⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-05-29 更新
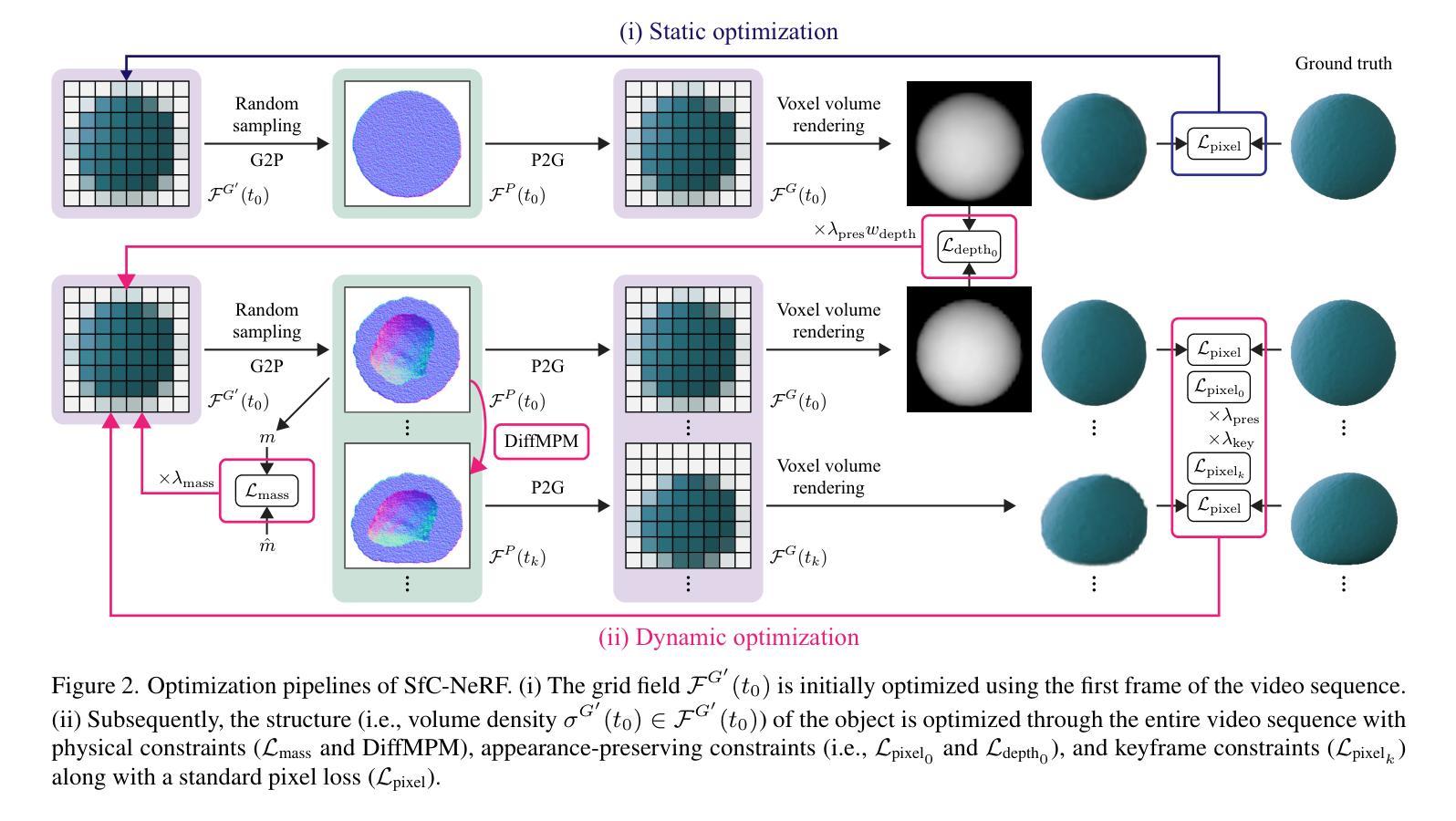
Structure from Collision
Authors:Takuhiro Kaneko
Recent advancements in neural 3D representations, such as neural radiance fields (NeRF) and 3D Gaussian splatting (3DGS), have enabled the accurate estimation of 3D structures from multiview images. However, this capability is limited to estimating the visible external structure, and identifying the invisible internal structure hidden behind the surface is difficult. To overcome this limitation, we address a new task called Structure from Collision (SfC), which aims to estimate the structure (including the invisible internal structure) of an object from appearance changes during collision. To solve this problem, we propose a novel model called SfC-NeRF that optimizes the invisible internal structure of an object through a video sequence under physical, appearance (i.e., visible external structure)-preserving, and keyframe constraints. In particular, to avoid falling into undesirable local optima owing to its ill-posed nature, we propose volume annealing; that is, searching for global optima by repeatedly reducing and expanding the volume. Extensive experiments on 115 objects involving diverse structures (i.e., various cavity shapes, locations, and sizes) and material properties revealed the properties of SfC and demonstrated the effectiveness of the proposed SfC-NeRF.
最近的神经三维表示技术,如神经辐射场(NeRF)和三维高斯贴图(3DGS),已经能够实现从多视角图像准确估计三维结构。然而,这项能力仅限于估计可见的外部结构,识别隐藏在表面之后的隐形内部结构仍然困难。为了克服这一局限性,我们解决了一项名为“碰撞结构”(SfC)的新任务,旨在从碰撞过程中的外观变化来估计物体的结构(包括隐形内部结构)。为了解决这个问题,我们提出了一种新型模型SfC-NeRF,它通过物理和外观(即可见外部结构)保持的视频序列以及关键帧约束来优化物体的隐形内部结构。特别是,为了避免因问题不适定而陷入不良的局部最优解,我们提出了体积退火法;即通过反复减少和扩大体积来寻找全局最优解。在涉及多种结构(即各种腔室形状、位置和大小)和材料特性的115个物体上进行的广泛实验揭示了SfC的特性,并证明了所提出的SfC-NeRF的有效性。
论文及项目相关链接
PDF Accepted to CVPR 2025 (Highlight). Project page: https://www.kecl.ntt.co.jp/people/kaneko.takuhiro/projects/sfc/
Summary
基于NeRF和3DGS等神经三维表征技术的最新进展,可以从多角度图像准确估计三维结构。然而,这些方法主要限于估计可见外部结构,难以识别隐藏在表面之后的不可见内部结构。为此,提出了一个新的任务称为SfC(从碰撞中重建结构),旨在通过物体在碰撞过程中的外观变化来估计其结构(包括不可见内部结构)。为解决此问题,提出了一种名为SfC-NeRF的新型模型,该模型通过视频序列在物理、外观保留、关键帧约束下优化物体的不可见内部结构。特别是为了避免因问题不适定而陷入局部最优解,提出了体积退火方法,即通过反复减小和扩大体积来寻找全局最优解。对涉及多种结构和材料属性的115个对象的广泛实验揭示了SfC的特性并证明了SfC-NeRF的有效性。
Key Takeaways
- NeRF等技术可基于多角度图像准确估计三维结构,但仅限于可见外部结构。
- 提出新的任务SfC,旨在通过碰撞中的外观变化估计物体的完整结构(包括不可见内部结构)。
- 为解决SfC问题,提出SfC-NeRF模型,结合视频序列在物理和外观保留等约束下优化内部结构。
- 避免陷入局部最优解,提出体积退火方法。
- 实验结果显示SfC-NeRF在多种结构和材料属性的物体上有效。
- SfC和SfC-NeRF的提出填补了从图像估计物体内部结构的技术空白。
点此查看论文截图


Leveraging GANs for citation intent classification and its impact on citation network analysis
Authors:Davi A. Bezerra, Filipi N. Silva, Diego R. Amancio
Citations play a fundamental role in the scientific ecosystem, serving as a foundation for tracking the flow of knowledge, acknowledging prior work, and assessing scholarly influence. In scientometrics, they are also central to the construction of quantitative indicators. Not all citations, however, serve the same function: some provide background, others introduce methods, or compare results. Therefore, understanding citation intent allows for a more nuanced interpretation of scientific impact. In this paper, we adopted a GAN-based method to classify citation intents. Our results revealed that the proposed method achieves competitive classification performance, closely matching state-of-the-art results with substantially fewer parameters. This demonstrates the effectiveness and efficiency of leveraging GAN architectures combined with contextual embeddings in intent classification task. We also investigated whether filtering citation intents affects the centrality of papers in citation networks. Analyzing the network constructed from the unArXiv dataset, we found that paper rankings can be significantly influenced by citation intent. All four centrality metrics examined- degree, PageRank, closeness, and betweenness - were sensitive to the filtering of citation types. The betweenness centrality displayed the greatest sensitivity, showing substantial changes in ranking when specific citation intents were removed.
引文在科学生态系统中发挥着至关重要的作用,它们作为追踪知识流动、承认先前工作和评估学术影响力的基础。在科学计量学中,它们也是构建量化指标的核心。然而,并非所有的引文都发挥着相同的功能:有些提供背景信息,其他的则介绍方法或比较结果。因此,理解引文意图能够对科学影响进行更细致的解释。在本文中,我们采用了一种基于生成对抗网络(GAN)的方法来分类引文意图。我们的结果表明,所提出的方法在分类性能方面表现出竞争力,以更少的参数紧密匹配了最先进的结果。这证明了利用GAN架构结合上下文嵌入在意图分类任务中的有效性和效率。我们还调查了过滤引文意图是否会影响论文在引文网络中的中心地位。通过对unArXiv数据集构建的网络进行分析,我们发现论文排名可能受到引文意图的显著影响。所研究的四种中心性度量指标——度数、PageRank、接近性和介数——都对过滤引文类型很敏感。介数中心性显示出最大的敏感性,当移除特定的引文意图时,排名发生了显著变化。
论文及项目相关链接
Summary
本文探讨了科学领域中的引文作用及其重要性,尤其是在知识追踪、前工作的认可、学术影响力评估等方面。为了更加精准地理解科学影响力,对引文意图的分类显得至关重要。该研究采用了基于GAN的方法对引文意图进行分类,不仅实现了颇具竞争力的分类效果,而且相较于前沿技术使用了更少的参数,凸显了GAN架构与语境嵌入相结合在分类任务中的高效性。此外,研究还探索了过滤引文意图对论文在引文网络中地位的影响,发现不同引文类型过滤会显著影响论文的排名,特别是网络的介数中心性显示出了高度的敏感性。
Key Takeaways
- 引文在科学领域中的作用重大,是知识追踪、前工作认可及学术影响力评估的基础。
- 引文意图的分类有助于更精准地理解科学影响力。
- 基于GAN的引文意图分类方法实现了显著效果,参数使用更少。
- GAN架构与语境嵌入结合在分类任务中展现高效性。
- 过滤引文意图会影响论文在引文网络中的地位。
- 不同引文类型的过滤会显著影响论文排名。
点此查看论文截图

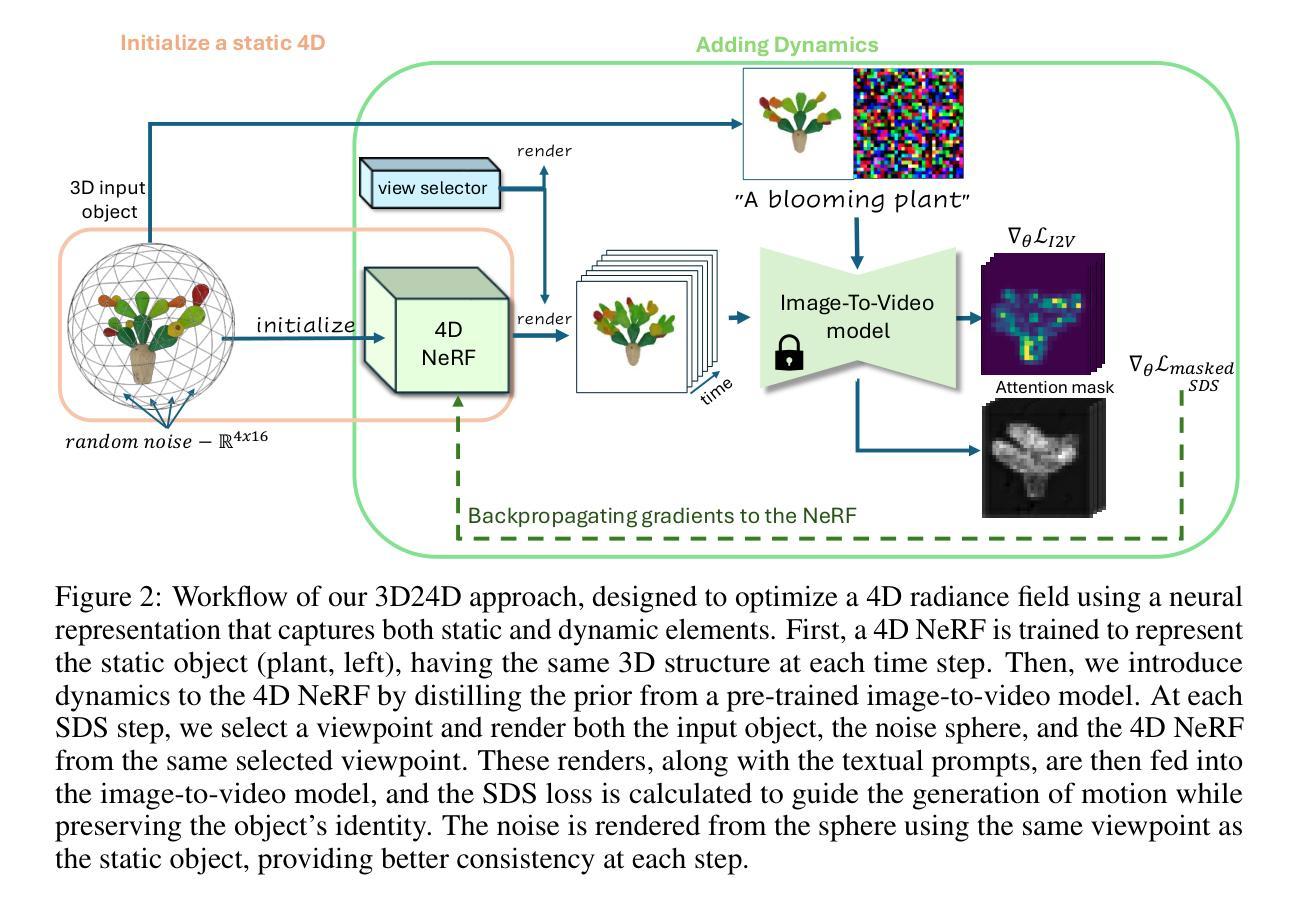
Bringing Objects to Life: training-free 4D generation from 3D objects through view consistent noise
Authors:Ohad Rahamim, Ori Malca, Dvir Samuel, Gal Chechik
Recent advancements in generative models have enabled the creation of dynamic 4D content - 3D objects in motion - based on text prompts, which holds potential for applications in virtual worlds, media, and gaming. Existing methods provide control over the appearance of generated content, including the ability to animate 3D objects. However, their ability to generate dynamics is limited to the mesh datasets they were trained on, lacking any growth or structural development capability. In this work, we introduce a training-free method for animating 3D objects by conditioning on textual prompts to guide 4D generation, enabling custom general scenes while maintaining the original object’s identity. We first convert a 3D mesh into a static 4D Neural Radiance Field (NeRF) that preserves the object’s visual attributes. Then, we animate the object using an Image-to-Video diffusion model driven by text. To improve motion realism, we introduce a view-consistent noising protocol that aligns object perspectives with the noising process to promote lifelike movement, and a masked Score Distillation Sampling (SDS) loss that leverages attention maps to focus optimization on relevant regions, better preserving the original object. We evaluate our model on two different 3D object datasets for temporal coherence, prompt adherence, and visual fidelity, and find that our method outperforms the baseline based on multiview training, achieving better consistency with the textual prompt in hard scenarios.
最新的生成模型进展使得基于文本提示创建动态4D内容(即运动的3D对象)成为可能,这有望在虚拟世界、媒体和游戏领域得到应用。现有方法可以控制生成内容的外貌,包括使3D对象动起来的能力。然而,它们生成动态的能力仅限于训练时使用的网格数据集,缺乏任何增长或结构发展能力。在这项工作中,我们介绍了一种无需训练即可使3D对象动起来的文本提示驱动方法,用于指导4D生成,既可实现自定义场景又能保持对象的原始身份。首先,我们将一个3D网格转换成静态的4D神经辐射场(NeRF),保留对象的视觉属性。然后,我们使用文本驱动的图像到视频的扩散模型使对象动画化。为了提高运动逼真性,我们引入了一种视角一致的噪声协议,该协议使对象视角与噪声过程对齐,以促进逼真的运动,以及一种带掩码的分数蒸馏采样(SDS)损失,利用注意力图来优化相关区域,更好地保持原始对象。我们在两个不同的数据集上评估了模型对时间的连贯性、对提示的遵循程度和视觉保真度。我们发现我们的方法在硬场景中优于基于多视角训练的基线方法,在文本提示一致性方面表现更好。
论文及项目相关链接
Summary
本文介绍了一种基于文本提示的无训练动画生成方法,可将三维物体转化为动态的神经辐射场(NeRF),并利用图像到视频的扩散模型驱动动画。此方法能提升动画的真实性,并能有效维持物体原有特征,使其适用于虚拟世界、媒体和游戏等领域。
Key Takeaways
- 生成模型最新进展可以实现基于文本提示创建动态四维内容(运动的3D对象)。
- 现存方法可以控制生成内容的外观,但动态生成能力受限于训练数据集,缺乏增长或结构发展能力。
- 本文提出了一种无训练动画生成方法,根据文本提示指导四维生成,可定制通用场景同时保持原始物体身份。
- 方法包括将3D网格转化为静态四维神经辐射场(NeRF),以及使用图像到视频的扩散模型驱动文本控制的动画。
- 为提高运动真实性,引入了视角一致的噪声协议和对关注区域的优化保存。
- 在两个不同的3D物体数据集上评估了模型的时间连贯性、提示遵循性和视觉保真度。
点此查看论文截图