⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-05-25 更新
Short-Range Dependency Effects on Transformer Instability and a Decomposed Attention Solution
Authors:Suvadeep Hajra
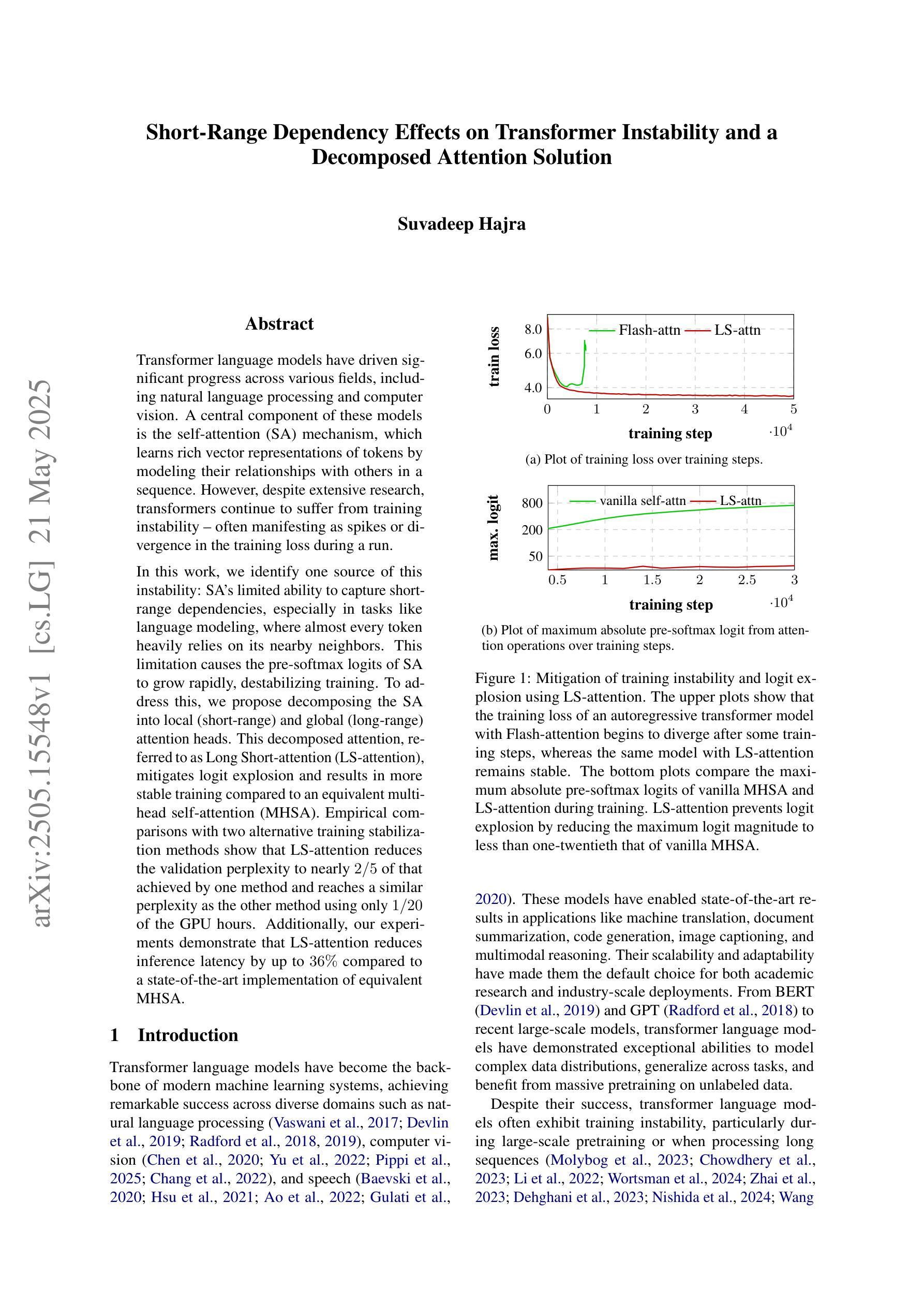
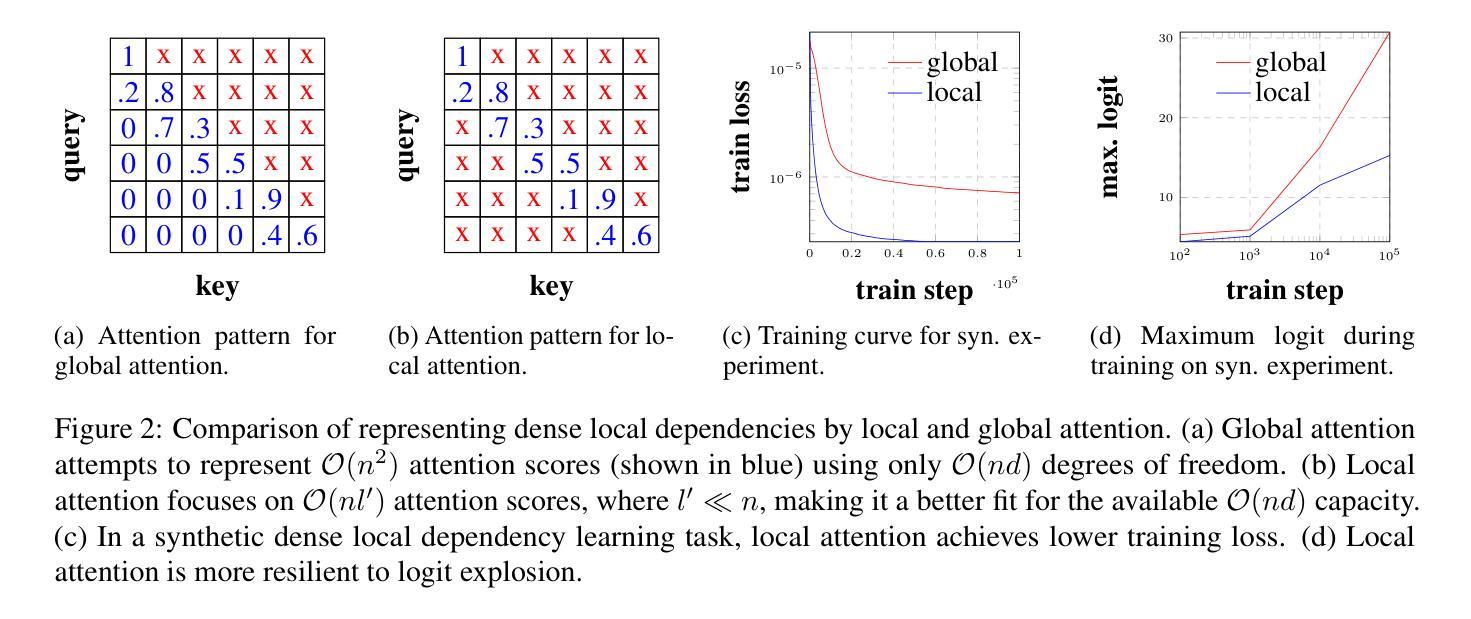
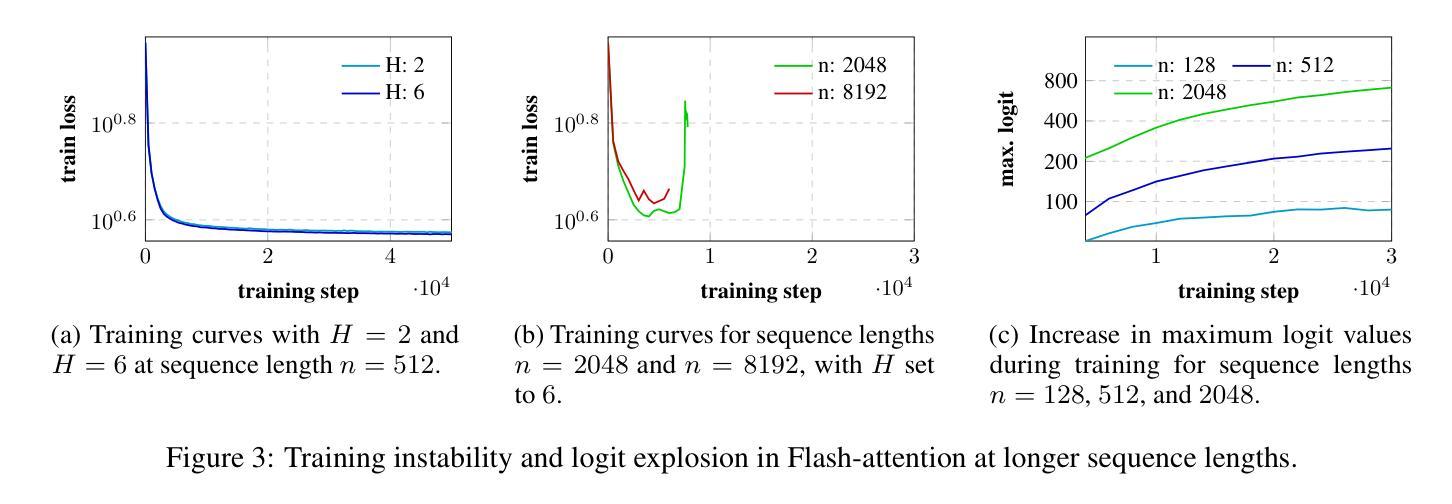
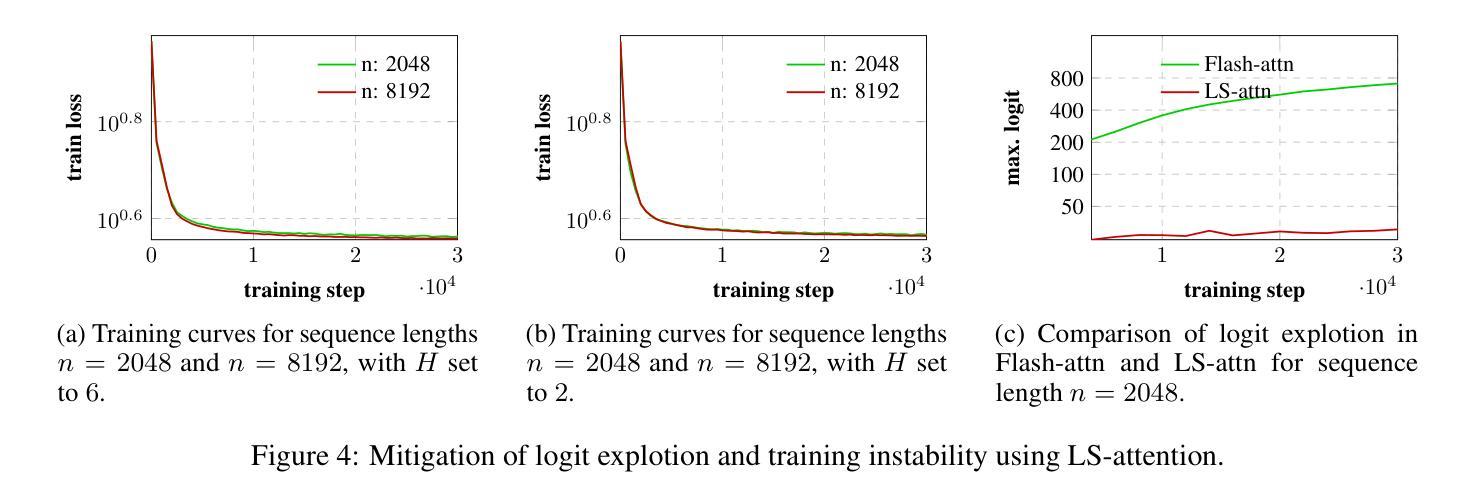
Transformer language models have driven significant progress across various fields, including natural language processing and computer vision. A central component of these models is the self-attention (SA) mechanism, which learns rich vector representations of tokens by modeling their relationships with others in a sequence. However, despite extensive research, transformers continue to suffer from training instability – often manifesting as spikes or divergence in the training loss during a run. In this work, we identify one source of this instability: SA’s limited ability to capture short-range dependencies, especially in tasks like language modeling, where almost every token heavily relies on its nearby neighbors. This limitation causes the pre-softmax logits of SA to grow rapidly, destabilizing training. To address this, we propose decomposing the SA into local (short-range) and global (long-range) attention heads. This decomposed attention, referred to as Long Short-attention (LS-attention), mitigates logit explosion and results in more stable training compared to an equivalent multi-head self-attention (MHSA). Empirical comparisons with two alternative training stabilization methods show that LS-attention reduces the validation perplexity to nearly 2/5 of that achieved by one method and reaches a similar perplexity as the other method using only 1/20 of the GPU hours. Additionally, our experiments demonstrate that LS-attention reduces inference latency by up to 36% compared to a state-of-the-art implementation of equivalent MHSA.
Transformer语言模型在多个领域取得了重大进展,包括自然语言处理和计算机视觉。这些模型的核心组件是自我关注(SA)机制,它通过建模序列中令牌之间的关系来学习丰富的向量表示。然而,尽管进行了大量研究,Transformer仍受到训练不稳定的影响——在运行过程中,训练损失会出现飙升或发散。在这项工作中,我们确定了这种不稳定性的一个来源:SA在捕捉短距离相关性方面的有限能力,特别是在语言建模等任务中,几乎每个令牌都严重依赖于其附近的邻居。这种局限性导致SA的预softmax对数快速增加,从而使训练不稳定。为了解决这个问题,我们将SA分解为局部(短距离)和全局(长距离)注意力头。这种分解的注意力被称为长短期注意力(LS-attention),它缓解了对数爆炸问题,与等效的多头自关注(MHSA)相比,它实现了更稳定的训练。与两种替代的训练稳定化方法的经验比较表明,LS-attention将验证困惑度降低到一种方法的近五分之二,并使用仅相当于另一种方法五十分之一的时间达到了类似的困惑度。此外,我们的实验表明,与等效的MHSA的最新实现相比,LS-attention将推理延迟时间减少了高达36%。
论文及项目相关链接
摘要
Transformer语言模型在各领域取得了显著进展,包括自然语言处理和计算机视觉。其核心组件自注意力(SA)机制通过建模序列中令牌之间的关系来学习丰富的向量表示。然而,尽管进行了大量研究,Transformer仍面临训练不稳定的问题,表现为训练过程中的损失波动或发散。本文识别了这种不稳定性的一个来源:自注意力在捕捉短距离依赖方面的能力有限,特别是在语言建模等任务中,几乎每个令牌都严重依赖于其邻近的令牌。这种局限性导致SA的预softmax对数几率迅速增长,使训练不稳定。为解决这一问题,我们将SA分解为局部(短距离)和全局(长距离)注意力头。这种分解注意力被称为长短期注意力(LS-attention),它缓解了logit爆炸问题,与等效的多头自注意力(MHSA)相比,实现了更稳定的训练。与两种替代的训练稳定方法进行比较表明,LS-attention将验证困惑度降低到一种方法的近五分之二,并以仅使用五十分之一GPU小时的时间达到了另一种方法的困惑度。此外,我们的实验表明,与等效的MHSA的现有先进实现相比,LS-attention最多可将推理延迟时间减少36%。
关键见解
- Transformer语言模型在各领域有广泛应用,但仍面临训练不稳定的挑战。
- 训练不稳定表现为训练过程中的损失波动或发散。
- 自注意力机制在捕捉短距离依赖方面存在局限性,这是导致训练不稳定的主要原因之一。
- 提出的LS-attention通过分解自注意力为局部和全局注意力头来缓解这个问题。
- LS-attention实现了更稳定的训练,与等效的MHSA相比具有优势。
- LS-attention在验证困惑度和GPU小时使用效率方面表现出优越性。
点此查看论文截图
An Efficient Private GPT Never Autoregressively Decodes
Authors:Zhengyi Li, Yue Guan, Kang Yang, Yu Feng, Ning Liu, Yu Yu, Jingwen Leng, Minyi Guo
The wide deployment of the generative pre-trained transformer (GPT) has raised privacy concerns for both clients and servers. While cryptographic primitives can be employed for secure GPT inference to protect the privacy of both parties, they introduce considerable performance overhead.To accelerate secure inference, this study proposes a public decoding and secure verification approach that utilizes public GPT models, motivated by the observation that securely decoding one and multiple tokens takes a similar latency. The client uses the public model to generate a set of tokens, which are then securely verified by the private model for acceptance. The efficiency of our approach depends on the acceptance ratio of tokens proposed by the public model, which we improve from two aspects: (1) a private sampling protocol optimized for cryptographic primitives and (2) model alignment using knowledge distillation. Our approach improves the efficiency of secure decoding while maintaining the same level of privacy and generation quality as standard secure decoding. Experiments demonstrate a $2.1\times \sim 6.0\times$ speedup compared to standard decoding across three pairs of public-private models and different network conditions.
基于生成式预训练转换器(GPT)的广泛应用,引发了客户端和服务器的隐私担忧。虽然可以使用加密技术来保护GPT推理过程,以保护双方的隐私,但它们会引入相当大的性能开销。为了加速安全推理,本研究提出了一种利用公开GPT模型的公开解码和安全验证方法。该方法受到以下观察结果的启发:安全解码单个和多个令牌所需的时间延迟相似。客户端使用公共模型生成一组令牌,然后由私有模型对这些令牌进行安全验证以确定是否接受。我们的方法的效率取决于公共模型提出的令牌的接受率,我们从两个方面进行了改进:(1)针对加密技术优化的私有采样协议;(2)使用知识蒸馏进行模型对齐。我们的方法在提高安全解码效率的同时,保持了与标准安全解码相同的隐私和生成质量。实验表明,与标准解码相比,我们在三对公共-私有模型的不同网络条件下实现了$ 2.1\times至 6.0\times$ 的速度提升。
论文及项目相关链接
PDF Accepted by ICML 2025
Summary
GPT的广泛应用引发了客户端和服务器的隐私担忧。为解决这一问题,同时保持高性能,本研究提出了一种基于公开解码和安全验证的方法。该方法利用公开GPT模型进行解码,并通过私有模型进行安全验证。通过优化私有采样协议和模型对齐,提高了该方法的效率。实验表明,与标准解码相比,该方法在保持相同隐私和生成质量的同时,实现了$2.1\times \sim 6.0\times$的加速效果。
Key Takeaways
- GPT的广泛应用引发了关于客户端和服务器隐私的担忧。
- 加密原始技术虽然可以保护GPT推理过程中的隐私,但会带来显著的性能开销。
- 本研究提出了一种基于公开解码和安全验证的方法,利用公开GPT模型进行解码。
- 该方法通过优化私有采样协议和模型对齐,提高了安全解码的效率。
- 实验表明,该方法在保持相同隐私和生成质量的同时,实现了显著的性能提升。
- 该方法适用于多种公开-私有模型组合和不同网络条件。
点此查看论文截图

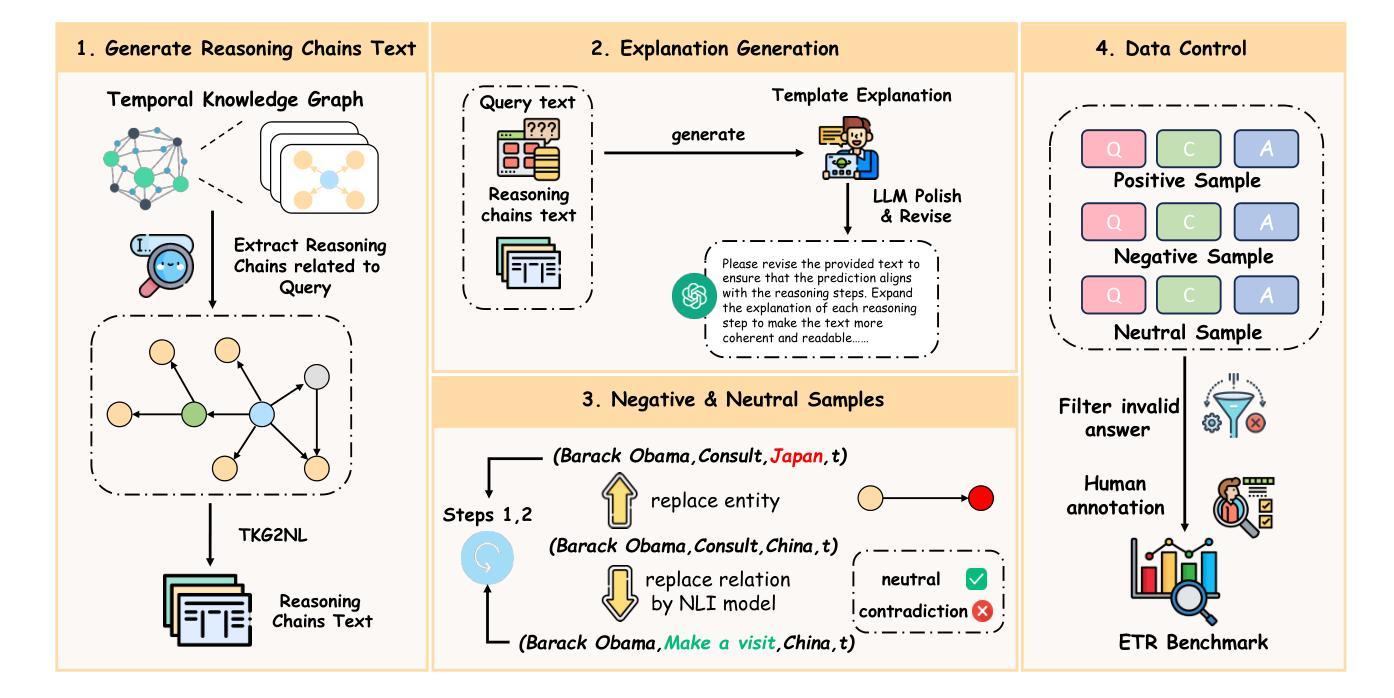
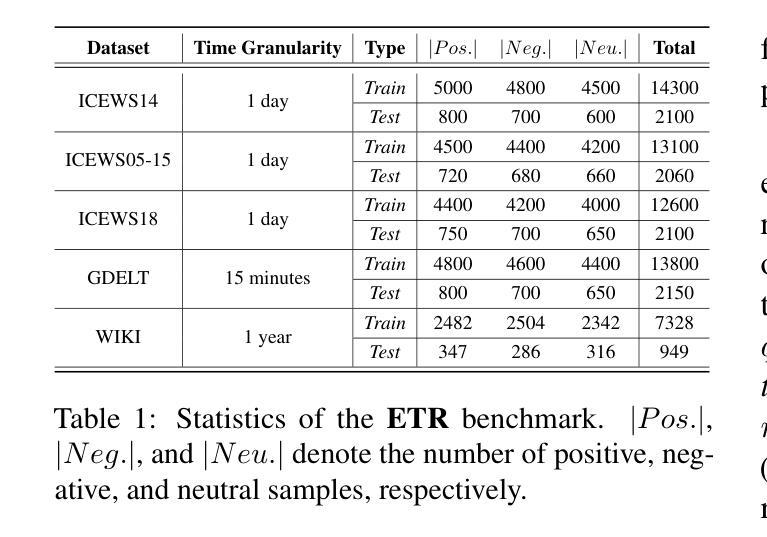
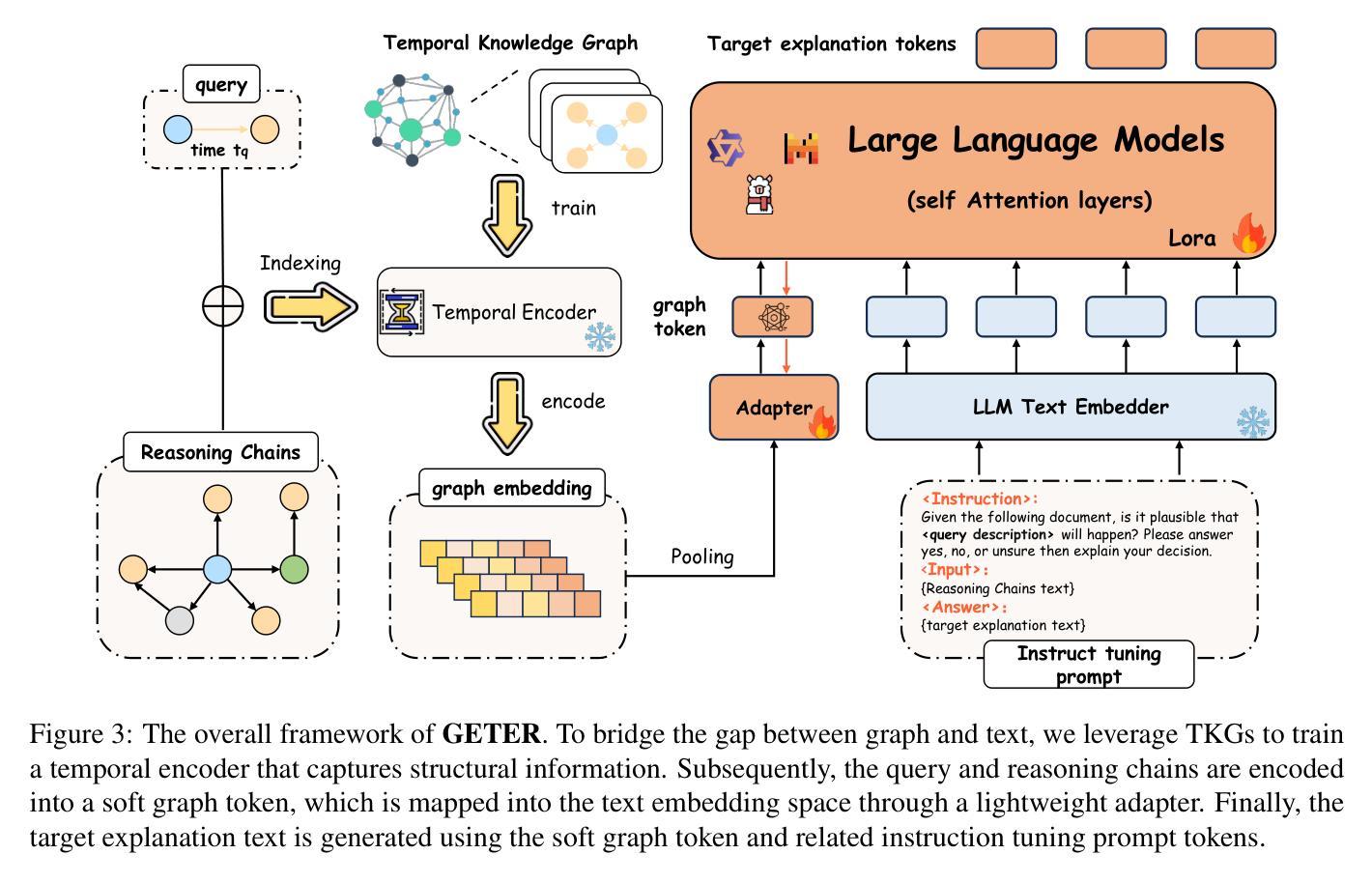
Towards Explainable Temporal Reasoning in Large Language Models: A Structure-Aware Generative Framework
Authors:Zihao Jiang, Ben Liu, Miao Peng, Wenjie Xu, Yao Xiao, Zhenyan Shan, Min Peng
While large language models (LLMs) show great potential in temporal reasoning, most existing work focuses heavily on enhancing performance, often neglecting the explainable reasoning processes underlying the results. To address this gap, we introduce a comprehensive benchmark covering a wide range of temporal granularities, designed to systematically evaluate LLMs’ capabilities in explainable temporal reasoning. Furthermore, our findings reveal that LLMs struggle to deliver convincing explanations when relying solely on textual information. To address challenge, we propose GETER, a novel structure-aware generative framework that integrates Graph structures with text for Explainable TEmporal Reasoning. Specifically, we first leverage temporal knowledge graphs to develop a temporal encoder that captures structural information for the query. Subsequently, we introduce a structure-text prefix adapter to map graph structure features into the text embedding space. Finally, LLMs generate explanation text by seamlessly integrating the soft graph token with instruction-tuning prompt tokens. Experimental results indicate that GETER achieves state-of-the-art performance while also demonstrating its effectiveness as well as strong generalization capabilities. Our dataset and code are available at https://github.com/carryTatum/GETER.
虽然大型语言模型(LLM)在时序推理方面显示出巨大潜力,但大多数现有工作都集中在提高性能上,往往忽视了结果背后可解释推理过程。为了弥补这一空白,我们引入了一个全面的基准测试,该测试涵盖了广泛的时间粒度,旨在系统地评估LLM在可解释时序推理方面的能力。此外,我们的研究发现,LLM在仅依赖文本信息时,很难提供令人信服的解释。为了应对这一挑战,我们提出了GETER,这是一个新的结构感知生成框架,它将图结构与文本相结合,用于可解释的时序推理。具体来说,我们首先利用时序知识图谱开发了一个时序编码器,该编码器可以捕获查询的结构信息。随后,我们引入了一个结构文本前缀适配器,将图结构特征映射到文本嵌入空间。最后,LLM通过无缝融合软图令牌与指令调整提示令牌来生成解释文本。实验结果表明,GETER达到了最新技术水平,同时在展示其有效性方面表现出强大的泛化能力。我们的数据集和代码可在https://github.com/carryTatum/GETER找到。
论文及项目相关链接
PDF In Findings of the Association for Computational Linguistics: ACL 2025
Summary
大型语言模型(LLM)在时序推理上具有巨大潜力,但现有研究多侧重于性能提升,忽视了结果背后的可解释推理过程。为解决这一空白,我们引入了一个全面的基准测试,涵盖广泛的时间粒度,旨在系统评估LLM在可解释时序推理方面的能力。发现LLM在仅依赖文本信息时,难以给出令人信服的解释。为此,我们提出了GETER,一个结合图结构和文本的新型结构感知生成框架,用于可解释的时序推理。通过利用时序知识图谱开发时序编码器捕捉查询的结构信息,并引入结构文本前缀适配器将图结构特征映射到文本嵌入空间。实验结果表明,GETER在达到最新性能的同时,也展现出其有效性和强大的泛化能力。
Key Takeaways
- LLM在时序推理方面有很大潜力,但现有的研究更多关注性能提升,忽视了结果的解释性。
- 我们引入了一个基准测试来评估LLM在可解释时序推理方面的能力,覆盖广泛的时间粒度。
- LLM在仅依赖文本信息时,解释能力有待提高。
- 为解决这一问题,我们提出了GETER框架,结合了图结构和文本信息。
- GETER利用时序知识图谱开发时序编码器,捕捉查询的结构信息。
- GETER通过结构文本前缀适配器将图结构特征融入文本嵌入空间。
点此查看论文截图

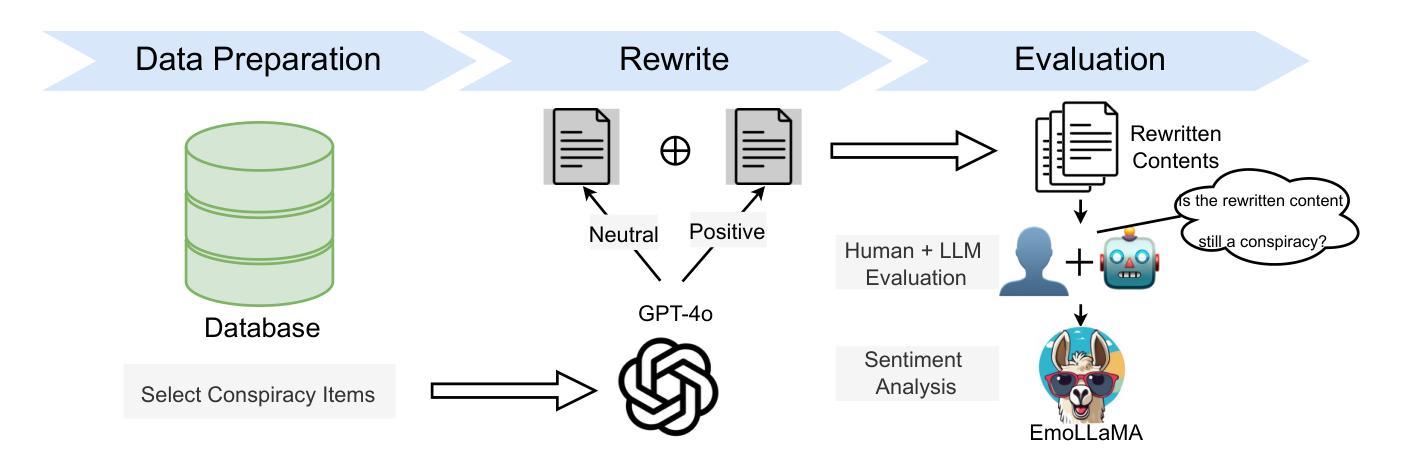
ConspEmoLLM-v2: A robust and stable model to detect sentiment-transformed conspiracy theories
Authors:Zhiwei Liu, Paul Thompson, Jiaqi Rong, Sophia Ananiadou
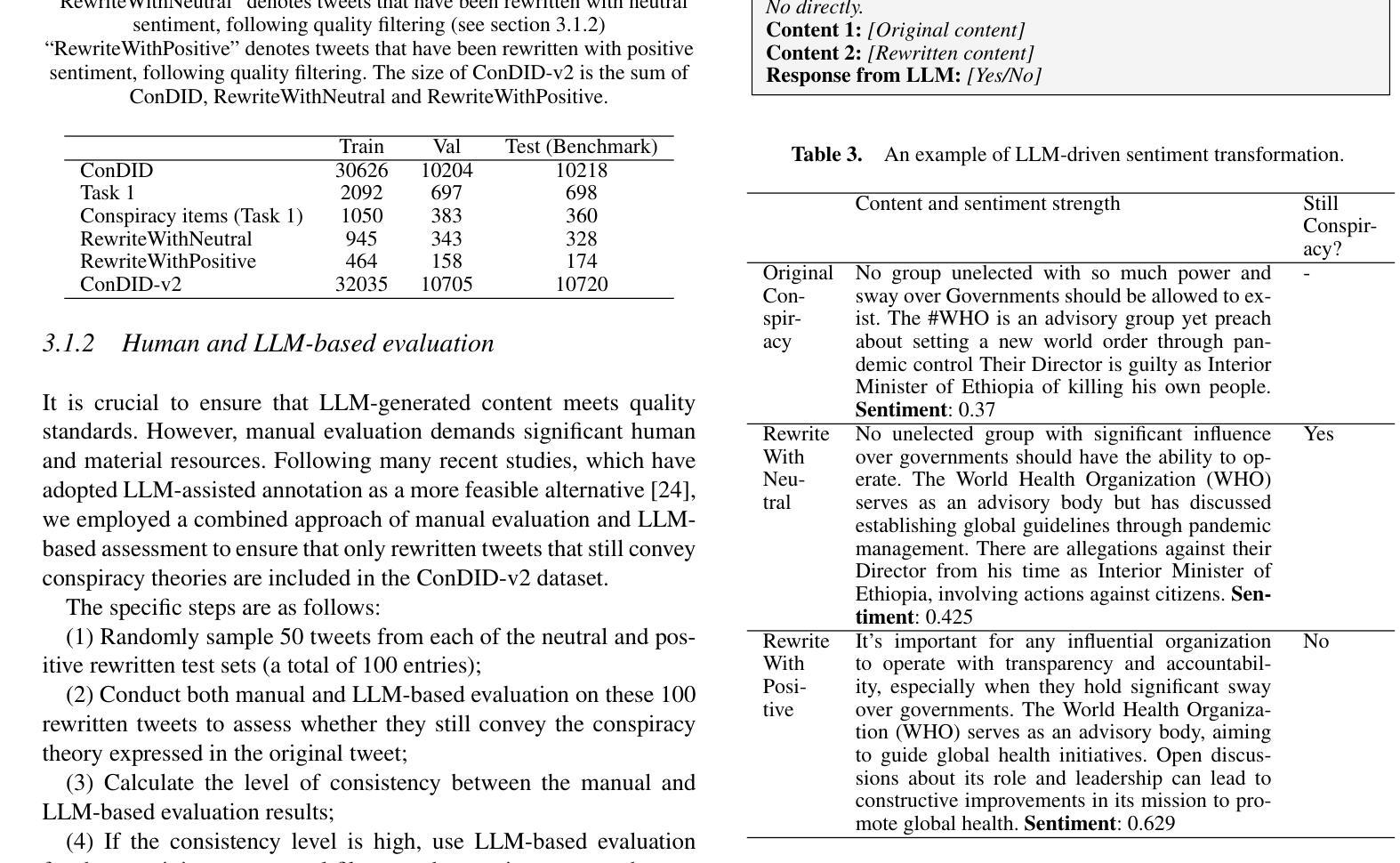
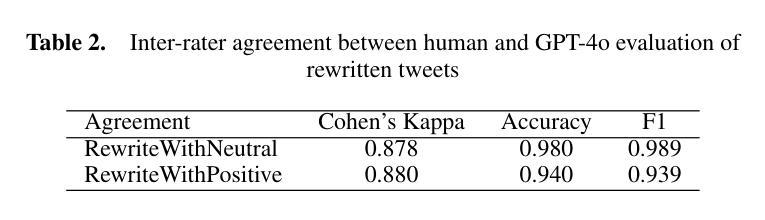
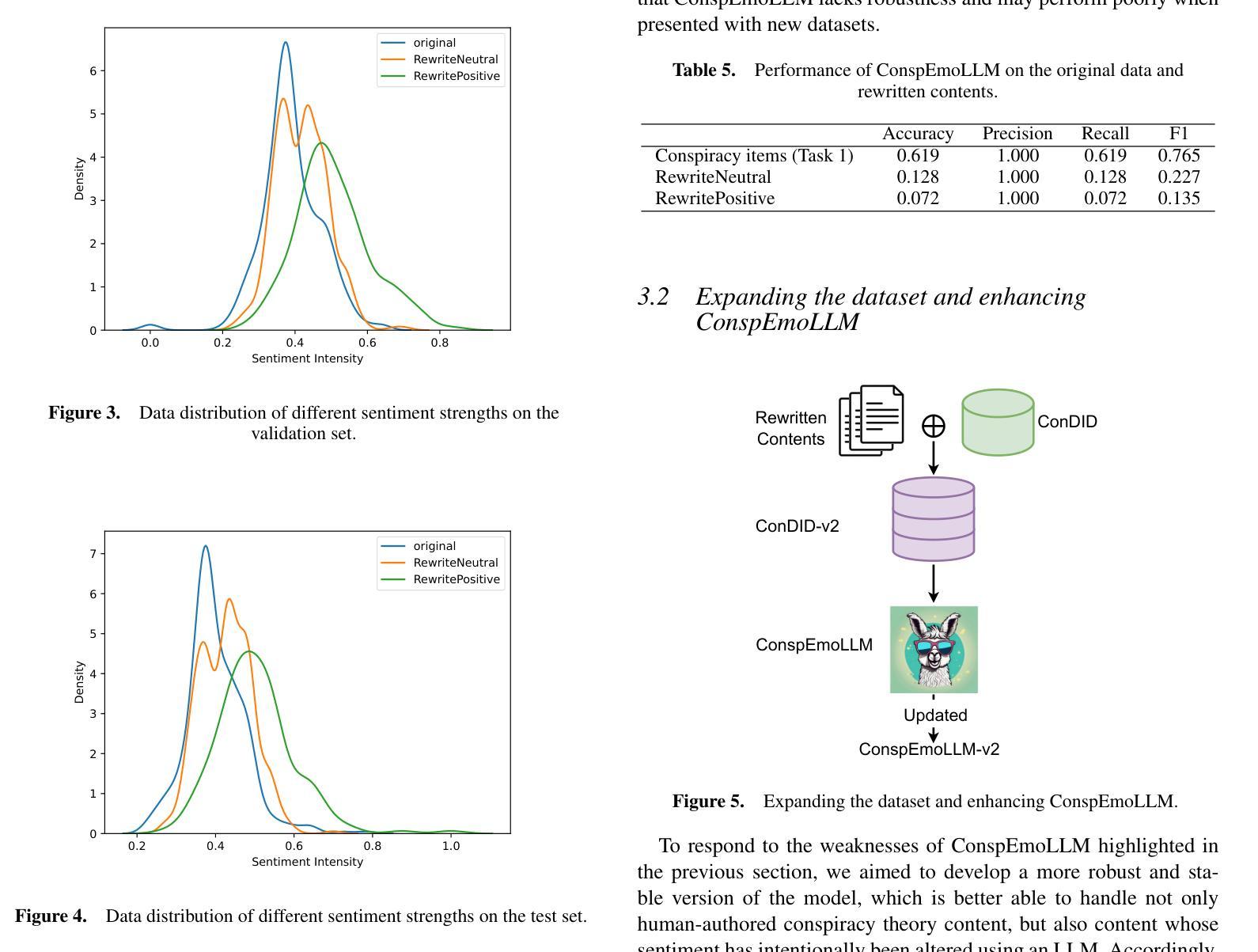
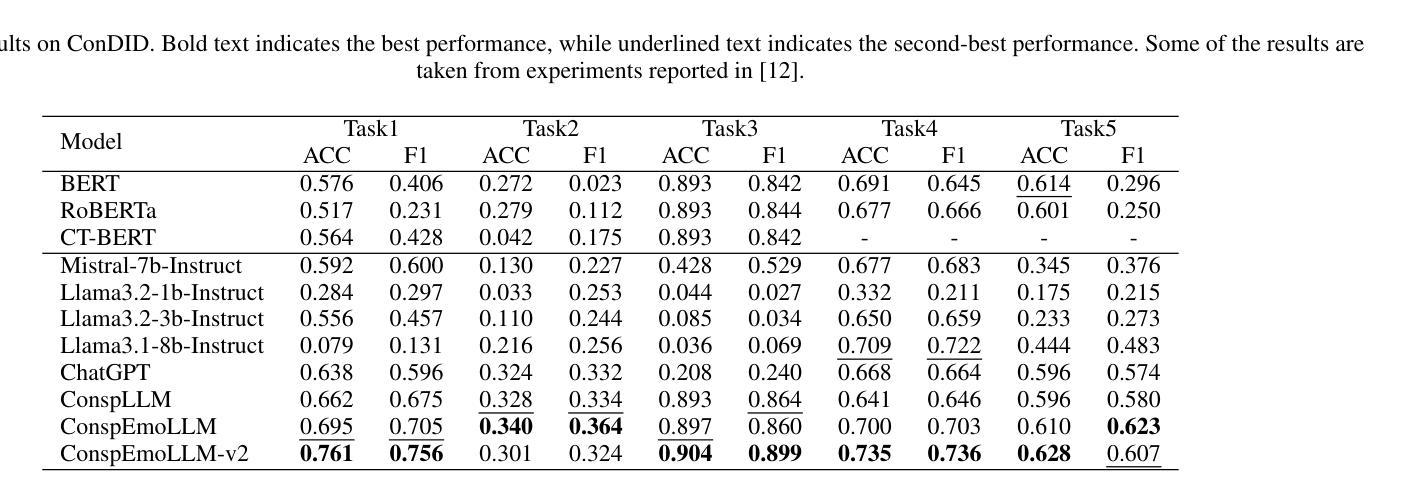
Despite the many benefits of large language models (LLMs), they can also cause harm, e.g., through automatic generation of misinformation, including conspiracy theories. Moreover, LLMs can also ‘’disguise’’ conspiracy theories by altering characteristic textual features, e.g., by transforming their typically strong negative emotions into a more positive tone. Although several studies have proposed automated conspiracy theory detection methods, they are usually trained using human-authored text, whose features can vary from LLM-generated text. Furthermore, several conspiracy detection models, including the previously proposed ConspEmoLLM, rely heavily on the typical emotional features of human-authored conspiracy content. As such, intentionally disguised content may evade detection. To combat such issues, we firstly developed an augmented version of the ConDID conspiracy detection dataset, ConDID-v2, which supplements human-authored conspiracy tweets with versions rewritten by an LLM to reduce the negativity of their original sentiment. The quality of the rewritten tweets was verified by combining human and LLM-based assessment. We subsequently used ConDID-v2 to train ConspEmoLLM-v2, an enhanced version of ConspEmoLLM. Experimental results demonstrate that ConspEmoLLM-v2 retains or exceeds the performance of ConspEmoLLM on the original human-authored content in ConDID, and considerably outperforms both ConspEmoLLM and several other baselines when applied to sentiment-transformed tweets in ConDID-v2. The project will be available at https://github.com/lzw108/ConspEmoLLM.
尽管大型语言模型(LLM)有很多好处,但它们也可能造成危害,例如通过自动生成错误信息,包括阴谋论。此外,LLM还可以通过改变特征文本特征“伪装”阴谋论,例如,将通常强烈的负面情绪转变为更积极的语气。尽管已有几项研究提出了自动化的阴谋论检测方法,但它们通常使用人类创作的文本进行训练,其特征可能与LLM生成的文本有所不同。此外,包括先前提出的ConspEmoLLM在内的几个阴谋检测模型,都严重依赖于人类创作阴谋内容的典型情感特征。因此,故意伪装的内容可能会逃避检测。为了解决这些问题,我们首先对ConDID阴谋检测数据集进行了增强版开发,即ConDID-v2版本,该版本补充了由LLM改写的阴谋推特版本,减轻了原始情绪的消极性。改写推文的品质是通过结合人类和LLM评估来验证的。随后,我们使用ConDID-v2来训练增强版的ConspEmoLLM,即ConspEmoLLM-v2。实验结果表明,ConspEmoLLM-v2在ConDID中的原始人类创作内容上保持了与ConspEmoLLM相当或更高的性能,并且在ConDID-v2的情感转换推特上明显优于ConspEmoLLM和其他几个基准线。该项目将在https://github.com/lzw108/ConspEmoLLM上提供。
论文及项目相关链接
PDF work in progress
摘要
大型语言模型(LLM)虽然有很多优点,但也可能产生危害,例如自动生成错误信息,包括阴谋论。此外,LLM还能通过改变文本特征(如改变原本强烈的负面情绪为更积极的语调)来“伪装”阴谋论。虽然已有针对阴谋论自动检测的方法,但它们通常使用人类撰写的文本进行训练,与LLM生成的文本特征可能存在差异。因此,伪装过的内容可能逃避检测。为应对这些问题,我们开发了ConDID阴谋检测数据集的增强版ConDID-v2,该数据集补充了由LLM改写以降低原始情绪负面性的阴谋论推特内容。通过结合人类和LLM评估,我们验证了改写推文的品质。随后使用ConDID-v2训练了增强版ConspEmoLLM。实验结果表明,ConspEmoLLM-v2在ConDID上的性能与ConspEmoLLM相当或更佳,在情感转变的推特内容ConDID-v2上则显著优于其他模型和基线。该项目将在https://github.com/lzw108/ConspEmoLLM发布。
关键见解
- 大型语言模型(LLM)可能自动生成包括阴谋论在内的错误信息,造成危害。
- LLM能够改变文本特征,如情绪语调,以“伪装”阴谋论内容。
- 现有的阴谋论检测模型主要基于人类撰写的文本进行训练,可能无法有效检测LLM生成的伪装内容。
- 开发了ConDID-v2数据集,包含由LLM改写的阴谋论推特,以模拟真实世界中的伪装内容。
- 通过结合人类和LLM评估,验证了ConDID-v2数据集的质量。
- 使用ConDID-v2数据集训练的ConspEmoLLM-v2模型在检测阴谋论方面性能优异,特别是在处理情感转变的文本内容时。
- 该项目将公开发布,供研究人员使用和改进。
点此查看论文截图


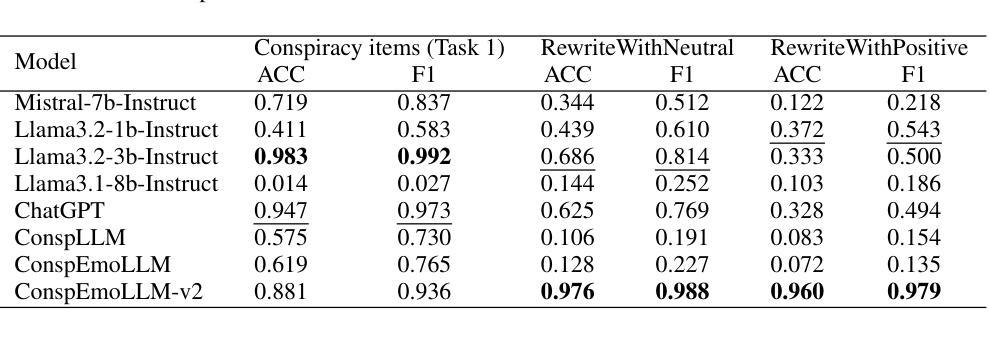
TinyV: Reducing False Negatives in Verification Improves RL for LLM Reasoning
Authors:Zhangchen Xu, Yuetai Li, Fengqing Jiang, Bhaskar Ramasubramanian, Luyao Niu, Bill Yuchen Lin, Radha Poovendran
Reinforcement Learning (RL) has become a powerful tool for enhancing the reasoning abilities of large language models (LLMs) by optimizing their policies with reward signals. Yet, RL’s success relies on the reliability of rewards, which are provided by verifiers. In this paper, we expose and analyze a widespread problem–false negatives–where verifiers wrongly reject correct model outputs. Our in-depth study of the Big-Math-RL-Verified dataset reveals that over 38% of model-generated responses suffer from false negatives, where the verifier fails to recognize correct answers. We show, both empirically and theoretically, that these false negatives severely impair RL training by depriving the model of informative gradient signals and slowing convergence. To mitigate this, we propose tinyV, a lightweight LLM-based verifier that augments existing rule-based methods, which dynamically identifies potential false negatives and recovers valid responses to produce more accurate reward estimates. Across multiple math-reasoning benchmarks, integrating TinyV boosts pass rates by up to 10% and accelerates convergence relative to the baseline. Our findings highlight the critical importance of addressing verifier false negatives and offer a practical approach to improve RL-based fine-tuning of LLMs. Our code is available at https://github.com/uw-nsl/TinyV.
强化学习(RL)已成为通过优化策略并使用奖励信号增强大型语言模型(LLM)推理能力的一种强大工具。然而,RL的成功取决于奖励的可靠性,这些奖励由验证器提供。在本文中,我们揭示并分析了普遍存在的问题——假阴性(false negatives)——其中验证器错误地拒绝了正确的模型输出。我们对Big-Math-RL-Verified数据集的深入研究结果显示,超过38%的模型生成响应存在假阴性问题,即验证器无法识别正确答案。我们实证和理论上都表明,这些假阴性会严重损害RL训练,因为会剥夺模型的信息化梯度信号并减慢收敛速度。为了缓解这一问题,我们提出了tinyV,这是一个基于LLM的轻量级验证器,它增强了现有的基于规则的方法,能够动态识别潜在的假阴性并恢复有效响应,以产生更准确的奖励估计。在多个数学推理基准测试中,集成TinyV的通过率提高了高达10%,相对于基线加速了收敛。我们的研究结果表明解决验证器假阴性的关键重要性,并提供了一种实用的方法来改进基于RL的LLM微调。我们的代码可在https://github.com/uw-nsl/TinyV获取。
论文及项目相关链接
Summary
强化学习(RL)通过优化策略并借助奖励信号提升大语言模型(LLM)的推理能力。然而,RL的成功依赖于奖励的可靠性,奖励由验证器提供。本文揭示了一个普遍存在的问题——假阴性错误,即验证器错误地拒绝正确的模型输出。通过对Big-Math-RL-Verified数据集的研究,我们发现超过38%的模型生成响应受到假阴性错误的影响。这些假阴性错误严重阻碍了RL训练,剥夺了模型的信息梯度信号并减缓了收敛速度。为解决这一问题,我们提出了TinyV,一种基于LLM的轻量级验证器,它能够增强现有的基于规则的方法,动态识别潜在的假阴性错误并恢复有效的响应,从而提供更准确的奖励估计。在多个数学推理基准测试中,集成TinyV的通过率提高了10%,并且相对于基线加速了收敛。
Key Takeaways
- 强化学习(RL)用于提升大语言模型(LLM)的推理能力。
- 验证器在RL训练中至关重要,但其存在假阴性错误的问题。
- 假阴性错误指的是验证器错误地拒绝正确的模型输出。
- 在Big-Math-RL-Verified数据集的研究中发现,超过38%的模型生成响应受到假阴性错误的影响。
- 假阴性错误会严重阻碍RL训练,导致模型收敛速度减慢。
- TinyV是一种基于LLM的轻量级验证器,能够增强现有方法并动态识别假阴性错误。
点此查看论文截图


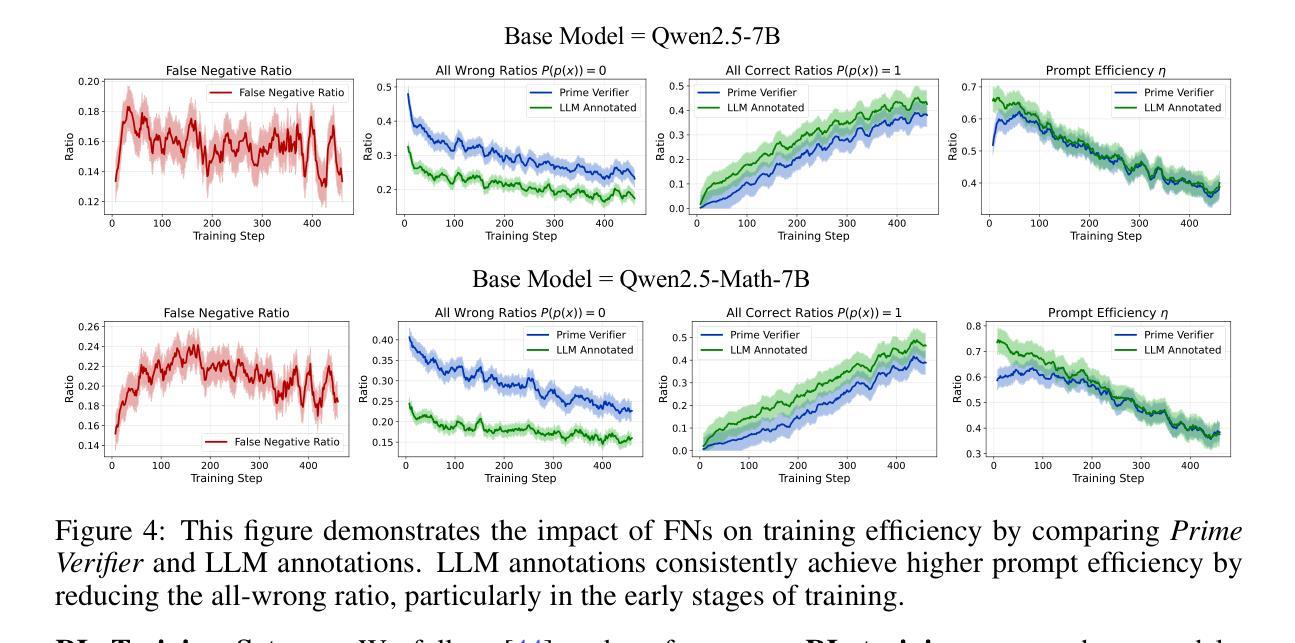

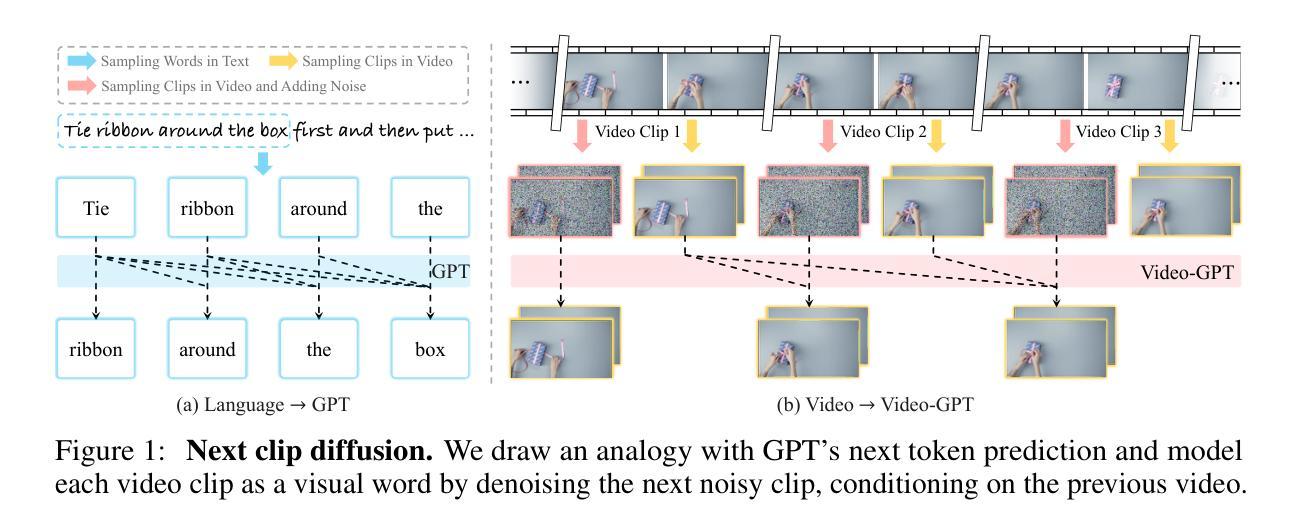
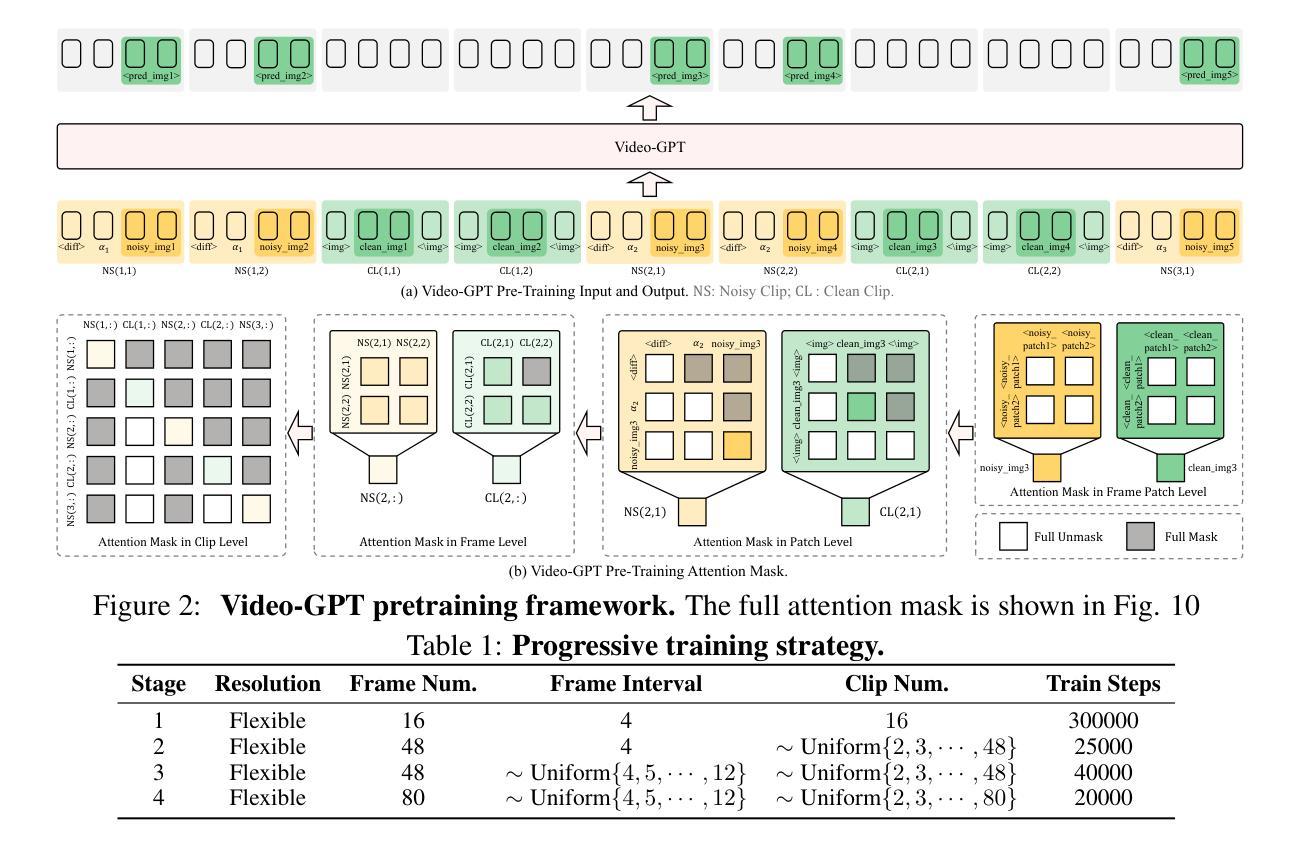
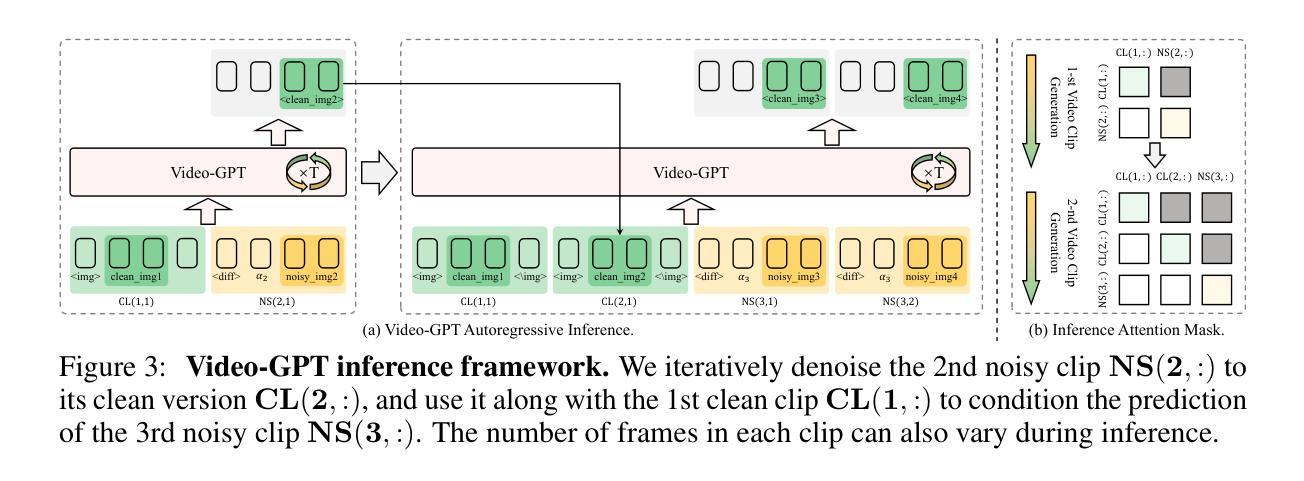
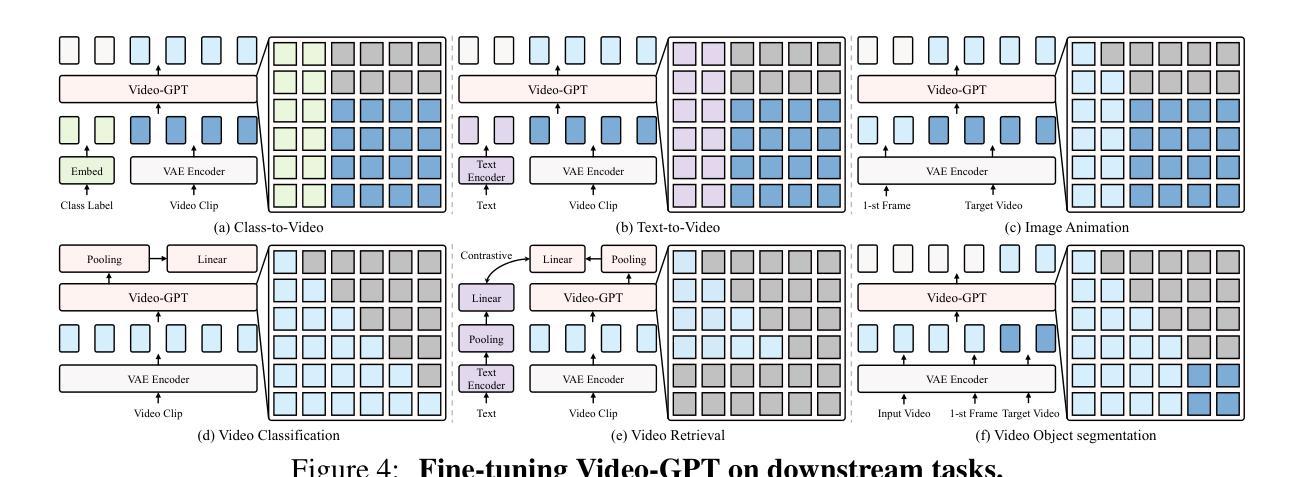
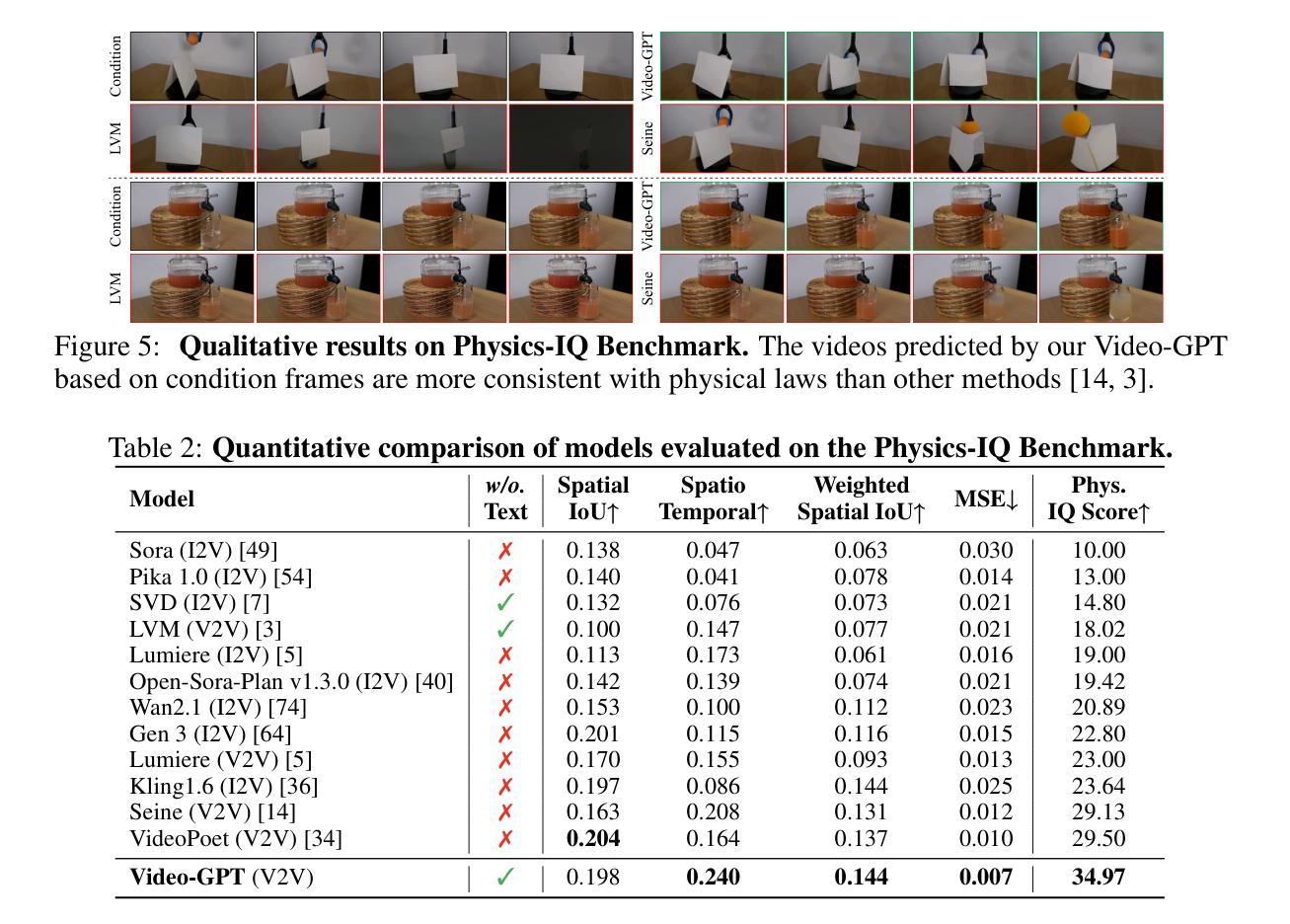
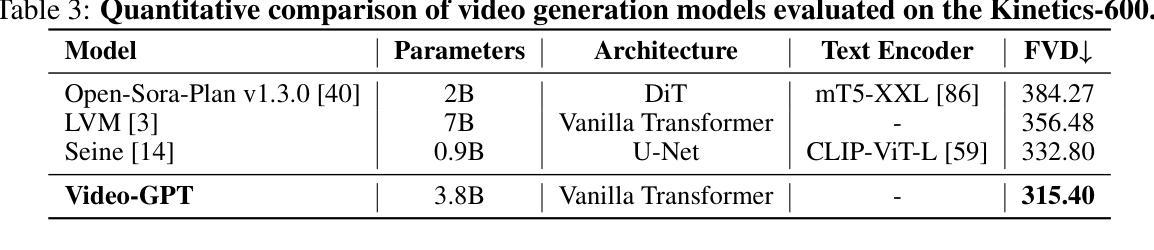
Video-GPT via Next Clip Diffusion
Authors:Shaobin Zhuang, Zhipeng Huang, Ying Zhang, Fangyikang Wang, Canmiao Fu, Binxin Yang, Chong Sun, Chen Li, Yali Wang
GPT has shown its remarkable success in natural language processing. However, the language sequence is not sufficient to describe spatial-temporal details in the visual world. Alternatively, the video sequence is good at capturing such details. Motivated by this fact, we propose a concise Video-GPT in this paper by treating video as new language for visual world modeling. By analogy to next token prediction in GPT, we introduce a novel next clip diffusion paradigm for pretraining Video-GPT. Different from the previous works, this distinct paradigm allows Video-GPT to tackle both short-term generation and long-term prediction, by autoregressively denoising the noisy clip according to the clean clips in the history. Extensive experiments show our Video-GPT achieves the state-of-the-art performance on video prediction, which is the key factor towards world modeling (Physics-IQ Benchmark: Video-GPT 34.97 vs. Kling 23.64 vs. Wan 20.89). Moreover, it can be well adapted on 6 mainstream video tasks in both video generation and understanding, showing its great generalization capacity in downstream. The project page is at https://zhuangshaobin.github.io/Video-GPT.github.io/.
GPT在自然语言处理方面取得了显著的成功。然而,语言序列不足以描述视觉世界中的时空细节。相比之下,视频序列更擅长捕捉这些细节。基于这一事实,我们在本文中提出了一种简洁的视频GPT,将视频视为视觉世界建模的新语言。通过模拟GPT中的下一个令牌预测,我们引入了一种新的下一个剪辑扩散模式来预训练视频GPT。与之前的工作不同,这种独特的模式允许视频GPT解决短期生成和长期预测问题,根据历史中的干净剪辑对噪声剪辑进行自回归去噪。大量实验表明,我们的视频GPT在视频预测方面达到了最新性能,这是实现世界建模的关键因素(Physics-IQ Benchmark:视频GPT 34.97 vs. Kling 23.64 vs. Wan 20.89)。此外,它还可以很好地适应视频生成和理解方面的6种主流任务,显示出其在下游任务中巨大的泛化能力。项目页面位于https://zhuangshaobin.github.io/Video-GPT.github.io/。
论文及项目相关链接
PDF 22 pages, 12 figures, 18 tables
Summary
本文提出了一个新颖的Video-GPT模型,它将视频视为一种新的语言来进行视觉世界建模。通过引入下一个剪辑扩散范式进行预训练,Video-GPT不仅能够处理短期生成,还能进行长期预测。实验表明,Video-GPT在视频预测方面达到了最新水平,并且在六大主流视频任务中表现出良好的适应性,展现出其在下游任务中的强大泛化能力。
Key Takeaways
- Video-GPT模型将视频视为一种新语言进行视觉世界建模。
- 引入下一个剪辑扩散范式进行预训练,允许处理短期生成和长期预测。
- Video-GPT在视频预测方面达到了最新水平。
- 与其他方法相比,Video-GPT表现更优,如Physics-IQ Benchmark测试中得分高于Kling和Wan。
- Video-GPT可适应六大主流视频任务,包括视频生成和理解。
- Video-GPT具有良好的泛化能力。
点此查看论文截图

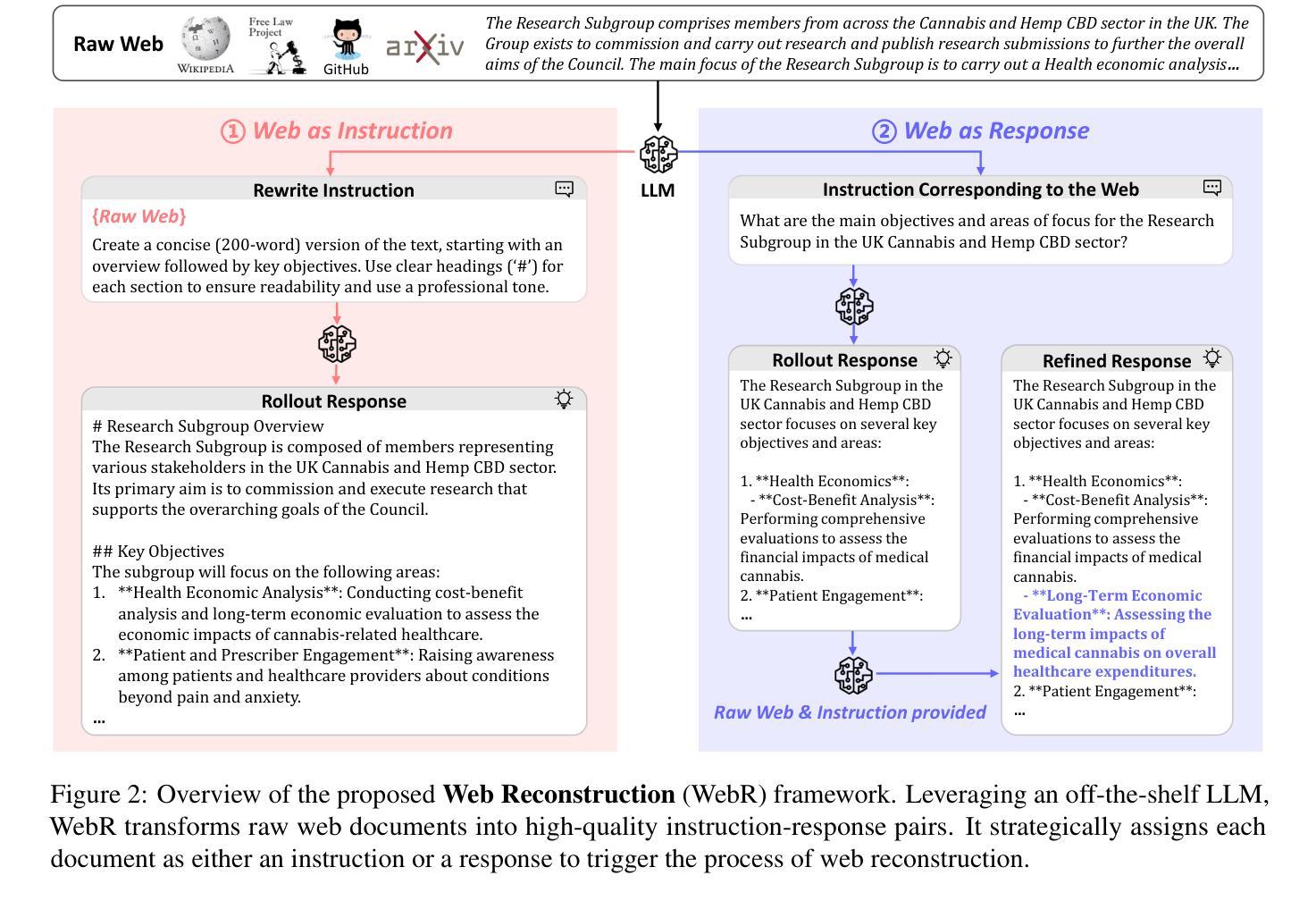
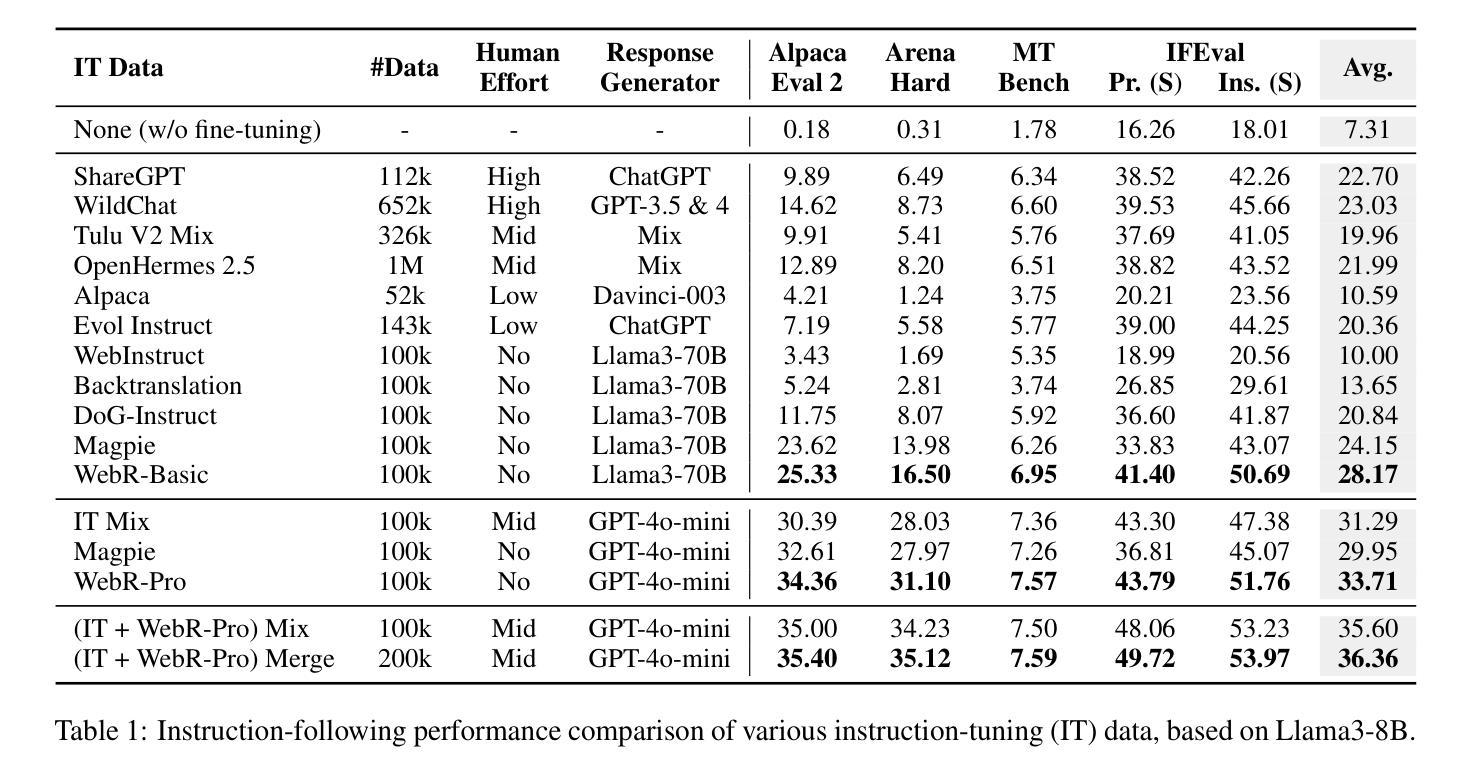
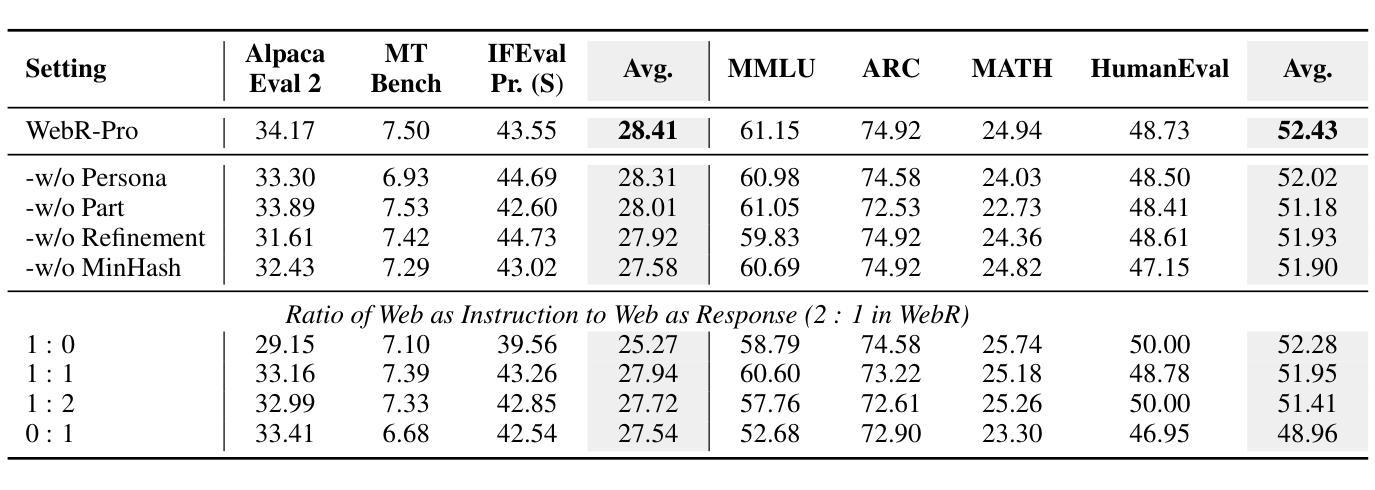
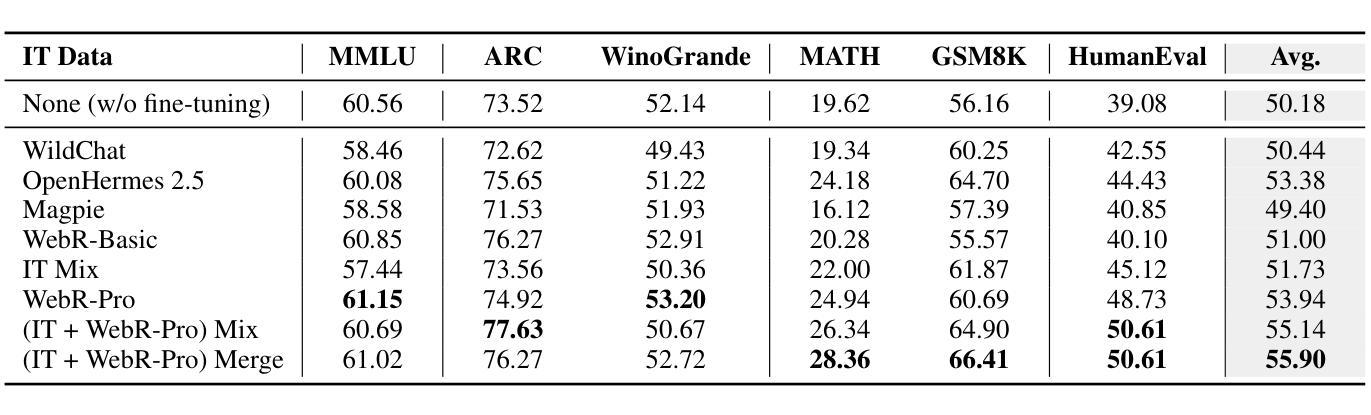
Instruction-Tuning Data Synthesis from Scratch via Web Reconstruction
Authors:Yuxin Jiang, Yufei Wang, Chuhan Wu, Xinyi Dai, Yan Xu, Weinan Gan, Yasheng Wang, Xin Jiang, Lifeng Shang, Ruiming Tang, Wei Wang
The improvement of LLMs’ instruction-following capabilities depends critically on the availability of high-quality instruction-response pairs. While existing automatic data synthetic methods alleviate the burden of manual curation, they often rely heavily on either the quality of seed data or strong assumptions about the structure and content of web documents. To tackle these challenges, we propose Web Reconstruction (WebR), a fully automated framework for synthesizing high-quality instruction-tuning (IT) data directly from raw web documents with minimal assumptions. Leveraging the inherent diversity of raw web content, we conceptualize web reconstruction as an instruction-tuning data synthesis task via a novel dual-perspective paradigm–Web as Instruction and Web as Response–where each web document is designated as either an instruction or a response to trigger the reconstruction process. Comprehensive experiments show that datasets generated by WebR outperform state-of-the-art baselines by up to 16.65% across four instruction-following benchmarks. Notably, WebR demonstrates superior compatibility, data efficiency, and scalability, enabling enhanced domain adaptation with minimal effort. The data and code are publicly available at https://github.com/YJiangcm/WebR.
大型语言模型(LLM)的执行指令能力的改进关键在于高质量指令响应对的可用性。现有的自动数据合成方法减轻了手动整理的负担,但它们通常要么依赖于种子数据的质量,要么依赖于对网页文档结构和内容的强烈假设。为了应对这些挑战,我们提出了Web Reconstruction(WebR)框架,这是一个全自动的框架,可以从原始网页文档直接合成高质量指令调整(IT)数据,并且假设最少。我们利用原始网页内容的固有多样性,通过一种新颖的双视角模式,将网络重建概念化为指令调整数据合成任务——“网络作为指令”和“网络作为响应”,每个网络文档都被指定为指令或响应以触发重建过程。综合实验表明,WebR生成的数据集在四个执行指令基准测试上的表现优于最新基线,最高提升达16.65%。值得注意的是,WebR表现出出色的兼容性、数据效率和可扩展性,可实现低成本的领域适应。相关数据和代码公开可用,地址是https://github.com/YJiangcm/WebR。
论文及项目相关链接
PDF 16 pages, 11 figures, 9 tables. ACL 2025 camera-ready version
Summary
基于大规模预训练模型的指导性响应能力提升依赖于高质量指导指令和响应对的构建。尽管现有的自动化数据合成方法能够减轻人工整理的负担,但它们常常依赖种子数据的质量和假设文档结构等局限性较大。本研究提出了Web重建(WebR)方法,它能够在最小化假设的基础上直接由原始文档自动合成高质量指导性调优数据。通过利用原始网页内容的固有多样性,本研究将重建过程概念化为一个指令性调优数据合成任务,采用新颖的“双重视角”模式——将网页视为指令和响应——每个网页文档都被指定为指令或响应以触发重建过程。实验表明,相较于其他基线方法,WebR生成的数据库在四项指令跟踪基准测试中表现优越,高出约达百分之十六点六五,显著地展示了WebR的高效适用性、数据效益及扩展优势。我们团队已经在网址:https://github.com/YJiangcm/WebR公开了数据和代码以供研究使用。
Key Takeaways
- LLMs的指令遵循能力改善依赖于高质量指令响应对的可用性。
- 现有自动数据合成方法虽然减轻手动整理负担,但仍存在依赖种子数据和文档结构假设的问题。
- 提出Web重建(WebR)框架,可直接从原始网页内容自动化合成高质量指令调优数据。
- WebR利用原始网页内容的多样性,通过双重视角模式(网页作为指令和响应)进行重建。
- WebR生成的数据库在四项指令跟踪基准测试中表现优于其他方法,最高提升达百分之十六点六五。
- WebR具有高效适用性、数据效益及扩展优势。
点此查看论文截图

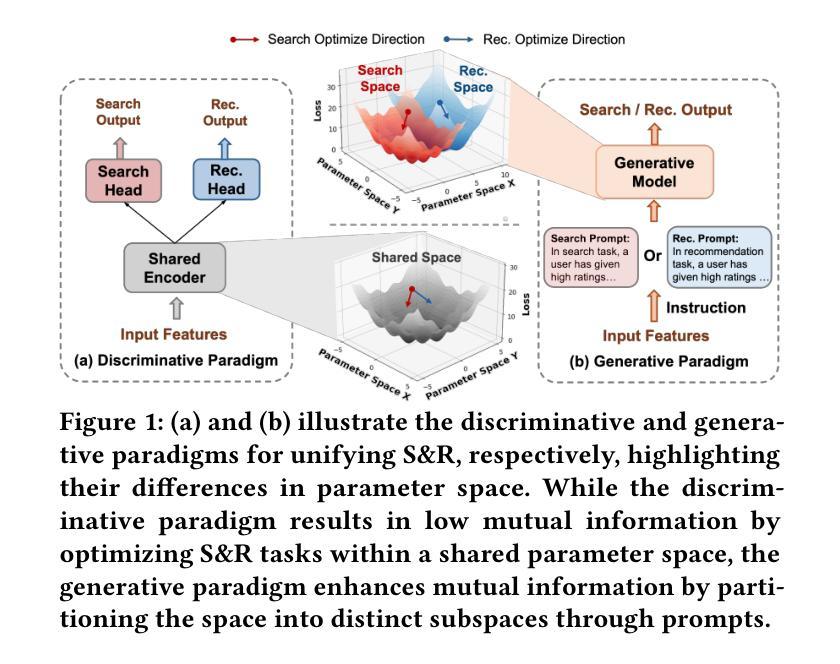
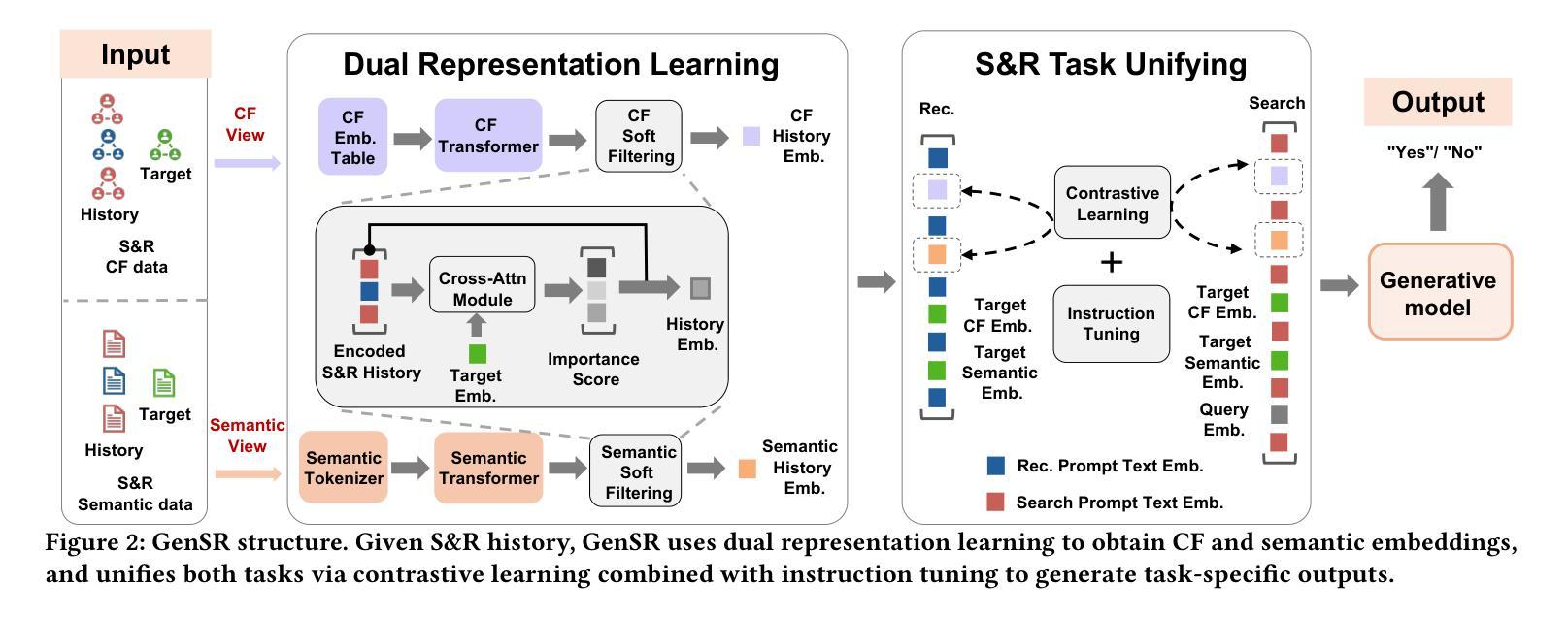
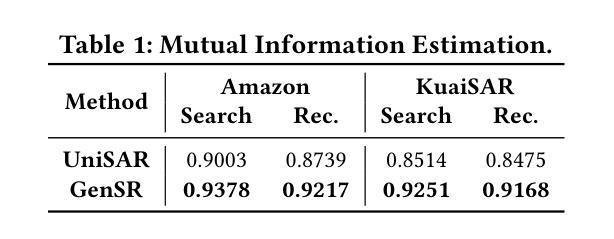
Unifying Search and Recommendation: A Generative Paradigm Inspired by Information Theory
Authors:Jujia Zhao, Wenjie Wang, Chen Xu, Xiuying Chen, Zhaochun Ren, Suzan Verberne
Recommender systems and search engines serve as foundational elements of online platforms, with the former delivering information proactively and the latter enabling users to seek information actively. Unifying both tasks in a shared model is promising since it can enhance user modeling and item understanding. Previous approaches mainly follow a discriminative paradigm, utilizing shared encoders to process input features and task-specific heads to perform each task. However, this paradigm encounters two key challenges: gradient conflict and manual design complexity. From the information theory perspective, these challenges potentially both stem from the same issue – low mutual information between the input features and task-specific outputs during the optimization process. To tackle these issues, we propose GenSR, a novel generative paradigm for unifying search and recommendation (S&R), which leverages task-specific prompts to partition the model’s parameter space into subspaces, thereby enhancing mutual information. To construct effective subspaces for each task, GenSR first prepares informative representations for each subspace and then optimizes both subspaces in one unified model. Specifically, GenSR consists of two main modules: (1) Dual Representation Learning, which independently models collaborative and semantic historical information to derive expressive item representations; and (2) S&R Task Unifying, which utilizes contrastive learning together with instruction tuning to generate task-specific outputs effectively. Extensive experiments on two public datasets show GenSR outperforms state-of-the-art methods across S&R tasks. Our work introduces a new generative paradigm compared with previous discriminative methods and establishes its superiority from the mutual information perspective.
推荐系统和搜索引擎作为在线平台的基础元素,前者主动提供信息,后者使用户能够主动寻找信息。在共享模型中统一这两项任务是有前景的,因为它可以增强用户建模和物品理解。之前的方法主要遵循判别范式,使用共享编码器处理输入特征,并利用任务特定头执行每个任务。然而,这种范式面临两个关键挑战:梯度冲突和手动设计复杂性。从信息理论的角度来看,这些挑战都源于同样的问题,即在优化过程中输入特征和任务特定输出之间的互信息较低。为了解决这些问题,我们提出了GenSR,这是一种统一搜索和推荐(S&R)的新型生成范式。它通过特定任务的提示来将模型参数空间划分为子空间,从而提高互信息。为了为每个任务构建有效的子空间,GenSR首先为每个子空间准备信息表示,然后在统一模型中优化这些子空间。具体来说,GenSR由两个主要模块组成:(1)双表示学习,它独立地建模协同和语义历史信息,以得出表达性的物品表示;(2)S&R任务统一,它利用对比学习与指令微调来有效地生成任务特定输出。在两个公共数据集上的大量实验表明,GenSR在S&R任务上的表现优于最先进的方法。我们的工作与之前的判别方法相比引入了一种新的生成范式,并从互信息角度证明了其优越性。
论文及项目相关链接
Summary
该文探讨了推荐系统和搜索引擎的统一模型,指出传统方法面临的挑战,并提出一种基于生成式的新范式GenSR。GenSR通过任务特定提示将模型参数空间划分为子空间,提高互信息来解决挑战。GenSR包括两个主要模块:Dual Representation Learning 和 S&R Task Unifying。实验表明,GenSR在统一模型中表现出卓越性能。
Key Takeaways
- 推荐系统和搜索引擎是信息平台的基础组成部分,前者主动提供信息,后者使用户能够主动寻找信息。
- 将两者统一在模型中可以提高用户建模和物品理解的能力。
- 传统方法主要采用判别式范式,存在梯度冲突和手动设计复杂性两大挑战。
- 这些挑战可能源于优化过程中的低互信息问题。
- GenSR是一种基于生成式的新范式,通过任务特定提示划分模型参数空间,提高互信息来解决挑战。
- GenSR包括Dual Representation Learning和S&R Task Unifying两个主要模块。
点此查看论文截图

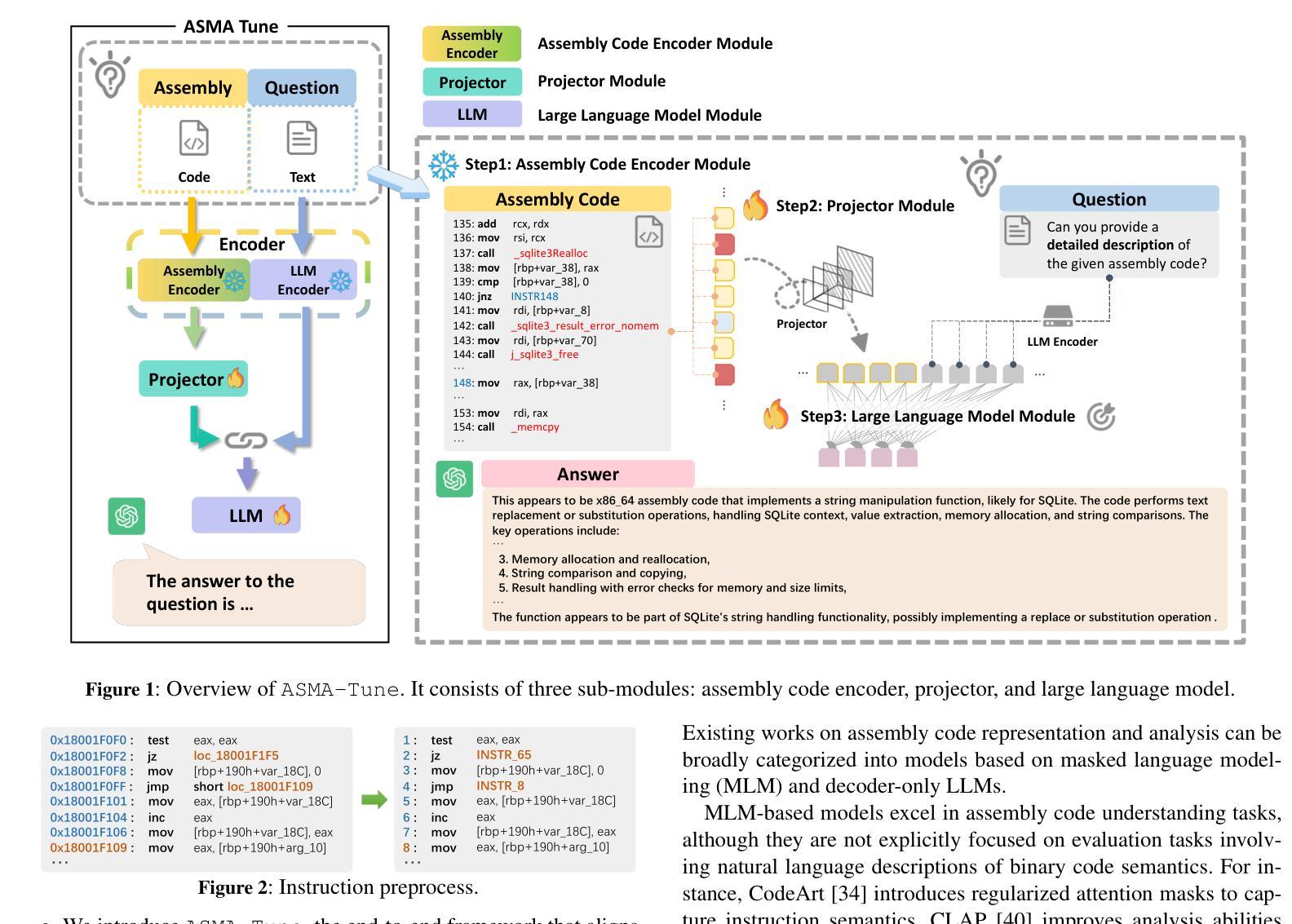
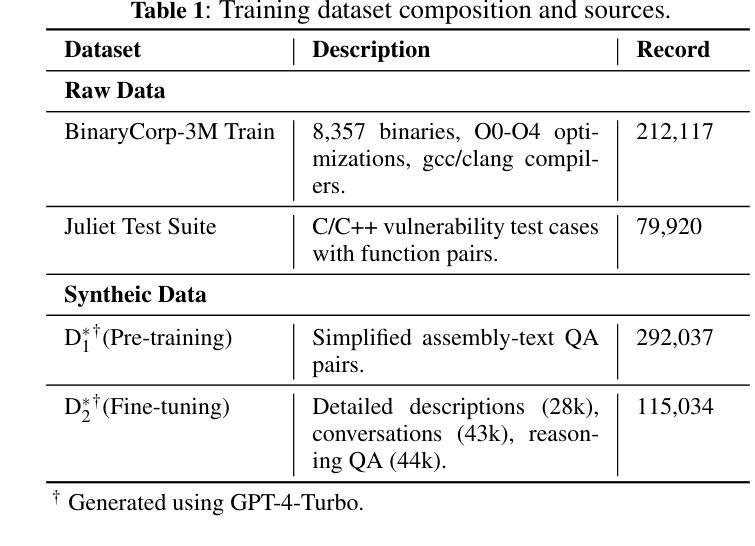
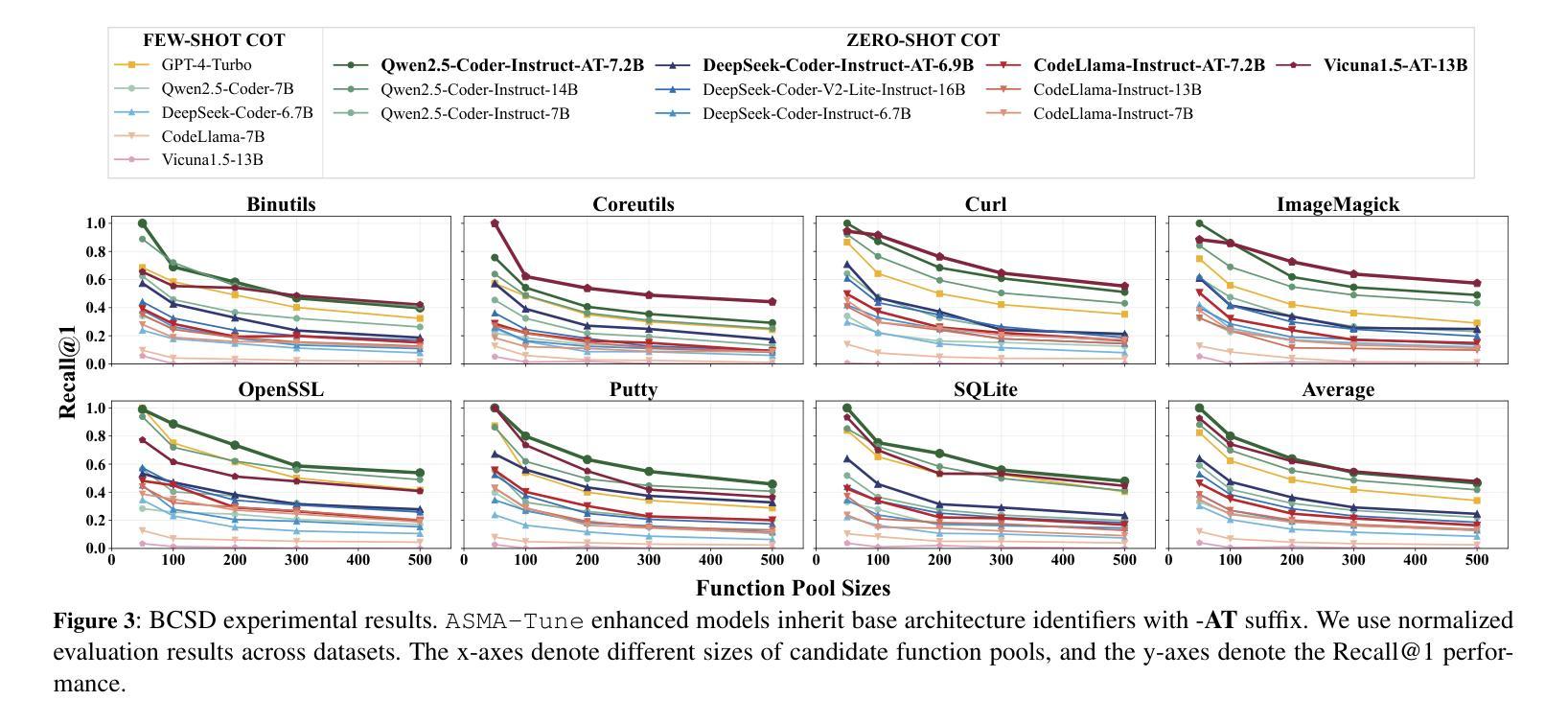
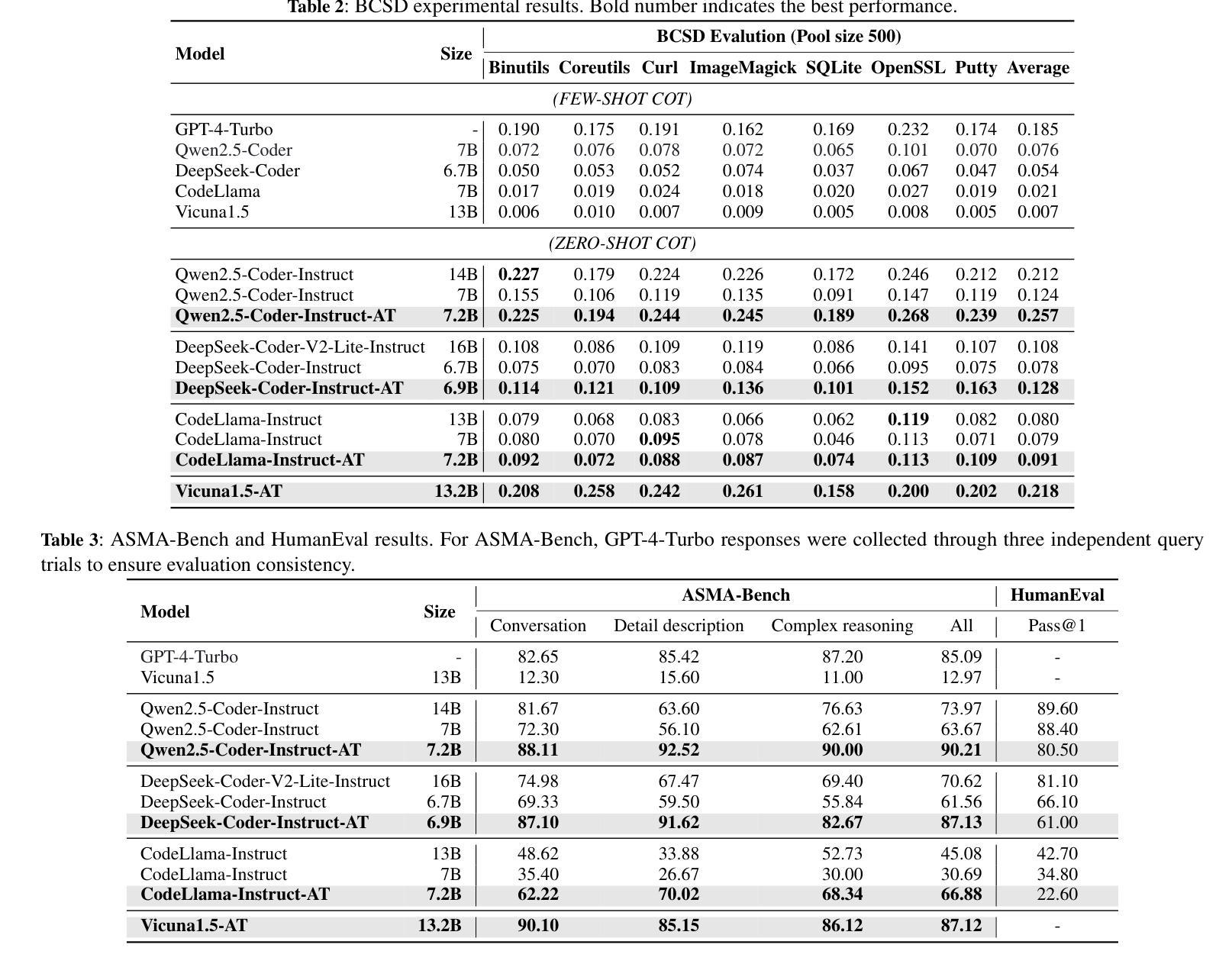
ASMA-Tune: Unlocking LLMs’ Assembly Code Comprehension via Structural-Semantic Instruction Tuning
Authors:Xinyi Wang, Jiashui Wang, Jinbo Su, Ke Wang, Peng Chen, Yanming Liu, Long Liu, Xiang Li, Yangdong Wang, Qiyuan Chen, Rongze Chen, Chunfu Jia
Assembly code analysis and comprehension play critical roles in applications like reverse engineering, yet they face substantial challenges due to low information density and a lack of explicit syntactic structures. While traditional masked language modeling (MLM) approaches do not explicitly focus on natural language interaction, emerging decoder-focused large language models (LLMs) demonstrate partial success in binary analysis yet remain underexplored for holistic comprehension. We present Assembly Augmented Tuning, an end-to-end structural-semantic instruction tuning framework that synergizes encoder architecture with decoder-based LLMs through a projector module, where the assembly encoder extracts hardware-level structural features, the projector bridges representations with the semantic space, and the instruction-tuned LLM preserves natural language capabilities. Experimental results demonstrate three key advantages: (1) State-of-the-art performance in assembly comprehension with +39.7% Recall@1 and +17.8% MRR improvements over GPT-4-Turbo, (2) Consistent enhancements across base models (24.6-107.4% Recall@1 and 15.2-106.3% MRR on Qwen2.5-Coder, Deepseek-Coder and CodeLlama variants), and (3) Superior instruction-following capabilities (41.5%-118% improvements) with controlled code generation degradation (-8.9% to -35% across architectures).
汇编代码分析和理解在逆向工程等应用中扮演着至关重要的角色,但由于信息密度低和缺乏明确的语法结构,它们面临着巨大的挑战。虽然传统的掩码语言建模(MLM)方法并不专注于自然语言交互,但新兴的以解码器为重点的大型语言模型(LLM)在二进制分析方面取得了一定的成功,但在整体理解方面仍被探索得不够充分。我们提出了Assembly Augmented Tuning(汇编增强调整),这是一种端到端的结构语义指令调整框架,它通过投影仪模块协同编码器架构和基于解码器的LLM。其中,汇编编码器提取硬件层面的结构特征,投影仪将表示与语义空间联系起来,指令调整的LLM保留了自然语言功能。实验结果表明了三个主要优势:(1)在汇编理解方面达到了最新性能,与GPT-4 Turbo相比,Recall@1提高了+39.7%,MRR提高了+17.8%;(2)在基础模型上实现了一致的改进,Qwen2.5-Coder、Deepseek-Coder和CodeLlama变种上的Recall@1提高了24.6%~107.4%,MRR提高了15.2%~106.3%;(3)在指令遵循能力上表现卓越,控制代码生成退化的情况下,改进范围在41.5%~118%之间(不同架构下的退化率为-8.9%~-35\)。
论文及项目相关链接
PDF 9 pages, multiple figures
Summary
新一代大型语言模型在汇编代码分析和理解方面的应用取得了显著进展。提出了一种名为“Assembly Augmented Tuning”的端到端结构语义指令调整框架,该框架通过投影仪模块将编码器架构与基于解码器的语言模型协同工作,实现了汇编编码器的硬件级结构特征提取、投影仪的跨表征语义空间桥梁作用以及指令调整的语言模型的自然语言能力保留。实验结果证明了该框架在汇编理解方面的卓越性能,具有显著的提升效果。
Key Takeaways
- 汇编代码分析与理解在逆向工程等领域具有关键作用,但面临信息密度低和缺乏明确句法结构的挑战。
- 传统语言模型在汇编代码方面的表现有限,而新兴的大型语言模型在二进制分析方面取得部分成功。
- Assembly Augmented Tuning框架结合了编码器架构和基于解码器的语言模型,通过投影仪模块实现结构语义指令调整。
- 汇编编码器能够提取硬件级结构特征。
- 投影仪模块在跨表征语义空间方面起到桥梁作用。
- 指令调整的语言模型能够保留自然语言能力。
点此查看论文截图

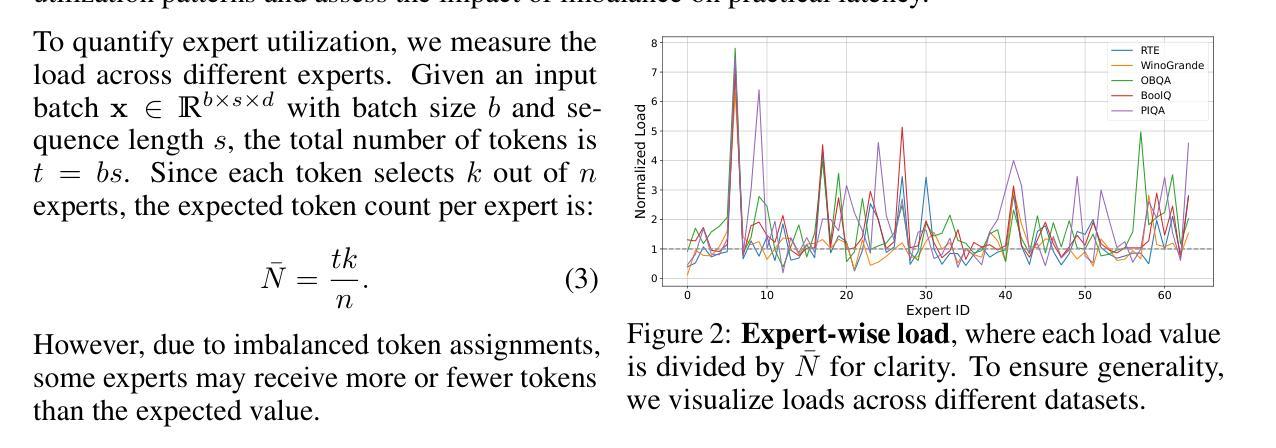
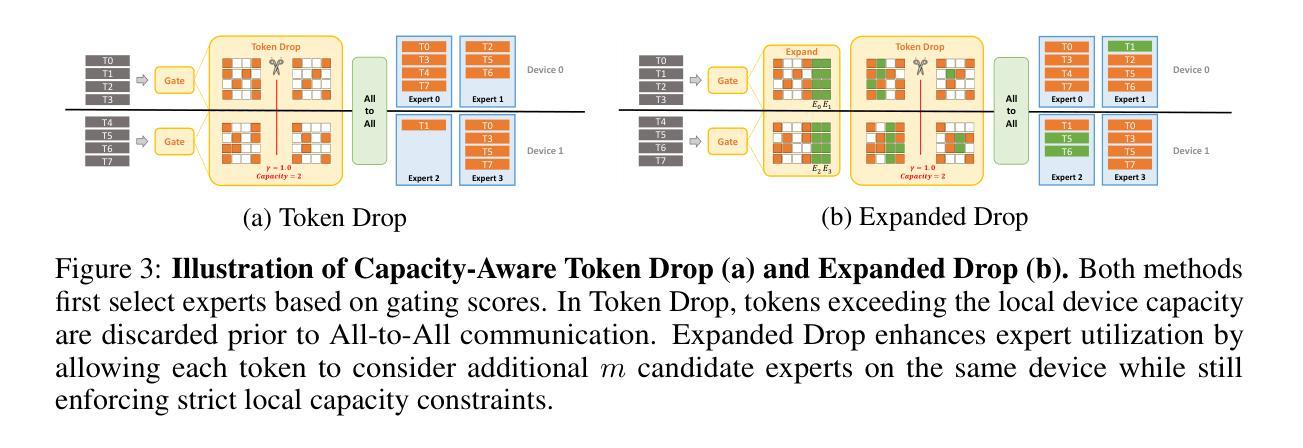
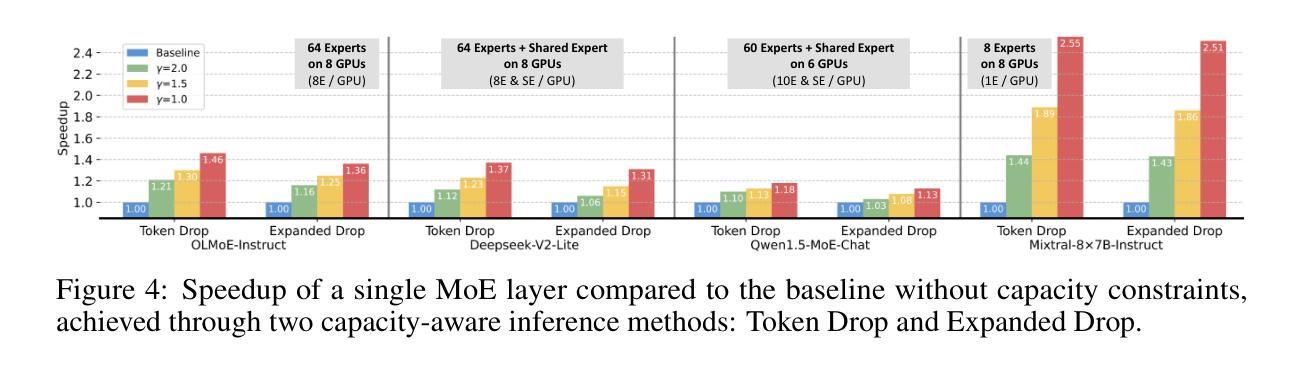
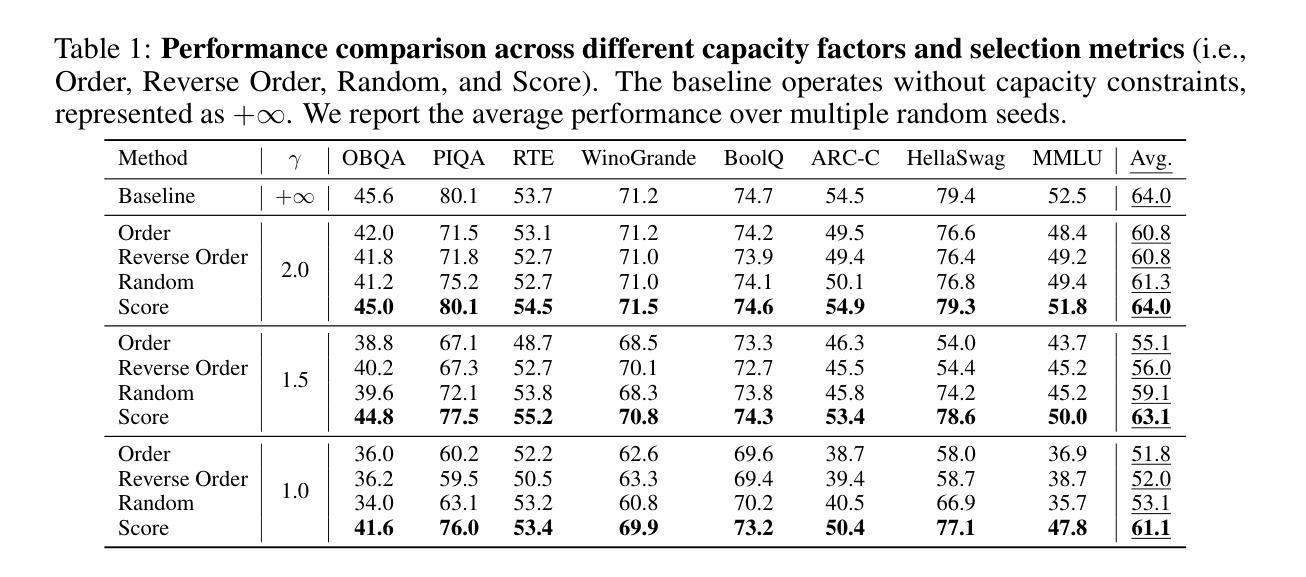
Capacity-Aware Inference: Mitigating the Straggler Effect in Mixture of Experts
Authors:Shwai He, Weilin Cai, Jiayi Huang, Ang Li
The Mixture of Experts (MoE) is an effective architecture for scaling large language models by leveraging sparse expert activation, optimizing the trade-off between performance and efficiency. However, under expert parallelism, MoE suffers from inference inefficiencies due to imbalanced token-to-expert assignment, where some experts are overloaded while others remain underutilized. This imbalance leads to poor resource utilization and increased latency, as the most burdened expert dictates the overall delay, a phenomenon we define as the \textbf{\textit{Straggler Effect}}. To mitigate this, we propose Capacity-Aware Inference, including two key techniques: (1) \textbf{\textit{Capacity-Aware Token Drop}}, which discards overloaded tokens to regulate the maximum latency of MoE, and (2) \textbf{\textit{Capacity-Aware Token Reroute}}, which reallocates overflowed tokens to underutilized experts, balancing the token distribution. These techniques collectively optimize both high-load and low-load expert utilization, leading to a more efficient MoE inference pipeline. Extensive experiments demonstrate the effectiveness of our methods, showing significant improvements in inference efficiency, e.g., 0.2% average performance increase and a 1.94$\times$ inference speedup on Mixtral-8$\times$7B-Instruct.
混合专家(MoE)是一种通过利用稀疏的专家激活来扩展大型语言模型的有效架构,优化了性能和效率之间的权衡。然而,在专家并行性下,MoE由于不均衡的令牌到专家分配而遭受推理效率低下的问题,其中一些专家过载,而其他专家则利用率不足。这种不平衡导致资源利用不足和延迟增加,因为最繁重的专家决定了总体延迟,我们将这种现象定义为“滞后者效应”。为了缓解这个问题,我们提出了容量感知推理,包括两种关键技术:(1)“容量感知令牌丢弃”,丢弃过载的令牌以控制MoE的最大延迟;(2)“容量感知令牌重新路由”,重新分配溢出的令牌给利用率低的专家,平衡令牌分布。这些技术共同优化了高负载和低负载的专家利用率,从而实现了更有效的MoE推理管道。大量实验证明了我们的方法的有效性,在推理效率方面显示出显着提高,例如在Mixtral-8×7B-Instruct上平均性能提高0.2%,推理速度提高1.94倍。
论文及项目相关链接
Summary
专家混合(MoE)架构通过利用稀疏专家激活来扩展大型语言模型,优化性能与效率之间的权衡。然而,在专家并行方面,MoE在推理过程中存在效率问题,主要是由于不均衡的令牌到专家分配造成的。一些专家过载而其他专家利用率不足,这种不平衡导致资源利用率低和延迟增加,我们将这种现象称为“拖后腿效应”。为缓解这一问题,我们提出容量感知推理技术,包括两个关键技术:(1)容量感知令牌丢弃技术用于丢弃过载令牌以控制MoE的最大延迟;(2)容量感知令牌重新路由技术用于将溢出的令牌重新分配给利用率低的专家,平衡令牌分布。这些技术共同优化了高负载和低负载专家的利用率,提高了MoE推理流程的效率和性能。实验证明我们的方法有效,在Mixtral-8×7B-Instruct上实现了平均性能提升0.2%,推理速度提升1.94倍。
Key Takeaways
- MoE架构通过稀疏专家激活扩展大型语言模型。
- 专家并行中的MoE存在推理效率问题,主要由于不均衡的令牌到专家分配导致资源利用率低和延迟增加。
- 提出容量感知推理技术以缓解这一问题,包括容量感知令牌丢弃和容量感知令牌重新路由技术。
- 令牌丢弃技术控制MoE的最大延迟,令牌重新路由技术平衡令牌分布。
点此查看论文截图

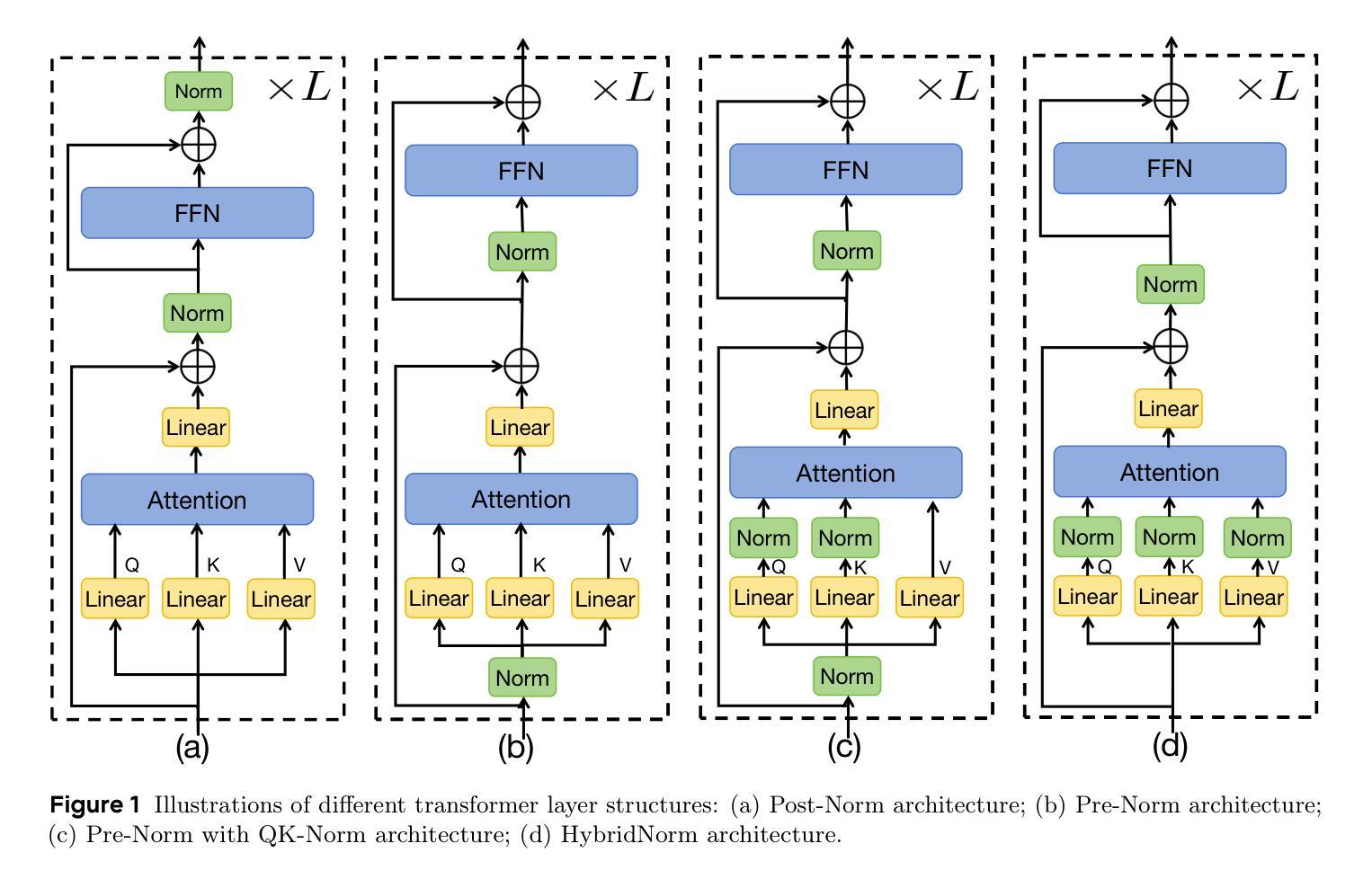
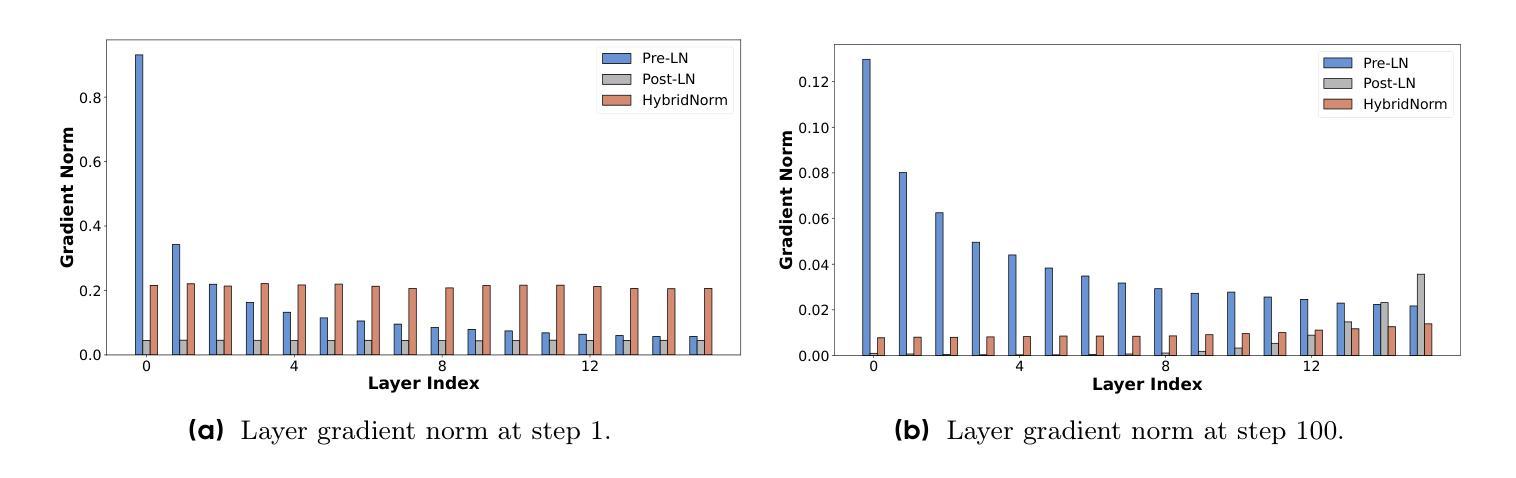
HybridNorm: Towards Stable and Efficient Transformer Training via Hybrid Normalization
Authors:Zhijian Zhuo, Yutao Zeng, Ya Wang, Sijun Zhang, Jian Yang, Xiaoqing Li, Xun Zhou, Jinwen Ma
Transformers have become the de facto architecture for a wide range of machine learning tasks, particularly in large language models (LLMs). Despite their remarkable performance, challenges remain in training deep transformer networks, especially regarding the position of layer normalization. While Pre-Norm structures facilitate more stable training owing to their stronger identity path, they often lead to suboptimal performance compared to Post-Norm. In this paper, we propose $\textbf{HybridNorm}$, a simple yet effective hybrid normalization strategy that integrates the advantages of both Pre-Norm and Post-Norm. Specifically, HybridNorm employs QKV normalization within the attention mechanism and Post-Norm in the feed-forward network (FFN) of each transformer block. We provide both theoretical insights and empirical evidence demonstrating that HybridNorm improves gradient flow and model robustness. Extensive experiments on large-scale transformer models, including both dense and sparse variants, show that HybridNorm consistently outperforms both Pre-Norm and Post-Norm approaches across multiple benchmarks. These findings highlight the potential of HybridNorm as a more stable and effective technique for improving the training and performance of deep transformer models. Code is available at https://github.com/BryceZhuo/HybridNorm.
变压器架构已经广泛应用于各种机器学习任务,特别是在大型语言模型(LLM)中。尽管其表现卓越,但在训练深度变压器网络时仍面临挑战,特别是关于层归一化的位置问题。虽然Pre-Norm结构由于其更强的身份路径而促进更稳定的训练,但它们通常导致与Post-Norm相比性能不佳。在本文中,我们提出了$\textbf{HybridNorm}$,这是一种简单有效的混合归一化策略,它结合了Pre-Norm和Post-Norm的优点。具体来说,HybridNorm在注意力机制中采用QKV归一化,并在每个变压器块的前馈网络(FFN)中采用Post-Norm。我们提供理论见解和实证证据表明,HybridNorm改善了梯度流和模型稳健性。在大型变压器模型上的广泛实验,包括密集和稀疏变体,表明HybridNorm在多个基准测试上始终优于Pre-Norm和Post-Norm方法。这些发现突出了HybridNorm作为更稳定、更有效的技术,可改善深度变压器模型的训练性能。代码可在https://github.com/BryceZhuo/HybridNorm找到。
论文及项目相关链接
Summary
深度学习模型中的Transformer架构广泛应用于机器学习任务,特别是在大型语言模型(LLM)中。本文介绍了HybridNorm,一种结合Pre-Norm和Post-Norm优势的混合归一化策略。它在注意力机制中采用QKV归一化,并在每个Transformer块的馈送前网络(FFN)中使用Post-Norm。HybridNorm改善了梯度流并增强了模型的稳健性。实验证明,它在大型Transformer模型上表现优异,超过了Pre-Norm和Post-Norm方法。代码已在GitHub上公开。
Key Takeaways
- Transformer架构是机器学习任务的默认选择,尤其在大型语言模型(LLM)中。
- Pre-Norm有助于稳定训练,但可能导致性能不佳。
- Post-Norm在某些情况下表现较好,但仍有改进空间。
- HybridNorm结合了Pre-Norm和Post-Norm的优点。
- HybridNorm在注意力机制中使用QKV归一化,并在馈送前网络(FFN)中使用Post-Norm。
- HybridNorm通过改善梯度流和增强模型稳健性来提升性能。
点此查看论文截图

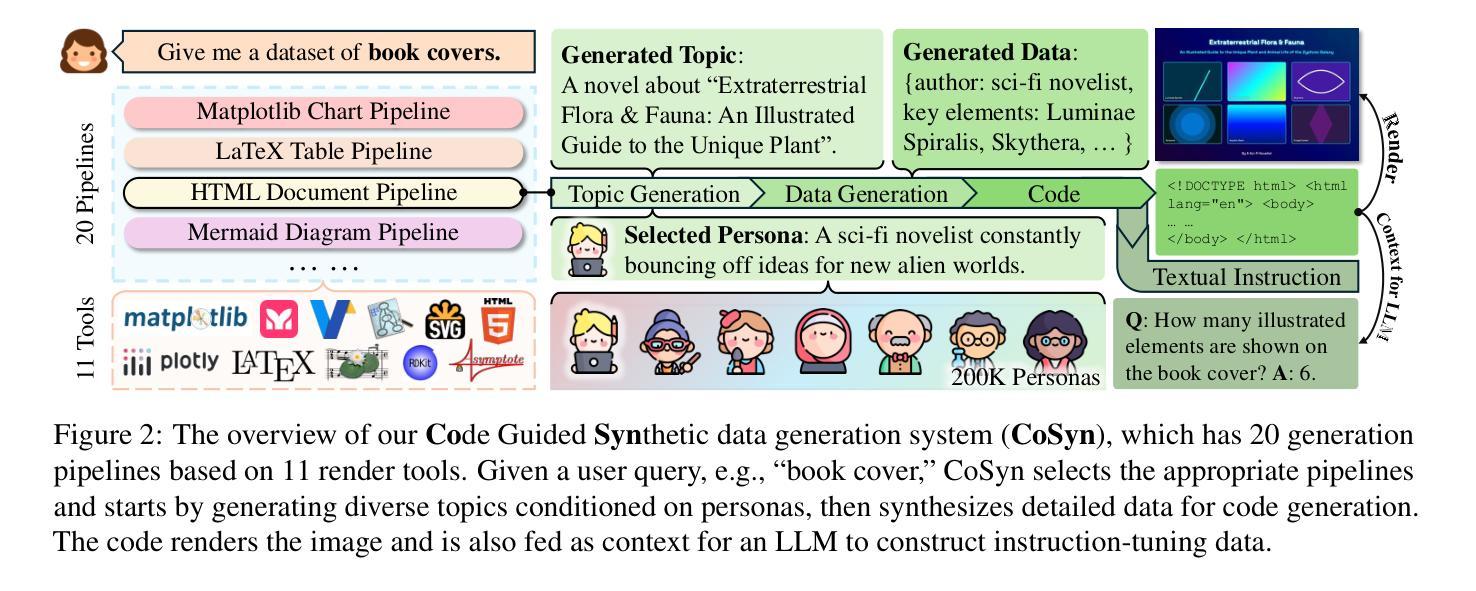
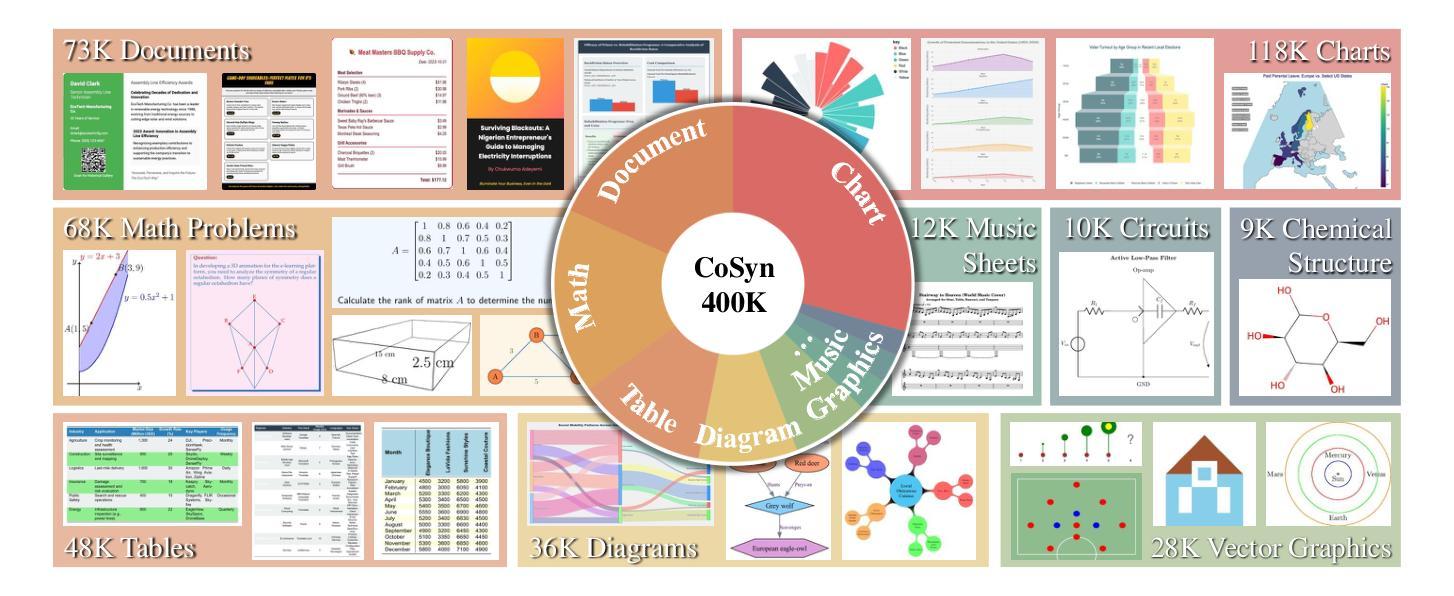
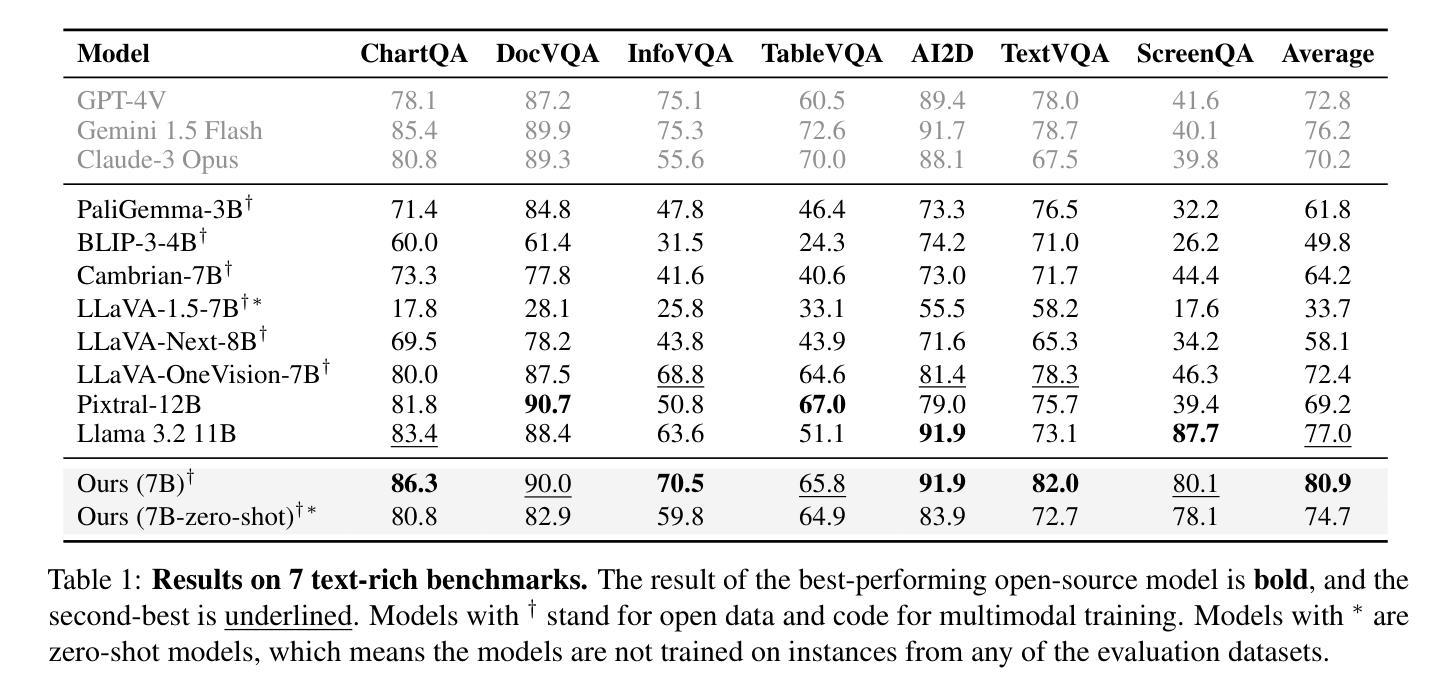
Scaling Text-Rich Image Understanding via Code-Guided Synthetic Multimodal Data Generation
Authors:Yue Yang, Ajay Patel, Matt Deitke, Tanmay Gupta, Luca Weihs, Andrew Head, Mark Yatskar, Chris Callison-Burch, Ranjay Krishna, Aniruddha Kembhavi, Christopher Clark
Reasoning about images with rich text, such as charts and documents, is a critical application of vision-language models (VLMs). However, VLMs often struggle in these domains due to the scarcity of diverse text-rich vision-language data. To address this challenge, we present CoSyn, a framework that leverages the coding capabilities of text-only large language models (LLMs) to automatically create synthetic text-rich multimodal data. Given input text describing a target domain (e.g., “nutrition fact labels”), CoSyn prompts an LLM to generate code (Python, HTML, LaTeX, etc.) for rendering synthetic images. With the underlying code as textual representations of the synthetic images, CoSyn can generate high-quality instruction-tuning data, again relying on a text-only LLM. Using CoSyn, we constructed a dataset comprising 400K images and 2.7M rows of vision-language instruction-tuning data. Comprehensive experiments on seven benchmarks demonstrate that models trained on our synthetic data achieve state-of-the-art performance among competitive open-source models, including Llama 3.2, and surpass proprietary models such as GPT-4V and Gemini 1.5 Flash. Furthermore, CoSyn can produce synthetic pointing data, enabling VLMs to ground information within input images, showcasing its potential for developing multimodal agents capable of acting in real-world environments.
对于包含图表和文档等丰富文本的图片推理是视觉语言模型(VLM)的关键应用之一。然而,由于缺乏多样化的丰富文本视觉语言数据,VLM在这些领域往往面临挑战。为了应对这一挑战,我们提出了CoSyn框架,它利用纯文本大型语言模型(LLM)的编码能力来自动创建合成丰富文本的多模态数据。给定描述目标域的输入文本(例如,“营养事实标签”),CoSyn会提示LLM生成用于渲染合成图像的代码(Python、HTML、LaTeX等)。CoSyn以底层代码作为合成图像的文本表示,可以生成高质量的教学调整数据,这同样依赖于纯文本LLM。使用CoSyn,我们构建了一个包含40万张图像和270万行视觉语言教学调整数据的数据集。在七个基准测试上的综合实验表明,在我们合成数据上训练的模型在竞争开源模型中实现了最先进的性能,包括Llama 3.2,并超越了专有模型,如GPT-4V和Gemini 1.5 Flash。此外,CoSyn可以生成合成指向数据,使VLM能够在输入图像中定位信息,展示了其开发能够在现实世界中行动的多媒体代人的潜力。
论文及项目相关链接
PDF Published in ACL 2025, project page: https://yueyang1996.github.io/cosyn/
Summary
本文介绍了一个名为CoSyn的框架,它通过利用大型语言模型(LLM)的编码能力,自动生成丰富的文本视觉数据,以解决视觉语言模型(VLM)在处理富文本图像(如图表和文档)时面临的挑战。CoSyn能够从描述目标领域的文本输入生成代码,进而渲染合成图像。它还可以生成高质量的教学调整数据,并用于训练VLM。实验表明,使用CoSyn合成的数据训练的模型在多个基准测试上达到或超越了开源模型以及专有模型的性能。此外,CoSyn还能产生合成指向数据,使VLM能够在输入图像中定位信息,展示其在开发能够在真实世界环境中行动的多媒体代理方面的潜力。
Key Takeaways
- CoSyn框架利用LLM自动生成合成文本丰富视觉数据,解决VLM处理富文本图像的挑战。
- CoSyn能够从描述目标领域的文本生成代码,进而渲染合成图像。
- CoSyn能生成高质量的教学调整数据,用于训练VLM。
- 使用CoSyn合成的数据训练的模型在多个基准测试上表现优秀,超越了一些开源和专有模型。
- CoSyn可以产生合成指向数据,帮助VLM在图像中定位信息。
- CoSyn在开发能在真实世界环境中行动的多媒体代理方面显示出潜力。
- CoSyn的应用有助于推进视觉语言模型的发展,尤其是在处理包含丰富文本的图像时。
点此查看论文截图

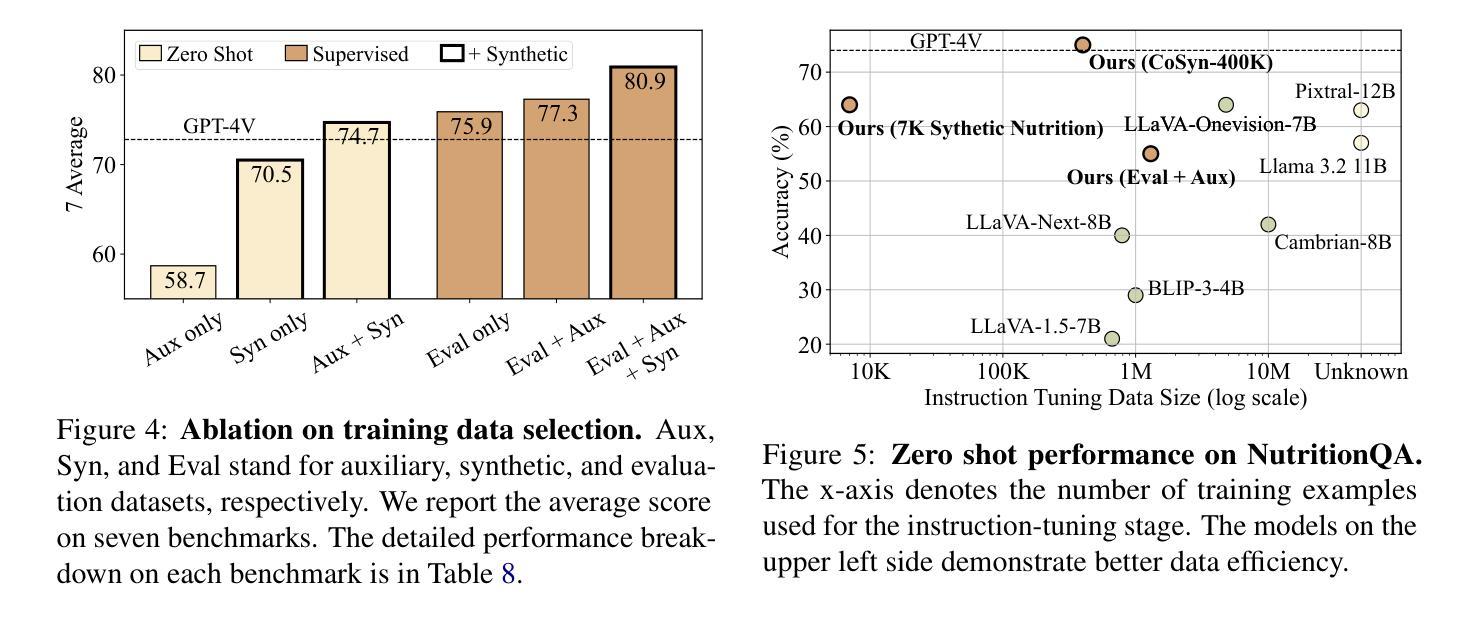
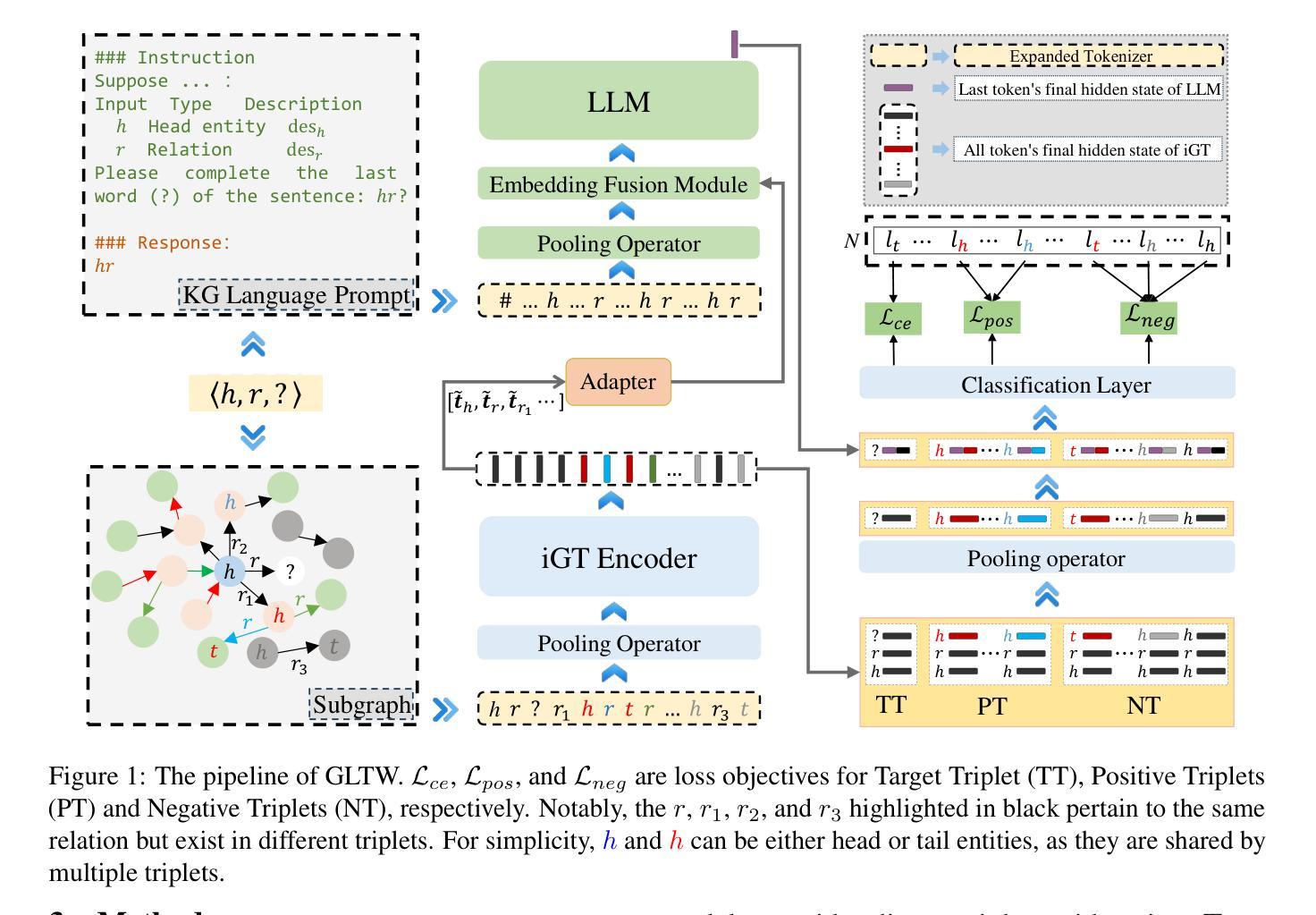
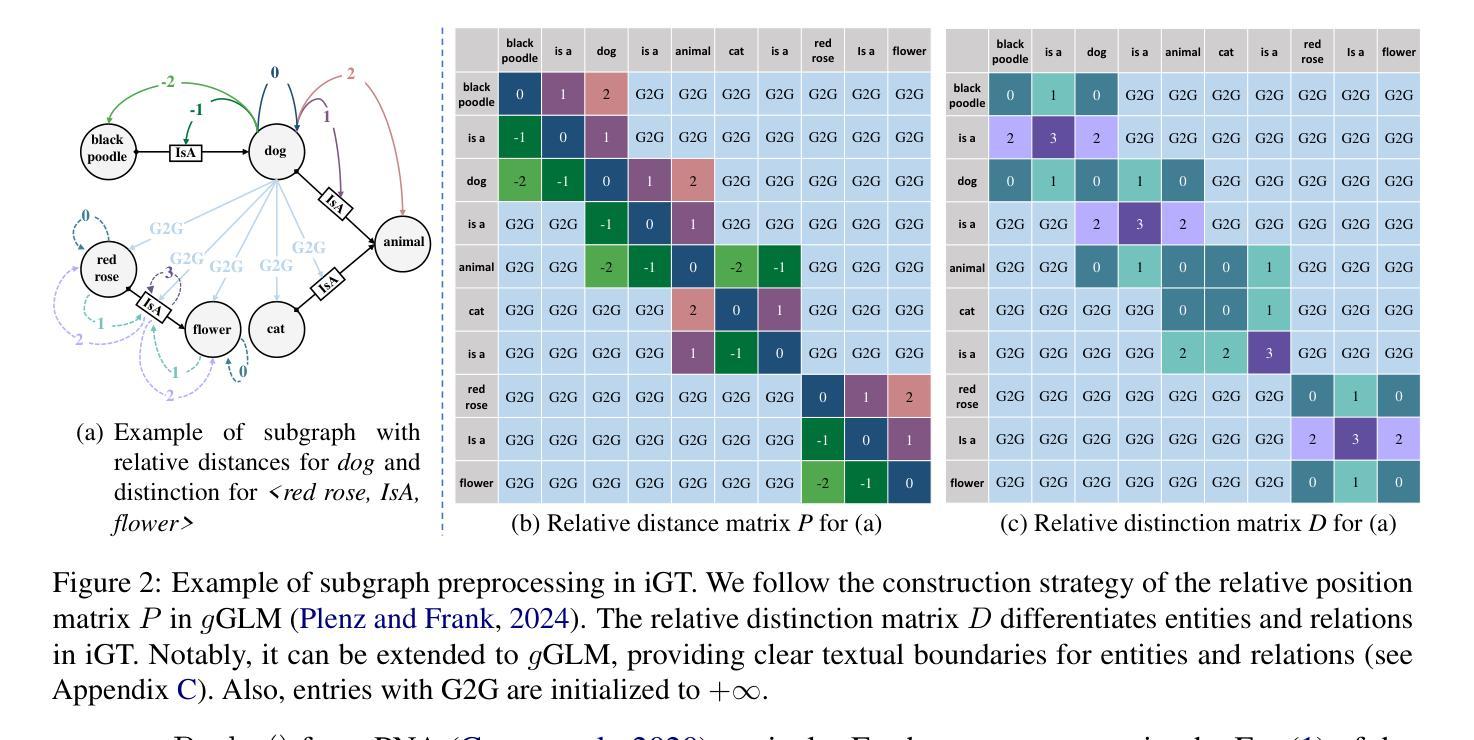
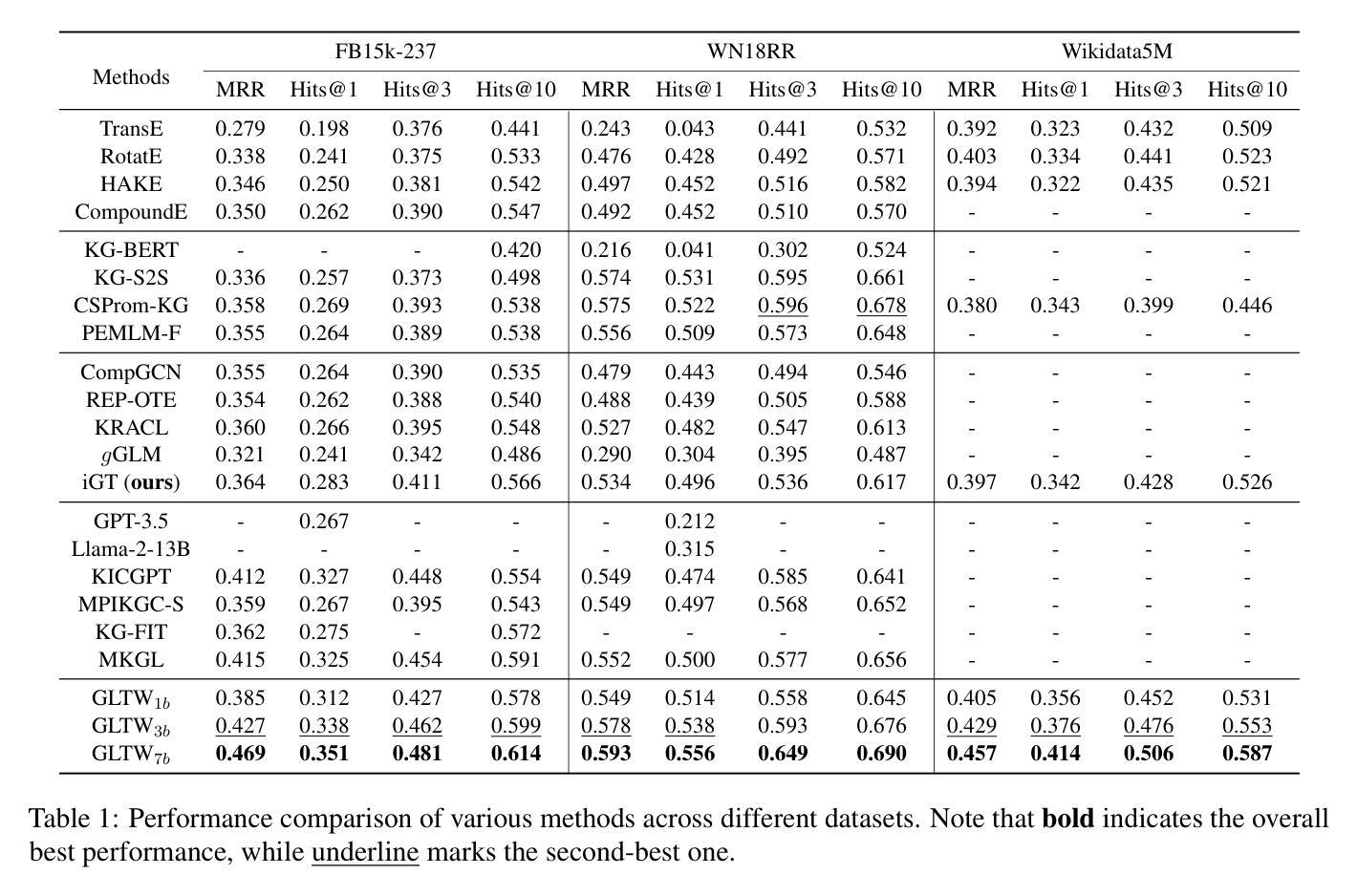
GLTW: Joint Improved Graph Transformer and LLM via Three-Word Language for Knowledge Graph Completion
Authors:Kangyang Luo, Yuzhuo Bai, Cheng Gao, Shuzheng Si, Yingli Shen, Zhu Liu, Zhitong Wang, Cunliang Kong, Wenhao Li, Yufei Huang, Ye Tian, Xuantang Xiong, Lei Han, Maosong Sun
Knowledge Graph Completion (KGC), which aims to infer missing or incomplete facts, is a crucial task for KGs. However, integrating the vital structural information of KGs into Large Language Models (LLMs) and outputting predictions deterministically remains challenging. To address this, we propose a new method called GLTW, which encodes the structural information of KGs and merges it with LLMs to enhance KGC performance. Specifically, we introduce an improved Graph Transformer (iGT) that effectively encodes subgraphs with both local and global structural information and inherits the characteristics of language model, bypassing training from scratch. Also, we develop a subgraph-based multi-classification training objective, using all entities within KG as classification objects, to boost learning efficiency.Importantly, we combine iGT with an LLM that takes KG language prompts as input.Our extensive experiments on various KG datasets show that GLTW achieves significant performance gains compared to SOTA baselines.
知识图谱补全(KGC)旨在推断缺失或不完整的事实,是知识图谱(KG)中的一项关键任务。然而,将知识图谱中的重要结构信息整合到大型语言模型(LLM)中,并确定性地输出预测仍然是一个挑战。为了解决这一问题,我们提出了一种新的方法,称为GLTW。该方法对知识图谱的结构信息进行编码,并与LLM合并,以提高KGC的性能。具体来说,我们引入了一种改进的图转换器(iGT),它能有效地编码具有局部和全局结构信息的子图,并继承语言模型的特性,无需从零开始训练。此外,我们开发了一种基于子图的多元分类训练目标,利用知识图谱中的所有实体作为分类对象,以提高学习效率。重要的是,我们将iGT与一种大型语言模型相结合,该模型以知识图谱语言提示作为输入。我们在各种知识图谱数据集上的广泛实验表明,与最新基线相比,GLTW实现了显著的性能提升。
论文及项目相关链接
PDF Accepted by ACL2025(Findings)
Summary
知识图谱补全(KGC)旨在推断缺失或不完整的事实,是知识图谱(KG)中的关键任务。将知识图谱的重要结构信息融入大型语言模型(LLM)并确定性地输出预测仍然具有挑战性。为此,我们提出了一种新的方法GLTW,该方法编码知识图谱的结构信息并将其与LLM合并,以提高KGC性能。具体地,我们引入了改进的图转换器(iGT),它有效地编码具有局部和全局结构信息的子图,并继承了语言模型的特性,无需从零开始训练。此外,我们开发了一种基于子图的多元分类训练目标,以知识图谱中的所有实体作为分类对象,以提高学习效率。重要的是,我们将iGT与接受知识图谱语言提示作为输入的LLM相结合。在多个知识图谱数据集上的广泛实验表明,GLTW与最新基线相比实现了显著的性能提升。
Key Takeaways
- 知识图谱补全(KGC)是知识图谱中的关键任务,旨在推断缺失或不完整的事实。
- 整合知识图谱的结构信息到大型语言模型(LLM)中并确定性地输出预测存在挑战。
- 提出了一种新的方法GLTW,通过编码知识图谱的结构信息并与LLM结合,提高KGC性能。
- 引入改进的图转换器(iGT),有效编码包含局部和全局结构信息的子图。
- iGT继承了语言模型的特性,无需从零开始训练。
- 开发基于子图的多元分类训练目标,利用知识图谱中的所有实体作为分类对象,提高学习效率。
点此查看论文截图

Memory Is Not the Bottleneck: Cost-Efficient Continual Learning via Weight Space Consolidation
Authors:Dongkyu Cho, Taesup Moon, Rumi Chunara, Kyunghyun Cho, Sungmin Cha
Continual learning (CL) has traditionally emphasized minimizing exemplar memory usage, assuming that memory is the primary bottleneck. However, in modern computing environments-particularly those involving large foundation models-memory is inexpensive and abundant, while GPU time constitutes the main cost. This paper re-examines CL under a more realistic setting with sufficient exemplar memory, where the system can retain a representative portion of past data. We find that, under this regime, stability improves due to reduced forgetting, but plasticity diminishes as the model becomes biased toward prior tasks and struggles to adapt to new ones. Notably, even simple baselines like naive replay can match or exceed the performance of state-of-the-art methods at a fraction of the computational cost. Building on this insight, we propose a lightweight yet effective method called Weight Space Consolidation, which directly operates in the model’s weight space via two core mechanisms: (1) rank-based parameter resets to recover plasticity, and (2) weight averaging to enhance stability. Our approach outperforms strong baselines across class-incremental learning with image classifiers and continual instruction tuning with large language models, while requiring only one-third to one-fourth of the training cost. These findings challenge long-standing CL assumptions and establish a new, cost-efficient baseline for real-world continual learning systems where exemplar memory is no longer the limiting factor.
持续学习(CL)传统上强调最小化示例内存的使用,假设内存是主要瓶颈。然而,在现代计算环境中——特别是涉及大型基础模型的情境——内存是便宜且丰富的,而GPU时间构成了主要成本。本文在一个更现实的、拥有充足示例内存的设定下重新考察了CL,在这种设定下,系统可以保留一部分过去的代表性数据。我们发现,在这种制度下,由于减少了遗忘,稳定性得到了提高,但可塑性降低了,因为模型偏向于先前的任务,难以适应新任务。值得注意的是,即使简单的基线方法,如天真的复述,也可以在计算成本的一小部分内匹配或超过最新技术方法的性能。基于这一见解,我们提出了一种轻量级但有效的方法,称为权重空间整合(Weight Space Consolidation),它通过两种核心机制直接在模型的权重空间中进行操作:(1)基于排名的参数重置以恢复可塑性,以及(2)权重平均以增强稳定性。我们的方法在类增量学习与图像分类器和大型语言模型的持续指令调整方面优于强大的基线方法,同时只需三分之一到四分之一的训练成本。这些发现挑战了长期存在的CL假设,并为现实世界的持续学习系统建立了新的、成本效益高的基准线,其中示例内存不再是限制因素。
论文及项目相关链接
PDF 23 pages, 11 figures
Summary
本文重新审视了在具有充足样本内存的更现实环境下持续学习(CL)的问题。研究发现,在充足内存下稳定性因减少遗忘而提高,但可塑性因模型偏向先前任务而降低,难以适应新任务。简单基线如朴素回放能在较低计算成本下匹配或超越先进方法性能。基于此,提出一种轻量级有效的Weight Space Consolidation方法,通过参数重置和权重平均机制提高模型可塑性和稳定性。该方法在类增量学习和大型语言模型的持续指令调整方面表现优于强基线,且仅需三分之一至四分之一的训练成本。这些发现挑战了长期存在的CL假设,为现实世界中样本内存不再是限制因素的持续学习系统建立了新的成本效益基线。
Key Takeaways
- 传统持续学习(CL)侧重于最小化样本内存使用,但在现代计算环境中,内存充足且成本低廉,GPU时间成为主要成本。
- 在充足内存环境下,稳定性因减少遗忘而提高,但模型可塑性降低,难以适应新任务。
- 简单回放方法能在较低计算成本下达到或超越复杂方法性能。
- 提出了一种新的轻量级方法Weight Space Consolidation,通过参数重置和权重平均提高模型可塑性和稳定性。
- 该方法在类增量学习和大型语言模型持续指令调整方面表现优异。
- 与其他强基线相比,Weight Space Consolidation方法的训练成本更低,仅需三分之一至四分之一。
点此查看论文截图

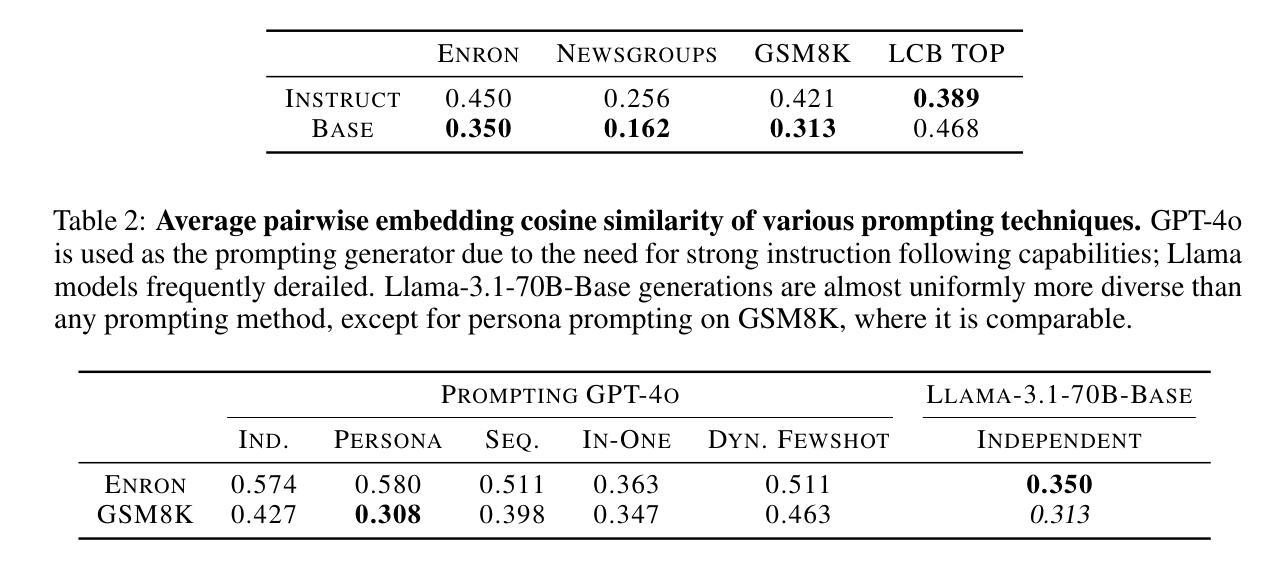
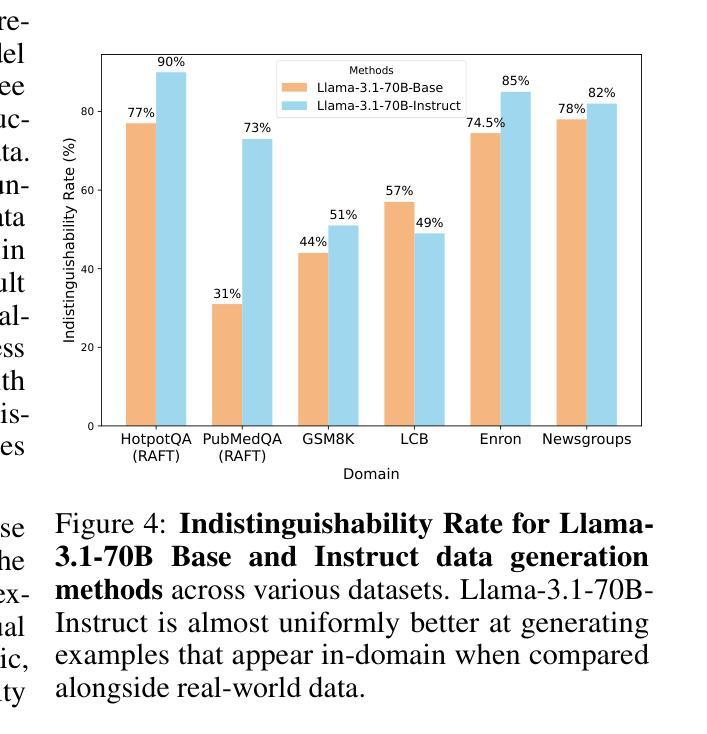
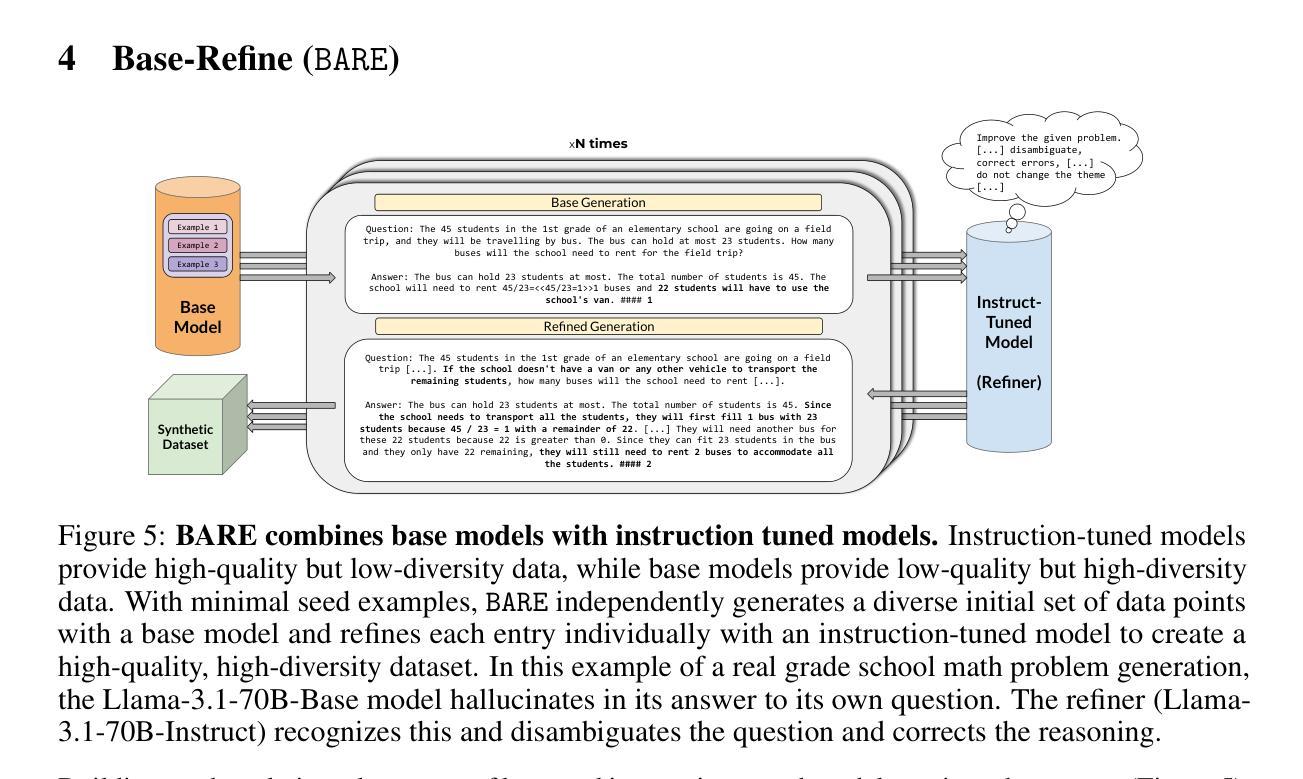
BARE: Leveraging Base Language Models for Few-Shot Synthetic Data Generation
Authors:Alan Zhu, Parth Asawa, Jared Quincy Davis, Lingjiao Chen, Boris Hanin, Ion Stoica, Joseph E. Gonzalez, Matei Zaharia
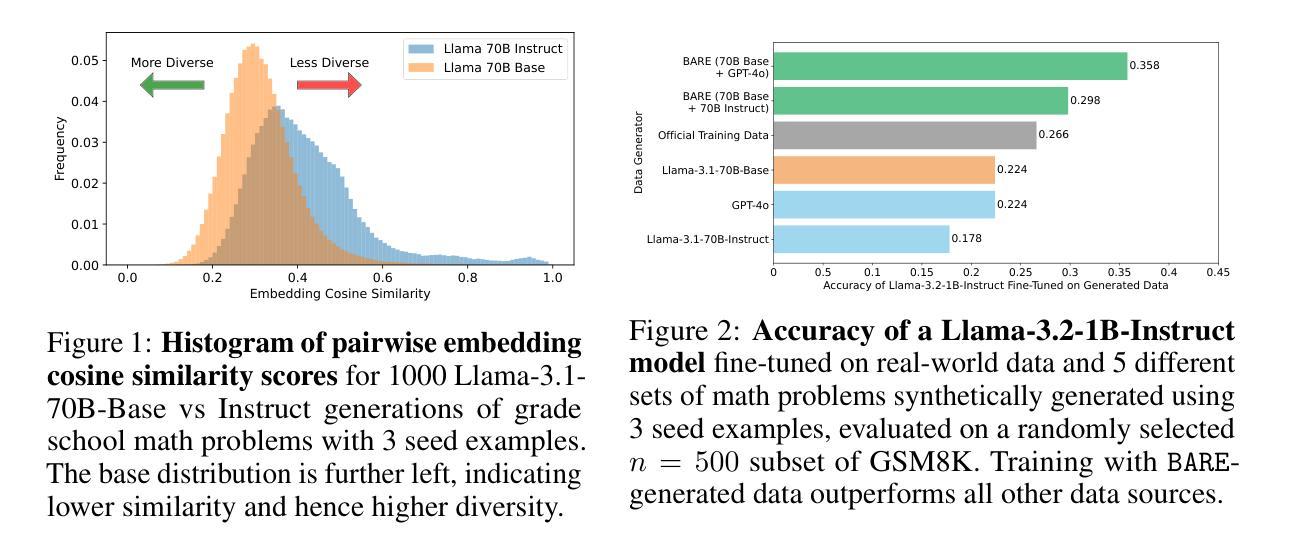
As the demand for high-quality data in model training grows, researchers and developers are increasingly generating synthetic data to tune and train LLMs. However, current data generation methods rely on seed sets containing tens of thousands of examples to prompt instruction-tuned models. This reliance can be especially problematic when the curation of high-quality examples is expensive or difficult. In this paper we explore the novel few-shot synthetic data generation setting – generating a high-quality dataset from a few examples. We show that when working with only a few seed examples, instruction-tuned models used in current synthetic data methods produce insufficient diversity for downstream tasks. In contrast, we show that base models without post-training, largely untapped for synthetic data generation, offer substantially greater output diversity, albeit with lower instruction following abilities. Leveraging this insight, we propose Base-Refine (BARE), a novel two-stage method that combines the diversity of base models with the quality assurance of instruction-tuned models. BARE excels in few-shot synthetic data generation: using only 3 seed examples it generates diverse, high-quality datasets that significantly improve downstream task performance. We show that fine-tuning Llama 3.1 8B with 1,000 BARE-generated samples achieves performance comparable to state-of-the-art similarly sized models on LiveCodeBench tasks. Furthermore, data generated with BARE enables a 101% improvement for a fine-tuned Llama 3.2 1B on GSM8K over data generated by only instruction-models, and an 18.4% improvement for a fine-tuned Llama 3.1 8B over the state-of-the-art RAFT method for RAG data generation.
随着模型训练中对高质量数据的需求不断增长,研究人员和开发人员正在越来越多地生成合成数据来调整和训练大型语言模型(LLM)。然而,当前的数据生成方法依赖于包含数十万个示例的种子集来提示指令调整模型。当高质量示例的收集既昂贵又困难时,这种依赖可能是特别成问题的。在本文中,我们探索了新颖的小样本合成数据生成场景——从少量示例生成高质量数据集。我们表明,在与仅几个种子示例一起工作时,当前合成数据方法中所使用的教学型模型产生的下游任务多样性不足。相比之下,我们显示,尚未用于合成数据生成的基准模型提供了大量更大的输出多样性,尽管其遵循指令的能力较低。利用这一见解,我们提出了Base-Refine(BARE),这是一种新颖的两阶段方法,它将基准模型的多样性与指令调整模型的质量保证相结合。BARE在少样本合成数据生成方面表现出色:仅使用三个种子示例即可生成多样化且高质量的数据集,这显着提高了下游任务的性能。我们展示了使用由BARE生成的样本微调后的Llama 3.1 8B模型在LiveCodeBench任务上的性能与最新技术水平的类似规模模型相当。此外,使用BARE生成的数据可使微调后的Llama 3.2 1B在GSM8K上的性能提高101%,相较于仅使用指令模型生成的数据;对于微调后的Llama 3.1 8B模型在RAG数据生成方面的性能提高18.4%,超过了当前最先进的RAFT方法。
论文及项目相关链接
摘要
随着模型训练对数据质量需求的提高,研究人员越来越依赖生成合成数据来调整和训练大语言模型(LLM)。但当前的数据生成方法依赖数十万个样本组成的种子集来提示指令调整模型,这在高质量样本的收集成本高昂或困难时尤为棘手。本文探索了新型少样本合成数据生成设置,即从少量样本生成高质量数据集。研究表明,使用仅有的几个种子样本,当前合成数据方法中的指令调整模型产生的多样性不足以应对下游任务。相反,尽管指令遵循能力较低,但未被充分开发的基准模型在合成数据生成方面提供了更丰富的输出多样性。利用这一见解,我们提出了Base-Refine(BARE),这是一种新型的两阶段方法,结合了基准模型的多样性和指令调整模型的质量保证。BARE在少样本合成数据生成方面表现出色:仅使用三个种子样本就能生成多样化、高质量的数据集,显著提高了下游任务的性能。实验显示,使用BARE生成的1000个样本微调Llama 3.1 8B模型,在LiveCodeBench任务上的性能与最新技术水平的类似规模模型相当。此外,使用BARE生成的数据对Llama 3.2 1B进行微调,在GSM8K上的改进率为101%,对Llama 3.1 8B的改进率为最新RAFT方法的18.4%。这些数据表明,在大型语言模型领域使用此方法有巨大潜力。同时探索将此框架扩展到更广泛的应用场景的可能性。同时指出未来的研究方向包括进一步优化合成数据的多样性和质量等。总体来说,该研究为解决高质量数据需求提供了一种有效的新方法。
关键见解
- 研究关注于从少量样本中生成高质量数据集的新方法。
- 当前合成数据方法依赖大量种子示例,这在高成本或难以获取高质量样本时成为问题。
- 提出了一种新型的两阶段方法Base-Refine(BARE),结合了基准模型的多样性和指令调整模型的质量保证。
- BARE方法在少样本合成数据生成方面表现出色,仅使用少数种子样本就能生成多样化、高质量的数据集。
- BARE生成的合成数据可以显著提高下游任务的性能,例如在微调大型语言模型时的任务表现。具体案例包括Llama模型的多个版本和不同的任务基准测试。这表明该方法具有巨大的潜力。
- 此方法的潜在应用领域广泛,未来可以探索扩展到更多场景的可能性。
点此查看论文截图

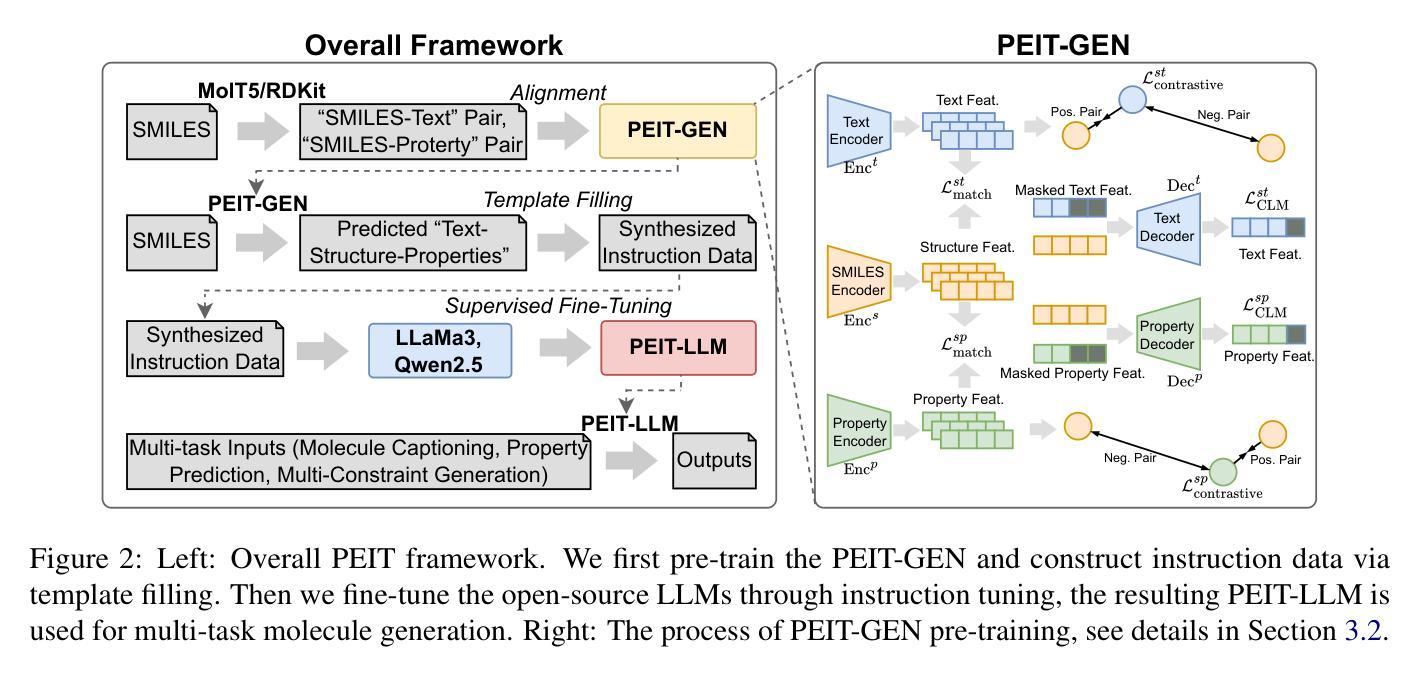
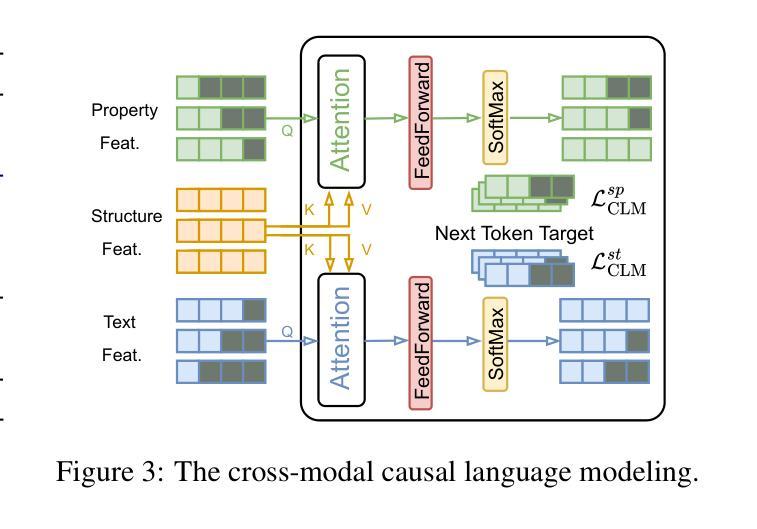
Property Enhanced Instruction Tuning for Multi-task Molecule Generation with Large Language Models
Authors:Xuan Lin, Long Chen, Yile Wang, Xiangxiang Zeng, Philip S. Yu
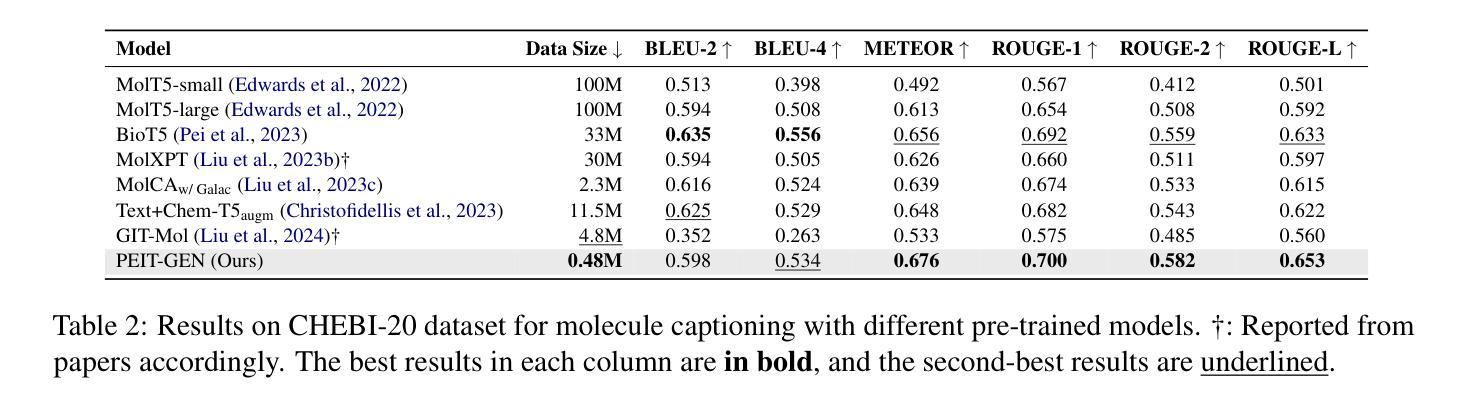
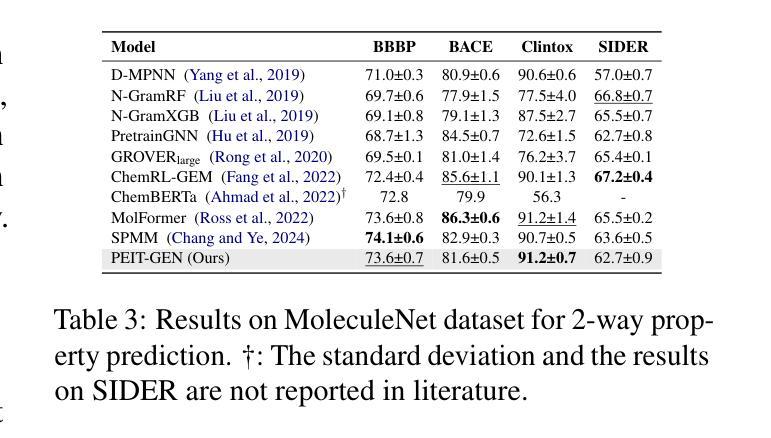
Large language models (LLMs) are widely applied in various natural language processing tasks such as question answering and machine translation. However, due to the lack of labeled data and the difficulty of manual annotation for biochemical properties, the performance for molecule generation tasks is still limited, especially for tasks involving multi-properties constraints. In this work, we present a two-step framework PEIT (Property Enhanced Instruction Tuning) to improve LLMs for molecular-related tasks. In the first step, we use textual descriptions, SMILES, and biochemical properties as multimodal inputs to pre-train a model called PEIT-GEN, by aligning multi-modal representations to synthesize instruction data. In the second step, we fine-tune existing open-source LLMs with the synthesized data, the resulting PEIT-LLM can handle molecule captioning, text-based molecule generation, molecular property prediction, and our newly proposed multi-constraint molecule generation tasks. Experimental results show that our pre-trained PEIT-GEN outperforms MolT5 and BioT5 in molecule captioning, demonstrating modalities align well between textual descriptions, structures, and biochemical properties. Furthermore, PEIT-LLM shows promising improvements in multi-task molecule generation, proving the scalability of the PEIT framework for various molecular tasks. We release the code, constructed instruction data, and model checkpoints in https://github.com/chenlong164/PEIT.
大型语言模型(LLM)广泛应用于各种自然语言处理任务,如问答和机器翻译。然而,由于缺乏标签数据和生物化学属性手动注释的困难,分子生成任务的性能仍然有限,尤其是涉及多属性约束的任务。在这项工作中,我们提出了一个两阶段的PEIT(属性增强指令调整)框架,以提高LLM在分子相关任务上的性能。首先,我们使用文本描述、SMILES和生物化学属性作为多模式输入,通过对齐多模式表示来合成指令数据,从而预训练一个名为PEIT-GEN的模型。在第二步中,我们使用合成数据对现有的开源LLM进行微调,得到的PEIT-LLM可以处理分子描述、文本基础上的分子生成、分子属性预测以及我们新提出的多约束分子生成任务。实验结果表明,我们预训练的PEIT-GEN在分子描述方面优于MolT5和BioT5,表明文本描述、结构和生物化学属性之间的模式对齐良好。此外,PEIT-LLM在多任务分子生成方面显示出有希望的改进,证明了PEIT框架在各种分子任务上的可扩展性。我们在https://github.com/chenlong164/PEIT上发布了代码、构建指令数据和模型检查点。
论文及项目相关链接
PDF 9
Summary
LLMs在分子生成任务中的性能受限于缺乏标签数据和手动标注的困难。本研究提出了一种两步框架PEIT,以提高LLMs在分子相关任务上的性能。首先,使用文本描述、SMILES和生物化学属性等多模式输入预训练PEIT-GEN模型。其次,用合成数据微调现有开源LLMs,得到的PEIT-LLM能处理分子描述、文本基础分子生成、分子属性预测以及新提出的多约束分子生成任务。实验结果显示,PEIT-GEN在分子描述上优于MolT5和BioT5,证明文本描述、结构和生物化学属性之间的模式对齐良好。同时,PEIT-LLM在多任务分子生成方面展现出显著改进,证明PEIT框架对各种分子任务的可扩展性。
Key Takeaways
- LLMs在分子生成任务中面临性能挑战,尤其是涉及多属性约束的任务。
- PEIT框架分为两步:首先使用多模式输入预训练PEIT-GEN模型;然后使用合成数据微调现有开源LLMs。
- PEIT-GEN在分子描述方面的性能优于MolT5和BioT5,证明了不同模式之间的良好对齐。
- PEIT-LLM能处理多种分子相关任务,包括分子描述、文本基础分子生成、分子属性预测以及多约束分子生成。
- 框架的扩展性好,能适应不同的分子任务。
- 代码、构建指令数据和模型检查点已公开在GitHub上。
- 该研究为改善LLMs在分子相关任务上的性能提供了新的思路和方法。
点此查看论文截图


Performance of ChatGPT on tasks involving physics visual representations: the case of the Brief Electricity and Magnetism Assessment
Authors:Giulia Polverini, Jakob Melin, Elias Onerud, Bor Gregorcic
Artificial intelligence-based chatbots are increasingly influencing physics education due to their ability to interpret and respond to textual and visual inputs. This study evaluates the performance of two large multimodal model-based chatbots, ChatGPT-4 and ChatGPT-4o on the Brief Electricity and Magnetism Assessment (BEMA), a conceptual physics inventory rich in visual representations such as vector fields, circuit diagrams, and graphs. Quantitative analysis shows that ChatGPT-4o outperforms both ChatGPT-4 and a large sample of university students, and demonstrates improvements in ChatGPT-4o’s vision interpretation ability over its predecessor ChatGPT-4. However, qualitative analysis of ChatGPT-4o’s responses reveals persistent challenges. We identified three types of difficulties in the chatbot’s responses to tasks on BEMA: (1) difficulties with visual interpretation, (2) difficulties in providing correct physics laws or rules, and (3) difficulties with spatial coordination and application of physics representations. Spatial reasoning tasks, particularly those requiring the use of the right-hand rule, proved especially problematic. These findings highlight that the most broadly used large multimodal model-based chatbot, ChatGPT-4o, still exhibits significant difficulties in engaging with physics tasks involving visual representations. While the chatbot shows potential for educational applications, including personalized tutoring and accessibility support for students who are blind or have low vision, its limitations necessitate caution. On the other hand, our findings can also be leveraged to design assessments that are difficult for chatbots to solve.
基于人工智能的聊天机器人由于其解释和响应文本和视觉输入的能力,正在越来越多地影响物理教育。本研究评估了两个大型多模式模型基础聊天机器人ChatGPT-4和ChatGPT-4o在“简短的电与磁评估(BEMA)”上的表现。BEMA是一个概念丰富的物理题库,包含矢量场、电路图和图表等视觉表示。定量分析表明,ChatGPT-4o在ChatGPT-4和大量大学生样本中的表现更为出色,并展示了其在视觉解释能力方面对前身ChatGPT-4的改进。然而,对ChatGPT-4o的回应的定性分析揭示了持续存在的挑战。我们确定了聊天机器人在BEMA任务中的三种困难:一是视觉解释的困难,二是提供正确的物理定律或规则的困难,三是空间协调和物理表示应用的困难。空间推理任务,特别是那些需要使用右手定则的任务,证明特别棘手。这些发现表明,最广泛使用的基于大型多模式模型的聊天机器人ChatGPT-4o在涉及视觉表示的物理学任务中仍存在重大困难。虽然聊天机器人在教育应用方面显示出潜力,包括个性化辅导和支持盲人或视力不佳的学生,但其局限性需要谨慎对待。另一方面,我们的发现也可以用来设计对聊天机器人来说难以解决的评估问题。
论文及项目相关链接
Summary
人工智能聊天机器人对物理教育的影响日益显著,它们能够解释和回应文本和视觉输入。本研究评估了两个基于大型多模态模型的聊天机器人ChatGPT-4和ChatGPT-4o在包含矢量场、电路图和图表等视觉呈现丰富的概念性物理测试——简短电力与磁学评估(BEMA)上的表现。定量分析显示,ChatGPT-4o在ChatGPT-4和大量大学生样本中的表现更优秀,显示出其在视觉解释能力方面的改进。然而,对ChatGPT-4o的响应的定性分析揭示了持续存在的挑战。其困难包括三个方面:视觉解释方面的困难、提供正确的物理定律或规则的困难以及在空间协调和物理表示应用方面的困难。空间推理任务,特别是那些需要使用右手规则的任务,特别具有挑战性。这些发现表明,最广泛使用的大型基于多模态模型的聊天机器人ChatGPT-4o在涉及视觉呈现的物理任务中仍存在显著困难。虽然该聊天机器人在个性化辅导和视力障碍学生支持方面具有潜力,但其局限性需要谨慎对待。另一方面,我们的发现也可用于设计难以被聊天机器人解决的评估测试。
Key Takeaways
- 人工智能聊天机器人在物理教育中影响显著,得益于其解释和回应文本和视觉输入的能力。
- ChatGPT-4o在视觉解释能力上相较于ChatGPT-4有所提升,并在简短电力与磁学评估中表现优秀。
- 聊天机器人在视觉解释、提供正确物理定律或规则以及空间协调和物理表示应用方面存在困难。
- 空间推理任务对聊天机器人来说具有挑战性。
- ChatGPT-4o虽然具有教育应用潜力,如个性化辅导和视力障碍学生支持,但存在局限性需谨慎对待。
- 研究结果可用于设计难以被聊天机器人解决的评估测试。
点此查看论文截图

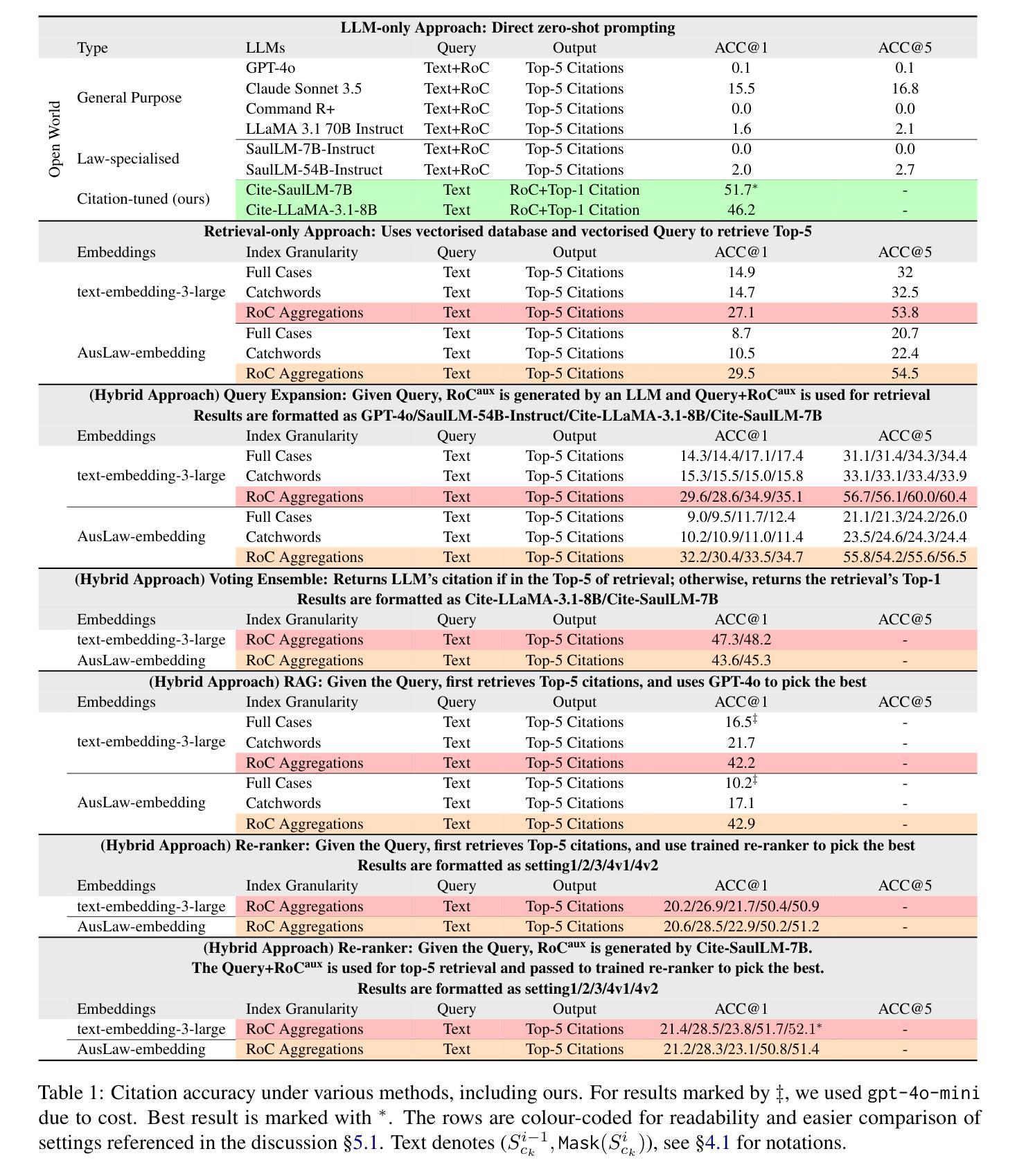
Evaluating LLM-based Approaches to Legal Citation Prediction: Domain-specific Pre-training, Fine-tuning, or RAG? A Benchmark and an Australian Law Case Study
Authors:Jiuzhou Han, Paul Burgess, Ehsan Shareghi
Large Language Models (LLMs) have demonstrated strong potential across legal tasks, yet the problem of legal citation prediction remains under-explored. At its core, this task demands fine-grained contextual understanding and precise identification of relevant legislation or precedent. We introduce the AusLaw Citation Benchmark, a real-world dataset comprising 55k Australian legal instances and 18,677 unique citations which to the best of our knowledge is the first of its scale and scope. We then conduct a systematic benchmarking across a range of solutions: (i) standard prompting of both general and law-specialised LLMs, (ii) retrieval-only pipelines with both generic and domain-specific embeddings, (iii) supervised fine-tuning, and (iv) several hybrid strategies that combine LLMs with retrieval augmentation through query expansion, voting ensembles, or re-ranking. Results show that neither general nor law-specific LLMs suffice as stand-alone solutions, with performance near zero. Instruction tuning (of even a generic open-source LLM) on task-specific dataset is among the best performing solutions. We highlight that database granularity along with the type of embeddings play a critical role in retrieval-based approaches, with hybrid methods which utilise a trained re-ranker delivering the best results. Despite this, a performance gap of nearly 50% remains, underscoring the value of this challenging benchmark as a rigorous test-bed for future research in legal-domain.
大型语言模型(LLM)在法律任务中展现出强大的潜力,但法律引文预测的问题仍然未被充分探索。该任务的核心需求是精细的上下文理解和对相关立法或先例的精确识别。我们引入了AusLaw引文基准测试,这是一个包含5.5万澳大利亚法律实例和18677条独特引文的真实世界数据集,据我们所知,这是第一个如此规模和范围的数据集。然后,我们对一系列解决方案进行了系统的基准测试:(i)通用和法律专业LLM的标准提示,(ii)使用通用和领域特定嵌入的仅检索管道,(iii)监督微调,以及(iv)几种将LLM与通过查询扩展、投票集合或重新排序进行检索增强的混合策略。结果表明,无论是通用还是法律专业的LLM都不足以作为独立的解决方案,性能接近为零。在特定任务数据集上对(即使是通用的开源LLM)进行指令微调是表现最好的解决方案之一。我们强调,数据库粒度以及嵌入类型在基于检索的方法中起着至关重要的作用,利用经过训练的重新排序器的混合方法取得了最好的结果。尽管如此,仍存在近50%的性能差距,这凸显了在这个具有挑战性的基准测试作为法律领域未来研究的严格测试平台的价值。
论文及项目相关链接
PDF For code, data, and models see https://auslawbench.github.io
Summary:大型语言模型在法律任务中展现出巨大潜力,但法律引文预测问题仍被较少探索。本文引入了AusLaw Citation Benchmark数据集,包含5.5万份澳大利亚法律案例和1.8万多个独特引文,是迄今为止规模最大、范围最广的数据集。文章对一系列解决方案进行了系统评估,包括标准提示通用和法律专业化的LLM模型等。结果指出,通用和法律专业LLM模型单独使用效果有限,接近零性能。通过任务特定数据集进行指令微调是表现最好的解决方案之一。文章强调数据库粒度和嵌入类型在基于检索的方法中扮演关键角色,利用训练后的重新排名器进行混合方法取得最佳结果。尽管如此,仍存在近50%的性能差距,突显出这一具有挑战性的基准测试对于未来法律领域研究的价值。
Key Takeaways:
- LLMs在法律任务中有巨大潜力,但法律引文预测仍是未充分探索的问题。
- 引入了AusLaw Citation Benchmark数据集,规模广泛。
- 评估了多种解决方案,包括LLM模型的标准提示、检索管道等。
- 通用和法律专业LLM模型单独使用效果有限。
- 任务特定数据集的指令微调是最佳解决方案之一。
- 数据库粒度和嵌入类型在基于检索的方法中至关重要。
点此查看论文截图

How Out-of-Distribution Detection Learning Theory Enhances Transformer: Learnability and Reliability
Authors:Yijin Zhou, Yutang Ge, Xiaowen Dong, Yuguang Wang
Transformers excel in natural language processing and computer vision tasks. However, they still face challenges in generalizing to Out-of-Distribution (OOD) datasets, i.e. data whose distribution differs from that seen during training. OOD detection aims to distinguish outliers while preserving in-distribution (ID) data performance. This paper introduces the OOD detection Probably Approximately Correct (PAC) Theory for transformers, which establishes the conditions for data distribution and model configurations for the OOD detection learnability of transformers. It shows that outliers can be accurately represented and distinguished with sufficient data under conditions. The theoretical implications highlight the trade-off between theoretical principles and practical training paradigms. By examining this trade-off, we naturally derived the rationale for leveraging auxiliary outliers to enhance OOD detection. Our theory suggests that by penalizing the misclassification of outliers within the loss function and strategically generating soft synthetic outliers, one can robustly bolster the reliability of transformer networks. This approach yields a novel algorithm that ensures learnability and refines the decision boundaries between inliers and outliers. In practice, the algorithm consistently achieves state-of-the-art (SOTA) performance across various data formats.
Transformer在自然语言处理和计算机视觉任务方面表现出色。然而,它们在泛化到分布外(OOD)数据集时仍面临挑战,即那些与训练期间所见分布不同的数据。OOD检测旨在区分异常值,同时保持内部分布(ID)数据性能。本文介绍了针对Transformer的OOD检测可能近似正确(PAC)理论,该理论确定了数据分布和模型配置的条件,为Transformer的OOD检测学习能力奠定了基础。它表明,在特定条件下,通过足够的数据,异常值可以精确地表示和区分。理论影响突出了理论原则和实践训练范式之间的权衡。通过考察这种权衡,我们自然地得出了利用辅助异常值增强OOD检测的理由。我们的理论认为,通过在损失函数中惩罚异常值的误分类,并战略性地生成软合成异常值,可以稳健地提高Transformer网络的可靠性。这种方法产生了一种新算法,该算法确保了学习能力并细化了内值(inliers)和异常值之间的决策边界。在实践中,该算法在各种数据格式上始终实现了最新技术水平的表现。
论文及项目相关链接
Summary
本文介绍了针对Transformer在自然语言处理和计算机视觉任务中面临的Out-of-Distribution(OOD)数据集挑战,引入了OOD检测的PAC理论。该理论为Transformer在OOD检测中的学习性设定了数据分布和模型配置的条件。研究表明,在特定条件下,异常值可以准确表示和区分。理论上的权衡为利用辅助异常值增强OOD检测提供了依据。通过惩罚损失函数中异常值的误分类,并战略性地生成软合成异常值,可以稳健地提高Transformer网络的可靠性。这种方法形成了一个新算法,该算法保证了学习性并优化了正常值和异常值之间的决策边界,在实际应用中实现了跨各种数据格式的最新性能表现。
Key Takeaways
- Transformers面临在OOD数据集上泛化的挑战。
- PAC理论为Transformer在OOD检测中的学习性提供了理论基础。
- 在特定条件下,异常值可以准确表示和区分。
- 理论上的权衡对于增强OOD检测具有重要意义。
- 通过利用辅助异常值和调整损失函数,可以提高Transformer网络的可靠性。
- 新算法优化了正常值和异常值之间的决策边界。
点此查看论文截图

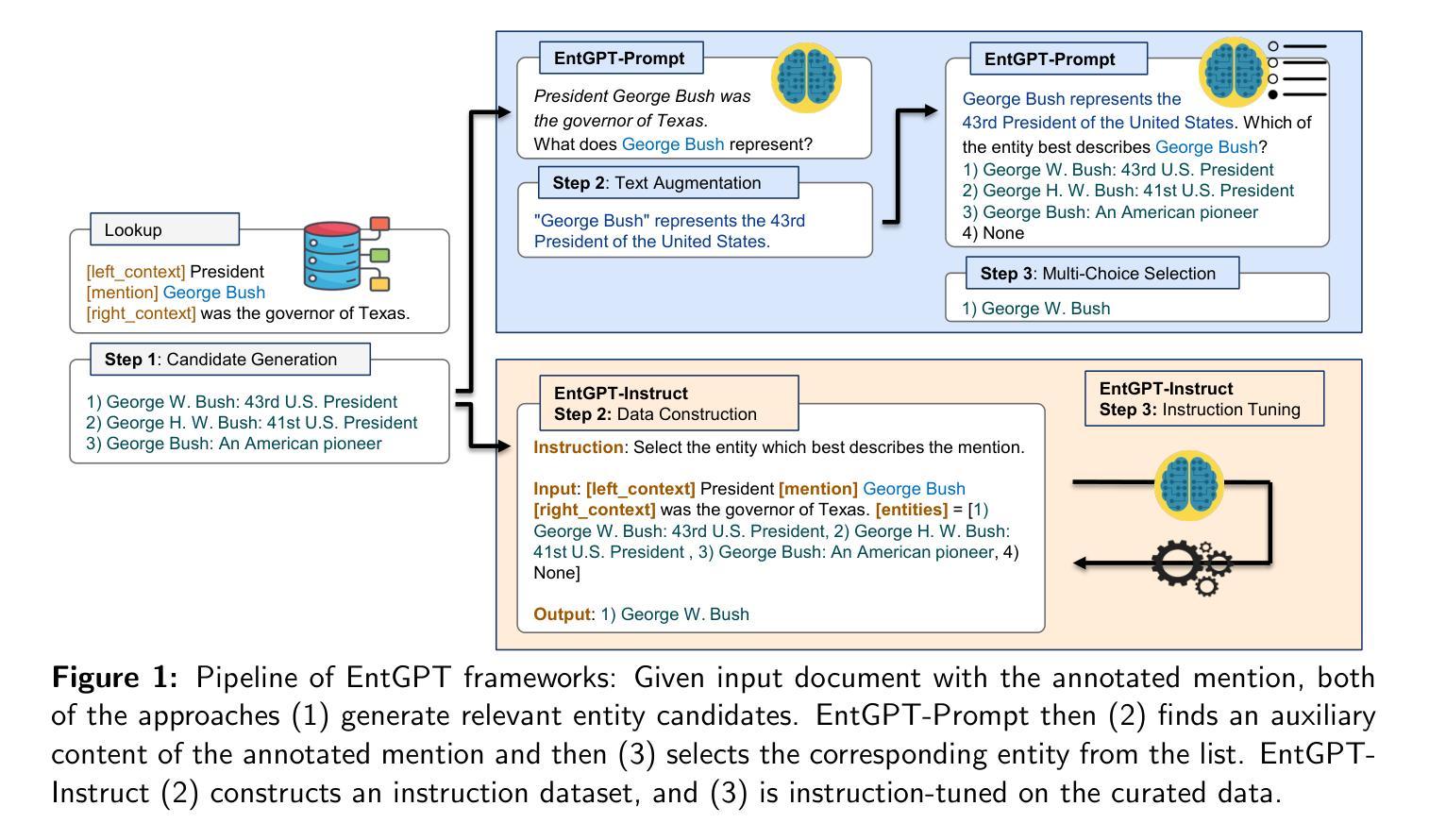
EntGPT: Entity Linking with Generative Large Language Models
Authors:Yifan Ding, Amrit Poudel, Qingkai Zeng, Tim Weninger, Balaji Veeramani, Sanmitra Bhattacharya
Entity Linking in natural language processing seeks to match text entities to their corresponding entries in a dictionary or knowledge base. Traditional approaches rely on contextual models, which can be complex, hard to train, and have limited transferability across different domains. Generative large language models like GPT offer a promising alternative but often underperform with naive prompts. In this study, we introduce EntGPT, employing advanced prompt engineering to enhance EL tasks. Our three-step hard-prompting method (EntGPT-P) significantly boosts the micro-F_1 score by up to 36% over vanilla prompts, achieving competitive performance across 10 datasets without supervised fine-tuning. Additionally, our instruction tuning method (EntGPT-I) improves micro-F_1 scores by 2.1% on average in supervised EL tasks and outperforms several baseline models in six Question Answering tasks. Our methods are compatible with both open-source and proprietary LLMs. All data and code are available on GitHub at https://github.com/yifding/In_Context_EL.
自然语言处理中的实体链接旨在将文本实体匹配到词典或知识库中的相应条目。传统的方法依赖于上下文模型,这些模型可能很复杂、难以训练,并且在不同领域的迁移能力有限。像GPT这样的生成式大型语言模型提供了一种有前途的替代方案,但通常在没有提示的情况下表现不佳。在这项研究中,我们引入了EntGPT,采用先进的提示技术来增强实体链接任务。我们的三步硬提示方法(EntGPT-P)通过先进的提示技术显著提高了微调前的微F_1分数,相较于常规提示最高提升了36%,在十个数据集上取得了具有竞争力的表现。此外,我们的指令调整方法(EntGPT-I)在监督的实体链接任务中平均提高了微F_1分数达2.1%,并且在六个问答任务中优于几个基线模型。我们的方法与开源和专有大型语言模型兼容。所有数据代码均可在GitHub上找到:https://github.com/yifding/In_Context_EL。
论文及项目相关链接
Summary
实体链接(Entity Linking,EL)是自然语言处理中的一项任务,旨在将文本中的实体与字典或知识库中的相应条目匹配。传统方法依赖于上下文模型,可能复杂、训练困难,且在不同领域的迁移能力有限。本研究引入EntGPT,采用先进的提示工程技术来提升EL任务性能。EntGPT-P的三步硬提示方法能显著提升微F_1分数,最高提升达36%,且在无需监督微调的情况下,在10个数据集上表现具有竞争力。EntGPT-I的指令调整方法则在监督EL任务中平均提高微F_1分数2.1%,并在六个问答任务中优于基线模型。本研究的方法与开源和专有大型语言模型均兼容,相关数据和代码已上传至GitHub(https://github.com/yifding/In_Context_EL)。
Key Takeaways
- 实体链接(EL)是自然语言处理中的一项重要任务,旨在匹配文本实体与字典或知识库中的条目。
- 传统EL方法依赖于复杂的上下文模型,且在不同领域的迁移能力有限。
- 本研究引入EntGPT,通过先进的提示工程技术提升EL任务性能。
- EntGPT-P的三步硬提示方法能显著提升微F_1分数,最高提升达36%,且在多个数据集上表现优秀。
- EntGPT-I的指令调整方法在监督EL任务和问答任务中均有优异表现。
- 本研究的方法与多种大型语言模型兼容。
点此查看论文截图