⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-05-27 更新
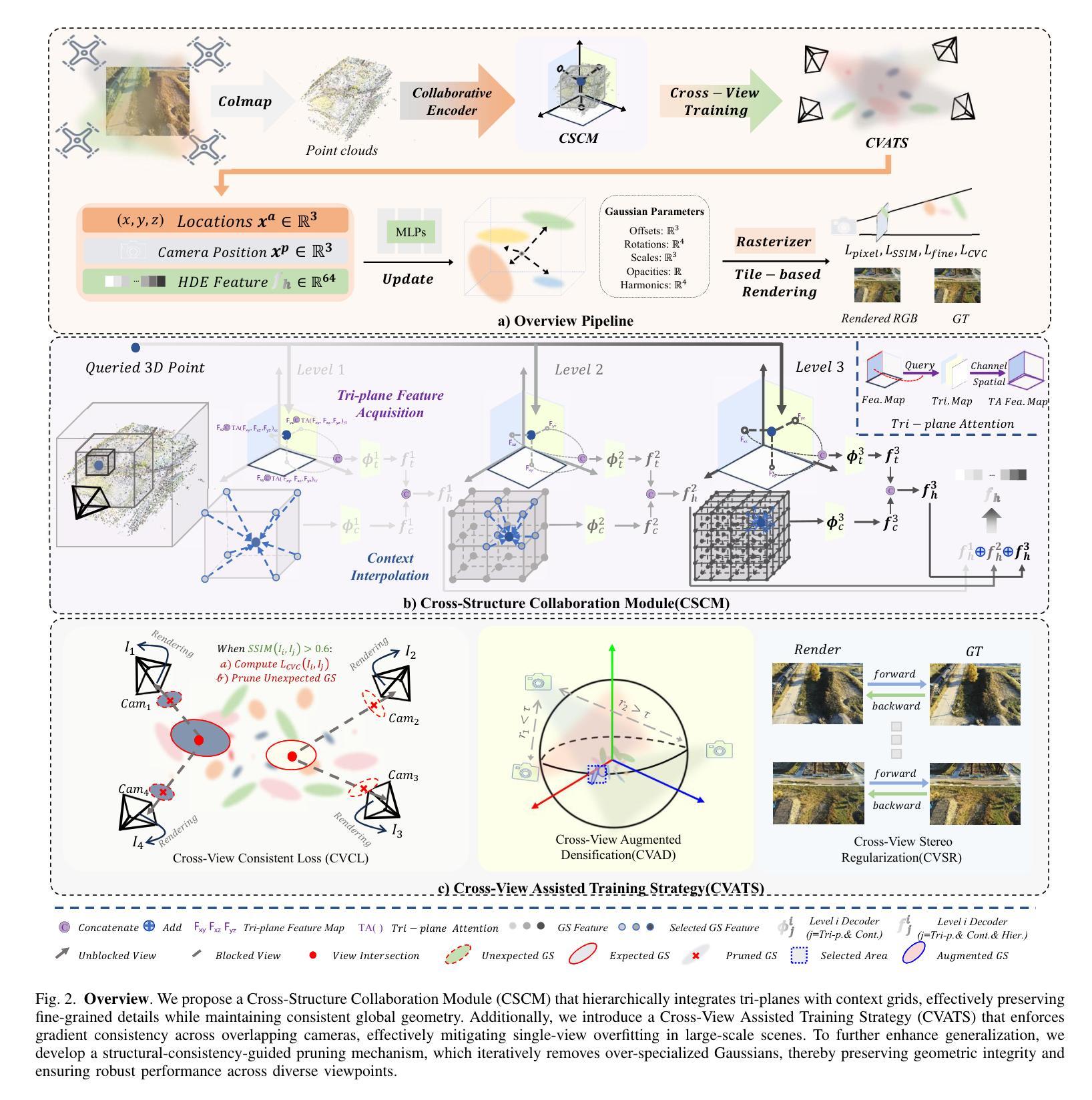
SplatCo: Structure-View Collaborative Gaussian Splatting for Detail-Preserving Rendering of Large-Scale Unbounded Scenes
Authors:Haihong Xiao, Jianan Zou, Yuxin Zhou, Ying He, Wenxiong Kang
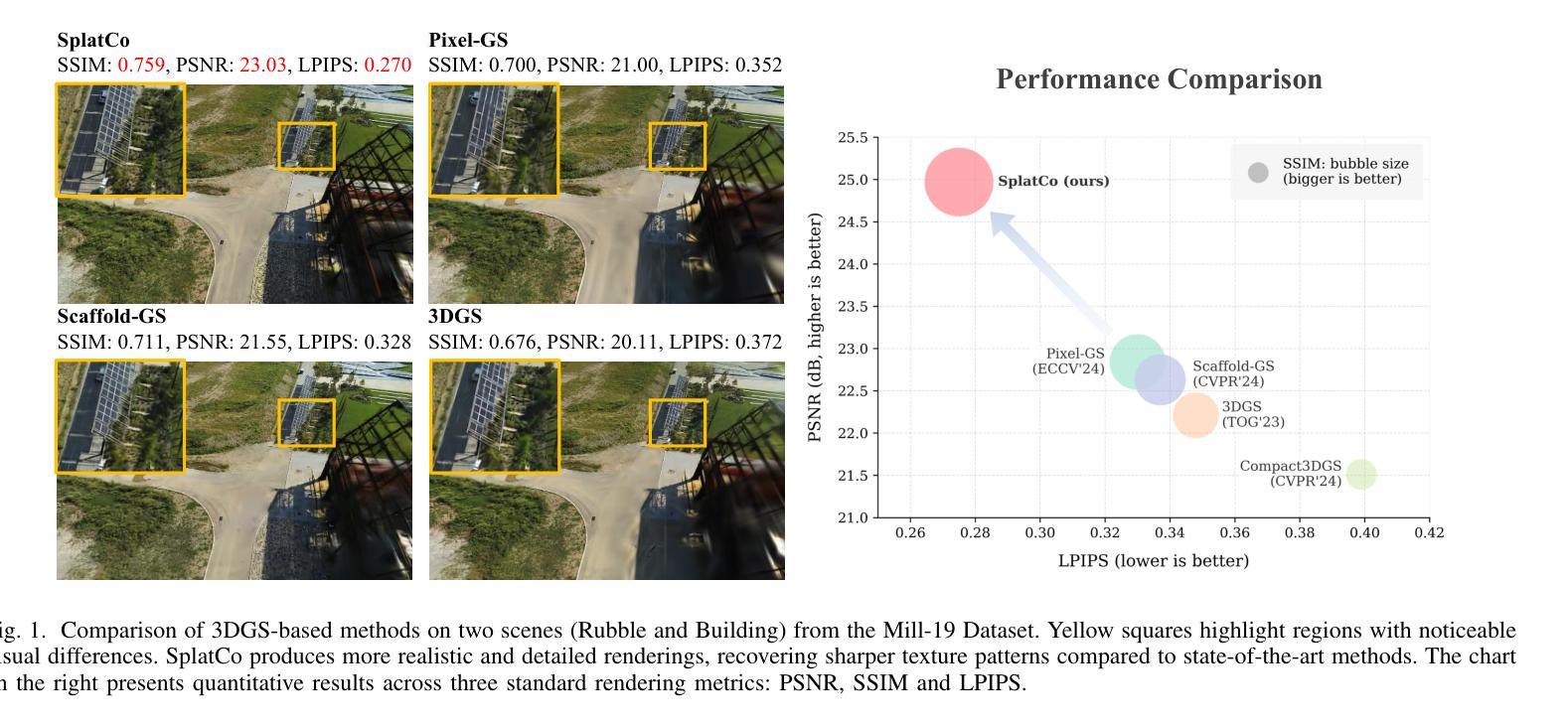
We present SplatCo, a structure-view collaborative Gaussian splatting framework for high-fidelity rendering of complex outdoor environments. SplatCo builds upon two novel components: (1) a cross-structure collaboration module that combines global tri-plane representations, which capture coarse scene layouts, with local context grid features that represent fine surface details. This fusion is achieved through a novel hierarchical compensation strategy, ensuring both global consistency and local detail preservation; and (2) a cross-view assisted training strategy that enhances multi-view consistency by synchronizing gradient updates across viewpoints, applying visibility-aware densification, and pruning overfitted or inaccurate Gaussians based on structural consistency. Through joint optimization of structural representation and multi-view coherence, SplatCo effectively reconstructs fine-grained geometric structures and complex textures in large-scale scenes. Comprehensive evaluations on 13 diverse large-scale scenes, including Mill19, MatrixCity, Tanks & Temples, WHU, and custom aerial captures, demonstrate that SplatCo consistently achieves higher reconstruction quality than state-of-the-art methods, with PSNR improvements of 1-2 dB and SSIM gains of 0.1 to 0.2. These results establish a new benchmark for high-fidelity rendering of large-scale unbounded scenes. Code and additional information are available at https://github.com/SCUT-BIP-Lab/SplatCo.
我们提出了SplatCo,这是一个用于复杂室外环境高保真渲染的结构视图协同高斯平铺框架。SplatCo建立在两个新颖组件之上:(1) 跨结构协作模块,该模块结合全局三平面表示(捕捉粗糙场景布局)和局部上下文网格特征(表示精细表面细节)。这种融合是通过一种新颖的分层次补偿策略实现的,确保全局一致性和局部细节保留;(2) 跨视图辅助训练策略,通过同步各视点的梯度更新、应用可见性感知加密以及基于结构一致性剔除过拟合或不准确的高斯,增强多视图一致性。通过结构表示和多视图一致性的联合优化,SplatCo有效地重建了大场景中的精细几何结构和复杂纹理。在包括Mill19、MatrixCity、Tanks & Temples、WHU和自定义航空拍摄在内的13个不同大规模场景上的综合评估表明,SplatCo的持续重建质量高于最新方法,PSNR提高1-2分贝,SSIM提高0.1至0.2。这些结果为大规模无界场景的高保真渲染建立了新的基准。代码和额外信息可在https://github.com/SCUT-BIP-Lab/SplatCo找到。
论文及项目相关链接
Summary
SplatCo是一个用于复杂户外环境高保真渲染的结构视图协同高斯拼贴框架。它通过融合全局三平面表示和局部上下文网格特征,实现结构表示的精细化。并采用跨视图辅助训练策略,增强多视角一致性。SplatCo在大型场景中的精细几何结构和复杂纹理重建方面表现出色,树立了高保真渲染大规模无界场景的新标杆。
Key Takeaways
- SplatCo是一个基于高斯拼贴的高保真渲染框架,适用于复杂户外环境。
- 它通过结合全局和局部特征,实现结构表示的精细化。
- 跨结构协作模块采用分层补偿策略,确保全局一致性和局部细节保留。
- 跨视图辅助训练策略增强了多视角一致性,通过同步梯度更新、实施可见性感知加密和基于结构一致性的过拟合或不准确的高斯剪枝来实现。
- SplatCo在大型场景的精细几何结构和复杂纹理重建方面表现出色。
- 与最新方法相比,SplatCo在PSNR和SSIM指标上实现了显著提高,分别为1-2dB和0.1-0.2。
点此查看论文截图

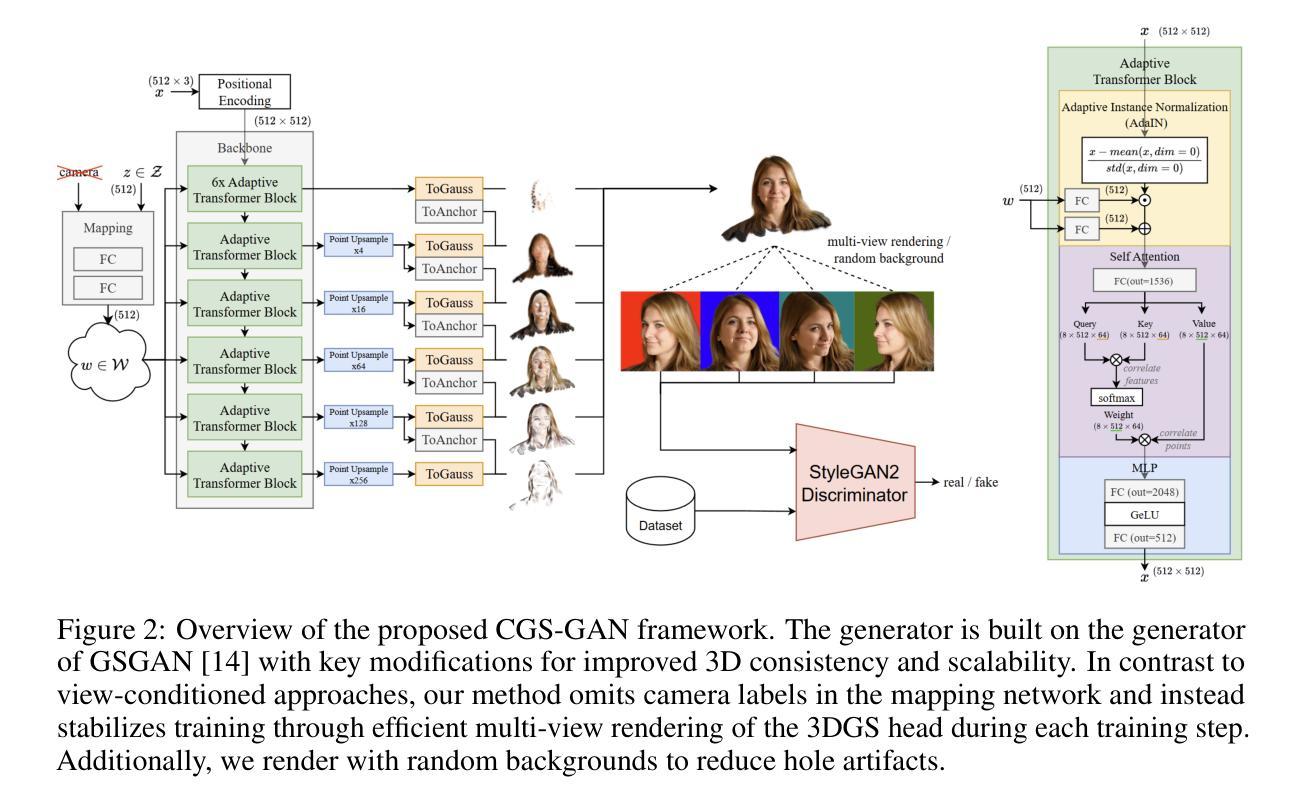
CGS-GAN: 3D Consistent Gaussian Splatting GANs for High Resolution Human Head Synthesis
Authors:Florian Barthel, Wieland Morgenstern, Paul Hinzer, Anna Hilsmann, Peter Eisert
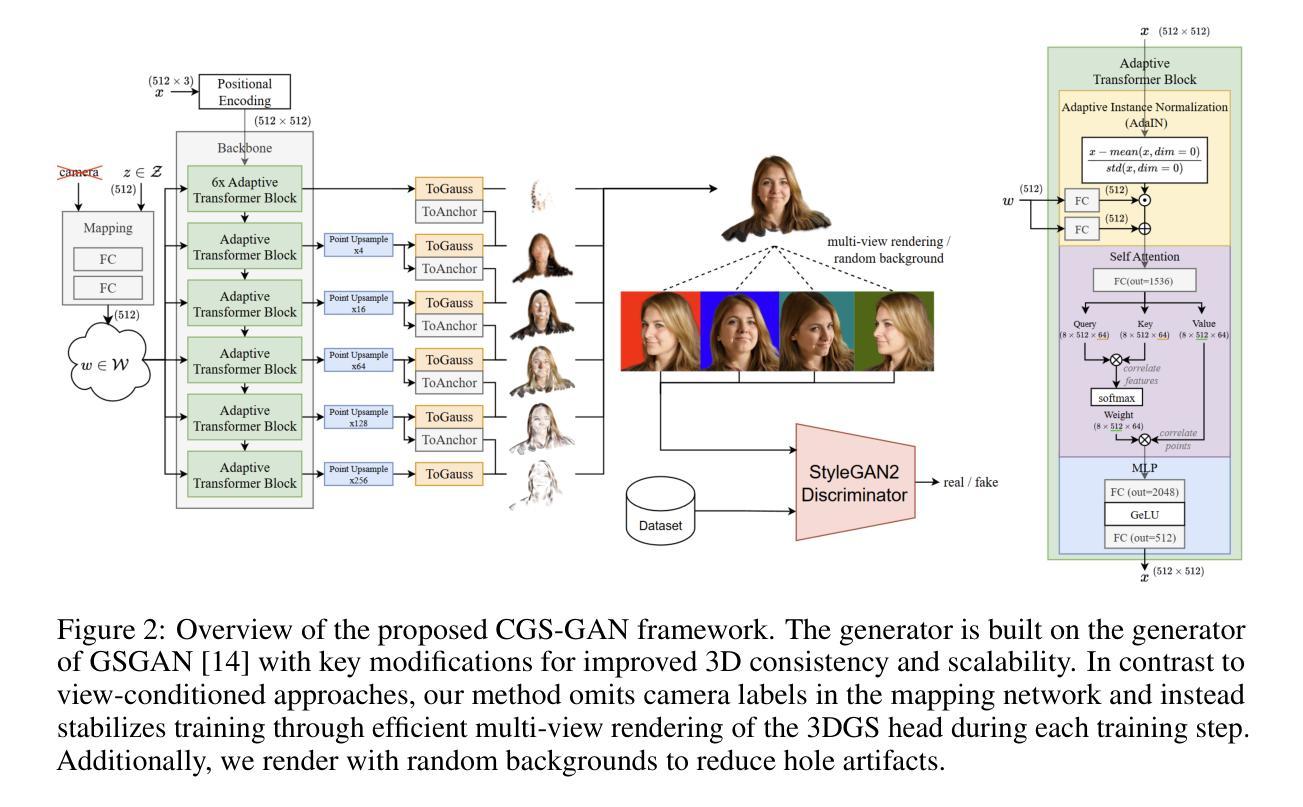
Recently, 3D GANs based on 3D Gaussian splatting have been proposed for high quality synthesis of human heads. However, existing methods stabilize training and enhance rendering quality from steep viewpoints by conditioning the random latent vector on the current camera position. This compromises 3D consistency, as we observe significant identity changes when re-synthesizing the 3D head with each camera shift. Conversely, fixing the camera to a single viewpoint yields high-quality renderings for that perspective but results in poor performance for novel views. Removing view-conditioning typically destabilizes GAN training, often causing the training to collapse. In response to these challenges, we introduce CGS-GAN, a novel 3D Gaussian Splatting GAN framework that enables stable training and high-quality 3D-consistent synthesis of human heads without relying on view-conditioning. To ensure training stability, we introduce a multi-view regularization technique that enhances generator convergence with minimal computational overhead. Additionally, we adapt the conditional loss used in existing 3D Gaussian splatting GANs and propose a generator architecture designed to not only stabilize training but also facilitate efficient rendering and straightforward scaling, enabling output resolutions up to $2048^2$. To evaluate the capabilities of CGS-GAN, we curate a new dataset derived from FFHQ. This dataset enables very high resolutions, focuses on larger portions of the human head, reduces view-dependent artifacts for improved 3D consistency, and excludes images where subjects are obscured by hands or other objects. As a result, our approach achieves very high rendering quality, supported by competitive FID scores, while ensuring consistent 3D scene generation. Check our our project page here: https://fraunhoferhhi.github.io/cgs-gan/
最近,基于3D高斯拼贴技术的高维生成对抗网络(GANs)已经被提出用于高质量合成人头。然而,现有的方法通过基于当前相机位置调整随机潜在向量来实现训练稳定性并提升从陡峭视角的渲染质量。这损害了三维一致性,因为我们观察到在每次相机移动后重新合成三维头部时,身份发生了显著变化。相反,将相机固定在单一视角上会为该视角生成高质量的渲染,但对新颖视角的效果较差。移除视角条件通常会导致GAN训练不稳定,甚至导致训练崩溃。为了应对这些挑战,我们引入了CGS-GAN,这是一种新型的3D高斯拼贴GAN框架,能够在不依赖视角条件的情况下实现稳定训练和高质量的3D一致的人头合成。为了确保训练稳定性,我们引入了一种多视角正则化技术,该技术可在最小计算开销的情况下增强生成器的收敛性。此外,我们适应现有的3D高斯拼贴GAN中的条件损失,并提出一种设计巧妙的生成器架构,不仅可以稳定训练,还可以促进高效渲染和直观缩放,支持高达$ 2048^2 $的输出分辨率。为了评估CGS-GAN的能力,我们从FFHQ中整理了一个新的数据集。该数据集可实现非常高的分辨率,重点聚焦于人头较大的部分,减少视角相关的伪影以提高三维一致性,并排除主体被手或其他物体遮挡的图像。因此,我们的方法实现了非常高的渲染质量,并得到了具有竞争力的FID得分,同时确保了一致的3D场景生成。请访问我们的项目页面了解更多信息:https://fraunhoferhhi.github.io/cgs-gan/。
论文及项目相关链接
PDF Main paper 12 pages, supplementary materials 8 pages
Summary
基于3D高斯涂抹技术的3D GANs已用于高质量的人头合成。然而,现有方法通过根据当前相机位置对随机潜在向量进行条件化处理来稳定训练和增强从陡峭视角的渲染质量,这影响了3D一致性。针对这些挑战,我们提出CGS-GAN框架,这是一个新颖的3D高斯涂抹GAN框架,无需依赖视图条件即可实现稳定训练和高质量、高一致性的3D人头合成。我们引入了一种多视角正则化技术,确保训练稳定性并增强生成器收敛性,同时最小化计算开销。此外,我们还改进了现有3D高斯涂抹GANs中的条件损失,并设计了一种生成器架构,该架构不仅能稳定训练,还能促进高效渲染和直观扩展,支持高达$ 2048^2 $的输出分辨率。为评估CGS-GAN的能力,我们从FFHQ中整理了一个新的数据集,该数据集可实现极高分辨率,重点关注人头较大部位,减少视角相关伪影以提高3D一致性,并排除主体被手或其他物体遮挡的图像。我们的方法在保证极高渲染质量的同时实现了一致的3D场景生成。更多详情可访问我们的项目页面:https://fraunhoferhhi.github.io/cgs-gan/。
Key Takeaways
- CGS-GAN是一个基于3D高斯涂抹技术的GAN框架,用于高质量的人头合成。
- 现有方法通过相机位置条件化来稳定训练和渲染质量,但会影响3D一致性。CGS-GAN解决了这一问题。
- CGS-GAN引入多视角正则化技术确保训练稳定性和生成器收敛性。
- 对现有条件损失进行改进,提高渲染效率并达到高输出分辨率。
- 提出新的数据集用于评估CGS-GAN的能力,关注人头大部位的高分辨率渲染。
- 数据集设计减少了视角相关伪影和遮挡问题,提高了渲染质量的一致性。
点此查看论文截图


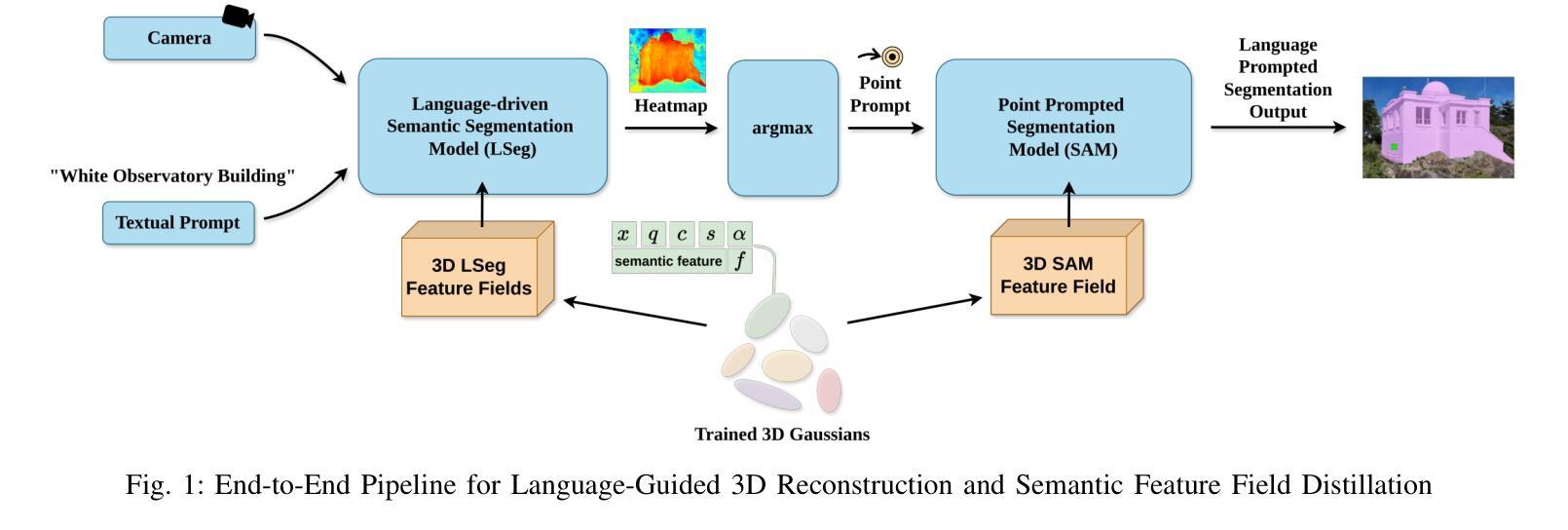
From Flight to Insight: Semantic 3D Reconstruction for Aerial Inspection via Gaussian Splatting and Language-Guided Segmentation
Authors:Mahmoud Chick Zaouali, Todd Charter, Homayoun Najjaran
High-fidelity 3D reconstruction is critical for aerial inspection tasks such as infrastructure monitoring, structural assessment, and environmental surveying. While traditional photogrammetry techniques enable geometric modeling, they lack semantic interpretability, limiting their effectiveness for automated inspection workflows. Recent advances in neural rendering and 3D Gaussian Splatting (3DGS) offer efficient, photorealistic reconstructions but similarly lack scene-level understanding. In this work, we present a UAV-based pipeline that extends Feature-3DGS for language-guided 3D segmentation. We leverage LSeg-based feature fields with CLIP embeddings to generate heatmaps in response to language prompts. These are thresholded to produce rough segmentations, and the highest-scoring point is then used as a prompt to SAM or SAM2 for refined 2D segmentation on novel view renderings. Our results highlight the strengths and limitations of various feature field backbones (CLIP-LSeg, SAM, SAM2) in capturing meaningful structure in large-scale outdoor environments. We demonstrate that this hybrid approach enables flexible, language-driven interaction with photorealistic 3D reconstructions, opening new possibilities for semantic aerial inspection and scene understanding.
高精度3D重建对于空中检查任务至关重要,如基础设施监测、结构评估和环境调查。虽然传统的摄影测量技术能够实现几何建模,但它们缺乏语义可解释性,限制了它们在自动化检查工作流程中的有效性。神经网络渲染和3D高斯贴图(3DGS)的最新进展提供了高效、逼真的重建,但同样缺乏场景级别的理解。在这项工作中,我们提出了一种基于无人机的管道,该管道扩展了Feature-3DGS,用于语言引导的3D分割。我们利用基于LSeg的特征字段和CLIP嵌入来生成响应语言提示的热图。这些热图通过阈值处理产生粗略的分割,然后得分最高的点被用作提示,以在新型视图渲染上进行精细的2D分割(使用SAM或SAM2)。我们的结果突出了各种特征字段主干(CLIP-LSeg、SAM、SAM2)在捕获大规模室外环境中的有意义结构方面的优势和局限性。我们证明,这种混合方法能够实现灵活、语言驱动的光照真实感3D重建交互,为语义空中检查和场景理解开启了新的可能性。
论文及项目相关链接
Summary
该文章介绍了一种基于无人机的语言引导三维分割管道,融合了特征三维高斯融合技术。利用LSeg特征场与CLIP嵌入技术生成响应语言提示的热图,通过阈值处理得到初步分割结果,并选择得分最高的点作为提示,通过SAM或SAM2技术进行精细化二维分割。该研究展示了不同特征场在大型户外环境中捕捉有意义结构的能力,并证明了该混合方法可实现灵活的语言驱动交互,为语义空中检测和场景理解提供了新的可能性。
Key Takeaways
- 高保真三维重建对于空中检测任务至关重要,如基础设施监测、结构评估和环境调查等。
- 传统摄影测量技术可实现几何建模,但缺乏语义解释性,限制了自动化检测流程的有效性。
- 神经渲染和三维高斯融合技术的最新进展提供了高效的光照真实感重建,但仍缺乏场景级别的理解。
- 提出的基于无人机的管道融合了特征三维高斯融合技术,实现了语言引导的三维分割。
- 利用LSeg特征场和CLIP嵌入技术生成热图,响应语言提示,通过阈值处理获得初步分割结果。
- 研究展示了不同特征场在大型户外环境中捕捉有意义结构的能力。
点此查看论文截图

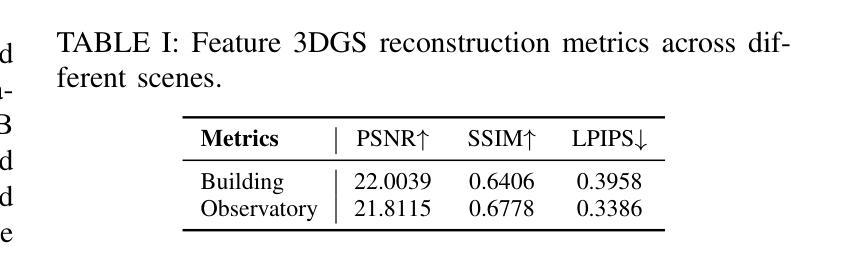



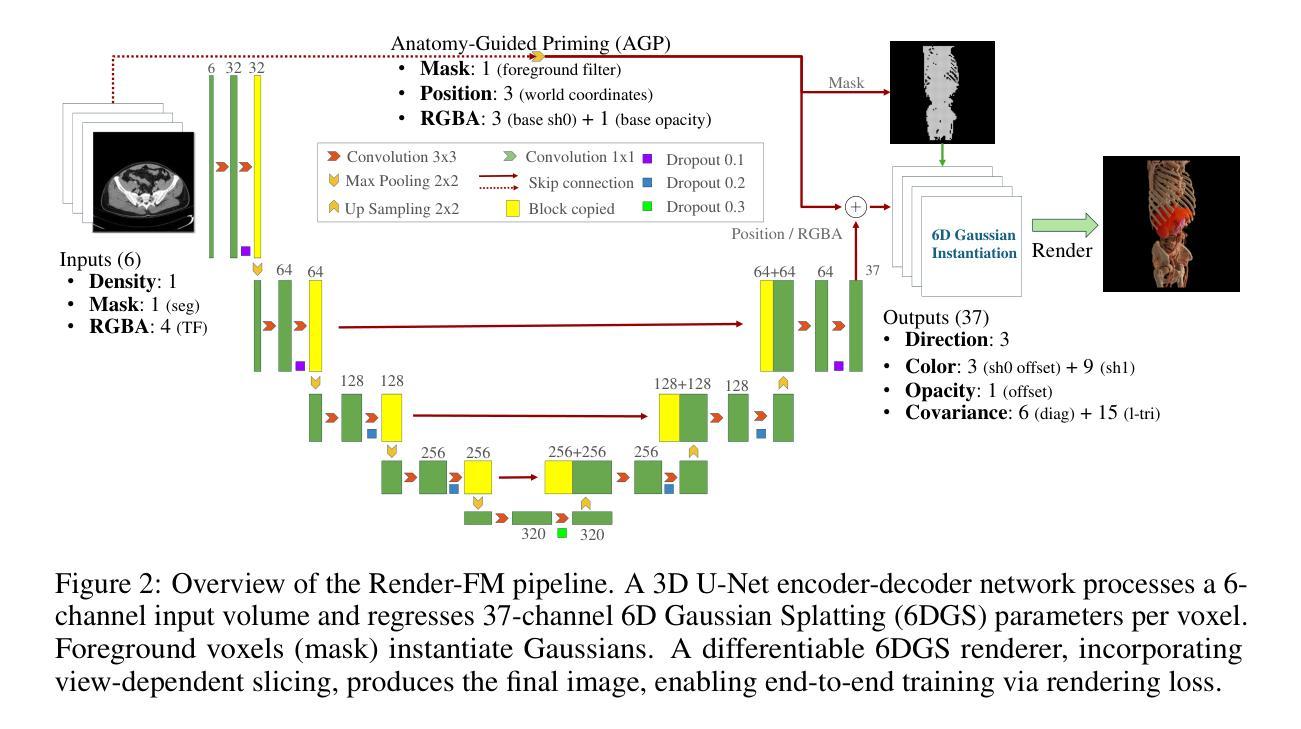
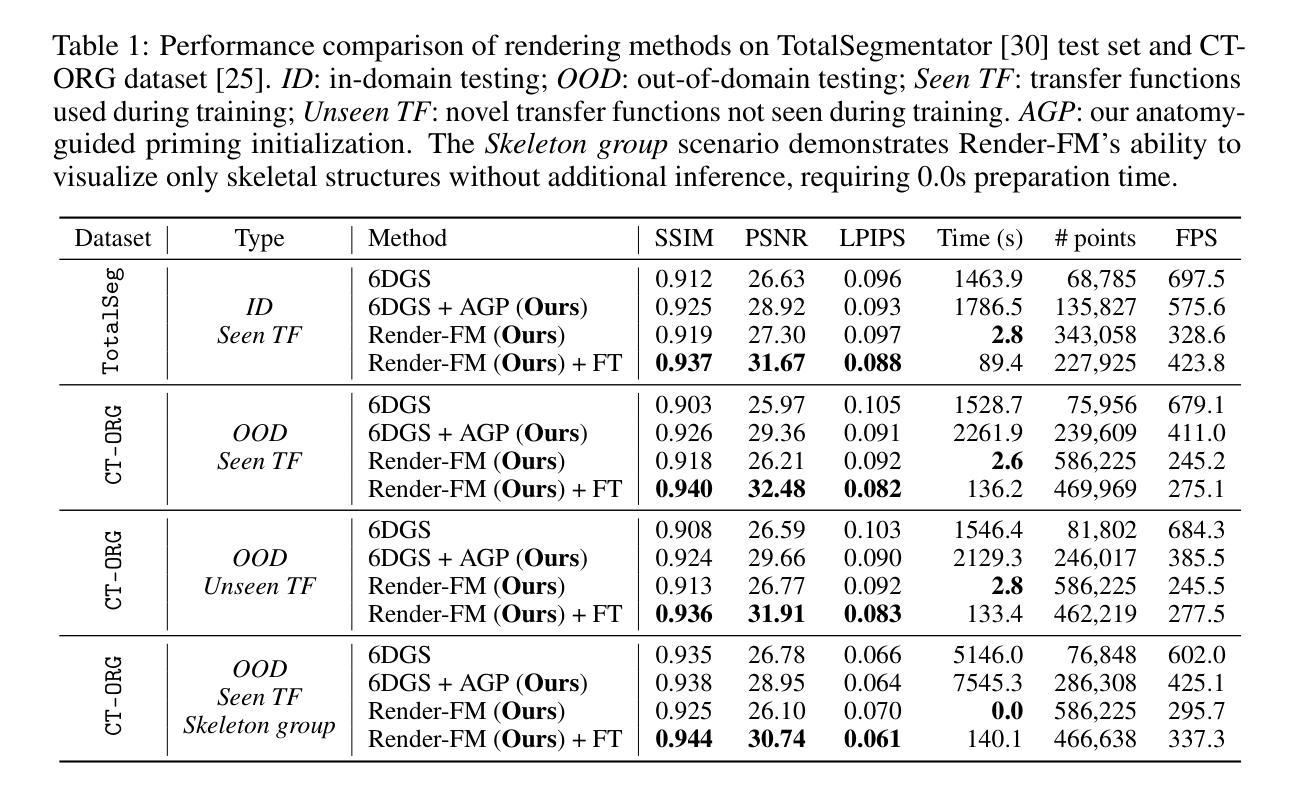
Render-FM: A Foundation Model for Real-time Photorealistic Volumetric Rendering
Authors:Zhongpai Gao, Meng Zheng, Benjamin Planche, Anwesa Choudhuri, Terrence Chen, Ziyan Wu
Volumetric rendering of Computed Tomography (CT) scans is crucial for visualizing complex 3D anatomical structures in medical imaging. Current high-fidelity approaches, especially neural rendering techniques, require time-consuming per-scene optimization, limiting clinical applicability due to computational demands and poor generalizability. We propose Render-FM, a novel foundation model for direct, real-time volumetric rendering of CT scans. Render-FM employs an encoder-decoder architecture that directly regresses 6D Gaussian Splatting (6DGS) parameters from CT volumes, eliminating per-scan optimization through large-scale pre-training on diverse medical data. By integrating robust feature extraction with the expressive power of 6DGS, our approach efficiently generates high-quality, real-time interactive 3D visualizations across diverse clinical CT data. Experiments demonstrate that Render-FM achieves visual fidelity comparable or superior to specialized per-scan methods while drastically reducing preparation time from nearly an hour to seconds for a single inference step. This advancement enables seamless integration into real-time surgical planning and diagnostic workflows. The project page is: https://gaozhongpai.github.io/renderfm/.
计算机断层扫描(CT)的体积渲染对于医学成像中复杂三维结构的可视化至关重要。当前的高保真方法,尤其是神经渲染技术,需要进行耗时的场景优化,由于计算需求高和通用性较差,限制了其在临床中的应用。我们提出了Render-FM,一种用于CT扫描直接实时体积渲染的新型基础模型。Render-FM采用编码器-解码器架构,直接从CT体积回归6D高斯拼贴(6DGS)参数,通过大规模预训练多样化医学数据,省去每次扫描的优化步骤。通过将稳健的特征提取与6DGS的表现力相结合,我们的方法能够有效地生成高质量、实时的三维交互可视化图像,适用于各种临床CT数据。实验表明,Render-FM的视觉保真度可与专业的逐次扫描方法相媲美甚至更优,同时将准备时间从近一个小时大幅缩短到几秒的单次推理时间。这一进展使得无缝集成到实时手术规划和诊断工作流程中成为可能。项目页面为:[https://gaozhongpai.github.io/renderfm/] 。
论文及项目相关链接
Summary
CT扫描的体积渲染对于医学成像中复杂三维结构的可视化至关重要。当前的高保真方法,尤其是神经渲染技术,需要进行耗时的场景优化,由于计算需求高和通用性差的限制,临床应用受限。我们提出了Render-FM,一种用于CT扫描直接实时体积渲染的新型基础模型。Render-FM采用编码器-解码器架构,直接从CT体积回归6D高斯喷绘(6DGS)参数,通过大规模预训练在多样医疗数据上省去每次扫描的优化步骤。通过结合稳健的特征提取和6DGS的表现力,我们的方法有效地生成了高质量、实时的三维可视化图像,适用于多种临床CT数据。实验表明,Render-FM的视觉保真度与专用扫描方法相当或更优,单次推理步骤的准备时间从近一个小时减少到几秒。这一进展可无缝集成到实时手术规划和诊断工作流程中。
Key Takeaways
- 体量渲染对于医学成像中三维结构的可视化非常重要。
- 当前的高保真渲染方法如神经渲染技术存在计算需求高和通用性差的限制。
- Render-FM是一种新型的基础模型,用于CT扫描的直接实时体积渲染。
- Render-FM采用编码器-解码器架构,直接从CT体积回归6D高斯喷绘(6DGS)参数。
- 该方法通过大规模预训练在多样医疗数据上省去每次扫描的优化步骤。
- Render-FM可以生成高质量、实时的三维可视化图像,适用于多种临床CT数据。
点此查看论文截图