⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-05-28 更新
Improvement Strategies for Few-Shot Learning in OCT Image Classification of Rare Retinal Diseases
Authors:Cheng-Yu Tai, Ching-Wen Chen, Chi-Chin Wu, Bo-Chen Chiu, Cheng-Hung, Lin, Cheng-Kai Lu, Jia-Kang Wang, Tzu-Lun Huang
This paper focuses on using few-shot learning to improve the accuracy of classifying OCT diagnosis images with major and rare classes. We used the GAN-based augmentation strategy as a baseline and introduced several novel methods to further enhance our model. The proposed strategy contains U-GAT-IT for improving the generative part and uses the data balance technique to narrow down the skew of accuracy between all categories. The best model obtained was built with CBAM attention mechanism and fine-tuned InceptionV3, and achieved an overall accuracy of 97.85%, representing a significant improvement over the original baseline.
本文重点关注使用少量样本学习来提高对OCT诊断图像中主要和罕见类别分类的准确性。我们采用了基于GAN的增强策略作为基线,并引入了几种新方法进一步改进我们的模型。提出的策略包含用于改进生成部分的U-GAT-IT,并使用数据平衡技术来缩小所有类别之间的准确率偏差。获得的最佳模型是采用CBAM注意力机制和微调过的InceptionV3构建的,总体准确率达到97.85%,相较于原始基线有了显著的提升。
论文及项目相关链接
Summary
这篇论文利用少样本学习技术提高了OCT诊断图像分类的准确性,特别是针对主要和罕见类别的分类。采用基于GAN的增强策略作为基线,并引入了几种新方法进一步提升模型性能。通过U-GAT-IT改进生成部分,并运用数据平衡技术缩小各类别准确度的偏差。最佳模型采用CBAM注意力机制和微调过的InceptionV3,总体准确度达到97.85%,较基线有显著改善。
Key Takeaways
- 论文关注于利用少样本学习提高OCT诊断图像分类的准确性。
- 采用基于GAN的增强策略作为基线方法。
- 引入U-GAT-IT改进生成模型部分。
- 运用数据平衡技术缩小各类别之间的准确度偏差。
- 最佳模型结合了CBAM注意力机制和微调过的InceptionV3。
- 最佳模型的总体准确度达到97.85%。
点此查看论文截图

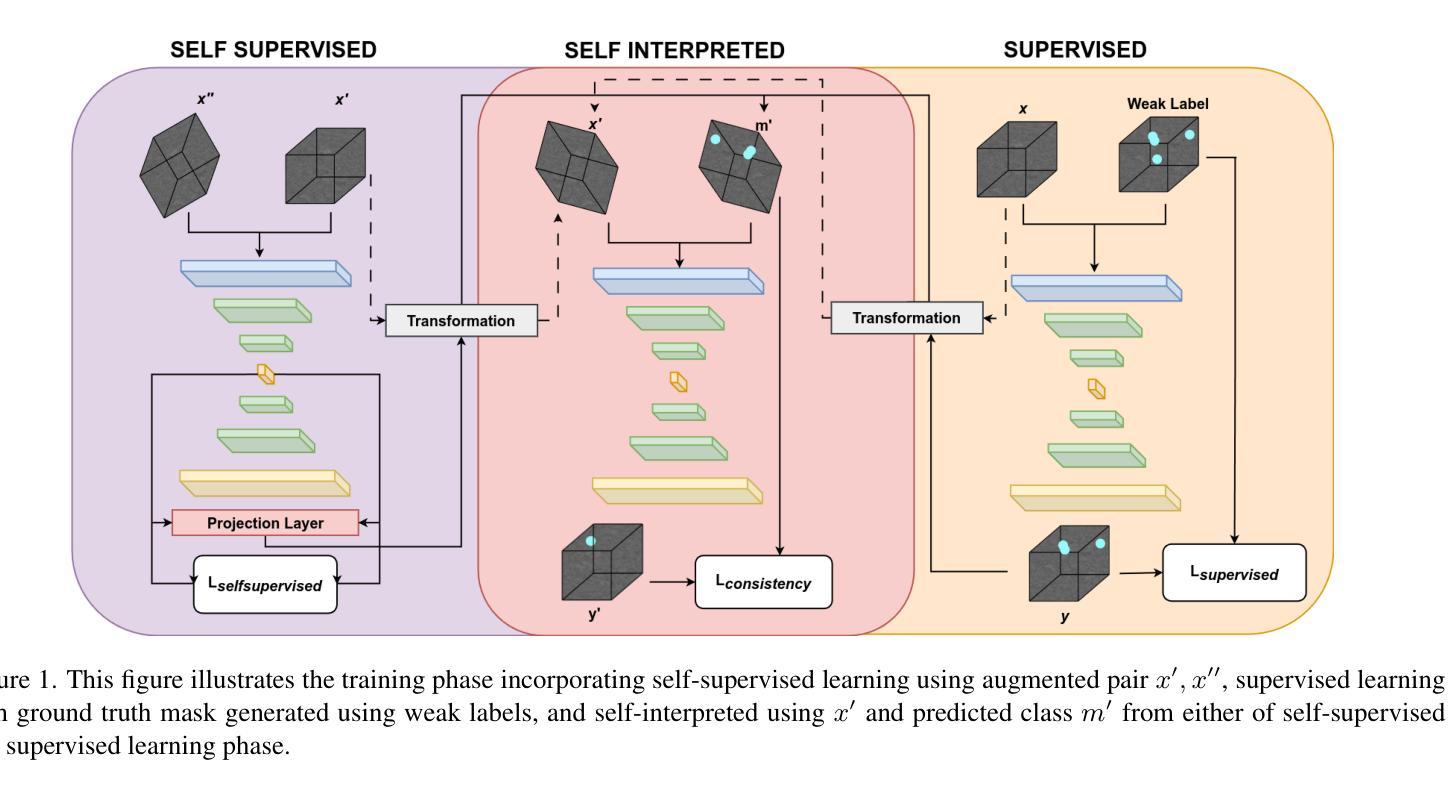
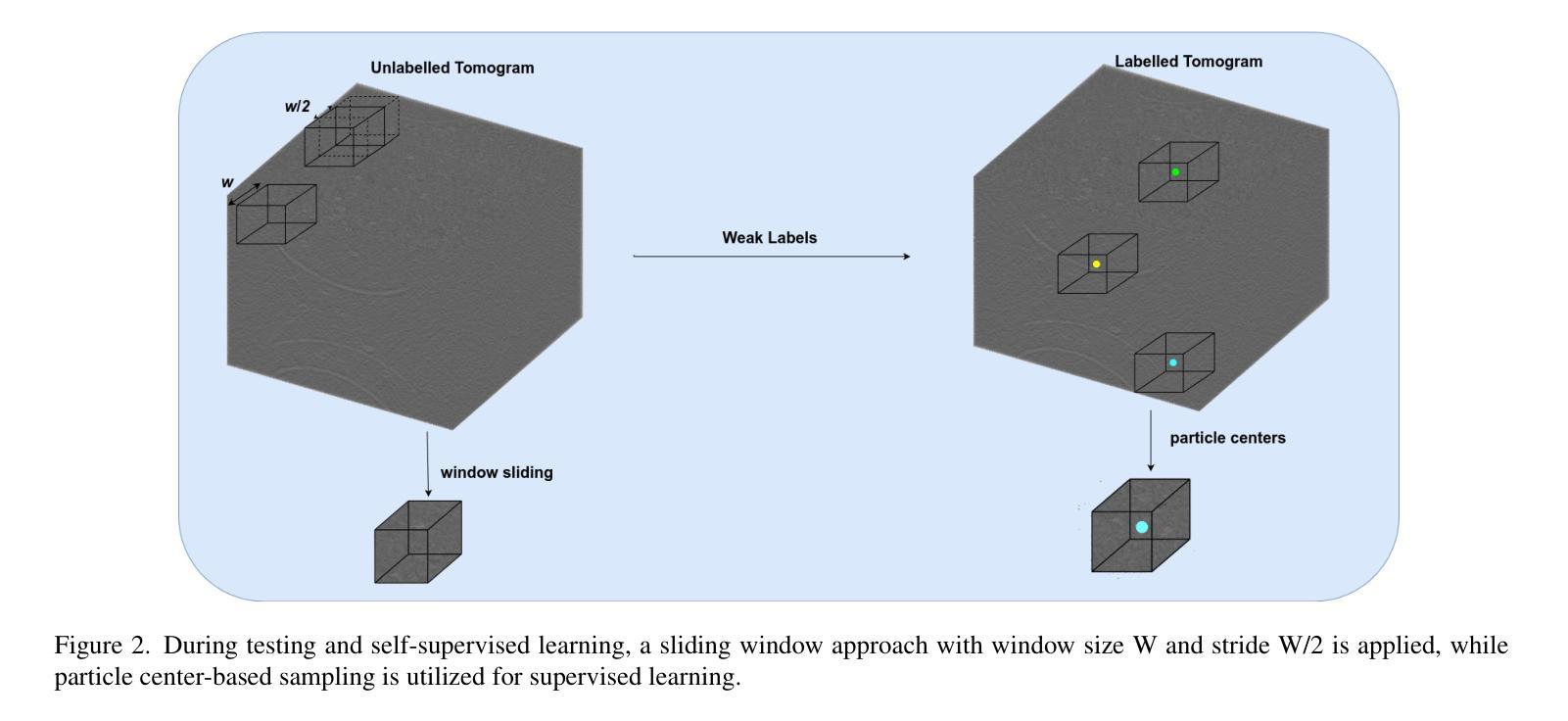
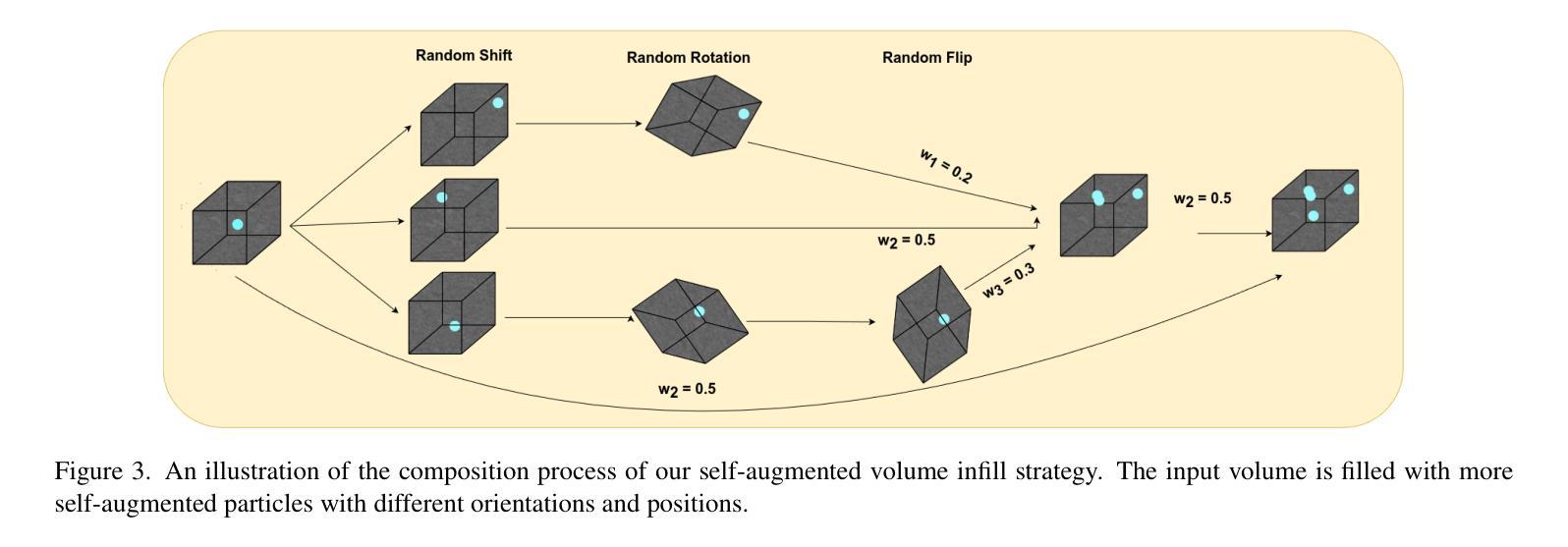
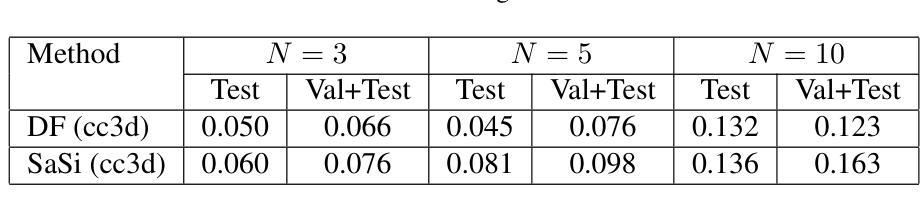
SaSi: A Self-augmented and Self-interpreted Deep Learning Approach for Few-shot Cryo-ET Particle Detection
Authors:Gokul Adethya, Bhanu Pratyush Mantha, Tianyang Wang, Xingjian Li, Min Xu
Cryo-electron tomography (cryo-ET) has emerged as a powerful technique for imaging macromolecular complexes in their near-native states. However, the localization of 3D particles in cellular environments still presents a significant challenge due to low signal-to-noise ratios and missing wedge artifacts. Deep learning approaches have shown great potential, but they need huge amounts of data, which can be a challenge in cryo-ET scenarios where labeled data is often scarce. In this paper, we propose a novel Self-augmented and Self-interpreted (SaSi) deep learning approach towards few-shot particle detection in 3D cryo-ET images. Our method builds upon self-augmentation techniques to further boost data utilization and introduces a self-interpreted segmentation strategy for alleviating dependency on labeled data, hence improving generalization and robustness. As demonstrated by experiments conducted on both simulated and real-world cryo-ET datasets, the SaSi approach significantly outperforms existing state-of-the-art methods for particle localization. This research increases understanding of how to detect particles with very few labels in cryo-ET and thus sets a new benchmark for few-shot learning in structural biology.
冷冻电子断层扫描(cryo-ET)已成为可视化近天然态大分子复合物的一种强大技术。然而,由于信噪比低和缺失的楔形伪影,在细胞环境中对三维粒子的定位仍然是一个巨大的挑战。深度学习的方法显示出巨大的潜力,但它们需要大量的数据,这在冷冻电镜技术场景中可能是一个挑战,因为标记的数据通常很稀缺。在本文中,我们提出了一种新型的自我增强和自我解释(SaSi)深度学习的方法,用于在少量3D冷冻电子断层扫描图像中进行粒子检测。我们的方法建立在自我增强技术之上,进一步提高了数据利用率,并引入了一种自我解释分割策略,以减轻对标记数据的依赖,从而提高泛化和鲁棒性。通过模拟和真实冷冻电镜数据集的实验证明,SaSi方法在粒子定位方面显著优于现有最先进的方法。该研究提高了在冷冻电镜中如何检测少量标签粒子的理解,从而为结构生物学中的小样本学习设定了一个新的基准。
论文及项目相关链接
Summary
本文提出一种新型的基于自增强和自解释(SaSi)的深度学习方法,用于在少量标注数据的情况下实现三维冷冻电子断层扫描(cryo-ET)图像中的粒子检测。该方法通过自增强技术进一步提高数据利用率,并引入自解释分割策略,减少对标注数据的依赖,从而提高模型的通用性和鲁棒性。实验证明,该方法在模拟和实际cryo-ET数据集上的表现均优于现有技术。该研究提高了在冷冻电镜中检测粒子的能力,为结构生物学中的小样本学习树立了新的标杆。
Key Takeaways
- 冷冻电子断层扫描(cryo-ET)技术用于成像大分子复合物。
- 在细胞环境中定位三维粒子存在挑战,主要由于低信噪比和缺失楔形伪影。
- 深度学习在解决此问题上显示出潜力,但需要大量数据,而冷冻电镜场景中的标注数据往往稀缺。
- 提出了新型的基于自增强和自解释(SaSi)的深度学习方法用于少样本粒子检测。
- SaSi方法通过自增强技术提高数据利用率,并引入自解释分割策略减少对标注数据的依赖。
- 实验证明SaSi方法在模拟和实际数据集上均表现优异。
点此查看论文截图

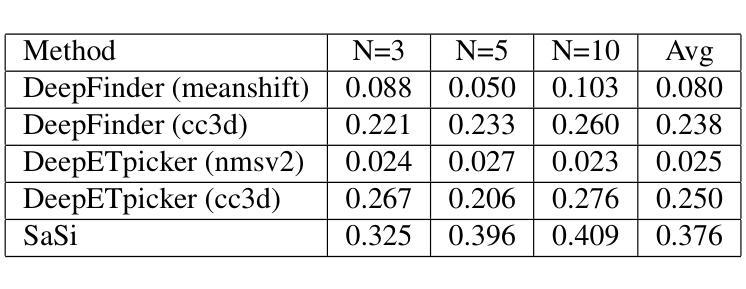
Large Language Models as Autonomous Spacecraft Operators in Kerbal Space Program
Authors:Alejandro Carrasco, Victor Rodriguez-Fernandez, Richard Linares
Recent trends are emerging in the use of Large Language Models (LLMs) as autonomous agents that take actions based on the content of the user text prompts. We intend to apply these concepts to the field of Control in space, enabling LLMs to play a significant role in the decision-making process for autonomous satellite operations. As a first step towards this goal, we have developed a pure LLM-based solution for the Kerbal Space Program Differential Games (KSPDG) challenge, a public software design competition where participants create autonomous agents for maneuvering satellites involved in non-cooperative space operations, running on the KSP game engine. Our approach leverages prompt engineering, few-shot prompting, and fine-tuning techniques to create an effective LLM-based agent that ranked 2nd in the competition. To the best of our knowledge, this work pioneers the integration of LLM agents into space research. The project comprises several open repositories to facilitate replication and further research. The codebase is accessible on \href{https://github.com/ARCLab-MIT/kspdg}{GitHub}, while the trained models and datasets are available on \href{https://huggingface.co/OhhTuRnz}{Hugging Face}. Additionally, experiment tracking and detailed results can be reviewed on \href{https://wandb.ai/carrusk/huggingface}{Weights & Biases
最近出现了使用大型语言模型(LLM)作为自主代理的趋势,这些代理会根据用户文本提示的内容采取行动。我们打算将这些概念应用于空间控制领域,使LLM在自主卫星操作的决策过程中发挥重要作用。作为实现这一目标的第一步,我们为Kerbal Space Program Differential Games(KSPDG)挑战开发了一种纯LLM解决方案。KSPDG是一场公开的软件设计竞赛,参赛者需为非合作空间操作创建自主代理卫星,该解决方案基于LLM在KSP游戏引擎上运行。我们的方法利用提示工程、少提示和微调技术创建了一个有效的基于LLM的代理,在比赛中排名第二。据我们所知,这项工作首创了将LLM代理集成到空间研究中。该项目包含多个开源仓库,以促进复制和进一步研究。代码库可在GitHub上访问([https://github.com/ARCLab-MIT/kspdg),而训练好的模型和数据集可在Hugging Face上找到(https://huggingface.co/OhhTuRnz)。此外,实验跟踪和详细结果可在Weights & Biases上查看(https://wandb.ai/carrusk/huggingface)。
论文及项目相关链接
PDF Non revised version for paper going to be published in Journal of Advances in Space Research
Summary
大型语言模型(LLM)被应用于空间控制领域,作为自主代理进行基于用户文本提示的行动决策。研究团队在Kerbal Space Program Differential Games挑战中,开发了一种纯LLM解决方案,利用提示工程、少样本提示和微调技术创建了一个有效的LLM代理,并在竞赛中取得了第二名。该项目为LLM代理在空间研究中的集成开辟了先河,其代码库、训练模型和数据集均已公开供研究使用。
Key Takeaways
- 大型语言模型(LLM)被应用于自主卫星操作的决策过程中。
- LLMs被用作自主代理,能够根据用户文本提示采取行动。
- 在Kerbal Space Program Differential Games挑战中,开发了一种基于LLM的纯解决方案。
- 该解决方案利用提示工程、少样本提示和微调技术,取得了竞赛第二名的好成绩。
- 此项目为LLM代理在空间研究中的集成提供了开创性的实践。
- 项目公开了代码库、训练模型和数据集以供研究使用。
点此查看论文截图

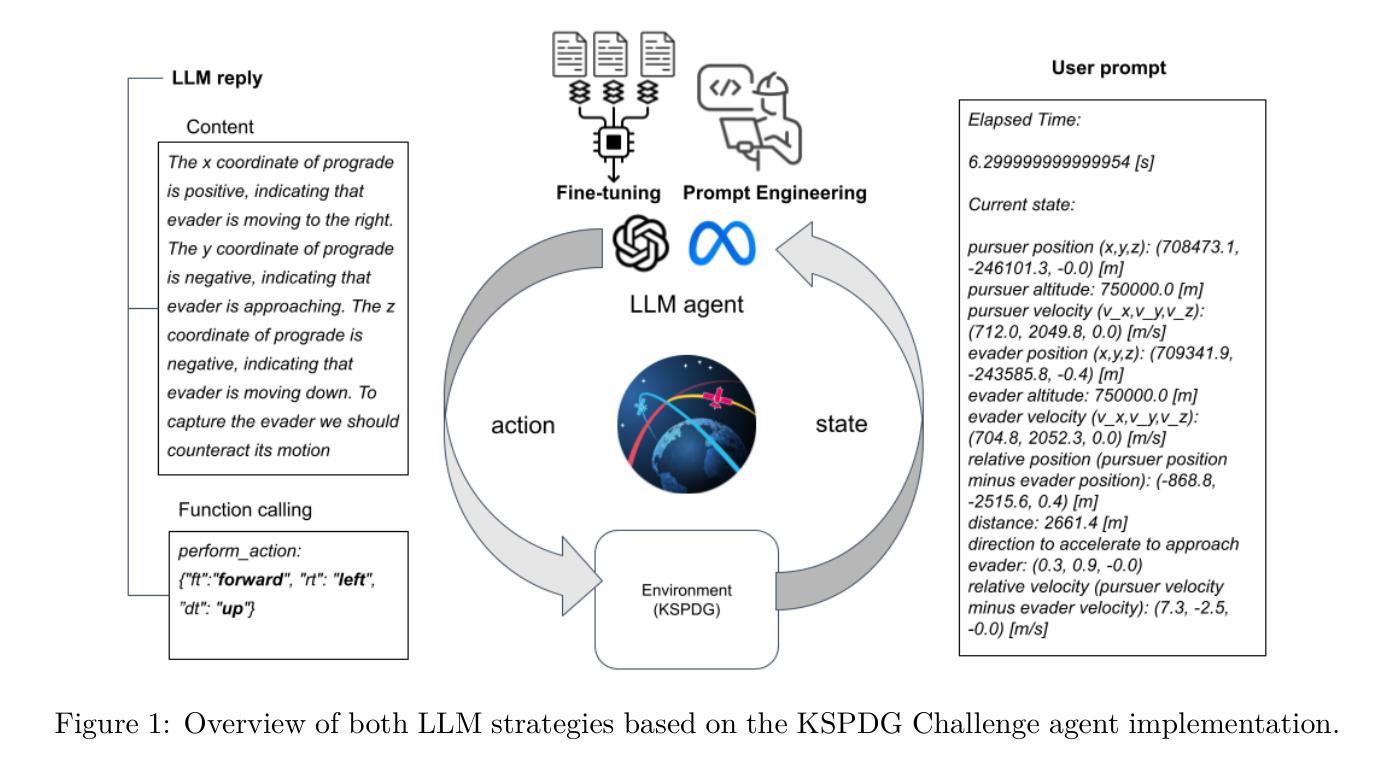
GoLF-NRT: Integrating Global Context and Local Geometry for Few-Shot View Synthesis
Authors:You Wang, Li Fang, Hao Zhu, Fei Hu, Long Ye, Zhan Ma
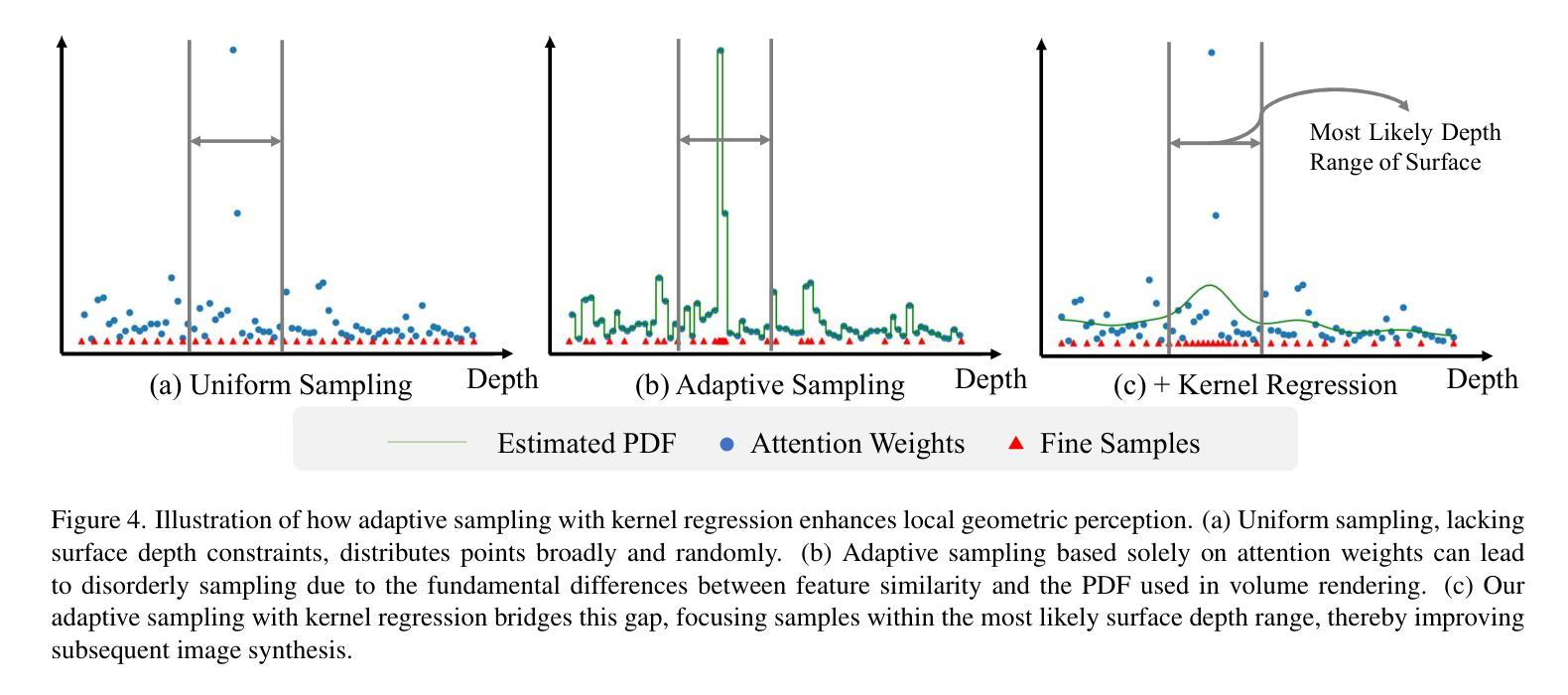
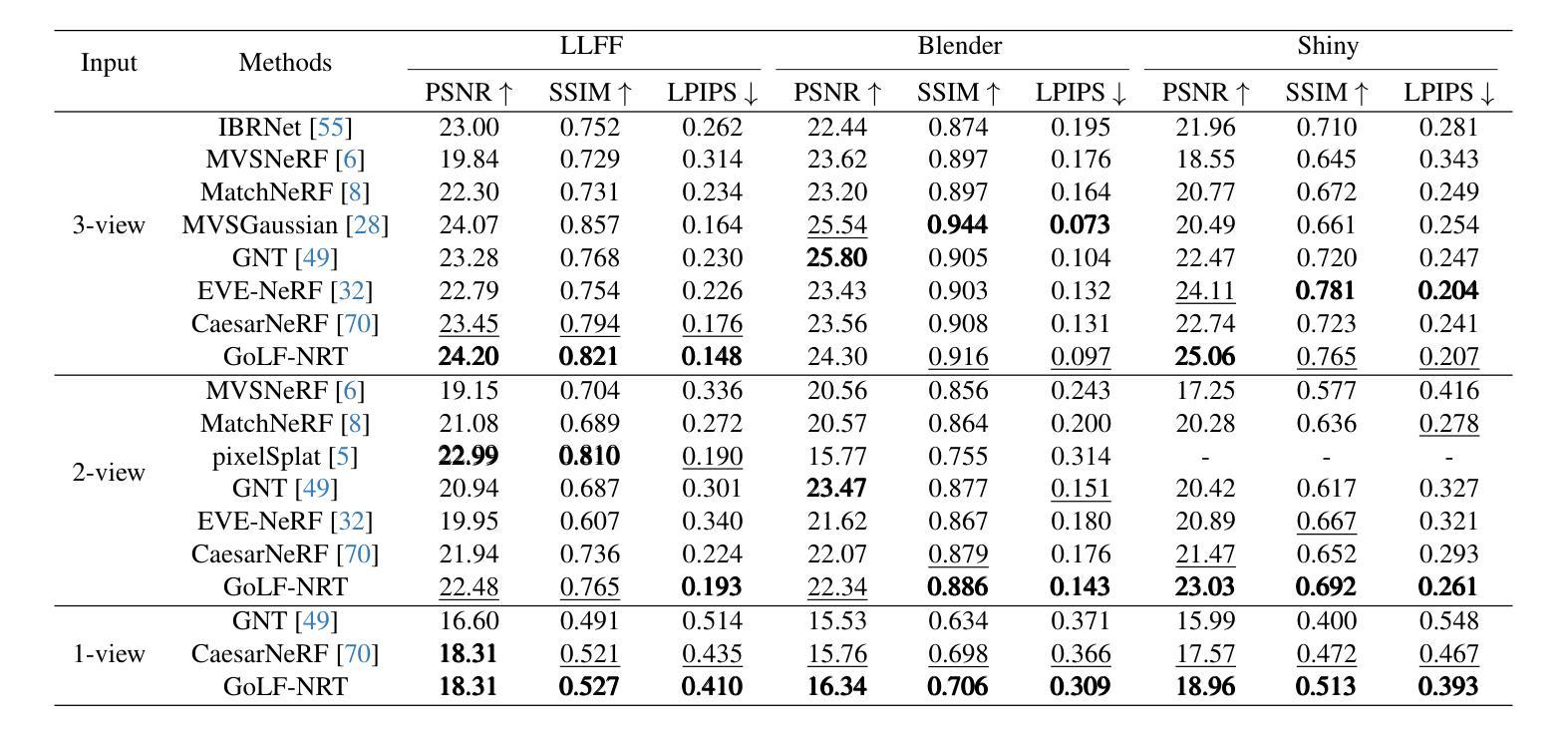
Neural Radiance Fields (NeRF) have transformed novel view synthesis by modeling scene-specific volumetric representations directly from images. While generalizable NeRF models can generate novel views across unknown scenes by learning latent ray representations, their performance heavily depends on a large number of multi-view observations. However, with limited input views, these methods experience significant degradation in rendering quality. To address this limitation, we propose GoLF-NRT: a Global and Local feature Fusion-based Neural Rendering Transformer. GoLF-NRT enhances generalizable neural rendering from few input views by leveraging a 3D transformer with efficient sparse attention to capture global scene context. In parallel, it integrates local geometric features extracted along the epipolar line, enabling high-quality scene reconstruction from as few as 1 to 3 input views. Furthermore, we introduce an adaptive sampling strategy based on attention weights and kernel regression, improving the accuracy of transformer-based neural rendering. Extensive experiments on public datasets show that GoLF-NRT achieves state-of-the-art performance across varying numbers of input views, highlighting the effectiveness and superiority of our approach. Code is available at https://github.com/KLMAV-CUC/GoLF-NRT.
神经辐射场(NeRF)通过直接从图像建模场景特定的体积表示,从而实现了新颖视图合成的变革。虽然通用NeRF模型可以通过学习潜在射线表示来生成未知场景的新颖视图,但其性能在很大程度上依赖于大量多视图观察。然而,在输入视图有限的情况下,这些方法在渲染质量方面会经历显著下降。为了解决这一局限性,我们提出了基于全局和局部特征融合的神经渲染转换器GoLF-NRT。GoLF-NRT通过利用具有高效稀疏注意力的3D转换器来增强从少数输入视图进行通用神经渲染,以捕捉场景的全局上下文。同时,它集成了沿极线提取的局部几何特征,从而能够从仅1到3个输入视图实现高质量的场景重建。此外,我们引入了一种基于注意力权重和核回归的自适应采样策略,提高了基于转换器的神经渲染的准确性。在公共数据集上的广泛实验表明,GoLF-NRT在不同数量的输入视图上实现了最先进的性能,凸显了我们方法的有效性和优越性。代码可访问https://github.com/KLMAV-CUC/GoLF-NRT。
论文及项目相关链接
PDF CVPR 2025
Summary
神经网络辐射场(NeRF)通过图像建模场景特定的体积表示,从而转变了新型视图合成技术。针对基于潜在射线表示的一般化NeRF模型在有限输入视图下生成新视图时性能显著下降的问题,提出了基于全局和局部特征融合的神经渲染转换器GoLF-NRT。GoLF-NRT通过高效的稀疏注意力3D转换器捕捉场景上下文,同时集成沿极线的局部几何特征,实现仅从一至三个输入视图的高质量场景重建。此外,还引入了一种基于注意力权重和核回归的自适应采样策略,提高了基于转换器的神经渲染的准确性。在公开数据集上的广泛实验表明,GoLF-NRT在不同输入视图数量上均达到最佳性能,凸显了该方法的有效性和优越性。
Key Takeaways
- NeRF技术通过图像建模场景特定的体积表示,实现了新型视图合成。
- 一般化的NeRF模型在有限输入视图下性能下降,需要更多视图来提高性能。
- GoLF-NRT通过全局和局部特征融合增强从有限输入视图进行神经渲染的能力。
- GoLF-NRT利用3D转换器捕捉场景上下文,并结合沿极线的局部几何特征。
- GoLF-NRT实现了仅从一至三个输入视图的高质量场景重建。
- GoLF-NRT引入了自适应采样策略,基于注意力权重和核回归,提高了神经渲染的准确性。
点此查看论文截图

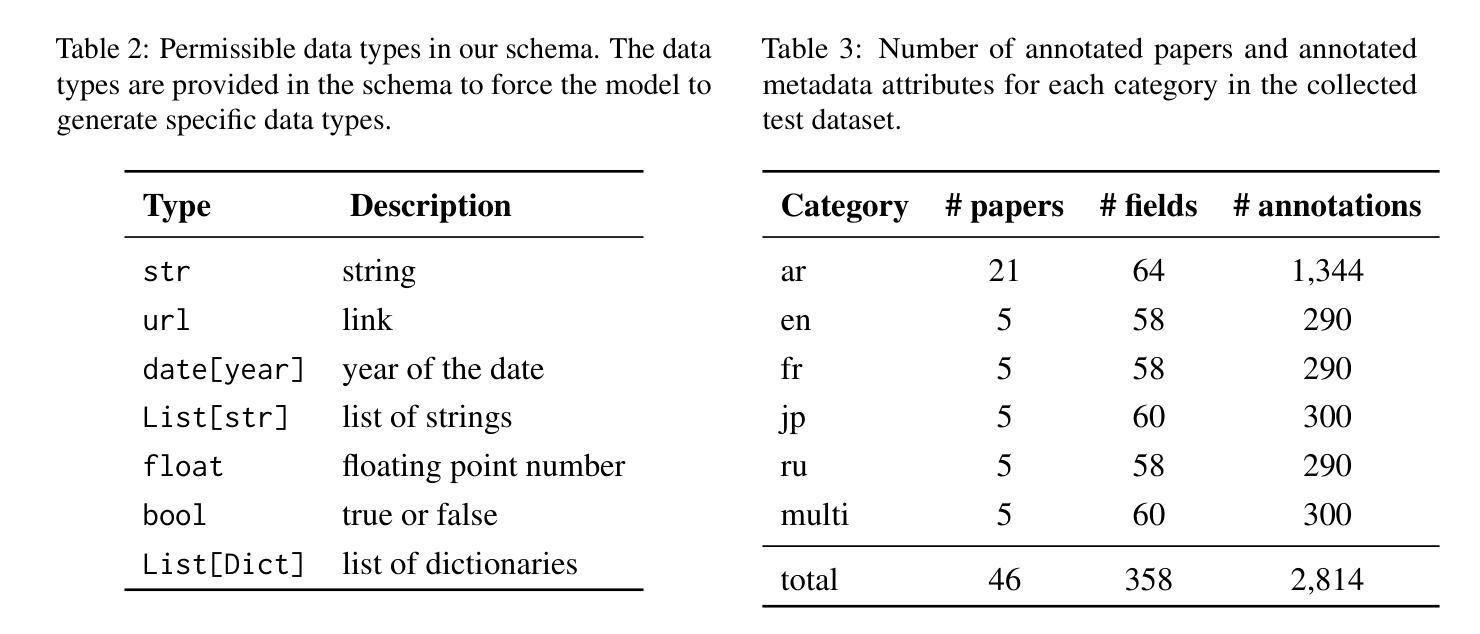
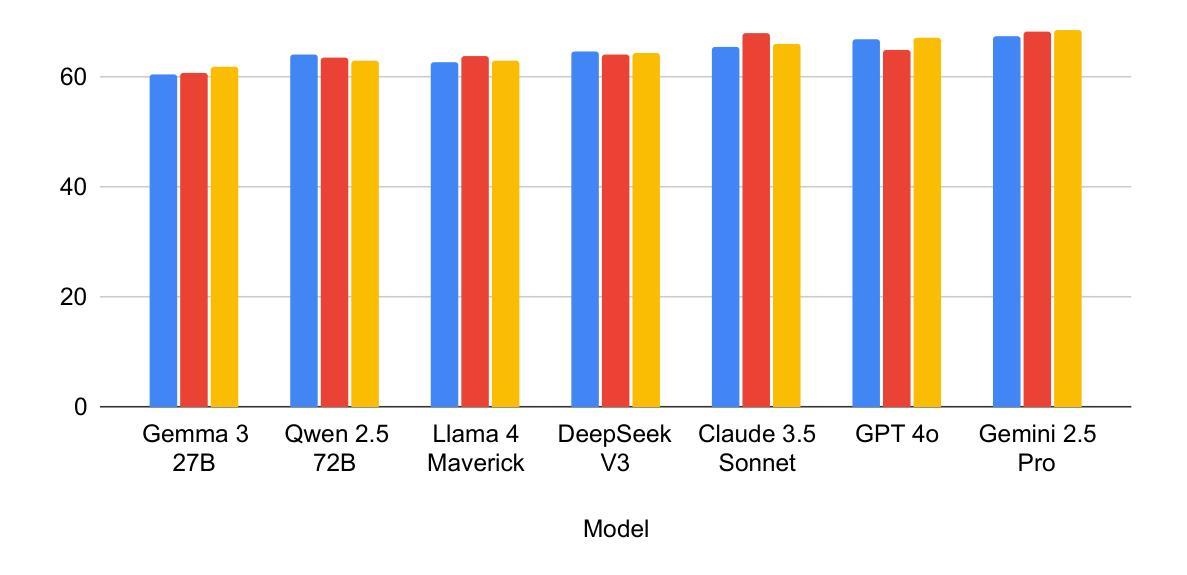
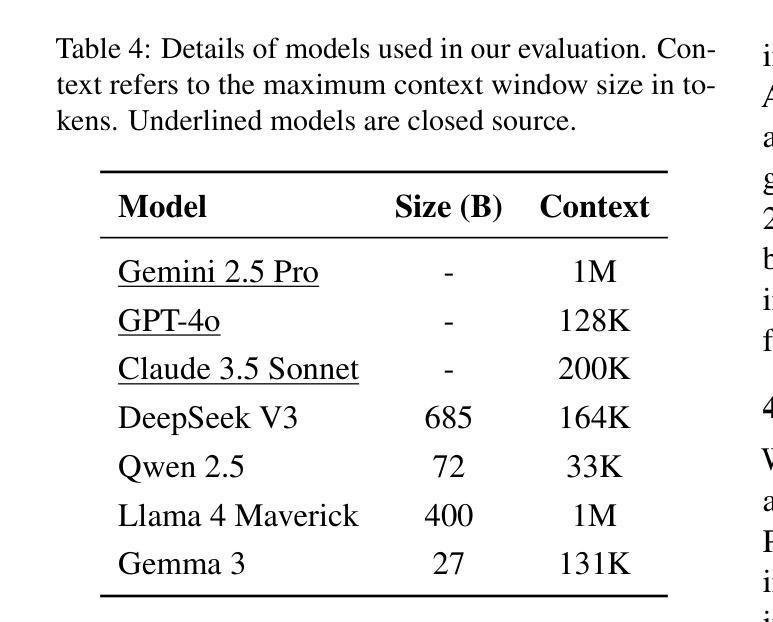
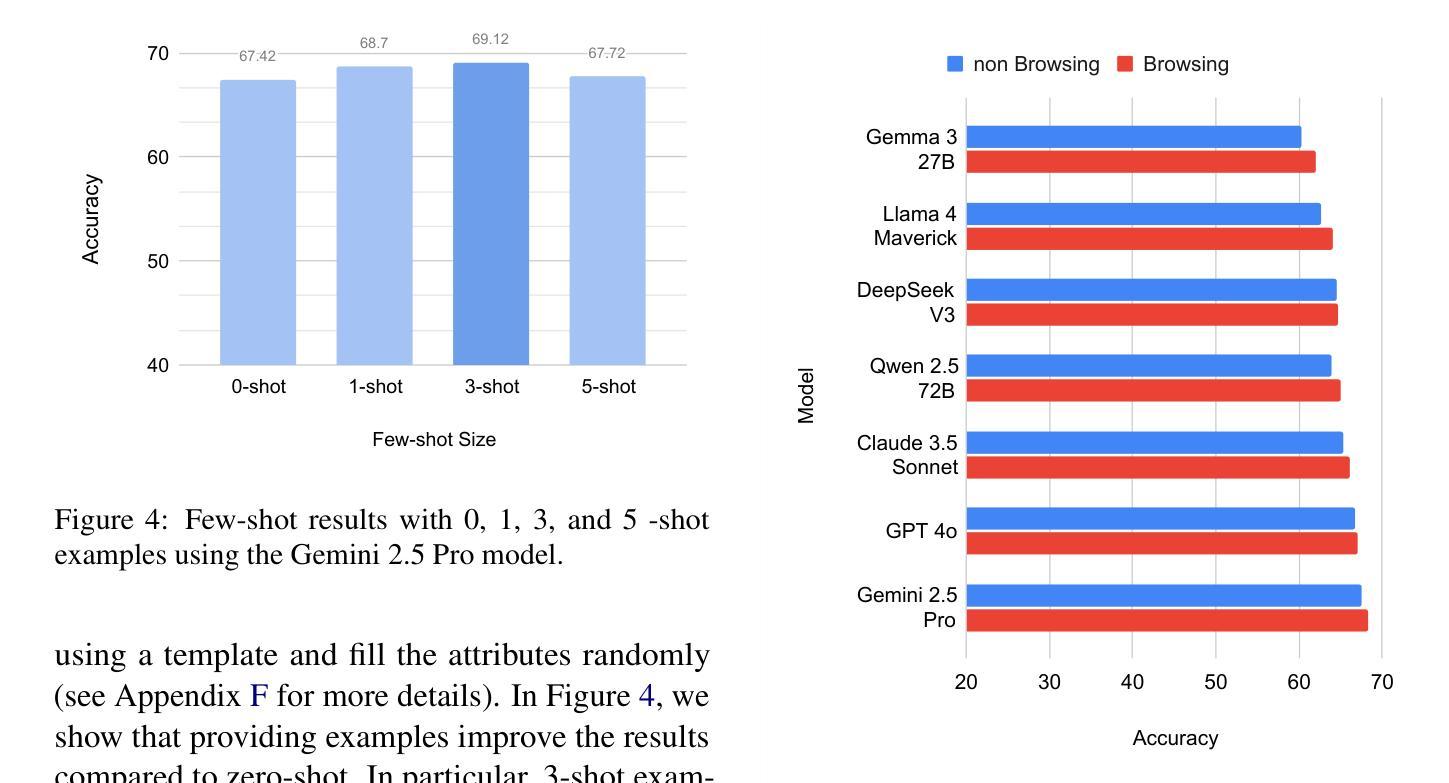
MOLE: Metadata Extraction and Validation in Scientific Papers Using LLMs
Authors:Zaid Alyafeai, Maged S. Al-Shaibani, Bernard Ghanem
Metadata extraction is essential for cataloging and preserving datasets, enabling effective research discovery and reproducibility, especially given the current exponential growth in scientific research. While Masader (Alyafeai et al.,2021) laid the groundwork for extracting a wide range of metadata attributes from Arabic NLP datasets’ scholarly articles, it relies heavily on manual annotation. In this paper, we present MOLE, a framework that leverages Large Language Models (LLMs) to automatically extract metadata attributes from scientific papers covering datasets of languages other than Arabic. Our schema-driven methodology processes entire documents across multiple input formats and incorporates robust validation mechanisms for consistent output. Additionally, we introduce a new benchmark to evaluate the research progress on this task. Through systematic analysis of context length, few-shot learning, and web browsing integration, we demonstrate that modern LLMs show promising results in automating this task, highlighting the need for further future work improvements to ensure consistent and reliable performance. We release the code: https://github.com/IVUL-KAUST/MOLE and dataset: https://huggingface.co/datasets/IVUL-KAUST/MOLE for the research community.
元数据提取对于数据集编目和保存至关重要,它促进了有效的研究发现和可重复性,尤其是在当前科学研究呈指数级增长的情况下。虽然Masader(Alyafeai等人,2021年)奠定了从阿拉伯语NLP数据集学术论文中提取广泛元数据属性的基础,但它主要依赖于人工标注。在本文中,我们介绍了MOLE框架,该框架利用大型语言模型(LLM)自动从非阿拉伯语数据集的科学论文中提取元数据属性。我们的基于模式的方法处理多种输入格式的整个文档,并纳入稳健的验证机制以实现一致输出。此外,我们还引入了一个新的基准测试来评估此任务的研究进展。通过对上下文长度、小样本学习和网页浏览整合的系统分析,我们证明了现代大型语言模型在该任务的自动化方面显示出有前途的结果,并强调了未来需要进一步改进工作以确保性能和可靠性的一致性。我们向研究社区发布了代码:https://github.com/IVUL-KAUST/MOLE和数据集:https://huggingface.co/datasets/IVUL-KAUST/MOLE。
论文及项目相关链接
Summary
元数据提取对于数据集的编目和保存、研究发现的效率和可重复性至关重要,尤其考虑到科学研究的指数级增长。面对此前阿拉伯语系NLP数据集的自动化提取大多依赖手动标注的问题,本文提出MOLE框架,利用大型语言模型(LLM)自动提取非阿拉伯语系的科学论文中的元数据属性。该框架采用基于架构的方法处理多种输入格式的文档,并具备稳健的验证机制以确保输出的一致性。同时引入新的基准测试来衡量此项研究的进展。通过上下文长度分析、小样学习法和网络浏览集成进行系统分析,展示现代大型语言模型在自动化此任务上的潜力,并指明未来改进方向以确保性能和可靠性。相关代码和数据集已发布供研究社区使用。
Key Takeaways
- 元数据提取对于数据集管理至关重要,有助于研究发现和可重复性。
- Masader主要侧重于阿拉伯NLP数据集的元数据提取,但依赖手动标注。
- MOLE框架利用大型语言模型自动提取非阿拉伯语系的科学论文中的元数据属性。
- MOLE框架具备处理多种输入格式文档的能力,并具备稳健的验证机制。
- 引入新的基准测试来衡量元数据提取的研究进展。
- 现代大型语言模型在自动化元数据提取任务上展现出潜力。
点此查看论文截图


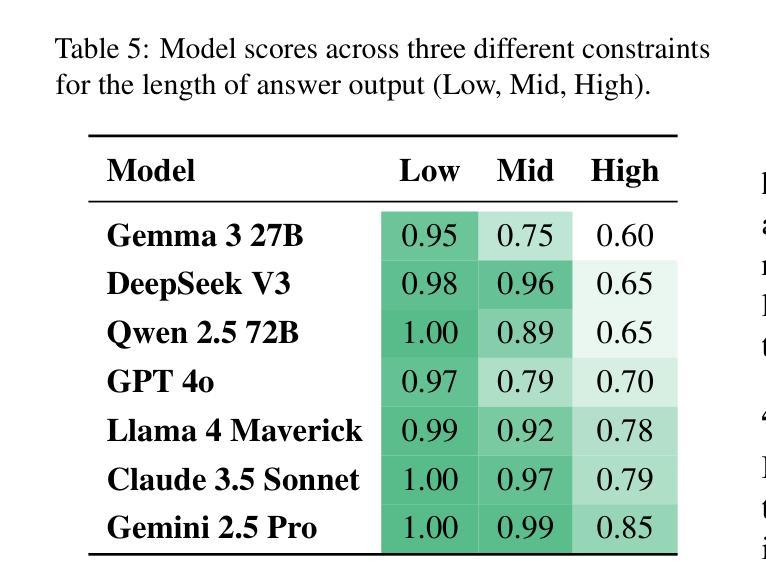
Few-Shot Class-Incremental Learning For Efficient SAR Automatic Target Recognition
Authors:George Karantaidis, Athanasios Pantsios, Ioannis Kompatsiaris, Symeon Papadopoulos
Synthetic aperture radar automatic target recognition (SAR-ATR) systems have rapidly evolved to tackle incremental recognition challenges in operational settings. Data scarcity remains a major hurdle that conventional SAR-ATR techniques struggle to address. To cope with this challenge, we propose a few-shot class-incremental learning (FSCIL) framework based on a dual-branch architecture that focuses on local feature extraction and leverages the discrete Fourier transform and global filters to capture long-term spatial dependencies. This incorporates a lightweight cross-attention mechanism that fuses domain-specific features with global dependencies to ensure robust feature interaction, while maintaining computational efficiency by introducing minimal scale-shift parameters. The framework combines focal loss for class distinction under imbalance and center loss for compact intra-class distributions to enhance class separation boundaries. Experimental results on the MSTAR benchmark dataset demonstrate that the proposed framework consistently outperforms state-of-the-art methods in FSCIL SAR-ATR, attesting to its effectiveness in real-world scenarios.
合成孔径雷达自动目标识别(SAR-ATR)系统已迅速进化,以应对操作环境中不断增长的识别挑战。数据稀缺仍是传统SAR-ATR技术难以解决的一大障碍。为了应对这一挑战,我们提出了一种基于双分支架构的少量类别增量学习(FSCIL)框架,侧重于局部特征提取,并利用离散傅里叶变换和全局滤波器捕获长期空间依赖性。这结合了轻量级的跨注意力机制,融合了领域特定特征与全局依赖性,以确保稳健的特征交互,同时通过引入最小的尺度偏移参数来保持计算效率。该框架结合了焦点损失,在不平衡情况下进行类别区分,以及中心损失,用于紧凑的类内分布,以增强类间分离边界。在MSTAR基准数据集上的实验结果表明,该框架在FSCIL SAR-ATR方面始终优于最新方法,证明了其在现实场景中的有效性。
论文及项目相关链接
Summary
SAR-ATR系统在面临现实场景中逐渐增强的识别挑战时,仍在迅速演进发展。为解决其中的数据稀缺难题,研究人员提出了基于双分支架构的少量类增量学习(FSCIL)框架。该框架通过离散傅里叶变换和全局滤波器,对局部特征进行提取,捕捉长期空间依赖性。同时,它融合了领域特定特征与全局依赖性,确保稳健的特征交互,并通过引入最小的尺度偏移参数维持计算效率。该框架结合了焦点损失与中心损失来提升类别之间的界限。在MSTAR基准数据集上的实验结果表明,所提出的框架在FSCIL SAR-ATR方面表现优于现有技术,证明了其在现实场景中的有效性。
Key Takeaways
- SAR-ATR系统面临数据稀缺的挑战。
- 提出了一种基于双分支架构的少量类增量学习(FSCIL)框架来解决数据稀缺问题。
- 利用离散傅里叶变换和全局滤波器捕捉长期空间依赖性。
- 通过融合领域特定特征和全局依赖性确保稳健的特征交互。
- 引入最小的尺度偏移参数以保持计算效率。
- 结合焦点损失和中心损失以增强类别之间的界限。
点此查看论文截图

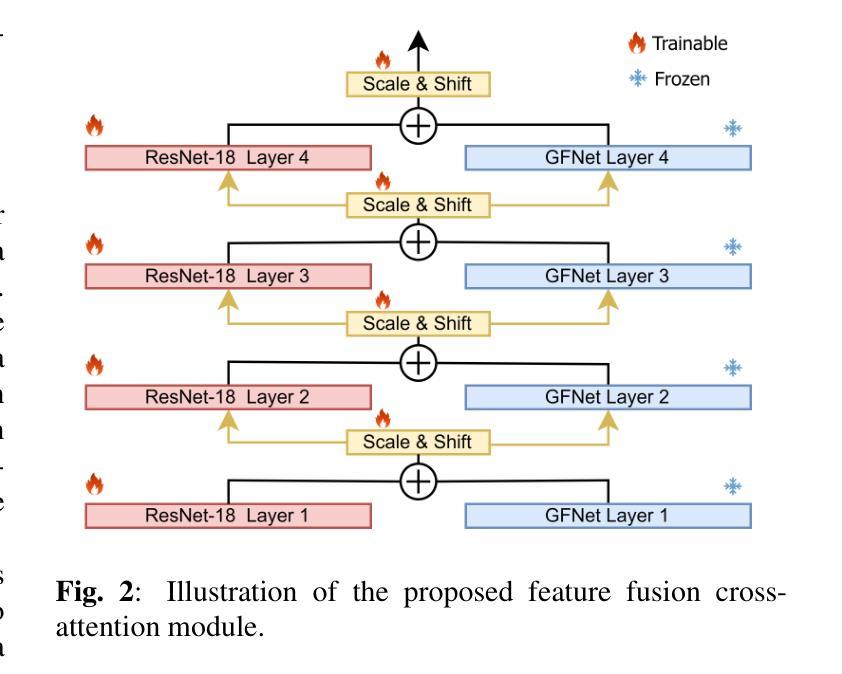
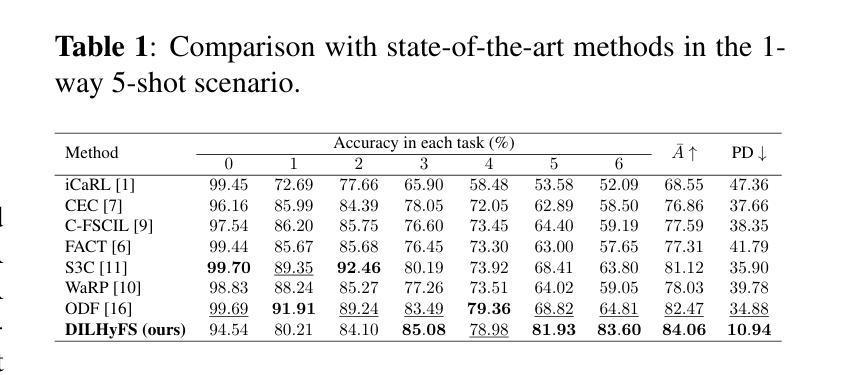
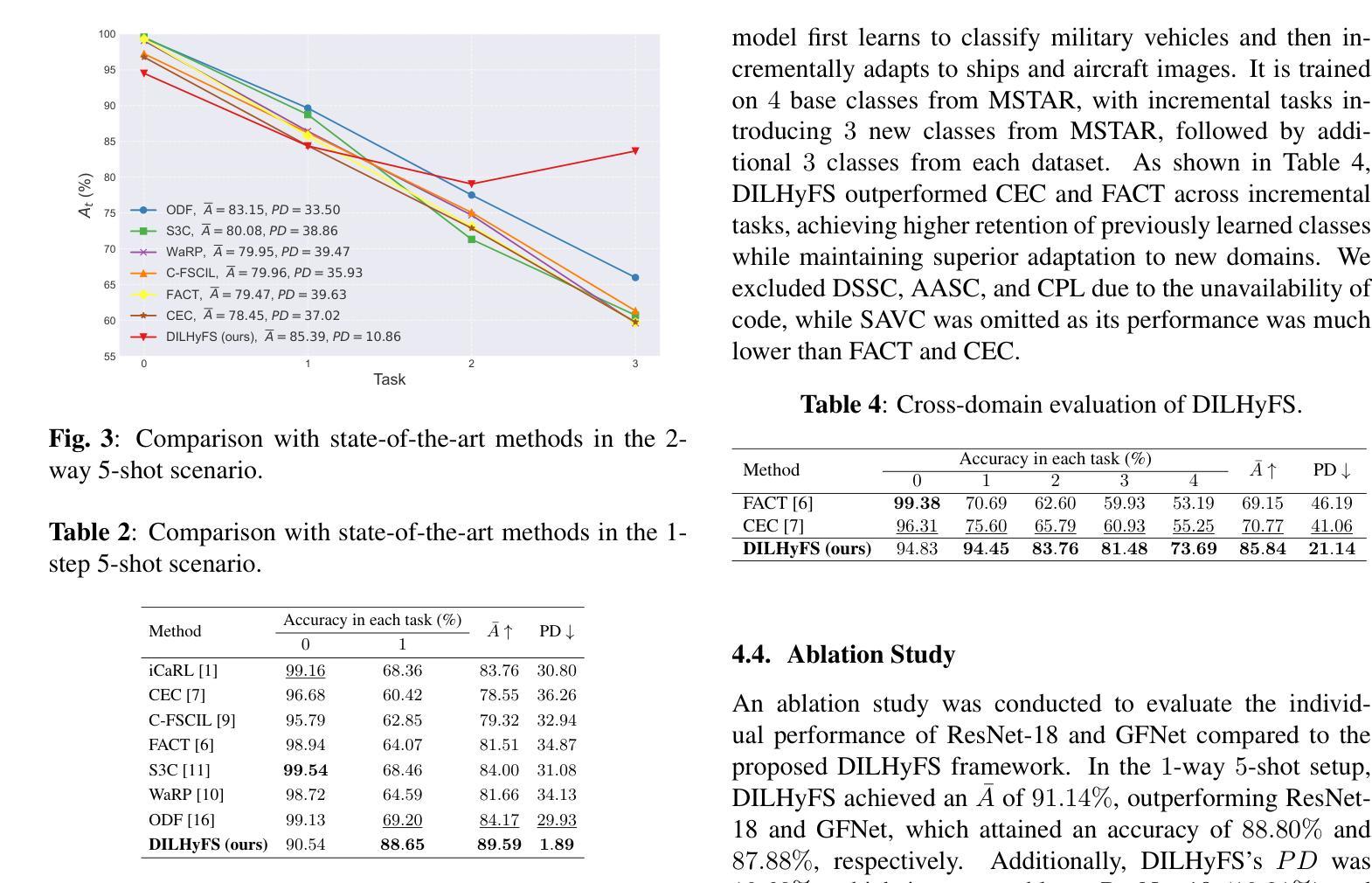
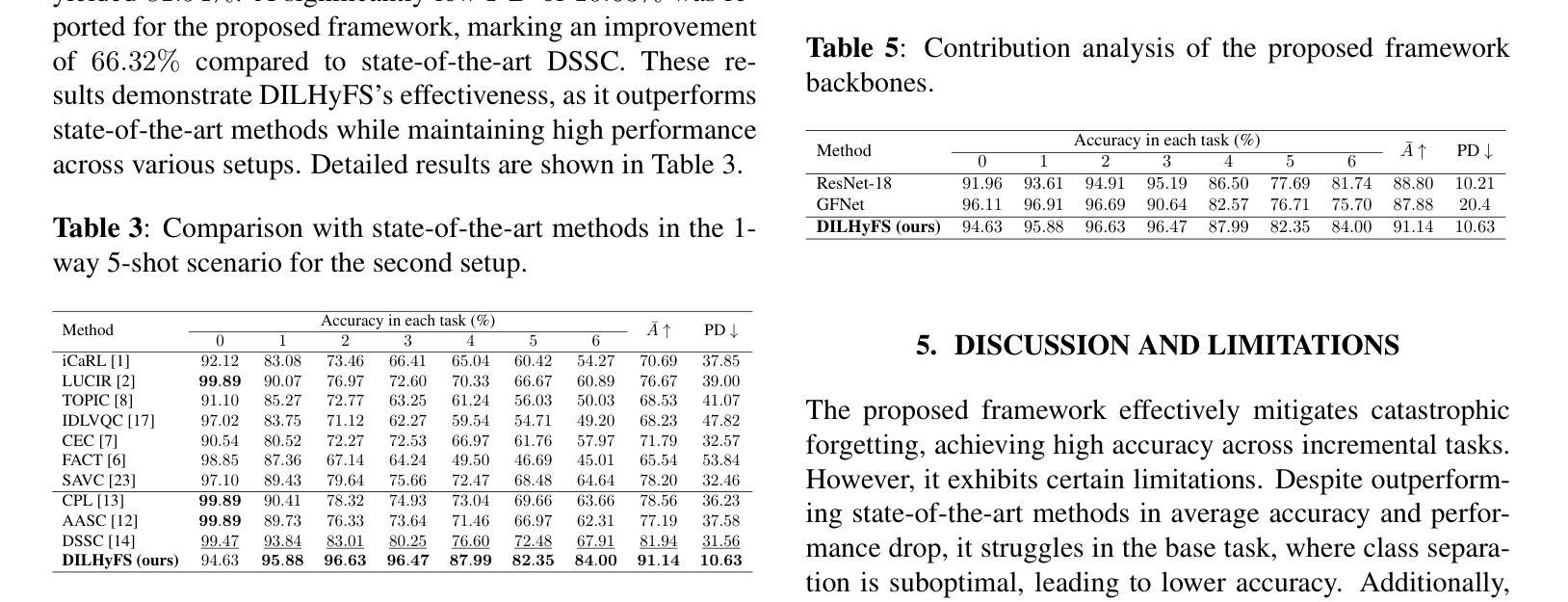
DiSa: Directional Saliency-Aware Prompt Learning for Generalizable Vision-Language Models
Authors:Niloufar Alipour Talemi, Hossein Kashiani, Hossein R. Nowdeh, Fatemeh Afghah
Prompt learning has emerged as a powerful paradigm for adapting vision-language models such as CLIP to downstream tasks. However, existing methods often overfit to seen data, leading to significant performance degradation when generalizing to novel classes or unseen domains. To address this limitation, we propose DiSa, a Directional Saliency-Aware Prompt Learning framework that integrates two complementary regularization strategies to enhance generalization. First, our Cross-Interactive Regularization (CIR) fosters cross-modal alignment by enabling cooperative learning between prompted and frozen encoders. Within CIR, a saliency-aware masking strategy guides the image encoder to prioritize semantically critical image regions, reducing reliance on less informative patches. Second, we introduce a directional regularization strategy that aligns visual embeddings with class-wise prototype features in a directional manner to prioritize consistency in feature orientation over strict proximity. This approach ensures robust generalization by leveraging stable prototype directions derived from class-mean statistics. Extensive evaluations on 11 diverse image classification benchmarks demonstrate that DiSa consistently outperforms state-of-the-art prompt learning methods across various settings, including base-to-novel generalization, cross-dataset transfer, domain generalization, and few-shot learning.
提示学习已经成为将CLIP等视觉语言模型适应下游任务的一种强大范式。然而,现有方法往往会对可见数据进行过度拟合,导致在适应新类别或未见领域时性能显著下降。为了解决这个问题,我们提出了DiSa,这是一个方向显著性感知提示学习框架,它集成了两种互补的正则化策略来提高泛化能力。首先,我们的跨交互式正则化(CIR)通过促进提示和冻结编码器之间的合作性学习来促进跨模态对齐。在CIR中,显著性感知掩码策略指导图像编码器优先处理语义上关键的图像区域,减少对信息较少区域的依赖。其次,我们引入了一种方向性正则化策略,该策略以方向方式对齐视觉嵌入和类原型特征,以优先确保特征方向的连续性而非严格接近。这种方法通过利用从类别均值统计得出的稳定原型方向来确保稳健泛化。在11个不同的图像分类基准测试上的广泛评估表明,DiSa在各种设置下始终优于最新提示学习方法,包括基本到新类别的泛化、跨数据集迁移、领域泛化和小样本学习。
论文及项目相关链接
PDF Accepted at the 31st ACM SIGKDD Conference on Knowledge Discovery and Data Mining (KDD 2025)
Summary
本文介绍了针对视觉语言模型(如CLIP)下游任务的提示学习范式,并提出了一种名为DiSa的方向性显著性感知提示学习框架,以增强模型的泛化能力。该框架结合了两种互补的正则化策略:一是跨交互式正则化(CIR),通过合作式学习促进提示和冻结编码器之间的跨模态对齐;二是方向性正则化策略,以方向性方式对齐视觉嵌入和类原型特征,强调特征方向的稳定性。在广泛的图像分类基准测试中,DiSa表现出卓越的性能,在各种设置中均优于最新的提示学习方法。
Key Takeaways
- DiSa是一个用于增强视觉语言模型泛化能力的方向性显著性感知提示学习框架。
- 结合两种互补的正则化策略:跨交互式正则化(CIR)和方向性正则化。
- CIR通过合作式学习促进跨模态对齐,并引入显著性感知掩码策略来指导图像编码器的关注重点。
- 方向性正则化策略强调特征方向的稳定性,使视觉嵌入与类原型特征对齐。
- DiSa通过利用稳定的原型方向,从类均值统计中衍生而来。
- 在广泛的图像分类基准测试中,DiSa在多种设置下均优于最新的提示学习方法。
点此查看论文截图

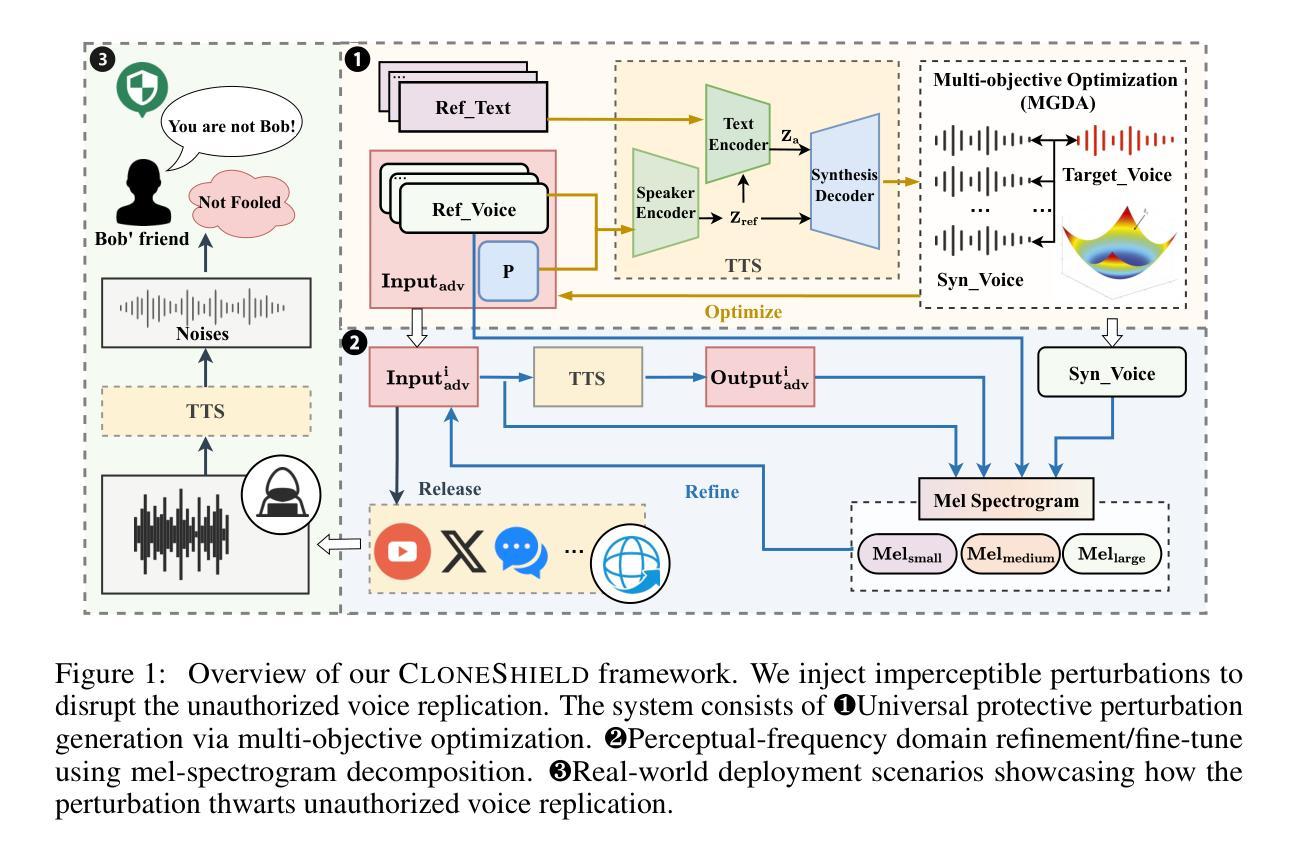
CloneShield: A Framework for Universal Perturbation Against Zero-Shot Voice Cloning
Authors:Renyuan Li, Zhibo Liang, Haichuan Zhang, Tianyu Shi, Zhiyuan Cheng, Jia Shi, Carl Yang, Mingjie Tang
Recent breakthroughs in text-to-speech (TTS) voice cloning have raised serious privacy concerns, allowing highly accurate vocal identity replication from just a few seconds of reference audio, while retaining the speaker’s vocal authenticity. In this paper, we introduce CloneShield, a universal time-domain adversarial perturbation framework specifically designed to defend against zero-shot voice cloning. Our method provides protection that is robust across speakers and utterances, without requiring any prior knowledge of the synthesized text. We formulate perturbation generation as a multi-objective optimization problem, and propose Multi-Gradient Descent Algorithm (MGDA) to ensure the robust protection across diverse utterances. To preserve natural auditory perception for users, we decompose the adversarial perturbation via Mel-spectrogram representations and fine-tune it for each sample. This design ensures imperceptibility while maintaining strong degradation effects on zero-shot cloned outputs. Experiments on three state-of-the-art zero-shot TTS systems, five benchmark datasets and evaluations from 60 human listeners demonstrate that our method preserves near-original audio quality in protected inputs (PESQ = 3.90, SRS = 0.93) while substantially degrading both speaker similarity and speech quality in cloned samples (PESQ = 1.07, SRS = 0.08).
在文本转语音(TTS)语音克隆领域的最新突破引发了严重的隐私担忧。该技术仅从几秒的参考音频就能实现高度精确的语音身份复制,同时保留说话者的语音真实性。本文介绍了CloneShield,这是一个专门设计用于防范零样本语音克隆的通用时域对抗扰动框架。我们的方法提供了跨说话者和话语的稳健保护,无需对合成文本有任何事先了解。我们将扰动生成制定为一个多目标优化问题,并提出多梯度下降算法(MGDA),以确保在不同的话语中提供稳健的保护。为了保持用户自然的听觉感知,我们通过梅尔频谱表示法分解对抗性扰动,并针对每个样本进行微调。这种设计确保了不可感知性,同时在对零样本克隆输出进行强降解时保持音频质量。在三个最先进的零样本TTS系统、五个基准数据集以及60名人类听者的评估实验表明,我们的方法在保证受保护输入接近原始音频质量的同时(PESQ = 3.90,SRS = 0.93),显著降低了克隆样本中的说话人相似度和语音质量(PESQ = 1.07,SRS = 0.08)。
论文及项目相关链接
PDF 10pages, 4figures
Summary
文本转语音(TTS)语音克隆技术的最新突破引发了严重的隐私担忧,因为仅需几秒的参考音频即可实现高度精确的语音身份复制,同时保持说话者的语音真实性。本文介绍了一种名为CloneShield的通用时间域对抗扰动框架,专门用于防范零样本语音克隆。该方法具有跨说话者和话语的鲁棒性保护能力,无需对合成文本有任何先验知识。我们制定扰动生成作为多目标优化问题,并提出多梯度下降算法(MGDA)以确保跨不同话语的鲁棒性保护。为了保持用户自然的听觉感知,我们通过梅尔频谱图表示将对抗性扰动分解,并针对每个样本进行微调。这一设计确保了不可察觉性,同时保持了对零样本克隆输出的强烈降解效果。
Key Takeaways
- 文本转语音(TTS)语音克隆技术的新进展引发了关于隐私的担忧,因为能够利用极短参考音频进行精确的语音身份复制。
- CloneShield框架被提出用于对抗零样本语音克隆,提供跨说话者和话语的鲁棒保护。
- CloneShield不需要对合成文本有先验知识。
- 通过多目标优化问题和多梯度下降算法(MGDA)确保鲁棒性保护。
- 对抗扰动通过梅尔频谱图表示进行分解,并针对每个样本微调,以维持自然听觉感知并抵抗零样本克隆攻击。
- 实验结果表明,该保护方法能够在保护输入时保持接近原始音频质量,同时显著降低了克隆样本的说话人相似性和语音质量。
点此查看论文截图



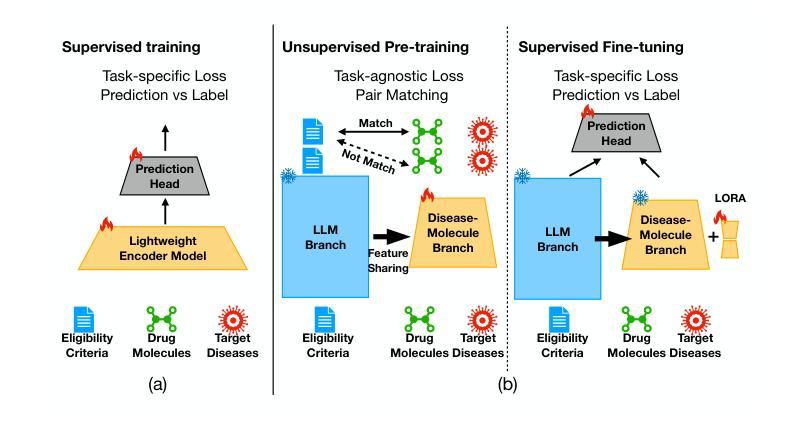
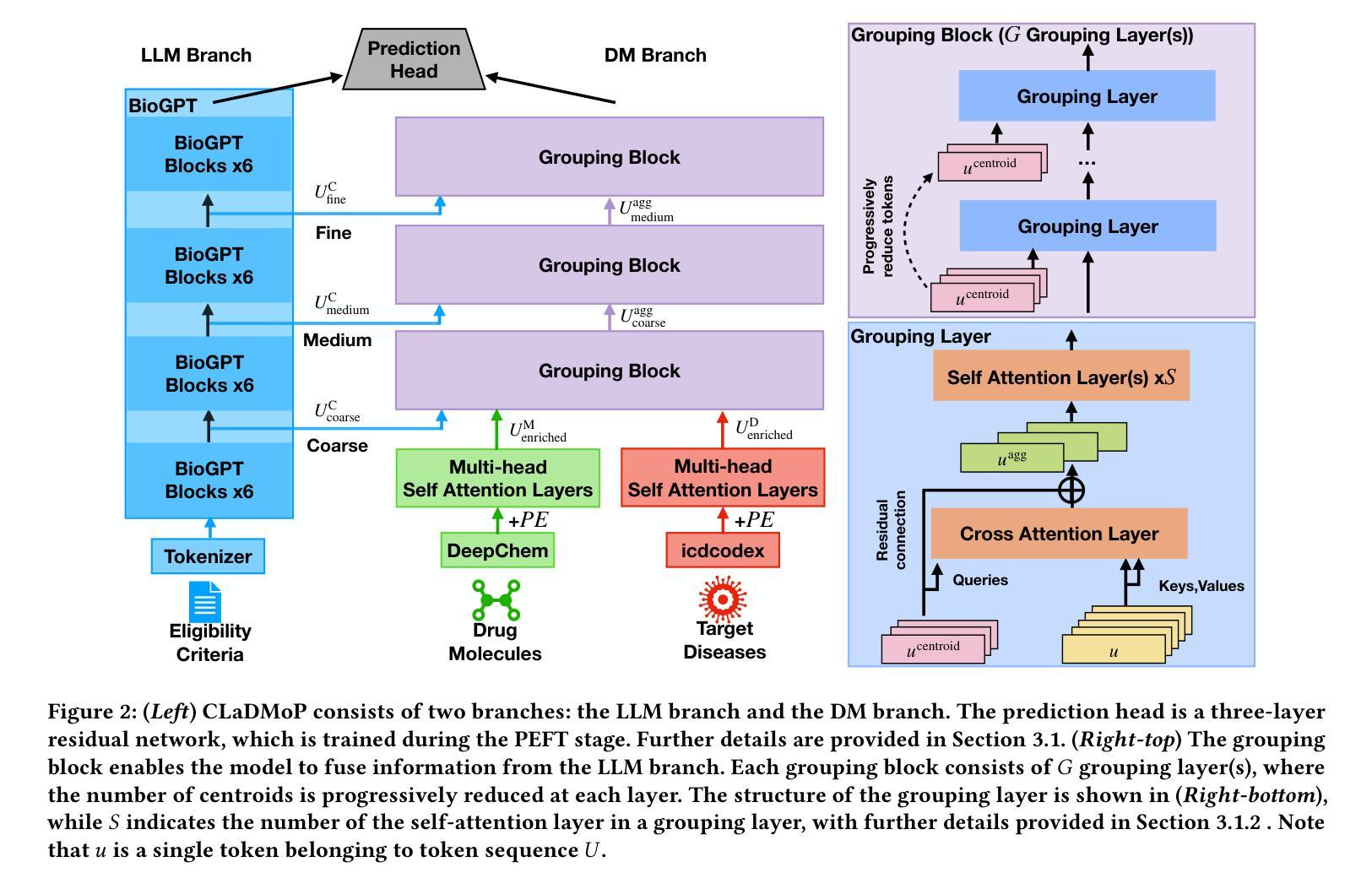
CLaDMoP: Learning Transferrable Models from Successful Clinical Trials via LLMs
Authors:Yiqing Zhang, Xiaozhong Liu, Fabricio Murai
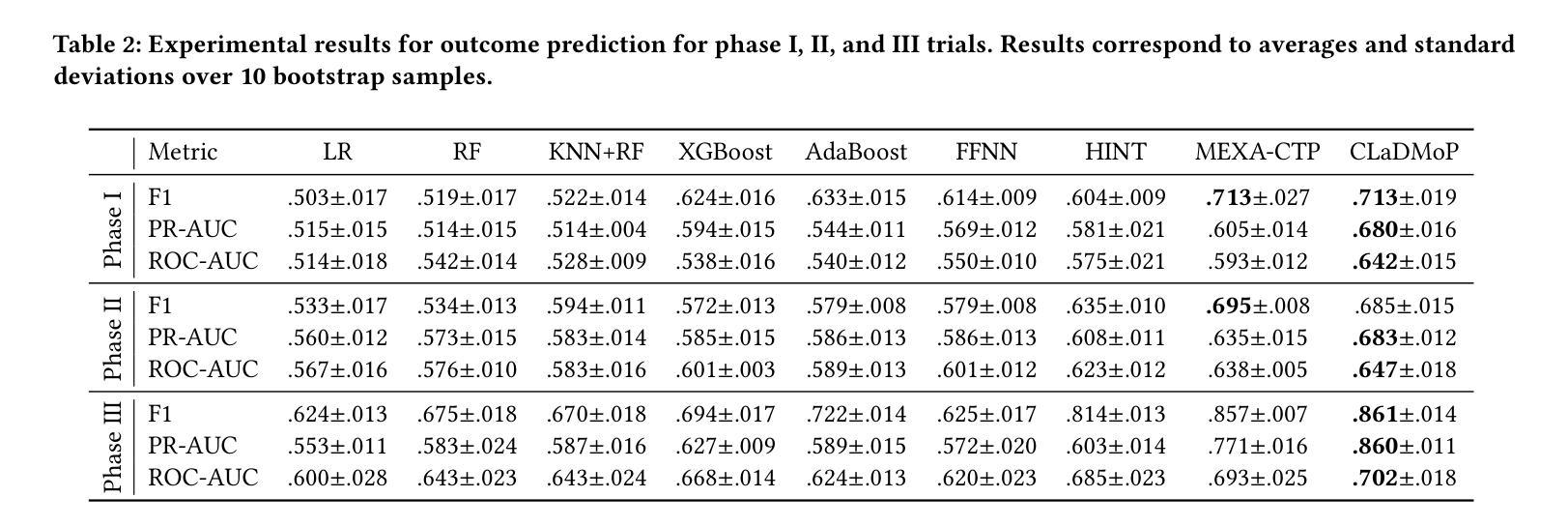
Many existing models for clinical trial outcome prediction are optimized using task-specific loss functions on trial phase-specific data. While this scheme may boost prediction for common diseases and drugs, it can hinder learning of generalizable representations, leading to more false positives/negatives. To address this limitation, we introduce CLaDMoP, a new pre-training approach for clinical trial outcome prediction, alongside the Successful Clinical Trials dataset(SCT), specifically designed for this task. CLaDMoP leverages a Large Language Model-to encode trials’ eligibility criteria-linked to a lightweight Drug-Molecule branch through a novel multi-level fusion technique. To efficiently fuse long embeddings across levels, we incorporate a grouping block, drastically reducing computational overhead. CLaDMoP avoids reliance on task-specific objectives by pre-training on a “pair matching” proxy task. Compared to established zero-shot and few-shot baselines, our method significantly improves both PR-AUC and ROC-AUC, especially for phase I and phase II trials. We further evaluate and perform ablation on CLaDMoP after Parameter-Efficient Fine-Tuning, comparing it to state-of-the-art supervised baselines, including MEXA-CTP, on the Trial Outcome Prediction(TOP) benchmark. CLaDMoP achieves up to 10.5% improvement in PR-AUC and 3.6% in ROC-AUC, while attaining comparable F1 score to MEXA-CTP, highlighting its potential for clinical trial outcome prediction. Code and SCT dataset can be downloaded from https://github.com/murai-lab/CLaDMoP.
现有许多用于临床试验结果预测的模型,它们通过使用针对特定任务的损失函数对特定试验阶段的数据进行优化。虽然这种方案可能会提高常见疾病和药物的预测能力,但它可能会阻碍通用表示的学习,从而导致更多的误报。为了解决这个问题,我们引入了CLaDMoP,这是一种新的临床试验结果预测预训练方法,以及为此任务专门设计的成功临床试验数据集(SCT)。CLaDMoP利用大型语言模型对试验资格标准进行编码,并与轻量级的药物分子分支通过新型的多层次融合技术相联系。为了有效地融合各级的长嵌入,我们引入了一个分组块,大大降低了计算开销。CLaDMoP通过在一个“配对匹配”代理任务上进行预训练,避免了依赖特定任务目标。与现有的零样本和少样本基线相比,我们的方法在PR-AUC和ROC-AUC上有了显著的提高,特别是在I期和II期试验阶段。我们进一步对CLaDMoP进行参数高效微调后的评估并进行消融实验,将其与包括MEXA-CTP在内的最新监督基线在临床试验结果预测基准测试集上进行比较。CLaDMoP在PR-AUC上提高了高达10.5%,在ROC-AUC上提高了3.6%,同时与MEXA-CTP的F1得分相当,这突显了其在临床试验结果预测方面的潜力。代码和SCT数据集可从https://github.com/murai-lab/CLaDMoP下载。
论文及项目相关链接
PDF Accepted and to be published in KDD2025
Summary
CLaDMoP是一种针对临床试验结果预测的新型预训练策略,它引入了大型语言模型来编码与药物分子相关的试验资格标准。通过多层次融合技术,CLaDMoP能够更有效地融合长嵌入信息,从而提高预测准确性。该策略避免了依赖特定任务目标,而是通过“配对匹配”代理任务进行预训练。与现有的零样本和少样本基线相比,CLaDMoP在PR-AUC和ROC-AUC上表现更优,特别是在早期临床试验阶段。经过参数有效微调后,CLaDMoP与当前先进的监督基线相比,在PR-AUC上提高了10.5%,ROC-AUC提高了3.6%,同时保持了与MEXA-CTP相当的F1分数。
Key Takeaways
- CLaDMoP是一种新的预训练策略,用于临床试验结果预测。
- 它结合了大型语言模型与药物分子信息,通过多层次融合技术处理数据。
- CLaDMoP采用“配对匹配”代理任务进行预训练,不依赖特定任务目标。
- 与其他基线相比,CLaDMoP在PR-AUC和ROC-AUC指标上表现更优秀。
- CLaDMoP在早期临床试验阶段(如I期和II期)具有显著优势。
- 经过参数有效微调后,CLaDMoP与当前先进的监督基线相比,取得了显著的性能提升。
- CLaDMoP的代码和所用数据集可从指定链接下载。
点此查看论文截图



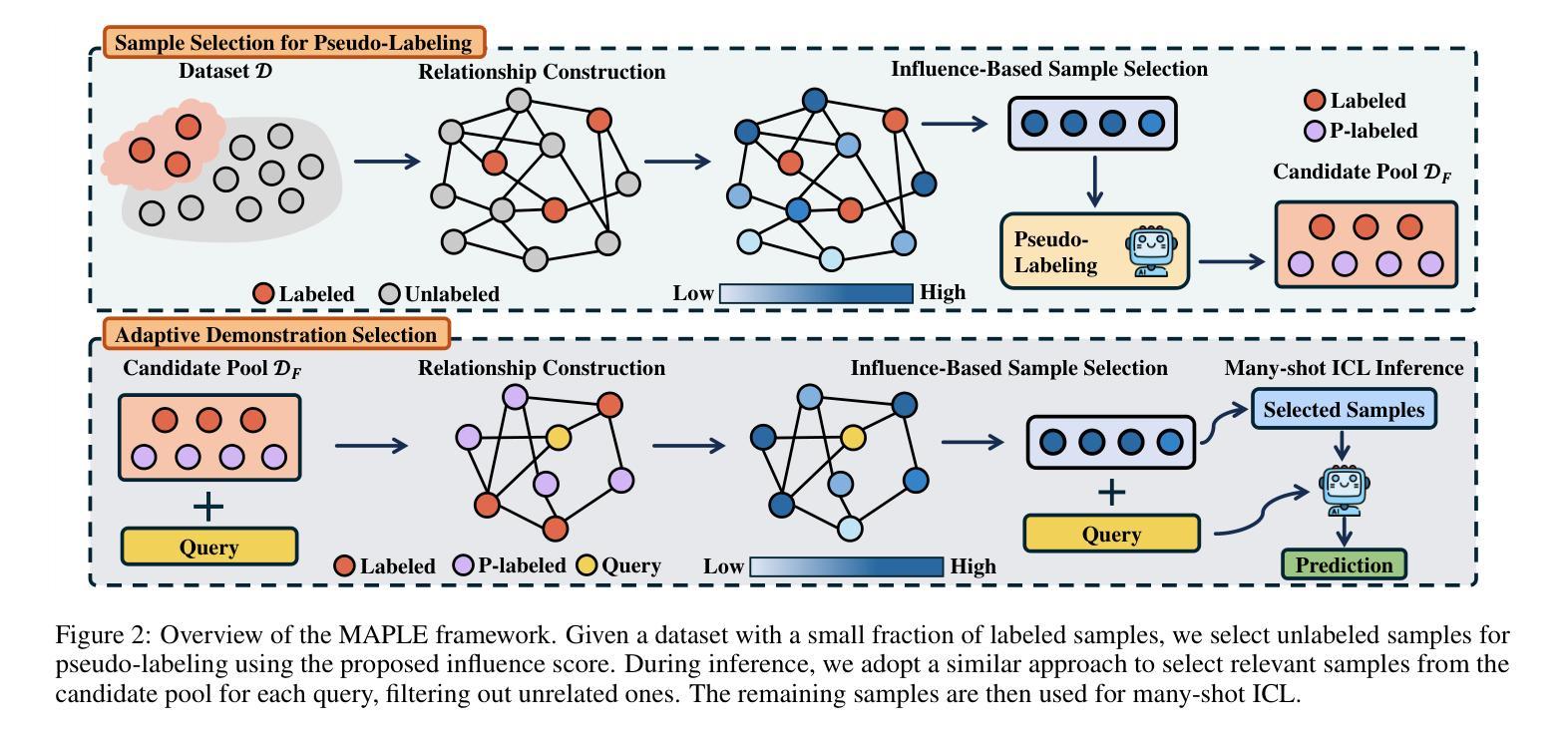
MAPLE: Many-Shot Adaptive Pseudo-Labeling for In-Context Learning
Authors:Zihan Chen, Song Wang, Zhen Tan, Jundong Li, Cong Shen
In-Context Learning (ICL) empowers Large Language Models (LLMs) to tackle diverse tasks by incorporating multiple input-output examples, known as demonstrations, into the input of LLMs. More recently, advancements in the expanded context windows of LLMs have led to many-shot ICL, which uses hundreds of demonstrations and outperforms few-shot ICL, which relies on fewer examples. However, this approach is often hindered by the high cost of obtaining large amounts of labeled data. To address this challenge, we propose Many-Shot Adaptive Pseudo-LabEling, namely MAPLE, a novel influence-based many-shot ICL framework that utilizes pseudo-labeled samples to compensate for the lack of label information. We first identify a subset of impactful unlabeled samples and perform pseudo-labeling on them by querying LLMs. These pseudo-labeled samples are then adaptively selected and tailored to each test query as input to improve the performance of many-shot ICL, without significant labeling costs. Extensive experiments on real-world datasets demonstrate the effectiveness of our framework, showcasing its ability to enhance LLM adaptability and performance with limited labeled data.
上下文学习(ICL)通过在大语言模型(LLM)的输入中融入多个输入输出示例(即演示),使其能够应对各种任务。最近,LLM扩展的上下文窗口的进步导致了多镜头ICL的出现,它使用数百个演示,并且表现优于依赖较少示例的少镜头ICL。然而,这种方法往往受到获取大量标记数据的高成本的阻碍。为了应对这一挑战,我们提出了基于影响的多镜头自适应伪标签技术(MAPLE)。这是一个新的多镜头ICL框架,它利用伪标签样本来弥补标签信息的缺失。我们首先识别出有影响力的未标记样本子集,并通过查询LLM对它们进行伪标签标注。这些伪标签样本随后被自适应地选择和定制为针对每个测试查询的输入,以提高多镜头ICL的性能,而无需增加大量的标记成本。在真实数据集上的大量实验证明了我们框架的有效性,展示了其在有限标记数据下提高LLM适应性和性能的能力。
论文及项目相关链接
Summary
在上下文学习(ICL)中,大型语言模型(LLM)通过融入多个输入输出示例(即示范)来处理各种任务。最近,LLM扩展的上下文窗口的进步导致了多示例ICL的出现,它使用数百个示范,并优于依赖较少示例的few-shot ICL。然而,获取大量标记数据的成本高昂常常成为该方法的瓶颈。为解决这一挑战,我们提出了名为MAPLE的新型基于影响的多示例ICL框架,利用伪标记样本来弥补标签信息的不足。我们首先识别出有影响力的未标记样本子集,并通过查询LLM对它们进行伪标记。这些伪标记的样本随后被自适应地选择和定制为针对每个测试查询的输入,以提高多示例ICL的性能,同时无需大量的标记成本。在真实世界数据集上的广泛实验证明了我们的框架的有效性,展示了其在有限标记数据下提高LLM适应性和性能的能力。
Key Takeaways
- ICL使LLM能够通过融入多个输入输出示例(即示范)来处理多种任务。
- 多示例ICL使用数百个示范,并通常优于few-shot ICL。
- 获取大量标记数据的成本高昂是ICL的一个挑战。
- MAPLE是一种新型多示例ICL框架,利用伪标记样本来弥补标签信息的不足。
- MAPLE通过识别有影响力的未标记样本并进行伪标记来工作。
- 伪标记的样本被自适应地选择和定制为针对每个测试查询的输入,提高多示例ICL的性能。
点此查看论文截图
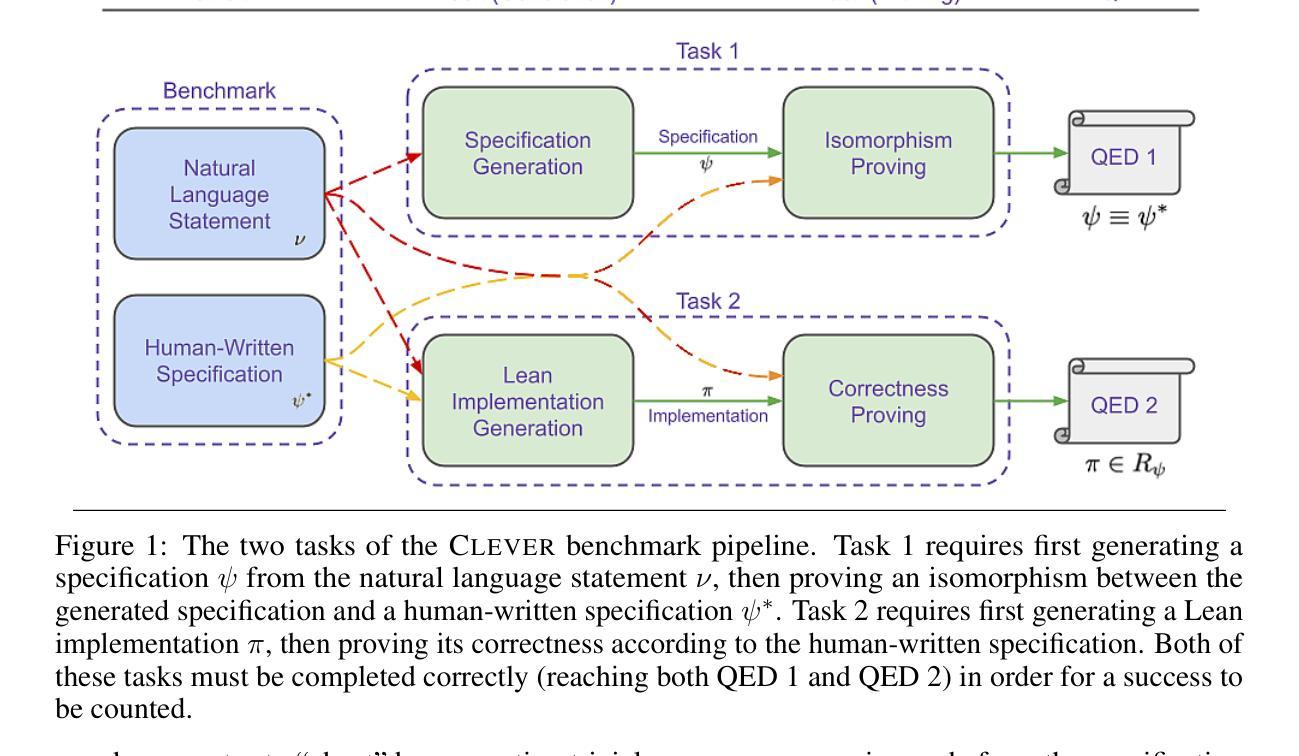
CLEVER: A Curated Benchmark for Formally Verified Code Generation
Authors:Amitayush Thakur, Jasper Lee, George Tsoukalas, Meghana Sistla, Matthew Zhao, Stefan Zetzsche, Greg Durrett, Yisong Yue, Swarat Chaudhuri
We introduce ${\rm C{\small LEVER}}$, a high-quality, curated benchmark of 161 problems for end-to-end verified code generation in Lean. Each problem consists of (1) the task of generating a specification that matches a held-out ground-truth specification, and (2) the task of generating a Lean implementation that provably satisfies this specification. Unlike prior benchmarks, ${\rm C{\small LEVER}}$ avoids test-case supervision, LLM-generated annotations, and specifications that leak implementation logic or allow vacuous solutions. All outputs are verified post-hoc using Lean’s type checker to ensure machine-checkable correctness. We use ${\rm C{\small LEVER}}$ to evaluate several few-shot and agentic approaches based on state-of-the-art language models. These methods all struggle to achieve full verification, establishing it as a challenging frontier benchmark for program synthesis and formal reasoning. Our benchmark can be found on GitHub(https://github.com/trishullab/clever) as well as HuggingFace(https://huggingface.co/datasets/amitayusht/clever). All our evaluation code is also available online(https://github.com/trishullab/clever-prover).
我们介绍了${\rm C{\small LEVER}}$,这是一个高质量的、经过筛选的包含161个问题的基准测试,用于端到端的Lean代码生成验证。每个问题由两部分组成:(1)生成与保留的真实规格相匹配的规格的任务;(2)生成可证明满足此规格要求的Lean实现的任务。不同于以往的基准测试,${\rm C{\small LEVER}}$避免了测试用例的监督、LLM生成的注释以及泄露实现逻辑或允许空洞解决方案的规格。所有输出都使用Lean的类型检查器进行事后验证,以确保可机器检查的正确性。我们使用${\rm C{\small LEVER}}$来评估基于最新语言模型的几种少镜头和自主方法。这些方法在全面实现验证方面均面临困难,这使其成为程序合成和形式推理的前瞻性挑战基准测试。我们的基准测试可以在GitHub(https://github.com/trishullab/clever)以及HuggingFace(https://huggingface.co/datasets/amitayusht/clever)上找到。所有的评估代码也都在网上可用(https://github.com/trishullab/clever-prover)。
论文及项目相关链接
Summary
${\rm C{\small LEVER}}$是一个高质量的、针对端对端验证的代码生成任务的基准测试集,包含161个问题。它避免了测试用例监督、大型语言模型生成的注解以及泄露实现逻辑或允许空洞解决方案的规格。所有输出都使用Lean的类型检查器进行事后验证,以确保机器可检查的正确性。该基准测试集用于评估基于最新语言模型的几种小样本和智能方法,但现有的方法都难以实现完全验证,使其成为程序合成和形式推理的具有挑战性的前沿基准测试集。
Key Takeaways
- ${\rm C{\small LEVER}}$是一个用于端到端验证的代码生成任务的基准测试集,包含161个高质量问题。
- 它避免了测试用例监督、大型语言模型生成的注解以及可能导致错误或空洞解决方案的规格。
- 所有输出都使用Lean的类型检查器进行事后验证,以确保机器可检查的正确性。
- ${\rm C{\small LEVER}}$被用来评估最新的语言模型在程序合成方面的能力。
- 目前的方法在完全验证方面存在困难,表明这是一个具有挑战性的前沿基准测试集。
- 该基准测试集可以在GitHub和HuggingFace上找到。
点此查看论文截图




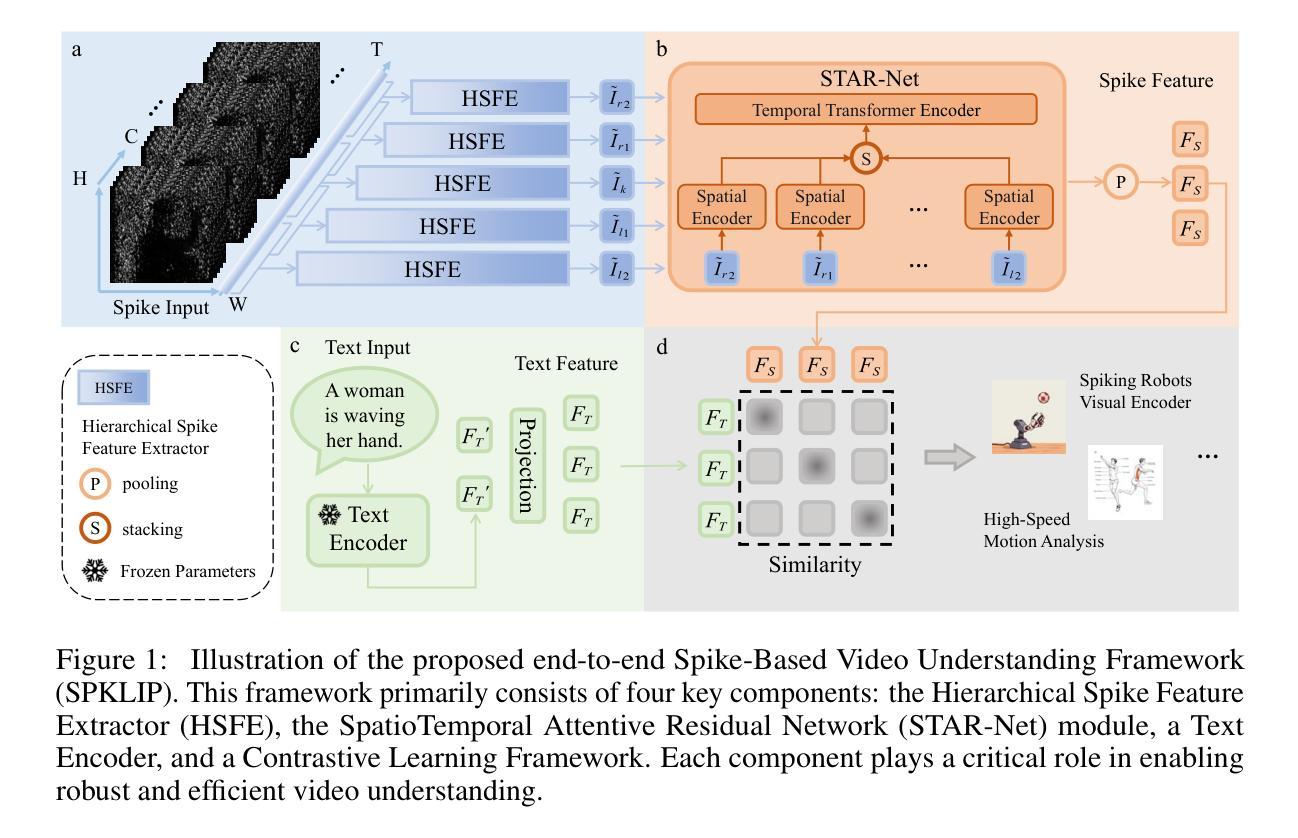
SPKLIP: Aligning Spike Video Streams with Natural Language
Authors:Yongchang Gao, Meiling Jin, Zhaofei Yu, Tiejun Huang, Guozhang Chen
Spike cameras offer unique sensing capabilities but their sparse, asynchronous output challenges semantic understanding, especially for Spike Video-Language Alignment (Spike-VLA) where models like CLIP underperform due to modality mismatch. We introduce SPKLIP, the first architecture specifically for Spike-VLA. SPKLIP employs a hierarchical spike feature extractor that adaptively models multi-scale temporal dynamics in event streams, and uses spike-text contrastive learning to directly align spike video with language, enabling effective few-shot learning. A full-spiking visual encoder variant, integrating SNN components into our pipeline, demonstrates enhanced energy efficiency. Experiments show state-of-the-art performance on benchmark spike datasets and strong few-shot generalization on a newly contributed real-world dataset. SPKLIP’s energy efficiency highlights its potential for neuromorphic deployment, advancing event-based multimodal research. The source code and dataset are available at [link removed for anonymity].
脉冲摄像头提供了独特的感知能力,但其稀疏、异步的输出给语义理解带来了挑战,特别是对于脉冲视频语言对齐(Spike-VLA)而言,CLIP等模型由于模态不匹配而表现不佳。我们引入了专门用于Spike-VLA的SPKLIP架构。SPKLIP采用分层脉冲特征提取器,自适应地模拟事件流中的多尺度时间动态,并使用脉冲文本对比学习来直接对齐脉冲视频和语言,从而实现有效的少样本学习。一种全脉冲视觉编码器变体将脉冲神经网络(SNN)组件集成到我们的流程中,展现了更高的能效。实验表明在基准脉冲数据集上达到了最先进的性能,并在新贡献的现实数据集上表现出强大的少样本泛化能力。SPKLIP的能效突显了其用于神经形态部署的潜力,推动了基于事件的多媒体研究的发展。源代码和数据集可通过[匿名链接]获取。
论文及项目相关链接
Summary
SPKLIP是针对Spike-VLA任务的首个架构,采用分层脉冲特征提取器自适应建模事件流中的多尺度时间动态,并利用脉冲文本对比学习直接对齐脉冲视频与语言,从而实现有效的少样本学习。推出全脉冲视觉编码器变体,将SNN组件集成到我们的流程中,展现了出色的能源效率。实验表明,该架构在基准脉冲数据集上表现领先,并在新推出的现实数据集上具有较强的少样本泛化能力。
Key Takeaways
- SPKLIP是专门为Spike-VLA设计的首个架构。
- 采用分层脉冲特征提取器自适应建模事件流中的多尺度时间动态。
- 利用脉冲文本对比学习直接对齐脉冲视频与语言,实现有效的少样本学习。
- 全脉冲视觉编码器变体集成了SNN组件,提高了能源效率。
- 在基准脉冲数据集上表现领先。
- 在新推出的现实数据集上具有较强的少样本泛化能力。
点此查看论文截图

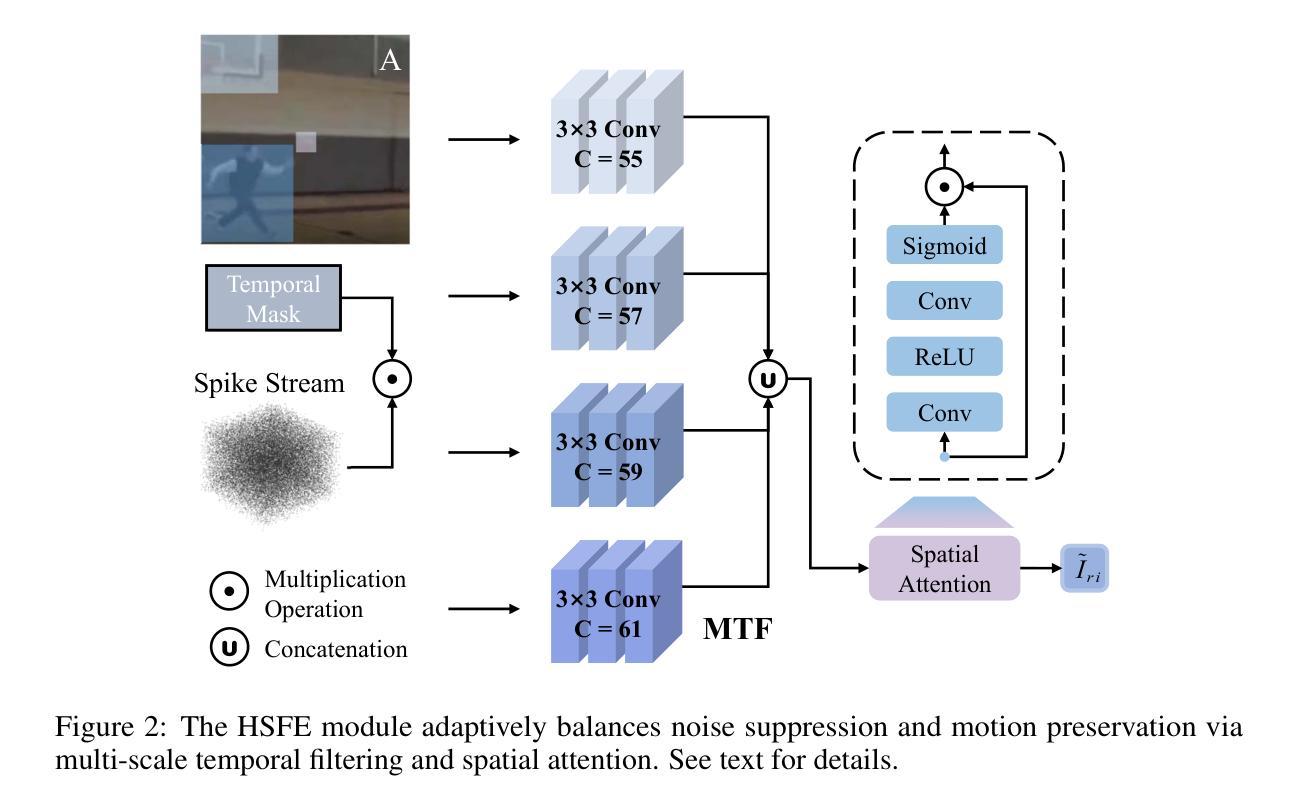
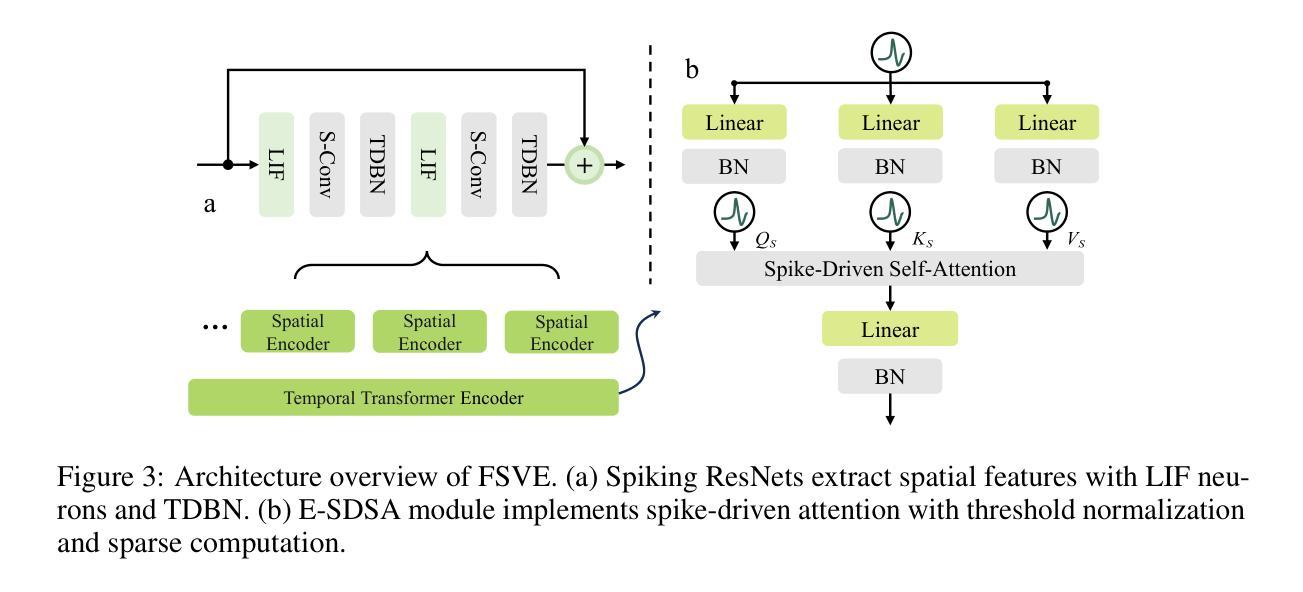
LLM-based Prompt Ensemble for Reliable Medical Entity Recognition from EHRs
Authors:K M Sajjadul Islam, Ayesha Siddika Nipu, Jiawei Wu, Praveen Madiraju
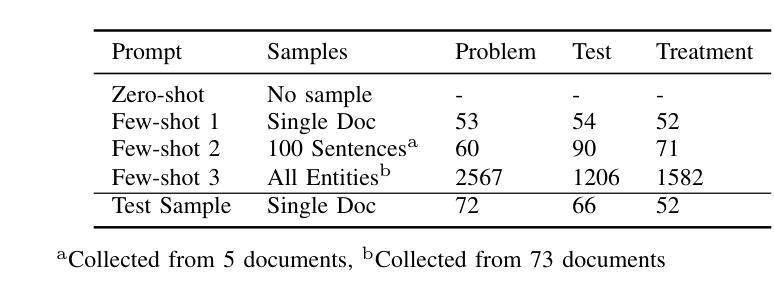
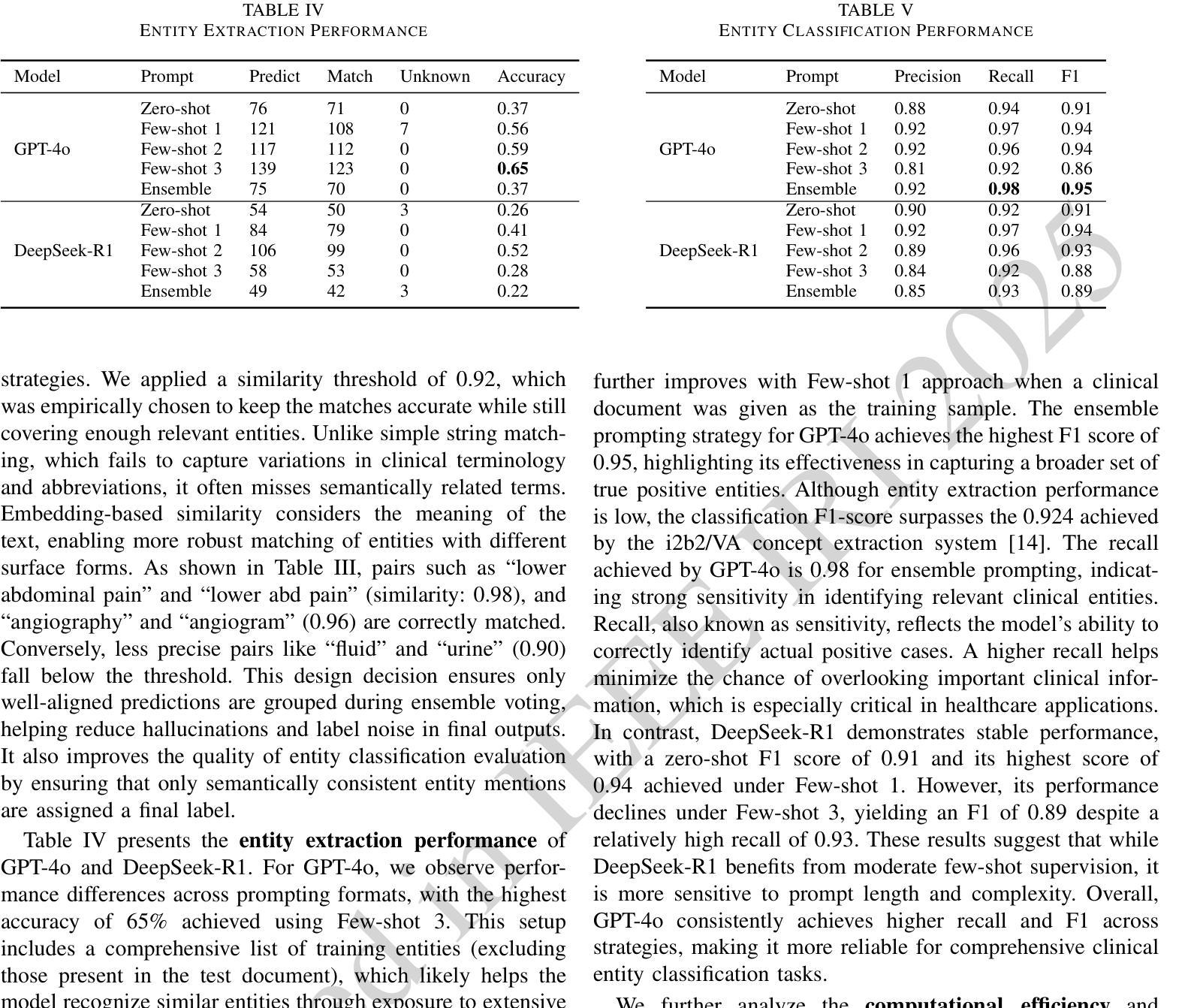
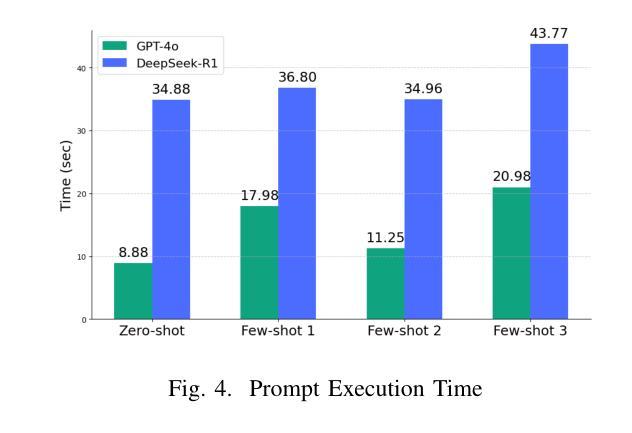
Electronic Health Records (EHRs) are digital records of patient information, often containing unstructured clinical text. Named Entity Recognition (NER) is essential in EHRs for extracting key medical entities like problems, tests, and treatments to support downstream clinical applications. This paper explores prompt-based medical entity recognition using large language models (LLMs), specifically GPT-4o and DeepSeek-R1, guided by various prompt engineering techniques, including zero-shot, few-shot, and an ensemble approach. Among all strategies, GPT-4o with prompt ensemble achieved the highest classification performance with an F1-score of 0.95 and recall of 0.98, outperforming DeepSeek-R1 on the task. The ensemble method improved reliability by aggregating outputs through embedding-based similarity and majority voting.
电子健康记录(EHRs)是患者信息的数字记录,通常包含非结构的临床文本。在EHRs中,命名实体识别(NER)对于提取关键医疗实体至关重要,如疾病、检查和治疗方法等,为下游临床应用提供支持。本文探讨了基于大型语言模型的医疗实体识别,尤其是使用各种提示工程技术指导的GPT-4o和DeepSeek-R1。这些技术包括零样本、少样本和集成方法。在所有策略中,GPT-4o与提示集成取得了最高的分类性能,F1分数为0.95,召回率为0.98,在任务上优于DeepSeek-R1。集成方法通过基于嵌入的相似性和多数投票法聚合输出,提高了可靠性。
论文及项目相关链接
PDF IEEE 26th International Conference on Information Reuse and Integration for Data Science (IRI 2025), San Jose, CA, USA
Summary
本文主要探讨了基于大型语言模型(LLMs)的命名实体识别技术在电子健康记录(EHRs)中的应用。通过采用GPT-4o模型和DeepSeek-R1模型,结合多种提示工程技术(如零样本、小样例和集成方法),进行医学实体识别的研究。结果显示,GPT-4o模型采用提示集成策略在分类性能上表现最佳,F1分数达到0.95,召回率达到0.98,优于DeepSeek-R1模型。集成方法通过基于嵌入的相似性和多数投票法聚合输出,提高了可靠性。
Key Takeaways
- 电子健康记录(EHRs)中的命名实体识别(NER)对于提取关键医疗实体至关重要,如问题、测试和治疗方法,以支持下游临床应用。
- 大型语言模型(LLMs)在医学实体识别中展现出潜力。
- GPT-4o模型和DeepSeek-R1模型被用于医学实体识别的研究。
- 提示工程技术,包括零样本、小样例和集成方法,在医学实体识别中发挥了作用。
- GPT-4o模型采用提示集成策略在分类性能上表现最佳,F1分数和召回率均较高。
- 集成方法通过基于嵌入的相似性和多数投票法提高了可靠性。
点此查看论文截图



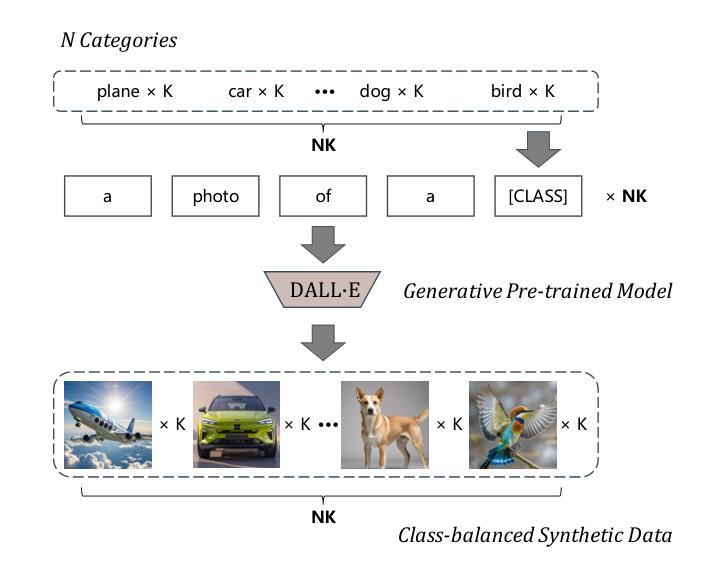
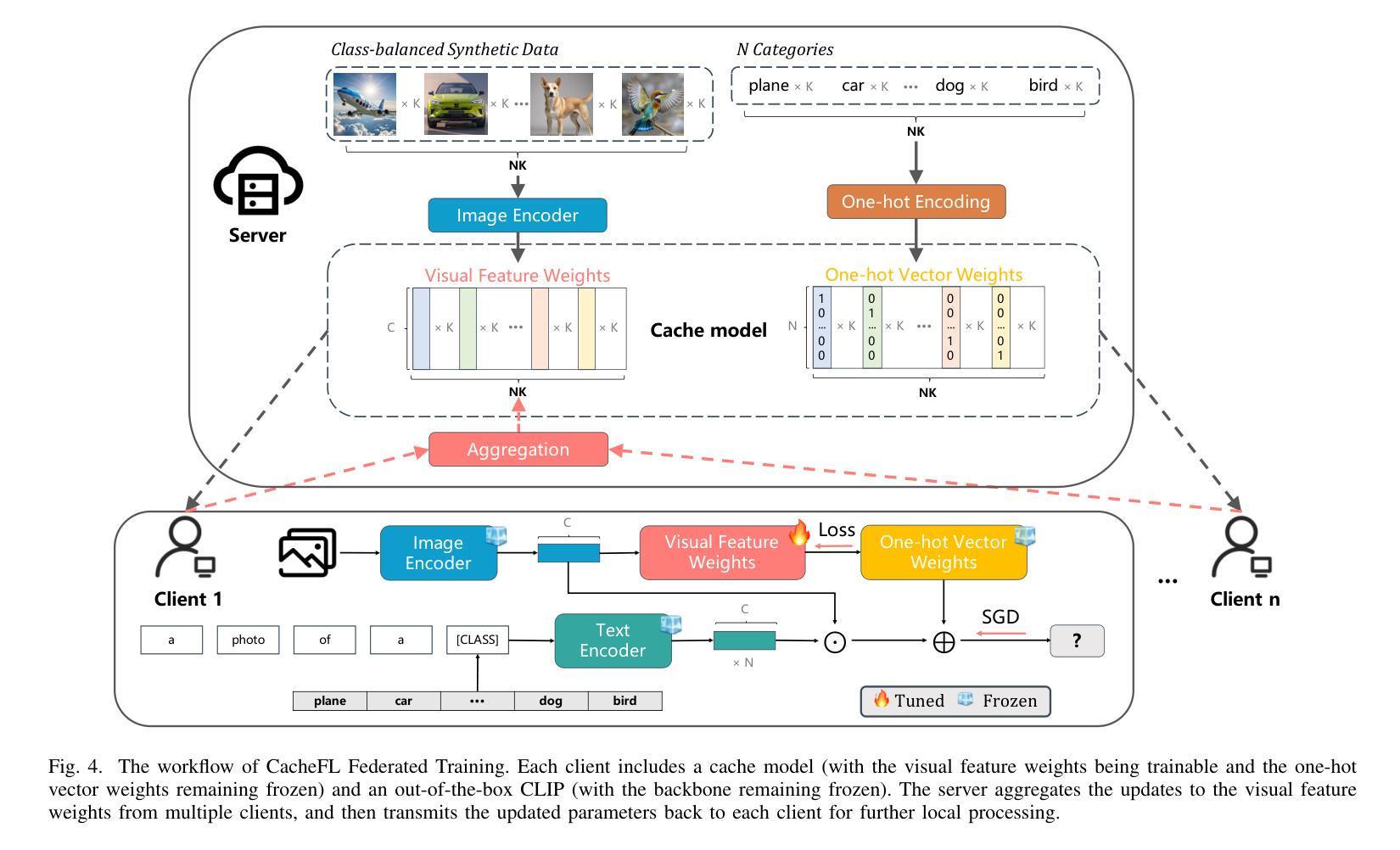
CacheFL: Privacy-Preserving and Efficient Federated Cache Model Fine-Tuning for Vision-Language Models
Authors:Mengjun Yi, Hanwen Zhang, Hui Dou, Jian Zhao, Furao Shen
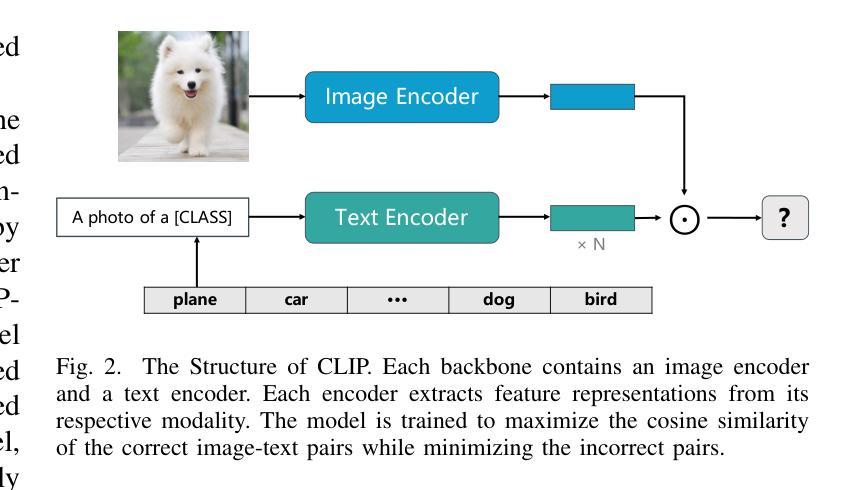
Large pre-trained Vision-Language Models (VLMs), such as Contrastive Language-Image Pre-training (CLIP), have exhibited remarkable zero-shot performance across various image classification tasks. Fine-tuning these models on domain-specific datasets further enhances their effectiveness for downstream applications. However, fine-tuning in cloud environments raises significant concerns regarding data security and privacy. Federated Learning (FL) offers a decentralized solution by enabling model training across local clients without centralizing sensitive data, but the high communication and computation costs of transmitting full pre-trained models during training limit its scalability. Additionally, non-Independent and Identically Distributed (non-IID) data across local clients can negatively impact model convergence and performance. To address these challenges, we propose CacheFL, a novel federated learning method that replaces traditional full model fine-tuning with lightweight cache model fine-tuning. The cache model is initialized using a class-balanced dataset generated by a generative pre-trained model, effectively mitigating the impact of non-IID data. This cache model is then distributed to local clients for fine-tuning, and the updated parameters from each client are aggregated on the server and redistributed. With the updated cache model, the classification performance of CLIP is improved after just a few epochs. By limiting the training and communication to the cache model, CacheFL significantly reduces resource demands while ensuring data privacy and security. Extensive experiments conducted on ImageNet and 10 additional datasets demonstrate that CacheFL outperforms traditional approaches in terms of classification accuracy, resource efficiency, and privacy preservation.
大型预训练视觉语言模型(VLMs),如对比语言图像预训练(CLIP),在各种图像分类任务中展现出了卓越的零样本性能。在特定领域数据集上对这些模型进行微调,可以进一步提高其下游应用的有效性。然而,在云环境中进行微调引发了关于数据安全和隐私的重大担忧。联邦学习(FL)提供了一种分散的解决方案,通过支持本地客户端的模型训练,无需集中敏感数据。然而,在训练过程中传输完整的预训练模型的高通信和计算成本限制了其可扩展性。此外,本地客户端之间的非独立同分布(non-IID)数据可能会对模型收敛和性能产生负面影响。为了解决这些挑战,我们提出了CacheFL,这是一种新型的联邦学习方法,它用轻量级的缓存模型微调取代了传统的全模型微调。缓存模型使用由生成式预训练模型生成的类别平衡数据集进行初始化,有效地减轻了非IID数据的影响。然后,该缓存模型将分发给本地客户端进行微调,从每个客户端更新的参数将在服务器上聚合并重新分发。仅通过几个周期的训练,CLIP的分类性能就能通过更新的缓存模型得到提高。通过将训练和通信限制在缓存模型上,CacheFL在降低资源需求的同时确保了数据隐私和安全。在ImageNet和另外10个数据集上进行的广泛实验表明,CacheFL在分类精度、资源效率和隐私保护方面均优于传统方法。
论文及项目相关链接
Summary
大型预训练视觉语言模型(VLMs),如CLIP,在不同图像分类任务中表现出出色的零样本性能。通过领域特定数据集进行微调可提高其在下游应用中的有效性。但在云环境中进行微调引发数据安全和隐私的忧虑。联邦学习(FL)通过本地客户端进行模型训练而不集中敏感数据来提供分散解决方案,但传输预训练模型时的通信和计算成本限制了其可扩展性。此外,本地客户端的非独立同分布(non-IID)数据可能不利于模型收敛和性能。为解决这些挑战,我们提出CacheFL这一新型联邦学习方法,以轻量化缓存模型微调替代传统全模型微调。缓存模型使用生成式预训练模型生成的类别平衡数据集进行初始化,有效减轻非IID数据的影响。缓存模型随后分发给本地客户端进行微调,从每个客户端更新的参数在服务器上聚合后重新分发。使用更新后的缓存模型,只需几个周期即可提高CLIP的分类性能。通过限制训练和通信仅限于缓存模型,CacheFL在资源需求方面大大减少了负担,同时确保了数据隐私和安全。在ImageNet和另外10个数据集上进行的广泛实验表明,CacheFL在分类精度、资源效率和隐私保护方面优于传统方法。
Key Takeaways
- 大型预训练视觉语言模型(VLMs)如CLIP在图像分类任务中表现出色,但需要通过微调进一步提高性能。
- 云环境中的模型微调引发数据安全和隐私的担忧。
- 联邦学习(FL)提供了一种解决方案,但在传输大型预训练模型时面临通信和计算成本高的挑战。
- CacheFL是一种新型联邦学习方法,通过轻量化缓存模型微调替代传统全模型微调,提高了资源效率和隐私保护。
- CacheFL使用生成式预训练模型和类别平衡数据集初始化缓存模型,有效应对非IID数据挑战。
- 缓存模型的更新参数通过聚合和重新分发,仅需要少量周期就能提高模型的分类性能。
点此查看论文截图


Identifying Legal Holdings with LLMs: A Systematic Study of Performance, Scale, and Memorization
Authors:Chuck Arvin
As large language models (LLMs) continue to advance in capabilities, it is essential to assess how they perform on established benchmarks. In this study, we present a suite of experiments to assess the performance of modern LLMs (ranging from 3B to 90B+ parameters) on CaseHOLD, a legal benchmark dataset for identifying case holdings. Our experiments demonstrate scaling effects - performance on this task improves with model size, with more capable models like GPT4o and AmazonNovaPro achieving macro F1 scores of 0.744 and 0.720 respectively. These scores are competitive with the best published results on this dataset, and do not require any technically sophisticated model training, fine-tuning or few-shot prompting. To ensure that these strong results are not due to memorization of judicial opinions contained in the training data, we develop and utilize a novel citation anonymization test that preserves semantic meaning while ensuring case names and citations are fictitious. Models maintain strong performance under these conditions (macro F1 of 0.728), suggesting the performance is not due to rote memorization. These findings demonstrate both the promise and current limitations of LLMs for legal tasks with important implications for the development and measurement of automated legal analytics and legal benchmarks.
随着大型语言模型(LLM)的能力不断提升,评估它们在既定基准测试上的表现变得至关重要。本研究中,我们进行了一系列实验,旨在评估现代LLM(参数范围从3B到90B+)在CaseHOLD这一法律基准数据集上的表现,该数据集用于识别判例法摘要。我们的实验展示了规模效益——随着模型规模的扩大,此任务的性能得到提升。更先进的模型如GPT4o和AmazonNovaPro分别获得了0.744和0.720的宏观F1分数。这些分数与数据集上的最佳已发布结果具有竞争力,并且不需要任何技术复杂模型的训练、微调或少样本提示。为确保这些强有力的结果并非由于训练数据中司法意见的机械化记忆,我们开发并利用了一种新型引文匿名测试,该测试在保留语义的同时确保案件名称和引文是虚构的。在这些条件下,模型保持强大的性能(宏观F1为0.728),表明其表现并非由于死记硬背。这些发现展示了LLM在法律任务上的潜力以及当前存在的局限性,对于自动法律分析和法律基准的开发和衡量具有重要意义。
论文及项目相关链接
PDF Presented as a short paper at International Conference on Artificial Intelligence and Law 2025 (Chicago, IL)
Summary
大型语言模型(LLMs)在能力上不断进步,本研究通过一系列实验评估了现代LLMs在CaseHOLD法律基准数据集上的表现,用于识别案例持有。实验表明,模型规模扩大有助于提高任务性能,GPT4o和AmazonNovaPro等更先进的模型取得了有竞争力的成绩。此外,模型表现出强大的性能,即使经过新型引文匿名化测试也依然如此。这为法律任务的自动化分析和基准测试提供了重要启示。
Key Takeaways
- 大型语言模型(LLMs)在CaseHOLD法律基准数据集上的性能评估很重要。
- 模型规模扩大有助于提高任务性能。
- GPT4o和AmazonNovaPro等先进模型在CaseHOLD数据集上取得了有竞争力的成绩。
- 模型表现出强大的性能,即使经过新型引文匿名化测试也依然稳健。
- 模型性能并非仅仅因为对训练数据中司法意见的刻板记忆。
- LLMs在法律任务上的潜力和当前局限性得到了展示。
点此查看论文截图





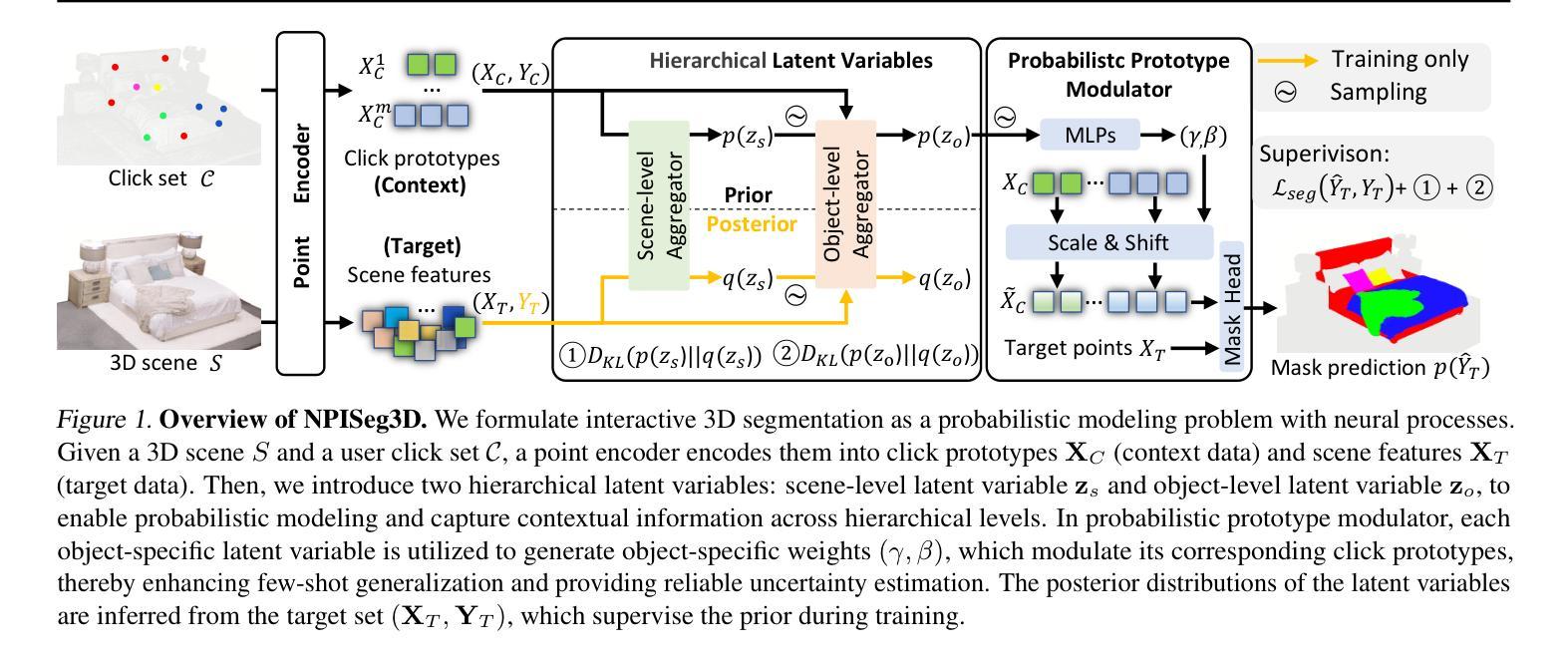
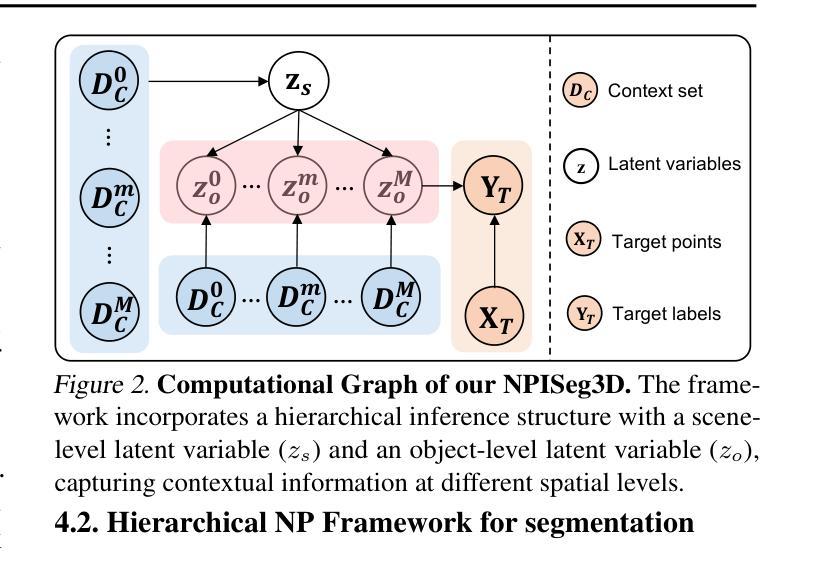
Probabilistic Interactive 3D Segmentation with Hierarchical Neural Processes
Authors:Jie Liu, Pan Zhou, Zehao Xiao, Jiayi Shen, Wenzhe Yin, Jan-Jakob Sonke, Efstratios Gavves
Interactive 3D segmentation has emerged as a promising solution for generating accurate object masks in complex 3D scenes by incorporating user-provided clicks. However, two critical challenges remain underexplored: (1) effectively generalizing from sparse user clicks to produce accurate segmentation, and (2) quantifying predictive uncertainty to help users identify unreliable regions. In this work, we propose NPISeg3D, a novel probabilistic framework that builds upon Neural Processes (NPs) to address these challenges. Specifically, NPISeg3D introduces a hierarchical latent variable structure with scene-specific and object-specific latent variables to enhance few-shot generalization by capturing both global context and object-specific characteristics. Additionally, we design a probabilistic prototype modulator that adaptively modulates click prototypes with object-specific latent variables, improving the model’s ability to capture object-aware context and quantify predictive uncertainty. Experiments on four 3D point cloud datasets demonstrate that NPISeg3D achieves superior segmentation performance with fewer clicks while providing reliable uncertainty estimations.
交互式3D分割技术通过结合用户提供的点击,在复杂的3D场景中生成精确的对象掩膜方面展现出巨大的潜力。然而,还有两个关键挑战尚未得到充分探索:(1)如何从稀疏的用户点击中有效概括出准确的分割结果;(2)量化预测不确定性,帮助用户识别不可靠的区域。在这项工作中,我们提出了NPISeg3D,一个基于神经网络过程(NPs)的新型概率框架,以解决这些挑战。具体来说,NPISeg3D引入了一种分层潜在变量结构,包括场景特定和对象特定的潜在变量,通过捕捉全局上下文和对象特定特征,增强小样本泛化能力。此外,我们设计了一个概率原型调制器,它自适应地利用对象特定的潜在变量调整点击原型,提高了模型捕捉对象感知上下文和量化预测不确定性的能力。在四个3D点云数据集上的实验表明,NPISeg3D在点击次数更少的情况下实现了优越的分割性能,同时提供了可靠的不确定性估计。
论文及项目相关链接
PDF ICML 2025 Proceedings
Summary
该文探讨了在复杂三维场景中进行交互式三维分割时面临的挑战,特别是从稀疏用户点击推广到准确分割以及量化预测不确定性两个关键问题。为此,提出了一种基于神经过程的概率框架NPISeg3D,通过引入层次化潜在变量结构和概率原型调制器,提高少样本推广能力和不确定性量化能力。实验证明,NPISeg3D在四个三维点云数据集上实现了更少的点击次数即可获得优越的分隔性能,同时提供了可靠的不确定性估计。
Key Takeaways
- 交互式三维分割是生成复杂三维场景中准确对象掩模的有前途的解决方案。
- 从稀疏用户点击推广到准确分割和量化预测不确定性是尚未充分研究的挑战。
- NPISeg3D是一种基于神经过程的概率框架,旨在解决这两个挑战。
- NPISeg3D通过引入层次化潜在变量结构,增强了对全局上下文和对象特定特征的捕捉能力。
- 概率原型调制器的设计能够自适应地调节点击原型与对象特定潜在变量,提高模型捕捉对象感知上下文和量化预测不确定性的能力。
- 实验证明NPISeg3D在四个三维点云数据集上实现了优越的分隔性能。
点此查看论文截图

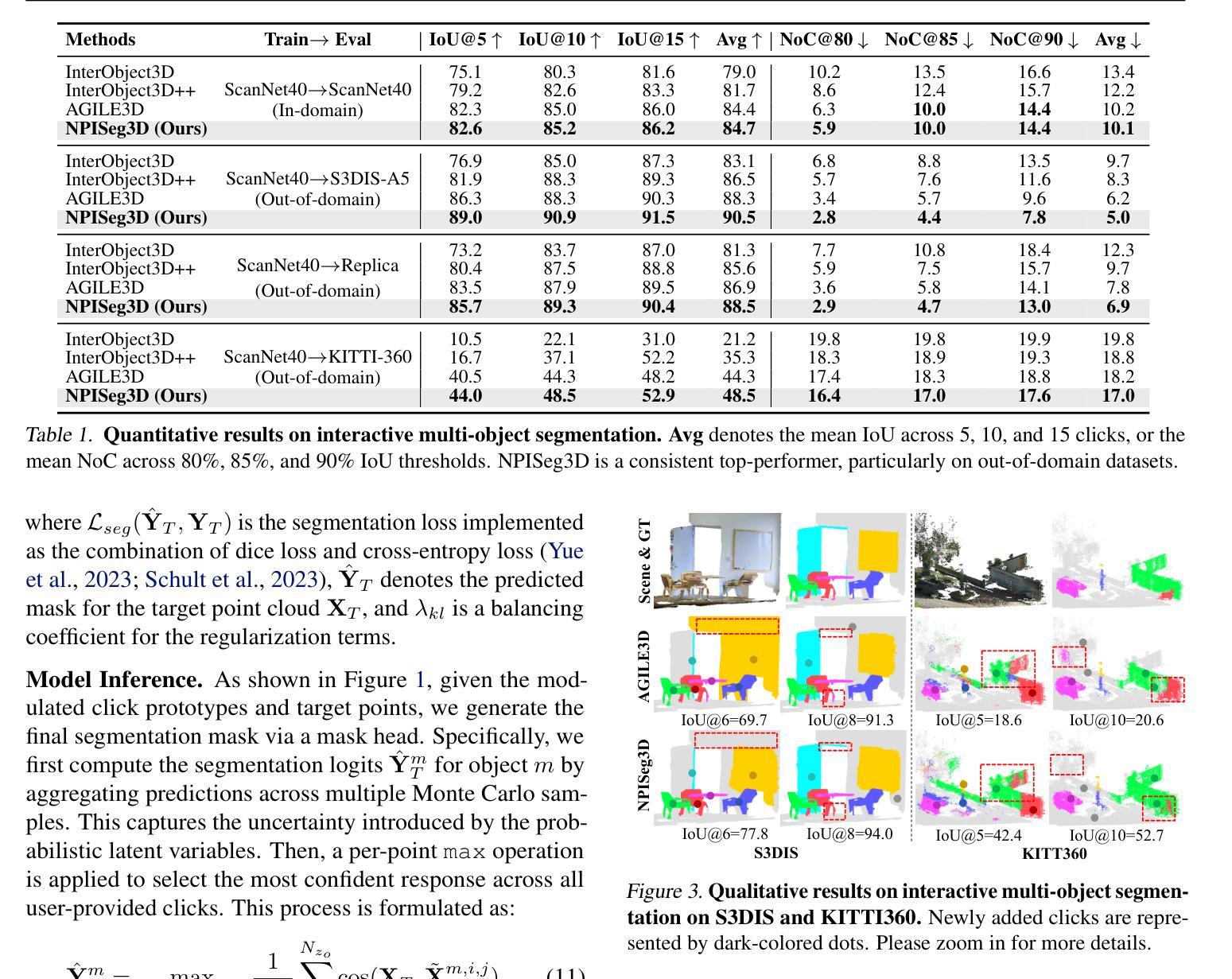
Single-Agent vs. Multi-Agent LLM Strategies for Automated Student Reflection Assessment
Authors:Gen Li, Li Chen, Cheng Tang, Valdemar Švábenský, Daisuke Deguchi, Takayoshi Yamashita, Atsushi Shimada
We explore the use of Large Language Models (LLMs) for automated assessment of open-text student reflections and prediction of academic performance. Traditional methods for evaluating reflections are time-consuming and may not scale effectively in educational settings. In this work, we employ LLMs to transform student reflections into quantitative scores using two assessment strategies (single-agent and multi-agent) and two prompting techniques (zero-shot and few-shot). Our experiments, conducted on a dataset of 5,278 reflections from 377 students over three academic terms, demonstrate that the single-agent with few-shot strategy achieves the highest match rate with human evaluations. Furthermore, models utilizing LLM-assessed reflection scores outperform baselines in both at-risk student identification and grade prediction tasks. These findings suggest that LLMs can effectively automate reflection assessment, reduce educators’ workload, and enable timely support for students who may need additional assistance. Our work emphasizes the potential of integrating advanced generative AI technologies into educational practices to enhance student engagement and academic success.
我们探讨了大型语言模型(LLM)在自动评估学生开放性反思和预测学业表现方面的应用。传统的反思评估方法耗时且在教育环境中可能无法有效扩展。在这项工作中,我们采用LLM,使用两种评估策略(单智能体和多智能体)和两种提示技术(零样本和少样本),将学生反思转化为量化分数。我们在包含来自377名学生在三个学术学期内共5,278篇反思的数据集上进行的实验表明,采用少样本策略的单智能体在人为评估方面的匹配率最高。此外,利用LLM评估的反思得分的模型在处于危险的学生识别和成绩预测任务中的表现均优于基线。这些发现表明,LLM可以有效地自动进行反思评估,减少教育工作者的工作量,并为可能需要额外帮助的学生提供及时的支持。我们的工作强调了将先进的生成式AI技术融入教育实践,以提高学生参与度和学业成就的可能性。
论文及项目相关链接
PDF Published in Proceedings of the 29th Pacific-Asia Conference on Knowledge Discovery and Data Mining (PAKDD 2025)
Summary
本文探讨了使用大型语言模型(LLMs)自动评估学生开放文本反思和预测学业成绩的方法。传统评估反思的方法耗时且难以在教育环境中有效扩展。本研究利用LLMs将学生的反思转化为量化分数,采用两种评估策略(单代理和多代理)和两种提示技术(零射击和少射击)。在来自377名学生三个学期的5278篇反思数据集上进行的实验表明,采用少射击策略的单代理方法与人类评价的匹配度最高。此外,利用LLM评估的反思分数的模型在风险学生识别和成绩预测任务中的表现均优于基线。这表明LLMs可以有效自动化反思评估,减轻教育工作者的工作量,并为可能需要额外帮助的学生提供及时的支持。本研究强调了将先进的生成性AI技术融入教育实践以提高学生参与度和学业成功的潜力。
Key Takeaways
- 大型语言模型(LLMs)可用于自动评估学生的开放文本反思和预测学业成绩。
- 传统评估反思的方法存在耗时且难以有效扩展的问题。
- 采用单代理和少射击策略的LLM在匹配人类评价方面表现最佳。
- LLMs在风险学生识别和成绩预测任务中的表现优于基线方法。
- LLMs能有效自动化反思评估,减轻教师的工作负担。
- LLMs可为学生提供及时的支持,特别是那些可能需要额外帮助的学生。
点此查看论文截图


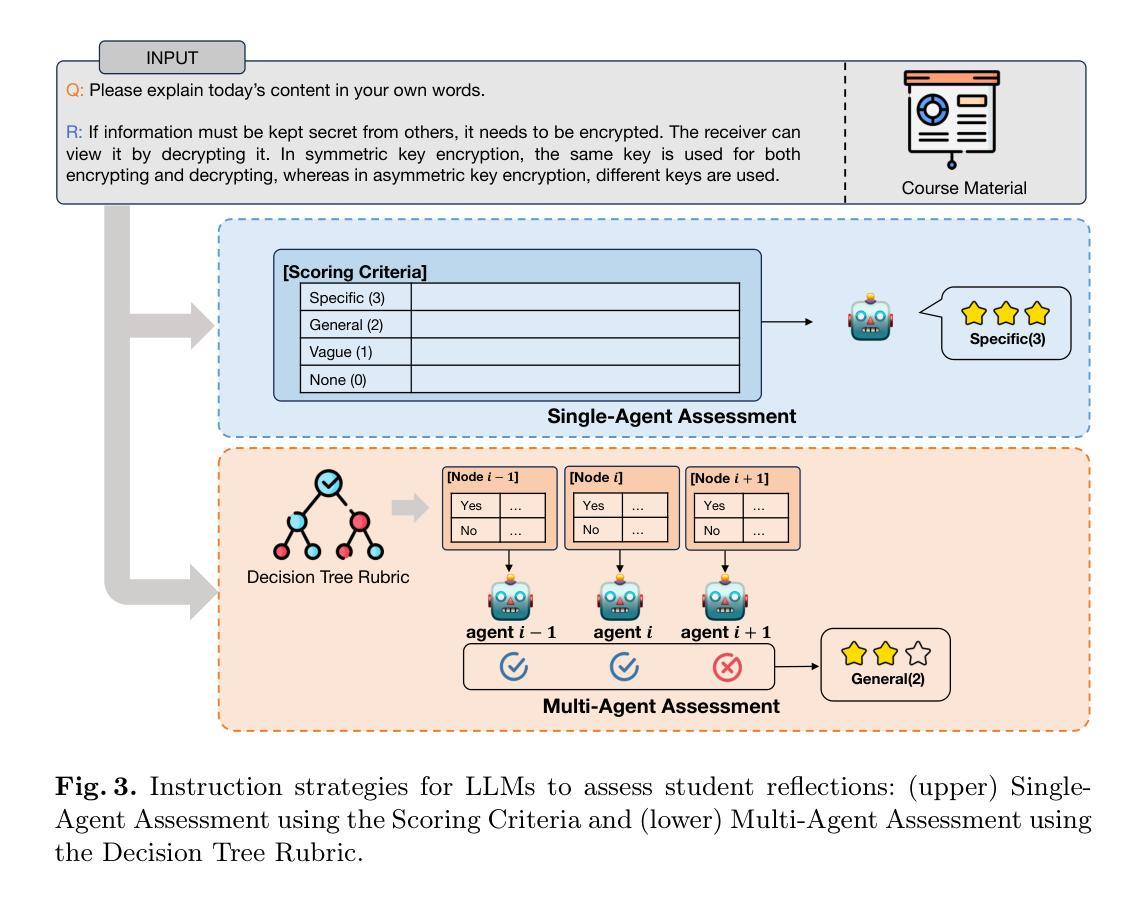
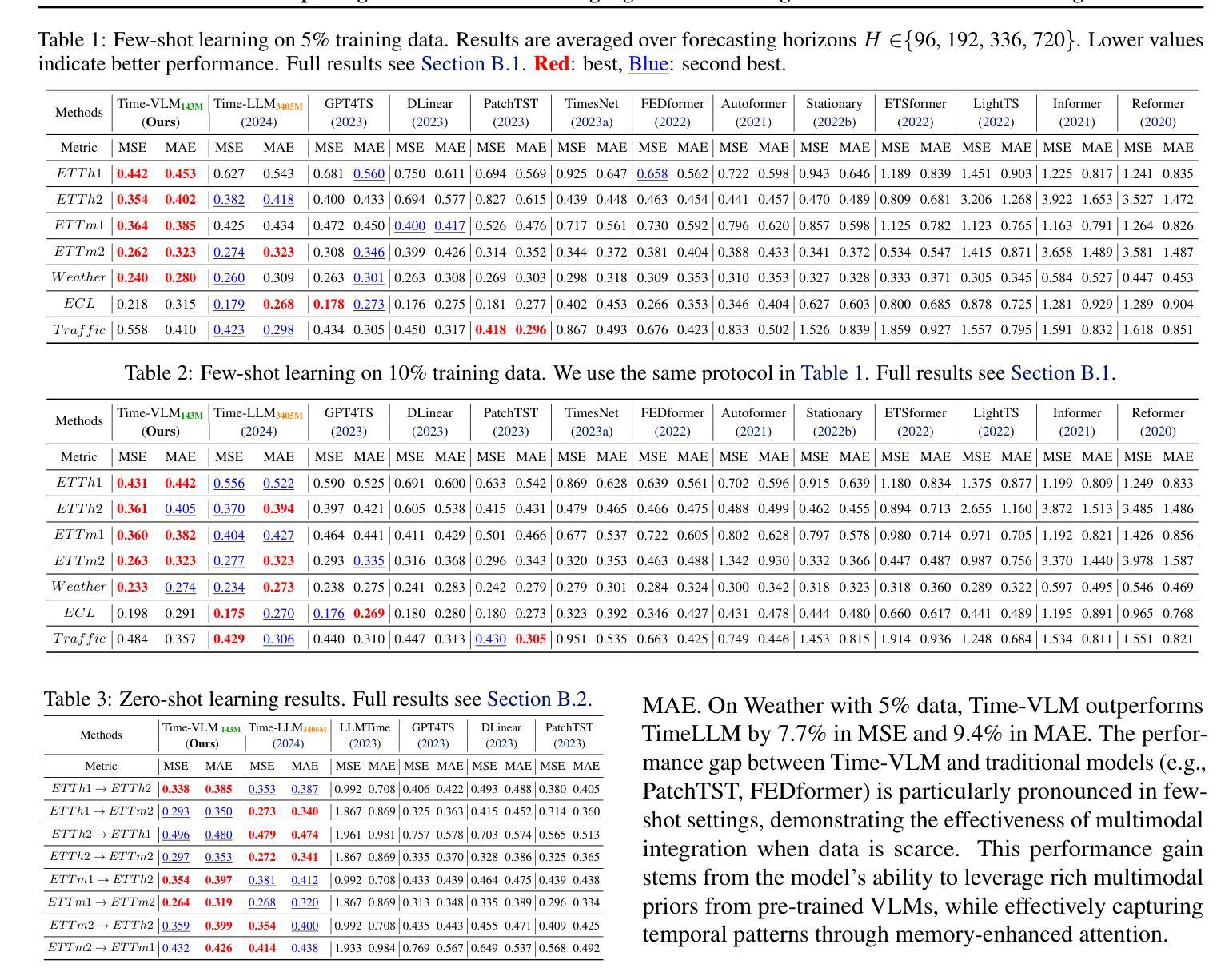
Time-VLM: Exploring Multimodal Vision-Language Models for Augmented Time Series Forecasting
Authors:Siru Zhong, Weilin Ruan, Ming Jin, Huan Li, Qingsong Wen, Yuxuan Liang
Recent advancements in time series forecasting have explored augmenting models with text or vision modalities to improve accuracy. While text provides contextual understanding, it often lacks fine-grained temporal details. Conversely, vision captures intricate temporal patterns but lacks semantic context, limiting the complementary potential of these modalities. To address this, we propose \method, a novel multimodal framework that leverages pre-trained Vision-Language Models (VLMs) to bridge temporal, visual, and textual modalities for enhanced forecasting. Our framework comprises three key components: (1) a Retrieval-Augmented Learner, which extracts enriched temporal features through memory bank interactions; (2) a Vision-Augmented Learner, which encodes time series as informative images; and (3) a Text-Augmented Learner, which generates contextual textual descriptions. These components collaborate with frozen pre-trained VLMs to produce multimodal embeddings, which are then fused with temporal features for final prediction. Extensive experiments demonstrate that Time-VLM achieves superior performance, particularly in few-shot and zero-shot scenarios, thereby establishing a new direction for multimodal time series forecasting. Code is available at https://github.com/CityMind-Lab/ICML25-TimeVLM.
近期时间序列预测领域的进展探索了通过添加文本或视觉模式来增强模型以提高预测精度的方法。虽然文本提供了上下文理解,但它常常缺乏精细的时间细节。相反,视觉模式捕捉到了复杂的时间模式,但缺乏语义上下文,限制了这些模式的互补潜力。为了解决这一问题,我们提出了\method(方法)这一新型多模式框架,它利用预训练的视觉语言模型(VLMs)来桥接时间、视觉和文本模式以增强预测能力。我们的框架包含三个关键组成部分:(1)检索增强学习者,它通过内存银行互动提取丰富的时间特征;(2)视觉增强学习者,它将时间序列编码为信息图像;(3)文本增强学习者,它生成上下文文本描述。这三个组成部分与冻结的预训练VLMs协作,生成多模式嵌入,然后其与时间特征融合以进行最终预测。大量实验表明,Time-VLM(时间-视觉语言模型)在少样本和无样本场景下实现了卓越的性能,为多媒体时间序列预测开辟了新的方向。代码可通过https://github.com/CityMind-Lab/ICML25-TimeVLM获取。
论文及项目相关链接
PDF 20 pages
Summary
本文介绍了针对时间序列预测的新进展,提出了一种新的多模态框架Time-VLM,该框架结合了预训练的视觉语言模型(VLMs)来融合时间、视觉和文本模态,以提高预测的准确性。该框架包括三个关键组件:检索增强学习者、视觉增强学习者和文本增强学习者。实验证明,Time-VLM在少样本和无样本场景下具有卓越性能,为多媒体时间序列预测提供了新的方向。
Key Takeaways
- 文本提供上下文理解但可能缺乏精细的时间细节,而视觉捕捉复杂的时间模式但缺乏语义上下文。
- Time-VLM框架利用预训练的视觉语言模型(VLMs)来融合时间、视觉和文本模态。
- Time-VLM框架包括三个关键组件:检索增强学习者、视觉增强学习者和文本增强学习者。
- 检索增强学习者通过内存银行交互提取丰富的时间特征。
- 视觉增强学习者将时间序列编码为信息图像。
- 文本增强学习者生成上下文文本描述。
- Time-VLM框架在少样本和无样本场景下的预测性能卓越,为多媒体时间序列预测提供了新的方向。
点此查看论文截图

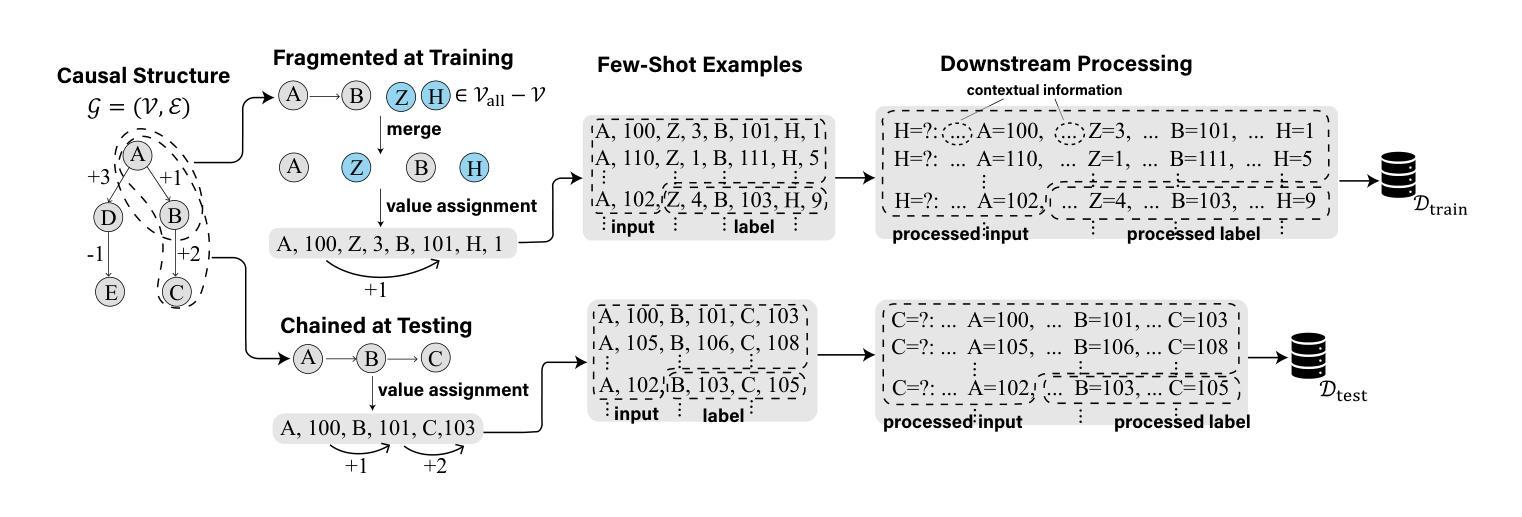
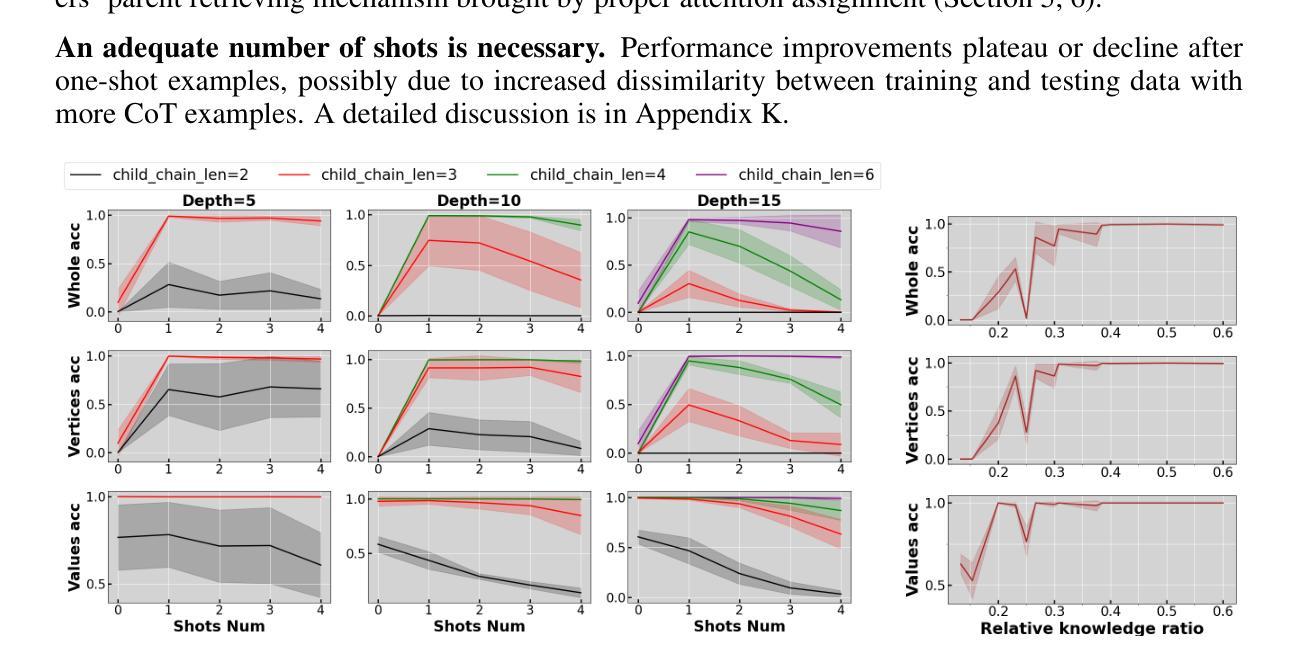
Are Transformers Able to Reason by Connecting Separated Knowledge in Training Data?
Authors:Yutong Yin, Zhaoran Wang
Humans exhibit remarkable compositional reasoning by integrating knowledge from various sources. For example, if someone learns ( B = f(A) ) from one source and ( C = g(B) ) from another, they can deduce ( C=g(B)=g(f(A)) ) even without encountering ( ABC ) together, showcasing the generalization ability of human intelligence. In this paper, we introduce a synthetic learning task, “FTCT” (Fragmented at Training, Chained at Testing), to validate the potential of Transformers in replicating this skill and interpret its inner mechanism. In the training phase, data consist of separated knowledge fragments from an overall causal graph. During testing, Transformers must infer complete causal graph traces by integrating these fragments. Our findings demonstrate that few-shot Chain-of-Thought prompting enables Transformers to perform compositional reasoning on FTCT by revealing correct combinations of fragments, even if such combinations were absent in the training data. Furthermore, the emergence of compositional reasoning ability is strongly correlated with the model complexity and training-testing data similarity. We propose, both theoretically and empirically, that Transformers learn an underlying generalizable program from training, enabling effective compositional reasoning during testing.
人类能够通过整合来自不同来源的知识展现出惊人的组合推理能力。例如,如果有人从某一来源学习到(B=f(A)),并从另一来源学习到(C=g(B)),那么即使没有同时遇到(ABC),他们也能推导出(C=g(B)=g(f(A))),这展示了人类智力的泛化能力。在本文中,我们引入了一项合成学习任务“FTCT”(训练时碎片化,测试时链接),以验证Transformer在复制这项技能方面的潜力并解释其内在机制。在训练阶段,数据由来自整体因果图的分离知识片段组成。在测试阶段,Transformer必须通过整合这些片段来推断完整的因果图轨迹。我们的研究结果表明,即使这些组合在训练数据中不存在,基于少量碎片的“Chain-of-Thought”提示也能使Transformer在FTCT上执行组合推理,揭示正确的碎片组合。此外,组合推理能力的出现与模型复杂度和训练-测试数据相似性密切相关。我们从理论和实践两方面提出,Transformer通过训练学习到一个可泛化的底层程序,从而在测试时能够实现有效的组合推理。
论文及项目相关链接
PDF Accepted by ICLR 2025
Summary
本文介绍了人类具有出色的组合推理能力,能够整合不同来源的知识。文中通过一个示例阐述了人类如何运用组合推理进行推理过程。针对这种能力,本文提出了一个名为“FTCT”(训练时碎片化,测试时串联化)的合成学习任务来验证Transformer模型是否具备这种能力并解释其内部机制。研究结果表明,少量的“思维链”(Chain-of-Thought)提示能够帮助Transformer在FTCT任务上进行组合推理,正确组合知识片段,即使这些组合在训练数据中不存在。此外,模型的复杂性和训练测试数据的相似性对组合推理能力的出现有重要影响。本文提出,Transformer从训练中学习了一种可推广的底层程序,从而在测试时能够进行有效的组合推理。
Key Takeaways
- 人类具有出色的组合推理能力,能够整合不同来源的知识进行推理。
- “FTCT”任务用于验证Transformer模型在组合推理方面的潜力。
- 少量“思维链”提示有助于Transformer在FTCT任务上正确组合知识片段。
- 模型复杂性和训练测试数据相似性对组合推理能力有重要影响。
- Transformer在训练中学习了一种可推广的底层程序。
- 这种底层程序使得Transformer在测试时能够进行有效的组合推理。
点此查看论文截图

Can LLMs assist with Ambiguity? A Quantitative Evaluation of various Large Language Models on Word Sense Disambiguation
Authors:T. G. D. K. Sumanathilaka, Nicholas Micallef, Julian Hough
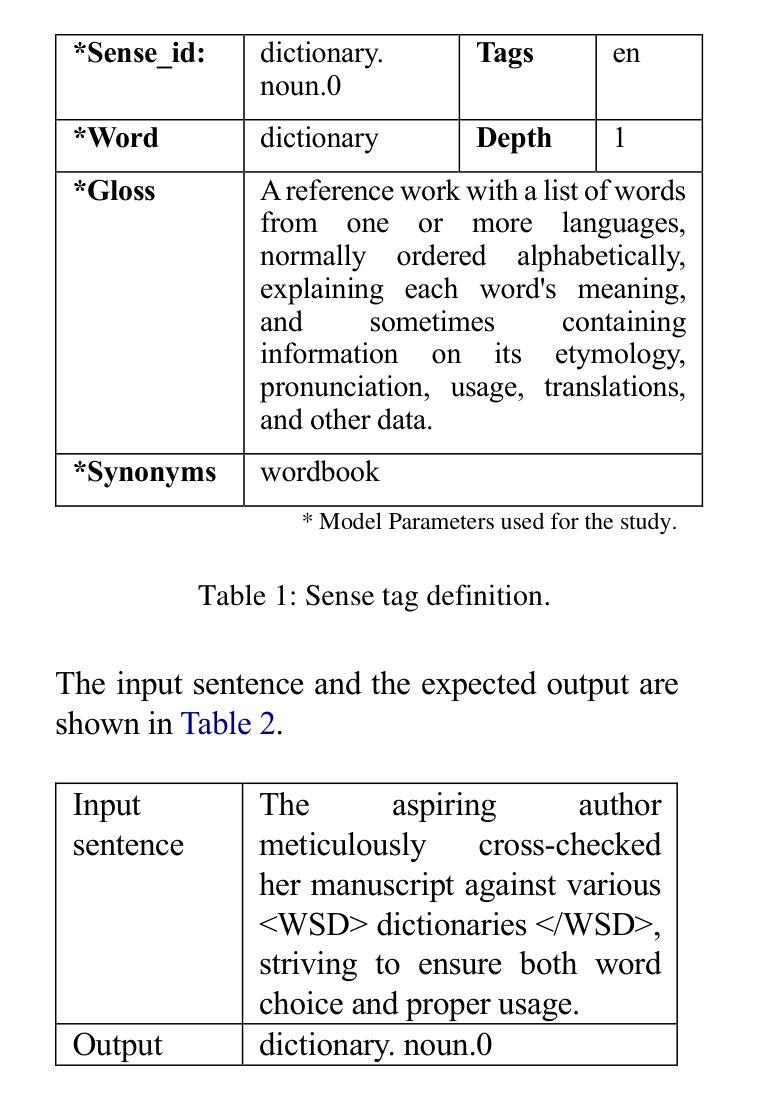
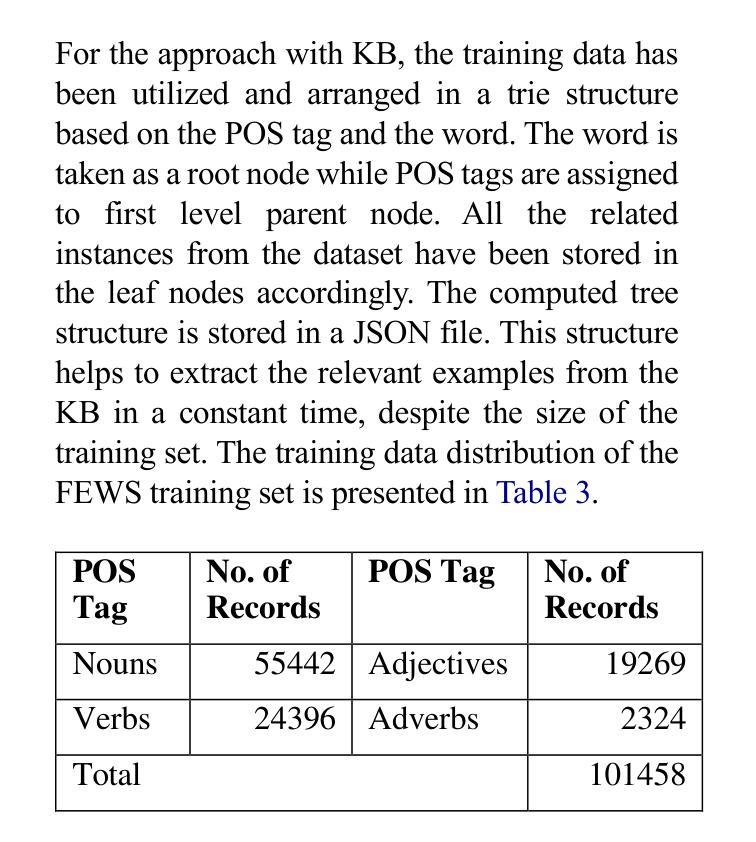
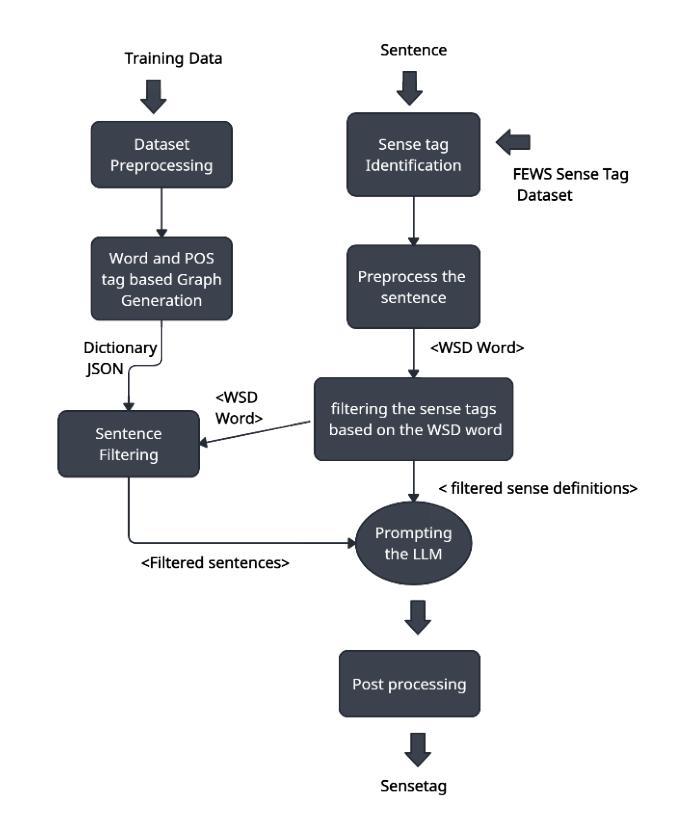
Ambiguous words are often found in modern digital communications. Lexical ambiguity challenges traditional Word Sense Disambiguation (WSD) methods, due to limited data. Consequently, the efficiency of translation, information retrieval, and question-answering systems is hindered by these limitations. This study investigates the use of Large Language Models (LLMs) to improve WSD using a novel approach combining a systematic prompt augmentation mechanism with a knowledge base (KB) consisting of different sense interpretations. The proposed method incorporates a human-in-loop approach for prompt augmentation where prompt is supported by Part-of-Speech (POS) tagging, synonyms of ambiguous words, aspect-based sense filtering and few-shot prompting to guide the LLM. By utilizing a few-shot Chain of Thought (COT) prompting-based approach, this work demonstrates a substantial improvement in performance. The evaluation was conducted using FEWS test data and sense tags. This research advances accurate word interpretation in social media and digital communication.
在现代数字通信中经常可以发现词义模糊的词语。由于数据有限,词汇的模糊性给传统的词义消歧(Word Sense Disambiguation, WSD)方法带来了挑战。因此,翻译、信息检索和问答系统的效率受到了这些限制的阻碍。本研究探讨了使用大型语言模型(LLMs)结合一种系统的提示增强机制和包含不同词义解释的知识库(KB)来改善词义消歧的方法。所提出的方法采用了一种人机循环的提示增强方法,其中提示得到词类标注、模糊词同义词、基于方面的词义过滤和少量提示的支持,以引导大型语言模型。通过采用基于少量思维的思维链(COT)提示方法,这项工作在性能上取得了显著改进。评估是使用FEWS测试数据和词义标签进行的。该研究推动了社交媒体和数字通信中的准确词义解读。
论文及项目相关链接
PDF 12 pages,6 tables, 1 figure, Proceedings of the 1st International Conference on NLP & AI for Cyber Security
Summary
本文探讨了现代数字通信中常见的词汇歧义问题。由于数据有限,传统的词语感知消歧(WSD)方法面临挑战。本研究采用大型语言模型(LLMs)结合系统提示增强机制和包含不同感知解读的知识库(KB)来改善WSD。通过结合人类参与的提示增强方法,利用词性标注、模糊词的同义词、基于方面的感知过滤和少量提示引导LLM。通过基于少量提示的思考链(COT)提示方法,该研究在性能上取得了显著改进。评估采用FEWS测试数据和感知标签进行。此研究有助于改进社交媒体和数字通信中的准确词汇解读。
Key Takeaways
- 词汇歧义在现代数字通信中是常见问题。
- 传统WSD方法因数据有限而面临挑战。
- 本研究采用大型语言模型(LLMs)改善WSD。
- 结合系统提示增强机制和知识库进行感知解读。
- 人类参与的提示增强方法包括词性标注、同义词等。
- 采用少量提示的思考链(COT)方法显著提高了性能。
点此查看论文截图