⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-05-28 更新
Zero-Shot Streaming Text to Speech Synthesis with Transducer and Auto-Regressive Modeling
Authors:Haiyang Sun, Shujie Hu, Shujie Liu, Lingwei Meng, Hui Wang, Bing Han, Yifan Yang, Yanqing Liu, Sheng Zhao, Yan Lu, Yanmin Qian
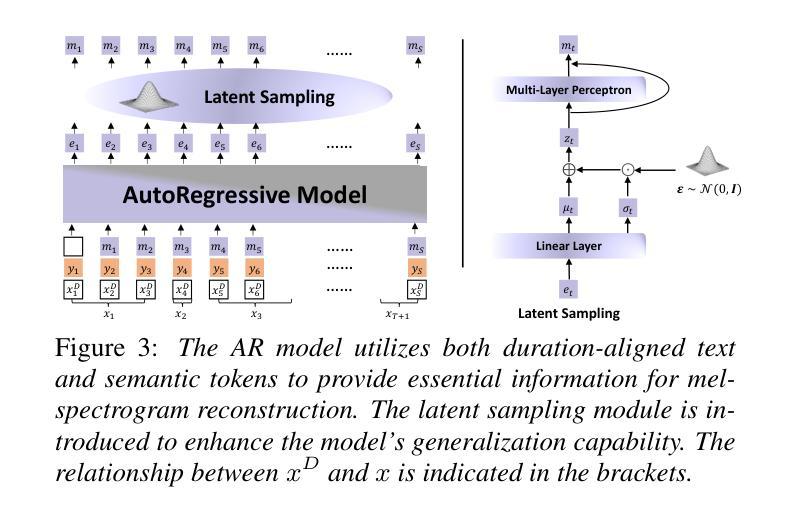
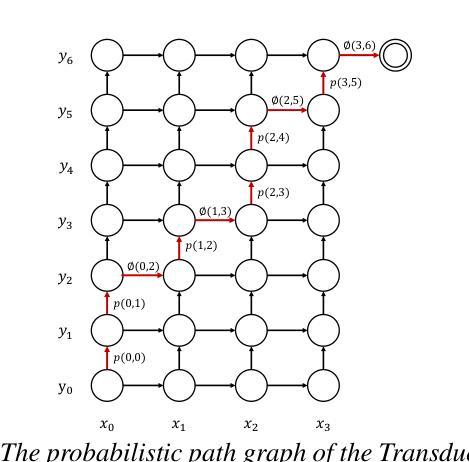
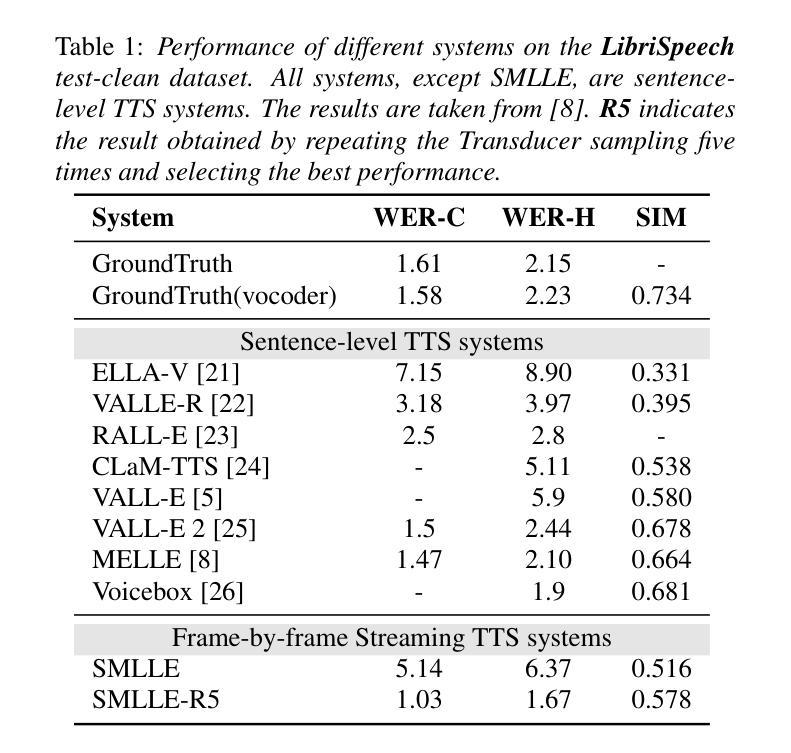
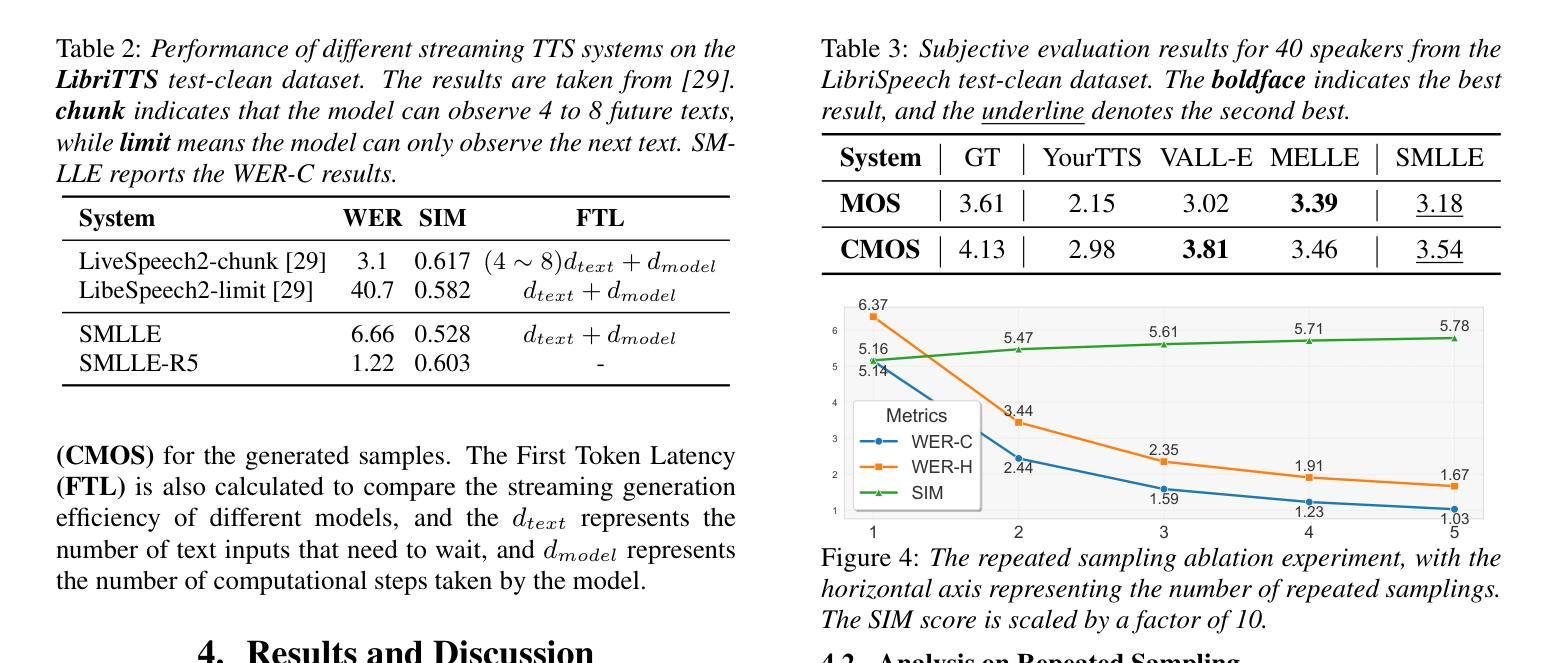
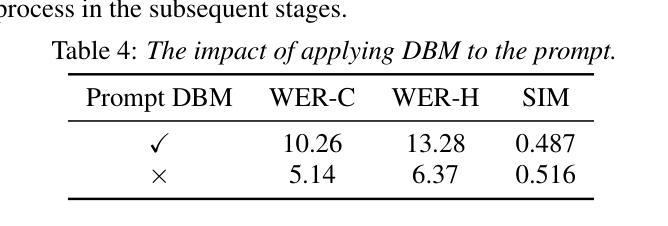
Zero-shot streaming text-to-speech is an important research topic in human-computer interaction. Existing methods primarily use a lookahead mechanism, relying on future text to achieve natural streaming speech synthesis, which introduces high processing latency. To address this issue, we propose SMLLE, a streaming framework for generating high-quality speech frame-by-frame. SMLLE employs a Transducer to convert text into semantic tokens in real time while simultaneously obtaining duration alignment information. The combined outputs are then fed into a fully autoregressive (AR) streaming model to reconstruct mel-spectrograms. To further stabilize the generation process, we design a Delete < Bos > Mechanism that allows the AR model to access future text introducing as minimal delay as possible. Experimental results suggest that the SMLLE outperforms current streaming TTS methods and achieves comparable performance over sentence-level TTS systems. Samples are available on https://anonymous.4open.science/w/demo_page-48B7/.
零样本流式文本到语音转换是计算机人机交互领域的一个重要研究课题。现有的方法主要使用前视机制,依靠未来的文本实现自然的流式语音合成,这引入了很高的处理延迟。为了解决这一问题,我们提出了SMLLE,这是一个用于逐帧生成高质量语音的流式框架。SMLLE使用转换器将文本实时转换为语义令牌,同时获得持续时间对齐信息。然后将这些组合输出馈入完全自回归(AR)流式模型,以重建梅尔频谱图。为了进一步稳定生成过程,我们设计了一种删除
机制,允许AR模型访问未来的文本,并尽量减少延迟。实验结果表明,SMLLE优于当前的流式TTS方法,并在句子级TTS系统上取得了相当的性能。样本可通过https://anonymous.4open.science/w/demo_page-48B7/访问。
论文及项目相关链接
Summary
本文提出一种名为SMLLE的零样本流式文本转语音生成框架,解决了现有方法处理延迟高的问题。通过实时将文本转换为语义标记并获取时长对齐信息,再输入全自回归(AR)流式模型重建梅尔频谱图,实现高质量语音帧生成。设计删除
Key Takeaways
- SMLLE是一个用于生成高质量语音的零样本流式文本转语音框架。
- 采用Transducer实时将文本转换为语义标记并获取时长对齐信息。
- 结合语义标记和时长对齐信息输入全自回归(AR)流式模型。
- 通过重建梅尔频谱图实现高质量语音帧生成。
- 设计删除
机制以稳定生成过程并减少延迟。 - 实验结果表明,SMLLE在流式TTS方法中表现优异。
点此查看论文截图

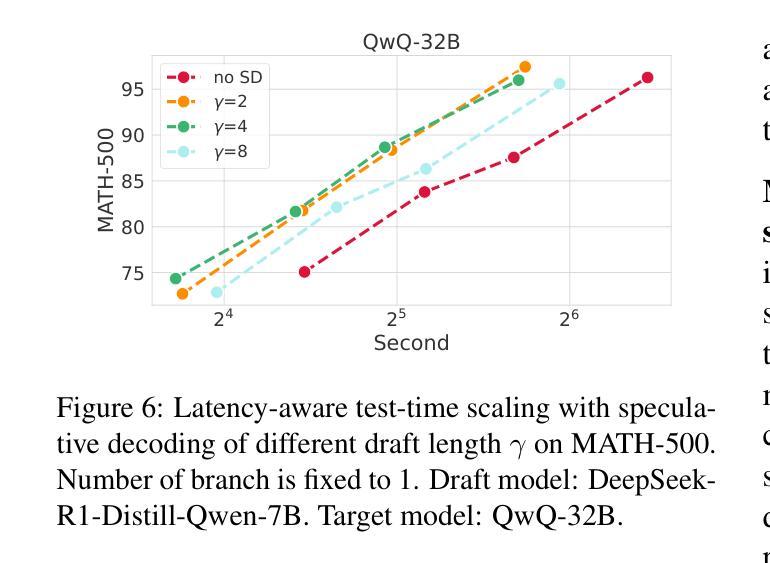
Faster and Better LLMs via Latency-Aware Test-Time Scaling
Authors:Zili Wang, Tianyu Zhang, Haoli Bai, Lu Hou, Xianzhi Yu, Wulong Liu, Shiming Xiang, Lei Zhu
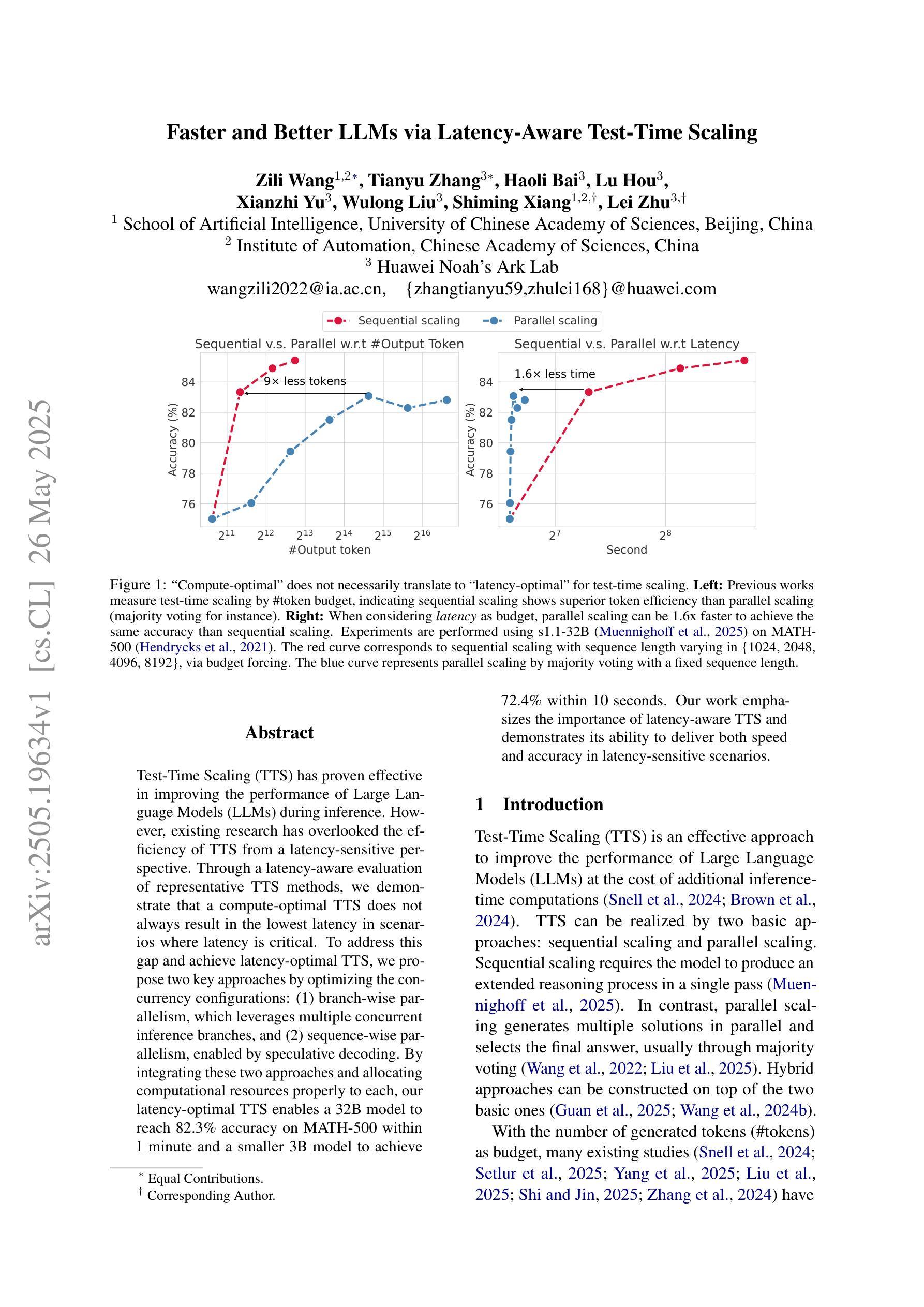
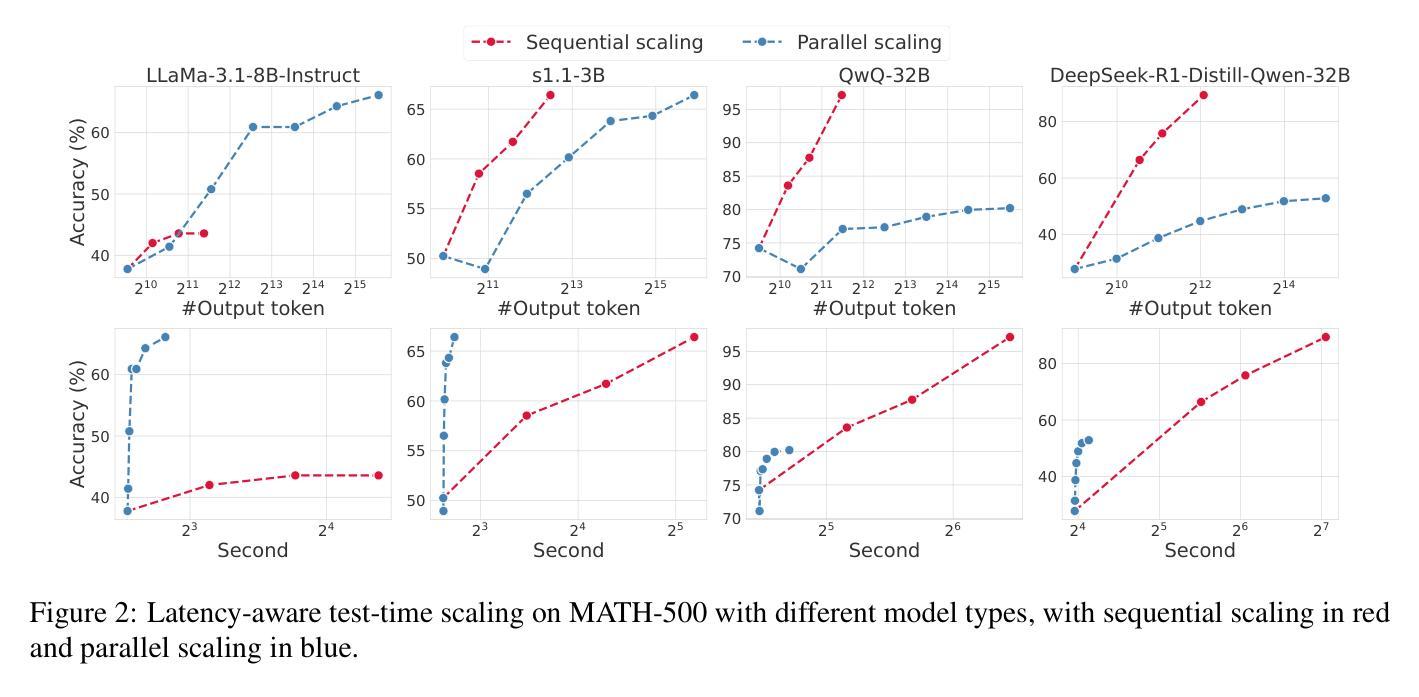
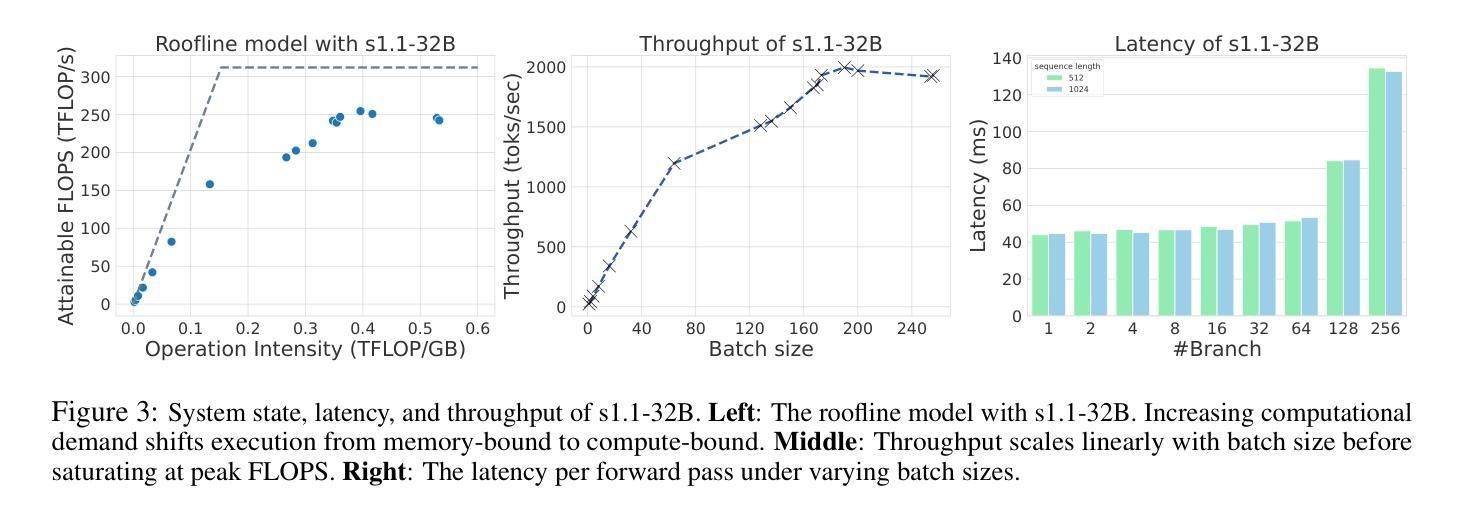
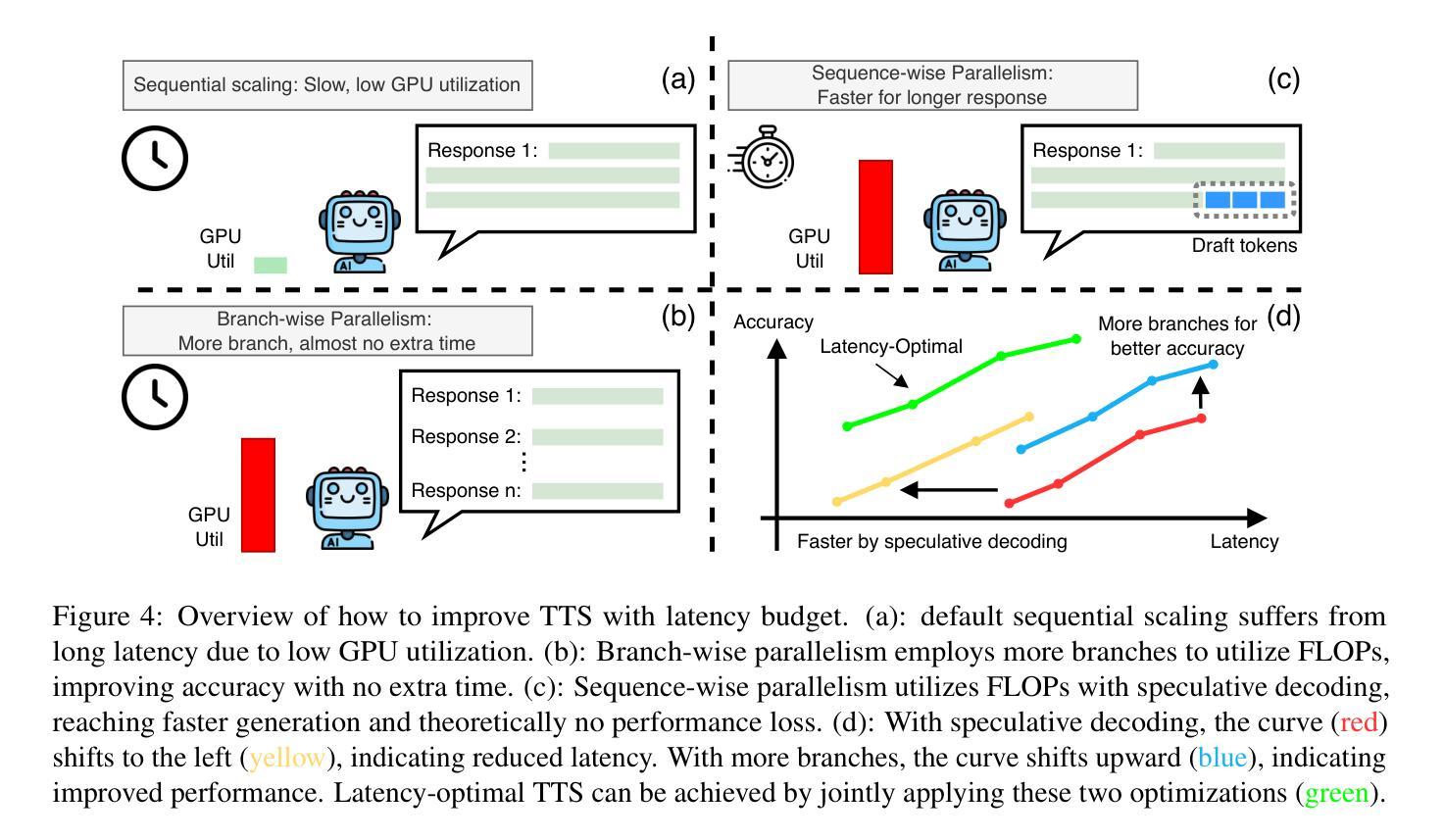
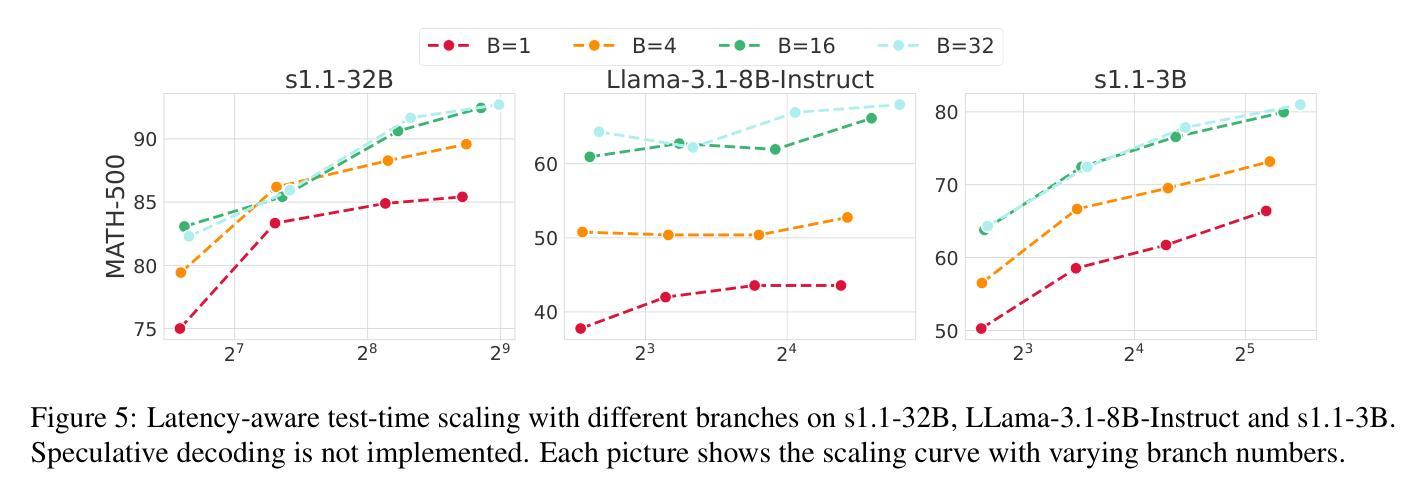
Test-Time Scaling (TTS) has proven effective in improving the performance of Large Language Models (LLMs) during inference. However, existing research has overlooked the efficiency of TTS from a latency-sensitive perspective. Through a latency-aware evaluation of representative TTS methods, we demonstrate that a compute-optimal TTS does not always result in the lowest latency in scenarios where latency is critical. To address this gap and achieve latency-optimal TTS, we propose two key approaches by optimizing the concurrency configurations: (1) branch-wise parallelism, which leverages multiple concurrent inference branches, and (2) sequence-wise parallelism, enabled by speculative decoding. By integrating these two approaches and allocating computational resources properly to each, our latency-optimal TTS enables a 32B model to reach 82.3% accuracy on MATH-500 within 1 minute and a smaller 3B model to achieve 72.4% within 10 seconds. Our work emphasizes the importance of latency-aware TTS and demonstrates its ability to deliver both speed and accuracy in latency-sensitive scenarios.
测试时间缩放(TTS)已被证明可以有效提高大型语言模型(LLM)在推理过程中的性能。然而,现有研究从延迟敏感的角度忽视了TTS的效率。通过对代表性TTS方法进行延迟感知评估,我们证明计算最优的TTS并不总是导致最低延迟,这在延迟至关重要的场景中尤为重要。为了解决这一差距并实现延迟最优的TTS,我们提出了两种通过优化并发配置的关键方法:(1)分支并行性,利用多个并发推理分支;(2)序列并行性,通过投机解码实现。通过整合这两种方法并为每种方法适当分配计算资源,我们的延迟最优TTS使32B模型在MATH-500上1分钟内达到82.3%的准确率,较小的3B模型在10秒内达到72.4%的准确率。我们的工作强调了延迟感知TTS的重要性,并展示了其在延迟敏感场景中实现速度和准确性的能力。
论文及项目相关链接
Summary
测试时间缩放(TTS)在提升大型语言模型(LLM)推理性能上效果显著。然而,现有研究从延迟敏感的角度忽视了TTS的效率。我们通过延迟感知的代表性TTS方法评估,证明了计算最优的TTS并不总是导致最低延迟,这在延迟至关重要的情况下尤为如此。为了弥补这一差距并实现延迟最优的TTS,我们提出了两种通过优化并发配置的关键方法:(1)分支并行性,利用多个并发推理分支;(2)序列并行性,通过投机解码实现。通过整合这两种方法并为每种方法适当分配计算资源,我们的延迟最优TTS使32B模型在MATH-500上1分钟内达到82.3%的准确率,较小的3B模型在10秒内达到72.4%的准确率。我们的工作强调了延迟感知TTS的重要性,并展示了其在延迟敏感场景中实现速度和准确性的能力。
Key Takeaways
- TTS在提高LLM推理性能上有效,但现有研究未充分关注其延迟效率。
- 计算最优的TTS并不总是导致最低延迟,特别是在延迟敏感的情况下。
- 提出两种优化TTS并发配置的方法:分支并行性和序列并行性。
- 分支并行性利用多个并发推理分支。
- 序列并行性通过投机解码实现。
- 整合这两种方法并适当分配计算资源,可实现延迟最优的TTS。
点此查看论文截图
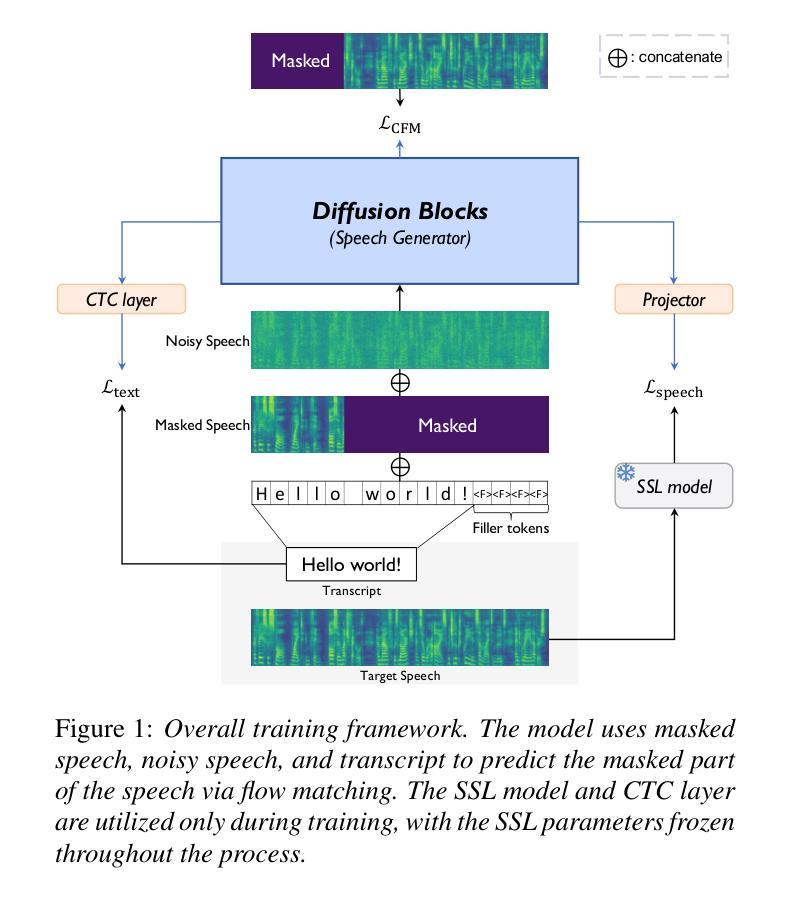
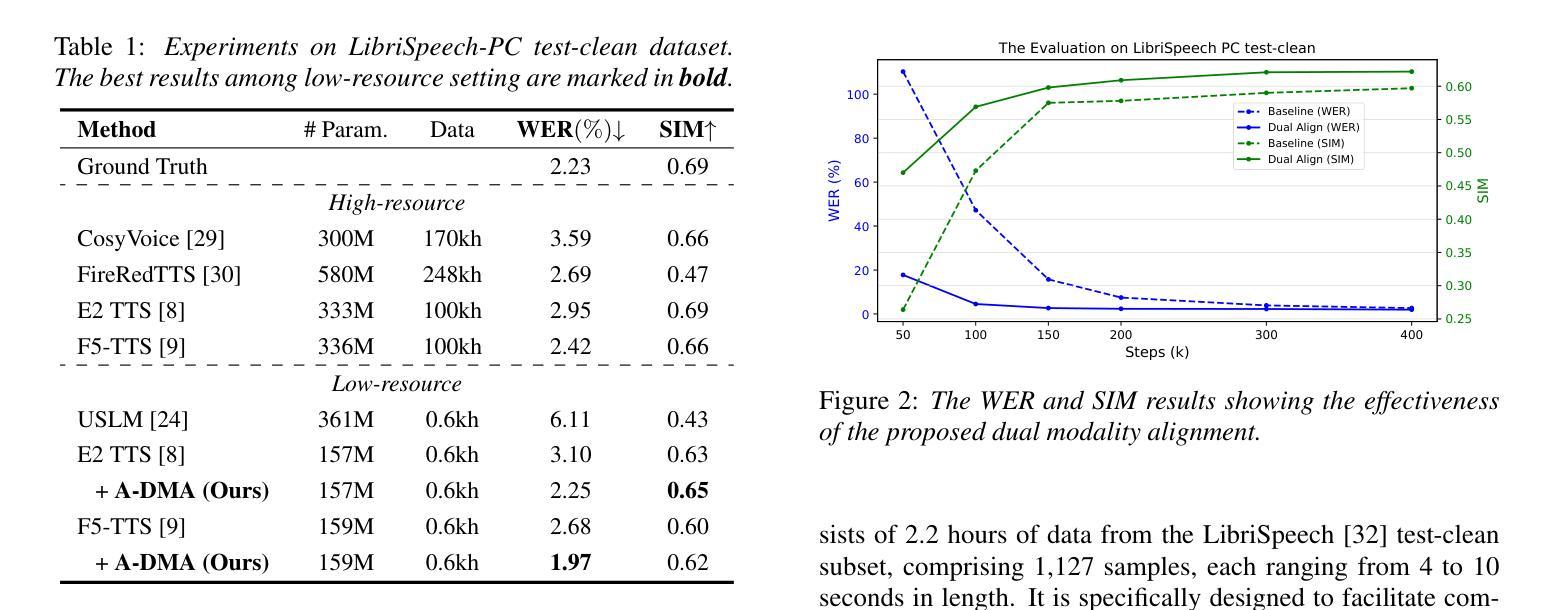
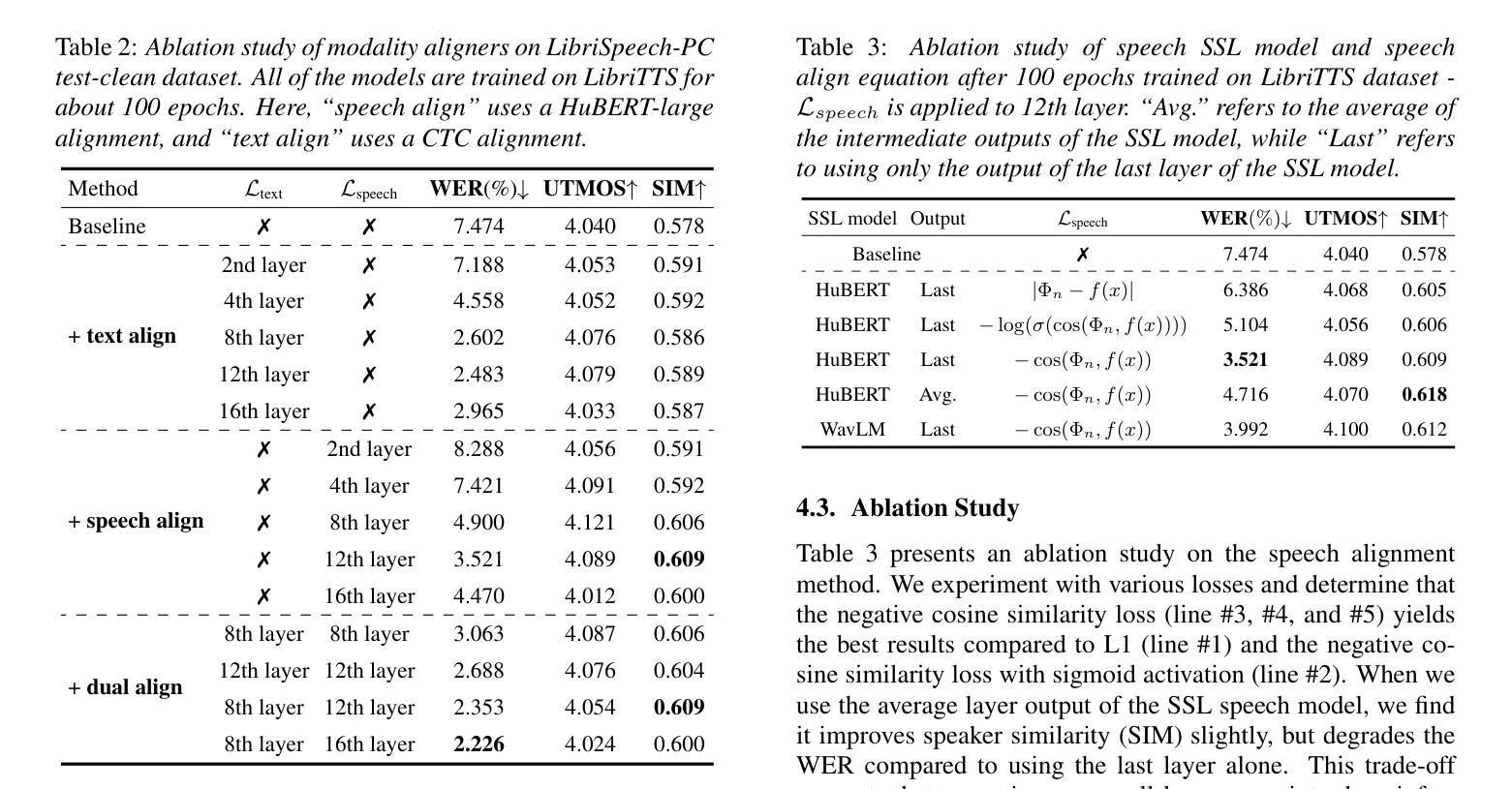
Accelerating Diffusion-based Text-to-Speech Model Training with Dual Modality Alignment
Authors:Jeongsoo Choi, Zhikang Niu, Ji-Hoon Kim, Chunhui Wang, Joon Son Chung, Chen Xie
The goal of this paper is to optimize the training process of diffusion-based text-to-speech models. While recent studies have achieved remarkable advancements, their training demands substantial time and computational costs, largely due to the implicit guidance of diffusion models in learning complex intermediate representations. To address this, we propose A-DMA, an effective strategy for Accelerating training with Dual Modality Alignment. Our method introduces a novel alignment pipeline leveraging both text and speech modalities: text-guided alignment, which incorporates contextual representations, and speech-guided alignment, which refines semantic representations. By aligning hidden states with discriminative features, our training scheme reduces the reliance on diffusion models for learning complex representations. Extensive experiments demonstrate that A-DMA doubles the convergence speed while achieving superior performance over baselines. Code and demo samples are available at: https://github.com/ZhikangNiu/A-DMA
本文的目标是优化基于扩散的文本到语音模型的训练过程。虽然最近的研究取得了显著的进步,但它们的训练需要大量的时间和计算成本,这主要是因为扩散模型在学习复杂中间表示时的隐式指导。为了解决这一问题,我们提出了A-DMA,一种利用双模态对齐加速训练的有效策略。我们的方法引入了一个新的对齐管道,利用文本和语音两种模式:文本引导对齐,它结合了上下文表示;语音引导对齐,它改进了语义表示。通过隐藏状态与判别特征的对齐,我们的训练方案减少了扩散模型在学习复杂表示上的依赖。大量实验表明,A-DMA的收敛速度提高了一倍,同时相对于基线达到了卓越的性能。代码和演示样本可在:<https://github.com/ZhikangNiu/A-DMA 观看。
论文及项目相关链接
PDF Interspeech 2025
Summary
文本主要介绍了如何优化基于扩散的文本到语音模型的训练过程。为了解决扩散模型训练时间长、计算成本高的痛点,提出了一种新的加速训练策略A-DMA。通过融合文本和语音模态的双模态对齐方式,加快模型收敛速度并提升性能。实验结果证明,使用A-DMA策略的模型训练速度翻倍,性能优于基线模型。相关代码和演示样本已上传至GitHub。
Key Takeaways
- 该论文旨在优化基于扩散的文本到语音模型的训练过程。
- 训练过程中存在时间长和计算成本高的痛点。
- 提出了一种新的加速训练策略A-DMA,通过双模态对齐方式融合文本和语音模态。
- A-DMA策略包括文本引导对齐和语音引导对齐两种方式。
- 通过与基线模型对比实验,证明使用A-DMA策略的模型训练速度翻倍且性能更优。
- A-DMA策略通过减少扩散模型对复杂表示的依赖,提高了模型的收敛速度和性能。
点此查看论文截图

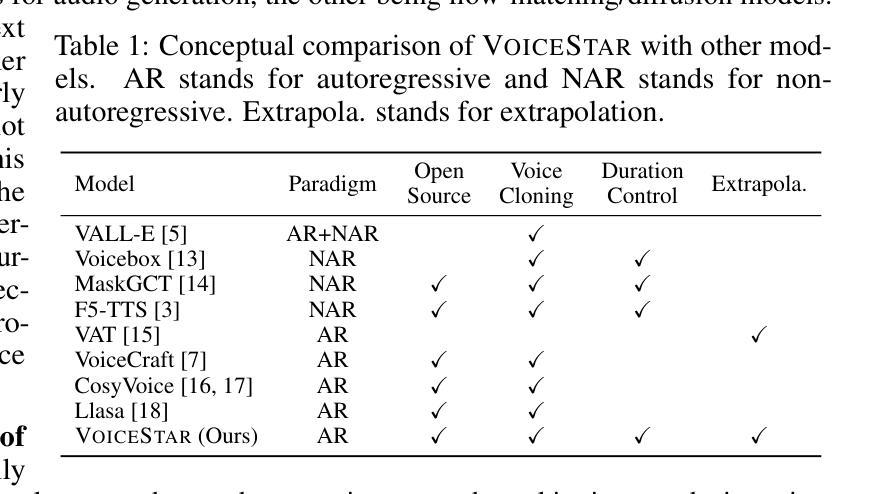
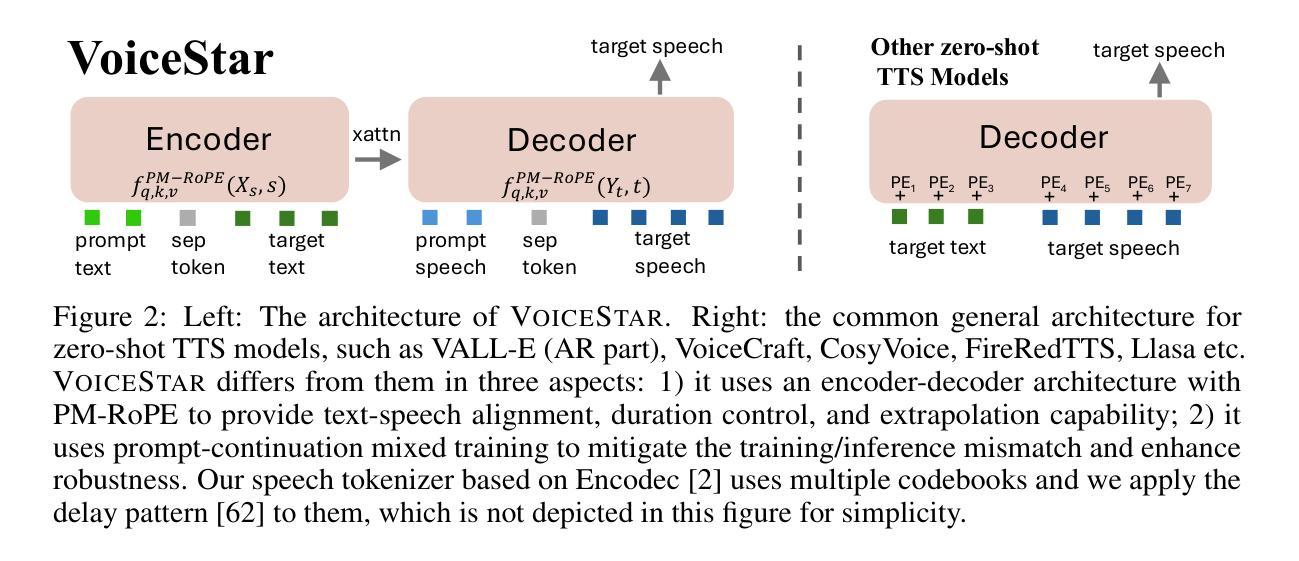
VoiceStar: Robust Zero-Shot Autoregressive TTS with Duration Control and Extrapolation
Authors:Puyuan Peng, Shang-Wen Li, Abdelrahman Mohamed, David Harwath
We present VoiceStar, the first zero-shot TTS model that achieves both output duration control and extrapolation. VoiceStar is an autoregressive encoder-decoder neural codec language model, that leverages a novel Progress-Monitoring Rotary Position Embedding (PM-RoPE) and is trained with Continuation-Prompt Mixed (CPM) training. PM-RoPE enables the model to better align text and speech tokens, indicates the target duration for the generated speech, and also allows the model to generate speech waveforms much longer in duration than those seen during. CPM training also helps to mitigate the training/inference mismatch, and significantly improves the quality of the generated speech in terms of speaker similarity and intelligibility. VoiceStar outperforms or is on par with current state-of-the-art models on short-form benchmarks such as Librispeech and Seed-TTS, and significantly outperforms these models on long-form/extrapolation benchmarks (20-50s) in terms of intelligibility and naturalness. Code and model weights: https://github.com/jasonppy/VoiceStar
我们推出了VoiceStar,这是第一个实现输出时长控制和外推功能的零样本TTS模型。VoiceStar是一种基于自回归编码器-解码器神经网络的语言模型,它采用新型进度监控旋转位置嵌入(PM-RoPE),并通过连续提示混合(CPM)进行训练。PM-RoPE使模型能够更好地对齐文本和语音标记,指示生成语音的目标时长,并允许模型生成比训练过程中更长的语音波形。CPM训练也有助于减轻训练/推断不匹配的问题,并显著提高生成语音的说话人相似度和清晰度。VoiceStar在诸如Librispeech和Seed-TTS等短期基准测试上的表现优于或相当于当前的最先进模型,在长期/外推基准测试(20-50秒)的清晰度和自然度方面则大大优于这些模型。代码和模型权重:https://github.com/jasonppy/VoiceStar
论文及项目相关链接
Summary
VoiceStar是一款零样本TTS模型,具备输出时长控制与外推能力。它采用自回归编码解码器神经网络模型结构,并运用新型Progress-Monitoring Rotary Position Embedding(PM-RoPE)技术与Continuation-Prompt Mixed(CPM)训练方法。PM-RoPE使模型能更好地对齐文本与语音标记,并指示生成语音的目标时长,同时能生成比训练过程中更长的语音波形。CPM训练有助于减轻训练/推理不匹配问题,并显著提高生成语音的说话人相似度与清晰度。VoiceStar在短形式基准测试(如Librispeech和Seed-TTS)上表现优异或相当,并在长形式/外推基准测试(20-50秒)上显著优于其他模型,在清晰度和自然度方面尤为突出。
Key Takeaways
- VoiceStar是首款实现输出时长控制与外推的零样本TTS模型。
- 采用自回归编码解码器神经网络模型结构。
- 引入Progress-Monitoring Rotary Position Embedding(PM-RoPE)技术,改善文本与语音标记的对齐,并指示目标时长。
- 使用Continuation-Prompt Mixed(CPM)训练方法,提高生成语音质量,并缓解训练/推理不匹配问题。
- VoiceStar在短形式基准测试上表现优秀,同时在长形式基准测试上显著优于其他模型。
- 模型仓库与权重公开,便于研究与应用。
点此查看论文截图

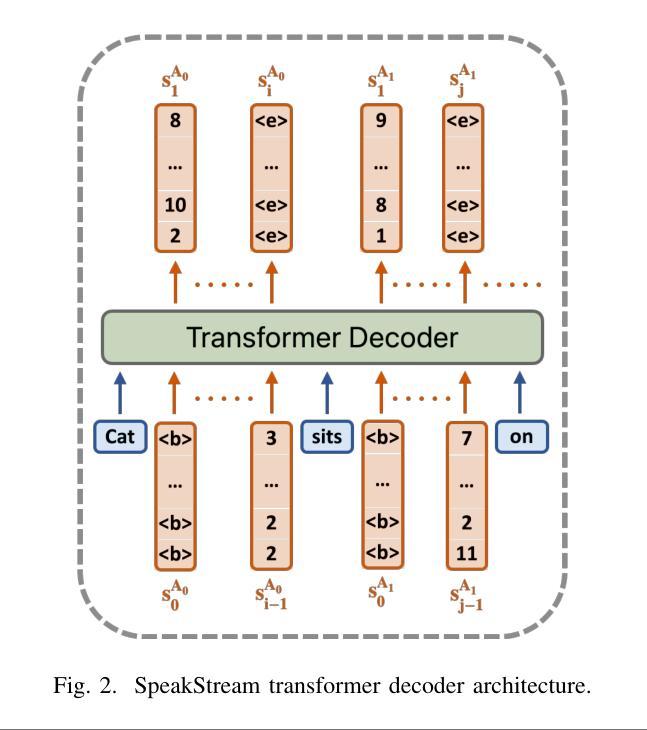
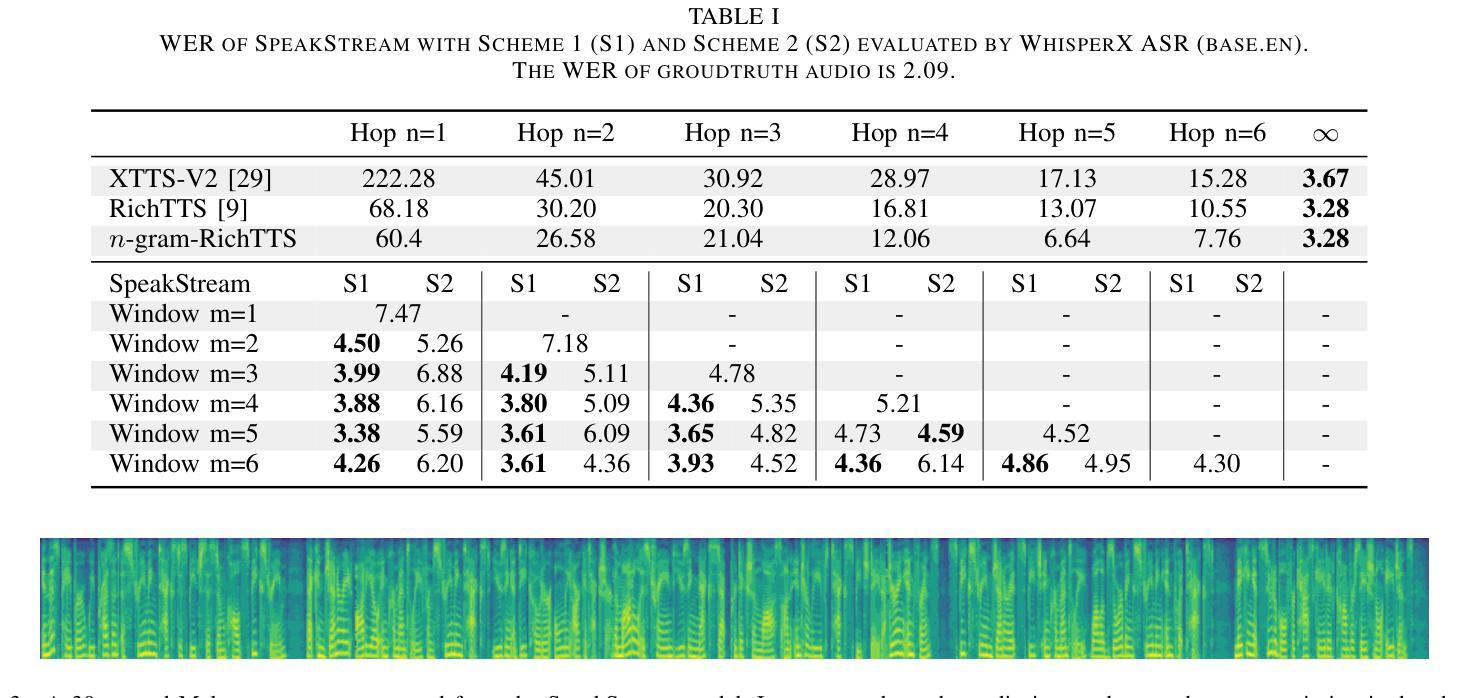
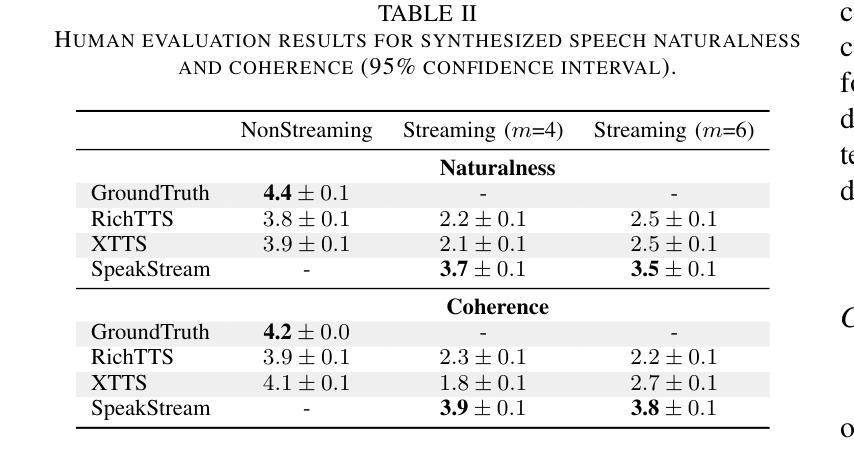
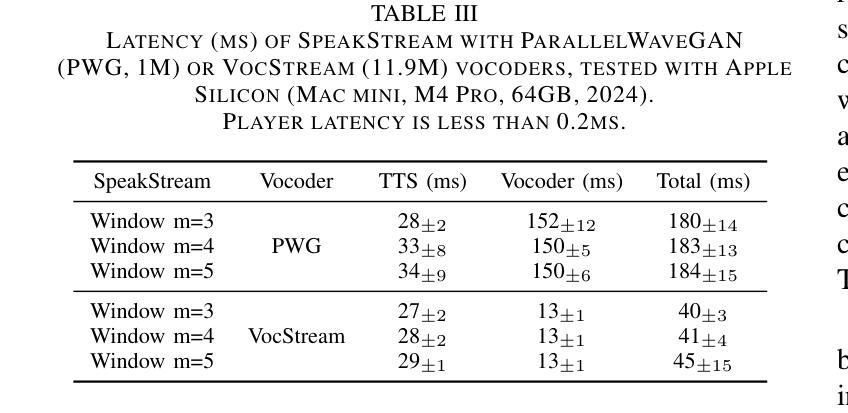
SpeakStream: Streaming Text-to-Speech with Interleaved Data
Authors:Richard He Bai, Zijin Gu, Tatiana Likhomanenko, Navdeep Jaitly
The latency bottleneck of traditional text-to-speech (TTS) systems fundamentally hinders the potential of streaming large language models (LLMs) in conversational AI. These TTS systems, typically trained and inferenced on complete utterances, introduce unacceptable delays, even with optimized inference speeds, when coupled with streaming LLM outputs. This is particularly problematic for creating responsive conversational agents where low first-token latency is critical. In this paper, we present SpeakStream, a streaming TTS system that generates audio incrementally from streaming text using a decoder-only architecture. SpeakStream is trained using a next-step prediction loss on interleaved text-speech data. During inference, it generates speech incrementally while absorbing streaming input text, making it particularly suitable for cascaded conversational AI agents where an LLM streams text to a TTS system. Our experiments demonstrate that SpeakStream achieves state-of-the-art latency results in terms of first-token latency while maintaining the quality of non-streaming TTS systems.
传统文本转语音(TTS)系统的延迟瓶颈从根本上阻碍了流式大型语言模型(LLM)在对话式人工智能中的潜力。这些TTS系统通常在对完整的发言进行训练和推理,当与流式LLM输出相结合时,即使以优化的推理速度,也会引入不可接受的延迟。这对于创建响应式的对话代理来说特别成问题,其中低首字延迟至关重要。在本文中,我们提出了SpeakStream,这是一个流式TTS系统,它使用仅解码器架构从流式文本中增量生成音频。SpeakStream使用交替的文本-语音数据上的下一步预测损失进行训练。在推理过程中,它在吸收流式输入文本的同时增量生成语音,因此特别适合用于级联对话AI代理,其中LLM将文本流式传输到TTS系统。我们的实验表明,SpeakStream在首字延迟方面达到了最先进的延迟结果,同时保持了非流式TTS系统的质量。
论文及项目相关链接
Summary
本文介绍了SpeakStream这一流式文本转语音(TTS)系统,它能从流式文本中增量生成音频。与传统的TTS系统相比,SpeakStream在生成语音时能够处理流式输入文本,解决了传统TTS系统延迟的问题,尤其适用于级联对话式AI代理。实验表明,SpeakStream在首字延迟方面达到了最先进的性能,同时保持了非流式TTS系统的质量。
Key Takeaways
- 传统TTS系统的延迟问题限制了其在对话式AI中流式大型语言模型(LLM)的潜力。
- SpeakStream是一种流式TTS系统,能从流式文本中增量生成音频,解决了延迟问题。
- SpeakStream采用解码器仅架构,使用下一步预测损失对交替的文本-语音数据进行训练。
- 在推理过程中,SpeakStream能增量生成语音,同时吸收流式输入文本。
- SpeakStream特别适用于级联对话式AI代理,其中LLM将文本流式传输到TTS系统。
- 实验表明,SpeakStream在首字延迟方面达到最新技术状态,同时保持语音质量。
点此查看论文截图

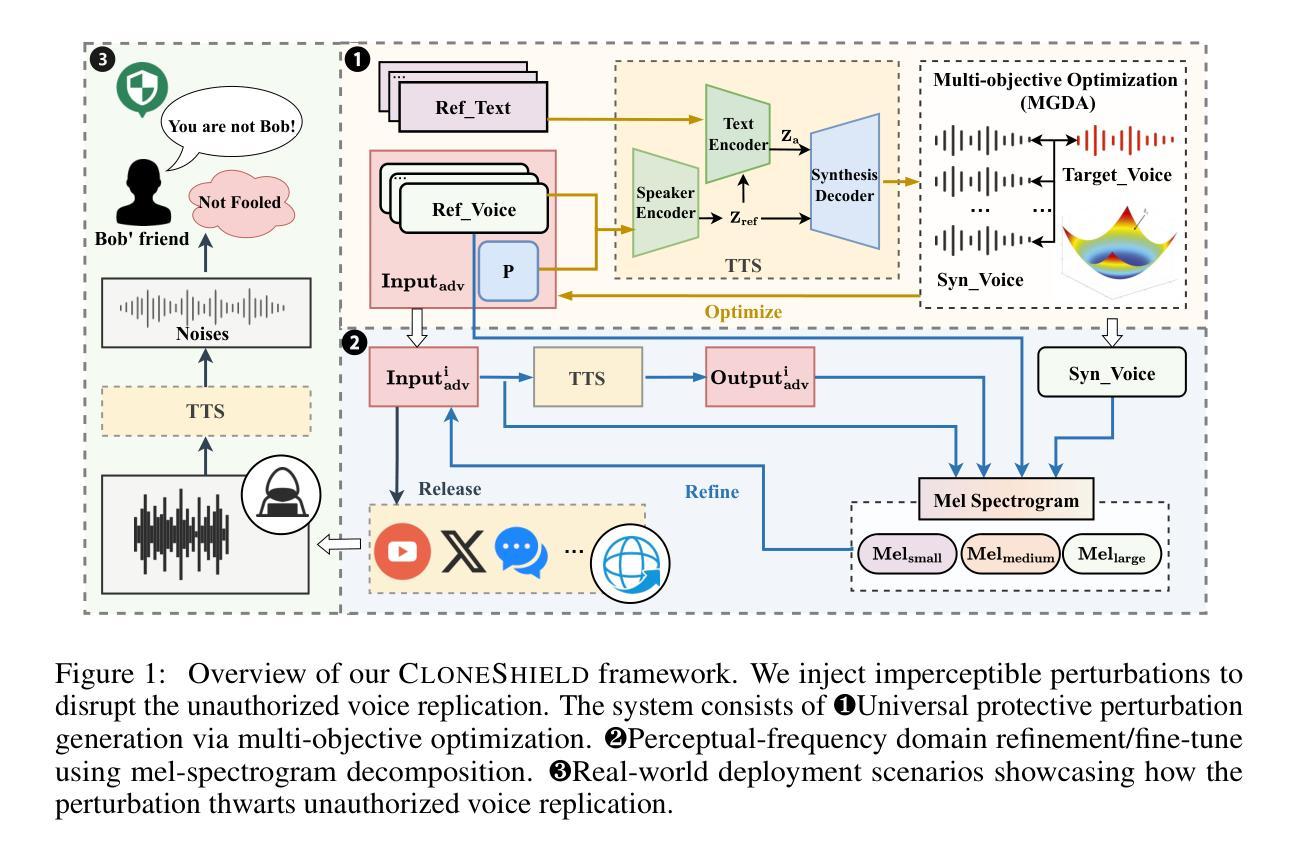
CloneShield: A Framework for Universal Perturbation Against Zero-Shot Voice Cloning
Authors:Renyuan Li, Zhibo Liang, Haichuan Zhang, Tianyu Shi, Zhiyuan Cheng, Jia Shi, Carl Yang, Mingjie Tang
Recent breakthroughs in text-to-speech (TTS) voice cloning have raised serious privacy concerns, allowing highly accurate vocal identity replication from just a few seconds of reference audio, while retaining the speaker’s vocal authenticity. In this paper, we introduce CloneShield, a universal time-domain adversarial perturbation framework specifically designed to defend against zero-shot voice cloning. Our method provides protection that is robust across speakers and utterances, without requiring any prior knowledge of the synthesized text. We formulate perturbation generation as a multi-objective optimization problem, and propose Multi-Gradient Descent Algorithm (MGDA) to ensure the robust protection across diverse utterances. To preserve natural auditory perception for users, we decompose the adversarial perturbation via Mel-spectrogram representations and fine-tune it for each sample. This design ensures imperceptibility while maintaining strong degradation effects on zero-shot cloned outputs. Experiments on three state-of-the-art zero-shot TTS systems, five benchmark datasets and evaluations from 60 human listeners demonstrate that our method preserves near-original audio quality in protected inputs (PESQ = 3.90, SRS = 0.93) while substantially degrading both speaker similarity and speech quality in cloned samples (PESQ = 1.07, SRS = 0.08).
在文本转语音(TTS)声音克隆方面的最新突破引发了严重的隐私担忧。现在只需几秒钟的参考音频,就可以实现高度精确的嗓音身份复制,同时保留说话者的嗓音真实性。本文介绍了CloneShield,这是一个专门设计用于防范零样本声音克隆的通用时间域对抗性扰动框架。我们的方法为跨说话者和话语提供了保护,无需对合成文本有任何先验知识。我们将扰动生成制定为一个多目标优化问题,并提出多梯度下降算法(MGDA),以确保在不同的话语中提供稳健的保护。为了保持用户自然的听觉感知,我们通过梅尔频谱表示法分解对抗性扰动,并针对每个样本进行微调。这种设计确保了不可察觉性,同时在对零样本克隆输出进行强烈降解时保持强大的保护效果。在三个最先进的零样本TTS系统、五个基准数据集以及60名人类听者的评估中进行的实验表明,我们的方法在保证受保护输入接近原始音频质量的同时(PESQ = 3.90,SRS = 0.93),大幅度降低了克隆样本中的说话人相似度和语音质量(PESQ = 1.07,SRS = 0.08)。
论文及项目相关链接
PDF 10pages, 4figures
Summary
最新文本转语音(TTS)语音克隆技术的突破引发了严重的隐私担忧,该技术仅需几秒的参考音频即可实现高度准确的语音身份复制,同时保留说话者的语音真实性。本文介绍CloneShield,一种专门针对零样本语音克隆的通用时间域对抗性扰动框架。该方法提供跨说话者和不同话语的鲁棒保护,无需了解合成文本的背景知识。通过制定多目标优化问题,提出了多梯度下降算法(MGDA),以确保在不同话语之间的强大保护能力。为了保留用户听觉的自然感知效果并保留每个样本的独特性,我们通过梅尔频谱图表示法分解对抗性扰动并进行微调。实验表明,该方法在保护输入音频质量的同时,对零样本克隆输出产生了显著的干扰效果。
Key Takeaways
- 最新TTS语音克隆技术引发隐私担忧,能仅通过几秒参考音频实现高度准确的语音身份复制。
- CloneShield是一个对抗性扰动框架,旨在防御零样本语音克隆,提供跨说话者和话语的鲁棒保护。
- CloneShield不需要了解合成文本的背景知识。
- 通过多目标优化问题制定扰动生成,并提出多梯度下降算法(MGDA)确保保护效果。
- 为保留自然听觉感知和用户体验,通过梅尔频谱图表示法分解并微调对抗性扰动。
- 实验证明CloneShield能有效保护输入音频质量,同时显著干扰零样本克隆输出。
点此查看论文截图



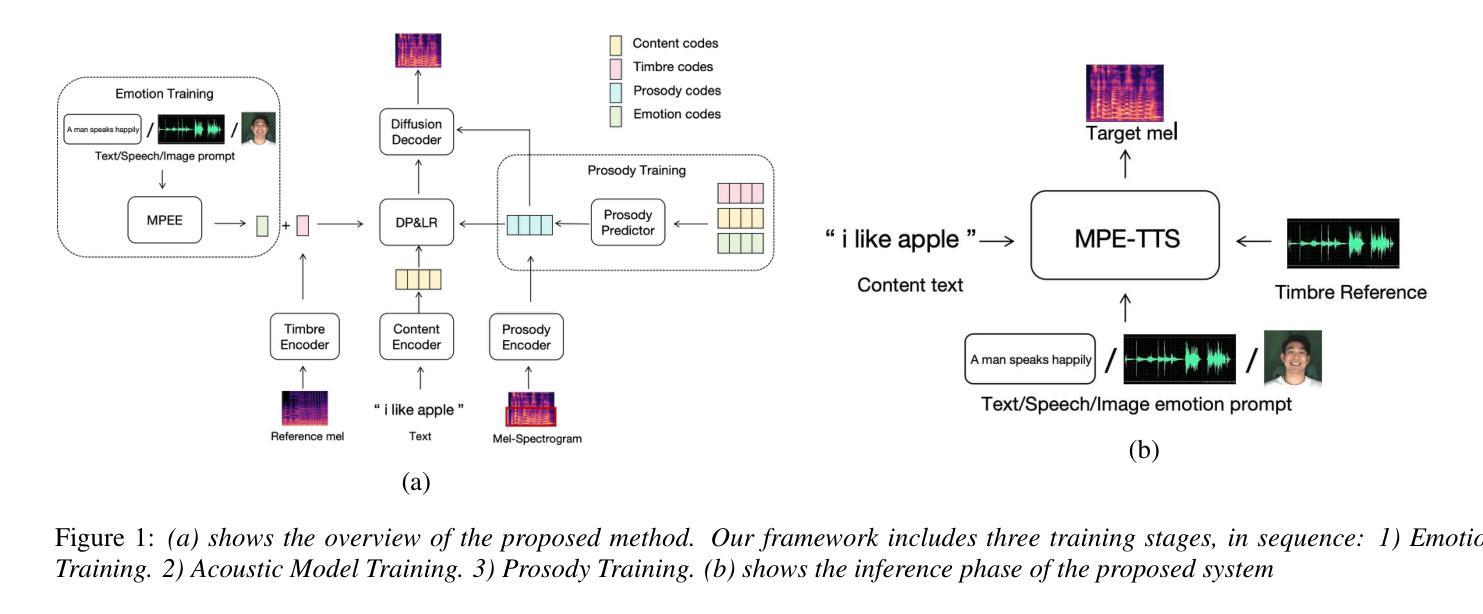
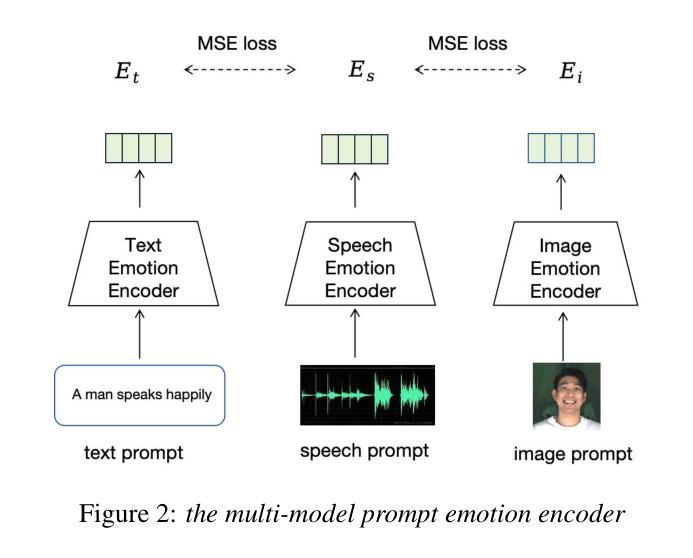
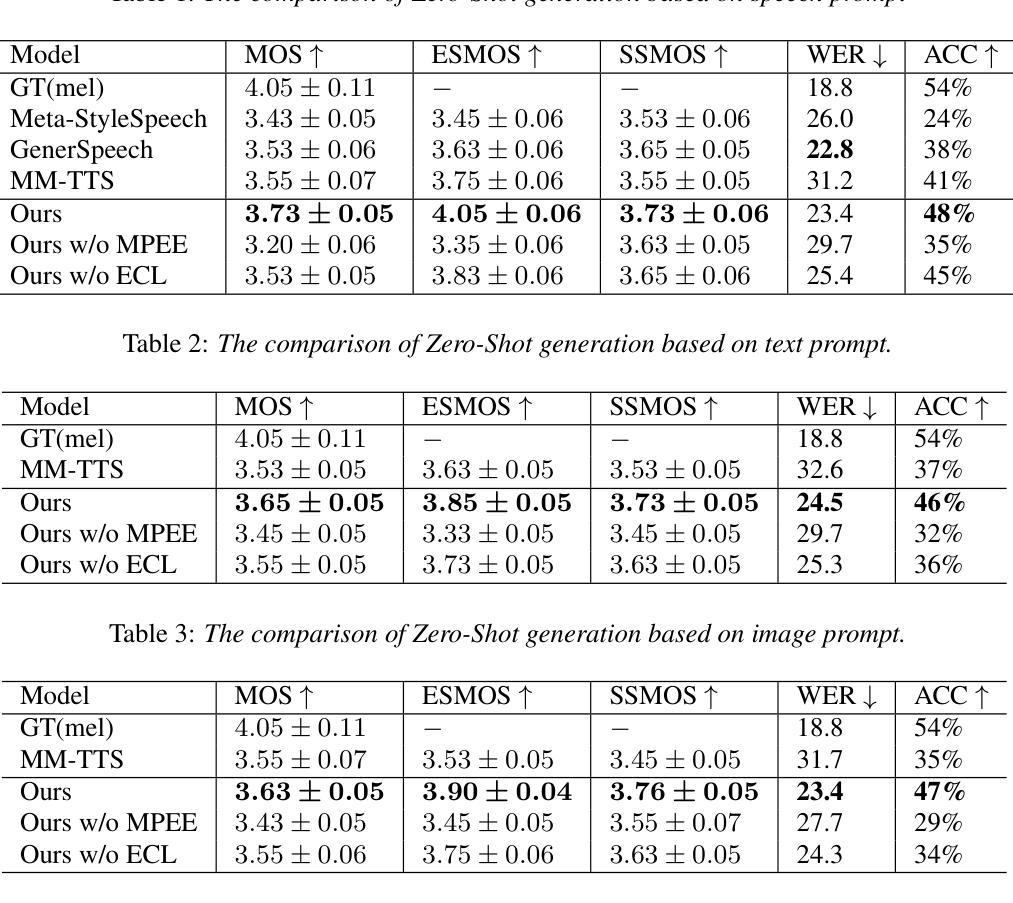
MPE-TTS: Customized Emotion Zero-Shot Text-To-Speech Using Multi-Modal Prompt
Authors:Zhichao Wu, Yueteng Kang, Songjun Cao, Long Ma, Qiulin Li, Qun Yang
Most existing Zero-Shot Text-To-Speech(ZS-TTS) systems generate the unseen speech based on single prompt, such as reference speech or text descriptions, which limits their flexibility. We propose a customized emotion ZS-TTS system based on multi-modal prompt. The system disentangles speech into the content, timbre, emotion and prosody, allowing emotion prompts to be provided as text, image or speech. To extract emotion information from different prompts, we propose a multi-modal prompt emotion encoder. Additionally, we introduce an prosody predictor to fit the distribution of prosody and propose an emotion consistency loss to preserve emotion information in the predicted prosody. A diffusion-based acoustic model is employed to generate the target mel-spectrogram. Both objective and subjective experiments demonstrate that our system outperforms existing systems in terms of naturalness and similarity. The samples are available at https://mpetts-demo.github.io/mpetts_demo/.
现有的大多数零样本文本转语音(ZS-TTS)系统都是基于单一提示(如参考语音或文本描述)来生成未见过的语音,这限制了它们的灵活性。我们提出了一种基于多模态提示的定制情感ZS-TTS系统。该系统将语音分解为内容、音色、情感和韵律,允许以文本、图像或语音的形式提供情感提示。为了从不同提示中提取情感信息,我们提出了一种多模态提示情感编码器。此外,我们引入了一个韵律预测器以适应韵律分布,并提出了一种情感一致性损失,以在预测的韵律中保留情感信息。采用基于扩散的声学模型来生成目标梅尔频谱图。客观和主观实验均表明,我们的系统在自然度和相似性方面优于现有系统。样本可通过链接https://mpetts-demo.github.io/mpetts 科普小验Demo试用版. 下载查看。
论文及项目相关链接
PDF Accepted by InterSpeech
Summary
本文提出一种基于多模态提示的定制情感Zero-Shot Text-To-Speech(ZS-TTS)系统。该系统将语音分解为内容、音质、情感和语调,允许以文本、图像或语音的形式提供情感提示。通过多模态提示情感编码器和情感一致性损失等技术,提高了系统的情感表达能力和自然度。采用扩散声学模型生成目标梅尔频谱图,在客观和主观实验中表现出优异性能。
Key Takeaways
- ZS-TTS系统通常基于单一提示生成未见语音,限制了其灵活性。
- 本文提出了一种基于多模态提示的定制情感ZS-TTS系统,可接收多种形式的情感提示(如文本、图像或语音)。
- 系统将语音分解为内容、音质、情感和语调,提高了情感表达的丰富性。
- 引入多模态提示情感编码器,用于从不同提示中提取情感信息。
- 引入语调预测器,以拟合语调分布。
- 通过情感一致性损失技术,保留预测语调中的情感信息。
点此查看论文截图

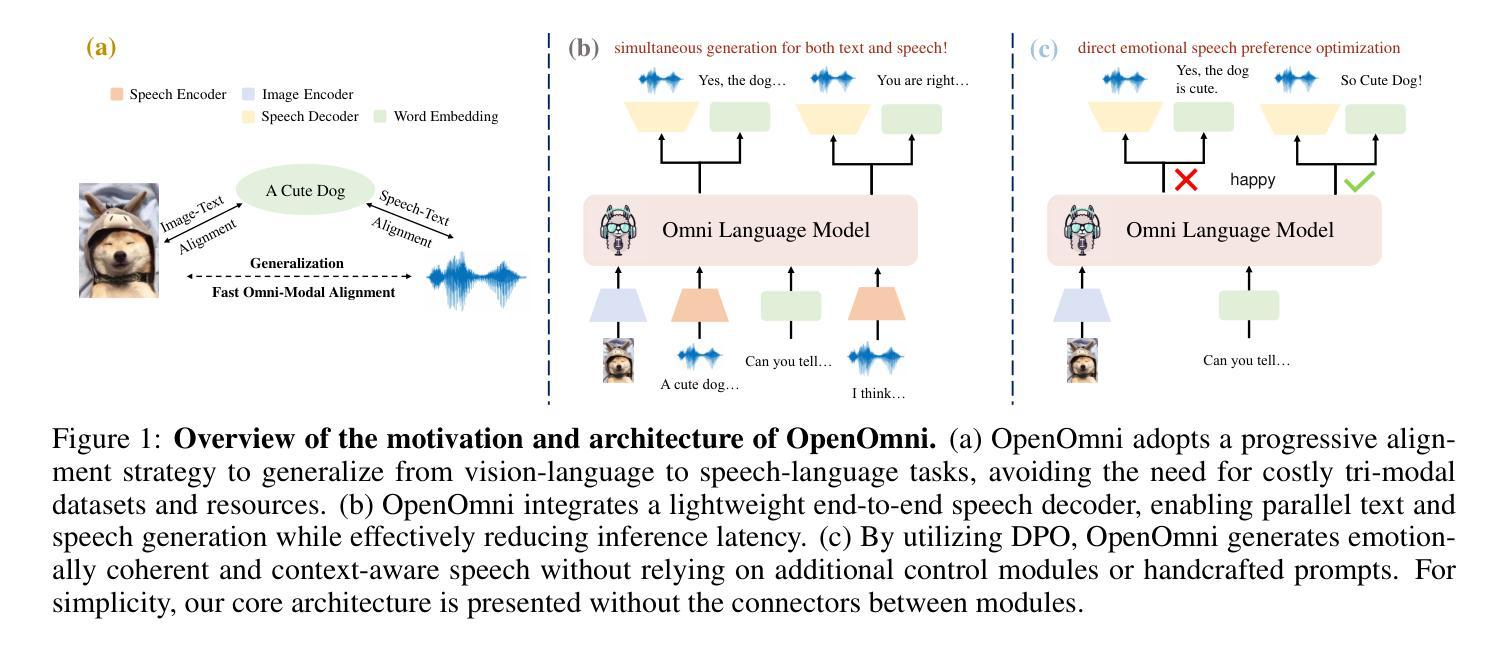
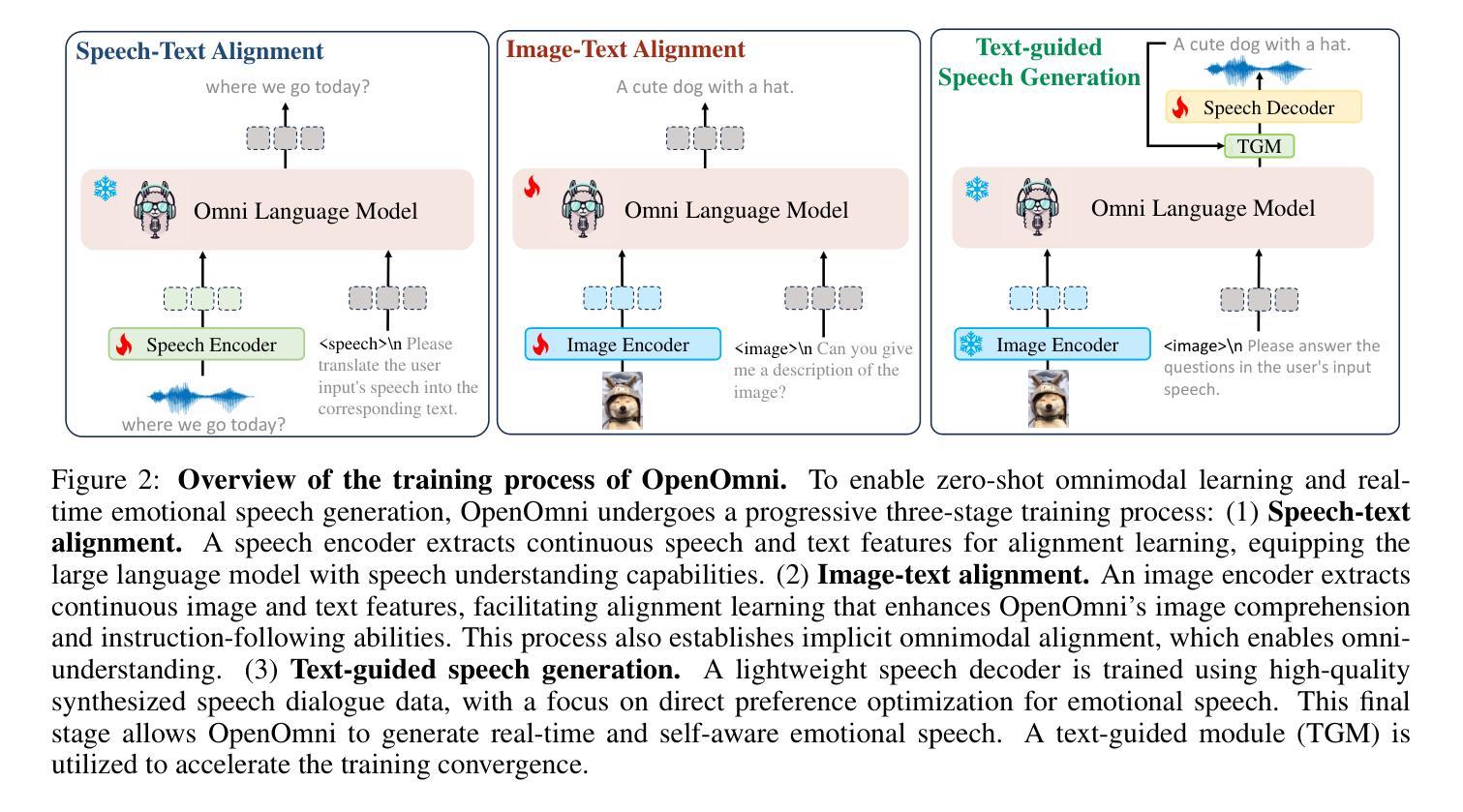
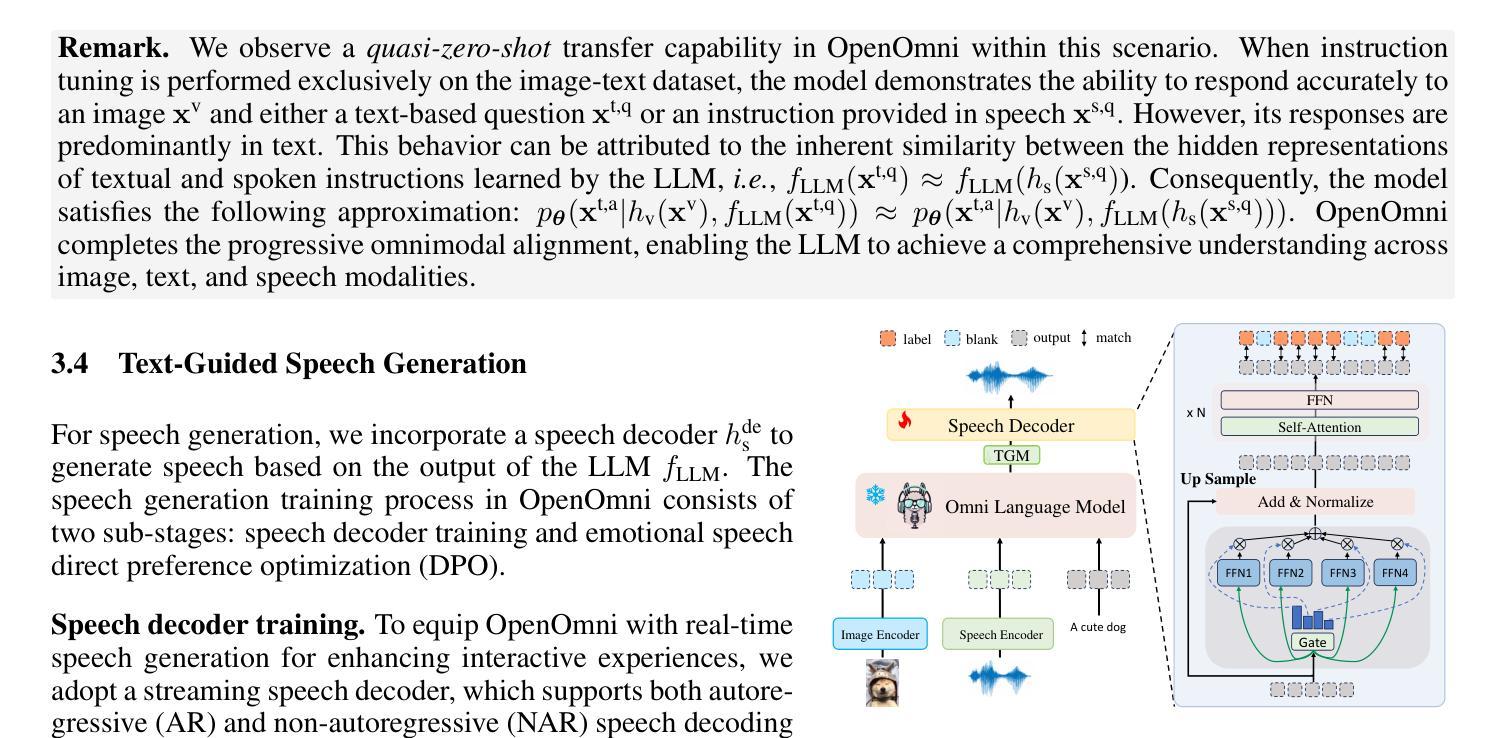
OpenOmni: Advancing Open-Source Omnimodal Large Language Models with Progressive Multimodal Alignment and Real-Time Self-Aware Emotional Speech Synthesis
Authors:Run Luo, Ting-En Lin, Haonan Zhang, Yuchuan Wu, Xiong Liu, Min Yang, Yongbin Li, Longze Chen, Jiaming Li, Lei Zhang, Yangyi Chen, Xiaobo Xia, Hamid Alinejad-Rokny, Fei Huang
Recent advancements in omnimodal learning have significantly improved understanding and generation across images, text, and speech, yet these developments remain predominantly confined to proprietary models. The lack of high-quality omnimodal datasets and the challenges of real-time emotional speech synthesis have notably hindered progress in open-source research. To address these limitations, we introduce \name, a two-stage training framework that integrates omnimodal alignment and speech generation to develop a state-of-the-art omnimodal large language model. In the alignment phase, a pre-trained speech model undergoes further training on text-image tasks, enabling (near) zero-shot generalization from vision to speech, outperforming models trained on tri-modal datasets. In the speech generation phase, a lightweight decoder is trained on speech tasks with direct preference optimization, enabling real-time emotional speech synthesis with high fidelity. Experiments show that \name surpasses state-of-the-art models across omnimodal, vision-language, and speech-language benchmarks. It achieves a 4-point absolute improvement on OmniBench over the leading open-source model VITA, despite using 5x fewer training samples and a smaller model size (7B vs. 7x8B). Additionally, \name achieves real-time speech generation with <1s latency at non-autoregressive mode, reducing inference time by 5x compared to autoregressive methods, and improves emotion classification accuracy by 7.7%
虽然近期多模态学习的进展在图像、文本和语音的理解与生成方面有了显著提升,但这些发展主要局限于专有模型。缺乏高质量的多模态数据集以及实时情感语音合成的挑战,显著阻碍了开源研究的进展。为了解决这些限制,我们引入了名为“XX”的两阶段训练框架,该框架融合了多模态对齐和语音生成,以开发先进的多模态大型语言模型。在对齐阶段,预训练的语音模型在文本-图像任务上接受进一步训练,实现了从视觉到语音的(接近)零样本泛化,超越了那些在三元模态数据集上训练的模型。在语音生成阶段,一个轻量级的解码器在语音任务上进行直接偏好优化训练,能够实现高保真度的实时情感语音合成。实验表明,“XX”在多模态、视觉语言和语音语言基准测试中超越了最先进的模型。尽管使用了较少的训练样本和较小的模型规模(7B vs. 7x8B),但在OmniBench上相对于领先的开源模型VITA仍有4个绝对点的改进。此外,“XX”在非自回归模式下实现了实时语音生成,延迟时间小于1秒,与自回归方法相比减少了5倍的推理时间,并提高了情感分类准确率7. 除此之外,“XX”在非自回归模式下实现了实时语音生成,延迟时间低于每秒一帧(小于1秒),相较于自回归方法减少了五倍的推理时间,并提升了情感分类准确率至百分之七点七。这是一个在多模态融合领域的重要突破,有望为未来的研究和应用开辟新的道路。
论文及项目相关链接
Summary
近期多模态学习领域的进展在图像、文本和语音的理解与生成方面取得了显著成果,但主要局限于专有模型。缺乏高质量的多模态数据集以及实时情感语音合成的挑战限制了开源研究的进展。为解决这些问题,我们推出了名为“名称”的两阶段训练框架,它融合了多模态对齐和语音生成,以开发先进的多模态大型语言模型。“名称”包含对齐阶段和语音生成阶段,通过对预训练语音模型进行文本-图像任务的进一步训练,实现了从视觉到语音的零样本或近似零样本泛化,并在三模态数据集上表现出优越性能。在语音生成阶段,使用轻量级解码器进行语音任务的直接偏好优化训练,实现了高保真度的实时情感语音合成。实验表明,“名称”在多模态、视觉语言和语音语言基准测试中超越了现有技术最先进的模型。相较于领先的开源模型VITA,“名称”在OmniBench上实现了4个点的绝对改进,尽管其使用的训练样本数量更少(5倍),模型规模也更小(7B对7x8B)。此外,“名称”实现了非自回归模式下的实时语音生成,延迟时间小于1秒,与自回归方法相比,推理时间缩短了5倍,情感分类准确率提高了7.7%。
Key Takeaways
- “名称”是一个两阶段的多模态训练框架,用于开发先进的大型语言模型。
- 对齐阶段通过文本-图像任务进一步训练预训练语音模型,实现视觉到语音的泛化。
- 在对齐阶段,“名称”表现优于三模态数据集上的模型。
- 语音生成阶段使用轻量级解码器进行直接偏好优化训练,实现实时情感语音合成。
- “名称”在多模态基准测试中表现出卓越性能,超越了现有技术最先进的模型。
- “名称”相较于其他模型使用更少的训练样本和更小的模型规模取得了优越的性能。
点此查看论文截图

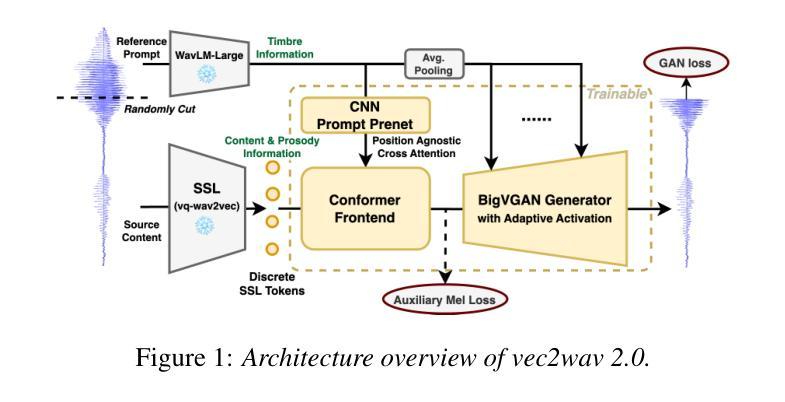
vec2wav 2.0: Advancing Voice Conversion via Discrete Token Vocoders
Authors:Yiwei Guo, Zhihan Li, Junjie Li, Chenpeng Du, Hankun Wang, Shuai Wang, Xie Chen, Kai Yu
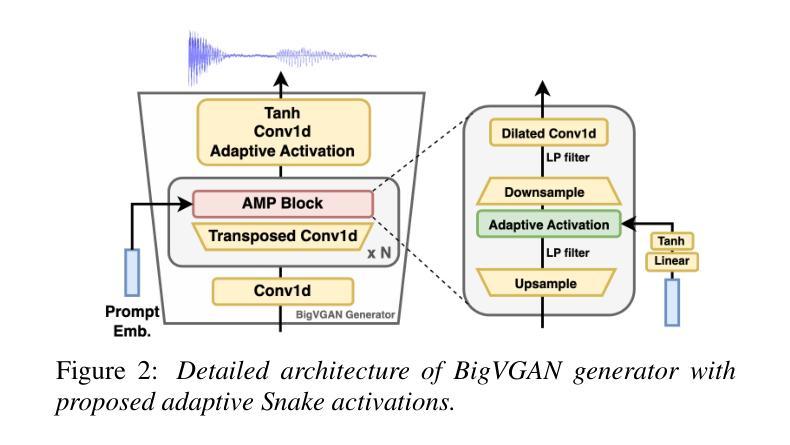
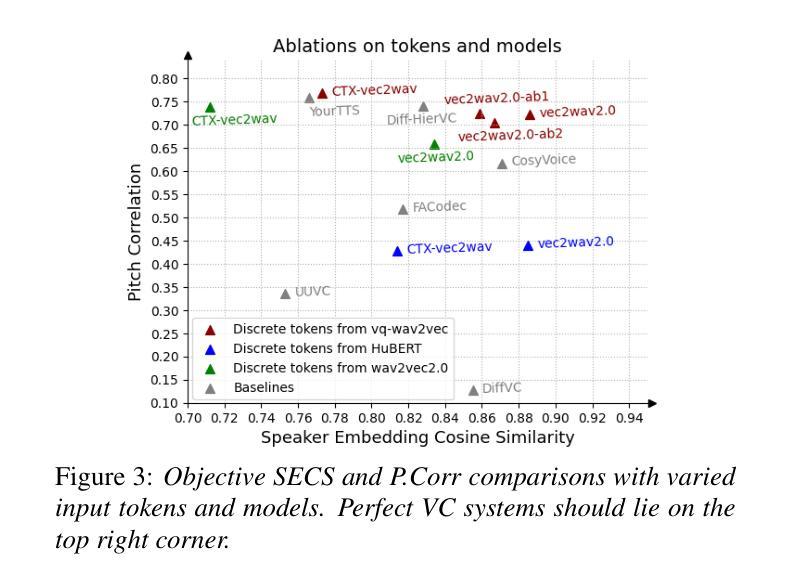
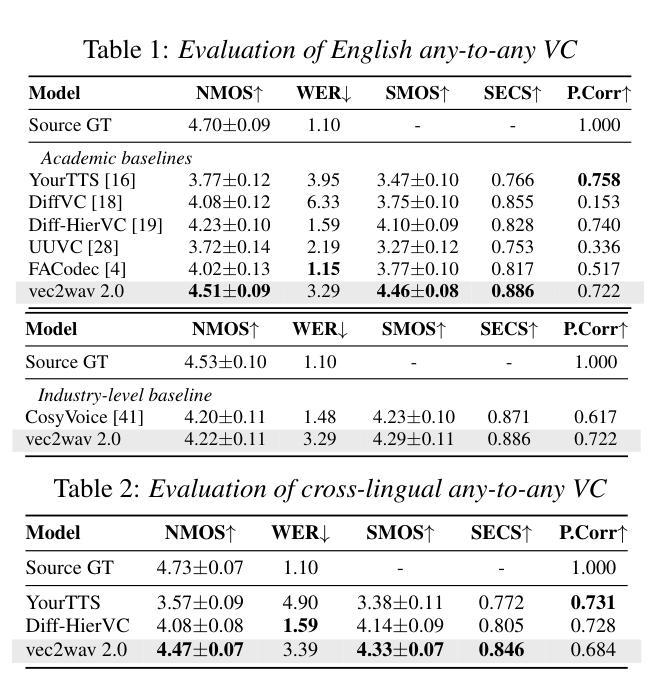
We propose a new speech discrete token vocoder, vec2wav 2.0, which advances voice conversion (VC). We use discrete tokens from speech self-supervised models as the content features of source speech, and treat VC as a prompted vocoding task. To amend the loss of speaker timbre in the content tokens, vec2wav 2.0 utilizes the WavLM features to provide strong timbre-dependent information. A novel adaptive Snake activation function is proposed to better incorporate timbre into the waveform reconstruction process. In this way, vec2wav 2.0 learns to alter the speaker timbre appropriately given different reference prompts. Also, no supervised data is required for vec2wav 2.0 to be effectively trained. Experimental results demonstrate that vec2wav 2.0 outperforms all other baselines to a considerable margin in terms of audio quality and speaker similarity in any-to-any VC. Ablation studies verify the effects made by the proposed techniques. Moreover, vec2wav 2.0 achieves competitive cross-lingual VC even only trained on monolingual corpus. Thus, vec2wav 2.0 shows timbre can potentially be manipulated only by speech token vocoders, pushing the frontiers of VC and speech synthesis.
我们提出了一种新的语音离散令牌编码器,vec2wav 2.0,它推进了语音转换(VC)的技术。我们使用语音自监督模型的离散令牌作为源语音的内容特征,并将VC视为一个提示性的编码任务。为了弥补内容令牌中说话者音色的损失,vec2wav 2.0利用WavLM特征提供强大的音色相关信息。提出了一种新型的自适应Snake激活函数,以更好地将音色融入波形重建过程。通过这种方式,vec2wav 2.0能够在给定不同的参考提示的情况下,学会适当地改变说话者的音色。此外,不需要监督数据来有效地训练vec2wav 2.0。实验结果表明,在任意到任意的VC中,vec2wav 2.0在音频质量和说话者相似性方面大大优于所有其他基线。消融研究验证了所提出技术的效果。此外,vec2wav 2.0即使在仅使用单语语料库进行训练的情况下,也实现了具有竞争力的跨语言VC。因此,vec2wav 2.0表明,音色可能仅通过语音令牌编码器进行操纵,从而推动了VC和语音合成的边界。
论文及项目相关链接
PDF 5 pages, 3 figures, 2 tables. Demo page: https://cantabile-kwok.github.io/vec2wav2/
Summary
基于离散令牌的新语音离散令牌编解码器vec2wav 2.0的提出推动了语音转换(VC)的进步。该编解码器使用语音自监督模型的离散令牌作为源语音的内容特征,并将VC视为提示编解码任务。为了弥补内容令牌中的说话者音色损失,vec2wav 2.0利用WavLM特征提供强大的音色相关信息。此外,提出了一种新的自适应Snake激活函数,以更好地将音色融入波形重建过程。因此,vec2wav 2.0能够在给定不同参考提示的情况下学习适当地改变说话者的音色。此外,训练vec2wav 2.0无需监督数据。实验结果证明,在任意到任意的VC中,vec2wav 2.0在音频质量和说话者相似性方面都大大优于所有其他基线。消融研究验证了所提出技术的效果。而且,即使在仅使用单语语料库进行训练的情况下,vec2wav 2.0也能实现跨语言VC的竞争性能。因此,vec2wav 2.0显示了音色仅通过语音令牌编解码器进行操作的可能性,推动了VC和语音合成的前沿。
Key Takeaways
- vec2wav 2.0是一种新的语音离散令牌编解码器,用于推动语音转换的进步。
- 它使用语音自监督模型的离散令牌作为源语音的内容特征,并将语音转换视为提示编解码任务。
- WavLM特征用于提供强大的音色相关信息,以弥补内容令牌中的音色损失。
- 引入了一种新的自适应Snake激活函数,以改善音色在波形重建过程中的融入。
- vec2wav 2.0能够在给定不同参考提示的情况下学习改变说话者的音色,且无需监督数据。
- 在音频质量和说话者相似性方面,vec2wav 2.0显著优于其他方法,实现了有竞争力的跨语言语音转换性能。
点此查看论文截图