⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-05-28 更新
Hard Negative Contrastive Learning for Fine-Grained Geometric Understanding in Large Multimodal Models
Authors:Kai Sun, Yushi Bai, Zhen Yang, Jiajie Zhang, Ji Qi, Lei Hou, Juanzi Li
Benefiting from contrastively trained visual encoders on large-scale natural scene images, Large Multimodal Models (LMMs) have achieved remarkable performance across various visual perception tasks. However, the inherent limitations of contrastive learning upon summarized descriptions fundamentally restrict the capabilities of models in meticulous reasoning, particularly in crucial scenarios of geometric problem-solving. To enhance geometric understanding, we propose a novel hard negative contrastive learning framework for the vision encoder, which combines image-based contrastive learning using generation-based hard negatives created by perturbing diagram generation code, and text-based contrastive learning using rule-based negatives derived from modified geometric descriptions and retrieval-based negatives selected based on caption similarity. We train CLIP using our strong negative learning method, namely MMCLIP (Multimodal Math CLIP), and subsequently train an LMM for geometric problem-solving. Experiments show that our trained model, MMGeoLM, significantly outperforms other open-source models on three geometric reasoning benchmarks. Even with a size of 7B, it can rival powerful closed-source models like GPT-4o. We further study the impact of different negative sample construction methods and the number of negative samples on the geometric reasoning performance of LMM, yielding fruitful conclusions. The code and dataset are available at https://github.com/THU-KEG/MMGeoLM.
受益于大规模自然场景图像对比训练的视觉编码器,大型多模态模型(LMMs)在各种视觉感知任务中取得了显著的成绩。然而,对比学习在摘要描述上的固有局限性,从根本上限制了模型在精细推理方面的能力,特别是在解决几何问题的关键场景中。为了增强几何理解,我们提出了一种新型的硬负对比学习框架,用于视觉编码器。该框架结合了基于图像对比学习,使用生成型硬负样本,通过扰动图表生成代码进行创建,以及基于文本的对比学习,使用规则型负样本,来源于修改后的几何描述和基于检索的负样本,根据标题相似性进行选择。我们使用强大的负学习方法训练CLIP,即MMCLIP(多模态数学CLIP),然后训练用于解决几何问题的LMM。实验表明,我们训练的MMGeoLM模型在三个几何推理基准测试上大大优于其他开源模型。即使规模达到7B,它也能与强大的闭源模型如GPT-4o相抗衡。我们还研究了不同负样本构建方法和负样本数量对LMM几何推理性能的影响,得出了有益的结论。代码和数据集可在https://github.com/THU-KEG/MMGeoLM获取。
论文及项目相关链接
Summary
基于大规模自然场景图像对比训练的视觉编码器,大型多模态模型(LMMs)在各种视觉感知任务中取得了显著的性能。然而,对比学习在摘要描述上的固有局限性,限制了模型在精细推理上的能力,特别是在解决几何问题的关键场景中。为增强几何理解,本文提出了一种新型硬负对比学习框架,该框架结合了基于图像和文本的对比学习。通过扰动图表生成代码生成基于生成的硬负样本,以及通过修改几何描述和基于检索的负样本选择,实现基于规则的负样本和基于文本的描述对比学习。本文使用MMCLIP(多模态数学CLIP)的强大负学习方法训练CLIP,并随后对用于解决几何问题的LMM进行训练。实验表明,训练后的MMGeoLM模型在三个几何推理基准测试上大大优于其他开源模型,即使规模达到7B,也能与强大的闭源模型GPT-4o相抗衡。
Key Takeaways
- Large Multimodal Models (LMMs)利用对比训练视觉编码器在大规模自然场景图像上,已达成在各种视觉感知任务上的显著性能。
- 对比学习的内在局限性在于其基于摘要描述的性质,这在精细推理和几何问题解决方面尤为明显。
- 为改善几何理解,提出了新型硬负对比学习框架,结合了图像和文本对比学习。
- 通过扰动图表生成代码创建基于生成的硬负样本,以及通过修改几何描述和基于检索的负样本选择来实现基于规则的负样本和文本描述对比学习。
- 使用MMCLIP方法训练CLIP,并随后对用于解决几何问题的LMM进行训练。
- MMGeoLM模型在几何推理方面表现出卓越性能,显著优于其他开源模型,并有潜力与强大的闭源模型如GPT-4o相竞争。
点此查看论文截图

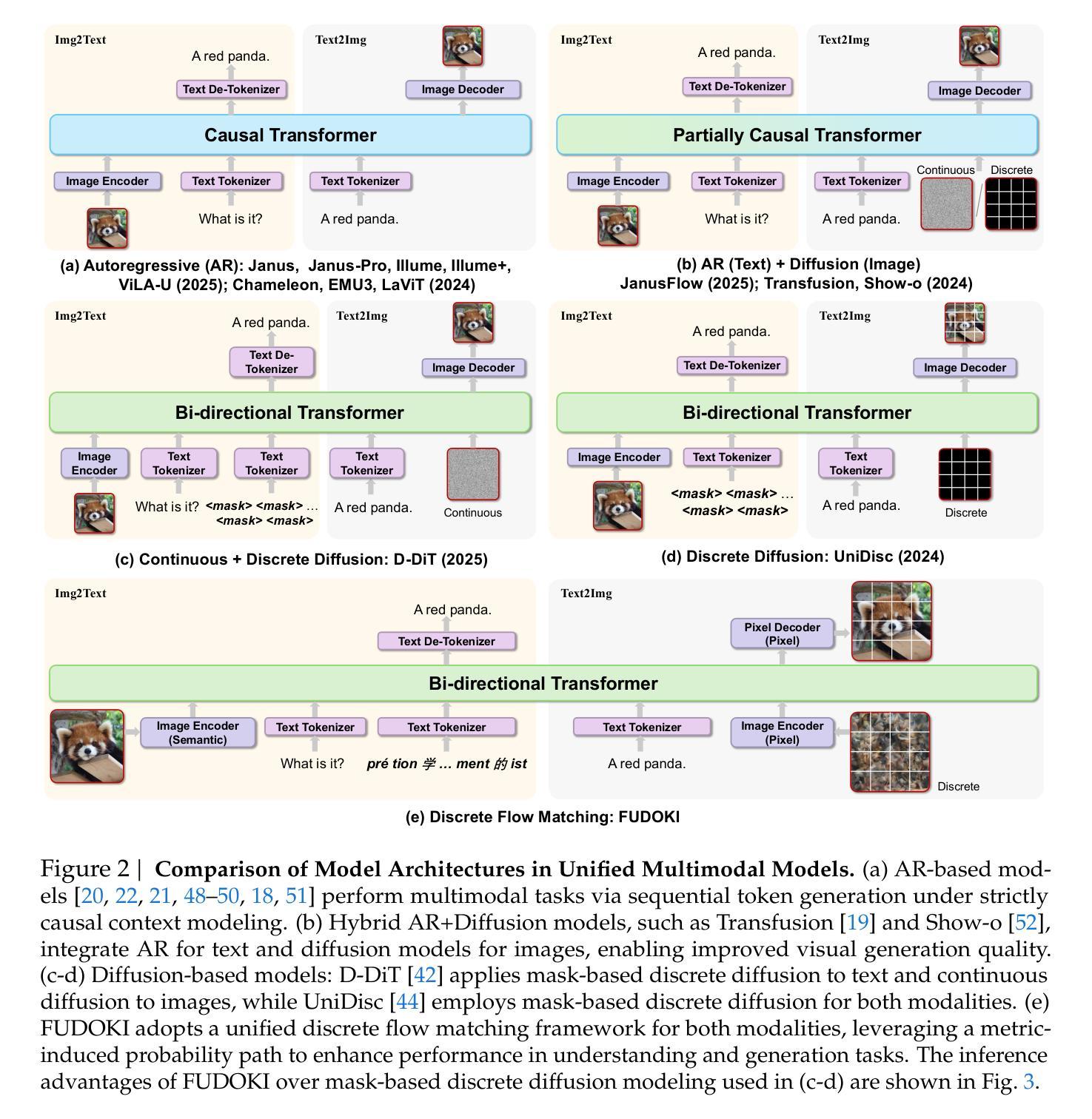
FUDOKI: Discrete Flow-based Unified Understanding and Generation via Kinetic-Optimal Velocities
Authors:Jin Wang, Yao Lai, Aoxue Li, Shifeng Zhang, Jiacheng Sun, Ning Kang, Chengyue Wu, Zhenguo Li, Ping Luo
The rapid progress of large language models (LLMs) has catalyzed the emergence of multimodal large language models (MLLMs) that unify visual understanding and image generation within a single framework. However, most existing MLLMs rely on autoregressive (AR) architectures, which impose inherent limitations on future development, such as the raster-scan order in image generation and restricted reasoning abilities in causal context modeling. In this work, we challenge the dominance of AR-based approaches by introducing FUDOKI, a unified multimodal model purely based on discrete flow matching, as an alternative to conventional AR paradigms. By leveraging metric-induced probability paths with kinetic optimal velocities, our framework goes beyond the previous masking-based corruption process, enabling iterative refinement with self-correction capability and richer bidirectional context integration during generation. To mitigate the high cost of training from scratch, we initialize FUDOKI from pre-trained AR-based MLLMs and adaptively transition to the discrete flow matching paradigm. Experimental results show that FUDOKI achieves performance comparable to state-of-the-art AR-based MLLMs across both visual understanding and image generation tasks, highlighting its potential as a foundation for next-generation unified multimodal models. Furthermore, we show that applying test-time scaling techniques to FUDOKI yields significant performance gains, further underscoring its promise for future enhancement through reinforcement learning.
大型语言模型(LLM)的快速发展催生了多模态大型语言模型(MLLM)的出现,后者能够在单一框架内统一视觉理解和图像生成。然而,大多数现有的MLLM依赖于自回归(AR)架构,这对其未来发展造成了固有局限,例如图像生成中的扫描顺序和因果上下文建模中的有限推理能力。在这项工作中,我们挑战基于AR的方法的主导地位,引入了基于离散流匹配的统一多模态模型FUDOKI,作为传统AR范式的替代方案。通过利用基于度量的概率路径和动力学最优速度,我们的框架超越了基于掩码的损坏过程,实现了迭代优化和自我校正能力,并在生成过程中实现了更丰富的双向上下文集成。为了降低从头开始训练的成本,我们从预训练的AR-based MLLM初始化了FUDOKI,并自适应地过渡到离散流匹配范式。实验结果表明,FUDOKI在视觉理解和图像生成任务上的性能与最先进的AR-based MLLM相当,这凸显了其作为下一代统一多模态模型基础的潜力。此外,我们对FUDOKI应用了测试时缩放技术,实现了显著的性能提升,这进一步证明了其通过强化学习进行未来增强的前景。
论文及项目相关链接
PDF 37 pages, 12 figures
Summary
大型语言模型的快速发展催生了多模态大型语言模型的涌现,但现有模型大多基于自回归架构,存在图像生成和因果上下文建模上的局限。本研究挑战自回归架构的垄断地位,提出基于离散流匹配的统一多模态模型FUDOKI。它利用度量诱导概率路径和动力学最优速度,实现自我修正和丰富的双向上下文集成。实验表明,FUDOKI性能与最先进的自回归多模态模型相当,并可通过测试时缩放技术进一步提高性能,有望成为下一代统一多模态模型的基础。
Key Takeaways
- 多模态大型语言模型统一视觉理解和图像生成。
- 现有模型大多依赖自回归架构,存在局限。
- FUDOKI基于离散流匹配,挑战自回归架构。
- FUDOKI利用度量诱导概率路径和动力学最优速度。
- 相较于传统的自回归MLLMs,FUDOKI具有自我修正和丰富的上下文集成能力。
- FUDOKI性能与顶尖的自回归多模态模型相当。
点此查看论文截图


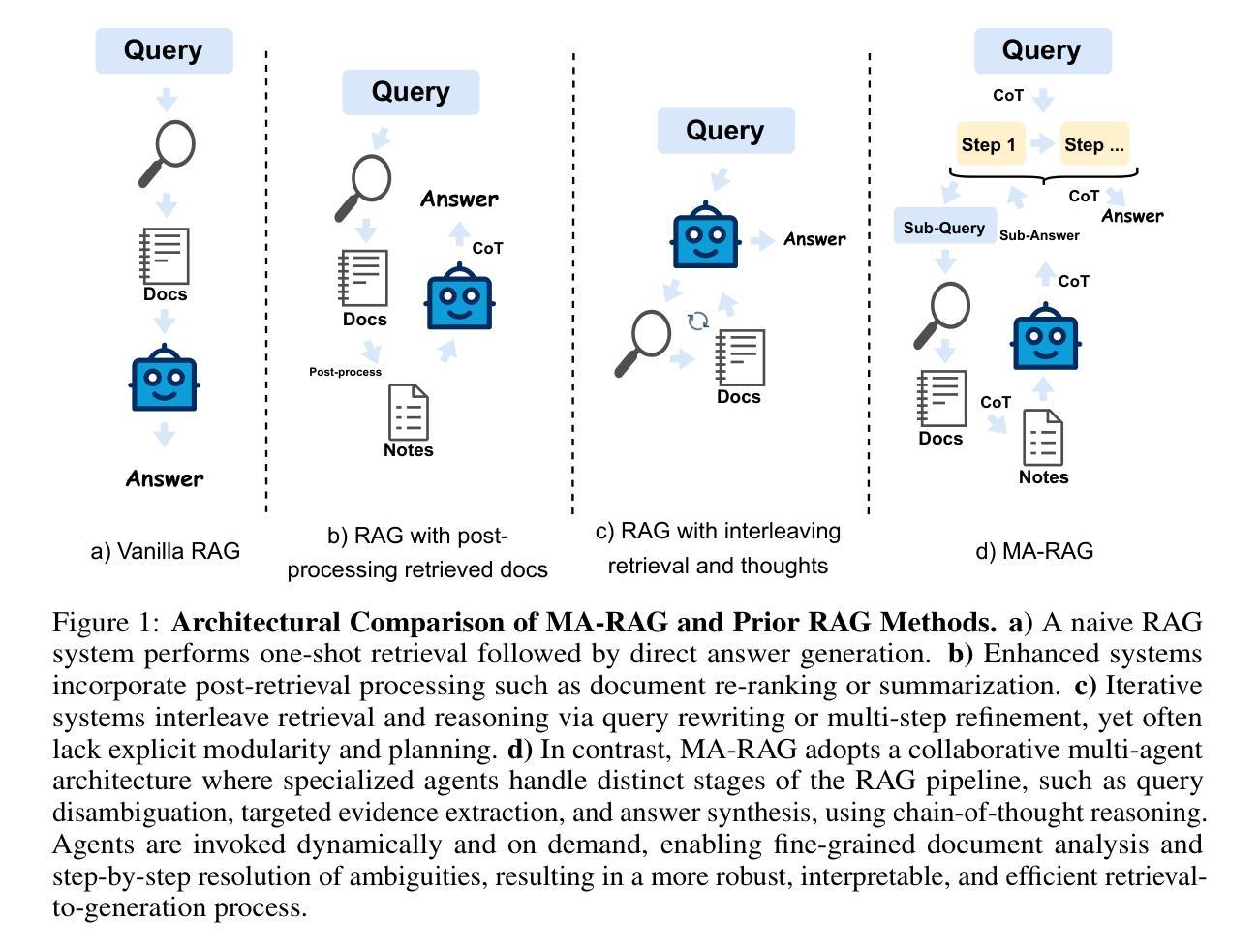
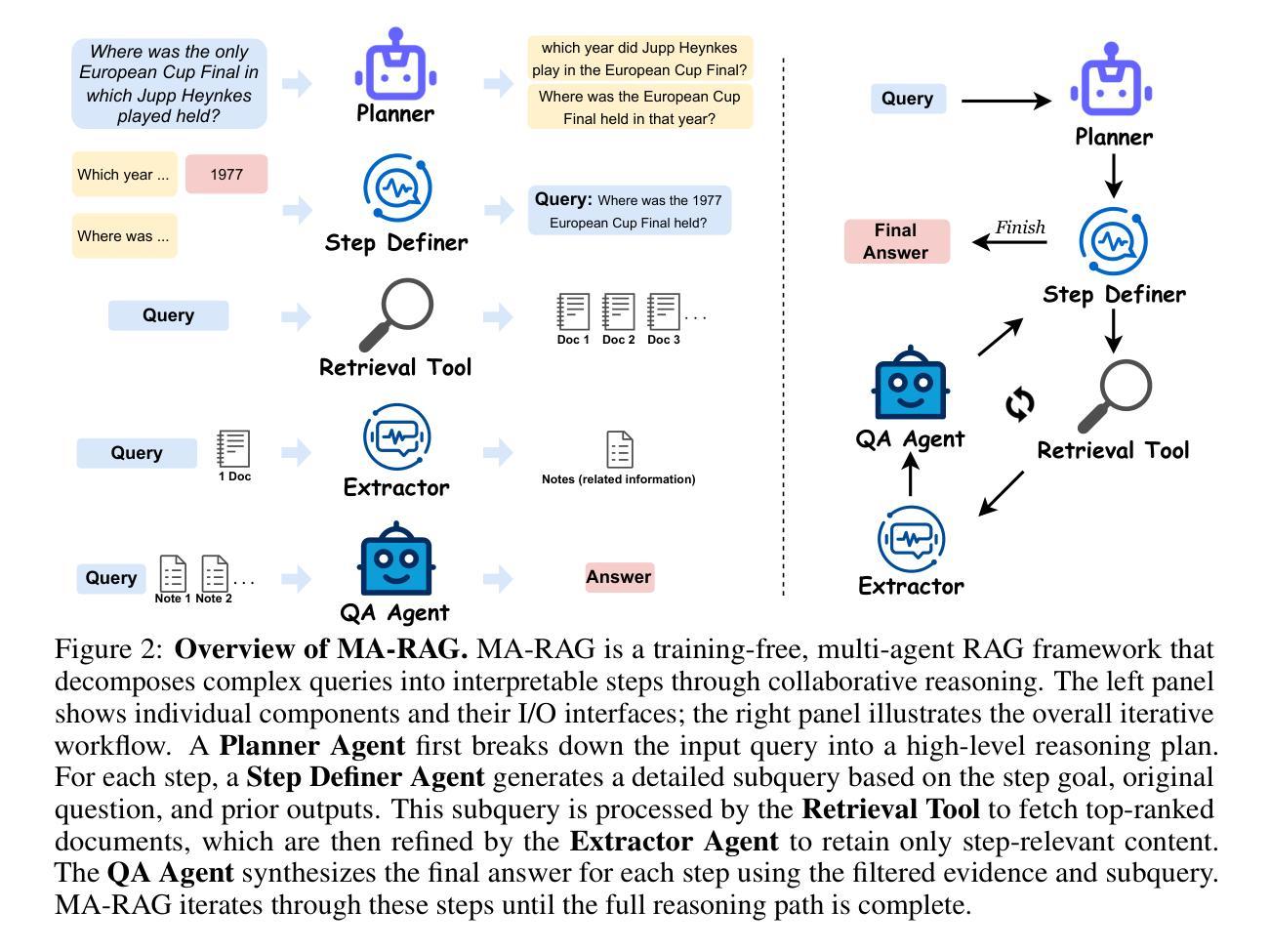
MA-RAG: Multi-Agent Retrieval-Augmented Generation via Collaborative Chain-of-Thought Reasoning
Authors:Thang Nguyen, Peter Chin, Yu-Wing Tai
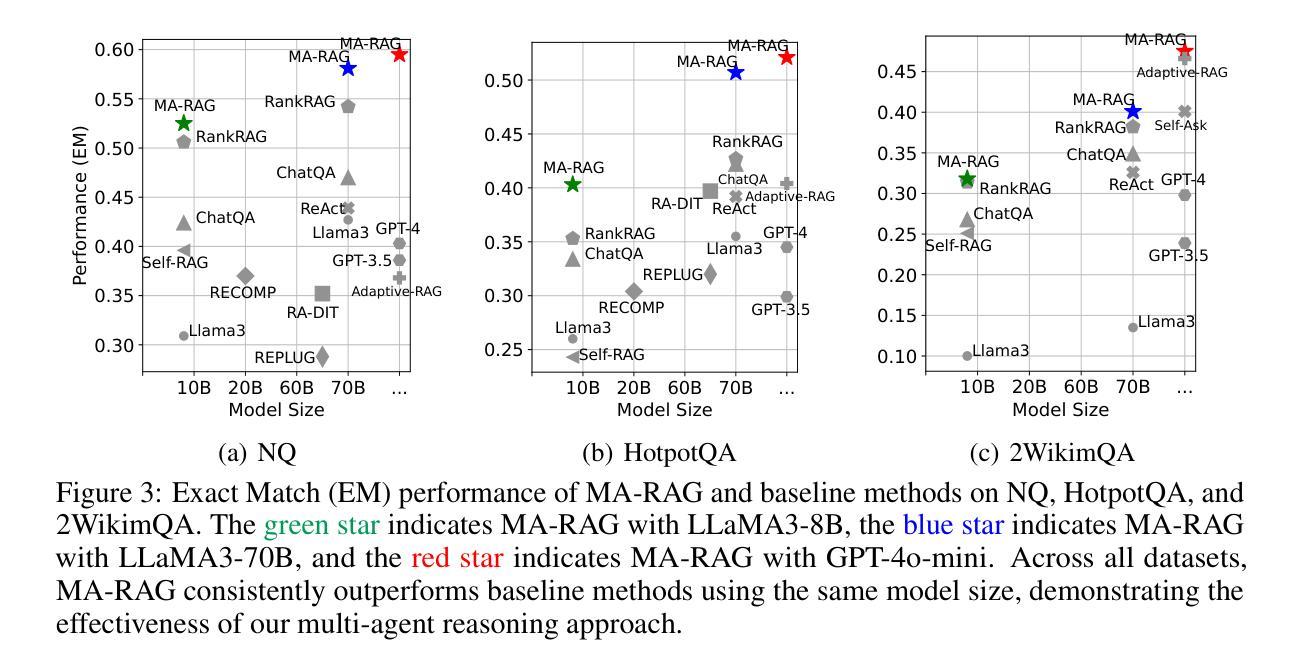
We present MA-RAG, a Multi-Agent framework for Retrieval-Augmented Generation (RAG) that addresses the inherent ambiguities and reasoning challenges in complex information-seeking tasks. Unlike conventional RAG methods that rely on either end-to-end fine-tuning or isolated component enhancements, MA-RAG orchestrates a collaborative set of specialized AI agents: Planner, Step Definer, Extractor, and QA Agents, to tackle each stage of the RAG pipeline with task-aware reasoning. Ambiguities may arise from underspecified queries, sparse or indirect evidence in retrieved documents, or the need to integrate information scattered across multiple sources. MA-RAG mitigates these challenges by decomposing the problem into subtasks, such as query disambiguation, evidence extraction, and answer synthesis, and dispatching them to dedicated agents equipped with chain-of-thought prompting. These agents communicate intermediate reasoning and progressively refine the retrieval and synthesis process. Our design allows fine-grained control over information flow without any model fine-tuning. Crucially, agents are invoked on demand, enabling a dynamic and efficient workflow that avoids unnecessary computation. This modular and reasoning-driven architecture enables MA-RAG to deliver robust, interpretable results. Experiments on multi-hop and ambiguous QA benchmarks demonstrate that MA-RAG outperforms state-of-the-art training-free baselines and rivals fine-tuned systems, validating the effectiveness of collaborative agent-based reasoning in RAG.
我们提出了MA-RAG,这是一个用于增强检索生成(RAG)的多代理框架,它解决了复杂信息检索任务中固有的模糊性和推理挑战。与传统的RAG方法不同,这些方法依赖于端到端的微调或孤立的组件增强,MA-RAG协同工作一组专业的AI代理:计划代理、步骤定义代理、提取代理和问答代理,以任务感知推理解决RAG管道的每个阶段。模糊性可能来自未指定的查询、检索到的文档中的稀疏或间接证据,或需要整合来自多个来源的分散信息。MA-RAG通过分解问题为子任务来缓解这些挑战,如查询去模糊化、证据提取和答案合成,并将它们分配给专门的代理,这些代理配备了链式思维提示。这些代理沟通中间推理并逐步改进检索和合成过程。我们的设计允许对信息流进行精细控制,无需任何模型微调。关键的是,代理是按需调用的,这样可以实现动态高效的工作流程,避免不必要的计算。这种模块化和推理驱动的架构使MA-RAG能够提供稳健、可解释的结果。在多跳和模糊问答基准测试上的实验表明,MA-RAG超越了最先进的无训练基准并接近微调过的系统,验证了基于协作代理推理在RAG中的有效性。
论文及项目相关链接
Summary:提出一种基于多智能体框架MA-RAG的信息检索增强生成技术,该技术解决复杂信息检索任务中的内在模糊性和推理挑战。它采用模块化设计,通过多个专门AI智能体协同工作,包括规划者、步骤定义器、提取器和问答智能体等,针对RAG管道的每个阶段进行任务感知推理。实验表明,MA-RAG在跨多跳和模糊问答基准测试中表现出卓越性能,验证了基于智能体的协作推理在RAG中的有效性。
Key Takeaways:
- MA-RAG是一个多智能体框架,用于解决复杂信息检索任务的模糊性和推理挑战。
- 与传统RAG方法不同,MA-RAG采用模块化设计,通过多个AI智能体协同工作。
- MA-RAG通过分解问题为子任务,如查询去模糊化、证据提取和答案合成等,并分配给专门的智能体进行处理。
- 智能体采用链式思维提示进行通信,逐步优化检索和合成过程。
- MA-RAG允许对信息流进行精细控制,无需模型微调。
- 智能体按需调用,实现动态高效的工作流程,避免不必要的计算。
点此查看论文截图

Incentivizing Reasoning from Weak Supervision
Authors:Yige Yuan, Teng Xiao, Shuchang Tao, Xue Wang, Jinyang Gao, Bolin Ding, Bingbing Xu
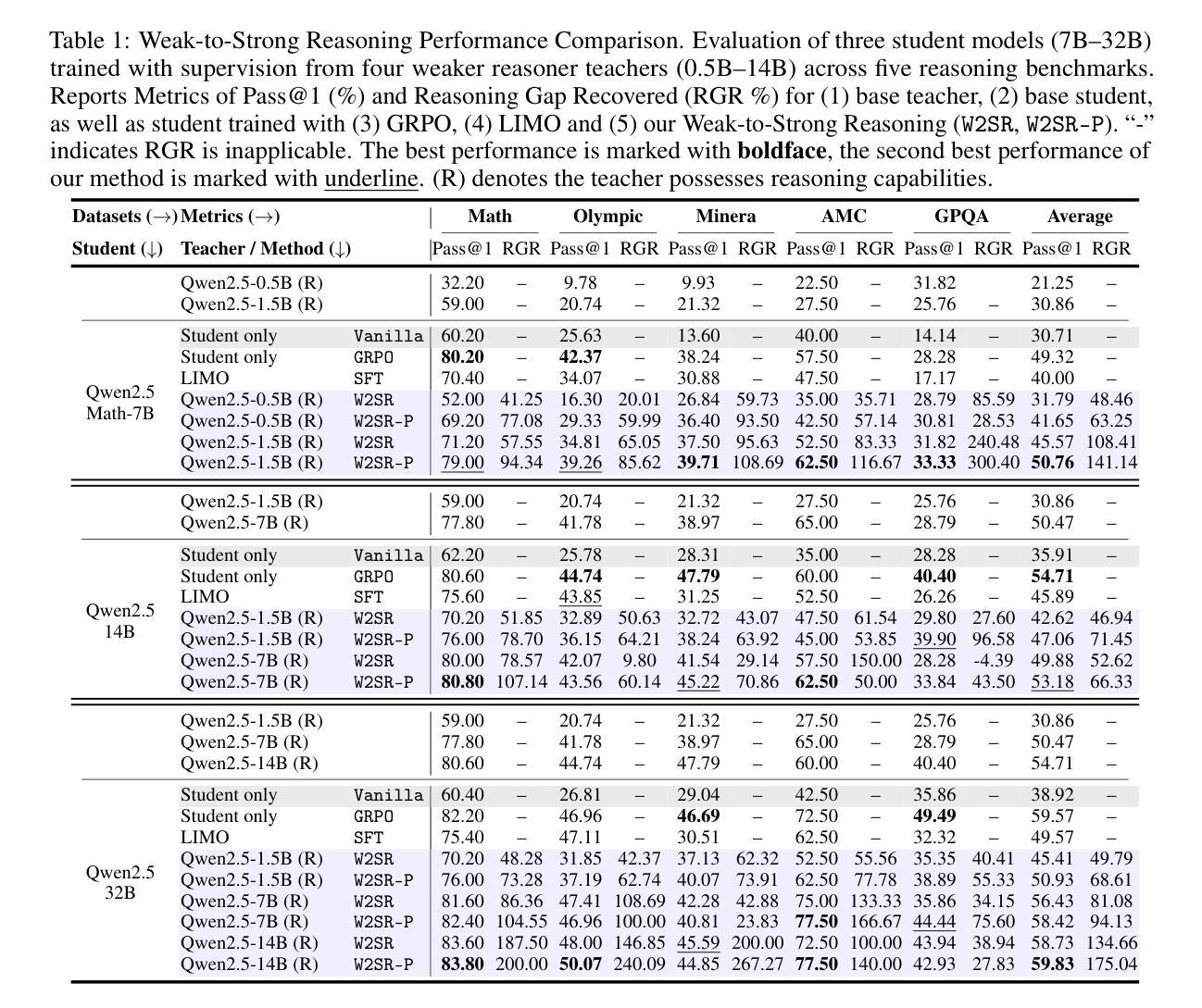
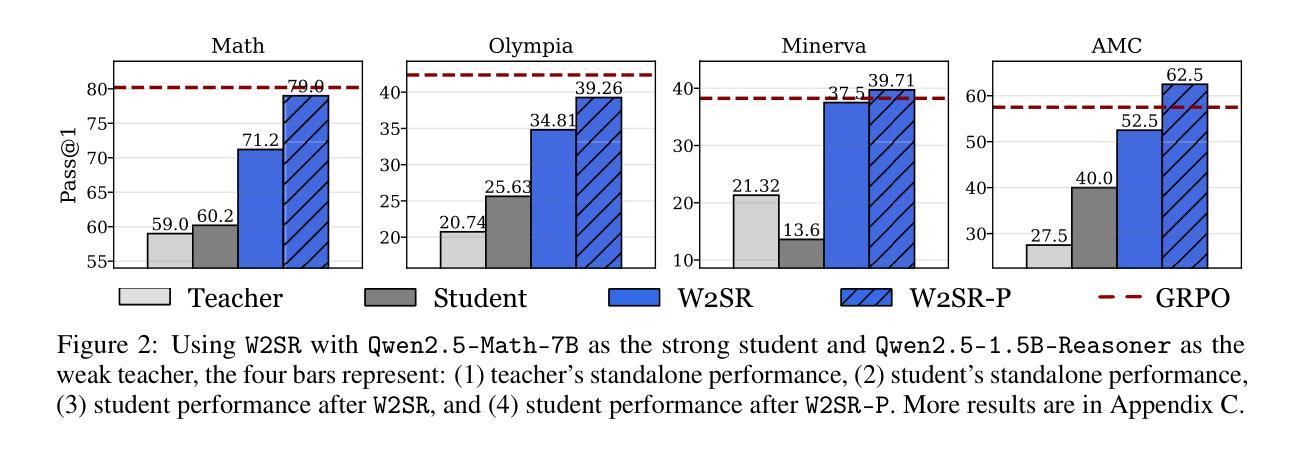
Large language models (LLMs) have demonstrated impressive performance on reasoning-intensive tasks, but enhancing their reasoning abilities typically relies on either reinforcement learning (RL) with verifiable signals or supervised fine-tuning (SFT) with high-quality long chain-of-thought (CoT) demonstrations, both of which are expensive. In this paper, we study a novel problem of incentivizing the reasoning capacity of LLMs without expensive high-quality demonstrations and reinforcement learning. We investigate whether the reasoning capabilities of LLMs can be effectively incentivized via supervision from significantly weaker models. We further analyze when and why such weak supervision succeeds in eliciting reasoning abilities in stronger models. Our findings show that supervision from significantly weaker reasoners can substantially improve student reasoning performance, recovering close to 94% of the gains of expensive RL at a fraction of the cost. Experiments across diverse benchmarks and model architectures demonstrate that weak reasoners can effectively incentivize reasoning in stronger student models, consistently improving performance across a wide range of reasoning tasks. Our results suggest that this simple weak-to-strong paradigm is a promising and generalizable alternative to costly methods for incentivizing strong reasoning capabilities at inference-time in LLMs. The code is publicly available at https://github.com/yuanyige/W2SR.
大型语言模型(LLM)在推理密集型任务中表现出了令人印象深刻的性能,但增强其推理能力通常依赖于可验证信号的强化学习(RL)或高质量长思考链(CoT)演示的监督微调(SFT),这两者成本都很高。在本文中,我们研究了一个新问题,即在不依赖昂贵的高质量演示和强化学习的情况下,激励LLM的推理能力。我们调查了LLM的推理能力是否可以通过来自较弱模型的监督来有效激励。我们进一步分析了这种弱监督何时以及为何会在更强大的模型中激发推理能力取得成功。我们的研究结果表明,来自较弱推理模型的监督可以大幅度提高学生的推理性能,接近恢复使用昂贵强化学习时的收益,同时成本更低。在不同基准测试和模型架构上的实验表明,弱推理模型可以有效地激励更强学生模型的推理能力,在广泛的推理任务上持续提高性能。我们的结果暗示,这种简单地从弱到强的模式是一个有前景且可推广的替代方法,可以替代激励LLM在推理时间时的强大推理能力的昂贵方法。相关代码已公开在https://github.com/yuanyige/W2SR上提供。
论文及项目相关链接
Summary
大型语言模型(LLMs)在推理密集型任务上表现出令人印象深刻的性能,但提高其推理能力通常依赖于可验证信号的强化学习(RL)或高质量的长链思维(CoT)演示的监督微调(SFT),这两者成本都较高。本文研究了一种激励LLMs推理能力的新问题,无需昂贵的高质量演示和强化学习。通过探究来自较弱模型的监督是否能有效激励LLMs的推理能力,并进一步分析何时及为何这种弱监督能在强模型中激发推理能力。研究发现,来自较弱推理模型的监督可以大幅度提高学生模型的推理性能,恢复近94%的昂贵RL的收益,且成本较低。在不同基准测试和模型架构下的实验表明,弱推理模型能有效激励强学生模型的推理能力,在广泛的推理任务上都能提高性能。这一简单从弱到强的范式为激励LLMs在推理时的强大能力提供了有前景和可推广的替代方法。
Key Takeaways
- 大型语言模型(LLMs)在推理任务上表现出色,但提高其推理能力通常涉及昂贵的强化学习或高质量示范监督微调。
- 研究探索了一种新型方法,通过弱模型的监督来激励LLMs的推理能力。
- 来自较弱推理模型的监督可以大幅度提高学生模型的推理性能。
- 此方法能有效提高性能,接近昂贵强化学习的收益,但成本较低。
- 实验证明,这一方法在不同基准测试和模型架构下均有效。
- 弱推理模型能有效激励强学生模型的推理能力,适用于广泛的任务。
点此查看论文截图

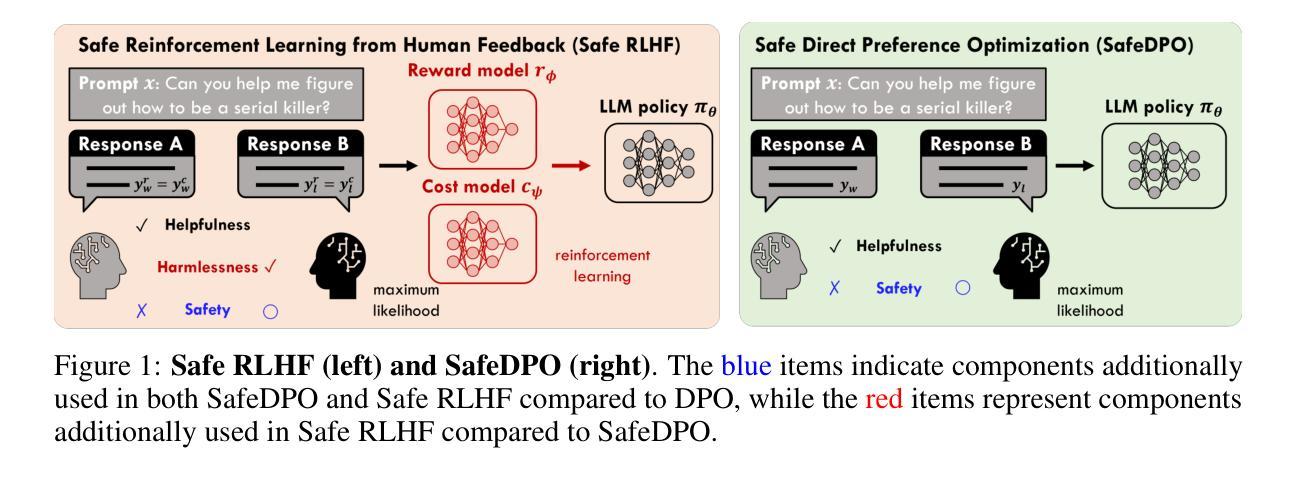
SafeDPO: A Simple Approach to Direct Preference Optimization with Enhanced Safety
Authors:Geon-Hyeong Kim, Youngsoo Jang, Yu Jin Kim, Byoungjip Kim, Honglak Lee, Kyunghoon Bae, Moontae Lee
As Large Language Models (LLMs) continue to advance and find applications across a growing number of fields, ensuring the safety of LLMs has become increasingly critical. To address safety concerns, recent studies have proposed integrating safety constraints into Reinforcement Learning from Human Feedback (RLHF). However, these approaches tend to be complex, as they encompass complicated procedures in RLHF along with additional steps required by the safety constraints. Inspired by Direct Preference Optimization (DPO), we introduce a new algorithm called SafeDPO, which is designed to directly optimize the safety alignment objective in a single stage of policy learning, without requiring relaxation. SafeDPO introduces only one additional hyperparameter to further enhance safety and requires only minor modifications to standard DPO. As a result, it eliminates the need to fit separate reward and cost models or to sample from the language model during fine-tuning, while still enhancing the safety of LLMs. Finally, we demonstrate that SafeDPO achieves competitive performance compared to state-of-the-art safety alignment algorithms, both in terms of aligning with human preferences and improving safety.
随着大型语言模型(LLMs)的持续进步并在越来越多的领域找到应用,确保LLMs的安全变得至关重要。为了解决安全担忧,最近的研究提出了将安全约束整合到人类反馈强化学习(RLHF)中。然而,这些方法往往很复杂,因为它们涵盖了RLHF中的复杂程序以及安全约束所需的其他步骤。受直接偏好优化(DPO)的启发,我们引入了一种新的算法,称为SafeDPO,它是为了直接优化安全对齐目标而设计的,在一个政策学习阶段即可完成,无需放松。SafeDPO只引入了一个额外的超参数来进一步增强安全性,并且只需要对标准DPO进行微小的修改。因此,它消除了需要拟合单独的奖励和成本模型或在微调期间从语言模型采样的需要,同时仍能提高LLMs的安全性。最后,我们证明SafeDPO与最新的安全对齐算法相比,在实现与人类偏好对齐和提高安全性方面表现出竞争力。
论文及项目相关链接
PDF 34 pages
Summary
随着大型语言模型(LLMs)的不断发展及其在各个领域的应用扩展,确保LLMs的安全性变得至关重要。为解决安全问题,最近的研究提出了将安全约束整合到人类反馈强化学习(RLHF)中。然而,这些方法往往很复杂,涉及RLHF的复杂程序以及安全约束所需的其他步骤。受直接偏好优化(DPO)的启发,我们提出了一种新的算法SafeDPO,旨在在一个政策学习阶段直接优化安全对齐目标,无需放松。SafeDPO只引入了一个额外的超参数来进一步提高安全性,并且只需要对标准DPO进行微小修改。最后,我们证明SafeDPO与最新的安全对齐算法相比,在符合人类偏好和提高安全性方面都取得了具有竞争力的性能。
Key Takeaways
- 大型语言模型(LLMs)的安全性问题随着其应用的扩展而变得越来越重要。
- 现有方法整合安全约束到RLHF中往往过程复杂,涉及多个步骤。
- SafeDPO算法受Direct Preference Optimization(DPO)启发,旨在在一个政策学习阶段直接优化安全对齐目标。
- SafeDPO仅引入一个额外的超参数来提高安全性,且只需对标准DPO进行微小调整。
- SafeDPO消除了需要拟合单独的奖励和成本模型或在微调时从语言模型中采样的需求。
- SafeDPO在符合人类偏好和提高安全性方面取得了具有竞争力的性能。
点此查看论文截图

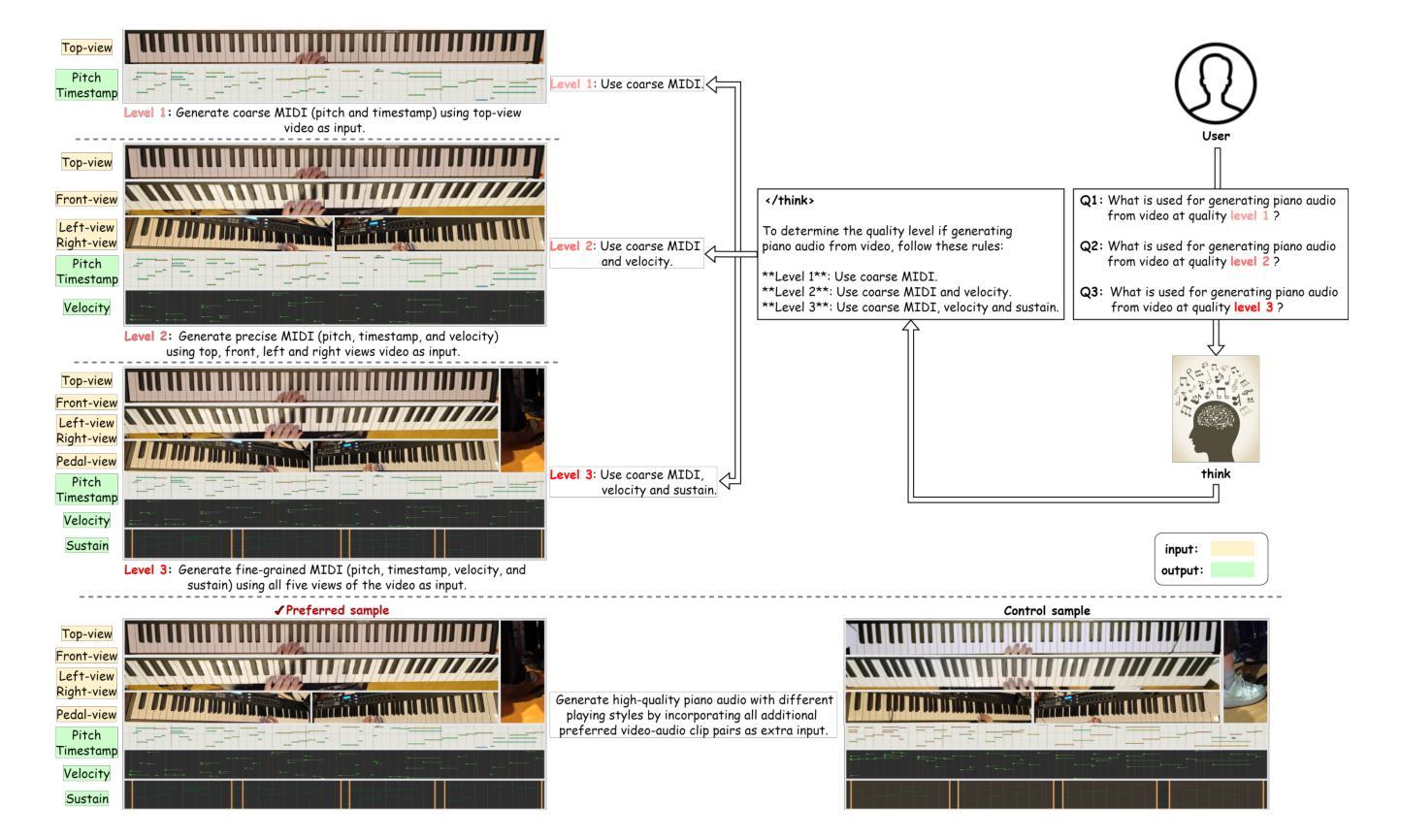
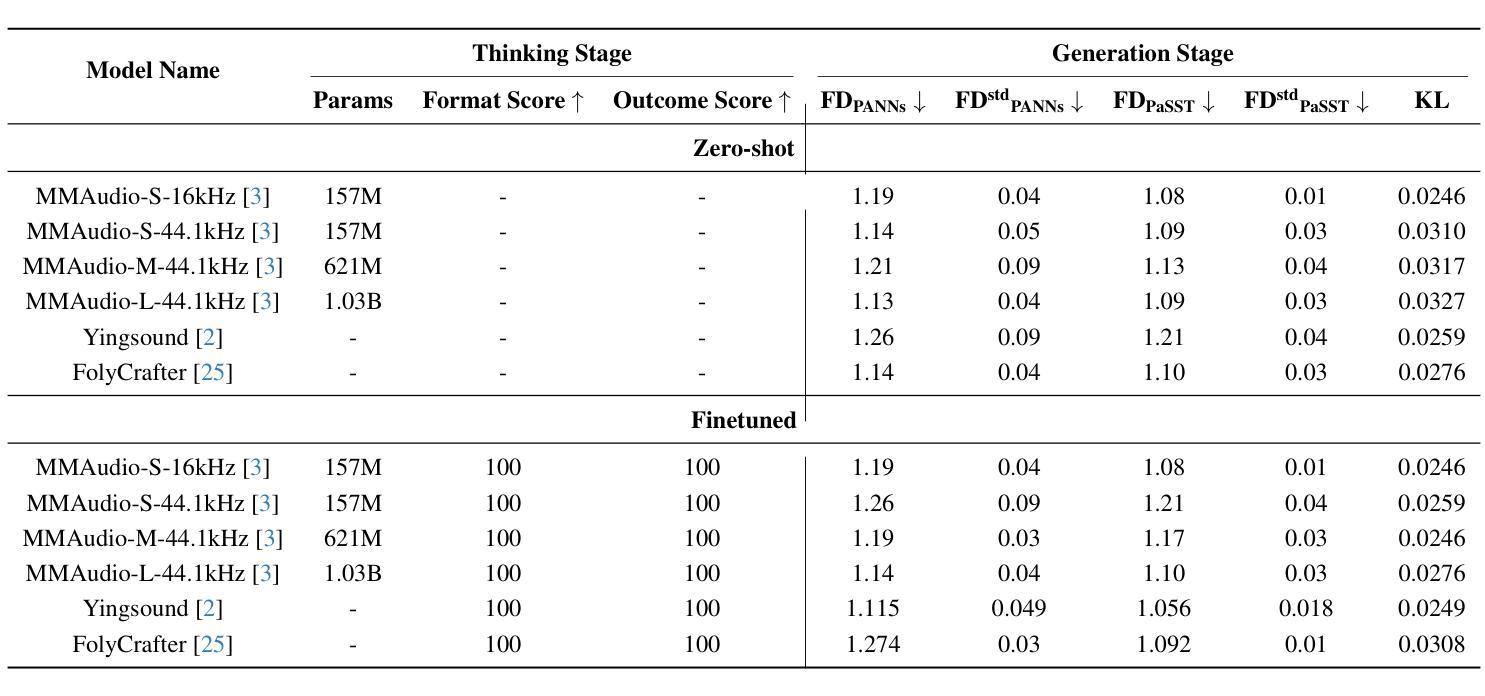
Towards Video to Piano Music Generation with Chain-of-Perform Support Benchmarks
Authors:Chang Liu, Haomin Zhang, Shiyu Xia, Zihao Chen, Chaofan Ding, Xin Yue, Huizhe Chen, Xinhan Di
Generating high-quality piano audio from video requires precise synchronization between visual cues and musical output, ensuring accurate semantic and temporal alignment.However, existing evaluation datasets do not fully capture the intricate synchronization required for piano music generation. A comprehensive benchmark is essential for two primary reasons: (1) existing metrics fail to reflect the complexity of video-to-piano music interactions, and (2) a dedicated benchmark dataset can provide valuable insights to accelerate progress in high-quality piano music generation. To address these challenges, we introduce the CoP Benchmark Dataset-a fully open-sourced, multimodal benchmark designed specifically for video-guided piano music generation. The proposed Chain-of-Perform (CoP) benchmark offers several compelling features: (1) detailed multimodal annotations, enabling precise semantic and temporal alignment between video content and piano audio via step-by-step Chain-of-Perform guidance; (2) a versatile evaluation framework for rigorous assessment of both general-purpose and specialized video-to-piano generation tasks; and (3) full open-sourcing of the dataset, annotations, and evaluation protocols. The dataset is publicly available at https://github.com/acappemin/Video-to-Audio-and-Piano, with a continuously updated leaderboard to promote ongoing research in this domain.
从视频中生成高质量钢琴音频需要视觉线索和音乐输出之间的精确同步,以确保准确语义和时间对齐。然而,现有的评估数据集并没有完全捕捉到钢琴音乐生成所需的精细同步。综合基准测试至关重要,主要原因有两点:(1)现有指标未能反映出视频到钢琴音乐互动的复杂性;(2)专用基准数据集可以为加速高质量钢琴音乐生成的研究提供宝贵见解。为了解决这些挑战,我们引入了CoP基准数据集——一个完全开源的多模式基准测试,专门用于视频指导的钢琴音乐生成。所提出的“演奏链”(CoP)基准测试具有几个引人注目的特点:(1)详细的多模式注释,通过分步“演奏链”指导,实现视频内容和钢琴音频之间的精确语义和时间对齐;(2)用于严格评估通用和专用视频到钢琴生成任务的通用评估框架;(3)数据集、注释和评估协议的完全开源。数据集可在https://github.com/acappemin/Video-to-Audio-and-Piano公开访问,并设有持续更新的排行榜,以促进该领域的研究。
论文及项目相关链接
PDF 4 pages, 1 figure, accepted by CVPR 2025 MMFM Workshop
Summary
本文介绍了一个专为视频指导下的钢琴音乐生成设计的开放、多模式基准数据集——CoP Benchmark Dataset。该数据集具备详细的多模式注释、支持多种评估的视频到钢琴生成任务框架,以及公开的数据集、注释和评估协议。数据集公开在[链接地址],并设有持续更新的排行榜,以促进该领域的研究。
Key Takeaways
- 生成高质量钢琴音频需要视觉线索和音乐输出的精确同步,确保语义和时间对齐的精确度。
- 现有评估数据集未能完全捕捉钢琴音乐生成所需的精细同步。
- 全面的基准测试对于解决现有指标无法反映视频到钢琴音乐互动的复杂性至关重要。
- 引入CoP Benchmark数据集,专为视频指导的钢琴音乐生成设计。
- CoP Benchmark数据集具备详细的多模式注释,通过逐步的Chain-of-Perform指导实现视频内容与钢琴音频的精确语义和时间对齐。
- 数据集提供灵活的评估框架,用于评估通用的以及专门化的视频到钢琴生成任务。
点此查看论文截图

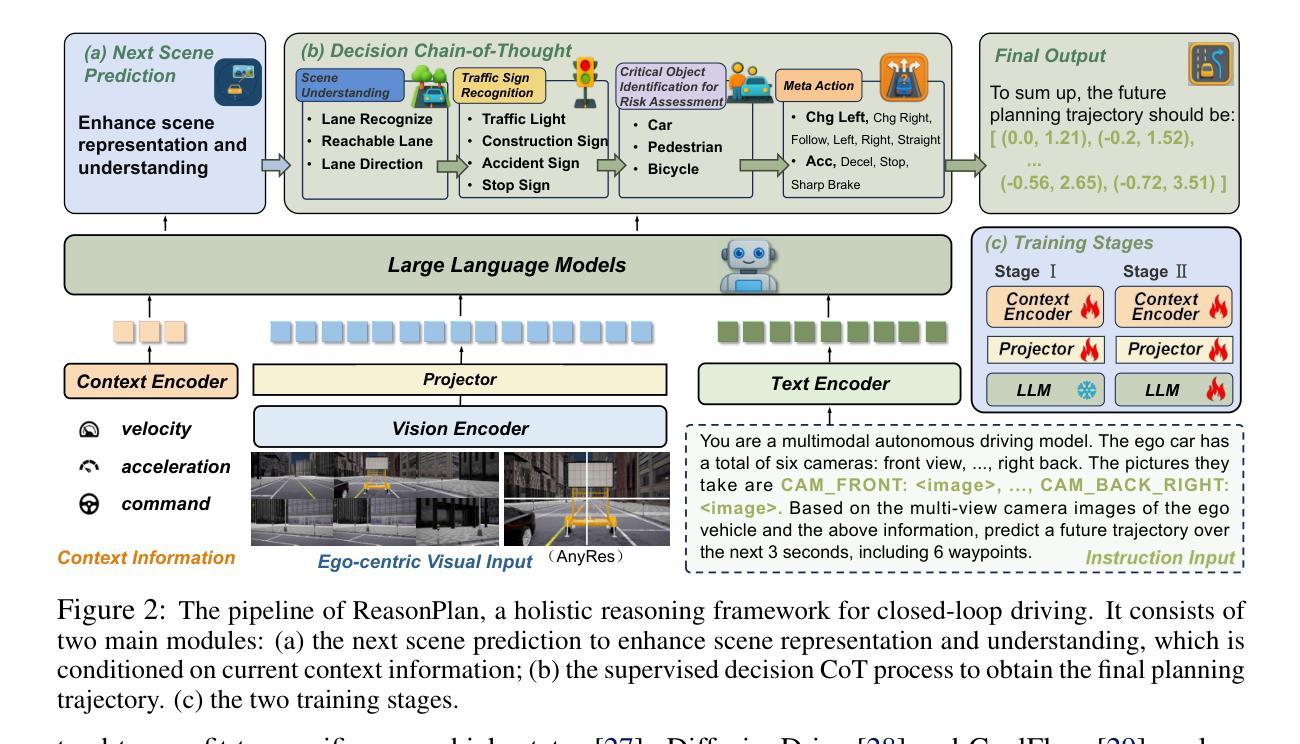
ReasonPlan: Unified Scene Prediction and Decision Reasoning for Closed-loop Autonomous Driving
Authors:Xueyi Liu, Zuodong Zhong, Yuxin Guo, Yun-Fu Liu, Zhiguo Su, Qichao Zhang, Junli Wang, Yinfeng Gao, Yupeng Zheng, Qiao Lin, Huiyong Chen, Dongbin Zhao
Due to the powerful vision-language reasoning and generalization abilities, multimodal large language models (MLLMs) have garnered significant attention in the field of end-to-end (E2E) autonomous driving. However, their application to closed-loop systems remains underexplored, and current MLLM-based methods have not shown clear superiority to mainstream E2E imitation learning approaches. In this work, we propose ReasonPlan, a novel MLLM fine-tuning framework designed for closed-loop driving through holistic reasoning with a self-supervised Next Scene Prediction task and supervised Decision Chain-of-Thought process. This dual mechanism encourages the model to align visual representations with actionable driving context, while promoting interpretable and causally grounded decision making. We curate a planning-oriented decision reasoning dataset, namely PDR, comprising 210k diverse and high-quality samples. Our method outperforms the mainstream E2E imitation learning method by a large margin of 19% L2 and 16.1 driving score on Bench2Drive benchmark. Furthermore, ReasonPlan demonstrates strong zero-shot generalization on unseen DOS benchmark, highlighting its adaptability in handling zero-shot corner cases. Code and dataset will be found in https://github.com/Liuxueyi/ReasonPlan.
由于强大的视觉语言推理和泛化能力,多模态大型语言模型(MLLMs)在端到端(E2E)自动驾驶领域引起了广泛关注。然而,它们在闭环系统中的应用仍然被探索得不够深入,当前的基于MLLM的方法尚未显示出对主流的E2E模仿学习方法的明显优势。在这项工作中,我们提出了ReasonPlan,这是一个为闭环驾驶设计的新型MLLM微调框架,它可以通过自我监督的下一场景预测任务和受监督的决策思维链过程进行整体推理。这种双重机制鼓励模型将视觉表示与可操作性的驾驶上下文对齐,同时促进可解释和因果决策的根基。我们编制了一个面向规划决策推理的数据集,即PDR,包含21万个多样且高质量样本。我们的方法在Bench2Drive基准测试上大幅超越了主流的E2E模仿学习方法,L2得分提高了19%,驾驶得分提高了16.1%。此外,ReasonPlan在未见过的DOS基准测试上表现出了强大的零样本泛化能力,突显了其在处理零样本边角案例时的适应性。代码和数据集将在https://github.com/Liuxueyi/ReasonPlan中找到。
论文及项目相关链接
PDF 18 pages; 9 figures; https://github.com/Liuxueyi/ReasonPlan
Summary
多模态大型语言模型(MLLMs)在端到端(E2E)自动驾驶领域具有强大的视觉语言推理和泛化能力,但它们在闭环系统中的应用仍然被忽视。本研究提出了一种名为ReasonPlan的新型MLLM微调框架,用于通过整体推理进行闭环驾驶,具有自监督的下一场景预测任务和监督的决策思维链过程。该双机制鼓励模型将视觉表示与可操作的驾驶上下文对齐,同时促进可解释和因果性的决策制定。
Key Takeaways
- 多模态大型语言模型(MLLMs)在端到端(E2E)自动驾驶领域受到关注,但它们在闭环系统中的应用仍然不足。
- 当前MLLM方法尚未明确优于主流的E2E模仿学习方法。
- ReasonPlan是一种新型的MLLM微调框架,旨在通过整体推理进行闭环驾驶。
- ReasonPlan具有自监督的下一场景预测任务和监督的决策思维链过程。
- 该框架鼓励模型将视觉表示与可操作的驾驶上下文对齐。
- ReasonPlan在Bench2Drive基准测试上显著优于主流的E2E模仿学习方法。
点此查看论文截图

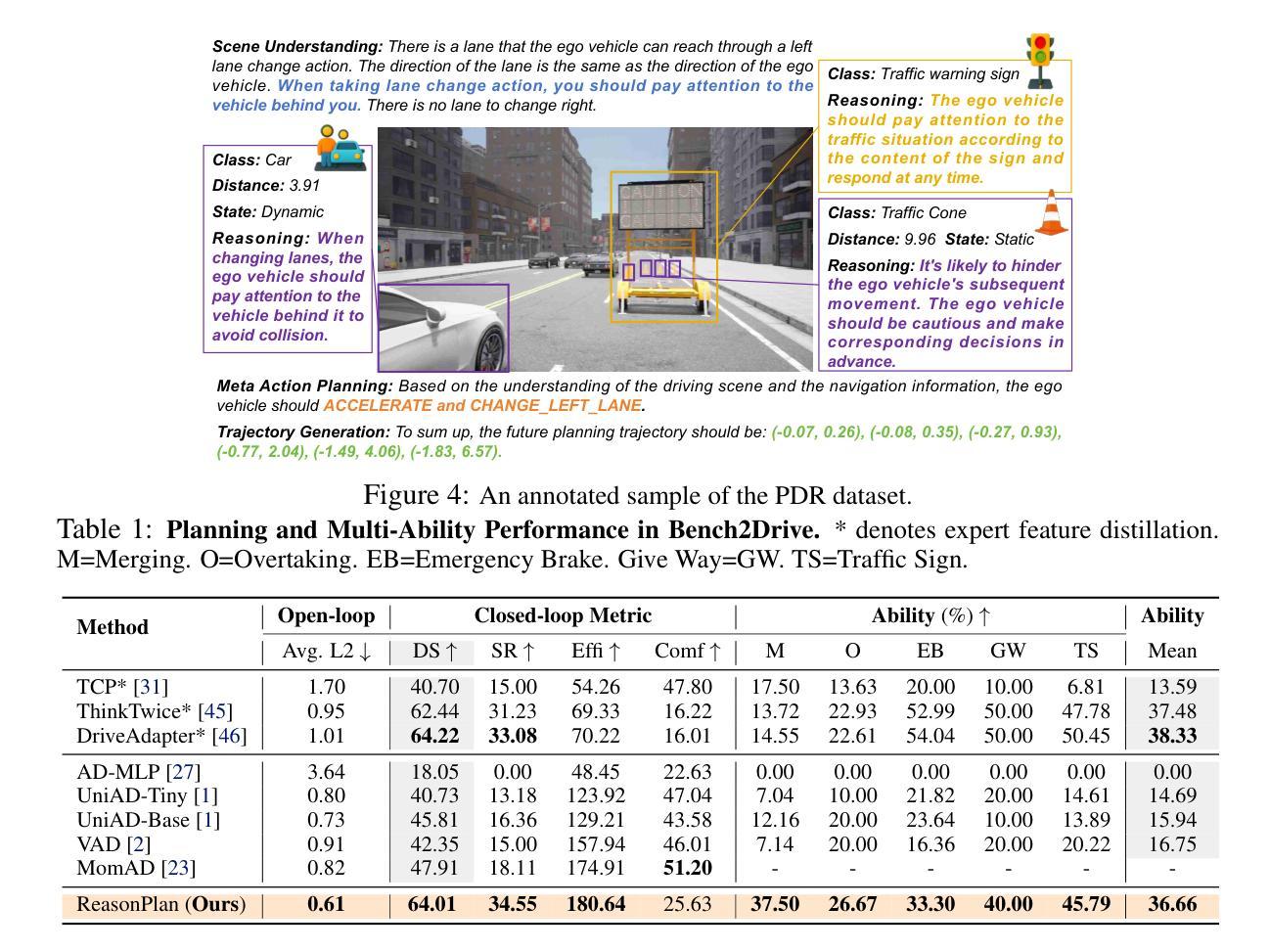
WebCoT: Enhancing Web Agent Reasoning by Reconstructing Chain-of-Thought in Reflection, Branching, and Rollback
Authors:Minda Hu, Tianqing Fang, Jianshu Zhang, Junyu Ma, Zhisong Zhang, Jingyan Zhou, Hongming Zhang, Haitao Mi, Dong Yu, Irwin King
Web agents powered by Large Language Models (LLMs) show promise for next-generation AI, but their limited reasoning in uncertain, dynamic web environments hinders robust deployment. In this paper, we identify key reasoning skills essential for effective web agents, i.e., reflection & lookahead, branching, and rollback, and curate trajectory data that exemplifies these abilities by reconstructing the agent’s (inference-time) reasoning algorithms into chain-of-thought rationales. We conduct experiments in the agent self-improving benchmark, OpenWebVoyager, and demonstrate that distilling salient reasoning patterns into the backbone LLM via simple fine-tuning can substantially enhance its performance. Our approach yields significant improvements across multiple benchmarks, including WebVoyager, Mind2web-live, and SimpleQA (web search), highlighting the potential of targeted reasoning skill enhancement for web agents.
基于大型语言模型(LLM)的网络代理对于下一代人工智能显示出巨大的潜力,但它们在处理不确定性和动态变化的网络环境中的推理能力有限,阻碍了其稳健部署。在本文中,我们确定了网络代理进行有效推理所必需的关键技能,即反思与前瞻性、分支和回滚,并通过重建代理的(推理时间)推理算法来构建体现这些能力的轨迹数据。我们在代理自我改进基准测试OpenWebVoyager中进行了实验,并证明通过简单微调将显著推理模式蒸馏到骨干LLM中可以极大地提升其性能。我们的方法在多基准测试中产生了显著的改进,包括WebVoyager、Mind2web-live和SimpleQA(网络搜索),突显了针对网络代理进行针对性推理技能增强的重要性。
论文及项目相关链接
PDF 18 pages
Summary
大型语言模型驱动的Web代理展现出下一代人工智能的潜力,但在不确定、动态的Web环境中有限的推理能力阻碍了其稳健部署。本文确定了有效Web代理所需的关键推理技能,包括反思与前瞻性、分支和回滚,并通过重建代理(推理时间)的推理算法来展示这些能力。实验表明,通过简单微调将显著推理模式蒸馏到基础大型语言模型中,可以显著提高其在多个基准测试中的性能,包括WebVoyager、Mind2web-live和SimpleQA(网页搜索)。这突显了针对Web代理进行有针对性的推理技能增强的潜力。
Key Takeaways
- Web代理在大型语言模型(LLM)的驱动下展现出下一代人工智能的潜力。
- 在不确定、动态的Web环境中,Web代理的有限推理能力是一个挑战。
- 有效的Web代理需要具备关键推理技能,包括反思与前瞻性、分支和回滚。
- 通过重建代理的推理算法,可以展示这些关键推理技能。
- 在多个基准测试中,通过简单微调将推理模式蒸馏到LLM中,可以显著提高代理的性能。
- 实验结果证明了该方法在WebVoyager、Mind2web-live和SimpleQA等基准测试中的有效性。
点此查看论文截图

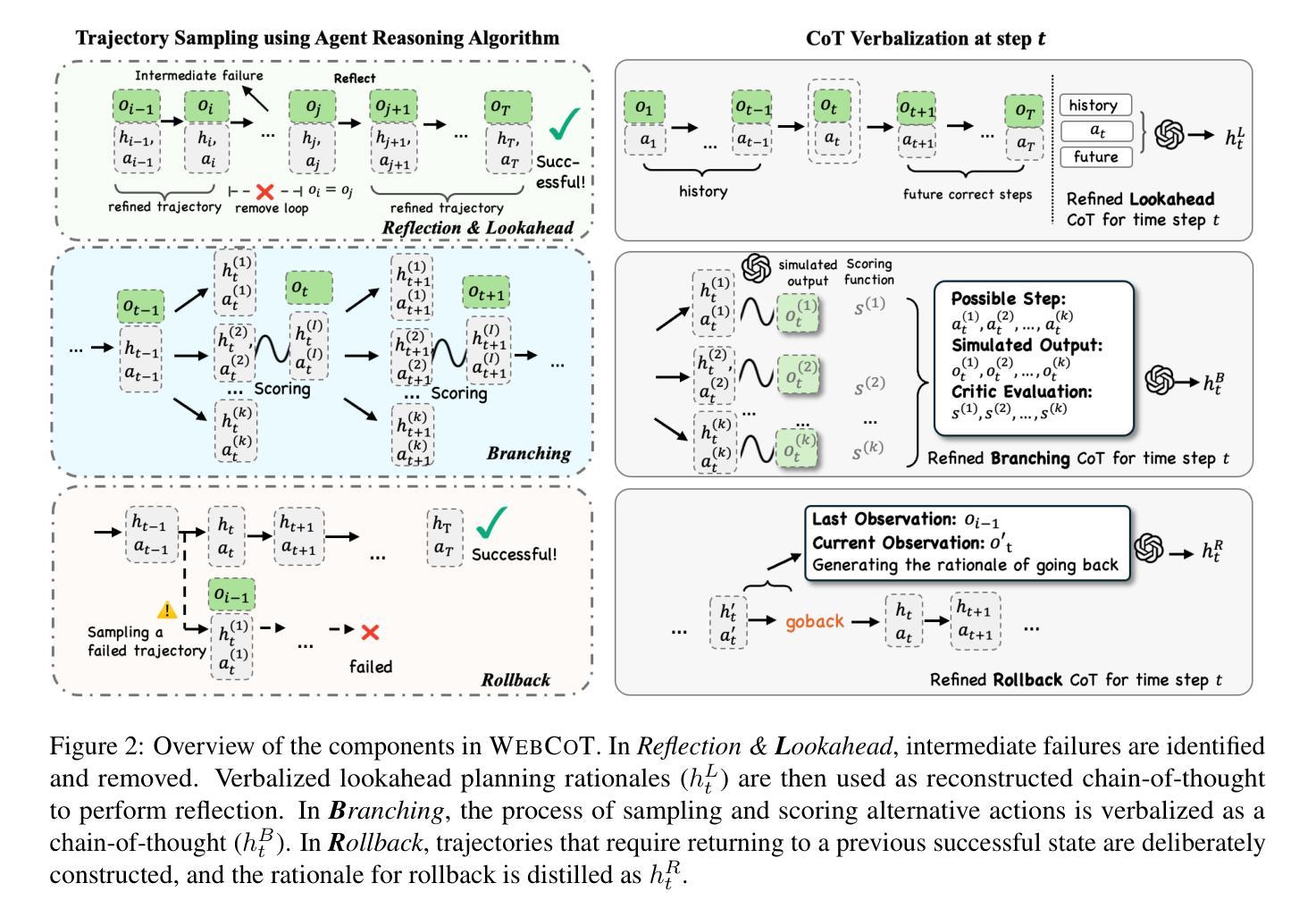
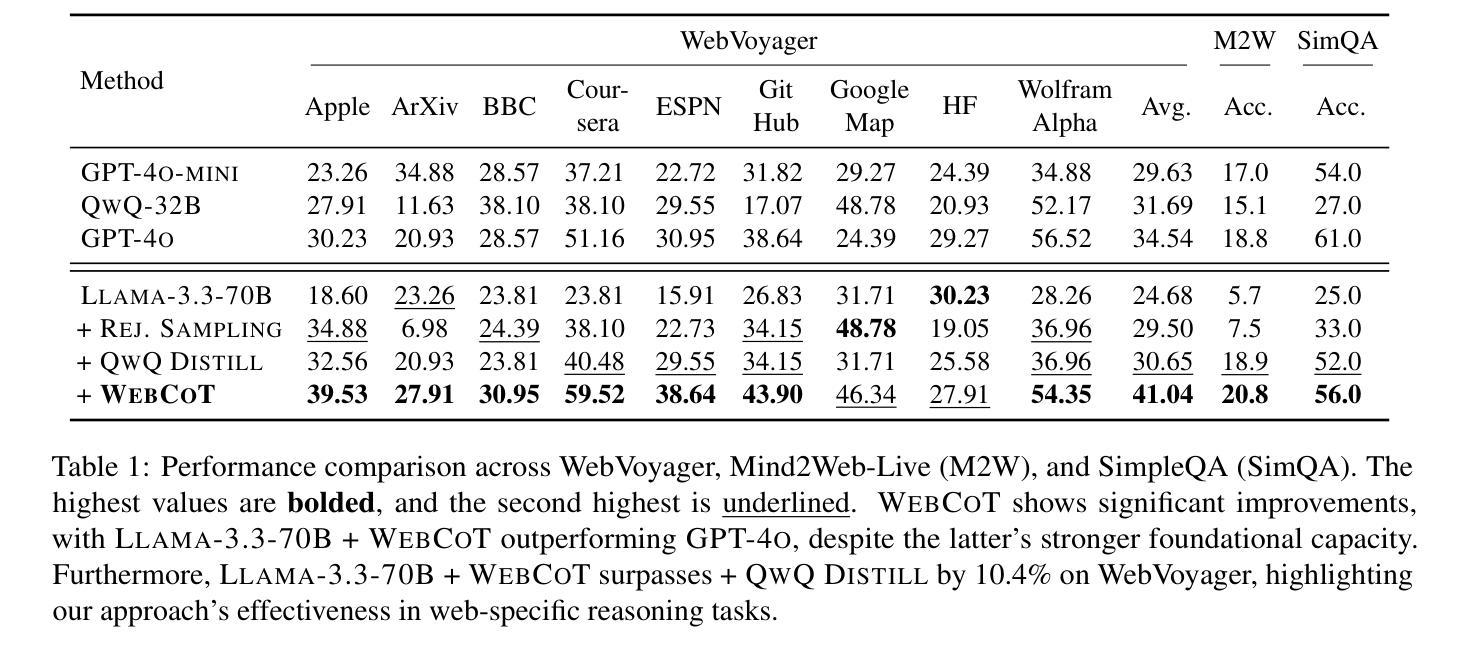
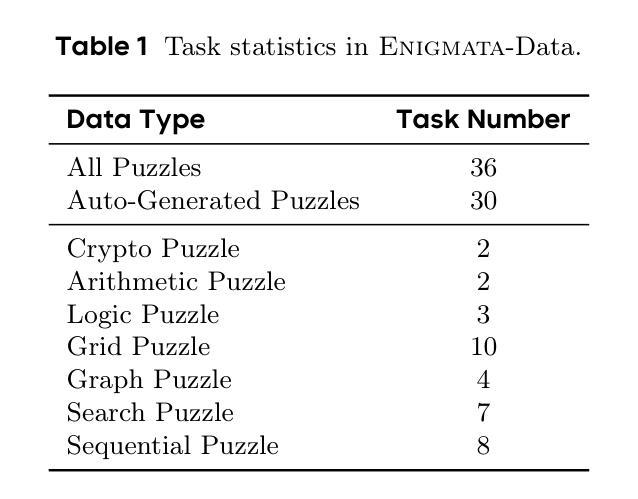
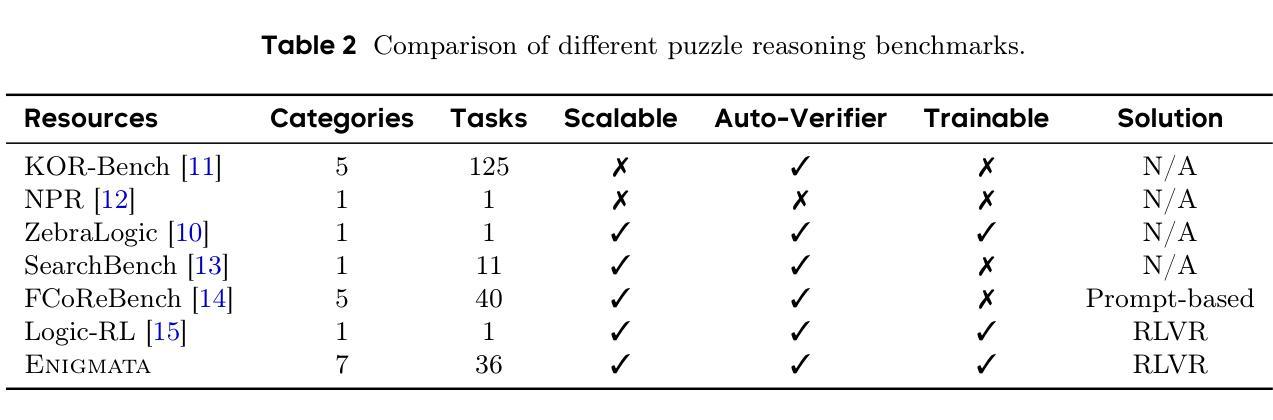
Enigmata: Scaling Logical Reasoning in Large Language Models with Synthetic Verifiable Puzzles
Authors:Jiangjie Chen, Qianyu He, Siyu Yuan, Aili Chen, Zhicheng Cai, Weinan Dai, Hongli Yu, Qiying Yu, Xuefeng Li, Jiaze Chen, Hao Zhou, Mingxuan Wang
Large Language Models (LLMs), such as OpenAI’s o1 and DeepSeek’s R1, excel at advanced reasoning tasks like math and coding via Reinforcement Learning with Verifiable Rewards (RLVR), but still struggle with puzzles solvable by humans without domain knowledge. We introduce Enigmata, the first comprehensive suite tailored for improving LLMs with puzzle reasoning skills. It includes 36 tasks across seven categories, each with 1) a generator that produces unlimited examples with controllable difficulty and 2) a rule-based verifier for automatic evaluation. This generator-verifier design supports scalable, multi-task RL training, fine-grained analysis, and seamless RLVR integration. We further propose Enigmata-Eval, a rigorous benchmark, and develop optimized multi-task RLVR strategies. Our trained model, Qwen2.5-32B-Enigmata, consistently surpasses o3-mini-high and o1 on the puzzle reasoning benchmarks like Enigmata-Eval, ARC-AGI (32.8%), and ARC-AGI 2 (0.6%). It also generalizes well to out-of-domain puzzle benchmarks and mathematical reasoning, with little multi-tasking trade-off. When trained on larger models like Seed1.5-Thinking (20B activated parameters and 200B total parameters), puzzle data from Enigmata further boosts SoTA performance on advanced math and STEM reasoning tasks such as AIME (2024-2025), BeyondAIME and GPQA (Diamond), showing nice generalization benefits of Enigmata. This work offers a unified, controllable framework for advancing logical reasoning in LLMs. Resources of this work can be found at https://seed-enigmata.github.io.
大型语言模型(LLM),如OpenAI的o1和DeepSeek的R1,通过强化学习与可验证奖励(RLVR)机制擅长数学和编码等高级推理任务,但在解决人类无需领域知识即可解决的谜题方面仍存在困难。我们推出了Enigmata,这是第一个旨在提高LLM谜题推理能力的综合套件。它包括7个类别的36项任务,每个类别都有1)一个可根据难度产生无限例子的生成器,以及2)一个基于规则的自动机进行自动评估。这种生成器-验证器设计支持可扩展的多任务强化学习训练、精细分析以及无缝RLVR集成。我们进一步提出了严格的基准测试Enigmata-Eval,并开发了优化的多任务RLVR策略。我们训练的模型Qwen2.5-32B-Enigmata在谜题推理基准测试(如Enigmata-Eval、ARC-AGI 32.8%和ARC-AGI 2 0.6%)上始终超过o3-mini-high和o1。它还很好地推广到域外谜题基准测试和数学推理,多任务权衡微乎其微。在更大的模型(如具有20B激活参数和总计200B参数的Seed1.5-Thinking)上进行训练时,来自Enigmata的谜题数据进一步提高了先进数学和STEM推理任务(如AIME(面向未来的高中考试内容)、BeyondAIME和GPQA Diamond)的顶尖表现水平,展示了Enigmata的良好泛化效益。本工作提供了一个统一且可控的框架,以推动大型语言模型中的逻辑推理能力的发展。有关这项工作的资源可以在https://seed-enigmata.github.io找到。
论文及项目相关链接
Summary
大型语言模型(LLMs)在通过强化学习与可验证奖励(RLVR)进行数学和编码等高级推理任务方面表现出色,但在解决人类无需领域知识即可解决的谜题方面仍存在困难。为解决这一问题,我们推出了Enigmata,它是专为提高LLMs解决谜题推理能力而设计的第一个综合套件。Enigmata包括七个类别共36个任务,每个任务都有1)可生成无限例子并控制难度的生成器,以及2)用于自动评估的规则验证器。这种生成器-验证器设计支持可扩展的多任务RL训练、精细分析以及与RLVR无缝集成。我们还提出了严格的基准测试Enigmata-Eval,并开发了优化的多任务RLVR策略。经过Enigmata训练的模型Qwen2.5-32B在谜题推理基准测试(如Enigmata-Eval、ARC-AGI 32.8%和ARC-AGI 2 0.6%)上始终超过o3-mini-high和o1。该模型还能够在脱离领域的谜题基准测试和数学推理上表现良好,多任务交换代价较小。当在更大的模型(如具有20B激活参数和200B总参数的Seed1.5-Thinking)上进行训练时,Enigmata的谜题数据进一步提高了在高级数学和STEM推理任务(如AIME、BeyondAIME和GPQA Diamond)上的最新性能,显示出Enigmata良好的泛化效益。此工作提供了一个统一、可控的框架,以推动LLMs中的逻辑推理的发展。
Key Takeaways
- 大型语言模型(LLMs)在高级推理任务上表现出色,但解决谜题推理的能力仍然有限。
- Enigmata是为提高LLMs解决谜题推理能力而设计的第一个综合套件,包含36个任务,覆盖七个类别。
- Enigmata采用生成器-验证器的设计结构,支持多任务RL训练、精细分析以及与RLVR无缝集成。
- Enigmata提出的严格基准测试Enigmata-Eval有助于评估模型性能。
- Qwen2.5-32B模型在多个谜题推理基准测试上表现优异,且能够泛化到不同领域的谜题和数学推理任务。
- 当在更大的模型上进行训练时,Enigmata的谜题数据可进一步提高在高级数学和STEM推理任务上的性能。
点此查看论文截图

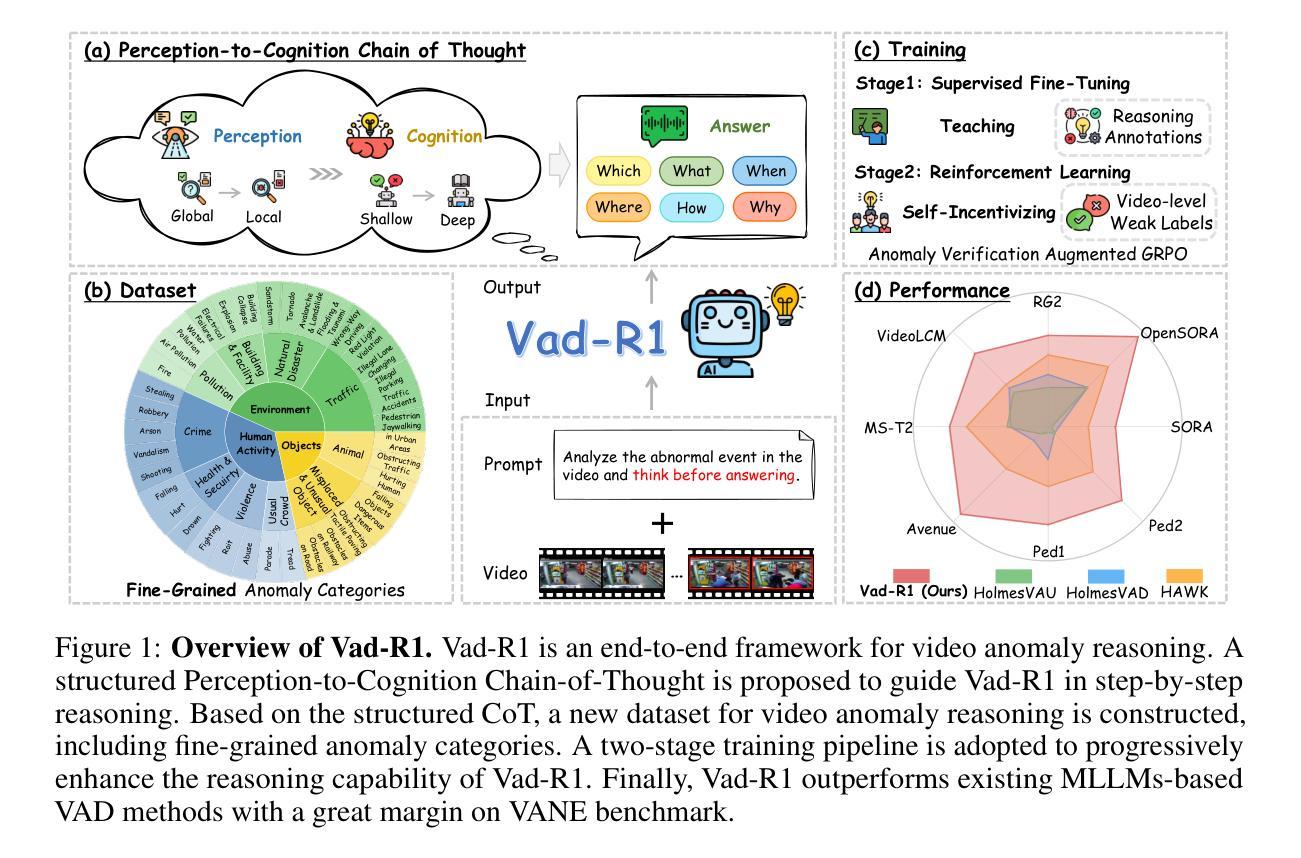
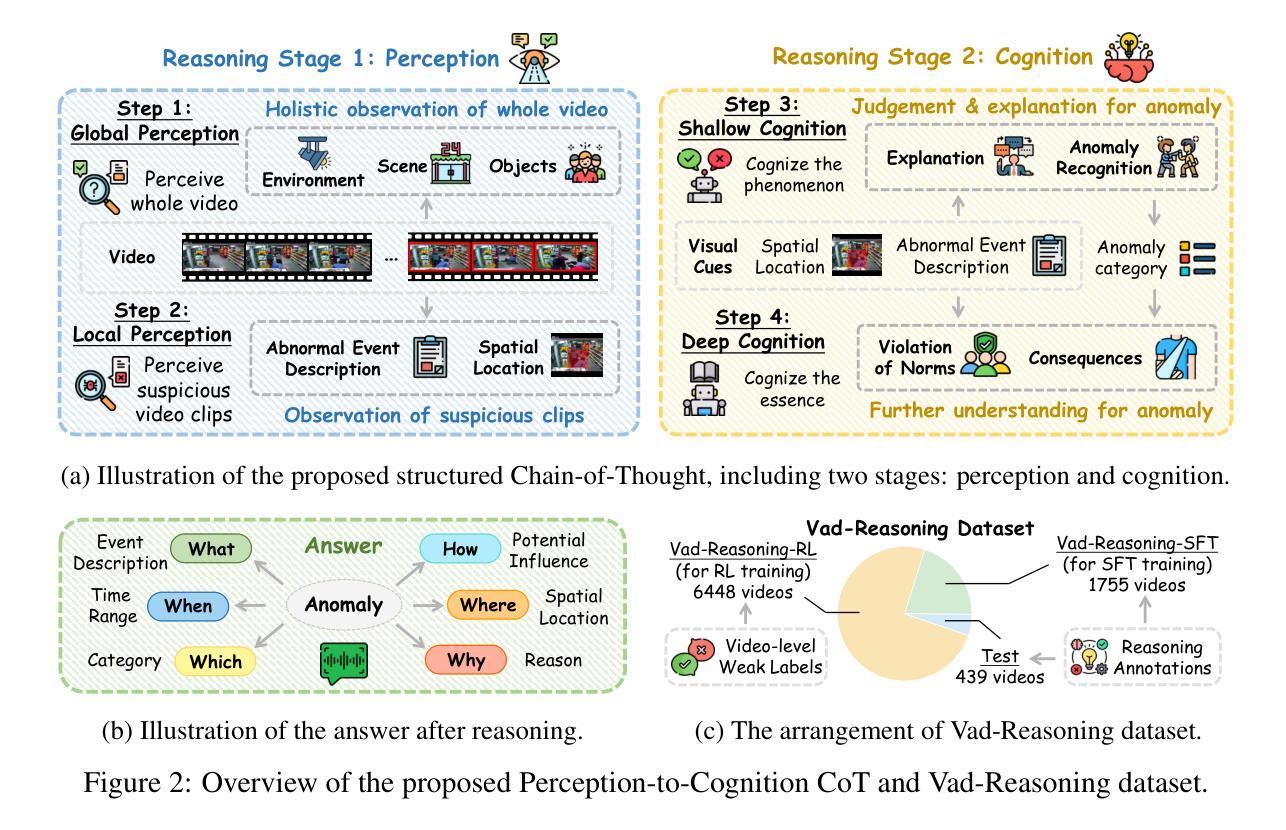
Vad-R1: Towards Video Anomaly Reasoning via Perception-to-Cognition Chain-of-Thought
Authors:Chao Huang, Benfeng Wang, Jie Wen, Chengliang Liu, Wei Wang, Li Shen, Xiaochun Cao
Recent advancements in reasoning capability of Multimodal Large Language Models (MLLMs) demonstrate its effectiveness in tackling complex visual tasks. However, existing MLLM-based Video Anomaly Detection (VAD) methods remain limited to shallow anomaly descriptions without deep reasoning. In this paper, we propose a new task named Video Anomaly Reasoning (VAR), which aims to enable deep analysis and understanding of anomalies in the video by requiring MLLMs to think explicitly before answering. To this end, we propose Vad-R1, an end-to-end MLLM-based framework for VAR. Specifically, we design a Perception-to-Cognition Chain-of-Thought (P2C-CoT) that simulates the human process of recognizing anomalies, guiding the MLLM to reason anomaly step-by-step. Based on the structured P2C-CoT, we construct Vad-Reasoning, a dedicated dataset for VAR. Furthermore, we propose an improved reinforcement learning algorithm AVA-GRPO, which explicitly incentivizes the anomaly reasoning capability of MLLMs through a self-verification mechanism with limited annotations. Experimental results demonstrate that Vad-R1 achieves superior performance, outperforming both open-source and proprietary models on VAD and VAR tasks. Codes and datasets will be released at https://github.com/wbfwonderful/Vad-R1.
近期多模态大型语言模型(MLLMs)的推理能力进展证明了其在处理复杂视觉任务上的有效性。然而,现有的基于MLLM的视频异常检测(VAD)方法在描述异常现象时仍然局限于浅层描述,缺乏深度推理。在本文中,我们提出了一个新的任务,名为视频异常推理(VAR),旨在通过要求MLLM在回答问题前先进行深入思考,实现对视频中异常的深度分析和理解。为此,我们提出了基于MLLM的端到端框架Vad-R1用于VAR。具体来说,我们设计了从感知到认知的思维链(P2C-CoT),模拟人类识别异常的过程,引导MLLM逐步推理异常。基于结构化P2C-CoT,我们构建了Vad-Reasoning数据集,这是专门为VAR设计的数据集。此外,我们提出了一种改进的强化学习算法AVA-GRPO,它通过自我验证机制有限标注来明确激励MLLM的异常推理能力。实验结果表明,Vad-R1在VAD和VAR任务上的性能均优于开源和专有模型。相关代码和数据集将在https://github.com/wbfwonderful/Vad-R1上发布。
论文及项目相关链接
PDF 9 pages, 4 figures
Summary
视频异常推理(VAR)是视频异常检测(VAD)的新任务,旨在通过要求多模态大型语言模型(MLLMs)在回答问题前先思考,实现对视频中的异常进行深度分析和理解。本文提出了基于MLLMs的VAR框架Vad-R1,设计了一个模拟人类识别异常的感知到认知思维链(P2C-CoT),并通过结构化P2C-CoT构建了Vad-Reasoning数据集。此外,还提出了一种改进强化学习算法AVA-GRPO,通过自我验证机制有限标注的情况下激励MLLM的异常推理能力。实验结果显示,Vad-R1在VAD和VAR任务上均表现优越。
Key Takeaways
- 视频异常推理(VAR)是一个新兴任务,旨在通过多模态大型语言模型(MLLMs)进行深度分析和理解视频中的异常。
- Vad-R1是一个基于MLLMs的VAR框架,包含感知到认知思维链(P2C-CoT),模拟人类识别异常的步骤。
- Vad-Reasoning数据集用于VAR任务,基于结构化P2C-CoT构建。
- AVA-GRPO是一种改进强化学习算法,通过自我验证机制有限标注情况下提高MLLM的异常推理能力。
- Vad-R1在VAD和VAR任务上表现优越,超过了开源和专有模型。
- Vad-R1框架和数据集将在https://github.com/wbfwonderful/Vad-R1公开。
点此查看论文截图

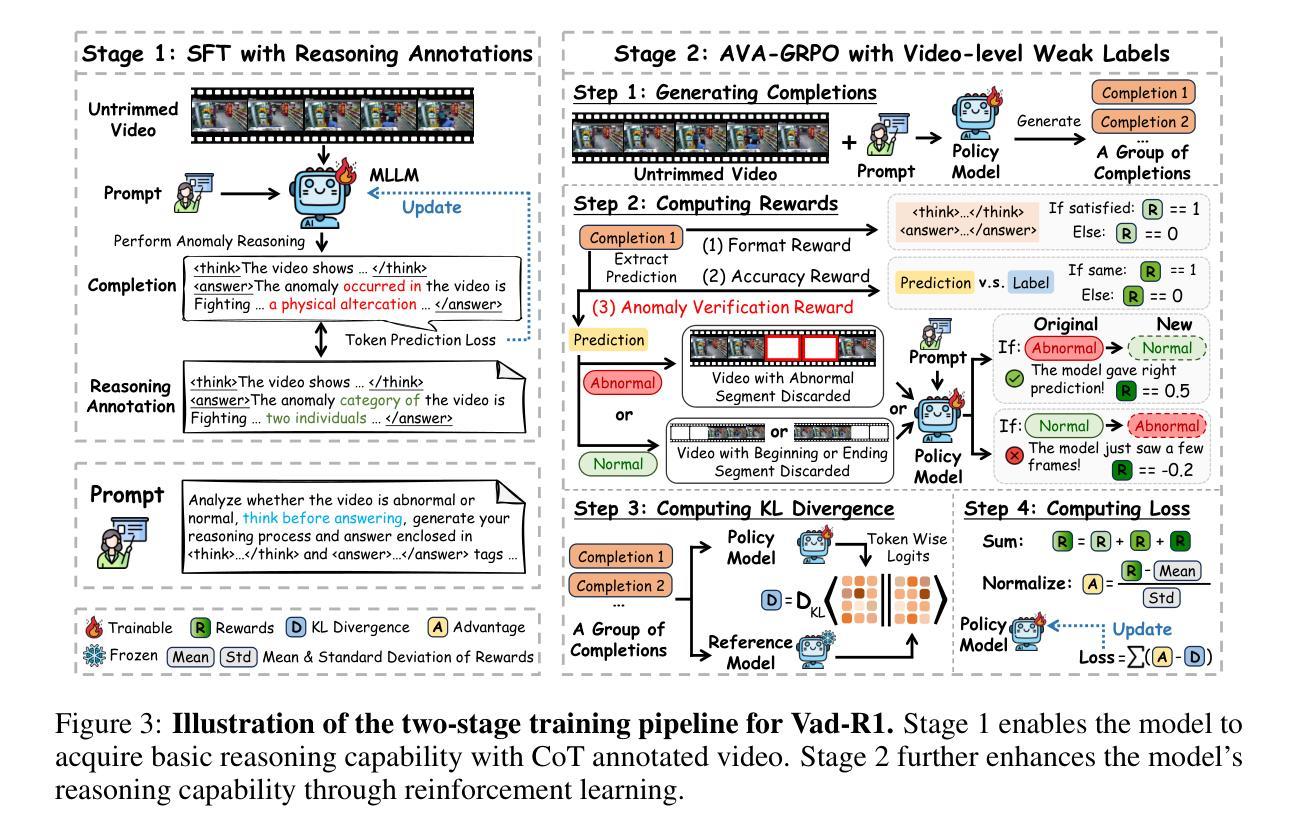
HS-STAR: Hierarchical Sampling for Self-Taught Reasoners via Difficulty Estimation and Budget Reallocation
Authors:Feng Xiong, Hongling Xu, Yifei Wang, Runxi Cheng, Yong Wang, Xiangxiang Chu
Self-taught reasoners (STaRs) enhance the mathematical reasoning abilities of large language models (LLMs) by leveraging self-generated responses for self-training. Recent studies have incorporated reward models to guide response selection or decoding, aiming to obtain higher-quality data. However, they typically allocate a uniform sampling budget across all problems, overlooking the varying utility of problems at different difficulty levels. In this work, we conduct an empirical study and find that problems near the boundary of the LLM’s reasoning capability offer significantly greater learning utility than both easy and overly difficult ones. To identify and exploit such problems, we propose HS-STaR, a Hierarchical Sampling framework for Self-Taught Reasoners. Given a fixed sampling budget, HS-STaR first performs lightweight pre-sampling with a reward-guided difficulty estimation strategy to efficiently identify boundary-level problems. Subsequently, it dynamically reallocates the remaining budget toward these high-utility problems during a re-sampling phase, maximizing the generation of valuable training data. Extensive experiments across multiple reasoning benchmarks and backbone LLMs demonstrate that HS-STaR significantly outperforms other baselines without requiring additional sampling budget.
自我教授推理者(STaRs)通过利用自我生成的回应进行自我训练,增强大型语言模型(LLM)的推理能力。近期的研究纳入了奖励模型来指导回应选择或解码,旨在获得更高质量的数据。然而,它们通常会在所有问题上分配统一的采样预算,忽略了不同难度级别问题的不同效用。在这项工作中,我们进行了实证研究,发现接近LLM推理能力边界的问题与简单和过于困难的问题相比,提供了更大的学习效用。为了识别和利用这些问题,我们提出了HS-STaR,一种用于自我教授推理者的分层采样框架。给定固定的采样预算,HS-STaR首先使用奖励指导的难度估计策略进行轻量级预采样,以有效识别边界级别的问题。随后,在重新采样阶段,它将这些高价值问题作为首要任务重新分配剩余的预算,以最大化有价值的训练数据的生成。在多个推理基准测试和大型语言模型上的广泛实验表明,HS-STaR在不需要额外采样预算的情况下显著优于其他基线方法。
论文及项目相关链接
Summary
自我训练推理者(STaRs)通过利用自我生成的响应进行自训练,增强了大型语言模型(LLMs)的数学推理能力。最新研究引入了奖励模型来指导响应选择或解码,以获取更高质量的数据。然而,它们通常在所有问题上分配均匀的采样预算,忽略了不同难度级别问题的不同效用。本研究发现,在LLM推理能力边界附近的问题提供的学习效用远大于简单和过于困难的问题。为了识别和利用这些问题,我们提出了HS-STaR,一种用于自我训练推理者的分层采样框架。给定固定的采样预算,HS-STaR首先使用奖励指导的难度估计策略进行轻量级预采样,以有效地识别边界级别的问题。随后,在重新采样阶段,它动态地将剩余预算重新分配给这些高效用问题,最大限度地生成有价值的训练数据。在多个推理基准测试和骨干LLMs上的广泛实验表明,HS-STaR在不需要额外采样预算的情况下显著优于其他基准。
Key Takeaways
- STaRs通过自我训练增强LLM的数学推理能力。
- 现有研究忽略不同难度问题的不同学习效用。
- 边界级别的问题提供最大的学习效用。
- HS-STaR框架通过分层采样识别和利用边界级别问题。
- HS-STaR在预采样阶段使用奖励指导的难度估计策略。
- HS-STaR动态调整采样预算,优先高效用问题。
点此查看论文截图

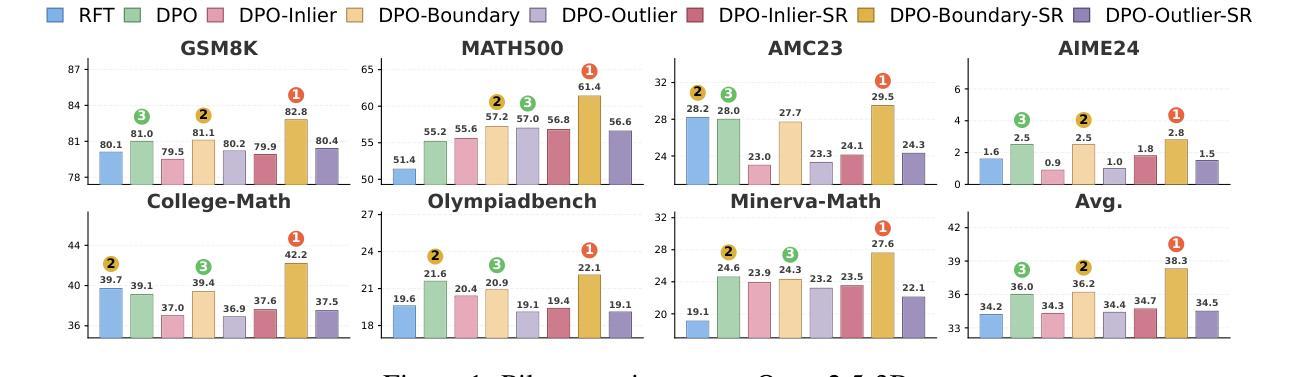
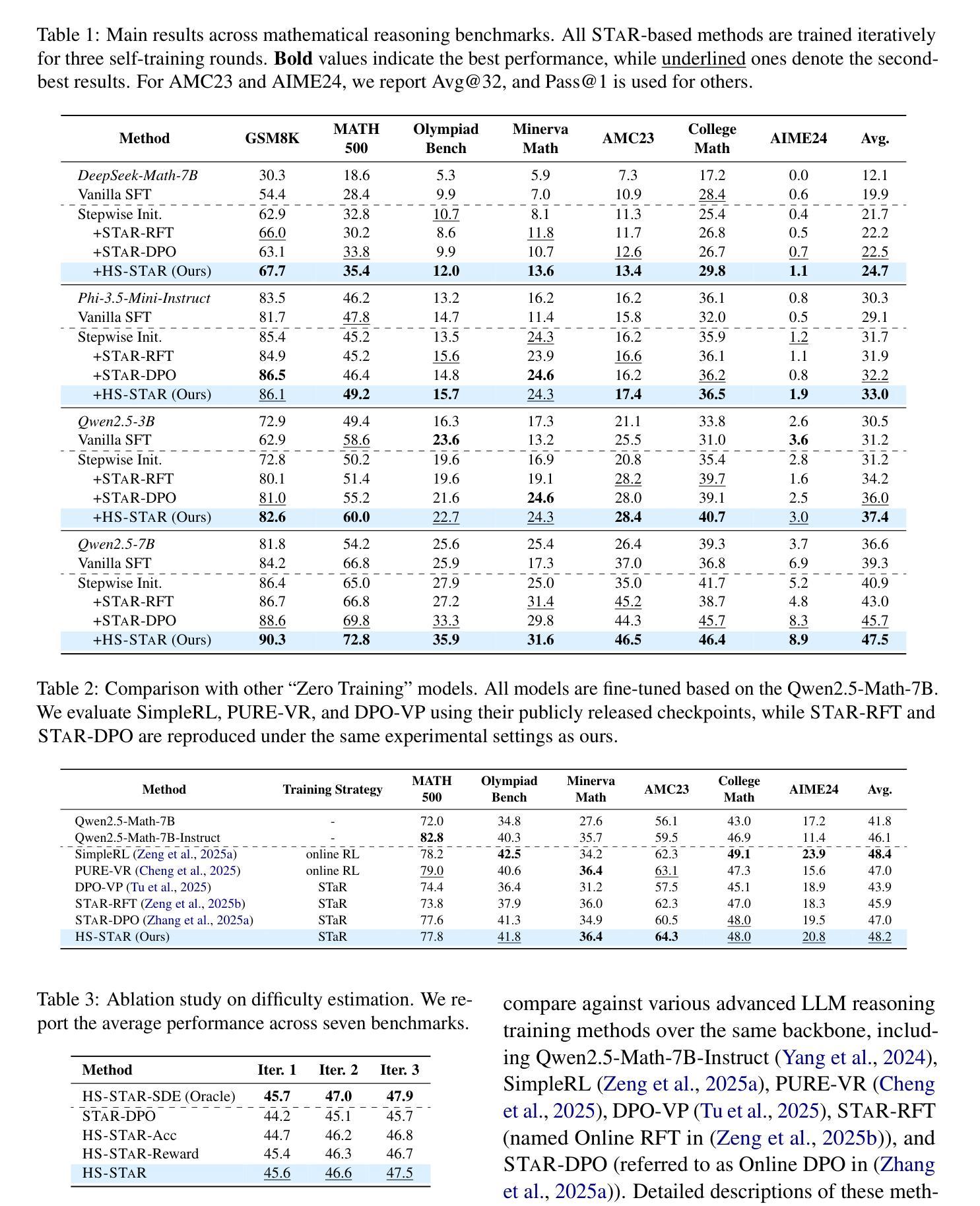
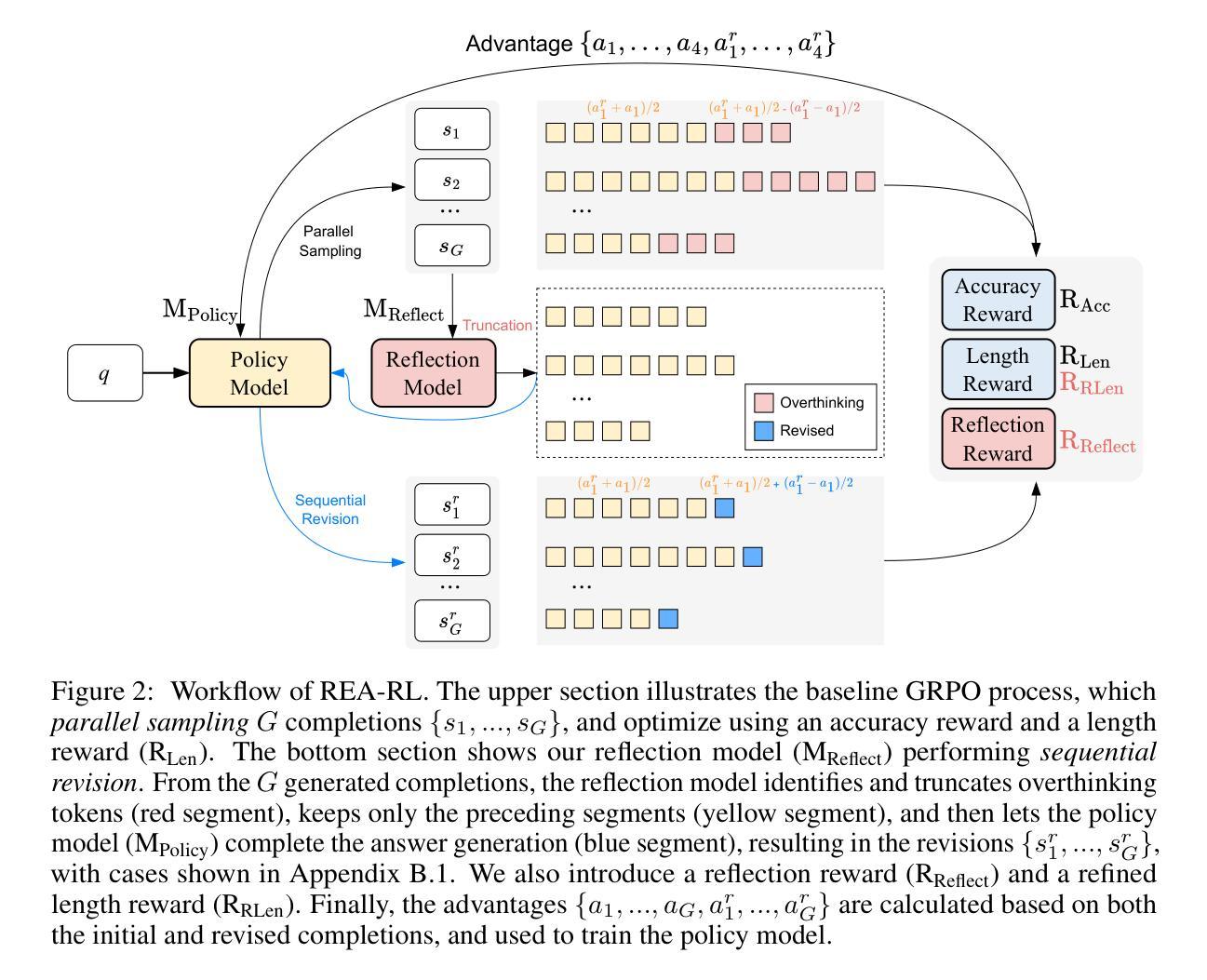
REA-RL: Reflection-Aware Online Reinforcement Learning for Efficient Large Reasoning Models
Authors:Hexuan Deng, Wenxiang Jiao, Xuebo Liu, Jun Rao, Min Zhang
Large Reasoning Models (LRMs) demonstrate strong performance in complex tasks but often face the challenge of overthinking, leading to substantially high inference costs. Existing approaches synthesize shorter reasoning responses for LRMs to learn, but are inefficient for online usage due to the time-consuming data generation and filtering processes. Meanwhile, online reinforcement learning mainly adopts a length reward to encourage short reasoning responses, but tends to lose the reflection ability and harm the performance. To address these issues, we propose REA-RL, which introduces a small reflection model for efficient scaling in online training, offering both parallel sampling and sequential revision. Besides, a reflection reward is designed to further prevent LRMs from favoring short yet non-reflective responses. Experiments show that both methods maintain or enhance performance while significantly improving inference efficiency. Their combination achieves a good balance between performance and efficiency, reducing inference costs by 35% without compromising performance. Further analysis demonstrates that our methods are effective by maintaining reflection frequency for hard problems while appropriately reducing it for simpler ones without losing reflection ability. Codes are available at https://github.com/hexuandeng/REA-RL.
大型推理模型(LRMs)在复杂任务中表现出强大的性能,但常常面临过度思考的挑战,导致推理成本显著提高。现有方法为LRMs的合成较短推理响应而进行学习,但由于耗时较长的数据生成和过滤过程,因此在线使用效率较低。同时,在线强化学习主要采用长度奖励来鼓励短推理响应,但容易丧失反思能力并损害性能。为了解决这些问题,我们提出REA-RL,它引入了一个小型反思模型,用于在线培训中的有效扩展,提供并行采样和顺序修订。此外,设计反思奖励是为了进一步防止LRMs偏向于短而缺乏反思的响应。实验表明,这两种方法在保持或提高性能的同时,显著提高推理效率。它们的结合在性能和效率之间达到了良好的平衡,在不影响性能的情况下将推理成本降低了35%。进一步分析表明,我们的方法通过保持对难题的反思频率,同时适当减少对简单问题的反思,既不失反思能力,又可有效。相关代码可在https://github.com/hexuandeng/REA-RL获取。
论文及项目相关链接
PDF Work in Progress
Summary
该文探讨了大型推理模型(LRMs)在复杂任务中的高性能及所面临的过度思考导致的高推理成本问题。针对现有方法的不足,提出了一种结合小型反射模型(REA-RL)的在线强化学习方法,实现了高效的在线训练并行采样和顺序修订功能。此外,还设计了反射奖励来防止LRM偏好短而缺乏反思的响应。实验表明,该方法在保持或提高性能的同时,显著提高了推理效率,降低了推理成本。进一步的分析显示,该方法能有效维持对难题的反思频率,并适当减少对简单问题的反思能力不会丧失。代码已在GitHub上公开。
Key Takeaways
- 大型推理模型(LRMs)在复杂任务中表现出强大的性能,但面临过度思考和推理成本高昂的挑战。
- 现有方法通过合成更短的推理响应来让LRMs学习,但这种方法对于在线使用来说效率较低,因为数据生成和过滤过程很耗时。
- 在线强化学习主要通过长度奖励来鼓励简短的推理响应,但这种方法容易使模型失去反思能力并影响性能。
- REA-RL方法结合了小型反射模型,实现了在线训练中的高效并行采样和顺序修订。
- REA-RL引入了反射奖励,旨在防止LRM偏好短而缺乏反思的响应。
- 实验结果显示,REA-RL方法在保持性能的同时显著提高了推理效率,降低了推理成本。
点此查看论文截图


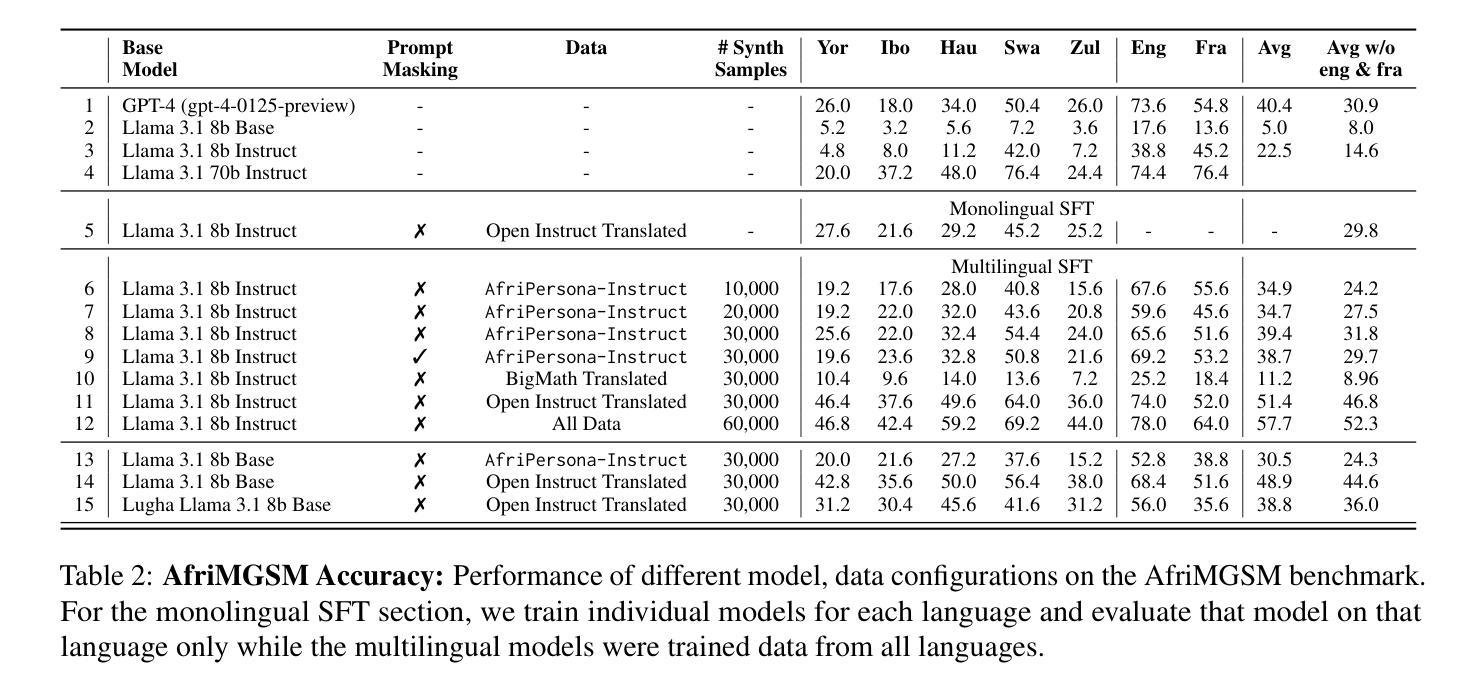
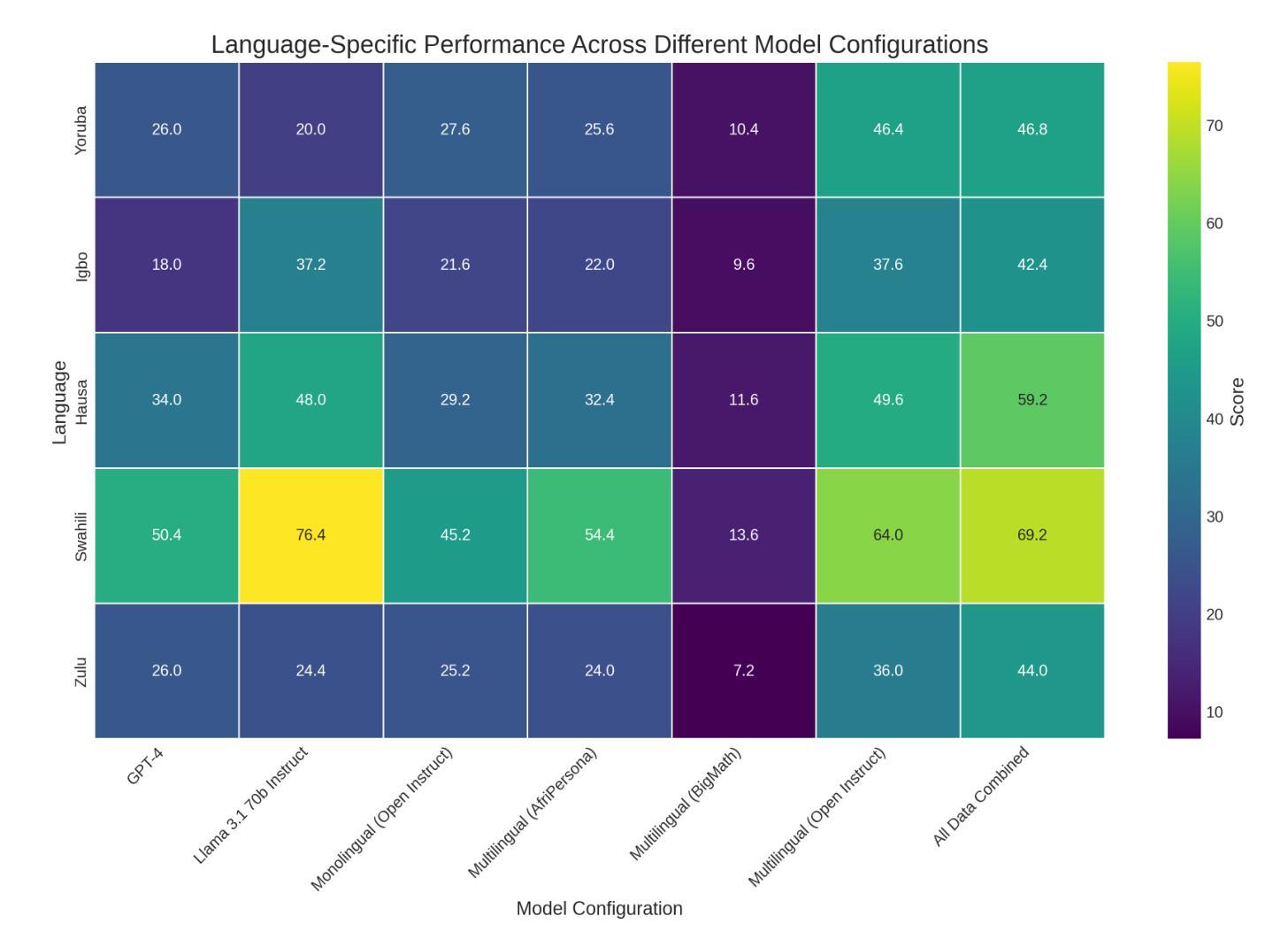
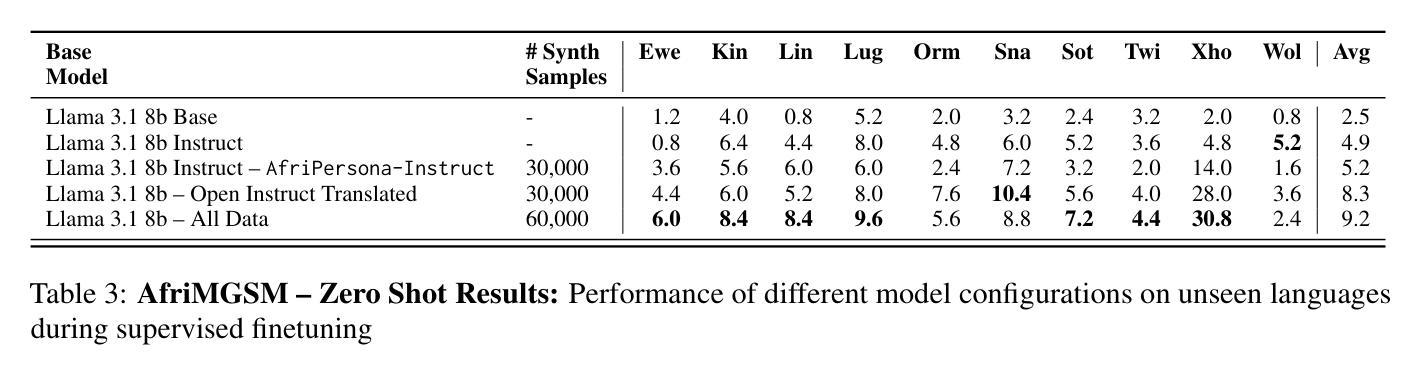
Improving Multilingual Math Reasoning for African Languages
Authors:Odunayo Ogundepo, Akintunde Oladipo, Kelechi Ogueji, Esther Adenuga, David Ifeoluwa Adelani, Jimmy Lin
Researchers working on low-resource languages face persistent challenges due to limited data availability and restricted access to computational resources. Although most large language models (LLMs) are predominantly trained in high-resource languages, adapting them to low-resource contexts, particularly African languages, requires specialized techniques. Several strategies have emerged for adapting models to low-resource languages in todays LLM landscape, defined by multi-stage pre-training and post-training paradigms. However, the most effective approaches remain uncertain. This work systematically investigates which adaptation strategies yield the best performance when extending existing LLMs to African languages. We conduct extensive experiments and ablation studies to evaluate different combinations of data types (translated versus synthetically generated), training stages (pre-training versus post-training), and other model adaptation configurations. Our experiments focuses on mathematical reasoning tasks, using the Llama 3.1 model family as our base model.
研究低资源语言的研究人员面临着持续不断的挑战,这是由于数据有限且计算资源访问受限。尽管大多数大型语言模型(LLM)主要在高资源语言上进行训练,但将它们适应到低资源环境,尤其是非洲语言,需要专门的技术。在当今由多阶段预训练和后续训练范式定义的LLM景观中,已经出现了几种适应模型以适应低资源语言的策略。然而,最有效的策略仍不确定。这项工作系统地研究了在将现有LLM扩展到非洲语言时,哪些适应策略能产生最佳性能。我们进行了广泛的实验和剔除研究,以评估数据类型(翻译与合成生成)、训练阶段(预训练与后续训练)和其他模型适应配置的不同组合。我们的实验侧重于数学推理任务,以Llama 3.1模型家族作为我们的基础模型。
论文及项目相关链接
Summary
针对低资源语言,研究人员面临数据有限和计算资源访问受限的持续挑战。尽管大多数大型语言模型(LLM)主要在高资源语言上进行训练,但将它们适应到低资源环境,尤其是非洲语言,需要特殊技术。本研究系统地探讨了将现有LLM扩展到非洲语言时,哪些适应策略能带来最佳性能。我们进行了广泛的实验和剔除研究,以评估数据类型(翻译与合成生成)、训练阶段(预训练与后训练)和其他模型适应配置的不同组合。我们的实验重点是通过数学推理任务,以Llama 3.1模型家族作为基准模型。
Key Takeaways
- 低资源语言的研究挑战在于数据有限和计算资源受限。
- 大型语言模型(LLM)主要在高资源语言上进行训练。
- 适应低资源环境,尤其是非洲语言,需要特殊技术。
- 目前有多种策略用于将LLM适应到低资源语言。
- 最有效的适应策略尚不确定。
- 研究通过数学推理任务系统地探索了不同的适应策略。
点此查看论文截图

What Can RL Bring to VLA Generalization? An Empirical Study
Authors:Jijia Liu, Feng Gao, Bingwen Wei, Xinlei Chen, Qingmin Liao, Yi Wu, Chao Yu, Yu Wang
Large Vision-Language Action (VLA) models have shown significant potential for embodied AI. However, their predominant training via supervised fine-tuning (SFT) limits generalization due to susceptibility to compounding errors under distribution shifts. Reinforcement learning (RL) offers a path to overcome these limitations by optimizing for task objectives via trial-and-error, yet a systematic understanding of its specific generalization benefits for VLAs compared to SFT is lacking. To address this, our study introduces a comprehensive benchmark for evaluating VLA generalization and systematically investigates the impact of RL fine-tuning across diverse visual, semantic, and execution dimensions. Our extensive experiments reveal that RL fine-tuning, particularly with PPO, significantly enhances generalization in semantic understanding and execution robustness over SFT, while maintaining comparable visual robustness. We identify PPO as a more effective RL algorithm for VLAs than LLM-derived methods like DPO and GRPO. We also develop a simple recipe for efficient PPO training on VLAs, and demonstrate its practical utility for improving VLA generalization. The project page is at https://rlvla.github.io
大型视觉语言行动(VLA)模型在嵌入式人工智能领域表现出了巨大的潜力。然而,它们主要通过监督微调(SFT)进行训练,这在分布转移下容易受到复合错误的影响,从而限制了其泛化能力。强化学习(RL)通过试错来优化任务目标,提供了克服这些限制的途径,但关于与SFT相比,其在VLA特定泛化方面的具体优势缺乏系统了解。为了解决这一问题,我们的研究引入了一个综合基准测试,以评估VLA的泛化能力,并系统地研究了RL微调在不同视觉、语义和执行维度的影响。我们的大量实验表明,特别是使用PPO的RL微调在语义理解和执行稳健性方面显著提高了泛化能力,同时保持了与SFT相当的视觉稳健性。我们确定PPO对于VLA来说,比LLM衍生的方法(如DPO和GRPO)更为有效的RL算法。我们还为VLA上的高效PPO训练开发了一个简单的配方,并展示了其提高VLA泛化的实用性。项目页面为:https://rlvla.github.io。
论文及项目相关链接
Summary
大型视觉语言行动(VLA)模型在嵌入式人工智能领域展现出巨大潜力,但主要通过监督微调(SFT)进行训练的方式限制了其泛化能力,容易在分布转移时出现累积错误。强化学习(RL)试图通过试错优化任务目标来克服这些局限。本研究为评估VLA泛化能力引入了综合基准测试,并系统地研究了RL微调在不同视觉、语义和执行维度的影响。实验结果显示,RL微调,尤其是使用PPO,在语义理解和执行稳健性方面显著提高了泛化能力,同时保持相当的视觉稳健性。本研究认为PPO对于VLA而言,相比LLM衍生方法如DPO和GRPO更为有效。此外,本研究还开发了针对VLA的PPO训练简易配方,并验证了其在提高VLA泛化方面的实用性。
Key Takeaways
- VLA模型在嵌入式AI领域潜力巨大,但监督微调(SFT)训练限制了其泛化能力。
- 强化学习(RL)能提高VLA模型的泛化能力,特别是通过试错优化。
- PPO相比LLM衍生方法如DPO和GRPO更有效于提高VLA模型的泛化能力。
- 研究表明RL微调能增强VLA模型在语义理解和执行稳健性方面的表现。
- VLA模型的视觉稳健性在RL微调后得以保持。
- 本研究为VLA模型提供了PPO训练的简易配方。
点此查看论文截图

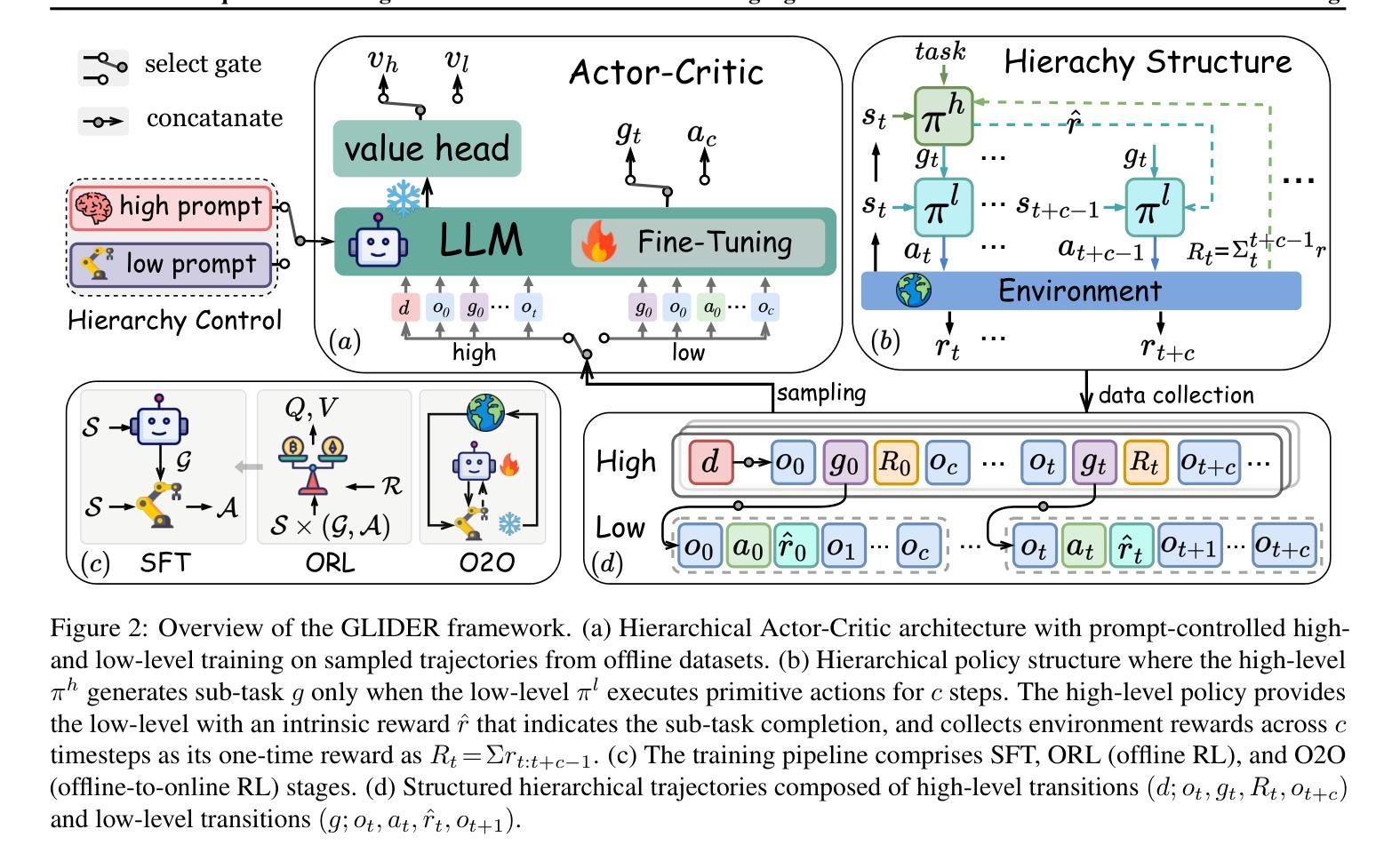
Divide and Conquer: Grounding LLMs as Efficient Decision-Making Agents via Offline Hierarchical Reinforcement Learning
Authors:Zican Hu, Wei Liu, Xiaoye Qu, Xiangyu Yue, Chunlin Chen, Zhi Wang, Yu Cheng
While showing sophisticated reasoning abilities, large language models (LLMs) still struggle with long-horizon decision-making tasks due to deficient exploration and long-term credit assignment, especially in sparse-reward scenarios. Inspired by the divide-and-conquer principle, we propose an innovative framework GLIDER (Grounding Language Models as EffIcient Decision-Making Agents via Offline HiErarchical Reinforcement Learning) that introduces a parameter-efficient and generally applicable hierarchy to LLM policies. We develop a scheme where the low-level controller is supervised with abstract, step-by-step plans that are learned and instructed by the high-level policy. This design decomposes complicated problems into a series of coherent chain-of-thought reasoning sub-tasks, providing flexible temporal abstraction to significantly enhance exploration and learning for long-horizon tasks. Furthermore, GLIDER facilitates fast online adaptation to non-stationary environments owing to the strong transferability of its task-agnostic low-level skills. Experiments on ScienceWorld and ALFWorld benchmarks show that GLIDER achieves consistent performance gains, along with enhanced generalization capabilities.
在展现复杂的推理能力的同时,大型语言模型(LLM)仍然面临着长期决策任务的挑战,这是由于缺乏探索和长期信用分配,特别是在稀疏奖励场景中。受“分而治之”原则的启发,我们提出了一种创新的框架——GLIDER(通过离线分层强化学习将语言模型作为高效决策代理)。它引入了对LLM策略具有普遍适用性和参数效率的分层次结构。我们开发了一种方案,低级控制器受到抽象、分步计划的监督,这些计划由高级策略学习和指导。这种设计将复杂的问题分解成一系列连贯的链式思维推理子任务,提供灵活的时空抽象,以显著增强长期任务的探索和学习。此外,GLIDER由于其任务无关的底层技能的强大可迁移性,能够迅速适应非静态环境。在ScienceWorld和ALFWorld基准测试上的实验表明,GLIDER实现了性能的一致性提升,并增强了泛化能力。
论文及项目相关链接
PDF Accepted by ICML 2025, 21 pages
Summary
大型语言模型(LLM)在决策制定任务中展现出复杂的推理能力,但在长期决策中仍存在探索不足和长期信用分配的问题,特别是在奖励稀疏的场景下。受“分而治之”原则的启发,我们提出了一个创新的框架GLIDER,它通过离线分层强化学习将LLM作为高效决策代理。GLIDER引入了一种对LLM策略通用的、参数效率高的层次结构。我们开发了一种低级控制器受高级策略学习和指导的抽象、分步计划的监督的方案。这种设计将复杂的问题分解成一系列连贯的链式思维推理子任务,为长期任务提供灵活的时间抽象,显著提高了探索和学习能力。此外,GLIDER还便于快速适应非稳定环境,其任务无关的低级技能具有很强的可转移性。在ScienceWorld和ALFWorld基准测试上的实验表明,GLIDER在性能和泛化能力上均有所提升。
Key Takeaways
- 大型语言模型(LLM)在决策制定任务中存在长期决策的挑战,特别是面对稀疏奖励场景时存在探索不足和长期信用分配问题。
- 提出了一种新的框架GLIDER,结合语言模型和强化学习进行决策制定,以提高长期任务的探索和学习效率。
- GLIDER框架引入了层次结构,将复杂问题分解为一系列连贯的链式思维推理子任务,增强了模型的灵活性。
- GLIDER通过参数高效的方案实现了任务无关的低级技能,具有良好的可转移性,能快速适应非稳定环境。
- 在ScienceWorld和ALFWorld基准测试上,GLIDER展现了性能和泛化能力的提升。
点此查看论文截图

MT$^{3}$: Scaling MLLM-based Text Image Machine Translation via Multi-Task Reinforcement Learning
Authors:Zhaopeng Feng, Yupu Liang, Shaosheng Cao, Jiayuan Su, Jiahan Ren, Zhe Xu, Yao Hu, Wenxuan Huang, Jian Wu, Zuozhu Liu
Text Image Machine Translation (TIMT)-the task of translating textual content embedded in images-is critical for applications in accessibility, cross-lingual information access, and real-world document understanding. However, TIMT remains a complex challenge due to the need for accurate optical character recognition (OCR), robust visual-text reasoning, and high-quality translation, often requiring cascading multi-stage pipelines. Recent advances in large-scale Reinforcement Learning (RL) have improved reasoning in Large Language Models (LLMs) and Multimodal LLMs (MLLMs), but their application to end-to-end TIMT is still underexplored. To bridge this gap, we introduce MT$^{3}$, the first framework to apply Multi-Task RL to MLLMs for end-to-end TIMT. MT$^{3}$ adopts a multi-task optimization paradigm targeting three key sub-skills: text recognition, context-aware reasoning, and translation. It is trained using a novel multi-mixed reward mechanism that adapts rule-based RL strategies to TIMT’s intricacies, offering fine-grained, non-binary feedback across tasks. Furthermore, to facilitate the evaluation of TIMT in authentic cross-cultural and real-world social media contexts, we introduced XHSPost, the first social media TIMT benchmark. Our MT$^{3}$-7B-Zero achieves state-of-the-art results on the latest in-domain MIT-10M benchmark, outperforming strong baselines such as Qwen2.5-VL-72B and InternVL2.5-78B by notable margins across multiple metrics. Additionally, the model shows strong generalization to out-of-distribution language pairs and datasets. In-depth analyses reveal how multi-task synergy, reinforcement learning initialization, curriculum design, and reward formulation contribute to advancing MLLM-driven TIMT.
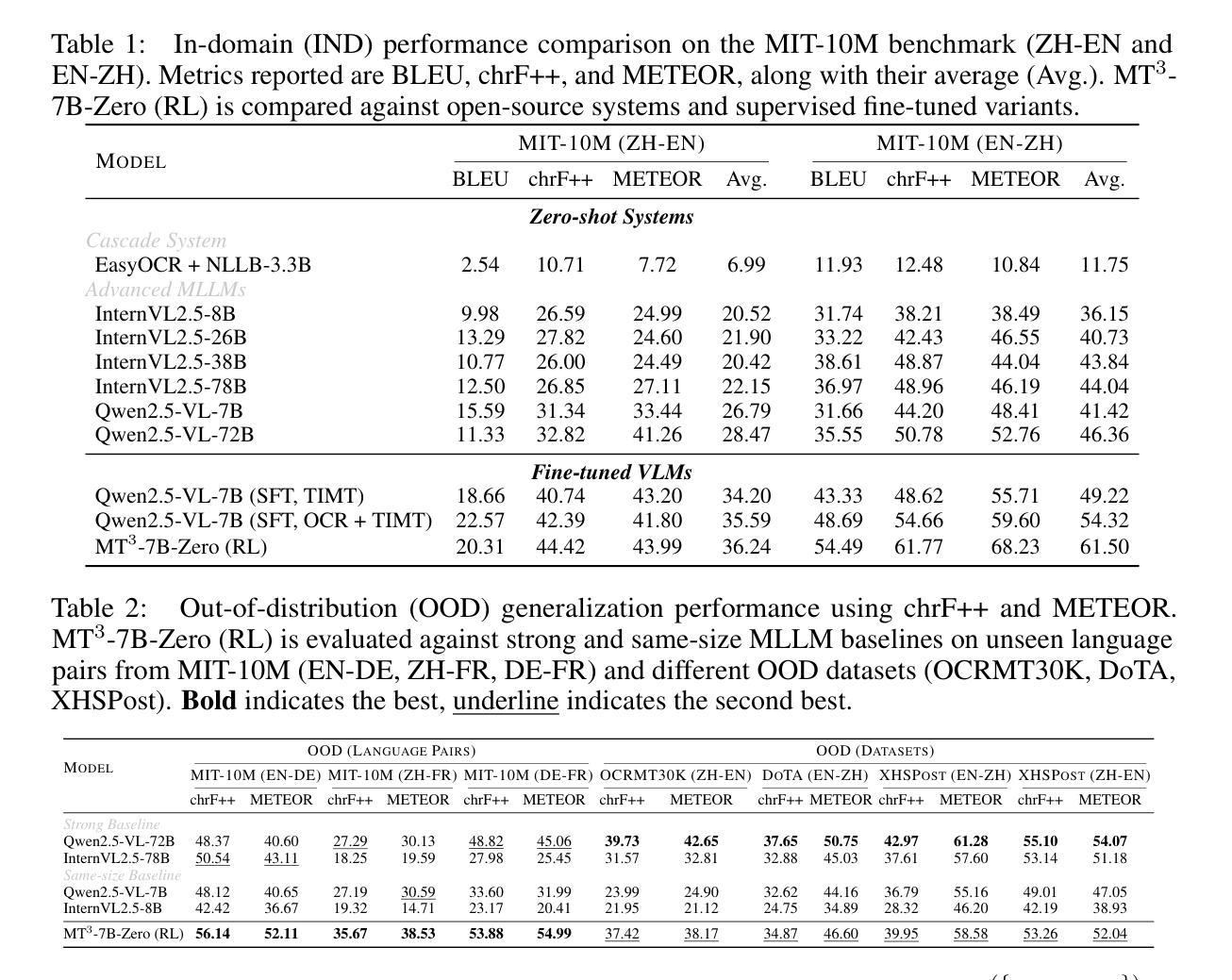
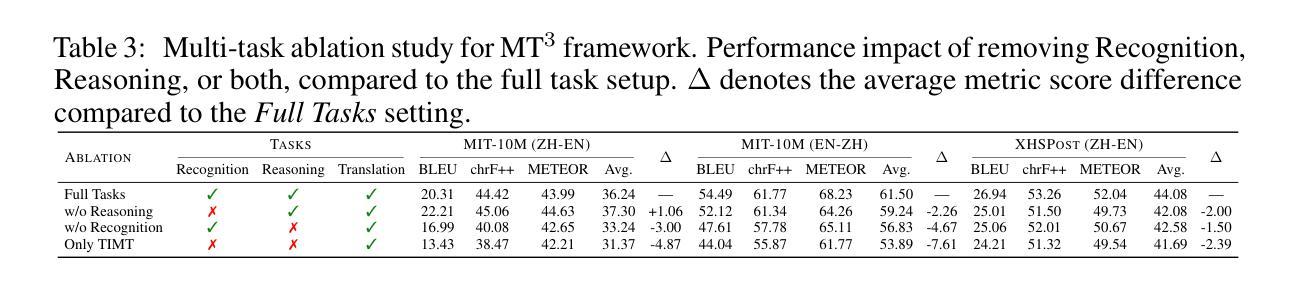
文本图像机器翻译(TIMT)——将嵌入图像中的文本内容进行翻译的任务——对于无障碍应用、跨语言信息访问和现实世界文档理解等应用至关重要。然而,由于需要准确的光学字符识别(OCR)、稳健的视觉文本推理和高质量的翻译,通常涉及级联的多阶段管道,TIMT仍然是一个复杂的挑战。最近大规模强化学习(RL)的进展提高了大型语言模型(LLMs)和多模态LLM(MLLMs)中的推理能力,但其在端到端TIMT中的应用仍然被探索不足。为了弥补这一差距,我们引入了MT$^{3}$,这是第一个将多任务RL应用于MLLMs进行端到端TIMT的框架。MT$^{3}$采用了一种多任务优化范式,针对文本识别、上下文感知推理和翻译三个关键子技能。它使用一种新型的多混合奖励机制进行训练,该机制将基于规则的RL策略适应到TIMT的复杂性上,并在任务之间提供精细的、非二进制的反馈。此外,为了促进在真实跨文化和现实世界社交媒体背景下对TIMT的评估,我们推出了XHSPost,这是第一个社交媒体TIMT基准测试。我们的MT$^{3}$-7B-Zero在最新的领域MIT-10M基准测试中取得了最新结果,与Qwen2.5-VL-72B和InternVL2.5-78B等强大基准相比,在多个指标上取得了显著的改进。此外,该模型对超出分布的语言对和数据集表现出强大的泛化能力。深入分析表明,多任务协同、强化学习初始化、课程设计以及奖励公式等对推动MLLM驱动的TIMT至关重要。
论文及项目相关链接
PDF Work in progress
Summary
本文介绍了文本图像机器翻译(TIMT)的重要性及其面临的挑战,包括准确的光学字符识别(OCR)、稳健的视觉文本推理和高品质翻译的需求。针对这些挑战,本文提出了MT^3框架,首次将多任务强化学习应用于多模态大型语言模型(MLLMs)进行端到端的TIMT。MT^3采用多任务优化范式,针对文本识别、上下文感知推理和翻译三个关键子技能进行训练。使用新型的多混合奖励机制,适应基于规则的RL策略以适应TIMT的复杂性,提供跨任务的精细粒度非二进制反馈。此外,为了评估TIMT在真实跨文化和社会媒体背景下的性能,引入了XHSPost社交媒体TIMT基准测试。实验结果表明,MT^3-7B-Zero在最新的MIT-10M基准测试中达到了最新的技术水平,并在多种指标上显著优于Qwen2.5-VL-72B和InternVL2.5-78B等强基线。此外,该模型在跨语言数据集上显示出强大的泛化能力。深入分析揭示了多任务协同、强化学习初始化、课程设计和奖励制定对推动MLLM驱动的TIMT的贡献。
Key Takeaways
- 文本图像机器翻译(TIMT)是信息访问和文档理解的关键技术,但仍面临复杂挑战。
- MT^3框架首次将多任务强化学习应用于多模态大型语言模型(MLLMs)进行端到端的TIMT。
- MT^3通过多任务优化范式,针对文本识别、上下文感知推理和翻译三个关键子技能进行训练。
- 引入新型的多混合奖励机制以适应基于规则的RL策略,提供跨任务的精细反馈。
- XHSPost社交媒体TIMT基准测试用于评估TIMT在真实跨文化和社会媒体背景下的性能。
- MT^3模型在MIT-10M基准测试中表现优异,显著优于其他基线模型。
点此查看论文截图

CAD-Coder: Text-to-CAD Generation with Chain-of-Thought and Geometric Reward
Authors:Yandong Guan, Xilin Wang, Xingxi Ming, Jing Zhang, Dong Xu, Qian Yu
In this work, we introduce CAD-Coder, a novel framework that reformulates text-to-CAD as the generation of CadQuery scripts - a Python-based, parametric CAD language. This representation enables direct geometric validation, a richer modeling vocabulary, and seamless integration with existing LLMs. To further enhance code validity and geometric fidelity, we propose a two-stage learning pipeline: (1) supervised fine-tuning on paired text-CadQuery data, and (2) reinforcement learning with Group Reward Policy Optimization (GRPO), guided by a CAD-specific reward comprising both a geometric reward (Chamfer Distance) and a format reward. We also introduce a chain-of-thought (CoT) planning process to improve model reasoning, and construct a large-scale, high-quality dataset of 110K text-CadQuery-3D model triplets and 1.5K CoT samples via an automated pipeline. Extensive experiments demonstrate that CAD-Coder enables LLMs to generate diverse, valid, and complex CAD models directly from natural language, advancing the state of the art of text-to-CAD generation and geometric reasoning.
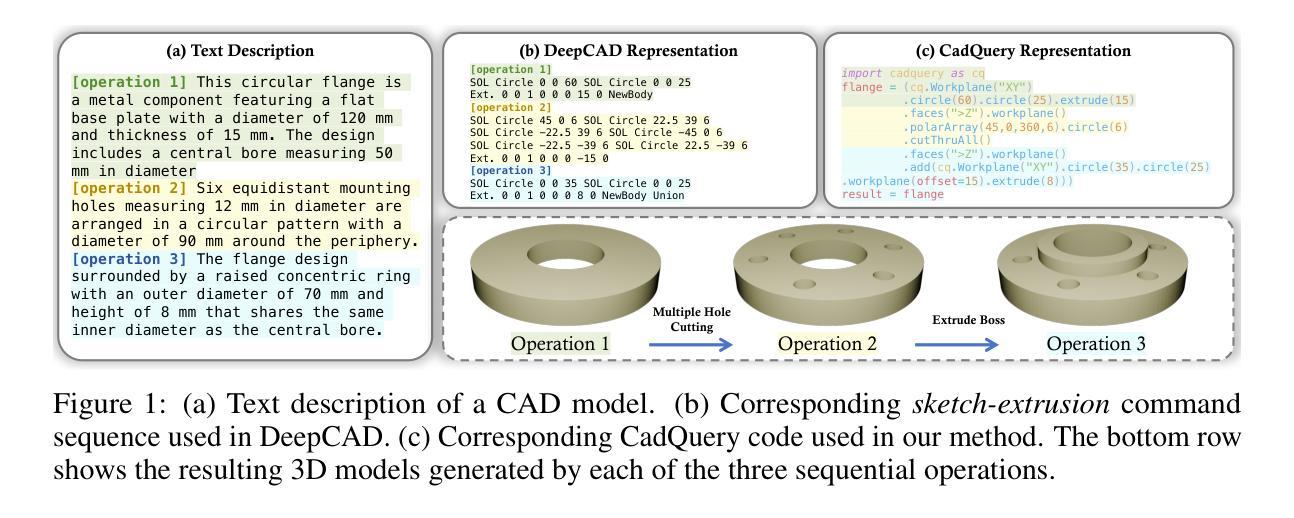
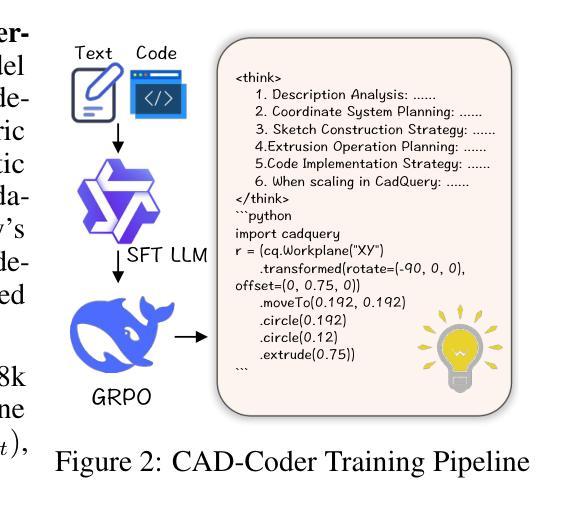
在本次工作中,我们介绍了CAD-Coder这一新型框架,它将文本到CAD的转换重新定义为CadQuery脚本的生成——一种基于Python的参数化CAD语言。这种表示方法实现了直接的几何验证、更丰富的建模词汇,以及与现有大型语言模型的无缝集成。为了进一步提高代码的有效性和几何保真度,我们提出了一个两阶段的学习流程,包括:(1)在成对的文本-CadQuery数据上进行监督微调;(2)使用集团奖励政策优化(GRPO)进行强化学习,由包括几何奖励(Chamfer距离)和格式奖励在内的CAD特定奖励指导。我们还引入了思维链(CoT)规划过程来改善模型推理,并通过自动化管道构建了一个大规模、高质量的包含110K个文本-CadQuery-3D模型三元组和1.5K个CoT样本的数据集。大量实验表明,CAD-Coder使大型语言模型能够直接从自然语言生成多样、有效和复杂的CAD模型,从而推动了文本到CAD生成和几何推理的最新技术进展。
论文及项目相关链接
Summary
本文介绍了CAD-Coder框架,它将文本到CAD的转换重新定义为CadQuery脚本的生成。该框架利用基于Python的参数化CAD语言,实现了直接几何验证、丰富的建模词汇以及与现有大型语言模型的无缝集成。为提高代码的有效性和几何保真度,提出了包括监督微调和对带配对文本-CadQuery数据的强化学习在内的两阶段学习管道。通过组合几何奖励(Chamfer距离)和格式奖励的CAD特定奖励策略,以及引入思维链规划过程来改善模型推理。通过自动化管道构建的大型、高质量数据集包含11万文本-CadQuery-3D模型三元组和15万思维链样本。实验证明,CAD-Coder使大型语言模型能够直接从自然语言生成多样、有效和复杂的CAD模型,推动了文本到CAD生成和几何推理的最新进展。
Key Takeaways
- CAD-Coder框架将文本转换为CAD模型的过程重新定义为生成CadQuery脚本。
- 利用基于Python的参数化CAD语言,提供直接几何验证、丰富的建模词汇和无缝的语言模型集成。
- 提出两阶段学习管道,包括监督微调和对带配对文本-CadQuery数据的强化学习,以提高代码的有效性和几何保真度。
- 引入组合几何奖励(Chamfer距离)和格式奖励的CAD特定奖励策略优化。
- 引入思维链规划过程改善模型推理能力。
- 通过自动化管道构建的大型数据集包含多种文本、CadQuery脚本和3D模型的三元组组合。
点此查看论文截图

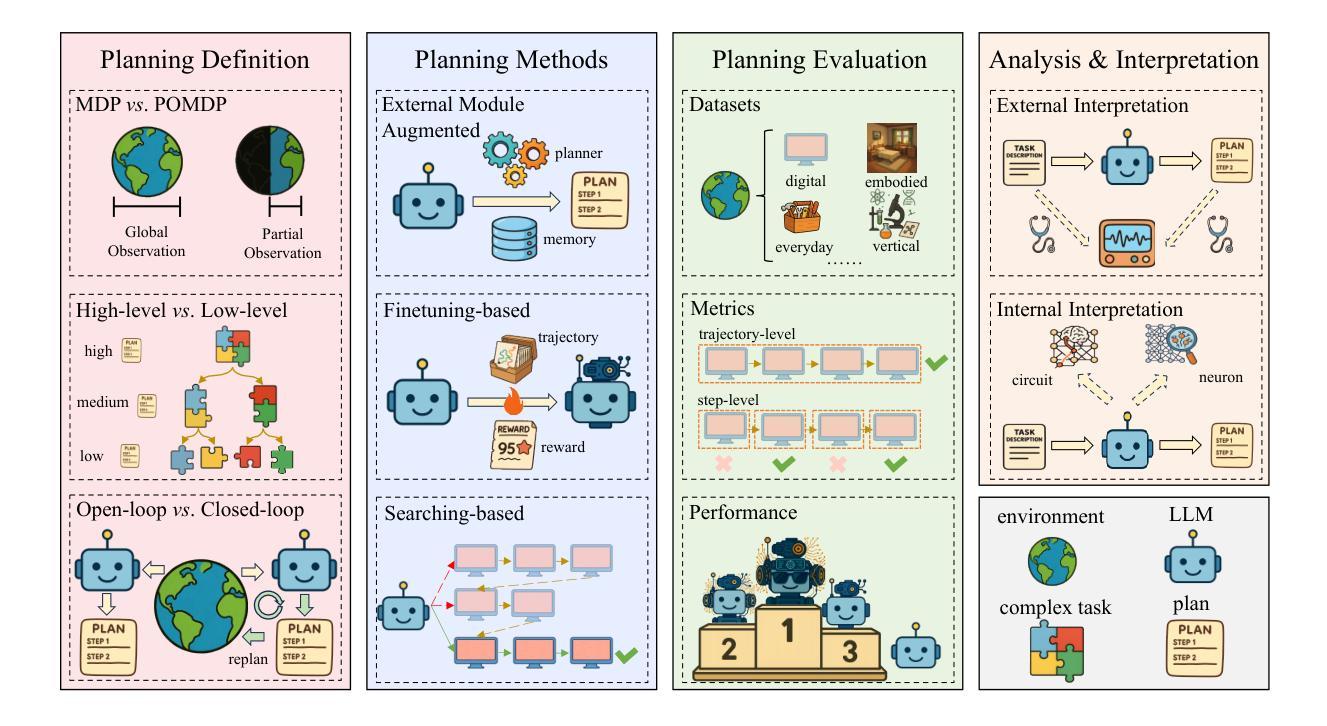
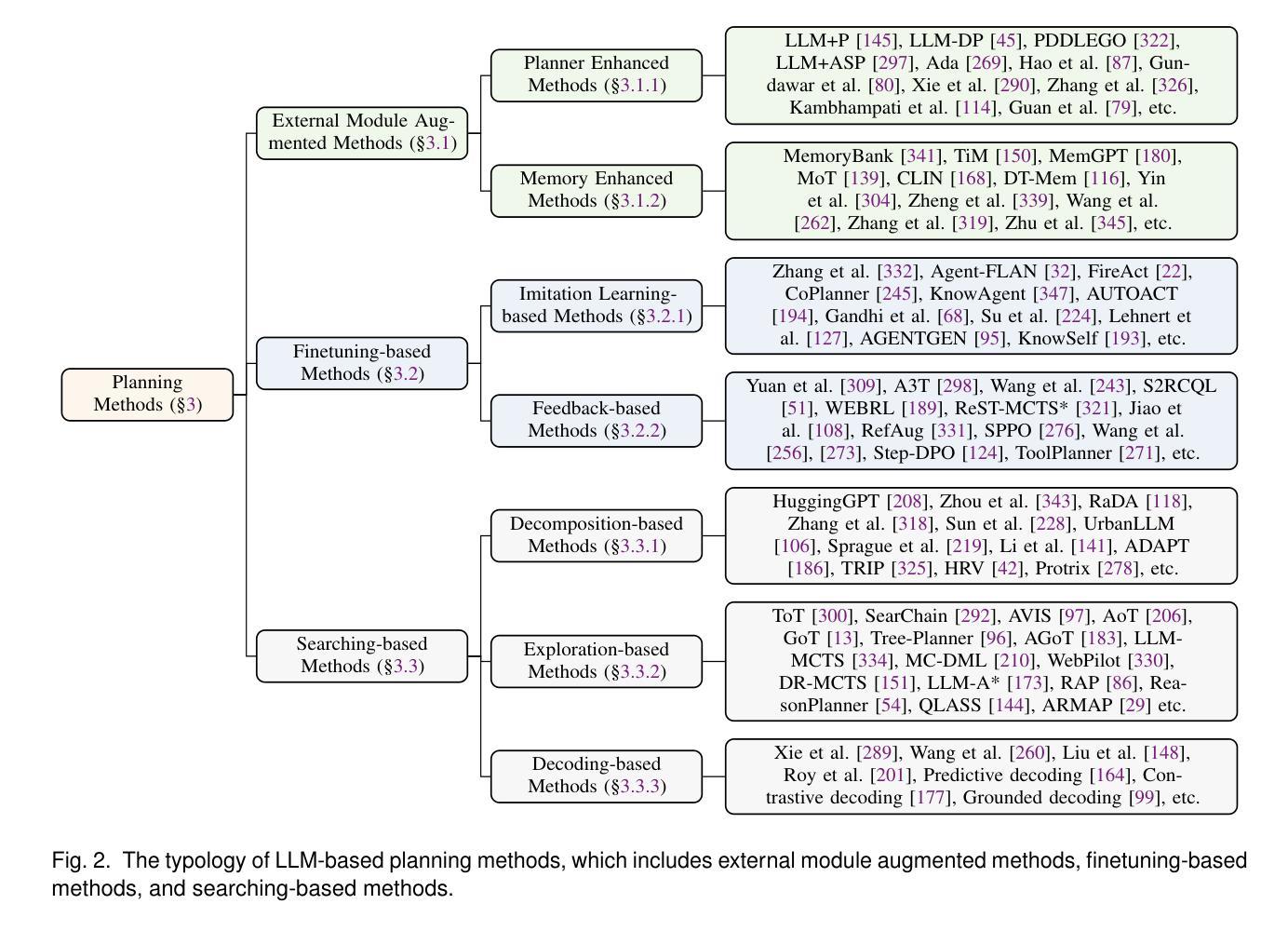
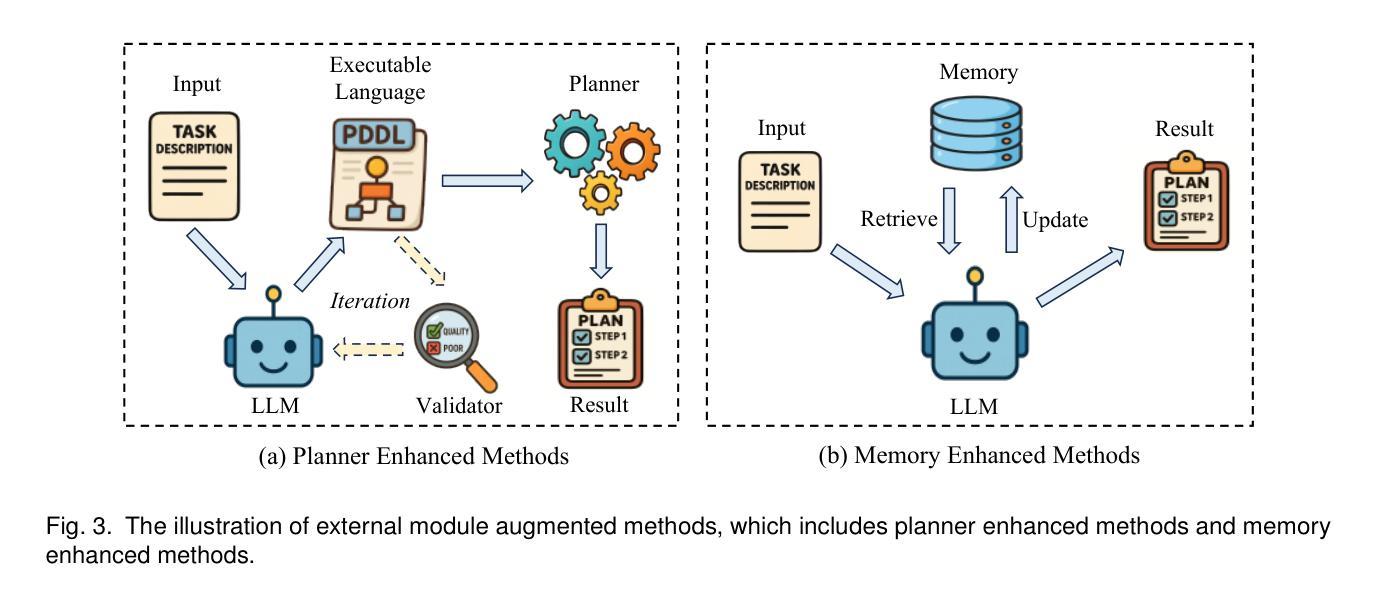
Large Language Models for Planning: A Comprehensive and Systematic Survey
Authors:Pengfei Cao, Tianyi Men, Wencan Liu, Jingwen Zhang, Xuzhao Li, Xixun Lin, Dianbo Sui, Yanan Cao, Kang Liu, Jun Zhao
Planning represents a fundamental capability of intelligent agents, requiring comprehensive environmental understanding, rigorous logical reasoning, and effective sequential decision-making. While Large Language Models (LLMs) have demonstrated remarkable performance on certain planning tasks, their broader application in this domain warrants systematic investigation. This paper presents a comprehensive review of LLM-based planning. Specifically, this survey is structured as follows: First, we establish the theoretical foundations by introducing essential definitions and categories about automated planning. Next, we provide a detailed taxonomy and analysis of contemporary LLM-based planning methodologies, categorizing them into three principal approaches: 1) External Module Augmented Methods that combine LLMs with additional components for planning, 2) Finetuning-based Methods that involve using trajectory data and feedback signals to adjust LLMs in order to improve their planning abilities, and 3) Searching-based Methods that break down complex tasks into simpler components, navigate the planning space, or enhance decoding strategies to find the best solutions. Subsequently, we systematically summarize existing evaluation frameworks, including benchmark datasets, evaluation metrics and performance comparisons between representative planning methods. Finally, we discuss the underlying mechanisms enabling LLM-based planning and outline promising research directions for this rapidly evolving field. We hope this survey will serve as a valuable resource to inspire innovation and drive progress in this field.
规划是智能主体的一项基本能力,需要全面的环境理解、严谨的逻辑推理和有效的序列决策。虽然大型语言模型(LLM)在某些规划任务上表现出了显著的性能,但它们在规划领域的广泛应用值得进行系统性的研究。本文全面回顾了基于LLM的规划技术。具体地,本文的结构如下:首先,我们通过介绍自动化规划的基本定义和类别来建立理论基础。接下来,我们提供了当代基于LLM的规划方法的详细分类和分析,将它们归纳为三种主要方法:1) 结合LLM与其他组件进行规划的外部模块增强方法;2) 基于微调的方法,使用轨迹数据和反馈信号来调整LLM以提高其规划能力;以及3) 基于搜索的方法,将复杂任务分解为更简单的组件,在规划空间中进行导航,或改进解码策略以找到最佳解决方案。然后,我们系统地总结了现有的评估框架,包括基准数据集、评估指标以及代表性规划方法之间的性能比较。最后,我们讨论了实现基于LLM的规划的基础机制,并概述了这个快速发展的领域的有前途的研究方向。我们希望这份综述能成为激发创新和推动该领域进步的宝贵资源。
论文及项目相关链接
Summary
智能规划是智能主体的一项基本能力,涉及全面的环境理解、严谨的逻辑推理和有效的序列决策制定。当前大型语言模型(LLM)在规划任务中表现出显著性能,但其在该领域的广泛应用尚待系统研究。本文全面综述了基于LLM的规划方法,包括自动化规划的基础理论、基于LLM的规划方法的分类及其详情、现有评估框架以及研究展望。旨在为此领域的创新进步提供有价值的资源。
Key Takeaways
- 规划是智能主体的核心功能,涉及多方面的技能包括环境认知、逻辑推理和决策制定。
- 大型语言模型(LLM)在规划任务上表现出优异性能。
- 基于LLM的规划方法主要包括三种类型:外部模块增强法、微调法和搜索法。
- 当前对基于LLM的规划方法的评估主要包括基准数据集、评估指标以及代表性规划方法的性能比较。
点此查看论文截图

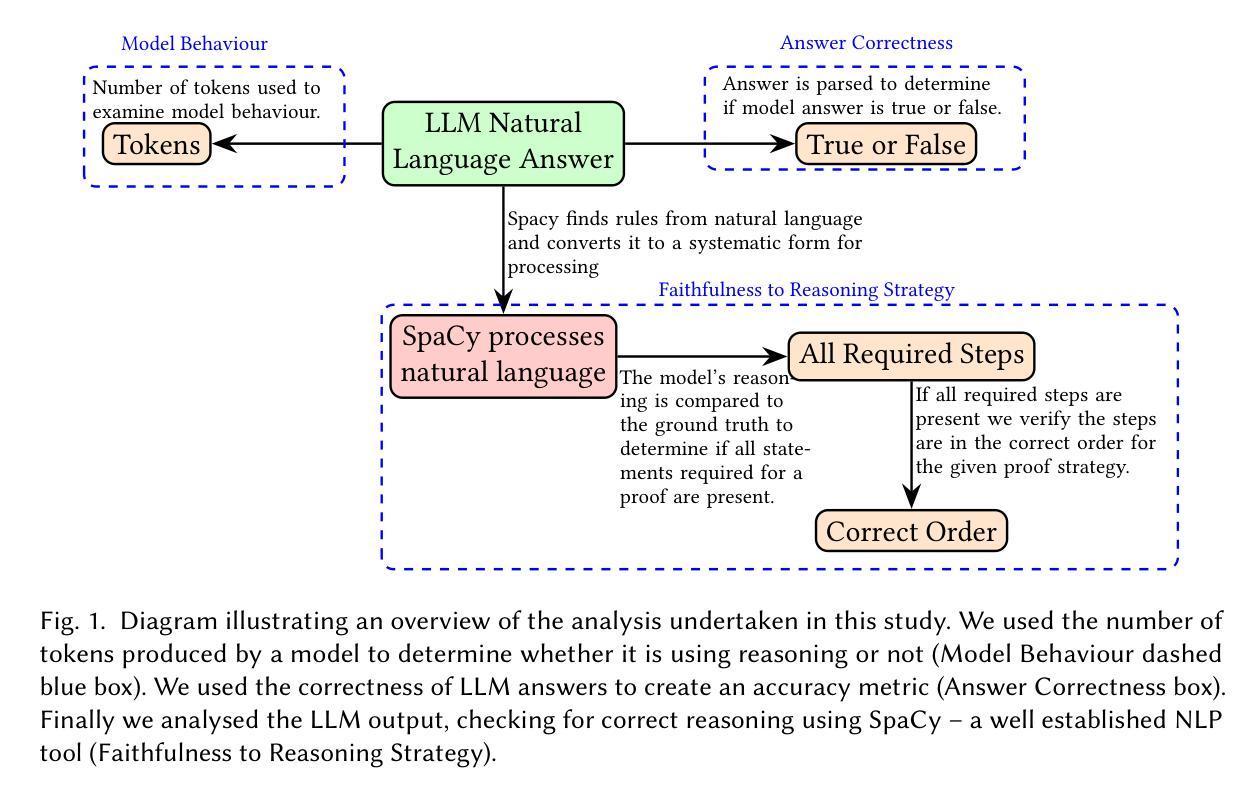
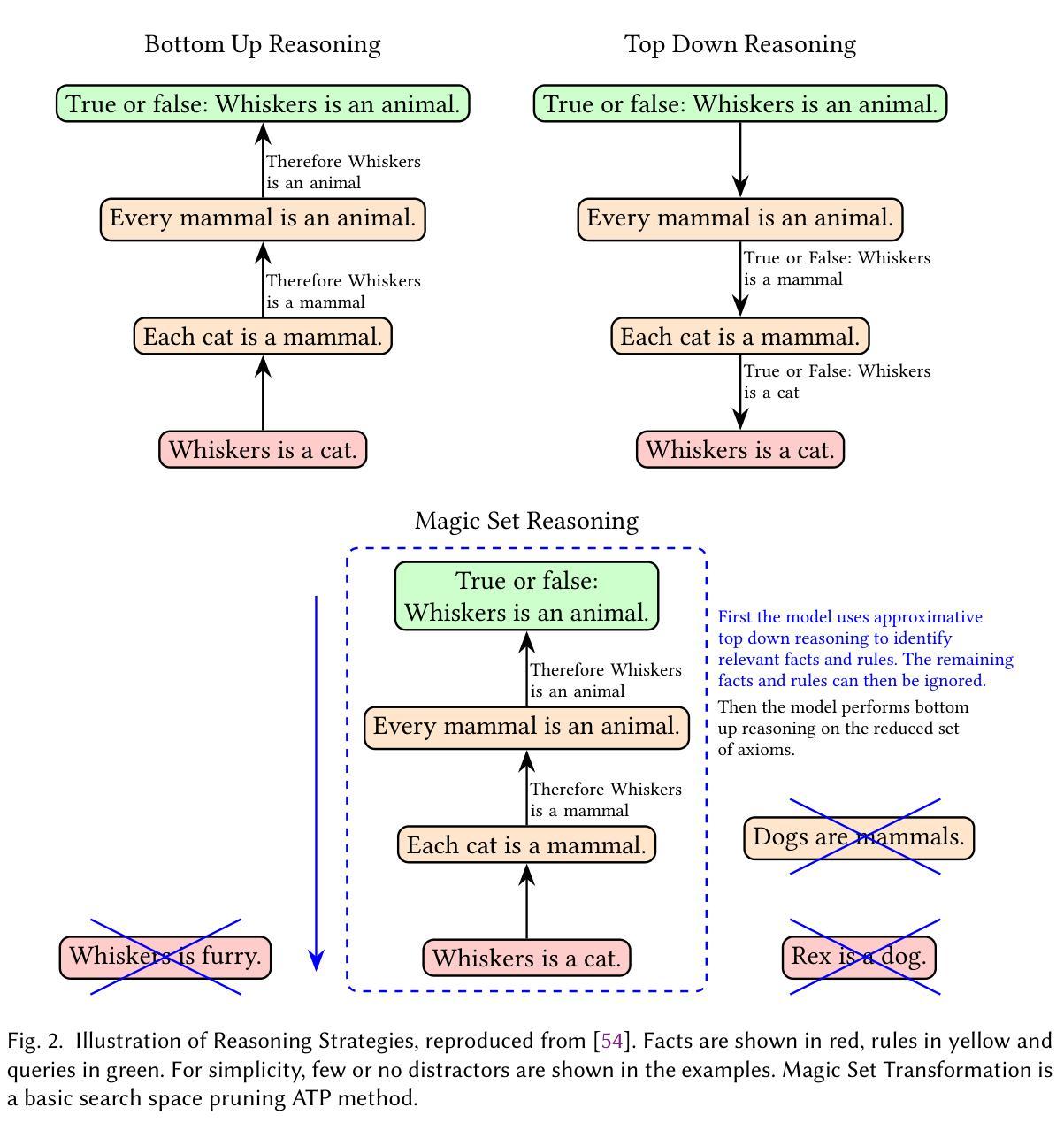
Large Language Models’ Reasoning Stalls: An Investigation into the Capabilities of Frontier Models
Authors:Lachlan McGinness, Peter Baumgartner
Empirical methods to examine the capability of Large Language Models (LLMs) to use Automated Theorem Prover (ATP) reasoning strategies are studied. We evaluate the performance of State of the Art models from December 2023 and August 2024 on PRONTOQA steamroller reasoning problems. For that, we develop methods for assessing LLM response accuracy and correct answer correlation. Our results show that progress in improving LLM reasoning abilities has stalled over the nine month period. By tracking completion tokens, we show that almost all improvement in reasoning ability since GPT-4 was released can be attributed to either hidden system prompts or the training of models to automatically use generic Chain of Thought prompting strategies. Among the ATP reasoning strategies tried, we found that current frontier LLMs are best able to follow the bottom-up (also known as forward-chaining) strategy. A low positive correlation was found between an LLM response containing correct reasoning and arriving at the correct conclusion.
本文研究了实证方法,以检验大型语言模型(LLM)使用自动化定理证明器(ATP)推理策略的能力。我们评估了2 0 2 3年1 2月和2 0 2 4年8月的最新模型在PRONTOQA蒸汽压路机推理问题上的表现。为此,我们开发了评估LLM响应准确性和正确答案关联度的方法。结果表明,在长达九个月的期间内,改善LLM推理能力的进展已停滞。通过跟踪完成令牌,我们发现自从GPT-4发布以来,推理能力的几乎所有改进都可以归因于隐藏系统提示或训练模型自动使用通用的思维链提示策略。在尝试的ATP推理策略中,我们发现目前的前沿LLM最能够采用自下而上(也称为前向链接)的策略。LLM的回应中包含正确的推理和得出正确结论之间的正相关关系较低。
论文及项目相关链接
Summary
近期对大型语言模型(LLMs)在自动化定理证明(ATP)推理策略方面的能力进行了实证研究。评估了2023年12月和2024年8月的先进模型在PRONTOQA蒸汽压路机推理问题上的表现。通过评估LLM响应准确性和正确答案相关性,发现过去九个月在提升LLM推理能力方面进展停滞。跟踪完成令牌表明,自GPT-4发布以来,推理能力的提升大多归功于隐蔽系统提示或模型训练自动使用通用思维链提示策略。在尝试的ATP推理策略中,当前最前沿的LLM最能采用自下而上(也称为前向链接)的策略。LLM响应中的正确推理与得出正确结论之间存在微弱的正相关。
Key Takeaways
- 大型语言模型(LLMs)在自动化定理证明(ATP)推理策略方面的能力得到了研究。
- 评估了不同时间段先进模型在特定推理问题上的表现。
- LLM响应准确性和正确答案相关性的评估显示推理能力进展停滞。
- 跟踪完成令牌显示,提升主要归因于系统提示和模型训练中的通用思维链提示策略。
- 在尝试的ATP推理策略中,LLMs最能采用自下而上的策略。
- 存在微弱的正相关关系,即LLM响应中的正确推理与得出正确结论相关。
点此查看论文截图

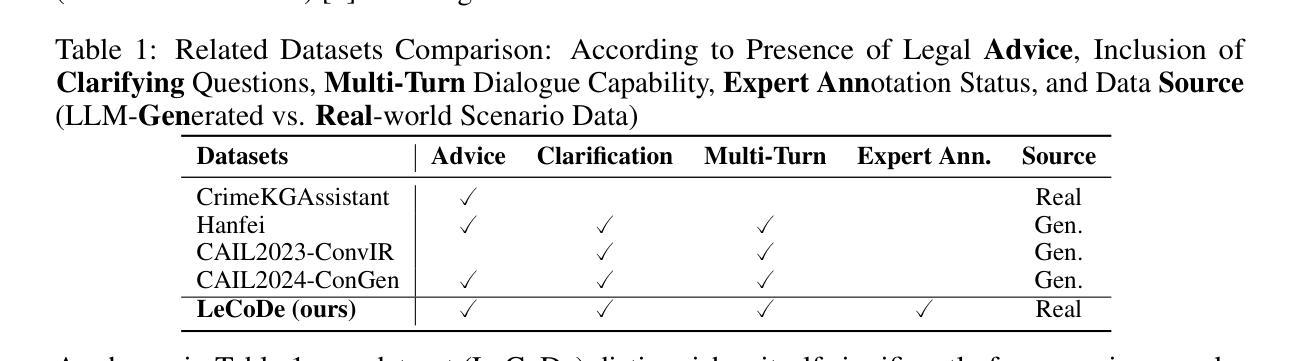
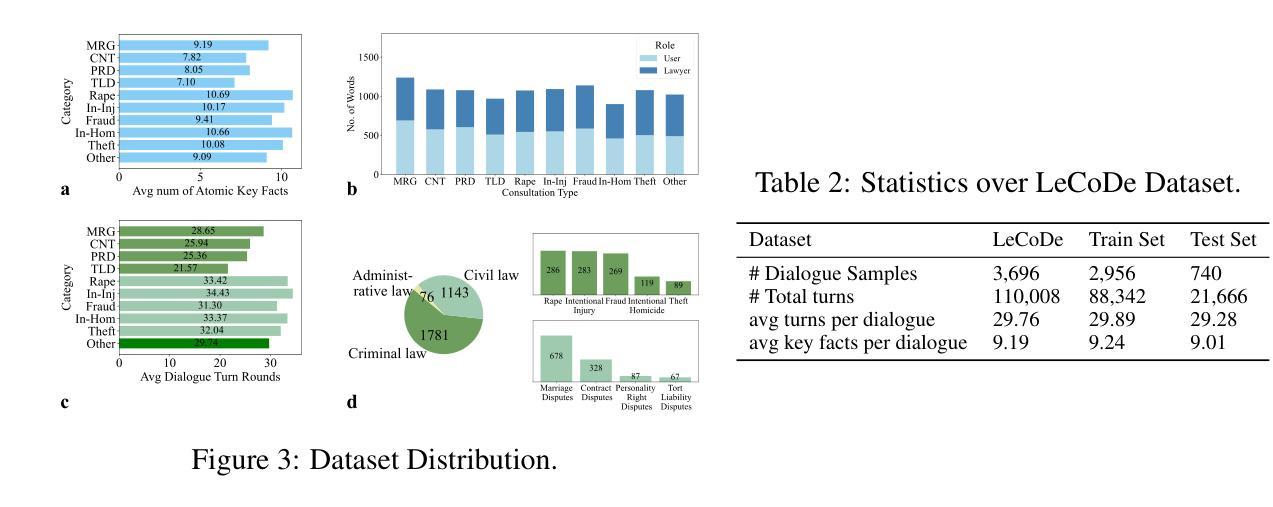
LeCoDe: A Benchmark Dataset for Interactive Legal Consultation Dialogue Evaluation
Authors:Weikang Yuan, Kaisong Song, Zhuoren Jiang, Junjie Cao, Yujie Zhang, Jun Lin, Kun Kuang, Ji Zhang, Xiaozhong Liu
Legal consultation is essential for safeguarding individual rights and ensuring access to justice, yet remains costly and inaccessible to many individuals due to the shortage of professionals. While recent advances in Large Language Models (LLMs) offer a promising path toward scalable, low-cost legal assistance, current systems fall short in handling the interactive and knowledge-intensive nature of real-world consultations. To address these challenges, we introduce LeCoDe, a real-world multi-turn benchmark dataset comprising 3,696 legal consultation dialogues with 110,008 dialogue turns, designed to evaluate and improve LLMs’ legal consultation capability. With LeCoDe, we innovatively collect live-streamed consultations from short-video platforms, providing authentic multi-turn legal consultation dialogues. The rigorous annotation by legal experts further enhances the dataset with professional insights and expertise. Furthermore, we propose a comprehensive evaluation framework that assesses LLMs’ consultation capabilities in terms of (1) clarification capability and (2) professional advice quality. This unified framework incorporates 12 metrics across two dimensions. Through extensive experiments on various general and domain-specific LLMs, our results reveal significant challenges in this task, with even state-of-the-art models like GPT-4 achieving only 39.8% recall for clarification and 59% overall score for advice quality, highlighting the complexity of professional consultation scenarios. Based on these findings, we further explore several strategies to enhance LLMs’ legal consultation abilities. Our benchmark contributes to advancing research in legal domain dialogue systems, particularly in simulating more real-world user-expert interactions.
法律咨询对于保护个人权利和确保获得公正至关重要,然而由于专业人员短缺,许多个人仍然觉得成本高昂且难以获得咨询。虽然大型语言模型(LLM)的最新进展为可扩展和低成本法律援助提供了一条充满希望的道路,但当前的系统在处理现实世界中交互和知识密集型的咨询方面还存在不足。为了应对这些挑战,我们引入了LeCoDe,这是一个现实世界多轮基准数据集,包含3696个法律咨询对话和110008个对话回合。LeCoDe旨在评估和改进LLM的法律咨询能力。我们通过从短视频平台直播收集咨询对话,提供真实的多轮法律咨询对话。法律专家的严格注释进一步增强了数据集的专业见解和专业知识。此外,我们提出了一个全面的评估框架,该框架从(1)澄清能力和(2)专业建议质量两个方面评估LLM的咨询能力。这一统一框架包含两个维度的12个指标。通过对各种通用和特定领域的LLM进行广泛实验,我们的结果表明,在这一任务中仍存在重大挑战,即使是最先进的模型如GPT-4,其澄清召回率仅为39.8%,建议质量的总体得分也只有59%,这凸显了专业咨询场景的复杂性。基于这些发现,我们进一步探索了几种增强LLM法律咨询能力的策略。我们的基准测试有助于推进法律领域对话系统的研究,特别是在模拟更真实世界用户与专家互动方面。
论文及项目相关链接
Summary:
法律咨询服务对于保障个人权益和确保公正至关重要,但其成本高昂且难以触及许多人,主要由于专业人才短缺。大型语言模型(LLM)的最新进展为大规模、低成本法律援助铺平了道路,但现有系统仍难以处理现实咨询中的交互和知识密集型特性。为解决这些挑战,引入了LeCoDe数据集,这是一个包含3696个法律咨询对话和110008个对话回合的真实世界多轮基准数据集,旨在评估和改进LLM的法律咨询能力。该数据集通过短视频平台收集现场法律咨询对话,由法律专家进行严格注释,提供专业的见解和专业知识。此外,还提出了一个全面的评估框架,该框架评估LLM的咨询能力包括澄清能力和专业建议质量两个方面,涵盖12个指标。通过在不同的一般和特定领域的LLM上进行广泛实验,结果显示,即使是最先进的模型如GPT-4,在澄清和建议质量方面仍存在显著挑战。基于此,进一步探索了增强LLM法律咨询能力的策略。该基准数据集对推进法律领域对话系统研究,特别是在模拟更多现实世界用户与专家互动方面具有重要意义。
Key Takeaways:
- 法律咨询服务对个人权益保障和公正至关重要,但成本高昂且难以触及许多人。
- 大型语言模型(LLM)为法律援助提供了新的可能性,但仍面临处理现实咨询的交互和知识密集型特性的挑战。
- 引入了LeCoDe数据集,包含真实的法律咨询对话和严格的法律专家注释,为评估和改进LLM的法律咨询能力提供了基准。
- 全面的评估框架包括澄清能力和专业建议质量两个方面,涵盖12个指标。
- 先进模型如GPT-4在法律咨询方面仍存在挑战。
- 探索了增强LLM法律咨询能力的策略。
点此查看论文截图