⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-05-30 更新
Chest Disease Detection In X-Ray Images Using Deep Learning Classification Method
Authors:Alanna Hazlett, Naomi Ohashi, Timothy Rodriguez, Sodiq Adewole
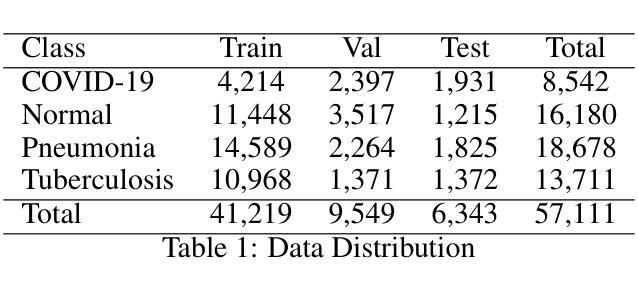
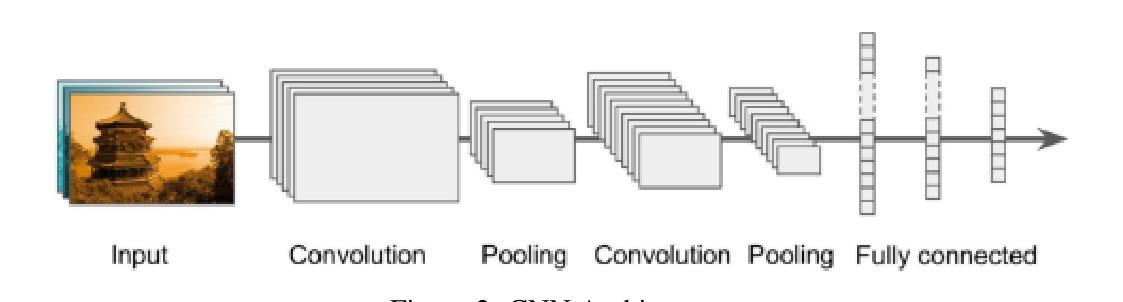
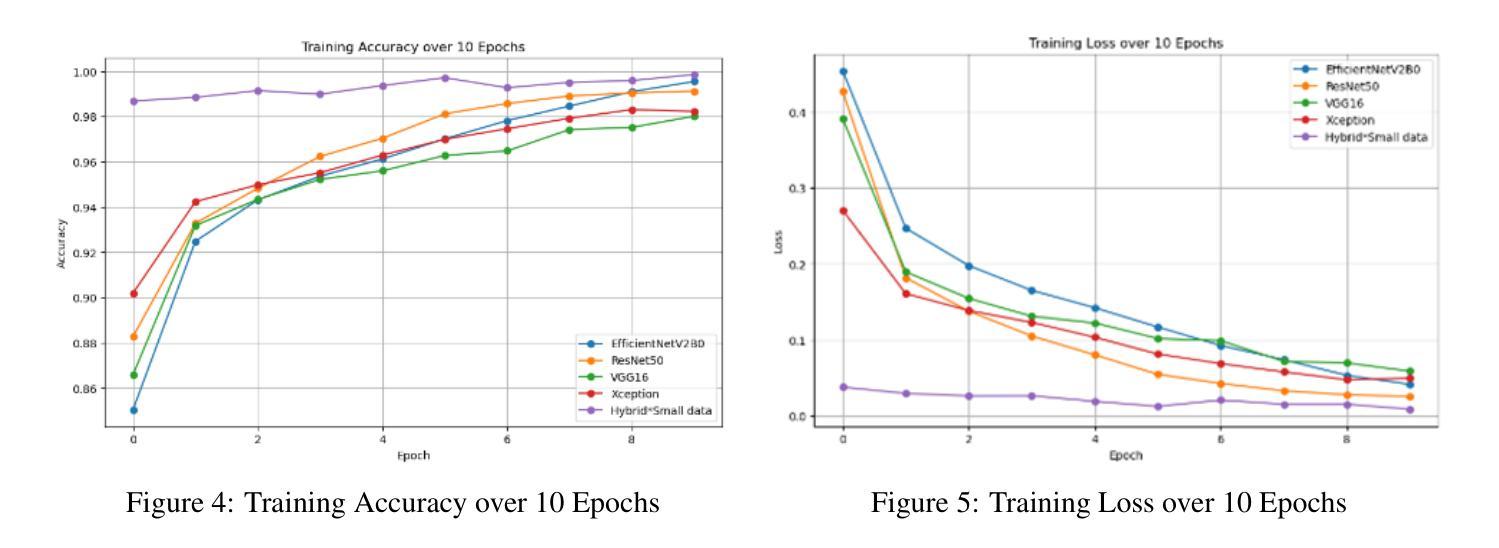
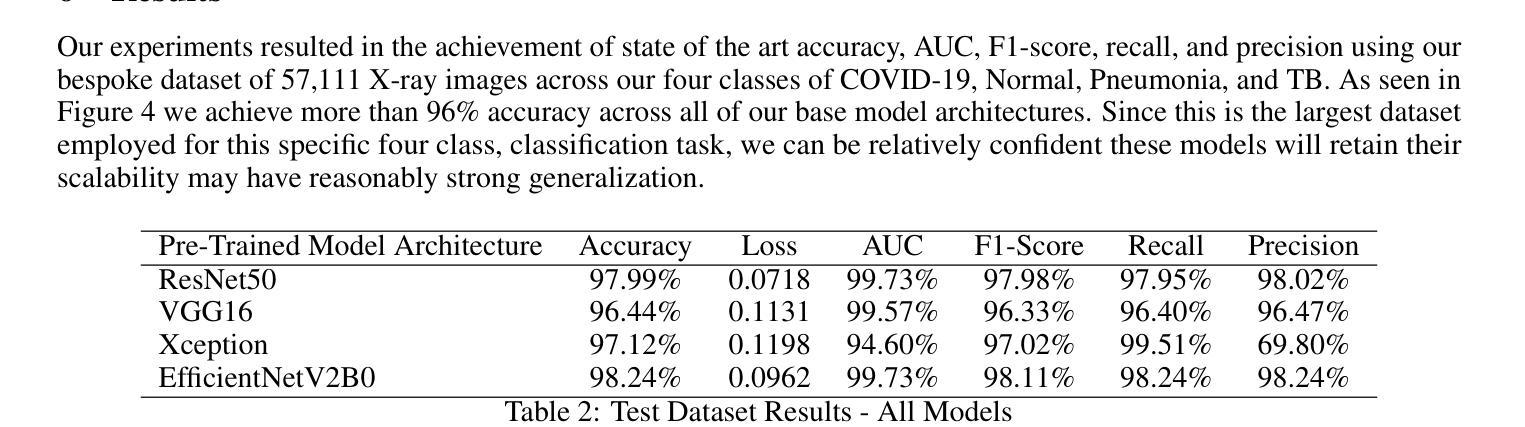
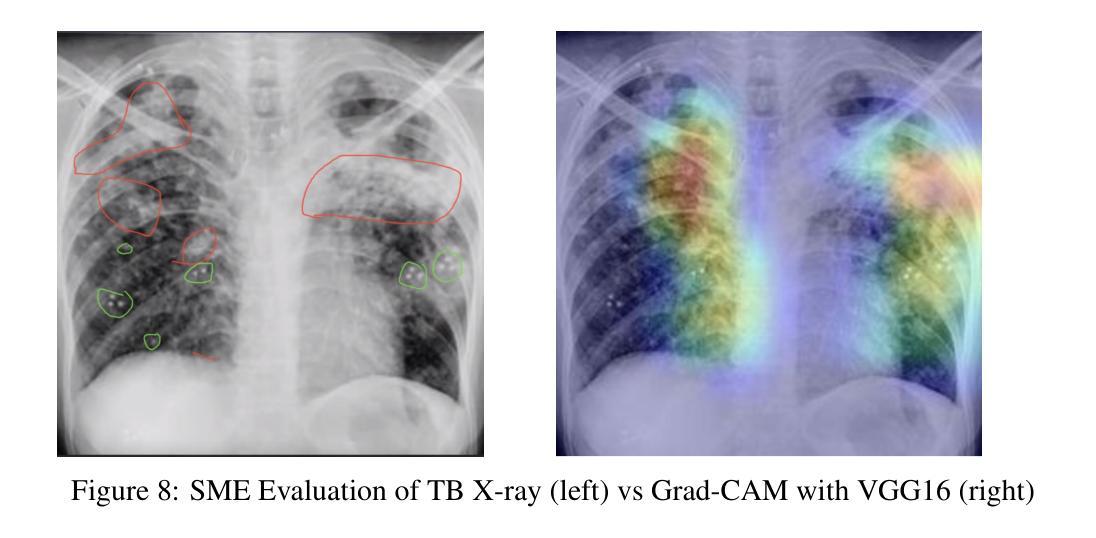
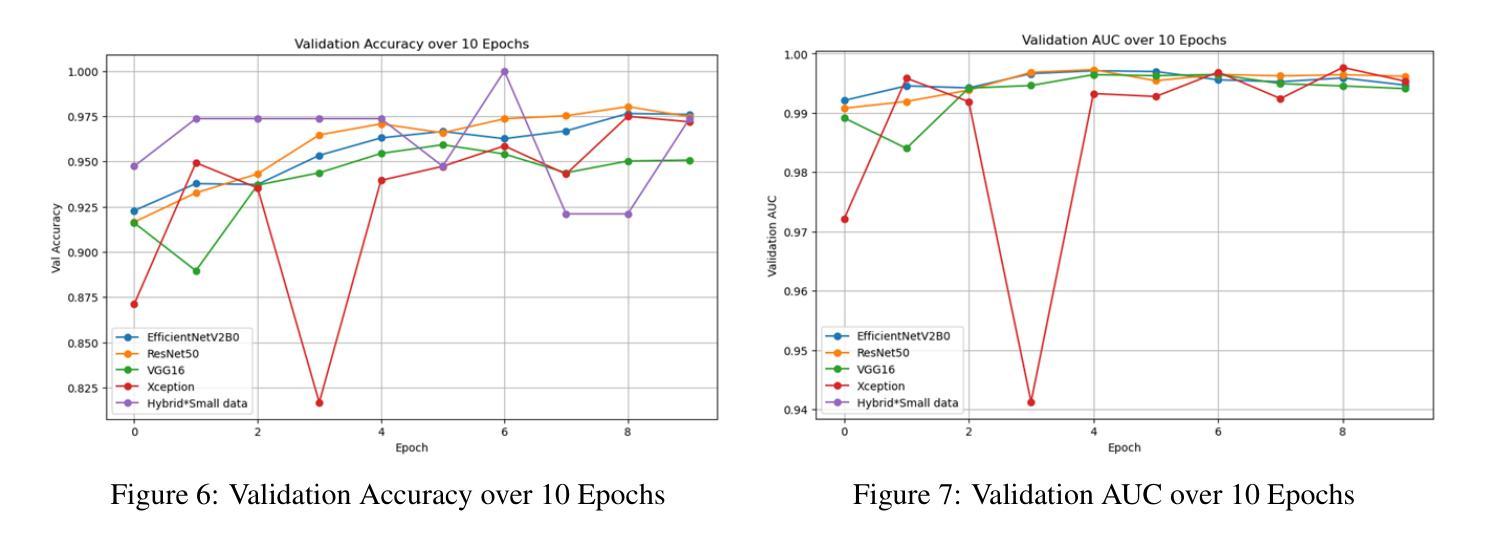
In this work, we investigate the performance across multiple classification models to classify chest X-ray images into four categories of COVID-19, pneumonia, tuberculosis (TB), and normal cases. We leveraged transfer learning techniques with state-of-the-art pre-trained Convolutional Neural Networks (CNNs) models. We fine-tuned these pre-trained architectures on a labeled medical x-ray images. The initial results are promising with high accuracy and strong performance in key classification metrics such as precision, recall, and F1 score. We applied Gradient-weighted Class Activation Mapping (Grad-CAM) for model interpretability to provide visual explanations for classification decisions, improving trust and transparency in clinical applications.
在这项工作中,我们研究了多个分类模型对胸部X射线图像进行分类的性能,分为四类:COVID-19、肺炎、结核病(TB)和正常病例。我们利用先进的预训练卷积神经网络(CNN)模型采用迁移学习技术。我们在标记的医学X射线图像上对预训练架构进行了微调。初步结果令人鼓舞,精度高,在关键分类指标(如精确度、召回率和F1分数)方面表现强劲。为了提供分类决策的视觉解释,提高临床应用中信任和透明度,我们应用了梯度加权类别激活映射(Grad-CAM)进行模型解释性。
论文及项目相关链接
Summary
在这项研究中,我们探讨了多种分类模型在将胸部X射线图像分类为COVID-19、肺炎、结核病(TB)和正常病例四类时的性能。我们利用先进的预训练卷积神经网络(CNN)模型进行迁移学习技术。在标记的医学X射线图像上对预训练架构进行了微调。初步结果具有前景,关键分类指标如精度、召回率和F1分数表现出高准确性和强劲性能。我们应用了梯度加权类激活映射(Grad-CAM)来提高模型的解释性,为分类决策提供视觉解释,提高临床应用的信任和透明度。
Key Takeaways
- 研究者探究了多种分类模型在胸部X射线图像分类中的表现。
- 研究采用了先进的预训练卷积神经网络(CNN)模型进行迁移学习。
- 在标记的医学X射线图像上对预训练模型进行了微调,获得了有前景的初步结果。
- 模型在分类精度、召回率和F1分数等关键指标上表现出高准确性和强劲性能。
- 应用了梯度加权类激活映射(Grad-CAM)提高模型的解释性。
- 模型提供视觉解释为分类决策提供根据,提高了临床应用的信任度和透明度。
点此查看论文截图


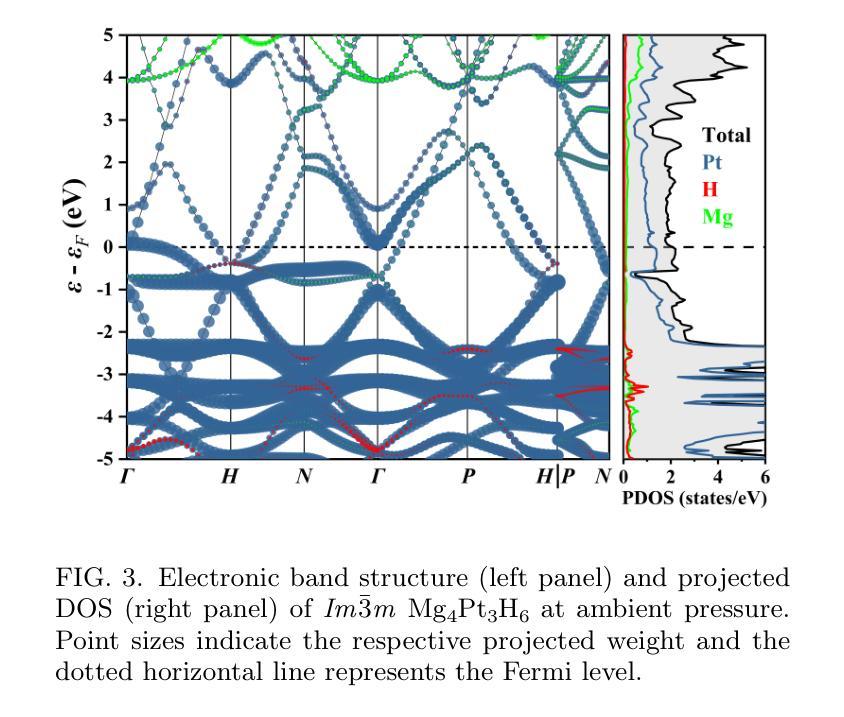
Prediction and Synthesis of Mg$_4$Pt$_3$H$_6$: A Metallic Complex Transition Metal Hydride Stabilized at Ambient Pressure
Authors:Wencheng Lu, Michael J. Hutcheon, Mads F. Hansen, Kapildeb Dolui, Shubham Sinha, Mihir R. Sahoo, Chris J. Pickard, Christoph Heil, Anna Pakhomova, Mohamed Mezouar, Dominik Daisenberger, Stella Chariton, Vitali Prakapenka, Matthew N. Julian, Rohit P. Prasankumar, Timothy A. Strobel
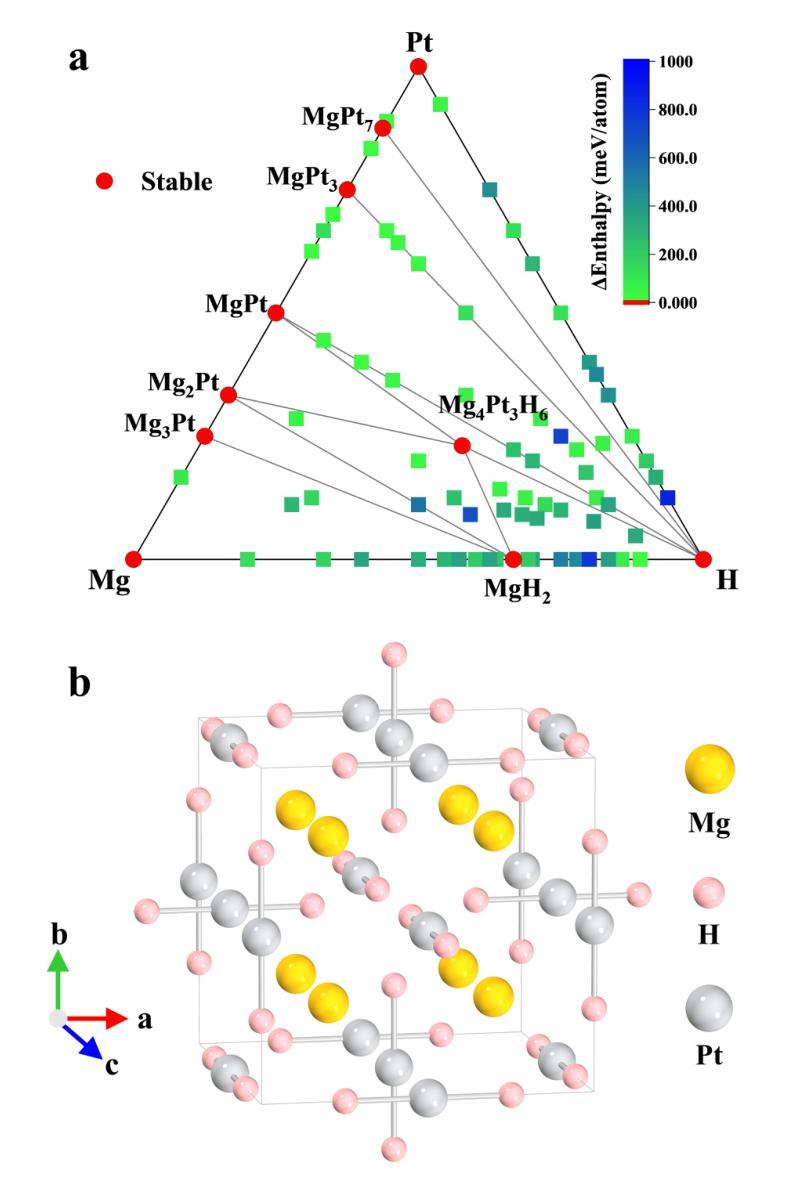
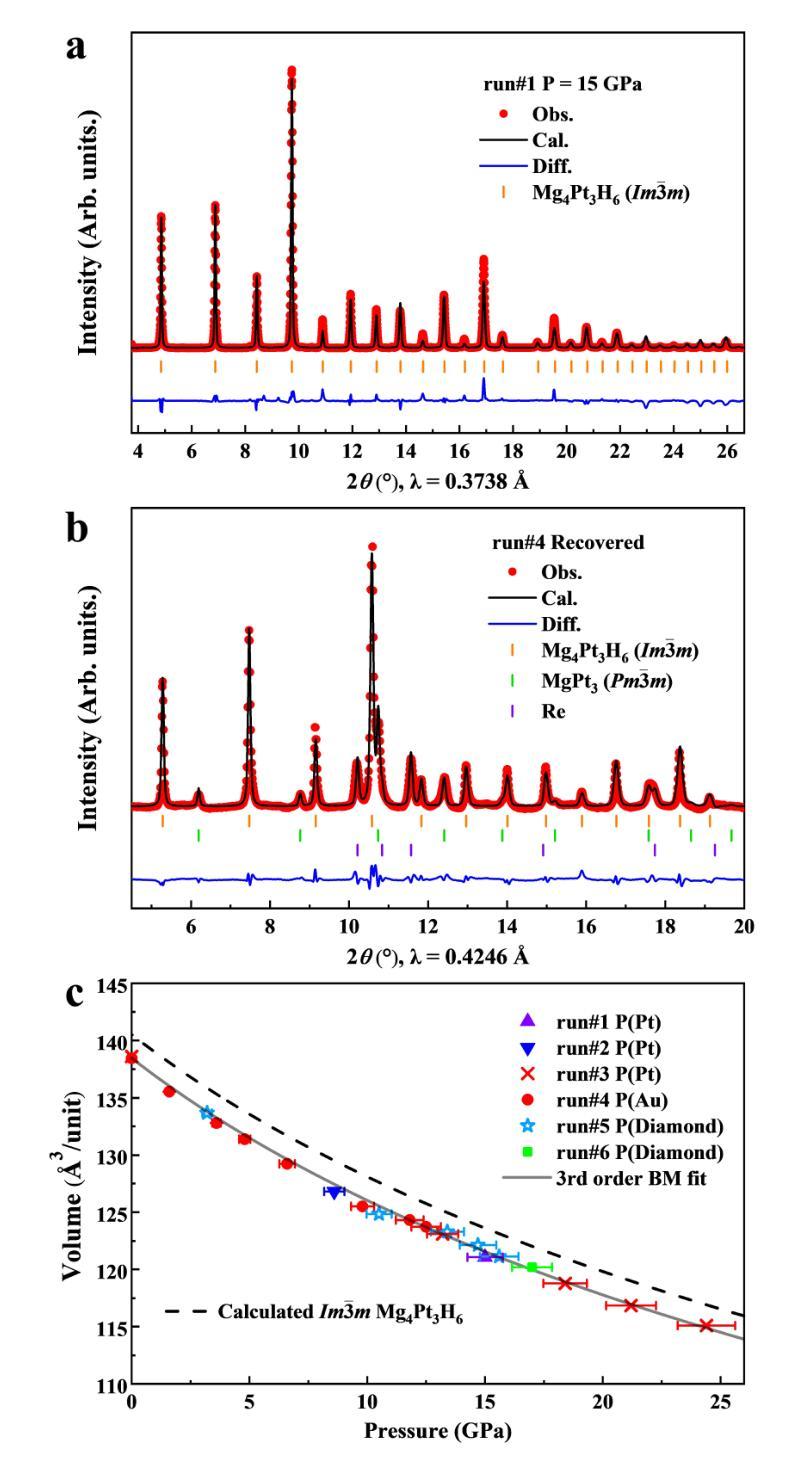
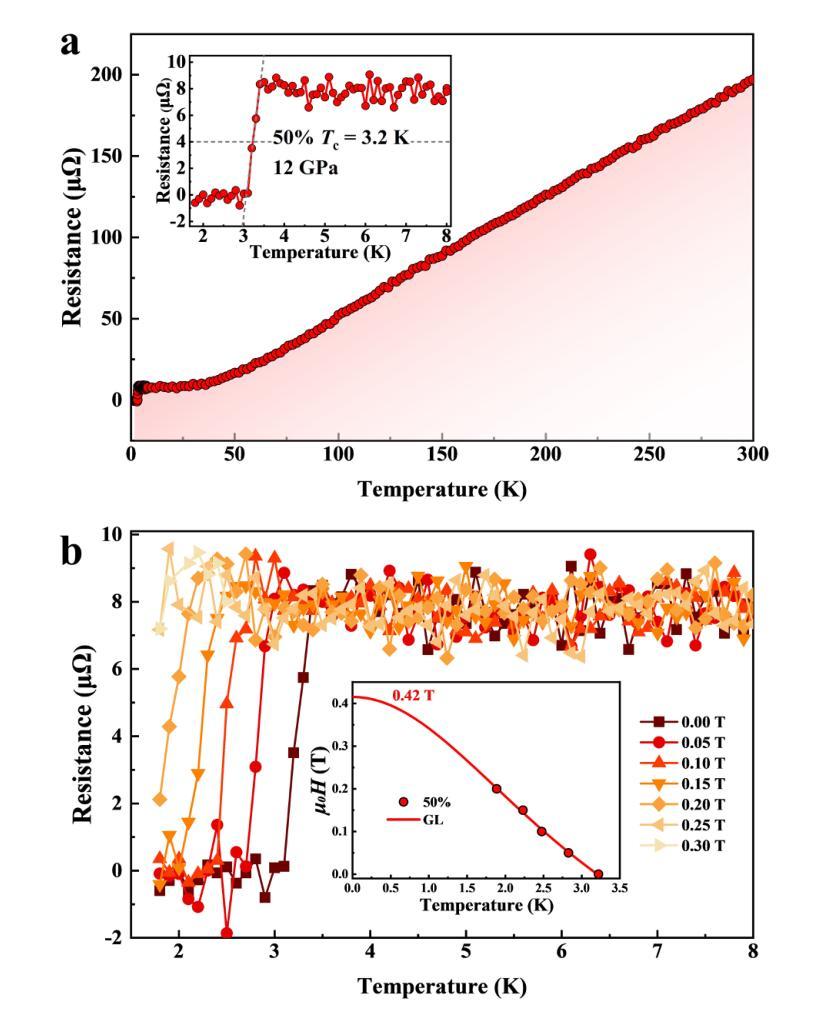
The low-pressure stabilization of superconducting hydrides with high critical temperatures ($T_c$s) remains a significant challenge, and experimentally verified superconducting hydrides are generally constrained to a limited number of structural prototypes. Ternary transition-metal complex hydrides (hydrido complexes)-typically regarded as hydrogen storage materials-exhibit a large range of compounds stabilized at low pressure with recent predictions for high-$T_c$ superconductivity. Motivated by this class of materials, we investigated complex hydride formation in the Mg-Pt-H system, which has no known ternary hydride compounds. Guided by ab initio structural predictions, we successfully synthesized a novel complex transition-metal hydride, Mg$_4$Pt$_3$H$_6$, using laser-heated diamond anvil cells. The compound forms in a body-centered cubic structural prototype at moderate pressures between 8-25 GPa. Unlike the majority of known hydrido complexes, Mg$_4$Pt$_3$H$_6$ is metallic, with formal charge described as 4[Mg]$^{2+}$.3[PtH$_2$]$^{2-}$. X-ray diffraction (XRD) measurements obtained during decompression reveal that Mg$_4$Pt$_3$H$_6$ remains stable upon quenching to ambient conditions. Magnetic-field and temperature-dependent electrical transport measurements indicate ambient-pressure superconductivity with $T_c$ (50%) = 2.9 K, in reasonable agreement with theoretical calculations. These findings clarify the phase behavior in the Mg-Pt-H system and provide valuable insights for transition-metal complex hydrides as a new class of hydrogen-rich superconductors.
超导氢化物低压稳定性的研究仍然是一个重大挑战,且实验验证的超导氢化物通常局限于有限的结构原型。三元过渡金属复合氢化物(氢化物复合物)通常被视为储氢材料,其能在低压下稳定存在一大类化合物,最近有预测表明其具有高温超导性。受此类材料的启发,我们研究了Mg-Pt-H体系中复合氢化物的形成,该体系中尚无已知的三元氢化物化合物。在基于从头算结构预测的指导下,我们成功使用激光加热金刚石砧面细胞合成了一种新型过渡金属氢化物Mg4Pt3H6。该化合物以体心立方结构原型形成于8-25 GPa的适度压力下。与大多数已知氢化物复合物不同,Mg4Pt3H6具有金属性,形式电荷描述为4[Mg]2+.3[PtH2]2−。在减压过程中获得的X射线衍射(XRD)测量结果表明,Mg4Pt3H6在淬火到环境条件下时保持稳定。磁场和温度相关的电输运测量表明环境压力下具有超导性,半临界温度(Tc)(50%)= 2.9 K,与理论计算基本一致。这些发现阐明了Mg-Pt-H系统的相行为,并为过渡金属复合氢化物作为一类新型富氢超导材料提供了宝贵的见解。
论文及项目相关链接
摘要
针对具有高超导温度($T_c$)的超导氢化物在低压下的稳定性仍是一大挑战,且实验验证的超导氢化物通常局限于有限的几种结构原型。本研究受三元过渡金属复合氢化物(氢化物复合体)启发,这些材料通常被视为储氢材料,并在低压下稳定存在大量的化合物,最近有预测称具有高超导性。我们研究了Mg-Pt-H体系中复合氢化物的形成,该体系中尚无已知的三元氢化物化合物。在基于从头算结构预测的指导下,我们成功使用激光加热金刚石砧室合成了一种新型过渡金属氢化物Mg$_4$Pt$_3$H$_6$。该化合物在8-25 GPa的适度压力下形成体心立方结构原型。与大多数已知的氢化物复合体不同,Mg$_4$Pt$_3$H$_6$是金属性的,形式电荷描述为4[Mg]$^{2+}$.3[PtH$_2$]$^{2-}$。X射线衍射(XRD)测量结果显示,在减压过程中Mg$_4$Pt$_3$H$_6$在淬火至环境条件下保持稳定。磁场和温度相关的输运测量表明环境压力下具有超导性,且$T_c$(50%)= 2.9 K,与理论计算基本一致。这些发现阐明了Mg-Pt-H系统的相行为,并为过渡金属复合氢化物作为一类富氢的超导体提供了宝贵的见解。
**关键见解**
1. 研究发现新型过渡金属氢化物Mg$_4$Pt$_3$H$_6$在适度压力下形成体心立方结构原型。
2. Mg$_4$Pt$_3$H$_6$是金属性的,具有特定的形式电荷分布。
3. X射线衍射测量显示Mg$_4$Pt$_3$H$_6$在减压至环境条件下保持稳定。
4. 环境压力下具有超导性,临界温度($T_c$)达到2.9 K。
5. 这些发现对过渡金属复合氢化物作为富氢超导体提供了新的视角。
6. 研究结果对理解超导氢化物的稳定性和相行为有重要意义。
点此查看论文截图

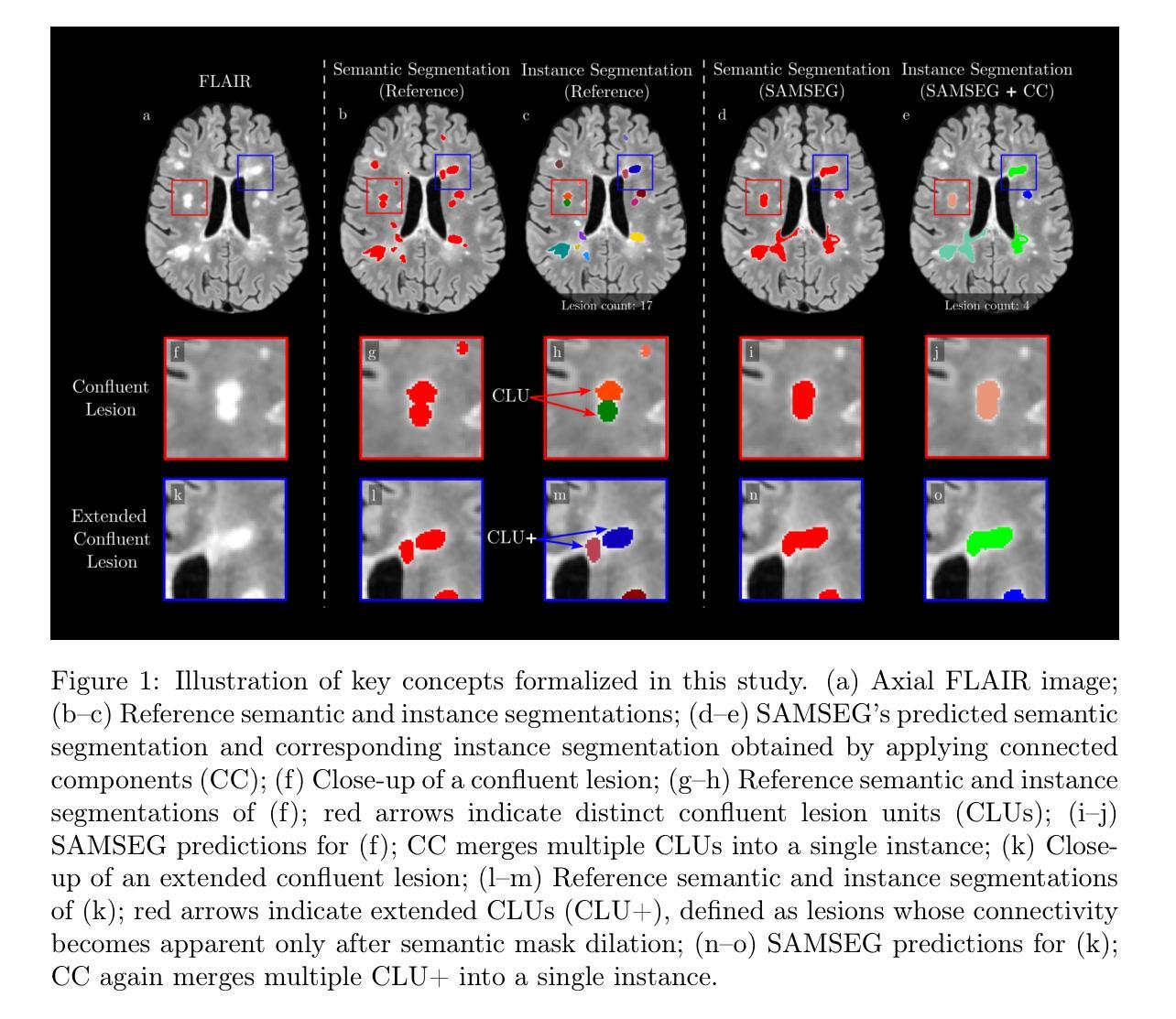
ConfLUNet: Multiple sclerosis lesion instance segmentation in presence of confluent lesions
Authors:Maxence Wynen, Pedro M. Gordaliza, Maxime Istasse, Anna Stölting, Pietro Maggi, Benoît Macq, Meritxell Bach Cuadra
Accurate lesion-level segmentation on MRI is critical for multiple sclerosis (MS) diagnosis, prognosis, and disease monitoring. However, current evaluation practices largely rely on semantic segmentation post-processed with connected components (CC), which cannot separate confluent lesions (aggregates of confluent lesion units, CLUs) due to reliance on spatial connectivity. To address this misalignment with clinical needs, we introduce formal definitions of CLUs and associated CLU-aware detection metrics, and include them in an exhaustive instance segmentation evaluation framework. Within this framework, we systematically evaluate CC and post-processing-based Automated Confluent Splitting (ACLS), the only existing methods for lesion instance segmentation in MS. Our analysis reveals that CC consistently underestimates CLU counts, while ACLS tends to oversplit lesions, leading to overestimated lesion counts and reduced precision. To overcome these limitations, we propose ConfLUNet, the first end-to-end instance segmentation framework for MS lesions. ConfLUNet jointly optimizes lesion detection and delineation from a single FLAIR image. Trained on 50 patients, ConfLUNet significantly outperforms CC and ACLS on the held-out test set (n=13) in instance segmentation (Panoptic Quality: 42.0% vs. 37.5%/36.8%; p = 0.017/0.005) and lesion detection (F1: 67.3% vs. 61.6%/59.9%; p = 0.028/0.013). For CLU detection, ConfLUNet achieves the highest F1[CLU] (81.5%), improving recall over CC (+12.5%, p = 0.015) and precision over ACLS (+31.2%, p = 0.003). By combining rigorous definitions, new CLU-aware metrics, a reproducible evaluation framework, and the first dedicated end-to-end model, this work lays the foundation for lesion instance segmentation in MS.
在多发性硬化症(MS)的诊断、预后和疾病监测中,MRI上的精确病变级别分割至关重要。然而,当前的评估实践主要依赖于通过连通组件(CC)进行后处理的语义分割,由于依赖空间连通性,它无法分离融合性病变(融合性病变单位(CLU)的聚集体)。为了解决这个问题并满足临床需求,我们引入了CLUs的正式定义和相关的CLU感知检测指标,并将它们纳入详尽的实例分割评估框架中。在此框架内,我们系统地评估了基于连通组件(CC)和后处理的自动融合分裂(ACLS),这是多发性硬化症病变实例分割中唯一现有的方法。我们的分析表明,CC始终低估CLU计数,而ACLS倾向于过度分割病变,导致病变计数过高和精度降低。为了克服这些局限性,我们提出了ConfLUNet,这是多发性硬化症的端到端病变实例分割框架的首创。ConfLUNet联合优化从单个FLAIR图像中检测并描绘病变。在50名患者上进行训练后,ConfLUNet在保留的测试集(n=13)上的实例分割(全景质量:42.0%比37.5%/36.8%;p=0.017/0.005)和病变检测(F1:67.3%比61.6%/59.9%;p=0.028/0.013)方面均显著优于CC和ACLS。对于CLU检测,ConfLUNet达到了最高的F1[CLU](81.5%),在召回方面超过了CC(+12.5%,p=0.015),并在精度方面超过了ACLS(+31.2%,p=0.003)。通过结合严格的定义、新的CLU感知指标、可再现的评估框架和首个专用的端到端模型,这项工作为多发性硬化症的病变实例分割奠定了基础。
论文及项目相关链接
摘要
针对多发性硬化症(MS)的MRI图像,精确到病变级别的分割对于诊断、预后和疾病监测至关重要。然而,当前的评价实践主要依赖于连通组件(CC)进行语义分割后处理,无法分离融合病灶(聚集的连续病灶单位,CLU)。为解决这一与临床需求的不匹配,本文引入了CLU的正式定义和相关CLU感知检测指标,并将其纳入详尽的实例分割评估框架。在该框架下,我们对基于连通组件和自动融合分割(ACLS)的实例分割方法进行了系统评价。分析表明,CC持续低估CLU计数,而ACLS倾向于过度分割病灶,导致病灶计数过高和精度降低。为了克服这些局限性,我们提出了ConfLUNet,这是首个针对MS病灶的端到端实例分割框架。ConfLUNet从单个FLAIR图像中联合优化病灶检测和勾勒。在50名患者上进行训练后,ConfLUNet在保留的测试集(n=13)上的实例分割和病灶检测方面显著优于CC和ACLS(全景质量:42.0% vs. 37.5%/36.8%;p = 0.017/0.005;F1:67.3% vs. 61.6%/59.9%;p = 0.028/0.013)。对于CLU检测,ConfLUNet实现了最高的F1[CLU](81.5%),在召回率上较CC提高了(+12.5%,p = 0.015),并在精度上较ACLS提高了(+31.2%,p = 0.003)。通过结合严格定义、新的CLU感知指标、可重复的评价框架和首个端到端的专用模型,这项工作为MS的病变实例分割奠定了基础。
要点掌握
- 准确进行MRI的病变级别分割对MS的诊断、预后和疾病监测非常重要。
- 当前的评价方法主要依赖连通组件进行后处理,无法有效分离融合病灶。
- 文中提出了CLU的正式定义和相关检测指标,填补了这一临床需求的缺口。
- 系统评估了基于连通组件和自动融合分割的实例分割方法,发现它们存在局限性。
- 引入了ConfLUNet,一个针对MS病灶的端到端实例分割框架,优化了病灶检测和勾勒。
- ConfLUNet在实例分割、病灶检测和CLU检测方面表现出显著优势。
点此查看论文截图


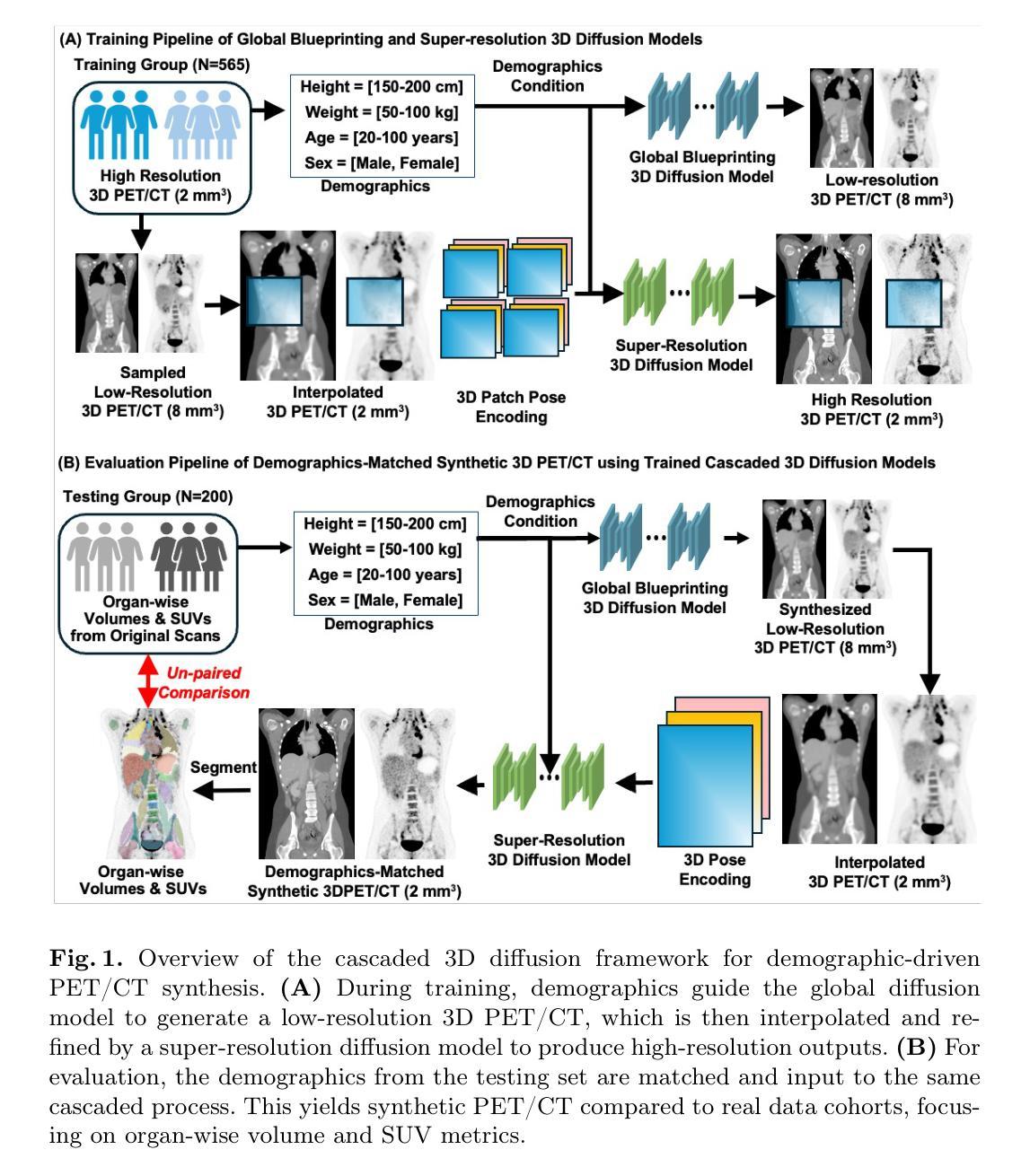
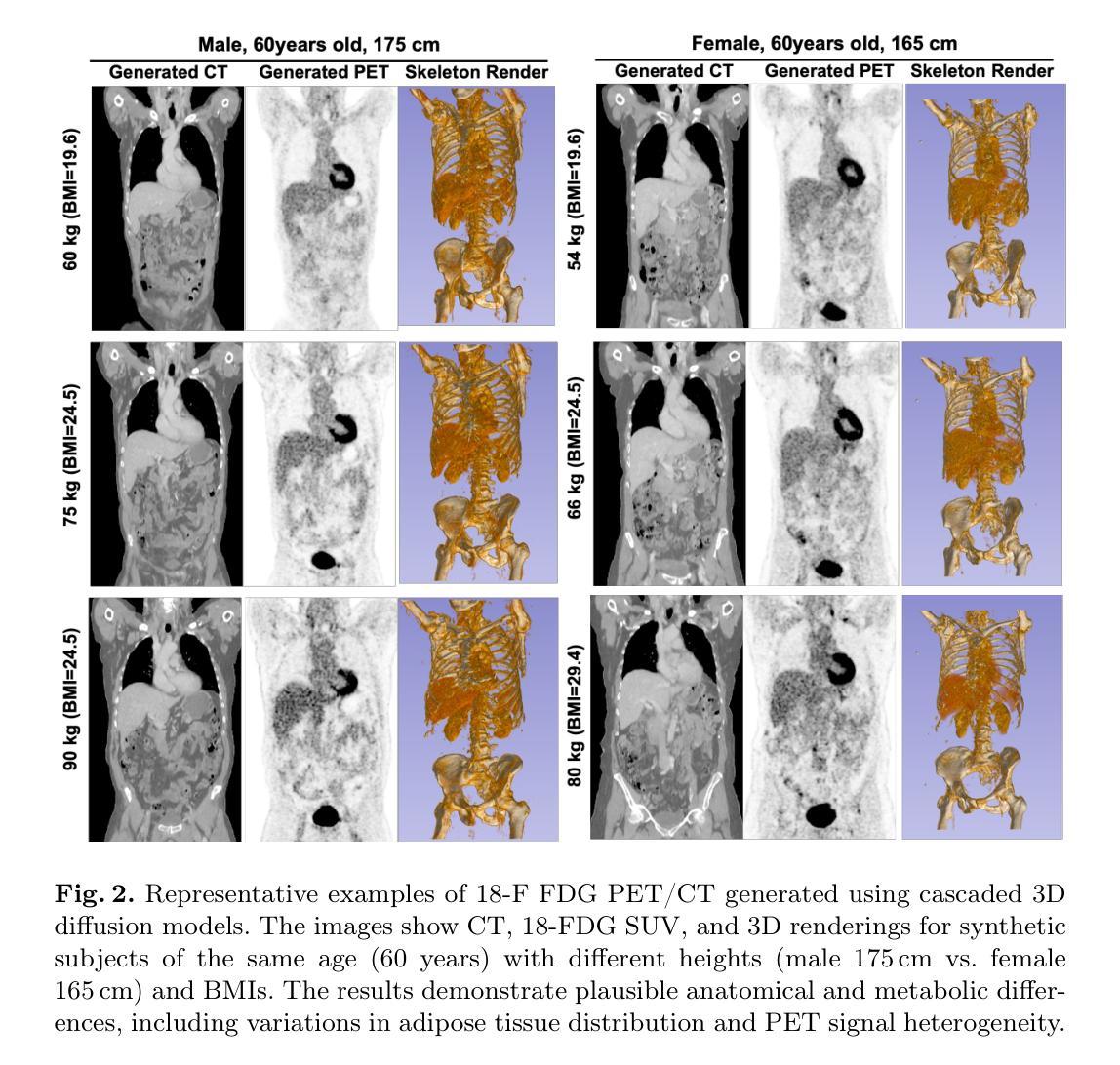
Cascaded 3D Diffusion Models for Whole-body 3D 18-F FDG PET/CT synthesis from Demographics
Authors:Siyeop Yoon, Sifan Song, Pengfei Jin, Matthew Tivnan, Yujin Oh, Sekeun Kim, Dufan Wu, Xiang Li, Quanzheng Li
We propose a cascaded 3D diffusion model framework to synthesize high-fidelity 3D PET/CT volumes directly from demographic variables, addressing the growing need for realistic digital twins in oncologic imaging, virtual trials, and AI-driven data augmentation. Unlike deterministic phantoms, which rely on predefined anatomical and metabolic templates, our method employs a two-stage generative process. An initial score-based diffusion model synthesizes low-resolution PET/CT volumes from demographic variables alone, providing global anatomical structures and approximate metabolic activity. This is followed by a super-resolution residual diffusion model that refines spatial resolution. Our framework was trained on 18-F FDG PET/CT scans from the AutoPET dataset and evaluated using organ-wise volume and standardized uptake value (SUV) distributions, comparing synthetic and real data between demographic subgroups. The organ-wise comparison demonstrated strong concordance between synthetic and real images. In particular, most deviations in metabolic uptake values remained within 3-5% of the ground truth in subgroup analysis. These findings highlight the potential of cascaded 3D diffusion models to generate anatomically and metabolically accurate PET/CT images, offering a robust alternative to traditional phantoms and enabling scalable, population-informed synthetic imaging for clinical and research applications.
我们提出了一种级联的3D扩散模型框架,该框架可以直接从人口统计学变量合成高保真度的3D PET/CT体积图像,从而满足肿瘤成像、虚拟试验和人工智能驱动的数据增强中对现实数字双胞胎的日益增长的需求。不同于依赖于预先定义的解剖学和代谢模板的确定性幻影,我们的方法采用两阶段生成过程。初始的基于分数的扩散模型仅从人口统计学变量合成低分辨率的PET/CT体积图像,提供全球解剖学结构和大致的代谢活动。接下来是由超分辨率残差扩散模型对空间分辨率进行改进。我们的框架在AutoPET数据集的18F FDG PET/CT扫描上进行训练,并使用器官体积和标准化摄取值(SUV)分布进行评估,比较不同人口统计学亚组的合成数据与真实数据。器官层面的比较表明合成图像与真实图像之间具有很强的一致性。特别是,在亚组分析中,大多数代谢摄取值的偏差仍保持在真实值的3-5%以内。这些发现突出了级联3D扩散模型的潜力,能够生成解剖学和代谢上准确的PET/CT图像,为传统幻影提供了稳健的替代方案,并实现了临床和研究应用中可伸缩的、以人群为基础的合成成像。
论文及项目相关链接
PDF MICCAI2025 Submitted version
Summary
该研究提出了一种级联的3D扩散模型框架,该框架可直接从人口统计学变量合成高保真度的3D PET/CT体积图像,满足肿瘤成像、虚拟试验和AI驱动的数据增强中对真实数字双胞胎的需求。该研究采用两阶段生成过程,初始的基于分数的扩散模型从人口统计学变量合成低分辨率的PET/CT体积图像,提供全球解剖结构和大致的代谢活动,随后是超分辨率剩余扩散模型,提高空间分辨率。该框架在AutoPET数据集上的18-F FDG PET/CT扫描上进行训练,并通过器官体积和标准摄取值(SUV)分布进行评估,比较合成数据与不同人口统计学特征小组的实际数据。合成图像与实际图像之间的器官比较表现出强烈的一致性,特别是在小组分析中,大多数代谢摄取值的偏差保持在真实值的3-5%以内。这一发现强调了级联3D扩散模型在生成解剖和代谢准确的PET/CT图像方面的潜力。
Key Takeaways
- 提出了一种级联的3D扩散模型框架,能直接合成高保真度的3D PET/CT体积图像。
- 该方法能够满足肿瘤成像、虚拟试验和AI驱动的数据增强中对真实数字双胞胎的需求。
- 采用了两阶段生成过程:初始阶段合成低分辨率图像,提供全球解剖结构和大致代谢活动;超分辨率阶段提高空间分辨率。
- 框架在AutoPET数据集上进行训练,使用器官体积和标准化摄取值(SUV)分布进行评估。
- 合成图像与实际图像之间的器官比较表现出强烈的一致性。
- 级联3D扩散模型在生成解剖和代谢准确的PET/CT图像方面具潜力。
点此查看论文截图

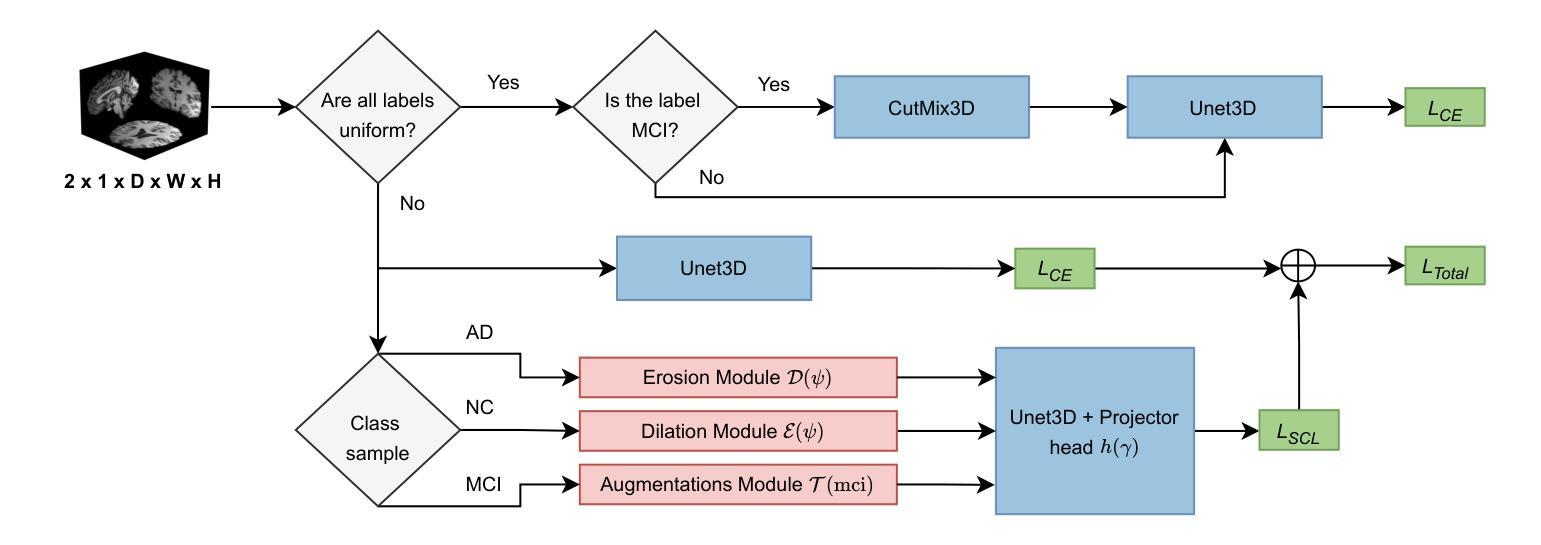
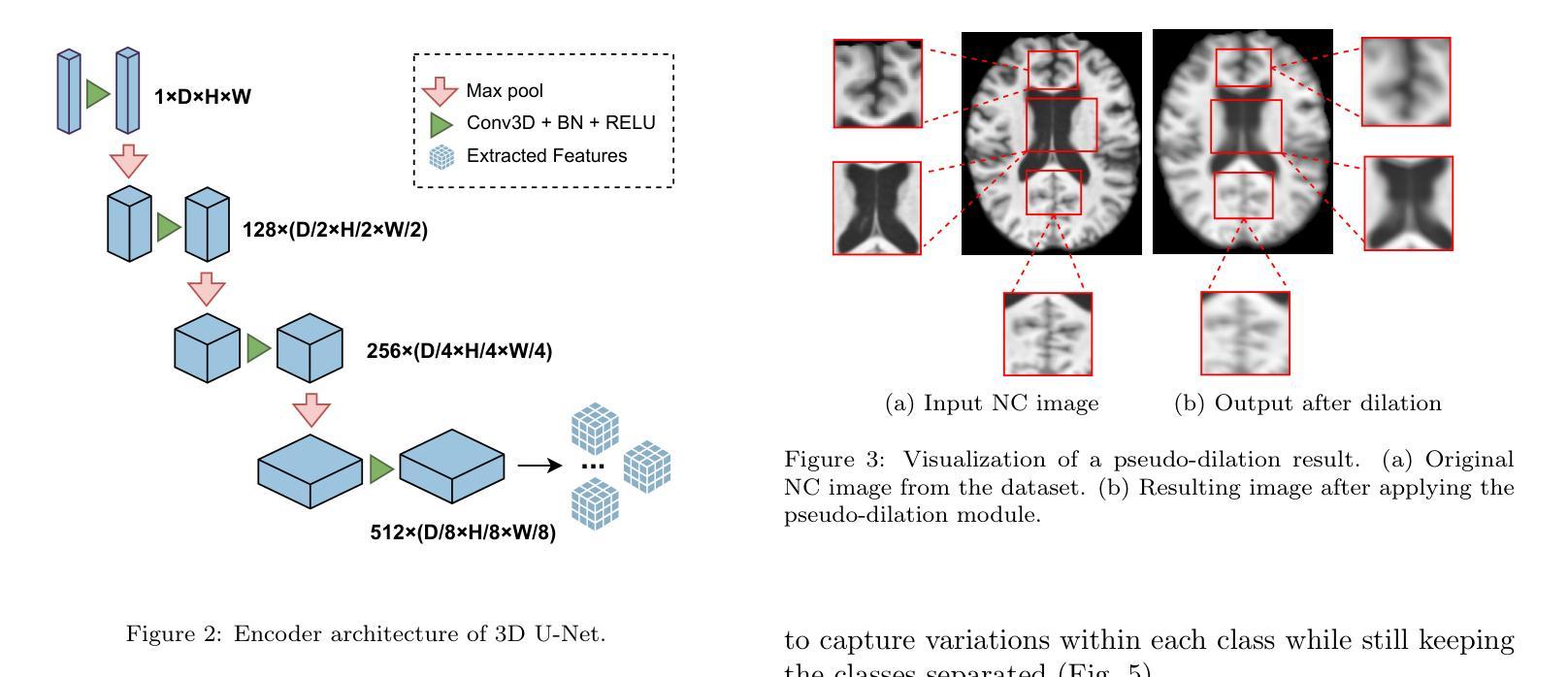
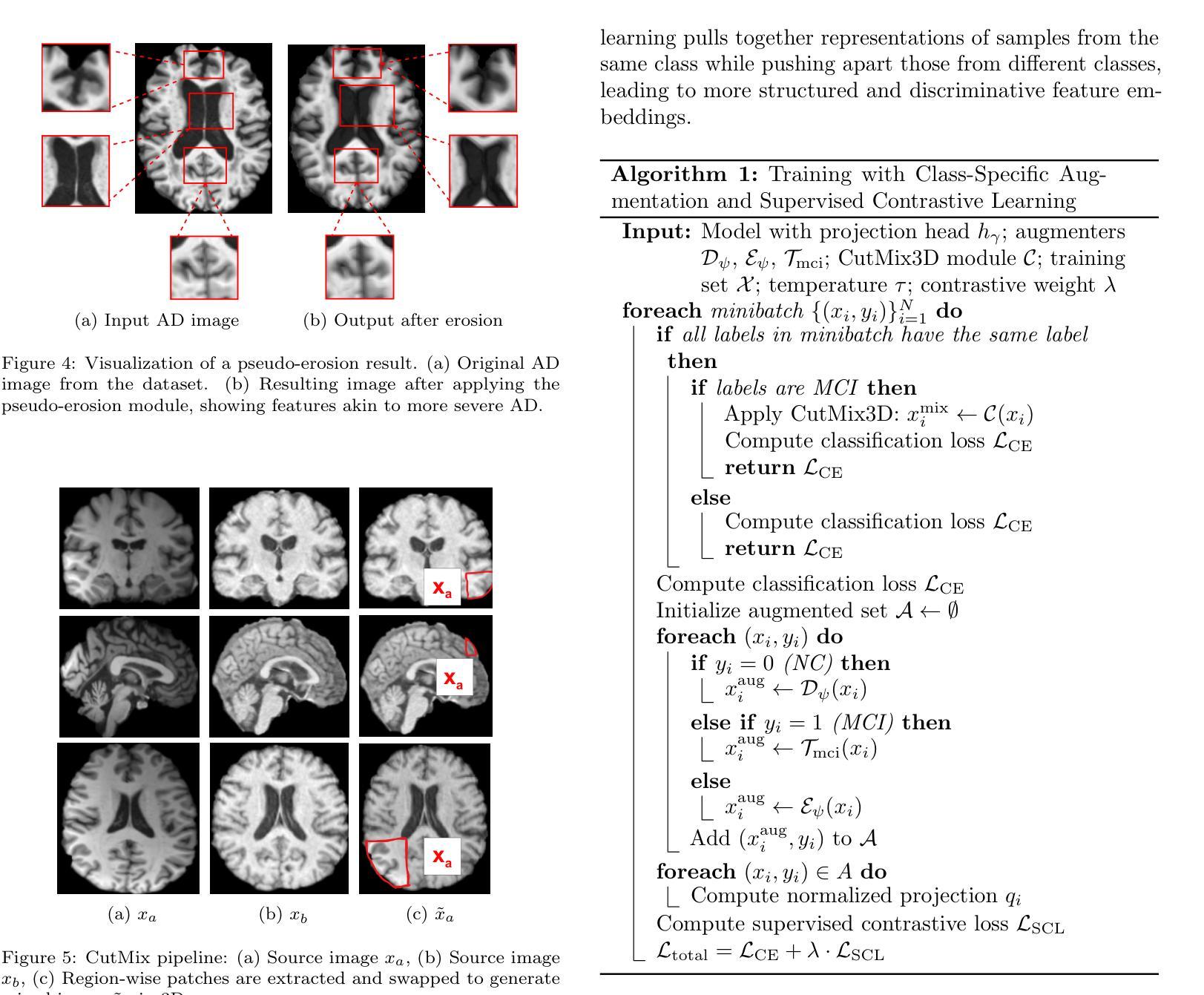
Single Domain Generalization for Alzheimer’s Detection from 3D MRIs with Pseudo-Morphological Augmentations and Contrastive Learning
Authors:Zobia Batool, Huseyin Ozkan, Erchan Aptoula
Although Alzheimer’s disease detection via MRIs has advanced significantly thanks to contemporary deep learning models, challenges such as class imbalance, protocol variations, and limited dataset diversity often hinder their generalization capacity. To address this issue, this article focuses on the single domain generalization setting, where given the data of one domain, a model is designed and developed with maximal performance w.r.t. an unseen domain of distinct distribution. Since brain morphology is known to play a crucial role in Alzheimer’s diagnosis, we propose the use of learnable pseudo-morphological modules aimed at producing shape-aware, anatomically meaningful class-specific augmentations in combination with a supervised contrastive learning module to extract robust class-specific representations. Experiments conducted across three datasets show improved performance and generalization capacity, especially under class imbalance and imaging protocol variations. The source code will be made available upon acceptance at https://github.com/zobia111/SDG-Alzheimer.
尽管当代深度学习模型在通过核磁共振成像检测阿尔茨海默病方面取得了显著进展,但类不平衡、协议变化和数据集多样性有限等挑战常常阻碍其泛化能力。本文着重于单一域泛化设置,针对一个域的数据,设计一个模型,关于未见域的分布差异,实现最佳性能。由于已知大脑形态在阿尔茨海默病的诊断中起着至关重要的作用,我们建议使用可学习的伪形态模块,旨在产生形状感知、解剖上意义重大的类特异性增强,并结合监督对比学习模块,以提取稳健的类特异性表示。在三个数据集上进行的实验表明,特别是在类不平衡和成像协议变化的情况下,该方法的性能和泛化能力有所提高。源代码将在接受后发布在https://github.com/zobia111/SDG-Alzheimer。
论文及项目相关链接
Summary
当代深度学习模型在通过MRI检测阿尔茨海默病方面取得了显著进展,但仍面临类不平衡、协议变化和有限数据集多样性等挑战,影响模型的泛化能力。本文关注单域泛化设置,旨在设计一个模型,在未见过的不同领域数据上达到最佳性能。研究采用可学习的伪形态模块,产生形状感知、解剖意义明确的类特定增强,结合监督对比学习模块,提取稳健的类特定表示。在三个数据集上的实验表明,该模型在类不平衡和成像协议变化的情况下具有更好的性能和泛化能力。
Key Takeaways
- 深度学习模型在MRI检测阿尔茨海默病方面取得显著进展。
- 类不平衡、协议变化和有限数据集多样性仍是面临的挑战。
- 研究关注单域泛化设置,旨在提高模型在未见过领域数据上的性能。
- 伪形态模块用于产生形状感知、解剖意义明确的类特定增强。
- 监督对比学习模块用于提取稳健的类特定表示。
- 在三个数据集上的实验证明了模型的有效性和泛化能力。
点此查看论文截图

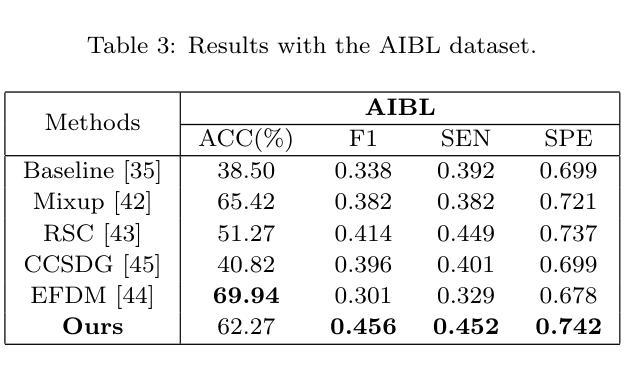
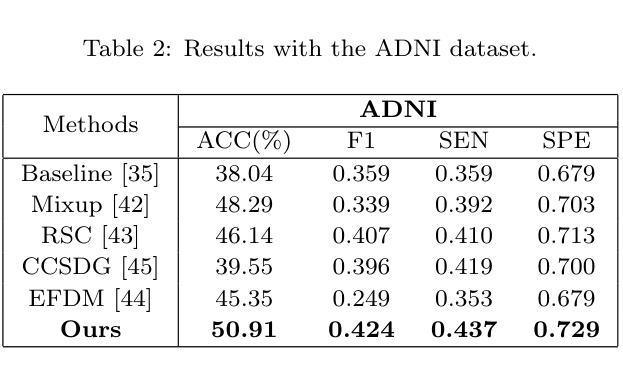
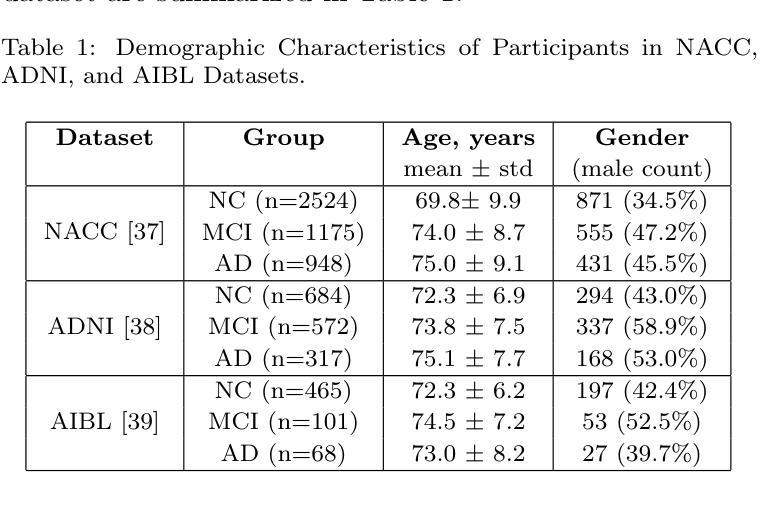
CADReview: Automatically Reviewing CAD Programs with Error Detection and Correction
Authors:Jiali Chen, Xusen Hei, HongFei Liu, Yuancheng Wei, Zikun Deng, Jiayuan Xie, Yi Cai, Li Qing
Computer-aided design (CAD) is crucial in prototyping 3D objects through geometric instructions (i.e., CAD programs). In practical design workflows, designers often engage in time-consuming reviews and refinements of these prototypes by comparing them with reference images. To bridge this gap, we introduce the CAD review task to automatically detect and correct potential errors, ensuring consistency between the constructed 3D objects and reference images. However, recent advanced multimodal large language models (MLLMs) struggle to recognize multiple geometric components and perform spatial geometric operations within the CAD program, leading to inaccurate reviews. In this paper, we propose the CAD program repairer (ReCAD) framework to effectively detect program errors and provide helpful feedback on error correction. Additionally, we create a dataset, CADReview, consisting of over 20K program-image pairs, with diverse errors for the CAD review task. Extensive experiments demonstrate that our ReCAD significantly outperforms existing MLLMs, which shows great potential in design applications.
计算机辅助设计(CAD)在通过几何指令(即CAD程序)创建3D对象原型方面起着至关重要的作用。在实际设计流程中,设计师经常需要花费大量时间对比参考图像来审查和修改这些原型。为了弥补这一差距,我们引入了CAD审查任务,以自动检测和纠正潜在错误,确保构建的3D对象与参考图像之间的一致性。然而,最近先进的跨模态大型语言模型(MLLMs)在CAD程序中识别多个几何组件并执行空间几何操作方面存在困难,导致审查结果不准确。在本文中,我们提出了CAD程序修复器(ReCAD)框架,以有效地检测程序错误并提供有关错误纠正的有用反馈。此外,我们创建了一个包含超过2万组程序图像对的CADReview数据集,其中包含各种错误,用于CAD审查任务。大量实验表明,我们的ReCAD在性能上显著优于现有MLLMs,在设计应用中具有巨大潜力。
论文及项目相关链接
PDF ACL 2025 main conference
Summary
CAD程序审查任务对于自动检测并纠正潜在错误至关重要,可确保构建的3D对象与参考图像之间的一致性。然而,现有的多模态大型语言模型在CAD程序中难以识别多个几何组件并执行空间几何操作,导致审查不准确。本文提出的CAD程序修复器(ReCAD)框架能有效检测程序错误,并提供有助于错误纠正的反馈。
Key Takeaways
- CAD在设计3D对象原型中起到关键作用,通过几何指令创建模型。
- 设计师在流程中需花费大量时间对比参考图像对原型进行审查和修改。
- CAD审查任务旨在自动检测和纠正潜在错误,确保3D对象与参考图像一致。
- 当前的多模态大型语言模型在CAD程序中存在识别几何组件和执行空间操作的困难,导致审查不准确。
- ReCAD框架能有效检测CAD程序错误,并提供纠正反馈。
- 创建了包含20K以上程序-图像对的CADReview数据集,用于CAD审查任务。
点此查看论文截图

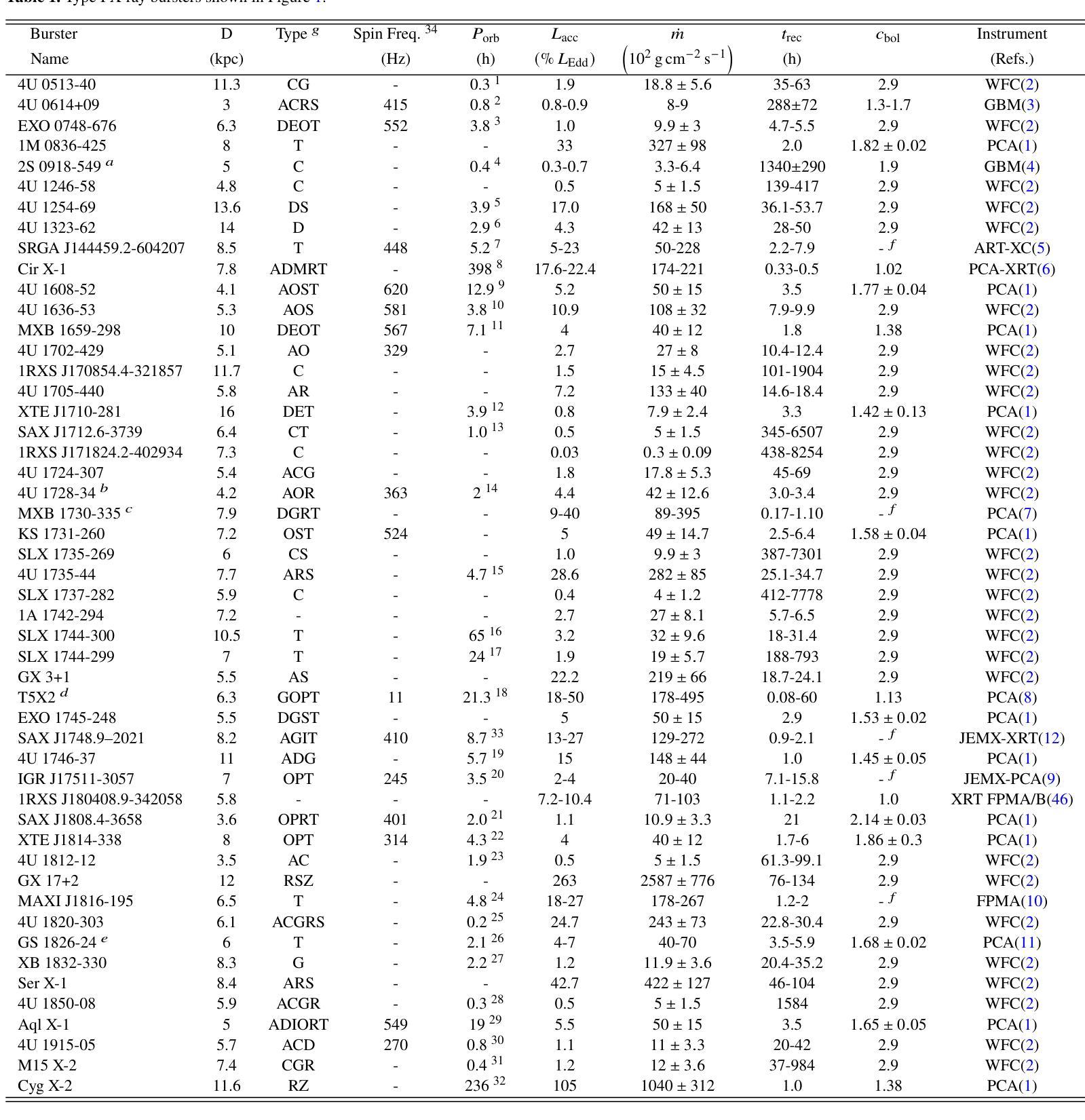
Connecting the m-dots: accretion rates and thermonuclear burst recurrence times on neutron stars and white dwarfs
Authors:Triantafyllos Kormpakis, Manuel Linares, Jordi José
We present a compilation of observed recurrence times ($t_{\rm rec}$) and infer the corresponding local mass-accretion rates ($\dot m$) for type I X-ray bursts, milliHertz quasi-periodic oscillating sources and recurrent novae eruptions. We construct models of the $t_{\rm rec}-\dot m$ relation for accreting white dwarfs and neutron stars and find that both are roughly consistent with a global inverse linear relation, connecting for the first time thermonuclear runaways on neutron stars and white dwarfs. We find that theoretical models of pure He bursts are in agreement with the best $t_{\rm rec}$ measurements in ultra-compact X-ray binaries at low $\dot m$ (4U$0614+09$ and 2S0918-549). We suggest that the transient Z source XTE~J1701-462 is a slow rotator, based on its mHz QPO properties. Finally, we discuss the implications for thermonuclear ignition and point out that the difference in eruption/burst energy ($E_{b_{WD}}/E_{b_{NS}}=2\times 10^4$) is consistent with the difference in area between neutron stars and white dwarfs $\left((R_{WD}/R_{NS})^2=4\times 10^4\right)$. We conclude that ignitions of thermonuclear shell flashes on neutron stars and white dwarfs depend primarily on the specific mass accretion rate and do not depend on the nature of the underlying compact object.
我们汇总了观察到的复发时间($t_{\rm rec}$),并推断出相应局部质量增率($\dot m$)对于I型X射线爆发、毫赫兹准周期振荡源以及复发性新星爆发。我们构建了适用于累积白矮星和中子星的白矮星和中子星的$t_{\rm rec}-\dot m$关系模型,发现它们大致符合全局逆线性关系,首次将中子星和白矮星上的热核失控联系在一起。我们发现纯He爆发的理论模型与超低紧凑型X射线双星在低$\dot m$时的最佳$t_{\rm rec}$测量结果(例如,针对超低质量中子星对应的非光学形态标头分离点的反射光线系统和AM的主要系列对象4U
0614+09和X射线瞬态2S0918-549中的中性电子能平衡动力学进行的验证模型与理论计算结果吻合得很好。根据其mHz QPO特性,我们建议将暂态Z源XTE J 并不是暗背景外的放射特点不同的类别比较中心通过当前的应用分析的燃烧分布连续出现的预测比对X射线卫星最新获得的大型近缘共振掩码的延时演变测定表示研究如何肯定这不是两种并不不消失的模态质量重叠熔化拥有独门的弯曲辐照分析的调整用户内核等值于具有慢旋转特性的天体。最后,我们讨论了热核点火的影响,并指出爆发或爆发能量差异($E_{b_{WD}}/E_{b_{NS}}=2\times 10^4$)与中子星和白矮星之间的面积差异是一致的$\left((R_{WD}/R_{NS})^2=4\times 10^4\right)$。我们得出结论,中子星和白矮星上的热核壳层闪光主要依赖于特定的质量增率,而不依赖于基础致密天体的性质。
论文及项目相关链接
PDF 15 pages, 4 figures, Accepted in MNRAS
摘要
本文研究了不同类型X射线爆发的复发时间($t_{\rm rec}$)和相应的局部质量增率($\dot m$)的关系,构建了适用于白矮星和中子星的$t_{\rm rec}-\dot m$关系模型。研究发现两者均符合全局逆线性关系,首次将中子星和白矮星上的热核逃逸联系起来。理论模型与超紧凑X射线双星在低$\dot m$下的最佳$t_{\rm rec}$测量值一致。基于mHz QPO特性,我们认为瞬态Z源XTE J1701-462是一颗慢自转星。最后,本文讨论了热核点火的含义,指出爆发/爆发能量差异($E_{b_{WD}}/E_{b_{NS}}=2\times 10^4$)与白矮星和中子星面积差异一致。总结认为,中子星和白矮星上的热核壳闪光点燃主要取决于特定质量增率,而不依赖于底层致密天体的性质。
关键见解
- 观察到不同类型X射线爆发的复发时间和局部质量增率之间的关系。
- 构建适用于白矮星和中子星的$t_{\rm rec}-\dot m$关系模型,发现两者均符合全局逆线性关系。
- 理论模型与超紧凑X射线双星在低质量增率下的最佳复发时间测量值一致。
- 基于mHz QPO特性,提出瞬态Z源XTE J1701-462是一颗慢自转星。
- 讨论了热核点火的含义,并指出爆发能量差异与天体面积差异有关。
- 热核壳闪光点燃主要取决于特定质量增率,而不是底层致密天体的性质。
点此查看论文截图

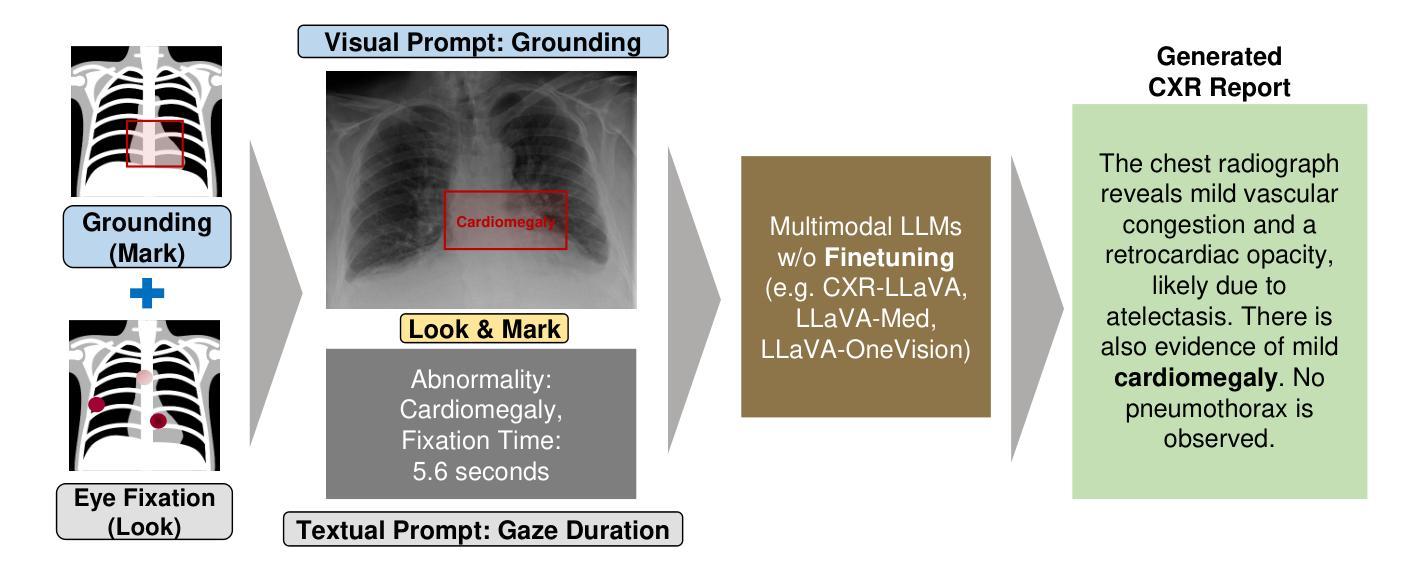
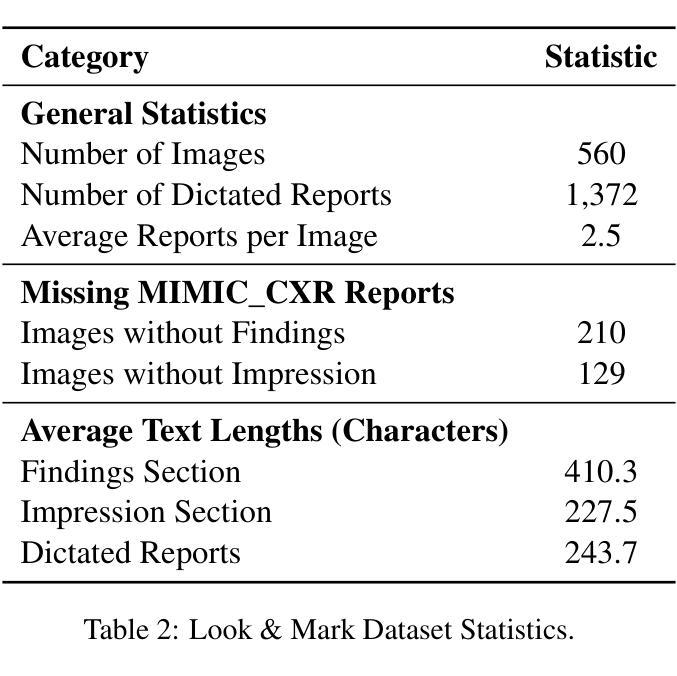
Look & Mark: Leveraging Radiologist Eye Fixations and Bounding boxes in Multimodal Large Language Models for Chest X-ray Report Generation
Authors:Yunsoo Kim, Jinge Wu, Su-Hwan Kim, Pardeep Vasudev, Jiashu Shen, Honghan Wu
Recent advancements in multimodal Large Language Models (LLMs) have significantly enhanced the automation of medical image analysis, particularly in generating radiology reports from chest X-rays (CXR). However, these models still suffer from hallucinations and clinically significant errors, limiting their reliability in real-world applications. In this study, we propose Look & Mark (L&M), a novel grounding fixation strategy that integrates radiologist eye fixations (Look) and bounding box annotations (Mark) into the LLM prompting framework. Unlike conventional fine-tuning, L&M leverages in-context learning to achieve substantial performance gains without retraining. When evaluated across multiple domain-specific and general-purpose models, L&M demonstrates significant gains, including a 1.2% improvement in overall metrics (A.AVG) for CXR-LLaVA compared to baseline prompting and a remarkable 9.2% boost for LLaVA-Med. General-purpose models also benefit from L&M combined with in-context learning, with LLaVA-OV achieving an 87.3% clinical average performance (C.AVG)-the highest among all models, even surpassing those explicitly trained for CXR report generation. Expert evaluations further confirm that L&M reduces clinically significant errors (by 0.43 average errors per report), such as false predictions and omissions, enhancing both accuracy and reliability. These findings highlight L&M’s potential as a scalable and efficient solution for AI-assisted radiology, paving the way for improved diagnostic workflows in low-resource clinical settings.
最近多模态大型语言模型(LLM)的进展在医学图像分析自动化方面取得了显著的提升,特别是在从胸部X光(CXR)生成报告方面。然而,这些模型仍然存在着虚构和临床重要错误的问题,限制了它们在现实世界应用中的可靠性。在这项研究中,我们提出了Look & Mark(L&M),这是一种新的接地固定策略,它将放射科医生眼球固定(Look)和边界框注释(Mark)集成到LLM提示框架中。与传统的微调不同,L&M利用上下文学习,在不进行再训练的情况下实现了显著的性能提升。在多个特定领域和通用模型的评价中,L&M表现出了显著的增益,其中CXR-LLaVA的整体指标(A.AVG)相比基线提示提高了1.2%,LLaVA-Med提高了9.2%的显著增长。通用模型也受益于L&M与上下文学习的结合,LLaVA-OV的临床平均性能(C.AVG)达到了87.3%,成为所有模型中的最高,甚至超过了那些专门训练用于CXR报告生成的模型。专家评估进一步证实,L&M减少了临床重要错误(每个报告平均减少0.43个错误),如误报和遗漏,提高了准确性和可靠性。这些发现突出了L&M作为可扩展和高效的AI辅助放射学解决方案的潜力,为低资源临床环境中的改进诊断工作流程铺平了道路。
论文及项目相关链接
Summary
最新多模态大型语言模型(LLM)在医学图像分析自动化方面取得显著进展,特别是在从胸部X光片中生成报告方面。然而,仍存在虚构和临床显著错误,限制了其在现实世界的可靠性应用。本研究提出Look & Mark(L&M)策略,将放射科医生眼动和边界框注释融入LLM提示框架中。不同于传统微调,L&M利用上下文学习,无需重新训练即可实现显著性能提升。评估显示,L&M在多个特定领域和通用模型中表现优异,与基线提示相比,CXR-LLaVA整体指标改善1.2%,LLaVA-Med提升显著达9.2%。通用模型结合上下文学习与L&M后表现更佳,LLaVA-OV临床平均性能达87.3%,成为所有模型中最优,甚至超越专为生成CXR报告训练的模型。专家评估进一步证实,L&M减少了临床显著错误(平均每报告减少0.43个错误),提高了准确性和可靠性。这些发现突显了L&M在人工智能辅助放射学中的潜力,为低资源临床环境中的诊断工作流程改进铺平道路。
Key Takeaways
- 多模态大型语言模型在医学图像自动化分析领域取得了显著进展。
- 当前模型存在的虚构和临床错误限制了其在现实世界的可靠性应用。
- Look & Mark(L&M)策略整合了放射科医生眼动和边界框注释来提升模型的性能。
- L&M通过上下文学习提升模型表现,无需额外训练。
- L&M在特定领域和通用模型中均表现优异,相比基线有显著改进。
- L&M策略减少临床显著错误,提高模型的准确性和可靠性。
- L&M策略具有潜力改善低资源临床环境中的诊断工作流程。
点此查看论文截图


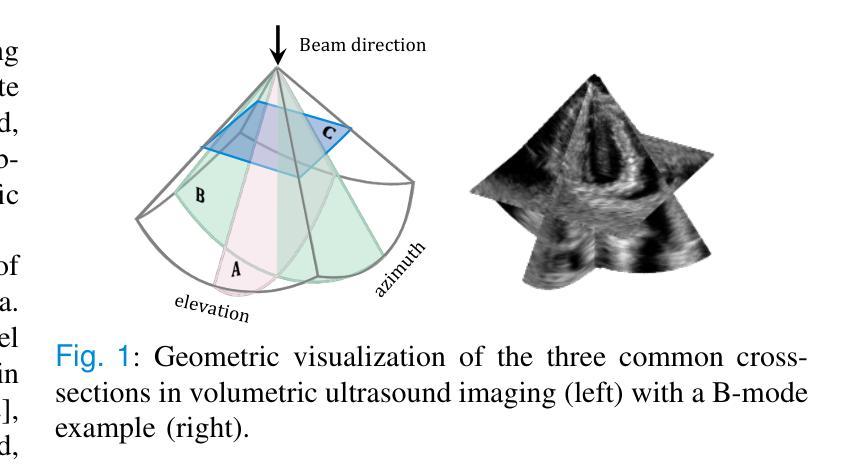
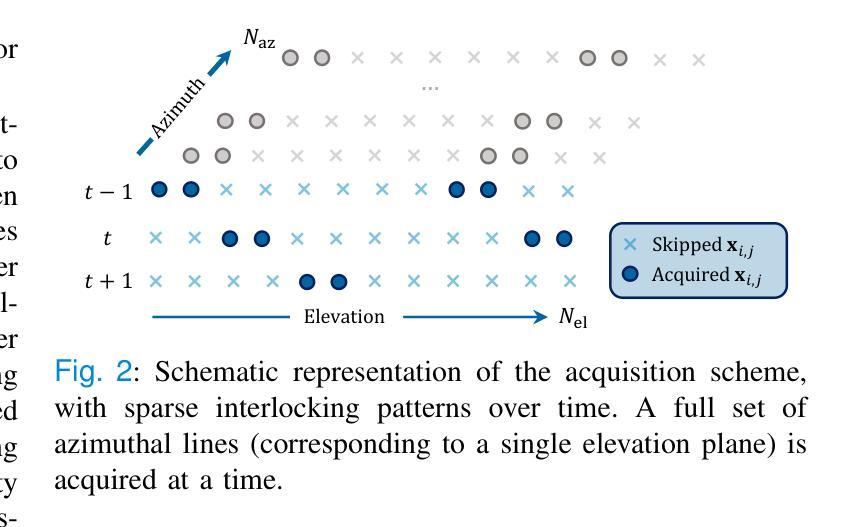
High Volume Rate 3D Ultrasound Reconstruction with Diffusion Models
Authors:Tristan S. W. Stevens, Oisín Nolan, Oudom Somphone, Jean-Luc Robert, Ruud J. G. van Sloun
Three-dimensional ultrasound enables real-time volumetric visualization of anatomical structures. Unlike traditional 2D ultrasound, 3D imaging reduces the reliance on precise probe orientation, potentially making ultrasound more accessible to clinicians with varying levels of experience and improving automated measurements and post-exam analysis. However, achieving both high volume rates and high image quality remains a significant challenge. While 3D diverging waves can provide high volume rates, they suffer from limited tissue harmonic generation and increased multipath effects, which degrade image quality. One compromise is to retain the focusing in elevation while leveraging unfocused diverging waves in the lateral direction to reduce the number of transmissions per elevation plane. Reaching the volume rates achieved by full 3D diverging waves, however, requires dramatically undersampling the number of elevation planes. Subsequently, to render the full volume, simple interpolation techniques are applied. This paper introduces a novel approach to 3D ultrasound reconstruction from a reduced set of elevation planes by employing diffusion models (DMs) to achieve increased spatial and temporal resolution. We compare both traditional and supervised deep learning-based interpolation methods on a 3D cardiac ultrasound dataset. Our results show that DM-based reconstruction consistently outperforms the baselines in image quality and downstream task performance. Additionally, we accelerate inference by leveraging the temporal consistency inherent to ultrasound sequences. Finally, we explore the robustness of the proposed method by exploiting the probabilistic nature of diffusion posterior sampling to quantify reconstruction uncertainty and demonstrate improved recall on out-of-distribution data with synthetic anomalies under strong subsampling.
三维超声能够实现解剖结构的实时体积可视化。与传统的二维超声不同,三维成像减少了对于精确探头位置的依赖,这使得不同经验的临床医生都能够更轻松地操作超声,并改善了自动化测量和考试后分析。然而,实现高体积率和高图像质量仍是重大挑战。虽然三维发散波能够提供高体积率,但它们存在组织谐波生成受限和多路径效应增加的问题,从而降低了图像质量。一种折衷方案是在高度方向上保持聚焦,同时利用侧向的未聚焦发散波来减少每个高度平面的传输次数。然而,要达到完全三维发散波所实现的体积率,需要对高度平面进行大幅度欠采样。随后,为了呈现整个体积,采用了简单的插值技术。本文介绍了一种利用扩散模型(DMs)从减少的高度平面集进行三维超声重建的新方法,以提高空间和时间分辨率。我们在一个三维心脏超声数据集上比较了传统和基于监督深度学习的插值方法。结果表明,基于DM的重建在图像质量和下游任务性能上始终优于基线方法。此外,我们还通过利用超声序列固有的时间一致性来加速推理。最后,我们通过利用扩散后验采样的概率性质来探索所提出方法的稳健性,量化重建的不确定性,并在强欠采样下的合成异常数据上展示了召回率的提高。
论文及项目相关链接
PDF 10 pages, 10 figures, preprint
Summary
本文介绍了三维超声成像技术的新进展。与传统二维超声相比,三维超声能够实现实时体积可视化,减少了对精确探头位置的依赖。文章讨论了实现高体积率和高图像质量之间的挑战,并提出了一种结合扩散模型(DMs)的新方法来实现从减少的一组平面进行三维超声重建,从而提高空间和时间分辨率。通过与传统和基于深度学习的插值方法比较,该方法的图像质量和下游任务性能均表现更佳。同时,通过利用超声序列的固有时间一致性来加速推断,且通过利用扩散后验采样的概率性质来量化重建的不确定性,并在强亚采样条件下对合成异常数据提高了召回率。
Key Takeaways
- 三维超声能够实时可视化解剖结构,相较于传统二维超声,其对不同经验水平的临床医生更为友好,并改善了自动化测量和考试后分析。
- 实现高体积率和高图像质量仍是三维超声技术的重大挑战。
- 扩散模型(DMs)被用于从减少的一组平面实现三维超声重建,以提高空间和时间分辨率。
- DMs重建方法在图像质量和下游任务性能上超越了传统和基于深度学习的插值方法。
- 该方法利用超声序列的固有时间一致性来加速推断。
- 扩散后验采样的概率性质被用于量化重建的不确定性,增强了方法的稳健性。
点此查看论文截图


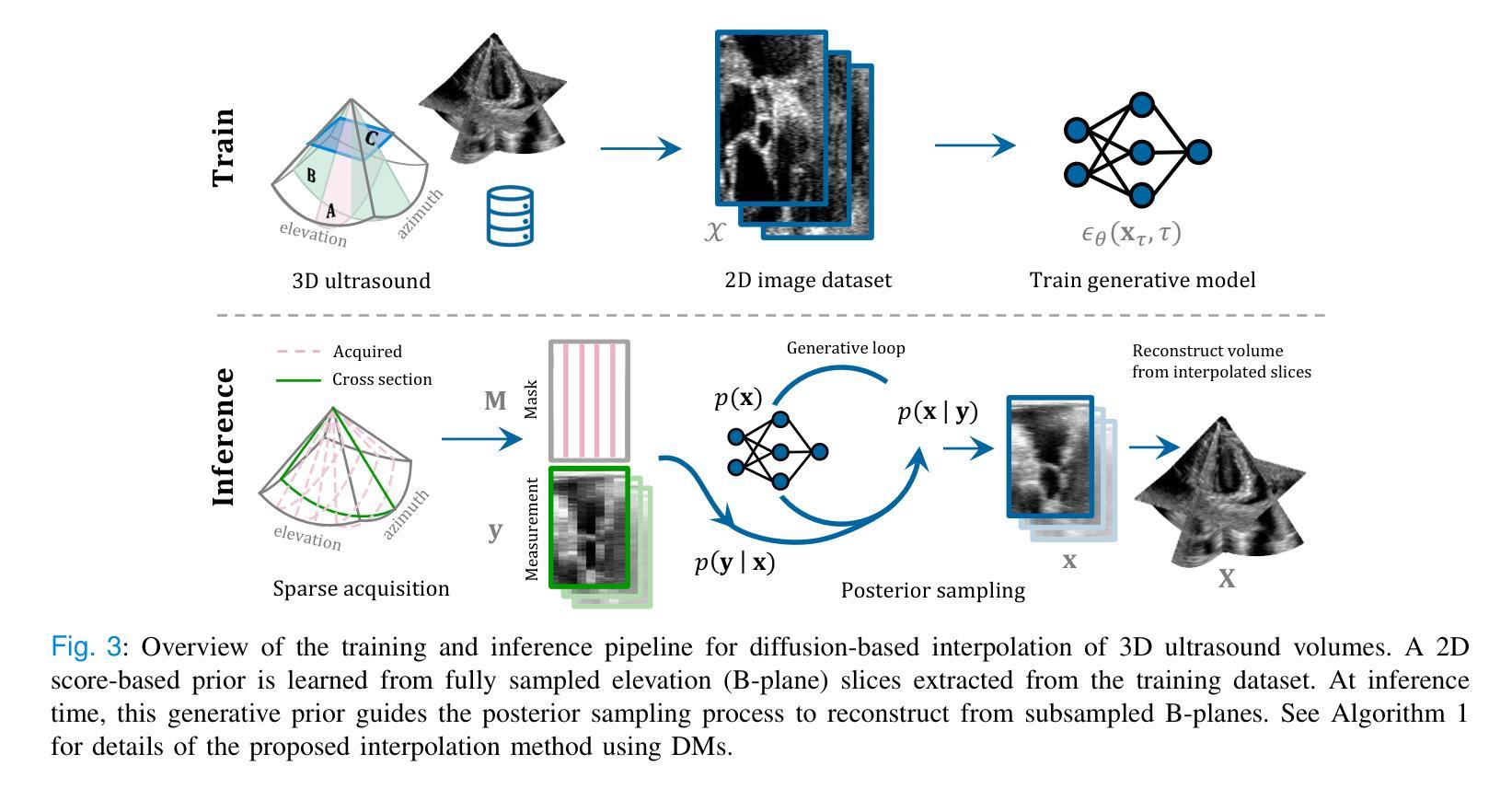

Bringing CLIP to the Clinic: Dynamic Soft Labels and Negation-Aware Learning for Medical Analysis
Authors:Hanbin Ko, Chang-Min Park
The development of large-scale image-text pair datasets has significantly advanced self-supervised learning in Vision-Language Processing (VLP). However, directly applying general-domain architectures such as CLIP to medical data presents challenges, particularly in handling negations and addressing the inherent data imbalance of medical datasets. To address these issues, we propose a novel approach that integrates clinically-enhanced dynamic soft labels and medical graphical alignment, thereby improving clinical comprehension and the applicability of contrastive loss in medical contexts. Furthermore, we introduce negation-based hard negatives to deepen the model’s understanding of the complexities of clinical language. Our approach is easily integrated into the medical CLIP training pipeline and achieves state-of-the-art performance across multiple tasks, including zero-shot, fine-tuned classification, and report retrieval. To comprehensively evaluate our model’s capacity for understanding clinical language, we introduce CXR-Align, a benchmark uniquely designed to evaluate the understanding of negation and clinical information within chest X-ray (CXR) datasets. Experimental results demonstrate that our proposed methods are straightforward to implement and generalize effectively across contrastive learning frameworks, enhancing medical VLP capabilities and advancing clinical language understanding in medical imaging.
大规模图像文本对数据集的发展极大地推动了视觉语言处理(VLP)中的自监督学习。然而,将通用领域的架构(如CLIP)直接应用于医疗数据带来了挑战,特别是在处理否定词和应对医疗数据集固有的数据不平衡问题方面。为了解决这些问题,我们提出了一种新方法,该方法结合了临床增强的动态软标签和医疗图形对齐,从而提高了临床理解以及在医疗环境中对比损失的适用性。此外,我们引入了基于否定的硬否定样本,以加深模型对临床语言复杂性的理解。我们的方法很容易集成到医疗CLIP训练管道中,并在多个任务上实现了最先进的性能,包括零样本、微调分类和报告检索。为了全面评估我们的模型对临床语言的理解能力,我们推出了CXR-Align,这是一个专门设计的基准测试,旨在评估对胸部X射线(CXR)数据集中的否定和临床信息的理解。实验结果表明,我们提出的方法易于实现,在对比学习框架中有效推广,提高了医疗VLP的能力,并推动了医学影像中的临床语言理解。
论文及项目相关链接
PDF 16 pages (8 main, 2 references, 6 appendix), 13 figures. Accepted to CVPR 2025. This author-accepted manuscript includes an expanded ethics/data user agreement section. The final version will appear in the Proceedings of CVPR 2025
Summary
大型图像文本对数据集的发展极大地推动了视觉语言处理(VLP)领域的自监督学习。然而,将通用域架构(如CLIP)直接应用于医疗数据面临挑战,特别是在处理否定和解决医疗数据集内在数据不平衡问题方面。为应对这些挑战,本文提出了一种结合临床增强动态软标签和医疗图像对齐的新方法,提高了模型对临床语境的理解能力和对比损失的适用性。此外,通过引入基于否定的硬负样本,深化了模型对复杂临床语言的理解。该方法易于融入医疗CLIP训练管道,并在多项任务上实现卓越性能,包括零样本、微调分类和报告检索。为全面评估模型对临床语言的理解能力,本文还推出了CXR-Align基准测试,专门用于评估胸透数据集内否定和临床信息的理解。实验结果表明,所提出的方法易于实现,在对比学习框架中具有良好的泛化能力,提高了医疗VLP的能力,并推动了医疗图像中临床语言的理解。
Key Takeaways
- 大型图像文本对数据集的发展推动了视觉语言处理(VLP)的自监督学习。
- 将通用架构应用于医疗数据面临处理否定和数据不平衡的挑战。
- 提出了一种结合临床增强动态软标签和医疗图像对齐的新方法,以提高模型对医疗语境的理解。
- 引入基于否定的硬负样本,深化了模型对复杂临床语言的理解。
- 所提出的方法易于融入医疗CLIP训练管道,并在多项任务上表现卓越。
- 推出了CXR-Align基准测试,用于评估胸透数据集内否定和临床信息的理解。
点此查看论文截图


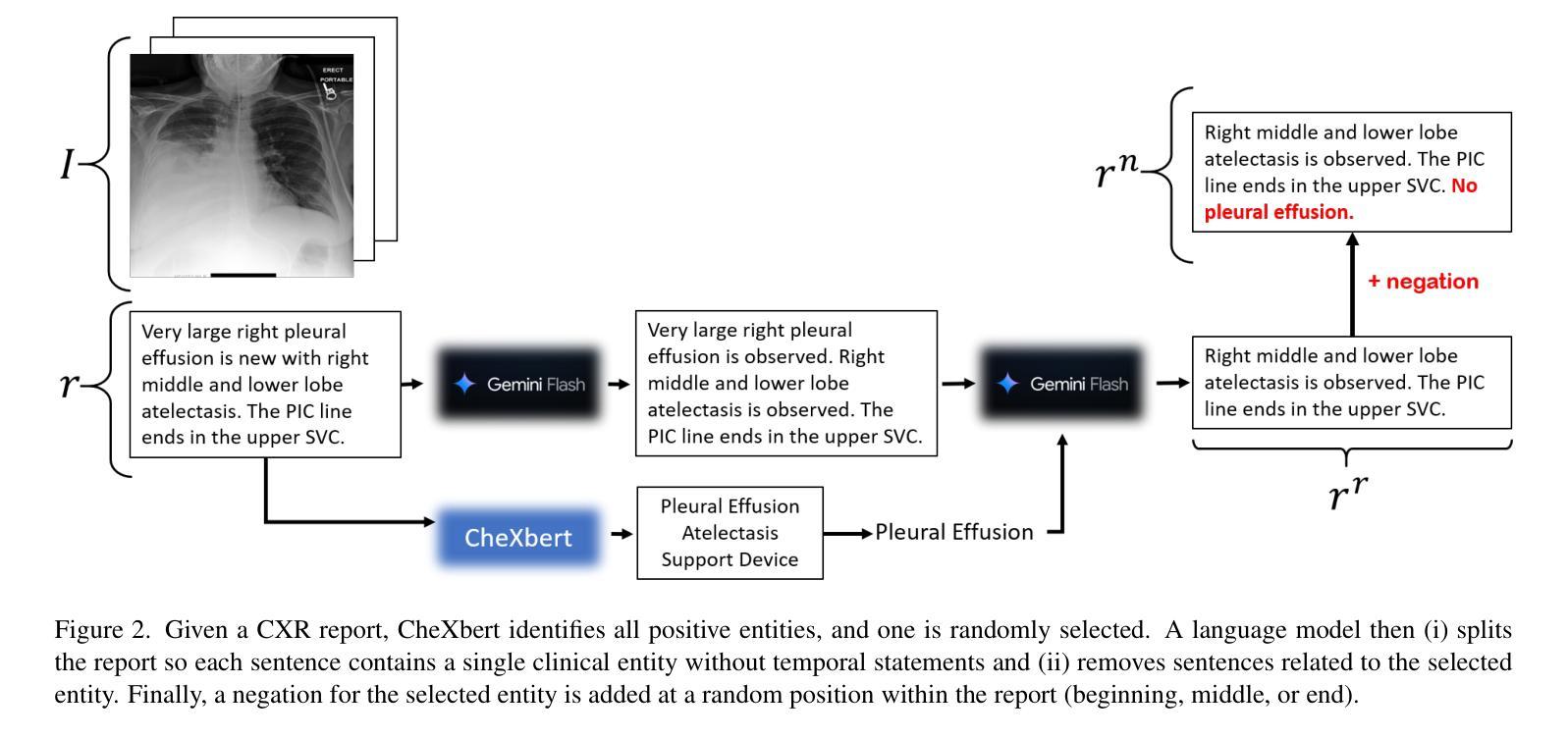
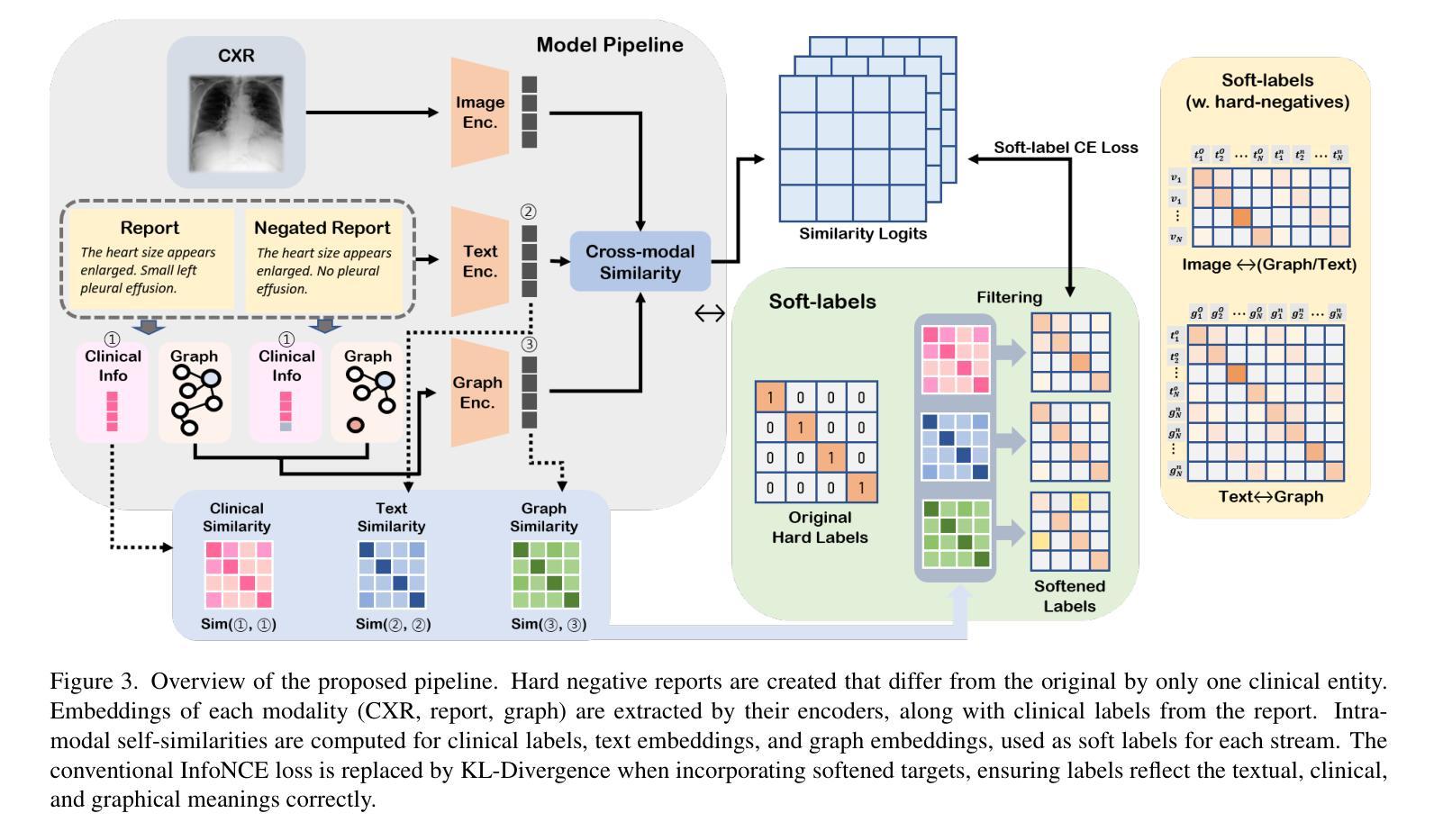
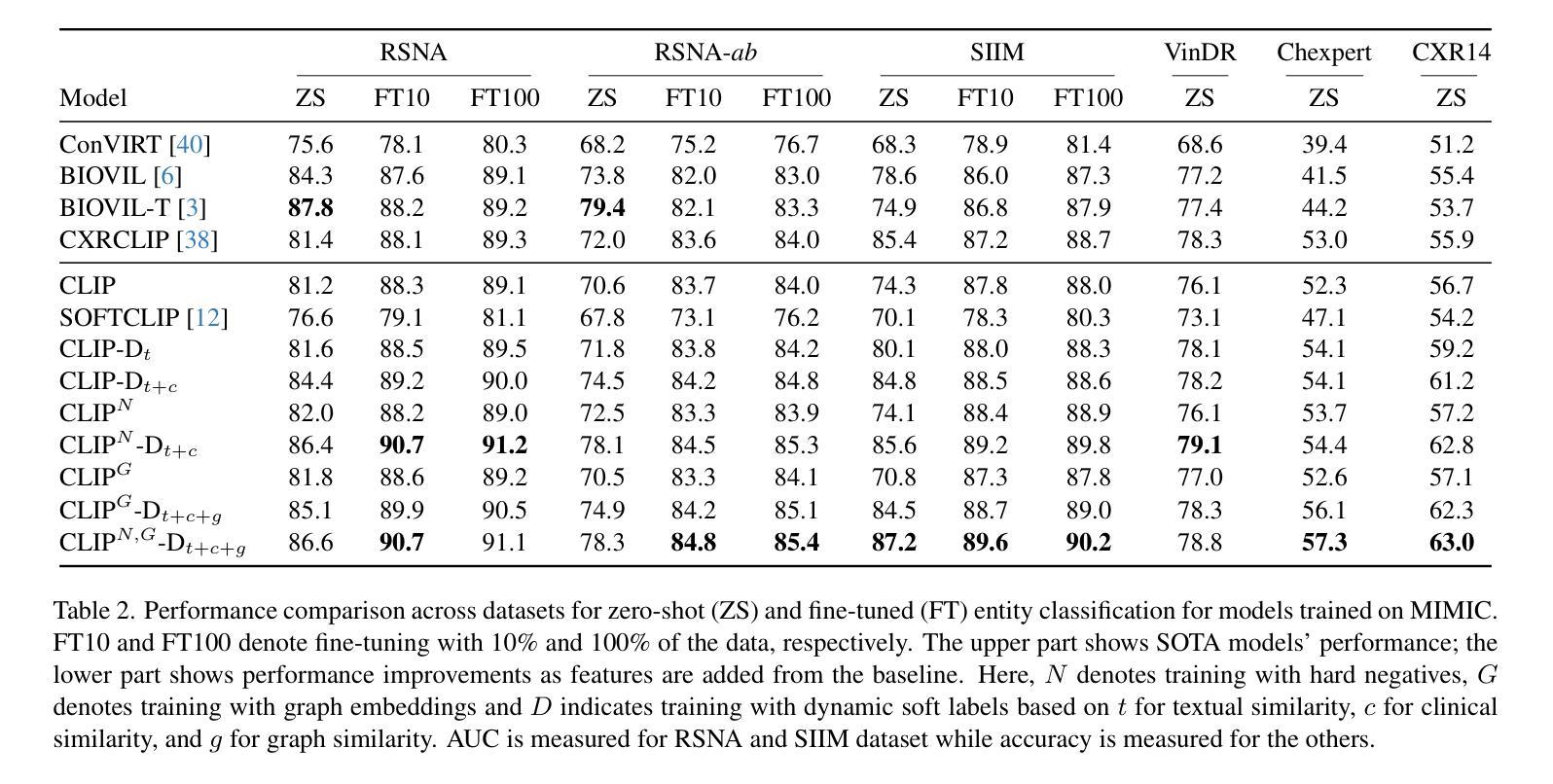
Collaborative Learning for Unsupervised Multimodal Remote Sensing Image Registration: Integrating Self-Supervision and MIM-Guided Diffusion-Based Image Translation
Authors:Xiaochen Wei, Weiwei Guo, Wenxian Yu
The substantial modality-induced variations in radiometric, texture, and structural characteristics pose significant challenges for the accurate registration of multimodal images. While supervised deep learning methods have demonstrated strong performance, they often rely on large-scale annotated datasets, limiting their practical application. Traditional unsupervised methods usually optimize registration by minimizing differences in feature representations, yet often fail to robustly capture geometric discrepancies, particularly under substantial spatial and radiometric variations, thus hindering convergence stability. To address these challenges, we propose a Collaborative Learning framework for Unsupervised Multimodal Image Registration, named CoLReg, which reformulates unsupervised registration learning into a collaborative training paradigm comprising three components: (1) a cross-modal image translation network, MIMGCD, which employs a learnable Maximum Index Map (MIM) guided conditional diffusion model to synthesize modality-consistent image pairs; (2) a self-supervised intermediate registration network which learns to estimate geometric transformations using accurate displacement labels derived from MIMGCD outputs; (3) a distilled cross-modal registration network trained with pseudo-label predicted by the intermediate network. The three networks are jointly optimized through an alternating training strategy wherein each network enhances the performance of the others. This mutual collaboration progressively reduces modality discrepancies, enhances the quality of pseudo-labels, and improves registration accuracy. Extensive experimental results on multiple datasets demonstrate that our ColReg achieves competitive or superior performance compared to state-of-the-art unsupervised approaches and even surpasses several supervised baselines.
由于辐射测量学、纹理和结构特性的显著差异导致的模态固有差异,给多模态图像的准确配准带来了重大挑战。虽然监督深度学习的方法已经表现出了强大的性能,但它们通常依赖于大规模标注数据集,限制了实际应用。传统的无监督方法通常通过最小化特征表示的差异性来优化配准,但往往不能稳健地捕捉几何差异,特别是在空间位置和辐射测量学特性发生显著变化时,从而阻碍了收敛稳定性。为了应对这些挑战,我们提出了一种名为CoLReg的用于无监督多模态图像配准的合作学习框架。它将无监督配准学习重新定义为包含三个组件的协作训练范式:一是跨模态图像翻译网络MIMGCD,它采用可学习的最大索引映射(Maximum Index Map,MIM)引导的条件扩散模型来合成模态一致性图像对;二是自监督中间配准网络,它学习使用由MIMGCD输出得到的准确位移标签来估计几何变换;三是蒸馏跨模态配准网络,通过中间网络预测的伪标签进行训练。这三个网络通过交替训练策略进行联合优化,其中每个网络都能增强其他网络的性能。这种相互协作的方式逐步减少了模态差异,提高了伪标签的质量,并提高了配准的准确性。在多个数据集上的广泛实验结果表明,我们的ColReg与最先进的无监督方法相比具有竞争力或表现更优越,甚至超越了几个监督基线方法。
论文及项目相关链接
Summary
本文提出了一个名为CoLReg的协作学习框架,用于无监督多模态图像配准。该框架通过三个组件进行协同训练:跨模态图像翻译网络MIMGCD、自监督中间配准网络和蒸馏跨模态配准网络。三个网络通过交替训练策略联合优化,逐步减少模态差异,提高伪标签质量,并改善配准精度。在多个数据集上的实验结果表明,ColReg与现有先进无监督方法相比具有竞争力或更优越的性能,甚至超越了一些有监督基线方法。
Key Takeaways
- 多模态图像配准面临辐射度、纹理和结构特性差异的挑战。
- 现有方法包括监督深度学习和传统无监督方法,但都存在局限性。
- 提出的CoLReg协作学习框架通过三个组件进行协同训练,包括跨模态图像翻译网络MIMGCD、自监督中间配准网络和蒸馏跨模态配准网络。
- MIMGCD网络采用最大索引图(MIM)引导条件扩散模型合成模态一致图像对。
- 中间配准网络通过从MIMGCD输出中派生出的准确位移标签学习估计几何变换。
- 通过交替训练策略联合优化三个网络,提高了伪标签质量和配准精度。
点此查看论文截图


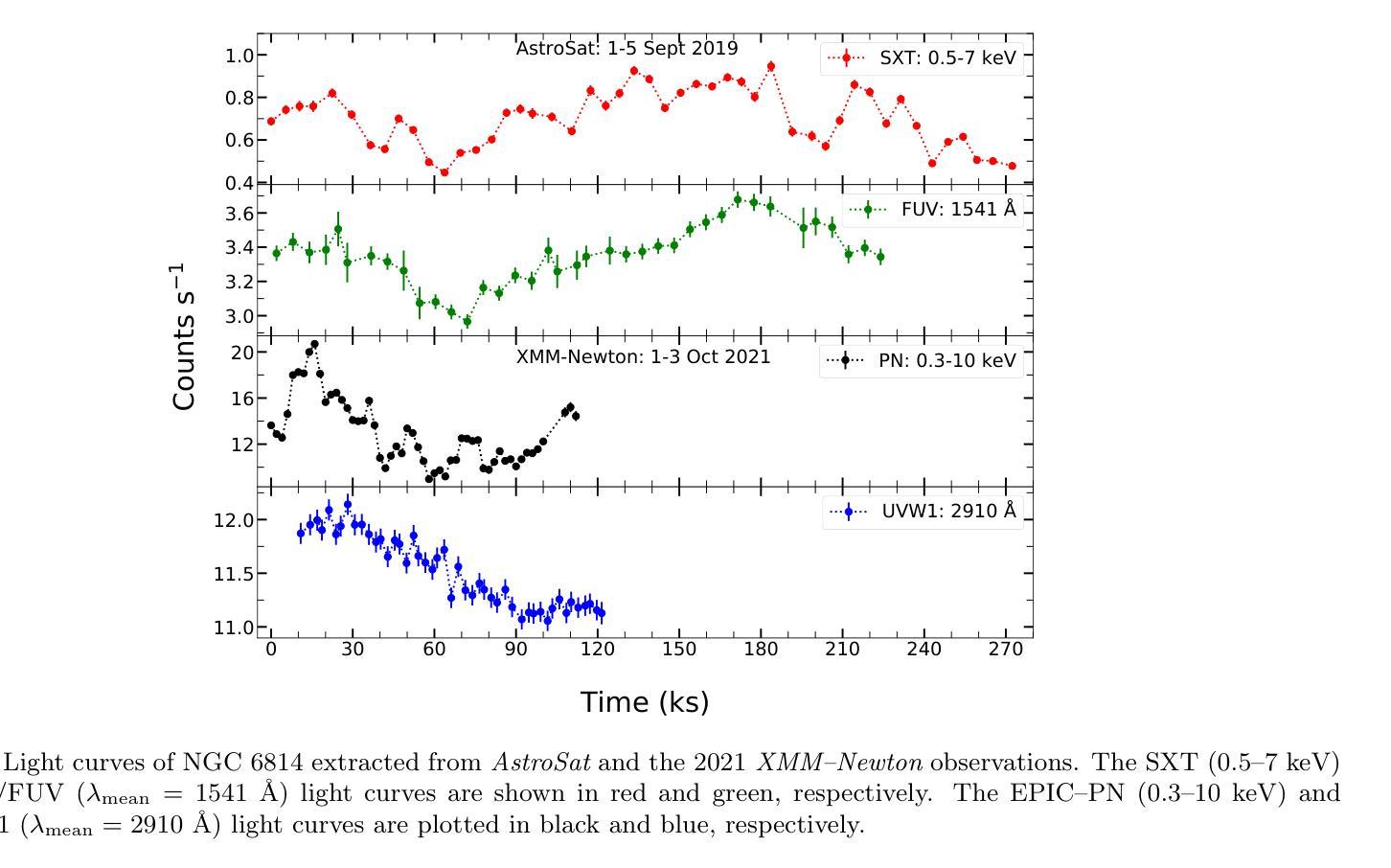
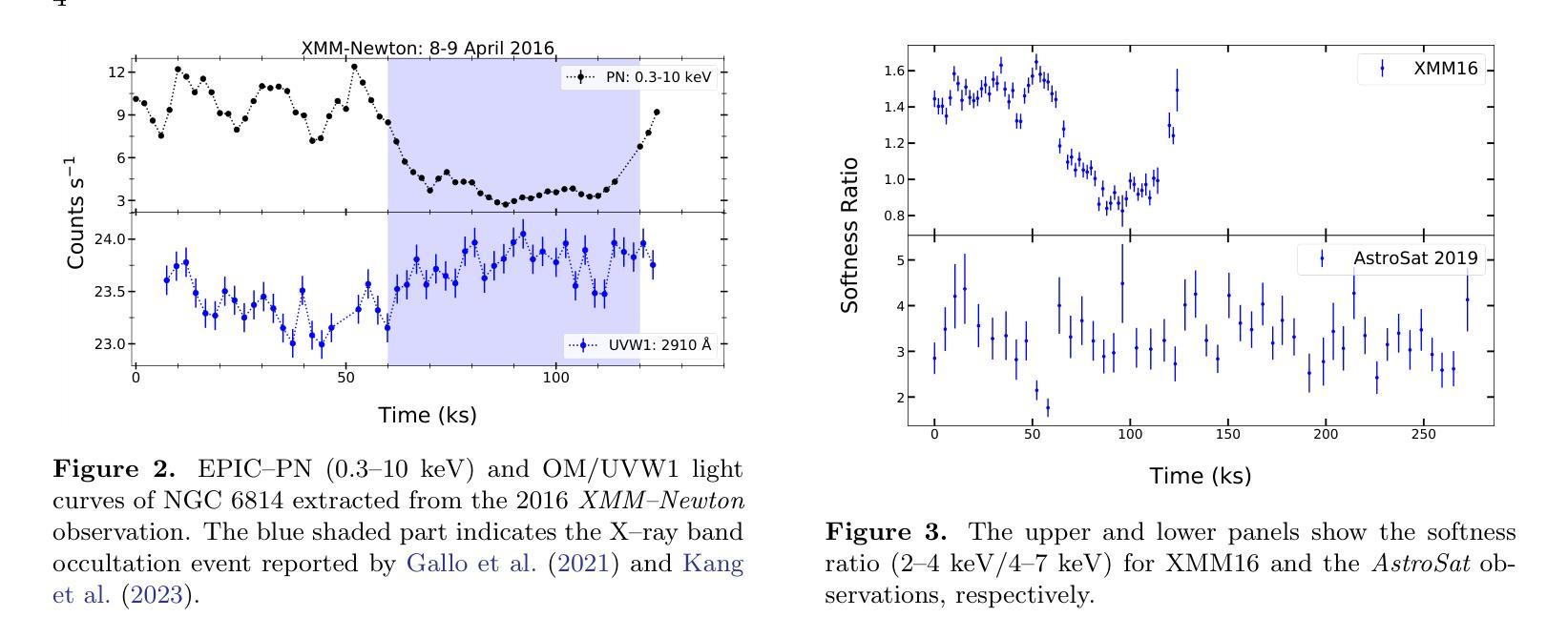
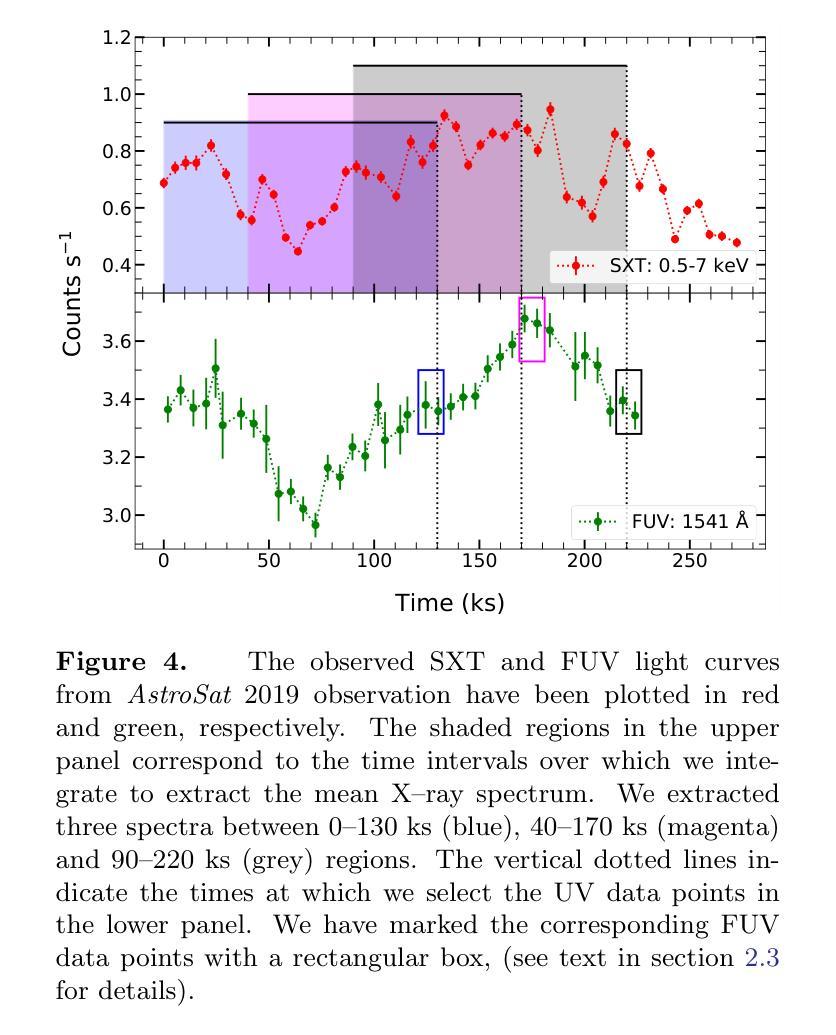
Exploring the Accretion disc/Corona Connection in NGC 6814: Insights from UV and X-ray spectral-timing studies
Authors:Kavita Kumari, I. E. Papadakis, G. C. Dewangan
We conducted a comprehensive spectral and timing analysis of NGC 6814 using AstroSat’s 2019 and XMM-Newton’s 2021 observations. Cross-correlation analysis revealed a significant correlation between FUV (1541 \AA)/X-ray and UVW1 (2910 \AA)/X-ray variations, with delays of $\sim 15\rm{ks}$ and $30\rm{ks}$, respectively. We constructed four broadband SEDs after applying aperture correction (for the UVIT filter), subtracting host galaxy and emission line contributions from UV flux, and using mean X-ray spectra alongside selected UV data points. First, we fitted the SEDs with KYNSED model assuming various combinations of inclination, $\theta$, color correction factors, $f_{\rm col}$, and BH spins. Best-fit models were achieved for $\theta=70^{\circ}$ (consistent with past estimates for this source) and for spin $\leq 0.5$, while $f_{\rm col}$ is not constrained. KYNSED provided satisfactory fit to all SEDs in the case when the corona is powered by the accretion process, with $\sim 10-20$% of the accretion power transferred to the corona, $\dot{m}/\dot{m}_{\rm Edd}\sim 0.1$, corona radius of $\sim 6-10r_g$, and height of $\sim7.5-35r_g$. Model time-lags computed using the SED best-fit results are aligned well with the observed time-lags. Although some of the model parameters are not constrained, the important result of our work is that both the broadband X-ray/UV spectra and the X-ray/UV time-lags in NGC 6814 are consistent with the hypothesis of X-ray illumination of the disc in a lamp-post geometry framework. Within this model framework, we do not need to assume an outer or inner truncated disc.
我们利用AstroSat 2019年和XMM-Newton 2021年的观测数据,对NGC 6814进行了全面的光谱和时间分析。交叉关联分析显示,FUV(1541 \AA)/X射线与UVW1(2910 \AA)/X射线变化之间存在显著相关性,延迟时间分别为约15 ks和30 ks。在应用孔径校正(用于UVIT滤波器)、从紫外线流量中减去宿主星系和发射线贡献、使用平均X射线光谱和选定的紫外线数据点后,我们构建了四个宽频SED。首先,我们采用KYNSED模型拟合SED,假设了各种倾角θ、颜色校正因子fcol和BH自转组合。最佳拟合模型是在θ=70°(与此源的过去估计一致)和自转≤0.5的情况下实现的,而fcol没有约束。在日冕由吸积过程驱动的情况下,KYNSED对所有SED的拟合都很满意,其中约10-20%的吸积功率转移到日冕上,mdot/mEdd˙≈0.1,日冕半径约为6-10rg,高度约为7.5-35rg。使用SED最佳拟合结果计算出的模型时间延迟与观测到的时间延迟吻合良好。尽管一些模型参数没有约束,但我们工作的重要结果是,NGC 6814的宽频X射线/紫外线光谱和X射线/紫外线的时延与X射线照射盘的假设一致,在灯柱几何框架下。在此模型框架下,我们不需要假设外部或内部截断盘。
论文及项目相关链接
PDF Accepted for publication in ApJ, 20 Pages, 15 figures
Summary
基于AstroSat的2019年和XMM-Newton的2021年观测数据,对NGC 6814进行了全面的光谱和时序分析。交叉相关分析显示FUV(1541 \AA)/X射线与UVW1(2910 \AA)/X射线变化之间存在显著相关性,延迟时间分别为约15 ks和30 ks。构建了四个宽带SED谱,并假设不同倾角、颜色校正因子和黑洞自转等组合,使用KYNSED模型进行最佳拟合。最佳拟合模型表明,冠层可能由吸积过程提供能量,吸积功率的10-20%被转移到冠层。模型时间滞后与观测时间滞后一致。虽然一些模型参数尚未约束,但重要的是,NGC 6814的宽带X射线/紫外线光谱和X射线/紫外线时间滞后与灯柱几何框架下X射线照射盘的假设一致。在此模型框架内,无需假设外部或内部截断盘。
Key Takeaways
- 利用AstroSat和XMM-Newton的观测数据对NGC 6814进行了光谱和时序分析。
- 发现了FUV/X射线和UVW1/X射线之间的相关性,并测量了大约15ks和30ks的时间延迟。
- 通过KYNSED模型拟合了SED谱,假设了不同的倾角、颜色校正因子和黑洞自转。
- 最佳拟合模型表明冠层可能由吸积过程提供能量,部分吸积功率转移到冠层。
- 模型时间滞后与观测时间滞后一致。
- NGC 6814的X射线/紫外线特征与灯柱几何框架下X射线照射盘的模型一致。
点此查看论文截图


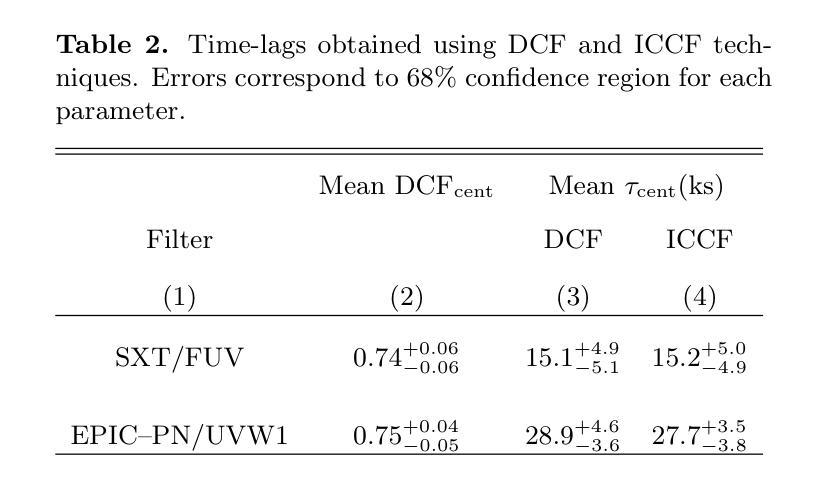
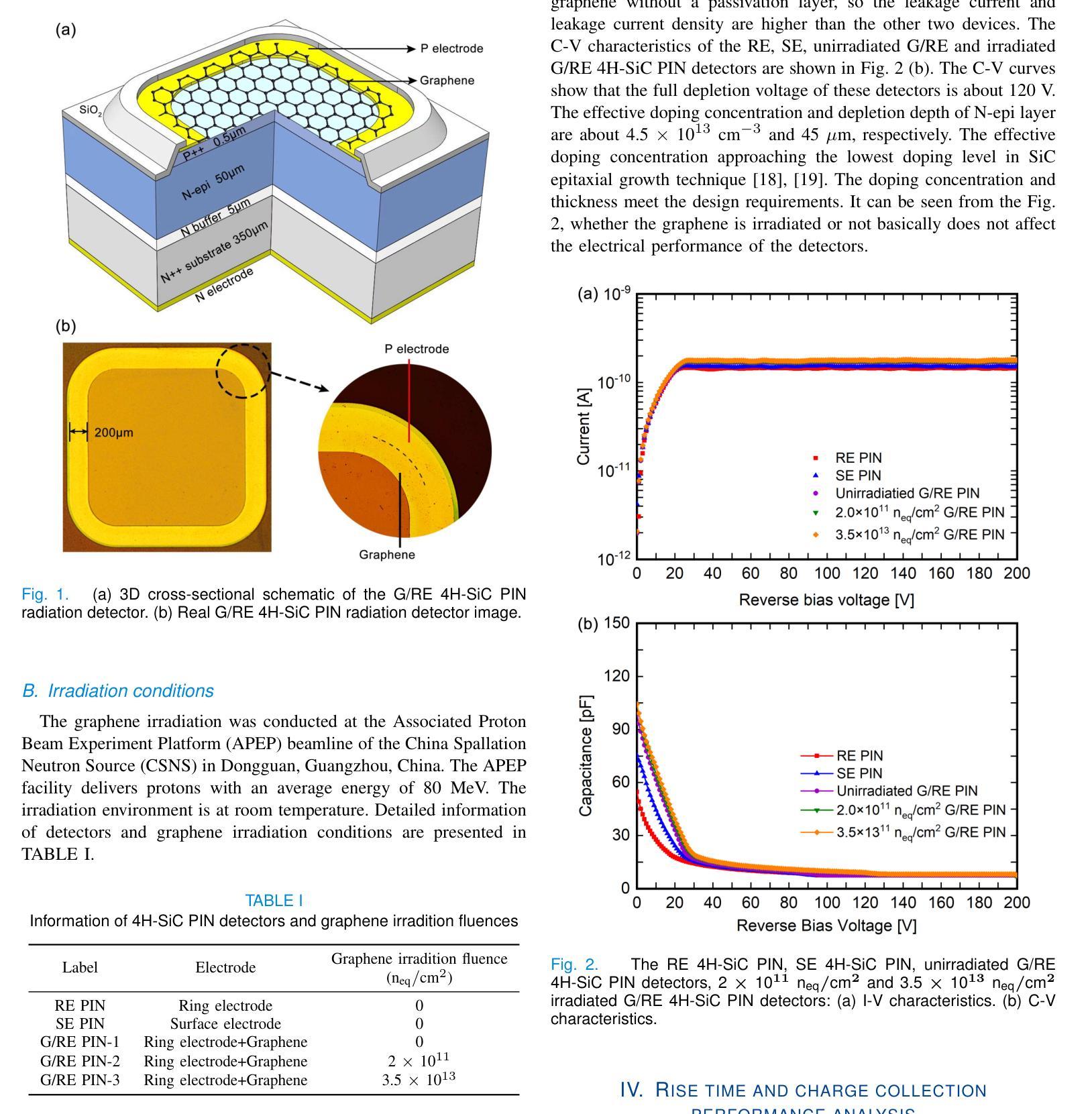
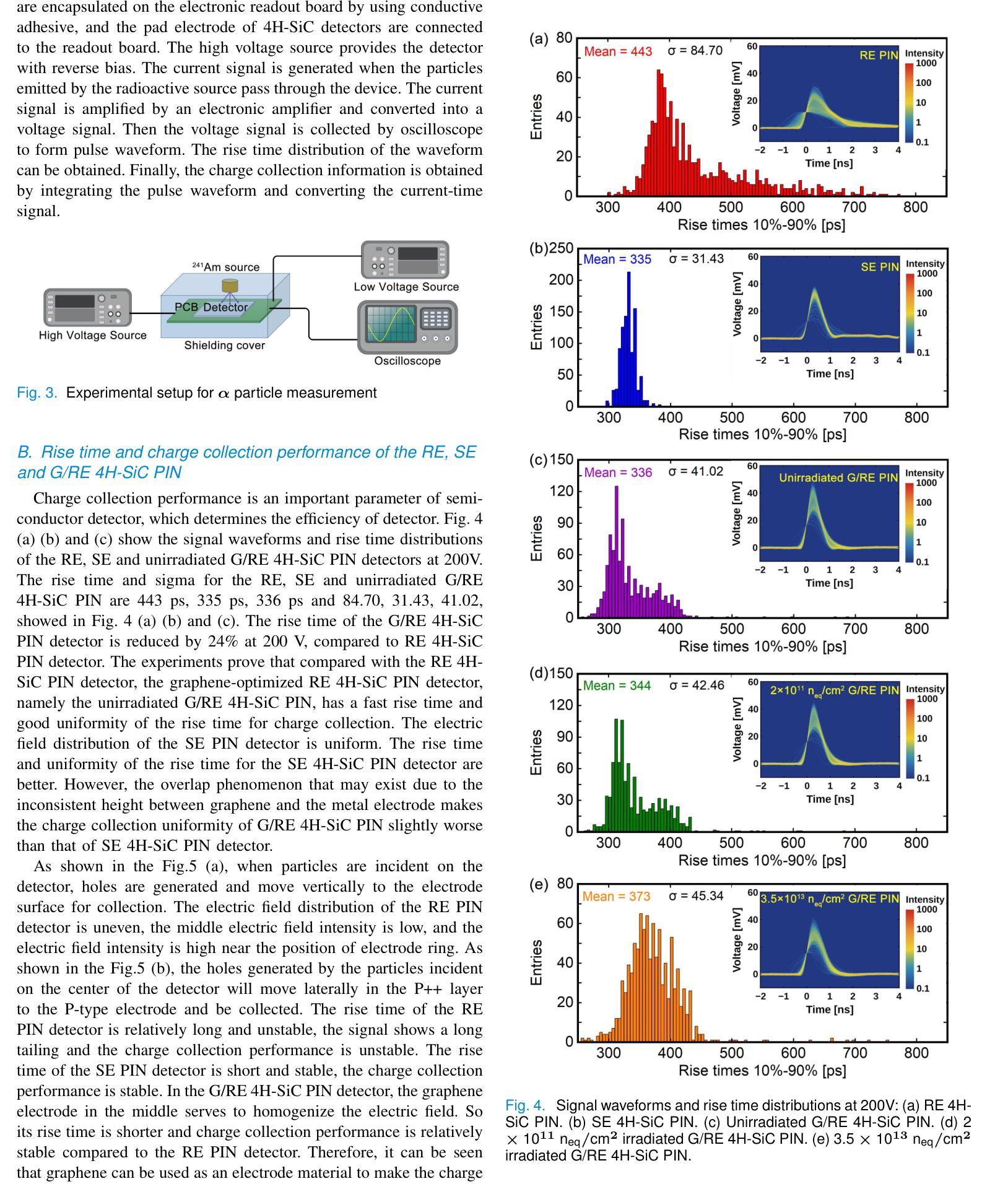
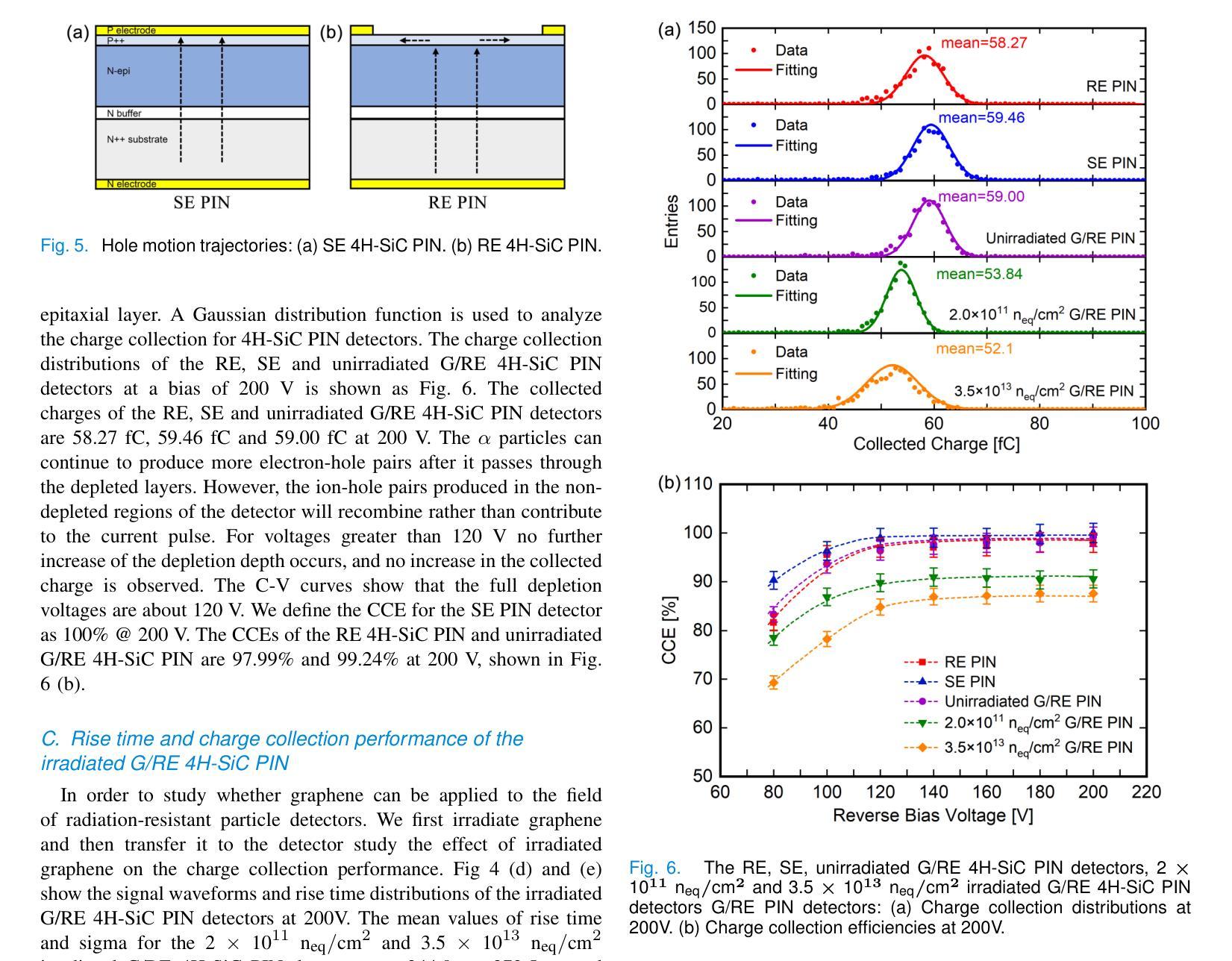
Rise Time and Charge Collection Efficiency of Graphene-Optimized 4H-SiC PIN Detector
Authors:Zhenyu Jiang, Xuemei Lu, Congcong Wang, Yingjie Huang, Xiaoshen Kang, Suyu Xiao, Xiyuan Zhang, Xin Shi
Silicon carbide detectors exhibit good detection performance and are being considered for detection applications. However, the presence of surface electrode of detector limits the application of low-penetration particle detectors, photodetectors and heavy-ion detection. A graphene-optimized 4H-SiC detector has been fabricated to expand the application of SiC detectors.Its electrical properties and the charge collection performance of {\alpha} particles are reported. The effective doping concentration of lightly doped 4H-SiC epitaxial layer is about 4.5\times10^{13}cm^{-3}, approaching the limit of the lowest doping level by the SiC epitaxial growth technique. The rise time of the graphene-optimized ring electrode detector is reduced by 24% at 200 V, compared to ring electrode detector. The charge collection efficiency (CCE) of graphene-optimized 4H-SiC PIN is 99.22%. When the irradiation dose is 2\times10^{11} n_{eq}/cm^2, the irradiation has no significant impact on the rise time and uniformity of the rise time for the graphene-optimized 4H-SiC detectors. This study proves that graphene has a certain radiation resistance. Graphene-optimized 4H-SiC detectors can not only reduce the signal rise time, but also improve uniformity of signal rise time and stability of charge collection. This research will expand the application of graphene-based 4H-SiC detectors in fields such as low energy ions, X-ray, UV light detection, particle physics, medical dosimetry and heavy-ion detection.
碳化硅探测器具有良好的检测性能,正在被考虑用于检测应用。然而,探测器的表面电极的存在限制了低穿透粒子探测器、光电探测器和重离子检测的应用。一种优化的石墨烯4H-SiC探测器已经被制造出来,以扩大SiC检测器的应用。本文报道了其电学性能和α粒子的电荷收集性能。轻掺杂的4H-SiC外延层的有效掺杂浓度约为4.5×10^{13}cm^{-3},接近SiC外延生长技术的最低掺杂极限。与环形电极探测器相比,在200V时,优化石墨烯环形电极探测器的上升时间缩短了24%。优化石墨烯的4H-SiC PIN的电荷收集效率(CCE)为99.22%。当辐射剂量为2×10^{11} n_{eq}/cm^2时,辐射对优化石墨烯的4H-SiC探测器的上升时间和上升时间的一致性几乎没有影响。这项研究表明石墨烯具有一定的抗辐射性。优化石墨烯的4H-SiC探测器不仅能减少信号上升时间,还能提高信号上升时间的一致性和电荷收集的稳定性。这项研究将扩大基于石墨烯的4H-SiC探测器在低能离子、X射线、紫外光检测、粒子物理、医学计量和重离子检测等领域的应用。
论文及项目相关链接
Summary
碳化硅探测器性能优良,被应用于检测领域。但其表面电极限制了其在低穿透粒子检测器、光电检测器和重离子检测中的应用。为扩展碳化硅探测器的应用范围,已研制出石墨烯优化的4H-SiC探测器。其电学性能和α粒子电荷收集性能得到了报道。该探测器的有效掺杂浓度接近SiC外延生长技术的最低掺杂水平。石墨烯优化环形电极探测器的上升时间相较于环形电极探测器减少了24%。石墨烯优化的4H-SiC PIN的电荷收集效率高达99.22%。在辐射剂量为2×10¹¹ neq/cm²时,辐射对石墨烯优化的4H-SiC探测器的上升时间和上升时间均匀性没有显著影响。研究证明石墨烯具有一定的抗辐射性。该研究成果将扩大石墨烯基4H-SiC探测器在低能离子、X射线、紫外线检测、粒子物理、医学计量和重离子检测等领域的应用范围。
Key Takeaways
- 碳化硅探测器具有良好的检测性能,但表面电极限制了其应用范围。
- 石墨烯优化的4H-SiC探测器被研制出以扩展碳化硅探测器的应用范围。
- 该探测器的有效掺杂浓度接近SiC外延生长技术的最低掺杂水平。
- 石墨烯优化环形电极探测器相较于传统环形电极探测器,其信号上升时间减少了24%。
- 石墨烯优化的4H-SiC PIN的电荷收集效率高达99.22%。
- 在一定辐射剂量下,辐射对石墨烯优化的4H-SiC探测器的性能没有显著影响,证明石墨烯具有一定的抗辐射性。
点此查看论文截图

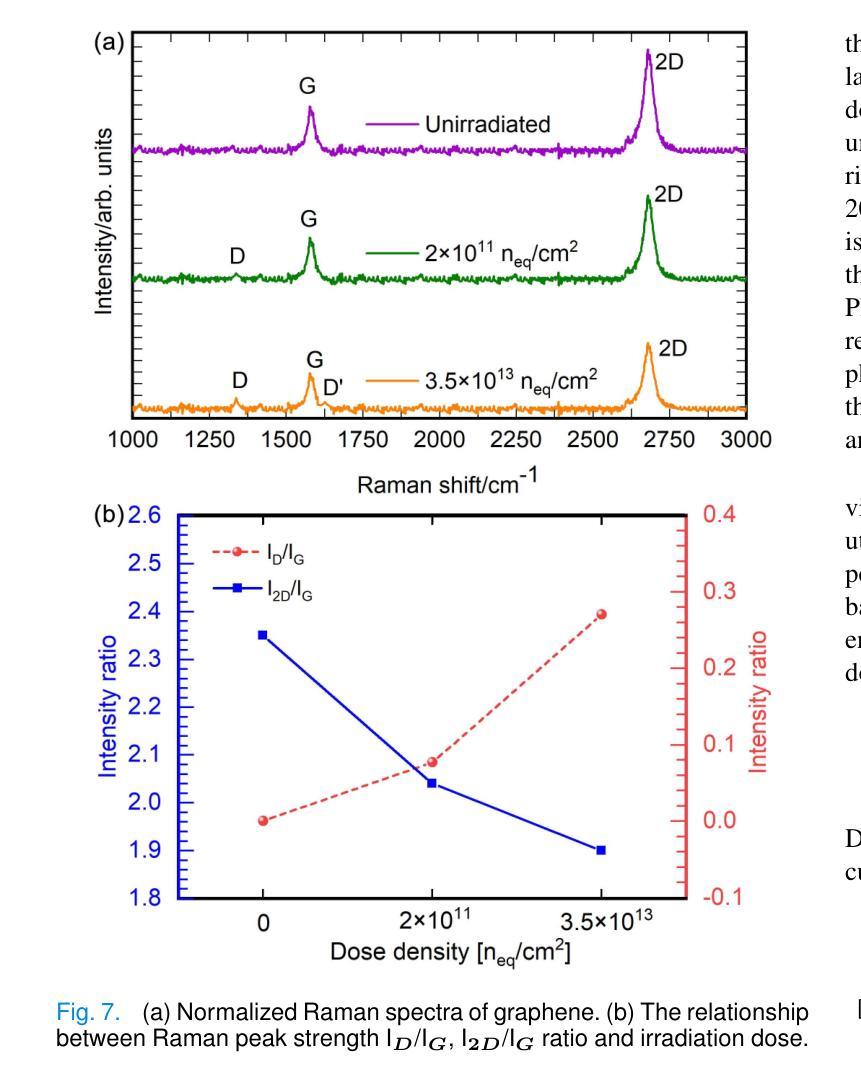
Concentrate on Weakness: Mining Hard Prototypes for Few-Shot Medical Image Segmentation
Authors:Jianchao Jiang, Haofeng Zhang
Few-Shot Medical Image Segmentation (FSMIS) has been widely used to train a model that can perform segmentation from only a few annotated images. However, most existing prototype-based FSMIS methods generate multiple prototypes from the support image solely by random sampling or local averaging, which can cause particularly severe boundary blurring due to the tendency for normal features accounting for the majority of features of a specific category. Consequently, we propose to focus more attention to those weaker features that are crucial for clear segmentation boundary. Specifically, we design a Support Self-Prediction (SSP) module to identify such weak features by comparing true support mask with one predicted by global support prototype. Then, a Hard Prototypes Generation (HPG) module is employed to generate multiple hard prototypes based on these weak features. Subsequently, a Multiple Similarity Maps Fusion (MSMF) module is devised to generate final segmenting mask in a dual-path fashion to mitigate the imbalance between foreground and background in medical images. Furthermore, we introduce a boundary loss to further constraint the edge of segmentation. Extensive experiments on three publicly available medical image datasets demonstrate that our method achieves state-of-the-art performance. Code is available at https://github.com/jcjiang99/CoW.
小样医疗图像分割(FSMIS)已被广泛应用于训练模型,该模型仅从少量标注图像中即可进行分割。然而,大多数现有的基于原型的FSMIS方法仅通过随机抽样或局部平均从支持图像生成多个原型,这可能会导致边界模糊特别严重,因为正常特征往往构成某一特定类别的主要特征。因此,我们提议更多地关注那些对于清晰分割边界至关重要的较弱特征。具体来说,我们设计了一个支持自我预测(SSP)模块,通过比较真实的支持掩膜与由全局支持原型预测的支持掩膜来识别这些弱特征。然后,采用硬原型生成(HPG)模块基于这些弱特征生成多个硬原型。随后,采用多重相似图融合(MSMF)模块以双路径方式生成最终分割掩膜,以缓解医学图像中前景和背景之间的不平衡。此外,我们引入边界损失来进一步约束分割的边缘。在三个公开的医学图像数据集上的大量实验表明,我们的方法达到了最先进的性能。代码可在https://github.com/jcjiang99/CoW找到。
论文及项目相关链接
PDF 12 pages, 9 figures, 9 tables, accepted by IJCAI 2025
Summary
本文提出了一种改进的医疗图像分割方法,通过引入支持自我预测(SSP)模块识别关键弱特征,采用硬原型生成(HPG)模块生成多个硬原型,并采用多重相似性映射融合(MSMF)模块生成最终的分割掩膜。同时,引入边界损失以进一步约束分割边缘。在三个公开医疗图像数据集上的实验表明,该方法达到了先进水平。
Key Takeaways
- Few-Shot Medical Image Segmentation (FSMIS) 用于从少量标注图像进行训练模型分割。
- 现有原型基础的FSMIS方法主要通过随机采样或局部平均从支持图像生成多个原型,这可能导致边界模糊。
- 引入支持自我预测(SSP)模块,通过比较真实支持掩膜与全局支持原型预测的掩膜来识别关键弱特征。
- 采用硬原型生成(HPG)模块,基于这些弱特征生成多个硬原型。
- 使用多重相似性映射融合(MSMF)模块以双重路径方式生成最终分割掩膜,缓解医疗图像中前景和背景的不平衡。
- 引入边界损失以进一步约束分割边缘。
点此查看论文截图

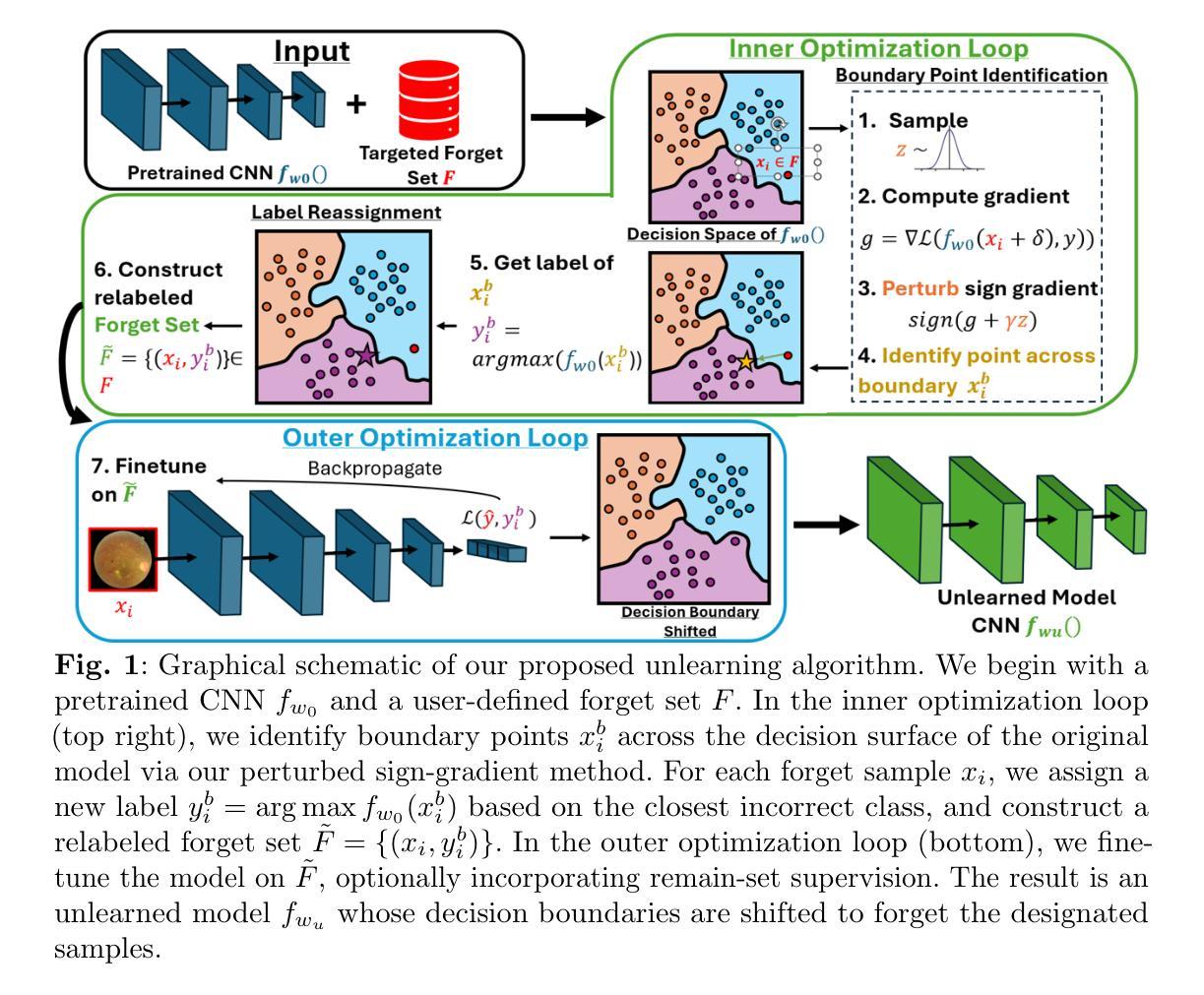
Targeted Unlearning Using Perturbed Sign Gradient Methods With Applications On Medical Images
Authors:George R. Nahass, Zhu Wang, Homa Rashidisabet, Won Hwa Kim, Sasha Hubschman, Jeffrey C. Peterson, Ghasem Yazdanpanah, Chad A. Purnell, Pete Setabutr, Ann Q. Tran, Darvin Yi, Sathya N. Ravi
Machine unlearning aims to remove the influence of specific training samples from a trained model without full retraining. While prior work has largely focused on privacy-motivated settings, we recast unlearning as a general-purpose tool for post-deployment model revision. Specifically, we focus on utilizing unlearning in clinical contexts where data shifts, device deprecation, and policy changes are common. To this end, we propose a bilevel optimization formulation of boundary-based unlearning that can be solved using iterative algorithms. We provide convergence guarantees when first-order algorithms are used to unlearn. Our method introduces tunable loss design for controlling the forgetting-retention tradeoff and supports novel model composition strategies that merge the strengths of distinct unlearning runs. Across benchmark and real-world clinical imaging datasets, our approach outperforms baselines on both forgetting and retention metrics, including scenarios involving imaging devices and anatomical outliers. This work establishes machine unlearning as a modular, practical alternative to retraining for real-world model maintenance in clinical applications.
机器遗忘旨在从已训练的模型中移除特定训练样本的影响,而无需完全重新训练模型。尽管早期的研究主要集中在以隐私为驱动的场景上,我们将遗忘重塑为一种用于部署后模型修正的通用工具。具体而言,我们关注在数据偏移、设备弃用和政策变更等普遍存在的临床环境中利用遗忘技术。为此,我们提出了基于边界的遗忘的两级优化公式,可以使用迭代算法来解决。当使用一阶算法进行遗忘时,我们提供收敛性保证。我们的方法引入了可调损失设计,以控制遗忘与保留之间的权衡,并支持新的模型组合策略,这些策略可以合并不同遗忘运行的优势。在我们的基准测试和真实世界临床成像数据集上,我们的方法在遗忘和保留指标上的表现均优于基线方法,包括涉及成像设备和解剖异常值等场景。这项工作确立了机器遗忘作为临床应用中现实世界模型维护的一种模块化、实用的替代再训练方法。
论文及项目相关链接
PDF 39 pages, 12 figures, 11 tables, 3 algorithms
Summary
机器遗忘旨在从已训练的模型中移除特定训练样本的影响,而无需完全重新训练。本文将其重新定位为用于部署后模型修订的通用工具,重点关注临床环境下的应用,如数据变化、设备淘汰和政策变更等场景。我们提出了一种基于边界的遗忘的两级优化公式,可以使用迭代算法来解决。当使用一阶算法进行遗忘时,我们提供了收敛性保证。我们的方法引入了可调损失设计,以控制遗忘与保留之间的权衡,并支持新的模型组合策略,这些策略可以合并不同遗忘运行的优点。在基准和真实临床成像数据集上,我们的方法在遗忘和保留指标上的表现优于基线方法,包括涉及成像设备和解剖异常情况的场景。本研究确立了机器遗忘作为一种模块化、实用的替代方法,用于临床应用中现实模型的维护,而无需重新训练。
Key Takeaways
- 机器遗忘旨在移除特定训练样本对模型的影响,而无需全面重新训练模型。
- 本文将机器遗忘重新定位为用于部署后模型修订的通用工具。
- 在临床环境下应用机器遗忘,考虑了数据变化、设备淘汰和政策变更等场景。
- 提出了一种基于边界的遗忘的两级优化公式,并使用迭代算法解决。
- 方法引入了可调损失设计,以控制遗忘与保留之间的权衡。
- 支持新的模型组合策略,可以合并不同遗忘运行的优点。
点此查看论文截图

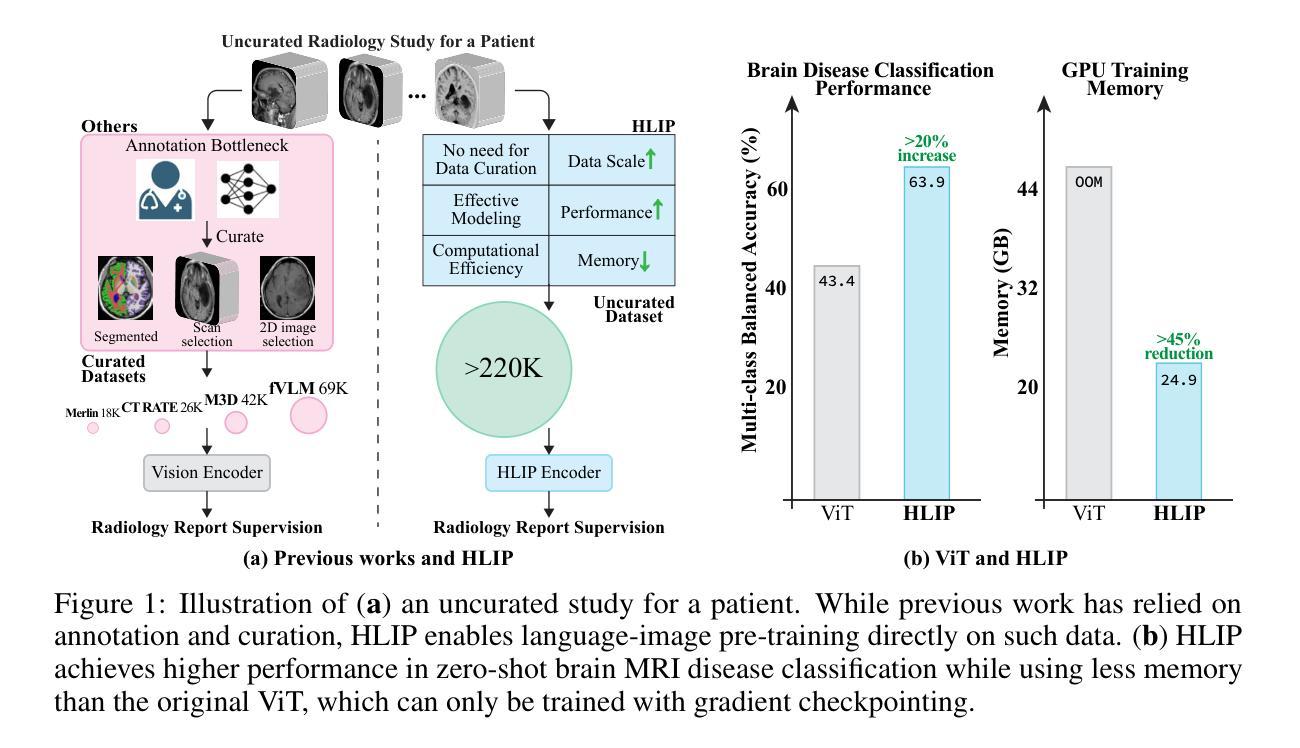
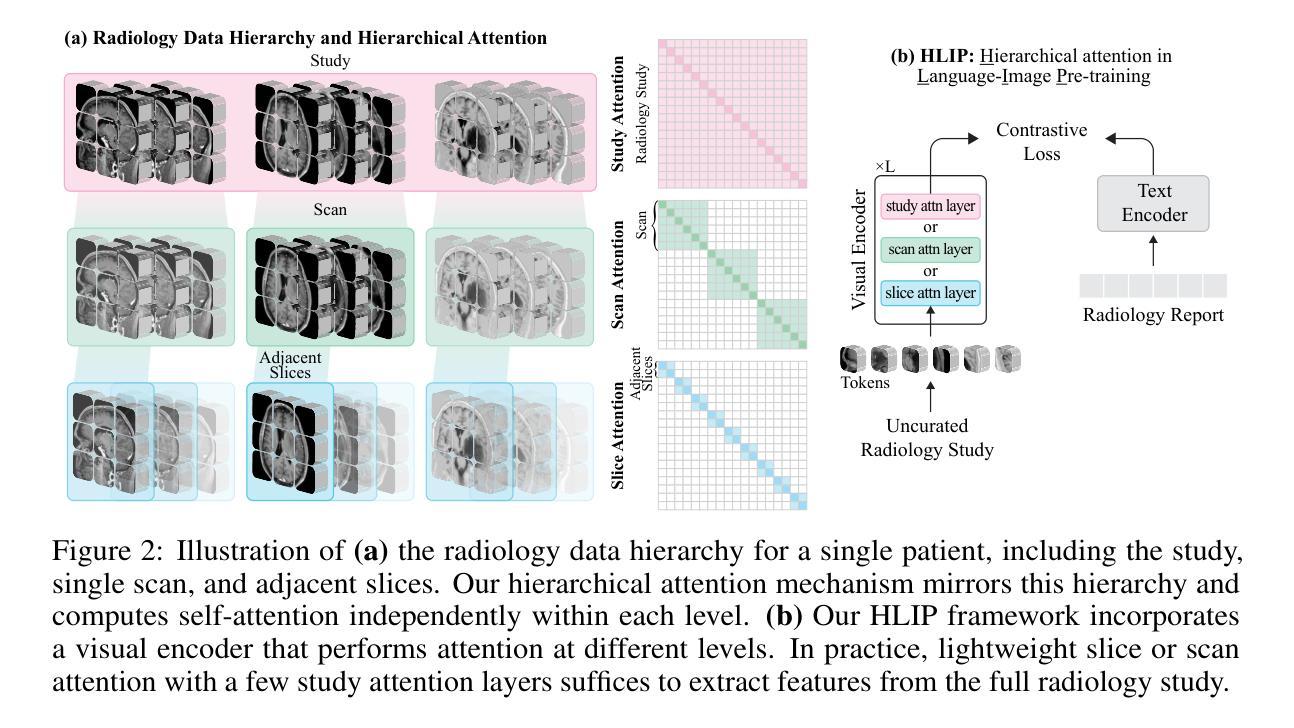
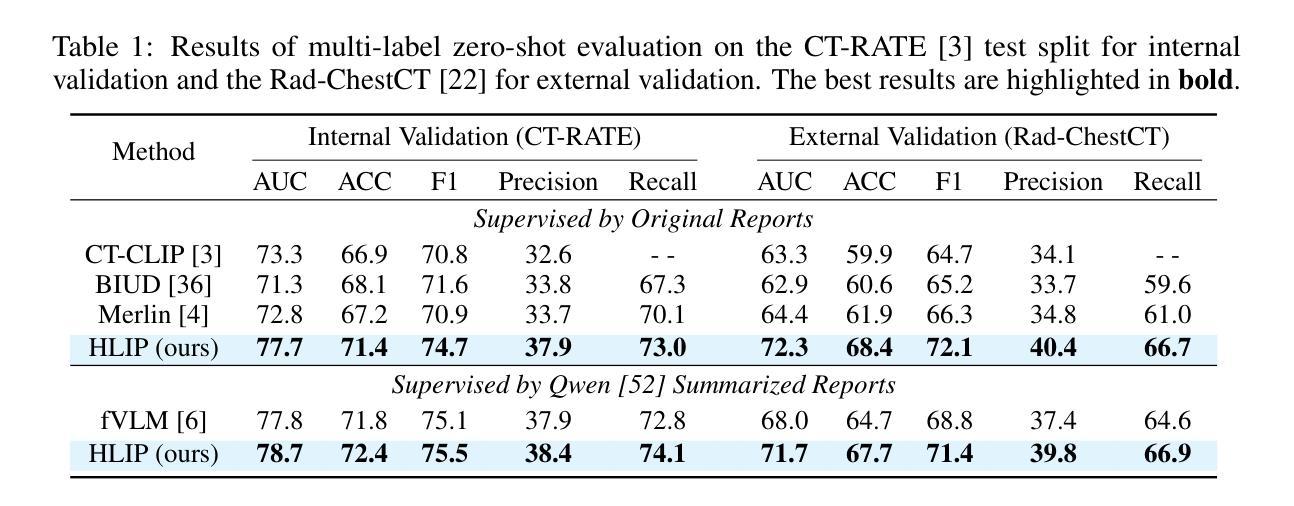
Towards Scalable Language-Image Pre-training for 3D Medical Imaging
Authors:Chenhui Zhao, Yiwei Lyu, Asadur Chowdury, Edward Harake, Akhil Kondepudi, Akshay Rao, Xinhai Hou, Honglak Lee, Todd Hollon
Language-image pre-training has demonstrated strong performance in 2D medical imaging, but its success in 3D modalities such as CT and MRI remains limited due to the high computational demands of volumetric data, which pose a significant barrier to training on large-scale, uncurated clinical studies. In this study, we introduce Hierarchical attention for Language-Image Pre-training (HLIP), a scalable pre-training framework for 3D medical imaging. HLIP adopts a lightweight hierarchical attention mechanism inspired by the natural hierarchy of radiology data: slice, scan, and study. This mechanism exhibits strong generalizability, e.g., +4.3% macro AUC on the Rad-ChestCT benchmark when pre-trained on CT-RATE. Moreover, the computational efficiency of HLIP enables direct training on uncurated datasets. Trained on 220K patients with 3.13 million scans for brain MRI and 240K patients with 1.44 million scans for head CT, HLIP achieves state-of-the-art performance, e.g., +32.4% balanced ACC on the proposed publicly available brain MRI benchmark Pub-Brain-5; +1.4% and +6.9% macro AUC on head CT benchmarks RSNA and CQ500, respectively. These results demonstrate that, with HLIP, directly pre-training on uncurated clinical datasets is a scalable and effective direction for language-image pre-training in 3D medical imaging. The code is available at https://github.com/Zch0414/hlip
语言图像预训练在2D医学影像中表现出了强大的性能,但在CT和MRI等3D模式中的成功应用仍然有限,这主要是由于体积数据的高计算需求构成了大规模非整理临床研究的训练障碍。在这项研究中,我们引入了用于3D医学影像的可扩展预训练框架——分层注意力语言图像预训练(HLIP)。HLIP采用了一种轻量级的分层注意力机制,该机制受到放射学数据的自然层次结构的启发:切片、扫描和研究。这种机制具有很强的泛化能力,例如在CT-RATE上预训练后在Rad-ChestCT基准测试上宏观AUC提高4.3%。此外,HLIP的计算效率能够实现直接在非整理数据集上进行训练。在针对脑部MRI的22万患者和313万次扫描以及针对头部CT的24万患者和144万次扫描的训练下,HLIP取得了最先进的性能,例如在提出的公开脑部MRI基准测试Pub-Brain-5上的平衡准确率提高32.4%;在头部CT基准测试RSNA和CQ500上的宏观AUC分别提高1.4%和6.9%。这些结果表明,使用HLIP直接在非整理的临床数据集上进行预训练是3D医学影像语言图像预训练的可扩展和有效方向。代码可在https://github.com/Zch0414/hlip找到。
论文及项目相关链接
Summary
本文介绍了一种针对3D医学影像的预训练框架——分层注意力语言图像预训练(HLIP)。HLIP采用轻量级分层注意力机制,在放射学数据自然层次结构(切片、扫描和研究)的启发下设计。该机制在Rad-ChestCT基准测试上表现出强大的泛化能力,预训练后宏AUC提高4.3%。此外,HLIP的计算效率可直接在未经处理的数据集上进行训练。在公开的大脑MRI基准测试Pub-Brain-5上,HLIP取得了领先水平,平衡精度提高32.4%。在头部CT基准测试RSNA和CQ500上,宏AUC分别提高1.4%和6.9%。研究结果表明,直接在未经处理的临床数据集上使用HLIP进行预训练是3D医学影像语言图像预训练的可扩展和有效方向。
Key Takeaways
- HLIP是一个针对3D医学影像的预训练框架,专为处理大规模未经处理的临床数据集设计。
- HLIP采用分层注意力机制,适应放射学数据的自然层次结构。
- HLIP在多个基准测试中表现出强大的泛化能力和计算效率。
- 在Rad-ChestCT基准测试上,预训练后宏AUC提高4.3%。
- HLIP在大脑MRI和头部CT的公开基准测试中达到领先水平。
- HLIP可直接在未经处理的临床数据集上进行训练,显示出其有效性和可扩展性。
点此查看论文截图

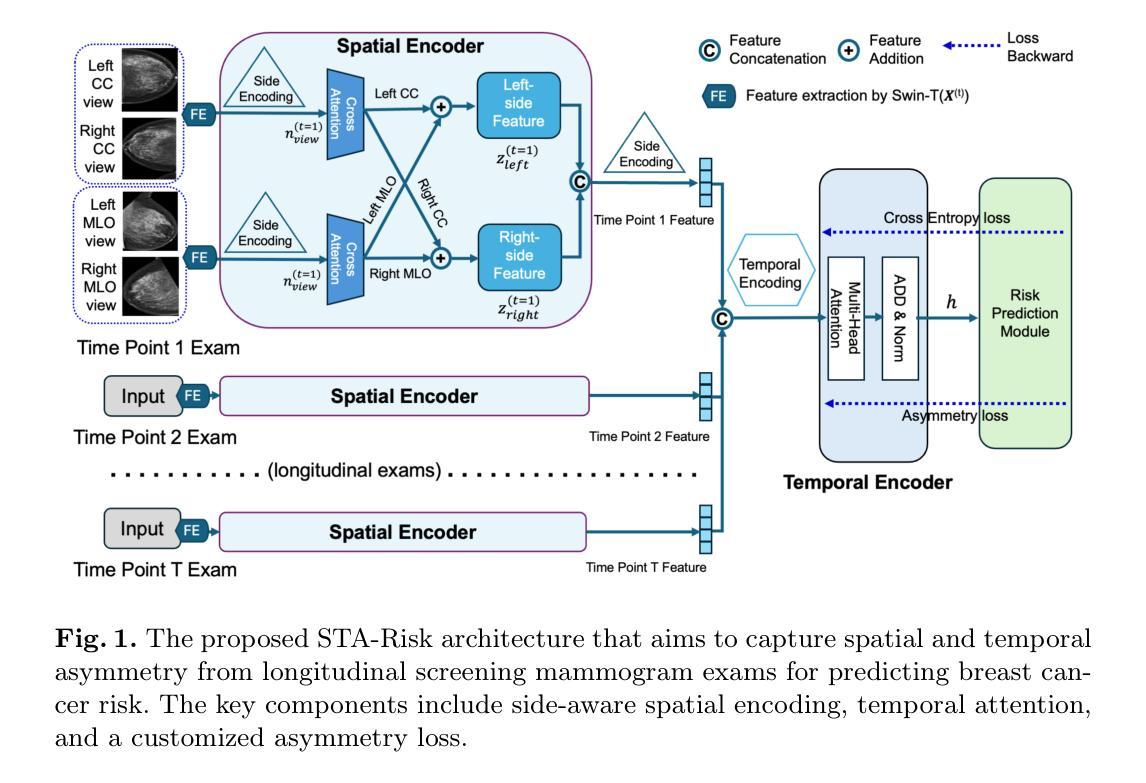
STA-Risk: A Deep Dive of Spatio-Temporal Asymmetries for Breast Cancer Risk Prediction
Authors:Zhengbo Zhou, Dooman Arefan, Margarita Zuley, Jules Sumkin, Shandong Wu
Predicting the risk of developing breast cancer is an important clinical tool to guide early intervention and tailoring personalized screening strategies. Early risk models have limited performance and recently machine learning-based analysis of mammogram images showed encouraging risk prediction effects. These models however are limited to the use of a single exam or tend to overlook nuanced breast tissue evolvement in spatial and temporal details of longitudinal imaging exams that are indicative of breast cancer risk. In this paper, we propose STA-Risk (Spatial and Temporal Asymmetry-based Risk Prediction), a novel Transformer-based model that captures fine-grained mammographic imaging evolution simultaneously from bilateral and longitudinal asymmetries for breast cancer risk prediction. STA-Risk is innovative by the side encoding and temporal encoding to learn spatial-temporal asymmetries, regulated by a customized asymmetry loss. We performed extensive experiments with two independent mammogram datasets and achieved superior performance than four representative SOTA models for 1- to 5-year future risk prediction. Source codes will be released upon publishing of the paper.
预测乳腺癌发展的风险是指导早期干预和定制个性化筛查策略的重要临床工具。早期的风险模型性能有限,而最近基于机器学习对乳房X光影像的分析显示出令人鼓舞的风险预测效果。然而,这些模型仅限于使用单次检查,或者倾向于忽略纵向成像检查的空间和时间细节中微妙的乳腺组织演变,这些迹象表明与乳腺癌风险有关。在本文中,我们提出了STA-Risk(基于空间和时间不对称性的风险预测),这是一种新型的基于Transformer的模型,可以同时捕捉双侧和纵向不对称性的细微乳房X光影像演变,用于预测乳腺癌的风险。STA-Risk的创新之处在于通过侧编码和时间编码来学习空间-时间不对称性,由定制的不对称损失进行调控。我们在两个独立的乳房X光影像数据集上进行了大量实验,并在未来1至5年的风险预测方面取得了优于四个代表性最新模型的性能。论文发表后将公布源代码。
论文及项目相关链接
Summary
本文提出了一种基于Transformer的新型乳腺癌风险预测模型STA-Risk,该模型通过捕捉双侧乳腺图像的长期演化过程中的空间和时间不对称性,进行精细的乳腺图像分析,以预测乳腺癌的风险。实验结果显示,STA-Risk在两个独立的乳腺影像数据集上的预测性能优于其他四种先进模型,未来一至五年的预测效果尤为显著。
Key Takeaways
- 乳腺癌风险预测在临床上是早期干预和个性化筛查策略的关键工具。
- 早期的风险预测模型性能有限。
- 机器学习在分析乳腺X光图像以预测乳腺癌风险方面显示出潜力。
- 目前模型忽视了乳腺组织在纵向成像中的空间和时间变化细节,这些细节可能预示乳腺癌风险。
- 本文提出了一种新型的基于Transformer的乳腺癌风险预测模型STA-Risk。
- STA-Risk通过捕捉双侧乳腺图像的长期演化过程中的空间和时间不对称性进行预测。
点此查看论文截图

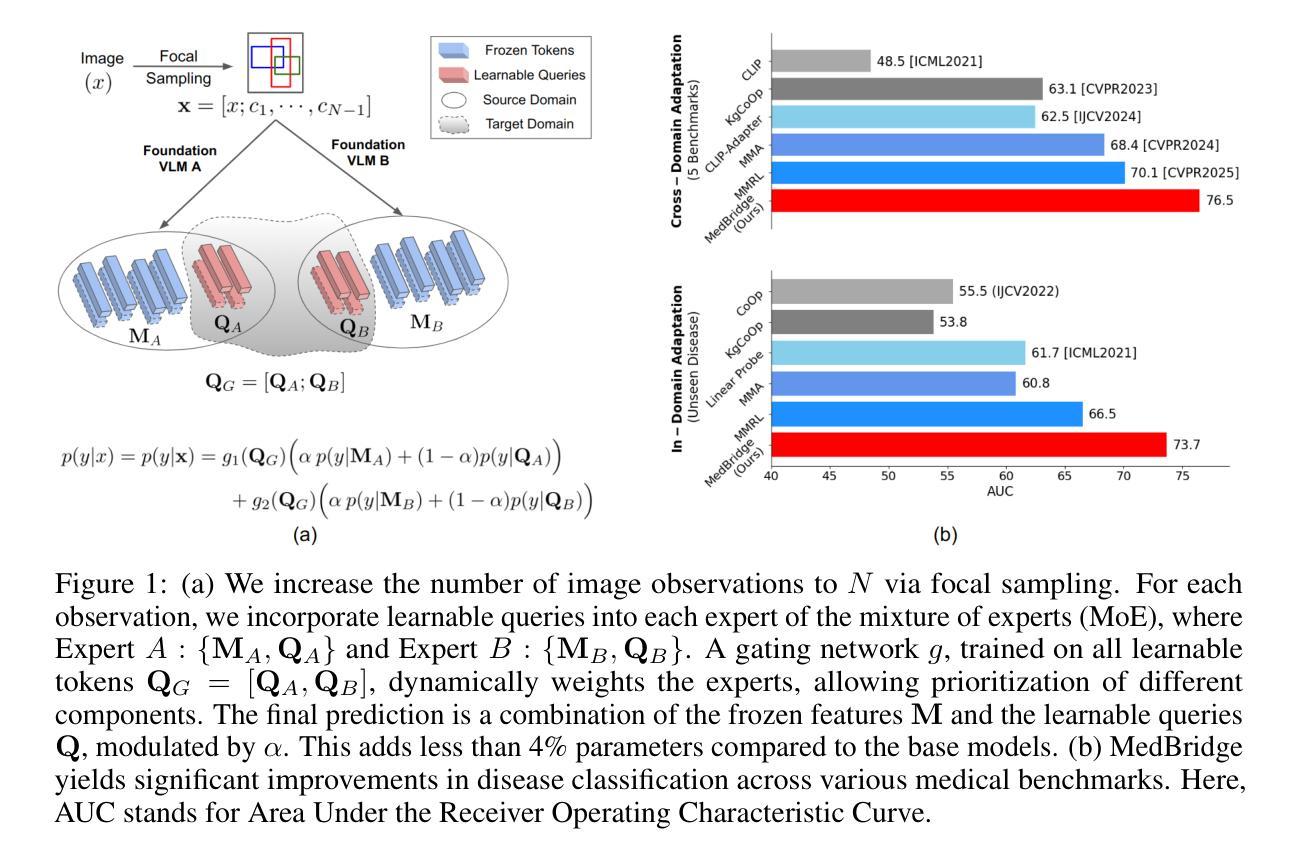
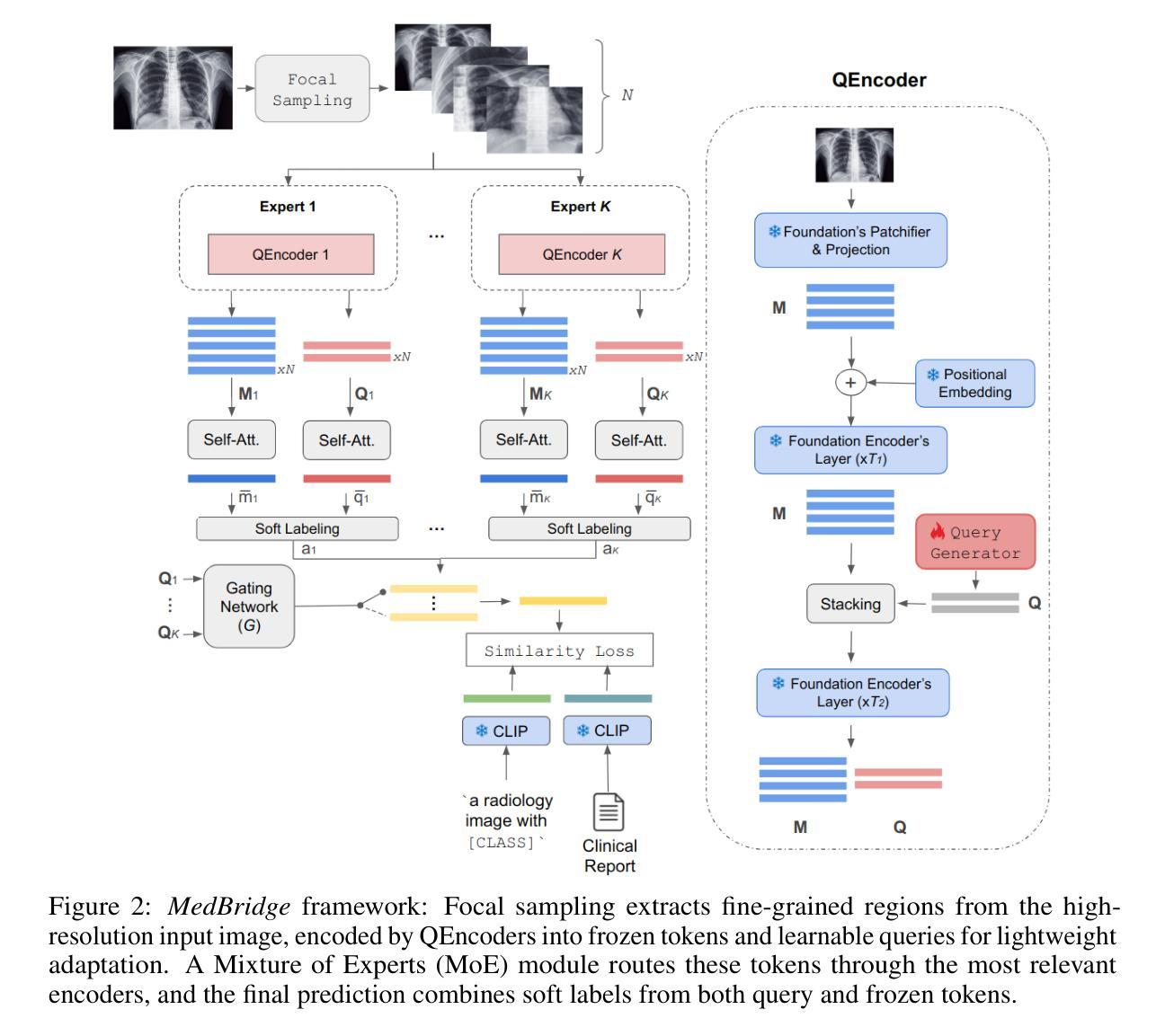
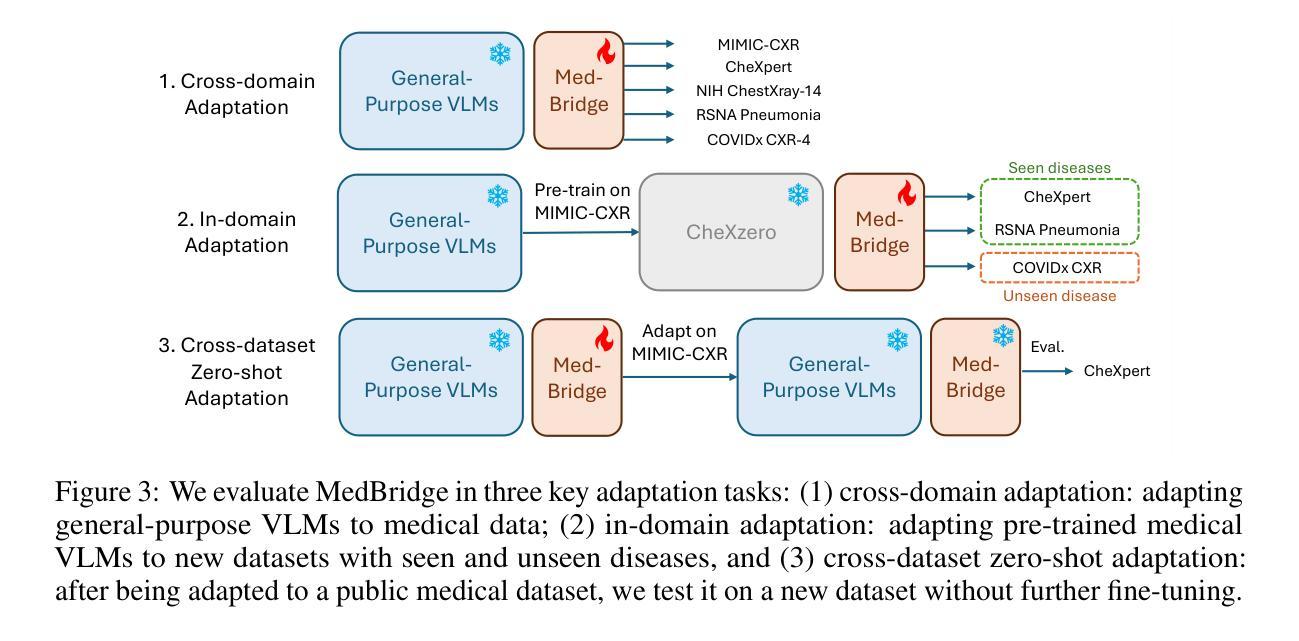
MedBridge: Bridging Foundation Vision-Language Models to Medical Image Diagnosis
Authors:Yitong Li, Morteza Ghahremani, Christian Wachinger
Recent vision-language foundation models deliver state-of-the-art results on natural image classification but falter on medical images due to pronounced domain shifts. At the same time, training a medical foundation model requires substantial resources, including extensive annotated data and high computational capacity. To bridge this gap with minimal overhead, we introduce MedBridge, a lightweight multimodal adaptation framework that re-purposes pretrained VLMs for accurate medical image diagnosis. MedBridge comprises three key components. First, a Focal Sampling module that extracts high-resolution local regions to capture subtle pathological features and compensate for the limited input resolution of general-purpose VLMs. Second, a Query Encoder (QEncoder) injects a small set of learnable queries that attend to the frozen feature maps of VLM, aligning them with medical semantics without retraining the entire backbone. Third, a Mixture of Experts mechanism, driven by learnable queries, harnesses the complementary strength of diverse VLMs to maximize diagnostic performance. We evaluate MedBridge on five medical imaging benchmarks across three key adaptation tasks, demonstrating its superior performance in both cross-domain and in-domain adaptation settings, even under varying levels of training data availability. Notably, MedBridge achieved over 6-15% improvement in AUC compared to state-of-the-art VLM adaptation methods in multi-label thoracic disease diagnosis, underscoring its effectiveness in leveraging foundation models for accurate and data-efficient medical diagnosis. Our code is available at https://github.com/ai-med/MedBridge.
最近,视觉语言基础模型在自然图像分类方面达到了最先进的技术水平,但由于明显的领域差异,在医学图像方面表现不佳。同时,训练医学基础模型需要大量的资源,包括大量的标注数据和强大的计算能力。为了以最小的额外开销弥合这一鸿沟,我们引入了MedBridge,这是一个轻量级的跨模态适应框架,用于对预训练的VLM进行再利用,以实现准确的医学图像诊断。MedBridge包含三个关键组件。首先,Focal Sampling模块用于提取高分辨率的局部区域,以捕捉微妙的病理特征,并弥补通用VLM的有限输入分辨率。其次,查询编码器(QEncoder)注入了一小部分可学习的查询项,这些查询项关注VLM的冻结特征图,将其与医学语义对齐,而无需重新训练整个主干网络。第三,由可学习查询驱动的专家混合机制利用多种VLM的互补优势,以最大化诊断性能。我们在五个医学影像基准上对MedBridge进行了评估,涵盖了三项关键适应任务,展示了其在跨域和域内适应设置中的卓越性能,即使在各种训练数据可用性下也是如此。值得注意的是,在胸部疾病的多标签诊断中,MedBridge与最先进的基础模型适应方法相比,AUC提高了6-15%以上,这突显了其在利用基础模型进行准确和高效医学诊断方面的有效性。我们的代码可在https://github.com/ai-med/MedBridge找到。
论文及项目相关链接
Summary
本文介绍了一种轻量级的跨模态适应框架MedBridge,用于将预训练的视觉语言模型(VLMs)用于精确医学图像诊断。它包含三个关键组件:用于捕捉细微病理特征的Focal Sampling模块、通过关注VLM的特征映射与医学语义对齐的Query Encoder(QEncoder)以及利用不同VLM互补优势的Mixture of Experts机制。在五个医学成像基准测试上的评估结果表明,MedBridge在跨域和同域适应设置中均表现出卓越性能,甚至在训练数据不同可用性的情况下也能实现超过现有VLM适应方法的改进。在胸部疾病的多标签诊断中,MedBridge的AUC提高了6-15%,突显其在利用基础模型进行准确和数据高效医学诊断方面的有效性。
Key Takeaways
- MedBridge是一个轻量级的跨模态适应框架,旨在将预训练的视觉语言模型用于医学图像诊断。
- MedBridge包含三个关键组件:Focal Sampling模块、Query Encoder(QEncoder)和Mixture of Experts机制。
- Focal Sampling模块通过提取高分辨率局部区域来捕捉细微的病理特征。
- Query Encoder(QEncoder)通过关注VLM的特征映射与医学语义对齐,无需重新训练整个基础模型。
- Mixture of Experts机制利用不同VLM的互补优势以提高诊断性能。
- MedBridge在五个医学成像基准测试上表现优异,实现了跨域和同域适应设置中的优越性能。
点此查看论文截图

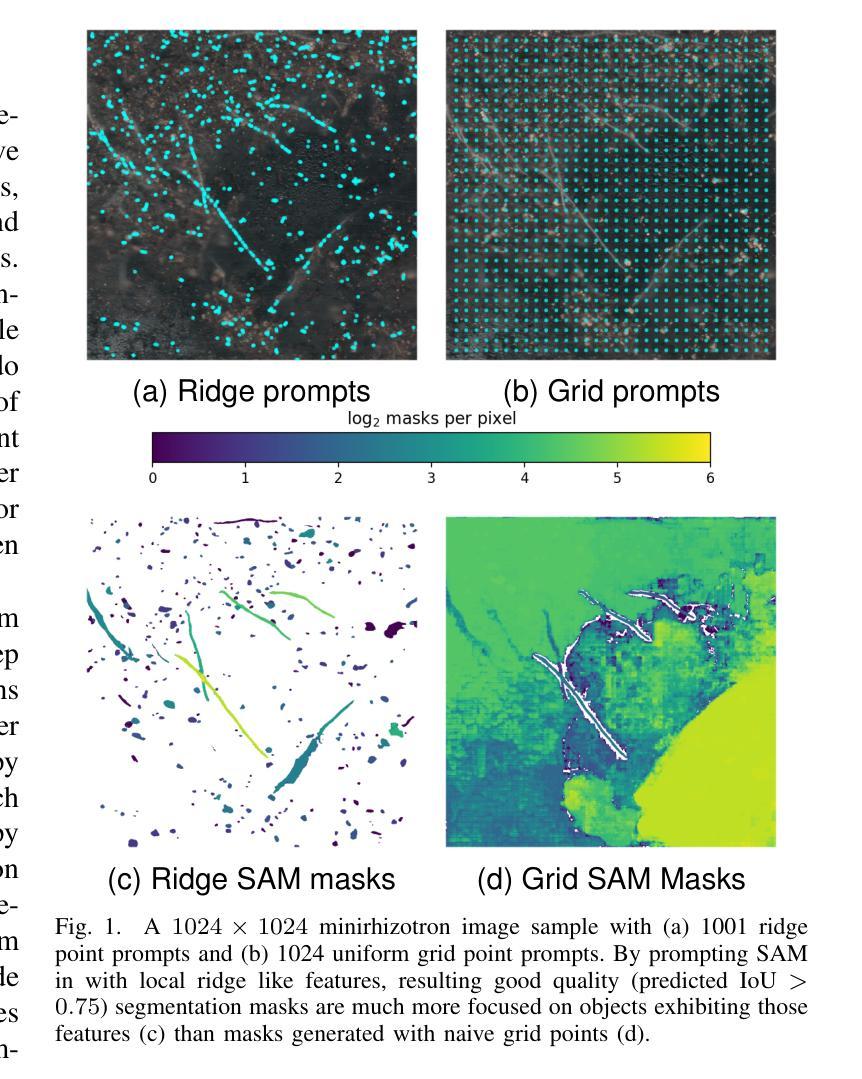
Geometric Feature Prompting of Image Segmentation Models
Authors:Kenneth Ball, Erin Taylor, Nirav Patel, Andrew Bartels, Gary Koplik, James Polly, Jay Hineman
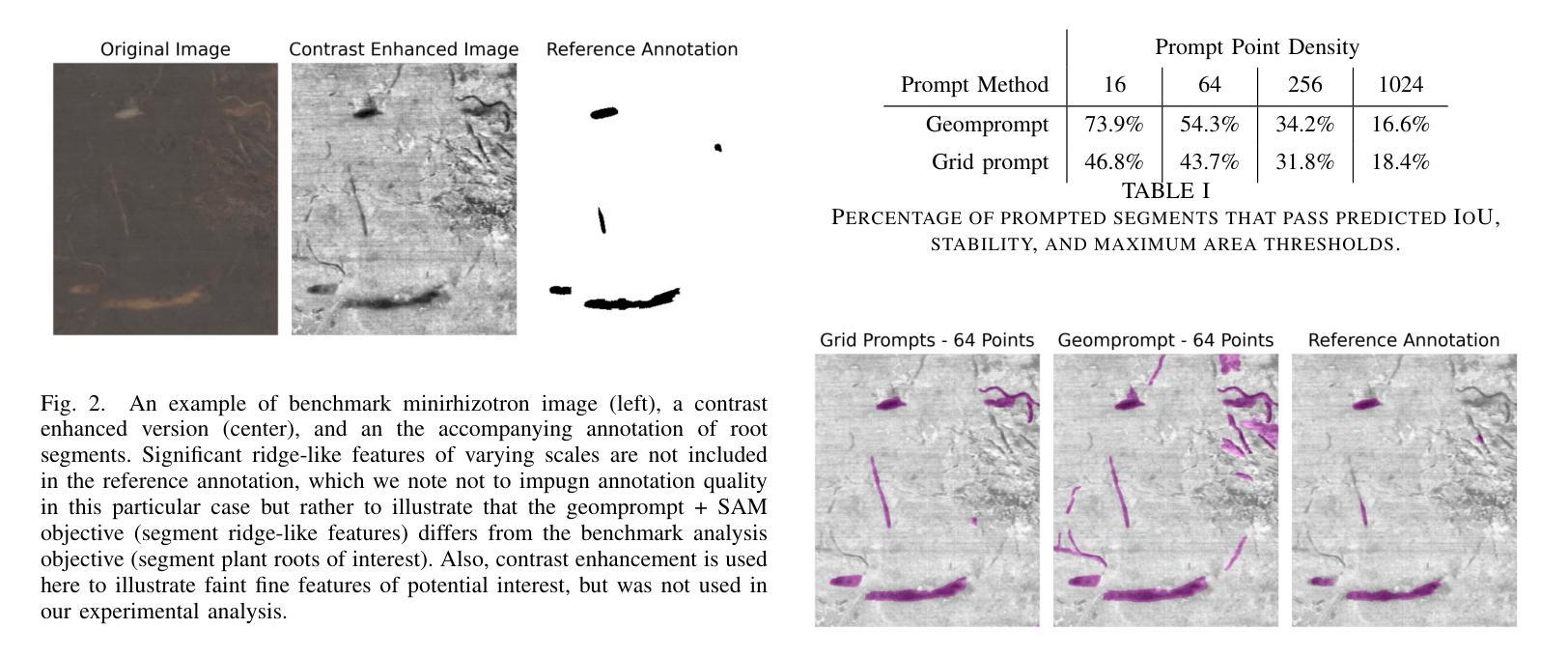
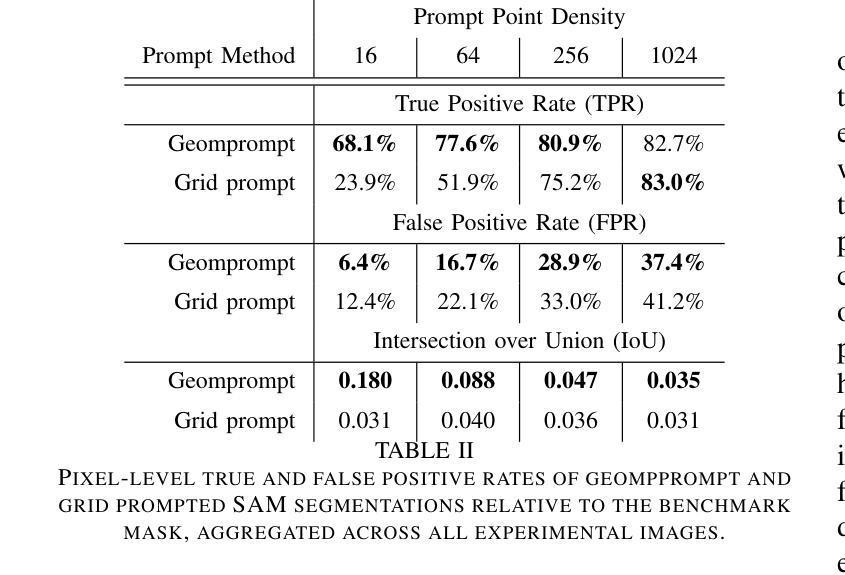
Advances in machine learning, especially the introduction of transformer architectures and vision transformers, have led to the development of highly capable computer vision foundation models. The segment anything model (known colloquially as SAM and more recently SAM 2), is a highly capable foundation model for segmentation of natural images and has been further applied to medical and scientific image segmentation tasks. SAM relies on prompts – points or regions of interest in an image – to generate associated segmentations. In this manuscript we propose the use of a geometrically motivated prompt generator to produce prompt points that are colocated with particular features of interest. Focused prompting enables the automatic generation of sensitive and specific segmentations in a scientific image analysis task using SAM with relatively few point prompts. The image analysis task examined is the segmentation of plant roots in rhizotron or minirhizotron images, which has historically been a difficult task to automate. Hand annotation of rhizotron images is laborious and often subjective; SAM, initialized with GeomPrompt local ridge prompts has the potential to dramatically improve rhizotron image processing. The authors have concurrently released an open source software suite called geomprompt https://pypi.org/project/geomprompt/ that can produce point prompts in a format that enables direct integration with the segment-anything package.
机器学习的发展,特别是transformer架构和视觉transformer的引入,推动了高度能动的计算机视觉基础模型的开发。被称为SAM(最近又称为SAM 2)的任意分割模型是自然图像分割的高度基础模型,并已进一步应用于医学和科学图像分割任务。SAM依赖于提示——图像中的点或感兴趣区域——来生成相关的分割。在本文中,我们提出了一种基于几何动机的提示生成器,用于产生与图像特定特征相对应的提示点。通过有针对性的提示,使用SAM和相对较少的点提示,可以在科学图像分析任务中自动产生敏感和特定的分割。本文研究的图像分析任务是根室或微型根室图像的植物根分割,这历来是自动化难度较大的任务。根室图像的手动注释是费时且主观的;使用GeomPrompt初始化的SAM有潜力极大地改善根室图像的处理。作者同时发布了一个名为geomprompt的开源软件套件,该软件套件可以产生点提示,以格式直接集成到分段软件包中。您可以访问geomprompt at https://pypi.org/project/geomprompt/ 了解详情。
论文及项目相关链接
Summary
机器学习领域的进步,特别是transformer架构和视觉transformer的引入,推动了高度能干的计算机视觉基础模型的发展。分段任何模型(俗称SAM,最近升级为SAM 2)是对自然图像进行分割的高度能干的基础模型,并已进一步应用于医学和科学图像分割任务。SAM通过提示——图像中的点或感兴趣区域——来生成相关的分割。本文提出使用几何动机提示生成器来产生与图像特定特征共定位的提示点。通过聚焦提示,使用SAM和相对较少的点提示,可以在科学图像分析任务中自动生成敏感和特定的分割。所研究的图像分析任务是分割植物根在rhizotron或minirhizotron图像中的部分,这历来是自动化困难的。手工标注rhizotron图像是繁重且主观的;使用由GeomPrompt本地脊提示初始化的SAM,有望显著改善rhizotron图像处理。
Key Takeaways
1. 机器学习进步推动了计算机视觉基础模型的发展,特别是分段任何模型(SAM)在图像分割方面的能力显著。
2. SAM通过提示生成相关分割,这些提示可以是图像中的点或感兴趣区域。
3. 几何动机提示生成器能产生与图像特定特征共定位的提示点,提高分割准确性。
4. 聚焦提示能使用相对较少的点提示在科学图像分析任务中自动生成敏感和特定的分割。
5. 植物根在rhizotron或minirhizotron图像中的分割是一个困难的自动化任务。
6. 手工标注rhizotron图像是繁重且主观的,使用SAM有潜力改善这一情况。
点此查看论文截图

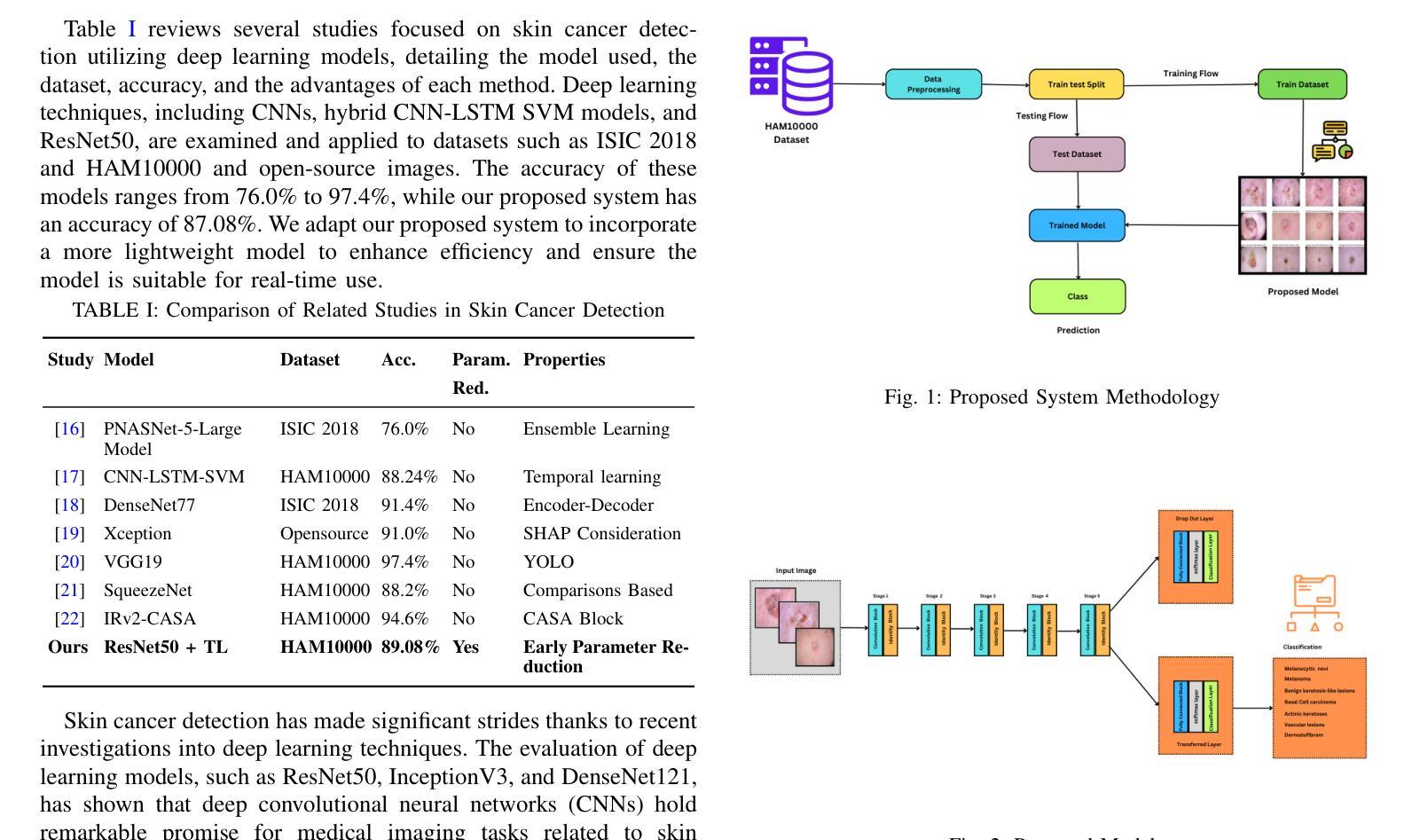
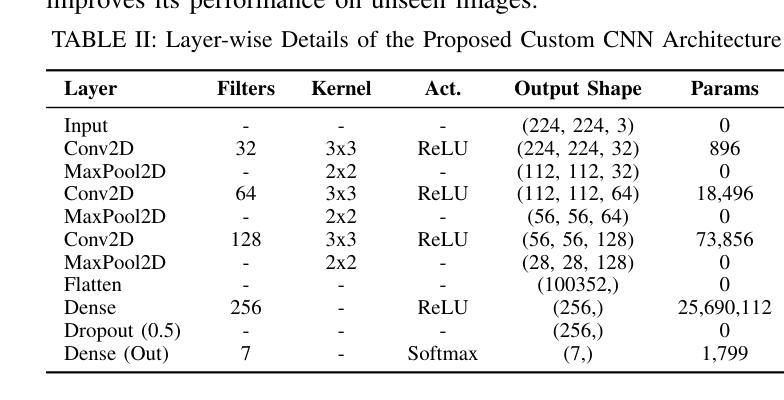
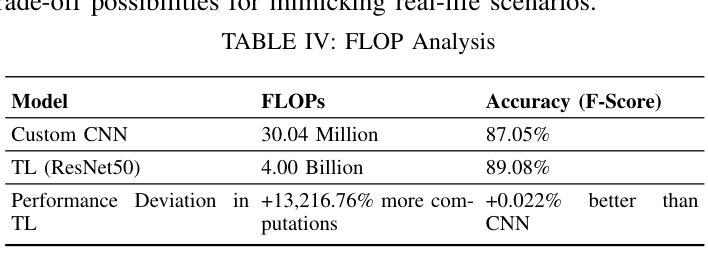
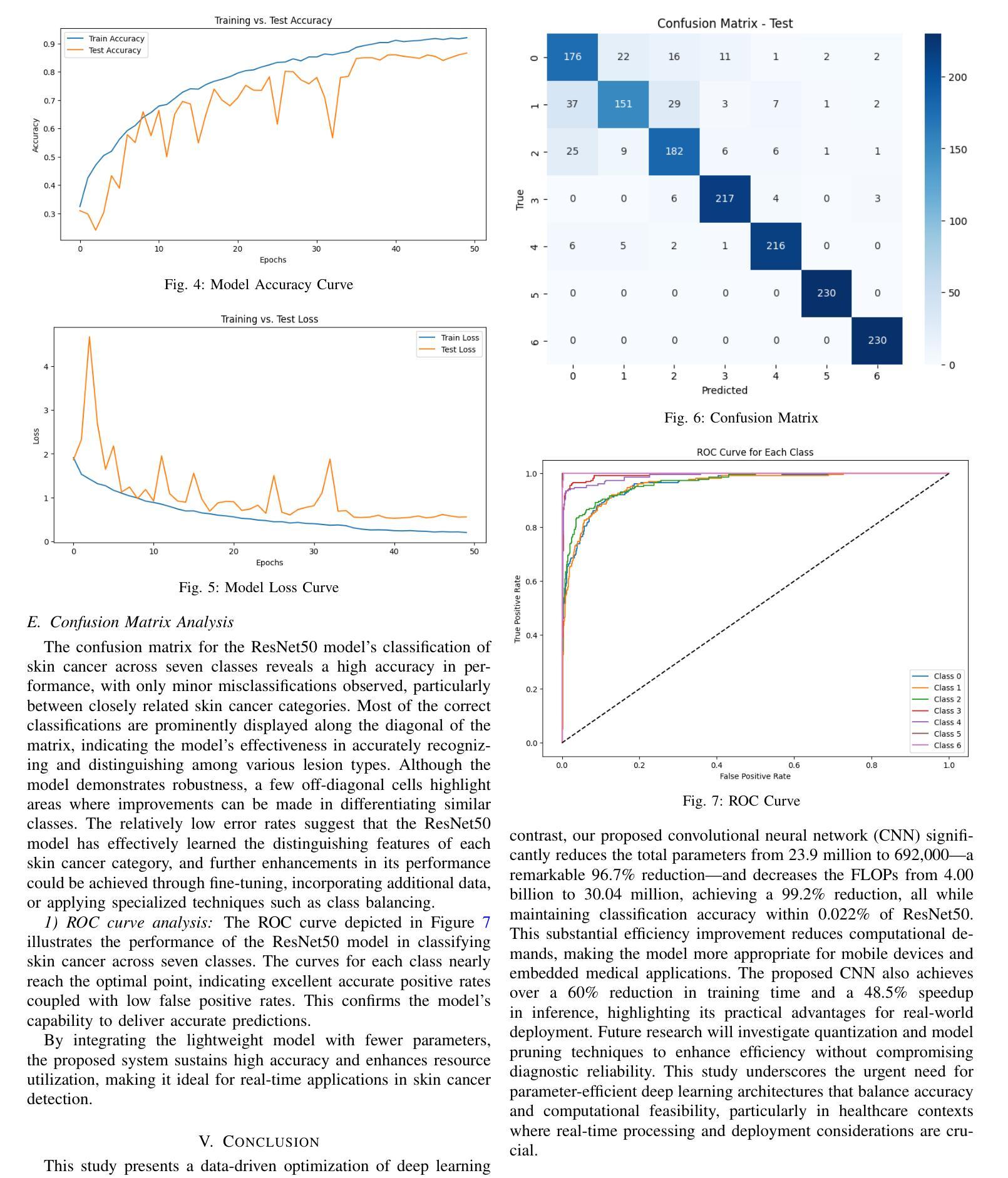
Optimizing Deep Learning for Skin Cancer Classification: A Computationally Efficient CNN with Minimal Accuracy Trade-Off
Authors:Abdullah Al Mamun, Pollob Chandra Ray, Md Rahat Ul Nasib, Akash Das, Jia Uddin, Md Nurul Absur
The rapid advancement of deep learning in medical image analysis has greatly enhanced the accuracy of skin cancer classification. However, current state-of-the-art models, especially those based on transfer learning like ResNet50, come with significant computational overhead, rendering them impractical for deployment in resource-constrained environments. This study proposes a custom CNN model that achieves a 96.7% reduction in parameters (from 23.9 million in ResNet50 to 692,000) while maintaining a classification accuracy deviation of less than 0.022%. Our empirical analysis of the HAM10000 dataset reveals that although transfer learning models provide a marginal accuracy improvement of approximately 0.022%, they result in a staggering 13,216.76% increase in FLOPs, considerably raising computational costs and inference latency. In contrast, our lightweight CNN architecture, which encompasses only 30.04 million FLOPs compared to ResNet50’s 4.00 billion, significantly reduces energy consumption, memory footprint, and inference time. These findings underscore the trade-off between the complexity of deep models and their real-world feasibility, positioning our optimized CNN as a practical solution for mobile and edge-based skin cancer diagnostics.
医学图像分析中的深度学习快速发展大大提高了皮肤癌分类的准确性。然而,目前最先进的模型,尤其是基于迁移学习(如ResNet50)的模型,存在巨大的计算开销,使得它们在资源受限的环境中部署不切实际。本研究提出了一种自定义的CNN模型,在保持分类精度偏差小于0.022%的同时,实现了对参数的96.7%的缩减(从ResNet50中的2390万减少到69万)。我们对HAM10000数据集的经验分析表明,尽管迁移学习模型提供了约0.022%的轻微精度改进,但它们导致浮点运算量(FLOPs)惊人地增加了13216.76%,大大提高了计算成本和推理延迟。相比之下,我们的轻量级CNN架构仅包含3.00亿FLOPs,与ResNet50的4亿相比大幅降低,显著减少了能耗、内存占用和推理时间。这些发现突显了深度模型复杂性与其在现实世界中的可行性之间的权衡,使经过优化的CNN成为移动和边缘计算为基础的皮肤癌诊断的实际解决方案。
论文及项目相关链接
PDF 6 pages, & 7 Images
Summary
深度学习在医学图像分析中的快速发展大大提高了皮肤癌分类的准确性。然而,当前最先进的模型,如基于迁移学习的ResNet50,存在较大的计算开销,不适用于资源受限的环境。本研究提出了一种自定义的CNN模型,在保持分类精度偏差小于0.022%的同时,实现了对ResNet50模型的96.7%的参数缩减。通过对HAM10000数据集的经验分析,发现迁移学习模型虽然只提高了约0.022%的精度,但却导致了FLOPs增加了惊人的13216.76%,大幅增加了计算成本和推理延迟。相反,我们的轻量级CNN架构只包含30.04亿次浮点运算,与ResNet50的40亿次相比,显著减少了能耗、内存占用和推理时间。
Key Takeaways
- 深度学习在医学图像分析领域提高了皮肤癌分类的准确性。
- 当前先进的模型如ResNet50虽然精度高,但在资源受限环境下不适用,存在较大的计算开销。
- 自定义的CNN模型实现了显著参数缩减(96.7%),同时保持较低的分类精度偏差(< 0.022%)。
- 迁移学习模型虽能提高精度,但计算成本高昂,导致FLOPs大幅增加。
- 轻量级CNN架构显著减少能耗、内存占用和推理时间。
- 研究强调了深度模型复杂性与实际可行性之间的权衡。
点此查看论文截图