⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-05-24 更新
Beyond Face Swapping: A Diffusion-Based Digital Human Benchmark for Multimodal Deepfake Detection
Authors:Jiaxin Liu, Jia Wang, Saihui Hou, Min Ren, Huijia Wu, Zhaofeng He
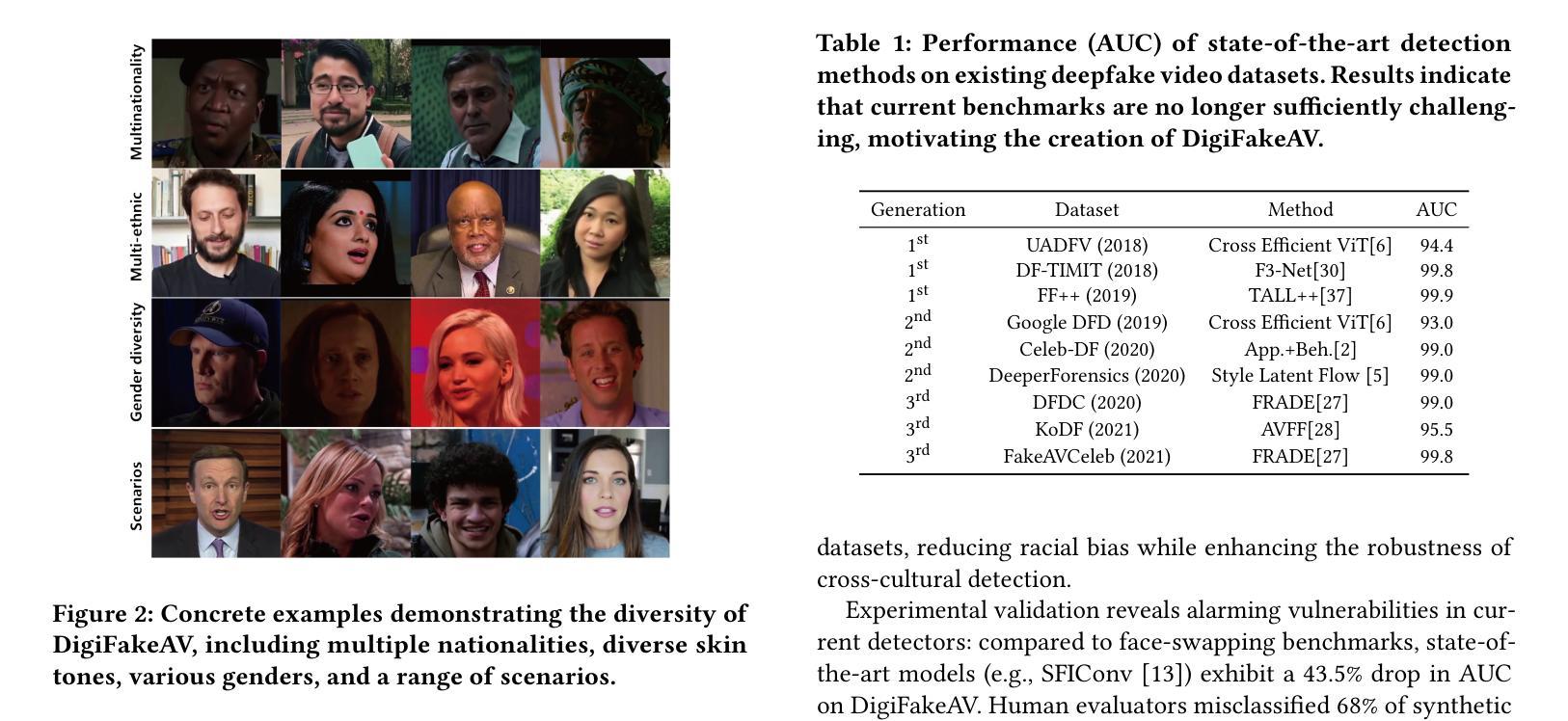
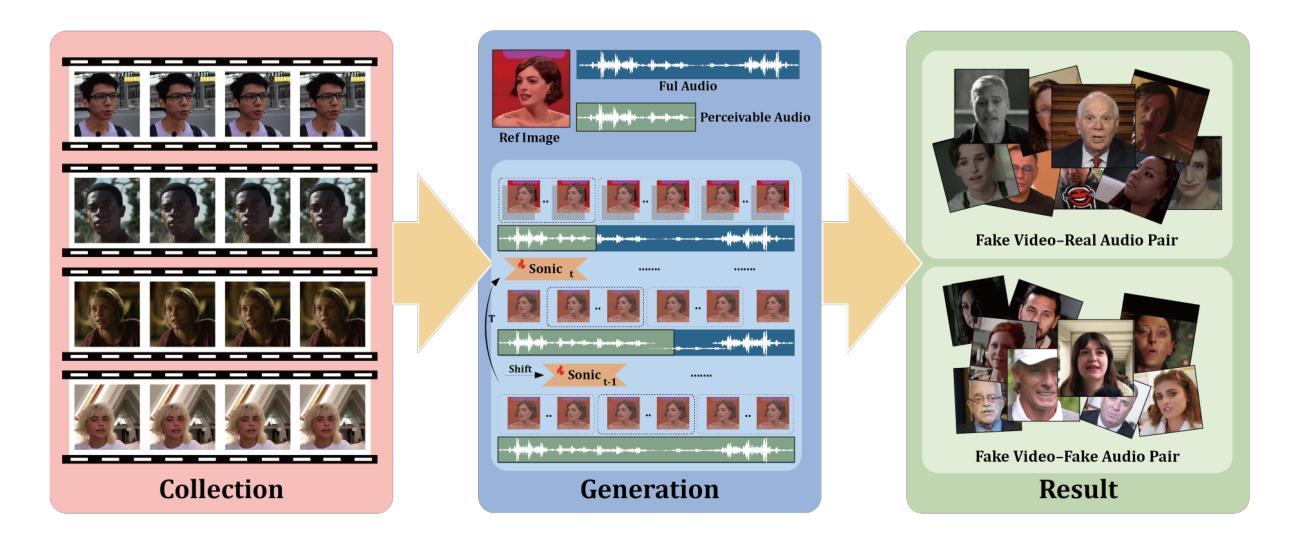
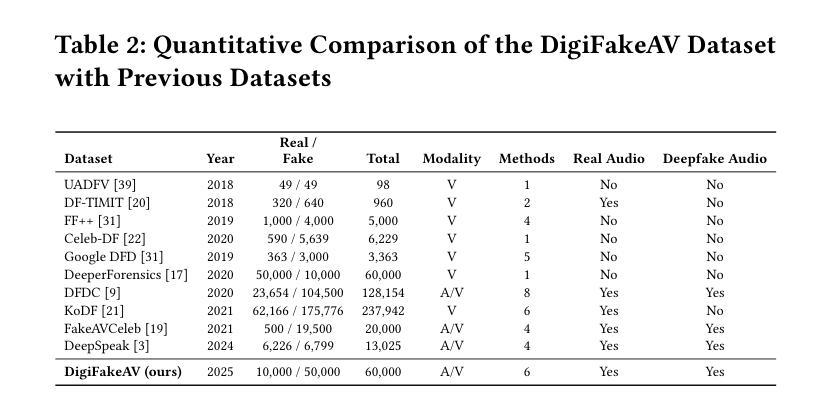
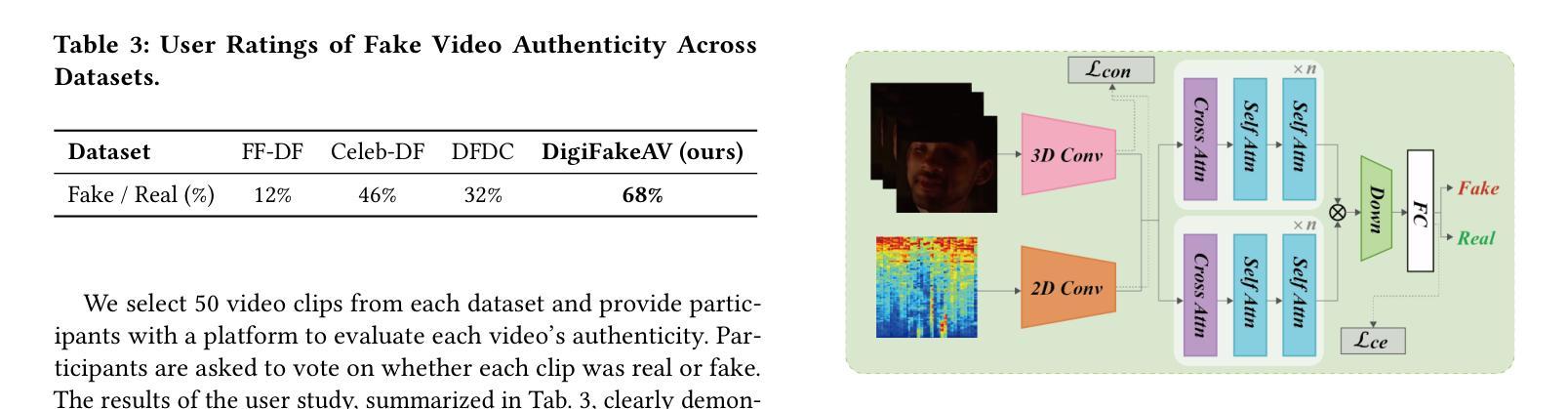
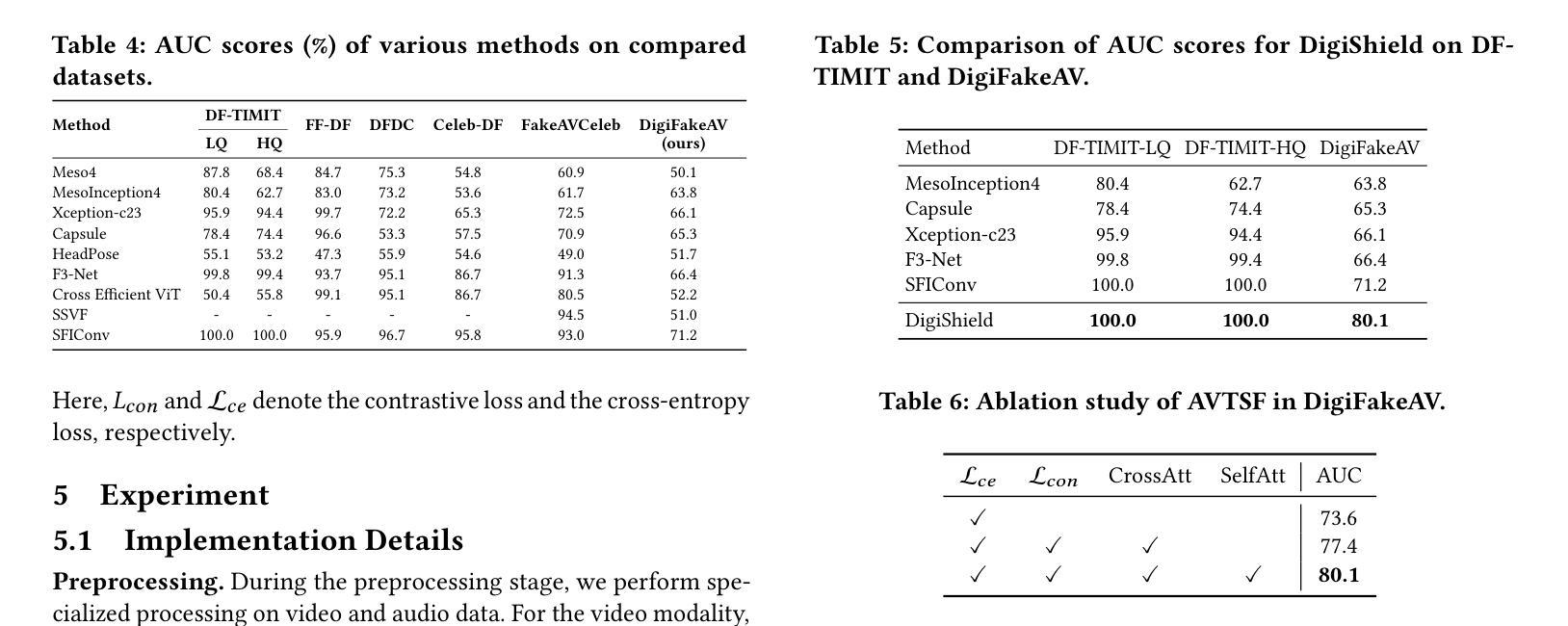
In recent years, the rapid development of deepfake technology has given rise to an emerging and serious threat to public security: diffusion model-based digital human generation. Unlike traditional face manipulation methods, such models can generate highly realistic videos with consistency through multimodal control signals. Their flexibility and covertness pose severe challenges to existing detection strategies. To bridge this gap, we introduce DigiFakeAV, the first large-scale multimodal digital human forgery dataset based on diffusion models. Employing five latest digital human generation methods (Sonic, Hallo, etc.) and voice cloning method, we systematically produce a dataset comprising 60,000 videos (8.4 million frames), covering multiple nationalities, skin tones, genders, and real-world scenarios, significantly enhancing data diversity and realism. User studies show that the confusion rate between forged and real videos reaches 68%, and existing state-of-the-art (SOTA) detection models exhibit large drops in AUC values on DigiFakeAV, highlighting the challenge of the dataset. To address this problem, we further propose DigiShield, a detection baseline based on spatiotemporal and cross-modal fusion. By jointly modeling the 3D spatiotemporal features of videos and the semantic-acoustic features of audio, DigiShield achieves SOTA performance on both the DigiFakeAV and DF-TIMIT datasets. Experiments show that this method effectively identifies covert artifacts through fine-grained analysis of the temporal evolution of facial features in synthetic videos.
近年来,深度伪造技术的快速发展对公共安全造成了新的严重威胁:基于扩散模型的数字人类生成。与传统的面部操纵方法不同,这些模型可以通过多模态控制信号生成高度逼真的视频并保持一致性。它们的灵活性和隐蔽性对现有检测策略构成了严峻挑战。为了弥补这一空白,我们推出了DigiFakeAV,这是基于扩散模型的首个大型多模态数字人类伪造数据集。我们采用五种最新的数字人类生成方法(Sonic、Hallo等)和声音克隆方法,系统地创建了一个包含60,000个视频(840万个帧)的数据集,涵盖了多种民族、肤色、性别和真实场景,显著提高了数据的多样性和逼真性。用户研究表明,伪造视频和真实视频之间的混淆率达到了68%,现有最先进的检测模型在DigiFakeAV上的AUC值大幅下降,突显了数据集的挑战。为了解决这个问题,我们进一步提出了DigiShield,这是一个基于时空和跨模态融合的检测基线。通过联合建模视频的3D时空特征和音频的语义-声学特征,DigiShield在DigiFakeAV和DF-TIMIT数据集上均达到了最先进的性能。实验表明,该方法通过精细分析合成视频中面部特征的时空演变,有效地识别出隐蔽的人工制品。
论文及项目相关链接
Summary
近年来,深度伪造技术的快速发展催生了对公共安全构成新兴严重威胁的扩散模型驱动的数字人类生成技术。不同于传统的面部操作方法,这类模型可通过多模态控制信号生成高度逼真的连续视频。其灵活性和隐蔽性对现有检测策略提出了严重挑战。为解决此问题,推出了基于扩散模型的DigiFakeAV大型数字人类伪造数据集。该数据集采用最新的数字人类生成方法和语音克隆方法,包含涵盖多国国籍、肤色、性别和真实场景的视频数据,增强了数据的多样性和逼真性。用户研究结果显示伪造视频与现实视频的混淆率高达68%,现有最先进的检测模型在DigiFakeAV上的AUC值大幅下降,凸显该数据集的挑战。为解决此问题,提出了基于时空和跨模态融合的DigiShield检测基线。通过联合建模视频的3D时空特征和音频的语义声学特征,DigiShield在DigiFakeAV和DF-TIMIT数据集上实现了最先进的性能表现。实验表明,该方法通过精细分析合成视频中的面部特征的时序变化,可有效识别隐蔽的伪像。
Key Takeaways
- 深度伪造技术的快速发展导致数字人类生成技术的出现,构成对公共安全的威胁。
- 不同于传统方法,扩散模型驱动的数字人类生成技术可通过多模态控制信号生成高度逼真的视频。
- 数据集DigiFakeAV包含多种国籍、肤色、性别和真实场景的视频数据,增强了数据的多样性和逼真性。
- 用户研究显示现有检测模型面临伪造视频的巨大挑战。
- DigiShield是基于时空和跨模态融合的先进检测基线。
- DigiShield联合建模视频的时空特征和音频特征,以提高检测性能。
点此查看论文截图

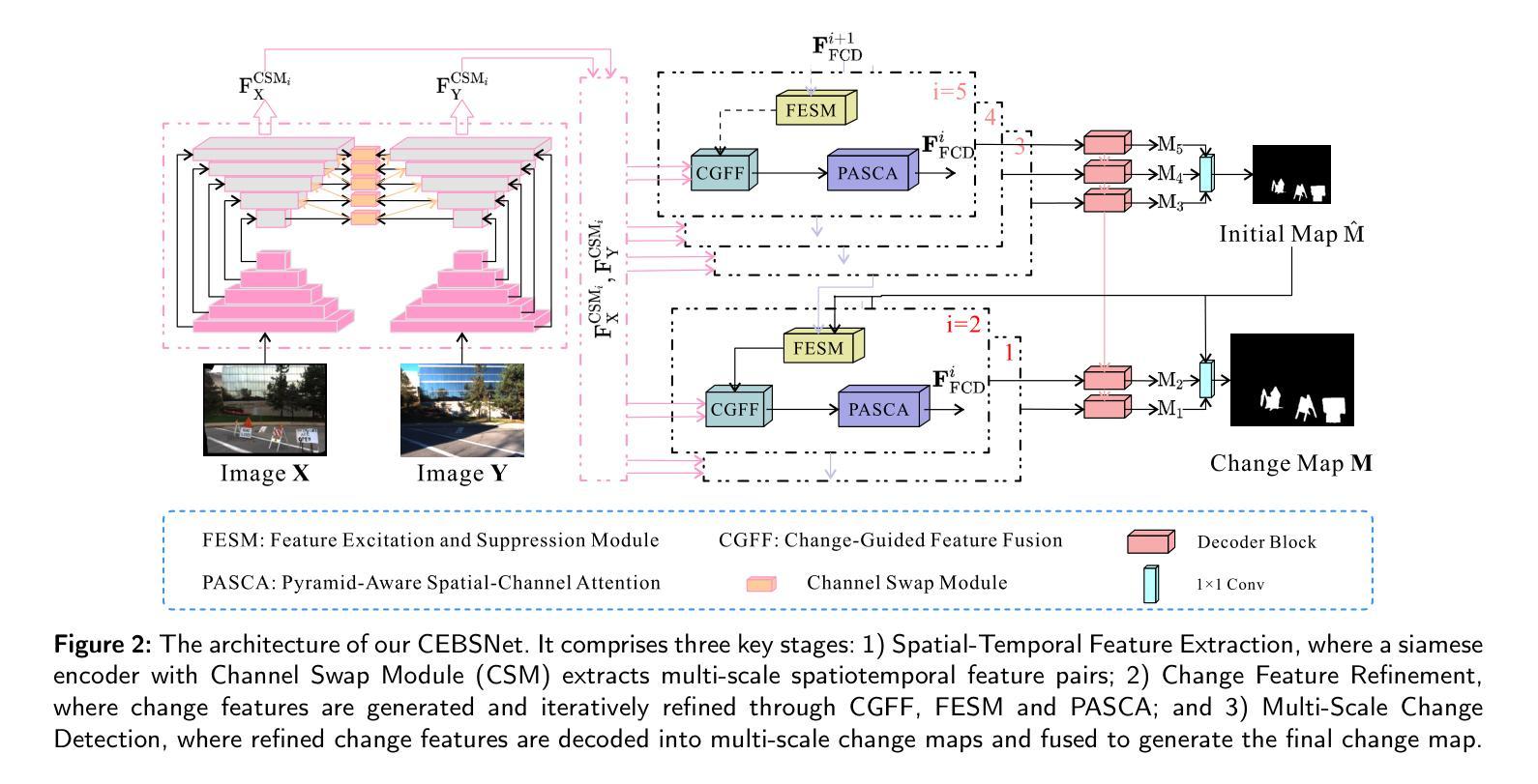
CEBSNet: Change-Excited and Background-Suppressed Network with Temporal Dependency Modeling for Bitemporal Change Detection
Authors:Qi’ao Xu, Yan Xing, Jiali Hu, Yunan Jia, Rui Huang
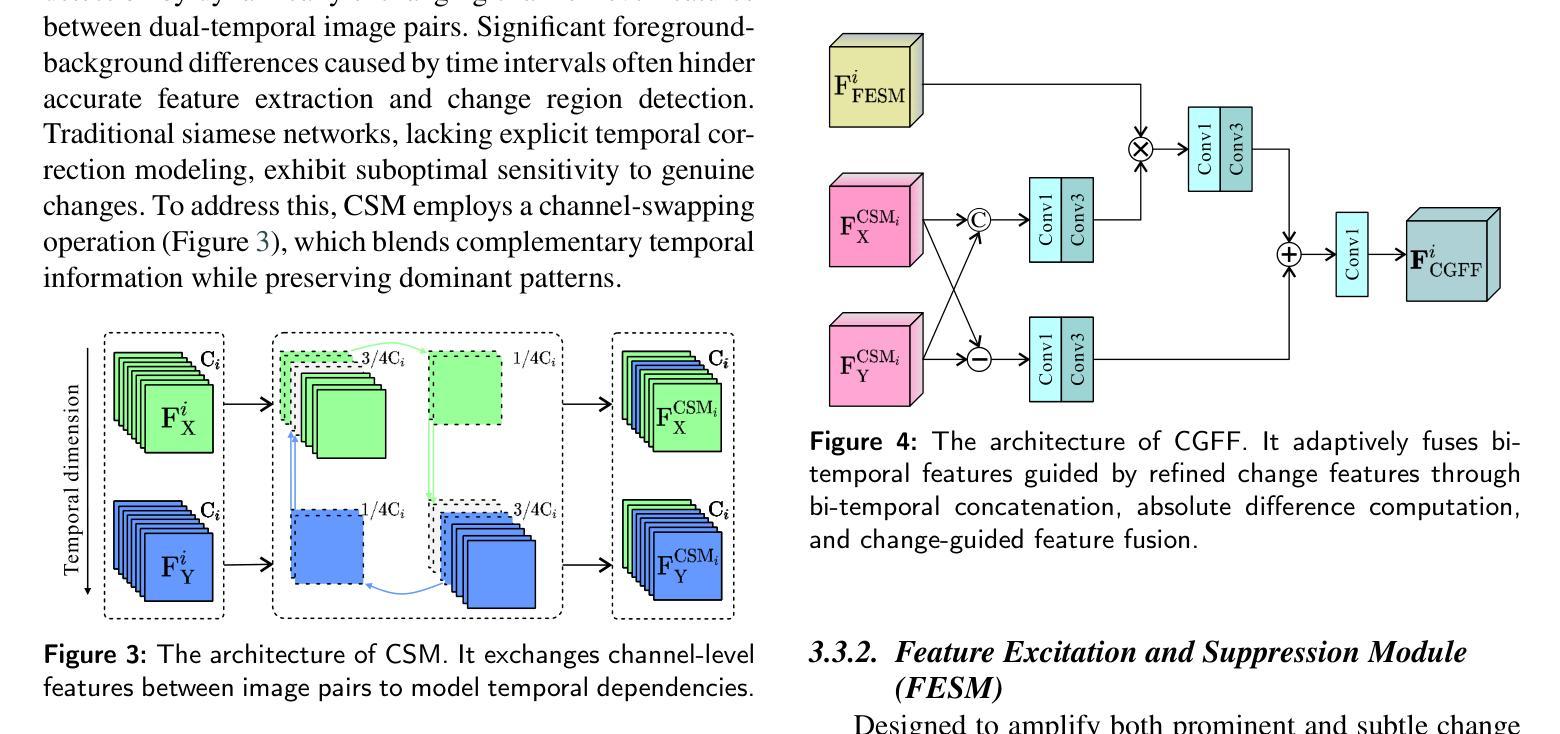
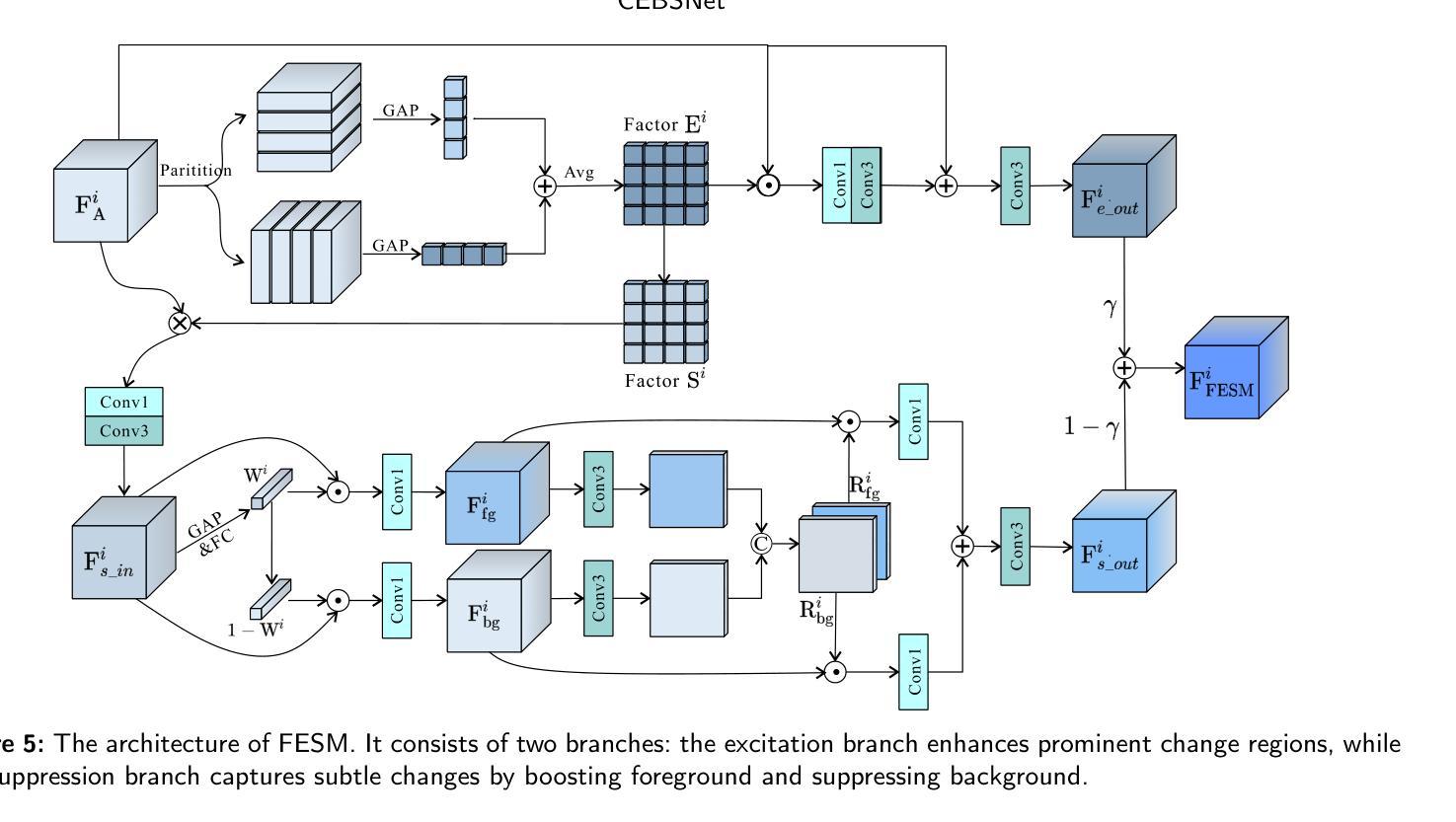
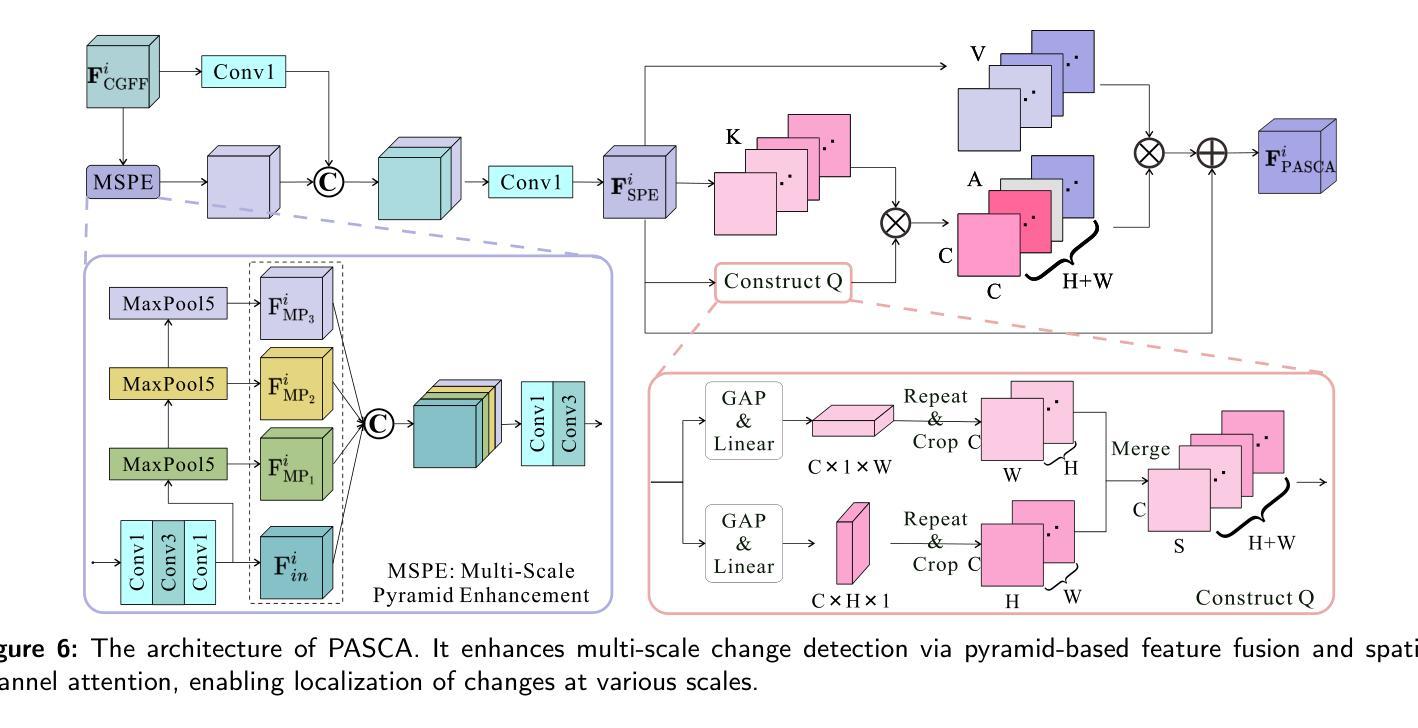
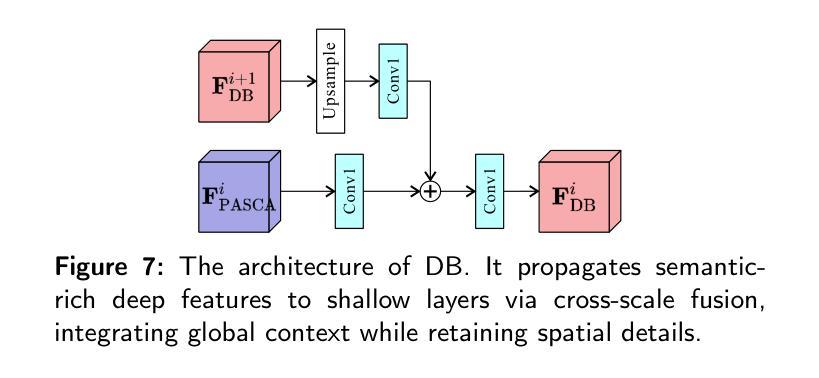
Change detection, a critical task in remote sensing and computer vision, aims to identify pixel-level differences between image pairs captured at the same geographic area but different times. It faces numerous challenges such as illumination variation, seasonal changes, background interference, and shooting angles, especially with a large time gap between images. While current methods have advanced, they often overlook temporal dependencies and overemphasize prominent changes while ignoring subtle but equally important changes. To address these limitations, we introduce \textbf{CEBSNet}, a novel change-excited and background-suppressed network with temporal dependency modeling for change detection. During the feature extraction, we utilize a simple Channel Swap Module (CSM) to model temporal dependency, reducing differences and noise. The Feature Excitation and Suppression Module (FESM) is developed to capture both obvious and subtle changes, maintaining the integrity of change regions. Additionally, we design a Pyramid-Aware Spatial-Channel Attention module (PASCA) to enhance the ability to detect change regions at different sizes and focus on critical regions. We conduct extensive experiments on three common street view datasets and two remote sensing datasets, and our method achieves the state-of-the-art performance.
变化检测是遥感与计算机视觉中的关键任务,其目标是识别同一地理区域在不同时间捕获的图像对之间的像素级差异。它面临着诸多挑战,如光照变化、季节变化、背景干扰和拍摄角度,尤其是图像间时间间隔较大时。尽管当前的方法已经有所进展,但它们往往忽略了时间的依赖性,过分强调显著变化,而忽略了同样重要的细微变化。为了解决这些局限性,我们引入了CEBSNet,这是一个具有时间依赖性建模功能的新型变化激发和背景抑制网络,用于变化检测。在特征提取过程中,我们利用简单的通道交换模块(CSM)对时间依赖性进行建模,以减少差异和噪声。我们开发了特征激发和抑制模块(FESM)来捕捉显著和细微的变化,保持变化区域的完整性。此外,我们还设计了一个金字塔感知空间通道注意模块(PASCA),以提高检测不同大小变化区域的能力,并关注关键区域。我们在三个常见的街头视图数据集和两个遥感数据集上进行了大量实验,我们的方法达到了最先进的性能。
论文及项目相关链接
Summary
本文介绍了针对遥感与计算机视觉中的变化检测任务,提出一种名为CEBSNet的新型网络,该网络具有变化激励和背景抑制功能,并建模时间依赖性以进行变化检测。通过特征提取中的通道交换模块(CSM)建模时间依赖性,减少差异和噪声。同时,开发了特征激励和抑制模块(FESM)以捕捉明显和细微的变化,保持变化区域的完整性。此外,还设计了一个金字塔感知空间通道注意力模块(PASCA),以提高在不同尺寸下检测变化区域的能力,并关注关键区域。在多个数据集上的实验表明,该方法达到了先进水平。
Key Takeaways
- 变化检测是遥感与计算机视觉中的关键任务,旨在识别同一地理区域在不同时间捕获的图像对之间的像素级差异。
- CEBSNet网络具有变化激励和背景抑制功能,通过建模时间依赖性以提高变化检测性能。
- CEBSNet采用通道交换模块(CSM)减少差异和噪声,在特征提取过程中建模时间依赖性。
- 特征激励和抑制模块(FESM)旨在捕捉明显和细微的变化,保持变化区域的完整性。
- 金字塔感知空间通道注意力模块(PASCA)用于增强在不同尺寸下检测变化区域的能力,并关注关键区域。
- 广泛实验证明,CEBSNet方法在多个数据集上实现了先进性能。
点此查看论文截图


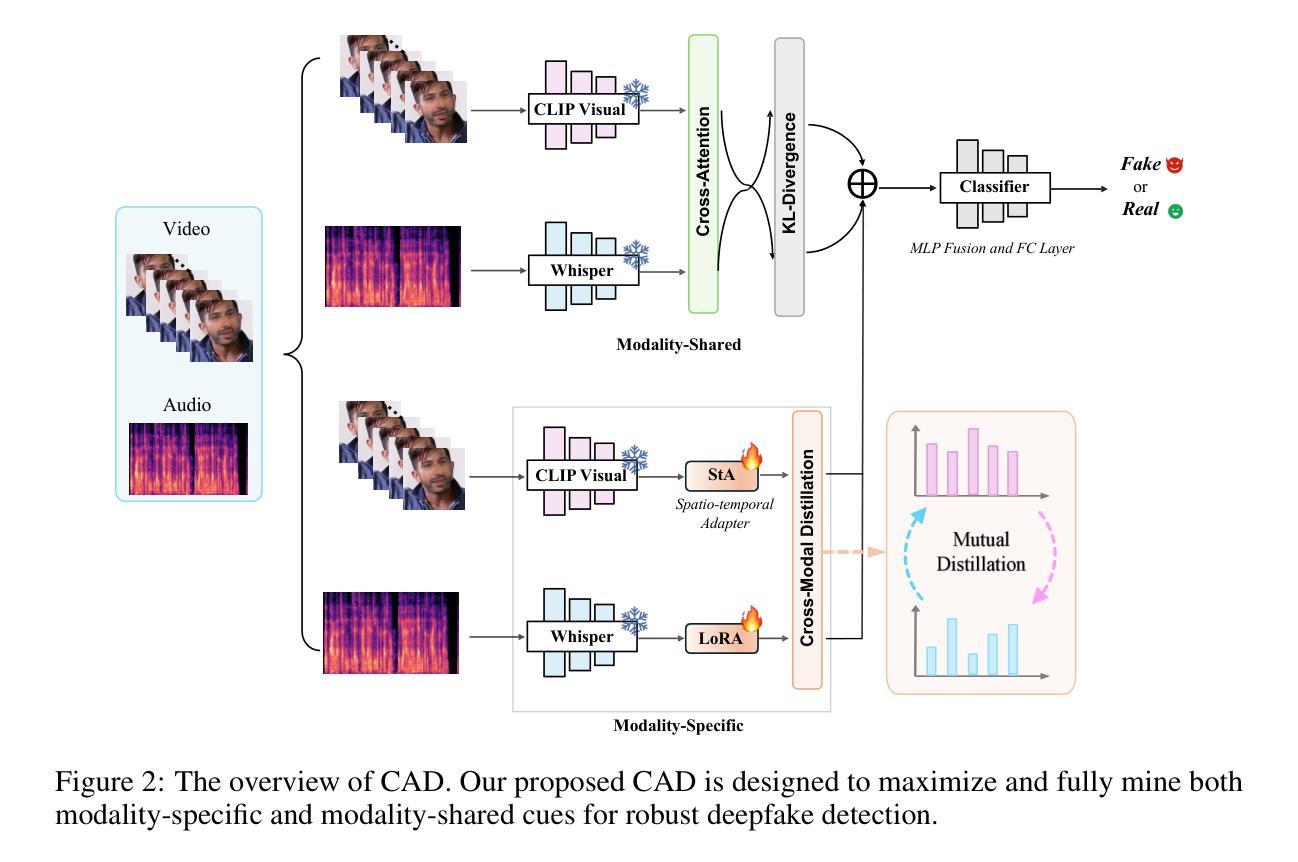
CAD: A General Multimodal Framework for Video Deepfake Detection via Cross-Modal Alignment and Distillation
Authors:Yuxuan Du, Zhendong Wang, Yuhao Luo, Caiyong Piao, Zhiyuan Yan, Hao Li, Li Yuan
The rapid emergence of multimodal deepfakes (visual and auditory content are manipulated in concert) undermines the reliability of existing detectors that rely solely on modality-specific artifacts or cross-modal inconsistencies. In this work, we first demonstrate that modality-specific forensic traces (e.g., face-swap artifacts or spectral distortions) and modality-shared semantic misalignments (e.g., lip-speech asynchrony) offer complementary evidence, and that neglecting either aspect limits detection performance. Existing approaches either naively fuse modality-specific features without reconciling their conflicting characteristics or focus predominantly on semantic misalignment at the expense of modality-specific fine-grained artifact cues. To address these shortcomings, we propose a general multimodal framework for video deepfake detection via Cross-Modal Alignment and Distillation (CAD). CAD comprises two core components: 1) Cross-modal alignment that identifies inconsistencies in high-level semantic synchronization (e.g., lip-speech mismatches); 2) Cross-modal distillation that mitigates feature conflicts during fusion while preserving modality-specific forensic traces (e.g., spectral distortions in synthetic audio). Extensive experiments on both multimodal and unimodal (e.g., image-only/video-only)deepfake benchmarks demonstrate that CAD significantly outperforms previous methods, validating the necessity of harmonious integration of multimodal complementary information.
多媒体深度伪造(同时操作视觉和听觉内容)的快速出现,破坏了现有检测器的可靠性,这些检测器仅依赖于模态特定伪造的物证或跨模态的不一致性。在这项工作中,我们首先证明模态特定法医痕迹(例如面部替换伪造的痕迹或光谱失真)和模态共享语义错位(例如唇语不同步)提供了互补证据,忽略任何一方面都会限制检测性能。现有方法要么天真地融合模态特定特征而没有解决其冲突特性,要么主要关注语义错位而忽略了模态特定的精细伪造的线索。为了解决这些不足,我们提出了通过跨模态对齐和蒸馏(CAD)进行视频深度伪造检测的一般多模态框架。CAD包含两个核心组件:1)跨模态对齐,用于识别高级语义同步的不一致性(例如唇语不匹配);2)跨模态蒸馏,在融合过程中缓解特征冲突的同时保留模态特定的法医痕迹(例如合成音频中的光谱失真)。在多媒体和单模态(例如仅图像/仅视频)的深度伪造基准测试上的大量实验表明,CAD显著优于以前的方法,验证了和谐整合多媒体互补信息的必要性。
论文及项目相关链接
Summary
本文指出多模态深度伪造技术的迅速崛起对现有检测器构成挑战,因为现有检测器主要依赖模态特定的人工制品或跨模态的不一致性。本研究提出了一种新的通用多模态框架——跨模态对齐与蒸馏(CAD),该框架包括跨模态对齐识别高级语义同步的不一致性以及跨模态蒸馏减轻融合时的特征冲突,同时保留模态特定的细微人工痕迹。通过广泛的实验验证,CAD在多模态和单模态深度伪造基准测试中显著优于以前的方法,证明了和谐整合多模态互补信息的必要性。
Key Takeaways
- 多模态深度伪造技术迅速崛起,对现有检测器构成挑战。
- 现有检测器主要依赖模态特定的人工制品或跨模态的不一致性,但存在局限性。
- 提出了一种新的通用多模态框架——跨模态对齐与蒸馏(CAD)。
- CAD包括两个核心组件:跨模态对齐和跨模态蒸馏。
- 跨模态对齐能够识别高级语义同步的不一致性。
- 跨模态蒸馏可以减小特征融合时的冲突,同时保留模态特定的细微痕迹。
- 广泛实验验证表明,CAD在多模态和单模态深度伪造检测中显著优于先前方法。
点此查看论文截图