⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-05-28 更新
Improvement Strategies for Few-Shot Learning in OCT Image Classification of Rare Retinal Diseases
Authors:Cheng-Yu Tai, Ching-Wen Chen, Chi-Chin Wu, Bo-Chen Chiu, Cheng-Hung, Lin, Cheng-Kai Lu, Jia-Kang Wang, Tzu-Lun Huang
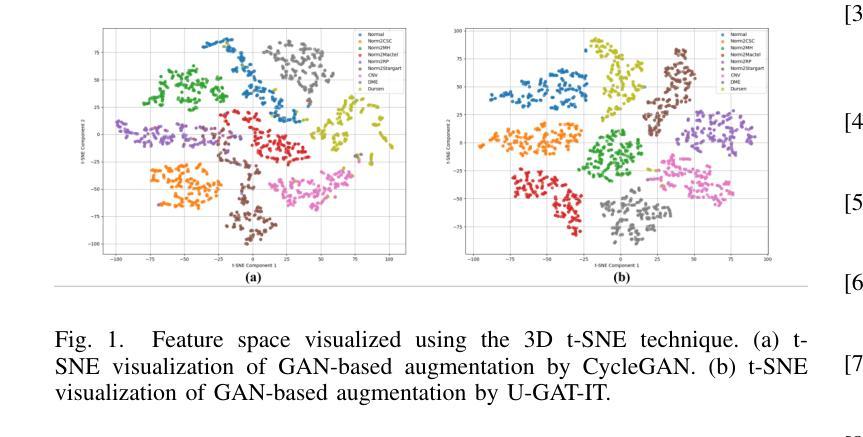
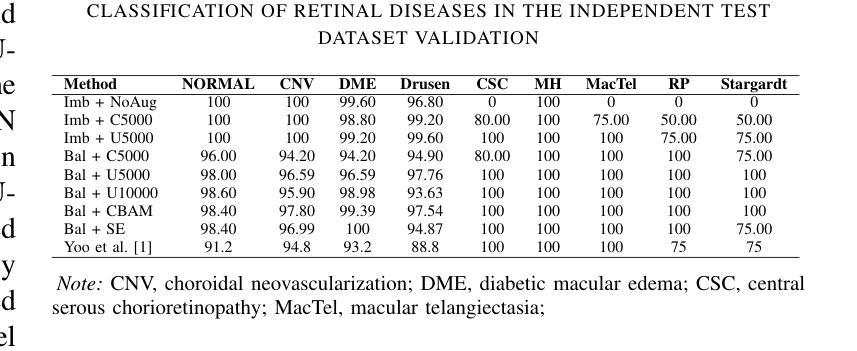
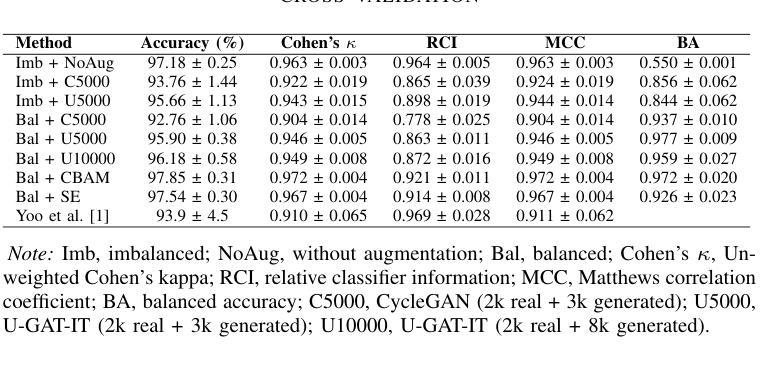
This paper focuses on using few-shot learning to improve the accuracy of classifying OCT diagnosis images with major and rare classes. We used the GAN-based augmentation strategy as a baseline and introduced several novel methods to further enhance our model. The proposed strategy contains U-GAT-IT for improving the generative part and uses the data balance technique to narrow down the skew of accuracy between all categories. The best model obtained was built with CBAM attention mechanism and fine-tuned InceptionV3, and achieved an overall accuracy of 97.85%, representing a significant improvement over the original baseline.
本文重点研究如何利用少样本学习来提高OCT诊断图像中主要和罕见类别分类的准确性。我们基于GAN的增强策略作为基线,并引入了几种新方法进一步提升模型性能。所提出的方法包含U-GAT-IT以提高生成部分的效果,并使用数据平衡技术缩小各类别准确度的偏差。最终建立的最好的模型是采用CBAM注意力机制和微调过的InceptionV3,总体准确度达到97.85%,相较于原始基线有了显著的提升。
论文及项目相关链接
Summary
本文探讨了利用少样本学习提高OCT诊断图像分类准确性的问题。基于GAN的增强策略作为基线,引入了几种新方法以进一步优化模型。采用U-GAT-IT改进生成部分,使用数据平衡技术缩小各类别准确率的偏差。最佳模型采用CBAM注意力机制和微调过的InceptionV3,总体准确率达到了97.85%,相较于原始基线有显著提升。
Key Takeaways
- 论文关注于使用少样本学习提高OCT诊断图像分类的准确性。
- GAN-based增强策略作为基线方法。
- 引入U-GAT-IT方法改进生成部分。
- 采用数据平衡技术缩小各类别准确率的偏差。
- 最佳模型结合了CBAM注意力机制和微调过的InceptionV3。
- 最佳模型的总体准确率达到了97.85%。
点此查看论文截图

Improving Heart Rejection Detection in XPCI Images Using Synthetic Data Augmentation
Authors:Jakov Samardžija, Donik Vršnak, Sven Lončarić
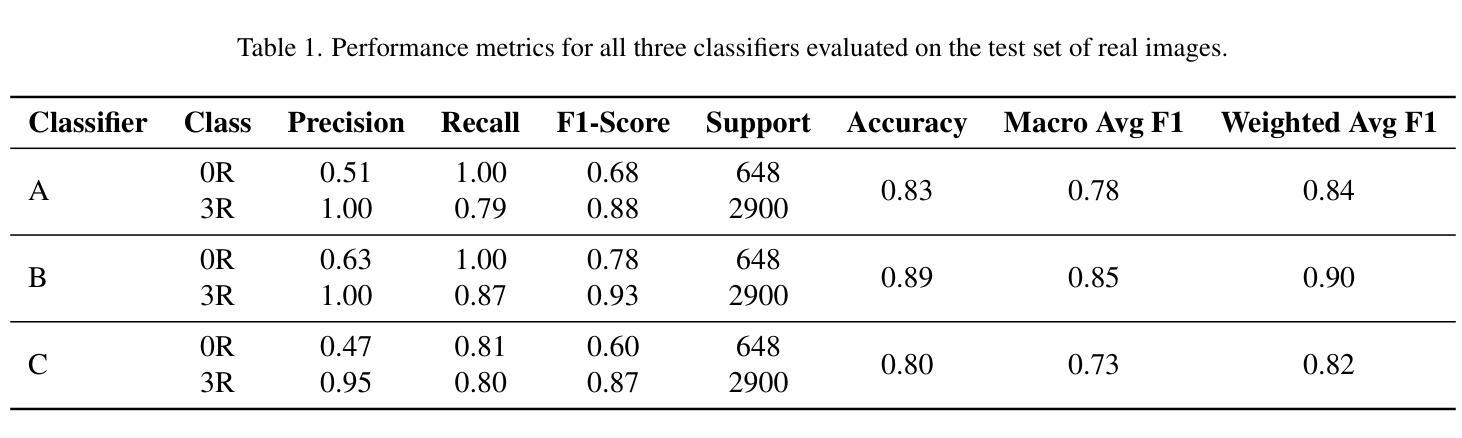
Accurate identification of acute cellular rejection (ACR) in endomyocardial biopsies is essential for effective management of heart transplant patients. However, the rarity of high-grade rejection cases (3R) presents a significant challenge for training robust deep learning models. This work addresses the class imbalance problem by leveraging synthetic data generation using StyleGAN to augment the limited number of real 3R images. Prior to GAN training, histogram equalization was applied to standardize image appearance and improve the consistency of tissue representation. StyleGAN was trained on available 3R biopsy patches and subsequently used to generate 10,000 realistic synthetic images. These were combined with real 0R samples, that is samples without rejection, in various configurations to train ResNet-18 classifiers for binary rejection classification. Three classifier variants were evaluated: one trained on real 0R and synthetic 3R images, another using both synthetic and additional real samples, and a third trained solely on real data. All models were tested on an independent set of real biopsy images. Results demonstrate that synthetic data improves classification performance, particularly when used in combination with real samples. The highest-performing model, which used both real and synthetic images, achieved strong precision and recall for both classes. These findings underscore the value of hybrid training strategies and highlight the potential of GAN-based data augmentation in biomedical image analysis, especially in domains constrained by limited annotated datasets.
在心肌内膜活检中对急性细胞排斥反应(ACR)的准确识别对于心脏移植患者的有效管理至关重要。然而,高级排斥反应案例(3R)的罕见性给训练稳健的深度学习模型带来了重大挑战。这项工作通过利用StyleGAN进行合成数据生成来解决类别不平衡问题,以增加有限的真实3R图像数量。在GAN训练之前,应用直方图均衡化以标准化图像外观并改善组织表示的连续性。StyleGAN在可用的3R活检斑块上进行训练,然后用于生成10,000个逼真的合成图像。这些图像与没有排斥反应的实0R样本相结合,以训练用于二元排斥分类的ResNet-18分类器。评估了三个分类器变体:一个用真实0R和合成3R图像进行训练,另一个同时使用合成图像和额外真实样本进行训练,第三个仅使用真实数据进行训练。所有模型都在一组独立的真实活检图像上进行了测试。结果表明,合成数据提高了分类性能,特别是在与真实样本结合使用时。表现最佳的模型使用真实和合成图像,为两个类别都实现了强大的精确度和召回率。这些发现强调了混合训练策略的价值,并突出了GAN基于数据增强的生物医学图像分析中的潜力,特别是在受限制的有标注数据集领域。
论文及项目相关链接
Summary
在心脏移植患者的管理中,准确识别急性细胞排斥反应(ACR)至关重要。本研究利用StyleGAN生成合成数据来解决高级排斥反应(3R)病例稀少带来的问题。通过对图像进行直方图均衡化预处理,标准化图像外观并改善组织表现的一致性。StyleGAN在可用的3R活检斑块上进行训练,然后生成1万张逼真的合成图像。这些图像与无排斥反应的0R样本结合,用于训练ResNet-18分类器进行二元排斥分类。评估了三个分类器变种,结果显示合成数据提高了分类性能,尤其是与真实样本结合使用时。使用真实和合成图像的最高性能模型为两个类别实现了强大的精度和召回率。研究强调了混合训练策略的价值,并突出了GAN基于数据增强的生物医学图像分析中的潜力,特别是在受限制数据集领域。
Key Takeaways
- StyleGAN被用于解决心脏移植病例中高级排斥反应(3R)稀少的问题,通过生成合成数据来增强有限的真实3R图像。
- 在训练GAN之前,使用直方图均衡化来标准化图像并改善组织表现的一致性。
- 通过结合真实0R样本和合成3R图像,训练了ResNet-18分类器进行二元排斥分类。
- 评估了三个不同的分类器变种,证明了合成数据在提高分类性能方面的作用,尤其是当与真实样本结合使用时。
- 最高性能的分类器在真实活检图像测试集上实现了强大的精度和召回率。
- 研究强调了混合训练策略的价值,即将真实和合成数据相结合进行模型训练。
点此查看论文截图




Distilling Textual Priors from LLM to Efficient Image Fusion
Authors:Ran Zhang, Xuanhua He, Ke Cao, Liu Liu, Li Zhang, Man Zhou, Jie Zhang
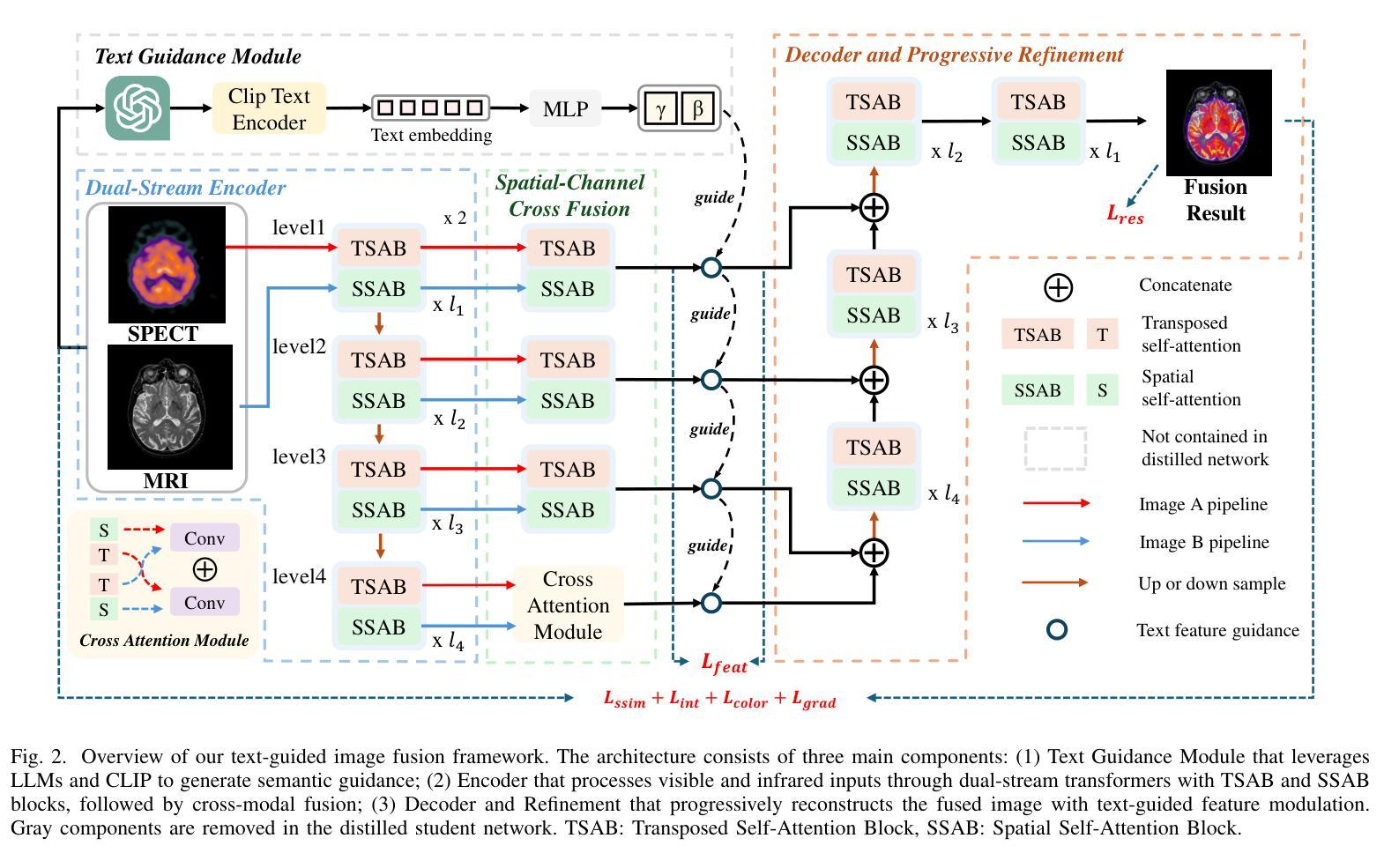
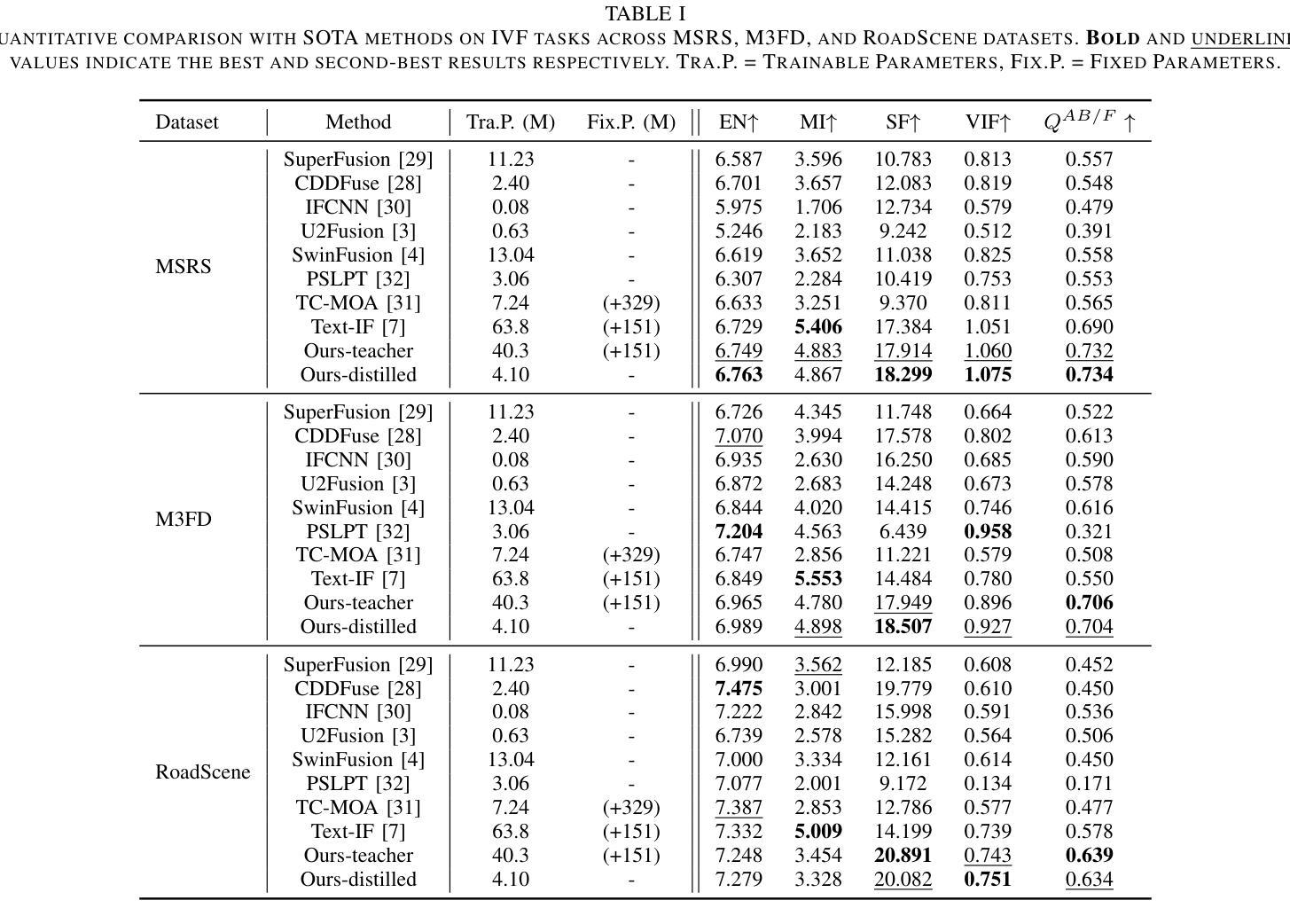
Multi-modality image fusion aims to synthesize a single, comprehensive image from multiple source inputs. Traditional approaches, such as CNNs and GANs, offer efficiency but struggle to handle low-quality or complex inputs. Recent advances in text-guided methods leverage large model priors to overcome these limitations, but at the cost of significant computational overhead, both in memory and inference time. To address this challenge, we propose a novel framework for distilling large model priors, eliminating the need for text guidance during inference while dramatically reducing model size. Our framework utilizes a teacher-student architecture, where the teacher network incorporates large model priors and transfers this knowledge to a smaller student network via a tailored distillation process. Additionally, we introduce spatial-channel cross-fusion module to enhance the model’s ability to leverage textual priors across both spatial and channel dimensions. Our method achieves a favorable trade-off between computational efficiency and fusion quality. The distilled network, requiring only 10% of the parameters and inference time of the teacher network, retains 90% of its performance and outperforms existing SOTA methods. Extensive experiments demonstrate the effectiveness of our approach. The implementation will be made publicly available as an open-source resource.
多模态图像融合旨在从多个源输入中合成一个单一、全面的图像。传统方法,如卷积神经网络和生成对抗网络,虽然效率高,但在处理低质量或复杂输入时遇到困难。最近的文本引导方法利用大型模型的先验知识来克服这些限制,但这需要内存和推理时间上的大量计算开销。为了应对这一挑战,我们提出了一种新型的大型模型先验知识提炼框架,它无需在推理过程中使用文本引导,同时显著减小了模型大小。我们的框架采用师徒架构,教师网络结合了大型模型的先验知识,并通过定制的提炼过程将这些知识转移到一个较小的学生网络。此外,我们引入了空间通道交叉融合模块,以提高模型在空间和通道维度上利用文本先验知识的能力。我们的方法在计算效率和融合质量之间实现了有利的权衡。蒸馏网络仅需要教师网络10%的参数和推理时间,就能保留90%的性能,并超越现有的最佳方法。大量实验证明了我们的方法的有效性。该实现将作为开源资源公开发布。
论文及项目相关链接
PDF Change to TCSVT format
Summary
该研究提出了一种新的多模态图像融合框架,通过蒸馏大型模型先验知识,消除推理过程中对文本指导的需求,并大幅减小模型体积。该研究采用师徒架构,通过定制蒸馏过程,将大型模型先验知识传递给小型学生网络。同时,引入空间通道交叉融合模块,提高模型在空间和通道维度上利用文本先验的能力。该方法在计算效率和融合质量之间取得了良好的平衡。
Key Takeaways
1.该研究致力于解决多模态图像融合问题,旨在从多个源输入中合成一个单一、全面的图像。
2.传统方法如卷积神经网络和生成对抗网络在处理低质量或复杂输入时存在困难。
3.最近出现的文本指导方法利用大型模型先验知识来克服这些限制,但计算和推理成本较高。
4.该研究提出了一种新的框架,通过蒸馏大型模型先验知识,消除推理过程中对文本指导的需求,并显著减小模型规模。
5.该研究采用师徒网络架构,通过定制蒸馏过程,将知识从教师网络转移到学生网络。
6.引入了空间通道交叉融合模块,提高模型在空间和通道维度上利用文本先验信息的能力。
点此查看论文截图


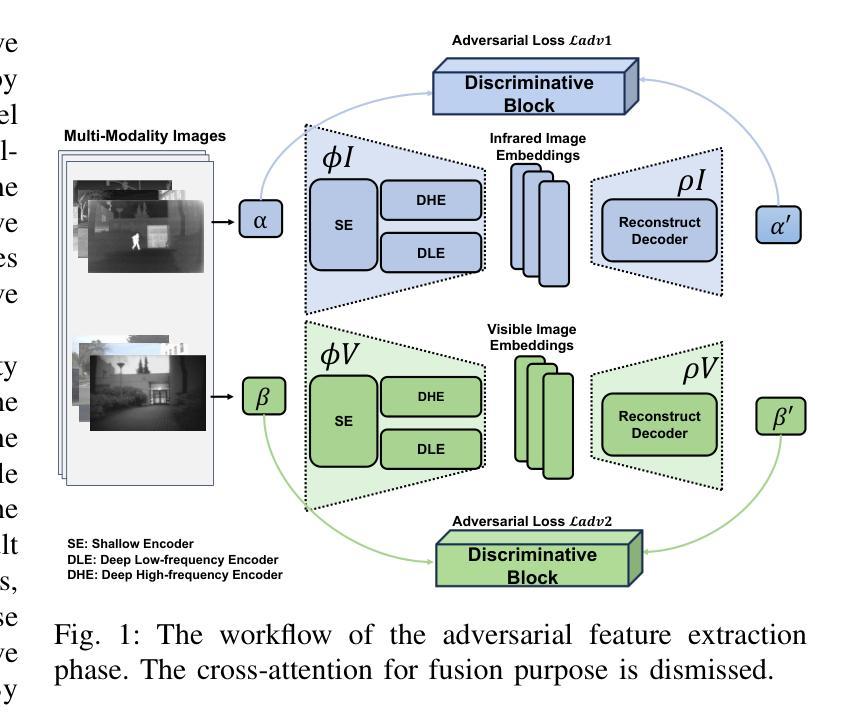
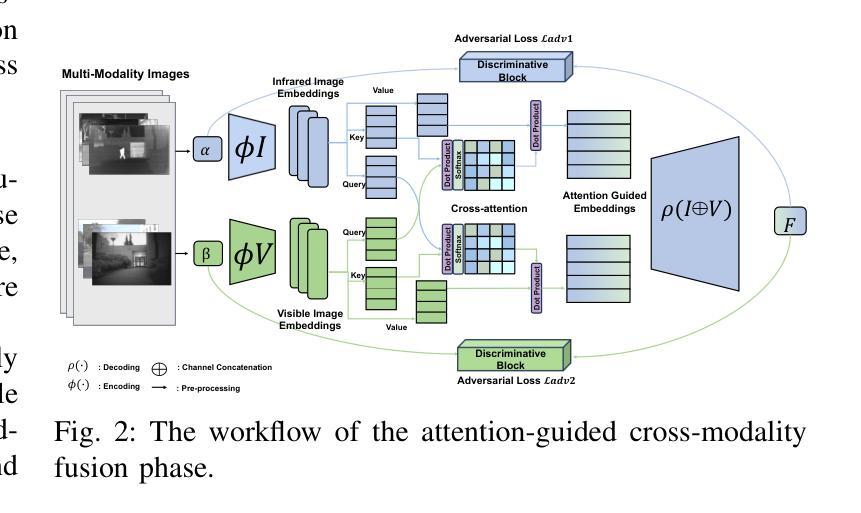
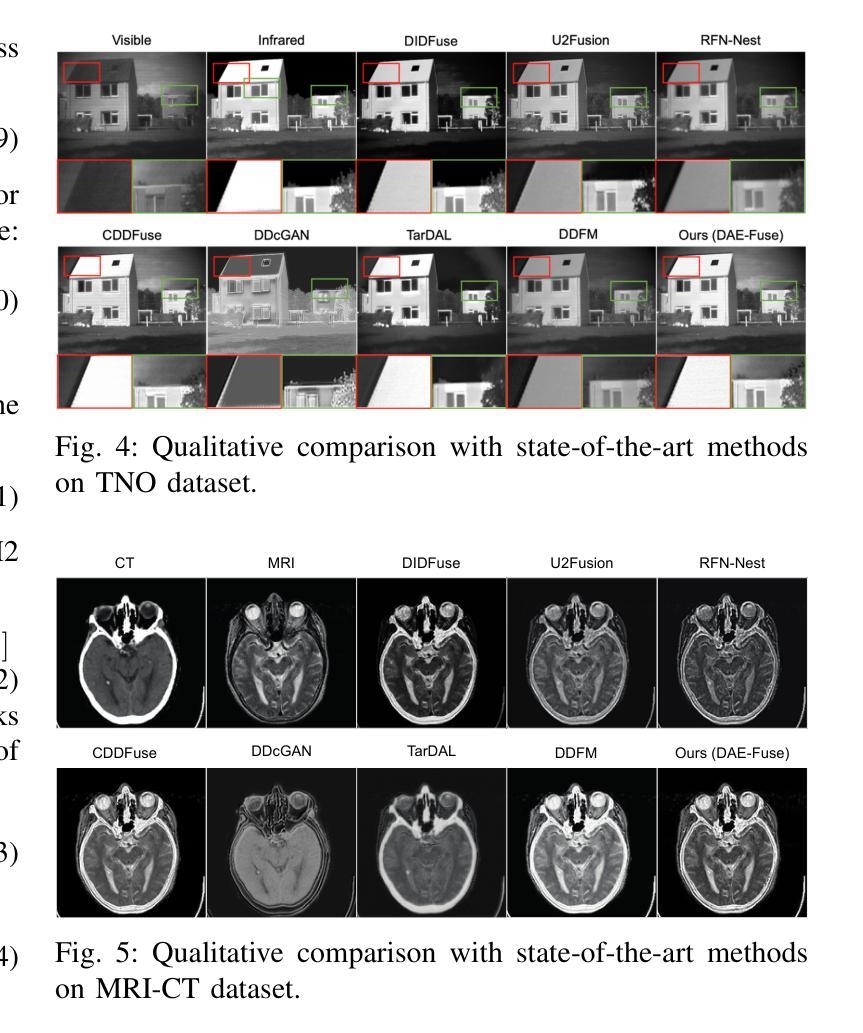
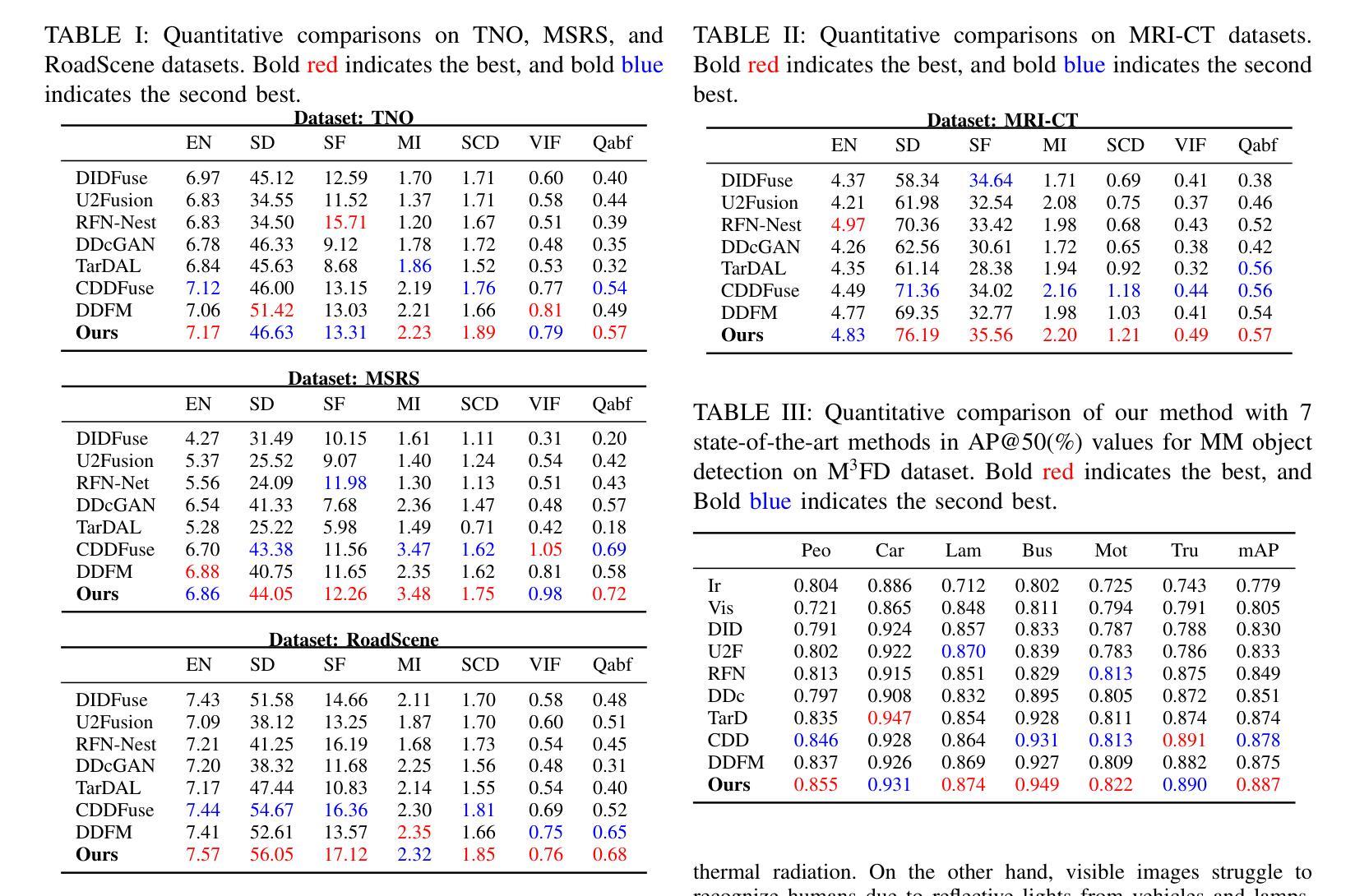
DAE-Fuse: An Adaptive Discriminative Autoencoder for Multi-Modality Image Fusion
Authors:Yuchen Guo, Ruoxiang Xu, Rongcheng Li, Weifeng Su
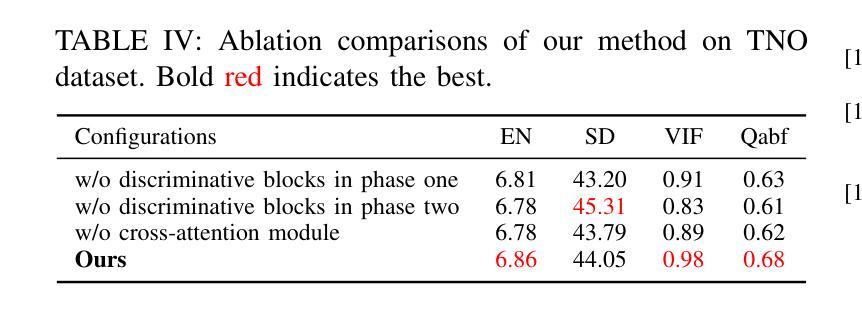
In extreme scenarios such as nighttime or low-visibility environments, achieving reliable perception is critical for applications like autonomous driving, robotics, and surveillance. Multi-modality image fusion, particularly integrating infrared imaging, offers a robust solution by combining complementary information from different modalities to enhance scene understanding and decision-making. However, current methods face significant limitations: GAN-based approaches often produce blurry images that lack fine-grained details, while AE-based methods may introduce bias toward specific modalities, leading to unnatural fusion results. To address these challenges, we propose DAE-Fuse, a novel two-phase discriminative autoencoder framework that generates sharp and natural fused images. Furthermore, We pioneer the extension of image fusion techniques from static images to the video domain while preserving temporal consistency across frames, thus advancing the perceptual capabilities required for autonomous navigation. Extensive experiments on public datasets demonstrate that DAE-Fuse achieves state-of-the-art performance on multiple benchmarks, with superior generalizability to tasks like medical image fusion.
在极端场景,如夜间或低可见度环境中,实现可靠的感知对于自动驾驶、机器人和监控等应用至关重要。多模式图像融合,特别是结合红外成像,通过结合不同模式的互补信息,增强场景理解和决策制定,提供了一种稳健的解决方案。然而,当前的方法存在重大局限:基于GAN的方法往往产生模糊图像,缺乏精细细节,而基于AE的方法可能偏向于特定模式,导致融合结果不自然。为了解决这些挑战,我们提出了DAE-Fuse,这是一种新型的两阶段判别式自编码器框架,可以生成清晰自然的融合图像。此外,我们率先将图像融合技术从静态图像扩展到视频领域,同时保持帧间的时间一致性,从而提高了自主导航所需的感知能力。在公共数据集上的广泛实验表明,DAE-Fuse在多个基准测试中实现了最先进的性能,并且在医疗图像融合等任务上具有出色的泛化能力。
论文及项目相关链接
Summary
在极端场景如夜间或低能见度环境下,多模态图像融合对自动驾驶、机器人和监控等应用至关重要。当前方法存在局限性,GAN方法常产生模糊图像,AE方法可能引入偏见导致不自然融合结果。我们提出DAE-Fuse,一种新型两阶段判别式自编码框架,生成清晰自然融合图像,并将图像融合技术从静态图像扩展到视频领域,保持帧间时间一致性,提高自主导航的感知能力。在公共数据集上的广泛实验表明,DAE-Fuse在多个基准测试中达到最佳性能,对医疗图像融合等任务具有出色的泛化能力。
Key Takeaways
- 在极端环境下,多模态图像融合对于自动驾驶、机器人和监控应用至关重要。
- 当前图像融合方法存在局限性,需要改进。
- DAE-Fuse是一种新型的两阶段判别式自编码框架,能够生成清晰自然的融合图像。
- DAE-Fuse将图像融合技术从静态图像扩展到视频领域。
- DAE-Fuse保持帧间时间一致性,提高自主导航的感知能力。
- 在公共数据集上的实验表明,DAE-Fuse在多个基准测试中表现最佳。
点此查看论文截图