⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-05-24 更新
GoT-R1: Unleashing Reasoning Capability of MLLM for Visual Generation with Reinforcement Learning
Authors:Chengqi Duan, Rongyao Fang, Yuqing Wang, Kun Wang, Linjiang Huang, Xingyu Zeng, Hongsheng Li, Xihui Liu
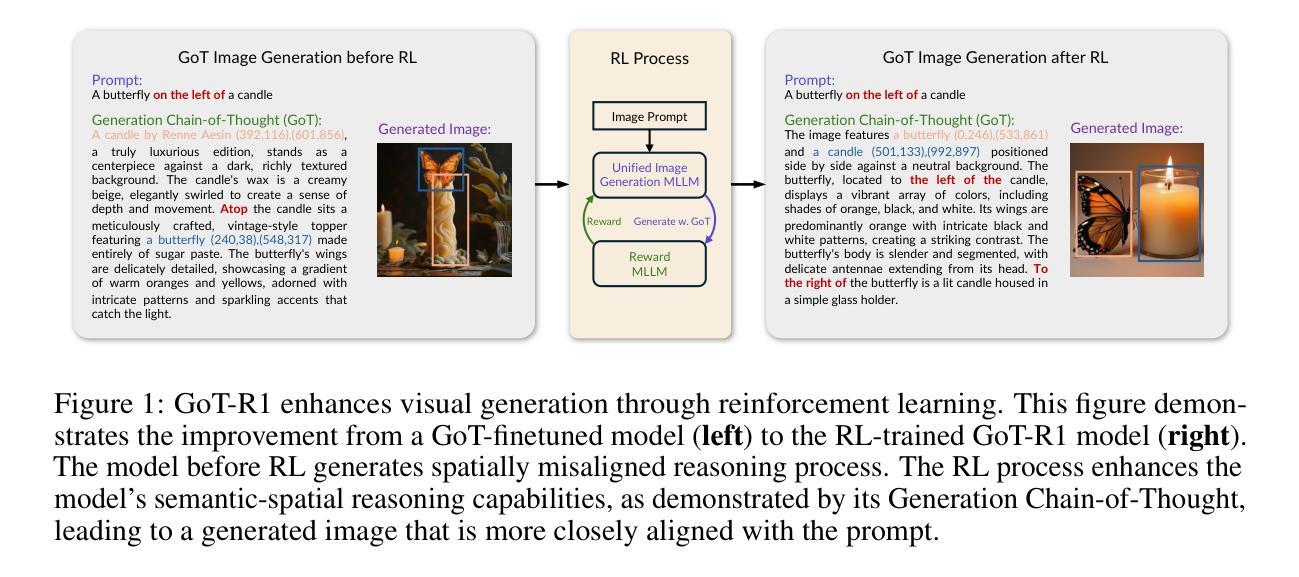
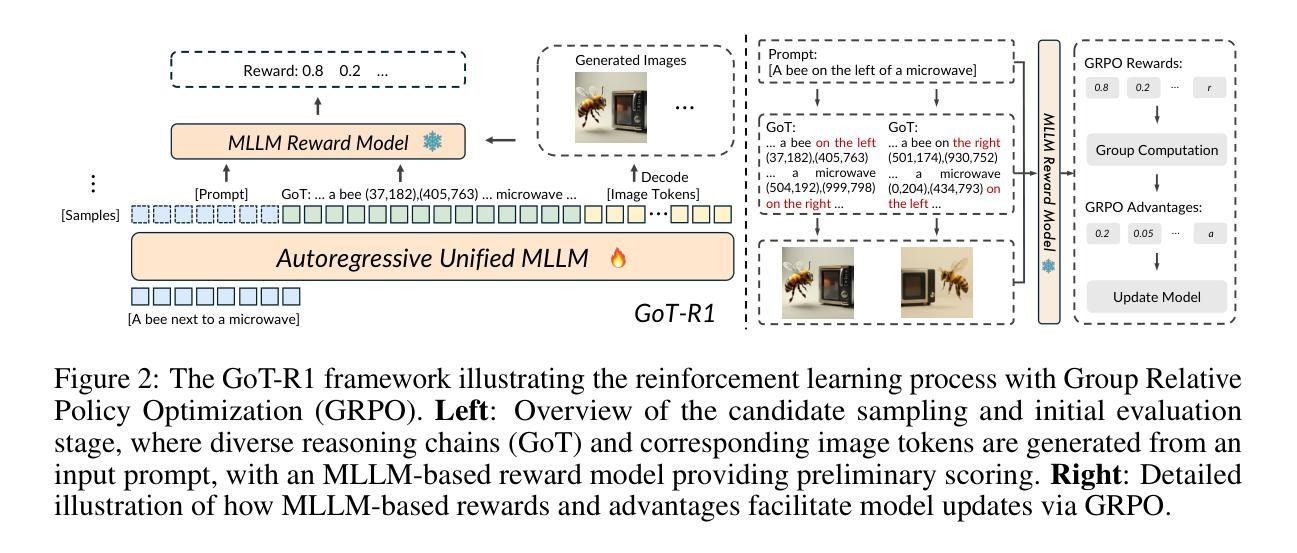
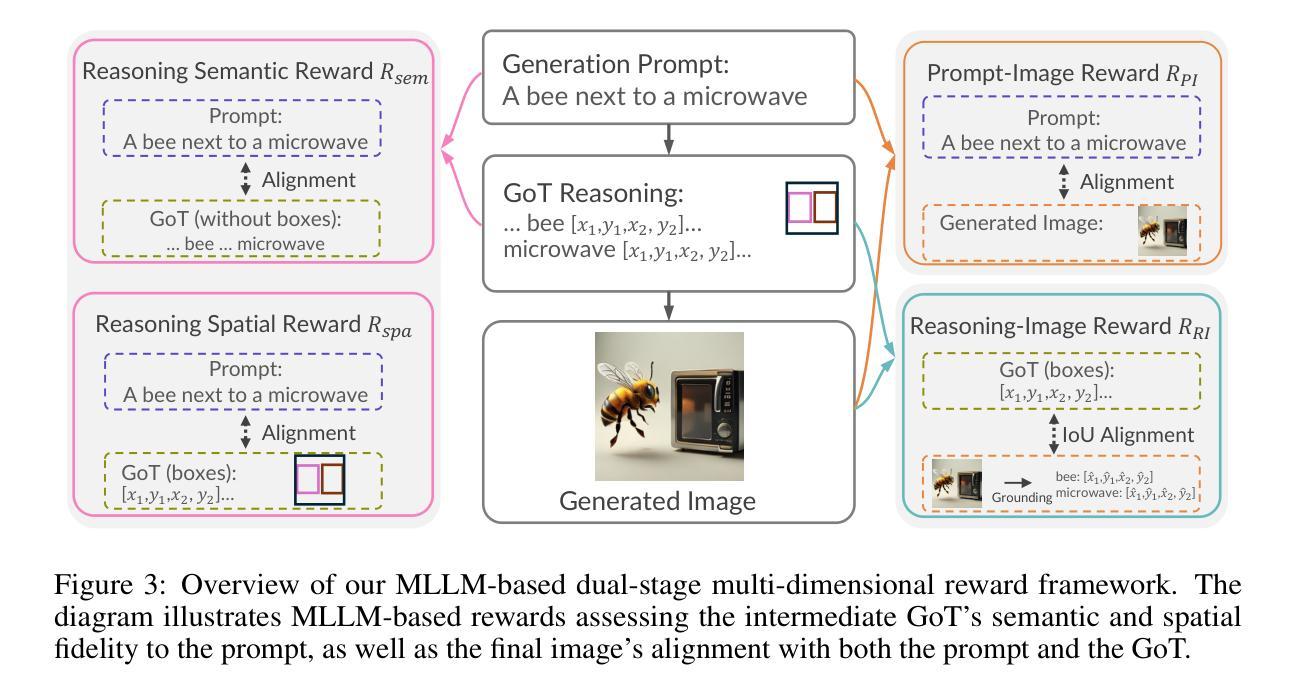
Visual generation models have made remarkable progress in creating realistic images from text prompts, yet struggle with complex prompts that specify multiple objects with precise spatial relationships and attributes. Effective handling of such prompts requires explicit reasoning about the semantic content and spatial layout. We present GoT-R1, a framework that applies reinforcement learning to enhance semantic-spatial reasoning in visual generation. Building upon the Generation Chain-of-Thought approach, GoT-R1 enables models to autonomously discover effective reasoning strategies beyond predefined templates through carefully designed reinforcement learning. To achieve this, we propose a dual-stage multi-dimensional reward framework that leverages MLLMs to evaluate both the reasoning process and final output, enabling effective supervision across the entire generation pipeline. The reward system assesses semantic alignment, spatial accuracy, and visual quality in a unified approach. Experimental results demonstrate significant improvements on T2I-CompBench benchmark, particularly in compositional tasks involving precise spatial relationships and attribute binding. GoT-R1 advances the state-of-the-art in image generation by successfully transferring sophisticated reasoning capabilities to the visual generation domain. To facilitate future research, we make our code and pretrained models publicly available at https://github.com/gogoduan/GoT-R1.
视觉生成模型在根据文本提示创建逼真的图像方面取得了显著的进步,但在处理复杂的提示方面仍面临挑战,这些提示指定了具有精确空间关系和属性的多个对象。有效处理这些提示需要对语义内容和空间布局进行明确的推理。我们提出了GoT-R1框架,该框架应用强化学习来增强视觉生成中的语义空间推理能力。基于思维生成链的方法,GoT-R1使模型能够通过精心设计的强化学习自主发现超越预定模板的有效推理策略。为此,我们提出了一个双阶段多维奖励框架,利用MLLMs来评估推理过程和最终输出,从而在整个生成管道中实现对有效监督的统一方法。奖励系统评估语义对齐、空间精度和视觉质量。实验结果表明,在T2I-CompBench基准测试中,特别是在涉及精确空间关系和属性绑定的组合任务中,GoT-R1取得了显著改进。GoT-R1通过将复杂的推理能力成功转移到视觉生成领域,从而推动了图像生成的最新技术。为了方便未来的研究,我们在https://github.com/gogoduan/GoT-R1公开我们的代码和预训练模型。
论文及项目相关链接
PDF Github page refer to: https://github.com/gogoduan/GoT-R1
Summary
文本描述了一种名为GoT-R1的框架,该框架采用强化学习来提高视觉生成中的语义空间推理能力。它在Generation Chain-of-Thought方法的基础上,使模型能够自主发现有效的推理策略,超越预设模板。通过精心设计强化学习,提出了一个双阶段多维度奖励框架,利用MLLMs评估推理过程和最终输出,实现整个生成管道的有效监督。奖励系统以统一的方式评估语义对齐、空间准确性和视觉质量。实验结果表明,GoT-R1在T2I-CompBench基准测试中表现显著改进,特别是在涉及精确空间关系和属性绑定的组合任务中。它为推动图像生成领域的先进技术做出了贡献,成功地将复杂的推理能力转移到视觉生成领域。相关的代码和预训练模型可以在https://github.com/gogoduan/GoT-R1公开获取。
Key Takeaways
- GoT-R1框架使用强化学习提升视觉生成中的语义空间推理能力。
- 该框架基于Generation Chain-of-Thought方法,使模型能够自主发现超越预设模板的有效推理策略。
- 提出了一个双阶段多维度奖励框架来评估推理过程和最终输出。
- 奖励系统同时考虑语义对齐、空间准确性和视觉质量。
- GoT-R1在T2I-CompBench基准测试中表现优异,尤其在涉及精确空间关系和属性绑定的任务上。
- GoT-R1为图像生成领域做出了贡献,成功转移复杂的推理能力至视觉生成。
点此查看论文截图

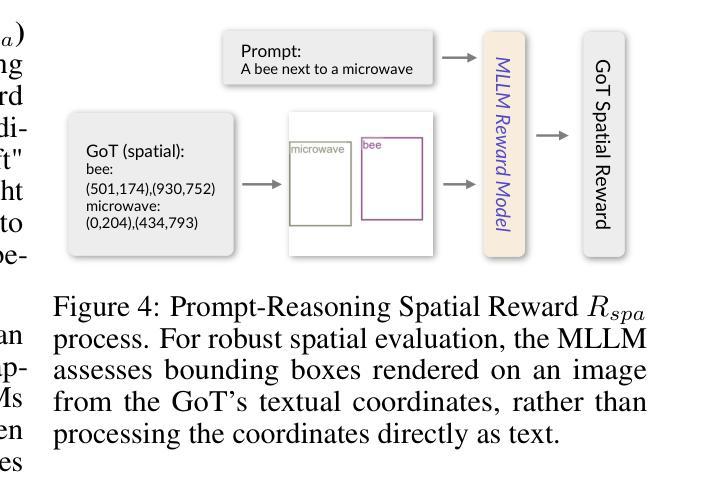
ARB: A Comprehensive Arabic Multimodal Reasoning Benchmark
Authors:Sara Ghaboura, Ketan More, Wafa Alghallabi, Omkar Thawakar, Jorma Laaksonen, Hisham Cholakkal, Salman Khan, Rao Muhammad Anwer
As Large Multimodal Models (LMMs) become more capable, there is growing interest in evaluating their reasoning processes alongside their final outputs. However, most benchmarks remain focused on English, overlooking languages with rich linguistic and cultural contexts, such as Arabic. To address this gap, we introduce the Comprehensive Arabic Multimodal Reasoning Benchmark (ARB), the first benchmark designed to evaluate step-by-step reasoning in Arabic across both textual and visual modalities. ARB spans 11 diverse domains, including visual reasoning, document understanding, OCR, scientific analysis, and cultural interpretation. It comprises 1,356 multimodal samples paired with 5,119 human-curated reasoning steps and corresponding actions. We evaluated 12 state-of-the-art open- and closed-source LMMs and found persistent challenges in coherence, faithfulness, and cultural grounding. ARB offers a structured framework for diagnosing multimodal reasoning in underrepresented languages and marks a critical step toward inclusive, transparent, and culturally aware AI systems. We release the benchmark, rubric, and evaluation suit to support future research and reproducibility. Code available at: https://github.com/mbzuai-oryx/ARB
随着大型多模态模型(LMMs)的功能越来越强大,人们对其推理过程及其最终输出的评估兴趣日益浓厚。然而,大多数基准测试仍然专注于英语,忽略了具有丰富语言和文化背景的语言,如阿拉伯语。为了弥补这一空白,我们推出了全面的阿拉伯语多模态推理基准测试(ARB),这是第一个旨在评估阿拉伯语中逐步推理的基准测试,涉及文本和视觉两种模式。ARB涵盖11个不同领域,包括视觉推理、文档理解、OCR、科学分析和文化解读。它由1356个多模态样本组成,配有5119个人工策划的推理步骤和相应行动。我们评估了12个最先进的开源和闭源LMMs,发现在连贯性、忠诚性和文化依据方面存在持续挑战。ARB为诊断代表性不足的语言中的多模态推理提供了结构化框架,朝着包容、透明和文化感知的AI系统迈出了重要一步。我们发布这个基准测试、细则和评估套件,以支持未来的研究和可重复性。代码可在https://github.com/mbzuai-oryx/ARB找到。
论文及项目相关链接
PDF Github : https://github.com/mbzuai-oryx/ARB, Huggingface: https://huggingface.co/datasets/MBZUAI/ARB
Summary
本文介绍了综合性阿拉伯语多模态推理基准测试(ARB),该基准测试旨在评估阿拉伯语中的逐步推理过程,涉及文本和视觉两种模式。ARB涵盖了11个不同领域,包括视觉推理、文档理解、OCR、科学分析和文化解读等。它包含了与人工推理步骤相对应的多种模式样本,以及大规模模型面临的多模态推理挑战。该基准测试为未来的研究和文化意识的AI系统提供了一个框架支持。ARB可在https://github.com/mbzuai-oryx/ARB上访问。
Key Takeaways
- 综合阿拉伯语多模态推理基准测试(ARB)是首个旨在评估阿拉伯语中逐步推理过程的基准测试。
- 该基准测试涵盖了文本和视觉两种模式的多模态样本。
- 它包括多种领域,如视觉推理、文档理解、OCR、科学分析和文化解读等。
- 该基准测试包含人工推理步骤和对应的行动,用于评估大规模模型的推理过程。
- 对多个先进的开放和封闭的大规模模型进行了评估,发现它们在连贯性、忠诚性和文化依据方面存在挑战。
- 该基准测试为未来的研究和文化意识的AI系统提供了框架支持。
点此查看论文截图




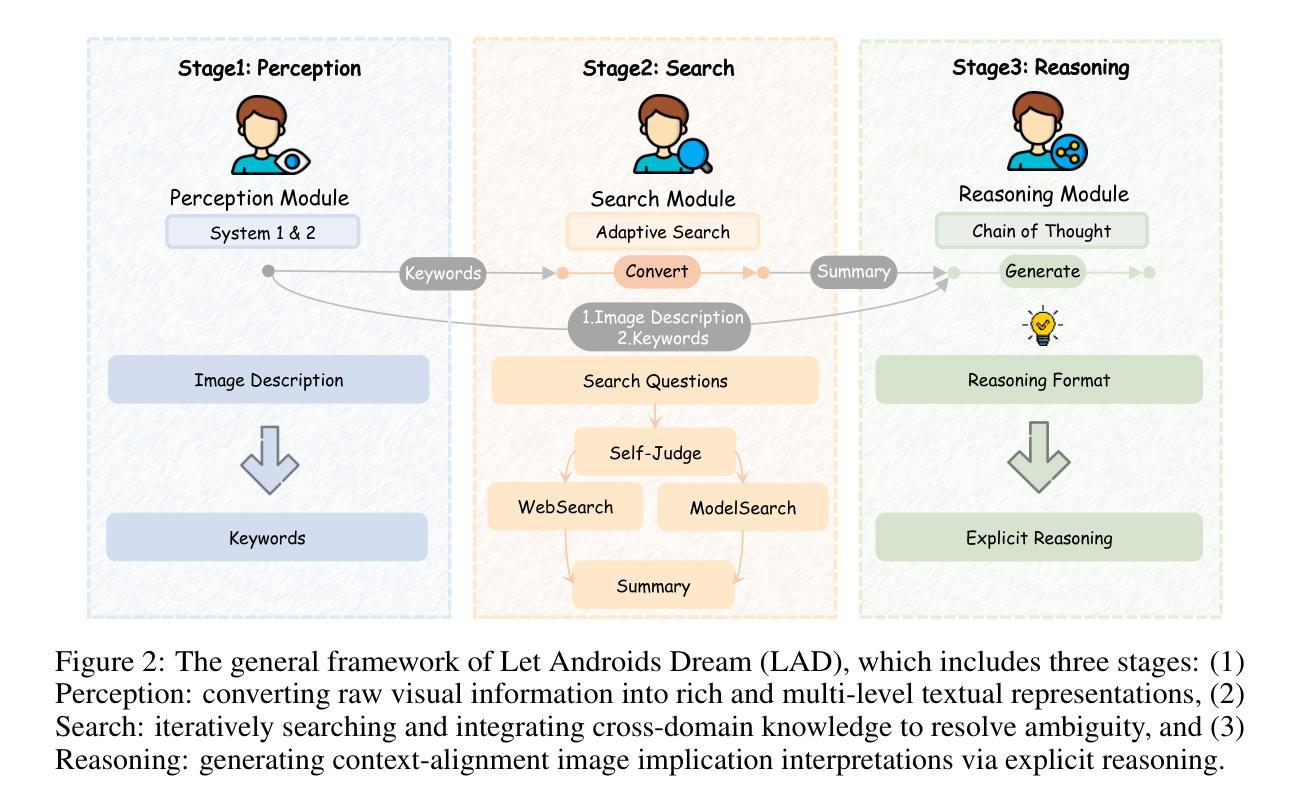
Let Androids Dream of Electric Sheep: A Human-like Image Implication Understanding and Reasoning Framework
Authors:Chenhao Zhang, Yazhe Niu
Metaphorical comprehension in images remains a critical challenge for AI systems, as existing models struggle to grasp the nuanced cultural, emotional, and contextual implications embedded in visual content. While multimodal large language models (MLLMs) excel in basic Visual Question Answer (VQA) tasks, they struggle with a fundamental limitation on image implication tasks: contextual gaps that obscure the relationships between different visual elements and their abstract meanings. Inspired by the human cognitive process, we propose Let Androids Dream (LAD), a novel framework for image implication understanding and reasoning. LAD addresses contextual missing through the three-stage framework: (1) Perception: converting visual information into rich and multi-level textual representations, (2) Search: iteratively searching and integrating cross-domain knowledge to resolve ambiguity, and (3) Reasoning: generating context-alignment image implication via explicit reasoning. Our framework with the lightweight GPT-4o-mini model achieves SOTA performance compared to 15+ MLLMs on English image implication benchmark and a huge improvement on Chinese benchmark, performing comparable with the GPT-4o model on Multiple-Choice Question (MCQ) and outperforms 36.7% on Open-Style Question (OSQ). Additionally, our work provides new insights into how AI can more effectively interpret image implications, advancing the field of vision-language reasoning and human-AI interaction. Our project is publicly available at https://github.com/MING-ZCH/Let-Androids-Dream-of-Electric-Sheep.
图像中的隐喻理解对人工智能系统来说仍然是一个关键挑战,因为现有模型很难把握视觉内容中嵌入的微妙文化、情感和上下文含义。尽管多模态大型语言模型(MLLM)在基本的视觉问答(VQA)任务上表现出色,但在图像含义任务上却存在基本局限:上下文缺失导致不同视觉元素及其抽象意义之间的关系模糊不清。我们受到人类认知过程的启发,提出了一种名为“让安卓做梦”(LAD)的新型图像含义理解和推理框架。LAD通过三个阶段解决上下文缺失问题:(1)感知:将视觉信息转换为丰富且多层次的文本表示;(2)搜索:迭代搜索并整合跨域知识以解决歧义;(3)推理:通过明确的推理生成与上下文对齐的图像含义。我们的框架使用轻量级的GPT-4o-mini模型,在英语图像含义基准测试上的性能达到最佳水平,并在中文基准测试上实现了巨大改进。在多选题方面,其表现与GPT-4o模型相当;在开放性问题方面的得分高出36.7%。此外,我们的工作提供了新的见解,探讨人工智能如何更有效地解释图像含义,推动了视觉语言推理和人机交互领域的发展。我们的项目可在https://github.com/MING-ZCH/Let-Androids-Dream-of-Electric-Sheep上公开访问。
论文及项目相关链接
PDF 16 pages, 9 figures. Code & Dataset: https://github.com/MING-ZCH/Let-Androids-Dream-of-Electric-Sheep
Summary
本文指出人工智能系统在理解图像隐喻方面存在挑战,现有模型难以把握视觉内容中的文化、情感和上下文含义。受人类认知过程的启发,提出了一种名为Let Androids Dream(LAD)的新型图像隐含理解和推理框架。LAD通过三个阶段解决上下文缺失问题:感知阶段将视觉信息转换为丰富且多层次的文本表示;搜索阶段迭代地搜索和整合跨域知识以解决歧义;推理阶段通过明确的推理生成与上下文对齐的图像含义。LAD框架与轻量级GPT-4o-mini模型相结合,在英语图像隐含基准测试上达到了最新性能,并在中文基准测试上有显著改善,在多选和开放风格问题上的表现令人印象深刻。此外,该研究为AI更有效地解释图像含义提供了新见解,推动了视觉语言推理和人机交互领域的发展。
Key Takeaways
- AI系统在理解图像隐喻方面存在困难,尤其是在捕捉文化、情感和上下文含义方面。
- Let Androids Dream(LAD)框架旨在解决这一问题,通过三个阶段处理图像隐含理解和推理。
- LAD框架包括感知阶段、搜索阶段和推理阶段,分别负责将视觉信息转换为文本表示、搜索和整合跨域知识以及生成上下文对齐的图像含义。
- LAD框架与轻量级GPT-4o-mini模型结合,在英语图像隐含基准测试上表现优异,并在中文基准测试上有显著改善。
- LAD在多选和开放风格问题上的表现突出。
6.该研究为AI更有效地解释图像含义提供了新见解,有助于推动视觉语言推理领域的发展。
点此查看论文截图

SophiaVL-R1: Reinforcing MLLMs Reasoning with Thinking Reward
Authors:Kaixuan Fan, Kaituo Feng, Haoming Lyu, Dongzhan Zhou, Xiangyu Yue
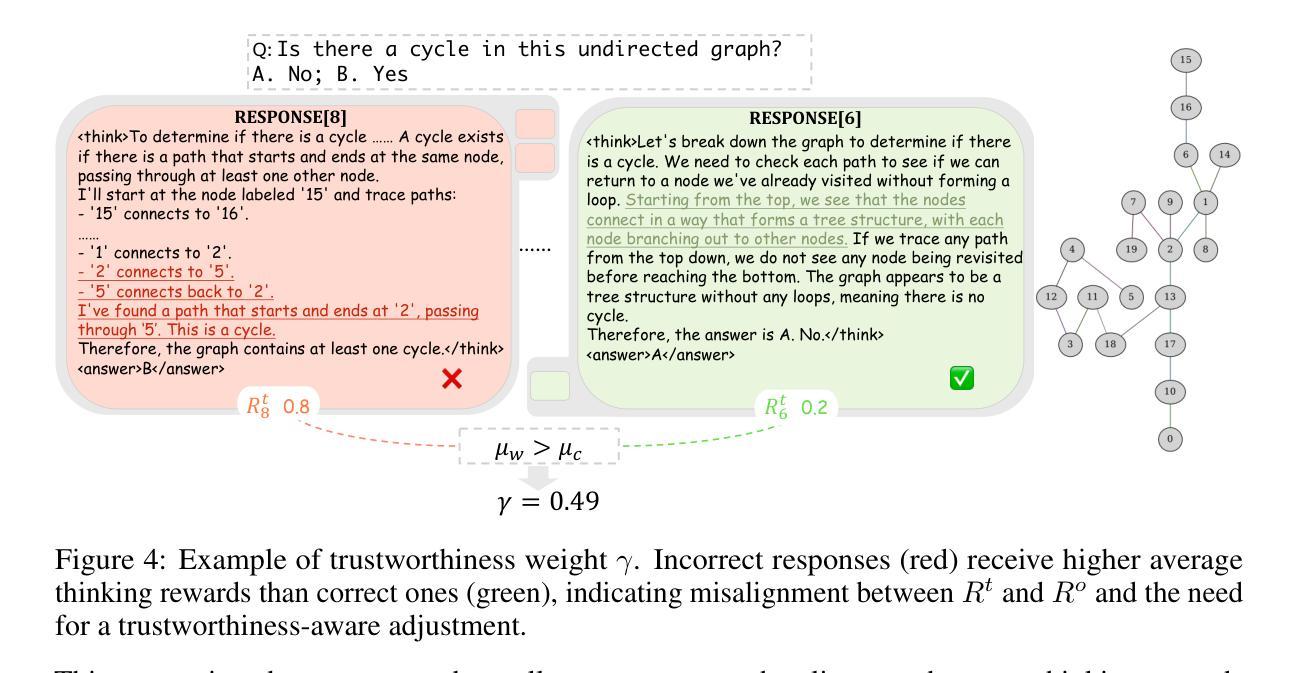
Recent advances have shown success in eliciting strong reasoning abilities in multimodal large language models (MLLMs) through rule-based reinforcement learning (RL) with outcome rewards. However, this paradigm typically lacks supervision over the thinking process leading to the final outcome.As a result, the model may learn sub-optimal reasoning strategies, which can hinder its generalization ability. In light of this, we propose SophiaVL-R1, as an attempt to add reward signals for the thinking process in this paradigm. To achieve this, we first train a thinking reward model that evaluates the quality of the entire thinking process. Given that the thinking reward may be unreliable for certain samples due to reward hacking, we propose the Trust-GRPO method, which assigns a trustworthiness weight to the thinking reward during training. This weight is computed based on the thinking reward comparison of responses leading to correct answers versus incorrect answers, helping to mitigate the impact of potentially unreliable thinking rewards. Moreover, we design an annealing training strategy that gradually reduces the thinking reward over time, allowing the model to rely more on the accurate rule-based outcome reward in later training stages. Experiments show that our SophiaVL-R1 surpasses a series of reasoning MLLMs on various benchmarks (e.g., MathVisita, MMMU), demonstrating strong reasoning and generalization capabilities. Notably, our SophiaVL-R1-7B even outperforms LLaVA-OneVision-72B on most benchmarks, despite the latter having 10 times more parameters. All code, models, and datasets are made publicly available at https://github.com/kxfan2002/SophiaVL-R1.
最近的研究进展表明,通过基于规则的强化学习(RL)与结果奖励相结合,可以在多模态大型语言模型(MLLMs)中激发出强大的推理能力。然而,这种范式通常缺乏对最终结果的思考过程的监督。因此,模型可能会学习次优的推理策略,这可能会阻碍其泛化能力。鉴于此,我们提出了SophiaVL-R1,试图在此范式中为思考过程增加奖励信号。为了实现这一点,我们首先训练了一个思考奖励模型,该模型评估整个思考过程的质量。由于某些样本的思考奖励可能存在因奖励作弊而不可靠的情况,我们提出了Trust-GRPO方法,该方法在训练过程中为思考奖励分配可信度权重。此权重是基于正确答案与错误答案导致的思考奖励的对比计算得出的,有助于缓解潜在的不可靠思考奖励的影响。此外,我们设计了一种退火训练策略,随着时间的推移逐渐降低思考奖励,使模型在后期训练阶段更多地依赖于准确的基于规则的成果奖励。实验表明,我们的SophiaVL-R1在各种基准测试(例如MathVisita、MMMU)上的表现超越了一系列推理MLLMs,显示出强大的推理和泛化能力。值得注意的是,我们的SophiaVL-R1-7B甚至在大多数基准测试上超过了参数多十倍的LLaVA-OneVision-72B。所有代码、模型和数据集均公开可在https://github.com/kxfan2002/SophiaVL-R1获取。
论文及项目相关链接
PDF Project page:https://github.com/kxfan2002/SophiaVL-R1
Summary
基于规则强化学习(RL)在模态大型语言模型(MLLMs)中引入推理能力的方法已取得成功,但这种方法缺乏对思考过程的监督,可能导致模型学习次优推理策略,从而影响其泛化能力。针对这一问题,我们提出了SophiaVL-R1方法,为这一范式增加思考过程的奖励信号。我们设计了一个思考奖励模型,用于评估整个思考过程的质量。针对某些样本中思考奖励可能存在的不可靠问题,我们提出了Trust-GRPO方法,该方法在训练过程中为思考奖励分配可信度权重。此外,我们还设计了退火训练策略,随着时间的推移逐渐降低思考奖励,使模型在后期更多地依赖于准确的规则结果奖励。实验表明,我们的SophiaVL-R1在各种基准测试上超越了多个推理MLLMs,展现出强大的推理和泛化能力。
Key Takeaways
- 通过规则强化学习引入推理能力在多模态大型语言模型中取得进展。
- 缺乏思考过程监督可能导致模型学习次优推理策略。
- SophiaVL-R1旨在添加思考过程的奖励信号以改进此问题。
- 设计了思考奖励模型以评估思考过程质量。
- 针对思考奖励可能存在的不可靠性,提出了Trust-GRPO方法来分配可信度权重。
- 采用退火训练策略来平衡思考和结果奖励的依赖度。
点此查看论文截图

Delving into RL for Image Generation with CoT: A Study on DPO vs. GRPO
Authors:Chengzhuo Tong, Ziyu Guo, Renrui Zhang, Wenyu Shan, Xinyu Wei, Zhenghao Xing, Hongsheng Li, Pheng-Ann Heng
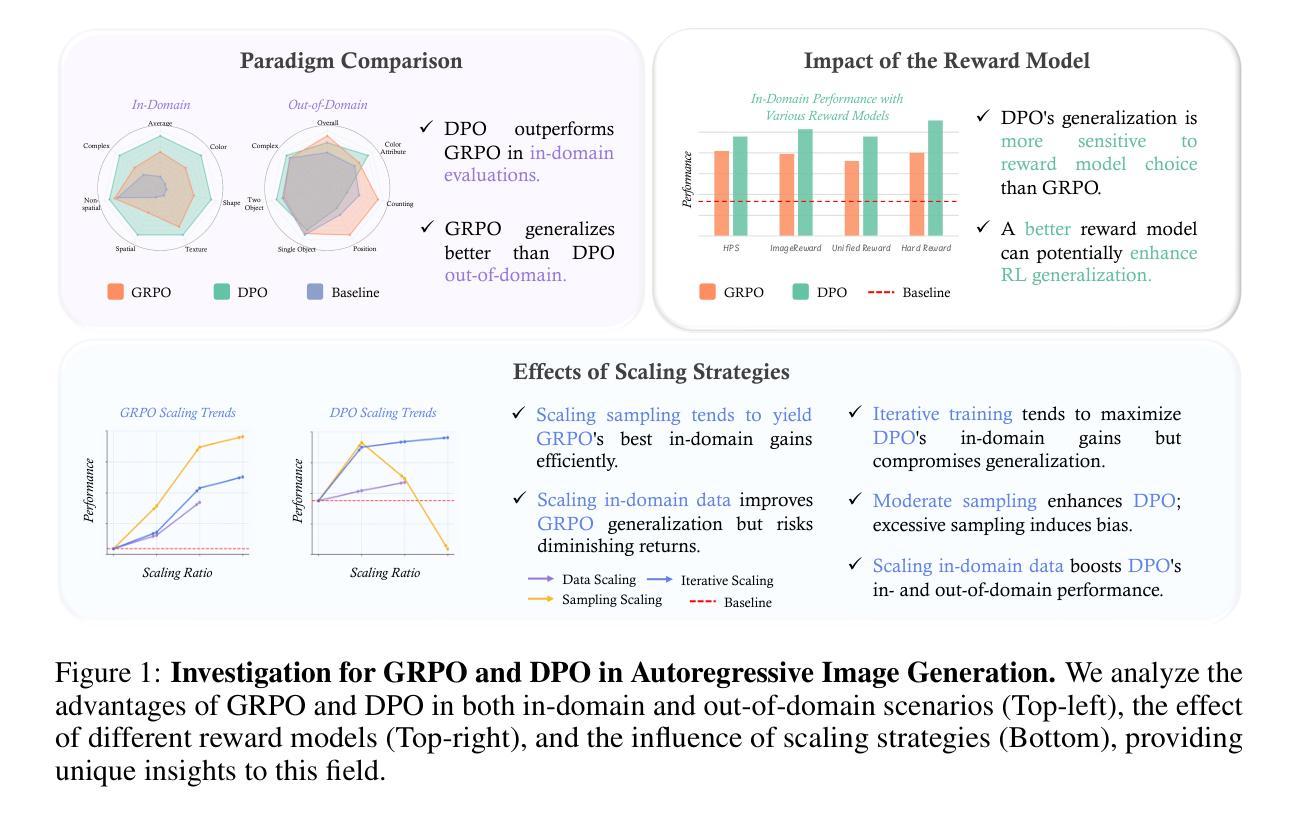
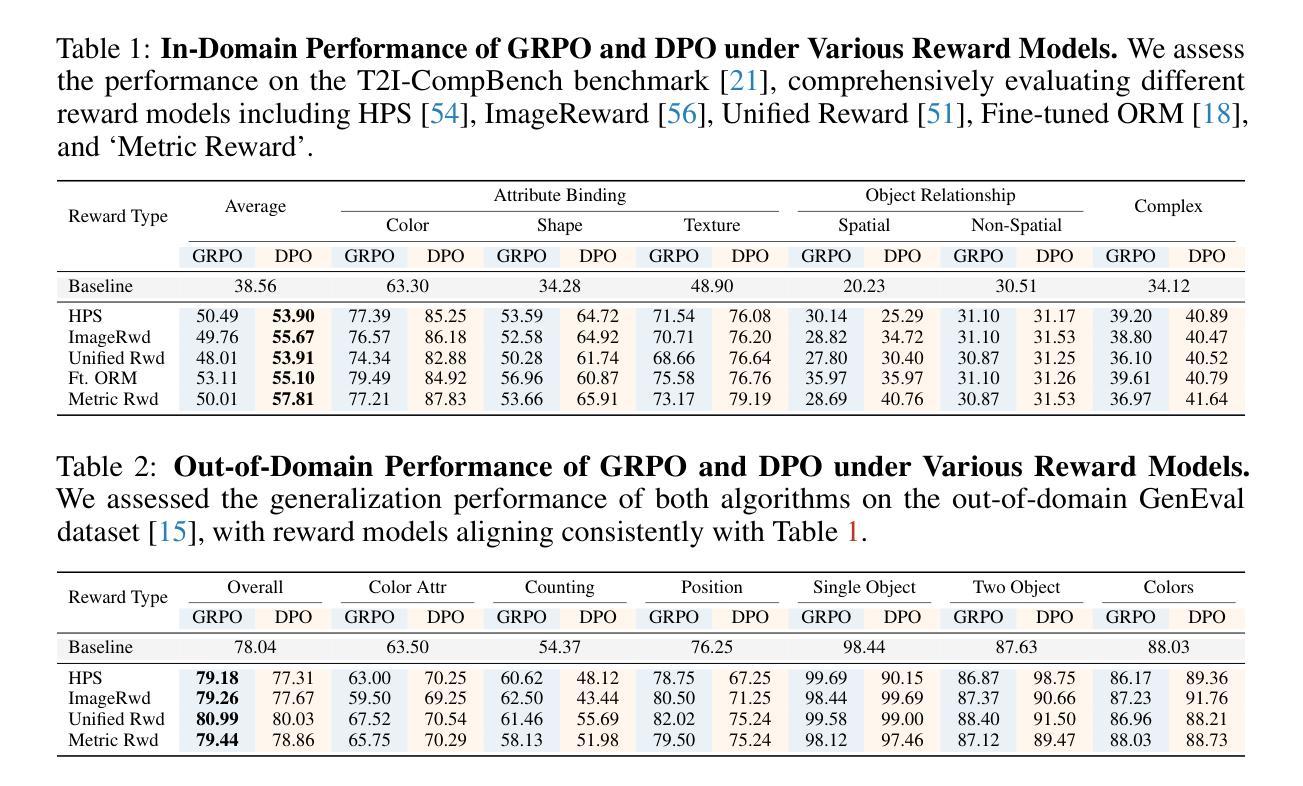
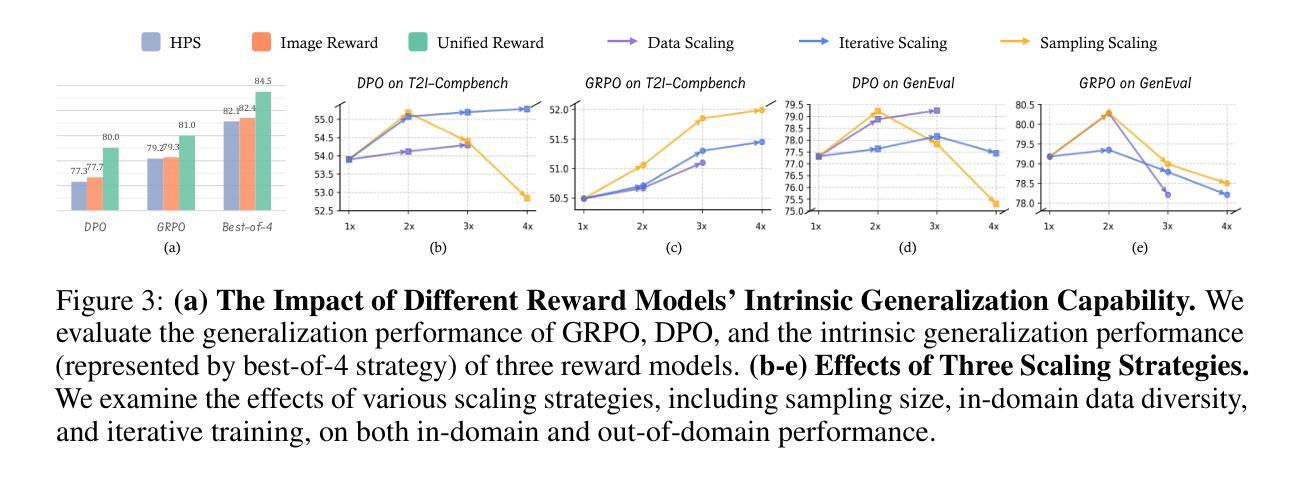
Recent advancements underscore the significant role of Reinforcement Learning (RL) in enhancing the Chain-of-Thought (CoT) reasoning capabilities of large language models (LLMs). Two prominent RL algorithms, Direct Preference Optimization (DPO) and Group Relative Policy Optimization (GRPO), are central to these developments, showcasing different pros and cons. Autoregressive image generation, also interpretable as a sequential CoT reasoning process, presents unique challenges distinct from LLM-based CoT reasoning. These encompass ensuring text-image consistency, improving image aesthetic quality, and designing sophisticated reward models, rather than relying on simpler rule-based rewards. While recent efforts have extended RL to this domain, these explorations typically lack an in-depth analysis of the domain-specific challenges and the characteristics of different RL strategies. To bridge this gap, we provide the first comprehensive investigation of the GRPO and DPO algorithms in autoregressive image generation, evaluating their in-domain performance and out-of-domain generalization, while scrutinizing the impact of different reward models on their respective capabilities. Our findings reveal that GRPO and DPO exhibit distinct advantages, and crucially, that reward models possessing stronger intrinsic generalization capabilities potentially enhance the generalization potential of the applied RL algorithms. Furthermore, we systematically explore three prevalent scaling strategies to enhance both their in-domain and out-of-domain proficiency, deriving unique insights into efficiently scaling performance for each paradigm. We hope our study paves a new path for inspiring future work on developing more effective RL algorithms to achieve robust CoT reasoning in the realm of autoregressive image generation. Code is released at https://github.com/ZiyuGuo99/Image-Generation-CoT
近期进展突显强化学习(RL)在提升大型语言模型(LLM)的链式思维(CoT)推理能力方面的重要作用。两种主要的RL算法——直接偏好优化(DPO)和群组相对策略优化(GRPO)——是这些发展的核心,展示了各自的优势和劣势。自动回归图像生成,也可解释为一种连续的CoT推理过程,呈现出与基于LLM的CoT推理截然不同的独特挑战。这些挑战包括确保文本与图像的一致性、提高图像的审美质量,以及设计精密的奖励模型,而不是依赖更简单的基于规则的奖励。尽管最近的努力已将RL扩展到此领域,但这些探索通常缺乏对特定领域挑战的深入分析以及对不同RL策略的特点的研究。为了弥补这一空白,我们对自动回归图像生成中的GRPO和DPO算法进行了首次全面调查,评估了它们的领域内性能和跨领域泛化能力,同时仔细研究了不同奖励模型对其各自能力的影响。我们的研究发现,GRPO和DPO具有各自独特的优势,并且重要的是,具有更强内在泛化能力的奖励模型可能提高了所应用RL算法的泛化潜力。此外,我们系统地探索了三种流行的扩展策略,以提高它们的领域内和跨领域熟练程度,为每种范式有效地扩展性能提供了独特的见解。我们希望我们的研究能为未来开发更有效的RL算法以实现自动回归图像生成领域的稳健CoT推理铺平道路。代码已发布在https://github.com/ZiyuGuo99/Image-Generation-CoT。
论文及项目相关链接
PDF Code is released at https://github.com/ZiyuGuo99/Image-Generation-CoT
Summary
在最新进展中,强化学习(RL)在提高大型语言模型的链式思维(CoT)推理能力方面扮演着重要角色。本文主要探讨了Direct Preference Optimization(DPO)和Group Relative Policy Optimization(GRPO)两种主要的RL算法在增强图像生成中的表现和应用前景。分析表明,GRPO和DPO各具优势,而具备更强内在泛化能力的奖励模型有助于提高应用RL算法的泛化潜力。本文还系统地探讨了三种常见的扩展策略,以提高它们的领域内外表现。
Key Takeaways
- 强化学习(RL)在提高大型语言模型的链式思维(CoT)推理能力方面扮演重要角色。
- Direct Preference Optimization(DPO)和Group Relative Policy Optimization(GRPO)是提升链式思维能力的关键RL算法。
- GRPO和DPO在图像生成领域具有不同的优势。
- 具备更强内在泛化能力的奖励模型有助于提高RL算法的泛化潜力。
- 三种常见的扩展策略可以提高算法在领域内的表现。
点此查看论文截图


R1-Searcher++: Incentivizing the Dynamic Knowledge Acquisition of LLMs via Reinforcement Learning
Authors:Huatong Song, Jinhao Jiang, Wenqing Tian, Zhipeng Chen, Yuhuan Wu, Jiahao Zhao, Yingqian Min, Wayne Xin Zhao, Lei Fang, Ji-Rong Wen
Large Language Models (LLMs) are powerful but prone to hallucinations due to static knowledge. Retrieval-Augmented Generation (RAG) helps by injecting external information, but current methods often are costly, generalize poorly, or ignore the internal knowledge of the model. In this paper, we introduce R1-Searcher++, a novel framework designed to train LLMs to adaptively leverage both internal and external knowledge sources. R1-Searcher++ employs a two-stage training strategy: an initial SFT Cold-start phase for preliminary format learning, followed by RL for Dynamic Knowledge Acquisition. The RL stage uses outcome-supervision to encourage exploration, incorporates a reward mechanism for internal knowledge utilization, and integrates a memorization mechanism to continuously assimilate retrieved information, thereby enriching the model’s internal knowledge. By leveraging internal knowledge and external search engine, the model continuously improves its capabilities, enabling efficient retrieval-augmented reasoning. Our experiments demonstrate that R1-Searcher++ outperforms previous RAG and reasoning methods and achieves efficient retrieval. The code is available at https://github.com/RUCAIBox/R1-Searcher-plus.
大型语言模型(LLM)虽然强大,但由于静态知识容易出现幻觉。检索增强生成(RAG)通过注入外部信息来帮助解决这一问题,但当前的方法往往成本高昂、推广性差或忽略了模型的内部知识。在本文中,我们介绍了R1-Searcher++,这是一个新型框架,旨在训练大型语言模型以自适应地利用内部和外部知识源。R1-Searcher++采用两阶段训练策略:初始SFT冷启动阶段用于初步格式学习,其次是用于动态知识获取的强化学习。强化学习阶段使用结果监督来鼓励探索,结合内部知识利用的奖励机制,并整合记忆机制以持续同化检索信息,从而丰富模型的内部知识。通过利用内部知识和外部搜索引擎,模型不断改善其能力,实现高效的检索增强推理。我们的实验表明,R1-Searcher++优于先前的RAG和推理方法,实现了高效的检索。代码可在https://github.com/RUCAIBox/R1-Searcher-plus找到。
论文及项目相关链接
Summary
大型语言模型(LLMs)具有强大的能力,但易受到静态知识导致的幻觉影响。检索增强生成(RAG)通过注入外部信息来帮助解决这一问题,但现有方法往往成本高昂、通用性差或忽略模型内部知识。本文介绍了一种新型框架R1-Searcher++,旨在训练LLMs自适应地利用内部和外部知识源。R1-Searcher++采用两阶段训练策略:初始SFT Cold-start阶段用于初步格式学习,然后是用于动态知识获取的RL阶段。RL阶段利用结果监督来鼓励探索,引入内部知识利用的奖励机制,并集成记忆机制以持续同化检索的信息,从而丰富模型的内部知识。通过利用内部知识和外部搜索引擎,模型不断提升其能力,实现高效的检索增强推理。实验表明,R1-Searcher++优于先前的RAG和推理方法,实现了高效的检索。
Key Takeaways
- 大型语言模型(LLMs)存在由于静态知识导致的幻觉问题。
- 检索增强生成(RAG)通过注入外部信息来解决这一问题。
- R1-Searcher++是一种新型框架,旨在训练LLMs自适应利用内部和外部知识源。
- R1-Searcher++采用两阶段训练策略:初始阶段进行格式学习,然后是动态知识获取的强化学习阶段。
- RL阶段采用结果监督鼓励探索,并引入内部知识利用的奖励机制和记忆机制。
- R1-Searcher++通过结合内部知识和外部搜索引擎,实现了高效的检索增强推理。
- 实验表明,R1-Searcher++在性能上超越了先前的RAG和推理方法。
点此查看论文截图

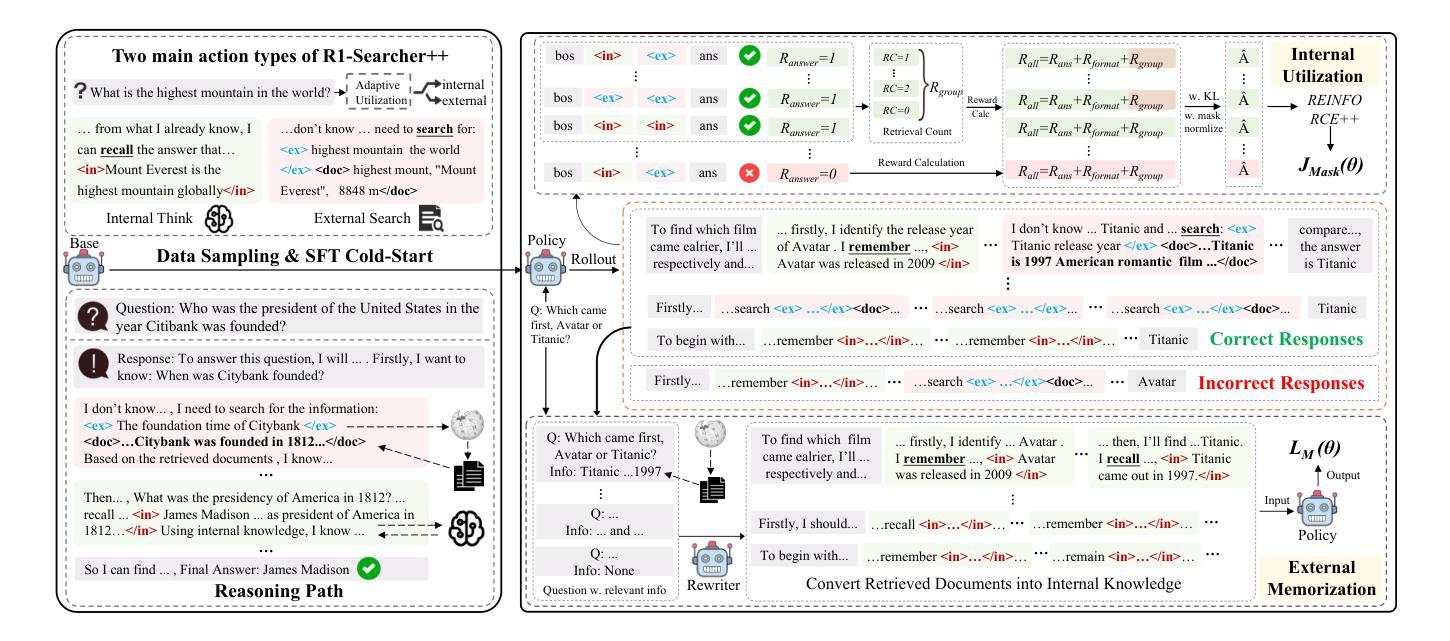
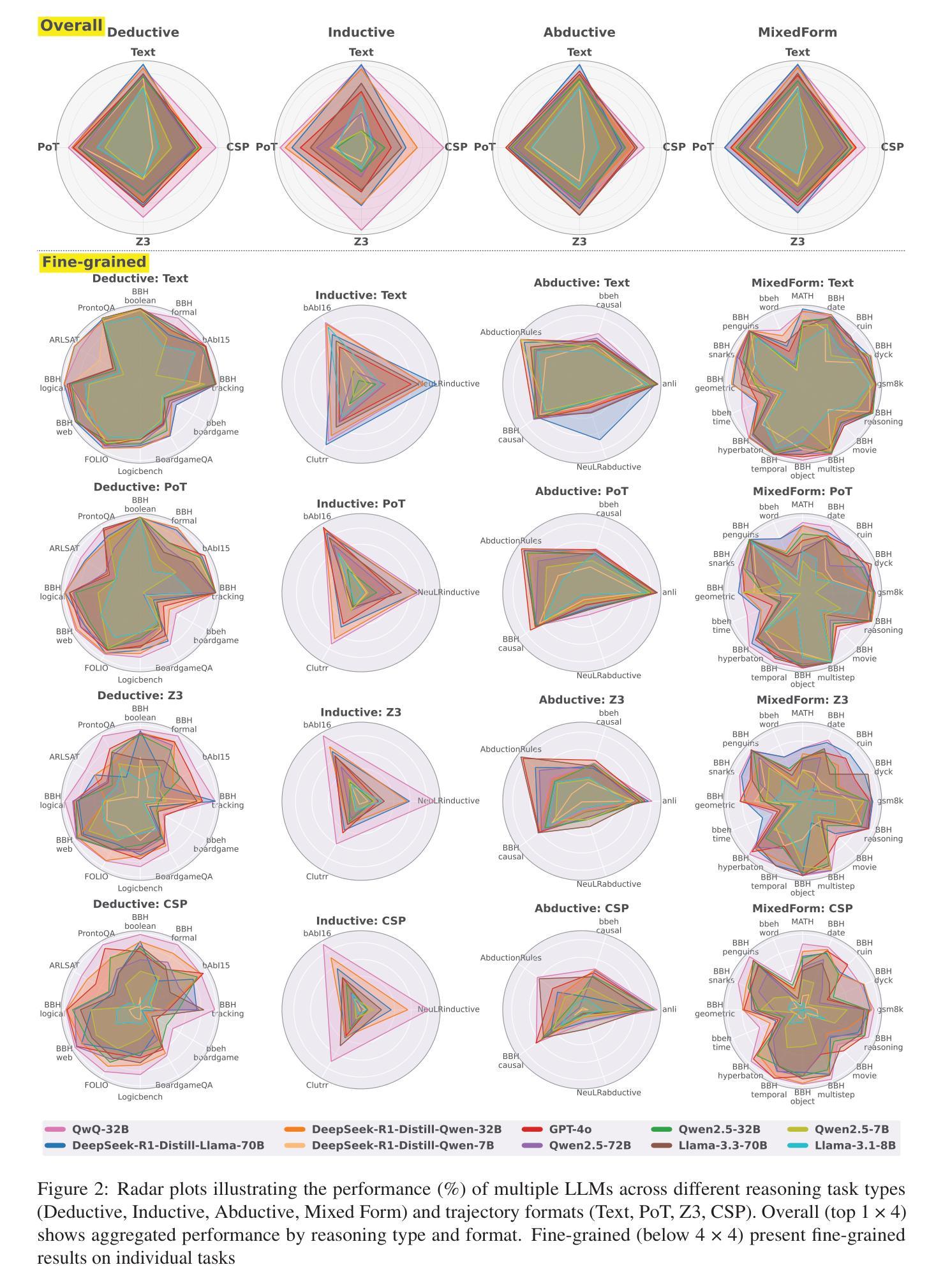
Do Large Language Models Excel in Complex Logical Reasoning with Formal Language?
Authors:Jin Jiang, Jianing Wang, Yuchen Yan, Yang Liu, Jianhua Zhu, Mengdi Zhang, Xunliang Cai, Liangcai Gao
Large Language Models (LLMs) have been shown to achieve breakthrough performance on complex logical reasoning tasks. Nevertheless, most existing research focuses on employing formal language to guide LLMs to derive reliable reasoning paths, while systematic evaluations of these capabilities are still limited. In this paper, we aim to conduct a comprehensive evaluation of LLMs across various logical reasoning problems utilizing formal languages. From the perspective of three dimensions, i.e., spectrum of LLMs, taxonomy of tasks, and format of trajectories, our key findings are: 1) Thinking models significantly outperform Instruct models, especially when formal language is employed; 2) All LLMs exhibit limitations in inductive reasoning capability, irrespective of whether they use a formal language; 3) Data with PoT format achieves the best generalization performance across other languages. Additionally, we also curate the formal-relative training data to further enhance the small language models, and the experimental results indicate that a simple rejected fine-tuning method can better enable LLMs to generalize across formal languages and achieve the best overall performance. Our codes and reports are available at https://github.com/jiangjin1999/FormalEval.
大型语言模型(LLMs)在复杂的逻辑推理任务中取得了突破性的表现。然而,现有的大多数研究主要集中在使用正式语言来指导LLMs推导可靠的推理路径,而对于这些能力的系统评价仍然有限。在本文中,我们旨在利用正式语言,对各种逻辑推理问题对LLMs进行全面评估。从三个维度来看,即LLM的频谱、任务分类和轨迹格式,我们的主要发现如下:1)思维模型在采用正式语言时显著优于指令模型;2)无论是否使用正式语言,所有LLM在归纳推理能力方面都表现出局限性;3)采用PoT格式的数据在其他语言中实现了最佳泛化性能。此外,我们还整理了与形式相关的训练数据,以进一步增强小型语言模型。实验结果表明,简单的拒绝微调方法能更好地使LLM在正式语言上泛化,并达到最佳的整体性能。我们的代码和报告可在https://github.com/jiangjin1999/FormalEval 中找到。
论文及项目相关链接
Summary
大型语言模型(LLMs)在复杂的逻辑推理任务中取得了突破性进展。然而,大多数现有研究侧重于使用正式语言来指导LLMs得出可靠的推理路径,而对这些能力的系统评估仍然有限。本文旨在从使用正式语言的多个维度全面评估LLMs在各种逻辑推理问题上的表现。我们的关键发现包括:1)Thinking模型在采用正式语言时显著优于Instruct模型;2)所有LLMs在归纳推理能力上均存在局限性,无论是否使用正式语言;3)采用PoT格式的数据在其他语言上取得了最佳泛化性能。此外,我们还整理了与形式相关的训练数据,以进一步提高小型语言模型的性能。实验结果表明,简单的拒绝微调方法能够更好地使LLMs在正式语言上实现泛化,并达到最佳的整体性能。
Key Takeaways
- LLMs在复杂的逻辑推理任务中表现出卓越的性能。
- 现有研究主要关注使用正式语言来指导LLMs进行推理。
- Thinking模型在采用正式语言时的性能优于Instruct模型。
- 所有LLMs在归纳推理方面存在局限性,无论是否使用正式语言。
- 采用PoT格式的数据在跨语言泛化方面表现最佳。
- 整理与形式相关的训练数据可进一步提高小型语言模型的性能。
点此查看论文截图

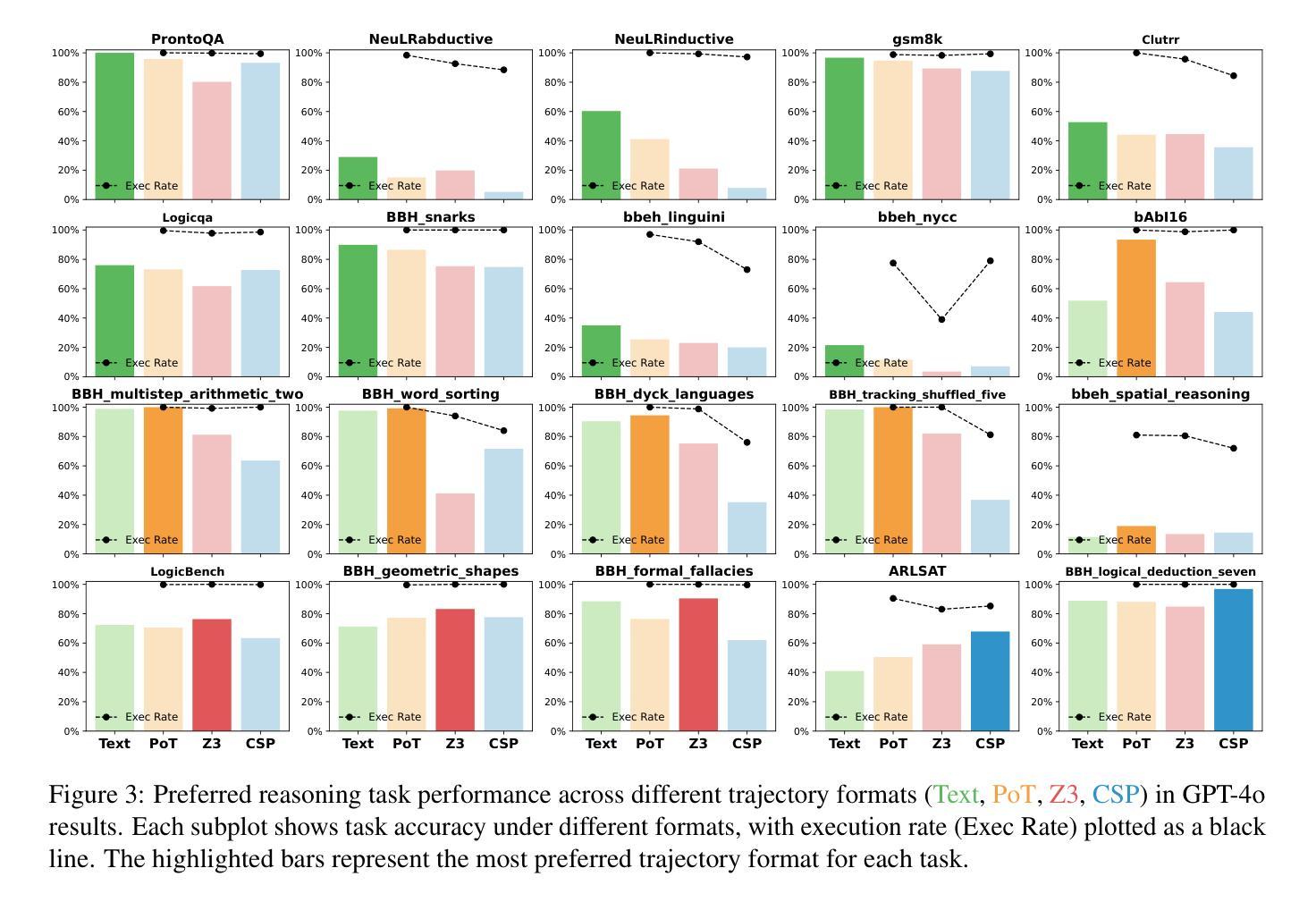
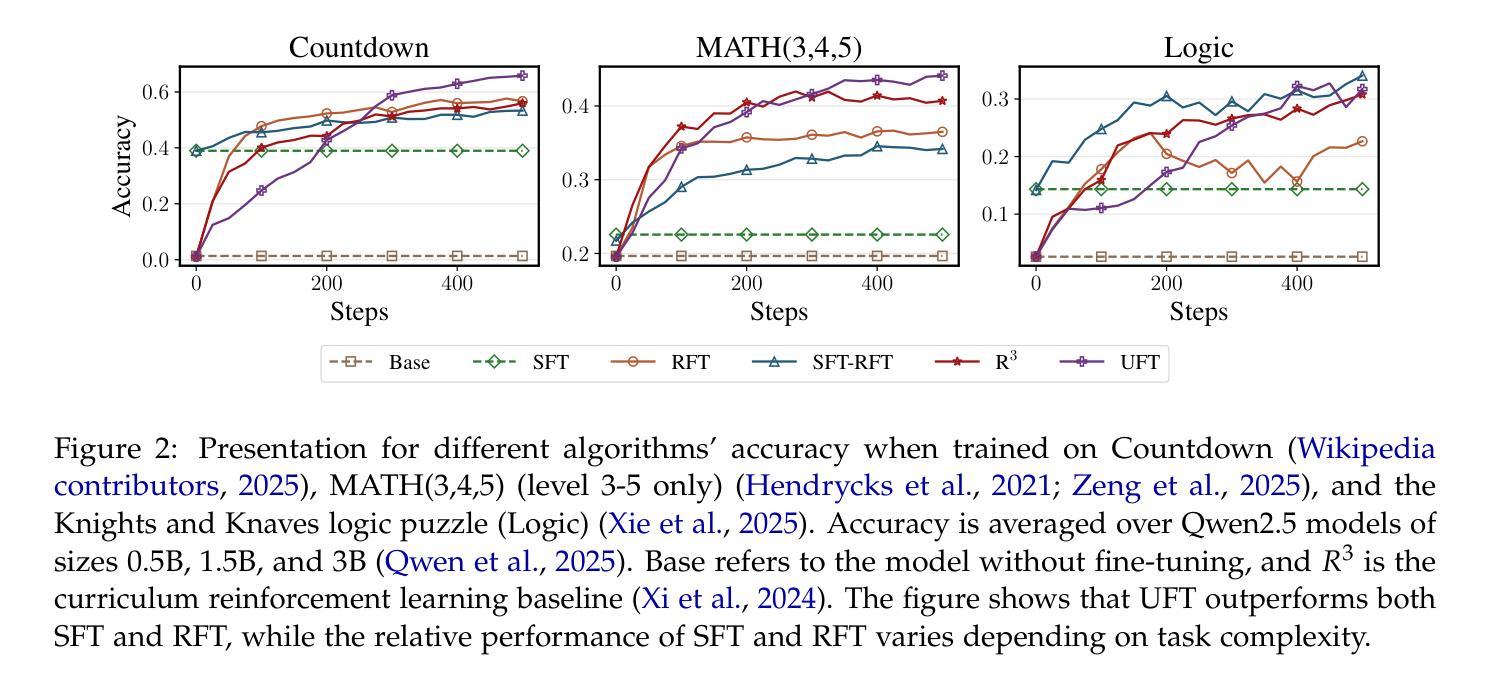
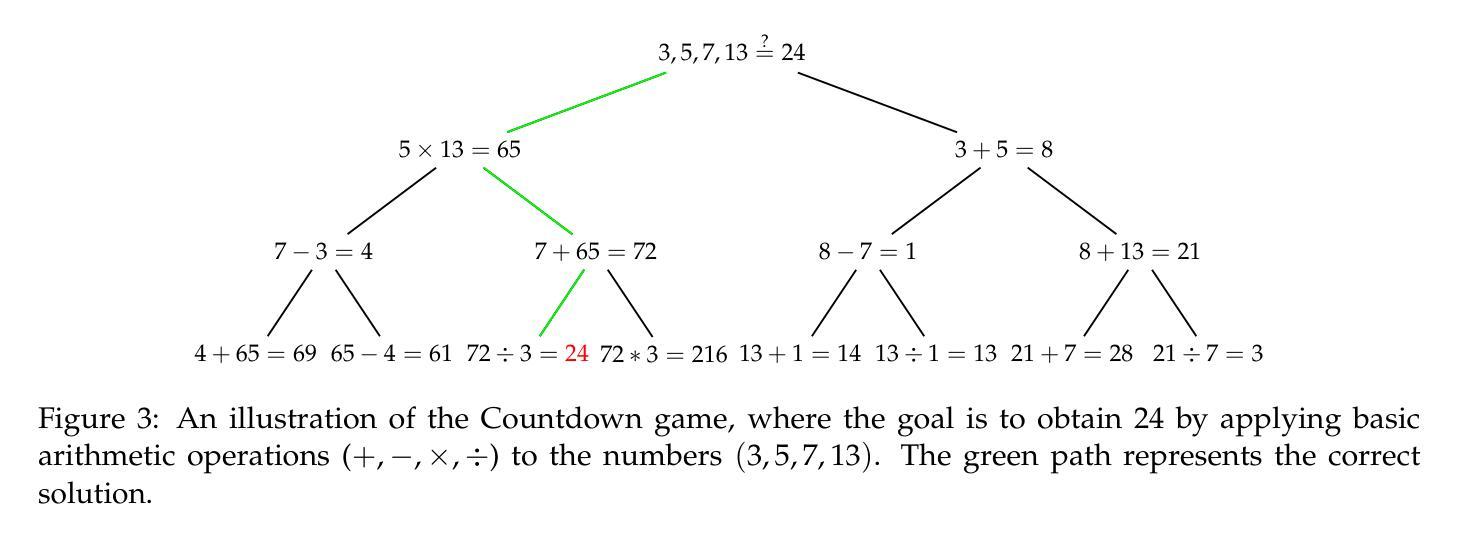
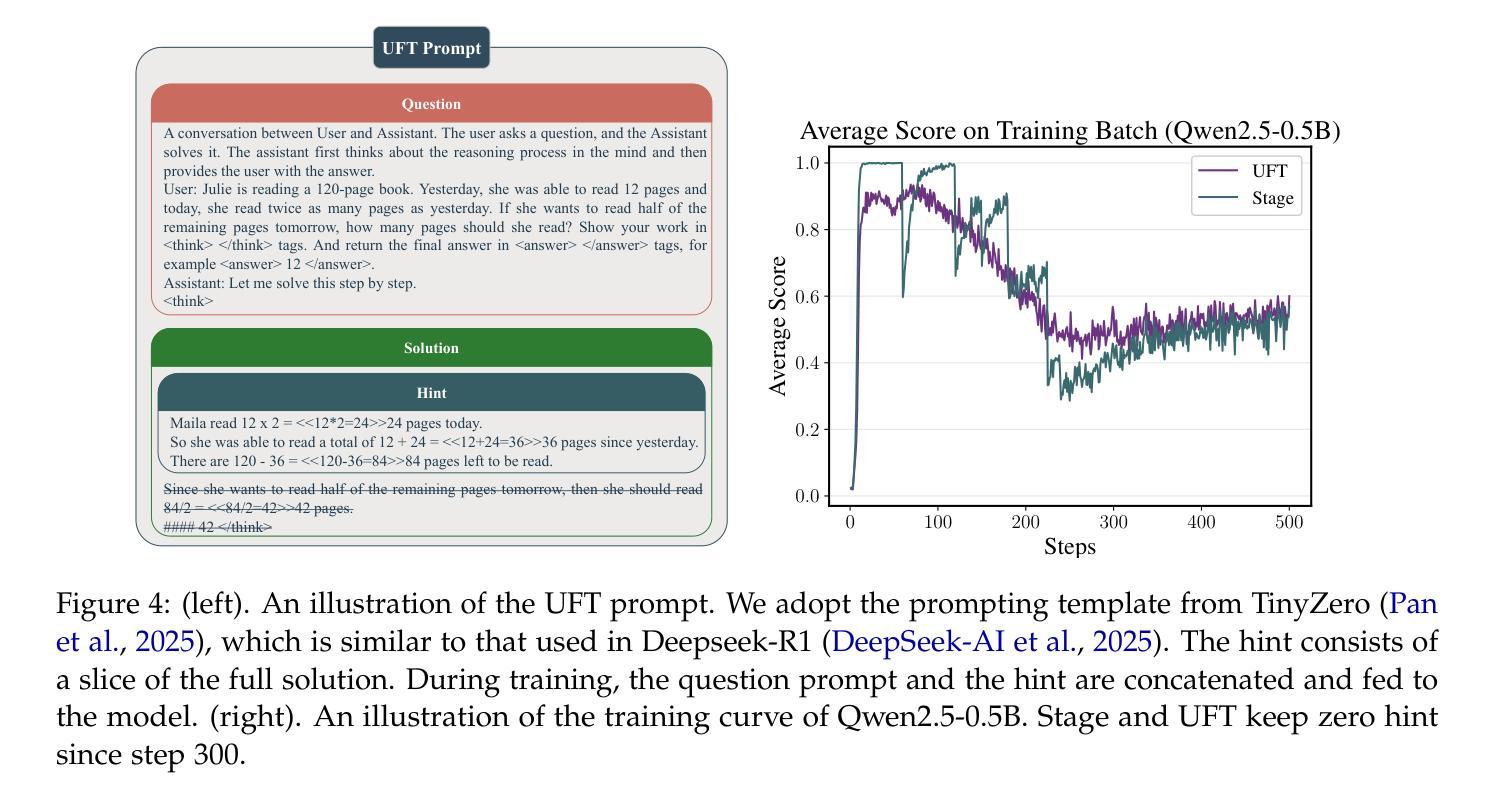
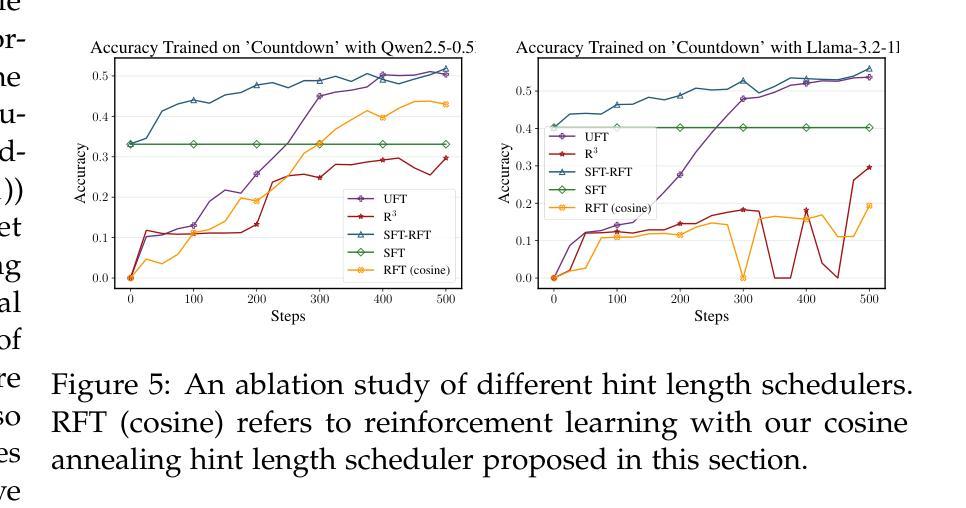
UFT: Unifying Supervised and Reinforcement Fine-Tuning
Authors:Mingyang Liu, Gabriele Farina, Asuman Ozdaglar
Post-training has demonstrated its importance in enhancing the reasoning capabilities of large language models (LLMs). The primary post-training methods can be categorized into supervised fine-tuning (SFT) and reinforcement fine-tuning (RFT). SFT is efficient and well-suited for small language models, but it may lead to overfitting and limit the reasoning abilities of larger models. In contrast, RFT generally yields better generalization but depends heavily on the strength of the base model. To address the limitations of SFT and RFT, we propose Unified Fine-Tuning (UFT), a novel post-training paradigm that unifies SFT and RFT into a single, integrated process. UFT enables the model to effectively explore solutions while incorporating informative supervision signals, bridging the gap between memorizing and thinking underlying existing methods. Notably, UFT outperforms both SFT and RFT in general, regardless of model sizes. Furthermore, we theoretically prove that UFT breaks RFT’s inherent exponential sample complexity bottleneck, showing for the first time that unified training can exponentially accelerate convergence on long-horizon reasoning tasks.
训练后的过程在大语言模型(LLM)的推理能力增强中表现出了其重要性。主要的训练后方法可以分为监督微调(SFT)和强化微调(RFT)。SFT效率高,非常适合小型语言模型,但可能会导致过拟合,并限制大型模型的推理能力。相比之下,RFT通常会产生更好的泛化能力,但严重依赖于基础模型的强度。为了解决SFT和RFT的局限性,我们提出了统一微调(UFT),这是一种新的训练后范式,它将SFT和RFT统一到一个单一的集成过程中。UFT使模型能够在引入信息监督信号的同时有效地探索解决方案,从而弥补了现有方法在记忆和思考方面的差距。值得注意的是,无论模型规模如何,UFT通常都优于SFT和RFT。此外,我们从理论上证明了UFT打破了RFT固有的指数样本复杂性瓶颈,首次展示了统一训练可以在长周期推理任务上实现指数级加速收敛。
论文及项目相关链接
Summary
大型语言模型的训练后过程对于提升其推理能力至关重要,主要方法包括监督微调(SFT)和强化微调(RFT)。SFT效率高且适用于小型语言模型,但可能导致过拟合并限制大型模型的推理能力。RFT则通常具有更好的泛化能力,但高度依赖于基础模型的强度。为解决SFT和RFT的局限性,提出了统一微调(UFT)这一新型训练后范式,它将SFT和RFT统一到一个集成过程中。UFT使模型能够在探索解决方案的同时融入信息丰富的监督信号,从而缩小现有方法记忆与思维之间的鸿沟。UFT在模型大小方面表现出优于SFT和RFT的通用性,并在理论上突破了RFT固有的指数样本复杂度瓶颈,首次展示了统一训练可以加速长期推理任务的收敛速度。
Key Takeaways
- 训练后过程对于提升大型语言模型的推理能力至关重要。
- 现有的监督微调(SFT)和强化微调(RFT)方法各有优缺点。
- SFT效率高且适用于小型语言模型,但可能过拟合大型模型的推理能力。
- RFT具有更好的泛化能力,但依赖基础模型的强度。
- 统一微调(UFT)是一种新型训练后范式,结合了SFT和RFT的优点。
- UFT能够在探索解决方案的同时融入监督信号,提高模型的推理能力。
点此查看论文截图

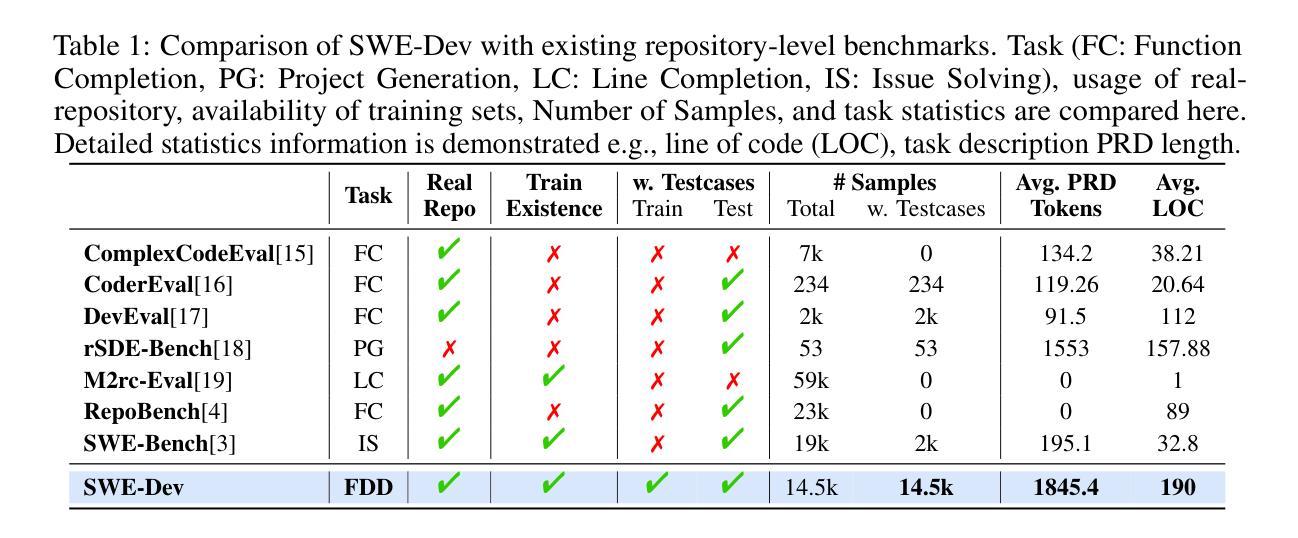
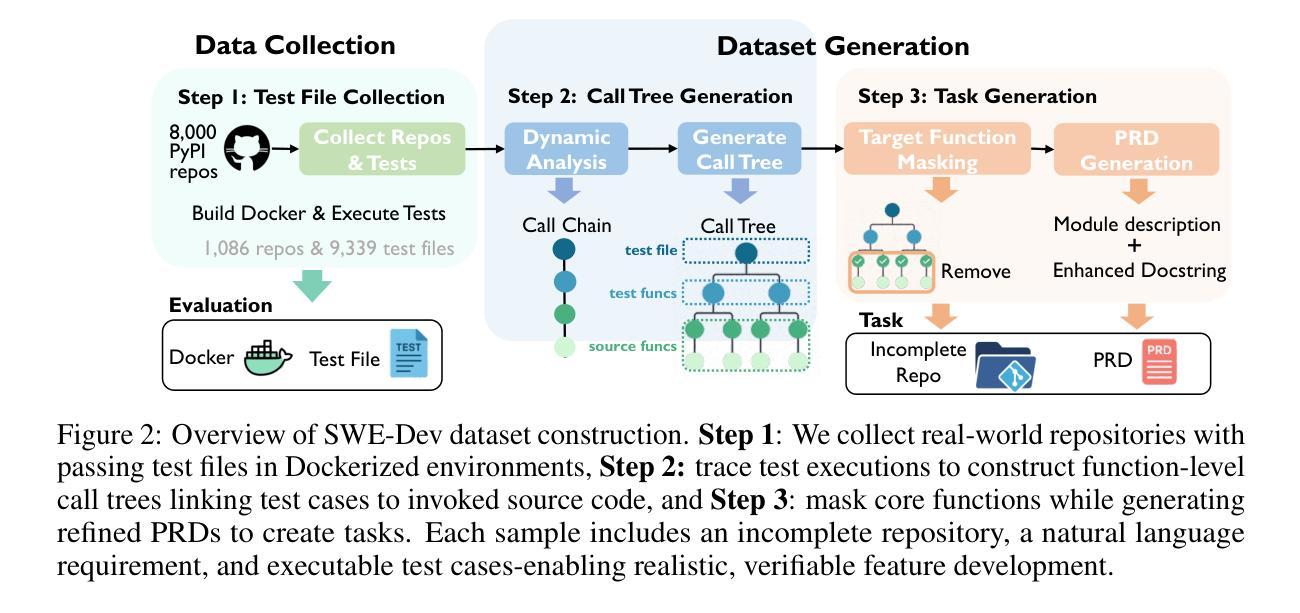
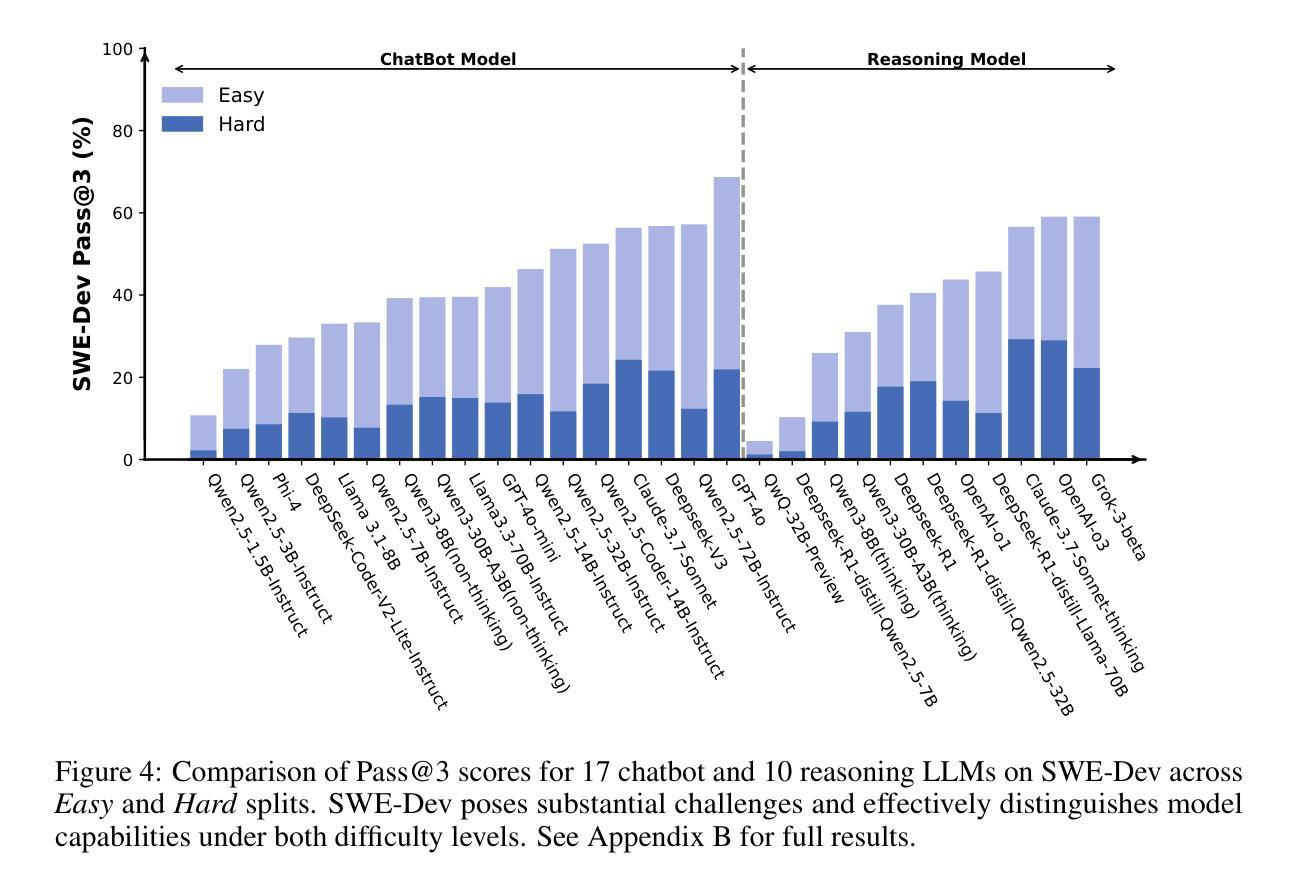
SWE-Dev: Evaluating and Training Autonomous Feature-Driven Software Development
Authors:Yaxin Du, Yuzhu Cai, Yifan Zhou, Cheng Wang, Yu Qian, Xianghe Pang, Qian Liu, Yue Hu, Siheng Chen
Large Language Models (LLMs) have shown strong capability in diverse software engineering tasks, e.g. code completion, bug fixing, and document generation. However, feature-driven development (FDD), a highly prevalent real-world task that involves developing new functionalities for large, existing codebases, remains underexplored. We therefore introduce SWE-Dev, the first large-scale dataset (with 14,000 training and 500 test samples) designed to evaluate and train autonomous coding systems on real-world feature development tasks. To ensure verifiable and diverse training, SWE-Dev uniquely provides all instances with a runnable environment and its developer-authored executable unit tests. This collection not only provides high-quality data for Supervised Fine-Tuning (SFT), but also enables Reinforcement Learning (RL) by delivering accurate reward signals from executable unit tests. Our extensive evaluations on SWE-Dev, covering 17 chatbot LLMs, 10 reasoning models, and 10 Multi-Agent Systems (MAS), reveal that FDD is a profoundly challenging frontier for current AI (e.g., Claude-3.7-Sonnet achieves only 22.45% Pass@3 on the hard test split). Crucially, we demonstrate that SWE-Dev serves as an effective platform for model improvement: fine-tuning on training set enabled a 7B model comparable to GPT-4o on \textit{hard} split, underscoring the value of its high-quality training data. Code is available here \href{https://github.com/justLittleWhite/SWE-Dev}{https://github.com/justLittleWhite/SWE-Dev}.
大型语言模型(LLM)在多种软件工程任务中表现出强大的能力,例如代码补全、故障修复和文档生成。然而,功能驱动开发(FDD)是一个在现实世界任务中非常普遍的存在,它为大型现有代码库开发新功能,仍然被研究得不够深入。因此,我们引入了SWE-Dev,这是第一个大规模数据集(包含14,000个训练样本和500个测试样本),旨在评估和培训用于现实世界功能开发任务的自主编码系统。为了确保可验证和多样化的训练,SWE-Dev独特地提供了可运行的环境和开发人员编写的可执行单元测试的所有实例。这一集合不仅为监督微调(SFT)提供了高质量的数据,而且通过提供可执行单元测试的精确奖励信号,使得强化学习(RL)成为可能。我们对SWE-Dev进行了广泛的评估,涵盖了17个聊天机器人LLM、10个推理模型和10个多智能体系统(MAS),结果表明FDD是当前AI的一个极具挑战性的前沿领域(例如,Claude-3.7-Sonnet在困难测试集上仅达到22.45%的通过率)。最重要的是,我们证明了SWE-Dev是一个有效的模型改进平台:在训练集上进行微调使一个与GPT-4o相当的7B模型能够在困难分割上取得进展,这凸显了其高质量训练数据的价值。代码可在以下链接中找到:https://github.com/justLittleWhite/SWE-Dev。
论文及项目相关链接
Summary
大型语言模型(LLMs)在软件工程技术任务中展现出强大的能力,如代码补全、故障修复和文档生成。但对于现实世界中涉及为大型现有代码库开发新功能的功能驱动开发(FDD)任务仍然缺乏探索。因此,我们引入了SWE-Dev,这是首个针对自主编码系统在真实世界功能开发任务上进行评估和训练的大规模数据集,包含14,000个训练样本和500个测试样本。SWE-Dev的独特之处在于为所有实例提供了一个可运行的环境和开发者编写的可执行单元测试,确保了可验证和多样化的训练。此外,SWE-Dev不仅为监督微调(SFT)提供了高质量的数据,而且还通过来自可执行单元测试的准确奖励信号实现了强化学习(RL)的可能。对现有模型在SWE-Dev上的广泛评估表明,FDD是当前AI的一个极具挑战性的前沿领域。同时,我们证明了SWE-Dev作为一个有效平台的价值,在训练集上进行微调使一个与GPT-4相当的7B模型在硬分割上取得了显著改进。
Key Takeaways
- 大型语言模型(LLMs)在软件工程技术任务中表现出强大的能力。
- 功能驱动开发(FDD)是一个现实世界中涉及大型代码库的新功能开发任务,目前被忽视。
- 引入SWE-Dev数据集,用于评估和训练自主编码系统在真实世界功能开发任务上的表现。
- SWE-Dev提供可运行环境及开发者编写的可执行单元测试,确保训练和验证的多样性和准确性。
- 该数据集支持监督微调(SFT)和强化学习(RL),提供高质量数据和准确奖励信号。
- FDD是一个对当前AI极具挑战性的领域,现有模型表现有待提高。
点此查看论文截图


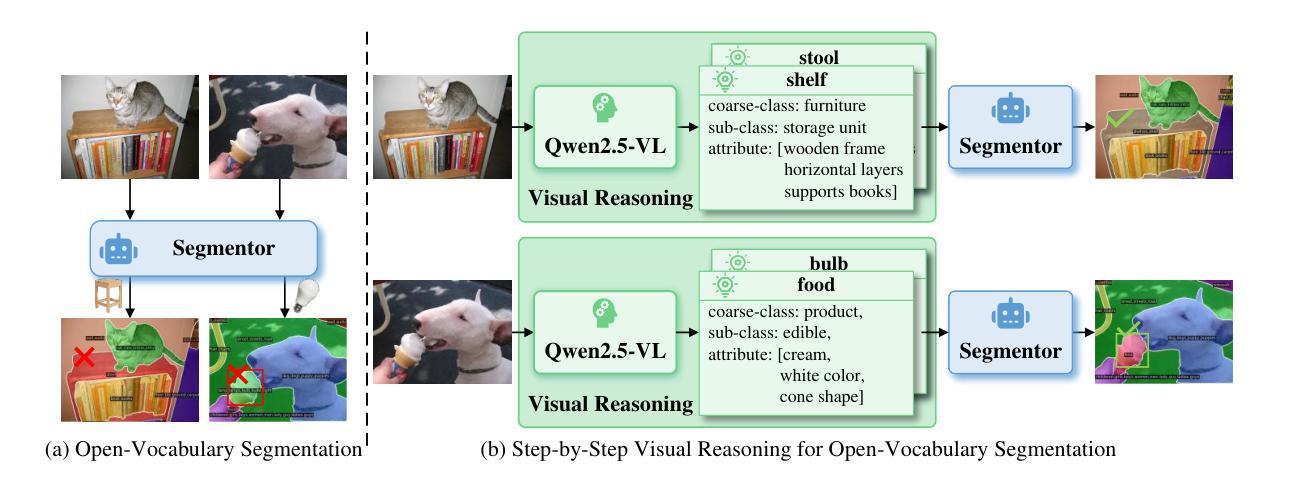
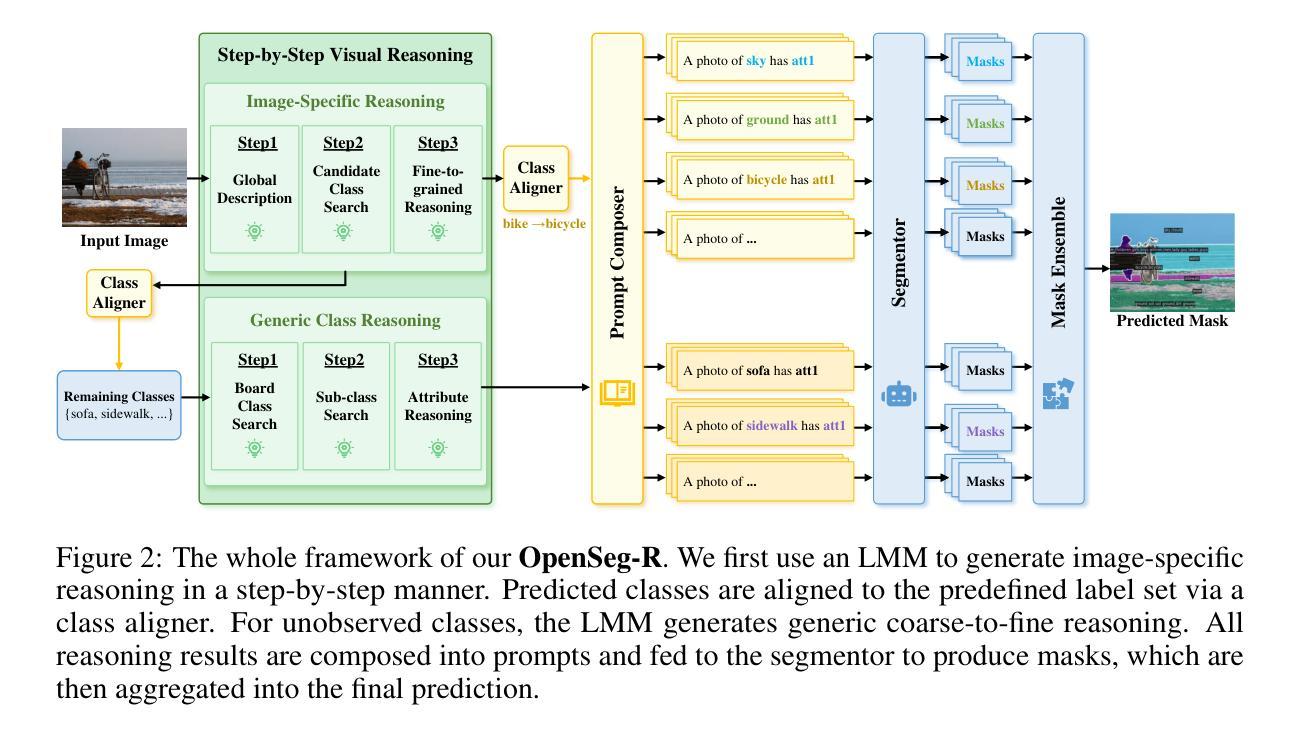
OpenSeg-R: Improving Open-Vocabulary Segmentation via Step-by-Step Visual Reasoning
Authors:Zongyan Han, Jiale Cao, Shuo Chen, Tong Wang, Jorma Laaksonen, Rao Muhammad Anwer
Open-Vocabulary Segmentation (OVS) has drawn increasing attention for its capacity to generalize segmentation beyond predefined categories. However, existing methods typically predict segmentation masks with simple forward inference, lacking explicit reasoning and interpretability. This makes it challenging for OVS model to distinguish similar categories in open-world settings due to the lack of contextual understanding and discriminative visual cues. To address this limitation, we propose a step-by-step visual reasoning framework for open-vocabulary segmentation, named OpenSeg-R. The proposed OpenSeg-R leverages Large Multimodal Models (LMMs) to perform hierarchical visual reasoning before segmentation. Specifically, we generate both generic and image-specific reasoning for each image, forming structured triplets that explain the visual reason for objects in a coarse-to-fine manner. Based on these reasoning steps, we can compose detailed description prompts, and feed them to the segmentor to produce more accurate segmentation masks. To the best of our knowledge, OpenSeg-R is the first framework to introduce explicit step-by-step visual reasoning into OVS. Experimental results demonstrate that OpenSeg-R significantly outperforms state-of-the-art methods on open-vocabulary semantic segmentation across five benchmark datasets. Moreover, it achieves consistent gains across all metrics on open-vocabulary panoptic segmentation. Qualitative results further highlight the effectiveness of our reasoning-guided framework in improving both segmentation precision and interpretability. Our code is publicly available at https://github.com/Hanzy1996/OpenSeg-R.
开放词汇分割(OVS)由于其超越预定类别的泛化分割能力而越来越受到关注。然而,现有方法通常通过简单的前向推理来预测分割掩膜,缺乏明确的推理和解释性。这使得OVS模型在开放世界环境下区分相似类别时面临挑战,因为缺乏上下文理解和判别性视觉线索。为了解决这一局限性,我们提出了一个用于开放词汇分割的逐步视觉推理框架,名为OpenSeg-R。所提出的OpenSeg-R利用大型多模态模型(LMMs)在分割之前进行分层视觉推理。具体来说,我们为每张图像生成通用和图像特定的推理,形成结构化三元组,以从粗略到精细的方式解释对象出现的视觉原因。基于这些推理步骤,我们可以组成详细的描述提示,并将其输入到分割器中以产生更准确的分割掩膜。据我们所知,OpenSeg-R是第一个将明确的逐步视觉推理引入到OVS中的框架。实验结果表明,OpenSeg-R在五个基准数据集的开放词汇语义分割上显著优于最先进的方法。此外,它在开放词汇全景分割的所有指标上都实现了持续的收益。定性结果进一步突出了我们的推理引导框架在提高分割精度和解释性方面的有效性。我们的代码公开在https://github.com/Hanzy1996/OpenSeg-R。
论文及项目相关链接
Summary
开放词汇分割(OVS)能够推广超越预设类别的分割能力而受到越来越多的关注。然而,现有方法通常通过简单的正向推理预测分割掩码,缺乏明确的推理和解释性。为了解决这一局限性,我们提出了一个名为OpenSeg-R的逐步视觉推理框架。该框架利用大型多模态模型(LMMs)进行分层视觉推理,然后进行分割。我们为每张图片生成通用和特定的视觉推理,形成解释图像中物体的结构化三元组,以从粗到细的方式解释视觉原因。基于这些推理步骤,我们可以组成详细的描述提示,并将其输入到分割器中,以产生更准确的分割掩码。据我们所知,OpenSeg-R是首个将明确的逐步视觉推理引入开放词汇分割的框架。实验结果表明,OpenSeg-R在五个基准数据集上的开放词汇语义分割以及开放词汇全景分割方面都显著优于现有方法。我们的代码已公开在https://github.com/Hanzy1996/OpenSeg-R。
Key Takeaways
- 开放词汇分割(OVS)能够推广分割能力超越预设类别。
- 现有OVS方法通常缺乏明确的推理和解释性,在开放世界环境中区分相似类别具有挑战性。
- OpenSeg-R框架利用大型多模态模型(LMMs)进行分层视觉推理,然后进行分割。
- OpenSeg-R生成结构化三元组,解释图像中物体的视觉原因,以从粗到细的方式提高分割精度和解释性。
- OpenSeg-R是首个将明确的逐步视觉推理引入开放词汇分割的框架。
- 实验结果表明,OpenSeg-R在多个数据集上的开放词汇语义分割和开放词汇全景分割方面显著优于现有方法。
点此查看论文截图

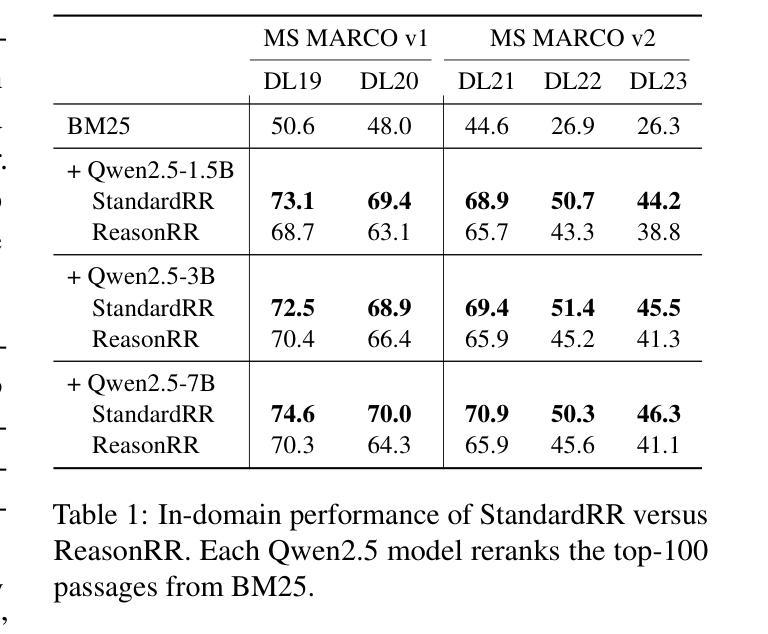
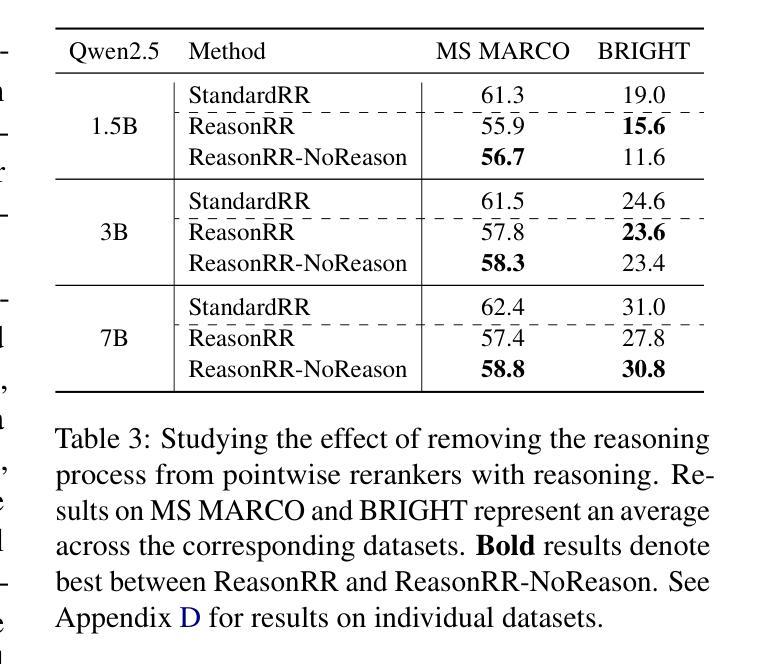
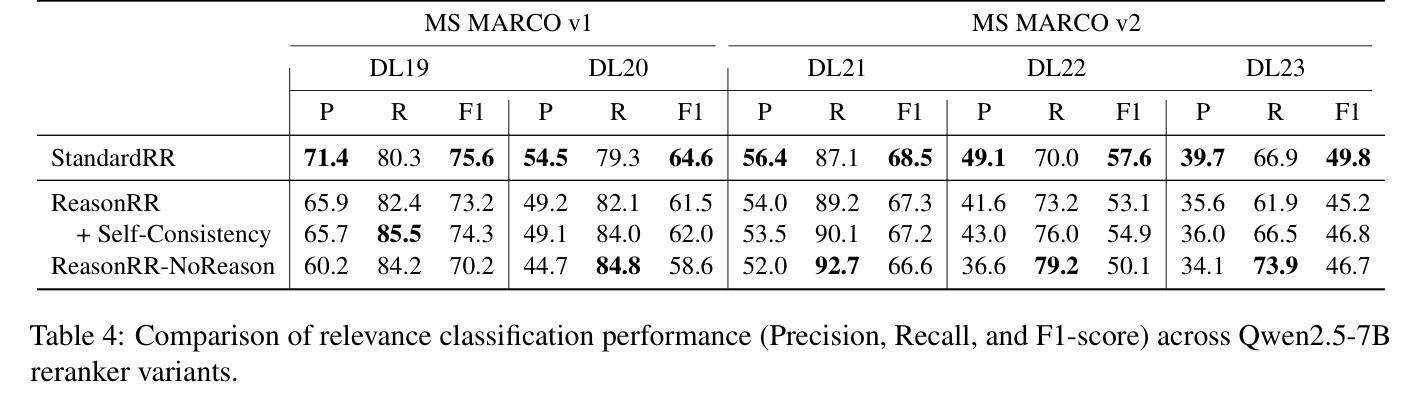
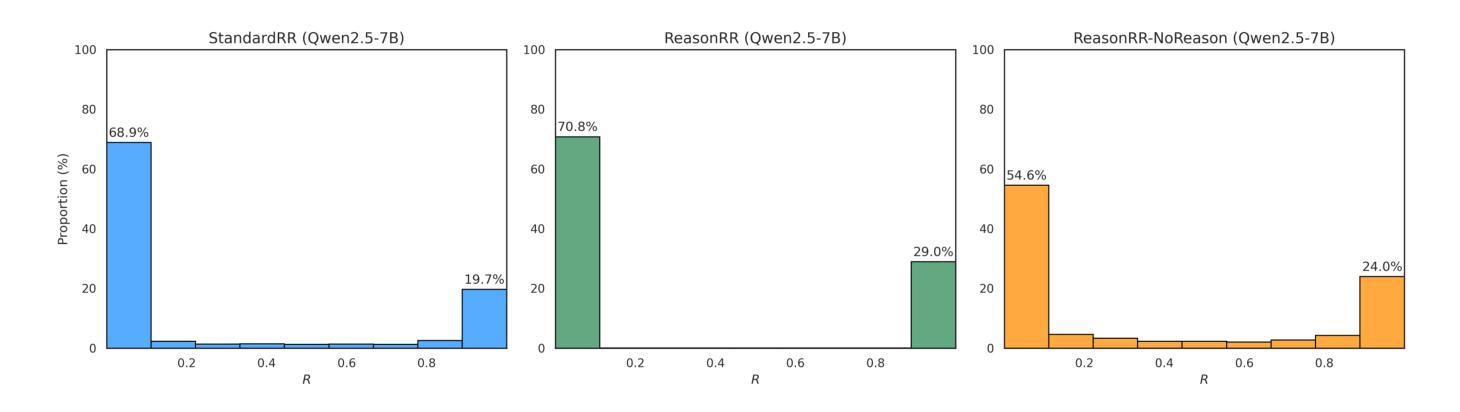
Don’t “Overthink” Passage Reranking: Is Reasoning Truly Necessary?
Authors:Nour Jedidi, Yung-Sung Chuang, James Glass, Jimmy Lin
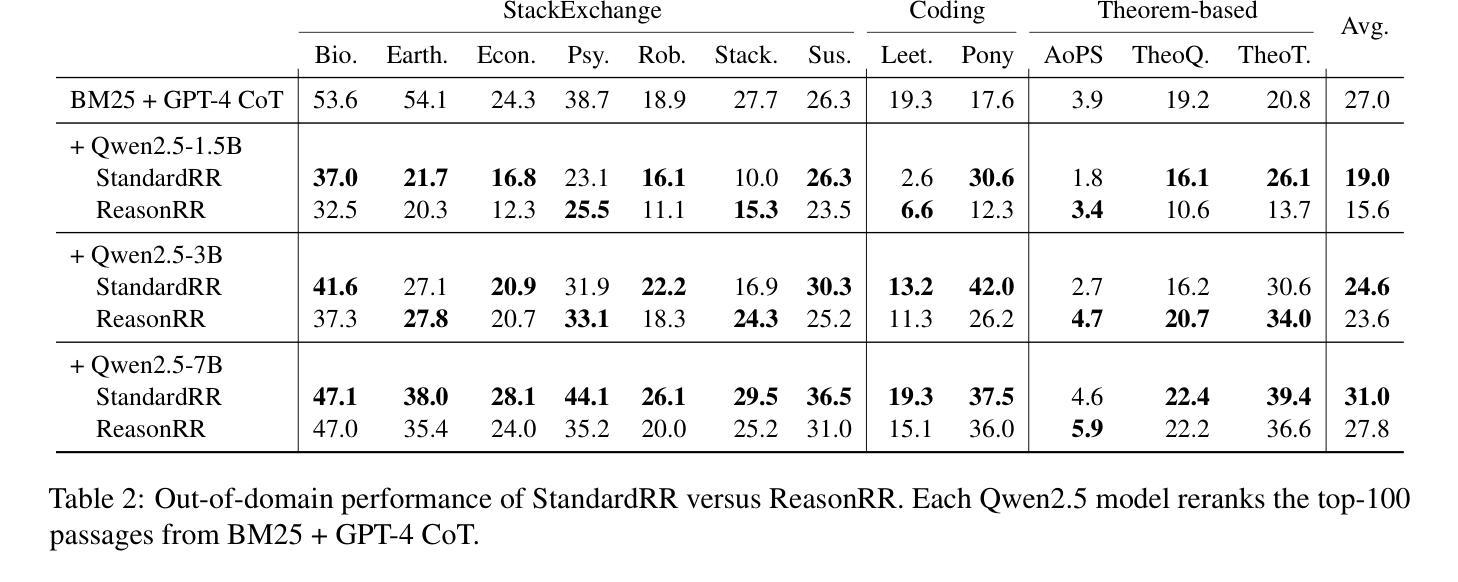
With the growing success of reasoning models across complex natural language tasks, researchers in the Information Retrieval (IR) community have begun exploring how similar reasoning capabilities can be integrated into passage rerankers built on Large Language Models (LLMs). These methods typically employ an LLM to produce an explicit, step-by-step reasoning process before arriving at a final relevance prediction. But, does reasoning actually improve reranking accuracy? In this paper, we dive deeper into this question, studying the impact of the reasoning process by comparing reasoning-based pointwise rerankers (ReasonRR) to standard, non-reasoning pointwise rerankers (StandardRR) under identical training conditions, and observe that StandardRR generally outperforms ReasonRR. Building on this observation, we then study the importance of reasoning to ReasonRR by disabling its reasoning process (ReasonRR-NoReason), and find that ReasonRR-NoReason is surprisingly more effective than ReasonRR. Examining the cause of this result, our findings reveal that reasoning-based rerankers are limited by the LLM’s reasoning process, which pushes it toward polarized relevance scores and thus fails to consider the partial relevance of passages, a key factor for the accuracy of pointwise rerankers.
随着推理模型在复杂的自然语言任务中越来越成功,信息检索(IR)领域的研究人员开始探索如何将类似的推理能力集成到基于大型语言模型(LLM)的段落重排器中。这些方法通常使用LLM来产生一个明确的、逐步的推理过程,然后再做出最终的关联预测。但是,推理实际上会提高重排准确率吗?在这篇论文中,我们对这个问题进行了深入研究,通过比较基于推理的点态重排器(ReasonRR)和相同训练条件下的标准非推理点态重排器(StandardRR),研究推理过程的影响。我们发现StandardRR通常优于ReasonRR。基于这一观察,我们通过禁用ReasonRR的推理过程来研究推理对ReasonRR的重要性,发现ReasonRR-NoReason出人意料地比ReasonRR更有效。分析造成这一结果的原因,我们发现基于推理的重排器受到LLM推理过程的限制,这导致它倾向于极端的关联分数,从而未能考虑到段落的局部关联性,这是点态重排器准确性的关键因素。
论文及项目相关链接
Summary
这篇论文探讨了将推理能力融入基于大型语言模型的段落重排系统(ReasonRR)的实际效果。论文比较了带有推理功能的点式重排器(ReasonRR)与不带推理功能的标准点式重排器(StandardRR),发现在相同训练条件下,StandardRR通常表现更好。进一步的研究发现,移除ReasonRR的推理过程(ReasonRR-NoReason)反而提升了其性能,这表明LLM的推理过程限制了ReasonRR的性能,使其倾向于产生两极化的相关性评分,忽略了段落的局部相关性,这是点式重排器准确性的关键因素。
Key Takeaways
- 研究者开始探索如何将推理能力融入基于大型语言模型的段落重排系统。
- 对比了带有推理功能的重排器(ReasonRR)与不带推理功能的标准重排器(StandardRR),发现StandardRR在相同训练条件下表现更佳。
- 移除ReasonRR的推理过程(ReasonRR-NoReason)反而提升了其性能,这表明推理过程可能是限制因素。
- LLM的推理过程可能导致过度两极化的相关性评分。
- 推理过程忽略了段落的局部相关性,这是点式重排器准确性的关键因素。
- 研究指出融合推理和重排系统时需要仔细权衡和优化。
点此查看论文截图
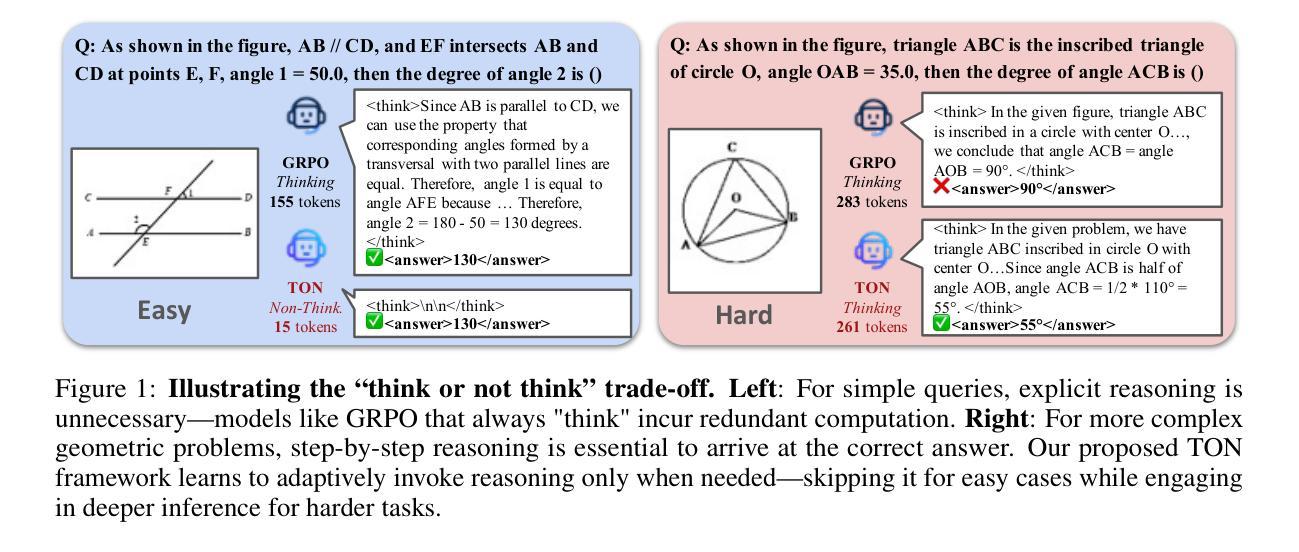
Think or Not? Selective Reasoning via Reinforcement Learning for Vision-Language Models
Authors:Jiaqi Wang, Kevin Qinghong Lin, James Cheng, Mike Zheng Shou
Reinforcement Learning (RL) has proven to be an effective post-training strategy for enhancing reasoning in vision-language models (VLMs). Group Relative Policy Optimization (GRPO) is a recent prominent method that encourages models to generate complete reasoning traces before answering, leading to increased token usage and computational cost. Inspired by the human-like thinking process-where people skip reasoning for easy questions but think carefully when needed-we explore how to enable VLMs to first decide when reasoning is necessary. To realize this, we propose TON, a two-stage training strategy: (i) a supervised fine-tuning (SFT) stage with a simple yet effective ‘thought dropout’ operation, where reasoning traces are randomly replaced with empty thoughts. This introduces a think-or-not format that serves as a cold start for selective reasoning; (ii) a GRPO stage that enables the model to freely explore when to think or not, while maximizing task-aware outcome rewards. Experimental results show that TON can reduce the completion length by up to 90% compared to vanilla GRPO, without sacrificing performance or even improving it. Further evaluations across diverse vision-language tasks-covering a range of reasoning difficulties under both 3B and 7B models-consistently reveal that the model progressively learns to bypass unnecessary reasoning steps as training advances. These findings shed light on the path toward human-like reasoning patterns in reinforcement learning approaches. Our code is available at https://github.com/kokolerk/TON.
强化学习(RL)已被证明是提升视觉语言模型(VLM)推理能力的有效后训练策略。近期备受瞩目的群体相对策略优化(GRPO)方法鼓励模型在回答问题前生成完整的推理过程,从而导致令牌使用量和计算成本的增加。人类思考过程通常是在面对简单问题时会跳过推理,在必要时才会仔细思考。受此启发,我们探索如何使VLM首先决定何时进行推理。为此,我们提出了TON,这是一种两阶段训练策略:(i)监督微调(SFT)阶段,采用简单有效的“思想丢失”操作,其中推理轨迹被随机替换为空洞思想。这引入了“思考与否”的格式,作为选择性推理的冷启动;(ii)GRPO阶段使模型能够自由探索何时思考或不思考,同时最大化任务感知结果奖励。实验结果表明,与常规GRPO相比,TON可以减少高达90%的完成长度,同时不牺牲性能甚至可能有所提高。在涵盖不同难度推理任务的视觉语言任务上进行的进一步评估,无论是使用3B还是7B模型,都一致表明随着训练的进行,模型逐渐学会绕过不必要的推理步骤。这些发现揭示了朝着强化学习中的人类式推理模式发展的道路。我们的代码可在https://github.com/kokolerk/TON获取。
论文及项目相关链接
Summary
本文探讨了强化学习在提升视觉语言模型推理能力方面的应用。针对现有方法如GRPO在计算成本和token使用上的不足,提出了一种新的两阶段训练策略TON。首先通过带有“思维丢失”操作的监督微调(SFT)进行冷启动选择性推理;然后采用GRPO,使模型能够自由探索何时进行推理,同时最大化任务感知结果奖励。实验表明,TON能有效减少高达90%的完成长度,同时不牺牲性能甚至可能有所提升。该策略在不同难度和类型的视觉语言任务上均表现出渐进学习绕过不必要推理步骤的能力。
Key Takeaways
- 强化学习被证明是提升视觉语言模型推理能力的有效策略。
- Group Relative Policy Optimization (GRPO)鼓励模型在回答问题前生成完整的推理过程,但导致更高的计算成本和token使用。
- TON是一种新的两阶段训练策略,旨在使视觉语言模型学会何时进行推理。
- TON通过监督微调(SFT)阶段引入“思维丢失”操作,作为选择性推理的冷启动。
- TON的第二阶段是GRPO,使模型能够自由探索何时进行推理,同时最大化任务感知结果奖励。
- 实验表明,TON能显著减少完成长度,同时保持或提高性能。
点此查看论文截图



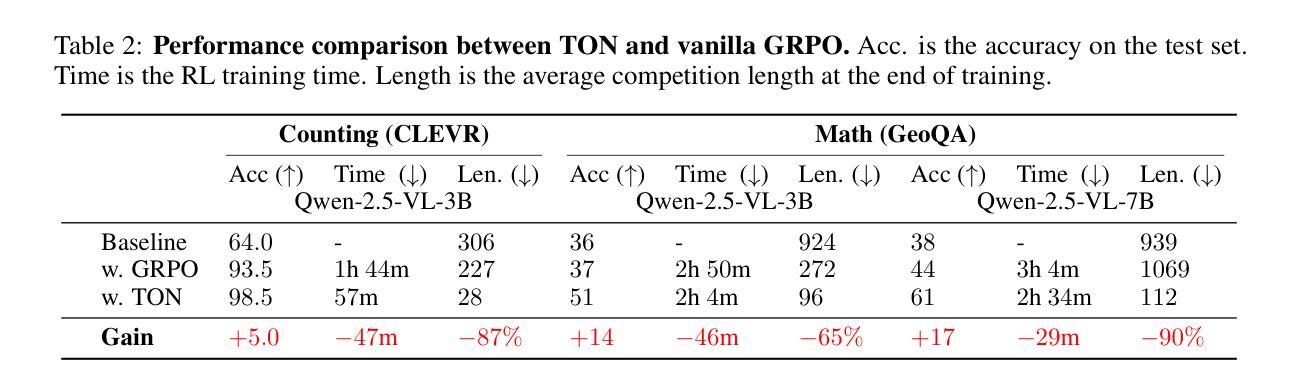

SimpleDeepSearcher: Deep Information Seeking via Web-Powered Reasoning Trajectory Synthesis
Authors:Shuang Sun, Huatong Song, Yuhao Wang, Ruiyang Ren, Jinhao Jiang, Junjie Zhang, Fei Bai, Jia Deng, Wayne Xin Zhao, Zheng Liu, Lei Fang, Zhongyuan Wang, Ji-Rong Wen
Retrieval-augmented generation (RAG) systems have advanced large language models (LLMs) in complex deep search scenarios requiring multi-step reasoning and iterative information retrieval. However, existing approaches face critical limitations that lack high-quality training trajectories or suffer from the distributional mismatches in simulated environments and prohibitive computational costs for real-world deployment. This paper introduces SimpleDeepSearcher, a lightweight yet effective framework that bridges this gap through strategic data engineering rather than complex training paradigms. Our approach synthesizes high-quality training data by simulating realistic user interactions in live web search environments, coupled with a multi-criteria curation strategy that optimizes the diversity and quality of input and output side. Experiments on five benchmarks across diverse domains demonstrate that SFT on only 871 curated samples yields significant improvements over RL-based baselines. Our work establishes SFT as a viable pathway by systematically addressing the data-scarce bottleneck, offering practical insights for efficient deep search systems. Our code is available at https://github.com/RUCAIBox/SimpleDeepSearcher.
增强检索生成(RAG)系统在需要多步骤推理和迭代信息检索的复杂深度搜索场景中推动了大型语言模型(LLM)的发展。然而,现有方法面临缺乏高质量训练轨迹的关键局限,或在模拟环境与真实世界部署中的分布不匹配,以及计算成本高昂的问题。本文介绍了SimpleDeepSearcher,这是一个轻便有效的框架,它通过战略数据工程而不是复杂的训练范式来弥合这一鸿沟。我们的方法通过模拟真实用户交互来合成高质量的训练数据,这在实时网络搜索环境中进行,同时采用多标准筛选策略,以优化输入和输出端的多样性和质量。在多个领域五个基准测试上的实验表明,仅在871个筛选样本上进行SFT即可获得对基于RL的基准测试的重大改进。我们的工作通过系统地解决数据稀缺瓶颈,建立了SFT作为一个可行的途径,为高效的深度搜索系统提供了实际见解。我们的代码可在https://github.com/RUCAIBox/SimpleDeepSearcher处获取。
论文及项目相关链接
Summary
SimpleDeepSearcher框架通过战略数据工程解决了大型语言模型在复杂深度搜索场景中面临的问题,如高质量训练轨迹缺乏、模拟环境与真实环境分布不匹配以及计算成本高昂等。该框架通过模拟真实用户交互和采用多标准筛选策略来合成高质量训练数据,优化输入和输出的多样性和质量。实验结果表明,仅在871个精选样本上进行软启动训练即可在五个基准测试上实现显著改进。
Key Takeaways
- SimpleDeepSearcher是一个用于大型语言模型的框架,旨在解决复杂深度搜索场景中的多步推理和迭代信息检索问题。
- 该框架通过战略数据工程来弥补现有方法的不足,而不是采用复杂的训练模式。
- SimpleDeepSearcher通过模拟真实用户交互和采用多标准筛选策略来合成高质量训练数据。
- 实验结果表明,仅在少量精选样本上进行软启动训练即可实现显著性能提升。
- 该框架在五个不同领域的基准测试中均表现出色。
- SimpleDeepSearcher为高效深度搜索系统提供了实用见解,为解决数据稀缺瓶颈提供了一种可行途径。
点此查看论文截图


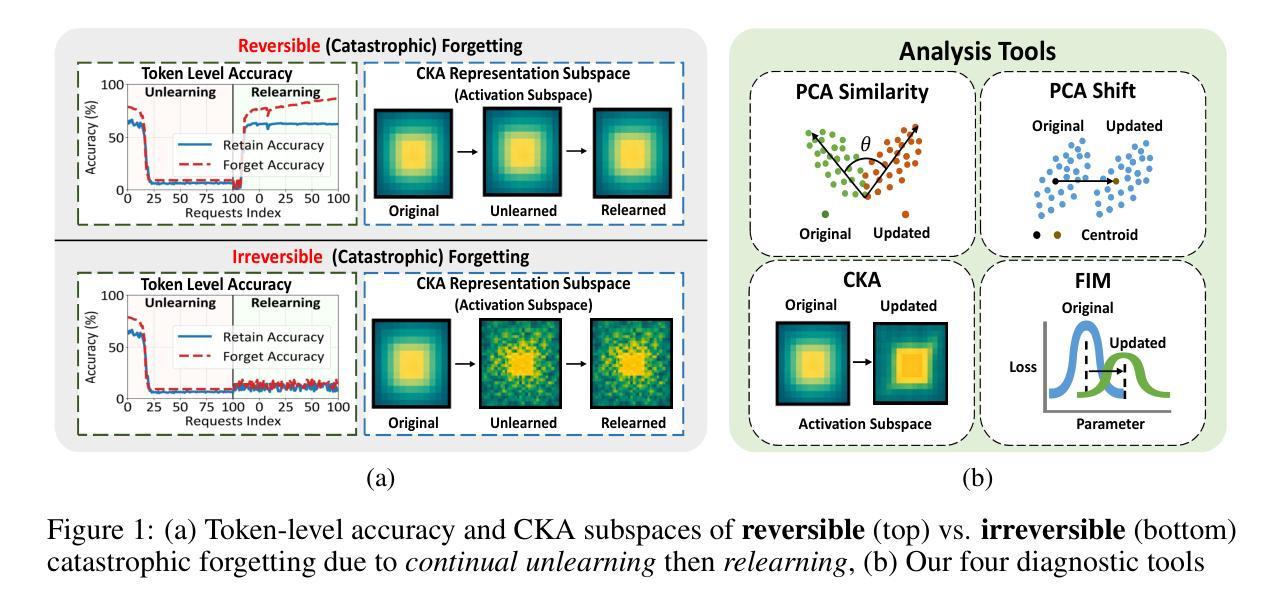
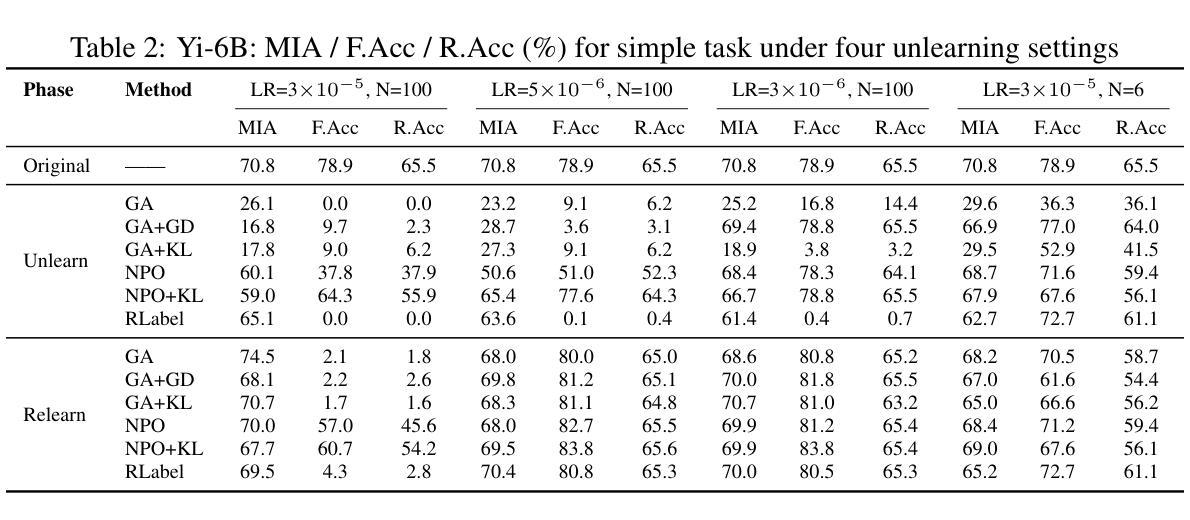
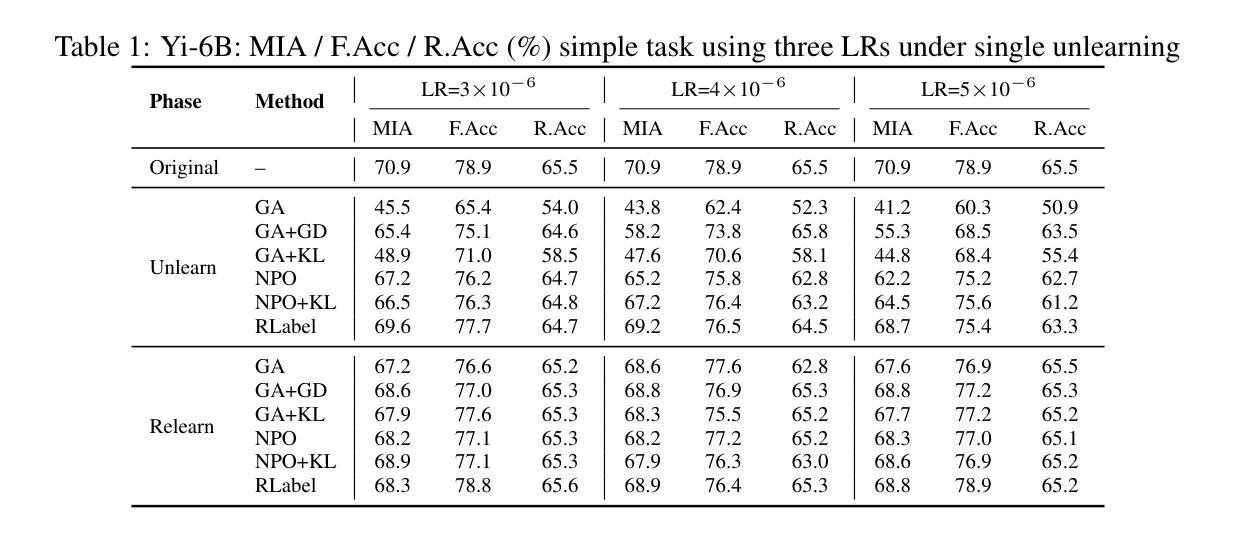
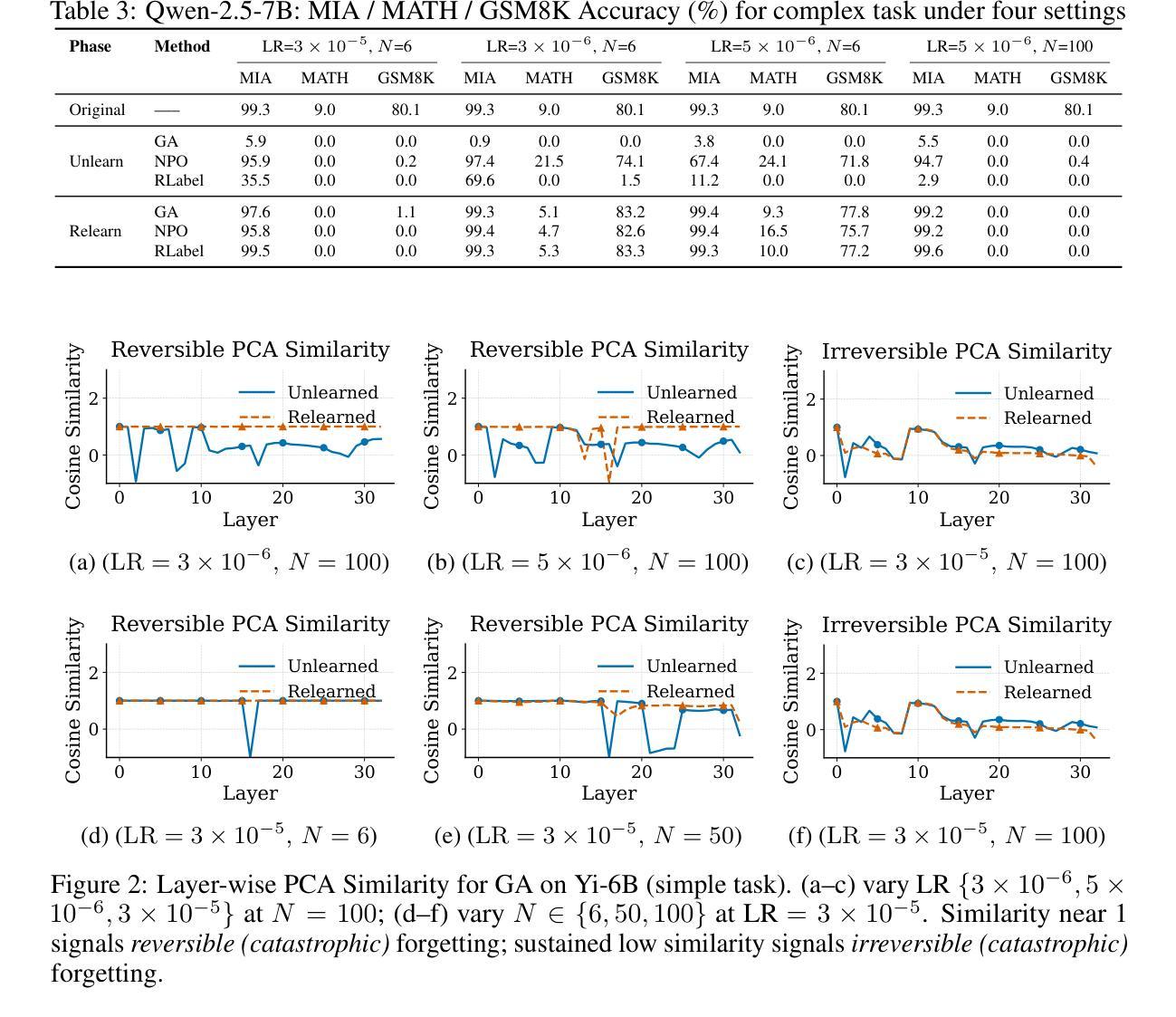
Unlearning Isn’t Deletion: Investigating Reversibility of Machine Unlearning in LLMs
Authors:Xiaoyu Xu, Xiang Yue, Yang Liu, Qingqing Ye, Haibo Hu, Minxin Du
Unlearning in large language models (LLMs) is intended to remove the influence of specific data, yet current evaluations rely heavily on token-level metrics such as accuracy and perplexity. We show that these metrics can be misleading: models often appear to forget, but their original behavior can be rapidly restored with minimal fine-tuning, revealing that unlearning may obscure information rather than erase it. To diagnose this phenomenon, we introduce a representation-level evaluation framework using PCA-based similarity and shift, centered kernel alignment, and Fisher information. Applying this toolkit across six unlearning methods, three domains (text, code, math), and two open-source LLMs, we uncover a critical distinction between reversible and irreversible forgetting. In reversible cases, models suffer token-level collapse yet retain latent features; in irreversible cases, deeper representational damage occurs. We further provide a theoretical account linking shallow weight perturbations near output layers to misleading unlearning signals, and show that reversibility is modulated by task type and hyperparameters. Our findings reveal a fundamental gap in current evaluation practices and establish a new diagnostic foundation for trustworthy unlearning in LLMs. We provide a unified toolkit for analyzing LLM representation changes under unlearning and relearning: https://github.com/XiaoyuXU1/Representational_Analysis_Tools.git.
在大语言模型中,”解学习”(unlearning)旨在消除特定数据的影响,然而当前的评估主要依赖于诸如准确率和困惑度之类的标记级指标。我们表明,这些指标可能会误导人:模型似乎忘记了某些信息,但通过微调很少的参数,其原始行为可以迅速恢复,这表明解学习可能只是掩盖了信息而不是真正删除它。为了诊断这种现象,我们引入了一个基于PCA的相似性变化和中心内核对齐以及Fisher信息的表示级评估框架。我们在六种解学习方法、三个领域(文本、代码、数学)和两个开源的大型语言模型中应用了这一工具包,发现了可逆和不可逆遗忘之间的关键区别。在可逆情况下,模型在标记层面崩溃但仍保留潜在特征;在不可逆情况下,更深层次的表示性损害会发生。我们还从理论上解释了输出层附近浅层权重扰动与误导解学习信号之间的联系,并表明可逆性受任务类型和超参数的影响。我们的研究揭示了当前评估实践中的基本差距,并为大型语言模型中可靠的解学习建立了新的诊断基础。我们提供了一个统一工具包,用于分析大型语言模型在解学习和再学习过程中的表示变化:https://github.com/XiaoyuXU1/Representational_Analysis_Tools.git。
论文及项目相关链接
PDF 44 pages
Summary
大型语言模型中的“遗忘学习”(Unlearning)旨在消除特定数据的影响,但现有评估主要依赖准确性等词级指标。研究指出这些指标具有误导性,因为模型看似遗忘,却可通过微调迅速恢复原有表现,表明遗忘可能只是掩盖信息而非真正擦除。为诊断此现象,研究引入基于PCA的相似性与变化、中心核对齐和Fisher信息的表征级评估框架。应用此工具包于六种遗忘方法、三个领域(文本、代码、数学)和两个开源大型语言模型,发现可逆与不可逆遗忘间存在关键差异。可逆案例中,模型词级表现崩溃但保留潜在特征;不可逆案例中,更深层次的表征受损。研究还从理论层面联系输出层附近的浅层权重扰动与误导性的遗忘信号,并表明可逆性受任务类型和超参数调制。研究揭示了当前评估实践的重大缺陷,并为大型语言模型中可信的遗忘学习提供了新的诊断基础。
Key Takeaways
- 大型语言模型的“遗忘学习”旨在消除特定数据影响。
- 当前评估主要依赖词级指标,如准确性和困惑度,这可能具有误导性。
- 模型看似遗忘,但可能只是通过微调迅速恢复原有表现,表明遗忘可能只是掩盖信息。
- 引入表征级评估框架以更准确地诊断遗忘现象。
- 可逆与不可逆遗忘之间存在关键差异:可逆案例中模型词级表现崩溃但保留潜在特征;不可逆案例中更深层次的表征受损。
- 浅层权重扰动可能导致误导性的遗忘信号。
点此查看论文截图

DeepRec: Towards a Deep Dive Into the Item Space with Large Language Model Based Recommendation
Authors:Bowen Zheng, Xiaolei Wang, Enze Liu, Xi Wang, Lu Hongyu, Yu Chen, Wayne Xin Zhao, Ji-Rong Wen
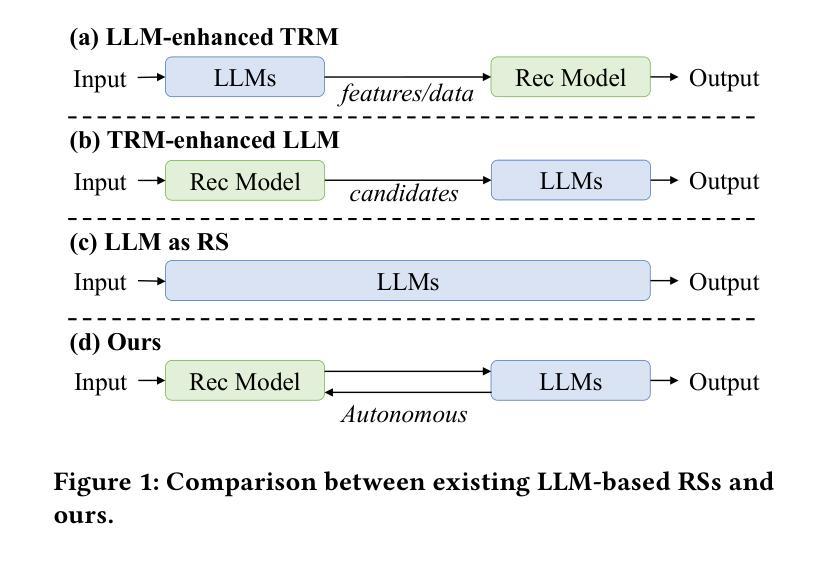
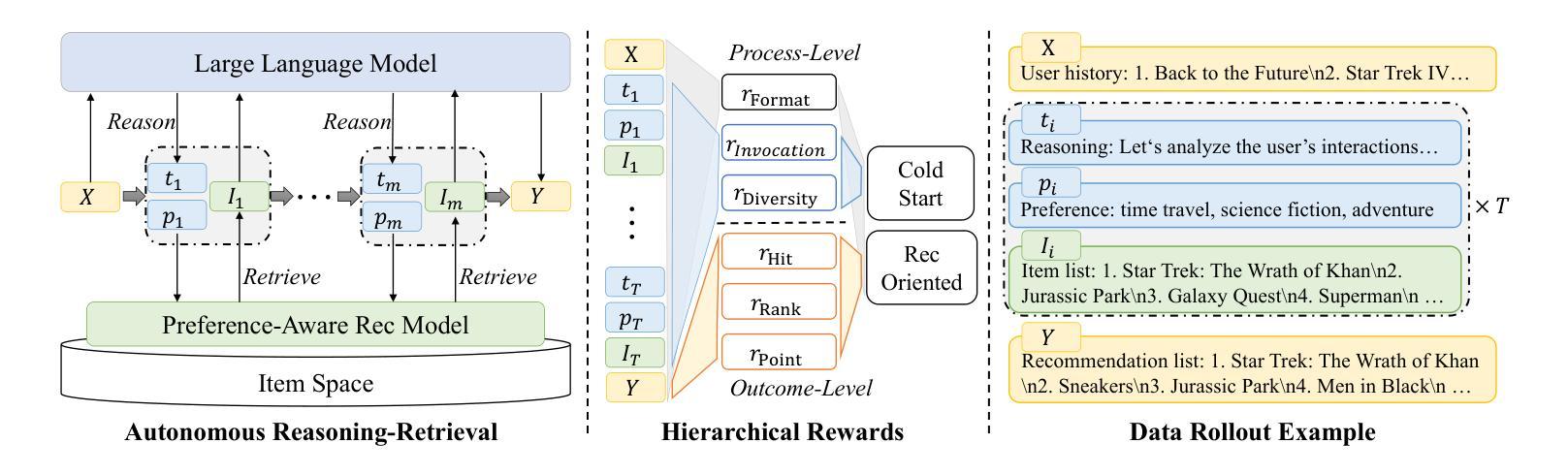
Recently, large language models (LLMs) have been introduced into recommender systems (RSs), either to enhance traditional recommendation models (TRMs) or serve as recommendation backbones. However, existing LLM-based RSs often do not fully exploit the complementary advantages of LLMs (e.g., world knowledge and reasoning) and TRMs (e.g., recommendation-specific knowledge and efficiency) to fully explore the item space. To address this, we propose DeepRec, a novel LLM-based RS that enables autonomous multi-turn interactions between LLMs and TRMs for deep exploration of the item space. In each interaction turn, LLMs reason over user preferences and interact with TRMs to retrieve candidate items. After multi-turn interactions, LLMs rank the retrieved items to generate the final recommendations. We adopt reinforcement learning(RL) based optimization and propose novel designs from three aspects: recommendation model based data rollout, recommendation-oriented hierarchical rewards, and a two-stage RL training strategy. For data rollout, we introduce a preference-aware TRM, with which LLMs interact to construct trajectory data. For rewards, we design a hierarchical reward function that involves both process-level and outcome-level rewards to optimize the interaction process and recommendation performance, respectively. For RL training, we develop a two-stage training strategy, where the first stage aims to guide LLMs to interact with TRMs and the second stage focuses on performance improvement. Experiments on public datasets demonstrate that DeepRec significantly outperforms both traditional and LLM-based baselines, offering a new paradigm for deep exploration in recommendation systems.
最近,大型语言模型(LLM)已被引入推荐系统(RS),无论是为了增强传统推荐模型(TRM)还是作为推荐系统的主干。然而,现有的基于LLM的推荐系统往往没有充分利用LLM(如世界知识和推理)和TRM(如特定于推荐的知识和效率)的互补优势,以充分探索物品空间。为了解决这一问题,我们提出了DeepRec,这是一种新型的基于LLM的推荐系统,它能够在LLM和TRM之间进行自主的多次交互,以深入探索物品空间。在每个交互回合中,LLM对用户的偏好进行推理,并与TRM进行交互以检索候选物品。在经过多次交互后,LLM对检索到的物品进行排名以生成最终推荐。我们采用基于强化学习(RL)的优化方法,并从三个方面提出新的设计:基于推荐模型的数据滚动、面向推荐的分层奖励和两阶段RL训练策略。对于数据滚动,我们引入了一个感知偏好的TRM,LLM与之交互以构建轨迹数据。对于奖励,我们设计了一个分层奖励函数,涉及过程级和结果级奖励,以分别优化交互过程和推荐性能。对于RL训练,我们采用了两阶段训练策略,第一阶段旨在指导LLM与TRM进行交互,第二阶段侧重于性能提升。在公开数据集上的实验表明,DeepRec显著优于传统和基于LLM的基线方法,为推荐系统的深入探索提供了新的范式。
论文及项目相关链接
Summary
大型语言模型(LLM)在推荐系统(RS)中的应用已引起关注,但现有LLM-based RS未能充分利用LLMs和传统的推荐模型(TRMs)的互补优势来全面探索物品空间。为此,本文提出DeepRec,一种新型LLM-based RS,实现LLMs和TRMs之间的自主多轮交互,以深度探索物品空间。通过强化学习(RL)优化,DeepRec从三个方面进行创新设计:基于推荐模型的数据滚动、面向推荐的分层奖励和两阶段RL训练策略。实验证明,DeepRec显著优于传统和LLM-based基线方法,为推荐系统的深度探索提供了新的范式。
Key Takeaways
- LLMs已应用于推荐系统,但未能充分利用其与TRMs的互补优势。
- DeepRec是一种新型LLM-based RS,实现LLMs和TRMs之间的多轮交互,深度探索物品空间。
- DeepRec采用强化学习进行优化,包括数据滚动、分层奖励和两阶段训练策略。
- 数据滚动通过LLMs与TRMs的交互构建轨迹数据。
- 分层奖励函数同时优化交互过程和推荐性能。
- 两阶段RL训练策略旨在指导LLMs与TRMs的交互并提高性能。
点此查看论文截图

Two-way Evidence self-Alignment based Dual-Gated Reasoning Enhancement
Authors:Kexin Zhang, Junlan Chen, Daifeng Li, Yuxuan Zhang, Yangyang Feng, Bowen Deng, Weixu Chen
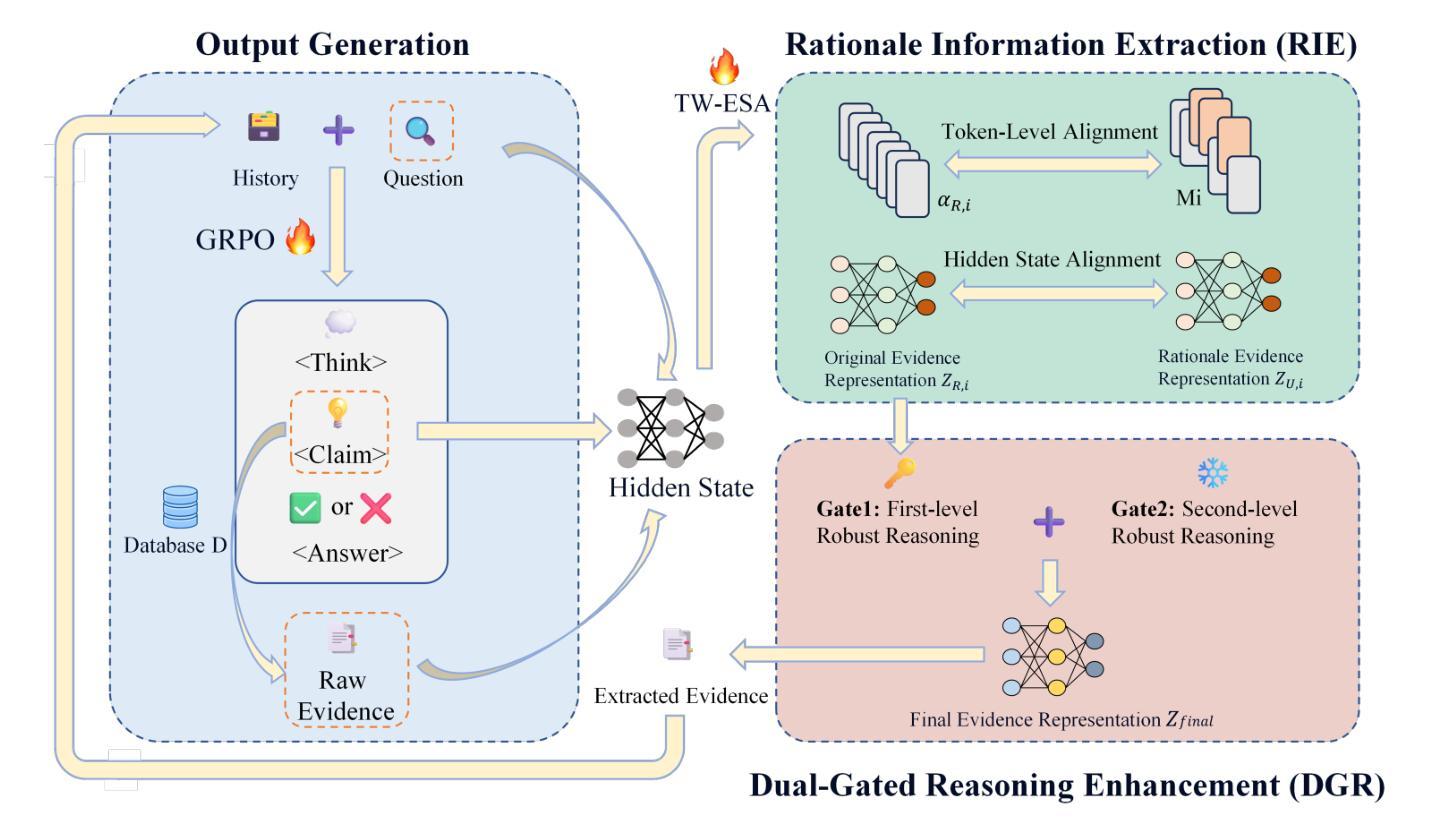
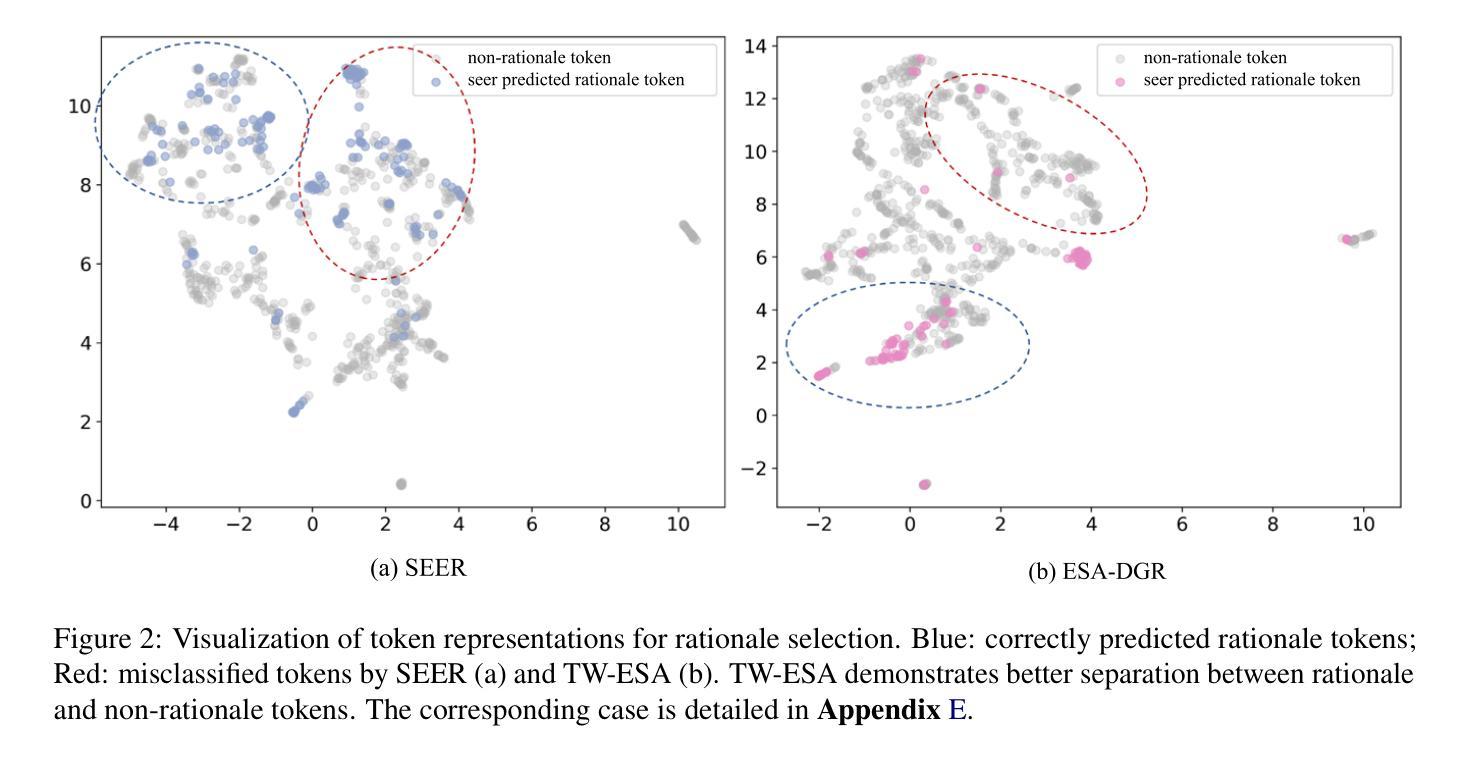
Large language models (LLMs) encounter difficulties in knowledge-intensive multi-step reasoning (KIMSR) tasks. One challenge is how to effectively extract and represent rationale evidence. The current methods often extract semantically relevant but logically irrelevant evidence, resulting in flawed reasoning and inaccurate responses. We propose a two-way evidence self-alignment (TW-ESA) module, which utilizes the mutual alignment between strict reasoning and LLM reasoning to enhance its understanding of the causal logic of evidence, thereby addressing the first challenge. Another challenge is how to utilize the rationale evidence and LLM’s intrinsic knowledge for accurate reasoning when the evidence contains uncertainty. We propose a dual-gated reasoning enhancement (DGR) module to gradually fuse useful knowledge of LLM within strict reasoning, which can enable the model to perform accurate reasoning by focusing on causal elements in the evidence and exhibit greater robustness. The two modules are collaboratively trained in a unified framework ESA-DGR. Extensive experiments on three diverse and challenging KIMSR datasets reveal that ESA-DGR significantly surpasses state-of-the-art LLM-based fine-tuning methods, with remarkable average improvements of 4% in exact match (EM) and 5% in F1 score. The implementation code is available at https://anonymous.4open.science/r/ESA-DGR-2BF8.
大型语言模型(LLM)在知识密集型多步推理(KIMSR)任务中遇到了困难。其中一个挑战是如何有效地提取和表示理性证据。当前的方法经常提取语义上相关但逻辑上不相关的证据,导致推理缺陷和响应不准确。我们提出了一种双向证据自我对齐(TW-ESA)模块,该模块利用严格推理和LLM推理之间的相互对齐,以增强其对证据因果逻辑的理解,从而解决第一个挑战。另一个挑战是,当证据包含不确定性时,如何利用理性证据和LLM的内在知识进行准确推理。我们提出了双门控推理增强(DGR)模块,以逐步融合LLM的有用知识于严格推理之中,使模型能够通过关注证据中的因果元素进行准确推理,并表现出更大的稳健性。两个模块在统一框架ESA-DGR中进行协同训练。在三个多样且具挑战性的KIMSR数据集上的广泛实验表明,ESA-DGR显著超越了基于LLM的最新微调方法,在精确匹配(EM)方面平均提高了4%,在F1分数方面提高了5%。实现代码可在https://anonymous.4open.science/r/ESA-DGR-2BF8找到。
论文及项目相关链接
Summary:大型语言模型在多步知识推理任务中面临挑战,存在证据理性提取和表示的问题。提出一种双向证据自我对齐模块(TW-ESA),利用严格推理与LLM推理之间的相互对齐,提高其对因果逻辑的理解。另一挑战是证据中的不确定性如何利用LLM的内在知识进行准确推理。提出一种双门推理增强(DGR)模块,使模型通过关注证据中的因果元素进行准确推理,并展现更强的稳健性。两个模块在统一框架ESA-DGR中协同训练,在三个具有挑战性的KIMSR数据集上的实验表明,ESA-DGR显著优于最新的LLM微调方法,在精确匹配和F1分数上平均提高4%和5%。
Key Takeaways:
- 大型语言模型(LLMs)在知识密集型多步推理(KIMSR)任务中面临挑战。
- 现有方法常常提取语义上相关但逻辑上无关的证据,导致推理错误和响应不准确。
- 提出一种双向证据自我对齐(TW-ESA)模块,通过严格推理与LLM推理的相互对齐,提高因果逻辑的理解。
- 另一挑战是如何处理证据中的不确定性,并利用LLM的内在知识进行准确推理。
- 提出一种双门推理增强(DGR)模块,能逐步融合LLM的有用知识进行准确推理,并展现更强的稳健性。
- ESA-DGR框架融合了TW-ESA和DGR两个模块,并在多个KIMSR数据集上表现出显著优势。
点此查看论文截图

Reasoning Beyond Language: A Comprehensive Survey on Latent Chain-of-Thought Reasoning
Authors:Xinghao Chen, Anhao Zhao, Heming Xia, Xuan Lu, Hanlin Wang, Yanjun Chen, Wei Zhang, Jian Wang, Wenjie Li, Xiaoyu Shen
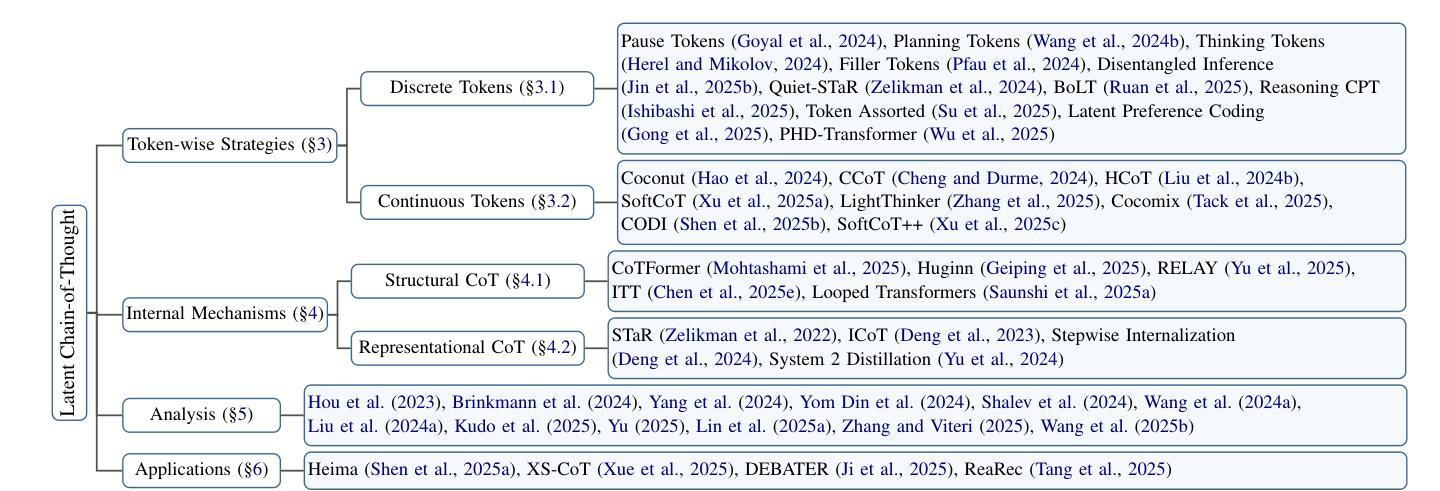
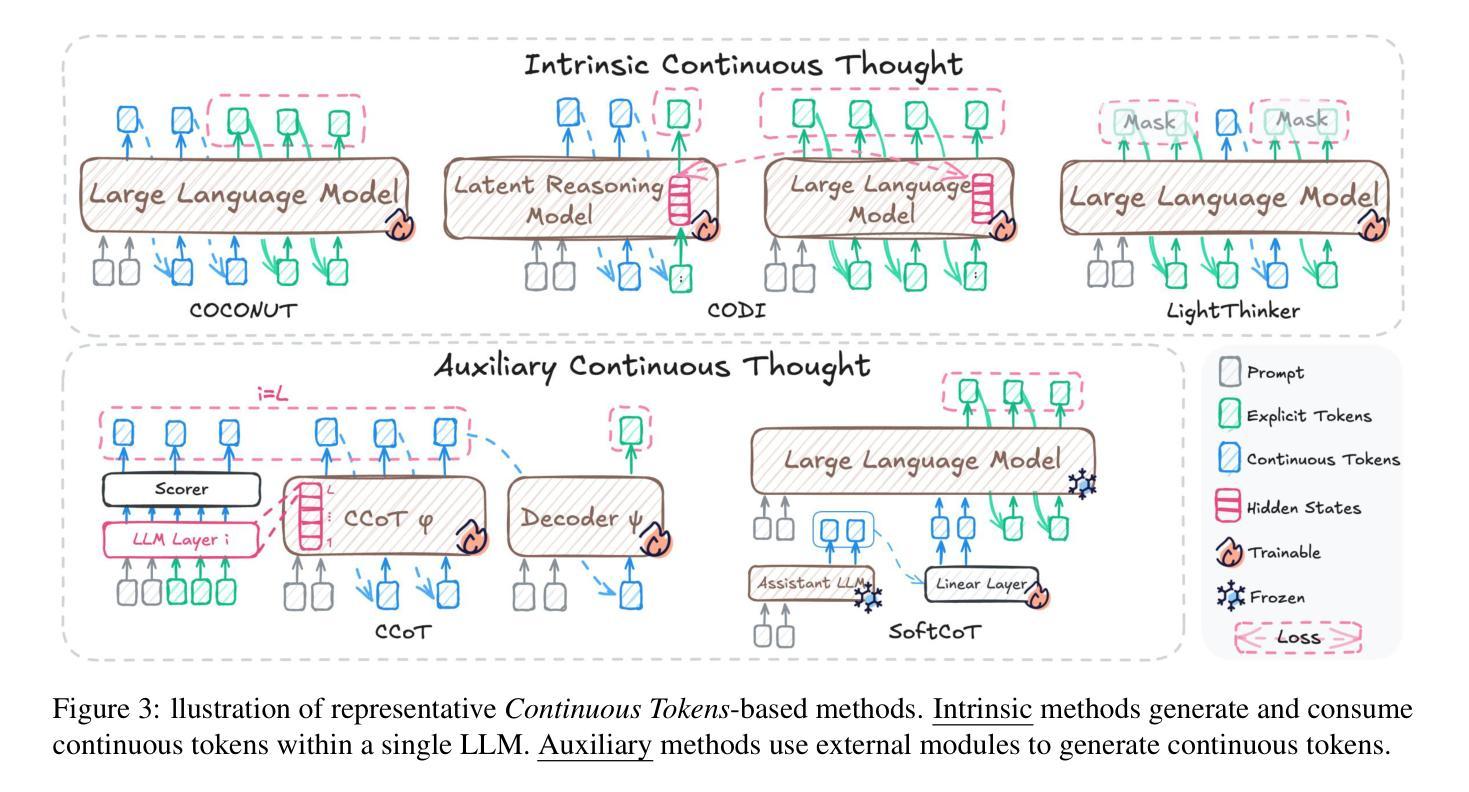
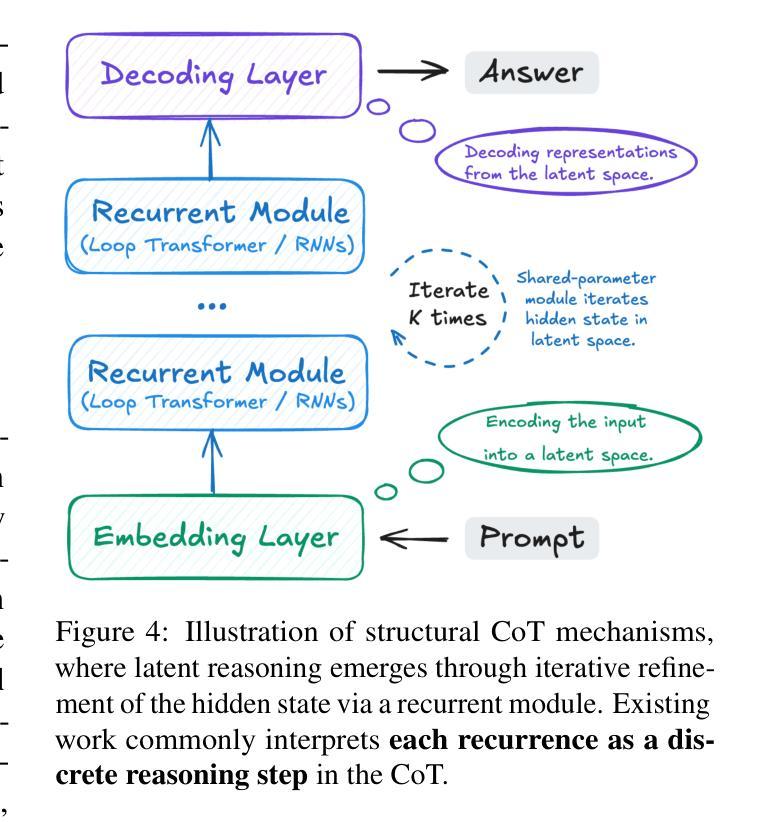
Large Language Models (LLMs) have achieved impressive performance on complex reasoning tasks with Chain-of-Thought (CoT) prompting. However, conventional CoT relies on reasoning steps explicitly verbalized in natural language, introducing inefficiencies and limiting its applicability to abstract reasoning. To address this, there has been growing research interest in latent CoT reasoning, where inference occurs within latent spaces. By decoupling reasoning from language, latent reasoning promises richer cognitive representations and more flexible, faster inference. Researchers have explored various directions in this promising field, including training methodologies, structural innovations, and internal reasoning mechanisms. This paper presents a comprehensive overview and analysis of this reasoning paradigm. We begin by proposing a unified taxonomy from four perspectives: token-wise strategies, internal mechanisms, analysis, and applications. We then provide in-depth discussions and comparative analyses of representative methods, highlighting their design patterns, strengths, and open challenges. We aim to provide a structured foundation for advancing this emerging direction in LLM reasoning. The relevant papers will be regularly updated at https://github.com/EIT-NLP/Awesome-Latent-CoT.
大型语言模型(LLM)通过思维链(CoT)提示,在复杂的推理任务上取得了令人印象深刻的性能。然而,传统的CoT依赖于自然语言明确表达的推理步骤,这引入了低效性并限制了其在抽象推理中的应用。为了解决这一问题,人们对潜在CoT推理的研究兴趣日益浓厚,推理过程发生在潜在空间内。通过将推理与语言解耦,潜在推理有望实现更丰富的认知表示和更灵活、更快的推理。研究人员在这个充满希望的领域探索了各个方向,包括训练方法论、结构创新以及内部推理机制。本文对这一推理范式进行了全面概述和分析。我们首先提出从四个方面:基于代币的策略、内部机制、分析与应用来进行统一分类。然后深入讨论和比较分析代表性的方法,突出其设计模式、优点和开放挑战。我们的目标是为推动LLM推理的这一新兴方向提供一个结构化的基础。相关论文将定期更新在https://github.com/EIT-NLP/Awesome-Latent-CoT上。
论文及项目相关链接
Summary
大规模语言模型(LLMs)通过链式思维(CoT)提示成功完成了复杂的推理任务。然而,传统的CoT依赖于自然语言中的明确表述步骤,引入效率低下,限制了其在抽象推理中的应用。为了解决这个问题,研究者对隐性CoT推理产生了浓厚的兴趣,推理过程发生在潜在空间内。通过将推理与语言解耦,潜在推理提供了更丰富认知表示和更灵活、快速的推理过程。本文从四个方面对隐性推理模式进行了全面概述和分析:基于标记的策略、内部机制、分析和应用。并对代表性方法进行了深入讨论和比较分析,突出了其设计模式、优势和开放挑战。我们旨在为推进这一新兴的语言模型推理方向提供结构化基础。相关论文将定期在https://github.com/EIT-NLP/Awesome-Latent-CoT更新。
Key Takeaways
- 大规模语言模型(LLMs)通过链式思维(CoT)提示展现出强大的复杂推理能力。
- 传统CoT依赖自然语言中的明确表述步骤,存在效率低下的问题。
- 隐性CoT推理是新兴研究方向,允许在潜在空间内完成推理过程。
- 隐性推理解耦了推理与语言,使认知表示更丰富,推理更灵活和快速。
- 论文从四个角度对隐性推理模式进行了全面概述和分析:基于标记的策略、内部机制、分析和应用。
- 论文深入讨论并比较了代表性方法的设计模式、优势和挑战。
点此查看论文截图

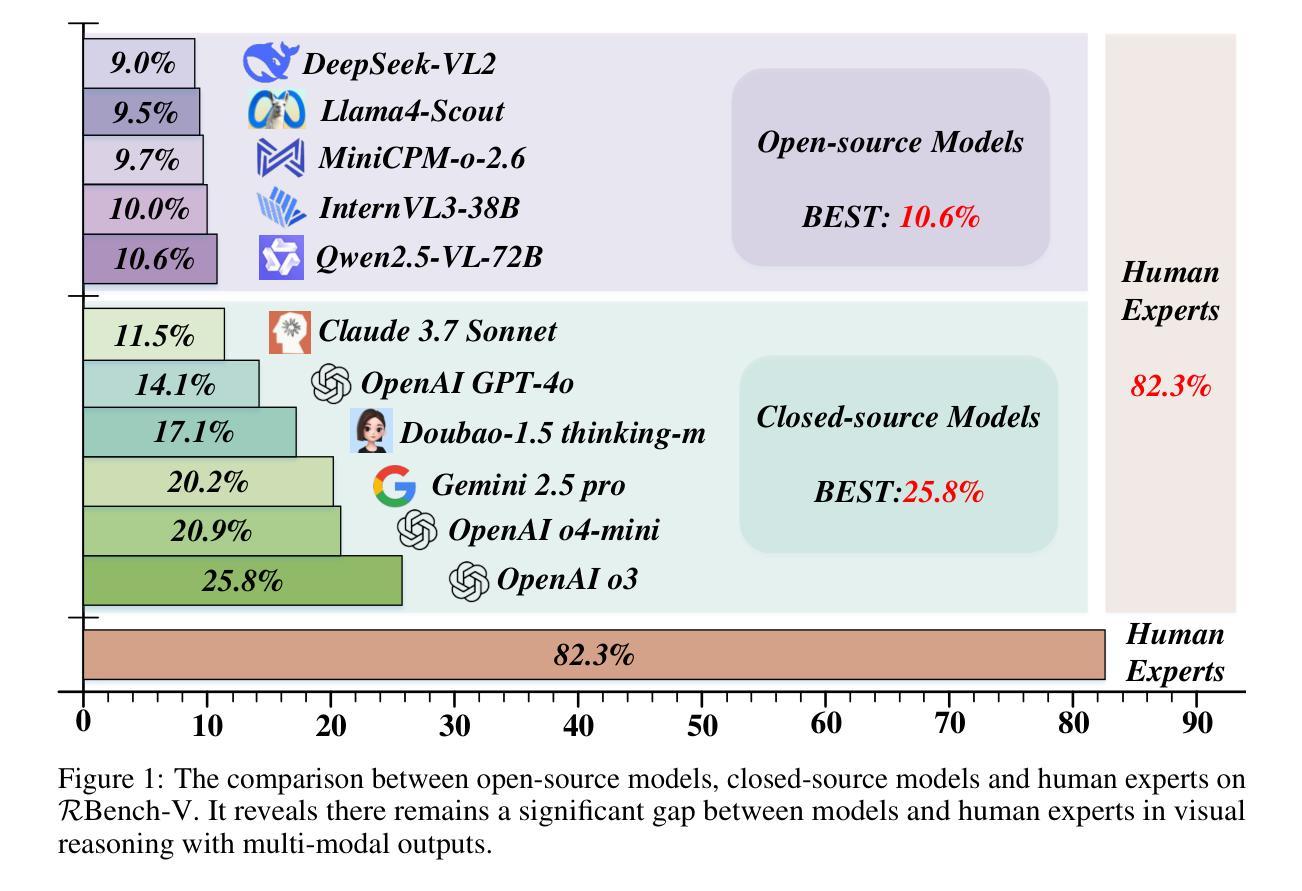
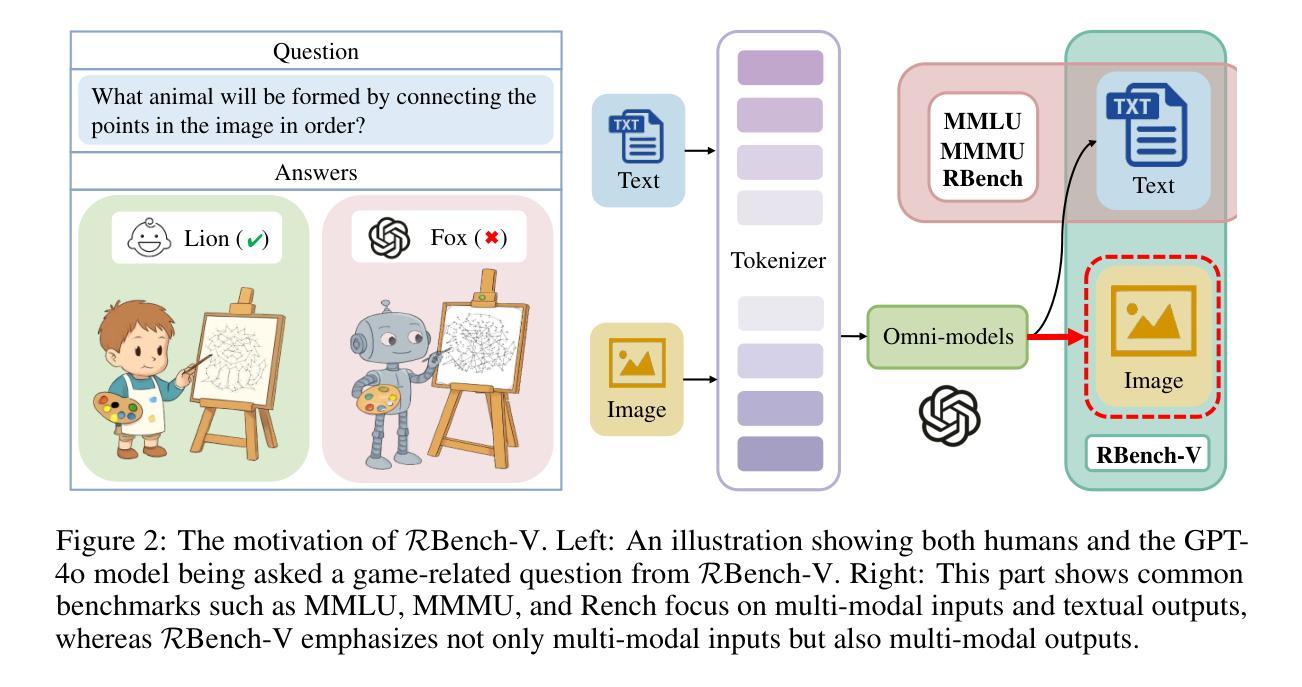
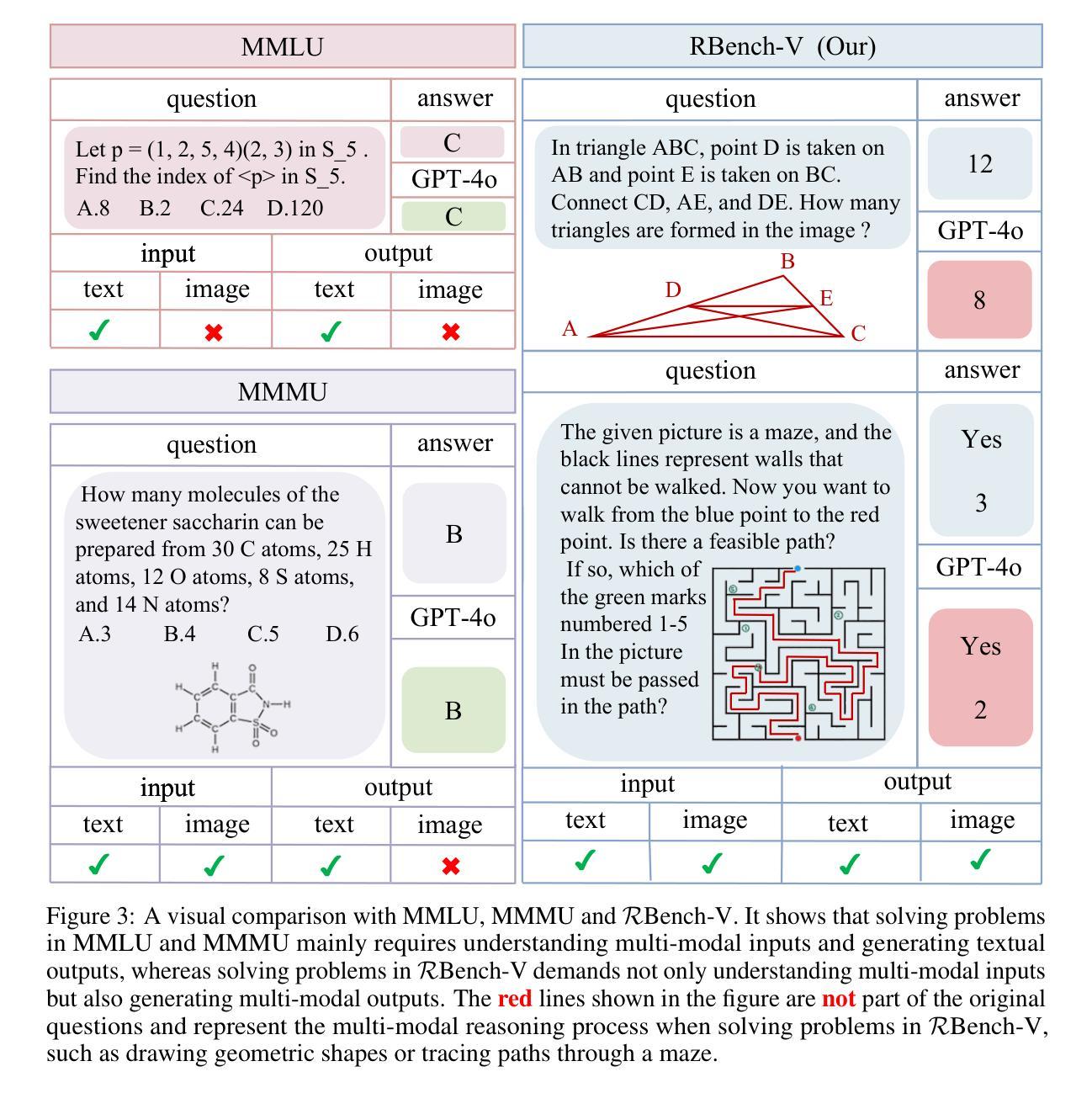
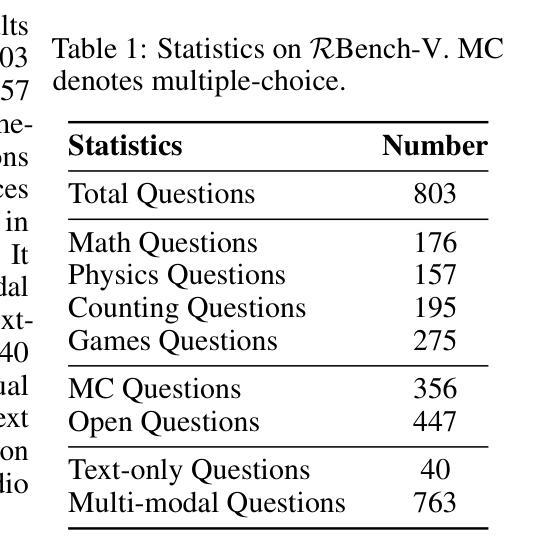
RBench-V: A Primary Assessment for Visual Reasoning Models with Multi-modal Outputs
Authors:Meng-Hao Guo, Xuanyu Chu, Qianrui Yang, Zhe-Han Mo, Yiqing Shen, Pei-lin Li, Xinjie Lin, Jinnian Zhang, Xin-Sheng Chen, Yi Zhang, Kiyohiro Nakayama, Zhengyang Geng, Houwen Peng, Han Hu, Shi-Nin Hu
The rapid advancement of native multi-modal models and omni-models, exemplified by GPT-4o, Gemini, and o3, with their capability to process and generate content across modalities such as text and images, marks a significant milestone in the evolution of intelligence. Systematic evaluation of their multi-modal output capabilities in visual thinking processes (also known as multi-modal chain of thought, M-CoT) becomes critically important. However, existing benchmarks for evaluating multi-modal models primarily focus on assessing multi-modal inputs and text-only reasoning while neglecting the importance of reasoning through multi-modal outputs. In this paper, we present a benchmark, dubbed RBench-V, designed to assess models’ vision-indispensable reasoning abilities. To construct RBench-V, we carefully hand-pick 803 questions covering math, physics, counting, and games. Unlike previous benchmarks that typically specify certain input modalities, RBench-V presents problems centered on multi-modal outputs, which require image manipulation such as generating novel images and constructing auxiliary lines to support the reasoning process. We evaluate numerous open- and closed-source models on RBench-V, including o3, Gemini 2.5 Pro, Qwen2.5-VL, etc. Even the best-performing model, o3, achieves only 25.8% accuracy on RBench-V, far below the human score of 82.3%, highlighting that current models struggle to leverage multi-modal reasoning. Data and code are available at https://evalmodels.github.io/rbenchv
随着本地多模态模型和全能模型(如GPT-4o、双子座和o3)的快速发展,它们具备处理生成文本和图像等多模态内容的能力,标志着智能领域的一个重要里程碑。对他们在视觉思维过程中的多模态输出能力(也称为多模态思维链,M-CoT)进行系统性评价变得至关重要。然而,现有的多模态模型评估基准主要关注多模态输入和纯文本推理,忽视了通过多模态输出来进行推理的重要性。在本文中,我们提出了一个评估基准,名为RBench-V,旨在评估模型的视觉不可或缺推理能力。为了构建RBench-V,我们精心挑选了803个涵盖数学、物理、计数和游戏的问题。与通常指定特定输入模态的先前基准不同,RBench-V以多模态输出为中心呈现问题,需要进行图像操作,如生成新图像和构建辅助线以支持推理过程。我们在RBench-V上评估了多个开源和闭源模型,包括o3、双子座2.5 Pro、Qwen2.5-VL等。即使在表现最佳的o3模型上,其在RBench-V上的准确率也只有25.8%,远低于人类的82.3%,这表明当前模型在利用多模态推理方面存在困难。数据和代码可通过https://evalmodels.github.io/rbenchv获取。
论文及项目相关链接
PDF 12 pages
Summary
随着本土多模态模型和通才模型(如GPT-4o、Gemini和o3)的快速发展,它们处理并生成文本和图像等多模态内容的能力,标志着人工智能领域的重要里程碑。系统评估这些模型在视觉思维过程(也称为多模态思维链,M-CoT)中的多模态输出能力变得至关重要。然而,现有的评估基准主要关注多模态输入和纯文本推理,忽视了通过多模态输出来进行推理的重要性。本文提出了一种名为RBench-V的基准测试,旨在评估模型的视觉不可或缺推理能力。该测试通过精心挑选的803个涉及数学、物理、计数和游戏的问题来构建,要求模型进行图像操作以支持推理过程。即使是最先进的模型在RBench-V上的准确率也只有25.8%,远低于人类的82.3%,突显出现有模型在多模态推理方面的不足。
Key Takeaways
- 多模态模型和通才模型的发展为人工智能领域带来重要里程碑。
- 系统评估模型在视觉思维过程(多模态思维链)中的多模态输出能力至关重要。
- 现有评估基准主要关注多模态输入和文本推理,忽视多模态输出的重要性。
- 本文提出了RBench-V基准测试,专注于评估模型的视觉不可或缺推理能力。
- RBench-V包含803个涉及数学、物理、计数和游戏的问题。
- 模型需要执行图像操作以支持推理过程。
点此查看论文截图


SPaRC: A Spatial Pathfinding Reasoning Challenge
Authors:Lars Benedikt Kaesberg, Jan Philip Wahle, Terry Ruas, Bela Gipp
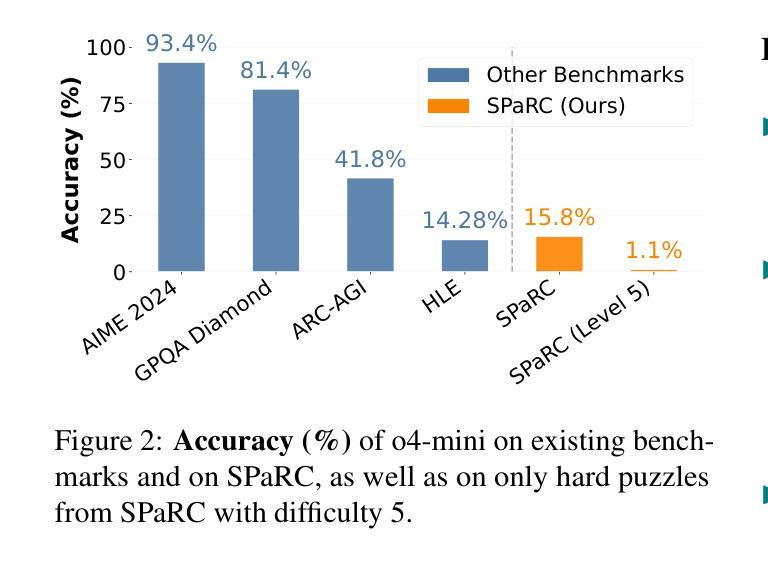
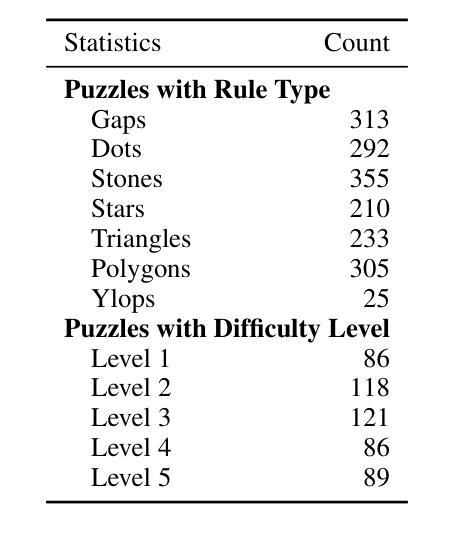
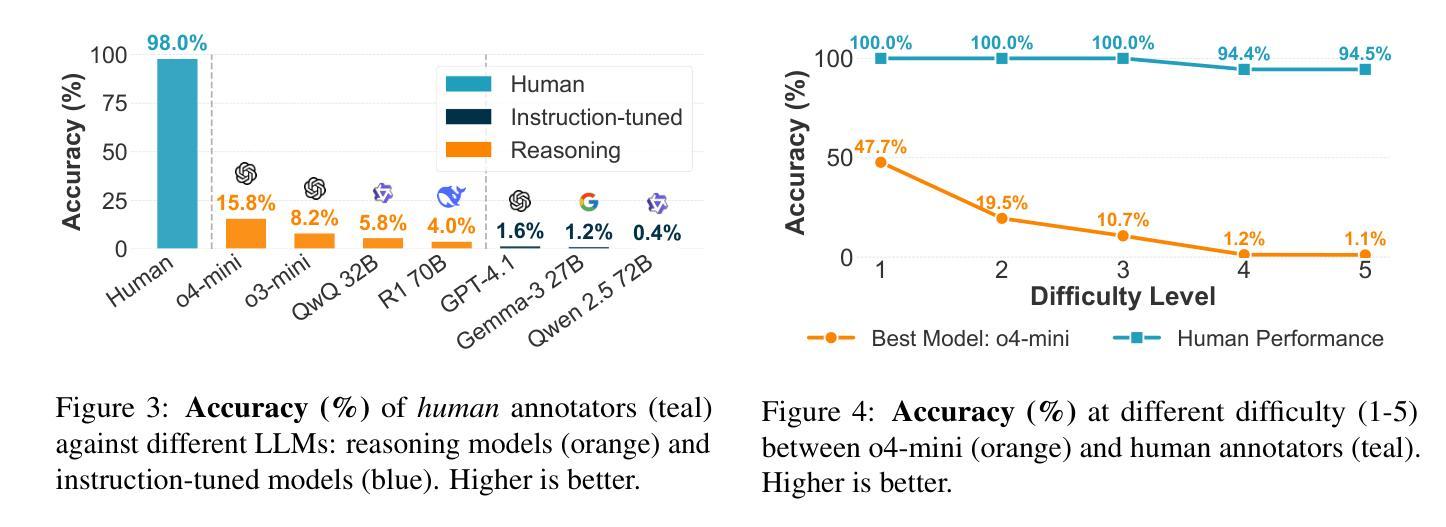
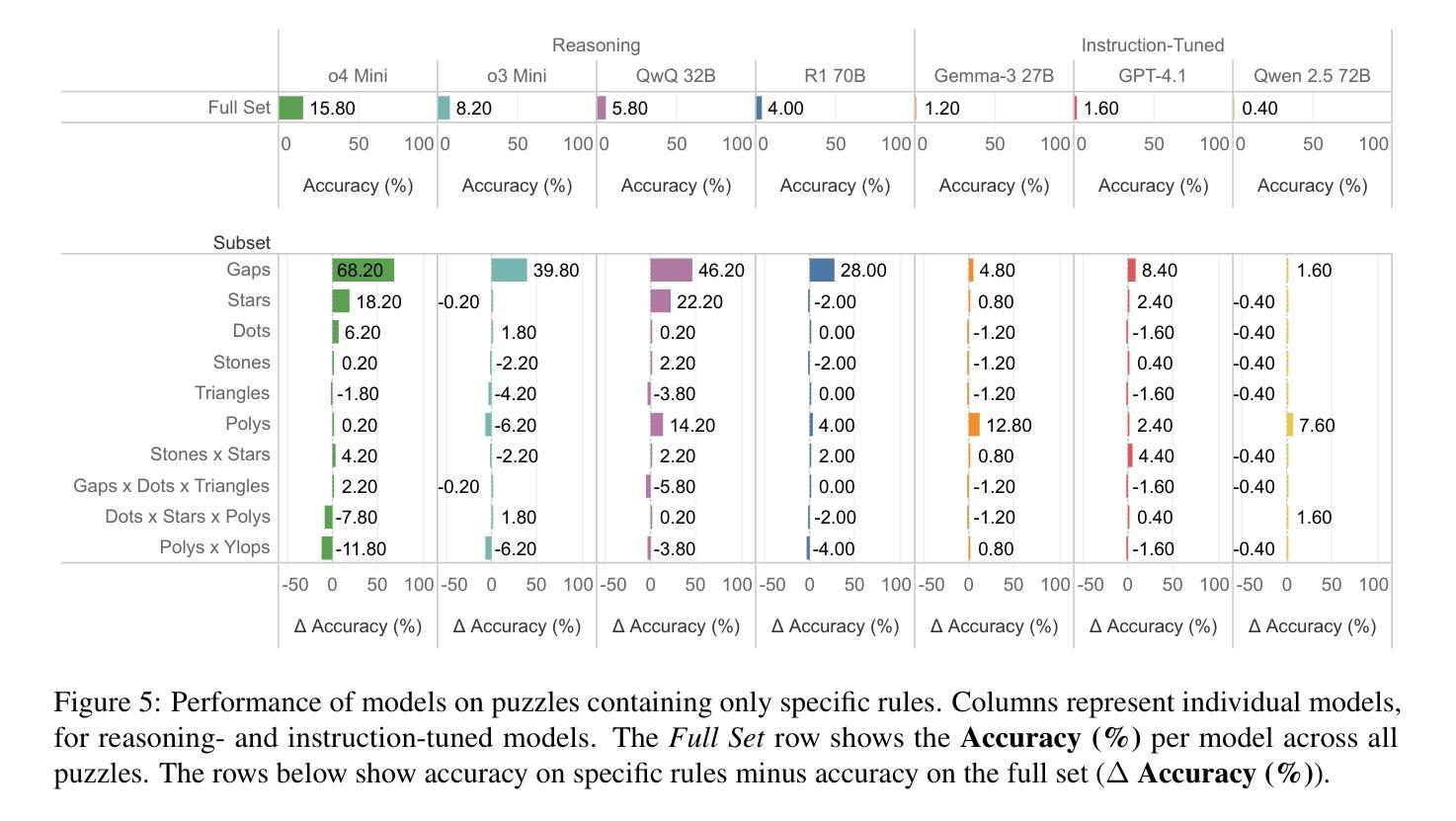
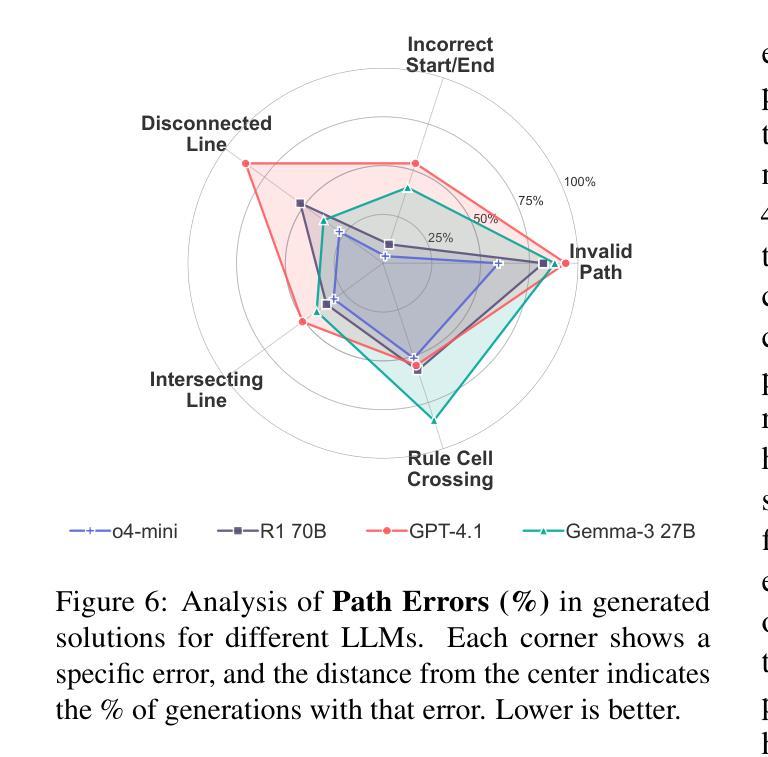
Existing reasoning datasets saturate and fail to test abstract, multi-step problems, especially pathfinding and complex rule constraint satisfaction. We introduce SPaRC (Spatial Pathfinding Reasoning Challenge), a dataset of 1,000 2D grid pathfinding puzzles to evaluate spatial and symbolic reasoning, requiring step-by-step planning with arithmetic and geometric rules. Humans achieve near-perfect accuracy (98.0%; 94.5% on hard puzzles), while the best reasoning models, such as o4-mini, struggle (15.8%; 1.1% on hard puzzles). Models often generate invalid paths (>50% of puzzles for o4-mini), and reasoning tokens reveal they make errors in navigation and spatial logic. Unlike humans, who take longer on hard puzzles, models fail to scale test-time compute with difficulty. Allowing models to make multiple solution attempts improves accuracy, suggesting potential for better spatial reasoning with improved training and efficient test-time scaling methods. SPaRC can be used as a window into models’ spatial reasoning limitations and drive research toward new methods that excel in abstract, multi-step problem-solving.
现有的推理数据集趋于饱和,并且在测试抽象、多步骤问题时表现不佳,尤其是在路径查找和复杂规则约束满足方面。我们推出了SPaRC(空间路径查找推理挑战)数据集,其中包含1000个二维网格路径查找谜题,用于评估空间与符号推理的能力,需要按步骤规划,涉及算术和几何规则。人类在谜题上的准确率接近完美(98.0%,在难题上为94.5%),而最佳的推理模型(如o4-mini)表现挣扎(准确率为15.8%,在难题上仅为1.1%)。模型经常生成无效路径(对于o4-mini而言超过50%),推理令牌显示它们在导航和空间逻辑方面犯了错误。不同于人类在难题上花费更多时间,模型难以随着难度的增加调整测试时间计算。允许模型进行多次解题尝试可提高准确性,这表明通过改进训练和高效的测试时间缩放方法,有可能实现更好的空间推理能力。SPaRC可以作为了解模型空间推理局限性的窗口,并推动研究开发出擅长抽象、多步骤问题解决的新方法。
论文及项目相关链接
Summary
本文介绍了SPaRC数据集,该数据集包含1000个二维网格路径寻找谜题,旨在评估空间与符号推理能力,需要逐步规划并遵循算术和几何规则。人类在此数据集上的准确率接近完美(98.0%,难题上94.5%),而最佳推理模型(如o4-mini)表现较差(15.8%,难题上1.1%)。模型常常生成无效路径,且在导航和空间逻辑方面出现错误。模型未能随难度增加调整测试时间计算,与人类不同,后者在难题上花费更多时间。允许模型多次尝试解答可提高准确率,表明通过改进训练和高效测试时间缩放方法,模型的空间推理能力有望提高。SPaRC可以作为了解模型空间推理局限性的窗口,并推动研究以开发擅长抽象多步骤问题解决的新方法。
Key Takeaways
- SPaRC数据集用于评估空间和符号推理能力,包含1000个二维网格路径寻找谜题。
- 人类在SPaRC数据集上的准确率很高(98.0%,难题上为94.5%)。
- 当前最佳推理模型(如o4-mini)在SPaRC上的表现较差,常常生成无效路径。
- 模型在导航和空间逻辑方面存在错误。
- 模型未能随着问题难度的增加调整其测试时间的计算。
- 允许模型多次尝试解答可以提高其准确率。
点此查看论文截图