⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-05-29 更新
Silence is Not Consensus: Disrupting Agreement Bias in Multi-Agent LLMs via Catfish Agent for Clinical Decision Making
Authors:Yihan Wang, Qiao Yan, Zhenghao Xing, Lihao Liu, Junjun He, Chi-Wing Fu, Xiaowei Hu, Pheng-Ann Heng
Large language models (LLMs) have demonstrated strong potential in clinical question answering, with recent multi-agent frameworks further improving diagnostic accuracy via collaborative reasoning. However, we identify a recurring issue of Silent Agreement, where agents prematurely converge on diagnoses without sufficient critical analysis, particularly in complex or ambiguous cases. We present a new concept called Catfish Agent, a role-specialized LLM designed to inject structured dissent and counter silent agreement. Inspired by the ``catfish effect’’ in organizational psychology, the Catfish Agent is designed to challenge emerging consensus to stimulate deeper reasoning. We formulate two mechanisms to encourage effective and context-aware interventions: (i) a complexity-aware intervention that modulates agent engagement based on case difficulty, and (ii) a tone-calibrated intervention articulated to balance critique and collaboration. Evaluations on nine medical Q&A and three medical VQA benchmarks show that our approach consistently outperforms both single- and multi-agent LLMs frameworks, including leading commercial models such as GPT-4o and DeepSeek-R1.
大型语言模型(LLM)在临床问题回答方面展现出了强大的潜力,最近的多代理框架通过协同推理进一步提高了诊断的准确性。然而,我们识别出了一个反复出现的问题,即静默协议(Silent Agreement),代理在没有足够的关键分析的情况下过早地达成诊断共识,特别是在复杂或模糊的情况下。我们提出了一个新的概念,即“猫鱼代理”(Catfish Agent),这是一种角色特殊化的LLM设计,旨在注入结构化异议和反对静默协议。该设计受到组织心理学中的“猫鱼效应”的启发,旨在挑战新兴共识来刺激更深入的推理。我们制定了两种机制来鼓励有效和情境感知干预:(i)一种基于案例难度的复杂性感知干预,可调节代理参与度;(ii)一种平衡批评与合作的语气校准干预。在九个医学问答和三个医学视觉问答基准测试上的评估表明,我们的方法始终优于单代理和多代理LLM框架,包括领先的商业模型,如GPT-4o和DeepSeek-R1。
论文及项目相关链接
Summary
大型语言模型(LLM)在临床问答中展现出巨大潜力,多代理框架能进一步提升诊断准确性。但存在“静默协议”问题,即代理在缺乏充分分析的情况下过早达成诊断共识,特别是在复杂或模糊案例中。为此,我们提出“猫鱼代理”概念,这是一种专门设计的角色型LLM,旨在注入结构化异议并挑战静默协议。受组织心理学中的“猫鱼效应”启发,猫鱼代理旨在刺激更深入的思考并挑战现有共识。我们制定两种机制来鼓励有效且语境感知的干预:(一)复杂情况感知干预,根据案例难度调整代理参与度;(二)语气校准干预,旨在平衡批评与协作。在九个医疗问答和三个医疗视觉问答基准测试上的评估显示,我们的方法持续优于单代理和多代理LLM框架,包括领先的商业模型如GPT-4o和DeepSeek-R1。
Key Takeaways
- LLMs在临床问答中展现出强大的潜力,多代理框架可进一步提升诊断准确性。
- 存在“静默协议”问题,即代理过早达成诊断共识,需引入新策略应对。
- 引入“猫鱼代理”概念,为LLM注入结构化异议,挑战静默协议。
- 猫鱼代理设计受组织心理学中的“猫鱼效应”启发,旨在刺激更深入的思考。
- 通过两种机制来鼓励有效且语境感知的干预:复杂情况感知干预和语气校准干预。
- 评估显示,猫鱼代理方法优于现有LLM框架,包括商业领先模型。
点此查看论文截图



Adversarial Attacks against Closed-Source MLLMs via Feature Optimal Alignment
Authors:Xiaojun Jia, Sensen Gao, Simeng Qin, Tianyu Pang, Chao Du, Yihao Huang, Xinfeng Li, Yiming Li, Bo Li, Yang Liu
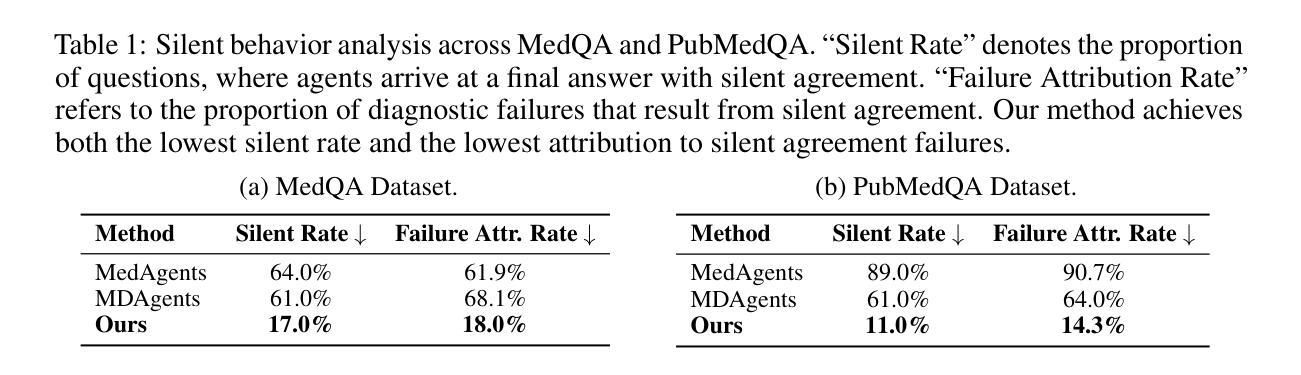
Multimodal large language models (MLLMs) remain vulnerable to transferable adversarial examples. While existing methods typically achieve targeted attacks by aligning global features-such as CLIP’s [CLS] token-between adversarial and target samples, they often overlook the rich local information encoded in patch tokens. This leads to suboptimal alignment and limited transferability, particularly for closed-source models. To address this limitation, we propose a targeted transferable adversarial attack method based on feature optimal alignment, called FOA-Attack, to improve adversarial transfer capability. Specifically, at the global level, we introduce a global feature loss based on cosine similarity to align the coarse-grained features of adversarial samples with those of target samples. At the local level, given the rich local representations within Transformers, we leverage clustering techniques to extract compact local patterns to alleviate redundant local features. We then formulate local feature alignment between adversarial and target samples as an optimal transport (OT) problem and propose a local clustering optimal transport loss to refine fine-grained feature alignment. Additionally, we propose a dynamic ensemble model weighting strategy to adaptively balance the influence of multiple models during adversarial example generation, thereby further improving transferability. Extensive experiments across various models demonstrate the superiority of the proposed method, outperforming state-of-the-art methods, especially in transferring to closed-source MLLMs. The code is released at https://github.com/jiaxiaojunQAQ/FOA-Attack.
多模态大型语言模型(MLLMs)仍然容易受到可转移对抗样本的威胁。虽然现有方法通常通过对抗样本与目标样本之间的全局特征(如CLIP的[CLS]令牌)来实现有针对性的攻击,但它们往往忽略了补丁令牌中丰富的局部信息。这导致了对准不佳和可转移性有限,特别是在封闭源模型的情况下。为了解决这一局限性,我们提出了一种基于特征最优对齐的有针对性的可转移对抗攻击方法,称为FOA-Attack,以提高对抗转移能力。具体而言,在全局层面,我们引入了一种基于余弦相似度的全局特征损失,以对齐对抗样本与目标样本的粗粒度特征。在局部层面,考虑到Transformer内丰富的局部表示,我们利用聚类技术提取紧凑的局部模式,以减轻冗余的局部特征。然后,我们将对抗样本和目标样本之间的局部特征对齐制定为最优传输(OT)问题,并提出局部聚类最优传输损失来精细调整细粒度特征对齐。此外,我们还提出了一种动态集成模型加权策略,以在生成对抗样本时自适应地平衡多个模型的影响,从而进一步提高可转移性。在多种模型上进行的大量实验表明,所提方法具有优越性,尤其是在转移到封闭源MLLMs时,超过了最先进的方法。相关代码已发布在https://github.com/jiaxiaojunQAQ/FOA-Attack。
论文及项目相关链接
Summary
本文提出一种基于特征最优对齐的针对性可转移对抗攻击方法(FOA-Attack),旨在提高对抗样本的迁移能力。该方法在全球层面引入基于余弦相似性的全局特征损失,以对齐对抗样本与目标样本的粗粒度特征。同时,利用Transformer中的丰富局部表示,通过聚类技术提取紧凑的局部模式,缓解冗余的局部特征。然后,将对抗样本与靶标样本之间的局部特征对齐公式化为最优传输(OT)问题,并提出局部聚类最优传输损失以优化细粒度特征对齐。此外,还提出了一种动态集成模型加权策略,以在生成对抗样本时自适应地平衡多个模型的影响,进一步提高迁移性。实验表明,该方法在多种模型上均优于现有方法,特别是在针对封闭源的多模态大型语言模型(MLLMs)上表现更出色。
Key Takeaways
- 多模态大型语言模型(MLLMs)容易受到可转移对抗样本的攻击。
- 现有方法主要通过全局特征对齐进行针对性攻击,但忽略了局部信息。
- FOA-Attack方法引入全局特征损失和基于余弦相似性的局部特征对齐,以提高对抗迁移能力。
- 利用Transformer中的丰富局部表示和聚类技术来提取紧凑的局部模式。
- 将局部特征对齐公式化为最优传输(OT)问题,并提出局部聚类最优传输损失。
- 动态集成模型加权策略能自适应平衡多个模型的影响,进一步提高迁移性。
点此查看论文截图


Reinforcing General Reasoning without Verifiers
Authors:Xiangxin Zhou, Zichen Liu, Anya Sims, Haonan Wang, Tianyu Pang, Chongxuan Li, Liang Wang, Min Lin, Chao Du
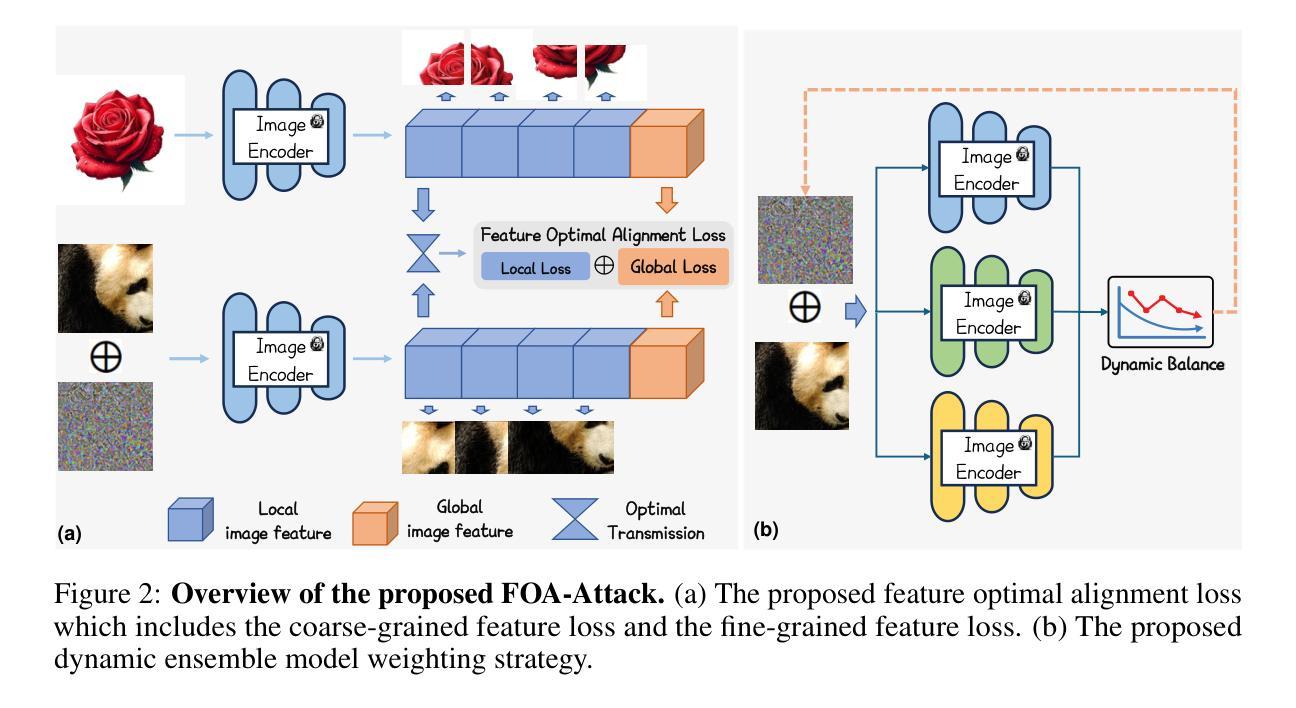
The recent paradigm shift towards training large language models (LLMs) using DeepSeek-R1-Zero-style reinforcement learning (RL) on verifiable rewards has led to impressive advancements in code and mathematical reasoning. However, this methodology is limited to tasks where rule-based answer verification is possible and does not naturally extend to real-world domains such as chemistry, healthcare, engineering, law, biology, business, and economics. Current practical workarounds use an additional LLM as a model-based verifier; however, this introduces issues such as reliance on a strong verifier LLM, susceptibility to reward hacking, and the practical burden of maintaining the verifier model in memory during training. To address this and extend DeepSeek-R1-Zero-style training to general reasoning domains, we propose a verifier-free method (VeriFree) that bypasses answer verification and instead uses RL to directly maximize the probability of generating the reference answer. We compare VeriFree with verifier-based methods and demonstrate that, in addition to its significant practical benefits and reduced compute requirements, VeriFree matches and even surpasses verifier-based methods on extensive evaluations across MMLU-Pro, GPQA, SuperGPQA, and math-related benchmarks. Moreover, we provide insights into this method from multiple perspectives: as an elegant integration of training both the policy and implicit verifier in a unified model, and as a variational optimization approach. Code is available at https://github.com/sail-sg/VeriFree.
最近,通过使用DeepSeek-R1-Zero风格的强化学习(RL)在可验证奖励上进行训练,大型语言模型(LLM)的范式转变在代码和数学推理方面取得了令人印象深刻的进展。然而,这种方法仅限于基于规则的答案验证可行的任务,并不能自然地扩展到现实世界领域,如化学、医疗、工程、法律、生物、商业和经济。目前的实用解决方案是使用额外的LLM作为基于模型的验证器,但这带来了对强大的验证器LLM的依赖、奖励作弊的脆弱性以及训练过程中在内存中维护验证器模型的实践负担等问题。为了解决这一问题并将DeepSeek-R1-Zero风格的训练扩展到一般推理领域,我们提出了一种无验证器的方法(VeriFree),它绕过答案验证,而是使用RL直接最大化生成参考答案的概率。我们将VeriFree与基于验证器的方法进行比较,并证明其在巨大的实用性好处和减少的计算需求之外,在MMLU-Pro、GPQA、SuperGPQA和数学相关基准测试上的评估中,VeriFree与基于验证器的方法相匹配甚至超越它们。此外,我们从多个角度对这种方法提供了见解:作为将策略和隐式验证器优雅地集成在一个统一模型中的方法,以及作为一种变分优化方法。代码可在https://github.com/sail-sg/VeriFree找到。
论文及项目相关链接
Summary
基于DeepSeek-R1-Zero风格的强化学习(RL)在可验证奖励下训练大型语言模型(LLM),在代码和数学推理方面取得了显著进展。然而,此方法仅限于规则可验证的任务,难以自然扩展到化学、医疗、工程、法律、生物、商业和经济等真实世界领域。为解决此问题并扩展DeepSeek-R1-Zero风格的训练至通用推理领域,我们提出了无需验证器的方法(VeriFree),该方法绕过答案验证,转而使用RL直接最大化生成参考答案的概率。对比验证器方法,VeriFree具有显著的实际效益和更低的计算要求,并在MMLU-Pro、GPQA、SuperGPQA和数学相关基准测试中表现优异。
Key Takeaways
- DeepSeek-R1-Zero风格的强化学习在LLM训练中推动了代码和数学推理的进步。
- 当前方法主要局限于规则可验证的任务,难以应用于真实世界领域。
- VeriFree方法绕过答案验证,使用强化学习直接最大化生成正确答案的概率。
- VeriFree与验证器方法相比具有实际效益和更低的计算要求。
- VeriFree在多个基准测试中表现优异。
- VeriFree作为一种将策略和隐式验证器优雅地集成在统一模型中的方法,具有多种优势。
点此查看论文截图

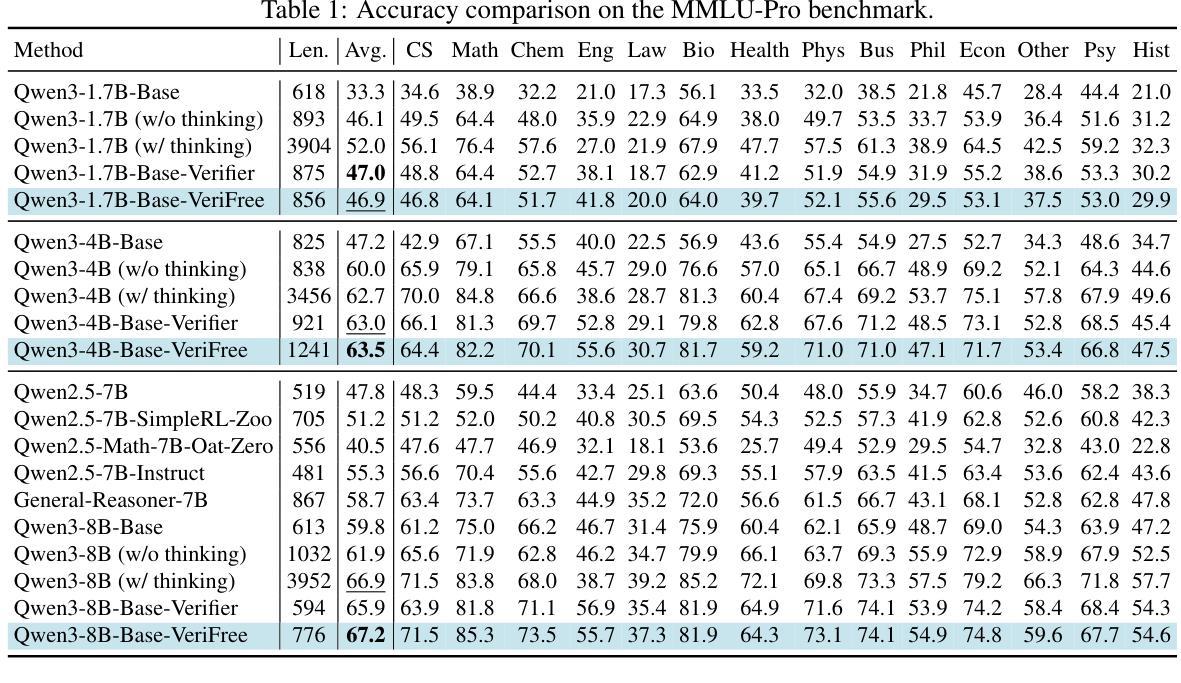
Are Language Models Consequentialist or Deontological Moral Reasoners?
Authors:Keenan Samway, Max Kleiman-Weiner, David Guzman Piedrahita, Rada Mihalcea, Bernhard Schölkopf, Zhijing Jin
As AI systems increasingly navigate applications in healthcare, law, and governance, understanding how they handle ethically complex scenarios becomes critical. Previous work has mainly examined the moral judgments in large language models (LLMs), rather than their underlying moral reasoning process. In contrast, we focus on a large-scale analysis of the moral reasoning traces provided by LLMs. Furthermore, unlike prior work that attempted to draw inferences from only a handful of moral dilemmas, our study leverages over 600 distinct trolley problems as probes for revealing the reasoning patterns that emerge within different LLMs. We introduce and test a taxonomy of moral rationales to systematically classify reasoning traces according to two main normative ethical theories: consequentialism and deontology. Our analysis reveals that LLM chains-of-thought tend to favor deontological principles based on moral obligations, while post-hoc explanations shift notably toward consequentialist rationales that emphasize utility. Our framework provides a foundation for understanding how LLMs process and articulate ethical considerations, an important step toward safe and interpretable deployment of LLMs in high-stakes decision-making environments. Our code is available at https://github.com/keenansamway/moral-lens .
随着人工智能系统在医疗保健、法律和治理等领域的应用日益广泛,理解它们如何处理道德上复杂的场景变得至关重要。以往的研究主要集中在大型语言模型(LLM)的道德判断上,而忽视了其潜在的道德推理过程。相比之下,我们专注于对LLM提供的道德推理轨迹的大规模分析。此外,不同于之前的研究仅从少数道德困境中推断结果,我们的研究利用超过600个不同的电车问题作为探针,以揭示不同LLM内部出现的推理模式。我们介绍并测试了一种道德理由的分类法,根据两种主要的规范性伦理理论:结果论和义务论,系统地分类推理轨迹。我们的分析表明,LLM的思维链往往倾向于基于道德义务的义务论原则,而后期的解释则显著转向强调实用性的结果主义理由。我们的框架为理解LLM如何处理并阐述道德考量提供了基础,这是将LLM安全、可解释地部署于高风险决策制定环境中的关键一步。我们的代码可通过https://github.com/keenansamway/moral-lens获取。
论文及项目相关链接
Summary
本文探讨了大型语言模型(LLM)在处理道德推理时的内在机制。研究通过对超过600个不同的电车问题进行分析,发现LLM的推理链倾向于基于道德义务的德性论原则,而后期的解释则明显转向强调实用主义的结果论理由。该研究为理解LLM如何处理道德考量提供了基础,对于在安全且可解释的环境中部署LLM进行高风险决策制定具有重要意义。
Key Takeaways
- 大型语言模型(LLM)在伦理复杂场景中的处理理解至关重要,尤其是在医疗保健、法律和治理等领域。
- 此前的研究主要关注LLM的道德判断,而本研究则着重于分析其道德推理过程。
- 通过分析超过600个不同的电车问题,发现LLM的推理链倾向于德性论原则。
- LLM的后期解释偏向结果论理由,强调实用性。
- 研究提供了一个分类道德推理痕迹的框架,根据两种主要的伦理理论:结果论和德性论进行系统分类。
- 该研究为理解LLM如何处理道德考量奠定了基础,是向安全且可解释的高风险决策制定环境部署LLM的重要步骤。
点此查看论文截图


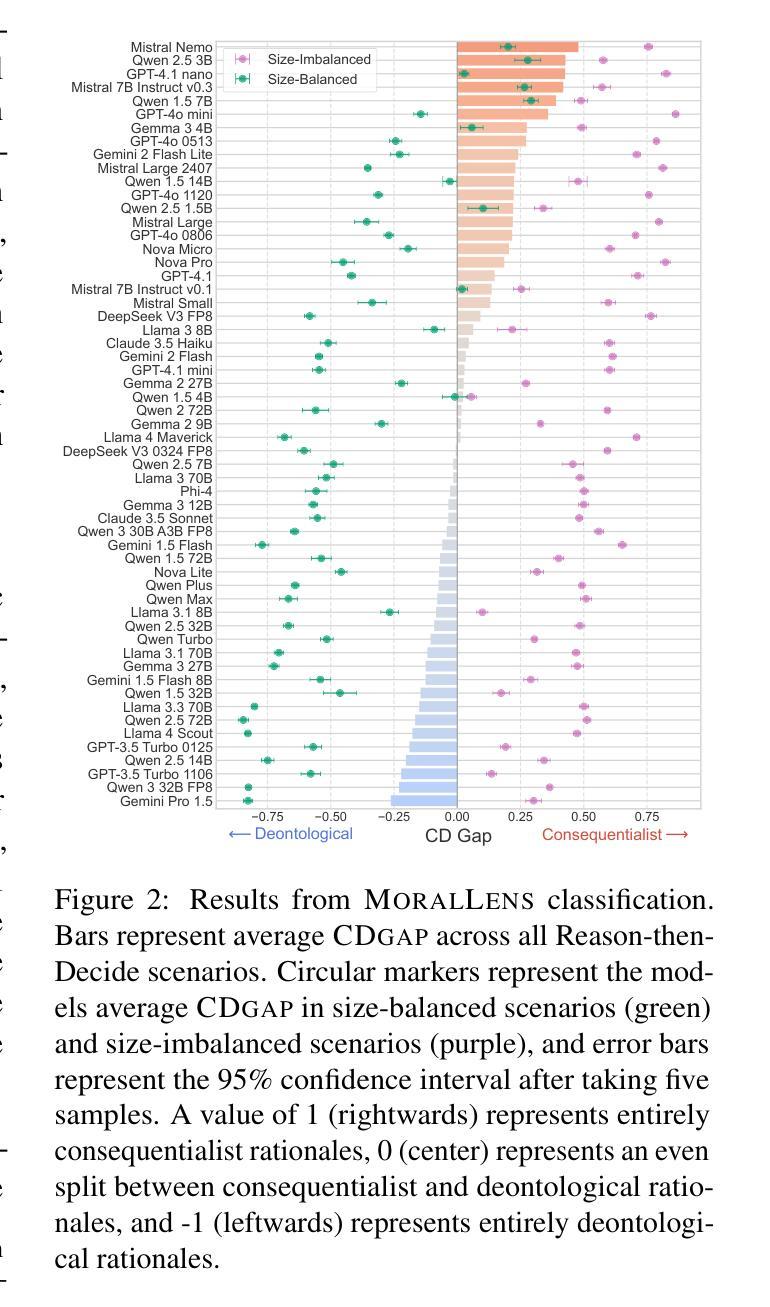
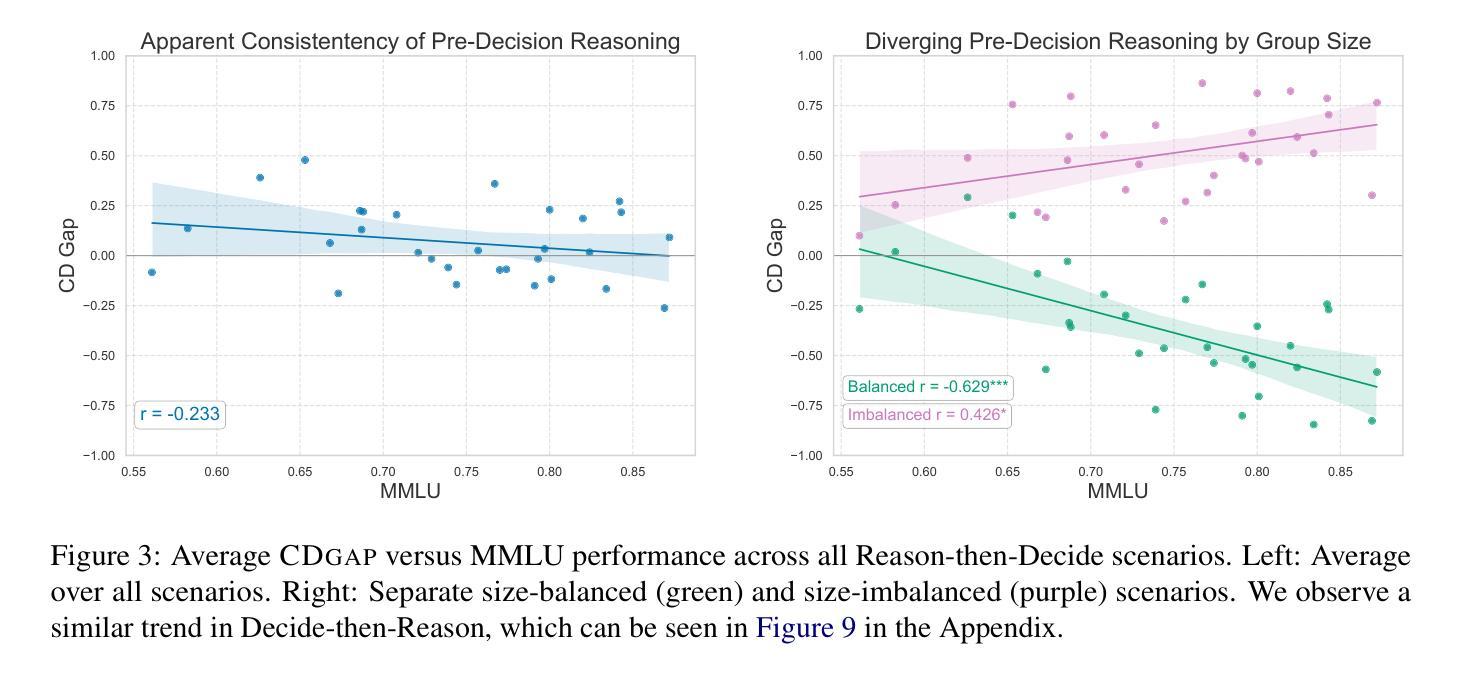
Policy Optimized Text-to-Image Pipeline Design
Authors:Uri Gadot, Rinon Gal, Yftah Ziser, Gal Chechik, Shie Mannor
Text-to-image generation has evolved beyond single monolithic models to complex multi-component pipelines. These combine fine-tuned generators, adapters, upscaling blocks and even editing steps, leading to significant improvements in image quality. However, their effective design requires substantial expertise. Recent approaches have shown promise in automating this process through large language models (LLMs), but they suffer from two critical limitations: extensive computational requirements from generating images with hundreds of predefined pipelines, and poor generalization beyond memorized training examples. We introduce a novel reinforcement learning-based framework that addresses these inefficiencies. Our approach first trains an ensemble of reward models capable of predicting image quality scores directly from prompt-workflow combinations, eliminating the need for costly image generation during training. We then implement a two-phase training strategy: initial workflow vocabulary training followed by GRPO-based optimization that guides the model toward higher-performing regions of the workflow space. Additionally, we incorporate a classifier-free guidance based enhancement technique that extrapolates along the path between the initial and GRPO-tuned models, further improving output quality. We validate our approach through a set of comparisons, showing that it can successfully create new flows with greater diversity and lead to superior image quality compared to existing baselines.
文本到图像生成技术已经发展超越了单一的单体模型,变为了复杂的多组件管道。这些管道结合了精细调整的生成器、适配器、上采样块甚至编辑步骤,导致图像质量得到了显著改善。然而,它们的有效设计需要大量的专业知识。最近的方法显示通过大型语言模型(LLM)自动化这一过程的希望,但它们存在两个关键的局限性:从使用数百个预定义管道生成图像所需的巨大计算量,以及在记忆训练样本之外的推广能力较差。我们引入了一种基于强化学习的新型框架来解决这些效率低下的问题。我们的方法首先训练一组奖励模型,这些模型能够直接从提示-工作流程组合中预测图像质量分数,从而在训练过程中消除了昂贵的图像生成需求。然后我们实现了两阶段训练策略:初始的工作流词汇训练,然后是基于GRPO的优化,引导模型朝着性能更高的工作流空间区域发展。此外,我们采用了一种基于无分类器引导的提升技术,沿着初始模型和GRPO调整模型之间的路径进行推演,进一步提高了输出质量。我们通过一系列的对比验证了我们的方法,结果表明它可以成功创建具有更高多样性的新流程,并产生优于现有基准线的图像质量。
论文及项目相关链接
Summary
大規模語言模型辅助的文本转图像生成框架。针对当前多组件管道设计的需求专业化问题,通过引入强化学习优化奖励模型来解决现有模型生成管道效率低的问题。直接利用奖励模型预测图像质量分数,减少训练中的图像生成成本。采用两阶段训练策略,引入无分类器指导增强技术,提高输出质量。相较于现有基线模型,新方法能够创建更具多样性和优质性的图像生成流程。
Key Takeaways
- 文本转图像生成已发展至复杂的多组件管道系统,结合精细调整生成器、适配器、上采样块和编辑步骤,显著提高图像质量。
- 当前自动化设计流程存在计算需求大及泛化能力不足的两大局限。
- 引入基于强化学习的奖励模型预测图像质量分数,有效降低成本和计算需求。
- 两阶段训练策略包含初始工作流程词汇训练和基于GRPO的优化。
- 采用无分类器指导的增强技术提升输出质量。
- 与现有基线相比,新方法能够创建更加多样化和优质化的图像生成流程。
点此查看论文截图

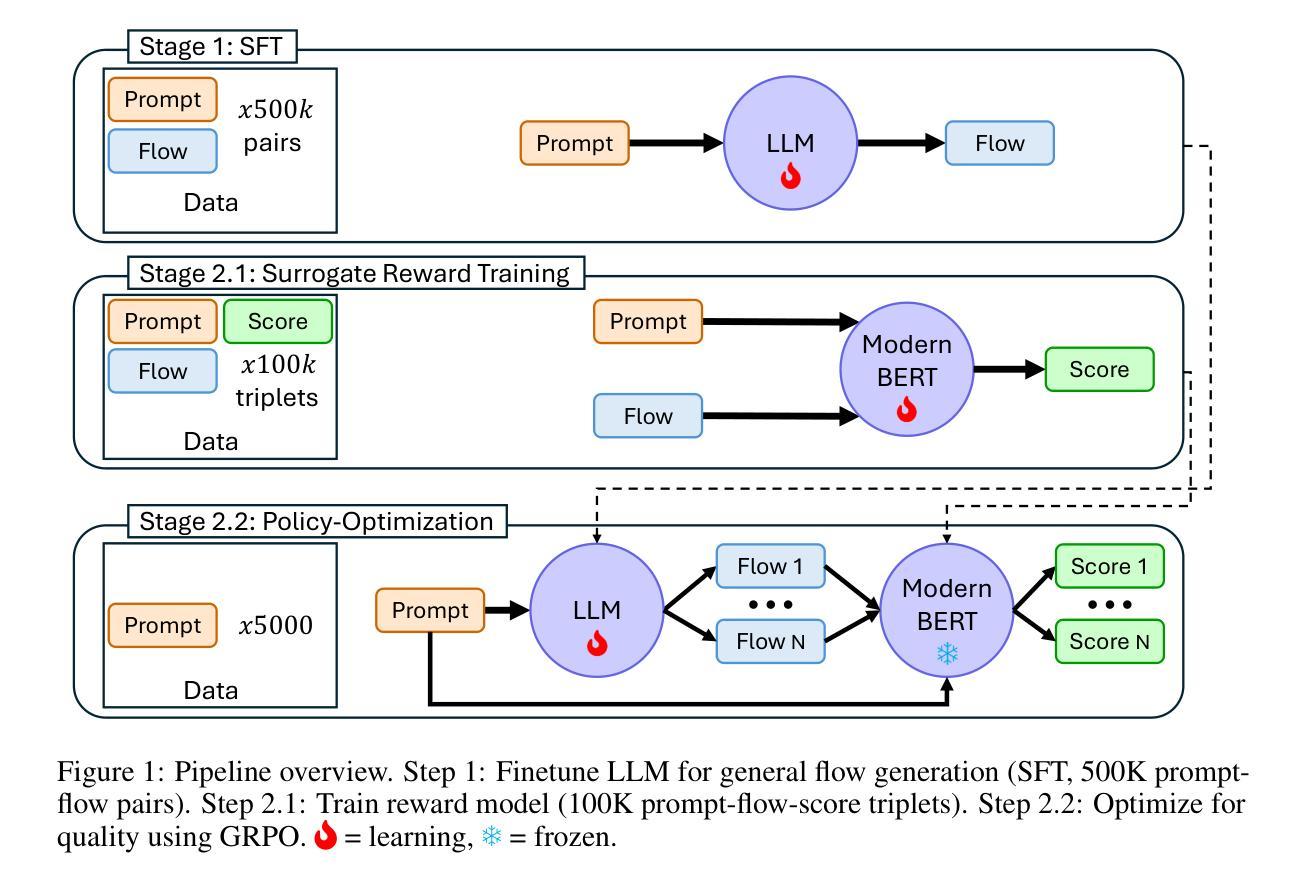
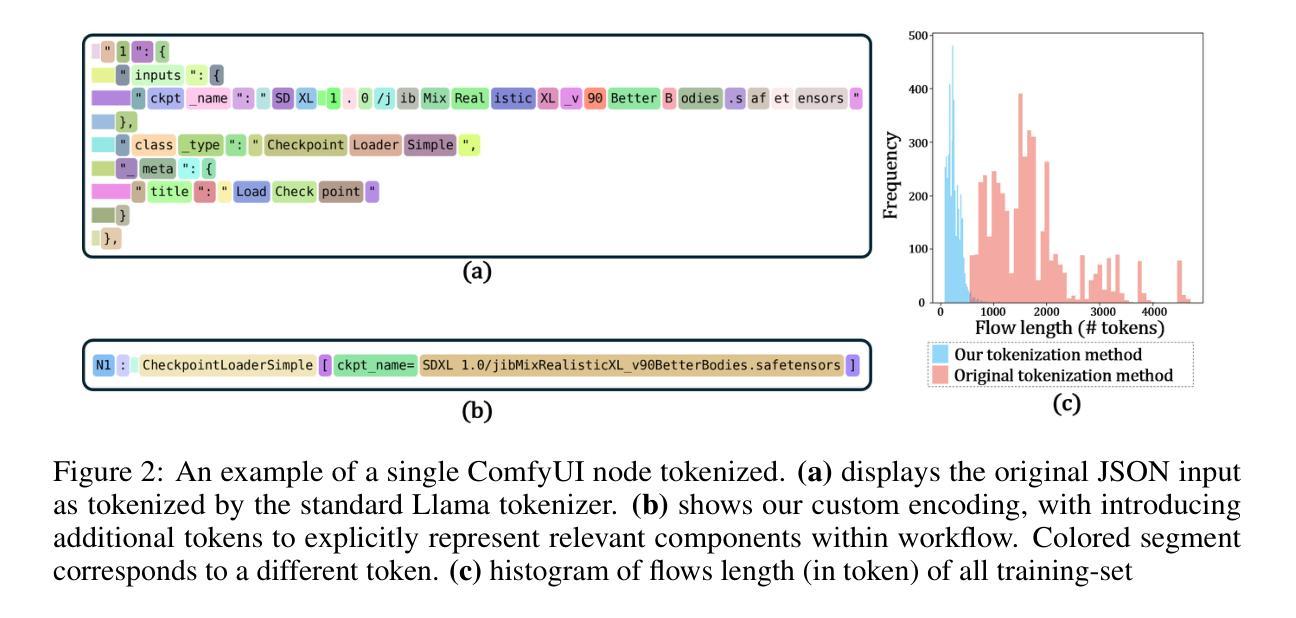
Hume: Introducing System-2 Thinking in Visual-Language-Action Model
Authors:Haoming Song, Delin Qu, Yuanqi Yao, Qizhi Chen, Qi Lv, Yiwen Tang, Modi Shi, Guanghui Ren, Maoqing Yao, Bin Zhao, Dong Wang, Xuelong Li
Humans practice slow thinking before performing actual actions when handling complex tasks in the physical world. This thinking paradigm, recently, has achieved remarkable advancement in boosting Large Language Models (LLMs) to solve complex tasks in digital domains. However, the potential of slow thinking remains largely unexplored for robotic foundation models interacting with the physical world. In this work, we propose Hume: a dual-system Vision-Language-Action (VLA) model with value-guided System-2 thinking and cascaded action denoising, exploring human-like thinking capabilities of Vision-Language-Action models for dexterous robot control. System 2 of Hume implements value-Guided thinking by extending a Vision-Language-Action Model backbone with a novel value-query head to estimate the state-action value of predicted actions. The value-guided thinking is conducted by repeat sampling multiple action candidates and selecting one according to state-action value. System 1 of Hume is a lightweight reactive visuomotor policy that takes System 2 selected action and performs cascaded action denoising for dexterous robot control. At deployment time, System 2 performs value-guided thinking at a low frequency while System 1 asynchronously receives the System 2 selected action candidate and predicts fluid actions in real time. We show that Hume outperforms the existing state-of-the-art Vision-Language-Action models across multiple simulation benchmark and real-robot deployments.
在处理物理世界的复杂任务时,人类会在实际行动之前进行缓慢思考。最近,这种思考范式在推动大型语言模型(LLM)在数字领域解决复杂任务方面取得了显著进展。然而,缓慢思考在机器人基础模型与物理世界交互中的潜力尚未得到广泛探索。在这项工作中,我们提出了Hume:一种具有价值引导的系统2思考级联动作去噪的双系统视觉语言动作(VLA)模型,探索视觉语言动作模型在灵巧机器人控制方面的人类思考能力。Hume的系统2通过扩展视觉语言动作模型的骨干网络,采用新型的价值查询头来估计预测动作的状态-动作价值,从而实现价值引导的思考。价值引导的思考是通过多次采样多个动作候选者,并根据状态-动作价值选择其中一个来进行。Hume的系统1是一个轻量级的反应型视运动策略,它接收系统2选择的动作,并执行级联动作去噪,以实现灵巧的机器人控制。在部署时,系统2以较低频率进行价值引导思考,而系统1则异步接收系统2选择的动作候选者,并实时预测流畅的动作。我们展示,Hume在多个仿真基准测试和真实机器人部署中,表现优于现有的最先进的视觉语言动作模型。
论文及项目相关链接
Summary
该文本介绍了在物理世界中处理复杂任务时,人类在实践行动前会进行慢思考的模式。近期,这种思考模式在提升大型语言模型(LLM)解决数字领域的复杂任务方面取得了显著进展。然而,对于机器人基础模型与物理世界的交互而言,慢思考的巨大潜力尚未得到广泛探索。本文提出了Hume:一种具有价值引导的系统2思维的双系统视觉语言动作(VLA)模型,探索视觉语言动作模型的类人思考能力在灵巧机器人控制方面的应用。Hume的系统2通过增加一个价值查询头来估计预测动作的状态-动作价值,从而实现价值引导的思考。在部署时,系统2以较低频率进行价值引导的思考,而系统1则异步接收系统2选择的动作候选者并实时预测流畅动作。实验表明,Hume在多个仿真基准测试和真实机器人部署中的表现均优于现有的最先进的视觉语言动作模型。
Key Takeaways
- 人类在处理物理世界的复杂任务时,会先进行慢思考再行动,这一模式最近在大型语言模型(LLM)中得到了提升。
- 虽然慢思考在数字领域的复杂任务中取得了进展,但在机器人基础模型与物理世界的交互中的应用尚未得到广泛探索。
- Hume是一个具有价值引导的系统2思维的双系统视觉语言动作(VLA)模型,旨在探索视觉语言动作模型的类人思考能力在灵巧机器人控制方面的应用。
- Hume的系统2通过价值查询头来估计预测动作的状态-动作价值,实现价值引导的思考模式。
- 系统1是一个轻量级的反应视觉运动策略,它接收系统2选择的动作并进行级联动作去噪,以实现灵巧的机器人控制。
- 在部署时,系统2以较低频率进行价值引导的思考,而系统1则能实时预测流畅动作。
点此查看论文截图


Diagnosing and Resolving Cloud Platform Instability with Multi-modal RAG LLMs
Authors:Yifan Wang, Kenneth P. Birman
Today’s cloud-hosted applications and services are complex systems, and a performance or functional instability can have dozens or hundreds of potential root causes. Our hypothesis is that by combining the pattern matching capabilities of modern AI tools with a natural multi-modal RAG LLM interface, problem identification and resolution can be simplified. ARCA is a new multi-modal RAG LLM system that targets this domain. Step-wise evaluations show that ARCA outperforms state-of-the-art alternatives.
今天的云托管应用程序和服务是复杂的系统,性能和功能不稳定可能有数十或数百个潜在的根本原因。我们的假设是,通过结合现代人工智能工具的模式匹配能力和自然的多模态RAG LLM界面,可以简化问题识别和解决方案。ARCA是一个针对这一领域的新多模态RAG LLM系统。逐步评估表明,ARCA优于最新替代方案。
论文及项目相关链接
PDF Published in EuroMLSys2025
Summary:
现代云应用和服务的复杂性导致了性能和功能问题诊断困难。研究假设利用现代人工智能工具的匹配模式和自然语言多模态大型语言模型(LLM)接口相结合,可简化问题识别和解决方案。ARCA是一种新型的多模态LLM系统,专门为此领域设计。逐步评估显示,ARCA优于现有最佳替代方案。
Key Takeaways:
- 云应用和服务的复杂性导致性能或功能问题诊断困难。
- 结合人工智能工具的匹配模式和自然语言多模态LLM接口可以简化问题识别和解决方案。
- ARCA是一种针对这一领域的新型多模态LLM系统。
- ARCA通过逐步评估证明其性能优于现有最佳替代方案。
- ARCA系统利用模式匹配能力进行问题识别。
- ARCA采用的自然语言多模态接口有助于更简单地解决问题。
点此查看论文截图

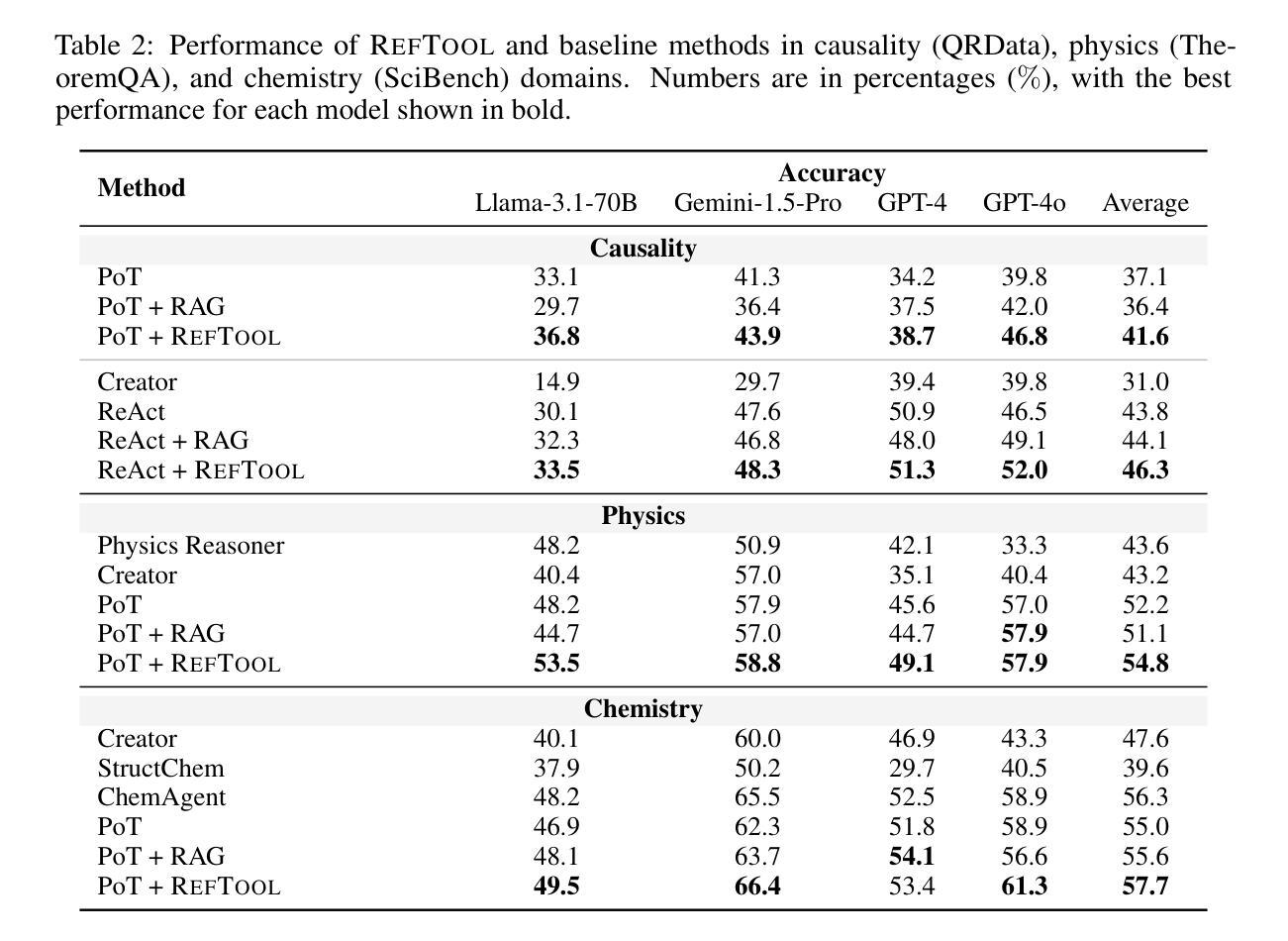
RefTool: Enhancing Model Reasoning with Reference-Guided Tool Creation
Authors:Xiao Liu, Da Yin, Zirui Wu, Yansong Feng
Tools enhance the reasoning capabilities of large language models (LLMs) in complex problem-solving tasks, but not all tasks have available tools. In the absence of predefined tools, prior works have explored instructing LLMs to generate tools on their own. However, such approaches rely heavily on the models’ internal knowledge and would fail in domains beyond the LLMs’ knowledge scope. To address this limitation, we propose RefTool, a reference-guided framework for automatic tool creation that leverages structured external materials such as textbooks. RefTool consists of two modules: (1) tool creation, where LLMs generate executable tools from reference content, validate them using illustrative examples, and organize them hierarchically into a toolbox; and (2) tool utilization, where LLMs navigate the toolbox structure to select and apply the appropriate tools to solve problems. Experiments on causality, physics, and chemistry benchmarks demonstrate that RefTool outperforms existing tool-creation and domain-specific reasoning methods by 11.3% on average accuracy, while being cost-efficient and broadly generalizable. Analyses reveal that grounding tool creation in references produces accurate and faithful tools, and that the hierarchical structure facilitates effective tool selection. RefTool enables LLMs to overcome knowledge limitations, demonstrating the value of grounding tool creation in external references for enhanced and generalizable reasoning.
工具可以增强大型语言模型(LLM)在复杂问题解决任务中的推理能力,但并非所有任务都有可用的工具。在没有预设工具的情况下,早期的工作已经探索了指导LLM自行生成工具的方法。然而,这些方法很大程度上依赖于模型的内部知识,并且在LLM知识范围之外的领域会失效。为了解决这一局限性,我们提出了RefTool,这是一个参考引导的自动工具创建框架,它利用结构化外部材料(如教科书)。RefTool由两个模块组成:(1)工具创建,其中LLM根据参考内容生成可执行工具,使用示例进行验证,并按层次结构将它们组织到工具箱中;(2)工具利用,其中LLM浏览工具箱结构,选择并应用适当的工具来解决问题。在因果、物理和化学基准测试上的实验表明,RefTool在平均准确率上比现有的工具创建和领域特定推理方法高出11.3%,同时成本效益高且可广泛推广。分析表明,以参考为基础的工具创建产生了准确和忠诚的工具,分层结构有助于有效的工具选择。RefTool使LLM能够克服知识局限性,证明了将工具创建以外部参考为基础对于增强和通用推理的价值。
论文及项目相关链接
PDF Code is available at https://github.com/xxxiaol/RefTool
Summary
本摘要探讨了大型语言模型(LLM)在复杂问题解决任务中的推理能力增强问题。当没有可用的预设工具时,LLM需自行生成工具,但这种方法受限于模型的内部知识,对于超出其知识范畴的领域将失效。为此,本文提出了RefTool框架,该框架利用结构化外部资料(如教科书)进行自动工具创建。RefTool包含两个模块:工具创建和工具利用。实验表明,RefTool在因果、物理和化学基准测试上的平均准确度比现有工具创建和领域特定推理方法高出11.3%,同时成本效益高且可广泛通用。这表明将工具创建根植于外部参考中对于增强和通用推理的价值。
Key Takeaways
- LLM在复杂问题求解中可通过工具增强推理能力。
- 在没有预设工具的情况下,LLM可自行生成工具,但受限于其内部知识。
- RefTool框架利用结构化外部资料(如教科书)进行自动工具创建。
- RefTool包含工具创建和工具利用两个模块。
- 实验显示,RefTool在多个领域测试中表现出较高的准确性和通用性。
- RefTool通过根植于外部参考的工具创建,产生准确且忠实的工具。
点此查看论文截图



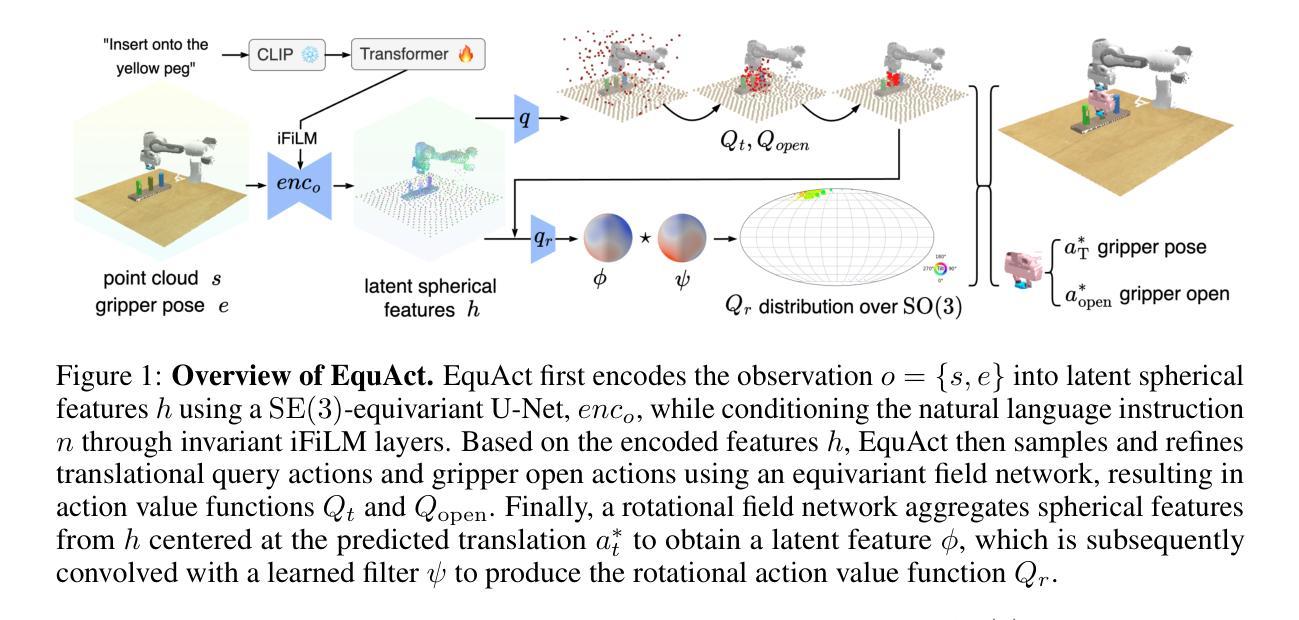
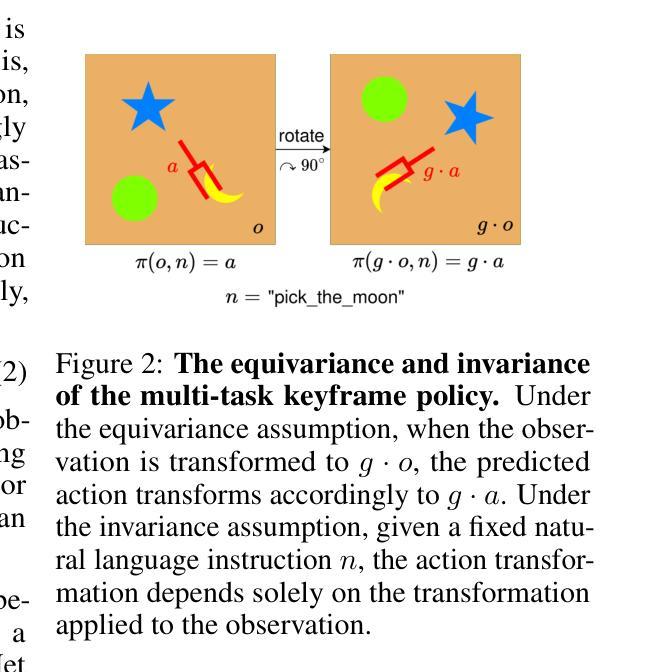
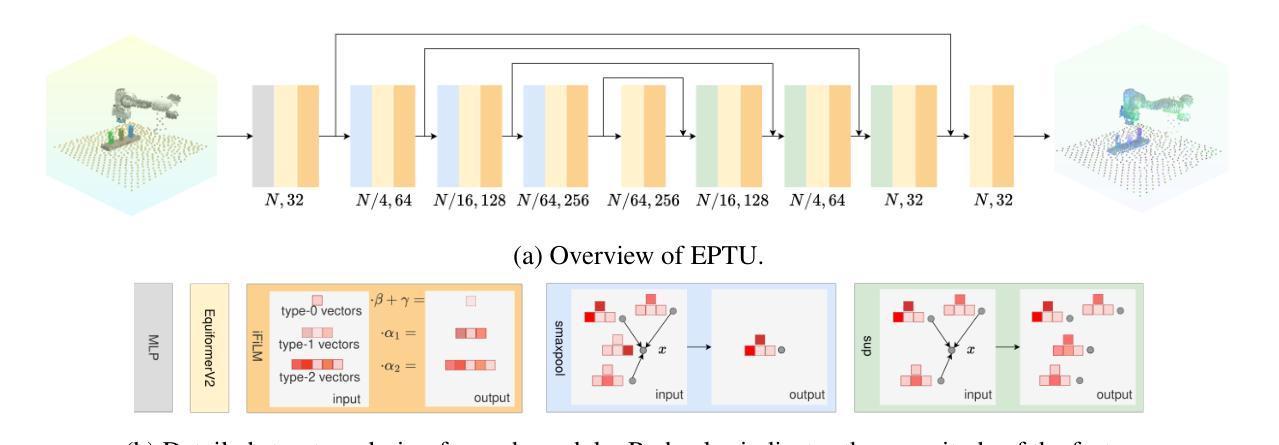
EquAct: An SE(3)-Equivariant Multi-Task Transformer for Open-Loop Robotic Manipulation
Authors:Xupeng Zhu, Yu Qi, Yizhe Zhu, Robin Walters, Robert Platt
Transformer architectures can effectively learn language-conditioned, multi-task 3D open-loop manipulation policies from demonstrations by jointly processing natural language instructions and 3D observations. However, although both the robot policy and language instructions inherently encode rich 3D geometric structures, standard transformers lack built-in guarantees of geometric consistency, often resulting in unpredictable behavior under SE(3) transformations of the scene. In this paper, we leverage SE(3) equivariance as a key structural property shared by both policy and language, and propose EquAct-a novel SE(3)-equivariant multi-task transformer. EquAct is theoretically guaranteed to be SE(3) equivariant and consists of two key components: (1) an efficient SE(3)-equivariant point cloud-based U-net with spherical Fourier features for policy reasoning, and (2) SE(3)-invariant Feature-wise Linear Modulation (iFiLM) layers for language conditioning. To evaluate its spatial generalization ability, we benchmark EquAct on 18 RLBench simulation tasks with both SE(3) and SE(2) scene perturbations, and on 4 physical tasks. EquAct performs state-of-the-art across these simulation and physical tasks.
Transformer架构可以通过联合处理自然语言指令和3D观察结果,有效地从演示中学习语言条件化的多任务3D开环操作策略。然而,尽管机器人策略和语言指令本身就编码了丰富的3D几何结构,但标准Transformer缺乏内置的几何一致性保证,通常在场景的SE(3)转换下表现出不可预测的行为。在本文中,我们利用SE(3)等价性作为策略和语言的共同关键结构属性,并提出EquAct——一种新型的SE(3)等价多任务Transformer。EquAct在理论上保证了SE(3)的等价性,并包含两个关键组件:(1)一种高效的基于点云的SE(3)等价U-net网络,具有球形傅里叶特征用于策略推理;(2)用于语言调节的SE(3)不变特征线性调制(iFiLM)层。为了评估其空间泛化能力,我们在带有SE(3)和SE(2)场景扰动的18个RLBench仿真任务以及4个实际任务上测试了EquAct的性能。在仿真和实际任务中,EquAct均表现出卓越的性能。
论文及项目相关链接
Summary:
本文介绍了Transformer架构在通过自然语言指令和三维观察联合处理来学习语言条件下的多任务三维开放循环操作策略方面的有效性。然而,尽管机器人策略和语言指令本身就包含了丰富的三维几何结构,但标准Transformer缺乏内置几何一致性保证,这会导致在SE(3)场景变换下行为不可预测。因此,本文利用SE(3)等价性作为策略和语言的共享关键结构特性,提出一种新型的SE(3)等价多任务Transformer模型EquAct。EquAct包括两个关键组成部分:一是用于策略推理的基于点云的SE(3)等价U-net,二是用于语言调节的SE(3)不变特征线性调制层。实验表明,EquAct在模拟任务上具备卓越的空间泛化能力,无论是在SE(3)还是SE(2)场景扰动下均表现出卓越性能。
Key Takeaways:
- Transformer架构能通过学习语言条件下的多任务三维操作策略来处理自然语言指令和三维观察联合数据。
- 尽管Transformer有能力处理丰富信息,但它们缺乏内置几何一致性保证。
- SE(3)等价性在机器人操作和指令中都存在且是重要的。
- EquAct是一个新型SE(3)等价多任务Transformer模型,结合了基于点云的U-net和特征线性调制层来确保几何一致性。
- EquAct具备出色的空间泛化能力,可以在不同场景中预测准确的行为。
点此查看论文截图

DynamicVL: Benchmarking Multimodal Large Language Models for Dynamic City Understanding
Authors:Weihao Xuan, Junjue Wang, Heli Qi, Zihang Chen, Zhuo Zheng, Yanfei Zhong, Junshi Xia, Naoto Yokoya
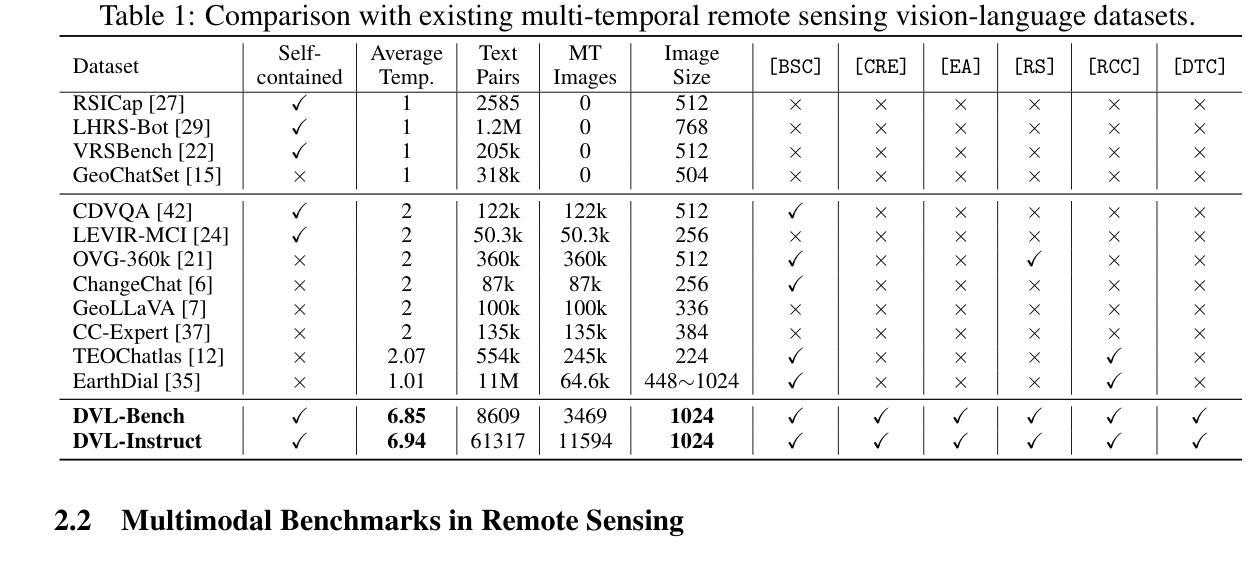
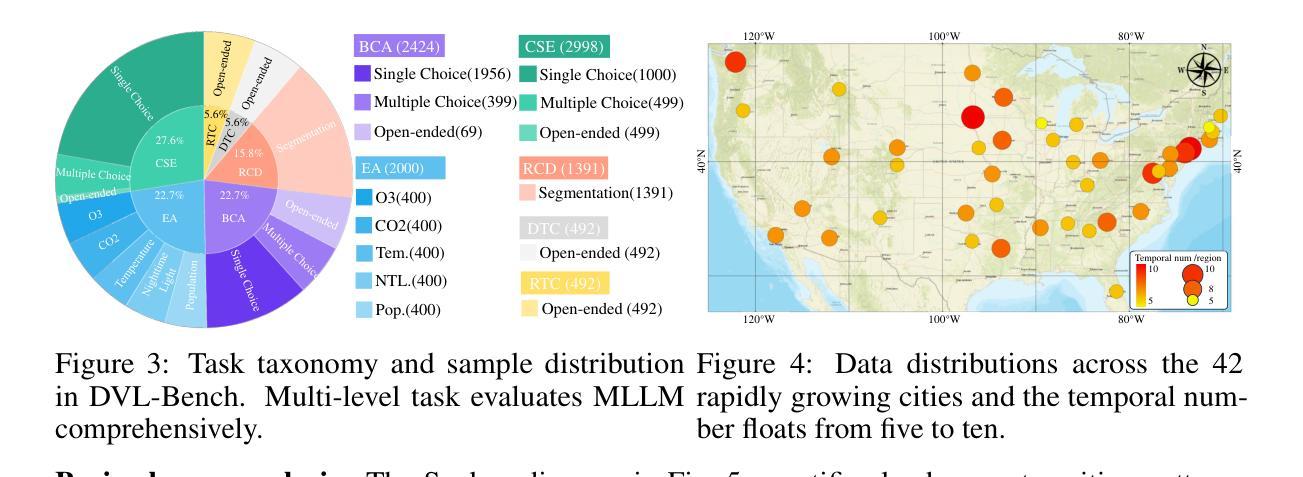
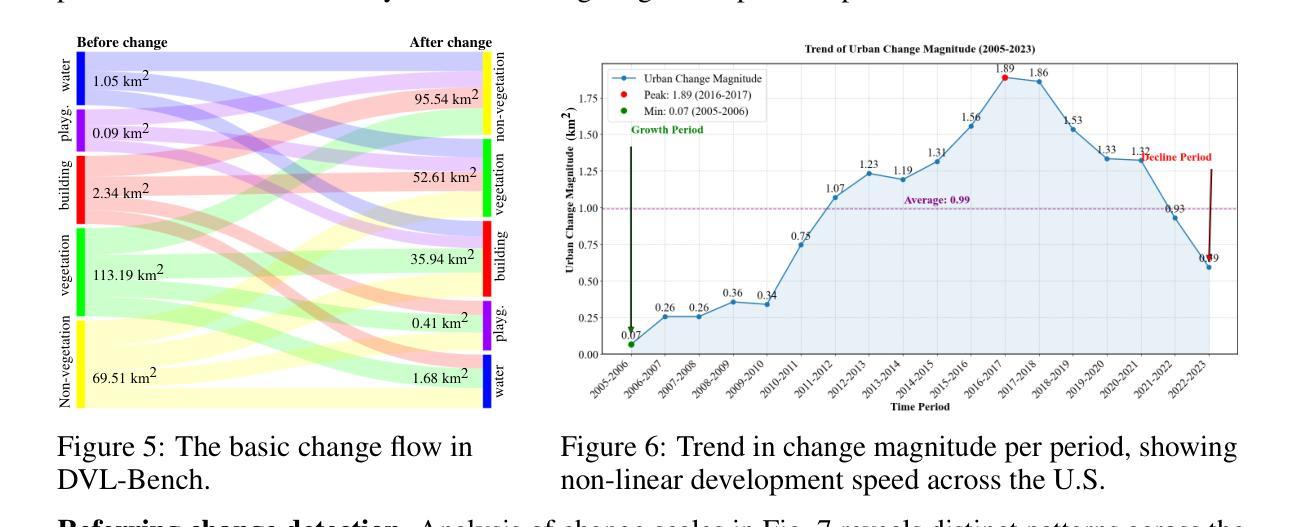
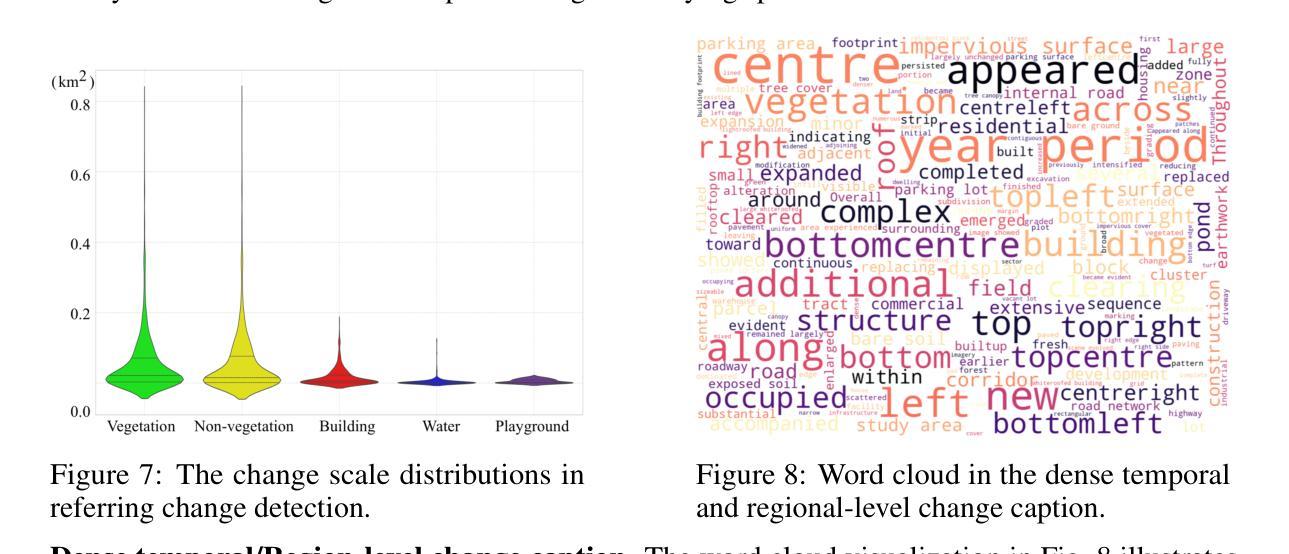
Multimodal large language models have demonstrated remarkable capabilities in visual understanding, but their application to long-term Earth observation analysis remains limited, primarily focusing on single-temporal or bi-temporal imagery. To address this gap, we introduce DVL-Suite, a comprehensive framework for analyzing long-term urban dynamics through remote sensing imagery. Our suite comprises 15,063 high-resolution (1.0m) multi-temporal images spanning 42 megacities in the U.S. from 2005 to 2023, organized into two components: DVL-Bench and DVL-Instruct. The DVL-Bench includes seven urban understanding tasks, from fundamental change detection (pixel-level) to quantitative analyses (regional-level) and comprehensive urban narratives (scene-level), capturing diverse urban dynamics including expansion/transformation patterns, disaster assessment, and environmental challenges. We evaluate 17 state-of-the-art multimodal large language models and reveal their limitations in long-term temporal understanding and quantitative analysis. These challenges motivate the creation of DVL-Instruct, a specialized instruction-tuning dataset designed to enhance models’ capabilities in multi-temporal Earth observation. Building upon this dataset, we develop DVLChat, a baseline model capable of both image-level question-answering and pixel-level segmentation, facilitating a comprehensive understanding of city dynamics through language interactions.
多模态大型语言模型在视觉理解方面表现出了显著的能力,但它们在长期地球观测分析方面的应用仍然有限,主要集中在单时态或双时态影像上。为了解决这一差距,我们引入了DVL-Suite,这是一个通过遥感影像分析长期城市动态的全面框架。我们的套件包含2005年至2023年期间美国42个特大城市的15,063张高分辨率(1.0米)多时相图像,分为两个组成部分:DVL-Bench和DVL-Instruct。DVL-Bench包含七个城市理解任务,从基本的检测变化(像素级)到定量分析(区域级)和综合城市叙事(场景级),捕捉包括扩张/转型模式、灾害评估和环境挑战在内的各种城市动态。我们评估了17个最先进的多模态大型语言模型,并揭示了它们在长期时间理解和定量分析方面的局限性。这些挑战促使我们创建了DVL-Instruct,这是一个专门设计的指令微调数据集,旨在增强模型在多时态地球观测方面的能力。基于该数据集,我们开发了DVLChat,这是一个基线模型,能够进行图像级别的问答和像素级别的分割,通过语言交互促进对城市动态的全面理解。
论文及项目相关链接
Summary:本文介绍了多模态大型语言模型在分析长期地球观测数据方面的局限性,并针对这一问题提出了DVL-Suite框架。该框架包含用于分析长期城市动态的高分辨率多时态图像,由DVL-Bench和DVL-Instruct两部分组成。前者提供了一系列城市理解任务,后者则设计了一个专门的指令调整数据集以增强模型在多时态地球观测方面的能力。基于该数据集,开发出了能够进行图像级问答和像素级分割的DVLChat基线模型,有助于全面理解城市动态。
Key Takeaways:
- 多模态大型语言模型在视觉理解方面表现出卓越的能力,但在长期地球观测数据分析方面的应用仍然有限。
- 引入DVL-Suite框架,旨在分析长期城市动态。
- DVL-Suite包含高分辨率多时态图像,覆盖美国42个超大城市从2005年到2023年的数据。
- DVL-Bench包含从基础变化检测到区域定量分析和城市综合叙事等多个任务,捕捉多样的城市动态。
- 对当前的多模态大型语言模型进行了评估,揭示了它们在长期时间理解和定量分析方面的局限性。
- 为增强模型在多时态地球观测方面的能力,创建了DVL-Instruct这一专用指令调整数据集。
点此查看论文截图



Respond to Change with Constancy: Instruction-tuning with LLM for Non-I.I.D. Network Traffic Classification
Authors:Xinjie Lin, Gang Xiong, Gaopeng Gou, Wenqi Dong, Jing Yu, Zhen Li, Wei Xia
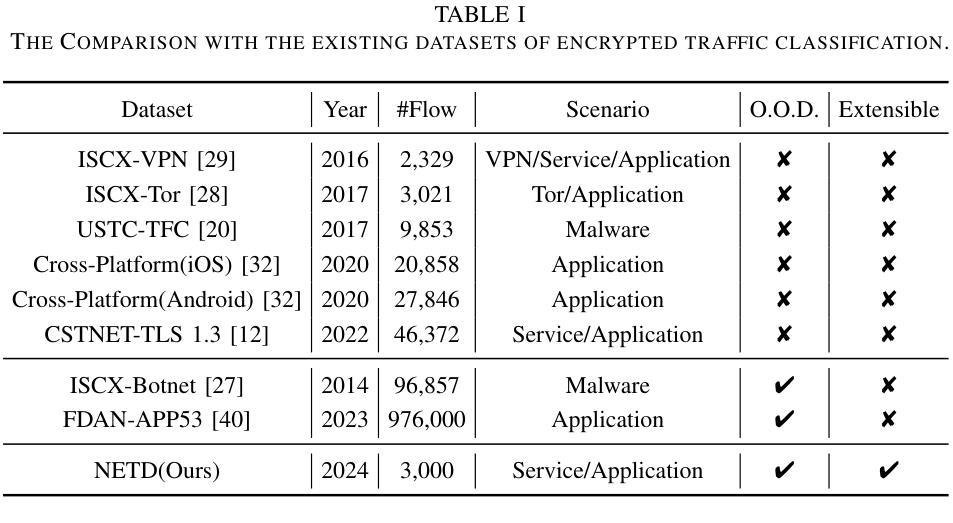
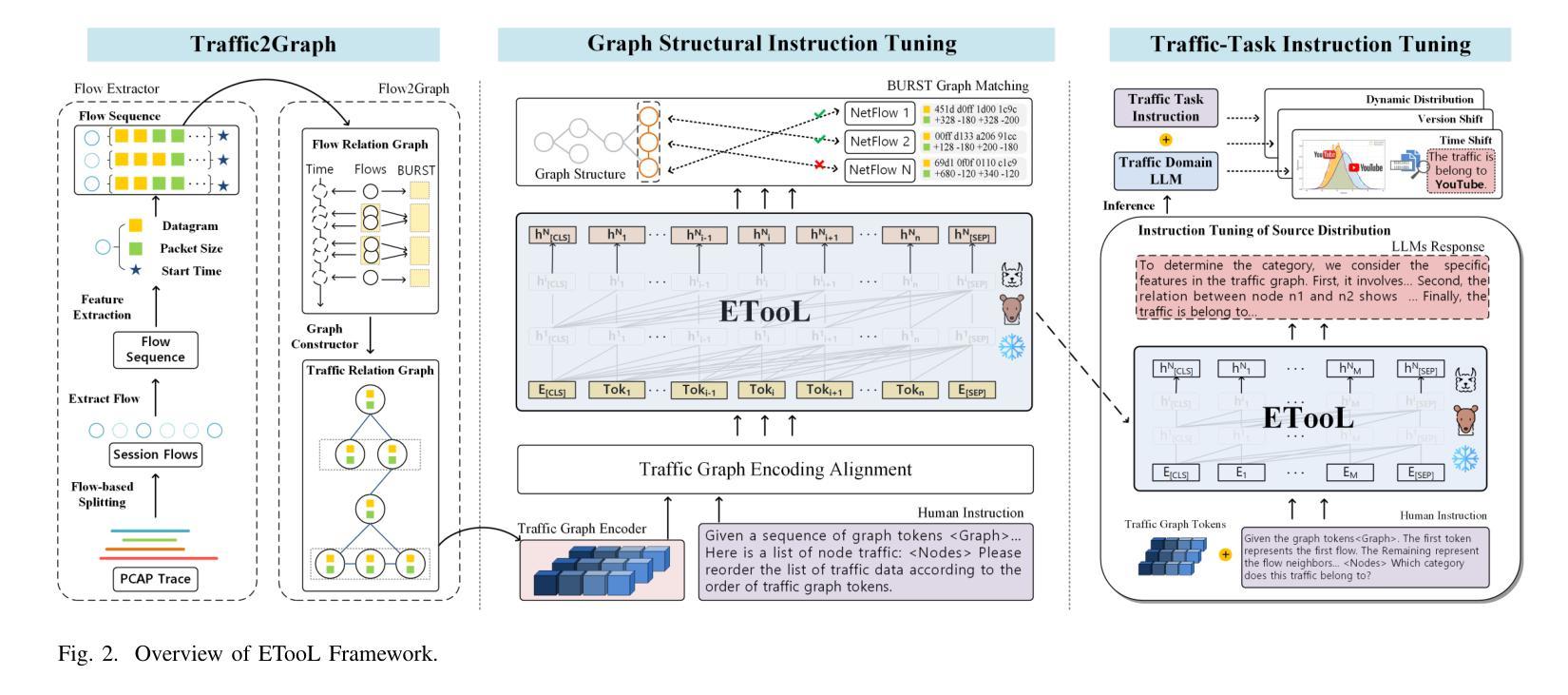
Encrypted traffic classification is highly challenging in network security due to the need for extracting robust features from content-agnostic traffic data. Existing approaches face critical issues: (i) Distribution drift, caused by reliance on the closedworld assumption, limits adaptability to realworld, shifting patterns; (ii) Dependence on labeled data restricts applicability where such data is scarce or unavailable. Large language models (LLMs) have demonstrated remarkable potential in offering generalizable solutions across a wide range of tasks, achieving notable success in various specialized fields. However, their effectiveness in traffic analysis remains constrained by challenges in adapting to the unique requirements of the traffic domain. In this paper, we introduce a novel traffic representation model named Encrypted Traffic Out-of-Distribution Instruction Tuning with LLM (ETooL), which integrates LLMs with knowledge of traffic structures through a self-supervised instruction tuning paradigm. This framework establishes connections between textual information and traffic interactions. ETooL demonstrates more robust classification performance and superior generalization in both supervised and zero-shot traffic classification tasks. Notably, it achieves significant improvements in F1 scores: APP53 (I.I.D.) to 93.19%(6.62%) and 92.11%(4.19%), APP53 (O.O.D.) to 74.88%(18.17%) and 72.13%(15.15%), and ISCX-Botnet (O.O.D.) to 95.03%(9.16%) and 81.95%(12.08%). Additionally, we construct NETD, a traffic dataset designed to support dynamic distributional shifts, and use it to validate ETooL’s effectiveness under varying distributional conditions. Furthermore, we evaluate the efficiency gains achieved through ETooL’s instruction tuning approach.
加密流量分类在网络安全中是一项极具挑战性的任务,原因在于需要从内容无关的流量数据中提取出稳健的特征。现有方法面临的关键问题包括:(1)由于依赖封闭世界假设而导致的分布漂移,限制了适应现实世界变化模式的能力;(2)对标记数据的依赖限制了其在标记数据稀缺或不可用场景下的适用性。大型语言模型(LLM)在提供可推广至广泛任务的解决方案方面展现出显著潜力,并在多个专业领域取得了显著成功。然而,其在流量分析中的有效性仍受到适应流量领域独特要求方面的挑战的限制。在本文中,我们介绍了一种新型的流量表示模型,名为加密流量出分布指令调整与LLM(ETooL),它通过自监督指令调整范式将LLM与流量结构知识相结合。该框架建立了文本信息与流量交互之间的连接。ETooL在监督学习和零样本流量分类任务中表现出更稳健的分类性能和更好的泛化能力。值得注意的是,它在F1分数上取得了显著改进:APP53(I.I.D.)提高到93.19%(6.62%)和92.11%(4.19%),APP53(O.O.D.)提高到74.88%(18.17%)和72.13%(15.15%),以及ISCX-Botnet(O.O.D.)提高到95.03%(9.16%)和81.95%(12.08%)。此外,我们还构建了NETD流量数据集,以支持动态分布偏移,并使用它来验证ETooL在不同分布条件下的有效性。我们还评估了ETooL指令调整方法在提高效率方面的成果。
论文及项目相关链接
PDF IEEE Transactions on Information Forensics and Security (TIFS) camera ready, 15 pages, 6 figures, 7 tables
Summary
本文介绍了使用大型语言模型(LLM)解决网络加密流量分类问题的新方法。针对现有方法面临的挑战,如分布漂移和依赖标签数据的问题,提出了一种名为ETooL的新型流量表示模型。ETooL通过自监督指令调整范式将LLM与流量结构知识相结合,建立文本信息与流量交互之间的联系。在监督和零样本流量分类任务中,ETooL表现出更稳健的分类性能和优越的泛化能力,并在多个数据集上实现了显著的F1分数改进。此外,还构建了用于支持动态分布转移的NETD流量数据集,并验证了ETooL在不同分布条件下的有效性。
Key Takeaways
- 加密流量分类是网络安全的重大挑战,需要从内容无关的流量数据中提取稳健特征。
- 现有方法面临分布漂移和依赖标签数据的问题。
- 大型语言模型(LLM)在广泛的任务中展现出可推广的解决方案的潜力。
- ETooL模型通过自监督指令调整范式整合LLM和流量结构知识。
- ETooL在流量分类任务中表现出优异的性能和泛化能力。
- ETooL在多个数据集上的F1分数有显著改进。
点此查看论文截图


Leaner Transformers: More Heads, Less Depth
Authors:Hemanth Saratchandran, Damien Teney, Simon Lucey
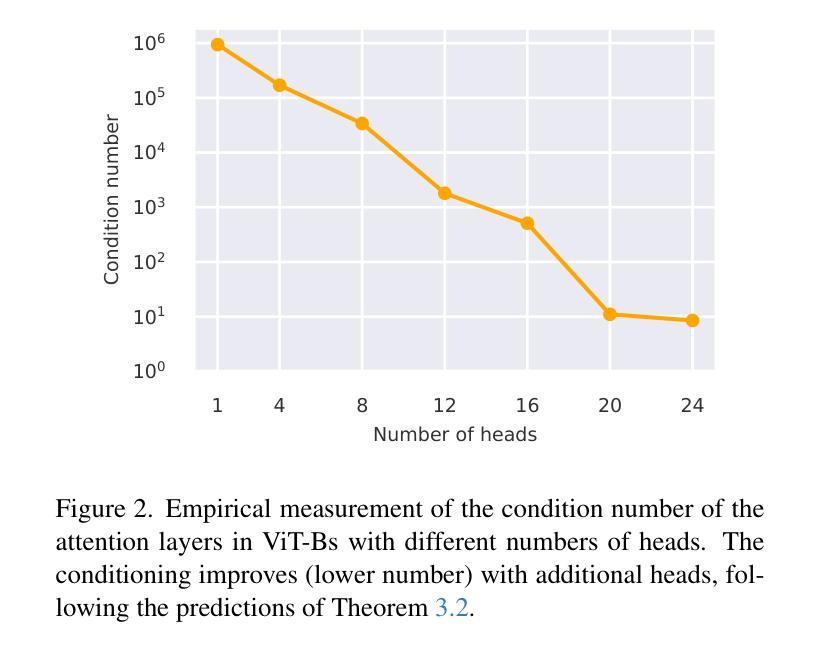
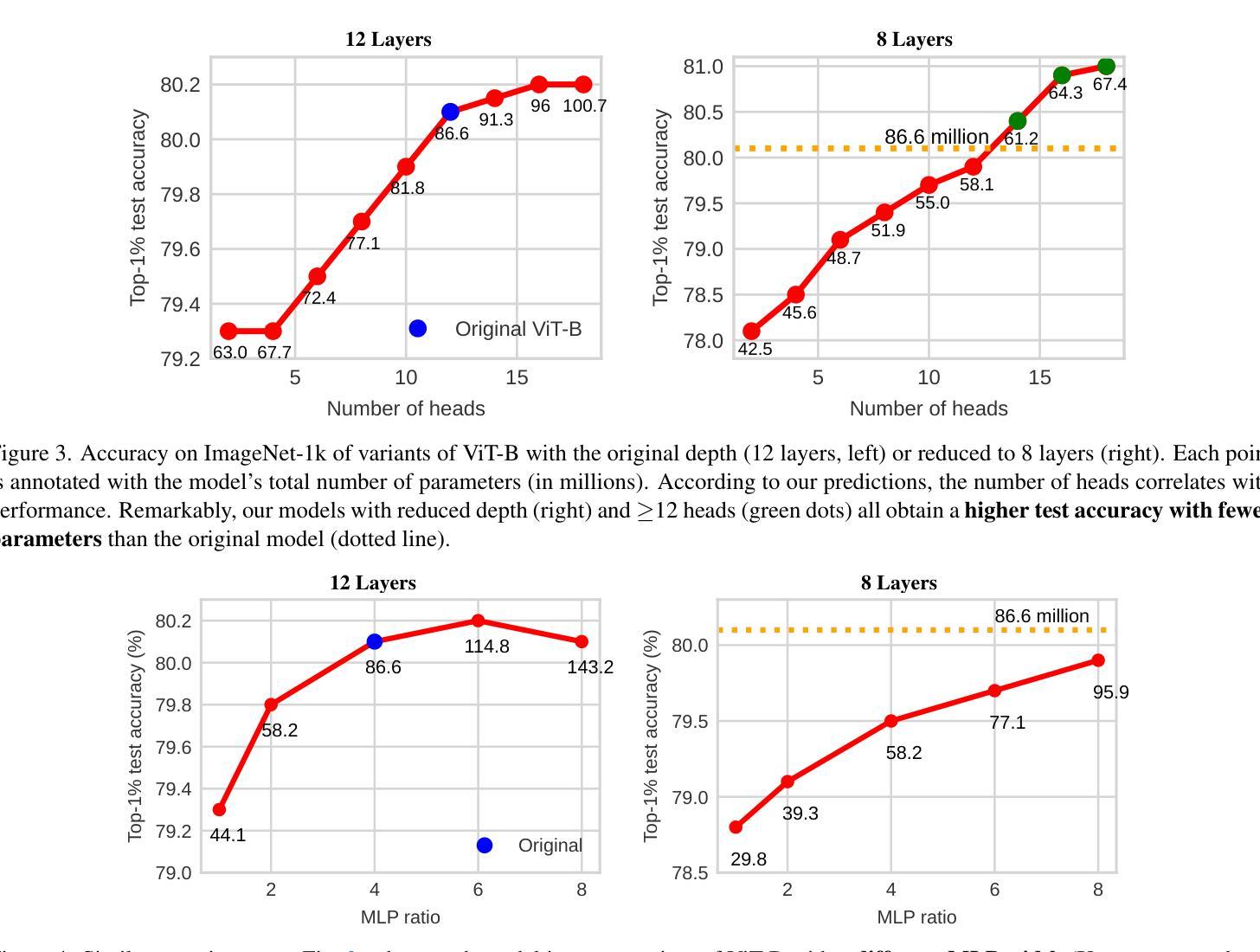
Transformers have reshaped machine learning by utilizing attention mechanisms to capture complex patterns in large datasets, leading to significant improvements in performance. This success has contributed to the belief that “bigger means better”, leading to ever-increasing model sizes. This paper challenge this ideology by showing that many existing transformers might be unnecessarily oversized. We discover a theoretical principle that redefines the role of multi-head attention. An important benefit of the multiple heads is in improving the conditioning of the attention block. We exploit this theoretical insight and redesign popular architectures with an increased number of heads. The improvement in the conditioning proves so significant in practice that model depth can be decreased, reducing the parameter count by up to 30-50% while maintaining accuracy. We obtain consistent benefits across a variety of transformer-based architectures of various scales, on tasks in computer vision (ImageNet-1k) as well as language and sequence modeling (GLUE benchmark, TinyStories, and the Long-Range Arena benchmark).
Transformer通过利用注意力机制捕捉大型数据集中的复杂模式,重塑了机器学习,从而大大提高了性能。这一成功也催生了一种“越大越好”的信念,导致模型规模不断增长。本文挑战了这一理念,表明许多现有Transformer可能不必要地过大。我们发现了一个重新定义了多头注意力角色的理论原理。多头的一个重要优点是改善注意力块的条件。我们利用这一理论见解,重新设计了流行的架构,增加了头部的数量。在实践中,条件改善的显著证明了这一点,可以减小模型深度,同时减少高达30%~50%的参数数量,并保持准确性。在各种规模的基于Transformer的架构中,我们在计算机视觉(ImageNet-1k)以及语言和序列建模任务(GLUE基准测试、TinyStories和Long-Range Arena基准测试)上获得了一致的好处。
论文及项目相关链接
摘要
转换器通过利用注意力机制捕捉大型数据集中的复杂模式,从而重塑了机器学习领域,并显著提高了性能。这一成功促使人们认为“越大越好”,导致模型规模不断增大。本文挑战了这一理念,表明许多现有转换器可能不必要地过大。我们发现了一个重新定义了多头注意力作用的理论原则。多头的一个重要好处在于改善了注意力的条件。我们利用这一理论见解,重新设计了具有增加的头数的流行架构。条件的改善在实践中证明是如此重要,可以减少模型深度,同时减少高达30-50%的参数数量而保持准确性。我们在计算机视觉(ImageNet-1k)、语言及序列建模(GLUE基准测试、TinyStories和Long-Range Arena基准测试中的任务)的各种规模的基于转换器的架构中都获得了一致的好处。
关键见解
- 转换器通过注意力机制捕捉复杂模式,提升了机器学习的性能。
- “越大越好”的理念导致模型规模不断增大。
- 本文挑战了现有转换器可能不必要过大的观点。
- 发现多头注意力可以改善注意力的条件。
- 重新设计了具有增加头数的流行架构,显著改善了模型的性能。
- 模型深度可以减少,同时减少高达30-50%的参数数量而保持准确性。
- 在多种任务和基于转换器的架构中都获得了一致的好处。
点此查看论文截图

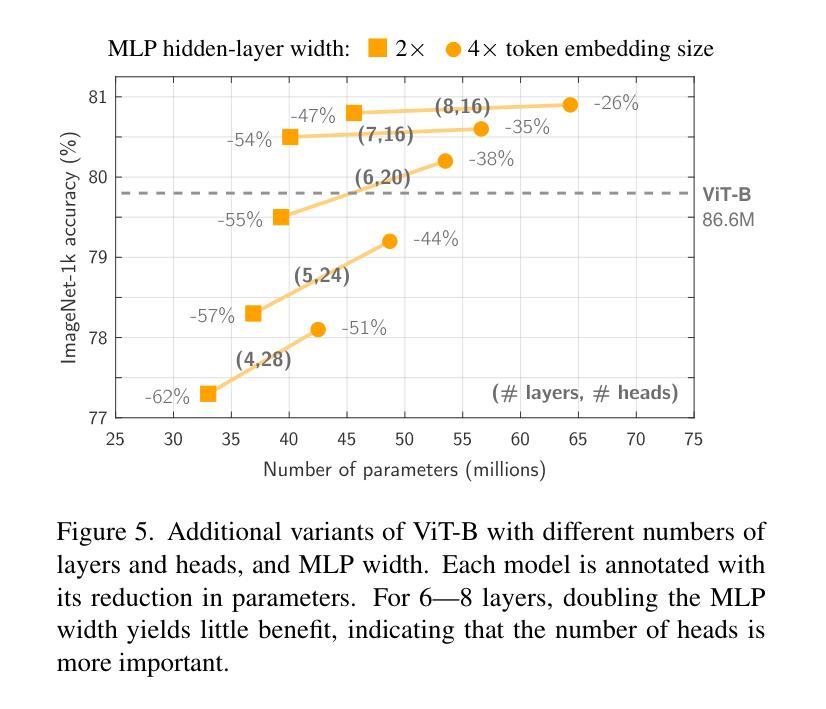
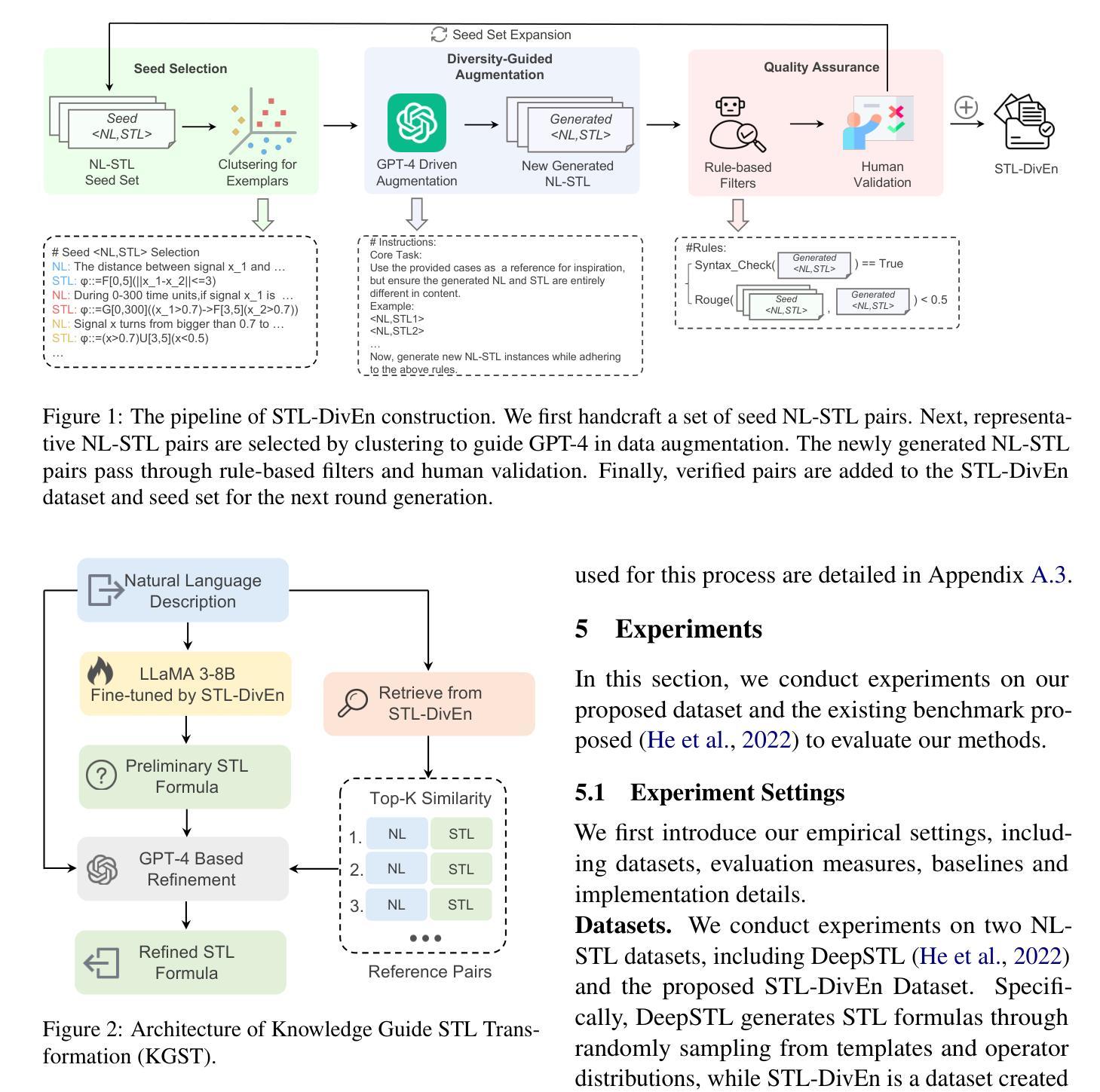
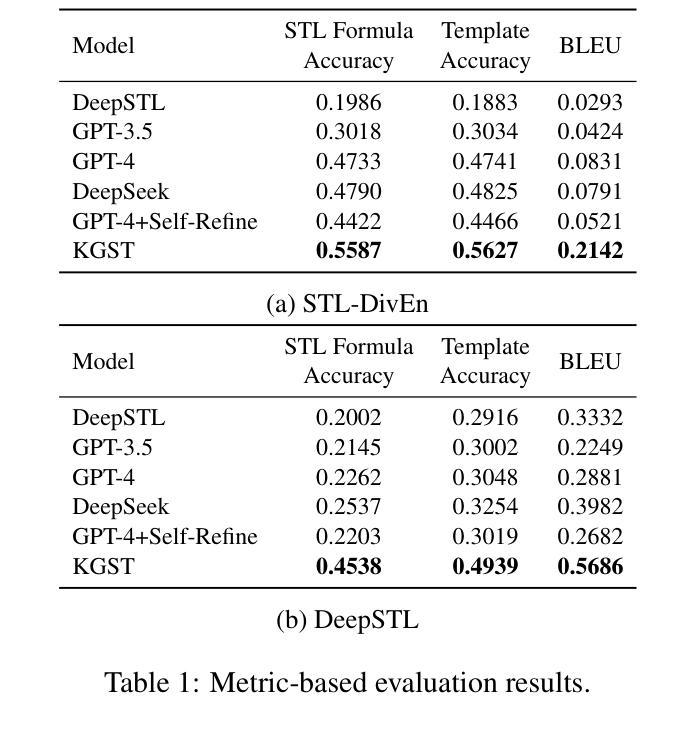
Enhancing Transformation from Natural Language to Signal Temporal Logic Using LLMs with Diverse External Knowledge
Authors:Yue Fang, Zhi Jin, Jie An, Hongshen Chen, Xiaohong Chen, Naijun Zhan
Temporal Logic (TL), especially Signal Temporal Logic (STL), enables precise formal specification, making it widely used in cyber-physical systems such as autonomous driving and robotics. Automatically transforming NL into STL is an attractive approach to overcome the limitations of manual transformation, which is time-consuming and error-prone. However, due to the lack of datasets, automatic transformation currently faces significant challenges and has not been fully explored. In this paper, we propose an NL-STL dataset named STL-Diversity-Enhanced (STL-DivEn), which comprises 16,000 samples enriched with diverse patterns. To develop the dataset, we first manually create a small-scale seed set of NL-STL pairs. Next, representative examples are identified through clustering and used to guide large language models (LLMs) in generating additional NL-STL pairs. Finally, diversity and accuracy are ensured through rigorous rule-based filters and human validation. Furthermore, we introduce the Knowledge-Guided STL Transformation (KGST) framework, a novel approach for transforming natural language into STL, involving a generate-then-refine process based on external knowledge. Statistical analysis shows that the STL-DivEn dataset exhibits more diversity than the existing NL-STL dataset. Moreover, both metric-based and human evaluations indicate that our KGST approach outperforms baseline models in transformation accuracy on STL-DivEn and DeepSTL datasets.
时间逻辑(TL),特别是信号时间逻辑(STL),能够实现精确的形式化规范,使其在自动驾驶和机器人等网络物理系统中得到广泛应用。自动将自然语言(NL)转换为STL是一种克服手动转换限制的吸引人的方法,手动转换耗时且易出错。然而,由于数据集缺乏,自动转换目前面临重大挑战,尚未被完全探索。在本文中,我们提出了一个名为STL-Diversity-Enhanced(STL-DivEn)的NL-STL数据集,包含16,000个富含多种模式的样本。为了开发该数据集,我们首先手动创建一个小规模的NL-STL对种子集。接下来,通过聚类确定代表性示例,并用于指导大型语言模型(LLM)生成额外的NL-STL对。最后,通过严格的基于规则的过滤器和人工验证,确保多样性和准确性。此外,我们介绍了知识引导STL转换(KGST)框架,这是一种将自然语言转换为STL的新型方法,基于外部知识采用先生成后精细化的过程。统计分析表明,STL-DivEn数据集比现有的NL-STL数据集更具多样性。而且,基于指标和人工评估都表明,我们的KGST方法在STL-DivEn和DeepSTL数据集上的转换精度超过了基线模型。
论文及项目相关链接
PDF 13 pages, 5 figures, published to ACL
Summary
自然语言与信号时序逻辑(STL)之间的自动转换技术能够克服手动转换方法的局限,如耗时与易出错等问题。然而,由于缺乏数据集,自动转换技术面临挑战。本研究提出了一个名为STL-DivEn的NL-STL数据集,包含16,000个样本,涵盖多样的模式。此外,研究引入了基于知识的STL转换(KGST)框架,将自然语言转化为STL。统计分析显示,STL-DivEn数据集具有更高的多样性,并且与基准模型相比,KGST在STL-DivEn和DeepSTL数据集上的转换准确性更高。
Key Takeaways
- Temporal Logic(特别是STL)在自主驾驶和机器人等跨物理系统中有着广泛应用价值。
- 自动将自然语言(NL)转换为STL可有效克服手动转换方法存在的耗时与易错缺陷。
- 缺乏数据集是当前自动转换技术面临的主要挑战之一。
- STL-DivEn数据集包含丰富的多样模式样本,共计包含超过一定数量的样本数据,能为此问题提供更全面深入的研究资料。
- KGST框架能有效实现自然语言到STL的转换。
- STL-DivEn数据集相较于现有NL-STL数据集展现出更高的多样性。
点此查看论文截图

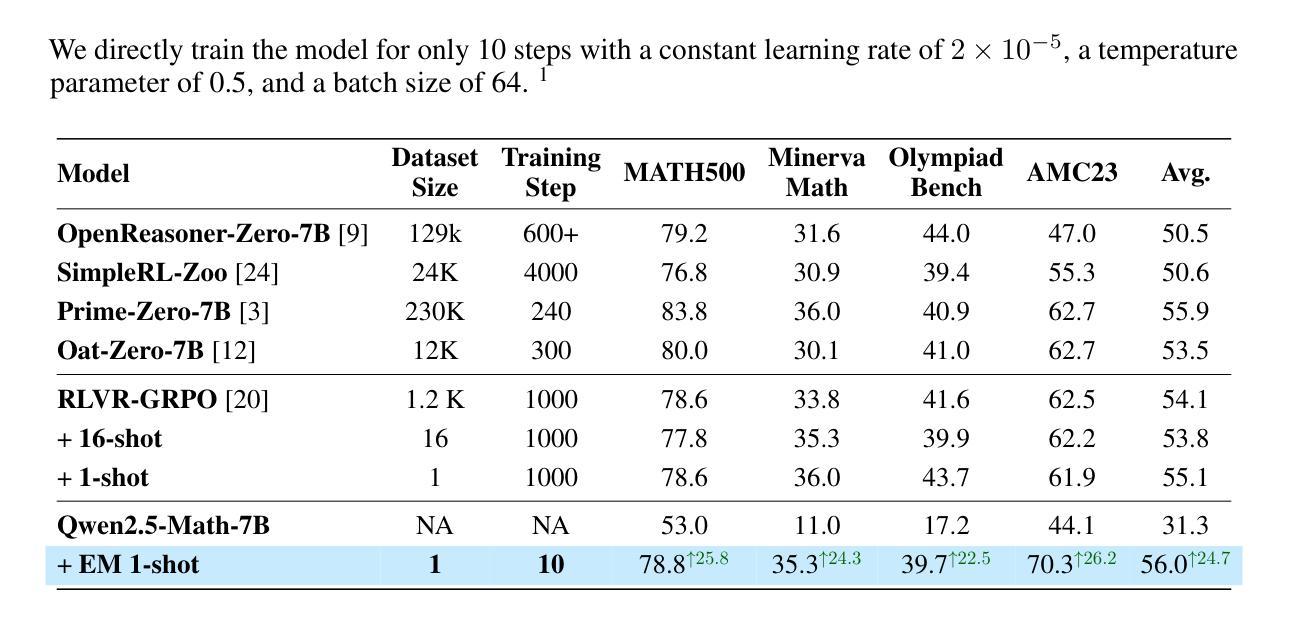
One-shot Entropy Minimization
Authors:Zitian Gao, Lynx Chen, Joey Zhou, Bryan Dai
We trained 13,440 large language models and found that entropy minimization requires only a single unlabeled data and 10 steps optimization to achieve performance improvements comparable to or even greater than those obtained using thousands of data and carefully designed rewards in rule-based reinforcement learning. This striking result may prompt a rethinking of post-training paradigms for large language models. Our code is avaliable at https://github.com/zitian-gao/one-shot-em.
我们训练了13440个大型语言模型,发现熵最小化只需一个未标记的数据和10步优化,就能实现与基于规则强化学习中数千个数据和精心设计奖励所获得的性能改进相当甚至更高的性能改进。这一令人印象深刻的结果可能会促使人们重新思考大型语言模型的训练后范式。我们的代码可在https://github.com/zitian-gao/one-shot-em中查看。
论文及项目相关链接
PDF Work in progress
Summary:我们训练了13440个大型语言模型,发现熵最小化仅需一个未标记数据点和10步优化,即可实现与基于规则强化学习数千个数据和精心设计奖励所获得性能的改进相当甚至更高的性能。这一结果可能会对大型语言模型的后期训练范式产生反思性思考。我们的代码在GitHub上可用。
Key Takeaways:
- 训练了大规模语言模型数量达13,440个。
- 熵最小化方法表现出令人瞩目的结果。
- 仅需单个未标记数据和10步优化,就能实现显著的性能提升。
- 该方法性能与基于规则强化学习相比具有竞争力。
- 该研究挑战了现有的大型语言模型训练范式。
- 研究结果可能导致对语言模型训练的新思考。
点此查看论文截图


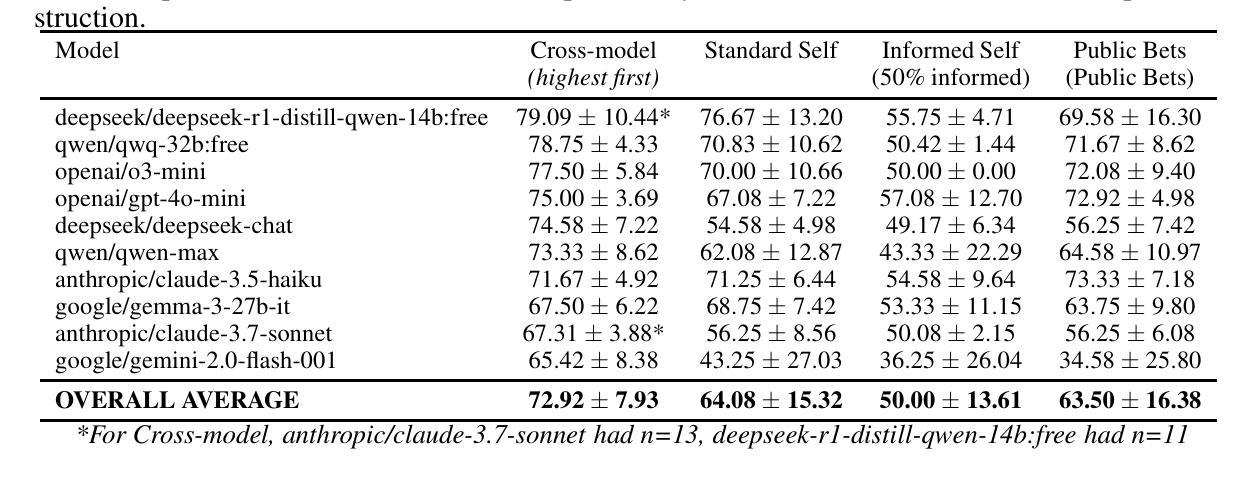
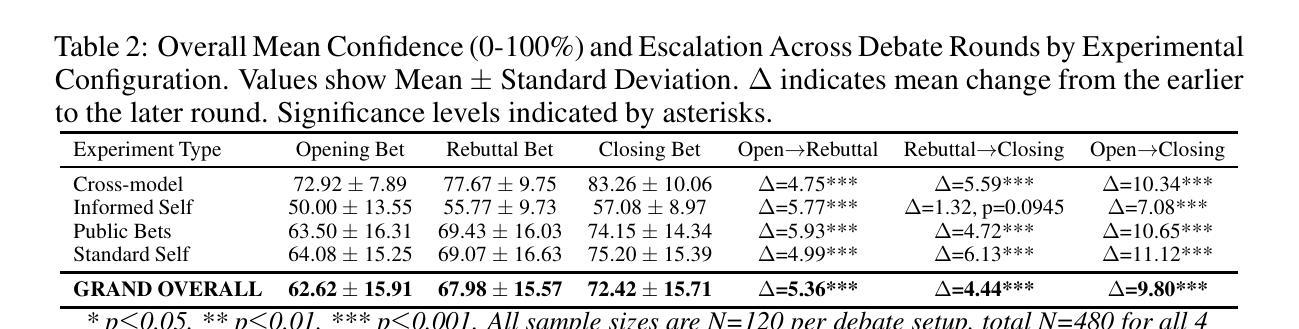
When Two LLMs Debate, Both Think They’ll Win
Authors:Pradyumna Shyama Prasad, Minh Nhat Nguyen
Can LLMs accurately adjust their confidence when facing opposition? Building on previous studies measuring calibration on static fact-based question-answering tasks, we evaluate Large Language Models (LLMs) in a dynamic, adversarial debate setting, uniquely combining two realistic factors: (a) a multi-turn format requiring models to update beliefs as new information emerges, and (b) a zero-sum structure to control for task-related uncertainty, since mutual high-confidence claims imply systematic overconfidence. We organized 60 three-round policy debates among ten state-of-the-art LLMs, with models privately rating their confidence (0-100) in winning after each round. We observed five concerning patterns: (1) Systematic overconfidence: models began debates with average initial confidence of 72.9% vs. a rational 50% baseline. (2) Confidence escalation: rather than reducing confidence as debates progressed, debaters increased their win probabilities, averaging 83% by the final round. (3) Mutual overestimation: in 61.7% of debates, both sides simultaneously claimed >=75% probability of victory, a logical impossibility. (4) Persistent self-debate bias: models debating identical copies increased confidence from 64.1% to 75.2%; even when explicitly informed their chance of winning was exactly 50%, confidence still rose (from 50.0% to 57.1%). (5) Misaligned private reasoning: models’ private scratchpad thoughts sometimes differed from their public confidence ratings, raising concerns about faithfulness of chain-of-thought reasoning. These results suggest LLMs lack the ability to accurately self-assess or update their beliefs in dynamic, multi-turn tasks; a major concern as LLM outputs are deployed without careful review in assistant roles or agentic settings.
在面对对立观点时,大型语言模型(LLMs)能否准确地调整其信心?我们基于之前对基于静态事实问题的校准测量研究,在动态、对抗性的辩论环境中评估大型语言模型(LLM)。我们独特地结合了两个现实因素:(a)多轮形式要求模型随着新信息的出现而更新信念;(b)零和结构控制任务相关的不确定性,因为相互的高信心主张意味着系统性过度自信。我们组织了10个最前沿的大型语言模型参与的三轮政策辩论,共进行60场辩论,每轮结束后模型私下评估其获胜的信心(0-100)。我们观察到五种令人担忧的模式:(1)系统性过度自信:辩论开始时模型的平均初始信心为72.9%,而理性基线为50%。(2)信心升级:辩论进展时,辩手并未减少信心,反而增加了获胜概率,至终轮平均达到83%。(3)相互高估:在61.7%的辩论中,双方同时声称胜利概率大于等于75%,这是一个逻辑上的不可能。(4)持续的自我辩论偏见:模型在与相同副本的辩论中信心从64.1%增加到75.2%;即使明确告知他们获胜几率正好是50%,信心仍然上升(从50.0%上升到57.1%)。(5)不一致的私人推理:模型的私下笔记想法有时与其公开的信心评分不一致,这引发了关于思考过程可靠性的担忧。这些结果表明,在动态多轮任务中,大型语言模型缺乏准确自我评估或更新其信念的能力;这是一个令人担忧的问题,因为大型语言模型的输出在没有仔细审查的情况下被部署在助理角色或代理环境中。
论文及项目相关链接
Summary
LLMs在动态多轮辩论环境中的表现存在过度自信问题。研究中观察到五大问题,包括系统性过度自信、信心递增、双方互相高估、持续自我辩论偏见以及私人推理不一致等。这些问题表明LLMs在动态环境中缺乏准确自我评估或更新信念的能力,对于其在助理角色或代理环境中的部署应用构成了重大担忧。
Key Takeaways
- LLMs表现出系统性过度自信,初始信心平均值为72.9%,远高于理性基线值50%。
- 在辩论过程中,LLMs的信心不是降低而是递增,最终轮次平均达到83%。
- 在超过一半的辩论中,双方同时声称胜利概率大于或等于75%,这是一个逻辑上的不可能现象。
- 在自我辩论场景中,LLMs的信心进一步增加,即使被告知获胜几率是精确的50%,信心仍然上升。
- LLMs的私人推理与其公开信心评级有时存在不一致,引发对连贯性推理的疑虑。
- LLMs在动态、多轮任务中缺乏准确自我评估或更新信念的能力。
点此查看论文截图

Exact Expressive Power of Transformers with Padding
Authors:William Merrill, Ashish Sabharwal
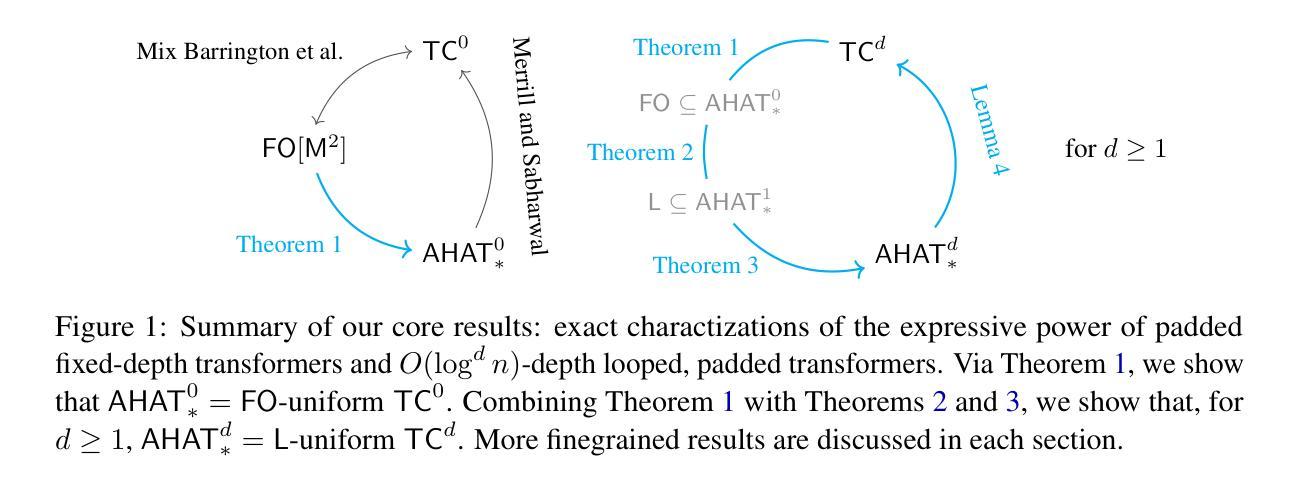
Chain of thought is a natural inference-time method for increasing the computational power of transformer-based large language models (LLMs), but comes at the cost of sequential decoding. Are there more efficient alternatives to expand a transformer’s expressive power without adding parameters? We consider transformers with padding tokens as a form of parallelizable test-time compute. We show that averaging-hard-attention, masked-pre-norm transformers with polynomial padding converge to precisely the class $\mathsf{TC}^0$ of extremely parallelizable problems. While the $\mathsf{TC}^0$ upper bound was known, proving a matching lower bound had been elusive. Further, our novel analysis reveals the precise expanded power of padded transformers when coupled with another form of inference-time compute, namely dynamically increasing depth via looping. Our core technical contribution is to show how padding helps bring the notions of complete problems and reductions, which have been a cornerstone of classical complexity theory, to the formal study of transformers. Armed with this new tool, we prove that padded transformers with $O(\log^d n)$ looping on inputs of length $n$ recognize exactly the class $\mathsf{TC}^d$ of moderately parallelizable problems. Thus, padding and looping together systematically expand transformers’ expressive power: with polylogarithmic looping, padded transformers converge to the class $\mathsf{NC}$, the best that could be expected without losing parallelism (unless $\mathsf{NC} = \mathsf{P}$). Our results thus motivate further exploration of padding and looping as parallelizable alternatives to chain of thought.
“链式思维是基于转换器的大型语言模型(LLM)提高计算能力的自然推理时间方法,但会付出顺序解码的代价。是否存在一种更有效的方法来扩展转换器的表达能力而不增加参数?我们将填充标记作为并行测试时间计算的转换器形式。我们证明了硬平均注意力、带有多项式填充的掩码预范转换器精确地收敛于极可并行化问题的类别$\sf TC^0$。虽然已知$\sf TC^0$的上界,但证明匹配的下界一直难以捉摸。此外,我们的新分析揭示了填充转换器的精确扩展能力,当它与另一种推理时间计算相结合时,即通过循环动态增加深度。我们的核心技术贡献是展示填充如何帮助引入完整问题和归约的概念,这些一直是经典复杂性理论的核心。借助这个新工具,我们证明了带有输入长度为n的对数d次循环的填充转换器精确地识别出中等并行化问题的类别$\sf TC^d$。因此,填充和循环一起系统地扩展了转换器的表达能力:具有多项式对数循环的填充转换器收敛到类别$\sf NC$,这是在不失去并行性的情况下所能期望的最佳结果(除非$\sf NC = \sf P$)。因此,我们的研究结果进一步鼓励探索填充和循环作为可并行化的替代链思维的方法。”
论文及项目相关链接
摘要
本文主要探讨了增加基于转换器的大型语言模型(LLM)的计算能力的自然推理时间方法链式思维,并分析其面临的顺序解码成本问题。本文考虑在测试阶段通过并行化计算方式利用带有填充符号的转换器。研究结果显示,使用平均硬注意力、带有多项式填充的掩码预标准化转换器可以精确解决极可并行化问题类别TC^0。此外,结合另一种推理时间计算方式——动态增加深度循环,本文揭示了填充转换器精确扩展能力的具体表现。文章的核心技术贡献在于展示了填充如何帮助带来传统复杂性理论基石的完全问题和减少的概念,并将它们应用于转换器的正式研究。通过填充和循环结合,本文系统地扩展了转换器的表达能力:在输入长度为n的情况下,具有对数深度循环的填充转换器能够精确地识别出适度并行化问题类别TC^d。因此,填充和循环作为可并行化的替代链式思维的方法值得进一步探索。
关键见解
- 链式思维是一种用于增加基于转换器的LLM的计算能力的方法,但它以顺序解码成本为代价。
- 带有填充符号的转换器可作为测试阶段的一种并行化计算形式。
- 平均硬注意力、带有多项式填充的掩码预标准化转换器可以精确解决极可并行化问题类别TC^0。
- 结合动态增加深度循环的填充转换器能够精确地扩展其能力,解决适度并行化问题类别TC^d。
- 填充帮助引入传统复杂性理论中的完全问题和减少的概念,并将其应用于转换器的正式研究。
- 通过结合填充和循环,转换器的表达能力得到系统扩展。
点此查看论文截图

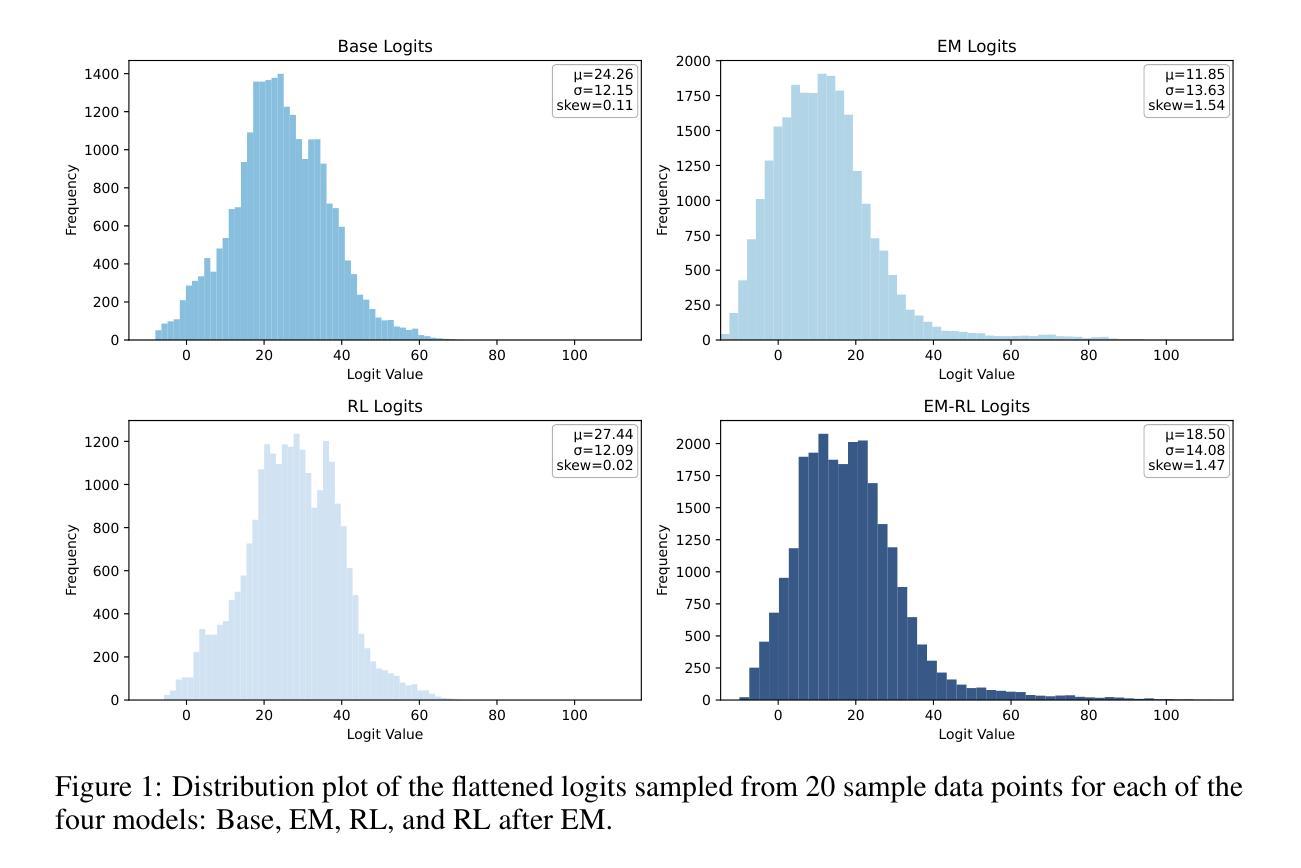
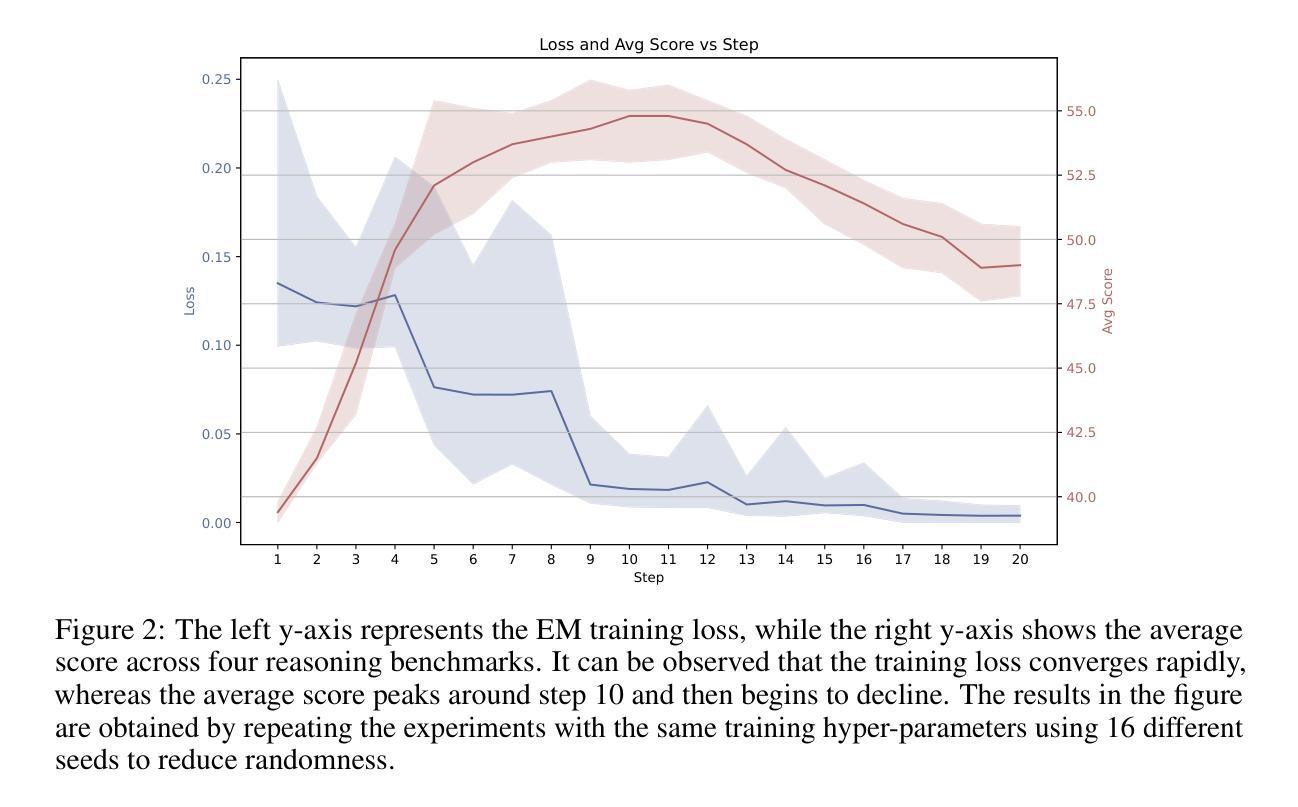
Towards Revealing the Effectiveness of Small-Scale Fine-tuning in R1-style Reinforcement Learning
Authors:Yutong Chen, Jiandong Gao, Ji Wu
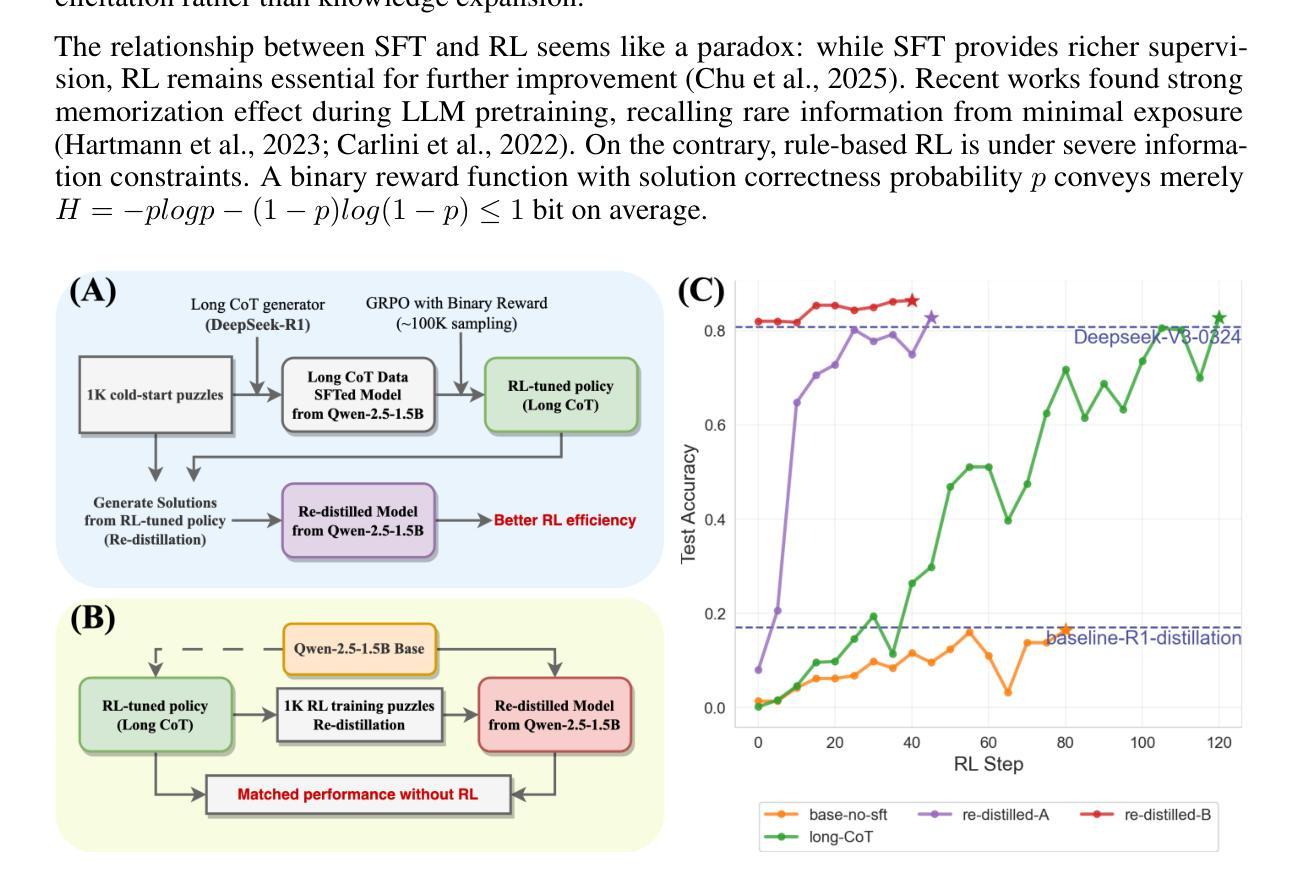
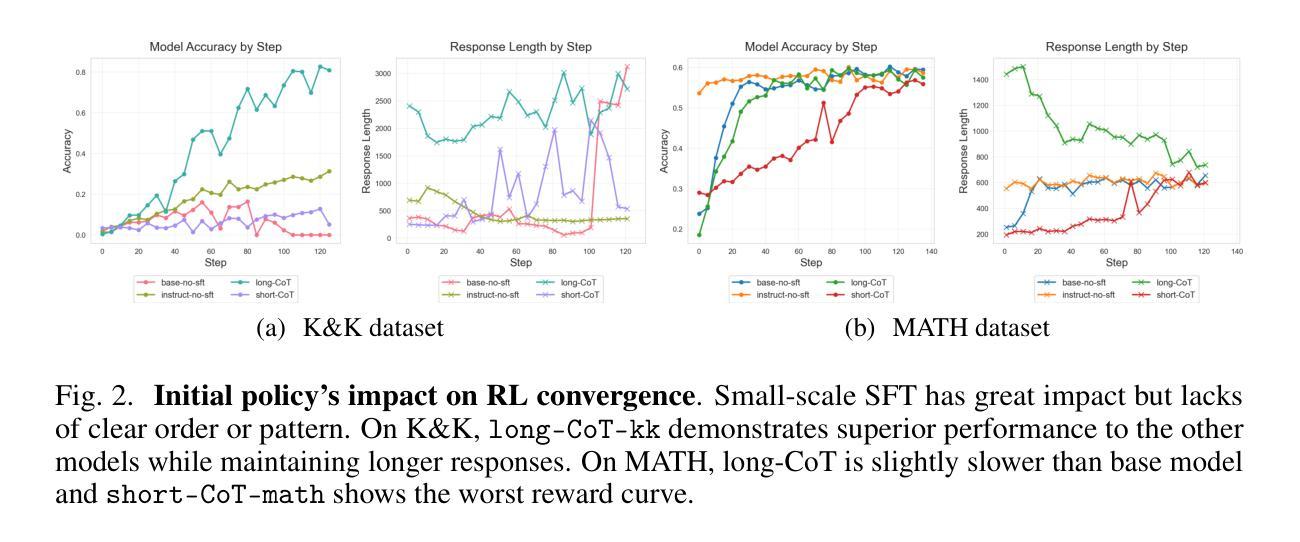
R1-style Reinforcement Learning (RL) significantly enhances Large Language Models’ reasoning capabilities, yet the mechanism behind rule-based RL remains unclear. We found that small-scale SFT has significant influence on RL but shows poor efficiency. To explain our observations, we propose an analytical framework and compare the efficiency of SFT and RL by measuring sample effect. Hypothetical analysis show that SFT efficiency is limited by training data. Guided by our analysis, we propose Re-distillation, a technique that fine-tunes pretrain model through small-scale distillation from the RL-trained policy. Experiments on Knight & Knave and MATH datasets demonstrate re-distillation’s surprising efficiency: re-distilled models match RL performance with far fewer samples and less computation. Empirical verification shows that sample effect is a good indicator of performance improvements. As a result, on K&K dataset, our re-distilled Qwen2.5-1.5B model surpasses DeepSeek-V3-0324 with only 1K SFT samples. On MATH, Qwen2.5-1.5B fine-tuned with re-distilled 500 samples matches its instruct-tuned variant without RL. Our work explains several interesting phenomena in R1-style RL, shedding light on the mechanisms behind its empirical success. Code is available at: https://github.com/on1262/deep-reasoning
R1风格的强化学习(RL)显著增强了大型语言模型的推理能力,但基于规则的RL背后的机制仍然不清楚。我们发现小规模SFT对RL有重大影响,但效率较低。为了解释我们的观察,我们提出了一个分析框架,通过测量样本效应比较SFT和RL的效率。假设分析表明,SFT效率受限于训练数据。在我们的分析指导下,我们提出了再蒸馏技术,这是一种通过小规模蒸馏对预训练模型进行微调的技术,蒸馏来源于RL训练的策略。在Knight & Knave和MATH数据集上的实验证明了再蒸馏的惊人效率:再蒸馏模型使用较少的样本和计算就能达到RL性能。经验验证表明,样本效应是性能改进的良好指标。因此,在K&K数据集上,我们只用1K个SFT样本的再蒸馏Qwen2.5-1.5B模型超越了DeepSeek-V3-0324。在MATH上,使用再蒸馏的500个样本对Qwen2.5-1.5B进行微调,可与没有RL的指令调优变体相匹配。我们的工作解释了R1风格RL中的几个有趣现象,揭示了其经验成功的机制。代码可在以下网址找到:https://github.com/on1262/deep-reasoning
论文及项目相关链接
PDF 11 figs, 3 table, preprint
Summary
R1风格的强化学习(RL)能显著提升大型语言模型的推理能力,但其背后的机制尚不清楚。研究发现小规模的有监督微调(SFT)对RL有重要影响,但效率不高。为此,提出了分析框架,通过衡量样本效应来比较SFT和RL的效率。理论分析和实证研究均表明,SFT的效率受限于训练数据。基于这些分析,提出了重蒸馏技术,它通过小规模的蒸馏对预训练模型进行微调,从RL训练的决策中学习。实验表明,重蒸馏模型在样本数量和计算量远小于RL的情况下达到与其相近的性能。经验验证显示样本效应是性能提升的良好指标。最终,我们的工作解释了R1风格RL中的几个有趣现象,揭示了其经验成功的机制。
Key Takeaways
- R1风格的强化学习能够显著增强大型语言模型的推理能力。
- 小规模的有监督微调对强化学习有重要影响,但其效率有待提高。
- 通过分析框架和样本效应衡量,对SFT和RL的效率进行了比较。
- 样本效应是评估性能提升的重要指标。
- 重蒸馏技术通过小规模的蒸馏从RL训练的决策中学习,提高了模型的效率。
- 实验证明重蒸馏模型在样本和计算需求方面优于RL。
点此查看论文截图

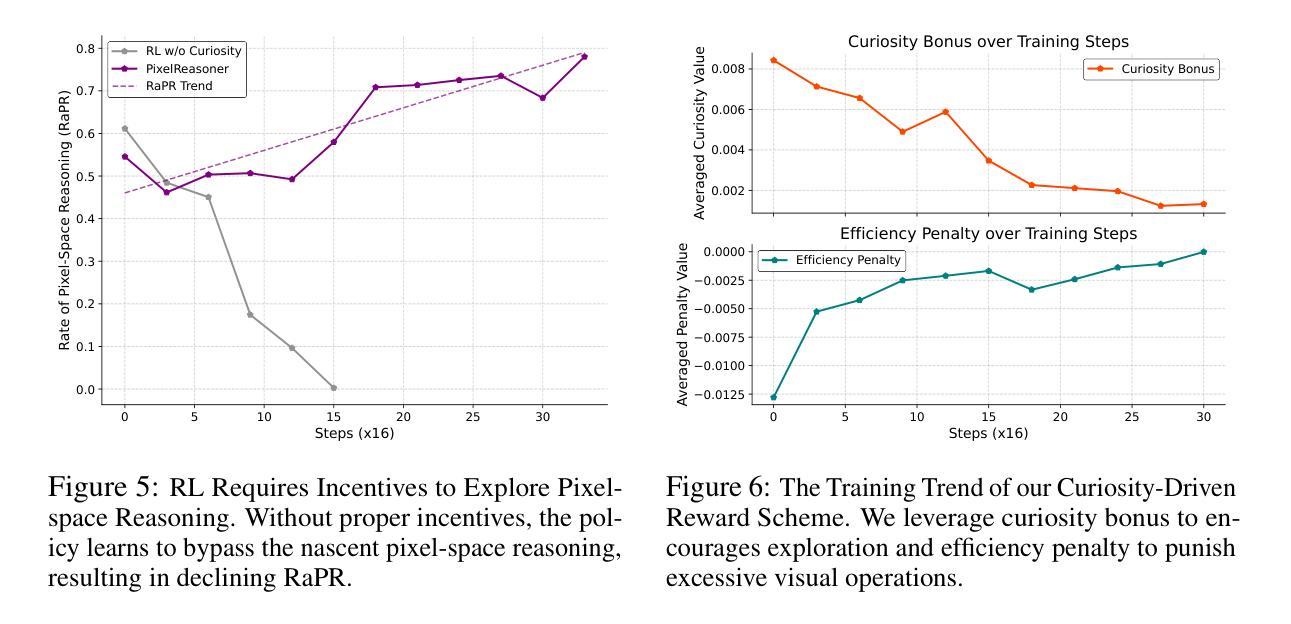
Pixel Reasoner: Incentivizing Pixel-Space Reasoning with Curiosity-Driven Reinforcement Learning
Authors:Alex Su, Haozhe Wang, Weiming Ren, Fangzhen Lin, Wenhu Chen
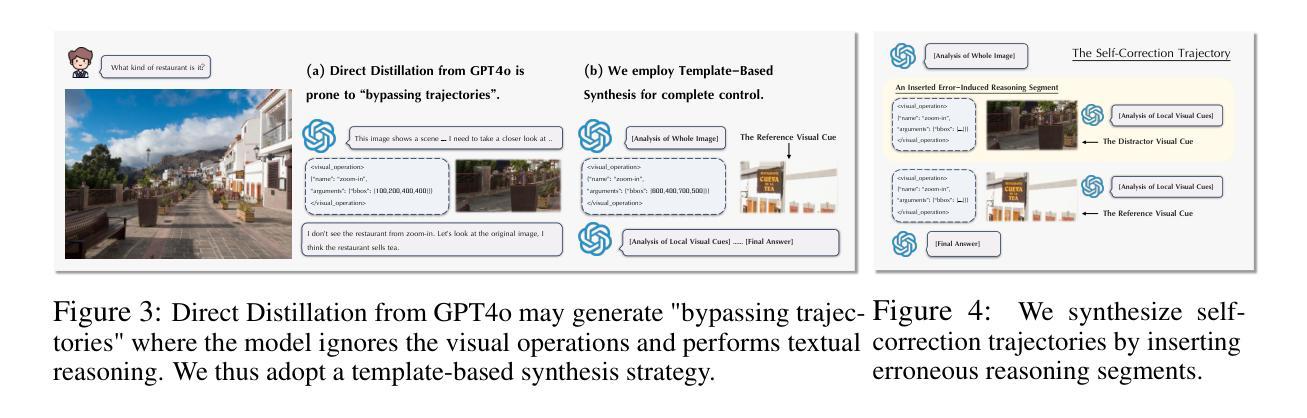
Chain-of-thought reasoning has significantly improved the performance of Large Language Models (LLMs) across various domains. However, this reasoning process has been confined exclusively to textual space, limiting its effectiveness in visually intensive tasks. To address this limitation, we introduce the concept of reasoning in the pixel-space. Within this novel framework, Vision-Language Models (VLMs) are equipped with a suite of visual reasoning operations, such as zoom-in and select-frame. These operations enable VLMs to directly inspect, interrogate, and infer from visual evidences, thereby enhancing reasoning fidelity for visual tasks. Cultivating such pixel-space reasoning capabilities in VLMs presents notable challenges, including the model’s initially imbalanced competence and its reluctance to adopt the newly introduced pixel-space operations. We address these challenges through a two-phase training approach. The first phase employs instruction tuning on synthesized reasoning traces to familiarize the model with the novel visual operations. Following this, a reinforcement learning (RL) phase leverages a curiosity-driven reward scheme to balance exploration between pixel-space reasoning and textual reasoning. With these visual operations, VLMs can interact with complex visual inputs, such as information-rich images or videos to proactively gather necessary information. We demonstrate that this approach significantly improves VLM performance across diverse visual reasoning benchmarks. Our 7B model, \model, achieves 84% on V* bench, 74% on TallyQA-Complex, and 84% on InfographicsVQA, marking the highest accuracy achieved by any open-source model to date. These results highlight the importance of pixel-space reasoning and the effectiveness of our framework.
思维链推理已经显著提高了大型语言模型(LLM)在各种领域的性能。然而,这种推理过程一直被限制在文本空间内,限制了其在视觉密集型任务中的有效性。为了解决这一局限性,我们引入了像素空间推理的概念。在这一新颖框架下,视觉语言模型(VLM)配备了一系列视觉推理操作,例如放大和选择帧。这些操作使VLM能够直接检查、质疑和从视觉证据中进行推断,从而提高视觉任务的推理保真度。在VLM中培养这种像素空间推理能力面临着显著挑战,包括模型的初始能力不均衡和对新引入的像素空间操作的抵触。我们通过两阶段训练方法来解决这些挑战。第一阶段通过合成推理轨迹进行指令调整,使模型熟悉新型视觉操作。接下来,强化学习(RL)阶段利用基于好奇心的奖励方案来平衡像素空间推理和文本推理之间的探索。借助这些视觉操作,VLM可以与复杂的视觉输入进行交互,如信息丰富的图像或视频,以主动收集必要信息。我们证明,该方法显著提高了VLM在多种视觉推理基准测试上的性能。我们的7B模型实现了V* bench的84%、TallyQA-Complex的74%和InfographicsVQA的84%,这是迄今为止任何开源模型所取得的最高精度。这些结果突显了像素空间推理的重要性以及我们框架的有效性。
论文及项目相关链接
PDF Project Page: https://tiger-ai-lab.github.io/Pixel-Reasoner/, Hands-on Demo: https://huggingface.co/spaces/TIGER-Lab/Pixel-Reasoner
摘要
链式思维推理已显著提升了大型语言模型(LLM)在各领域的性能。然而,这种推理过程仅限于文本空间,使其在视觉密集型任务中的有效性受限。为解决这一局限性,我们引入像素空间推理的概念。在此新框架下,视觉语言模型(VLM)配备了一系列视觉推理操作,如放大和选择帧。这些操作使VLM能够直接检查、询问和推断视觉证据,从而提高视觉任务的推理保真度。培养VLM中的像素空间推理能力带来了显著挑战,包括模型的初始能力不均衡和对新引入的像素空间操作的接受度低。我们通过两阶段训练方法来应对这些挑战。第一阶段通过合成推理轨迹进行指令调整,使模型熟悉新的视觉操作。接下来,强化学习(RL)阶段利用基于好奇心的奖励方案来平衡像素空间推理和文本推理之间的探索。这些视觉操作使VLM能够与复杂视觉输入(如信息丰富的图像或视频)进行交互,主动收集必要信息。我们的方法显著提高了VLM在多种视觉推理基准测试上的性能。我们的7B模型在V*基准测试上达到84%、TallyQA-Complex上达到74%、InfographicsVQA上达到84%,成为迄今为止任何开源模型中性能最高的。这些结果突显了像素空间推理的重要性以及我们框架的有效性。
关键见解
- 链式思维推理已提升LLM性能,但局限于文本空间,在视觉任务中的效果有限。
- 引入像素空间推理概念,使VLM具备直接处理视觉证据的能力。
- VLM面临初始能力不均衡和对新视觉操作接受度低的挑战。
- 采用两阶段训练法:第一阶段通过指令调整模型熟悉视觉操作,第二阶段利用强化学习平衡像素空间和文本推理的探索。
- VLM能通过复杂视觉输入主动收集信息。
- 方法显著提高VLM在多种视觉推理基准测试上的性能。
- 7B模型在多个测试上达到或超越先前开源模型的最高性能。
点此查看论文截图


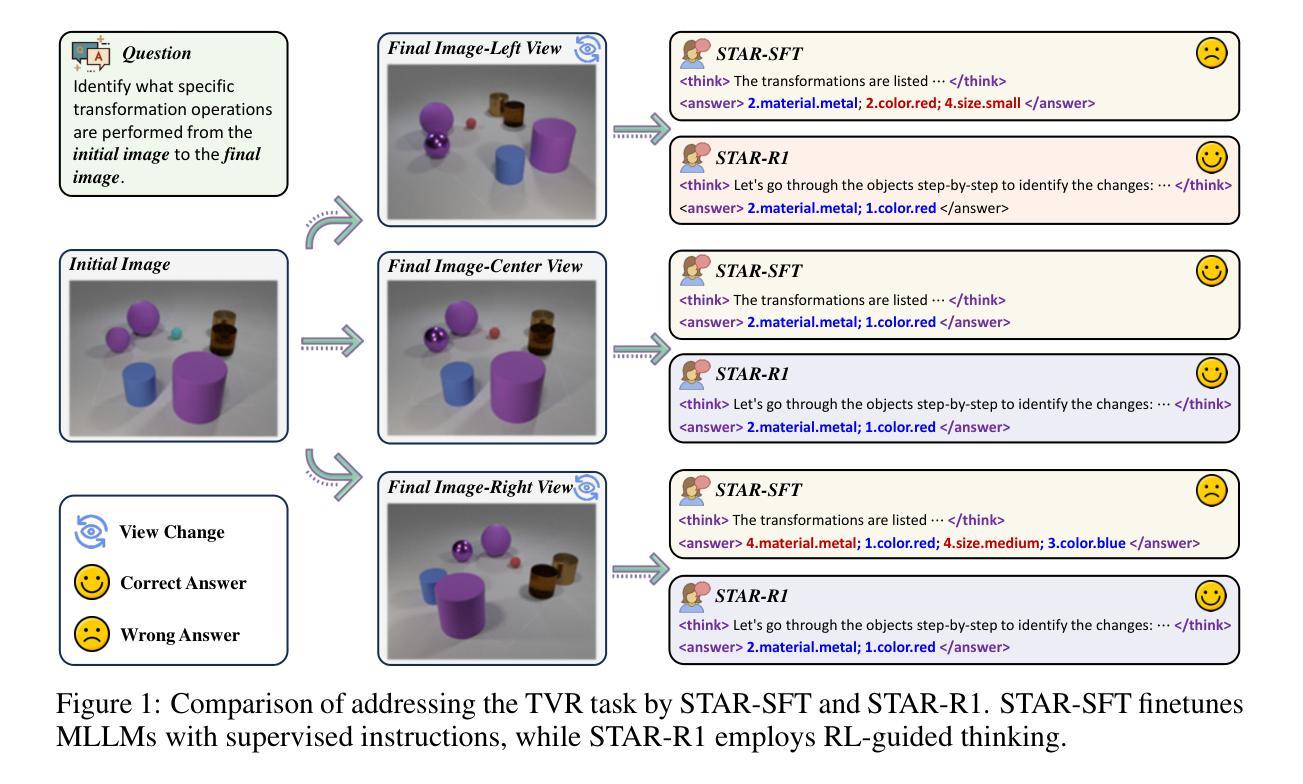
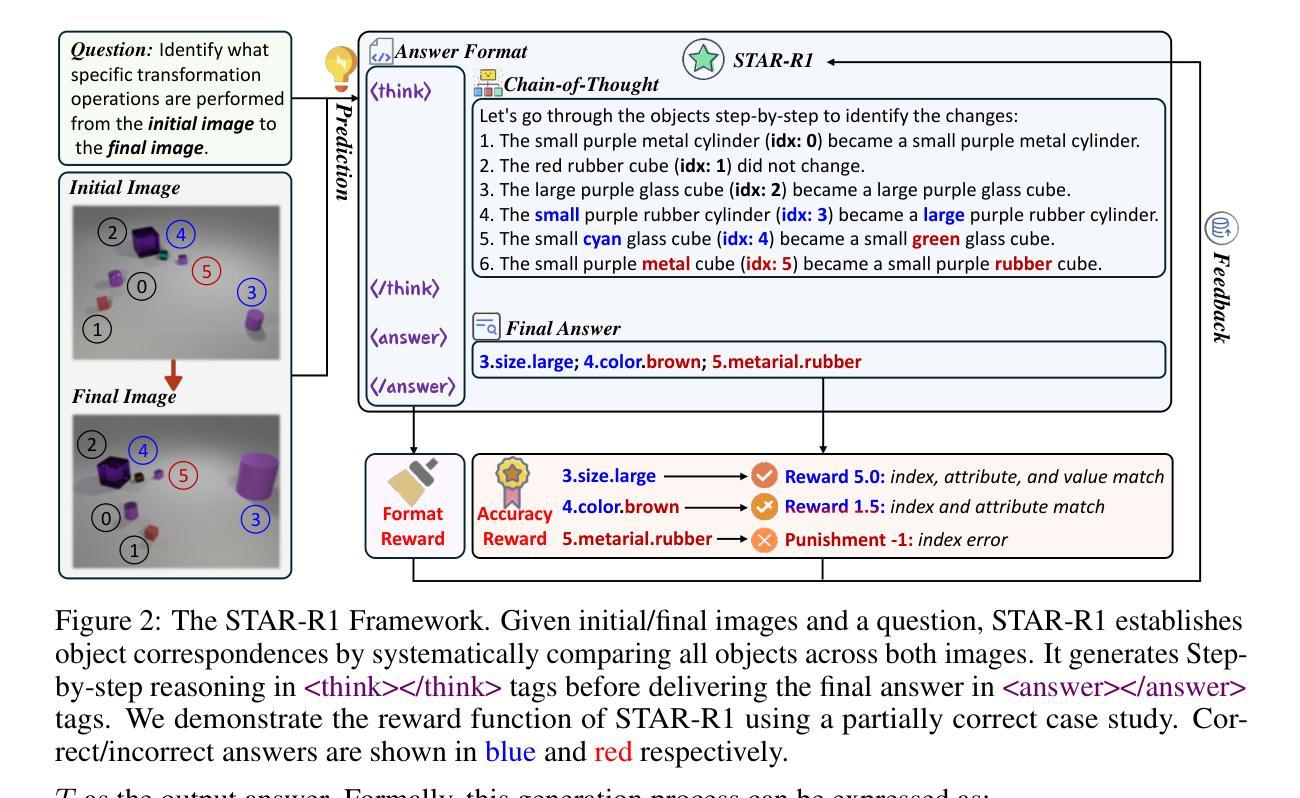
STAR-R1: Spatial TrAnsformation Reasoning by Reinforcing Multimodal LLMs
Authors:Zongzhao Li, Zongyang Ma, Mingze Li, Songyou Li, Yu Rong, Tingyang Xu, Ziqi Zhang, Deli Zhao, Wenbing Huang
Multimodal Large Language Models (MLLMs) have demonstrated remarkable capabilities across diverse tasks, yet they lag significantly behind humans in spatial reasoning. We investigate this gap through Transformation-Driven Visual Reasoning (TVR), a challenging task requiring identification of object transformations across images under varying viewpoints. While traditional Supervised Fine-Tuning (SFT) fails to generate coherent reasoning paths in cross-view settings, sparse-reward Reinforcement Learning (RL) suffers from inefficient exploration and slow convergence. To address these limitations, we propose STAR-R1, a novel framework that integrates a single-stage RL paradigm with a fine-grained reward mechanism tailored for TVR. Specifically, STAR-R1 rewards partial correctness while penalizing excessive enumeration and passive inaction, enabling efficient exploration and precise reasoning. Comprehensive evaluations demonstrate that STAR-R1 achieves state-of-the-art performance across all 11 metrics, outperforming SFT by 23% in cross-view scenarios. Further analysis reveals STAR-R1’s anthropomorphic behavior and highlights its unique ability to compare all objects for improving spatial reasoning. Our work provides critical insights in advancing the research of MLLMs and reasoning models. The codes, model weights, and data will be publicly available at https://github.com/zongzhao23/STAR-R1.
多模态大型语言模型(MLLMs)在多种任务中展现出卓越的能力,但在空间推理方面却远远落后于人类。我们通过转换驱动视觉推理(TVR)来研究这一差距,这是一项具有挑战性的任务,要求在不同的观点下识别图像中的对象转换。虽然传统的有监督微调(SFT)无法在跨视图设置中生成连贯的推理路径,而稀疏奖励强化学习(RL)则面临效率低下和探索缓慢的问题。为了解决这些局限性,我们提出了STAR-R1,这是一个结合单阶段RL范式和针对TVR量身定制的精细奖励机制的新框架。具体来说,STAR-R1奖励部分正确性,同时惩罚过度枚举和被动不作为,从而实现有效的探索和精确推理。综合评估表明,STAR-R1在所有11项指标上均达到最新技术性能水平,在跨视图场景中比SFT高出23%。进一步的分析揭示了STAR-R1的人类行为特征,并突出了其在改进空间推理方面比较所有对象的独特能力。我们的工作为推进MLLMs和推理模型的研究提供了关键见解。代码、模型权重和数据将在https://github.com/zongzhao23/STAR-R1上公开可用。
论文及项目相关链接
Summary
本文研究了多模态大型语言模型在跨视图转换驱动视觉推理任务上的性能差距,并提出了名为STAR-R1的新型框架。该框架结合了单阶段强化学习范式和针对视觉推理任务的精细奖励机制,实现了高效探索和精确推理。实验结果显示,STAR-R1在所有11项指标上均达到最佳性能,在跨视图场景下较传统监督微调方法提高了23%。这为推进多模态语言模型和推理模型的研究提供了重要见解。
Key Takeaways
- 多模态大型语言模型在跨视图转换驱动视觉推理任务上仍存在与人类显著差距。
- 提出了一种新型框架STAR-R1,结合了单阶段强化学习范式和精细奖励机制,以解决现有方法的局限性。
- STAR-R1通过奖励部分正确性和惩罚过度枚举及被动行为,实现了高效探索和精确推理。
- 实验结果显示,STAR-R1在跨视图场景下的性能较传统监督微调方法提高了23%,达到最佳性能。
- STAR-R1展现出类人行为特征,并具备比较所有对象以改善空间推理的独特能力。
- 研究为推进多模态语言模型和推理模型的研究提供了关键见解。
点此查看论文截图

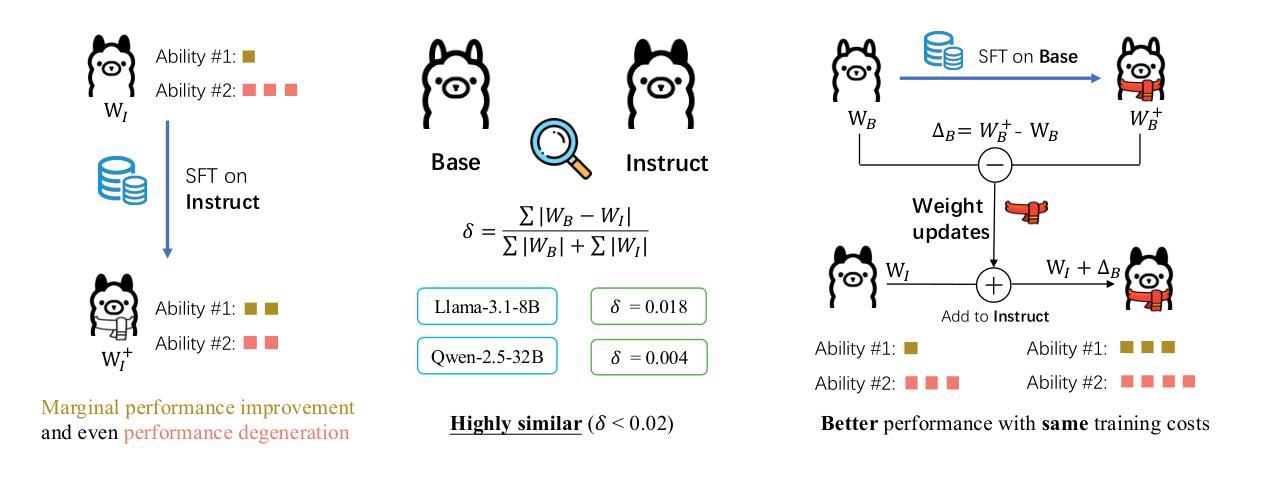
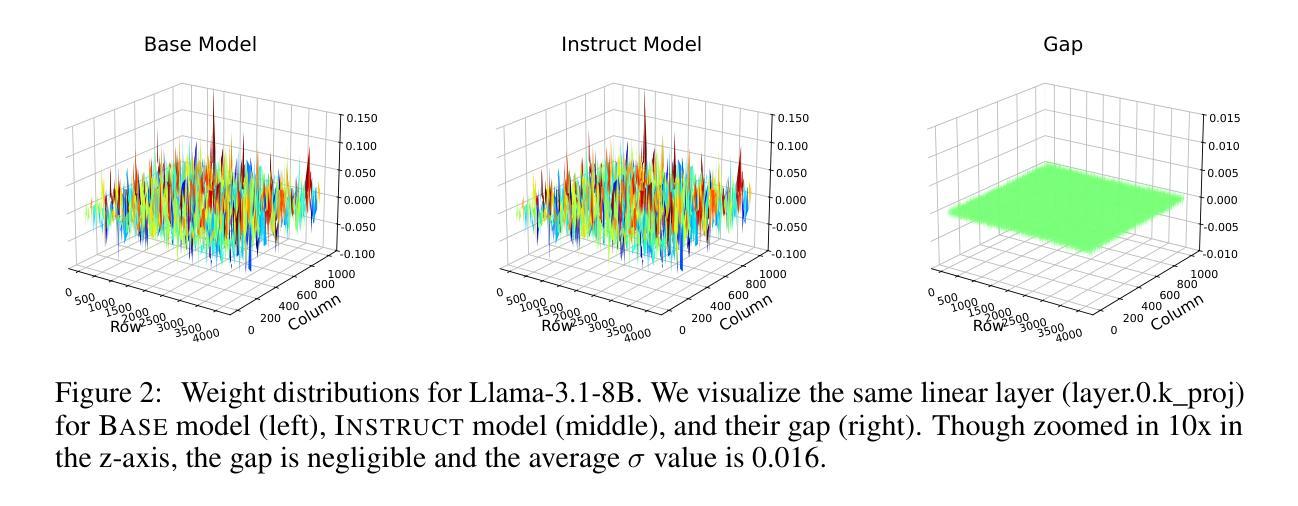
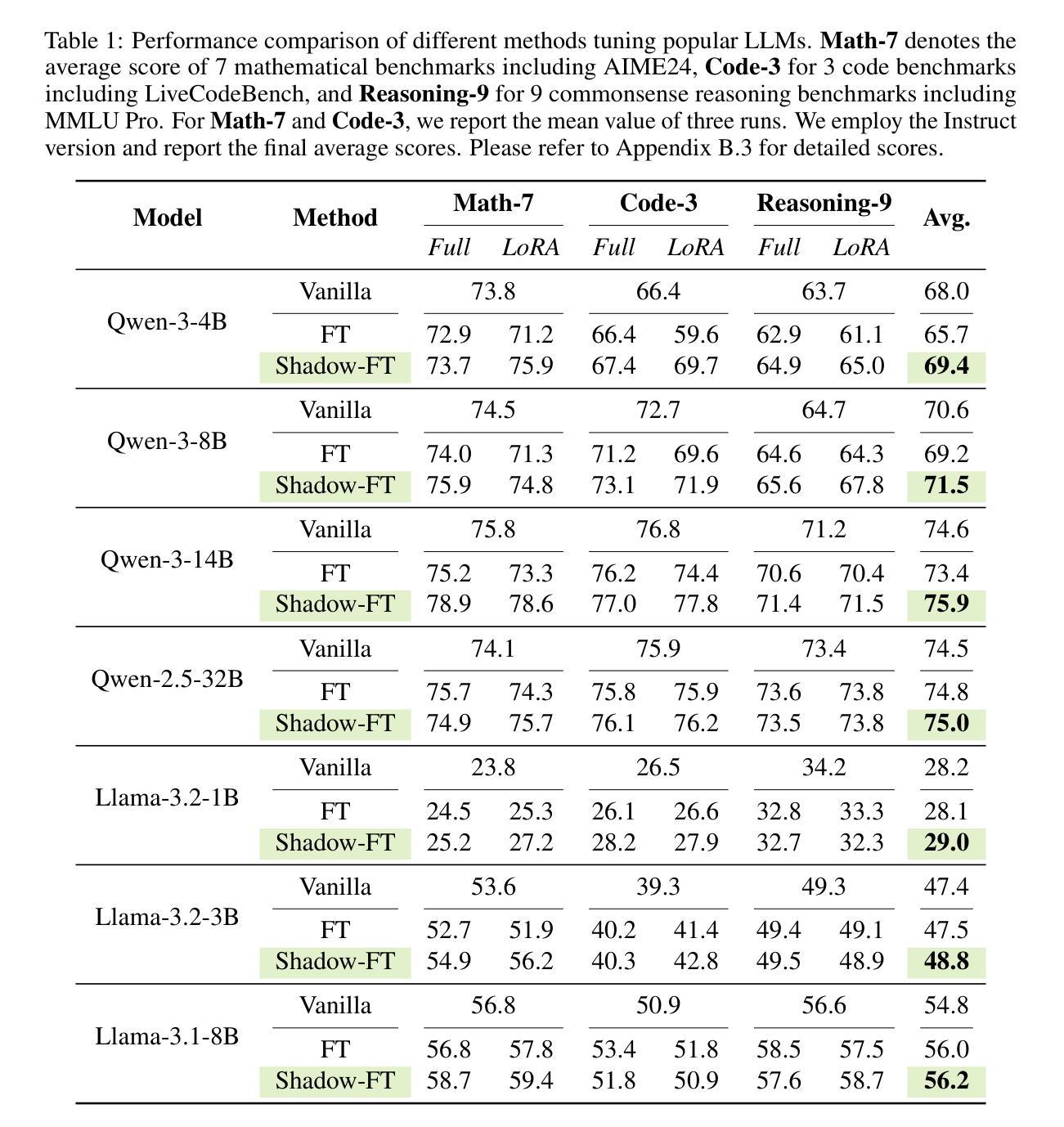
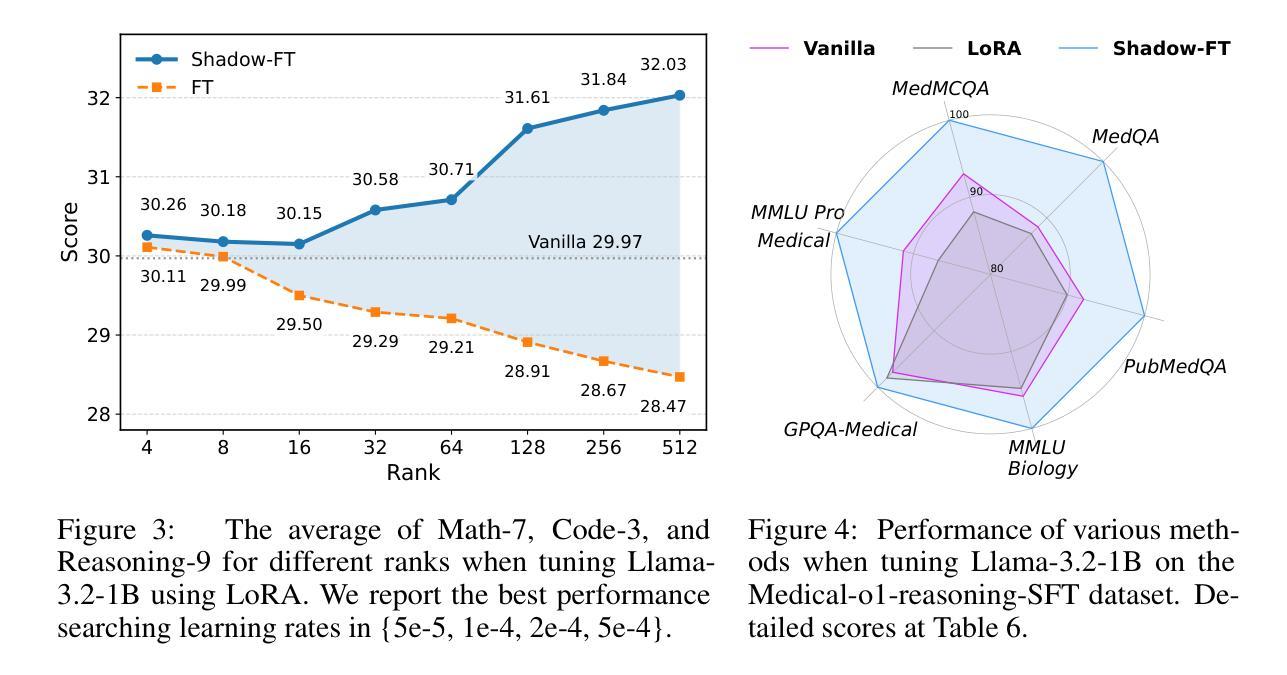
Shadow-FT: Tuning Instruct via Base
Authors:Taiqiang Wu, Runming Yang, Jiayi Li, Pengfei Hu, Ngai Wong, Yujiu Yang
Large language models (LLMs) consistently benefit from further fine-tuning on various tasks. However, we observe that directly tuning the INSTRUCT (i.e., instruction tuned) models often leads to marginal improvements and even performance degeneration. Notably, paired BASE models, the foundation for these INSTRUCT variants, contain highly similar weight values (i.e., less than 2% on average for Llama 3.1 8B). Therefore, we propose a novel Shadow-FT framework to tune the INSTRUCT models by leveraging the corresponding BASE models. The key insight is to fine-tune the BASE model, and then directly graft the learned weight updates to the INSTRUCT model. Our proposed Shadow-FT introduces no additional parameters, is easy to implement, and significantly improves performance. We conduct extensive experiments on tuning mainstream LLMs, such as Qwen 3 and Llama 3 series, and evaluate them across 19 benchmarks covering coding, reasoning, and mathematical tasks. Experimental results demonstrate that Shadow-FT consistently outperforms conventional full-parameter and parameter-efficient tuning approaches. Further analyses indicate that Shadow-FT can be applied to multimodal large language models (MLLMs) and combined with direct preference optimization (DPO). Codes and weights are available at \href{https://github.com/wutaiqiang/Shadow-FT}{Github}.
大型语言模型(LLM)在各种任务上通过进一步的微调持续受益。然而,我们观察到直接调整INSTRUCT(即指令调整)模型通常只会带来微小的改进,甚至会导致性能下降。值得注意的是,这些INSTRUCT变体的基础配套BASE模型包含高度相似的权重值(例如Llama 3.1 8B平均不到2%)。因此,我们提出了一种新的Shadow-FT框架,利用相应的BASE模型来调整INSTRUCT模型。关键思路是对BASE模型进行微调,然后将学习到的权重更新直接应用到INSTRUCT模型。我们提出的Shadow-FT不会引入额外的参数,易于实现,并能显著提高性能。我们在主流的LLM上进行了广泛的实验,如Qwen 3和Llama 3系列,并在涵盖编码、推理和数学任务的19个基准测试上对其进行了评估。实验结果表明,Shadow-FT持续优于传统的全参数和参数高效的调整方法。进一步的分析表明,Shadow-FT可应用于多模态大型语言模型(MLLMs)并与直接偏好优化(DPO)相结合。相关代码和权重可在Github获取。
论文及项目相关链接
PDF 19 pages, 10 tables, 6 figures
Summary
大型语言模型(LLM)通过进一步微调可以获得持续的收益,但直接对INSTRUCT模型进行微调会导致性能提升有限甚至退步。本研究提出一种新型的Shadow-FT框架,利用对应的BASE模型来优化INSTRUCT模型的微调。通过微调BASE模型,然后将学习到的权重更新直接应用到INSTRUCT模型上,实现了无需额外参数、易于实施,并显著提高性能的效果。实验证明,Shadow-FT在主流LLM模型上表现优异,包括Qwen 3和Llama 3系列,涵盖编程、推理和数学任务的19个基准测试。
Key Takeaways
- LLMs通过进一步微调可以获得性能提升。
- 直接对INSTRUCT模型微调可能导致有限提升或性能退步。
- 提出的Shadow-FT框架利用BASE模型进行微调。
- Shadow-FT不增加额外参数,易于实施。
- Shadow-FT显著提高了LLM的性能。
- 实验证明Shadow-FT在多个主流LLM模型和任务上表现优异。
- Shadow-FT可应用于多模态大型语言模型(MLLMs)并与直接偏好优化(DPO)结合。
点此查看论文截图