⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-05-26 更新
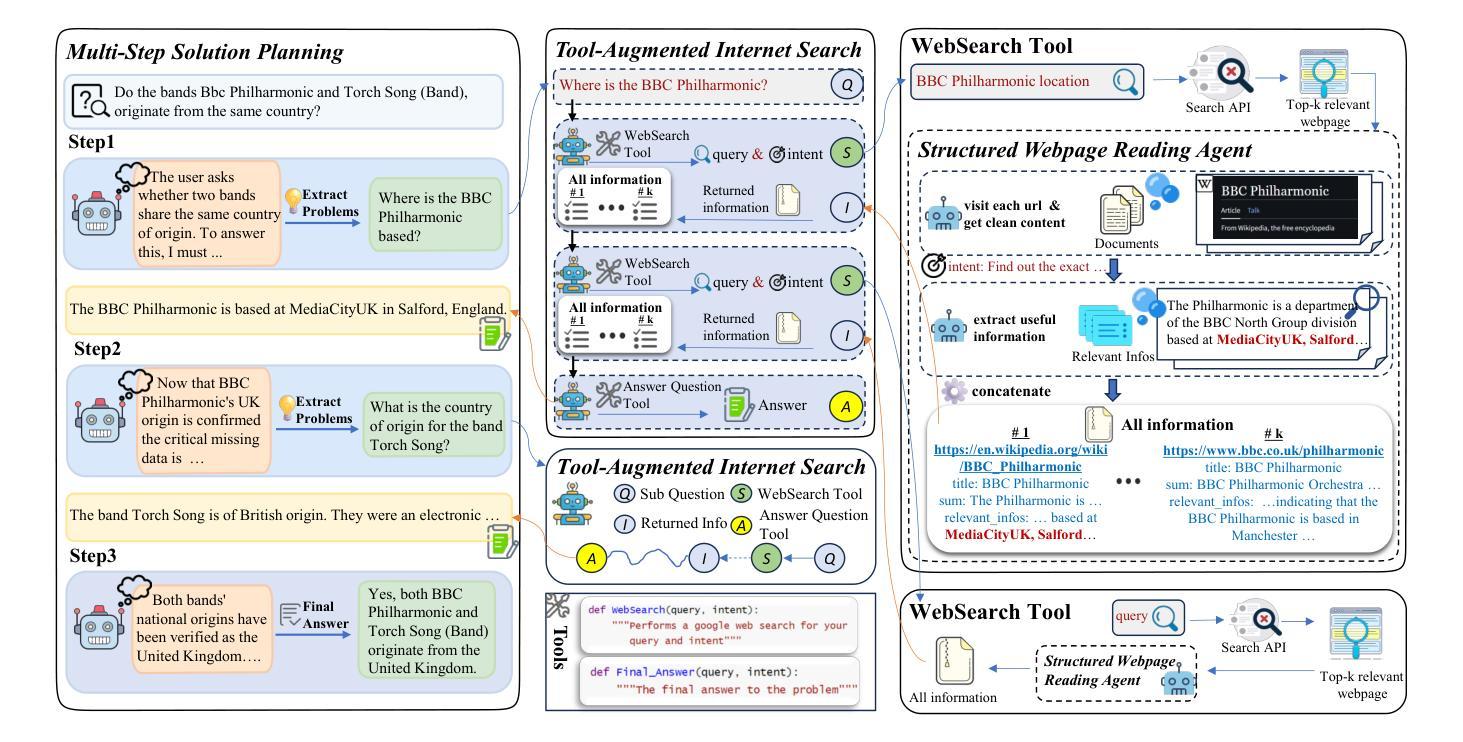
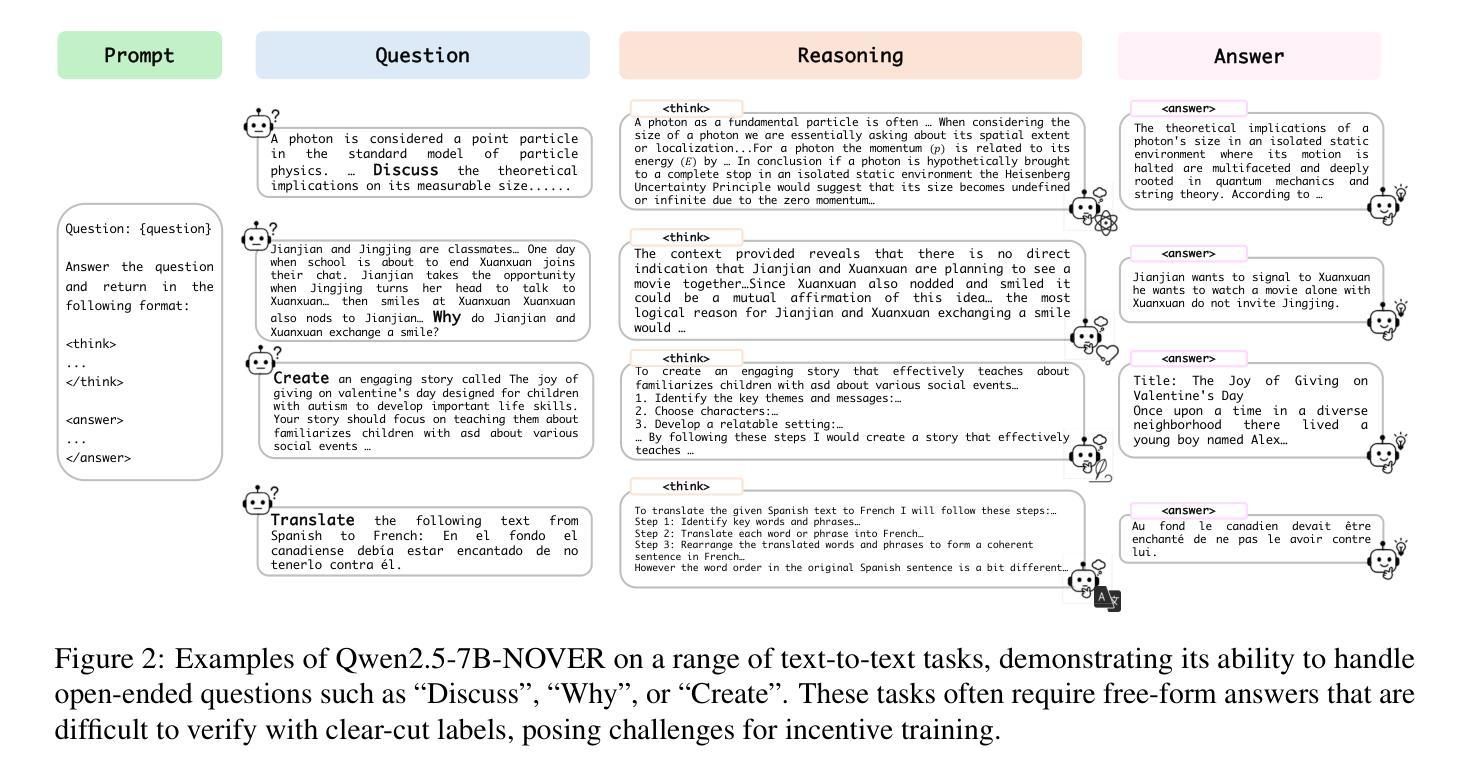
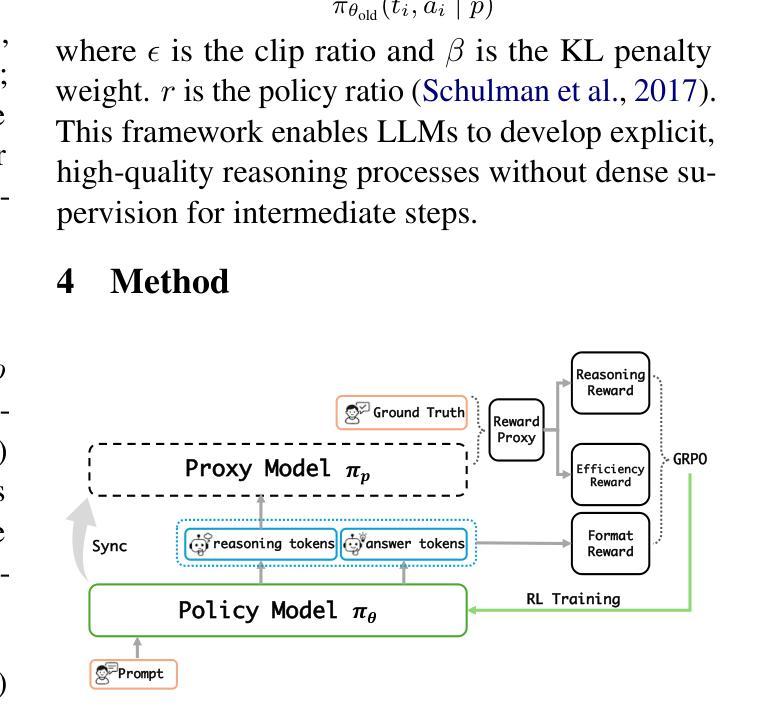
NOVER: Incentive Training for Language Models via Verifier-Free Reinforcement Learning
Authors:Wei Liu, Siya Qi, Xinyu Wang, Chen Qian, Yali Du, Yulan He
Recent advances such as DeepSeek R1-Zero highlight the effectiveness of incentive training, a reinforcement learning paradigm that computes rewards solely based on the final answer part of a language model’s output, thereby encouraging the generation of intermediate reasoning steps. However, these methods fundamentally rely on external verifiers, which limits their applicability to domains like mathematics and coding where such verifiers are readily available. Although reward models can serve as verifiers, they require high-quality annotated data and are costly to train. In this work, we propose NOVER, NO-VERifier Reinforcement Learning, a general reinforcement learning framework that requires only standard supervised fine-tuning data with no need for an external verifier. NOVER enables incentive training across a wide range of text-to-text tasks and outperforms the model of the same size distilled from large reasoning models such as DeepSeek R1 671B by 7.7 percent. Moreover, the flexibility of NOVER enables new possibilities for optimizing large language models, such as inverse incentive training.
最近的进展,如DeepSeek R1-Zero,凸显了激励训练的有效性。激励训练是一种基于最终答案的语言模型输出部分来计算奖励的强化学习范式,从而鼓励生成中间推理步骤。然而,这些方法从根本上依赖于外部验证器,这限制了它们在诸如数学和编码等领域的应用,在这些领域可以很容易地获得这样的验证器。虽然奖励模型可以作为验证器使用,但它们需要大量的高质量注释数据,并且训练成本高昂。在这项工作中,我们提出了NOVER(无需验证器的强化学习),这是一个一般的强化学习框架,它只需要标准的有监督微调数据,无需外部验证器。NOVER可以在广泛的文本到文本任务中进行激励训练,并优于使用大型推理模型(如DeepSeek R1 671B)蒸馏得到的相同大小的模型,性能提高了7.7%。此外,NOVER的灵活性为优化大型语言模型提供了新的可能性,如逆向激励训练。
论文及项目相关链接
PDF 20 pages, 5 tables, 12 figures
Summary
在强化学习领域,激励训练的方法近来受到广泛关注,例如DeepSeek R1-Zero,其仅基于最终答案来评估语言模型的输出。但这种方法依赖于外部验证器,限制了其在如数学和编程等领域的应用。本文提出NOVER(无需验证器的强化学习)框架,只需标准监督微调数据,无需外部验证器即可进行激励训练。NOVER在广泛的文本到文本任务中表现优异,并且相比DeepSeek R1 671B蒸馏出的模型,性能提升了7.7%。此外,NOVER的灵活性还为优化大型语言模型带来了新的可能性,如反向激励训练。
Key Takeaways
- 激励训练在强化学习领域备受关注,如DeepSeek R1-Zero方法基于最终答案进行奖励计算。
- 现有方法依赖于外部验证器,限制了应用范围,特别是在数学和编程等领域。
- 提出NOVER框架,无需外部验证器即可进行激励训练。
- NOVER框架适用于广泛的文本到文本任务,性能优异。
- 与DeepSeek R1 671B模型相比,NOVER性能提升7.7%。
- NOVER框架的灵活性为优化大型语言模型带来新机会。
点此查看论文截图

Pixel Reasoner: Incentivizing Pixel-Space Reasoning with Curiosity-Driven Reinforcement Learning
Authors:Alex Su, Haozhe Wang, Weimin Ren, Fangzhen Lin, Wenhu Chen
Chain-of-thought reasoning has significantly improved the performance of Large Language Models (LLMs) across various domains. However, this reasoning process has been confined exclusively to textual space, limiting its effectiveness in visually intensive tasks. To address this limitation, we introduce the concept of reasoning in the pixel-space. Within this novel framework, Vision-Language Models (VLMs) are equipped with a suite of visual reasoning operations, such as zoom-in and select-frame. These operations enable VLMs to directly inspect, interrogate, and infer from visual evidences, thereby enhancing reasoning fidelity for visual tasks. Cultivating such pixel-space reasoning capabilities in VLMs presents notable challenges, including the model’s initially imbalanced competence and its reluctance to adopt the newly introduced pixel-space operations. We address these challenges through a two-phase training approach. The first phase employs instruction tuning on synthesized reasoning traces to familiarize the model with the novel visual operations. Following this, a reinforcement learning (RL) phase leverages a curiosity-driven reward scheme to balance exploration between pixel-space reasoning and textual reasoning. With these visual operations, VLMs can interact with complex visual inputs, such as information-rich images or videos to proactively gather necessary information. We demonstrate that this approach significantly improves VLM performance across diverse visual reasoning benchmarks. Our 7B model, \model, achieves 84% on V* bench, 74% on TallyQA-Complex, and 84% on InfographicsVQA, marking the highest accuracy achieved by any open-source model to date. These results highlight the importance of pixel-space reasoning and the effectiveness of our framework.
链式思维推理已经显著提高了大型语言模型(LLM)在不同领域的性能。然而,这种推理过程一直被限制在文本空间内,使其在视觉密集型任务中的有效性受到限制。为了解决这个问题,我们引入了像素空间推理的概念。在这一新框架下,视觉语言模型(VLM)配备了一系列视觉推理操作,如放大和选择帧。这些操作使VLM能够直接从视觉证据中进行检查、询问和推断,从而提高视觉任务的推理保真度。在VLM中培养这种像素空间推理能力面临着显著挑战,包括模型初始能力的不平衡及其对新引入的像素空间操作的抵触。我们通过两阶段训练方法来应对这些挑战。第一阶段采用合成推理轨迹的指令调整,使模型熟悉新的视觉操作。接下来,强化学习(RL)阶段利用基于好奇心的奖励方案来平衡像素空间推理和文本推理之间的探索。有了这些视觉操作,VLM可以与复杂的视觉输入进行交互,如信息丰富的图像或视频,以主动收集必要的信息。我们证明,该方法显著提高了VLM在多种视觉推理基准测试上的性能。我们的7B模型实现了V*基准测试84%、TallyQA-Complex基准测试74%、InfographicsVQA基准测试84%的准确率,这是迄今为止任何开源模型所取得的最高准确率。这些结果突显了像素空间推理的重要性以及我们框架的有效性。
论文及项目相关链接
PDF Haozhe Wang and Alex Su contributed equally and listed alphabetically
Summary
该文介绍了链式思维(Chain-of-thought reasoning)对大型语言模型(LLM)性能的改进。然而,该推理过程局限于文本空间,在视觉密集型任务中的效果有限。为应对这一局限,文中提出了像素空间推理的概念,并为视觉语言模型(VLM)配备了一系列视觉推理操作,如放大、选择帧等。这些操作使VLM能够直接从视觉证据中检查、询问和推断,从而提高视觉任务的推理保真度。培养VLM的像素空间推理能力面临挑战,包括模型的初始能力不均衡和对新引入的像素空间操作的接受度低。为应对这些挑战,文中采用两阶段训练方法。第一阶段通过合成推理轨迹进行指令调整,使模型熟悉新的视觉操作。接下来是强化学习(RL)阶段,采用基于好奇心的奖励方案,在像素空间推理和文本推理之间实现平衡探索。这种方法显著提高了VLM在多种视觉推理基准测试上的表现。例如,其7B模型在V*基准测试上达到84%、在复杂计数问答任务上达到74%、在信息图表视觉问答任务上达到84%,成为迄今为止公开模型中表现最高的。结果突显了像素空间推理的重要性及该框架的有效性。
Key Takeaways
- 链式思维对大型语言模型的性能提升有重要作用,但在视觉密集型任务中受限。
- 为应对这一局限,引入了像素空间推理的概念,并为视觉语言模型配备视觉推理操作。
- 视觉推理操作包括放大、选择帧等,使模型能够直接从视觉证据中检查、询问和推断。
- 培养视觉语言模型的像素空间推理能力面临挑战,如初始能力不均衡和对新操作的接受度低。
- 采用两阶段训练方法来应对这些挑战,包括通过合成推理轨迹进行指令调整和强化学习阶段。
- 这种方法显著提高了视觉语言模型在多种视觉推理基准测试上的表现。
点此查看论文截图


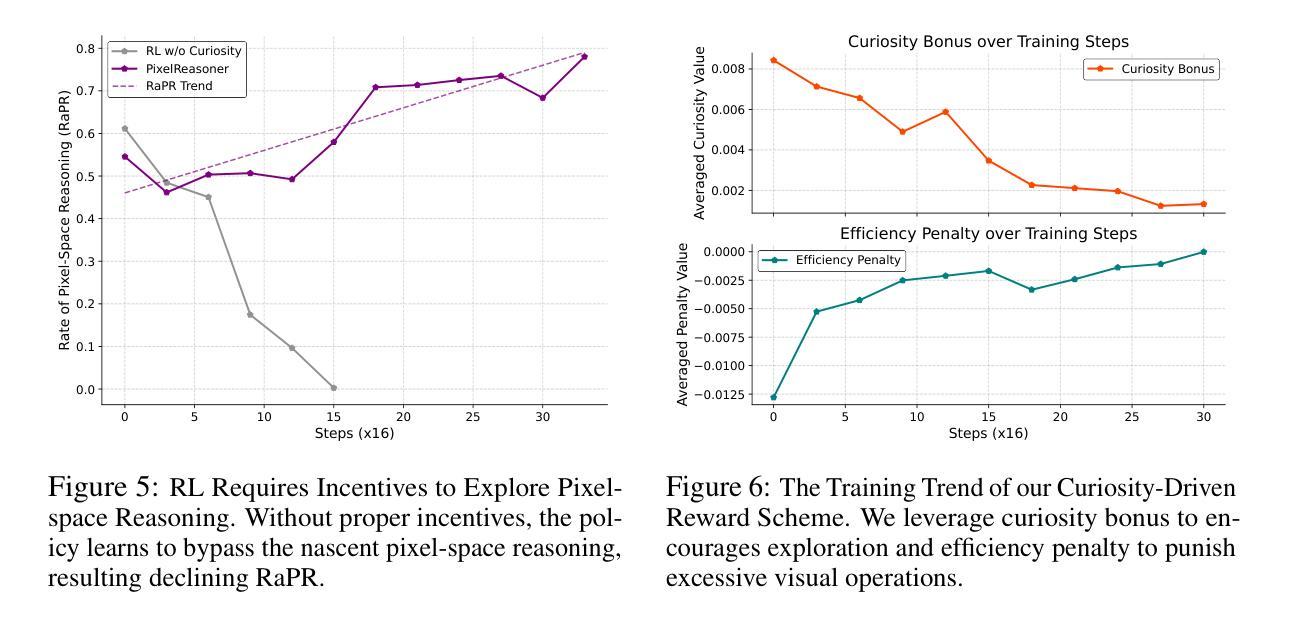
Aligning Dialogue Agents with Global Feedback via Large Language Model Reward Decomposition
Authors:Dong Won Lee, Hae Won Park, Cynthia Breazeal, Louis-Philippe Morency
We propose a large language model based reward decomposition framework for aligning dialogue agents using only a single session-level feedback signal. We leverage the reasoning capabilities of a frozen, pretrained large language model (LLM) to infer fine-grained local implicit rewards by decomposing global, session-level feedback. Our first text-only variant prompts the LLM to perform reward decomposition using only the dialogue transcript. The second multimodal variant incorporates additional behavioral cues, such as pitch, gaze, and facial affect, expressed as natural language descriptions. These inferred turn-level rewards are distilled into a lightweight reward model, which we utilize for RL-based fine-tuning for dialogue generation. We evaluate both text-only and multimodal variants against state-of-the-art reward decomposition methods and demonstrate notable improvements in human evaluations of conversation quality, suggesting that LLMs are strong reward decomposers that obviate the need for manual reward shaping and granular human feedback.
我们提出了一个基于大型语言模型的奖励分解框架,该框架仅使用单个会话级别的反馈信号来对对话代理进行对齐。我们利用冻结的预训练大型语言模型(LLM)的推理能力,通过分解全局会话级别的反馈来推断精细的局部隐含奖励。我们的第一种纯文本变体提示LLM仅使用对话记录进行奖励分解。第二种多模式变体则结合了额外的行为线索,如音调、凝视和面部表情,以自然语言描述的形式表达。这些推断出的回合级奖励被提炼成一个轻量级的奖励模型,我们将其用于基于强化学习的对话生成微调。我们将纯文本和多模态变体与最新的奖励分解方法进行了评估对比,在人类对话质量评价中取得了显著的改进,这表明LLM是强大的奖励分解器,无需手动奖励塑形和精细的人类反馈。
论文及项目相关链接
PDF 9 pages, 3 figures, 3 tables
Summary:
提出一种基于大型语言模型的奖励分解框架,仅使用单个会话级反馈信号来对对话代理进行对齐。利用冻结的预训练大型语言模型(LLM)的推理能力,通过分解全局会话级反馈来推断精细的局部隐式奖励。提出文本模态和多媒体模态两种变体,前者仅使用对话文本来提示LLM进行奖励分解,后者则结合了额外的行为线索,如音调、眼神和面部表情等自然语言描述。将这些推断出的轮级奖励蒸馏到一个轻量级的奖励模型中,用于基于强化学习的对话生成微调。评估结果表明,相较于最新的奖励分解方法,该方法在人类对话质量评价上有显著改进,表明LLM是强大的奖励分解器,无需手动奖励塑形和详细的人类反馈。
Key Takeaways:
- 利用大型语言模型进行奖励分解,实现对对话代理的对齐。
- 通过分解全局会话级反馈来推断局部隐式奖励。
- 提出文本模态和多媒体模态两种奖励分解方法。
- 文本模态仅使用对话文本,而多媒体模态则结合行为线索。
- 将推断的轮级奖励蒸馏到轻量级奖励模型中。
- 使用强化学习对对话生成进行微调。
- 在人类对话质量评价上,该方法显著优于其他最新奖励分解方法。
点此查看论文截图

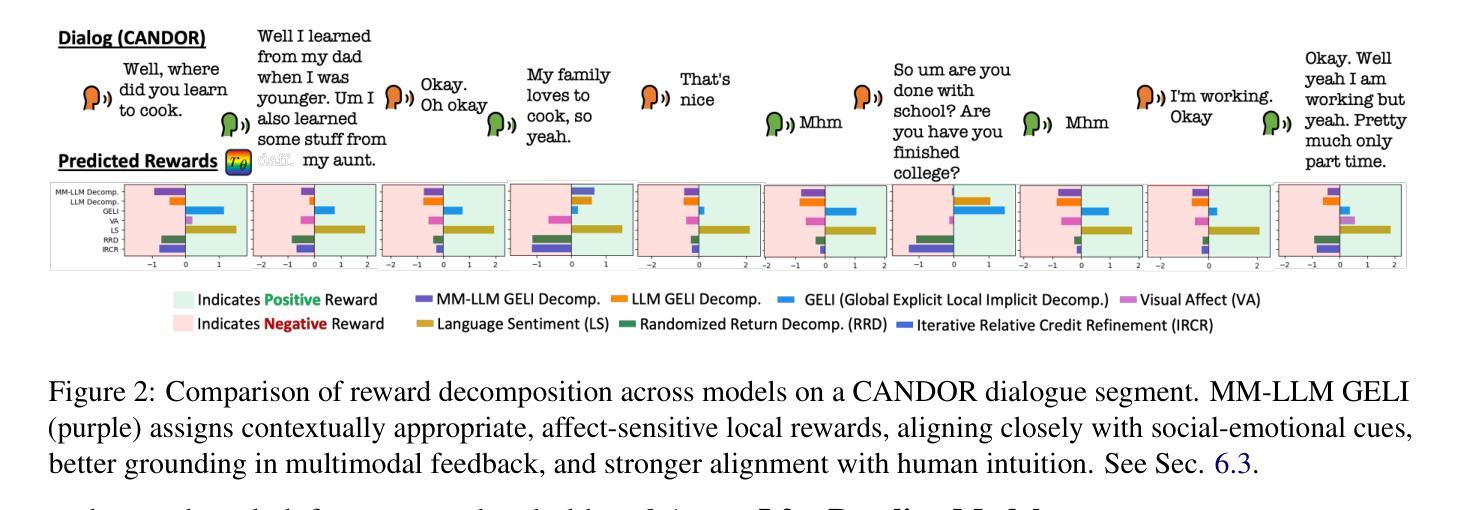
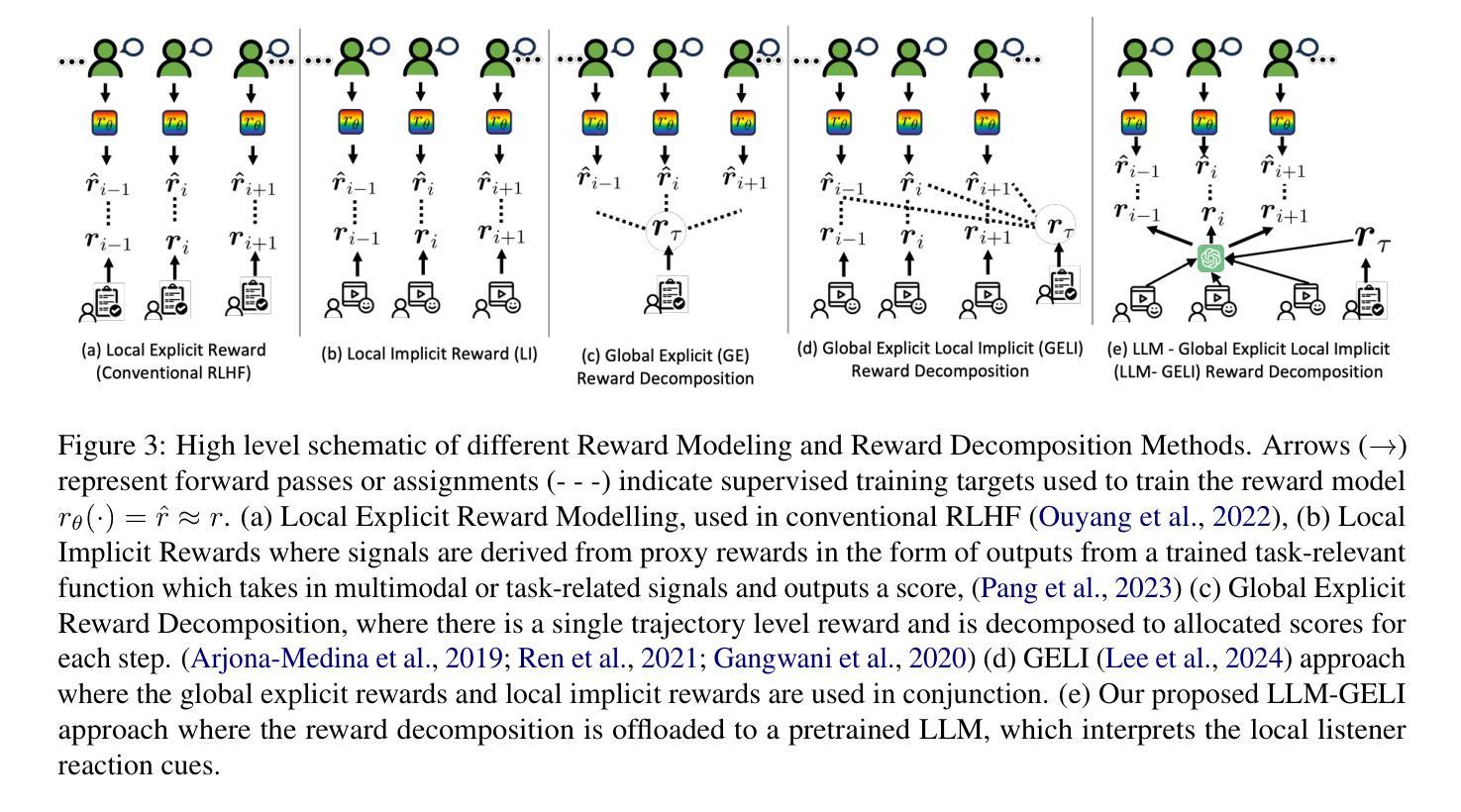
Learning to Reason via Mixture-of-Thought for Logical Reasoning
Authors:Tong Zheng, Lichang Chen, Simeng Han, R. Thomas McCoy, Heng Huang
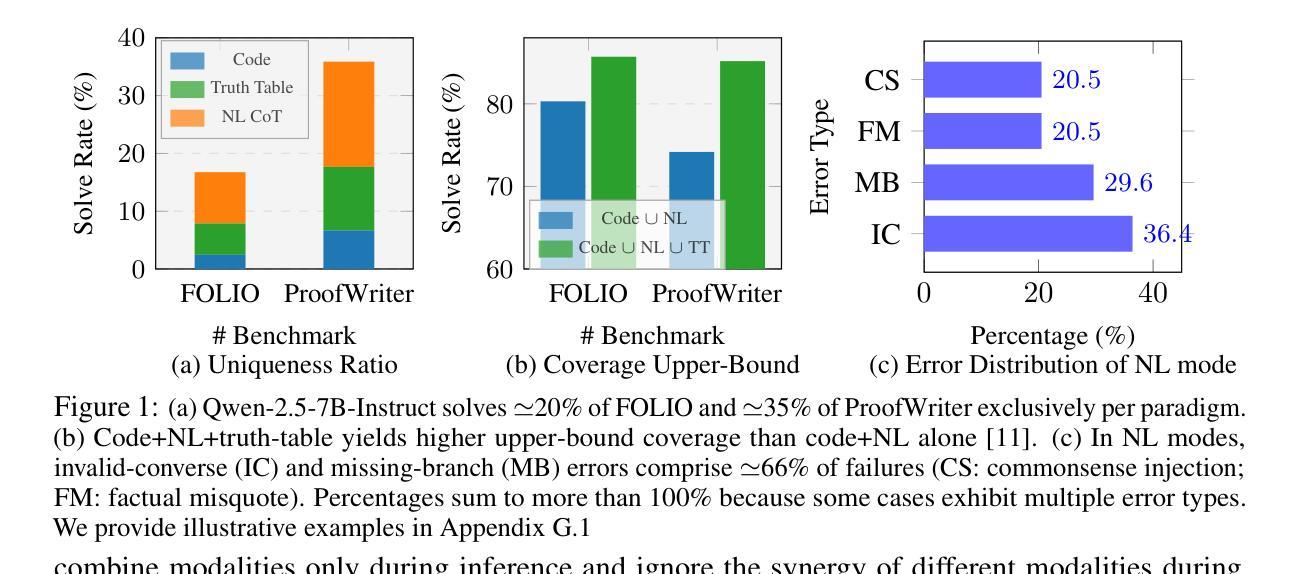
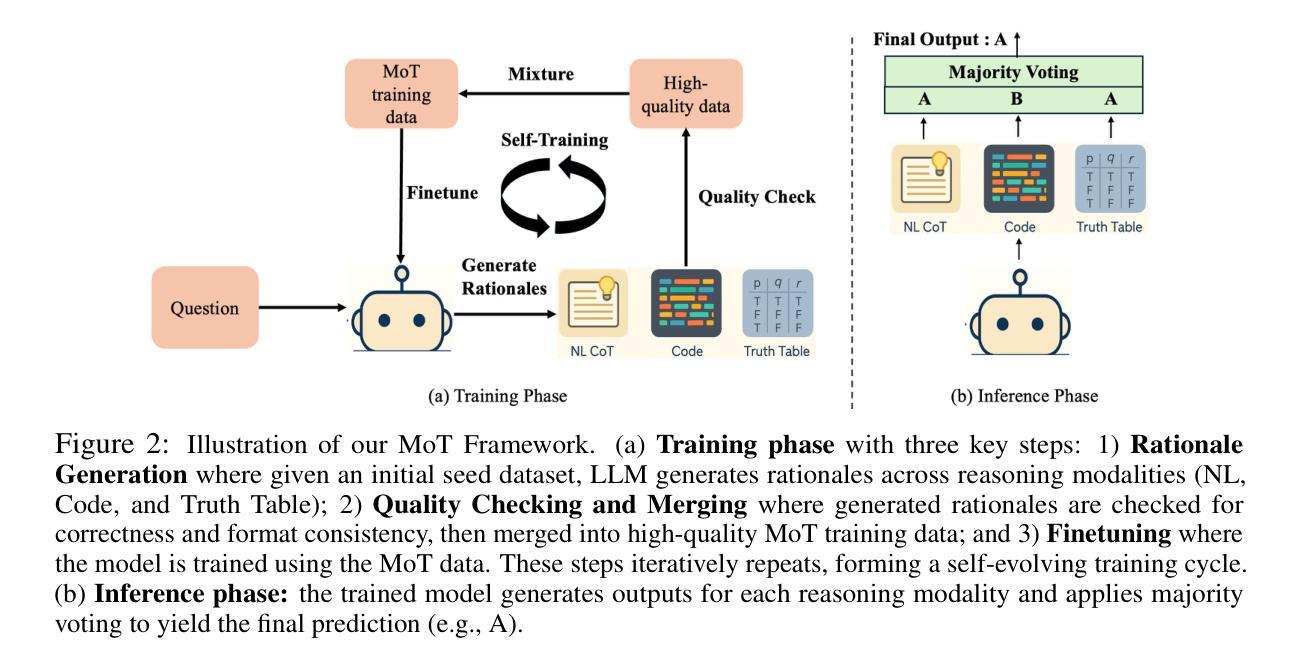
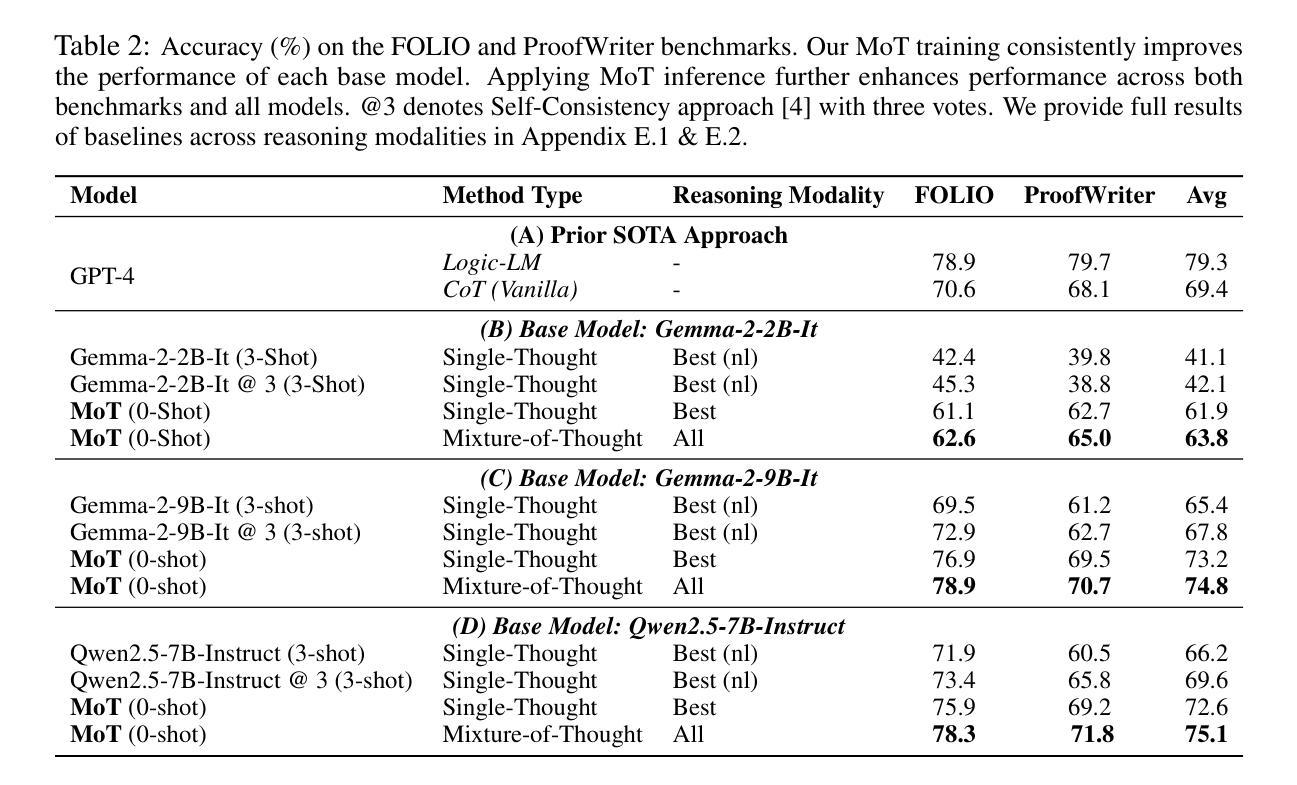
Human beings naturally utilize multiple reasoning modalities to learn and solve logical problems, i.e., different representational formats such as natural language, code, and symbolic logic. In contrast, most existing LLM-based approaches operate with a single reasoning modality during training, typically natural language. Although some methods explored modality selection or augmentation at inference time, the training process remains modality-blind, limiting synergy among modalities. To fill in this gap, we propose Mixture-of-Thought (MoT), a framework that enables LLMs to reason across three complementary modalities: natural language, code, and a newly introduced symbolic modality, truth-table, which systematically enumerates logical cases and partially mitigates key failure modes in natural language reasoning. MoT adopts a two-phase design: (1) self-evolving MoT training, which jointly learns from filtered, self-generated rationales across modalities; and (2) MoT inference, which fully leverages the synergy of three modalities to produce better predictions. Experiments on logical reasoning benchmarks including FOLIO and ProofWriter demonstrate that our MoT framework consistently and significantly outperforms strong LLM baselines with single-modality chain-of-thought approaches, achieving up to +11.7pp average accuracy gain. Further analyses show that our MoT framework benefits both training and inference stages; that it is particularly effective on harder logical reasoning problems; and that different modalities contribute complementary strengths, with truth-table reasoning helping to overcome key bottlenecks in natural language inference.
人类自然运用多种推理模式来学习和解决逻辑问题,例如自然语言、代码和符号逻辑等不同的表示格式。相比之下,大多数现有的基于大型语言模型的方法在训练过程中只使用单一的推理模式,通常是自然语言。尽管一些方法在推理时间探索了模式选择或增强,但训练过程仍然对模式是盲目的,限制了模式之间的协同作用。为了填补这一空白,我们提出了“思维混合”(MoT)框架,它使大型语言模型能够在三种互补模式中进行推理:自然语言、代码,以及新引入的符号模式——真值表。真值表系统地枚举逻辑情况,部分缓解了自然语言推理中的关键失败模式。MoT采用两阶段设计:(1)自我进化的MoT训练,从跨模式的过滤、自我生成的理性中联合学习;(2)MoT推理,充分利用三种模式的协同作用来产生更好的预测。在逻辑推理基准测试,包括FOLIO和ProofWriter上的实验表明,我们的MoT框架在单模态思维链方法中始终且显著地优于强大的大型语言模型基准测试,平均准确率提高了+11.7pp。进一步的分析表明,我们的MoT框架对训练和推理阶段都有益;它特别适用于更复杂的逻辑推理问题;不同的模式贡献出互补的优势,真值表推理有助于克服自然语言推理中的关键瓶颈。
论文及项目相关链接
PDF 38 pages
Summary
本文提出一种名为Mixture-of-Thought(MoT)的框架,该框架使LLMs能够在自然语言、代码和符号三种互补模态中进行推理。MoT采用自我进化的训练方法和MoT推理过程,实现了跨模态的协同工作。在逻辑基准测试中,MoT框架相较于单一模态的推理方法表现更优,尤其是在解决复杂逻辑问题时效果更显著。
Key Takeaways
- 人类利用多种推理模态学习和解决逻辑问题,而大多数LLM方法仅使用单一模态进行训练。
- MoT框架填补了这一空白,允许LLMs在自然语言、代码和符号三种模态中进行推理。
- MoT采用自我进化的训练方法和MoT推理过程,提高了跨模态协同工作的能力。
- 在逻辑基准测试中,MoT框架相较于单一模态的推理方法表现出显著优势,平均准确度提高了11.7%。
- MoT框架对训练和推理阶段都有益。
- 符号模态在解决自然语言推理中的关键瓶颈方面发挥了作用。
点此查看论文截图


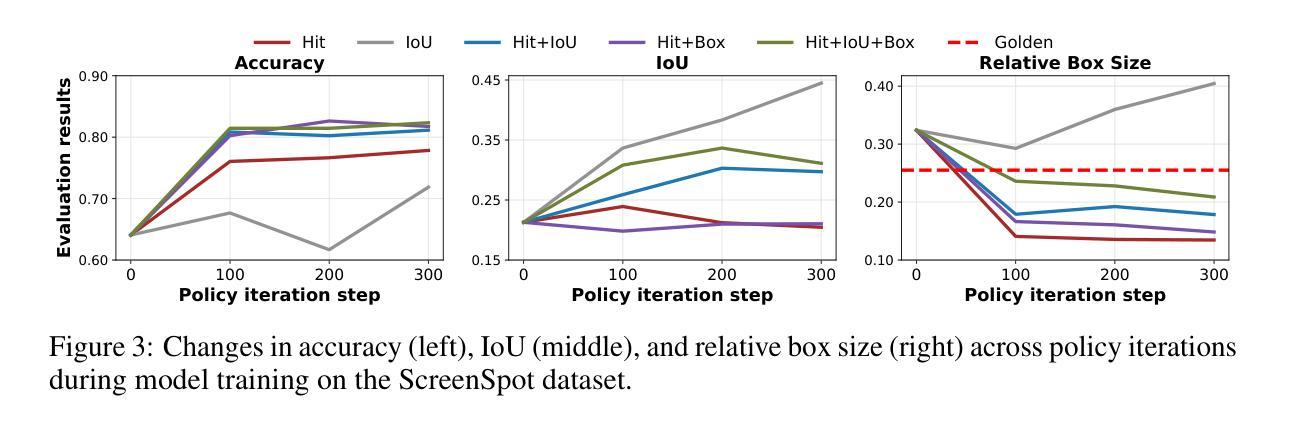
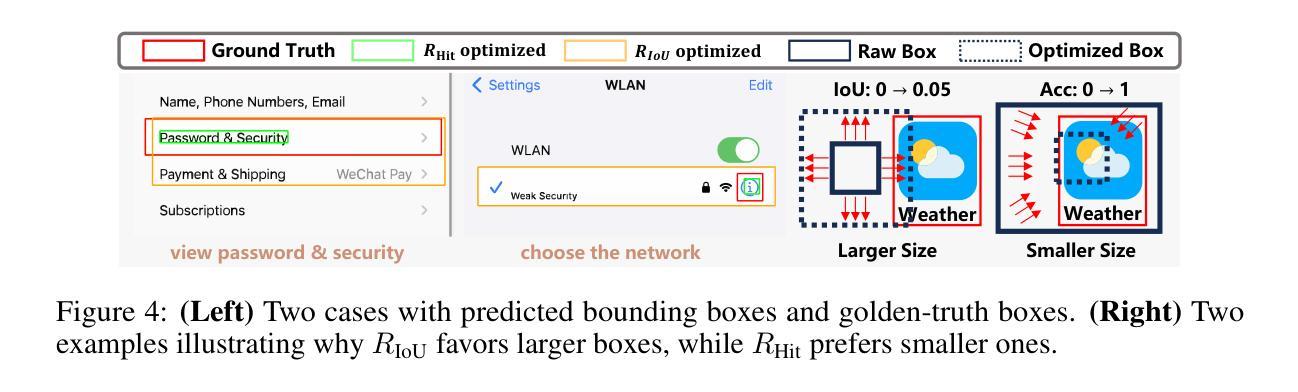
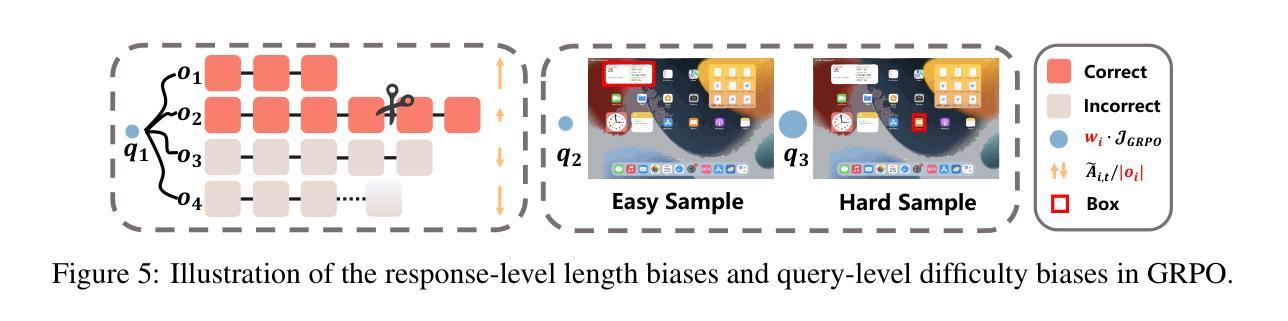
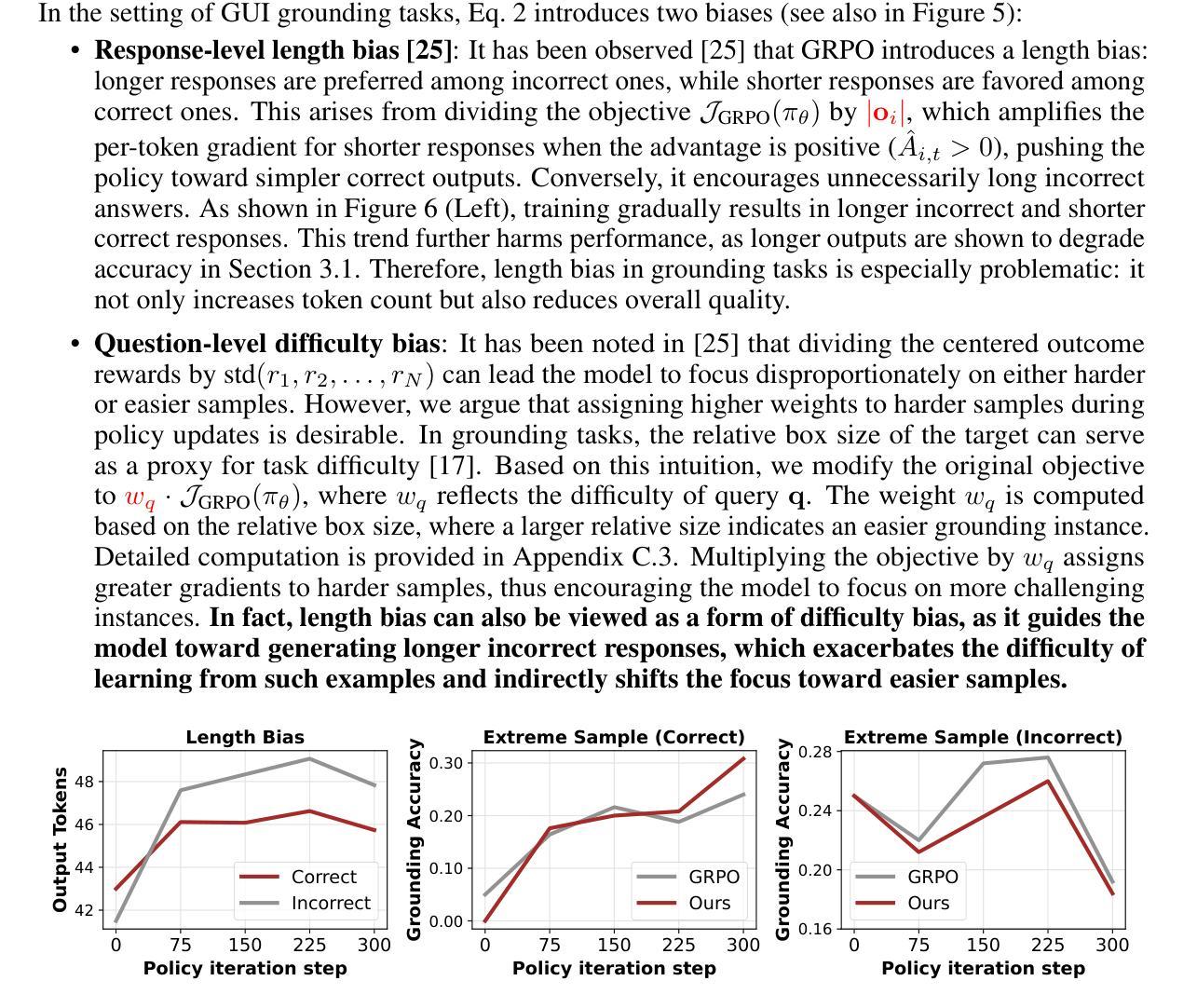
GUI-G1: Understanding R1-Zero-Like Training for Visual Grounding in GUI Agents
Authors:Yuqi Zhou, Sunhao Dai, Shuai Wang, Kaiwen Zhou, Qinglin Jia, Jun Xu
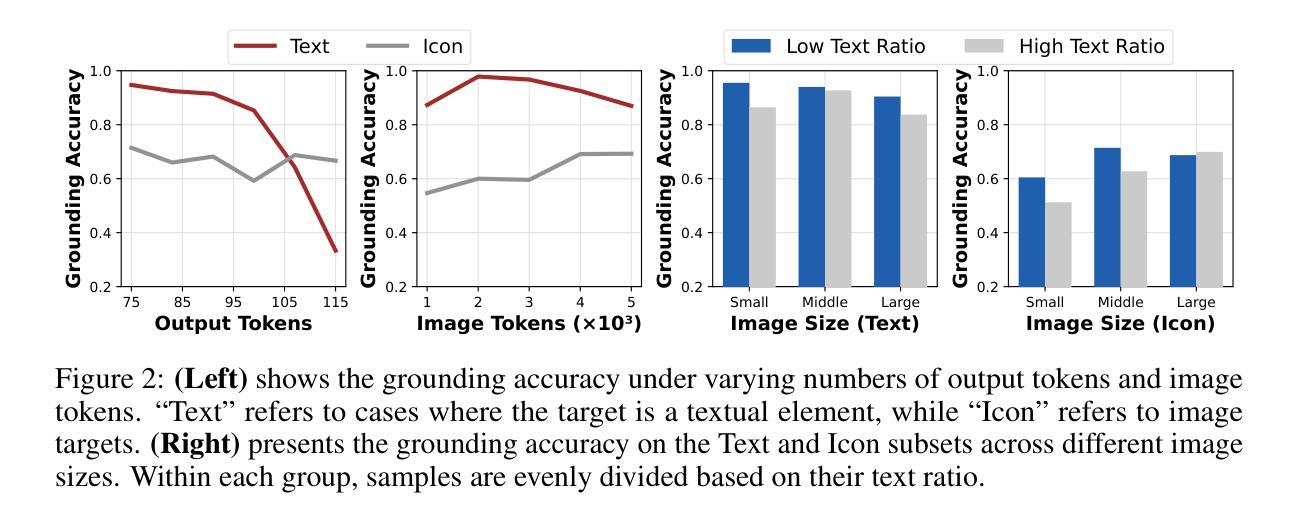
Recent Graphical User Interface (GUI) agents replicate the R1-Zero paradigm, coupling online Reinforcement Learning (RL) with explicit chain-of-thought reasoning prior to object grounding and thereby achieving substantial performance gains. In this paper, we first conduct extensive analysis experiments of three key components of that training pipeline: input design, output evaluation, and policy update-each revealing distinct challenges arising from blindly applying general-purpose RL without adapting to GUI grounding tasks. Input design: Current templates encourage the model to generate chain-of-thought reasoning, but longer chains unexpectedly lead to worse grounding performance. Output evaluation: Reward functions based on hit signals or box area allow models to exploit box size, leading to reward hacking and poor localization quality. Policy update: Online RL tends to overfit easy examples due to biases in length and sample difficulty, leading to under-optimization on harder cases. To address these issues, we propose three targeted solutions. First, we adopt a Fast Thinking Template that encourages direct answer generation, reducing excessive reasoning during training. Second, we incorporate a box size constraint into the reward function to mitigate reward hacking. Third, we revise the RL objective by adjusting length normalization and adding a difficulty-aware scaling factor, enabling better optimization on hard samples. Our GUI-G1-3B, trained on 17K public samples with Qwen2.5-VL-3B-Instruct, achieves 90.3% accuracy on ScreenSpot and 37.1% on ScreenSpot-Pro. This surpasses all prior models of similar size and even outperforms the larger UI-TARS-7B, establishing a new state-of-the-art in GUI agent grounding. The project repository is available at https://github.com/Yuqi-Zhou/GUI-G1.
近期,图形用户界面(GUI)代理复制了R1-Zero范式,将在线强化学习(RL)与对象定位之前的显式链式推理相结合,从而实现了显著的性能提升。在本文中,我们首先对训练管道的三个关键组件进行广泛的分析实验:输入设计、输出评估和策略更新——每一个都揭示了由于盲目应用通用RL而没有适应GUI定位任务而产生的独特挑战。输入设计:当前模板鼓励模型生成链式推理,但更长的链条出乎意料地导致定位性能下降。输出评估:基于命中信号或框区域的奖励函数允许模型利用框大小,导致奖励作弊和定位质量差。策略更新:在线RL由于长度和样本难度的偏见,往往会对简单示例进行过度拟合,导致在更复杂情况下的优化不足。为了解决这些问题,我们提出了三种有针对性的解决方案。首先,我们采用快速思考模板,鼓励直接答案生成,减少训练过程中的过度推理。其次,我们将框大小约束纳入奖励函数,以减轻奖励作弊。第三,我们通过调整长度归一化并添加一个难度感知缩放因子来修订RL目标,从而在困难样本上实现更好的优化。我们的GUI-G1-3B在17K公共样本上使用Qwen2.5-VL-3B-Instruct进行训练,在ScreenSpot上达到了90.3%的准确率,在ScreenSpot-Pro上达到了37.1%的准确率。这超越了类似大小的先前所有模型,甚至超越了更大的UI-TARS-7B,在GUI代理定位方面建立了新的最先进的水平。项目仓库可在https://github.com/Yuqi-Zhou/GUI-G1找到。
论文及项目相关链接
Summary
本文探讨了基于图形用户界面(GUI)的代理模型在对象定位方面的挑战,并提出了针对训练管道中三个关键组件的解决方案。通过改进输入设计、输出评估和策略更新,成功提高了模型的性能。新的解决方案包括采用快速思考模板减少过度推理、将盒大小约束纳入奖励函数以及调整RL目标以适应困难样本的优化。该研究实现了GUI-G1-3B模型的新性能,并在ScreenSpot和ScreenSpot-Pro上实现了超过先前所有类似大小模型的表现。
Key Takeaways
- GUI代理模型通过结合在线强化学习与明确的链式思维推理,实现了显著的性能提升。
- 输入设计:过长的推理链可能导致定位性能下降,需要平衡推理长度与模型性能。
- 输出评估:基于命中信号或框区域的奖励函数可能导致模型利用框大小进行“奖励黑客”行为,需要改进奖励函数以改善定位质量。
- 策略更新:在线RL易于对简单样本过拟合,需要在目标函数中考虑样本长度和难度的调整。
- 提出针对性解决方案,包括快速思考模板、盒大小约束的奖励函数以及优化困难样本的RL目标调整。
- GUI-G1-3B模型在ScreenSpot和ScreenSpot-Pro上实现了卓越性能,达到或超越先前所有类似大小模型的表现。
点此查看论文截图


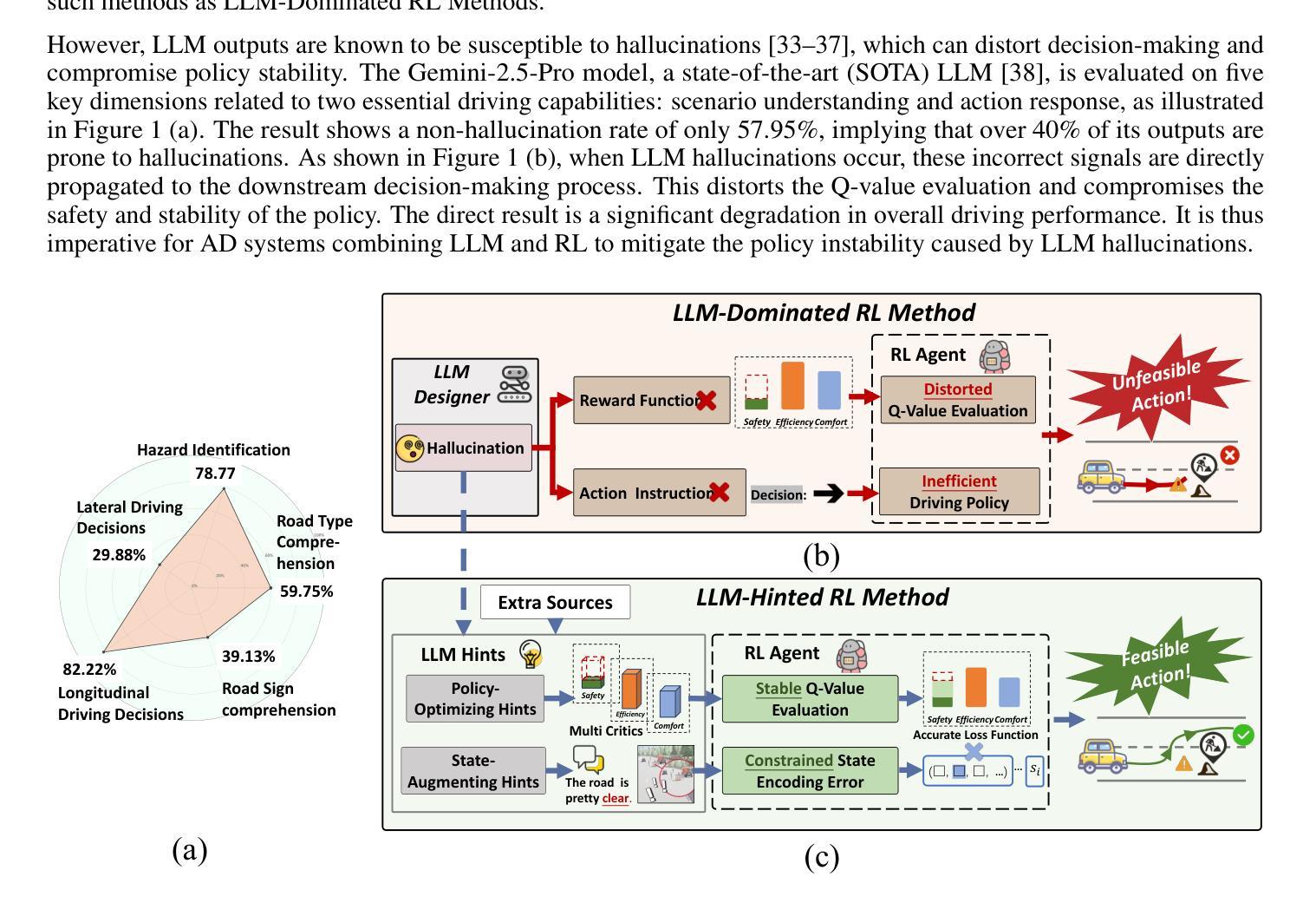
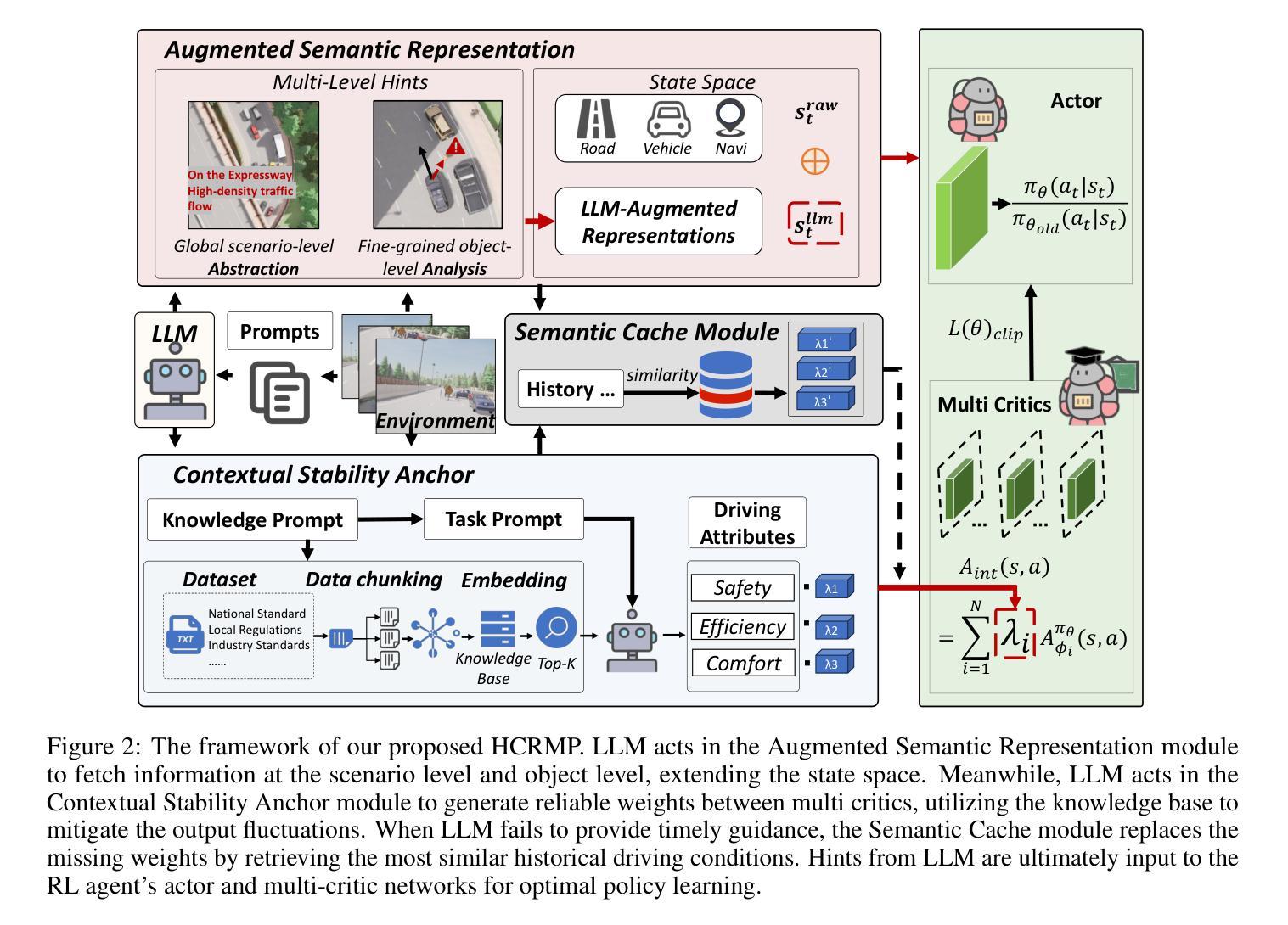
HCRMP: A LLM-Hinted Contextual Reinforcement Learning Framework for Autonomous Driving
Authors:Zhiwen Chen, Bo Leng, Zhuoren Li, Hanming Deng, Guizhe Jin, Ran Yu, Huanxi Wen
Integrating Large Language Models (LLMs) with Reinforcement Learning (RL) can enhance autonomous driving (AD) performance in complex scenarios. However, current LLM-Dominated RL methods over-rely on LLM outputs, which are prone to hallucinations. Evaluations show that state-of-the-art LLM indicates a non-hallucination rate of only approximately 57.95% when assessed on essential driving-related tasks. Thus, in these methods, hallucinations from the LLM can directly jeopardize the performance of driving policies. This paper argues that maintaining relative independence between the LLM and the RL is vital for solving the hallucinations problem. Consequently, this paper is devoted to propose a novel LLM-Hinted RL paradigm. The LLM is used to generate semantic hints for state augmentation and policy optimization to assist RL agent in motion planning, while the RL agent counteracts potential erroneous semantic indications through policy learning to achieve excellent driving performance. Based on this paradigm, we propose the HCRMP (LLM-Hinted Contextual Reinforcement Learning Motion Planner) architecture, which is designed that includes Augmented Semantic Representation Module to extend state space. Contextual Stability Anchor Module enhances the reliability of multi-critic weight hints by utilizing information from the knowledge base. Semantic Cache Module is employed to seamlessly integrate LLM low-frequency guidance with RL high-frequency control. Extensive experiments in CARLA validate HCRMP’s strong overall driving performance. HCRMP achieves a task success rate of up to 80.3% under diverse driving conditions with different traffic densities. Under safety-critical driving conditions, HCRMP significantly reduces the collision rate by 11.4%, which effectively improves the driving performance in complex scenarios.
将大型语言模型(LLM)与强化学习(RL)相结合,可以在复杂场景中提高自动驾驶(AD)的性能。然而,目前的以LLM为主的RL方法过于依赖LLM的输出,这些输出容易产生幻觉。评估表明,在关键的驾驶相关任务中,最先进LLM的非幻觉率只有大约57.95%。因此,在这些方法中,LLM的幻觉会直接危及驾驶策略的性能。本文认为,保持LLM和RL之间的相对独立性对于解决幻觉问题至关重要。因此,本文致力于提出一种新型的LLM提示RL范式。LLM用于生成语义提示,用于状态扩充和政策优化,以协助RL代理进行运动规划,而RL代理则通过政策学习来对抗潜在的错误语义指示,以实现卓越的驾驶性能。基于此范式,我们提出了HCRMP(LLM提示的上下文强化学习运动规划器)架构,该架构包括扩展状态空间的增强语义表示模块。上下文稳定性锚模块利用知识库中的信息来提高多批评家权重提示的可靠性。语义缓存模块无缝集成了LLM的低频指南和RL的高频控制。在CARLA进行的广泛实验验证了HCRMP强大的整体驾驶性能。在各种驾驶条件下,HCRMP的任务成功率高达80.3%。在安全关键的驾驶条件下,HCRMP将碰撞率降低了11.4%,这有效地提高了复杂场景中的驾驶性能。
论文及项目相关链接
Summary
在复杂场景中,整合大型语言模型(LLMs)与强化学习(RL)可以提高自动驾驶(AD)性能。然而,当前LLM主导的RL方法过于依赖LLM输出,容易产生幻觉。评估显示,最先进的LLM在关键驾驶任务上的非幻觉率仅为约57.95%。因此,LLM的幻觉会直接危及驾驶策略的性能。本文提出保持LLM和RL之间的相对独立性是解决幻觉问题的关键。基于此,提出了一种新型的LLM提示RL范式。LLM用于生成状态增强和政策优化的语义提示,协助RL代理进行运动规划,而RL代理则通过政策学习来对抗潜在的错误语义提示,以实现卓越的驾驶性能。基于这一范式,提出了HCRMP(LLM提示的上下文强化学习运动规划器)架构。该架构包括扩展状态空间的增强语义表示模块、增强多批判权重提示的可靠性上下文稳定性锚模块,以及无缝整合LLM低频指导和RL高频控制的语义缓存模块。在CARLA进行的广泛实验验证了HCRMP强大的整体驾驶性能。
Key Takeaways
- LLM与RL的结合可以提高自动驾驶在复杂场景中的性能。
- 当前LLM主导的RL方法存在过度依赖LLM输出的问题,导致幻觉。
- LLM的幻觉会直接影响驾驶策略的性能。
- 保持LLM和RL之间的相对独立性是解决幻觉问题的关键。
- 提出了一种新型的LLM提示RL范式,其中LLM用于生成语义提示,协助RL代理进行运动规划。
- 基于该范式,提出了HCRMP架构,包括多个模块以增强驾驶性能。
点此查看论文截图

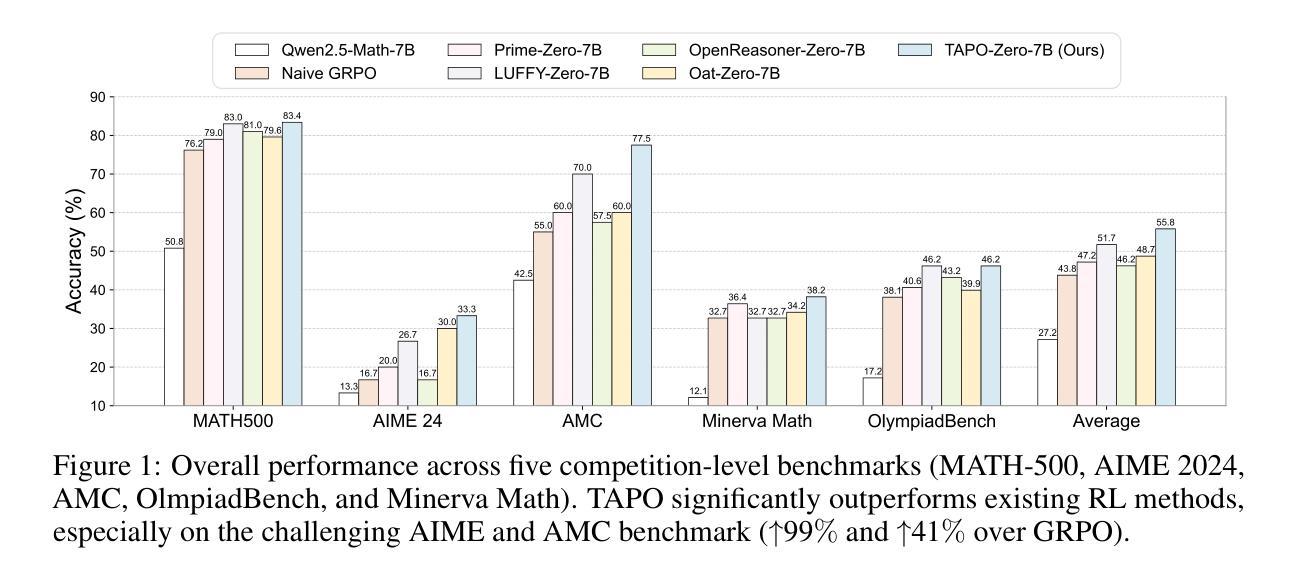
Thought-Augmented Policy Optimization: Bridging External Guidance and Internal Capabilities
Authors:Jinyang Wu, Chonghua Liao, Mingkuan Feng, Shuai Zhang, Zhengqi Wen, Pengpeng Shao, Huazhe Xu, Jianhua Tao
Reinforcement learning (RL) has emerged as an effective method for training reasoning models. However, existing RL approaches typically bias the model’s output distribution toward reward-maximizing paths without introducing external knowledge. This limits their exploration capacity and results in a narrower reasoning capability boundary compared to base models. To address this limitation, we propose TAPO (Thought-Augmented Policy Optimization), a novel framework that augments RL by incorporating external high-level guidance (“thought patterns”). By adaptively integrating structured thoughts during training, TAPO effectively balances model-internal exploration and external guidance exploitation. Extensive experiments show that our approach significantly outperforms GRPO by 99% on AIME, 41% on AMC, and 17% on Minerva Math. Notably, these high-level thought patterns, abstracted from only 500 prior samples, generalize effectively across various tasks and models. This highlights TAPO’s potential for broader applications across multiple tasks and domains. Our further analysis reveals that introducing external guidance produces powerful reasoning models with superior explainability of inference behavior and enhanced output readability.
强化学习(RL)已经成为训练推理模型的一种有效方法。然而,现有的强化学习方法通常偏向于奖励最大化的路径,而没有引入外部知识,这限制了模型的探索能力,与基础模型相比,其推理能力边界较窄。为了解决这一局限性,我们提出了TAPO(增强型策略优化),这是一种通过融入外部高级指导(即“思维模式”)来增强强化学习的新型框架。通过在训练过程中自适应地整合结构化思维,TAPO有效地平衡了模型内部的探索和外部指导的利用。大量实验表明,我们的方法在AIME上比GRPO高出99%,在AMC上高出41%,在Minerva Math上高出17%。值得注意的是,这些高级思维模式仅从500个先验样本中抽象出来,能有效地应用于各种任务和模型,这突显了TAPO在多个任务和领域中的更广泛应用潜力。我们的进一步分析表明,引入外部指导产生了强大的推理模型,具有出色的推理行为解释性和增强的输出可读性。
论文及项目相关链接
摘要
强化学习(RL)已成为训练推理模型的有效方法。然而,现有的RL方法通常偏向奖励最大化的路径,不引入外部知识,这限制了模型的探索能力,导致其推理能力边界较基础模型更窄。为解决这一局限性,我们提出了TAPO(思维增强策略优化)这一新型框架,它通过引入外部高级指导(“思维模式”)来增强RL。TAPO在训练过程中自适应地集成结构化思维,有效地平衡了模型内部的探索和外部指导的利用。大量实验表明,我们的方法在AIME上较GRPO高出99%,在AMC上高出41%,在Minerva Math上高出17%。值得注意的是,这些高级思维模式仅从500个先验样本中抽象出来,可有效地应用于各种任务和模型。这凸显了TAPO在跨多个任务和领域的更广泛应用潜力。我们的进一步分析表明,引入外部指导产生了强大的推理模型,具有出色的推理行为解释性和增强的输出可读性。
关键见解
- 强化学习是有效的训练推理模型方法。
- 现有RL方法存在偏向奖励最大化路径的问题,缺乏外部知识引入。
- TAPO框架通过引入外部高级指导(思维模式)来增强RL。
- TAPO自适应地集成结构化思维,平衡模型内部探索和外部指导利用。
- TAPO在多个任务上表现优越,仅从少量先验样本中抽象出的思维模式可泛化到不同任务和模型。
- TAPO有助于产生强大的推理模型,具有出色的推理行为解释性和输出可读性。
- TAPO具有跨多个任务和领域的更广泛应用潜力。
点此查看论文截图

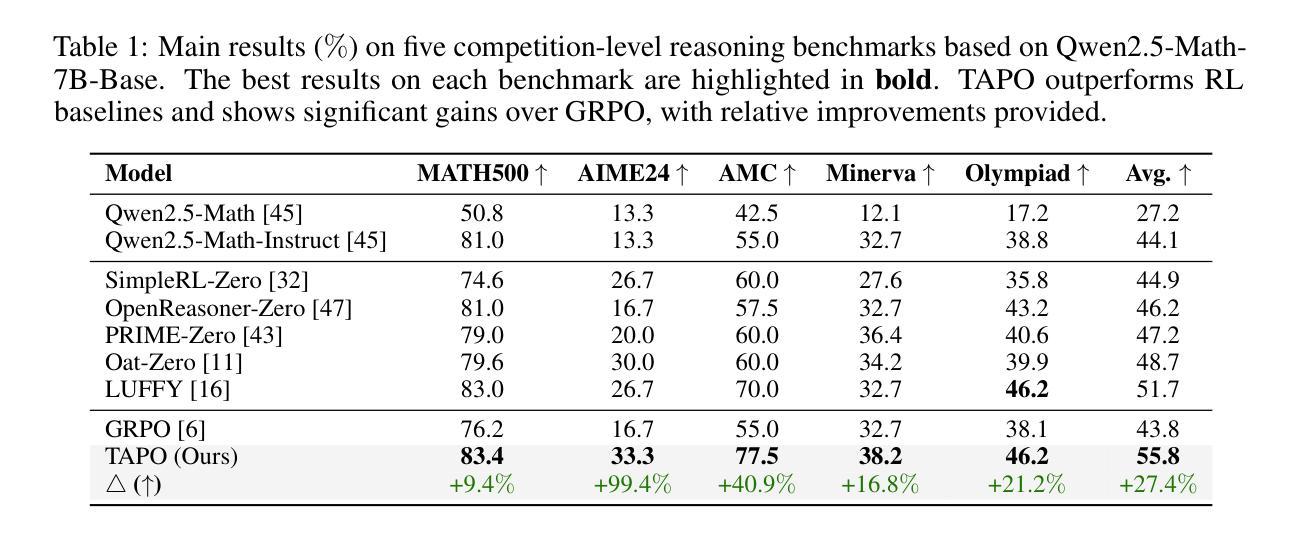
Learn to Reason Efficiently with Adaptive Length-based Reward Shaping
Authors:Wei Liu, Ruochen Zhou, Yiyun Deng, Yuzhen Huang, Junteng Liu, Yuntian Deng, Yizhe Zhang, Junxian He
Large Reasoning Models (LRMs) have shown remarkable capabilities in solving complex problems through reinforcement learning (RL), particularly by generating long reasoning traces. However, these extended outputs often exhibit substantial redundancy, which limits the efficiency of LRMs. In this paper, we investigate RL-based approaches to promote reasoning efficiency. Specifically, we first present a unified framework that formulates various efficient reasoning methods through the lens of length-based reward shaping. Building on this perspective, we propose a novel Length-bAsed StEp Reward shaping method (LASER), which employs a step function as the reward, controlled by a target length. LASER surpasses previous methods, achieving a superior Pareto-optimal balance between performance and efficiency. Next, we further extend LASER based on two key intuitions: (1) The reasoning behavior of the model evolves during training, necessitating reward specifications that are also adaptive and dynamic; (2) Rather than uniformly encouraging shorter or longer chains of thought (CoT), we posit that length-based reward shaping should be difficulty-aware i.e., it should penalize lengthy CoTs more for easy queries. This approach is expected to facilitate a combination of fast and slow thinking, leading to a better overall tradeoff. The resulting method is termed LASER-D (Dynamic and Difficulty-aware). Experiments on DeepSeek-R1-Distill-Qwen-1.5B, DeepSeek-R1-Distill-Qwen-7B, and DeepSeek-R1-Distill-Qwen-32B show that our approach significantly enhances both reasoning performance and response length efficiency. For instance, LASER-D and its variant achieve a +6.1 improvement on AIME2024 while reducing token usage by 63%. Further analysis reveals our RL-based compression produces more concise reasoning patterns with less redundant “self-reflections”. Resources are at https://github.com/hkust-nlp/Laser.
大规模推理模型(LRMs)通过强化学习(RL)表现出了解决复杂问题的显著能力,尤其是通过生成长的推理轨迹。然而,这些扩展输出常常表现出大量的冗余,这限制了LRMs的效率。在本文中,我们调查了基于RL的方法来提升推理效率。具体来说,我们首先提出了一个通过长度基础奖励塑造来制定各种高效推理方法的统一框架。在此基础上,我们提出了一种新型的基于长度的步进奖励塑造方法(LASER),它采用步进函数作为奖励,由目标长度控制。LASER超越了之前的方法,在性能和效率之间达到了帕累托最优平衡。接下来,我们进一步基于两个关键直觉扩展了LASER:(1)模型的推理行为在训练过程中会发生变化,需要奖励规格也是自适应和动态的;(2)而不是统一地鼓励更短或更长的思维链(CoT),我们认为基于长度的奖励塑造应该是难度感知的,即对于简单的查询,它应该更严厉地惩罚冗长的CoT。这种方法预计会促进快速和慢速思维的结合,从而实现更好的整体权衡。得到的方法被称为LASER-D(动态和难度感知)。在DeepSeek-R1-Distill-Qwen-1.5B、DeepSeek-R1-Distill-Qwen-7B和DeepSeek-R1-Distill-Qwen-32B上的实验表明,我们的方法显著提高了推理性能和响应长度效率。例如,LASER-D及其变体在AIME2024上实现了+6.1的改进,同时减少了63%的令牌使用。进一步的分析表明,我们的基于RL的压缩产生了更简洁的推理模式,减少了冗余的“自我反思”。相关资源见:https://github.com/hkust-nlp/Laser。
论文及项目相关链接
Summary
大型推理模型(LRMs)通过强化学习(RL)解决复杂问题的能力令人瞩目,尤其是在生成长推理轨迹方面。然而,这些扩展输出常常存在大量冗余,限制了LRMs的效率。本文研究RL方法来提升推理效率。我们提出一种基于长度的步进奖励塑造方法(LASER),利用步函数作为奖励进行控制,在性能与效率之间达到帕累托最优平衡。此外,我们还进一步扩展了LASER,考虑到模型在训练过程中的推理行为变化,提出了动态和难度感知的长度基础奖励塑造方法(LASER-D)。实验结果表明,该方法显著提高了推理性能和响应长度效率。
Key Takeaways
- 大型推理模型(LRMs)在解决复杂问题上表现出强大的能力,但存在冗余输出,影响效率。
- 通过强化学习(RL)方法,提出一种基于长度的步进奖励塑造(LASER),以提高推理效率。
- LASER方法在性能与效率之间达到帕累托最优平衡。
- 模型的推理行为在训练过程中会变化,需要动态和难度感知的长度基础奖励塑造方法(LASER-D)。
- LASER-D方法显著提高了推理性能和响应长度效率。
- 实验结果包括在多个数据集上的性能提升和令牌使用效率的提高。
点此查看论文截图

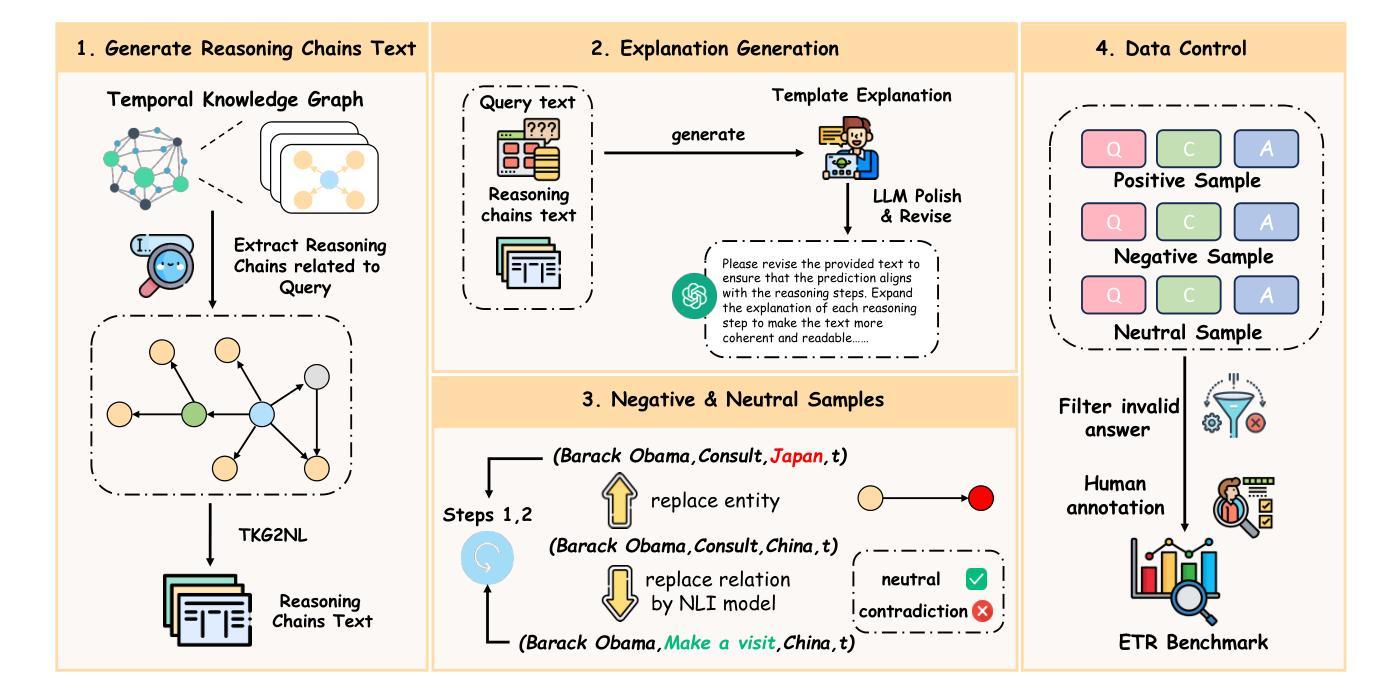
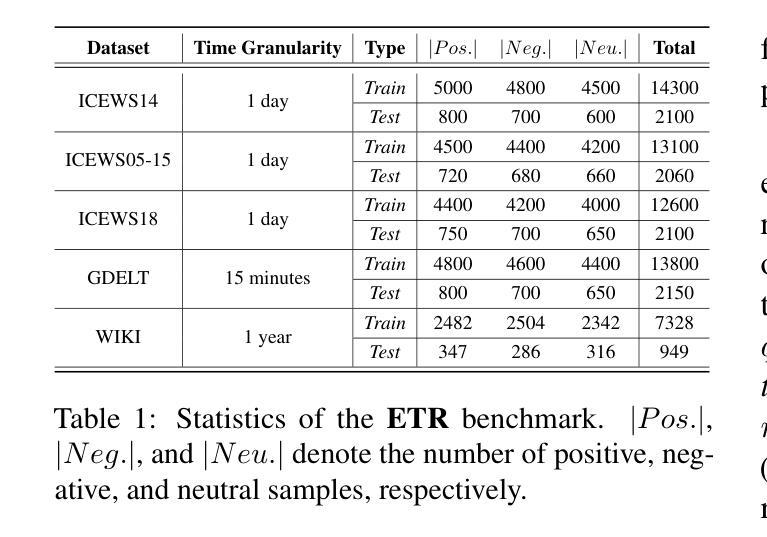
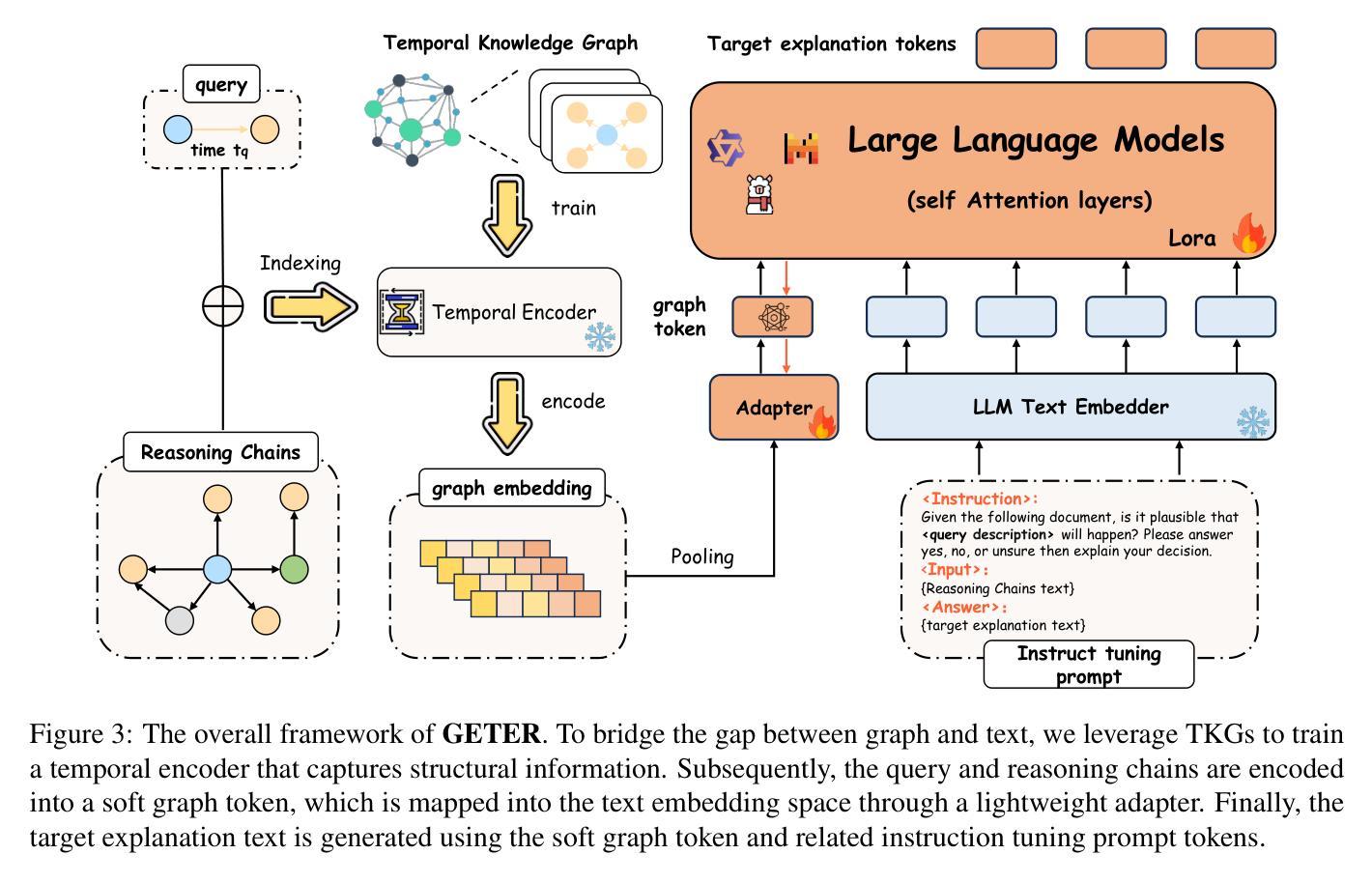
Towards Explainable Temporal Reasoning in Large Language Models: A Structure-Aware Generative Framework
Authors:Zihao Jiang, Ben Liu, Miao Peng, Wenjie Xu, Yao Xiao, Zhenyan Shan, Min Peng
While large language models (LLMs) show great potential in temporal reasoning, most existing work focuses heavily on enhancing performance, often neglecting the explainable reasoning processes underlying the results. To address this gap, we introduce a comprehensive benchmark covering a wide range of temporal granularities, designed to systematically evaluate LLMs’ capabilities in explainable temporal reasoning. Furthermore, our findings reveal that LLMs struggle to deliver convincing explanations when relying solely on textual information. To address challenge, we propose GETER, a novel structure-aware generative framework that integrates Graph structures with text for Explainable TEmporal Reasoning. Specifically, we first leverage temporal knowledge graphs to develop a temporal encoder that captures structural information for the query. Subsequently, we introduce a structure-text prefix adapter to map graph structure features into the text embedding space. Finally, LLMs generate explanation text by seamlessly integrating the soft graph token with instruction-tuning prompt tokens. Experimental results indicate that GETER achieves state-of-the-art performance while also demonstrating its effectiveness as well as strong generalization capabilities. Our dataset and code are available at https://github.com/carryTatum/GETER.
虽然大型语言模型(LLM)在时序推理方面显示出巨大潜力,但大多数现有工作都集中在提高性能上,往往忽视了结果背后可解释推理过程。为了弥补这一空白,我们引入了一个全面的基准测试,涵盖了各种时序粒度,旨在系统地评估LLM在可解释时序推理方面的能力。此外,我们的研究发现,LLM在仅依赖文本信息时,很难提供令人信服的解释。为了应对这一挑战,我们提出了GETER,这是一个新的结构感知生成框架,它将图结构与文本集成在一起,用于可解释的时序推理。具体来说,我们首先利用时序知识图谱开发了一个时序编码器,该编码器可以捕捉查询的结构信息。随后,我们引入了一个结构文本前缀适配器,将图结构特征映射到文本嵌入空间。最后,LLM通过无缝融合软图令牌与指令调整提示令牌来生成解释文本。实验结果表明,GETER达到了最先进的性能,同时证明了其有效性和强大的泛化能力。我们的数据集和代码可在https://github.com/carryTatum/GETER找到。
论文及项目相关链接
PDF In Findings of the Association for Computational Linguistics: ACL 2025
Summary
大型语言模型(LLM)在时序推理领域具有巨大潜力,但现有研究主要关注性能提升,忽视了结果背后的可解释推理过程。为弥补这一不足,我们设计了一个全面的基准测试,涵盖各种时序粒度,旨在系统评估LLM在可解释时序推理方面的能力。研究发现,LLM在仅依赖文本信息时,难以给出令人信服的解释。为解决这一挑战,我们提出了GETER,一个结合图结构与文本的结构感知生成框架。GETER利用时序知识图谱开发时序编码器,捕捉查询的结构信息,并通过结构文本前缀适配器将图结构特征映射到文本嵌入空间。实验结果表明,GETER在达到最佳性能的同时,也展示了其有效性和强大的泛化能力。我们的数据集和代码已在GitHub上公开。
Key Takeaways
- 大型语言模型(LLM)在时序推理方面具有潜力,但缺乏可解释性。
- 现有研究过于关注性能提升,忽视了结果背后的推理过程。
- 提出一个全面的基准测试来评估LLM在可解释时序推理方面的能力。
- LLM在仅依赖文本信息时难以给出令人信服的解释。
- 引入GETER框架,结合图结构与文本,提高LLM在时序推理方面的性能。
- GETER利用时序知识图谱开发时序编码器,并捕捉查询的结构信息。
点此查看论文截图

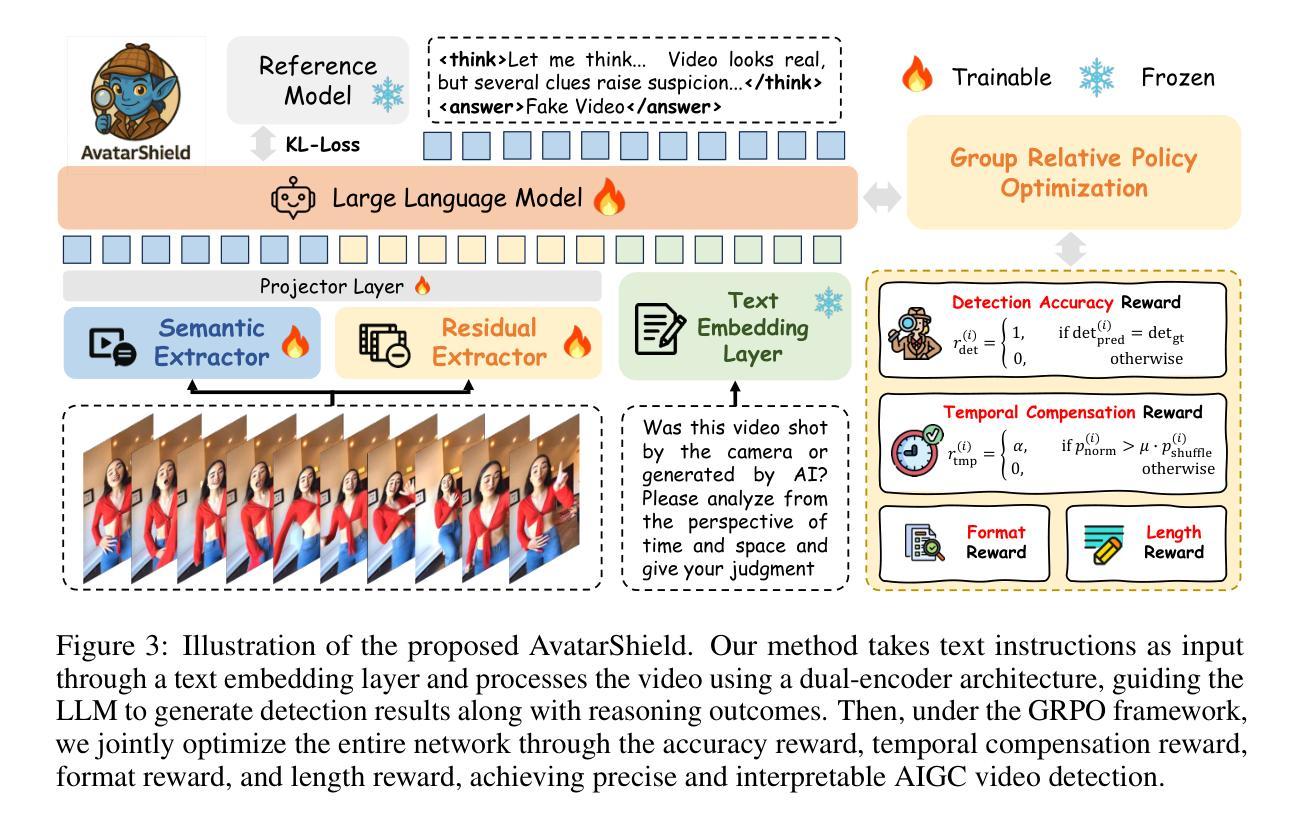
AvatarShield: Visual Reinforcement Learning for Human-Centric Video Forgery Detection
Authors:Zhipei Xu, Xuanyu Zhang, Xing Zhou, Jian Zhang
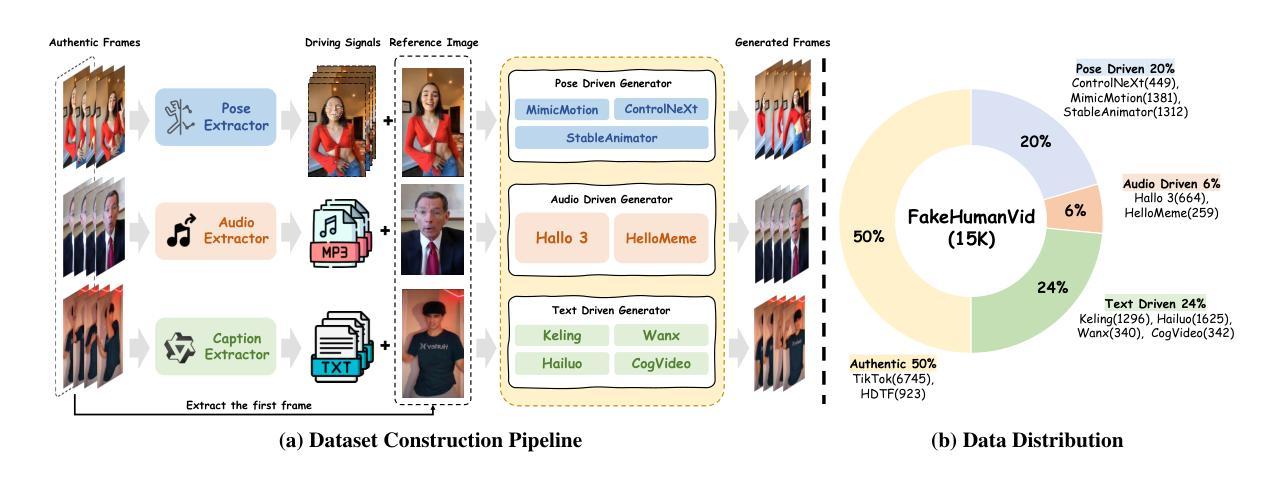
The rapid advancement of Artificial Intelligence Generated Content (AIGC) technologies, particularly in video generation, has led to unprecedented creative capabilities but also increased threats to information integrity, identity security, and public trust. Existing detection methods, while effective in general scenarios, lack robust solutions for human-centric videos, which pose greater risks due to their realism and potential for legal and ethical misuse. Moreover, current detection approaches often suffer from poor generalization, limited scalability, and reliance on labor-intensive supervised fine-tuning. To address these challenges, we propose AvatarShield, the first interpretable MLLM-based framework for detecting human-centric fake videos, enhanced via Group Relative Policy Optimization (GRPO). Through our carefully designed accuracy detection reward and temporal compensation reward, it effectively avoids the use of high-cost text annotation data, enabling precise temporal modeling and forgery detection. Meanwhile, we design a dual-encoder architecture, combining high-level semantic reasoning and low-level artifact amplification to guide MLLMs in effective forgery detection. We further collect FakeHumanVid, a large-scale human-centric video benchmark that includes synthesis methods guided by pose, audio, and text inputs, enabling rigorous evaluation of detection methods in real-world scenes. Extensive experiments show that AvatarShield significantly outperforms existing approaches in both in-domain and cross-domain detection, setting a new standard for human-centric video forensics.
随着人工智能生成内容(AIGC)技术的快速发展,尤其是在视频生成领域,这带来了前所未有的创造力,但同时也增加了信息完整性、身份安全和公众信任的威胁。尽管现有检测方法在一般场景中有效,但它们对于以人类为中心的视频缺乏稳健解决方案,这些视频由于真实感和潜在的滥用风险而构成更大威胁。此外,当前的检测方法往往存在泛化能力差、可扩展性有限、依赖于劳动密集型的监督微调等问题。为了应对这些挑战,我们提出了AvatarShield,这是第一个基于可解释多模态语言模型(MLLM)的检测人类为中心的虚假视频的框架,通过群组相对策略优化(GRPO)得到增强。通过我们精心设计的精度检测奖励和时间补偿奖励,它有效地避免了使用高成本文本注释数据,实现了精确的时间建模和伪造检测。同时,我们设计了双编码器架构,结合高级语义推理和低级伪影放大,以指导MLLM进行有效的伪造检测。我们还收集了FakeHumanVid,这是一个大规模的人类为中心的视频基准测试,包括由姿势、音频和文本输入引导的合成方法,能对检测方法在真实场景中的表现进行严格的评估。大量实验表明,AvatarShield在域内和跨域检测方面都显著优于现有方法,为人类为中心的视频取证设定了新的标准。
论文及项目相关链接
Summary
随着人工智能生成内容(AIGC)技术的快速发展,特别是在视频生成领域,虽然带来了前所未有的创造力,但也增加了信息完整性、身份安全和公众信任的威胁。现有的检测方法对于以人类为中心的视频缺乏稳健解决方案,因此存在更大的风险。为解决此问题,提出了AvatarShield框架,通过组合MLLM技术和Group Relative Policy Optimization(GRPO)方法,实现精确的时间建模和伪造检测。设计了一种双编码器架构,结合高级语义推理和低级伪影放大,以指导MLLM进行有效检测。同时,还推出了大型人类为中心的视频基准测试FakeHumanVid。实验证明,AvatarShield在域内和跨域检测方面都大大优于现有方法,为以人为中心的视频取证树立了新标准。
Key Takeaways
- AIGC技术的发展在视频生成领域带来了前所未有的创造力,但也带来了信息完整性、身份安全和公众信任的威胁。
- 现有检测方法对于以人类为中心的视频缺乏稳健解决方案,存在更大的风险。
- AvatarShield框架通过MLLM技术和GRPO方法实现了精确的时间建模和伪造检测。
- AvatarShield设计了双编码器架构,结合高级语义推理和低级伪影放大,提高检测效率。
- FakeHumanVid基准测试用于严格评估现实场景中的检测方法。
- 实验证明,AvatarShield在域内和跨域检测方面都大大优于现有方法。
点此查看论文截图


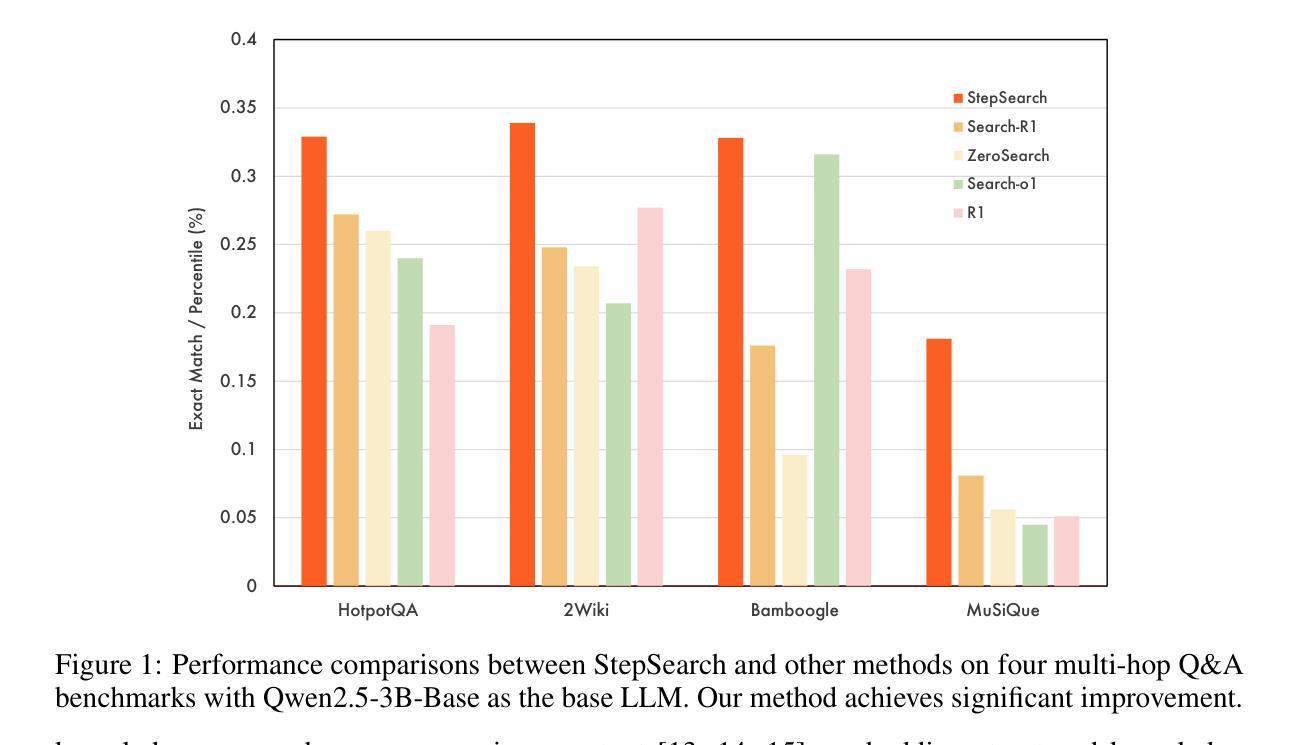
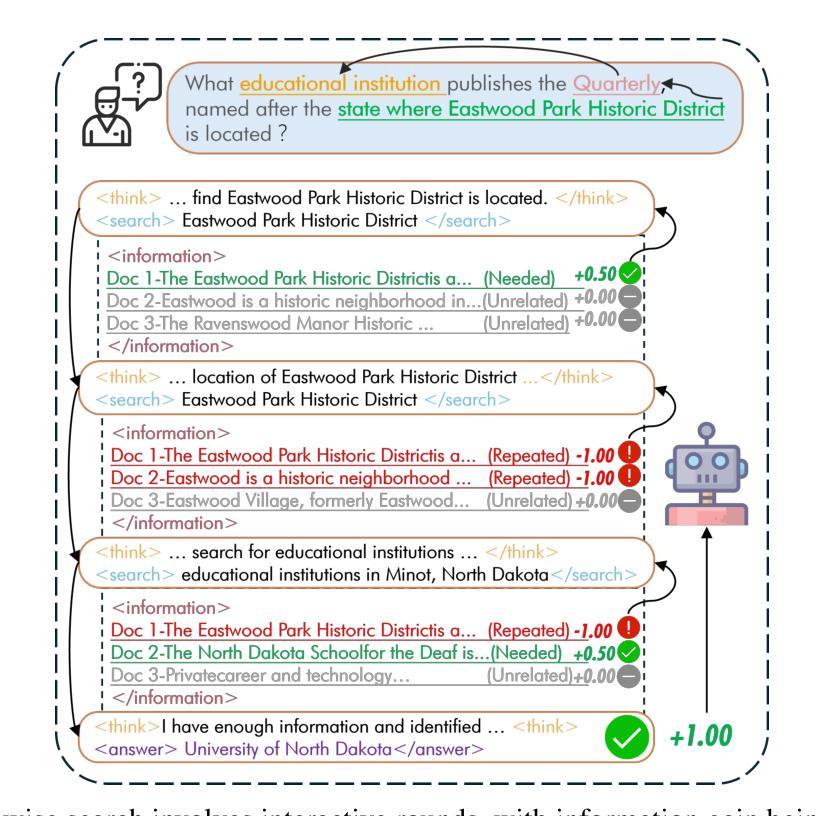
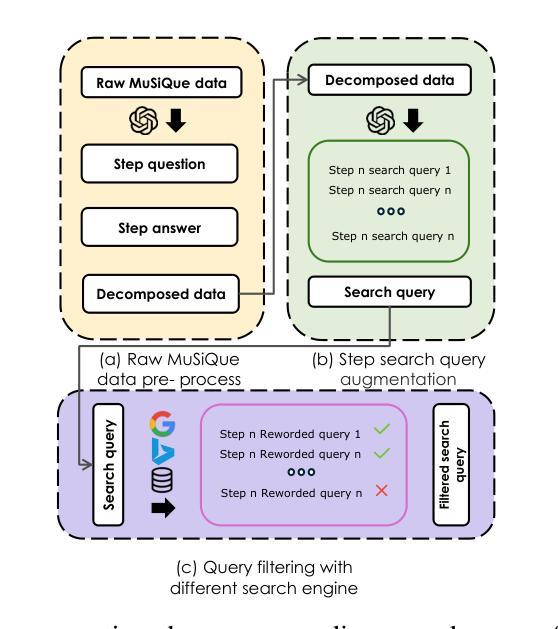
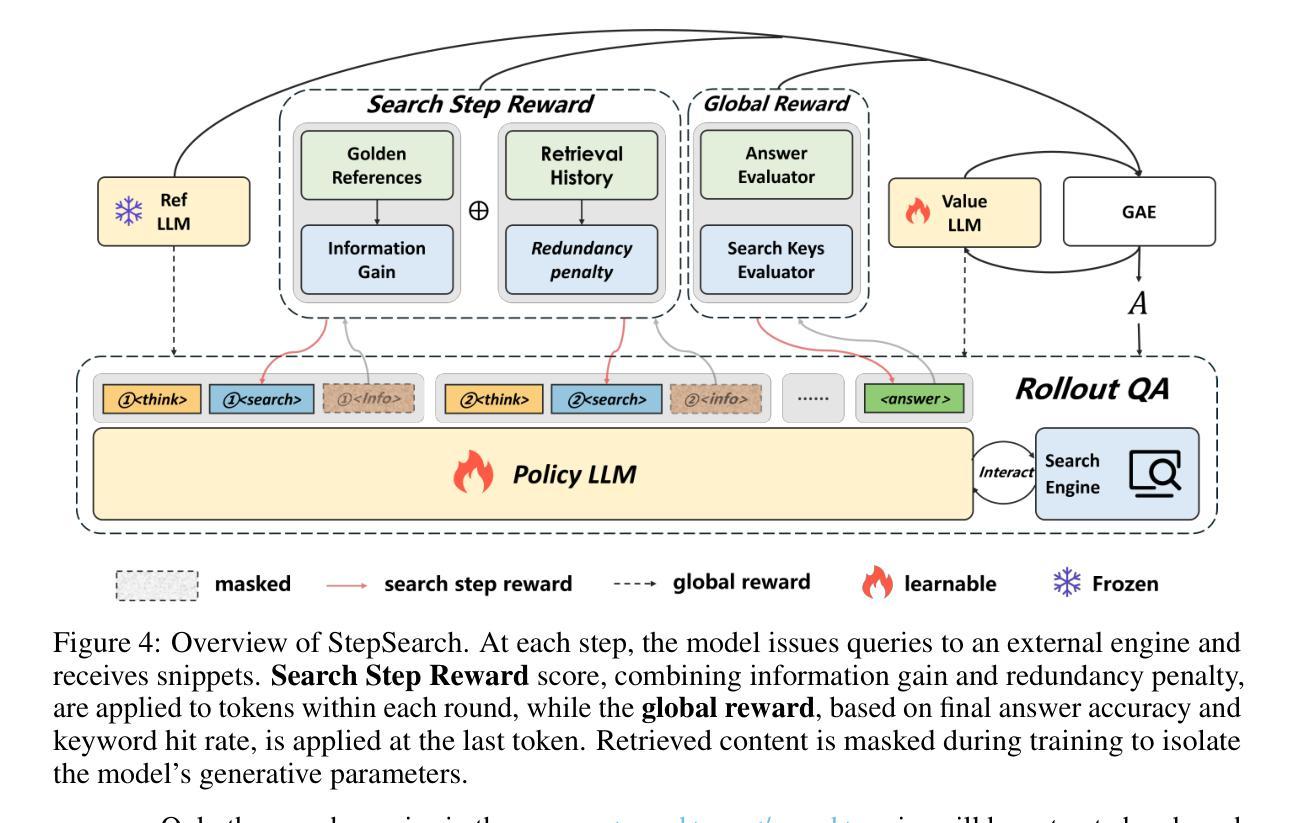
StepSearch: Igniting LLMs Search Ability via Step-Wise Proximal Policy Optimization
Authors:Ziliang Wang, Xuhui Zheng, Kang An, Cijun Ouyang, Jialu Cai, Yuhang Wang, Yichao Wu
Efficient multi-hop reasoning requires Large Language Models (LLMs) based agents to acquire high-value external knowledge iteratively. Previous work has explored reinforcement learning (RL) to train LLMs to perform search-based document retrieval, achieving notable improvements in QA performance, but underperform on complex, multi-hop QA resulting from the sparse rewards from global signal only. To address this gap in existing research, we introduce StepSearch, a framework for search LLMs that trained with step-wise proximal policy optimization method. It consists of richer and more detailed intermediate search rewards and token-level process supervision based on information gain and redundancy penalties to better guide each search step. We constructed a fine-grained question-answering dataset containing sub-question-level search trajectories based on open source datasets through a set of data pipeline method. On standard multi-hop QA benchmarks, it significantly outperforms global-reward baselines, achieving 11.2% and 4.2% absolute improvements for 3B and 7B models over various search with RL baselines using only 19k training data, demonstrating the effectiveness of fine-grained, stepwise supervision in optimizing deep search LLMs. Our implementation is publicly available at https://github.com/zxh20001117/StepSearch.
高效的多跳推理需要基于大型语言模型(LLM)的代理程序来迭代地获取高价值外部知识。之前的研究已经探索了强化学习(RL)来训练LLM执行基于搜索的文档检索,从而在问答性能上取得了显著的改进,但在复杂的多跳问答方面表现不佳,这仅源于全局信号的稀疏奖励。为了解决现有研究中的这一空白,我们引入了StepSearch,这是一个用逐步近端策略优化方法训练的搜索LLM框架。它包含更丰富和更详细的中间搜索奖励,以及基于信息增益和冗余惩罚的基于令牌级别的过程监督,以更好地引导每个搜索步骤。我们构建了一个基于开放源代码数据集通过一系列数据管道方法的精细粒度问答数据集,其中包含子问题级别的搜索轨迹。在标准的多跳问答基准测试中,与仅使用全局奖励基线相比,我们的方法在训练数据仅有少量(仅使用训练数据的前19k)的情况下,对基线模型进行了显著的改进,在模型规模为大型语言模型以及更大型语言模型时,分别实现了绝对改善幅度为百分之十一点二和百分之四点二。这证明了在优化深度搜索LLM时,精细粒度的逐步监督的有效性。我们的实现可以在以下网址公开访问:https://github.com/zxh20001117/StepSearch 。
论文及项目相关链接
PDF 20 pages, 6 figures
Summary
大型语言模型(LLM)在高效的多跳推理中需要迭代地获取高价值外部知识。针对现有研究中存在的稀疏奖励问题,我们提出了StepSearch框架,采用基于步骤的近端策略优化方法训练LLM进行搜索。该框架包含丰富的中间搜索奖励和基于信息增益和冗余惩罚的令牌级过程监督,以更好地指导每次搜索步骤。我们在基于开源数据集构建的精细粒度的问答数据集上构建了包含子问题级别的搜索轨迹的数据管道方法。在标准的多跳问答基准测试中,与全局奖励的基线相比,StepSearch实现了显著的改进,使用仅19k训练数据,对3B和7B模型的绝对改进分别为11.2%和4.2%,证明了在优化深度搜索LLM方面,精细粒度的分步监督的有效性。
Key Takeaways
- 大型语言模型(LLM)在高效的多跳推理中需要获取高价值外部知识。
- 强化学习(RL)在训练LLM进行基于搜索的文档检索方面已有显著成效,但在处理复杂的多跳问答方面仍存在不足。
- StepSearch框架通过采用基于步骤的近端策略优化方法来解决这一差距。
- StepSearch包含丰富的中间搜索奖励和基于信息增益及冗余惩罚的令牌级过程监督,以指导每次搜索步骤。
- 构建了基于开源数据集的精细粒度的问答数据集,包含子问题级别的搜索轨迹。
- 在标准多跳问答测试中,StepSearch显著优于全局奖励基线,证明了精细粒度的分步监督在优化深度搜索LLM方面的有效性。
点此查看论文截图

DISCO Balances the Scales: Adaptive Domain- and Difficulty-Aware Reinforcement Learning on Imbalanced Data
Authors:Yuhang Zhou, Jing Zhu, Shengyi Qian, Zhuokai Zhao, Xiyao Wang, Xiaoyu Liu, Ming Li, Paiheng Xu, Wei Ai, Furong Huang
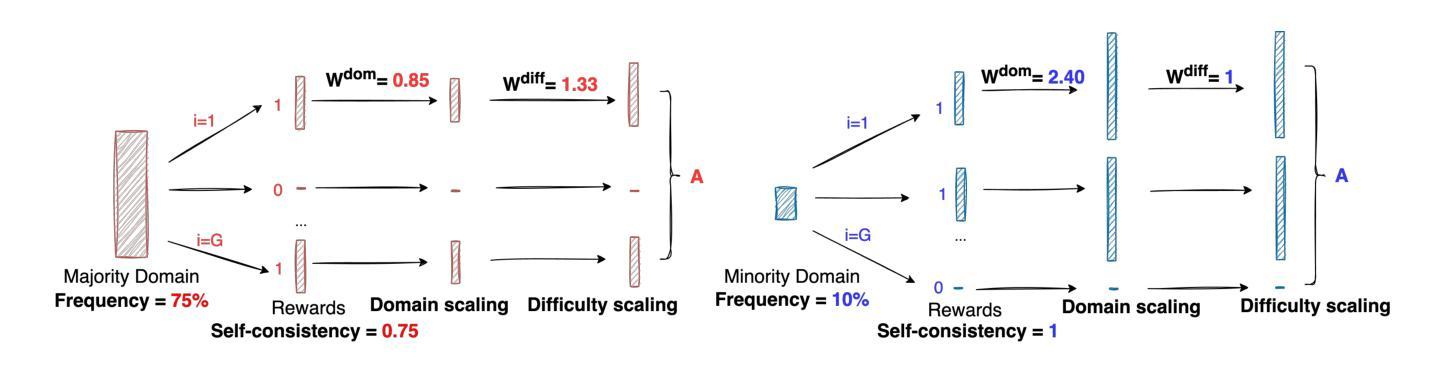
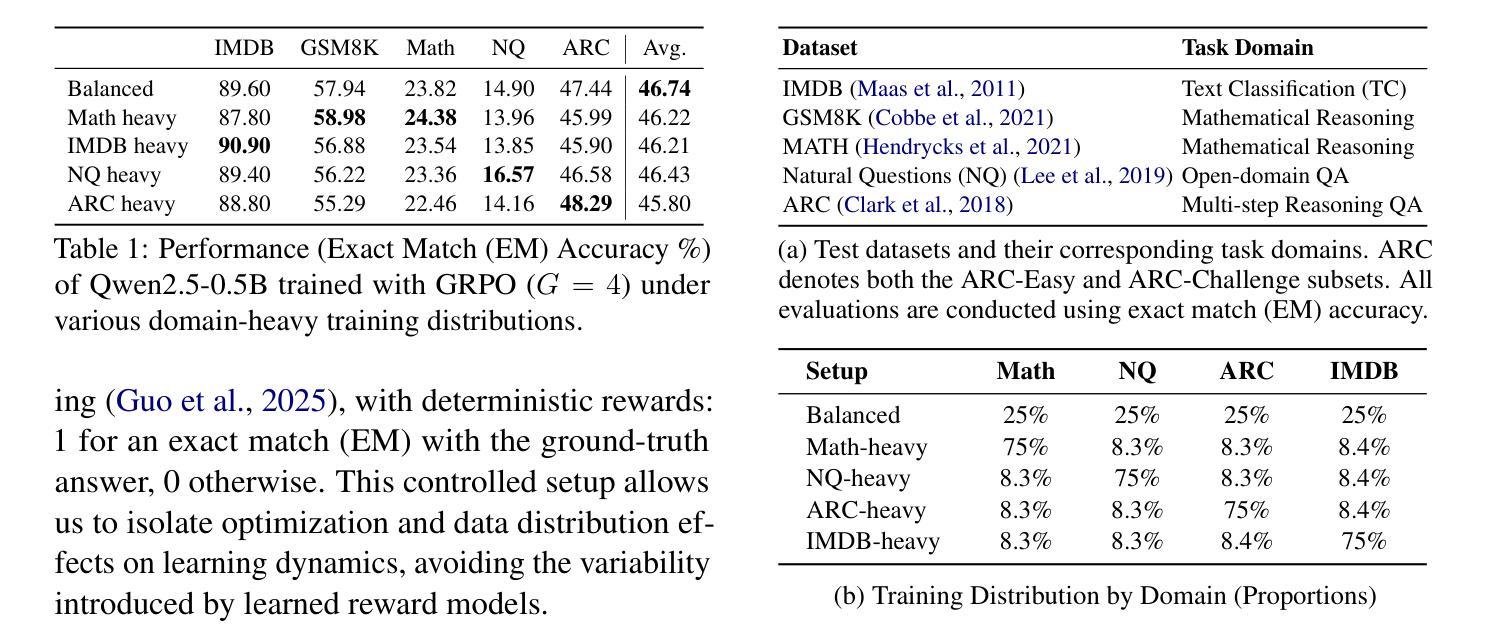
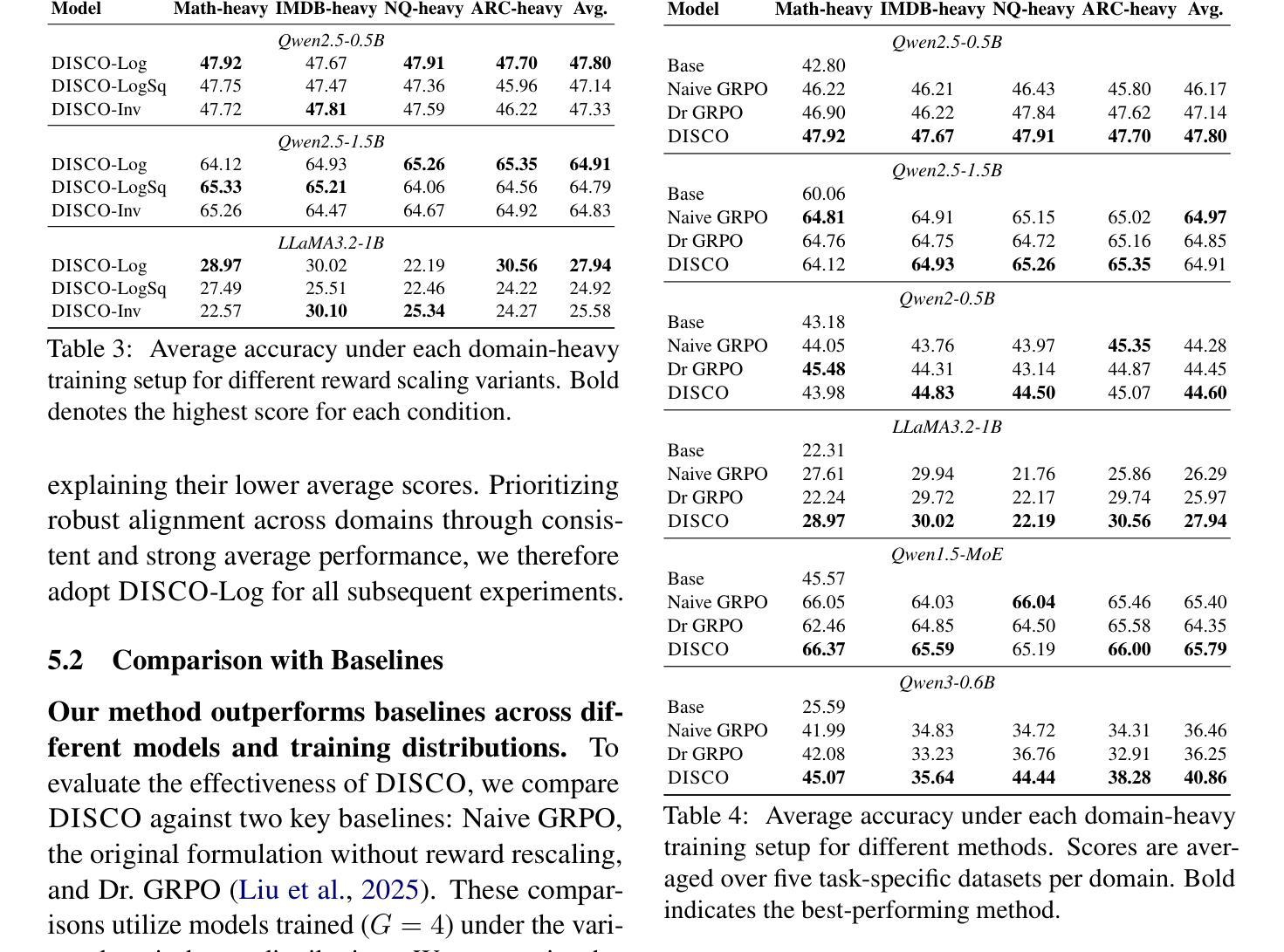
Large Language Models (LLMs) are increasingly aligned with human preferences through Reinforcement Learning from Human Feedback (RLHF). Among RLHF methods, Group Relative Policy Optimization (GRPO) has gained attention for its simplicity and strong performance, notably eliminating the need for a learned value function. However, GRPO implicitly assumes a balanced domain distribution and uniform semantic alignment across groups - assumptions that rarely hold in real-world datasets. When applied to multi-domain, imbalanced data, GRPO disproportionately optimizes for dominant domains, neglecting underrepresented ones and resulting in poor generalization and fairness. We propose Domain-Informed Self-Consistency Policy Optimization (DISCO), a principled extension to GRPO that addresses inter-group imbalance with two key innovations. Domain-aware reward scaling counteracts frequency bias by reweighting optimization based on domain prevalence. Difficulty-aware reward scaling leverages prompt-level self-consistency to identify and prioritize uncertain prompts that offer greater learning value. Together, these strategies promote more equitable and effective policy learning across domains. Extensive experiments across multiple LLMs and skewed training distributions show that DISCO improves generalization, outperforms existing GRPO variants by 5% on Qwen3 models, and sets new state-of-the-art results on multi-domain alignment benchmarks.
随着通过人类反馈强化学习(RLHF)的不断应用,大型语言模型(LLM)越来越符合人类的偏好。在RLHF方法中,群体相对策略优化(GRPO)因其简单性和出色的性能而受到关注,特别是它不需要学习价值函数。然而,GRPO隐含地假设了域分布的平衡和跨群体的语义对齐的统一性,这些假设在真实世界的数据集中很少成立。当应用于多域、不平衡数据时,GRPO会过度优化主导域,忽略代表性不足的域,导致泛化和公平性较差。我们提出了领域信息自我一致性策略优化(DISCO),这是对GRPO的一种原则性扩展,通过两个关键创新来解决组间不平衡问题。领域感知奖励缩放通过根据领域的普及程度重新调整优化来抵消频率偏见。难度感知奖励缩放利用提示级别的自我一致性来识别和优先处理具有更大学习价值的不确定提示。这两种策略共同促进了跨领域的更公平和有效的策略学习。在多个LLM和偏态训练分布上的广泛实验表明,DISCO提高了泛化能力,在Qwen3模型上比现有GRPO变体高出5%,并在多域对齐基准测试中取得了最新的最佳结果。
论文及项目相关链接
PDF 13 pages, 3 figures
Summary
大型语言模型(LLM)通过强化学习从人类反馈(RLHF)中进行对齐人类偏好。GRPO方法因其简单性和出色性能而受到关注,尤其是不需要学习价值函数。然而,GRPO隐含假设领域分布平衡和跨组语义对齐一致,这在现实世界中很少成立。在多领域、不均衡数据中应用GRPO会过度优化主导领域,忽视代表性不足的领域,导致泛化和公平性较差。为此,我们提出了DISCO(领域信息自我一致性策略优化),这是GRPO的一种原则性扩展,解决了组间不平衡问题,其中包括两个关键创新点:领域感知奖励缩放和难度感知奖励缩放。这两个策略一起促进了更公平和有效的跨领域策略学习。在多个LLM和偏斜训练分布上的实验表明,DISCO提高了泛化能力,在Qwen3模型上优于现有GRPO变体5%,并在多领域对齐基准测试中达到了新的最佳水平。
Key Takeaways
- 大型语言模型(LLM)采用强化学习从人类反馈(RLHF)中对齐人类偏好。
- Group Relative Policy Optimization (GRPO) 方法具有简单性和出色性能,但不考虑现实世界中领域分布的不平衡性。
- GRPO在多领域、不均衡数据的应用中存在问题,会过度优化主导领域而忽略代表性不足的领域。
- DISCO是GRPO的一种扩展,通过领域感知奖励缩放和难度感知奖励缩放解决GRPO的问题。
- DISCO能提高模型的泛化能力,并在多领域对齐基准测试中表现优异。
- DISCO在Qwen3模型上的表现优于现有GRPO变体。
点此查看论文截图

General-Reasoner: Advancing LLM Reasoning Across All Domains
Authors:Xueguang Ma, Qian Liu, Dongfu Jiang, Ge Zhang, Zejun Ma, Wenhu Chen
Reinforcement learning (RL) has recently demonstrated strong potential in enhancing the reasoning capabilities of large language models (LLMs). Particularly, the “Zero” reinforcement learning introduced by Deepseek-R1-Zero, enables direct RL training of base LLMs without relying on an intermediate supervised fine-tuning stage. Despite these advancements, current works for LLM reasoning mainly focus on mathematical and coding domains, largely due to data abundance and the ease of answer verification. This limits the applicability and generalization of such models to broader domains, where questions often have diverse answer representations, and data is more scarce. In this paper, we propose General-Reasoner, a novel training paradigm designed to enhance LLM reasoning capabilities across diverse domains. Our key contributions include: (1) constructing a large-scale, high-quality dataset of questions with verifiable answers curated by web crawling, covering a wide range of disciplines; and (2) developing a generative model-based answer verifier, which replaces traditional rule-based verification with the capability of chain-of-thought and context-awareness. We train a series of models and evaluate them on a wide range of datasets covering wide domains like physics, chemistry, finance, electronics etc. Our comprehensive evaluation across these 12 benchmarks (e.g. MMLU-Pro, GPQA, SuperGPQA, TheoremQA, BBEH and MATH AMC) demonstrates that General-Reasoner outperforms existing baseline methods, achieving robust and generalizable reasoning performance while maintaining superior effectiveness in mathematical reasoning tasks.
强化学习(RL)最近在提高大型语言模型(LLM)的推理能力方面表现出了强大的潜力。特别是Deepseek-R1-Zero引入的”Zero”强化学习,能够实现基于LLM的基础RL训练,而无需依赖中间监督微调阶段。尽管有了这些进展,但目前LLM推理的研究主要集中在数学和编码领域,这主要是因为数据丰富且答案易于验证。这限制了此类模型在更广泛领域的应用和泛化能力,在这些领域中,问题的答案表示形式往往多种多样,而且数据更加稀缺。在本文中,我们提出了General-Reasoner,这是一种旨在提高LLM在多个领域推理能力的新型训练范式。我们的主要贡献包括:(1)通过网页爬虫构建了一个大规模、高质量的问题数据集,其中包含可验证的答案,涵盖广泛的学科;以及(2)开发了一种基于生成模型的答案验证器,它用基于思维链和上下文感知的能力取代了传统的基于规则的验证。我们在多个数据集上训练了一系列模型,并在涵盖物理、化学、金融、电子等领域的12个基准测试集(如MMLU-Pro、GPQA、SuperGPQA、TheoremQA、BBEH和MATH AMC)上进行了评估。综合评估结果表明,General-Reasoner在多种基准测试集上的表现均优于现有基线方法,实现了稳健且可泛化的推理性能,同时在数学推理任务中保持了较高的有效性。
论文及项目相关链接
Summary
强化学习在提升大型语言模型的推理能力方面具有巨大潜力。Deepseek-R1-Zero提出的“零强化学习”方法能够直接对基础语言模型进行强化学习训练,无需依赖中间监督微调阶段。当前的研究主要集中在数学和编码领域,这限制了模型在更广泛领域的适用性。本文提出General-Reasoner,一种旨在提升语言模型在多样领域推理能力的新型训练范式。其主要贡献包括构建大规模高质量数据集和基于生成模型的答案验证器。在涵盖物理、化学、金融、电子等多个领域的广泛数据集上进行的实验表明,General-Reasoner在多个基准测试上表现优异,实现了稳健且可推广的推理性能。
Key Takeaways
- 强化学习增强了大型语言模型的推理能力。
- Deepseek-R1-Zero提出了“零强化学习”方法,可直接训练语言模型,无需中间监督微调。
- 当前LLM推理研究主要集中在数学和编码领域,存在领域适用性的限制。
- General-Reasoner是一种新型训练范式,旨在提升语言模型在多样领域的推理能力。
- General-Reasoner的主要贡献包括构建大规模、高质量的问题数据集和基于生成模型的答案验证器。
- General-Reasoner在多个基准测试上表现优异,实现了稳健且可推广的推理性能。
点此查看论文截图


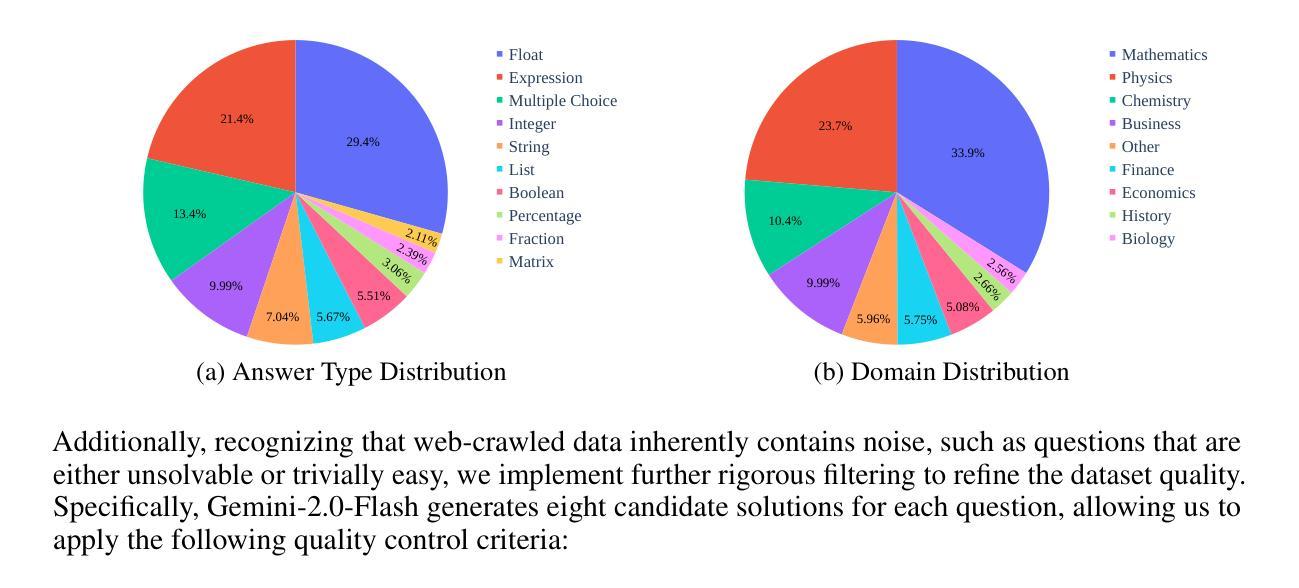

Think Only When You Need with Large Hybrid-Reasoning Models
Authors:Lingjie Jiang, Xun Wu, Shaohan Huang, Qingxiu Dong, Zewen Chi, Li Dong, Xingxing Zhang, Tengchao Lv, Lei Cui, Furu Wei
Recent Large Reasoning Models (LRMs) have shown substantially improved reasoning capabilities over traditional Large Language Models (LLMs) by incorporating extended thinking processes prior to producing final responses. However, excessively lengthy thinking introduces substantial overhead in terms of token consumption and latency, which is particularly unnecessary for simple queries. In this work, we introduce Large Hybrid-Reasoning Models (LHRMs), the first kind of model capable of adaptively determining whether to perform thinking based on the contextual information of user queries. To achieve this, we propose a two-stage training pipeline comprising Hybrid Fine-Tuning (HFT) as a cold start, followed by online reinforcement learning with the proposed Hybrid Group Policy Optimization (HGPO) to implicitly learn to select the appropriate thinking mode. Furthermore, we introduce a metric called Hybrid Accuracy to quantitatively assess the model’s capability for hybrid thinking. Extensive experimental results show that LHRMs can adaptively perform hybrid thinking on queries of varying difficulty and type. It outperforms existing LRMs and LLMs in reasoning and general capabilities while significantly improving efficiency. Together, our work advocates for a reconsideration of the appropriate use of extended thinking processes and provides a solid starting point for building hybrid thinking systems.
最近的大型推理模型(LRM)通过融入最终响应之前的扩展思考过程,在推理能力上相较于传统的大型语言模型(LLM)有了显著的提升。然而,过度冗长的思考过程会导致大量的符号消耗和延迟,这在简单的查询上显得尤为不必要。在本研究中,我们引入了大型混合推理模型(LHRM),这是第一种能够自适应地根据用户查询的上下文信息来决定是否进行思考的模型。为了实现这一点,我们提出了一个两阶段的训练流程,首先是混合微调(HFT)的冷启动,随后是采用所提出的混合组策略优化(HGPO)的在线强化学习,以隐式学习选择适当的思考模式。此外,我们还引入了一个名为混合准确率的指标来定量评估模型的混合思考能力。广泛的实验结果表明,LHRM可以在不同类型的查询上自适应地进行混合思考,并在推理和一般能力上优于现有的LRM和LLM,同时显著提高效率。总的来说,我们的研究重新考虑了扩展思考过程的适当使用,并为构建混合思考系统提供了一个坚实的起点。
论文及项目相关链接
Summary
大型混合推理模型(LHRMs)的引入,能够根据用户查询的上下文信息自适应地决定是否进行推理。该模型通过两阶段训练管道实现,包括混合微调(HFT)的冷启动,以及使用混合组策略优化(HGPO)的在线强化学习,以隐式学习选择适当的思考模式。此外,还引入了一个名为混合准确率的指标来定量评估模型的混合思维能力。实验结果表明,LHRMs能够在不同类型的查询上自适应地进行混合思维,在推理和通用能力上优于现有的大型推理模型(LRMs)和大型语言模型(LLMs),并且大大提高了效率。
Key Takeaways
- 大型混合推理模型(LHRMs)能够自适应地根据用户查询的上下文信息决定是否需要推理。
- LHRMs通过两阶段训练,包括混合微调(HFT)和在线强化学习(HGPO)来实现这种自适应推理。
- LHRMs隐式学习选择适当的思考模式,以适应不同类型的查询和难度级别。
- 混合准确率是一个新指标,用于定量评估模型的混合思维能力。
- LHRMs在推理和通用能力上优于现有的大型推理模型(LRMs)和大型语言模型(LLMs)。
- LHRMs大大提高了效率,特别是在处理简单查询时避免了不必要的过长推理。
点此查看论文截图


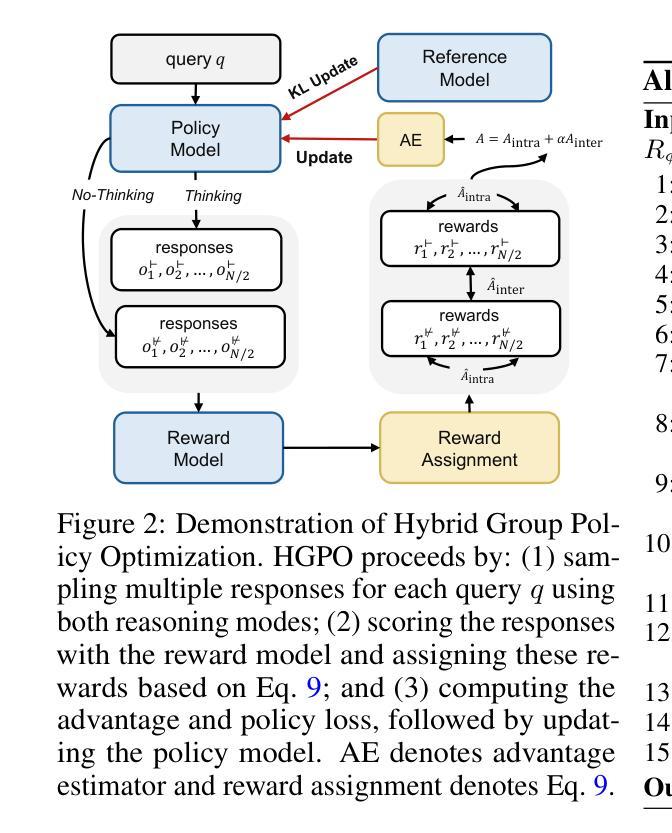
TinyV: Reducing False Negatives in Verification Improves RL for LLM Reasoning
Authors:Zhangchen Xu, Yuetai Li, Fengqing Jiang, Bhaskar Ramasubramanian, Luyao Niu, Bill Yuchen Lin, Radha Poovendran
Reinforcement Learning (RL) has become a powerful tool for enhancing the reasoning abilities of large language models (LLMs) by optimizing their policies with reward signals. Yet, RL’s success relies on the reliability of rewards, which are provided by verifiers. In this paper, we expose and analyze a widespread problem–false negatives–where verifiers wrongly reject correct model outputs. Our in-depth study of the Big-Math-RL-Verified dataset reveals that over 38% of model-generated responses suffer from false negatives, where the verifier fails to recognize correct answers. We show, both empirically and theoretically, that these false negatives severely impair RL training by depriving the model of informative gradient signals and slowing convergence. To mitigate this, we propose tinyV, a lightweight LLM-based verifier that augments existing rule-based methods, which dynamically identifies potential false negatives and recovers valid responses to produce more accurate reward estimates. Across multiple math-reasoning benchmarks, integrating TinyV boosts pass rates by up to 10% and accelerates convergence relative to the baseline. Our findings highlight the critical importance of addressing verifier false negatives and offer a practical approach to improve RL-based fine-tuning of LLMs. Our code is available at https://github.com/uw-nsl/TinyV.
强化学习(RL)已成为通过奖励信号优化策略来提升大型语言模型(LLM)推理能力的一种强大工具。然而,RL的成功依赖于奖励的可靠性,这些奖励由验证器提供。在本文中,我们暴露并分析了一个普遍存在的问题——假阴性(False Negative)——其中验证器错误地拒绝了正确的模型输出。我们对Big-Math-RL-Verified数据集的深入研究揭示,超过3procent的模型生成响应存在假阴性问题,即验证器未能识别出正确答案。我们通过实证和理论证明,这些假阴性会严重损害RL训练,因为剥夺了模型的信息化梯度信号并减缓了收敛速度。为了缓解这一问题,我们提出了TinyV,一个基于LLM的轻型验证器,它可以增强现有的基于规则的方法,动态识别潜在的假阴性并恢复有效的响应,以产生更准确的奖励估计。在多个数学推理基准测试中,集成TinyV将通过率提高了高达10%,并与基线相比加速了收敛。我们的研究结果表明解决验证器假阴性至关重要,并提供了一种实用的方法来改进基于RL的LLM微调。我们的代码位于https://github.com/uw-nsl/TinyV。
论文及项目相关链接
Summary
强化学习(RL)通过优化策略和使用奖励信号提升了大型语言模型(LLM)的推理能力。然而,RL的成功取决于奖励的可靠性,这些奖励由验证器提供。本文揭示了一个普遍存在的问题——假阴性(False Negative),即验证器错误地拒绝了正确的模型输出。通过对Big-Math-RL-Verified数据集的研究,我们发现超过38%的模型生成响应受到假阴性的影响。本文实证和理论地证明了假阴性会严重损害RL训练,剥夺模型的梯度信号并减慢收敛速度。为了缓解这一问题,我们提出了TinyV,一个基于LLM的轻量级验证器,它通过增强现有的基于规则的方法,能够动态识别潜在的假阴性并恢复有效的响应,从而生成更准确的奖励估计。在多个数学推理基准测试中,集成TinyV可将通过率提高10%,并相对于基线加速收敛。
Key Takeaways
- 强化学习(RL)用于提升大型语言模型(LLM)的推理能力。
- 验证器在RL训练中起着关键作用,但其可靠性是一个挑战。
- 假阴性现象普遍存在于验证器的使用过程中,其中验证器会错误地拒绝正确的模型输出。
- 假阴性问题严重影响了RL训练的效果,包括剥夺模型的梯度信号和减慢收敛速度。
- TinyV是一个基于LLM的轻量级验证器,旨在解决假阴性问题。
- 集成TinyV可以提高模型的通过率并加速收敛。
点此查看论文截图


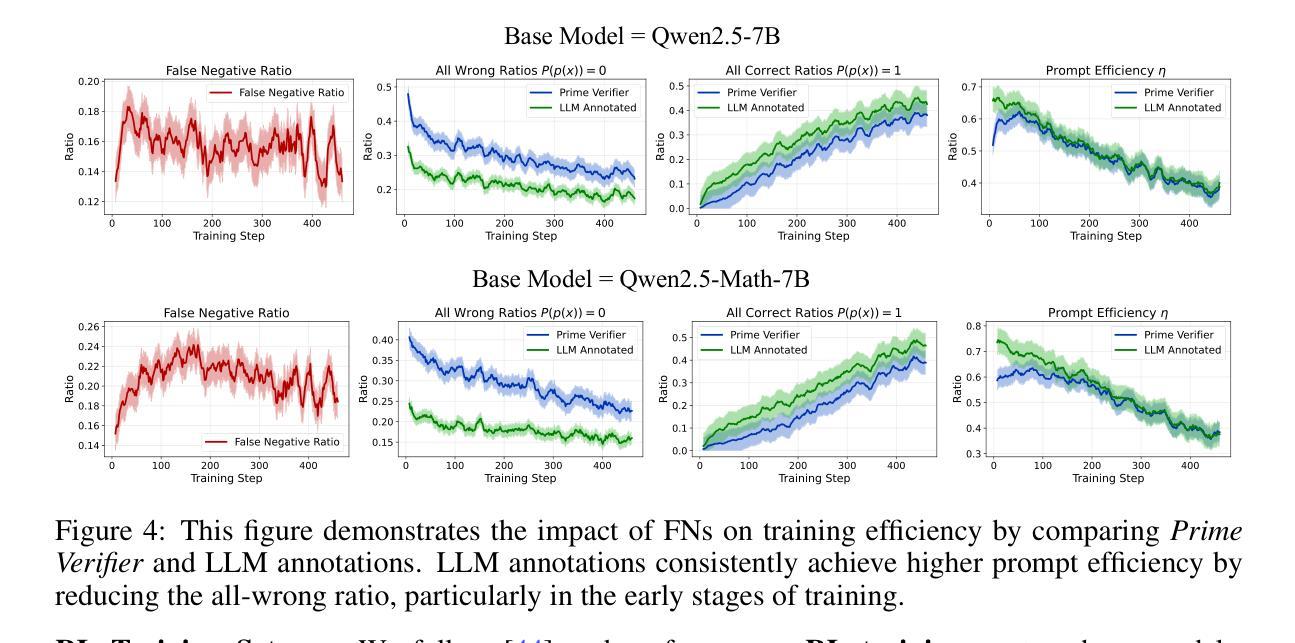

Not All Correct Answers Are Equal: Why Your Distillation Source Matters
Authors:Xiaoyu Tian, Yunjie Ji, Haotian Wang, Shuaiting Chen, Sitong Zhao, Yiping Peng, Han Zhao, Xiangang Li
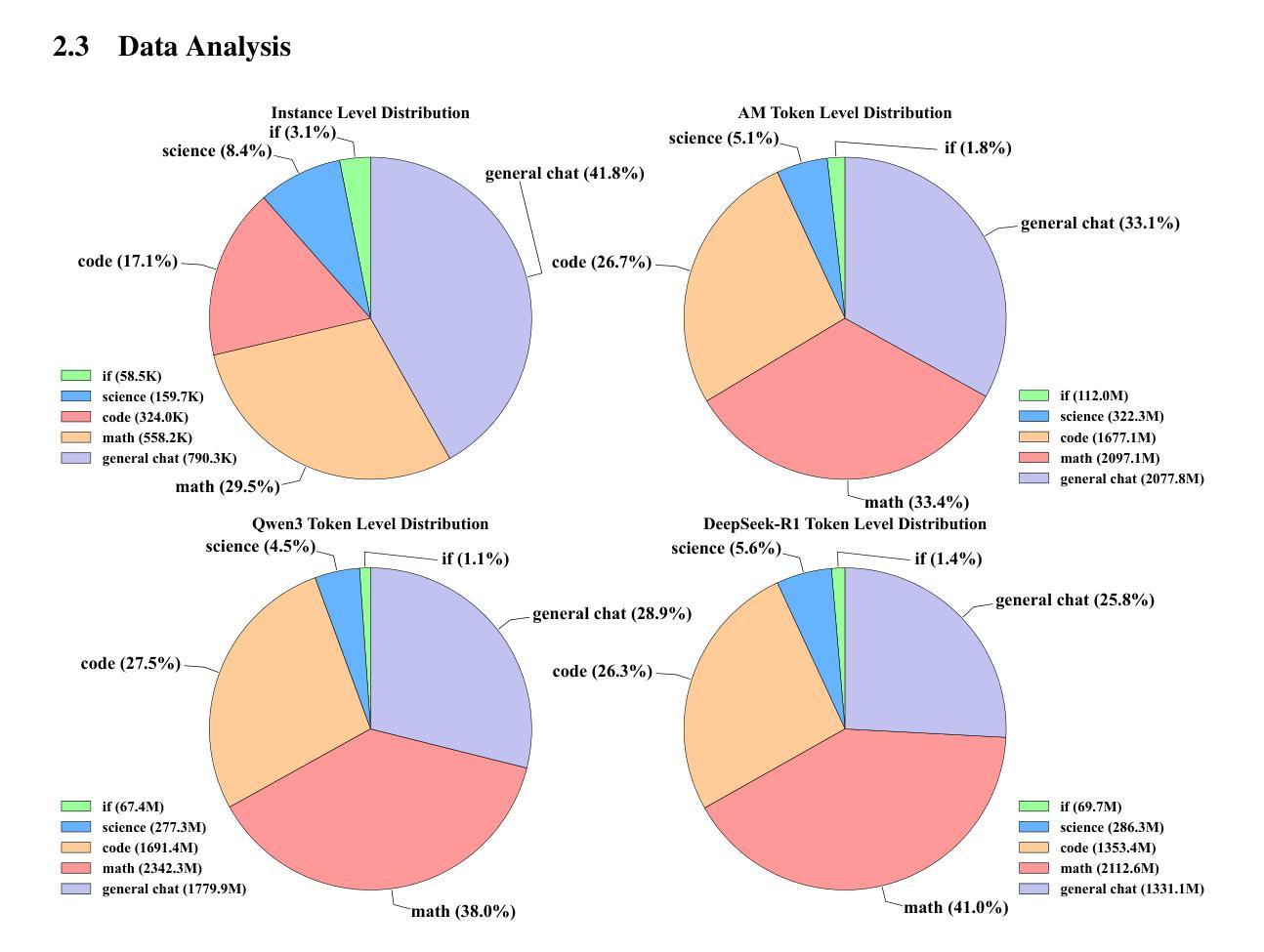
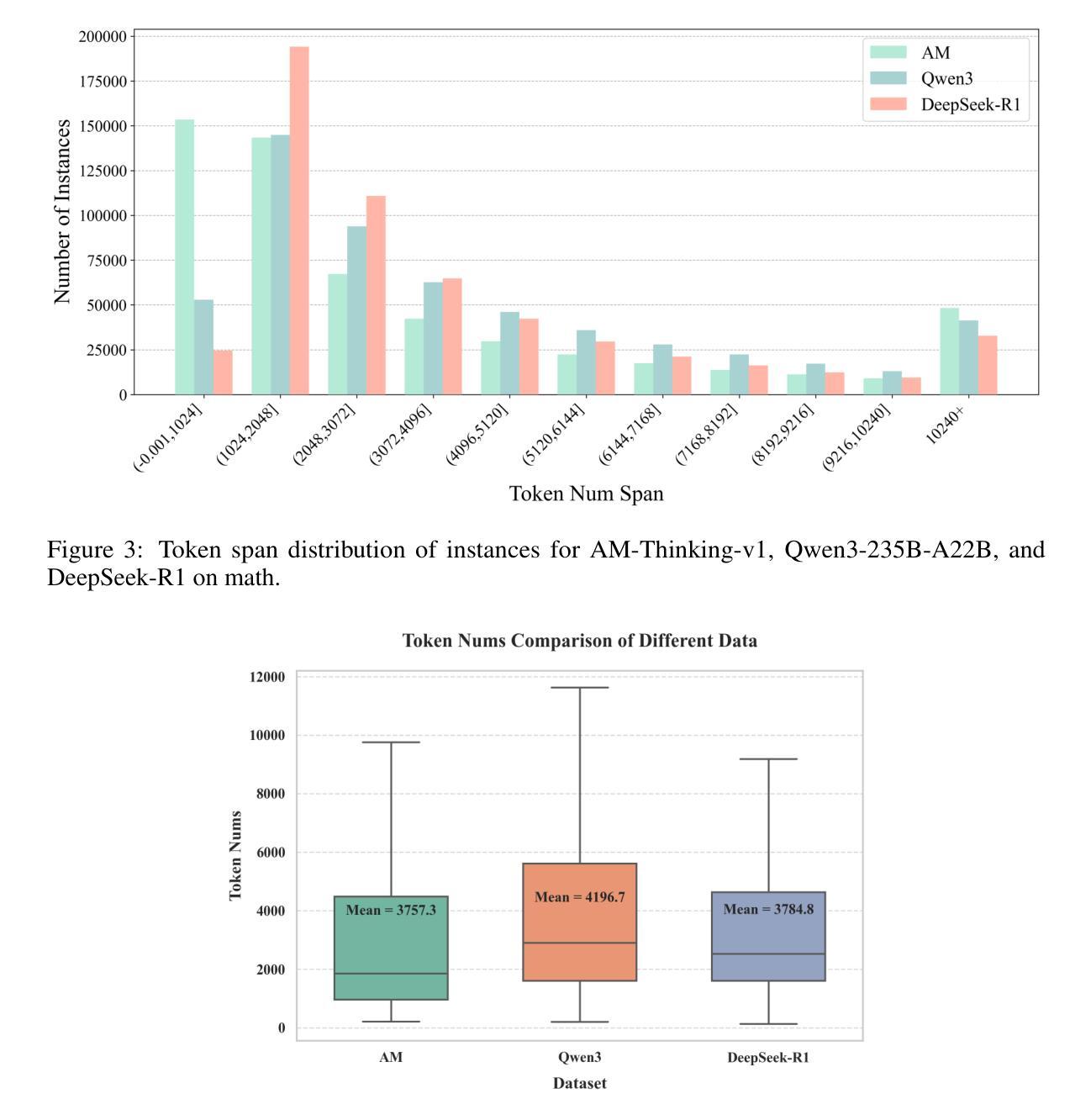
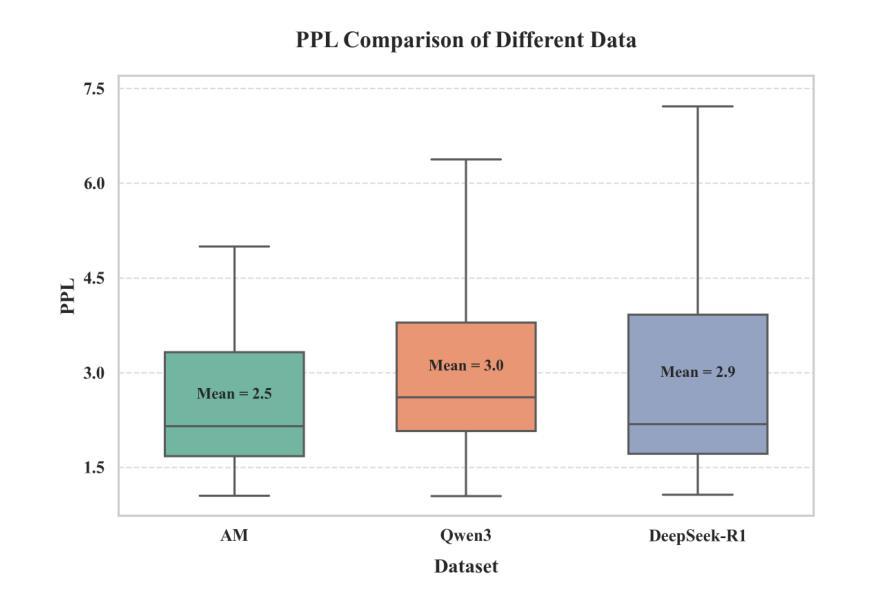
Distillation has emerged as a practical and effective approach to enhance the reasoning capabilities of open-source language models. In this work, we conduct a large-scale empirical study on reasoning data distillation by collecting verified outputs from three state-of-the-art teacher models-AM-Thinking-v1, Qwen3-235B-A22B, and DeepSeek-R1-on a shared corpus of 1.89 million queries. We construct three parallel datasets and analyze their distributions, revealing that AM-Thinking-v1-distilled data exhibits greater token length diversity and lower perplexity. Student models trained on each dataset are evaluated on reasoning benchmarks including AIME2024, AIME2025, MATH500, and LiveCodeBench. The model distilled from AM-Thinking-v1 consistently achieves the best performance (e.g., 84.3 on AIME2024, 72.2 on AIME2025, 98.4 on MATH500, and 65.9 on LiveCodeBench) and demonstrates adaptive output behavior-producing longer responses for harder tasks and shorter ones for simpler tasks. These findings highlight the value of high-quality, verified reasoning traces. We release the AM-Thinking-v1 and Qwen3-235B-A22B distilled datasets to support future research on open and high-performing reasoning-oriented language models. The datasets are publicly available on Hugging Face\footnote{Datasets are available on Hugging Face: \href{https://huggingface.co/datasets/a-m-team/AM-Thinking-v1-Distilled}{AM-Thinking-v1-Distilled}, \href{https://huggingface.co/datasets/a-m-team/AM-Qwen3-Distilled}{AM-Qwen3-Distilled}.}.
摘要提炼作为一种实用而有效的方法,已经展现出提高开源语言模型推理能力的潜力。在这项工作中,我们对推理数据提炼进行了大规模实证研究,通过收集来自三个顶尖教师模型(AM-Thinking-v1、Qwen3-235B-A22B和DeepSeek-R1)的验证输出,在包含189万个查询的共享语料库上进行对比分析。我们构建了三个并行数据集并对其分布进行了分析,发现由AM-Thinking-v1提炼的数据具有更大的令牌长度多样性和更低的困惑度。在包括AIME2024、AIME2025、MATH500和LiveCodeBench等推理基准测试上,对基于各数据集训练的模型进行了评估。由AM-Thinking-v1提炼的模型表现最佳(例如,AIME2024上的得分为84.3,AIME2025上的得分为72.2,MATH500上的得分为98.4,LiveCodeBench上的得分为65.9),并展现出自适应输出行为——为更困难的任务生成更长的响应,为更简单任务生成更短的响应。这些发现突显了高质量验证推理轨迹的价值。我们发布了AM-Thinking-v1和Qwen3-235B-A22B提炼的数据集,以支持未来对高性能推理导向的语言模型的研究。数据集已在Hugging Face上公开^[数据集已在Hugging Face上公开:链接为AM-Thinking-v1提炼数据集,AM-Qwen3提炼数据集。]^。
论文及项目相关链接
Summary
该文研究了利用推理数据蒸馏技术提升开源语言模型推理能力的方法。通过对三种先进教师模型(AM-Thinking-v1、Qwen3-235B-A22B和DeepSeek-R1)的验证输出进行大规模实证研究,构建了三个并行数据集,并分析了它们的分布特性。结果显示,基于AM-Thinking-v1蒸馏的数据展现出更高的令牌长度多样性和更低的困惑度。在学生模型的评价中,基于AM-Thinking-v1蒸馏的模型在多个推理基准测试上表现最佳,如AIME2024、AIME2025、MATH500和LiveCodeBench。该模型能够自适应输出行为,针对复杂任务产生更长的响应,针对简单任务产生更短的响应。最后,公开发布了AM-Thinking-v1和Qwen3-235B-A22B蒸馏数据集,以支持未来对高性能推理导向的语言模型的研究。
Key Takeaways
- 蒸馏技术被证实为一种提升语言模型推理能力的有效方法。
- 通过收集三个先进教师模型的验证输出,构建了三个并行数据集。
- AM-Thinking-v1蒸馏数据展现出更高的令牌长度多样性和更低的困惑度。
- 基于AM-Thinking-v1蒸馏的模型在多个推理基准测试上表现最佳。
- 该模型能够自适应输出行为,针对任务复杂度调整响应长度。
- 公开了AM-Thinking-v1和Qwen3-235B-A22B蒸馏数据集,以支持未来研究。
点此查看论文截图
Towards Omnidirectional Reasoning with 360-R1: A Dataset, Benchmark, and GRPO-based Method
Authors:Xinshen Zhang, Zhen Ye, Xu Zheng
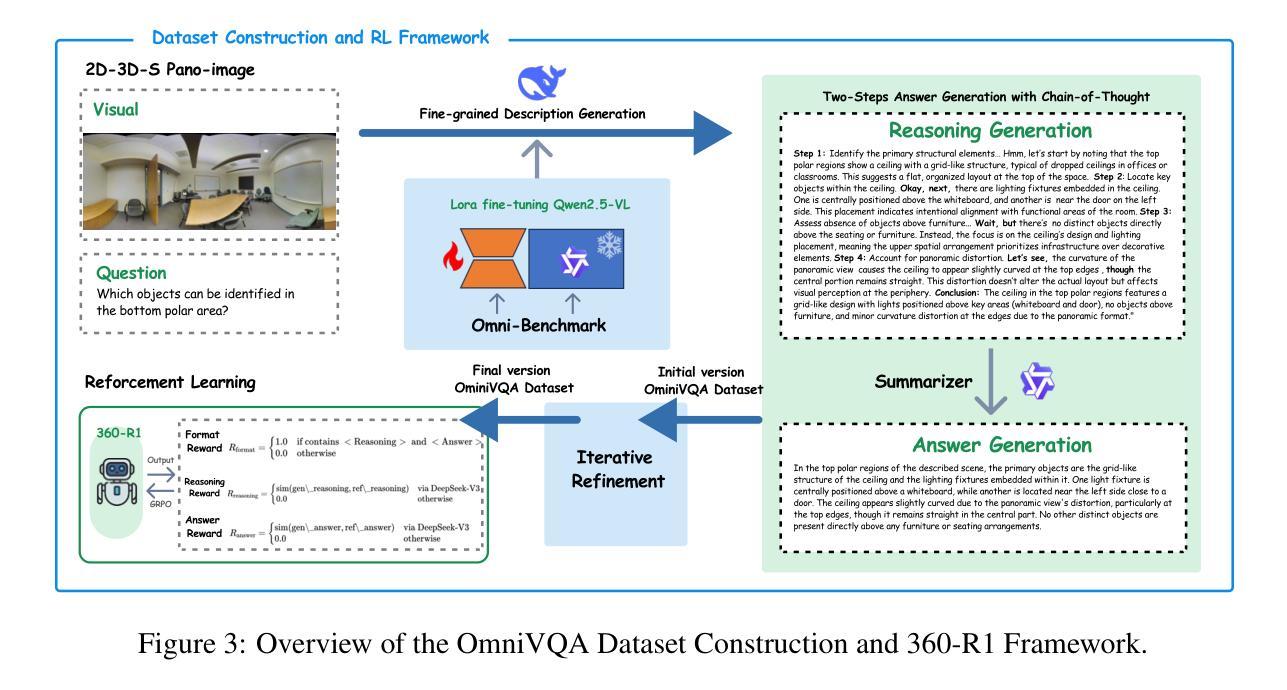
Omnidirectional images (ODIs), with their 360{\deg} field of view, provide unparalleled spatial awareness for immersive applications like augmented reality and embodied AI. However, the capability of existing multi-modal large language models (MLLMs) to comprehend and reason about such panoramic scenes remains underexplored. This paper addresses this gap by introducing OmniVQA, the first dataset and conducting the first benchmark for omnidirectional visual question answering. Our evaluation of state-of-the-art MLLMs reveals significant limitations in handling omnidirectional visual question answering, highlighting persistent challenges in object localization, feature extraction, and hallucination suppression within panoramic contexts. These results underscore the disconnect between current MLLM capabilities and the demands of omnidirectional visual understanding, which calls for dedicated architectural or training innovations tailored to 360{\deg} imagery. Building on the OmniVQA dataset and benchmark, we further introduce a rule-based reinforcement learning method, 360-R1, based on Qwen2.5-VL-Instruct. Concretely, we modify the group relative policy optimization (GRPO) by proposing three novel reward functions: (1) reasoning process similarity reward, (2) answer semantic accuracy reward, and (3) structured format compliance reward. Extensive experiments on our OmniVQA demonstrate the superiority of our proposed method in omnidirectional space (+6% improvement).
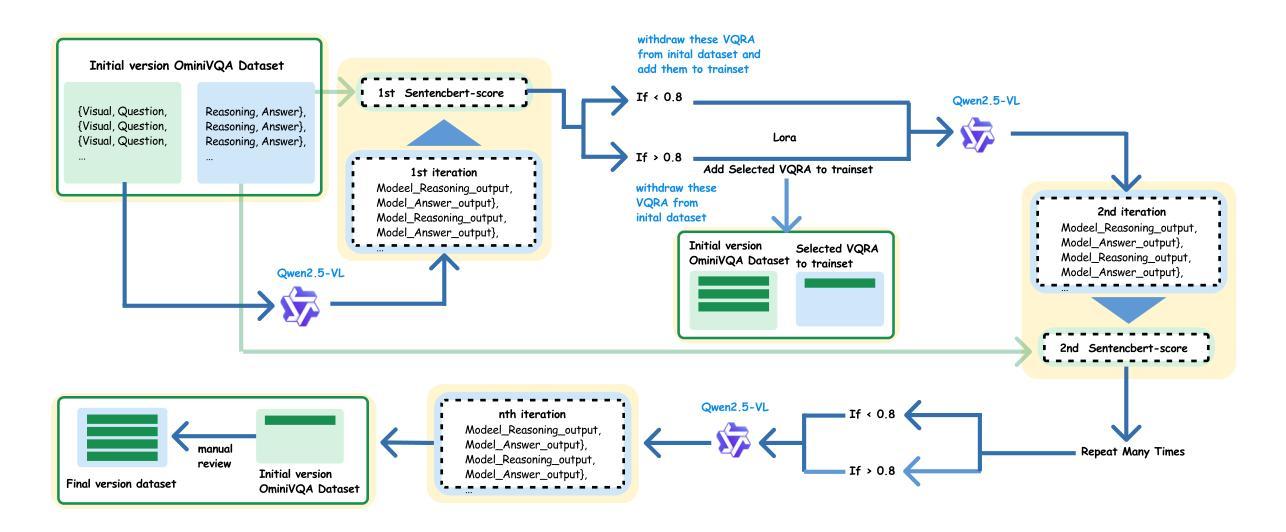
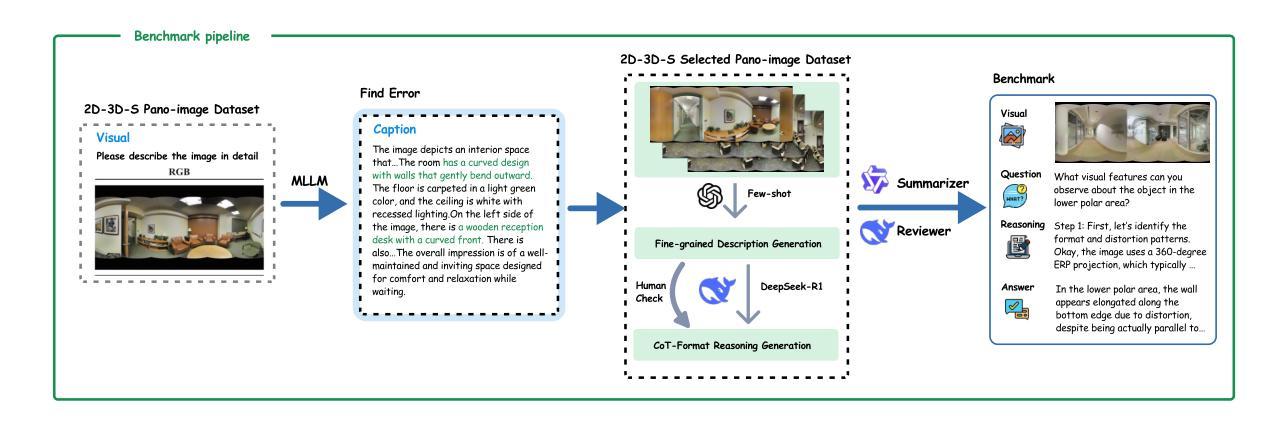
全景图像(ODIs)具有360°的视野,为增强现实和嵌入式人工智能等沉浸式应用提供了无与伦比的空间感知能力。然而,现有多模态大型语言模型(MLLMs)对全景场景的理解和推理能力仍然被探索不足。本文通过引入OmniVQA数据集和开展全景视觉问答的首个基准测试来解决这一差距。我们对最新MLLMs的评估显示,在全景视觉问答方面存在重大局限,突显了在全景上下文中物体定位、特征提取和幻觉抑制方面的持续挑战。这些结果强调了当前MLLM能力与全景视觉理解需求之间的脱节,这要求针对360°图像量身定制专门的架构或培训创新。基于OmniVQA数据集和基准测试,我们进一步引入了基于规则强化学习的方法360-R1,该方法基于Qwen2.5-VL-Instruct。具体来说,我们通过提出三个新的奖励函数来修改组相对策略优化(GRPO):(1)推理过程相似性奖励;(2)答案语义准确性奖励;(3)结构化格式合规性奖励。在我们的OmniVQA上进行的大量实验证明了所提出方法在全景空间中的优越性(+6%的提升)。
论文及项目相关链接
Summary
本文介绍了OmniVQA数据集和全景视觉问答的基准测试,用于评估多模态大型语言模型在全景场景中的理解和推理能力。现有模型的局限性在于处理全景视觉问答的能力,尤其在物体定位、特征提取和幻觉抑制方面存在挑战。为应对这些挑战,引入了基于规则强化学习的360度学习方法——360-R1。它通过三个奖励函数提升了现有的相对策略优化方法,提高了在全景空间中的性能表现。实验证明,此方法优于现有模型,提升了约6%。
Key Takeaways
- 多模态大型语言模型在全景视觉问答上的应用仍有较大差距。现有的模型在全景场景中处理问答时面临物体定位、特征提取和幻觉抑制方面的挑战。
- OmniVQA数据集为全景视觉问答提供了首个基准测试平台,用于评估模型性能。
- 引入了一种基于规则强化学习的全景学习方法——360-R1,此方法对现有的策略优化进行了改进。加入了三个新的奖励函数以改进模型的表现:推理过程相似性奖励、答案语义准确性奖励和结构格式遵守奖励。
点此查看论文截图



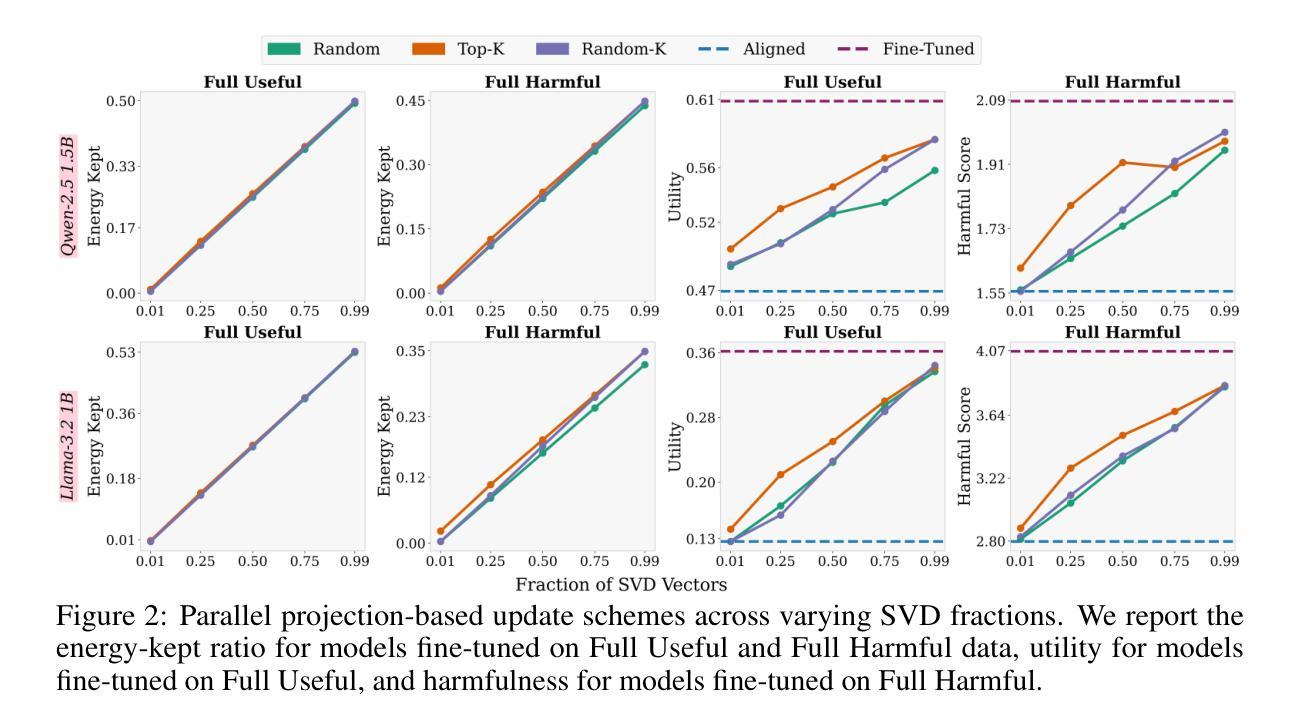
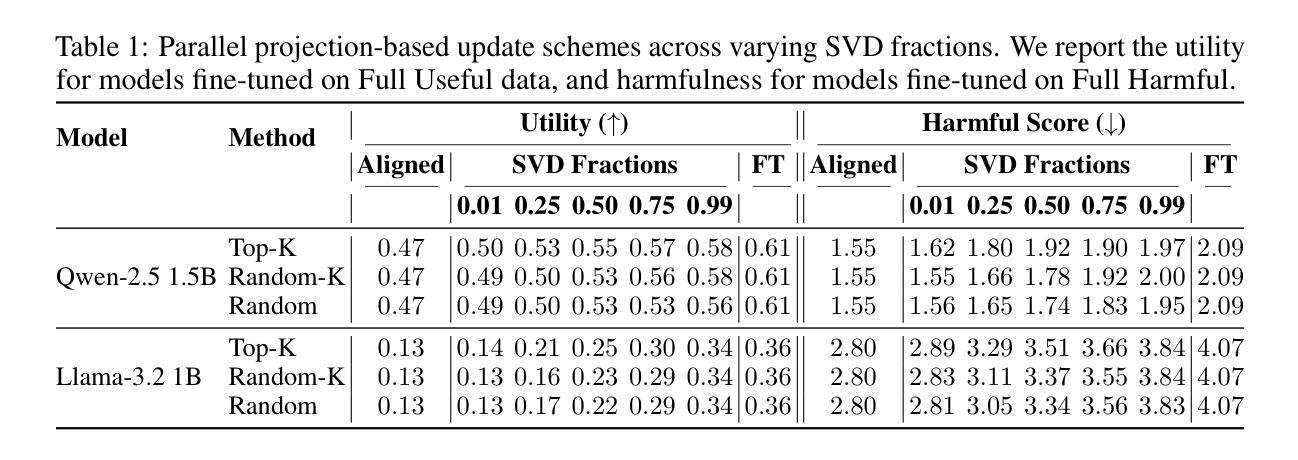
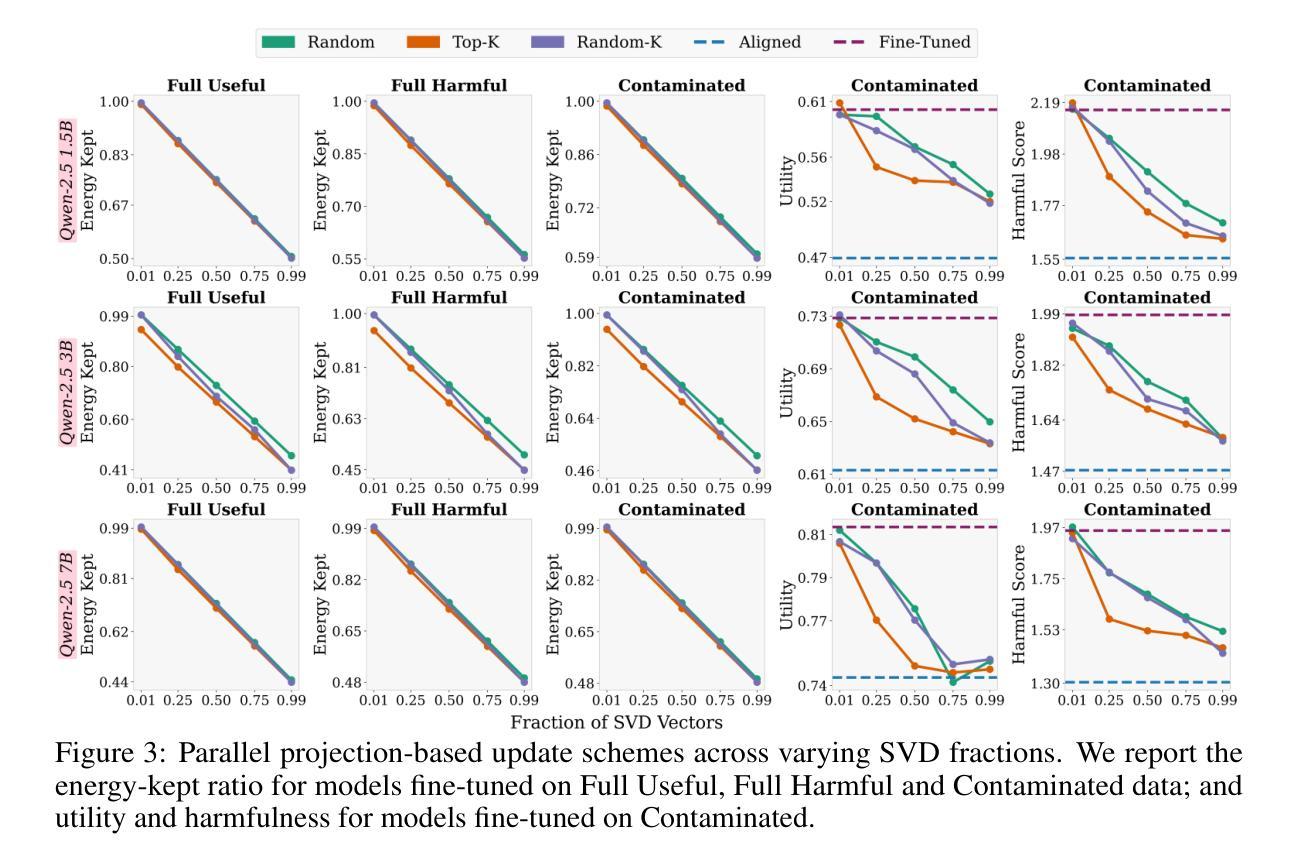
Safety Subspaces are Not Distinct: A Fine-Tuning Case Study
Authors:Kaustubh Ponkshe, Shaan Shah, Raghav Singhal, Praneeth Vepakomma
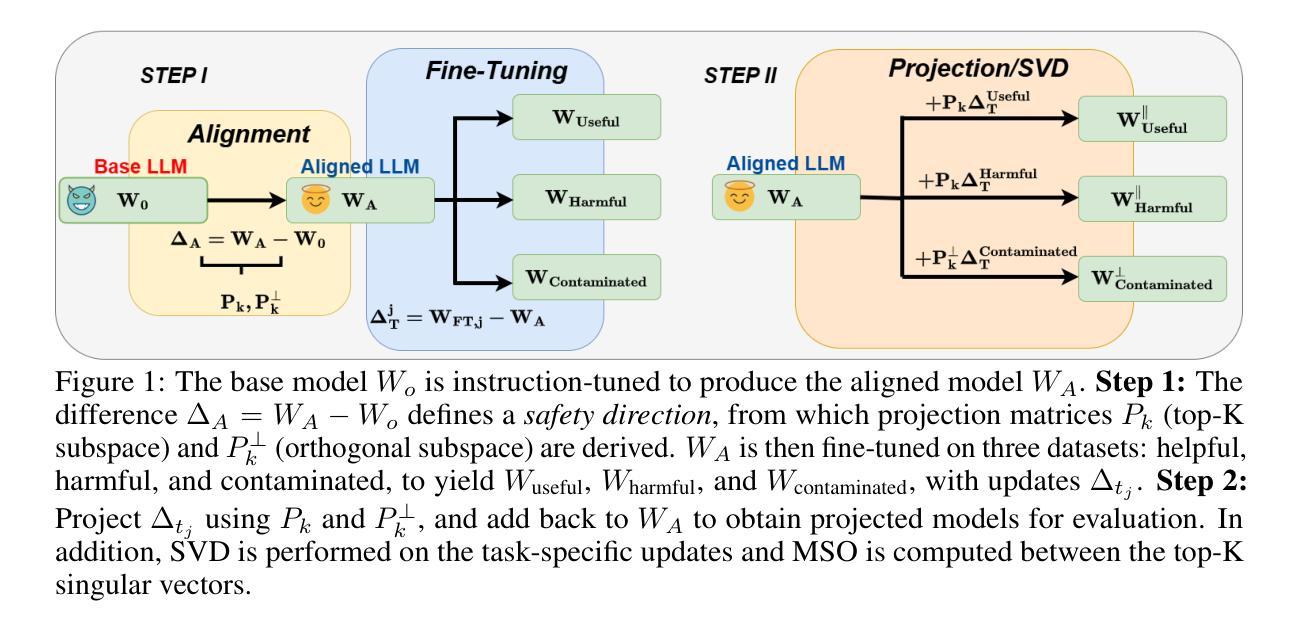
Large Language Models (LLMs) rely on safety alignment to produce socially acceptable responses. This is typically achieved through instruction tuning and reinforcement learning from human feedback. However, this alignment is known to be brittle: further fine-tuning, even on benign or lightly contaminated data, can degrade safety and reintroduce harmful behaviors. A growing body of work suggests that alignment may correspond to identifiable geometric directions in weight space, forming subspaces that could, in principle, be isolated or preserved to defend against misalignment. In this work, we conduct a comprehensive empirical study of this geometric perspective. We examine whether safety-relevant behavior is concentrated in specific subspaces, whether it can be separated from general-purpose learning, and whether harmfulness arises from distinguishable patterns in internal representations. Across both parameter and activation space, our findings are consistent: subspaces that amplify safe behaviors also amplify unsafe ones, and prompts with different safety implications activate overlapping representations. We find no evidence of a subspace that selectively governs safety. These results challenge the assumption that alignment is geometrically localized. Rather than residing in distinct directions, safety appears to emerge from entangled, high-impact components of the model’s broader learning dynamics. This suggests that subspace-based defenses may face fundamental limitations and underscores the need for alternative strategies to preserve alignment under continued training. We corroborate these findings through multiple experiments on five open-source LLMs. Our code is publicly available at: https://github.com/CERT-Lab/safety-subspaces.
大型语言模型(LLM)依赖于安全对齐来产生社会可接受的回应。这通常是通过指令调整和人类反馈的强化学习来实现的。然而,这种对齐是脆弱的:即使在良性或轻度污染的数据上进行进一步的微调,也可能会降低安全性并重新引入有害行为。越来越多的研究表明,对齐可能与权重空间中的可识别几何方向相对应,形成子空间,在原则上可以被隔离或保护以防范错位。在这项工作中,我们对这一几何观点进行了全面的实证研究。我们研究了安全相关的行为是否集中在特定的子空间中,是否可以与通用学习分离,以及有害性是否源于内部表示中的可识别模式。在参数空间和激活空间上,我们的发现是一致的:放大安全行为的子空间也会放大不安全的行为,具有不同安全含义的提示会激活重叠的表示。我们没有发现选择性地控制安全的子空间证据。这些结果挑战了对齐在几何上定位的假设。安全似乎并非来自不同的方向,而是来自于模型更广泛学习动态中的纠缠、高影响力的组成部分。这暗示基于子空间的防御可能面临根本性的限制,并强调了继续训练时保留对齐的替代策略的需要。我们在五个开源的大型语言模型上通过多次实验证实了这些发现。我们的代码在公共可用:https://github.com/CERT-Lab/safety-subspaces。
论文及项目相关链接
PDF Kaustubh Ponkshe, Shaan Shah, and Raghav Singhal contributed equally to this work
Summary
大型语言模型(LLM)依赖安全对齐来生成社会可接受的回应,这通常通过指令调整和人类反馈的强化学习来实现。然而,这种对齐是脆弱的:即使在良性或轻度污染的数据上进行进一步的微调,也可能会破坏安全性并重新引入有害行为。本研究从几何角度对这一现象进行了全面的实证研究。我们没有发现只控制安全性的子空间,这意味着安全性并非局限于特定的几何方向,而是源于模型学习动力学的复杂纠缠和高影响力成分。这挑战了现有的几何定位假设,并为继续训练时保持对齐提出了新挑战。我们的代码可在CERT-Lab/safety-subspaces公开访问。
Key Takeaways
- 大型语言模型(LLM)需要安全对齐以产生社会可接受响应。
- 通过指令调整和人类反馈强化学习实现安全对齐。
- 安全对齐是脆弱的,进一步微调可能破坏安全性。
- 从几何角度研究安全性的子空间,发现安全性并非局限于特定方向。
- 安全行为并非孤立存在,而是模型学习动力学的复杂纠缠和高影响力成分的结果。
- 需要新的策略来在继续训练时保持对齐。
点此查看论文截图

Prior Prompt Engineering for Reinforcement Fine-Tuning
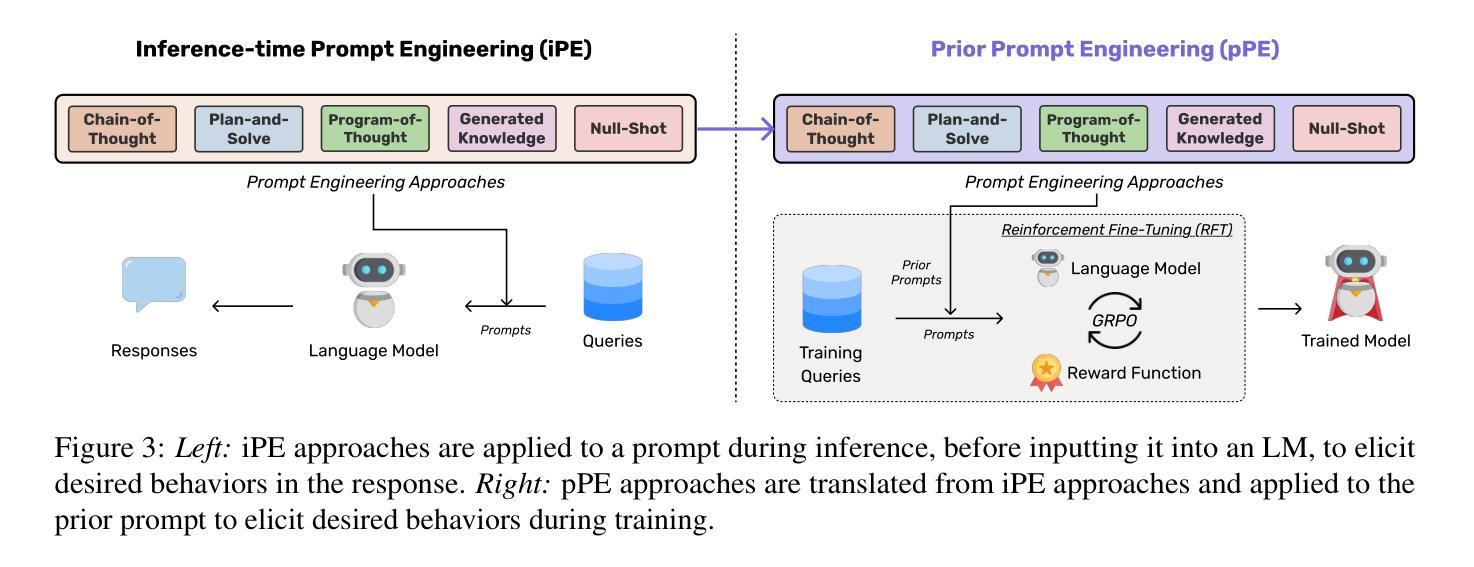
Authors:Pittawat Taveekitworachai, Potsawee Manakul, Sarana Nutanong, Kunat Pipatanakul
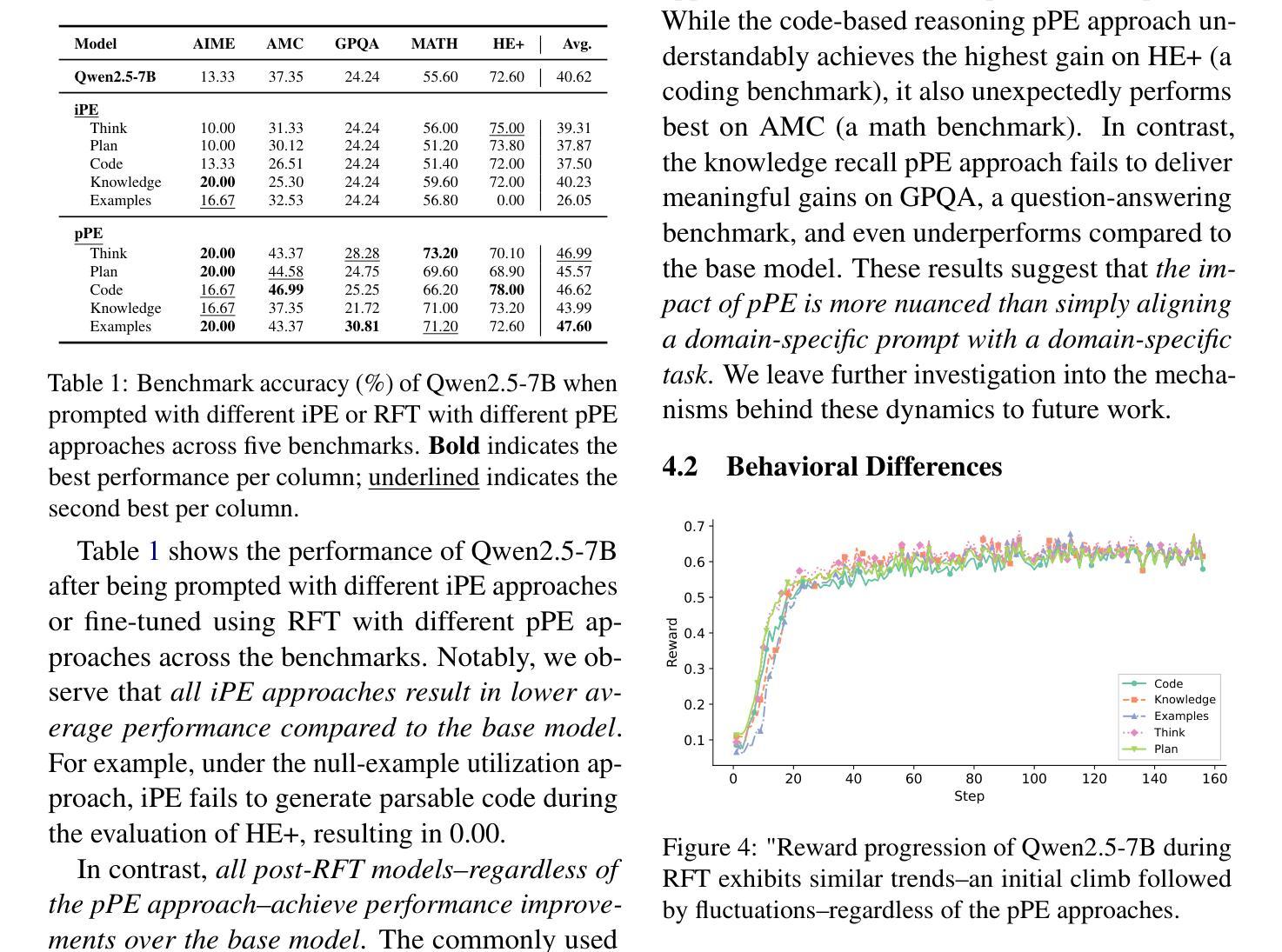
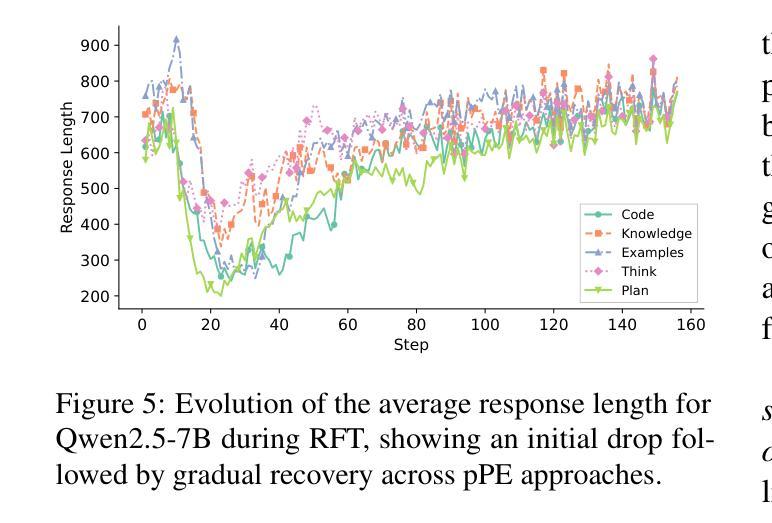
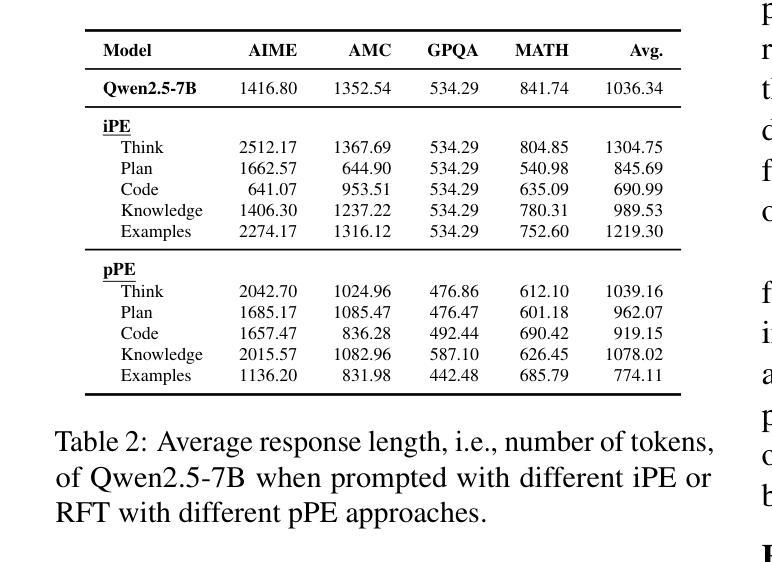
This paper investigates prior prompt engineering (pPE) in the context of reinforcement fine-tuning (RFT), where language models (LMs) are incentivized to exhibit behaviors that maximize performance through reward signals. While existing RFT research has primarily focused on algorithms, reward shaping, and data curation, the design of the prior prompt–the instructions prepended to queries during training to elicit behaviors such as step-by-step reasoning–remains underexplored. We investigate whether different pPE approaches can guide LMs to internalize distinct behaviors after RFT. Inspired by inference-time prompt engineering (iPE), we translate five representative iPE strategies–reasoning, planning, code-based reasoning, knowledge recall, and null-example utilization–into corresponding pPE approaches. We experiment with Qwen2.5-7B using each of the pPE approaches, then evaluate performance on in-domain and out-of-domain benchmarks (e.g., AIME2024, HumanEval+, and GPQA-Diamond). Our results show that all pPE-trained models surpass their iPE-prompted counterparts, with the null-example pPE approach achieving the largest average performance gain and the highest improvement on AIME2024 and GPQA-Diamond, surpassing the commonly used reasoning approach. Furthermore, by adapting a behavior-classification framework, we demonstrate that different pPE strategies instill distinct behavioral styles in the resulting models. These findings position pPE as a powerful yet understudied axis for RFT.
本文探讨了强化微调(RFT)背景下的先验提示工程(pPE),在强化微调中,通过奖励信号激励语言模型(LMs)表现出最大化性能的行为。虽然现有的RFT研究主要集中在算法、奖励塑造和数据整理上,但先验提示的设计,即在训练期间查询之前添加的指导步骤行为(如逐步推理),仍未得到充分探索。我们调查不同的pPE方法是否能在RFT后引导语言模型内化不同的行为。我们受到推理时间提示工程(iPE)的启发,将五种代表性的iPE策略(推理、规划、基于代码的推理、知识回忆和空例利用)翻译成相应的pPE方法。我们使用Qwen2.5-7B进行试验,分别采用各种pPE方法,然后在域内和域外基准测试(例如AIME2024、HumanEval+和GPQA-Diamond)上评估性能。我们的结果表明,所有pPE训练的模型都超过了iPE提示的对应模型,其中空例pPE方法取得了最大的平均性能提升,并在AIME2024和GPQA-Diamond上的改进最高,超过了常用的推理方法。此外,通过采用行为分类框架,我们证明了不同的pPE策略在结果模型中形成了不同的行为风格。这些发现将pPE定位为RFT中一个强大而尚未充分研究的轴。
论文及项目相关链接
PDF 25 pages, 42 figures
Summary:
本文探讨了强化微调(RFT)背景下的前期提示工程(pPE),研究如何通过奖励信号激励语言模型(LMs)展现出最大化性能的行为。文章发现现有研究主要集中在算法、奖励塑造和数据收集方面,而前期提示的设计仍被忽视。本研究通过翻译五种即时提示工程策略为相应的前期提示工程方法,探讨了不同pPE方法是否能引导语言模型在强化微调后内化不同行为。实验结果显示,所有使用pPE训练的模型在特定领域和跨领域基准测试中均超越了使用iPE提示的模型,其中基于null-example的pPE方法取得了最大的平均性能提升和最高的改进。此外,通过行为分类框架,研究证明了不同的pPE策略对模型的最终行为风格有影响。这表明前期提示工程是强化微调中一个强大但尚未被充分研究的领域。
Key Takeaways:
- 该研究探索了前期提示工程(pPE)在强化微调(RFT)中的作用,主要关注如何通过奖励信号激励语言模型展现出最大化性能的行为。
- 文章发现现有研究主要集中在算法、奖励塑造和数据收集方面,前期提示设计尚未得到充分研究。
- 通过翻译五种即时提示工程策略为相应的前期提示工程方法,研究了不同pPE方法是否能引导语言模型内化不同行为。
- 使用pPE训练的模型在特定领域和跨领域基准测试中表现优越,其中null-example的pPE方法取得了最大的性能提升。
- 通过行为分类框架的研究显示,不同的pPE策略影响模型的最终行为风格。
- 实验结果证明前期提示工程在强化微调中具有重要作用。
点此查看论文截图