⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-05-28 更新
TUNA: Comprehensive Fine-grained Temporal Understanding Evaluation on Dense Dynamic Videos
Authors:Fanheng Kong, Jingyuan Zhang, Hongzhi Zhang, Shi Feng, Daling Wang, Linhao Yu, Xingguang Ji, Yu Tian, Qi Wang, Fuzheng Zhang
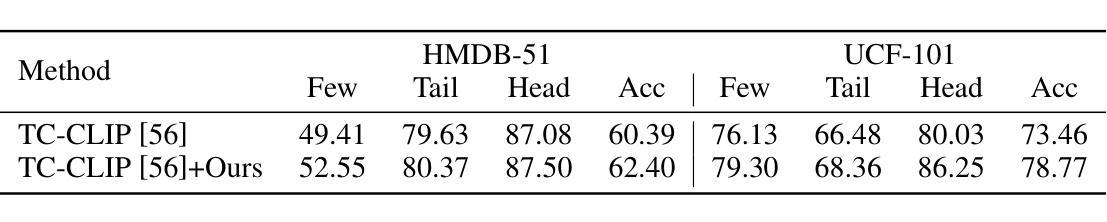
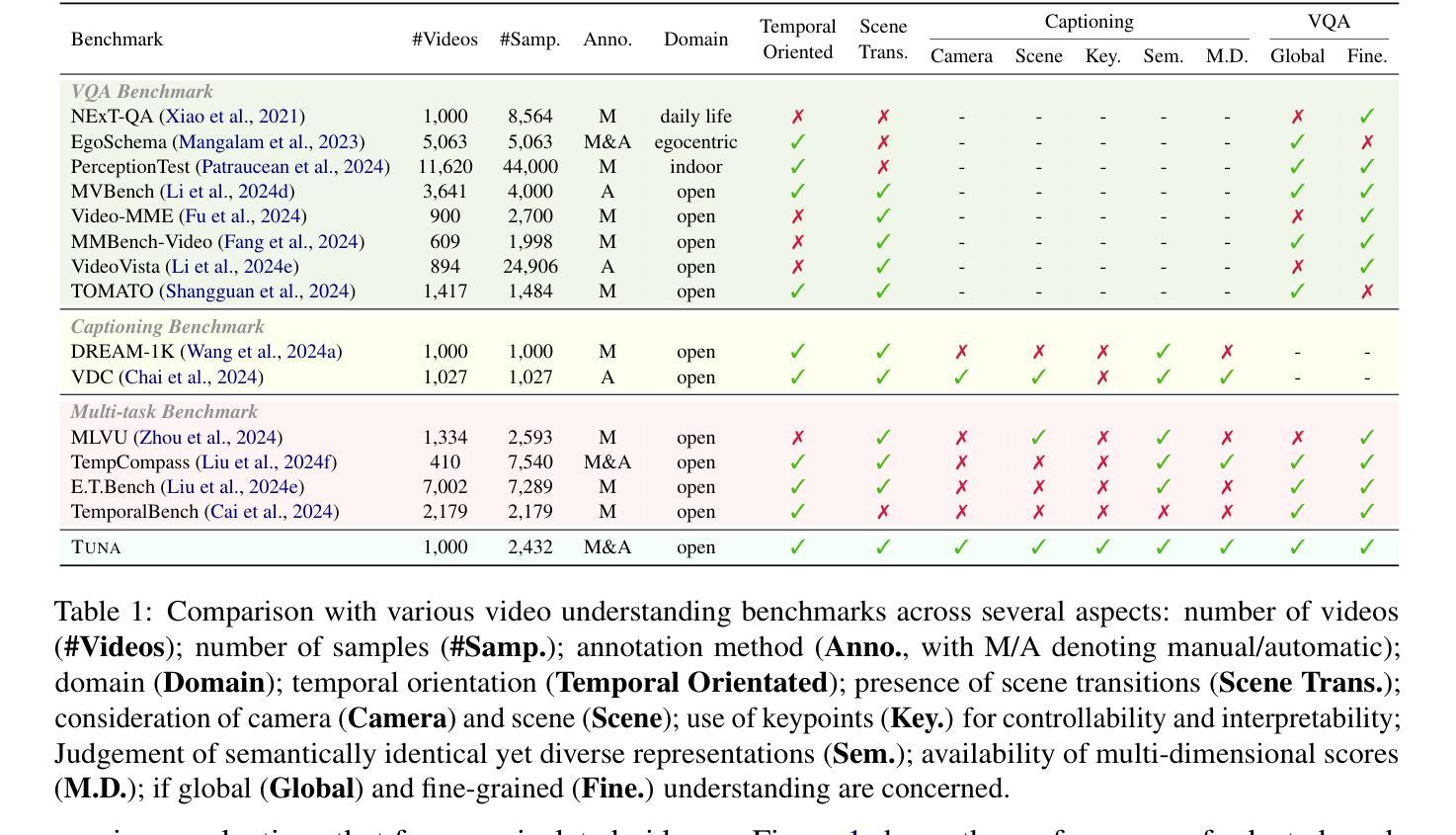
Videos are unique in their integration of temporal elements, including camera, scene, action, and attribute, along with their dynamic relationships over time. However, existing benchmarks for video understanding often treat these properties separately or narrowly focus on specific aspects, overlooking the holistic nature of video content. To address this, we introduce TUNA, a temporal-oriented benchmark for fine-grained understanding on dense dynamic videos, with two complementary tasks: captioning and QA. Our TUNA features diverse video scenarios and dynamics, assisted by interpretable and robust evaluation criteria. We evaluate several leading models on our benchmark, providing fine-grained performance assessments across various dimensions. This evaluation reveals key challenges in video temporal understanding, such as limited action description, inadequate multi-subject understanding, and insensitivity to camera motion, offering valuable insights for improving video understanding models. The data and code are available at https://friedrichor.github.io/projects/TUNA.
视频因其结合了时间元素而具有独特性,包括相机、场景、动作和属性,以及它们随时间变化的动态关系。然而,现有的视频理解基准测试通常将这些属性分开处理,或者仅关注特定方面,忽略了视频内容的整体性质。为了解决这一问题,我们引入了TUNA,这是一个针对密集动态视频的精细粒度理解的时序导向基准测试,包括两个互补任务:描述和问答。我们的TUNA具有多样化的视频场景和动态,辅以可解释和稳健的评估标准。我们在基准测试上评估了几种领先模型,提供了跨各种维度的精细性能评估。这一评估揭示了视频时序理解的关键挑战,如动作描述有限、多主体理解不足以及忽视相机运动等,为改进视频理解模型提供了宝贵的见解。数据和代码可在https://friedrichor.github.io/projects/TUNA上获取。
论文及项目相关链接
PDF Accepted to CVPR 2025 Main. Project page: https://friedrichor.github.io/projects/TUNA
摘要
视频融合了时间元素,包括摄像机、场景、动作和属性及其随时间变化的动态关系。然而,现有的视频理解基准测试通常将这些属性分开处理,或者仅关注特定方面,忽略了视频内容的整体性质。为解决此问题,我们推出了TUNA基准测试,这是一个针对密集动态视频的精细理解的时间导向基准测试,包括描述和问答两个互补任务。TUNA具有多样化的视频场景和动态性,辅以可解释和稳健的评估标准。我们在基准测试上评估了几种领先模型,提供了跨不同维度的精细性能评估。这一评估揭示了视频时间理解的关键挑战,如动作描述有限、多主题理解不足和对相机运动的敏感性低,为改进视频理解模型提供了宝贵见解。数据和代码可通过链接获得:数据链接。
要点掌握
- 视频理解需要整合时间元素,包括摄像机、场景、动作和属性及其随时间变化的动态关系。
- 现有基准测试通常忽略视频内容的整体性质,将属性分开处理或仅关注特定方面。
- TUNA基准测试针对密集动态视频的精细理解,包括描述和问答两个任务,旨在解决上述问题。
- TUNA具有多样化的视频场景和动态性,辅助以可解释和稳健的评估标准。
- 在TUNA基准测试上评估的领先模型表现揭示出视频时间理解的三大关键挑战:动作描述有限、多主题理解不足以及对相机运动的敏感性低。
- 这些挑战为改进视频理解模型提供了有价值的见解。
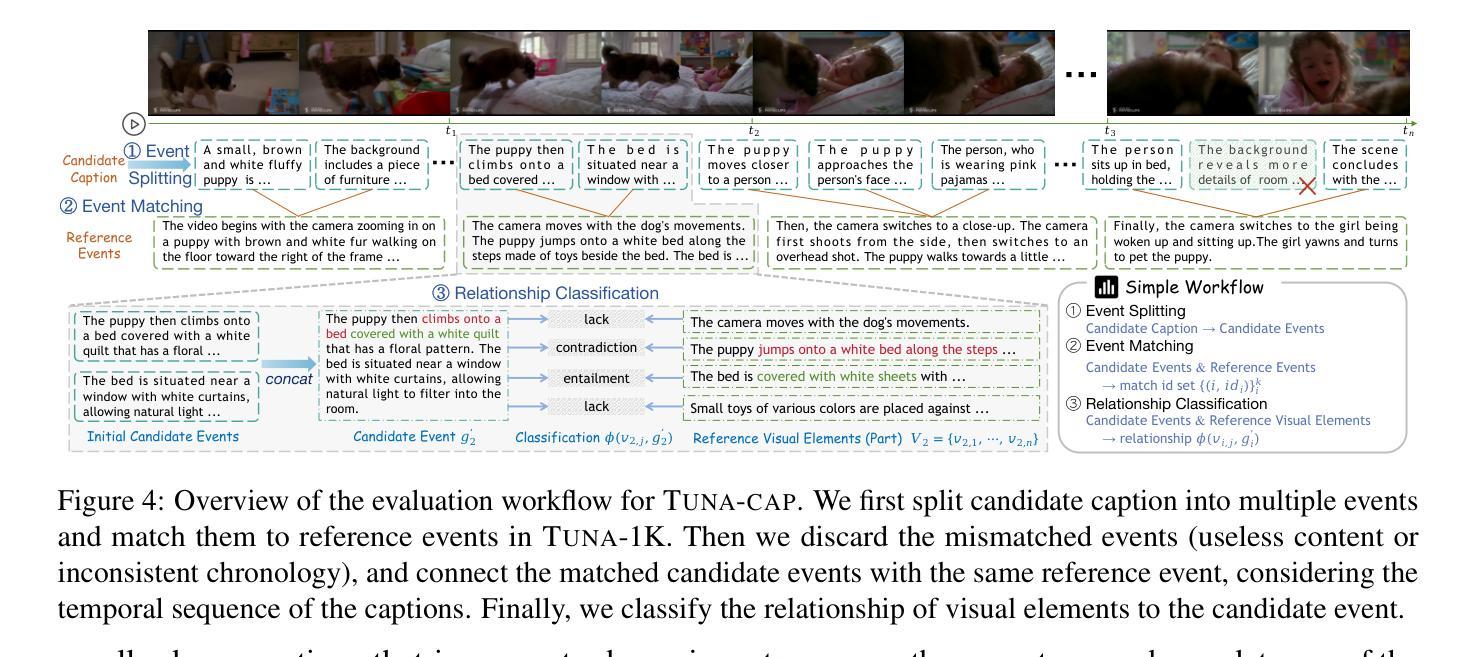
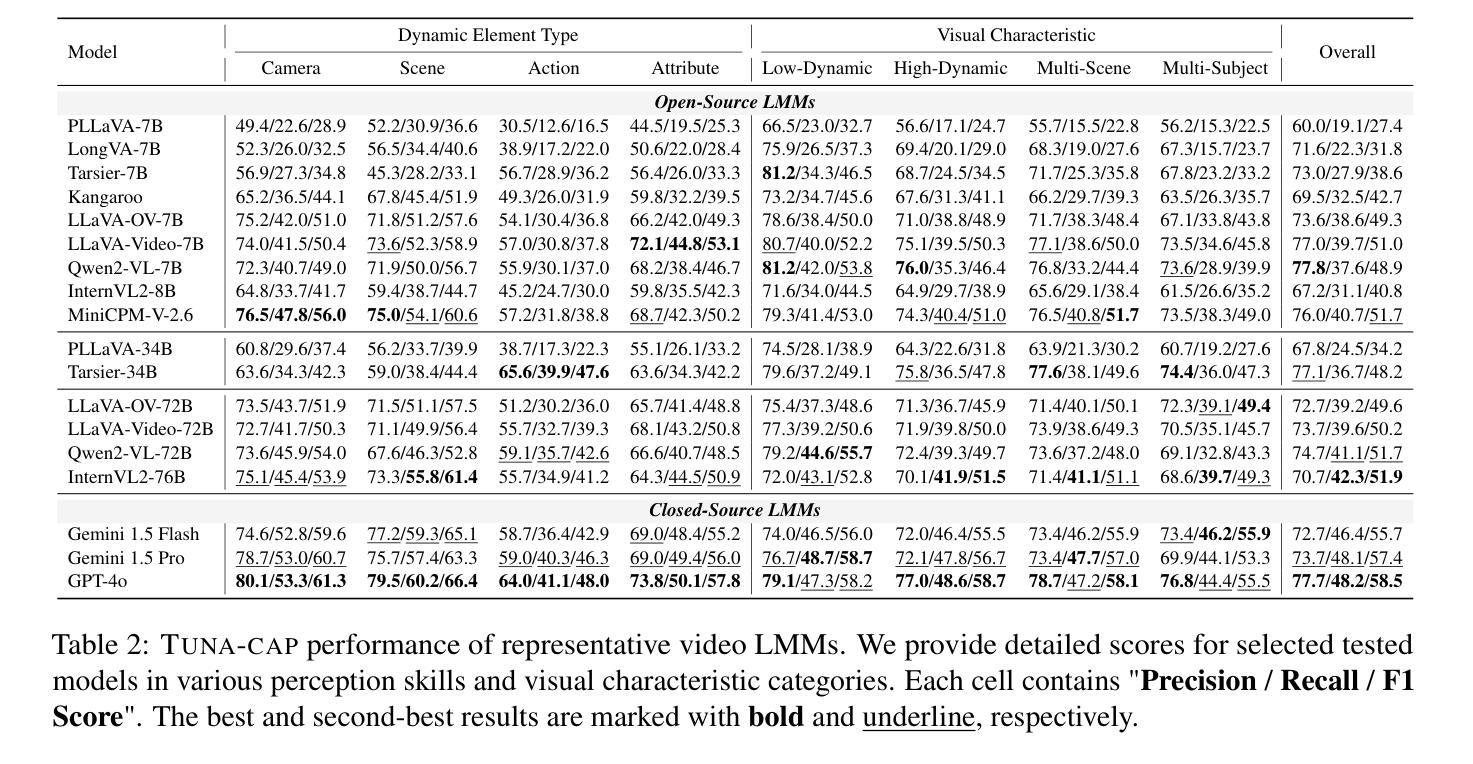
点此查看论文截图



The Role of Video Generation in Enhancing Data-Limited Action Understanding
Authors:Wei Li, Dezhao Luo, Dongbao Yang, Zhenhang Li, Weiping Wang, Yu Zhou
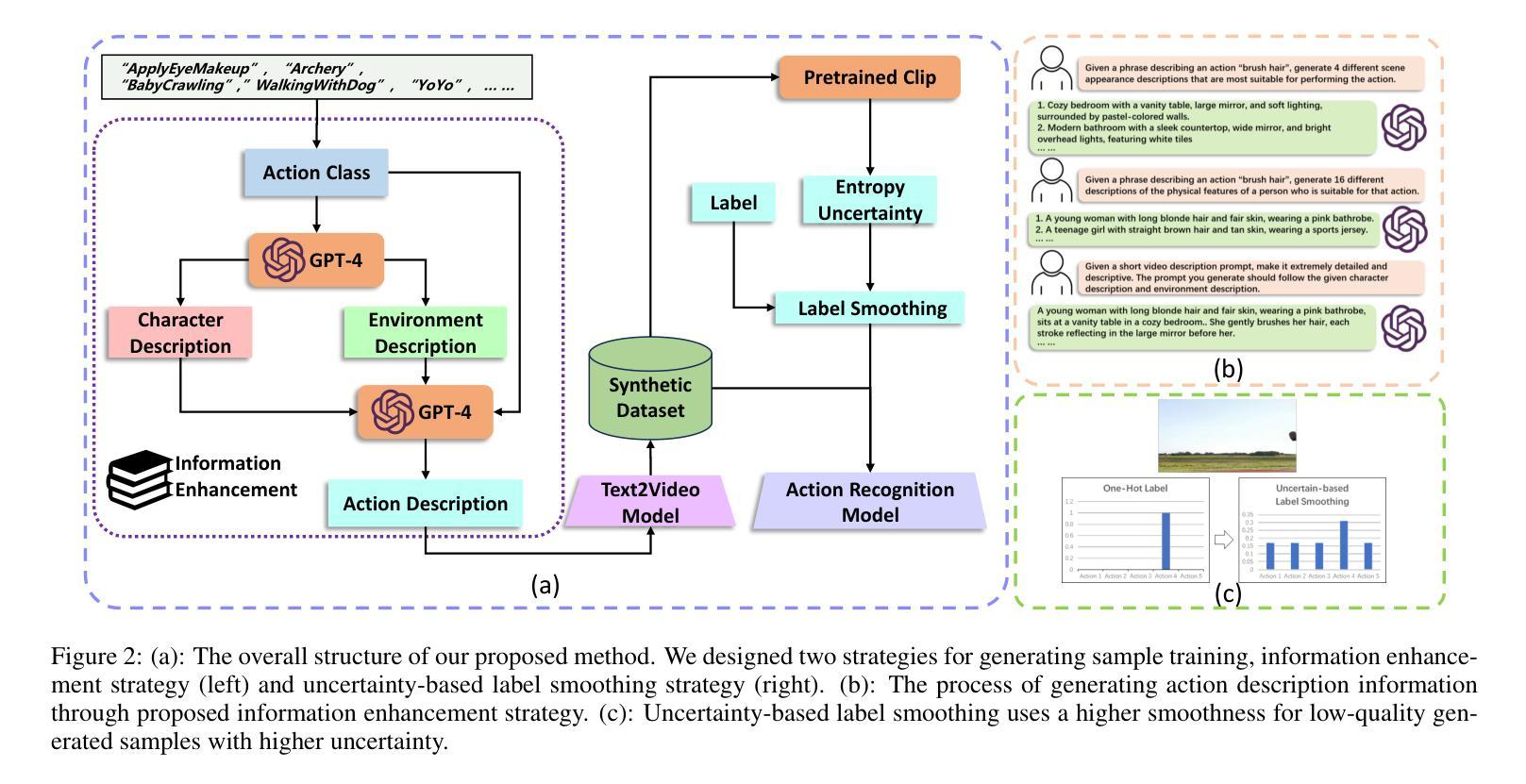
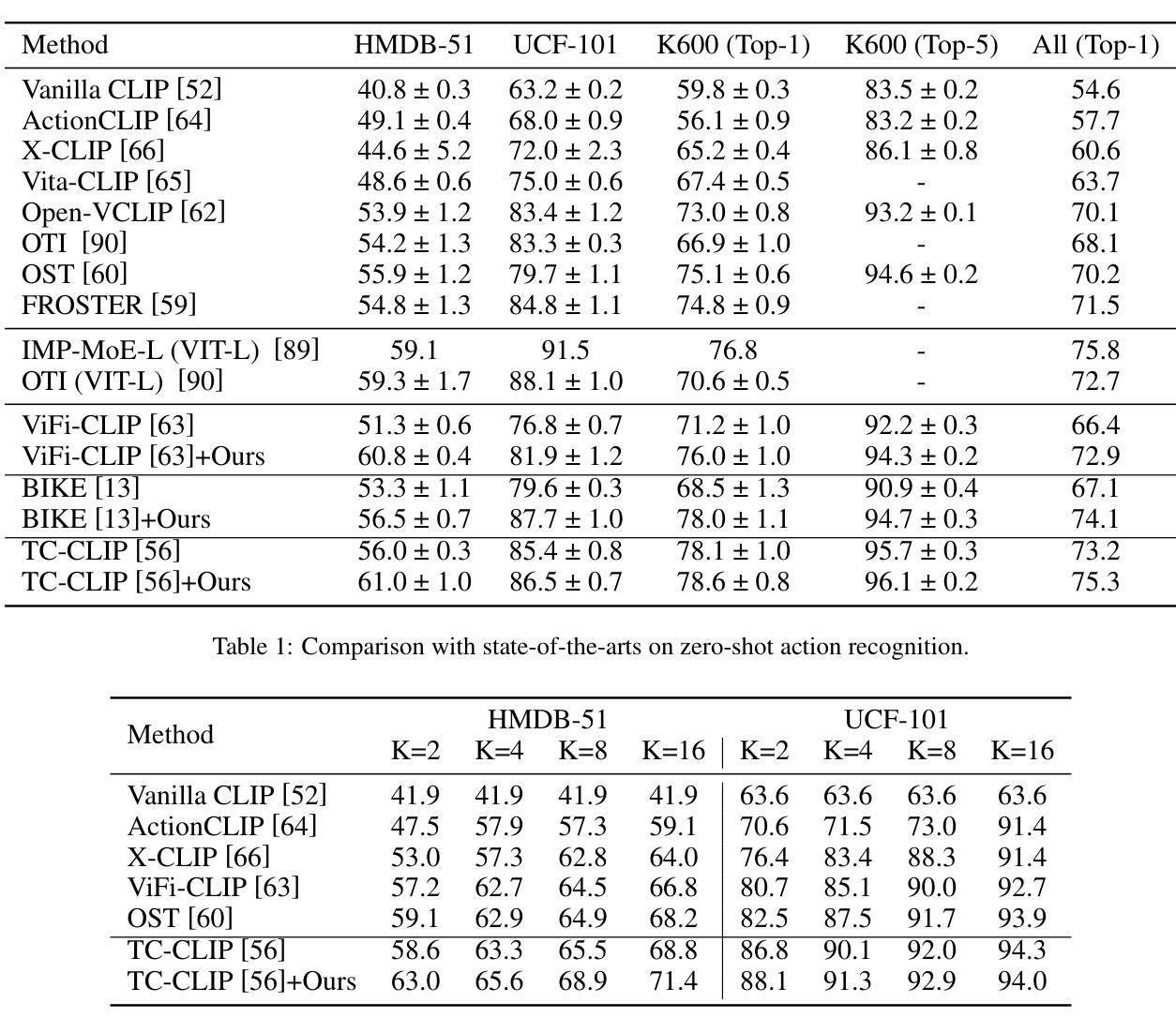
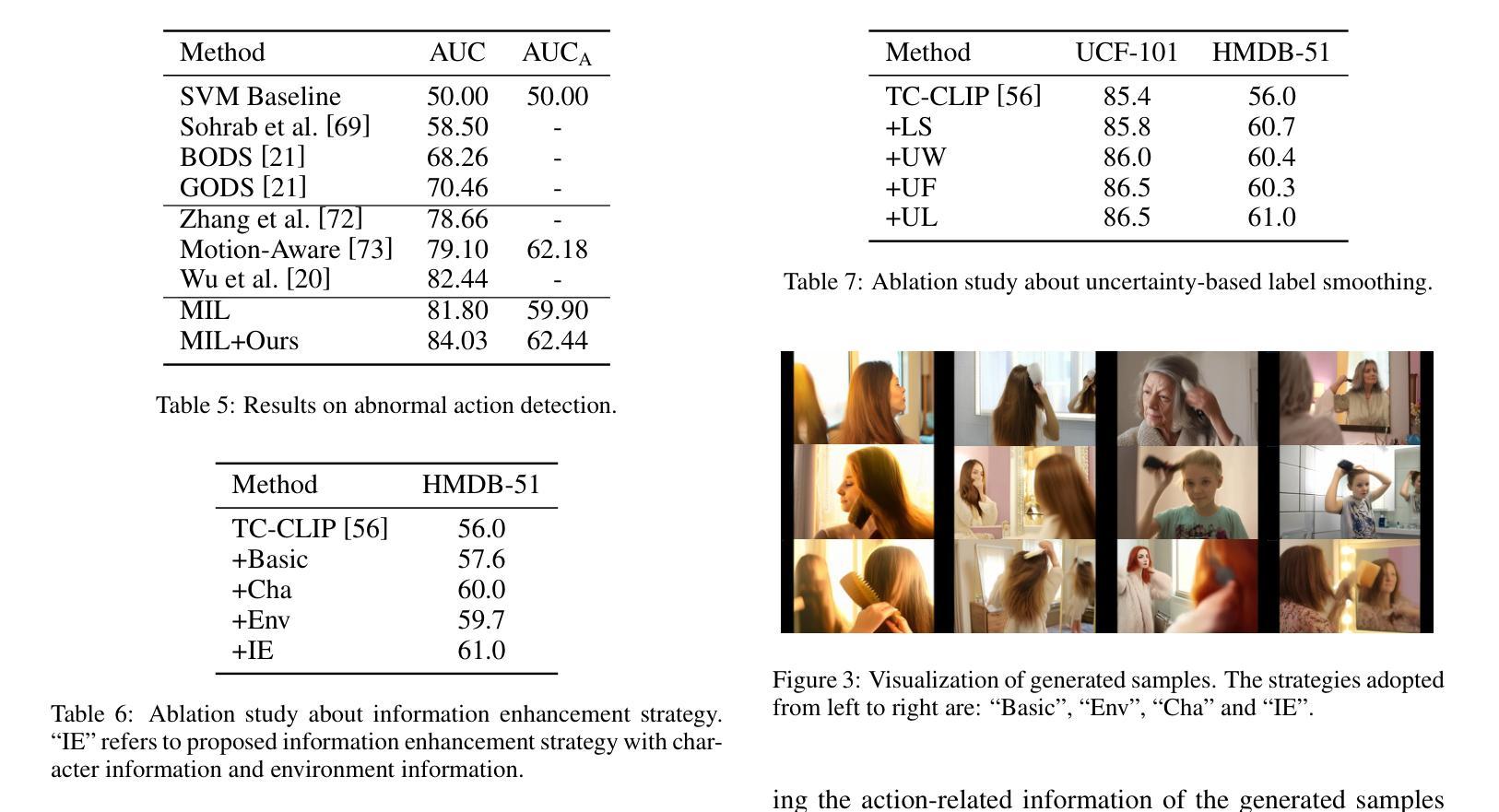
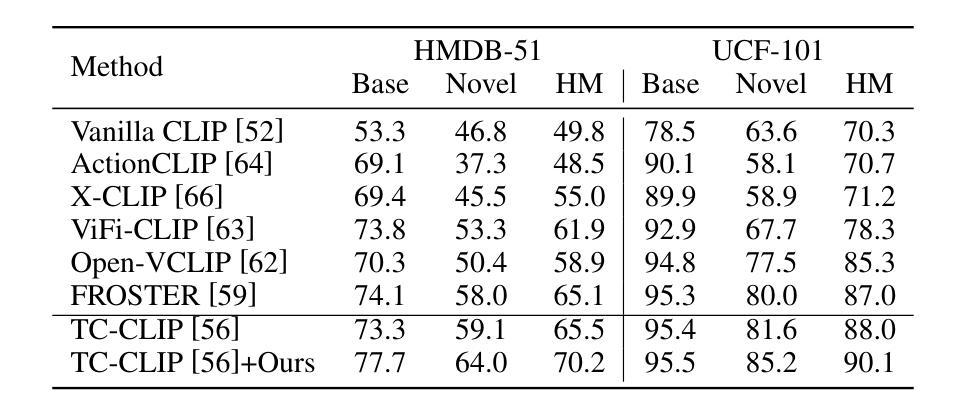
Video action understanding tasks in real-world scenarios always suffer data limitations. In this paper, we address the data-limited action understanding problem by bridging data scarcity. We propose a novel method that employs a text-to-video diffusion transformer to generate annotated data for model training. This paradigm enables the generation of realistic annotated data on an infinite scale without human intervention. We proposed the information enhancement strategy and the uncertainty-based label smoothing tailored to generate sample training. Through quantitative and qualitative analysis, we observed that real samples generally contain a richer level of information than generated samples. Based on this observation, the information enhancement strategy is proposed to enhance the informative content of the generated samples from two aspects: the environments and the characters. Furthermore, we observed that some low-quality generated samples might negatively affect model training. To address this, we devised the uncertainty-based label smoothing strategy to increase the smoothing of these samples, thus reducing their impact. We demonstrate the effectiveness of the proposed method on four datasets across five tasks and achieve state-of-the-art performance for zero-shot action recognition.
在现实世界的视频动作理解任务中,数据限制始终是一个挑战。本文针对数据有限的动作理解问题,通过解决数据稀缺的问题进行了研究。我们提出了一种新的方法,采用文本到视频的扩散变压器生成注释数据用于模型训练。这种范式能够在无需人工干预的情况下,生成无限规模的现实注释数据。我们提出了信息增强策略和基于不确定性的标签平滑,以定制生成样本训练。通过定量和定性分析,我们发现真实样本通常包含比生成样本更丰富的信息。基于此观察,我们提出了信息增强策略,从环境和角色两个方面增强生成样本的信息含量。此外,我们还发现一些低质量的生成样本可能会对模型训练产生负面影响。为解决这一问题,我们设计了基于不确定性的标签平滑策略,以增加这些样本的平滑度,从而降低其影响。我们在五个任务中的四个数据集上验证了所提出方法的有效性,并在零样本动作识别领域取得了最先进的性能。
论文及项目相关链接
PDF IJCAI2025
Summary
本文解决了视频理解中数据受限的问题,通过采用文本到视频的扩散变换器生成标注数据,使得在没有人为干预的情况下实现真实标注数据的无限规模生成。并提出信息增强策略和基于不确定性的标签平滑策略来优化生成的训练样本,从而提高模型的性能。实验结果显示该方法在四个数据集上的五个任务均达到了最先进的性能水平。
Key Takeaways
- 针对视频理解中数据受限的问题,提出了文本到视频的扩散变换器生成标注数据的方法。
- 实现了真实标注数据的无限规模生成,无需人为干预。
- 提出信息增强策略,从环境和角色两个方面提高生成样本的信息含量。
- 针对某些低质量生成样本可能对模型训练产生负面影响的问题,提出了基于不确定性的标签平滑策略。
- 在四个数据集上的五个任务进行了实验验证,取得了最先进的性能水平。
- 观察到真实样本通常包含比生成样本更丰富的信息。
点此查看论文截图