⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-05-29 更新
Towards Robust Automated Perceptual Voice Quality Assessment with Deep Learning
Authors:Whenty Ariyanti, Kuan-Yu Chen, Sabato Marco Siniscalchi, Hsin-Min Wang, Yu Tsao
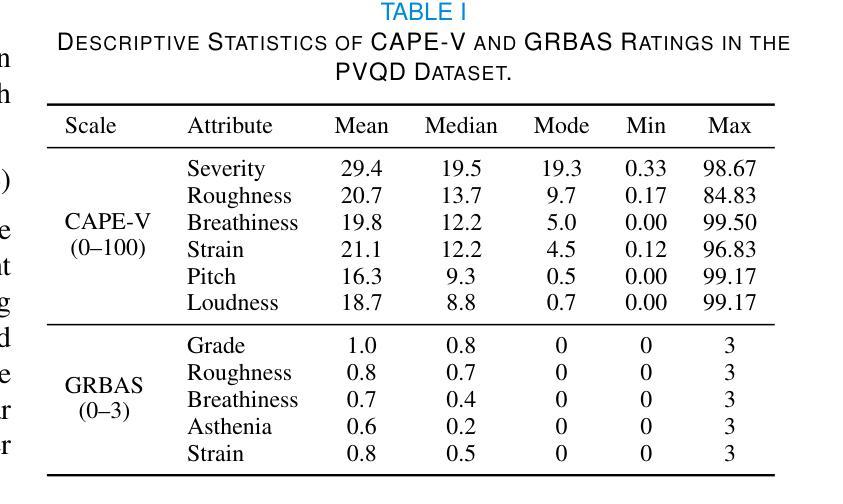
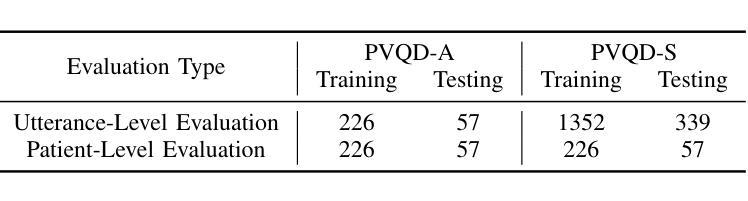
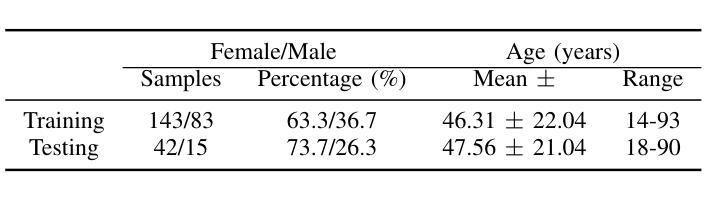
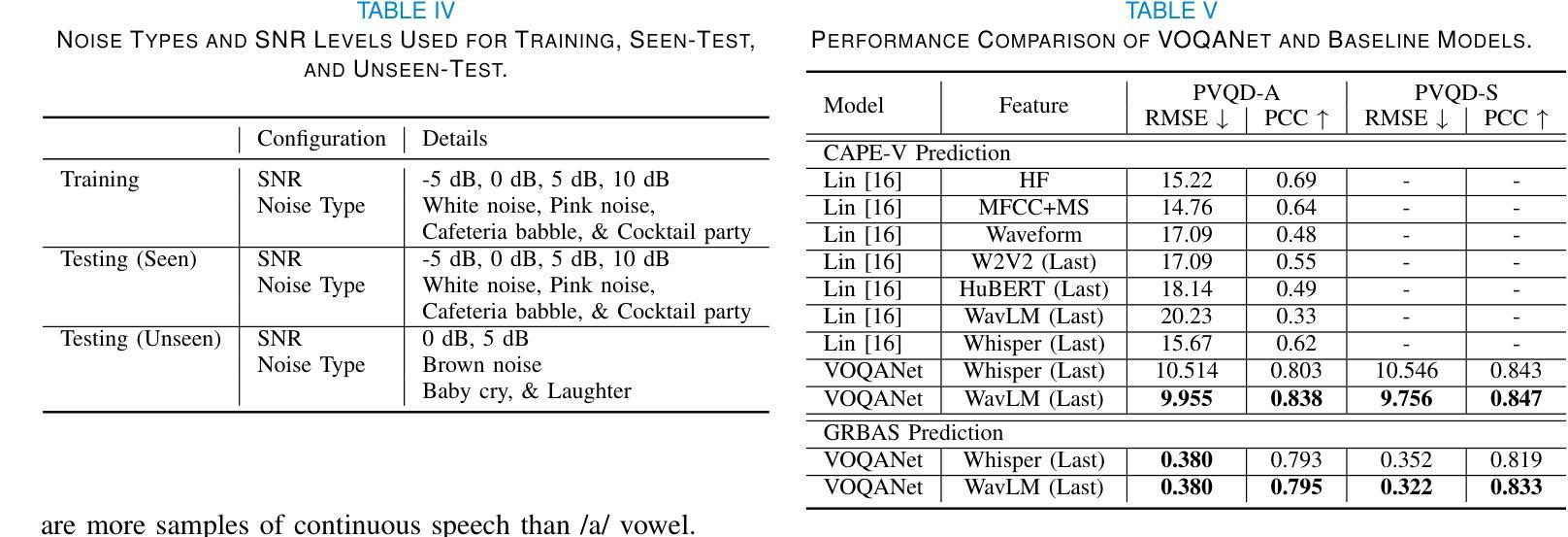
Objective: Perceptual voice quality assessment plays a critical role in diagnosing and monitoring voice disorders by providing standardized evaluation of vocal function. Traditionally, this process relies on expert raters utilizing standard scales, such as the Consensus Auditory-Perceptual Evaluation of Voice (CAPE-V) and Grade, Roughness, Breathiness, Asthenia, and Strain (GRBAS). However, these metrics are inherently subjective and susceptible to inter-rater variability, motivating the need for automated and objective assessment methods. Methods: We propose Voice Quality Assessment Network (VOQANet), a deep learning-based framework with an attention mechanism that leverages a Speech Foundation Model (SFM) to capture high-level acoustic and prosodic information from raw speech. To enhance robustness and interpretability, we present VOQANet+, which integrates handcrafted acoustic features such as jitter, shimmer, and harmonics-to-noise ratio (HNR) with SFM embeddings. Results: Sentence-based input yields stronger performance than vowel-based input, especially at the patient level. VOQANet consistently outperforms baseline methods in RMSE and PCC, while VOQANet+ performs even better and maintains robustness under noisy conditions. Conclusion: Combining SFM embeddings with domain-informed acoustic features improves interpretability and resilience. Significance: VOQANet+ shows strong potential for deployment in real-world and telehealth settings, addressing the limitations of subjective perceptual assessments with an interpretable and noise-resilient solution.
目标:感知语音质量评估在通过标准化评估语音功能来诊断和监测语音障碍方面发挥着至关重要的作用。传统上,这一过程依赖于专家评估者使用标准量表,如语音共识感知评估(CAPE-V)和等级、粗糙度、气息、虚弱和紧张度(GRBAS)。然而,这些指标本质上是主观的,容易出现评估者间变异,这激发了对自动化和客观评估方法的需求。方法:我们提出了基于深度学习的语音质量评估网络(VOQANet),该网络具有注意力机制,利用语音基础模型(SFM)从原始语音中捕获高级声音和韵律信息。为了提高稳健性和可解释性,我们推出了VOQANet+,它将手工制作的声学特征(如抖动、颤抖和谐波与噪声比(HNR))与SFM嵌入相结合。结果:基于句子的输入比基于元音的输入表现更好,特别是在患者层面。VOQANet在RMSE和PCC方面的表现一直优于基线方法,而VOQANet+表现更佳,并在嘈杂条件下保持稳健性。结论:将SFM嵌入与领域知识驱动的声学特征相结合,提高了可解释性和稳健性。意义:VOQANet+在现实世界和远程医疗环境中具有很强的部署潜力,为解决主观感知评估的局限性提供了一种可解释和噪声顽强的解决方案。
论文及项目相关链接
摘要
本文提出一种基于深度学习和注意力机制的语音质量评估网络(VOQANet),用于标准化评估嗓音功能,对嗓音障碍的诊断和监测起到关键作用。研究引入语音基础模型(SFM)捕捉原始语音中的高级声学特征,并集成手工制作的声学特征,如抖动、闪烁和谐波噪声比(HNR),以增强模型的稳健性和可解释性。研究结果显示,基于句子的输入相比基于元音的输入性能更优,特别是在患者层面。VOQANet在RMSE和PCC上持续优于基线方法,而结合领域知识的VOQANet+(集成声学特征的版本)表现更佳,并在噪声环境下保持稳健性。研究为自动化和客观评估语音质量提供了有力支持,具有在真实世界和远程医疗环境中部署的潜力。
关键见解
- 语音质量评估在嗓音障碍的诊断和监测中至关重要。
- 传统评估方法依赖于专家评估者使用标准量表,存在主观性和评分者间变异性的缺点。
- 提出的VOQANet利用深度学习和注意力机制进行自动化评估,引入SFM捕捉高级声学特征。
- 结合手工制作的声学特征(如抖动、闪烁和HNR)增强了模型的稳健性和可解释性。
- 基于句子的输入在性能上优于基于元音的输入,尤其在患者层面表现更佳。
- VOQANet在各种评估指标上优于基线方法,特别是在噪声环境下的表现稳健。
点此查看论文截图

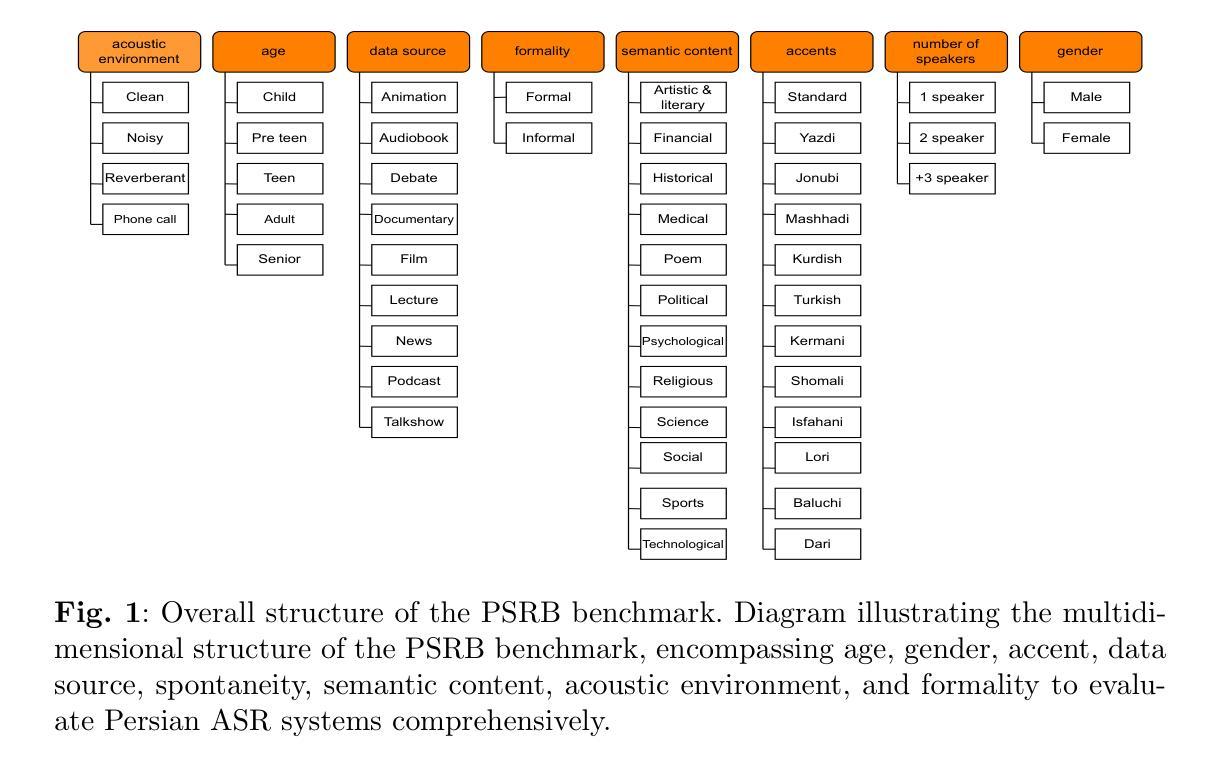
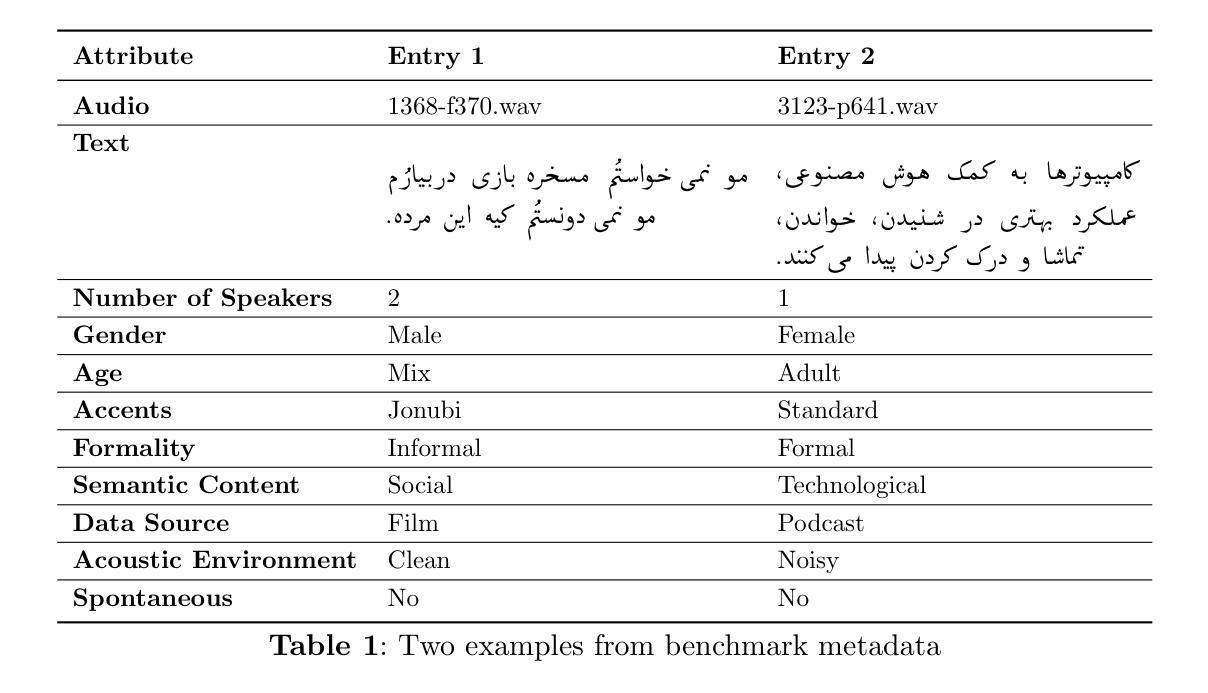
PSRB: A Comprehensive Benchmark for Evaluating Persian ASR Systems
Authors:Nima Sedghiyeh, Sara Sadeghi, Reza Khodadadi, Farzin Kashani, Omid Aghdaei, Somayeh Rahimi, Mohammad Sadegh Safari
Although Automatic Speech Recognition (ASR) systems have become an integral part of modern technology, their evaluation remains challenging, particularly for low-resource languages such as Persian. This paper introduces Persian Speech Recognition Benchmark(PSRB), a comprehensive benchmark designed to address this gap by incorporating diverse linguistic and acoustic conditions. We evaluate ten ASR systems, including state-of-the-art commercial and open-source models, to examine performance variations and inherent biases. Additionally, we conduct an in-depth analysis of Persian ASR transcriptions, identifying key error types and proposing a novel metric that weights substitution errors. This metric enhances evaluation robustness by reducing the impact of minor and partial errors, thereby improving the precision of performance assessment. Our findings indicate that while ASR models generally perform well on standard Persian, they struggle with regional accents, children’s speech, and specific linguistic challenges. These results highlight the necessity of fine-tuning and incorporating diverse, representative training datasets to mitigate biases and enhance overall ASR performance. PSRB provides a valuable resource for advancing ASR research in Persian and serves as a framework for developing benchmarks in other low-resource languages. A subset of the PSRB dataset is publicly available at https://huggingface.co/datasets/PartAI/PSRB.
尽管自动语音识别(ASR)系统已成为现代技术的核心组成部分,但其评估仍然具有挑战性,特别是对于波斯语这样的资源贫乏的语言而言。本文介绍了波斯语音识别基准测试(PSRB),这是一个全面的基准测试,通过融入多种语言和声学条件,旨在解决这一空白。我们评估了10个ASR系统,包括最先进的商业和开源模型,以检查性能变化和固有偏见。此外,我们对波斯语ASR转录进行了深入分析,确定了主要的错误类型,并提出了一个新的度量标准,该标准对替换错误进行加权。此度量标准通过减少微小和局部错误的影响,提高了评估的稳健性,从而提高了性能评估的准确性。我们的研究结果表明,虽然ASR模型在标准波斯语上的表现较好,但在区域性口音、儿童语言和特定语言挑战方面存在困难。这些结果强调了对细微调整以及引入多样化和具有代表性的训练数据集的需要,以减轻偏见并增强ASR的整体性能。PSRB为波斯语ASR研究的发展提供了宝贵的资源,并为其他资源贫乏的语言开发基准测试提供了框架。PSRB数据集的一个子集可在https://huggingface.co/datasets/PartAI/PSRB公开访问。
论文及项目相关链接
PDF 25 pages, 7 figures
Summary:
本文介绍了波斯语语音识别基准测试(PSRB),这是一个全面的基准测试,旨在解决对低资源语言(如波斯语)的语音识别系统的评估挑战。文章评价了十种波斯语语音识别系统,包括最先进的商用和开源模型,并对它们的性能变化和固有偏见进行了深入的分析。同时,通过对波斯语语音识别转录的深入分析,文章确定了主要错误类型,并提出了一种新的权重替代错误评价指标。这一指标降低了轻微和局部错误的影响,提高了性能评估的准确性。研究发现,虽然ASR模型在标准波斯语上表现良好,但在区域性口音、儿童语音和特定语言挑战方面仍存在困难。这强调了微调和使用多样化、具有代表性的训练数据集来减轻偏见和提高整体ASR性能的必要性。PSRB为波斯语语音识别研究的发展提供了宝贵的资源,并为其他低资源语言开发基准测试提供了框架。部分PSRB数据集可在https://huggingface.co/datasets/PartAI/PSRB公开访问。
Key Takeaways:
- 波斯语语音识别基准测试(PSRB)是解决低资源语言语音识别系统评估挑战的全面基准测试。
- PSRB评价了十种波斯语语音识别系统,发现它们在处理区域性口音、儿童语音和特定语言挑战时存在困难。
- 文章提出了一种新的权重替代错误评价指标,以提高性能评估的准确性和鲁棒性。
- PSRB数据集部分公开可用,为波斯语语音识别研究的发展提供了宝贵资源。
- 研究强调了微调和使用多样化、具有代表性的训练数据集在改善ASR性能方面的必要性。
- PSRB为其他低资源语言开发基准测试提供了框架。
点此查看论文截图

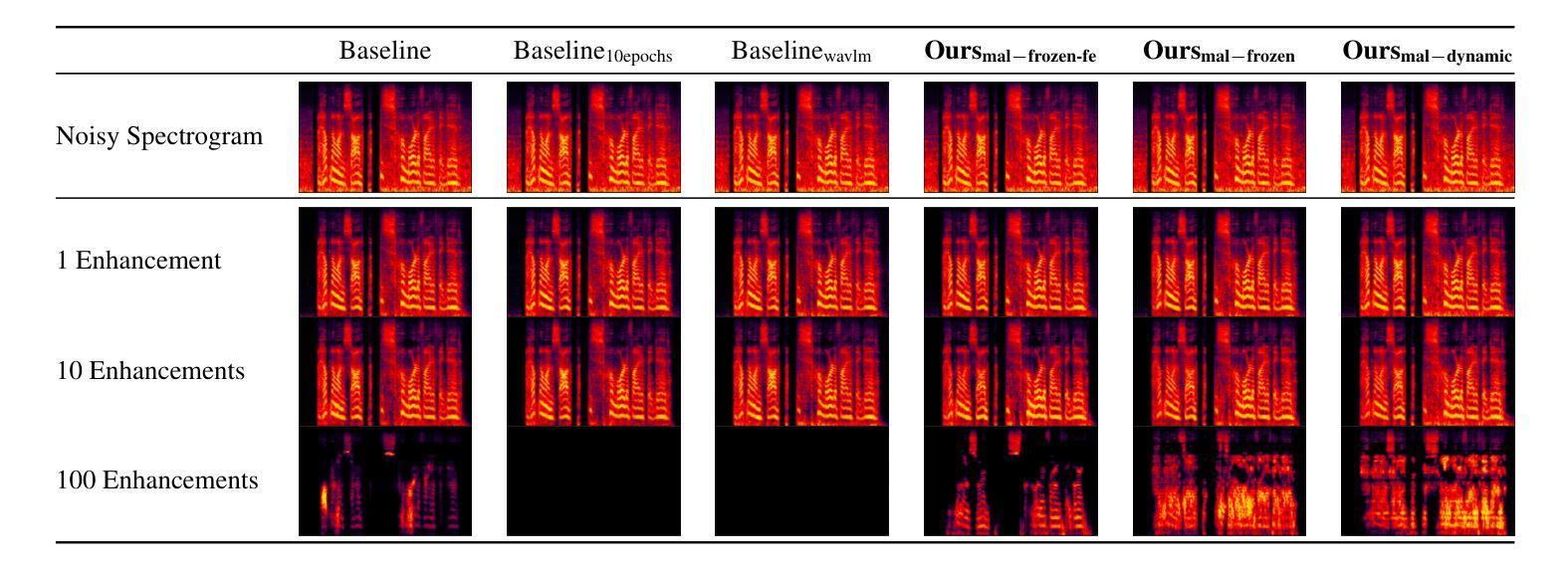
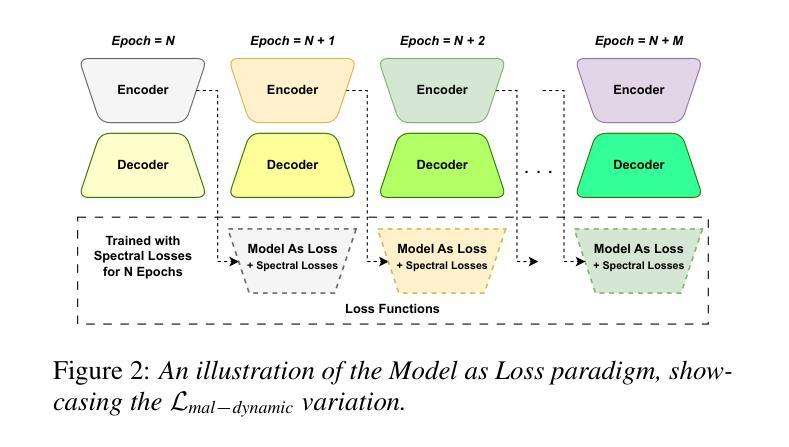
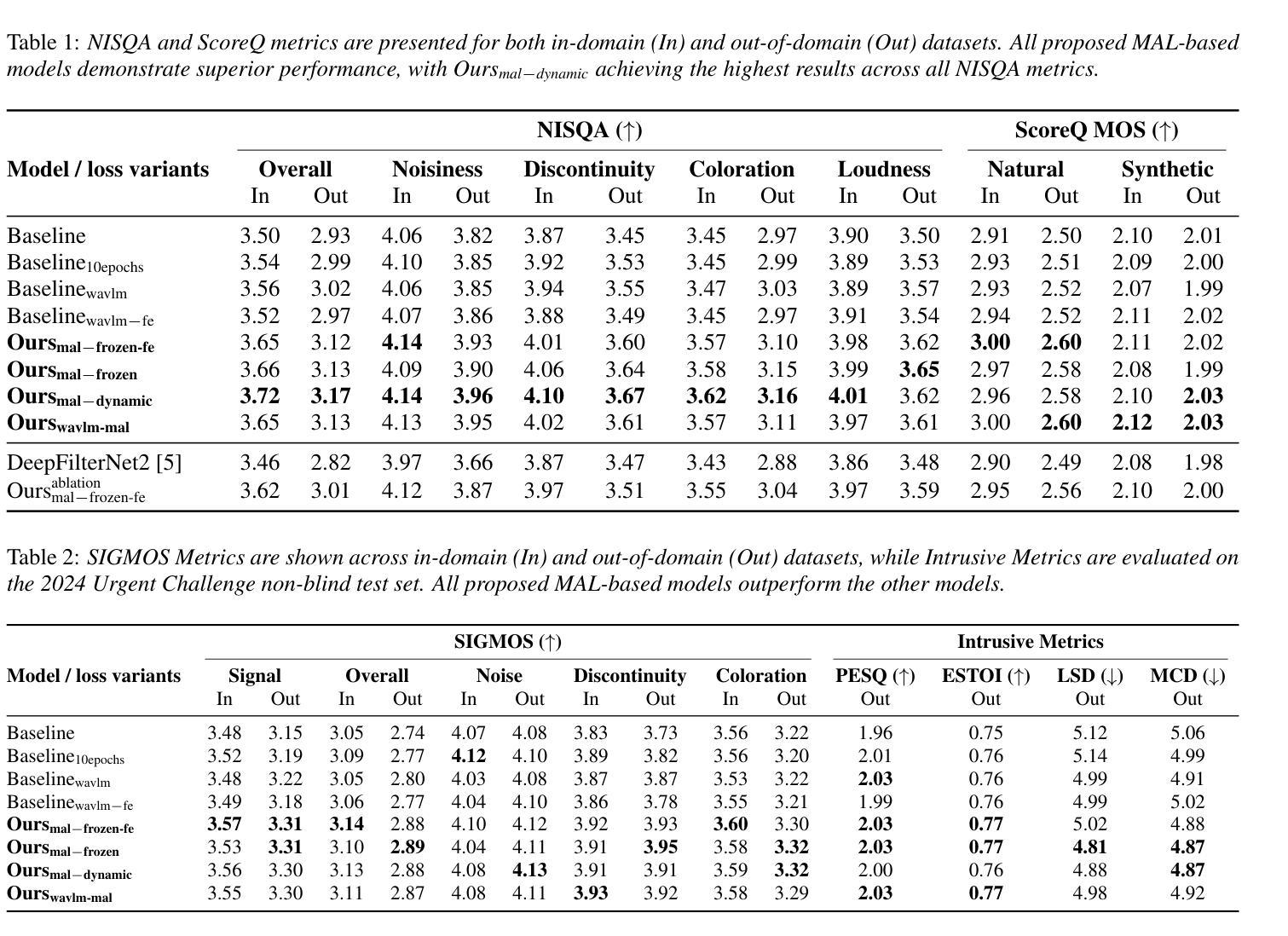
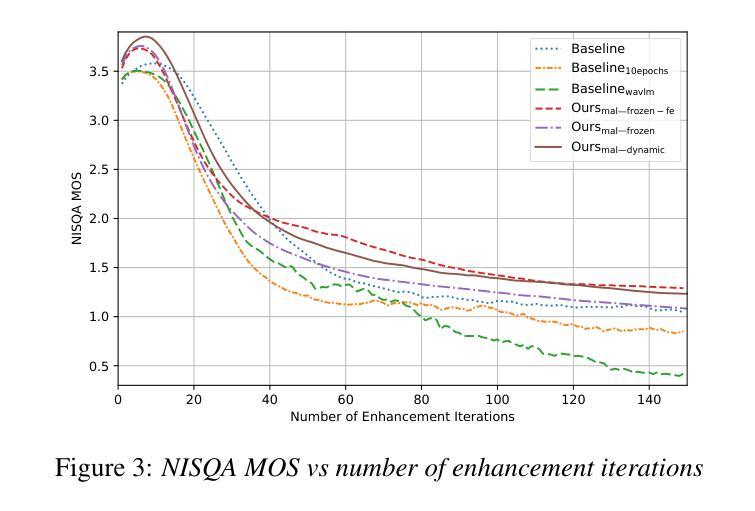
Model as Loss: A Self-Consistent Training Paradigm
Authors:Saisamarth Rajesh Phaye, Milos Cernak, Andrew Harper
Conventional methods for speech enhancement rely on handcrafted loss functions (e.g., time or frequency domain losses) or deep feature losses (e.g., using WavLM or wav2vec), which often fail to capture subtle signal properties essential for optimal performance. To address this, we propose Model as Loss, a novel training paradigm that utilizes the encoder from the same model as a loss function to guide the training. The Model as Loss paradigm leverages the encoder’s task-specific feature space, optimizing the decoder to produce output consistent with perceptual and task-relevant characteristics of the clean signal. By using the encoder’s learned features as a loss function, this framework enforces self-consistency between the clean reference speech and the enhanced model output. Our approach outperforms pre-trained deep feature losses on standard speech enhancement benchmarks, offering better perceptual quality and robust generalization to both in-domain and out-of-domain datasets.
传统的语音增强方法依赖于手工设计的损失函数(例如,时间或频率域损失)或深度特征损失(例如,使用WavLM或wav2vec),这些方法往往无法捕捉到对最佳性能至关重要的细微信号属性。为解决这一问题,我们提出了“模型即损失”(Model as Loss)这一新型训练范式,它利用同一模型的编码器作为损失函数来指导训练。 “模型即损失”范式利用编码器的任务特定特征空间,优化解码器以产生与清洁信号的感知和任务相关特性一致的输出。通过利用编码器学习到的特征作为损失函数,该框架确保了清洁参考语音和增强模型输出之间的自我一致性。我们的方法在标准语音增强基准测试上的表现优于预训练的深度特征损失,提供了更好的感知质量和对域内和域外数据集的稳健泛化能力。
论文及项目相关链接
PDF Accepted in Interspeech 2025
摘要
该文介绍了传统的语音增强方法主要依赖于手工设计的损失函数或深度特征损失,这些常常难以捕捉到细微的信号特征以达到最佳性能。为此,我们提出一种名为“模型作为损失”的新训练范式,它利用同一模型的编码器作为损失函数来指导训练。该范式利用编码器的任务特定特征空间,优化解码器以产生与清洁信号的感知和任务相关特性一致的输出。通过使用编码器学习到的特征作为损失函数,该框架确保了清洁参考语音和增强模型输出之间的自我一致性。我们的方法在标准语音增强基准测试中优于预训练的深度特征损失,提供了更好的感知质量和对域内和域外数据集的稳健泛化能力。
要点
- 传统语音增强方法依赖手工损失函数或深度特征损失,存在性能局限。
- 提出“模型作为损失”的新训练范式,利用同一模型的编码器作为损失函数。
- 该范式利用编码器的任务特定特征空间,优化解码器输出与清洁信号的感知和任务相关特性一致。
- 编码器学习到的特征作为损失函数确保了清洁参考语音和增强模型输出的自我一致性。
- 在标准语音增强基准测试中,该方法优于预训练的深度特征损失。
- 该方法提供了更好的感知质量。
点此查看论文截图

Leveraging LLM and Self-Supervised Training Models for Speech Recognition in Chinese Dialects: A Comparative Analysis
Authors:Tianyi Xu, Hongjie Chen, Wang Qing, Lv Hang, Jian Kang, Li Jie, Zhennan Lin, Yongxiang Li, Xie Lei
Large-scale training corpora have significantly improved the performance of ASR models. Unfortunately, due to the relative scarcity of data, Chinese accents and dialects remain a challenge for most ASR models. Recent advancements in self-supervised learning have shown that self-supervised pre- training, combined with large language models (LLM), can effectively enhance ASR performance in low-resource scenarios. We aim to investigate the effectiveness of this paradigm for Chinese dialects. Specifically, we pre-train a Data2vec2 model on 300,000 hours of unlabeled dialect and accented speech data and do alignment training on a supervised dataset of 40,000 hours. Then, we systematically examine the impact of various projectors and LLMs on Mandarin, dialect, and accented speech recognition performance under this paradigm. Our method achieved SOTA results on multiple dialect datasets, including Kespeech. We will open-source our work to promote reproducible research
大规模训练语料库已经显著提高了语音识别模型(ASR)的性能。然而,由于数据的相对稀缺,中文口音和方言仍然是大多数语音识别模型的挑战。最近自监督学习的进步表明,自监督预训练与大型语言模型(LLM)的结合,可以在资源稀缺的情况下有效增强ASR的性能。我们旨在研究这种范式在中文方言中的应用效果。具体来说,我们在30万小时的无标签方言和带口音的语音数据上预训练了一个Data2vec2模型,并在一个4万小时的监督数据集上进行对齐训练。然后,我们系统地研究了在这种范式下,不同的投影器和LLM对普通话、方言和带口音语音识别性能的影响。我们的方法在多个方言数据集上取得了最新结果,包括Kespeech。我们将开源我们的工作以促进可复制的研究。
论文及项目相关链接
Summary
大规模训练语料库已经显著提高了语音识别模型(ASR)的性能。但由于中文方言口音数据相对稀缺,仍然面临挑战。最新进展表明,利用大规模语言模型(LLM)的自监督预训练可有效提高低资源场景的ASR性能。本研究旨在探讨这一模式在中文方言口音上的应用效果。我们采用Data2vec2模型在未经标注的方言口音语音数据上进行预训练,并利用标注数据集进行对齐训练。实验显示,该模式在多种方言口音数据集上取得了卓越表现,包括Kespeech数据集。我们将公开我们的研究成果以促进可复现性研究。
Key Takeaways
- 大型训练语料库增强了ASR模型的性能。
- 中文方言和口音的数据稀缺是ASR模型面临的挑战。
- 自监督预训练和大规模语言模型(LLM)在低资源场景的ASR性能提升上显示出有效性。
- 研究集中在探讨这一模式在中文方言口音上的应用效果。
- 采用Data2vec2模型进行预训练,并在方言口音语音数据上进行对齐训练。
- 实验显示该模式在多种方言口音数据集上表现优异。
点此查看论文截图

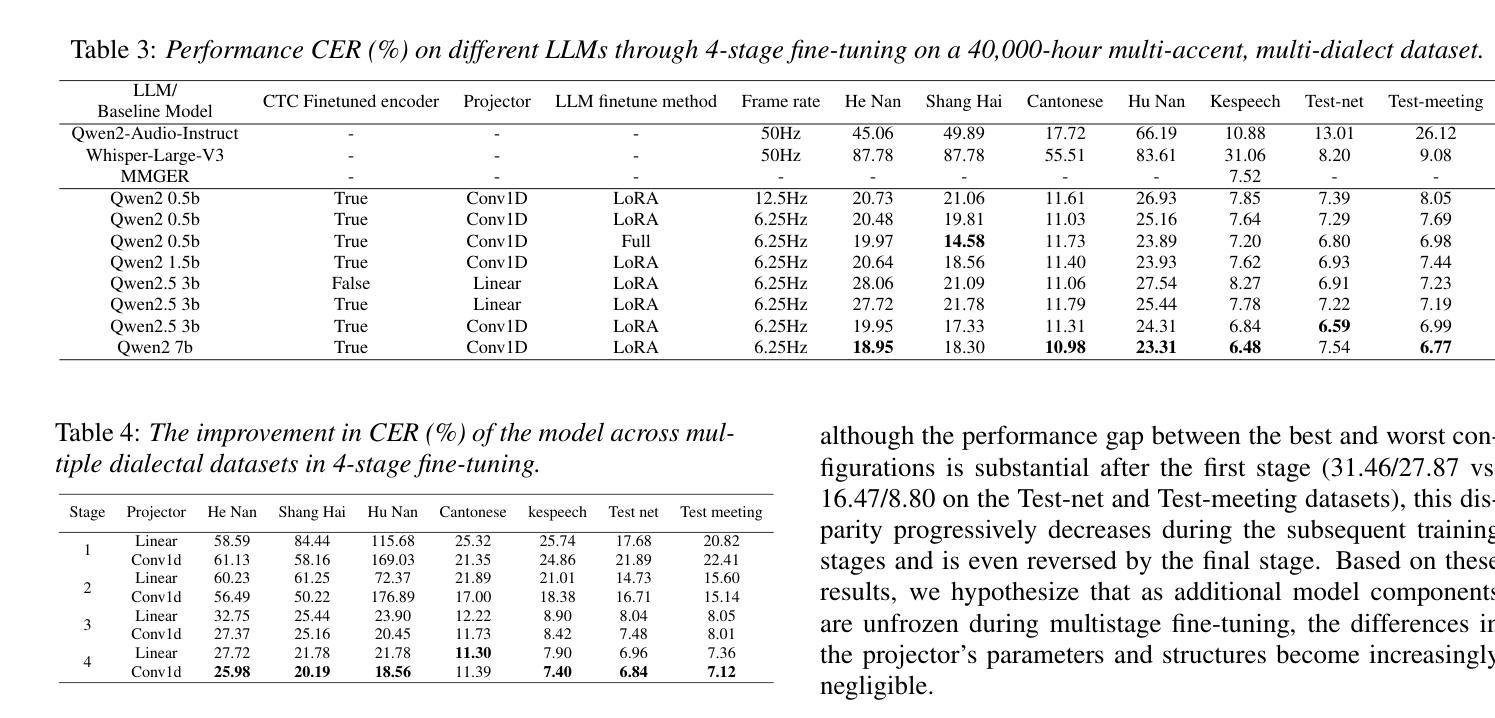
Multimodal Assessment of Speech Impairment in ALS Using Audio-Visual and Machine Learning Approaches
Authors:Francesco Pierotti, Andrea Bandini
The analysis of speech in individuals with amyotrophic lateral sclerosis is a powerful tool to support clinicians in the assessment of bulbar dysfunction. However, current methods used in clinical practice consist of subjective evaluations or expensive instrumentation. This study investigates different approaches combining audio-visual analysis and machine learning to predict the speech impairment evaluation performed by clinicians. Using a small dataset of acoustic and kinematic features extracted from audio and video recordings of speech tasks, we trained and tested some regression models. The best performance was achieved using the extreme boosting machine regressor with multimodal features, which resulted in a root mean squared error of 0.93 on a scale ranging from 5 to 25. Results suggest that integrating audio-video analysis enhances speech impairment assessment, providing an objective tool for early detection and monitoring of bulbar dysfunction, also in home settings.
针对患有肌萎缩侧索硬化症(ALS)的个体的言语分析是支持临床医生评估球部功能障碍的有力工具。然而,目前临床实践中使用的方法包括主观评估或昂贵的仪器。本研究调查了结合视听分析和机器学习的不同方法,以预测临床医生进行的言语障碍评估。我们使用从语音任务的音频和视频记录中提取的少量声学和运动学特征数据集来训练和测试一些回归模型。使用极端增强机回归器进行多模式特征时获得最佳性能,在5到25的范围内得出的均方根误差为0.93。结果表明,结合音视频分析可提高言语障碍评估水平,为在家庭环境中早期检测和监测球部功能障碍提供客观工具。
论文及项目相关链接
PDF Submitted to Interspeech
Summary
本研究探讨了结合视听分析与机器学习的方法,以预测临床医生对运动神经元病患者的言语障碍评估。通过对音频和视频记录中提取的声学和运动特征进行回归模型的训练和测试,使用极端增强机回归器和多模式特征取得了最佳性能,在5至25的范围内均方根误差为0.93。研究结果表明,结合视听分析能够提高言语障碍评估的准确性,为早期发现和监测运动神经元病患者的言语障碍提供客观工具,也适用于家庭环境。
Key Takeaways
- 分析运动神经元病患者的言语对于临床医生评估具有重要意义。
- 当前临床实践中使用的评估方法主要包括主观评价和昂贵的仪器检测。
- 本研究结合了视听分析和机器学习的方法,旨在提高言语障碍评估的准确性。
- 通过使用极端增强机回归器和多模式特征,取得了最佳性能。
- 视听分析结合的方法在评估运动神经元病患者的言语障碍方面表现出良好的潜力。
- 该方法可为早期发现和监测运动神经元病患者的言语障碍提供客观工具。
点此查看论文截图

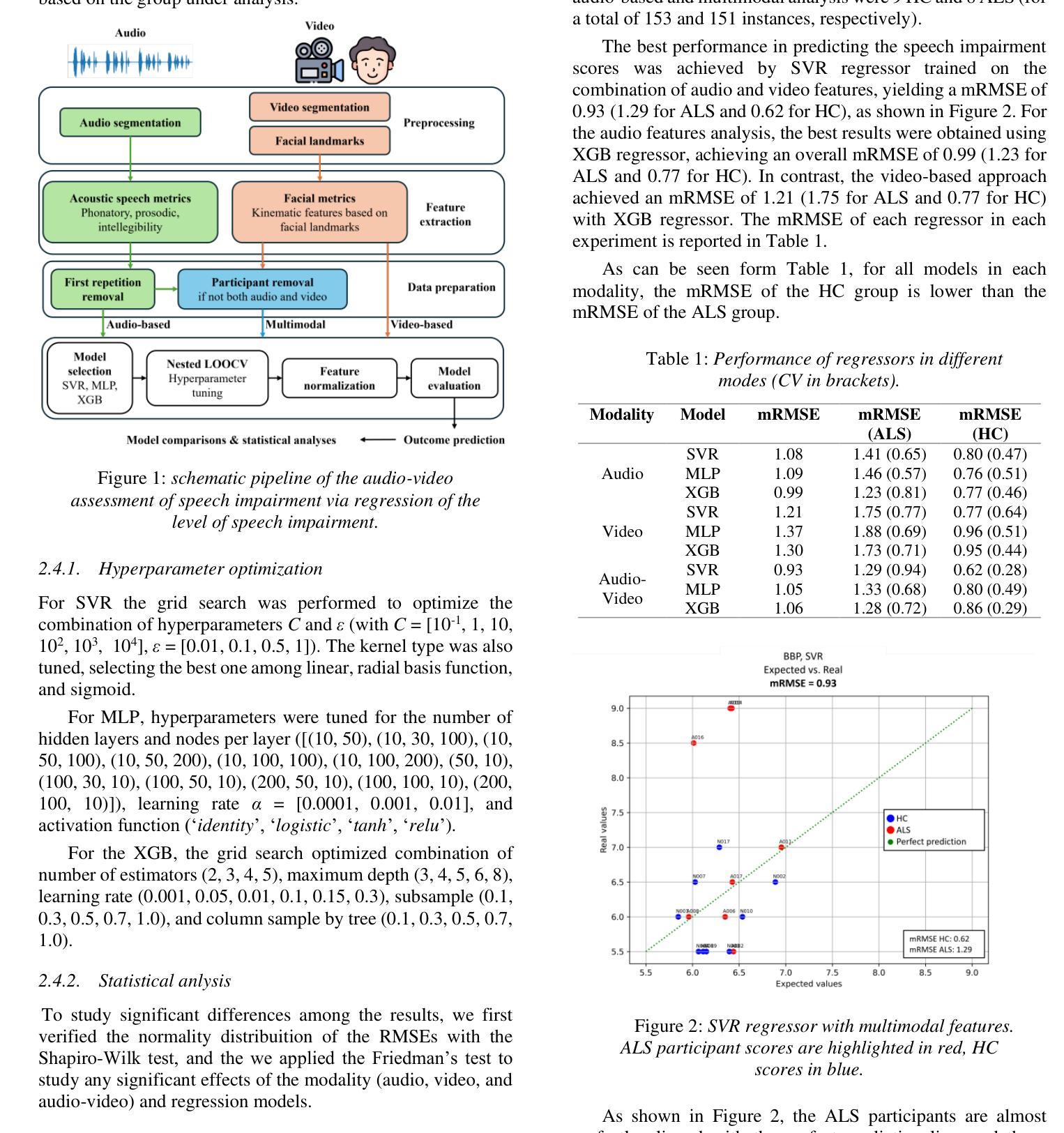
Study of Lightweight Transformer Architectures for Single-Channel Speech Enhancement
Authors:Haixin Zhao, Nilesh Madhu
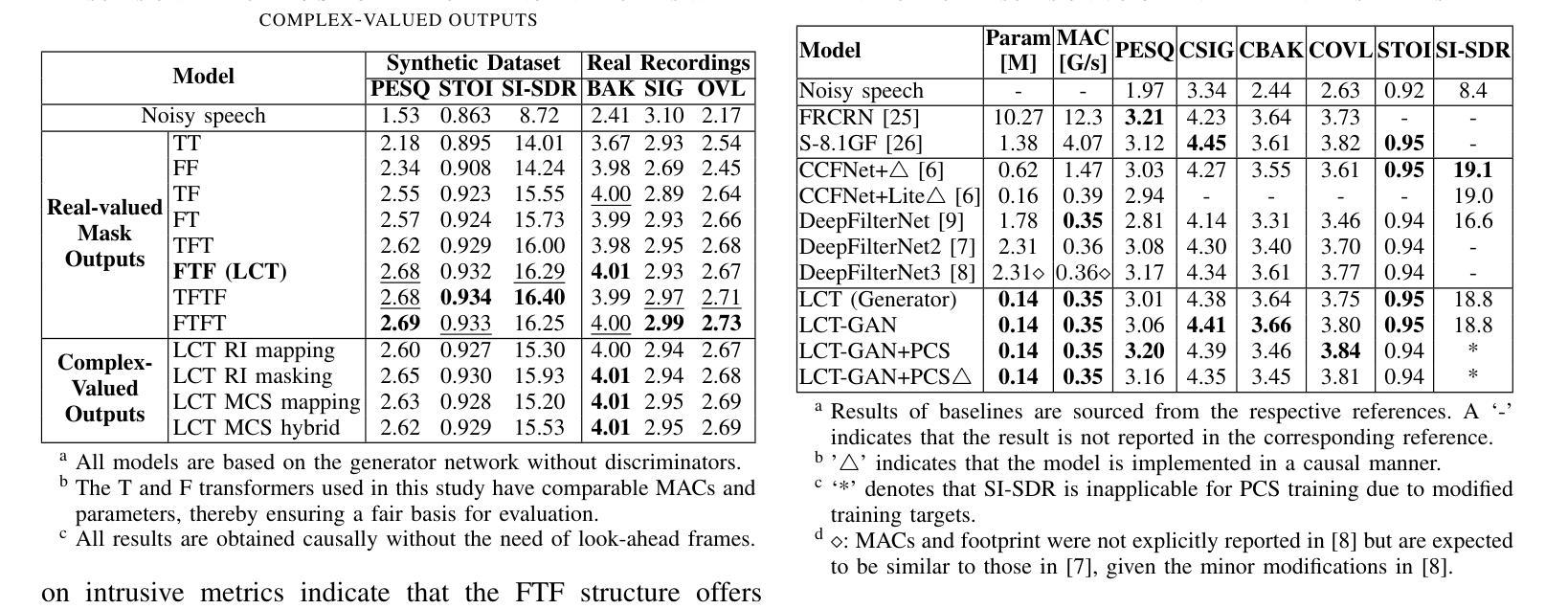
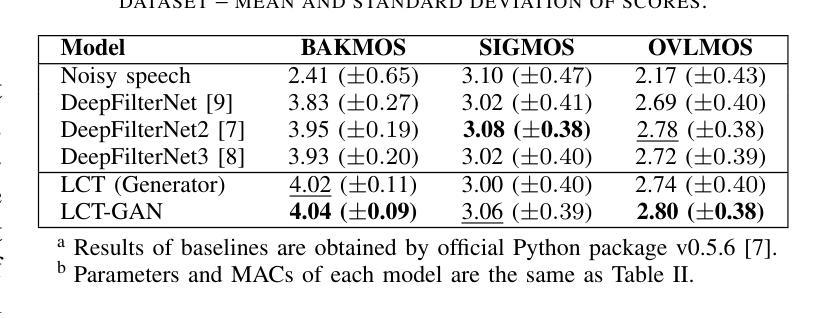
In speech enhancement, achieving state-of-the-art (SotA) performance while adhering to the computational constraints on edge devices remains a formidable challenge. Networks integrating stacked temporal and spectral modelling effectively leverage improved architectures such as transformers; however, they inevitably incur substantial computational complexity and model expansion. Through systematic ablation analysis on transformer-based temporal and spectral modelling, we demonstrate that the architecture employing streamlined Frequency-Time-Frequency (FTF) stacked transformers efficiently learns global dependencies within causal context, while avoiding considerable computational demands. Utilising discriminators in training further improves learning efficacy and enhancement without introducing additional complexity during inference. The proposed lightweight, causal, transformer-based architecture with adversarial training (LCT-GAN) yields SoTA performance on instrumental metrics among contemporary lightweight models, but with far less overhead. Compared to DeepFilterNet2, the LCT-GAN only requires 6% of the parameters, at similar complexity and performance. Against CCFNet+(Lite), LCT-GAN saves 9% in parameters and 10% in multiply-accumulate operations yet yielding improved performance. Further, the LCT-GAN even outperforms more complex, common baseline models on widely used test datasets.
在语音增强领域,在满足边缘设备的计算约束的同时实现最新前沿技术(SotA)性能仍然是一个巨大的挑战。网络集成了堆叠的时间模型和光谱模型,有效地利用了改进的结构如变压器;然而,这不可避免地会导致大量的计算复杂性和模型扩展。通过对基于变压器的时序和光谱建模进行系统消融分析,我们证明采用简化型频时频(FTF)堆叠变压器的架构能够在因果上下文中有效地学习全局依赖性,同时避免了巨大的计算需求。在训练中利用鉴别器进一步提高了学习效率,增强了学习效果,而不会引入推理过程中的额外复杂性。所提出的基于轻量级、因果性、对抗训练的变压器架构(LCT-GAN)在当代轻量级模型中获得了仪器指标的前沿性能,但开销大大降低。与DeepFilterNet2相比,LCT-GAN仅需要6%的参数,在复杂性和性能上相似。与CCFNet+(Lite)相比,LCT-GAN节省了9%的参数和10%的乘积累操作,同时却取得了更好的性能。此外,LCT-GAN甚至在广泛使用的测试数据集上表现优于更复杂、常见的基线模型。
论文及项目相关链接
PDF Accepted by EUSIPCO 2025
Summary
在语音增强领域,尽管存在许多基于神经网络的技术能够利用先进架构(如变压器)实现最新技术水平(SotA)的性能,但在边缘设备上实现计算约束的同时保持高性能仍然是一个挑战。本研究通过系统性分析变压器在时序和频谱建模中的应用,提出了一种采用流线化频时频(FTF)堆叠变压器架构的方法,能够在因果上下文中高效学习全局依赖关系,同时避免计算复杂度过高的问题。在训练过程中引入鉴别器提高了学习效率并增强了效果,且在推理过程中不会增加额外的复杂性。所提出基于对抗性训练的轻量级因果变压器架构(LCT-GAN)在现代轻量级模型中实现了领先水平的表现。与DeepFilterNet2相比,LCT-GAN的参数需求仅占其6%,在复杂性和性能上与之相当或更优。相较于更复杂的基线模型CCFNet+(Lite),LCT-GAN在参数和乘积累加运算上分别节省了9%和10%,同时表现更佳。
Key Takeaways
- 在语音增强领域,实现计算约束下的最新技术水平性能是一大挑战。
- 基于变压器的频时频(FTF)堆叠架构能高效学习全局依赖关系,并减少计算复杂度。
- 在训练中加入鉴别器有助于提高学习效率并增强效果,且不影响推理阶段的复杂性。
- LCT-GAN架构在现代轻量级模型中表现出领先水平。
- 与DeepFilterNet2相比,LCT-GAN在参数需求上大幅降低,同时保持相当的复杂性和性能。
- LCT-GAN相较于更复杂的基线模型CCFNet+(Lite)在参数和运算效率上有所改善,同时性能更佳。
点此查看论文截图

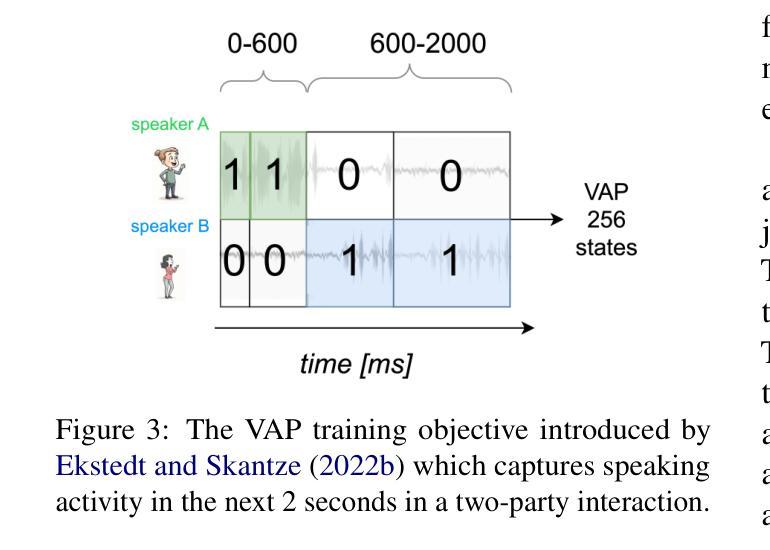
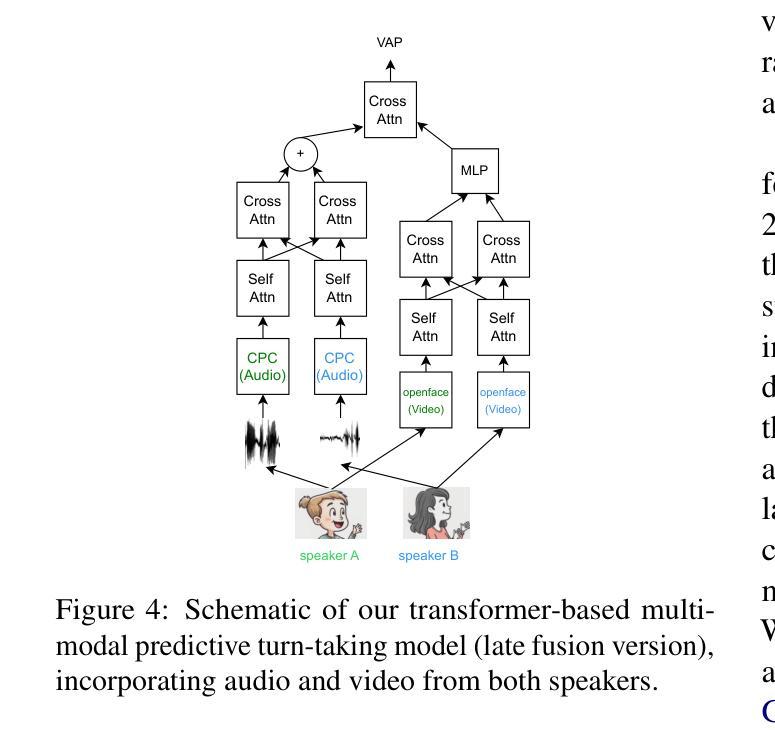
Visual Cues Enhance Predictive Turn-Taking for Two-Party Human Interaction
Authors:Sam O’Connor Russell, Naomi Harte
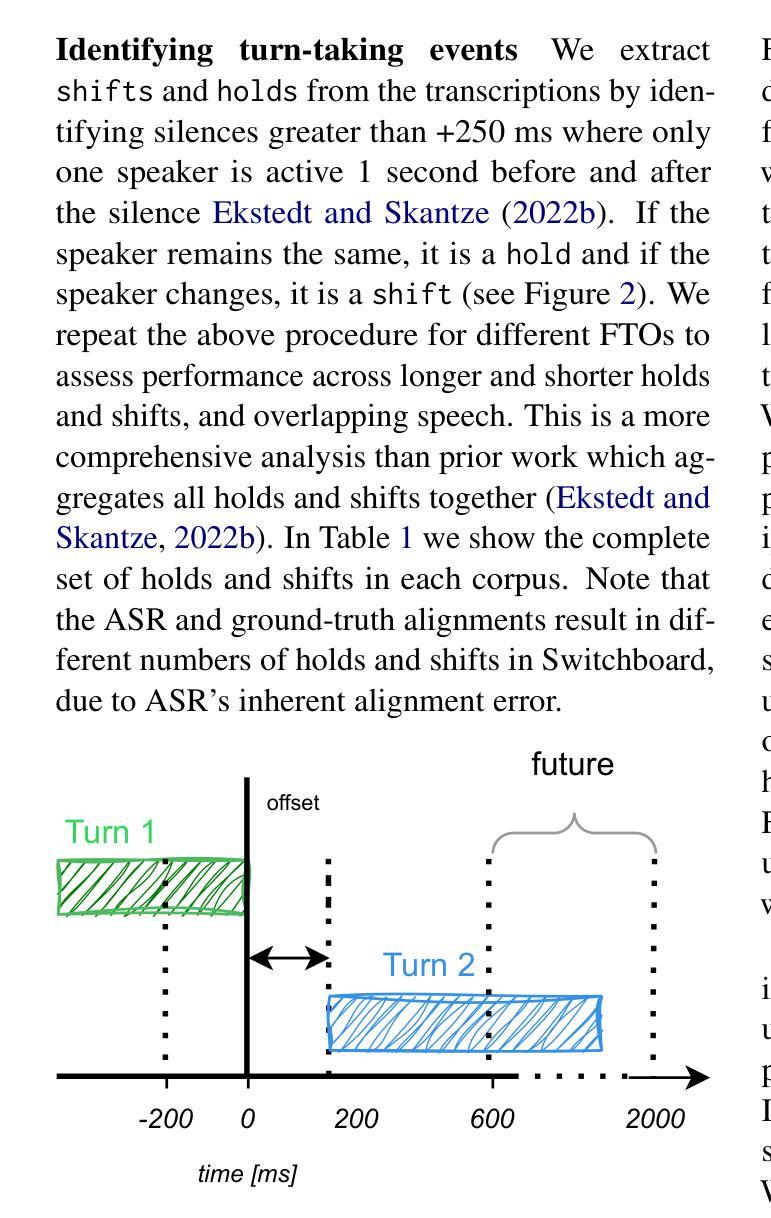
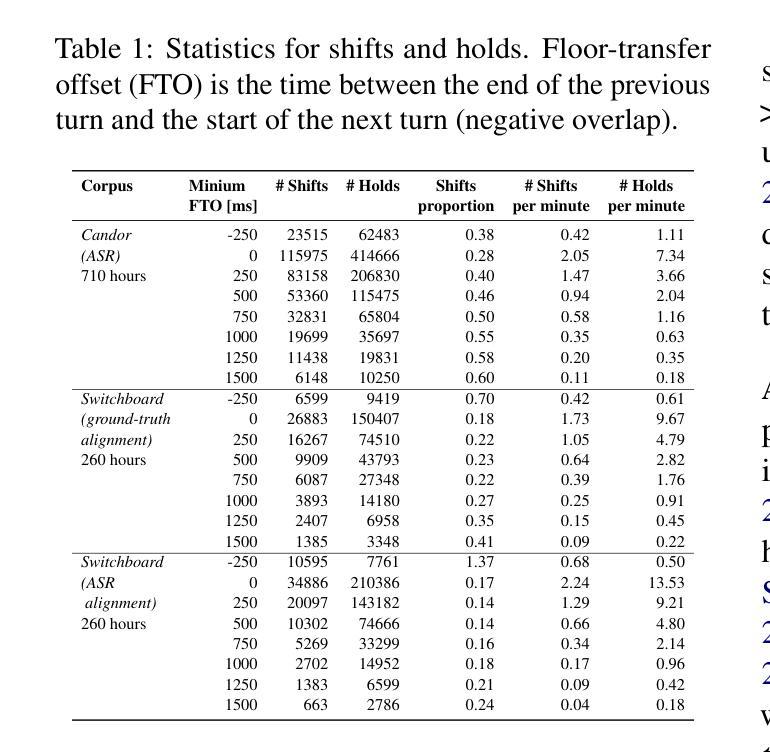
Turn-taking is richly multimodal. Predictive turn-taking models (PTTMs) facilitate naturalistic human-robot interaction, yet most rely solely on speech. We introduce MM-VAP, a multimodal PTTM which combines speech with visual cues including facial expression, head pose and gaze. We find that it outperforms the state-of-the-art audio-only in videoconferencing interactions (84% vs. 79% hold/shift prediction accuracy). Unlike prior work which aggregates all holds and shifts, we group by duration of silence between turns. This reveals that through the inclusion of visual features, MM-VAP outperforms a state-of-the-art audio-only turn-taking model across all durations of speaker transitions. We conduct a detailed ablation study, which reveals that facial expression features contribute the most to model performance. Thus, our working hypothesis is that when interlocutors can see one another, visual cues are vital for turn-taking and must therefore be included for accurate turn-taking prediction. We additionally validate the suitability of automatic speech alignment for PTTM training using telephone speech. This work represents the first comprehensive analysis of multimodal PTTMs. We discuss implications for future work and make all code publicly available.
会话交替是多模式的。预测会话交替模型(PTTMs)促进了人类与机器人的自然交互,但大多数仅依赖于语音。我们引入了MM-VAP(多模态预测会话交替模型),这是一种结合了语音与视觉线索(包括面部表情、头部姿态和目光注视)的多模式预测会话交替模型。我们发现它在视频会议交互中超过了当前领先的仅依赖音频的模型(保持/转换预测准确率为84% vs. 79%)。与以往将所有保持和转变汇总的研究不同,我们按不同会话间的沉默时长进行分组。这表明通过包含视觉特征,MM-VAP在所有发言者过渡时长中,都超过了仅依赖音频的预测会话交替模型的最佳表现。我们进行了详细的切除研究,结果显示面部表情特征对模型性能贡献最大。因此,我们的假设是,当对话者可以相互看见时,视觉线索对于会话交替至关重要,因此必须包含以进行准确的会话交替预测。我们还验证了自动语音对齐在PTTM训练中的适用性,使用电话语音。这项工作代表了首个对多模式PTTM的全面分析。我们讨论了未来工作的启示并使所有代码公开可用。
论文及项目相关链接
Summary
本文介绍了一种多模态预测性对话模型MM-VAP,它结合了语音、面部表情、头部姿态和目光等多模态信息来进行对话中的发言者切换预测。相较于仅依赖语音的模型,MM-VAP在视频会议交互中表现更佳,预测准确率提高了从百分之几到百分之几十不等。此外,该研究还探讨了不同视觉特征对模型性能的影响,发现面部表情特征对模型性能贡献最大。最后,该研究还验证了利用电话语音进行自动语音对齐以训练预测性对话模型的可行性。此项工作为多模态预测性对话模型的首个综合分析。
Key Takeaways
- MM-VAP是一种多模态预测性对话模型,融合了语音、面部表情、头部姿态和目光等多模态信息。
- MM-VAP在视频会议交互中的表现优于仅依赖语音的模型,预测准确率有所提升。
- 相较于先前的研究,MM-VAP能够根据发言者转换的持续时间分组进行预测,提高了预测的准确性。
- 通过研究不同视觉特征对模型性能的影响,发现面部表情特征对模型性能贡献最大。
- 当对话者能够相互看见时,视觉线索对于对话中的发言者切换预测至关重要。
- 该研究验证了利用电话语音进行自动语音对齐以训练预测性对话模型的可行性。
点此查看论文截图


ClearSphere: Multi-Earphone Synergy for Enhanced Conversational Clarity
Authors:Lixing He
In crowded places such as conferences, background noise, overlapping voices, and lively interactions make it difficult to have clear conversations. This situation often worsens the phenomenon known as “cocktail party deafness.” We present ClearSphere, the collaborative system that enhances speech at the conversation level with multi-earphones. Real-time conversation enhancement requires a holistic modeling of all the members in the conversation, and an effective way to extract the speech from the mixture. ClearSphere bridges the acoustic sensor system and state-of-the-art deep learning for target speech extraction by making two key contributions: 1) a conversation-driven network protocol, and 2) a robust target conversation extraction model. Our networking protocol enables mobile, infrastructure-free coordination among earphone devices. Our conversation extraction model can leverage the relay audio in a bandwidth-efficient way. ClearSphere is evaluated in both real-world experiments and simulations. Results show that our conversation network obtains more than 90% accuracy in group formation, improves the speech quality by up to 8.8 dB over state-of-the-art baselines, and demonstrates real-time performance on a mobile device. In a user study with 20 participants, ClearSphere has a much higher score than baseline with good usability.
在会议等拥挤场所,背景噪音、声音重叠以及活跃的互动使得进行清晰的对话变得困难。这种情况往往会加剧所谓的“鸡尾酒会耳聋”现象。我们推出了ClearSphere,这是一款协作系统,通过多耳机在对话级别上增强语音。实时对话增强需要对所有对话成员进行整体建模,以及从混合语音中有效提取语音的有效方法。ClearSphere通过两项关键贡献——1)对话驱动的网络协议和2)稳健的目标对话提取模型,架设了声学传感器系统和最新的深度学习目标语音提取之间的桥梁。我们的网络协议实现了耳机设备之间无需基础设施的移动协调。我们的对话提取模型能够以带宽有效的方式利用中继音频。ClearSphere在真实实验和模拟中都得到了评估。结果表明,我们的对话网络在群体形成方面达到了超过90%的准确率,在最新基线的基础上提高了高达8.8分贝的语音质量,并在移动设备上实现了实时性能。在20名参与者的一项用户研究中,ClearSphere的得分远高于基线,具有良好的可用性。
论文及项目相关链接
Summary:
清晰球体系统是一款面向对话场景的语音增强协作系统,通过移动设备实现对话成员间的实时交流。该系统采用先进的深度学习技术提取目标语音,并引入新型网络协议,以改善背景噪音和多人对话时的听力问题。实验结果显示,该系统在群体识别上有超过90%的准确率,相对于其他基准方案改善了语音质量达8.8分贝,同时展示了出色的实时性能和使用体验。这项创新将有助于改善多人场景下的听力困难。
Key Takeaways:
- 清晰球体系统采用先进的深度学习技术提升语音增强能力。
- 系统引入新型网络协议,实现移动设备间的实时交流协作。
- 实验结果显示,该系统在群体识别上有超过90%的准确率。
- 与其他基准方案相比,语音质量提高了高达8.8分贝。
- 系统展示了出色的实时性能和使用体验。
- 该系统能有效改善多人场景下的听力困难问题。
点此查看论文截图

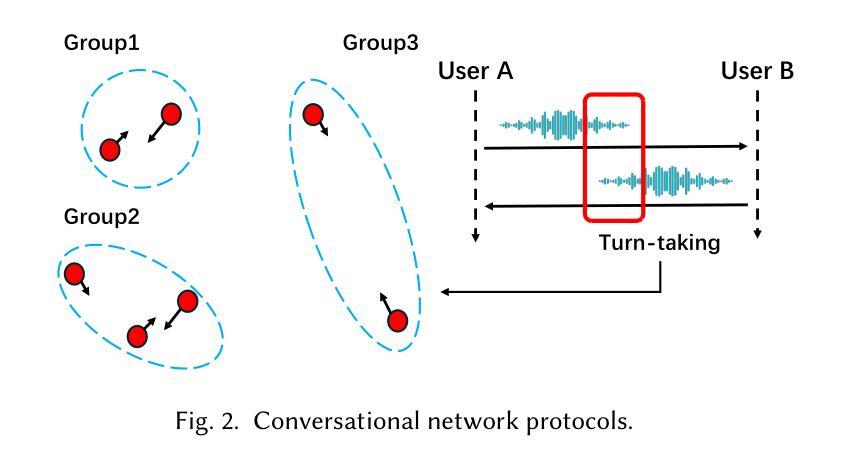
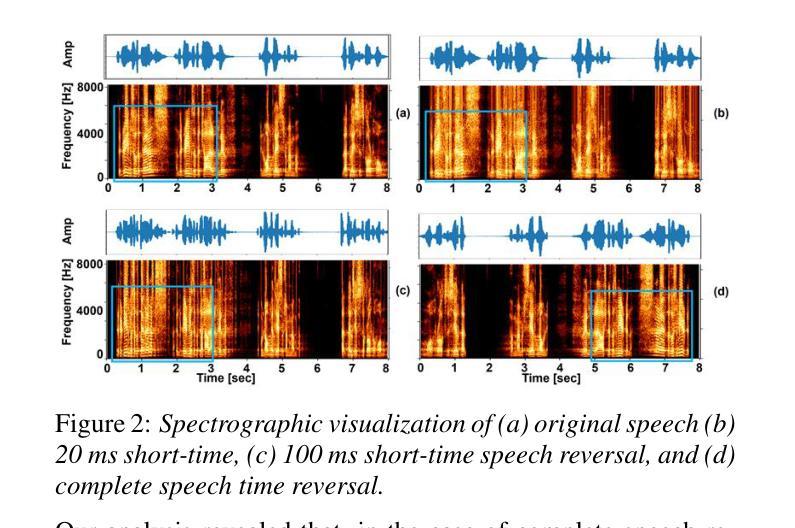
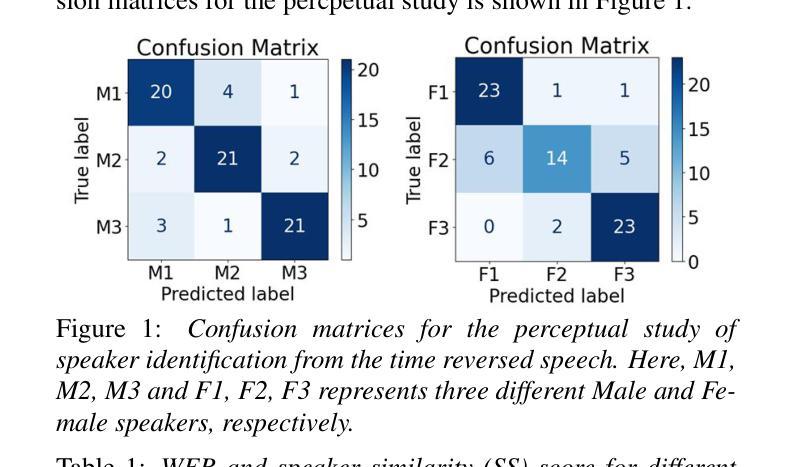
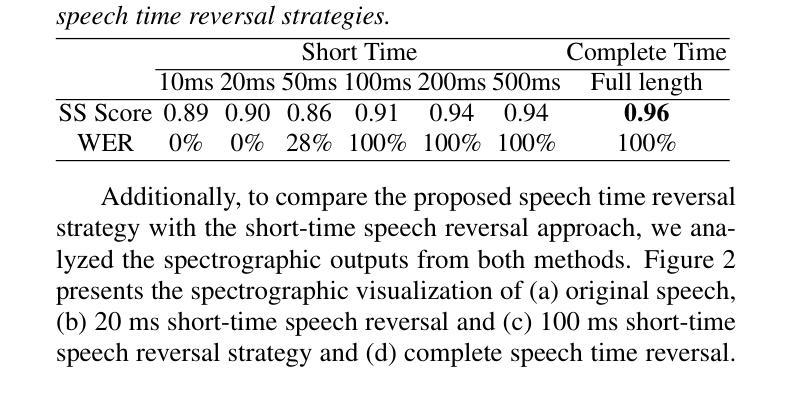
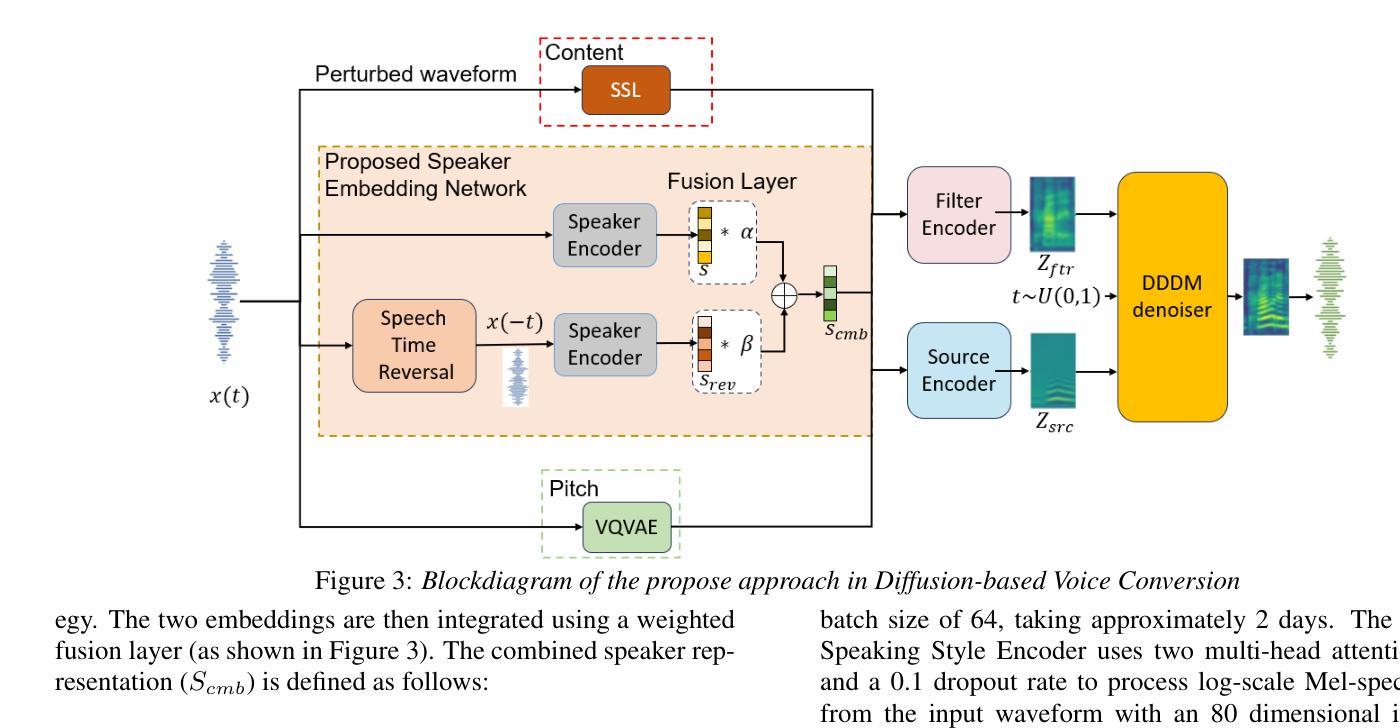
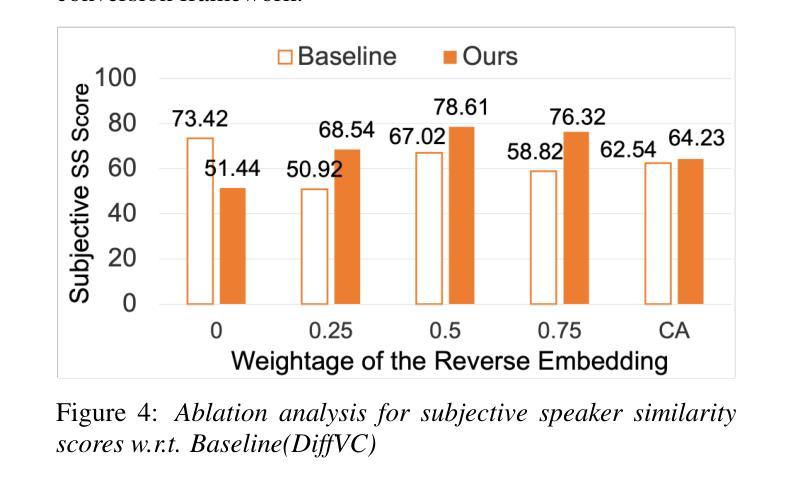
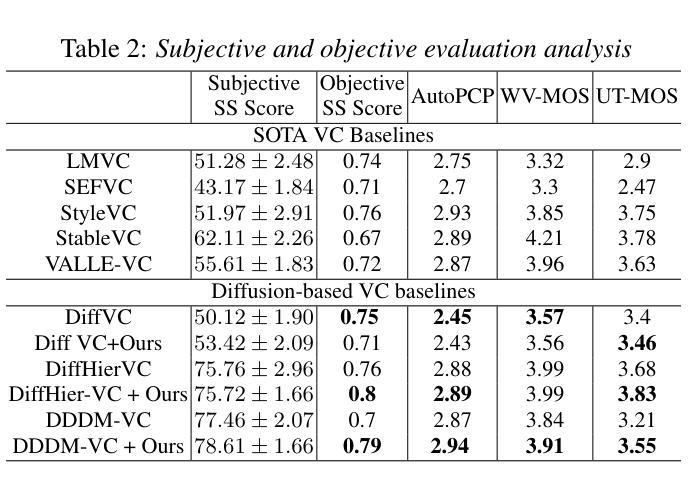
REWIND: Speech Time Reversal for Enhancing Speaker Representations in Diffusion-based Voice Conversion
Authors:Ishan D. Biyani, Nirmesh J. Shah, Ashishkumar P. Gudmalwar, Pankaj Wasnik, Rajiv R. Shah
Speech time reversal refers to the process of reversing the entire speech signal in time, causing it to play backward. Such signals are completely unintelligible since the fundamental structures of phonemes and syllables are destroyed. However, they still retain tonal patterns that enable perceptual speaker identification despite losing linguistic content. In this paper, we propose leveraging speaker representations learned from time reversed speech as an augmentation strategy to enhance speaker representation. Notably, speaker and language disentanglement in voice conversion (VC) is essential to accurately preserve a speaker’s unique vocal traits while minimizing interference from linguistic content. The effectiveness of the proposed approach is evaluated in the context of state-of-the-art diffusion-based VC models. Experimental results indicate that the proposed approach significantly improves speaker similarity-related scores while maintaining high speech quality.
语音时间反转是指将整个语音信号在时间上倒转,使其倒放。由于音素和音节的基本结构被破坏,这种信号是完全不可理解的。然而,它们仍然保留能够感知说话人身份的语调模式,尽管失去了语言内容。在本文中,我们提出利用从时间反转语音中学习到的说话人表征作为一种增强策略,以提高说话人表征。值得注意的是,在语音转换(VC)中,说话人和语言的去耦是关键,这样可以准确保留说话人独特的嗓音特征,同时最小化语言内容的干扰。所提出方法的有效性在基于最先进的扩散的VC模型背景下进行了评估。实验结果表明,该方法在保持高语音质量的同时,显著提高了与说话人相似性相关的分数。
论文及项目相关链接
PDF Accepted in INTERSPEECH 2025
Summary:
语音时间反转是指将整个语音信号在时间上进行反转,使其向后播放。虽然这种信号无法理解,但它们仍然保留了音调的模式,可以进行说话者感知识别,尽管失去了语言内容。本文提出了利用从时间反转语音中学习到的说话者表征作为增强策略,以提高说话者表征。在基于扩散的语音转换模型中评估了该方法的有效性,实验结果表明,该方法在保持高语音质量的同时,显著提高了与说话者相似性相关的分数。
Key Takeaways:
- 语音时间反转是指将语音信号反向播放,导致信号不可理解,但仍可识别说话者。
- 时间反转的语音保留了音调的模式,使得说话者能够被识别。
- 说话者和语言的分离在语音转换中是关键,旨在准确保留说话者的独特嗓音特征,同时尽量减少语言内容的干扰。
- 论文提出了一种利用从时间反转语音中学习到的说话者表征作为增强策略的方法。
- 该方法在基于扩散的语音转换模型中进行评估。
- 实验结果表明,该方法显著提高了说话者相似性相关的分数。
点此查看论文截图

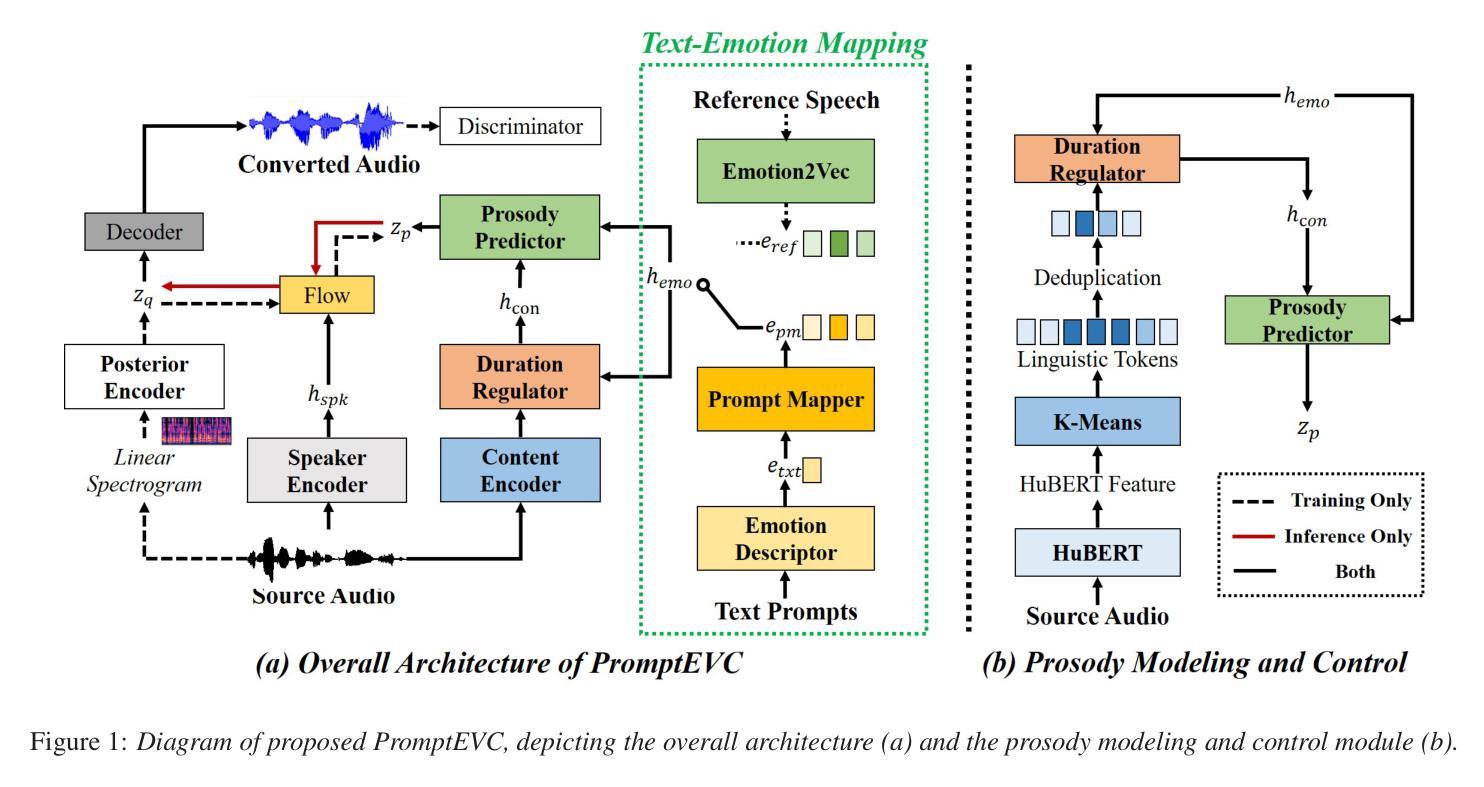
PromptEVC: Controllable Emotional Voice Conversion with Natural Language Prompts
Authors:Tianhua Qi, Shiyan Wang, Cheng Lu, Tengfei Song, Hao Yang, Zhanglin Wu, Wenming Zheng
Controllable emotional voice conversion (EVC) aims to manipulate emotional expressions to increase the diversity of synthesized speech. Existing methods typically rely on predefined labels, reference audios, or prespecified factor values, often overlooking individual differences in emotion perception and expression. In this paper, we introduce PromptEVC that utilizes natural language prompts for precise and flexible emotion control. To bridge text descriptions with emotional speech, we propose emotion descriptor and prompt mapper to generate fine-grained emotion embeddings, trained jointly with reference embeddings. To enhance naturalness, we present a prosody modeling and control pipeline that adjusts the rhythm based on linguistic content and emotional cues. Additionally, a speaker encoder is incorporated to preserve identity. Experimental results demonstrate that PromptEVC outperforms state-of-the-art controllable EVC methods in emotion conversion, intensity control, mixed emotion synthesis, and prosody manipulation. Speech samples are available at https://jeremychee4.github.io/PromptEVC/.
可控情感语音转换(EVC)旨在通过操纵情感表达来增加合成语音的多样性。现有方法通常依赖于预定义的标签、参考音频或预先设定的因子值,往往忽视了情感感知和表达的个体差异。在本文中,我们介绍了PromptEVC,它利用自然语言提示来进行精确和灵活的情绪控制。为了架起文本描述与情感语音之间的桥梁,我们提出了情感描述符和提示映射器,以生成精细的情绪嵌入,与参考嵌入联合训练。为了提高自然度,我们提出了一种语调建模和控制流程,该流程根据语言内容和情感线索调整节奏。此外,还融入了说话人编码器以保留身份。实验结果表明,在情感转换、强度控制、混合情感合成和语调操纵方面,PromptEVC优于最新的可控EVC方法。语音样本可在https://jeremychee4.github.io/PromptEVC/找到。
论文及项目相关链接
PDF Accepted to INTERSPEECH2025
Summary
情感可控的语音转换(EVC)旨在通过操纵情感表达来增加合成语音的多样性。传统方法通常依赖于预设标签、参考音频或预设因子值,往往忽略了情感感知和表达的个体差异。本文介绍了一种利用自然语言提示进行精确灵活的情感控制的PromptEVC方法。为了将文本描述与情感语音相结合,我们提出了情绪描述符和提示映射器来生成精细的情绪嵌入,与参考嵌入联合训练。为了提高自然度,我们提出了一种韵律建模和控制管道,根据语言内容和情感线索调整节奏。此外,还融入了说话人编码器以保留身份特征。实验结果表明,PromptEVC在情感转换、强度控制、混合情感合成和韵律操控方面优于现有的可控EVC方法。语音样本可在https://jeremychee4.github.io/PromptEVC/找到。
Key Takeaways
- PromptEVC方法利用自然语言提示进行情感控制的精确和灵活转换。
- 通过情绪描述符和提示映射器生成精细情绪嵌入,与参考嵌入联合训练。
- 提出了韵律建模和控制管道,根据语言内容和情感线索调整节奏,增强语音的自然度。
- 融入了说话人编码器以保留身份特征。
- 实验结果表明,PromptEVC在情感转换、强度控制等方面优于现有方法。
- 提供了一个在线语音样本库供公众访问,展示了研究成果的实际应用。
点此查看论文截图

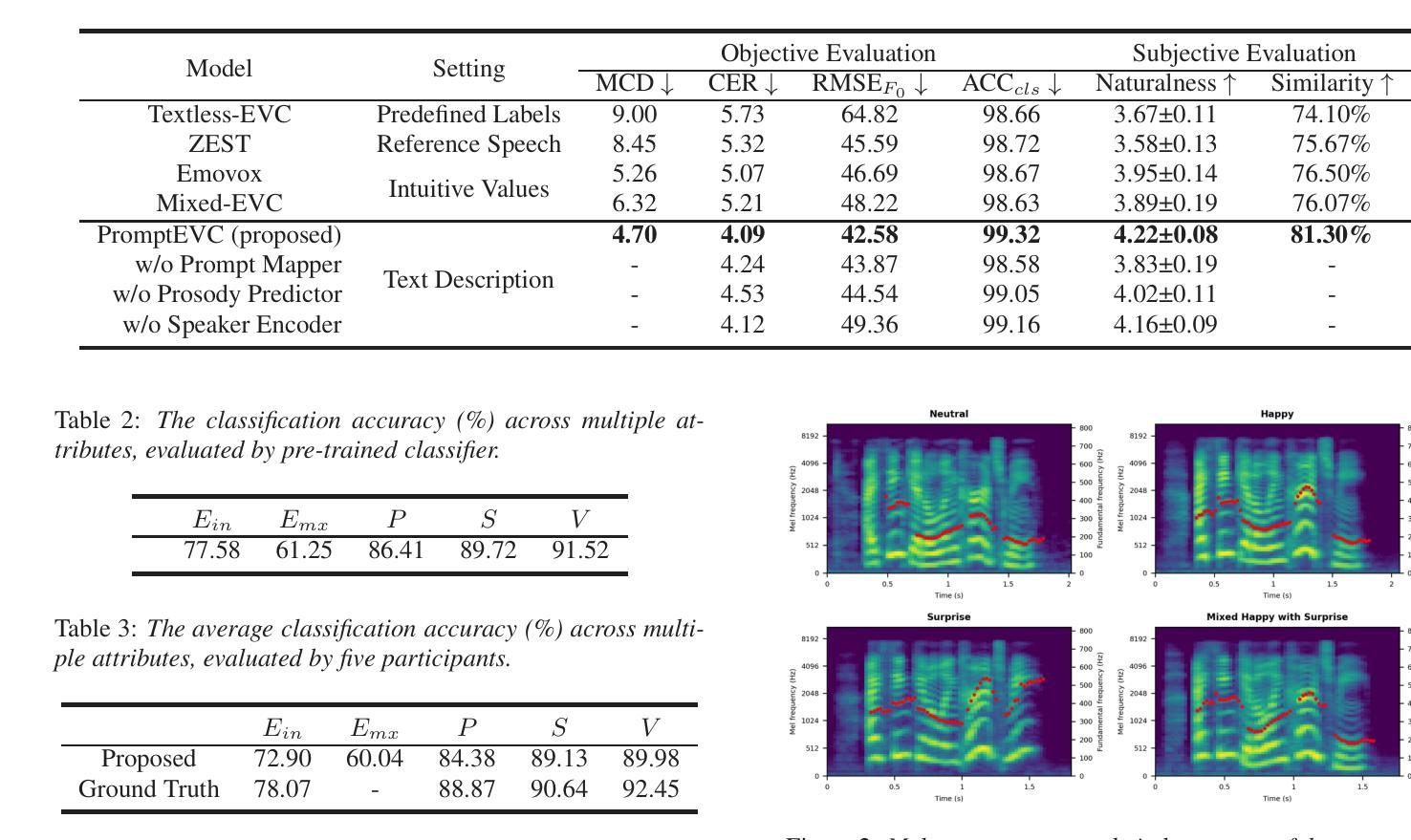
Robust fine-tuning of speech recognition models via model merging: application to disordered speech
Authors:Alexandre Ducorroy, Rachid Riad
Automatic Speech Recognition (ASR) has advanced with Speech Foundation Models (SFMs), yet performance degrades on dysarthric speech due to variability and limited data. This study as part of the submission to the Speech Accessibility challenge, explored model merging to improve ASR generalization using Whisper as the base SFM. We compared fine-tuning with single-trajectory merging, combining models from one fine-tuning path, and multi-run merging, merging independently trained models. Our best multi-run merging approach achieved a 12% relative decrease of WER over classic fine-tuning, and a 16.2% relative decrease on long-form audios, a major loss contributor in dysarthric ASR. Merging more and more models led to continuous gains, remained effective in low-data regimes, and generalized across model architectures. These results highlight model merging as an easily replicable adaptation method that consistently improves ASR without additional inference cost or hyperparameter tuning.
自动语音识别(ASR)随着语音基础模型(SFM)的发展而进步,但由于变异性和数据有限,它在构音障碍语音上的性能会下降。本研究作为提交给语音可访问性挑战的一部分,探索了通过模型合并使用whisper作为基本SFM来提高ASR泛化的方法。我们比较了微调与单轨迹合并,即来自一条微调路径的模型合并,以及多运行合并,即合并独立训练的模型。我们最好的多运行合并方法实现了相对字词错误率(WER)比经典微调降低12%,在长音频上降低了16.2%,而长音频是构音障碍自动语音识别中的主要损失来源。合并越来越多的模型带来了持续的收益,在低数据环境中仍然有效,并且适用于各种模型架构。这些结果强调了模型合并作为一种易于复制的适应方法,能够在不增加推理成本或超参数调整的情况下,持续提高ASR性能。
论文及项目相关链接
PDF Accepted to Interspeech 2025
Summary:
本研究探索了通过模型融合提高自动语音识别(ASR)泛化能力的方法,特别是针对发音障碍人士的语音。使用Whisper作为基础语音模型,通过单一轨迹融合、单路径微调模型融合以及多路径独立训练模型融合的方法进行比较。其中多路径融合方法相较于传统微调方法取得了词错误率(WER)相对下降12%,在长篇音频上的相对下降更是达到了惊人的16.2%。模型融合在低数据环境下依然有效,且可跨模型架构推广,成为一种易于复制且稳定的适应策略,持续提高ASR性能,且无需额外推理成本和超参数调整。
Key Takeaways:
- 模型融合在自动语音识别中用于提高泛化能力。
- 研究针对发音障碍人士的语音进行了模型融合的探索。
- 使用Whisper作为基础语音模型进行试验。
- 多路径融合方法相较于传统微调方法取得了显著效果。
- 模型融合在长篇音频上的性能提升尤为显著。
- 模型融合在低数据环境下依然有效,并可以跨模型架构推广。
点此查看论文截图

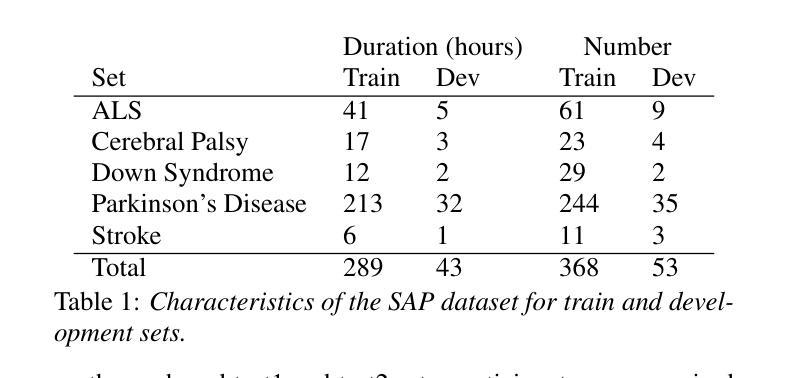
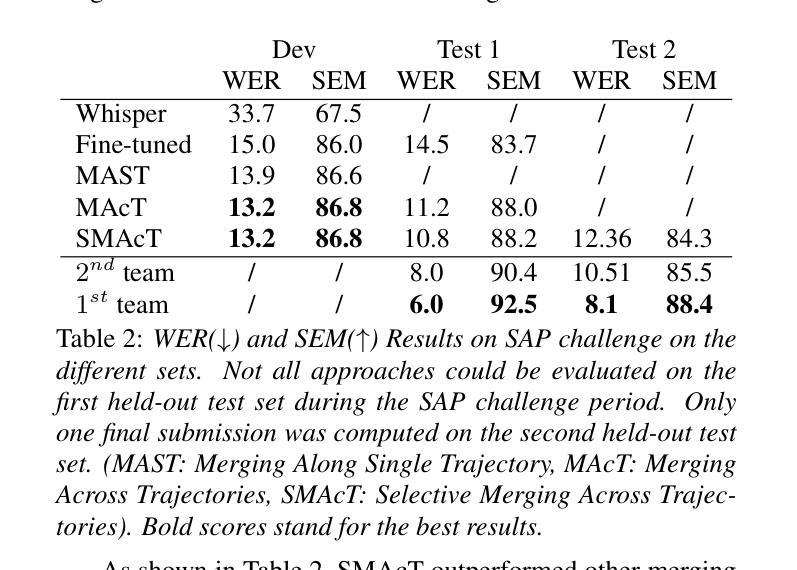
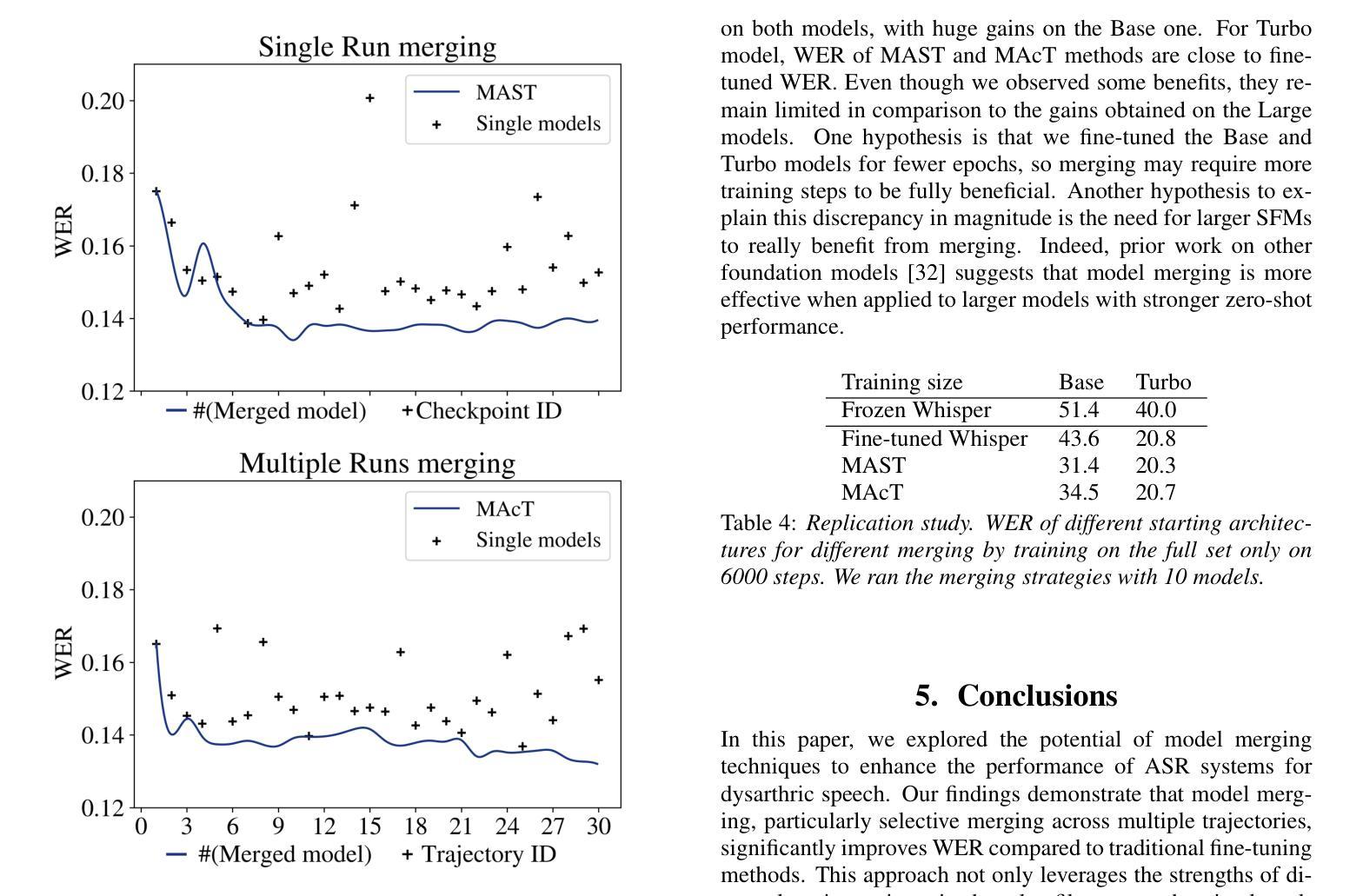
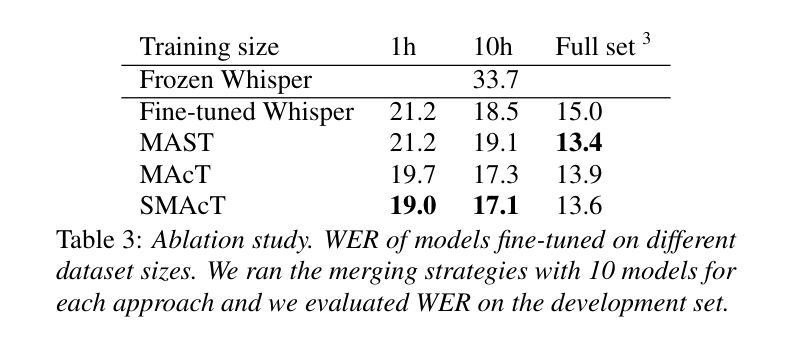
In-context Language Learning for Endangered Languages in Speech Recognition
Authors:Zhaolin Li, Jan Niehues
With approximately 7,000 languages spoken worldwide, current large language models (LLMs) support only a small subset. Prior research indicates LLMs can learn new languages for certain tasks without supervised data. We extend this investigation to speech recognition, investigating whether LLMs can learn unseen, low-resource languages through in-context learning (ICL). With experiments on four diverse endangered languages that LLMs have not been trained on, we find that providing more relevant text samples enhances performance in both language modelling and Automatic Speech Recognition (ASR) tasks. Furthermore, we show that the probability-based approach outperforms the traditional instruction-based approach in language learning. Lastly, we show ICL enables LLMs to achieve ASR performance that is comparable to or even surpasses dedicated language models trained specifically for these languages, while preserving the original capabilities of the LLMs.
全世界大约有7000种语言,而当前的大型语言模型(LLM)只支持一小部分。先前的研究表明,LLM可以在没有监督数据的情况下为某些任务学习新的语言。我们将其扩展到语音识别领域,研究LLM是否可以通过上下文学习(ICL)来学习未见过的低资源语言。我们在四种多样的濒危语言上对实验进行了测试,这些语言并未用于训练LLM,我们发现提供相关的文本样本可以提高语言建模和自动语音识别(ASR)任务的效果。此外,我们还表明基于概率的方法在语言学习方面的表现优于传统的基于指令的方法。最后,我们证明了上下文学习使LLM能够实现的ASR性能可以与专门针对这些语言训练的专用语言模型相当甚至超越,同时保留LLM的原始能力。
论文及项目相关链接
Summary
大型语言模型(LLMs)虽然能够支持多种语言,但仅限于一小部分已知语言。本研究探索了LLMs在语音辨识方面能否学习未知、低资源的语言,通过上下文学习(ICL)。实验表明,在提供更为相关的文本样本后,LLMs在语言建模和自动语音识别(ASR)任务上的表现都有所提升。此外,概率性方法相较于传统的指令性方法,在语言学习上表现更优。同时,ICL使得LLMs的ASR性能可与针对这些语言专门训练的模型相媲美,甚至超越它们,同时保留了LLMs的原始能力。
Key Takeaways
- 大型语言模型(LLMs)目前仅支持一小部分语言,对于未知的低资源语言的学习能力尚待探索。
- 通过上下文学习(ICL),LLMs能够学习并识别未受过训练的语言。
- 提供更多相关的文本样本可以提升LLMs在语言建模和自动语音识别(ASR)任务上的表现。
- 在语言学习上,概率性方法相较于传统的指令性方法表现更优。
- 通过上下文学习,LLMs的ASR性能可以达到与专门针对这些语言训练的模型相媲美甚至超越的水平。
- LLMs在学习的过程中能够保持其原有的能力。
点此查看论文截图


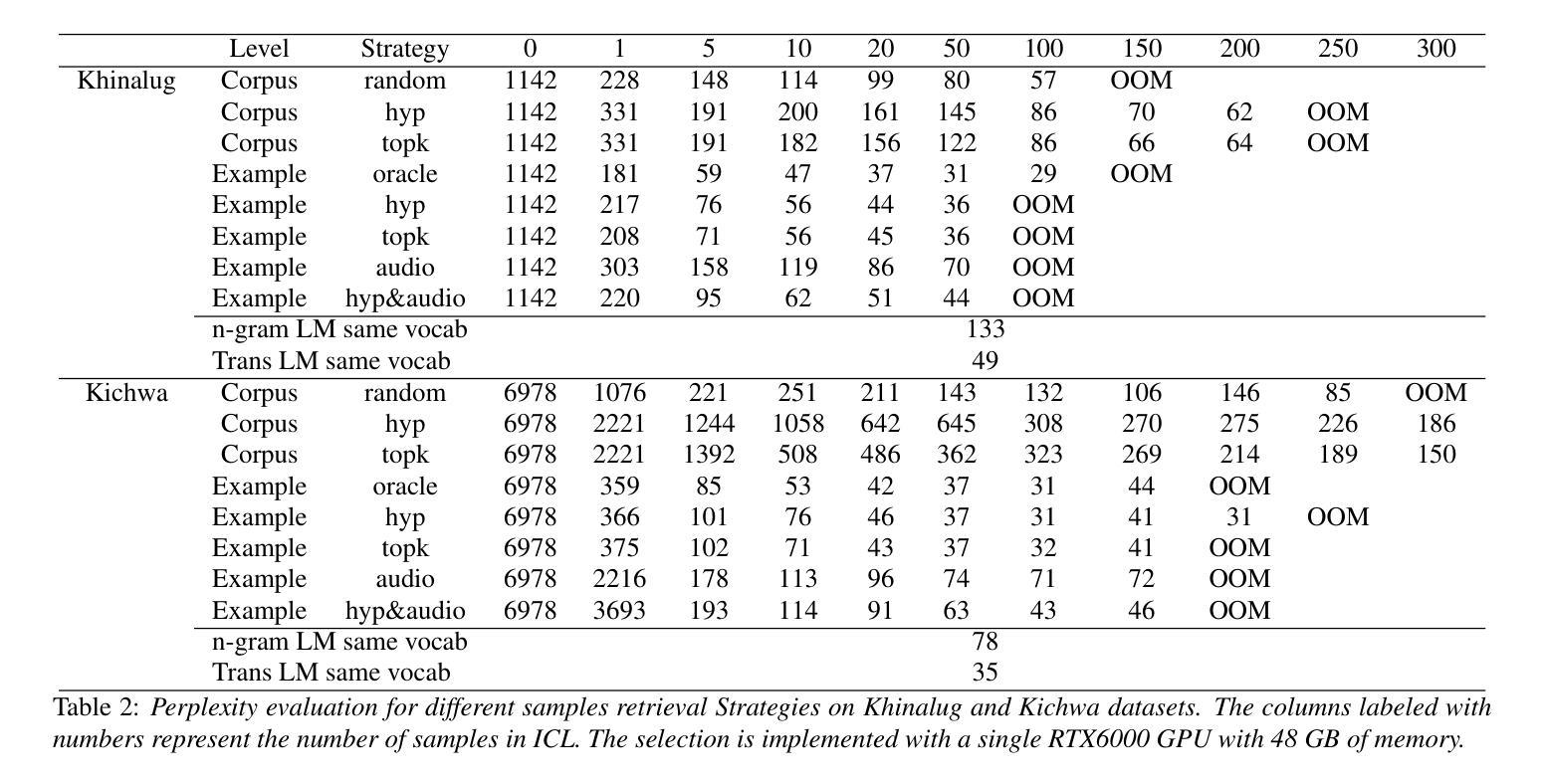
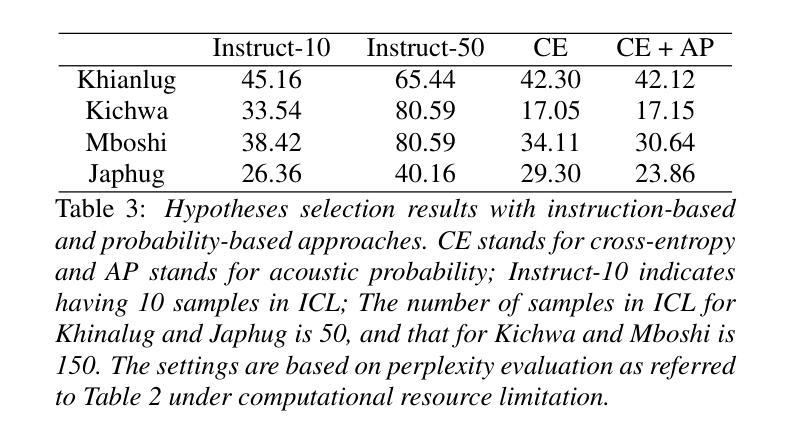

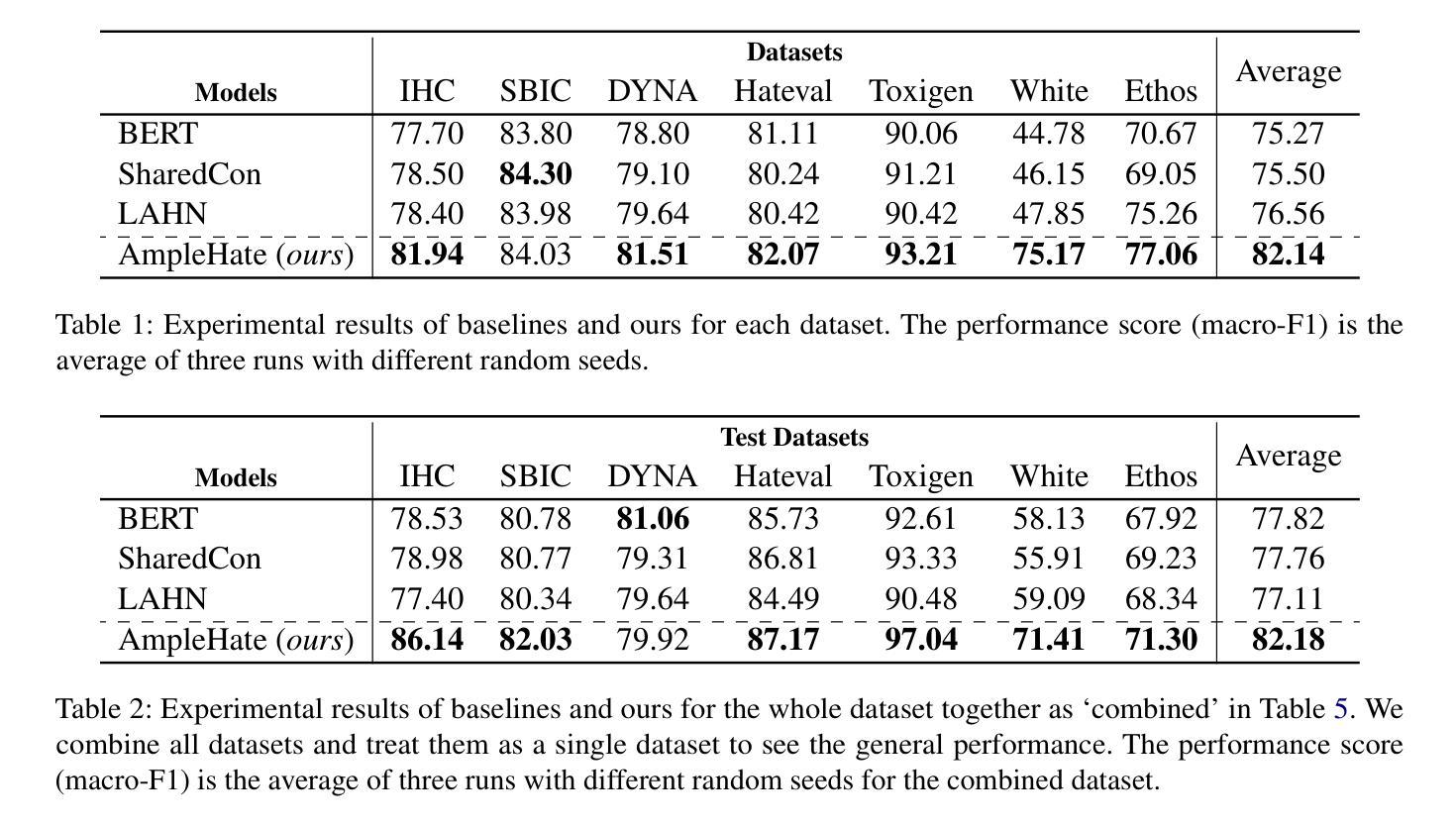
AmpleHate: Amplifying the Attention for Versatile Implicit Hate Detection
Authors:Yejin Lee, Joonghyuk Hahn, Hyeseon Ahn, Yo-Sub Han
Implicit hate speech detection is challenging due to its subtlety and reliance on contextual interpretation rather than explicit offensive words. Current approaches rely on contrastive learning, which are shown to be effective on distinguishing hate and non-hate sentences. Humans, however, detect implicit hate speech by first identifying specific targets within the text and subsequently interpreting how these target relate to their surrounding context. Motivated by this reasoning process, we propose AmpleHate, a novel approach designed to mirror human inference for implicit hate detection. AmpleHate identifies explicit target using a pretrained Named Entity Recognition model and capture implicit target information via [CLS] tokens. It computes attention-based relationships between explicit, implicit targets and sentence context and then, directly injects these relational vectors into the final sentence representation. This amplifies the critical signals of target-context relations for determining implicit hate. Experiments demonstrate that AmpleHate achieves state-of-the-art performance, outperforming contrastive learning baselines by an average of 82.14% and achieve faster convergence. Qualitative analyses further reveal that attention patterns produced by AmpleHate closely align with human judgement, underscoring its interpretability and robustness.
隐晦仇恨言论的检测颇具挑战性,因为它的隐蔽性,并且依赖于语境解读而非明显的冒犯性词汇。当前的方法依赖于对比学习,已证明在区分仇恨和非仇恨句子方面非常有效。然而,人类检测隐晦仇恨言论是先识别文本中的特定目标,然后解释这些目标是如何与周围的上下文相关联的。受这种推理过程的启发,我们提出了AmpleHate,这是一种旨在模拟人类推理进行隐晦仇恨检测的新方法。AmpleHate使用预训练的命名实体识别模型来识别明确的目标,并通过[CLS]令牌获取隐晦目标信息。它计算明确、隐晦目标与句子上下文之间的基于注意力的关系,然后将这些关系向量直接注入最终的句子表示中。这放大了确定隐晦仇恨时的目标-上下文关系的关键信号。实验表明,AmpleHate达到了最先进的性能,平均超出对比学习基准82.14%,并且实现了更快的收敛速度。定性分析进一步表明,AmpleHate产生的注意力模式与人类判断高度一致,突出了其可解释性和稳健性。
论文及项目相关链接
PDF 13 pages, 4 figures, Under Review
Summary
本文介绍了针对隐性仇恨言论检测的新方法AmpleHate。该方法利用预训练的命名实体识别模型识别显式目标,并通过[CLS]令牌捕获隐性目标信息。它计算显式、隐性目标与句子上下文之间的注意力关系,然后将这些关系向量直接注入最终的句子表示中,从而放大目标上下文关系的关键信号,以确定隐性仇恨。实验表明,AmpleHate实现了最先进的性能,平均比对比学习基线高出82.14%,并且收敛速度更快。
Key Takeaways
- 隐性仇恨言论检测具有挑战性,因其微妙性和对上下文解读的依赖,而非明显的冒犯性词汇。
- 当前方法主要依赖对比学习,在区分仇恨和非仇恨句子方面有效。
- 人类检测隐性仇恨言论首先识别文本中的特定目标,然后解读这些目标与其上下文的关系。
- AmpleHate方法设计旨在模仿人类推理过程,用于隐性仇恨检测。
- AmpleHate使用预训练的命名实体识别模型识别显式目标,并通过[CLS]令牌捕获隐性目标信息。
- AmpleHate计算目标(显性和隐性)与句子上下文之间的注意力关系,并将这些关系注入句子表示中,以强化隐性仇恨的判定。
点此查看论文截图

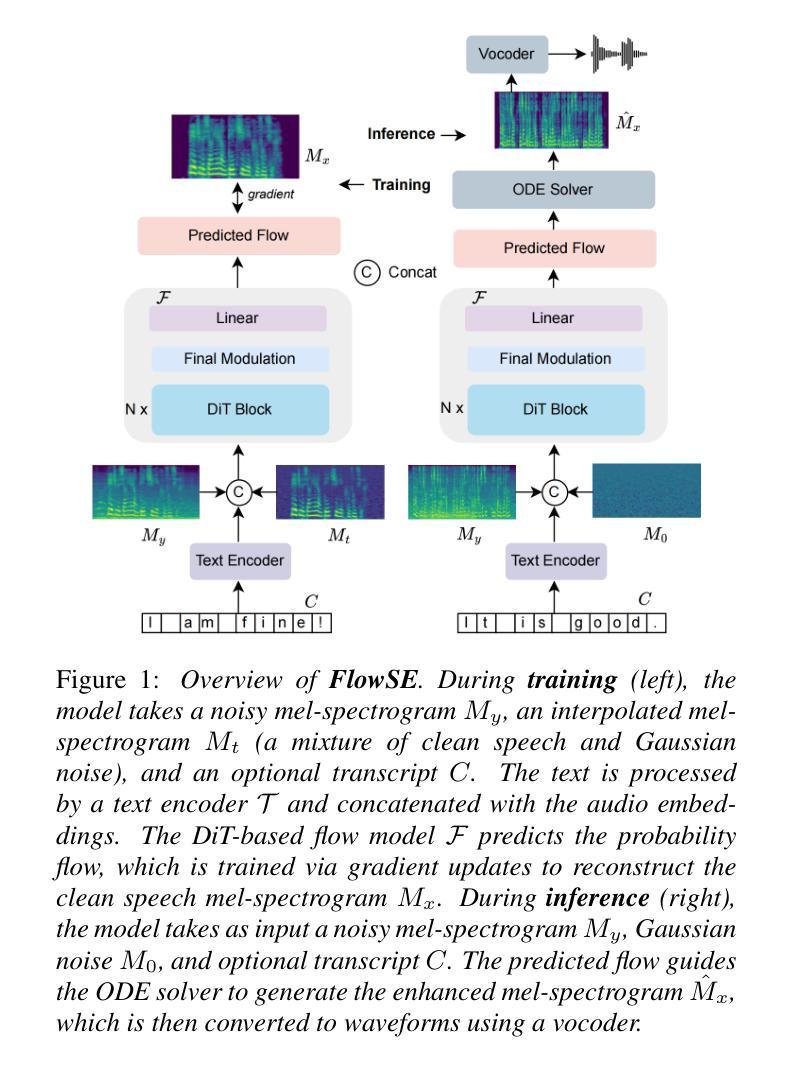
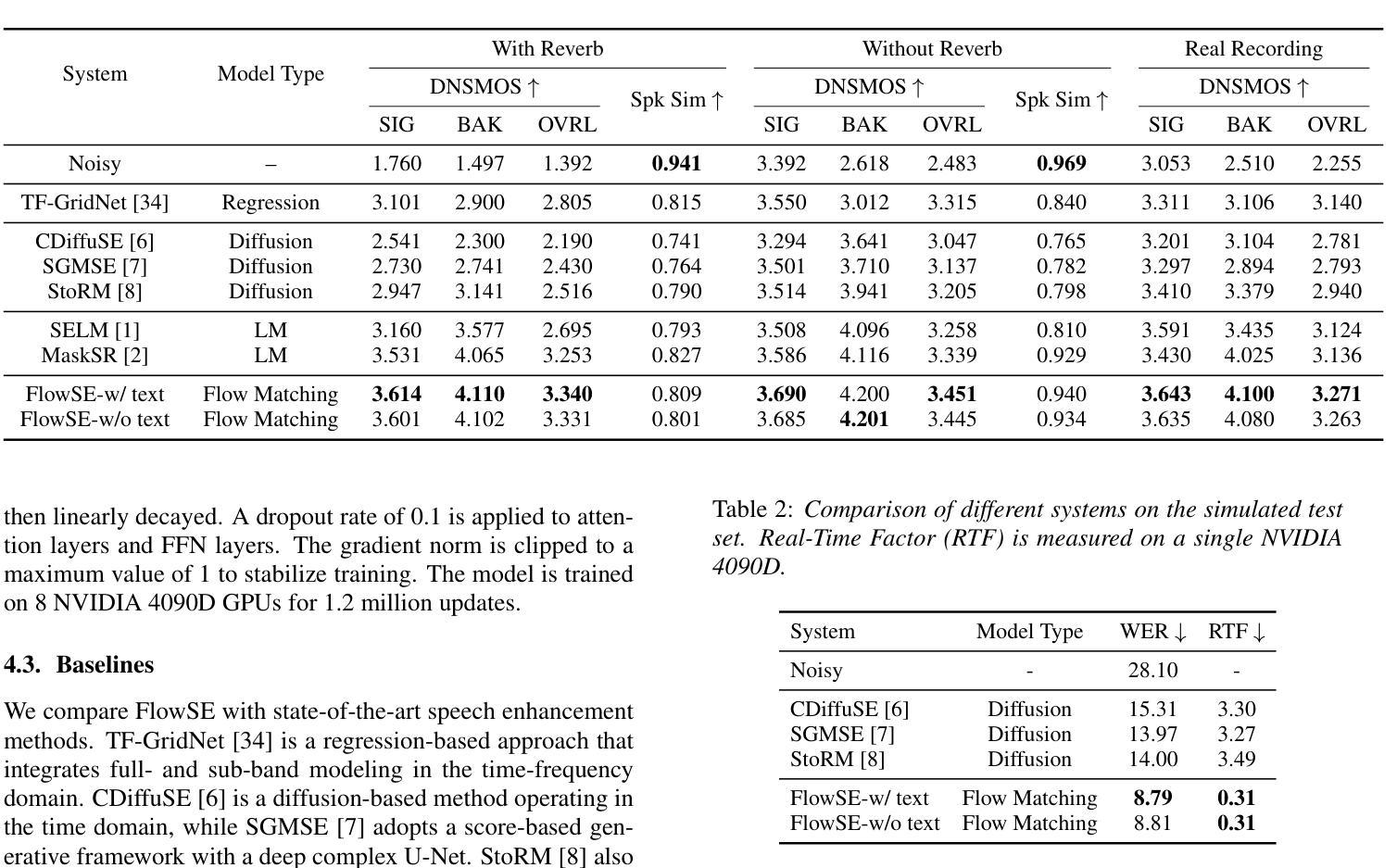
FlowSE: Efficient and High-Quality Speech Enhancement via Flow Matching
Authors:Ziqian Wang, Zikai Liu, Xinfa Zhu, Yike Zhu, Mingshuai Liu, Jun Chen, Longshuai Xiao, Chao Weng, Lei Xie
Generative models have excelled in audio tasks using approaches such as language models, diffusion, and flow matching. However, existing generative approaches for speech enhancement (SE) face notable challenges: language model-based methods suffer from quantization loss, leading to compromised speaker similarity and intelligibility, while diffusion models require complex training and high inference latency. To address these challenges, we propose FlowSE, a flow-matching-based model for SE. Flow matching learns a continuous transformation between noisy and clean speech distributions in a single pass, significantly reducing inference latency while maintaining high-quality reconstruction. Specifically, FlowSE trains on noisy mel spectrograms and optional character sequences, optimizing a conditional flow matching loss with ground-truth mel spectrograms as supervision. It implicitly learns speech’s temporal-spectral structure and text-speech alignment. During inference, FlowSE can operate with or without textual information, achieving impressive results in both scenarios, with further improvements when transcripts are available. Extensive experiments demonstrate that FlowSE significantly outperforms state-of-the-art generative methods, establishing a new paradigm for generative-based SE and demonstrating the potential of flow matching to advance the field. Our code, pre-trained checkpoints, and audio samples are available.
生成模型在音频任务方面表现出色,采用了语言模型、扩散和流匹配等方法。然而,现有的语音增强(SE)生成方法面临显著挑战:基于语言模型的方法遭受量化损失,导致说话人相似性和可懂度受损,而扩散模型则需要复杂的训练和较高的推理延迟。为了解决这些挑战,我们提出了FlowSE,这是一种用于SE的基于流匹配的方法。流匹配在单次传递中学习噪声和干净语音分布之间的连续转换,在保持高质量重建的同时,显著减少了推理延迟。具体来说,FlowSE在带有噪声的梅尔频谱和可选字符序列上进行训练,以地面真实梅尔频谱作为监督来优化条件流匹配损失。它隐式地学习语音的时空结构以及文本与语音的对齐。在推理过程中,FlowSE可以带有或不带文本信息进行操作,在这两种情况下都取得了令人印象深刻的结果,在有文字稿的情况下进一步改进。大量实验表明,FlowSE显著优于最新的生成方法,为基于生成的SE建立了新的范式,并展示了流匹配在该领域的潜力。我们的代码、预训练检查点和音频样本可供使用。
论文及项目相关链接
PDF Accepted to InterSpeech 2025
Summary
本文提出一种基于流匹配(FlowSE)的语音增强模型,解决了现有生成模型面临的挑战。FlowSE通过学习和转换噪声和清洁语音分布之间的连续转换,实现了高质量的语音重建,同时降低了推理延迟。该模型通过训练噪声梅尔频谱和可选字符序列,优化条件流匹配损失,并隐式学习语音的时空谱结构和文本语音对齐。实验表明,FlowSE在有无文本信息的情况下均表现出色,且在提供转录时进一步改进。它显著优于当前主流的生成方法,为基于生成的语音增强提供了新的范例,并展示了流匹配在该领域的潜力。
Key Takeaways
- 生成模型在音频任务中表现出色,使用语言模型、扩散和流匹配等方法。
- 现有语音增强(SE)的生成方法面临挑战,如语言模型的量化损失和扩散模型的复杂训练和推理延迟。
- FlowSE是一个基于流匹配的SE模型,通过学习和转换噪声和清洁语音分布之间的连续转换来解决这些挑战。
- FlowSE通过训练噪声梅尔频谱和字符序列优化条件流匹配损失,隐式学习语音的时空谱结构和文本语音对齐。
- FlowSE在有无文本信息的情况下均可运行,且在提供转录时性能更佳。
- FlowSE显著优于当前主流的生成方法,为基于生成的语音增强提供了新的范例。
点此查看论文截图

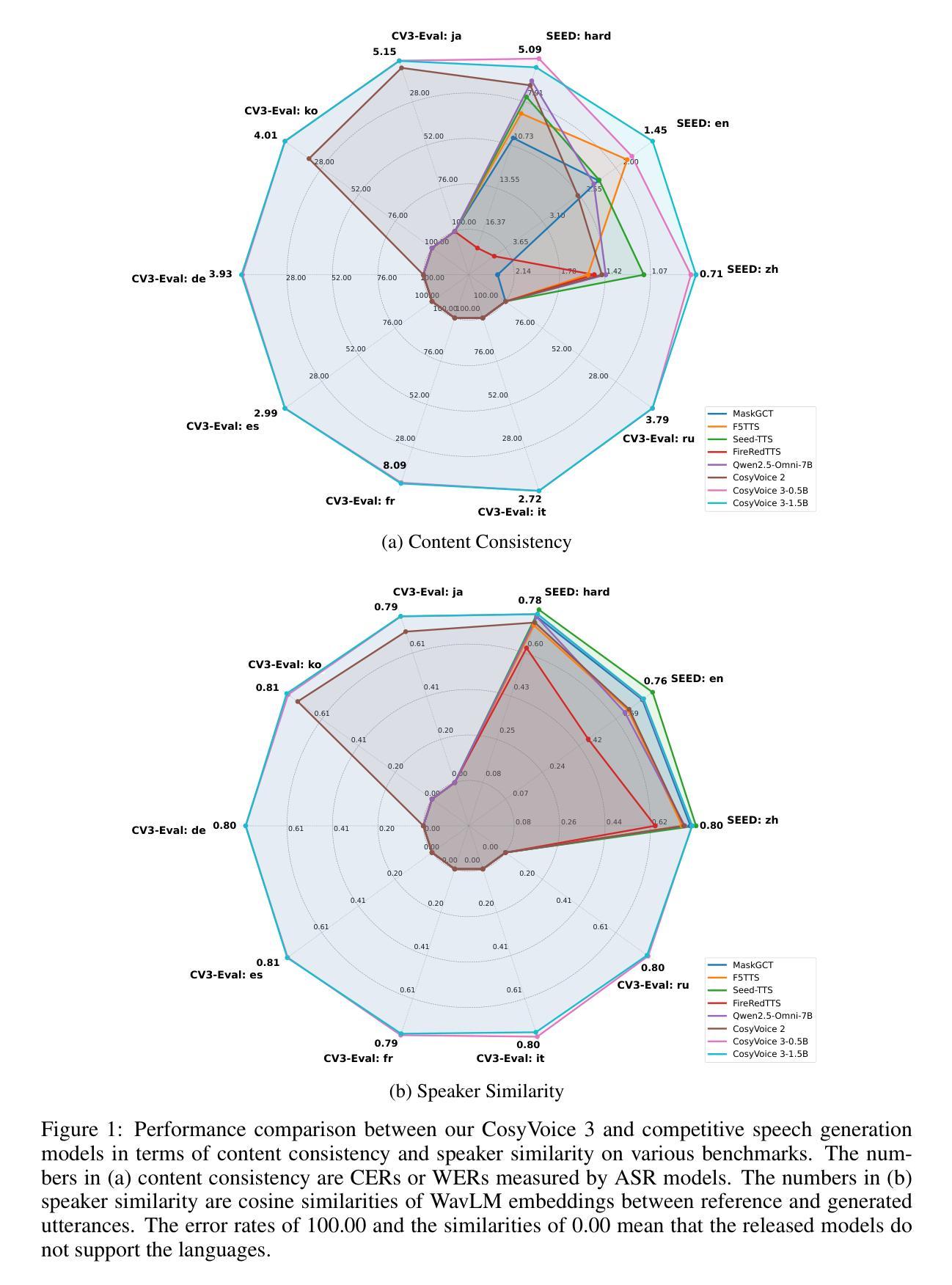
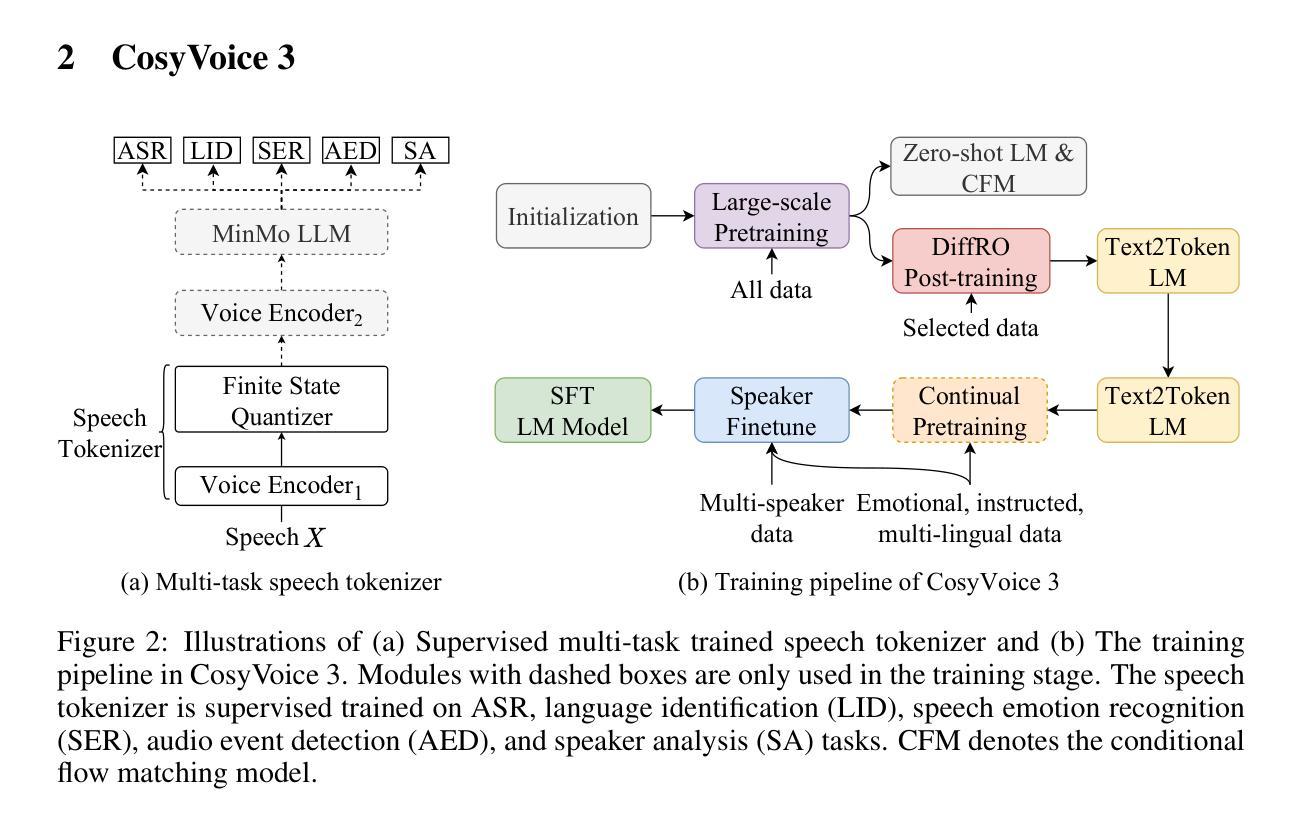
CosyVoice 3: Towards In-the-wild Speech Generation via Scaling-up and Post-training
Authors:Zhihao Du, Changfeng Gao, Yuxuan Wang, Fan Yu, Tianyu Zhao, Hao Wang, Xiang Lv, Hui Wang, Chongjia Ni, Xian Shi, Keyu An, Guanrou Yang, Yabin Li, Yanni Chen, Zhifu Gao, Qian Chen, Yue Gu, Mengzhe Chen, Yafeng Chen, Shiliang Zhang, Wen Wang, Jieping Ye
In our prior works, we introduced a scalable streaming speech synthesis model, CosyVoice 2, which integrates a large language model (LLM) and a chunk-aware flow matching (FM) model, and achieves low-latency bi-streaming speech synthesis and human-parity quality. Despite these advancements, CosyVoice 2 exhibits limitations in language coverage, domain diversity, data volume, text formats, and post-training techniques. In this paper, we present CosyVoice 3, an improved model designed for zero-shot multilingual speech synthesis in the wild, surpassing its predecessor in content consistency, speaker similarity, and prosody naturalness. Key features of CosyVoice 3 include: 1) A novel speech tokenizer to improve prosody naturalness, developed via supervised multi-task training, including automatic speech recognition, speech emotion recognition, language identification, audio event detection, and speaker analysis. 2) A new differentiable reward model for post-training applicable not only to CosyVoice 3 but also to other LLM-based speech synthesis models. 3) Dataset Size Scaling: Training data is expanded from ten thousand hours to one million hours, encompassing 9 languages and 18 Chinese dialects across various domains and text formats. 4) Model Size Scaling: Model parameters are increased from 0.5 billion to 1.5 billion, resulting in enhanced performance on our multilingual benchmark due to the larger model capacity. These advancements contribute significantly to the progress of speech synthesis in the wild. We encourage readers to listen to the demo at https://funaudiollm.github.io/cosyvoice3.
在我们之前的工作中,我们介绍了一种可扩展的流式语音合成模型CosyVoice 2,它集成了一个大型语言模型(LLM)和基于分块的流匹配(FM)模型,实现了低延迟的双流语音合成和人质量相当的效果。尽管取得了这些进展,CosyVoice 2在语言覆盖、领域多样性、数据量、文本格式和训练后技术方面仍存在局限性。在本文中,我们介绍了CosyVoice 3,这是一个改进型的模型,旨在实现野外零启动多语种语音合成,在内容一致性、演讲者相似性和韵律自然性方面超过了其前身。CosyVoice 3的主要特点包括:1)一种新型语音标记器,通过监督多任务训练开发,旨在提高韵律的自然性,包括自动语音识别、语音情感识别、语言识别、音频事件检测和说话人分析。2)一个新的可微奖励模型,适用于训练后的应用,不仅适用于CosyVoice 3,而且适用于其他基于LLM的语音合成模型。3)数据集大小扩展:训练数据从一万小时扩展到一百万小时,涵盖9种语言和18种中文方言,跨越各种领域和文本格式。4)模型大小扩展:模型参数从0.5亿增加到1.5亿,由于模型容量更大,我们的多语种基准测试性能得到提升。这些进展对野外语音合成的进步做出了重大贡献。我们鼓励读者通过https://funaudiollm.github.io/cosyvoice3聆听演示。
论文及项目相关链接
PDF Preprint, work in progress
摘要
本文介绍了CosyVoice 3模型,该模型在上一代语音合成模型CosyVoice 2的基础上进行了改进,旨在实现零样本多语种野外语音合成。CosyVoice 3在内容一致性、演讲者相似性和语调自然性方面超越了其前身。主要特点包括:一、采用新型语音分词器,通过包括自动语音识别、语音情感识别、语言识别、音频事件检测和说话人分析在内的监督多任务训练来提高语调自然度;二、开发新的可微奖励模型,用于后期训练,不仅适用于CosyVoice 3,也适用于其他基于LLM的语音合成模型;三、数据集大小扩展,训练数据从一万小时扩大到一百万小时,涵盖9种语言和18种中文方言,以及多种领域和文本格式;四、模型大小扩展,模型参数从0.5亿增加到1.5亿,由于模型容量更大,因此在我们的多语种基准测试中表现增强。
关键见解
- CosyVoice 3模型被介绍为一种改进的零样本多语种野外语音合成模型,超越了先前的CosyVoice 2模型。
- CosyVoice 3采用了新型语音分词器,通过监督多任务训练提高语调自然度。
- 引入了新的可微奖励模型,用于后期训练,适用于多种语音合成模型。
- 训练数据集大小从十万小时扩展至百万小时,涵盖多种语言和中文方言、领域及文本格式。
- 模型参数从0.5亿增加到1.5亿,提升了在多语种基准测试中的表现。
- 这些改进对野外语音合成领域有显著贡献。
- 读者可通过https://funaudiollm.github.io/cosyvoice3聆听Demo。
点此查看论文截图

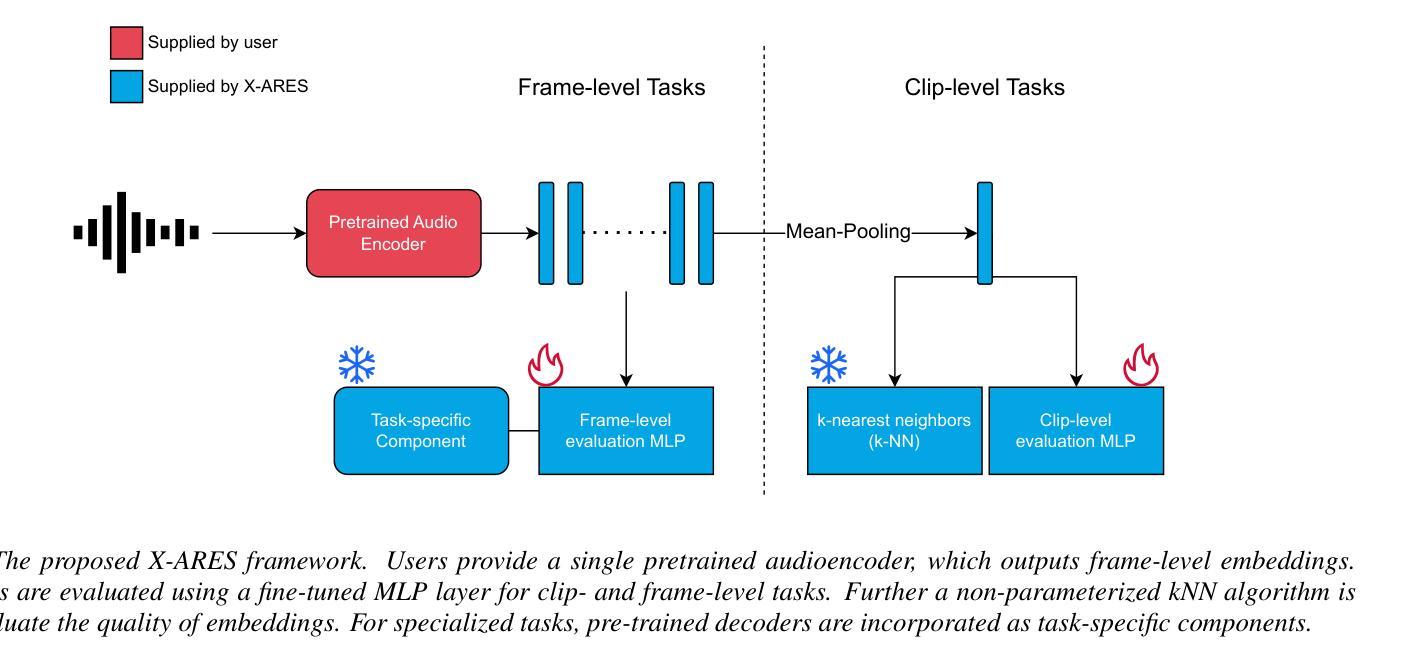
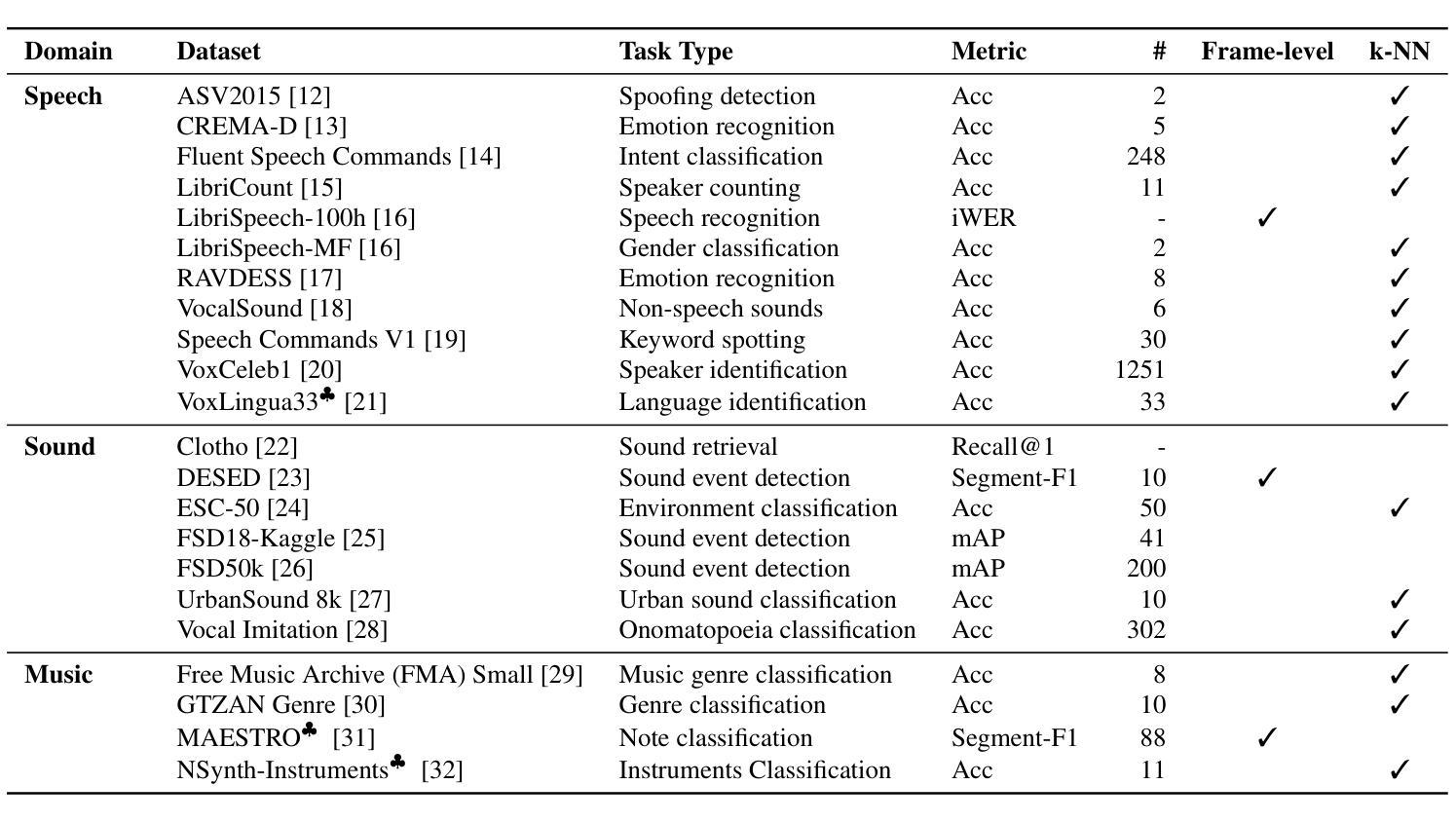
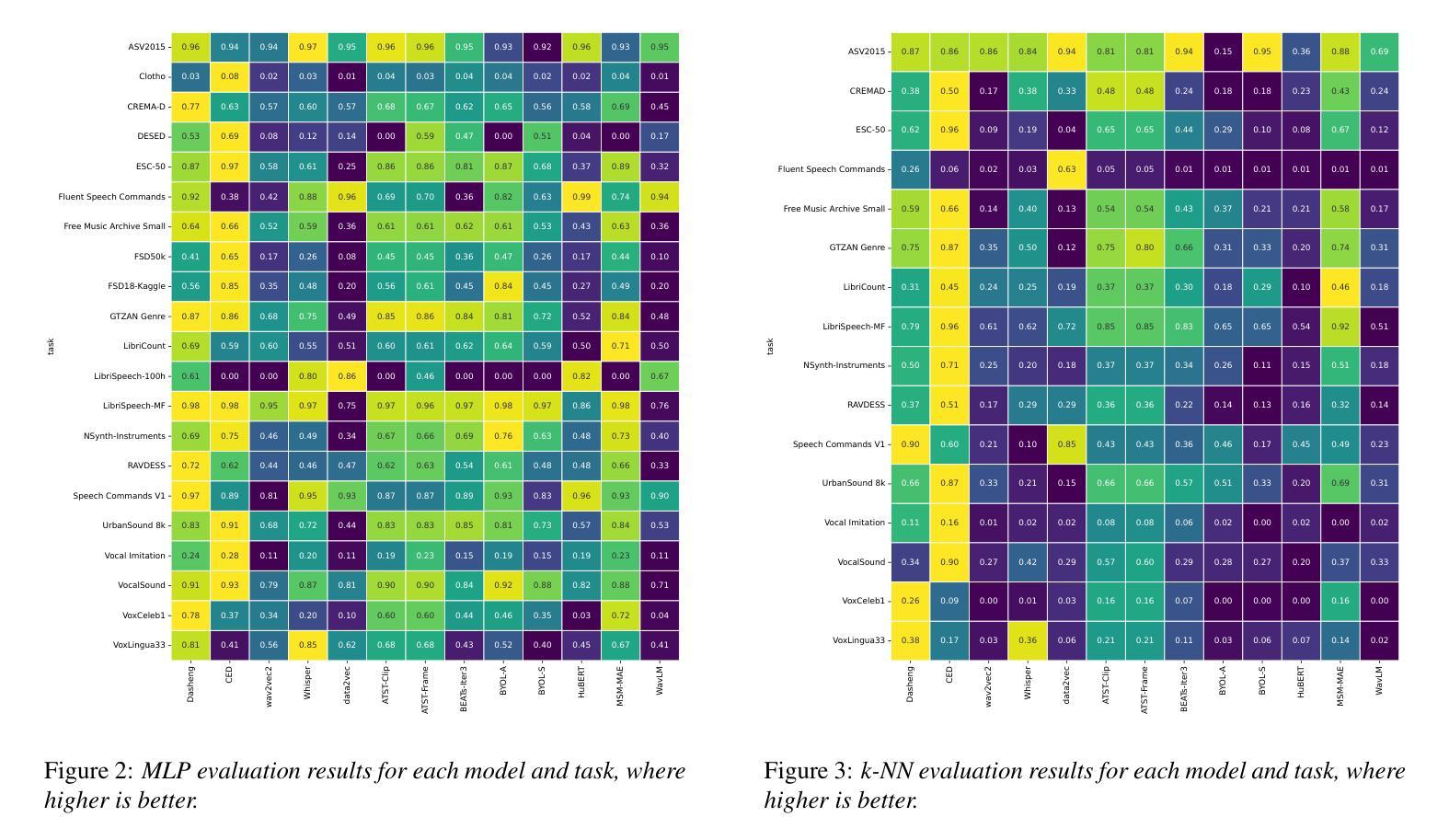
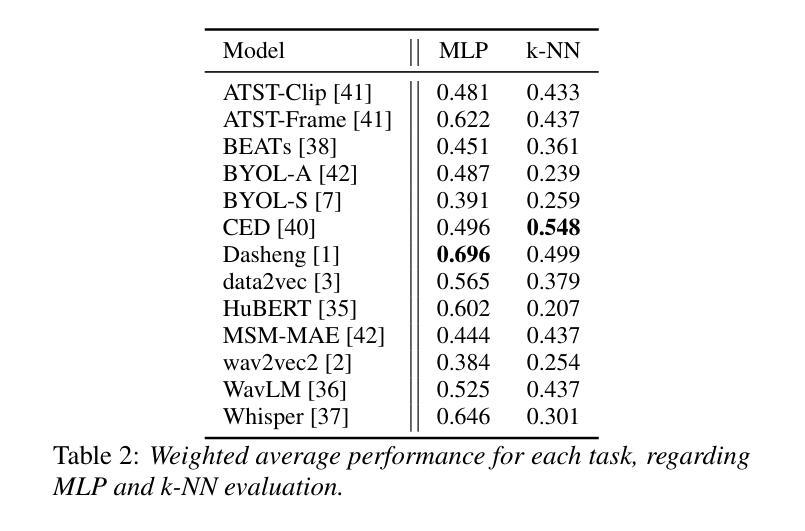
X-ARES: A Comprehensive Framework for Assessing Audio Encoder Performance
Authors:Junbo Zhang, Heinrich Dinkel, Yadong Niu, Chenyu Liu, Si Cheng, Anbei Zhao, Jian Luan
We introduces X-ARES (eXtensive Audio Representation and Evaluation Suite), a novel open-source benchmark designed to systematically assess audio encoder performance across diverse domains. By encompassing tasks spanning speech, environmental sounds, and music, X-ARES provides two evaluation approaches for evaluating audio representations: linear fine-tuning and unparameterized evaluation. The framework includes 22 distinct tasks that cover essential aspects of audio processing, from speech recognition and emotion detection to sound event classification and music genre identification. Our extensive evaluation of state-of-the-art audio encoders reveals significant performance variations across different tasks and domains, highlighting the complexity of general audio representation learning.
我们介绍了X-ARES(扩展音频表示和评估套件),这是一个新型开源基准测试,旨在系统地评估不同领域音频编码器的性能。X-ARES涵盖了语音、环境声音和音乐等任务,为评估音频表示提供了两种评估方法:线性微调和无参数评估。该框架包括涵盖音频处理各个方面的22个不同任务,从语音识别和情感检测到声音事件分类和音乐风格识别。我们对最先进的音频编码器的广泛评估表明,不同任务和领域之间的性能存在很大差异,这突出了通用音频表示学习的复杂性。
论文及项目相关链接
PDF Accepted by Interspeech 2025
Summary
X-ARES是一个用于全面评估音频编码器性能的新开放源代码基准测试平台。它涵盖了涵盖语音、环境声音和音乐等领域的任务,提供了线性微调和无参数评估两种评估音频表示的方法。该框架包括涵盖音频处理各个方面的22个不同任务,如语音识别、情感检测、声音事件分类和音乐流派识别等。对最先进的音频编码器的全面评估显示,不同任务和领域之间的性能差异很大,这突出了通用音频表示学习的复杂性。
Key Takeaways
- X-ARES是一个开放源代码的基准测试平台。
- 它旨在系统地评估音频编码器在多样化领域的性能。
- X-ARES提供了线性微调和无参数评估两种评估音频表示的方法。
- 该平台涵盖了语音、环境声音和音乐等领域的任务。
- 框架包含涵盖音频处理各个方面的22个任务。
- 对音频编码器的全面评估显示,不同任务和领域之间的性能差异显著。
点此查看论文截图

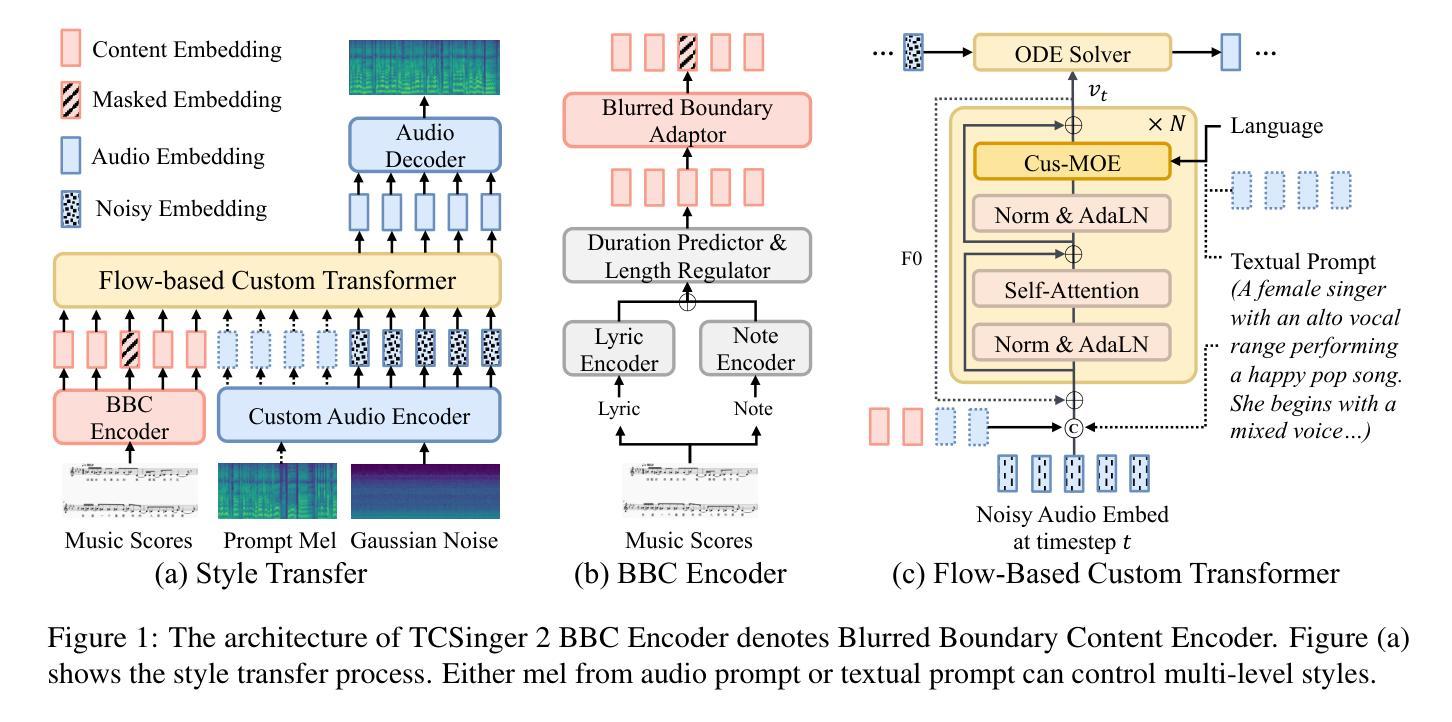
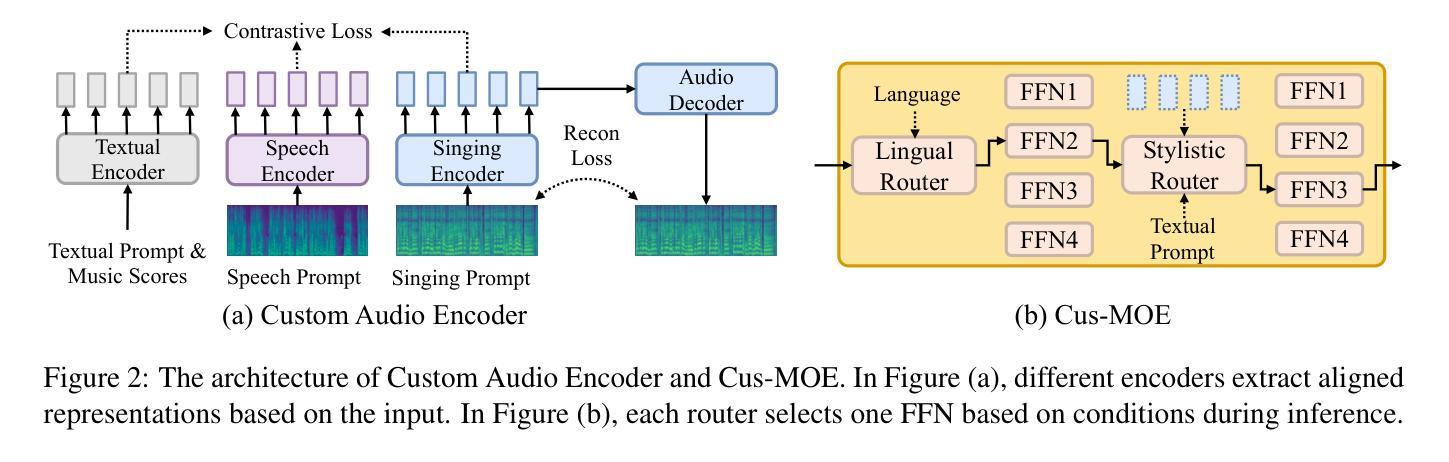
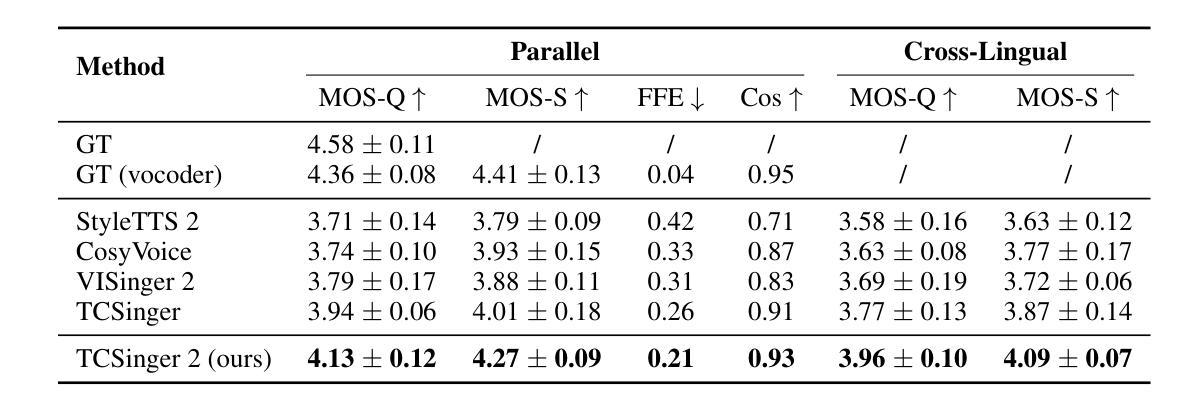
TCSinger 2: Customizable Multilingual Zero-shot Singing Voice Synthesis
Authors:Yu Zhang, Wenxiang Guo, Changhao Pan, Dongyu Yao, Zhiyuan Zhu, Ziyue Jiang, Yuhan Wang, Tao Jin, Zhou Zhao
Customizable multilingual zero-shot singing voice synthesis (SVS) has various potential applications in music composition and short video dubbing. However, existing SVS models overly depend on phoneme and note boundary annotations, limiting their robustness in zero-shot scenarios and producing poor transitions between phonemes and notes. Moreover, they also lack effective multi-level style control via diverse prompts. To overcome these challenges, we introduce TCSinger 2, a multi-task multilingual zero-shot SVS model with style transfer and style control based on various prompts. TCSinger 2 mainly includes three key modules: 1) Blurred Boundary Content (BBC) Encoder, predicts duration, extends content embedding, and applies masking to the boundaries to enable smooth transitions. 2) Custom Audio Encoder, uses contrastive learning to extract aligned representations from singing, speech, and textual prompts. 3) Flow-based Custom Transformer, leverages Cus-MOE, with F0 supervision, enhancing both the synthesis quality and style modeling of the generated singing voice. Experimental results show that TCSinger 2 outperforms baseline models in both subjective and objective metrics across multiple related tasks. Singing voice samples are available at https://aaronz345.github.io/TCSinger2Demo/.
可定制的多语言零样本歌声合成(SVS)在音乐创作和短视频配音等方面具有各种潜在应用。然而,现有的SVS模型过于依赖音素和音符边界注释,这限制了它们在零样本场景中的稳健性,并导致音素和音符之间的过渡不自然。此外,它们还缺乏通过不同提示进行有效的多级风格控制。为了克服这些挑战,我们引入了TCSinger 2,这是一个基于不同提示进行风格转换和风格控制的多任务多语言零样本SVS模型。TCSinger 2主要包括三个关键模块:1)模糊边界内容(BBC)编码器,它预测持续时间,扩展内容嵌入,并对边界应用掩码以实现平滑过渡。2)自定义音频编码器,利用对比学习从歌声、语音和文本提示中提取对齐表示。3)基于流的自定义转换器,利用Cus-MOE和F0监督,提高生成歌声的合成质量和风格建模。实验结果表明,TCSinger 2在多个相关任务的主观和客观指标上均优于基准模型。歌声样本可在https://aaronz345.github.io/TCSinger2Demo/上找到。
论文及项目相关链接
PDF Accepted by Findings of ACL 2025
Summary
基于多任务的多语种零样本演唱声音合成(SVS)模型TCSinger 2,具备风格迁移和基于不同提示的风格控制功能,可广泛应用于音乐创作和短视频配音。它通过模糊边界内容编码器、自定义音频编码器和基于流的自定义转换器等技术,解决了现有SVS模型过度依赖音素和音符边界注释、缺乏多层次风格控制等问题,提高了零样本场景下的鲁棒性和合成演唱声音的质感。
Key Takeaways
- Customizable multilingual zero-shot singing voice synthesis (SVS) has potential applications in music composition and short video dubbing.
- Existing SVS models rely heavily on phoneme and note boundary annotations, limiting their performance in zero-shot scenarios.
- TCSinger 2 model is introduced to overcome these challenges, with three key modules: Blurred Boundary Content Encoder, Custom Audio Encoder, and Flow-based Custom Transformer.
- The Blurred Boundary Content Encoder enables smooth transitions between phonemes and notes.
- The Custom Audio Encoder uses contrastive learning for effective representations from singing, speech, and textual prompts.
- The Flow-based Custom Transformer leverages Cus-MOE with F0 supervision to enhance synthesis quality and style modeling.
- Experimental results show that TCSinger 2 outperforms baseline models in multiple related tasks, and singing voice samples are available at https://aaronz345.github.io/TCSinger2Demo/.
点此查看论文截图

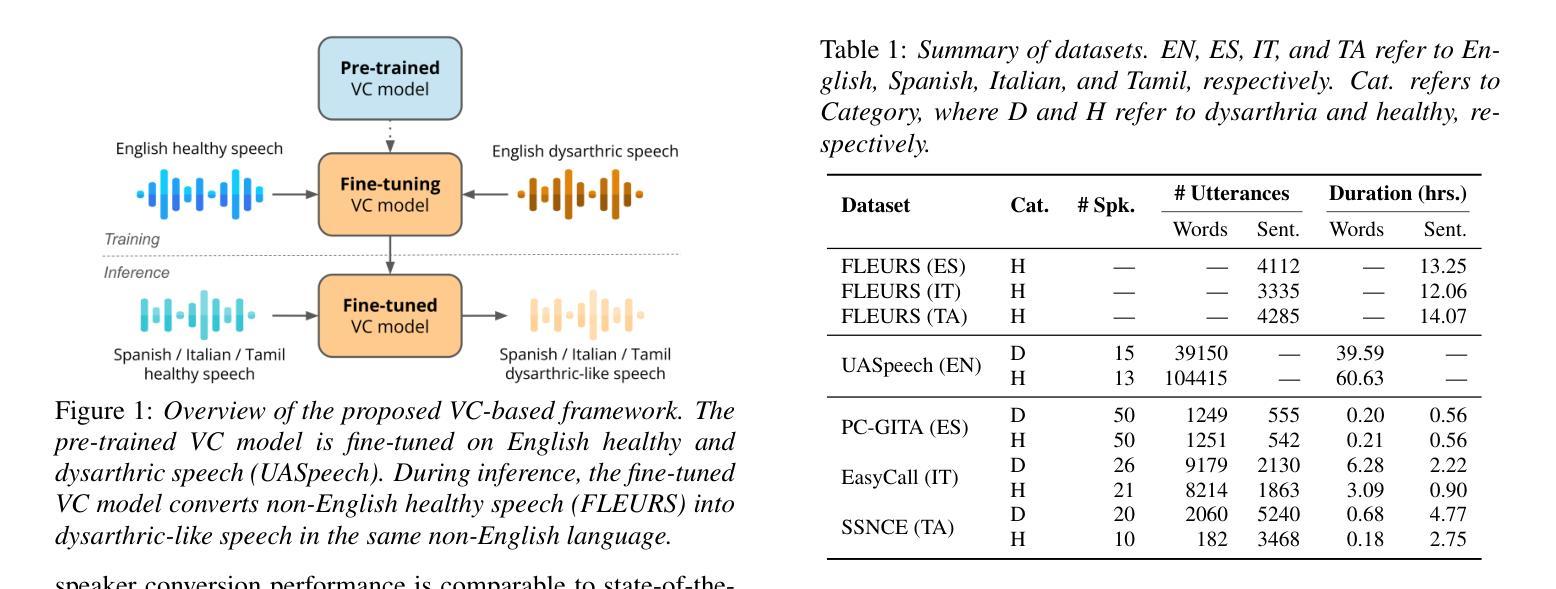
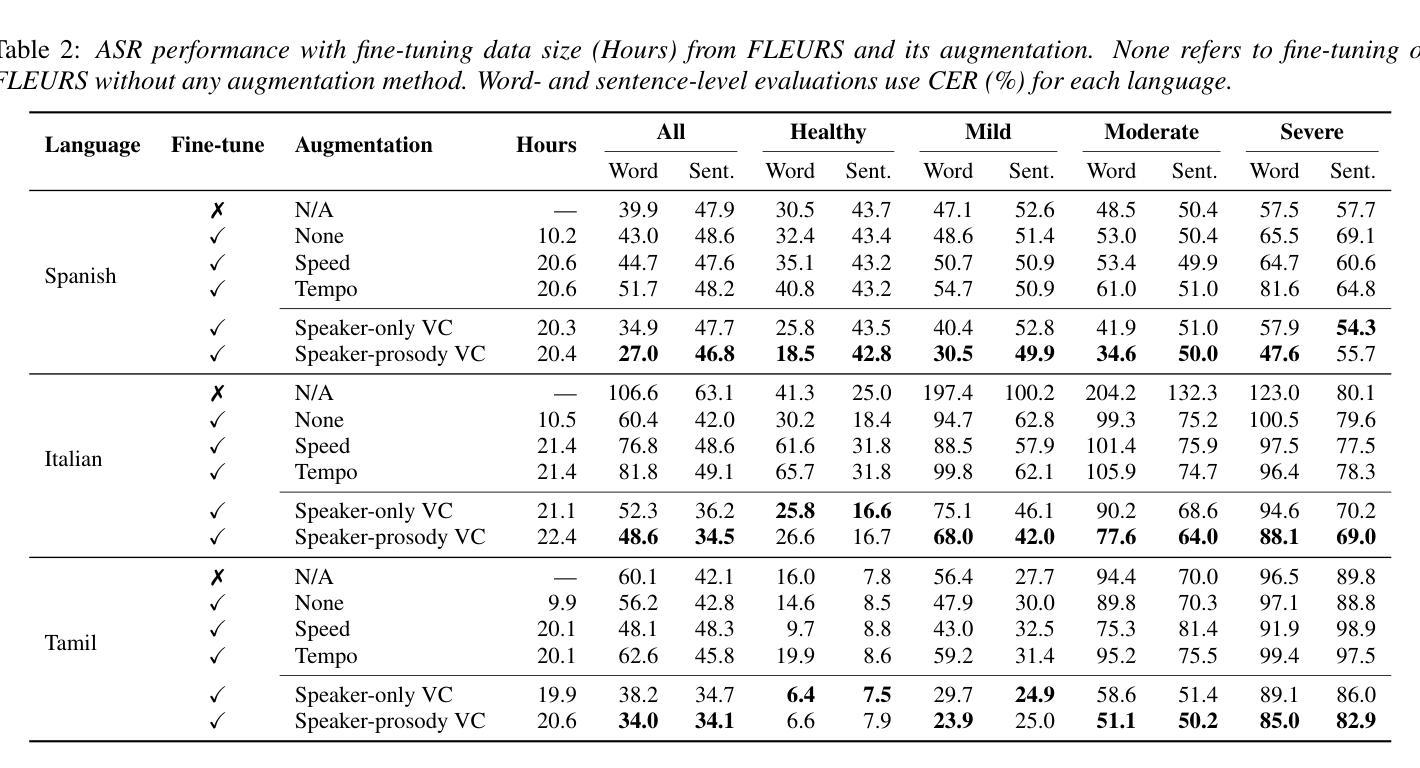
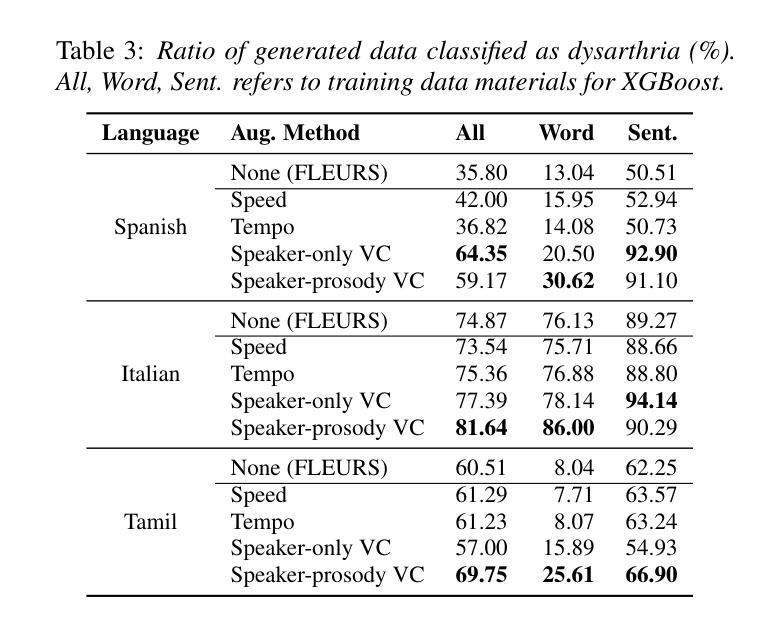
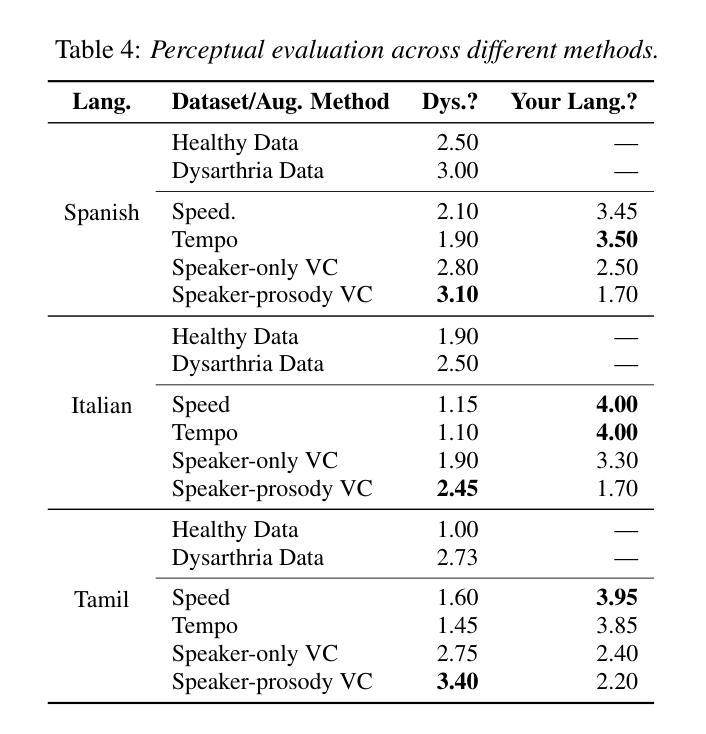
Towards Inclusive ASR: Investigating Voice Conversion for Dysarthric Speech Recognition in Low-Resource Languages
Authors:Chin-Jou Li, Eunjung Yeo, Kwanghee Choi, Paula Andrea Pérez-Toro, Masao Someki, Rohan Kumar Das, Zhengjun Yue, Juan Rafael Orozco-Arroyave, Elmar Nöth, David R. Mortensen
Automatic speech recognition (ASR) for dysarthric speech remains challenging due to data scarcity, particularly in non-English languages. To address this, we fine-tune a voice conversion model on English dysarthric speech (UASpeech) to encode both speaker characteristics and prosodic distortions, then apply it to convert healthy non-English speech (FLEURS) into non-English dysarthric-like speech. The generated data is then used to fine-tune a multilingual ASR model, Massively Multilingual Speech (MMS), for improved dysarthric speech recognition. Evaluation on PC-GITA (Spanish), EasyCall (Italian), and SSNCE (Tamil) demonstrates that VC with both speaker and prosody conversion significantly outperforms the off-the-shelf MMS performance and conventional augmentation techniques such as speed and tempo perturbation. Objective and subjective analyses of the generated data further confirm that the generated speech simulates dysarthric characteristics.
针对发音困难者使用的自动语音识别(ASR)在非英语语言的数据稀缺问题上面临挑战。为了解决这一问题,我们首先对英文发音困难语音(UASpeech)进行微调,训练语音转换模型,使其能够编码说话人的特征和韵律扭曲,然后将此模型应用于将健康的非英语语音(FLEURS)转换为非英语发音困难语音。生成的数据随后被用于微调多语言自动语音识别模型Massively Multilingual Speech(MMS),以提高对发音困难语音的识别能力。在PC-GITA(西班牙语)、EasyCall(意大利语)和SSNCE(泰米尔语)上的评估表明,同时实现说话人和韵律转换的语音转换方法显著优于现成的MMS性能和传统的增强技术,如速度和节奏扰动。对生成数据的客观和主观分析进一步证实,生成的语音模拟了发音困难的特征。
论文及项目相关链接
PDF 5 pages, 1 figure, Accepted to Interspeech 2025
Summary
本文介绍了针对非英语语言的发音障碍语音自动语音识别(ASR)所面临的挑战。为了解决这个问题,研究人员在英语发音障碍语音(UASpeech)上微调了一个语音转换模型,该模型可以编码说话人的特性和韵律扭曲。然后,他们使用该模型将健康的非英语语音(FLEURS)转换为非英语的发音障碍语音。生成的数据用于微调多语言ASR模型Massively Multilingual Speech(MMS),以提高对发音障碍语音的识别能力。在PC-GITA(西班牙语)、EasyCall(意大利语)和SSNCE(泰米尔语)上的评估表明,同时转换说话人和韵律的语音转换(VC)显著优于现成的MMS性能和传统的增强技术,如速度和节奏扰动。对生成数据的客观和主观分析进一步证实,生成的语音模拟了发音障碍的特性。
Key Takeaways
- 非英语发音障碍语音的ASR面临数据稀缺的挑战。
- 通过在英语发音障碍语音上微调一个同时编码说话人特性和韵律扭曲的语音转换模型来解决此问题。
- 使用该模型将健康非英语语音转换为非英语的发音障碍语音,生成的数据用于进一步微调多语言ASR模型。
- 评估显示,结合说话人和韵律转换的语音转换技术显著提高了ASR性能。
- 相较于传统的ASR增强技术和现成的多语言ASR模型,该方法的性能表现更优。
- 生成数据的客观和主观分析证实了该模型模拟的发音障碍语音的真实性。
点此查看论文截图

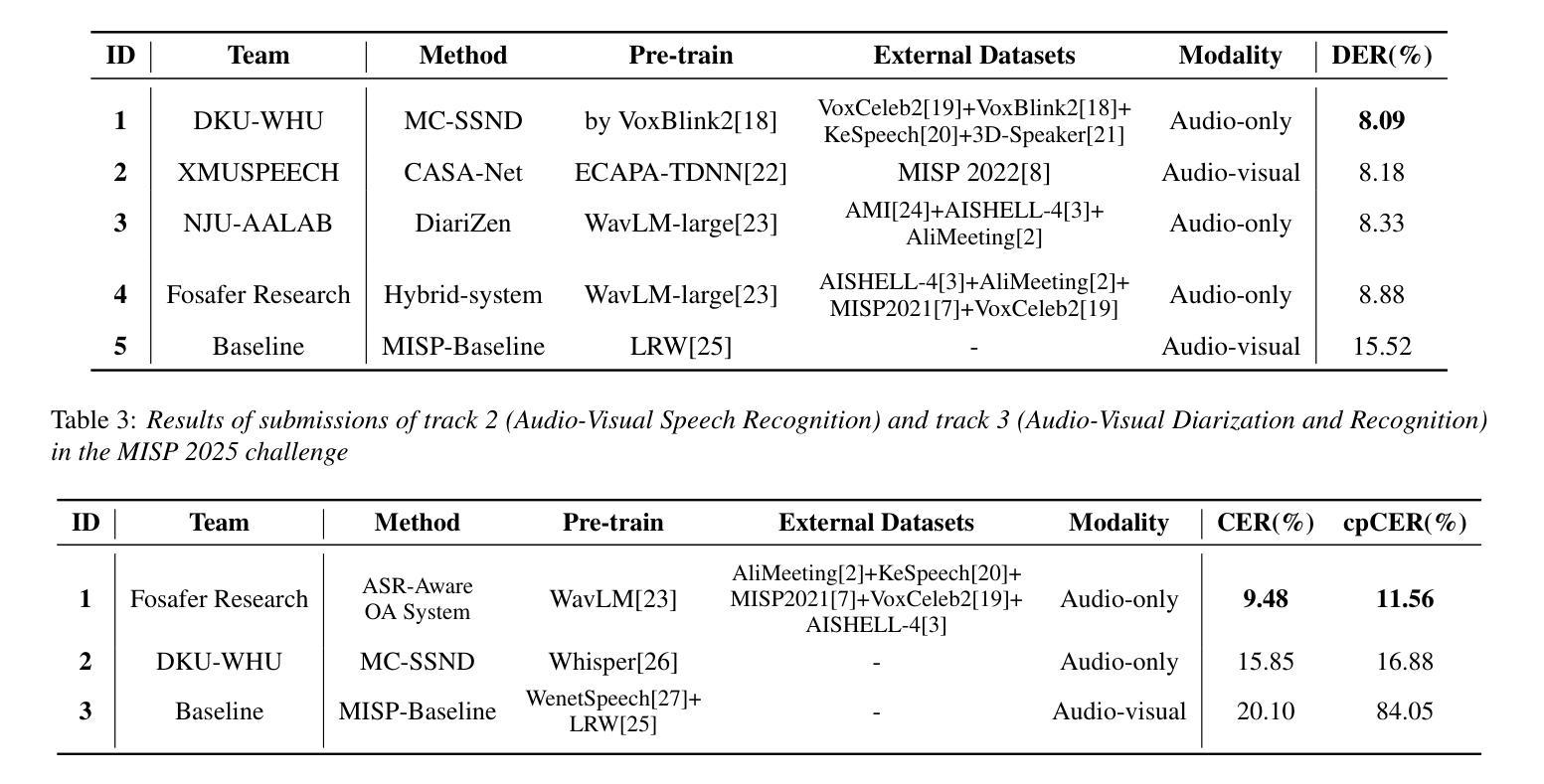
The Multimodal Information Based Speech Processing (MISP) 2025 Challenge: Audio-Visual Diarization and Recognition
Authors:Ming Gao, Shilong Wu, Hang Chen, Jun Du, Chin-Hui Lee, Shinji Watanabe, Jingdong Chen, Siniscalchi Sabato Marco, Odette Scharenborg
Meetings are a valuable yet challenging scenario for speech applications due to complex acoustic conditions. This paper summarizes the outcomes of the MISP 2025 Challenge, hosted at Interspeech 2025, which focuses on multi-modal, multi-device meeting transcription by incorporating video modality alongside audio. The tasks include Audio-Visual Speaker Diarization (AVSD), Audio-Visual Speech Recognition (AVSR), and Audio-Visual Diarization and Recognition (AVDR). We present the challenge’s objectives, tasks, dataset, baseline systems, and solutions proposed by participants. The best-performing systems achieved significant improvements over the baseline: the top AVSD model achieved a Diarization Error Rate (DER) of 8.09%, improving by 7.43%; the top AVSR system achieved a Character Error Rate (CER) of 9.48%, improving by 10.62%; and the best AVDR system achieved a concatenated minimum-permutation Character Error Rate (cpCER) of 11.56%, improving by 72.49%.
会议对于语音应用来说是一个宝贵且充满挑战的场景,由于存在复杂的声学条件。本文总结了MISP 2025挑战的成果,该挑战于Interspeech 2025举办,侧重于结合视频模式的多模态、多设备会议转录。任务包括音频-视频说话人定位(AVSD)、音频-视频语音识别(AVSR)和音频-视频定位与识别(AVDR)。我们介绍了挑战的目标、任务、数据集、基准系统以及参与者提出的解决方案。表现最佳的系统的性能实现了显著提高:最佳AVSD模型的说话人分割错误率(DER)达到了8.09%,提高了7.43%;最佳AVSR系统的字符错误率(CER)达到了9.48%,提高了10.62%;最佳AVDR系统的串联最小排列字符错误率(cpCER)达到了11.56%,提高了72.49%。
论文及项目相关链接
PDF Accepted by Interspeech 2025. Camera-ready version
Summary
本文总结了MISP 2025挑战的成果,该挑战聚焦于多模态、多设备的会议转录技术,结合了视频模态与音频。挑战任务包括音频视觉说话人识别(AVSD)、音频视觉语音识别(AVSR)和音频视觉说话人识别和语音识别(AVDR)。本文介绍了挑战的目标、任务、数据集、基准系统和参与者提出的解决方案。最佳系统表现显著优于基准系统,其中AVSD模型最佳结果的DER为8.09%,AVSR系统的CER为9.48%,而AVDR系统的cpCER为最低值。这些改进证明了多模态技术在会议场景的应用潜力。
Key Takeaways
以下是关于文本的主要观点摘要:
- MISP 2025挑战在会议场景的语音识别技术上进行了多方面的尝试和研究。这涉及视频与音频结合的识别技术,有助于更好地解析和解释语音信号在复杂环境中的变化。
- 该挑战包括三个主要任务:音频视觉说话人识别(AVSD)、音频视觉语音识别(AVSR)和结合二者的识别任务(AVDR)。这三个任务都对识别复杂性和准确度提出了较高要求。
- 挑战的目标是推进多模态和多设备在会议场景的应用能力,这包括了复杂声学条件下的多模态信息处理技术。
- 最佳系统表现显著优于基准系统,这证明了多模态技术在会议场景的应用潜力巨大。具体来说,AVSD模型在说话人识别上取得了显著的进步,而AVSR系统在语音识别方面也有显著的改进。同时,AVDR系统的性能提升最为显著,这为未来的研究提供了重要的方向。
点此查看论文截图

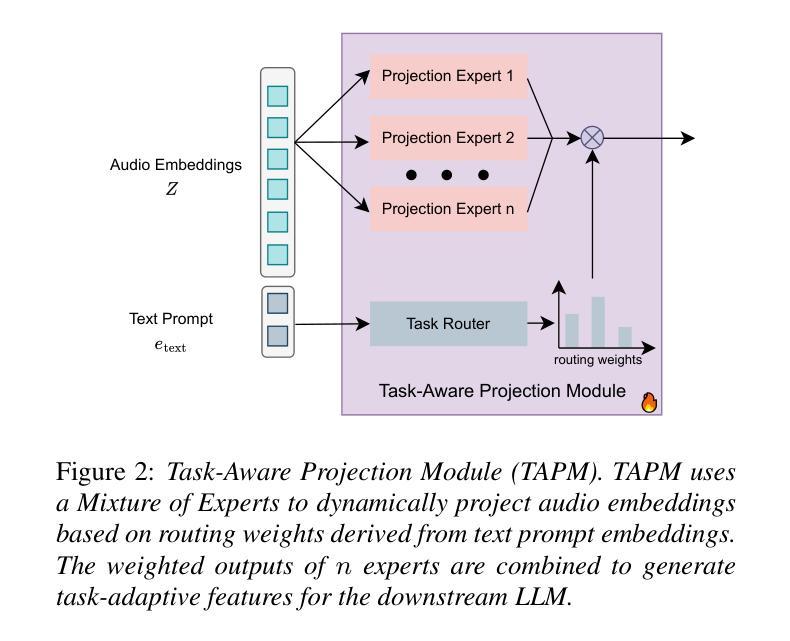
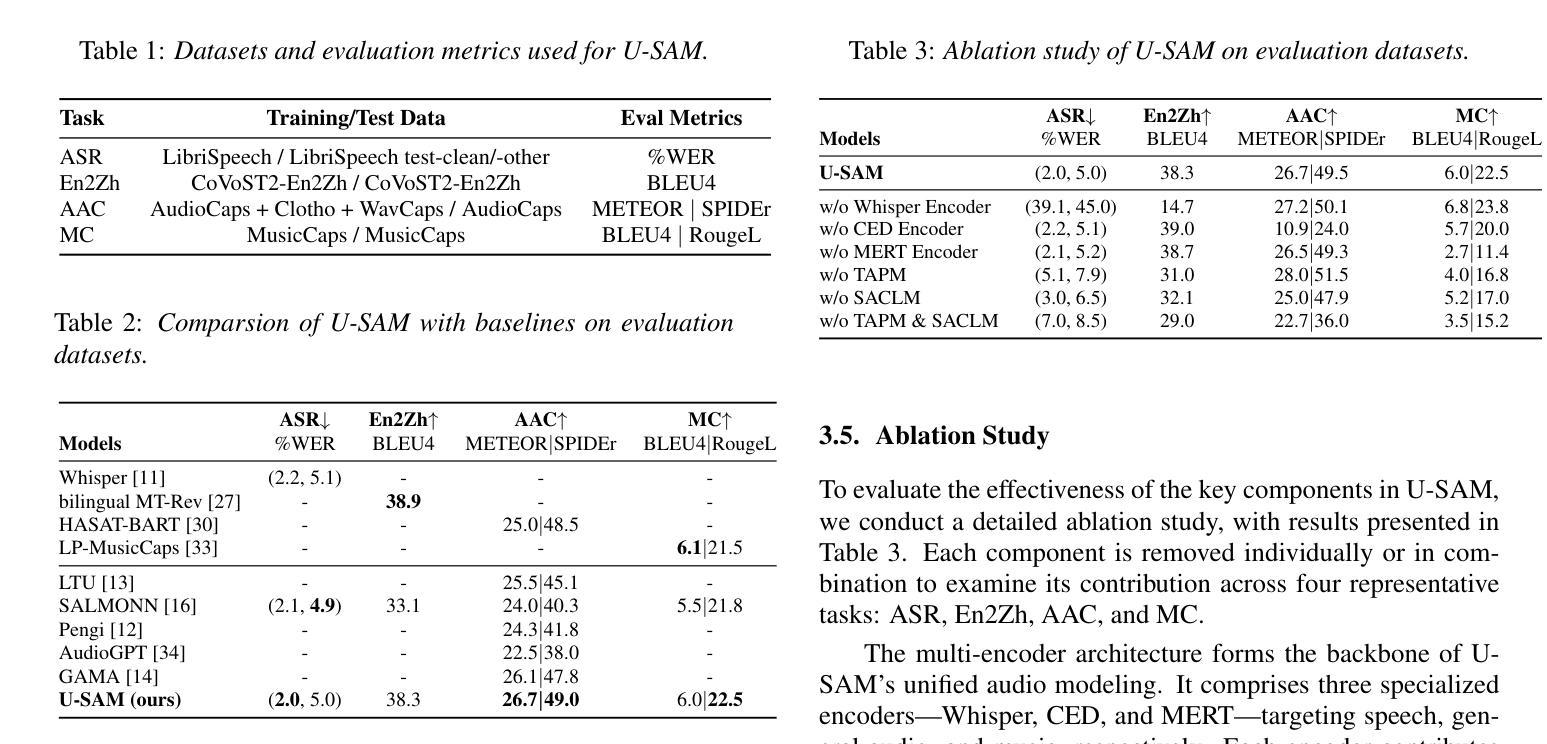
U-SAM: An audio language Model for Unified Speech, Audio, and Music Understanding
Authors:Ziqian Wang, Xianjun Xia, Xinfa Zhu, Lei Xie
The text generation paradigm for audio tasks has opened new possibilities for unified audio understanding. However, existing models face significant challenges in achieving a comprehensive understanding across diverse audio types, such as speech, general audio events, and music. Furthermore, their exclusive reliance on cross-entropy loss for alignment often falls short, as it treats all tokens equally and fails to account for redundant audio features, leading to weaker cross-modal alignment. To deal with the above challenges, this paper introduces U-SAM, an advanced audio language model that integrates specialized encoders for speech, audio, and music with a pre-trained large language model (LLM). U-SAM employs a Mixture of Experts (MoE) projector for task-aware feature fusion, dynamically routing and integrating the domain-specific encoder outputs. Additionally, U-SAM incorporates a Semantic-Aware Contrastive Loss Module, which explicitly identifies redundant audio features under language supervision and rectifies their semantic and spectral representations to enhance cross-modal alignment. Extensive experiments demonstrate that U-SAM consistently outperforms both specialized models and existing audio language models across multiple benchmarks. Moreover, it exhibits emergent capabilities on unseen tasks, showcasing its generalization potential. Code is available (https://github.com/Honee-W/U-SAM/).
音频任务文本生成范式为统一音频理解开辟了新的可能性。然而,现有模型在实现不同类型音频的全面理解方面面临重大挑战,如语音、一般音频事件和音乐。此外,它们对交叉熵损失的过度依赖往往会导致对齐不足,因为交叉熵损失平等对待所有令牌,并且无法处理冗余的音频特征,从而导致跨模态对齐较弱。为了应对上述挑战,本文介绍了U-SAM,这是一个先进的音频语言模型,它结合了针对语音、音频和音乐的专业编码器,以及一个预训练的大型语言模型(LLM)。U-SAM采用混合专家(MoE)投影仪进行任务感知特征融合,动态路由和集成领域特定的编码器输出。此外,U-SAM还采用语义感知对比损失模块,该模块在语言监督下明确识别冗余音频特征,并纠正其语义和光谱表示,以增强跨模态对齐。大量实验表明,U-SAM在多个基准测试上始终优于专业模型和现有音频语言模型。此外,它在未见过的任务上展现出新兴能力,展示了其泛化潜力。代码可用(https://github.com/Honee-W/U-SAM/)。
论文及项目相关链接
PDF Accepted to Interspeech 2025
Summary
该文本介绍了针对音频任务的新型文本生成范式,并指出其在统一音频理解方面的新可能性。现有模型在处理不同类型的音频(如语音、通用音频事件和音乐)时面临挑战,其基于交叉熵损失的单一对齐方法常常难以应对复杂多变的音频特征,导致跨模态对齐性能受限。为解决这些问题,本文提出了U-SAM高级音频语言模型,该模型集成了针对语音、音频和音乐的专门编码器以及预训练的大型语言模型(LLM)。U-SAM利用混合专家(MoE)投影仪进行任务感知特征融合,动态路由和集成特定领域的编码器输出。此外,U-SAM还引入了语义感知对比损失模块,该模块在语言学监督下明确识别冗余音频特征,校正其语义和光谱表示,以增强跨模态对齐。实验表明,U-SAM在多基准测试中始终优于专业模型和现有音频语言模型。此外,U-SAM在未见任务上展现出潜在的泛化能力。
Key Takeaways
- 音频任务文本生成范式为统一音频理解带来了新机会。
- 现有模型在处理多样音频类型时面临挑战。
- U-SAM模型集成了专门编码器与大型语言模型(LLM)。
- U-SAM采用混合专家投影仪进行任务感知特征融合。
- U-SAM引入了语义感知对比损失模块增强跨模态对齐。
- U-SAM在多基准测试中表现优异。
- U-SAM在未见任务上展现出泛化潜力。
点此查看论文截图