⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-05-24 更新
MM-MovieDubber: Towards Multi-Modal Learning for Multi-Modal Movie Dubbing
Authors:Junjie Zheng, Zihao Chen, Chaofan Ding, Yunming Liang, Yihan Fan, Huan Yang, Lei Xie, Xinhan Di
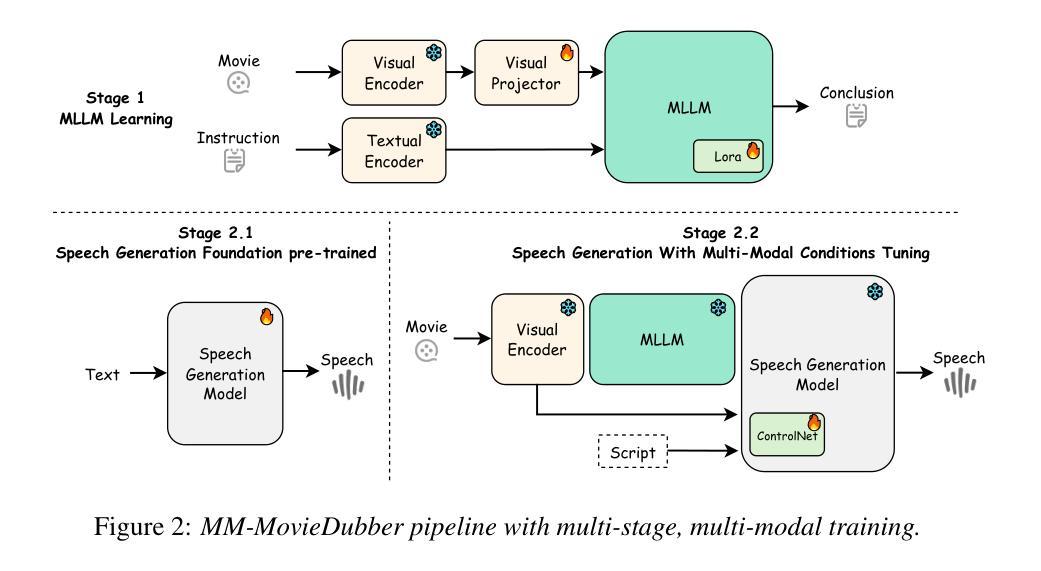
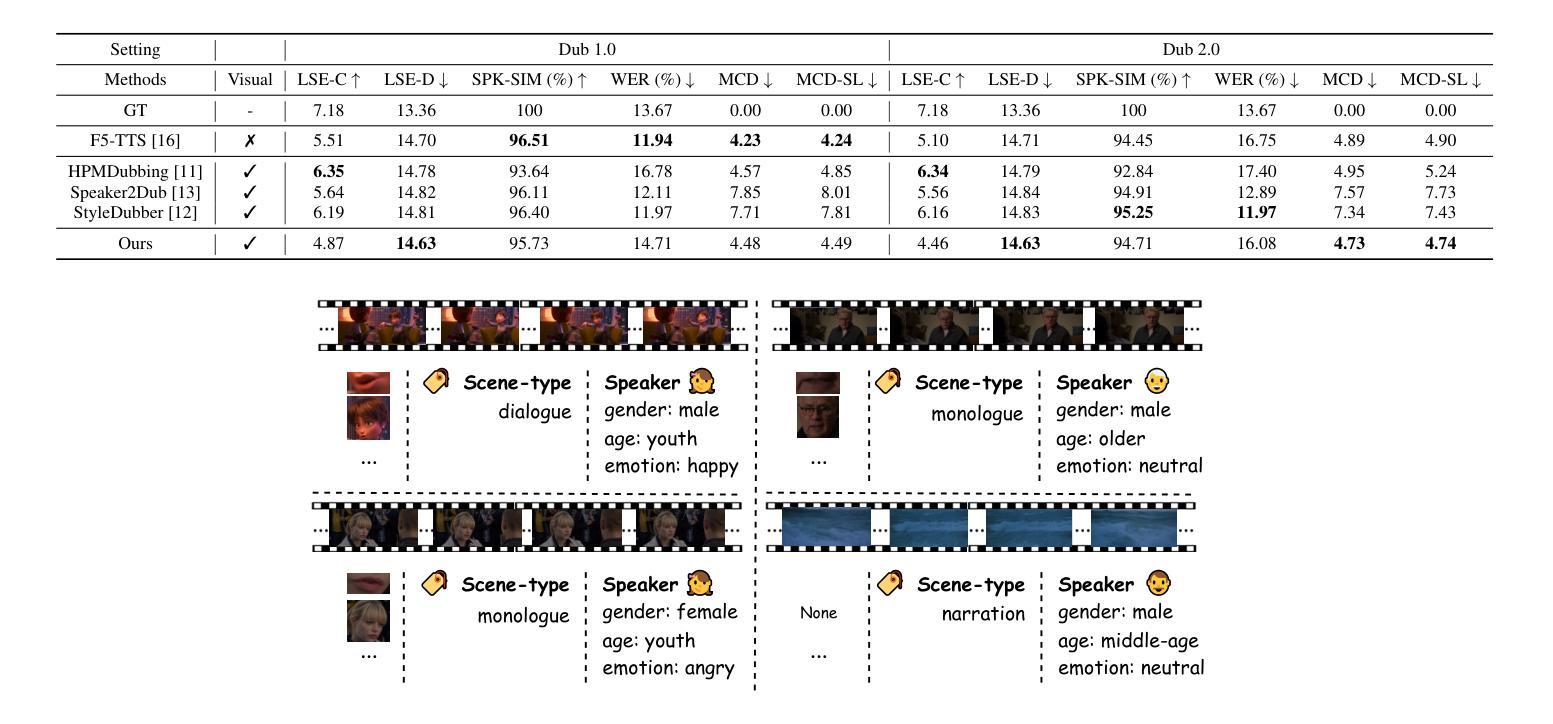
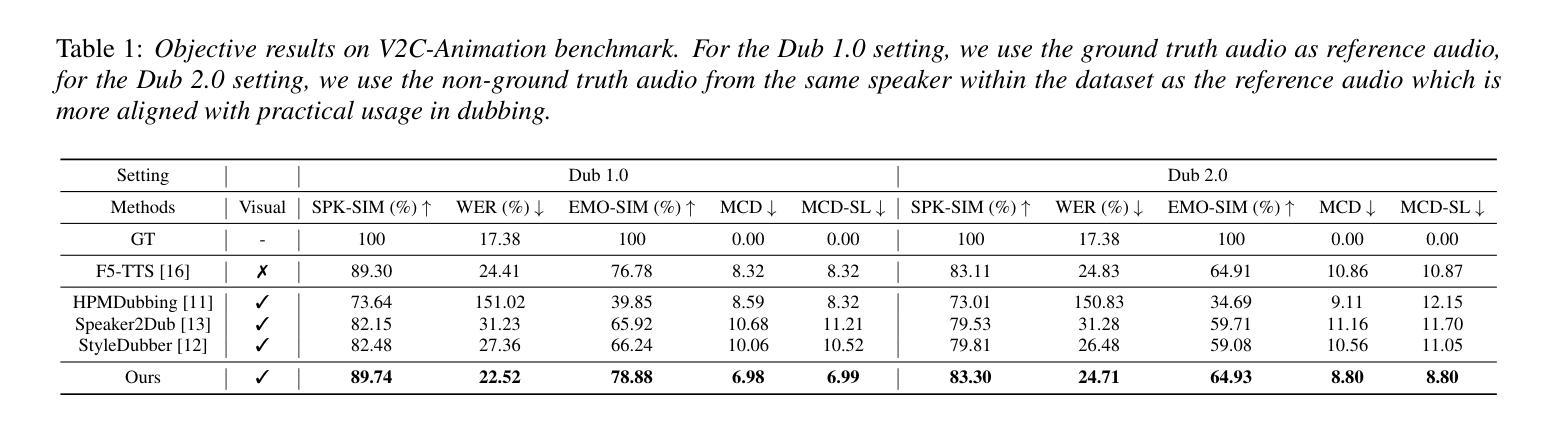
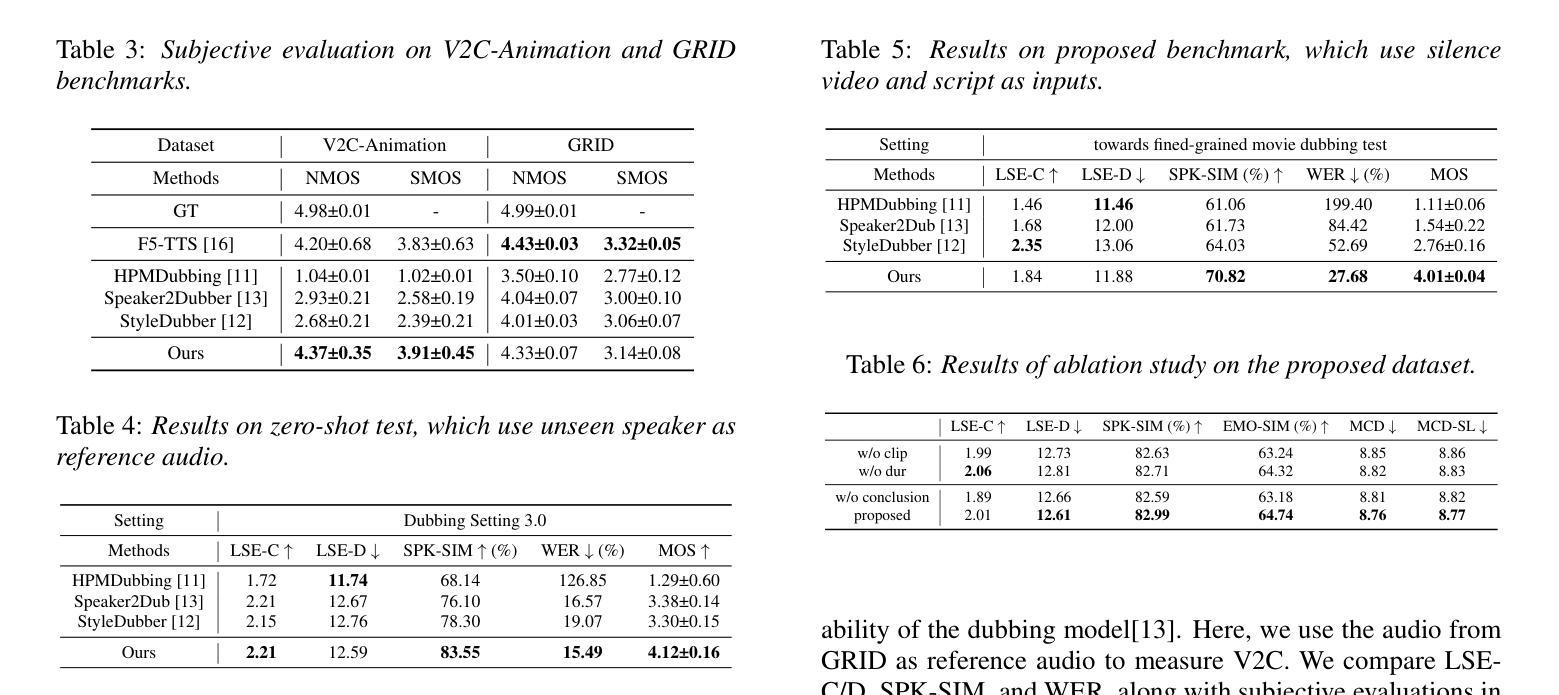
Current movie dubbing technology can produce the desired speech using a reference voice and input video, maintaining perfect synchronization with the visuals while effectively conveying the intended emotions. However, crucial aspects of movie dubbing, including adaptation to various dubbing styles, effective handling of dialogue, narration, and monologues, as well as consideration of subtle details such as speaker age and gender, remain insufficiently explored. To tackle these challenges, we introduce a multi-modal generative framework. First, it utilizes a multi-modal large vision-language model (VLM) to analyze visual inputs, enabling the recognition of dubbing types and fine-grained attributes. Second, it produces high-quality dubbing using large speech generation models, guided by multi-modal inputs. Additionally, a movie dubbing dataset with annotations for dubbing types and subtle details is constructed to enhance movie understanding and improve dubbing quality for the proposed multi-modal framework. Experimental results across multiple benchmark datasets show superior performance compared to state-of-the-art (SOTA) methods. In details, the LSE-D, SPK-SIM, EMO-SIM, and MCD exhibit improvements of up to 1.09%, 8.80%, 19.08%, and 18.74%, respectively.
当前电影配音技术可以使用参考声音和输入视频来生成所需的语音,与视觉效果保持完美的同步,同时有效地传达预期的情绪。然而,电影配音的关键方面,包括适应不同的配音风格、有效地处理对话、旁白和独白,以及考虑如演讲者年龄和性别等细微细节,仍没有得到充分的探索。为了应对这些挑战,我们引入了一种多模态生成框架。首先,它利用多模态大型视觉语言模型(VLM)来分析视觉输入,能够识别配音类型和精细属性。其次,它使用大型语音生成模型来生成高质量的配音,并由多模态输入进行引导。此外,还构建了一个包含配音类型和细微细节注释的电影配音数据集,以提高电影理解和提高所提出的多模态框架的配音质量。在多个基准数据集上的实验结果表明,与最先进的方法相比,其性能表现更优越。具体而言,LSE-D、SPK-SIM、EMO-SIM和MCD的改进分别高达1.09%、8.80%、19.08%和18.74%。
论文及项目相关链接
PDF 5 pages, 4 figures, accepted by Interspeech 2025
Summary
当前电影配音技术已能通过参考声音和输入视频产生所需的语音,保持与视觉的完美同步并有效传达预期情感。然而,电影配音的关键方面,如适应不同的配音风格、有效处理对话、旁白和独白,以及考虑演讲者的年龄和性别等细微之处,仍探索不足。为应对这些挑战,我们提出了一种多模式生成框架,该框架利用多模式大型视觉语言模型分析视觉输入,以识别配音类型和精细属性,并使用大型语音生成模型产生高质量配音。此外,还构建了一个包含配音类型和细微之处的注释的电影配音数据集,以提高电影理解和配音质量。实验结果表明,与最新方法相比,该框架在多个基准数据集上表现卓越。
Key Takeaways
- 当前电影配音技术在语音生成、同步和情感传达方面已取得显著进展。
- 电影配音仍面临适应不同配音风格、处理对话、旁白和独白的挑战。
- 提出的多模式生成框架利用视觉语言模型识别配音类型和精细属性。
- 该框架利用大型语音生成模型产生高质量配音,受多模式输入指导。
- 构建了一个包含配音类型和细微之处的注释的电影配音数据集。
- 实验结果表明,与现有方法相比,该框架在多个数据集上的表现有显著提升。
点此查看论文截图

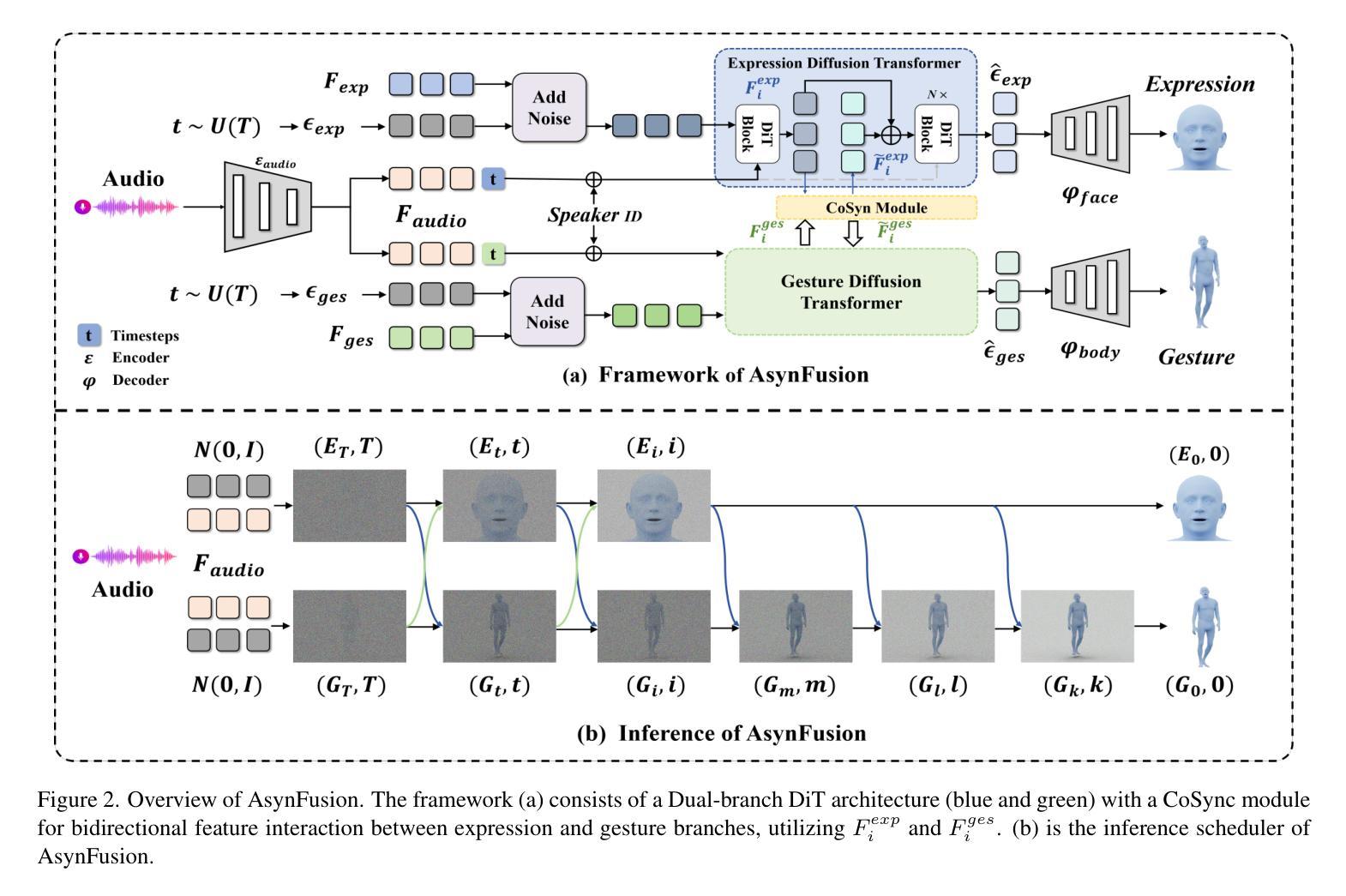
AsynFusion: Towards Asynchronous Latent Consistency Models for Decoupled Whole-Body Audio-Driven Avatars
Authors:Tianbao Zhang, Jian Zhao, Yuer Li, Zheng Zhu, Ping Hu, Zhaoxin Fan, Wenjun Wu, Xuelong Li
Whole-body audio-driven avatar pose and expression generation is a critical task for creating lifelike digital humans and enhancing the capabilities of interactive virtual agents, with wide-ranging applications in virtual reality, digital entertainment, and remote communication. Existing approaches often generate audio-driven facial expressions and gestures independently, which introduces a significant limitation: the lack of seamless coordination between facial and gestural elements, resulting in less natural and cohesive animations. To address this limitation, we propose AsynFusion, a novel framework that leverages diffusion transformers to achieve harmonious expression and gesture synthesis. The proposed method is built upon a dual-branch DiT architecture, which enables the parallel generation of facial expressions and gestures. Within the model, we introduce a Cooperative Synchronization Module to facilitate bidirectional feature interaction between the two modalities, and an Asynchronous LCM Sampling strategy to reduce computational overhead while maintaining high-quality outputs. Extensive experiments demonstrate that AsynFusion achieves state-of-the-art performance in generating real-time, synchronized whole-body animations, consistently outperforming existing methods in both quantitative and qualitative evaluations.
全身音频驱动的角色姿态和表情生成对于创建逼真的数字人类并增强交互式虚拟代理的能力是一项至关重要的任务,在虚拟现实、数字娱乐和远程通信等领域具有广泛的应用。现有方法通常独立生成音频驱动的面部表情和动作,这引入了一个重要的局限性:面部表情和动作元素之间缺乏无缝协调,导致动画效果不那么自然和连贯。为了解决这一局限性,我们提出了AsynFusion,这是一个利用扩散变压器实现和谐表情和动作合成的新框架。该方法建立在双分支DiT架构之上,能够实现面部表情和动作的并行生成。在模型中,我们引入了一个合作同步模块,以促进两种模式之间的双向特征交互,以及一种异步LCM采样策略,以减少计算开销同时保持高质量输出。大量实验表明,AsynFusion在生成实时同步的全身动画方面达到了最先进水平,在定量和定性评估中均优于现有方法。
论文及项目相关链接
PDF 11pages, conference
Summary
本文介绍了全音频驱动的角色姿态与表情生成技术的重要性及其在虚拟现实、数字娱乐和远程通信等领域的应用。针对现有技术面部与手势分离的问题,提出了基于扩散变换器的AsynFusion框架,实现了面部表情与手势的和谐合成。该框架采用双分支DiT架构,引入合作同步模块和异步LCM采样策略,实现了实时同步全身动画的生成。实验证明,AsynFusion在生成真实同步的全身动画方面达到了领先水平。
Key Takeaways
- 音频驱动的角色姿态与表情生成对于创建逼真的数字人类和增强虚拟代理的交互能力至关重要。
- 现有技术常常独立生成面部表情和手势,导致动作缺乏连贯性。
- AsynFusion框架利用扩散变换器实现面部表情与手势的和谐合成,提高了动作的自然性和连贯性。
- 双分支DiT架构实现面部和手势的并行生成。
- 合作同步模块促进了面部和手势两种模态之间的双向特征交互。
- 异步LCM采样策略减少了计算开销同时保持高质量输出。
- AsynFusion在生成实时同步全身动画方面达到了领先水平。
点此查看论文截图

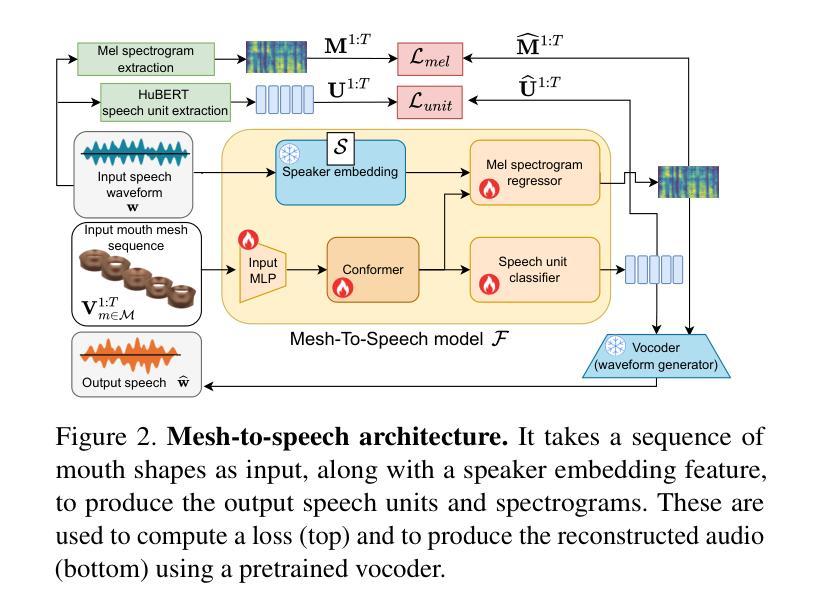
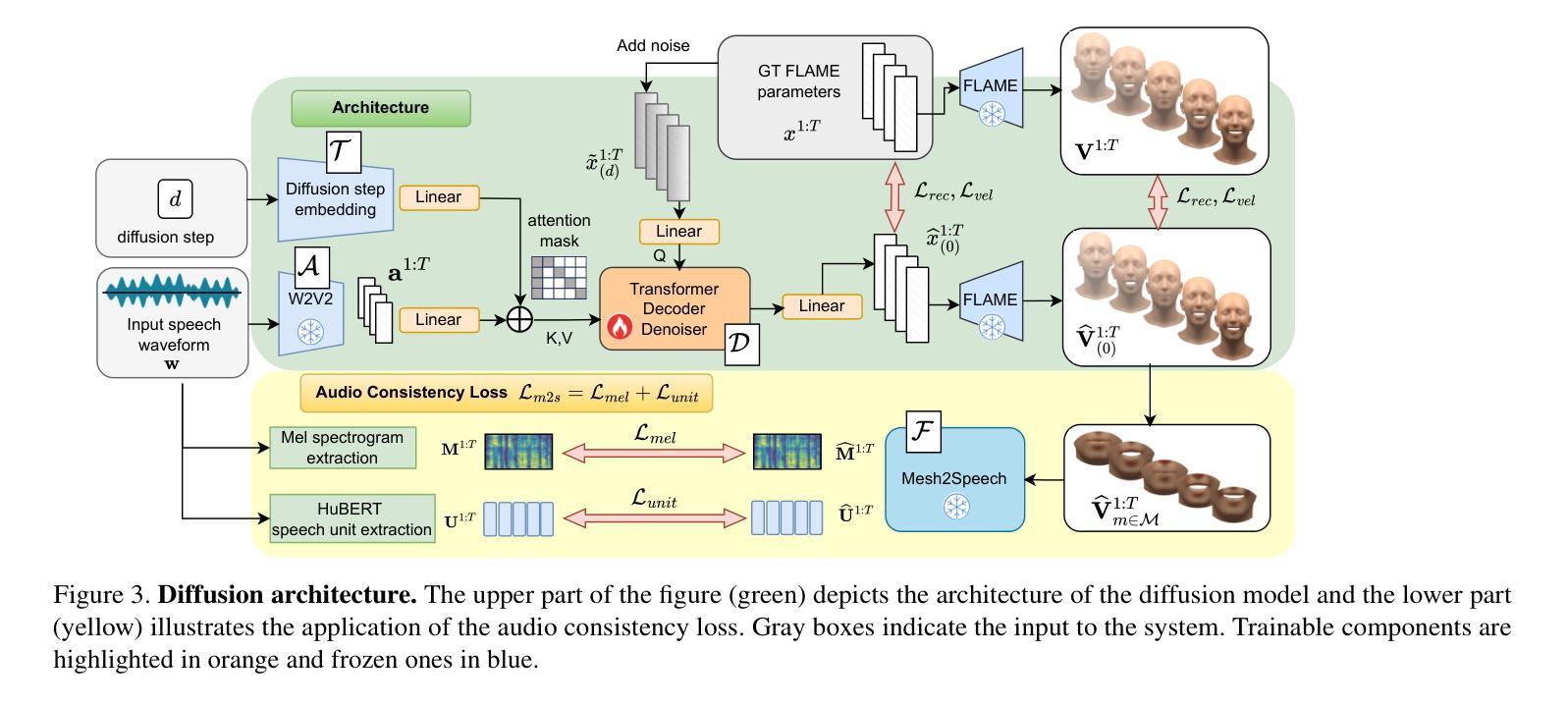
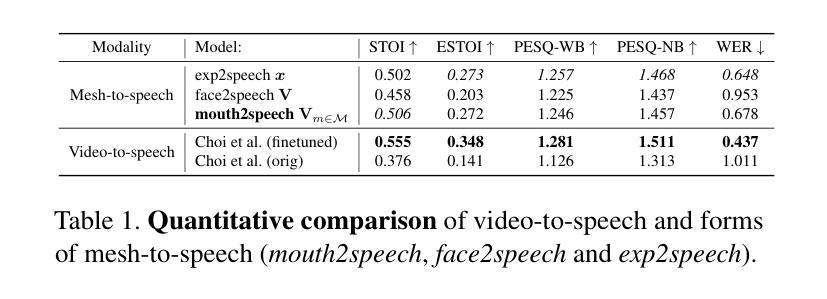
Supervising 3D Talking Head Avatars with Analysis-by-Audio-Synthesis
Authors:Radek Daněček, Carolin Schmitt, Senya Polikovsky, Michael J. Black
In order to be widely applicable, speech-driven 3D head avatars must articulate their lips in accordance with speech, while also conveying the appropriate emotions with dynamically changing facial expressions. The key problem is that deterministic models produce high-quality lip-sync but without rich expressions, whereas stochastic models generate diverse expressions but with lower lip-sync quality. To get the best of both, we seek a stochastic model with accurate lip-sync. To that end, we develop a new approach based on the following observation: if a method generates realistic 3D lip motions, it should be possible to infer the spoken audio from the lip motion. The inferred speech should match the original input audio, and erroneous predictions create a novel supervision signal for training 3D talking head avatars with accurate lip-sync. To demonstrate this effect, we propose THUNDER (Talking Heads Under Neural Differentiable Elocution Reconstruction), a 3D talking head avatar framework that introduces a novel supervision mechanism via differentiable sound production. First, we train a novel mesh-to-speech model that regresses audio from facial animation. Then, we incorporate this model into a diffusion-based talking avatar framework. During training, the mesh-to-speech model takes the generated animation and produces a sound that is compared to the input speech, creating a differentiable analysis-by-audio-synthesis supervision loop. Our extensive qualitative and quantitative experiments demonstrate that THUNDER significantly improves the quality of the lip-sync of talking head avatars while still allowing for generation of diverse, high-quality, expressive facial animations. The code and models will be available at https://thunder.is.tue.mpg.de/
为了具有广泛的应用性,语音驱动的三维头部化身必须根据语音清晰地发音,同时通过动态变化的面部表情传达适当的情绪。关键问题在于确定性模型虽然能产生高质量的唇同步效果,但缺乏丰富的表情;而随机模型虽然能生成多样化的表情,但唇同步质量较低。为了两者兼顾,我们寻找具有准确唇同步的随机模型。为此,我们基于以下观察结果开发了一种新方法:如果一种方法可以生成逼真的三维嘴唇运动,那么应该可以从嘴唇运动中推断出语音。推断出的语音应与原始输入音频相匹配,错误的预测可以作为一种新型监督信号来训练具有准确唇同步的三维对话头部化身。为了展示这种效果,我们提出了THUNDER(神经可微语音重建下的对话头部,Talking Heads Under Neural Differentiable Elocution Reconstruction),这是一个三维对话头部化身框架,通过可微声音产生引入了一种新型监督机制。首先,我们训练了一个新颖的网格到语音模型,该模型可以从面部动画中回归音频。然后,我们将此模型纳入基于扩散的对话化身框架中。在训练过程中,网格到语音模型会接收生成的动画并产生声音,该声音会与输入语音进行比较,从而创建一个可微的音频合成分析监督循环。我们的广泛定性和定量实验表明,THUNDER在改进对话头部化身的唇同步质量的同时,仍然能够生成多样化、高质量、富有表现力的面部动画。代码和模型将在https://thunder.is.tue.mpg.de/上提供。
论文及项目相关链接
Summary
本文探讨了在创建语音驱动的3D头像时面临的挑战,即需要同步唇动与语音,并展现相应的情绪表情。文章提出了一种新的方法THUNDER,通过结合确定性模型与随机模型的优势,实现了高质量的唇音同步与多样化的表情表达。该方法通过引入一个新型的监督机制——可微声音产生,提高了3D头像的说话质量。
Key Takeaways
- 语音驱动的3D头像需要同步唇动与语音,并展现适当的情绪表情。
- 现有模型在唇音同步与表情表达上存有限制,确定性模型缺乏表情多样性,而随机模型唇音同步质量较低。
- THUNDER方法结合了确定性模型与随机模型的优势,旨在实现高质量的唇音同步与多样化的表情表达。
- THUNDER通过引入可微声音产生的新型监督机制,提高了3D头像的说话质量。
- 该方法通过训练一个从面部动画回归音频的模型,将其融入基于扩散的说话头像框架中。
- 在训练过程中,产生的动画通过音频合成监督循环与输入语音进行比较,从而实现了可微分的音频分析。
点此查看论文截图

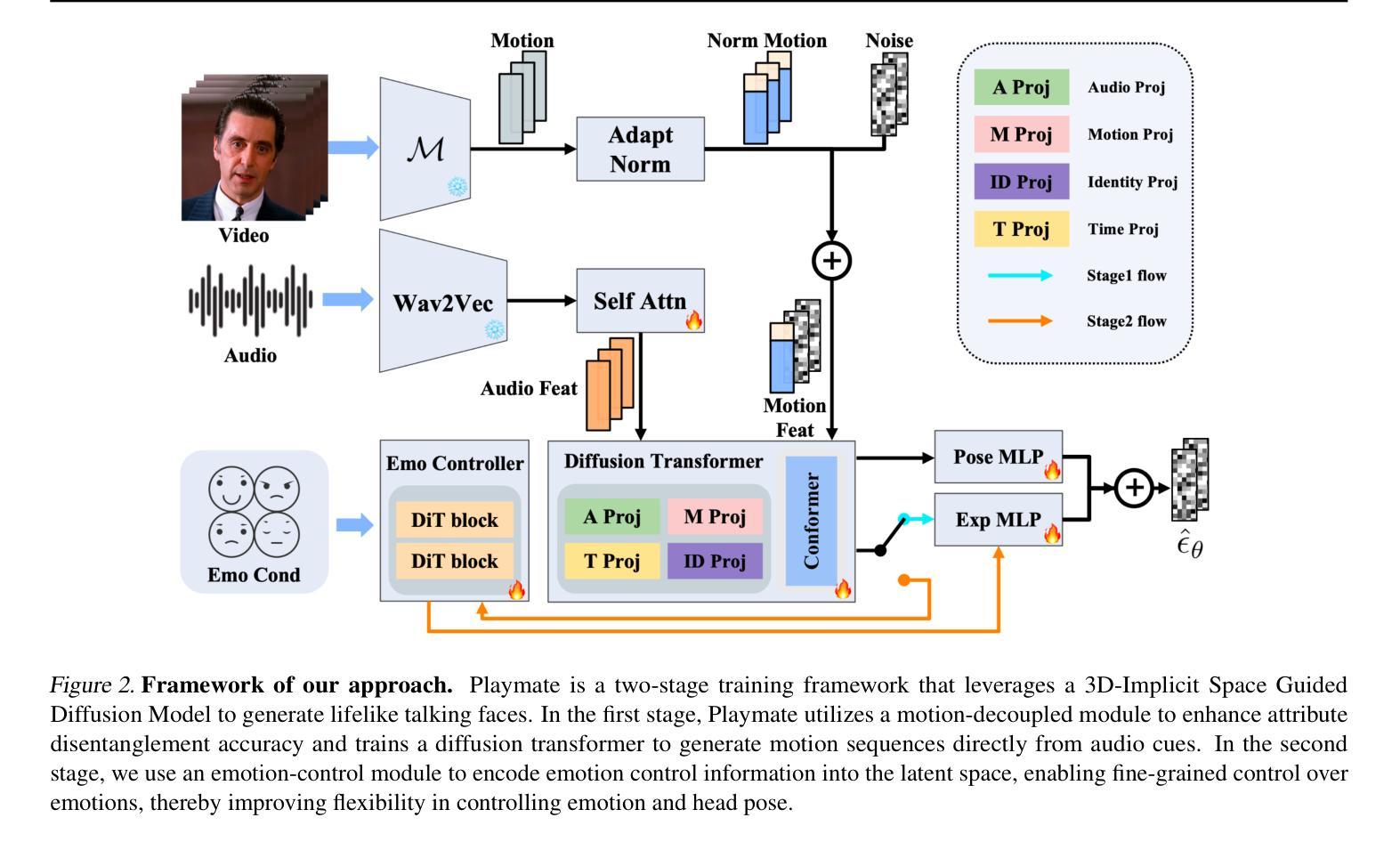
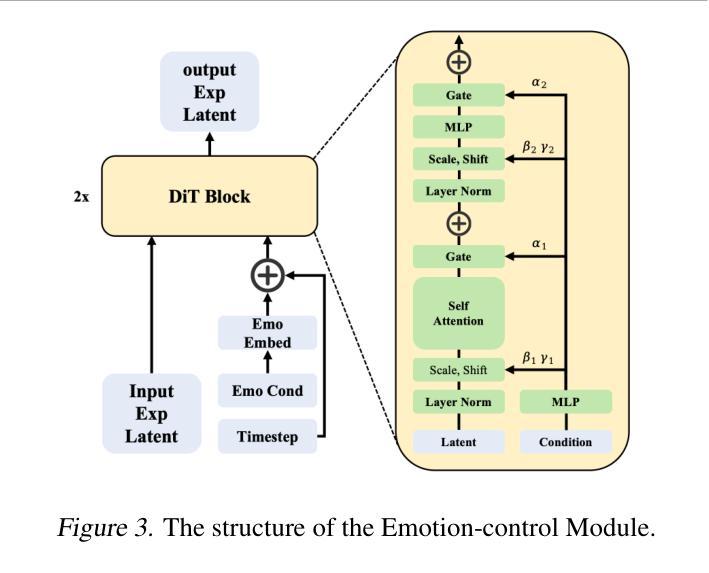
Playmate: Flexible Control of Portrait Animation via 3D-Implicit Space Guided Diffusion
Authors:Xingpei Ma, Jiaran Cai, Yuansheng Guan, Shenneng Huang, Qiang Zhang, Shunsi Zhang
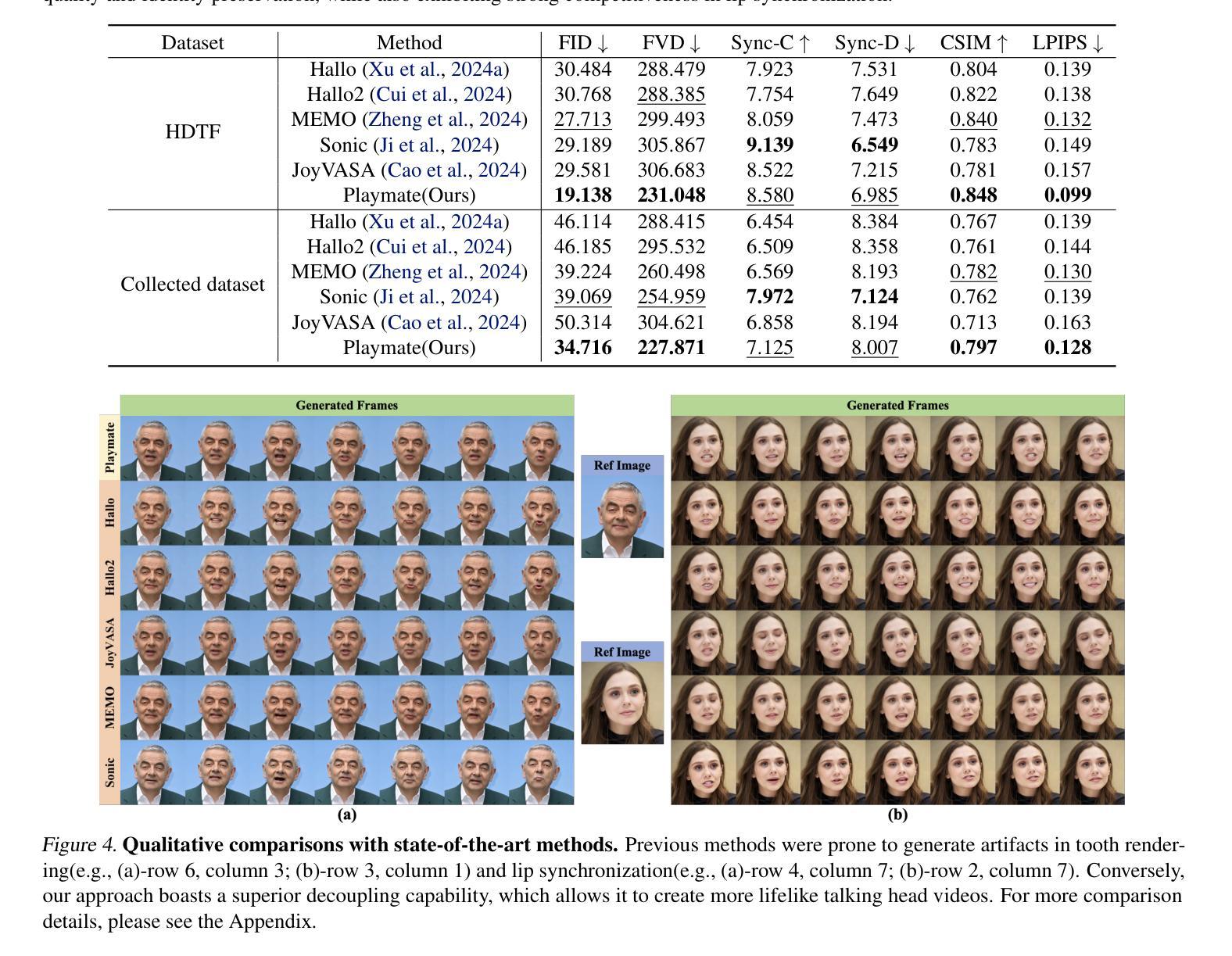
Recent diffusion-based talking face generation models have demonstrated impressive potential in synthesizing videos that accurately match a speech audio clip with a given reference identity. However, existing approaches still encounter significant challenges due to uncontrollable factors, such as inaccurate lip-sync, inappropriate head posture and the lack of fine-grained control over facial expressions. In order to introduce more face-guided conditions beyond speech audio clips, a novel two-stage training framework Playmate is proposed to generate more lifelike facial expressions and talking faces. In the first stage, we introduce a decoupled implicit 3D representation along with a meticulously designed motion-decoupled module to facilitate more accurate attribute disentanglement and generate expressive talking videos directly from audio cues. Then, in the second stage, we introduce an emotion-control module to encode emotion control information into the latent space, enabling fine-grained control over emotions and thereby achieving the ability to generate talking videos with desired emotion. Extensive experiments demonstrate that Playmate not only outperforms existing state-of-the-art methods in terms of video quality, but also exhibits strong competitiveness in lip synchronization while offering improved flexibility in controlling emotion and head pose. The code will be available at https://github.com/Playmate111/Playmate.
近期基于扩散的说话人脸生成模型在合成视频方面展现出了令人印象深刻的潜力,能够准确地将给定的参考身份与语音音频片段相匹配。然而,现有方法仍然面临着由不可控因素带来的重大挑战,例如唇音同步不准确、头部姿势不自然以及对面部表情的精细控制不足。为了引入除语音音频片段之外更多的人脸引导条件,我们提出了一种新颖的两阶段训练框架Playmate,以生成更逼真的面部表情和说话人脸。在第一阶段,我们引入了一个解耦的隐式3D表示以及一个精心设计的运动解耦模块,以促进更精确的属性分解,并直接从音频线索生成富有表现力的说话视频。然后,在第二阶段,我们引入了一个情感控制模块,将情感控制信息编码到潜在空间中,实现对情感的精细控制,从而能够生成具有所需情感的说话视频。大量实验表明,Playmate不仅在视频质量方面超越了现有的最先进方法,而且在唇同步方面也表现出强大的竞争力,同时在控制情绪和头部姿势方面提供了更高的灵活性。代码将在https://github.com/Playmate111/Playmate上提供。
论文及项目相关链接
Summary
基于扩散的说话人脸生成模型已展现出合成视频与语音音频剪辑匹配的潜力,但仍面临不准确的人脸同步、不适当的头部姿势和面部表情精细控制等挑战。为引入更多面部指导条件,提出一种新型的两阶段训练框架Playmate,生成更逼真的面部表情和说话人脸。首先,引入解耦隐式3D表示和精心设计运动解耦模块,促进更准确属性分离,直接从音频线索生成表情说话视频。然后,在第二阶段引入情感控制模块,将情感控制信息编码到潜在空间,实现对情绪的精细控制,从而生成具有所需情感的说话视频。实验表明,Playmate不仅在视频质量方面优于现有最先进的方法,而且在唇同步方面也表现出强大的竞争力,同时提供情绪控制的灵活性。代码将在https://github.com/Playmate111/Playmate上提供。
Key Takeaways
- 说话人脸生成模型在合成视频与语音匹配方面展现出显著潜力。
- 现有方法面临不准确的人脸同步、头部姿势和面部表情控制等挑战。
- Playmate模型采用两阶段训练框架,生成更逼真的面部表情和说话人脸。
- 第一阶段通过解耦隐式3D表示和运动解耦模块促进准确属性分离。
- 第二阶段引入情感控制模块,实现对情绪的精细控制。
- Playmate在视频质量、唇同步方面优于现有方法,并提供情绪控制的灵活性。
点此查看论文截图