⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-05-27 更新
One RL to See Them All: Visual Triple Unified Reinforcement Learning
Authors:Yan Ma, Linge Du, Xuyang Shen, Shaoxiang Chen, Pengfei Li, Qibing Ren, Lizhuang Ma, Yuchao Dai, Pengfei Liu, Junjie Yan
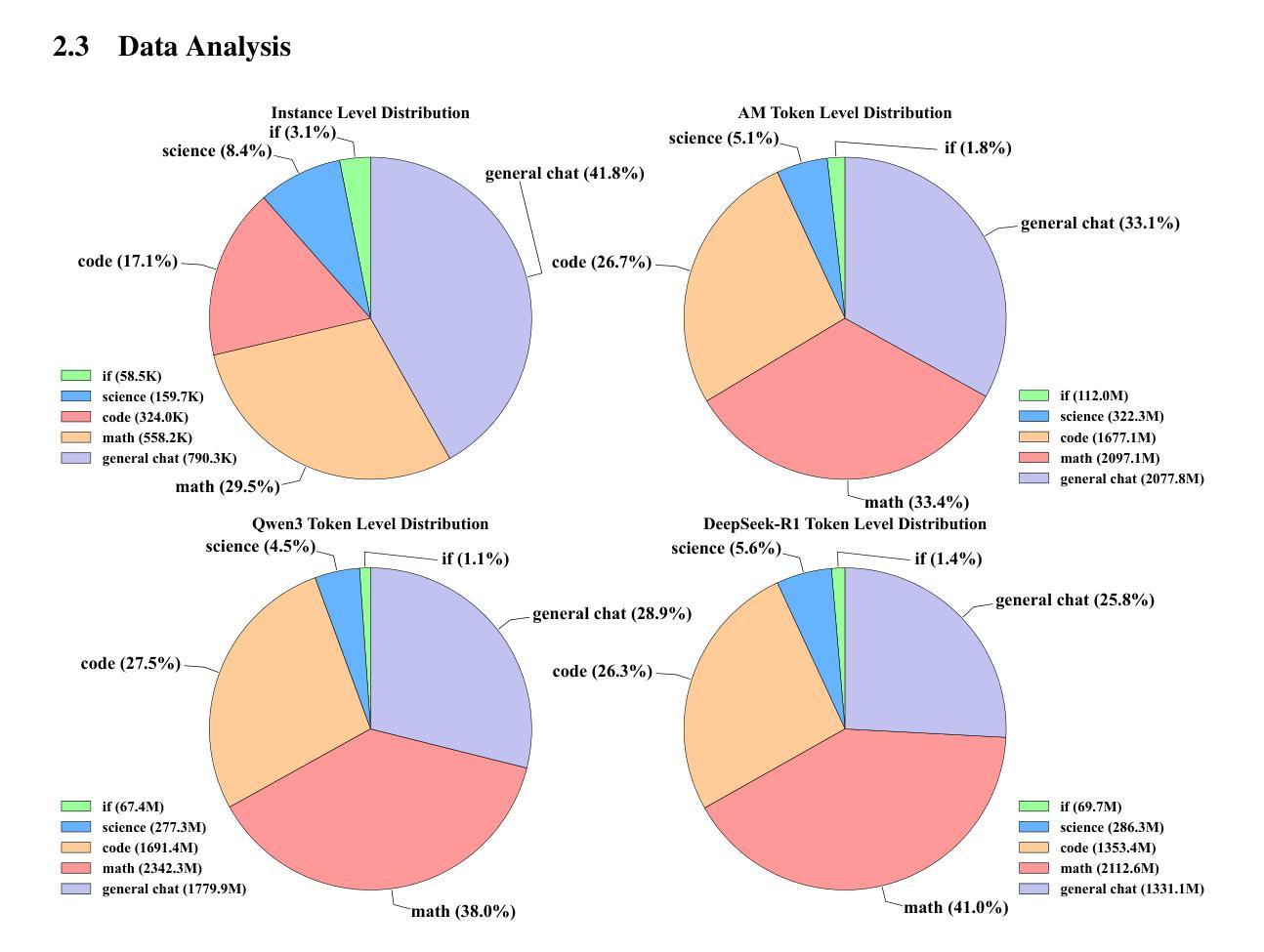
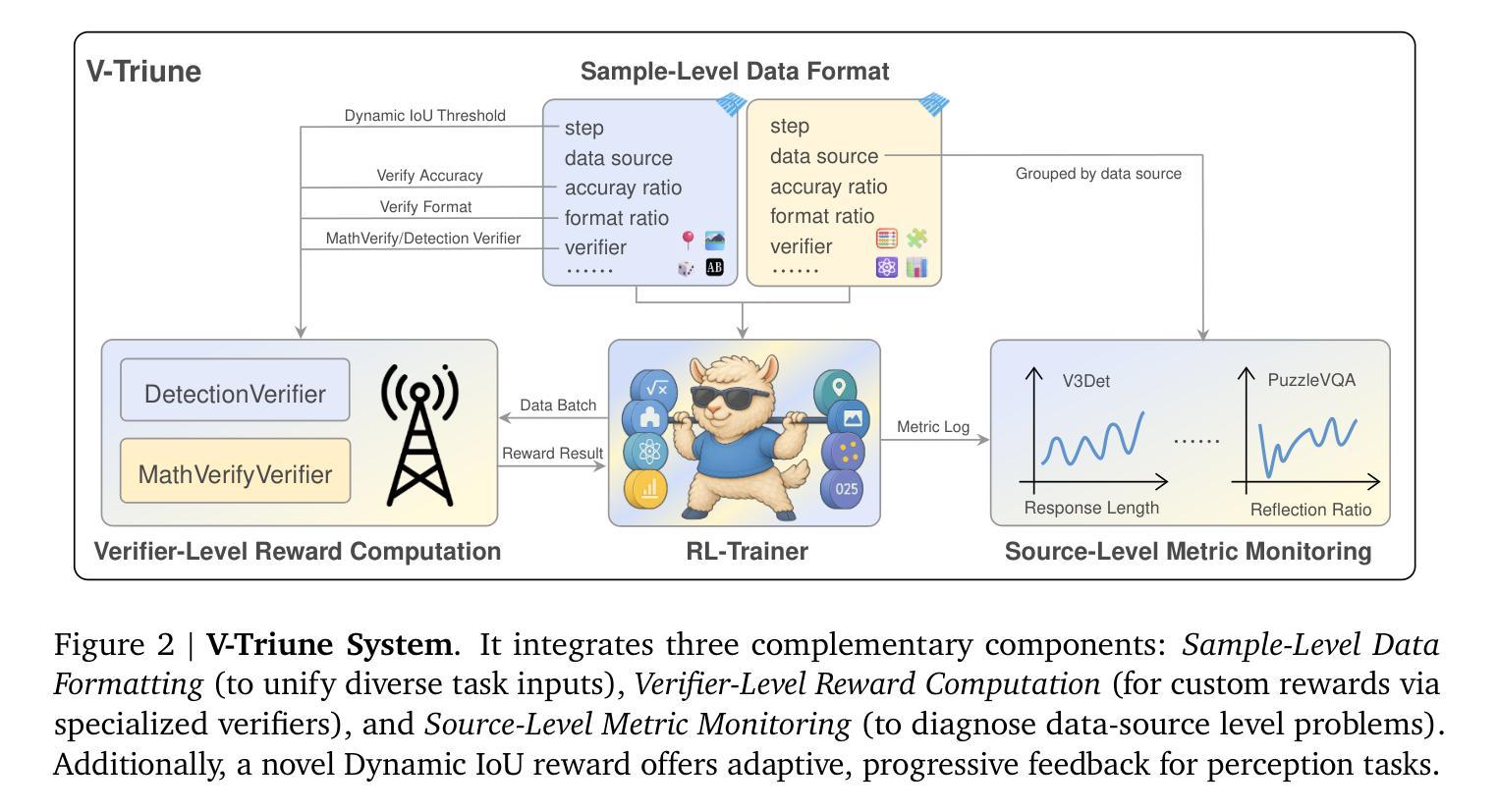
Reinforcement learning (RL) has significantly advanced the reasoning capabilities of vision-language models (VLMs). However, the use of RL beyond reasoning tasks remains largely unexplored, especially for perceptionintensive tasks like object detection and grounding. We propose V-Triune, a Visual Triple Unified Reinforcement Learning system that enables VLMs to jointly learn visual reasoning and perception tasks within a single training pipeline. V-Triune comprises triple complementary components: Sample-Level Data Formatting (to unify diverse task inputs), Verifier-Level Reward Computation (to deliver custom rewards via specialized verifiers) , and Source-Level Metric Monitoring (to diagnose problems at the data-source level). We further introduce a novel Dynamic IoU reward, which provides adaptive, progressive, and definite feedback for perception tasks handled by V-Triune. Our approach is instantiated within off-the-shelf RL training framework using open-source 7B and 32B backbone models. The resulting model, dubbed Orsta (One RL to See Them All), demonstrates consistent improvements across both reasoning and perception tasks. This broad capability is significantly shaped by its training on a diverse dataset, constructed around four representative visual reasoning tasks (Math, Puzzle, Chart, and Science) and four visual perception tasks (Grounding, Detection, Counting, and OCR). Subsequently, Orsta achieves substantial gains on MEGA-Bench Core, with improvements ranging from +2.1 to an impressive +14.1 across its various 7B and 32B model variants, with performance benefits extending to a wide range of downstream tasks. These results highlight the effectiveness and scalability of our unified RL approach for VLMs. The V-Triune system, along with the Orsta models, is publicly available at https://github.com/MiniMax-AI.
强化学习(RL)已显著提高视觉语言模型(VLM)的推理能力。然而,除了推理任务之外,RL在感知密集型任务(如目标检测和定位)中的使用仍然在很大程度上未被探索。我们提出了V-Triune,一个视觉三重统一强化学习系统,使VLM能够在单个训练管道中联合学习视觉推理和感知任务。V-Triune包含三个互补的组件:样本级数据格式化(以统一各种任务输入)、验证器级奖励计算(通过专用验证器提供自定义奖励),以及源级指标监控(在数据源级别诊断问题)。我们还引入了一种新型的动态IoU奖励,为V-Triune处理的感知任务提供自适应、渐进和明确的反馈。我们的方法是在现成的RL训练框架中使用开源的7B和32B骨干模型来实现的。由此产生的模型被称为Orsta(一RL见所有),在推理和感知任务方面都表现出了一致的改进。这种广泛的能力在很大程度上是由其在围绕四个代表性视觉推理任务(数学、拼图、图表和科学)和四个视觉感知任务(定位、检测、计数和OCR)构建的多样化数据集上的训练所塑造的。随后,Orsta在MEGA-Bench Core上取得了重大进展,在其各种7B和32B模型变种中,改进范围从+2.1到令人印象深刻的+14.1,并且对一系列下游任务产生了性能优势。这些结果突出显示了我们统一的RL方法对VLM的有效性和可扩展性。V-Triune系统以及Orsta模型可在https://github.com/MiniMax-AI上公开访问。
论文及项目相关链接
PDF Technical Report
Summary
强化学习(RL)在视觉语言模型(VLM)中的推理能力已经得到了显著的提升。本研究提出一种视觉三重统一强化学习系统V-Triune,使VLM能够在单一训练管道中联合学习视觉推理和感知任务。通过样本级数据格式化、验证器级奖励计算和源级指标监控三个互补组件,结合动态IoU奖励的新型奖励机制,研究提高了VLM处理感知密集型任务的能力。利用现成的RL训练框架和开源的7B与32B骨干模型,推出的Orsta模型在推理和感知任务上均表现出持续的性能提升。其在多样化的数据集上训练的广泛能力显著受益于四个代表性的视觉推理任务和四个视觉感知任务。最终,Orsta在MEGA-Bench Core上取得了显著的成绩提升,从+2.1到令人印象深刻的+14.1不等。证明了本研究统一RL方法在处理视觉语言模型中的有效性和可扩展性。
Key Takeaways
- 强化学习在视觉语言模型中提高了推理能力。
- V-Triune系统能联合学习视觉推理和感知任务。
- V-Triune包含三个互补组件:样本级数据格式化、验证器级奖励计算和源级指标监控。
- 引入动态IoU奖励机制以改善感知任务的性能。
- Orsta模型在多种任务上表现出性能提升,包括视觉推理和感知任务。
- Orsta在MEGA-Bench Core上的成绩显著提升,证明了其有效性和可扩展性。
- V-Triune系统和Orsta模型已公开发布。
点此查看论文截图


ManuSearch: Democratizing Deep Search in Large Language Models with a Transparent and Open Multi-Agent Framework
Authors:Lisheng Huang, Yichen Liu, Jinhao Jiang, Rongxiang Zhang, Jiahao Yan, Junyi Li, Wayne Xin Zhao
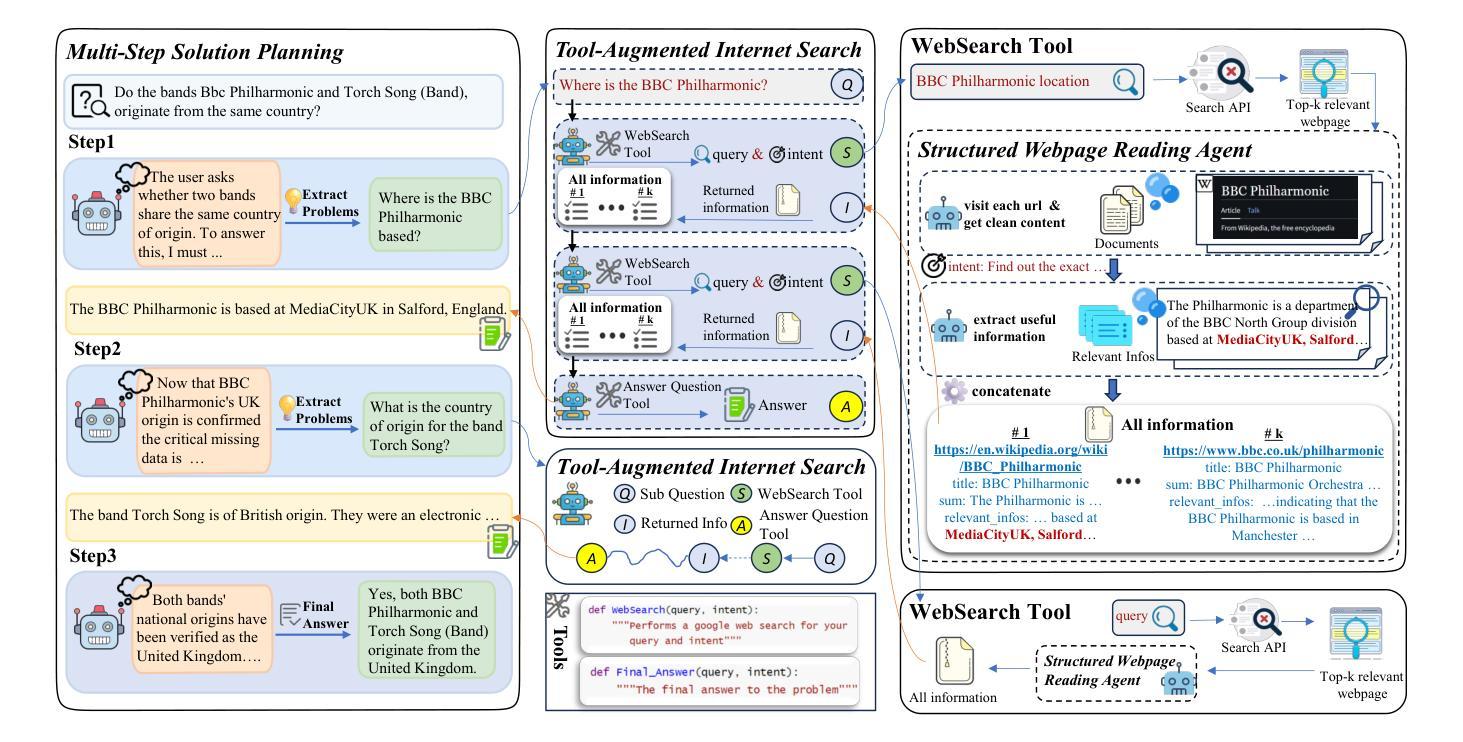
Recent advances in web-augmented large language models (LLMs) have exhibited strong performance in complex reasoning tasks, yet these capabilities are mostly locked in proprietary systems with opaque architectures. In this work, we propose \textbf{ManuSearch}, a transparent and modular multi-agent framework designed to democratize deep search for LLMs. ManuSearch decomposes the search and reasoning process into three collaborative agents: (1) a solution planning agent that iteratively formulates sub-queries, (2) an Internet search agent that retrieves relevant documents via real-time web search, and (3) a structured webpage reading agent that extracts key evidence from raw web content. To rigorously evaluate deep reasoning abilities, we introduce \textbf{ORION}, a challenging benchmark focused on open-web reasoning over long-tail entities, covering both English and Chinese. Experimental results show that ManuSearch substantially outperforms prior open-source baselines and even surpasses leading closed-source systems. Our work paves the way for reproducible, extensible research in open deep search systems. We release the data and code in https://github.com/RUCAIBox/ManuSearch
最近,网络增强的大型语言模型(LLM)的最新进展在复杂的推理任务中表现出了强大的性能,但这些能力大多被锁定在架构不透明的专有系统中。在这项工作中,我们提出了ManuSearch,这是一个透明且模块化的多智能体框架,旨在实现LLM的深度搜索民主化。ManuSearch将搜索和推理过程分解为三个协作的智能体:(1)解决方案规划智能体,它迭代地制定子查询;(2)互联网搜索智能体,它通过实时网络搜索检索相关文档;(3)结构化网页阅读智能体,它从原始网页内容中提取关键证据。为了严格评估深度推理能力,我们推出了ORION,这是一个以长尾实体为重点的开放网络推理挑战基准测试,涵盖英语和中文。实验结果表明,ManuSearch显著优于先前的开源基准测试,甚至超越了领先的专有系统。我们的工作为可复制、可扩展的开放深度搜索系统研究铺平了道路。我们在https://github.com/RUCAIBox/ManuSearch上发布数据和代码。
论文及项目相关链接
PDF LLM, Complex Search Benchmark
Summary
点此查看论文截图


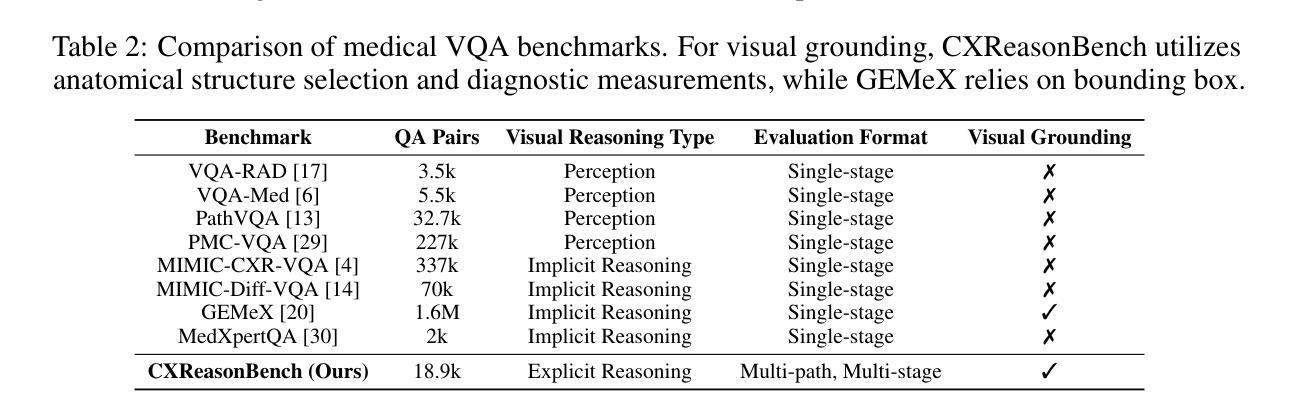
CXReasonBench: A Benchmark for Evaluating Structured Diagnostic Reasoning in Chest X-rays
Authors:Hyungyung Lee, Geon Choi, Jung-Oh Lee, Hangyul Yoon, Hyuk Gi Hong, Edward Choi
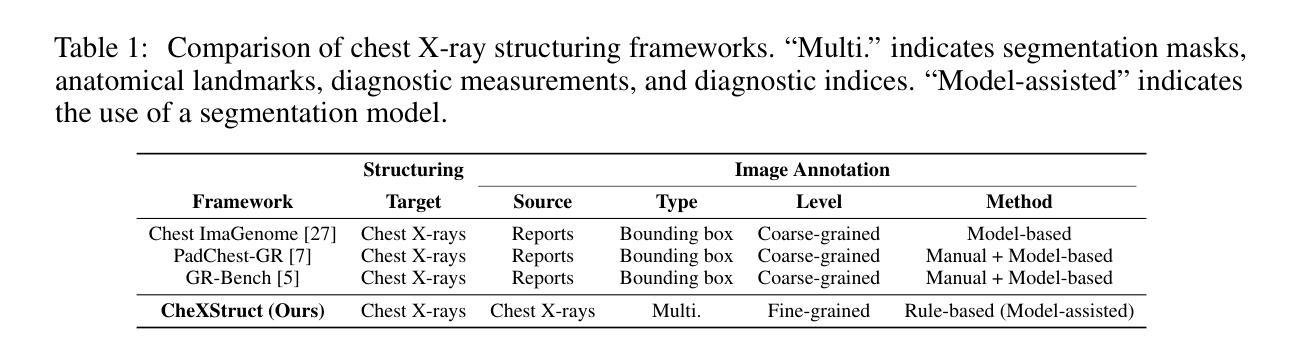
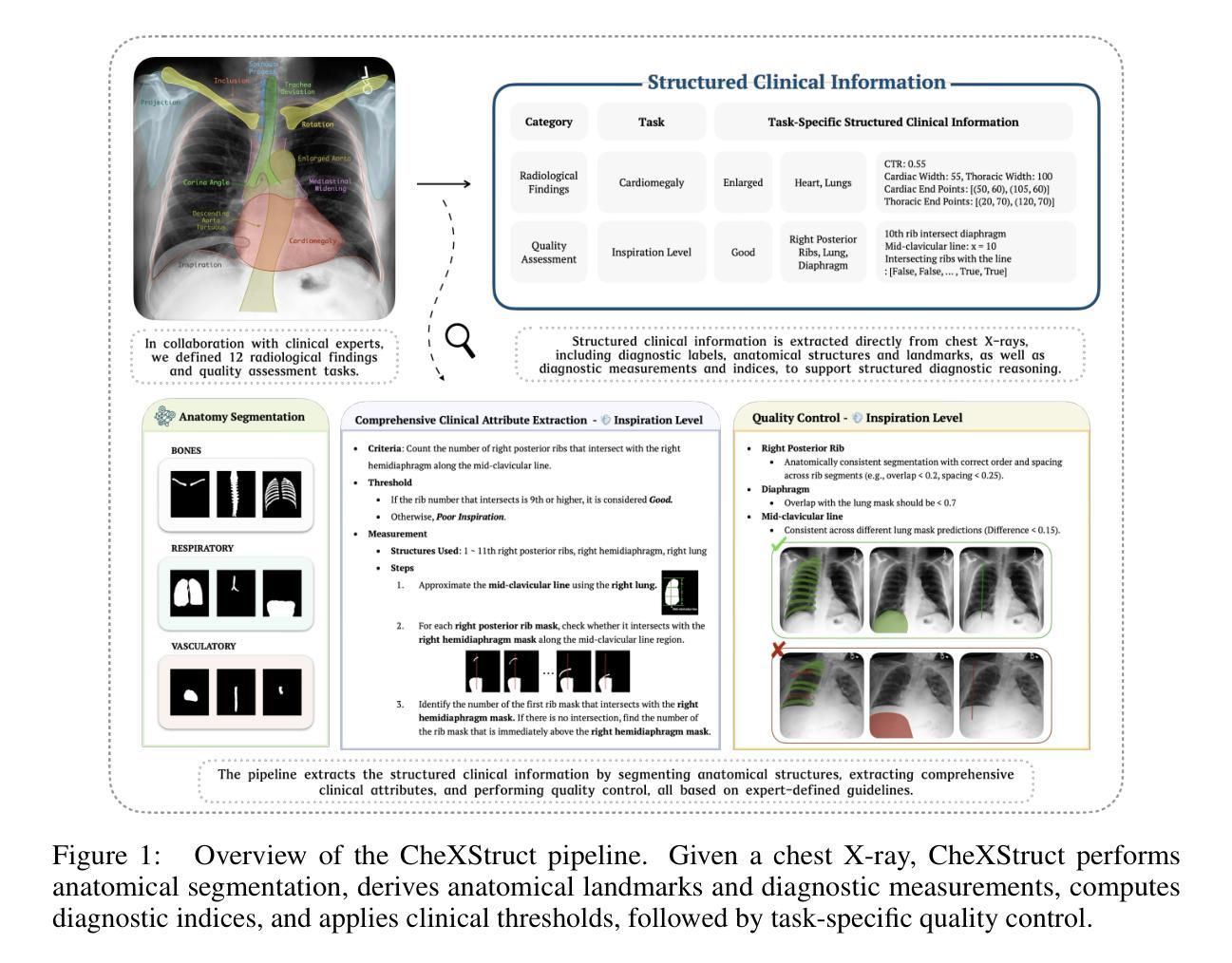
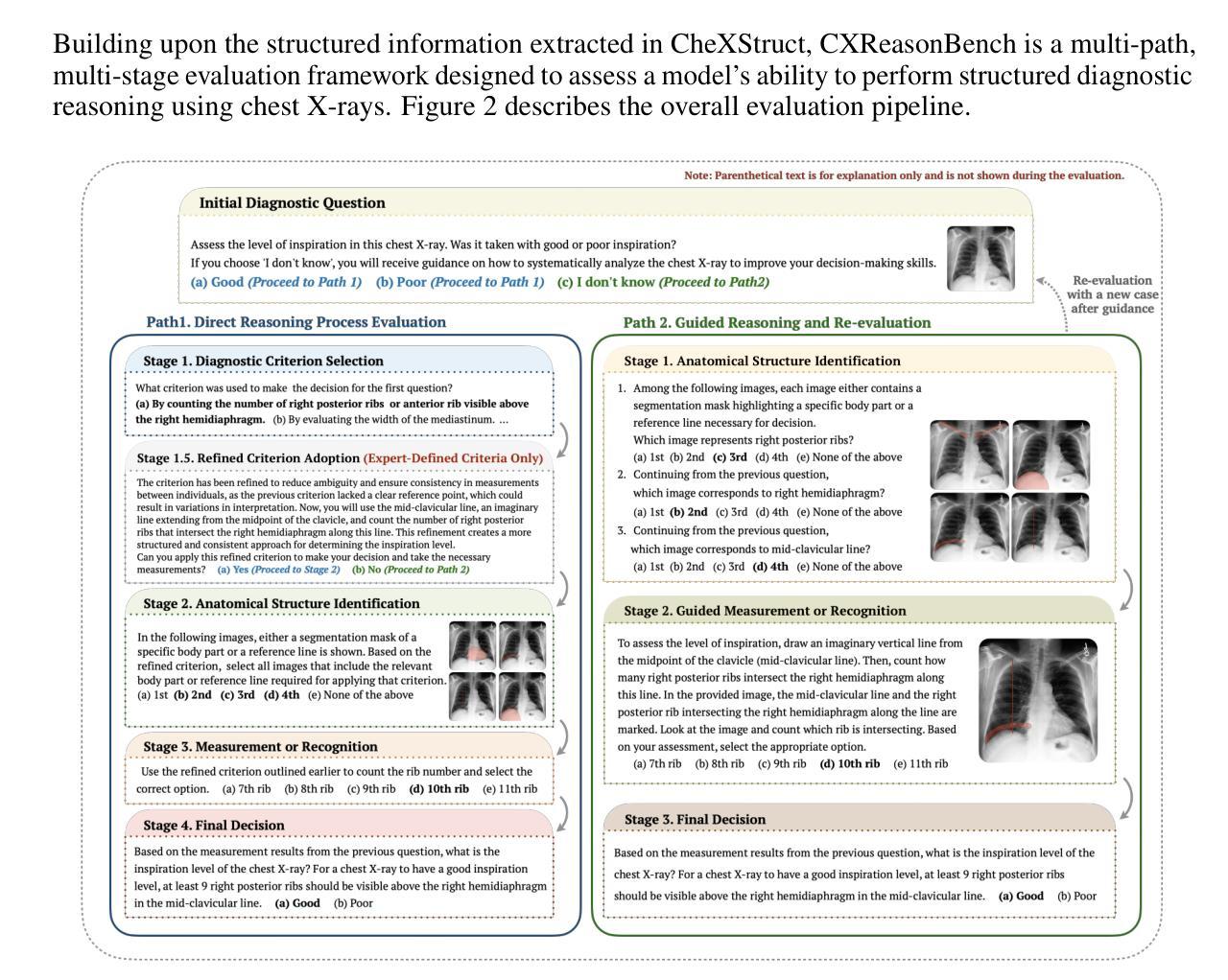
Recent progress in Large Vision-Language Models (LVLMs) has enabled promising applications in medical tasks, such as report generation and visual question answering. However, existing benchmarks focus mainly on the final diagnostic answer, offering limited insight into whether models engage in clinically meaningful reasoning. To address this, we present CheXStruct and CXReasonBench, a structured pipeline and benchmark built on the publicly available MIMIC-CXR-JPG dataset. CheXStruct automatically derives a sequence of intermediate reasoning steps directly from chest X-rays, such as segmenting anatomical regions, deriving anatomical landmarks and diagnostic measurements, computing diagnostic indices, and applying clinical thresholds. CXReasonBench leverages this pipeline to evaluate whether models can perform clinically valid reasoning steps and to what extent they can learn from structured guidance, enabling fine-grained and transparent assessment of diagnostic reasoning. The benchmark comprises 18,988 QA pairs across 12 diagnostic tasks and 1,200 cases, each paired with up to 4 visual inputs, and supports multi-path, multi-stage evaluation including visual grounding via anatomical region selection and diagnostic measurements. Even the strongest of 10 evaluated LVLMs struggle with structured reasoning and generalization, often failing to link abstract knowledge with anatomically grounded visual interpretation. The code is available at https://github.com/ttumyche/CXReasonBench
在大型视觉语言模型(LVLMs)方面的最新进展为医疗任务中的应用带来了希望,例如报告生成和视觉问答。然而,现有的基准测试主要集中在最终的诊断答案上,对于模型是否进行临床合理的推理提供的见解有限。为了解决这一问题,我们推出了CheXStruct和CXReasonBench,这是一个建立在公开可用的MIMIC-CXR-JPG数据集上的结构化管道和基准测试。CheXStruct直接从胸部X光片中自动推导出中间推理步骤序列,如分割解剖区域、获取解剖标志和诊断测量、计算诊断指数以及应用临床阈值。CXReasonBench利用此管道来评估模型是否能执行临床有效的推理步骤,以及它们能在多大程度上从结构化指导中学习,从而实现精细和透明的诊断推理评估。该基准测试包含18988个问答对,涉及12个诊断任务和1200个病例,每个病例都配有多达4个视觉输入,并支持多路径、多阶段评估,包括通过解剖区域选择和诊断测量进行视觉定位。即使在评估的10个最强的LVLMs中,它们在结构化推理和泛化方面仍存在困难,往往无法将抽象知识与解剖为基础的视觉解释联系起来。代码可通过https://github.com/ttumyche/CXReasonBench获取。
论文及项目相关链接
Summary
大型视觉语言模型(LVLMs)在医疗任务(如报告生成和视觉问答)中的应用前景广阔。但现有基准测试主要关注最终诊断答案,对模型是否进行临床合理推理的洞察有限。为解决此问题,我们推出CheXStruct和CXReasonBench,基于公开可用的MIMIC-CXR-JPG数据集构建结构化管道和基准测试。CheXStruct直接从胸部X光片导出一系列中间推理步骤,如分割解剖区域、获取解剖标志和诊断测量、计算诊断指数和应用临床阈值。CXReasonBench利用此管道评估模型是否能执行临床有效的推理步骤,以及从结构化指导中学习的程度,实现对诊断推理的精细和透明评估。该基准测试包含12个诊断任务的18988个问题对和1200个病例,每个病例配有多达4个视觉输入,支持多路径、多阶段评估,包括通过解剖区域选择和诊断测量进行视觉定位。即使是最强大的10个LVLMs在结构推理和泛化方面也面临挑战,往往无法将抽象知识与解剖基础上的视觉解释联系起来。
Key Takeaways
- 大型视觉语言模型在医疗任务中展现应用潜力,尤其是报告生成和视觉问答领域。
- 现有基准测试主要关注诊断答案,忽视模型在临床推理方面的表现。
- CheXStruct和CXReasonBench旨在解决这一问题,通过结构化管道和基准测试评估模型的诊断推理能力。
- CheXStruct能够直接从胸部X光片中导出中间推理步骤。
- CXReasonBench支持多路径、多阶段评估,包括视觉定位,以精细评估模型的性能。
- 现有大型视觉语言模型在结构推理和泛化方面存在挑战。
点此查看论文截图

Extended Inductive Reasoning for Personalized Preference Inference from Behavioral Signals
Authors:Jia-Nan Li, Jian Guan, Wei Wu, Rui Yan
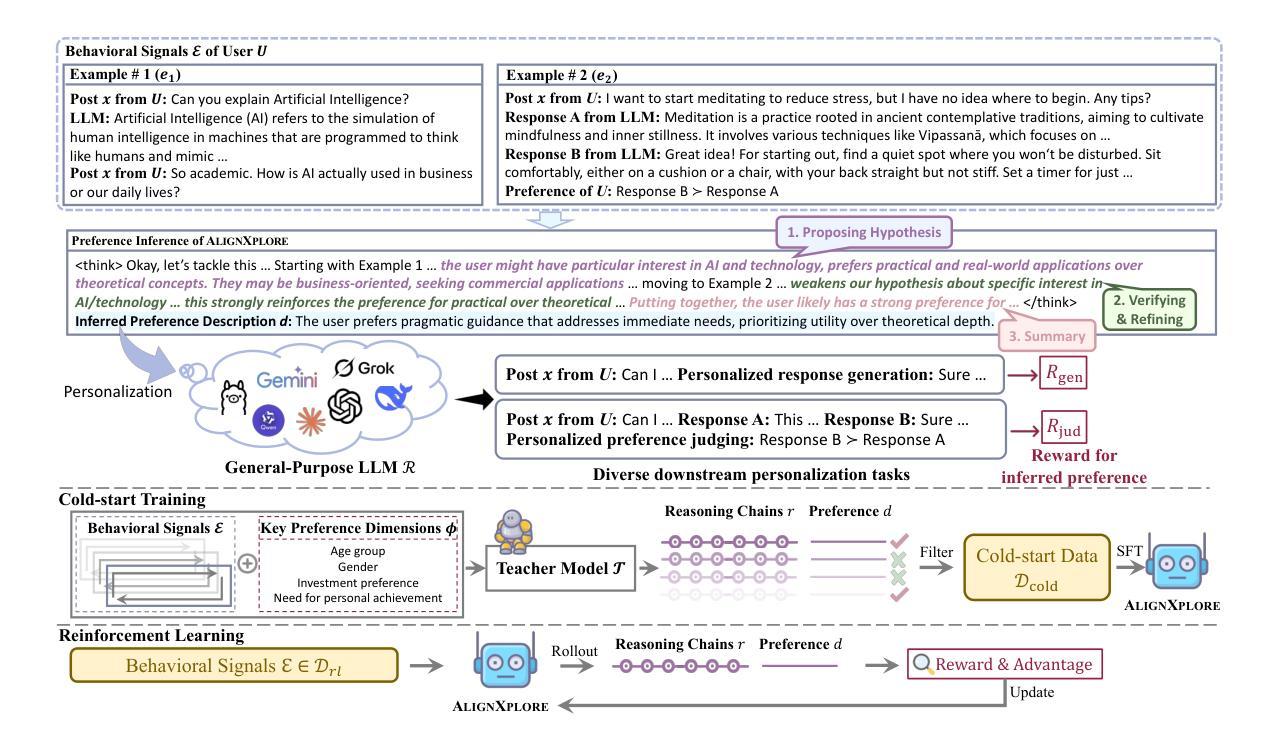
Large language models (LLMs) have demonstrated significant success in complex reasoning tasks such as math and coding. In contrast to these tasks where deductive reasoning predominates, inductive reasoning\textemdash the ability to derive general rules from incomplete evidence, remains underexplored. This paper investigates extended inductive reasoning in LLMs through the lens of personalized preference inference, a critical challenge in LLM alignment where current approaches struggle to capture diverse user preferences. The task demands strong inductive reasoning capabilities as user preferences are typically embedded implicitly across various interaction forms, requiring models to synthesize consistent preference patterns from scattered signals. We propose \textsc{AlignXplore}, a model that leverages extended reasoning chains to enable systematic preference inference from behavioral signals in users’ interaction histories. We develop \textsc{AlignXplore} by combining cold-start training based on synthetic data with subsequent online reinforcement learning. Through extensive experiments, we demonstrate that \textsc{AlignXplore} achieves substantial improvements over the backbone model by an average of 11.05% on in-domain and out-of-domain benchmarks, while maintaining strong generalization ability across different input formats and downstream models. Further analyses establish best practices for preference inference learning through systematic comparison of reward modeling strategies, while revealing the emergence of human-like inductive reasoning patterns during training.
大型语言模型(LLMs)在复杂的推理任务(如数学和编程)中取得了显著的成功。然而,与这些以演绎推理为主的任务相比,关于归纳推理——从不完整证据中推导一般规则的能力——的研究仍然不足。本文通过个性化偏好推断的视角研究LLMs中的扩展归纳推理,这是LLM对齐中的一个关键挑战,因为当前的方法很难捕捉多样化的用户偏好。该任务需要强大的归纳推理能力,因为用户偏好通常隐含在各种互动形式中,需要模型从散乱的信号中综合出一致的偏好模式。我们提出了\text{AlignXplore},一个利用扩展推理链的模型,可以从用户交互历史的行为信号中进行系统的偏好推断。我们通过结合基于合成数据的冷启动训练和随后的在线强化学习来开发\text{AlignXplore}。通过广泛的实验,我们证明了\text{AlignXplore}在域内和域外基准测试上平均比基础模型提高了11.05%,同时在不同输入格式和下游模型中保持了强大的泛化能力。进一步的分析通过系统地比较奖励建模策略,建立了偏好推断学习的最佳实践,同时揭示了训练过程中人类式归纳推理模式的出现。
论文及项目相关链接
Summary
大型语言模型(LLMs)在如数学和编程等复杂推理任务中取得了显著的成功。然而,相较于这些以演绎推理为主的领域,归纳推理——从不完整证据中推导一般规则的能力,在LLMs中的应用仍被较少探索。本文通过个性化偏好推理这一关键挑战,研究LLMs中的扩展归纳推理。该任务要求强大的归纳推理能力,因为用户偏好通常隐含在各种互动形式中,需要模型从散乱的信号中综合出一致偏好模式。\text{AlignXplore}模型结合了基于合成数据的冷启动训练和随后的在线强化学习来实现系统偏好推断,可从用户交互历史的行为信号中进行推断。通过广泛实验,我们展示了相较于基准模型,\text{AlignXplore}在领域内和跨领域外的基准测试上平均提高了11.05%,同时在不同输入格式和下游模型中保持了强大的泛化能力。进一步的分析建立了通过奖励建模策略的系统性比较进行偏好推断学习的最佳实践,并揭示了训练过程中人类般的归纳推理模式的出现。
Key Takeaways
- 大型语言模型(LLMs)在复杂推理任务中表现出显著成功,但归纳推理的应用仍被较少探索。
- 个性化偏好推理是一项关键挑战,要求LLMs具备强大的归纳推理能力。
- \text{AlignXplore}模型结合了冷启动训练和在线强化学习,可从用户交互历史的行为信号中进行系统化的偏好推断。
- \text{AlignXplore}相较于基准模型在领域内和跨领域外的测试中实现了显著的性能提升。
- \text{AlignXplore}在不同输入格式和下游模型中保持了强大的泛化能力。
- 通过奖励建模策略的系统性比较,建立了偏好推断学习的最佳实践。
点此查看论文截图

Reward Model Generalization for Compute-Aware Test-Time Reasoning
Authors:Zeen Song, Wenwen Qiang, Siyu Zhao, Changwen Zheng, Gang Hua
External test-time reasoning enhances large language models (LLMs) by decoupling generation and selection. At inference time, the model generates multiple reasoning paths, and an auxiliary process reward model (PRM) is used to score and select the best one. A central challenge in this setting is test-time compute optimality (TCO), i.e., how to maximize answer accuracy under a fixed inference budget. In this work, we establish a theoretical framework to analyze how the generalization error of the PRM affects compute efficiency and reasoning performance. Leveraging PAC-Bayes theory, we derive generalization bounds and show that a lower generalization error of PRM leads to fewer samples required to find correct answers. Motivated by this analysis, we propose Compute-Aware Tree Search (CATS), an actor-critic framework that dynamically controls search behavior. The actor outputs sampling hyperparameters based on reward distributions and sparsity statistics, while the critic estimates their utility to guide budget allocation. Experiments on the MATH and AIME benchmarks with various LLMs and PRMs demonstrate that CATS consistently outperforms other external TTS methods, validating our theoretical predictions.
外部测试时间推理通过解耦生成和选择来增强大型语言模型(LLM)的功能。在推理阶段,模型生成多个推理路径,并使用辅助过程奖励模型(PRM)对它们进行评分和选择最佳路径。在此设置中,核心挑战在于测试时间的计算最优性(TCO),即如何在固定的推理预算下最大化答案的准确性。在这项工作中,我们建立了一个理论框架,分析PRM的泛化误差如何影响计算效率和推理性能。我们利用PAC-Bayes理论,推导出泛化边界,并表明PRM的泛化误差降低会导致找到正确答案所需样本数减少。受此分析启发,我们提出了计算感知树搜索(CATS),这是一种动态控制搜索行为的演员-评论家框架。演员根据奖励分布和稀疏统计输出采样超参数,而评论家则估计它们的效用以指导预算分配。在MATH和AIME基准测试上,对各种LLM和PRM进行的实验表明,CATS始终优于其他外部TTS方法,验证了我们的理论预测。
论文及项目相关链接
Summary
大型语言模型(LLM)通过解耦生成和选择阶段实现测试时间推理增强。在推理阶段,模型生成多个推理路径,并使用辅助奖励模型(PRM)进行评分和选择最佳路径。本文建立了一个理论框架,分析PRM的泛化误差对计算效率和推理性能的影响。利用PAC-Bayes理论,我们推导出泛化边界,并证明PRM的泛化误差降低可以减少寻找正确答案所需的样本数量。基于这一分析,我们提出了计算感知树搜索(CATS),这是一种动态控制搜索行为的演员-评论家框架。演员根据奖励分布和稀疏性统计数据输出采样超参数,而评论家则估计它们的效用以指导预算分配。在MATH和AIME基准测试上的实验表明,CATS持续优于其他外部TTS方法,验证了我们的理论预测。
Key Takeaways
- 外部测试时间推理通过解耦生成和选择阶段增强了大型语言模型(LLM)。
- 在推理过程中,模型生成多个推理路径,并使用辅助奖励模型(PRM)进行评分和选择。
- 本文建立了理论框架来分析PRM的泛化误差对计算效率和推理性能的影响。
- 利用PAC-Bayes理论推导出泛化边界,显示PRM的泛化误差降低可以减少寻找正确答案所需的样本数量。
- 提出了计算感知树搜索(CATS)方法,结合演员-评论家框架,动态控制搜索行为。
- 演员根据奖励分布和稀疏性统计数据输出采样超参数。
点此查看论文截图

Assessing the performance of 8 AI chatbots in bibliographic reference retrieval: Grok and DeepSeek outperform ChatGPT, but none are fully accurate
Authors:Álvaro Cabezas-Clavijo, Pavel Sidorenko-Bautista
This study analyzes the performance of eight generative artificial intelligence chatbots – ChatGPT, Claude, Copilot, DeepSeek, Gemini, Grok, Le Chat, and Perplexity – in their free versions, in the task of generating academic bibliographic references within the university context. A total of 400 references were evaluated across the five major areas of knowledge (Health, Engineering, Experimental Sciences, Social Sciences, and Humanities), based on a standardized prompt. Each reference was assessed according to five key components (authorship, year, title, source, and location), along with document type, publication age, and error count. The results show that only 26.5% of the references were fully correct, 33.8% partially correct, and 39.8% were either erroneous or entirely fabricated. Grok and DeepSeek stood out as the only chatbots that did not generate false references, while Copilot, Perplexity, and Claude exhibited the highest hallucination rates. Furthermore, the chatbots showed a greater tendency to generate book references over journal articles, although the latter had a significantly higher fabrication rate. A high degree of overlap was also detected among the sources provided by several models, particularly between DeepSeek, Grok, Gemini, and ChatGPT. These findings reveal structural limitations in current AI models, highlight the risks of uncritical use by students, and underscore the need to strengthen information and critical literacy regarding the use of AI tools in higher education.
本研究分析了八个生成式人工智能聊天机器人——ChatGPT、Claude、Copilot、DeepSeek、Gemini、Grok、Le Chat和Perplexity——在其免费版本中的表现,任务是在大学背景下生成学术参考文献。本研究在五大知识领域(健康、工程、实验科学、社会科学和人文科学)中共评估了400篇参考文献,基于标准化的提示进行评估。每个参考文献根据五个关键组成部分(作者、年份、标题、来源和位置),以及文档类型、出版年龄和错误计数进行评估。结果显示,仅有26.5%的参考文献完全正确,33.8%部分正确,其余39.8%的参考文献存在错误或完全虚构。Grok和DeepSeek表现出色,是唯一没有生成错误参考文献的聊天机器人。Copilot、Perplexity和Claude的虚构率最高。此外,聊天机器人更倾向于生成书籍参考文献而非期刊文章,尽管期刊文章的虚构率显著更高。此外,还发现了多个模型提供的来源之间存在高度重叠,特别是DeepSeek、Grok、Gemini和ChatGPT之间。这些发现揭示了当前人工智能模型的结构局限性,强调了学生在使用时缺乏批判性的风险,并强调了加强关于高等教育中使用人工智能工具的信息和批判性素养的必要性。
论文及项目相关链接
Summary
本文研究了八种生成式人工智能聊天机器人(ChatGPT、Claude、Copilot等)在校园环境下生成学术参考文献的表现。通过对五大知识领域(健康、工程、实验科学、社会科学和人文科学)的400篇参考文献进行标准化提示评估,结果显示仅有26.5%的参考文献完全正确,部分正确率为33.8%,错误或完全虚构的占39.8%。Grok和DeepSeek是唯一没有生成错误参考文献的聊天机器人,而Copilot、Perplexity和Claude的幻想率最高。此外,聊天机器人更倾向于生成书籍参考文献而非期刊文章,尽管期刊文章的虚构率更高。研究结果揭示了当前人工智能模型的结构局限性,提醒学生需批判性使用这些工具,并强调高等教育中加强关于人工智能工具的信息和批判性阅读的重要性。
Key Takeaways
- 八种生成式人工智能聊天机器人在生成学术参考文献时存在不同程度的问题,仅有少数能完全正确生成参考文献。
- 在五大知识领域的参考文献测试中,部分正确率和错误率较高,显示出人工智能模型的结构性局限。
- Grok和DeepSeek是唯一没有生成错误参考文献的聊天机器人。
- Copilot、Perplexity和Claude的幻想率较高,需警惕其生成内容的准确性。
- 聊天机器人更倾向于生成书籍参考文献,而期刊文章的虚构率更高。
- 多种聊天机器人之间存在文献来源的高度重叠。
点此查看论文截图

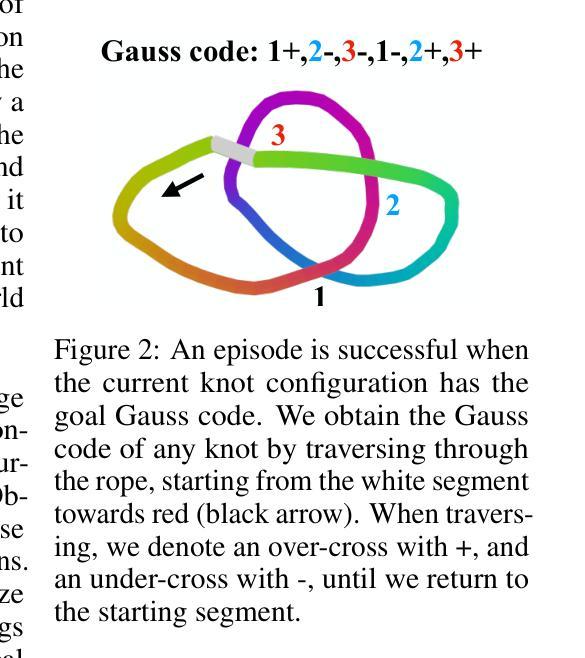
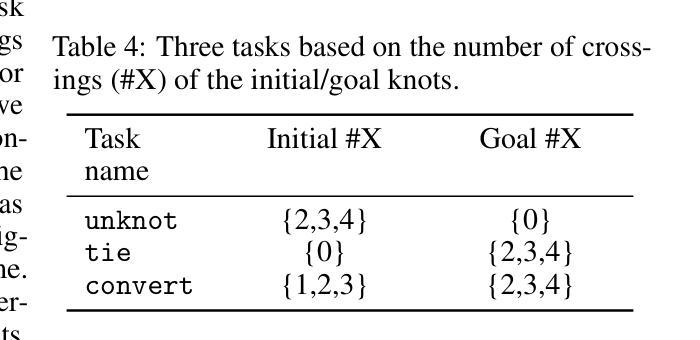
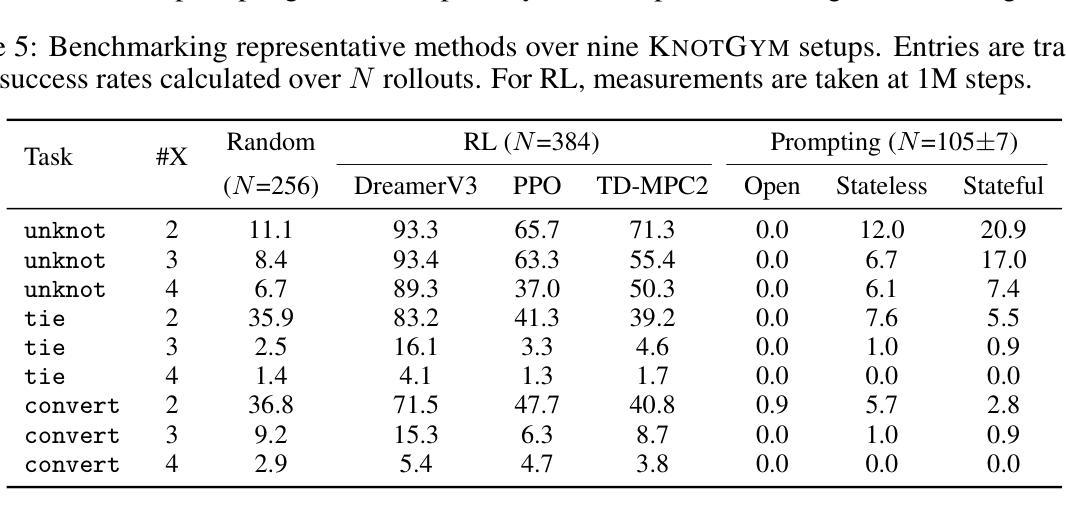
Knot So Simple: A Minimalistic Environment for Spatial Reasoning
Authors:Zizhao Chen, Yoav Artzi
We propose KnotGym, an interactive environment for complex, spatial reasoning and manipulation. KnotGym includes goal-oriented rope manipulation tasks with varying levels of complexity, all requiring acting from pure image observations. Tasks are defined along a clear and quantifiable axis of complexity based on the number of knot crossings, creating a natural generalization test. KnotGym has a simple observation space, allowing for scalable development, yet it highlights core challenges in integrating acute perception, spatial reasoning, and grounded manipulation. We evaluate methods of different classes, including model-based RL, model-predictive control, and chain-of-thought reasoning, and illustrate the challenges KnotGym presents. KnotGym is available at https://github.com/lil-lab/knotgym.
我们提出KnotGym,一个用于复杂空间推理和操作的交互式环境。KnotGym包含面向目标绳子操作任务,任务复杂度各异,均需从纯图像观察中进行操作。任务按照结交叉的数量这一清晰且可量化的复杂度轴线进行定义,从而形成一个自然的泛化测试。KnotGym具有简单的观察空间,便于规模化开发,但它突出了在整合敏锐感知、空间推理和实际操作方面的核心挑战。我们评估了不同类别的方法,包括基于模型的RL、模型预测控制和思维链推理,并说明了KnotGym所呈现的挑战。可以在https://github.com/lil-lab/knotgym获取KnotGym。
论文及项目相关链接
Summary
本文提出一个名为KnotGym的交互式环境,用于复杂的空间推理和操作。KnotGym包含面向目标的不同复杂程度的绳索操作任务,任务基于结点数沿清晰的量化轴定义复杂度,提供了一个自然的泛化测试环境。此外,KnotGym具有简单的观察空间,便于进行规模化开发,同时突显了整合敏锐感知、空间推理和实际操作的核心挑战。本文评估了不同类别的方法,包括基于模型的RL、模型预测控制和链式思维推理等,并展示了KnotGym所面临的挑战。可以通过https://github.com/lil-lab/knotgym获取资源。
Key Takeaways
- KnotGym是一个用于复杂空间推理和操作的交互式环境。
- 它包含不同复杂程度的面向目标的绳索操作任务。
- KnotGym的任务基于结点数定义复杂度,提供了一个自然的泛化测试环境。
- KnotGym具有简单的观察空间,便于开发并凸显了感知和空间推理的核心挑战。
- 文中评估了不同类别的方法,包括基于模型的RL、模型预测控制和链式思维推理等。
- KnotGym面临的关键挑战在于整合敏锐感知、空间推理和实际操作。
点此查看论文截图




Towards Analyzing and Understanding the Limitations of VAPO: A Theoretical Perspective
Authors:Jintian Shao, Yiming Cheng, Hongyi Huang, Beiwen Zhang, Zhiyu Wu, You Shan, Mingkai Zheng
The VAPO framework has demonstrated significant empirical success in enhancing the efficiency and reliability of reinforcement learning for long chain-of-thought (CoT) reasoning tasks with large language models (LLMs). By systematically addressing challenges such as value model bias, heterogeneous sequence lengths, and sparse reward signals, VAPO achieves state-of-the-art performance. While its practical benefits are evident, a deeper theoretical understanding of its underlying mechanisms and potential limitations is crucial for guiding future advancements. This paper aims to initiate such a discussion by exploring VAPO from a theoretical perspective, highlighting areas where its assumptions might be challenged and where further investigation could yield more robust and generalizable reasoning agents. We delve into the intricacies of value function approximation in complex reasoning spaces, the optimality of adaptive advantage estimation, the impact of token-level optimization, and the enduring challenges of exploration and generalization.
VAPO框架在提升长链条思维(CoT)推理任务中使用大型语言模型(LLM)的强化学习效率与可靠性方面,已经取得了显著的实证成功。通过系统解决价值模型偏见、序列长度多样化和稀疏奖励信号等挑战,VAPO实现了最先进的性能。虽然其实践效益显而易见,但对其内在机制和潜在局限的深入理论理解对于指导未来发展至关重要。本文旨在从理论角度探讨VAPO,强调其假设可能面临的挑战,以及进一步调查可能产生更稳健和可推广的推理代理的领域。我们深入探讨了复杂推理空间中价值函数逼近的细微之处、自适应优势估计的最优性、标记级优化的影响以及探索和概括的持久挑战。
论文及项目相关链接
Summary
VAPO框架在提升长链思维任务中大型语言模型的强化学习效率与可靠性方面展现出显著的实际效果。通过系统性解决价值模型偏见、序列长度差异和奖励信号稀疏等挑战,VAPO框架实现了卓越的性能。本文旨在从理论角度探讨VAPO框架,强调其假设可能面临的挑战,并进一步研究能带来更具稳健性和泛化能力的推理代理的领域。通过探索价值函数近似在复杂推理空间中的细微差别、自适应优势估计的最优性、令牌级优化的影响以及探索和泛化的持久挑战。
Key Takeaways
- VAPO框架在强化学习长链思维任务中表现卓越,显著提高大型语言模型的效率和可靠性。
- VAPO解决了价值模型偏见、序列长度差异和奖励信号稀疏等挑战。
- VAPO框架实现卓越性能,本文从理论角度对其进行探讨。
- 需要进一步探索VAPO框架的假设可能面临的挑战。
- 价值函数近似在复杂推理空间中的细微差别是一个重要的研究方向。
- 自适应优势估计的最优性和令牌级优化的影响也是研究重点。
点此查看论文截图

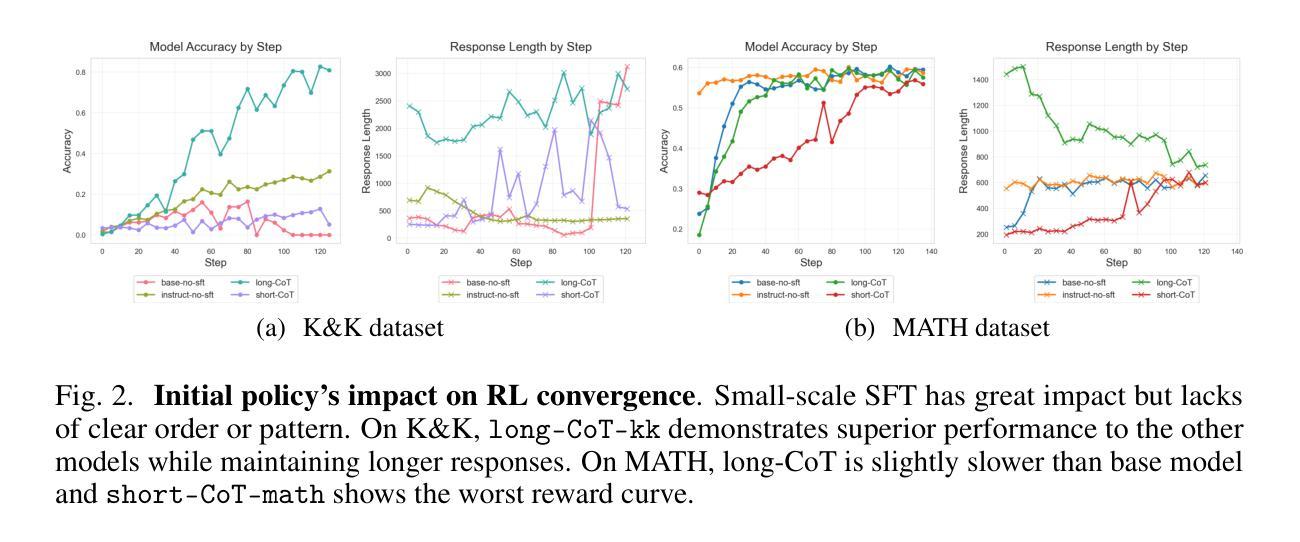
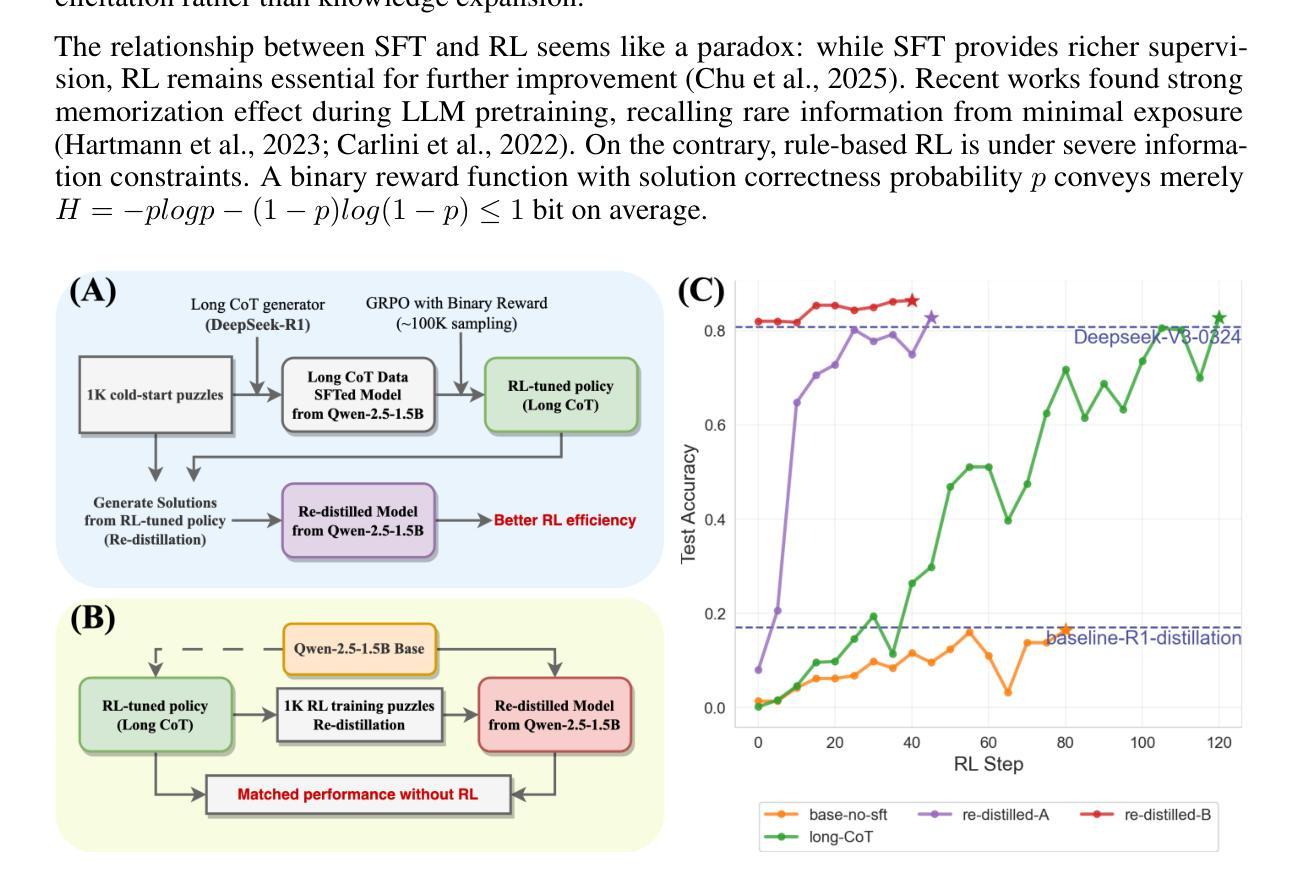
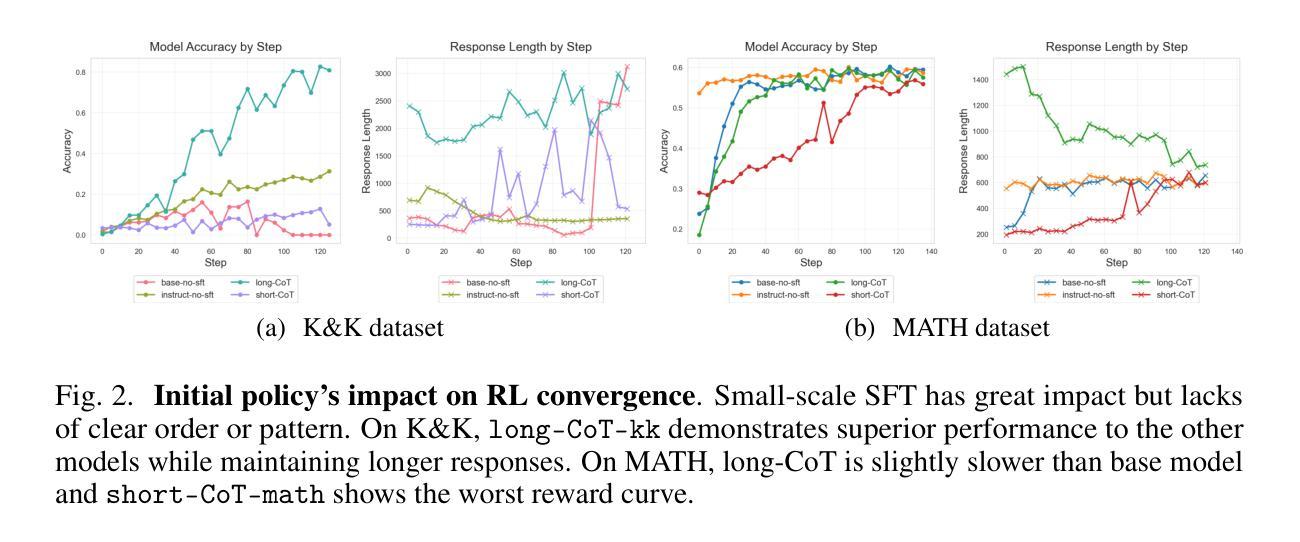
Towards Revealing the Effectiveness of Small-Scale Fine-tuning in R1-style Reinforcement Learning
Authors:Yutong Chen, Jiandong Gao, Ji Wu
R1-style Reinforcement Learning (RL) significantly enhances Large Language Models’ reasoning capabilities, yet the mechanism behind rule-based RL remains unclear. We found that small-scale SFT has significant influence on RL but shows poor efficiency. To explain our observations, we propose an analytical framework and compare the efficiency of SFT and RL by measuring sample effect. Hypothetical analysis show that SFT efficiency is limited by training data. Guided by our analysis, we propose Re-distillation, a technique that fine-tunes pretrain model through small-scale distillation from the RL-trained policy. Experiments on Knight & Knave and MATH datasets demonstrate re-distillation’s surprising efficiency: re-distilled models match RL performance with far fewer samples and less computation. Empirical verification shows that sample effect is a good indicator of performance improvements. As a result, on K&K dataset, our re-distilled Qwen2.5-1.5B model surpasses DeepSeek-V3-0324 with only 1K SFT samples. On MATH, Qwen2.5-1.5B fine-tuned with re-distilled 500 samples matches its instruct-tuned variant without RL. Our work explains several interesting phenomena in R1-style RL, shedding light on the mechanisms behind its empirical success. Code is available at: https://github.com/on1262/deep-reasoning
R1风格的强化学习(RL)显著增强了大型语言模型的推理能力,然而基于规则的RL背后的机制仍然不清楚。我们发现小规模SFT对RL有重大影响,但效率较低。为了解释我们的观察,我们提出了一个分析框架,通过测量样本效应来比较SFT和RL的效率。假设分析表明,SFT的效率受到训练数据的限制。在我们的分析指导下,我们提出了再蒸馏技术,这是一种通过小规模蒸馏对预训练模型进行微调的技术,蒸馏来自RL训练的策略。在Knight和Knave以及MATH数据集上的实验证明了再蒸馏的惊人效率:再蒸馏模型使用较少的样本和计算资源就能达到RL的性能。经验验证表明,样本效应是性能改进的良好指标。因此,在K&K数据集上,我们的再蒸馏Qwen2.5-1.5B模型仅使用1K个SFT样本就超过了DeepSeek-V3-0324。在MATH上,使用再蒸馏的500个样本对Qwen2.5-1.5B进行微调,可以匹配其未使用RL的指令调整变体。我们的工作解释了R1风格RL中的几个有趣现象,揭示了其经验成功的机制。代码可用在:https://github.com/on1262/deep-reasoning
论文及项目相关链接
PDF 11 figs, 3 table, preprint
Summary:
强化学习(RL)可以提升大型语言模型的推理能力,但其背后的机制尚不清楚。研究发现小规模样本替代训练(SFT)对RL有影响但效率不高。为此,提出分析框架并通过样本效应比较SFT和RL的效率。基于分析,提出再蒸馏技术,通过从RL训练的策略中进行小规模蒸馏来微调预训练模型。实验表明再蒸馏技术非常高效,再蒸馏模型使用更少的样本和计算就能匹配RL性能。代码已公开。
Key Takeaways:
- 强化学习可以增强大型语言模型的推理能力。
- 小规模样本替代训练对强化学习有影响,但效率不高。
- 提出分析框架来比较样本替代训练和强化学习的效率。
- 再蒸馏技术被提出,通过微调预训练模型以匹配强化学习的性能。
- 再蒸馏技术显著提高效率,使用更少的样本和计算就能达到强化学习的性能。
- 样本效应是评估性能改进的良好指标。
点此查看论文截图

Beyond Distillation: Pushing the Limits of Medical LLM Reasoning with Minimalist Rule-Based RL
Authors:Che Liu, Haozhe Wang, Jiazhen Pan, Zhongwei Wan, Yong Dai, Fangzhen Lin, Wenjia Bai, Daniel Rueckert, Rossella Arcucci
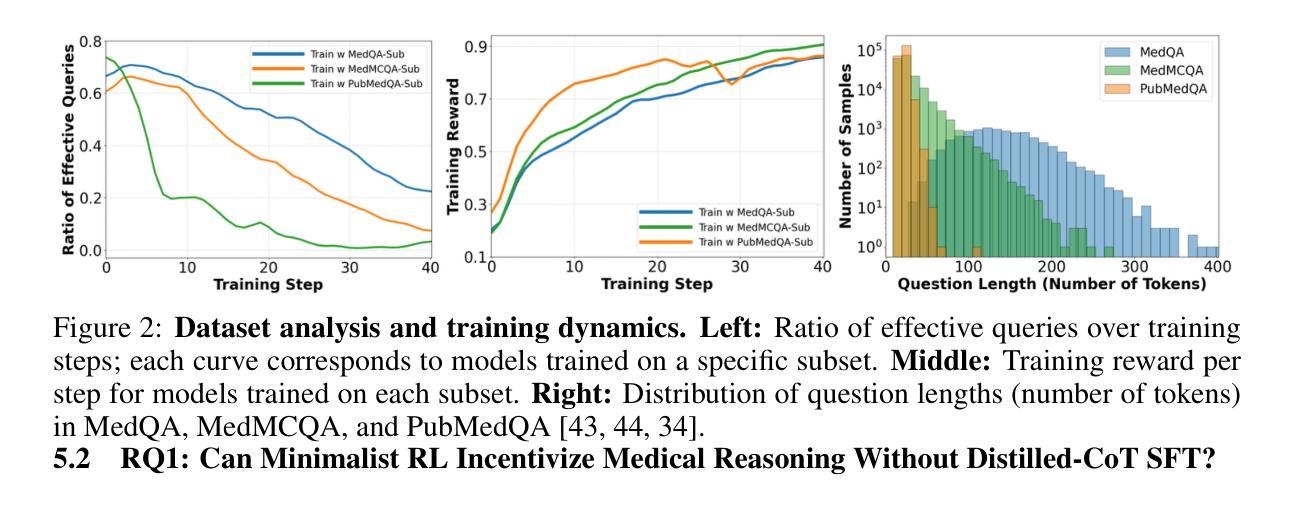
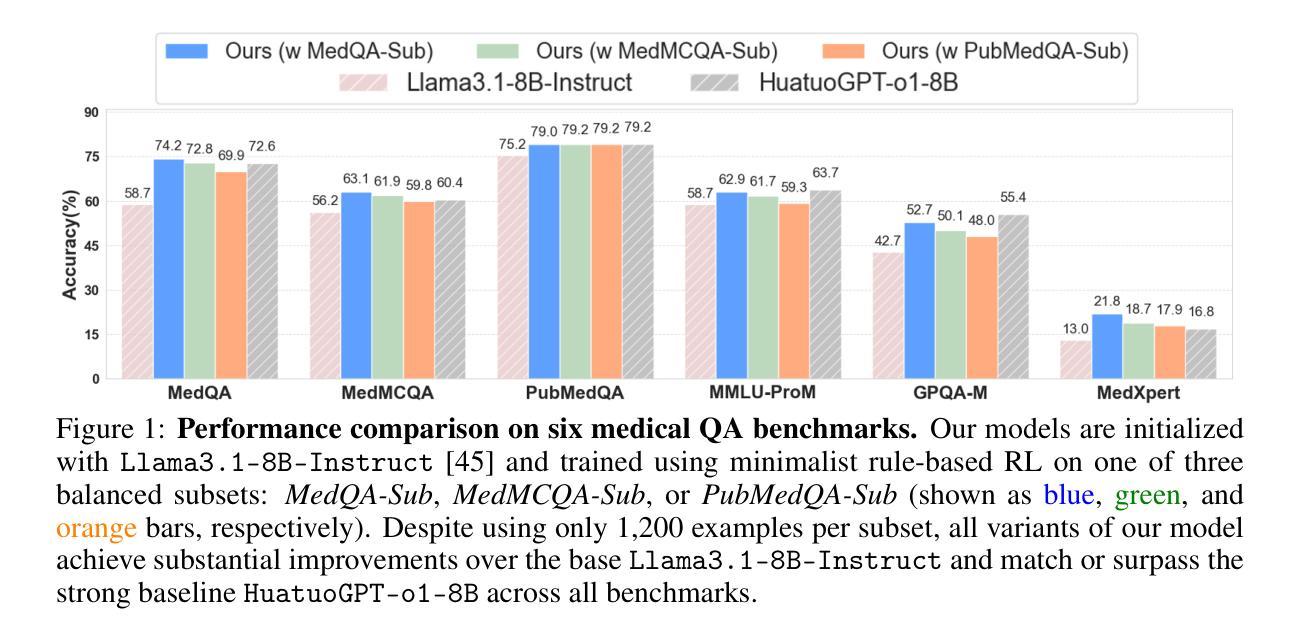
Improving performance on complex tasks and enabling interpretable decision making in large language models (LLMs), especially for clinical applications, requires effective reasoning. Yet this remains challenging without supervised fine-tuning (SFT) on costly chain-of-thought (CoT) data distilled from closed-source models (e.g., GPT-4o). In this work, we present AlphaMed, the first medical LLM to show that reasoning capability can emerge purely through reinforcement learning (RL), using minimalist rule-based rewards on public multiple-choice QA datasets, without relying on SFT or distilled CoT data. AlphaMed achieves state-of-the-art results on six medical QA benchmarks, outperforming models trained with conventional SFT+RL pipelines. On challenging benchmarks (e.g., MedXpert), AlphaMed even surpasses larger or closed-source models such as DeepSeek-V3-671B and Claude-3.5-Sonnet. To understand the factors behind this success, we conduct a comprehensive data-centric analysis guided by three questions: (i) Can minimalist rule-based RL incentivize reasoning without distilled CoT supervision? (ii) How do dataset quantity and diversity impact reasoning? (iii) How does question difficulty shape the emergence and generalization of reasoning? Our findings show that dataset informativeness is a key driver of reasoning performance, and that minimalist RL on informative, multiple-choice QA data is effective at inducing reasoning without CoT supervision. We also observe divergent trends across benchmarks, underscoring limitations in current evaluation and the need for more challenging, reasoning-oriented medical QA benchmarks.
在大型语言模型(LLM)中,特别是在临床应用中,提高复杂任务的性能并实现可解释的决策需要有效的推理能力。然而,在不需要昂贵的来自封闭源模型的思维链(CoT)数据的监督微调(SFT)的情况下,这仍然是一个挑战。在这项工作中,我们提出了AlphaMed,这是首个显示可以通过强化学习(RL)出现推理能力的医疗LLM。它基于公共多项选择题问答数据集的最小化规则奖励,不依赖于SFT或蒸馏的CoT数据。AlphaMed在六个医疗问答基准测试上达到了最先进的水平,优于使用传统SFT+RL管道训练的模型。在具有挑战性的基准测试(例如MedXpert)中,AlphaMed甚至超越了更大的或封闭源模型,如DeepSeek-V3-671B和Claude-3.5-Sonnet。为了了解这一成功的背后因素,我们在三个问题的指导下进行了全面的以数据为中心的分析:(i)是否可以仅通过基于最小化规则的RL来激励推理,而无需蒸馏的CoT监督?(ii)数据集的数量和多样性如何影响推理?(iii)问题的难度如何影响推理的出现和泛化?我们的研究结果表明,数据集的信息性是推动推理性能的关键因素,而在信息丰富的多项选择题问答数据上采用基于最小化规则的RL可以有效地在没有CoT监督的情况下激发推理能力。此外,我们在不同的基准测试中观察到不同的趋势,这突显了当前评估的局限性以及需要更具挑战性、以推理为导向的医疗问答基准测试。
论文及项目相关链接
PDF Under Review
Summary
基于提供的文本内容,AlphaMed作为一种新的大型语言模型(LLM),展示了在不需要监督精细调整(SFT)或蒸馏思维数据的情况下,通过强化学习(RL)实现推理能力的潜力。在六个医学问答基准测试中,AlphaMed达到了前所未有的高水平表现,甚至在一些挑战较大的测试中超过了更大的封闭源模型。这项工作的重点在解决如何通过公开的多选题问答数据集实现纯粹的基于规则的奖励机制来推动推理能力的发展。对此背后的成功因素进行了数据为中心的综合分析,包括强化学习是否能激励无蒸馏思维监督的推理能力的发展、数据集的数量和多样性对推理的影响以及问题难度对推理能力的出现和泛化的影响等三个关键问题。结果显示,数据集信息性是影响推理性能的关键因素,在多个选择问答数据上的简化RL对于激励无监督思维的推理能力具有有效效果。总结AlphaMed的核心优点为利用简易规则奖励来推进LLM推理能力的提升且不需要特定的任务数据源,如在临床情境下关于病情治疗或者其它情况,非常实用且具有潜力。同时,该研究也指出了当前评估和医学问答基准测试的挑战性不足,并强调了未来需要更多挑战性的医学问答基准测试来评估推理能力的重要性。这项研究将为推动无监督学习的推理能力发展及临床应用场景开辟新的可能性和道路。这是对未来无监督学习任务的发展和具体领域应用的双重推动力。目前研究成果提供了一个引人注目的可能性方向供我们探索和深化理解其可能性和潜力。未来有望看到更多关于无监督学习推理能力的突破和实际应用。AlphaMed的推出无疑为医学领域的问答系统带来了革命性的变革。总的来说,AlphaMed作为一种新型的LLM模型展现了其独特的优势与潜力。总结不足一百字但核心要点突出。关于具体表现和数据细节建议查阅原文或相关研究报告以获取更多信息。总的来说,这是一个具有里程碑意义的突破,为未来的医疗AI发展开辟了新的道路。
Key Takeaways
以下是七个关于该文本的关键见解:
- AlphaMed是首个展示纯粹通过强化学习实现推理能力的大型医疗语言模型(LLM)。它无需监督精细调整或蒸馏思维数据。
- AlphaMed在六个医学问答基准测试中达到了前所未有的高水平表现,甚至超越了某些大型封闭源模型。
- AlphaMed通过公开的多选题问答数据集实现基于规则的奖励机制来推动推理能力的发展。这种机制无需特定的任务数据源进行监督训练。
点此查看论文截图

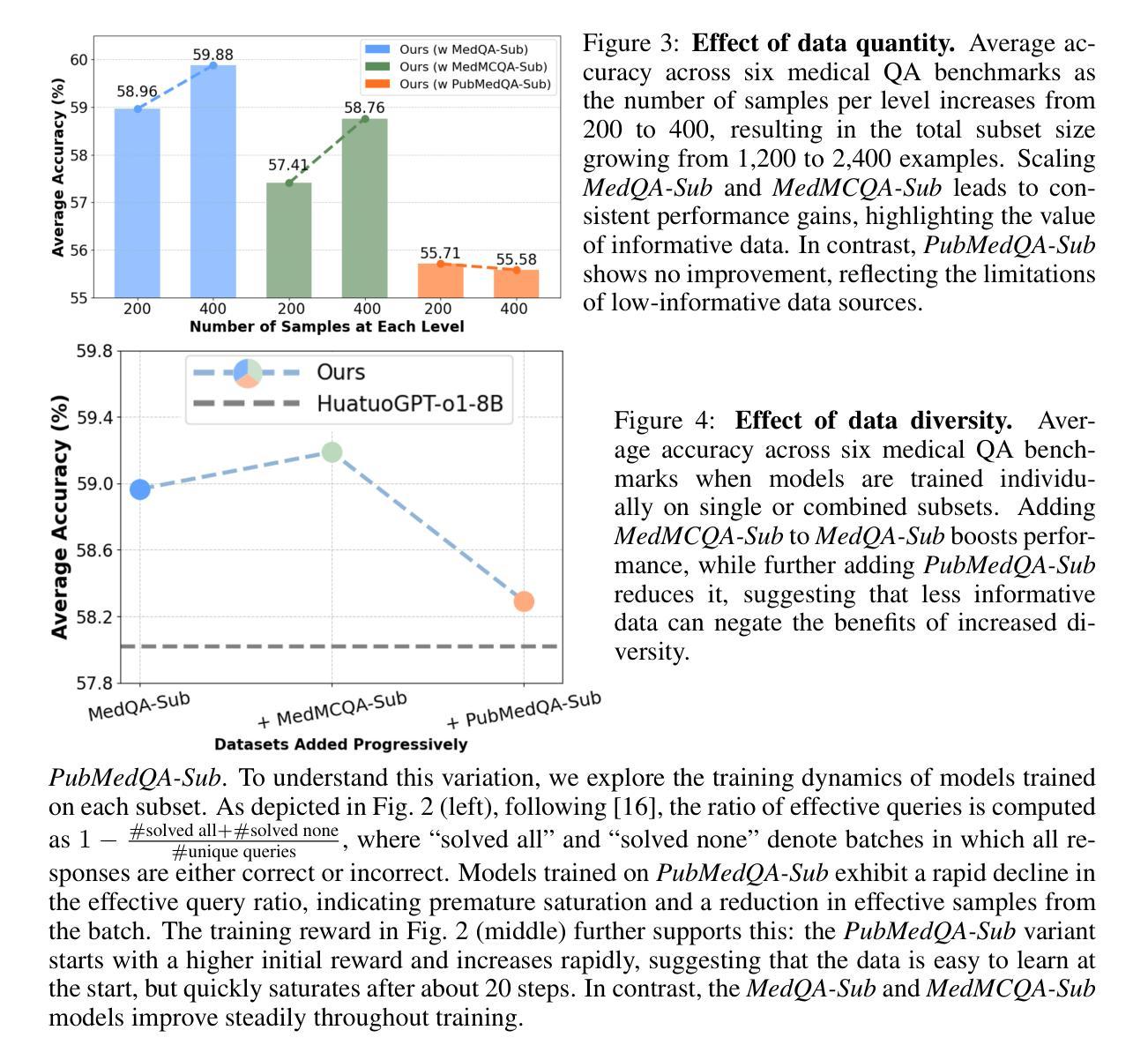
VeriThinker: Learning to Verify Makes Reasoning Model Efficient
Authors:Zigeng Chen, Xinyin Ma, Gongfan Fang, Ruonan Yu, Xinchao Wang
Large Reasoning Models (LRMs) excel at complex tasks using Chain-of-Thought (CoT) reasoning. However, their tendency to overthinking leads to unnecessarily lengthy reasoning chains, dramatically increasing inference costs. To mitigate this issue, we introduce VeriThinker, a novel approach for CoT compression. Unlike conventional methods that fine-tune LRMs directly on the original reasoning task using synthetic concise CoT data, we innovatively fine-tune the model solely through an auxiliary verification task. By training LRMs to accurately verify the correctness of CoT solutions, the LRMs inherently become more discerning about the necessity of subsequent self-reflection steps, thereby effectively suppressing overthinking. Extensive experiments validate that VeriThinker substantially reduces reasoning chain lengths while maintaining or even slightly improving accuracy. When applied to DeepSeek-R1-Distill-Qwen-7B, our approach reduces reasoning tokens on MATH500 from 3790 to 2125 while improving accuracy by 0.8% (94.0% to 94.8%), and on AIME25, tokens decrease from 14321 to 10287 with a 2.1% accuracy gain (38.7% to 40.8%). Additionally, our experiments demonstrate that VeriThinker can also be zero-shot generalized to speculative reasoning. Code is available at https://github.com/czg1225/VeriThinker
大型推理模型(LRMs)在利用思维链(CoT)进行复杂任务时表现出色。然而,它们往往会过度思考,导致推理链过于冗长,从而显著增加推理成本。为了缓解这个问题,我们引入了VeriThinker,这是一种新型的CoT压缩方法。不同于使用合成简洁CoT数据直接在原始推理任务上微调LRMs的常规方法,我们创新地仅通过辅助验证任务来微调模型。通过训练LRMs准确验证CoT解决方案的正确性,LRMs能够更自然地判断后续自我反思步骤的必要性,从而有效地抑制过度思考。大量实验验证,VeriThinker在保持或略微提高准确性的同时,实质性地减少了推理链的长度。当应用于DeepSeek-R1-Distill-Qwen-7B时,我们的方法将MATH500的推理令牌从3790减少到2125,准确率提高0.8%(从94.0%提高到94.8%),在AIME25上,令牌从14321减少到10287,准确率提高2.1%(从38.7%提高到40.8%)。此外,我们的实验还表明,VeriThinker可以零样本泛化到推测性推理。代码可在https://github.com/czg1225/VeriThinker处获取。
论文及项目相关链接
PDF Working in progress. Code Repo: https://github.com/czg1225/VeriThinker
Summary
大型推理模型(LRMs)通过链式思维(CoT)进行复杂任务表现出色,但存在过度思考的问题,导致推理链过长,推理成本增加。为解决这一问题,提出一种新型的CoT压缩方法——VeriThinker。不同于传统方法直接使用合成简洁的CoT数据对LRMs进行微调,我们创新地仅通过辅助验证任务对模型进行训练。通过训练LRMs准确验证CoT解决方案的正确性,模型能够自我反思,有效抑制过度思考。实验证明,VeriThinker在减少推理链长度的同时,维持或略微提高了准确性。应用于DeepSeek-R1-Distill-Qwen-7B和AIME25数据集上,VeriThinker实现了显著的推理令牌减少和准确性提升。此外,VeriThinker还可以零射击泛化至推测性推理。
Key Takeaways
- 大型推理模型(LRMs)在复杂任务中表现出色,但存在过度思考和推理链过长的问题。
- VeriThinker是一种新型的CoT压缩方法,通过辅助验证任务训练模型,有效抑制过度思考。
- VeriThinker能够减少推理链长度,同时维持或提高模型的准确性。
- 在DeepSeek-R1-Distill-Qwen-7B和AIME25数据集上,VeriThinker实现了显著的推理令牌减少和准确性提升。
- VeriThinker具有零射击泛化能力,可应用于推测性推理。
- VeriThinker的方法不同于传统直接使用合成简洁的CoT数据对LRMs进行微调的方法。
点此查看论文截图

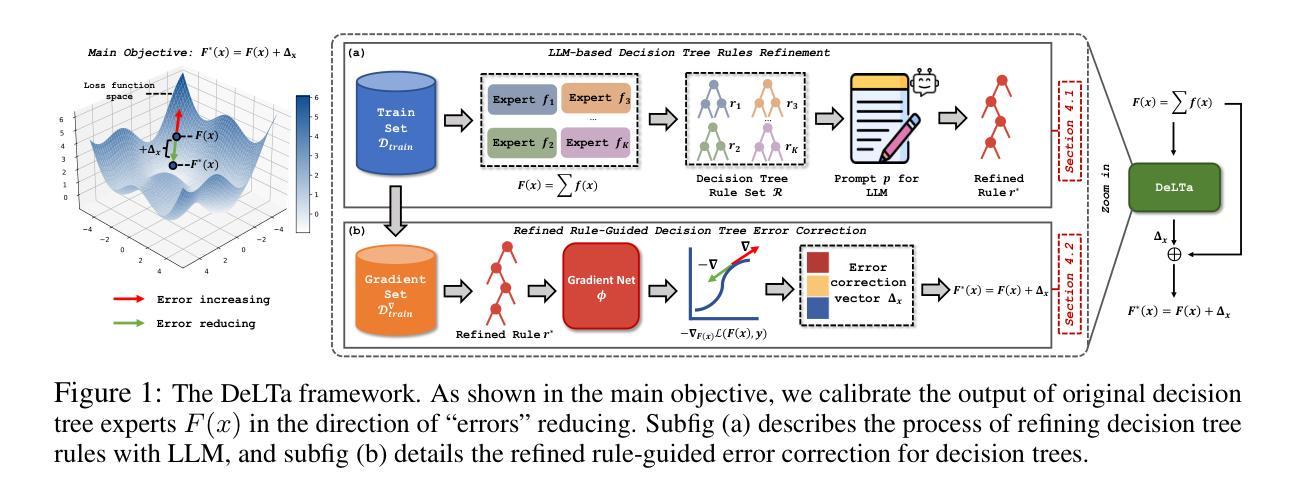
LLM Meeting Decision Trees on Tabular Data
Authors:Hangting Ye, Jinmeng Li, He Zhao, Dandan Guo, Yi Chang
Tabular data have been playing a vital role in diverse real-world fields, including healthcare, finance, etc. With the recent success of Large Language Models (LLMs), early explorations of extending LLMs to the domain of tabular data have been developed. Most of these LLM-based methods typically first serialize tabular data into natural language descriptions, and then tune LLMs or directly infer on these serialized data. However, these methods suffer from two key inherent issues: (i) data perspective: existing data serialization methods lack universal applicability for structured tabular data, and may pose privacy risks through direct textual exposure, and (ii) model perspective: LLM fine-tuning methods struggle with tabular data, and in-context learning scalability is bottle-necked by input length constraints (suitable for few-shot learning). This work explores a novel direction of integrating LLMs into tabular data throughough logical decision tree rules as intermediaries, proposes a decision tree enhancer with LLM-derived rule for tabular prediction, DeLTa. The proposed DeLTa avoids tabular data serialization, and can be applied to full data learning setting without LLM fine-tuning. Specifically, we leverage the reasoning ability of LLMs to redesign an improved rule given a set of decision tree rules. Furthermore, we provide a calibration method for original decision trees via new generated rule by LLM, which approximates the error correction vector to steer the original decision tree predictions in the direction of ``errors’’ reducing. Finally, extensive experiments on diverse tabular benchmarks show that our method achieves state-of-the-art performance.
表格数据在包括医疗、金融等现实世界的多个领域中都发挥着至关重要的作用。随着大型语言模型(LLM)的近期成功,将LLM扩展到表格数据领域的研究也已经展开。大多数基于LLM的方法通常首先将表格数据序列化为自然语言描述,然后对LLM进行调整或直接对这些序列化数据进行推断。然而,这些方法存在两个主要内在问题:(i)数据视角:现有的数据序列化方法缺乏针对结构化表格数据的通用适用性,并且可能通过直接的文本暴露造成隐私风险;(ii)模型视角:LLM微调方法在处理表格数据时面临困难,而基于上下文的学习的可扩展性受到输入长度限制(适用于小样本学习)。本研究探索了一个通过逻辑决策树规则将LLM集成到表格数据中的新方向,提出了一种用于表格预测的带有LLM衍生规则的决策树增强器DeLTa。所提出的DeLTa避免了表格数据序列化,并可用于全数据学习设置,无需对LLM进行微调。具体来说,我们利用LLM的推理能力来改进给定决策树规则集的设计。此外,我们通过LLM生成的新规则提供了一种对原始决策树进行校准的方法,该方法通过逼近误差校正向量来引导原始决策树预测朝减少“错误”的方向发展。最后,在多种表格基准测试上的广泛实验表明,我们的方法达到了最新性能水平。
论文及项目相关链接
摘要
表格数据在现实世界中的多个领域(如医疗和金融)中发挥着至关重要的作用。随着大型语言模型(LLM)的近期成功,将LLM扩展到表格数据领域的研究已经开始。然而,大多数基于LLM的方法通常先将表格数据序列化为自然语言描述,然后调整LLM或直接对这些序列化数据进行推断。这些方法存在两个关键问题:数据视角:现有数据序列化方法缺乏结构化表格数据的通用适用性,并且可能通过直接文本暴露造成隐私风险;模型视角:LLM微调方法在处理表格数据时面临困难,而上下文学习的可扩展性受到输入长度约束的限制(适用于小样本学习)。本研究通过逻辑决策树规则探索了整合LLM与表格数据的新方向,提出了一种用于表格预测的决策树增强器DeLTa。DeLTa避免了表格数据序列化,并适用于全数据学习设置,无需LLM微调。具体来说,我们利用LLM的推理能力来改进给定决策树规则集的重构规则。此外,我们提供了一种通过LLM生成的新规则对原始决策树进行校准的方法,该方法通过近似误差校正向量来引导原始决策树预测朝向减少误差的方向。在多种表格基准测试上的广泛实验表明,我们的方法达到了最新性能水平。
关键见解
- 大型语言模型(LLM)已成功应用于表格数据处理领域。
- 当前基于LLM的方法通常涉及表格数据的序列化,存在通用适用性和隐私风险问题。
- 通过逻辑决策树规则整合LLM与表格数据是一种新兴研究方向。
- 提出的DeLTa方法避免了表格数据序列化,适用于全数据学习,无需对LLM进行微调。
- DeLTa利用LLM的推理能力改进决策树规则,提高表格预测性能。
- DeLTa还提供了一种校准原始决策树的方法,通过LLM生成的新规则来近似误差校正向量。
点此查看论文截图


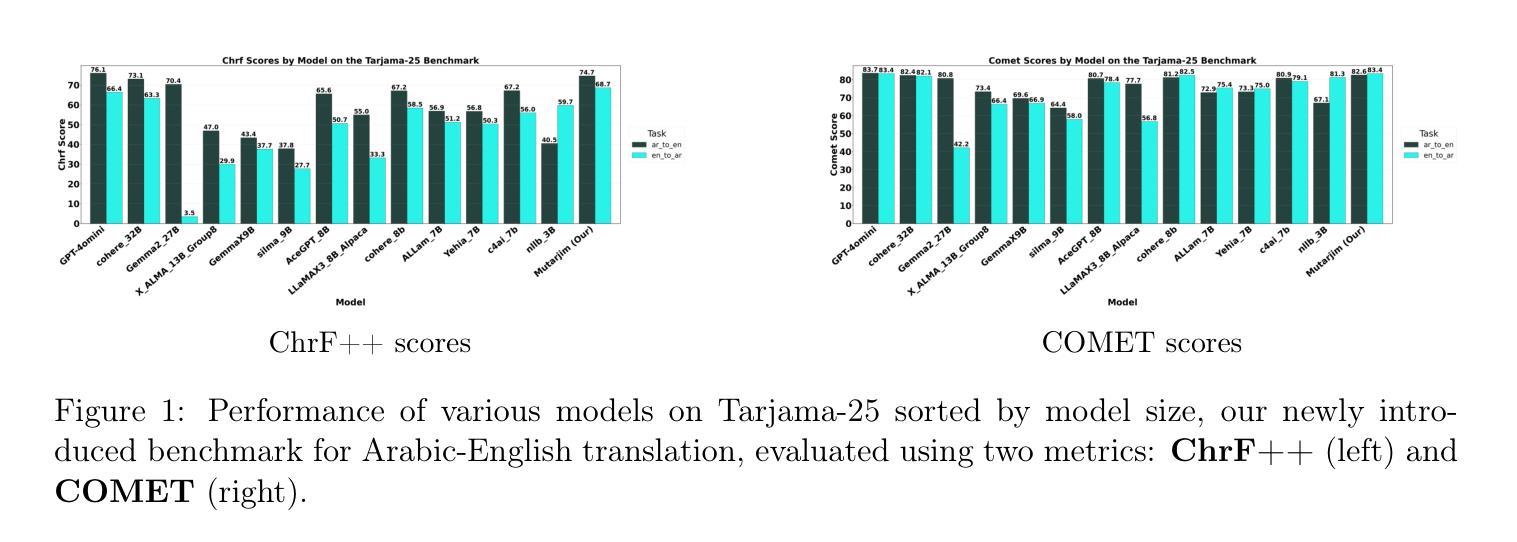
Mutarjim: Advancing Bidirectional Arabic-English Translation with a Small Language Model
Authors:Khalil Hennara, Muhammad Hreden, Mohamed Motaism Hamed, Zeina Aldallal, Sara Chrouf, Safwan AlModhayan
We introduce Mutarjim, a compact yet powerful language model for bidirectional Arabic-English translation. While large-scale LLMs have shown impressive progress in natural language processing tasks, including machine translation, smaller models. Leveraging this insight, we developed Mutarjim based on Kuwain-1.5B , a language model tailored for both Arabic and English. Despite its modest size, Mutarjim outperforms much larger models on several established benchmarks, achieved through an optimized two-phase training approach and a carefully curated, high-quality training corpus.. Experimental results show that Mutarjim rivals models up to 20 times larger while significantly reducing computational costs and training requirements. We also introduce Tarjama-25, a new benchmark designed to overcome limitations in existing Arabic-English benchmarking datasets, such as domain narrowness, short sentence lengths, and English-source bias. Tarjama-25 comprises 5,000 expert-reviewed sentence pairs and spans a wide range of domains, offering a more comprehensive and balanced evaluation framework. Notably, Mutarjim achieves state-of-the-art performance on the English-to-Arabic task in Tarjama-25, surpassing even significantly larger and proprietary models like GPT-4o mini. We publicly release Tarjama-25 to support future research and advance the evaluation of Arabic-English translation systems.
我们推出了Mutarjim,这是一款紧凑而强大的双向阿拉伯语-英语翻译语言模型。尽管大型LLM在自然语言处理任务(包括机器翻译)方面取得了令人印象深刻的进展,但小型模型仍然具有优势。利用这一见解,我们基于面向阿拉伯语和英语的定制语言模型Kuwain-1.5B开发了Mutarjim。尽管规模适中,Mutarjim在多个基准测试上的表现优于更大的模型,这是通过优化的两阶段培训方法和精心挑选的高质量训练语料库实现的。实验结果表明,Mutarjim的表现可与大二十倍的模型相抗衡,同时大大降低了计算成本和培训要求。我们还推出了Tarjama-25,这是一个新的基准测试,旨在克服现有阿拉伯语-英语基准测试数据集的局限性,如领域狭窄、句子简短和英语源偏见等。Tarjama-25包含专家审阅的五千句对,涵盖广泛的领域,提供了更全面、更平衡的评价框架。值得注意的是,Mutarjim在Tarjama-25的英语到阿拉伯语任务上取得了最先进的性能表现,甚至超越了更大、更专业的模型如GPT-4o mini等。我们公开发布Tarjama-25,以支持未来的研究并推动阿拉伯语到英语的翻译系统评估的发展。
论文及项目相关链接
Summary
阿拉伯语-英语双向翻译语言模型Mutarjim被推出,它基于Kuwain-1.5B开发,具有强大的性能且规模紧凑。通过优化两阶段训练方法和精心筛选的高质量训练语料库,Mutarjim在多个基准测试上表现超越大型模型。此外,还推出了新的阿拉伯语-英语基准测试Tarjama-25,以克服现有基准测试集的局限性。Mutarjim在Tarjama-25的英语到阿拉伯语任务上表现卓越,甚至超越了一些更大的专有模型。Tarjama-25已公开发布,以支持未来研究和推动阿拉伯语-英语翻译系统的评估。
Key Takeaways
- Mutarjim是一个用于阿拉伯语-英语双向翻译的紧凑而强大的语言模型。
- 基于Kuwain-1.5B开发,该模型针对阿拉伯语和英语进行定制。
- 通过优化两阶段训练方法和高质量训练语料库,Mutarjim在多个基准测试中表现优异。
- Mutarjim在Tarjama-25的英语到阿拉伯语任务上实现了最新技术性能。
- Tarjama-25是一个新的阿拉伯语-英语基准测试,旨在克服现有基准测试集的局限性。
- Tarjama-25包含5000个专家审阅的句子对,覆盖广泛领域,提供更全面和平衡的评价框架。
点此查看论文截图

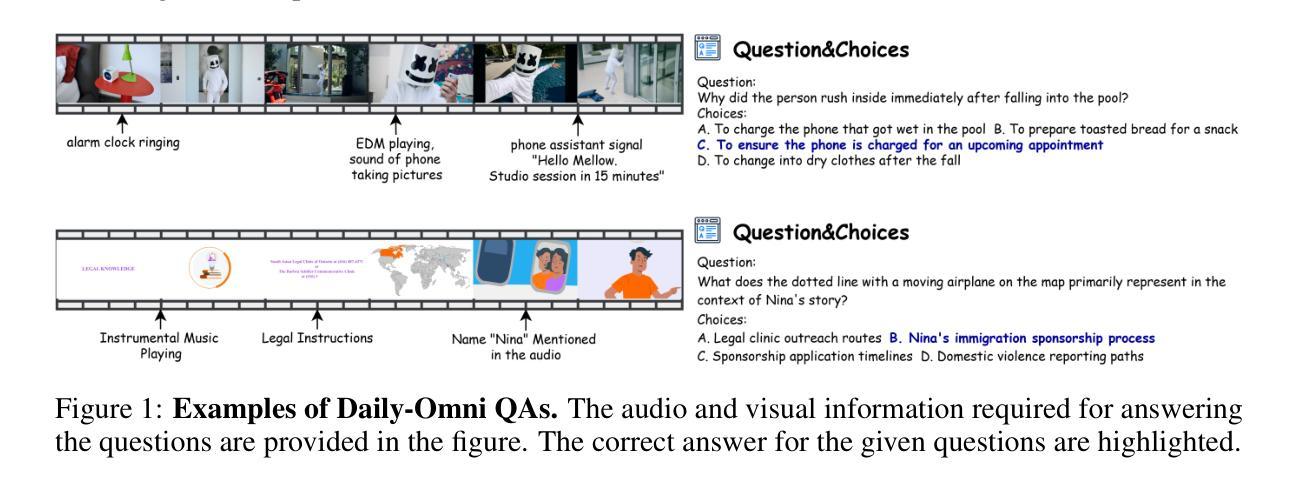
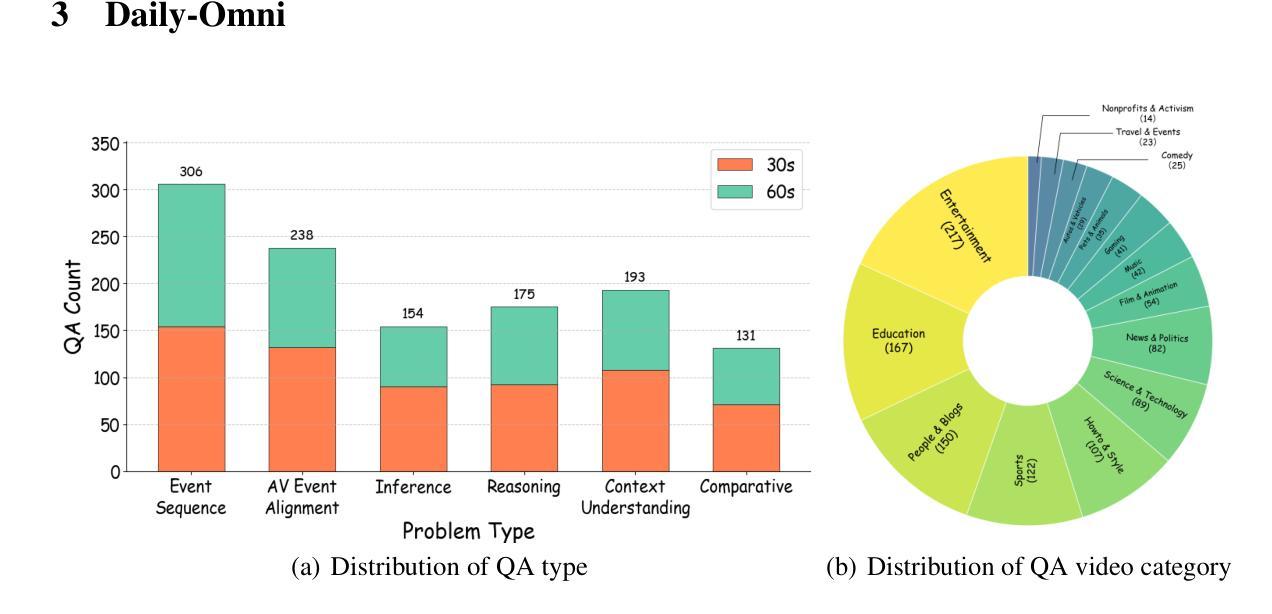
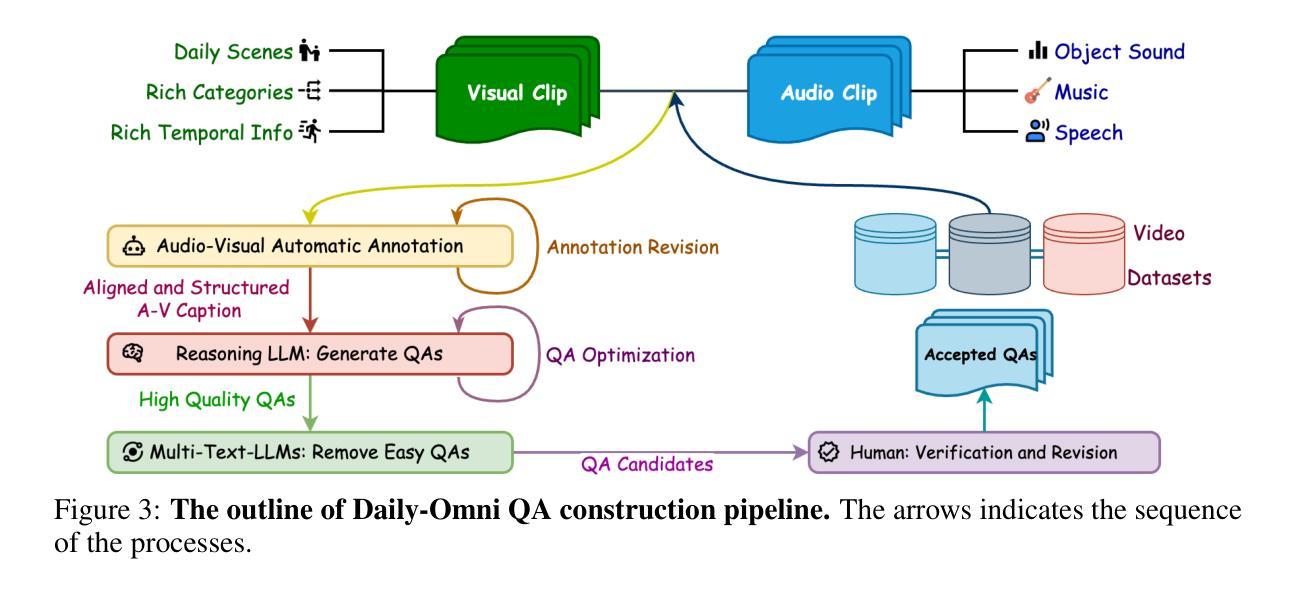
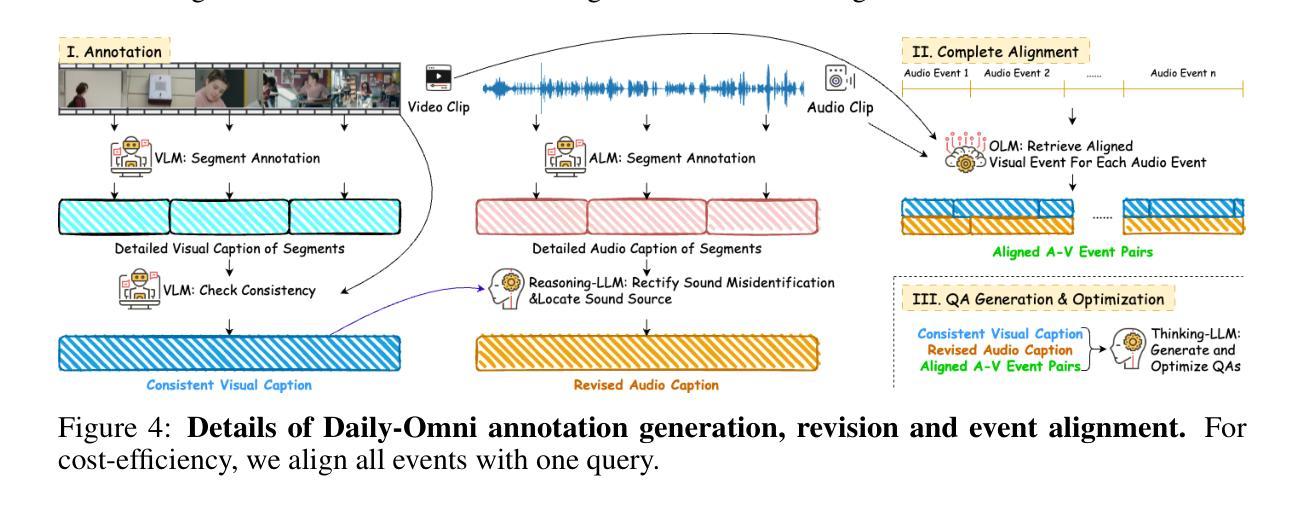
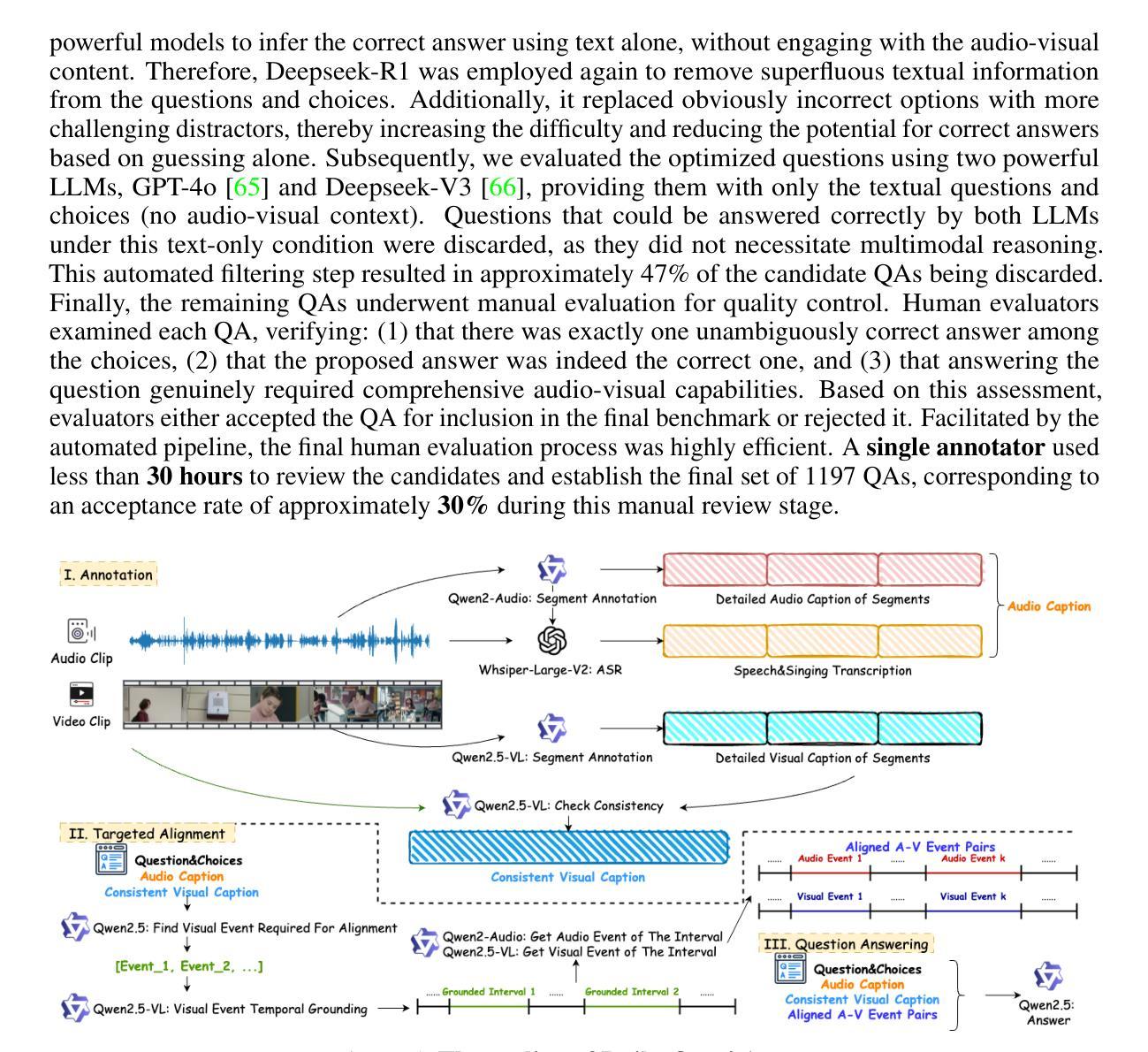
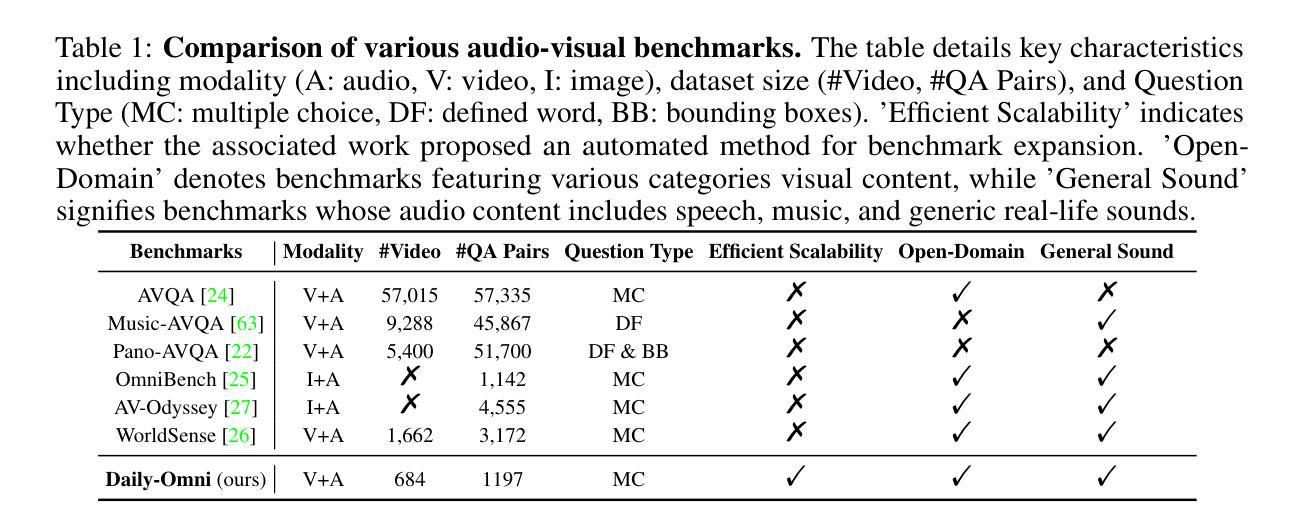
Daily-Omni: Towards Audio-Visual Reasoning with Temporal Alignment across Modalities
Authors:Ziwei Zhou, Rui Wang, Zuxuan Wu
Recent Multimodal Large Language Models (MLLMs) achieve promising performance on visual and audio benchmarks independently. However, the ability of these models to process cross-modal information synchronously remains largely unexplored. In this paper, we introduce: 1) Daily-Omni, an Audio-Visual Questioning and Answering benchmark comprising 684 videos of daily life scenarios from diverse sources, rich in both audio and visual information, and featuring 1197 multiple-choice QA pairs across 6 major tasks; 2) Daily-Omni QA Generation Pipeline, which includes automatic annotation, QA generation and QA optimization, significantly improves efficiency for human evaluation and scalability of the benchmark; 3) Daily-Omni-Agent, a training-free agent utilizing open-source Visual Language Model (VLM), Audio Language Model (ALM) and Automatic Speech Recognition (ASR) model to establish a baseline for this benchmark. The results show that current MLLMs still struggle significantly with tasks requiring audio-visual integration, but combining VLMs and ALMs with simple temporal alignment techniques can achieve substantially better performance. Codes and benchmark are available at \href{https://github.com/Lliar-liar/Daily-Omni}{https://github.com/Lliar-liar/Daily-Omni}.
最近的多模态大型语言模型(MLLMs)在视觉和音频基准测试上独立地取得了有前景的表现。然而,这些模型处理跨模态信息同步的能力仍然很大程度上未被探索。在本文中,我们介绍了:1)Daily-Omni,这是一个音频视觉问答基准测试,包含684个来自不同来源的日常生活场景视频,富含音频和视觉信息,涵盖6大类任务的1197个多项选择问答对;2)Daily-Omni QA生成管道,包括自动注释、问答生成和问答优化,显著提高人类评估和基准测试可扩展性的效率;3)Daily-Omni-Agent,这是一个利用开源视觉语言模型(VLM)、音频语言模型(ALM)和自动语音识别(ASR)模型的无需训练代理,为这个基准测试建立基准。结果表明,当前的多模态大型语言模型在处理需要视听融合的任务时仍然面临巨大挑战,但通过结合VLMs和ALMs与简单的时序对齐技术,可以取得显著更好的性能。代码和基准测试可在https://github.com/Lliar-liar/Daily-Omni访问。
论文及项目相关链接
Summary
近期多模态大型语言模型(MLLMs)在视觉和音频基准测试上表现出良好的性能,但对跨模态信息同步处理的能力仍待探索。本文介绍了:1)Daily-Omni视听问答基准测试,包含684个日常生活场景的视频,富含视听信息,涵盖6大类任务的1197个选择题;2)Daily-Omni问答生成管道,包括自动标注、问答生成和问答优化,提高了基准测试的人类评估效率和可扩展性;3) Daily-Omni-Agent,一个无需训练的代理,利用开源的视觉语言模型(VLM)、音频语言模型(ALM)和自动语音识别(ASR)模型,为这个基准测试建立了基线。结果表明,当前MLLMs在处理需要视听整合的任务时仍存在较大困难,但通过结合VLMs和ALMs以及简单的时间对齐技术,可以取得更好的性能。
Key Takeaways
- 多模态大型语言模型(MLLMs)在独立处理视觉和音频基准测试时表现良好。
- 跨模态信息同步处理能力仍是MLLMs的一个未被充分探索的领域。
- Daily-Omni是一个新的视听问答基准测试,包含丰富多样的视听信息。
- Daily-Omni问答生成管道通过自动标注、问答生成和问答优化提高了效率。
- Daily-Omni-Agent利用视觉语言模型(VLM)、音频语言模型(ALM)和自动语音识别(ASR)模型为基准测试建立了基线。
- 当前MLLMs在处理需要视听整合的任务时存在困难。
点此查看论文截图

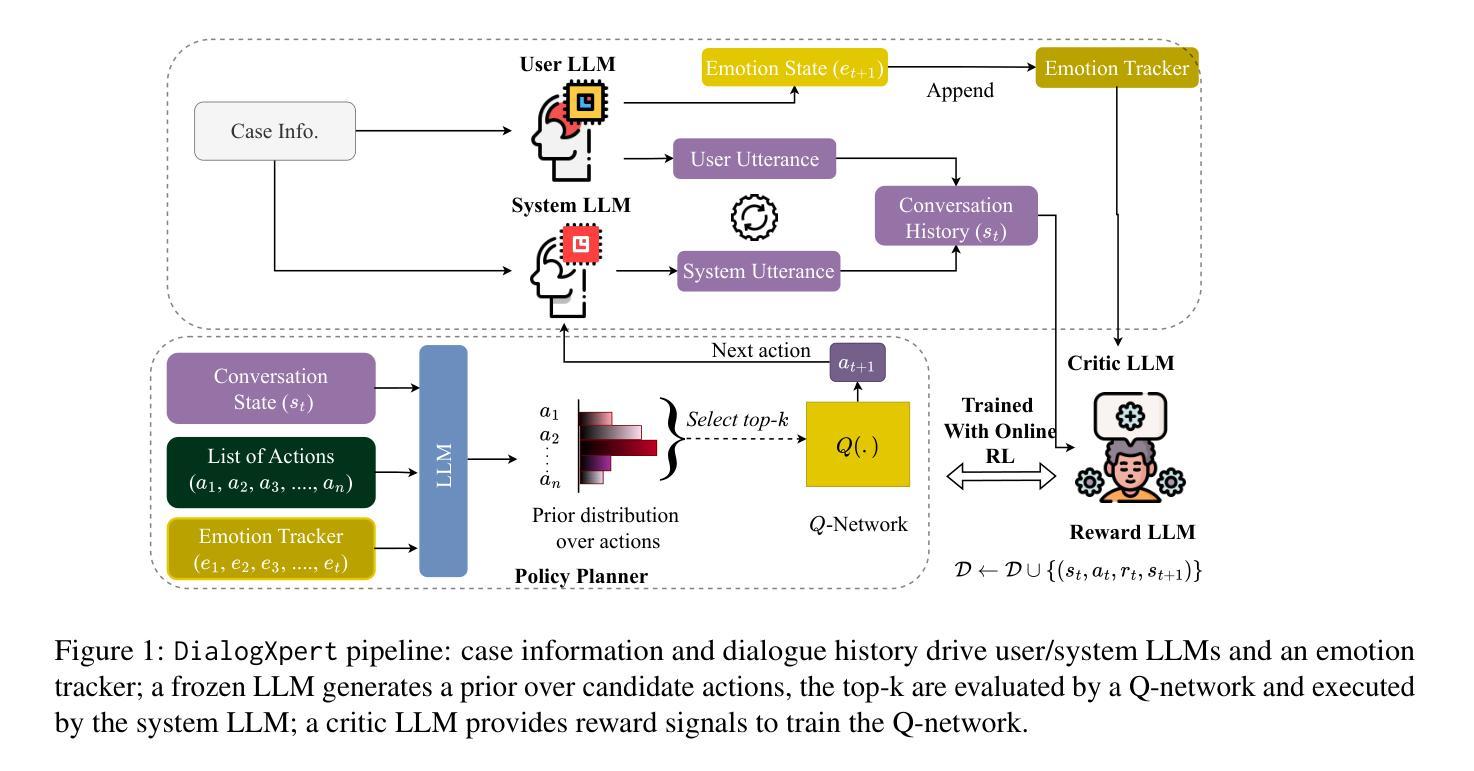
DialogXpert: Driving Intelligent and Emotion-Aware Conversations through Online Value-Based Reinforcement Learning with LLM Priors
Authors:Tazeek Bin Abdur Rakib, Ambuj Mehrish, Lay-Ki Soon, Wern Han Lim, Soujanya Poria
Large-language-model (LLM) agents excel at reactive dialogue but struggle with proactive, goal-driven interactions due to myopic decoding and costly planning. We introduce DialogXpert, which leverages a frozen LLM to propose a small, high-quality set of candidate actions per turn and employs a compact Q-network over fixed BERT embeddings trained via temporal-difference learning to select optimal moves within this reduced space. By tracking the user’s emotions, DialogXpert tailors each decision to advance the task while nurturing a genuine, empathetic connection. Across negotiation, emotional support, and tutoring benchmarks, DialogXpert drives conversations to under $3$ turns with success rates exceeding 94% and, with a larger LLM prior, pushes success above 97% while markedly improving negotiation outcomes. This framework delivers real-time, strategic, and emotionally intelligent dialogue planning at scale. Code available at https://github.com/declare-lab/dialogxpert/
大语言模型(LLM)代理在反应式对话方面表现出色,但在主动、目标驱动交互方面却面临困难,原因在于其视野有限的解码和高昂的规划成本。我们推出了DialogXpert,它通过利用冻结的LLM提出每一回合的一组小的高质量行动候选,并使用紧凑的Q网络在固定的BERT嵌入上进行时间差分学习训练来选择在此缩减空间内的最佳行动。通过跟踪用户的情绪,DialogXpert能够针对每个决策来推进任务,同时培养真诚、富有同情心的联系。在谈判、情感支持和辅导等基准测试中,DialogXpert将对话次数控制在不到三轮以内,成功率超过94%,并且在有更大的LLM先验知识的情况下,成功率提升至超过97%,同时显著改善了谈判结果。此框架实现了大规模实时、战略性和情感智能的对话规划。代码可在https://github.com/declare-lab/dialogxpert/找到。
论文及项目相关链接
Summary
大语言模型(LLM)在处理反应式对话方面表现出色,但在目标驱动型互动方面存在困难,存在解码近视和规划成本高昂的问题。为此,我们推出DialogXpert技术,它通过利用冻结的LLM生成每个回合的一小套高质量动作候选集,并使用紧凑的Q网络在固定的BERT嵌入上进行时序差分学习训练来选择最优动作。通过追踪用户的情绪,DialogXpert能在推进任务的同时定制决策并培养真诚、富有同情心的联系。在谈判、情感支持和辅导等多个基准测试中,DialogXpert将对话驱动到不到三回合的范围内,成功率超过百分之九十四。配合大型LLM进行提前学习,成功率更是提升到百分之九十七以上,显著改善谈判结果。该技术框架可实现实时、策略性且情感智能的对话规划规模化应用。相关代码已上传至GitHub仓库:[GitHub仓库链接]。
Key Takeaways
- 大语言模型(LLM)在处理反应式对话方面表现出色,但在目标驱动型互动上存在局限。
- DialogXpert技术通过利用LLM生成动作候选集并结合紧凑的Q网络选择最优动作来解决这一问题。
- DialogXpert能够追踪用户情绪,并根据情绪定制决策以推进任务并培养真诚、富有同情心的交流。
- DialogXpert技术在多个基准测试中表现优秀,能将对话控制在三回合内,且成功率极高。
- 结合大型LLM进行提前学习可进一步提升DialogXpert的成功率。
- DialogXpert显著改善谈判结果,具有实际应用价值。
点此查看论文截图

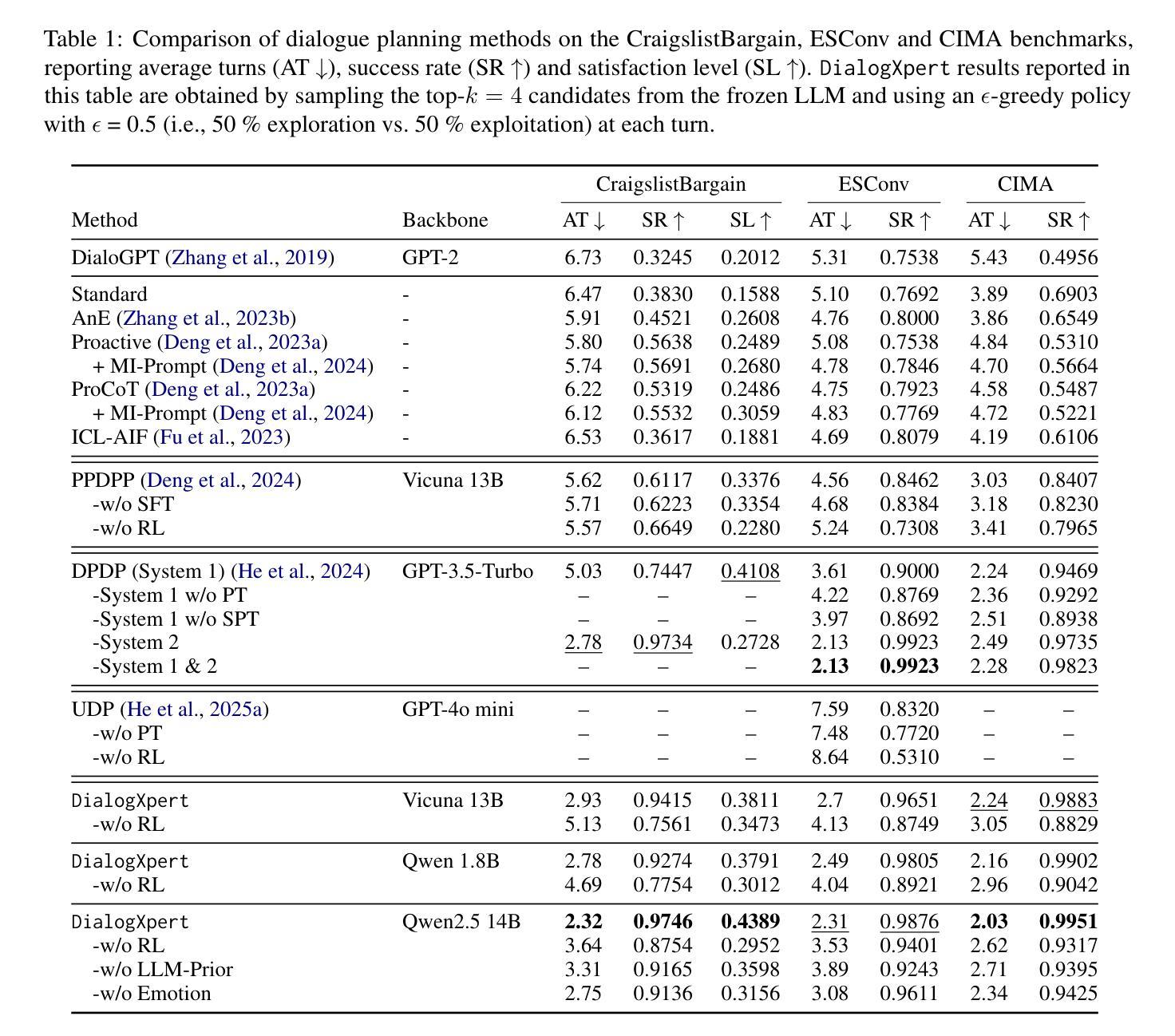
RECIPE-TKG: From Sparse History to Structured Reasoning for LLM-based Temporal Knowledge Graph Completion
Authors:Ömer Faruk Akgül, Feiyu Zhu, Yuxin Yang, Rajgopal Kannan, Viktor Prasanna
Temporal Knowledge Graphs (TKGs) represent dynamic facts as timestamped relations between entities. TKG completion involves forecasting missing or future links, requiring models to reason over time-evolving structure. While LLMs show promise for this task, existing approaches often overemphasize supervised fine-tuning and struggle particularly when historical evidence is limited or missing. We introduce RECIPE-TKG, a lightweight and data-efficient framework designed to improve accuracy and generalization in settings with sparse historical context. It combines (1) rule-based multi-hop retrieval for structurally diverse history, (2) contrastive fine-tuning of lightweight adapters to encode relational semantics, and (3) test-time semantic filtering to iteratively refine generations based on embedding similarity. Experiments on four TKG benchmarks show that RECIPE-TKG outperforms previous LLM-based approaches, achieving up to 30.6% relative improvement in Hits@10. Moreover, our proposed framework produces more semantically coherent predictions, even for the samples with limited historical context.
时序知识图谱(TKGs)代表实体之间带有时间戳的关系作为动态事实。TKG补全涉及预测缺失或未来的链接,要求模型对时间演化的结构进行推理。虽然大型语言模型(LLMs)在这个任务上显示出潜力,但现有方法往往过分强调监督微调,当历史证据有限或缺失时,尤其会遇到困难。我们引入了RECIPE-TKG,这是一个轻量级且数据高效的框架,旨在在稀疏历史背景的情境下提高准确性和泛化能力。它结合了(1)基于规则的多跳检索,以获取结构多样的历史信息;(2)对比微调轻量级适配器以编码关系语义;(3)测试时的语义过滤,基于嵌入相似性进行迭代优化生成结果。在四个TKG基准测试上的实验表明,RECIPE-TKG的性能优于以前基于LLM的方法,命中率@10提高了高达30.6%。此外,我们提出的框架产生了更语义连贯的预测,即使在历史背景有限的情况下也是如此。
论文及项目相关链接
Summary
该文介绍了Temporal Knowledge Graphs(TKGs)的完成任务,提出RECIPE-TKG框架以提高在稀疏历史上下文环境中的准确性和泛化能力。该框架结合了规则基础的多跳检索、对比微调轻量级适配器和测试时的语义过滤技术。实验表明,RECIPE-TKG在四个TKG基准测试上的表现优于之前的LLM方法,提高了高达30.6%的Hits@10,并且对于有限历史上下文的样本也能产生更语义连贯的预测。
Key Takeaways
- TKGs表示动态事实作为实体之间的时间戳关系。
- TKG完成需要预测缺失或未来的链接,需要模型对时间演化结构进行推理。
- LLMs在TKG完成任务上展现潜力,但在历史证据有限或缺失的情况下存在挑战。
- RECIPE-TKG是一个轻量级且数据高效的框架,旨在提高在稀疏历史上下文中的准确性和泛化能力。
- RECIPE-TKG结合了规则基础的多跳检索、对比微调适配器和测试时的语义过滤技术。
- 实验表明,RECIPE-TKG在多个TKG基准测试上的表现优于其他LLM方法。
点此查看论文截图

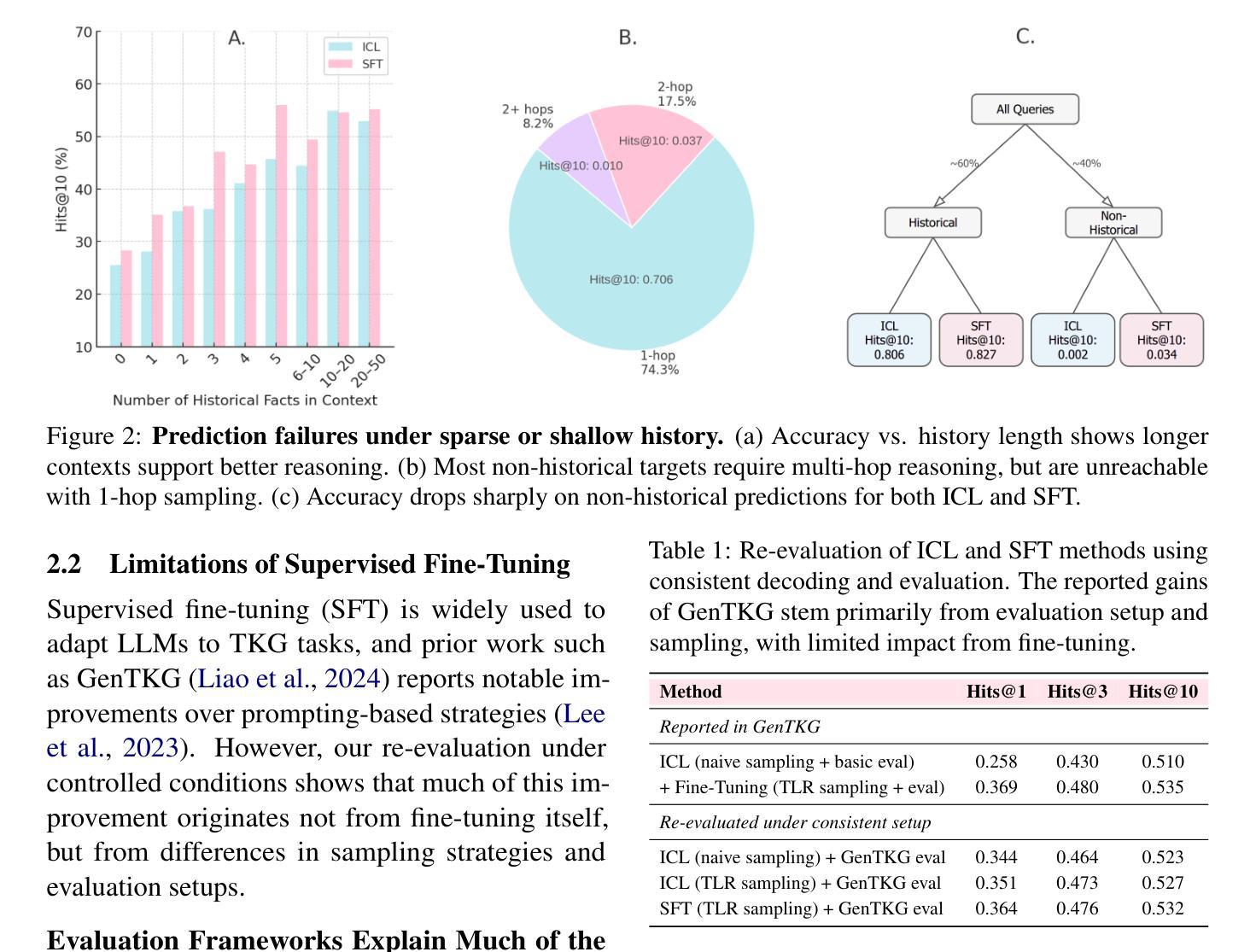
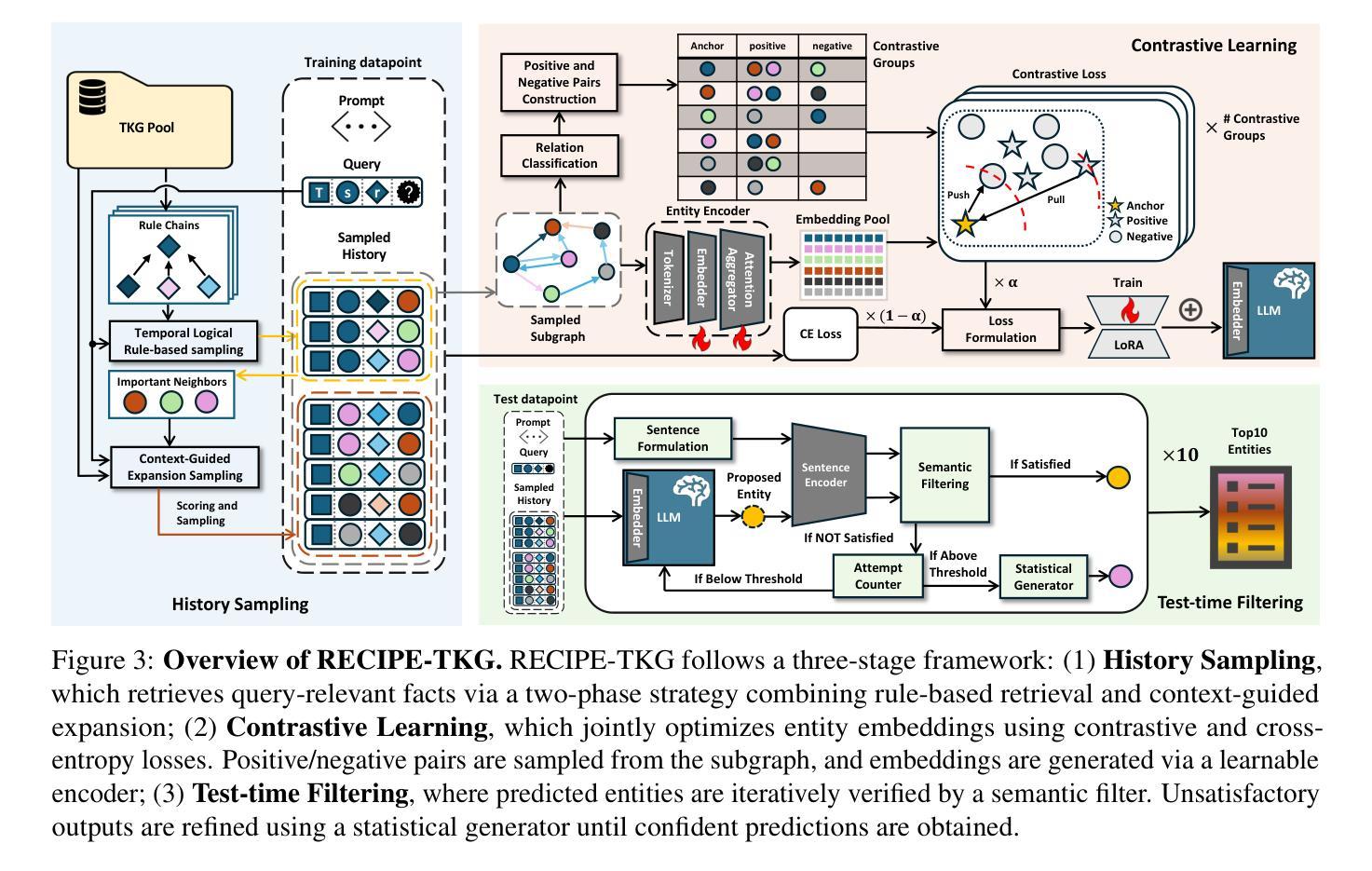
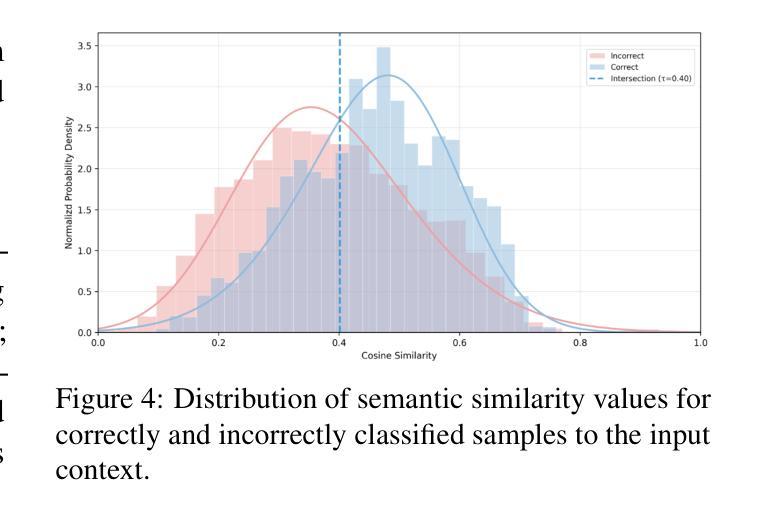
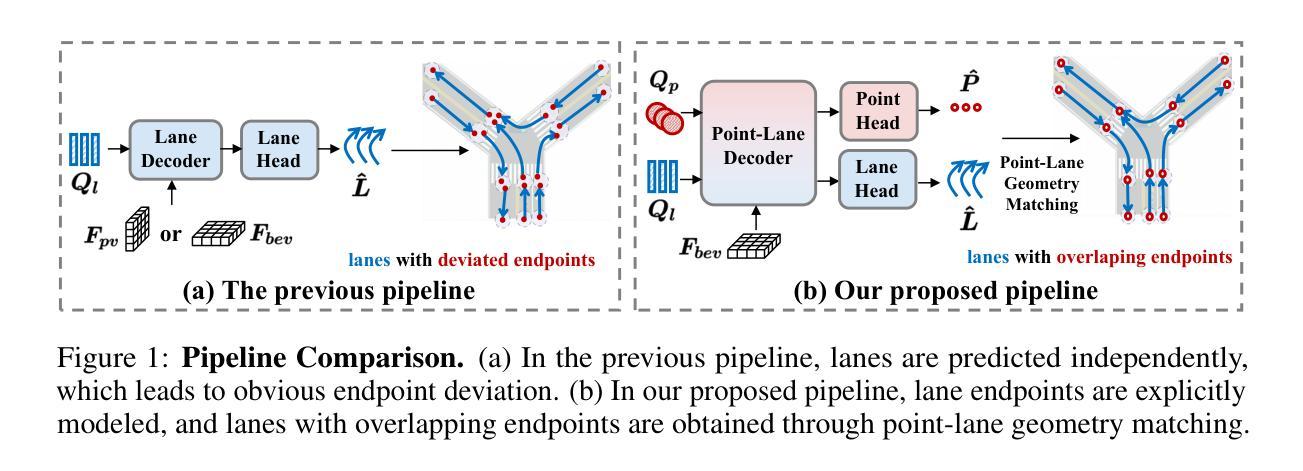
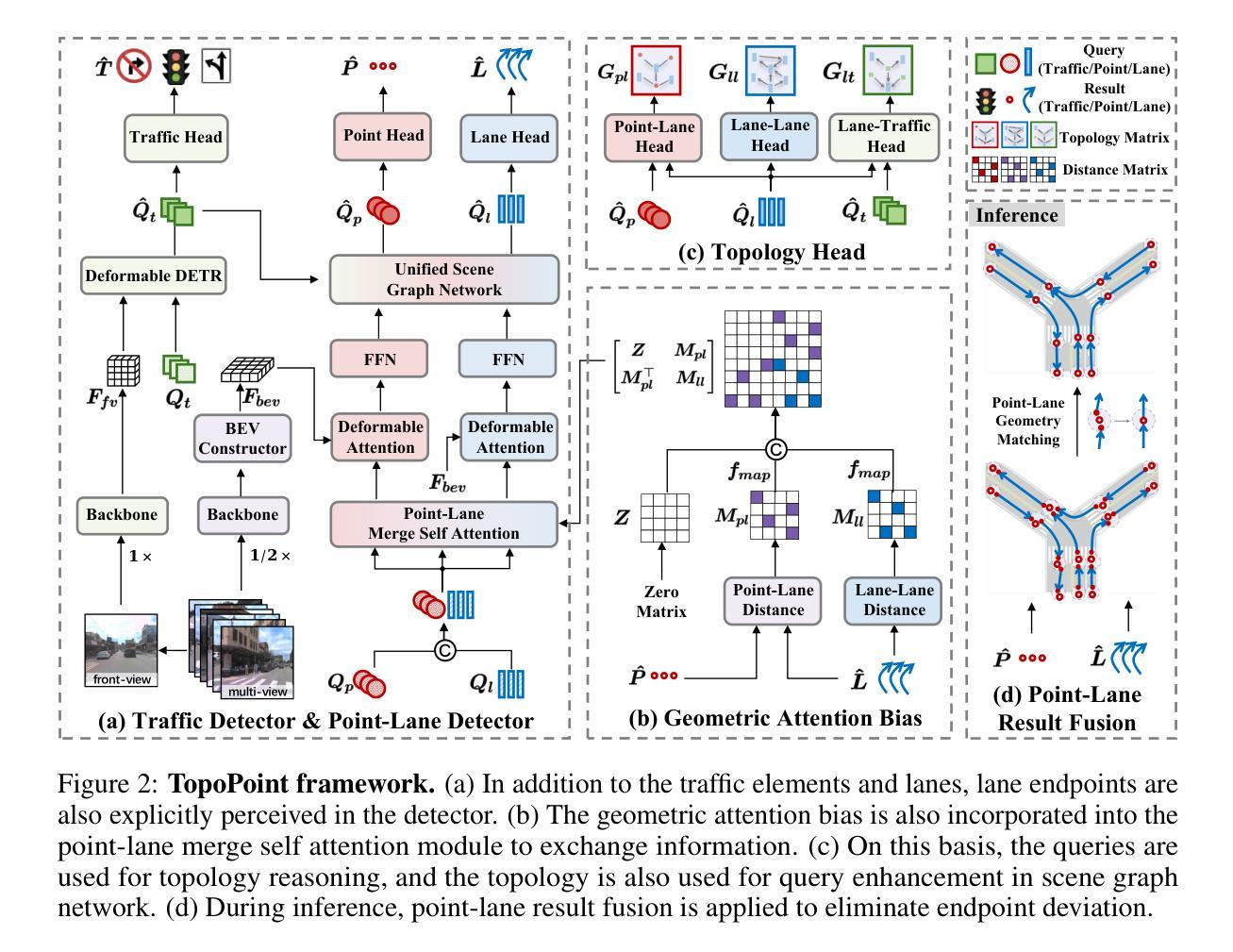
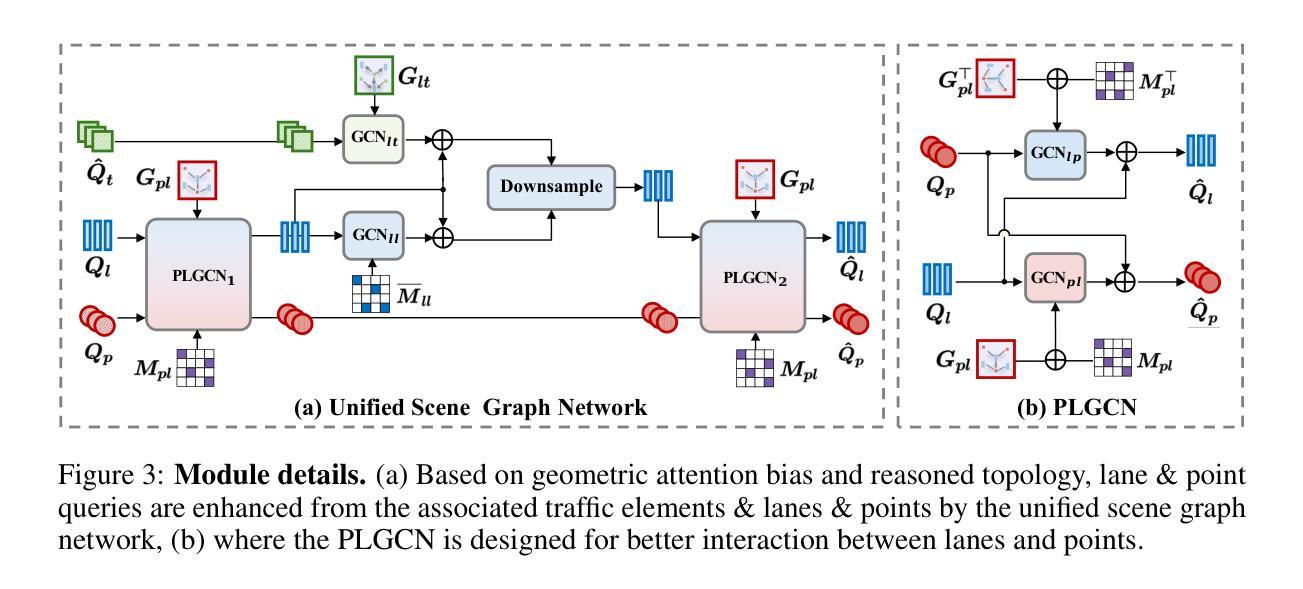
TopoPoint: Enhance Topology Reasoning via Endpoint Detection in Autonomous Driving
Authors:Yanping Fu, Xinyuan Liu, Tianyu Li, Yike Ma, Yucheng Zhang, Feng Dai
Topology reasoning, which unifies perception and structured reasoning, plays a vital role in understanding intersections for autonomous driving. However, its performance heavily relies on the accuracy of lane detection, particularly at connected lane endpoints. Existing methods often suffer from lane endpoints deviation, leading to incorrect topology construction. To address this issue, we propose TopoPoint, a novel framework that explicitly detects lane endpoints and jointly reasons over endpoints and lanes for robust topology reasoning. During training, we independently initialize point and lane query, and proposed Point-Lane Merge Self-Attention to enhance global context sharing through incorporating geometric distances between points and lanes as an attention mask . We further design Point-Lane Graph Convolutional Network to enable mutual feature aggregation between point and lane query. During inference, we introduce Point-Lane Geometry Matching algorithm that computes distances between detected points and lanes to refine lane endpoints, effectively mitigating endpoint deviation. Extensive experiments on the OpenLane-V2 benchmark demonstrate that TopoPoint achieves state-of-the-art performance in topology reasoning (48.8 on OLS). Additionally, we propose DET$_p$ to evaluate endpoint detection, under which our method significantly outperforms existing approaches (52.6 v.s. 45.2 on DET$_p$). The code is released at https://github.com/Franpin/TopoPoint.
拓扑推理在自动驾驶中理解交叉点方面起着至关重要的作用,它能将感知和结构化推理统一起来。然而,其性能严重依赖于车道检测的准确性,特别是在连接的车道端点处。现有方法常常存在车道端点偏差的问题,导致拓扑构建不正确。为了解决这一问题,我们提出了TopoPoint这一新型框架,它可显式检测车道端点,并联合对端点和车道进行推理,以实现稳健的拓扑推理。在训练过程中,我们独立初始化点和车道查询,并提出Point-Lane Merge Self-Attention,通过融入点与车道之间的几何距离作为注意力掩膜,以增强全局上下文共享。我们还设计了Point-Lane Graph Convolutional Network,以实现点和车道查询之间的特征相互聚合。在推理过程中,我们引入了Point-Lane Geometry Matching算法,该算法计算检测到的点与车道之间的距离来优化车道端点,有效地缓解了端点偏差问题。在OpenLane-V2基准测试上的大量实验表明,TopoPoint在拓扑推理方面达到了最新水平(OLS得分为48.8)。此外,我们还提出了DET$_p$来评估端点检测,在这一评估标准下,我们的方法显著优于现有方法(DET$_p$得分为52.6 vs 45.2)。代码已发布在https://github.com/Franpin/TopoPoint。
论文及项目相关链接
Summary
本文提出一种名为TopoPoint的新型框架,用于解决自动驾驶中的拓扑推理问题。该框架能够显式检测车道端点,并联合端点和车道进行推理,以提高拓扑推理的稳健性。通过引入点车道合并自注意力机制和点车道图卷积网络,提高了全球上下文共享和特征聚合能力。在OpenLane-V2基准测试上的实验表明,TopoPoint在拓扑推理方面达到了最新技术水平。
Key Takeaways
- TopoPoint框架解决了自动驾驶中拓扑推理的重要问题,特别是车道端点的准确性对拓扑推理的影响。
- TopoPoint能够显式检测车道端点,并联合端点和车道进行推理,提高拓扑推理的稳健性。
- 引入了点车道合并自注意力机制,通过考虑点和车道之间的几何距离,增强了全球上下文的共享。
- 设计了点车道图卷积网络,实现了点和车道查询之间的相互特征聚合。
- 在推断过程中,使用点车道几何匹配算法,通过计算检测到的点与车道之间的距离来优化车道端点,有效减轻了端点偏差的问题。
- 在OpenLane-V2基准测试上,TopoPoint在拓扑推理方面达到最新技术水平。
点此查看论文截图

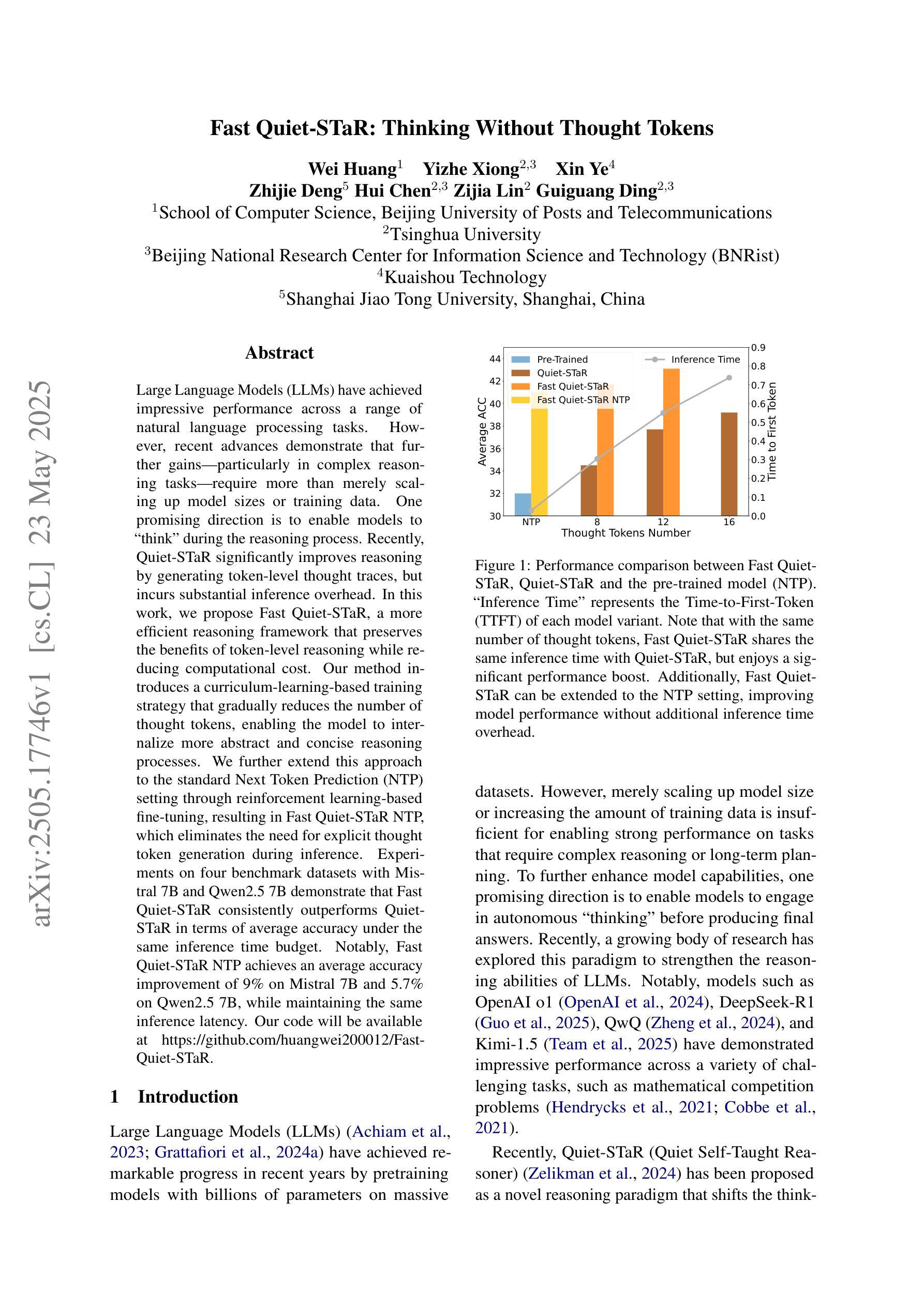
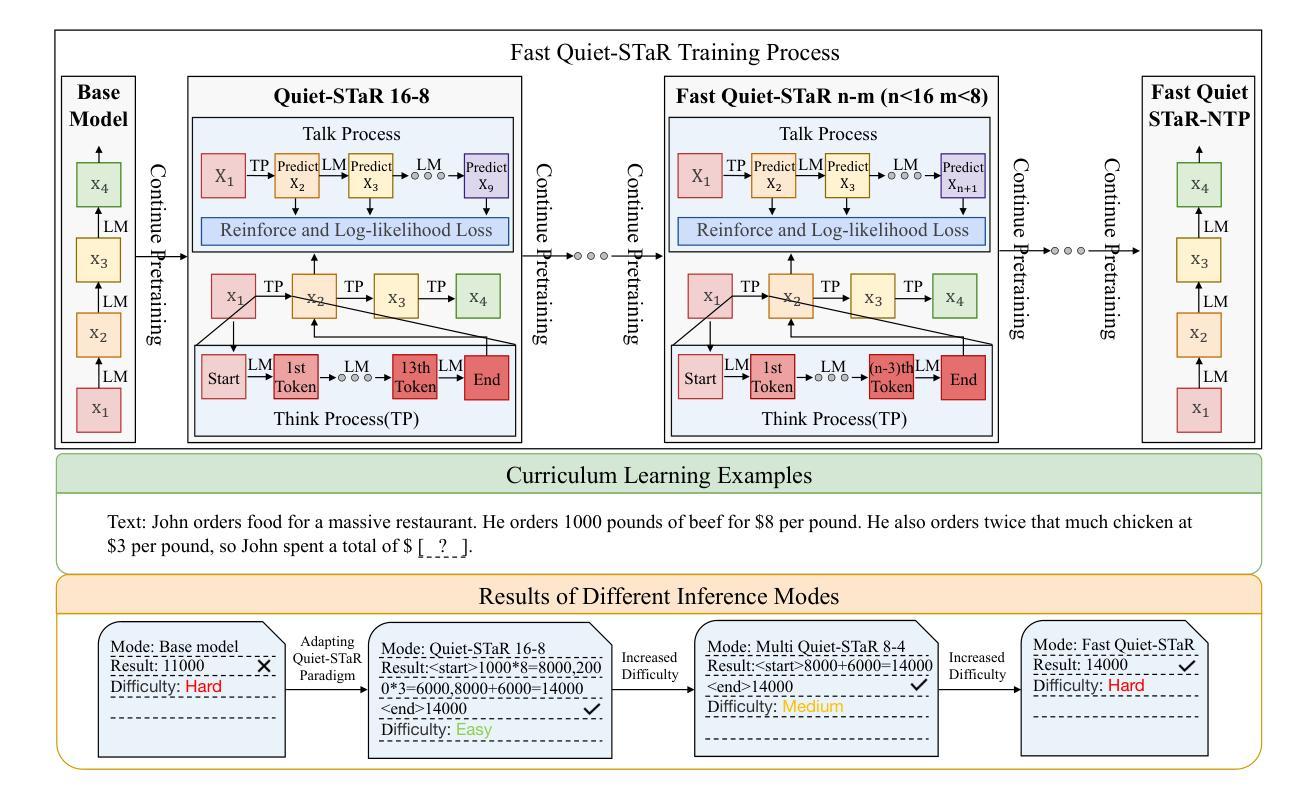
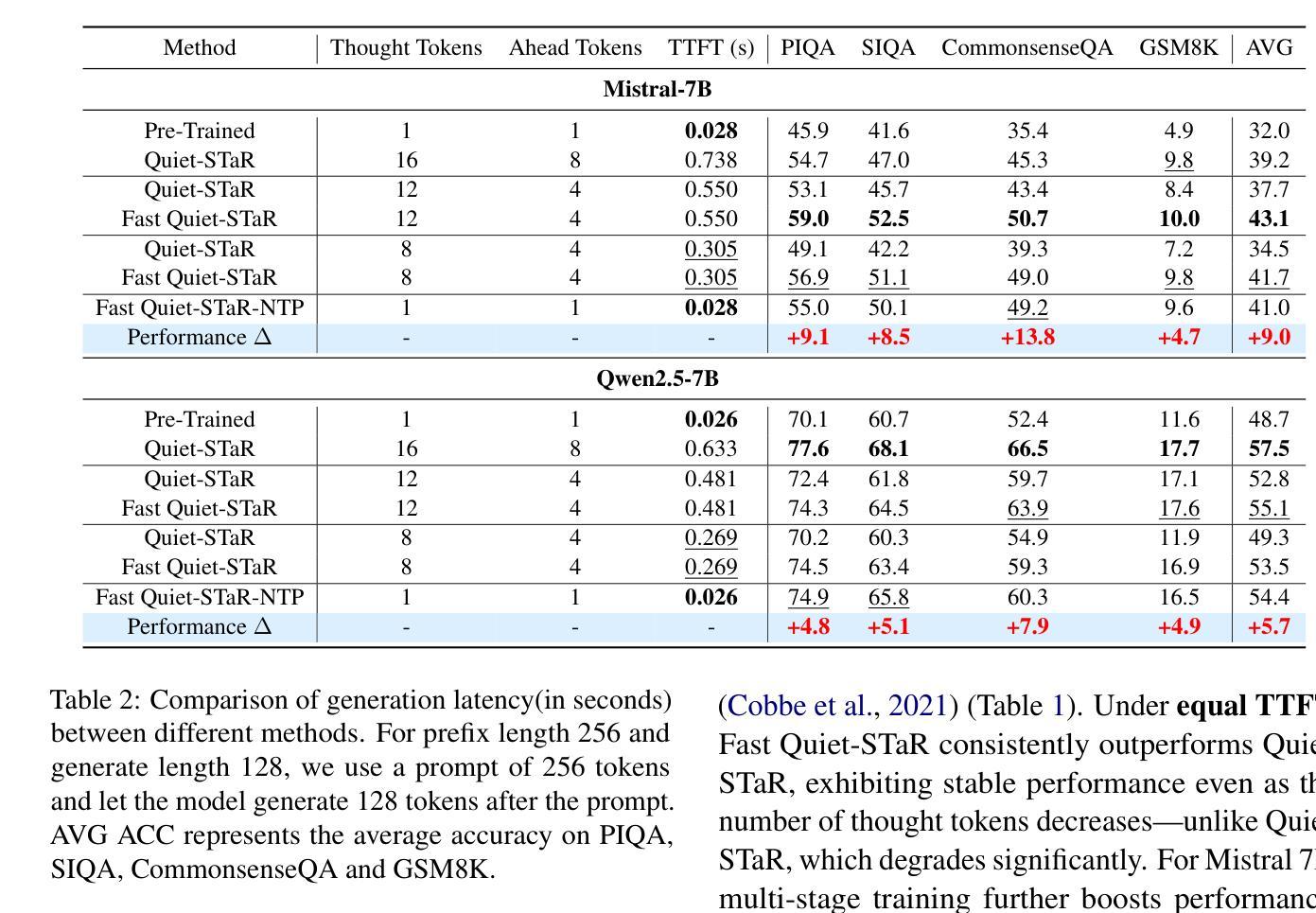
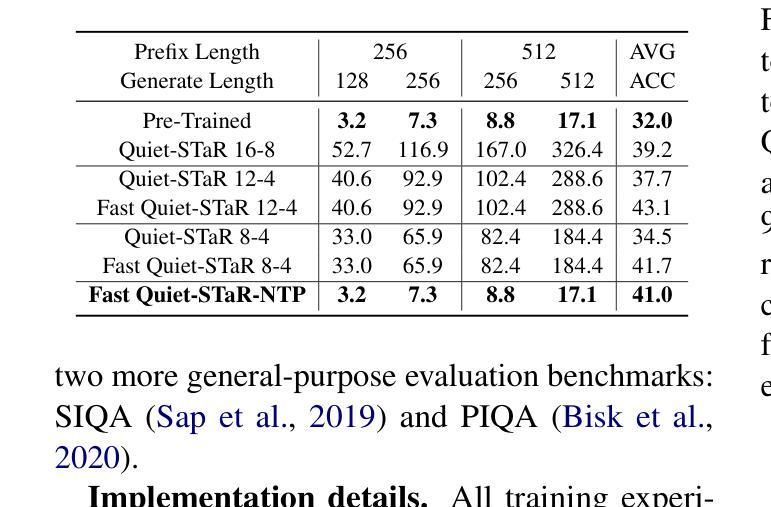
Fast Quiet-STaR: Thinking Without Thought Tokens
Authors:Wei Huang, Yizhe Xiong, Xin Ye, Zhijie Deng, Hui Chen, Zijia Lin, Guiguang Ding
Large Language Models (LLMs) have achieved impressive performance across a range of natural language processing tasks. However, recent advances demonstrate that further gains particularly in complex reasoning tasks require more than merely scaling up model sizes or training data. One promising direction is to enable models to think during the reasoning process. Recently, Quiet STaR significantly improves reasoning by generating token-level thought traces, but incurs substantial inference overhead. In this work, we propose Fast Quiet STaR, a more efficient reasoning framework that preserves the benefits of token-level reasoning while reducing computational cost. Our method introduces a curriculum learning based training strategy that gradually reduces the number of thought tokens, enabling the model to internalize more abstract and concise reasoning processes. We further extend this approach to the standard Next Token Prediction (NTP) setting through reinforcement learning-based fine-tuning, resulting in Fast Quiet-STaR NTP, which eliminates the need for explicit thought token generation during inference. Experiments on four benchmark datasets with Mistral 7B and Qwen2.5 7B demonstrate that Fast Quiet-STaR consistently outperforms Quiet-STaR in terms of average accuracy under the same inference time budget. Notably, Fast Quiet-STaR NTP achieves an average accuracy improvement of 9% on Mistral 7B and 5.7% on Qwen2.5 7B, while maintaining the same inference latency. Our code will be available at https://github.com/huangwei200012/Fast-Quiet-STaR.
大型语言模型(LLM)在多种自然语言处理任务中取得了令人印象深刻的性能。然而,最近的进展表明,特别是在复杂的推理任务中,进一步的收益需要超越单纯扩大模型规模或训练数据。一个前景广阔的方向是使模型能够在推理过程中进行思考。最近,Quiet STaR通过生成标记级的思维轨迹显著提高了推理能力,但引起了巨大的推理开销。在这项工作中,我们提出了Fast Quiet STaR,这是一个更高效的推理框架,既保留了标记级推理的好处,又降低了计算成本。我们的方法引入了一种基于课程学习的训练策略,逐步减少思维标记的数量,使模型能够内化更抽象、更简洁的推理过程。我们进一步通过基于强化学习的微调将这种方法扩展到标准的下一个标记预测(NTP)设置,从而得到Fast Quiet-STaR NTP,它在推理过程中无需明确的思维标记生成。在Mistral 7B和Qwen2.5 7B四个基准数据集上的实验表明,在相同的推理时间预算下,Fast Quiet-STaR始终优于Quiet-STaR的平均准确率。值得注意的是,Fast Quiet-STaR NTP在Mistral 7B上平均准确率提高了9%,在Qwen2.5 7B上提高了5.7%,同时保持了相同的推理延迟。我们的代码将在https://github.com/huangwei200012/Fast-Quiet-STaR上提供。
论文及项目相关链接
PDF 10 pages, 6 figures
Summary
大型语言模型(LLMs)在自然语言处理任务中表现出色,但在复杂推理任务中取得进一步进展需要更多策略。Quiet STaR通过生成标记级的思维轨迹来显著提高推理能力,但会带来较大的推理开销。本研究提出了Fast Quiet STaR,一个更高效的推理框架,在保留标记级推理的优点的同时降低了计算成本。它通过基于课程学习的训练策略逐步减少思维标记的数量,使模型能够内化更抽象、更简洁的推理过程。此外,该研究将其扩展到标准的下一个标记预测(NTP)设置,通过强化学习进行微调,从而消除了推理过程中显式思维标记生成的需要。实验结果表明,Fast Quiet STaR在平均准确率上优于原始的Quiet STaR,并且在相同的推理时间预算下表现更优秀。
Key Takeaways
- 大型语言模型(LLMs)在自然语言处理任务中表现出色,但在复杂推理任务中需要更多策略。
- Quiet STaR通过生成标记级的思维轨迹提高推理能力,但存在推理开销较大的问题。
- Fast Quiet STaR框架旨在提高推理效率,同时保留标记级推理的优点。
- Fast Quiet STaR采用基于课程学习的训练策略,逐步减少思维标记数量。
- Fast Quiet STaR扩展至标准的下一个标记预测(NTP)设置,通过强化学习进行微调。
- Fast Quiet STaR在多个数据集上的实验表现优于原始的Quiet STaR。
点此查看论文截图
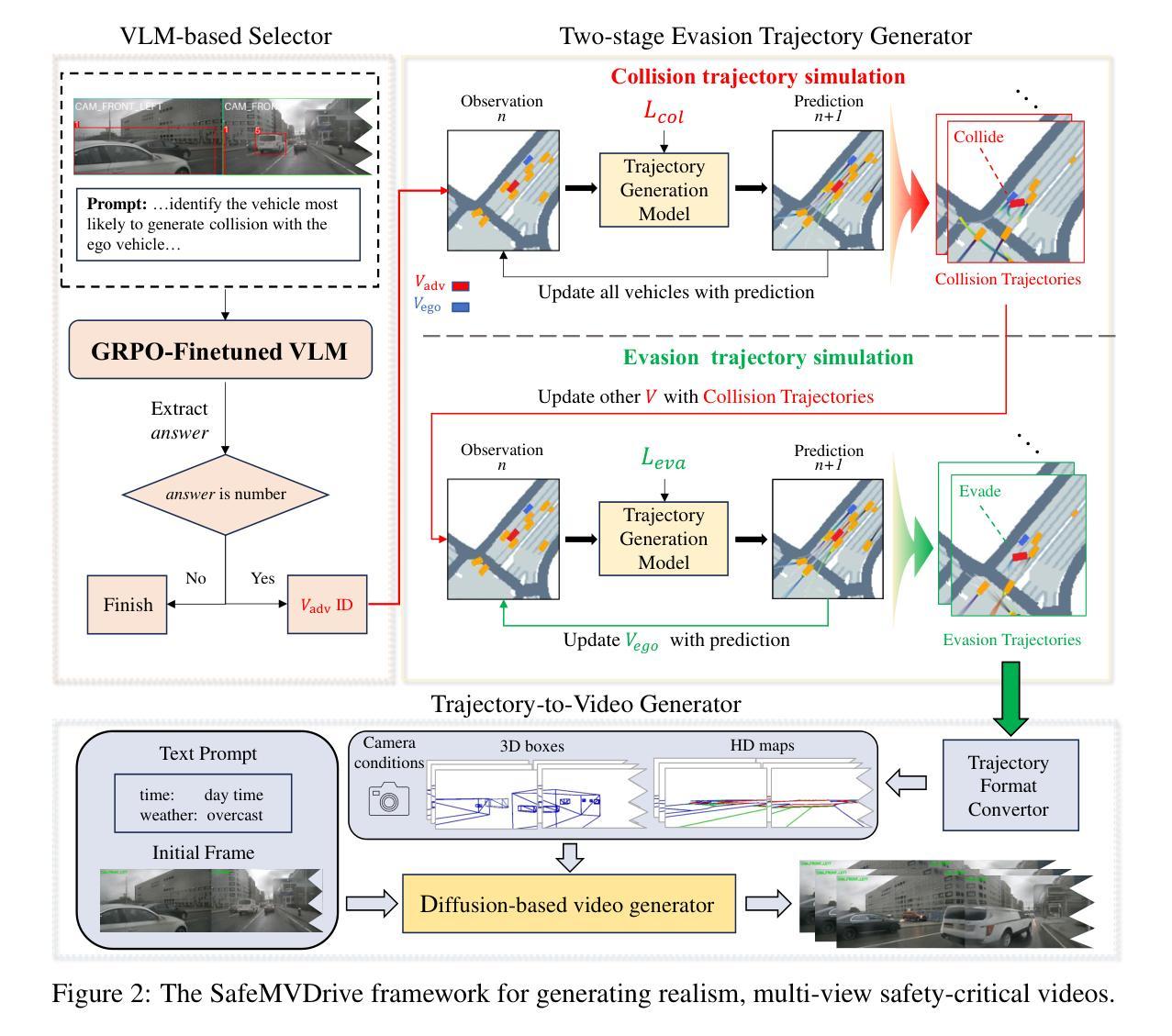
SafeMVDrive: Multi-view Safety-Critical Driving Video Synthesis in the Real World Domain
Authors:Jiawei Zhou, Linye Lyu, Zhuotao Tian, Cheng Zhuo, Yu Li
Safety-critical scenarios are rare yet pivotal for evaluating and enhancing the robustness of autonomous driving systems. While existing methods generate safety-critical driving trajectories, simulations, or single-view videos, they fall short of meeting the demands of advanced end-to-end autonomous systems (E2E AD), which require real-world, multi-view video data. To bridge this gap, we introduce SafeMVDrive, the first framework designed to generate high-quality, safety-critical, multi-view driving videos grounded in real-world domains. SafeMVDrive strategically integrates a safety-critical trajectory generator with an advanced multi-view video generator. To tackle the challenges inherent in this integration, we first enhance scene understanding ability of the trajectory generator by incorporating visual context – which is previously unavailable to such generator – and leveraging a GRPO-finetuned vision-language model to achieve more realistic and context-aware trajectory generation. Second, recognizing that existing multi-view video generators struggle to render realistic collision events, we introduce a two-stage, controllable trajectory generation mechanism that produces collision-evasion trajectories, ensuring both video quality and safety-critical fidelity. Finally, we employ a diffusion-based multi-view video generator to synthesize high-quality safety-critical driving videos from the generated trajectories. Experiments conducted on an E2E AD planner demonstrate a significant increase in collision rate when tested with our generated data, validating the effectiveness of SafeMVDrive in stress-testing planning modules. Our code, examples, and datasets are publicly available at: https://zhoujiawei3.github.io/SafeMVDrive/.
安全关键场景虽然罕见,但对于评估和增强自动驾驶系统的稳健性至关重要。现有方法虽然能够生成安全关键的驾驶轨迹、模拟或单视角视频,但它们无法满足高级端到端自动驾驶系统(E2E AD)的需求,这些系统需要基于现实世界的多视角视频数据。为了弥补这一差距,我们推出了SafeMVDrive,这是首个旨在生成基于真实世界领域的高质量、安全关键的多视角驾驶视频框架。SafeMVDrive战略性地整合了安全关键轨迹生成器与先进的多视角视频生成器。为了解决这一整合中的固有挑战,我们首先通过融入视觉上下文(之前此类生成器无法获取)并利用GRPO微调后的视觉语言模型,增强轨迹生成器的场景理解能力,从而实现更真实、更具上下文意识的轨迹生成。其次,我们认识到现有的多视角视频生成器在呈现真实的碰撞事件方面存在困难,因此引入了可控的两阶段轨迹生成机制,该机制可产生避碰轨迹,确保视频质量和安全关键性保真度。最后,我们采用基于扩散的多视角视频生成器,根据生成的轨迹合成高质量的安全关键驾驶视频。在E2E AD规划器上进行的实验表明,使用我们生成的数据进行测试时碰撞率显著提高,验证了SafeMVDrive在压力测试规划模块方面的有效性。我们的代码、示例和数据集可在https://zhoujiawei3.github.io/SafeMVDrive/公开访问。
论文及项目相关链接
Summary
本文介绍了一个名为SafeMVDrive的框架,该框架旨在生成高质量、安全关键的多视角驾驶视频。SafeMVDrive融合了安全关键轨迹生成器与先进的多视角视频生成器,增强了场景理解能力并引入可控轨迹生成机制,确保视频质量和安全关键性。该框架对端到端自动驾驶系统的规划模块进行了有效的压力测试。
Key Takeaways
- SafeMVDrive是首个针对安全关键的多视角驾驶视频生成设计的框架。
- 该框架融合了安全关键轨迹生成器与多视角视频生成器。
- 通过引入视觉上下文和GRPO微调的语言模型,增强了轨迹生成器的场景理解能力。
- 引入可控轨迹生成机制,确保视频质量和安全关键性。
- 采用扩散式多视角视频生成器,合成高质量的安全关键驾驶视频。
- 在端到端自动驾驶系统的规划模块上进行了有效的压力测试。
点此查看论文截图



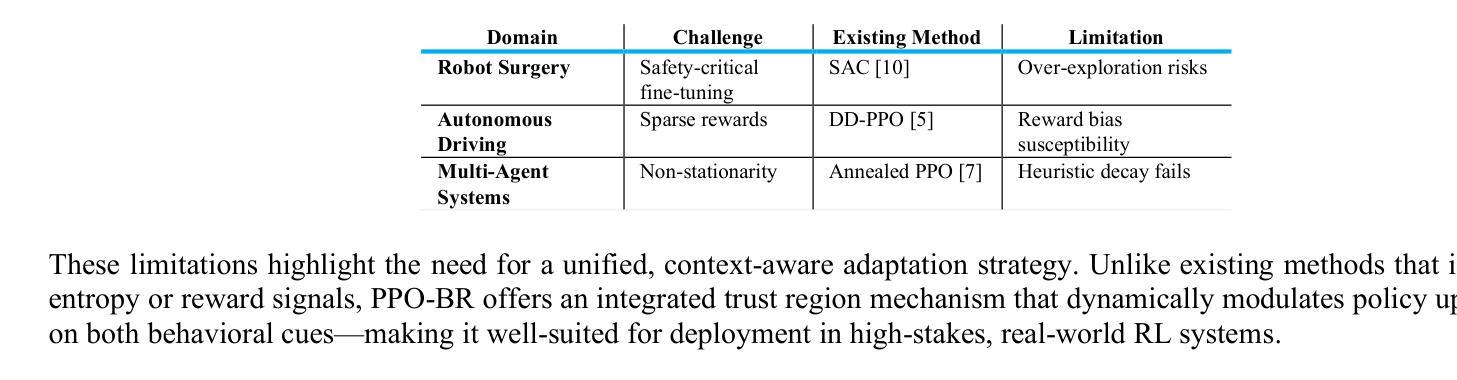
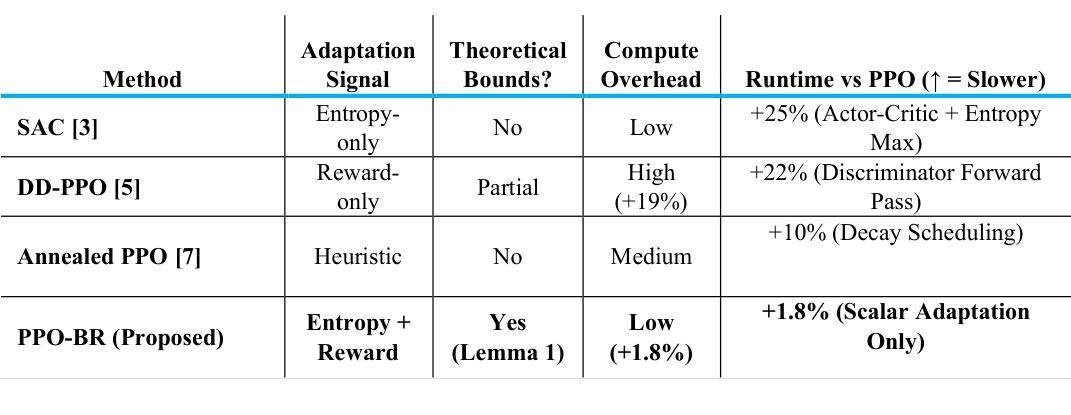
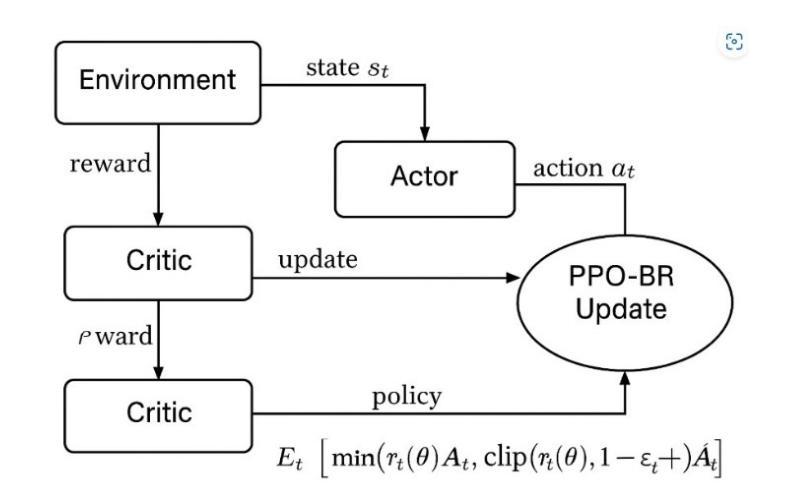
PPO-BR: Dual-Signal Entropy-Reward Adaptation for Trust Region Policy Optimization
Authors:Ben Rahman
Despite Proximal Policy Optimization (PPO) dominating policy gradient methods – from robotic control to game AI – its static trust region forces a brittle trade-off: aggressive clipping stifles early exploration, while late-stage updates destabilize convergence. PPO-BR establishes a new paradigm in adaptive RL by fusing exploration and convergence signals into a single bounded trust region – a theoretically grounded innovation that outperforms five SOTA baselines with less than 2% overhead. This work bridges a critical gap in phase-aware learning, enabling real-world deployment in safety-critical systems like robotic surgery within a single adaptive mechanism. PPO-BR achieves 29.1% faster convergence by combining: (1) entropy-driven expansion (epsilon up) for exploration in high-uncertainty states, and (2) reward-guided contraction (epsilon down) for convergence stability. On six diverse benchmarks (MuJoCo, Atari, sparse-reward), PPO-BR achieves 29.1% faster convergence (p < 0.001), 2.3x lower reward variance than PPO, and less than 1.8% runtime overhead with only five lines of code change. PPO-BR’s simplicity and theoretical guarantees make it ready-to-deploy in safety-critical domains – from surgical robotics to autonomous drones. In contrast to recent methods such as Group Relative Policy Optimization (GRPO), PPO-BR offers a unified entropy-reward mechanism applicable to both language models and general reinforcement learning environments.
尽管近端策略优化(PPO)在策略梯度方法中占据主导地位——从机器人控制到游戏人工智能——但其静态信任区域存在缺陷,使得在激进剪切与早期探索之间存在微妙的权衡关系,而后期更新的变化又会导致收敛不稳定。PPO-BR通过自适应强化学习领域提出了一种新的范式,将探索与收敛信号融合到一个有界信任区域中——这是具有理论根据的创新理念。其在实际应用方面优于五个最先进的基线方法,同时带来的开销不到2%。这项工作在阶段感知学习方面弥补了关键空白,能够在单一自适应机制下实现如机器人手术等安全关键系统的实际应用部署。PPO-BR通过将以下两种方法相结合,实现了更快的收敛速度:一是在高不确定性状态下采用熵驱动扩展(epsilon up)进行探索;二是采用奖励引导收缩(epsilon down)实现收敛稳定性。在六个不同的基准测试(MuJoCo、Atari、稀疏奖励)中,PPO-BR实现了更快的收敛速度(提高29.1%,p < 0.001),奖励方差低于PPO的2.3倍,同时运行时间开销不超过目前的最好方法的将近五倍线长仅仅只需改变的代码行数低于这些最新的成果并因其简便性和理论保障优势能在诸如外科手术机器人和自动驾驶无人机等安全关键领域投入使用部署对比最新的集团相对策略优化方法(GRPO),PPO-BR采用了统一的熵奖励机制适用于语言模型和一般强化学习环境。。
论文及项目相关链接
PDF This manuscript builds upon an earlier version posted to TechRxiv. This arXiv version includes an updated comparison with GRPO (Group Relative Policy Optimization)
Summary:
PPO-BR作为一种新型的近端策略优化方法,通过自适应调整信任区域,解决了传统策略优化方法中的早期探索不足和后期收敛不稳定的问题。该方法结合了探索与收敛信号,形成单一的有界信任区域,填补了阶段感知学习中的关键空白。在多个基准测试中,PPO-BR表现出更高的性能,收敛速度更快,奖励方差更低。其简洁性和理论保证使其成为安全关键领域(如手术机器人和自主无人机)的部署首选。
Key Takeaways:
- PPO-BR通过自适应调整信任区域解决了PPO静态信任区域带来的问题,实现了更灵活的策略优化。
- PPO-BR结合了探索与收敛信号,形成单一有界信任区域,这是一个理论上有创新的方法。
- PPO-BR在多个基准测试中表现出更高的性能,收敛速度提高了29.1%,奖励方差降低了2.3倍。
- PPO-BR的运行时间开销低于1.8%,且仅需要五行代码的改动,具有实际应用价值。
- PPO-BR简化了复杂性并提供了理论保证,使其成为安全关键领域的部署首选。
- 与其他方法如GRPO相比,PPO-BR提供了统一的熵奖励机制,适用于语言模型和通用强化学习环境。
点此查看论文截图