⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-05-29 更新
Contrastive Desensitization Learning for Cross Domain Face Forgery Detection
Authors:Lingyu Qiu, Ke Jiang, Xiaoyang Tan
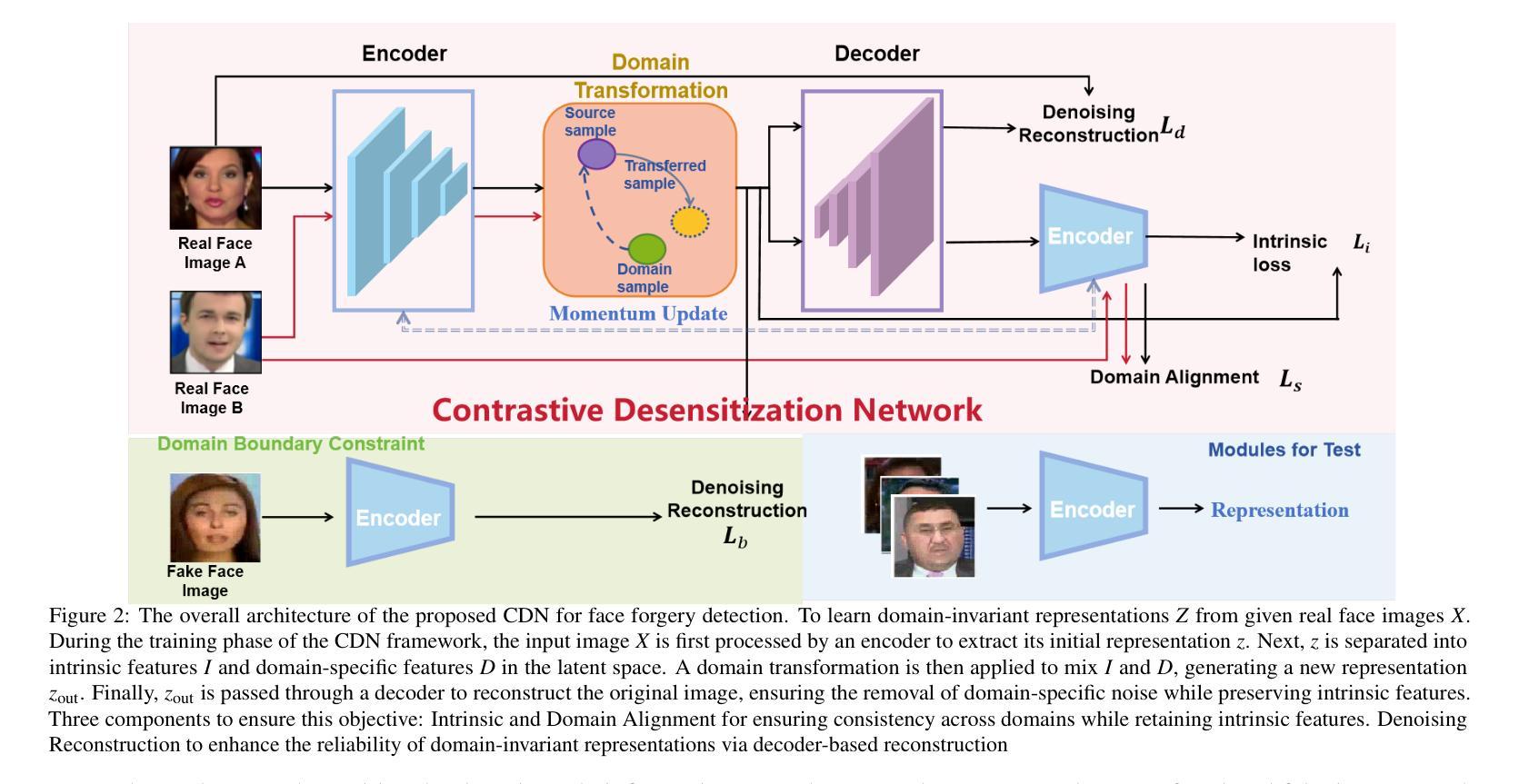
In this paper, we propose a new cross-domain face forgery detection method that is insensitive to different and possibly unseen forgery methods while ensuring an acceptable low false positive rate. Although existing face forgery detection methods are applicable to multiple domains to some degree, they often come with a high false positive rate, which can greatly disrupt the usability of the system. To address this issue, we propose an Contrastive Desensitization Network (CDN) based on a robust desensitization algorithm, which captures the essential domain characteristics through learning them from domain transformation over pairs of genuine face images. One advantage of CDN lies in that the learnt face representation is theoretical justified with regard to the its robustness against the domain changes. Extensive experiments over large-scale benchmark datasets demonstrate that our method achieves a much lower false alarm rate with improved detection accuracy compared to several state-of-the-art methods.
在这篇论文中,我们提出了一种新的跨域面部伪造检测法,它对不同的、甚至可能是未见过的伪造方法具有鲁棒性,同时确保了可接受的低误报率。尽管现有的面部伪造检测法在一定程度上适用于多个领域,但它们往往存在较高的误报率,这可能会极大地影响系统的可用性。为了解决这个问题,我们提出了一种基于稳健脱敏算法的对比脱敏网络(CDN),它通过从成对的真实面部图像进行域转换来学习捕捉关键域特征。CDN的一个优势在于,其学习的面部表征在理论上经过验证,对于抵抗域变化具有很强的稳健性。在大规模基准数据集上的大量实验表明,与几种最新方法相比,我们的方法实现了更低的误报率并提高了检测精度。
论文及项目相关链接
总结
本文提出了一种新的跨域人脸伪造检测法,该方法对不同且可能未见过的伪造方法具有不敏感性,同时保证了较低的误报率。现有的人脸伪造检测法虽然可以在一定程度上应用于多个领域,但它们往往存在较高的误报率,极大地破坏了系统的可用性。为解决这一问题,本文提出了基于稳健脱敏算法的对比脱敏网络(CDN),通过从成对的真实人脸图像中学习领域转换来捕捉关键领域特征。CDN的一个优点是,其学习的面部表征在理论上证明了其对领域变化的稳健性。在大规模基准数据集上的广泛实验表明,与几种最新方法相比,我们的方法实现了更低的误报率并提高了检测准确性。
关键见解
- 论文提出了一种新的跨域人脸伪造检测法,旨在解决现有方法的高误报率问题。
- 该方法基于对比脱敏网络(CDN)和稳健脱敏算法。
- CDN通过从真实人脸图像成对学习领域转换来捕捉关键领域特征。
- 所学面部表征具有理论支持,证明了其对领域变化的稳健性。
- 在大规模基准数据集上的实验表明,该方法实现了较低的误报率并提高了检测准确性。
- 与其他先进方法相比,该方法具有优越性。
点此查看论文截图

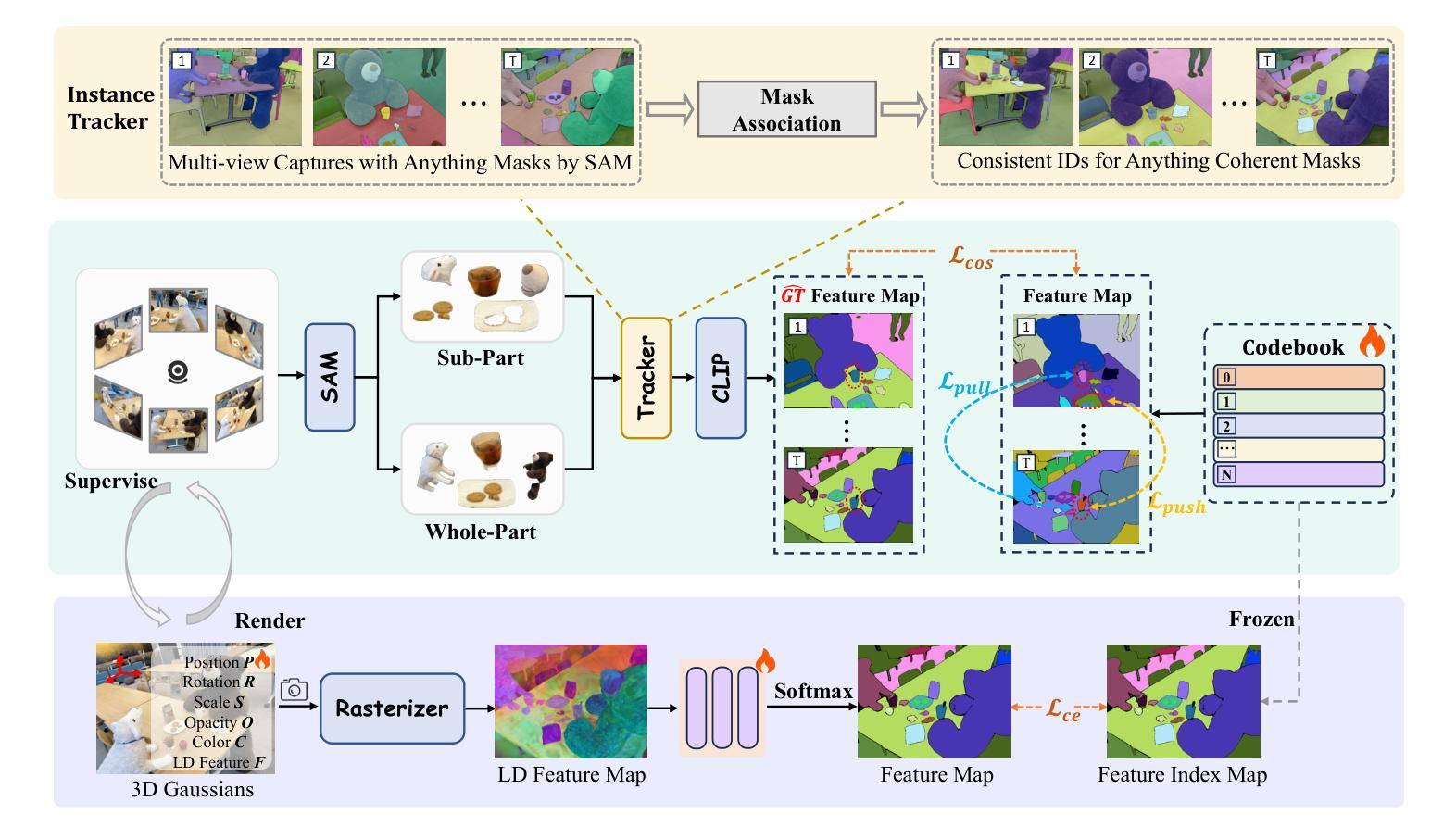
CCL-LGS: Contrastive Codebook Learning for 3D Language Gaussian Splatting
Authors:Lei Tian, Xiaomin Li, Liqian Ma, Hefei Huang, Zirui Zheng, Hao Yin, Taiqing Li, Huchuan Lu, Xu Jia
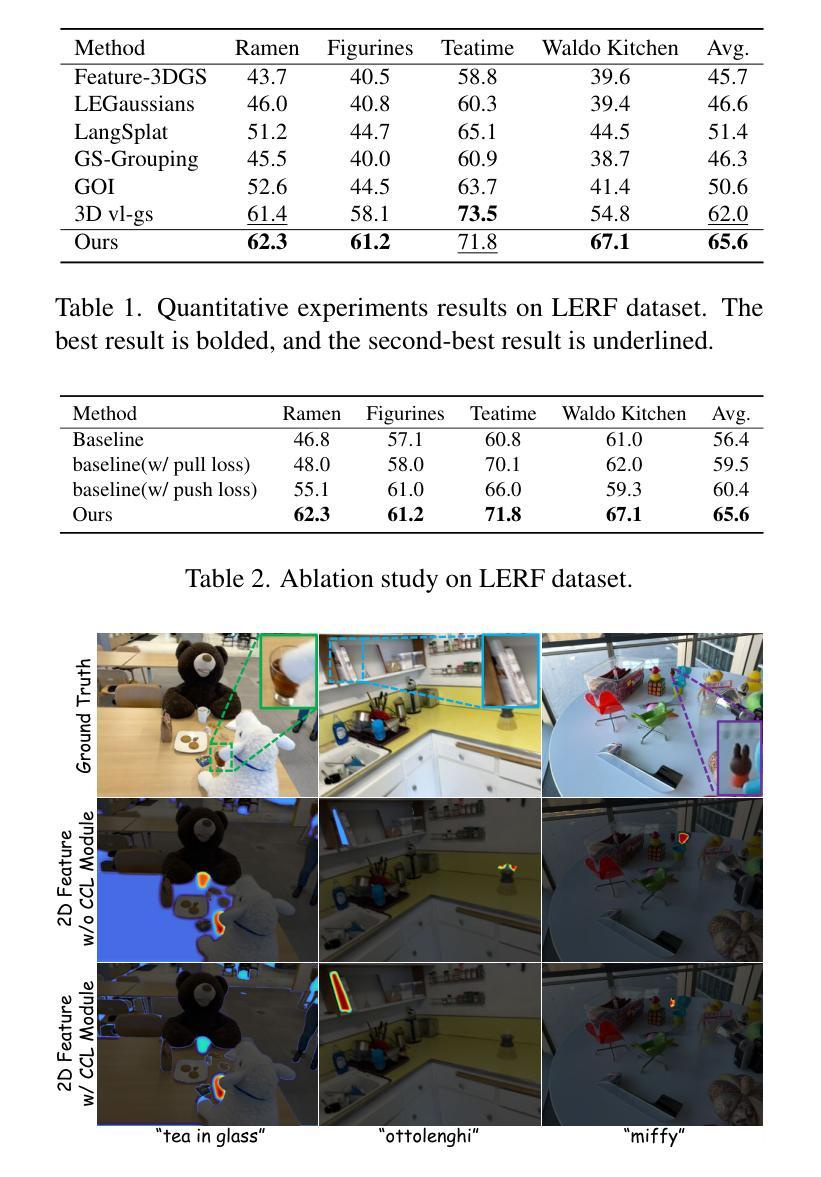
Recent advances in 3D reconstruction techniques and vision-language models have fueled significant progress in 3D semantic understanding, a capability critical to robotics, autonomous driving, and virtual/augmented reality. However, methods that rely on 2D priors are prone to a critical challenge: cross-view semantic inconsistencies induced by occlusion, image blur, and view-dependent variations. These inconsistencies, when propagated via projection supervision, deteriorate the quality of 3D Gaussian semantic fields and introduce artifacts in the rendered outputs. To mitigate this limitation, we propose CCL-LGS, a novel framework that enforces view-consistent semantic supervision by integrating multi-view semantic cues. Specifically, our approach first employs a zero-shot tracker to align a set of SAM-generated 2D masks and reliably identify their corresponding categories. Next, we utilize CLIP to extract robust semantic encodings across views. Finally, our Contrastive Codebook Learning (CCL) module distills discriminative semantic features by enforcing intra-class compactness and inter-class distinctiveness. In contrast to previous methods that directly apply CLIP to imperfect masks, our framework explicitly resolves semantic conflicts while preserving category discriminability. Extensive experiments demonstrate that CCL-LGS outperforms previous state-of-the-art methods. Our project page is available at https://epsilontl.github.io/CCL-LGS/.
近年来,三维重建技术和视觉语言模型的进步推动了三维语义理解能力的显著发展,这对机器人技术、自动驾驶和虚拟/增强现实至关重要。然而,依赖二维先验知识的方法面临一个关键挑战:由于遮挡、图像模糊和视角相关的变化导致的跨视图语义不一致性。这些不一致性通过投影监督进行传播时,会恶化三维高斯语义场的质量,并在渲染输出中引入伪影。为了缓解这一局限性,我们提出了CCL-LGS这一新型框架,它通过集成多视图语义线索来执行视图一致的语义监督。具体来说,我们的方法首先采用零样本跟踪器来对齐一组由SAM生成的二维掩膜,并可靠地识别其对应的类别。然后,我们使用CLIP来提取跨视图的稳健语义编码。最后,我们的对比代码本学习(CCL)模块通过强制同类紧凑性和不同类差异性来提炼判别语义特征。与之前直接应用CLIP到不完美掩膜的方法不同,我们的框架显式解决语义冲突,同时保留类别可分辨性。大量实验表明,CCL-LGS优于以前的最先进方法。我们的项目页面可在https://epsilontl.github.io/CCL-LGS/找到。
论文及项目相关链接
Summary
本文介绍了在三维重建技术和视觉语言模型方面的最新进展对三维语义理解的重要性,并指出依赖二维先验的方法面临跨视图语义不一致的挑战。为解决这一问题,提出了CCL-LGS框架,通过整合多视图语义线索来执行视图一致的语义监督。实验表明,CCL-LGS优于之前的方法。
Key Takeaways
- 3D重建技术和视觉语言模型的最新进展推动了三维语义理解领域的显著进步。
- 依赖二维先验的方法在跨视图时面临语义不一致的挑战,主要由于遮挡、图像模糊和视角变化引起。
- 传播到投影监督中的这些不一致性会损害三维高斯语义场的品质并在渲染输出中引入伪像。
- CCL-LGS框架通过整合多视图语义线索来强制执行视图一致的语义监督,以缓解上述问题。
- CCL-LGS首先使用零样本跟踪器对齐一组SAM生成的二维掩膜并可靠地识别其对应的类别。
- 利用CLIP提取跨视图的稳健语义编码,以增强语义理解的准确性。
点此查看论文截图