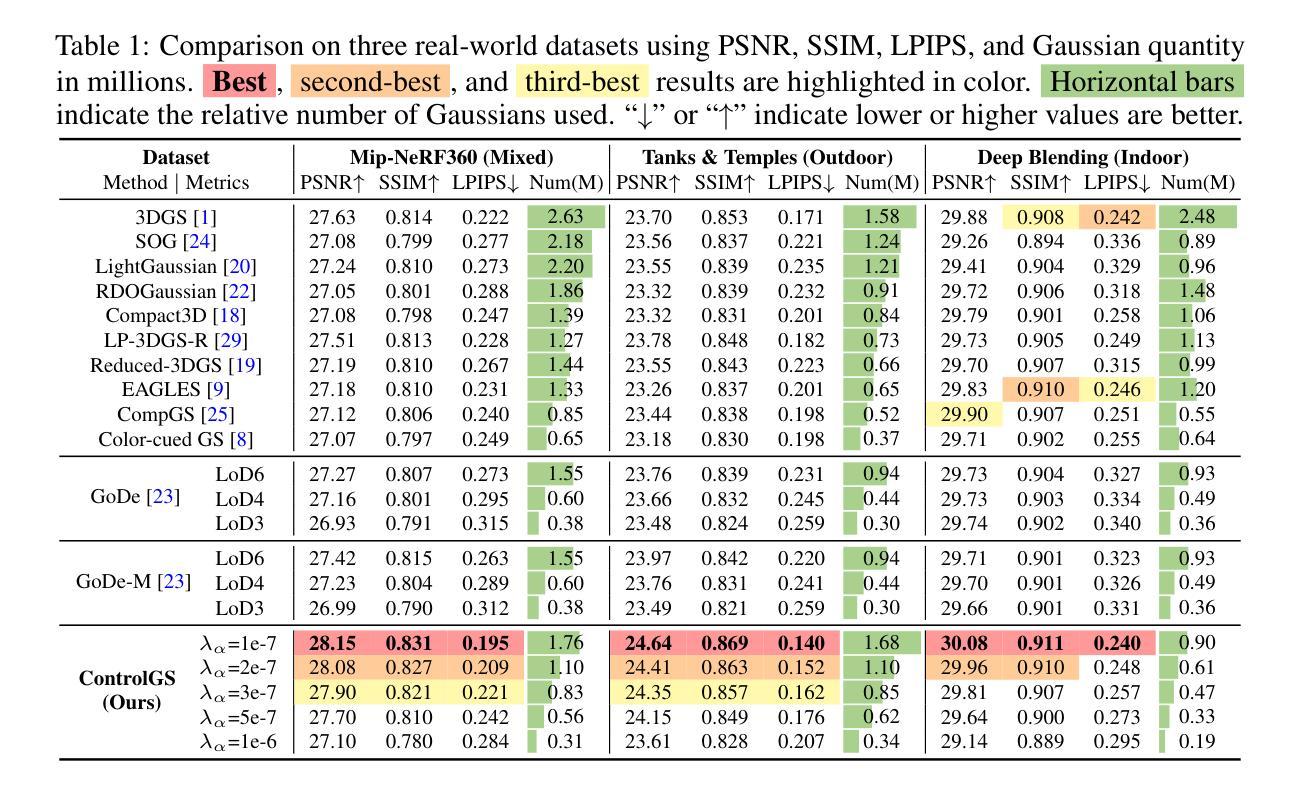
Consistent Quantity-Quality Control across Scenes for Deployment-Aware Gaussian Splatting
Authors:Fengdi Zhang, Hongkun Cao, Ruqi Huang
To reduce storage and computational costs, 3D Gaussian splatting (3DGS) seeks to minimize the number of Gaussians used while preserving high rendering quality, introducing an inherent trade-off between Gaussian quantity and rendering quality. Existing methods strive for better quantity-quality performance, but lack the ability for users to intuitively adjust this trade-off to suit practical needs such as model deployment under diverse hardware and communication constraints. Here, we present ControlGS, a 3DGS optimization method that achieves semantically meaningful and cross-scene consistent quantity-quality control. Through a single training run using a fixed setup and a user-specified hyperparameter reflecting quantity-quality preference, ControlGS can automatically find desirable quantity-quality trade-off points across diverse scenes, from compact objects to large outdoor scenes. It also outperforms baselines by achieving higher rendering quality with fewer Gaussians, and supports a broad adjustment range with stepless control over the trade-off. Project page: https://zhang-fengdi.github.io/ControlGS/
为了减少存储和计算成本,3D高斯贴图(3DGS)旨在减少使用的高斯数量,同时保持高渲染质量,从而在高斯数量和渲染质量之间引入固有的权衡。现有方法努力提升数量与质量的性能,但缺乏让用户能够直观地调整这种权衡以适应实际需求的能力,例如在各种硬件和通信约束下进行模型部署。在这里,我们提出了ControlGS,这是一种3DGS优化方法,实现了语义上有意义和跨场景一致的数量与质量控制。通过一次固定的设置和用户指定的反映数量与质量偏好的超参数训练运行,ControlGS可以在各种场景中自动找到理想的质量与数量权衡点,从紧凑的对象到大型室外场景。它还通过用更少的高斯实现更高的渲染质量超越了基线,并支持广泛的调整范围和无缝控制权衡。项目页面:https://zhang-fengdi.github.io/ControlGS/
论文及项目相关链接
PDF 16 pages, 7 figures, 7 tables. Project page available at https://zhang-fengdi.github.io/ControlGS/
Summary
该文介绍了控制3D高斯拼接(ControlGS)方法,此方法旨在优化渲染质量和使用的高斯数量之间的权衡。ControlGS能够在一次训练运行中自动找到场景间的最佳平衡,并提供用户可调节的偏好参数,以实现灵活的高斯数量与渲染质量之间的平衡。同时,ControlGS实现了更高质量的渲染,使用了更少的高斯数量,并且提供了广泛的调整范围和连续的控制权衡能力。
Key Takeaways
- ControlGS是一种优化方法,用于控制三维高斯拼接中的高斯数量和渲染质量之间的权衡。
- 用户可以通过指定的超参数反映其对数量与质量的偏好。
- ControlGS能够在不同场景之间自动找到最佳数量与质量之间的平衡。
- 该方法通过单次训练即可实现这一目标,并且可以在紧凑物体和大型室外场景等不同场景下应用。
- ControlGS在渲染质量方面优于基准方法,同时使用了更少的高斯数量。
点此查看论文截图

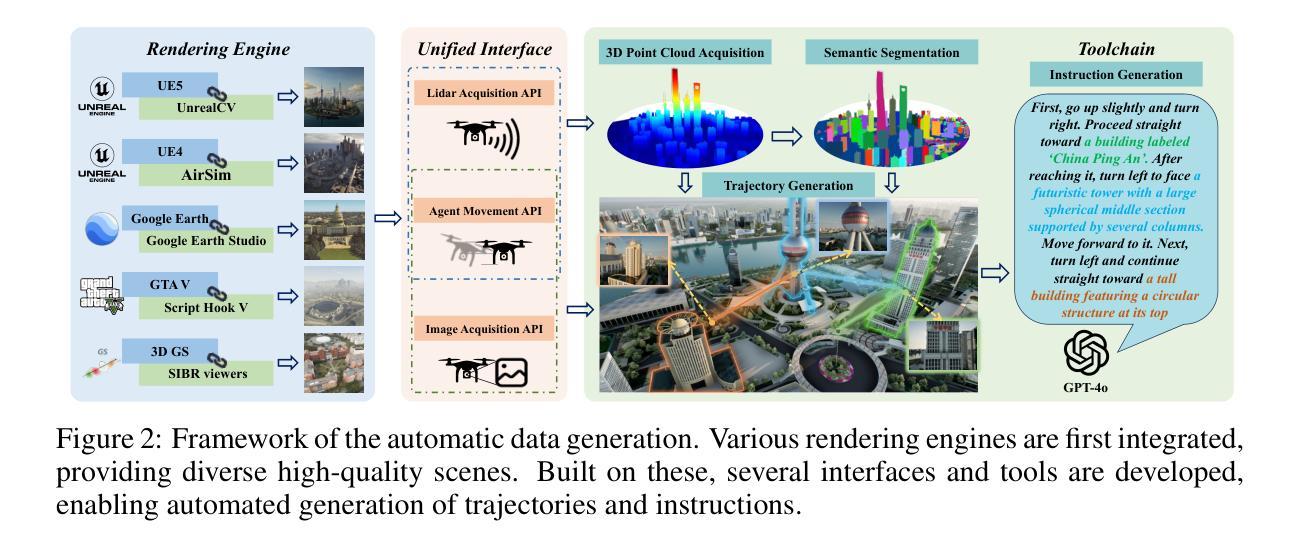
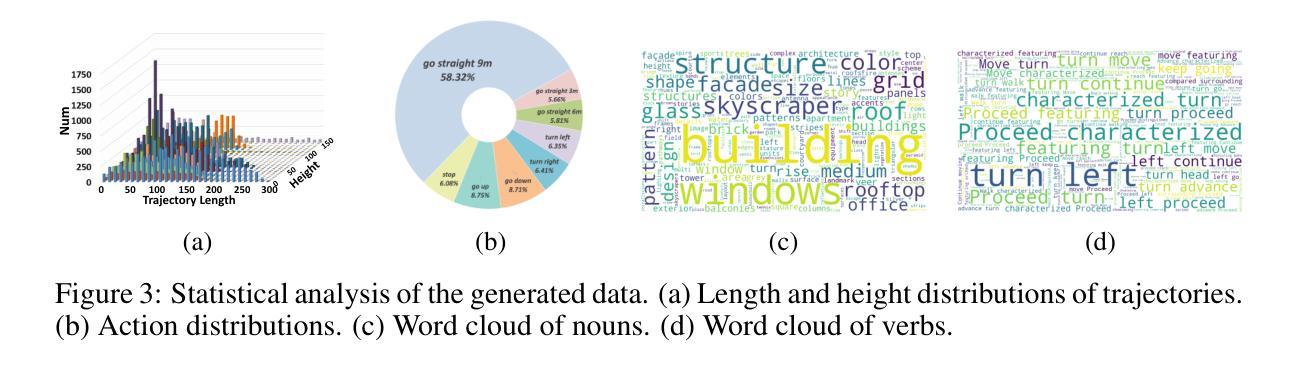
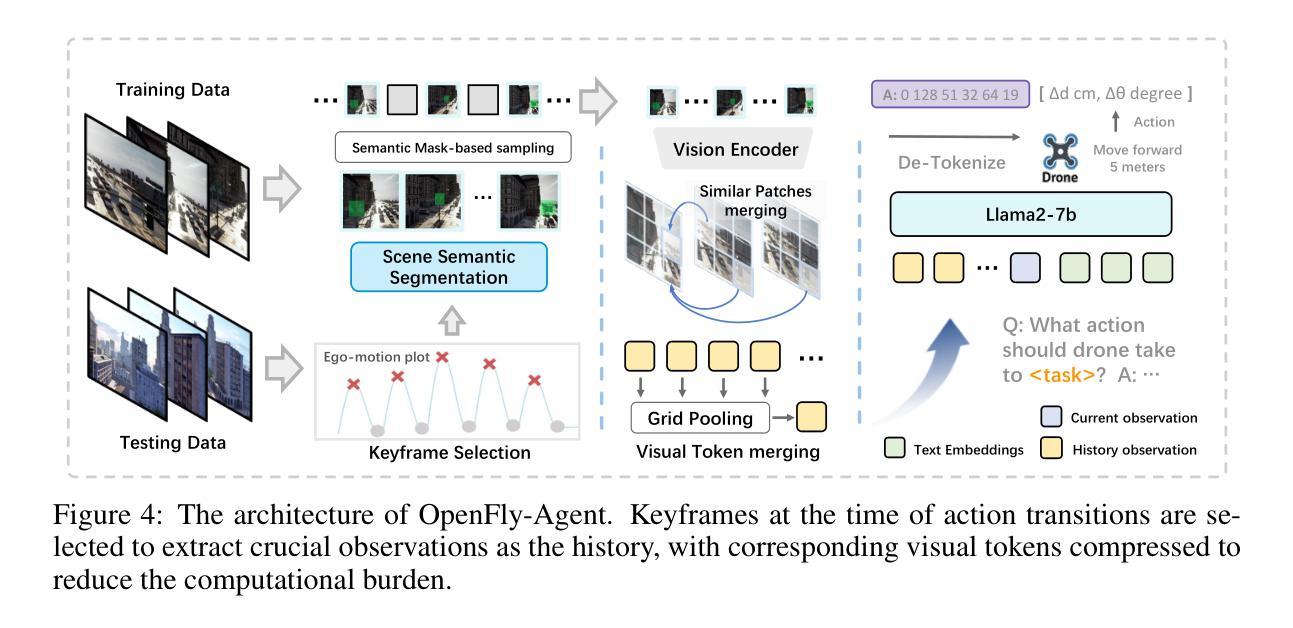
OpenFly: A Comprehensive Platform for Aerial Vision-Language Navigation
Authors:Yunpeng Gao, Chenhui Li, Zhongrui You, Junli Liu, Zhen Li, Pengan Chen, Qizhi Chen, Zhonghan Tang, Liansheng Wang, Penghui Yang, Yiwen Tang, Yuhang Tang, Shuai Liang, Songyi Zhu, Ziqin Xiong, Yifei Su, Xinyi Ye, Jianan Li, Yan Ding, Dong Wang, Zhigang Wang, Bin Zhao, Xuelong Li
Vision-Language Navigation (VLN) aims to guide agents by leveraging language instructions and visual cues, playing a pivotal role in embodied AI. Indoor VLN has been extensively studied, whereas outdoor aerial VLN remains underexplored. The potential reason is that outdoor aerial view encompasses vast areas, making data collection more challenging, which results in a lack of benchmarks. To address this problem, we propose OpenFly, a platform comprising various rendering engines, a versatile toolchain, and a large-scale benchmark for aerial VLN. Firstly, we integrate diverse rendering engines and advanced techniques for environment simulation, including Unreal Engine, GTA V, Google Earth, and 3D Gaussian Splatting (3D GS). Particularly, 3D GS supports real-to-sim rendering, further enhancing the realism of our environments. Secondly, we develop a highly automated toolchain for aerial VLN data collection, streamlining point cloud acquisition, scene semantic segmentation, flight trajectory creation, and instruction generation. Thirdly, based on the toolchain, we construct a large-scale aerial VLN dataset with 100k trajectories, covering diverse heights and lengths across 18 scenes. Moreover, we propose OpenFly-Agent, a keyframe-aware VLN model emphasizing key observations during flight. For benchmarking, extensive experiments and analyses are conducted, evaluating several recent VLN methods and showcasing the superiority of our OpenFly platform and agent. The toolchain, dataset, and codes will be open-sourced.
视觉语言导航(VLN)旨在通过语言指令和视觉线索来引导代理,在嵌入式人工智能中扮演着至关重要的角色。室内VLN已经得到了广泛的研究,而户外空中VLN仍然被较少探索。可能的原因是户外空中视角涉及大片区域,使得数据收集更具挑战性,从而导致缺乏基准测试。为了解决这个问题,我们提出了OpenFly平台,该平台包括各种渲染引擎、通用工具链和用于空中VLN的大规模基准测试。首先,我们集成了多种渲染引擎和先进的环境模拟技术,包括Unreal Engine、GTA V、Google Earth和3D高斯平板印刷术(3D GS)。特别是,3D GS支持真实到模拟渲染,进一步增强了我们的环境真实性。其次,我们开发了一个高度自动化的空中VLN数据收集工具链,用于点云采集、场景语义分割、飞行轨迹创建和指令生成。第三,基于工具链,我们构建了一个大规模的空中VLN数据集,包含10万条轨迹,覆盖18个场景的多种高度和长度。此外,我们提出了OpenFly-Agent,一个关键帧感知的VLN模型,强调飞行过程中的关键观察。为了进行基准测试,我们进行了广泛的实验和分析,评估了几种最新的VLN方法,并展示了我们的OpenFly平台和代理的优势。工具链、数据集和代码将开源。
论文及项目相关链接
Summary
该文介绍了视觉语言导航(VLN)的研究,特别强调了户外高空视角导航的潜在价值及其挑战。文章提出一个名为OpenFly的平台,集成多种渲染引擎、先进仿真技术和一个大规模的空中VLN数据集,为数据收集和环境模拟提供便捷的工具链。该平台包含一个针对高空视角导航设计的导航模型,并通过实验验证了其优越性。文章旨在推动空中VLN的研究进展。
Key Takeaways
- VLN结合了语言指令和视觉线索,对于实际机器人的行为具有重要意义。室内研究充分,而高空视角下的研究不足是由于高空数据收集的复杂性所致。提出一个新的OpenFly平台,解决数据收集的问题。
- OpenFly平台包含多种渲染引擎和仿真技术,包括Unreal Engine、GTA V等先进引擎以及专为高空视角设计的实时模拟渲染技术(如3D GS)。这些技术增强了环境的真实感。
- OpenFly开发了一个高度自动化的工具链,用于高空VLN数据收集,包括点云获取、场景语义分割、飞行轨迹创建和指令生成等环节。这使得构建大规模高空VLN数据集变得高效且可能。OpenFly基于这个工具链创建了一个大规模的高空VLN数据集,包含覆盖不同高度和长度的场景达到1万条轨迹。
点此查看论文截图

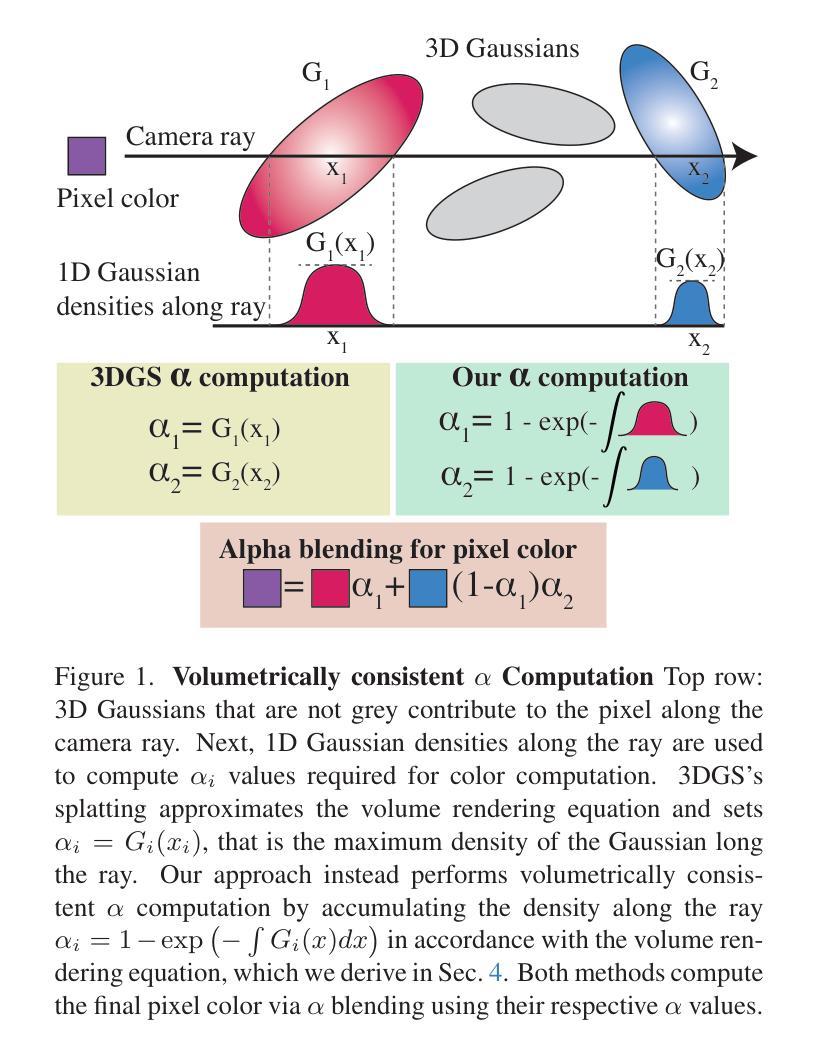
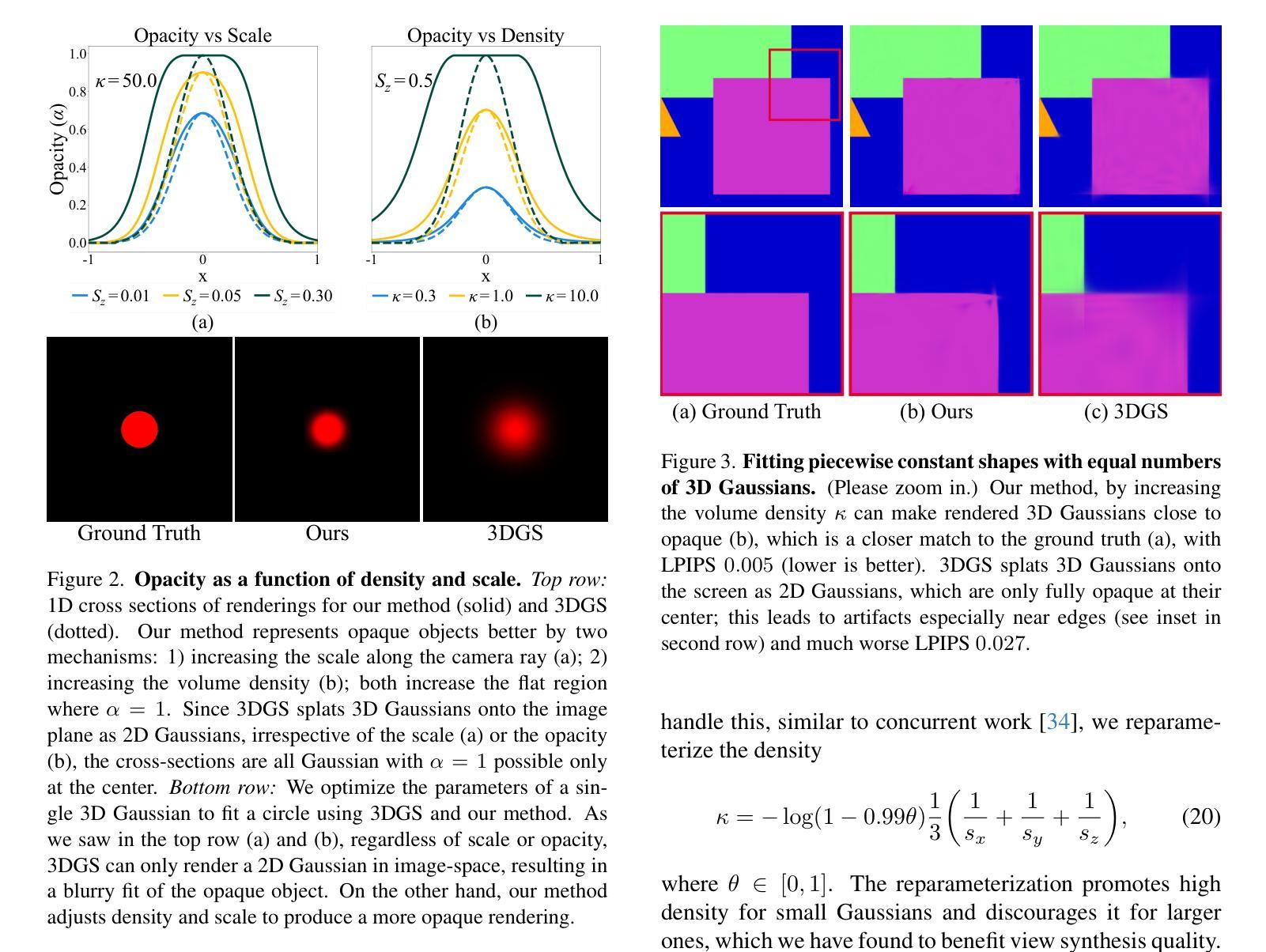
Volumetrically Consistent 3D Gaussian Rasterization
Authors:Chinmay Talegaonkar, Yash Belhe, Ravi Ramamoorthi, Nicholas Antipa
Recently, 3D Gaussian Splatting (3DGS) has enabled photorealistic view synthesis at high inference speeds. However, its splatting-based rendering model makes several approximations to the rendering equation, reducing physical accuracy. We show that the core approximations in splatting are unnecessary, even within a rasterizer; We instead volumetrically integrate 3D Gaussians directly to compute the transmittance across them analytically. We use this analytic transmittance to derive more physically-accurate alpha values than 3DGS, which can directly be used within their framework. The result is a method that more closely follows the volume rendering equation (similar to ray-tracing) while enjoying the speed benefits of rasterization. Our method represents opaque surfaces with higher accuracy and fewer points than 3DGS. This enables it to outperform 3DGS for view synthesis (measured in SSIM and LPIPS). Being volumetrically consistent also enables our method to work out of the box for tomography. We match the state-of-the-art 3DGS-based tomography method with fewer points. Our code is publicly available at: https://github.com/chinmay0301ucsd/Vol3DGS
最近,3D高斯Splatting(3DGS)已经实现了快速推理下的逼真视图合成。然而,其基于Splatting的渲染模型对渲染方程进行了多个近似处理,降低了物理准确性。我们显示,Splatting中的核心近似值在光栅化器中是不必要的;相反,我们直接在体积内积分3D高斯值,以分析计算其透射率。我们使用这种分析透射率来得出比3DGS更准确的alpha值,并可在其框架内直接使用。结果是一种更紧密地遵循体积渲染方程(类似于光线追踪)的方法,同时享受光栅化的速度优势。我们的方法能够以更高的精度和更少的点数代表不透明表面,超过了用于视图合成的3DGS(在SSIM和LPIPS中测量)。其体积一致性还使我们的方法能够轻松应用于断层扫描。我们使用较少的点与最先进的基于3DGS的断层扫描方法相匹配。我们的代码可在以下网址公开访问:https://github.com/chinmay0301ucsd/Vol3DGS。
论文及项目相关链接
Summary
基于高斯的3D渲染方法近期被提出,虽然能够实现逼真的场景合成并拥有高效的推理速度,但在渲染方程的处理过程中存在一定程度的近似处理,从而影响其物理准确性。本研究直接对三维高斯进行体积积分,解析计算其透射率,旨在提供更精确的物理模型。该方法的提出结合了高准确性的光线追踪技术同时拥有高效渲染的速度优势。与传统的基于点近似的方法相比,我们的方法对于不透明表面的表示更为准确且使用更少的点。此外,其体积一致性还使其能应用于层析成像技术并达到优秀的性能表现。
Key Takeaways
- 3DGS能够实现逼真的场景合成并拥有高效的推理速度,但在物理准确性方面存在不足。
- 研究通过直接对三维高斯进行体积积分计算透射率来提高物理准确性。
- 方法结合了光线追踪的高准确性以及高效渲染的速度优势。
- 对于不透明表面的表示相比传统方法更为准确且使用更少的点。
- 该方法的体积一致性使其能适用于层析成像技术并展现出卓越性能。
点此查看论文截图

VisionPAD: A Vision-Centric Pre-training Paradigm for Autonomous Driving
Authors:Haiming Zhang, Wending Zhou, Yiyao Zhu, Xu Yan, Jiantao Gao, Dongfeng Bai, Yingjie Cai, Bingbing Liu, Shuguang Cui, Zhen Li
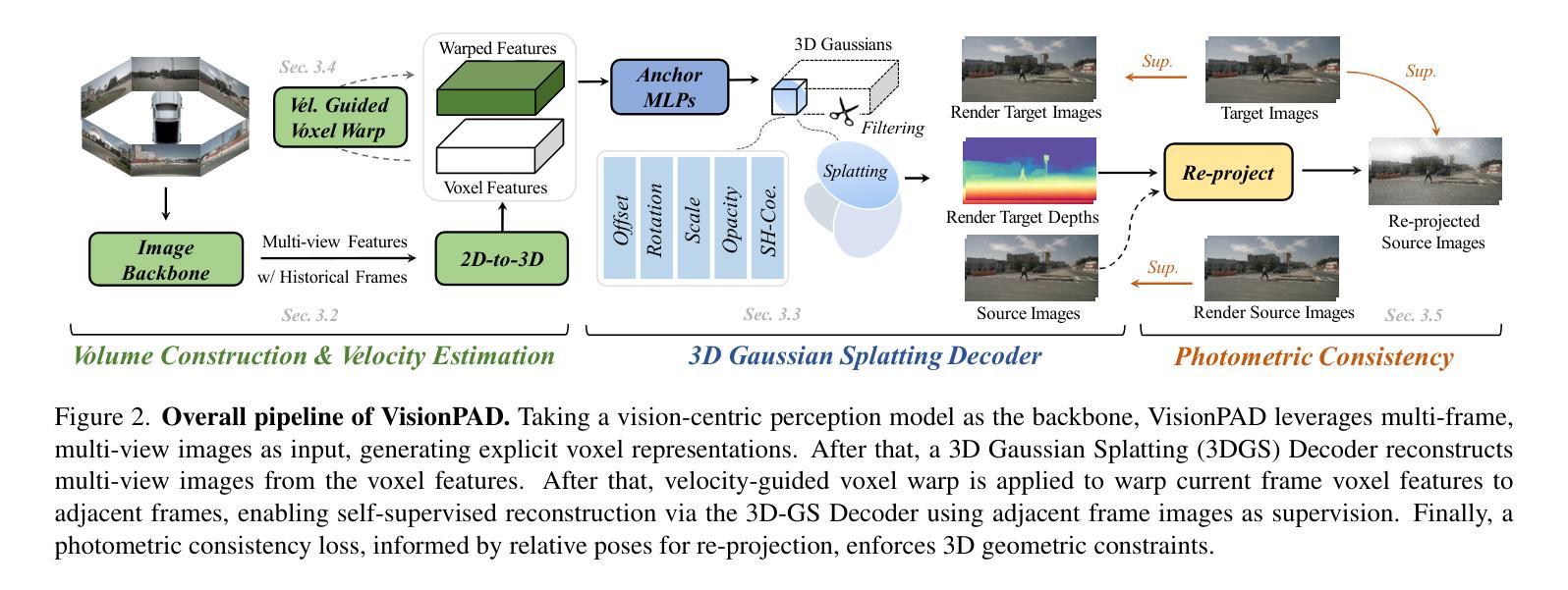
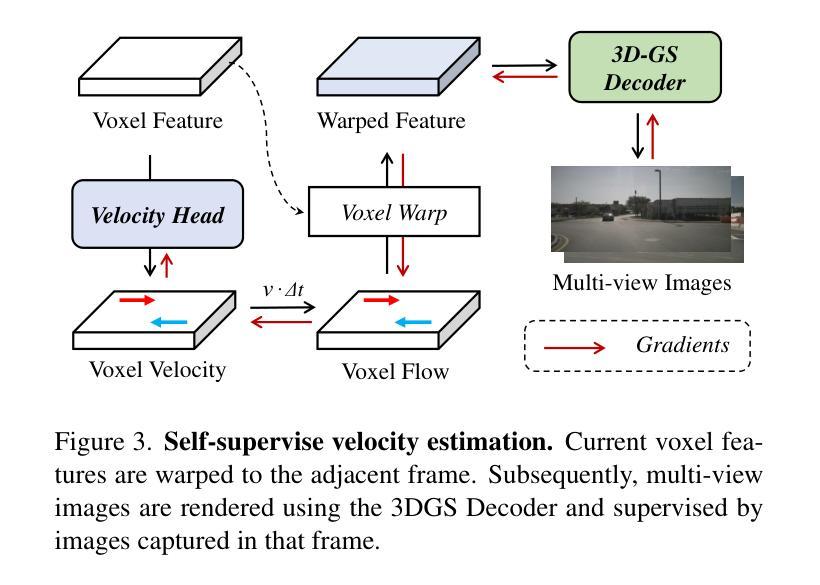
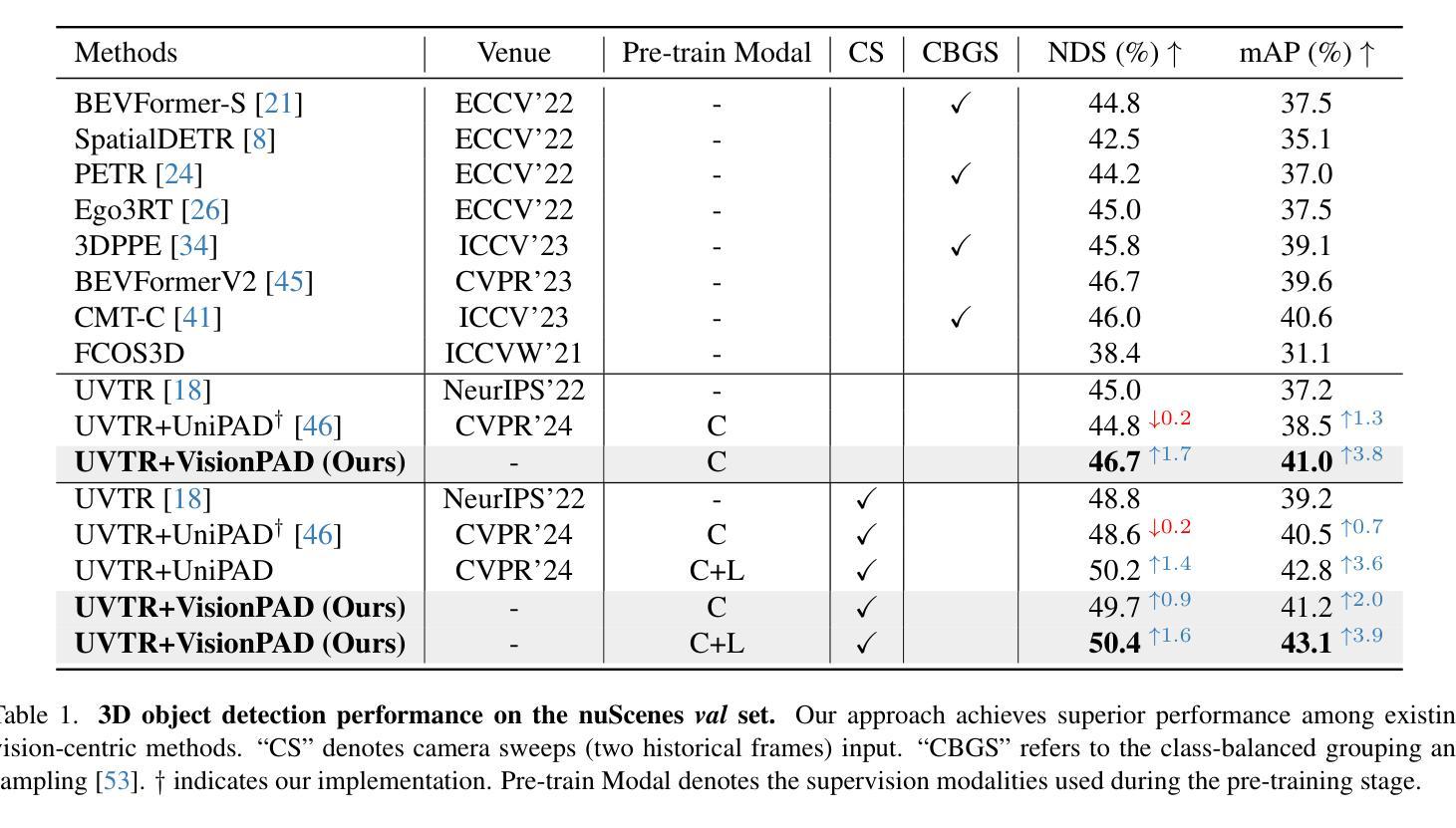
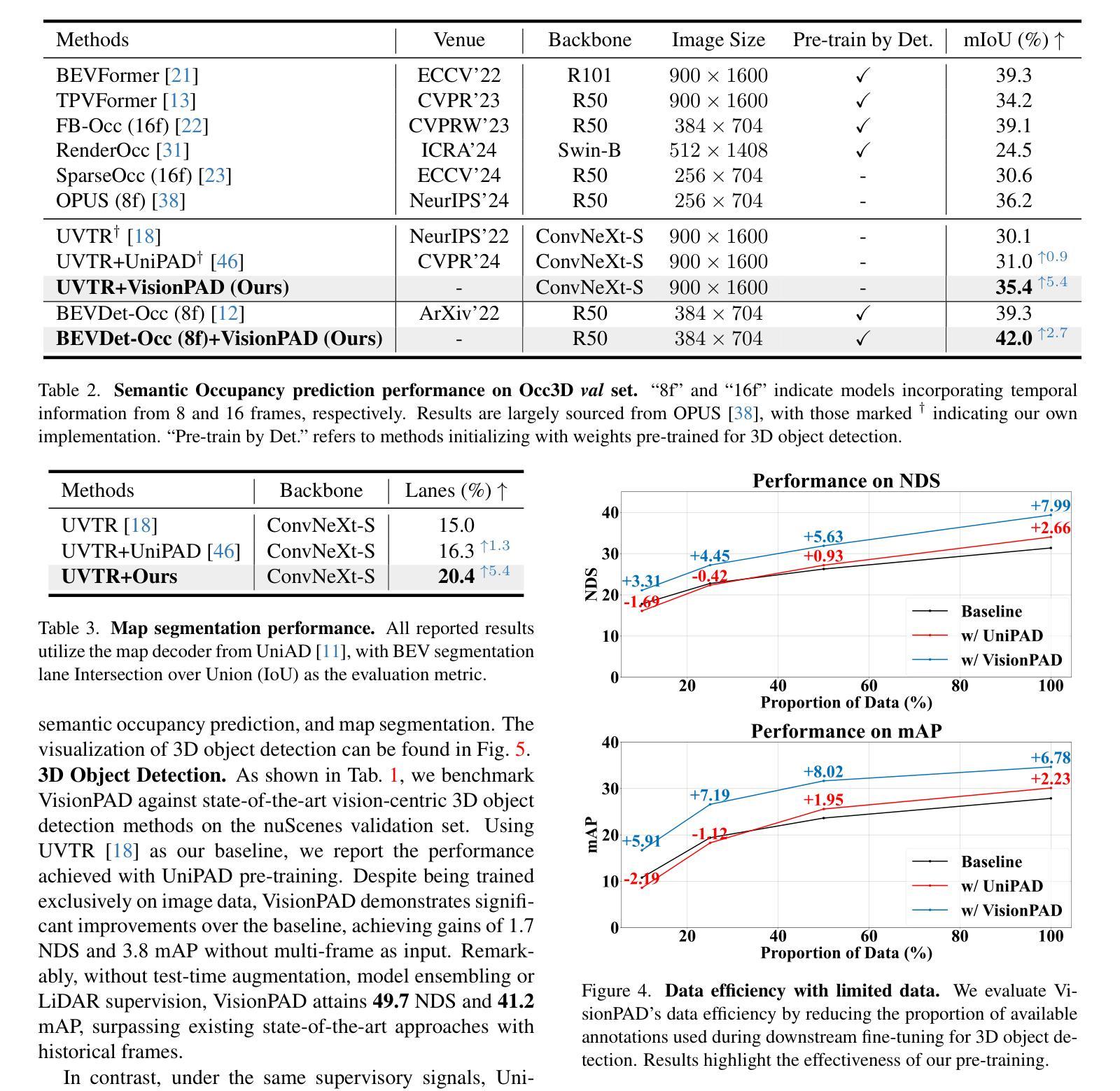
This paper introduces VisionPAD, a novel self-supervised pre-training paradigm designed for vision-centric algorithms in autonomous driving. In contrast to previous approaches that employ neural rendering with explicit depth supervision, VisionPAD utilizes more efficient 3D Gaussian Splatting to reconstruct multi-view representations using only images as supervision. Specifically, we introduce a self-supervised method for voxel velocity estimation. By warping voxels to adjacent frames and supervising the rendered outputs, the model effectively learns motion cues in the sequential data. Furthermore, we adopt a multi-frame photometric consistency approach to enhance geometric perception. It projects adjacent frames to the current frame based on rendered depths and relative poses, boosting the 3D geometric representation through pure image supervision. Extensive experiments on autonomous driving datasets demonstrate that VisionPAD significantly improves performance in 3D object detection, occupancy prediction and map segmentation, surpassing state-of-the-art pre-training strategies by a considerable margin.
本文介绍了VisionPAD,这是一种为自动驾驶中的以视觉为中心的算法设计的新型自监督预训练范式。与之前采用具有明确深度监督的神经渲染方法不同,VisionPAD利用更有效的3D高斯Splatting技术,仅使用图像作为监督来重建多视图表示。具体来说,我们为体素速度估计提出了一种自监督方法。通过将体素变形到相邻帧并对渲染输出进行监督,模型有效地学习了序列数据中的运动线索。此外,我们采用多帧光度一致性方法来增强几何感知。它根据渲染深度和相对姿态将相邻帧投影到当前帧,通过纯图像监督增强3D几何表示。在自动驾驶数据集上的广泛实验表明,VisionPAD在3D目标检测、占用预测和地图分割方面的性能得到了显著提高,显著超越了最先进的预训练策略。
论文及项目相关链接
PDF Accepted at CVPR 2025
Summary
本文提出了VisionPAD,这是一种针对自动驾驶中视觉算法的新型自监督预训练范式。与以往采用明确深度监督的神经渲染方法不同,VisionPAD利用更有效的3D高斯Splatting技术,仅使用图像作为监督来重建多视角表示。具体地,我们引入了一种自监督的体素速度估计方法。通过邻帧变形和监督渲染输出,模型有效地学习了序列数据中的运动线索。此外,我们采用多帧光度一致性方法,以提高几何感知能力。它将相邻帧投影到当前帧上,基于渲染深度和相对姿态,通过纯图像监督增强3D几何表示。在自动驾驶数据集上的大量实验表明,VisionPAD在3D目标检测、占用预测和地图分割方面的性能得到显著提升,优于其他先进的预训练策略。
Key Takeaways
- VisionPAD是一种针对自动驾驶视觉算法的自监督预训练范式。
- 与传统方法不同,VisionPAD采用3D高斯Splatting技术重建多视角表示。
- VisionPAD利用自监督方法估计体素速度,学习序列数据中的运动线索。
- 通过多帧光度一致性方法增强几何感知能力。
- VisionPAD通过投影相邻帧到当前帧来提高3D几何表示。
- 在自动驾驶数据集上,VisionPAD显著提高了3D目标检测、占用预测和地图分割的性能。
点此查看论文截图