⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-05-24 更新
An Effective Training Framework for Light-Weight Automatic Speech Recognition Models
Authors:Abdul Hannan, Alessio Brutti, Shah Nawaz, Mubashir Noman
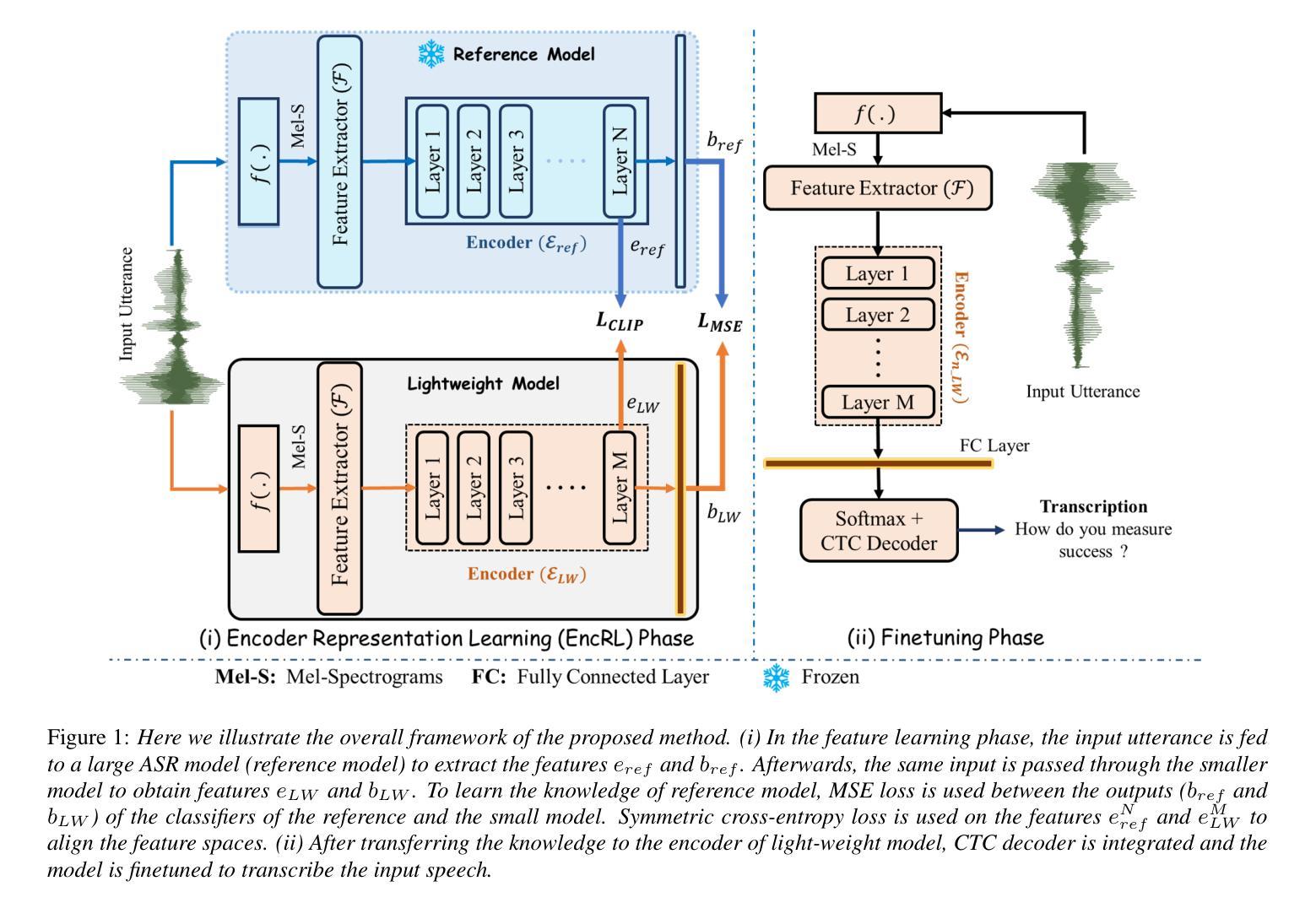
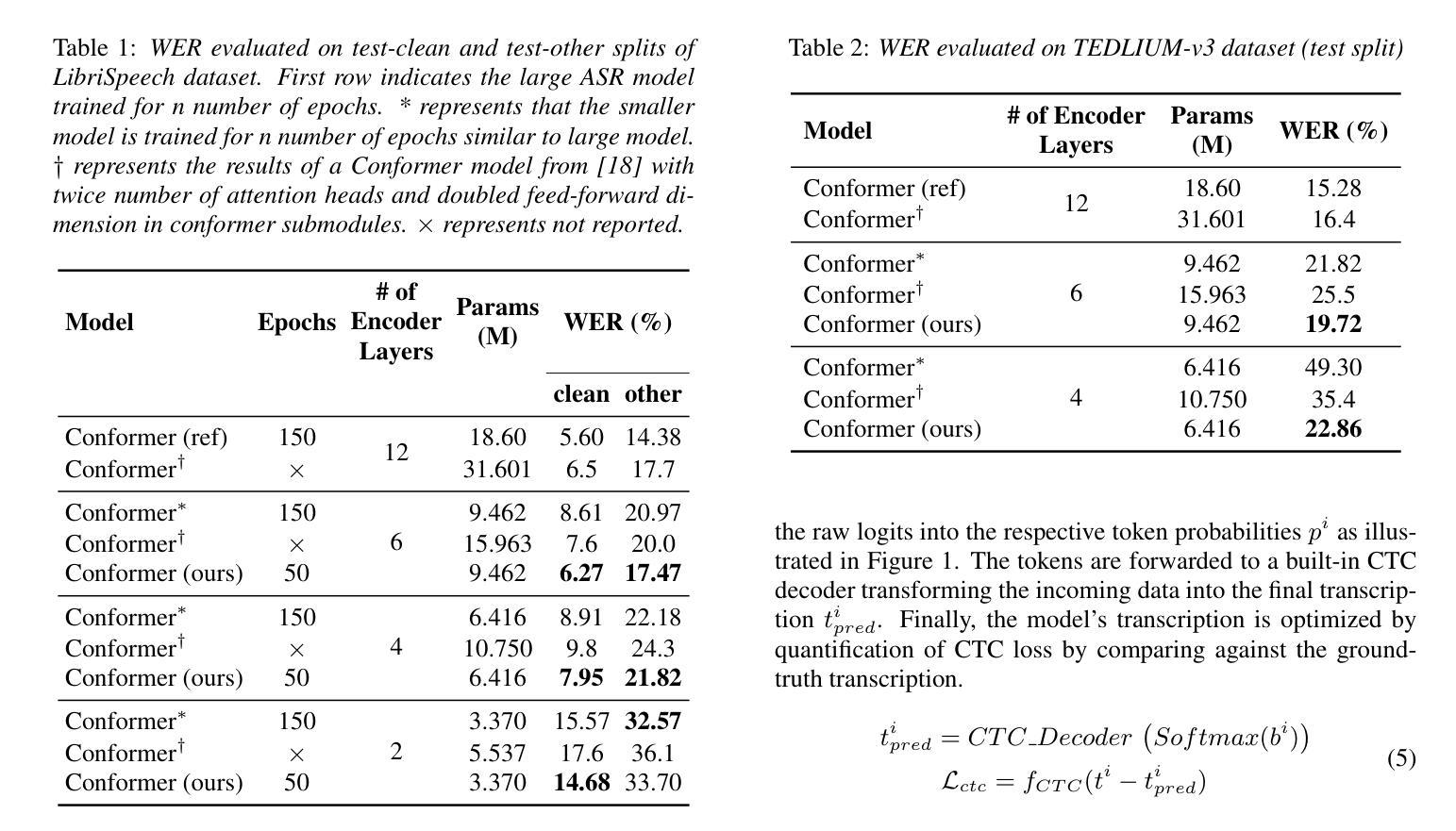
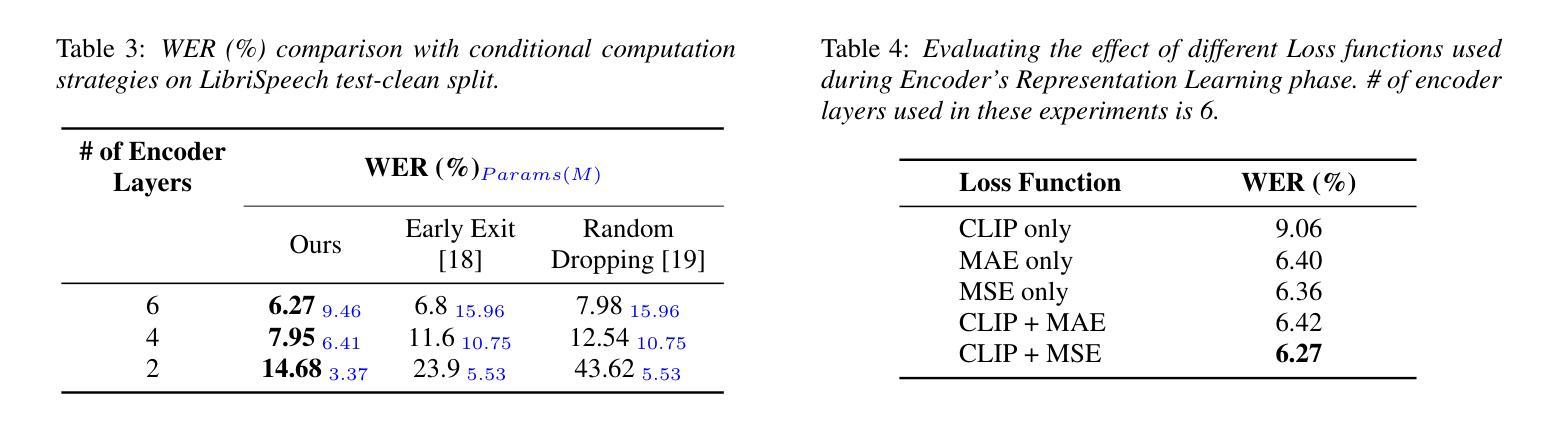
Recent advancement in deep learning encouraged developing large automatic speech recognition (ASR) models that achieve promising results while ignoring computational and memory constraints. However, deploying such models on low resource devices is impractical despite of their favorable performance. Existing approaches (pruning, distillation, layer skip etc.) transform the large models into smaller ones at the cost of significant performance degradation or require prolonged training of smaller models for better performance. To address these issues, we introduce an efficacious two-step representation learning based approach capable of producing several small sized models from a single large model ensuring considerably better performance in limited number of epochs. Comprehensive experimentation on ASR benchmarks reveals the efficacy of our approach, achieving three-fold training speed-up and up to 12.54% word error rate improvement.
近期深度学习的发展促进了大型自动语音识别(ASR)模型的开发,这些模型在忽略计算和内存限制的情况下取得了令人鼓舞的结果。然而,将这种模型部署在资源有限的设备上并不实用,尽管它们的性能表现良好。现有方法(如修剪、蒸馏、层跳过等)将大型模型转化为小型模型,但要以性能显著下降为代价,或者需要对小型模型进行更长时间的训练以获得更好的性能。为了解决这些问题,我们引入了一种有效的两步表示学习的方法,能够从单一的大型模型中生成多个小型模型,并在有限的迭代次数内确保性能显著提升。在ASR基准测试上的综合实验表明了我们方法的有效性,实现了三倍的训练速度提升和最高达到12.54%的词错误率改进。
论文及项目相关链接
PDF Accepted at InterSpeech 2025
Summary:
深度学习领域的最新进展推动了大型自动语音识别(ASR)模型的发展,这些模型在忽略计算和内存约束的情况下取得了令人鼓舞的结果。然而,将这些模型部署在资源有限的设备上并不实用。现有方法(如剪枝、蒸馏、层跳过等)将大型模型转换为小型模型,但牺牲了性能或需要延长小型模型的训练时间。为解决这些问题,我们提出了一种有效的两步表示学习法,能从单一大型模型中生成多个小型模型,并在有限的训练周期内实现显著的性能提升。实验证明,我们的方法实现了三倍的训练速度提升和最高达12.54%的词错误率改进。
Key Takeaways:
- 深度学习推动大型ASR模型发展,但资源有限设备的部署不实用。
- 现有方法转换大型模型到小型模型会牺牲性能或需要延长训练时间。
- 提出了一个基于表示学习的两步方法,从单一大型模型生成多个小型模型。
- 方法实现了显著的性能提升和训练速度提升。
- 实验证明该方法在ASR基准测试上有效。
- 该方法在保证性能的同时,实现了模型的快速训练和部署。
点此查看论文截图

On Multilingual Encoder Language Model Compression for Low-Resource Languages
Authors:Daniil Gurgurov, Michal Gregor, Josef van Genabith, Simon Ostermann
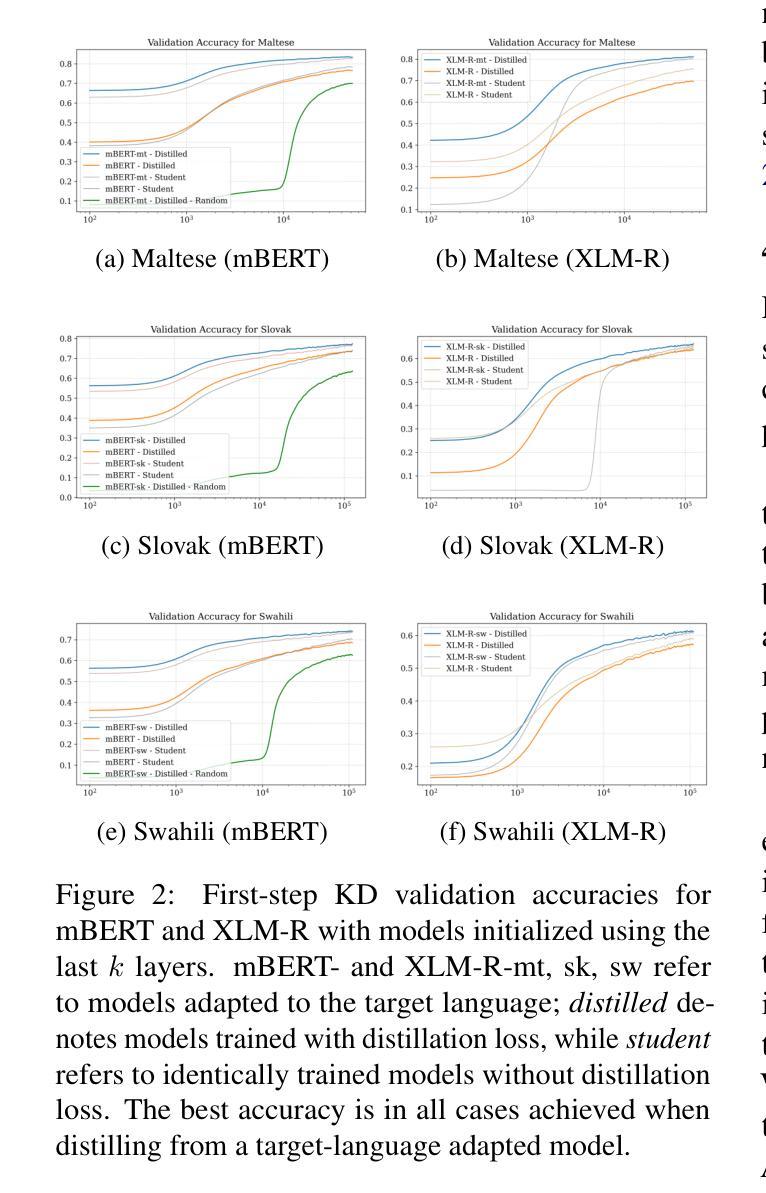
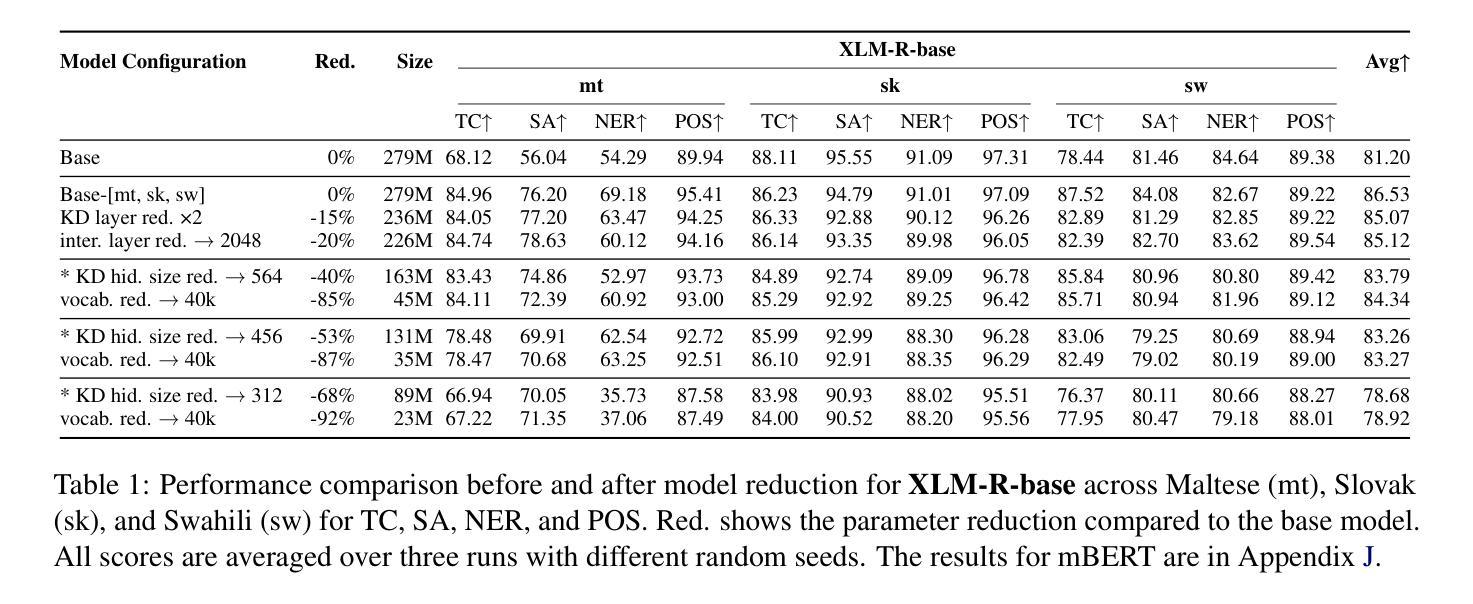
In this paper, we combine two-step knowledge distillation, structured pruning, truncation, and vocabulary trimming for extremely compressing multilingual encoder-only language models for low-resource languages. Our novel approach systematically combines existing techniques and takes them to the extreme, reducing layer depth, feed-forward hidden size, and intermediate layer embedding size to create significantly smaller monolingual models while retaining essential language-specific knowledge. We achieve compression rates of up to 92% with only a marginal performance drop of 2-10% in four downstream tasks, including sentiment analysis, topic classification, named entity recognition, and part-of-speech tagging, across three low-resource languages. Notably, the performance degradation correlates with the amount of language-specific data in the teacher model, with larger datasets resulting in smaller performance losses. Additionally, we conduct extensive ablation studies to identify best practices for multilingual model compression using these techniques.
在这篇论文中,我们结合了两步知识蒸馏、结构化剪枝、截断和词汇缩减等技术,对多语言编码器仅有语言模型进行了极致压缩,适用于资源有限的语言。我们的新方法系统地结合了现有技术并将其推向极致,通过减少层深度、前馈隐藏大小和中间层嵌入大小,在保留关键语言特定知识的同时,创建了显著更小的单语种模型。我们在四种下游任务中实现了高达92%的压缩率,性能仅下降了2-10%,包括情感分析、主题分类、命名实体识别和词性标注,涉及三种资源有限的语言。值得注意的是,性能下降与教师模型中的语言特定数据量相关,更大的数据集导致更小的性能损失。此外,我们还进行了广泛的消融研究,以识别使用这些技术进行多语种模型压缩的最佳实践。
论文及项目相关链接
PDF Pre-print
Summary:
本研究通过结合两步知识蒸馏、结构化剪枝、截断和词汇缩减等技术,对多语言编码器仅语言模型进行极端压缩,适用于低资源语言。通过减少层深度、前馈隐藏大小和中间层嵌入大小,创建显著更小的单语言模型,同时保留关键的语言特定知识。在情感分析、主题分类、命名实体识别和词性标注等四个下游任务中,仅在三种低资源语言上有2-10%的性能下降,实现了高达92%的压缩率。性能下降与教师模型中的语言特定数据量有关,较大数据集导致的性能损失较小。此外,还进行了广泛的研究以确定使用这些技术的多语言模型压缩的最佳实践。
Key Takeaways:
- 本研究通过结合多种技术,实现了对多语言编码器仅语言模型的极端压缩,适用于低资源语言。
- 通过减少模型层深度、前馈隐藏大小和中间层嵌入大小,创建了显著更小的单语言模型。
- 在四个下游任务中实现了高达92%的压缩率,同时性能下降仅为2-10%。
- 性能下降与教师模型中的语言特定数据量有关。
- 在低资源语言上,较大数据集能减小性能损失。
- 研究通过广泛的研究确定了使用多种技术压缩多语言模型的最佳实践。
点此查看论文截图

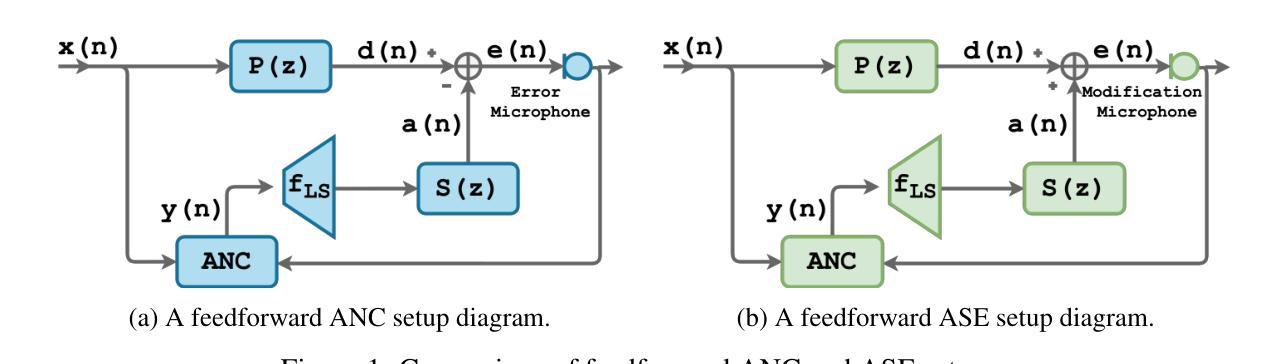
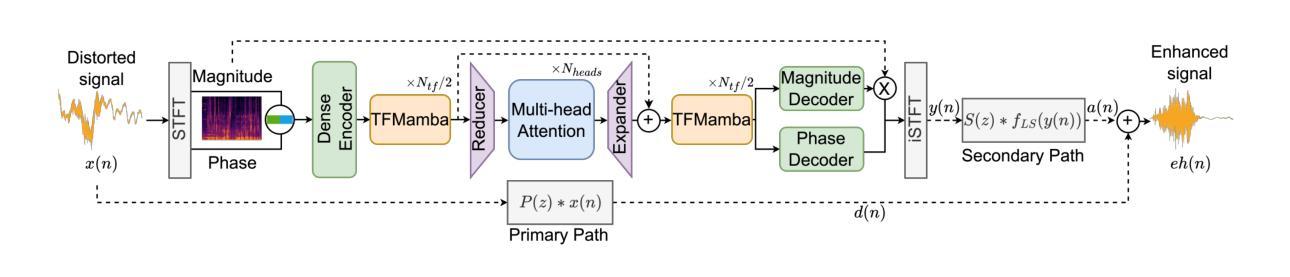
Active Speech Enhancement: Active Speech Denoising Decliping and Deveraberation
Authors:Ofir Yaish, Yehuda Mishaly, Eliya Nachmani
We introduce a new paradigm for active sound modification: Active Speech Enhancement (ASE). While Active Noise Cancellation (ANC) algorithms focus on suppressing external interference, ASE goes further by actively shaping the speech signal – both attenuating unwanted noise components and amplifying speech-relevant frequencies – to improve intelligibility and perceptual quality. To enable this, we propose a novel Transformer-Mamba-based architecture, along with a task-specific loss function designed to jointly optimize interference suppression and signal enrichment. Our method outperforms existing baselines across multiple speech processing tasks – including denoising, dereverberation, and declipping – demonstrating the effectiveness of active, targeted modulation in challenging acoustic environments.
我们介绍了一种主动声音修改的新范式:主动语音增强(ASE)。而主动降噪(ANC)算法主要侧重于抑制外部干扰,ASE更进一步,通过积极塑造语音信号——既减弱不需要的噪声成分,又放大语音相关的频率——来提高可懂度和感知质量。为此,我们提出了一种基于Transformer-Mamba的架构,以及一种针对特定任务的损失函数,旨在联合优化干扰抑制和信号增强。我们的方法在多个语音处理任务上的表现超过了现有基线,包括去噪、去混响和消抖动,证明了在具有挑战性的声学环境中主动、针对性调制的有效性。
论文及项目相关链接
Summary
本文介绍了一种新的主动声音修改范式:主动语音增强(ASE)。与主动噪声消除(ANC)算法侧重于抑制外部干扰不同,ASE通过积极塑造语音信号来提高语音的清晰度和感知质量,既减弱了不需要的噪声成分,又放大了语音相关的频率。为实现这一目标,提出了一种基于Transformer-Mamba的新型架构,以及一种针对干扰抑制和信号丰富联合优化的特定任务损失函数。该方法在多个语音处理任务上优于现有基线,包括去噪、去混响和去剪辑,证明了在具有挑战性的声学环境中进行主动、针对性调制的有效性。
Key Takeaways
- 介绍了主动语音增强(ASE)这一新的声音修改范式。
- 与主动噪声消除(ANC)不同,ASE旨在积极塑造语音信号。
- ASE能同时减弱不需要的噪声成分并放大语音相关的频率。
- 提出了一种基于Transformer-Mamba的新型架构来实现ASE。
- 损失函数的设计能联合优化干扰抑制和信号丰富。
- 该方法在多个语音处理任务上的表现优于现有基线。
点此查看论文截图

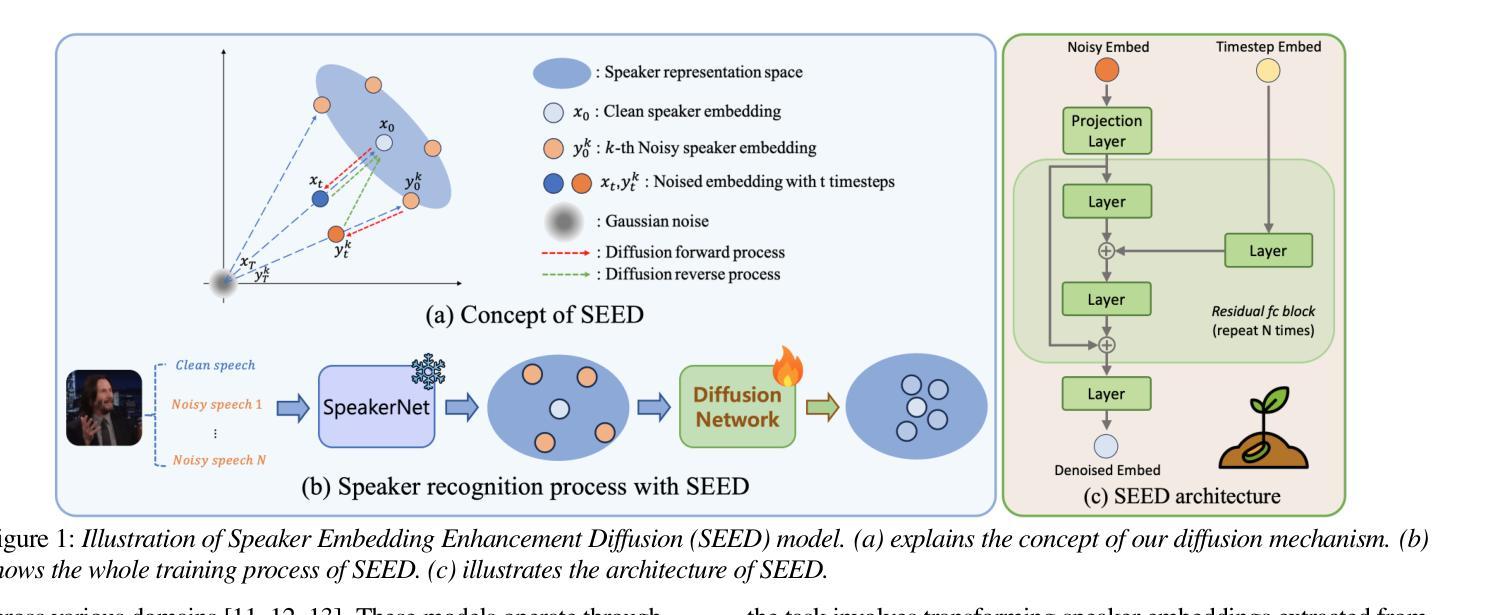
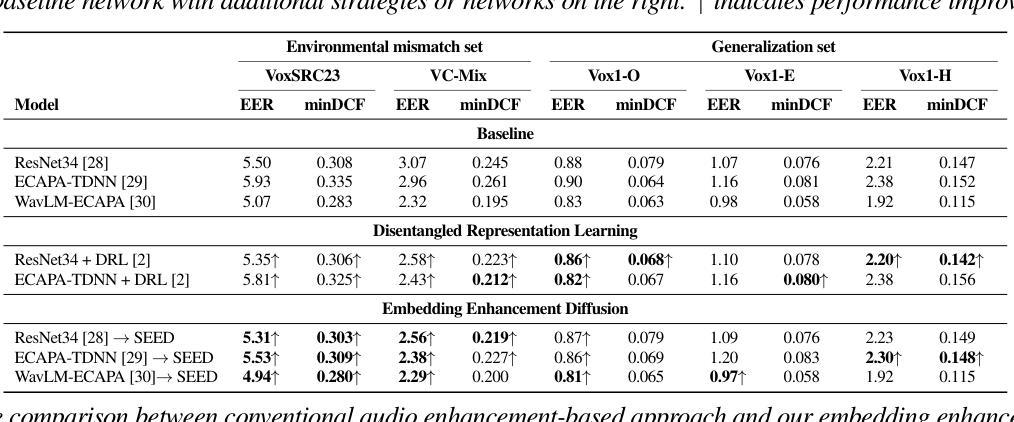
SEED: Speaker Embedding Enhancement Diffusion Model
Authors:KiHyun Nam, Jungwoo Heo, Jee-weon Jung, Gangin Park, Chaeyoung Jung, Ha-Jin Yu, Joon Son Chung
A primary challenge when deploying speaker recognition systems in real-world applications is performance degradation caused by environmental mismatch. We propose a diffusion-based method that takes speaker embeddings extracted from a pre-trained speaker recognition model and generates refined embeddings. For training, our approach progressively adds Gaussian noise to both clean and noisy speaker embeddings extracted from clean and noisy speech, respectively, via forward process of a diffusion model, and then reconstructs them to clean embeddings in the reverse process. While inferencing, all embeddings are regenerated via diffusion process. Our method needs neither speaker label nor any modification to the existing speaker recognition pipeline. Experiments on evaluation sets simulating environment mismatch scenarios show that our method can improve recognition accuracy by up to 19.6% over baseline models while retaining performance on conventional scenarios. We publish our code here https://github.com/kaistmm/seed-pytorch
在现实世界应用中部署语音识别系统时面临的主要挑战是环境不匹配导致的性能下降。我们提出了一种基于扩散的方法,该方法采用从预训练的语音识别模型中提取的说话人嵌入,并生成精细的嵌入。在训练过程中,我们的方法通过扩散模型的正向过程,逐步向干净和带有噪音的语音中提取的干净和带噪音的说话人嵌入添加高斯噪音,然后在反向过程中将它们重建为干净的嵌入。在推理过程中,所有嵌入都是通过扩散过程重新生成的。我们的方法既不需要说话人标签,也不需要修改现有的语音识别管道。在模拟环境不匹配场景的评价集上进行的实验表明,我们的方法可以在保持传统场景性能的同时,将基线模型的识别准确率提高高达19.6%。我们已将代码发布在https://github.com/kaistmm/seed-pytorch上。
论文及项目相关链接
PDF Accepted to Interspeech 2025. The official code can be found at https://github.com/kaistmm/seed-pytorch
Summary
本论文提出了一种基于扩散模型的优化方法,用于改善实际部署中的说话人识别系统因环境不匹配导致的性能下降问题。该方法利用预训练的说话人识别模型提取说话人嵌入,并通过扩散过程生成精细化的嵌入。训练过程中,对干净和带噪声的说话人嵌入逐步添加高斯噪声,再通过扩散模型的逆向过程重建为干净嵌入。在推断阶段,所有嵌入都通过扩散过程重新生成。该方法既不需要说话人标签,也不需要对现有的说话人识别流程进行修改。实验结果表明,该方法在模拟环境不匹配场景的评估集上,相较于基准模型,识别准确率提高了高达19.6%,同时在常规场景上保持了性能。
Key Takeaways
- 说话人识别系统在现实应用中的主要挑战之一是环境不匹配导致的性能下降。
- 论文提出了一种基于扩散模型的优化方法,用于改善因环境不匹配导致的性能问题。
- 该方法利用预训练的说话人识别模型提取嵌入,并通过扩散过程生成精细化的嵌入。
- 训练过程中,干净和带噪声的说话人嵌入会受到高斯噪声的干扰,然后通过逆向过程重建为干净嵌入。
- 在推断阶段,所有嵌入都通过扩散过程重新生成,无需额外的标签或修改现有流程。
- 实验结果表明,该方法在模拟环境不匹配场景的评估集上显著提高了识别准确率。
点此查看论文截图

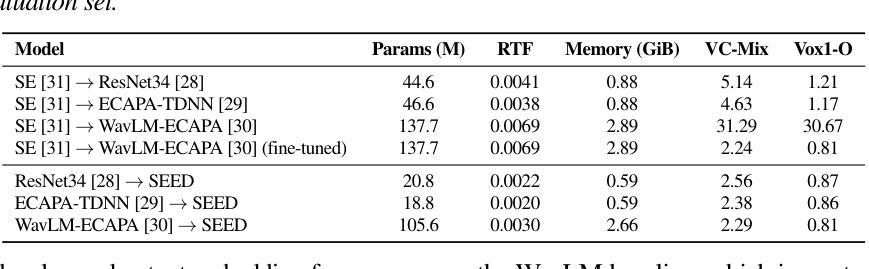
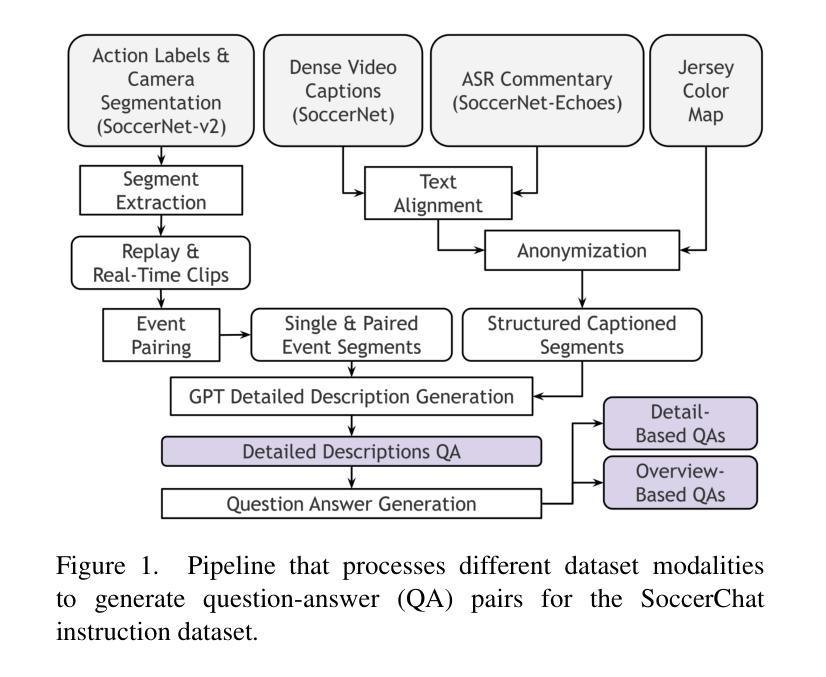
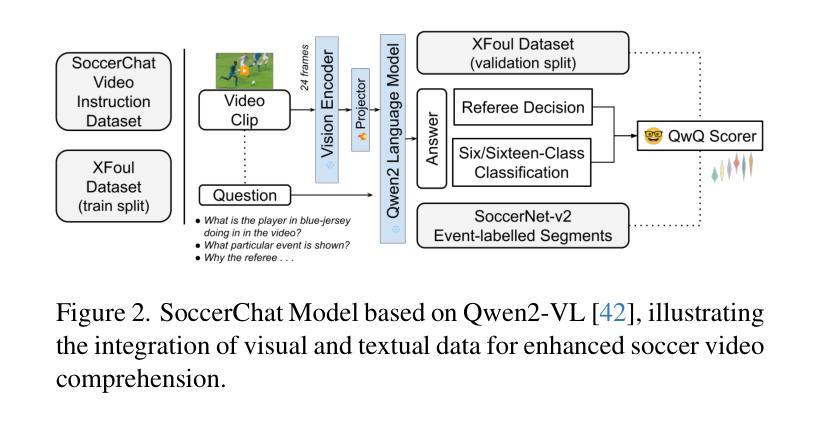
SoccerChat: Integrating Multimodal Data for Enhanced Soccer Game Understanding
Authors:Sushant Gautam, Cise Midoglu, Vajira Thambawita, Michael A. Riegler, Pål Halvorsen, Mubarak Shah
The integration of artificial intelligence in sports analytics has transformed soccer video understanding, enabling real-time, automated insights into complex game dynamics. Traditional approaches rely on isolated data streams, limiting their effectiveness in capturing the full context of a match. To address this, we introduce SoccerChat, a multimodal conversational AI framework that integrates visual and textual data for enhanced soccer video comprehension. Leveraging the extensive SoccerNet dataset, enriched with jersey color annotations and automatic speech recognition (ASR) transcripts, SoccerChat is fine-tuned on a structured video instruction dataset to facilitate accurate game understanding, event classification, and referee decision making. We benchmark SoccerChat on action classification and referee decision-making tasks, demonstrating its performance in general soccer event comprehension while maintaining competitive accuracy in referee decision making. Our findings highlight the importance of multimodal integration in advancing soccer analytics, paving the way for more interactive and explainable AI-driven sports analysis. https://github.com/simula/SoccerChat
将人工智能融入体育分析已经改变了对足球视频的理解方式,能够实现针对复杂比赛动态的实时自动化洞察。传统方法依赖于孤立的数据流,在捕捉比赛的完整上下文方面存在局限性。为了解决这一问题,我们推出了SoccerChat,这是一个多模式对话人工智能框架,融合了视觉和文本数据,以提高足球视频的理解能力。借助丰富的SoccerNet数据集,通过增加球衣颜色注释和自动语音识别(ASR)转录本进行丰富,SoccerChat在结构化视频指令数据集上进行微调,以促进准确的比赛理解、事件分类和裁判决策制定。我们在动作分类和裁判决策制定任务上对SoccerChat进行了基准测试,证明了其在一般足球事件理解方面的性能,同时在裁判决策制定方面保持了竞争性的准确性。我们的研究强调了多模式融合在推进足球分析方面的重要性,为更交互和可解释的AI驱动的体育分析铺平了道路。相关链接:https://github.com/simula/SoccerChat。
论文及项目相关链接
Summary
人工智能在体育分析领域的应用已经转变了人们对足球比赛视频的理解方式,通过实时、自动化的复杂比赛动态洞察。传统方法依赖于孤立的数据流,无法全面捕捉比赛上下文。为此,我们推出SoccerChat——一个多模式对话式人工智能框架,融合了视觉和文字数据,以提高足球视频的理解能力。借助丰富的SoccerNet数据集,通过球衣颜色标注和自动语音识别(ASR)转录进行丰富,SoccerChat在结构化视频指令数据集上进行微调,以促进准确的游戏理解、事件分类和裁判决策。我们在动作分类和裁判决策任务上对SoccerChat进行了评估,证明了它在一般足球事件理解方面的表现,同时在裁判决策制定方面保持竞争性的准确性。我们的研究突出了多模式融合在推动足球分析方面的重要性,为更加交互和可解释的AI驱动的体育分析铺平了道路。
Key Takeaways
- 人工智能在体育分析领域的应用已经改变了对足球视频的理解方式。
- 传统方法难以全面捕捉足球比赛的上下文信息。
- SoccerChat是一个多模式对话式AI框架,融合了视觉和文字数据来提高足球视频理解。
- SoccerChat利用SoccerNet数据集和自动语音识别技术进行优化。
- SoccerChat在动作分类和裁判决策任务上表现出良好的性能。
- 多模式融合对于提高足球分析的重要性。
点此查看论文截图

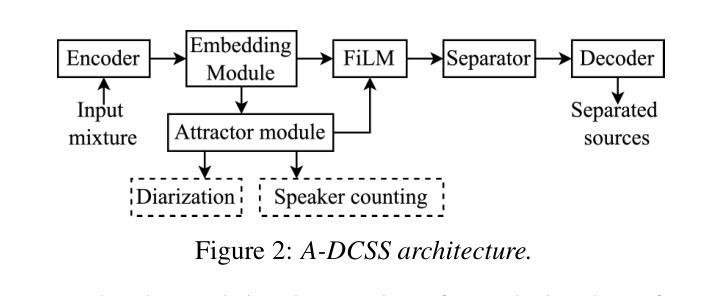
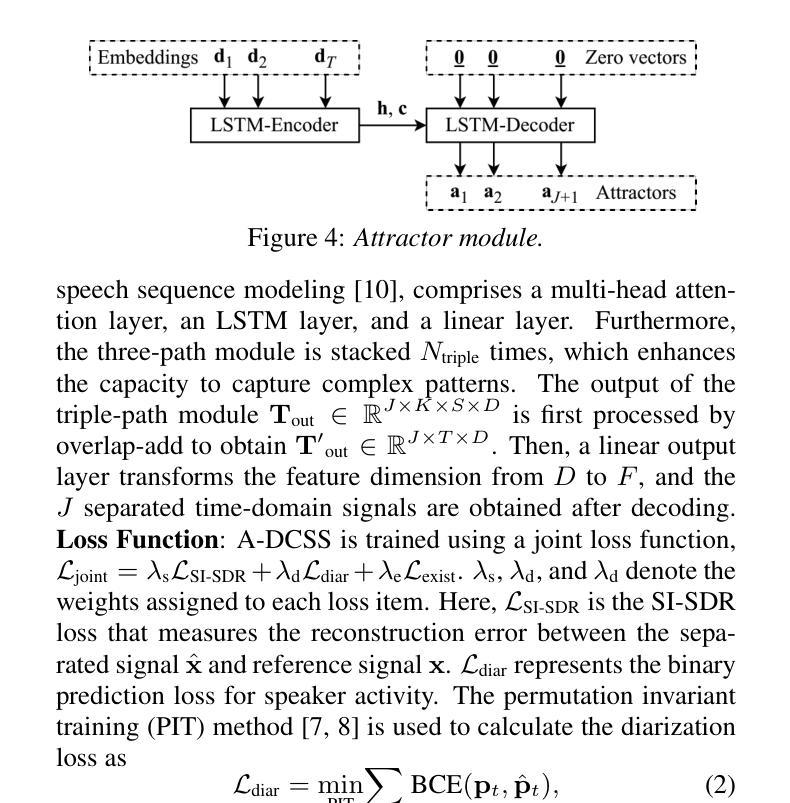
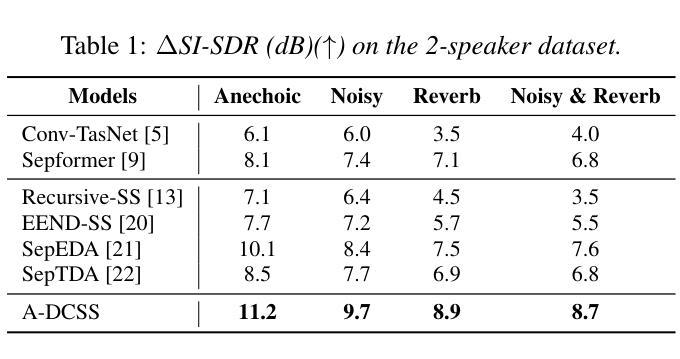
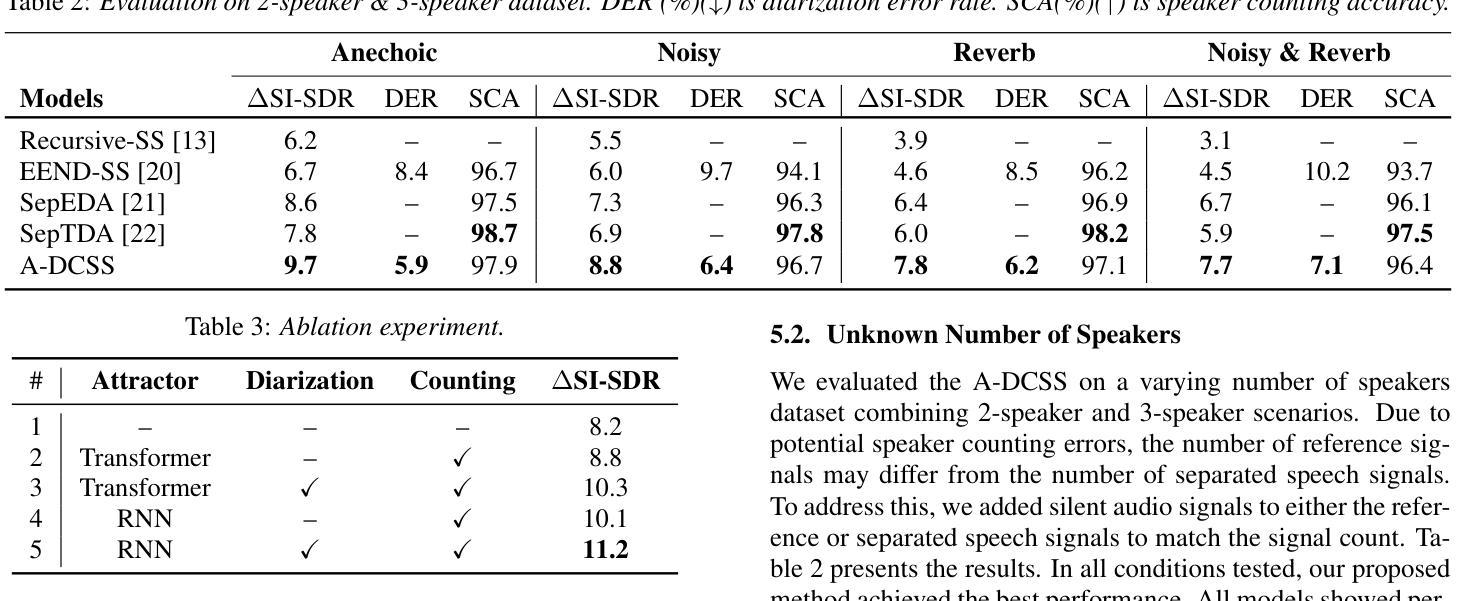
Attractor-Based Speech Separation of Multiple Utterances by Unknown Number of Speakers
Authors:Yuzhu Wang, Archontis Politis, Konstantinos Drossos, Tuomas Virtanen
This paper addresses the problem of single-channel speech separation, where the number of speakers is unknown, and each speaker may speak multiple utterances. We propose a speech separation model that simultaneously performs separation, dynamically estimates the number of speakers, and detects individual speaker activities by integrating an attractor module. The proposed system outperforms existing methods by introducing an attractor-based architecture that effectively combines local and global temporal modeling for multi-utterance scenarios. To evaluate the method in reverberant and noisy conditions, a multi-speaker multi-utterance dataset was synthesized by combining Librispeech speech signals with WHAM! noise signals. The results demonstrate that the proposed system accurately estimates the number of sources. The system effectively detects source activities and separates the corresponding utterances into correct outputs in both known and unknown source count scenarios.
本文解决了单通道语音分离的问题,其中未知说话人数量,每个说话人可能会发出多次话语。我们提出了一种语音分离模型,该模型通过集成吸引模块,同时执行分离、动态估计说话人数以及检测单个说话人的活动。通过引入基于吸引器的架构,有效结合局部和全局时间建模,为多重话语场景提供多话语场景数据集,所提出系统在性能上优于现有方法。为了评估在混响和噪音条件下的方法,我们通过结合Librispeech语音信号和WHAM!噪音信号合成多说话人多话语数据集。结果表明,该系统准确估计了源数量。系统有效地检测源活动,并将相应的讲话内容分离为已知和未知源数的正确输出。
论文及项目相关链接
PDF 5 pages, 4 figures, accepted by Interspeech 2025
总结
本文提出了一种解决单通道语音分离问题的方法,其中未知说话人数量,且每个说话人可能发出多次连续说话。通过集成吸引模块,该语音分离模型可同时实现分离、动态估计说话人数和检测单个说话人的活动。该模型引入基于吸引器的架构,有效结合本地和全局时间建模,为多连续发言场景提供优势,从而超越现有方法。为评估该模型在混响和噪音条件下的性能,合成了一个多发言人连续发言数据集,结合了Librispeech语音信号与WHAM!噪音信号。实验结果表明,该模型能准确估计源的数量,并在已知和未知源计数场景下有效检测源活动和将相应的连续发言正确分离。
关键见解
- 论文解决的是单通道语音分离问题,其中说话人的数量未知,且每个说话人可能连续发言。
- 提出了一种语音分离模型,该模型通过集成吸引模块实现多种功能,包括语音分离、动态估计说话人数和检测单个说话人的活动。
- 模型采用基于吸引器的架构,有效结合本地和全局时间建模,以处理多连续发言场景。
- 模型在合成数据集上进行了评估,该数据集结合了Librispeech和WHAM!的语音和噪音信号,以模拟真实环境中的混响和噪音影响。
- 模型能准确估计源的数量,即使在源数量未知的情况下也能有效工作。
- 模型可以有效地检测源活动并将连续发言正确分离为不同的输出。
- 该模型在语音分离领域展现出优异的性能,可能为未来相关研究提供新的方向。
点此查看论文截图

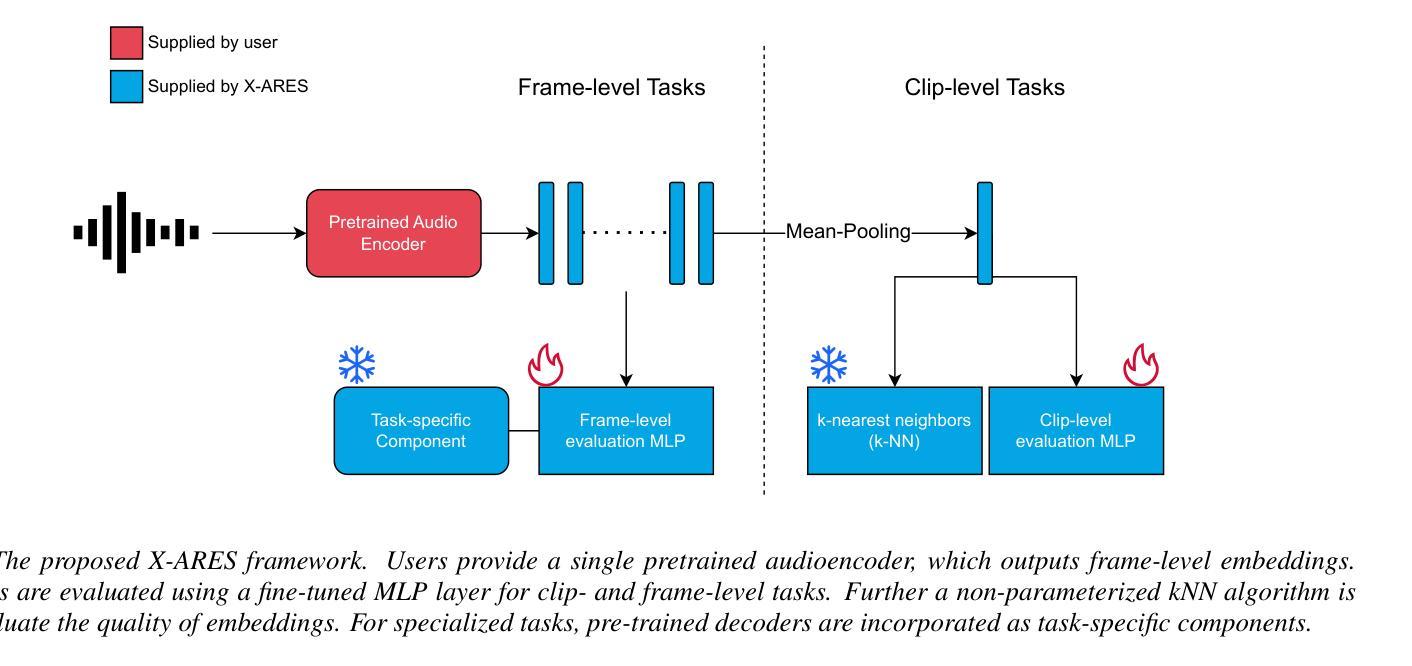
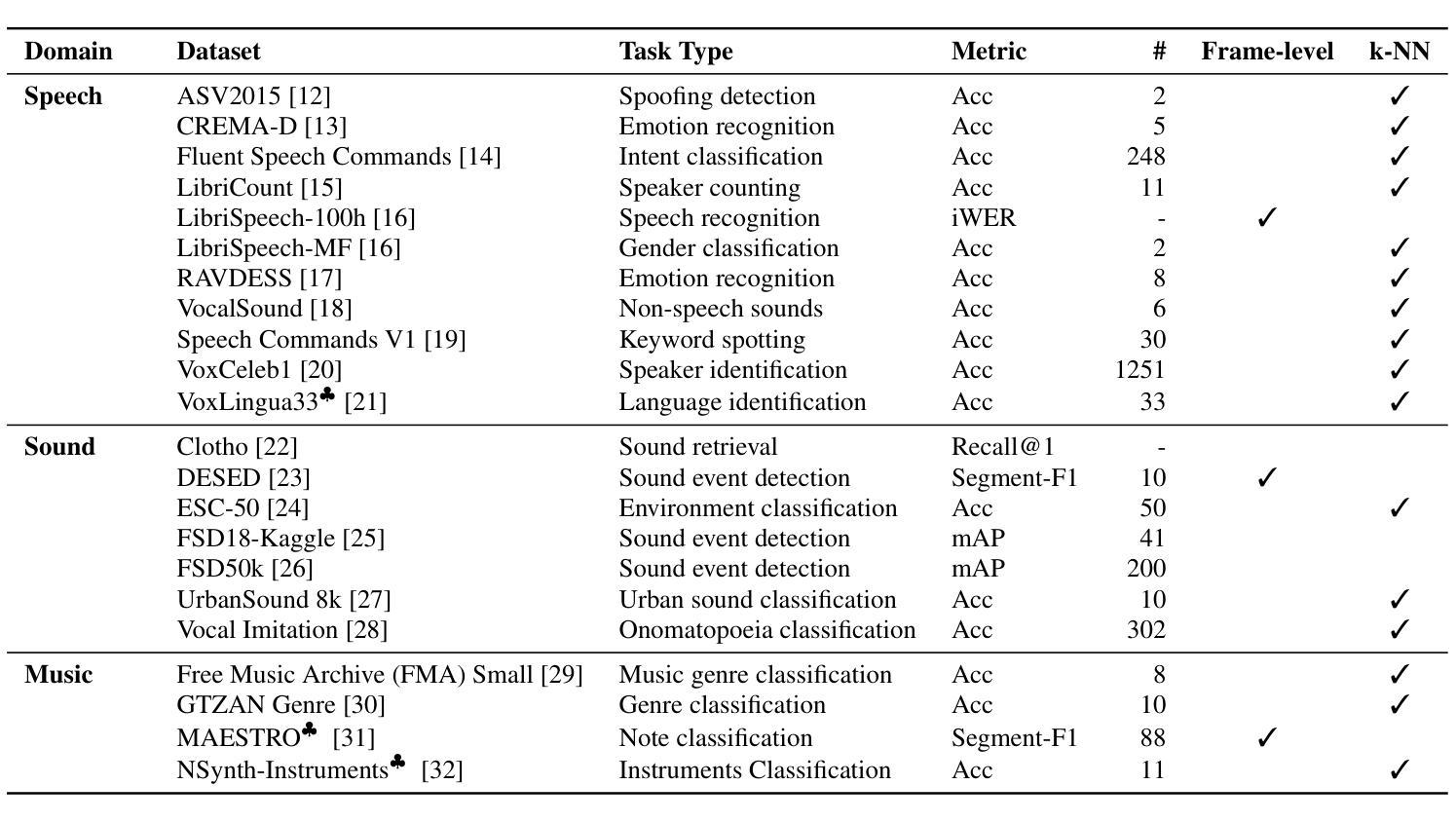
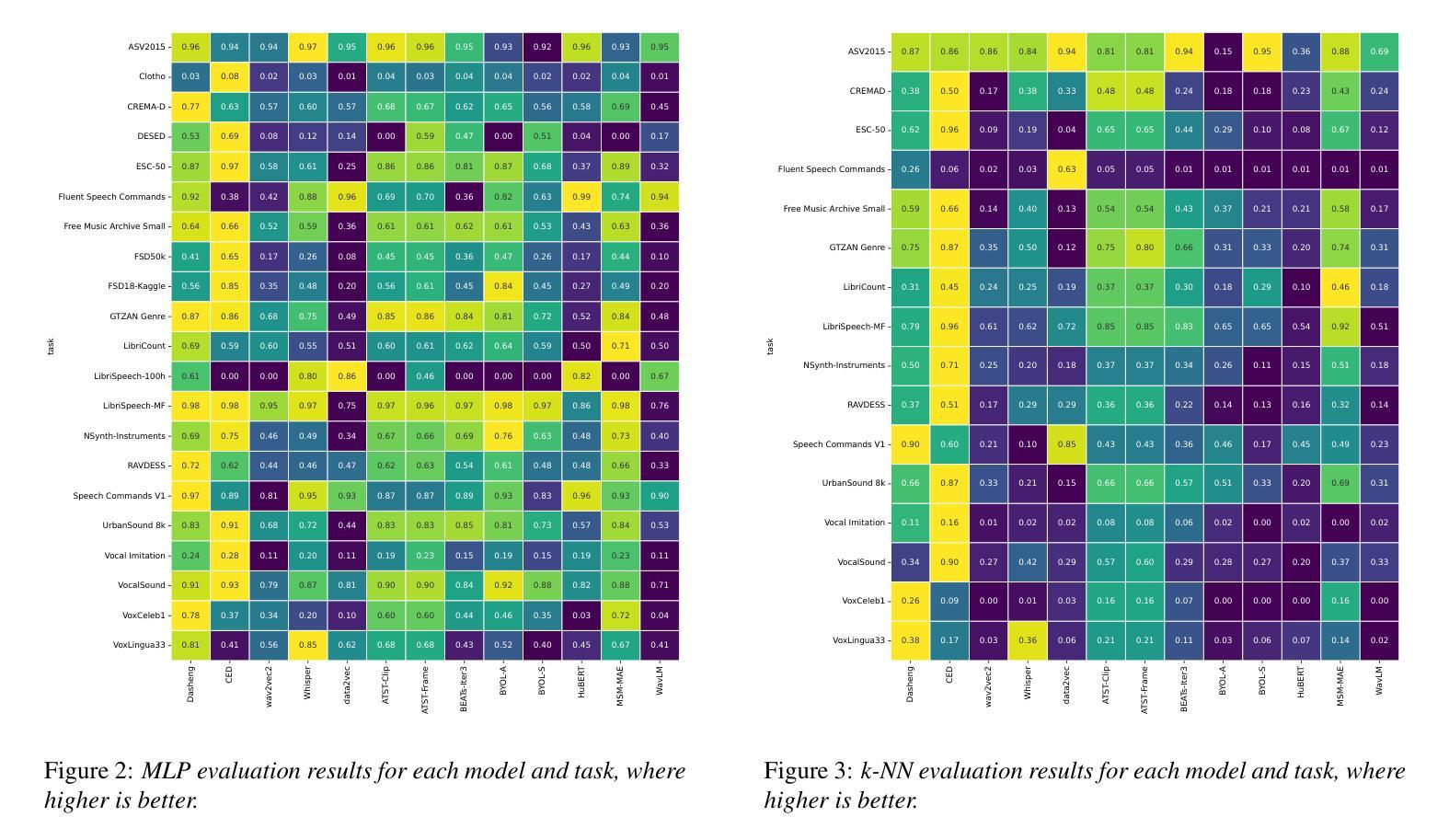
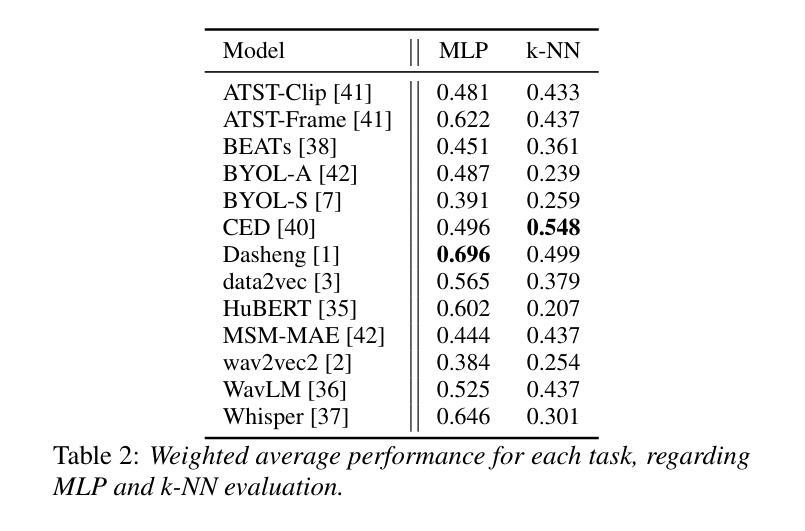
X-ARES: A Comprehensive Framework for Assessing Audio Encoder Performance
Authors:Junbo Zhang, Heinrich Dinkel, Yadong Niu, Chenyu Liu, Si Cheng, Anbei Zhao, Jian Luan
We introduces X-ARES (eXtensive Audio Representation and Evaluation Suite), a novel open-source benchmark designed to systematically assess audio encoder performance across diverse domains. By encompassing tasks spanning speech, environmental sounds, and music, X-ARES provides two evaluation approaches for evaluating audio representations: linear fine-tuning and unparameterized evaluation. The framework includes 22 distinct tasks that cover essential aspects of audio processing, from speech recognition and emotion detection to sound event classification and music genre identification. Our extensive evaluation of state-of-the-art audio encoders reveals significant performance variations across different tasks and domains, highlighting the complexity of general audio representation learning.
我们介绍了X-ARES(扩展音频表示和评估套件),这是一个新型开源基准测试,旨在系统地评估不同领域音频编码器的性能。X-ARES涵盖了语音、环境声音和音乐等任务,为评估音频表示提供了两种评估方法:线性微调和无参数评估。该框架包括涵盖音频处理各个方面的22个不同任务,从语音识别和情感检测到声音事件分类和音乐风格识别。我们对最先进的音频编码器的广泛评估表明,不同任务和领域之间的性能存在很大差异,这突出了通用音频表示学习的复杂性。
论文及项目相关链接
PDF Accepted by Interspeech 2025
Summary
本文介绍了X-ARES(广泛音频表示和评估套件),这是一个新型的开源基准测试,旨在系统地评估不同领域音频编码器的性能。X-ARES涵盖了涵盖语音、环境声音和音乐的任务,提供了两种评估音频表示的方法:线性微调和无参数评估。该框架包括22个不同的任务,涵盖音频处理的重要方面,如语音识别、情感检测、声音事件分类和音乐风格识别。对最先进的音频编码器的广泛评估表明,不同任务和领域之间的性能存在显著差异,突出了通用音频表示学习复杂性。
Key Takeaways
- X-ARES是一个新型的开源基准测试,旨在评估音频编码器的性能。
- X-ARES涵盖了语音、环境声音和音乐等多种领域的任务。
- X-ARES提供了两种评估音频表示的方法:线性微调和无参数评估。
- 框架包含22个不同的任务,涵盖音频处理的重要方面,如语音识别、情感检测、声音事件分类和音乐风格识别。
- 广泛评估显示,不同任务和领域之间音频编码器的性能存在显著差异。
- 评估结果强调了通用音频表示学习的复杂性。
点此查看论文截图

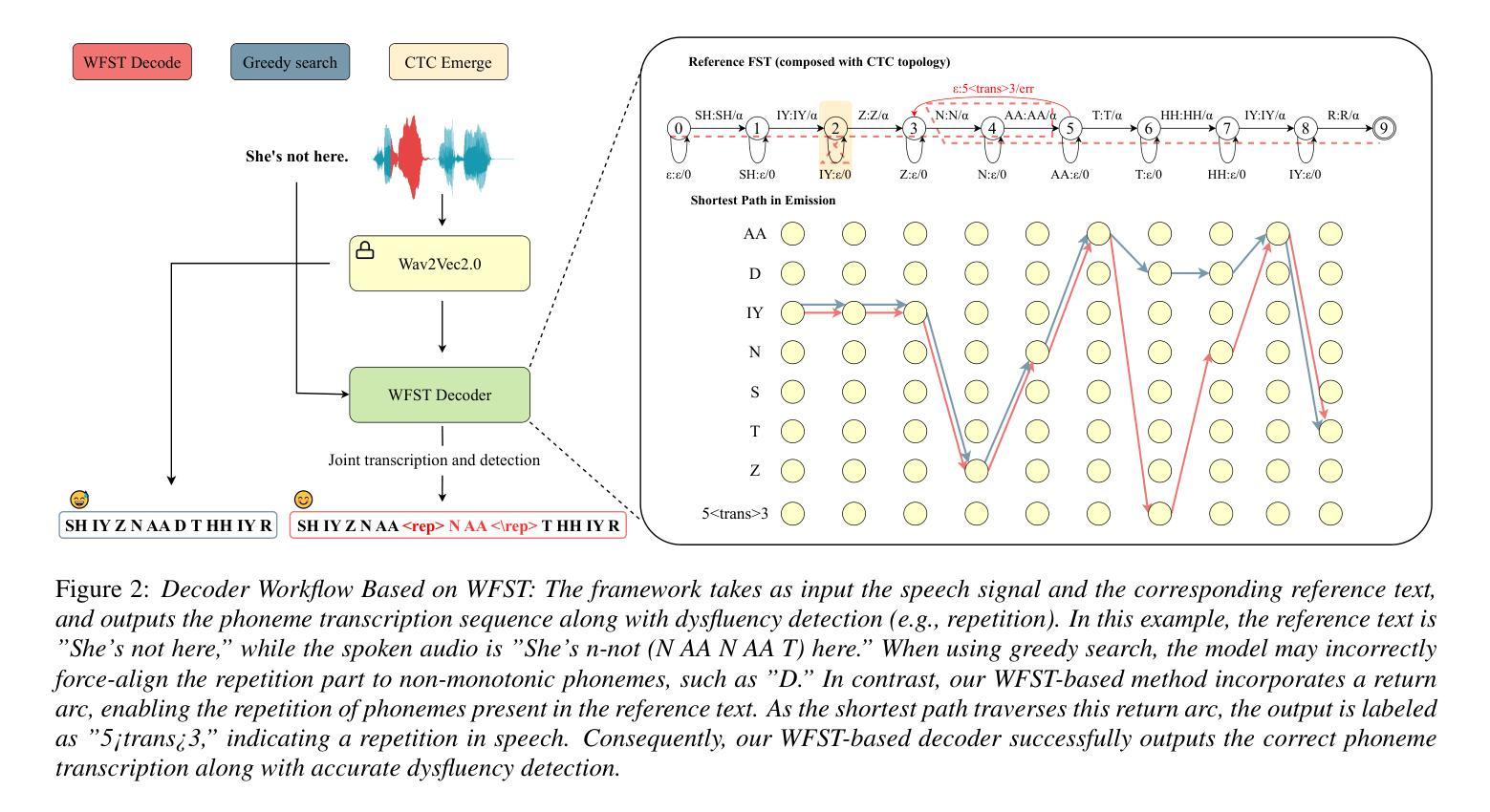
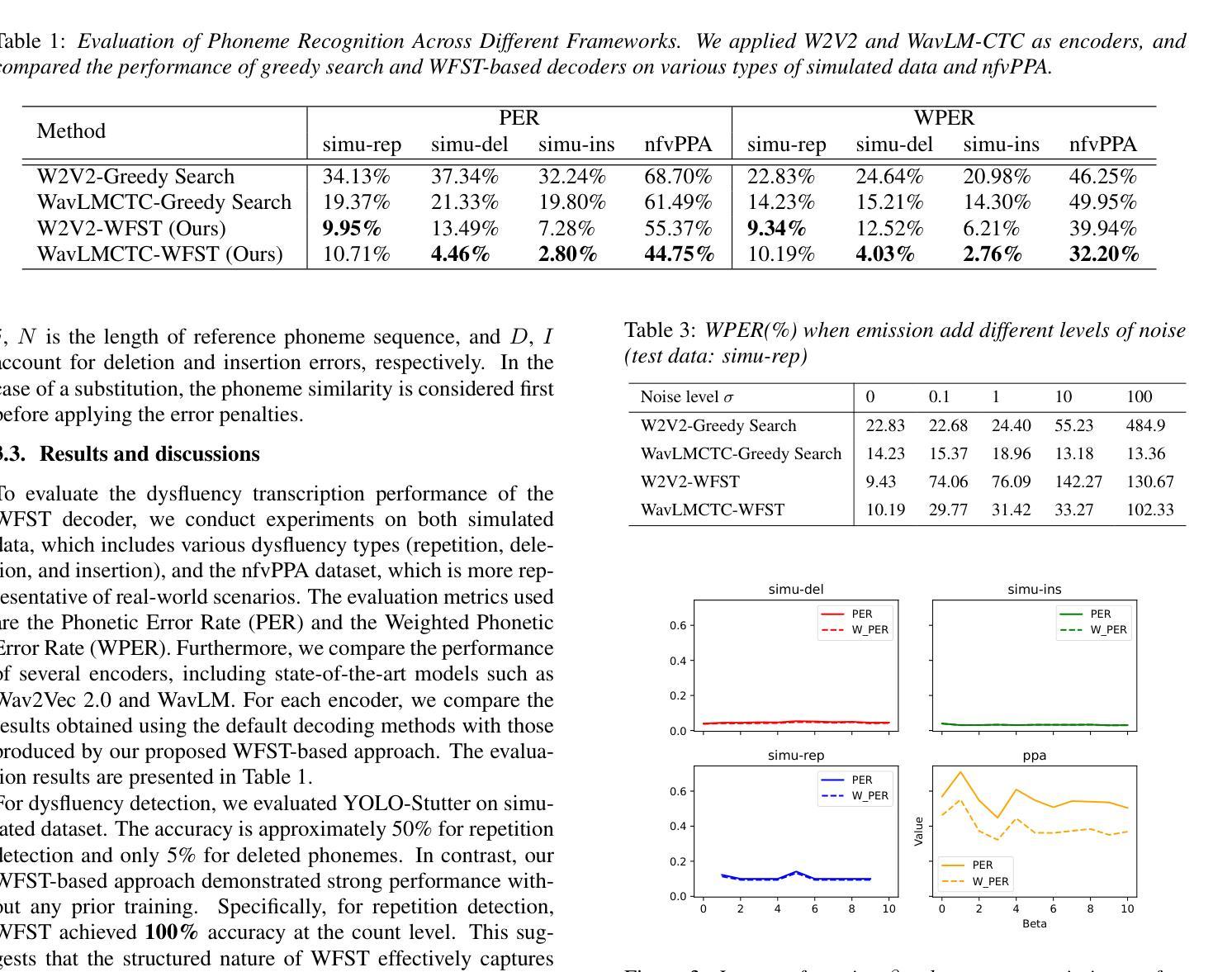
Dysfluent WFST: A Framework for Zero-Shot Speech Dysfluency Transcription and Detection
Authors:Chenxu Guo, Jiachen Lian, Xuanru Zhou, Jinming Zhang, Shuhe Li, Zongli Ye, Hwi Joo Park, Anaisha Das, Zoe Ezzes, Jet Vonk, Brittany Morin, Rian Bogley, Lisa Wauters, Zachary Miller, Maria Gorno-Tempini, Gopala Anumanchipalli
Automatic detection of speech dysfluency aids speech-language pathologists in efficient transcription of disordered speech, enhancing diagnostics and treatment planning. Traditional methods, often limited to classification, provide insufficient clinical insight, and text-independent models misclassify dysfluency, especially in context-dependent cases. This work introduces Dysfluent-WFST, a zero-shot decoder that simultaneously transcribes phonemes and detects dysfluency. Unlike previous models, Dysfluent-WFST operates with upstream encoders like WavLM and requires no additional training. It achieves state-of-the-art performance in both phonetic error rate and dysfluency detection on simulated and real speech data. Our approach is lightweight, interpretable, and effective, demonstrating that explicit modeling of pronunciation behavior in decoding, rather than complex architectures, is key to improving dysfluency processing systems.
自动检测语言流畅性障碍有助于语言病理学家有效地转录障碍性语言,提高诊断和制定治疗方案。传统的方法通常仅限于分类,提供的临床见解不足,并且文本独立模型容易误判语言流畅性障碍,特别是在依赖语境的案例中。本研究引入了Dysfluent-WFST,这是一种零样本解码器,可以同时转录音素并检测语言流畅性障碍。不同于之前的模型,Dysfluent-WFST与上游编码器(如WavLM)一起运行,无需额外训练。它在模拟和真实语音数据上达到了语音错误率和语言流畅性检测方面的最佳性能。我们的方法轻便、可解释性强且有效,表明在解码过程中明确建模发音行为,而不是使用复杂的架构,是提高语言流畅性处理系统的关键。
论文及项目相关链接
Summary
自动检测语言流畅性障碍有助于语言病理学家高效地转录障碍性语言,从而提高诊断和制定治疗方案。传统方法往往局限于分类,提供不足的临床见解,而独立于文本的模型在上下文相关的案例中误判语言流畅性障碍。本研究引入Dysfluent-WFST模型,一种零射击解码器可同时转录音素并检测语言流畅性障碍。与其他模型不同,Dysfluent-WFST与上游编码器如WavLM协同工作,无需额外训练。它在模拟和实际语音数据上均实现了语音错误率和语言流畅性障碍检测的卓越性能。我们的方法具有轻便性、解释性和有效性,证明了解码过程中显式建模发音行为而非复杂架构是提高语言流畅性处理系统的关键。
Key Takeaways
- 自动检测语言流畅性障碍可提高诊断与治疗效率。
- 传统方法在分类上存在局限性,需要新方法提供更深入的见解。
点此查看论文截图



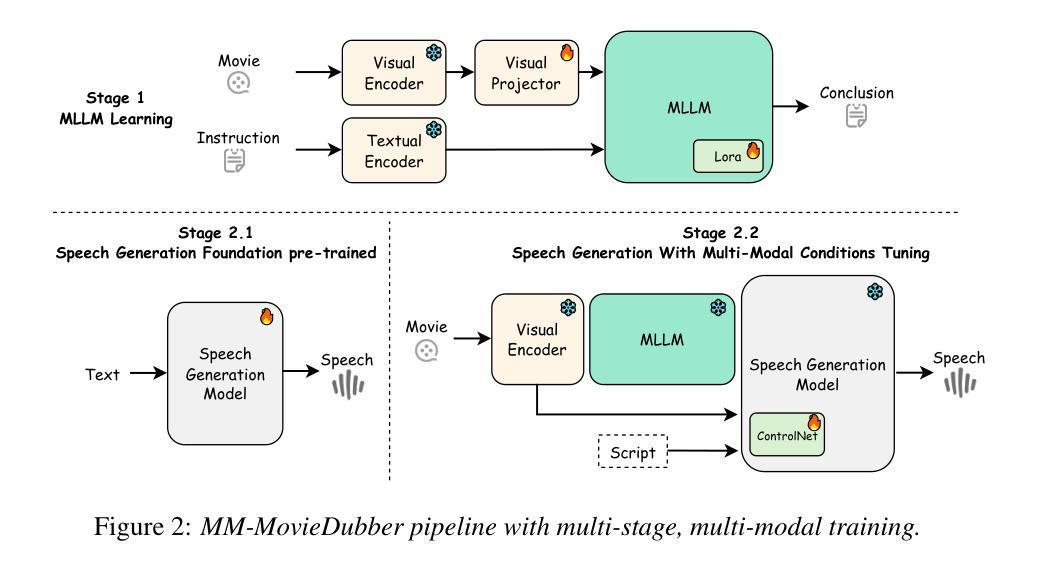
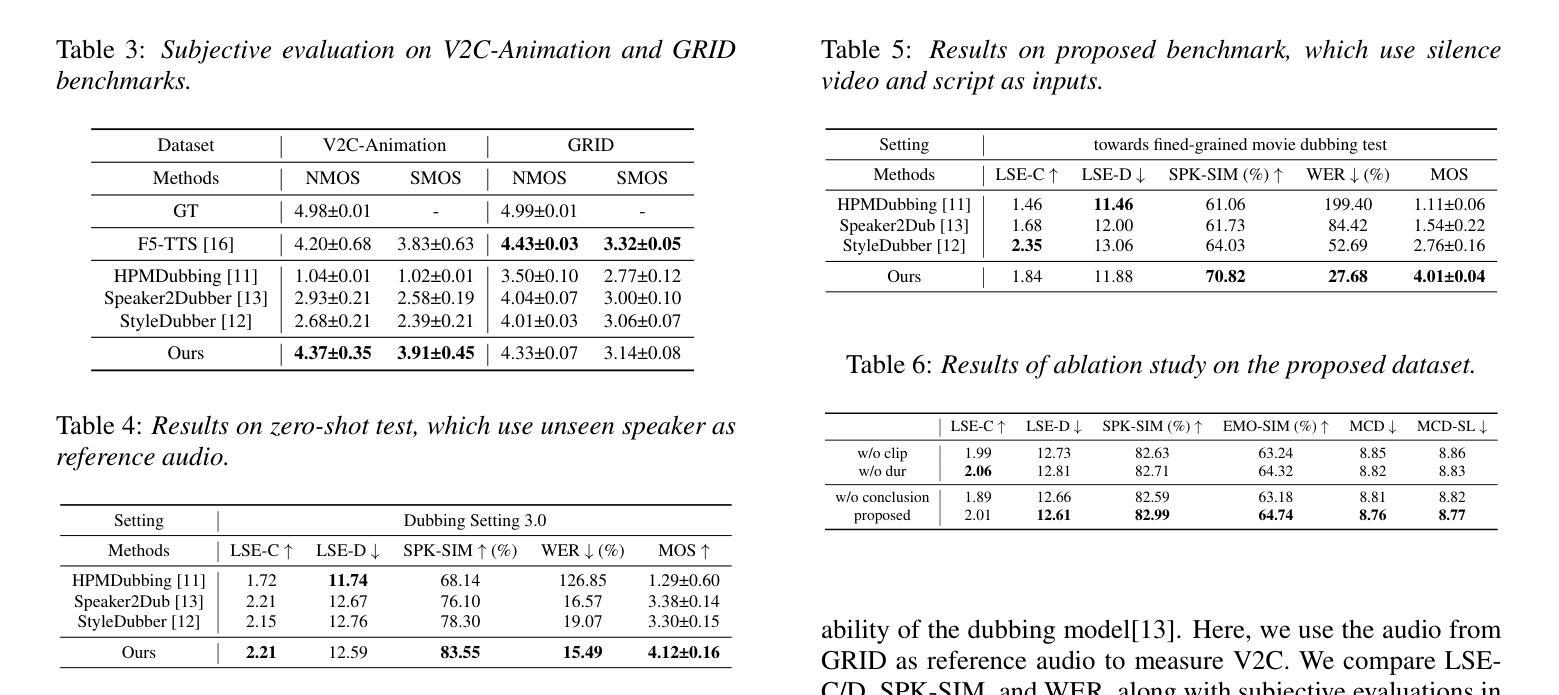
MM-MovieDubber: Towards Multi-Modal Learning for Multi-Modal Movie Dubbing
Authors:Junjie Zheng, Zihao Chen, Chaofan Ding, Yunming Liang, Yihan Fan, Huan Yang, Lei Xie, Xinhan Di
Current movie dubbing technology can produce the desired speech using a reference voice and input video, maintaining perfect synchronization with the visuals while effectively conveying the intended emotions. However, crucial aspects of movie dubbing, including adaptation to various dubbing styles, effective handling of dialogue, narration, and monologues, as well as consideration of subtle details such as speaker age and gender, remain insufficiently explored. To tackle these challenges, we introduce a multi-modal generative framework. First, it utilizes a multi-modal large vision-language model (VLM) to analyze visual inputs, enabling the recognition of dubbing types and fine-grained attributes. Second, it produces high-quality dubbing using large speech generation models, guided by multi-modal inputs. Additionally, a movie dubbing dataset with annotations for dubbing types and subtle details is constructed to enhance movie understanding and improve dubbing quality for the proposed multi-modal framework. Experimental results across multiple benchmark datasets show superior performance compared to state-of-the-art (SOTA) methods. In details, the LSE-D, SPK-SIM, EMO-SIM, and MCD exhibit improvements of up to 1.09%, 8.80%, 19.08%, and 18.74%, respectively.
当前的电影配音技术可以使用参考声音和输入视频来生成所需的语音,在视觉效果上保持完美的同步,同时有效地传达预期的情感。然而,电影配音的关键方面,包括适应各种配音风格、有效处理对话、旁白和独白,以及考虑诸如演讲者年龄和性别等细微细节,仍然没有得到足够的探索。为了应对这些挑战,我们引入了一种多模态生成框架。首先,它利用多模态大型视觉语言模型(VLM)来分析视觉输入,能够识别配音类型和精细属性。其次,它使用大型语音生成模型生成高质量的配音,这些模型受到多模态输入的指导。此外,还构建了一个包含配音类型和细微细节注释的电影配音数据集,以提高电影理解和提高所提出的多模态框架的配音质量。在多个基准数据集上的实验结果表明,与最新方法相比,该框架具有卓越的性能。具体来说,LSE-D、SPK-SIM、EMO-SIM和MCD分别提高了高达1.09%、8.80%、19.08%和18.74%。
论文及项目相关链接
PDF 5 pages, 4 figures, accepted by Interspeech 2025
Summary
当前电影配音技术已能通过参考声音和输入视频产生所需的语音,保持与视觉画面的完美同步,并有效传达预期的情绪。然而,电影配音的关键方面,如适应不同的配音风格、有效处理对话、旁白和独白,以及考虑演讲者的年龄和性别等细微之处,仍探索不足。为解决这些挑战,我们提出了一种多模态生成框架,它首先利用多模态大型视觉语言模型分析视觉输入,识别配音类型和精细属性。其次,利用大型语音生成模型产生高质量配音,受多模态输入的指导。此外,还构建了一个包含配音类型和细微之处注释的电影配音数据集,以提高电影理解和提升配音质量。实验结果显示,与最新方法相比,该框架在多个基准数据集上表现卓越。
Key Takeaways
- 当前电影配音技术能够同步视频并传达情绪。
- 电影配音仍面临适应不同配音风格、处理对话、旁白和独白的挑战。
- 提出的多模态生成框架利用视觉语言模型识别配音类型和精细属性。
- 该框架通过大型语音生成模型产生高质量配音。
- 构建了一个包含配音类型和细微之处的电影配音数据集。
- 实验结果显示该框架在多个数据集上表现优于最新方法。
点此查看论文截图



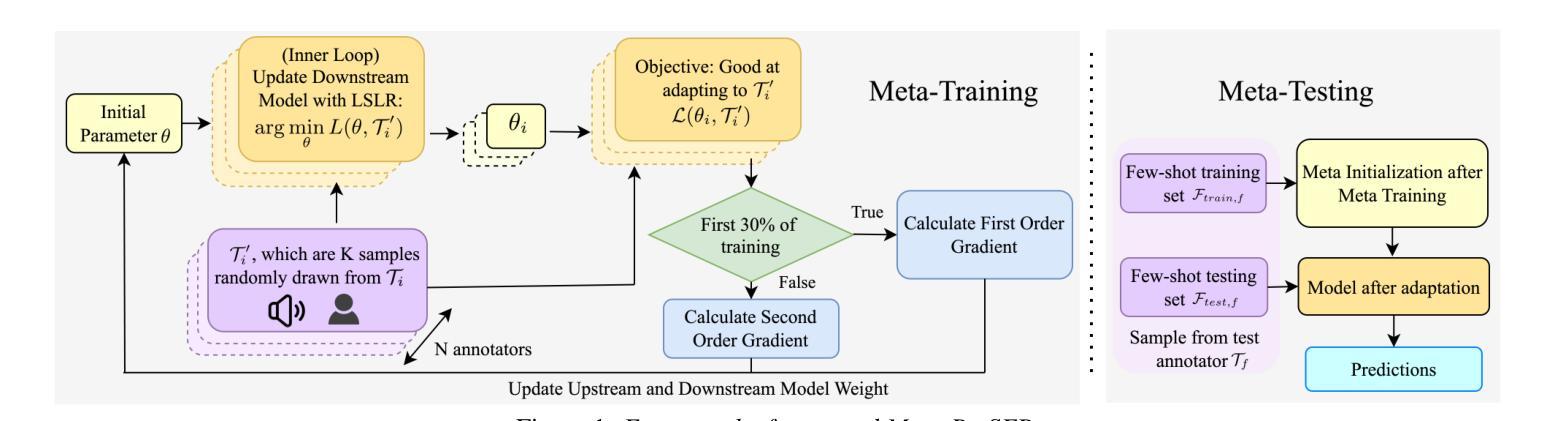
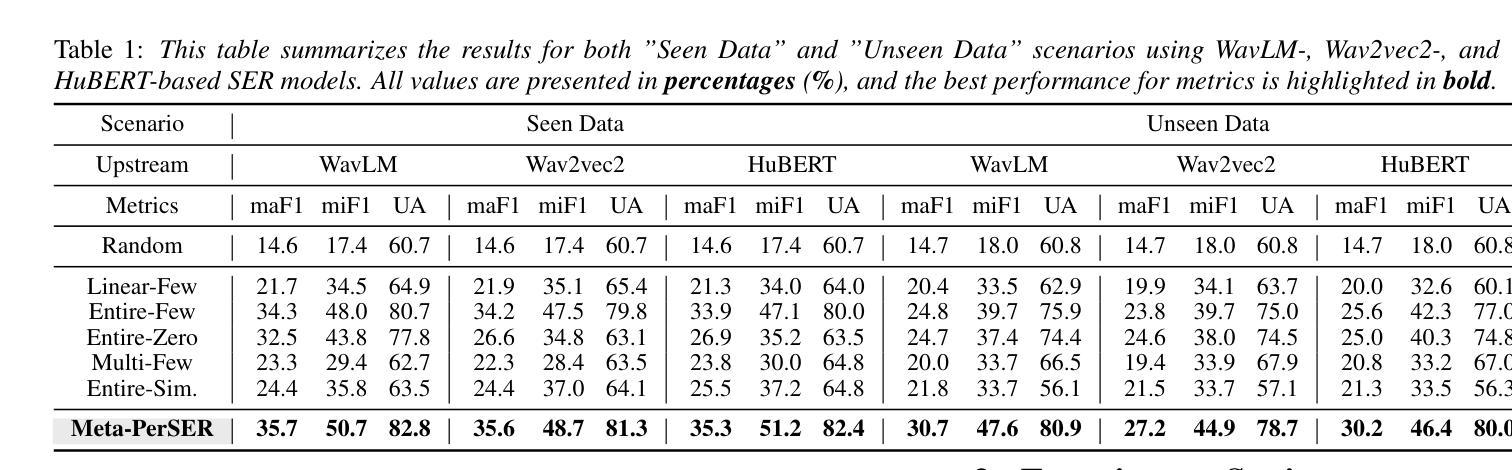
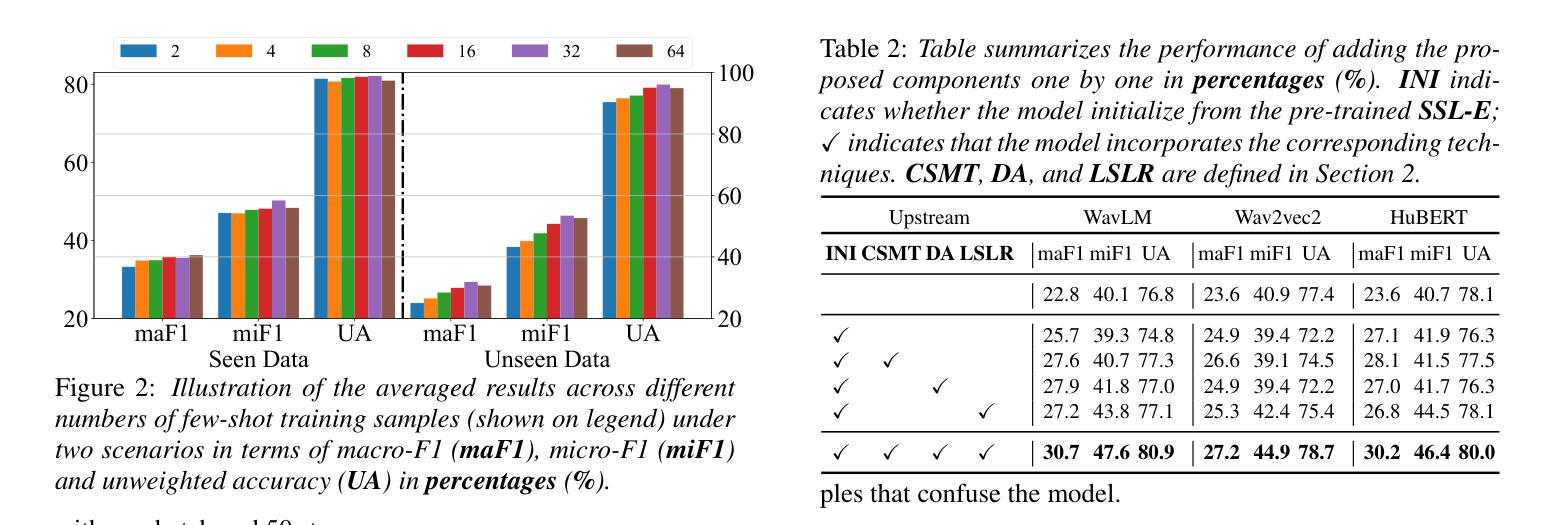
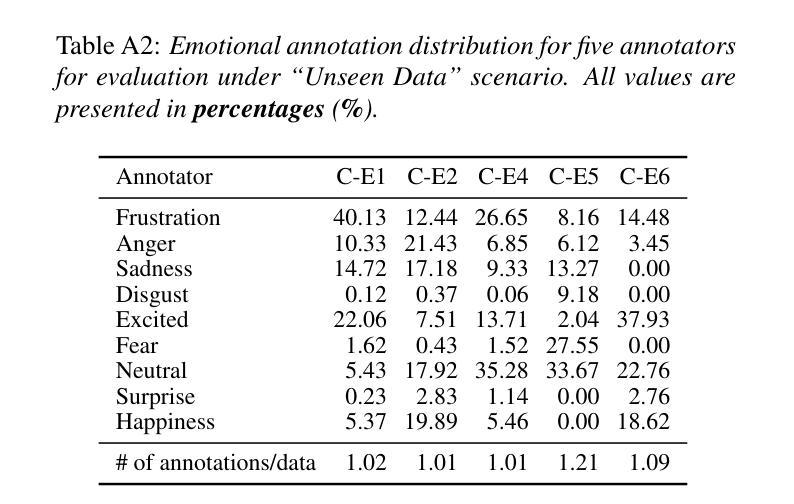
Meta-PerSER: Few-Shot Listener Personalized Speech Emotion Recognition via Meta-learning
Authors:Liang-Yeh Shen, Shi-Xin Fang, Yi-Cheng Lin, Huang-Cheng Chou, Hung-yi Lee
This paper introduces Meta-PerSER, a novel meta-learning framework that personalizes Speech Emotion Recognition (SER) by adapting to each listener’s unique way of interpreting emotion. Conventional SER systems rely on aggregated annotations, which often overlook individual subtleties and lead to inconsistent predictions. In contrast, Meta-PerSER leverages a Model-Agnostic Meta-Learning (MAML) approach enhanced with Combined-Set Meta-Training, Derivative Annealing, and per-layer per-step learning rates, enabling rapid adaptation with only a few labeled examples. By integrating robust representations from pre-trained self-supervised models, our framework first captures general emotional cues and then fine-tunes itself to personal annotation styles. Experiments on the IEMOCAP corpus demonstrate that Meta-PerSER significantly outperforms baseline methods in both seen and unseen data scenarios, highlighting its promise for personalized emotion recognition.
本文介绍了Meta-PerSER,这是一种新型的元学习框架,通过适应每个听众独特的情感解读方式,对语音情感识别(SER)进行个性化处理。传统的SER系统依赖于聚合注释,这往往忽略了个人细微差别,并导致预测结果不一致。相比之下,Meta-PerSER利用模型无关的元学习(MAML)方法,并结合集合元训练、导数退火和逐层每步学习率,仅通过少量有标签的样本即可实现快速适应。通过整合预训练自监督模型的稳健表示,我们的框架首先捕捉一般的情感线索,然后对自己进行微调以适应个人注释风格。在IEMOCAP语料库上的实验表明,Meta-PerSER在可见和未见数据场景中均显著优于基准方法,凸显其在个性化情感识别方面的潜力。
论文及项目相关链接
PDF Accepted by INTERSPEECH 2025. 7 pages, including 2 pages of appendix
总结
本文介绍了Meta-PerSER,这是一个新的元学习框架,通过适应每个听众对情绪解读的独特方式,个性化地应用于语音情绪识别(SER)。与传统的SER系统依赖于聚合注释不同,这常常忽略了个人细微差别并导致预测不一致。相比之下,Meta-PerSER采用模型无关的元学习方法,并结合组合集元训练、导数退火和逐层逐步的学习率,仅通过少量标注样本即可实现快速适应。通过整合预训练自监督模型的稳健表示,我们的框架首先捕捉一般情绪线索,然后细化自身以适应个人注释风格。在IEMOCAP语料库上的实验表明,Meta-PerSER在已见和未见的数据场景中均显著优于基准方法,凸显其在个性化情绪识别方面的潜力。
关键见解
- Meta-PerSER是一个新的元学习框架,用于个性化语音情绪识别(SER)。
- 传统的SER系统依赖于聚合注释,这可能导致预测的不一致。
- Meta-PerSER采用模型无关的元学习方法,并结合多种技术实现快速适应。
- 该框架通过整合预训练自监督模型的稳健表示,捕捉一般情绪线索并适应个人注释风格。
- 实验表明,Meta-PerSER在已见和未见的数据场景中均优于基准方法。
- Meta-PerSER通过适应每个听众对情绪解读的独特方式,提高了情绪识别的个性化程度。
点此查看论文截图



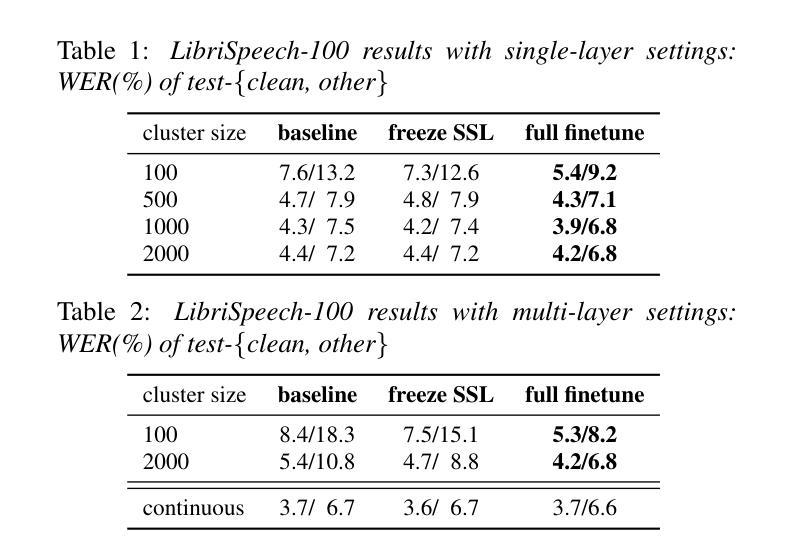
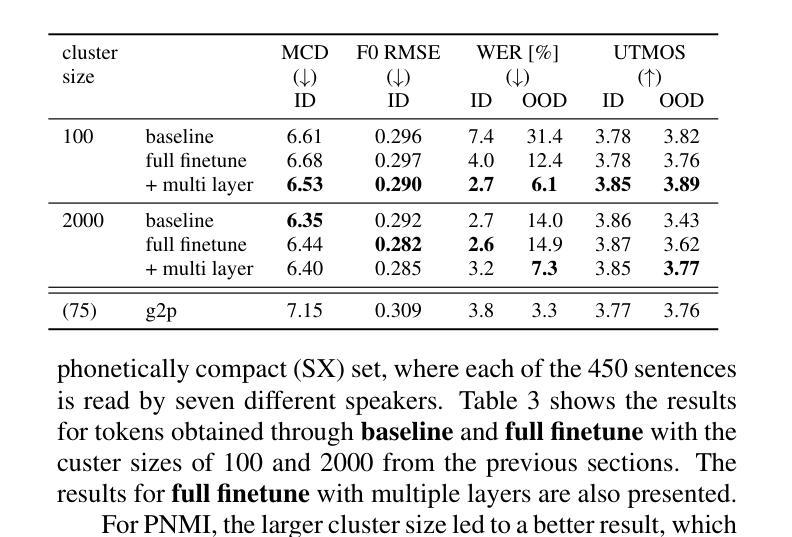
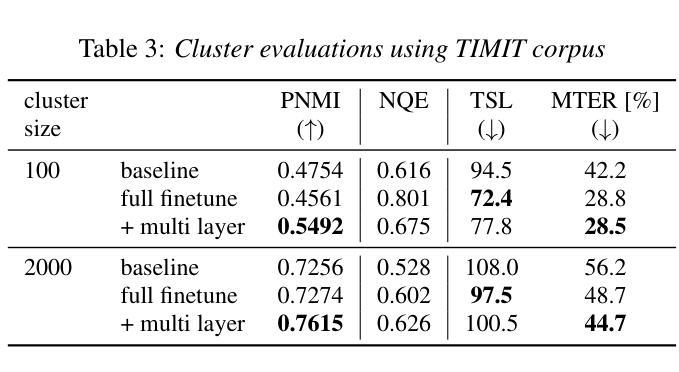
Differentiable K-means for Fully-optimized Discrete Token-based ASR
Authors:Kentaro Onda, Yosuke Kashiwagi, Emiru Tsunoo, Hayato Futami, Shinji Watanabe
Recent studies have highlighted the potential of discrete tokens derived from self-supervised learning (SSL) models for various speech-related tasks. These tokens serve not only as substitutes for text in language modeling but also as intermediate representations for tasks such as automatic speech recognition (ASR). However, discrete tokens are typically obtained via k-means clustering of SSL features independently of downstream tasks, making them suboptimal for specific applications. This paper proposes the use of differentiable k-means, enabling the joint optimization of tokenization and downstream tasks. This approach enables the fine-tuning of the SSL parameters and learning weights for outputs from multiple SSL layers. Experiments were conducted with ASR as a downstream task. ASR accuracy successfully improved owing to the optimized tokens. The acquired tokens also exhibited greater purity of phonetic information, which were found to be useful even in speech resynthesis.
最近的研究已经突出了自监督学习(SSL)模型生成的离散标记在多种语音相关任务中的潜力。这些标记不仅用作语言建模中的文本替代,还用作自动语音识别(ASR)等任务的中间表示。然而,离散标记通常是通过独立于下游任务的SSL特征的k-均值聚类获得的,这使得它们对于特定应用而言并不理想。本文建议使用可微分的k-均值方法,实现对标记化和下游任务的联合优化。这种方法能够微调SSL参数并学习来自多个SSL层的输出的权重。以ASR作为下游任务进行的实验表明,由于优化的标记,ASR准确率成功提高。所获得的标记还表现出更高的语音信息纯度,即使在语音重建中也被发现非常有用。
论文及项目相关链接
PDF Accepted by Interspeech2025
Summary
本文探讨了基于自监督学习(SSL)模型的离散标记在语音相关任务中的潜力。这些标记不仅可作为语言建模中的文本替代品,还可作为自动语音识别(ASR)等任务的中间表示形式。然而,传统的离散标记是通过独立于下游任务的SSL特征进行k-均值聚类获得的,这使得它们对于特定应用程序而言并不理想。本文提出使用可微分的k-均值方法,实现标记化与下游任务的联合优化。这种方法可以微调SSL参数并学习来自多个SSL层的输出权重。在下游任务(如ASR)上进行实验发现,优化的标记显著提高了ASR的准确率。此外,获得的标记具有更高的语音信息纯度,在语音合成中同样展现出良好的表现。
Key Takeaways
- 自监督学习模型的离散标记在语音任务中有广泛应用潜力。
- 传统离散标记的获取方式独立于下游任务,可能不适用于特定应用。
- 可微分的k-均值方法用于联合优化标记化与下游任务,提高性能。
- 优化后的标记能提升自动语音识别(ASR)的准确率。
- 获得的标记具有更高的语音信息纯度,可用于语音合成。
- SSL参数可以通过该方法进行微调,同时学习多个SSL层的输出权重。
- 该方法对于改进基于自监督学习的语音任务具有积极意义。
点此查看论文截图


Prosodically Enhanced Foreign Accent Simulation by Discrete Token-based Resynthesis Only with Native Speech Corpora
Authors:Kentaro Onda, Keisuke Imoto, Satoru Fukayama, Daisuke Saito, Nobuaki Minematsu
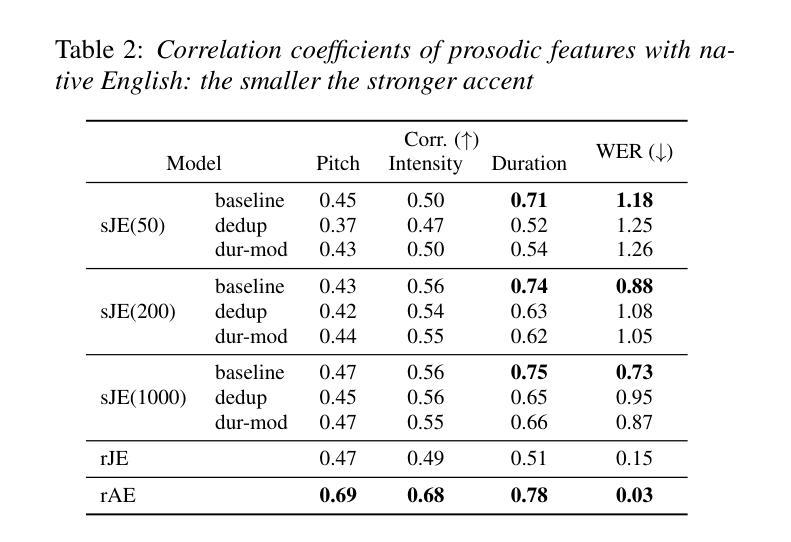
Recently, a method for synthesizing foreign-accented speech only with native speech data using discrete tokens obtained from self-supervised learning (SSL) models was proposed. Considering limited availability of accented speech data, this method is expected to make it much easier to simulate foreign accents. By using the synthesized accented speech as listening materials for humans or training data for automatic speech recognition (ASR), both of them will acquire higher robustness against foreign accents. However, the previous method has a fatal flaw that it cannot reproduce duration-related accents. Durational accents are commonly seen when L2 speakers, whose native language has syllable-timed or mora-timed rhythm, speak stress-timed languages, such as English. In this paper, we integrate duration modification to the previous method to simulate foreign accents more accurately. Experiments show that the proposed method successfully replicates durational accents seen in real L2 speech.
最近,提出一种仅使用从自监督学习(SSL)模型中获得的离散令牌合成带有外国口音的语音的方法,该方法以原生语音数据为基础。考虑到口音语音数据的可用性有限,此方法可以极大地简化模拟外来口音的过程。通过使用合成的口音语音作为人类的听力材料或自动语音识别(ASR)的训练数据,两者都可以提高对外来口音的鲁棒性。然而,之前的方法存在一个重大缺陷,即无法重现与持续时间相关的口音。当二语(L2)说话者(其母语具有音节定时或摩拉定时节奏)说以音节间隔定时为主的如英语这样的语言时,通常会遇到持续性口音。在本文中,我们将持续时间修改整合到之前的方法中,以更准确地模拟外来口音。实验表明,所提出的方法成功地复制了现实中二语语音中所见的持续性口音。
论文及项目相关链接
PDF Accepted by Interspeech2025
Summary
语音合成技术取得新进展,能够通过自监督学习模型获取的离散标记,仅使用原生语音数据合成带口音的语音。新方法解决了以往不能重现与持续时间相关的口音的问题,能够更准确地模拟外语口音,提高人类听众或语音识别系统的稳健性。
Key Takeaways
- 新的语音合成方法利用自监督学习模型生成的离散标记仅使用原生语音数据。
- 新方法解决了不能准确模拟外语口音的问题,特别是持续时间相关的口音。
- 新方法可应用于为听力训练材料或语音识别训练提供更高稳健性的带口音语音模拟。
- L2语言(非母语)学习者在学习以英语为代表的压力定时语言时可能遇到的口音问题得到关注。
- 实验表明新方法能够成功模拟真实L2语音中的持续口音。
点此查看论文截图


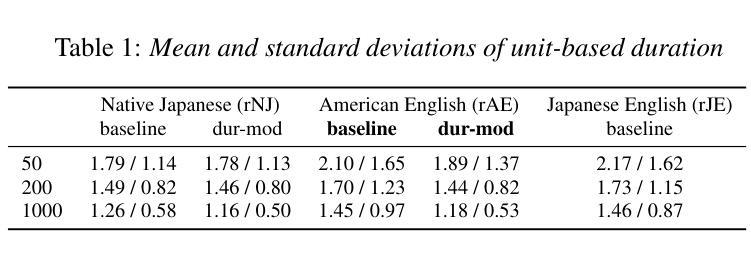
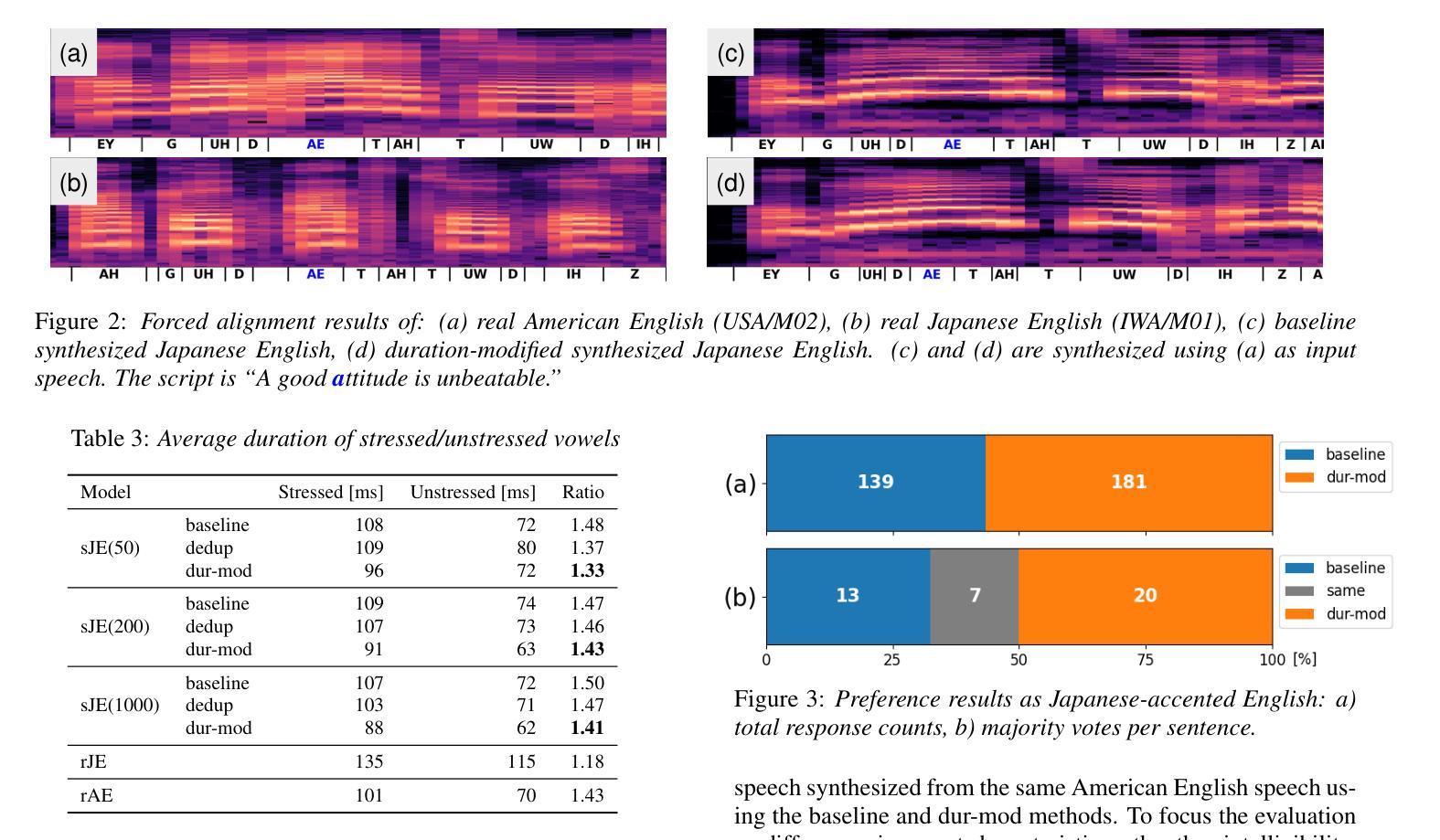
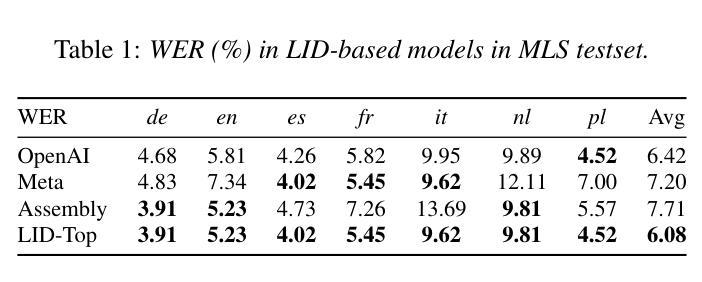
Selective Invocation for Multilingual ASR: A Cost-effective Approach Adapting to Speech Recognition Difficulty
Authors:Hongfei Xue, Yufeng Tang, Jun Zhang, Xuelong Geng, Lei Xie
Although multilingual automatic speech recognition (ASR) systems have significantly advanced, enabling a single model to handle multiple languages, inherent linguistic differences and data imbalances challenge SOTA performance across all languages. While language identification (LID) models can route speech to the appropriate ASR model, they incur high costs from invoking SOTA commercial models and suffer from inaccuracies due to misclassification. To overcome these, we propose SIMA, a selective invocation for multilingual ASR that adapts to the difficulty level of the input speech. Built on a spoken large language model (SLLM), SIMA evaluates whether the input is simple enough for direct transcription or requires the invocation of a SOTA ASR model. Our approach reduces word error rates by 18.7% compared to the SLLM and halves invocation costs compared to LID-based methods. Tests on three datasets show that SIMA is a scalable, cost-effective solution for multilingual ASR applications.
虽然多语言自动语音识别(ASR)系统已经取得了重大进展,使得单一模型能够处理多种语言,但固有的语言差异和数据不平衡仍然对所有语言的最新技术水平(SOTA)性能构成了挑战。虽然语言识别(LID)模型可以将语音路由到适当的ASR模型,但它们会因调用最新技术的商业模型而产生高昂的成本,并且由于误分类而面临不精确的问题。为了克服这些问题,我们提出了SIMA,这是一种用于多语言ASR的选择性调用方法,它能够适应输入语音的难度水平。基于口语大型语言模型(SLLM),SIMA评估输入是否足够简单以进行直接转录,或者是否需要调用最新技术的ASR模型。我们的方法与SLLM相比,将单词错误率降低了18.7%,并将基于LID的方法的调用成本减半。在三个数据集上的测试表明,SIMA是一种可用于多语言ASR应用的可扩展且经济高效的解决方案。
论文及项目相关链接
PDF Accepted by INTERSPEECH 2025
Summary
本文介绍了多语言自动语音识别(ASR)系统的挑战,包括语言差异和数据不平衡问题。虽然语言识别(LID)模型可以将语音路由到适当的ASR模型,但它们调用先进商业模型的成本高昂,并且由于误分类而存在不准确的问题。为此,本文提出了SIMA,一种适应输入语音难度级别的选择性调用多语言ASR的方法。SIMA建立在口语大型语言模型(SLLM)之上,评估输入是否简单到可以直接转录,还是需要调用高级ASR模型。该方法将字词错误率降低了18.7%,与SLLM相比,并将调用成本降低了一半。在三个数据集上的测试表明,SIMA是一种可扩展且经济实惠的多语言ASR应用程序解决方案。
Key Takeaways
- 多语言ASR系统虽然有所发展,但仍面临语言差异和数据不平衡的挑战。
- LID模型在路由语音到适当的ASR模型时,存在高成本和误分类的问题。
- SIMA是一种基于口语大型语言模型(SLLM)的选择性调用方法,适应输入语音的难度级别。
- SIMA能够评估输入是否简单到可以直接转录,或需要调用高级ASR模型。
- SIMA将字词错误率降低了18.7%,与SLLM相比具有优越性。
- SIMA将调用成本降低了一半,相比LID-based方法更具成本效益。
点此查看论文截图


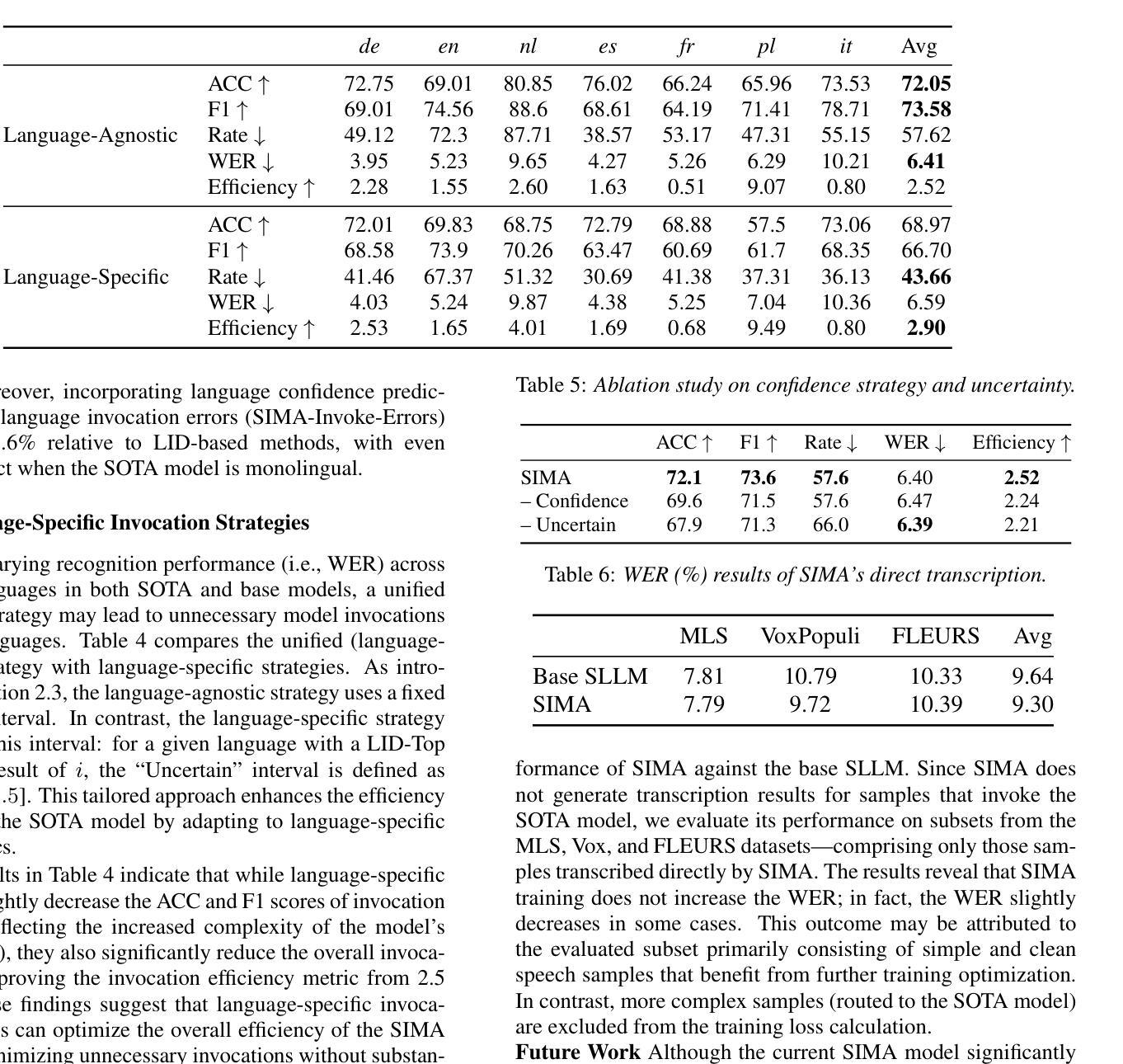
Efficient and Direct Duplex Modeling for Speech-to-Speech Language Model
Authors:Ke Hu, Ehsan Hosseini-Asl, Chen Chen, Edresson Casanova, Subhankar Ghosh, Piotr Żelasko, Zhehuai Chen, Jason Li, Jagadeesh Balam, Boris Ginsburg
Spoken dialogue is an intuitive form of human-computer interaction, yet current speech language models often remain constrained to turn-based exchanges, lacking real-time adaptability such as user barge-in. We propose a novel duplex speech to speech (S2S) architecture featuring continuous user inputs and codec agent outputs with channel fusion that directly models simultaneous user and agent streams. Using a pretrained streaming encoder for user input enables the first duplex S2S model without requiring speech pretrain. Separate architectures for agent and user modeling facilitate codec fine-tuning for better agent voices and halve the bitrate (0.6 kbps) compared to previous works. Experimental results show that the proposed model outperforms previous duplex models in reasoning, turn-taking, and barge-in abilities. The model requires significantly less speech data, as speech pretrain is skipped, which markedly simplifies the process of building a duplex S2S model from any LLMs. Finally, it is the first openly available duplex S2S model with training and inference code to foster reproducibility.
口语对话是人类与计算机交互的一种直观形式。然而,当前的语音语言模型通常仅限于基于回合的交互,缺乏实时适应性,如用户抢话等。我们提出了一种新型的双语语音到语音(S2S)架构,具有连续用户输入和编解码器代理输出,通过通道融合直接模拟用户和代理的同时流。使用预训练的流式编码器进行用户输入,使得第一个双语S2S模型无需语音预训练。为代理和用户建模提供单独的结构,便于编解码器微调以获取更好的代理语音,与以前的工作相比,比特率减半(0.6kbps)。实验结果表明,该模型在推理、话轮转换和抢话能力方面优于之前的双语模型。该模型需要的语音数据大大减少,因为跳过了语音预训练,这极大地简化了从任何大型语言模型构建双语S2S模型的过程。最后,它是第一个公开可用的带有训练和推理代码的双语S2S模型,有利于促进可重复性。
论文及项目相关链接
PDF Accepted to Interspeech 2025
Summary
文章提出一种新型双工语音到语音(S2S)架构,支持连续用户输入和编码解码器输出,通过信道融合直接模拟用户和代理的实时交互流。该架构使用预训练的流式编码器实现用户输入,无需语音预训练即可构建首个双工S2S模型。通过分别构建代理和用户模型,优化编码解码器以改善代理语音质量,同时与以往工作相比将比特率减半(降至0.6kbps)。实验结果显示,该模型在推理、轮替和打断能力上优于之前的双工模型。此外,由于省略了语音预训练,该模型所需语音数据量大大减少,显著简化了从任何大型语言模型构建双工S2S模型的过程。这是首个公开可用的双工S2S模型,附有训练和推理代码,便于重复实验和进一步发展。
Key Takeaways
- 提出一种新型双工语音到语音(S2S)架构,支持连续用户输入和编码解码器输出。
- 通过信道融合实现用户和代理的实时交互流模拟。
- 使用预训练的流式编码器,无需语音预训练即可构建双工S2S模型。
- 分离代理和用户建模优化编码解码器,改善代理语音质量并降低比特率。
- 实验证明该模型在推理、轮替和打断能力上超越之前的双工模型。
- 所需语音数据量减少,简化从大型语言模型构建双工S2S模型的过程。
点此查看论文截图





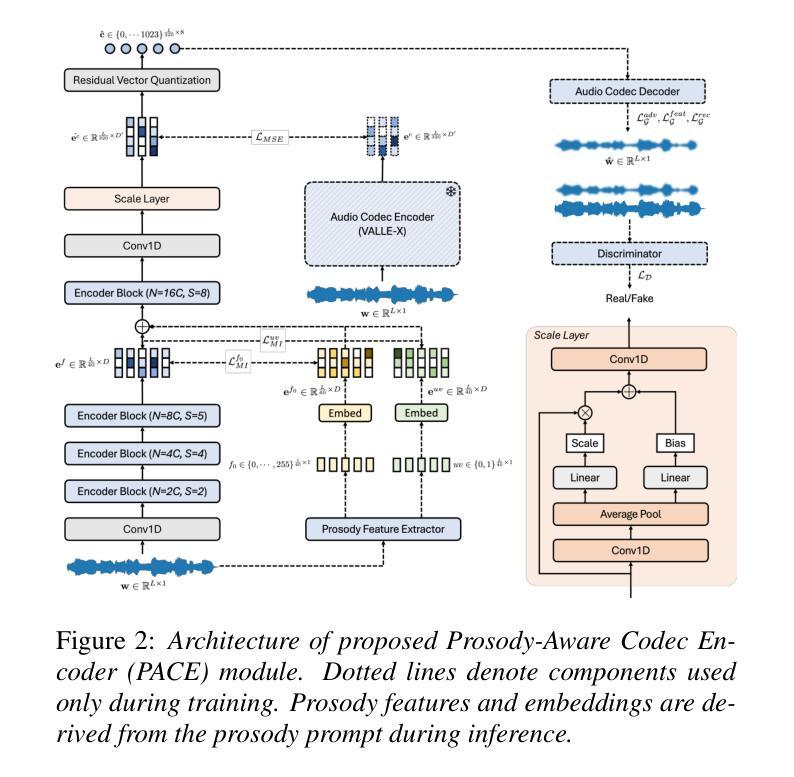
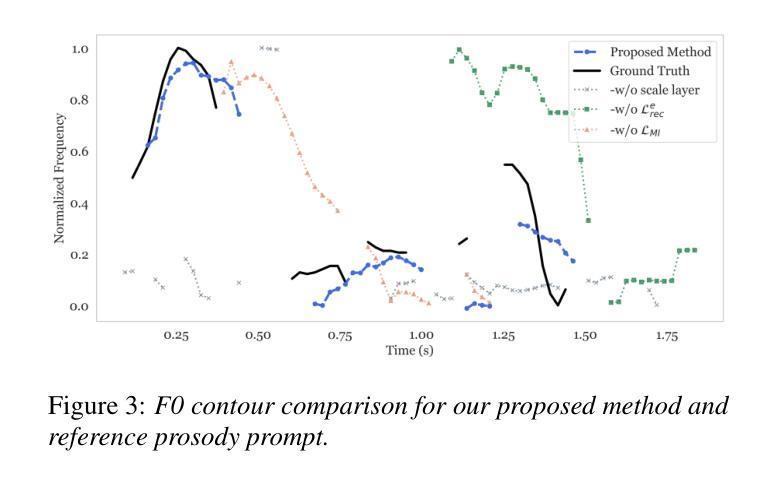
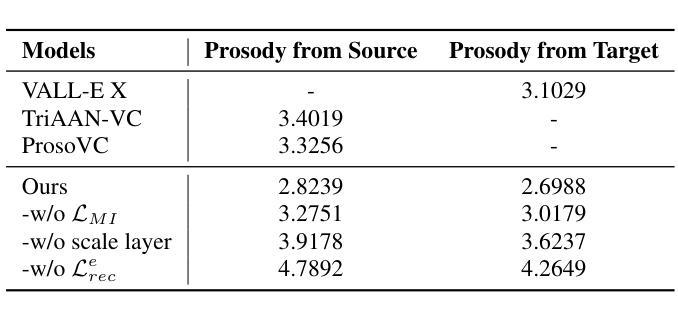
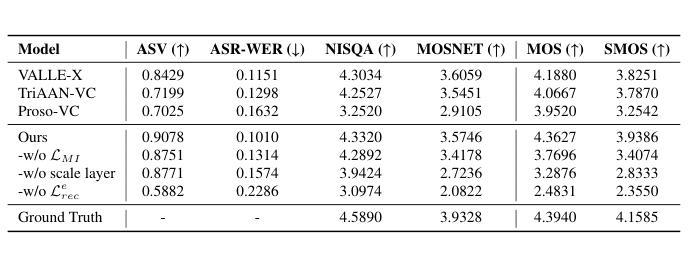
Prosody-Adaptable Audio Codecs for Zero-Shot Voice Conversion via In-Context Learning
Authors:Junchuan Zhao, Xintong Wang, Ye Wang
Recent advances in discrete audio codecs have significantly improved speech representation modeling, while codec language models have enabled in-context learning for zero-shot speech synthesis. Inspired by this, we propose a voice conversion (VC) model within the VALLE-X framework, leveraging its strong in-context learning capabilities for speaker adaptation. To enhance prosody control, we introduce a prosody-aware audio codec encoder (PACE) module, which isolates and refines prosody from other sources, improving expressiveness and control. By integrating PACE into our VC model, we achieve greater flexibility in prosody manipulation while preserving speaker timbre. Experimental evaluation results demonstrate that our approach outperforms baseline VC systems in prosody preservation, timbre consistency, and overall naturalness, surpassing baseline VC systems.
近期离散音频编解码器的进展极大地改进了语音表示建模,而编解码器语言模型已经实现了零射击语音合成的上下文学习。受此启发,我们在VALLE-X框架内提出了一个语音转换(VC)模型,利用其强大的上下文学习能力进行说话人适配。为了增强韵律控制,我们引入了一个韵律感知音频编解码器编码器(PACE)模块,该模块可以隔离并优化韵律的来源,从而提高表达力和控制力。通过将PACE集成到我们的VC模型中,我们在韵律操纵方面实现了更大的灵活性,同时保留了说话人的音色。实验评估结果表明,我们的方法在韵律保持、音色一致性和整体自然度方面超过了基线VC系统。
论文及项目相关链接
PDF 5 pages, 3 figures
Summary
最新的离散音频编解码器技术的进展为语音表现建模带来了重大改进,编解码器语言模型实现了零样本语音合成的上下文学习。受此启发,我们在VALLE-X框架内提出了一种语音转换(VC)模型,利用其强大的上下文学习能力进行自适应说话人适配。为了增强韵律控制,我们引入了韵律感知音频编解码器编码器(PACE)模块,该模块能隔离并精炼韵律来源,提高了表达力和控制力。将PACE集成到我们的VC模型中,实现了在保持说话人音质的同时,韵律操控更加灵活。实验评估结果表明,我们的方法在保持韵律、音质一致性和整体自然度方面超越了基线VC系统。
Key Takeaways
- 离散音频编解码器的最新进展显著改进了语音表现建模。
- 编解码器语言模型实现了零样本语音合成的上下文学习。
- 提出了在VALLE-X框架内的语音转换(VC)模型,具有强大的上下文学习能力,用于自适应说话人适配。
- 引入了韵律感知音频编解码器编码器(PACE)模块,以提高韵律控制和表达力。
- PACE集成到VC模型中,实现了更灵活的韵律操控,同时保持说话人音质。
- 实验结果表明,该方法的韵律保持、音质一致性和自然度均超越基线VC系统。
点此查看论文截图

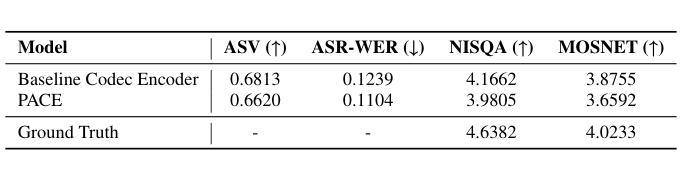
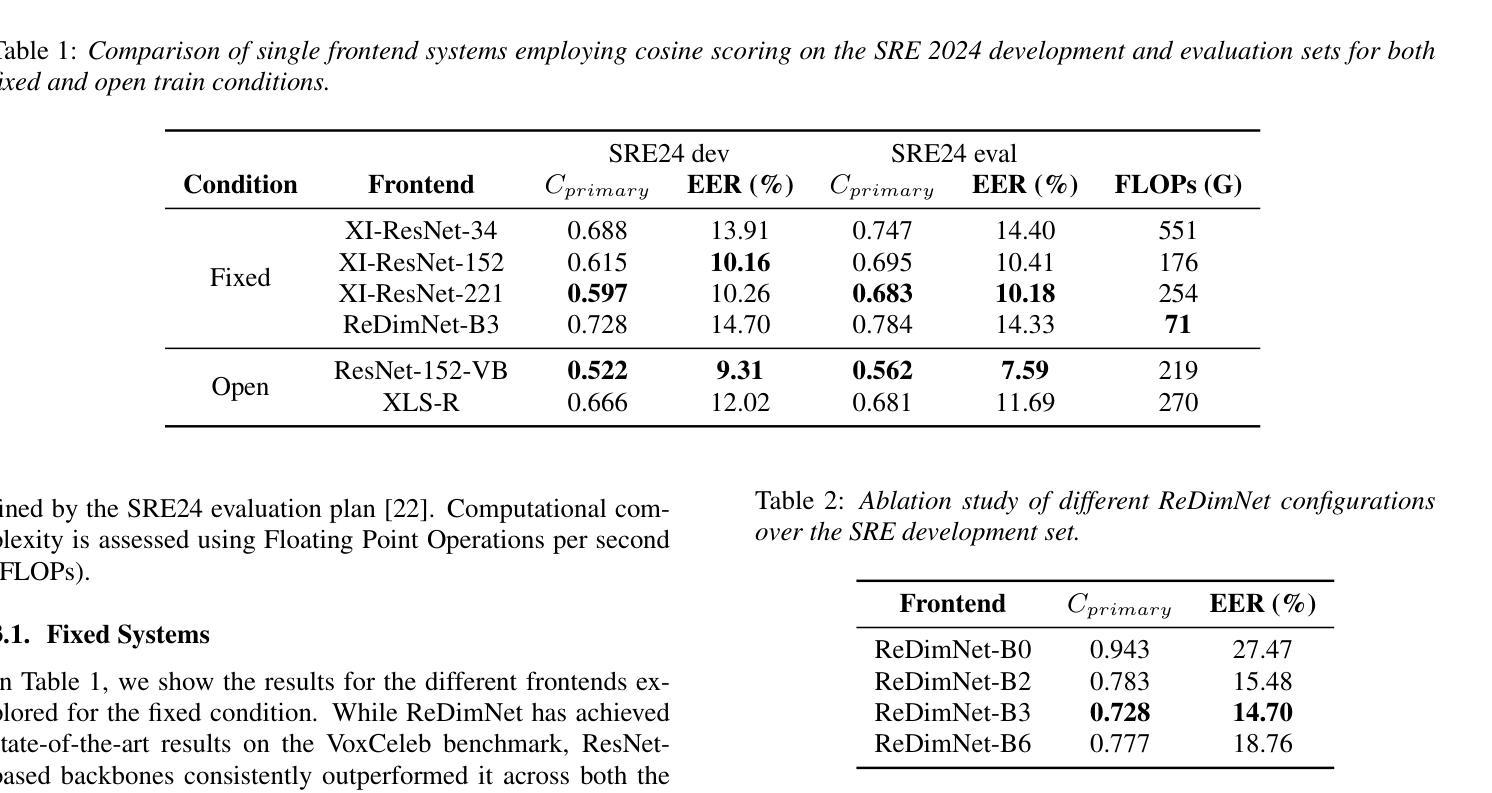
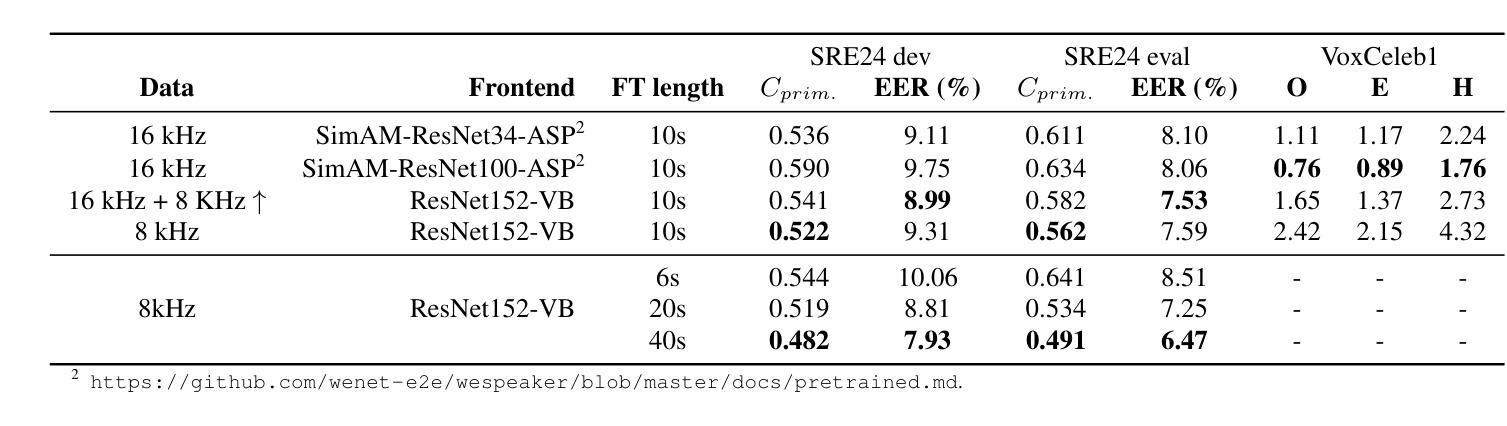
Analysis of ABC Frontend Audio Systems for the NIST-SRE24
Authors:Sara Barahona, Anna Silnova, Ladislav Mošner, Junyi Peng, Oldřich Plchot, Johan Rohdin, Lin Zhang, Jiangyu Han, Petr Palka, Federico Landini, Lukáš Burget, Themos Stafylakis, Sandro Cumani, Dominik Boboš, Miroslav Hlavaček, Martin Kodovsky, Tomáš Pavlíček
We present a comprehensive analysis of the embedding extractors (frontends) developed by the ABC team for the audio track of NIST SRE 2024. We follow the two scenarios imposed by NIST: using only a provided set of telephone recordings for training (fixed) or adding publicly available data (open condition). Under these constraints, we develop the best possible speaker embedding extractors for the pre-dominant conversational telephone speech (CTS) domain. We explored architectures based on ResNet with different pooling mechanisms, recently introduced ReDimNet architecture, as well as a system based on the XLS-R model, which represents the family of large pre-trained self-supervised models. In open condition, we train on VoxBlink2 dataset, containing 110 thousand speakers across multiple languages. We observed a good performance and robustness of VoxBlink-trained models, and our experiments show practical recipes for developing state-of-the-art frontends for speaker recognition.
我们对ABC团队为NIST SRE 2024音频轨道开发嵌入提取器(前端)进行了综合分析。我们遵循NIST规定的两种场景:仅使用提供的电话录音集进行训练(固定)或添加公开数据(开放条件)。在这些约束下,我们为主要的对话电话语音(CTS)领域开发最佳的语音嵌入提取器。我们探索了基于ResNet的不同池化机制架构、最近推出的ReDimNet架构,以及基于XLS-R模型的系统,它代表了一类大型预训练自监督模型。在开放条件下,我们在包含多种语言的VoxBlink2数据集上进行训练。我们观察到VoxBlink训练模型的良好性能和稳健性,并且我们的实验为开发先进的前端语音识别提供了实用方案。
论文及项目相关链接
PDF Accepted at Interspeech 2025
Summary
本文介绍了ABC团队针对NIST SRE 2024音频轨道开发的嵌入提取器(前端)的综合分析。文章遵循NIST设定的两种场景,一种是仅使用提供的电话录音集进行训练(固定),另一种是加入公开数据(开放条件)。在这些限制下,团队为主要的对话电话语音(CTS)领域开发了最佳可能的说话人嵌入提取器。文章探索了基于ResNet的不同池化机制架构、新推出的ReDimNet架构,以及基于预训练自监督模型家族的XLS-R模型的体系。在开放条件下,团队对包含多种语言的VoxBlink2数据集进行了训练,观察到良好性能和稳健性,实验展示了开发前沿说话人识别技术的实用方案。
Key Takeaways
- 介绍了ABC团队针对NIST SRE 2024音频轨道的嵌入提取器开发。
- 遵循NIST设定的两种场景:固定场景和开放条件场景。
- 在对话电话语音(CTS)领域开发最佳说话人嵌入提取器。
- 探索了多种架构,包括基于ResNet的池化机制、ReDimNet架构和XLS-R模型。
- 在开放条件下使用VoxBlink2数据集进行训练,该数据集包含多种语言的110千名说话人。
- VoxBlink训练模型表现出良好的性能和稳健性。
点此查看论文截图


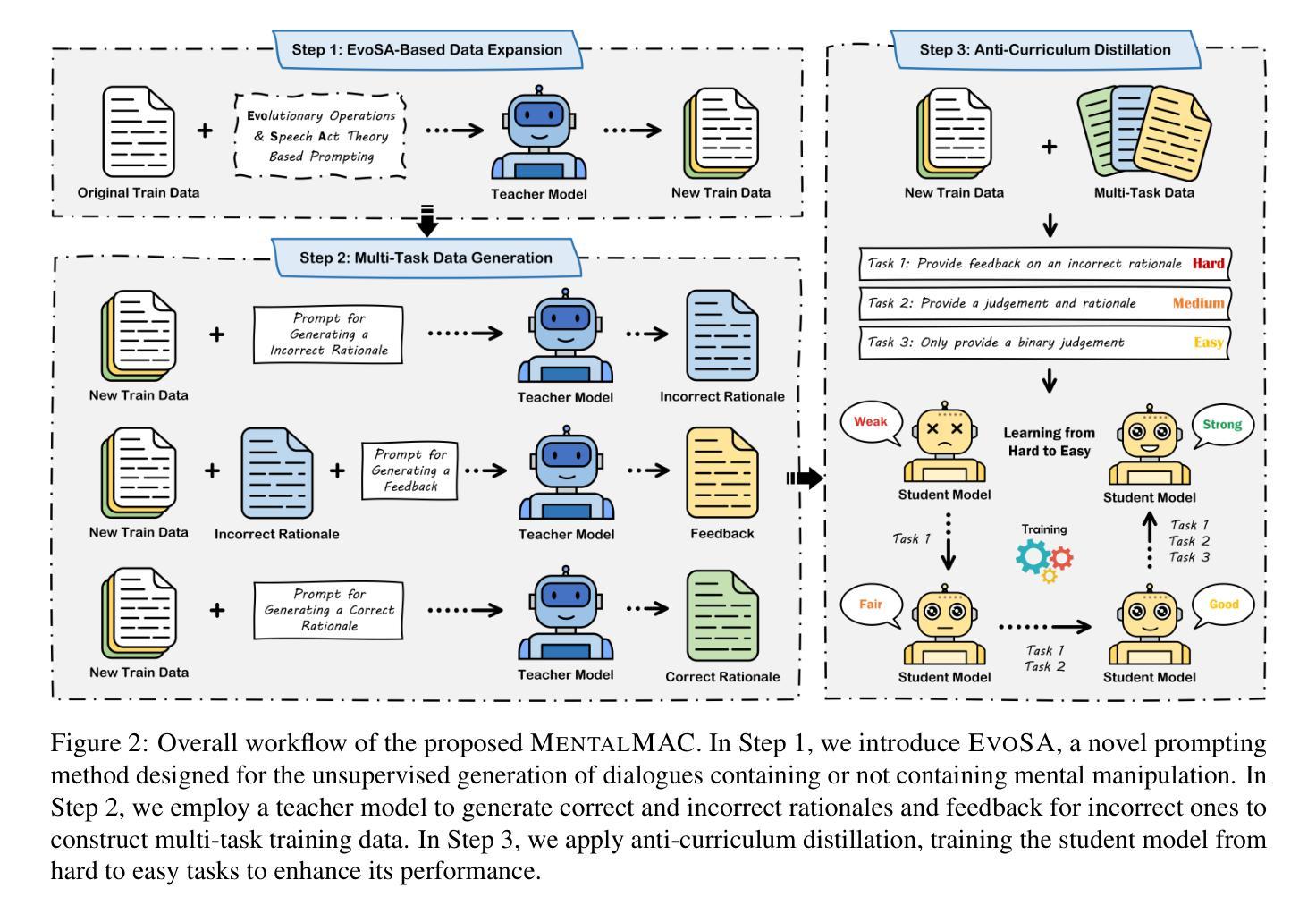
MentalMAC: Enhancing Large Language Models for Detecting Mental Manipulation via Multi-Task Anti-Curriculum Distillation
Authors:Yuansheng Gao, Han Bao, Tong Zhang, Bin Li, Zonghui Wang, Wenzhi Chen
Mental manipulation is a subtle yet pervasive form of psychological abuse that poses serious threats to mental health. Its covert nature and the complexity of manipulation strategies make it challenging to detect, even for state-of-the-art large language models (LLMs). This concealment also hinders the manual collection of large-scale, high-quality annotations essential for training effective models. Although recent efforts have sought to improve LLMs’ performance on this task, progress remains limited due to the scarcity of real-world annotated datasets. To address these challenges, we propose MentalMAC, a multi-task anti-curriculum distillation method that enhances LLMs’ ability to detect mental manipulation in multi-turn dialogue. Our approach includes: (i) EvoSA, an unsupervised data expansion method based on evolutionary operations and speech act theory; (ii) teacher model-generated multi-task supervision; and (iii) progressive knowledge distillation from complex to simpler tasks. We then constructed the ReaMent dataset with 5,000 real-world dialogue samples, using a MentalMAC-distilled model to assist human annotation. Vast experiments demonstrate that our method significantly narrows the gap between student and teacher models and outperforms competitive LLMs across key evaluation metrics. All code, datasets, and checkpoints will be released upon paper acceptance. Warning: This paper contains content that may be offensive to readers.
心理操控是一种微妙而普遍的心理虐待形式,对心理健康构成严重威胁。其隐蔽性和策略复杂性使得检测变得具有挑战,即使是最先进的大型语言模型(LLM)也难以识别。这种隐蔽性也阻碍了手动收集大规模高质量注释,这对训练有效模型至关重要。尽管近期努力旨在提高LLM在此任务上的性能,但由于缺乏真实世界的注释数据集,进展仍然有限。为了解决这些挑战,我们提出了MentalMAC,这是一种多任务反向课程蒸馏方法,可增强LLM在多轮对话中检测心理操控的能力。我们的方法包括:(i) EvoSA,一种基于进化操作和言语行为理论的无监督数据扩展方法;(ii)教师模型生成的多任务监督;(iii)从复杂到简单任务的知识渐进蒸馏。然后,我们使用MentalMAC蒸馏的模型协助人工注释,构建了包含5000个真实世界对话样本的ReaMent数据集。大量实验表明,我们的方法显著缩小了学生模型与教师模型之间的差距,并在关键评估指标上优于其他LLM。论文接受后,我们将公开所有代码、数据集和检查点。警告:本论文含有可能对读者造成不适的内容。
论文及项目相关链接
Summary:
本文探讨了心理操纵对心理健康的严重威胁,以及现有技术下检测心理操纵的难度。针对这些问题,提出了一种多任务反课程蒸馏方法MentalMAC,用于提高大型语言模型(LLM)在多轮对话中检测心理操纵的能力。该方法包括数据扩展方法EvoSA、教师模型生成的多任务监督以及从复杂到简单任务的知识蒸馏。同时构建了RealMent数据集用于训练和评估模型。实验证明,该方法显著缩小了学生与教师模型之间的差距,并在关键评估指标上优于其他LLM。
Key Takeaways:
- 心理操纵是一种隐蔽且普遍的心理虐待形式,对心理健康构成严重威胁。
- 检测心理操纵是一个挑战,特别是对于大型语言模型(LLM)。
- 提出了一个多任务反课程蒸馏方法MentalMAC,旨在提高LLM检测心理操纵的能力。
- MentalMAC包括数据扩展方法EvoSA、教师模型生成的多任务监督以及渐进的知识蒸馏技术。
- 构建了RealMent数据集用于训练和评估模型,其中包含5000个真实对话样本。
- 实验证明,MentalMAC方法显著提高了模型的性能,并在关键评估指标上优于其他LLM。
点此查看论文截图


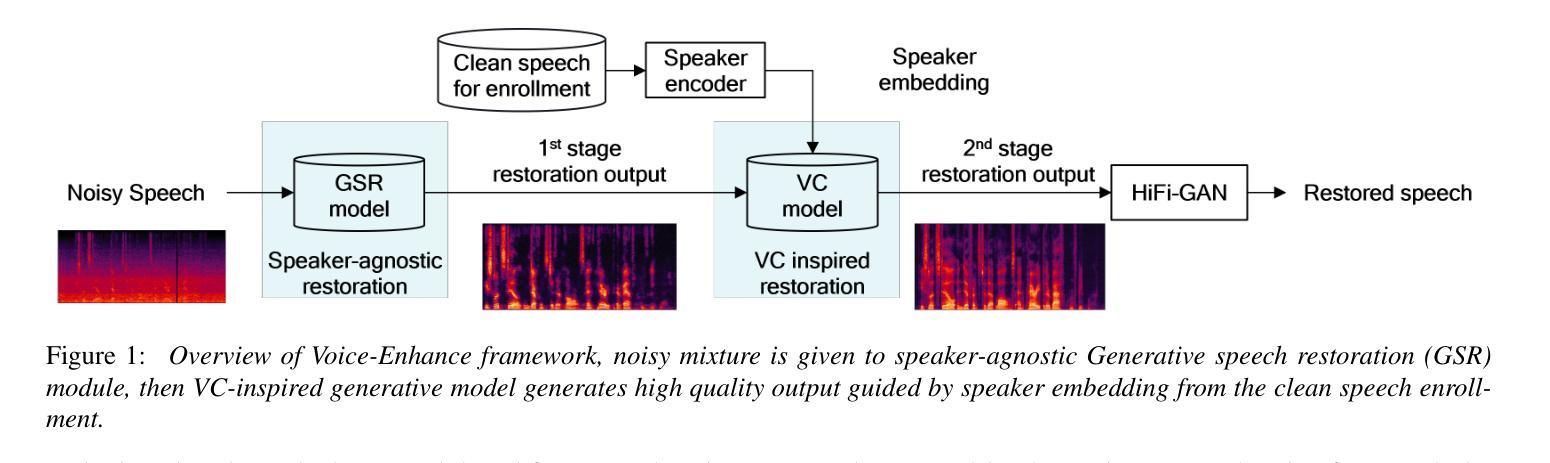
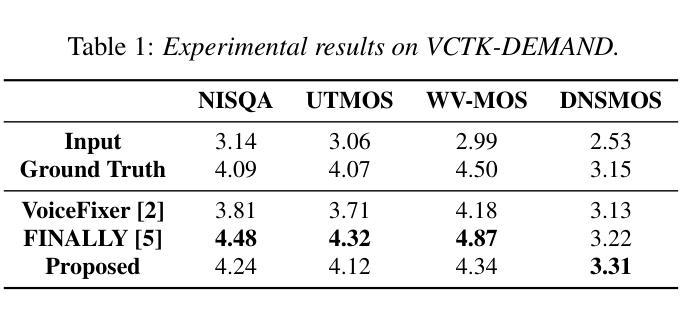
Voice-ENHANCE: Speech Restoration using a Diffusion-based Voice Conversion Framework
Authors:Kyungguen Byun, Jason Filos, Erik Visser, Sunkuk Moon
We propose a speech enhancement system that combines speaker-agnostic speech restoration with voice conversion (VC) to obtain a studio-level quality speech signal. While voice conversion models are typically used to change speaker characteristics, they can also serve as a means of speech restoration when the target speaker is the same as the source speaker. However, since VC models are vulnerable to noisy conditions, we have included a generative speech restoration (GSR) model at the front end of our proposed system. The GSR model performs noise suppression and restores speech damage incurred during that process without knowledge about the target speaker. The VC stage then uses guidance from clean speaker embeddings to further restore the output speech. By employing this two-stage approach, we have achieved speech quality objective metric scores comparable to state-of-the-art (SOTA) methods across multiple datasets.
我们提出了一种结合说话者无关的语音恢复和语音转换(VC)的语音增强系统,以获得工作室级别的语音信号。虽然语音转换模型通常用于改变说话人的特征,但当目标说话人与源说话人相同时,它们也可以作为语音恢复的一种手段。然而,由于VC模型对噪声条件很敏感,我们在所提出系统的前端加入了一个生成式语音恢复(GSR)模型。GSR模型执行噪声抑制,并在无需了解目标说话人的情况下恢复在过程中出现的语音损伤。VC阶段然后使用干净的说话人嵌入作为指导,进一步恢复输出语音。通过采用这种两阶段的方法,我们在多个数据集上达到了与最新方法相当的语音质量客观指标得分。
论文及项目相关链接
PDF 5 pages, 3 figures, Accepted to INTERSPEECH 2025
Summary
本文提出一种结合无特定人语音恢复与语音转换(VC)的语音增强系统,旨在获得工作室级别的语音信号质量。系统前端采用生成式语音恢复(GSR)模型进行降噪和恢复语音损伤,无需了解目标说话人的信息。接着,VC阶段利用干净说话人的嵌入引导进一步恢复输出语音。通过采用两阶段方法,实现了与多个数据集上的最新方法相当的语音质量客观度量分数。
Key Takeaways
- 提出结合无特定人语音恢复与语音转换的语音增强系统。
- 采用生成式语音恢复(GSR)模型进行降噪和恢复语音损伤。
- GSR模型在不知道目标说话人的情况下,对语音进行恢复。
- 语音转换(VC)阶段使用干净说话人的嵌入进行进一步的语音恢复。
- 通过两阶段方法实现了高质量的语音恢复效果。
- 系统性能在多个数据集上达到或超过现有技术水平的客观度量分数。
点此查看论文截图


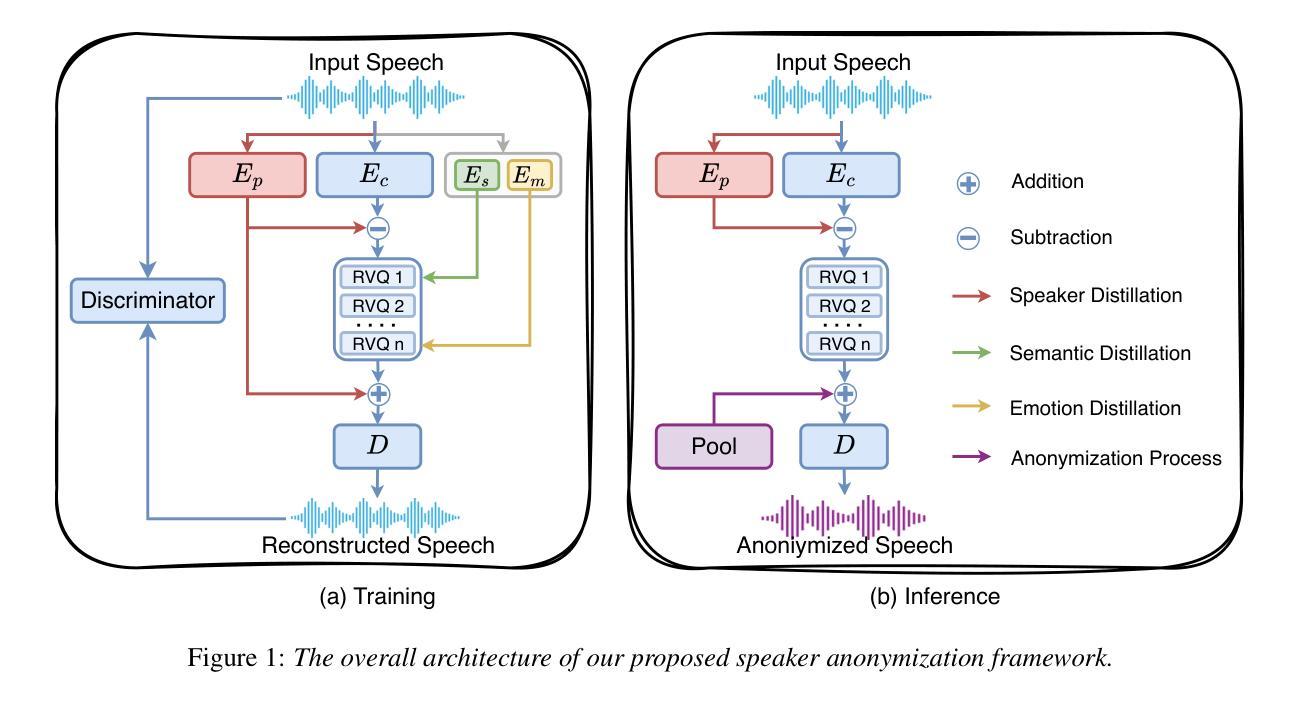
EASY: Emotion-aware Speaker Anonymization via Factorized Distillation
Authors:Jixun Yao, Hexin Liu, Eng Siong Chng, Lei Xie
Emotion plays a significant role in speech interaction, conveyed through tone, pitch, and rhythm, enabling the expression of feelings and intentions beyond words to create a more personalized experience. However, most existing speaker anonymization systems employ parallel disentanglement methods, which only separate speech into linguistic content and speaker identity, often neglecting the preservation of the original emotional state. In this study, we introduce EASY, an emotion-aware speaker anonymization framework. EASY employs a novel sequential disentanglement process to disentangle speaker identity, linguistic content, and emotional representation, modeling each speech attribute in distinct subspaces through a factorized distillation approach. By independently constraining speaker identity and emotional representation, EASY minimizes information leakage, enhancing privacy protection while preserving original linguistic content and emotional state. Experimental results on the VoicePrivacy Challenge official datasets demonstrate that our proposed approach outperforms all baseline systems, effectively protecting speaker privacy while maintaining linguistic content and emotional state.
情感在语音交互中扮演着重要角色,通过语调、音高和节奏来传达,使人们在言语之外能够表达感受和意图,从而创造更加个性化的体验。然而,大多数现有的说话人匿名化系统采用并行解耦方法,仅将语音分离为语言内容和说话人身份,往往忽视了原始情感状态的保持。在本研究中,我们引入了EASY,一个情感感知的说话人匿名化框架。EASY采用新颖的顺序解耦过程来解耦说话人身份、语言内容和情感表示,通过因子蒸馏法将每种语音属性建模在不同的子空间中。通过独立约束说话人身份和情感表示,EASY减少了信息泄露,在保持原始语言内容和情感状态的同时增强了隐私保护。在VoicePrivacy Challenge官方数据集上的实验结果表明,我们提出的方法优于所有基线系统,有效保护说话人隐私的同时保持了语言内容和情感状态。
论文及项目相关链接
PDF Accepted by INTERSPEECH 2025
Summary
情绪在语音交互中扮演着重要的角色,通过语调、音高和节奏来表达情感和意图,使体验更加个性化。然而,现有的大多数说话人匿名化系统采用并行分离方法,仅将语音分离为语言内容和说话人身份,忽视了原始情绪状态的保留。本研究介绍了EASY,一种情感感知的说话人匿名化框架。EASY采用新颖的顺序分离过程,将说话人身份、语言内容和情感表示进行分离,通过因子蒸馏法将每种语音属性建模在不同的子空间中。通过独立约束说话人身份和情感表示,EASY减少了信息泄露,增强了隐私保护,同时保留了原始的语言内容和情感状态。实验结果表明,在VoicePrivacy Challenge官方数据集上,本研究提出的方法优于所有基线系统,有效地保护了说话人的隐私,同时保持了语言内容和情感状态。
Key Takeaways
- 情感在语音交互中起到重要作用,通过语调、音高和节奏表达情感和意图。
- 现有的说话人匿名化系统主要关注于分离语言内容和说话人身份,容易忽视原始情感状态的保留。
- EASY框架是一种情感感知的说话人匿名化方法,能够分离说话人身份、语言内容和情感表示。
- EASY采用因子蒸馏法,将每种语音属性建模在独立的子空间中。
- EASY通过独立约束说话人身份和情感表示,减少了信息泄露,增强了隐私保护。
- 实验结果表明,EASY在保护说话人隐私的同时,能够保持语言内容和情感状态。
点此查看论文截图



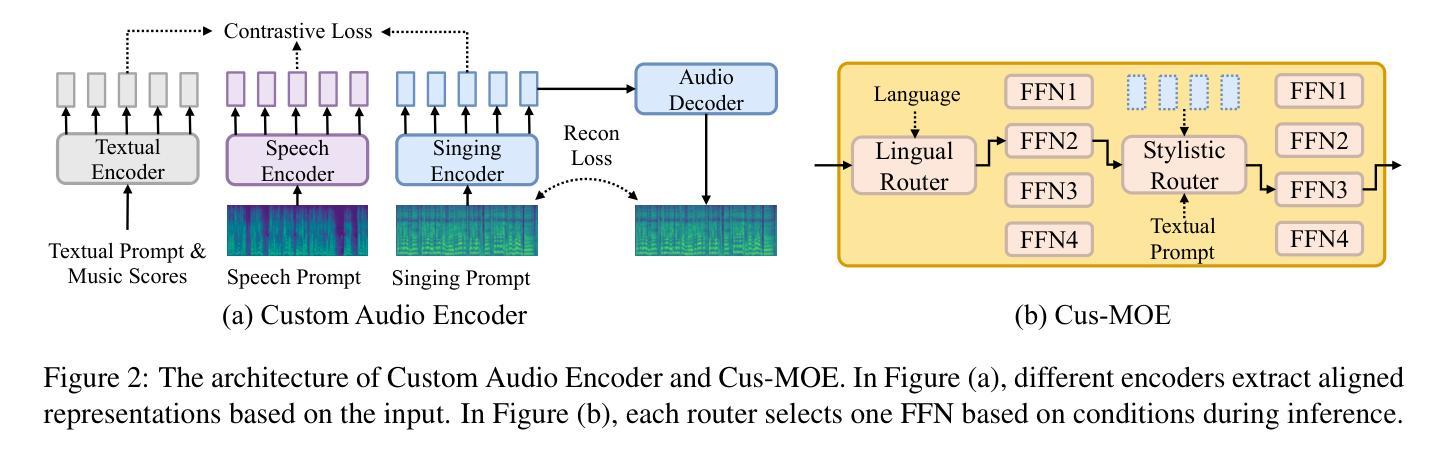
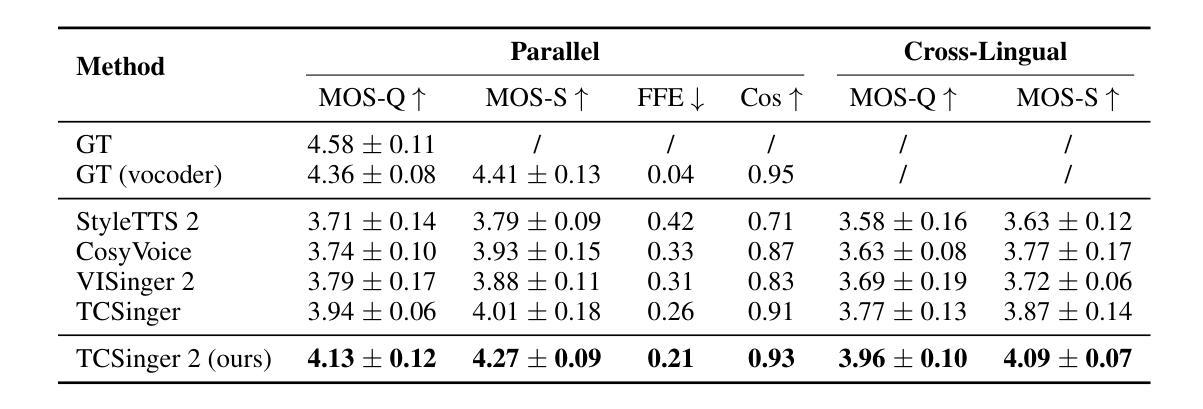
TCSinger 2: Customizable Multilingual Zero-shot Singing Voice Synthesis
Authors:Yu Zhang, Wenxiang Guo, Changhao Pan, Dongyu Yao, Zhiyuan Zhu, Ziyue Jiang, Yuhan Wang, Tao Jin, Zhou Zhao
Customizable multilingual zero-shot singing voice synthesis (SVS) has various potential applications in music composition and short video dubbing. However, existing SVS models overly depend on phoneme and note boundary annotations, limiting their robustness in zero-shot scenarios and producing poor transitions between phonemes and notes. Moreover, they also lack effective multi-level style control via diverse prompts. To overcome these challenges, we introduce TCSinger 2, a multi-task multilingual zero-shot SVS model with style transfer and style control based on various prompts. TCSinger 2 mainly includes three key modules: 1) Blurred Boundary Content (BBC) Encoder, predicts duration, extends content embedding, and applies masking to the boundaries to enable smooth transitions. 2) Custom Audio Encoder, uses contrastive learning to extract aligned representations from singing, speech, and textual prompts. 3) Flow-based Custom Transformer, leverages Cus-MOE, with F0 supervision, enhancing both the synthesis quality and style modeling of the generated singing voice. Experimental results show that TCSinger 2 outperforms baseline models in both subjective and objective metrics across multiple related tasks.
可定制的多语种零样本歌唱声音合成(SVS)在音乐创作和短视频配音等领域具有多种潜在应用。然而,现有的SVS模型过于依赖音素和音符边界注释,这限制了它们在零样本场景中的稳健性,并导致音素和音符之间的过渡不自然。此外,它们还缺乏通过不同提示进行有效的多级风格控制。为了克服这些挑战,我们引入了TCSinger 2,这是一个基于不同提示进行风格迁移和风格控制的多任务多语种零样本SVS模型。TCSinger 2主要包括三个关键模块:1)模糊边界内容(BBC)编码器,预测持续时间,扩展内容嵌入,并对边界应用掩码以实现平滑过渡。2)自定义音频编码器,利用对比学习从歌唱、语音和文本提示中提取对齐表示。3)基于流的自定义Transformer,利用Cus-MOE和F0监督,提高生成歌唱声音的合成质量和风格建模。实验结果表明,TCSinger 2在多个相关任务中的主观和客观指标上均优于基准模型。
论文及项目相关链接
PDF Accepted by ACL 2025
Summary
TCSinger 2是一款多任务多语言零样本歌唱声音合成模型,具有风格迁移和基于不同提示的风格控制功能。该模型通过引入BBC编码器、自定义音频编码器和基于流的自定义转换器等技术,提高了语音合成的质量和灵活性,可应用于音乐创作和短视频配音等领域。
Key Takeaways
- TCSinger 2是一款多语言零样本歌唱声音合成模型,适用于音乐创作和短视频配音。
- 现有SVS模型过于依赖音素和音符边界注释,限制了其在零样本场景中的稳健性。
- TCSinger 2通过引入BBC编码器实现平滑过渡,延长内容嵌入并应用边界掩码。
- 自定义音频编码器使用对比学习从歌唱、语音和文本提示中提取对齐表示。
- 流式自定义转换器利用Cus-MOE和F0监督,提高合成质量和风格建模。
- 实验结果表明,TCSinger 2在多项任务中主观和客观指标上均优于基准模型。
点此查看论文截图