⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-05-27 更新
FullFront: Benchmarking MLLMs Across the Full Front-End Engineering Workflow
Authors:Haoyu Sun, Huichen Will Wang, Jiawei Gu, Linjie Li, Yu Cheng
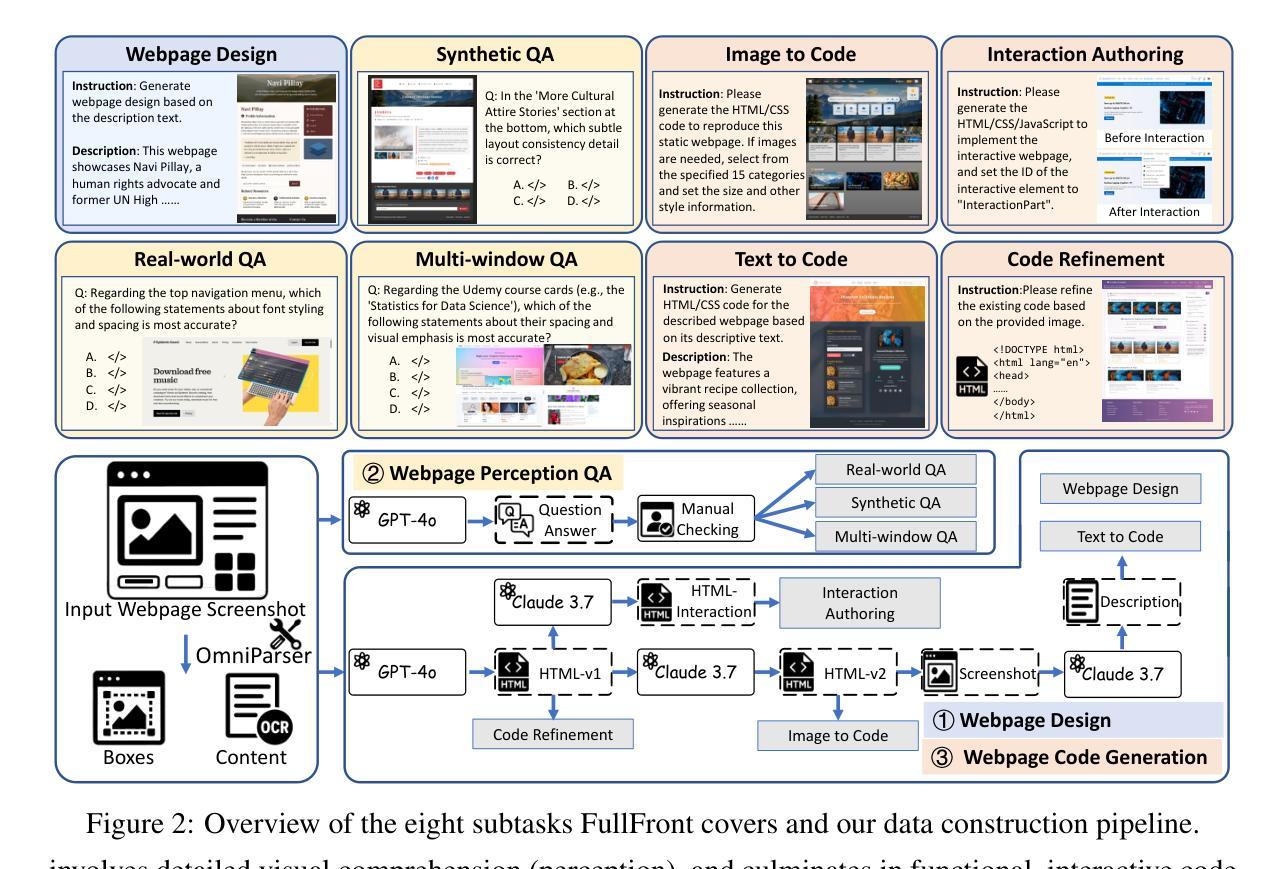
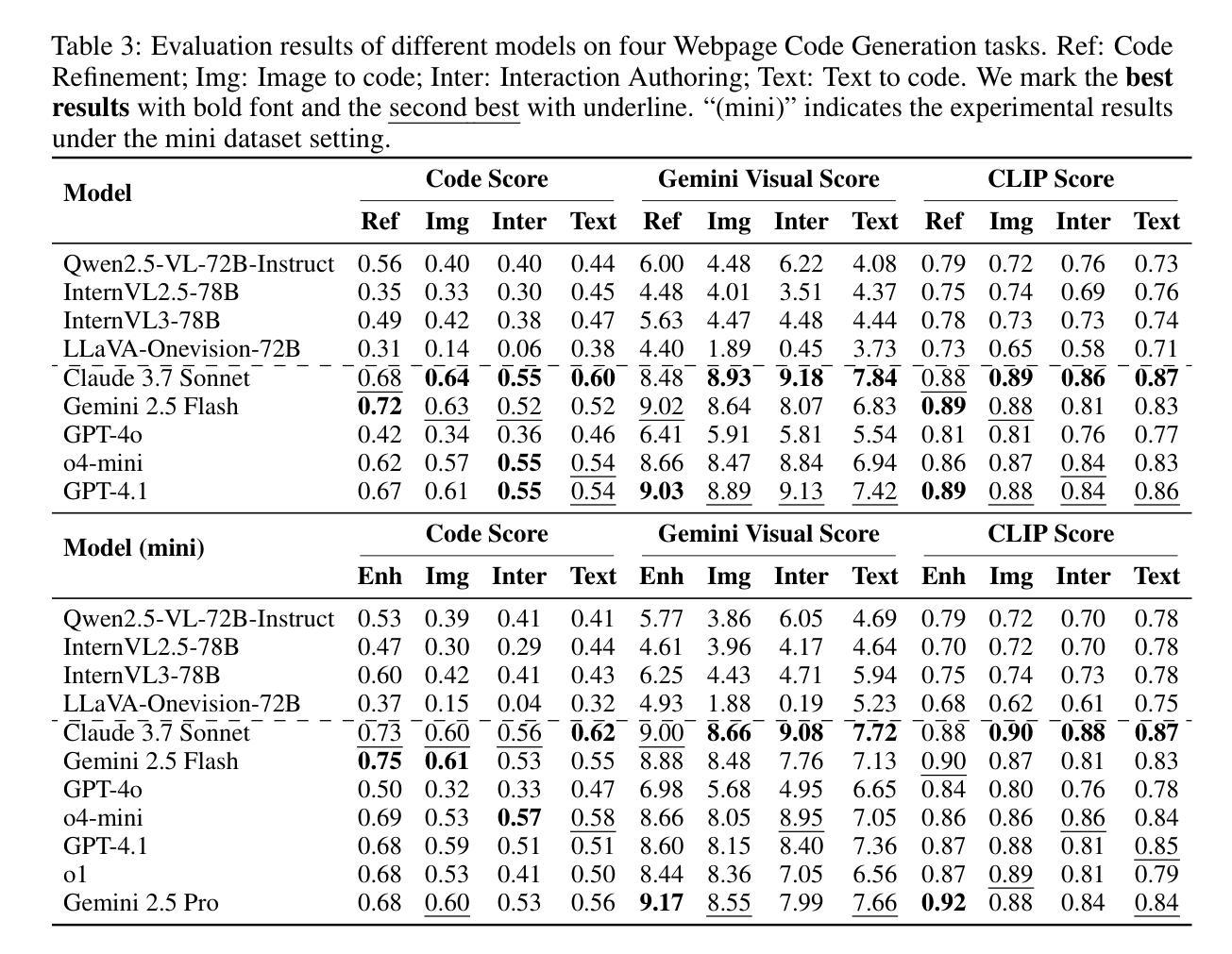
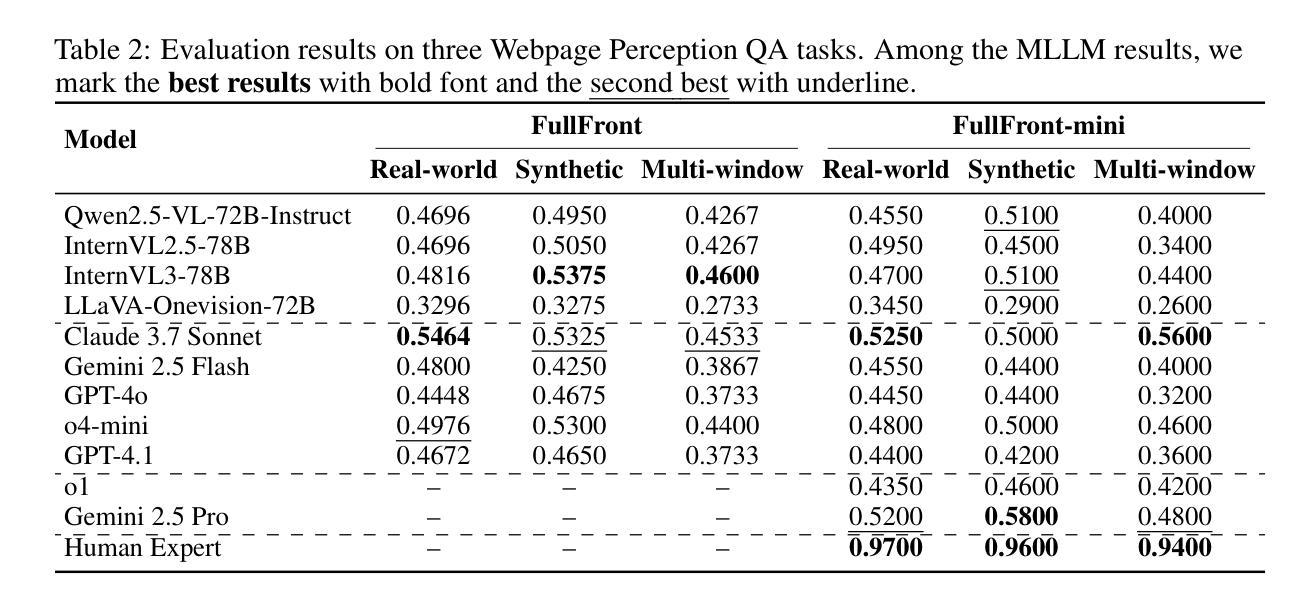
Front-end engineering involves a complex workflow where engineers conceptualize designs, translate them into code, and iteratively refine the implementation. While recent benchmarks primarily focus on converting visual designs to code, we present FullFront, a benchmark designed to evaluate Multimodal Large Language Models (MLLMs) \textbf{across the full front-end development pipeline}. FullFront assesses three fundamental tasks that map directly to the front-end engineering pipeline: Webpage Design (conceptualization phase), Webpage Perception QA (comprehension of visual organization and elements), and Webpage Code Generation (implementation phase). Unlike existing benchmarks that use either scraped websites with bloated code or oversimplified LLM-generated HTML, FullFront employs a novel, two-stage process to transform real-world webpages into clean, standardized HTML while maintaining diverse visual designs and avoiding copyright issues. Extensive testing of state-of-the-art MLLMs reveals significant limitations in page perception, code generation (particularly for image handling and layout), and interaction implementation. Our results quantitatively demonstrate performance disparities across models and tasks, and highlight a substantial gap between current MLLM capabilities and human expert performance in front-end engineering. The FullFront benchmark and code are available in https://github.com/Mikivishy/FullFront.
前端工程涉及复杂的流程,工程师需要构思设计,将它们翻译成代码,并迭代优化实现。虽然最近的基准测试主要关注将视觉设计转换为代码,但我们推出了FullFront,这是一个旨在评估跨整个前端开发管道的多模式大型语言模型(MLLMs)的基准测试。FullFront评估三个直接对应前端工程管道的基本任务:网页设计(概念化阶段)、网页感知问答(对视觉组织和元素的理解)和网页代码生成(实现阶段)。与现有基准测试使用带有冗长代码的扒取网站或过于简化的LLM生成HTML不同,FullFront采用新颖的两阶段流程,将现实世界中的网页转换为干净、标准化的HTML,同时保持多样的视觉设计,并避免版权问题。对最新MLLM的广泛测试显示,在页面感知、代码生成(尤其是图像处理布局)和交互实现方面存在重大局限性。我们的结果定量地显示了模型和任务之间的性能差异,并突出了当前MLLM能力与前端工程专家之间的差距。FullFront基准测试和代码可在https://github.com/Mikivishy/FullFront中获取。
论文及项目相关链接
Summary:
前端工程包含复杂的流程,包括设计概念化、代码转换和迭代实现。现有基准测试主要集中在视觉设计到代码的转换上,我们提出FullFront基准测试,旨在评估跨整个前端开发流程的多模态大型语言模型(MLLMs)。FullFront评估三个与前端工程流程直接对应的基本任务:网页设计(概念化阶段)、网页感知质量(对视觉组织和元素的理解)和网页代码生成(实现阶段)。它通过一种新颖的两阶段过程将现实世界网页转化为简洁、标准化的HTML,同时保持多样的视觉设计并避免版权问题。测试显示,MLLMs在网页感知、代码生成(尤其是图像处理和布局)和交互实现方面存在显著局限性。我们的结果定量展示了不同模型和任务之间的性能差异,并突出了当前MLLM在前端工程方面的能力与人类专家之间的差距。FullFront基准测试和代码可在链接中获取。
Key Takeaways:
- FullFront是一种针对前端工程全流程的基准测试,旨在评估多模态大型语言模型(MLLMs)的性能。
- FullFront涵盖三个基本任务:网页设计、网页感知质量和网页代码生成,与前端工程流程直接对应。
- FullFront采用新颖的两阶段过程处理现实网页,转化为简洁、标准化的HTML。
- 现有MLLMs在网页感知、代码生成及交互实现方面存在显著局限性。
- 不同模型和任务之间性能存在差异,突出MLLMs与前端工程领域人类专家之间的差距。
- FullFront测试结果显示,MLLMs在图像处理和布局方面的能力尤为不足。
点此查看论文截图