⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-05-24 更新
Four Eyes Are Better Than Two: Harnessing the Collaborative Potential of Large Models via Differentiated Thinking and Complementary Ensembles
Authors:Jun Xie, Xiongjun Guan, Yingjian Zhu, Zhaoran Zhao, Xinming Wang, Feng Chen, Zhepeng Wang
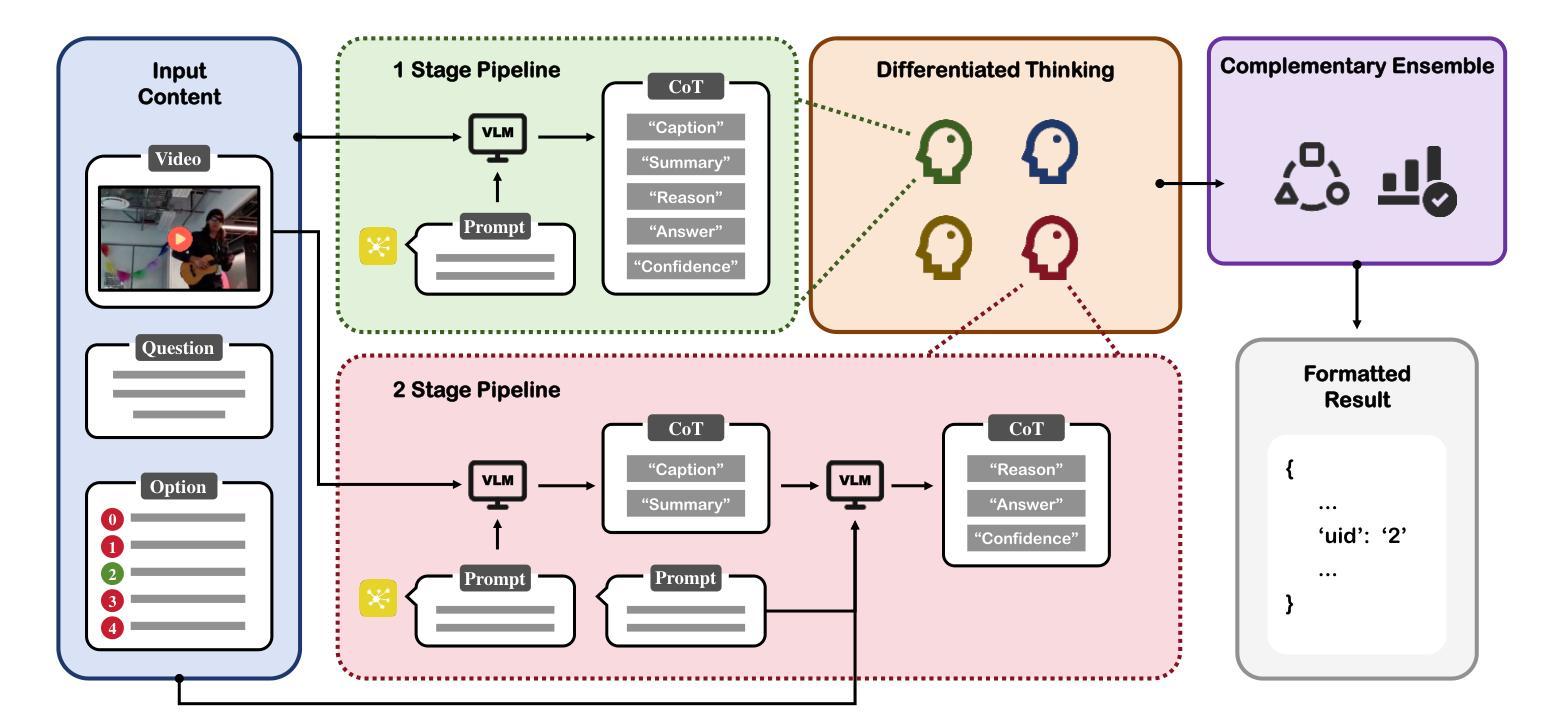
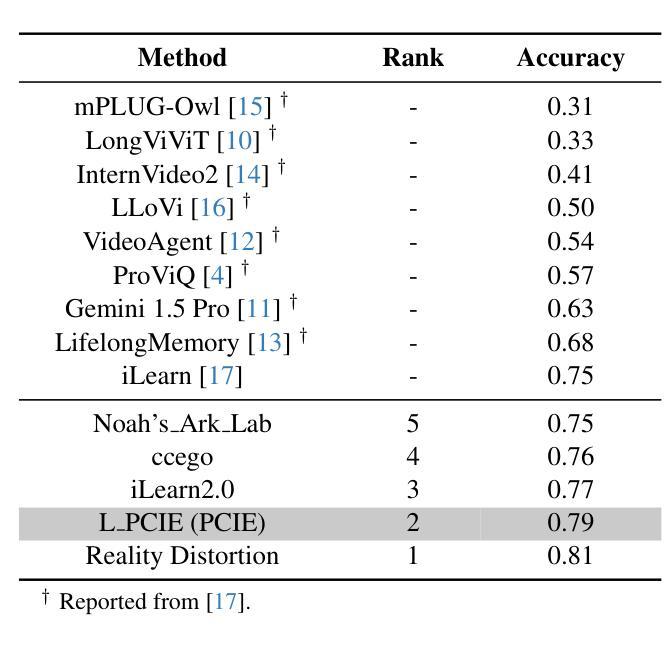
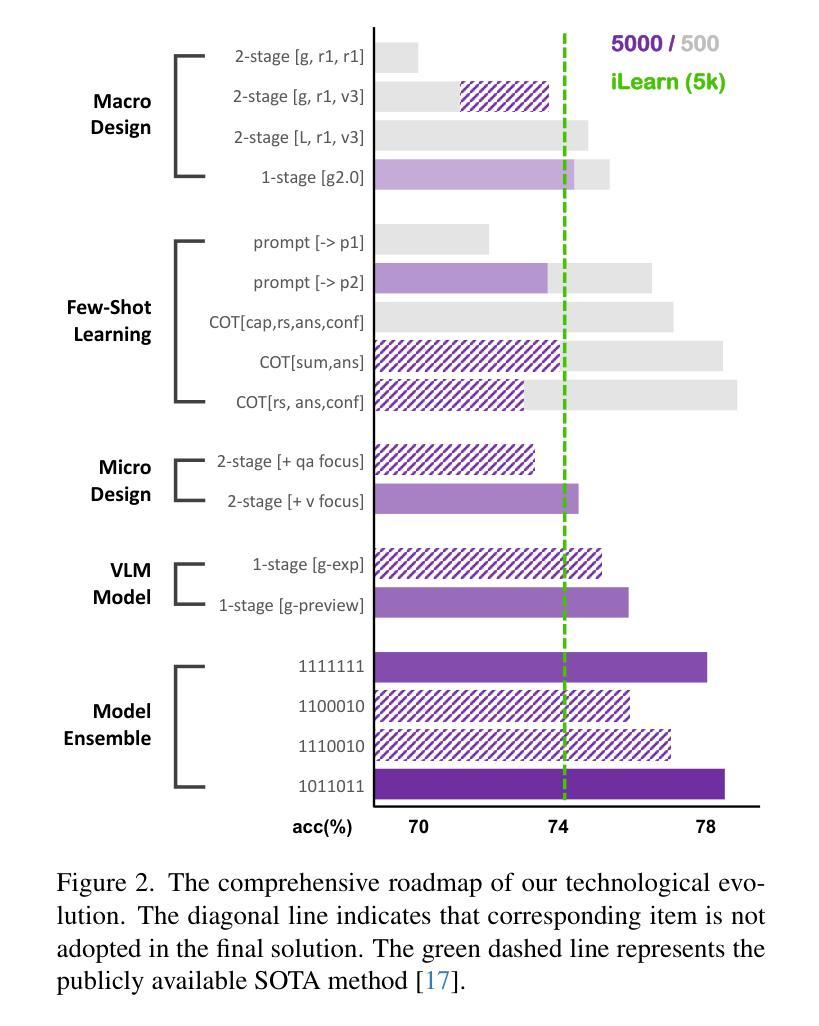
In this paper, we present the runner-up solution for the Ego4D EgoSchema Challenge at CVPR 2025 (Confirmed on May 20, 2025). Inspired by the success of large models, we evaluate and leverage leading accessible multimodal large models and adapt them to video understanding tasks via few-shot learning and model ensemble strategies. Specifically, diversified prompt styles and process paradigms are systematically explored and evaluated to effectively guide the attention of large models, fully unleashing their powerful generalization and adaptability abilities. Experimental results demonstrate that, with our carefully designed approach, directly utilizing an individual multimodal model already outperforms the previous state-of-the-art (SOTA) method which includes several additional processes. Besides, an additional stage is further introduced that facilitates the cooperation and ensemble of periodic results, which achieves impressive performance improvements. We hope this work serves as a valuable reference for the practical application of large models and inspires future research in the field.
本文介绍了我们在CVPR 2025年会(确认于2025年5月20日举行)上提出的Ego4D EgoSchema挑战赛的第二名解决方案。我们受到大型模型成功的启发,评估并采用了前沿的易于访问的多模态大型模型,并通过小样本学习和模型集成策略将它们适应到视频理解任务中。具体来说,系统地探索并评估多样化的提示风格和流程范式,以有效地引导大型模型的注意力,充分发挥它们强大的泛化和适应性能力。实验结果表明,通过我们精心设计的方法,直接使用单个多模态模型已经超越了之前最先进的(SOTA)方法,后者包括几个额外的流程。此外,还引入了额外的阶段,促进了周期性结果的合作和集成,取得了令人印象深刻的性能提升。我们希望这项工作能够为大型模型的实际应用提供有价值的参考,并激发该领域的未来研究灵感。
论文及项目相关链接
Summary
该论文介绍了在CVPR 2025的Ego4D EgoSchema挑战中荣获第二名的解决方案。该方案通过评估和充分利用前沿的多模态大型模型,并借助少样本学习和模型集成策略,适应视频理解任务。通过实验证明,利用个别单一的多模态模型的表现已超越先前的先进方法。此外,还引入了促进周期结果的合作和集成的额外阶段,取得了显著的性能提升。这项工作将为大型模型的实际应用提供有价值的参考,并激发该领域的未来研究灵感。
Key Takeaways
- 该论文是CVPR 2025的Ego4D EgoSchema挑战中的第二名解决方案。
- 利用前沿的多模态大型模型并借助少样本学习和模型集成策略来适应视频理解任务。
- 通过实验证明利用单一多模态模型已超越先前的方法。
- 引入额外的阶段促进周期结果的合作和集成,以提高性能。
- 这项工作旨在为大型模型的实际应用提供参考价值。
- 该论文展示了多样化的提示风格和流程范式,以有效地引导大型模型的注意力。
点此查看论文截图



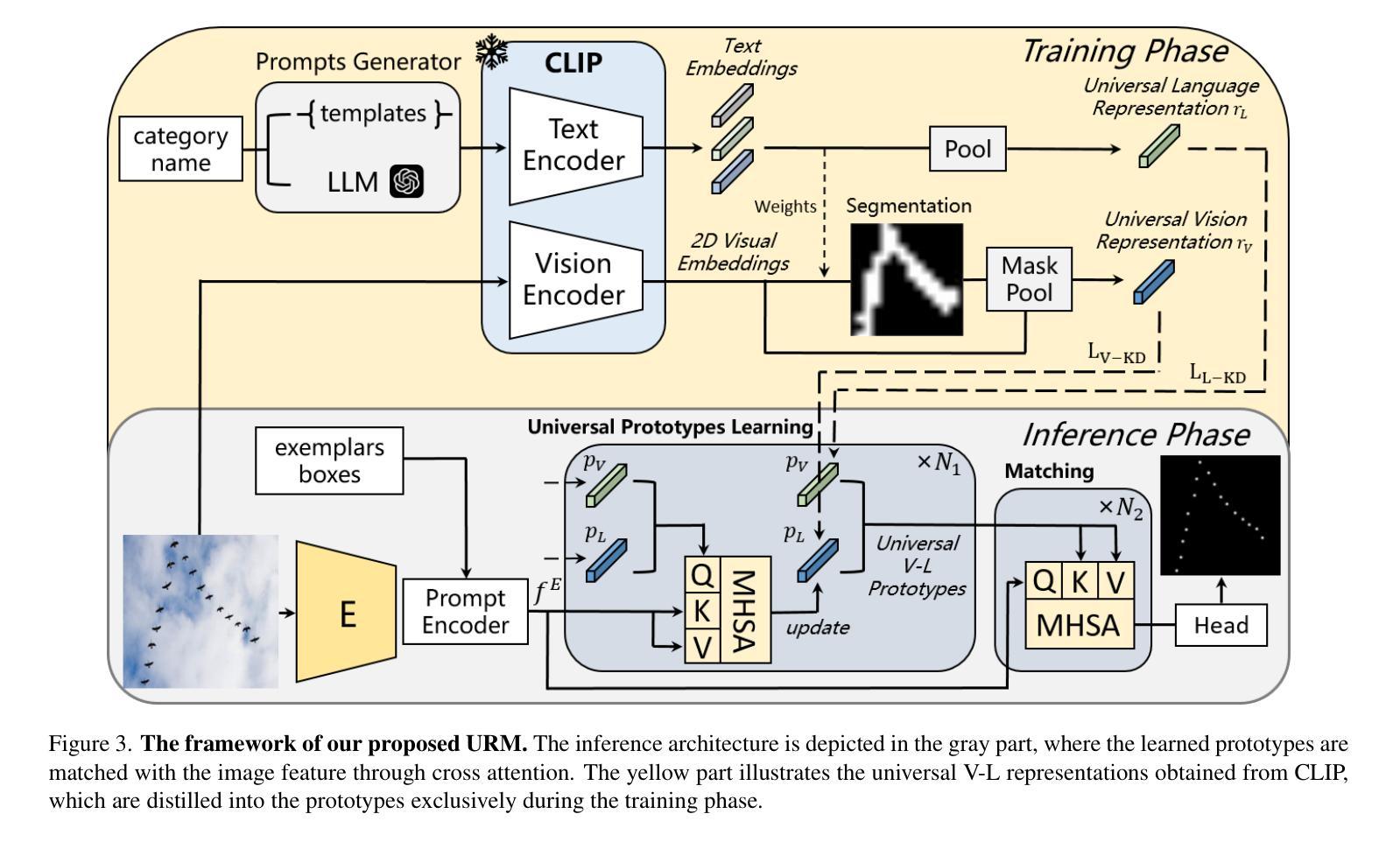
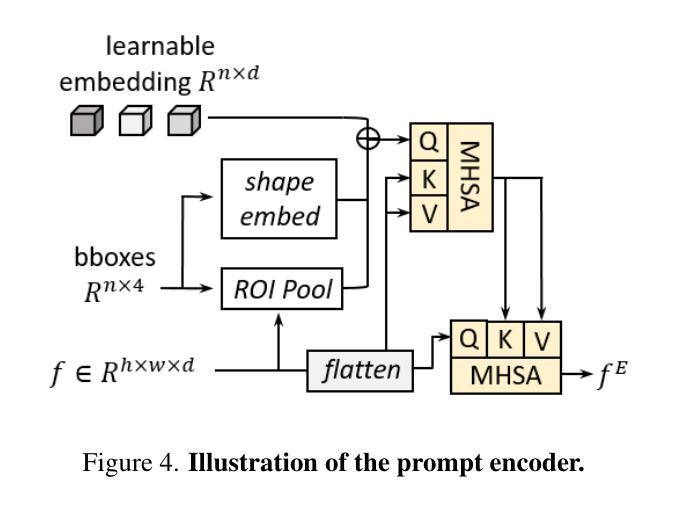
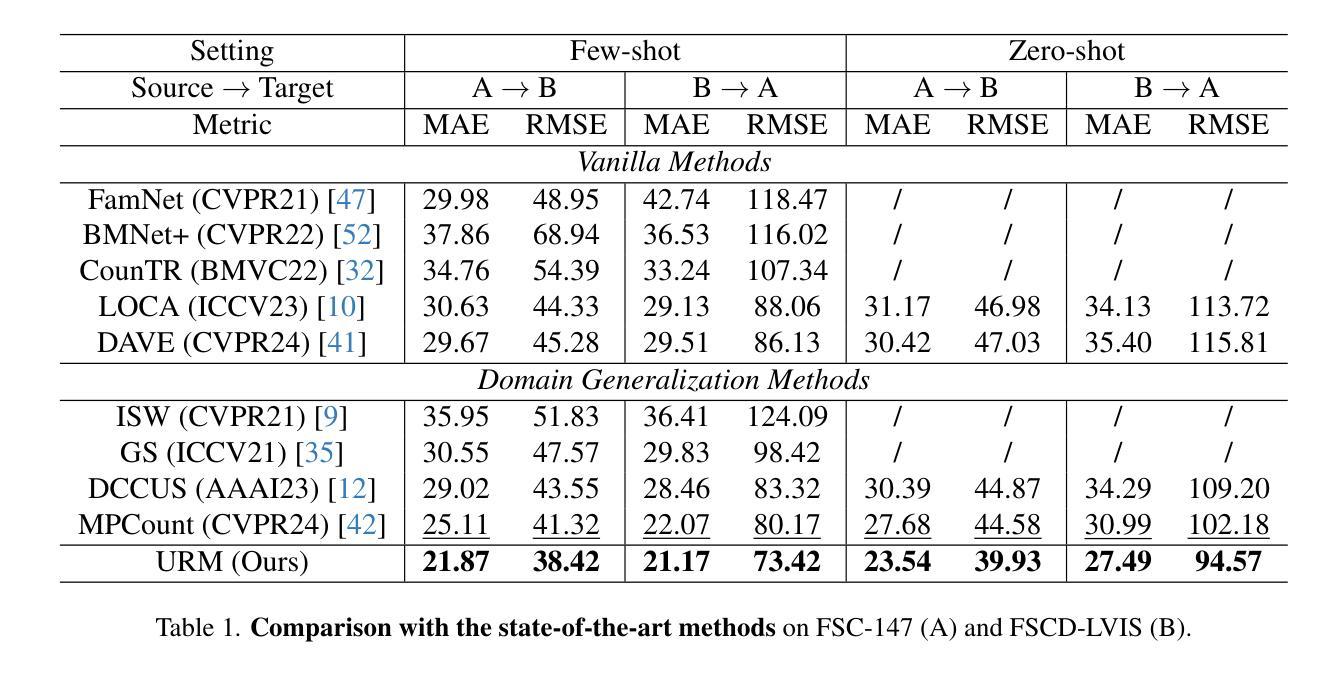
Single Domain Generalization for Few-Shot Counting via Universal Representation Matching
Authors:Xianing Chen, Si Huo, Borui Jiang, Hailin Hu, Xinghao Chen
Few-shot counting estimates the number of target objects in an image using only a few annotated exemplars. However, domain shift severely hinders existing methods to generalize to unseen scenarios. This falls into the realm of single domain generalization that remains unexplored in few-shot counting. To solve this problem, we begin by analyzing the main limitations of current methods, which typically follow a standard pipeline that extract the object prototypes from exemplars and then match them with image feature to construct the correlation map. We argue that existing methods overlook the significance of learning highly generalized prototypes. Building on this insight, we propose the first single domain generalization few-shot counting model, Universal Representation Matching, termed URM. Our primary contribution is the discovery that incorporating universal vision-language representations distilled from a large scale pretrained vision-language model into the correlation construction process substantially improves robustness to domain shifts without compromising in domain performance. As a result, URM achieves state-of-the-art performance on both in domain and the newly introduced domain generalization setting.
少量样本计数仅使用少量已标注样本估计图像中目标对象的数量。然而,领域偏移严重阻碍了现有方法推广到未见场景的能力。这属于少量样本计数中尚未探索的单域泛化领域。为了解决这个问题,我们首先分析了当前方法的主要局限性,这些方法通常遵循标准流程,从样本中提取对象原型,然后与图像特征匹配以构建关联映射图。我们认为现有方法忽视了学习高度通用原型的重要性。基于这一见解,我们提出了第一个用于单域泛化的少量样本计数模型——通用表示匹配(URM)。我们的主要贡献是发现将来自大规模预训练视觉语言模型的通用视觉语言表示融入关联构建过程,可以显著提高对领域偏移的鲁棒性,同时不损害领域性能。因此,URM在现有的领域内以及新引入的领域泛化设置中都达到了最先进的性能。
论文及项目相关链接
PDF CVPR 2025
Summary
少量样本计数通过仅使用少量标注样本估计图像中的目标对象数量。然而,领域差异严重阻碍了现有方法推广到未见场景的能力,这归属于未见领域的一般化问题,在少量样本计数中尚未被探索。为了解决这一问题,本文分析了当前方法的主要局限性,它们通常遵循从样本中提取对象原型并与图像特征匹配以构建关联图的管道。本文认为现有方法忽视了学习高度通用原型的重要性。基于此,我们提出了首个用于单领域泛化的少量样本计数模型——通用表示匹配(URM)。我们的主要贡献是发现将来自大规模预训练视觉语言模型的通用视觉语言表示融入关联构建过程,可大幅提高对不同领域的适应性,同时不损失原有领域的性能。因此,URM在原有领域和全新引入的领域泛化设置上都达到了最佳性能。
Key Takeaways
- 少量样本计数旨在利用少量标注样本估计图像中的目标数量。
- 领域差异是当前方法的推广瓶颈,尤其是在未见领域的一般化问题上。
- 当前方法主要局限于标准管道,即从样本中提取对象原型并与图像特征匹配以构建关联图。
- 现有方法忽视了学习高度通用的原型的重要性。
- 提出首个用于单领域泛化的少量样本计数模型——URM。
- URM通过将通用视觉语言表示融入关联构建过程,提高了对不同领域的适应性。
点此查看论文截图


Meta-reinforcement learning with minimum attention
Authors:Pilhwa Lee, Shashank Gupta
Minimum attention applies the least action principle in the changes of control concerning state and time, first proposed by Brockett. The involved regularization is highly relevant in emulating biological control, such as motor learning. We apply minimum attention in reinforcement learning (RL) as part of the rewards and investigate its connection to meta-learning and stabilization. Specifically, model-based meta-learning with minimum attention is explored in high-dimensional nonlinear dynamics. Ensemble-based model learning and gradient-based meta-policy learning are alternately performed. Empirically, we show that the minimum attention does show outperforming competence in comparison to the state-of-the-art algorithms in model-free and model-based RL, i.e., fast adaptation in few shots and variance reduction from the perturbations of the model and environment. Furthermore, the minimum attention demonstrates the improvement in energy efficiency.
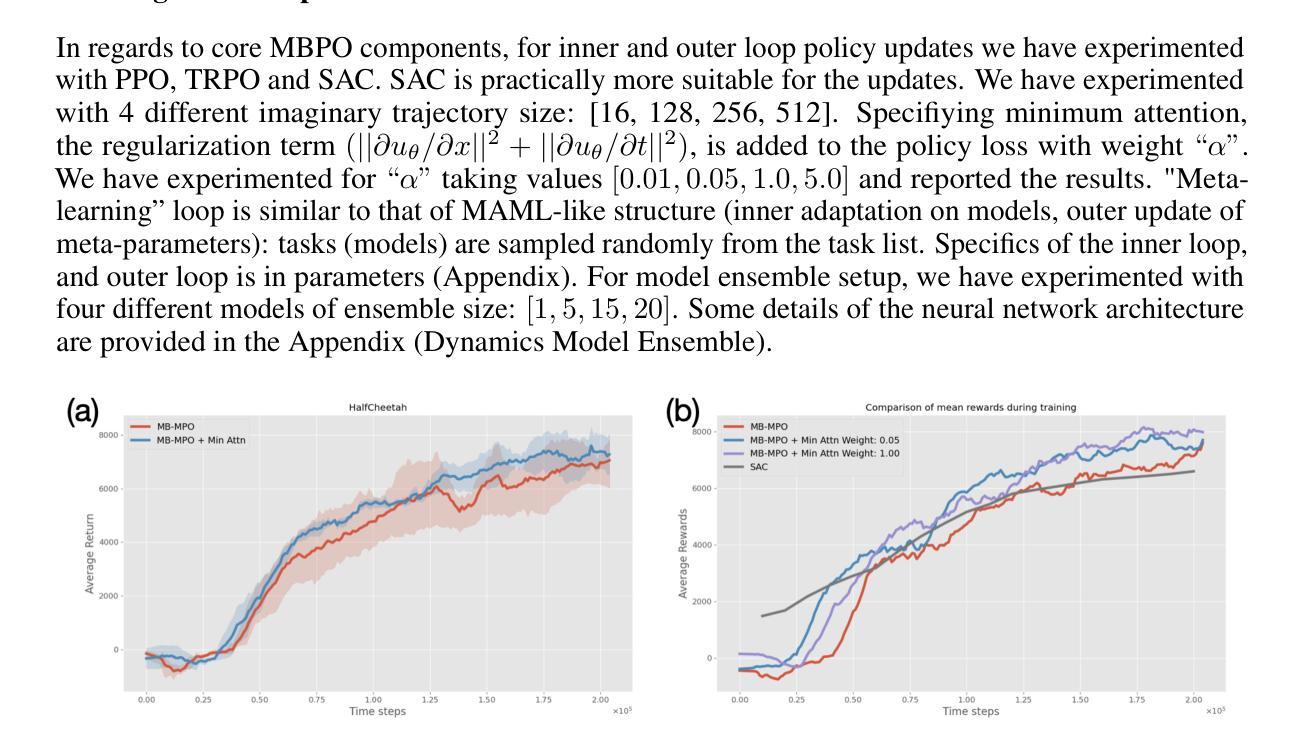
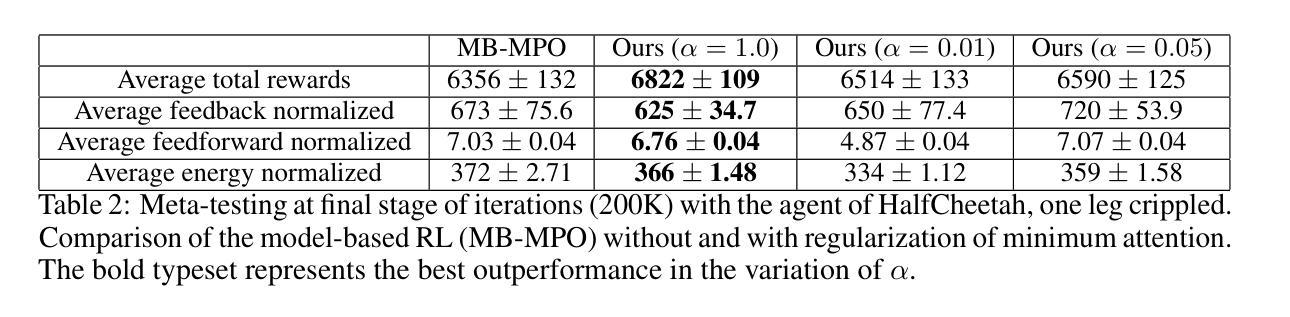
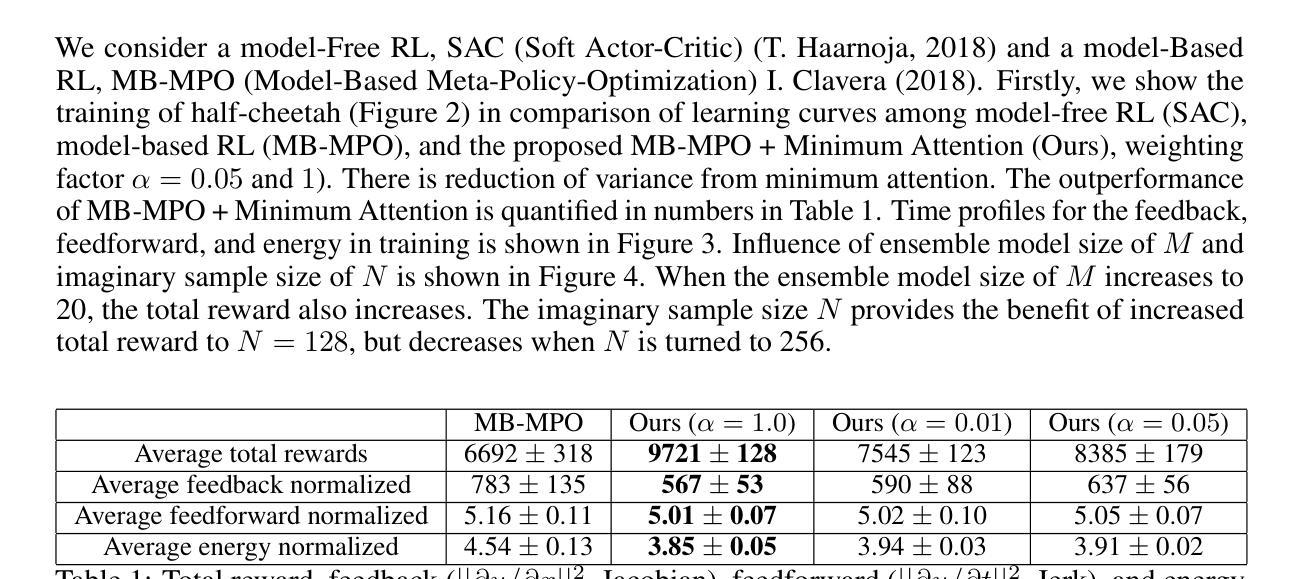
最小注意力遵循布罗克特(Brockett)提出的关于状态和时间的控制变化中的最小作用原则。这种涉及的规则化与模拟生物控制(如运动学习)密切相关。我们将最小注意力应用于强化学习(RL)作为奖励的一部分,并研究其与元学习和稳定化的联系。具体来说,在高维非线性动力学中探索了基于模型的元学习与最小注意力的结合。基于集合的模型学习和基于梯度的元策略学习交替进行。从实证上看,我们证明了最小注意力在与无模型和基于模型的最新RL算法的比较中表现出优越的竞争力,例如快速适应少数样本和减少模型和环境的扰动带来的方差。此外,最小注意力还证明了其在能效方面的提升。
论文及项目相关链接
PDF 10 pages, 7 figures
Summary
最小注意力原理将最少行动原则应用于状态和时间控制的变化中,最早由Brockett提出。该原理在模拟生物控制,如运动学习方面具有很高的相关性。我们在强化学习(RL)中应用最小注意力作为奖励的一部分,并研究其与元学习和稳定化的联系。特别是在高维非线性动力学中,探索了基于模型的元学习与最小注意力的结合。本文交替进行基于集合的模型学习和基于梯度的元策略学习。经验表明,与最新的模型无关和基于模型的RL算法相比,最小注意力在快速适应和减少模型和环境的扰动引起的方差方面表现出更高的性能。此外,最小注意力在提高能源效率方面也显示出改进。
Key Takeaways
- 最小注意力原理涉及最少行动原则,应用于状态和时间控制的改变。
- 最小注意力在强化学习中作为奖励的一部分被研究,并与元学习和稳定化有关联。
- 在高维非线性动力学中,基于模型的元学习与最小注意力相结合进行了探索。
- 研究中交替进行了基于集合的模型学习和基于梯度的元策略学习。
- 最小注意力在快速适应和减少模型及环境扰动引起的方差方面表现出优越性能。
- 最小注意力在提高能源效率方面有所改进。
点此查看论文截图

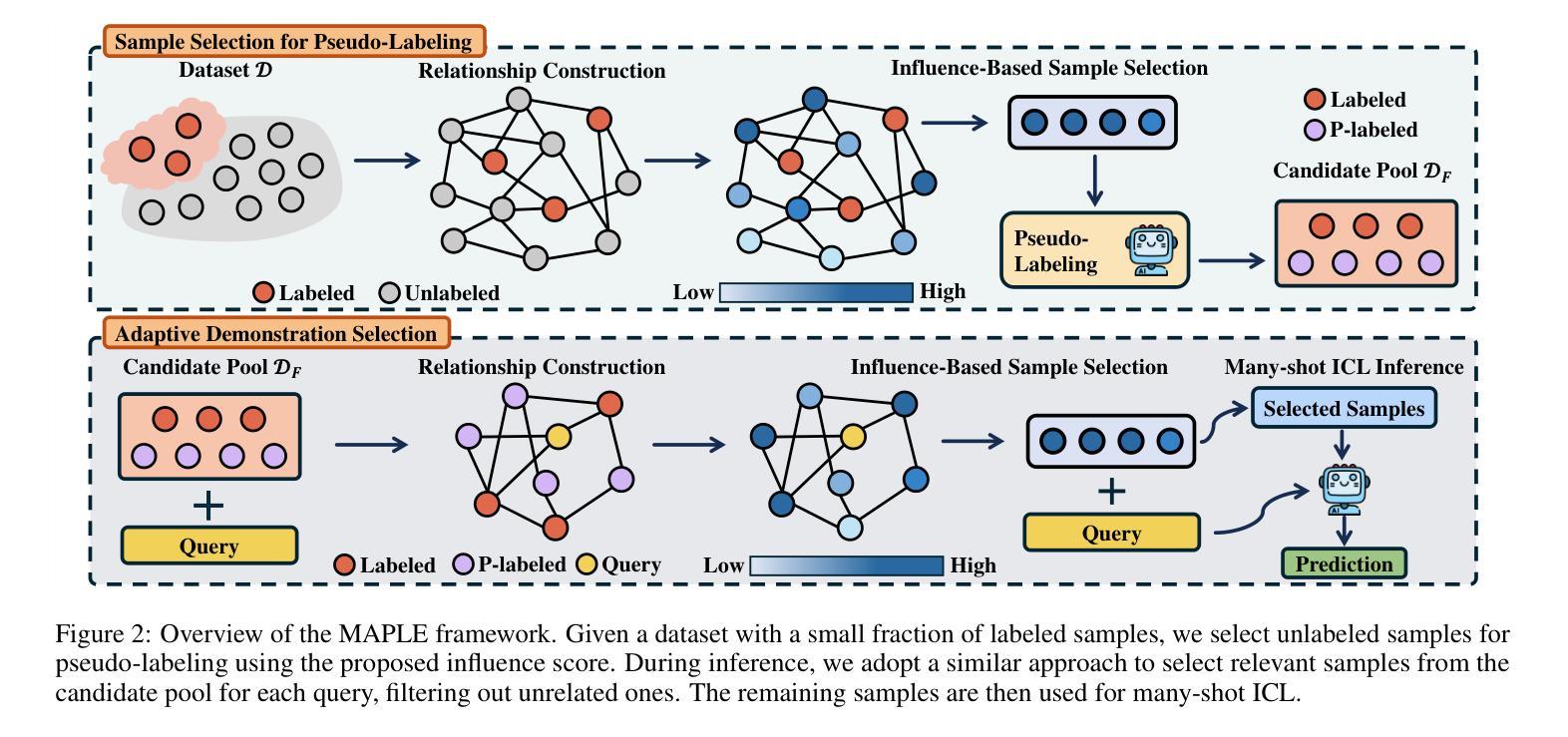
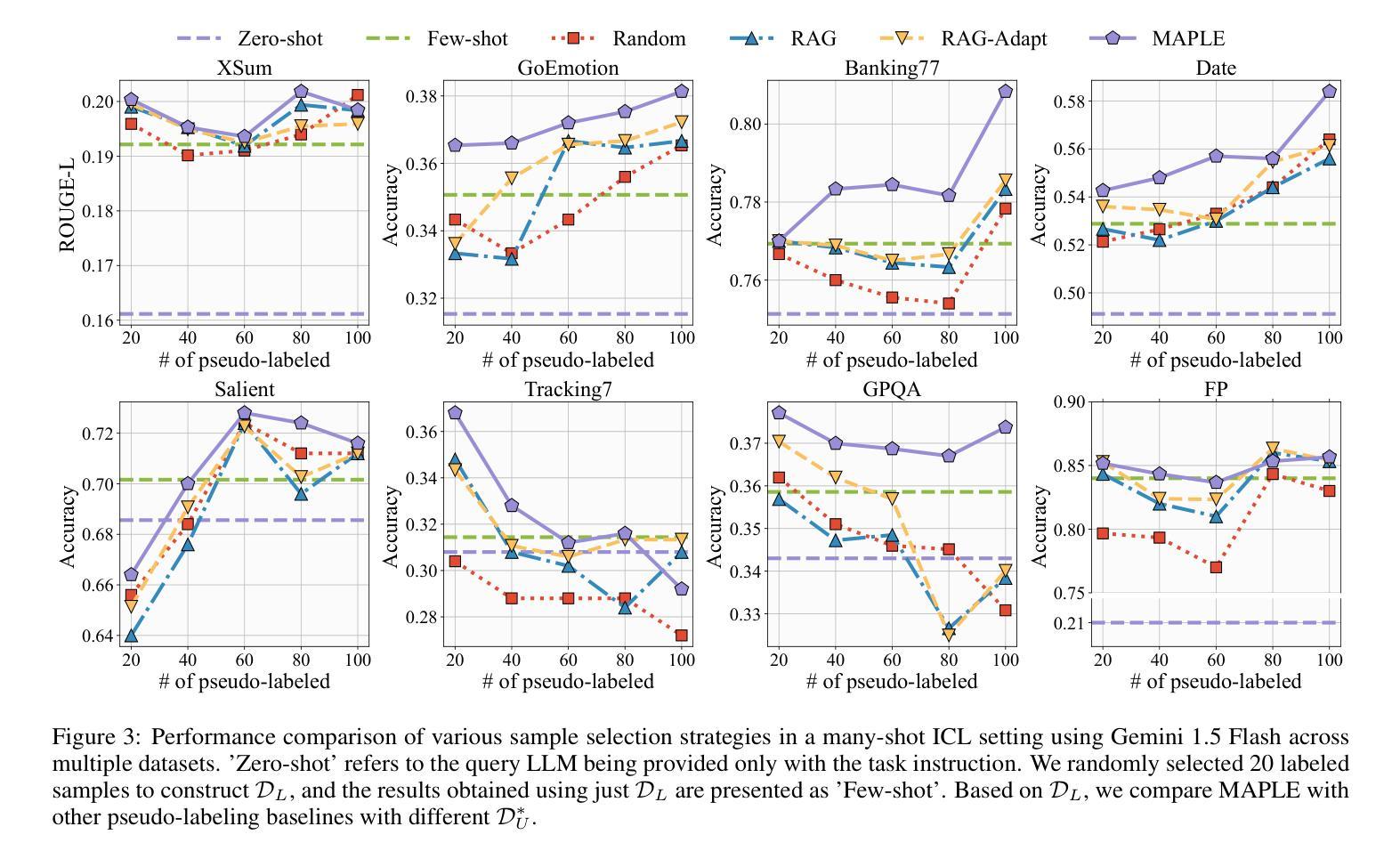
MAPLE: Many-Shot Adaptive Pseudo-Labeling for In-Context Learning
Authors:Zihan Chen, Song Wang, Zhen Tan, Jundong Li, Cong Shen
In-Context Learning (ICL) empowers Large Language Models (LLMs) to tackle diverse tasks by incorporating multiple input-output examples, known as demonstrations, into the input of LLMs. More recently, advancements in the expanded context windows of LLMs have led to many-shot ICL, which uses hundreds of demonstrations and outperforms few-shot ICL, which relies on fewer examples. However, this approach is often hindered by the high cost of obtaining large amounts of labeled data. To address this challenge, we propose Many-Shot Adaptive Pseudo-LabEling, namely MAPLE, a novel influence-based many-shot ICL framework that utilizes pseudo-labeled samples to compensate for the lack of label information. We first identify a subset of impactful unlabeled samples and perform pseudo-labeling on them by querying LLMs. These pseudo-labeled samples are then adaptively selected and tailored to each test query as input to improve the performance of many-shot ICL, without significant labeling costs. Extensive experiments on real-world datasets demonstrate the effectiveness of our framework, showcasing its ability to enhance LLM adaptability and performance with limited labeled data.
上下文学习(ICL)通过融入多个输入输出示例(也称为演示)到大型语言模型(LLM)的输入中,使LLM能够处理多样化任务。最近,LLM扩展的上下文窗口的进步导致了多示例ICL的出现,它使用数百个演示,并优于少示例ICL,后者依赖于较少的例子。然而,这种方法常常受到获取大量标记数据的高成本的阻碍。为了解决这一挑战,我们提出了基于影响的多示例自适应伪标签技术(MAPLE),这是一种新型的多示例ICL框架,它利用伪标签样本来弥补标签信息的缺乏。我们首先识别出有影响力的未标记样本子集,并通过查询LLM对它们进行伪标记。这些伪标记的样本随后被自适应地选择和针对每个测试查询作为输入,以提高多示例ICL的性能,而无需承担大量的标记成本。在真实数据集上的广泛实验证明了我们框架的有效性,展示了其在有限标记数据下提高LLM适应性和性能的能力。
论文及项目相关链接
Summary
大型语言模型(LLM)通过结合多个输入输出范例(即演示)来执行多种任务。最近,LLM扩展的上下文窗口导致出现多示例上下文学习(ICL),它使用数百个演示,并优于少示例ICL。然而,获取大量标记数据的成本很高,成为一大挑战。为解决这一问题,我们提出了名为MAPLE的新型基于影响的多示例ICL框架,利用伪标记样本来弥补标签信息的缺乏。我们首先识别出有影响力的未标记样本子集并对它们进行伪标记查询LLM。这些伪标记样本随后被自适应选择并针对每个测试查询进行输入,以提高多示例ICL的性能,同时无需大量标记成本。在真实数据集上的广泛实验证明了框架的有效性,展示了其在有限标记数据下提高LLM适应性和性能的能力。
Key Takeaways
- In-Context Learning (ICL)允许大型语言模型(LLMs)结合多个输入输出范例来执行多样化任务。
- 多示例ICL使用数百个演示样本,并表现出优于少示例ICL的性能。
- 获取大量标记数据的成本高昂,是ICL的主要挑战之一。
- MAPLE框架利用伪标记样本来弥补标签信息的缺乏,提高多示例ICL的性能。
- MAPLE通过识别有影响力的未标记样本并进行伪标记查询LLM,来适应每个测试查询。
- 广泛实验证明MAPLE框架的有效性,在真实数据集上提高了LLM的适应性和性能。
点此查看论文截图

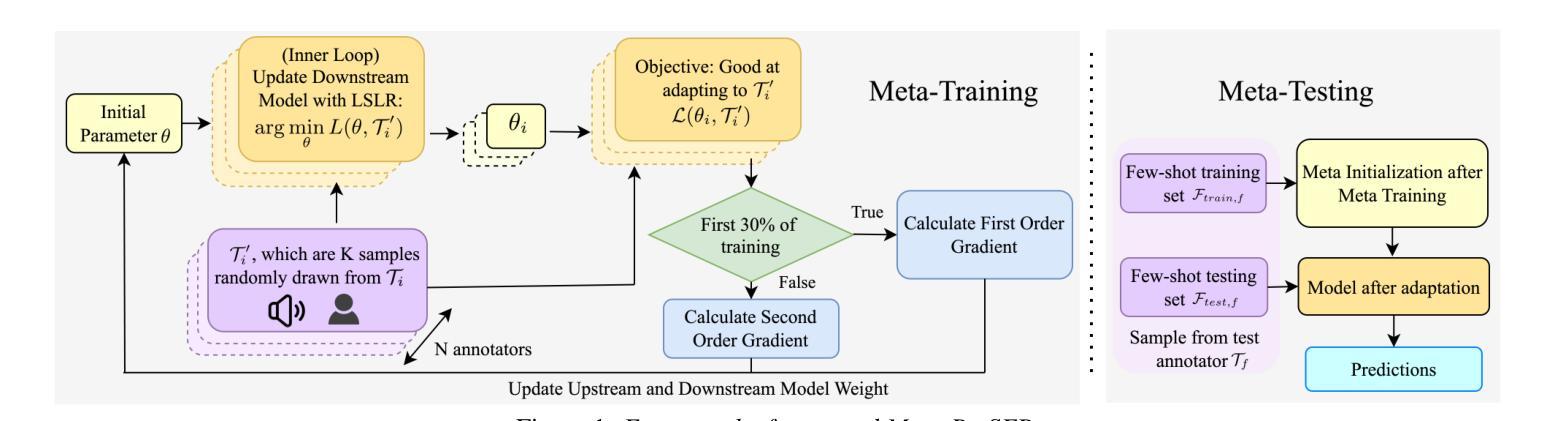
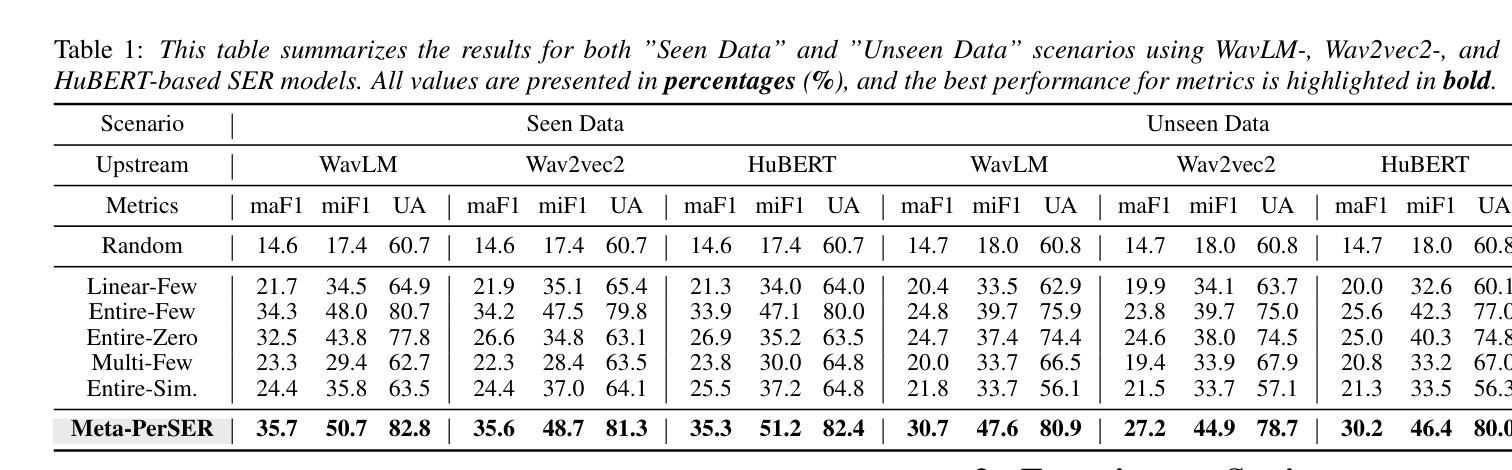
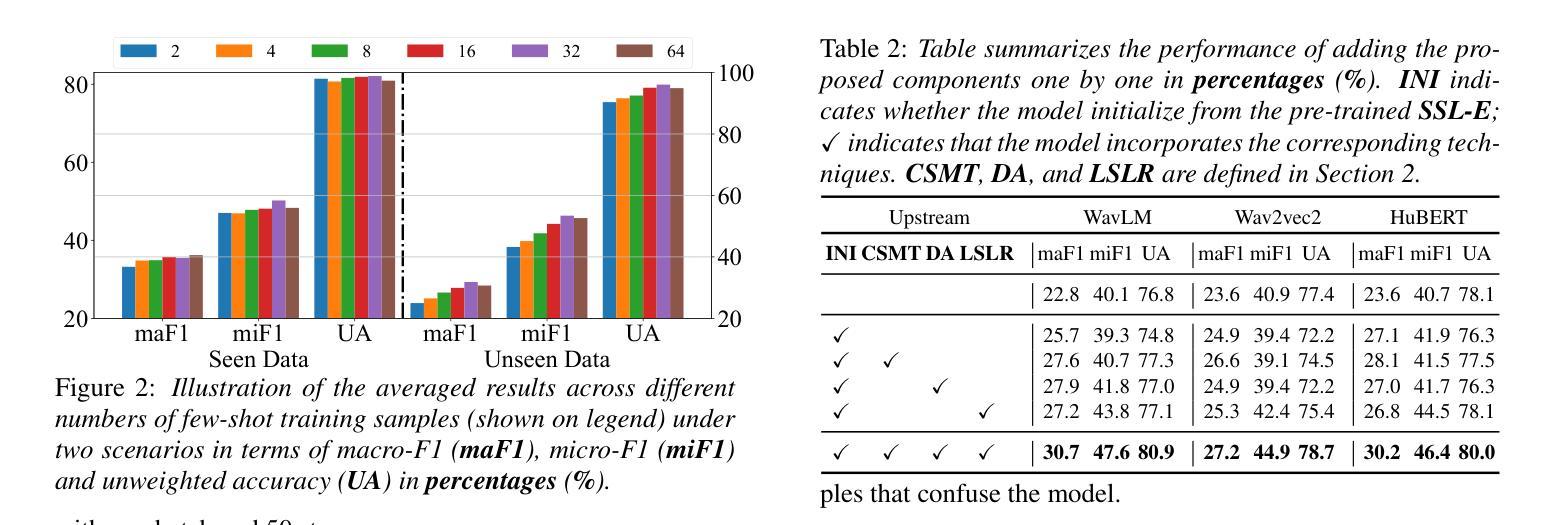
Meta-PerSER: Few-Shot Listener Personalized Speech Emotion Recognition via Meta-learning
Authors:Liang-Yeh Shen, Shi-Xin Fang, Yi-Cheng Lin, Huang-Cheng Chou, Hung-yi Lee
This paper introduces Meta-PerSER, a novel meta-learning framework that personalizes Speech Emotion Recognition (SER) by adapting to each listener’s unique way of interpreting emotion. Conventional SER systems rely on aggregated annotations, which often overlook individual subtleties and lead to inconsistent predictions. In contrast, Meta-PerSER leverages a Model-Agnostic Meta-Learning (MAML) approach enhanced with Combined-Set Meta-Training, Derivative Annealing, and per-layer per-step learning rates, enabling rapid adaptation with only a few labeled examples. By integrating robust representations from pre-trained self-supervised models, our framework first captures general emotional cues and then fine-tunes itself to personal annotation styles. Experiments on the IEMOCAP corpus demonstrate that Meta-PerSER significantly outperforms baseline methods in both seen and unseen data scenarios, highlighting its promise for personalized emotion recognition.
本文介绍了Meta-PerSER,这是一种新型元学习框架,通过适应每个听众独特的情感解读方式来个性化语音情感识别(SER)。传统的SER系统依赖于聚合注释,这往往会忽略个体细微差别并导致预测结果不一致。相比之下,Meta-PerSER利用结合集合元训练、导数退火和逐层分步学习率的模型无关元学习方法(MAML),仅通过少量标注样本即可实现快速适应。通过整合预训练自监督模型的稳健表示,我们的框架首先捕获一般情感线索,然后对自身进行微调以适应个人注释风格。在IEMOCAP语料库上的实验表明,Meta-PerSER在已见和未见数据场景中均显著优于基准方法,凸显其在个性化情感识别方面的潜力。
论文及项目相关链接
PDF Accepted by INTERSPEECH 2025. 7 pages, including 2 pages of appendix
Summary
本文主要介绍了一种新型的元学习框架Meta-PerSER,它通过个性化语音情感识别(SER)来适应每个听众独特的情感解读方式。该框架采用模型无关的元学习方法,并结合集合元训练、导数退火以及分层分步骤的学习率调整技术,能在仅使用少量标注样本的情况下快速适应新任务。此外,通过引入预训练自监督模型的稳健表示,Meta-PerSER不仅能捕捉一般情感线索,还能针对个人标注风格进行微调。在IEMOCAP语料库上的实验表明,Meta-PerSER在可见和未见数据场景下均显著优于基准方法,展现出个性化情感识别的潜力。
Key Takeaways
- Meta-PerSER是一种新颖的元学习框架,用于个性化语音情感识别(SER)。
- 该框架通过适应每个听众独特的情感解读方式,提高了SER系统的性能。
- Meta-PerSER采用模型无关的元学习方法,并结合多种技术,如集合元训练、导数退火和分层分步骤的学习率调整,实现快速适应新任务的能力。
- 通过引入预训练自监督模型的稳健表示,Meta-PerSER能捕捉一般情感线索并适应个人标注风格。
- 实验表明,Meta-PerSER在可见和未见数据场景下均显著优于传统方法。
- Meta-PerSER在个性化情感识别领域展现出巨大潜力。
点此查看论文截图

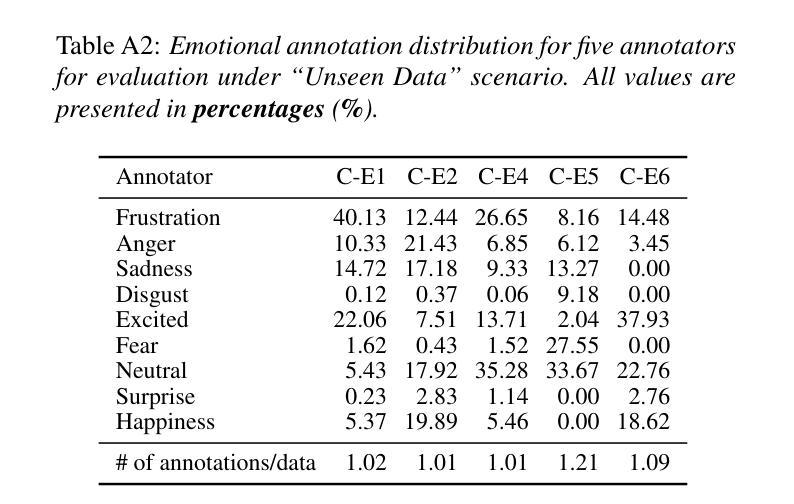
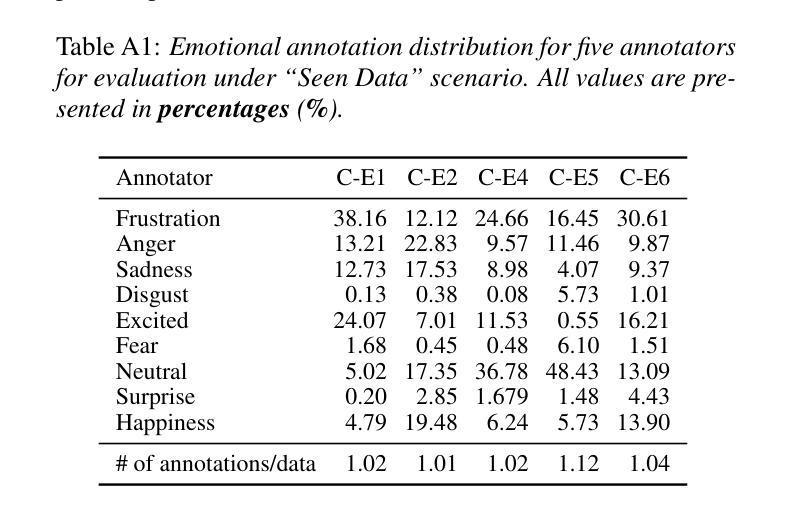

VLM-R$^3$: Region Recognition, Reasoning, and Refinement for Enhanced Multimodal Chain-of-Thought
Authors:Chaoya Jiang, Yongrui Heng, Wei Ye, Han Yang, Haiyang Xu, Ming Yan, Ji Zhang, Fei Huang, Shikun Zhang
Recently, reasoning-based MLLMs have achieved a degree of success in generating long-form textual reasoning chains. However, they still struggle with complex tasks that necessitate dynamic and iterative focusing on and revisiting of visual regions to achieve precise grounding of textual reasoning in visual evidence. We introduce \textbf{VLM-R$^3$} (\textbf{V}isual \textbf{L}anguage \textbf{M}odel with \textbf{R}egion \textbf{R}ecognition and \textbf{R}easoning), a framework that equips an MLLM with the ability to (i) decide \emph{when} additional visual evidence is needed, (ii) determine \emph{where} to ground within the image, and (iii) seamlessly weave the relevant sub-image content back into an interleaved chain-of-thought. The core of our method is \textbf{Region-Conditioned Reinforcement Policy Optimization (R-GRPO)}, a training paradigm that rewards the model for selecting informative regions, formulating appropriate transformations (e.g.\ crop, zoom), and integrating the resulting visual context into subsequent reasoning steps. To bootstrap this policy, we compile a modest but carefully curated Visuo-Lingual Interleaved Rationale (VLIR) corpus that provides step-level supervision on region selection and textual justification. Extensive experiments on MathVista, ScienceQA, and other benchmarks show that VLM-R$^3$ sets a new state of the art in zero-shot and few-shot settings, with the largest gains appearing on questions demanding subtle spatial reasoning or fine-grained visual cue extraction.
最近,基于推理的MLLMs(Masked Language Modeling)在生成长文本推理链方面取得了一定的成功。然而,它们在处理复杂的任务时仍然面临挑战,这些任务需要动态和迭代地关注并回顾视觉区域,以实现文本推理在视觉证据中的精确定位。我们引入了VLM-R$^3$(带区域识别和推理的视觉语言模型),这一框架使MLLM具备以下能力:(i)决定何时需要额外的视觉证据;(ii)确定在图像中的定位位置;(iii)无缝地将相关的子图像内容重新编织成连贯的推理链。我们的方法的核心是区域条件强化策略优化(R-GRPO),这是一种训练范式,奖励模型选择信息区域、制定适当的转换(例如裁剪、放大)并将所得的视觉上下文集成到随后的推理步骤中。为了引导策略,我们整理了一个规模不大但精心策划的Visuo-Lingual Interleaved Rationale(VLIR)语料库,该语料库为区域选择和文本论证提供了步骤级的监督。在MathVista、ScienceQA和其他基准测试上的广泛实验表明,VLM-R$^3$在零样本和少样本设置上创下了新的技术纪录,特别是在需要微妙的空间推理或精细的视觉线索提取的问题上,其增益最为显著。
论文及项目相关链接
Summary
在基于文本的大型语言模型取得长期推理链生成的成功之后,面对需要在视觉证据中进行精确文本推理的复杂任务,它们仍然面临挑战。为此,我们推出了VLM-R³框架,该框架为大型语言模型配备了三项能力:决定何时需要额外的视觉证据、确定在图像中的定位,以及无缝地将相关子图像内容融入思维链中。该框架的核心是区域条件强化政策优化(R-GRPO)训练范式,奖励模型选择信息区域、制定适当的转换(如裁剪、缩放),并将所得的视觉上下文融入后续推理步骤。为了引导政策,我们精心编制了Visuo-Lingual交互式论证语料库,为区域选择和文本论证提供步骤层面的监督。在数学景观、科学问答等基准测试上的大量实验表明,VLM-R³在零样本和少样本设置中树立了新的技术标杆,尤其是在需要精细空间推理或精细视觉线索提取的问题上,其增益最为显著。
Key Takeaways
- VLM-R³框架为大型语言模型配备了动态迭代聚焦和回访视觉区域的能力,以实现文本推理在视觉证据中的精确定位。
- 核心方法Region-Conditioned Reinforcement Policy Optimization (R-GRPO)鼓励模型选择信息区域、进行转换并整合视觉上下文。
- Visuo-Lingual Interleaved Rationale (VLIR)语料库的创建为区域选择和文本论证提供了步骤层面的监督。
- VLM-R³在数学景观、科学问答等基准测试上表现卓越,尤其在需要精细空间推理或视觉线索提取的问题上增益显著。
- 该框架的引入解决了大型语言模型在处理复杂视觉任务时的局限性。
- VLM-R³能够无缝地将子图像内容融入思维链中,增强了模型的推理能力。
- R-GRPO训练范式通过奖励机制优化模型在视觉任务中的决策过程。
点此查看论文截图


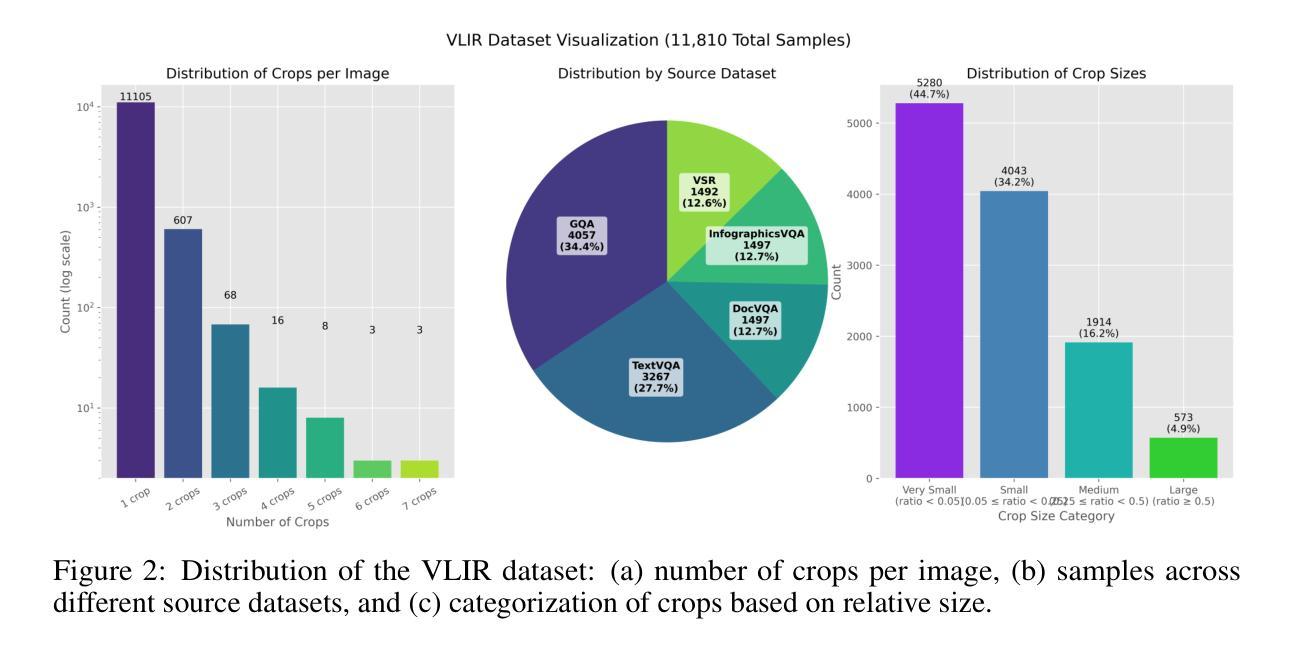
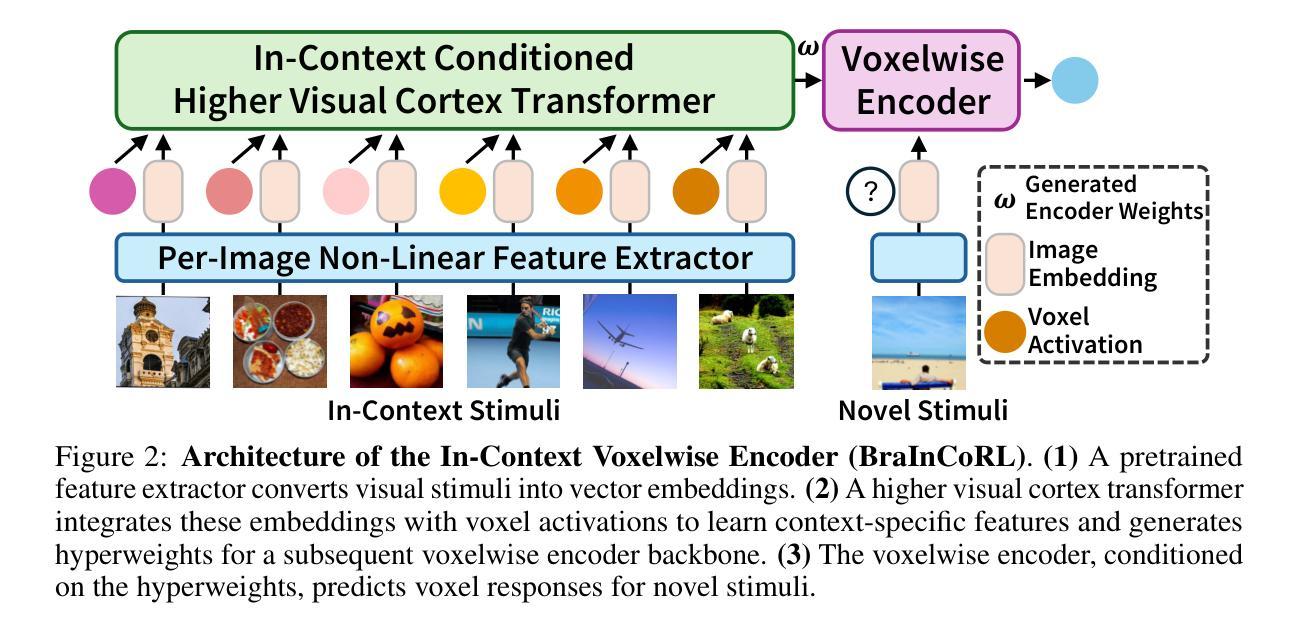
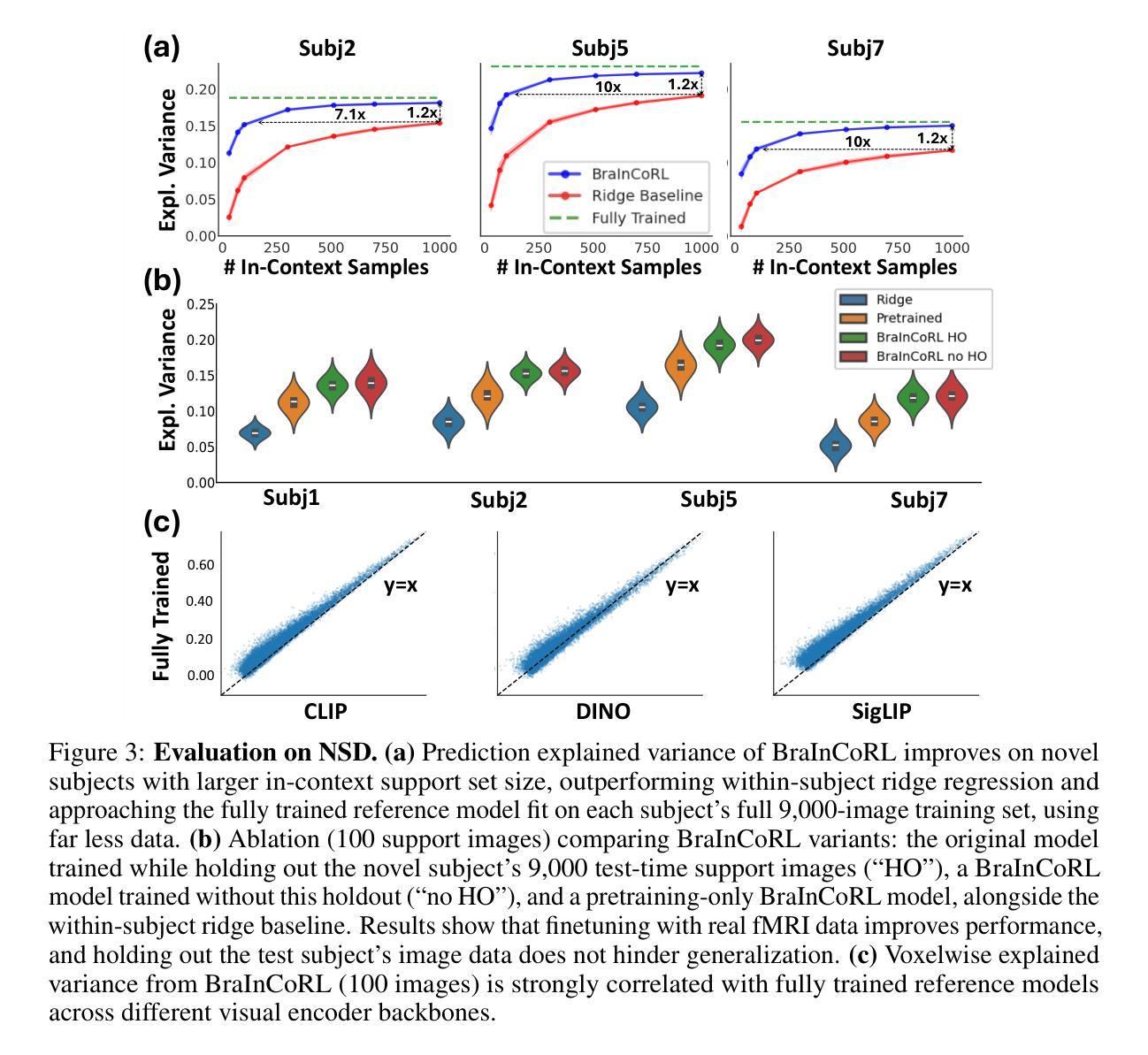
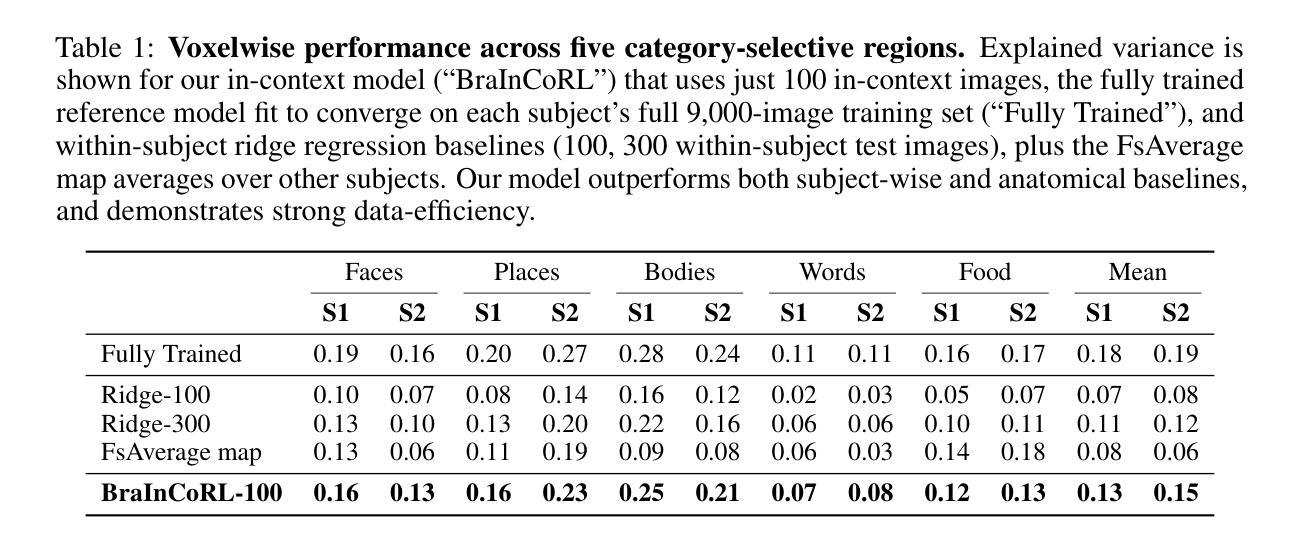
Meta-Learning an In-Context Transformer Model of Human Higher Visual Cortex
Authors:Muquan Yu, Mu Nan, Hossein Adeli, Jacob S. Prince, John A. Pyles, Leila Wehbe, Margaret M. Henderson, Michael J. Tarr, Andrew F. Luo
Understanding functional representations within higher visual cortex is a fundamental question in computational neuroscience. While artificial neural networks pretrained on large-scale datasets exhibit striking representational alignment with human neural responses, learning image-computable models of visual cortex relies on individual-level, large-scale fMRI datasets. The necessity for expensive, time-intensive, and often impractical data acquisition limits the generalizability of encoders to new subjects and stimuli. BraInCoRL uses in-context learning to predict voxelwise neural responses from few-shot examples without any additional finetuning for novel subjects and stimuli. We leverage a transformer architecture that can flexibly condition on a variable number of in-context image stimuli, learning an inductive bias over multiple subjects. During training, we explicitly optimize the model for in-context learning. By jointly conditioning on image features and voxel activations, our model learns to directly generate better performing voxelwise models of higher visual cortex. We demonstrate that BraInCoRL consistently outperforms existing voxelwise encoder designs in a low-data regime when evaluated on entirely novel images, while also exhibiting strong test-time scaling behavior. The model also generalizes to an entirely new visual fMRI dataset, which uses different subjects and fMRI data acquisition parameters. Further, BraInCoRL facilitates better interpretability of neural signals in higher visual cortex by attending to semantically relevant stimuli. Finally, we show that our framework enables interpretable mappings from natural language queries to voxel selectivity.
理解高级视觉皮层中的功能表征是计算神经科学中的一个基本问题。虽然基于大规模数据集进行预训练的人工神经网络与人的神经反应表现出了惊人的表征一致性,但学习视觉皮层的图像计算模型依赖于个体层面的大规模功能性磁共振成像(fMRI)数据集。昂贵、耗时且通常不切实际的数据采集需求限制了编码器对新手和刺激的推广能力。BraInCoRL使用上下文学习来预测少数样本的体素神经反应,无需对新主体和刺激进行任何额外的微调。我们采用了一种变压器架构,可以灵活地适应不同数量的上下文图像刺激,并在多个主体上形成归纳偏见。在训练过程中,我们明确地对模型进行了上下文学习优化。通过联合图像特征和体素激活物,我们的模型学会了直接生成高级视觉皮层的性能更好的体素模型。我们在全新图像上的评估结果表明,BraInCoRL在数据缺乏的情况下始终优于现有的体素编码器设计,同时在测试时表现出强大的扩展行为。该模型还可以推广到一个全新的视觉fMRI数据集,该数据集使用不同的主体和fMRI数据采集参数。此外,BraInCoRL通过关注语义相关的刺激,提高了高级视觉皮层神经信号的解读性。最后,我们展示了我们的框架能够实现从自然语言查询到体素选择性的可解释映射。
论文及项目相关链接
Summary
本文探讨了计算神经科学中的基本问题,即理解高级视觉皮层中的功能表征。研究指出,预训练于大规模数据集的人工神经网络与人脑神经响应具有显著的一致性。然而,建立可视皮层的图像计算模型依赖于个体层面的大规模fMRI数据集,这限制了编码器对新主体和刺激的推广能力。BraInCoRL使用上下文学习技术,仅通过少量样本就能预测神经响应,无需对新主体和刺激进行微调。利用变压器架构,该模型可灵活适应不同数量的上下文图像刺激,并在多个主体之间建立归纳偏见。通过联合图像特征和体素激活,模型可直接生成高级视觉皮层的体素模型。实验表明,BraInCoRL在低数据环境中持续优于现有体素编码器设计,在全新图像上的表现尤为出色,并具有强大的测试规模行为。此外,该模型可推广到使用不同主体和fMRI数据采集参数的新视觉fMRI数据集,并有助于更好地解释高级视觉皮层的神经信号。最后,研究展示了该框架可实现自然语言查询到体素选择性的可解释映射。
Key Takeaways
- 理解高级视觉皮层中的功能表征是计算神经科学的基本问题。
- 人工神经网络预训练于大规模数据集与人脑神经响应具有一致性。
- 学习图像计算模型依赖于个体层面的大规模fMRI数据集,这限制了编码器的推广能力。
- BraInCoRL使用上下文学习技术,通过少量样本预测神经响应,无需对新主体和刺激进行微调。
- BraInCoRL利用变压器架构,可灵活适应不同数量的上下文图像刺激,并在多个主体间建立归纳偏见。
- BraInCoRL在低数据环境中表现优异,并能在全新图像上展示强大的性能。
点此查看论文截图

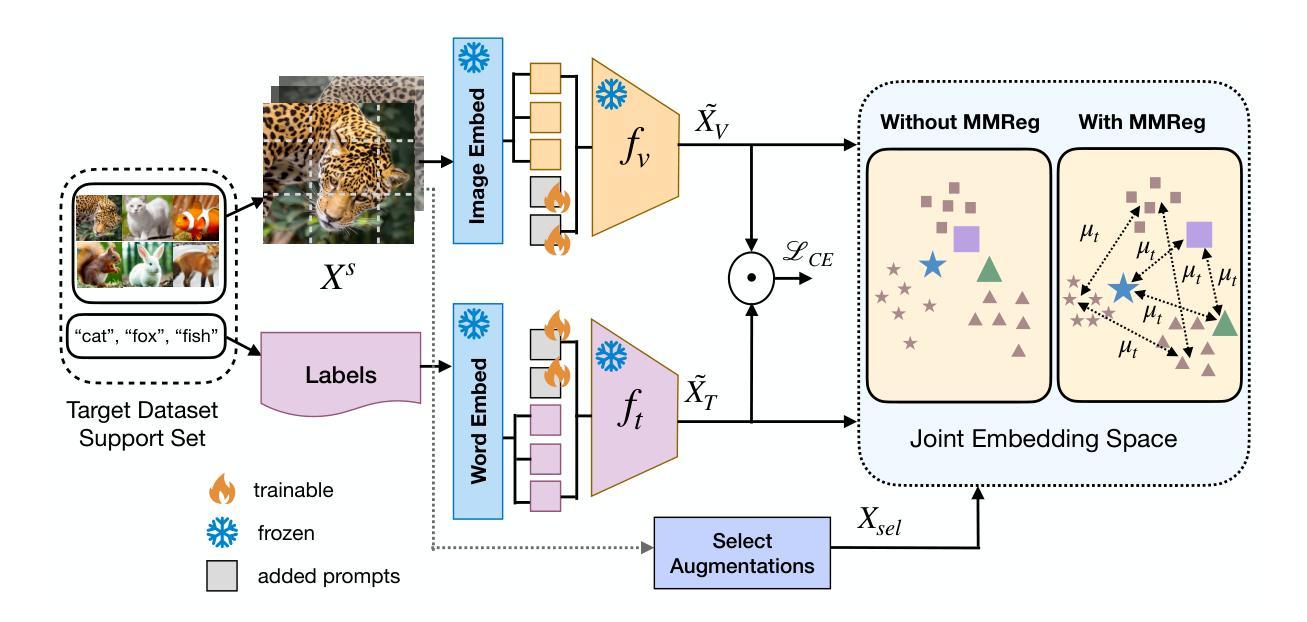
Prompt Tuning Vision Language Models with Margin Regularizer for Few-Shot Learning under Distribution Shifts
Authors:Debarshi Brahma, Anuska Roy, Soma Biswas
Recently, Vision-Language foundation models like CLIP and ALIGN, which are pre-trained on large-scale data have shown remarkable zero-shot generalization to diverse datasets with different classes and even domains. In this work, we take a step further and analyze whether these models can be adapted to target datasets having very different distributions and classes compared to what these models have been trained on, using only a few labeled examples from the target dataset. In such scenarios, finetuning large pretrained models is challenging due to problems of overfitting as well as loss of generalization, and has not been well explored in prior literature. Since, the pre-training data of such models are unavailable, it is difficult to comprehend the performance on various downstream datasets. First, we try to answer the question: Given a target dataset with a few labelled examples, can we estimate whether further fine-tuning can enhance the performance compared to zero-shot evaluation? by analyzing the common vision-language embedding space. Based on the analysis, we propose a novel prompt-tuning method, PromptMargin for adapting such large-scale VLMs directly on the few target samples. PromptMargin effectively tunes the text as well as visual prompts for this task, and has two main modules: 1) Firstly, we use a selective augmentation strategy to complement the few training samples in each task; 2) Additionally, to ensure robust training in the presence of unfamiliar class names, we increase the inter-class margin for improved class discrimination using a novel Multimodal Margin Regularizer. Extensive experiments and analysis across fifteen target benchmark datasets, with varying degrees of distribution shifts from natural images, shows the effectiveness of the proposed framework over the existing state-of-the-art approaches applied to this setting. github.com/debarshigit/PromptMargin.
最近,诸如CLIP和ALIGN之类的视觉语言基础模型在大规模数据上进行预训练后,在对具有不同类别甚至域的各种数据集上进行零样本泛化方面表现出色。在这项工作中,我们更进一步地分析,使用目标数据集中仅有的少数标记样本,这些模型是否可以被适应于与目标数据集具有不同分布和类别的数据集。在这样的场景中,微调大规模的预训练模型具有挑战性,因为存在过拟合和泛化损失的问题,并且在先前的文献中尚未得到很好的探索。由于此类模型的预训练数据不可用,因此难以在各种下游数据集上理解其性能。首先,我们试图回答以下问题:给定一个具有少量标记样本的目标数据集,我们能否通过分析常见的视觉语言嵌入空间来估计与零样本评估相比,进一步的微调是否能提高性能?基于此分析,我们提出了一种新型的提示调整方法PromptMargin,用于直接在少量目标样本上适应大规模视觉语言模型。PromptMargin有效地针对此任务调整了文本和视觉提示,并有两个主要模块:1)首先,我们使用选择性增强策略来补充每个任务中的少量训练样本;2)此外,为了确保在不熟悉的类名存在的情况下进行稳健训练,我们通过使用新型的多模态边距调节器来增加类间间距,以实现改进后的类间鉴别。在来自自然图像的十五个目标基准数据集上进行的广泛实验和分析,显示出所提出的框架在现有最先进的适用于此场景的方法中的有效性。github.com/debarshigit/PromptMargin。
论文及项目相关链接
PDF Published in TMLR (2025)
Summary
视觉语言基础模型如CLIP和ALIGN在大型数据上的预训练表现出对多种数据集的零样本泛化能力。本研究进一步探讨这些模型在目标数据集上的适应性,目标数据集与模型训练时的数据分布和类别差异显著,仅使用目标数据集的少量标记样本。提出一种新颖的提示调整方法PromptMargin,直接在少量目标样本上适应大规模视觉语言模型。该方法通过选择性增强策略补充每个任务的少量训练样本,并通过多模态边距正则化器提高类间间距,从而提高类之间的鉴别能力。在十五个目标基准数据集上的实验和分析表明,该方法在面临与原始数据集不同的分布转移时,比现有方法更有效。
Key Takeaways
- 视觉语言基础模型如CLIP和ALIGN具有零样本泛化能力,能应对不同类别和领域的数据集。
- 在目标数据集与预训练数据分布和类别差异显著的情况下,这些模型的适应性受到挑战。
- 研究提出了一种新颖的提示调整方法PromptMargin,用于在少量目标样本上直接适应大规模视觉语言模型。
- PromptMargin通过选择性增强策略补充少量训练样本,提高模型性能。
- 多模态边距正则化器用于提高类间鉴别能力,确保在存在不熟悉的类名时也能进行稳健训练。
- 在多个目标数据集上的实验表明,PromptMargin比现有方法更有效。
- 该研究为处理分布转移问题提供了一种新的思路和方法。
点此查看论文截图

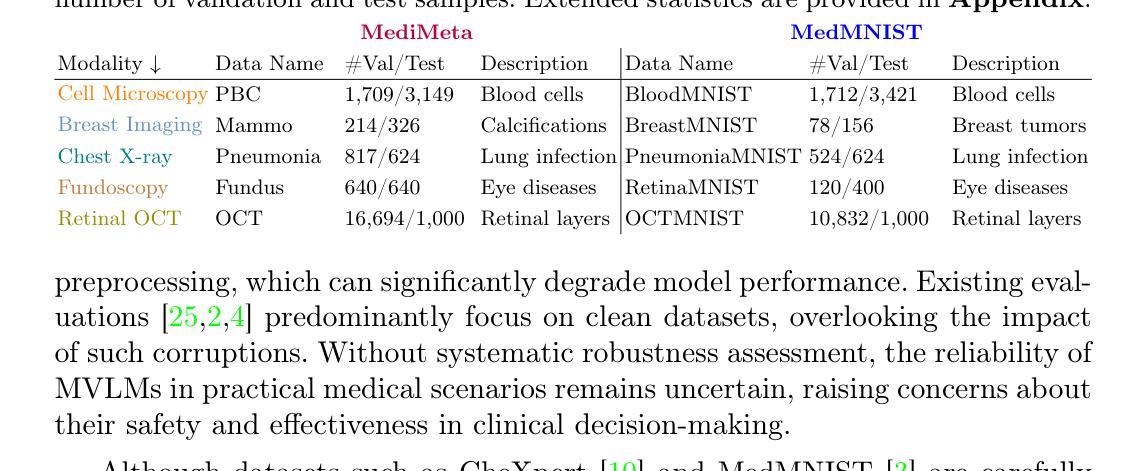
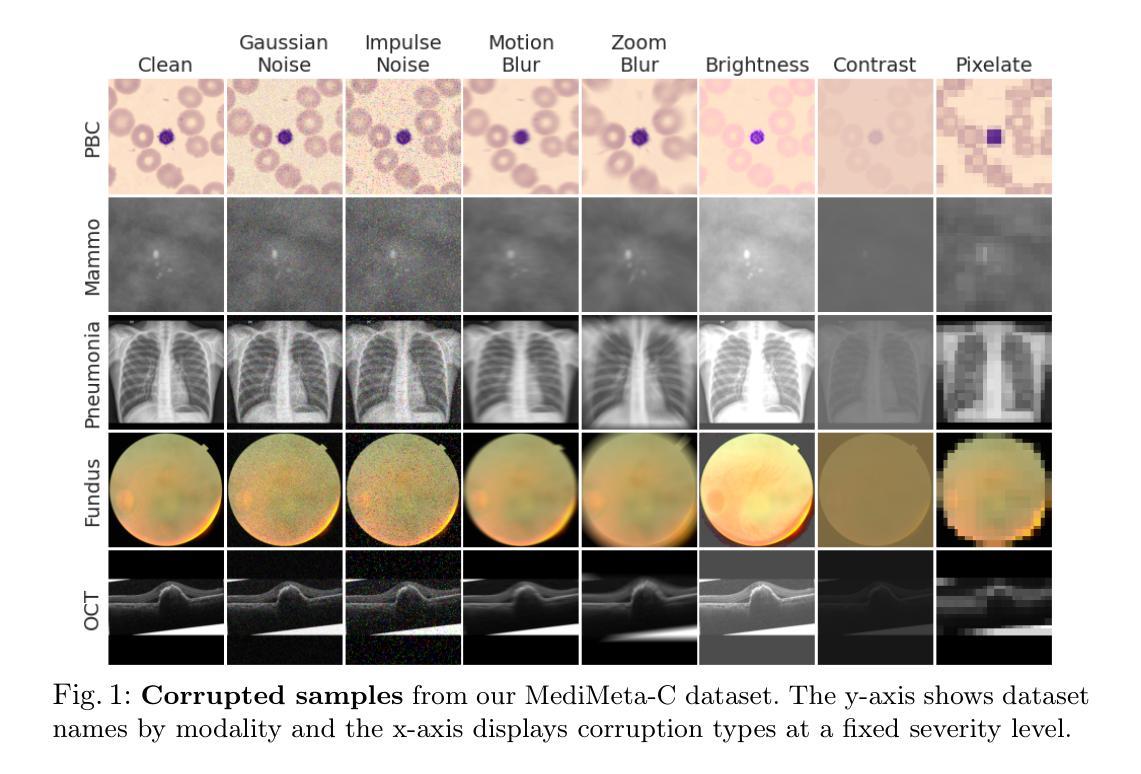
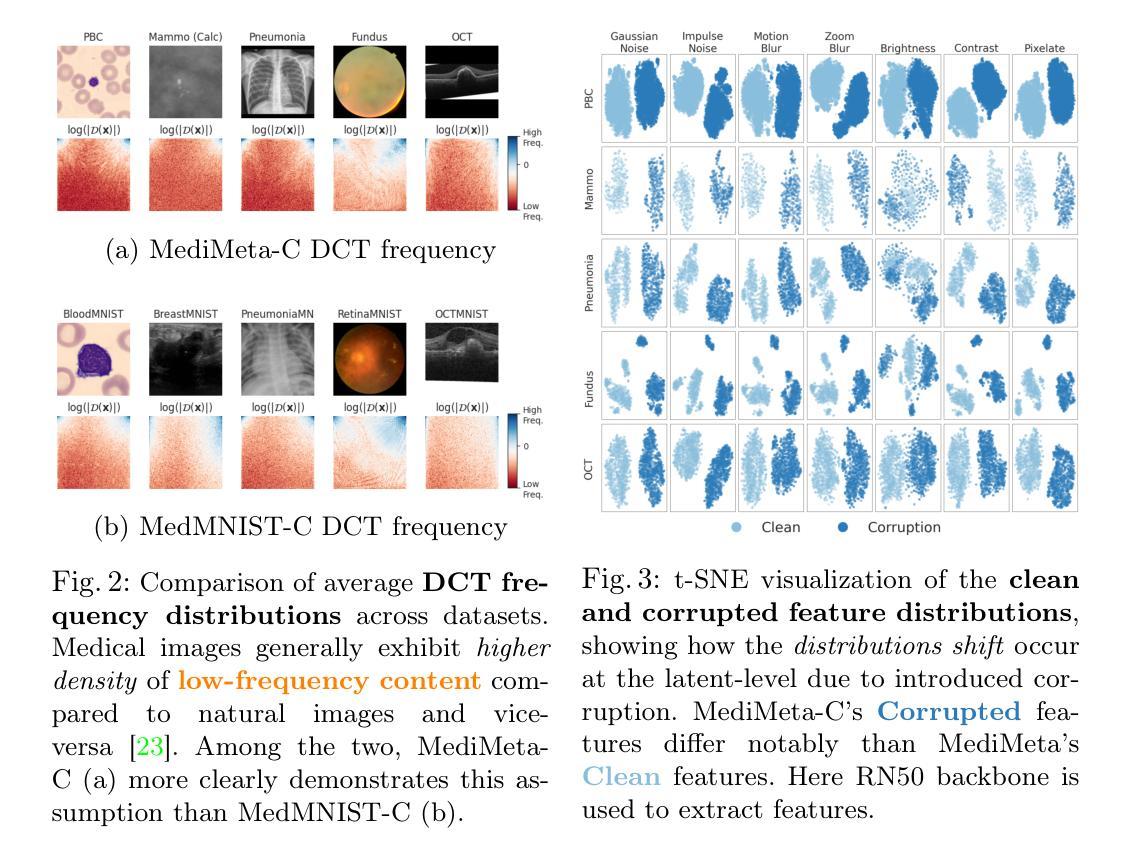
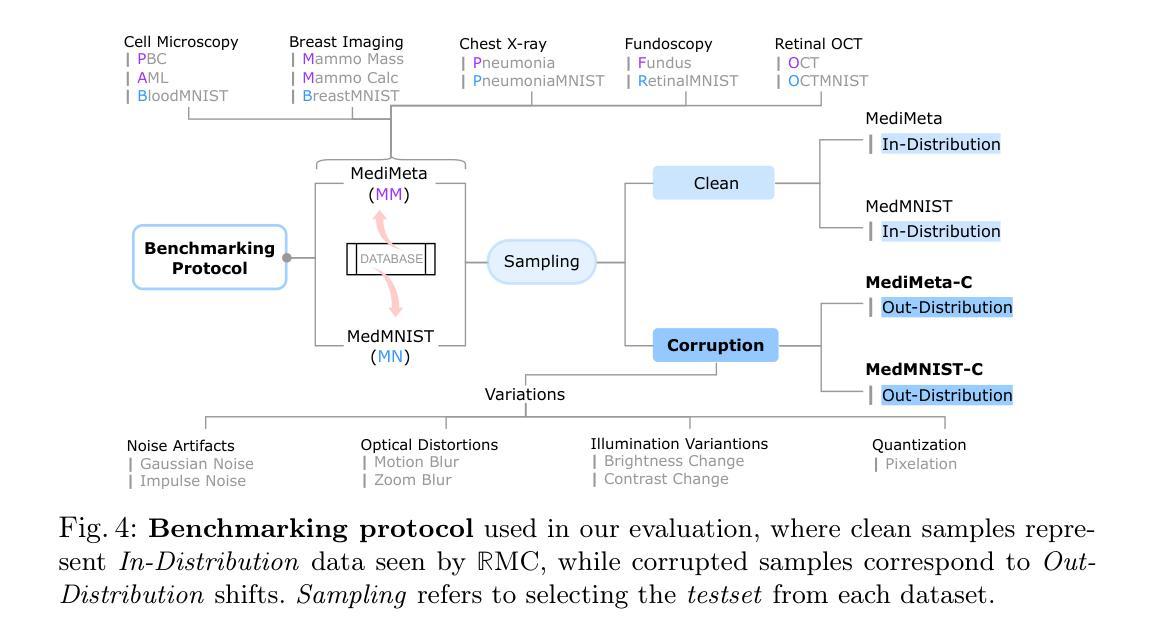
On the Robustness of Medical Vision-Language Models: Are they Truly Generalizable?
Authors:Raza Imam, Rufael Marew, Mohammad Yaqub
Medical Vision-Language Models (MVLMs) have achieved par excellence generalization in medical image analysis, yet their performance under noisy, corrupted conditions remains largely untested. Clinical imaging is inherently susceptible to acquisition artifacts and noise; however, existing evaluations predominantly assess generally clean datasets, overlooking robustness – i.e., the model’s ability to perform under real-world distortions. To address this gap, we first introduce MediMeta-C, a corruption benchmark that systematically applies several perturbations across multiple medical imaging datasets. Combined with MedMNIST-C, this establishes a comprehensive robustness evaluation framework for MVLMs. We further propose RobustMedCLIP, a visual encoder adaptation of a pretrained MVLM that incorporates few-shot tuning to enhance resilience against corruptions. Through extensive experiments, we benchmark 5 major MVLMs across 5 medical imaging modalities, revealing that existing models exhibit severe degradation under corruption and struggle with domain-modality tradeoffs. Our findings highlight the necessity of diverse training and robust adaptation strategies, demonstrating that efficient low-rank adaptation when paired with few-shot tuning, improves robustness while preserving generalization across modalities.
医疗视觉语言模型(MVLM)在医学图像分析方面已经达到了卓越的泛化性能,但在噪声和损坏条件下的性能仍然没有得到充分的测试。临床成像本质上容易受到采集伪影和噪声的影响;然而,现有的评估主要侧重于对通常干净数据集的评价,忽略了模型的稳健性,即模型在现实世界失真情况下的性能。为了弥补这一空白,我们首先引入了MediMeta-C,这是一个腐败基准测试,它系统地应用于多个医学成像数据集的多重扰动。结合MedMNIST-C,这为MVLM建立了一个全面的稳健性评估框架。我们进一步提出了RobustMedCLIP,这是一个视觉编码器适应的预训练MVLM,它结合了少量样本微调技术,以提高对损坏的抵抗力。通过大量实验,我们对5种主要的MVLM在5种医学成像模态上进行了基准测试,结果显示现有模型在损坏情况下存在严重退化,并且在领域模态权衡方面面临困难。我们的研究结果表明,多样化的训练策略和稳健的适应策略是必要的,同时证明有效的低秩适应技术与少量样本微调相结合,可以在提高稳健性的同时,保持跨模态的泛化能力。
论文及项目相关链接
PDF Dataset and Code is available at https://github.com/BioMedIA-MBZUAI/RobustMedCLIP Accepted at: Medical Image Understanding and Analysis (MIUA) 2025
Summary
本文关注医疗视觉语言模型(MVLMs)在噪声、失真环境下的性能。为评估模型在实际扭曲情况下的稳健性,引入MediMeta-C腐蚀基准,结合MedMNIST-C,建立全面的MVLMs稳健性评估框架。同时提出RobustMedCLIP,通过微调预训练的MVLM的视觉编码器,增强其对抗腐蚀的韧性。实验表明,现有模型在腐蚀环境下性能严重下降,且存在域模态权衡问题。研究强调多样训练和稳健适应策略的必要性,有效低秩适应结合少量微调,在提高稳健性的同时,保持跨模态的泛化能力。
Key Takeaways
- 医疗视觉语言模型(MVLMs)在医学图像分析中具有出色的泛化能力,但在噪声、失真环境下的性能尚未得到充分测试。
- 引入MediMeta-C腐蚀基准和MedMNIST-C,建立MVLMs的稳健性评估框架。
- 提出RobustMedCLIP,通过微调预训练MVLM的视觉编码器,增强模型对抗腐蚀的韧性。
- 实验表明现有模型在腐蚀环境下性能严重下降,需要多样训练和稳健适应策略。
- 域模态权衡问题存在,需要解决不同医学成像模态之间的差异。
- 有效低秩适应结合少量微调可以提高模型的稳健性并保留跨模态泛化能力。
点此查看论文截图

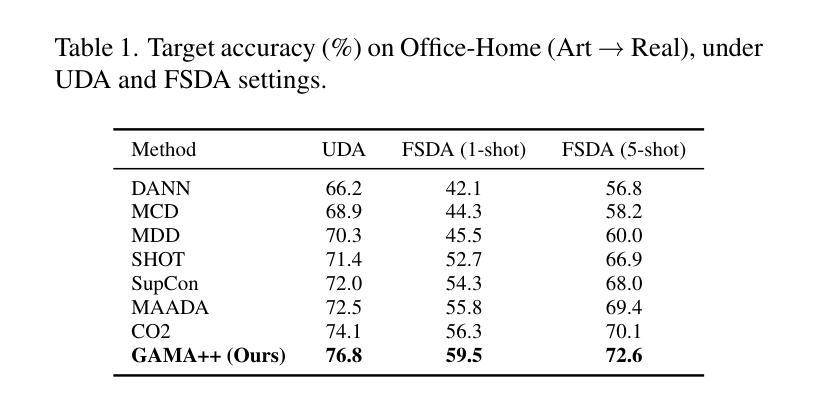
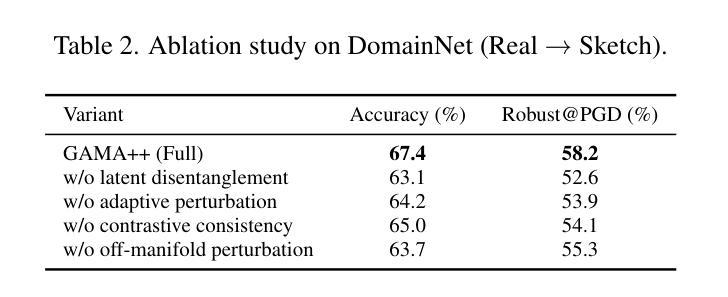
GAMA++: Disentangled Geometric Alignment with Adaptive Contrastive Perturbation for Reliable Domain Transfer
Authors:Kim Yun, Hana Satou, F Monkey
Despite progress in geometry-aware domain adaptation, current methods such as GAMA still suffer from two unresolved issues: (1) insufficient disentanglement of task-relevant and task-irrelevant manifold dimensions, and (2) rigid perturbation schemes that ignore per-class alignment asymmetries. To address this, we propose GAMA++, a novel framework that introduces (i) latent space disentanglement to isolate label-consistent manifold directions from nuisance factors, and (ii) an adaptive contrastive perturbation strategy that tailors both on- and off-manifold exploration to class-specific manifold curvature and alignment discrepancy. We further propose a cross-domain contrastive consistency loss that encourages local semantic clusters to align while preserving intra-domain diversity. Our method achieves state-of-the-art results on DomainNet, Office-Home, and VisDA benchmarks under both standard and few-shot settings, with notable improvements in class-level alignment fidelity and boundary robustness. GAMA++ sets a new standard for semantic geometry alignment in transfer learning.
尽管几何感知领域自适应方面已有所进展,但当前的方法,如GAMA,仍然面临两个未解决的问题:(1)任务相关和任务不相关的流形维度解耦不足;(2)忽略了每类对齐不对称性的刚性扰动方案。为了解决这一问题,我们提出了GAMA++,一个引入(i)潜在空间解耦的新框架,以从干扰因素中隔离出标签一致的流形方向;(ii)自适应对比扰动策略,根据类特定的流形曲率和对齐差异,定制流形内和流形外的探索。我们还提出了一种跨域对比一致性损失,鼓励局部语义集群对齐,同时保留域内多样性。我们的方法在DomainNet、Office-Home和VisDA基准测试下,无论是在标准还是小样本设置下,都实现了最新结果,在类级对齐保真性和边界稳健性方面取得了显著改进。GAMA++为迁移学习中的语义几何对齐设定了新的标准。
论文及项目相关链接
Summary
几何感知领域自适应虽然有所进展,但当前方法如GAMA仍存在两大问题:一是任务相关和任务不相关的流形维度解耦不足,二是忽略了每类对齐不对称性的刚性扰动方案。为解决这些问题,我们提出了GAMA++框架,引入潜在空间解耦来隔离标签一致的流形方向并消除干扰因素;同时采用自适应对比扰动策略,根据类特定的流形曲率和对齐差异进行流形内和流形外的探索。此外,我们还提出了跨域对比一致性损失,鼓励局部语义集群对齐,同时保持域内多样性。GAMA++在DomainNet、Office-Home和VisDA等多个基准测试中都达到了前所未有的结果,尤其是在类级别对齐保真性和边界稳健性方面有了显著提高。GAMA++为迁移学习中的语义几何对齐设定了新的标准。
Key Takeaways
- 当前几何感知领域自适应方法存在两大问题:任务相关和任务不相关的流形维度解耦不足,以及忽略类对齐不对称性的刚性扰动方案。
- GAMA++框架通过引入潜在空间解耦和自适应对比扰动策略来解决这两个问题。
- 潜在空间解耦用于隔离标签一致的流形方向并消除干扰因素。
- 自适应对比扰动策略根据类特定的流形曲率和对齐差异进行流形内和流形外的探索。
- 跨域对比一致性损失鼓励局部语义集群对齐,同时保持域内多样性。
- GAMA++在多个基准测试中达到前所未有的结果,特别是在类级别对齐和边界稳健性方面。
点此查看论文截图

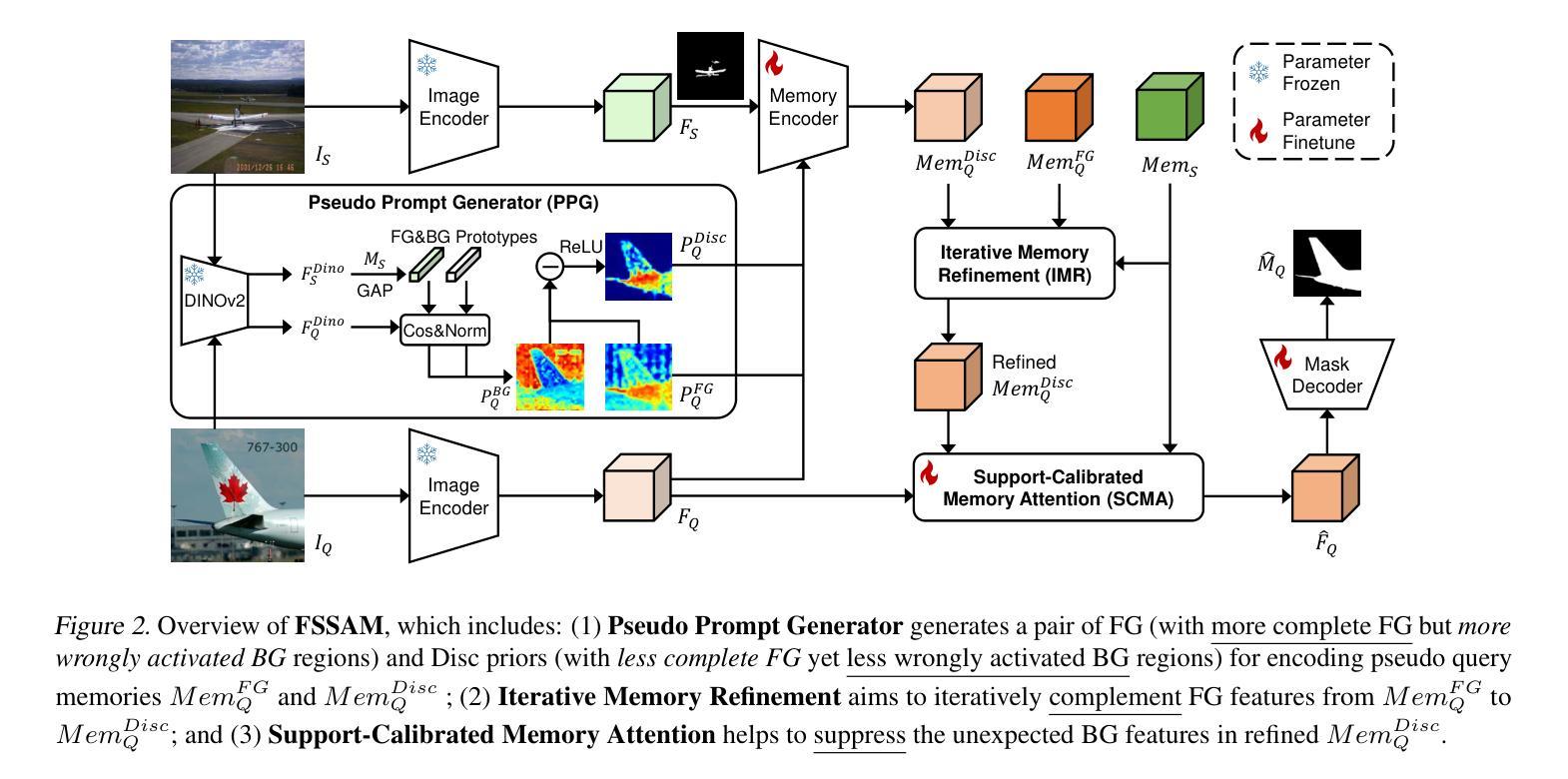
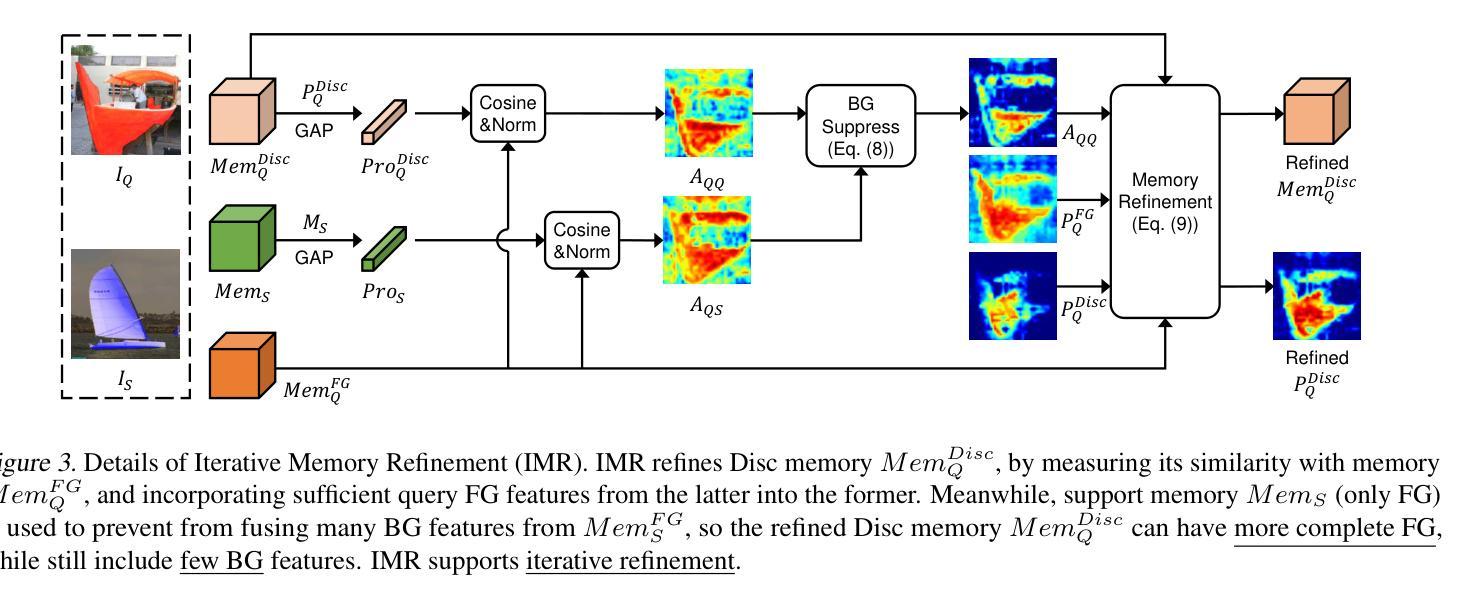
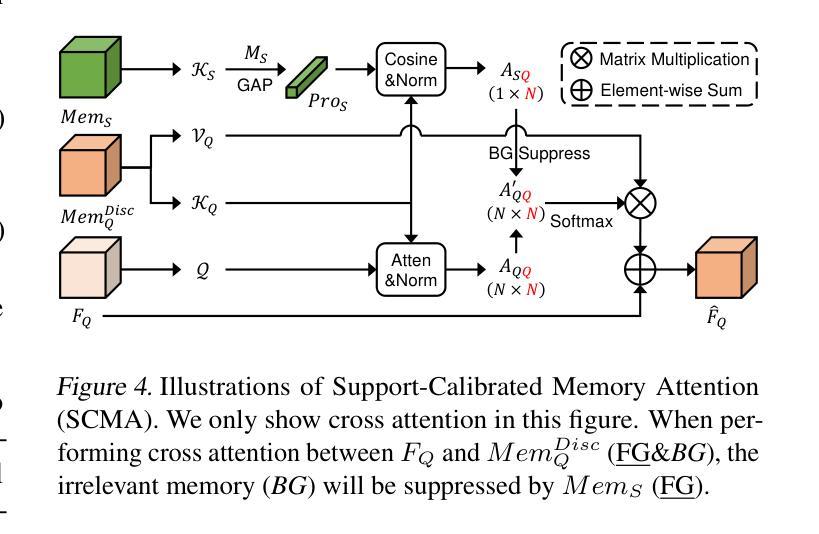
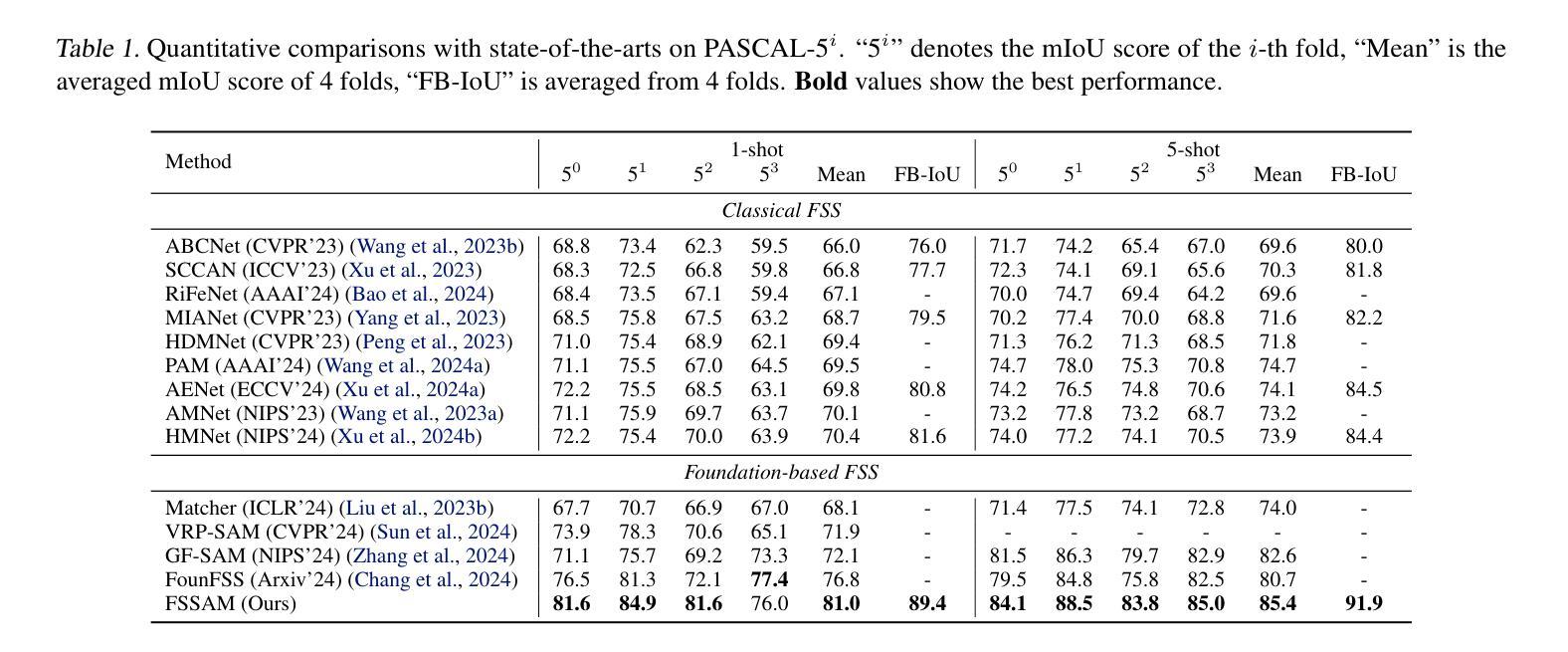
Unlocking the Power of SAM 2 for Few-Shot Segmentation
Authors:Qianxiong Xu, Lanyun Zhu, Xuanyi Liu, Guosheng Lin, Cheng Long, Ziyue Li, Rui Zhao
Few-Shot Segmentation (FSS) aims to learn class-agnostic segmentation on few classes to segment arbitrary classes, but at the risk of overfitting. To address this, some methods use the well-learned knowledge of foundation models (e.g., SAM) to simplify the learning process. Recently, SAM 2 has extended SAM by supporting video segmentation, whose class-agnostic matching ability is useful to FSS. A simple idea is to encode support foreground (FG) features as memory, with which query FG features are matched and fused. Unfortunately, the FG objects in different frames of SAM 2’s video data are always the same identity, while those in FSS are different identities, i.e., the matching step is incompatible. Therefore, we design Pseudo Prompt Generator to encode pseudo query memory, matching with query features in a compatible way. However, the memories can never be as accurate as the real ones, i.e., they are likely to contain incomplete query FG, and some unexpected query background (BG) features, leading to wrong segmentation. Hence, we further design Iterative Memory Refinement to fuse more query FG features into the memory, and devise a Support-Calibrated Memory Attention to suppress the unexpected query BG features in memory. Extensive experiments have been conducted on PASCAL-5$^i$ and COCO-20$^i$ to validate the effectiveness of our design, e.g., the 1-shot mIoU can be 4.2% better than the best baseline.
少数镜头分割(FSS)的目标是学会对少数类别进行类别无关的分割,以实现对任意类别的分割,但存在过拟合的风险。为了解决这一问题,一些方法使用基础模型的良好知识来简化学习过程(例如SAM)。最近,SAM 2通过支持视频分割扩展了SAM的应用,其类别无关的匹配能力对FSS很有用。一个简单的想法是将支持前景(FG)特征编码为内存,通过查询前景特征与内存进行匹配和融合。然而,不幸的是,SAM 2的视频数据不同帧中的前景对象总是相同的身份,而FSS中的则是不同的身份,即匹配步骤是不兼容的。因此,我们设计了伪提示生成器来编码伪查询内存,以与查询特征进行兼容的匹配。然而,这些记忆永远无法像真实的那样准确,即它们可能包含不完整查询前景和一些意外的查询背景(BG)特征,从而导致错误的分割。因此,我们进一步设计了迭代内存优化技术,将更多查询前景特征融合到内存中,并设计了一种支持校准内存注意力机制来抑制内存中意外的查询背景特征。在PASCAL-5i和COCO-20i上进行了大量实验,验证了我们的设计有效性,例如,与最佳基线相比,我们的方法在单镜头下的平均交并比(mIoU)可以提高4.2%。
论文及项目相关链接
PDF This paper is accepted by ICML’25
Summary
本文讨论了Few-Shot Segmentation(FSS)的目标和方法。虽然旨在学习少类别类不相关的分割来分割任意类别,但存在过拟合的风险。为解决这个问题,一些方法使用基础模型的先验知识简化学习过程。最近SAM 2扩展了SAM,支持视频分割,但其类不相关的匹配能力与FSS不兼容。因此,设计伪提示生成器来编码伪查询内存,与查询特征进行兼容匹配。然而,记忆无法像真实数据那样准确,可能包含不完整的查询前景和一些意外的查询背景特征,导致错误分割。因此,进一步设计了迭代内存优化和校准记忆注意力来完善设计和优化性能。
Key Takeaways
- Few-Shot Segmentation(FSS)的目标是学习对任意类别的类不相关分割,但存在过拟合风险。
- 使用基础模型的先验知识可以解决此问题。
- SAM 2扩展了SAM支持视频分割,但其在视频数据与FSS中的匹配步骤不兼容。
- 设计了伪提示生成器以编码伪查询内存来进行匹配。但记忆可能包含不完整的查询前景和一些意外的查询背景特征。
- 为解决记忆的不准确性问题,设计了迭代内存优化和校准记忆注意力机制。
- 在PASCAL-5$^i$和COCO-20$^i$上进行了大量实验验证了设计的有效性。
点此查看论文截图

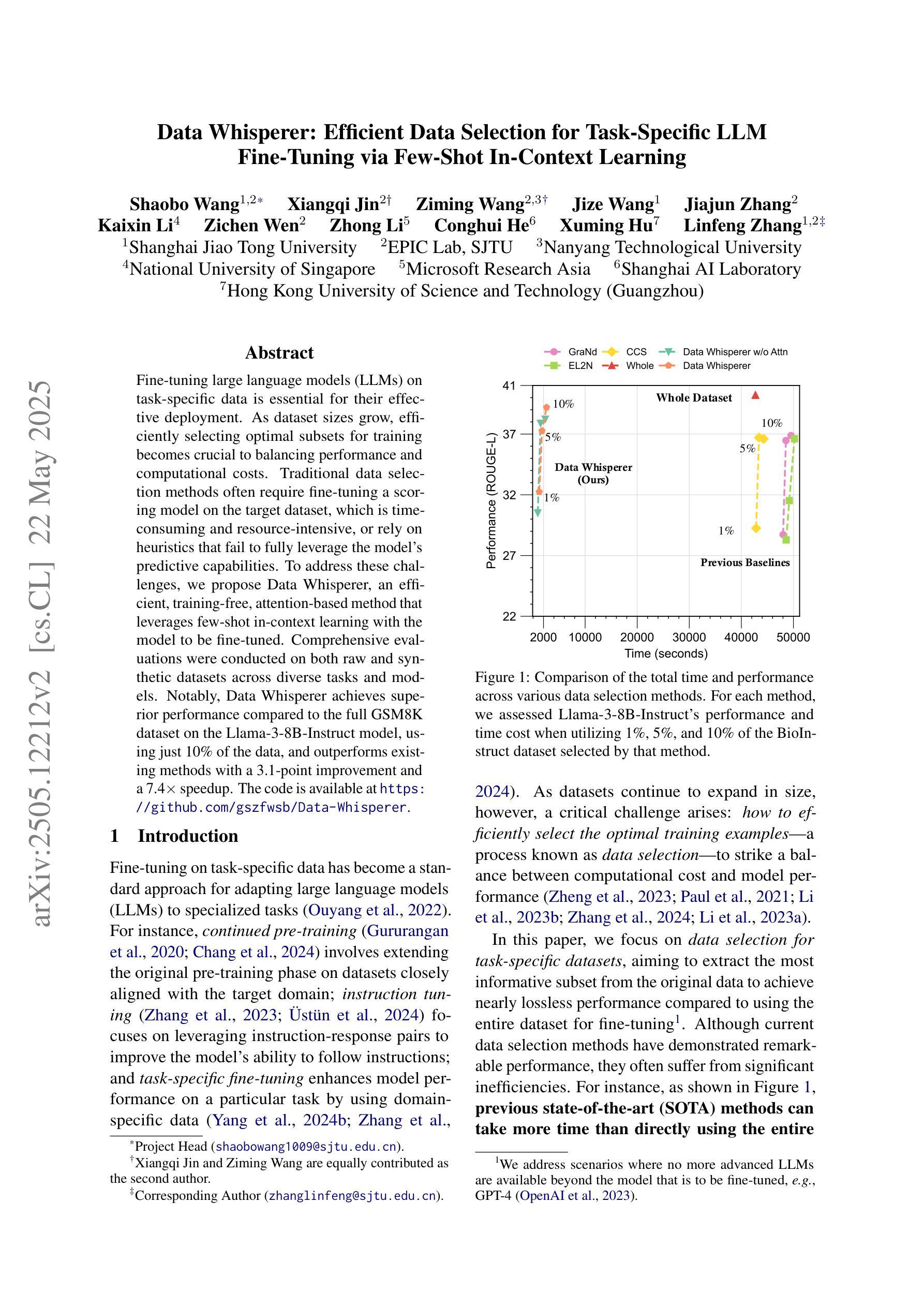
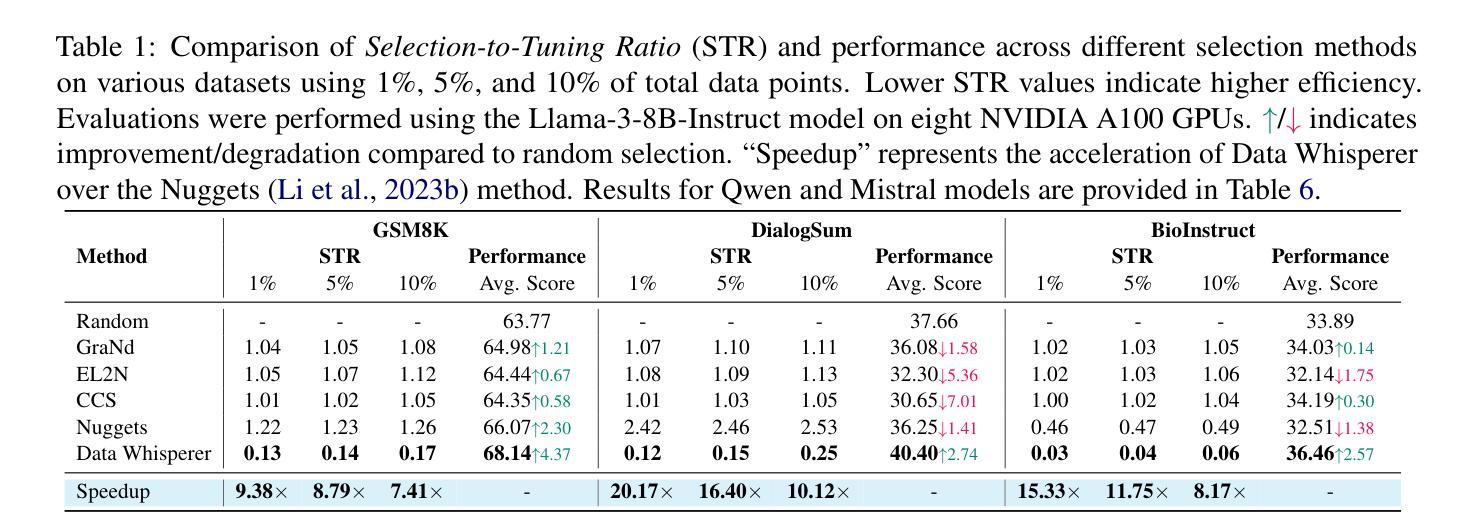
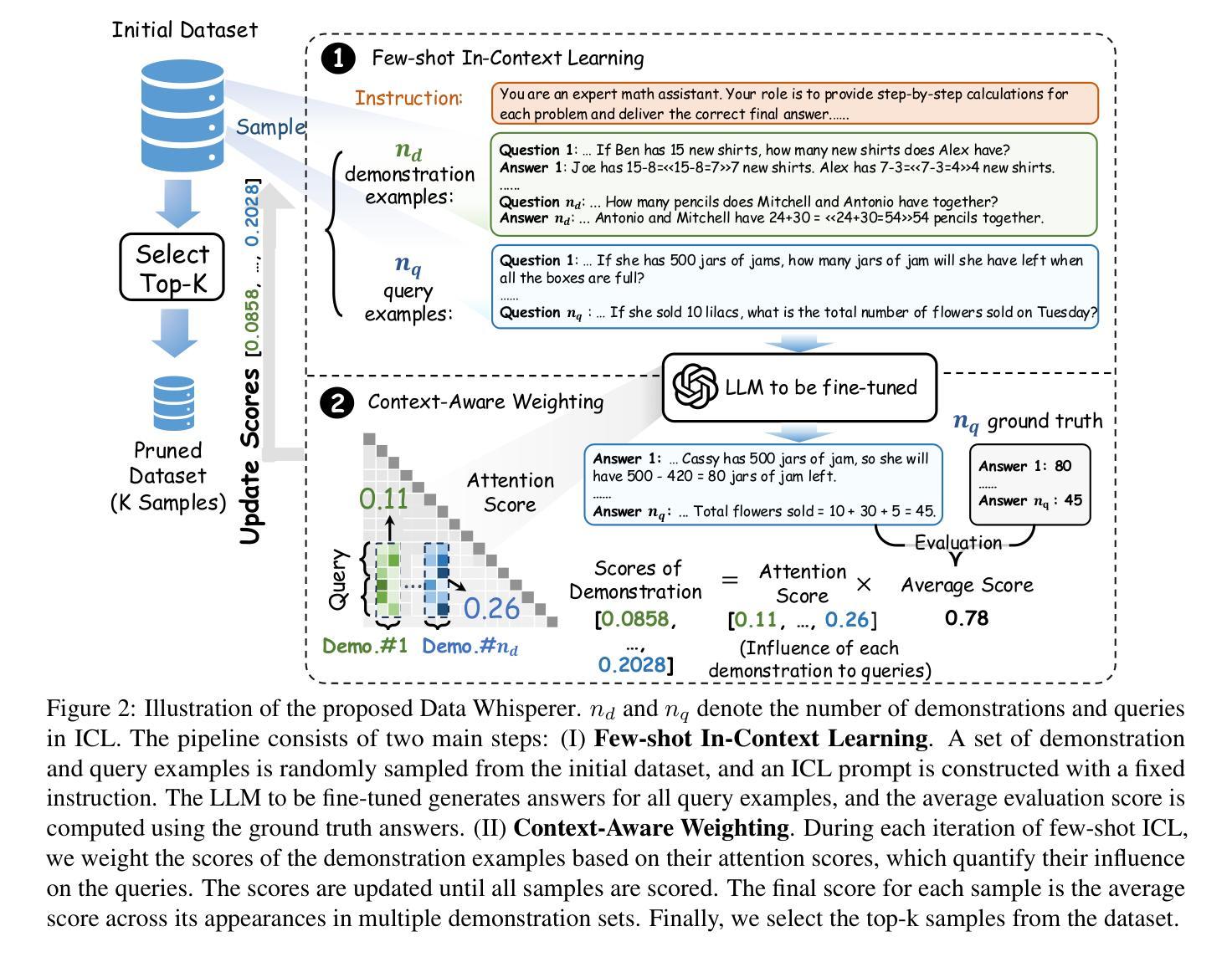
Data Whisperer: Efficient Data Selection for Task-Specific LLM Fine-Tuning via Few-Shot In-Context Learning
Authors:Shaobo Wang, Xiangqi Jin, Ziming Wang, Jize Wang, Jiajun Zhang, Kaixin Li, Zichen Wen, Zhong Li, Conghui He, Xuming Hu, Linfeng Zhang
Fine-tuning large language models (LLMs) on task-specific data is essential for their effective deployment. As dataset sizes grow, efficiently selecting optimal subsets for training becomes crucial to balancing performance and computational costs. Traditional data selection methods often require fine-tuning a scoring model on the target dataset, which is time-consuming and resource-intensive, or rely on heuristics that fail to fully leverage the model’s predictive capabilities. To address these challenges, we propose Data Whisperer, an efficient, training-free, attention-based method that leverages few-shot in-context learning with the model to be fine-tuned. Comprehensive evaluations were conducted on both raw and synthetic datasets across diverse tasks and models. Notably, Data Whisperer achieves superior performance compared to the full GSM8K dataset on the Llama-3-8B-Instruct model, using just 10% of the data, and outperforms existing methods with a 3.1-point improvement and a 7.4$\times$ speedup.
对大型语言模型(LLM)进行针对特定任务的微调是其有效部署的关键。随着数据集规模的增长,有效选择最佳子集进行训练对于平衡性能和计算成本至关重要。传统数据选择方法通常需要针对目标数据集对评分模型进行微调,这不仅耗时而且资源密集,或者依赖于未能充分利用模型预测能力的启发式方法。为了解决这些挑战,我们提出了Data Whisperer,这是一种高效、无需训练、基于注意力的方法,它利用少量上下文学习,与待微调模型相结合。我们在原始和合成数据集上进行了多样化的任务和模型的全面评估。值得注意的是,Data Whisperer在只使用10%数据的情况下,在Llama-3-8B-Instruct模型上实现了对GSM8K数据集的优越性能,并且与传统方法相比,实现了3.1点的性能提升和7.4倍的加速。
论文及项目相关链接
PDF Accepted by ACL 2025 main, 18 pages, 8 figures, 6 tables
Summary
大型语言模型(LLM)在特定任务数据上进行微调对于其有效部署至关重要。随着数据集规模的增长,如何有效地选择最优子集进行训练已成为平衡性能和计算成本的关键。为解决传统数据选择方法耗时、资源密集或无法充分利用模型预测能力的问题,我们提出了Data Whisperer,这是一种高效、无需训练、基于注意力的方法,利用少样本上下文学习与待微调模型相结合。在原始和合成数据集上的多样化任务和模型的综合评估表明,Data Whisperer在仅使用10%数据的情况下,在Llama-3-8B-Instruct模型上实现了对GSM8K数据集的卓越性能,并相对于现有方法实现了3.1个点的改进和7.4倍的加速。
Key Takeaways
- 大型语言模型(LLMs)的微调对于其在特定任务上的有效部署非常重要。
- 数据集规模的增加使得选择最佳子集进行训练变得至关重要,以平衡性能和计算成本。
- 传统数据选择方法存在耗时、资源密集或无法充分利用模型预测能力的问题。
- Data Whisperer是一种高效、无需训练、基于注意力的方法,利用少样本上下文学习。
- Data Whisperer在多样化任务和模型的综合评估中表现出卓越性能。
- Data Whisperer在Llama-3-8B-Instruct模型上的性能超越了GSM8K数据集,仅使用10%的数据。
- Data Whisperer相对于现有方法实现了显著的改进和加速。
点此查看论文截图
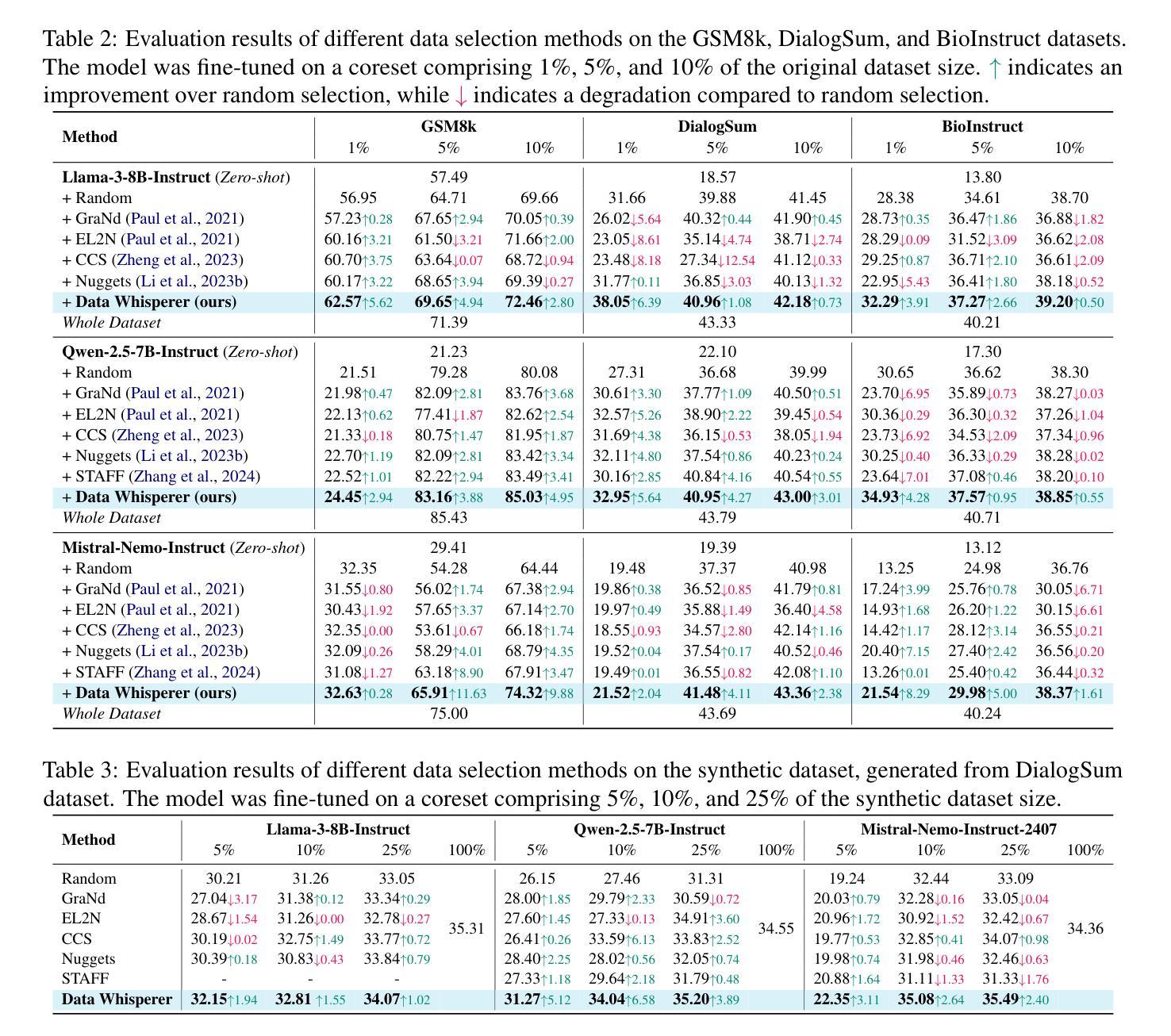
Do different prompting methods yield a common task representation in language models?
Authors:Guy Davidson, Todd M. Gureckis, Brenden M. Lake, Adina Williams
Demonstrations and instructions are two primary approaches for prompting language models to perform in-context learning (ICL) tasks. Do identical tasks elicited in different ways result in similar representations of the task? An improved understanding of task representation mechanisms would offer interpretability insights and may aid in steering models. We study this through \textit{function vectors} (FVs), recently proposed as a mechanism to extract few-shot ICL task representations. We generalize FVs to alternative task presentations, focusing on short textual instruction prompts, and successfully extract instruction function vectors that promote zero-shot task accuracy. We find evidence that demonstration- and instruction-based function vectors leverage different model components, and offer several controls to dissociate their contributions to task performance. Our results suggest that different task promptings forms do not induce a common task representation through FVs but elicit different, partly overlapping mechanisms. Our findings offer principled support to the practice of combining instructions and task demonstrations, imply challenges in universally monitoring task inference across presentation forms, and encourage further examinations of LLM task inference mechanisms.
演示和指令是提示语言模型执行上下文学习(ICL)任务的主要两种方法。以不同方式呈现相同任务是否会导致对任务的相似表示?对任务表示机制的理解可以提供解释性洞察并可能有助于引导模型。我们通过最近提出的用于提取少样本ICL任务表示的“功能向量”(FV)来研究这一点。我们将FV推广到替代任务展示中,重点关注简短的文本指令提示,并成功提取出能提升零样本任务准确度的指令功能向量。我们发现基于演示和指令的功能向量利用不同的模型组件,并提供了一些控制方法来分离它们对任务性能的贡献。我们的结果表明,不同的任务提示形式不会通过FV产生共同的任务表示,而是引发部分重叠的不同机制。我们的研究为结合指令和任务演示的实践提供了原则支持,暗示了在各种呈现形式下普遍监测任务推理的挑战性,并鼓励进一步考察LLM的任务推理机制。
论文及项目相关链接
PDF 9 pages, 4 figures; under review
Summary
本文探讨了通过演示和指令两种不同方式呈现任务时,语言模型进行上下文学习(ICL)的表现。通过功能向量(FVs)这一机制,研究发现在不同任务呈现方式下,演示和指令对语言模型的任务表现有着不同的影响。研究发现指令功能向量有助于提高零样本任务准确率,而演示和指令功能向量利用模型的不同组成部分。这表明不同任务呈现方式不会形成通用的任务表示,而是激发部分重叠的机制。这为结合指令和任务演示的实践提供了理论支持,同时也对跨不同呈现形式的任务推理提出了挑战。
Key Takeaways
- 演示和指令是引导语言模型进行上下文学习的两种主要方式。
- 功能向量(FVs)被用来提取任务表示。
- 指令功能向量可以提高零样本任务的准确率。
- 演示和指令功能向量利用模型的不同部分。
- 不同任务呈现方式不会形成通用的任务表示,而是激发部分重叠的机制。
- 结合指令和任务演示的实践可以得到更好的效果。
点此查看论文截图



Identifying Legal Holdings with LLMs: A Systematic Study of Performance, Scale, and Memorization
Authors:Chuck Arvin
As large language models (LLMs) continue to advance in capabilities, it is essential to assess how they perform on established benchmarks. In this study, we present a suite of experiments to assess the performance of modern LLMs (ranging from 3B to 90B+ parameters) on CaseHOLD, a legal benchmark dataset for identifying case holdings. Our experiments demonstrate ``scaling effects’’ - performance on this task improves with model size, with more capable models like GPT4o and AmazonNovaPro achieving macro F1 scores of 0.744 and 0.720 respectively. These scores are competitive with the best published results on this dataset, and do not require any technically sophisticated model training, fine-tuning or few-shot prompting. To ensure that these strong results are not due to memorization of judicial opinions contained in the training data, we develop and utilize a novel citation anonymization test that preserves semantic meaning while ensuring case names and citations are fictitious. Models maintain strong performance under these conditions (macro F1 of 0.728), suggesting the performance is not due to rote memorization. These findings demonstrate both the promise and current limitations of LLMs for legal tasks with important implications for the development and measurement of automated legal analytics and legal benchmarks.
随着大型语言模型(LLM)的能力不断提升,评估它们在现有基准测试上的表现变得至关重要。本研究呈现了一系列实验,旨在评估现代LLM(参数范围从3B到90B+)在CaseHOLD这一法律基准数据集上的表现,该数据集用于识别判例法摘要。我们的实验展示了“规模效应”——在此任务上的表现会随着模型规模的扩大而提高,更强大的模型如GPT4o和AmazonNovaPro分别取得了宏观F1分数为0.744和0.720。这些分数与该数据集上已发布的最佳结果具有竞争力,并且不需要任何技术复杂模型的训练、微调或少样本提示。为确保这些强有力的结果并非由于训练数据中司法意见的记忆,我们开发并利用了一种新型的引用匿名测试,该测试保留了语义含义,同时确保案例名称和引用是虚构的。在这些条件下,模型仍保持良好的表现(宏观F1分数为0.728),这表明表现并非由于死记硬背。这些发现展示了LLM在法律任务上的潜力和当前局限性,对于自动化法律分析和法律基准的开发和衡量具有重要意义。
论文及项目相关链接
PDF Presented as a short paper at International Conference on Artificial Intelligence and Law 2025 (Chicago, IL)
Summary
现代大型语言模型(LLM)在法律任务上的性能评估至关重要。本研究通过一系列实验,评估了从3B到90B+参数的现代LLM在CaseHOLD法律基准数据集上的表现。实验表明,模型性能随规模扩大而提升,GPT4o和AmazonNovaPro等更先进的模型取得了具有竞争力的宏观F1分数。模型训练无需复杂技术,且通过新型引用匿名测试证明表现稳健,暗示模型表现并非仅依靠对训练数据的记忆。此研究对自动化法律分析和法律基准的发展具有重要意义。
Key Takeaways
- 大型语言模型(LLM)在法律任务上的性能评估是关键的。
- 实验评估了不同规模的现代LLM在CaseHOLD法律基准数据集上的表现。
- 模型性能随规模扩大而提升,GPT4o和AmazonNovaPro等模型取得宏观F1分数展现出竞争力。
- 最佳模型的表现不需要复杂的技术训练,且无需求助于精细调整或少样本提示。
- 通过新型引用匿名测试证明模型表现稳健,暗示其并非仅依靠记忆训练数据来取得表现。
- 研究结果揭示了LLM在法律任务上的潜力和当前限制。
点此查看论文截图





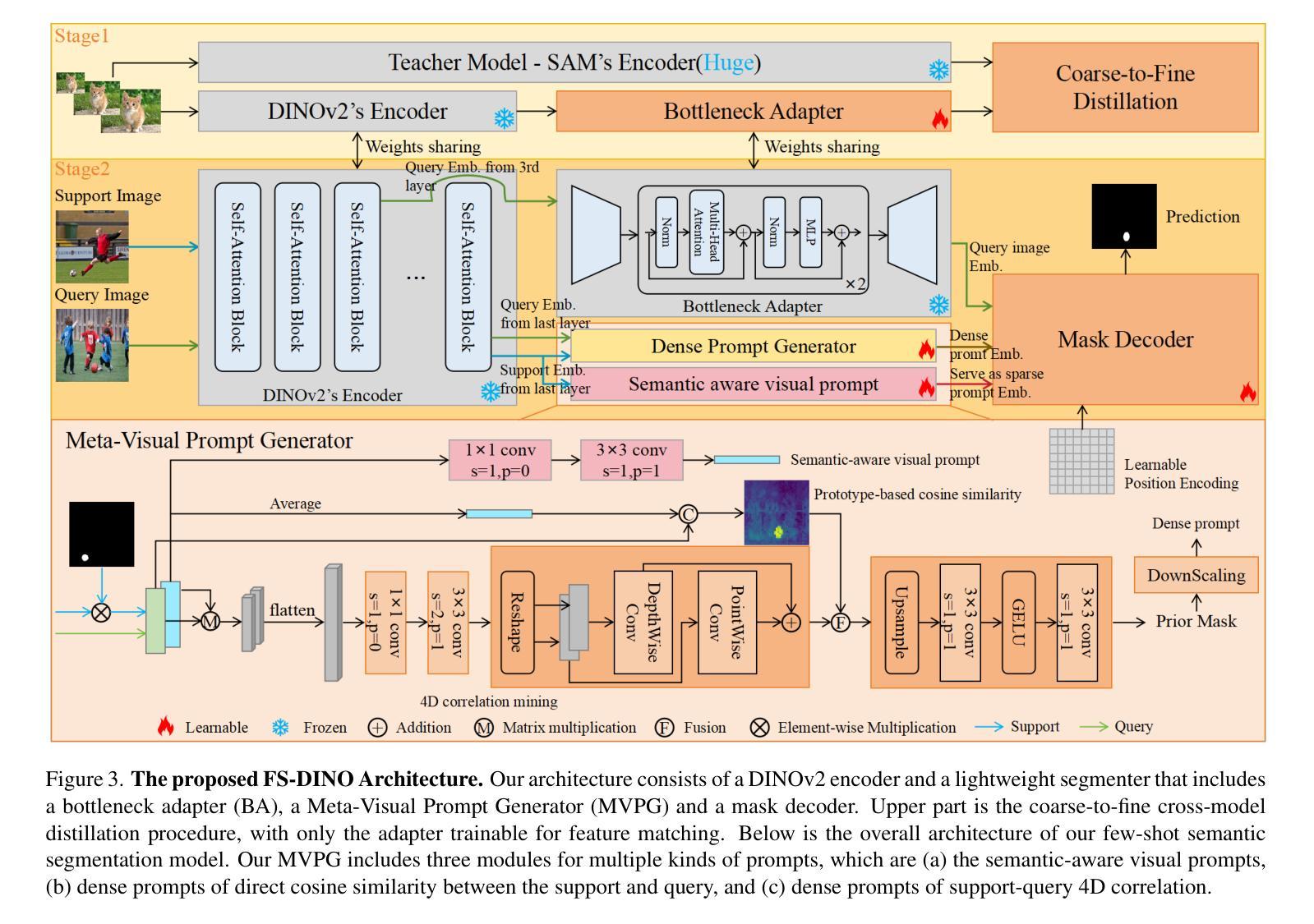
DINOv2-powered Few-Shot Semantic Segmentation: A Unified Framework via Cross-Model Distillation and 4D Correlation Mining
Authors:Wei Zhuo, Zhiyue Tang, Wufeng Xue, Hao Ding, Linlin Shen
Few-shot semantic segmentation has gained increasing interest due to its generalization capability, i.e., segmenting pixels of novel classes requiring only a few annotated images. Prior work has focused on meta-learning for support-query matching, with extensive development in both prototype-based and aggregation-based methods. To address data scarcity, recent approaches have turned to foundation models to enhance representation transferability for novel class segmentation. Among them, a hybrid dual-modal framework including both DINOv2 and SAM has garnered attention due to their complementary capabilities. We wonder “can we build a unified model with knowledge from both foundation models?” To this end, we propose FS-DINO, with only DINOv2’s encoder and a lightweight segmenter. The segmenter features a bottleneck adapter, a meta-visual prompt generator based on dense similarities and semantic embeddings, and a decoder. Through coarse-to-fine cross-model distillation, we effectively integrate SAM’s knowledge into our lightweight segmenter, which can be further enhanced by 4D correlation mining on support-query pairs. Extensive experiments on COCO-20i, PASCAL-5i, and FSS-1000 demonstrate the effectiveness and superiority of our method.
少样本语义分割因其泛化能力而受到越来越多的关注,即只需要少量标注图像就能对新型类别的像素进行分割。早期的研究主要集中在支持查询匹配的元学习上,并在基于原型和基于聚合的方法上进行了大量开发。为了解决数据稀缺的问题,最近的方法已经转向基础模型,以增强新型类别分割的表示可迁移性。其中,一个包含DINOv2和SAM的混合双模态框架因其互补能力而受到关注。我们想知道“我们能否建立一个统一的模型,同时拥有这两种基础模型的知识?”为此,我们提出了FS-DINO模型,它仅采用DINOv2的编码器和轻量级分割器。分割器具有瓶颈适配器、基于密集相似性和语义嵌入的元视觉提示生成器以及解码器。通过粗到细的跨模型蒸馏,我们有效地将SAM的知识集成到我们的轻量级分割器中,通过支持查询对上的4D关联挖掘可以进一步增强其性能。在COCO-20i、PASCAL-5i和FSS-1000上的大量实验证明了我们方法的有效性和优越性。
论文及项目相关链接
Summary
少样本语义分割模型的研究已经取得了很大进展,尤其在利用基础模型提高对新类别数据的泛化能力方面。提出了FS-DINO模型,通过结合DINOv2编码器和轻量级分割器来实现。该模型通过跨模型蒸馏技术,融合了SAM模型的知识,进一步提高性能。实验证明,该方法在COCO-20i、PASCAL-5i和FSS-1000数据集上表现优异。
Key Takeaways
- 少样本语义分割模型的泛化能力得到关注。
- 前置工作主要集中在支持查询匹配、原型基础和聚合基础方法上。
- 基础模型被用于解决数据稀缺问题,提高新类别数据的表示迁移能力。
- 提出了FS-DINO模型,结合DINOv2编码器和轻量级分割器。
- 模型利用跨模型蒸馏技术融合了SAM模型的知识。
- 通过粗到细的跨模型蒸馏和4D关联挖掘技术增强了模型性能。
点此查看论文截图


SQL-o1: A Self-Reward Heuristic Dynamic Search Method for Text-to-SQL
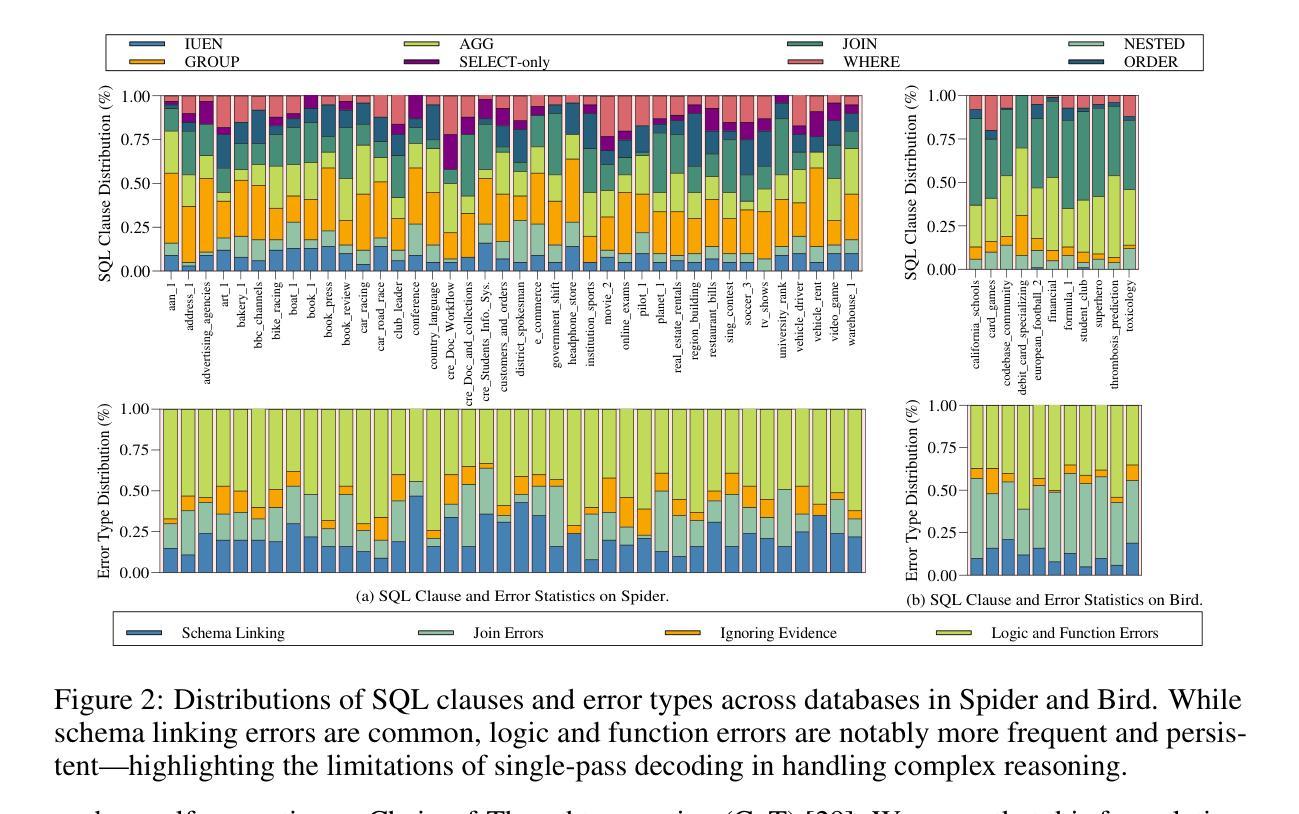
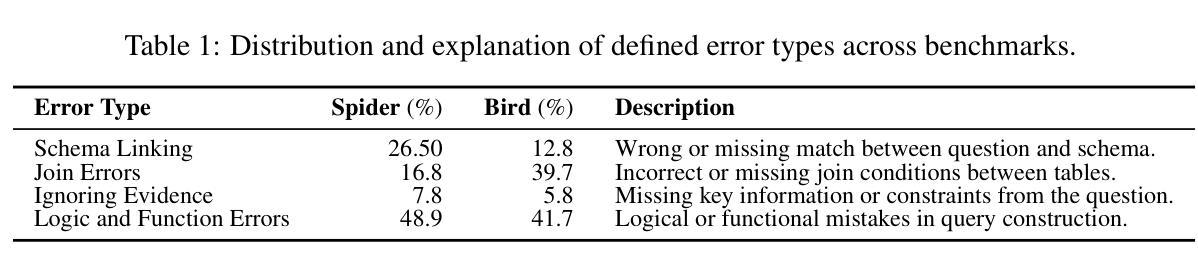
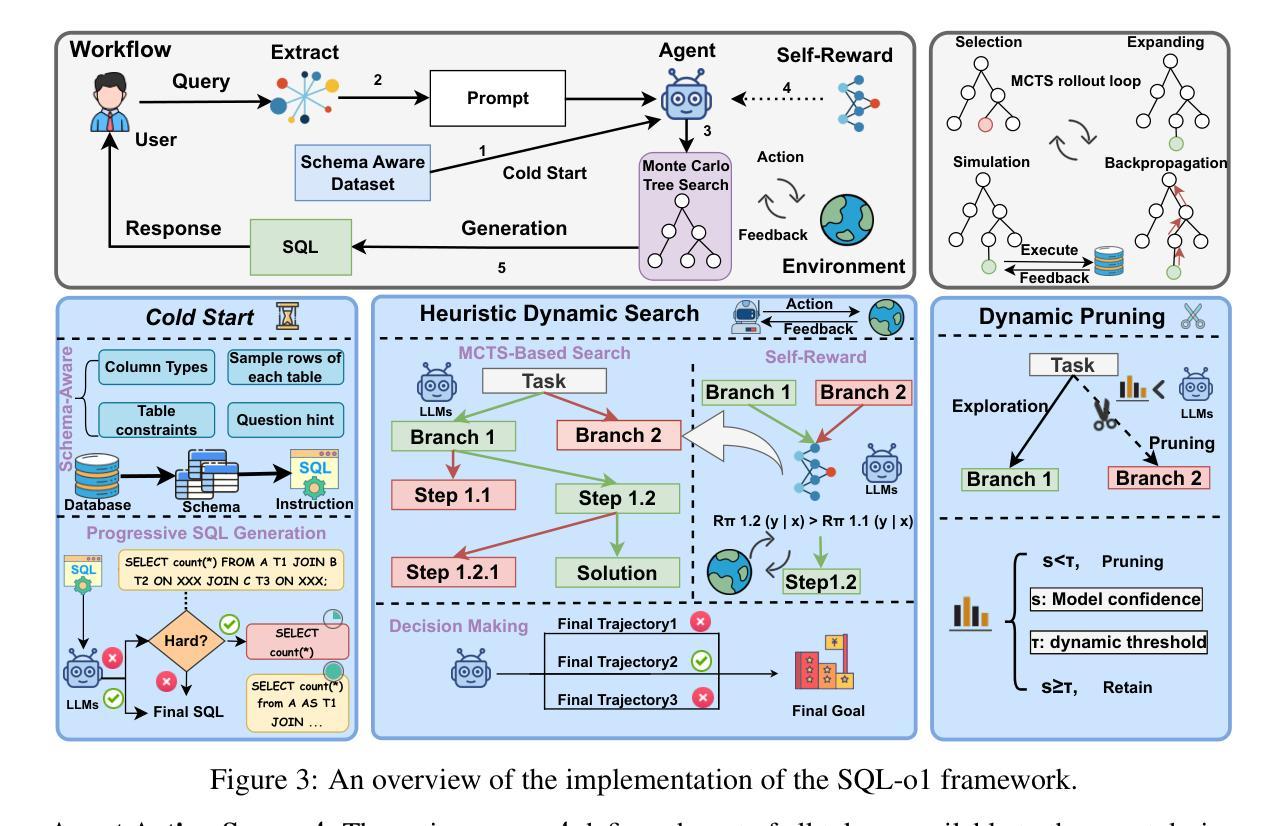
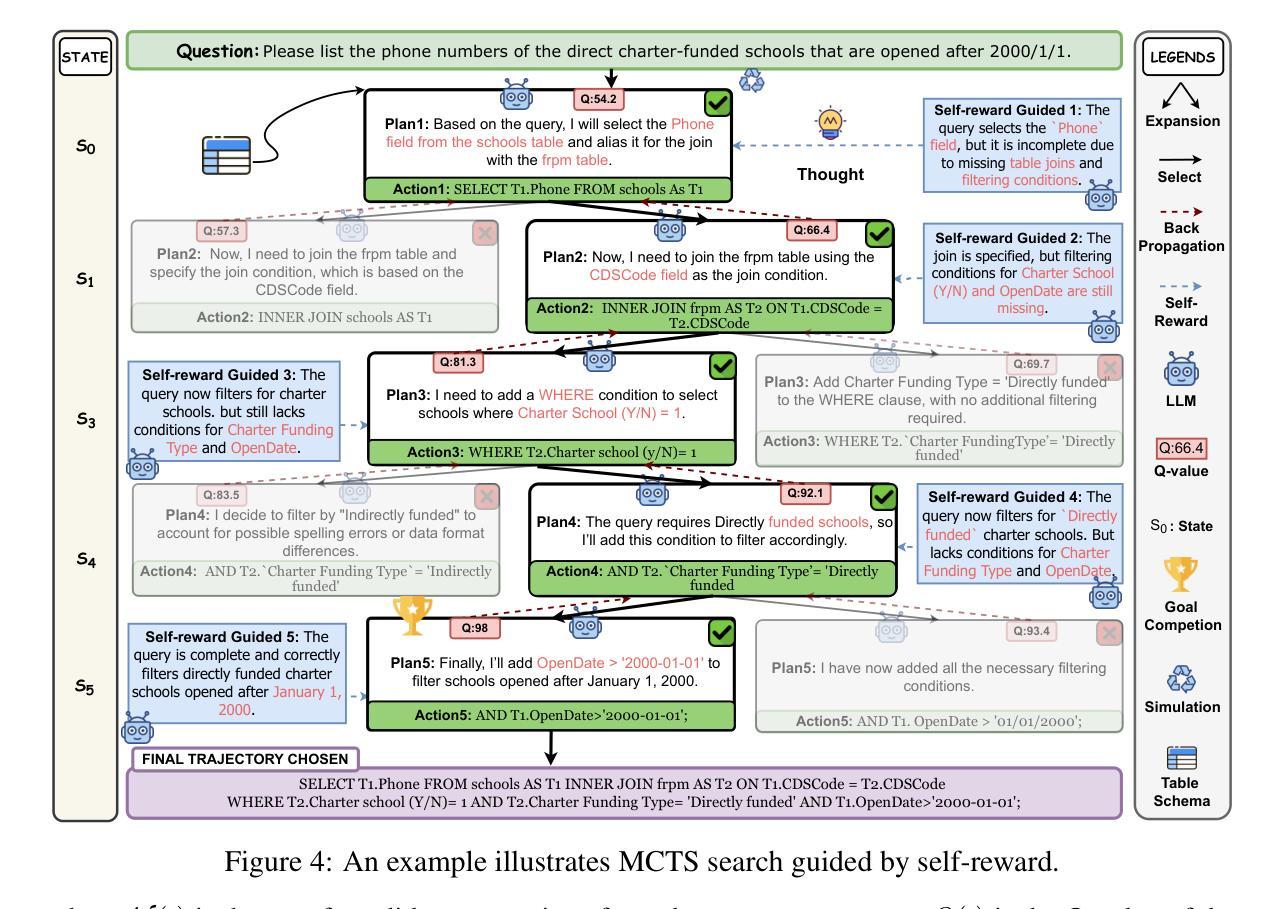
Authors:Shuai Lyu, Haoran Luo, Ripeng Li, Zhonghong Ou, Jiangfeng Sun, Yang Qin, Xiaoran Shang, Meina Song, Yifan Zhu
Text-to-SQL (Text2SQL) aims to map natural language questions to executable SQL queries. Although large language models (LLMs) have driven significant progress, current approaches struggle with poor transferability to open-source LLMs, limited robustness against logic and function errors in complex queries, and inefficiencies in structured search. We introduce SQL-o1, a self-reward-driven heuristic search framework built on an agent-based architecture to enhance model reasoning capabilities. SQL-o1 leverages Monte Carlo Tree Search (MCTS) for structured, multi-step exploration, and incorporates a dynamic pruning strategy to accelerate inference without sacrificing accuracy. On the Spider and Bird benchmarks, SQL-o1 achieves a +10.8 execution accuracy improvement on the complex Bird dataset, surpassing even GPT-4-based models. Notably, it exhibits strong few-shot generalization and robust cross-model transferability across open-source LLMs. Our code is available at:https://github.com/ShuaiLyu0110/SQL-o1.
文本到SQL(Text2SQL)旨在将自然语言问题映射为可执行的SQL查询。尽管大型语言模型(LLMs)已经取得了显著进展,但当前的方法在开源LLMs的迁移性方面表现较差,在复杂查询中的逻辑和功能错误方面的稳健性有限,以及结构化搜索的效率低下。我们引入了SQL-o1,这是一个基于代理架构的自我奖励驱动启发式搜索框架,旨在增强模型的推理能力。SQL-o1利用蒙特卡洛树搜索(MCTS)进行结构化、多步骤的探索,并采用了动态剪枝策略来加速推理,同时不牺牲准确性。在Spider和Bird基准测试中,SQL-o1在复杂的Bird数据集上实现了+10.8的执行准确性改进,甚至超越了GPT-4模型。值得注意的是,它表现出强大的少样本泛化能力和跨模型的稳健迁移性。我们的代码可在:[https://github.com/ShuaiLyu011
论文及项目相关链接
PDF 28 pages,12 figures
Summary
基于文本到SQL(Text2SQL)的目标是将自然语言问题映射到可执行的SQL查询。当前的大型语言模型(LLMs)虽然有所进展,但在开源LLMs的迁移性、复杂查询中的逻辑和功能错误抗性,以及结构化搜索的效率方面存在挑战。我们引入了SQL-o1,一个基于代理架构的自奖励驱动启发式搜索框架,以提高模型的推理能力。SQL-o1利用蒙特卡洛树搜索(MCTS)进行结构化、多步骤的探索,并采用动态剪枝策略以加速推理而不损失精度。在Spider和Bird基准测试中,SQL-o1在复杂的Bird数据集上实现了+10.8的执行精度提升,超越了GPT-4模型。此外,它展现出强大的小样本泛化能力和跨模型的开放性迁移能力。
Key Takeaways
- Text-to-SQL旨在将自然语言问题转换为SQL查询。
- 当前LLMs在Text-to-SQL领域面临迁移性、复杂查询中的逻辑和功能错误抗性以及搜索效率的挑战。
- SQL-o1是一个自奖励驱动启发式搜索框架,用于增强模型的推理能力。
- SQL-o1利用蒙特卡洛树搜索(MCTS)进行结构化、多步骤探索。
- 动态剪枝策略被用于加速推理过程而不损失精度。
- 在基准测试中,SQL-o1在复杂数据集上实现了显著的性能提升,超越了GPT-4模型。
点此查看论文截图

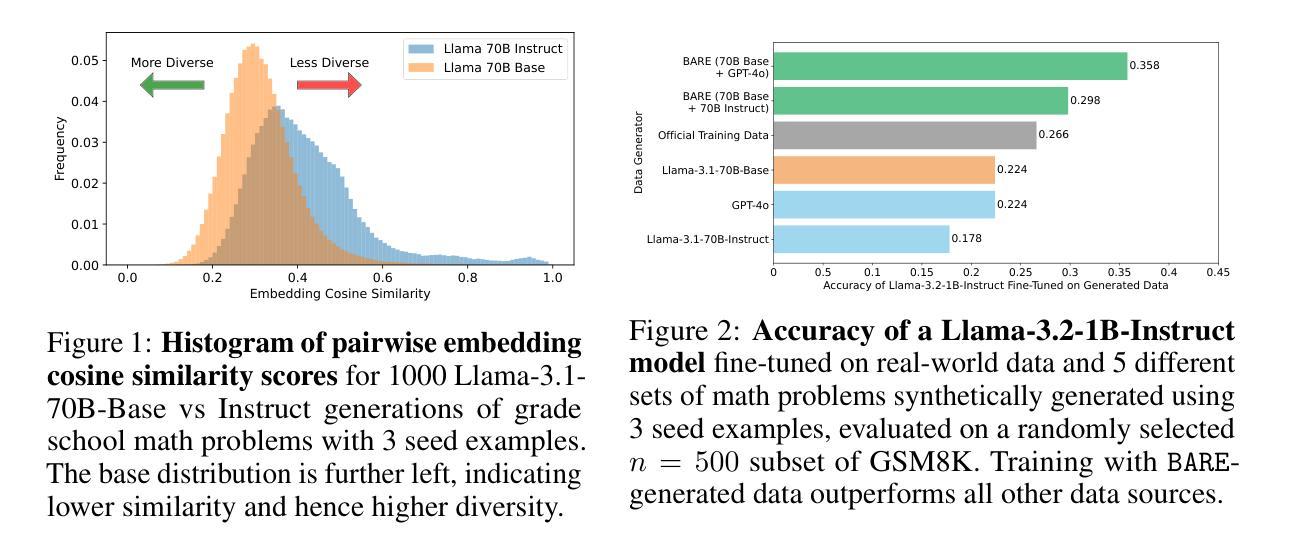
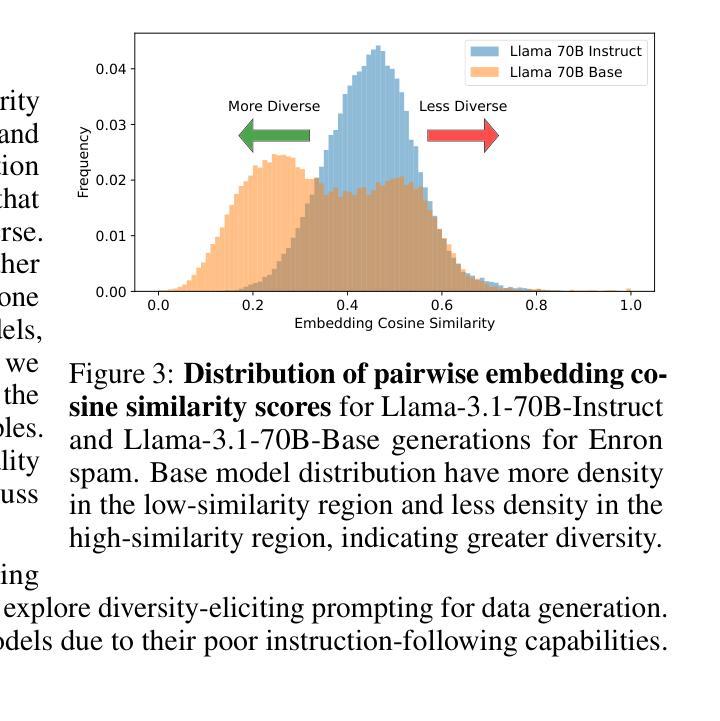
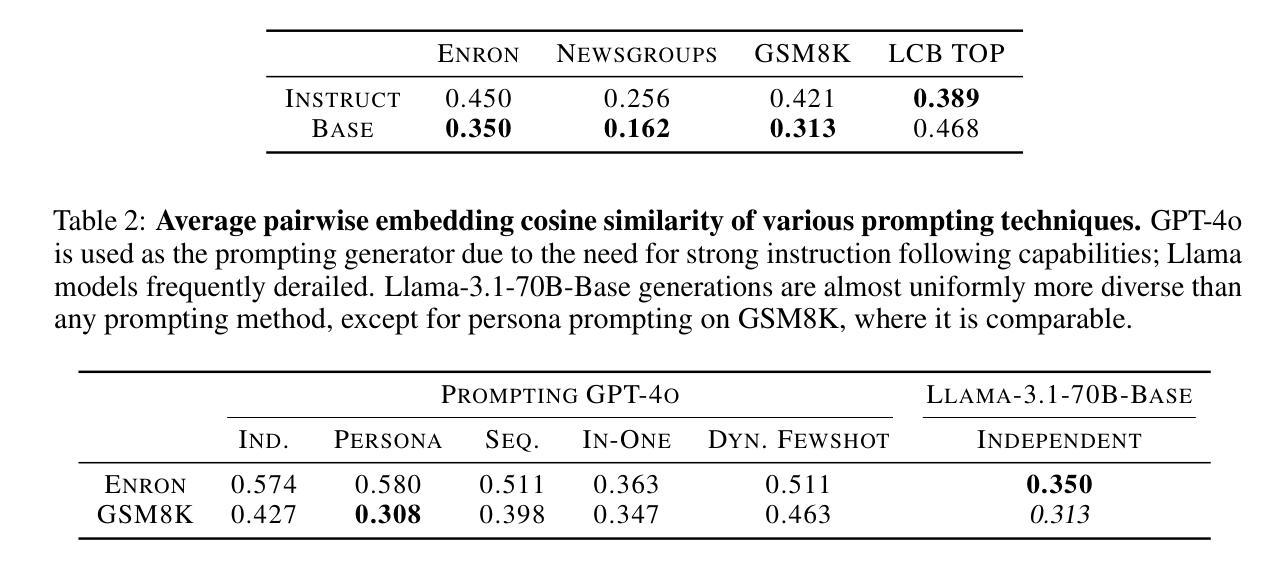
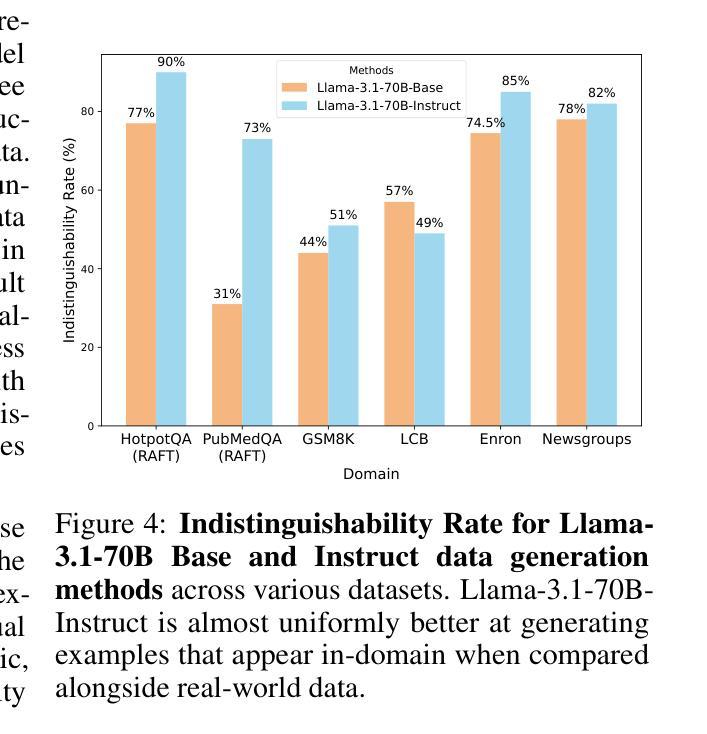
BARE: Leveraging Base Language Models for Few-Shot Synthetic Data Generation
Authors:Alan Zhu, Parth Asawa, Jared Quincy Davis, Lingjiao Chen, Boris Hanin, Ion Stoica, Joseph E. Gonzalez, Matei Zaharia
As the demand for high-quality data in model training grows, researchers and developers are increasingly generating synthetic data to tune and train LLMs. However, current data generation methods rely on seed sets containing tens of thousands of examples to prompt instruction-tuned models. This reliance can be especially problematic when the curation of high-quality examples is expensive or difficult. In this paper we explore the novel few-shot synthetic data generation setting – generating a high-quality dataset from a few examples. We show that when working with only a few seed examples, instruction-tuned models used in current synthetic data methods produce insufficient diversity for downstream tasks. In contrast, we show that base models without post-training, largely untapped for synthetic data generation, offer substantially greater output diversity, albeit with lower instruction following abilities. Leveraging this insight, we propose Base-Refine (BARE), a novel two-stage method that combines the diversity of base models with the quality assurance of instruction-tuned models. BARE excels in few-shot synthetic data generation: using only 3 seed examples it generates diverse, high-quality datasets that significantly improve downstream task performance. We show that fine-tuning Llama 3.1 8B with 1,000 BARE-generated samples achieves performance comparable to state-of-the-art similarly sized models on LiveCodeBench tasks. Furthermore, data generated with BARE enables a 101% improvement for a fine-tuned Llama 3.2 1B on GSM8K over data generated by only instruction-models, and an 18.4% improvement for a fine-tuned Llama 3.1 8B over the state-of-the-art RAFT method for RAG data generation.
随着模型训练中对高质量数据的需求不断增长,研究人员和开发人员越来越多地生成合成数据来调整和培训大型语言模型。然而,当前的数据生成方法依赖于包含数十万个示例的种子集来提示指令调整模型。当高质量示例的收集既昂贵又困难时,这种依赖可能会特别成问题。在本文中,我们探索了新型少样本合成数据生成设置——从少量示例生成高质量数据集。我们表明,在与仅几个种子示例一起工作时,当前合成数据方法中使用指令调整模型会产生下游任务不足的多样性。相比之下,我们证明,未经训练的基础模型在合成数据生成方面尚未得到充分利用,可以提供更大的输出多样性,尽管其指令执行能力较低。利用这一见解,我们提出了Base-Refine(BARE),这是一种新型的两阶段方法,结合了基础模型的多样性和指令调整模型的质量保证。BARE在少样本合成数据生成方面表现出色:仅使用三个种子示例即可生成多样化且高质量的数据集,这些数据集可以显著提高下游任务性能。我们展示了仅使用经过BARE生成的样本微调过的Llama 3.1 8B的性能可以与LiveCodeBench任务上表现卓越的大型相似模型相媲美。此外,使用BARE生成的数据可以使经过微调后的Llama 3.2 1B在GSM8K上的性能提升幅度达到101%,高于仅由指令模型生成的数据生成的样本,而对于经过微调后的Llama 3.1 8B在RAG数据生成方面的性能提升幅度为18.4%,超过了当前最先进的RAFT方法。
论文及项目相关链接
Summary
本文探索了基于少数样本的合成数据生成方法。研究发现,当前合成数据生成方法依赖于大量高质量样本进行训练,成本高昂或难以获取高质量样本时存在问题。本文提出了结合基础模型的多样性和指令微调模型的质量保证的Base-Refine(BARE)方法,能在仅使用少数样本的情况下生成高质量、多样化的数据集。实验表明,BARE在生成少量合成数据方面表现出色,仅使用三个样本即可生成高质量的数据集,显著提高下游任务性能。
Key Takeaways
- 当前合成数据生成方法依赖于大量高质量样本进行训练,成本高昂或难以获取时存在问题。
- 基于少数样本的合成数据生成方法受到关注,成为研究热点。
- 基础模型在未经过指令微调时展现出更高的输出多样性。
- BARE结合了基础模型的多样性和指令微调模型的质量保证,能在仅使用少数样本的情况下生成高质量的数据集。
- BARE方法在多个实验任务中表现出显著优势,如LiveCodeBench任务和GSM8K任务等。
点此查看论文截图

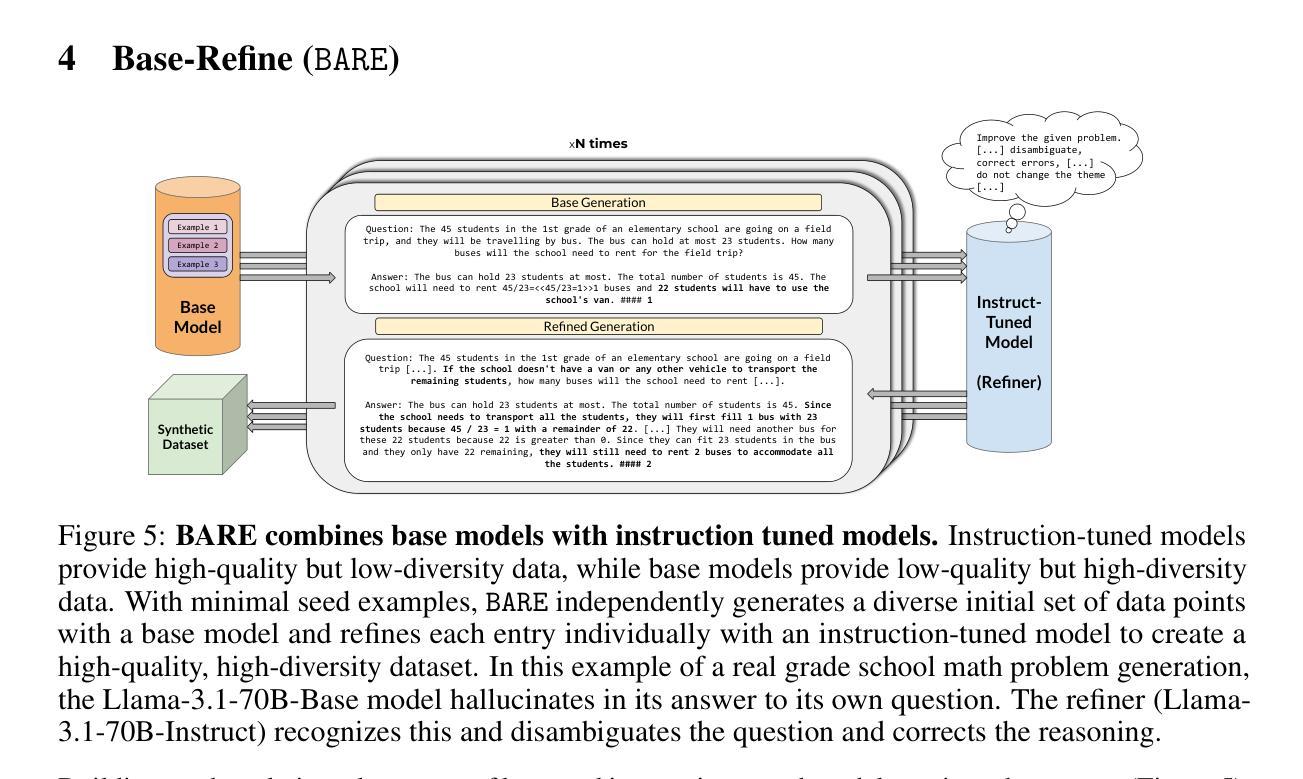
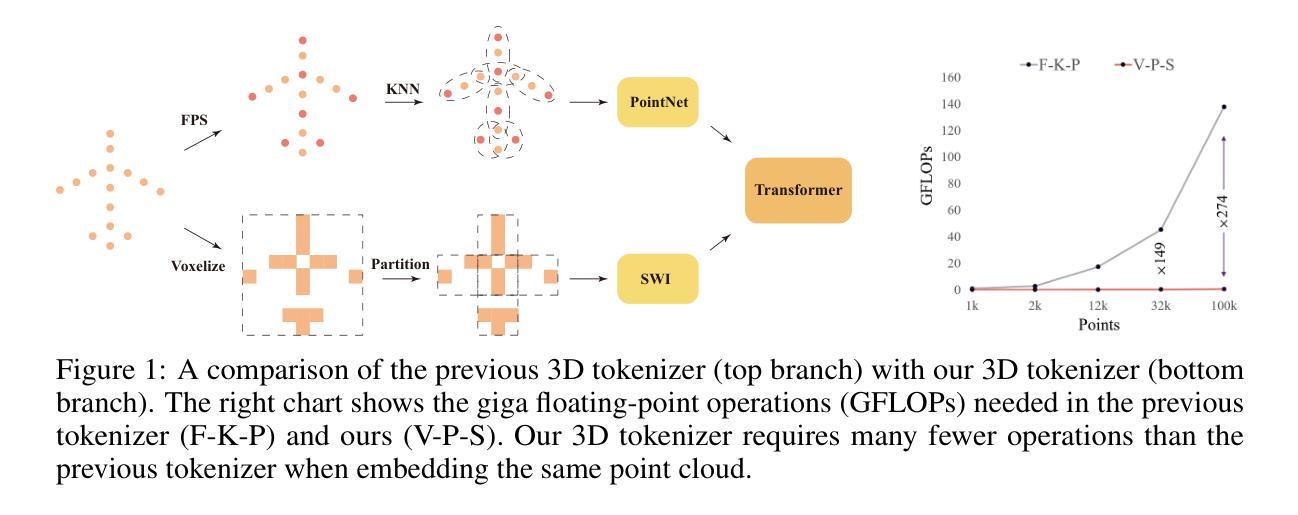
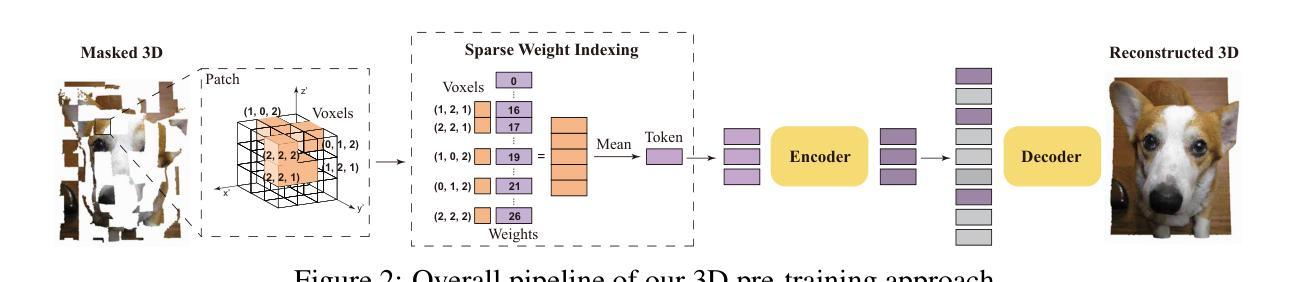
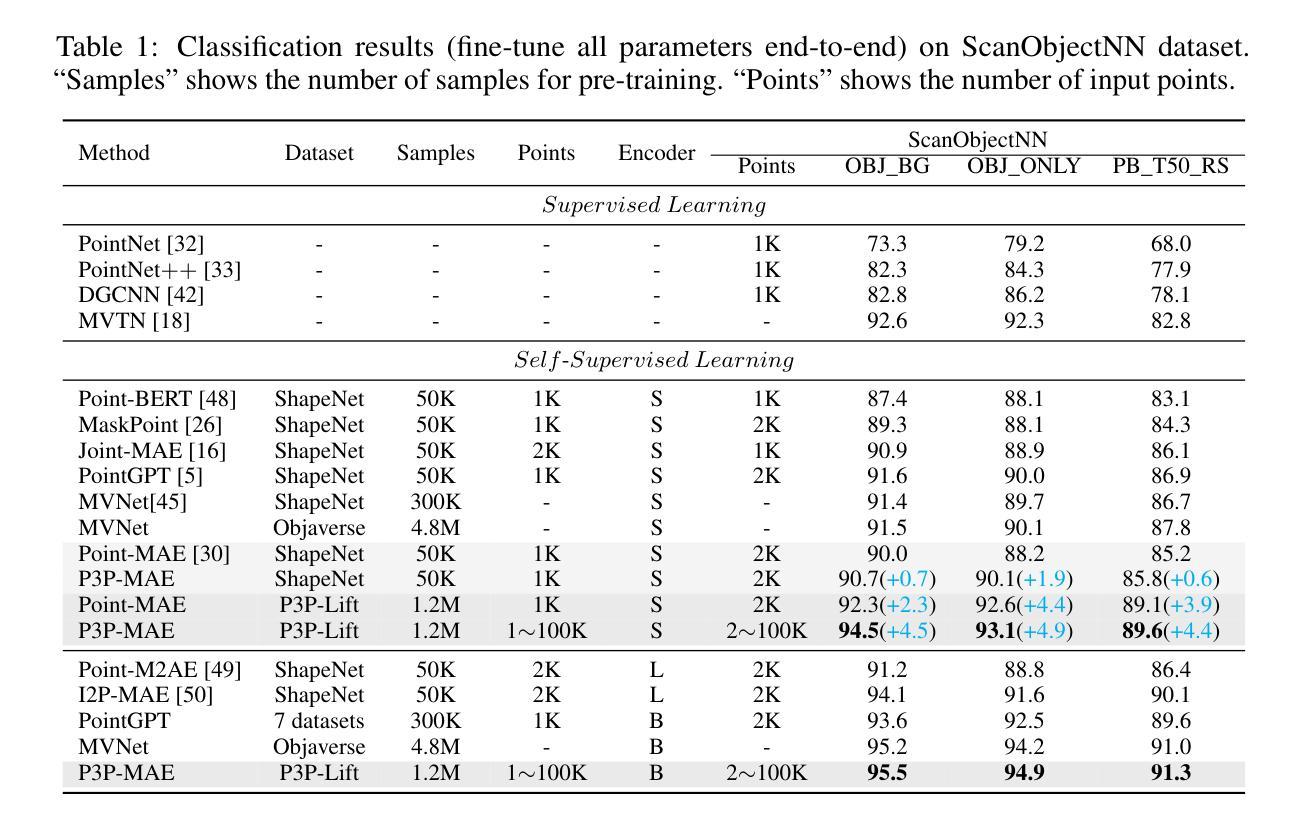
P3P: Pseudo-3D Pre-training for Scaling 3D Voxel-based Masked Autoencoders
Authors:Xuechao Chen, Ying Chen, Jialin Li, Qiang Nie, Hanqiu Deng, Yong Liu, Qixing Huang, Yang Li
3D pre-training is crucial to 3D perception tasks. Nevertheless, limited by the difficulties in collecting clean and complete 3D data, 3D pre-training has persistently faced data scaling challenges. In this work, we introduce a novel self-supervised pre-training framework that incorporates millions of images into 3D pre-training corpora by leveraging a large depth estimation model. New pre-training corpora encounter new challenges in representation ability and embedding efficiency of models. Previous pre-training methods rely on farthest point sampling and k-nearest neighbors to embed a fixed number of 3D tokens. However, these approaches prove inadequate when it comes to embedding millions of samples that feature a diverse range of point numbers, spanning from 1,000 to 100,000. In contrast, we propose a tokenizer with linear-time complexity, which enables the efficient embedding of a flexible number of tokens. Accordingly, a new 3D reconstruction target is proposed to cooperate with our 3D tokenizer. Our method achieves state-of-the-art performance in 3D classification, few-shot learning, and 3D segmentation. Code is available at https://github.com/XuechaoChen/P3P-MAE.
3D预训练对3D感知任务至关重要。然而,受限于收集干净且完整的3D数据的困难,3D预训练一直面临着数据规模扩大的挑战。在这项工作中,我们引入了一种新型自监督预训练框架,该框架利用深度估计模型将数百万张图像纳入3D预训练语料库中。新的预训练语料库在模型的表示能力和嵌入效率方面遇到了新的挑战。之前的预训练方法依赖于最远点采样和k近邻来嵌入固定数量的3D令牌。然而,当需要嵌入数量从1000到100000不等的数百万样本时,这些方法证明是无效的。相反,我们提出了一种具有线性时间复杂度的标记器,可以实现灵活数量的令牌的高效嵌入。因此,提出了一种新的3D重建目标,以配合我们的3D令牌化器使用。我们的方法在3D分类、小样本学习和3D分割方面达到了最先进的性能。代码可在https://github.com/XuechaoChen/P3P-MAE找到。
论文及项目相关链接
PDF Under review. Pre-print
Summary
本文介绍了一种利用大规模深度估计模型将数百万图像纳入3D预训练语料库的新型自监督预训练框架。针对新预训练语料库所带来的模型表征能力和嵌入效率问题,提出了一种具有线性时间复杂度的分词器,实现了灵活数量的标记的高效嵌入,并提出了一种新的3D重建目标与之配合。该方法在3D分类、小样本学习和3D分割方面取得了最先进的性能。
Key Takeaways
- 3D预训练对3D感知任务至关重要,但受限于缺乏干净完整的3D数据,面临数据规模扩展的挑战。
- 提出了一种新型自监督预训练框架,该框架利用大规模深度估计模型将数百万图像纳入3D预训练语料库。
- 新预训练语料库带来了模型表征能力和嵌入效率的挑战。
- 现有预训练方法依赖最远点采样和k近邻来嵌入固定数量的3D标记,但对于嵌入数量范围广泛的数百万样本显得不足。
- 提出了一种具有线性时间复杂度的分词器,实现了高效嵌入灵活数量的标记。
- 提出了一种新的3D重建目标,与3D分词器配合使用。
点此查看论文截图

VITAL: Interactive Few-Shot Imitation Learning via Visual Human-in-the-Loop Corrections
Authors:Hamidreza Kasaei, Mohammadreza Kasaei
Imitation Learning (IL) has emerged as a powerful approach in robotics, allowing robots to acquire new skills by mimicking human actions. Despite its potential, the data collection process for IL remains a significant challenge due to the logistical difficulties and high costs associated with obtaining high-quality demonstrations. To address these issues, we propose a large-scale data generation from a handful of demonstrations through data augmentation in simulation. Our approach leverages affordable hardware and visual processing techniques to collect demonstrations, which are then augmented to create extensive training datasets for imitation learning. By utilizing both real and simulated environments, along with human-in-the-loop corrections, we enhance the generalizability and robustness of the learned policies. We evaluated our method through several rounds of experiments in both simulated and real-robot settings, focusing on tasks of varying complexity, including bottle collecting, stacking objects, and hammering. Our experimental results validate the effectiveness of our approach in learning robust robot policies from simulated data, significantly improved by human-in-the-loop corrections and real-world data integration. Additionally, we demonstrate the framework’s capability to generalize to new tasks, such as setting a drink tray, showcasing its adaptability and potential for handling a wide range of real-world manipulation tasks. A video of the experiments can be found at: https://youtu.be/YeVAMRqRe64?si=R179xDlEGc7nPu8i
模仿学习(IL)作为机器人技术中的一种强大方法已经出现,它允许机器人通过模仿人类行为来习得新技能。尽管潜力巨大,但IL的数据收集过程仍然是一个巨大的挑战,这主要是因为获取高质量演示的物流困难和成本高昂。为了解决这些问题,我们提出了一种通过模拟中的数据增强从少量演示中生成大规模数据的方法。我们的方法利用廉价的硬件和视觉处理技术来收集演示,然后通过增强这些演示来创建用于模仿学习的广泛训练数据集。通过结合真实和模拟环境以及人为的实时校正,我们提高了学习策略的通用性和稳健性。我们在模拟和真实机器人环境中进行了多轮实验,评估了我们的方法,重点研究了不同复杂度的任务,包括捡瓶子、堆叠物体和锤击。我们的实验结果验证了我们的方法从模拟数据中学习稳健的机器人策略的有效性,人为的实时校正和真实世界数据集成对此有很大的提升。此外,我们展示了该框架能够推广到新的任务,如设置饮料托盘,展示了其适应性和处理各种现实世界操作任务的潜力。实验视频可在:https://youtu.be/YeVAMRqRe64?si=R179xDlEGc7nPu8i 找到。
论文及项目相关链接
Summary
机器人通过模仿人类动作进行技能学习的方法被称为模仿学习(IL)。然而,数据收集是IL的一大挑战,因为获取高质量演示的物流困难和成本高昂。为解决这一问题,我们提出通过模拟中的数据增强从少量演示中生成大规模数据的方法。该方法利用廉价硬件和视觉处理技术收集演示,并通过模拟环境和人为修正增强训练数据集。在模拟和真实机器人环境中进行的实验证明,该方法学习到的策略具有广泛的适用性和鲁棒性。实验结果证实,人为修正和真实世界数据集成能提高策略质量。此外,该方法能够适应各种现实世界操控任务并泛化到新任务。观看实验的视频请点击链接。
Key Takeaways
1. 模仿学习(IL)是机器人学习的一种强大方法,允许机器人通过模仿人类动作获取新技能。
2. 数据收集是IL面临的主要挑战之一,因为获取高质量演示的成本较高且存在物流困难。
3. 提出了一种通过模拟中的数据增强从少量演示生成大规模数据的方法来解决上述问题。
4. 该方法利用廉价硬件和视觉处理技术收集演示,并通过模拟环境和人为修正增强训练数据集。
5. 实验证明,该方法能够学习适应性强、鲁棒性高的策略。
6. 人为修正和真实世界数据集成有助于提高策略质量。
点此查看论文截图



Make-An-Agent: A Generalizable Policy Network Generator with Behavior-Prompted Diffusion
Authors:Yongyuan Liang, Tingqiang Xu, Kaizhe Hu, Guangqi Jiang, Furong Huang, Huazhe Xu
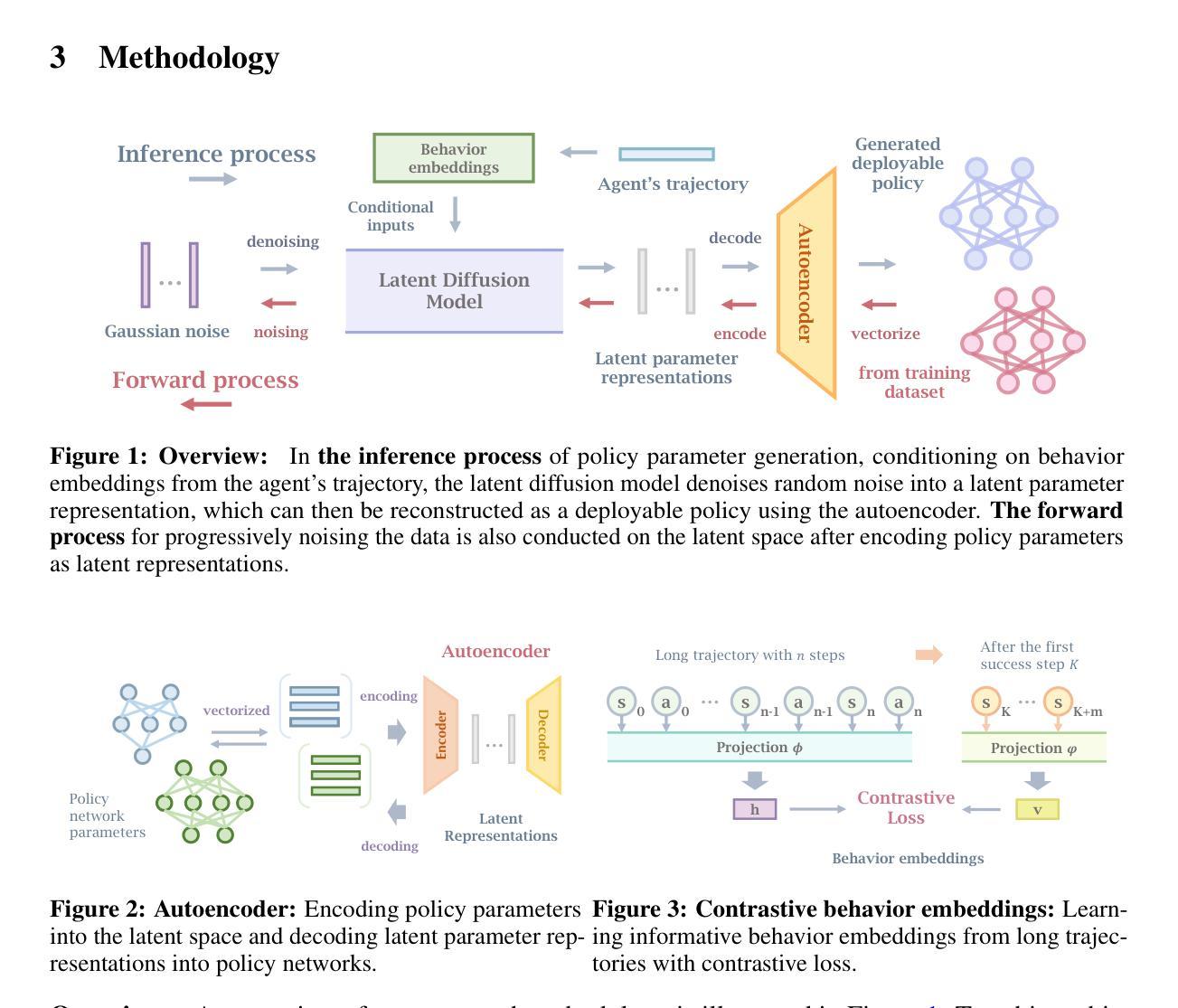
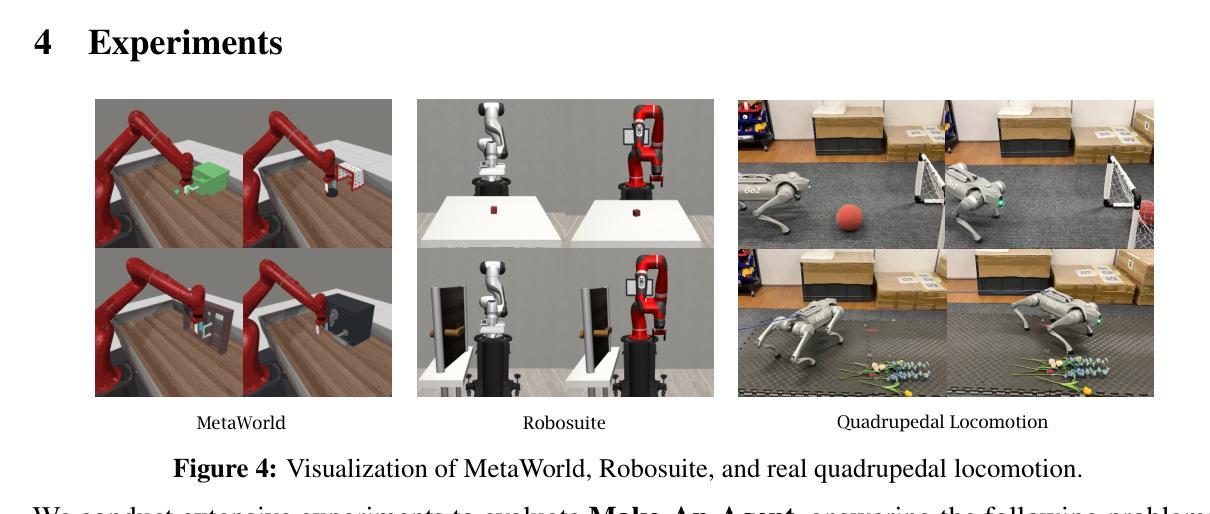
Can we generate a control policy for an agent using just one demonstration of desired behaviors as a prompt, as effortlessly as creating an image from a textual description? In this paper, we present Make-An-Agent, a novel policy parameter generator that leverages the power of conditional diffusion models for behavior-to-policy generation. Guided by behavior embeddings that encode trajectory information, our policy generator synthesizes latent parameter representations, which can then be decoded into policy networks. Trained on policy network checkpoints and their corresponding trajectories, our generation model demonstrates remarkable versatility and scalability on multiple tasks and has a strong generalization ability on unseen tasks to output well-performed policies with only few-shot demonstrations as inputs. We showcase its efficacy and efficiency on various domains and tasks, including varying objectives, behaviors, and even across different robot manipulators. Beyond simulation, we directly deploy policies generated by Make-An-Agent onto real-world robots on locomotion tasks. Project page: https://cheryyunl.github.io/make-an-agent/
我们可以像从文本描述中创建图像一样,仅使用一个期望行为的演示作为提示来为代理生成一个控制策略吗?在本文中,我们提出了Make-An-Agent,这是一个新型的策略参数生成器,它利用条件扩散模型的力量来进行行为到策略的生成。在行为嵌入(编码轨迹信息)的指导下,我们的策略生成器能够合成潜在的参数表示,然后可以将其解码为策略网络。我们的生成模型在多个任务上表现出卓越的多功能性和可扩展性,并且在仅使用少量演示作为输入的情况下,在未见过的任务上具有很强的泛化能力。我们在各种领域和任务中展示了它的功效和效率,包括不同的目标、行为和不同的机器人操纵器。除了模拟环境外,我们还直接将Make-An-Agent生成的策略部署到真实世界的机器人上进行运动任务。项目页面:https://cheryyunl.github.io/make-an-agent/
论文及项目相关链接
PDF Annual Conference on Neural Information Processing Systems 38
Summary
基于条件扩散模型的策略参数生成器Make-An-Agent,通过利用行为嵌入轨迹信息来合成潜在参数表示,进而解码为策略网络。该生成模型在多任务上表现出强大的通用性和可扩展性,仅需少量演示即可输出表现良好的策略,并对未见任务具有较强的泛化能力。
Key Takeaways
- Make-An-Agent利用条件扩散模型进行行为到策略生成。
- 通过行为嵌入轨迹信息来合成潜在参数表示。
- 模型能够解码潜在参数表示形成策略网络。
- 生成模型在多任务上表现出强大的通用性和可扩展性。
- 仅需少量演示即可输出表现良好的策略。
- 模型对未见任务具有较强的泛化能力。
点此查看论文截图