⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-05-29 更新
Roboflow100-VL: A Multi-Domain Object Detection Benchmark for Vision-Language Models
Authors:Peter Robicheaux, Matvei Popov, Anish Madan, Isaac Robinson, Joseph Nelson, Deva Ramanan, Neehar Peri
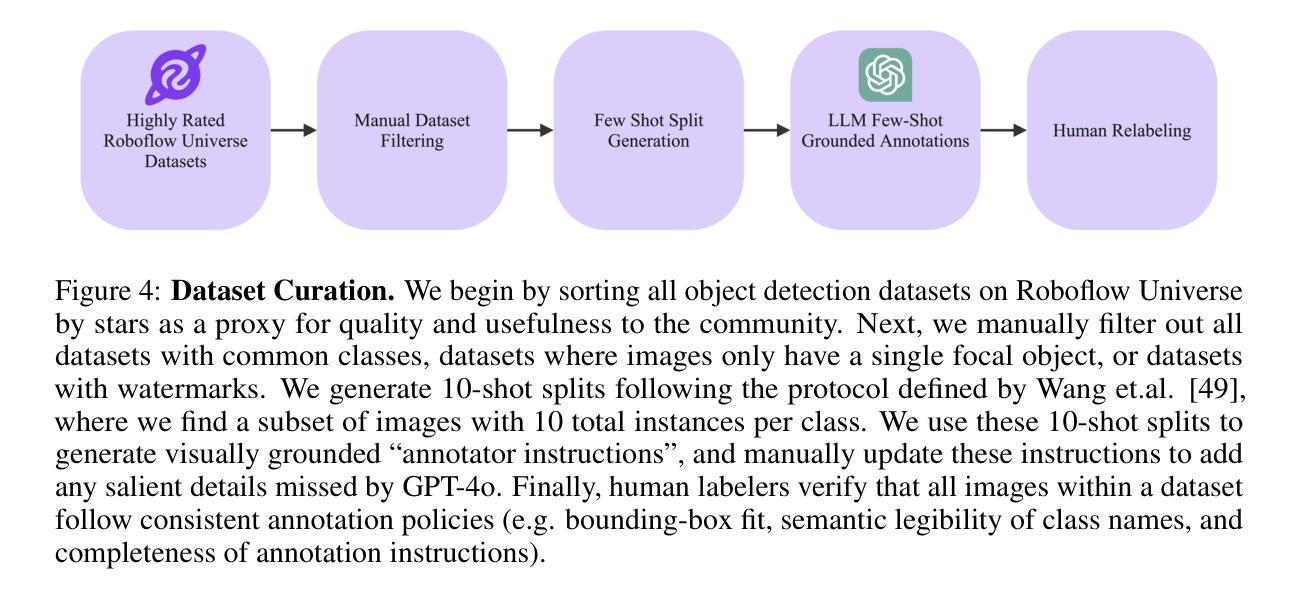
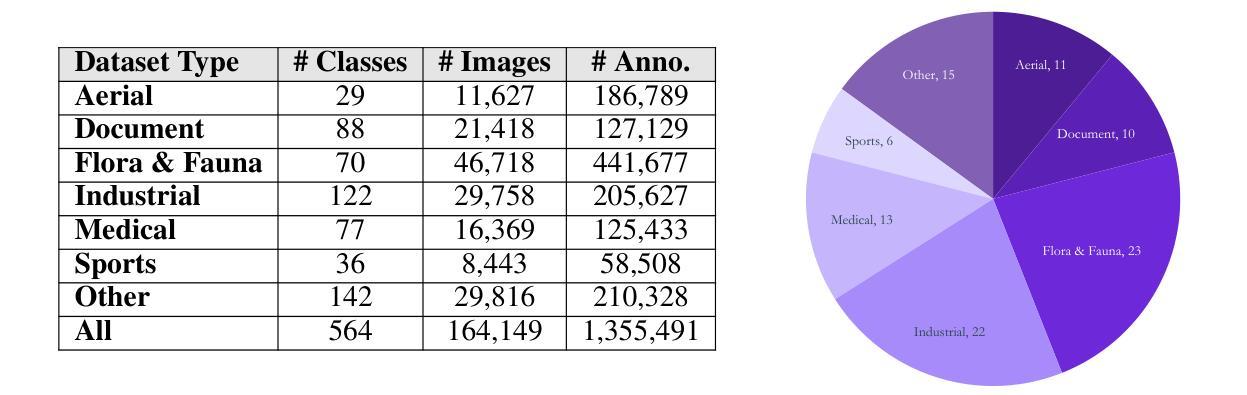
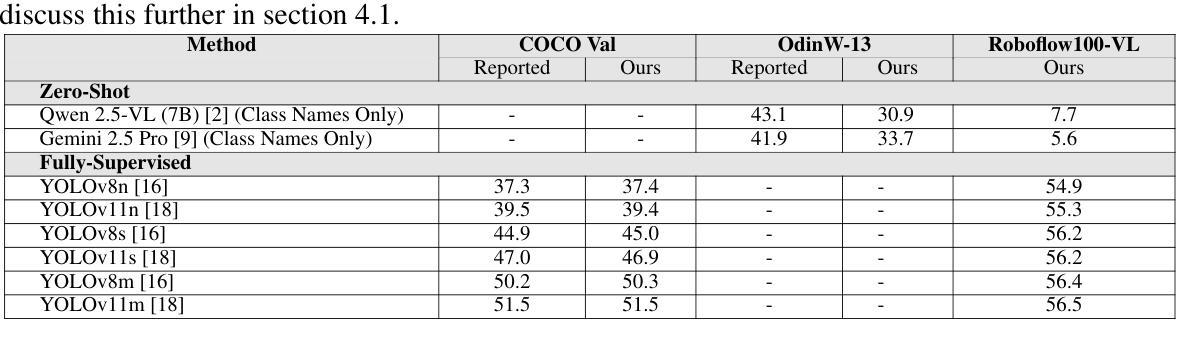
Vision-language models (VLMs) trained on internet-scale data achieve remarkable zero-shot detection performance on common objects like car, truck, and pedestrian. However, state-of-the-art models still struggle to generalize to out-of-distribution classes, tasks and imaging modalities not typically found in their pre-training. Rather than simply re-training VLMs on more visual data, we argue that one should align VLMs to new concepts with annotation instructions containing a few visual examples and rich textual descriptions. To this end, we introduce Roboflow100-VL, a large-scale collection of 100 multi-modal object detection datasets with diverse concepts not commonly found in VLM pre-training. We evaluate state-of-the-art models on our benchmark in zero-shot, few-shot, semi-supervised, and fully-supervised settings, allowing for comparison across data regimes. Notably, we find that VLMs like GroundingDINO and Qwen2.5-VL achieve less than 2% zero-shot accuracy on challenging medical imaging datasets within Roboflow100-VL, demonstrating the need for few-shot concept alignment. Our code and dataset are available at https://github.com/roboflow/rf100-vl/ and https://universe.roboflow.com/rf100-vl/
基于互联网规模数据训练的视觉语言模型(VLMs)在常见对象(如汽车、卡车和行人)上实现了令人印象深刻的零样本检测性能。然而,最先进的模型仍然难以推广到不在其预训练范围内的类别、任务和成像模式。我们主张不应仅仅通过更多的视觉数据重新训练VLMs,而应该通过包含少量视觉示例和丰富文本描述的注释指令来对齐VLMs以理解新概念。为此,我们推出了Roboflow100-VL,这是一个包含100个多模式对象检测数据集的大规模集合,其中包含了许多在VLM预训练中不常见的多样化概念。我们在我们的基准测试上对最先进的模型进行了零样本、少样本、半监督和全监督设置下的评估,这使得不同数据状态下的模型表现可以相互比较。值得注意的是,我们发现GroundingDINO和Qwen2.5-VL等VLM在Roboflow100-VL中具有挑战性的医学影像数据集上的零样本准确率低于2%,这显示出需要对新概念进行小样本对齐的需求。我们的代码和数据集可在https://github.com/roboflow/rf100-vl/和https://universe.roboflow.com/rf100-vl/获取。
论文及项目相关链接
PDF The first two authors contributed equally
Summary:视觉语言模型在常见物体上的零样本检测性能显著,但在面对超出分布范围的新类别、任务和成像模式时仍面临挑战。为解决这一问题,我们引入了Roboflow100-VL这一大型多模态目标检测数据集,包含罕见概念的多模态数据集。通过在不同数据条件下评估前沿模型,我们发现某些模型在具有挑战性的医学影像数据集上的零样本准确率低于2%,突显了概念对齐的必要性。我们的代码和数据集可在相应链接下载。
Key Takeaways:
- VLM在常见物体上的零样本检测性能优异。
- 当前模型在面对未见类别、任务和成像模式时泛化能力受限。
- Roboflow100-VL数据集用于解决上述问题,包含罕见概念的多模态数据。
- 在不同数据条件下评估模型性能是必要的。
- 部分模型在医学影像数据集上的零样本准确率较低。
- 需要通过概念对齐来提高模型的泛化能力。
点此查看论文截图




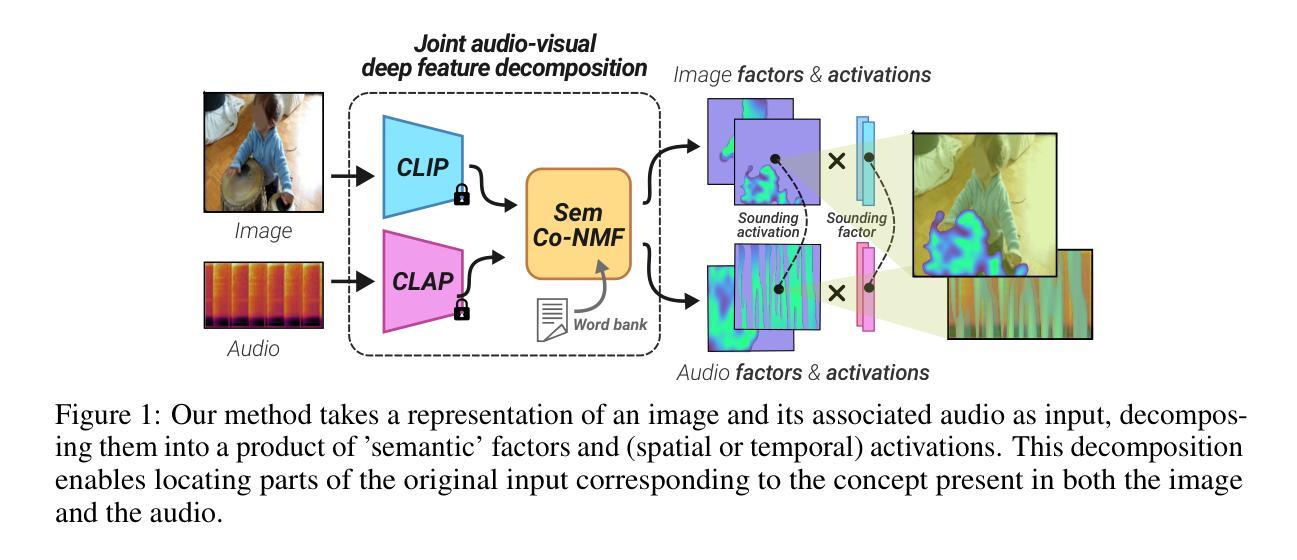
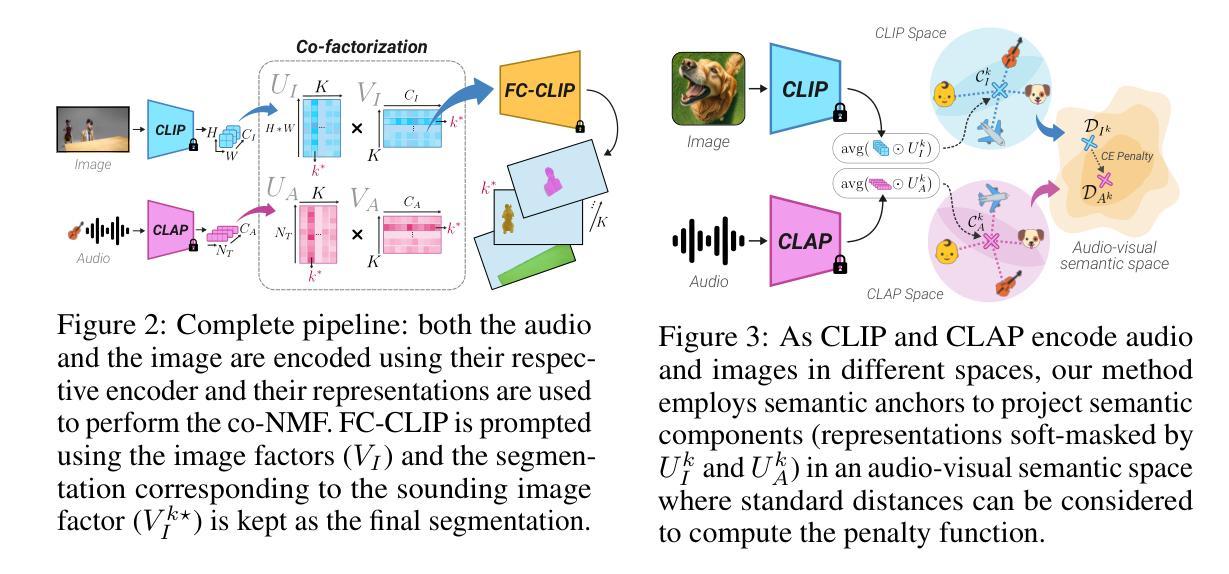
TACO: Training-free Sound Prompted Segmentation via Semantically Constrained Audio-visual CO-factorization
Authors:Hugo Malard, Michel Olvera, Stephane Lathuiliere, Slim Essid
Large-scale pre-trained audio and image models demonstrate an unprecedented degree of generalization, making them suitable for a wide range of applications. Here, we tackle the specific task of sound-prompted segmentation, aiming to segment image regions corresponding to objects heard in an audio signal. Most existing approaches tackle this problem by fine-tuning pre-trained models or by training additional modules specifically for the task. We adopt a different strategy: we introduce a training-free approach that leverages Non-negative Matrix Factorization (NMF) to co-factorize audio and visual features from pre-trained models so as to reveal shared interpretable concepts. These concepts are passed on to an open-vocabulary segmentation model for precise segmentation maps. By using frozen pre-trained models, our method achieves high generalization and establishes state-of-the-art performance in unsupervised sound-prompted segmentation, significantly surpassing previous unsupervised methods.
大规模预训练音频和图像模型表现出了前所未有的泛化程度,使其适用于广泛的应用。在这里,我们解决声音提示分割这一特定任务,旨在将音频信号中听到的对象对应的图像区域进行分割。大多数现有方法都是通过微调预训练模型或针对任务训练特定模块来解决这个问题。我们采用了不同的策略:我们引入了一种无需训练的方法,该方法利用非负矩阵分解(NMF)来共同分解预训练模型的音频和视觉特征,以揭示共享的可解释概念。这些概念被传递给开放词汇分割模型,以生成精确的分割图。通过使用固定的预训练模型,我们的方法实现了高泛化能力,并在无监督的声音提示分割中达到了最先进的性能,显著超越了之前的无监督方法。
论文及项目相关链接
Summary
本文介绍了一种无需训练的方法,利用非负矩阵分解(NMF)对预训练的音频和图像模型进行协同分解,以揭示共享的可解释概念,进而实现声音提示的图像分割。该方法利用预训练模型的高泛化性能,实现了高精度的声音提示图像分割,并达到了最新技术水平。
Key Takeaways
- 预训练的音频和图像模型具有高度的泛化能力,适用于广泛的应用。
- 声音提示的图像分割是一个特定任务,旨在根据听到的音频信号对图像区域进行分割。
- 现有方法大多通过微调预训练模型或训练特定任务的额外模块来解决这个问题。
- 本文提出了一种新的策略,即采用无需训练的NMF方法协同分解音频和视觉特征。
- 该方法揭示了共享的可解释概念,并将其传递给开放词汇分割模型以生成精确分割图。
- 使用冻结的预训练模型,该方法实现了高泛化性能。
点此查看论文截图