⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-05-27 更新
Enhancing Adversarial Robustness of Vision Language Models via Adversarial Mixture Prompt Tuning
Authors:Shiji Zhao, Qihui Zhu, Shukun Xiong, Shouwei Ruan, Yize Fan, Ranjie Duan, Qing Guo, Xingxing Wei
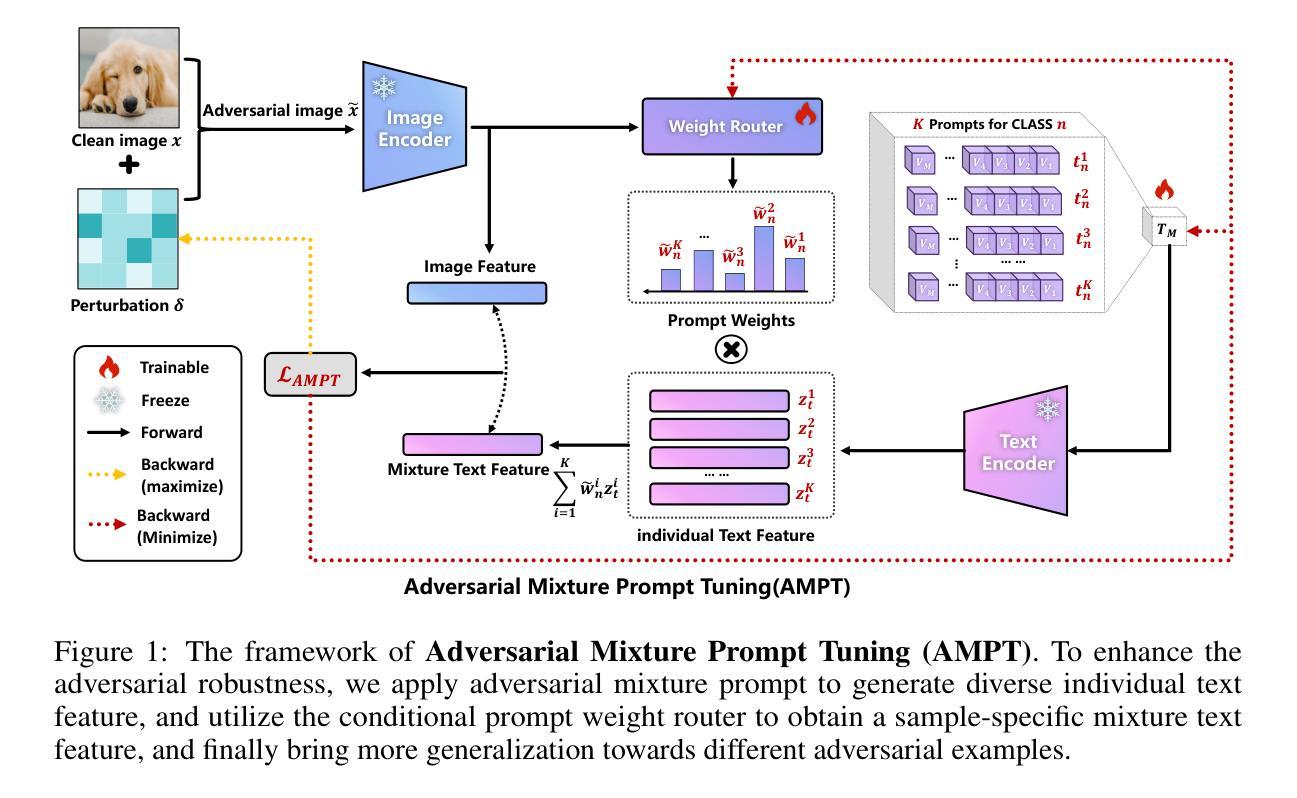
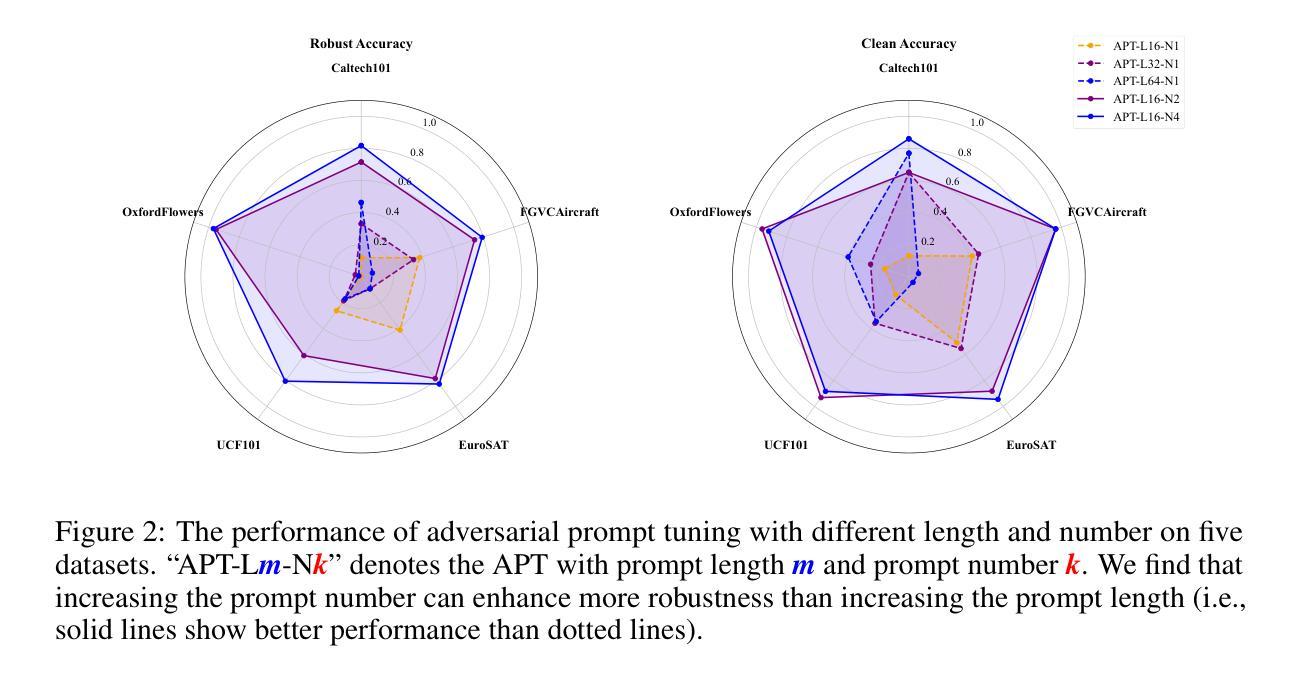
Large pre-trained Vision Language Models (VLMs) have excellent generalization capabilities but are highly susceptible to adversarial examples, presenting potential security risks. To improve the robustness of VLMs against adversarial examples, adversarial prompt tuning methods are proposed to align the text feature with the adversarial image feature without changing model parameters. However, when facing various adversarial attacks, a single learnable text prompt has insufficient generalization to align well with all adversarial image features, which finally leads to the overfitting phenomenon. To address the above challenge, in this paper, we empirically find that increasing the number of learned prompts can bring more robustness improvement than a longer prompt. Then we propose an adversarial tuning method named Adversarial Mixture Prompt Tuning (AMPT) to enhance the generalization towards various adversarial attacks for VLMs. AMPT aims to learn mixture text prompts to obtain more robust text features. To further enhance the adaptability, we propose a conditional weight router based on the input adversarial image to predict the mixture weights of multiple learned prompts, which helps obtain sample-specific aggregated text features aligning with different adversarial image features. A series of experiments show that our method can achieve better adversarial robustness than state-of-the-art methods on 11 datasets under different experimental settings.
大型预训练视觉语言模型(VLMs)具有良好的泛化能力,但非常容易受到对抗样本的影响,存在潜在的安全风险。为了增强VLMs对抗对样本的鲁棒性,提出了对抗性提示调整方法,使文本特征能够与对抗图像特征对齐,而无需更改模型参数。然而,在面对各种对抗攻击时,单一的可学习文本提示在对所有对抗图像特征进行对齐时泛化不足,最终导致过拟合现象。针对上述挑战,本文实证发现,增加学习到的提示数量可以带来比更长的提示更多的鲁棒性改进。然后,我们提出了一种名为对抗性混合提示调整(AMPT)的对抗性调整方法,以提高VLMs对各种对抗攻击的泛化能力。AMPT旨在学习混合文本提示以获得更稳健的文本特征。为了进一步增强适应性,我们提出了一种基于输入对抗图像的条件权重路由器,用于预测多个学习到的提示的混合权重,这有助于获得与不同对抗图像特征对齐的样本特定聚合文本特征。一系列实验表明,我们的方法在11个数据集的不同实验设置下,相较于最先进的方法,可以实现更好的对抗性鲁棒性。
论文及项目相关链接
Summary
大型预训练视觉语言模型(VLMs)具有良好的泛化能力,但易受对抗样本的影响,存在潜在的安全风险。为提升VLMs对抗对对抗样本的鲁棒性,提出了对抗性提示调参方法,该方法能够对文本特征与对抗性图像特征进行对齐,而无需更改模型参数。然而,面对多种对抗攻击时,单一的可学习文本提示的泛化能力不足以与所有对抗性图像特征对齐,最终导致过拟合现象。为解决此挑战,本文实证发现,增加学习到的提示数量比使用更长的提示能带来更多的鲁棒性提升。于是,我们提出了一种名为AMPT(对抗性混合提示调参)的对抗性调参方法,旨在提升VLMs对各种对抗攻击的泛化能力。AMPT旨在学习混合文本提示,以获得更稳健的文本特征。为进一步增强适应性,我们提出了一种基于输入对抗性图像的条件权重路由器,用于预测多个学习到的提示的混合权重,这有助于获得与不同对抗性图像特征对齐的样本特定聚合文本特征。实验表明,该方法在11个数据集的不同实验设置下,较现有方法具有更好的对抗鲁棒性。
Key Takeaways
- 大型预训练视觉语言模型(VLMs)虽然具有良好的泛化能力,但易受对抗样本攻击,存在安全风险。
- 对抗性提示调参方法旨在提高VLMs的鲁棒性,通过对文本特征与对抗性图像特征进行对齐。
- 单一的可学习文本提示在应对多种对抗攻击时泛化能力不足,易导致过拟合。
- 增加学习到的提示数量能提升模型的鲁棒性,较使用更长的单一提示更有效。
- 提出了AMPT方法,通过混合文本提示学习以增强VLMs对各种对抗攻击的泛化能力。
- 条件权重路由器根据输入对抗图像预测混合提示的权重,实现样本特定的聚合文本特征。
点此查看论文截图

Wildfire Detection Using Vision Transformer with the Wildfire Dataset
Authors:Gowtham Raj Vuppari, Navarun Gupta, Ahmed El-Sayed, Xingguo Xiong
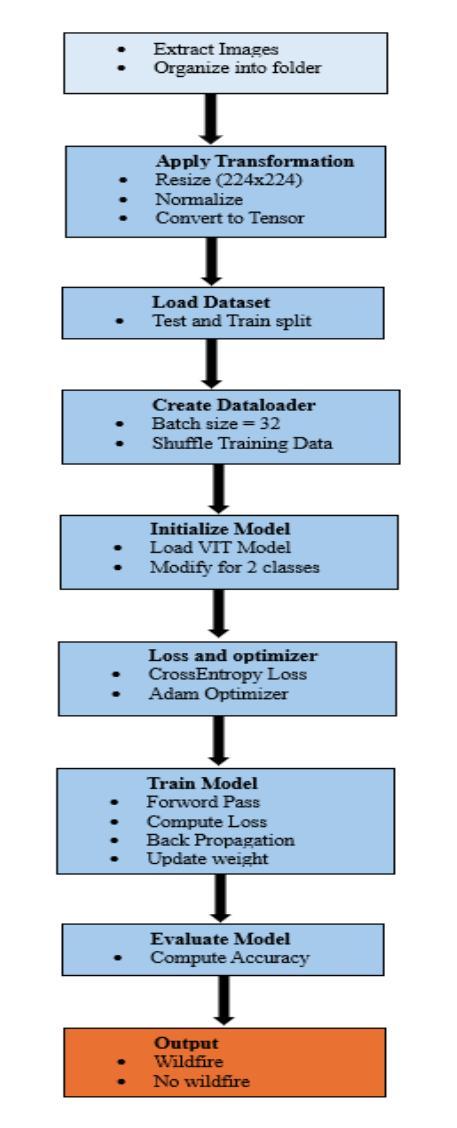
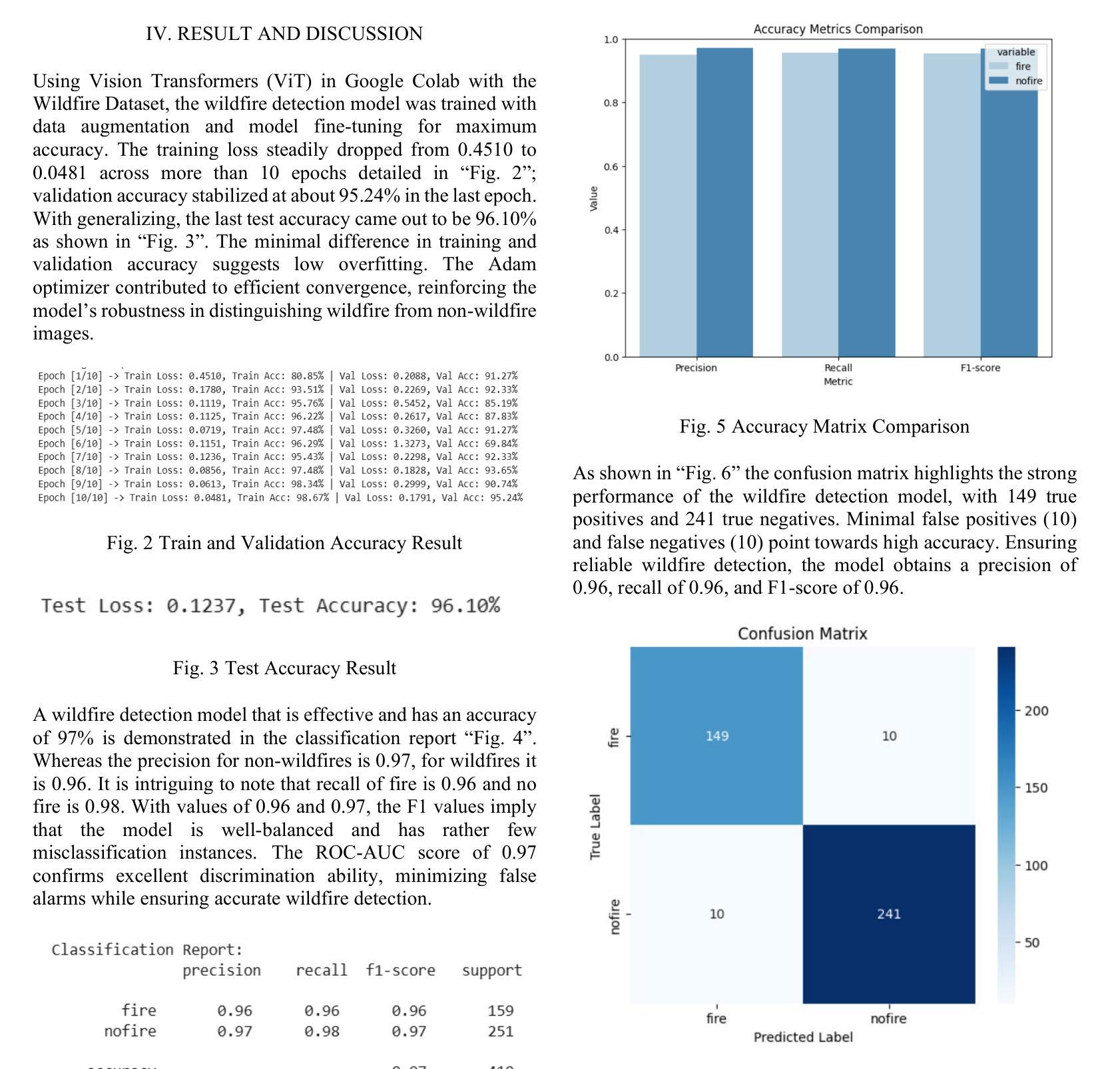
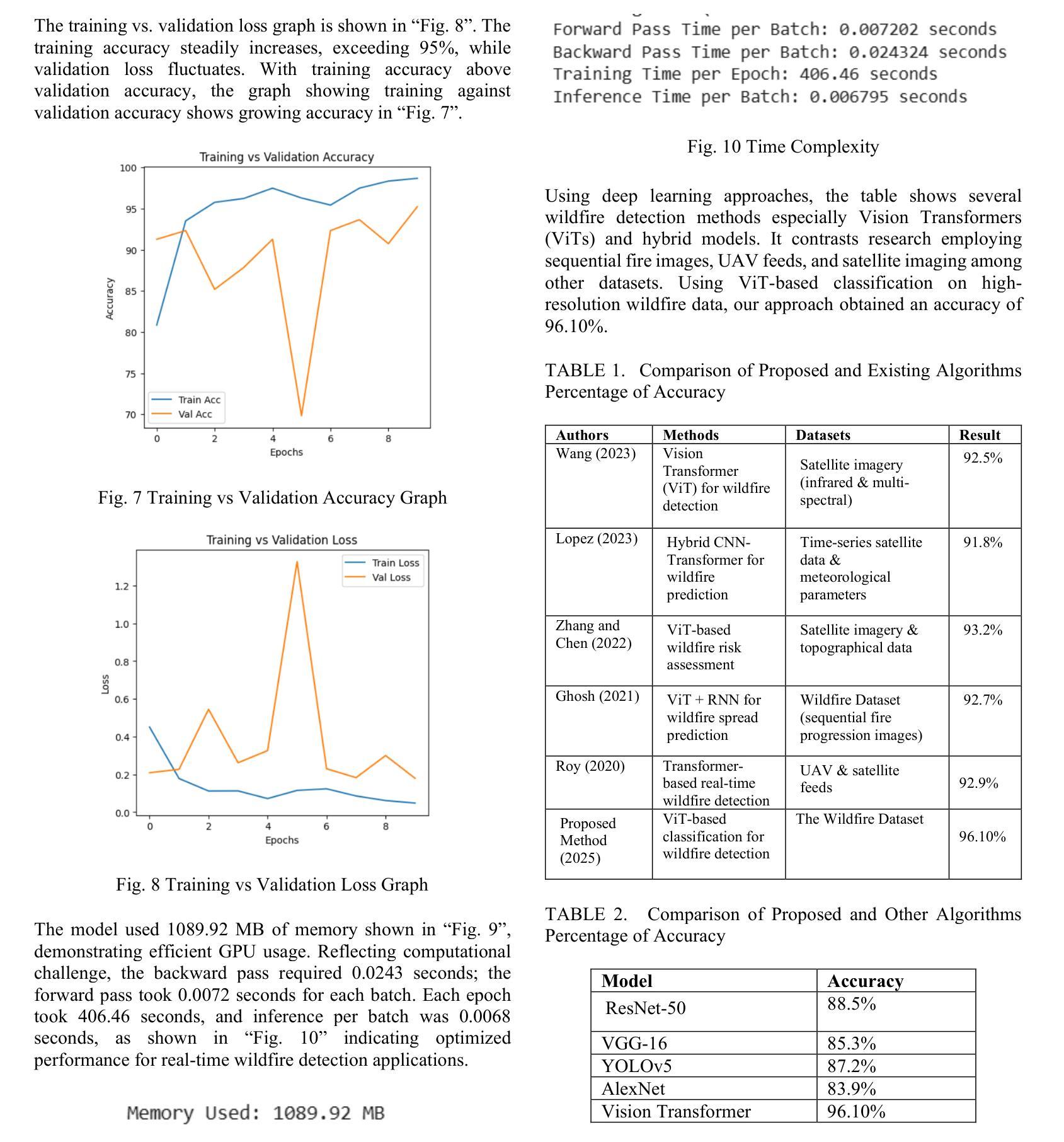
The critical need for sophisticated detection techniques has been highlighted by the rising frequency and intensity of wildfires in the US, especially in California. In 2023, wildfires caused 130 deaths nationwide, the highest since 1990. In January 2025, Los Angeles wildfires which included the Palisades and Eaton fires burnt approximately 40,000 acres and 12,000 buildings, and caused loss of human lives. The devastation underscores the urgent need for effective detection and prevention strategies. Deep learning models, such as Vision Transformers (ViTs), can enhance early detection by processing complex image data with high accuracy. However, wildfire detection faces challenges, including the availability of high-quality, real-time data. Wildfires often occur in remote areas with limited sensor coverage, and environmental factors like smoke and cloud cover can hinder detection. Additionally, training deep learning models is computationally expensive, and issues like false positives/negatives and scaling remain concerns. Integrating detection systems with real-time alert mechanisms also poses difficulties. In this work, we used the wildfire dataset consisting of 10.74 GB high-resolution images categorized into ‘fire’ and ‘nofire’ classes is used for training the ViT model. To prepare the data, images are resized to 224 x 224 pixels, converted into tensor format, and normalized using ImageNet statistics.
随着美国野火的发生频率和强度的不断上升,特别是在加利福尼亚州,对先进检测技术的迫切需求已经凸显。在2023年,全国范围内野火造成了自1990年以来的最高死亡人数,达到130人。在2025年一月,包括帕利塞德斯和伊顿火灾在内的洛杉矶野火烧毁了大约4万英亩土地和一万两千座建筑,并造成人员伤亡。这种破坏强调了需要有效的检测和预防策略。深度学习模型,如视觉转换器(ViTs),可以通过处理复杂图像数据来提高早期检测的准确性。然而,野火检测面临着挑战,包括高质量实时数据的可用性。野火往往发生在传感器覆盖有限的偏远地区,环境因素如烟雾和云层覆盖可能会阻碍检测。此外,训练深度学习模型在计算上很昂贵,假阳性/假阴性问题和规模问题仍然令人担忧。将检测系统与实时警报机制相结合也构成了一些困难。在这项工作中,我们使用了由分类为“火灾”和“无火灾”类别的10.74GB高分辨率图像组成的野火数据集来训练ViT模型。为了准备数据,图像被重新调整为224 x 224像素大小,转换为张量格式,并使用ImageNet统计数据进行了归一化。
论文及项目相关链接
PDF Published at ASEE NE 2025
Summary
本文强调了美国,特别是加利福尼亚州,野火频发且日益严重,造成的破坏和伤亡不断增加,突显了先进探测技术的迫切需求。文章提出,通过深度学习模型如Vision Transformer (ViT)进行早期精确图像数据处理可提高野火探测能力。然而,ViT在野火探测应用中面临诸多挑战,包括高质量实时数据的获取、偏远地区的传感器覆盖不足、环境因素影响如烟雾和云层遮挡、深度学习模型训练的计算成本高昂、误报漏报以及扩展问题等。研究人员使用了包含“火灾”和“无火灾”分类的10.74GB高分辨率图像数据集训练ViT模型,并对图像进行尺寸调整、格式转换和标准化处理。
Key Takeaways
以下是基于文本内容的七个关键见解:
- 美国野火频发,尤其是加利福尼亚州,造成的伤亡和损失不断上升。
- 当前迫切需要先进的探测技术来提高对野火的早期发现和预防能力。
- Vision Transformer (ViT)作为一种深度学习模型,在野火探测中具有潜力,可通过处理复杂图像数据实现高准确性检测。
- 野火探测面临诸多挑战,包括高质量实时数据的获取难度、偏远地区传感器覆盖不足等。
- 环境因素如烟雾和云层遮挡会影响野火的探测效果。
- 深度学习模型训练计算成本高昂,存在误报漏报和扩展性问题。
点此查看论文截图

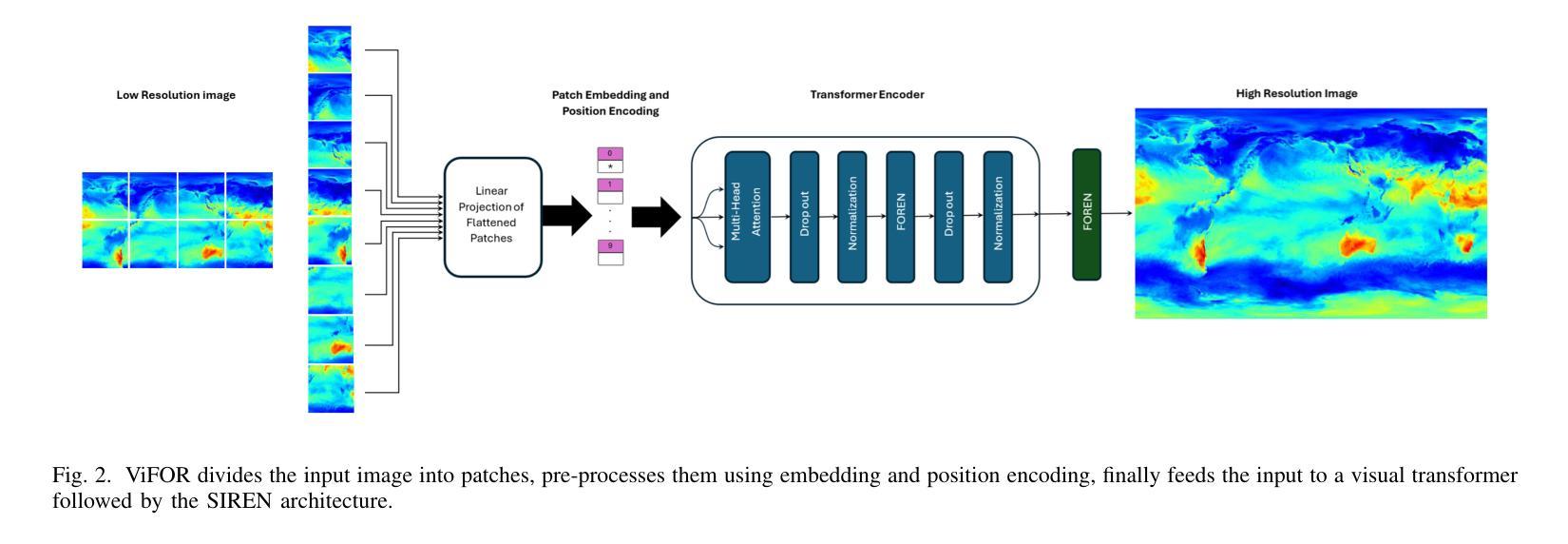
ViFOR: A Fourier-Enhanced Vision Transformer for Multi-Image Super-Resolution in Earth System
Authors:Ehsan Zeraatkar, Salah A Faroughi, Jelena Tešić
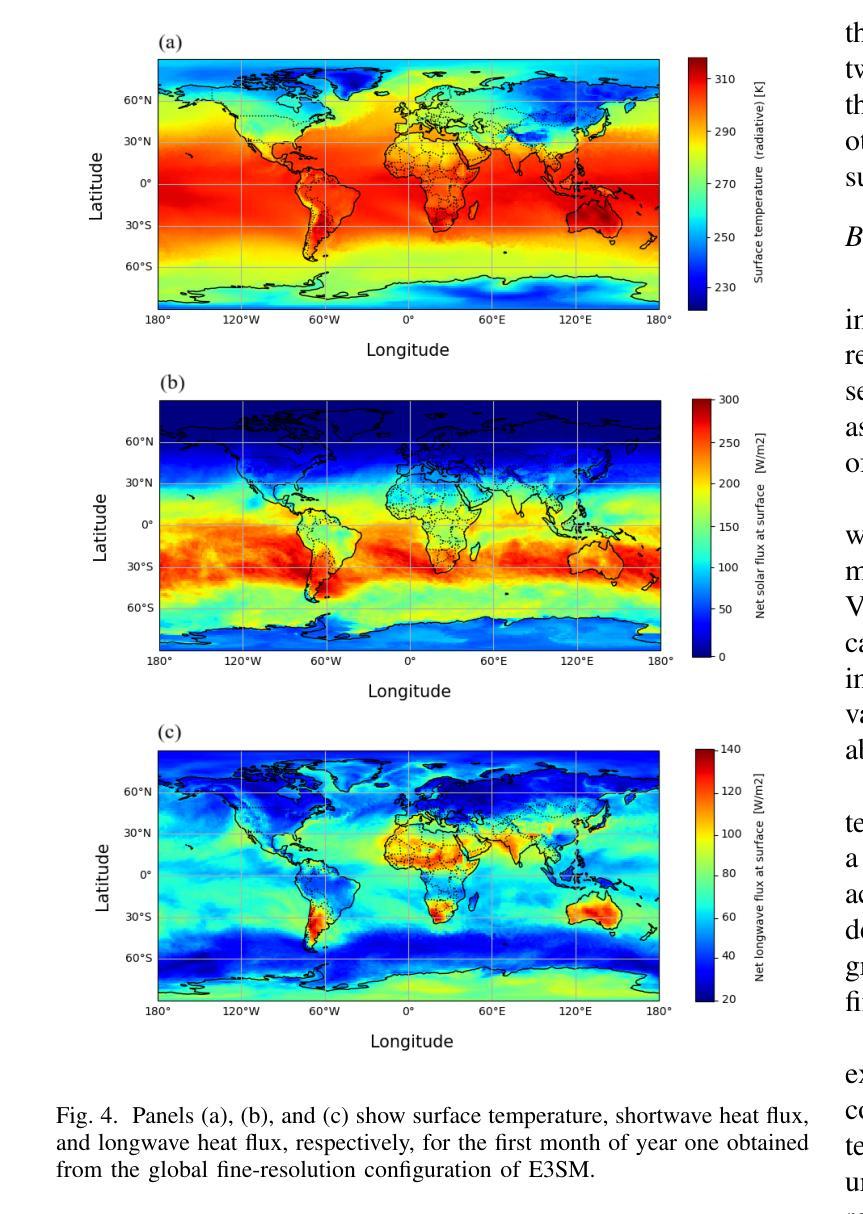
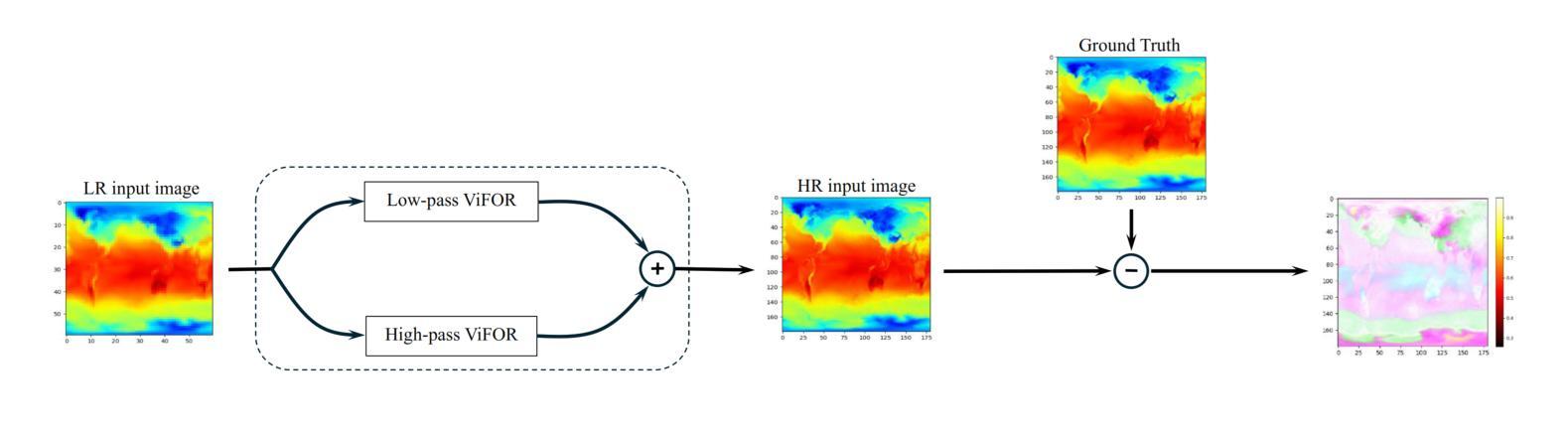
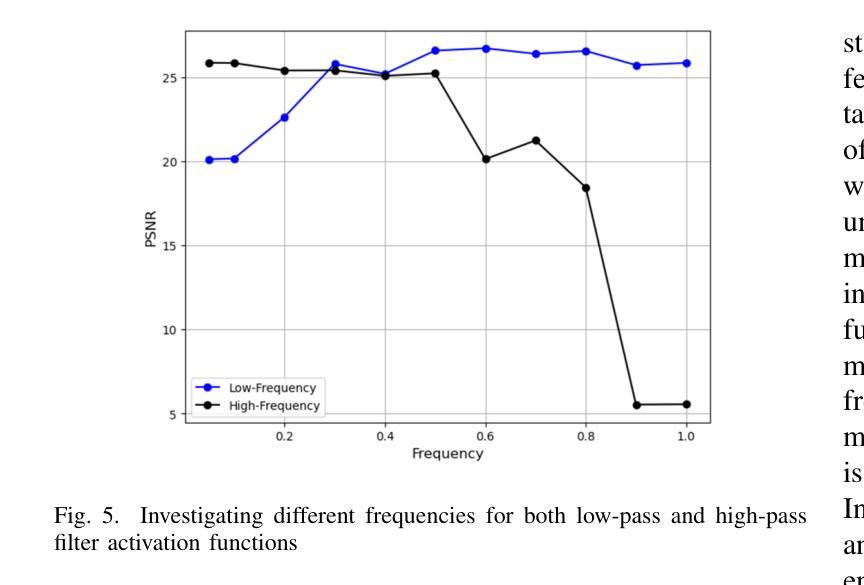
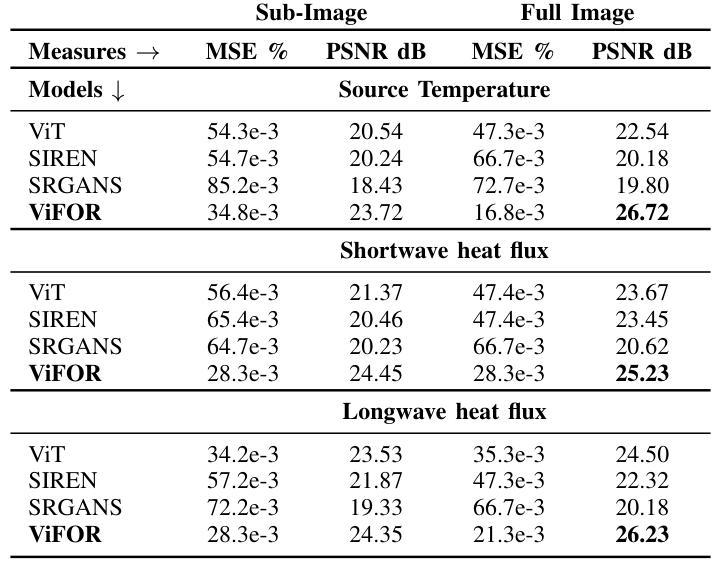
Super-resolution (SR) techniques are essential for improving Earth System Model (ESM) data’s spatial resolution, which helps better understand complex environmental processes. This paper presents a new algorithm, ViFOR, which combines Vision Transformers (ViT) and Fourier-based Implicit Neural Representation Networks (INRs) to generate High-Resolution (HR) images from Low-Resolution (LR) inputs. ViFOR introduces a novel integration of Fourier-based activation functions within the Vision Transformer architecture, enabling it to effectively capture global context and high-frequency details critical for accurate SR reconstruction. The results show that ViFOR outperforms state-of-the-art methods such as ViT, Sinusoidal Representation Networks (SIREN), and SR Generative Adversarial Networks (SRGANs) based on metrics like Peak Signal-to-Noise Ratio (PSNR) and Mean Squared Error (MSE) both for global as well as the local imagery. ViFOR improves PSNR of up to 4.18 dB, 1.56 dB, and 1.73 dB over ViT for full images in the Source Temperature, Shortwave, and Longwave Flux.
超分辨率(SR)技术对于提高地球系统模型(ESM)数据的空间分辨率至关重要,这有助于更好地理解复杂的环境过程。本文提出了一种新的算法ViFOR,它将视觉变压器(ViT)和基于傅里叶隐式神经网络表示(INR)相结合,从低分辨率(LR)输入生成高分辨率(HR)图像。ViFOR在视觉转换器架构中引入了基于傅里叶激活函数的新颖集成,使其能够有效捕获全局上下文和对于准确SR重建至关重要的高频细节。结果表明,ViFOR在峰值信噪比(PSNR)和均方误差(MSE)等指标上优于最先进的方法,如ViT、正弦表示网络(SIREN)和SR生成对抗网络(SRGANs),适用于全局和局部图像。在源温度、短波和长波流量等全图中,ViFOR将PSNR提高了高达4.18 dB、1.56 dB和1.73 dB。
论文及项目相关链接
Summary
一种新的名为ViFOR的算法结合了Vision Transformer(ViT)和基于傅里叶隐神经表示网络(INR),旨在提高地球系统模型(ESM)数据的空间分辨率。它通过引入傅里叶激活函数,有效捕捉全局上下文和高频细节,实现超分辨率重建。相较于其他前沿方法,ViFOR在图像全局和局部上都有更优表现。
Key Takeaways
- ViFOR算法结合了Vision Transformer和傅里叶隐神经表示网络,旨在提高ESM数据的空间分辨率。
- ViFOR引入了傅里叶激活函数,有效结合全局上下文和高频细节捕捉。
- ViFOR在超分辨率重建方面表现出卓越性能,优于其他前沿方法。
- ViFOR在全图源温度、短波和长波通量上的PSNR提升分别高达4.18 dB、1.56 dB和1.73 dB。
- 该算法能够生成高质量的高分辨率图像。
- ViFOR算法在复杂环境过程的理解中有潜在应用价值。
点此查看论文截图