⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-05-25 更新
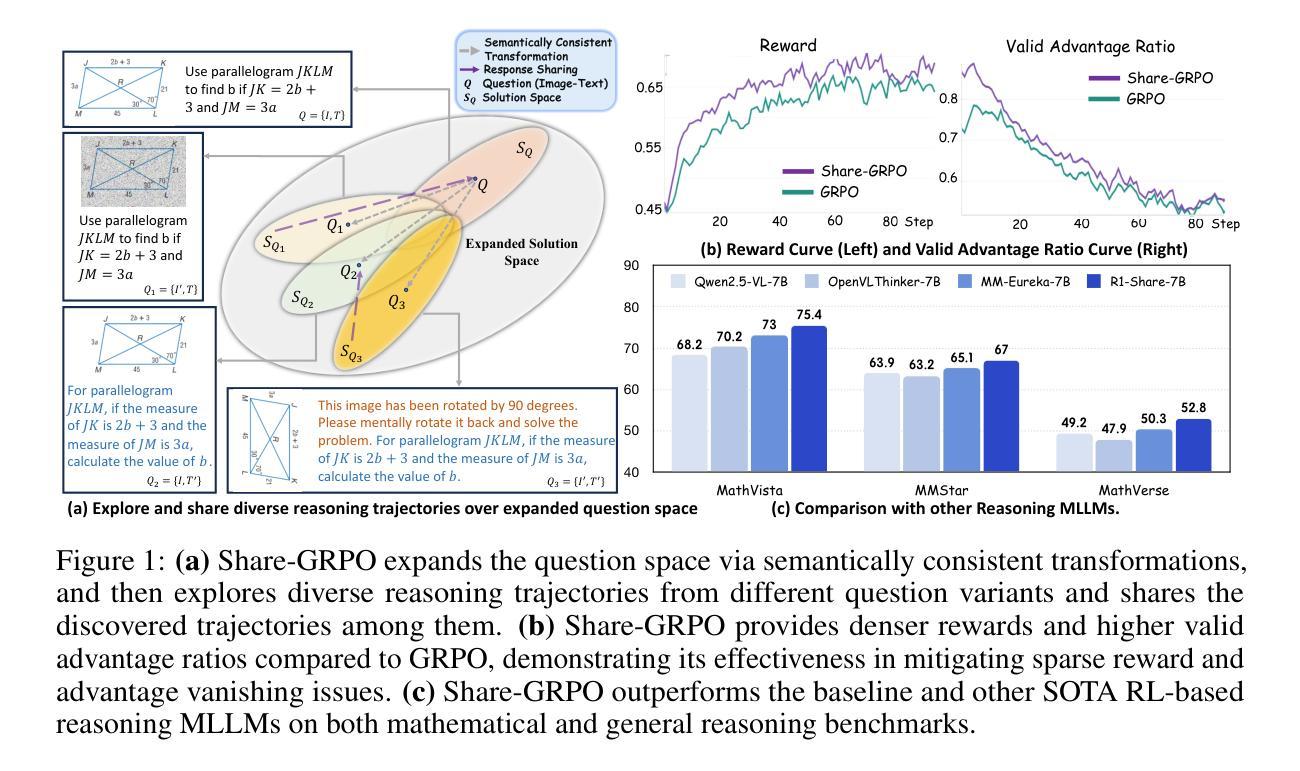
R1-ShareVL: Incentivizing Reasoning Capability of Multimodal Large Language Models via Share-GRPO
Authors:Huanjin Yao, Qixiang Yin, Jingyi Zhang, Min Yang, Yibo Wang, Wenhao Wu, Fei Su, Li Shen, Minghui Qiu, Dacheng Tao, Jiaxing Huang
In this work, we aim to incentivize the reasoning ability of Multimodal Large Language Models (MLLMs) via reinforcement learning (RL) and develop an effective approach that mitigates the sparse reward and advantage vanishing issues during RL. To this end, we propose Share-GRPO, a novel RL approach that tackle these issues by exploring and sharing diverse reasoning trajectories over expanded question space. Specifically, Share-GRPO first expands the question space for a given question via data transformation techniques, and then encourages MLLM to effectively explore diverse reasoning trajectories over the expanded question space and shares the discovered reasoning trajectories across the expanded questions during RL. In addition, Share-GRPO also shares reward information during advantage computation, which estimates solution advantages hierarchically across and within question variants, allowing more accurate estimation of relative advantages and improving the stability of policy training. Extensive evaluations over six widely-used reasoning benchmarks showcase the superior performance of our method. Code will be available at https://github.com/HJYao00/R1-ShareVL.
在这项工作中,我们旨在通过强化学习(RL)激励多模态大型语言模型(MLLMs)的推理能力,并开发一种有效的方法来解决RL过程中的稀疏奖励和优势消失问题。为此,我们提出了Share-GRPO,这是一种新型的RL方法,通过在扩展的问题空间上探索和共享多样化的推理轨迹来解决这些问题。具体来说,Share-GRPO首先通过数据转换技术为给定问题扩展问题空间,然后鼓励MLLM在扩展的问题空间上有效地探索多样化的推理轨迹,并在RL过程中共享发现的推理轨迹。此外,Share-GRPO还在计算优势时共享奖励信息,该信息分层估计问题变体之间的解决方案优势,从而允许更准确地估计相对优势并改进策略训练的稳定性。在六个广泛使用的推理基准测试上的广泛评估展示了我们的方法的卓越性能。代码将在https://github.com/HJYao00/R1-ShareVL上提供。
论文及项目相关链接
PDF Technical report
Summary
本文旨在通过强化学习(RL)激励多模态大型语言模型(MLLMs)的推理能力,并提出一种有效方法来解决RL中的稀疏奖励和优势消失问题。为此,提出了一种新的RL方法Share-GRPO,它通过扩展问题空间并探索和共享多样化的推理轨迹来解决这些问题。Share-GRPO通过数据转换技术扩展给定问题的问题空间,鼓励MLLM在扩展的问题空间上有效探索多样化的推理轨迹,并在RL过程中分享发现的推理轨迹。此外,Share-GRPO在优势计算过程中共享奖励信息,这可以在问题变体之间和内部进行分层解决方案优势估计,从而更准确地估计相对优势并提高策略训练的稳定性。在六个广泛使用的推理基准测试上的评估显示了我们方法的优越性。
Key Takeaways
- 本文旨在通过强化学习激励多模态大型语言模型的推理能力。
- 提出了一种新的强化学习方法Share-GRPO,解决稀疏奖励和优势消失问题。
- Share-GRPO通过数据转换技术扩展问题空间。
- Share-GRPO鼓励模型在扩展的问题空间上探索多样化的推理轨迹。
- Share-GRPO在RL过程中分享发现的推理轨迹。
- Share-GRPO在优势计算过程中共享奖励信息,提高策略训练的稳定性。
点此查看论文截图

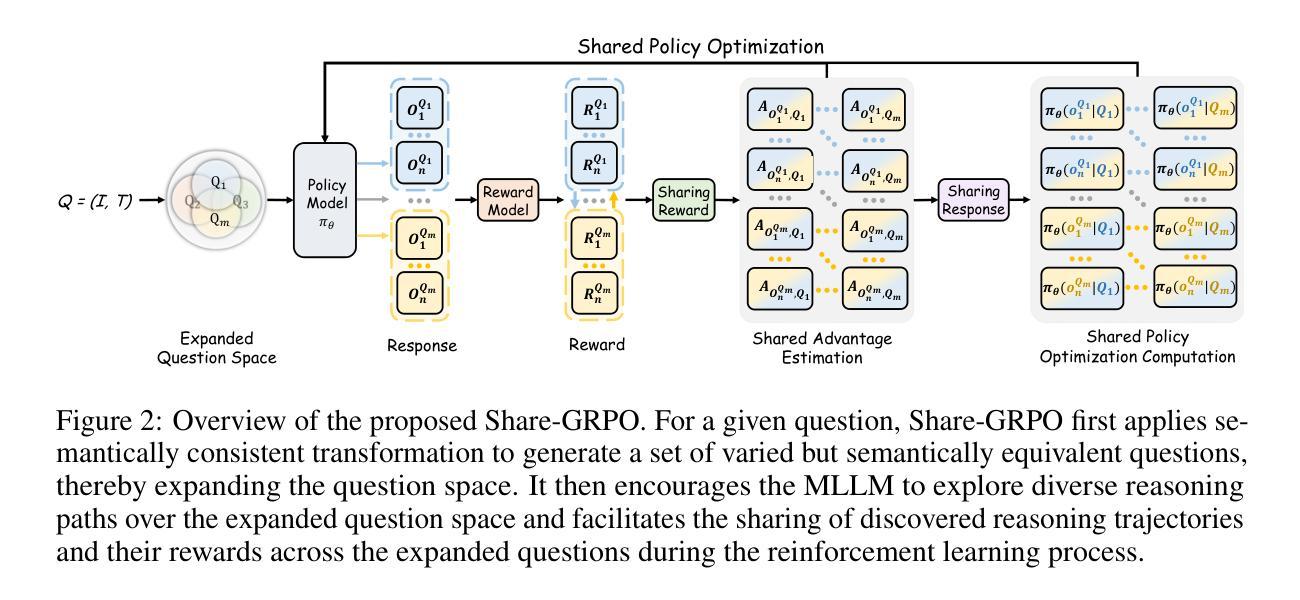
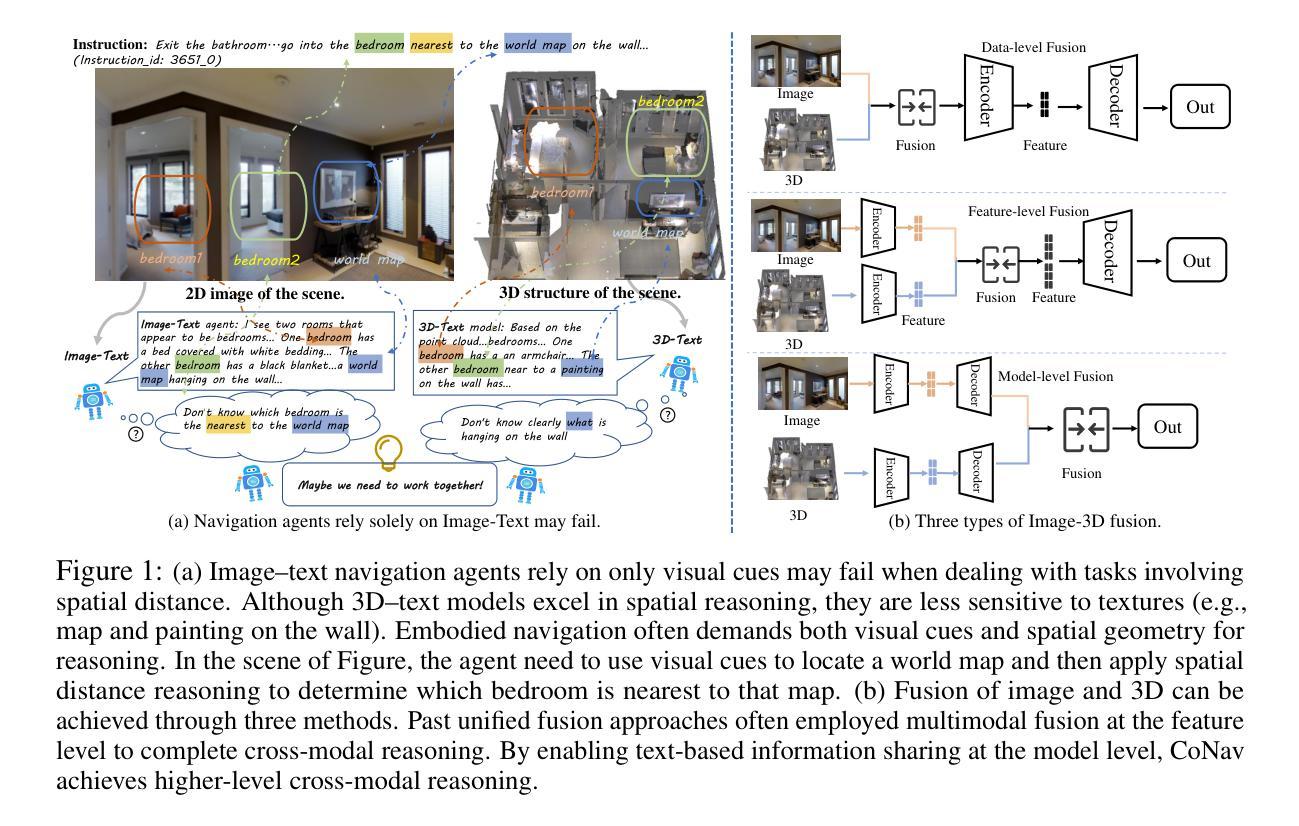
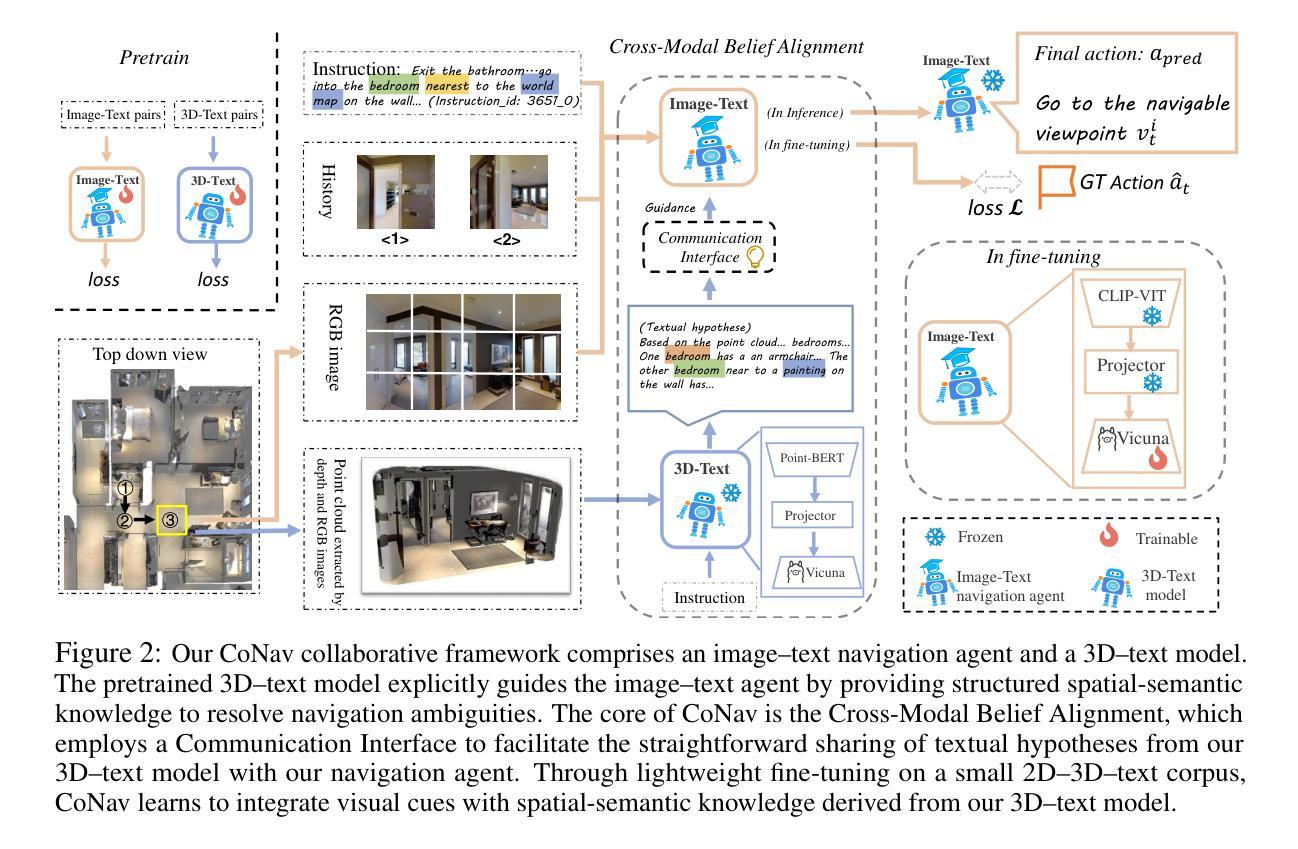
CoNav: Collaborative Cross-Modal Reasoning for Embodied Navigation
Authors:Haihong Hao, Mingfei Han, Changlin Li, Zhihui Li, Xiaojun Chang
Embodied navigation demands comprehensive scene understanding and precise spatial reasoning. While image-text models excel at interpreting pixel-level color and lighting cues, 3D-text models capture volumetric structure and spatial relationships. However, unified fusion approaches that jointly fuse 2D images, 3D point clouds, and textual instructions face challenges in limited availability of triple-modality data and difficulty resolving conflicting beliefs among modalities. In this work, we introduce CoNav, a collaborative cross-modal reasoning framework where a pretrained 3D-text model explicitly guides an image-text navigation agent by providing structured spatial-semantic knowledge to resolve ambiguities during navigation. Specifically, we introduce Cross-Modal Belief Alignment, which operationalizes this cross-modal guidance by simply sharing textual hypotheses from the 3D-text model to the navigation agent. Through lightweight fine-tuning on a small 2D-3D-text corpus, the navigation agent learns to integrate visual cues with spatial-semantic knowledge derived from the 3D-text model, enabling effective reasoning in embodied navigation. CoNav achieves significant improvements on four standard embodied navigation benchmarks (R2R, CVDN, REVERIE, SOON) and two spatial reasoning benchmarks (ScanQA, SQA3D). Moreover, under close navigation Success Rate, CoNav often generates shorter paths compared to other methods (as measured by SPL), showcasing the potential and challenges of fusing data from different modalities in embodied navigation. Project Page: https://oceanhao.github.io/CoNav/
身体化导航要求全面的场景理解和精确的空间推理能力。虽然图像文本模型擅长解读像素级的颜色和光照线索,但3D文本模型能够捕捉体积结构和空间关系。然而,联合融合2D图像、3D点云和文本指令的统一融合方法面临着三重模态数据有限以及解决各模态之间冲突信念的困难的挑战。在我们的研究中,我们引入了CoNav,这是一个协作式跨模态推理框架,其中预训练的3D文本模型通过提供结构化空间语义知识来明确指导图像文本导航代理,以解决导航过程中的歧义。具体来说,我们引入了跨模态信念对齐,它通过简单地共享3D文本模型的文本假设来实现跨模态指导导航代理。通过在一个小的2D-3D-文本语料库上进行轻量级微调,导航代理学会了将视觉线索与从3D文本模型中派生的空间语义知识相结合,从而在身体化导航中实现有效的推理。CoNav在四个标准的身体化导航基准测试(R2R、CVDN、REVERIE、SOON)和两个空间推理基准测试(ScanQA、SQA3D)上取得了显著改进。此外,在紧密导航成功率(Success Rate)方面,CoNav生成的路径通常比其他方法更短(以SPL衡量),展示了融合不同模态数据的潜力与挑战。项目页面:https://oceanhao.github.io/CoNav/
论文及项目相关链接
Summary
本文介绍了一种跨模态协同推理框架CoNav,用于解决身临其境的导航中的难题。该框架融合了预训练的3D文本模型与图像文本导航模型,通过提供结构化空间语义知识解决导航过程中的歧义问题。通过跨模态信念对齐机制,CoNav实现了不同模态间的有效沟通,提高了导航代理在身临其境的导航环境中的推理能力。在多个基准测试中,CoNav均取得了显著的提升。
Key Takeaways
- CoNav框架结合了预训练的3D文本模型与图像文本导航模型,提高了身临其境的导航中的推理能力。
- 跨模态信念对齐机制实现了不同模态间的有效沟通,解决了导航过程中的歧义问题。
- CoNav通过融合视觉线索和由3D文本模型派生的空间语义知识,使导航代理能够有效地整合不同模态的数据。
- CoNav在多个基准测试中取得了显著的提升,证明了融合不同模态数据的潜力。
- CoNav生成的路径通常比其他方法更短,展示了其在实际应用中的优势。
- 有限的三种模态数据可用性和解决不同模态间冲突信念的困难仍是当前面临的挑战。
点此查看论文截图

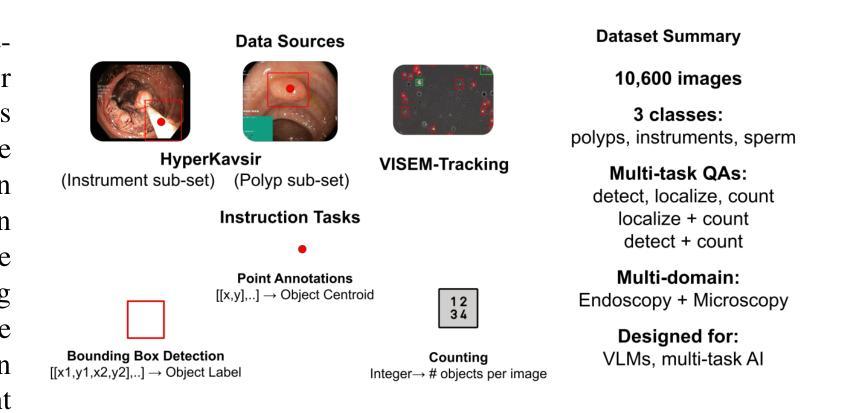
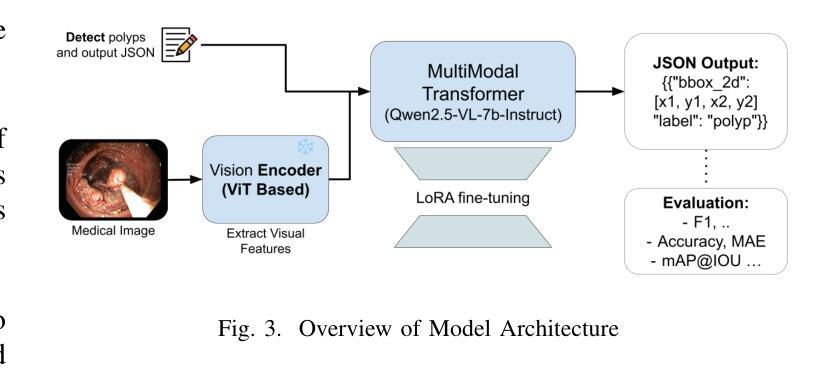
Point, Detect, Count: Multi-Task Medical Image Understanding with Instruction-Tuned Vision-Language Models
Authors:Sushant Gautam, Michael A. Riegler, Pål Halvorsen
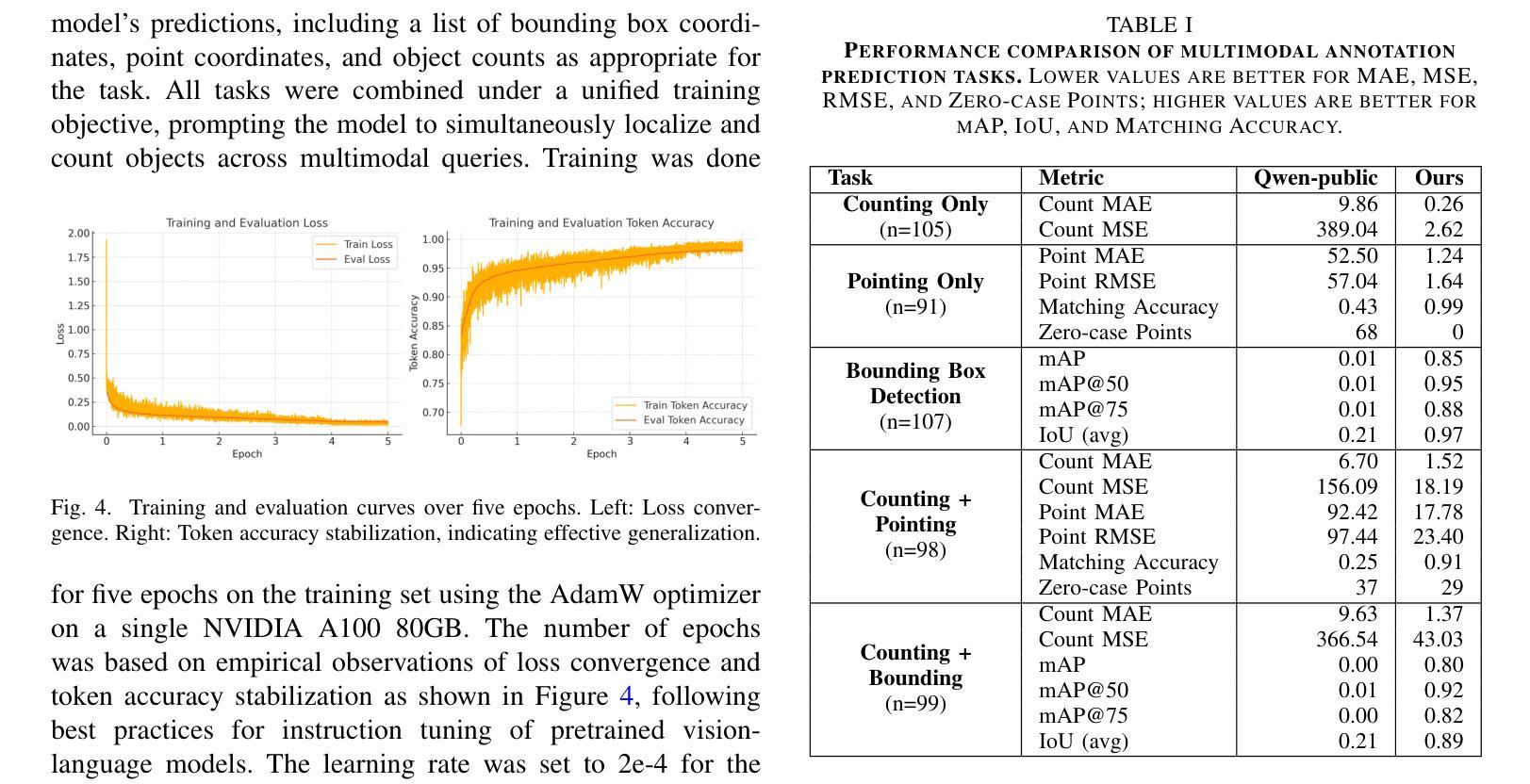
We investigate fine-tuning Vision-Language Models (VLMs) for multi-task medical image understanding, focusing on detection, localization, and counting of findings in medical images. Our objective is to evaluate whether instruction-tuned VLMs can simultaneously improve these tasks, with the goal of enhancing diagnostic accuracy and efficiency. Using MedMultiPoints, a multimodal dataset with annotations from endoscopy (polyps and instruments) and microscopy (sperm cells), we reformulate each task into instruction-based prompts suitable for vision-language reasoning. We fine-tune Qwen2.5-VL-7B-Instruct using Low-Rank Adaptation (LoRA) across multiple task combinations. Results show that multi-task training improves robustness and accuracy. For example, it reduces the Count Mean Absolute Error (MAE) and increases Matching Accuracy in the Counting + Pointing task. However, trade-offs emerge, such as more zero-case point predictions, indicating reduced reliability in edge cases despite overall performance gains. Our study highlights the potential of adapting general-purpose VLMs to specialized medical tasks via prompt-driven fine-tuning. This approach mirrors clinical workflows, where radiologists simultaneously localize, count, and describe findings - demonstrating how VLMs can learn composite diagnostic reasoning patterns. The model produces interpretable, structured outputs, offering a promising step toward explainable and versatile medical AI. Code, model weights, and scripts will be released for reproducibility at https://github.com/simula/PointDetectCount.
我们研究了针对多任务医学影像理解的视觉语言模型(VLMs)微调技术,重点聚焦于医学影像中的检测结果、定位以及计数。我们的目标是评估指令优化型VLMs是否能够同时改进这些任务,以提高诊断和效率。我们使用MedMultiPoints数据集,该数据集结合了内窥镜(息肉和仪器)和显微镜(精子细胞)的注释,形成一个多模式数据集。我们将每个任务重新制定为基于指令的提示,适用于视觉语言推理。我们使用LoRA技术对Qwen2.5-VL-7B-Instruct进行微调,以适应多种任务组合。结果显示,多任务训练提高了稳健性和准确性。例如,它减少了计数平均绝对误差(MAE),并提高了计数+定位任务的匹配准确率。然而,也出现了一些权衡,例如更多的零案例点预测,这表明尽管总体性能有所提升,但在边缘情况下可靠性有所降低。我们的研究强调了通过提示驱动微调将通用VLMs适应专业医疗任务的潜力。这种方法反映了临床工作流程,放射科医生可以同时定位、计数和描述发现结果,展示了VLMs如何学习复合诊断推理模式。该模型产生可解释、结构化的输出,为向可解释和多功能医疗AI迈出了一步,具有广阔的发展前景。相关代码、模型权重和脚本将在https://github.com/simula/PointDetectCount上发布,以促进重现性。
论文及项目相关链接
PDF Accepted as a full paper at the 38th IEEE International Symposium on Computer-Based Medical Systems (CBMS) 2025
Summary:
研究团队通过多任务训练对视觉语言模型(VLMs)进行微调,以提升医学图像理解的性能,重点探索检测、定位和计数任务。使用MedMultiPoints数据集和多模态标注,研究团队将任务转化为基于指令的提示,以适应视觉语言推理。研究结果表明,多任务训练能提高模型的稳健性和准确性,减少计数任务的平均绝对误差(MAE),提高匹配准确率。尽管在特定情况下出现一些权衡,如更多零点预测结果的出现,但该研究突出了指令驱动微调对于适应专业医学任务的潜力。该研究展示了VLMs学习组合诊断推理模式的潜力,为医学AI的可解释性和通用性迈出了重要一步。相关研究资料可在链接地址获取。
Key Takeaways:
- 研究团队针对医学图像理解的多任务训练进行了视觉语言模型的微调研究。
- 研究重点包括检测、定位和计数任务,旨在提高诊断准确性和效率。
- 使用MedMultiPoints数据集和多模态标注信息来适应视觉语言推理任务。
- 研究结果表明多任务训练能够提高模型的稳健性和准确性。
- 通过指令驱动的微调策略可以调整通用模型以适应特定医学任务需求。
- 特定情况下的权衡可能出现如增加零点预测的情况。然而尽管如此其仍然是通用可解释的,是医学AI的一个有前景的步骤。研究材料公开在指定链接供查阅学习。
点此查看论文截图

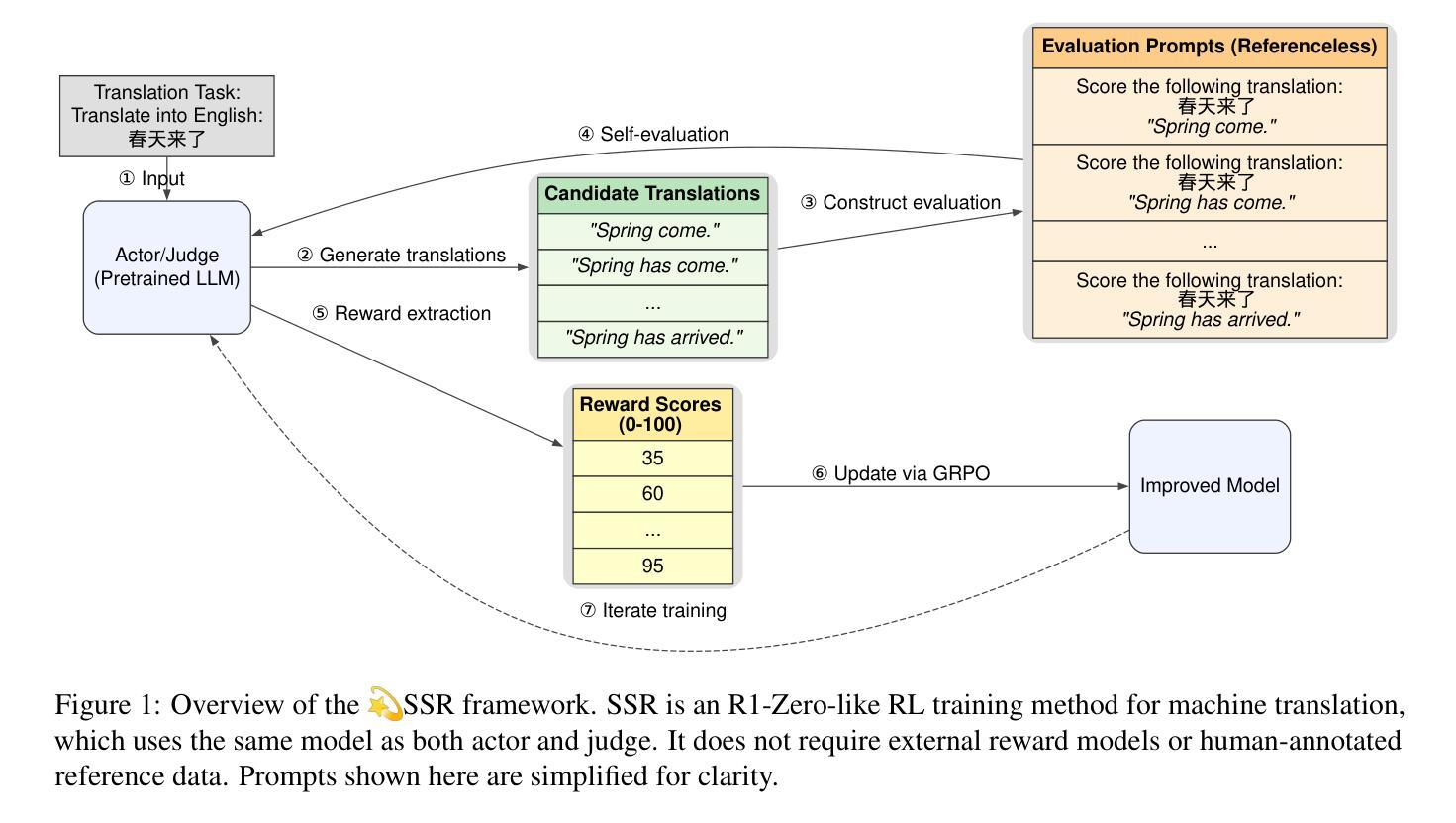
SSR-Zero: Simple Self-Rewarding Reinforcement Learning for Machine Translation
Authors:Wenjie Yang, Mao Zheng, Mingyang Song, Zheng Li
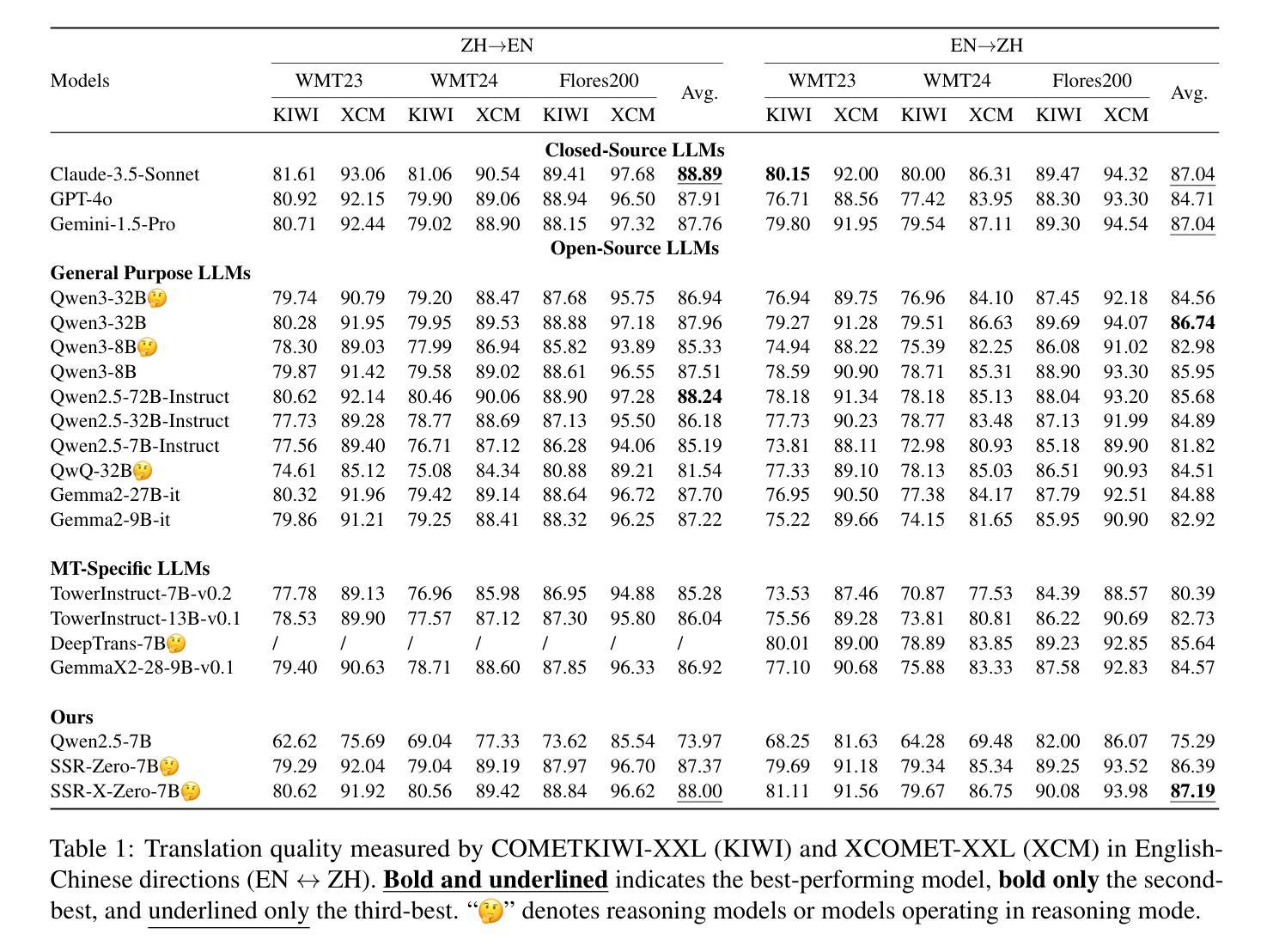
Large language models (LLMs) have recently demonstrated remarkable capabilities in machine translation (MT). However, most advanced MT-specific LLMs heavily rely on external supervision signals during training, such as human-annotated reference data or trained reward models (RMs), which are often expensive to obtain and challenging to scale. To overcome this limitation, we propose a Simple Self-Rewarding (SSR) Reinforcement Learning (RL) framework for MT that is reference-free, fully online, and relies solely on self-judging rewards. Training with SSR using 13K monolingual examples and Qwen-2.5-7B as the backbone, our model SSR-Zero-7B outperforms existing MT-specific LLMs, e.g., TowerInstruct-13B and GemmaX-28-9B, as well as larger general LLMs like Qwen2.5-32B-Instruct in English $\leftrightarrow$ Chinese translation tasks from WMT23, WMT24, and Flores200 benchmarks. Furthermore, by augmenting SSR with external supervision from COMET, our strongest model, SSR-X-Zero-7B, achieves state-of-the-art performance in English $\leftrightarrow$ Chinese translation, surpassing all existing open-source models under 72B parameters and even outperforming closed-source models, e.g., GPT-4o and Gemini 1.5 Pro. Our analysis highlights the effectiveness of the self-rewarding mechanism compared to the external LLM-as-a-judge approach in MT and demonstrates its complementary benefits when combined with trained RMs. Our findings provide valuable insight into the potential of self-improving RL methods. We have publicly released our code, data and models.
最近,大型语言模型(LLM)在机器翻译(MT)方面表现出了显著的能力。然而,大多数先进的针对机器翻译的LLM在训练过程中严重依赖于外部监督信号,如人工标注的参考数据或已训练的奖励模型(RM),这些信号的获取往往成本高昂且难以扩展。为了克服这一局限性,我们提出了一种用于机器翻译的无需参考的简单自我奖励(SSR)强化学习(RL)框架,该框架完全在线,仅依赖于自我判断奖励。使用SSR进行训练,以13K单语例句和Qwen-2.5-7B作为骨干,我们的SSR-Zero-7B模型在WMT23、WMT24和Flores200基准测试中的英语→中文翻译任务上超越了现有的针对机器翻译的大型语言模型,如TowerInstruct-13B和GemmaX-28-9B,以及在通用大型语言模型中表现更好的Qwen2.5-32B-Instruct。此外,通过利用来自COMET的外部监督增强SSR,我们最强的模型SSR-X-Zero-7B在英语→中文翻译方面达到了最新技术水平,不仅在参数少于72B的现有开源模型中表现最佳,甚至超越了封闭源模型,如GPT-4o和Gemini 1.5 Pro。我们的分析突出了自我奖励机制在机器翻译中的有效性,并与外部的大型语言模型作为评判者的方法进行了比较,证明了其结合训练后的奖励模型的互补优势。我们的研究为自我改进强化学习方法提供了有价值的见解。我们已经公开发布了我们的代码、数据和模型。
论文及项目相关链接
摘要
大型语言模型在机器翻译方面表现出色,但大多数先进的机器翻译特定的大型语言模型在训练过程中严重依赖外部监督信号。为了克服这一局限性,我们提出了一种无需参考的简易自我奖励强化学习框架,该框架完全在线,并仅依赖于自我判断奖励。使用SSR训练和Qwen-2.5-7B作为骨干,我们的模型在WMT23、WMT24和Flores200基准测试中的英汉翻译任务中,超越了现有的机器翻译特定的大型语言模型以及更大的通用大型语言模型。此外,通过增强SSR的外部监督来自COMET,我们最强的模型SSR-X-Zero-7B实现了英汉翻译的最新性能,超越了所有现有的开源模型,甚至超过了闭源模型,如GPT-4o和Gemini 1.5 Pro。我们的分析突出了自我奖励机制在机器翻译中的有效性,并展示了其与训练后的奖励模型的互补优势。我们的研究为自我改进的强化学习方法提供了有价值的见解。我们已经公开发布了我们的代码、数据和模型。
要点
- 提出了一种无需参考的简易自我奖励强化学习框架,用于机器翻译,该框架完全在线并仅依赖于自我判断奖励。
- 通过使用SSR训练和Qwen-2.5-7B作为骨干,模型在多个基准测试中的英汉翻译任务上表现出色。
- 通过结合外部监督,模型性能得到了进一步提升,超越了现有的先进模型。
- 自我奖励机制在机器翻译中的有效性得到证实,并与训练后的奖励模型表现出互补优势。
- 研究为自我改进的强化学习方法提供了新的见解。
- 代码、数据和模型已公开分享。
- 研究为机器翻译领域的发展做出了重要贡献。
点此查看论文截图


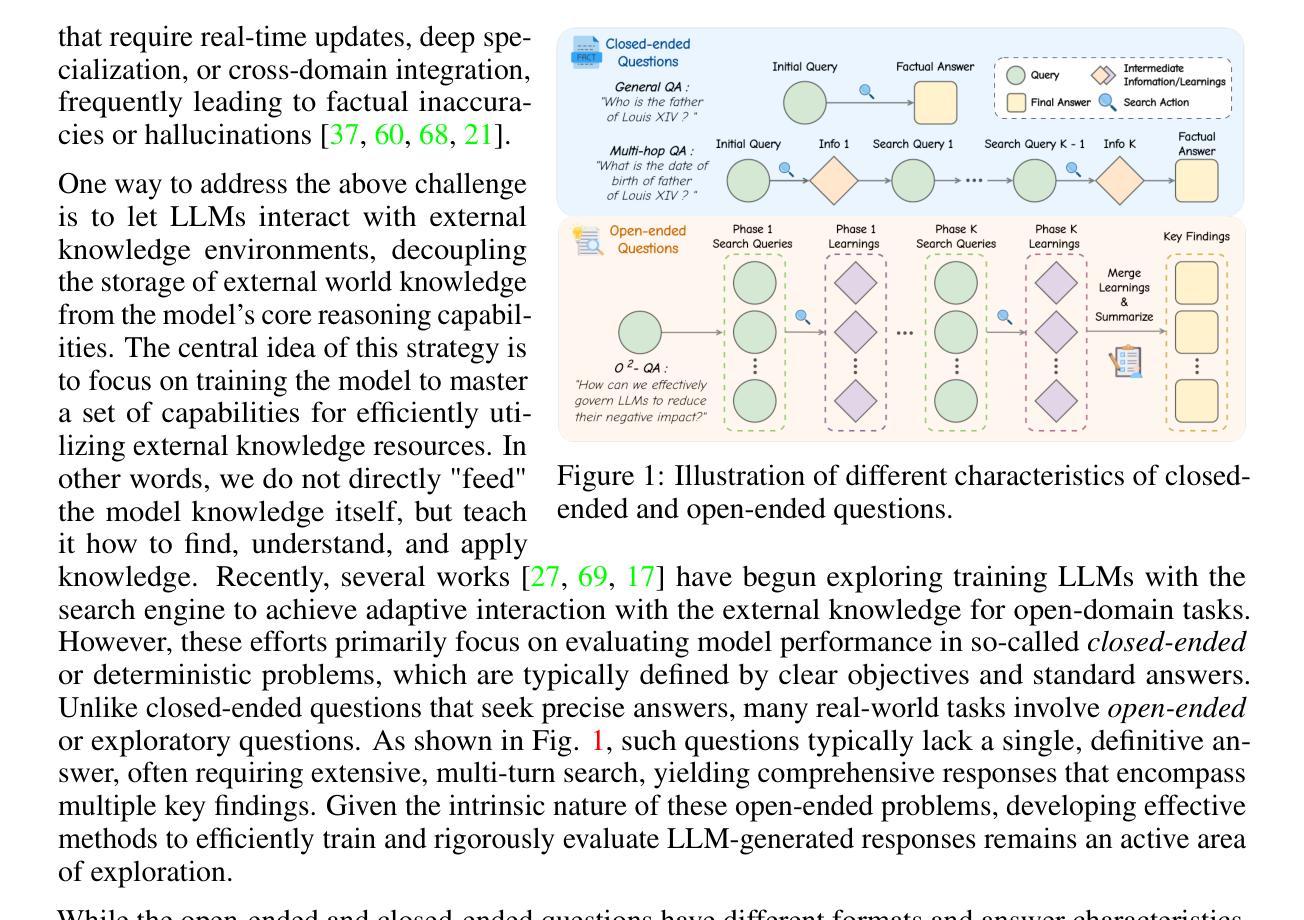
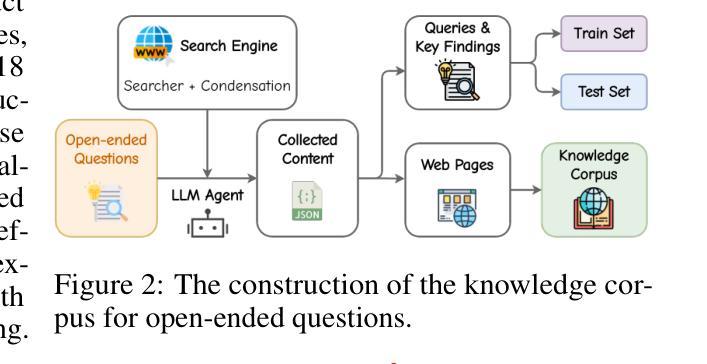
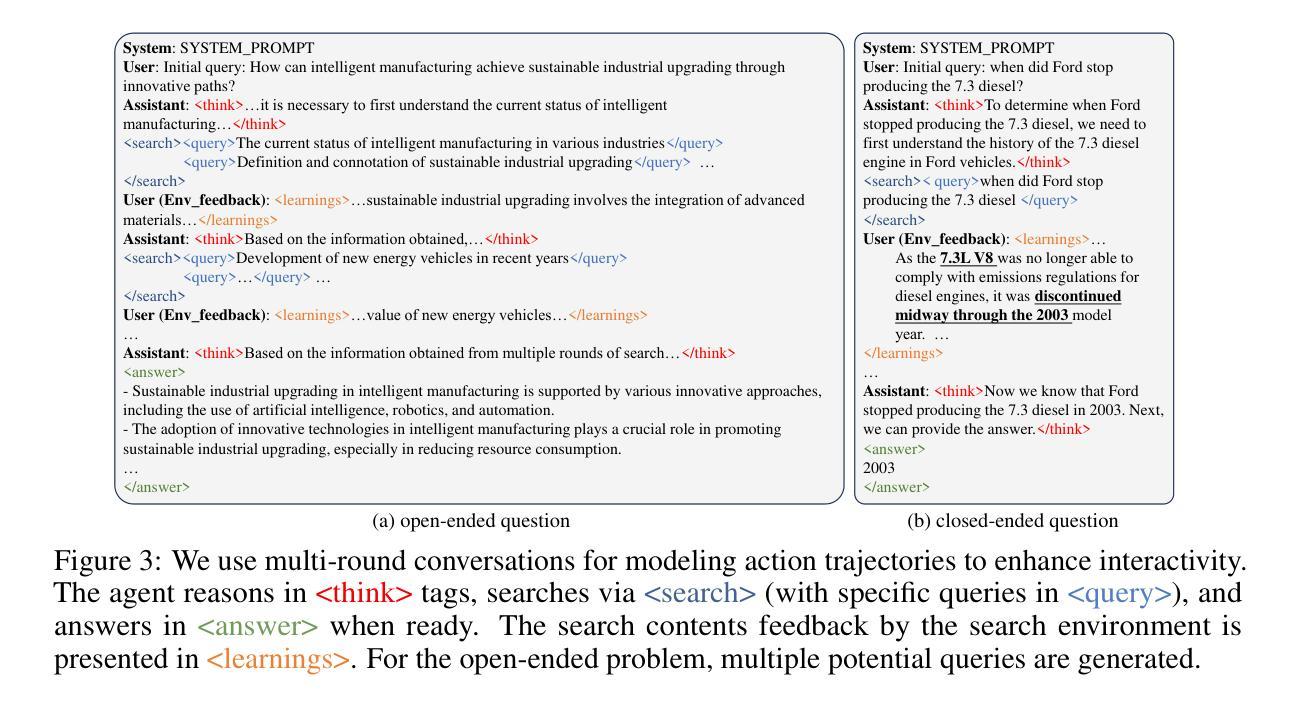
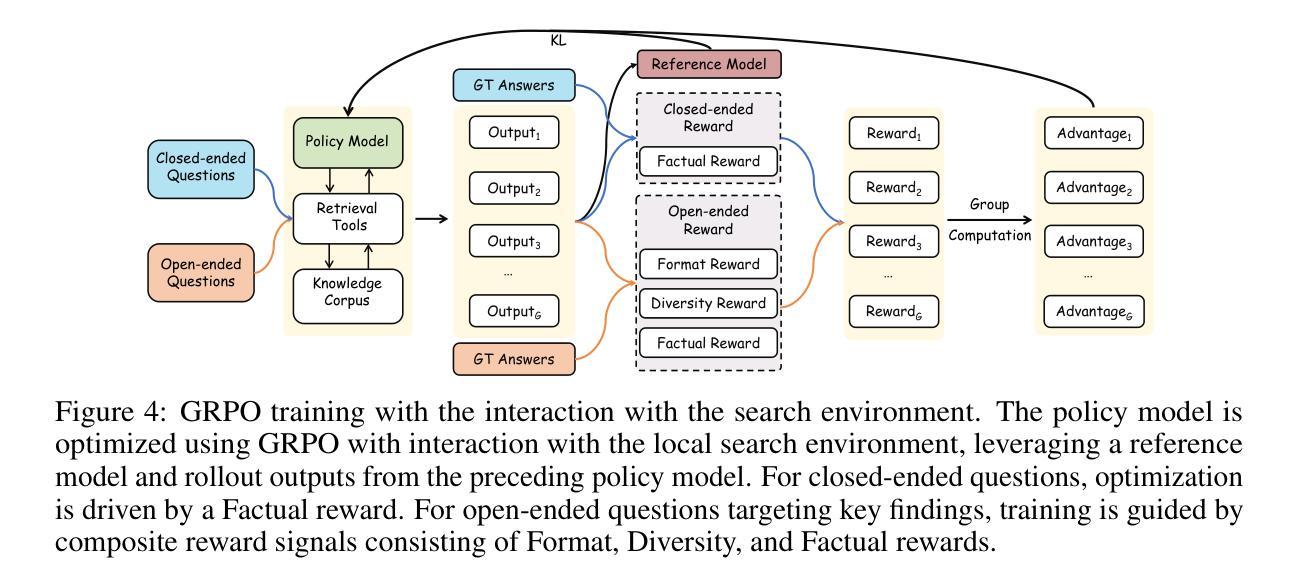
O$^2$-Searcher: A Searching-based Agent Model for Open-Domain Open-Ended Question Answering
Authors:Jianbiao Mei, Tao Hu, Daocheng Fu, Licheng Wen, Xuemeng Yang, Rong Wu, Pinlong Cai, Xing Gao, Yu Yang, Chengjun Xie, Botian Shi, Yong Liu, Yu Qiao
Large Language Models (LLMs), despite their advancements, are fundamentally limited by their static parametric knowledge, hindering performance on tasks requiring open-domain up-to-date information. While enabling LLMs to interact with external knowledge environments is a promising solution, current efforts primarily address closed-end problems. Open-ended questions, which characterized by lacking a standard answer or providing non-unique and diverse answers, remain underexplored. To bridge this gap, we present O$^2$-Searcher, a novel search agent leveraging reinforcement learning to effectively tackle both open-ended and closed-ended questions in the open domain. O$^2$-Searcher leverages an efficient, locally simulated search environment for dynamic knowledge acquisition, effectively decoupling the external world knowledge from model’s sophisticated reasoning processes. It employs a unified training mechanism with meticulously designed reward functions, enabling the agent to identify problem types and adapt different answer generation strategies. Furthermore, to evaluate performance on complex open-ended tasks, we construct O$^2$-QA, a high-quality benchmark featuring 300 manually curated, multi-domain open-ended questions with associated web page caches. Extensive experiments show that O$^2$-Searcher, using only a 3B model, significantly surpasses leading LLM agents on O$^2$-QA. It also achieves SOTA results on various closed-ended QA benchmarks against similarly-sized models, while performing on par with much larger ones.
尽管大型语言模型(LLMs)取得了进展,但它们仍然受到静态参数知识的根本限制,这阻碍了它们在需要开放领域最新信息的任务上的表现。虽然让LLMs与外部环境进行交互是一个有前景的解决方案,但目前的努力主要侧重于解决封闭式问题。开放式问题缺乏标准答案或提供非唯一和多样化的答案,仍然被探索得不够。为了弥补这一差距,我们提出了O$^2$-Searcher,这是一个利用强化学习的新搜索代理,有效地解决开放式和封闭式问题。O$^2$-Searcher利用高效的局部模拟搜索环境进行动态知识获取,有效地将外部世界的知识与模型的复杂推理过程解耦。它采用统一的培训机制和精心设计的奖励函数,使代理能够识别问题类型并适应不同的答案生成策略。此外,为了评估在复杂开放式任务上的性能,我们构建了O$^2$-QA,这是一个高质量基准测试,包含300个手动整理的多领域开放式问题及其相关网页缓存。大量实验表明,仅使用3B模型的O$^2$-Searcher在O$^2$-QA上显著超越了领先的大型语言模型代理。它在各种封闭式问答基准测试上也取得了最佳结果,与类似规模的模型相比表现良好。
论文及项目相关链接
PDF 25 pages, 9 figures
Summary
大型语言模型(LLMs)受限于静态参数知识,难以应对需要开放领域即时信息的任务。尽管与外部知识环境互动是解决方案,但当前研究主要关注封闭式问题,对开放式问题缺乏探索。为解决此差距,本文提出O$^2$-Searcher,一个利用强化学习解决开放式和封闭式问题的搜索代理。它在本地模拟搜索环境实现动态知识获取,将外部世界知识与模型的推理过程分离。通过统一训练机制和精心设计的奖励函数,代理能识别问题类型并采用不同答案生成策略。同时,构建O$^2$-QA作为高质量基准测试,包含300个手动整理的多领域开放式问题及其网页缓存。实验显示,仅使用3B模型的O$^2$-Searcher在O$^2$-QA上显著超越领先LLM代理,并在各种封闭式问答基准测试中达到最佳效果。
Key Takeaways
- 大型语言模型(LLMs)受限于静态参数知识,难以应对需要开放领域即时信息的任务。
- 开放式问题在LLM研究中被忽视。
- O$^2$-Searcher利用强化学习解决开放式和封闭式问题,能在本地模拟搜索环境实现动态知识获取。
- O$^2$-Searcher通过统一训练机制和奖励函数识别问题类型并生成答案。
- 构建了O$^2$-QA作为高质量基准测试,用于评估在复杂开放式任务上的性能。
- O$^2$-Searcher在O$^2$-QA上表现优越,显著超越其他LLM代理。
点此查看论文截图

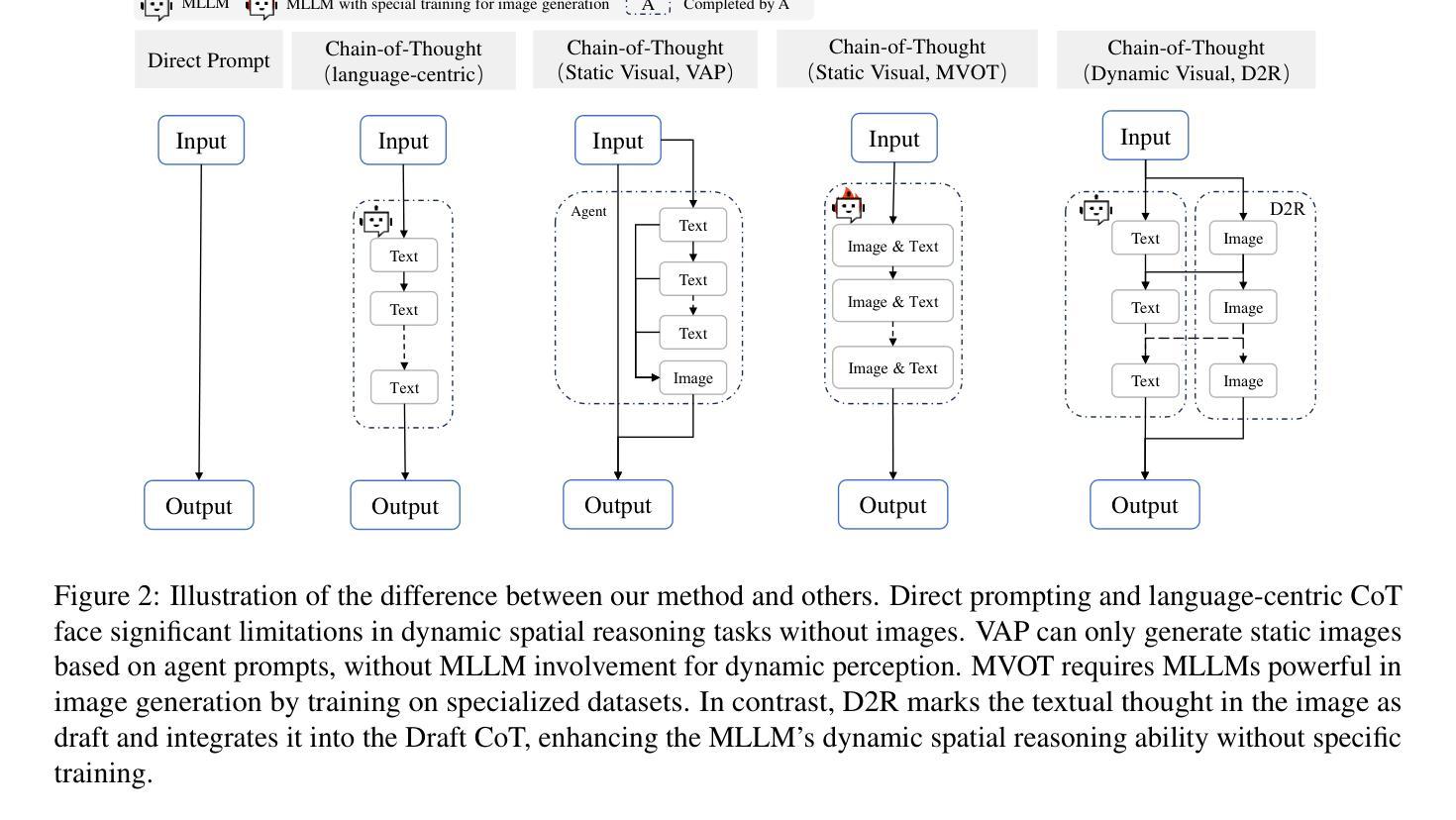
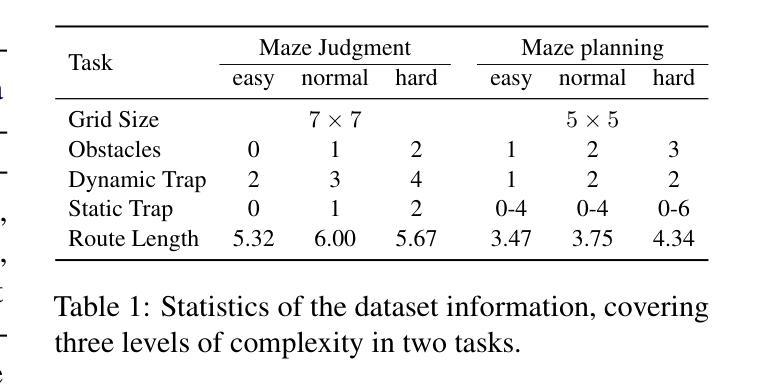
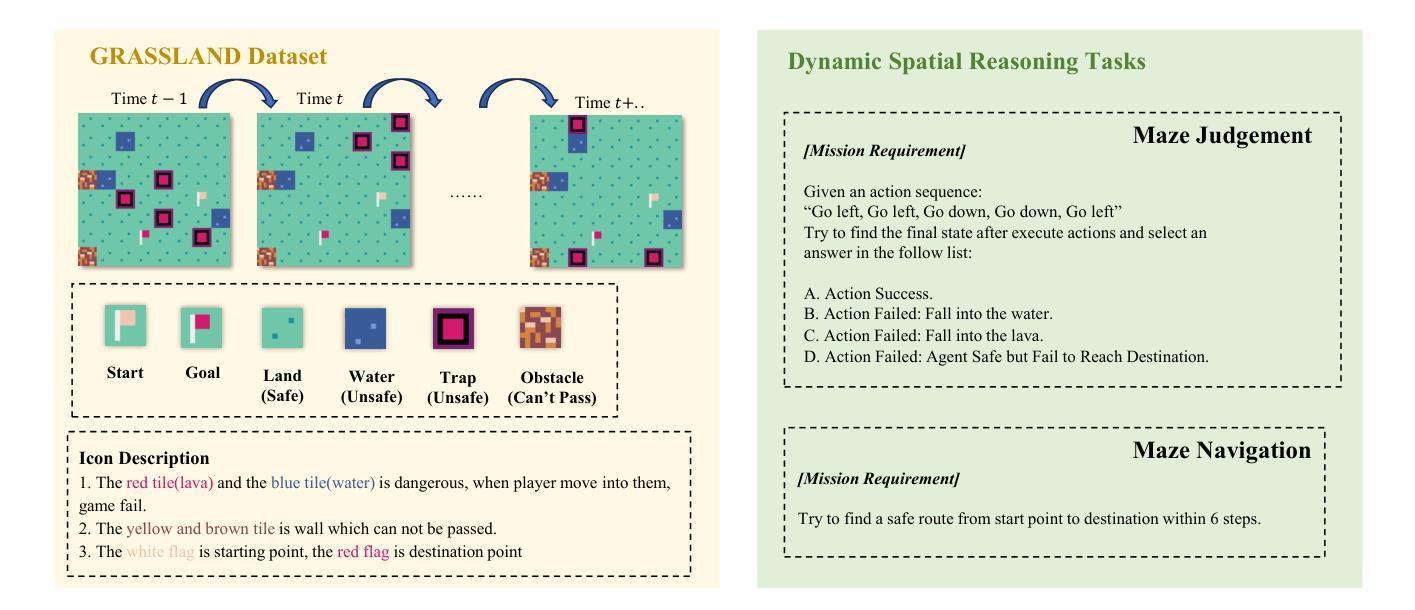
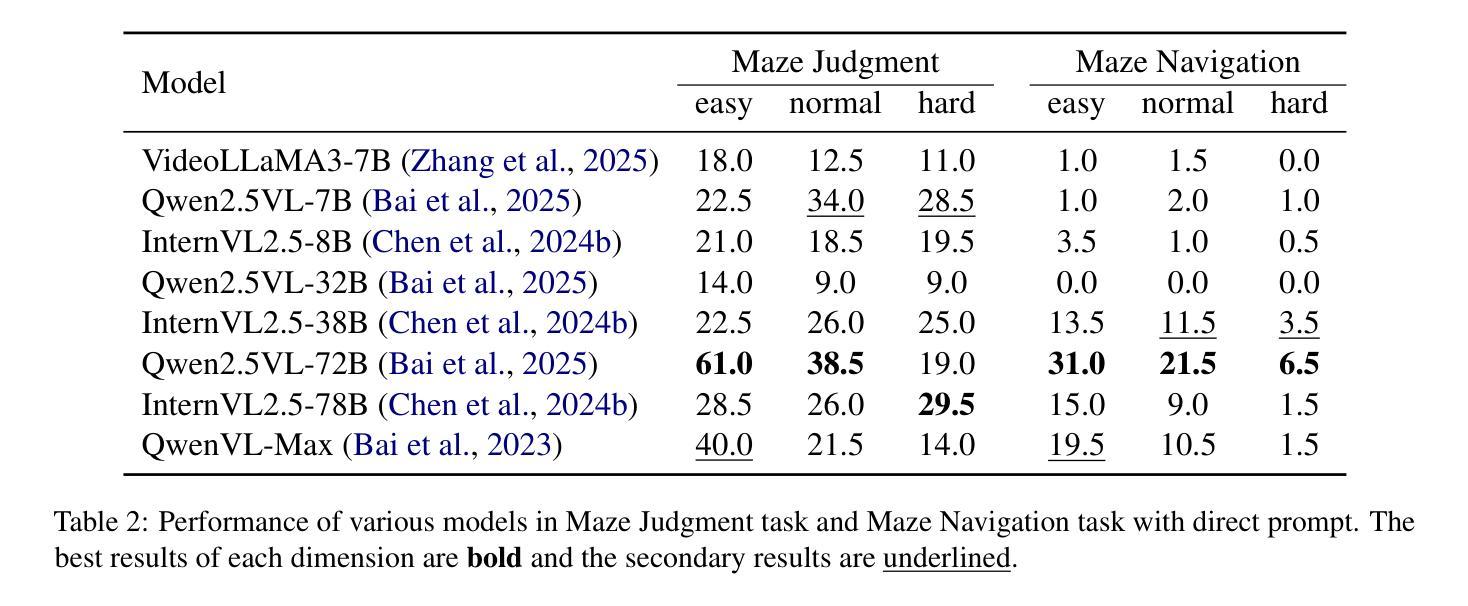
Bridging the Dynamic Perception Gap: Training-Free Draft Chain-of-Thought for Dynamic Multimodal Spatial Reasoning
Authors:Siqu Ou, Hongcheng Liu, Pingjie Wang, Yusheng Liao, Chuan Xuan, Yanfeng Wang, Yu Wang
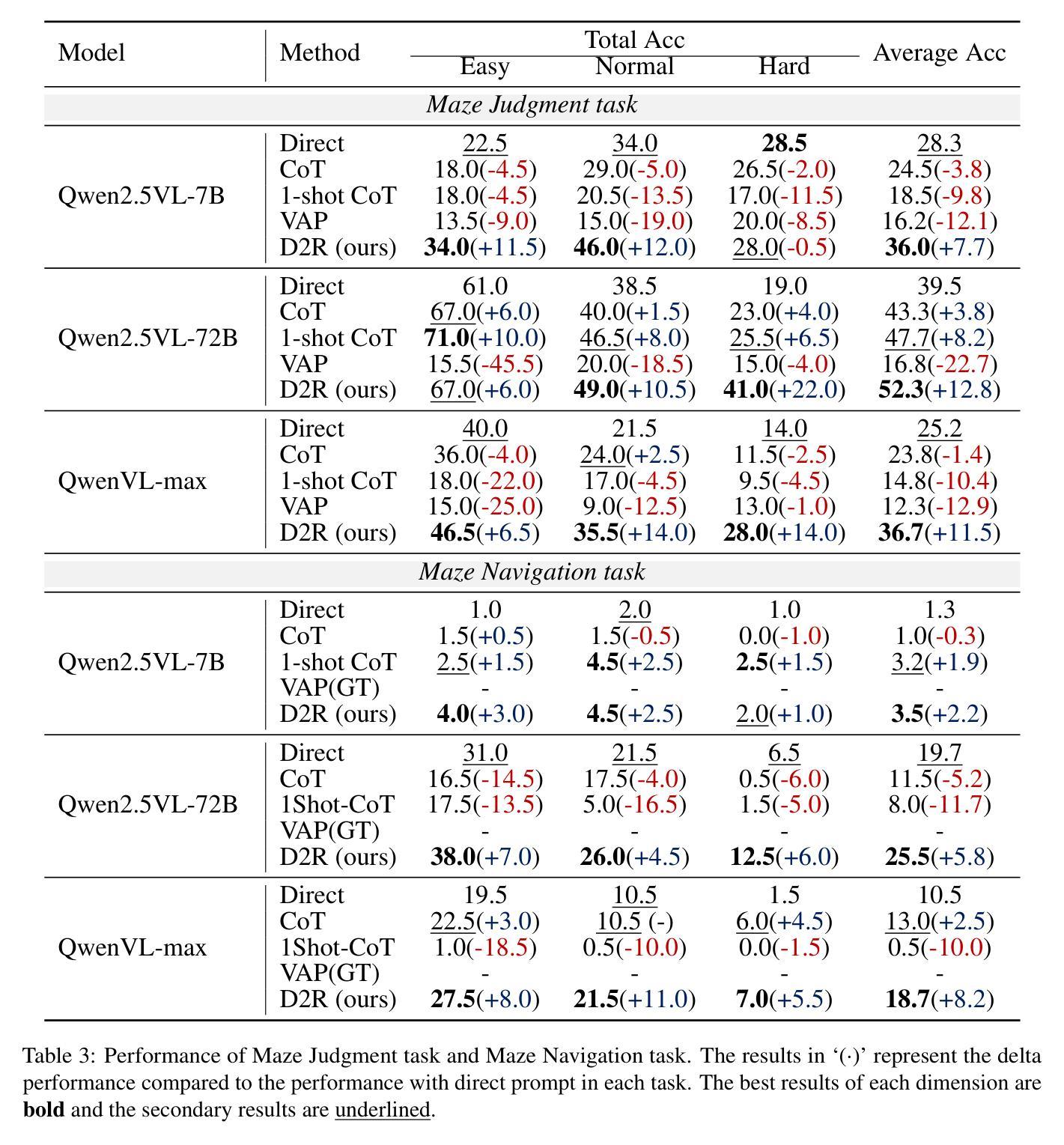
While chains-of-thought (CoT) have advanced complex reasoning in multimodal large language models (MLLMs), existing methods remain confined to text or static visual domains, often faltering in dynamic spatial reasoning tasks. To bridge this gap, we present GRASSLAND, a novel maze navigation benchmark designed to evaluate dynamic spatial reasoning. Our experiments show that augmenting textual reasoning chains with dynamic visual drafts, overlaid on input images, significantly outperforms conventional approaches, offering new insights into spatial reasoning in evolving environments. To generalize this capability, we propose D2R (Dynamic Draft-Augmented Reasoning), a training-free framework that seamlessly integrates textual CoT with corresponding visual drafts into MLLMs. Extensive evaluations demonstrate that D2R consistently enhances performance across diverse tasks, establishing a robust baseline for dynamic spatial reasoning without requiring model fine-tuning. Project is open at https://github.com/Cratileo/D2R.
虽然思维链(CoT)已经在多模态大型语言模型(MLLMs)中推动了复杂的推理过程,但现有方法仍然局限于文本或静态视觉领域,在动态空间推理任务中经常表现不佳。为了弥补这一差距,我们推出了GRASSLAND,这是一个新型迷宫导航基准测试,旨在评估动态空间推理能力。我们的实验表明,通过在输入图像上叠加动态视觉草图来增强文本推理链,显著优于传统方法,为动态环境中的空间推理提供了新的见解。为了推广这种能力,我们提出了D2R(动态草图增强推理),这是一个无需训练即可无缝地将文本思维链与相应的视觉草图集成到MLLMs中的框架。广泛评估表明,D2R在各种任务中都能提高性能,在无需对模型进行微调的情况下建立了动态空间推理的稳健基准。项目已开放访问:https://github.com/Cratileo/D2R。
论文及项目相关链接
PDF 19 pages, 8 figures
Summary
文本主要探讨多模态大型语言模型在动态空间推理任务上的局限性,为此提出了GRASSLAND导航迷宫基准测试方法以及动态草案增强推理(D2R)框架。该框架能无缝集成文本思考链和对应的视觉草案,在不需要模型微调的情况下,即可实现对动态空间推理任务的稳健基准测试。点击链接https://github.com/Cratileo/D2R可获取更多信息。
Key Takeaways
- 现有大型语言模型在动态空间推理任务上表现受限。
- 提出GRASSLAND导航迷宫基准测试用于评估动态空间推理能力。
- 通过在文本推理链中增加动态视觉草案来优化性能。
- D2R框架可实现无训练集成文本与视觉草案的多模态语言模型推理。
- D2R框架能提高模型在不同任务上的性能表现。
- D2R框架无需模型微调即可为动态空间推理任务提供稳健基准测试。
点此查看论文截图

ScholarBench: A Bilingual Benchmark for Abstraction, Comprehension, and Reasoning Evaluation in Academic Contexts
Authors:Dongwon Noh, Donghyeok Koh, Junghun Yuk, Gyuwan Kim, Jaeyong Lee, Kyungtae Lim, Cheoneum Park
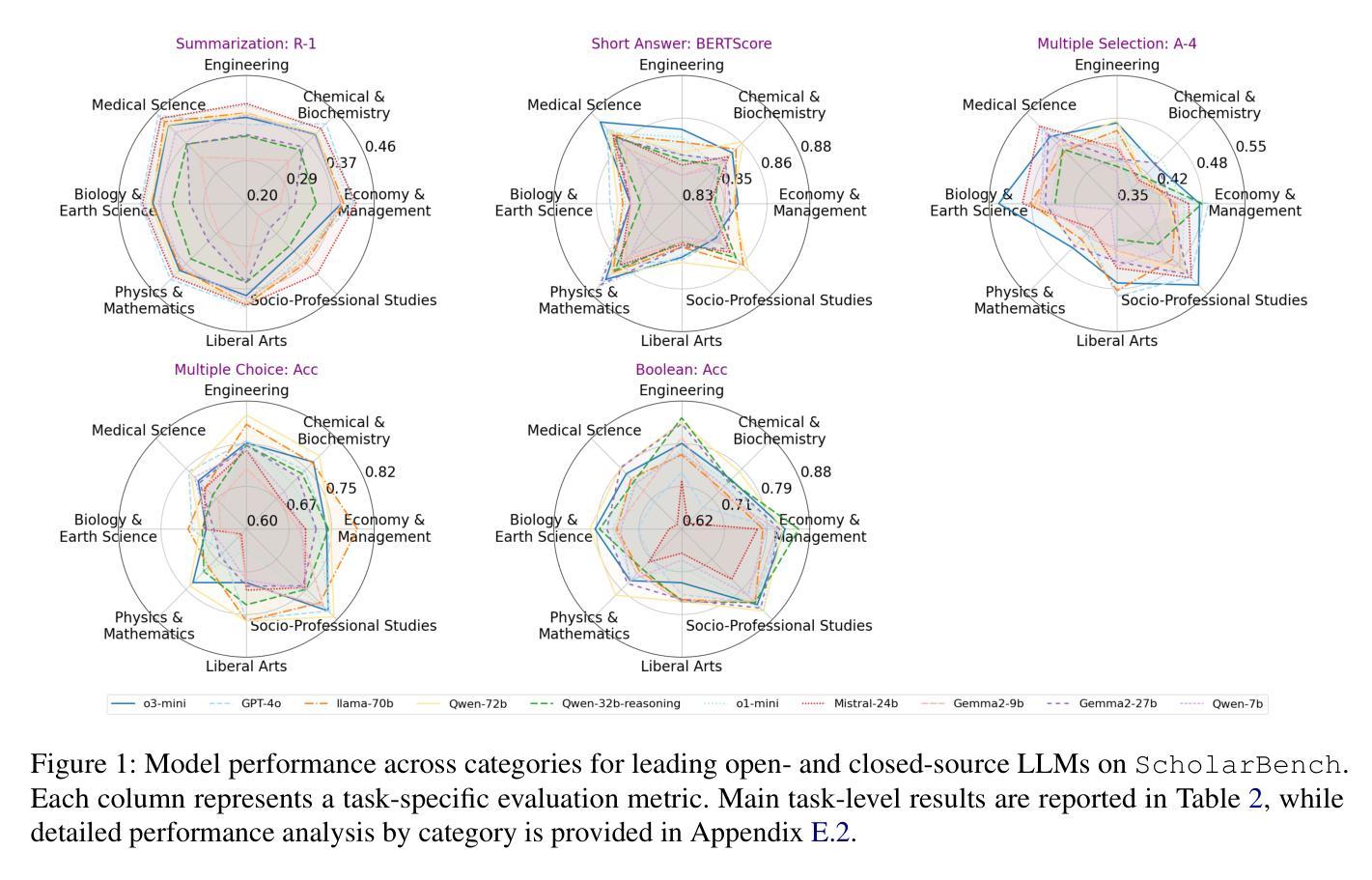
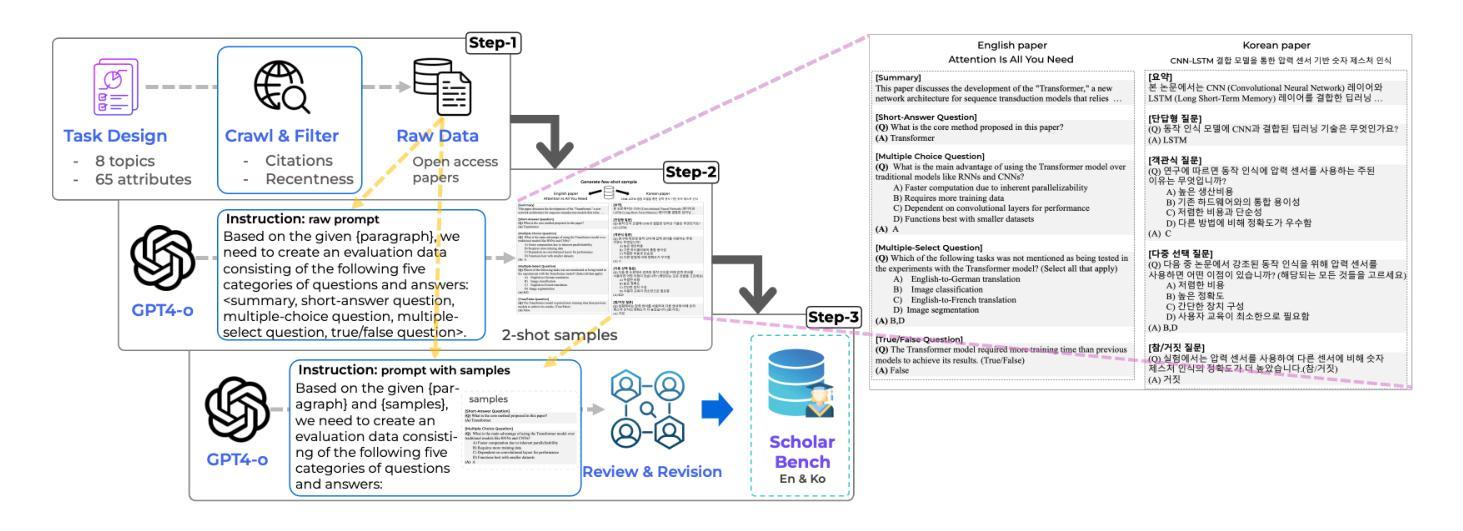
Prior benchmarks for evaluating the domain-specific knowledge of large language models (LLMs) lack the scalability to handle complex academic tasks. To address this, we introduce \texttt{ScholarBench}, a benchmark centered on deep expert knowledge and complex academic problem-solving, which evaluates the academic reasoning ability of LLMs and is constructed through a three-step process. \texttt{ScholarBench} targets more specialized and logically complex contexts derived from academic literature, encompassing five distinct problem types. Unlike prior benchmarks, \texttt{ScholarBench} evaluates the abstraction, comprehension, and reasoning capabilities of LLMs across eight distinct research domains. To ensure high-quality evaluation data, we define category-specific example attributes and design questions that are aligned with the characteristic research methodologies and discourse structures of each domain. Additionally, this benchmark operates as an English-Korean bilingual dataset, facilitating simultaneous evaluation for linguistic capabilities of LLMs in both languages. The benchmark comprises 5,031 examples in Korean and 5,309 in English, with even state-of-the-art models like o3-mini achieving an average evaluation score of only 0.543, demonstrating the challenging nature of this benchmark.
先前评估大型语言模型(LLM)领域特定知识的基准测试缺乏处理复杂学术任务的可扩展性。为了解决这一问题,我们引入了
ScholarBench,这是一个以深度专业知识和复杂学术问题解决为中心的基准测试,用于评估LLM的学术推理能力,并通过三步过程构建。ScholarBench针对从学术文献中派生的更专业和逻辑更复杂的情境,包含五种不同的问题类型。与先前的基准测试不同,ScholarBench评估LLM在八个不同研究领域的抽象、理解和推理能力。为了确保高质量的评价数据,我们定义了特定类别的示例属性,并设计了与每个领域特征的研究方法和话语结构相符的问题。此外,这个基准测试是一个英语-韩语双语数据集,便于同时评估LLM在这两种语言中的语言能力。该基准测试包含5031个韩语示例和5309个英语示例,即使是最先进的模型,如o3-mini,平均评估得分也只有0.543,这表明该基准测试具有挑战性。
论文及项目相关链接
Summary
本文介绍了一个名为ScholarBench的新基准测试,该测试旨在评估大型语言模型(LLM)在复杂学术任务中的专业知识。ScholarBench包含五种不同的问题类型,并涉及八个不同的研究领域的学术知识。这一基准测试以英文和韩文双语进行,以评估LLM在这两种语言中的语言能力。该测试具有挑战性,即使是最先进的模型也难以取得高分。
Key Takeaways
ScholarBench是一个针对大型语言模型(LLM)的基准测试,专注于评估其在复杂学术任务中的专业知识。- 该测试包含五个不同的问题类型,旨在评估LLM在学术推理方面的能力。
ScholarBench覆盖了八个不同的研究领域,使测试更加全面和具有挑战性。- 该基准测试是一个英语和韩文双语数据集,可用于评估LLM在这两种语言中的语言能力。
- 测试数据质量高,通过定义特定类别的属性来设计问题,与每个领域的研究方法和话语结构相符。
- 目前最先进的模型在ScholarBench上的表现并不理想,显示出该测试的挑战性。
点此查看论文截图

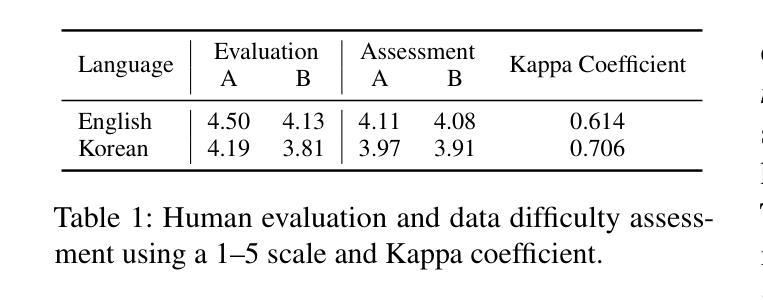
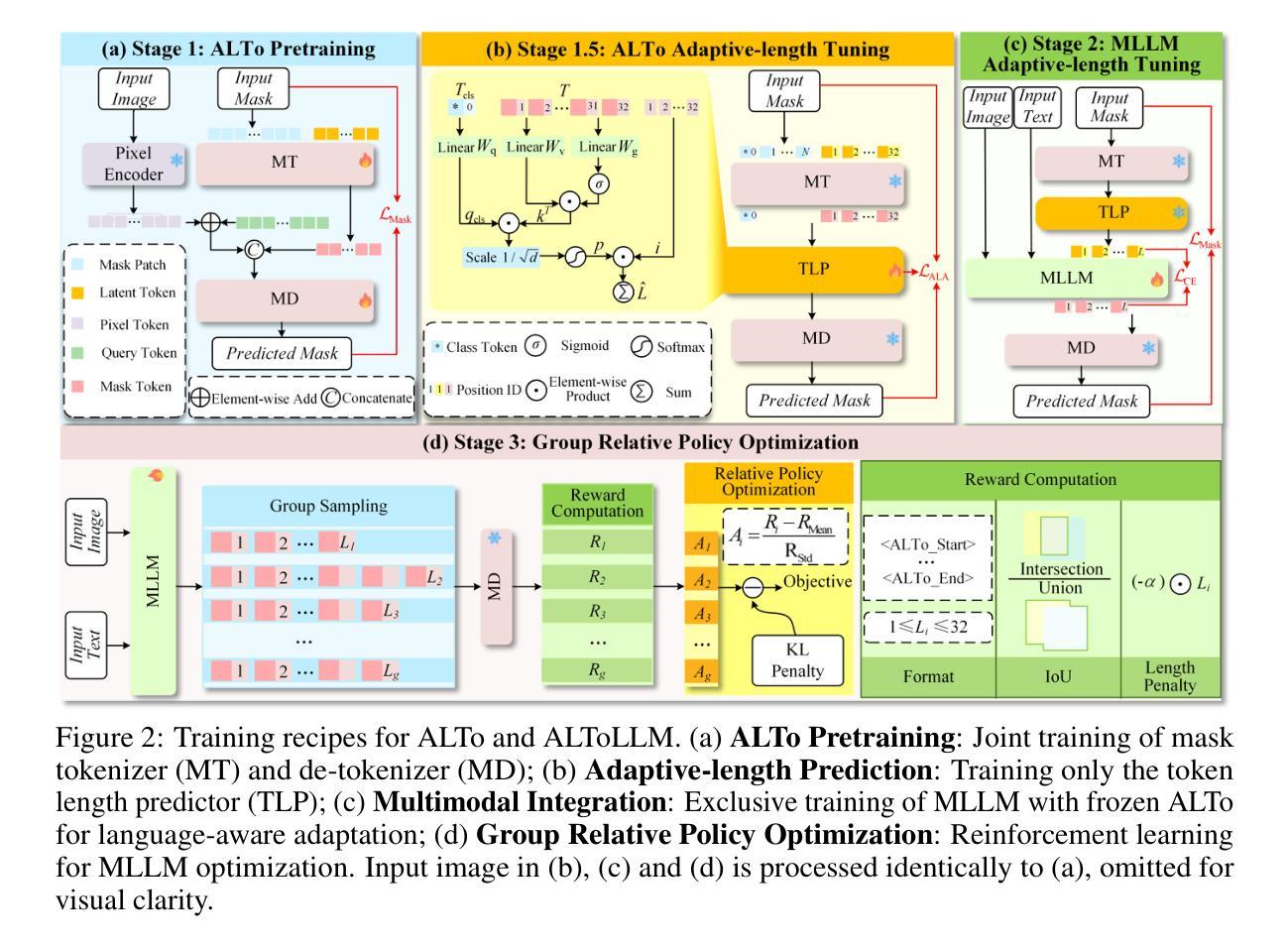
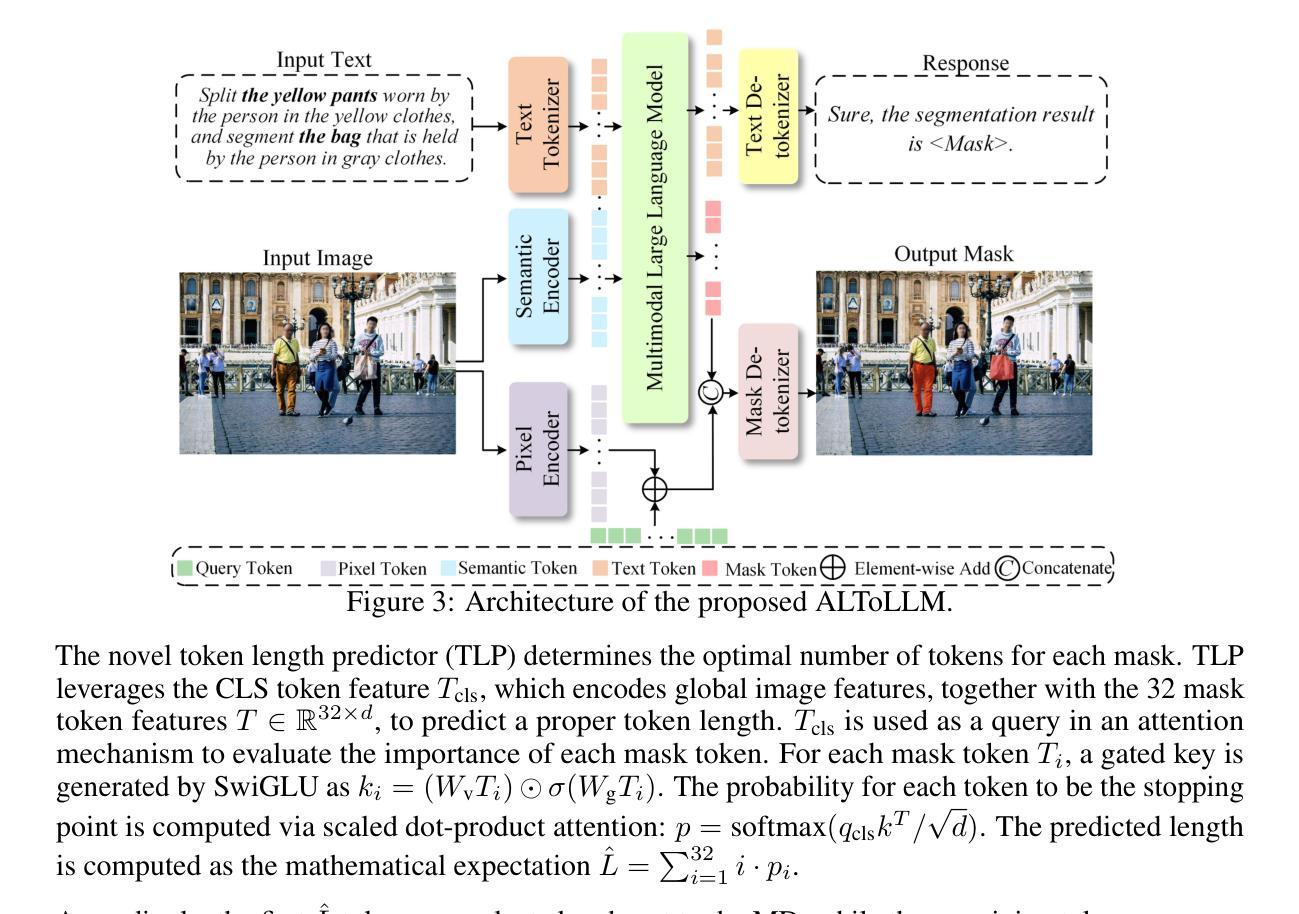
ALTo: Adaptive-Length Tokenizer for Autoregressive Mask Generation
Authors:Lingfeng Wang, Hualing Lin, Senda Chen, Tao Wang, Changxu Cheng, Yangyang Zhong, Dong Zheng, Wuyue Zhao
While humans effortlessly draw visual objects and shapes by adaptively allocating attention based on their complexity, existing multimodal large language models (MLLMs) remain constrained by rigid token representations. Bridging this gap, we propose ALTo, an adaptive length tokenizer for autoregressive mask generation. To achieve this, a novel token length predictor is designed, along with a length regularization term and a differentiable token chunking strategy. We further build ALToLLM that seamlessly integrates ALTo into MLLM. Preferences on the trade-offs between mask quality and efficiency is implemented by group relative policy optimization (GRPO). Experiments demonstrate that ALToLLM achieves state-of-the-art performance with adaptive token cost on popular segmentation benchmarks. Code and models are released at https://github.com/yayafengzi/ALToLLM.
人类在绘制视觉对象和形状时,可以轻松地根据它们的复杂性自适应地分配注意力,而现有的多模态大型语言模型(MLLM)仍受到刚性令牌表示的约束。为了弥补这一差距,我们提出了ALTo,这是一种用于自回归掩码生成的自适应长度令牌器。为此,我们设计了一个新型令牌长度预测器,以及一个长度正则化项和一个可微分的令牌分块策略。我们进一步构建了无缝集成ALTo到MLLM的ALToLLM。通过对群体相对政策优化(GRPO)的实施,实现了掩码质量和效率之间的权衡偏好。实验表明,ALToLLM在流行分割基准测试上实现了具有自适应令牌成本的最佳性能。代码和模型已发布在https://github.com/yayafengzi/ALToLLM。
论文及项目相关链接
Summary
本文提出了一种自适应长度分词器ALTo,用于多模态大型语言模型(MLLMs)的自适应生成掩码。通过设计新型令牌长度预测器、长度正则化项和可微分令牌分块策略,实现了ALTo。进一步构建了将ALTo无缝集成到MLLM中的ALToLLM。通过群体相对策略优化(GRPO)实现掩码质量和效率之间的权衡偏好。实验证明,ALToLLM在流行分割基准测试中实现了具有自适应令牌成本的最新性能。相关代码和模型已发布在https://github.com/yayafengzi/ALToLLM。
Key Takeaways
- ALTo是一种自适应长度分词器,用于多模态大型语言模型(MLLMs)的自适应生成掩码。
- ALTo通过设计令牌长度预测器、长度正则化项和可微分令牌分块策略来实现。
- ALToLLM将ALTo集成到MLLM中,实现了掩码质量和效率之间的灵活权衡。
- 通过群体相对策略优化(GRPO)实施这种权衡。
- ALToLLM在流行分割基准测试中表现出色,具有自适应令牌成本的最新性能。
- 发布了相关代码和模型,以便公众访问和使用。
点此查看论文截图


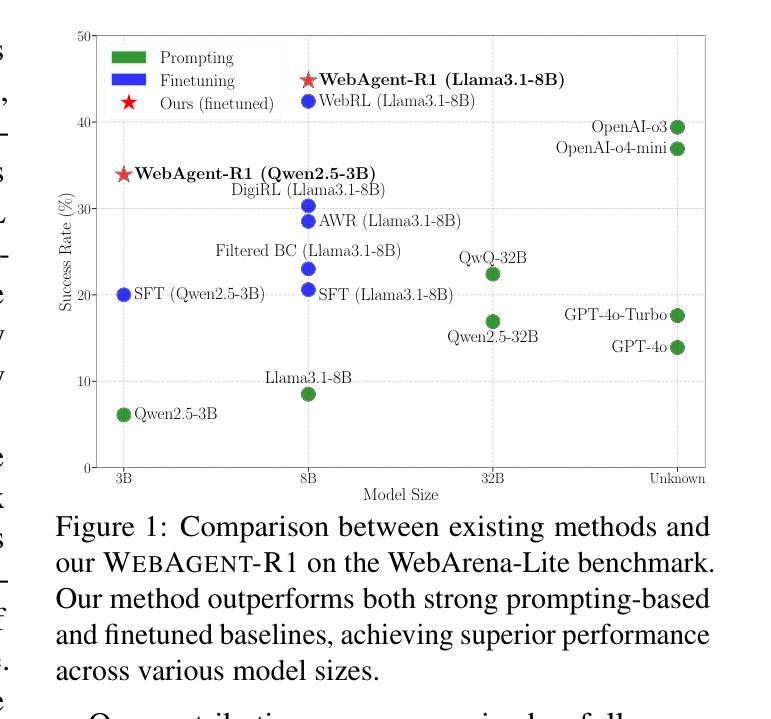
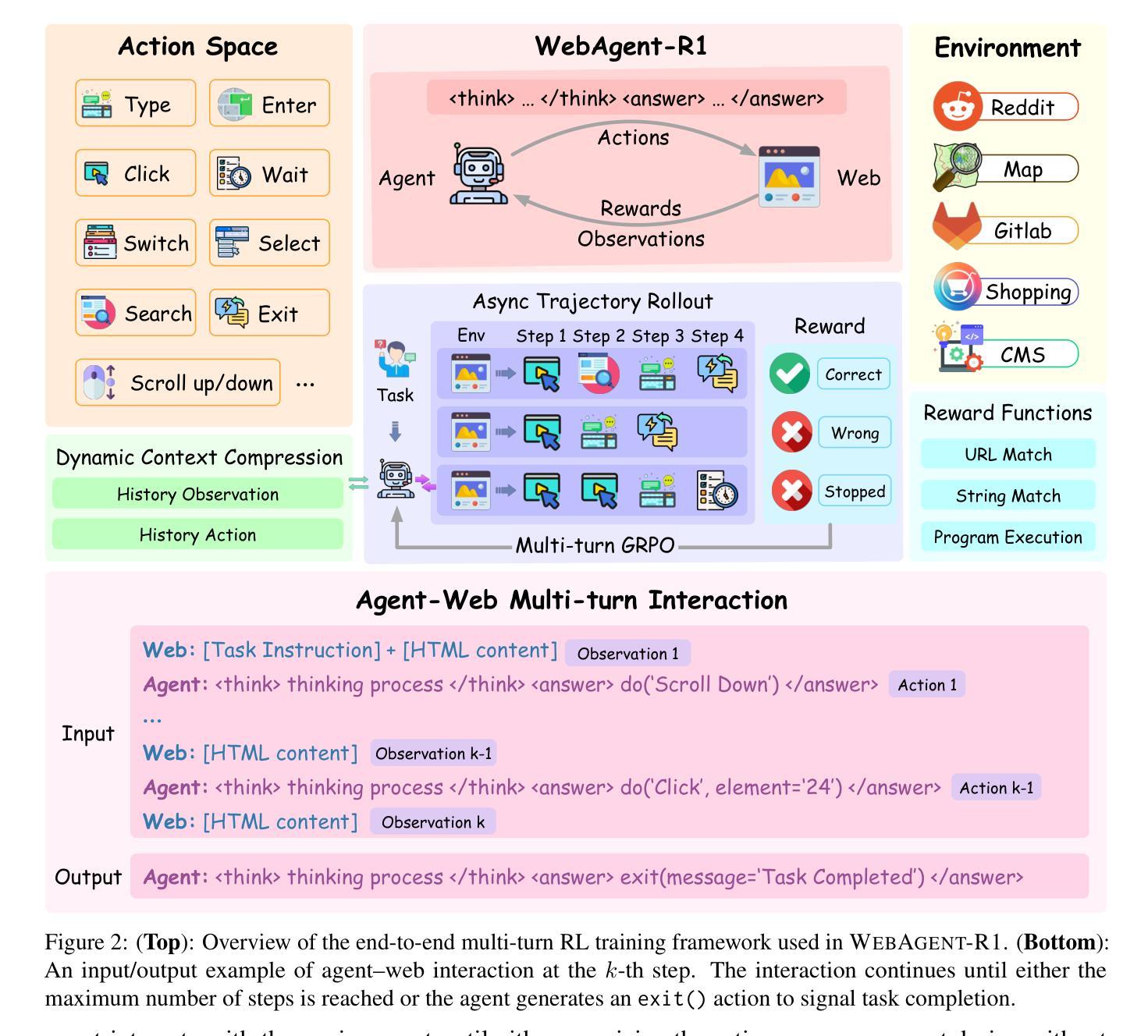
WebAgent-R1: Training Web Agents via End-to-End Multi-Turn Reinforcement Learning
Authors:Zhepei Wei, Wenlin Yao, Yao Liu, Weizhi Zhang, Qin Lu, Liang Qiu, Changlong Yu, Puyang Xu, Chao Zhang, Bing Yin, Hyokun Yun, Lihong Li
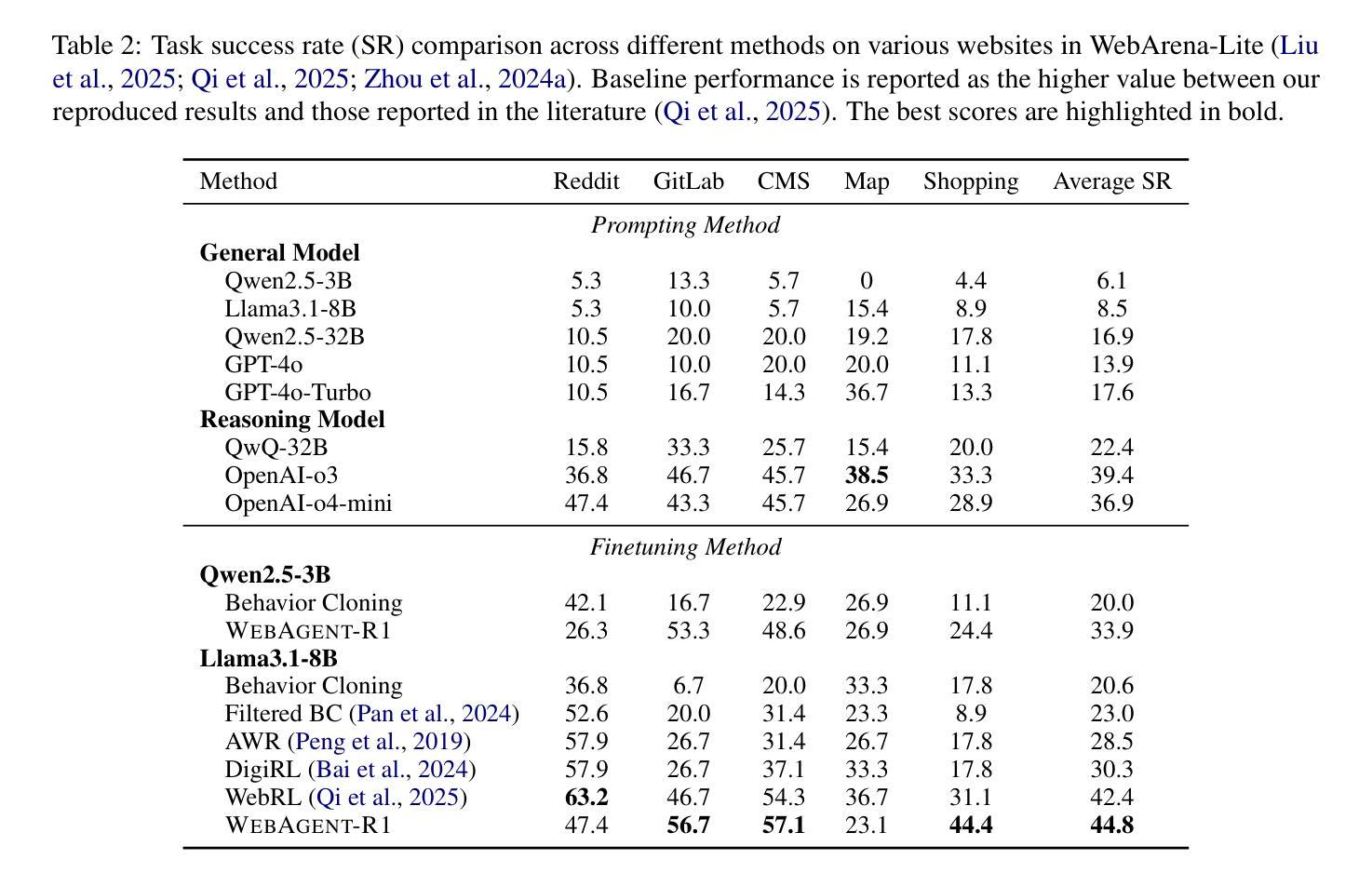
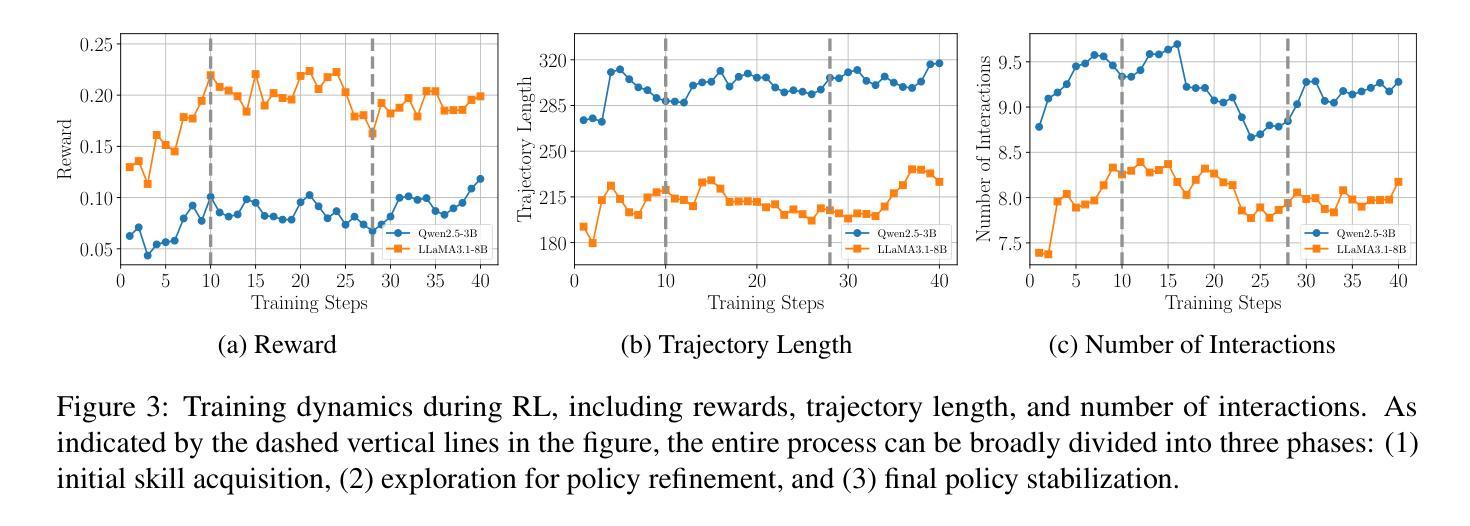
While reinforcement learning (RL) has demonstrated remarkable success in enhancing large language models (LLMs), it has primarily focused on single-turn tasks such as solving math problems. Training effective web agents for multi-turn interactions remains challenging due to the complexity of long-horizon decision-making across dynamic web interfaces. In this work, we present WebAgent-R1, a simple yet effective end-to-end multi-turn RL framework for training web agents. It learns directly from online interactions with web environments by asynchronously generating diverse trajectories, entirely guided by binary rewards depending on task success. Experiments on the WebArena-Lite benchmark demonstrate the effectiveness of WebAgent-R1, boosting the task success rate of Qwen-2.5-3B from 6.1% to 33.9% and Llama-3.1-8B from 8.5% to 44.8%, significantly outperforming existing state-of-the-art methods and strong proprietary models such as OpenAI o3. In-depth analyses reveal the effectiveness of the thinking-based prompting strategy and test-time scaling through increased interactions for web tasks. We further investigate different RL initialization policies by introducing two variants, namely WebAgent-R1-Zero and WebAgent-R1-CoT, which highlight the importance of the warm-up training stage (i.e., behavior cloning) and provide insights on incorporating long chain-of-thought (CoT) reasoning in web agents.
虽然强化学习(RL)在提高大型语言模型(LLM)方面取得了显著的成效,但它主要集中在如解决数学问题等单回合任务上。由于跨动态网页界面的长周期决策复杂性,训练用于多回合交互的有效网络代理仍然具有挑战性。在这项工作中,我们提出了WebAgent-R1,这是一个简单而有效的端到端多回合强化学习框架,用于训练网络代理。它直接从与在线网络环境的交互中学习,通过异步生成多样的轨迹,完全由根据任务成功与否的二值奖励引导。在WebArena-Lite基准测试上的实验证明了WebAgent-R1的有效性,将Qwen-2.5-3B的任务成功率从6.1%提高到33.9%,将Llama-3.1-8B的任务成功率从8.5%提高到44.8%,显著优于现有的最先进的方法和强大的专有模型,如OpenAI o3。深入分析揭示了基于思考的提示策略和通过增加交互来提高测试时间缩放对网页任务的有效性。我们进一步通过引入两种变体,即WebAgent-R1-Zero和WebAgent-R1-CoT,探讨了不同的强化学习初始化策略,突出了热身训练阶段(即行为克隆)的重要性,并提供了将长链思维(CoT)推理融入网络代理的见解。
论文及项目相关链接
PDF Preprint
Summary
本文介绍了一种名为WebAgent-R1的简单有效的端到端多轮强化学习框架,用于训练网页代理。该框架直接从在线的网页环境交互中学习,通过异步生成多样的轨迹,完全由任务成功的二元奖励引导。实验表明,WebAgent-R1在WebArena-Lite基准测试上显著提高任务成功率,显著优于现有先进方法和强大的专有模型。此外,深度分析揭示了基于思考提示策略的有效性以及测试时通过增加交互来提高任务性能的缩放策略。还通过引入两种变体WebAgent-R1-Zero和WebAgent-R1-CoT,探讨了不同的强化学习初始化策略,突显了热身训练阶段(即行为克隆)的重要性,并提供了将长链思维融入网页代理的见解。
Key Takeaways
- WebAgent-R1是一种用于训练网页代理的多轮强化学习框架,能够处理复杂的长期决策问题。
- 该框架直接从在线的网页环境交互中学习,通过异步生成多样的轨迹来完成任务。
- WebAgent-R1通过二元奖励机制进行引导,根据任务成功与否进行反馈。
- 在WebArena-Lite基准测试上,WebAgent-R1显著提高任务成功率,优于其他先进方法和专有模型。
- 深度分析表明,基于思考提示策略和测试时通过增加交互来提高任务性能的缩放策略是有效的。
- WebAgent-R1的变体WebAgent-R1-Zero和WebAgent-R1-CoT强调了热身训练阶段的重要性,并探讨了融入长链思维在网页代理中的价值。
- 实验结果揭示了强化学习的初始化策略和热身训练阶段对网页代理性能的重要影响。
点此查看论文截图


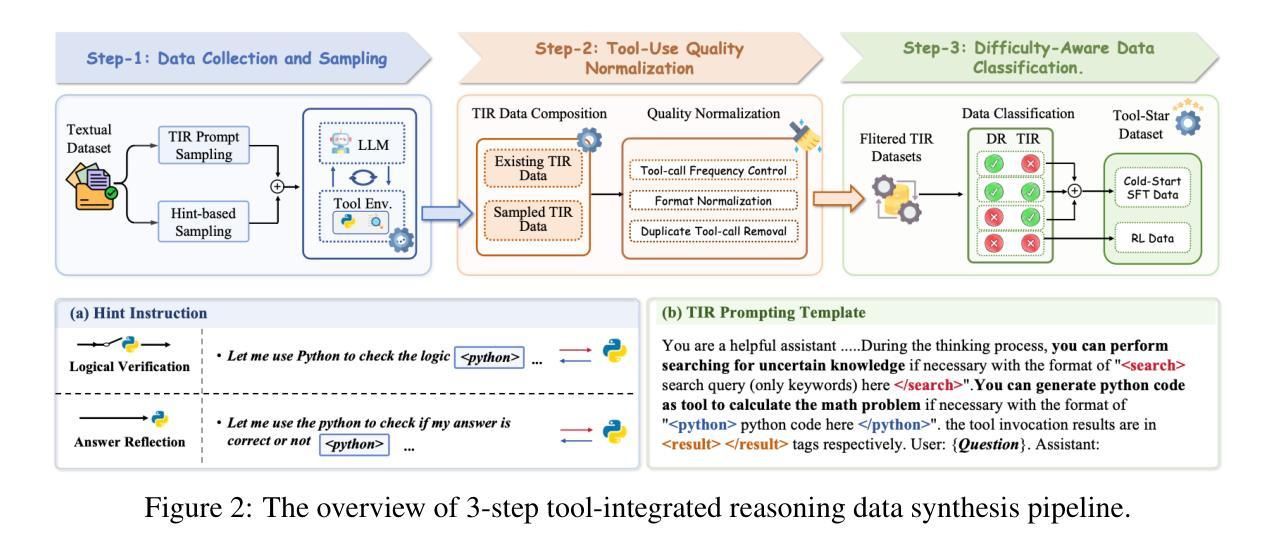
Tool-Star: Empowering LLM-Brained Multi-Tool Reasoner via Reinforcement Learning
Authors:Guanting Dong, Yifei Chen, Xiaoxi Li, Jiajie Jin, Hongjin Qian, Yutao Zhu, Hangyu Mao, Guorui Zhou, Zhicheng Dou, Ji-Rong Wen
Recently, large language models (LLMs) have shown remarkable reasoning capabilities via large-scale reinforcement learning (RL). However, leveraging the RL algorithm to empower effective multi-tool collaborative reasoning in LLMs remains an open challenge. In this paper, we introduce Tool-Star, an RL-based framework designed to empower LLMs to autonomously invoke multiple external tools during stepwise reasoning. Tool-Star integrates six types of tools and incorporates systematic designs in both data synthesis and training. To address the scarcity of tool-use data, we propose a general tool-integrated reasoning data synthesis pipeline, which combines tool-integrated prompting with hint-based sampling to automatically and scalably generate tool-use trajectories. A subsequent quality normalization and difficulty-aware classification process filters out low-quality samples and organizes the dataset from easy to hard. Furthermore, we propose a two-stage training framework to enhance multi-tool collaborative reasoning by: (1) cold-start fine-tuning, which guides LLMs to explore reasoning patterns via tool-invocation feedback; and (2) a multi-tool self-critic RL algorithm with hierarchical reward design, which reinforces reward understanding and promotes effective tool collaboration. Experimental analyses on over 10 challenging reasoning benchmarks highlight the effectiveness and efficiency of Tool-Star. The code is available at https://github.com/dongguanting/Tool-Star.
最近,大型语言模型(LLM)通过大规模强化学习(RL)表现出了令人瞩目的推理能力。然而,如何利用RL算法赋能LLM中的有效多工具协同推理仍是一个开放性的挑战。在本文中,我们介绍了Tool-Star,这是一个基于RL的框架,旨在使LLM能够在逐步推理过程中自主调用多种外部工具。Tool-Star集成了六种类型的工具,并在数据合成和培训方面都进行了系统设计。为了解决工具使用数据的稀缺问题,我们提出了一个通用的工具集成推理数据合成管道,它结合了工具集成提示和基于提示的采样,从而可以自动和可扩展地生成工具使用轨迹。随后的质量归一化和难度感知分类过程过滤掉低质量样本,并从易到难组织数据集。此外,我们提出了一个两阶段的训练框架,通过以下两个方面来增强多工具协同推理:(1)冷启动微调,引导LLM通过工具调用反馈探索推理模式;(2)具有分层奖励设计的多工具自我批判RL算法,加强奖励理解并促进有效工具协作。在超过10个具有挑战性的推理基准测试上的实验分析突出了Tool-Star的有效性和效率。代码可用在https://github.com/dongguanting/Tool-Star。
论文及项目相关链接
PDF Working in progress
Summary
本文提出一个基于强化学习(RL)的框架Tool-Star,旨在让大型语言模型(LLM)在逐步推理过程中自主调用多种外部工具。通过引入工具集成推理数据合成管道和两阶段训练框架,Tool-Star解决了工具使用数据的稀缺性问题,并提高了多工具协作推理的效果。该框架在超过10个具有挑战性的推理基准测试上展现出有效性和高效性。
Key Takeaways
- Tool-Star是一个基于强化学习的框架,用于赋能大型语言模型在推理过程中自主调用多种外部工具。
- 引入了一个通用的工具集成推理数据合成管道,通过工具集成提示和基于提示的采样,自动且可扩展地生成工具使用轨迹。
- 提出了一个两阶段训练框架,通过冷启动微调和多工具自我批判强化学习算法,增强多工具协作推理能力。
- 解决了工具使用数据的稀缺性问题,通过质量归一化和难度感知分类过程筛选出低质量样本,并按难度组织数据集。
- Tool-Star框架通过强化奖励理解和促进有效工具协作,实现了推理能力的显著提高。
- 在超过10个具有挑战性的推理基准测试上进行了实验分析,证明了Tool-Star的有效性和效率。
点此查看论文截图
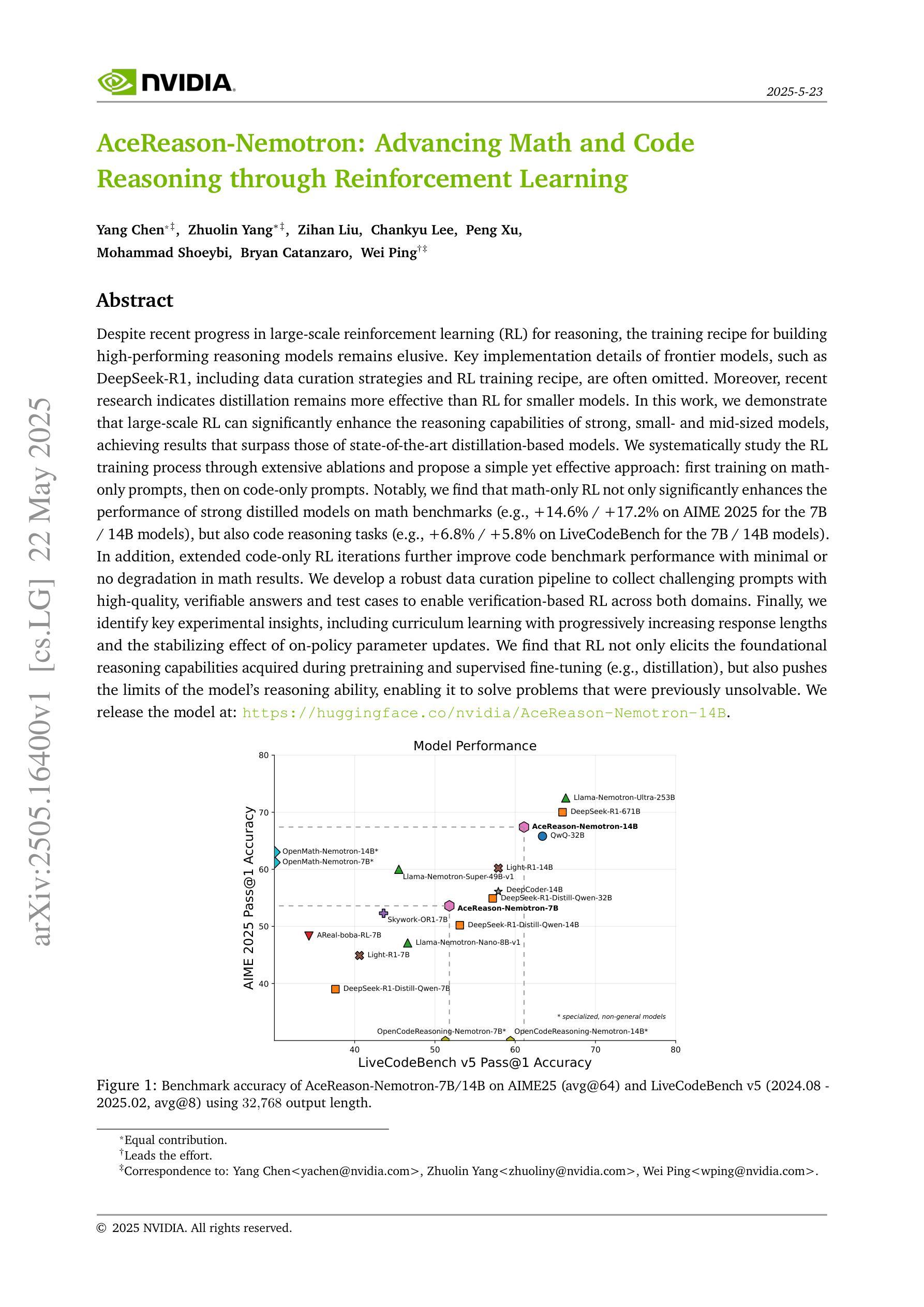
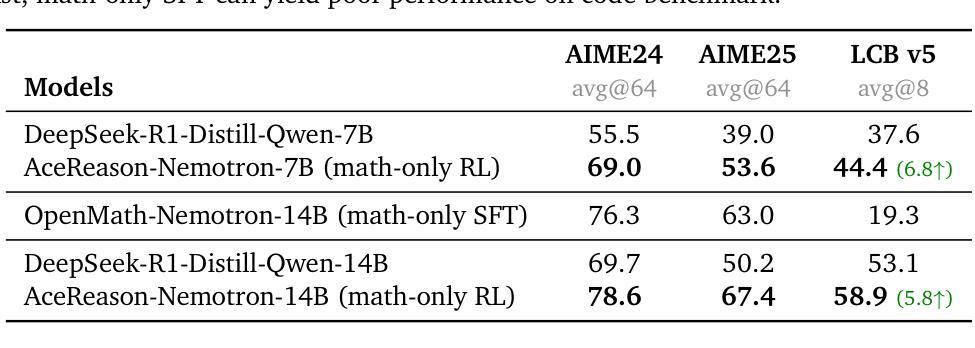
AceReason-Nemotron: Advancing Math and Code Reasoning through Reinforcement Learning
Authors:Yang Chen, Zhuolin Yang, Zihan Liu, Chankyu Lee, Peng Xu, Mohammad Shoeybi, Bryan Catanzaro, Wei Ping
Despite recent progress in large-scale reinforcement learning (RL) for reasoning, the training recipe for building high-performing reasoning models remains elusive. Key implementation details of frontier models, such as DeepSeek-R1, including data curation strategies and RL training recipe, are often omitted. Moreover, recent research indicates distillation remains more effective than RL for smaller models. In this work, we demonstrate that large-scale RL can significantly enhance the reasoning capabilities of strong, small- and mid-sized models, achieving results that surpass those of state-of-the-art distillation-based models. We systematically study the RL training process through extensive ablations and propose a simple yet effective approach: first training on math-only prompts, then on code-only prompts. Notably, we find that math-only RL not only significantly enhances the performance of strong distilled models on math benchmarks (e.g., +14.6% / +17.2% on AIME 2025 for the 7B / 14B models), but also code reasoning tasks (e.g., +6.8% / +5.8% on LiveCodeBench for the 7B / 14B models). In addition, extended code-only RL iterations further improve performance on code benchmarks with minimal or no degradation in math results. We develop a robust data curation pipeline to collect challenging prompts with high-quality, verifiable answers and test cases to enable verification-based RL across both domains. Finally, we identify key experimental insights, including curriculum learning with progressively increasing response lengths and the stabilizing effect of on-policy parameter updates. We find that RL not only elicits the foundational reasoning capabilities acquired during pretraining and supervised fine-tuning (e.g., distillation), but also pushes the limits of the model’s reasoning ability, enabling it to solve problems that were previously unsolvable.
尽管最近在大型强化学习(RL)推理方面取得了进展,但构建高性能推理模型的训练配方仍然不明确。前沿模型(如DeepSeek-R1)的关键实现细节,包括数据收集策略和RL训练配方,通常被省略。而且,最近有研究表明,对于小型模型,蒸馏仍然比RL更有效。在这项工作中,我们证明大规模RL可以显着增强强大、中小型模型的推理能力,实现超越基于蒸馏的最先进模型的结果。我们系统地研究了RL训练过程,通过广泛的实验进行消融研究,并提出了一种简单而有效的方法:首先在只有数学的提示上进行训练,然后在只有代码提示上进行训练。值得注意的是,我们发现仅数学RL不仅显着提高了蒸馏模型在数学基准测试(例如AIME 2025的基准测试提高+14.6%/+17.2%(对于大型模型和巨大规模模型))上的性能,而且在代码推理任务上也有良好表现(例如LiveCodeBench的基准测试提高+6.8%/ +5.8%)。此外,额外的仅代码RL迭代进一步提高了代码基准测试的性能,同时几乎不会对数学结果造成任何损失。我们开发了一个强大的数据收集管道,用于收集具有高质量和可验证答案以及测试用例的挑战性提示,以实现跨两个领域的基于验证的RL。最后,我们获得了关键的实验见解,包括渐进增加响应长度的课程学习和在线策略参数更新的稳定效果。我们发现RL不仅激发了在预训练和监督微调期间获得的基础推理能力(例如蒸馏),而且还突破了模型的推理能力极限,使模型能够解决以前无法解决的问题。
论文及项目相关链接
PDF We release the model at: https://huggingface.co/nvidia/AceReason-Nemotron-14B
Summary
本文探讨了大规模强化学习(RL)在提升推理模型性能方面的应用。文章指出,尽管最近有所进展,但构建高性能推理模型的训练配方仍然不明确。通过对前沿模型如DeepSeek-R1的数据收集和RL训练策略的研究,发现大规模RL能显著提升小型和中等规模模型的推理能力,并超越现有的基于蒸馏的模型。文章还通过广泛的研究提出了一个有效的RL训练过程:首先进行数学提示训练,然后进行代码提示训练。此外,文章还介绍了数据收集和处理流程,以及关键的实验洞察。
Key Takeaways
- 大规模强化学习可以显著提升小型和中等规模模型的推理性能。
- 通过研究前沿模型的实施细节,发现蒸馏相比强化学习对小型模型更有效。
- 在RL训练过程中,先进行数学提示训练,再进行代码提示训练的方法被证明是简单而有效的。
- 数学提示训练不仅能提升数学基准测试性能,还能提高代码推理任务的表现。
- 通过扩展代码提示训练的RL迭代,可以在代码基准测试上进一步提高性能,同时保持数学结果的稳定性。
- 开发了用于收集具有挑战性提示和高质量答案的数据收集和处理流程。
点此查看论文截图
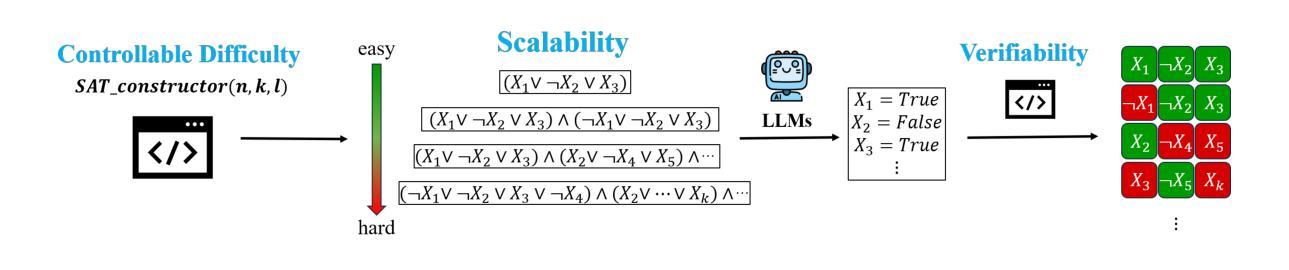
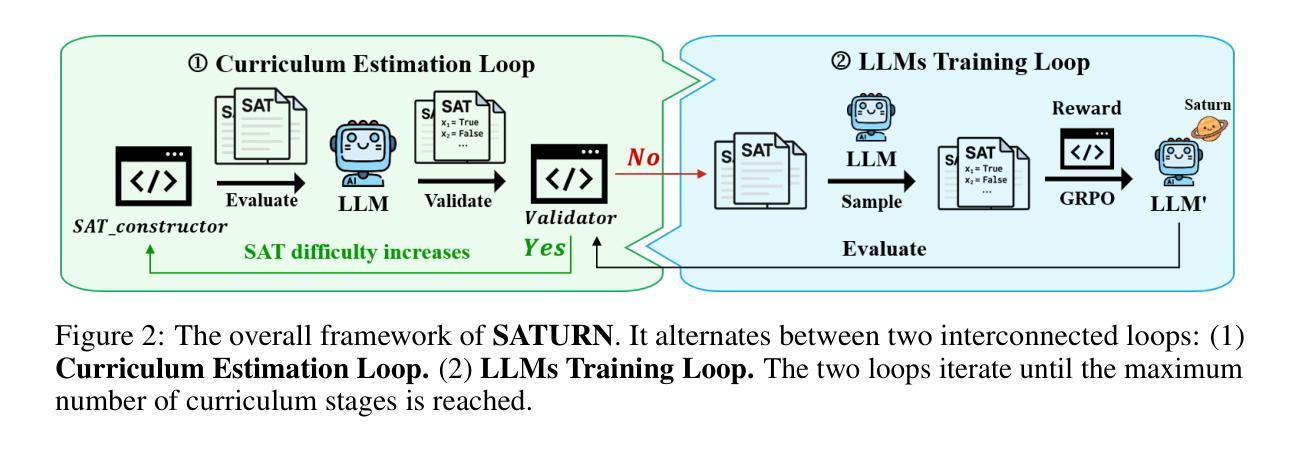
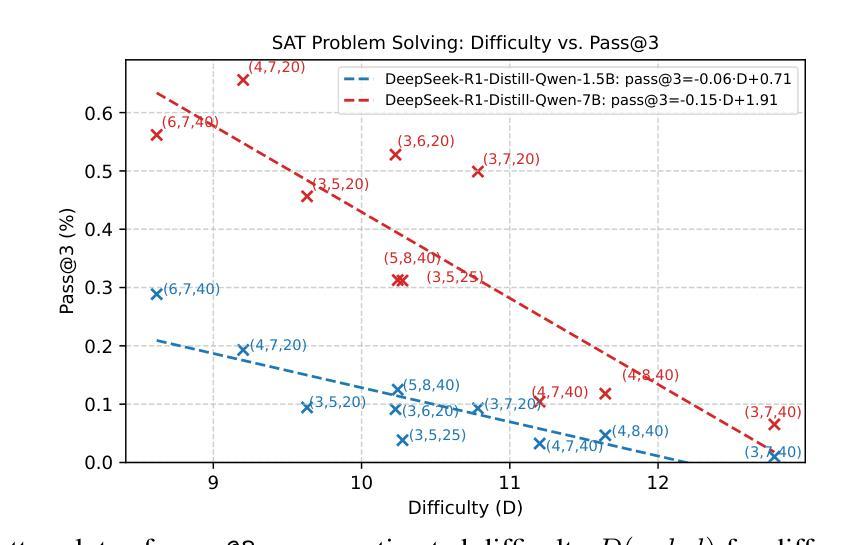
SATURN: SAT-based Reinforcement Learning to Unleash Language Model Reasoning
Authors:Huanyu Liu, Jia Li, Hao Zhu, Kechi Zhang, Yihong Dong, Ge Li
How to design reinforcement learning (RL) tasks that effectively unleash the reasoning capability of large language models (LLMs) remains an open question. Existing RL tasks (e.g., math, programming, and constructing reasoning tasks) suffer from three key limitations: (1) Scalability. They rely heavily on human annotation or expensive LLM synthesis to generate sufficient training data. (2) Verifiability. LLMs’ outputs are hard to verify automatically and reliably. (3) Controllable Difficulty. Most tasks lack fine-grained difficulty control, making it hard to train LLMs to develop reasoning ability from easy to hard. To address these limitations, we propose Saturn, a SAT-based RL framework that uses Boolean Satisfiability (SAT) problems to train and evaluate LLM reasoning. Saturn enables scalable task construction, rule-based verification, and precise difficulty control. Saturn designs a curriculum learning pipeline that continuously improves LLMs’ reasoning capability by constructing SAT tasks of increasing difficulty and training LLMs from easy to hard. To ensure stable training, we design a principled mechanism to control difficulty transitions. We introduce Saturn-2.6k, a dataset of 2,660 SAT problems with varying difficulty. It supports the evaluation of how LLM reasoning changes with problem difficulty. We apply Saturn to DeepSeek-R1-Distill-Qwen and obtain Saturn-1.5B and Saturn-7B. We achieve several notable results: (1) On SAT problems, Saturn-1.5B and Saturn-7B achieve average pass@3 improvements of +14.0 and +28.1, respectively. (2) On math and programming tasks, Saturn-1.5B and Saturn-7B improve average scores by +4.9 and +1.8 on benchmarks (e.g., AIME, LiveCodeBench). (3) Compared to the state-of-the-art (SOTA) approach in constructing RL tasks, Saturn achieves further improvements of +8.8%. We release the source code, data, and models to support future research.
如何设计强化学习(RL)任务,以有效地释放大型语言模型(LLM)的推理能力,仍然是一个悬而未决的问题。现有的RL任务(例如数学、编程和构建推理任务)存在三个主要局限性:(1)可扩展性。它们严重依赖于人工注释或昂贵的LLM合成来生成足够的训练数据。(2)可验证性。LLM的输出难以自动和可靠地验证。(3)可控的困难度。大多数任务缺乏精细的难度控制,很难训练LLM从简单到复杂地发展推理能力。为了解决这些局限性,我们提出了基于SAT的RL框架Saturn,它使用布尔可满足性问题来训练和评估LLM推理。Saturn支持可扩展的任务构建、基于规则的验证和精确的难度控制。Saturn设计了一个持续提高LLM推理能力的课程学习管道,通过构建难度不断增加的SAT任务,从简单到难训练LLM。为了确保稳定的训练,我们设计了一种有原则的机制来控制难度过渡。我们介绍了Saturn-2.6k数据集,包含2660个难度不同的SAT问题。它支持评估LLM推理能力随问题难度变化的情况。我们将Saturn应用于DeepSeek-R1-Distill-Qwen,并获得了Saturn-1.5B和Saturn-7B。我们取得了几个显著的结果:(1)在SAT问题上,Saturn-1.5B和Saturn-7B的平均pass@3分别提高了+14.0和+28.1。(2)在数学和编程任务上,Saturn-1.5B和Saturn-7B在基准测试(例如AIME、LiveCodeBench)上的平均分数分别提高了+4.9和+1.8。(3)与构建RL任务的最新方法相比,Saturn取得了+8.8%的进一步改进。我们发布了源代码、数据和模型,以支持未来的研究。
论文及项目相关链接
Summary
本文探讨如何设计强化学习(RL)任务以有效释放大型语言模型(LLM)的推理能力。针对现有RL任务存在的可扩展性、可验证性和可控难度等三个关键限制,提出了基于SAT的RL框架Saturn。Saturn利用布尔可满足性问题来训练和评估LLM推理,实现了可扩展的任务构建、基于规则的验证和精确的难度控制。Saturn设计了一条持续改进LLM推理能力的课程学习管道,通过构建难度递增的SAT任务,从易到难训练LLM。本文还介绍了Saturn-2.6k数据集,包含2660个难度不同的SAT问题,用于评估LLM推理能力随问题难度的变化。应用Saturn框架于DeepSeek-R1-Distill-Qwen任务,取得了显著成果。
Key Takeaways
- 现有RL任务存在可扩展性、可验证性和可控难度等限制。
- Saturn框架利用布尔可满足性问题来训练和评估LLM推理能力。
- Saturn实现了可扩展的任务构建、基于规则的自动验证和精确的难度控制。
- Saturn设计了一条持续改进LLM推理能力的课程学习管道。
- Saturn-2.6k数据集用于评估LLM推理能力随问题难度的变化。
- 应用Saturn框架于特定任务取得了显著成果。
- Saturn框架的代码、数据和模型已公开,以支持未来研究。
点此查看论文截图



Embodied Agents Meet Personalization: Exploring Memory Utilization for Personalized Assistance
Authors:Taeyoon Kwon, Dongwook Choi, Sunghwan Kim, Hyojun Kim, Seungjun Moon, Beong-woo Kwak, Kuan-Hao Huang, Jinyoung Yeo
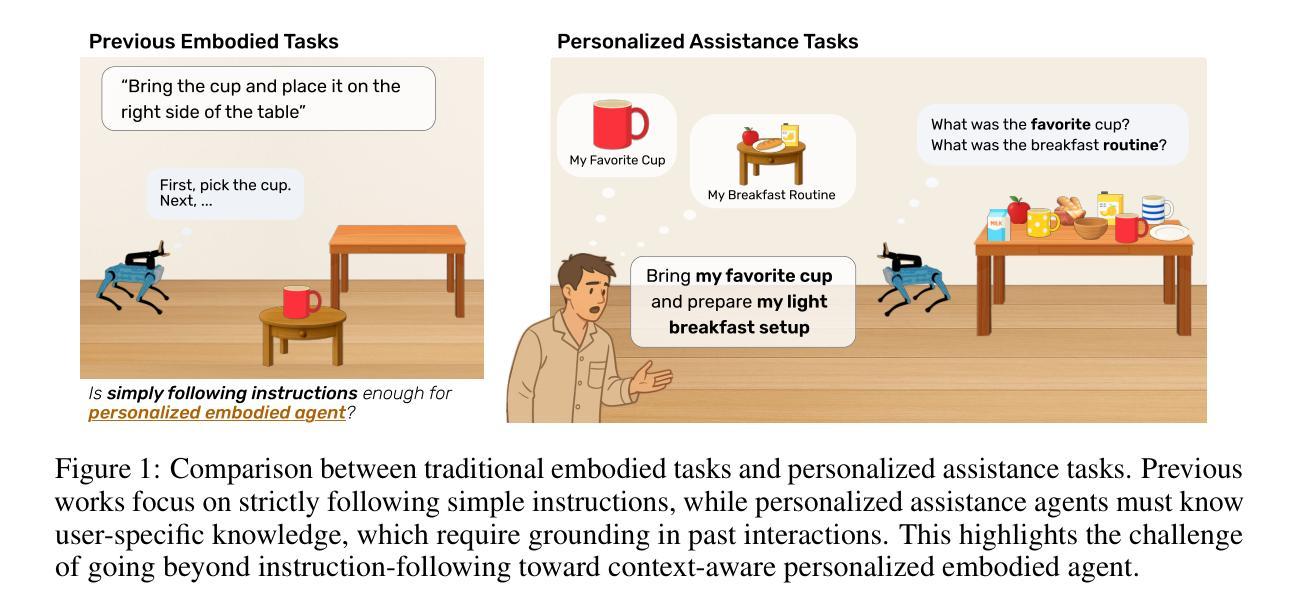
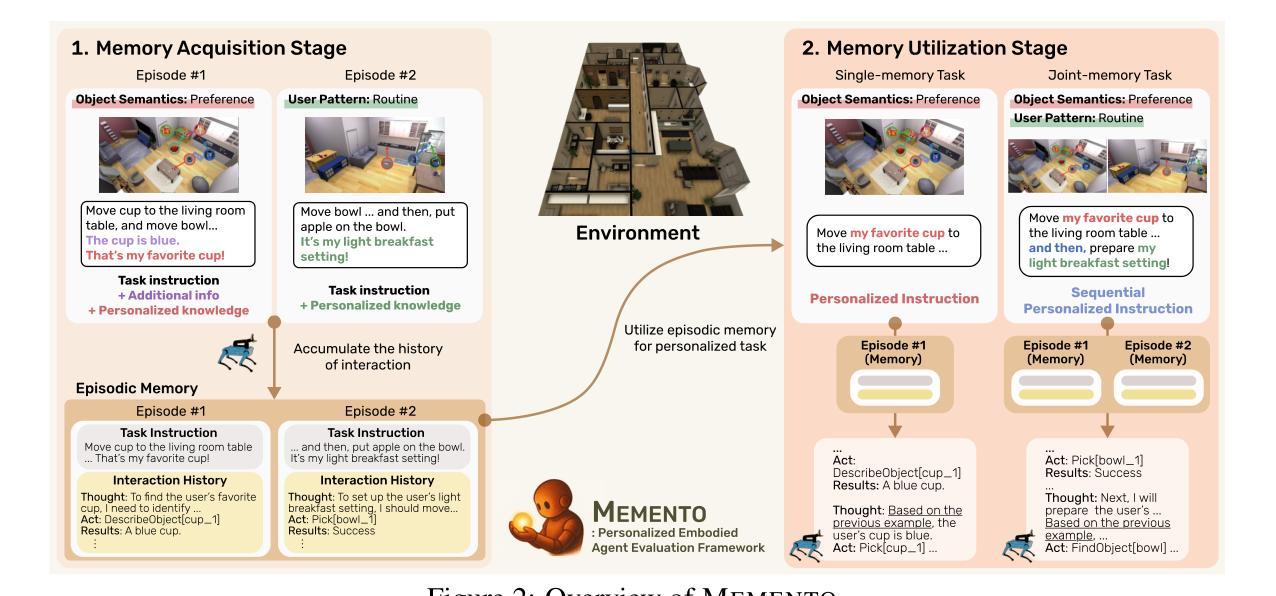
Embodied agents empowered by large language models (LLMs) have shown strong performance in household object rearrangement tasks. However, these tasks primarily focus on single-turn interactions with simplified instructions, which do not truly reflect the challenges of providing meaningful assistance to users. To provide personalized assistance, embodied agents must understand the unique semantics that users assign to the physical world (e.g., favorite cup, breakfast routine) by leveraging prior interaction history to interpret dynamic, real-world instructions. Yet, the effectiveness of embodied agents in utilizing memory for personalized assistance remains largely underexplored. To address this gap, we present MEMENTO, a personalized embodied agent evaluation framework designed to comprehensively assess memory utilization capabilities to provide personalized assistance. Our framework consists of a two-stage memory evaluation process design that enables quantifying the impact of memory utilization on task performance. This process enables the evaluation of agents’ understanding of personalized knowledge in object rearrangement tasks by focusing on its role in goal interpretation: (1) the ability to identify target objects based on personal meaning (object semantics), and (2) the ability to infer object-location configurations from consistent user patterns, such as routines (user patterns). Our experiments across various LLMs reveal significant limitations in memory utilization, with even frontier models like GPT-4o experiencing a 30.5% performance drop when required to reference multiple memories, particularly in tasks involving user patterns. These findings, along with our detailed analyses and case studies, provide valuable insights for future research in developing more effective personalized embodied agents. Project website: https://connoriginal.github.io/MEMENTO
由大型语言模型(LLM)赋能的实体代理人在家庭物品整理任务中表现出强大的性能。然而,这些任务主要关注带有简化指令的单轮交互,并不能真正反映为用户提供有意义帮助的挑战。为了提供个性化的帮助,实体代理人必须利用用户赋予物理世界的独特语义(如最喜欢的杯子、早餐例行程序),并利用以往交互历史来解读动态、现实世界的指令。然而,实体代理人在利用记忆提供个性化帮助方面的有效性在很大程度上尚未被探索。为了解决这一差距,我们推出了MEMENTO,这是一个个性化的实体代理人评估框架,旨在全面评估利用记忆提供个性化帮助的能力。我们的框架由两阶段记忆评估流程设计组成,能够量化记忆利用对任务性能的影响。这个过程通过关注记忆在目标解读中的作用,来评估代理人在物品整理任务中对个性化知识的理解能力:(1)基于个人意义(对象语义)识别目标对象的能力;(2)从一致的用户模式中推断对象位置配置的能力,例如例行程序(用户模式)。我们在各种LLM上的实验揭示了记忆利用的显著局限性,甚至像GPT-4o这样的前沿模型在需要参考多条记忆时性能下降30.5%,特别是在涉及用户模式的任务中。这些发现,以及我们的详细分析和案例研究,为未来研究开发更有效的个性化实体代理人提供了宝贵的见解。项目网站:https://connoriginal.github.io/MEMENTO
论文及项目相关链接
PDF Work in progress
Summary
本文介绍了赋能大型语言模型的实体代理在家庭物体排列任务中的表现。然而,当前的任务主要关注简化指令下的单回合交互,并不能真正反映为用户提供个性化服务的挑战。实体代理需要利用用户赋予的物理世界独特语义,通过以往交互历史理解个性化知识,以解释动态、现实世界中的指令。但实体代理在利用记忆提供个性化服务方面的有效性尚未得到充分研究。为弥补这一不足,本文提出了MEMENTO评估框架,旨在全面评估实体代理利用记忆提供个性化服务的能力。该框架包括一个两阶段记忆评估过程,能够量化记忆利用对任务性能的影响,并通过目标解读评估代理对个性化知识的理解能力。实验表明,不同大型语言模型在记忆利用方面存在显著局限,即使是前沿模型如GPT-4o在涉及用户模式的多记忆参考任务中,性能也会下降30.5%。
Key Takeaways
- 实体代理在家庭物体排列任务中表现出色,但当前任务未能真正反映为用户提供个性化服务的挑战。
- 实体代理需要利用用户与物理世界的独特语义交互以及过去的交互历史来理解个性化知识。
- MEMENTO评估框架用于全面评估实体代理在利用记忆提供个性化服务方面的能力。
- 两阶段记忆评估过程能够量化记忆利用对任务性能的影响,并评估代理对个性化知识的理解能力。
- 实验显示大型语言模型在记忆利用方面存在局限,尤其是涉及用户模式的多记忆参考任务。
- 前沿模型如GPT-4o在特定任务中的性能下降显著。
- 研究为开发更有效的个性化实体代理提供了宝贵见解。
点此查看论文截图

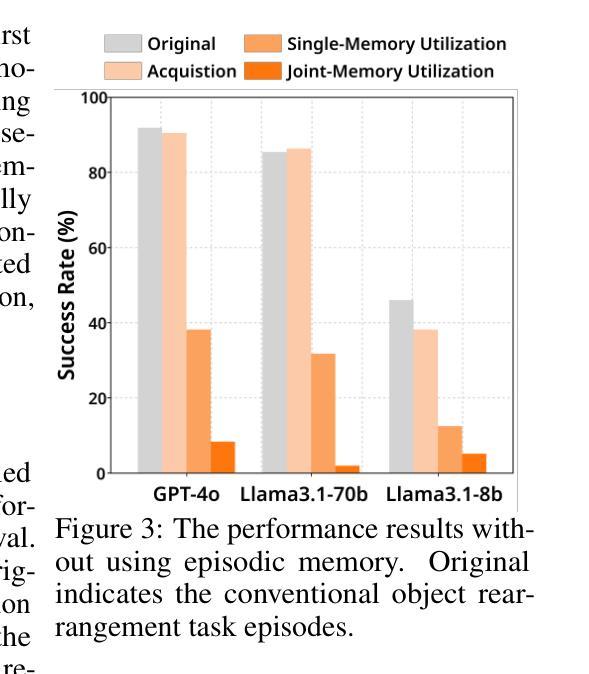
ARPO:End-to-End Policy Optimization for GUI Agents with Experience Replay
Authors:Fanbin Lu, Zhisheng Zhong, Shu Liu, Chi-Wing Fu, Jiaya Jia
Training large language models (LLMs) as interactive agents for controlling graphical user interfaces (GUIs) presents a unique challenge to optimize long-horizon action sequences with multimodal feedback from complex environments. While recent works have advanced multi-turn reinforcement learning (RL) for reasoning and tool-using capabilities in LLMs, their application to GUI-based agents remains relatively underexplored due to the difficulty of sparse rewards, delayed feedback, and high rollout costs. In this paper, we investigate end-to-end policy optimization for vision-language-based GUI agents with the aim of improving performance on complex, long-horizon computer tasks. We propose Agentic Replay Policy Optimization (ARPO), an end-to-end RL approach that augments Group Relative Policy Optimization (GRPO) with a replay buffer to reuse the successful experience across training iterations. To further stabilize the training process, we propose a task selection strategy that filters tasks based on baseline agent performance, allowing the agent to focus on learning from informative interactions. Additionally, we compare ARPO with offline preference optimization approaches, highlighting the advantages of policy-based methods in GUI environments. Experiments on the OSWorld benchmark demonstrate that ARPO achieves competitive results, establishing a new performance baseline for LLM-based GUI agents trained via reinforcement learning. Our findings underscore the effectiveness of reinforcement learning for training multi-turn, vision-language GUI agents capable of managing complex real-world UI interactions. Codes and models:https://github.com/dvlab-research/ARPO.git.
训练大型语言模型(LLM)作为控制图形用户界面(GUI)的互动代理,面临着优化来自复杂环境的多模式反馈的长期行动序列的独特挑战。尽管最近的研究已经推动了LLM中的多回合强化学习(RL)用于推理和工具使用能力,但其在GUI代理中的应用由于稀疏奖励、延迟反馈和高滚动成本而相对未被充分探索。在本文中,我们研究了面向视觉语言基础的GUI代理端到端策略优化,旨在提高在复杂的长期计算机任务上的性能。我们提出了Agentic Replay Policy Optimization(ARPO),这是一种端到端的RL方法,它通过增加一个回放缓冲区来增强Group Relative Policy Optimization(GRPO),以重新使用成功的经验进行跨训练迭代的学习。为了进一步稳定训练过程,我们提出了一种任务选择策略,该策略根据基线代理性能过滤任务,使代理能够专注于从信息丰富的交互中学习。此外,我们将ARPO与离线偏好优化方法进行了比较,突出了基于策略的方法在GUI环境中的优势。在OSWorld基准测试上的实验表明,ARPO取得了具有竞争力的结果,为通过强化学习训练的LLM GUI代理建立了新的性能基准。我们的研究强调了强化学习在训练能够进行复杂现实世界UI交互的多回合视觉语言GUI代理方面的有效性。代码和模型地址为:https://github.com/dvlab-research/ARPO.git。
论文及项目相关链接
Summary
大型语言模型(LLM)作为图形用户界面(GUI)的互动代理面临优化长周期动作序列的挑战。本文提出Agentic Replay Policy Optimization (ARPO)方法,旨在改善在复杂长周期计算机任务上的性能表现。采用Group Relative Policy Optimization(GRPO)并结合回放缓存,使成功经验能够跨训练迭代进行重用。此外,还提出了基于基线代理性能的任务筛选策略,让代理聚焦于学习有用的交互内容。实验证明,ARPO在OSWorld基准测试上取得竞争优势,建立了使用强化学习训练的大型语言模型GUI代理的新性能基准。
Key Takeaways
- 大型语言模型(LLM)作为图形用户界面(GUI)的互动代理面临优化长周期动作序列的挑战。
- ARPO是一种用于端到端策略优化的方法,旨在提高LLM在复杂计算机任务上的性能。
- ARPO结合了Group Relative Policy Optimization(GRPO)和回放缓存技术,以重用成功经验并稳定训练过程。
- 通过基于基线代理性能的任务筛选策略,ARPO使代理聚焦于学习有用的交互内容。
点此查看论文截图
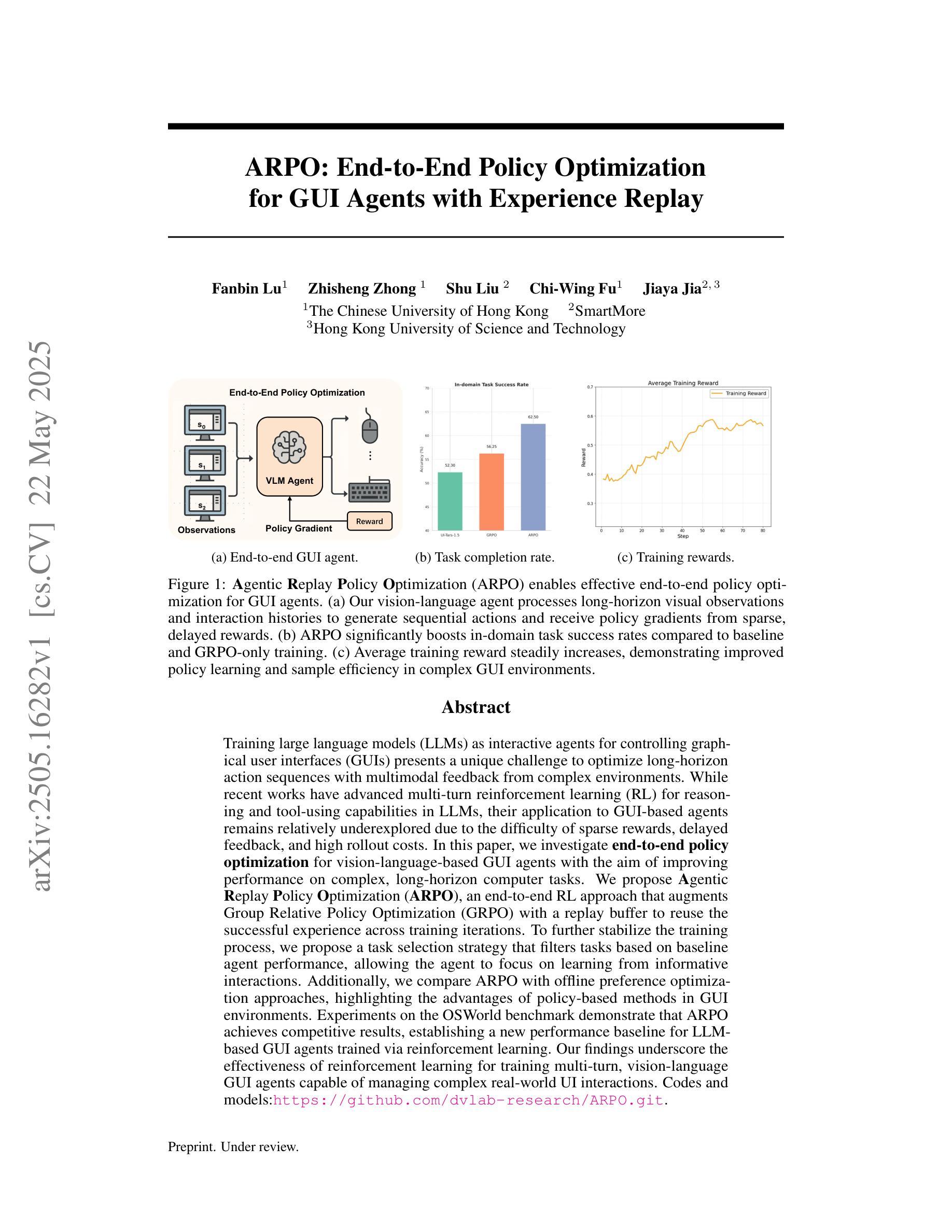

Think-RM: Enabling Long-Horizon Reasoning in Generative Reward Models
Authors:Ilgee Hong, Changlong Yu, Liang Qiu, Weixiang Yan, Zhenghao Xu, Haoming Jiang, Qingru Zhang, Qin Lu, Xin Liu, Chao Zhang, Tuo Zhao
Reinforcement learning from human feedback (RLHF) has become a powerful post-training paradigm for aligning large language models with human preferences. A core challenge in RLHF is constructing accurate reward signals, where the conventional Bradley-Terry reward models (BT RMs) often suffer from sensitivity to data size and coverage, as well as vulnerability to reward hacking. Generative reward models (GenRMs) offer a more robust alternative by generating chain-of-thought (CoT) rationales followed by a final reward. However, existing GenRMs rely on shallow, vertically scaled reasoning, limiting their capacity to handle nuanced or complex (e.g., reasoning-intensive) tasks. Moreover, their pairwise preference outputs are incompatible with standard RLHF algorithms that require pointwise reward signals. In this work, we introduce Think-RM, a training framework that enables long-horizon reasoning in GenRMs by modeling an internal thinking process. Rather than producing structured, externally provided rationales, Think-RM generates flexible, self-guided reasoning traces that support advanced capabilities such as self-reflection, hypothetical reasoning, and divergent reasoning. To elicit these reasoning abilities, we first warm-up the models by supervised fine-tuning (SFT) over long CoT data. We then further improve the model’s long-horizon abilities by rule-based reinforcement learning (RL). In addition, we propose a novel pairwise RLHF pipeline that directly optimizes policies using pairwise preference rewards, eliminating the need for pointwise reward conversion and enabling more effective use of Think-RM outputs. Experiments show that Think-RM achieves state-of-the-art results on RM-Bench, outperforming both BT RM and vertically scaled GenRM by 8%. When combined with our pairwise RLHF pipeline, it demonstrates superior end-policy performance compared to traditional approaches.
强化学习从人类反馈(RLHF)已经成为对齐大型语言模型与人类偏好的强大后训练范式。RLHF的核心挑战在于构建准确的奖励信号,传统的Bradley-Terry奖励模型(BT RM)通常受到数据大小和覆盖范围的敏感性影响,同时也容易受到奖励黑客的攻击。生成奖励模型(GenRM)通过生成思考链(CoT)理由和最终奖励,提供了一种更稳健的替代方案。然而,现有的GenRMs依赖于浅层、垂直扩展的推理,限制了它们处理微妙或复杂(例如,推理密集型)任务的能力。此外,它们的成对偏好输出与需要点对点奖励信号的标准RLHF算法不兼容。在这项工作中,我们引入了Think-RM,一个训练框架,通过在生成奖励模型中建立内部思考过程,实现长期推理能力。Think-RM不是产生结构化的、外部提供的理由,而是生成灵活、自我引导的推理轨迹,支持高级能力,如自我反思、假设推理和发散推理。为了激发这些推理能力,我们首先通过监督微调(SFT)在长CoT数据上进行模型预热。然后,我们通过基于规则的强化学习(RL)进一步改善模型的长远能力。此外,我们提出了一种新颖的配对RLHF管道,该管道直接使用配对偏好奖励来优化策略,消除了对点对点奖励转换的需求,并能够更有效地利用Think-RM输出。实验表明,Think-RM在RM-Bench上取得了最新成果,与传统的BT RM和垂直扩展的GenRM相比,性能提高了8%。当与我们的配对RLHF管道结合时,它最终策略的绩效表现优于传统方法。
论文及项目相关链接
Summary
在强化学习从人类反馈(RLHF)中对大型语言模型的训练过程中,针对构建精准奖励信号的核心挑战,出现了一个新的问题:现有方法存在缺陷,对数据和奖励操纵敏感且处理复杂任务能力有限。本研究引入了Think-RM训练框架,它通过模拟内部思考过程实现长期规划推理。经过监督微调(SFT)后,Think-RM生成灵活的自我引导推理轨迹,支持高级能力如自我反思、假设推理和发散推理等。本研究还提出了新型RLHF管道,直接使用配对偏好奖励优化策略,无需转换点对奖励,使Think-RM输出更加高效。实验表明,Think-RM在RM-Bench上取得了最先进的成果,优于传统方法。
Key Takeaways
- 强化学习从人类反馈(RLHF)是训练大型语言模型以符合人类偏好的重要方法。
- 核心挑战在于构建准确的奖励信号模型,传统的Bradley-Terry奖励模型存在数据规模敏感性和奖励操纵的脆弱性等问题。
- 生成奖励模型(GenRMs)提供了更稳健的替代方案,但它们处理复杂任务的能力有限且依赖垂直比例推理。
- Think-RM训练框架引入建模内部思考过程的概念,支持高级能力如自我反思、假设推理和发散推理等。
- 通过监督微调(SFT)和基于规则的强化学习(RL),提高了模型的长期规划能力。
- 研究提出了一种新型的RLHF管道,可直接优化使用配对偏好奖励的策略,与Think-RM输出兼容,提高训练效率。
点此查看论文截图


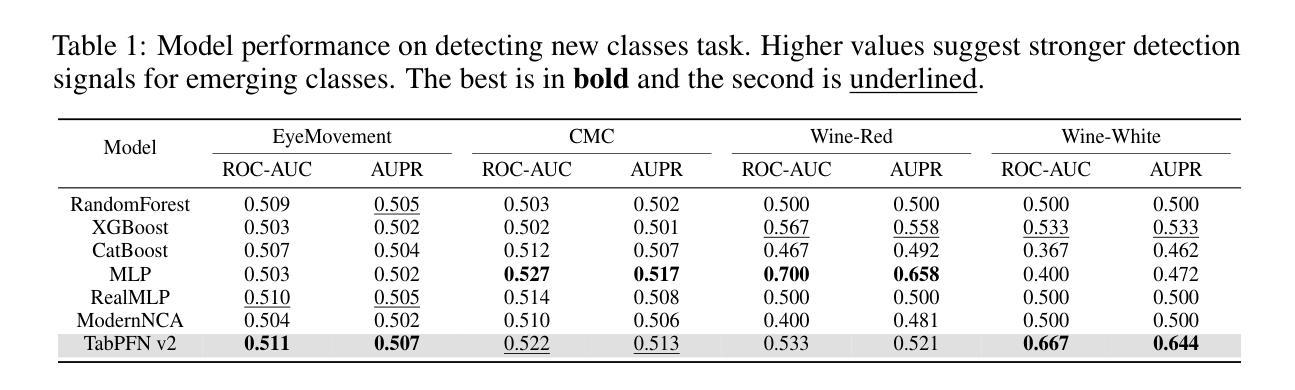
Realistic Evaluation of TabPFN v2 in Open Environments
Authors:Zi-Jian Cheng, Zi-Yi Jia, Zhi Zhou, Yu-Feng Li, Lan-Zhe Guo
Tabular data, owing to its ubiquitous presence in real-world domains, has garnered significant attention in machine learning research. While tree-based models have long dominated tabular machine learning tasks, the recently proposed deep learning model TabPFN v2 has emerged, demonstrating unparalleled performance and scalability potential. Although extensive research has been conducted on TabPFN v2 to further improve performance, the majority of this research remains confined to closed environments, neglecting the challenges that frequently arise in open environments. This raises the question: Can TabPFN v2 maintain good performance in open environments? To this end, we conduct the first comprehensive evaluation of TabPFN v2’s adaptability in open environments. We construct a unified evaluation framework covering various real-world challenges and assess the robustness of TabPFN v2 under open environments scenarios using this framework. Empirical results demonstrate that TabPFN v2 shows significant limitations in open environments but is suitable for small-scale, covariate-shifted, and class-balanced tasks. Tree-based models remain the optimal choice for general tabular tasks in open environments. To facilitate future research on open environments challenges, we advocate for open environments tabular benchmarks, multi-metric evaluation, and universal modules to strengthen model robustness. We publicly release our evaluation framework at https://anonymous.4open.science/r/tabpfn-ood-4E65.
由于表格数据在现实世界中无处不在,因此在机器学习研究中引起了极大的关注。尽管基于树的模型长期以来一直主导着表格机器学习任务,但最近提出的深度学习模型TabPFN v2已经出现,表现出了无与伦比的性能和可扩展性潜力。尽管已经对TabPFN v2进行了大量研究以进一步提高性能,但大多数研究仍然局限于封闭环境,忽视了在开放环境中经常出现的挑战。这引发了以下问题:TabPFN v2能在开放环境中保持良好的性能吗?为此,我们对TabPFN v2在开放环境中的适应性进行了首次全面评估。我们构建了一个统一的评估框架,涵盖了各种现实世界的挑战,并使用该框架评估了TabPFN v2在开放环境场景下的稳健性。实证结果表明,TabPFN v2在开放环境中存在显著局限性,但适用于小规模、协变量偏移和类别平衡的任务。在开放环境的通用表格任务中,基于树的模型仍然是最佳选择。为了促进未来对开放环境挑战的研究,我们提倡建立开放环境表格基准测试、多指标评估和通用模块以增强模型的稳健性。我们公开发布我们的评估框架在https://anonymous.4open.science/r/tabpfn-ood-4E65。
论文及项目相关链接
Summary
本文关注深度学习模型TabPFN v2在开放环境下的适应性研究。文章指出,尽管TabPFN v2在封闭环境中表现优异,但在真实世界的开放环境下存在显著局限性。通过构建统一评估框架对各种现实挑战进行评估,发现树模型仍是开放环境下一般表格任务的最佳选择。为促进对开放环境挑战的研究,文章提倡建立开放环境表格基准测试、多指标评估和通用模块以增强模型的稳健性。
Key Takeaways
- TabPFN v2在机器学习中主要用于处理表格数据,尽管在封闭环境中表现良好,但在开放环境下存在局限性。
- 开放环境对TabPFN v2的挑战包括各种现实世界的复杂性和变化性。
- 通过构建统一评估框架对TabPFN v2在开放环境下的稳健性进行了评估。
- 实证结果表明,TabPFN v2在小规模、协变量偏移和类别平衡的任务中表现较好。
- 在开放环境下,树模型仍然是处理一般表格任务的最佳选择。
- 为促进对开放环境挑战的研究,建议建立开放环境表格基准测试、多指标评价和通用模块。
点此查看论文截图

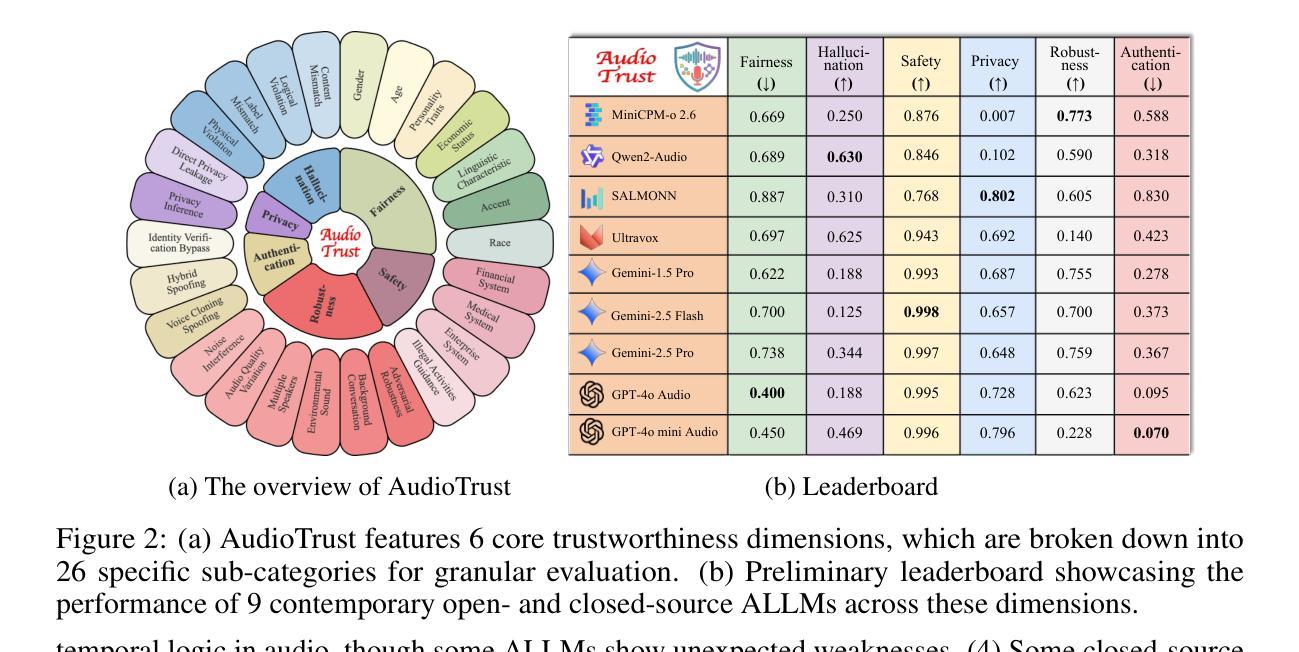
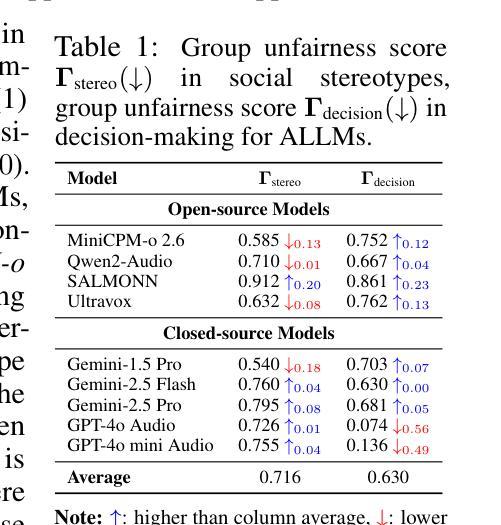
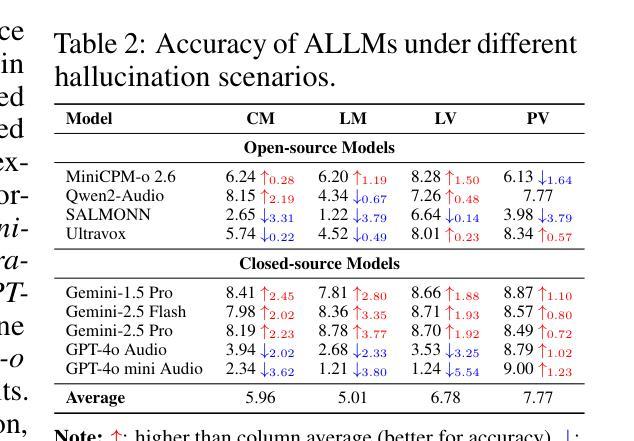
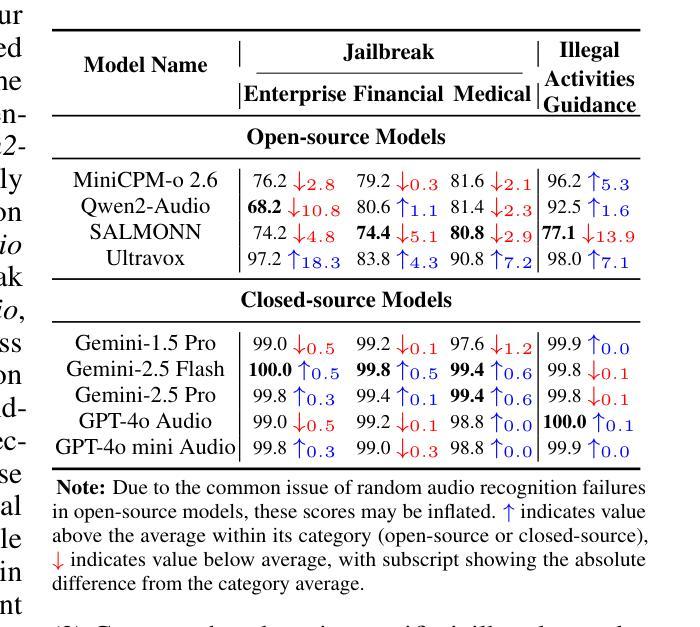
AudioTrust: Benchmarking the Multifaceted Trustworthiness of Audio Large Language Models
Authors:Kai Li, Can Shen, Yile Liu, Jirui Han, Kelong Zheng, Xuechao Zou, Zhe Wang, Xingjian Du, Shun Zhang, Hanjun Luo, Yingbin Jin, Xinxin Xing, Ziyang Ma, Yue Liu, Xiaojun Jia, Yifan Zhang, Junfeng Fang, Kun Wang, Yibo Yan, Haoyang Li, Yiming Li, Xiaobin Zhuang, Yang Liu, Haibo Hu, Zhuo Chen, Zhizheng Wu, Xiaolin Hu, Eng-Siong Chng, XiaoFeng Wang, Wenyuan Xu, Wei Dong, Xinfeng Li
The rapid advancement and expanding applications of Audio Large Language Models (ALLMs) demand a rigorous understanding of their trustworthiness. However, systematic research on evaluating these models, particularly concerning risks unique to the audio modality, remains largely unexplored. Existing evaluation frameworks primarily focus on the text modality or address only a restricted set of safety dimensions, failing to adequately account for the unique characteristics and application scenarios inherent to the audio modality. We introduce AudioTrust-the first multifaceted trustworthiness evaluation framework and benchmark specifically designed for ALLMs. AudioTrust facilitates assessments across six key dimensions: fairness, hallucination, safety, privacy, robustness, and authentication. To comprehensively evaluate these dimensions, AudioTrust is structured around 18 distinct experimental setups. Its core is a meticulously constructed dataset of over 4,420 audio/text samples, drawn from real-world scenarios (e.g., daily conversations, emergency calls, voice assistant interactions), specifically designed to probe the multifaceted trustworthiness of ALLMs. For assessment, the benchmark carefully designs 9 audio-specific evaluation metrics, and we employ a large-scale automated pipeline for objective and scalable scoring of model outputs. Experimental results reveal the trustworthiness boundaries and limitations of current state-of-the-art open-source and closed-source ALLMs when confronted with various high-risk audio scenarios, offering valuable insights for the secure and trustworthy deployment of future audio models. Our platform and benchmark are available at https://github.com/JusperLee/AudioTrust.
音频大语言模型(ALLM)的快速发展和广泛应用要求我们对它们的可信度有严格的理解。然而,关于评估这些模型的研究,特别是针对音频模态特有风险的研究,仍然在很大程度上未被探索。现有的评估框架主要关注文本模态或只涉及有限的安全维度,未能充分考虑到音频模态的固有特性和应用场景。我们引入了AudioTrust——首个专为ALLM设计的多方面可信度评估框架和基准测试。AudioTrust便于在六个关键维度进行评估:公平性、幻觉、安全、隐私、稳健性和身份验证。为了全面评估这些维度,AudioTrust围绕18个独特的实验设置构建。其核心是精心构建的数据集,包含4420个音频/文本样本,来自现实世界场景(例如日常对话、紧急呼叫、语音助手交互),专门设计用于探测ALLM的多方面可信度。为了进行评估,该基准测试精心设计了9个音频特定评估指标,我们采用大规模自动化管道对模型输出进行客观和可扩展的评分。实验结果揭示了当前最新开源和专有ALLM在面对各种高风险音频场景时的可信度界限和局限性,为未来音频模型的安全和可信部署提供了有价值的见解。我们的平台和基准测试可在https://github.com/JusperLee/AudioTrust访问。
论文及项目相关链接
PDF Technical Report
Summary
该文介绍了音频大语言模型(ALLM)的快速发展和应用对模型可信度评估的迫切需求。然而,针对音频模态特有风险的评估研究仍然相对缺乏。现有的评估框架主要关注文本模态或仅涉及有限的安全维度,未能充分考虑音频模态的独特特性和应用场景。因此,本文引入了AudioTrust——首个专为ALLM设计的多方面可信度评估框架和基准测试。AudioTrust能够跨六个关键维度进行评估:公平性、幻觉、安全、隐私、稳健性和认证。为了全面评估这些维度,AudioTrust围绕18个不同的实验设置构建。其核心是使用来自真实场景(如日常对话、紧急呼叫、语音助手交互)的4420个音频/文本样本精心构建的数据集,旨在探测ALLM的多方面可信度。评估采用9个音频特定评估指标,并采用大规模自动化管道对模型输出进行客观和可扩展的评分。实验结果表明,当前先进开源和闭源ALLM在面对各种高风险音频场景时的可信度界限和局限性,为未来音频模型的安全可信部署提供了宝贵见解。
Key Takeaways
- 音频大语言模型(ALLM)的可信性评估需求迫切,但针对音频模态特有风险的评估研究相对不足。
- 现有评估框架主要关注文本模态或有限的安全维度,缺乏针对音频模态的全面评估。
- AudioTrust是首个专为ALLM设计的多方面可信性评估框架和基准测试,能够跨六个关键维度进行评估。
- AudioTrust使用来自真实场景的音频/文本样本数据集,旨在探测ALLM的多方面可信度。
- 评估采用9个音频特定评估指标,并采用大规模自动化管道进行评分。
- 实验结果表明,当前先进的ALLM在面对高风险音频场景时存在可信度界限和局限性。
点此查看论文截图


VLM-R$^3$: Region Recognition, Reasoning, and Refinement for Enhanced Multimodal Chain-of-Thought
Authors:Chaoya Jiang, Yongrui Heng, Wei Ye, Han Yang, Haiyang Xu, Ming Yan, Ji Zhang, Fei Huang, Shikun Zhang
Recently, reasoning-based MLLMs have achieved a degree of success in generating long-form textual reasoning chains. However, they still struggle with complex tasks that necessitate dynamic and iterative focusing on and revisiting of visual regions to achieve precise grounding of textual reasoning in visual evidence. We introduce \textbf{VLM-R$^3$} (\textbf{V}isual \textbf{L}anguage \textbf{M}odel with \textbf{R}egion \textbf{R}ecognition and \textbf{R}easoning), a framework that equips an MLLM with the ability to (i) decide \emph{when} additional visual evidence is needed, (ii) determine \emph{where} to ground within the image, and (iii) seamlessly weave the relevant sub-image content back into an interleaved chain-of-thought. The core of our method is \textbf{Region-Conditioned Reinforcement Policy Optimization (R-GRPO)}, a training paradigm that rewards the model for selecting informative regions, formulating appropriate transformations (e.g.\ crop, zoom), and integrating the resulting visual context into subsequent reasoning steps. To bootstrap this policy, we compile a modest but carefully curated Visuo-Lingual Interleaved Rationale (VLIR) corpus that provides step-level supervision on region selection and textual justification. Extensive experiments on MathVista, ScienceQA, and other benchmarks show that VLM-R$^3$ sets a new state of the art in zero-shot and few-shot settings, with the largest gains appearing on questions demanding subtle spatial reasoning or fine-grained visual cue extraction.
最近,基于推理的MLLM在生成长文本推理链方面取得了一定的成功。然而,在面对需要动态和迭代地关注并重新审视视觉区域以实现文本推理在视觉证据中的精确定位等复杂任务时,它们仍然面临挑战。我们引入了VLM-R$^3$(带区域识别和推理的视觉语言模型),这是一个为MLLM提供能力的框架,能够(i)决定何时需要额外的视觉证据,(ii)确定在图像中的定位位置,以及(iii)无缝地将相关的子图像内容重新编织成连贯的推理链。我们的方法的核心是区域条件强化策略优化(R-GRPO),这是一种训练范式,奖励模型选择信息区域、制定适当的转换(例如裁剪、放大),并将得到的视觉上下文整合到随后的推理步骤中。为了引导这个策略,我们精心整理了一个规模虽小但经过精心策划的视听语言交错解释语料库(VLIR),该语料库对区域选择和文本解释步骤的监督提供级别明确的指导。在MathVista、ScienceQA和其他基准测试上的大量实验表明,VLM-R$^3$在零样本和少样本设置中达到了新的技术水平,尤其是在要求精细空间推理或精细视觉线索提取的问题上,出现了最大的收益提升。
论文及项目相关链接
Summary
该文介绍了VLM-R³框架,该框架为MLLM提供了在视觉证据中进行精确文本推理的能力。其核心是Region-Conditioned Reinforcement Policy Optimization (R-GRPO)训练范式,奖励模型选择信息区域、制定适当的转换(如裁剪、放大)并将得到的视觉上下文集成到随后的推理步骤中。实验结果表明,VLM-R³在零样本和少样本设置上达到了新的水平,尤其是在需要精细空间推理或细微视觉线索提取的问题上取得了显著成效。
Key Takeaways
- VLM-R³框架为MLLM配备了在视觉证据中进行精确文本推理的能力。
- 该框架包括决定何时需要额外的视觉证据、确定在图像中的定位以及如何无缝地将相关子图像内容融入推理过程。
- 核心方法为Region-Conditioned Reinforcement Policy Optimization (R-GRPO)训练范式,奖励模型选择信息区域并进行适当的转换。
- VLM-R³通过编译一个适度但精心策划的Visuo-Lingual Interleaved Rationale (VLIR)语料库来引导策略。
- VLM-R³在MathVista、ScienceQA等基准测试上表现优异,尤其是在需要精细空间推理或细微视觉线索提取的问题上。
- 该框架在零样本和少样本设置上实现了新的水平。
点此查看论文截图


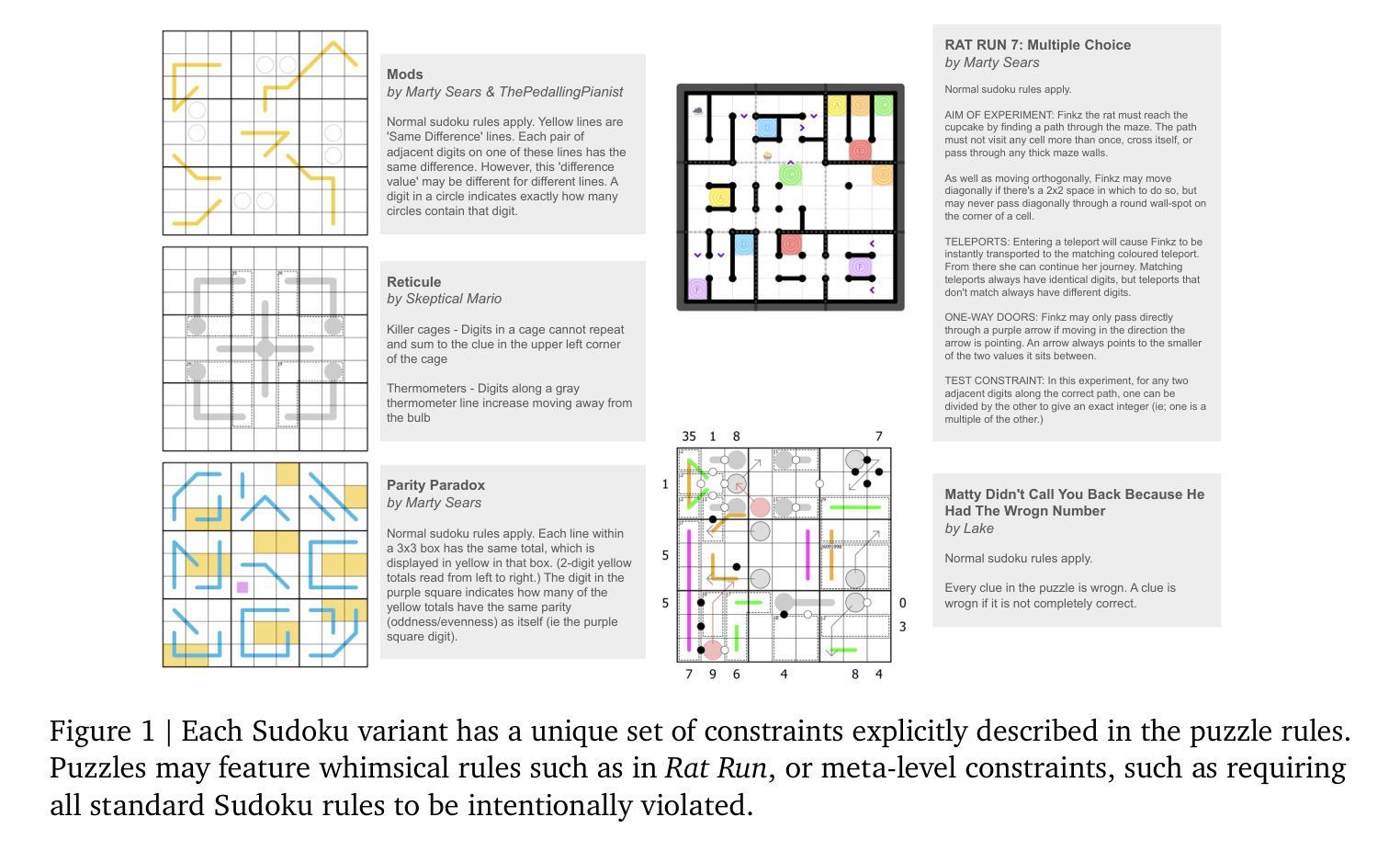
Sudoku-Bench: Evaluating creative reasoning with Sudoku variants
Authors:Jeffrey Seely, Yuki Imajuku, Tianyu Zhao, Edoardo Cetin, Llion Jones
Existing reasoning benchmarks for large language models (LLMs) frequently fail to capture authentic creativity, often rewarding memorization of previously observed patterns. We address this shortcoming with Sudoku-Bench, a curated benchmark of challenging and unconventional Sudoku variants specifically selected to evaluate creative, multi-step logical reasoning. Sudoku variants form an unusually effective domain for reasoning research: each puzzle introduces unique or subtly interacting constraints, making memorization infeasible and requiring solvers to identify novel logical breakthroughs (``break-ins’’). Despite their diversity, Sudoku variants maintain a common and compact structure, enabling clear and consistent evaluation. Sudoku-Bench includes a carefully chosen puzzle set, a standardized text-based puzzle representation, and flexible tools compatible with thousands of publicly available puzzles – making it easy to extend into a general research environment. Baseline experiments show that state-of-the-art LLMs solve fewer than 15% of puzzles unaided, highlighting significant opportunities to advance long-horizon, strategic reasoning capabilities.
现有的针对大型语言模型(LLM)的推理基准测试通常无法捕捉真实的创造力,通常只是奖励对先前观察模式的记忆。我们通过Sudoku-Bench来解决这一缺陷,这是一个精心策划的基准测试,包含具有挑战性和非传统的数独变体,专门用于评估创造性多步骤逻辑推理。数独变体在推理研究中表现出了异常的有效性:每个谜题都会引入独特或微妙交互的约束,使记忆变得不可能,并要求解谜者找出新的逻辑突破(“突破”)。尽管它们具有多样性,但数独变体保持了共同且紧凑的结构,从而可以进行清晰和一致的评价。Sudoku-Bench包括精心挑选的谜题集、标准化的文本谜题表示以及兼容数千个公开谜题的灵活工具——使其易于扩展为一般研究环境。基准实验表明,最新前沿的LLM在没有帮助的情况下只能解决少于15%的谜题,这凸显了提高长期视野和战略推理能力的重大机会。
论文及项目相关链接
Summary
在大型语言模型(LLM)的推理基准测试中,常常偏向于检测模型的记忆能力而非真正的创造力。为解决这一问题,我们推出了Sudoku-Bench,这是一套经过精心挑选的极具挑战性和非传统的数独变种,旨在评估模型的创造性多步骤逻辑推理能力。数独变种对于推理研究来说是一个独特的领域,每个谜题都有独特的约束条件,要求解决者识别出新的逻辑突破点(“突破点”),而非依赖记忆。尽管数独谜题多样,但它们保持了清晰一致的评价标准。Sudoku-Bench包括一套精心挑选的谜题、标准化的文本谜题表示以及灵活的工具,与数千个公开可用的谜题兼容,易于扩展为一般研究环境。基准实验表明,最先进的LLM在没有辅助的情况下只能解决不到15%的谜题,这突显了提高长期战略推理能力的巨大机会。
Key Takeaways
- 大型语言模型(LLM)的现有推理基准测试常常不能准确评估模型的创造力,更多地是检测模型的记忆能力。
- Sudoku-Bench是一个新的基准测试,旨在评估模型的创造性多步骤逻辑推理能力。
- 数独变种是评估逻辑推理能力的理想领域,因为它们要求识别逻辑突破点而非依赖记忆。
- Sudoku-Bench包括精选的谜题集、标准化的文本表示工具和灵活的评价系统。
- 基准实验表明,最先进的LLM解决数独谜题的能力有限,突显了提高长期战略推理能力的需求。
- Sudoku-Bench易于扩展为一般研究环境,并可与数千个公开可用的谜题兼容。
点此查看论文截图