⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-05-29 更新
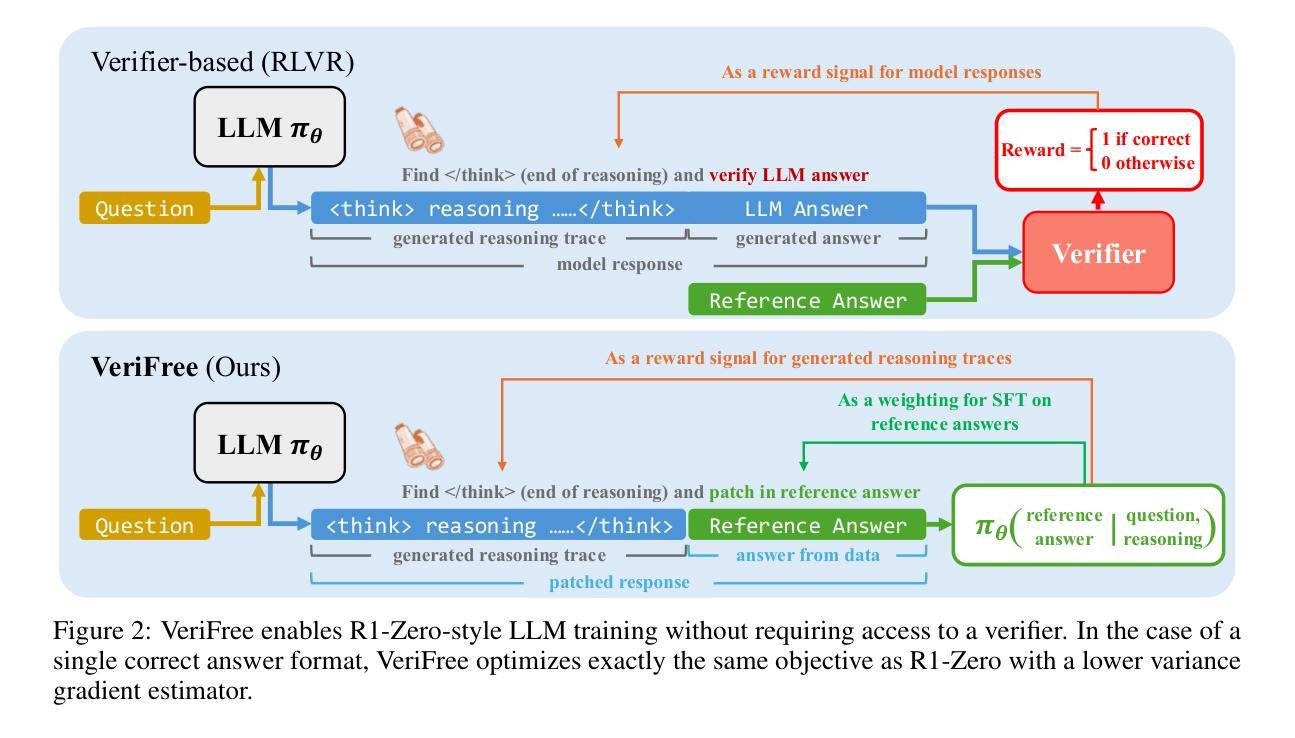
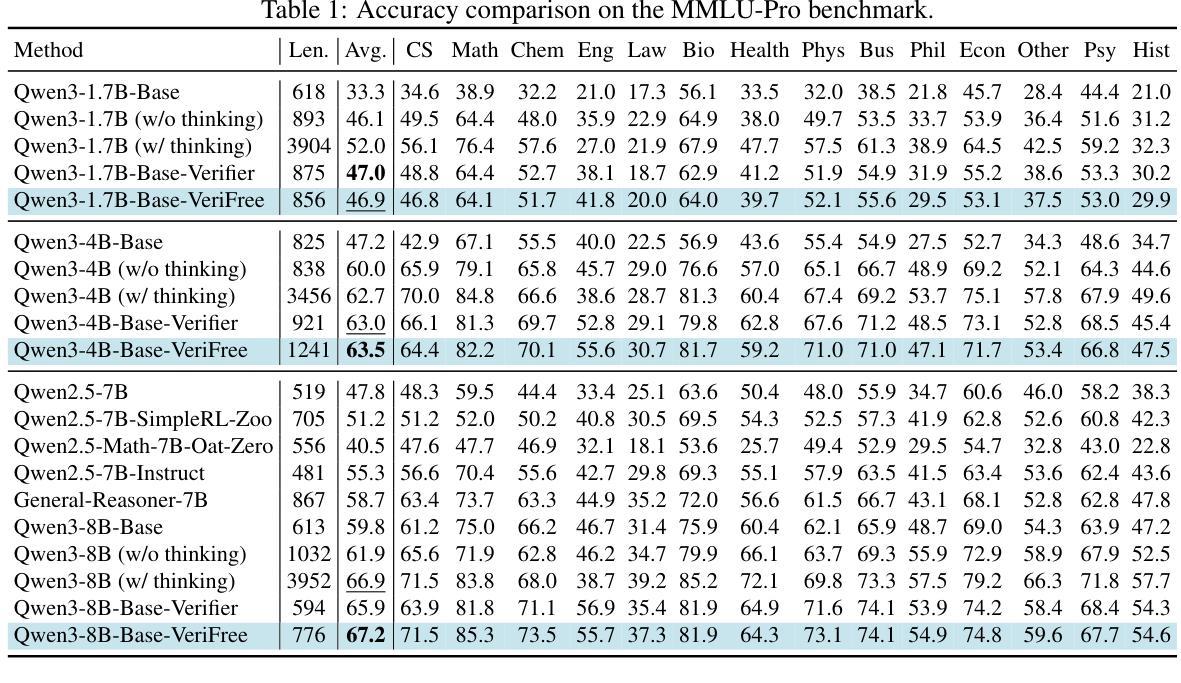
Reinforcing General Reasoning without Verifiers
Authors:Xiangxin Zhou, Zichen Liu, Anya Sims, Haonan Wang, Tianyu Pang, Chongxuan Li, Liang Wang, Min Lin, Chao Du
The recent paradigm shift towards training large language models (LLMs) using DeepSeek-R1-Zero-style reinforcement learning (RL) on verifiable rewards has led to impressive advancements in code and mathematical reasoning. However, this methodology is limited to tasks where rule-based answer verification is possible and does not naturally extend to real-world domains such as chemistry, healthcare, engineering, law, biology, business, and economics. Current practical workarounds use an additional LLM as a model-based verifier; however, this introduces issues such as reliance on a strong verifier LLM, susceptibility to reward hacking, and the practical burden of maintaining the verifier model in memory during training. To address this and extend DeepSeek-R1-Zero-style training to general reasoning domains, we propose a verifier-free method (VeriFree) that bypasses answer verification and instead uses RL to directly maximize the probability of generating the reference answer. We compare VeriFree with verifier-based methods and demonstrate that, in addition to its significant practical benefits and reduced compute requirements, VeriFree matches and even surpasses verifier-based methods on extensive evaluations across MMLU-Pro, GPQA, SuperGPQA, and math-related benchmarks. Moreover, we provide insights into this method from multiple perspectives: as an elegant integration of training both the policy and implicit verifier in a unified model, and as a variational optimization approach. Code is available at https://github.com/sail-sg/VeriFree.
最近,利用DeepSeek-R1-Zero风格的强化学习(RL)在可验证奖励上进行大规模语言模型(LLM)训练的范式转变,在代码和数学推理方面取得了令人印象深刻的进展。然而,这种方法仅限于基于规则的答案验证可行的任务,并不能自然地扩展到现实世界领域,如化学、医疗、工程、法律、生物、商业和经济学。目前的实用解决方案是使用额外的LLM作为模型验证器,但这带来了对强大的验证器LLM的依赖、奖励破解的易感性以及在训练过程中在内存中维护验证器模型的实践负担等问题。为了解决这一问题,并将DeepSeek-R1-Zero风格的培训扩展到一般推理领域,我们提出了一种无需验证器的方法(VeriFree),它绕过答案验证,而是使用RL直接最大化生成参考答案的概率。我们将VeriFree与基于验证器的方法进行比较,并证明VeriFree除了具有显著的实践效益和减少计算需求外,在MMLU-Pro、GPQA、SuperGPQA和数学相关基准测试的全面评估中,甚至超越了基于验证器的方法。此外,我们从多个角度对这种方法进行了深入洞察:作为将策略和隐式验证器整合到统一模型中的巧妙集成,以及作为一种变分优化方法。代码可访问 https://github.com/sail-sg/VeriFree。
论文及项目相关链接
Summary
本文介绍了使用DeepSeek-R1-Zero风格的强化学习(RL)在可验证奖励下训练大型语言模型(LLM)的最新进展,该方法在代码和数学推理方面取得了令人印象深刻的进步。然而,这种方法仅限于规则可验证的任务,无法自然扩展到化学、医疗、工程、法律、生物、商业和经济等真实世界领域。为解决这一问题并扩展DeepSeek-R1-Zero风格的训练至通用推理领域,提出了一种无需验证器的方法(VeriFree),该方法绕过答案验证,直接使用强化学习最大化生成参考答案的概率。对比基于验证器的方法,VeriFree不仅在实际应用和计算需求方面具有显著优势,而且在广泛的评估中甚至超越了基于验证器的方法。
Key Takeaways
- 大型语言模型(LLM)使用DeepSeek-R1-Zero风格的强化学习在可验证奖励下取得了在代码和数学推理方面的显著进步。
- 当前方法主要局限于规则可验证的任务,难以应用于真实世界领域如化学、医疗等。
- 为解决此问题,提出了无需验证器的方法(VeriFree),通过强化学习直接最大化生成正确答案的概率。
- VeriFree与基于验证器的方法相比,具有实际应用和计算需求上的优势,并在广泛的评估中表现出卓越性能。
- VeriFree作为一种优雅地将策略和隐式验证器集成在统一模型中的方法,具有很高的实用性。
- VeriFree提供了一种变分优化方法的视角,为语言模型训练提供了新的思路。
点此查看论文截图

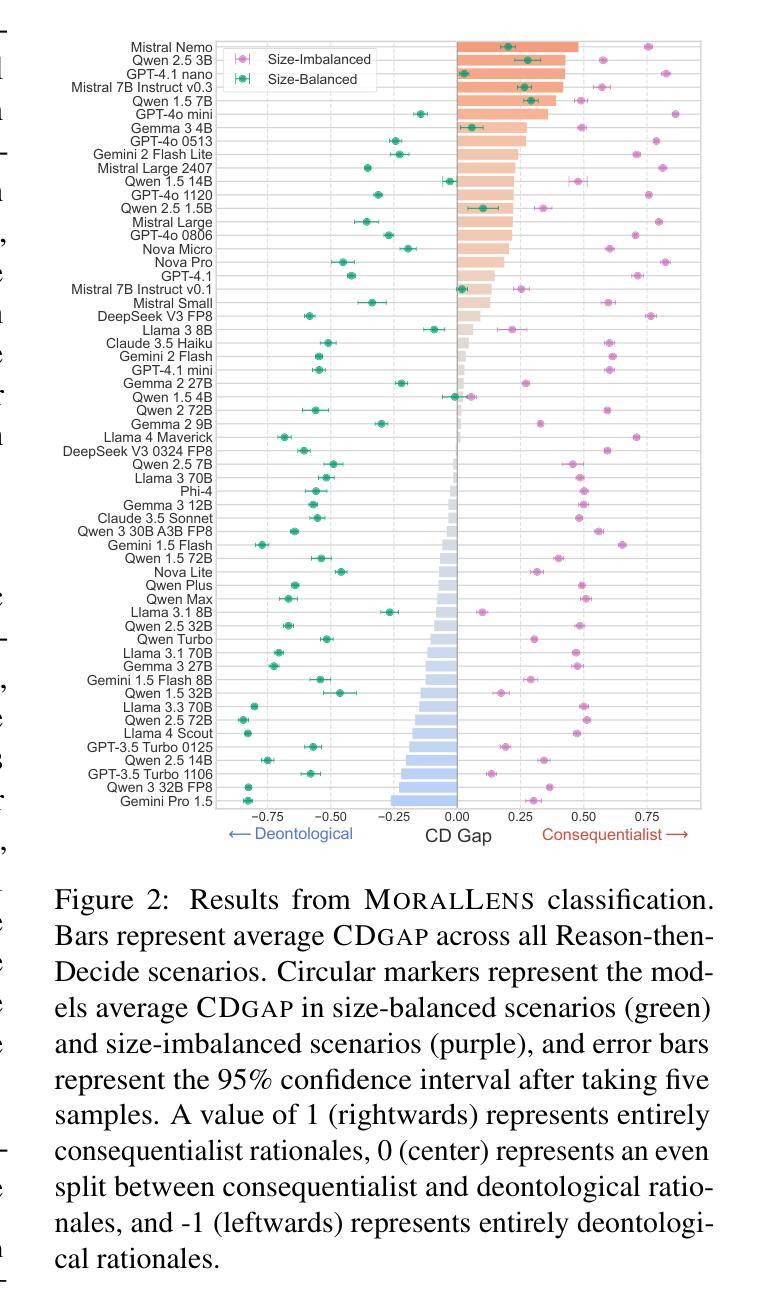
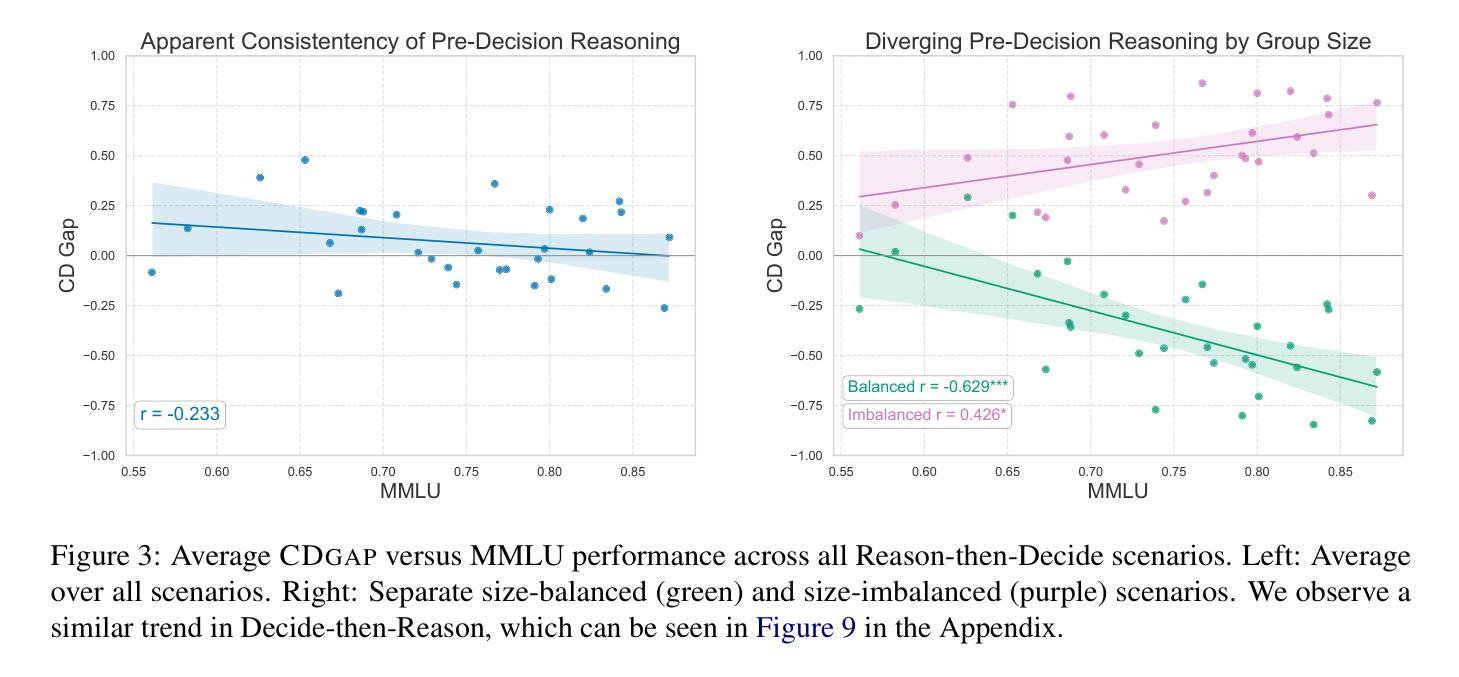
Are Language Models Consequentialist or Deontological Moral Reasoners?
Authors:Keenan Samway, Max Kleiman-Weiner, David Guzman Piedrahita, Rada Mihalcea, Bernhard Schölkopf, Zhijing Jin
As AI systems increasingly navigate applications in healthcare, law, and governance, understanding how they handle ethically complex scenarios becomes critical. Previous work has mainly examined the moral judgments in large language models (LLMs), rather than their underlying moral reasoning process. In contrast, we focus on a large-scale analysis of the moral reasoning traces provided by LLMs. Furthermore, unlike prior work that attempted to draw inferences from only a handful of moral dilemmas, our study leverages over 600 distinct trolley problems as probes for revealing the reasoning patterns that emerge within different LLMs. We introduce and test a taxonomy of moral rationales to systematically classify reasoning traces according to two main normative ethical theories: consequentialism and deontology. Our analysis reveals that LLM chains-of-thought tend to favor deontological principles based on moral obligations, while post-hoc explanations shift notably toward consequentialist rationales that emphasize utility. Our framework provides a foundation for understanding how LLMs process and articulate ethical considerations, an important step toward safe and interpretable deployment of LLMs in high-stakes decision-making environments. Our code is available at https://github.com/keenansamway/moral-lens .
随着人工智能系统在医疗保健、法律和治理等领域的应用日益广泛,理解它们如何处理道德上复杂的场景变得至关重要。以前的研究主要关注大型语言模型(LLM)的道德判断,而非其潜在的道德推理过程。相比之下,我们专注于对LLM提供的道德推理轨迹的大规模分析。此外,不同于之前的研究仅从少数道德困境中推断结果,我们的研究利用超过600个不同的电车问题作为探针,以揭示不同LLM内部出现的推理模式。我们介绍并测试了一种道德理由的分类法,根据两种主要的规范性伦理理论,即后果主义和道义论来系统地分类推理轨迹。我们的分析表明,LLM的思维链往往倾向于基于道德义务的道义论原则,而后期的解释则显著转向强调实用性的后果主义理由。我们的框架为理解LLM如何处理并阐述道德考量提供了基础,这是将LLM安全且可解释地部署于高风险决策环境的重要步骤。我们的代码可通过https://github.com/keenansamway/moral-lens获取。
论文及项目相关链接
Summary
本文探讨了大型语言模型(LLMs)在伦理复杂场景中的道德推理过程。通过对超过600个不同的电车问题的分析,作者发现LLM的思考链往往倾向于基于道德义务的原则,而后期的解释则明显转向强调实用主义的后果主义理由。这为理解LLMs如何处理并表达伦理考虑提供了基础,是安全且可解释地在高风险决策环境中部署LLMs的重要一步。
Key Takeaways
- 大型语言模型(LLMs)在伦理复杂场景中的道德推理至关重要。
- LLM的思考链倾向于基于道德义务的原则(deontological principles)。
- 与早期研究相比,本研究使用了超过600个电车问题来揭示不同LLM中的推理模式。
- 引入并测试了道德理由的分类法,以系统地根据两种主要的伦理理论(后果主义和道义论)对推理轨迹进行分类。
- 后期的解释明显转向强调实用主义的后果主义理由(consequentialist rationales)。
- 该研究提供了一个理解LLM如何处理并表达伦理考虑的基础。
点此查看论文截图


Policy Optimized Text-to-Image Pipeline Design
Authors:Uri Gadot, Rinon Gal, Yftah Ziser, Gal Chechik, Shie Mannor
Text-to-image generation has evolved beyond single monolithic models to complex multi-component pipelines. These combine fine-tuned generators, adapters, upscaling blocks and even editing steps, leading to significant improvements in image quality. However, their effective design requires substantial expertise. Recent approaches have shown promise in automating this process through large language models (LLMs), but they suffer from two critical limitations: extensive computational requirements from generating images with hundreds of predefined pipelines, and poor generalization beyond memorized training examples. We introduce a novel reinforcement learning-based framework that addresses these inefficiencies. Our approach first trains an ensemble of reward models capable of predicting image quality scores directly from prompt-workflow combinations, eliminating the need for costly image generation during training. We then implement a two-phase training strategy: initial workflow vocabulary training followed by GRPO-based optimization that guides the model toward higher-performing regions of the workflow space. Additionally, we incorporate a classifier-free guidance based enhancement technique that extrapolates along the path between the initial and GRPO-tuned models, further improving output quality. We validate our approach through a set of comparisons, showing that it can successfully create new flows with greater diversity and lead to superior image quality compared to existing baselines.
文本到图像生成已经发展超越了单一的整体模型,形成了复杂的多组件管道。这些管道结合了精细调整的生成器、适配器、放大块甚至编辑步骤,导致图像质量得到显著改善。然而,它们的有效设计需要大量的专业知识。最近的方法在通过大型语言模型(LLM)自动化这个过程方面显示出希望,但它们存在两个关键的局限性:一是从数百个预定义管道生成图像需要大量的计算资源,二是对记忆训练示例之外的推广能力较差。我们引入了一种基于强化学习的新框架来解决这些低效问题。我们的方法首先训练一个奖励模型集合,能够直接从提示-工作流程组合中预测图像质量分数,从而消除训练期间昂贵的图像生成需求。然后,我们采用两阶段训练策略:初始工作流程词汇训练,然后是基于GRPO的优化,引导模型向性能更高的工作流程空间区域发展。此外,我们采用了一种基于无分类器指导的增强技术,沿着初始模型和GRPO调整模型之间的路径进行推断,进一步提高输出质量。我们通过一系列对比验证了我们的方法,结果表明它成功地创建了具有更高多样性的新流程,并导致图像质量优于现有基线。
论文及项目相关链接
Summary
文本介绍了文本到图像生成领域的发展,包括多组件管道、精细的生成器、适配器和放大块等。然而,它们的有效设计需要大量专业知识。最新方法虽试图通过大型语言模型自动化这一过程,但仍存在计算需求大、泛化能力差的局限性。为此,研究团队提出了一种基于强化学习的新框架来解决这些问题。该框架通过训练一组奖励模型来预测图像质量分数,从而减少训练过程中的图像生成成本。同时采用两阶段训练策略,初始工作流程词汇训练,接着是GPRO优化,最后引入一种基于无分类器引导技术的增强技术,进一步提高输出质量。验证了新方法能够创建更具多样性和高质量图像的工作流程。
Key Takeaways
- 文本到图像生成已从单一模型演变为复杂的多组件管道,包括精细的生成器、适配器和放大块等。
- 现有自动化方法存在计算需求大、泛化能力差的局限性。
- 新框架采用强化学习来解决这些问题,通过训练奖励模型预测图像质量分数来减少训练成本。
- 采用两阶段训练策略:初始工作流程词汇训练,然后是GRPO优化。
- 引入基于无分类器引导技术的增强技术,进一步提高输出质量。
- 新方法能够创建具有多样性和高质量图像的新工作流程。
点此查看论文截图

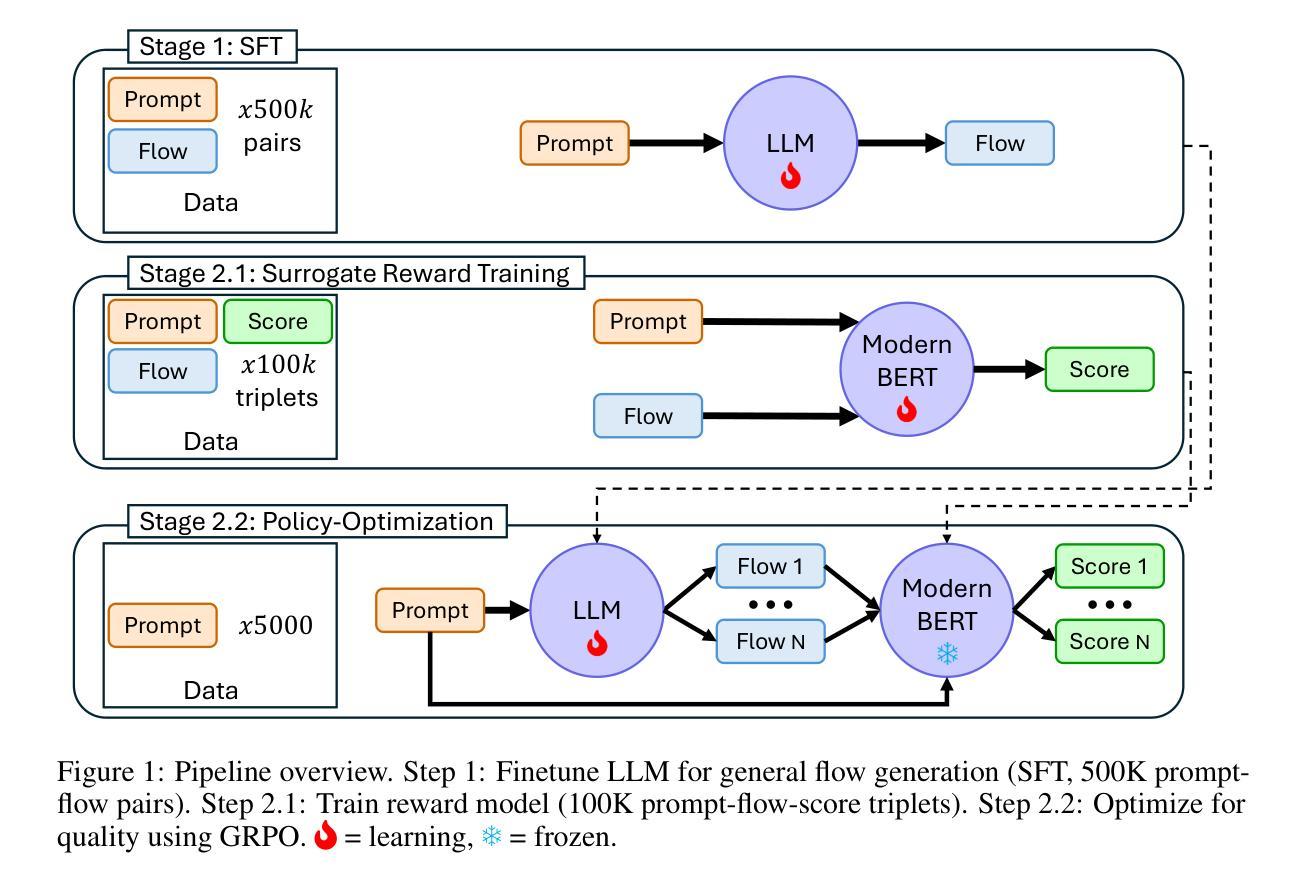
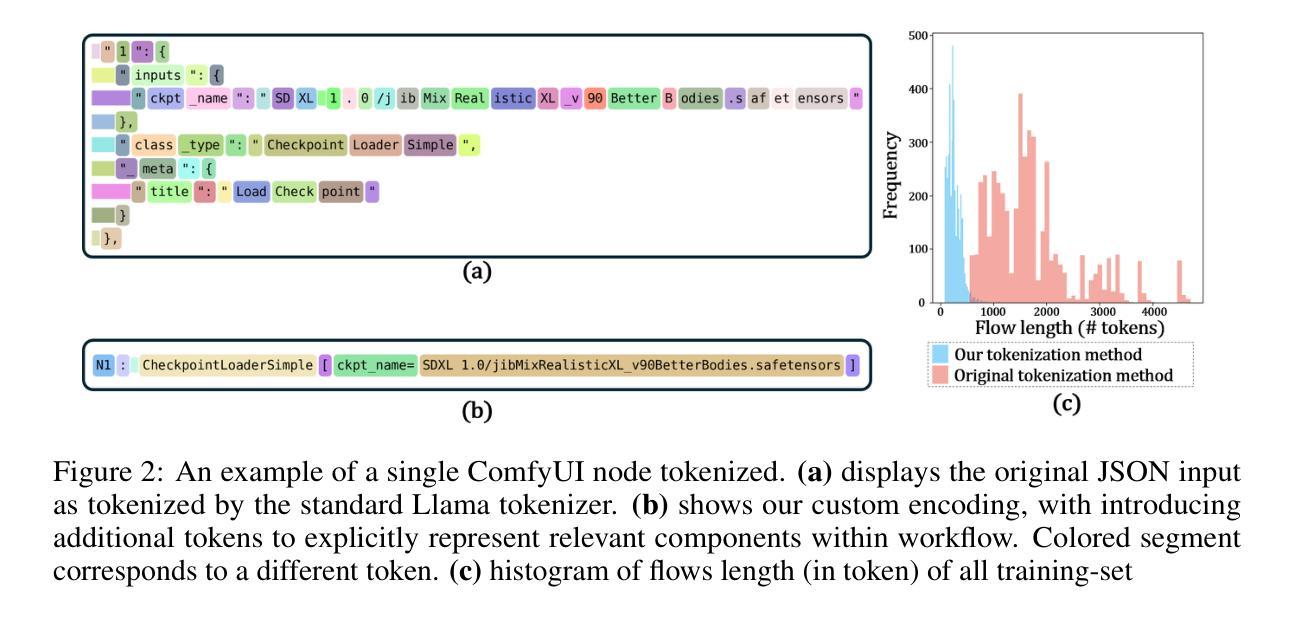
PropMolFlow: Property-guided Molecule Generation with Geometry-Complete Flow Matching
Authors:Cheng Zeng, Jirui Jin, George Karypis, Mark Transtrum, Ellad B. Tadmor, Richard G. Hennig, Adrian Roitberg, Stefano Martiniani, Mingjie Liu
Molecule generation is advancing rapidly in chemical discovery and drug design. Flow matching methods have recently set the state of the art (SOTA) in unconditional molecule generation, surpassing score-based diffusion models. However, diffusion models still lead in property-guided generation. In this work, we introduce PropMolFlow, a novel approach for property-guided molecule generation based on geometry-complete SE(3)-equivariant flow matching. Integrating five different property embedding methods with a Gaussian expansion of scalar properties, PropMolFlow outperforms previous SOTA diffusion models in conditional molecule generation across various properties while preserving the stability and validity of the generated molecules, consistent with its unconditional counterpart. Additionally, it enables faster inference with significantly fewer time steps compared to baseline models. We highlight the importance of validating the properties of generated molecules through DFT calculations performed at the same level of theory as the training data. Specifically, our analysis identifies properties that require DFT validation and others where a pretrained SE(3) geometric vector perceptron regressors provide sufficiently accurate predictions on generated molecules. Furthermore, we introduce a new property metric designed to assess the model’s ability to propose molecules with underrepresented property values, assessing its capacity for out-of-distribution generalization. Our findings reveal shortcomings in existing structural metrics, which mistakenly validate open-shell molecules or molecules with invalid valence-charge configurations, underscoring the need for improved evaluation frameworks. Overall, this work paves the way for developing targeted property-guided generation methods, enhancing the design of molecular generative models for diverse applications.
分子生成在化学发现和药物设计领域正迅速推进。最近,流量匹配方法在无条件分子生成领域已经处于最新技术状态(SOTA),超越了基于分数的扩散模型。然而,扩散模型在属性导向生成方面仍占优势。在这项工作中,我们介绍了PropMolFlow,这是一种基于几何完全SE(3)等价流匹配的新颖属性导向分子生成方法。通过将五种不同的属性嵌入方法与标量属性的高斯扩展相结合,PropMolFlow在多种属性的有条件分子生成方面超越了之前的SOTA扩散模型,同时保持了生成分子的稳定性和有效性,与其无条件对应物相一致。此外,与基准模型相比,它实现了更快的推理,并且显著减少了时间步骤。我们强调通过与实施训练数据相同理论水平的DFT计算验证生成分子属性的重要性。具体来说,我们的分析确定了需要进行DFT验证的属性,以及其他使用预训练的SE(3)几何向量感知器回归器对生成的分子提供足够准确预测的属性。此外,我们引入了一个新的属性指标,旨在评估模型提出具有代表性不足的属性值的分子的能力,评估其偏离分布泛化的能力。我们的研究结果揭示了现有结构指标的不足,这些指标错误地验证了开壳分子或具有无效价电荷配置的分子,强调了对改进评估框架的需求。总体而言,这项工作为开发有针对性的属性导向生成方法铺平了道路,增强了分子生成模型在各种应用中的设计。
论文及项目相关链接
Summary:
本文介绍了在化学发现和药物设计中,分子生成领域的新进展。文章提出一种新型的方法PropMolFlow,基于几何完全SE(3)等价流匹配,用于属性导向的分子生成。此方法在融合五种属性嵌入方法和标量属性的高斯扩展后,在条件分子生成的各种属性上超越了当前最佳扩散模型,同时保持了生成分子的稳定性和有效性。此外,它实现了更快的推理速度,并且显著减少了与基线模型相比的时间步骤。文章强调了通过DFT计算验证生成分子属性的重要性,并分析了哪些属性需要DFT验证,哪些属性可以使用预训练的SE(3)几何向量感知回归器提供足够准确的预测。该研究还引入了一个新的属性指标,旨在评估模型提出具有代表性属性值的分子的能力,并揭示了现有结构指标的不足,强调了需要改进评估框架。
Key Takeaways:
- 分子生成领域正在快速发展,尤其在化学发现和药物设计中。
- PropMolFlow是一种新的属性导向的分子生成方法,基于几何完全SE(3)等价流匹配。
- PropMolFlow在条件分子生成的各种属性上超越了当前最佳扩散模型。
- PropMolFlow能更快地进行推理,并且显著减少了时间步骤。
- DFT计算对于验证生成分子的属性至关重要。
- 需要区分哪些属性需要DFT验证,哪些可以使用预训练的SE(3)几何向量感知回归器进行预测。
点此查看论文截图

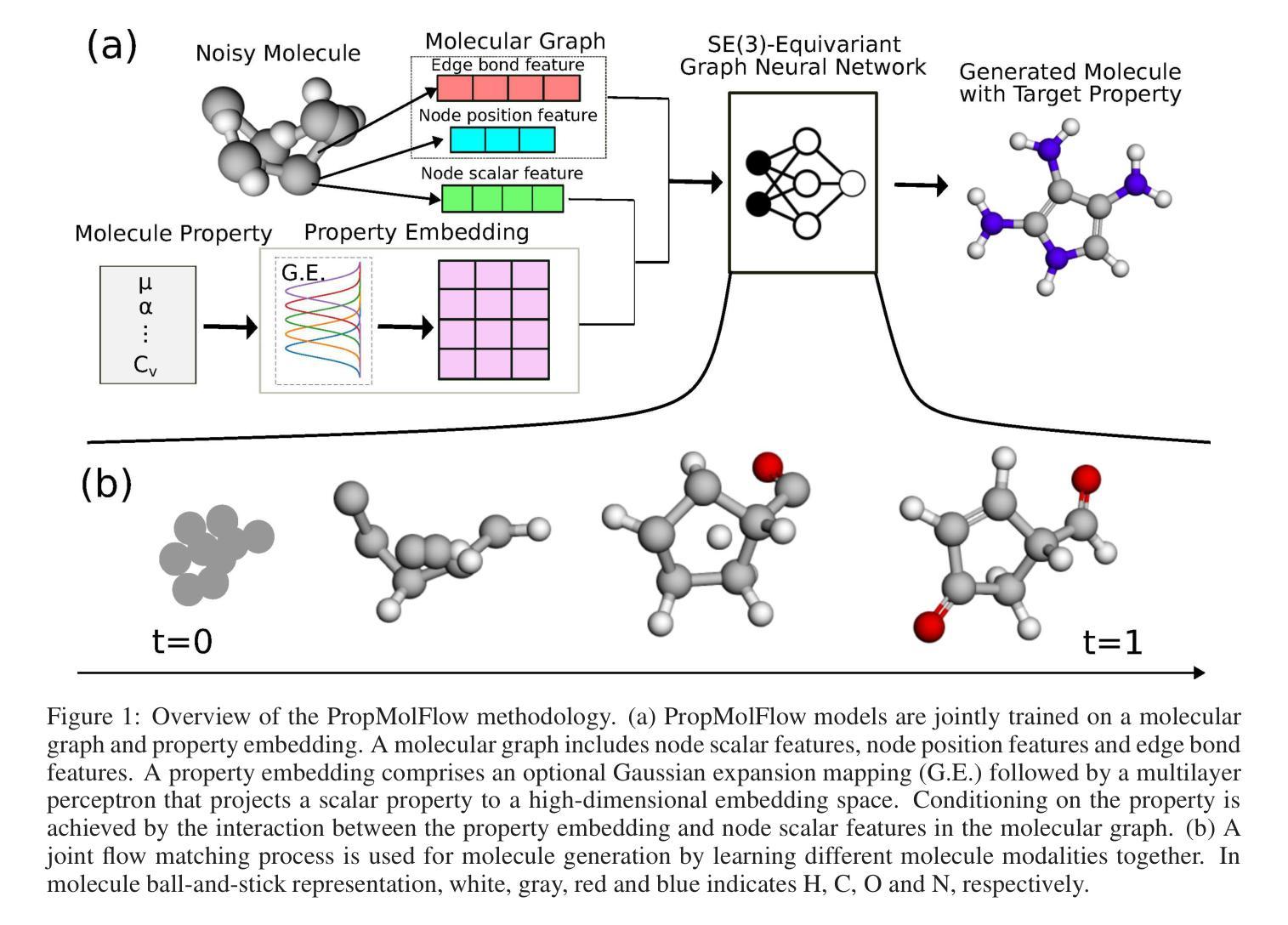
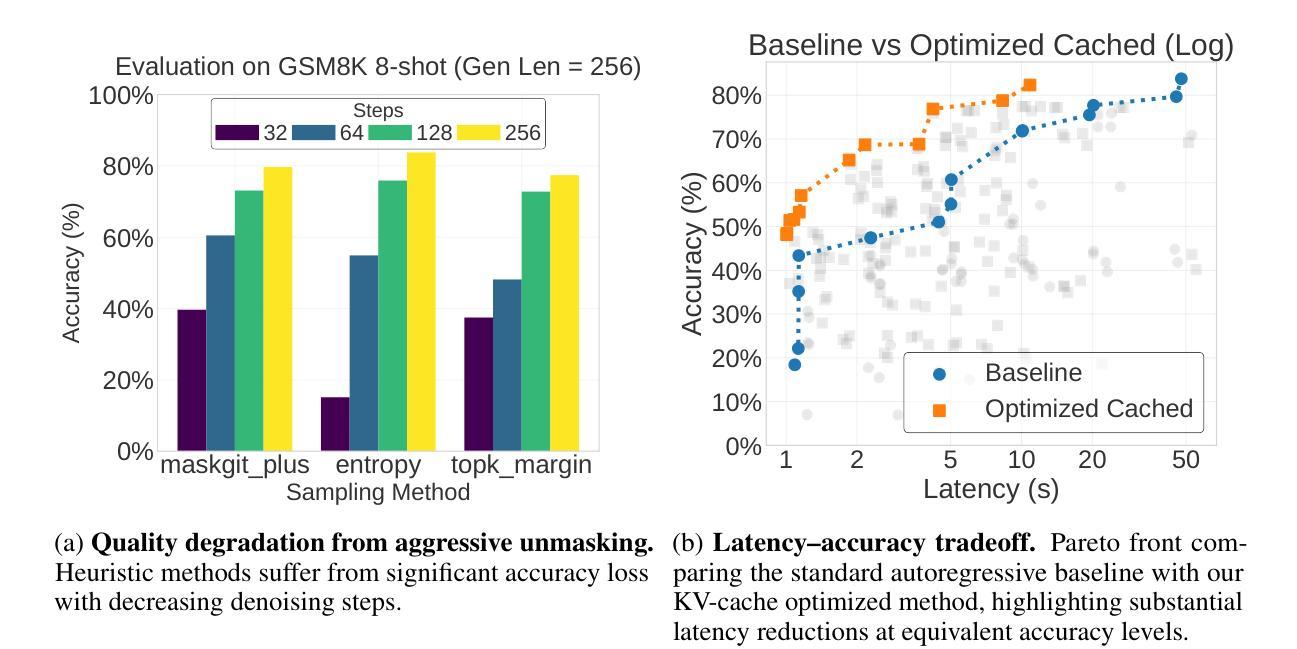
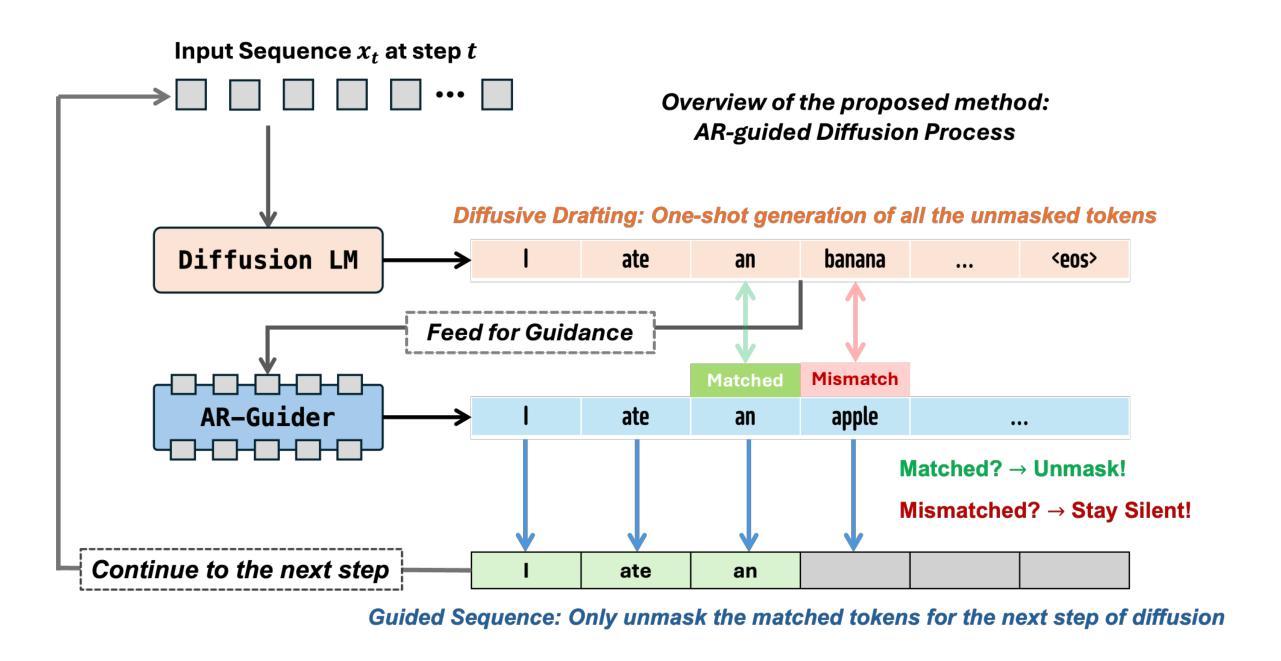
Accelerating Diffusion Language Model Inference via Efficient KV Caching and Guided Diffusion
Authors:Zhanqiu Hu, Jian Meng, Yash Akhauri, Mohamed S. Abdelfattah, Jae-sun Seo, Zhiru Zhang, Udit Gupta
Diffusion language models offer parallel token generation and inherent bidirectionality, promising more efficient and powerful sequence modeling compared to autoregressive approaches. However, state-of-the-art diffusion models (e.g., Dream 7B, LLaDA 8B) suffer from slow inference. While they match the quality of similarly sized Autoregressive (AR) Models (e.g., Qwen2.5 7B, Llama3 8B), their iterative denoising requires multiple full-sequence forward passes, resulting in high computational costs and latency, particularly for long input prompts and long-context scenarios. Furthermore, parallel token generation introduces token incoherence problems, and current sampling heuristics suffer from significant quality drops with decreasing denoising steps. We address these limitations with two training-free techniques. First, we propose FreeCache, a Key-Value (KV) approximation caching technique that reuses stable KV projections across denoising steps, effectively reducing the computational cost of DLM inference. Second, we introduce Guided Diffusion, a training-free method that uses a lightweight pretrained autoregressive model to supervise token unmasking, dramatically reducing the total number of denoising iterations without sacrificing quality. We conduct extensive evaluations on open-source reasoning benchmarks, and our combined methods deliver up to a 34x end-to-end speedup without compromising accuracy. For the first time, diffusion language models achieve a comparable and even faster latency as the widely adopted autoregressive models. Our work successfully paved the way for scaling up the diffusion language model to a broader scope of applications across different domains.
扩散语言模型具有并行令牌生成和内在双向性的优点,与自回归方法相比,它们提供了更高效和强大的序列建模。然而,最先进的扩散模型(例如Dream 7B、LLaDA 8B)存在推理速度慢的问题。尽管它们在质量上可以与规模相似的自回归模型(例如Qwen2.5 7B、Llama3 8B)相匹配,但由于它们的迭代降噪需要大量完整序列的前向传递过程,导致了计算成本高和延迟问题,尤其是在输入提示长以及长期上下文场景中更为突出。此外,并行令牌生成会导致令牌不一致问题,当前采样启发式策略在减少降噪步骤时会出现显著的质量下降。我们采用两种无需训练的技术来解决这些局限性。首先,我们提出了一种名为FreeCache的键值(KV)近似缓存技术,它可以在降噪步骤中重复使用稳定的KV投影,有效降低扩散语言模型推理的计算成本。其次,我们引入了Guided Diffusion方法,这是一种无需训练的监督令牌去掩码方法,使用轻量级预训练自回归模型进行监督,大大降低了降噪迭代次数,同时不牺牲质量。我们在开源推理基准测试上进行了广泛评估,我们的组合方法在不损害准确性的情况下实现了高达34倍的端到端加速。扩散语言模型首次实现了与广泛采用的自回归模型相当的甚至更快的延迟时间。我们的工作成功为扩散语言模型在跨不同领域的更广泛应用铺平了道路。
论文及项目相关链接
Summary
本文介绍了扩散语言模型(Diffusion Language Models,简称DLMs)的特点及其在序列建模中的优势。尽管它们具备并行标记生成和固有的双向性,但与现有的自回归模型相比,它们在推理过程中存在速度慢的问题。为解决这些问题,本文提出了两种训练无关的技术:FreeCache和Guided Diffusion。前者通过重用稳定的键值投影来减少计算成本,后者使用轻量级的预训练自回归模型来监督标记去掩码过程,从而减少去噪迭代次数而不损失质量。结合这两种方法,实现了高达34倍端到端的加速,使扩散语言模型的延迟与广泛采用的自回归模型相当甚至更快。这为扩散语言模型在跨不同领域的应用提供了更广阔的可能性。
Key Takeaways
- 扩散语言模型具备并行标记生成和固有的双向性,可实现更高效和强大的序列建模。
- 当前扩散模型在推理过程中存在速度慢的问题,主要由于迭代去噪需要多次全序列前向传递。
- FreeCache技术通过重用稳定的键值投影来减少计算成本,提高扩散模型的推理速度。
- Guided Diffusion方法使用预训练的自回归模型来监督标记去掩码过程,减少去噪迭代次数,同时保持质量。
- 结合两种方法,实现了高达34倍的端到端加速,使扩散语言模型的延迟与自回归模型相当。
- 扩散语言模型的改进为其在跨不同领域的应用提供了更广阔的可能性。
点此查看论文截图



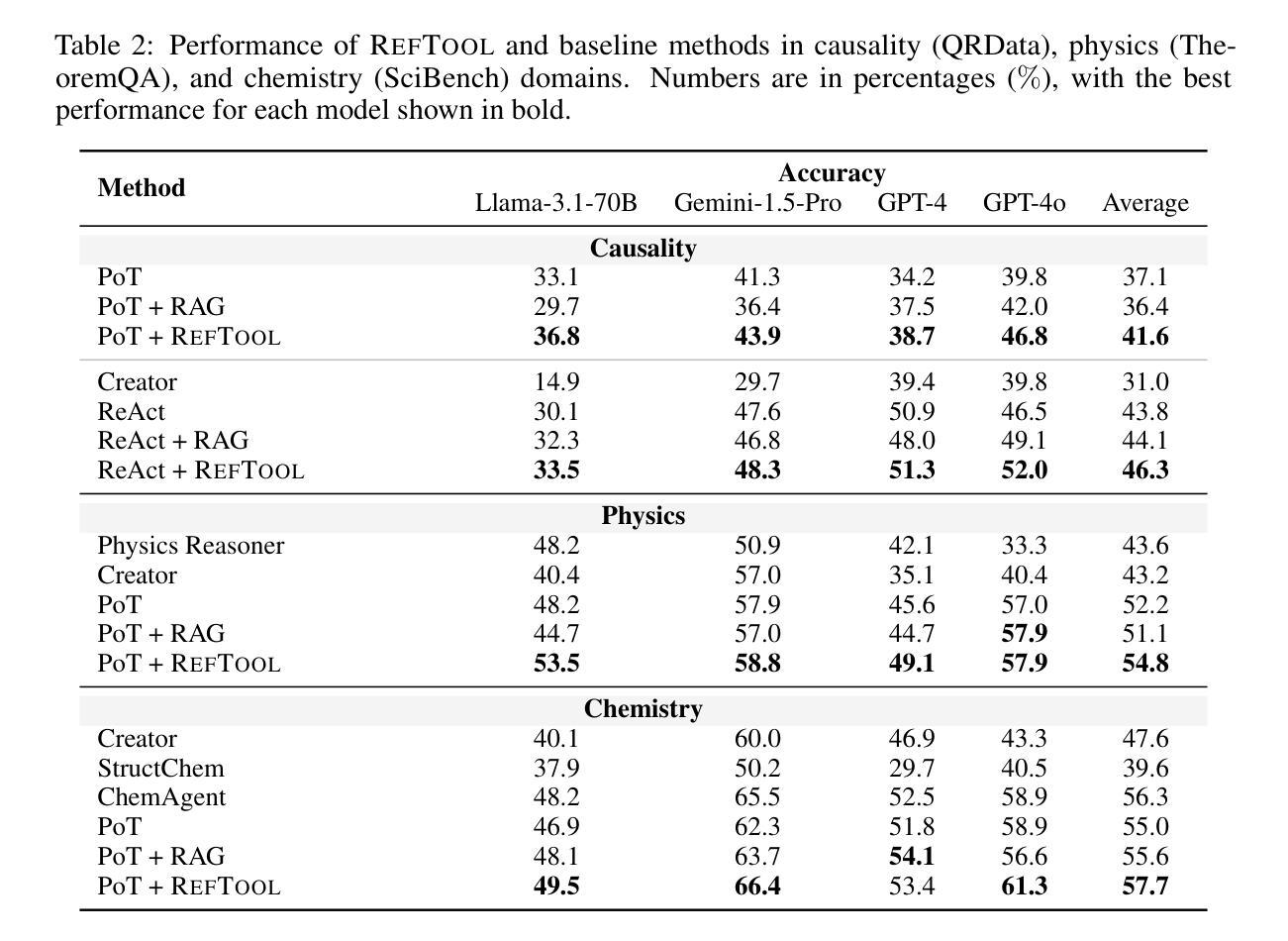
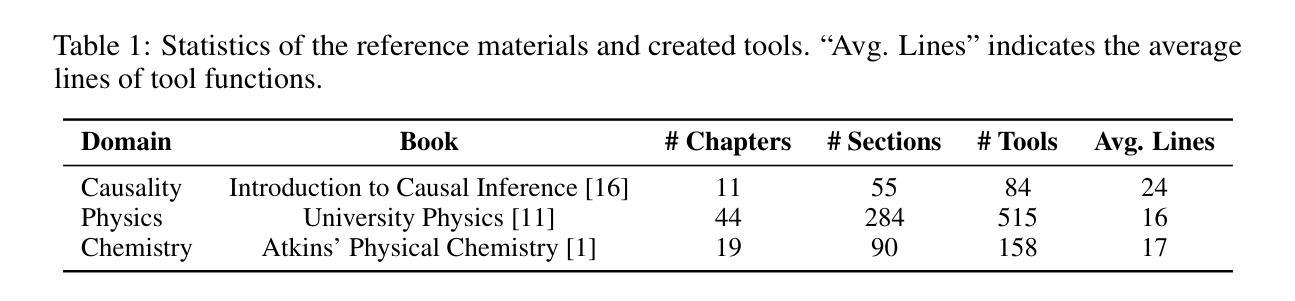
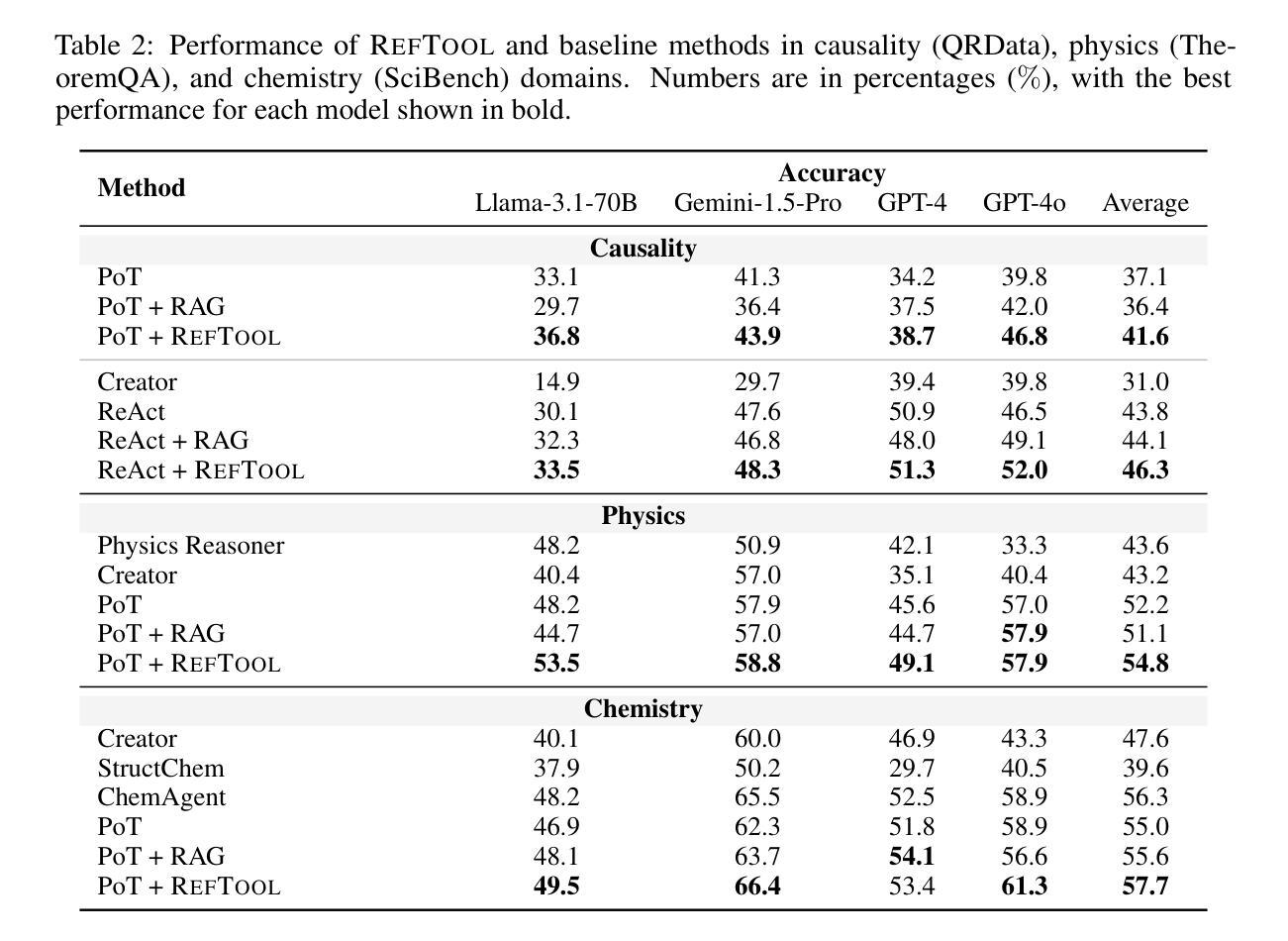
RefTool: Enhancing Model Reasoning with Reference-Guided Tool Creation
Authors:Xiao Liu, Da Yin, Zirui Wu, Yansong Feng
Tools enhance the reasoning capabilities of large language models (LLMs) in complex problem-solving tasks, but not all tasks have available tools. In the absence of predefined tools, prior works have explored instructing LLMs to generate tools on their own. However, such approaches rely heavily on the models’ internal knowledge and would fail in domains beyond the LLMs’ knowledge scope. To address this limitation, we propose RefTool, a reference-guided framework for automatic tool creation that leverages structured external materials such as textbooks. RefTool consists of two modules: (1) tool creation, where LLMs generate executable tools from reference content, validate them using illustrative examples, and organize them hierarchically into a toolbox; and (2) tool utilization, where LLMs navigate the toolbox structure to select and apply the appropriate tools to solve problems. Experiments on causality, physics, and chemistry benchmarks demonstrate that RefTool outperforms existing tool-creation and domain-specific reasoning methods by 11.3% on average accuracy, while being cost-efficient and broadly generalizable. Analyses reveal that grounding tool creation in references produces accurate and faithful tools, and that the hierarchical structure facilitates effective tool selection. RefTool enables LLMs to overcome knowledge limitations, demonstrating the value of grounding tool creation in external references for enhanced and generalizable reasoning.
工具可以增强大型语言模型(LLM)在复杂问题解决任务中的推理能力,但并不是所有的任务都有可用的工具。在没有预设工具的情况下,早期的研究工作已经探索了指导LLM自行生成工具的方法。然而,这些方法很大程度上依赖于模型的内部知识,并且在LLM知识范围之外的领域会失效。为了解决这一局限性,我们提出了RefTool,这是一个参考引导的自动工具创建框架,它利用结构化的外部材料(如教科书)。RefTool由两个模块组成:(1)工具创建,其中LLM根据参考内容生成可执行工具,使用示例进行验证,并将其按层次结构组织成工具箱;(2)工具利用,其中LLM浏览工具箱结构,选择并应用适当的工具来解决问题。在因果、物理和化学基准测试上的实验表明,RefTool在平均准确率上比现有的工具创建和领域特定推理方法高出11.3%,同时成本效益高且可广泛推广。分析表明,以参考为基础的工具创建产生了准确和忠诚的工具,层次结构有助于有效的工具选择。RefTool使LLM能够克服知识局限性,证明了以外部参考为基础的工具创建对于增强和通用推理的价值。
论文及项目相关链接
PDF Code is available at https://github.com/xxxiaol/RefTool
Summary
本文介绍了一种名为RefTool的参考引导框架,用于在大型语言模型(LLM)中自动生成工具。该框架借助结构化外部材料(如教科书)来创建工具,并通过实验证明其在因果、物理和化学等领域的效果优于现有工具创建和特定领域推理方法。RefTool解决了在缺乏预先定义的工具时LLM的知识局限性问题,通过参考内容生成可执行工具,并以层次结构组织工具箱,使LLM能够选择并应用适当的工具来解决问题。
Key Takeaways
- RefTool是一个参考引导框架,用于大型语言模型(LLM)自动生成工具。
- 该框架通过结构化外部材料(如教科书)来创建工具。
- RefTool包括两个模块:工具创建和工具利用。
- 工具创建模块使LLM从参考内容生成工具,并用示例验证其有效性,以层次结构组织工具箱。
- 工具利用模块使LLM能够选择并应用适当的工具来解决问题。
- 实验表明,RefTool在因果、物理和化学等领域优于现有方法,平均准确度提高11.3%。
- RefTool解决了LLM的知识局限性问题,通过参考内容生成工具增强了推理能力。
点此查看论文截图



A Structured Unplugged Approach for Foundational AI Literacy in Primary Education
Authors:Maria Cristina Carrisi, Mirko Marras, Sara Vergallo
Younger generations are growing up in a world increasingly shaped by intelligent technologies, making early AI literacy crucial for developing the skills to critically understand and navigate them. However, education in this field often emphasizes tool-based learning, prioritizing usage over understanding the underlying concepts. This lack of knowledge leaves non-experts, especially children, prone to misconceptions, unrealistic expectations, and difficulties in recognizing biases and stereotypes. In this paper, we propose a structured and replicable teaching approach that fosters foundational AI literacy in primary students, by building upon core mathematical elements closely connected to and of interest in primary curricula, to strengthen conceptualization, data representation, classification reasoning, and evaluation of AI. To assess the effectiveness of our approach, we conducted an empirical study with thirty-one fifth-grade students across two classes, evaluating their progress through a post-test and a satisfaction survey. Our results indicate improvements in terminology understanding and usage, features description, logical reasoning, and evaluative skills, with students showing a deeper comprehension of decision-making processes and their limitations. Moreover, the approach proved engaging, with students particularly enjoying activities that linked AI concepts to real-world reasoning. Materials: https://github.com/tail-unica/ai-literacy-primary-ed.
年轻一代正在一个由智能技术日益塑造的世界中成长,因此早期的人工智能素养对于发展批判性理解和驾驭这些技术的能力至关重要。然而,该领域的教育往往强调基于工具的学习,优先考虑使用而非理解基本概念。这种知识的缺乏使得非专家,尤其是儿童,容易受到误解、产生不切实际的期望,并且在识别偏见和刻板印象时遇到困难。在本文中,我们提出了一种结构化且可复制的教学方法,通过在核心数学元素的基础上,结合小学课程中的紧密相关和感兴趣的内容,促进小学生的人工智能素养发展,以加强概念化、数据表示、分类推理和人工智能评估。为了评估我们方法的有效性,我们对两个班级的三十一名五年级学生进行了实证研究,通过课后测试和满意度调查来评估他们的进步。我们的结果表明,学生在术语理解和使用、特征描述、逻辑推理和评估技能方面有所提高,学生对决策过程及其局限性有了更深的理解。此外,该方法证明是吸引人的,学生特别喜欢将人工智能概念与现实世界的推理联系起来的活动。材料:链接
论文及项目相关链接
PDF Under review
Summary:年轻一代正生活在一个智能技术日益普及的世界,早期的人工智能素养对于培养批判理解和应对这些技术的能力至关重要。然而,教育领域往往注重工具性学习,优先考虑使用而非理解基础概念。本文提出了一种结构化、可复制的教学方法,旨在通过小学数学的核心元素来培养小学生的人工智能素养,强化概念化、数据表示、分类推理和人工智能评估。我们对两个班级共31名五年级学生进行了实证研究,通过测试和后测试满意度调查来评估其效果。结果显示学生在术语理解和使用、特征描述、逻辑推理和评估技能方面有所提高,对决策过程及其局限性有了更深的理解。此外,该方法受到学生的欢迎,尤其是那些将人工智能概念与现实生活相结合的活动。
Key Takeaways:
- 早期AI素养教育对年轻一代理解和应对智能技术至关重要。
- 当前教育领域在AI教育上过于强调工具使用,忽视基础概念的理解。
- 提议采用结构化、可复制的教学方法培养小学生AI素养。
- 通过小学数学的核心元素来教授AI,强化概念化、数据表示、分类推理和AI评估技能。
- 实证研究证明该方法能提高学生AI术语的理解和使用、特征描述、逻辑推理和评估技能。
- 学生能更深入地理解AI决策过程及其局限性。
- 该教学方法受到学生的欢迎,尤其是与现实生活相结合的活动。
点此查看论文截图


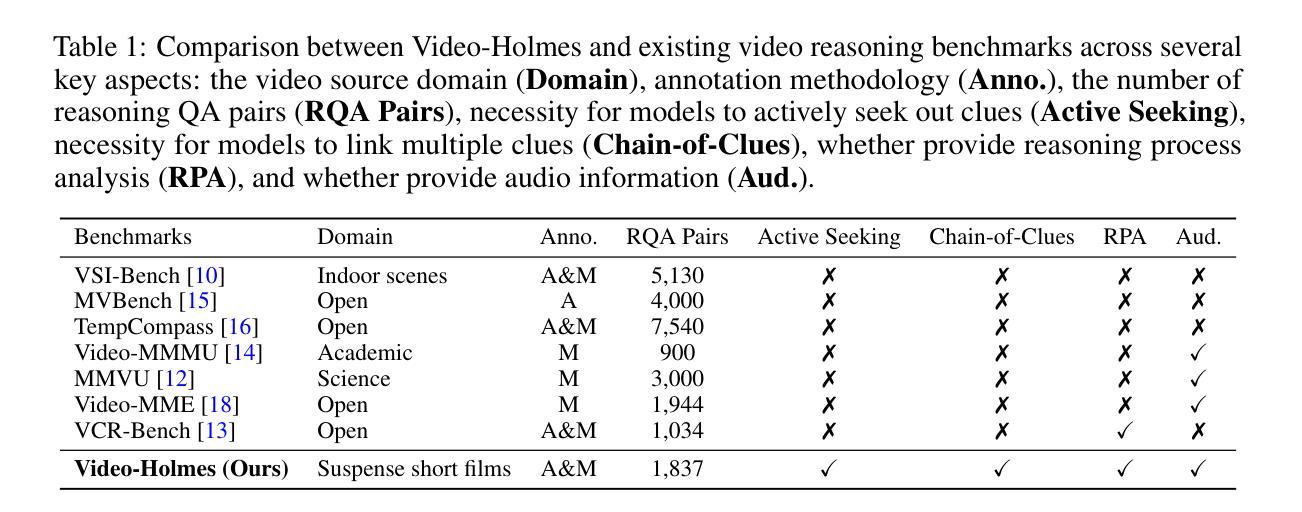
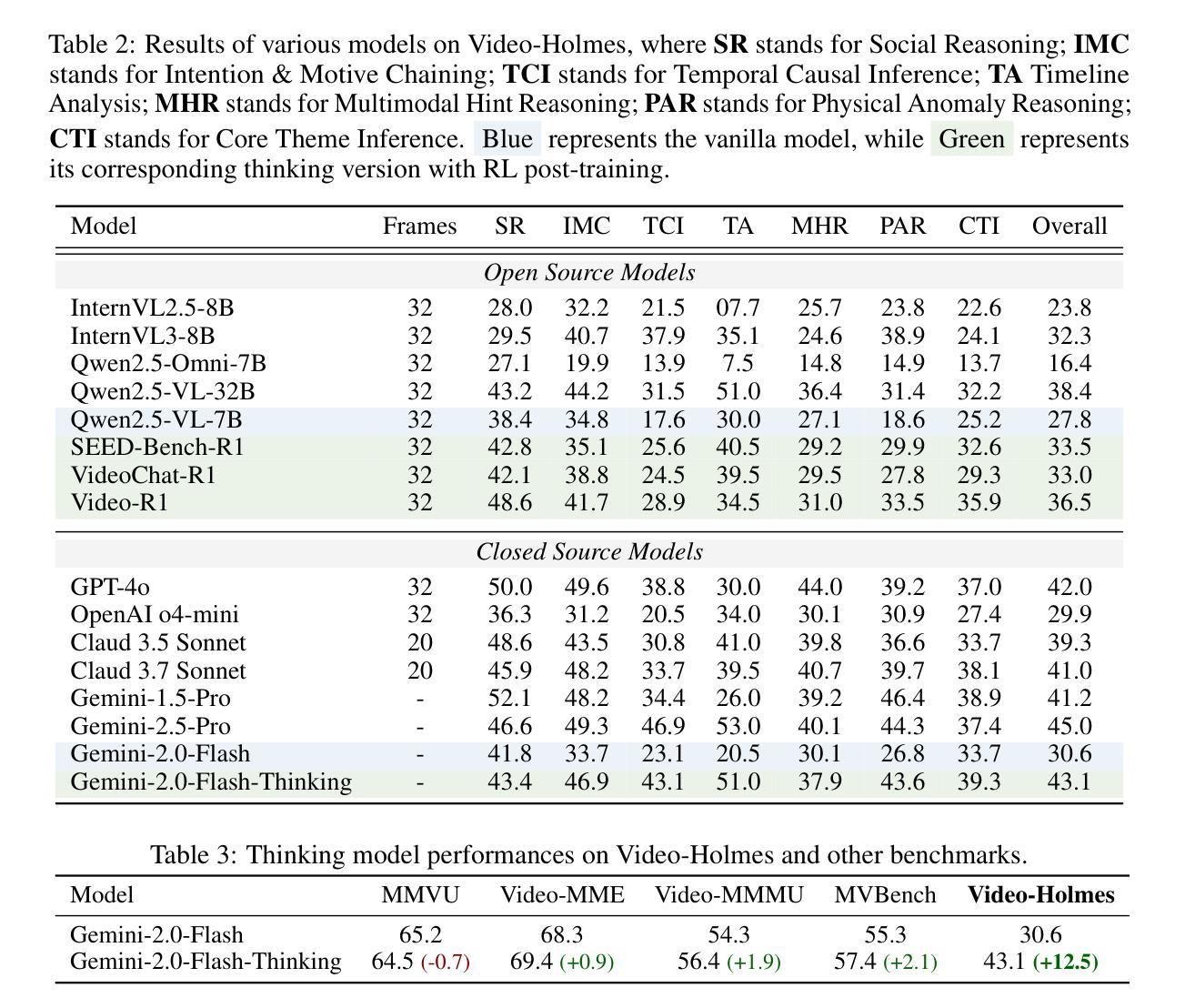
Video-Holmes: Can MLLM Think Like Holmes for Complex Video Reasoning?
Authors:Junhao Cheng, Yuying Ge, Teng Wang, Yixiao Ge, Jing Liao, Ying Shan
Recent advances in CoT reasoning and RL post-training have been reported to enhance video reasoning capabilities of MLLMs. This progress naturally raises a question: can these models perform complex video reasoning in a manner comparable to human experts? However, existing video benchmarks primarily evaluate visual perception and grounding abilities, with questions that can be answered based on explicit prompts or isolated visual cues. Such benchmarks do not fully capture the intricacies of real-world reasoning, where humans must actively search for, integrate, and analyze multiple clues before reaching a conclusion. To address this issue, we present Video-Holmes, a benchmark inspired by the reasoning process of Sherlock Holmes, designed to evaluate the complex video reasoning capabilities of MLLMs. Video-Holmes consists of 1,837 questions derived from 270 manually annotated suspense short films, which spans seven carefully designed tasks. Each task is constructed by first identifying key events and causal relationships within films, and then designing questions that require models to actively locate and connect multiple relevant visual clues scattered across different video segments. Our comprehensive evaluation of state-of-the-art MLLMs reveals that, while these models generally excel at visual perception, they encounter substantial difficulties with integrating information and often miss critical clues. For example, the best-performing model, Gemini-2.5-Pro, achieves an accuracy of only 45%, with most models scoring below 40%. We aim that Video-Holmes can serve as a “Holmes-test” for multimodal reasoning, motivating models to reason more like humans and emphasizing the ongoing challenges in this field. The benchmark is released in https://github.com/TencentARC/Video-Holmes.
最近报道了认知推理(CoT)和强化学习(RL)后训练在增强大型多模态语言模型(MLLMs)的视频推理能力方面的进展。这一进展自然引发了一个问题:这些模型能否以与人类专家相当的方式进行复杂的视频推理?然而,现有的视频基准测试主要评估视觉感知和定位能力,问题可以基于明确的提示或孤立的视觉线索来回答。这样的基准测试并不能完全捕捉到现实世界推理的复杂性,其中人类必须在得出结论之前积极寻找、整合和分析多个线索。为了解决这一问题,我们推出了Video-Holmes基准测试,该测试以福尔摩斯侦探的推理过程为灵感,旨在评估大型多模态语言模型的复杂视频推理能力。Video-Holmes包含从精心挑选的270部悬疑短片中衍生出的1837个问题,涵盖了七个精心设计的任务。每个任务首先识别电影中的关键事件和因果关系,然后设计问题,要求模型主动定位并连接散布在不同视频片段中的多个相关视觉线索。我们对最先进的MLLMs的综合评估表明,虽然这些模型在视觉感知方面表现出色,但在整合信息和经常遗漏关键线索方面遇到了很大的困难。例如,表现最佳的模型Gemini-2.5 Pro准确率仅为45%,大多数模型的得分低于40%。我们希望通过Video-Holmes作为多模态推理的“福尔摩斯测试”,激励模型像人类一样进行推理,并强调这一领域的持续挑战。该基准测试已在https://github.com/TencentARC/Video-Holmes发布。
论文及项目相关链接
PDF Homepage: https://github.com/TencentARC/Video-Holmes
Summary
视频推理能力在多媒体大型语言模型(MLLMs)中逐渐受到关注。为评估模型的复杂视频推理能力,推出了Video-Holmes基准测试。该测试从270部悬疑短片中手动标注了关键事件和因果关系,设计了包含七大任务的问题集。尽管模型在视觉感知方面表现出色,但在整合信息和寻找关键线索方面存在困难。最好的模型准确率仅为45%,大多数模型得分低于40%。Video-Holmes旨在为多媒体推理提供一个“霍姆斯测试”,强调模型需要像人类一样进行推理,并突出这一领域的挑战。该基准测试已在GitHub上发布。
Key Takeaways
- Video-Holmes是一个旨在评估多媒体大型语言模型(MLLMs)复杂视频推理能力的基准测试。
- 测试包含从悬疑短片中手动标注的七大任务,涉及关键事件和因果关系的识别。
- 尽管模型在视觉感知方面表现出色,但在整合信息和寻找关键线索方面存在困难。
- 目前最好的模型在Video-Holmes上的准确率为45%,大多数模型得分低于此。
- Video-Holmes旨在作为多媒体推理的“霍姆斯测试”,鼓励模型像人类一样进行推理。
- 此基准测试的发布强调了多媒体推理领域的挑战和发展需求。
点此查看论文截图



Leveraging Large Language Models for Bengali Math Word Problem Solving with Chain of Thought Reasoning
Authors:Bidyarthi Paul, Jalisha Jashim Era, Mirazur Rahman Zim, Tahmid Sattar Aothoi, Faisal Muhammad Shah
Solving Bengali Math Word Problems (MWPs) remains a major challenge in natural language processing (NLP) due to the language’s low-resource status and the multi-step reasoning required. Existing models struggle with complex Bengali MWPs, largely because no human-annotated Bengali dataset has previously addressed this task. This gap has limited progress in Bengali mathematical reasoning. To address this, we created SOMADHAN, a dataset of 8792 complex Bengali MWPs with manually written, step-by-step solutions. We designed this dataset to support reasoning-focused evaluation and model development in a linguistically underrepresented context. Using SOMADHAN, we evaluated a range of large language models (LLMs) - including GPT-4o, GPT-3.5 Turbo, LLaMA series models, Deepseek, and Qwen - through both zero-shot and few-shot prompting with and without Chain of Thought (CoT) reasoning. CoT prompting consistently improved performance over standard prompting, especially in tasks requiring multi-step logic. LLaMA-3.3 70B achieved the highest accuracy of 88% with few-shot CoT prompting. We also applied Low-Rank Adaptation (LoRA) to fine-tune models efficiently, enabling them to adapt to Bengali MWPs with minimal computational cost. Our work fills a critical gap in Bengali NLP by providing a high-quality reasoning dataset and a scalable framework for solving complex MWPs. We aim to advance equitable research in low-resource languages and enhance reasoning capabilities in educational and language technologies.
解决孟加拉数学文字题(MWPs)仍然是自然语言处理(NLP)领域的一个主要挑战,这是由于孟加拉语的资源相对较少以及需要多步骤推理。现有模型在处理复杂的孟加拉数学文字题时面临困难,很大程度上是因为之前没有人对孟加拉数据集进行标注来解决此任务。这一差距限制了孟加拉数学推理的进展。为了解决这个问题,我们创建了SOMADHAN数据集,其中包含8792个复杂的孟加拉数学文字题以及手动编写的逐步解决方案。我们设计这个数据集是为了支持在语言表示不足的情境中进行推理评估导向和模型开发。使用SOMADHAN数据集,我们评估了一系列大型语言模型(LLM),包括GPT-4o、GPT-3.5 Turbo、LLaMA系列模型、Deepseek和Qwen等,通过零样本和少样本提示以及有无思维链(CoT)推理进行测试。思维链提示一致地提高了性能,尤其是在需要多步骤逻辑的任务中。LLaMA-3.3 70B在少样本思维链提示下取得了最高的准确率,达到88%。我们还应用了低秩适应(LoRA)技术来高效微调模型,使它们能够适应孟加拉数学文字题并具有最小的计算成本。我们的工作通过提供高质量推理数据集和解决复杂数学文字题的可扩展框架来填补孟加拉NLP领域的空白。我们的目标是推动低资源语言的公平研究,并提升教育和语言技术中的推理能力。
论文及项目相关链接
Summary
本文介绍了解决孟加拉数学文字题(MWPs)的挑战,指出由于孟加拉语的资源匮乏和多步骤推理的需求,现有模型难以应对复杂问题。为应对这一挑战,创建了SOMADHAN数据集,包含8792个复杂的孟加拉数学文字题和手动编写的逐步解答。该数据集旨在支持语言代表性不足的情境中的推理评估模型发展。通过一系列大型语言模型的评估,发现链式思维(CoT)提示在解决需要多步骤逻辑的问题时表现卓越。LLaMA-3.3 70B通过有限的计算成本使用LoRA技术实现较高的准确度。该研究填补了孟加拉语自然语言处理的空白,提供了高质量的推理数据集和复杂的文字题解决框架。目标是推动低资源语言的均衡研究,提高教育和语言技术的推理能力。
Key Takeaways
- 孟加拉数学文字题处理是自然语言处理中的一大挑战,主要由于孟加拉语的资源匮乏和多步骤推理需求。
- SOMADHAN数据集包含复杂孟加拉数学文字题及其手动逐步解答,旨在支持语言代表性不足的情境中的推理评估模型发展。
- 链式思维(CoT)提示在解决需要多步骤逻辑的问题时表现卓越。
- LLaMA-3.3 70B通过结合CoT提示和LoRA技术实现较高的准确度。
- LoRA技术用于高效地微调模型,使其能够适应孟加拉数学文字题,同时保持较低的计算成本。
- 该研究填补了孟加拉语自然语言处理的空白,提供了一个重要的数据集和框架来解决复杂的数学文字题。
点此查看论文截图


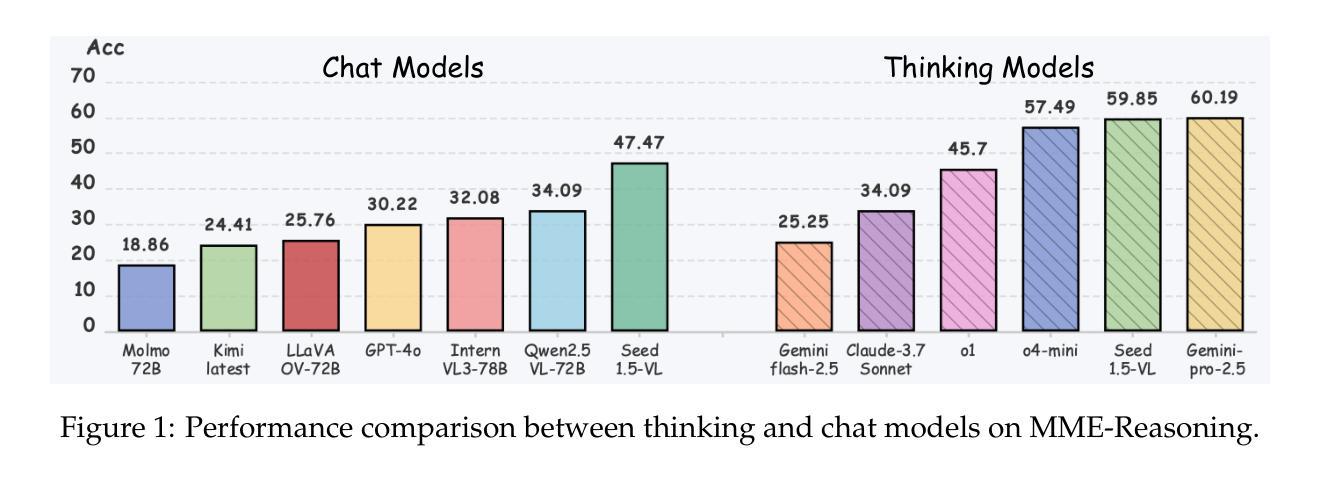
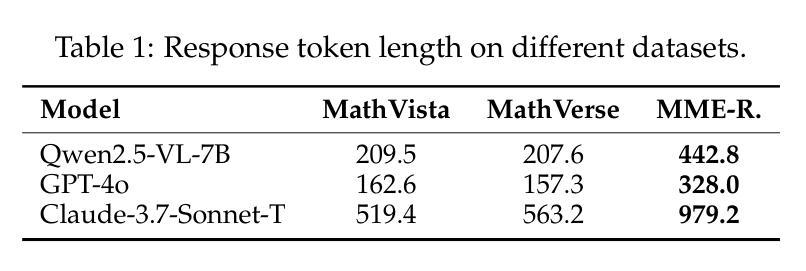
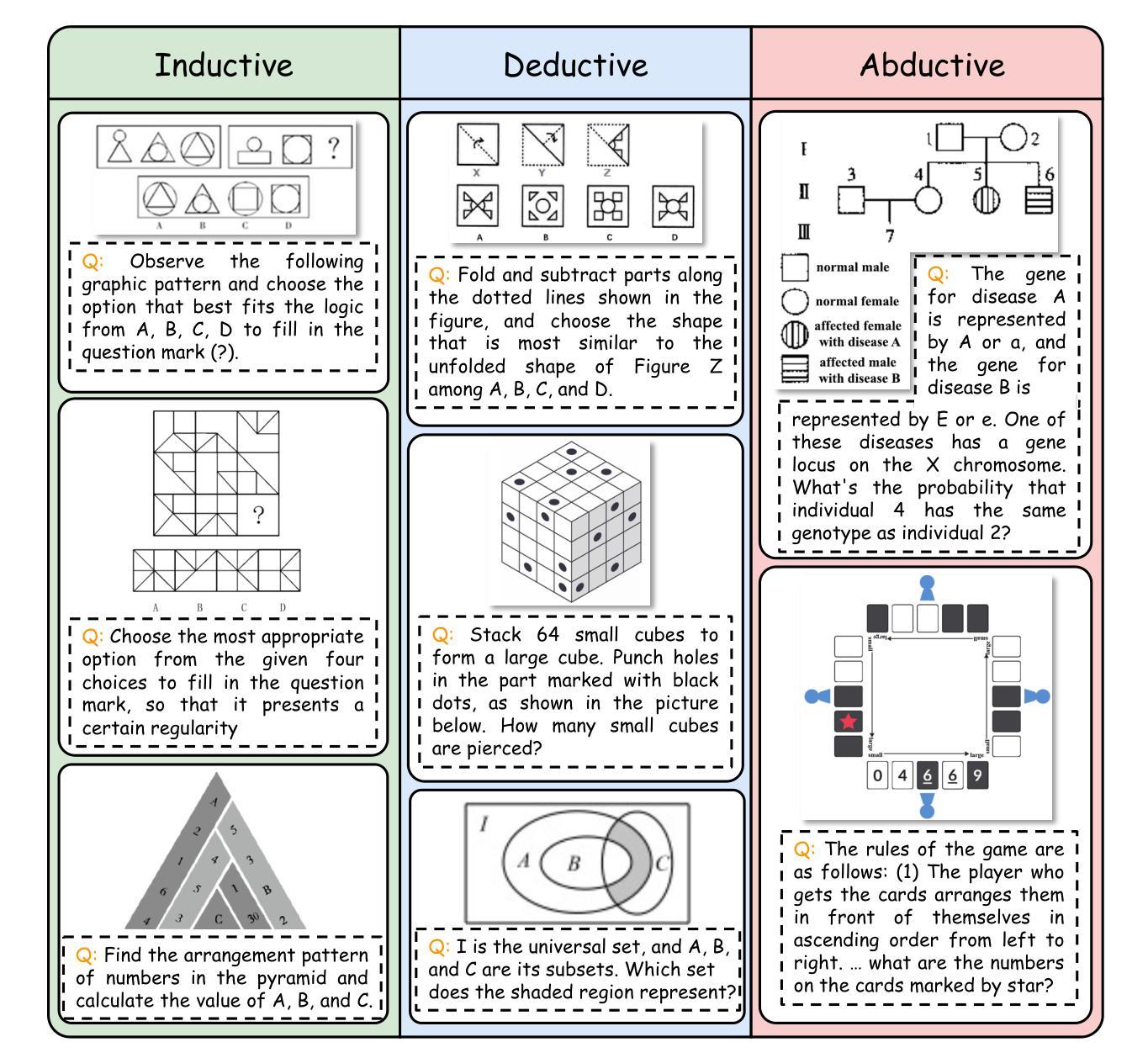
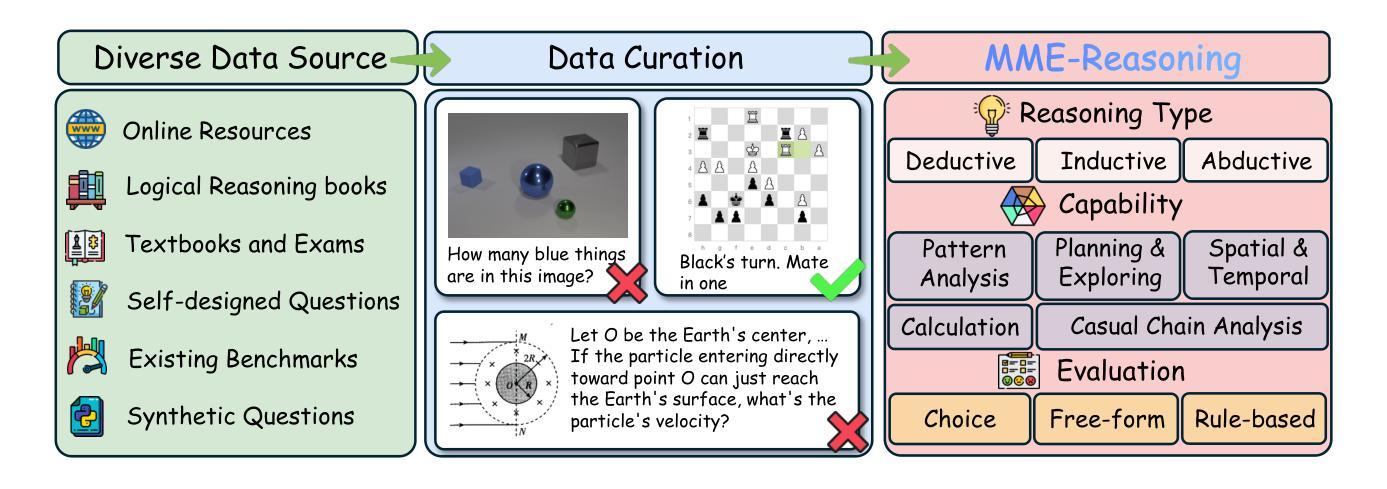
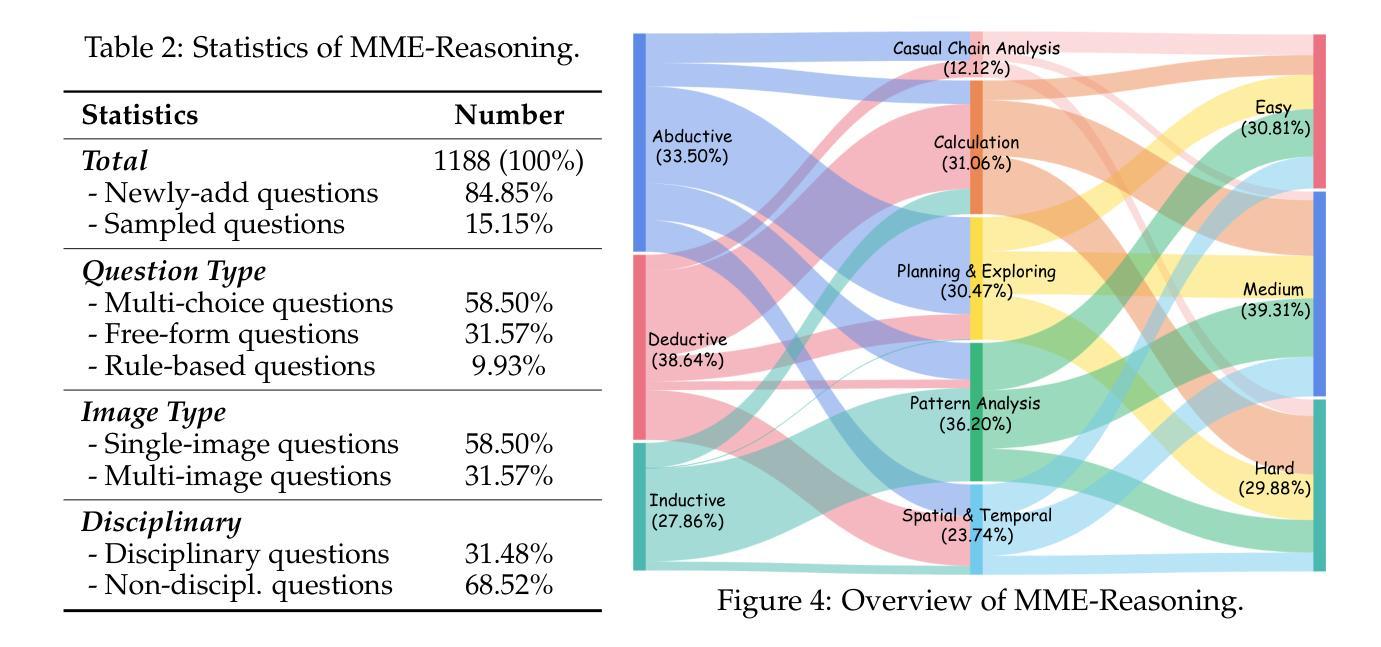
MME-Reasoning: A Comprehensive Benchmark for Logical Reasoning in MLLMs
Authors:Jiakang Yuan, Tianshuo Peng, Yilei Jiang, Yiting Lu, Renrui Zhang, Kaituo Feng, Chaoyou Fu, Tao Chen, Lei Bai, Bo Zhang, Xiangyu Yue
Logical reasoning is a fundamental aspect of human intelligence and an essential capability for multimodal large language models (MLLMs). Despite the significant advancement in multimodal reasoning, existing benchmarks fail to comprehensively evaluate their reasoning abilities due to the lack of explicit categorization for logical reasoning types and an unclear understanding of reasoning. To address these issues, we introduce MME-Reasoning, a comprehensive benchmark designed to evaluate the reasoning ability of MLLMs, which covers all three types of reasoning (i.e., inductive, deductive, and abductive) in its questions. We carefully curate the data to ensure that each question effectively evaluates reasoning ability rather than perceptual skills or knowledge breadth, and extend the evaluation protocols to cover the evaluation of diverse questions. Our evaluation reveals substantial limitations of state-of-the-art MLLMs when subjected to holistic assessments of logical reasoning capabilities. Even the most advanced MLLMs show limited performance in comprehensive logical reasoning, with notable performance imbalances across reasoning types. In addition, we conducted an in-depth analysis of approaches such as ``thinking mode’’ and Rule-based RL, which are commonly believed to enhance reasoning abilities. These findings highlight the critical limitations and performance imbalances of current MLLMs in diverse logical reasoning scenarios, providing comprehensive and systematic insights into the understanding and evaluation of reasoning capabilities.
逻辑推理是人类智能的一个基本方面,也是多模态大型语言模型(MLLMs)的核心能力。尽管多模态推理取得了重大进展,但由于缺乏明确的逻辑推理类型分类和对推理的清晰理解,现有的基准测试未能全面评估它们的推理能力。为了解决这些问题,我们推出了MME-Reasoning,这是一个旨在评估MLLMs推理能力的全面基准测试,其问题涵盖了三种推理类型(即归纳推理、演绎推理和溯因推理)。我们精心筛选数据,以确保每个问题都能有效地评估推理能力,而不是感知能力或知识广度,并扩展评估协议以涵盖对不同问题的评估。我们的评估显示,当进行全面的逻辑推理能力评估时,最先进的多模态大型语言模型存在重大局限性。即使是最先进的MLLMs在综合逻辑推理方面的表现也有限,不同推理类型之间的性能不平衡现象尤为突出。此外,我们对一些普遍认为能增强推理能力的方法(如“思考模式”和基于规则的强化学习)进行了深入分析。这些发现突显了当前多模态大型语言模型在不同逻辑推理场景中的关键局限性和性能不平衡问题,为理解和评估推理能力提供了全面和系统的见解。
论文及项目相关链接
Summary:
推出一个评估多模态大型语言模型(MLLMs)推理能力的新基准——MME-Reasoning,涵盖了归纳、演绎和溯因三种推理类型的问题。对现有MLLMs的推理能力进行了全面评估,发现仍存在显著局限和性能不均衡的问题。深入分析了一些提升推理能力的常用方法,如“思考模式”和基于规则的强化学习等。此研究揭示了MLLMs在多样逻辑推理场景下的关键局限和性能不均衡问题,为理解和评估推理能力提供了全面系统的见解。
Key Takeaways:
- MME-Reasoning基准被推出,旨在全面评估MLLMs的推理能力,包括归纳、演绎和溯因推理。
- 现有MLLMs在逻辑推理能力方面存在显著局限性。
- 即使在最先进的MLLMs中,推理能力的表现也不均衡,特别是在不同类型的推理之间。
- 深入分析了增强MLLMs推理能力的常用方法。
- 研究揭示了MLLMs在多样逻辑推理场景下的关键局限。
- 此研究为理解和评估MLLMs的推理能力提供了全面系统的见解。
点此查看论文截图

rStar-Coder: Scaling Competitive Code Reasoning with a Large-Scale Verified Dataset
Authors:Yifei Liu, Li Lyna Zhang, Yi Zhu, Bingcheng Dong, Xudong Zhou, Ning Shang, Fan Yang, Mao Yang
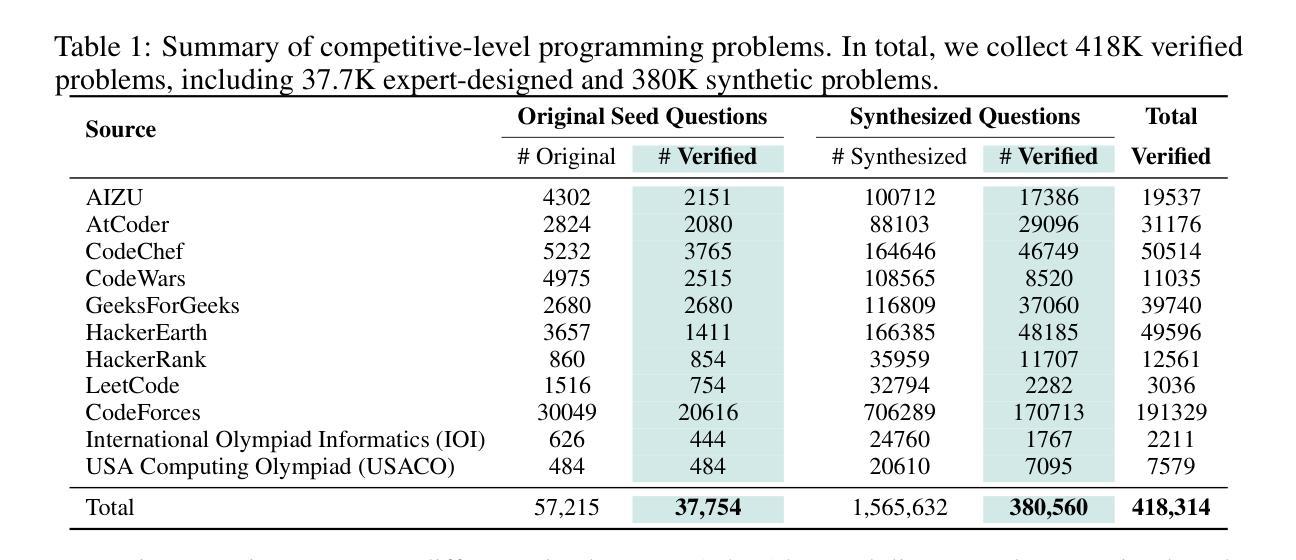
Advancing code reasoning in large language models (LLMs) is fundamentally limited by the scarcity of high-difficulty datasets, especially those with verifiable input-output test cases necessary for rigorous solution validation at scale. We introduce rStar-Coder, which significantly improves LLM code reasoning capabilities by constructing a large-scale, verified dataset of 418K competition-level code problems, 580K long-reasoning solutions along with rich test cases of varying difficulty. This is achieved through three core contributions: (1) we curate competitive programming code problems and oracle solutions to synthesize new, solvable problems; (2) we introduce a reliable input-output test case synthesis pipeline that decouples the generation into a three-step input generation method and a mutual verification mechanism for effective output labeling; (3) we augment problems with high-quality, test-case-verified long-reasoning solutions. Extensive experiments on Qwen models (1.5B-14B) across various code reasoning benchmarks demonstrate the superiority of rStar-Coder dataset, achieving leading performance comparable to frontier reasoning LLMs with much smaller model sizes. On LiveCodeBench, rStar-Coder improves Qwen2.5-7B from 17.4% to an impressive 57.3%, and Qwen2.5-14B from 23.3% to 62.5%, surpassing o3-mini (low) by3.1%. On the more challenging USA Computing Olympiad, our 7B model achieves an average pass@1 accuracy of 16.15%, outperforming the frontier-level QWQ-32B. Code and the dataset will be released at https://github.com/microsoft/rStar.
推动大型语言模型(LLM)中的代码推理能力,从根本上受限于高质量数据集的稀缺性,尤其是那些具有可验证的输入输出测试用例,这些用例对于大规模严格解决方案验证是必不可少的。我们引入了rStar-Coder,它通过构建包含41.8万个竞赛级代码问题、58万个长期推理解决方案以及不同难度丰富的测试用例的大规模验证数据集,显著提高了LLM的代码推理能力。这是通过三个核心贡献实现的:(1)我们精选竞赛编程代码问题和标准解决方案,合成新的可解决问题;(2)我们引入了一个可靠的输入输出测试用例合成管道,将生成解耦为三步输入生成方法和有效的输出标签互验证机制;(3)我们为问题增加了高质量、测试用例验证的长期推理解决方案。在Qwen模型(1.5B-14B)上的广泛实验,以及各种代码推理基准测试表明,rStar-Coder数据集具有卓越性,其性能领先,甚至在一些较小的模型大小方面也达到了前沿推理LLM的水平。在LiveCodeBench上,rStar-Coder将Qwen2.5-7B的性能从17.4%提高到令人印象深刻的57.3%,将Qwen2.5-14B的性能从23.3%提高到62.5%,超过了o3-mini (low) 3.1%。在更具挑战性的美国计算奥林匹克竞赛中,我们的7B模型平均pass@1准确率达到了16.15%,超越了前沿的QWQ-32B。代码和数据集将在https://github.com/microsoft/rStar上发布。
简化翻译
论文及项目相关链接
Summary
文本介绍了微软推出的rStar-Coder数据集,它通过构建大规模验证数据集显著提高了LLM的代码推理能力。数据集包含41.8万个竞赛级别的代码问题,以及丰富的测试用例和验证过的长推理解决方案。rStar-Coder通过三个核心贡献实现这一目标:从竞争性编程中筛选问题和解决方案合成新问题;引入可靠的输入-输出测试用例合成管道;为问题提供高质量、测试案例验证的长推理解决方案。实验证明,rStar-Coder数据集在多个代码推理基准测试中表现优越。
Key Takeaways
- rStar-Coder通过构建大规模验证数据集提升了LLM的代码推理能力。
- 数据集包含超过41.8万个竞赛级别的代码问题,涵盖丰富的测试用例和验证过的长推理解决方案。
- rStar-Coder通过三个核心方法实现性能提升:筛选竞赛级编程问题、合成新的测试用例,并为这些问题提供可靠验证的长推理解决方案。
- 实验表明,rStar-Coder在各种代码推理基准测试中表现领先。在特定基准测试中,它比最前沿的推理LLM表现更为出色。它尤其能显著提高小型模型的性能。例如,在LiveCodeBench上,模型性能从不到四分之一提高到超过一半。在美国计算奥林匹竞赛上,一个中等规模的模型表现出强大的性能,平均准确率超过百分之十六点一五,超过了最前沿的大型模型。
点此查看论文截图




Walk Before You Run! Concise LLM Reasoning via Reinforcement Learning
Authors:Mingyang Song, Mao Zheng
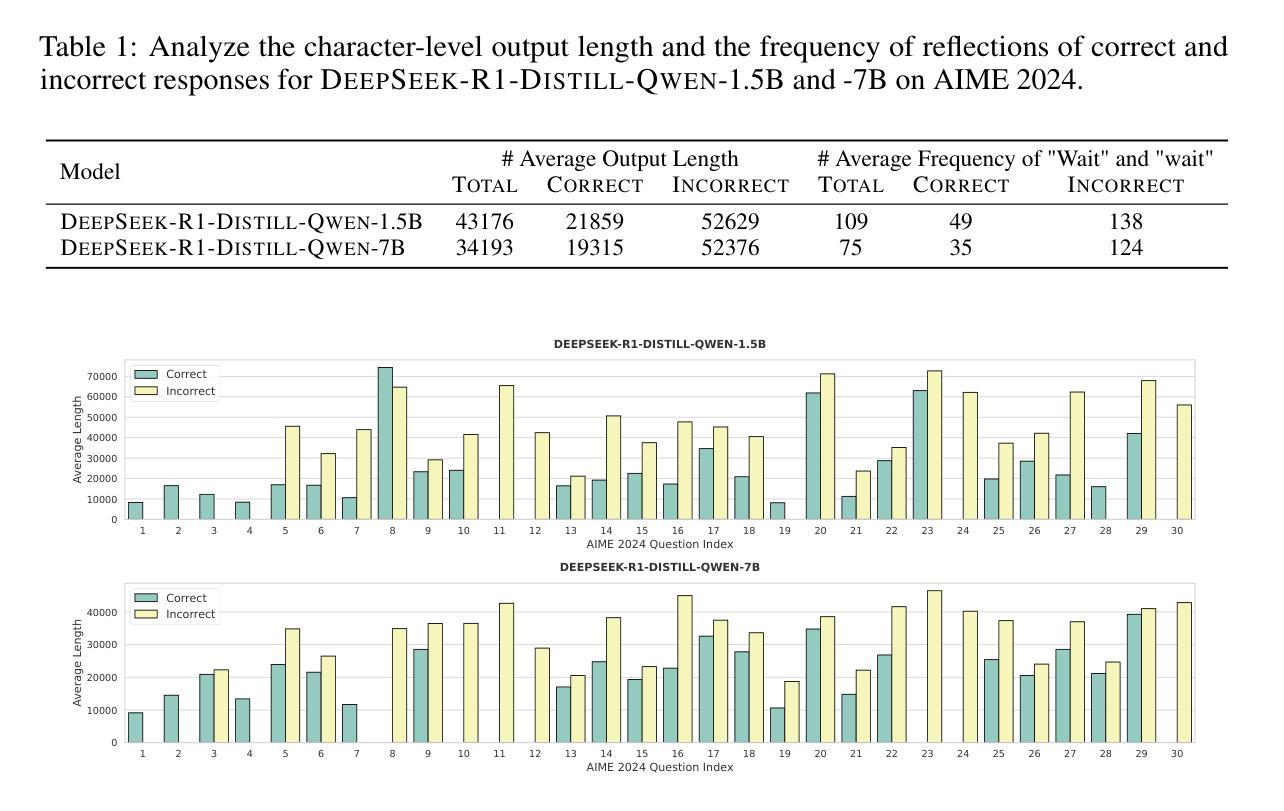
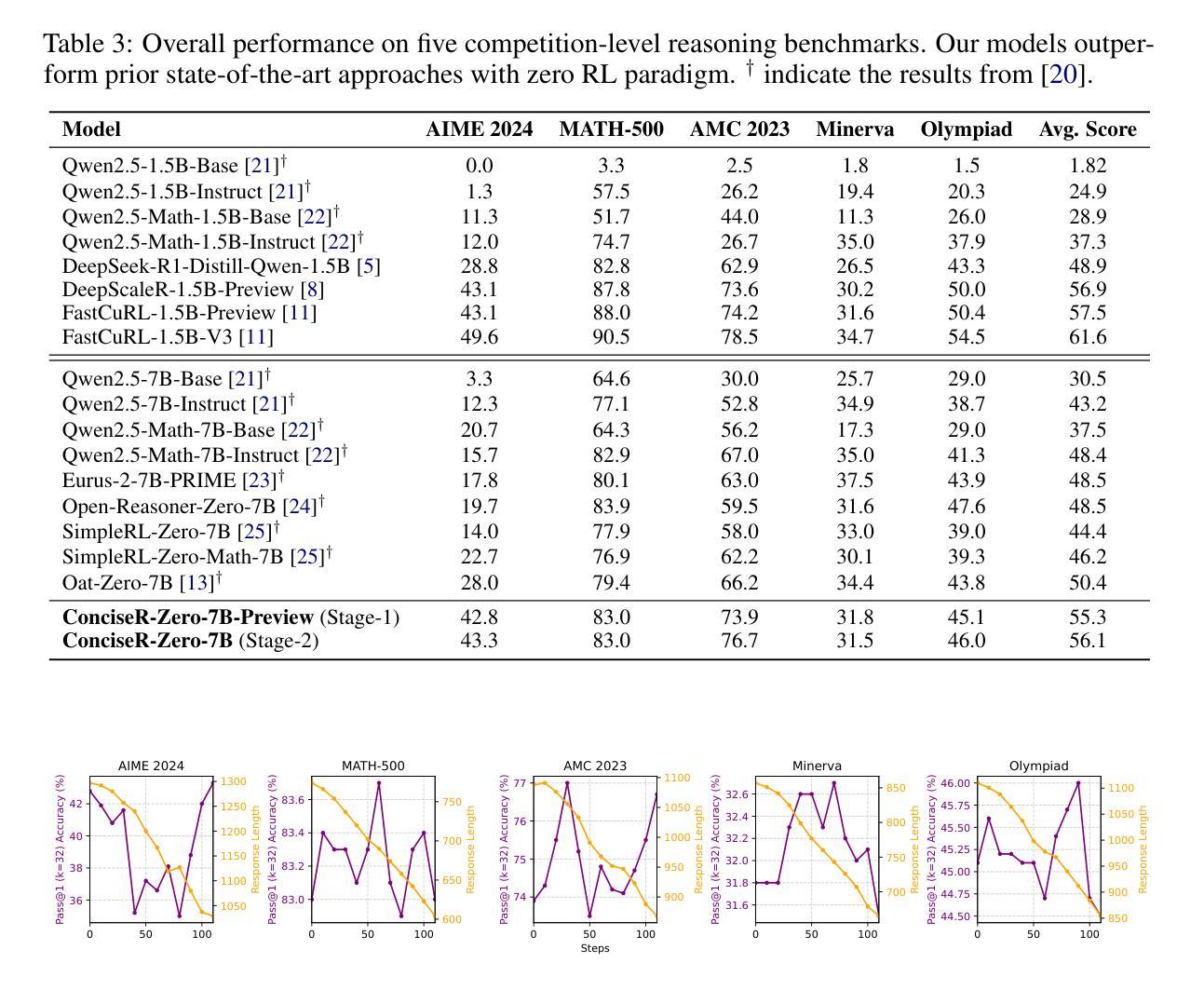
As test-time scaling becomes a pivotal research frontier in Large Language Models (LLMs) development, contemporary and advanced post-training methodologies increasingly focus on extending the generation length of long Chain-of-Thought (CoT) responses to enhance reasoning capabilities toward DeepSeek R1-like performance. However, recent studies reveal a persistent overthinking phenomenon in state-of-the-art reasoning models, manifesting as excessive redundancy or repetitive thinking patterns in long CoT responses. To address this issue, in this paper, we propose a simple yet effective two-stage reinforcement learning framework for achieving concise reasoning in LLMs, named ConciseR. Specifically, the first stage, using more training steps, aims to incentivize the model’s reasoning capabilities via Group Relative Policy Optimization with clip-higher and dynamic sampling components (GRPO++), and the second stage, using fewer training steps, explicitly enforces conciseness and improves efficiency via Length-aware Group Relative Policy Optimization (L-GRPO). Significantly, ConciseR only optimizes response length once all rollouts of a sample are correct, following the “walk before you run” principle. Extensive experimental results demonstrate that our ConciseR model, which generates more concise CoT reasoning responses, outperforms recent state-of-the-art reasoning models with zero RL paradigm across AIME 2024, MATH-500, AMC 2023, Minerva, and Olympiad benchmarks.
随着测试时缩放成为大型语言模型(LLM)发展的核心研究前沿,当代先进的后训练方法论越来越关注扩展长思维链(CoT)响应的生成长度,以提高向DeepSeek R1等性能的推理能力。然而,最近的研究表明,最先进的推理模型中存在一种持续过度思考的现象,表现为长CoT响应中的过度冗余或重复思考模式。为了解决这一问题,本文提出了一种简单有效的两阶段强化学习框架,用于在LLM中实现简洁推理,名为ConciseR。具体来说,第一阶段使用更多的训练步骤,旨在通过带有剪辑更高和动态采样组件的群组相对策略优化(GRPO++)来激励模型的推理能力;第二阶段使用较少的训练步骤,通过长度感知群组相对策略优化(L-GRPO)明确强调简洁性并提高效率。值得注意的是,ConciseR仅在样本所有rollouts都正确的情况下优化响应长度,遵循“走在你跑之前”的原则。广泛的实验结果表明,我们的ConciseR模型生成了更简洁的CoT推理响应,在AIME 2024、MATH-500、AMC 2023、Minerva和Olympiad等多个基准测试中,超越了无强化学习范式下的最新先进推理模型。
论文及项目相关链接
PDF Ongoing Work
Summary
本文探讨了在大型语言模型(LLM)发展中,测试时缩放技术的重要性。针对当前先进的训练后方法在提高推理能力时产生的过度思考现象,本文提出了一种简单有效的两阶段强化学习框架ConciseR。第一阶段通过集团相对策略优化(GRPO++)激励模型的推理能力,第二阶段通过长度感知集团相对策略优化(L-GRPO)促进简洁性和效率。实验结果表明,ConciseR模型在AIME 2024、MATH-500、AMC 2023、Minerva和Olympiad等多个基准测试中优于最近的先进推理模型。
Key Takeaways
- 大型语言模型(LLM)的发展中,测试时缩放技术是关键的研究前沿。
- 当代先进的训练后方法致力于通过扩展生成长度来提高Chain-of-Thought(CoT)响应的推理能力。
- 在CoT响应中出现了过度思考现象,表现为冗余或重复思考模式。
- 提出了一种新的强化学习框架ConciseR来解决这一问题。
- ConciseR分为两个阶段:第一阶段激励模型的推理能力,第二阶段促进简洁性和效率。
- ConciseR只在所有样本的所有rollout正确后优化响应长度,遵循“先走再跑”的原则。
点此查看论文截图


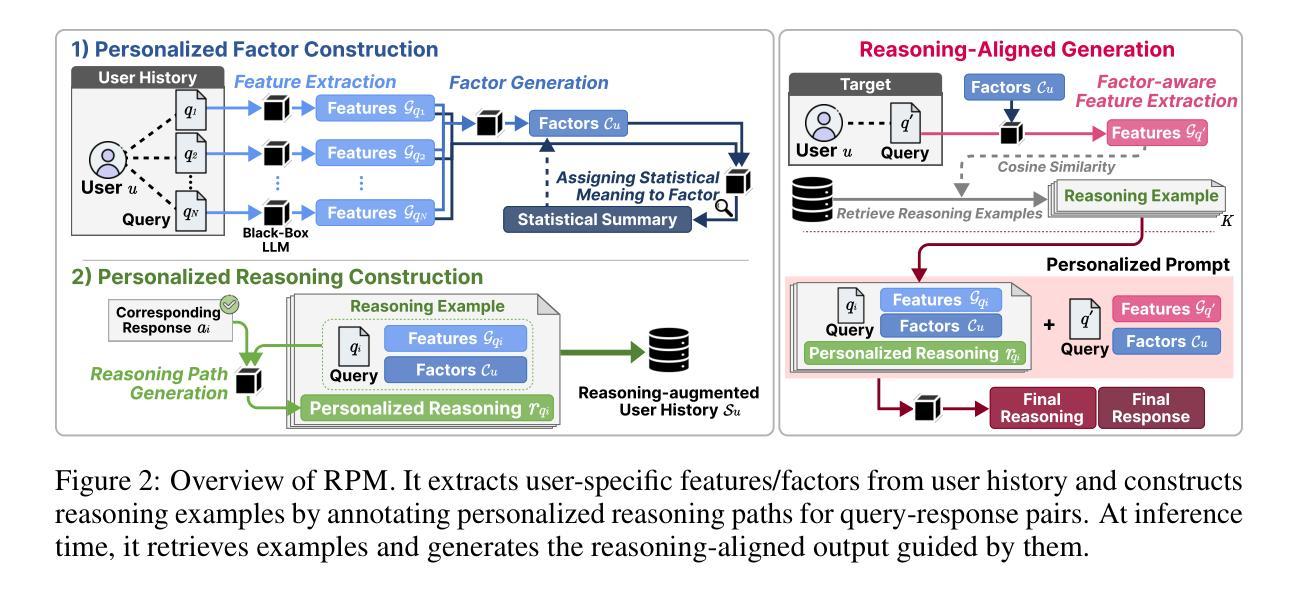
LLMs Think, But Not In Your Flow: Reasoning-Level Personalization for Black-Box Large Language Models
Authors:Jieyong Kim, Tongyoung Kim, Soonjin Yoon, Jaehyung Kim, Dongha Lee
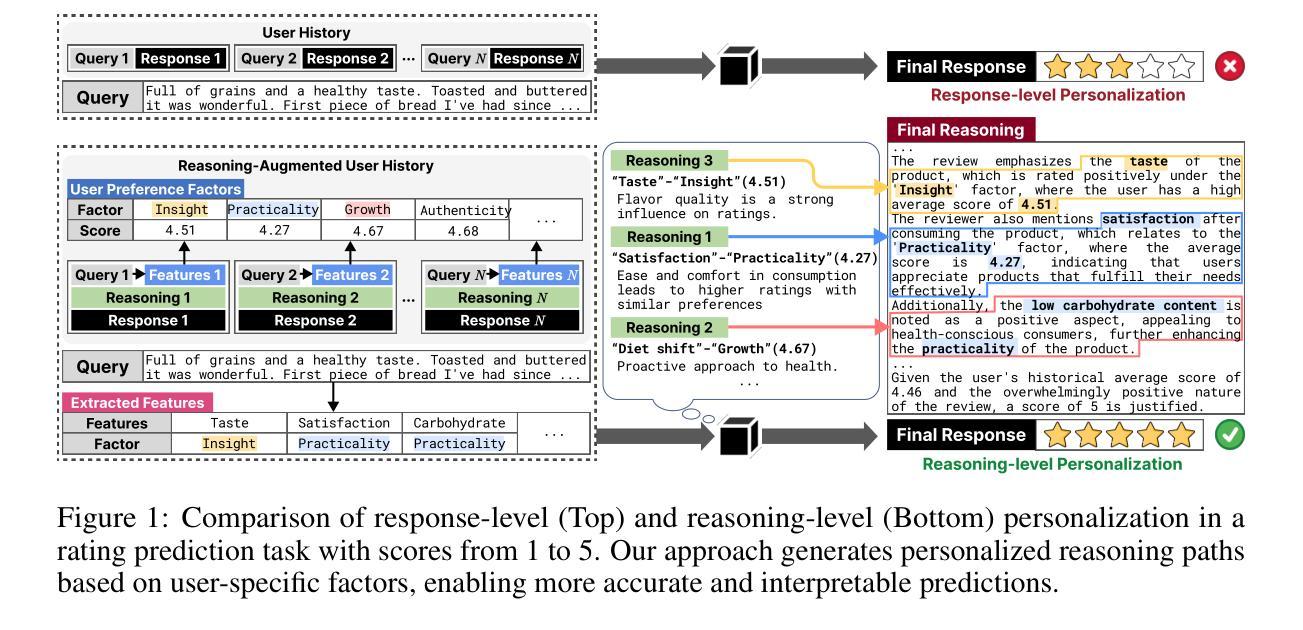
Large language models (LLMs) have recently achieved impressive performance across a wide range of natural language tasks and are now widely used in real-world applications. Among them, black-box LLMs–served via APIs without access to model internals–are especially dominant due to their scalability and ease of deployment. Despite their strong capabilities, these models typically produce generalized responses that overlook personal preferences and reasoning styles. This has led to growing interest in black-box LLM personalization, which aims to tailor model outputs to user-specific context without modifying model parameters. However, existing approaches primarily focus on response-level personalization, attempting to match final outputs without modeling personal thought process. To address this limitation, we propose RPM, a framework for reasoning-level personalization that aligns the model’s reasoning process with a user’s personalized logic. RPM first constructs statistical user-specific factors by extracting and grouping response-influential features from user history. It then builds personalized reasoning paths that reflect how these factors are used in context. In the inference stage, RPM retrieves reasoning-aligned examples for new queries via feature-level similarity and performs inference conditioned on the structured factors and retrieved reasoning paths, enabling the model to follow user-specific reasoning trajectories. This reasoning-level personalization enhances both predictive accuracy and interpretability by grounding model outputs in user-specific logic through structured information. Extensive experiments across diverse tasks show that RPM consistently outperforms response-level personalization methods, demonstrating the effectiveness of reasoning-level personalization in black-box LLMs.
大型语言模型(LLM)最近在多种自然语言任务中取得了令人印象深刻的性能,并现在广泛应用于实际世界应用。其中,黑盒LLM(通过API提供服务,无法访问模型内部)由于其可扩展性和易于部署的特点而尤其占据主导地位。尽管这些模型具有强大的能力,但它们通常会产生忽略个人偏好和推理风格的通用响应。这引发了人们对黑盒LLM个性化的兴趣不断增长,其目标是针对用户特定上下文定制模型输出,而不修改模型参数。然而,现有方法主要侧重于响应级个性化,试图匹配最终输出,而没有对个人的思考过程进行建模。为了解决这一局限性,我们提出了RPM,一个用于推理级个性化的框架,它将模型的推理过程与用户个性化的逻辑对齐。RPM首先通过从用户历史中提取和分组影响响应的特征来构建用户特定的统计因素。然后,它建立反映这些因子如何在上下文中使用的个性化推理路径。在推理阶段,RPM通过特征级别的相似性检索与新查询相匹配的推理对齐示例,并在结构化因素和检索到的推理路径的条件下进行推理,使模型能够遵循用户特定的推理轨迹。这种推理级个性化通过结构化信息将模型输出根植于用户特定的逻辑中,提高了预测准确性和可解释性。在多种任务上的广泛实验表明,RPM始终优于响应级个性化方法,证明了在黑盒LLM中进行推理级个性化的有效性。
论文及项目相关链接
Summary
大型语言模型(LLM)在多种自然语言任务中表现出卓越性能,并在实际应用中广泛使用。其中,黑盒LLM(通过API提供服务,无法访问模型内部)因其可扩展性和易于部署的特点尤其占据主导地位。然而,这些模型通常产生忽略个人偏好和推理风格的通用响应。为解决这一问题,提出了RPM框架,实现推理级个性化,使模型推理过程与用户个性化逻辑相匹配。RPM通过提取和分组用户历史中的响应影响因素来构建用户特定因素,并建立反映这些因素如何在上下文中使用的个性化推理路径。在推理阶段,RPM通过特征级别相似性检索与推理相匹配的示例,并在结构化因素和检索到的推理路径上进行推理,使模型遵循用户特定的推理轨迹。这种推理级个性化通过结构化信息提高预测准确性和可解释性,使模型输出根植于用户特定逻辑。
Key Takeaways
- 大型语言模型(LLM)在自然语言任务中表现优异,并在实际应用中广泛应用。
- 黑盒LLM因其可扩展性和易于部署而尤为受欢迎,但缺乏个性化响应。
- 现有方法主要关注响应级个性化,尝试匹配最终输出,但未建模个人思维过程。
- 提出RPM框架实现推理级个性化,与用户的个性化逻辑相匹配。
- RPM构建用户特定因素并建立个性化推理路径,反映用户历史中的响应影响因素和上下文使用方式。
- RPM通过特征级别相似性检索推理匹配的示例,并在结构化因素和检索到的推理路径上进行推理。
点此查看论文截图

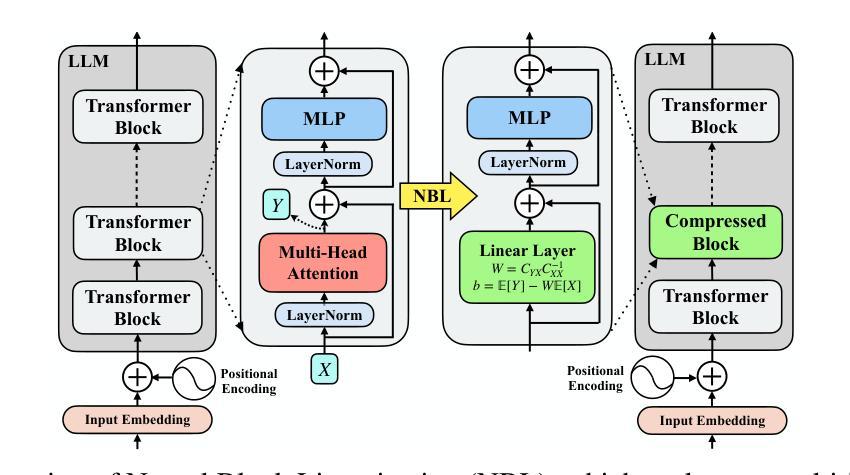
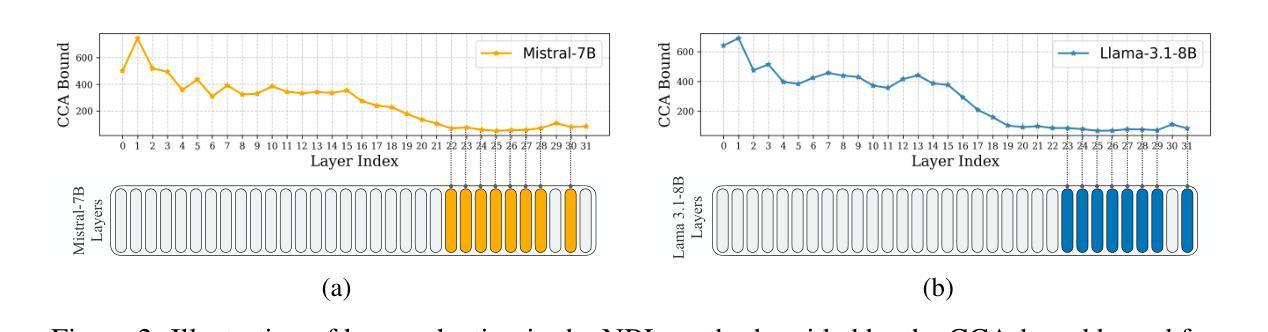
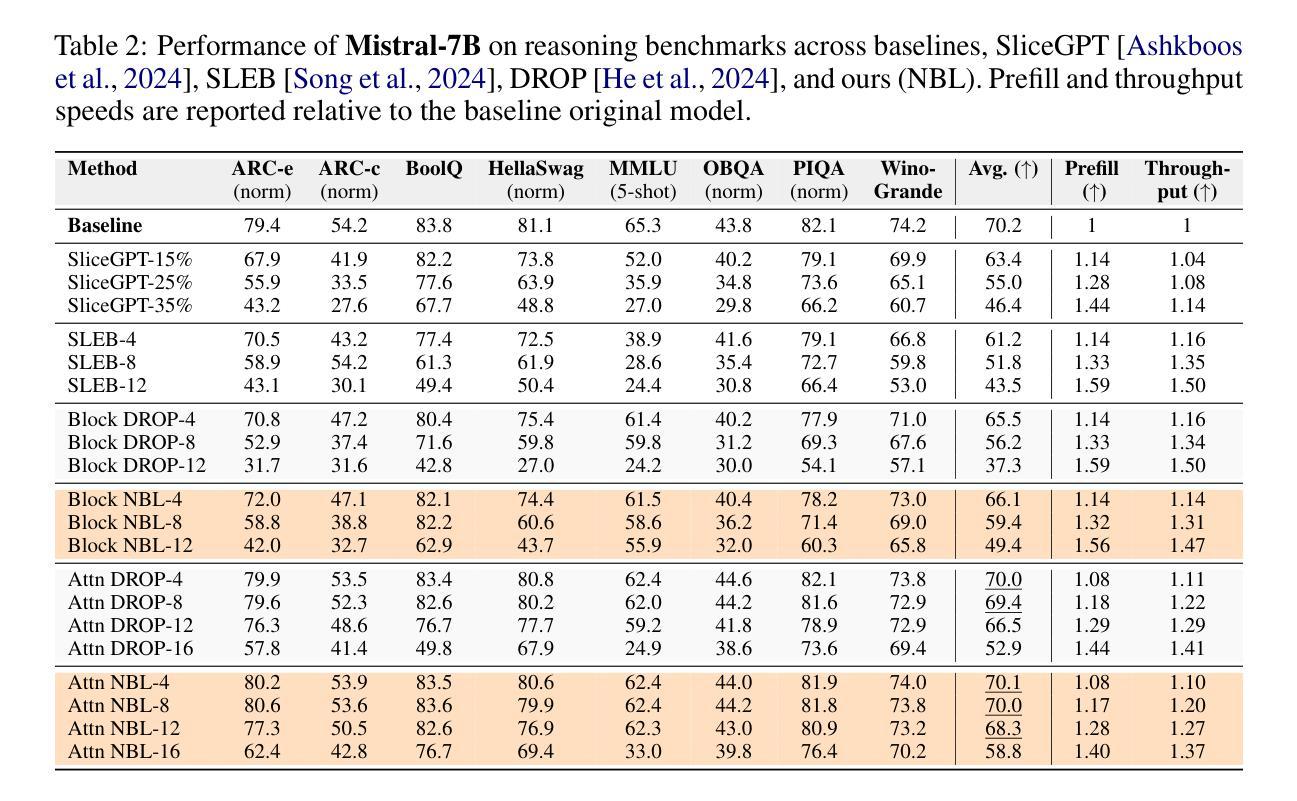
Efficient Large Language Model Inference with Neural Block Linearization
Authors:Mete Erdogan, Francesco Tonin, Volkan Cevher
The high inference demands of transformer-based Large Language Models (LLMs) pose substantial challenges in their deployment. To this end, we introduce Neural Block Linearization (NBL), a novel framework for accelerating transformer model inference by replacing self-attention layers with linear approximations derived from Linear Minimum Mean Squared Error estimators. NBL leverages Canonical Correlation Analysis to compute a theoretical upper bound on the approximation error. Then, we use this bound as a criterion for substitution, selecting the LLM layers with the lowest linearization error. NBL can be efficiently applied to pre-trained LLMs without the need for fine-tuning. In experiments, NBL achieves notable computational speed-ups while preserving competitive accuracy on multiple reasoning benchmarks. For instance, applying NBL to 12 self-attention layers in DeepSeek-R1-Distill-Llama-8B increases the inference speed by 32% with less than 1% accuracy trade-off, making it a flexible and promising solution to improve the inference efficiency of LLMs.
基于Transformer的大型语言模型(LLM)的高推理需求在其部署过程中带来了很大的挑战。为了解决这一问题,我们引入了神经块线性化(NBL)这一新型框架,通过用基于线性最小均方误差估计的线性近似值替换自注意力层来加速Transformer模型的推理。NBL利用典型相关性分析来计算近似误差的理论上限。然后,我们将这个界限作为替代标准,选择线性化误差最低的LLM层。NBL可以高效应用于预训练的LLM,无需微调。在实验中,NBL在多个推理基准测试中实现了显著的计算速度提升,同时保持了竞争力。例如,将NBL应用于DeepSeek-R1-Distill-Llama-8B的12个自注意力层,在仅牺牲不到1%准确率的情况下,推理速度提高了32%,使其成为提高LLM推理效率的一种灵活且具前景的解决方案。
论文及项目相关链接
Summary
神经网络块线性化(NBL)是一种用于加速基于Transformer的大型语言模型(LLM)推理的新型框架。它通过利用线性最小均方误差估计器产生的线性近似替换自注意力层来实现推理加速。NBL使用典型相关性分析计算近似误差的理论上限,并以此作为替换标准,选择线性化误差最低的LLM层。实验表明,NBL在保持竞争力的同时显著提高了计算速度。例如,将NBL应用于DeepSeek-R1-Distill-Llama-8B的12个自注意力层,可在仅损失不到1%准确率的情况下提高32%的推理速度。
Key Takeaways
- 神经网络块线性化(NBL)旨在加速基于Transformer的大型语言模型(LLM)的推理过程。
- NBL通过用线性最小均方误差估计产生的线性近似替换自注意力层来实现推理加速。
- NBL使用典型相关性分析计算理论上的近似误差上限,作为选择替换层的标准。
- NBL可高效应用于预训练LLM,无需微调。
- 实验表明,NBL在多个推理基准测试中实现了显著的计算速度提升,同时保持了竞争力。
- 在DeepSeek-R1-Distill-Llama-8B模型中应用NBL,可提高32%的推理速度,仅损失不到1%的准确率。
点此查看论文截图


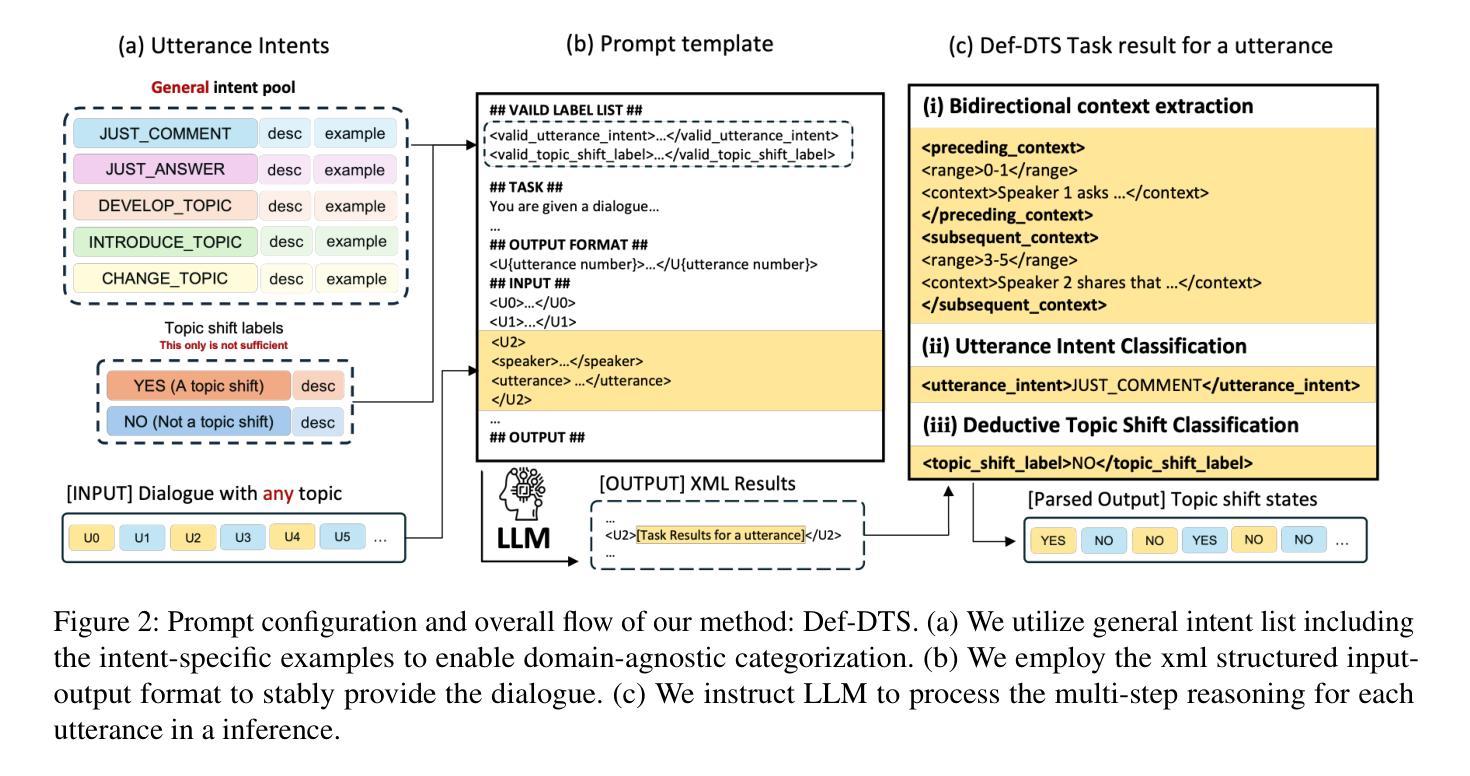
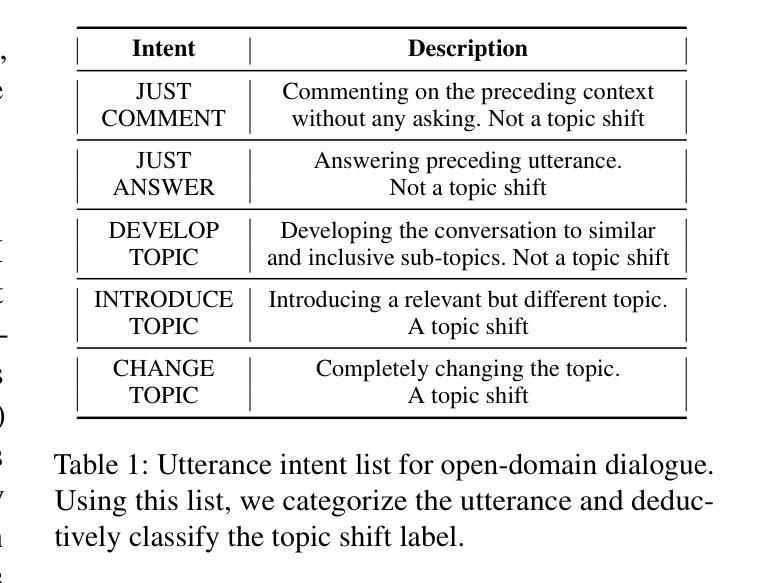
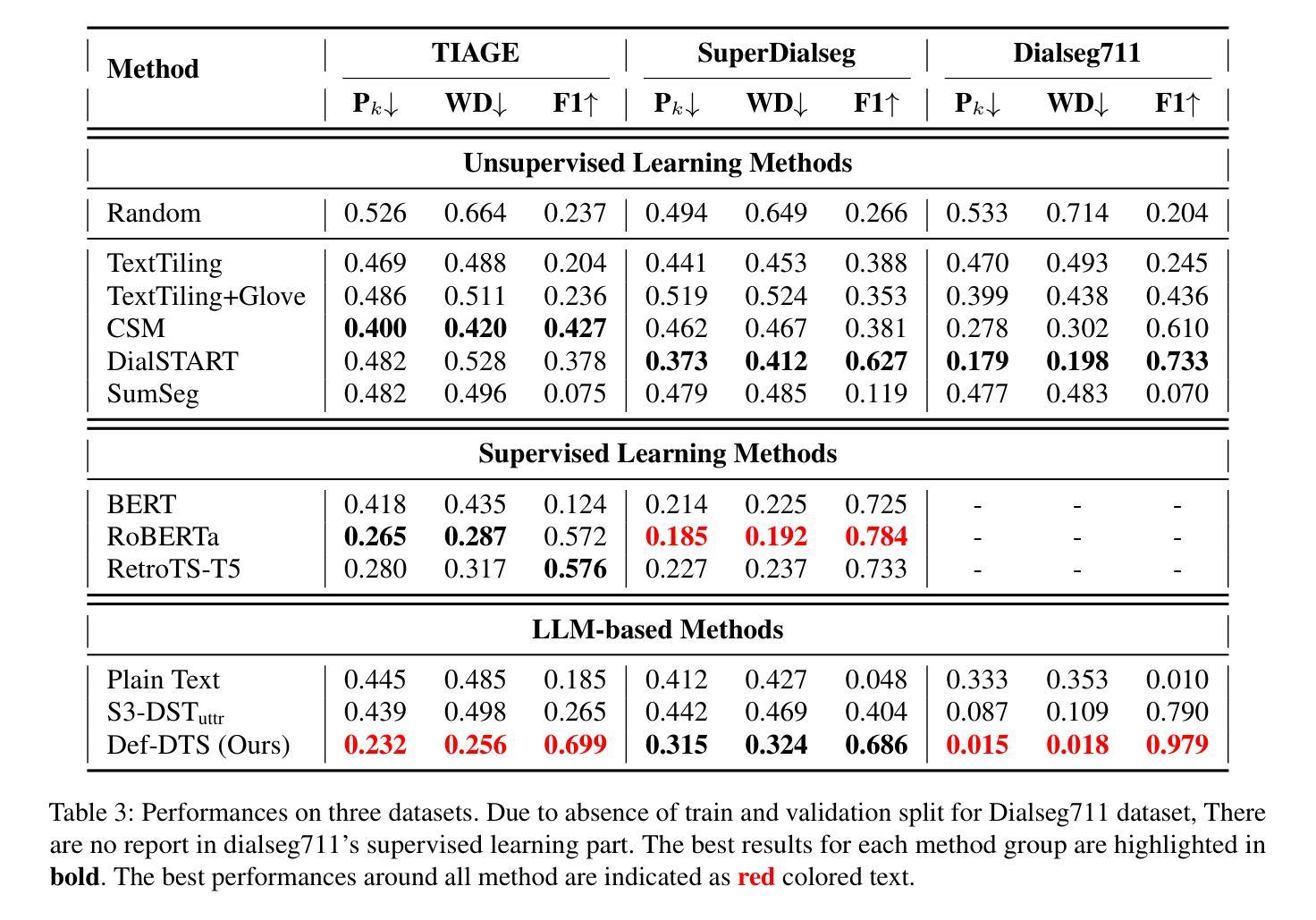
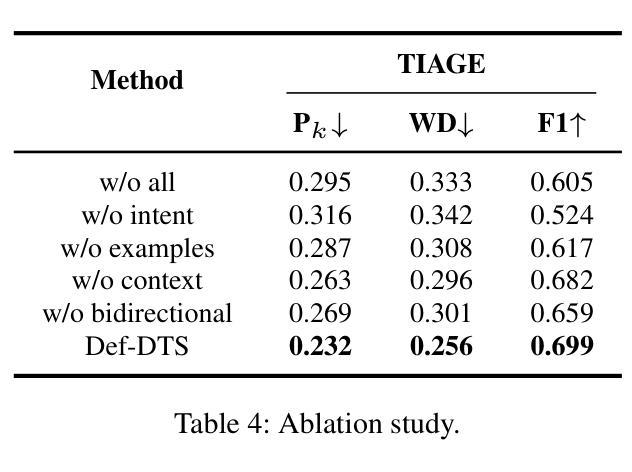
Def-DTS: Deductive Reasoning for Open-domain Dialogue Topic Segmentation
Authors:Seungmin Lee, Yongsang Yoo, Minhwa Jung, Min Song
Dialogue Topic Segmentation (DTS) aims to divide dialogues into coherent segments. DTS plays a crucial role in various NLP downstream tasks, but suffers from chronic problems: data shortage, labeling ambiguity, and incremental complexity of recently proposed solutions. On the other hand, Despite advances in Large Language Models (LLMs) and reasoning strategies, these have rarely been applied to DTS. This paper introduces Def-DTS: Deductive Reasoning for Open-domain Dialogue Topic Segmentation, which utilizes LLM-based multi-step deductive reasoning to enhance DTS performance and enable case study using intermediate result. Our method employs a structured prompting approach for bidirectional context summarization, utterance intent classification, and deductive topic shift detection. In the intent classification process, we propose the generalizable intent list for domain-agnostic dialogue intent classification. Experiments in various dialogue settings demonstrate that Def-DTS consistently outperforms traditional and state-of-the-art approaches, with each subtask contributing to improved performance, particularly in reducing type 2 error. We also explore the potential for autolabeling, emphasizing the importance of LLM reasoning techniques in DTS.
对话主题分段(DTS)旨在将对话划分为连贯的段落。DTS在各种NLP下游任务中扮演着至关重要的角色,但它也面临着一些长期存在的问题:数据短缺、标签模糊以及最近提出的解决方案的复杂性不断增加。另一方面,尽管大型语言模型(LLM)和推理策略有所进展,但它们很少被应用于DTS。本文介绍了Def-DTS:基于开放域对话主题的归纳推理分段方法,该方法利用基于LLM的多步归纳推理来提高DTS的性能,并使用中间结果进行案例研究。我们的方法采用结构化提示方法进行双向上下文摘要、话语意图分类和归纳主题转移检测。在意图分类过程中,我们提出了用于领域无关的对话意图分类的可推广意图列表。在各种对话场景中的实验表明,Def-DTS始终优于传统和最新方法,每个子任务都对性能提升有所贡献,特别是在减少第二类错误方面。我们还探索了自动标签的潜力,强调LLM推理技术在DTS中的重要性。
论文及项目相关链接
PDF 19 pages, 3 figures, Accepted to Findings of the ACL 2025
Summary:
本文介绍了Def-DTS方法,该方法利用基于大型语言模型的多步演绎推理,旨在提高对话主题分割的性能。该方法通过结构化提示进行双向上下文摘要、话语意图分类和演绎主题转移检测。实验表明,Def-DTS在多种对话场景中始终优于传统和最新的方法,特别是减少了第二类错误的出现。同时探讨了自动标注的潜力,强调LLM推理技术在DTS中的重要性。
Key Takeaways:
- Def-DTS方法旨在利用大型语言模型的多步演绎推理提高对话主题分割的性能。
- 该方法通过结构化提示进行双向上下文摘要,有助于理解对话的连贯性和上下文关系。
- Def-DTS包括话语意图分类的任务,并提出了通用的意图列表,用于非特定领域的对话意图分类。
- 演绎主题转移检测是Def-DTS的重要组成部分,有助于准确识别对话主题的转变。
- 实验结果显示,Def-DTS在多种对话场景中表现优异,优于传统和最新的方法。
- Def-DTS通过减少第二类错误,提高了对话主题分割的准确性和性能。
点此查看论文截图

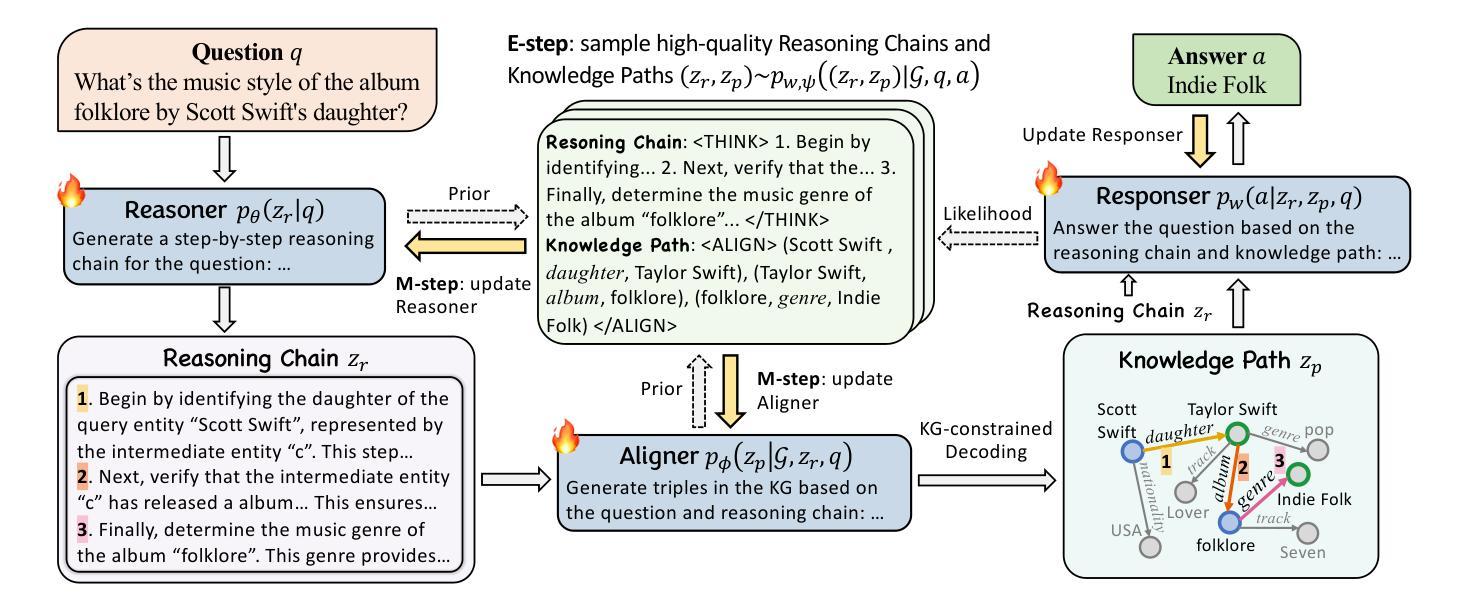
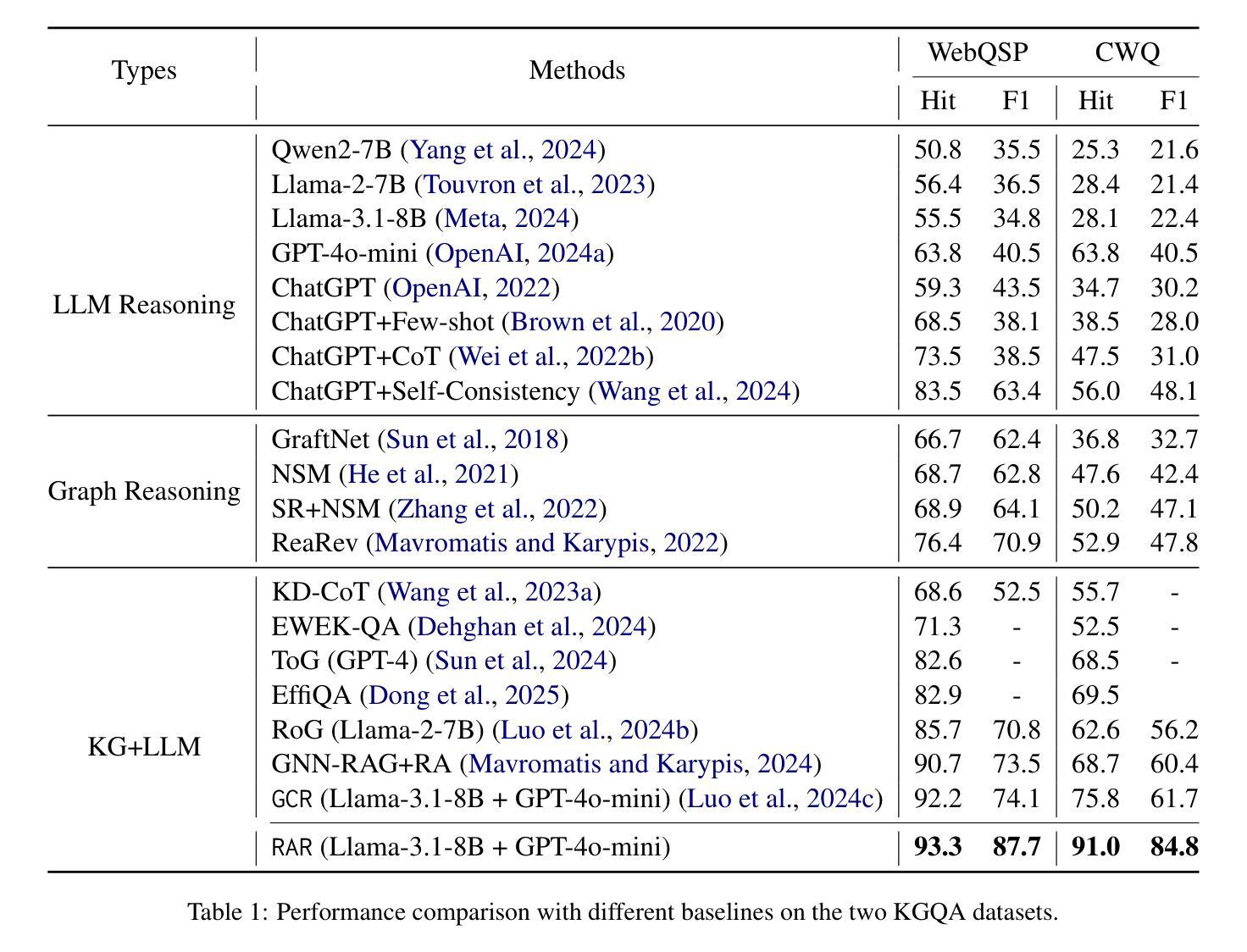
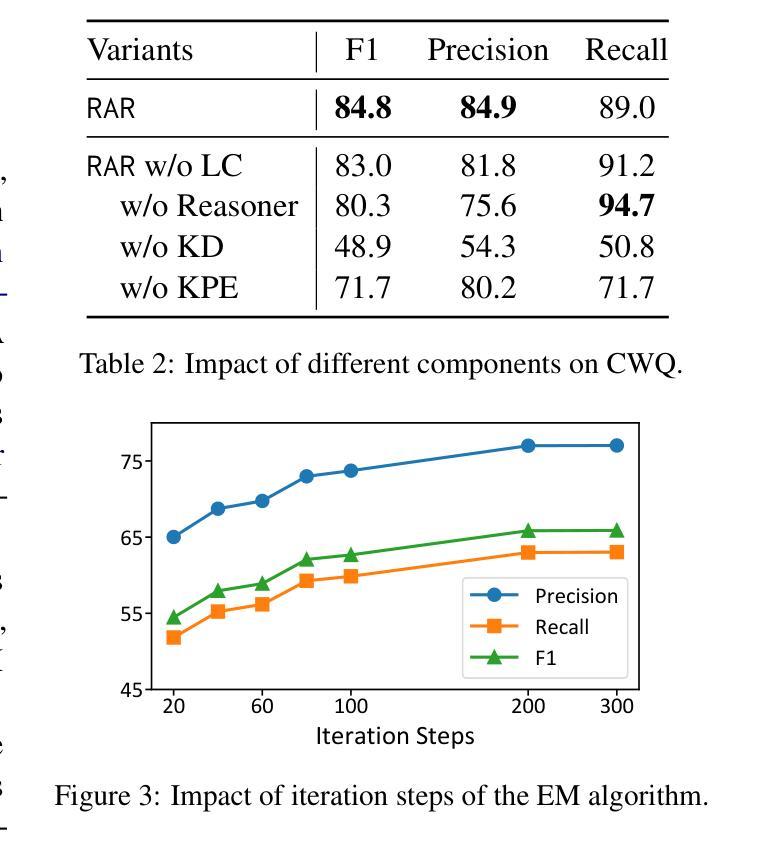
Reason-Align-Respond: Aligning LLM Reasoning with Knowledge Graphs for KGQA
Authors:Xiangqing Shen, Fanfan Wang, Rui Xia
LLMs have demonstrated remarkable capabilities in complex reasoning tasks, yet they often suffer from hallucinations and lack reliable factual grounding. Meanwhile, knowledge graphs (KGs) provide structured factual knowledge but lack the flexible reasoning abilities of LLMs. In this paper, we present Reason-Align-Respond (RAR), a novel framework that systematically integrates LLM reasoning with knowledge graphs for KGQA. Our approach consists of three key components: a Reasoner that generates human-like reasoning chains, an Aligner that maps these chains to valid KG paths, and a Responser that synthesizes the final answer. We formulate this process as a probabilistic model and optimize it using the Expectation-Maximization algorithm, which iteratively refines the reasoning chains and knowledge paths. Extensive experiments on multiple benchmarks demonstrate the effectiveness of RAR, achieving state-of-the-art performance with Hit@1 scores of 93.3% and 91.0% on WebQSP and CWQ respectively. Human evaluation confirms that RAR generates high-quality, interpretable reasoning chains well-aligned with KG paths. Furthermore, RAR exhibits strong zero-shot generalization capabilities and maintains computational efficiency during inference.
大型语言模型(LLMs)在复杂的推理任务中表现出了显著的能力,但它们常常出现幻觉,缺乏可靠的的事实基础。同时,知识图谱(KGs)提供了结构化的事实知识,但缺乏LLMs的灵活推理能力。在本文中,我们提出了Reason-Align-Respond(RAR)框架,该框架系统地整合了LLM推理和知识图谱,用于知识图谱问答(KGQA)。我们的方法由三个关键组件组成:生成类似人类的推理链的推理器,将这些链映射到有效的知识图谱路径的对齐器,以及合成最终答案的响应器。我们将这个过程制定为概率模型,并使用期望最大化算法进行优化,该算法通过迭代改进推理链和知识路径。在多个基准测试上的大量实验证明了RAR的有效性,在WebQSP和CWQ上的命中率得分分别为93.3%和91.0%,达到了最先进的性能。人类评估证实,RAR生成的推理链高质量且可解释性强,与知识图谱路径很好地对齐。此外,RAR具有较强的零样本泛化能力,并在推理过程中保持了计算效率。
论文及项目相关链接
Summary
LLMs与知识图谱(KGs)结合展现出色性能。新框架Reason-Align-Respond(RAR)整合了LLM推理与知识图谱,用于知识图谱问答(KGQA)。RAR包括三个关键组件:生成人类式推理链的Reasoner,将这些链映射到有效KG路径的Aligner,以及合成最终答案的Respond。此过程被公式化为概率模型并使用期望最大化算法进行优化,提高了性能并展示出强泛化能力和计算效率。实验表明RAR表现优秀。
Key Takeaways
- LLMs与知识图谱结合能够提高性能。
- RAR框架整合了LLM推理与知识图谱用于KGQA任务。
- RAR包含三个关键组件:Reasoner,Aligner和Responder。
- RAR采用概率模型并使用期望最大化算法优化过程。
- RAR实现高水平性能,达到WebQSP和CWQ基准测试的最优水平。
- RAR生成高质量、可解释的推理链,与人类知识图谱路径对齐良好。
点此查看论文截图

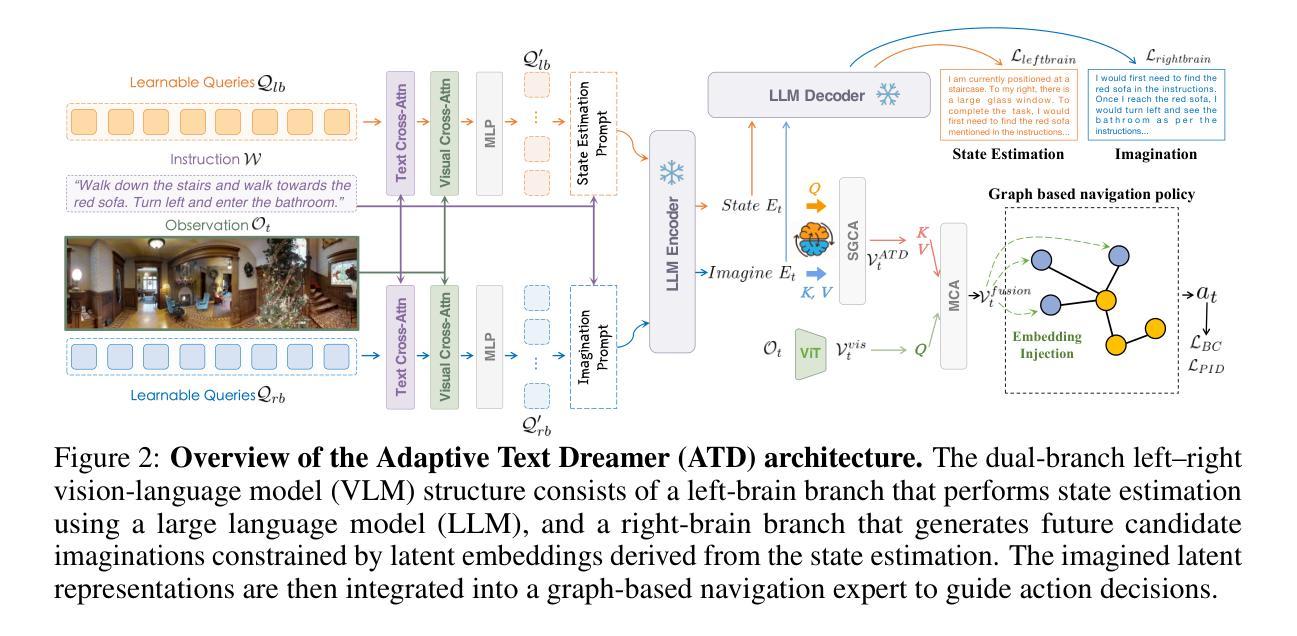
Cross from Left to Right Brain: Adaptive Text Dreamer for Vision-and-Language Navigation
Authors:Pingrui Zhang, Yifei Su, Pengyuan Wu, Dong An, Li Zhang, Zhigang Wang, Dong Wang, Yan Ding, Bin Zhao, Xuelong Li
Vision-and-Language Navigation (VLN) requires the agent to navigate by following natural instructions under partial observability, making it difficult to align perception with language. Recent methods mitigate this by imagining future scenes, yet they rely on vision-based synthesis, leading to high computational cost and redundant details. To this end, we propose to adaptively imagine key environmental semantics via \textit{language} form, enabling a more reliable and efficient strategy. Specifically, we introduce a novel Adaptive Text Dreamer (ATD), a dual-branch self-guided imagination policy built upon a large language model (LLM). ATD is designed with a human-like left-right brain architecture, where the left brain focuses on logical integration, and the right brain is responsible for imaginative prediction of future scenes. To achieve this, we fine-tune only the Q-former within both brains to efficiently activate domain-specific knowledge in the LLM, enabling dynamic updates of logical reasoning and imagination during navigation. Furthermore, we introduce a cross-interaction mechanism to regularize the imagined outputs and inject them into a navigation expert module, allowing ATD to jointly exploit both the reasoning capacity of the LLM and the expertise of the navigation model. We conduct extensive experiments on the R2R benchmark, where ATD achieves state-of-the-art performance with fewer parameters. The code is \href{https://github.com/zhangpingrui/Adaptive-Text-Dreamer}{here}.
视觉与语言导航(VLN)要求智能体在部分可观察性的情况下遵循自然语言指令进行导航,这使得感知与语言的对齐变得困难。最近的方法通过想象未来的场景来缓解这一问题,但它们依赖于基于视觉的合成,导致计算成本高昂和细节冗余。为此,我们提出通过语言形式来适应性地想象关键环境语义,从而实现更可靠和高效的策略。具体来说,我们引入了一种新型的自适应文本梦想家(ATD),这是一种基于大型语言模型(LLM)的双分支自我引导想象策略。ATD的设计具有人类左右脑架构,其中左脑专注于逻辑整合,右脑负责对未来场景进行想象预测。为了实现这一点,我们只微调了左右脑中的Q-former,以有效激活LLM中的领域特定知识,从而在导航过程中实现逻辑和想象的动态更新。此外,我们引入了一种交叉交互机制来规范想象输出并将其注入导航专家模块,使ATD能够联合利用LLM的推理能力和导航模型的专长。我们在R2R基准测试上进行了大量实验,ATD以较少的参数实现了最先进的性能。代码详见:https://github.com/zhangpingrui/Adaptive-Text-Dreamer。
简化翻译(更简洁的版本):
论文及项目相关链接
Summary
文本讨论了Vision-and-Language Navigation的问题,包括通过语言指导进行导航的难度和挑战。提出了一个自适应文本梦想家模型来解决这一问题,采用基于语言形式的未来场景想象,减少了计算成本和冗余细节。该模型通过自我引导策略生成左右脑协同工作实现逻辑推理和想象能力。在R2R基准测试中取得了最佳性能。具体信息可访问提供的链接。
Key Takeaways
- Vision-and-Language Navigation面临感知与语言对齐的挑战。
- 自适应文本梦想家模型通过基于语言形式的未来场景想象解决此问题。
- 模型采用双分支自我引导策略,模拟人类左右脑功能实现逻辑推理和想象。
- 模型引入交叉互动机制,结合大型语言模型的推理能力和导航模型的专长。
- 在R2R基准测试中,自适应文本梦想家模型性能达到最佳水平。
点此查看论文截图


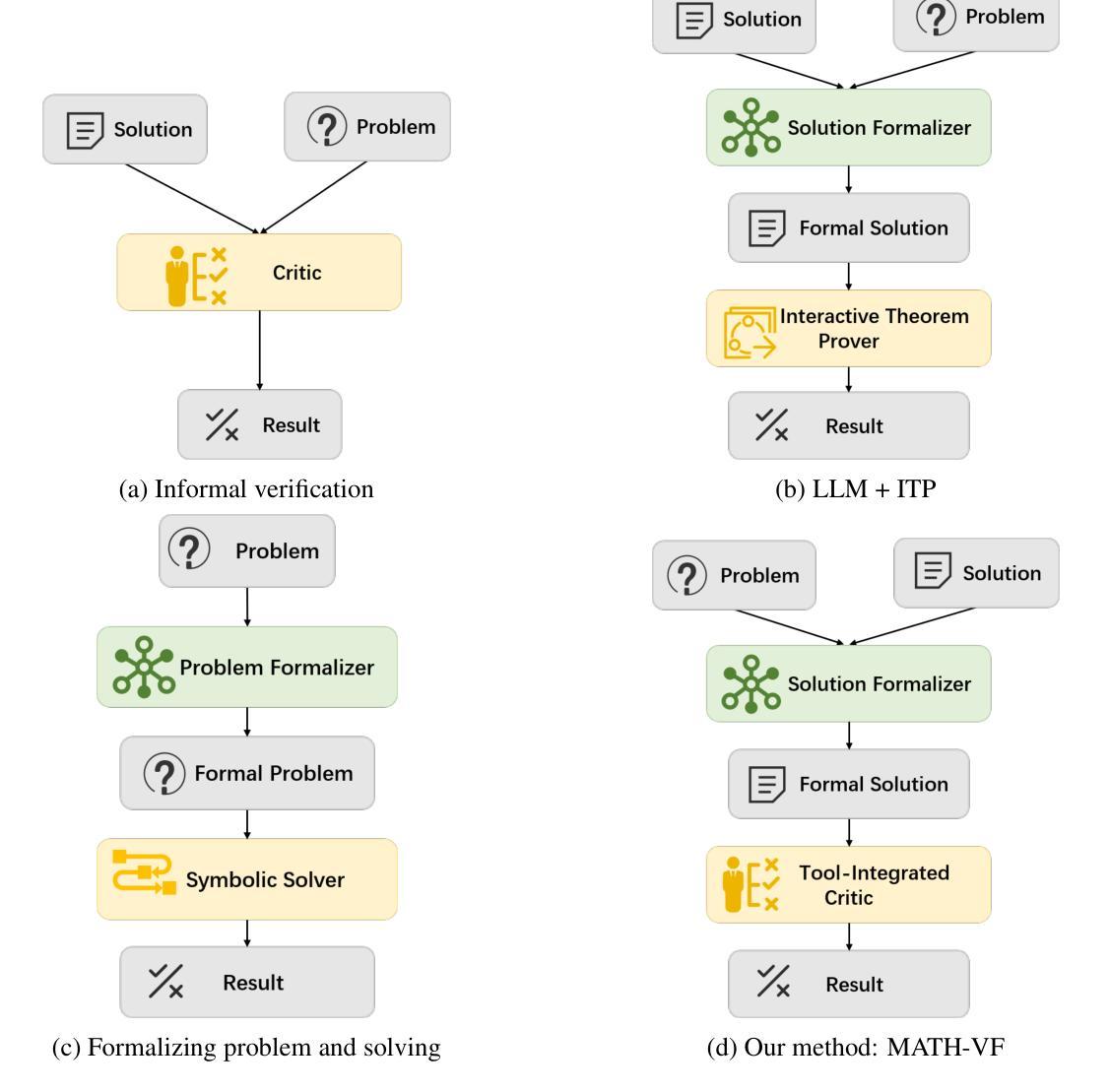
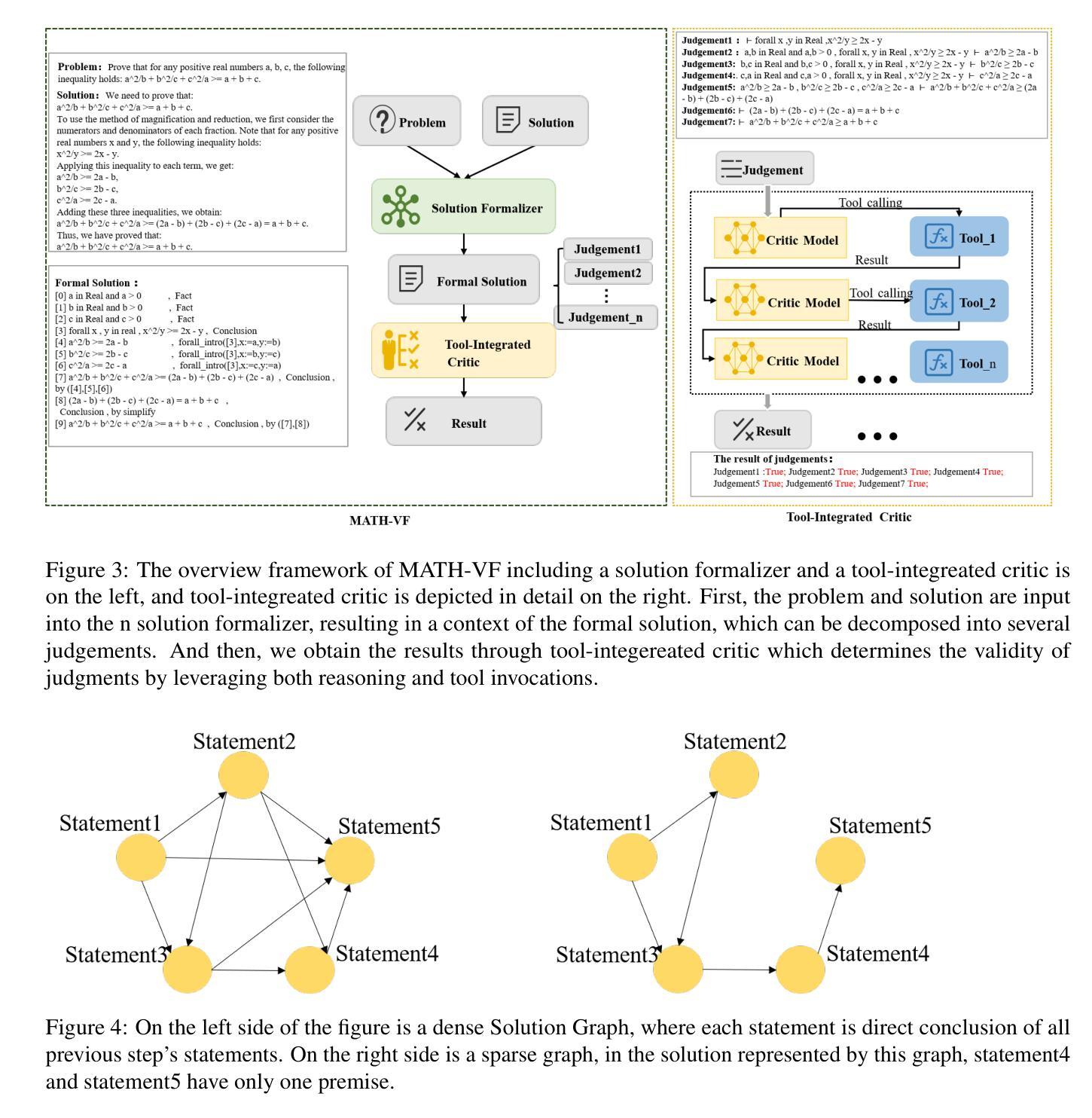
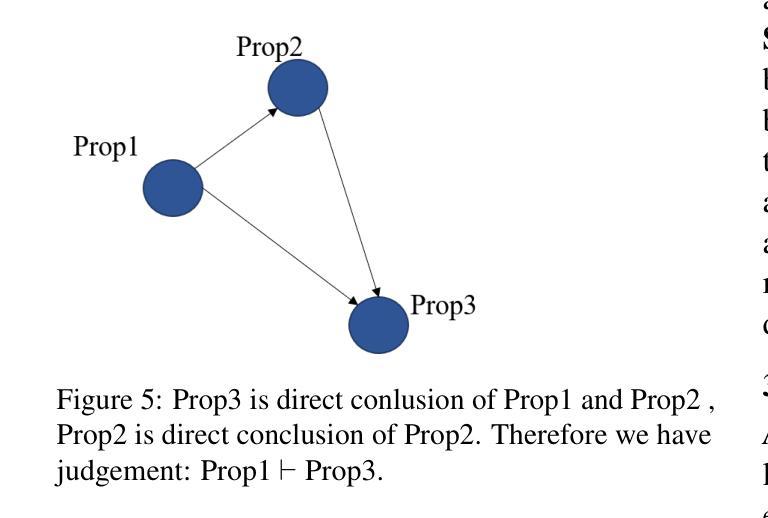
Step-Wise Formal Verification for LLM-Based Mathematical Problem Solving
Authors:Kuo Zhou, Lu Zhang
Large Language Models (LLMs) have demonstrated formidable capabilities in solving mathematical problems, yet they may still commit logical reasoning and computational errors during the problem-solving process. Thus, this paper proposes a framework, MATH-VF, which includes a Formalizer and a Critic, for formally verifying the correctness of the solutions generated by large language models. Our framework first utilizes a Formalizer which employs an LLM to translate a natural language solution into a formal context. Afterward, our Critic (which integrates various external tools such as a Computer Algebra System and an SMT solver) evaluates the correctness of each statement within the formal context, and when a statement is incorrect, our Critic provides corrective feedback. We empirically investigate the effectiveness of MATH-VF in two scenarios: 1) Verification: MATH-VF is utilized to determine the correctness of a solution to a given problem. 2) Refinement: When MATH-VF identifies errors in the solution generated by an LLM-based solution generator for a given problem, it submits the corrective suggestions proposed by the Critic to the solution generator to regenerate the solution. We evaluate our framework on widely used mathematical benchmarks: MATH500 and ProcessBench, demonstrating the superiority of our approach over existing approaches.
大型语言模型(LLM)在解决数学问题方面表现出了强大的能力,但在问题解决过程中仍可能出现逻辑推理和计算错误。因此,本文提出了一个名为MATH-VF的框架,该框架包括一个格式化器和一个批判家,用于验证大型语言模型生成的解决方案的正确性。我们的框架首先使用一个格式化器,它利用大型语言模型将自然语言解决方案转换为正式语境。随后,我们的批判家(集成了各种外部工具,如计算机代数系统和SMT求解器)评估正式语境中每个语句的正确性,并在语句错误时提供反馈。我们通过实证研究验证了MATH-VF在两种场景中的有效性:1)验证:使用MATH-VF确定给定问题的解决方案是否正确。2)精进:当MATH-VF识别出大型语言模型生成的给定问题解决方案中的错误时,它将批判家提出的修正建议提交给解决方案生成器以重新生成解决方案。我们在广泛使用的数学基准测试MATH500和ProcessBench上评估了我们的框架,证明了我们的方法优于现有方法。
论文及项目相关链接
Summary
大型语言模型(LLMs)在解决数学问题方面展现出强大能力,但在逻辑推理和计算过程中仍可能出现错误。本文提出一个名为MATH-VF的框架,包括形式化器和评审器,用于验证大型语言模型生成的解决方案的正确性。该框架首先使用形式化器将自然语言解决方案转化为正式语境,然后评审器结合计算机代数系统和SMT求解器等外部工具评估正式语境中的每个陈述,一旦发现错误,即提供反馈。本文通过验证和细化两个场景实证研究了MATH-VF的有效性,并在MATH500和ProcessBench等常用数学基准测试上展示了其优越性。
Key Takeaways
- 大型语言模型(LLMs)在解决数学问题方面展现出强大能力,但存在逻辑推理和计算错误。
- MATH-VF框架包括形式化器和评审器,用于验证LLM生成的解决方案的正确性。
- 形式化器将自然语言解决方案转化为正式语境。
- 评审器结合外部工具如计算机代数系统和SMT求解器评估陈述的正确性,并提供反馈。
- MATH-VF框架在验证和细化两个场景中具有有效性。
- MATH-VF框架在MATH500和ProcessBench等数学基准测试上表现出优越性。
- 该框架有助于提升LLM在解决数学问题时的准确性和可靠性。
点此查看论文截图


Reinforced Informativeness Optimization for Long-Form Retrieval-Augmented Generation
Authors:Yuhao Wang, Ruiyang Ren, Yucheng Wang, Wayne Xin Zhao, Jing Liu, Hua Wu, Haifeng Wang
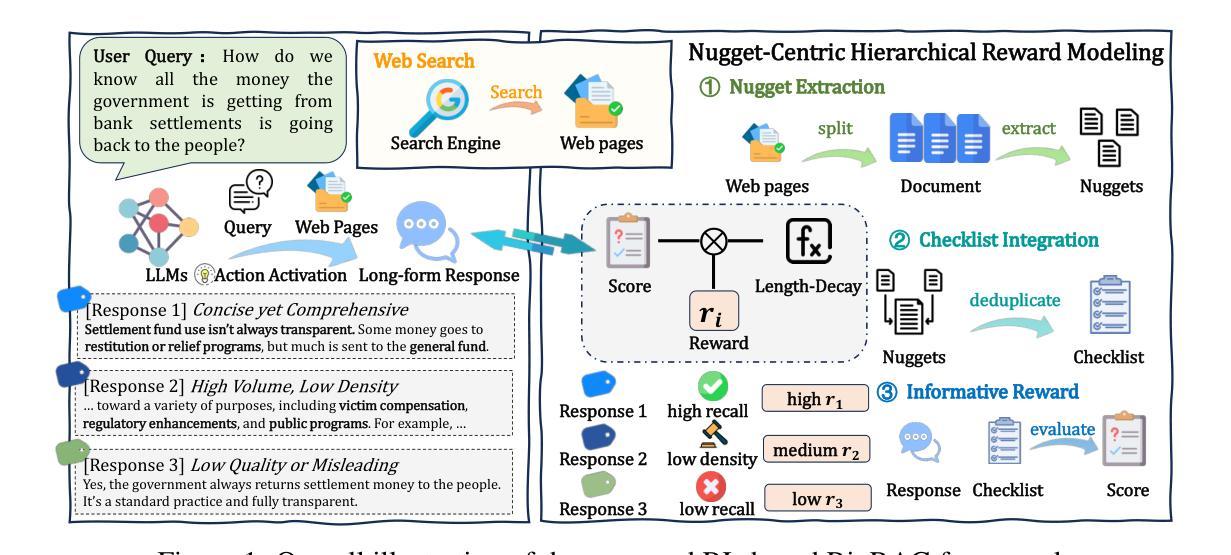
Long-form question answering (LFQA) presents unique challenges for large language models, requiring the synthesis of coherent, paragraph-length answers. While retrieval-augmented generation (RAG) systems have emerged as a promising solution, existing research struggles with key limitations: the scarcity of high-quality training data for long-form generation, the compounding risk of hallucination in extended outputs, and the absence of reliable evaluation metrics for factual completeness. In this paper, we propose RioRAG, a novel reinforcement learning (RL) framework that advances long-form RAG through reinforced informativeness optimization. Our approach introduces two fundamental innovations to address the core challenges. First, we develop an RL training paradigm of reinforced informativeness optimization that directly optimizes informativeness and effectively addresses the slow-thinking deficit in conventional RAG systems, bypassing the need for expensive supervised data. Second, we propose a nugget-centric hierarchical reward modeling approach that enables precise assessment of long-form answers through a three-stage process: extracting the nugget from every source webpage, constructing a nugget claim checklist, and computing rewards based on factual alignment. Extensive experiments on two LFQA benchmarks LongFact and RAGChecker demonstrate the effectiveness of the proposed method. Our codes are available at https://github.com/RUCAIBox/RioRAG.
长问答(LFQA)为大语言模型带来了独特的挑战,要求合成连贯的、段落长度的答案。虽然基于检索的生成(RAG)系统已成为一种有前景的解决方案,但现有研究在关键方面存在局限:高质量训练数据缺乏用于长形式生成,扩展输出中的幻想风险累积,以及缺乏可靠的评价指标来评估事实完整性。在本文中,我们提出了RioRAG,这是一种新型强化学习(RL)框架,通过强化信息优化推进长形式RAG。我们的方法引入了两个基本创新来解决核心挑战。首先,我们开发了一种强化信息优化的RL训练范式,直接优化信息性,有效解决传统RAG系统中的慢思考缺陷,无需昂贵的监督数据。其次,我们提出了一种以片段为中心的分层奖励建模方法,通过三个阶段的过程精确评估长形式答案:从每个源网页中提取片段、构建片段声明清单、根据事实一致性计算奖励。在LongFact和RAGChecker两个LFQA基准测试上的大量实验证明了所提方法的有效性。我们的代码可在https://github.com/RUCAIBox/RioRAG找到。
论文及项目相关链接
Summary
在长篇问答(LFQA)中,大型语言模型面临独特挑战,需要合成连贯的、段落长度的答案。虽然检索增强生成(RAG)系统已成为一种有前景的解决方案,但现有研究面临关键限制:高质量训练数据缺乏、长输出中的虚构风险以及缺乏可靠的评价指标来评估事实完整性。本文提出RioRAG,一种新型的强化学习(RL)框架,通过强化信息优化来推进长篇RAG。我们的方法引入了两个基本创新点来解决核心挑战:首先,我们开发了一种强化信息优化的RL训练范式,直接优化信息性,有效解决传统RAG系统中的慢思考缺陷,无需昂贵的监督数据;其次,我们提出了一种以片段为中心的分层奖励建模方法,通过三个阶段的过程精确评估长篇答案:从每个源网页中提取片段、构建片段声明清单、根据事实对齐计算奖励。在LongFact和RAGChecker两个LFQA基准测试上的实验证明了该方法的有效性。
Key Takeaways
- 长篇问答(LFQA)对大型语言模型提出独特挑战,需要生成连贯的、段落长度的答案。
- 检索增强生成(RAG)系统虽为有前途的解决方案,但存在高质量训练数据缺乏、长输出中的虚构风险及评价指标缺失等限制。
- RioRAG框架通过强化信息优化解决这些挑战,引入强化学习(RL)训练范式和分层奖励建模方法。
- RL训练范式直接优化信息性,提升传统RAG系统的性能,降低对昂贵监督数据的依赖。
- 分层奖励建模方法通过提取、构建和计算奖励三个阶段精确评估长篇答案。
- 在LongFact和RAGChecker基准测试上的实验证明了RioRAG框架的有效性。
点此查看论文截图

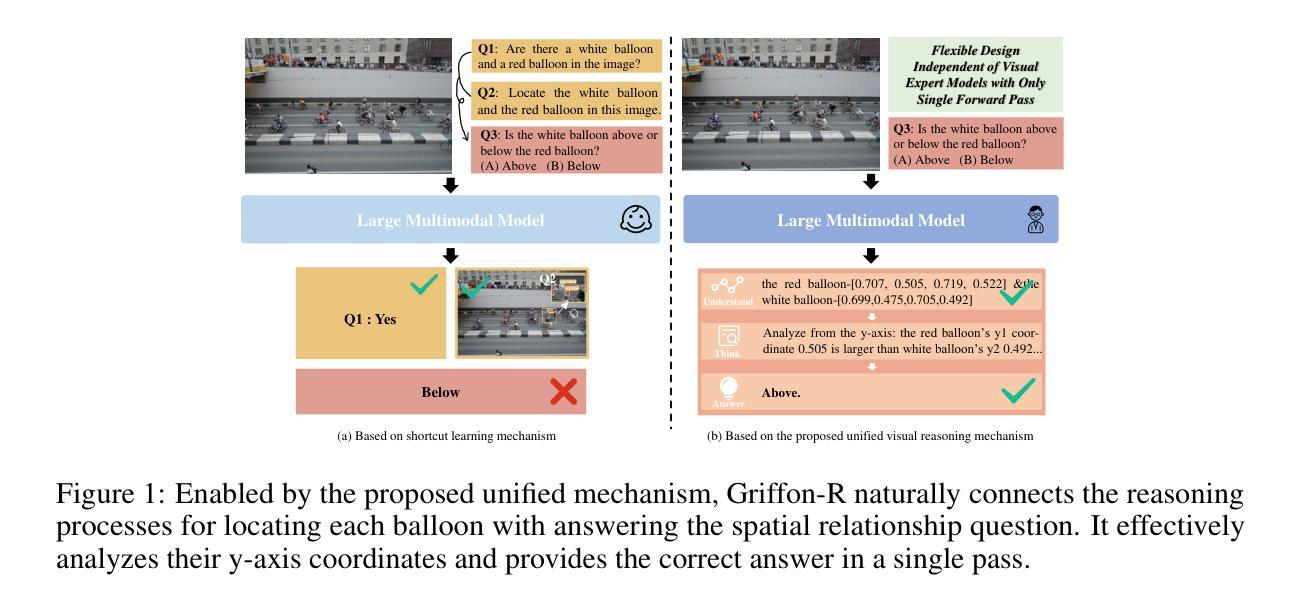
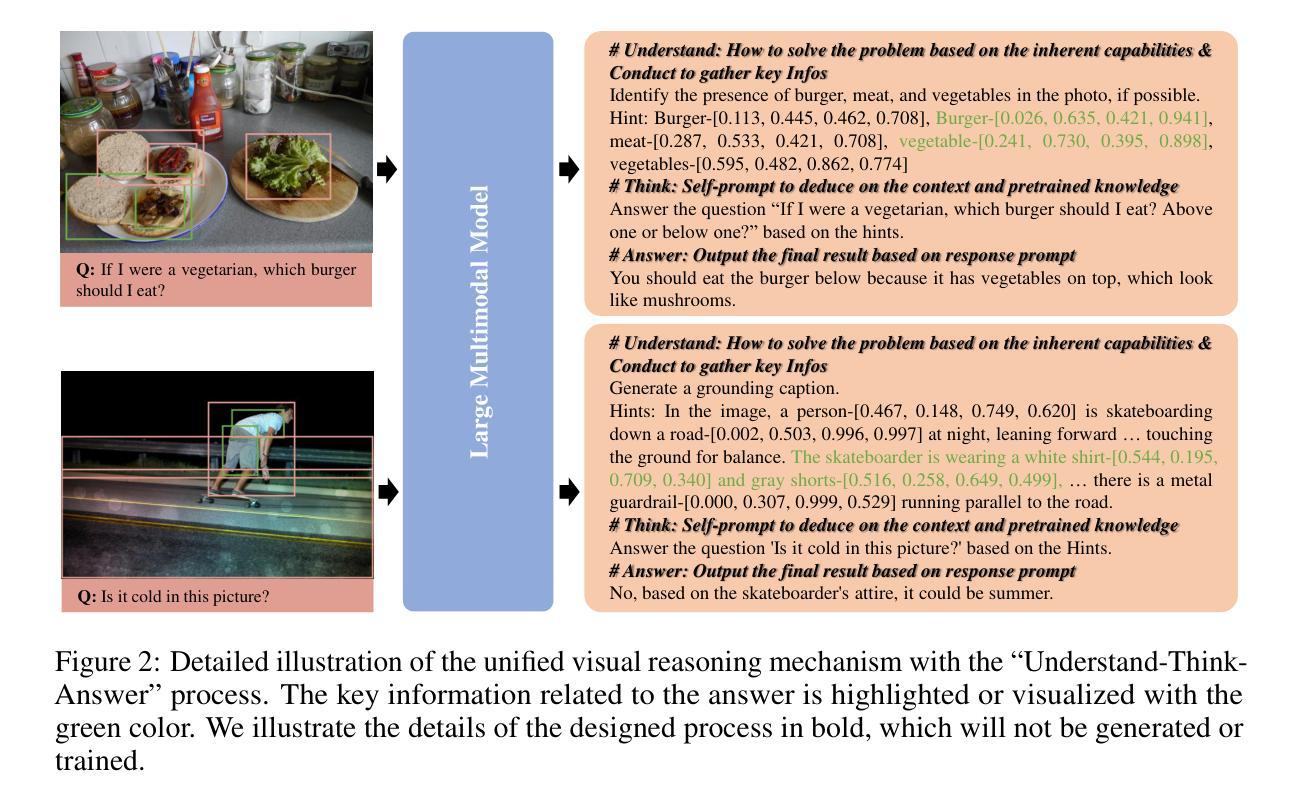
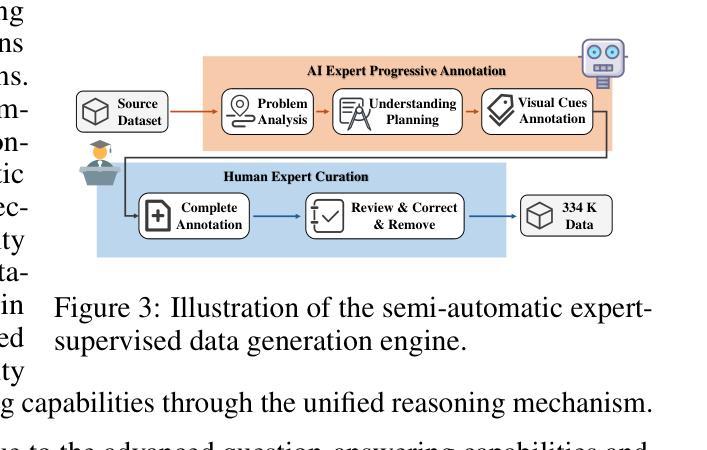
Understand, Think, and Answer: Advancing Visual Reasoning with Large Multimodal Models
Authors:Yufei Zhan, Hongyin Zhao, Yousong Zhu, Shurong Zheng, Fan Yang, Ming Tang, Jinqiao Wang
Large Multimodal Models (LMMs) have recently demonstrated remarkable visual understanding performance on both vision-language and vision-centric tasks. However, they often fall short in integrating advanced, task-specific capabilities for compositional reasoning, which hinders their progress toward truly competent general vision models. To address this, we present a unified visual reasoning mechanism that enables LMMs to solve complicated compositional problems by leveraging their intrinsic capabilities (e.g. grounding and visual understanding capabilities). Different from the previous shortcut learning mechanism, our approach introduces a human-like understanding-thinking-answering process, allowing the model to complete all steps in a single pass forwarding without the need for multiple inferences or external tools. This design bridges the gap between foundational visual capabilities and general question answering, encouraging LMMs to generate faithful and traceable responses for complex visual reasoning. Meanwhile, we curate 334K visual instruction samples covering both general scenes and text-rich scenes and involving multiple foundational visual capabilities. Our trained model, Griffon-R, has the ability of end-to-end automatic understanding, self-thinking, and reasoning answers. Comprehensive experiments show that Griffon-R not only achieves advancing performance on complex visual reasoning benchmarks including VSR and CLEVR, but also enhances multimodal capabilities across various benchmarks like MMBench and ScienceQA. Data, models, and codes will be release at https://github.com/jefferyZhan/Griffon/tree/master/Griffon-R soon.
大型多模态模型(LMM)最近在视觉语言任务和以视觉为中心的任务上都表现出了显著的理解性能。然而,它们在整合用于组合推理的先进、特定任务功能方面常常不足,这阻碍了它们成为真正有能力的一般视觉模型。为了解决这一问题,我们提出了一种统一的视觉推理机制,使LMM能够通过利用其内在能力(例如定位和视觉理解能力)来解决复杂的组合问题。不同于之前的捷径学习机制,我们的方法引入了一种类似人类的“理解-思考-回答”过程,使模型能够在单次前向传递中完成所有步骤,无需多次推理或外部工具。这种设计缩小了基本视觉能力和通用问答之间的差距,鼓励LMM为复杂的视觉推理生成忠实可靠的答案。同时,我们精心制作了包含一般场景和文本丰富场景的视觉指令样本,涉及多种基本视觉能力。我们训练的模型Griffon-R具有端到端自动理解、自我思考和推理回答的能力。综合实验表明,Griffon-R不仅在包括VSR和CLEVR的复杂视觉推理基准测试中取得了进展,而且在各种基准测试中增强了多模态能力,如MMBench和ScienceQA。数据、模型和代码将很快在https://github.com/jefferyZhan/Griffon/tree/master/Griffon-R发布。
论文及项目相关链接
PDF Tech report
Summary
本文介绍了大型多模态模型(LMMs)在视觉理解和视觉任务上的出色表现,但其在组合推理方面存在不足。为此,提出了一种统一的视觉推理机制,使LMMs能够解决复杂的组合问题,并利用其内在能力(如接地和视觉理解能力)。该方法不同于以往的捷径学习机制,引入人类般的理解、思考和回答过程,使模型一次前向传递即可完成所有步骤,无需多次推理或外部工具。同时,为了训练模型Griffon-R,收集了33.4万份视觉指令样本,涵盖一般场景和文本丰富场景,涉及多种基础视觉能力。实验表明,Griffon-R在复杂视觉推理基准测试上取得了先进性能,并增强了多模态能力。
Key Takeaways
- 大型多模态模型(LMMs)在视觉理解和任务上表现优异,但在组合推理方面存在不足。
- 提出一种统一的视觉推理机制,使LMMs能够解决复杂的组合问题。
- 该机制不同于以往的捷径学习,引入人类般的理解、思考和回答过程。
- 模型Griffon-R通过一次前向传递完成所有步骤,无需多次推理或外部工具。
- 为了训练Griffon-R,收集了涵盖多种场景的33.4万份视觉指令样本。
- 实验表明Griffon-R在复杂视觉推理基准测试上取得了先进性能。
点此查看论文截图