⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-05-27 更新
Clip4Retrofit: Enabling Real-Time Image Labeling on Edge Devices via Cross-Architecture CLIP Distillation
Authors:Li Zhong, Ahmed Ghazal, Jun-Jun Wan, Frederik Zilly, Patrick Mackens, Joachim E. Vollrath, Bogdan Sorin Coseriu
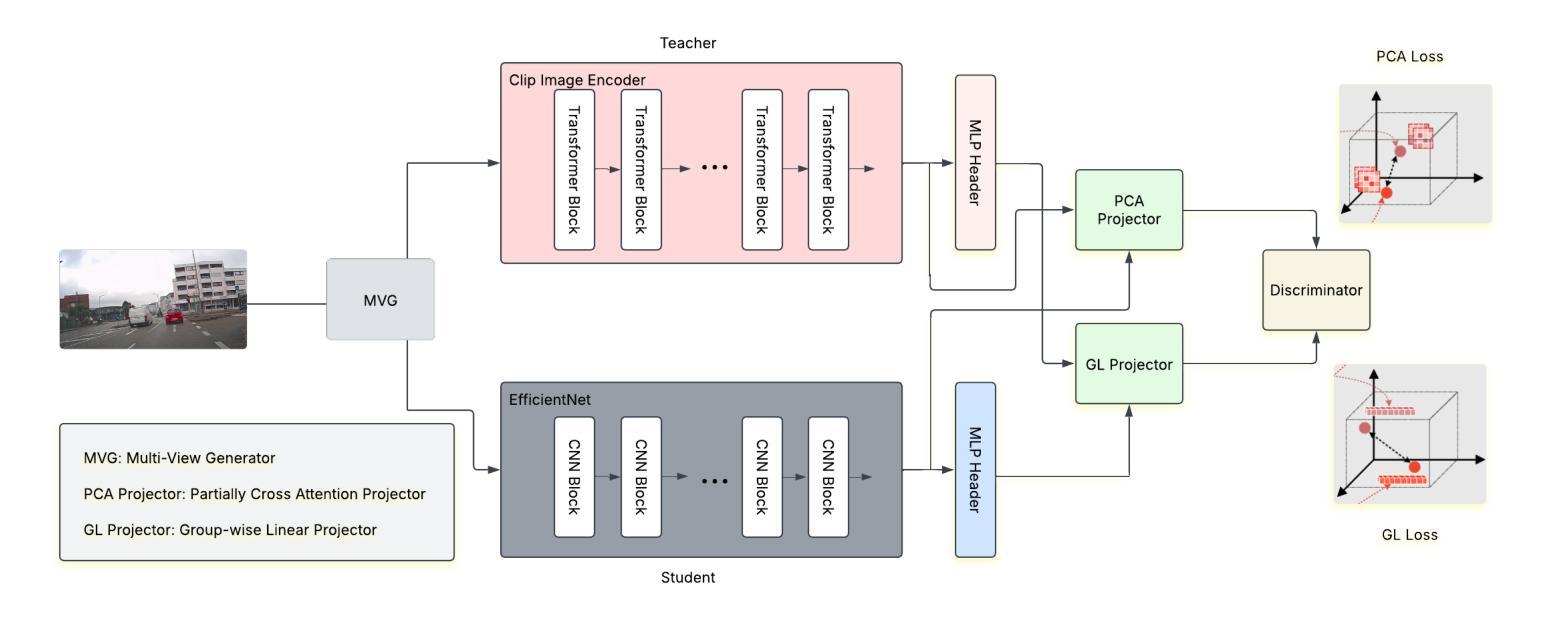
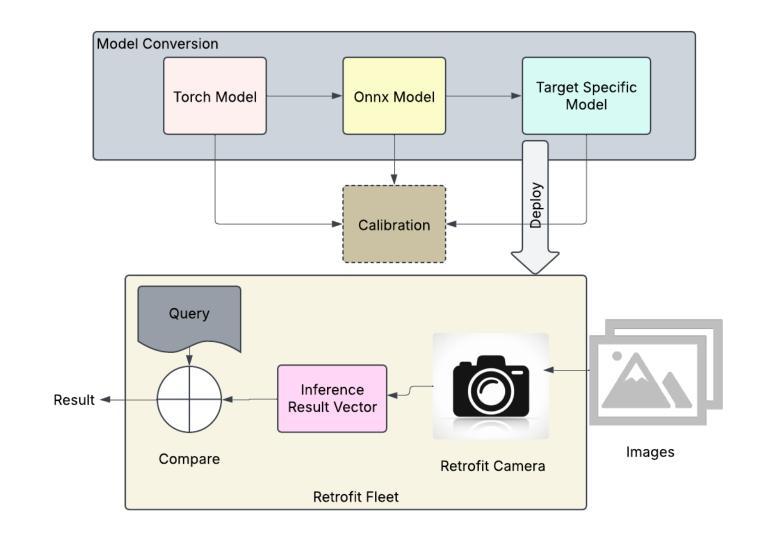
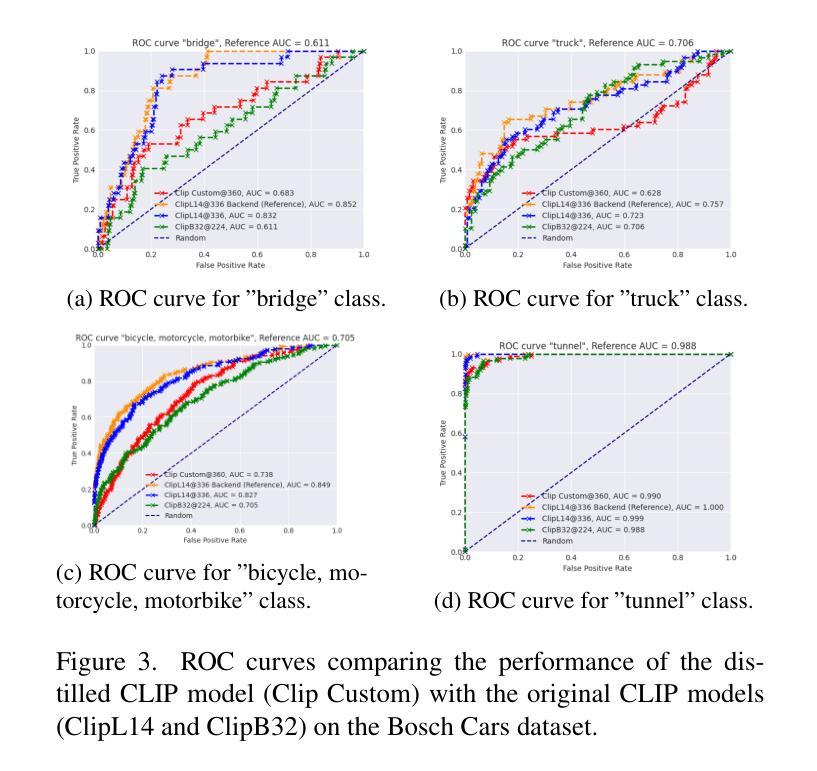
Foundation models like CLIP (Contrastive Language-Image Pretraining) have revolutionized vision-language tasks by enabling zero-shot and few-shot learning through cross-modal alignment. However, their computational complexity and large memory footprint make them unsuitable for deployment on resource-constrained edge devices, such as in-car cameras used for image collection and real-time processing. To address this challenge, we propose Clip4Retrofit, an efficient model distillation framework that enables real-time image labeling on edge devices. The framework is deployed on the Retrofit camera, a cost-effective edge device retrofitted into thousands of vehicles, despite strict limitations on compute performance and memory. Our approach distills the knowledge of the CLIP model into a lightweight student model, combining EfficientNet-B3 with multi-layer perceptron (MLP) projection heads to preserve cross-modal alignment while significantly reducing computational requirements. We demonstrate that our distilled model achieves a balance between efficiency and performance, making it ideal for deployment in real-world scenarios. Experimental results show that Clip4Retrofit can perform real-time image labeling and object identification on edge devices with limited resources, offering a practical solution for applications such as autonomous driving and retrofitting existing systems. This work bridges the gap between state-of-the-art vision-language models and their deployment in resource-constrained environments, paving the way for broader adoption of foundation models in edge computing.
像CLIP(对比语言图像预训练)这样的基础模型通过跨模态对齐实现了零样本和少样本学习,从而彻底改变了视觉语言任务。然而,它们的计算复杂性和较大的内存占用使得它们不适合在资源受限的边缘设备上部署,例如在用于图像采集和实时处理的汽车摄像头中。为了应对这一挑战,我们提出了Clip4Retrofit,这是一个高效的模型蒸馏框架,能够在边缘设备上实现实时图像标签。该框架部署在Retrofit摄像头(一种改装到数千辆汽车中的经济型边缘设备)上,尽管在计算性能和内存方面存在严格限制。我们的方法将CLIP模型的知识蒸馏到一个轻量级的学生模型中,结合EfficientNet-B3和多层感知机(MLP)投影头,在保持跨模态对齐的同时显著降低计算要求。我们证明,我们的蒸馏模型在效率和性能之间取得了平衡,使其成为在现实场景部署的理想选择。实验结果表明,Clip4Retrofit可以在资源有限的边缘设备上实现实时图像标签和对象识别,为自动驾驶和现有系统改造等应用提供了实用解决方案。这项工作填补了最先进的视觉语言模型及其在资源受限环境中部署之间的空白,为边缘计算中基础模型的更广泛采用铺平了道路。
论文及项目相关链接
Summary
CLIP等模型通过跨模态对齐实现了零样本和少样本学习,在视觉语言任务中掀起革命。但其在边缘设备上部署面临计算复杂和内存占用大的挑战。为解决此问题,我们提出Clip4Retrofit模型蒸馏框架,能在边缘设备上实现实时图像标注。该框架部署在改装摄像头中,即使面临严格的计算和内存限制,也能在数千辆汽车中使用。我们通过蒸馏CLIP模型知识到轻量级学生模型,结合EfficientNet-B3和多层感知机投影头,在降低计算要求的同时保持跨模态对齐。实验证明,蒸馏模型在效率和性能之间取得平衡,适合在资源受限的边缘设备上部署,为自动驾驶和现有系统改造等应用提供实用解决方案。
Key Takeaways
- CLIP等模型通过跨模态对齐实现零样本和少样本学习,推动视觉语言任务发展。
- 这些模型在边缘设备上面临计算复杂和内存占用大的挑战。
- Clip4Retrofit框架解决了这一问题,能在资源受限的边缘设备上实现实时图像标注。
- 该框架部署在改装摄像头中,适用于数千辆汽车。
- 通过蒸馏CLIP模型知识到轻量级学生模型,保持跨模态对齐的同时降低计算要求。
- 实验证明蒸馏模型在效率和性能间取得平衡。
点此查看论文截图

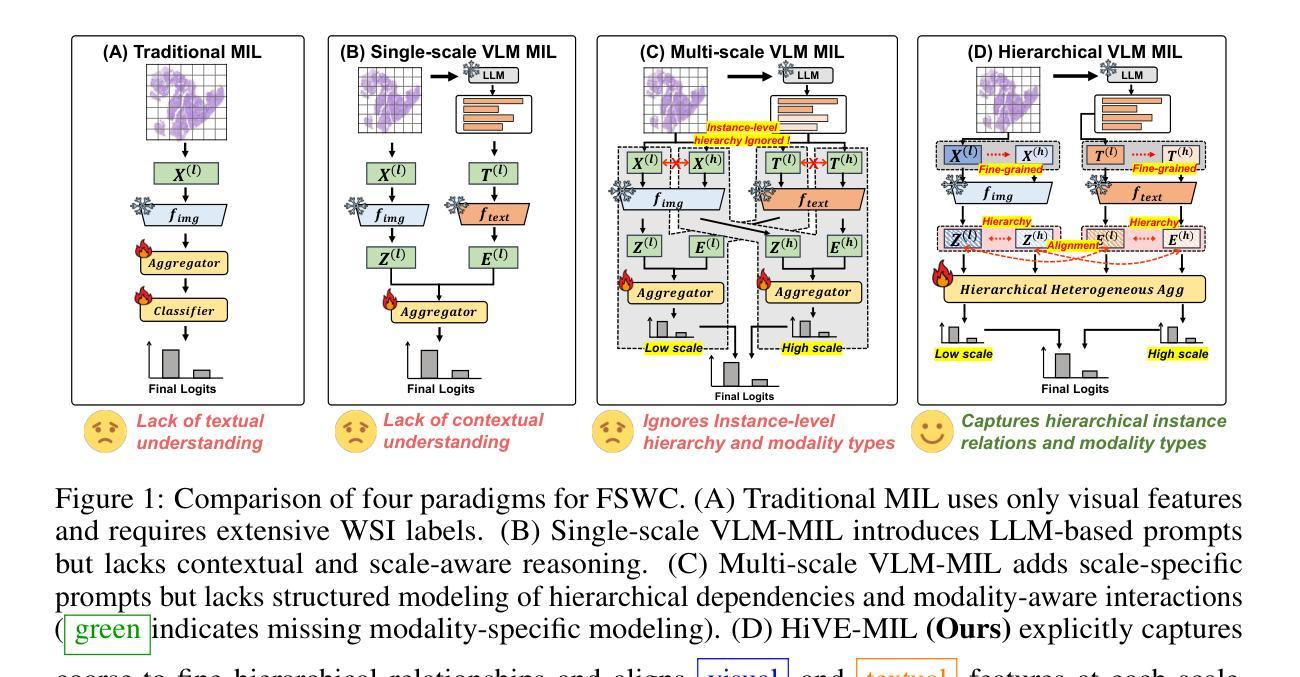
Few-Shot Learning from Gigapixel Images via Hierarchical Vision-Language Alignment and Modeling
Authors:Bryan Wong, Jong Woo Kim, Huazhu Fu, Mun Yong Yi
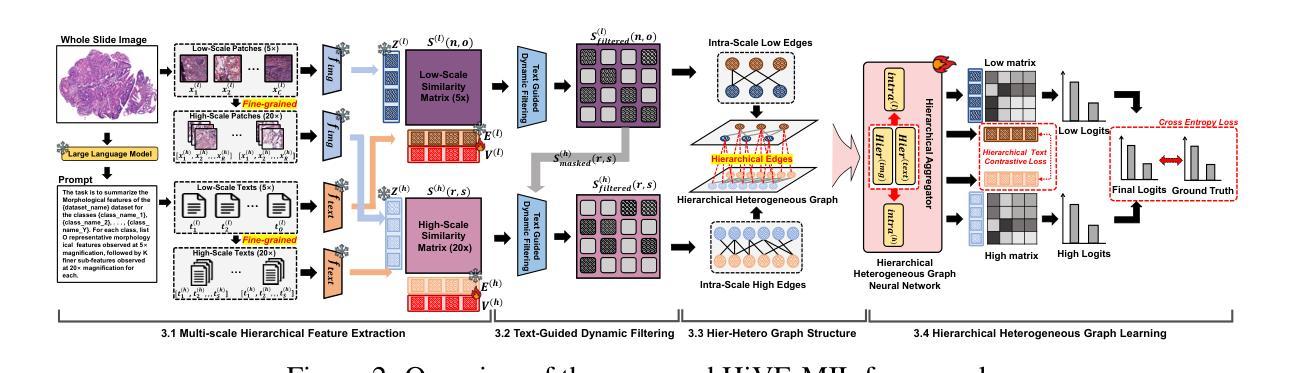
Vision-language models (VLMs) have recently been integrated into multiple instance learning (MIL) frameworks to address the challenge of few-shot, weakly supervised classification of whole slide images (WSIs). A key trend involves leveraging multi-scale information to better represent hierarchical tissue structures. However, existing methods often face two key limitations: (1) insufficient modeling of interactions within the same modalities across scales (e.g., 5x and 20x) and (2) inadequate alignment between visual and textual modalities on the same scale. To address these gaps, we propose HiVE-MIL, a hierarchical vision-language framework that constructs a unified graph consisting of (1) parent-child links between coarse (5x) and fine (20x) visual/textual nodes to capture hierarchical relationships, and (2) heterogeneous intra-scale edges linking visual and textual nodes on the same scale. To further enhance semantic consistency, HiVE-MIL incorporates a two-stage, text-guided dynamic filtering mechanism that removes weakly correlated patch-text pairs, and introduces a hierarchical contrastive loss to align textual semantics across scales. Extensive experiments on TCGA breast, lung, and kidney cancer datasets demonstrate that HiVE-MIL consistently outperforms both traditional MIL and recent VLM-based MIL approaches, achieving gains of up to 4.1% in macro F1 under 16-shot settings. Our results demonstrate the value of jointly modeling hierarchical structure and multimodal alignment for efficient and scalable learning from limited pathology data. The code is available at https://github.com/bryanwong17/HiVE-MIL
视觉语言模型(VLMs)最近已被纳入多重实例学习(MIL)框架,以解决对全幻灯片图像(WSIs)进行少量弱监督分类的挑战。一种关键趋势是,利用多尺度信息来更好地表示层次化的组织结构。然而,现有方法常常面临两个主要局限:(1)对同一模态内不同尺度(例如5倍和20倍)之间交互的建模不足;(2)在同一尺度上视觉和文本模态之间对齐不足。为了解决这些不足,我们提出了HiVE-MIL,这是一种层次化的视觉语言框架,它构建了一个统一图,包括(1)粗尺度(5倍)和细尺度(20倍)视觉/文本节点之间的父子链接,以捕捉层次关系,以及(2)在同一尺度上连接视觉和文本节点的异质内尺度边。为了进一步增强语义一致性,HiVE-MIL采用了一种两阶段的文本引导动态过滤机制,该机制可以去除弱相关的补丁-文本对,并引入了一种层次对比损失,以对齐不同尺度的文本语义。在TCGA乳腺癌、肺癌和肾癌数据集上的大量实验表明,HiVE-MIL始终优于传统的MIL和最新的基于VLM的MIL方法,在16次拍摄的宏观F1得分提高了高达4.1%。我们的结果证明了联合建模层次结构和多模态对齐对于从有限病理数据中实现高效和可扩展学习的价值。代码可在https://github.com/bryanwong17/HiVE-MIL找到。
论文及项目相关链接
Summary
该文本介绍了近期在少数样本和弱监督情况下,使用视觉语言模型(VLMs)对全幻灯片图像(WSIs)进行分类的挑战。为了解决现有方法的不足,提出了一种名为HiVE-MIL的层次化视觉语言框架,通过构建统一图模型和多尺度信息来优化交互建模和模态对齐问题。该框架包括父母节点和子节点之间的链接以及同一尺度上的异质内尺度边缘,增强了语义一致性并实现了跨尺度的文本语义对齐。在癌症数据集上的实验表明,HiVE-MIL在少数样本下的表现优于传统方法和基于VLM的方法。总结了使用多模态对齐和层次结构建模进行高效、可扩展学习的价值。
Key Takeaways
以下是关于该文本的关键见解:
- 视觉语言模型(VLMs)已经被纳入多次实例学习(MIL)框架,用于解决少量样本对全幻灯片图像的分类挑战。主要问题在于多尺度信息的有效利用和模态间的对齐问题。
- HiVE-MIL框架通过构建统一图模型来解决上述问题,包括跨尺度的父母节点和子节点之间的链接以及同一尺度上的异质内尺度边缘。
- 该框架采用两阶段的文本引导动态过滤机制,去除弱相关的补丁文本对,并使用层次对比损失来对齐跨尺度的文本语义。这种机制增强了语义一致性。
点此查看论文截图

LLM Meeting Decision Trees on Tabular Data
Authors:Hangting Ye, Jinmeng Li, He Zhao, Dandan Guo, Yi Chang
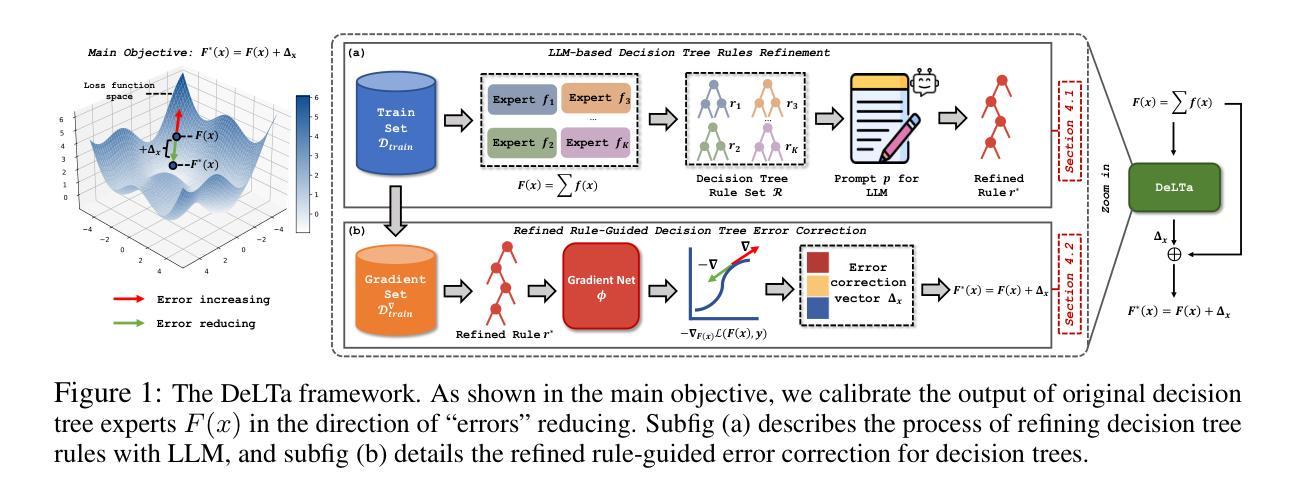
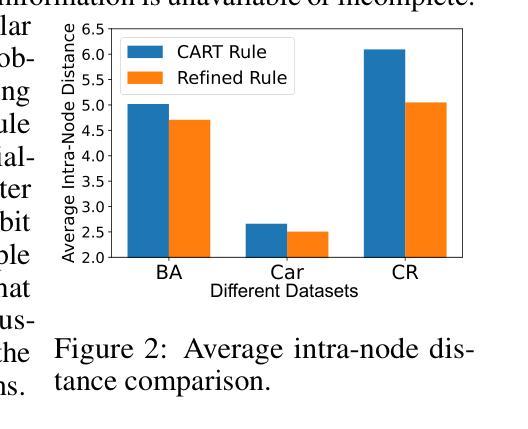
Tabular data have been playing a vital role in diverse real-world fields, including healthcare, finance, etc. With the recent success of Large Language Models (LLMs), early explorations of extending LLMs to the domain of tabular data have been developed. Most of these LLM-based methods typically first serialize tabular data into natural language descriptions, and then tune LLMs or directly infer on these serialized data. However, these methods suffer from two key inherent issues: (i) data perspective: existing data serialization methods lack universal applicability for structured tabular data, and may pose privacy risks through direct textual exposure, and (ii) model perspective: LLM fine-tuning methods struggle with tabular data, and in-context learning scalability is bottle-necked by input length constraints (suitable for few-shot learning). This work explores a novel direction of integrating LLMs into tabular data throughough logical decision tree rules as intermediaries, proposes a decision tree enhancer with LLM-derived rule for tabular prediction, DeLTa. The proposed DeLTa avoids tabular data serialization, and can be applied to full data learning setting without LLM fine-tuning. Specifically, we leverage the reasoning ability of LLMs to redesign an improved rule given a set of decision tree rules. Furthermore, we provide a calibration method for original decision trees via new generated rule by LLM, which approximates the error correction vector to steer the original decision tree predictions in the direction of ``errors’’ reducing. Finally, extensive experiments on diverse tabular benchmarks show that our method achieves state-of-the-art performance.
表格数据在真实世界的多个领域中都扮演着至关重要的角色,包括医疗保健、金融等。随着大型语言模型(LLM)近期的成功,将LLM扩展到表格数据领域的早期探索已经得到发展。大多数基于LLM的方法通常先将表格数据序列化为自然语言描述,然后调整LLM或直接对这些序列化数据进行推断。然而,这些方法存在两个主要内在问题:
(i)数据角度:现有数据序列化方法缺乏针对结构化表格数据的通用适用性,并且可能通过直接文本暴露造成隐私风险;
(ii)模型角度:LLM微调方法在处理表格数据时遇到困难,上下文学习的可扩展性受到输入长度约束的限制(适用于小样本学习)。
论文及项目相关链接
Summary
本摘要主要探讨了大型语言模型在表格数据领域的应用问题。针对表格数据的序列化处理方法存在缺乏通用性和隐私泄露风险的问题,以及传统的LLM微调方法处理表格数据存在困难等问题,本研究提出了一种通过逻辑决策树规则将LLM集成到表格数据中的新方法,即决策树增强器DeLTa。该方法避免了表格数据的序列化,并适用于全数据学习设置,无需对LLM进行微调。具体而言,它利用LLM的推理能力来改进给定决策树规则集的设计,并为原始决策树提供了一种校准方法,通过LLM生成的新规则来近似误差校正向量,从而将原始决策树预测导向减少误差的方向。在多个表格基准测试上的实验表明,该方法达到了最先进的性能。
Key Takeaways
- 大型语言模型(LLMs)在表格数据领域的应用已成为研究热点。
- 现有方法通过序列化表格数据到自然语言描述来处理,但存在缺乏通用性和隐私泄露风险的问题。
- DeLTa方法通过逻辑决策树规则集成LLMs处理表格数据,避免了数据序列化。
- DeLTa适用于全数据学习设置,无需对LLM进行微调。
- LLMs的推理能力用于改进决策树规则设计,并且提供对原始决策树的校准方法。
- 新方法通过近似误差校正向量,可引导决策树预测减少误差。
点此查看论文截图


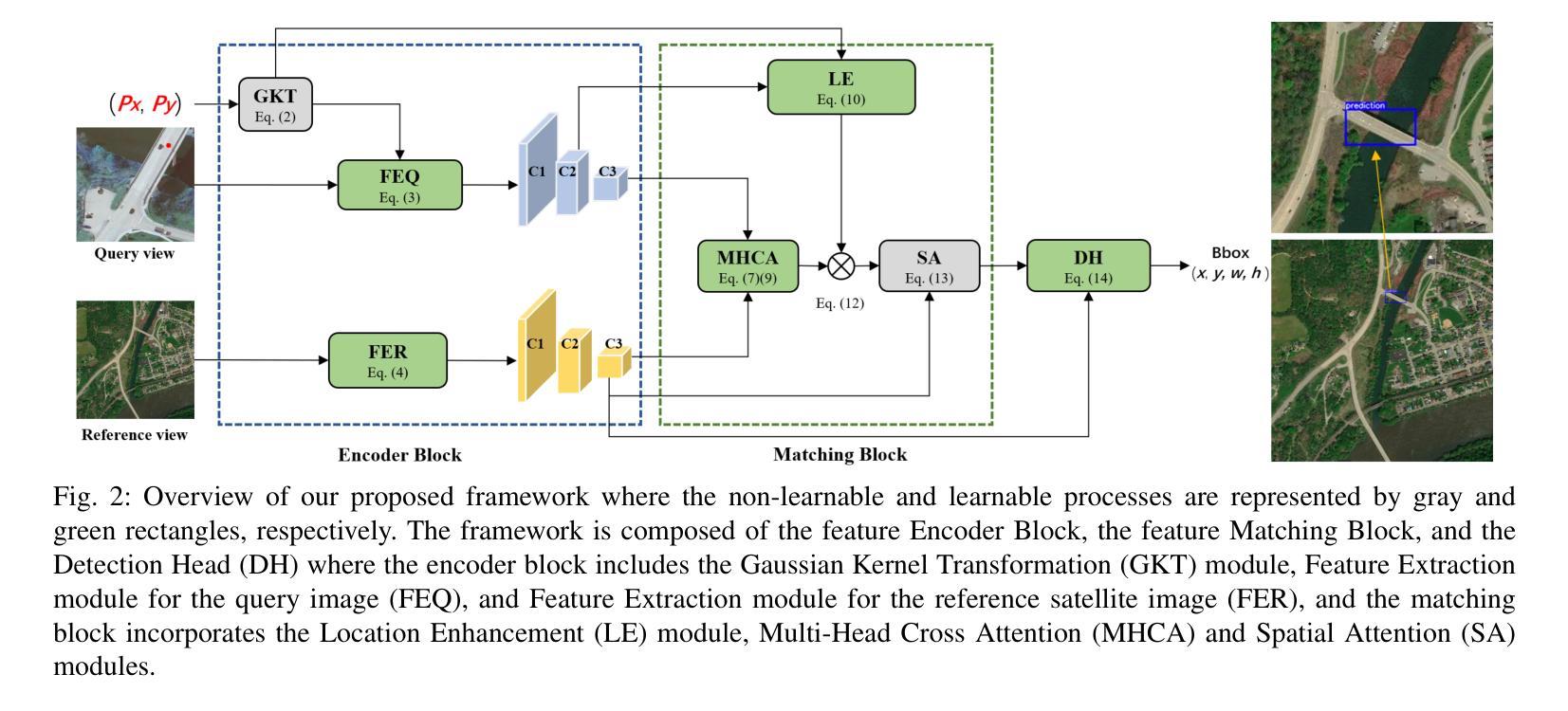
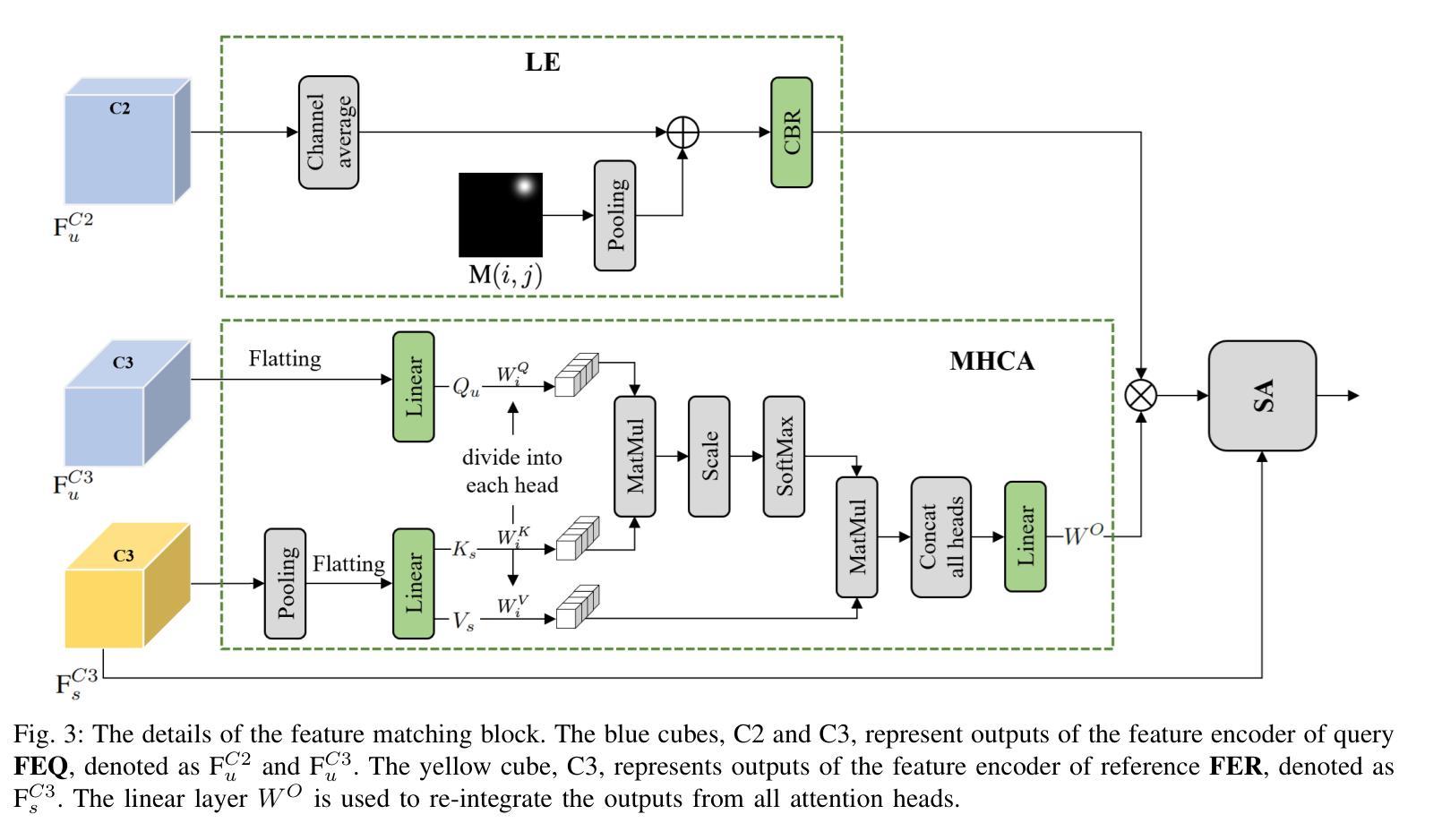
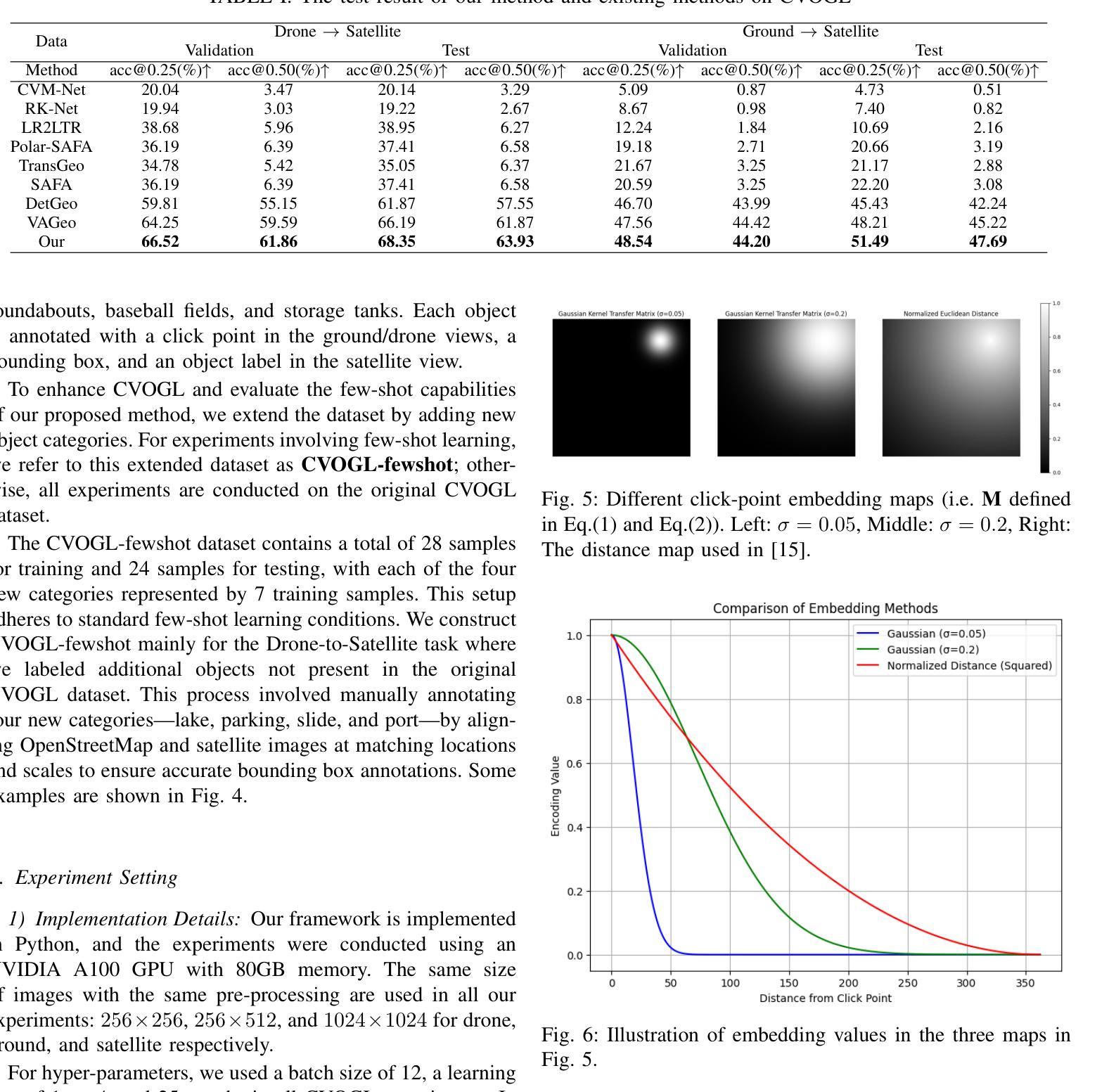
Object-level Cross-view Geo-localization with Location Enhancement and Multi-Head Cross Attention
Authors:Zheyang Huang, Jagannath Aryal, Saeid Nahavandi, Xuequan Lu, Chee Peng Lim, Lei Wei, Hailing Zhou
Cross-view geo-localization determines the location of a query image, captured by a drone or ground-based camera, by matching it to a geo-referenced satellite image. While traditional approaches focus on image-level localization, many applications, such as search-and-rescue, infrastructure inspection, and precision delivery, demand object-level accuracy. This enables users to prompt a specific object with a single click on a drone image to retrieve precise geo-tagged information of the object. However, variations in viewpoints, timing, and imaging conditions pose significant challenges, especially when identifying visually similar objects in extensive satellite imagery. To address these challenges, we propose an Object-level Cross-view Geo-localization Network (OCGNet). It integrates user-specified click locations using Gaussian Kernel Transfer (GKT) to preserve location information throughout the network. This cue is dually embedded into the feature encoder and feature matching blocks, ensuring robust object-specific localization. Additionally, OCGNet incorporates a Location Enhancement (LE) module and a Multi-Head Cross Attention (MHCA) module to adaptively emphasize object-specific features or expand focus to relevant contextual regions when necessary. OCGNet achieves state-of-the-art performance on a public dataset, CVOGL. It also demonstrates few-shot learning capabilities, effectively generalizing from limited examples, making it suitable for diverse applications (https://github.com/ZheyangH/OCGNet).
跨视图地理定位(Cross-view geo-localization)是通过将无人机或地面相机捕获的查询图像与地理参考卫星图像进行匹配,确定其位置。虽然传统的方法主要关注图像级别的定位,但许多应用(如搜救、基础设施检查和精确配送)需要对象级别的精确度。这使用户可以通过单击无人机图像上的特定对象来检索该对象的精确地理标记信息。然而,视角、时间和成像条件的差异带来了重大挑战,特别是在广泛的卫星图像中识别视觉上相似的对象时。为了应对这些挑战,我们提出了一种对象级别的跨视图地理定位网络(Object-level Cross-view Geo-localization Network,简称OCGNet)。它通过高斯核转移(Gaussian Kernel Transfer,简称GKT)整合用户指定的点击位置,以在网络中保留位置信息。这一线索被嵌入到特征编码器和特征匹配块中,确保稳健的对象特定定位。此外,OCGNet还融入了一个位置增强(Location Enhancement,简称LE)模块和一个多头交叉注意力(Multi-Head Cross Attention,简称MHCA)模块,以自适应地突出对象特定特征或在必要时扩大关注相关上下文区域。OCGNet在公共数据集CVOGL上达到了最新性能水平,并展示了出色的少样本学习能力,能够有效地从有限样本中泛化,使其适用于各种应用。(https://github.com/ZheyangH/OCGNet)
论文及项目相关链接
Summary
基于无人机或地面相机拍摄的查询图像,通过与其匹配的地理参考卫星图像进行跨视图地理定位,确定其位置。为应对搜索与救援、基础设施检测以及精准投递等应用需求,本文提出了一种对象级别的跨视图地理定位网络(OCGNet)。此方法整合用户指定的点击位置,并运用高斯核转移(GKT)技术保留位置信息在网络中。此外,OCGNet还包含定位增强模块和跨头注意力模块,以自适应突出对象特定特征或在必要时扩大关注相关上下文区域。在公共数据集CVOGL上,OCGNet取得了最先进的性能表现,并展示了其少样本学习能力,能够从有限的例子中有效泛化。
Key Takeaways
- 跨视图地理定位技术通过匹配查询图像与地理参考卫星图像确定位置。
- 对象级别的定位需求在多个领域(如搜索与救援、基础设施检测及精准投递)中至关重要。
- OCGNet网络通过整合用户指定的点击位置并利用高斯核转移技术,实现位置信息的保留。
- OCGNet包含定位增强模块和跨头注意力模块,能自适应突出对象特征或关注上下文。
- OCGNet在公共数据集CVOGL上表现出卓越性能,具有领先的定位精度。
- OCGNet具备少样本学习能力,能够从有限例子中有效泛化。
点此查看论文截图


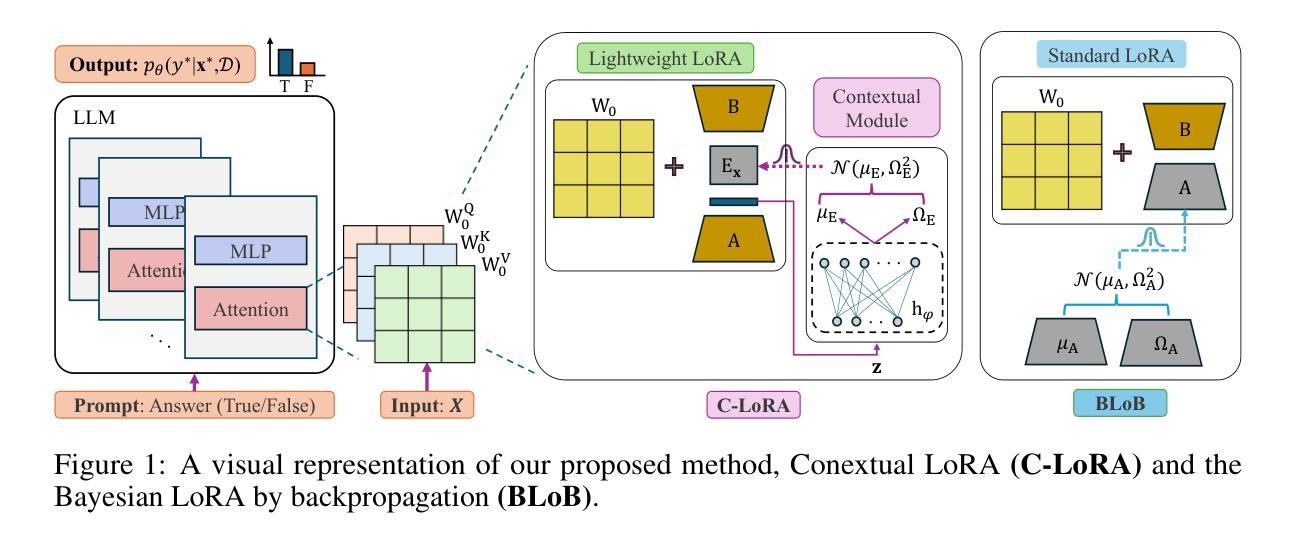
C-LoRA: Contextual Low-Rank Adaptation for Uncertainty Estimation in Large Language Models
Authors:Amir Hossein Rahmati, Sanket Jantre, Weifeng Zhang, Yucheng Wang, Byung-Jun Yoon, Nathan M. Urban, Xiaoning Qian
Low-Rank Adaptation (LoRA) offers a cost-effective solution for fine-tuning large language models (LLMs), but it often produces overconfident predictions in data-scarce few-shot settings. To address this issue, several classical statistical learning approaches have been repurposed for scalable uncertainty-aware LoRA fine-tuning. However, these approaches neglect how input characteristics affect the predictive uncertainty estimates. To address this limitation, we propose Contextual Low-Rank Adaptation (\textbf{C-LoRA}) as a novel uncertainty-aware and parameter efficient fine-tuning approach, by developing new lightweight LoRA modules contextualized to each input data sample to dynamically adapt uncertainty estimates. Incorporating data-driven contexts into the parameter posteriors, C-LoRA mitigates overfitting, achieves well-calibrated uncertainties, and yields robust predictions. Extensive experiments demonstrate that C-LoRA consistently outperforms the state-of-the-art uncertainty-aware LoRA methods in both uncertainty quantification and model generalization. Ablation studies further confirm the critical role of our contextual modules in capturing sample-specific uncertainties. C-LoRA sets a new standard for robust, uncertainty-aware LLM fine-tuning in few-shot regimes.
低秩适应(LoRA)为微调大型语言模型(LLM)提供了具有成本效益的解决方案,但在数据稀缺的少量样本环境中通常会产生过于自信的预测。为解决这一问题,几种经典的统计学习方法已被重新用于可扩展的具有不确定性的LoRA微调。然而,这些方法忽略了输入特征如何影响预测不确定性估计。为解决这一局限性,我们提出上下文低秩适应(C-LoRA)作为一种新型的具有不确定性的参数高效微调方法,通过开发针对每个输入数据样本进行上下文定制的新型轻量化LoRA模块来动态适应不确定性估计。通过将数据驱动上下文纳入参数后验分布,C-LoRA缓解了过拟合问题,实现了校准良好的不确定性,并产生了稳健的预测。大量实验表明,在不确定度量化和模型泛化方面,C-LoRA始终优于最新的一流具有不确定性的LoRA方法。消融研究进一步证实了我们的上下文模块在捕获样本特定不确定性方面的关键作用。C-LoRA为少数情况下的稳健、具有不确定性的LLM微调设定了新的标准。
论文及项目相关链接
Summary
LoRA方法在为大型语言模型进行微调时存在过于自信预测的问题,特别是在数据稀缺的少量样本环境中。为解决这一问题,研究者提出了C-LoRA方法,它通过开发新的轻量级LoRA模块来动态适应不确定性估计,并引入数据驱动上下文信息来调整参数后验分布。C-LoRA能有效缓解过拟合问题,实现良好校准的不确定性,产生稳健的预测。在不确定度量模型和模型泛化方面,C-LoRA均优于现有的不确定性感知LoRA方法。
Key Takeaways
- LoRA为大型语言模型的微调提供了经济高效的解决方案,但在少量样本环境中会产生过于自信的预测。
- 传统的统计学习方法在解决不确定性感知的LoRA微调时忽略了输入特性的影响。
- C-LoRA作为一种新的不确定性感知和参数有效的微调方法,通过开发针对每个输入数据样本的轻量级LoRA模块来动态适应不确定性估计。
- C-LoRA引入数据驱动的上下文信息到参数后验分布中,提高了模型的稳健性和不确定性量化能力。
- C-LoRA能有效缓解过拟合问题,实现良好校准的不确定性。
- 实验证明,C-LoRA在不确定度评估和模型泛化方面均优于现有方法。
点此查看论文截图

PathoSCOPE: Few-Shot Pathology Detection via Self-Supervised Contrastive Learning and Pathology-Informed Synthetic Embeddings
Authors:Sinchee Chin, Yinuo Ma, Xiaochen Yang, Jing-Hao Xue, Wenming Yang
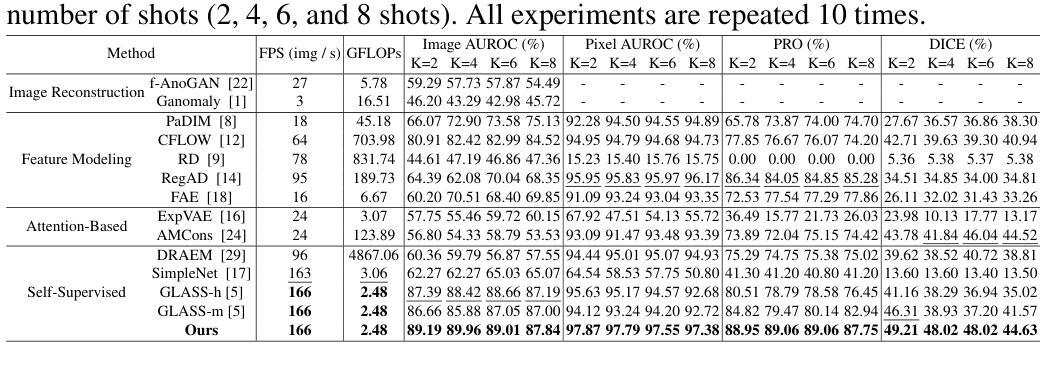
Unsupervised pathology detection trains models on non-pathological data to flag deviations as pathologies, offering strong generalizability for identifying novel diseases and avoiding costly annotations. However, building reliable normality models requires vast healthy datasets, as hospitals’ data is inherently biased toward symptomatic populations, while privacy regulations hinder the assembly of representative healthy cohorts. To address this limitation, we propose PathoSCOPE, a few-shot unsupervised pathology detection framework that requires only a small set of non-pathological samples (minimum 2 shots), significantly improving data efficiency. We introduce Global-Local Contrastive Loss (GLCL), comprised of a Local Contrastive Loss to reduce the variability of non-pathological embeddings and a Global Contrastive Loss to enhance the discrimination of pathological regions. We also propose a Pathology-informed Embedding Generation (PiEG) module that synthesizes pathological embeddings guided by the global loss, better exploiting the limited non-pathological samples. Evaluated on the BraTS2020 and ChestXray8 datasets, PathoSCOPE achieves state-of-the-art performance among unsupervised methods while maintaining computational efficiency (2.48 GFLOPs, 166 FPS).
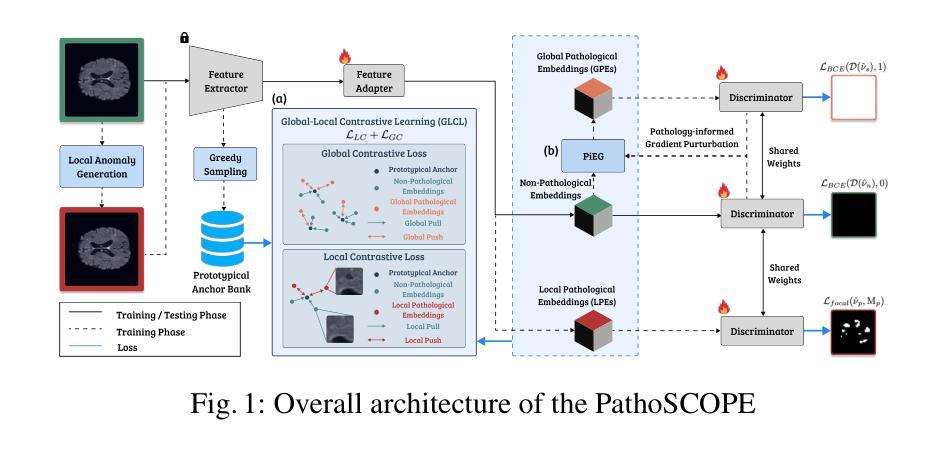
无监督病理检测通过对非病理数据进行训练模型,将偏差标记为病理特征,为识别新型疾病和避免昂贵的标注提供了强大的泛化能力。然而,建立可靠的正常模型需要大量的健康数据集,因为医院的数据本质上偏向于有症状的人群,而隐私法规阻碍了代表性健康人群数据的汇集。为了解决这一局限性,我们提出了PathoSCOPE,这是一个少数镜头无监督病理检测框架,只需要一小部分非病理样本(最少2个镜头),大大提高了数据效率。我们引入了全局局部对比损失(GLCL),它由局部对比损失组成,用于减少非病理嵌入的变异性,以及全局对比损失,用于增强病理区域的辨别力。我们还提出了病理信息嵌入生成(PiEG)模块,该模块通过全局损失引导合成病理嵌入,更好地利用有限的非病理样本。在BraTS2020和ChestXray8数据集上评估,PathoSCOPE在无监督方法中实现了最先进的性能,同时保持了计算效率(2.48 GFLOPs,每秒处理图像数达166张)。
论文及项目相关链接
Summary
基于无监督病理检测原理,训练模型在不含病理的样本上能够检测到偏差进而判定出病理学症状,显示其对新兴疾病的强泛化识别能力和避免昂贵标注的成本优势。但建立可靠的正常模型需要海量的健康数据集,医院的资料倾向于以症状患者为主,隐私法规也限制了代表性健康人群的汇集。为解决此局限,我们提出PathoSCOPE方案,只需少量非病理样本(最少两例)即可进行少数派无监督病理检测,大幅提高数据效率。结合全局局部对比损失(GLCL),通过局部对比损失降低非病理嵌体变量的同时,以全局对比损失提升对病变区域的辨别能力。此外,我们引入了病理学引导嵌入生成(PiEG)模块,由全局损失指导合成病理性嵌体,更好利用有限的非病理样本。在BraTS2020和ChestXray8数据集上的评估表明,PathoSCOPE在无监督方法中达到最佳性能,同时保持计算效率(2.48 GFLOPs,166 FPS)。
Key Takeaways
- 无监督病理检测利用非病理数据训练模型,有效识别新兴疾病并降低成本。
- 建立可靠的正常模型需要大量健康数据集,但医院数据偏向症状患者,隐私法规限制代表性健康人群汇集。
- PathoSCOPE方案仅需要少量非病理样本进行少数派无监督病理检测,提高数据效率。
- 提出全局局部对比损失(GLCL),结合局部对比损失和全局对比损失来增强辨别能力。
- 引入病理学引导嵌入生成(PiEG)模块,合成病理性嵌体以利用有限的非病理样本。
- 在BraTS2020和ChestXray8数据集上评估显示,PathoSCOPE性能达到无监督方法最佳水平。
点此查看论文截图


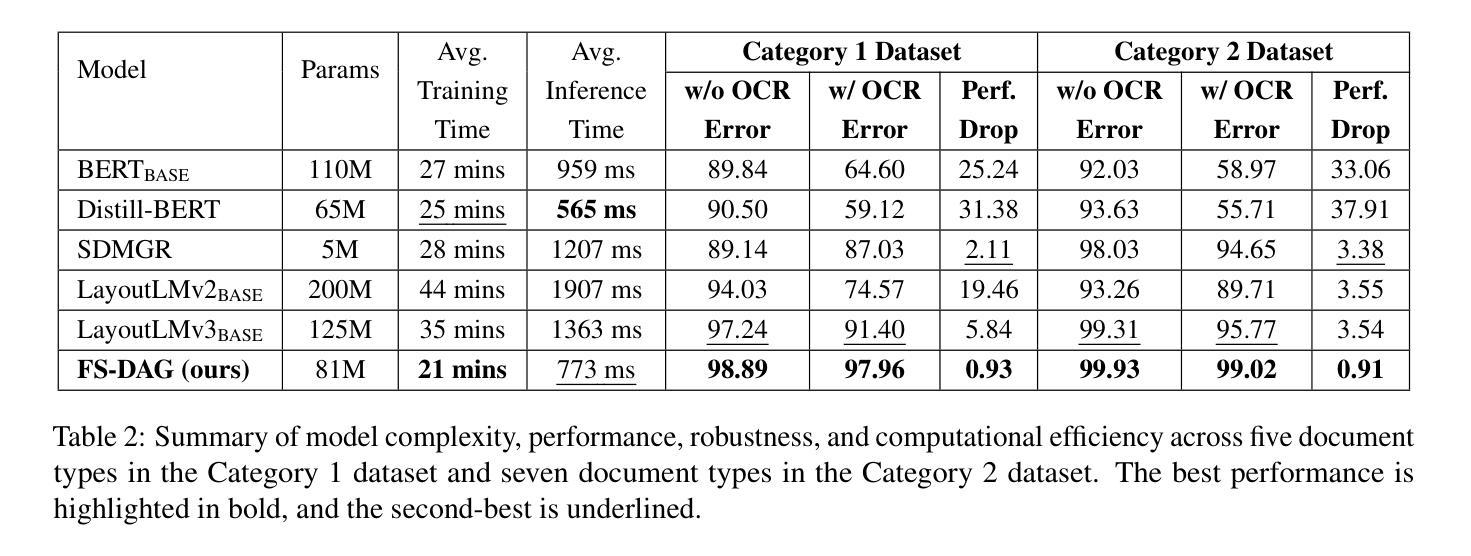
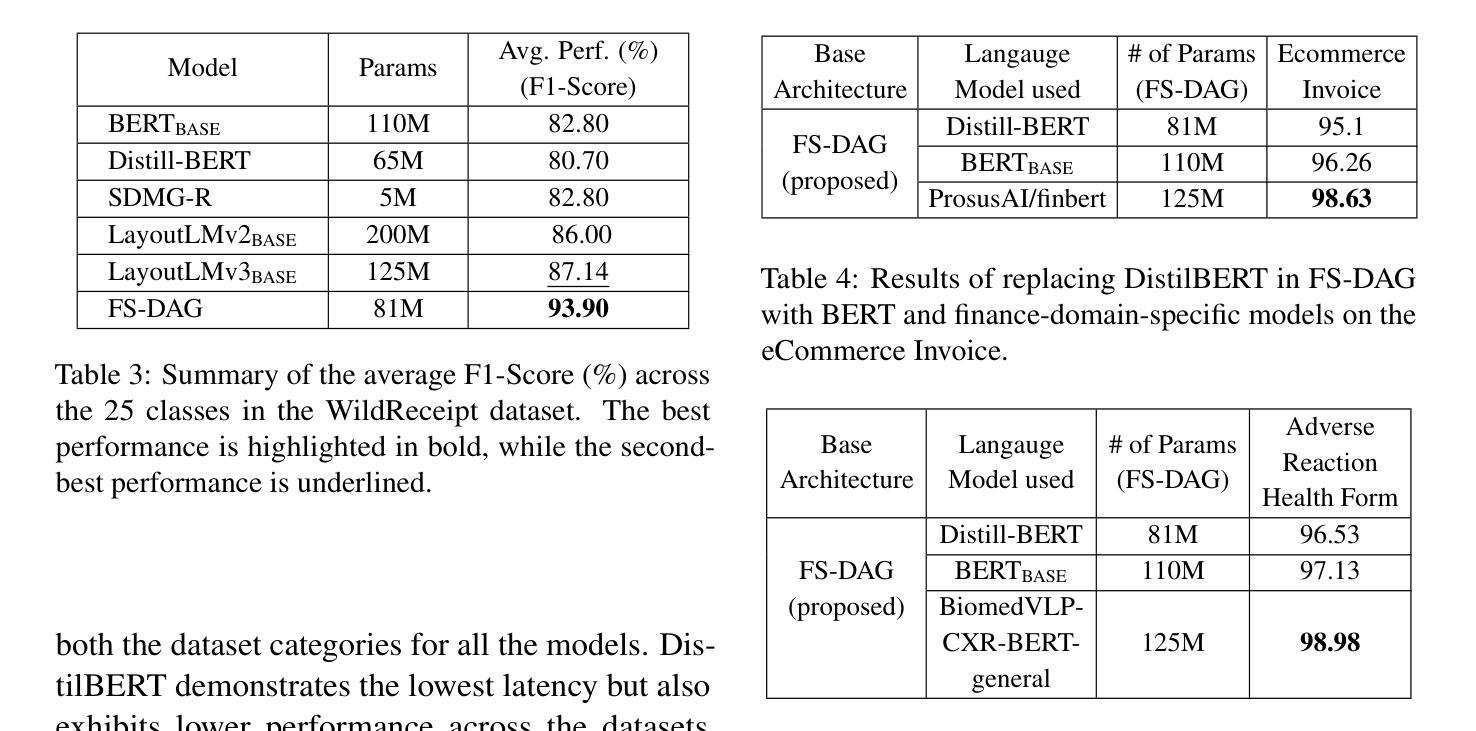
FS-DAG: Few Shot Domain Adapting Graph Networks for Visually Rich Document Understanding
Authors:Amit Agarwal, Srikant Panda, Kulbhushan Pachauri
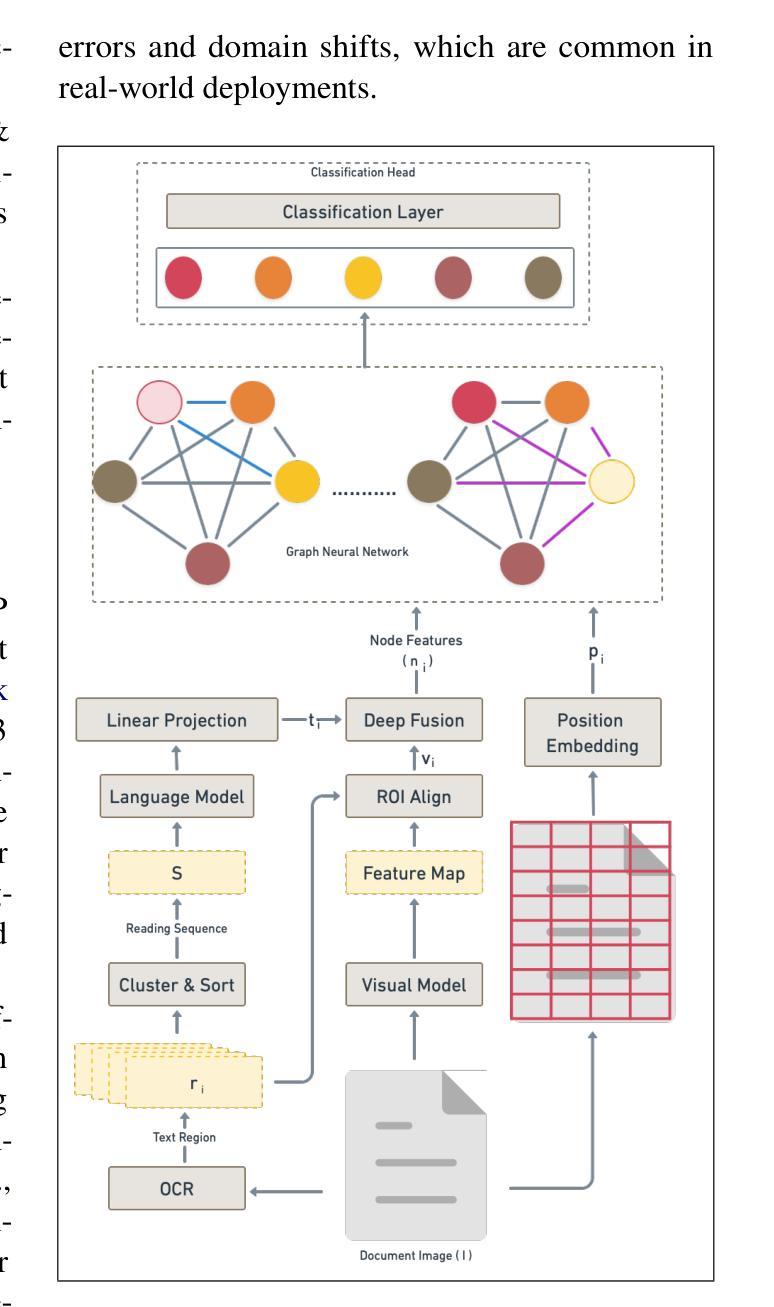
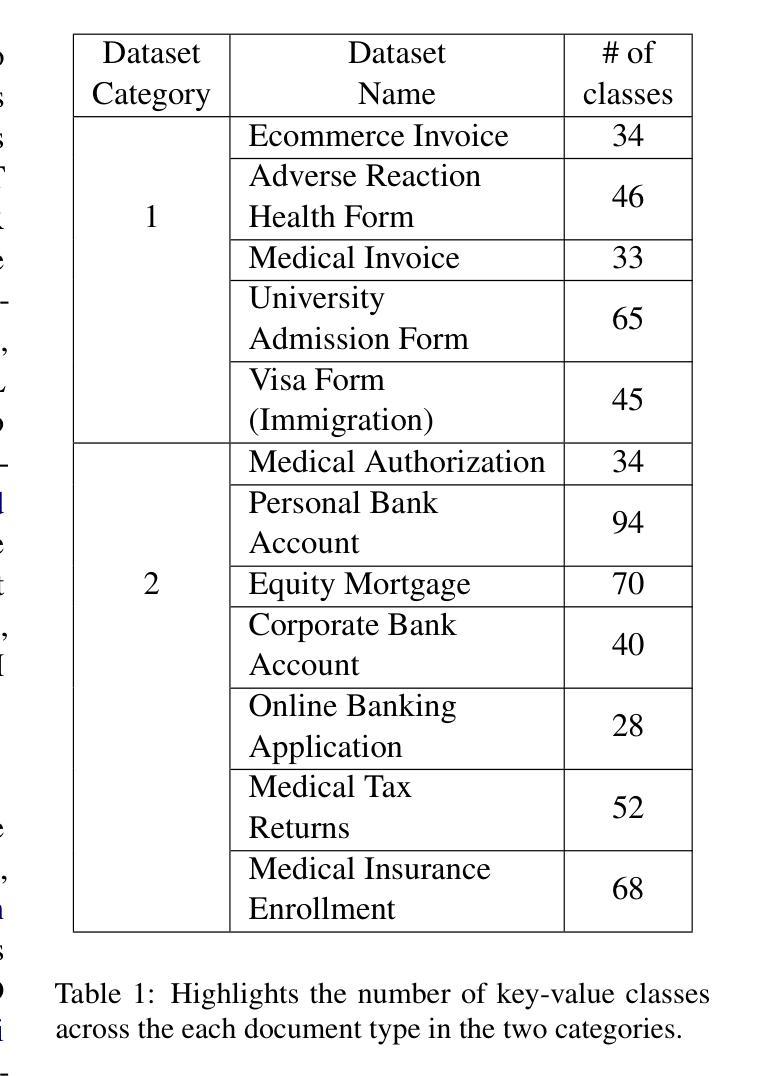
In this work, we propose Few Shot Domain Adapting Graph (FS-DAG), a scalable and efficient model architecture for visually rich document understanding (VRDU) in few-shot settings. FS-DAG leverages domain-specific and language/vision specific backbones within a modular framework to adapt to diverse document types with minimal data. The model is robust to practical challenges such as handling OCR errors, misspellings, and domain shifts, which are critical in real-world deployments. FS-DAG is highly performant with less than 90M parameters, making it well-suited for complex real-world applications for Information Extraction (IE) tasks where computational resources are limited. We demonstrate FS-DAG’s capability through extensive experiments for information extraction task, showing significant improvements in convergence speed and performance compared to state-of-the-art methods. Additionally, this work highlights the ongoing progress in developing smaller, more efficient models that do not compromise on performance. Code : https://github.com/oracle-samples/fs-dag
在这项工作中,我们提出了少样本领域自适应图(FS-DAG),这是一种用于少样本设置下视觉丰富文档理解(VRDU)的可扩展且高效的模型架构。FS-DAG利用模块化框架中的特定领域和特定语言/视觉的主干网络,以适应多样化的文档类型,同时所需数据极少。该模型对处理实际挑战具有很强的鲁棒性,如OCR错误、拼写错误和领域变化等,这在现实世界的部署中至关重要。FS-DAG性能高超,参数少于90M,非常适合计算资源有限的现实世界信息提取(IE)任务中的复杂应用。我们通过广泛的信息提取任务实验展示了FS-DAG的能力,与最新方法相比,其在收敛速度和性能上均显示出显著改进。此外,这项工作还强调了开发更小、更高效的模型的不断进步,这些模型在性能上并无妥协。代码:https://github.com/oracle-samples/fs-dag
论文及项目相关链接
PDF Published in the Proceedings of the 31st International Conference on Computational Linguistics (COLING 2025), Industry Track, pages 100-114
Summary
少量样本下的领域自适应图(FS-DAG)模型在视觉丰富文档理解(VRDU)中的研究与实现。FS-DAG提出一种模块化框架,结合特定领域和语言视觉支持模块快速适应多样文档类型的小样本环境,克服实际应用中如OCR错误、拼写错误以及领域变化等问题,并以较低计算资源和高效的性能处理信息抽取任务。实验证明FS-DAG模型在收敛速度和性能上均优于现有技术。同时,该研究展示了发展小尺寸但性能强大的模型这一领域的研究进展。关于模型的详细信息可访问链接:https://github.com/oracle-samples/fs-dag。
Key Takeaways
以下是七个关键观点的摘要列表:
- 研究提出了一种新的模型架构名为少量样本下的领域自适应图(FS-DAG)。此模型特别针对视觉丰富文档理解(VRDU)进行设计和优化。它特别适用于信息抽取任务的小样本环境。此模型包含特定领域的模块和语言视觉支持模块,使其能够快速适应不同的文档类型。
- FS-DAG模型能够应对实际应用中的多种挑战,如OCR错误、拼写错误和领域变化等问题,具有很高的实际应用价值。这意味着它在进行文本处理和识别任务时具有很高的稳健性。
- 此模型的计算需求低且高性能的特性使其在有限的计算资源条件下也可以有效地应用在复杂现实世界中。其参数数量少于9亿个,确保了其在信息抽取任务中的高效性能。
- 研究通过实验证明了FS-DAG模型在收敛速度和性能上均优于现有的技术方法,这进一步证明了其在实际应用中的优势。这些实验展示了模型在各种任务中的优异表现。
- 研究提供了一个公开的模型代码链接,方便公众获取和进一步开发研究FS-DAG模型。这有助于推动该领域的进一步发展和研究。
- 此研究展示了在开发小尺寸但性能强大的模型方面的研究进展。这种模型设计趋势表明了对效率和性能的平衡的追求正在成为研究的重要方向。
点此查看论文截图

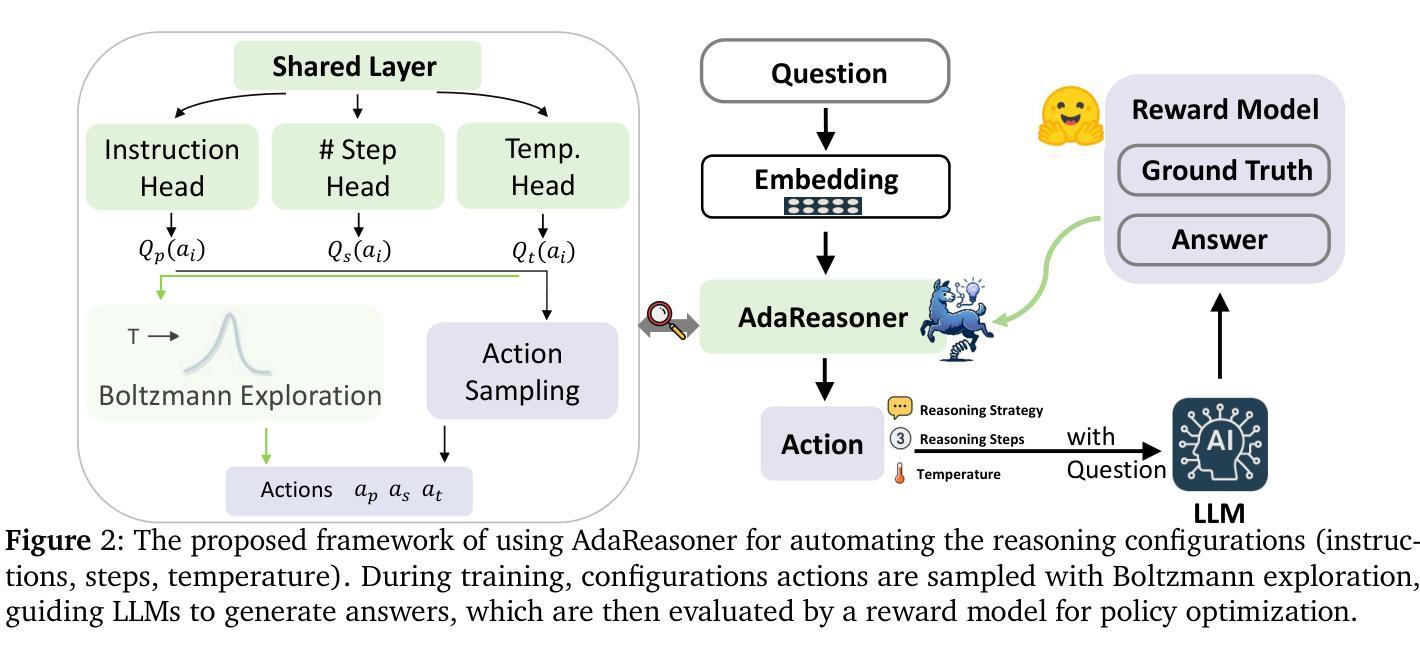
AdaReasoner: Adaptive Reasoning Enables More Flexible Thinking
Authors:Xiangqi Wang, Yue Huang, Yanbo Wang, Xiaonan Luo, Kehan Guo, Yujun Zhou, Xiangliang Zhang
LLMs often need effective configurations, like temperature and reasoning steps, to handle tasks requiring sophisticated reasoning and problem-solving, ranging from joke generation to mathematical reasoning. Existing prompting approaches usually adopt general-purpose, fixed configurations that work ‘well enough’ across tasks but seldom achieve task-specific optimality. To address this gap, we introduce AdaReasoner, an LLM-agnostic plugin designed for any LLM to automate adaptive reasoning configurations for tasks requiring different types of thinking. AdaReasoner is trained using a reinforcement learning (RL) framework, combining a factorized action space with a targeted exploration strategy, along with a pretrained reward model to optimize the policy model for reasoning configurations with only a few-shot guide. AdaReasoner is backed by theoretical guarantees and experiments of fast convergence and a sublinear policy gap. Across six different LLMs and a variety of reasoning tasks, it consistently outperforms standard baselines, preserves out-of-distribution robustness, and yield gains on knowledge-intensive tasks through tailored prompts.
大型语言模型(LLMs)通常需要有效的配置,如温度和推理步骤,来处理从笑话生成到数学推理等需要复杂推理和问题解决能力的任务。现有的提示方法通常采用通用、固定的配置,这些配置在各项任务中“表现足够好”,但很少实现针对特定任务的优化。为了解决这一差距,我们推出了AdaReasoner,这是一款适用于任何大型语言模型的插件,旨在自动化适应需要不同类型思考的任务的推理配置。AdaReasoner使用强化学习(RL)框架进行训练,结合分解的动作空间和有针对性的探索策略,以及预训练的奖励模型,以优化策略模型进行推理配置,只需少数镜头指导即可。AdaReasoner有理论保证和实验支持快速收敛和次线性策略差距。在六个不同的大型语言模型和多种推理任务上,它始终超越标准基线,保持超出分布范围的稳健性,并通过量身定制的提示在知识密集型任务上取得收益。
论文及项目相关链接
Summary
适应不同任务需求的LLM配置研究。针对现有通用配置难以达到任务特定最优的问题,提出AdaReasoner插件,采用强化学习训练策略实现自适应调整LLM配置的目标。通过少样本引导进行优化,能在不同类型任务中取得良好表现。
Key Takeaways
- LLMs在处理需要复杂推理和问题解决的任务时,需要有效的配置,如温度和推理步骤。
- 现有提示方法通常采用通用配置,难以达到任务特定最优。
- AdaReasoner是一个针对任何LLM的插件,用于自动化适应任务需求的推理配置。
- AdaReasoner采用强化学习框架训练,结合动作空间分解、目标探索策略和预训练奖励模型进行优化。
- AdaReasoner有理论保障,实验证明其快速收敛和策略差距呈亚线性。
- 在六个不同的LLMs和各种推理任务上,AdaReasoner表现优于标准基线,并具有健壮性和针对知识密集型任务的增益。
点此查看论文截图

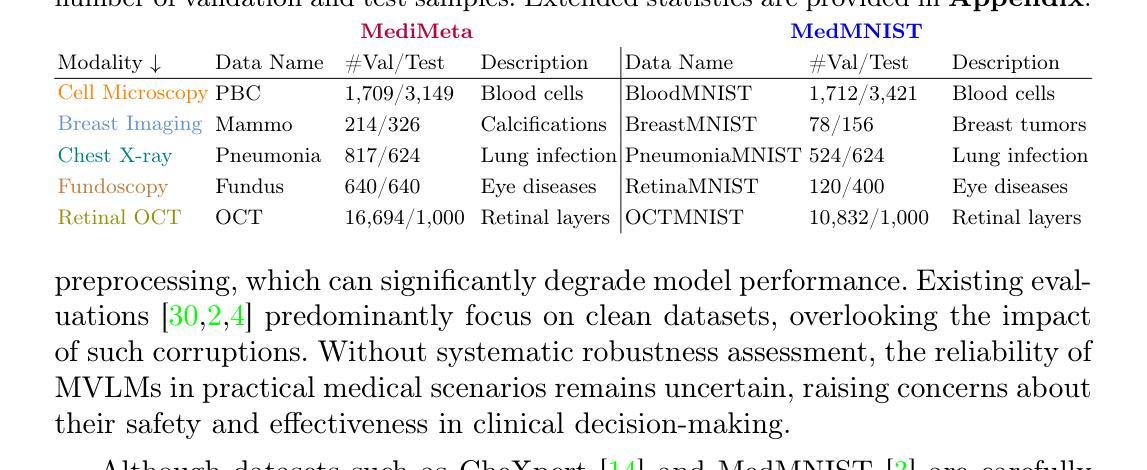
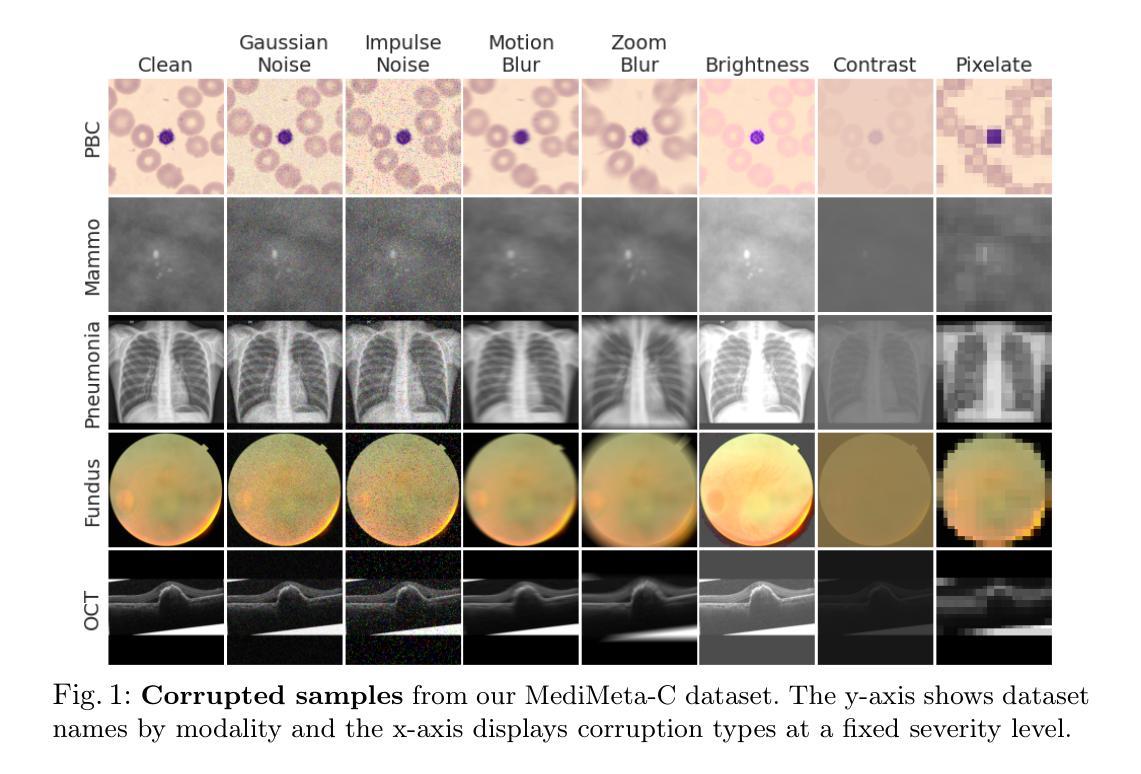
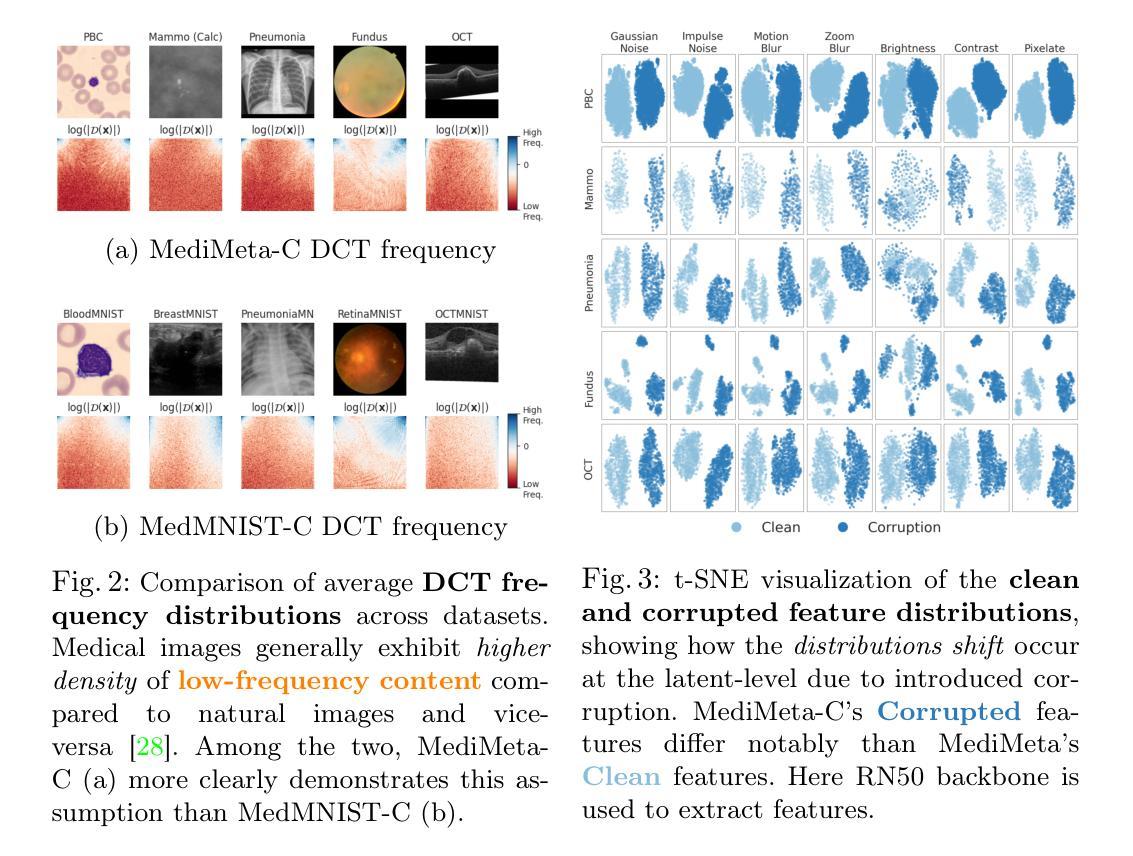
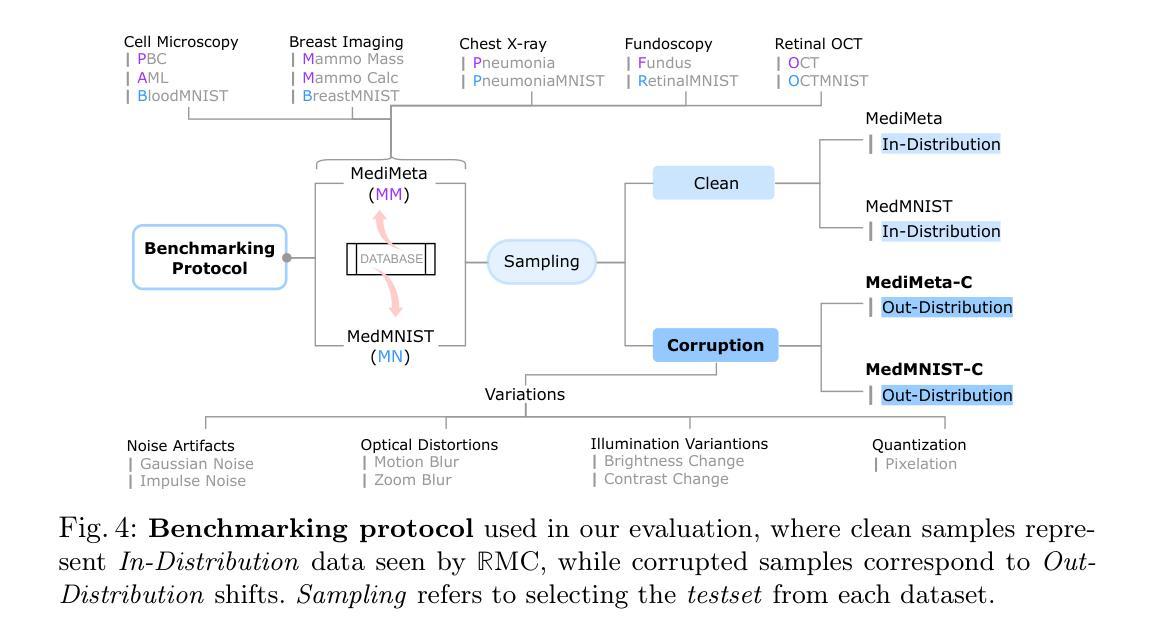
On the Robustness of Medical Vision-Language Models: Are they Truly Generalizable?
Authors:Raza Imam, Rufael Marew, Mohammad Yaqub
Medical Vision-Language Models (MVLMs) have achieved par excellence generalization in medical image analysis, yet their performance under noisy, corrupted conditions remains largely untested. Clinical imaging is inherently susceptible to acquisition artifacts and noise; however, existing evaluations predominantly assess generally clean datasets, overlooking robustness – i.e., the model’s ability to perform under real-world distortions. To address this gap, we first introduce MediMeta-C, a corruption benchmark that systematically applies several perturbations across multiple medical imaging datasets. Combined with MedMNIST-C, this establishes a comprehensive robustness evaluation framework for MVLMs. We further propose RobustMedCLIP, a visual encoder adaptation of a pretrained MVLM that incorporates few-shot tuning to enhance resilience against corruptions. Through extensive experiments, we benchmark 5 major MVLMs across 5 medical imaging modalities, revealing that existing models exhibit severe degradation under corruption and struggle with domain-modality tradeoffs. Our findings highlight the necessity of diverse training and robust adaptation strategies, demonstrating that efficient low-rank adaptation when paired with few-shot tuning, improves robustness while preserving generalization across modalities.
医疗视觉语言模型(MVLM)在医学图像分析方面已经达到了卓越的泛化性能,但在噪声和损坏条件下的性能仍然没有得到充分的测试。临床成像本质上容易受到采集伪影和噪声的影响;然而,现有的评估主要侧重于对通常干净数据集的评价,忽略了模型的稳健性,即模型在现实世界中失真情况下的性能。为了弥补这一空白,我们首先引入了MediMeta-C,这是一个腐败基准测试,它系统地应用于多个医学成像数据集的各种扰动。结合MedMNIST-C,这为MVLM建立了一个全面的稳健性评估框架。我们进一步提出了RobustMedCLIP,这是一个视觉编码器适应的预训练MVLM,它结合了少量的调整来增强对损坏的抵抗力。通过大量的实验,我们对五大医学成像模态的五大MVLM进行了基准测试,发现现有模型在受到腐蚀时会出现严重的性能下降,并且在领域模态转换方面遇到困难。我们的研究结果表明了多样训练和稳健适应策略的必要性,显示当与少量调整相结合时,有效的低秩适应能提高稳健性,同时保留跨模态的泛化能力。
论文及项目相关链接
PDF Dataset and Code is available at https://github.com/BioMedIA-MBZUAI/RobustMedCLIP Accepted at: Medical Image Understanding and Analysis (MIUA) 2025
Summary
本文关注医疗视觉语言模型(MVLMs)在噪声、失真环境下的性能。为评估模型在实际扭曲情况下的稳健性,文章引入了MediMeta-C基准测试,并结合MedMNIST-C建立一个全面的评估框架。同时,提出了RobustMedCLIP方法,通过微调预训练的MVLM的视觉编码器,增强其对抗干扰的能力。实验表明,现有模型在腐蚀环境下性能严重下降,且存在域模态权衡问题。文章强调多样训练和稳健适应策略的重要性,并指出低阶适应结合少量调优可有效提高稳健性,同时保持跨模态的泛化能力。
Key Takeaways
- 医疗视觉语言模型(MVLMs)在噪声、失真环境下的性能尚待测试。
- 现有评估主要关注清洁数据集,忽略了模型的稳健性。
- 引入MediMeta-C基准测试并建立了一个全面的评估框架来评估MVLM的稳健性。
- 提出RobustMedCLIP方法,通过微调预训练MVLM的视觉编码器来提高其对抗干扰的能力。
- 实验显示现有模型在腐蚀环境下性能严重下降,存在域模态权衡问题。
- 多样训练和稳健适应策略的重要性被强调。
点此查看论文截图

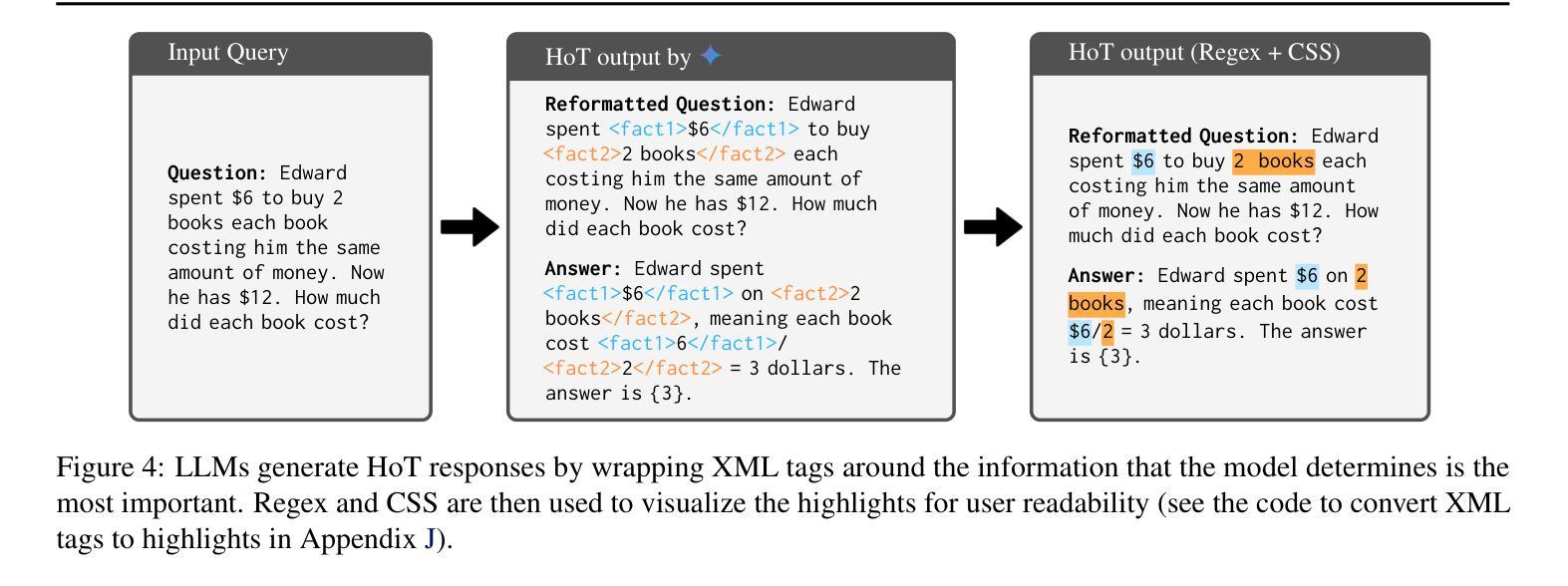
HoT: Highlighted Chain of Thought for Referencing Supporting Facts from Inputs
Authors:Tin Nguyen, Logan Bolton, Mohammad Reza Taesiri, Anh Totti Nguyen
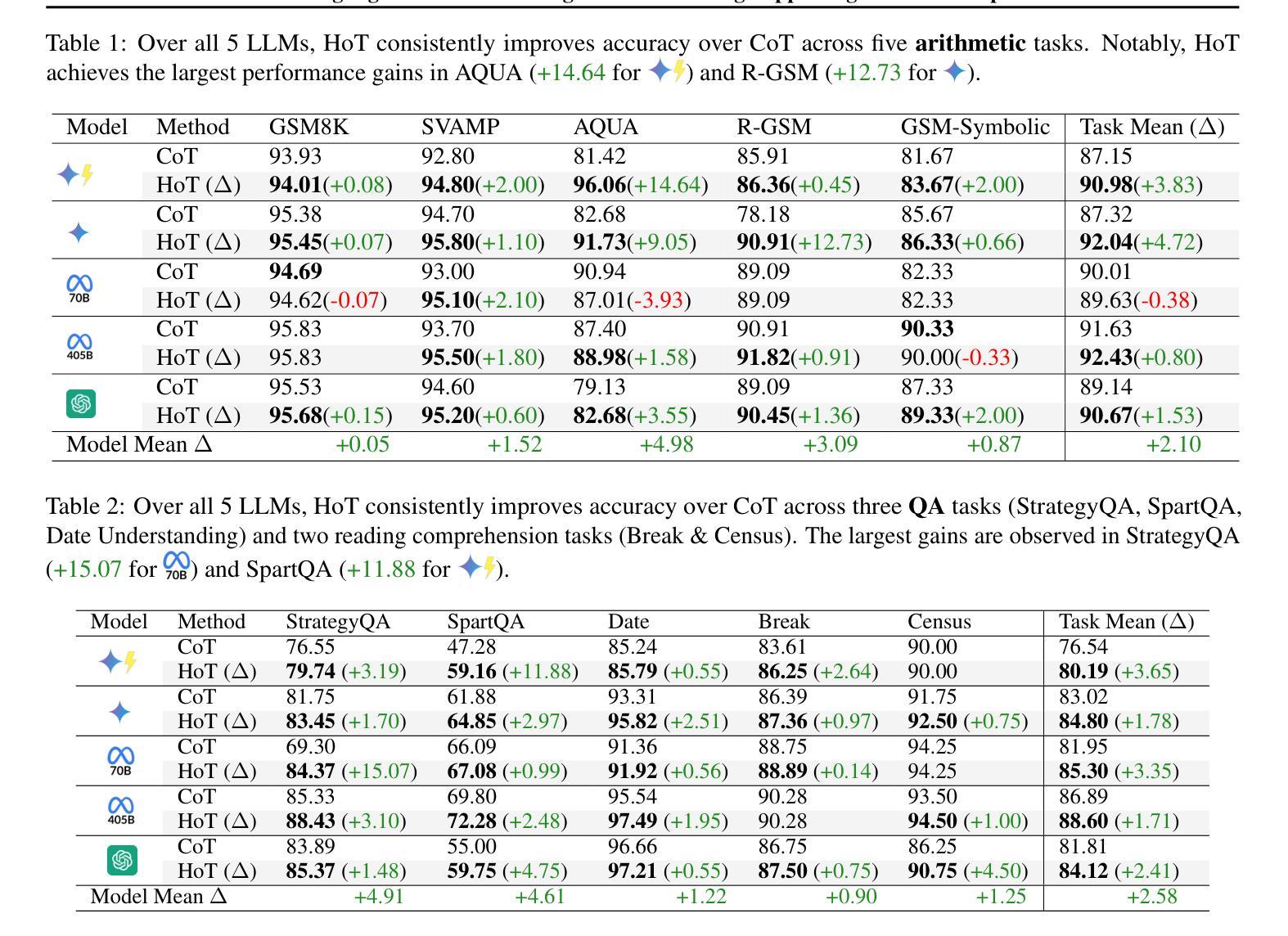
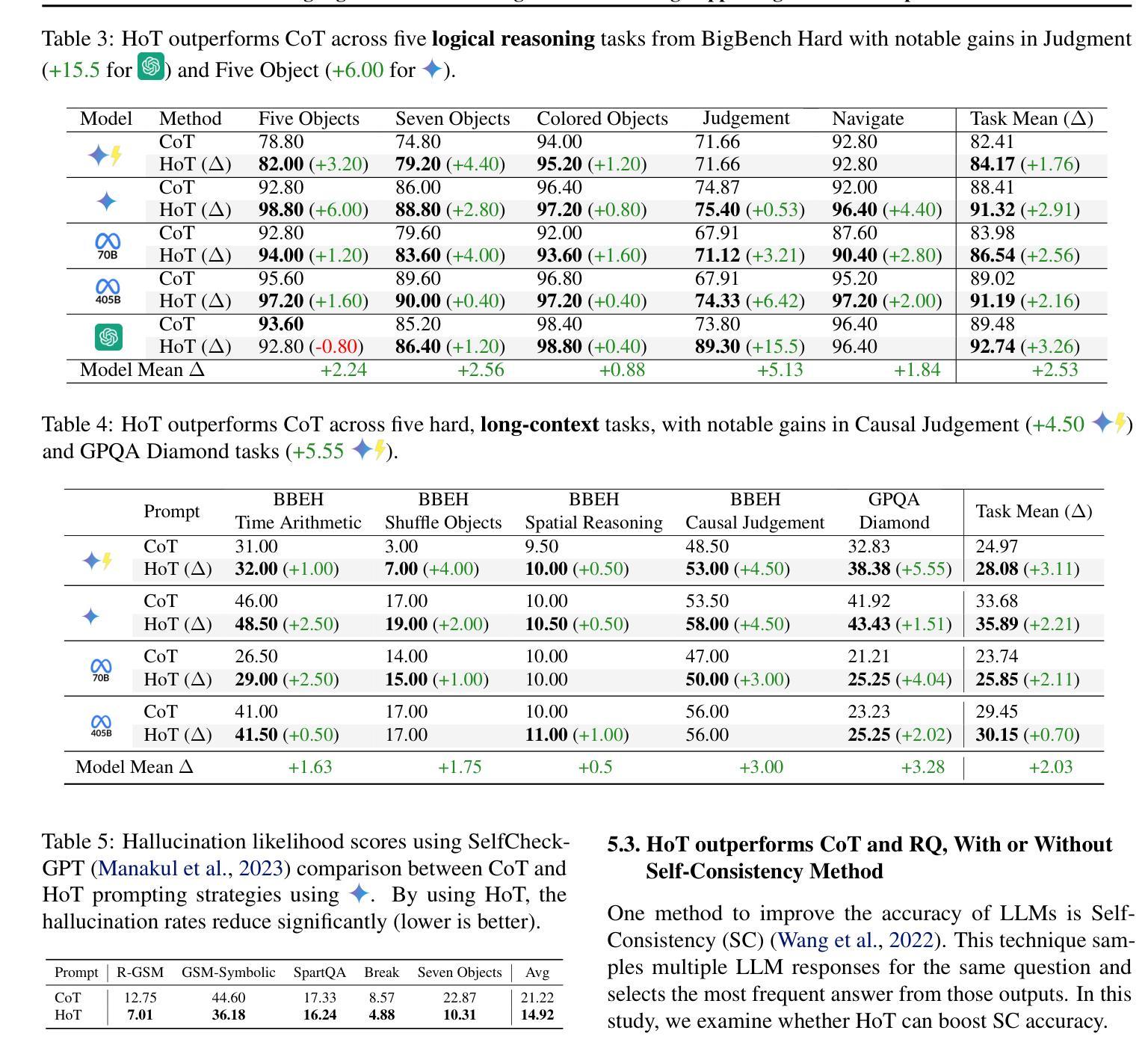
An Achilles heel of Large Language Models (LLMs) is their tendency to hallucinate non-factual statements. A response mixed of factual and non-factual statements poses a challenge for humans to verify and accurately base their decisions on. To combat this problem, we propose Highlighted Chain-of-Thought Prompting (HoT), a technique for prompting LLMs to generate responses with XML tags that ground facts to those provided in the query. That is, given an input question, LLMs would first re-format the question to add XML tags highlighting key facts, and then, generate a response with highlights over the facts referenced from the input. Interestingly, in few-shot settings, HoT outperforms vanilla chain of thought prompting (CoT) on a wide range of 17 tasks from arithmetic, reading comprehension to logical reasoning. When asking humans to verify LLM responses, highlights help time-limited participants to more accurately and efficiently recognize when LLMs are correct. Yet, surprisingly, when LLMs are wrong, HoTs tend to make users believe that an answer is correct.
大型语言模型(LLM)的一个致命弱点是它们倾向于产生非事实性的陈述。由事实和虚构陈述组成的回应给人类带来了验证和准确做出决策的挑战。为了解决这个问题,我们提出了突出重点思考提示(HoT)技术,这是一种提示LLM生成带有XML标签的响应的方法,这些标签将事实依据与查询中提供的事实相结合。也就是说,给定一个输入问题,LLM会首先重新格式化问题,添加突出关键事实的XML标签,然后生成包含从输入中引用的重点事实的回应。有趣的是,在少量样本的情况下,HoT在算术、阅读理解到逻辑推理等17项任务上的表现优于普通的思维链提示(CoT)。当要求人类验证LLM的回应时,重点提示有助于时间有限的参与者更准确、高效地识别LLM的正确性。然而,令人惊讶的是,当LLM错误时,HoT往往使用户认为答案是正确的。
论文及项目相关链接
Summary
大型语言模型(LLM)的一个弱点是它们倾向于产生非事实性的陈述,这使得它们的回应难以验证并准确作为决策依据。为解决这一问题,我们提出了带有XML标签的“高亮思维链提示”(HoT)技术,该技术能使LLM在回应时基于查询中的事实进行回应。在少量样本的情况下,HoT在算术、阅读理解到逻辑推理的17项任务上的表现优于基础思维链提示(CoT)。人类验证者使用高亮提示可以更准确快速地判断LLM的正确性,但有趣的是,当LLM错误时,HoT往往使用户认为答案是正确的。
Key Takeaways
- 大型语言模型(LLM)存在生成非事实性陈述的问题。
- Highlighted Chain-of-Thought Prompting(HoT)技术通过添加XML标签来引导LLM基于事实进行回应。
- 在少量样本的情况下,HoT在多种任务上的表现优于基础思维链提示(CoT)。
- 高亮提示有助于人类验证者更准确快速地判断LLM的正确性。
- HoT技术可以提高LLM回应的透明度,使其更易于理解。
- 当LLM给出错误回应时,HoT技术可能会使用户产生误解。
点此查看论文截图


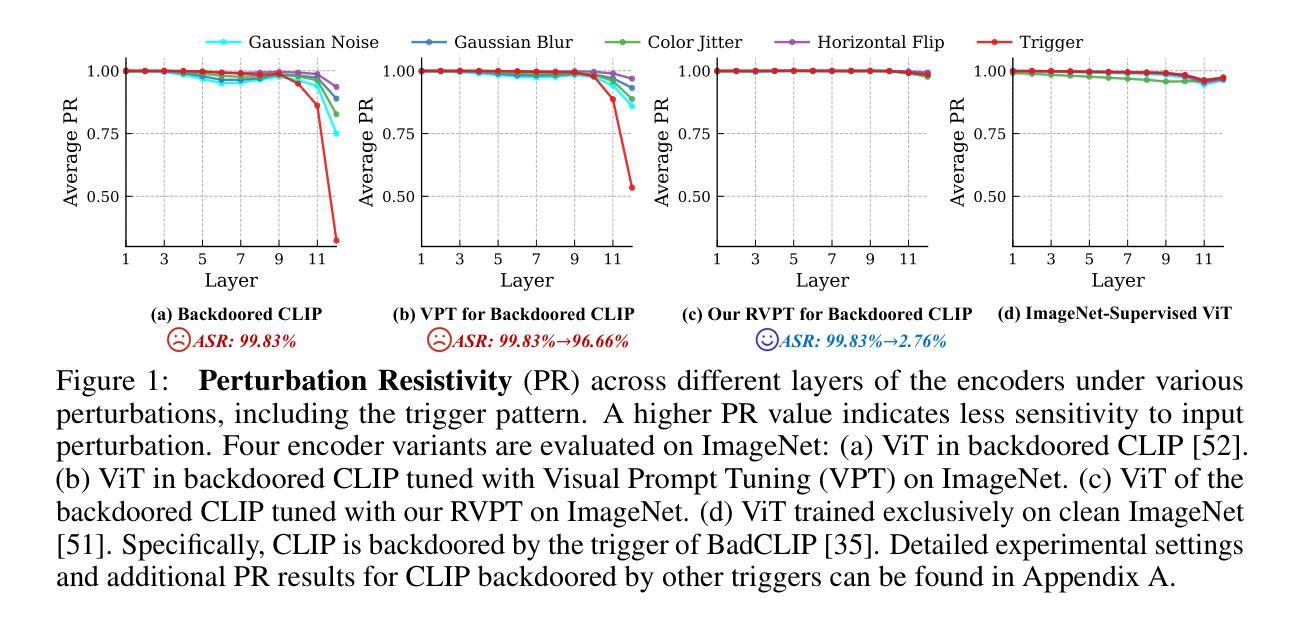
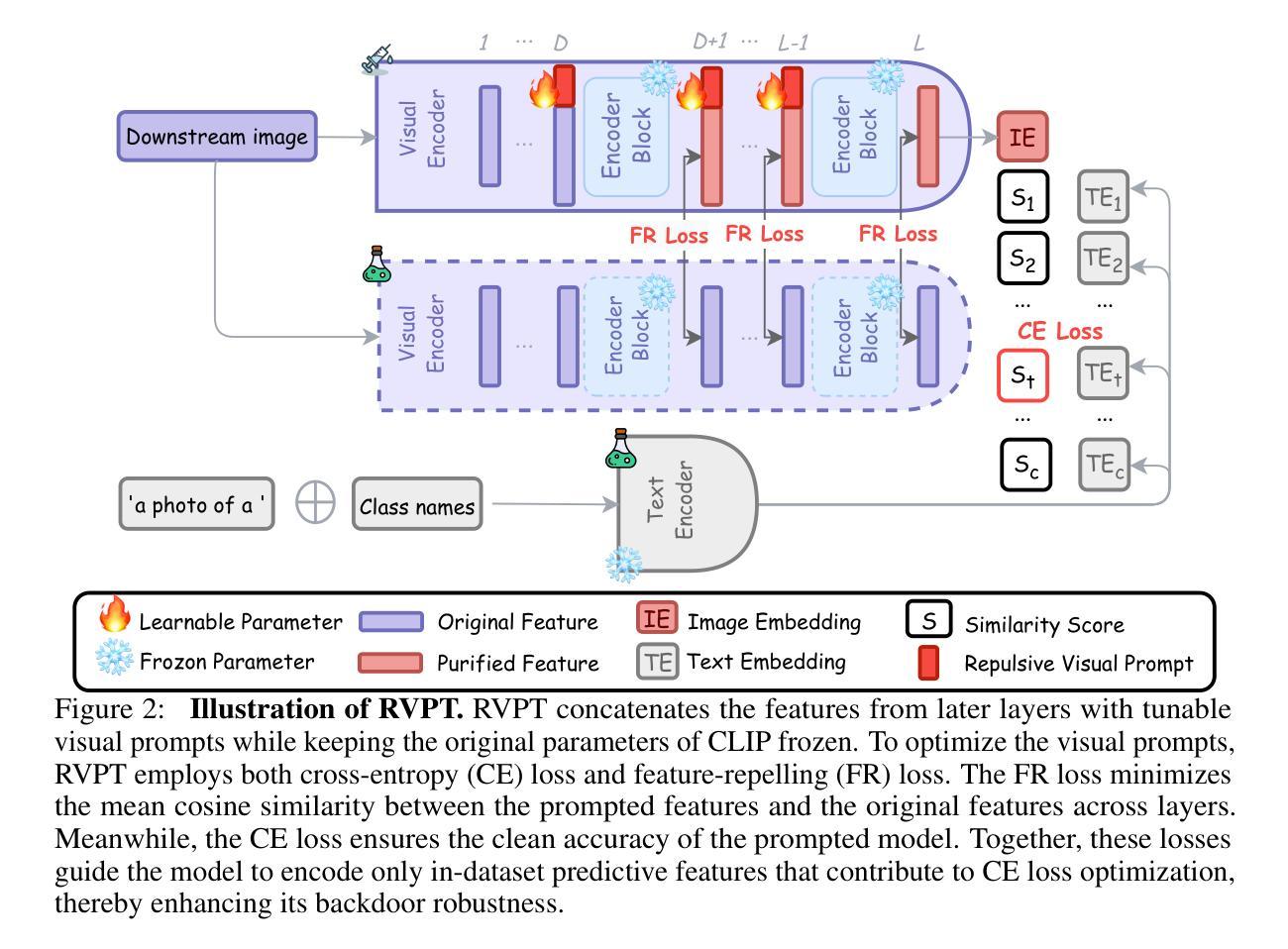
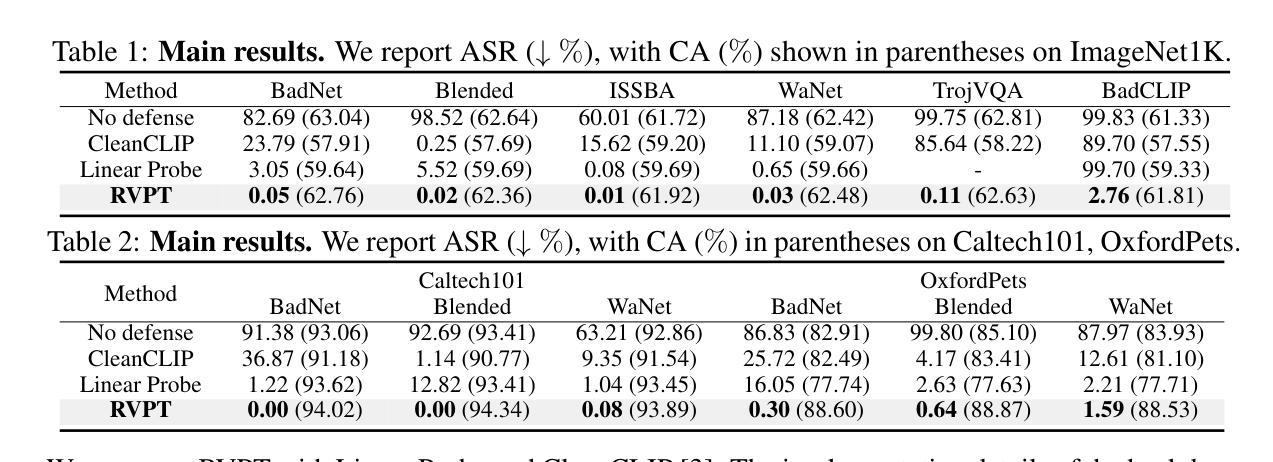
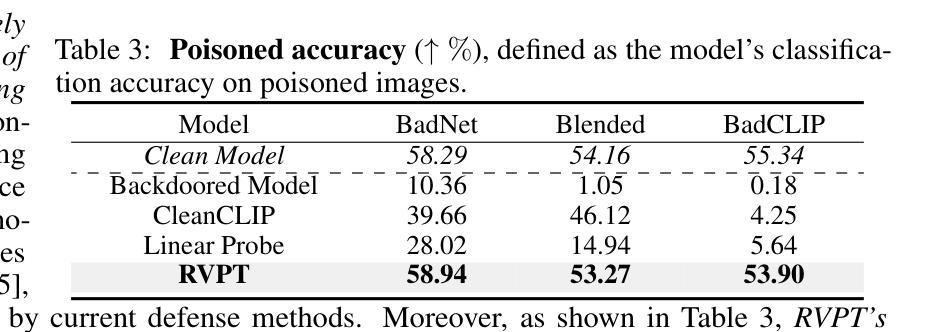
Defending Multimodal Backdoored Models by Repulsive Visual Prompt Tuning
Authors:Zhifang Zhang, Shuo He, Haobo Wang, Bingquan Shen, Lei Feng
Multimodal contrastive learning models (e.g., CLIP) can learn high-quality representations from large-scale image-text datasets, while they exhibit significant vulnerabilities to backdoor attacks, raising serious safety concerns. In this paper, we reveal that CLIP’s vulnerabilities primarily stem from its tendency to encode features beyond in-dataset predictive patterns, compromising its visual feature resistivity to input perturbations. This makes its encoded features highly susceptible to being reshaped by backdoor triggers. To address this challenge, we propose Repulsive Visual Prompt Tuning (RVPT), a novel defense approach that employs deep visual prompt tuning with a specially designed feature-repelling loss. Specifically, RVPT adversarially repels the encoded features from deeper layers while optimizing the standard cross-entropy loss, ensuring that only predictive features in downstream tasks are encoded, thereby enhancing CLIP’s visual feature resistivity against input perturbations and mitigating its susceptibility to backdoor attacks. Unlike existing multimodal backdoor defense methods that typically require the availability of poisoned data or involve fine-tuning the entire model, RVPT leverages few-shot downstream clean samples and only tunes a small number of parameters. Empirical results demonstrate that RVPT tunes only 0.27% of the parameters in CLIP, yet it significantly outperforms state-of-the-art defense methods, reducing the attack success rate from 89.70% to 2.76% against the most advanced multimodal attacks on ImageNet and effectively generalizes its defensive capabilities across multiple datasets.
多模态对比学习模型(例如CLIP)可以从大规模图像文本数据集中学习高质量表示,但它们对后门攻击表现出显著脆弱性,引发了严重的安全担忧。在本文中,我们揭示CLIP的脆弱性主要源于其编码数据集内预测模式以外特征的倾向,这损害了其对输入扰动的视觉特征抗性。这使得其编码的特征很容易被后门触发信号重塑。为了应对这一挑战,我们提出了名为Repulsive Visual Prompt Tuning(RVPT)的新型防御方法,该方法采用深度视觉提示调节与特殊设计的特征排斥损失相结合。具体而言,RVPT在优化标准交叉熵损失的同时,对抗性地排斥深层编码特征,以确保仅对下游任务中的预测特征进行编码,从而提高CLIP对输入扰动的视觉特征抗性,并减轻其对后门攻击的敏感性。与通常需要中毒数据或涉及对整个模型进行微调的多模态后门防御方法不同,RVPT利用下游的少量清洁样本,并且仅调整少量参数。经验结果表明,RVPT仅调整CLIP的0.27%参数,即可显著优于最先进的防御方法,将攻击成功率从89.70%降低到2.76%,对抗ImageNet上最先进的多模态攻击,并在多个数据集上有效推广其防御能力。
论文及项目相关链接
Summary
基于CLIP等多模态对比学习模型的图像-文本数据集学习高质量表示时存在严重的安全漏洞,容易受到后门攻击的影响。本文揭示了CLIP的漏洞主要源于其编码超出数据集预测模式特征的趋势,导致其视觉特征抵抗输入扰动的能力受损。为此,本文提出了一种名为Repulsive Visual Prompt Tuning(RVPT)的新型防御方法,通过深度视觉提示调整和特殊设计的特征排斥损失来对抗这一问题。RVPT在优化标准交叉熵损失的同时,对抗性地排斥编码特征,确保仅编码下游任务的预测特征,从而提高CLIP对输入扰动的视觉特征抵抗力,并减轻其受到后门攻击的影响。与其他多模态后门防御方法不同,RVPT仅使用少量下游清洁样本,并且只调整少量参数。实验结果证明,RVPT仅调整CLIP的0.27%参数,即可显著优于现有最先进的防御方法,将攻击成功率从89.70%降低到2.76%,并在多个数据集上有效推广其防御能力。
Key Takeaways
- 多模态对比学习模型(如CLIP)能从大规模图像-文本数据集中学习高质量表示,但存在严重的安全漏洞,容易受到后门攻击影响。
- CLIP的漏洞主要源于其编码超出数据集预测模式特征的趋势,使其对输入扰动和后门攻击的抵抗力降低。
- 本文提出了RVPT方法,通过深度视觉提示调整和特征排斥损失来提高CLIP对输入扰动的视觉特征抵抗力。
- RVPT优化标准交叉熵损失的同时,对抗性地排斥编码特征,确保仅编码下游任务的预测特征。
- RVPT方法仅需使用少量下游清洁样本,且仅调整模型少量参数,即可显著提高模型的防御能力。
- 实验结果表明,RVPT显著优于现有最先进的防御方法,能有效降低攻击成功率。
点此查看论文截图