⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-05-25 更新
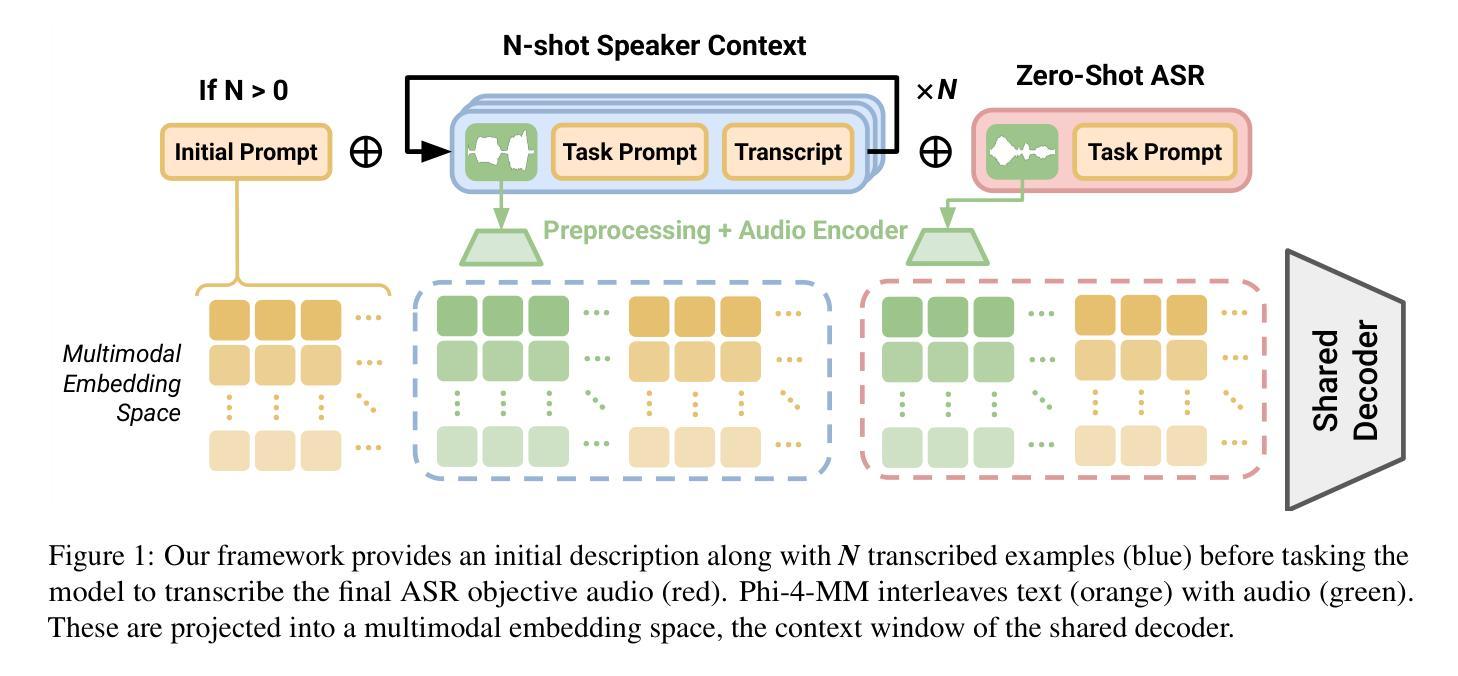
In-Context Learning Boosts Speech Recognition via Human-like Adaptation to Speakers and Language Varieties
Authors:Nathan Roll, Calbert Graham, Yuka Tatsumi, Kim Tien Nguyen, Meghan Sumner, Dan Jurafsky
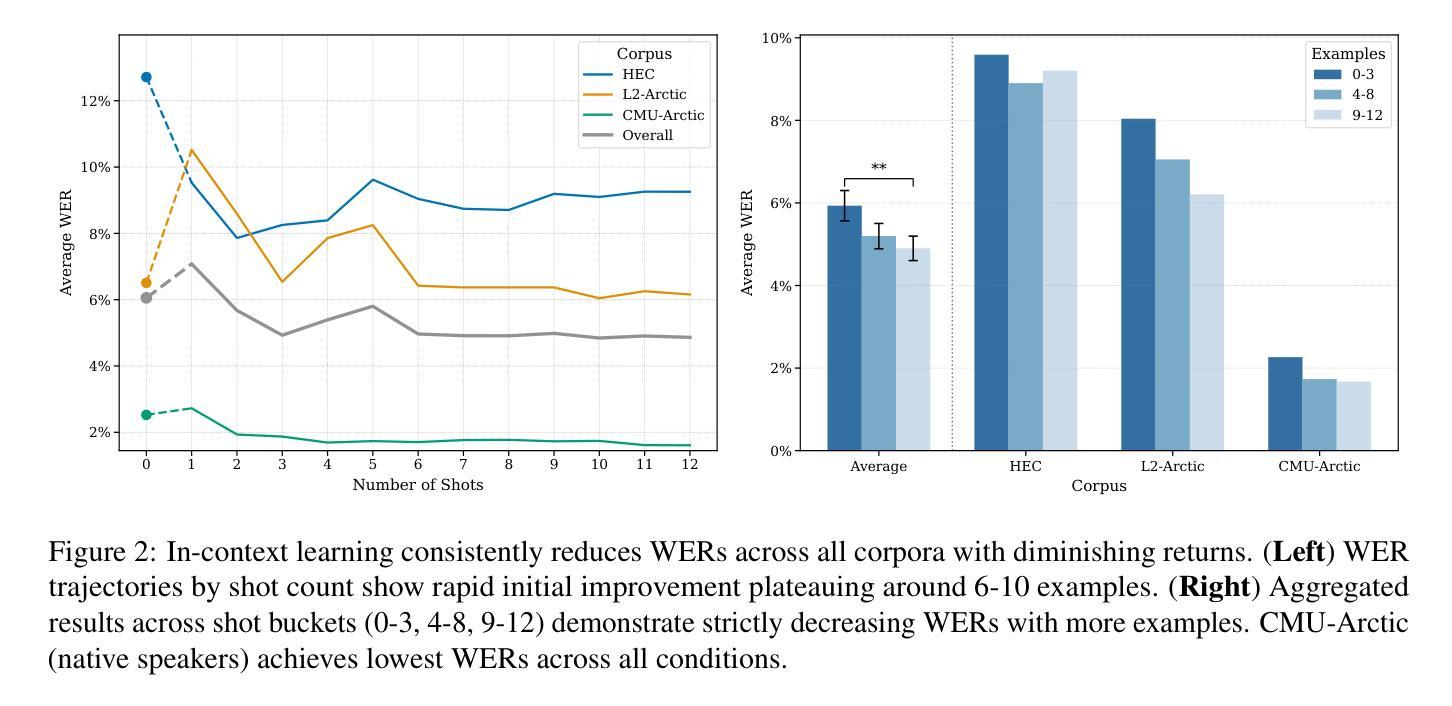
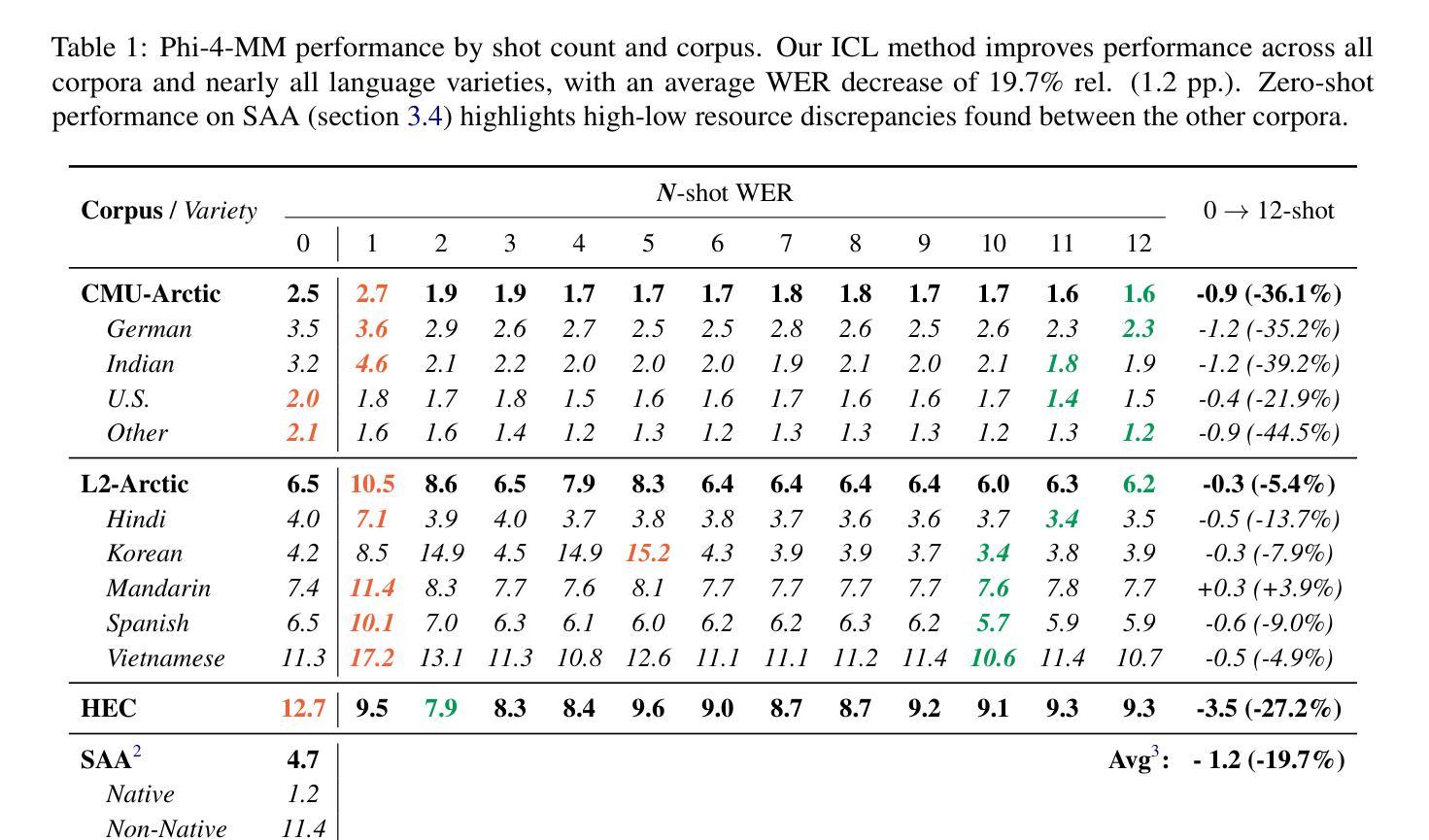
Human listeners readily adjust to unfamiliar speakers and language varieties through exposure, but do these adaptation benefits extend to state-of-the-art spoken language models? We introduce a scalable framework that allows for in-context learning (ICL) in Phi-4 Multimodal using interleaved task prompts and audio-text pairs, and find that as few as 12 example utterances (~50 seconds) at inference time reduce word error rates by a relative 19.7% (1.2 pp.) on average across diverse English corpora. These improvements are most pronounced in low-resource varieties, when the context and target speaker match, and when more examples are provided–though scaling our procedure yields diminishing marginal returns to context length. Overall, we find that our novel ICL adaptation scheme (1) reveals a similar performance profile to human listeners, and (2) demonstrates consistent improvements to automatic speech recognition (ASR) robustness across diverse speakers and language backgrounds. While adaptation succeeds broadly, significant gaps remain for certain varieties, revealing where current models still fall short of human flexibility. We release our prompts and code on GitHub.
人类听众通过接触很容易适应不熟悉的说话者和语言变体,但这些适应好处是否延伸到最先进的口语模型呢?我们引入了一个可扩展的框架,允许在Phi-4多模式中使用上下文学习(ICL),通过交替的任务提示和音频文本对进行学习,我们发现,在推理时间只需12个示例话语(约50秒),就可以在多种英语语料库中平均降低相对字错误率19.7%(1.2个百分点)。这些改进在低资源变体中最为明显,当上下文和目标说话者匹配时,以及提供更多示例时——尽管扩大我们的程序会给上下文长度带来边际递减的收益。总的来说,我们发现我们新颖的ICL适应方案(1)展现了与人类听众相似的性能特征,(2)在多种说话者和语言背景下,对自动语音识别(ASR)稳健性表现出了持续的改进。虽然适应大体上是成功的,但对于某些变体仍存在较大差距,这揭示了当前模型在灵活性方面仍然不及人类。我们在GitHub上发布了我们的提示和代码。
论文及项目相关链接
PDF 15 pages; 3 figures
Summary
本文介绍了一个可扩展的框架,该框架允许在Phi-4多模式中使用上下文学习(ICL)来适应不熟悉的语言模型。通过间隔的任务提示和音频文本对,发现只需在推理时间提供少量的示例话语(约50秒),平均降低相对词错误率为降低词错误率的百分比比未改进的基线降低了19.7%(减少百分之一),减少了在多样化的英语语料库上的误差率。改善最大的场合是在资源和目标演讲者相匹配时提供更多示例的场合,而增加上下文长度则产生边际收益递减效应。总体而言,本文提出的ICL适应方案(1)表现出与人类听众相似的性能特征,(2)证明了在多样化和背景各异的演讲者中自动语音识别(ASR)稳健性的持续改进。尽管适应是成功的,但对于某些语言变体仍然存在显著的差距,揭示了当前模型仍然无法与人类灵活性完全匹配的地方。我们已在GitHub上发布了提示和代码。
Key Takeaways
- 介绍了一个可扩展的框架,允许使用上下文学习(ICL)来增强语言模型的适应性。
- 通过间隔的任务提示和音频文本对,少量示例话语即可改善语言模型的性能。
- 平均降低词错误率显著,尤其是在资源和目标演讲者相匹配的情况下提供更多示例时改善更明显。但上下文长度的边际效益有所递减。
点此查看论文截图

Towards Inclusive ASR: Investigating Voice Conversion for Dysarthric Speech Recognition in Low-Resource Languages
Authors:Chin-Jou Li, Eunjung Yeo, Kwanghee Choi, Paula Andrea Pérez-Toro, Masao Someki, Rohan Kumar Das, Zhengjun Yue, Juan Rafael Orozco-Arroyave, Elmar Nöth, David R. Mortensen
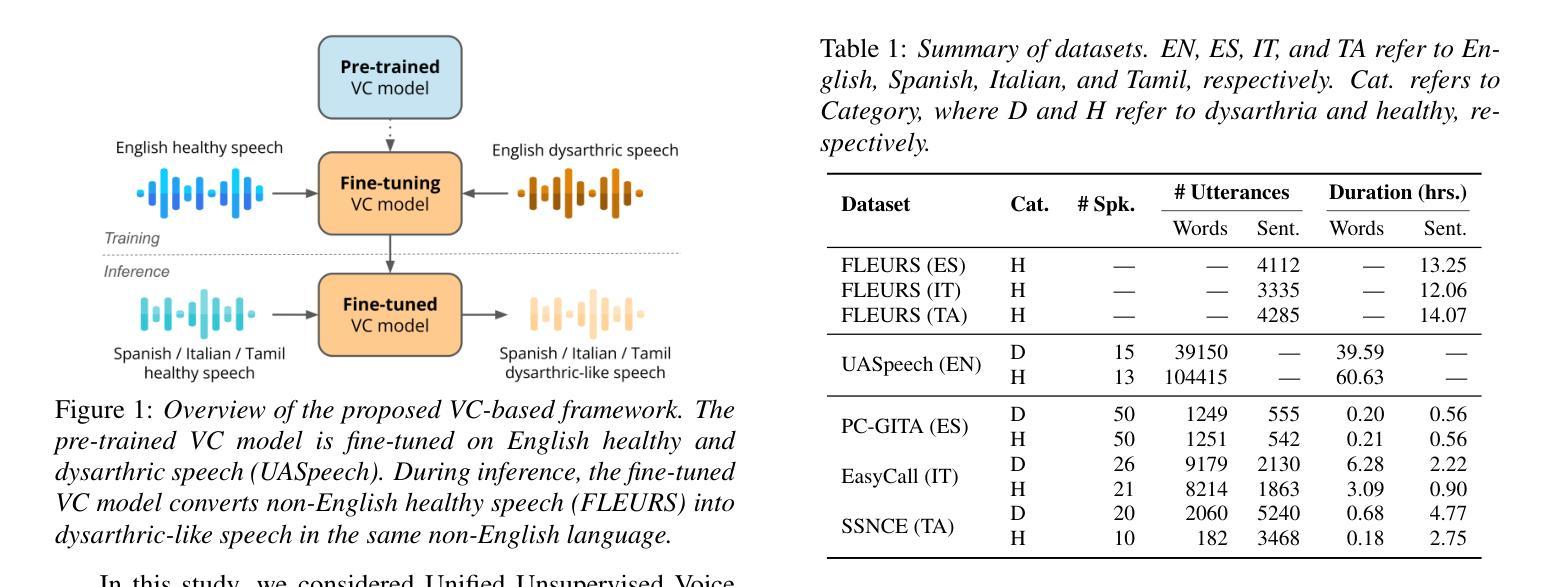
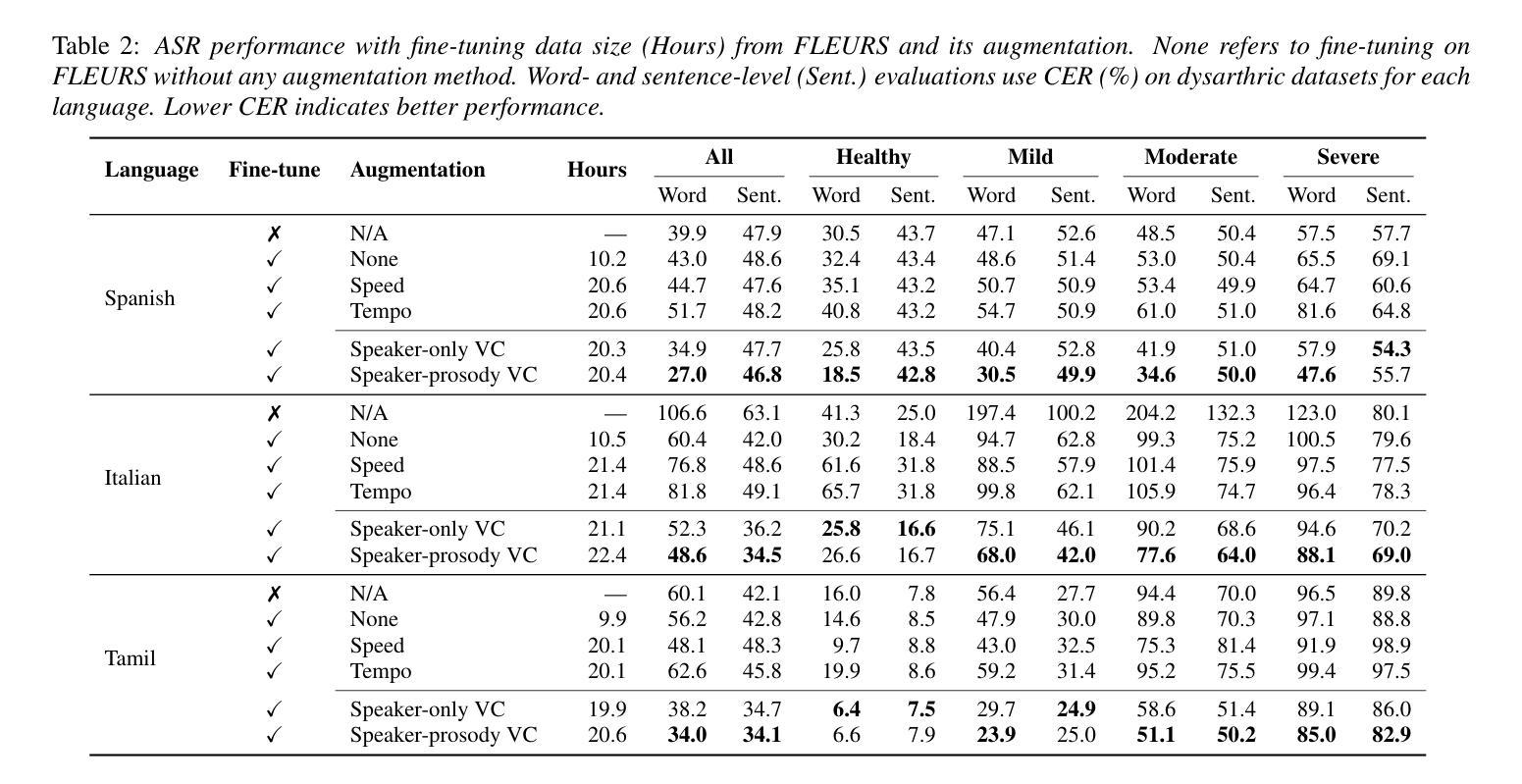
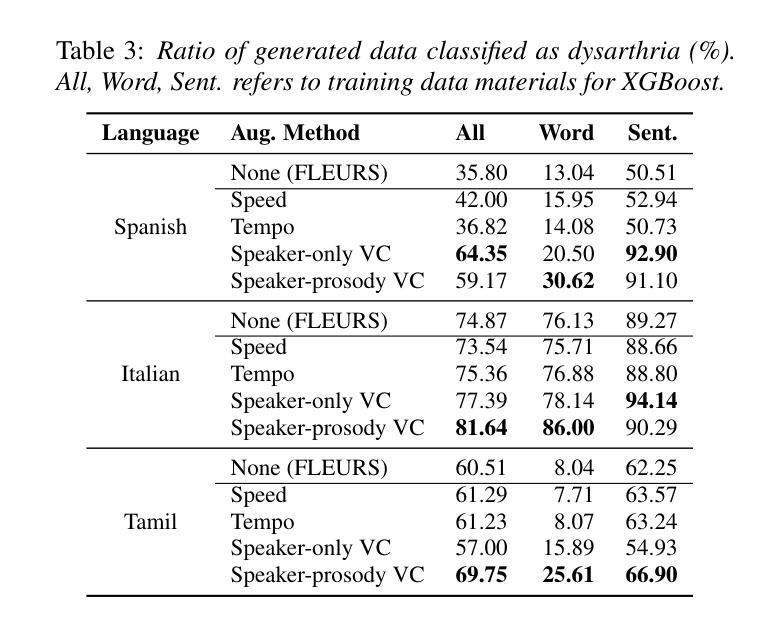
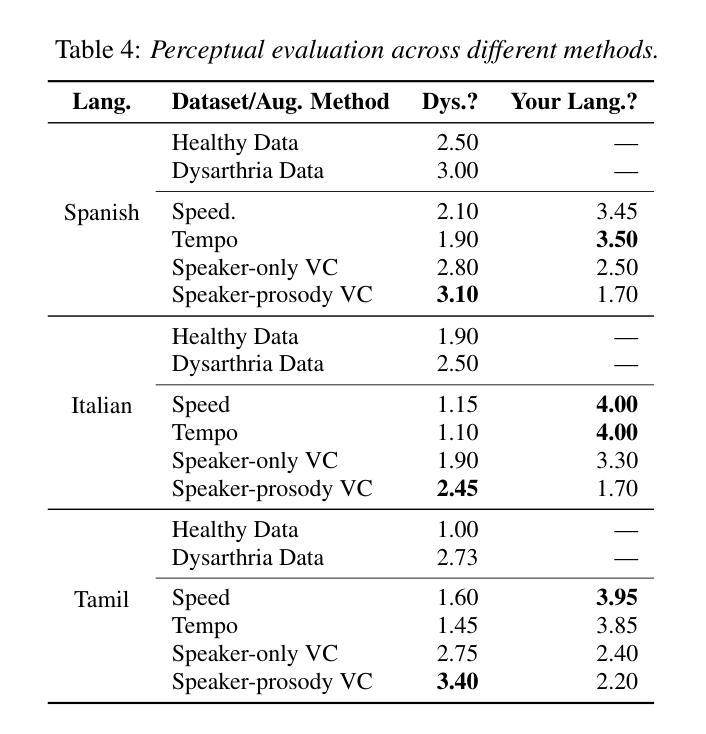
Automatic speech recognition (ASR) for dysarthric speech remains challenging due to data scarcity, particularly in non-English languages. To address this, we fine-tune a voice conversion model on English dysarthric speech (UASpeech) to encode both speaker characteristics and prosodic distortions, then apply it to convert healthy non-English speech (FLEURS) into non-English dysarthric-like speech. The generated data is then used to fine-tune a multilingual ASR model, Massively Multilingual Speech (MMS), for improved dysarthric speech recognition. Evaluation on PC-GITA (Spanish), EasyCall (Italian), and SSNCE (Tamil) demonstrates that VC with both speaker and prosody conversion significantly outperforms the off-the-shelf MMS performance and conventional augmentation techniques such as speed and tempo perturbation. Objective and subjective analyses of the generated data further confirm that the generated speech simulates dysarthric characteristics.
针对发音困难(发音障碍)语音的自动语音识别(ASR)由于其数据稀缺性仍然具有挑战性,特别是在非英语环境中更是如此。为解决这一问题,我们在英语发音困难语音(UASpeech)上对语音转换模型进行微调,以编码说话人的特性和韵律失真,然后将其应用于将健康的非英语语音(FLEURS)转换为非英语发音障碍类语音。然后使用生成的数据对多语种自动语音识别模型Massively Multilingual Speech(MMS)进行微调,以提高对发音障碍语音的识别能力。在PC-GITA(西班牙语)、EasyCall(意大利语)和SSNCE(泰米尔语)上的评估表明,同时实现说话人和韵律转换的语音转换方法显著优于现成的MMS性能和传统的增强技术,如速度和节奏扰动。对生成数据的客观和主观分析进一步证实,生成的语音模拟了发音障碍的特征。
论文及项目相关链接
PDF 5 pages, 1 figure, Accepted to Interspeech 2025
Summary
本文主要介绍了如何利用英语发音障碍语音(UASpeech)训练语音转换模型,该模型可以编码说话人的特征和韵律扭曲。然后,将此模型应用于将健康的非英语语音(FLEURS)转换为非英语的发音障碍语音。生成的语音数据用于微调多语言自动语音识别(ASR)模型Massively Multilingual Speech(MMS),以提高对发音障碍语音的识别能力。评估结果表明,同时转换说话人和韵律的语音转换(VC)显著优于现成的MMS性能和传统的增强技术,如速度和节奏扰动。对生成数据的客观和主观分析进一步证实,生成的语音模拟了发音障碍的特征。
Key Takeaways
- 数据稀缺是非英语发音障碍语音自动语音识别(ASR)的主要挑战。
- 通过英语发音障碍语音(UASpeech)训练语音转换模型以编码说话人的特征和韵律扭曲。
- 模型应用于将健康非英语语音转换为非英语的发音障碍语音。
- 生成的语音数据用于微调多语言ASR模型Massively Multilingual Speech(MMS)。
- 语音转换(VC)在转换说话人和韵律方面显著提高了ASR性能。
- 评估结果表明,VC方法优于传统的增强技术和现成的ASR模型。
点此查看论文截图

Mitigating Subgroup Disparities in Multi-Label Speech Emotion Recognition: A Pseudo-Labeling and Unsupervised Learning Approach
Authors:Yi-Cheng Lin, Huang-Cheng Chou, Hung-yi Lee
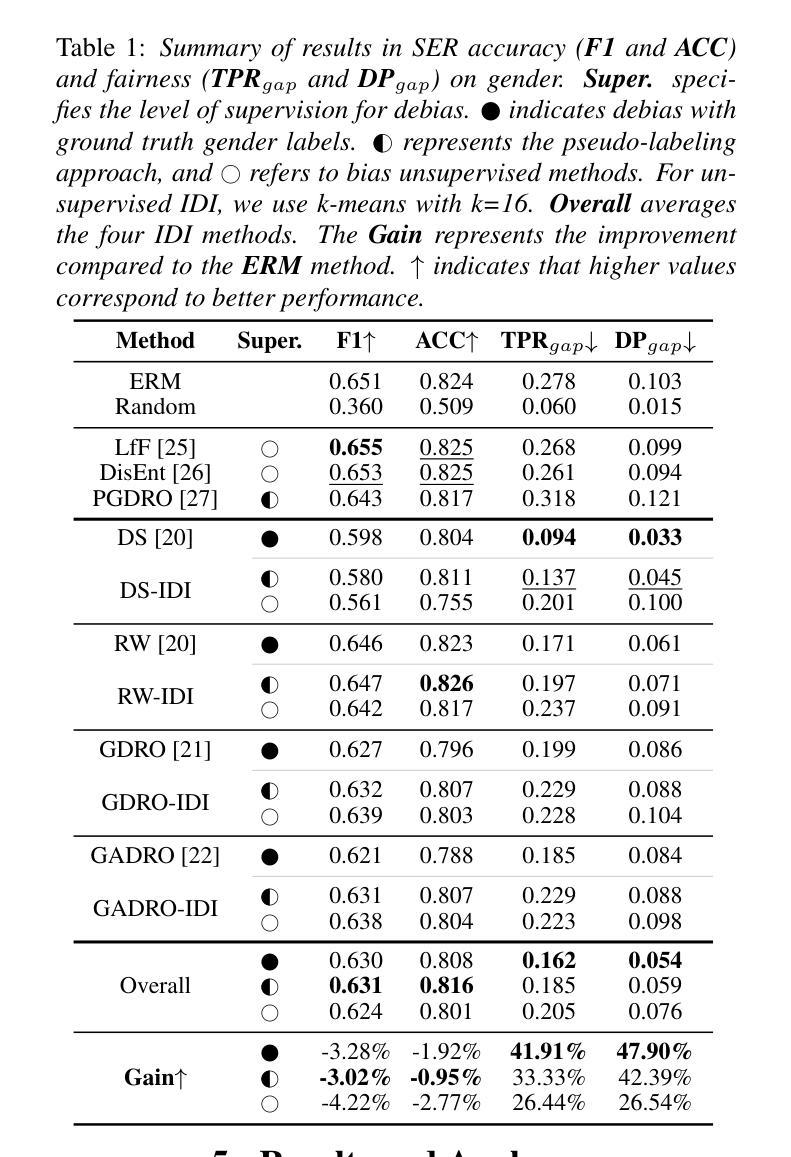
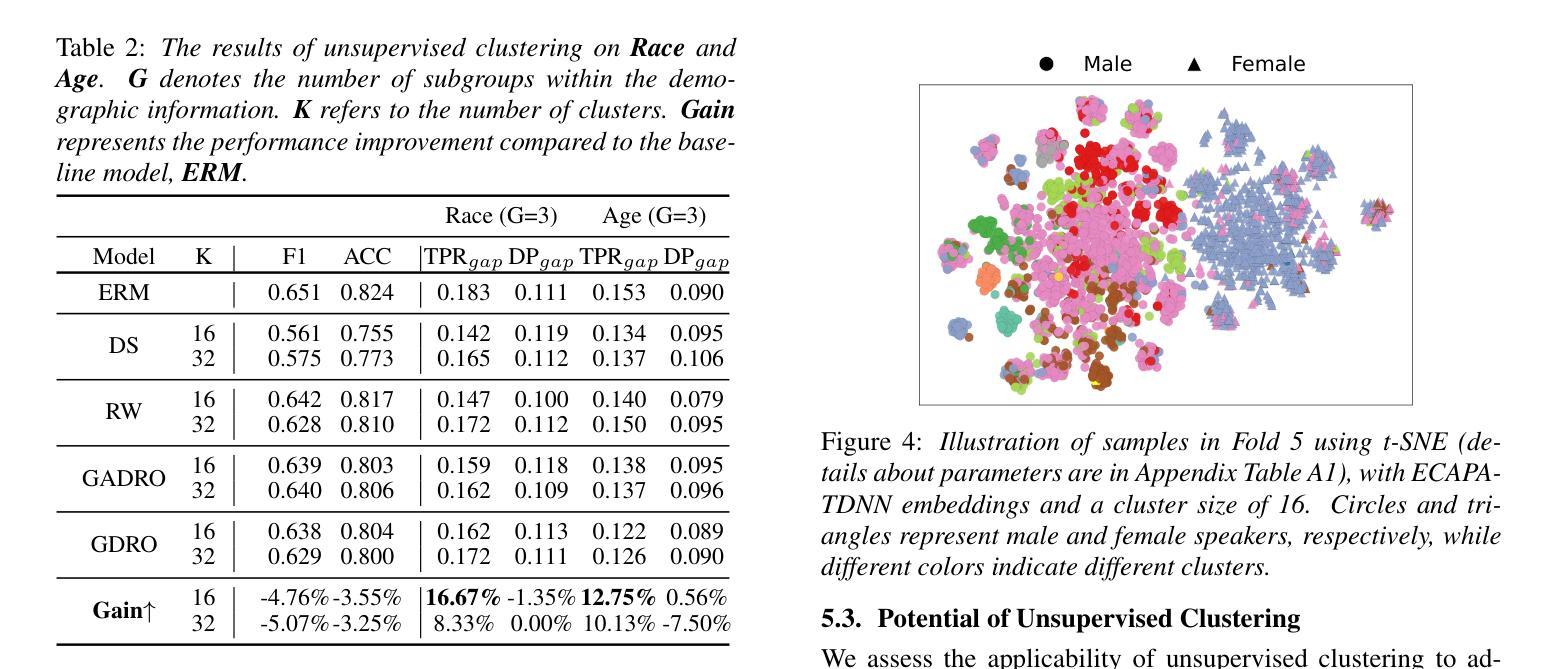
While subgroup disparities and performance bias are increasingly studied in computational research, fairness in categorical Speech Emotion Recognition (SER) remains underexplored. Existing methods often rely on explicit demographic labels, which are difficult to obtain due to privacy concerns. To address this limitation, we introduce an Implicit Demography Inference (IDI) module that leverages pseudo-labeling from a pre-trained model and unsupervised learning using k-means clustering to mitigate bias in SER. Our experiments show that pseudo-labeling IDI reduces subgroup disparities, improving fairness metrics by over 33% with less than a 3% decrease in SER accuracy. Also, the unsupervised IDI yields more than a 26% improvement in fairness metrics with a drop of less than 4% in SER performance. Further analyses reveal that the unsupervised IDI consistently mitigates race and age disparities, demonstrating its potential in scenarios where explicit demographic information is unavailable.
在计算研究中,虽然对子群体差异和性能偏见的研究越来越多,但在分类语音情感识别(SER)中的公平性仍然被忽视。现有方法通常依赖于明确的人口统计标签,但由于隐私担忧,这些标签很难获得。为了解决这一局限性,我们引入了一个隐式人口统计推断(IDI)模块,该模块利用预训练模型的伪标签和通过k-means聚类进行无监督学习,以减轻SER中的偏见。我们的实验表明,伪标签IDI减少了子群体差异,通过提高超过33%的公平性指标,同时SER准确率下降不到3%。此外,无监督的IDI在公平性指标上提高了超过26%,同时SER性能下降不到4%。进一步的分析表明,无监督的IDI持续缓解了种族和年龄差异,证明了在缺乏明确人口统计信息的情况下,其潜在的应用价值。
论文及项目相关链接
PDF Accepted by InterSpeech 2025. 7 pages including 2 pages of appendix
摘要
该文本主要探讨了在计算研究中越来越受关注的子群差异和性能偏差问题,并指出分类语音情感识别(SER)中的公平性尚未得到充分探索。现有方法往往依赖于难以获得的明确人口统计标签。为解决这一局限性,我们引入了隐式人口统计推断(IDI)模块,该模块利用预训练模型的伪标签和K均值聚类等无监督学习技术来缓解SER中的偏见。实验表明,伪标签化的IDI能够减少子群差异,在公平度指标上提高超过百分之三十三的同时仅降低SER准确率不到百分之三。此外,无监督的IDI在公平度指标上提高了超过百分之二十六,且只降低了不到百分之四的SER性能。进一步分析表明,无监督的IDI在缓解种族和年龄差异方面表现稳定,显示出在缺乏明确人口统计信息的情况下具有潜力。
关键见解
- 当前研究的关注点是识别和分析计算研究中日益凸显的子群差异和性能偏差问题,并指出了现有的分类语音情感识别(SER)方法在处理公平性方面的不足。
- 现有方法过于依赖难以获取的人口统计标签作为输入,因此存在局限性。为解决这一问题,引入了一种名为隐式人口统计推断(IDI)的新模块。该模块使用预训练模型的伪标签和无监督学习技术来缓解偏见问题。
- 通过实验验证了伪标签化的IDI在减少子群差异和提高公平性方面的有效性,其改进效果显著且对SER准确率的影响较小。
- 无监督的IDI在公平度指标上表现出更好的效果,并且在维持相对较高的SER性能的同时进行改进。这表明无监督学习方法在处理缺乏明确人口统计信息的情况时具有优势。
点此查看论文截图

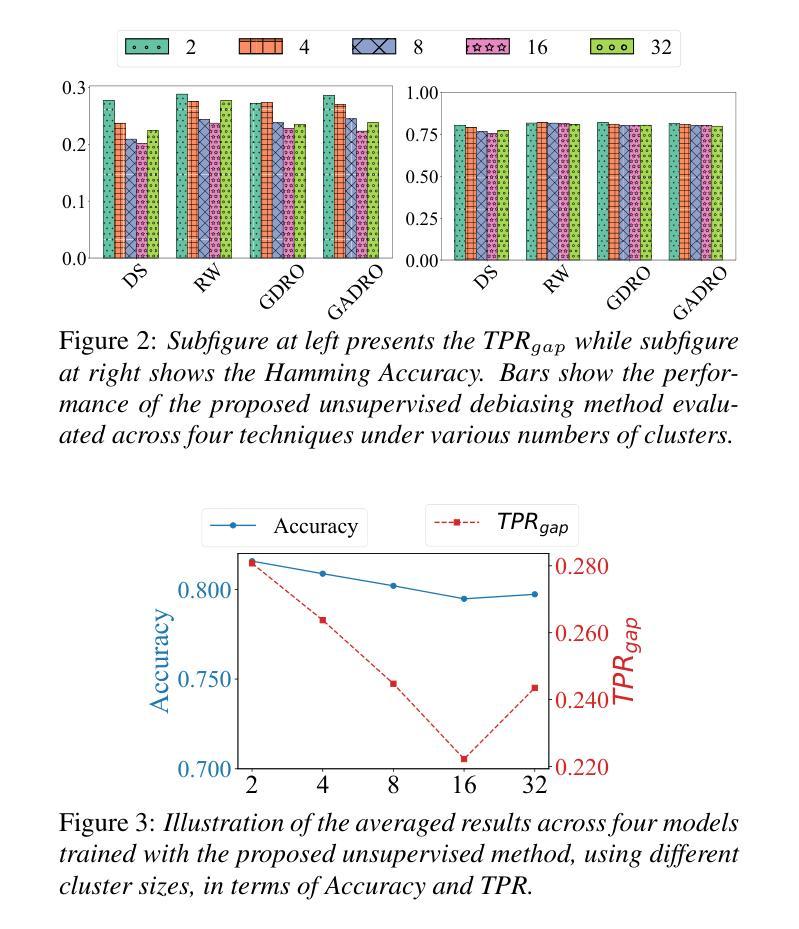
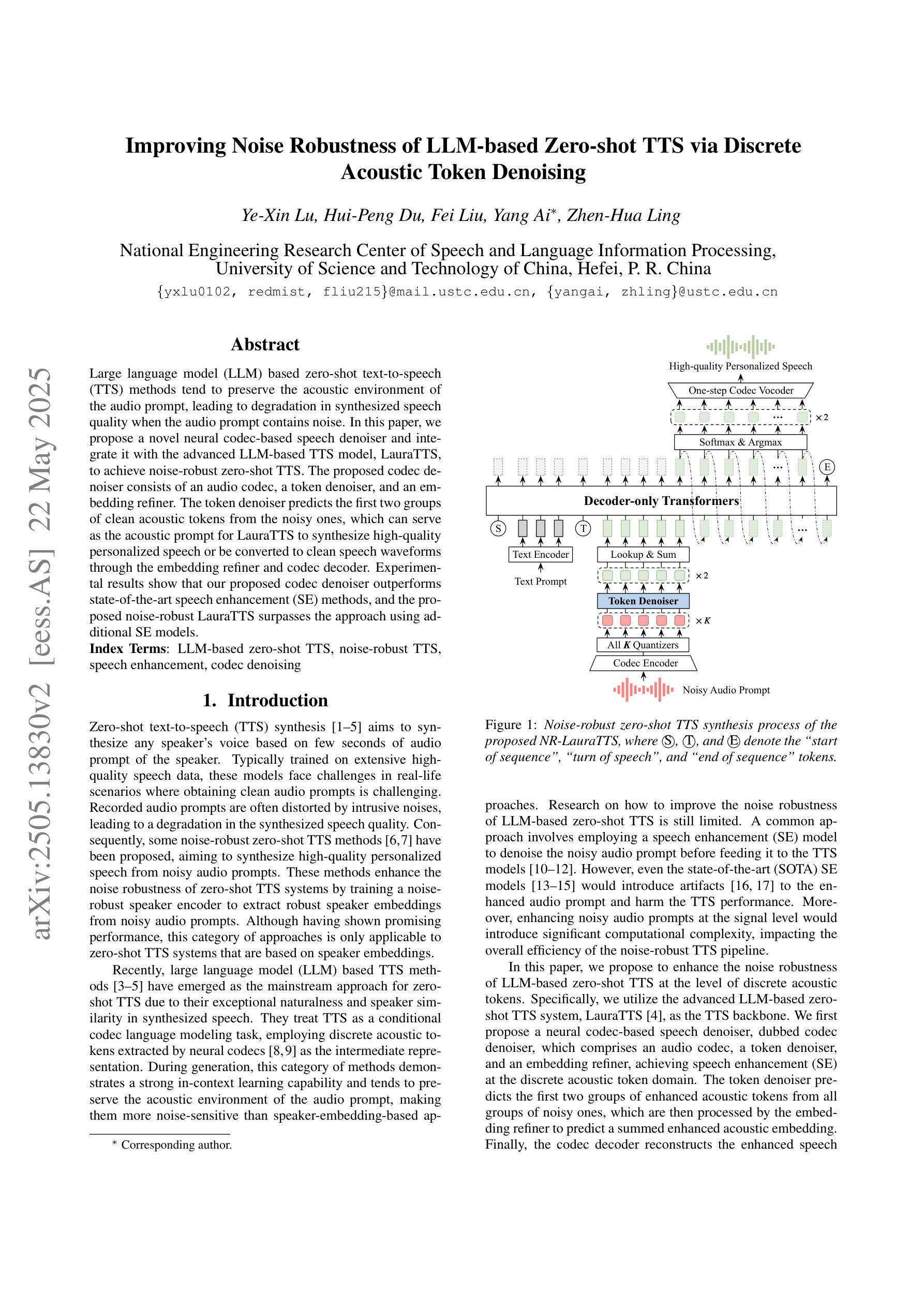
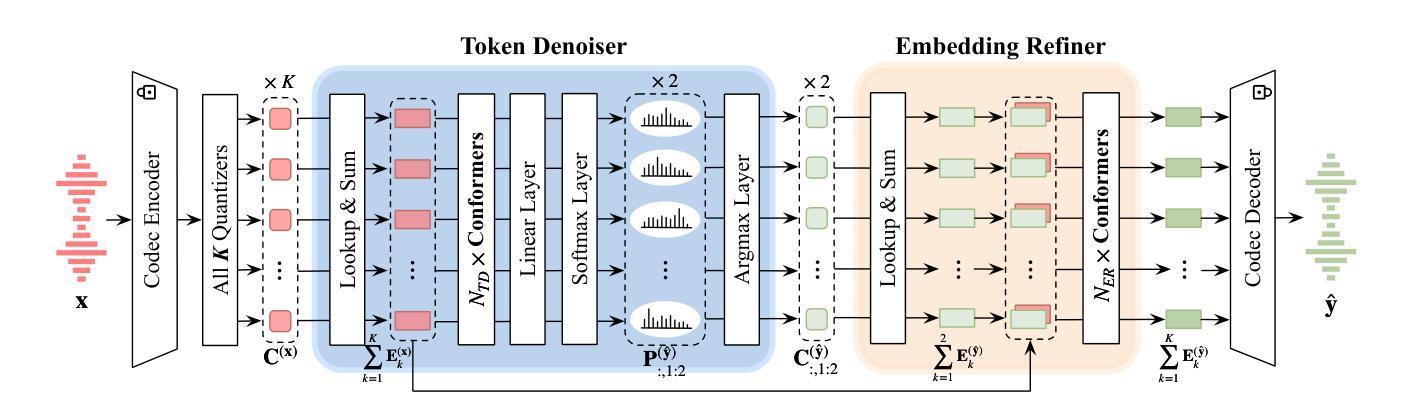
Improving Noise Robustness of LLM-based Zero-shot TTS via Discrete Acoustic Token Denoising
Authors:Ye-Xin Lu, Hui-Peng Du, Fei Liu, Yang Ai, Zhen-Hua Ling
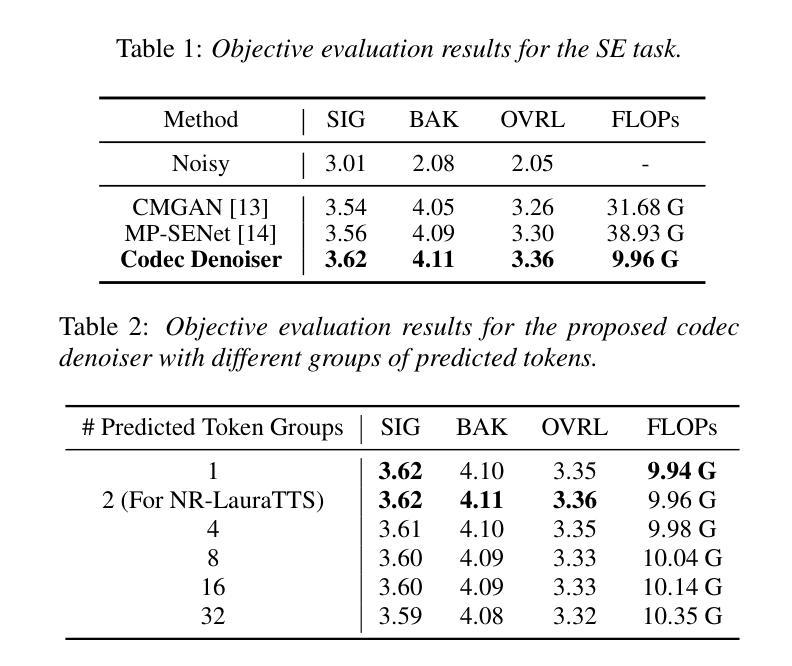
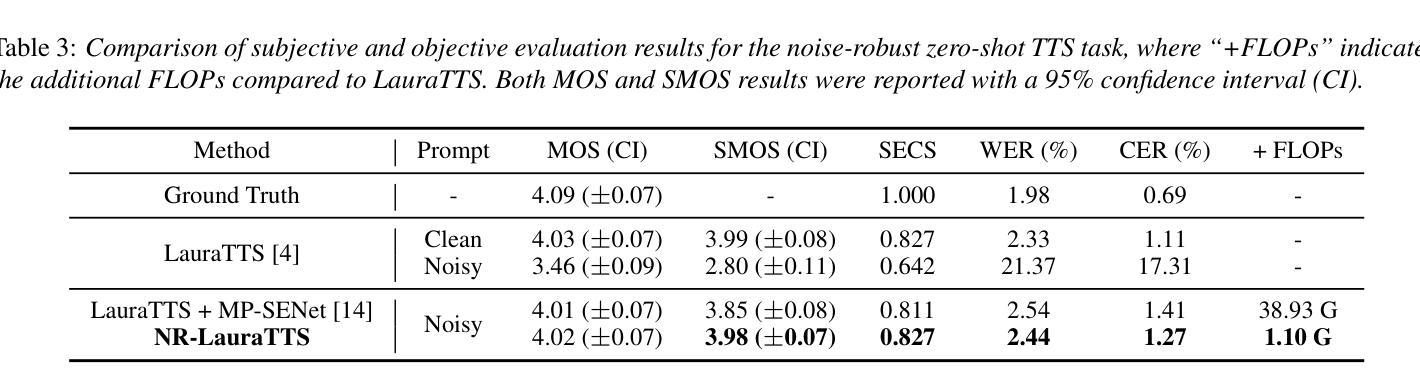
Large language model (LLM) based zero-shot text-to-speech (TTS) methods tend to preserve the acoustic environment of the audio prompt, leading to degradation in synthesized speech quality when the audio prompt contains noise. In this paper, we propose a novel neural codec-based speech denoiser and integrate it with the advanced LLM-based TTS model, LauraTTS, to achieve noise-robust zero-shot TTS. The proposed codec denoiser consists of an audio codec, a token denoiser, and an embedding refiner. The token denoiser predicts the first two groups of clean acoustic tokens from the noisy ones, which can serve as the acoustic prompt for LauraTTS to synthesize high-quality personalized speech or be converted to clean speech waveforms through the embedding refiner and codec decoder. Experimental results show that our proposed codec denoiser outperforms state-of-the-art speech enhancement (SE) methods, and the proposed noise-robust LauraTTS surpasses the approach using additional SE models.
基于大型语言模型(LLM)的零样本文本到语音(TTS)方法倾向于保留音频提示的声学环境,但当音频提示包含噪声时,会导致合成语音质量下降。在本文中,我们提出了一种新型的基于神经网络编解码器的语音去噪器,并将其与先进的LLM-based TTS模型LauraTTS相结合,实现了噪声鲁棒的零样本TTS。所提出的编解码器去噪器由音频编解码器、令牌去噪器和嵌入精炼器组成。令牌去噪器从嘈杂的令牌中预测前两个组的干净声学令牌,这可以作为LauraTTS合成高质量个性化语音的声学提示,或通过嵌入精炼器和编解码器解码器转换为干净的语音波形。实验结果表明,我们提出的编解码器去噪器优于最新的语音增强(SE)方法,并且所提出的噪声鲁棒的LauraTTS超过了使用附加SE模型的方法。
论文及项目相关链接
PDF Accepted by Interspeech 2025
Summary
本文提出了一种基于神经网络编解码器的语音去噪器,并将其与先进的LLM-based TTS模型LauraTTS相结合,实现了噪声鲁棒的零样本TTS。该编解码器去噪器包括音频编解码器、令牌去噪器和嵌入精炼器。实验结果表明,所提出的编解码器去噪器优于现有的语音增强方法,而提出的噪声鲁棒的LauraTTS则超越了使用附加SE模型的方法。
Key Takeaways
- LLM-based TTS方法会保留音频提示的声学环境,导致合成语音质量下降。
- 提出了一种新型的基于神经网络编解码器的语音去噪器,包括音频编解码器、令牌去噪器和嵌入精炼器。
- 令牌去噪器能从含噪音频中预测出清洁的声学令牌,可作为LauraTTS的高质语音合成或清洁语音波形的转换依据。
- 实验结果显示,所提出的编解码器去噪器在性能上超越了现有的语音增强方法。
- 整合编解码器去噪器和LauraTTS模型后,实现了噪声鲁棒的零样本TTS。
- 噪声鲁棒的LauraTTS模型在性能上超越了使用附加语音增强模型的方法。
- 该方法对于提高语音合成质量,尤其在含噪音频提示的情况下具有重要意义。
点此查看论文截图
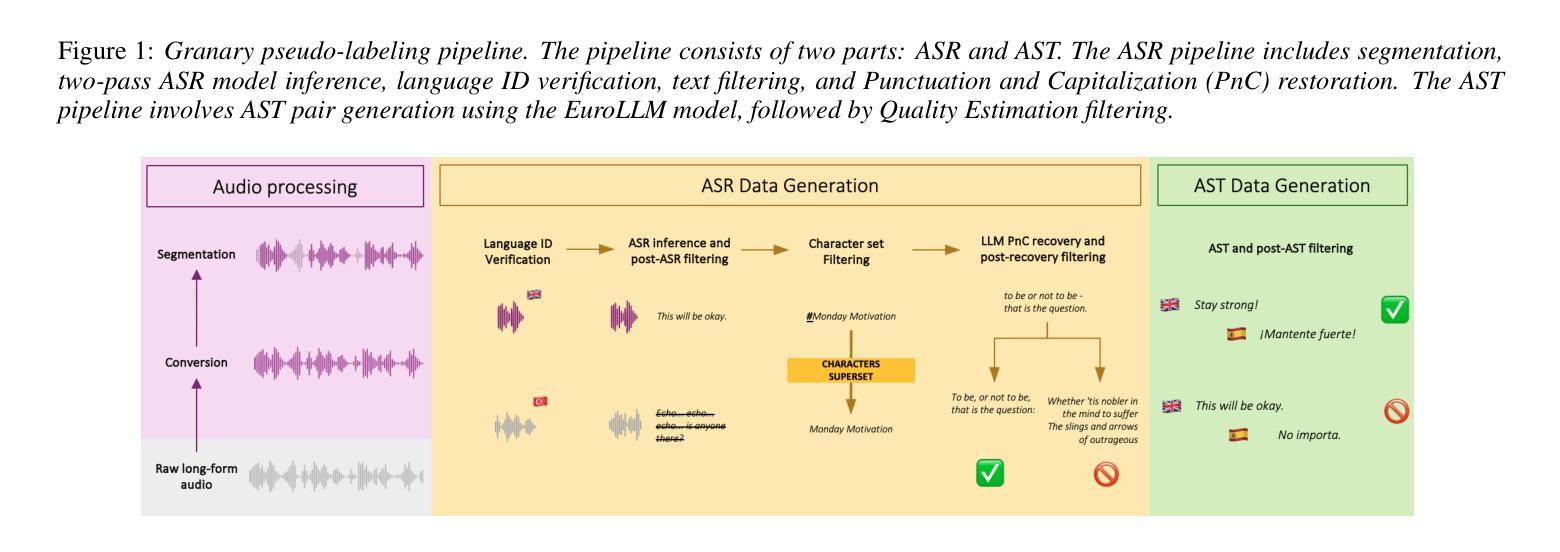
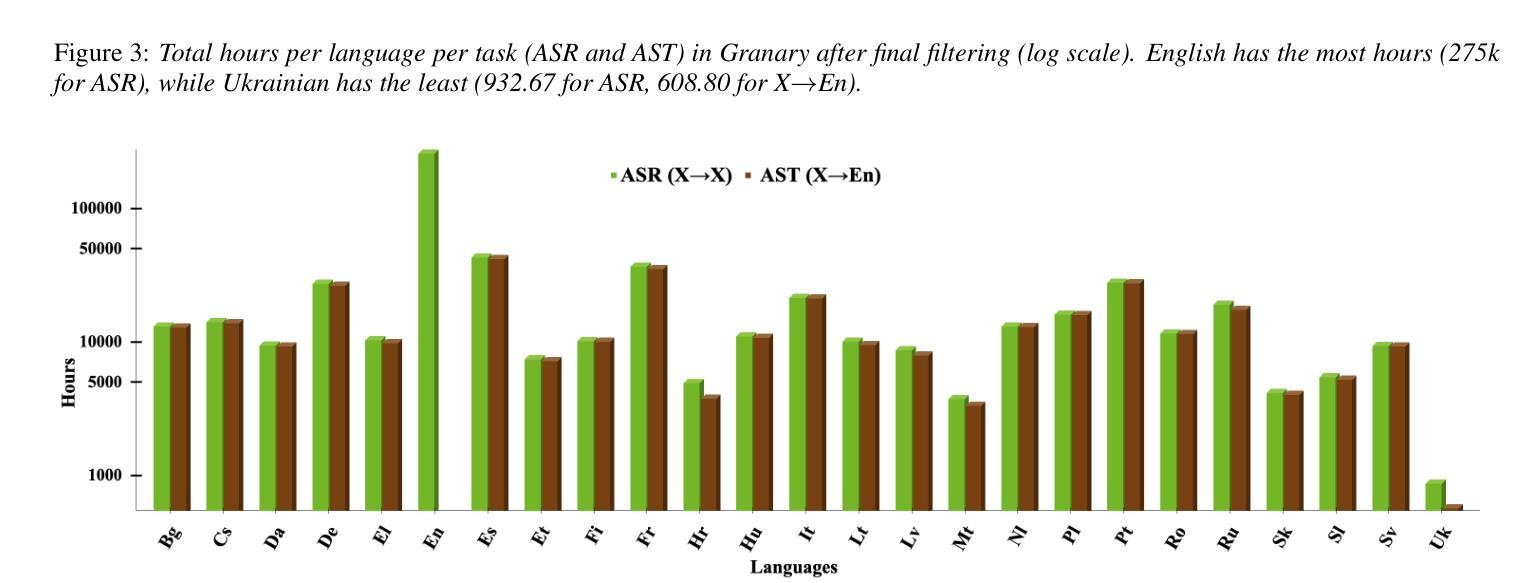
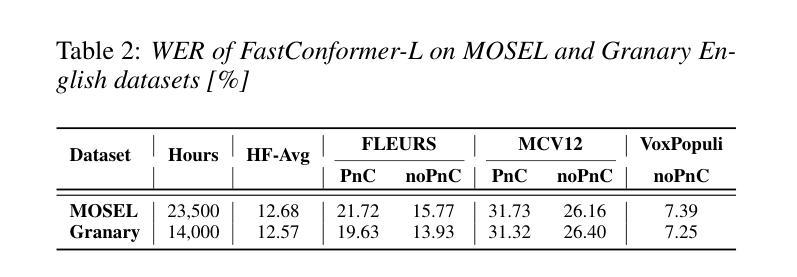
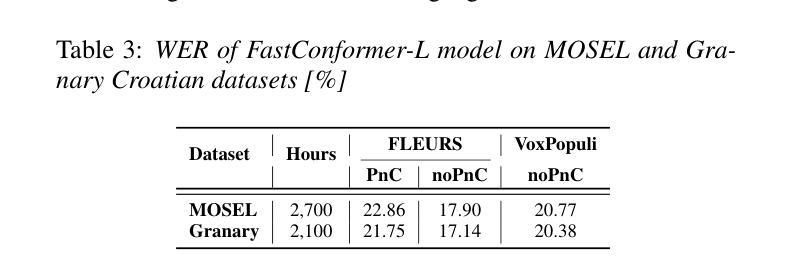
Granary: Speech Recognition and Translation Dataset in 25 European Languages
Authors:Nithin Rao Koluguri, Monica Sekoyan, George Zelenfroynd, Sasha Meister, Shuoyang Ding, Sofia Kostandian, He Huang, Nikolay Karpov, Jagadeesh Balam, Vitaly Lavrukhin, Yifan Peng, Sara Papi, Marco Gaido, Alessio Brutti, Boris Ginsburg
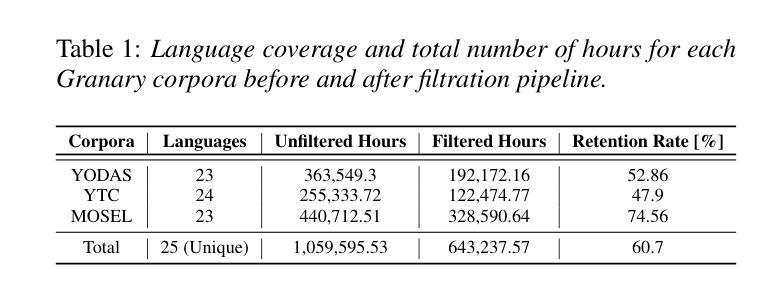
Multi-task and multilingual approaches benefit large models, yet speech processing for low-resource languages remains underexplored due to data scarcity. To address this, we present Granary, a large-scale collection of speech datasets for recognition and translation across 25 European languages. This is the first open-source effort at this scale for both transcription and translation. We enhance data quality using a pseudo-labeling pipeline with segmentation, two-pass inference, hallucination filtering, and punctuation restoration. We further generate translation pairs from pseudo-labeled transcriptions using EuroLLM, followed by a data filtration pipeline. Designed for efficiency, our pipeline processes vast amount of data within hours. We assess models trained on processed data by comparing their performance on previously curated datasets for both high- and low-resource languages. Our findings show that these models achieve similar performance using approx. 50% less data. Dataset will be made available at https://hf.co/datasets/nvidia/Granary
多任务和多语言方法对于大型模型有益,但由于数据稀缺,针对低资源语言的语音处理仍然被忽视。为了解决这个问题,我们推出了Granary,这是一个涵盖25种欧洲语言的语音数据集的大规模集合,用于语音识别和翻译。这是转录和翻译领域这一规模的首次开源努力。我们使用包含分割、二次推断、虚构过滤和标点恢复的伪标签管道来提高数据质量。我们进一步使用EuroLLM对伪标签转录生成翻译配对,随后进行数据过滤管道处理。我们的管道设计高效,能在数小时内处理大量数据。我们通过在为高资源和低资源语言先前整理的数据集上评估经过处理的数据训练的模型,对模型进行评估。我们的研究发现,这些模型使用约少一半的数据便实现了相似性能。数据集将发布在:https://hf.co/datasets/nvidia/Granary。
论文及项目相关链接
PDF Accepted at Interspeech 2025 v2: Added links
Summary
本文介绍了针对语音识别和翻译的开源大规模语音数据集Granary,覆盖25种欧洲语言。通过使用伪标签管道增强数据质量,并使用EuroLLM生成翻译配对。研究发现,在处理后的数据上训练的模型在高低资源语言上都能实现相似的性能,而且只需要使用约50%的数据。数据集可用于训练更高效的语言模型,地址多语种场景下资源匮乏的问题。数据可用在该网址:https://hf.co/datasets/nvidia/Granary。
Key Takeaways
- 介绍了一种名为Granary的大规模语音数据集,支持跨25种欧洲语言的语音识别和翻译。
- 数据集通过伪标签管道增强数据质量,包括分割、二次推断、幻觉过滤和标点恢复等步骤。
- 利用EuroLLM生成伪标签转录的翻译配对。
- 通过效率高的管道处理大量数据,短时间内完成。
- 在高、低资源语言数据集上的评估显示,使用处理后的数据训练的模型性能良好,仅需要约50%的数据即可达到相似性能。
- 数据集解决了多语言场景下资源匮乏的问题。
点此查看论文截图

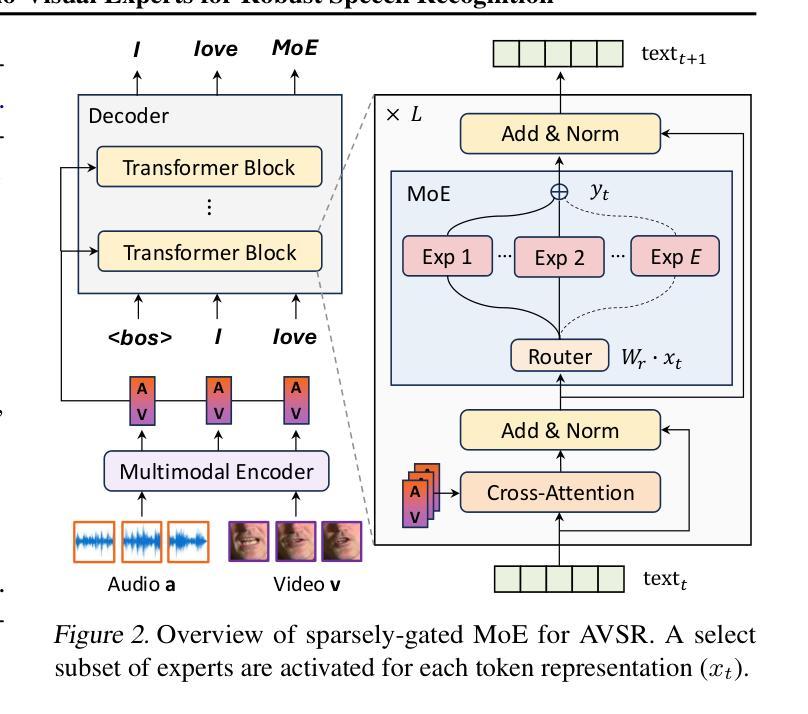
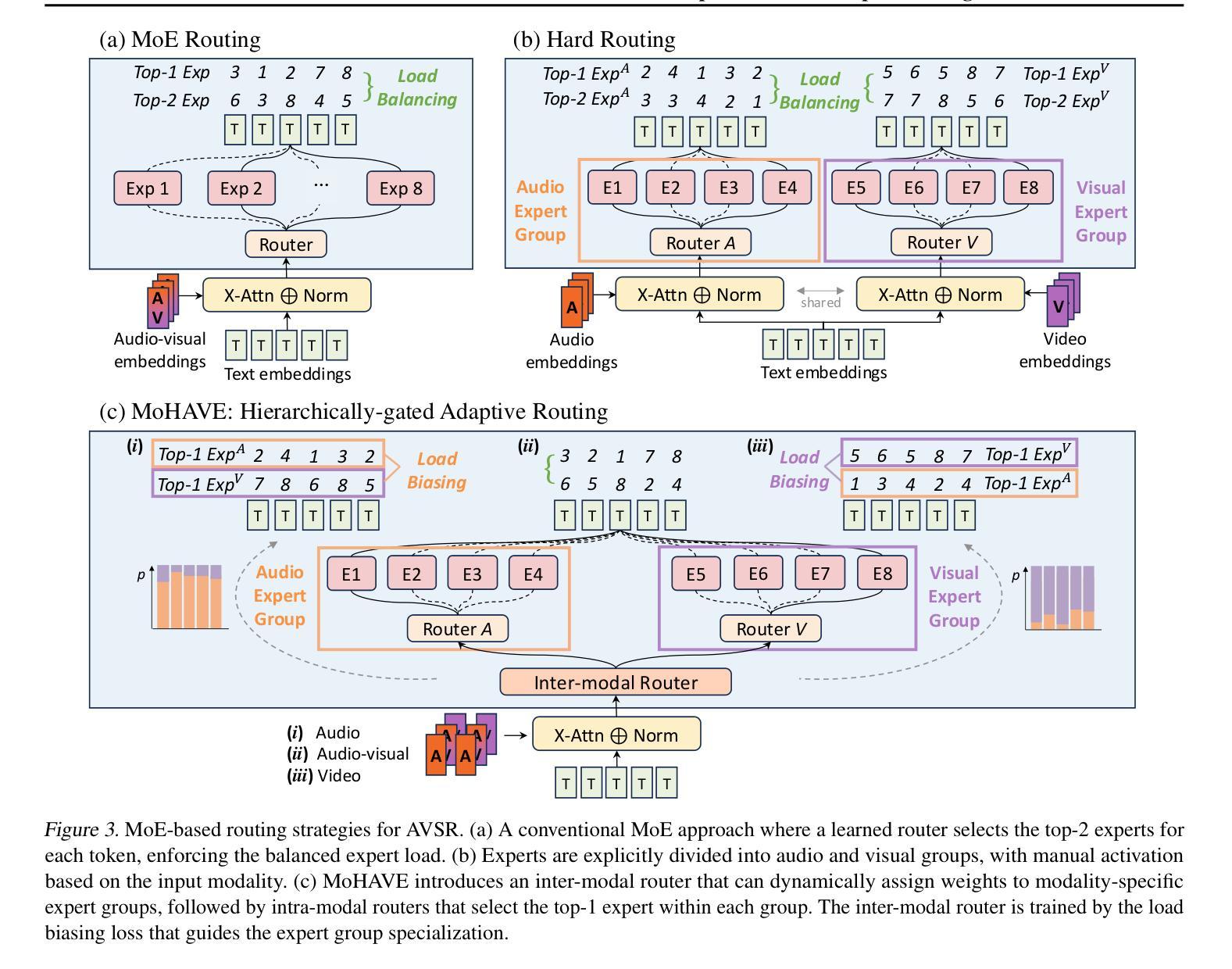
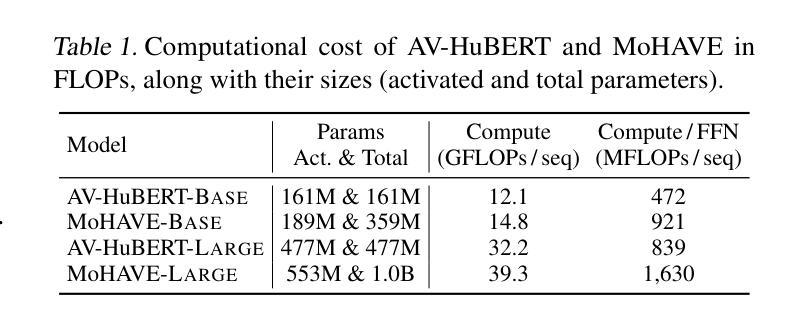
MoHAVE: Mixture of Hierarchical Audio-Visual Experts for Robust Speech Recognition
Authors:Sungnyun Kim, Kangwook Jang, Sangmin Bae, Sungwoo Cho, Se-Young Yun
Audio-visual speech recognition (AVSR) has become critical for enhancing speech recognition in noisy environments by integrating both auditory and visual modalities. However, existing AVSR systems struggle to scale up without compromising computational efficiency. In this study, we introduce MoHAVE (Mixture of Hierarchical Audio-Visual Experts), a novel robust AVSR framework designed to address these scalability constraints. By leveraging a Mixture-of-Experts (MoE) architecture, MoHAVE activates modality-specific expert groups, ensuring dynamic adaptation to various audio-visual inputs with minimal computational overhead. Key contributions of MoHAVE include: (1) a sparse MoE framework that efficiently scales AVSR model capacity, (2) a hierarchical gating mechanism that dynamically utilizes the expert groups based on input context, enhancing adaptability and robustness, and (3) remarkable performance across robust AVSR benchmarks, including LRS3 and MuAViC transcription and translation tasks, setting a new standard for scalable speech recognition systems.
视听语音识别(AVSR)通过结合听觉和视觉模式,在增强噪声环境中的语音识别方面发挥着至关重要的作用。然而,现有的AVSR系统在扩大规模时往往难以保证计算效率。在这项研究中,我们引入了MoHAVE(分层视听专家混合物),这是一种新型稳健的AVSR框架,旨在解决这些可扩展性约束。通过利用专家混合物(MoE)架构,MoHAVE激活了特定的专家小组,确保以最小的计算开销动态适应各种视听输入。MoHAVE的主要贡献包括:(1)一个稀疏的MoE框架,有效地扩展了AVSR模型的容量;(2)一种基于输入上下文的分层门控机制,动态利用专家小组,提高适应性和稳健性;(3)在包括LRS3和MuAViC转录和翻译任务在内的稳健AVSR基准测试上表现出卓越的性能,为可扩展的语音识别系统设定了新的标准。
论文及项目相关链接
PDF Accepted to ICML 2025
Summary
本文介绍了MoHAVE(基于层次音频视觉专家的混合模型),这是一种新型的稳健的视听语音识别框架,旨在解决可扩展性方面的限制。该框架利用混合专家(MoE)架构,激活模态特定的专家组,确保对各种视听输入的动态适应并具有较低的计算开销。其核心贡献包括构建高效的稀疏MoE框架,采用基于输入上下文的分层门控机制动态利用专家组,以及在多个稳健的视听语音识别基准测试中表现卓越。该模型在语音识别领域设定了新的可扩展性标准。
Key Takeaways
- MoHAVE是一个新颖的视听语音识别框架,结合了音频和视觉模态以增强在嘈杂环境中的语音识别能力。
- MoHAVE利用混合专家(MoE)架构来解决现有AVSR系统的可扩展性问题。
- MoHAVE通过激活模态特定的专家组,确保对不同的视听输入进行动态适应,同时具有较低的计算开销。
- MoHAVE包含一个稀疏MoE框架,可以高效地扩展AVSR模型的容量。
- MoHAVE采用分层门控机制,根据输入上下文动态利用专家组,增强了适应性和稳健性。
- MoHAVE在多个视听语音识别基准测试中表现突出,包括LRS3和MuAViC转录和翻译任务。
点此查看论文截图

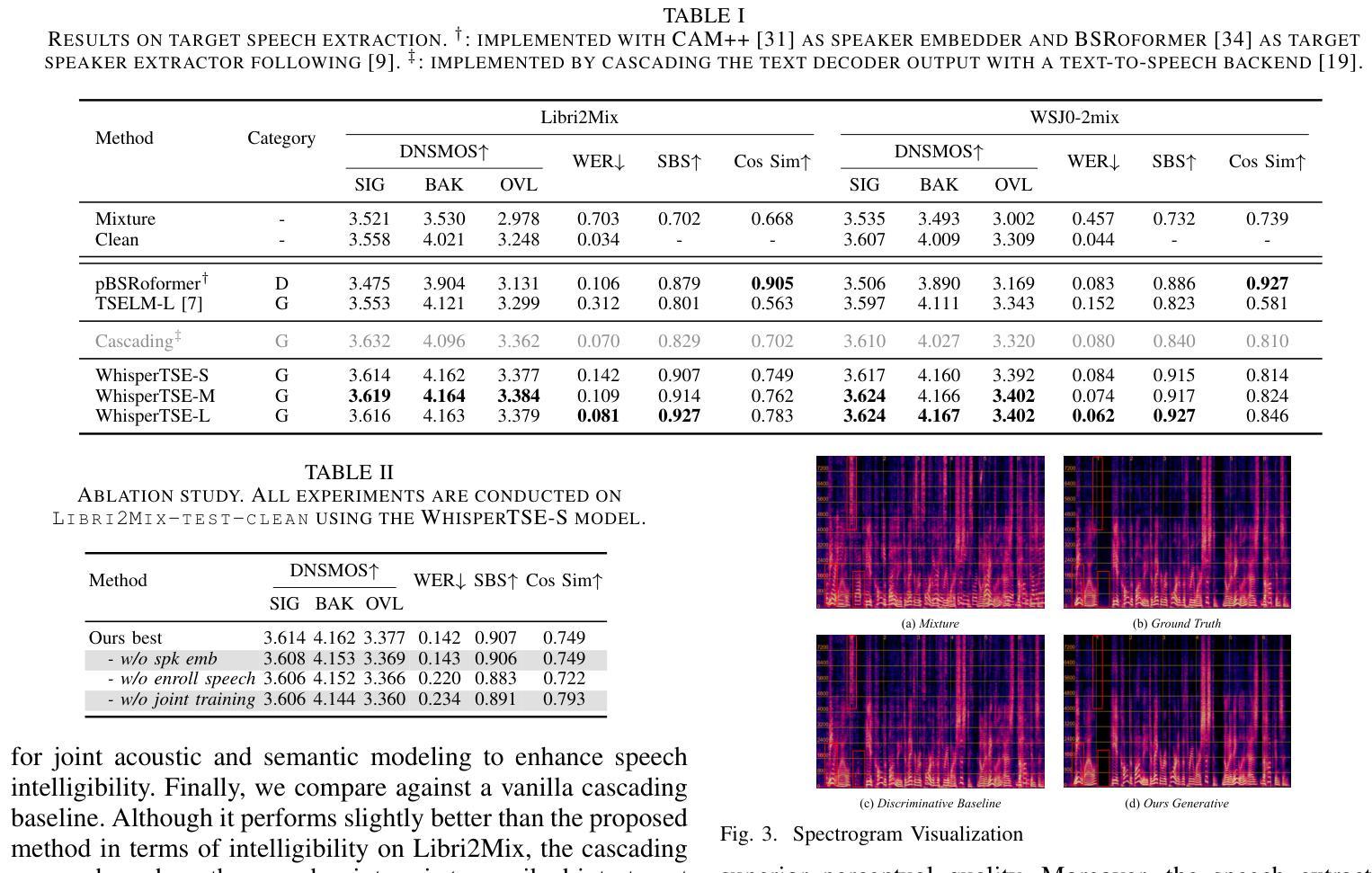
Enhancing Intelligibility for Generative Target Speech Extraction via Joint Optimization with Target Speaker ASR
Authors:Hao Ma, Rujin Chen, Xiao-Lei Zhang, Ju Liu, Xuelong Li
Target speech extraction (TSE) isolates the speech of a specific speaker from a multi-talker overlapped speech mixture. Most existing TSE models rely on discriminative methods, typically predicting a time-frequency spectrogram mask for the target speech. However, imperfections in these masks often result in over-/under-suppression of target/non-target speech, degrading perceptual quality. Generative methods, by contrast, re-synthesize target speech based on the mixture and target speaker cues, achieving superior perceptual quality. Nevertheless, these methods often overlook speech intelligibility, leading to alterations or loss of semantic content in the re-synthesized speech. Inspired by the Whisper model’s success in target speaker ASR, we propose a generative TSE framework based on the pre-trained Whisper model to address the above issues. This framework integrates semantic modeling with flow-based acoustic modeling to achieve both high intelligibility and perceptual quality. Results from multiple benchmarks demonstrate that the proposed method outperforms existing generative and discriminative baselines. We present speech samples on https://aisaka0v0.github.io/GenerativeTSE_demo/.
目标语音提取(TSE)从多说话人重叠的语音混合中分离出特定说话人的语音。现有的大多数TSE模型依赖于判别方法,通常预测目标语音的时间-频率谱图掩膜。然而,这些掩膜的不完美往往导致目标语音或非目标语音的过抑制/欠抑制,降低感知质量。相比之下,生成方法基于混合和目标说话人线索重新合成目标语音,实现优越的感知质量。然而,这些方法往往忽视了语音的可懂度,导致重新合成的语音中的语义内容发生改变或丢失。受Whisper模型在目标说话人语音识别中的成功启发,我们提出了基于预训练Whisper模型的生成TSE框架,以解决上述问题。该框架将语义建模与基于流的声学建模相结合,实现高可懂度和感知质量。来自多个基准测试的结果表明,所提出的方法优于现有的生成型和判别型基准方法。语音样本请访问:[https://aisaka0v0.github.io/GenerativeTSE_demo/。]
论文及项目相关链接
PDF Submitted to IEEE Signal Processing Letters
Summary
本文提出一种基于预训练Whisper模型的生成式目标语音提取框架,该框架结合了语义建模和基于流的声学建模,旨在提高目标语音提取的智听性和感知质量。该方法在多基准测试中的表现优于现有的生成式和判别式基线。
Key Takeaways
- 目标语音提取(TSE)是从多说话人重叠语音中分离特定说话人的语音。
- 现有TSE模型大多依赖于判别式方法,通过预测时间-频率谱图掩膜来提取目标语音。
- 判别式方法存在的缺陷是掩膜不完美,可能导致目标语音或非目标语音的过度/不足抑制,影响感知质量。
- 生成式方法通过混合语音和目标说话人线索重新合成目标语音,可以达到较高的感知质量。
- 然而,生成式方法常常忽视语音的清晰度,导致重新合成的语音中语义内容的改变或丢失。
- 本文受Whisper模型在目标说话人语音识别中的成功启发,提出一种基于预训练Whisper模型的生成式TSE框架。
点此查看论文截图

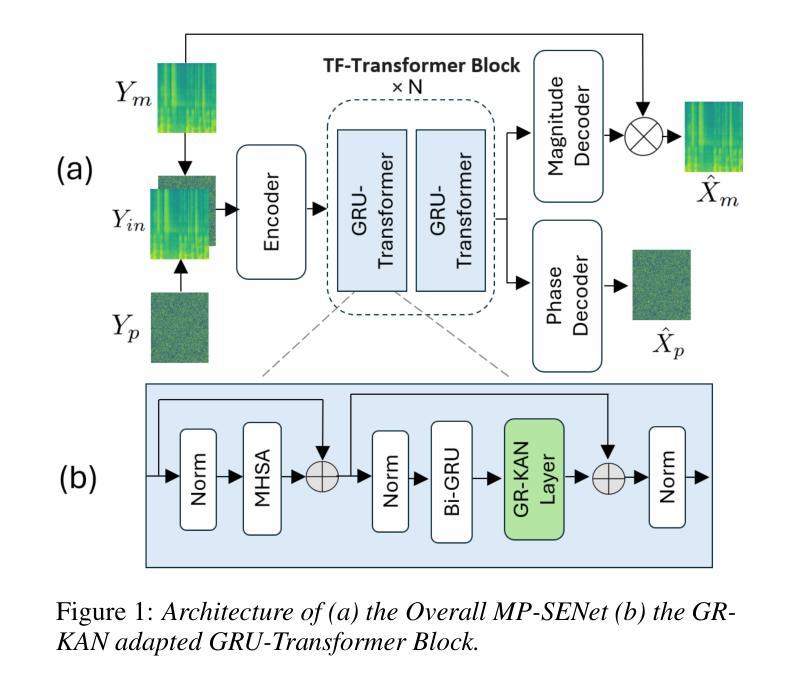
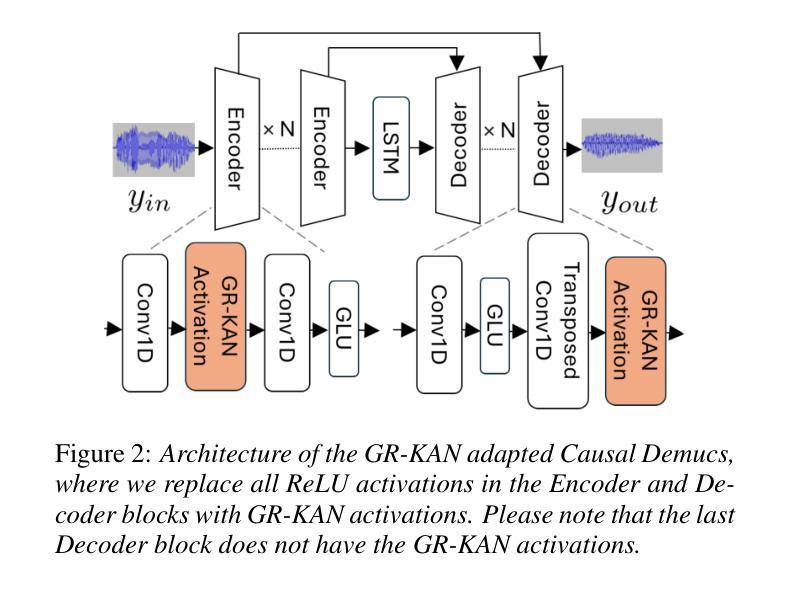
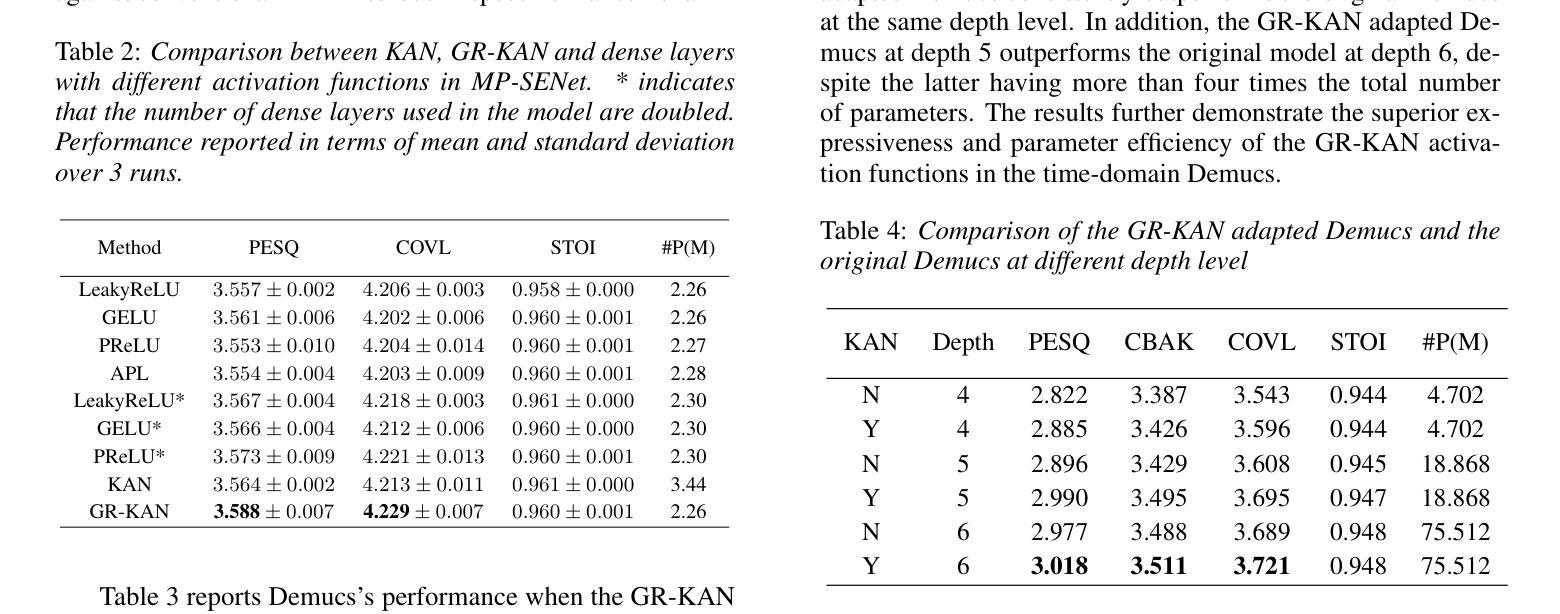
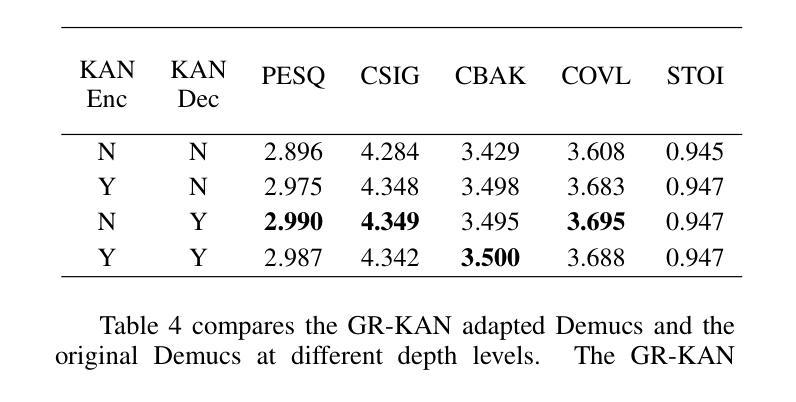
From KAN to GR-KAN: Advancing Speech Enhancement with KAN-Based Methodology
Authors:Haoyang Li, Yuchen Hu, Chen Chen, Sabato Marco Siniscalchi, Songting Liu, Eng Siong Chng
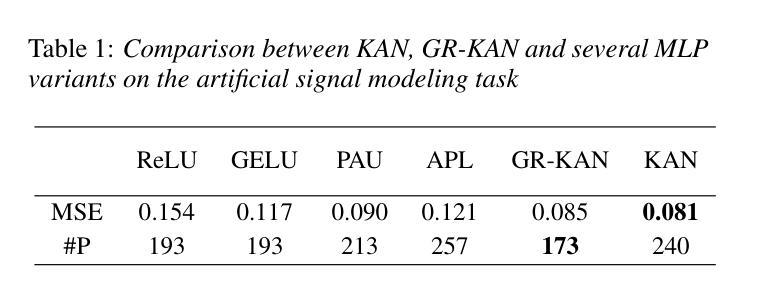
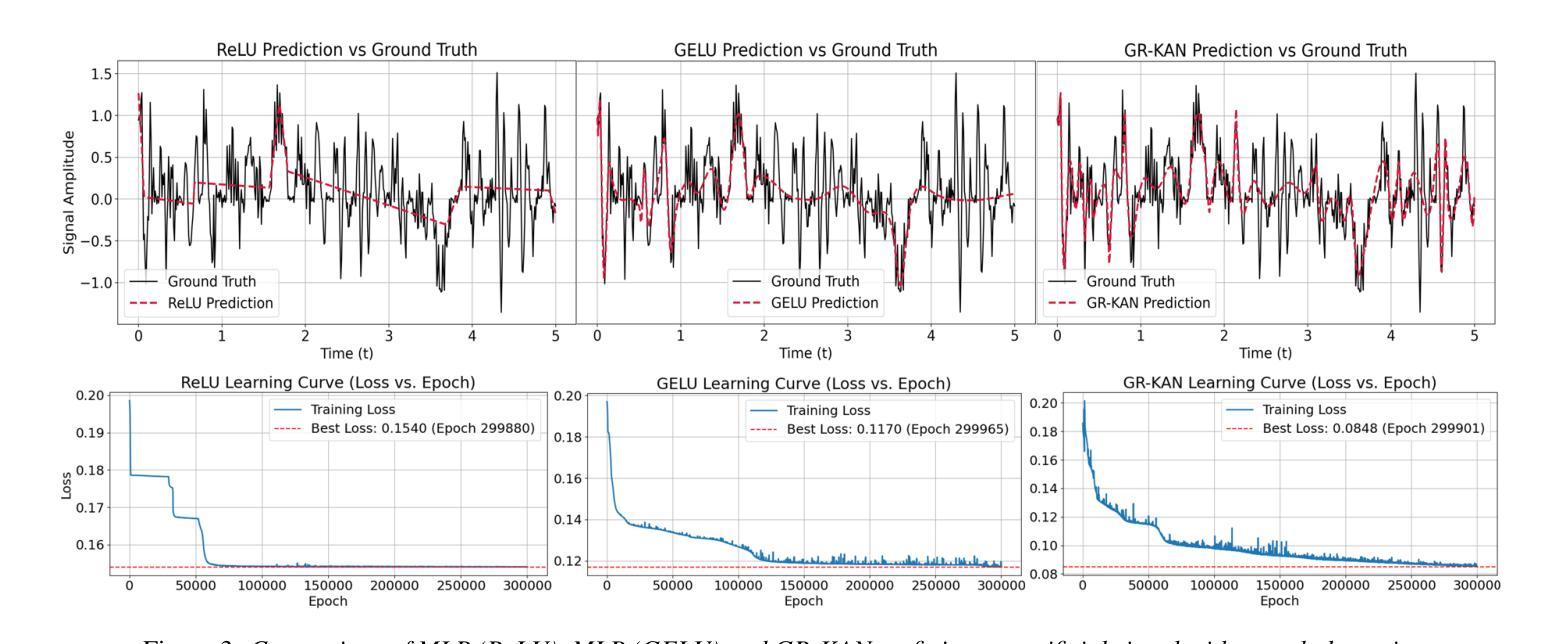
Deep neural network (DNN)-based speech enhancement (SE) usually uses conventional activation functions, which lack the expressiveness to capture complex multiscale structures needed for high-fidelity SE. Group-Rational KAN (GR-KAN), a variant of Kolmogorov-Arnold Networks (KAN), retains KAN’s expressiveness while improving scalability on complex tasks. We adapt GR-KAN to existing DNN-based SE by replacing dense layers with GR-KAN layers in the time-frequency (T-F) domain MP-SENet and adapting GR-KAN’s activations into the 1D CNN layers in the time-domain Demucs. Results on Voicebank-DEMAND show that GR-KAN requires up to 4x fewer parameters while improving PESQ by up to 0.1. In contrast, KAN, facing scalability issues, outperforms MLP on a small-scale signal modeling task but fails to improve MP-SENet. We demonstrate the first successful use of KAN-based methods for consistent improvement in both time- and SoTA TF-domain SE, establishing GR-KAN as a promising alternative for SE.
基于深度神经网络(DNN)的语音增强(SE)通常使用传统的激活函数,这些函数缺乏表达复杂多尺度结构所需的表达能力,无法用于高保真SE。Group-Rational KAN(GR-KAN)是Kolmogorov-Arnold Networks(KAN)的一种变体,在复杂任务上保留了KAN的表达能力并提高了可扩展性。我们通过将时间-频率(T-F)域MP-SENet中的密集层替换为GR-KAN层,并将GR-KAN的激活适应到时间域Demucs的1D CNN层,将GR-KAN适应到现有的基于DNN的SE。在Voicebank-DEMAND上的结果表明,GR-KAN在改进PESQ高达0.1的同时,参数减少了高达4倍。相比之下,KAN面临可扩展性问题,在小规模信号建模任务上优于MLP,但未能改进MP-SENet。我们展示了基于KAN的方法在时间和当前TF域SE中的持续改进的首例成功应用,证明了GR-KAN在SE中的有前途的替代方案。
论文及项目相关链接
PDF Accepted to Interspeech2025
Summary
基于深度神经网络(DNN)的语音增强(SE)通常使用传统的激活函数,难以捕捉复杂的多尺度结构以实现高保真SE。 Group-Rational KAN(GR-KAN)作为Kolmogorov-Arnold网络(KAN)的变体,在保留KAN表达力的同时,提高了在复杂任务上的可扩展性。我们通过将现有DNN-based SE中的密集层替换为GR-KAN层,并适应GR-KAN激活到时间域Demucs的1D CNN层和时间-频率(T-F)域MP-SENet,实现了GR-KAN在SE中的应用。在Voicebank-DEMAND上的结果显示,GR-KAN的参数需求少达4倍,同时PESQ提高达0.1。尽管KAN在小规模信号建模任务中表现优于MLP,但在改善MP-SENet方面并未成功。我们首次成功使用基于KAN的方法,在时间和当前TF域SE中都实现了改进,确立了GR-KAN在SE中的有前途的替代方案地位。
Key Takeaways
- 深度神经网络(DNN)在语音增强(SE)中使用的传统激活函数难以捕捉复杂的多尺度结构。
- Group-Rational KAN(GR-KAN)保留了Kolmogorov-Arnold网络(KAN)的表达能力并提高了其在复杂任务上的可扩展性。
- 通过将GR-KAN层替换密集层并适应GR-KAN激活到现有DNN-based SE的不同架构中,实现了GR-KAN在SE中的首次应用。
- 在Voicebank-DEMAND上的实验表明,GR-KAN的参数需求更少且性能有所提升。
- 虽然KAN在小规模信号建模任务中表现良好,但在改善MP-SENet方面并未达到预期效果。
- 基于KAN的方法在时间和当前TF域SE中都实现了改进,为SE领域提供了新的视角。
点此查看论文截图