⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-05-28 更新
HunyuanVideo-Avatar: High-Fidelity Audio-Driven Human Animation for Multiple Characters
Authors:Yi Chen, Sen Liang, Zixiang Zhou, Ziyao Huang, Yifeng Ma, Junshu Tang, Qin Lin, Yuan Zhou, Qinglin Lu
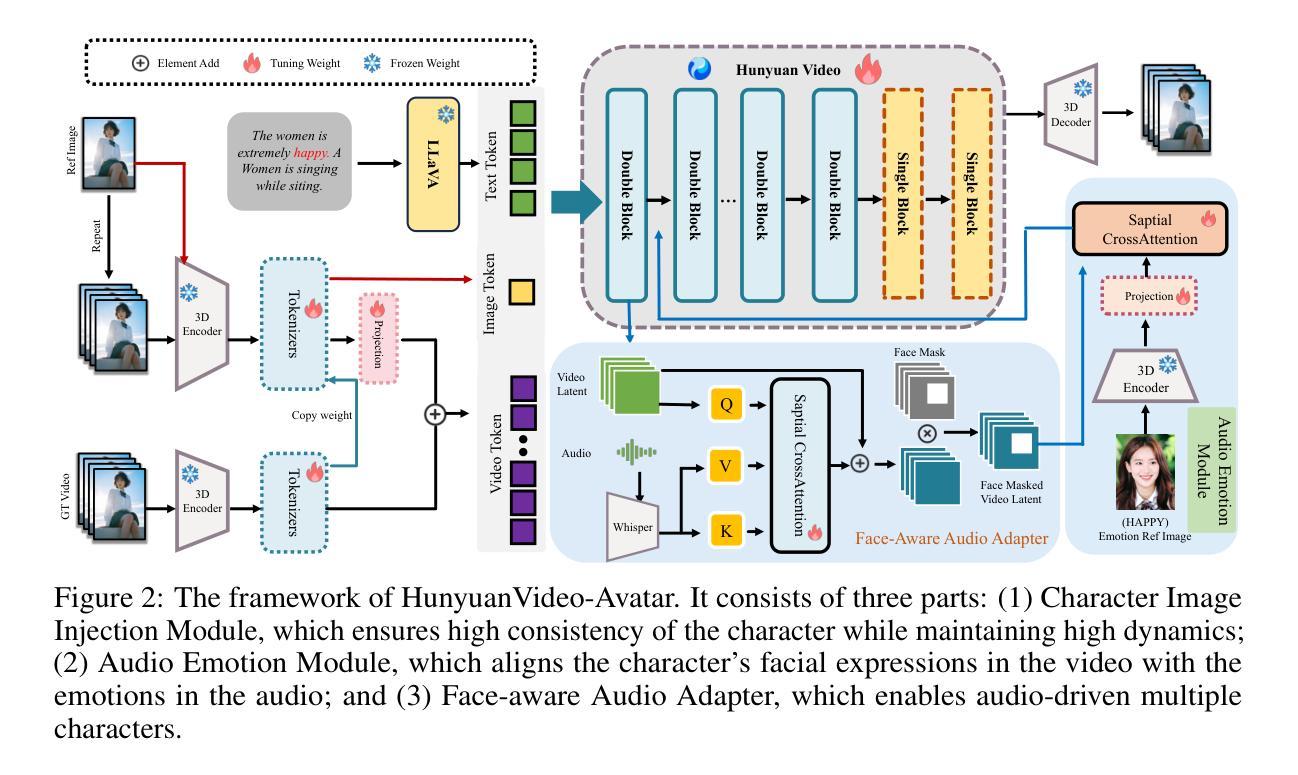
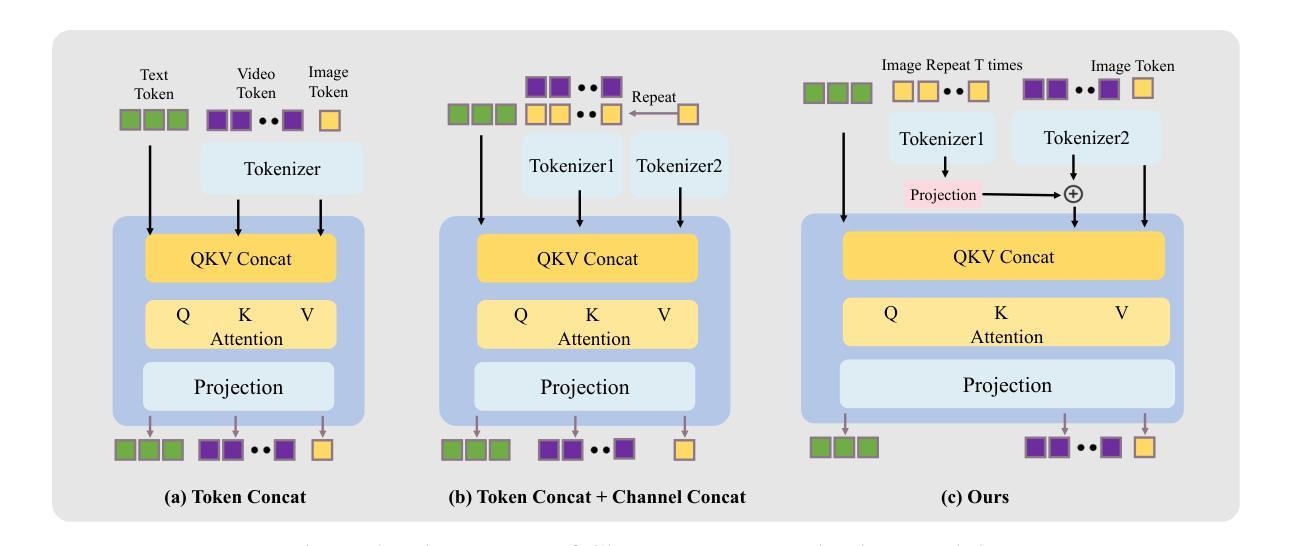
Recent years have witnessed significant progress in audio-driven human animation. However, critical challenges remain in (i) generating highly dynamic videos while preserving character consistency, (ii) achieving precise emotion alignment between characters and audio, and (iii) enabling multi-character audio-driven animation. To address these challenges, we propose HunyuanVideo-Avatar, a multimodal diffusion transformer (MM-DiT)-based model capable of simultaneously generating dynamic, emotion-controllable, and multi-character dialogue videos. Concretely, HunyuanVideo-Avatar introduces three key innovations: (i) A character image injection module is designed to replace the conventional addition-based character conditioning scheme, eliminating the inherent condition mismatch between training and inference. This ensures the dynamic motion and strong character consistency; (ii) An Audio Emotion Module (AEM) is introduced to extract and transfer the emotional cues from an emotion reference image to the target generated video, enabling fine-grained and accurate emotion style control; (iii) A Face-Aware Audio Adapter (FAA) is proposed to isolate the audio-driven character with latent-level face mask, enabling independent audio injection via cross-attention for multi-character scenarios. These innovations empower HunyuanVideo-Avatar to surpass state-of-the-art methods on benchmark datasets and a newly proposed wild dataset, generating realistic avatars in dynamic, immersive scenarios.
近年来,音频驱动的人物动画领域取得了显著进展。然而,仍存在以下关键挑战:(i)在保持角色一致性的同时生成高度动态的视频;(ii)实现角色和音频之间的精确情感对齐;(iii)实现多角色音频驱动动画。为了解决这些挑战,我们提出了基于多模态扩散变压器(MM-DiT)的“胡源视频化身”(HunyuanVideo-Avatar),它能够同时生成动态、情感可控和多角色对话视频。具体来说,胡源视频化身引入了三项关键创新:(i)设计了一个角色图像注入模块,取代了传统基于添加的角色条件方案,消除了训练和推理之间固有的条件不匹配问题。这确保了动态运动和强烈的人物一致性;(ii)引入音频情感模块(AEM),从情感参考图像中提取并转移情感线索到目标生成视频,实现精细和准确的情感风格控制;(iii)提出了Face-Aware音频适配器(FAA),通过潜在层面的面部遮挡来隔离音频驱动的角色,实现多角色场景中的独立音频注入通过交叉注意力机制。这些创新使胡源视频化身在基准数据集和新提出的野生数据集上超越了最先进的方法,在动态、沉浸式场景中生成逼真的化身。
论文及项目相关链接
Summary:近年音频驱动的人脸动画技术取得显著进展,但仍面临动态视频生成、精准情绪对齐和多角色音频驱动等挑战。为此,我们提出基于多模态扩散变压器(MM-DiT)的HunyuanVideo-Avatar模型,能同时生成动态、情绪可控、多角色的对话视频。模型引入三大创新点:角色图像注入模块确保动态运动和强角色一致性;音频情绪模块实现精细粒度的情绪风格控制;面部感知音频适配器可在多角色场景中实现独立音频注入。这些创新使模型在基准数据集和新提出的野生数据集上超越现有方法,生成逼真的动态角色。
Key Takeaways:
- 音频驱动的人脸动画技术持续进步,但仍面临挑战,包括生成高度动态视频时的角色一致性、情绪对齐和多角色音频驱动的精准性。
- HunyuanVideo-Avatar模型基于多模态扩散变压器(MM-DiT),可生成动态、情绪可控、多角色的对话视频。
- 模型通过引入角色图像注入模块,解决了训练与推理阶段条件不匹配的问题,确保动态运动和强角色一致性。
- 音频情绪模块(AEM)能够从情绪参考图像中提取并转移情感线索到目标生成视频,实现精细粒度的情感风格控制。
- 面部感知音频适配器(FAA)能够通过潜在层面的面部掩膜来隔离音频驱动的角色,实现在多角色场景中的独立音频注入。
- 模型在基准数据集和新提出的野生数据集上的表现超越了现有方法,能够生成逼真的动态角色。
点此查看论文截图

DualTalk: Dual-Speaker Interaction for 3D Talking Head Conversations
Authors:Ziqiao Peng, Yanbo Fan, Haoyu Wu, Xuan Wang, Hongyan Liu, Jun He, Zhaoxin Fan
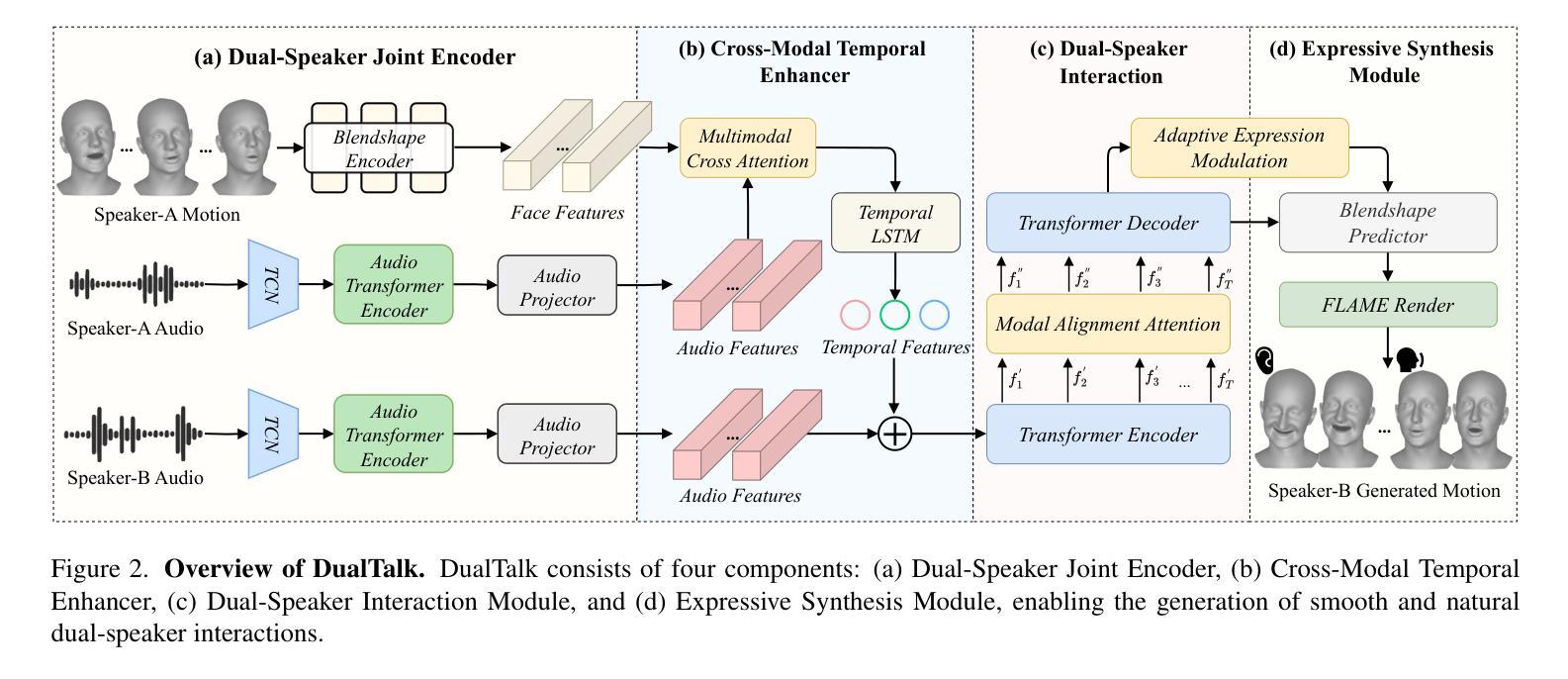
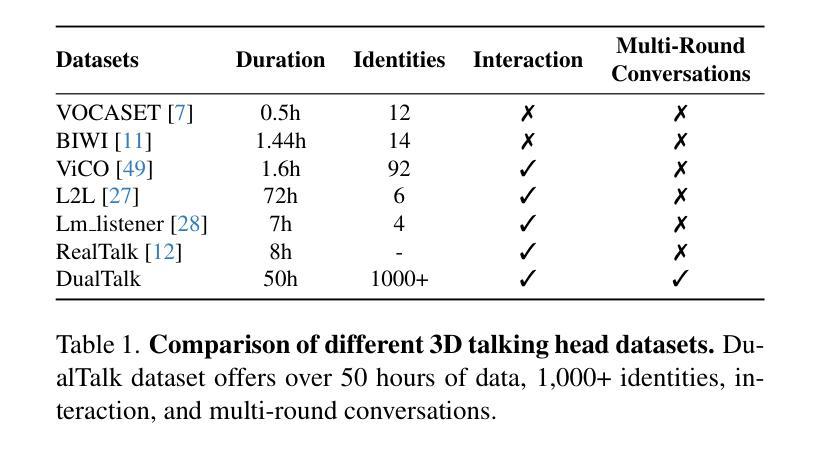
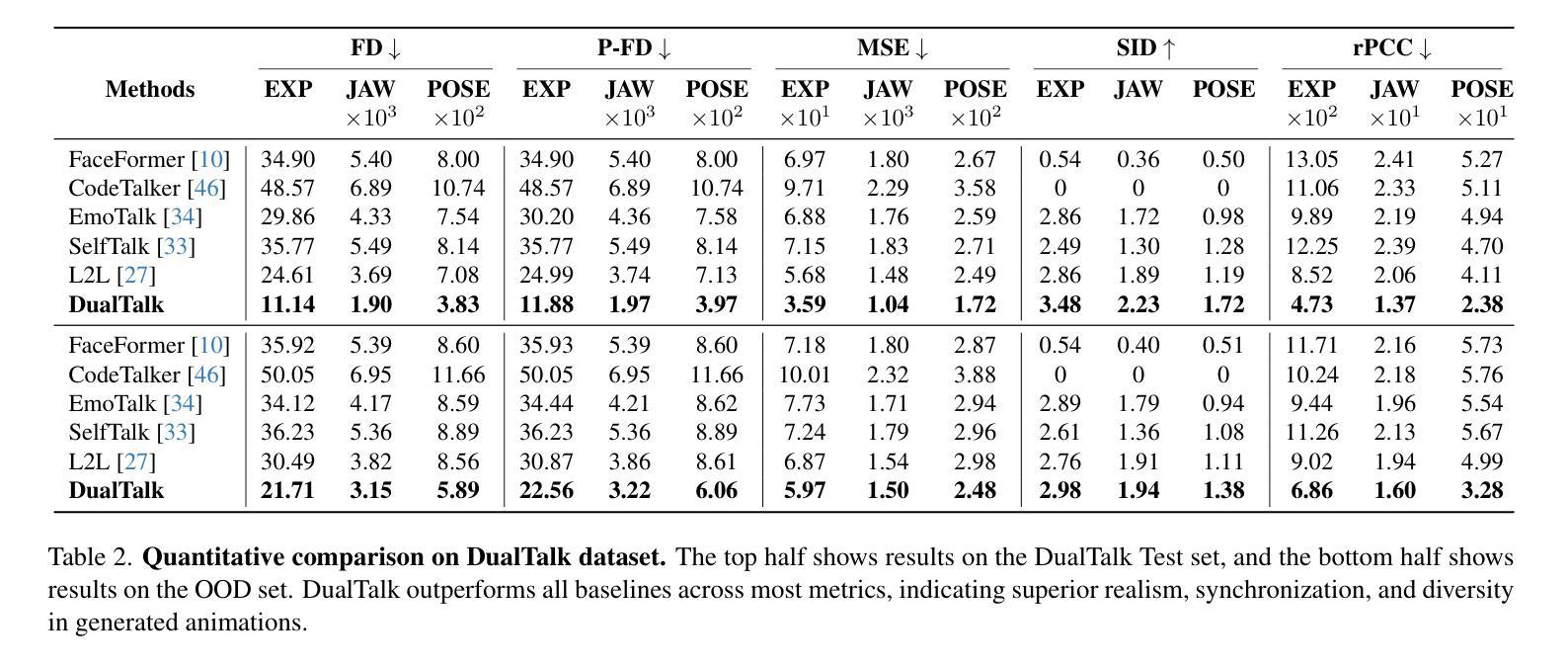
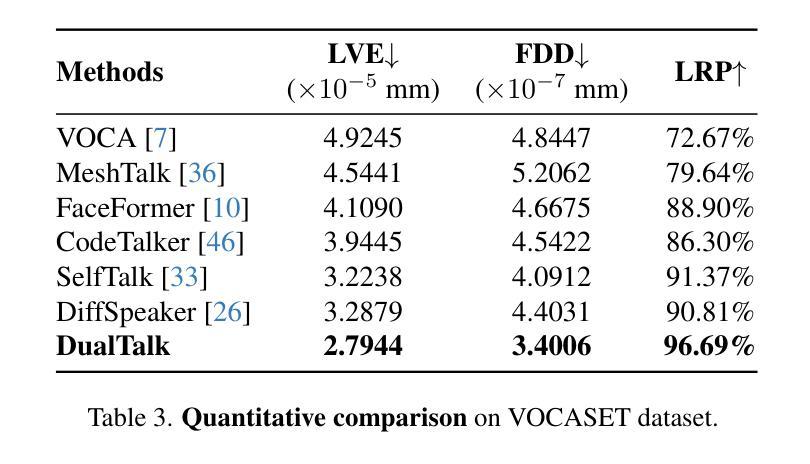
In face-to-face conversations, individuals need to switch between speaking and listening roles seamlessly. Existing 3D talking head generation models focus solely on speaking or listening, neglecting the natural dynamics of interactive conversation, which leads to unnatural interactions and awkward transitions. To address this issue, we propose a new task – multi-round dual-speaker interaction for 3D talking head generation – which requires models to handle and generate both speaking and listening behaviors in continuous conversation. To solve this task, we introduce DualTalk, a novel unified framework that integrates the dynamic behaviors of speakers and listeners to simulate realistic and coherent dialogue interactions. This framework not only synthesizes lifelike talking heads when speaking but also generates continuous and vivid non-verbal feedback when listening, effectively capturing the interplay between the roles. We also create a new dataset featuring 50 hours of multi-round conversations with over 1,000 characters, where participants continuously switch between speaking and listening roles. Extensive experiments demonstrate that our method significantly enhances the naturalness and expressiveness of 3D talking heads in dual-speaker conversations. We recommend watching the supplementary video: https://ziqiaopeng.github.io/dualtalk.
在面对面交谈中,人们需要在说话和倾听的角色之间无缝切换。现有的3D对话头模型只专注于说话或倾听,忽略了互动对话的自然动态,导致互动不自然和过渡尴尬。为了解决这个问题,我们提出了一个新的任务——用于3D对话头生成的多轮双人对话任务,要求模型在连续对话中处理并生成说话和倾听行为。为了解决这个问题,我们引入了DualTalk,这是一个新颖的统一框架,它集成了说话者和倾听者的动态行为来模拟现实和连贯的对话互动。此框架不仅在说话时合成逼真的对话头,而且在倾听时生成连续和生动的非语言反馈,有效地捕捉角色之间的相互作用。我们还创建了一个包含超过一千个角色五百小时的多轮对话新数据集,参与者持续在说话和倾听角色之间切换。大量实验表明,我们的方法在双人对话的3D对话头中显著提高了自然性和表现力。建议观看补充视频:https://ziqiaopeng.github.io/dualtalk。
论文及项目相关链接
PDF Accepted by CVPR 2025
Summary
基于当前对话模型在模拟真实对话互动时存在的不自然和过渡生硬的问题,我们提出了一个新的任务——多轮双人对话场景下的三维动态头部生成任务。为了应对这一任务,我们提出了DualTalk框架,该框架不仅可以在说话时合成逼真的头部动作,而且在倾听时也能生成连续且真实的非言语反馈。我们创建了一个包含超过一千个角色和五十小时多轮对话的新数据集。实验证明,我们的方法显著提高了双人对话场景中三维动态头部的自然度和表现力。详情请参见补充视频。
Key Takeaways
- 当前对话模型在模拟真实对话互动时存在缺陷,缺乏自然动态。
- 提出新的任务:多轮双人对话场景下的三维动态头部生成任务。
- 引入DualTalk框架以应对这一新任务,合成逼真的头部动作和真实的非言语反馈。
- 创建了一个新的数据集,包含超过一千个角色和五十小时的多轮对话数据。
- 实验证明,DualTalk框架显著提高三维动态头部的自然度和表现力。
点此查看论文截图


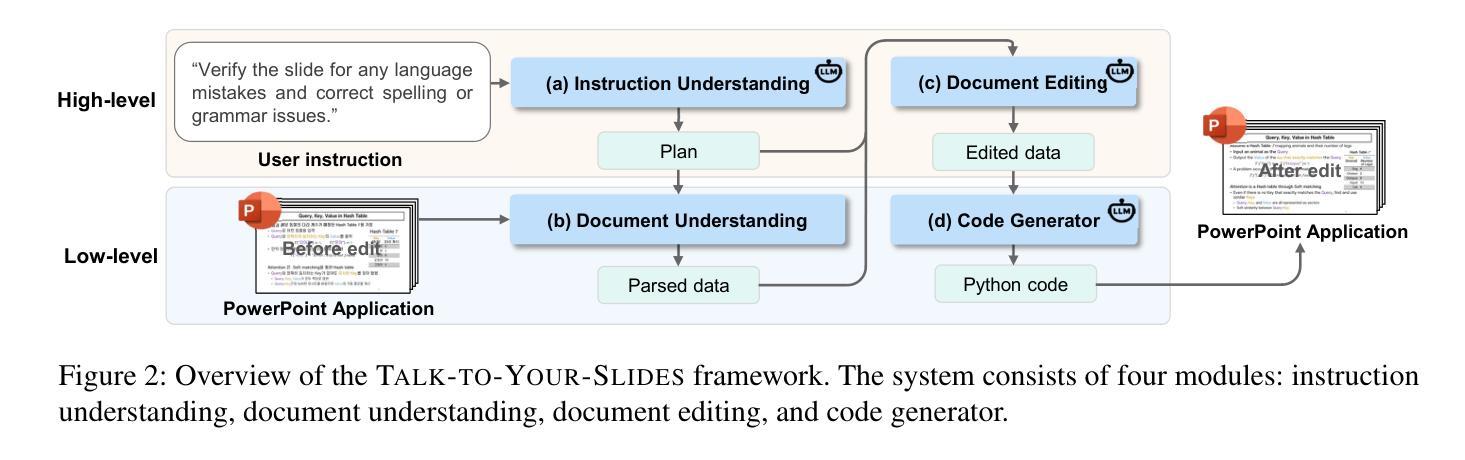
Talk to Your Slides: Language-Driven Agents for Efficient Slide Editing
Authors:Kyudan Jung, Hojun Cho, Jooyeol Yun, Soyoung Yang, Jaehyeok Jang, Jaegul Choo
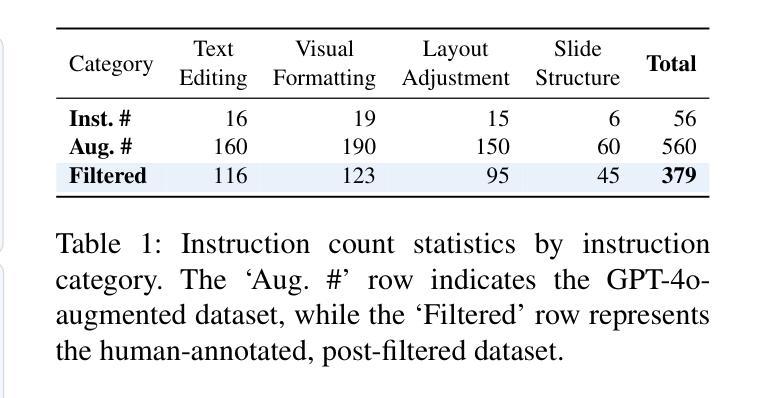
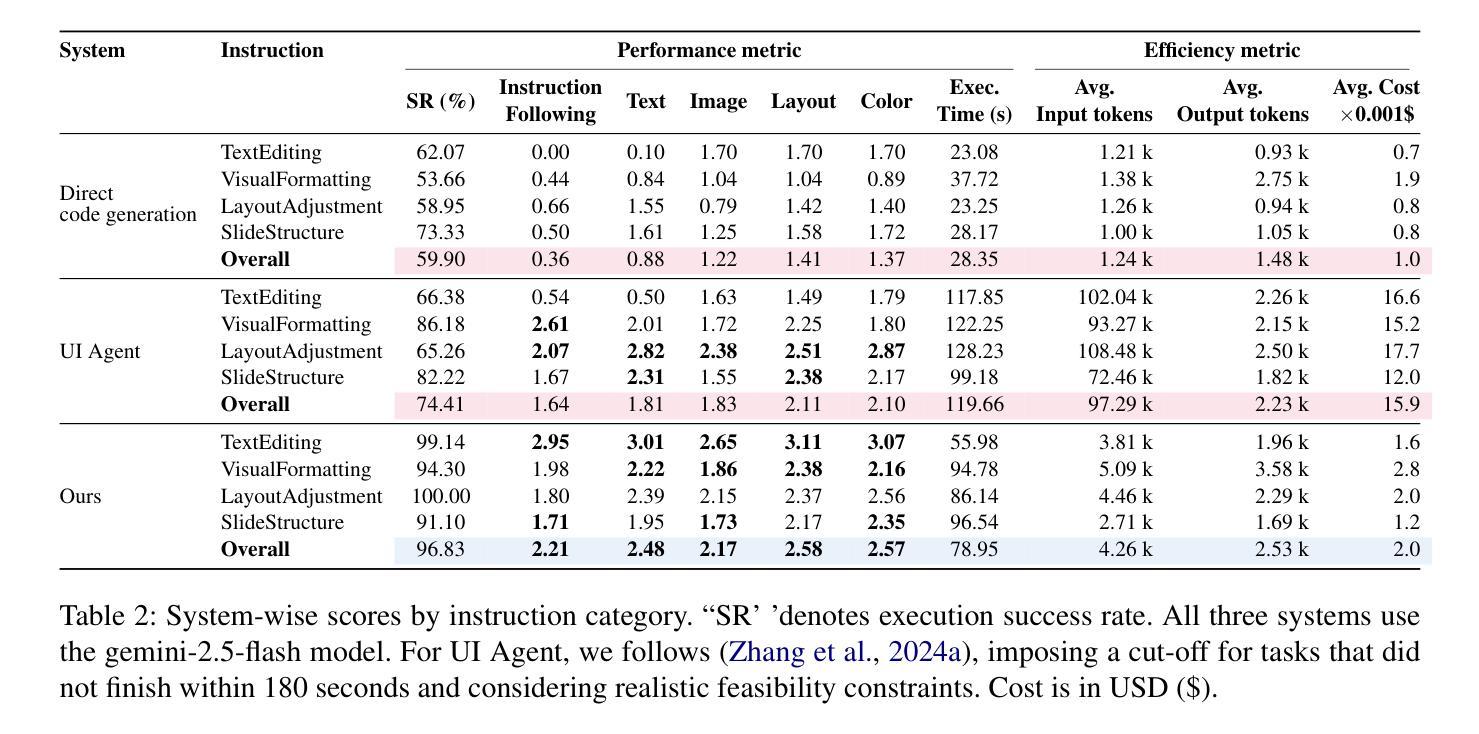
Editing presentation slides remains one of the most common and time-consuming tasks faced by millions of users daily, despite significant advances in automated slide generation. Existing approaches have successfully demonstrated slide editing via graphic user interface (GUI)-based agents, offering intuitive visual control. However, such methods often suffer from high computational cost and latency. In this paper, we propose Talk-to-Your-Slides, an LLM-powered agent designed to edit slides %in active PowerPoint sessions by leveraging structured information about slide objects rather than relying on image modality. The key insight of our work is designing the editing process with distinct high-level and low-level layers to facilitate interaction between user commands and slide objects. By providing direct access to application objects rather than screen pixels, our system enables 34.02% faster processing, 34.76% better instruction fidelity, and 87.42% cheaper operation than baselines. To evaluate slide editing capabilities, we introduce TSBench, a human-annotated dataset comprising 379 diverse editing instructions paired with corresponding slide variations in four categories. Our code, benchmark and demos are available at https://anonymous.4open.science/r/Talk-to-Your-Slides-0F4C.
尽管在自动幻灯片生成方面取得了重大进展,但编辑演示文稿幻灯片仍然是数百万用户日常面临的最常见且最耗时的任务之一。现有方法已经通过基于图形用户界面(GUI)的代理成功实现了幻灯片的编辑,提供了直观的视觉控制。然而,这些方法常常面临高计算成本和延迟的问题。在本文中,我们提出了Talk-to-Your-Slides,这是一个由大型语言模型驱动代理,旨在通过利用有关幻灯片对象的结构化信息而不是依赖图像模式来编辑活动PowerPoint会话中的幻灯片。我们工作的关键见解是以高级和低级层设计编辑过程,以促进用户命令和幻灯片对象之间的交互。通过直接访问应用程序对象而不是屏幕像素,我们的系统比基线加快了34.02%的处理速度,提高了34.76%的指令保真度,并降低了87.42%的操作成本。为了评估幻灯片编辑能力,我们引入了TSBench,这是一个由人类注释的数据集,包含四大类别中与幻灯片变体相对应的379个不同编辑指令。我们的代码、基准测试和演示可在https://anonymous.4open.science/r/Talk-to-Your-Slides-0F4C上找到。
论文及项目相关链接
PDF 20 pages, 14 figures
Summary
本文主要介绍了一种名为Talk-to-Your-Slides的LLM驱动代理技术,用于编辑PowerPoint演示文稿中的幻灯片。该技术通过利用结构化信息来编辑幻灯片对象,而不是依赖于图像模式,实现了高效的幻灯片编辑。通过设计高级和低级层次分明的编辑过程,用户命令与幻灯片对象之间的交互更加便捷。与现有方法相比,该系统具有更快的处理速度、更高的指令保真度和更低的操作成本。此外,本文还介绍了用于评估幻灯片编辑能力的TSBench数据集。
Key Takeaways
- Talk-to-Your-Slides是一个LLM驱动的代理,旨在通过利用结构化信息编辑PowerPoint中的幻灯片对象,提高幻灯片编辑效率。
- 该技术通过设计高级和低级层次分明的编辑过程,简化了用户命令与幻灯片对象之间的交互。
- 与现有方法相比,Talk-to-Your-Slides处理速度更快、指令保真度更高、操作成本更低。
- TSBench数据集的引入为评估幻灯片编辑能力提供了标准。
- Talk-to-Your-Slides系统支持在活跃的PowerPoint会话中编辑幻灯片。
- 该系统通过提供对应用程序对象的直接访问,实现了高效的幻灯片编辑。
点此查看论文截图




What Is That Talk About? A Video-to-Text Summarization Dataset for Scientific Presentations
Authors:Dongqi Liu, Chenxi Whitehouse, Xi Yu, Louis Mahon, Rohit Saxena, Zheng Zhao, Yifu Qiu, Mirella Lapata, Vera Demberg
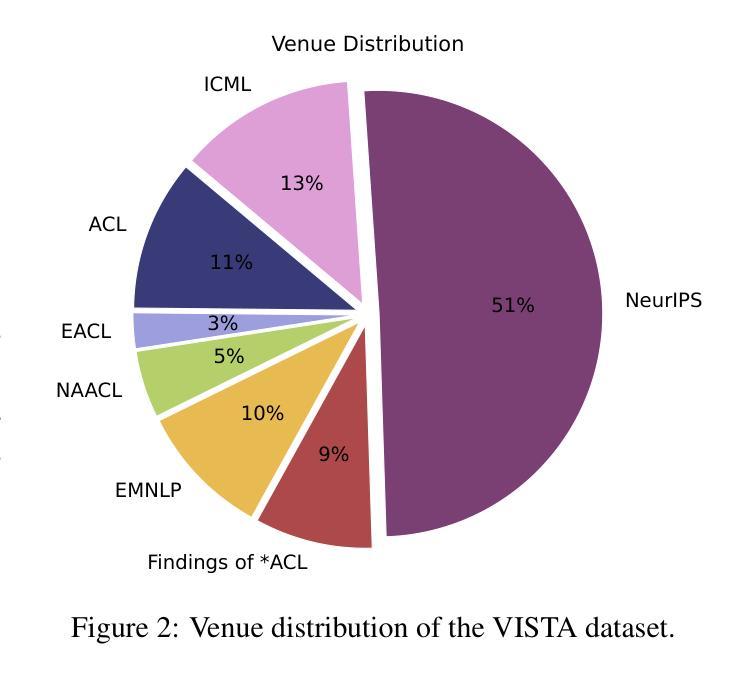
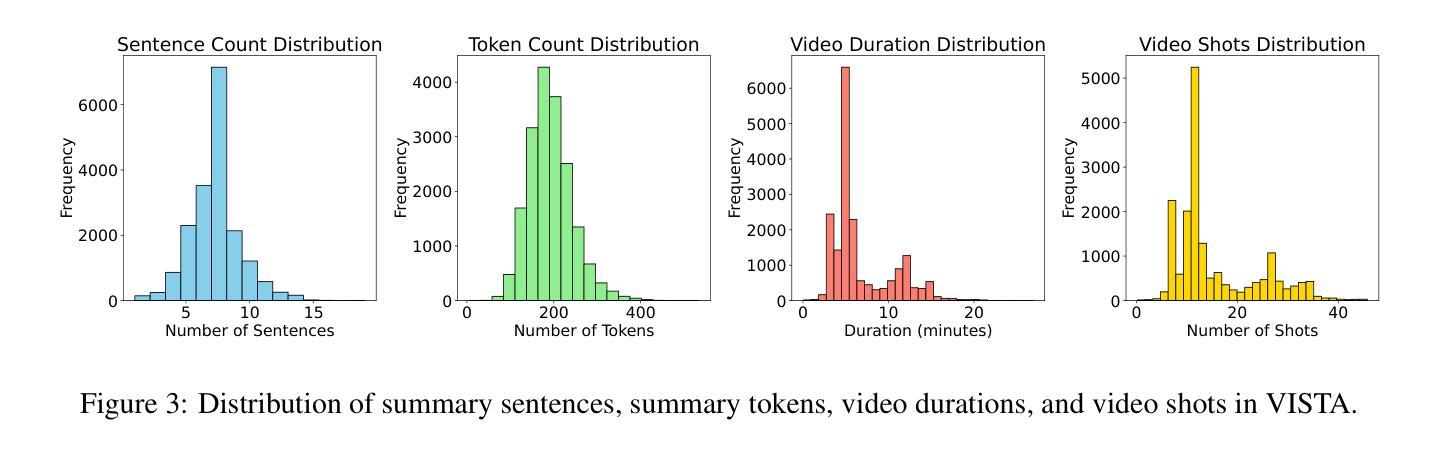
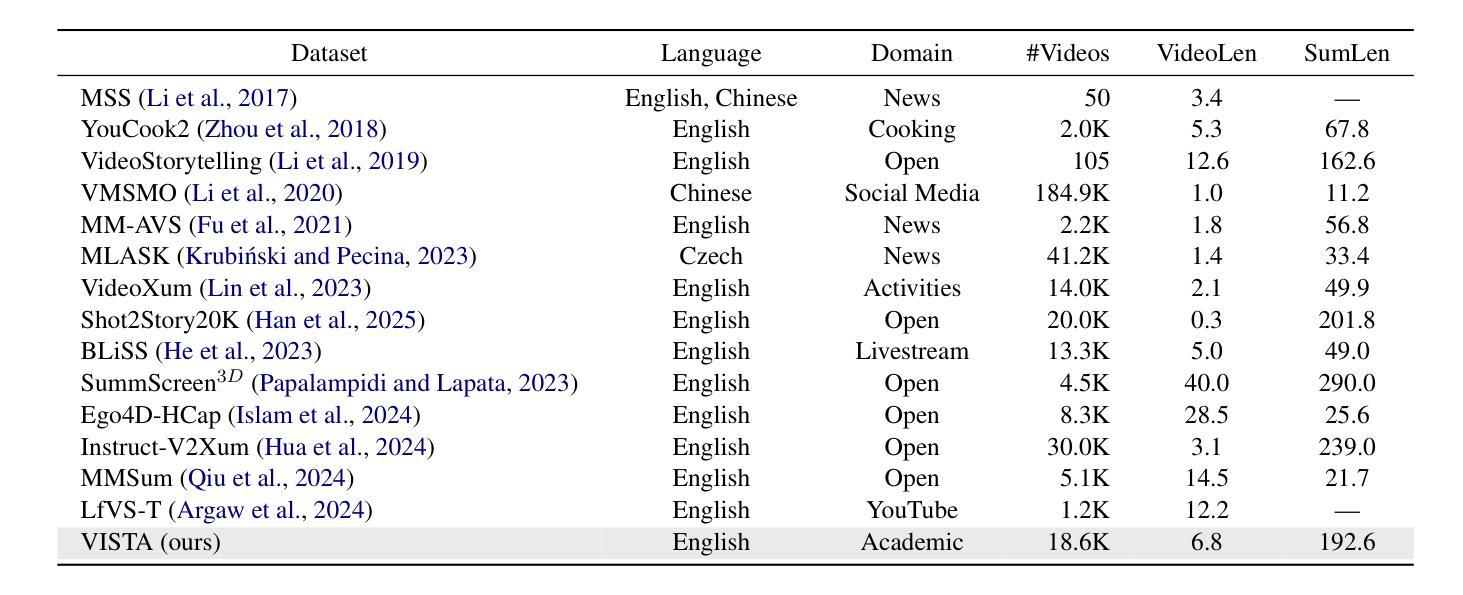
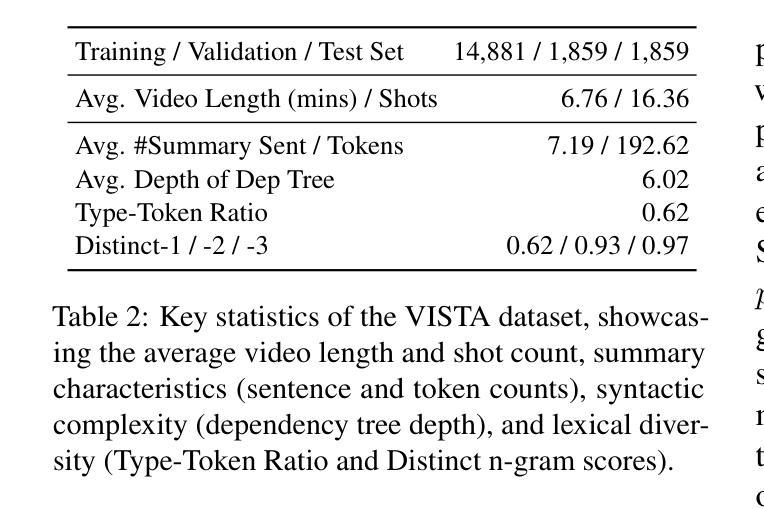
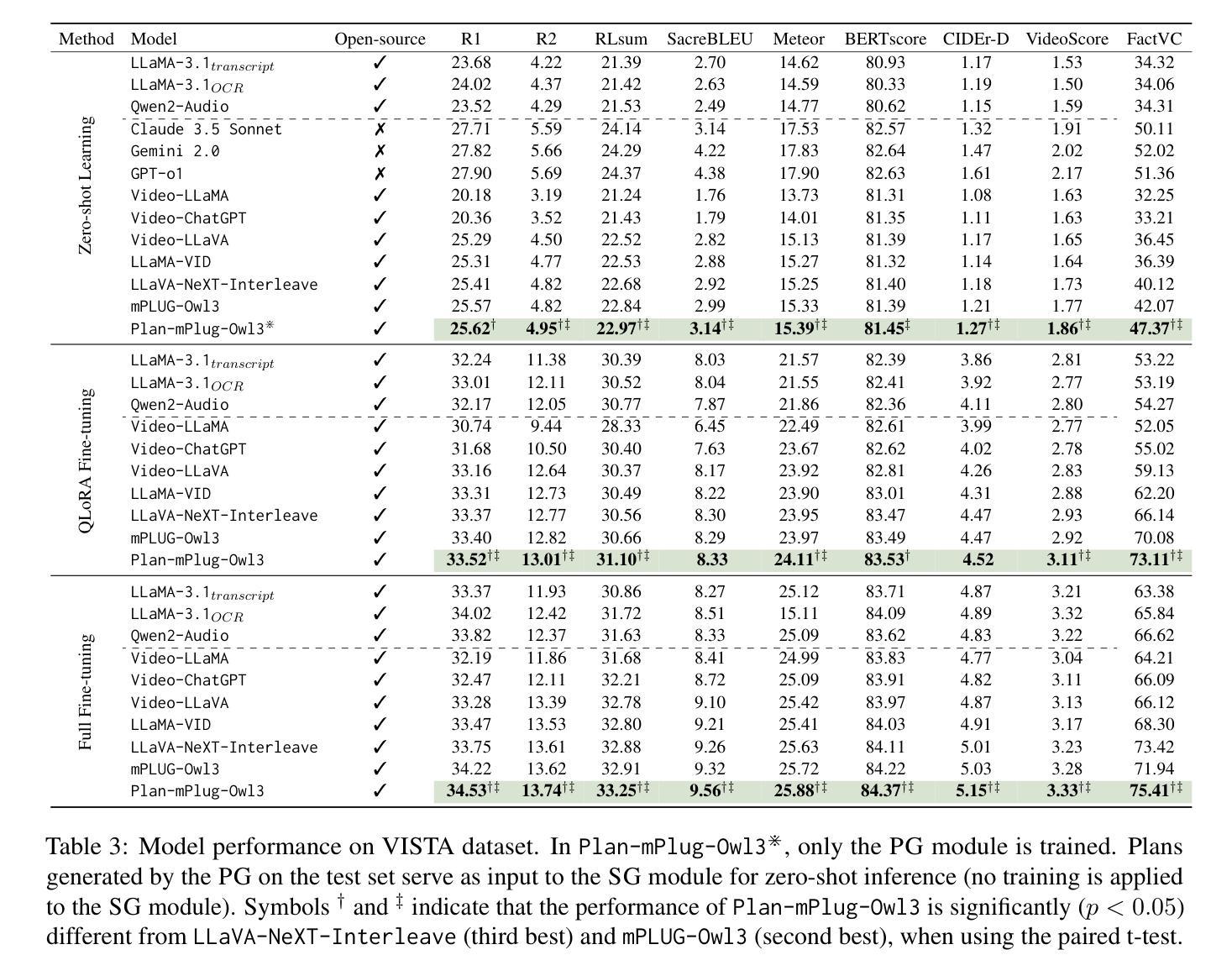
Transforming recorded videos into concise and accurate textual summaries is a growing challenge in multimodal learning. This paper introduces VISTA, a dataset specifically designed for video-to-text summarization in scientific domains. VISTA contains 18,599 recorded AI conference presentations paired with their corresponding paper abstracts. We benchmark the performance of state-of-the-art large models and apply a plan-based framework to better capture the structured nature of abstracts. Both human and automated evaluations confirm that explicit planning enhances summary quality and factual consistency. However, a considerable gap remains between models and human performance, highlighting the challenges of our dataset. This study aims to pave the way for future research on scientific video-to-text summarization.
将录制视频转化为简洁准确的文本摘要,是多模态学习中的一个日益增长的挑战。本文介绍了VISTA数据集,该数据集专为科学领域的视频到文本摘要而设计。VISTA包含18599个录制的AI会议演讲与其对应的论文摘要配对。我们评估了最先进的大型模型的表现,并应用基于计划的框架来更好地捕捉摘要的结构性。人类和自动化评估都证实,明确的计划可以提高摘要的质量和事实一致性。然而,模型与人类表现之间仍存在很大差距,这突显了我们数据集面临的挑战。本研究旨在为未来的科学视频到文本摘要研究铺平道路。
论文及项目相关链接
PDF ACL 2025 Main & Long Conference Paper
Summary
视频转文本摘要在多模态学习中是一项日益重要的挑战。本文介绍了专为科学领域视频转文本摘要设计的VISTA数据集。该数据集包含与论文摘要相对应的AI会议演讲视频记录,涵盖多达1万篇视频摘要。文章对最新大型模型进行了基准测试,并采用基于计划的框架以更好地捕捉摘要的结构性特征。通过人类评估和自动化评估证明,明确的计划有助于提高摘要质量和事实一致性。然而,模型与人类表现之间仍存在较大差距,凸显出该数据集的挑战。本研究旨在为科学视频转文本摘要的未来研究铺平道路。
Key Takeaways
- 该论文引入了专为科学领域视频转文本摘要设计的VISTA数据集,包含AI会议演讲视频和对应的论文摘要。
- 文章使用基于计划的框架来捕捉摘要的结构性特征,以提高摘要质量。
- 通过人类评估和自动化评估证明,明确的计划有助于提高摘要的一致性和准确性。
- 最新大型模型在该数据集上的表现尚不理想,显示研究在该领域的挑战性。
- VISTA数据集对理解和评估多媒体领域的视频转文本技术具有关键作用。
- 视频转文本摘要技术需要进一步提高以缩小与模型性能之间的差距。
点此查看论文截图