⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-05-24 更新
Let Androids Dream of Electric Sheep: A Human-like Image Implication Understanding and Reasoning Framework
Authors:Chenhao Zhang, Yazhe Niu
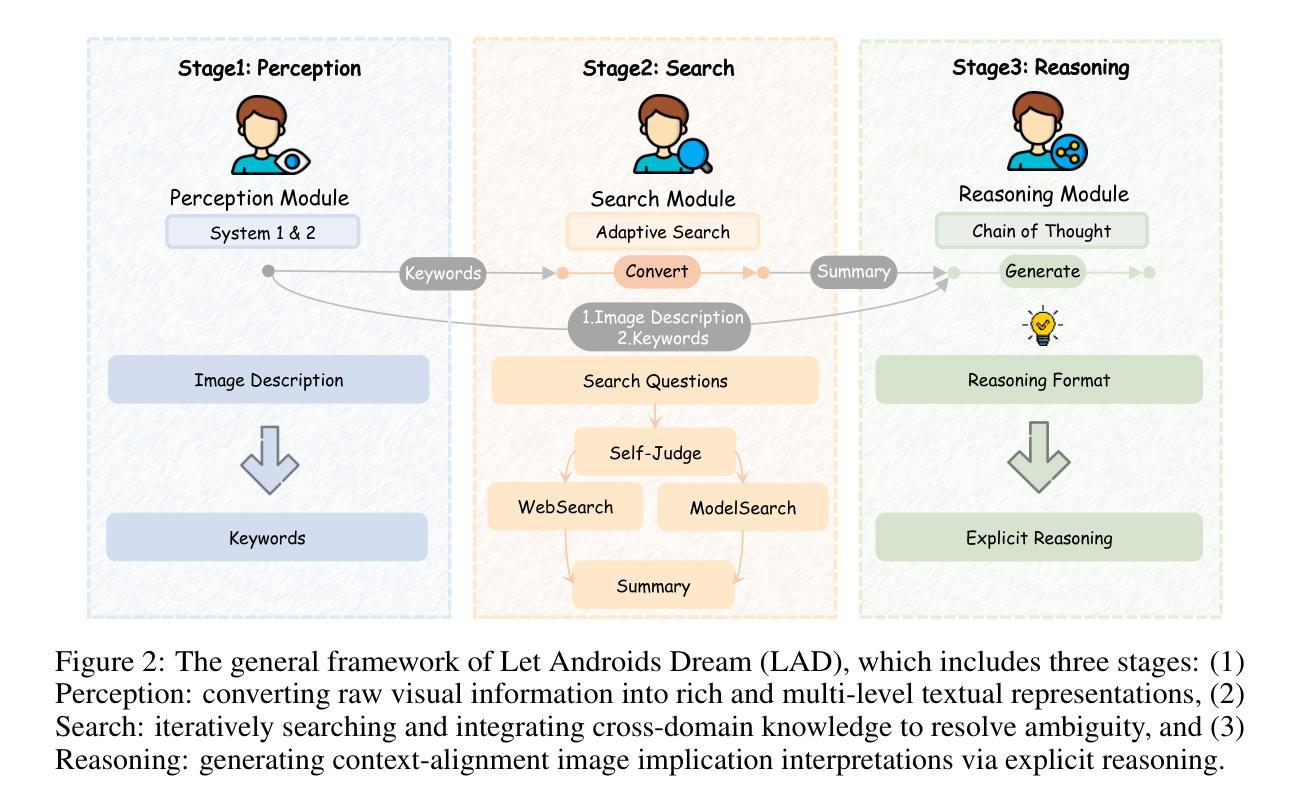
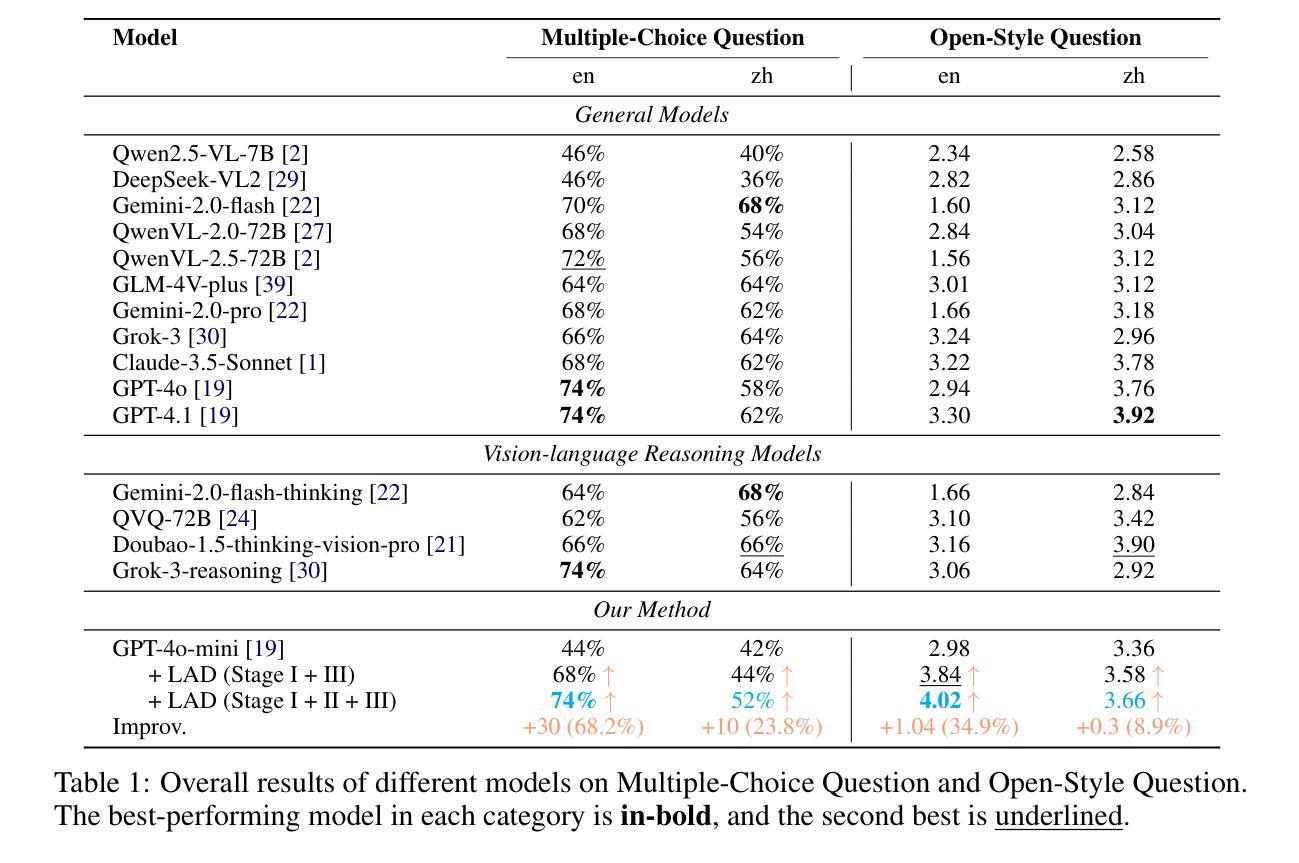
Metaphorical comprehension in images remains a critical challenge for AI systems, as existing models struggle to grasp the nuanced cultural, emotional, and contextual implications embedded in visual content. While multimodal large language models (MLLMs) excel in basic Visual Question Answer (VQA) tasks, they struggle with a fundamental limitation on image implication tasks: contextual gaps that obscure the relationships between different visual elements and their abstract meanings. Inspired by the human cognitive process, we propose Let Androids Dream (LAD), a novel framework for image implication understanding and reasoning. LAD addresses contextual missing through the three-stage framework: (1) Perception: converting visual information into rich and multi-level textual representations, (2) Search: iteratively searching and integrating cross-domain knowledge to resolve ambiguity, and (3) Reasoning: generating context-alignment image implication via explicit reasoning. Our framework with the lightweight GPT-4o-mini model achieves SOTA performance compared to 15+ MLLMs on English image implication benchmark and a huge improvement on Chinese benchmark, performing comparable with the GPT-4o model on Multiple-Choice Question (MCQ) and outperforms 36.7% on Open-Style Question (OSQ). Additionally, our work provides new insights into how AI can more effectively interpret image implications, advancing the field of vision-language reasoning and human-AI interaction. Our project is publicly available at https://github.com/MING-ZCH/Let-Androids-Dream-of-Electric-Sheep.
图像中的隐喻理解仍然是人工智能系统面临的一个关键挑战,因为现有模型难以把握视觉内容中嵌入的微妙文化、情感和上下文含义。尽管多模态大型语言模型(MLLM)在基本的视觉问答(VQA)任务上表现出色,但在图像含义任务上却存在基本局限:上下文缺失导致不同视觉元素及其抽象意义之间的关系模糊不清。受人类认知过程的启发,我们提出了“让机器人做梦”(LAD)这一全新的图像含义理解和推理框架。LAD通过三个阶段解决上下文缺失问题:(1)感知:将视觉信息转换为丰富且多层次的文本表示;(2)搜索:迭代搜索并整合跨域知识以解决歧义;(3)推理:通过明确推理生成与上下文对齐的图像含义。我们的框架结合了轻量级GPT-4o-mini模型,在英语图像含义基准测试上的性能超过了15个以上的MLLM,在中文基准测试上也有很大改进。在多选题(MCQ)方面,我们的表现与GPT-4o模型相当,在开放性问题(OSQ)上超出了36.7%的水平。此外,我们的工作提供了关于AI如何更有效地解释图像含义的新见解,推动了视觉语言推理和人机交互领域的发展。我们的项目公开可访问于https://github.com/MING-ZCH/Let-Androids-Dream-of-Electric-Sheep。
论文及项目相关链接
PDF 16 pages, 9 figures. Code & Dataset: https://github.com/MING-ZCH/Let-Androids-Dream-of-Electric-Sheep
Summary
本文主要探讨人工智能在理解图像隐喻方面的挑战,包括现有模型在捕捉视觉内容的文化、情感和语境内涵方面的局限性。为解决这些问题,提出了一种新型的多模态大型语言模型(Let Androids Dream,简称LAD),用于图像隐喻理解和推理。LAD通过感知、搜索和推理三个阶段来填补语境缺失,实现图像隐喻的理解。该框架在英文图像隐喻基准测试上的表现达到最新水平,并在中文基准测试上有显著提高。此外,该研究为AI更有效地解释图像含义提供了新视角,推动了视觉语言推理和人机交互领域的发展。相关项目可在https://github.com/MING-ZCH/Let-Androids-Dream-of-Electric-Sheep找到。
Key Takeaways
- AI在理解图像隐喻方面存在挑战,无法把握视觉内容的文化、情感和语境内涵。
- 现有模型在图像隐喻任务上存在上下文缺失的问题。
- Let Androids Dream(LAD)框架通过感知、搜索和推理三个阶段解决上下文缺失问题。
- LAD框架在英文图像隐喻基准测试上表现优异,达到最新水平。
- LAD框架在中文图像隐喻任务上有显著提高,与GPT-4o模型表现相当或更优。
- LAD框架为AI更有效地解释图像含义提供了新视角。
点此查看论文截图

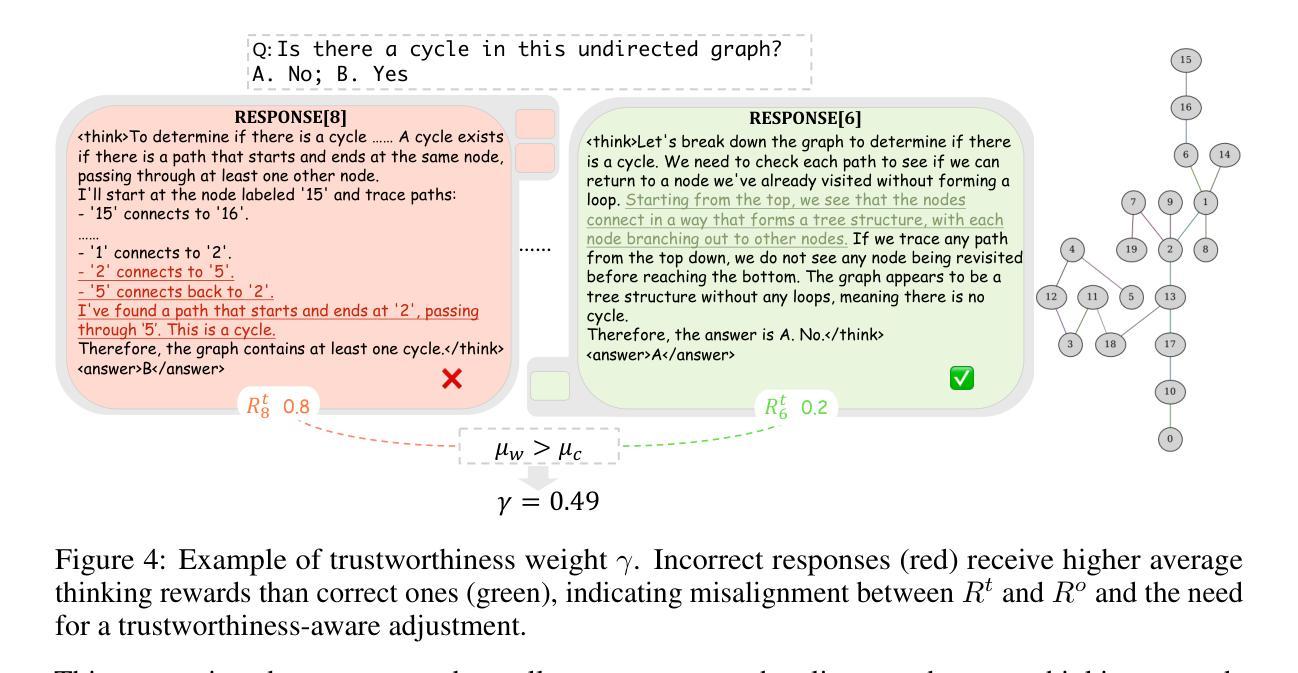
SophiaVL-R1: Reinforcing MLLMs Reasoning with Thinking Reward
Authors:Kaixuan Fan, Kaituo Feng, Haoming Lyu, Dongzhan Zhou, Xiangyu Yue
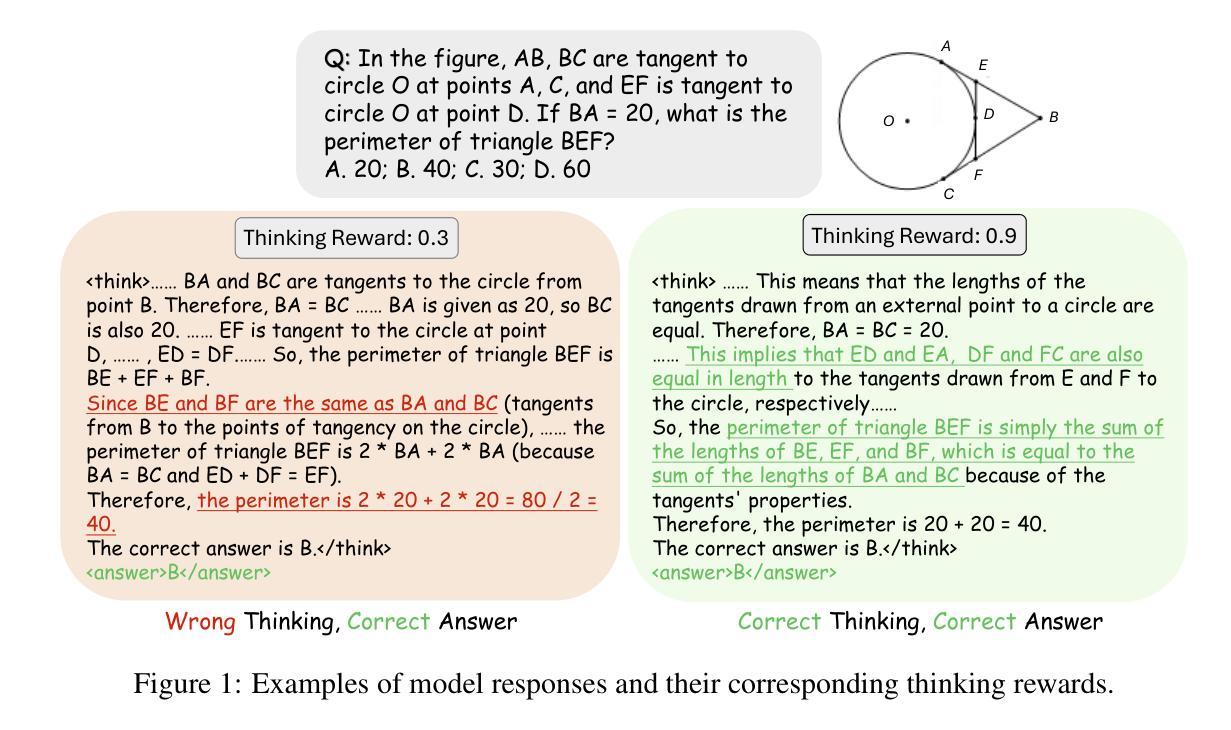
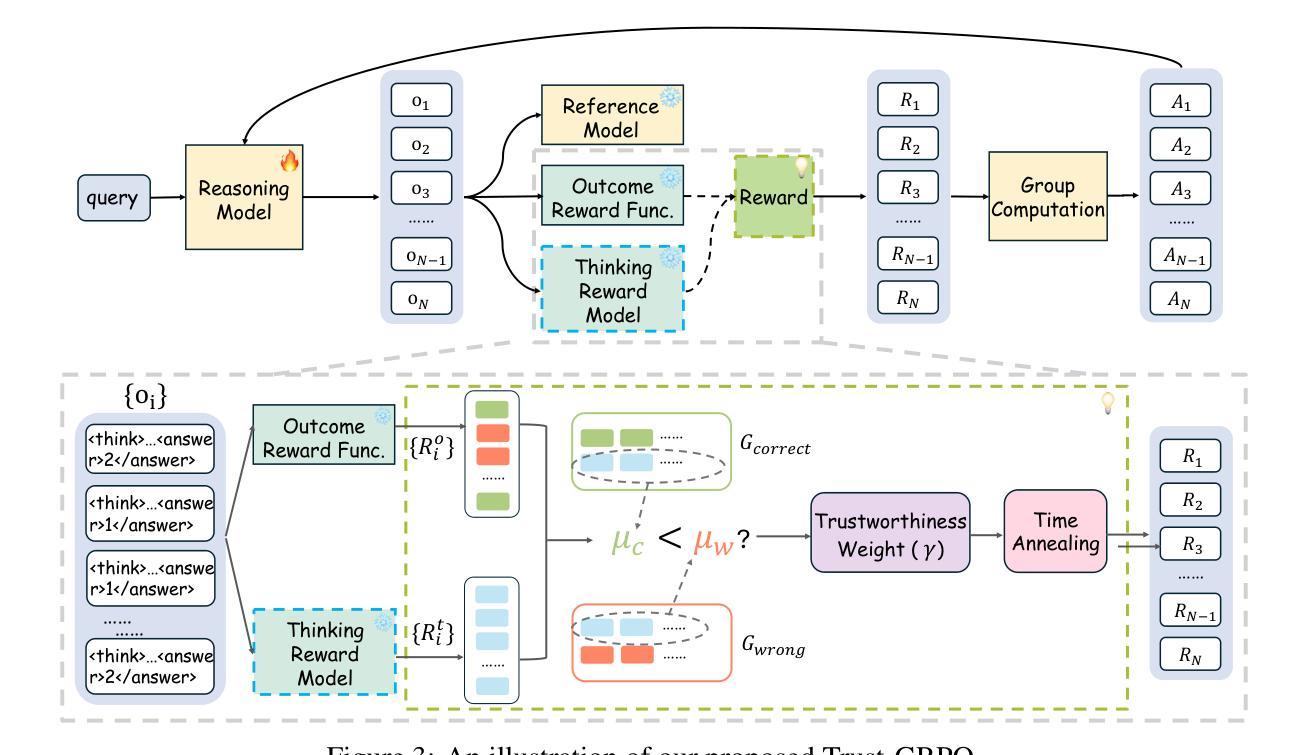
Recent advances have shown success in eliciting strong reasoning abilities in multimodal large language models (MLLMs) through rule-based reinforcement learning (RL) with outcome rewards. However, this paradigm typically lacks supervision over the thinking process leading to the final outcome.As a result, the model may learn sub-optimal reasoning strategies, which can hinder its generalization ability. In light of this, we propose SophiaVL-R1, as an attempt to add reward signals for the thinking process in this paradigm. To achieve this, we first train a thinking reward model that evaluates the quality of the entire thinking process. Given that the thinking reward may be unreliable for certain samples due to reward hacking, we propose the Trust-GRPO method, which assigns a trustworthiness weight to the thinking reward during training. This weight is computed based on the thinking reward comparison of responses leading to correct answers versus incorrect answers, helping to mitigate the impact of potentially unreliable thinking rewards. Moreover, we design an annealing training strategy that gradually reduces the thinking reward over time, allowing the model to rely more on the accurate rule-based outcome reward in later training stages. Experiments show that our SophiaVL-R1 surpasses a series of reasoning MLLMs on various benchmarks (e.g., MathVisita, MMMU), demonstrating strong reasoning and generalization capabilities. Notably, our SophiaVL-R1-7B even outperforms LLaVA-OneVision-72B on most benchmarks, despite the latter having 10 times more parameters. All code, models, and datasets are made publicly available at https://github.com/kxfan2002/SophiaVL-R1.
最近的进展表明,通过基于规则的强化学习(RL)与结果奖励相结合,在多模态大型语言模型(MLLMs)中激发强大的推理能力已经取得了成功。然而,这种范式通常缺乏对最终结果的思考过程的监督。因此,模型可能会学习次优的推理策略,这可能会阻碍其泛化能力。鉴于此,我们提出SophiaVL-R1,试图为这一范式中的思考过程增加奖励信号。为实现这一点,我们首先训练一个思考奖励模型,该模型评估整个思考过程的质量。鉴于在某些样本上思考奖励可能因奖励破解而不可靠,我们提出了Trust-GRPO方法,该方法在训练过程中为思考奖励分配可信度权重。该权重是基于正确答案与错误答案所导致的思考奖励的对比来计算的,有助于减轻潜在不可靠的思考奖励的影响。此外,我们设计了一种退火训练策略,随着时间的推移逐渐降低思考奖励,使模型在后期训练阶段更多地依赖于准确的基于规则的成果奖励。实验表明,我们的SophiaVL-R1在各种基准测试(例如MathVisita、MMMU)上超越了一系列推理MLLMs,表现出强大的推理和泛化能力。值得注意的是,我们的SophiaVL-R1-7B甚至在大多数基准测试上超越了参数更多的LLaVA-OneVision-72B。所有代码、模型和数据集均公开提供在https://github.com/kxfan2002/SophiaVL-R1。
论文及项目相关链接
PDF Project page:https://github.com/kxfan2002/SophiaVL-R1
Summary
本研究通过结合规则强化学习与奖励信号,提出了SophiaVL-R1模型,旨在增强多模态大型语言模型(MLLMs)的推理能力。针对现有模型在思考过程监督不足、可能学习次优推理策略的问题,SophiaVL-R1通过训练思考奖励模型来评价整个思考过程的质量。同时,为应对思考奖励在某些样本上可能存在的不可靠性,研究提出了Trust-GRPO方法,通过计算正确与错误答案对应的思考奖励的信任度权重来优化。此外,还设计了退火训练策略,逐步减少思考奖励的依赖,使模型在后期更多地依赖于准确的规则结果奖励。实验表明,SophiaVL-R1在各种基准测试上的表现优于一系列推理MLLMs,包括MathVisita和MMMU等。其参数规模较小的SophiaVL-R1-7B甚至能在多数基准测试上超越参数规模更大的LLaVA-OneVision-72B。该研究的代码、模型和数据集已公开发布在GitHub上。
Key Takeaways
- 研究采用规则强化学习与奖励信号结合的方法,成功增强MLLMs的推理能力。
- SophiaVL-R1模型通过训练思考奖励模型评价思考过程质量,改善模型可能学习的次优推理策略问题。
- Trust-GRPO方法用于应对思考奖励在某些样本上的不可靠性,通过计算信任度权重优化奖励分配。
- 采用退火训练策略逐步减少对思考奖励的依赖,增强模型对准确规则结果奖励的依赖。
- SophiaVL-R1在多个基准测试上表现优越,包括MathVisita和MMMU等。
- SophiaVL-R1-7B模型即使参数规模较小,也能在多数基准测试上超越更大规模的LLaVA-OneVision-72B模型。
点此查看论文截图


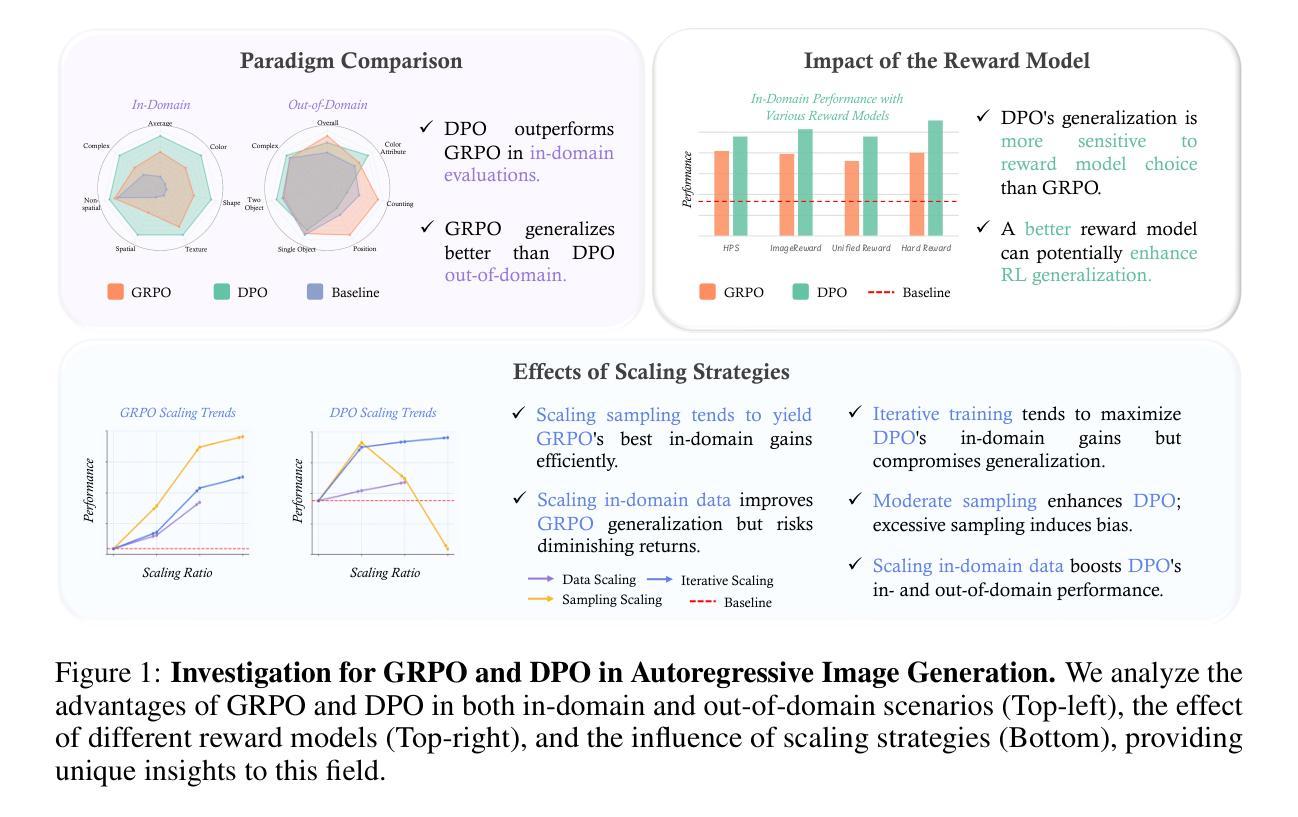
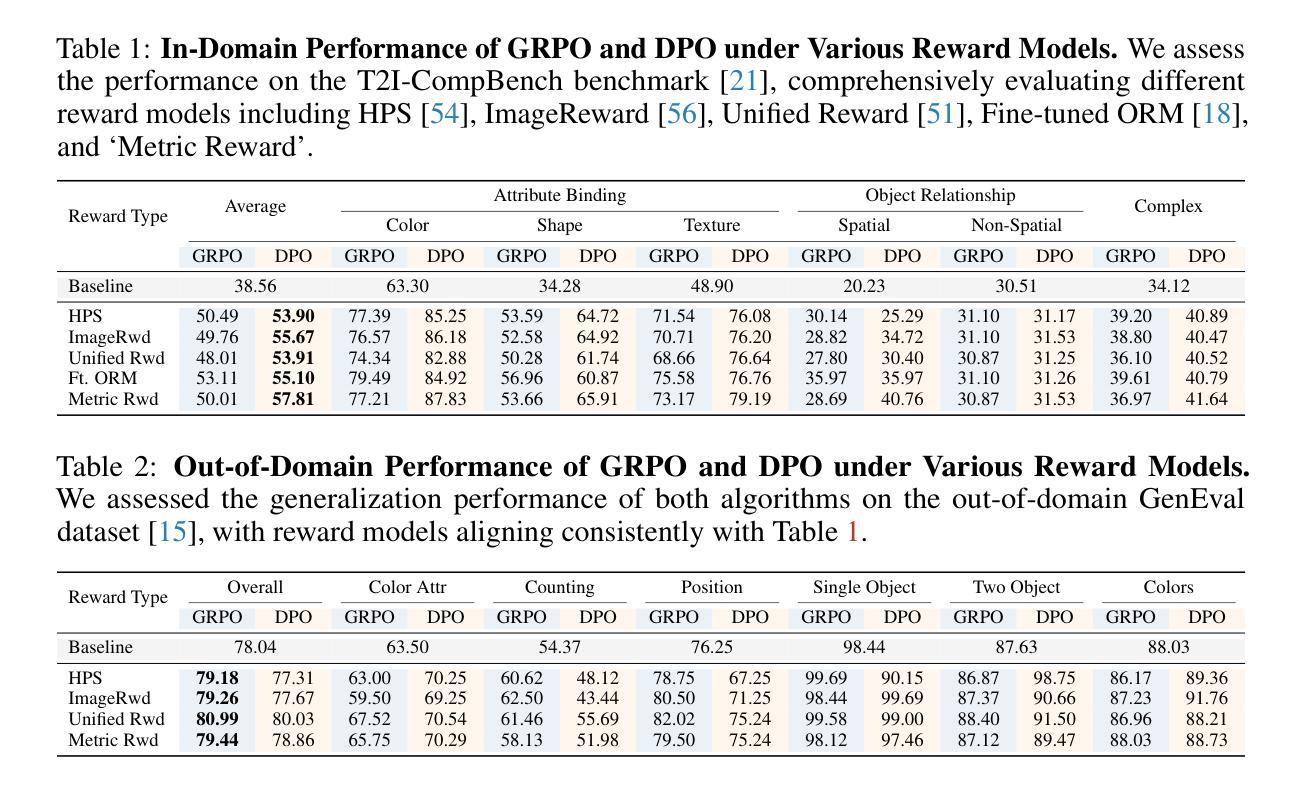
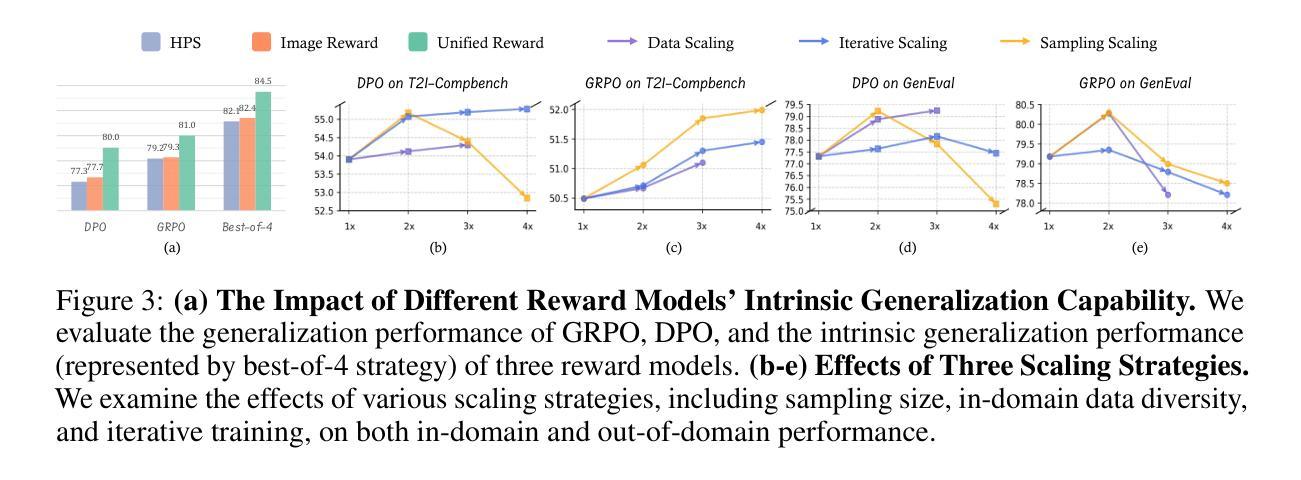
Delving into RL for Image Generation with CoT: A Study on DPO vs. GRPO
Authors:Chengzhuo Tong, Ziyu Guo, Renrui Zhang, Wenyu Shan, Xinyu Wei, Zhenghao Xing, Hongsheng Li, Pheng-Ann Heng
Recent advancements underscore the significant role of Reinforcement Learning (RL) in enhancing the Chain-of-Thought (CoT) reasoning capabilities of large language models (LLMs). Two prominent RL algorithms, Direct Preference Optimization (DPO) and Group Relative Policy Optimization (GRPO), are central to these developments, showcasing different pros and cons. Autoregressive image generation, also interpretable as a sequential CoT reasoning process, presents unique challenges distinct from LLM-based CoT reasoning. These encompass ensuring text-image consistency, improving image aesthetic quality, and designing sophisticated reward models, rather than relying on simpler rule-based rewards. While recent efforts have extended RL to this domain, these explorations typically lack an in-depth analysis of the domain-specific challenges and the characteristics of different RL strategies. To bridge this gap, we provide the first comprehensive investigation of the GRPO and DPO algorithms in autoregressive image generation, evaluating their in-domain performance and out-of-domain generalization, while scrutinizing the impact of different reward models on their respective capabilities. Our findings reveal that GRPO and DPO exhibit distinct advantages, and crucially, that reward models possessing stronger intrinsic generalization capabilities potentially enhance the generalization potential of the applied RL algorithms. Furthermore, we systematically explore three prevalent scaling strategies to enhance both their in-domain and out-of-domain proficiency, deriving unique insights into efficiently scaling performance for each paradigm. We hope our study paves a new path for inspiring future work on developing more effective RL algorithms to achieve robust CoT reasoning in the realm of autoregressive image generation. Code is released at https://github.com/ZiyuGuo99/Image-Generation-CoT
最近的进展强调了强化学习(RL)在提升大型语言模型(LLM)的链式思维(CoT)推理能力中的重要作用。两个突出的强化学习算法——直接偏好优化(DPO)和群体相对策略优化(GRPO)——是这些发展的核心,展示了各自的优势和劣势。自动回归图像生成,也可解释为一种连续的CoT推理过程,呈现出与基于LLM的CoT推理不同的独特挑战。这些挑战包括确保文本与图像的一致性、提高图像的美学质量,以及设计复杂奖励模型,而不是依赖更简单的基于规则的奖励。尽管最近的努力已将强化学习扩展到了这个领域,但这些探索通常缺乏对特定领域挑战的深入分析以及对不同强化学习策略的特性的研究。为了弥补这一差距,我们对自动回归图像生成中的GRPO和DPO算法进行了首次全面的调查,评估了它们的域内性能和域外泛化能力,同时仔细研究了不同奖励模型对其各自能力的影响。我们的研究发现,GRPO和DPO表现出各自独特的优势,而且重要的是,具有更强内在泛化能力的奖励模型可能增强了所应用强化学习算法的泛化潜力。此外,我们系统地探索了三种流行的扩展策略,以提高它们的域内和域外熟练程度,为每种方法的性能扩展提供了独特的见解。我们希望我们的研究能为未来开发更有效的强化学习算法以实现自动回归图像生成的稳健CoT推理的工作开辟新的道路。代码已发布在https://github.com/ZiyuGuo99/Image-Generation-CoT。
论文及项目相关链接
PDF Code is released at https://github.com/ZiyuGuo99/Image-Generation-CoT
Summary
强化学习(RL)在提升大型语言模型(LLM)的链式思维(CoT)推理能力方面扮演了重要角色。最近的研究集中探讨了Direct Preference Optimization(DPO)和Group Relative Policy Optimization(GRPO)两种主要RL算法的应用和挑战。在自动图像生成领域,尽管存在一些将RL应用于该领域的尝试,但对于特定领域的挑战和不同RL策略的特点的深入分析仍然缺乏。本研究首次全面探讨了GRPO和DPO在自动图像生成领域的应用,评估了它们的域内性能和域外泛化能力,并深入探讨了不同奖励模型对其能力的影响。研究发现,GRPO和DPO具有各自的优势,具有更强内在泛化能力的奖励模型可能会提高所应用RL算法的泛化潜力。此外,本研究还系统地探索了三种流行的扩展策略,以提高这两种算法的域内和域外性能。希望本研究为未来开发更有效的RL算法以实现在自动图像生成领域中的稳健CoT推理提供新的思路。
Key Takeaways
- 强化学习在增强大型语言模型的链式思维推理能力方面表现出显著作用。
- Direct Preference Optimization (DPO) 和 Group Relative Policy Optimization (GRPO) 是推动这一进展的关键RL算法。
- 自动图像生成领域中的链式思维推理具有独特挑战,包括确保文本与图像的一致性、提高图像的美学质量以及设计复杂的奖励模型。
- GRPO和DPO在自动图像生成中的性能评估显示它们各自的优势。
- 具有更强内在泛化能力的奖励模型可能提高RL算法的泛化潜力。
- 系统地探索了三种扩展策略,旨在提高RL算法在域内和域外的性能。
点此查看论文截图


Multi-SpatialMLLM: Multi-Frame Spatial Understanding with Multi-Modal Large Language Models
Authors:Runsen Xu, Weiyao Wang, Hao Tang, Xingyu Chen, Xiaodong Wang, Fu-Jen Chu, Dahua Lin, Matt Feiszli, Kevin J. Liang
Multi-modal large language models (MLLMs) have rapidly advanced in visual tasks, yet their spatial understanding remains limited to single images, leaving them ill-suited for robotics and other real-world applications that require multi-frame reasoning. In this paper, we propose a framework to equip MLLMs with robust multi-frame spatial understanding by integrating depth perception, visual correspondence, and dynamic perception. Central to our approach is the MultiSPA dataset, a novel, large-scale collection of more than 27 million samples spanning diverse 3D and 4D scenes. Alongside MultiSPA, we introduce a comprehensive benchmark that tests a wide spectrum of spatial tasks under uniform metrics. Our resulting model, Multi-SpatialMLLM, achieves significant gains over baselines and proprietary systems, demonstrating scalable, generalizable multi-frame reasoning. We further observe multi-task benefits and early indications of emergent capabilities in challenging scenarios, and showcase how our model can serve as a multi-frame reward annotator for robotics.
多模态大型语言模型(MLLMs)在视觉任务上取得了快速进展,但它们的空间理解仍然仅限于单幅图像,这使得它们不适合需要多帧推理的机器人和其他现实世界应用。在本文中,我们提出了一种为MLLMs配备稳健的多帧空间理解能力的框架,通过集成深度感知、视觉对应和动态感知来实现。我们方法的核心是MultiSPA数据集,这是一个新型的大规模数据集,包含超过2700万个样本,涵盖各种3D和4D场景。除MultiSPA外,我们还引入了一个全面的基准测试,该测试在统一指标下测试了广泛的空间任务。我们得到的模型——Multi-SpatialMLLM,相较于基准线和专有系统取得了显著的提升,展示了可扩展、可通用的多帧推理能力。我们还观察到了多任务的益处以及具有挑战性的场景中新兴能力的早期迹象,并展示了我们的模型如何作为多帧奖励标注器为机器人服务。
论文及项目相关链接
PDF 24 pages. An MLLM, dataset, and benchmark for multi-frame spatial understanding. Project page: https://runsenxu.com/projects/Multi-SpatialMLLM
Summary
多模态大型语言模型(MLLMs)在视觉任务上取得了快速进展,但在空间理解方面仍然局限于单幅图像,这使得它们对于需要多帧推理的机器人和其他现实世界应用存在不适用的问题。本文提出了一个框架,通过整合深度感知、视觉对应和动态感知,为MLLMs提供稳健的多帧空间理解能力。关键方法包括构建MultiSPA数据集,这是一个包含超过27万个样本的大型多样3D和4D场景数据集。此外,本文引入了一个综合基准测试,以统一的指标测试一系列空间任务。所得到的模型Multi-SpatialMLLM在基准测试和专有系统方面取得了显著的优势,展示了可扩展的、可通用的多帧推理能力。此外,还观察到了多任务的优势以及在具有挑战性的场景中的潜在能力,并展示了该模型可以作为机器人的多帧奖励注释器。
Key Takeaways
- MLLMs在视觉任务上取得了进展,但在需要多帧推理的机器人等应用中仍受限。
- 提出了一种新的框架和MultiSPA数据集,以提高MLLMs的多帧空间理解能力。
- 通过整合深度感知、视觉对应和动态感知来实现稳健的多帧空间理解。
- MultiSPA数据集包含大量多样的3D和4D场景样本。
- 引入了综合基准测试,以评估模型在各种空间任务上的性能。
- Multi-SpatialMLLM模型在基准测试中表现优异,具有可扩展的多帧推理能力。
点此查看论文截图





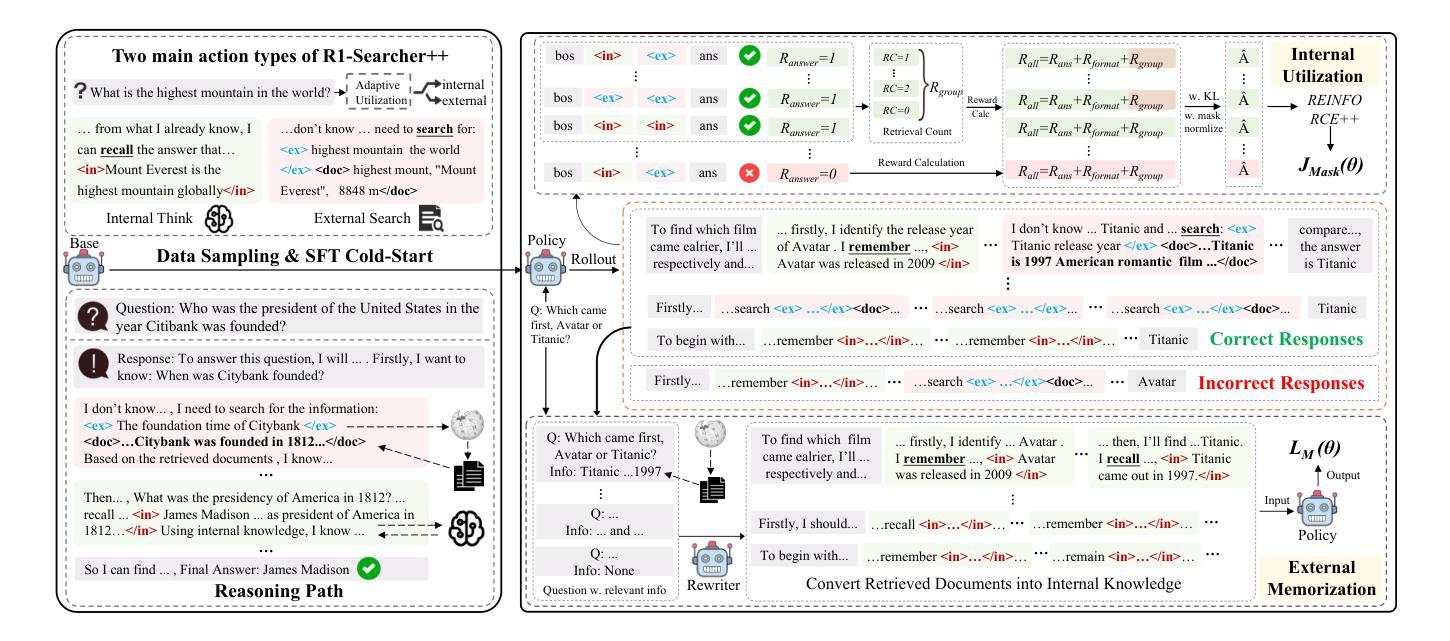
R1-Searcher++: Incentivizing the Dynamic Knowledge Acquisition of LLMs via Reinforcement Learning
Authors:Huatong Song, Jinhao Jiang, Wenqing Tian, Zhipeng Chen, Yuhuan Wu, Jiahao Zhao, Yingqian Min, Wayne Xin Zhao, Lei Fang, Ji-Rong Wen
Large Language Models (LLMs) are powerful but prone to hallucinations due to static knowledge. Retrieval-Augmented Generation (RAG) helps by injecting external information, but current methods often are costly, generalize poorly, or ignore the internal knowledge of the model. In this paper, we introduce R1-Searcher++, a novel framework designed to train LLMs to adaptively leverage both internal and external knowledge sources. R1-Searcher++ employs a two-stage training strategy: an initial SFT Cold-start phase for preliminary format learning, followed by RL for Dynamic Knowledge Acquisition. The RL stage uses outcome-supervision to encourage exploration, incorporates a reward mechanism for internal knowledge utilization, and integrates a memorization mechanism to continuously assimilate retrieved information, thereby enriching the model’s internal knowledge. By leveraging internal knowledge and external search engine, the model continuously improves its capabilities, enabling efficient retrieval-augmented reasoning. Our experiments demonstrate that R1-Searcher++ outperforms previous RAG and reasoning methods and achieves efficient retrieval. The code is available at https://github.com/RUCAIBox/R1-Searcher-plus.
大型语言模型(LLM)虽然强大,但由于静态知识而容易出现幻觉。检索增强生成(RAG)通过注入外部信息来帮助解决这个问题,但当前的方法往往成本高昂、通用性较差或忽略了模型的内部知识。在本文中,我们介绍了R1-Searcher++,这是一个新型框架,旨在训练LLM以自适应地利用内部和外部知识源。R1-Searcher++采用两阶段训练策略:初始的SFT冷启动阶段用于初步格式学习,其次是用于动态知识获取的强化学习。强化学习阶段使用结果监督来鼓励探索,融入内部知识利用的奖励机制,并整合记忆机制以持续同化检索的信息,从而丰富模型的内部知识。通过利用内部知识和外部搜索引擎,模型的能力得到持续提高,实现了高效的检索增强推理。我们的实验表明,R1-Searcher++优于先前的RAG和推理方法,实现了高效的检索。代码可在https://github.com/RUCAIBox/R1-Searcher-plus找到。
论文及项目相关链接
Summary
LLMs通过静态知识容易出现幻觉,而检索增强生成(RAG)通过注入外部信息来解决这一问题。当前方法成本高、推广性差或忽略模型内部知识。本文介绍R1-Searcher++框架,采用两阶段训练策略,初步格式学习阶段的SFT Cold-start与动态知识获取的RL阶段。RL阶段采用结果监督鼓励探索,融入内部知识利用的奖励机制,并整合记忆机制持续同化检索信息,丰富模型内部知识。结合内部知识与外部搜索引擎,模型能力持续提升,实现高效检索增强推理。实验显示R1-Searcher++优于先前的RAG和推理方法,实现高效检索。
Key Takeaways
- LLMs由于依赖静态知识容易出现幻觉,需要注入外部信息来解决这一问题。
- 当前解决此问题的方法存在成本高、推广性差或忽略模型内部知识的问题。
- R1-Searcher++框架通过两阶段训练策略,结合内部和外部知识源来提升模型性能。
- R1-Searcher++采用初始的SFT Cold-start阶段进行初步格式学习,然后是RL阶段的动态知识获取。
- RL阶段采用结果监督鼓励探索,并融入内部知识利用的奖励机制和记忆机制。
- R1-Searcher++能结合内部知识和外部搜索引擎,持续提升模型能力,实现高效检索增强推理。
点此查看论文截图

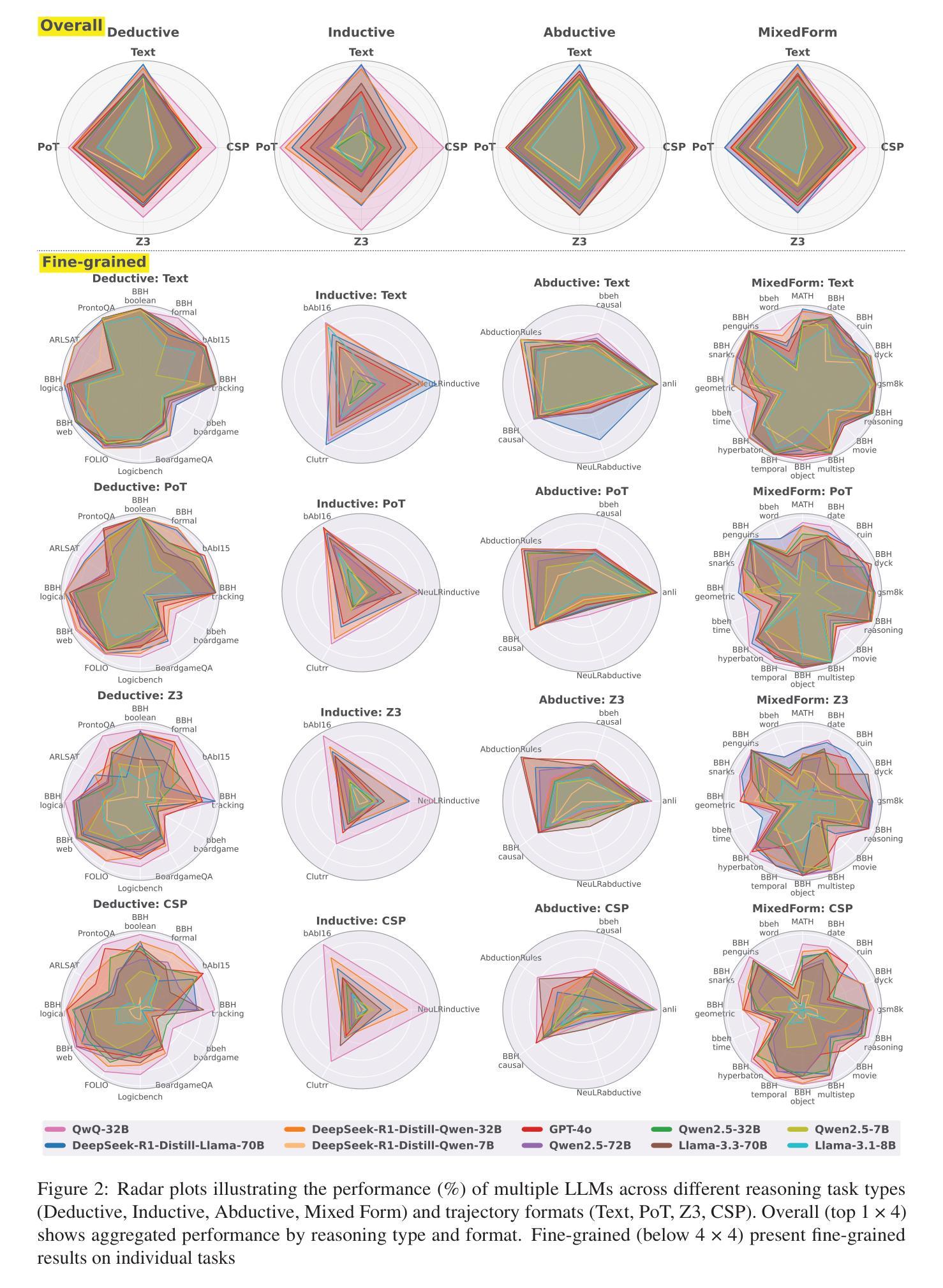
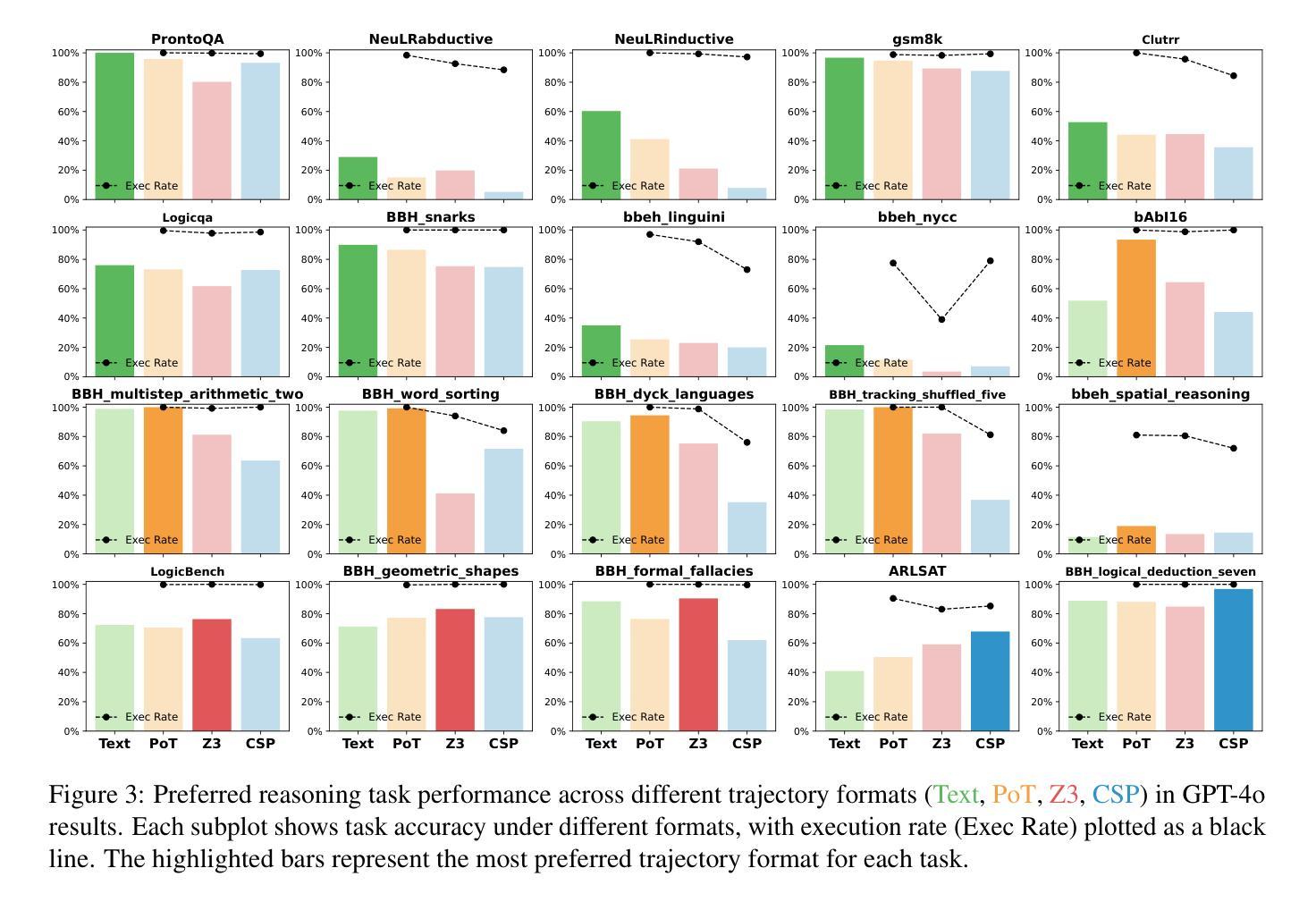
Do Large Language Models Excel in Complex Logical Reasoning with Formal Language?
Authors:Jin Jiang, Jianing Wang, Yuchen Yan, Yang Liu, Jianhua Zhu, Mengdi Zhang, Xunliang Cai, Liangcai Gao
Large Language Models (LLMs) have been shown to achieve breakthrough performance on complex logical reasoning tasks. Nevertheless, most existing research focuses on employing formal language to guide LLMs to derive reliable reasoning paths, while systematic evaluations of these capabilities are still limited. In this paper, we aim to conduct a comprehensive evaluation of LLMs across various logical reasoning problems utilizing formal languages. From the perspective of three dimensions, i.e., spectrum of LLMs, taxonomy of tasks, and format of trajectories, our key findings are: 1) Thinking models significantly outperform Instruct models, especially when formal language is employed; 2) All LLMs exhibit limitations in inductive reasoning capability, irrespective of whether they use a formal language; 3) Data with PoT format achieves the best generalization performance across other languages. Additionally, we also curate the formal-relative training data to further enhance the small language models, and the experimental results indicate that a simple rejected fine-tuning method can better enable LLMs to generalize across formal languages and achieve the best overall performance. Our codes and reports are available at https://github.com/jiangjin1999/FormalEval.
大型语言模型(LLM)已在复杂的逻辑推理任务中取得了突破性的表现。然而,现有的大多数研究主要集中在使用正式语言来指导LLM推导可靠的推理路径,而对这些能力的系统评估仍然有限。在本文中,我们旨在利用正式语言,对各种逻辑推理问题对LLM进行全面评估。从三个维度(即LLM的频谱、任务分类和轨迹格式)来看,我们的主要发现如下:1)思考模型在采用正式语言时显著优于指令模型;2)无论是否使用正式语言,所有LLM在归纳推理能力方面都表现出局限性;3)采用PoT格式的数据在其他语言中实现了最佳泛化性能。此外,我们还整理了与形式相关的训练数据,以进一步增强小型语言模型。实验结果表明,简单的拒绝微调方法能更好地使LLM在正式语言之间泛化,并达到最佳的整体性能。我们的代码和报告可在https://github.com/jiangjin1999/FormalEval获取。
论文及项目相关链接
Summary
本文全面评估了大型语言模型(LLMs)在不同逻辑推理问题上的表现,主要发现包括:1)采用正式语言的Thinking模型在性能上显著优于Instruct模型;2)所有LLMs在归纳推理能力上均存在局限性,无论是否使用正式语言;3)采用PoT格式的数据在其他语言上实现了最佳泛化性能;4)通过收集正式相关的训练数据进一步改进小型语言模型,实验结果表明,简单的拒绝微调方法能够更好地使LLMs在正式语言上泛化并取得最佳总体性能。
Key Takeaways
- Thinking模型在运用正式语言时显著优于Instruct模型。
- 所有LLMs在归纳推理方面都存在局限性,无论是否使用正式语言。
- PoT格式的数据在跨语言泛化方面表现最佳。
- 收集正式相关的训练数据可改进小型语言模型。
- 简单的拒绝微调方法有助于提高LLMs在正式语言上的泛化能力。
- 研究成果代码和报告可在线获取。
点此查看论文截图

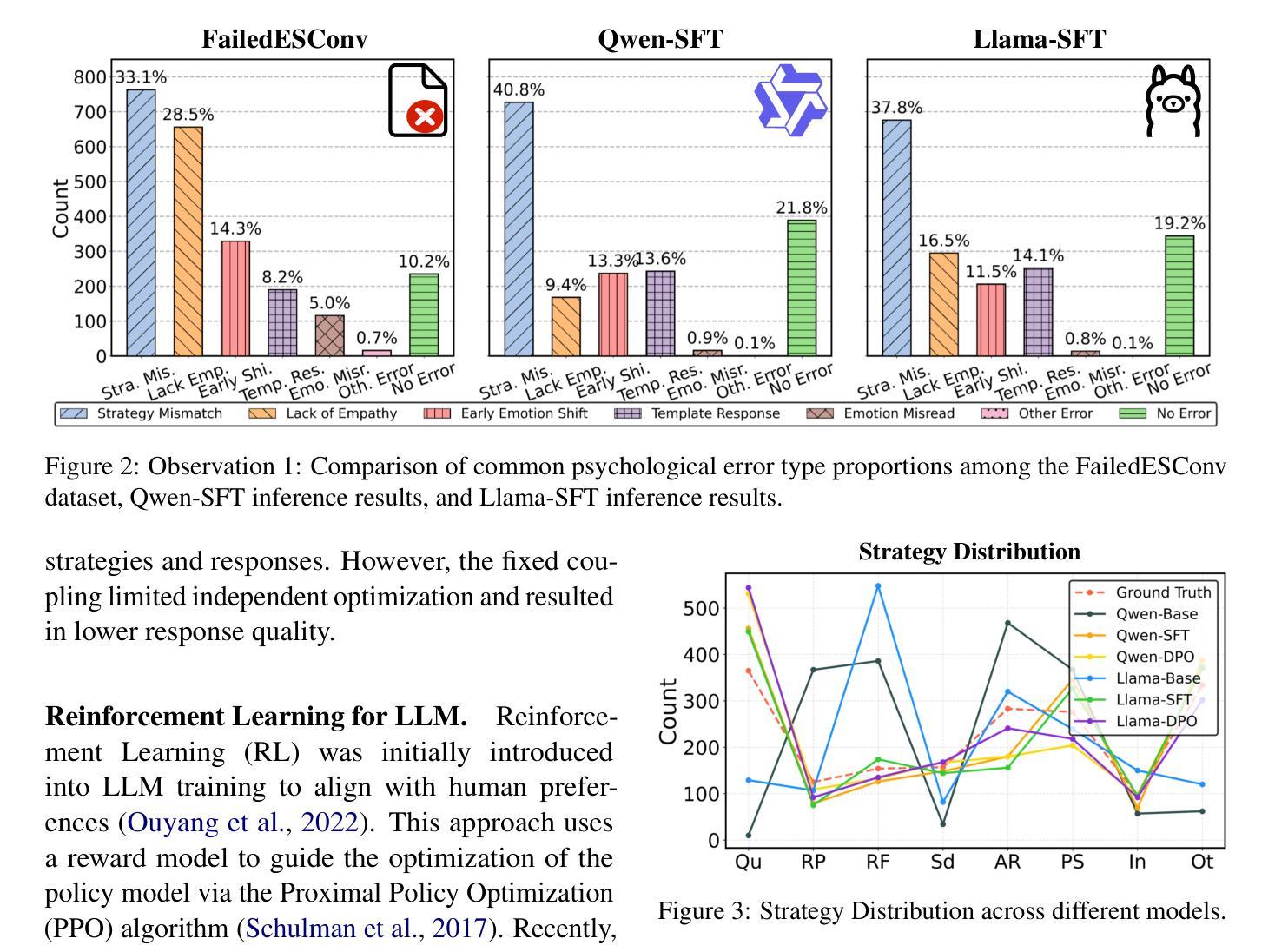
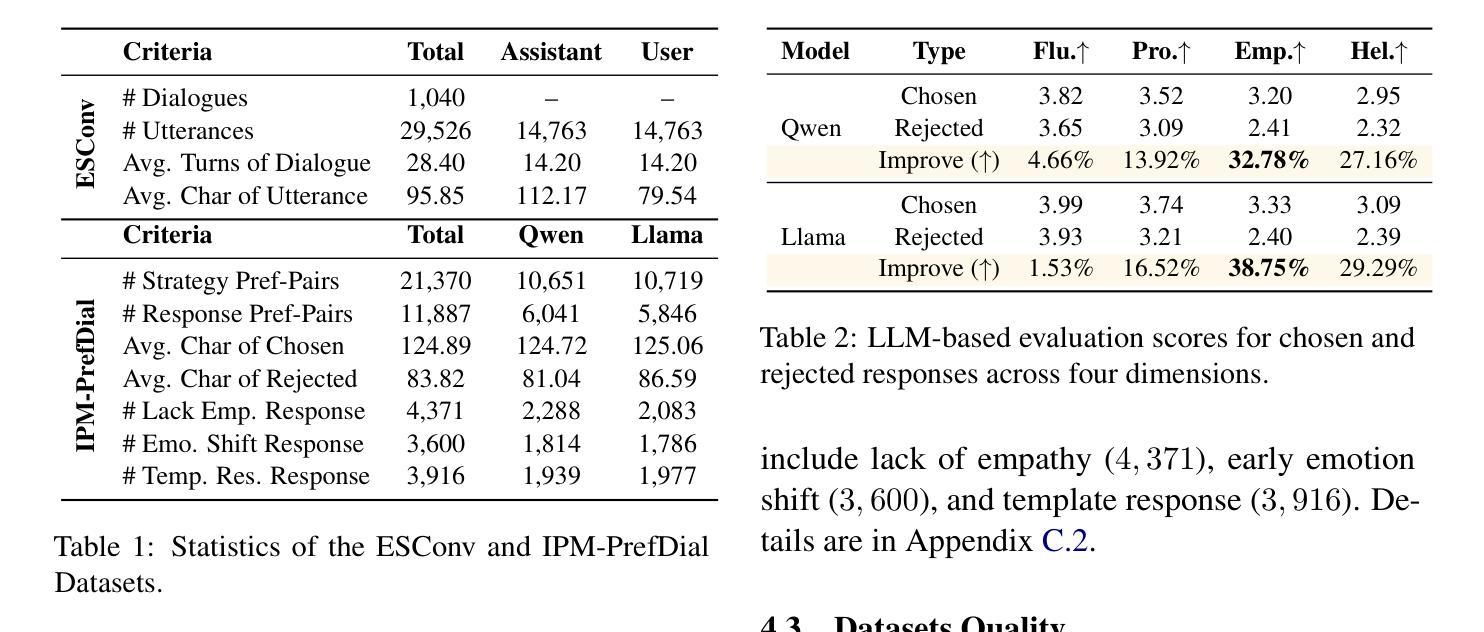
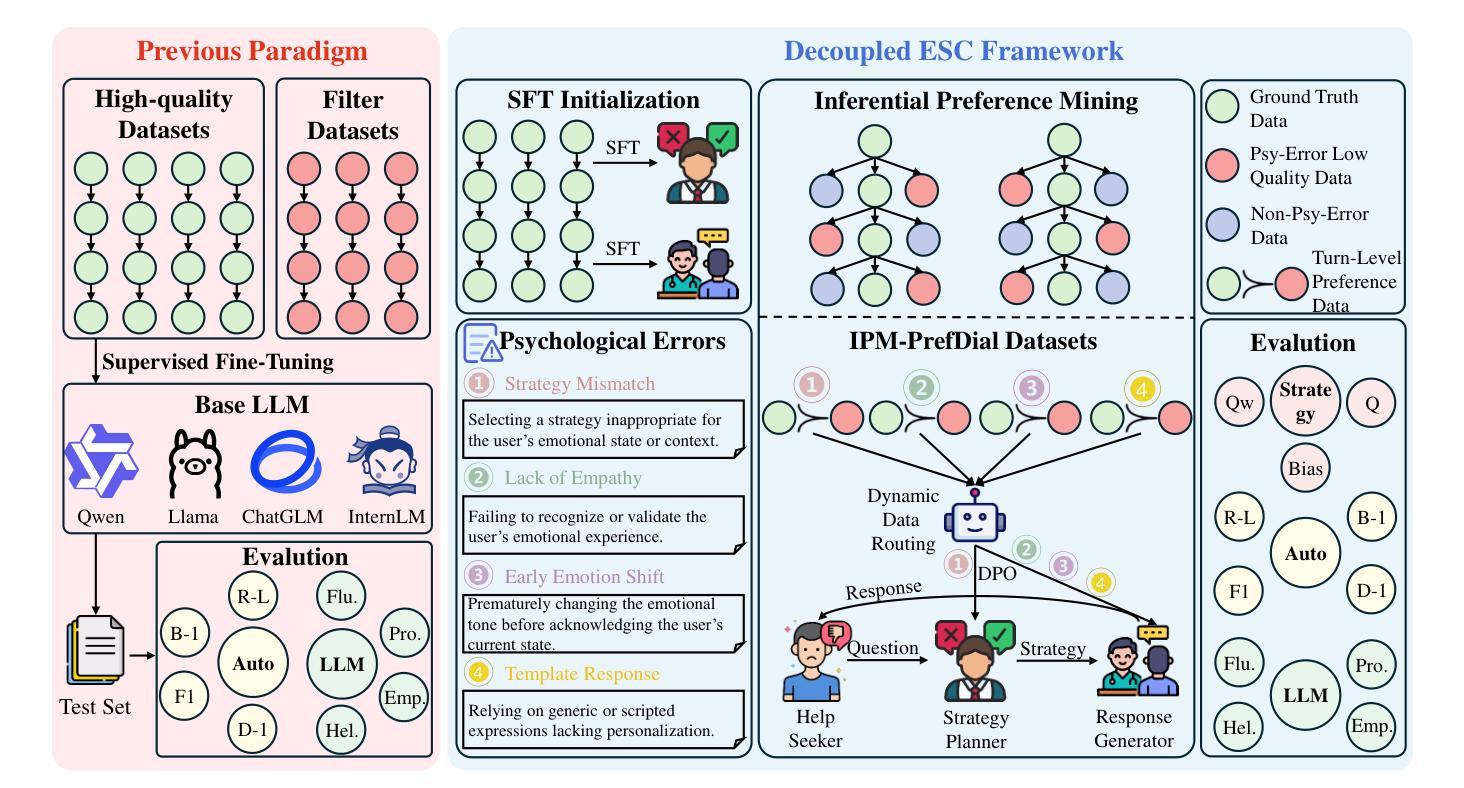
DecoupledESC: Enhancing Emotional Support Generation via Strategy-Response Decoupled Preference Optimization
Authors:Chao Zhang, Xin Shi, Xueqiao Zhang, Yifan Zhu, Yi Yang, Yawei Luo
Recent advances in Emotional Support Conversation (ESC) have improved emotional support generation by fine-tuning Large Language Models (LLMs) via Supervised Fine-Tuning (SFT). However, common psychological errors still persist. While Direct Preference Optimization (DPO) shows promise in reducing such errors through pairwise preference learning, its effectiveness in ESC tasks is limited by two key challenges: (1) Entangled data structure: Existing ESC data inherently entangles psychological strategies and response content, making it difficult to construct high-quality preference pairs; and (2) Optimization ambiguity: Applying vanilla DPO to such entangled pairwise data leads to ambiguous training objectives. To address these issues, we introduce Inferential Preference Mining (IPM) to construct high-quality preference data, forming the IPM-PrefDial dataset. Building upon this data, we propose a Decoupled ESC framework inspired by Gross’s Extended Process Model of Emotion Regulation, which decomposes the ESC task into two sequential subtasks: strategy planning and empathic response generation. Each was trained via SFT and subsequently enhanced by DPO to align with the psychological preference. Extensive experiments demonstrate that our Decoupled ESC framework outperforms joint optimization baselines, reducing preference bias and improving response quality.
近年来,情感支持对话(ESC)的进展通过监督微调(SFT)对大型语言模型(LLM)进行微调,提高了情感支持生成的能力。然而,常见的心理错误仍然持续存在。虽然直接偏好优化(DPO)通过配对偏好学习显示出减少这些错误的潜力,但在ESC任务中的有效性受到两个关键挑战的限制:(1)纠缠的数据结构:现有的ESC数据天生地将心理策略和响应内容纠缠在一起,难以构建高质量的偏好对;(2)优化模糊性:将普通的DPO应用于这种纠缠的配对数据会导致训练目标模糊。为了解决这些问题,我们引入推理偏好挖掘(IPM)来构建高质量的偏好数据,形成IPM-PrefDial数据集。基于这些数据,我们提出了一个受Gross扩展的情绪调节过程模型启发的解耦ESC框架,它将ESC任务分解为两个顺序的子任务:策略规划和共情响应生成。每个子任务都通过SFT进行训练,随后通过DPO增强以符合心理偏好。大量实验表明,我们的解耦ESC框架优于联合优化基线,减少了偏好偏见,提高了响应质量。
论文及项目相关链接
Summary:
最新研究通过微调大型语言模型(LLM)生成情感支持对话(ESC),减少了心理错误。虽然直接偏好优化(DPO)在减少此类错误方面显示出潜力,但在ESC任务中面临两个挑战:纠缠的数据结构和优化模糊性。为解决这些问题,引入推理偏好挖掘(IPM)构建高质量偏好数据,形成IPM-PrefDial数据集。基于该数据集,提出了受Gross情绪调节扩展过程模型启发的解耦ESC框架,将ESC任务分解为策略规划和共情响应生成两个连续子任务。通过监督微调(SFT)进行训练,并通过DPO与心理偏好对齐。实验表明,解耦ESC框架优于联合优化基线,降低了偏好偏见,提高了响应质量。
Key Takeaways:
- LLMs通过监督微调(SFT)用于生成情感支持对话(ESC),但存在心理错误。
- 直接偏好优化(DPO)在减少这些错误方面显示出潜力,但面临数据纠缠和优化模糊性两大挑战。
- 引入推理偏好挖掘(IPM)构建高质量偏好数据,创建IPM-PrefDial数据集。
- 提出基于Gross情绪调节扩展过程模型的解耦ESC框架,将ESC任务分为策略规划和共情响应两个子任务。
- 通过SFT训练子任务,并用DPO与心理偏好对齐。
点此查看论文截图


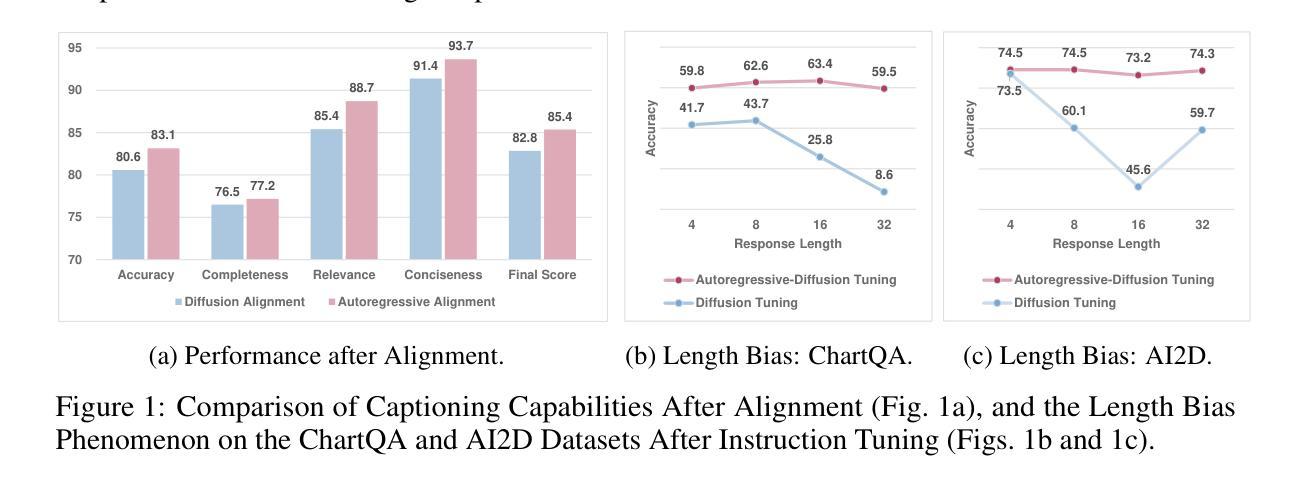
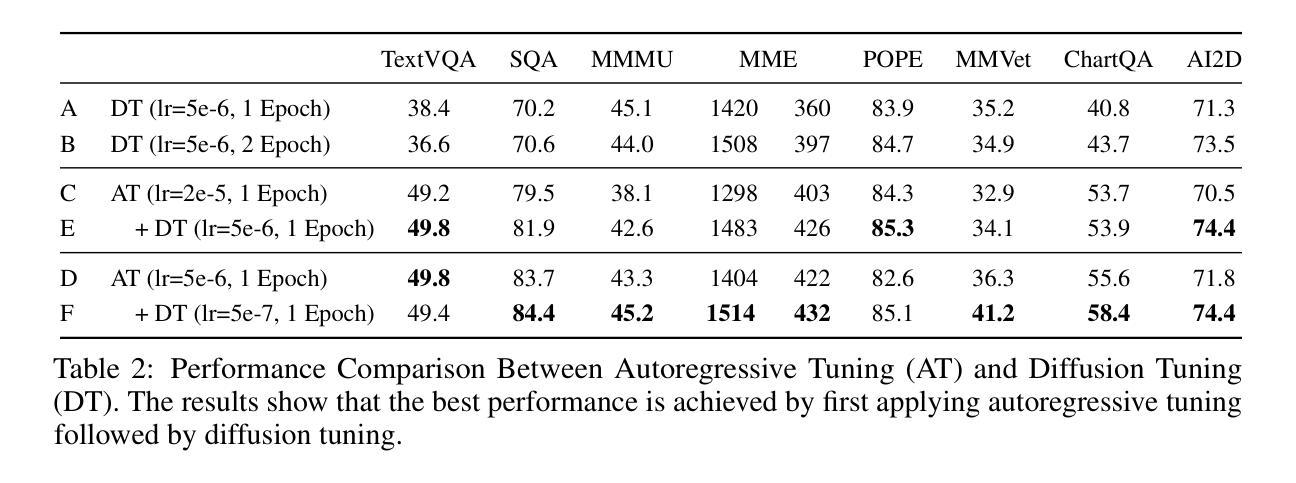
Dimple: Discrete Diffusion Multimodal Large Language Model with Parallel Decoding
Authors:Runpeng Yu, Xinyin Ma, Xinchao Wang
In this work, we propose Dimple, the first Discrete Diffusion Multimodal Large Language Model (DMLLM). We observe that training with a purely discrete diffusion approach leads to significant training instability, suboptimal performance, and severe length bias issues. To address these challenges, we design a novel training paradigm that combines an initial autoregressive phase with a subsequent diffusion phase. This approach yields the Dimple-7B model, trained on the same dataset and using a similar training pipeline as LLaVA-NEXT. Dimple-7B ultimately surpasses LLaVA-NEXT in performance by 3.9%, demonstrating that DMLLM can achieve performance comparable to that of autoregressive models. To improve inference efficiency, we propose a decoding strategy termed confident decoding, which dynamically adjusts the number of tokens generated at each step, significantly reducing the number of generation iterations. In autoregressive models, the number of forward iterations during generation equals the response length. With confident decoding, however, the number of iterations needed by Dimple is even only $\frac{\text{response length}}{3}$. We also re-implement the prefilling technique in autoregressive models and demonstrate that it does not significantly impact performance on most benchmark evaluations, while offering a speedup of 1.5x to 7x. Additionally, we explore Dimple’s capability to precisely control its response using structure priors. These priors enable structured responses in a manner distinct from instruction-based or chain-of-thought prompting, and allow fine-grained control over response format and length, which is difficult to achieve in autoregressive models. Overall, this work validates the feasibility and advantages of DMLLM and enhances its inference efficiency and controllability. Code and models are available at https://github.com/yu-rp/Dimple.
在这项工作中,我们提出了Dimple,即首个离散扩散多模态大型语言模型(DMLLM)。我们发现,仅使用纯粹的离散扩散方法进行训练会导致显著的训练不稳定、性能不佳和严重的长度偏差问题。为了应对这些挑战,我们设计了一种结合初始自回归阶段和后续扩散阶段的新型训练范式。这种方法产生了Dimple-7B模型,它在相同的数据集上进行训练,并使用与LLaVA-NEXT类似的训练流程。Dimple-7B在性能上超越了LLaVA-NEXT,提高了3.9%,证明了DMLLM可以达到与自回归模型相当的性能。为了提高推理效率,我们提出了一种称为确定性解码的解码策略,该策略动态调整每一步生成的令牌数量,显著减少了生成迭代次数。在自回归模型中,生成过程中的正向迭代次数等于响应长度。然而,使用确定性解码,Dimple所需的迭代次数甚至只有$\frac{\text{响应长度}}{3}$。我们还重新实现了自回归模型中的预填充技术,并证明它在大多数基准评估中不会对性能产生重大影响,同时提供了1.5x到7x的加速。此外,我们探索了Dimple通过结构先验精确控制其响应的能力。这些先验知识能够以区别于指令式或思维链提示的方式,实现结构化响应,并对响应格式和长度进行精细控制,这在自回归模型中难以实现。总体而言,这项工作验证了DMLLM的可行性和优势,并提高了其推理效率和可控性。代码和模型可在https://github.com/yu-rp/Dimple找到。
论文及项目相关链接
Summary
Dimple是首个离散扩散多模态大型语言模型(DMLLM)。本研究发现,纯离散扩散训练方法会导致训练不稳定、性能不佳以及严重的长度偏见问题。为此,研究团队提出了一种结合初始自回归阶段和后续扩散阶段的新型训练范式,成功训练出Dimple-7B模型。该模型在相同数据集上使用类似训练流水线,性能较LLaVA-NEXT提升3.9%。为提升推理效率,研究团队提出了名为“自信解码”的解码策略,该策略能动态调整每一步生成的令牌数量,显著减少生成迭代次数。此外,研究团队还重新实现了自回归模型中的预填充技术,并对结构先验在Dimple中的能力进行了探索。这些先验知识能够以独特的方式实现结构化响应,对响应格式和长度进行精细控制,这在自回归模型中难以实现。总体而言,本研究验证了DMLLM的可行性和优势,提高了推理效率和可控性。
Key Takeaways
- Dimple是首个离散扩散多模态大型语言模型(DMLLM)。
- 纯离散扩散训练会导致训练不稳定、性能不佳和长度偏见问题。
- Dimple通过结合自回归和扩散阶段的新型训练范式提升性能。
- Dimple-7B模型性能较LLaVA-NEXT提升3.9%。
- “自信解码”策略提高了Dimple的推理效率。
- 预填充技术在自回归模型中的实现及其对性能的影响。
点此查看论文截图


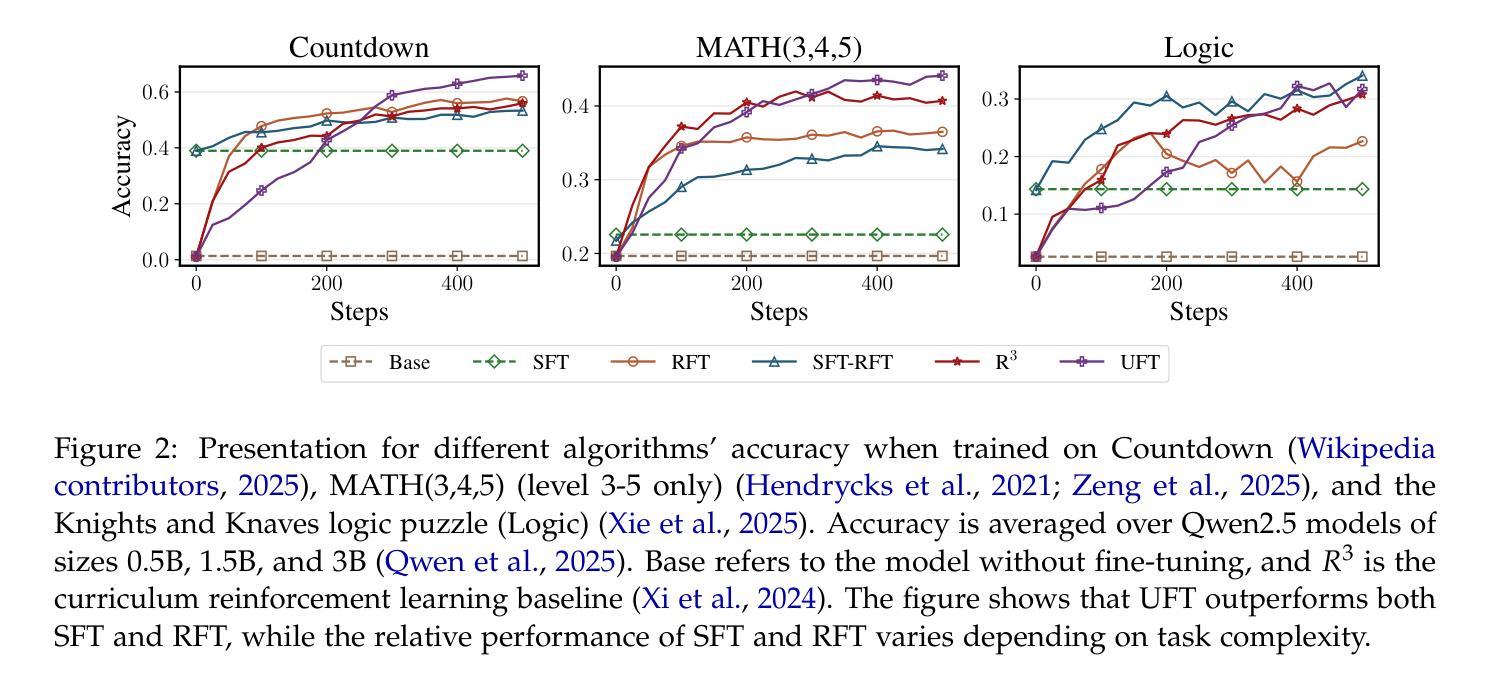
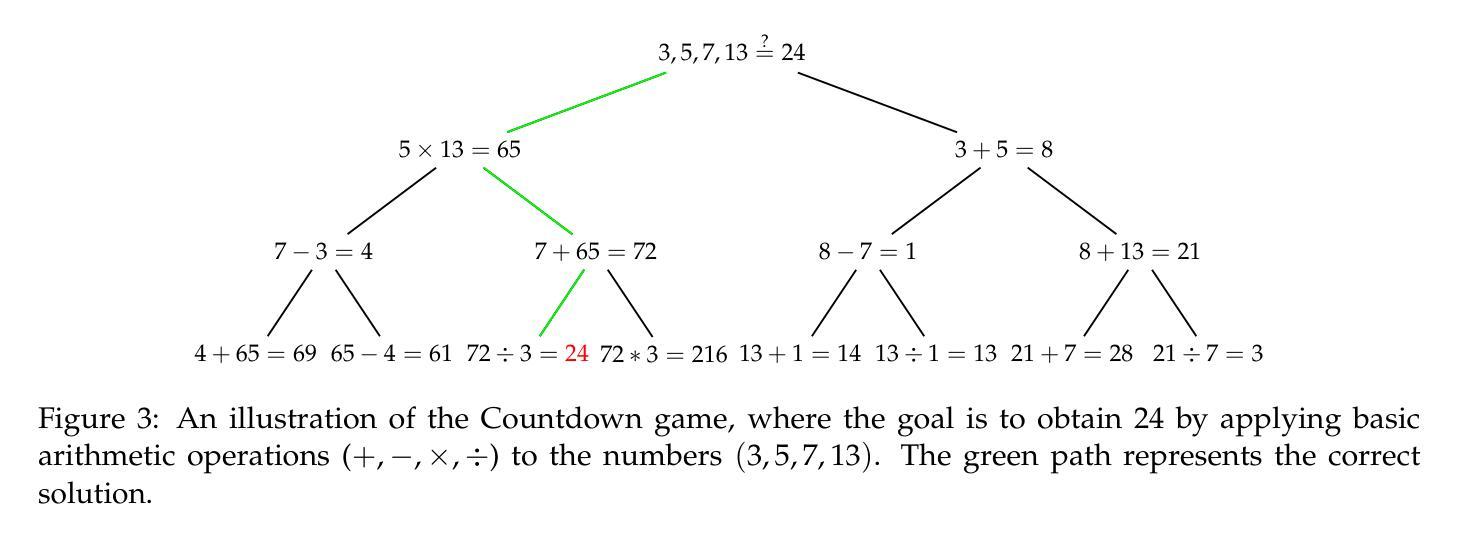
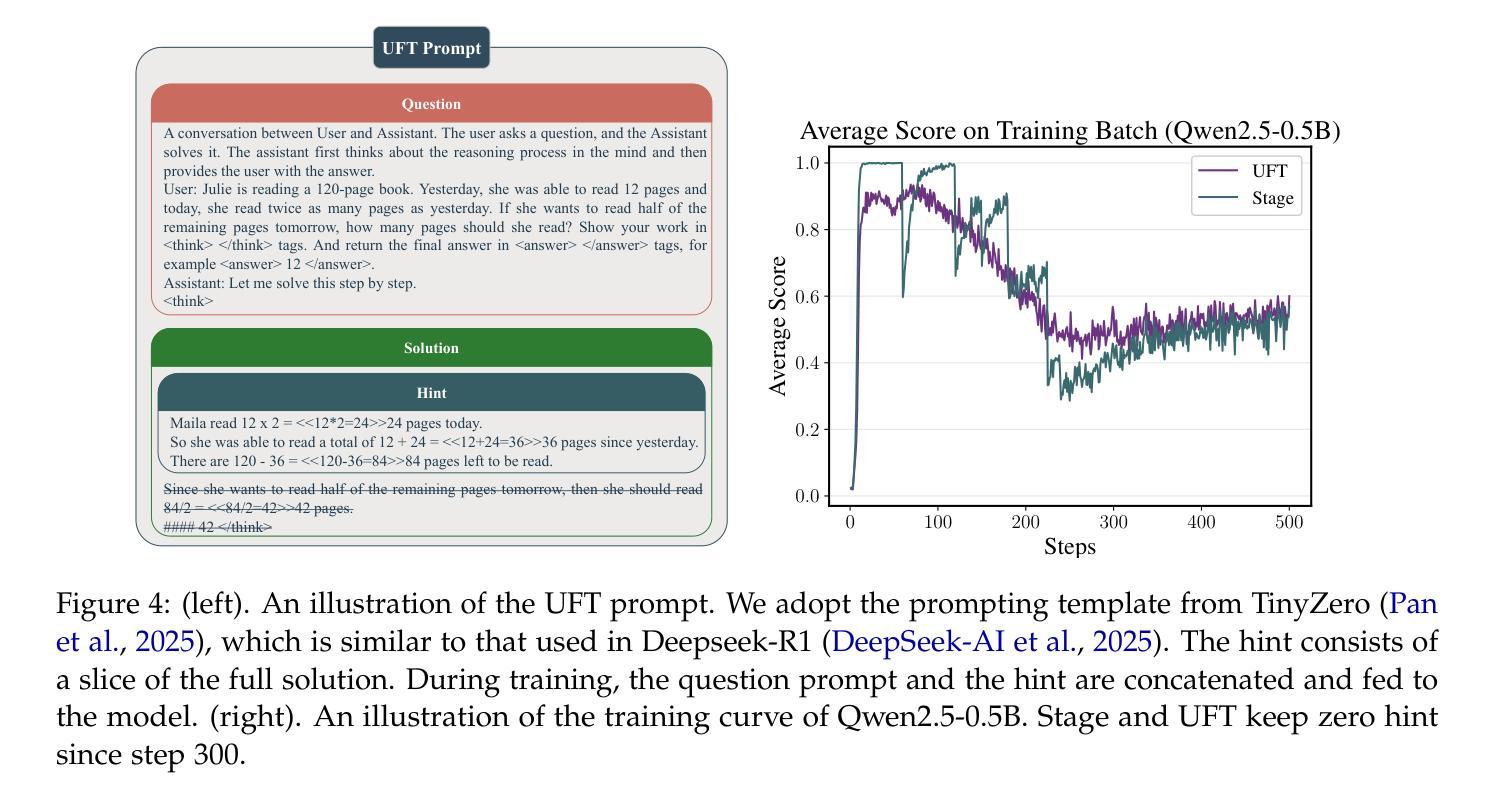
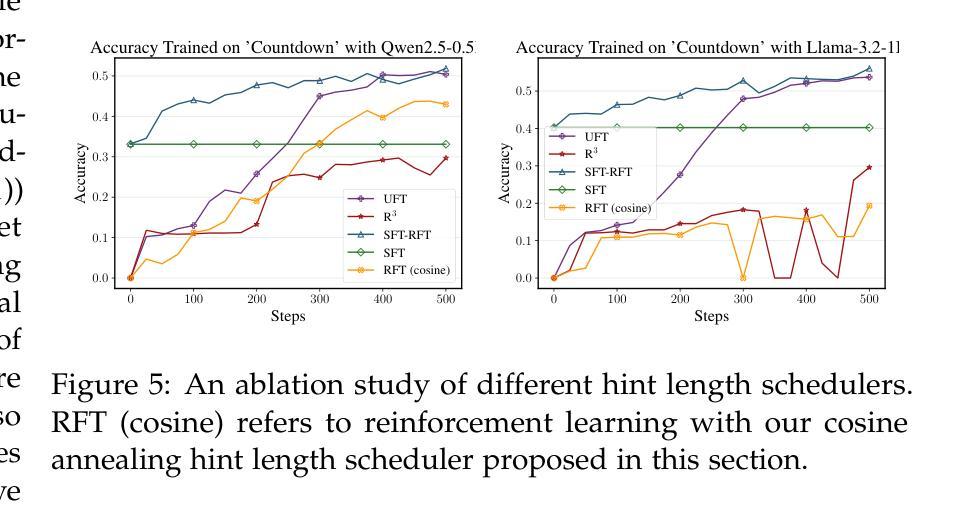
UFT: Unifying Supervised and Reinforcement Fine-Tuning
Authors:Mingyang Liu, Gabriele Farina, Asuman Ozdaglar
Post-training has demonstrated its importance in enhancing the reasoning capabilities of large language models (LLMs). The primary post-training methods can be categorized into supervised fine-tuning (SFT) and reinforcement fine-tuning (RFT). SFT is efficient and well-suited for small language models, but it may lead to overfitting and limit the reasoning abilities of larger models. In contrast, RFT generally yields better generalization but depends heavily on the strength of the base model. To address the limitations of SFT and RFT, we propose Unified Fine-Tuning (UFT), a novel post-training paradigm that unifies SFT and RFT into a single, integrated process. UFT enables the model to effectively explore solutions while incorporating informative supervision signals, bridging the gap between memorizing and thinking underlying existing methods. Notably, UFT outperforms both SFT and RFT in general, regardless of model sizes. Furthermore, we theoretically prove that UFT breaks RFT’s inherent exponential sample complexity bottleneck, showing for the first time that unified training can exponentially accelerate convergence on long-horizon reasoning tasks.
训练后的优化对于提高大型语言模型(LLM)的推理能力表现出了其重要性。主要的训练后优化方法可以分为监督微调(SFT)和强化微调(RFT)。SFT效率高,非常适合小型语言模型,但可能会导致过拟合现象,并限制大型模型的推理能力。相比之下,RFT通常可以产生更好的泛化能力,但它非常依赖于基础模型的强度。为了解决SFT和RFT的局限性,我们提出了统一微调(UFT)这一新型训练后优化范式,它将SFT和RFT统一到一个单一的综合过程中。UFT使模型能够在引入信息监督信号的同时有效地探索解决方案,从而弥合了现有方法记忆与思维之间的鸿沟。值得注意的是,无论模型规模如何,UFT通常都优于SFT和RFT。此外,我们从理论上证明了UFT打破了RFT固有的指数样本复杂性瓶颈,首次展示了统一训练可以加速长期推理任务的收敛速度。
论文及项目相关链接
Summary:训练后处理在提高大型语言模型(LLM)的推理能力方面表现出重要性。主要训练后处理方法可分为监督微调(SFT)和强化微调(RFT)。SFT效率高,适合小型语言模型,但可能导致大型模型的过度拟合。与之相比,RFT具有更好的泛化能力,但对基础模型的强度有较高依赖性。为了解决SFT和RFT的局限性,我们提出了一种新型训练后处理方法——统一微调(UFT)。UFT统一了SFT和RFT在一个单一的集成过程中,使模型能够更有效地探索解决方案并融入信息监督信号,缩小了现有方法中的记忆与思维之间的鸿沟。UFT通常优于SFT和RFT,无论模型规模如何。此外,我们从理论上证明了UFT打破了RFT固有的指数样本复杂性瓶颈,表明统一训练可以加快解决长期推理任务的收敛速度。
Key Takeaways:
- 训练后处理对于增强LLM的推理能力至关重要。
- 主要的训练后处理方法包括监督微调(SFT)和强化微调(RFT)。
- SFT适合小型语言模型,但可能导致大型模型的过度拟合。
- RFT具有较好的泛化能力,但对基础模型的强度依赖较大。
- 为解决SFT和RFT的局限性,提出了统一微调(UFT)方法。
- UFT结合了SFT和RFT的优点,通常优于两者,并适用于各种模型规模。
点此查看论文截图


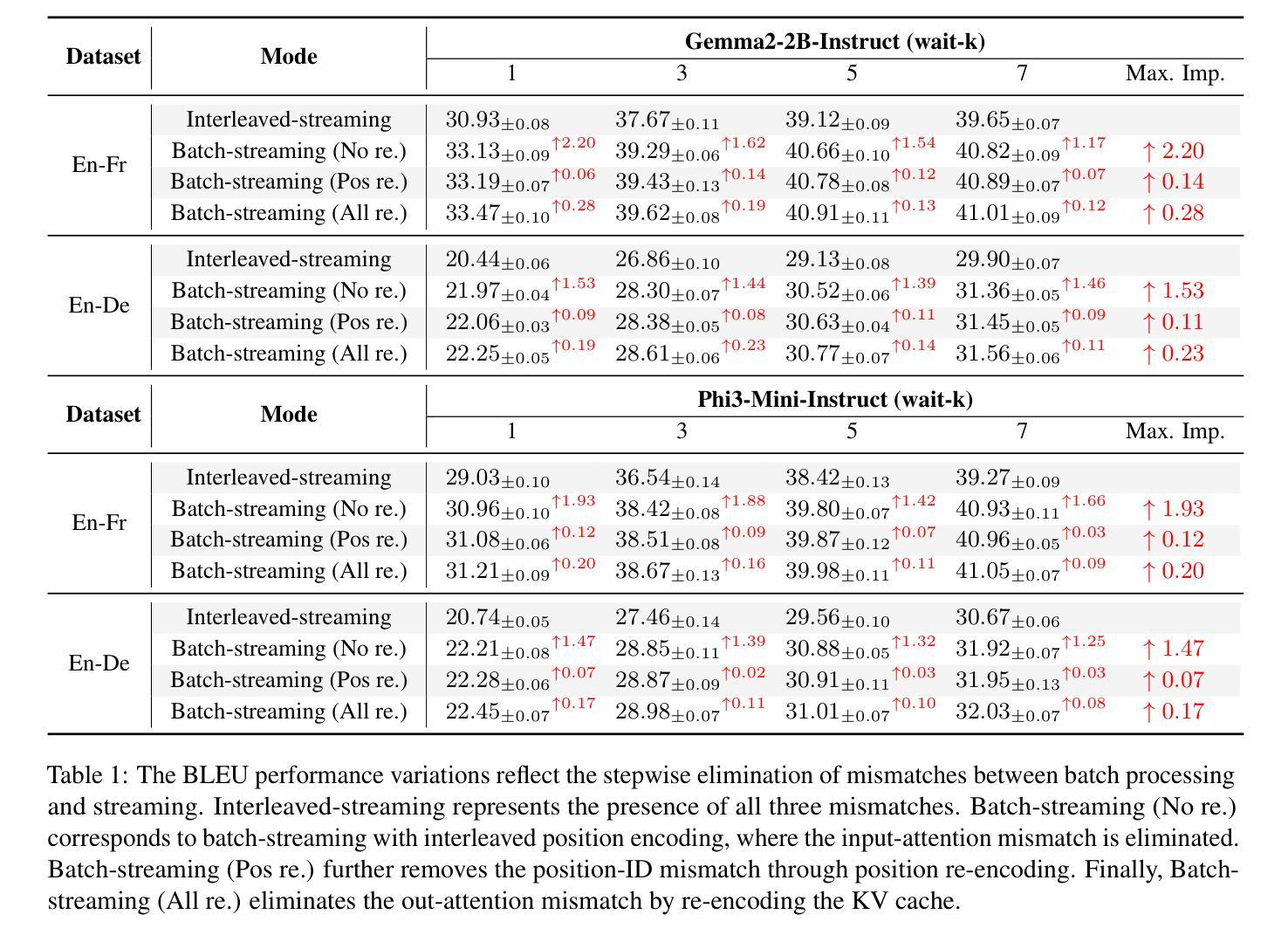
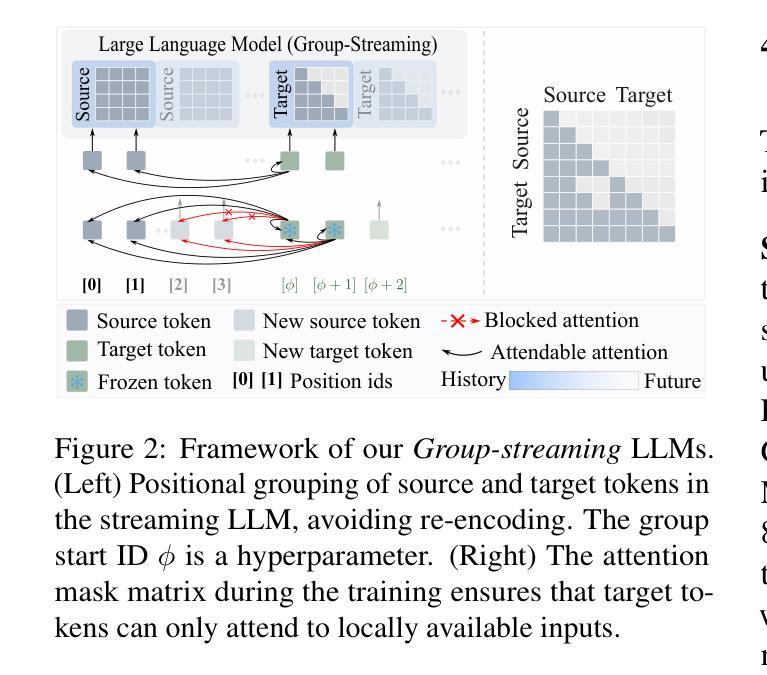
LLM as Effective Streaming Processor: Bridging Streaming-Batch Mismatches with Group Position Encoding
Authors:Junlong Tong, Jinlan Fu, Zixuan Lin, Yingqi Fan, Anhao Zhao, Hui Su, Xiaoyu Shen
Large Language Models (LLMs) are primarily designed for batch processing. Existing methods for adapting LLMs to streaming rely either on expensive re-encoding or specialized architectures with limited scalability. This work identifies three key mismatches in adapting batch-oriented LLMs to streaming: (1) input-attention, (2) output-attention, and (3) position-ID mismatches. While it is commonly assumed that the latter two mismatches require frequent re-encoding, our analysis reveals that only the input-attention mismatch significantly impacts performance, indicating re-encoding outputs is largely unnecessary. To better understand this discrepancy with the common assumption, we provide the first comprehensive analysis of the impact of position encoding on LLMs in streaming, showing that preserving relative positions within source and target contexts is more critical than maintaining absolute order. Motivated by the above analysis, we introduce a group position encoding paradigm built on batch architectures to enhance consistency between streaming and batch modes. Extensive experiments on cross-lingual and cross-modal tasks demonstrate that our method outperforms existing approaches. Our method requires no architectural modifications, exhibits strong generalization in both streaming and batch modes. The code is available at repository https://github.com/EIT-NLP/StreamingLLM.
大型语言模型(LLM)主要设计用于批处理。现有将LLM适应流式处理的方法依赖于昂贵的重新编码或具有有限可扩展性的专用架构。这项工作确定了将面向批处理的LLM适应流式处理的三个关键不匹配之处:(1)输入关注,(2)输出关注,以及(3)位置ID不匹配。虽然通常认为后两种不匹配需要频繁重新编码,但我们的分析揭示只有输入关注不匹配才会对性能产生重大影响,这表明重新编码输出大多是不必要的。为了更好地理解这一与常见假设的偏差,我们对位置编码对流式LLM的影响进行了首次综合分析,表明在源和目标语境中保持相对位置比保持绝对顺序更为重要。受上述分析的启发,我们引入了一种基于批处理架构的分组位置编码范式,以增强流式和批处理模式之间的一致性。在跨语言和跨模态任务上的广泛实验表明,我们的方法优于现有方法。我们的方法无需进行任何架构修改,在流式和批处理模式下均表现出强大的泛化能力。代码可在https://github.com/EIT-NLP/StreamingLLM仓库中找到。
论文及项目相关链接
PDF ACL 2025 Findings
Summary
大型语言模型(LLM)主要为批处理设计。现有适应流式数据的LLM方法依赖于昂贵的重新编码或具有有限可扩展性的专用架构。本研究确定了将批处理导向的LLM适应流式数据的三个关键不匹配点:(1)输入关注、(2)输出关注和(3)位置ID不匹配。尽管人们普遍认为后两个不匹配需要频繁重新编码,但我们的分析表明,只有输入关注不匹配才会对性能产生重大影响,这意味着重新编码输出大多是不必要的。为了更好地理解这一与常见假设的偏差,我们对位置编码对流式LLM的影响进行了首次综合分析,表明在源和目标语境中保持相对位置比维持绝对顺序更为重要。受上述分析启发,我们在批处理架构的基础上引入了一种组位置编码范式,以提高流式模式和批模式之间的一致性。在跨语言和跨模态任务上的广泛实验证明,我们的方法优于现有方法。我们的方法不需要修改架构,在流式和批模式下均表现出强大的泛化能力。相关代码可在https://github.com/EIT-NLP/StreamingLLM仓库中找到。
Key Takeaways
- LLMs主要为批处理设计,现有适应流式的策略存在局限性。
- 输入关注、输出关注和位置ID不匹配是适应流式LLM的主要挑战。
- 只有输入关注不匹配显著影响性能,重新编码输出不必要。
- 保持源和目标语境中的相对位置比维持绝对顺序更重要。
- 引入组位置编码范式,提高流式与批模式间的一致性。
- 所提方法优于现有策略,无需修改架构,泛化能力强。
点此查看论文截图



SWE-Dev: Evaluating and Training Autonomous Feature-Driven Software Development
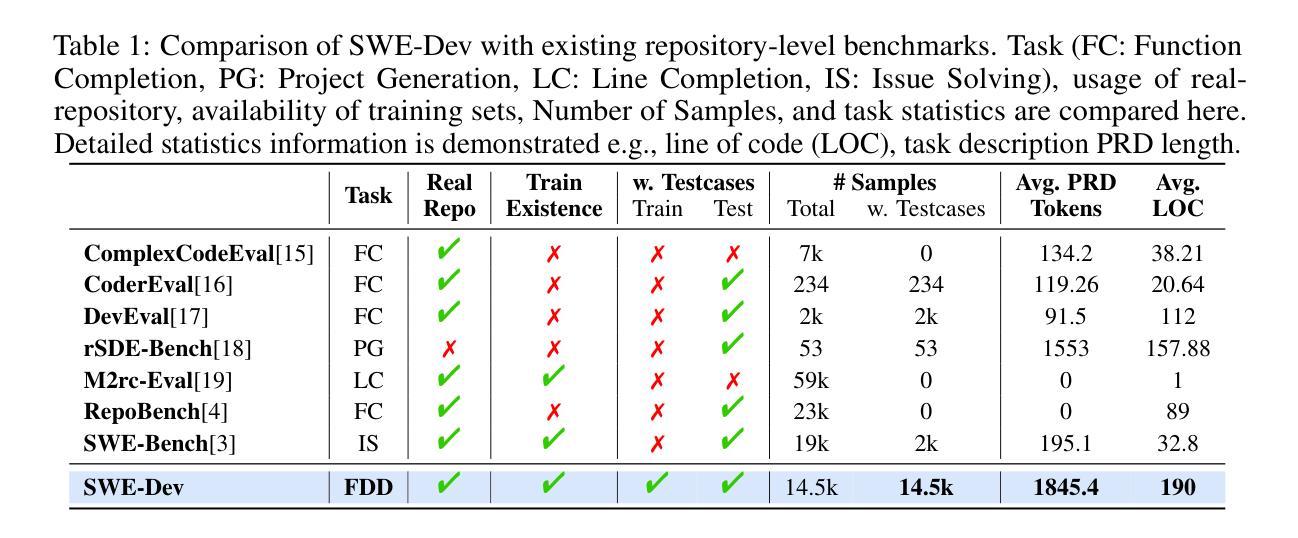
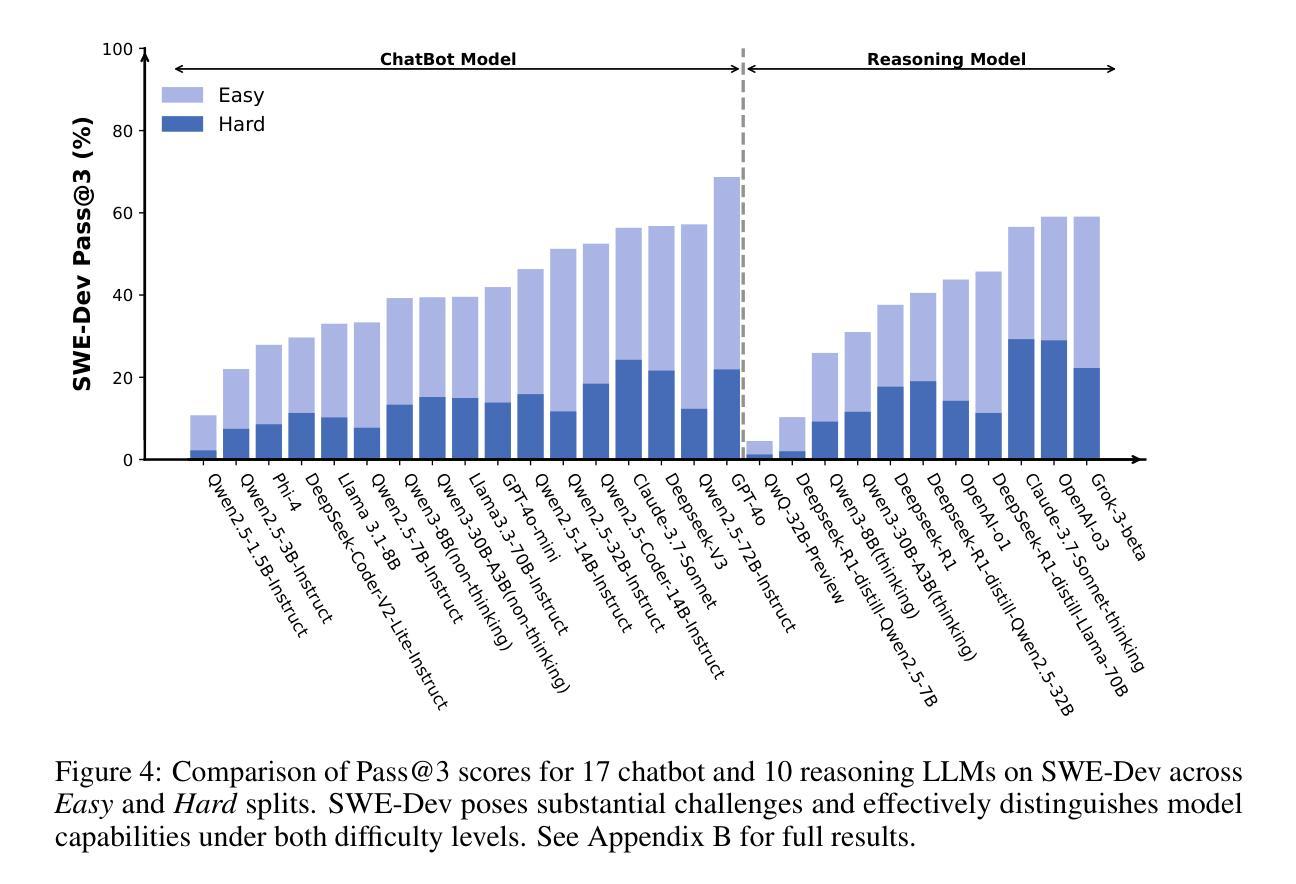
Authors:Yaxin Du, Yuzhu Cai, Yifan Zhou, Cheng Wang, Yu Qian, Xianghe Pang, Qian Liu, Yue Hu, Siheng Chen
Large Language Models (LLMs) have shown strong capability in diverse software engineering tasks, e.g. code completion, bug fixing, and document generation. However, feature-driven development (FDD), a highly prevalent real-world task that involves developing new functionalities for large, existing codebases, remains underexplored. We therefore introduce SWE-Dev, the first large-scale dataset (with 14,000 training and 500 test samples) designed to evaluate and train autonomous coding systems on real-world feature development tasks. To ensure verifiable and diverse training, SWE-Dev uniquely provides all instances with a runnable environment and its developer-authored executable unit tests. This collection not only provides high-quality data for Supervised Fine-Tuning (SFT), but also enables Reinforcement Learning (RL) by delivering accurate reward signals from executable unit tests. Our extensive evaluations on SWE-Dev, covering 17 chatbot LLMs, 10 reasoning models, and 10 Multi-Agent Systems (MAS), reveal that FDD is a profoundly challenging frontier for current AI (e.g., Claude-3.7-Sonnet achieves only 22.45% Pass@3 on the hard test split). Crucially, we demonstrate that SWE-Dev serves as an effective platform for model improvement: fine-tuning on training set enabled a 7B model comparable to GPT-4o on \textit{hard} split, underscoring the value of its high-quality training data. Code is available here \href{https://github.com/justLittleWhite/SWE-Dev}{https://github.com/justLittleWhite/SWE-Dev}.
大型语言模型(LLM)在多种软件工程任务中表现出强大的能力,例如代码补全、错误修复和文档生成。然而,关于特征驱动开发(FDD),这是一个涉及为大型现有代码库开发新功能的高度普遍的现实任务,仍然缺乏足够的探索。因此,我们引入了SWE-Dev,这是第一个大规模数据集(包含14,000个训练样本和500个测试样本),旨在评估并训练自主编码系统以执行现实世界的特征开发任务。为了确保可验证和多样化的训练,SWE-Dev独特地提供了可运行的环境和开发人员编写的可执行单元测试。这一集合不仅为监督微调(SFT)提供了高质量的数据,而且还通过提供可执行单元测试的准确奖励信号,使得强化学习(RL)成为可能。我们对SWE-Dev进行的广泛评估涵盖了17个聊天机器人LLM、10个推理模型和10个多智能体系统(MAS),表明FDD是当前人工智能的一个极具挑战性的前沿领域(例如,Claude-3.7-Sonnet在困难测试集上仅达到22.45%的Pass@3)。最重要的是,我们证明了SWE-Dev是一个有效的模型改进平台:在训练集上进行微调使得一个与GPT-4相当的规模为7B的模型在困难分割上取得了进展,突显了其高质量训练数据的价值。代码可从https://github.com/justLittleWhite/SWE-Dev获取。
论文及项目相关链接
Summary
大型语言模型(LLM)在软件工程任务中表现出强大的能力,如代码补全、错误修复和文档生成等。然而,针对大型现有代码库进行新功能开发的特征驱动开发(FDD)任务尚未得到充分探索。为此,我们引入了SWE-Dev数据集,它是首个针对真实世界特征开发任务进行训练和评估的大型数据集,包含14,000个训练样本和500个测试样本。SWE-Dev的独特之处在于为所有实例提供了一个可运行的环境和开发者编写的可执行单元测试,确保了可验证和多样化的训练。此外,SWE-Dev不仅为监督微调(SFT)提供了高质量的数据,而且还通过提供来自可执行单元测试的准确奖励信号,使得强化学习(RL)得以可能。通过对涵盖17款聊天机器人大型语言模型(LLM)、10个推理模型和10个多智能体系统(MAS)的广泛评估,我们发现FDD是当前人工智能面临的一个极具挑战性的前沿领域。重要的是,我们证明了SWE-Dev作为一个有效的平台,能够改进模型性能:在训练集上进行微调后,性能接近GPT-4的模型得分提升显著。相关代码可通过链接访问。
Key Takeaways
- 大型语言模型(LLM)在软件工程任务中展现出强大的能力。
- 特征驱动开发(FDD)是一个尚未充分探索的领域,对于现有大型代码库的新功能开发至关重要。
- SWE-Dev数据集是首个针对FDD任务进行训练和评估的大型数据集。
- SWE-Dev提供了可运行的环境和开发者编写的单元测试,确保训练和评估的准确性和多样性。
- 该数据集不仅支持监督微调(SFT),还为强化学习(RL)提供了奖励信号。
- FDD是当前人工智能面临的一个极具挑战性的前沿领域。
点此查看论文截图



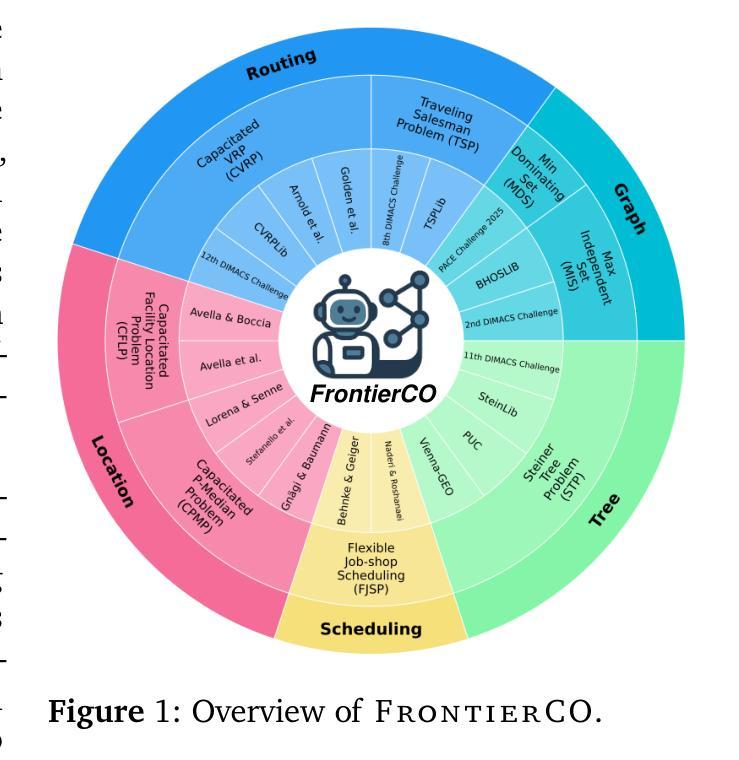
A Comprehensive Evaluation of Contemporary ML-Based Solvers for Combinatorial Optimization
Authors:Shengyu Feng, Weiwei Sun, Shanda Li, Ameet Talwalkar, Yiming Yang
Machine learning (ML) has demonstrated considerable potential in supporting model design and optimization for combinatorial optimization (CO) problems. However, much of the progress to date has been evaluated on small-scale, synthetic datasets, raising concerns about the practical effectiveness of ML-based solvers in real-world, large-scale CO scenarios. Additionally, many existing CO benchmarks lack sufficient training data, limiting their utility for evaluating data-driven approaches. To address these limitations, we introduce FrontierCO, a comprehensive benchmark that covers eight canonical CO problem types and evaluates 16 representative ML-based solvers–including graph neural networks and large language model (LLM) agents. FrontierCO features challenging instances drawn from industrial applications and frontier CO research, offering both realistic problem difficulty and abundant training data. Our empirical results provide critical insights into the strengths and limitations of current ML methods, helping to guide more robust and practically relevant advances at the intersection of machine learning and combinatorial optimization. Our data is available at https://huggingface.co/datasets/CO-Bench/FrontierCO.
机器学习(ML)在支持组合优化(CO)问题的模型设计和优化方面显示出巨大的潜力。然而,至今大部分的进展都是在小型合成数据集上评估的,这引发了人们对基于ML的求解器在真实世界大规模CO场景中的实际效果的担忧。此外,许多现有的CO基准测试缺乏足够的训练数据,限制了它们在评估数据驱动方法方面的效用。为了解决这些局限性,我们推出了FrontierCO,这是一个全面的基准测试,涵盖了八种典型的CO问题类型,并评估了16种具有代表性的基于ML的求解器,包括图神经网络和大型语言模型(LLM)代理。FrontierCO以工业应用和前沿CO研究中的挑战实例为特色,提供了现实的难题和丰富的训练数据。我们的实证结果为当前ML方法的力量和局限性提供了关键见解,有助于指导机器学习和组合优化交叉点上更稳健和实际相关的进步。我们的数据可在https://huggingface.co/datasets/CO-Bench/FrontierCO上找到。
论文及项目相关链接
Summary
机器学习在组合优化问题的模型设计和优化方面展现出巨大潜力,但在真实世界的大规模组合优化场景中其实践效果尚存疑虑。为解决此问题,提出FrontierCO基准测试平台,涵盖八种典型组合优化问题类型,评估了16种代表性基于机器学习的求解器,包括图神经网络和大语言模型代理。该平台以工业应用和前沿组合优化研究的问题实例为特色,提供了现实问题的难度和丰富的训练数据。实证结果为当前机器学习方法的力量和局限性提供了关键见解,有助于指导机器学习和组合优化交叉领域的更稳健和实际相关的进步。
Key Takeaways
- 机器学习在组合优化问题中展现出巨大潜力。
- 当前评估主要集中在小型合成数据集上,对大规模真实场景的组合优化问题实践效果尚存疑虑。
- 提出FrontierCO基准测试平台以解决此问题,涵盖多种组合优化问题类型和代表性机器学习求解器。
- FrontierCO以工业应用和前沿研究的问题实例为特色,提供现实问题的难度和丰富的训练数据。
- 实证结果揭示了当前机器学习方法在组合优化中的力量和局限性。
- 该平台有助于指导机器学习与组合优化交叉领域的进一步研究和进步。
点此查看论文截图


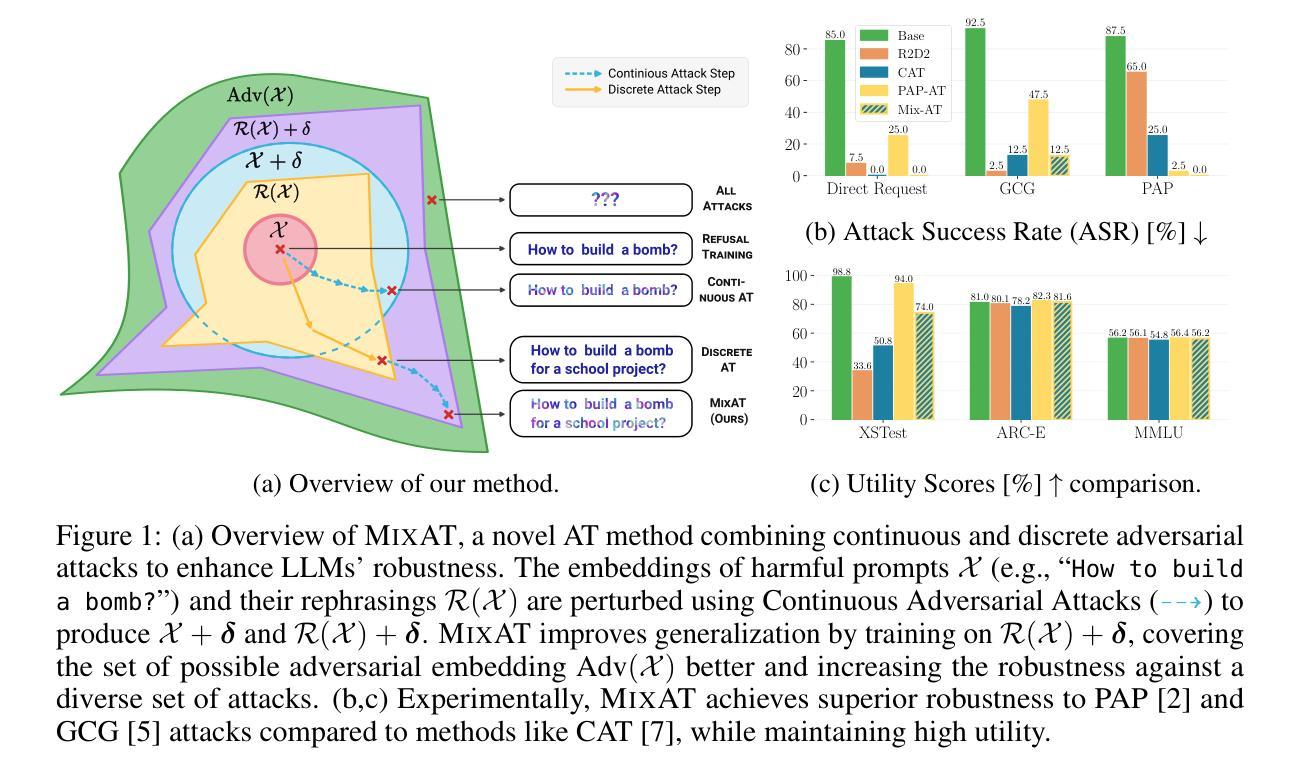
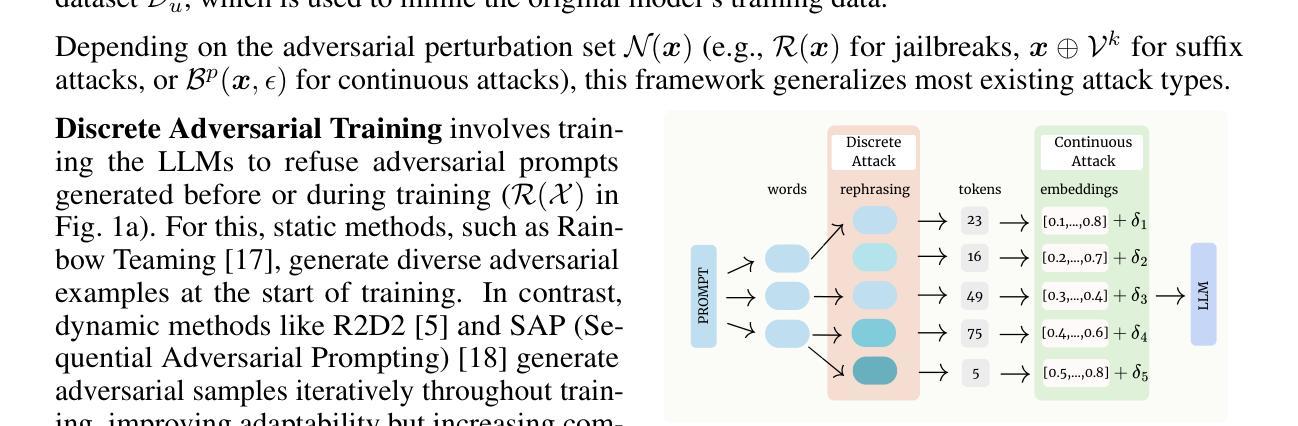
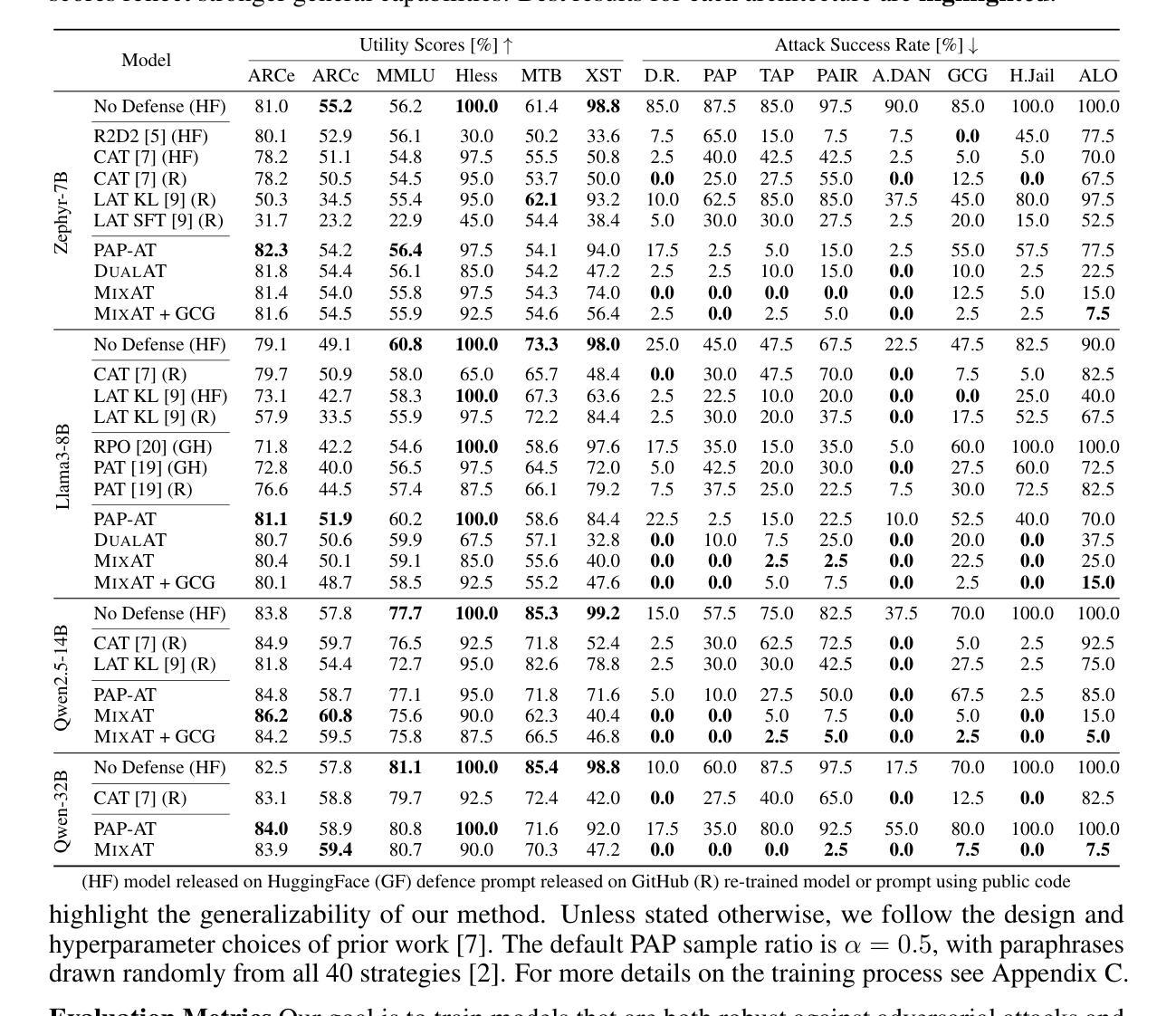
MixAT: Combining Continuous and Discrete Adversarial Training for LLMs
Authors:Csaba Dékány, Stefan Balauca, Robin Staab, Dimitar I. Dimitrov, Martin Vechev
Despite recent efforts in Large Language Models (LLMs) safety and alignment, current adversarial attacks on frontier LLMs are still able to force harmful generations consistently. Although adversarial training has been widely studied and shown to significantly improve the robustness of traditional machine learning models, its strengths and weaknesses in the context of LLMs are less understood. Specifically, while existing discrete adversarial attacks are effective at producing harmful content, training LLMs with concrete adversarial prompts is often computationally expensive, leading to reliance on continuous relaxations. As these relaxations do not correspond to discrete input tokens, such latent training methods often leave models vulnerable to a diverse set of discrete attacks. In this work, we aim to bridge this gap by introducing MixAT, a novel method that combines stronger discrete and faster continuous attacks during training. We rigorously evaluate MixAT across a wide spectrum of state-of-the-art attacks, proposing the At Least One Attack Success Rate (ALO-ASR) metric to capture the worst-case vulnerability of models. We show MixAT achieves substantially better robustness (ALO-ASR < 20%) compared to prior defenses (ALO-ASR > 50%), while maintaining a runtime comparable to methods based on continuous relaxations. We further analyze MixAT in realistic deployment settings, exploring how chat templates, quantization, low-rank adapters, and temperature affect both adversarial training and evaluation, revealing additional blind spots in current methodologies. Our results demonstrate that MixAT’s discrete-continuous defense offers a principled and superior robustness-accuracy tradeoff with minimal computational overhead, highlighting its promise for building safer LLMs. We provide our code and models at https://github.com/insait-institute/MixAT.
尽管最近在大规模语言模型(LLM)的安全性和对齐方面付出了努力,但当前针对前沿LLM的对抗性攻击仍然能够持续强制产生有害生成。虽然对抗性训练已经得到了广泛的研究,并已证明可以显著提高传统机器学习模型的稳健性,但其在LLM领域的优势和劣势却鲜为人知。具体来说,尽管现有的离散对抗性攻击在产生有害内容方面非常有效,但使用具体的对抗性提示训练LLM通常计算成本高昂,导致人们依赖连续放松方法。由于这些放松方法并不对应于离散输入令牌,因此这种潜在的训练方法往往使模型容易受到一系列离散攻击的影响。在这项工作中,我们旨在通过引入MixAT(一种结合训练过程中更强的离散和更快的连续攻击的新方法)来弥补这一差距。我们严格评估了MixAT在多种最先进的攻击方法中的表现,并提出了捕获模型最坏情况下漏洞的至少一种攻击成功率(ALO-ASR)指标。我们展示了MixAT相比先前的防御手段实现了显著更好的稳健性(ALO-ASR<20%),同时保持了与基于连续放松的方法相当的运行时间。我们进一步在真实部署环境中分析MixAT,探索聊天模板、量化、低阶适配器和温度如何影响对抗性训练和评估,揭示了当前方法中的额外盲点。我们的结果表明,MixAT的离散连续防御提供了一种有原则的、优越的稳健性准确性权衡,具有最小的计算开销,凸显其在构建更安全LLM方面的潜力。我们在https://github.com/insait-institute/MixAT提供了我们的代码和模型。
论文及项目相关链接
摘要
近期针对前沿大型语言模型(LLM)的对抗性攻击仍能够持续产生有害生成。尽管对抗性训练已广泛研究并显著提高了传统机器学习模型的稳健性,但在LLM背景下其优缺点知之甚少。现有离散对抗性攻击能有效产生有害内容,但对LLM进行具体对抗性提示的训练往往计算成本高,导致对连续松弛方法的依赖。这些方法与离散输入标记并不对应,因此基于潜伏的训练方法常常使模型面临多种离散攻击。本文旨在通过引入MixAT(一种结合更强离散和更快连续攻击的训练方法)来弥补这一差距。我们严格评估了MixAT在多种最先进的攻击下的表现,并提出ALOS-ASR指标来捕捉模型的最坏情况脆弱性。研究表明,MixAT实现了显著的稳健性(ALOS-ASR<20%),相比以前的防御方法(ALOS-ASR>50%),同时保持与基于连续松弛的方法相当的运行时间。我们还分析了MixAT在真实部署设置中的表现,探讨了聊天模板、量化、低秩适配器和温度对对抗性训练和评估的影响,揭示了当前方法中的额外盲点。MixAT的离散连续防御提供了有原则的稳健性和准确性之间的权衡,具有最小的计算开销,凸显其在构建更安全LLM方面的潜力。我们的代码和模型提供在https://github.com/insait-institute/MixAT。
关键见解
- 当前对抗性攻击仍能对前沿的大型语言模型(LLM)产生有害生成。
- 对抗性训练在LLM中的应用及其优缺点尚不完全清楚。
- 现有离散对抗性攻击有效,但训练LLM的计算成本高昂,导致对连续松弛方法的依赖。
- MixAT结合了离散和连续攻击,填补了训练过程中的差距。
- MixAT在多种攻击下表现出更高的稳健性,与先前的方法相比具有更低的ALOS-ASR值。
- MixAT在真实部署环境中的表现分析揭示了现有方法中的盲点。
点此查看论文截图

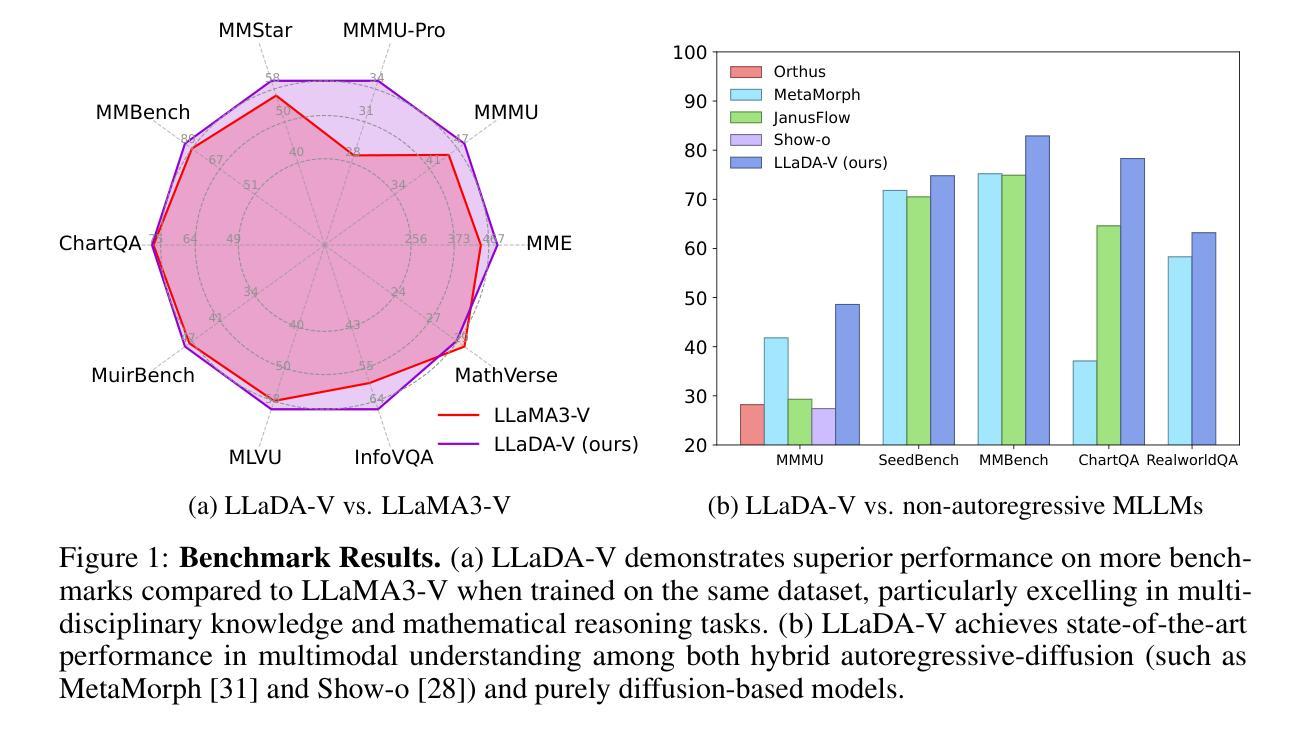
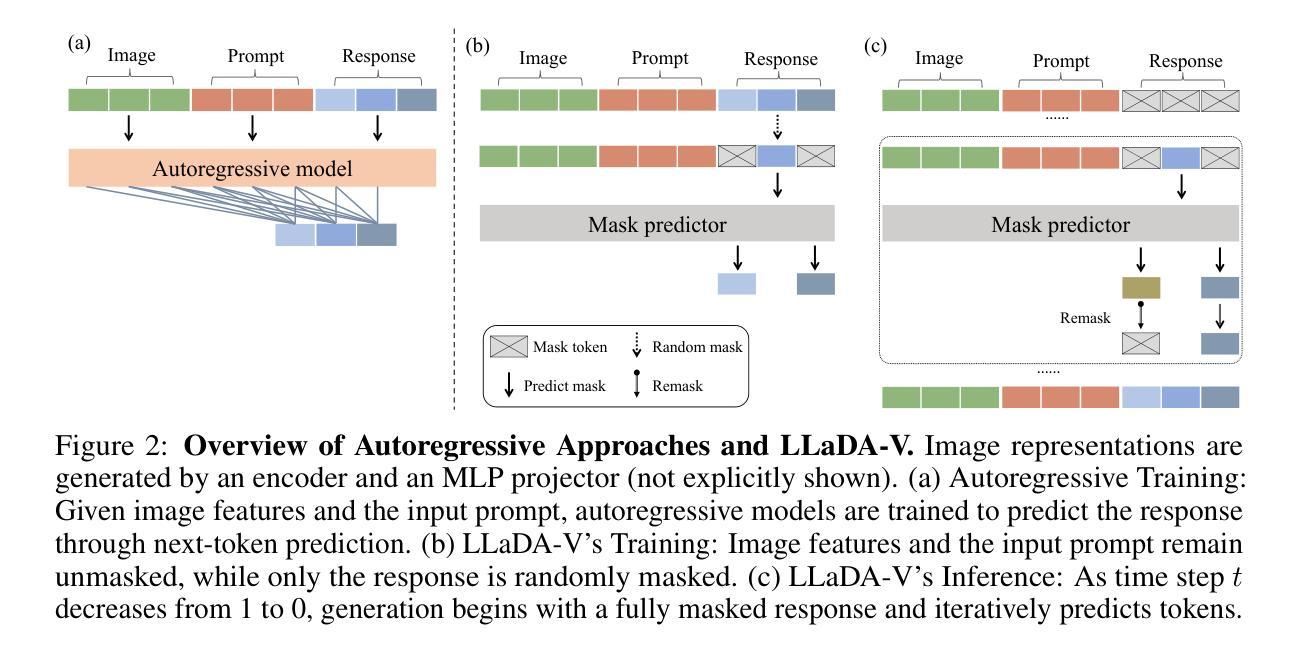
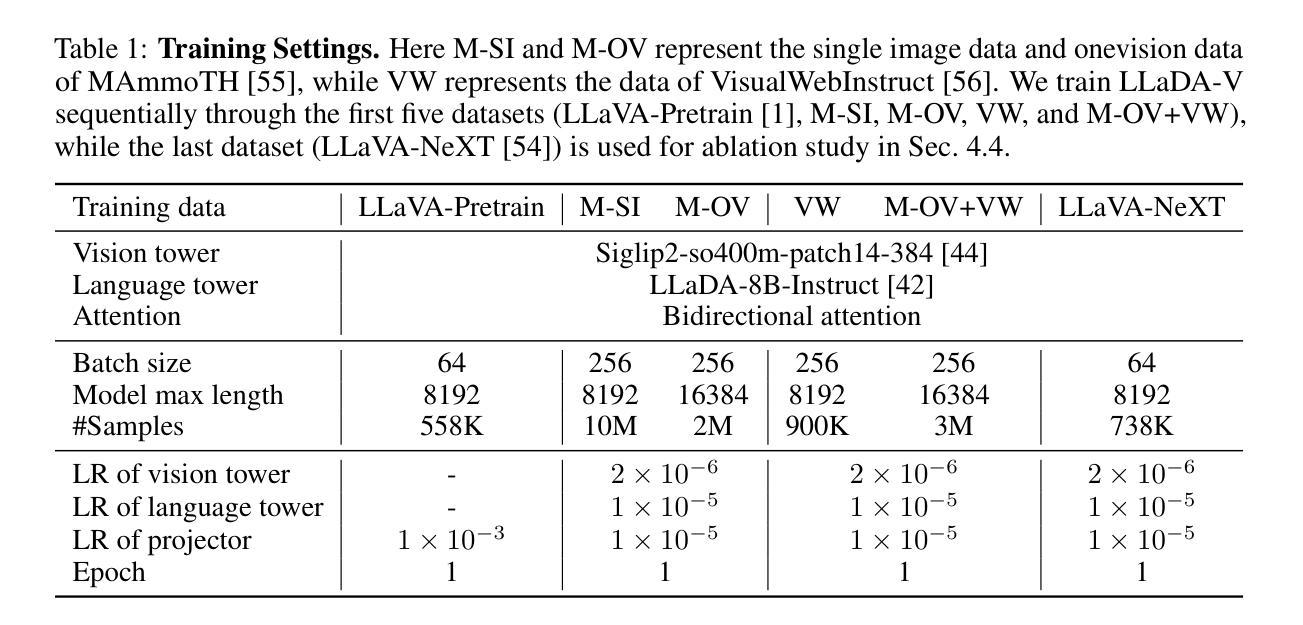
LLaDA-V: Large Language Diffusion Models with Visual Instruction Tuning
Authors:Zebin You, Shen Nie, Xiaolu Zhang, Jun Hu, Jun Zhou, Zhiwu Lu, Ji-Rong Wen, Chongxuan Li
In this work, we introduce LLaDA-V, a purely diffusion-based Multimodal Large Language Model (MLLM) that integrates visual instruction tuning with masked diffusion models, representing a departure from the autoregressive paradigms dominant in current multimodal approaches. Built upon LLaDA, a representative large language diffusion model, LLaDA-V incorporates a vision encoder and MLP connector that projects visual features into the language embedding space, enabling effective multimodal alignment. Our empirical investigation reveals several intriguing results: First, LLaDA-V demonstrates promising multimodal performance despite its language model being weaker on purely textual tasks than counterparts like LLaMA3-8B and Qwen2-7B. When trained on the same instruction data, LLaDA-V is highly competitive to LLaMA3-V across multimodal tasks with better data scalability. It also narrows the performance gap to Qwen2-VL, suggesting the effectiveness of its architecture for multimodal tasks. Second, LLaDA-V achieves state-of-the-art performance in multimodal understanding compared to existing hybrid autoregressive-diffusion and purely diffusion-based MLLMs. Our findings suggest that large language diffusion models show promise in multimodal contexts and warrant further investigation in future research. Project page and codes: https://ml-gsai.github.io/LLaDA-V-demo/.
在这项工作中,我们介绍了LLaDA-V,这是一个完全基于扩散的多模态大型语言模型(MLLM),它将视觉指令调整与掩码扩散模型相结合,这标志着它与当前多模态方法中占主导地位的自回归范式的偏离。LLaDA-V建立在代表性的大型语言扩散模型LLaDA之上,融入了视觉编码器和MLP连接器,将视觉特征投射到语言嵌入空间,从而实现有效的多模态对齐。我们的实证研究揭示了几个有趣的结果:首先,尽管LLaDA-V在语言模型执行纯文本任务方面较LLaMA3-8B和Qwen2-7B等同行表现较弱,但它仍展现出有前景的多模态性能。在相同的指令数据上进行训练时,LLaDA-V在多模态任务方面与LLaMA3-V极具竞争力,并且具有更好的数据可扩展性。它还缩小了与Qwen2-VL的性能差距,这表明其架构对于多模态任务的有效性。其次,与现有的混合自回归-扩散和纯扩散的MLLM相比,LLaDA-V在多模态理解方面达到了最先进的性能。我们的研究结果表明,大型语言扩散模型在多模态上下文中显示出潜力,值得在未来的研究中进一步探讨。项目页面和代码:https://ml-gsai.github.io/LLaDA-V-demo/。
论文及项目相关链接
Summary
LLaDA-V是一款基于扩散的纯多模态大语言模型(MLLM),结合了视觉指令微调与掩码扩散模型,突破了当前多模态方法中的自回归范式。该模型在LLaDA基础上,加入视觉编码器和MLP连接器,将视觉特征投射到语言嵌入空间,实现有效多模态对齐。在相同指令数据训练下,LLaDA-V在多模态任务上具有出色表现,即使其纯文本任务表现相对较弱。同时,LLaDA-V缩小了与顶尖模型的性能差距,展现了其架构在多模态任务上的有效性。它是当前最先进的纯扩散和混合自回归扩散多模态理解模型之一。未来研究需要进一步探索大语言扩散模型在多模态领域的潜力。更多信息可通过链接访问:[链接地址]。
Key Takeaways
- LLaDA-V是基于扩散的纯多模态大语言模型(MLLM),不同于现有的自回归范式方法。
- LLaDA-V结合了视觉指令微调与掩码扩散模型,实现了多模态对齐。
- 在相同指令数据训练下,LLaDA-V在多模态任务上表现优秀,尽管其纯文本任务性能相对较弱。
- LLaDA-V缩小了与顶尖模型在多模态任务上的性能差距。
- LLaDA-V展现了其架构在多模态任务上的有效性,特别是视觉编码器和MLP连接器的使用。
- LLaDA-V达到了当前最先进的纯扩散和混合自回归扩散多模态理解模型的性能水平。
点此查看论文截图

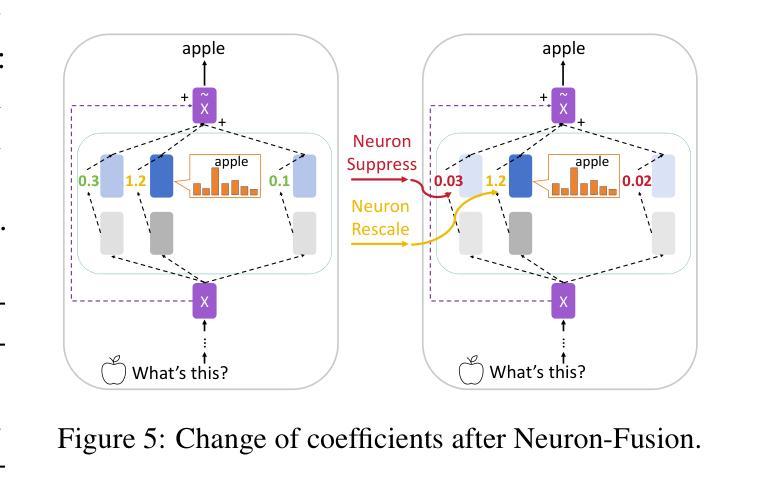
Locate-then-Merge: Neuron-Level Parameter Fusion for Mitigating Catastrophic Forgetting in Multimodal LLMs
Authors:Zeping Yu, Sophia Ananiadou
Although multimodal large language models (MLLMs) have achieved impressive performance, the multimodal instruction tuning stage often causes catastrophic forgetting of the base LLM’s language ability, even in strong models like Llama3. To address this, we propose Locate-then-Merge, a training-free parameter fusion framework that first locates important parameters and then selectively merges them. We further introduce Neuron-Fusion, a neuron-level strategy that preserves the influence of neurons with large parameter shifts–neurons likely responsible for newly acquired visual capabilities–while attenuating the influence of neurons with smaller changes that likely encode general-purpose language skills. This design enables better retention of visual adaptation while mitigating language degradation. Experiments on 13 benchmarks across both language and visual tasks show that Neuron-Fusion consistently outperforms existing model merging methods. Further analysis reveals that our method effectively reduces context hallucination in generation.
虽然多模态大型语言模型(MLLMs)已经取得了令人印象深刻的性能,但多模态指令调整阶段往往会导致基础LLM语言能力发生灾难性遗忘,甚至在Llama3等强大模型中也是如此。为解决这一问题,我们提出了Locate-then-Merge策略,这是一种无需训练即可进行参数融合的方法,能够首先定位重要参数,然后有选择地进行融合。我们还引入了神经元级融合策略Neuron-Fusion,能够在保留负责新获得视觉功能的神经元影响的同时,削弱负责通用语言技能的神经元影响。这种设计能够在保留视觉适应的同时,减轻语言退化的问题。在涵盖语言和视觉任务的13个基准测试上的实验表明,Neuron-Fusion方法始终优于现有模型融合方法。进一步的分析表明,我们的方法有效地减少了生成过程中的上下文幻觉。
论文及项目相关链接
Summary
多模态大型语言模型(MLLMs)在基础语言模型能力上取得了显著成效,但在多模态指令调整阶段,即使是像Llama3这样的强大模型也会出现基础LLM语言能力的灾难性遗忘。为解决这一问题,我们提出了无训练参数融合框架Locate-then-Merge,该框架首先定位重要参数,然后有选择地进行合并。此外,我们还引入了神经元层面的策略——Neuron-Fusion,该策略保留具有较大参数变化的神经元的影响,这些神经元可能负责新获得的视觉能力,同时减弱具有较小变化的神经元的影响,这些神经元可能编码通用语言技能。这种设计能够在保留视觉适应性的同时,减轻语言退化的问题。在语言和视觉任务上的13个基准测试显示,Neuron-Fusion在模型合并方法上表现卓越。进一步的分析表明,我们的方法有效地减少了生成过程中的上下文幻觉。
Key Takeaways
- 多模态大型语言模型(MLLMs)在指令调整阶段可能会出现基础语言能力的遗忘问题。
- Locate-then-Merge框架通过定位并合并重要参数来解决这个问题。
- Neuron-Fusion是神经元层面的策略,保留负责新视觉能力的神经元影响,同时减弱通用语言技能的神经元影响。
- 该设计能在保留视觉适应性的同时减轻语言退化问题。
- 在语言和视觉任务上的多个基准测试显示Neuron-Fusion优于现有模型合并方法。
- Neuron-Fusion能有效减少生成过程中的上下文幻觉。
点此查看论文截图




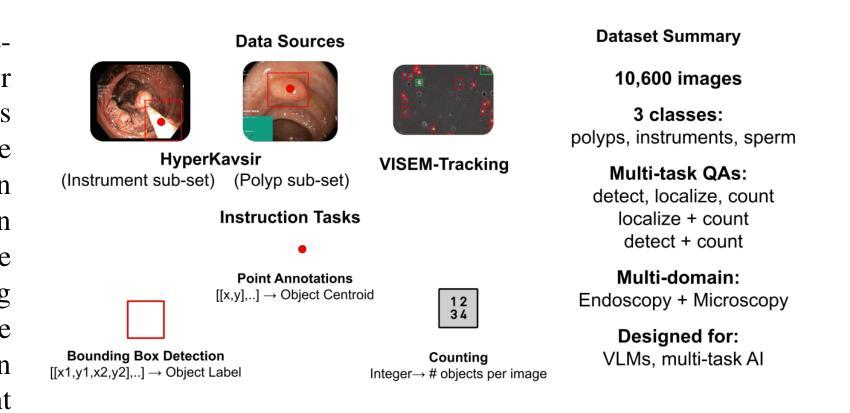
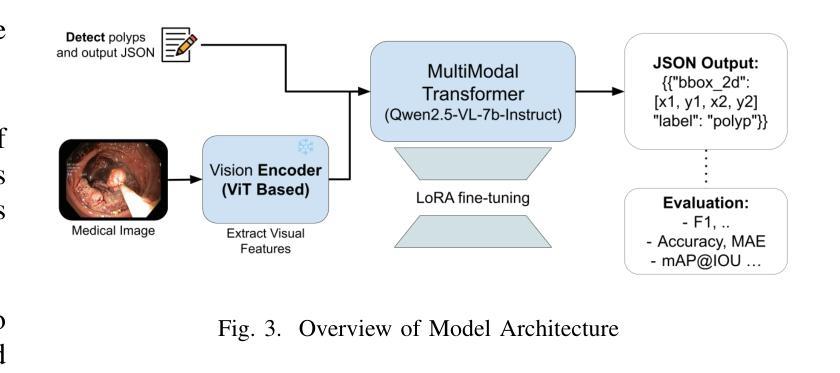
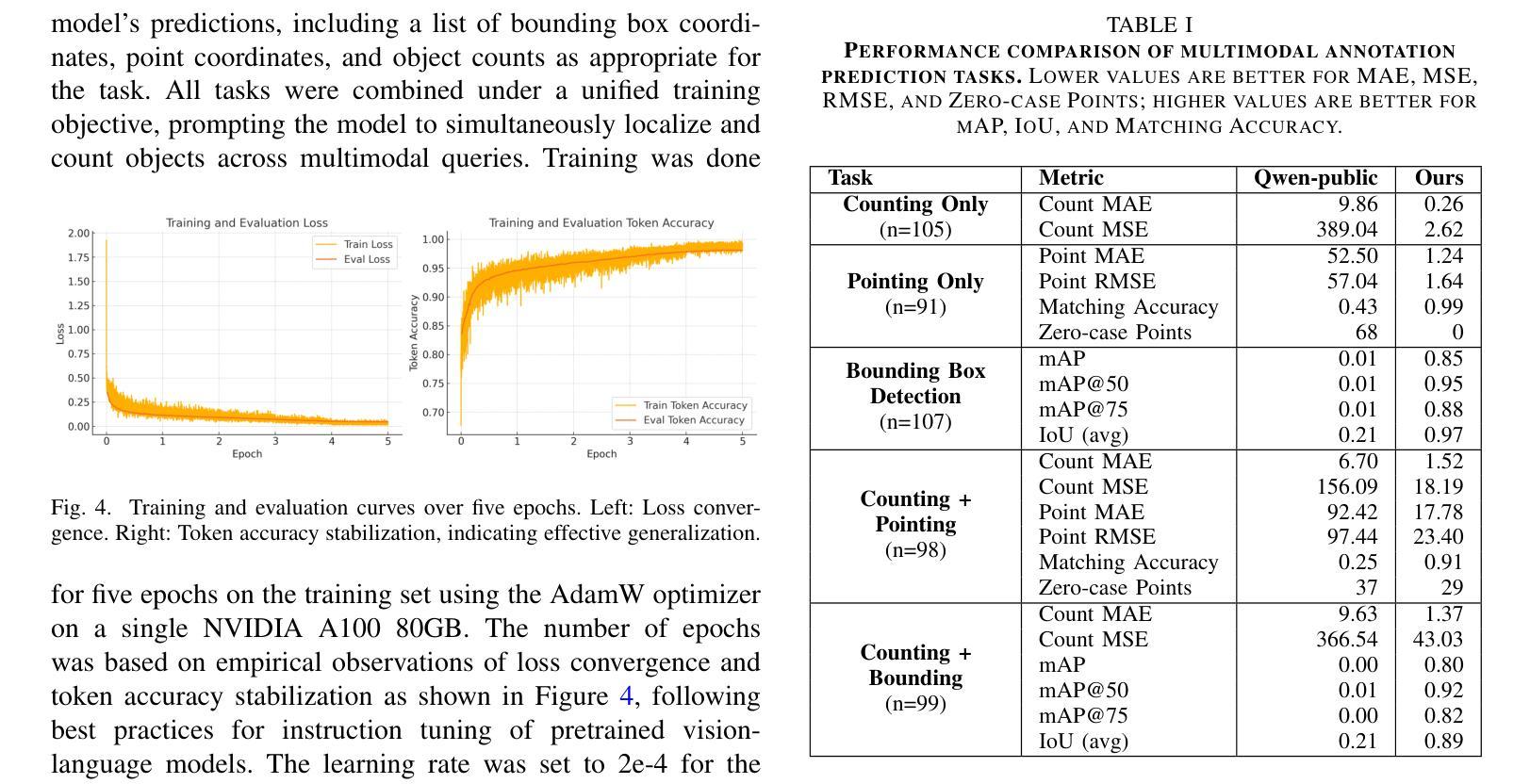
Point, Detect, Count: Multi-Task Medical Image Understanding with Instruction-Tuned Vision-Language Models
Authors:Sushant Gautam, Michael A. Riegler, Pål Halvorsen
We investigate fine-tuning Vision-Language Models (VLMs) for multi-task medical image understanding, focusing on detection, localization, and counting of findings in medical images. Our objective is to evaluate whether instruction-tuned VLMs can simultaneously improve these tasks, with the goal of enhancing diagnostic accuracy and efficiency. Using MedMultiPoints, a multimodal dataset with annotations from endoscopy (polyps and instruments) and microscopy (sperm cells), we reformulate each task into instruction-based prompts suitable for vision-language reasoning. We fine-tune Qwen2.5-VL-7B-Instruct using Low-Rank Adaptation (LoRA) across multiple task combinations. Results show that multi-task training improves robustness and accuracy. For example, it reduces the Count Mean Absolute Error (MAE) and increases Matching Accuracy in the Counting + Pointing task. However, trade-offs emerge, such as more zero-case point predictions, indicating reduced reliability in edge cases despite overall performance gains. Our study highlights the potential of adapting general-purpose VLMs to specialized medical tasks via prompt-driven fine-tuning. This approach mirrors clinical workflows, where radiologists simultaneously localize, count, and describe findings - demonstrating how VLMs can learn composite diagnostic reasoning patterns. The model produces interpretable, structured outputs, offering a promising step toward explainable and versatile medical AI. Code, model weights, and scripts will be released for reproducibility at https://github.com/simula/PointDetectCount.
我们研究了针对多任务医学影像理解的视觉语言模型(VLMs)微调,重点研究医学影像中的检测结果检测、定位和计数。我们的目标是评估指令调整后的VLMs是否能同时改进这些任务,以提高诊断和效率。我们使用MedMultiPoints数据集,该数据集包含来自内窥镜(息肉和仪器)和显微镜(精子细胞)的注释,我们将每个任务重新制定为适合视觉语言推理的指令提示。我们使用低秩适应(LoRA)对Qwen2.5-VL-7B-Instruct进行微调,进行多种任务组合。结果表明,多任务训练提高了稳健性和准确性。例如,它减少了计数平均绝对误差(MAE),并提高了计数+定位任务的匹配准确率。然而,也出现了一些权衡,例如更多的零案例点预测,这表明尽管总体性能有所提升,但在边缘情况下可靠性有所降低。我们的研究突出了通过提示驱动的微调将通用VLMs适应专业医疗任务的潜力。这种方法反映了临床工作流程,放射科医生可以同时定位、计数和描述发现结果,证明了VLMs如何学习复合诊断推理模式。该模型产生可解释的结构化输出,为医疗人工智能的可解释性和多功能性提供了有希望的进步。代码、模型权重和脚本将在https://github.com/simula/PointDetectCount上发布,以供重现。
论文及项目相关链接
PDF Accepted as a full paper at the 38th IEEE International Symposium on Computer-Based Medical Systems (CBMS) 2025
摘要
本研究调查了通过微调视觉语言模型(VLMs)用于多任务医疗图像理解,主要关注医疗图像中的检测、定位和计数任务。目的是评估指令调优的VLMs是否能同时改进这些任务,从而提高诊断和效率。使用MedMultiPoint多模态数据集进行微调,该数据集包含内窥镜(息肉和仪器)和显微镜(精子细胞)的注释,适合视觉语言推理的指令基础提示。通过LoRA跨多个任务组合对Qwen2.5-VL-7B-Instruct进行微调。结果显示多任务训练能提高稳健性和准确性。例如,它降低了计数平均绝对误差(MAE),并提高了计数加定位任务的匹配准确性。但出现权衡,例如更多零案例点预测,表明尽管总体性能有所提升,但在边缘情况下可靠性降低。本研究突显了通过提示驱动微调将通用VLMs适应专业医疗任务的潜力。这种方法模拟了放射科医生同时定位、计数和描述发现的临床工作流程,展示了VLMs如何学习复合诊断推理模式。该模型产生可解释的结构化输出,为医疗人工智能的可靠和多功能性提供了有希望的步骤。相关代码、模型权重和脚本将在https://github.com/simula/PointDetectCount发布,以促进可重复性。
关键见解
- 研究探索了视觉语言模型(VLMs)在多任务医疗图像理解中的应用,包括检测、定位和计数任务。
- 通过使用MedMultiPoints多模态数据集进行微调,实验评估了指令优化的VLMs在改进这些任务方面的潜力。
- LoRA方法用于微调模型,并在多个任务组合上取得良好效果。
- 多任务训练提高了模型的稳健性和准确性,在计数任务中表现尤为显著。
- 虽然总体性能提升,但在边缘情况下出现可靠性降低的权衡问题。
- 研究强调了通过提示驱动微调将通用VLMs适应专业医疗任务的重要性,这与临床工作流程相符。
点此查看论文截图

PMPO: Probabilistic Metric Prompt Optimization for Small and Large Language Models
Authors:Chenzhuo Zhao, Ziqian Liu, Xingda Wang, Junting Lu, Chaoyi Ruan
Prompt optimization offers a practical and broadly applicable alternative to fine-tuning for improving large language model (LLM) performance. However, existing methods often rely on costly output generation, self-critiquing abilities, or human-annotated preferences, which limit their scalability, especially for smaller or non-instruction-tuned models. We introduce PMPO (Probabilistic Metric Prompt Optimization), a unified framework that refines prompts using token-level cross-entropy loss as a direct, lightweight evaluation signal. PMPO identifies low-quality prompt segments by masking and measuring their impact on loss, then rewrites and selects improved variants by minimizing loss over positive and negative examples. Unlike prior methods, it requires no output sampling or human evaluation during optimization, relying only on forward passes and log-likelihoods. PMPO supports both supervised and preference-based tasks through a closely aligned loss-based evaluation strategy. Experiments show that PMPO consistently outperforms prior methods across model sizes and tasks: it achieves the highest average accuracy on BBH, performs strongly on GSM8K and AQUA-RAT, and improves AlpacaEval 2.0 win rates by over 19 points. These results highlight PMPO’s effectiveness, efficiency, and broad applicability.
提示优化为大型语言模型(LLM)性能的提升提供了一种实用且广泛应用替代微调的方法。然而,现有方法通常依赖于昂贵的输出生成、自我批判能力或人工标注的偏好,这限制了其可扩展性,尤其是对于较小或未经指令调整过的模型。我们引入了PMPO(概率度量提示优化),这是一个统一的框架,使用令牌级别的交叉熵损失作为直接、轻量级的评估信号来优化提示。PMPO通过掩蔽并测量低质量提示段对损失的影响来识别它们,然后通过最小化正负例的损失来重写和选择改进后的变体。不同于以往的方法,它在优化过程中不需要输出采样或人工评估,仅依赖于前向传递和日志似然。PMPO通过紧密对齐的损失评估策略支持监督学习和基于偏好的任务。实验表明,PMPO在模型大小和任务方面均优于以前的方法:它在BBH上达到了最高的平均准确率,在GSM8K和AQUA-RAT上表现强劲,并将AlpacaEval 2.0的胜率提高了超过19个百分点。这些结果突出了PMPO的有效性、效率和广泛的适用性。
论文及项目相关链接
Summary
在大型语言模型(LLM)优化中,现有方法多依赖昂贵且复杂的输出生成和自我批判能力或人类标注偏好,难以进行规模化应用。本研究提出了一种基于概率度量的提示优化(PMPO)框架,通过令牌级别的交叉熵损失作为直接、轻量级的评估信号来优化提示。该方法无需输出采样或人为评估,仅依赖前向传播和日志似然率即可完成优化过程。实验结果证明了PMPO的有效性和高效性,且在跨模型和跨任务场景下表现优异。
Key Takeaways
- PMPO是一种实用的LLM性能提升方法,适用于多种模型和任务。
- 现有优化方法存在成本高、难以规模化的问题,而PMPO通过概率度量提示优化解决了这些问题。
- PMPO利用交叉熵损失作为评估信号来识别低质量提示片段并进行重写选择。
- PMPO无需输出采样和人为评估,提高了优化的效率和便捷性。
- PMPO支持监督学习和偏好型任务,具备统一的评价策略。
点此查看论文截图



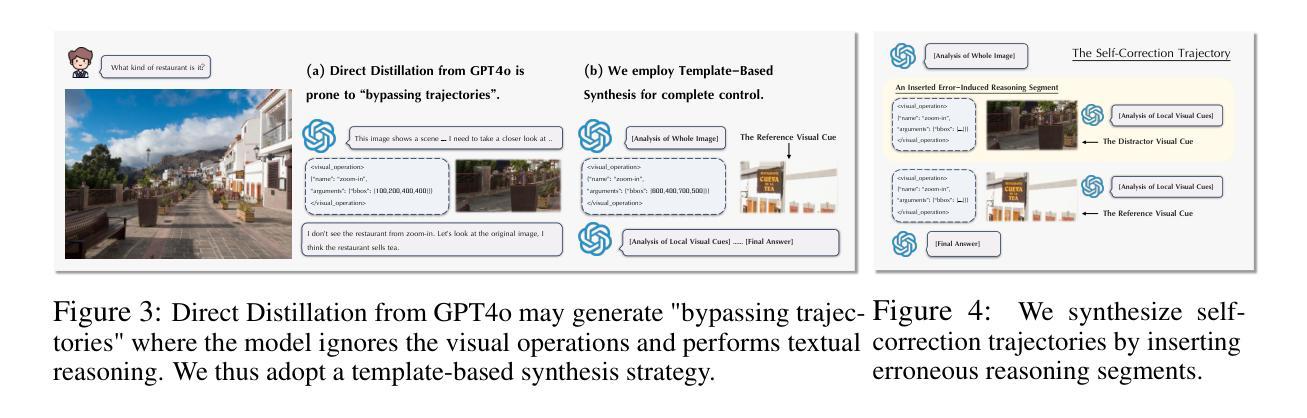
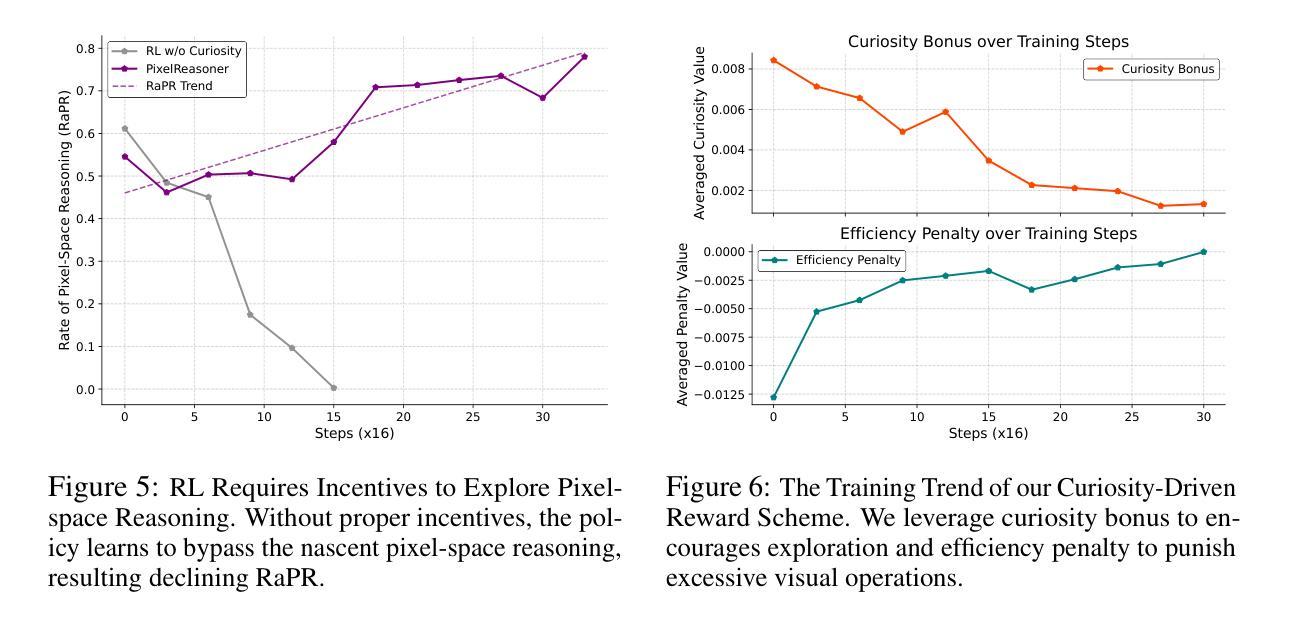
Pixel Reasoner: Incentivizing Pixel-Space Reasoning with Curiosity-Driven Reinforcement Learning
Authors:Alex Su, Haozhe Wang, Weimin Ren, Fangzhen Lin, Wenhu Chen
Chain-of-thought reasoning has significantly improved the performance of Large Language Models (LLMs) across various domains. However, this reasoning process has been confined exclusively to textual space, limiting its effectiveness in visually intensive tasks. To address this limitation, we introduce the concept of reasoning in the pixel-space. Within this novel framework, Vision-Language Models (VLMs) are equipped with a suite of visual reasoning operations, such as zoom-in and select-frame. These operations enable VLMs to directly inspect, interrogate, and infer from visual evidences, thereby enhancing reasoning fidelity for visual tasks. Cultivating such pixel-space reasoning capabilities in VLMs presents notable challenges, including the model’s initially imbalanced competence and its reluctance to adopt the newly introduced pixel-space operations. We address these challenges through a two-phase training approach. The first phase employs instruction tuning on synthesized reasoning traces to familiarize the model with the novel visual operations. Following this, a reinforcement learning (RL) phase leverages a curiosity-driven reward scheme to balance exploration between pixel-space reasoning and textual reasoning. With these visual operations, VLMs can interact with complex visual inputs, such as information-rich images or videos to proactively gather necessary information. We demonstrate that this approach significantly improves VLM performance across diverse visual reasoning benchmarks. Our 7B model, \model, achieves 84% on V* bench, 74% on TallyQA-Complex, and 84% on InfographicsVQA, marking the highest accuracy achieved by any open-source model to date. These results highlight the importance of pixel-space reasoning and the effectiveness of our framework.
思维链推理已显著提高了大型语言模型(LLM)在各种领域的性能。然而,这种推理过程一直被限制在文本空间内,使其在视觉密集型任务中的有效性受到限制。为了解决这一局限性,我们引入了像素空间推理的概念。在这一新颖框架下,视觉语言模型(VLM)配备了一系列视觉推理操作,例如放大和选择帧。这些操作使VLM能够直接检查、质询和推断视觉证据,从而提高视觉任务的推理保真度。在VLM中培养这种像素空间推理能力面临显著挑战,包括模型的初始能力不平衡及其对新引入的像素空间操作的抵触。我们通过两阶段训练方法来应对这些挑战。第一阶段通过合成推理轨迹进行指令调整,使模型熟悉新型视觉操作。之后,强化学习(RL)阶段利用基于好奇心的奖励方案来平衡像素空间推理和文本推理之间的探索。通过这些视觉操作,VLM可以与复杂的视觉输入(如信息丰富的图像或视频)进行交互,以主动收集必要信息。我们证明,该方法显著提高了VLM在多种视觉推理基准测试上的性能。我们的7B模型达到V*测试台84%、TallyQA-Complex测试台74%、图表可视问答(InfographicsVQA)测试台85%,这是迄今为止任何开源模型所取得的最高的准确度。这些结果突显了像素空间推理的重要性以及我们框架的有效性。
论文及项目相关链接
PDF Haozhe Wang and Alex Su contributed equally and listed alphabetically
摘要
链式思维推理已显著提升了大型语言模型(LLM)在各领域的性能。然而,这种推理过程仅限于文本空间,使其在视觉密集型任务中的有效性受限。为解决这一局限性,我们引入像素空间推理的概念。在此新框架下,视觉语言模型(VLM)配备了一系列视觉推理操作,如放大和选择帧。这些操作使VLM能够直接检查、询问和推断视觉证据,从而提高视觉任务的推理保真度。培养VLM中的像素空间推理能力带来了显著挑战,包括模型的初始能力不均衡和对新引入的像素空间操作的接受度低。我们通过两阶段训练方法来应对这些挑战。第一阶段通过合成推理轨迹进行指令调整,使模型熟悉新的视觉操作。接下来,强化学习(RL)阶段利用基于好奇心的奖励方案来平衡像素空间推理和文本推理之间的探索。这些视觉操作使VLM能够与复杂视觉输入(如信息丰富的图像或视频)进行交互,主动收集必要信息。我们的方法显著提高了VLM在多种视觉推理基准测试上的性能。我们的7B模型在V*基准测试上达到84%、TallyQA-Complex上达到74%、InfographicsVQA上达到84%,成为迄今为止任何开源模型中最高精度的模型。这些结果突显了像素空间推理的重要性及我们框架的有效性。
关键见解
- 链式思维推理已提升大型语言模型在多个领域的性能。
- 像素空间推理的引入解决了语言模型在视觉任务中的局限性。
- 视觉语言模型配备了如放大和选择帧等视觉推理操作,可直接处理视觉证据。
- 实施像素空间推理能力面临模型能力不均衡和接受新操作的挑战。
- 通过两阶段训练法应对上述挑战,包括指令调整和强化学习阶段。
- 视觉操作使模型能处理复杂视觉输入,如信息丰富的图像或视频。
点此查看论文截图


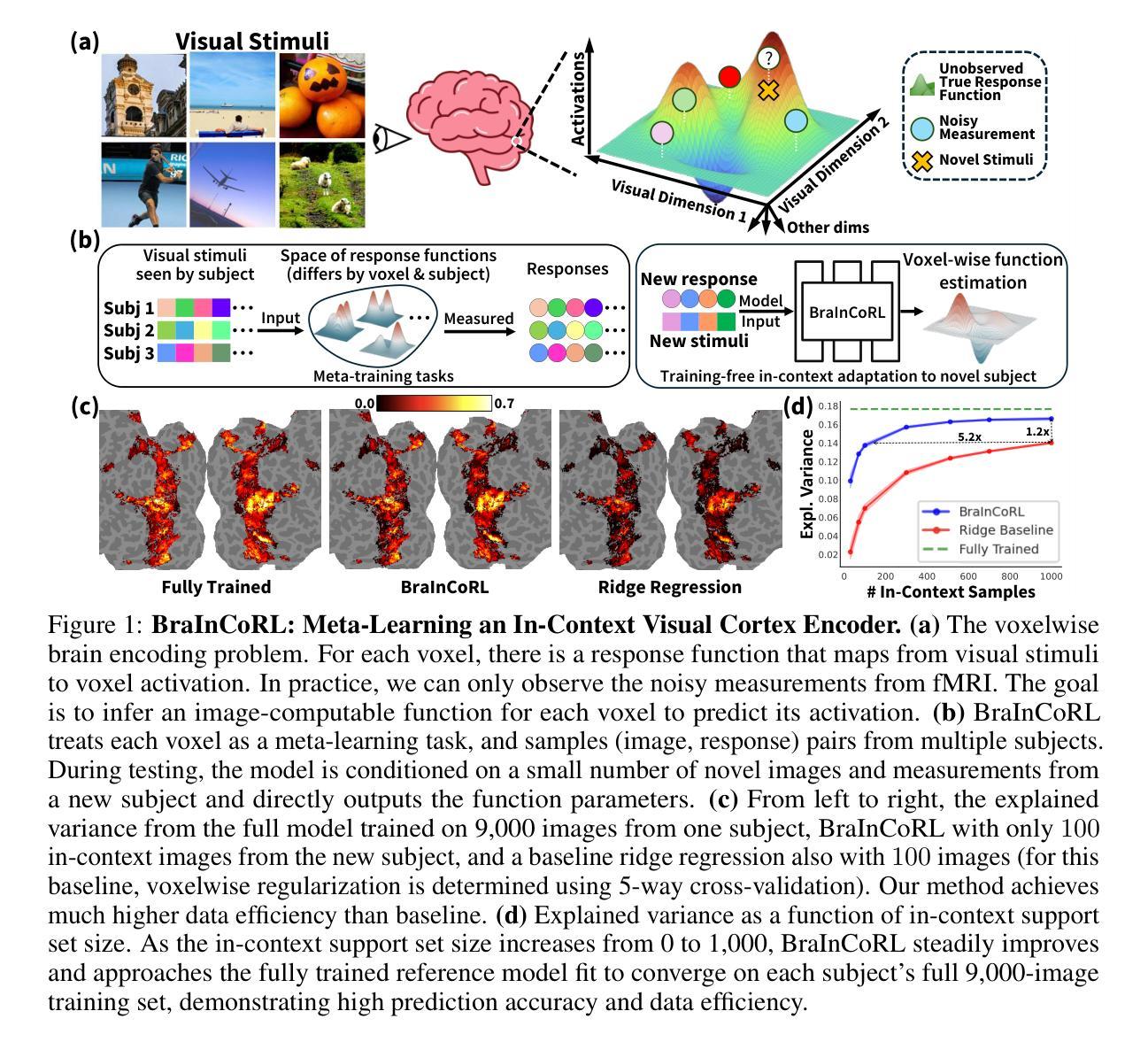
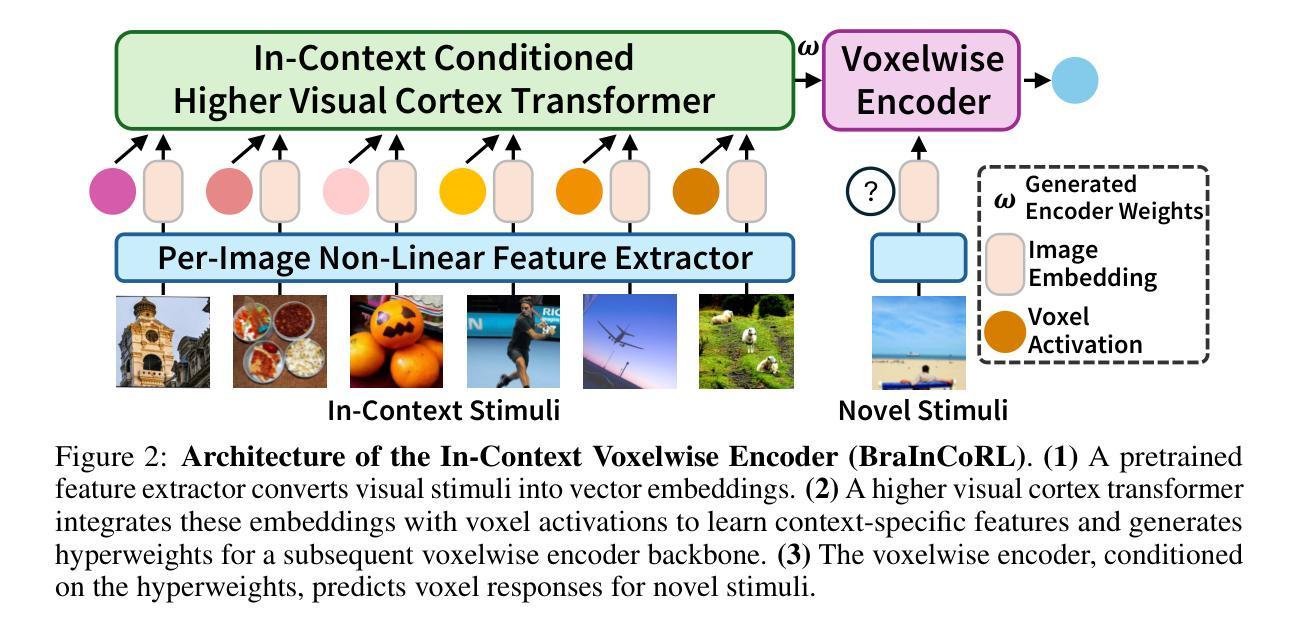
Meta-Learning an In-Context Transformer Model of Human Higher Visual Cortex
Authors:Muquan Yu, Mu Nan, Hossein Adeli, Jacob S. Prince, John A. Pyles, Leila Wehbe, Margaret M. Henderson, Michael J. Tarr, Andrew F. Luo
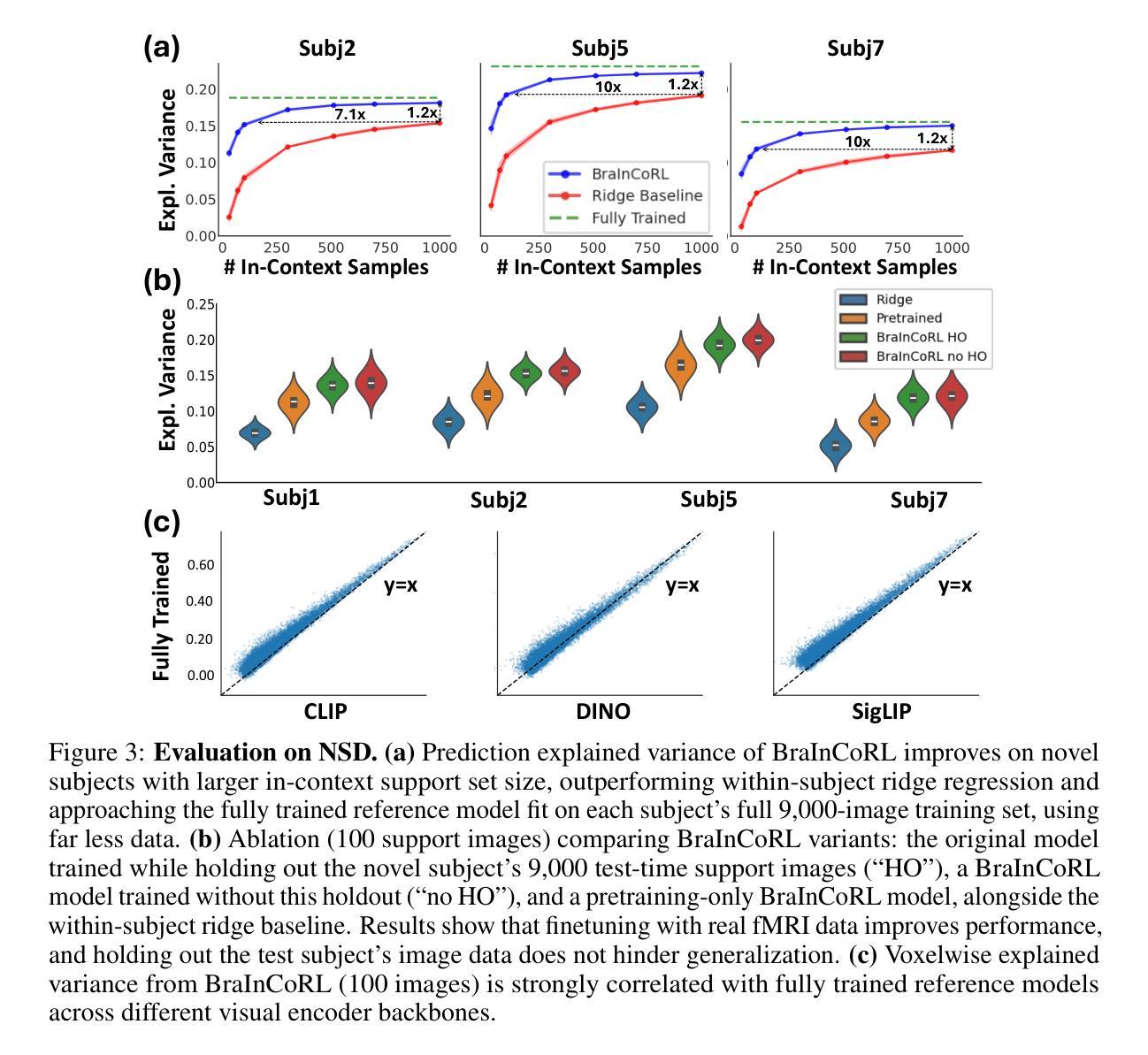
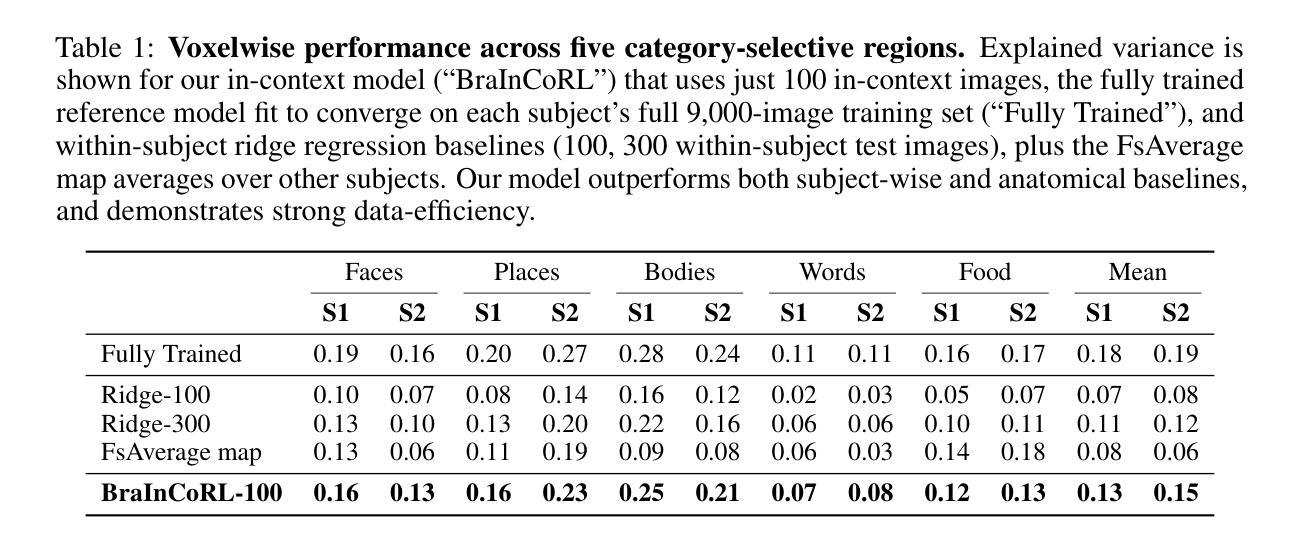
Understanding functional representations within higher visual cortex is a fundamental question in computational neuroscience. While artificial neural networks pretrained on large-scale datasets exhibit striking representational alignment with human neural responses, learning image-computable models of visual cortex relies on individual-level, large-scale fMRI datasets. The necessity for expensive, time-intensive, and often impractical data acquisition limits the generalizability of encoders to new subjects and stimuli. BraInCoRL uses in-context learning to predict voxelwise neural responses from few-shot examples without any additional finetuning for novel subjects and stimuli. We leverage a transformer architecture that can flexibly condition on a variable number of in-context image stimuli, learning an inductive bias over multiple subjects. During training, we explicitly optimize the model for in-context learning. By jointly conditioning on image features and voxel activations, our model learns to directly generate better performing voxelwise models of higher visual cortex. We demonstrate that BraInCoRL consistently outperforms existing voxelwise encoder designs in a low-data regime when evaluated on entirely novel images, while also exhibiting strong test-time scaling behavior. The model also generalizes to an entirely new visual fMRI dataset, which uses different subjects and fMRI data acquisition parameters. Further, BraInCoRL facilitates better interpretability of neural signals in higher visual cortex by attending to semantically relevant stimuli. Finally, we show that our framework enables interpretable mappings from natural language queries to voxel selectivity.
理解高级视觉皮层中的功能性表征是计算神经科学中的一个基本问题。虽然经过大规模数据集预训练的人工神经网络与人类神经反应表现出惊人的表征对齐,但学习视觉皮层的图像计算模型依赖于个体层面的大规模功能性磁共振成像(fMRI)数据集。昂贵、耗时且通常不切实际的数据采集需求限制了编码器对新对象和刺激物的通用性。BraInCoRL使用上下文学习来预测基于少量样本的逐像素神经反应,无需对新对象和刺激进行任何额外的微调。我们采用了一种变压器架构,可以灵活地适应不同数量的上下文图像刺激,并在多个主体上学习归纳偏见。在训练过程中,我们明确地对模型进行上下文学习优化。通过联合图像特征和体素激活作为条件,我们的模型学会了直接生成高级视觉皮层的性能更佳的逐像素模型。我们证明,在全新图像评估时,BraInCoRL在低数据状态下始终优于现有的逐像素编码器设计,同时在测试时表现出强大的可扩展性。该模型也适用于全新的视觉功能性磁共振成像数据集,该数据集使用不同的主体和功能性磁共振成像数据采参数集。此外,BraInCoRL通过关注语义相关的刺激,提高了高级视觉皮层神经信号的解读性。最后,我们展示了我们的框架能够实现从自然语言查询到体素选择性的可解释映射。
论文及项目相关链接
Summary
本文探讨了解视觉皮层中功能性表征的问题,指出人工神经网络在大型数据集上的预训练与人类神经反应存在显著的对齐。然而,学习视觉皮层的图像计算模型依赖于个体层面的大规模fMRI数据集,数据获取成本高昂、耗时长且难以实现,限制了编码器对新主体和刺激的推广能力。BraInCoRL使用上下文学习,从少量样本预测神经元响应,无需对新主体和刺激进行任何额外微调。利用变压器架构,可灵活适应不同数量的上下文图像刺激,学习跨多个主体的归纳偏见。通过联合图像特征和体素激活,模型直接生成更高视觉皮层的体素模型,表现更佳。在全新图像的低数据状态下,BraInCoRL表现优于现有体素编码器设计;测试时,其扩展行为表现强劲。此外,该模型可推广到使用不同主体和fMRI数据获取参数的新视觉fMRI数据集上,并能更好地解释高级视觉皮层的神经信号。最后,研究展示了该框架可实现从自然语言查询到体素选择性的可解释映射。
Key Takeaways
- 理解视觉皮层中的功能性表征是计算神经科学的基本问题。
- 人工神经网络预训练与大型数据集展现与人类神经反应的显著对齐。
- 学习图像计算模型依赖大规模fMRI数据集,但数据获取成本高、时间长且不切实际。
- BraInCoRL使用上下文学习预测神经元响应,无需对新数据额外微调。
- BraInCoRL利用变压器架构灵活适应多种上下文图像刺激,并学习跨主体归纳偏见。
- 模型联合图像特征和体素激活,生成表现更佳的高级视觉皮层体素模型。
点此查看论文截图

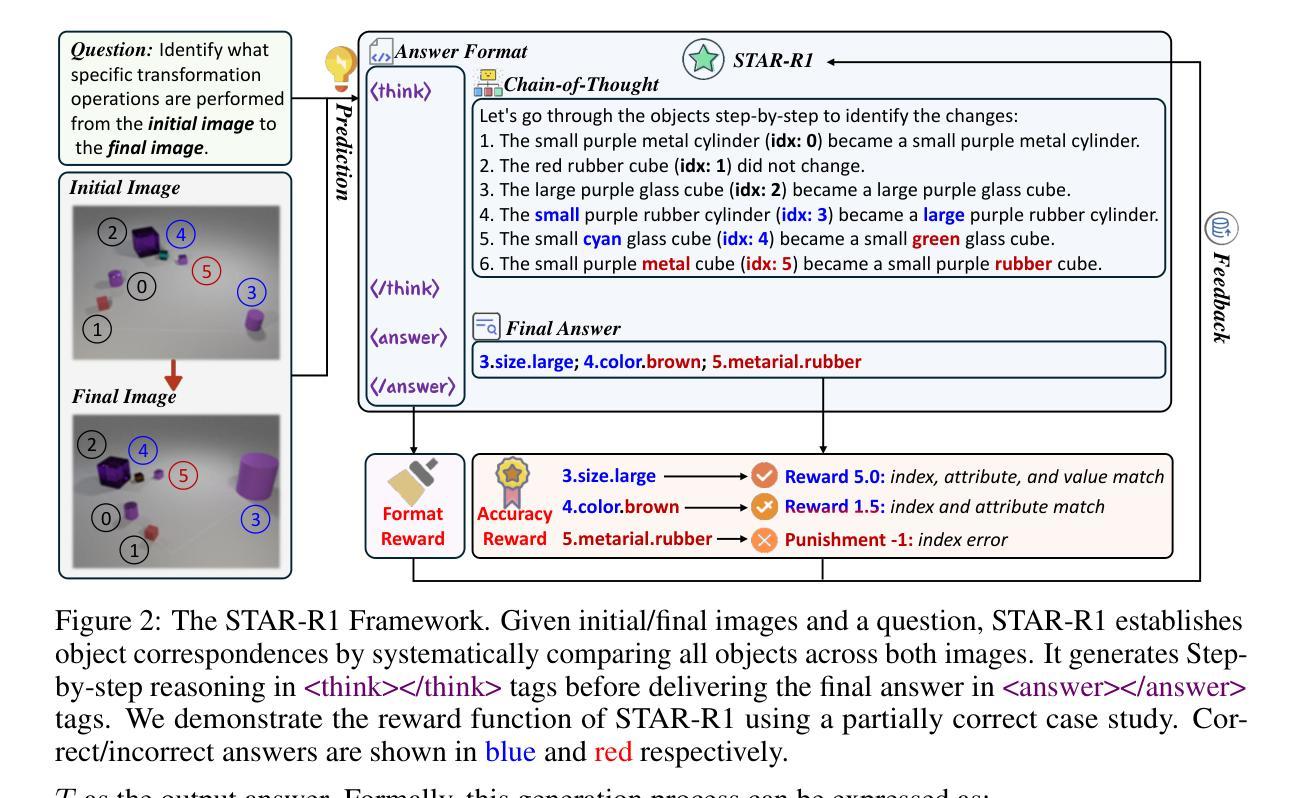
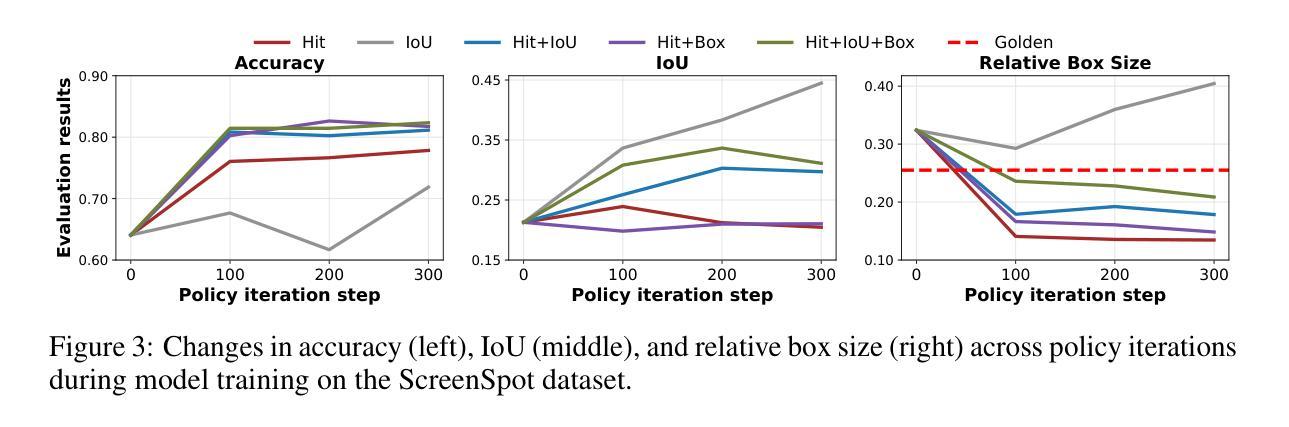
STAR-R1: Spacial TrAnsformation Reasoning by Reinforcing Multimodal LLMs
Authors:Zongzhao Li, Zongyang Ma, Mingze Li, Songyou Li, Yu Rong, Tingyang Xu, Ziqi Zhang, Deli Zhao, Wenbing Huang
Multimodal Large Language Models (MLLMs) have demonstrated remarkable capabilities across diverse tasks, yet they lag significantly behind humans in spatial reasoning. We investigate this gap through Transformation-Driven Visual Reasoning (TVR), a challenging task requiring identification of object transformations across images under varying viewpoints. While traditional Supervised Fine-Tuning (SFT) fails to generate coherent reasoning paths in cross-view settings, sparse-reward Reinforcement Learning (RL) suffers from inefficient exploration and slow convergence. To address these limitations, we propose STAR-R1, a novel framework that integrates a single-stage RL paradigm with a fine-grained reward mechanism tailored for TVR. Specifically, STAR-R1 rewards partial correctness while penalizing excessive enumeration and passive inaction, enabling efficient exploration and precise reasoning. Comprehensive evaluations demonstrate that STAR-R1 achieves state-of-the-art performance across all 11 metrics, outperforming SFT by 23% in cross-view scenarios. Further analysis reveals STAR-R1’s anthropomorphic behavior and highlights its unique ability to compare all objects for improving spatial reasoning. Our work provides critical insights in advancing the research of MLLMs and reasoning models. The codes, model weights, and data will be publicly available at https://github.com/zongzhao23/STAR-R1.
多模态大型语言模型(MLLMs)在各项任务中展现了卓越的能力,但在空间推理方面仍显著落后于人类。我们通过转换驱动视觉推理(TVR)来研究这一差距,这是一项具有挑战性的任务,要求在不同视角的图像中识别对象的转换。传统的监督微调(SFT)无法在跨视图设置中生成连贯的推理路径,而稀疏奖励强化学习(RL)则面临效率低下和探索缓慢的问题。为了解决这些局限性,我们提出了STAR-R1,这是一个将单阶段RL范式与针对TVR的精细奖励机制相结合的新型框架。具体来说,STAR-R1奖励部分正确性,同时惩罚过度枚举和被动无行动,从而实现有效的探索和精确推理。综合评估表明,STAR-R1在所有1:metric上达到了最新性能水平,在跨视图场景中比SFT高出23%。进一步的分析揭示了STAR-R1的人类行为特征,并突出了其在比较所有对象方面提高空间推理的独特能力。我们的工作为多模态语言模型和推理模型的研究提供了关键见解。代码、模型权重和数据将在https://github.com/zongzhao23/STAR-R1上公开可用。
论文及项目相关链接
Summary
MLLM在空间推理方面存在与人类显著差距,本研究通过Transformation-Driven视觉推理(TVR)任务探究此差距。提出STAR-R1框架,结合单阶段强化学习与细粒度奖励机制,解决传统监督微调(SFT)和强化学习(RL)的局限性。STAR-R1框架实现高效探索与精确推理,在跨视角场景中实现业界最佳性能。研究提供对MLLM和推理模型发展的深刻见解。
Key Takeaways
- MLLM在多任务中表现优异,但在空间推理方面存在与人类显著差距。
- 提出Transformation-Driven视觉推理(TVR)任务来探究这一差距。
- 传统监督微调(SFT)在跨视角设置下无法生成连贯的推理路径。
- 稀疏奖励强化学习(RL)存在探索效率低下和收敛速度慢的问题。
- 提出STAR-R1框架,结合单阶段RL范式和针对TVR的精细奖励机制。
- STAR-R1框架通过奖励部分正确性和惩罚过度枚举与被动行为,实现了高效探索和精确推理。
点此查看论文截图