⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-05-28 更新
Eye-See-You: Reverse Pass-Through VR and Head Avatars
Authors:Ankan Dash, Jingyi Gu, Guiling Wang, Chen Chen
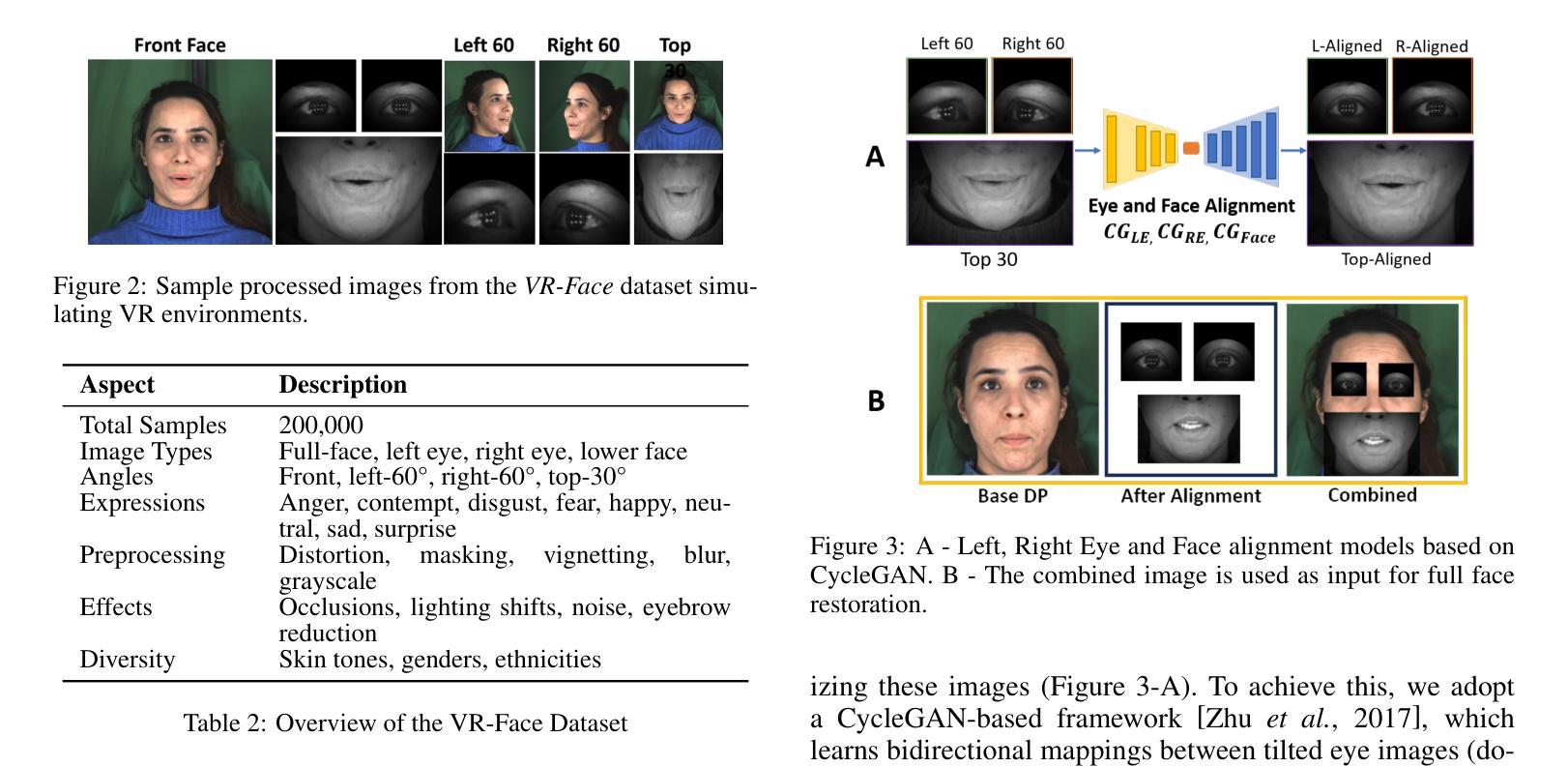
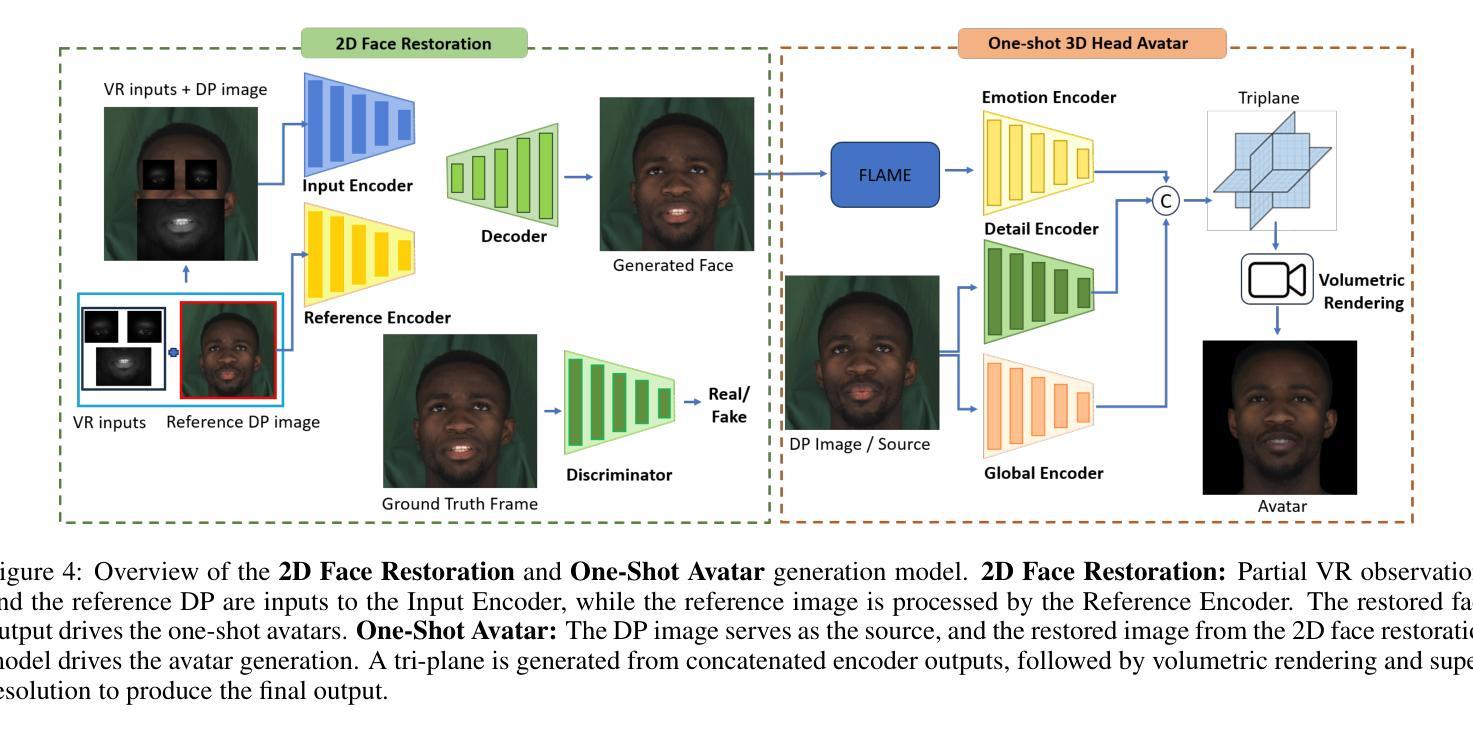
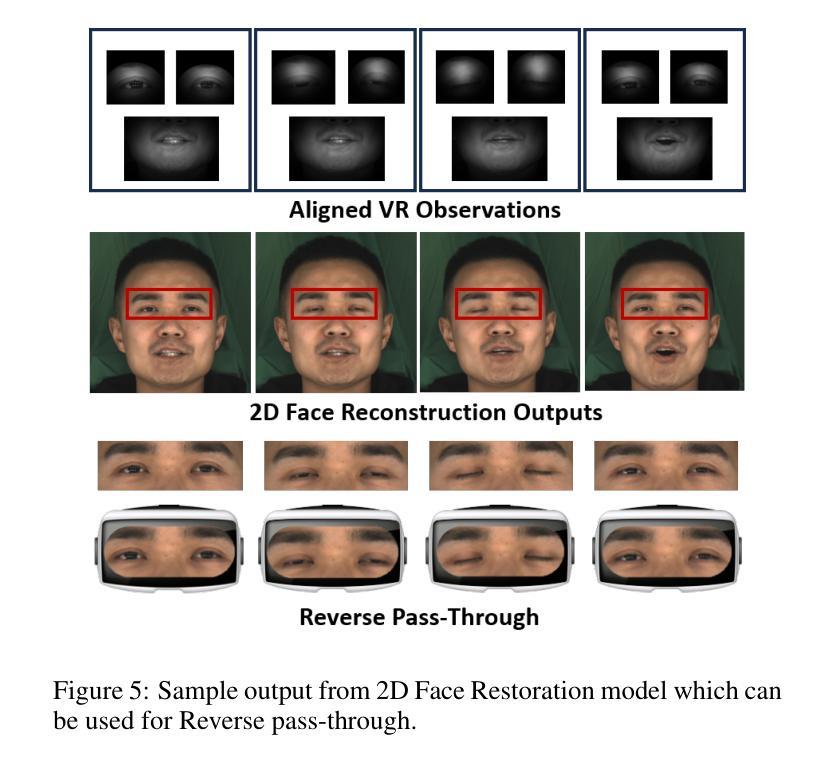
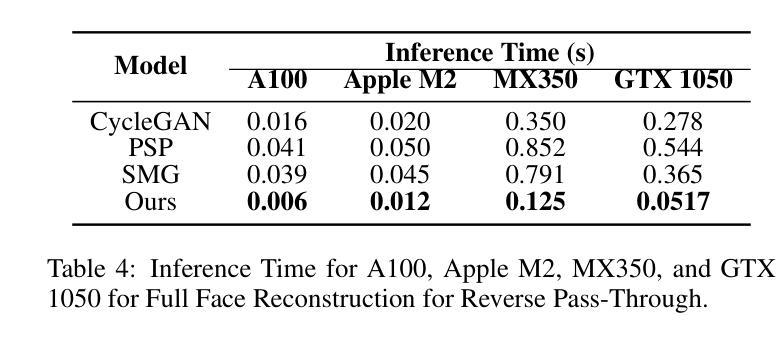
Virtual Reality (VR) headsets, while integral to the evolving digital ecosystem, present a critical challenge: the occlusion of users’ eyes and portions of their faces, which hinders visual communication and may contribute to social isolation. To address this, we introduce RevAvatar, an innovative framework that leverages AI methodologies to enable reverse pass-through technology, fundamentally transforming VR headset design and interaction paradigms. RevAvatar integrates state-of-the-art generative models and multimodal AI techniques to reconstruct high-fidelity 2D facial images and generate accurate 3D head avatars from partially observed eye and lower-face regions. This framework represents a significant advancement in AI4Tech by enabling seamless interaction between virtual and physical environments, fostering immersive experiences such as VR meetings and social engagements. Additionally, we present VR-Face, a novel dataset comprising 200,000 samples designed to emulate diverse VR-specific conditions, including occlusions, lighting variations, and distortions. By addressing fundamental limitations in current VR systems, RevAvatar exemplifies the transformative synergy between AI and next-generation technologies, offering a robust platform for enhancing human connection and interaction in virtual environments.
虚拟现实(VR)耳机虽然是不断发展的数字生态系统的重要组成部分,但它们也带来了一项关键挑战:遮挡用户的眼睛和部分面部,这阻碍了视觉交流并可能导致社交隔离。为了解决这一问题,我们推出了RevAvatar,这是一个创新框架,它利用人工智能方法实现反向传递技术,从根本上改变VR耳机的设计和交互模式。RevAvatar集成了最先进的生成模型和多媒体人工智能技术,可以从部分观察到的眼睛和下半张脸区域重建高保真2D面部图像,并生成准确的3D头部化身。该框架通过实现虚拟环境和物理环境之间的无缝交互,促进了沉浸式体验,如VR会议和社交活动,在人工智能推动技术方面代表了重大进展。此外,我们还推出了VR-Face数据集,这是一个包含20万样本的新数据集,旨在模拟多样化的VR特定条件,包括遮挡、光照变化和失真。通过解决当前VR系统的基本局限性,RevAvatar展示了人工智能和下一代技术之间的变革协同作用,为增强虚拟环境中的人类连接和交互提供了稳健的平台。
论文及项目相关链接
PDF 34th International Joint Conference on Artificial Intelligence, IJCAI 2025
Summary
随着虚拟现实技术的不断发展,VR头盔为用户带来了全新的体验,但同时也带来了社交隔离的问题。为解决这一问题,本文提出了RevAvatar框架,利用人工智能技术实现反向传递技术,实现了VR头盔设计和交互方式的根本性变革。该框架结合了最先进的生成模型和跨模态AI技术,可以重建用户面部的高保真2D图像并生成精确的头部化身,同时应对眼睛和部分面部遮挡的挑战。此外,本文还介绍了VR-Face数据集,模拟了多样化的VR特定条件,包括遮挡物、光照变化和失真等。RevAvatar框架通过解决当前VR系统的基本限制,展示了人工智能和下一代技术之间的协同作用,为增强虚拟环境中的人类连接和交互提供了强大的平台。
Key Takeaways
- VR头盔带来了社交隔离的问题,需要新技术来解决。
- RevAvatar框架利用人工智能技术实现反向传递技术,改变了VR头盔的设计和交互方式。
- RevAvatar可以重建高保真2D面部图像并生成精确的头部化身。
- VR-Face数据集模拟了多样化的VR特定条件,用于训练和测试RevAvatar技术。
- RevAvatar解决了当前VR系统的基本限制。
- RevAvatar展示了人工智能和下一代技术的协同作用。
点此查看论文截图



Barbie: Text to Barbie-Style 3D Avatars
Authors:Xiaokun Sun, Zhenyu Zhang, Ying Tai, Hao Tang, Zili Yi, Jian Yang
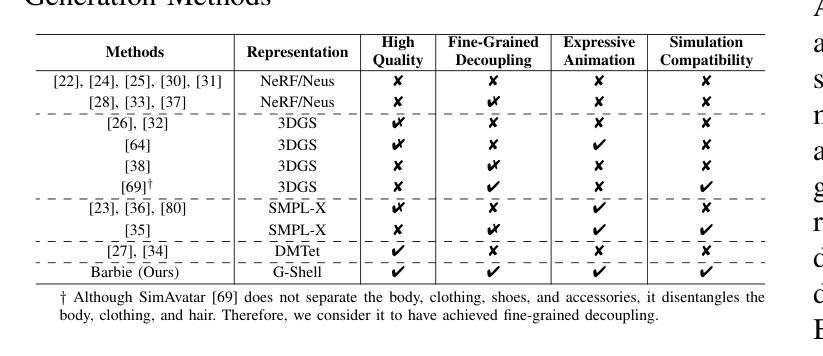
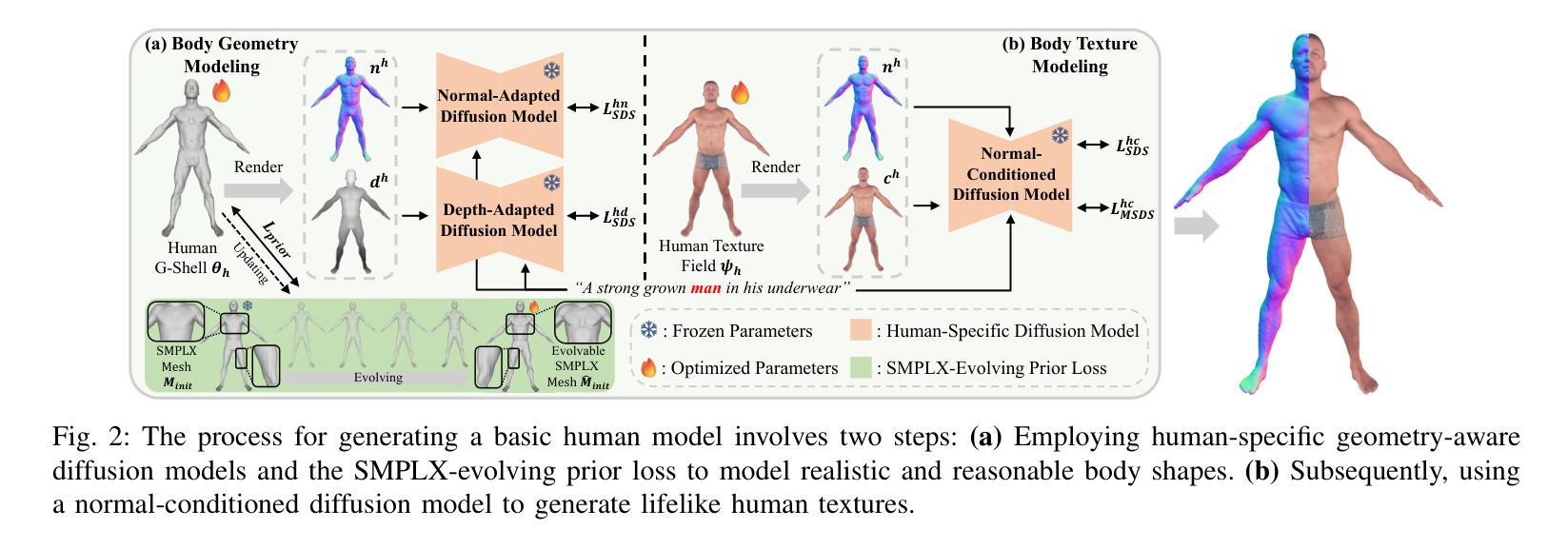
To integrate digital humans into everyday life, there is a strong demand for generating high-quality, fine-grained disentangled 3D avatars that support expressive animation and simulation capabilities, ideally from low-cost textual inputs. Although text-driven 3D avatar generation has made significant progress by leveraging 2D generative priors, existing methods still struggle to fulfill all these requirements simultaneously. To address this challenge, we propose Barbie, a novel text-driven framework for generating animatable 3D avatars with separable shoes, accessories, and simulation-ready garments, truly capturing the iconic ``Barbie doll’’ aesthetic. The core of our framework lies in an expressive 3D representation combined with appropriate modeling constraints. Unlike previous methods, we innovatively employ G-Shell to uniformly model both watertight components (e.g., bodies, shoes, and accessories) and non-watertight garments compatible with simulation. Furthermore, we introduce a well-designed initialization and a hole regularization loss to ensure clean open surface modeling. These disentangled 3D representations are then optimized by specialized expert diffusion models tailored to each domain, ensuring high-fidelity outputs. To mitigate geometric artifacts and texture conflicts when combining different expert models, we further propose several effective geometric losses and strategies. Extensive experiments demonstrate that Barbie outperforms existing methods in both dressed human and outfit generation. Our framework further enables diverse applications, including apparel combination, editing, expressive animation, and physical simulation. Our project page is: https://xiaokunsun.github.io/Barbie.github.io
要将数字人类融入日常生活,对生成高质量、精细化的3D化身有着强烈的需求,这些化身需要支持表情动画和模拟功能,理想情况下是从低成本的文本输入中生成。尽管文本驱动的3D化身生成借助二维生成先验取得了显著进展,但现有方法仍然难以同时满足所有这些要求。为了解决这一挑战,我们提出了Barbie,这是一个新颖的文本驱动框架,用于生成具有可分离鞋子、配饰和模拟准备服装的动画3D化身,真正捕捉标志性的“芭比娃娃”美学。我们的框架的核心在于表达性的3D表示与适当的建模约束的结合。与以前的方法不同,我们创新地采用G-Shell来统一建模防水部件(例如身体、鞋子和配饰)以及与模拟兼容的非防水服装。此外,我们引入了一个精心设计的初始化和孔正则损失来确保干净的开放表面建模。这些解耦的3D表示然后通过针对每个领域定制的专家扩散模型进行优化,以确保高保真输出。为了减少组合不同专家模型时出现的几何伪影和纹理冲突,我们进一步提出了几种有效的几何损失和策略。大量实验表明,Barbie在着装人物和服装生成方面都优于现有方法。我们的框架还支持多种应用,包括服装组合、编辑、表情动画和物理模拟。我们的项目页面是:https://xiaokunsun.github.io/Barbie.github.io
论文及项目相关链接
PDF Project page: https://xiaokunsun.github.io/Barbie.github.io
Summary
文本提出了一项名为Barbie的新型文本驱动框架,用于生成具有可分离鞋、配饰和模拟准备服装的可动态3D阿凡达。其核心在于结合表达性3D表示和适当的建模约束,能够模拟真实的Barbie doll效果。该框架能够同时对水密组件和非水密服装进行建模,并引入初始化和空洞正则化损失确保清洁开放的表面建模。此外,它还通过针对每个领域定制的专业扩散模型优化这些分离的3D表示,以确保高保真输出。该框架能应用于多种场景,如服装组合、编辑、动态动画和物理模拟等。
Key Takeaways
- Barbie是一个文本驱动的框架,用于生成高质量的、精细粒度的、解纠缠的3D阿凡达。
- 该框架支持表达性动画和模拟能力,可以从低成本的文本输入生成阿凡达。
- Barbie框架的核心是结合表达性3D表示和适当的建模约束,以模拟真实的Barbie doll效果。
- Barbie能够同时对水密组件和非水密服装进行建模,确保清洁开放的表面建模。
- 该框架使用针对每个领域定制的专业扩散模型来优化3D表示,确保高保真输出。
- Barbie在装扮人类和服装生成方面优于现有方法,并提供了多种应用,如服装组合、编辑、动态动画和物理模拟等。
点此查看论文截图