⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-05-30 更新
Single Domain Generalization for Alzheimer’s Detection from 3D MRIs with Pseudo-Morphological Augmentations and Contrastive Learning
Authors:Zobia Batool, Huseyin Ozkan, Erchan Aptoula
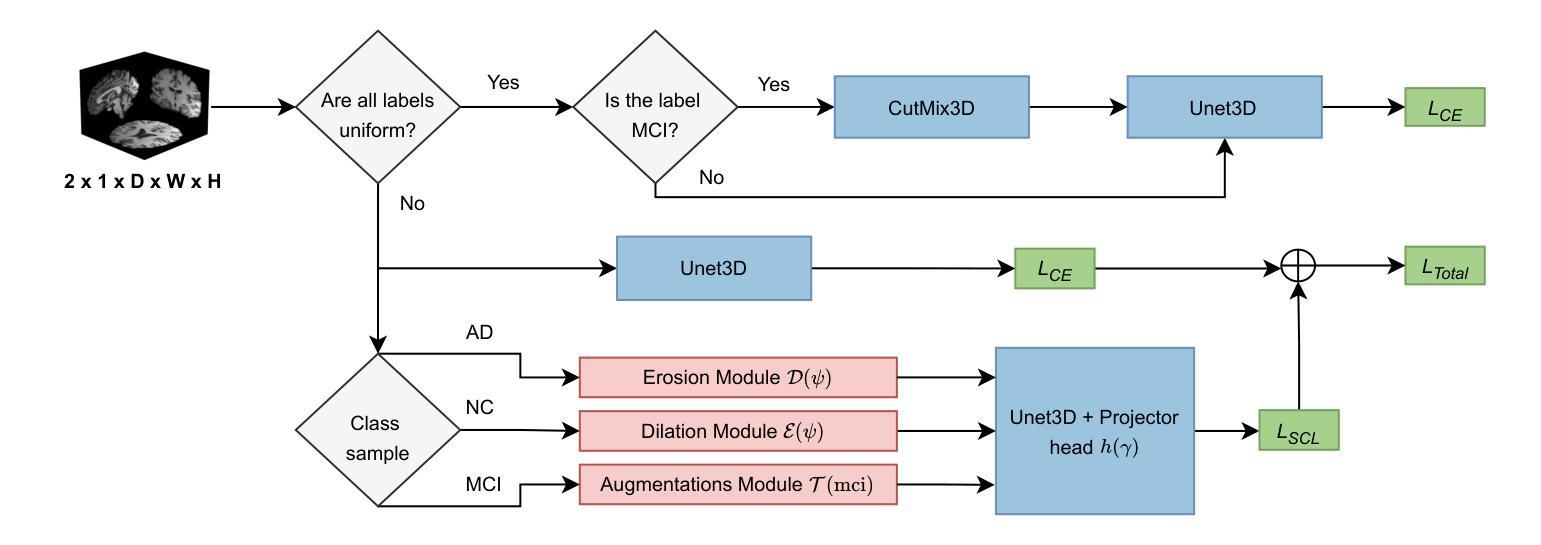
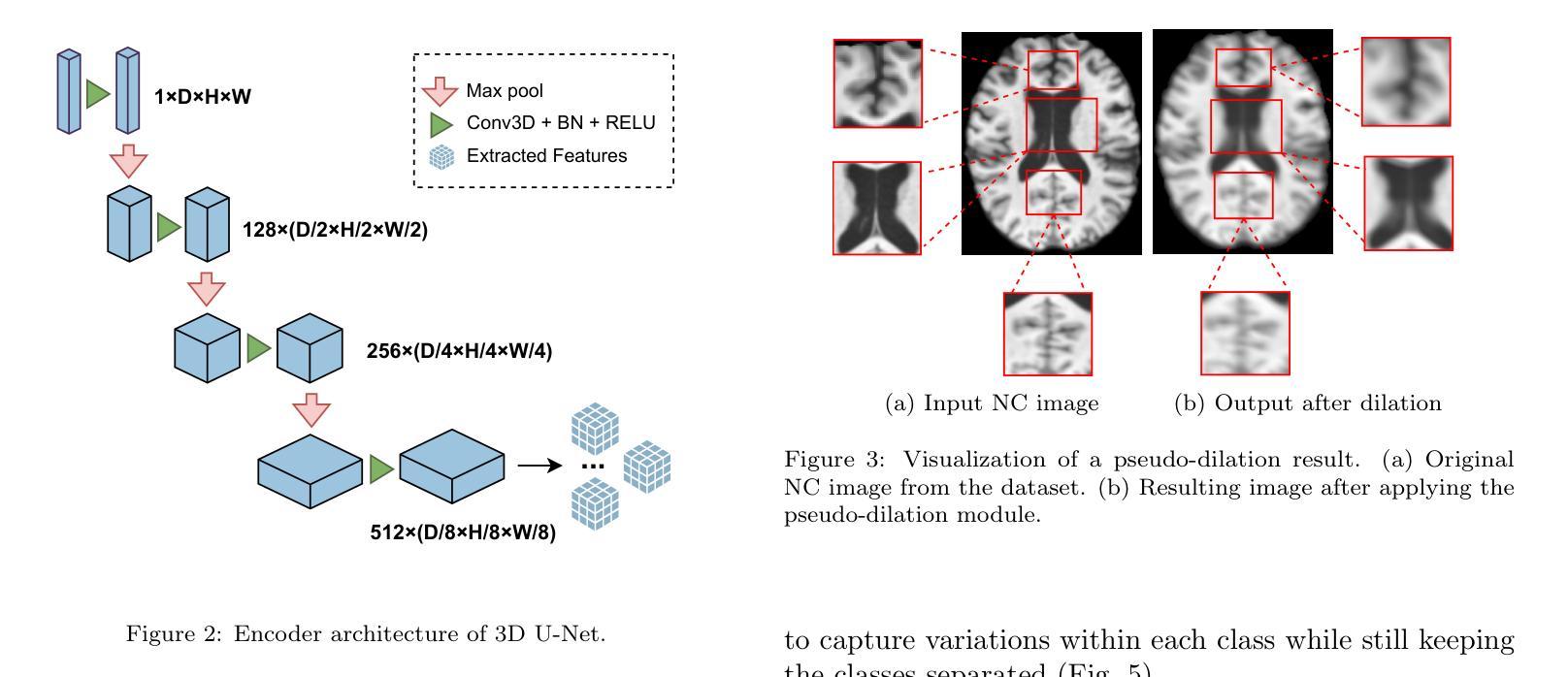
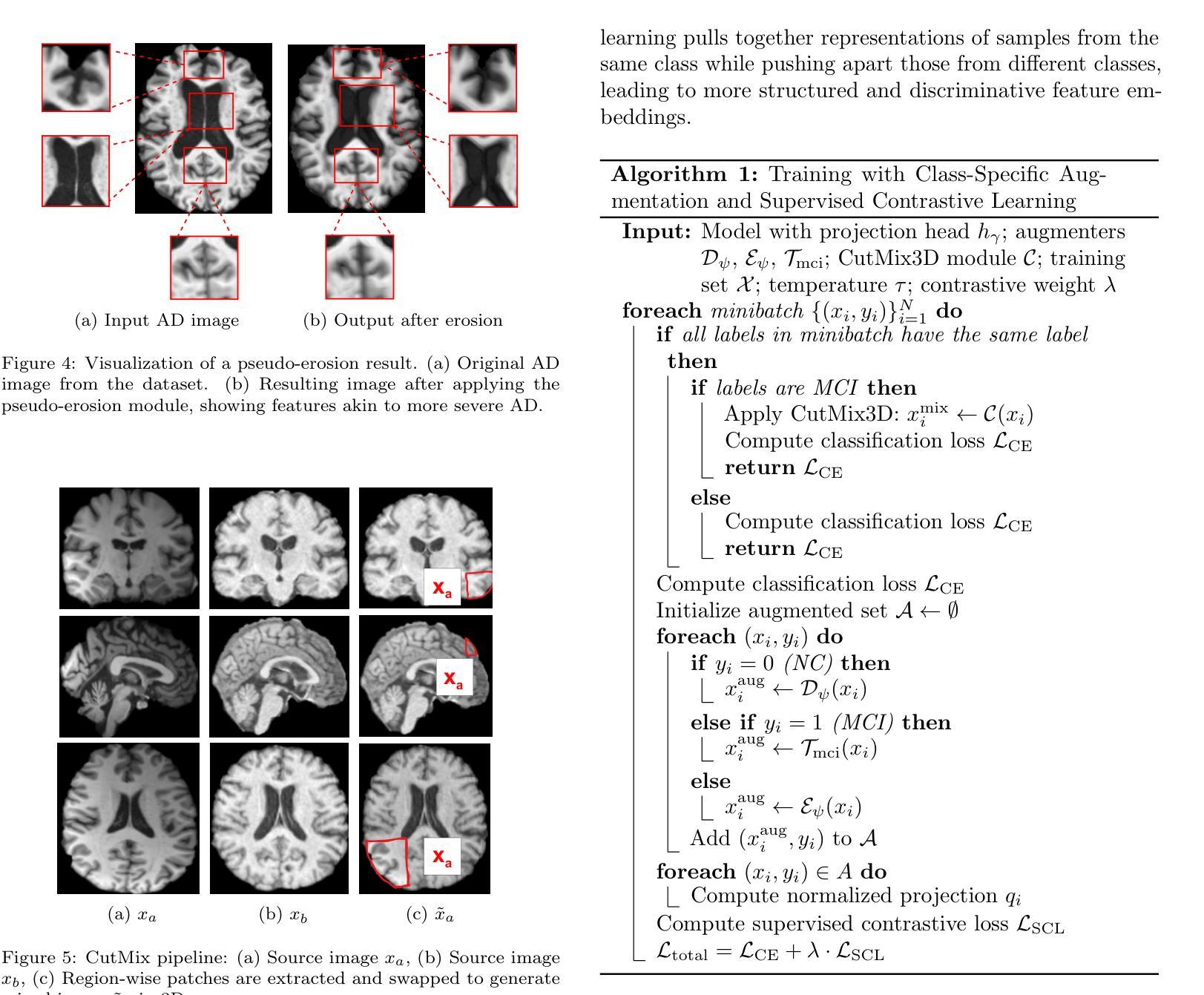
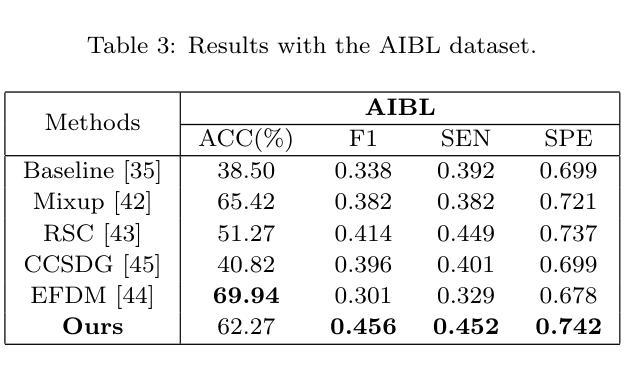
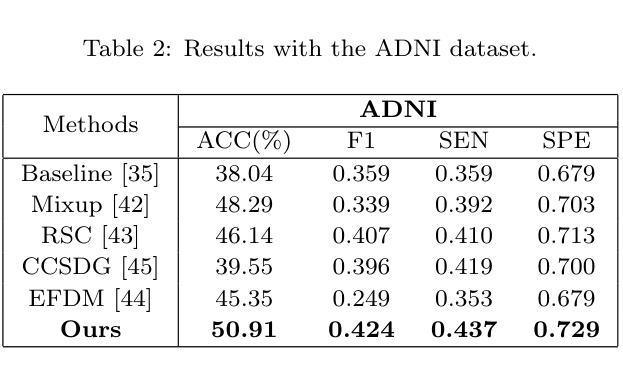
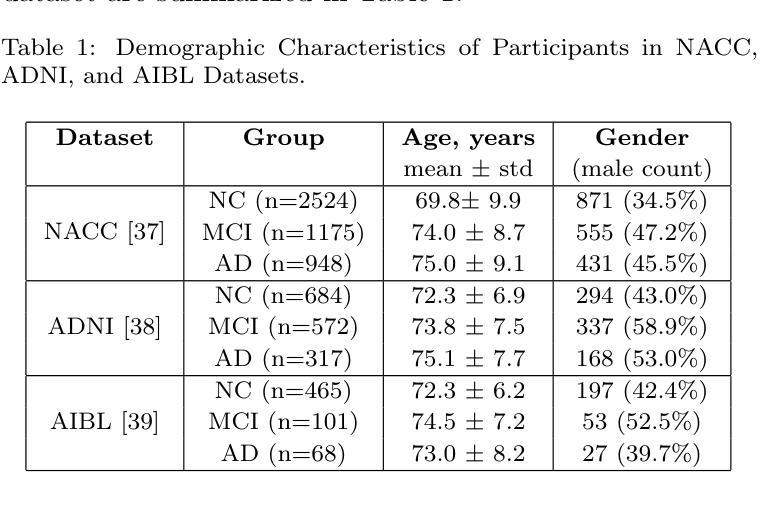
Although Alzheimer’s disease detection via MRIs has advanced significantly thanks to contemporary deep learning models, challenges such as class imbalance, protocol variations, and limited dataset diversity often hinder their generalization capacity. To address this issue, this article focuses on the single domain generalization setting, where given the data of one domain, a model is designed and developed with maximal performance w.r.t. an unseen domain of distinct distribution. Since brain morphology is known to play a crucial role in Alzheimer’s diagnosis, we propose the use of learnable pseudo-morphological modules aimed at producing shape-aware, anatomically meaningful class-specific augmentations in combination with a supervised contrastive learning module to extract robust class-specific representations. Experiments conducted across three datasets show improved performance and generalization capacity, especially under class imbalance and imaging protocol variations. The source code will be made available upon acceptance at https://github.com/zobia111/SDG-Alzheimer.
尽管借助当代深度学习模型,通过核磁共振成像检测阿尔茨海默病已经取得了显著进展,但类别不平衡、协议变化和数据集多样性有限等挑战往往阻碍了其泛化能力。本文专注于单域泛化设置,旨在解决这一问题。在此设置中,给定一个域的数据,设计一个模型以在未知分布域方面实现最佳性能。已知大脑形态在阿尔茨海默病的诊断中起关键作用,因此我们提出使用可学习的伪形态模块来产生形状感知的、解剖结构有意义的类特定增强,并结合监督对比学习模块来提取稳健的类特定表示。在三个数据集上进行的实验表明,特别是在类别不平衡和成像协议变化的情况下,该方法的性能和泛化能力得到了提高。源代码将在接受后发布于:https://github.com/zobia111/SDG-Alzheimer。
论文及项目相关链接
Summary
本文探讨了使用当代深度学习模型通过MRI检测阿尔茨海默病的问题。针对数据集中的类不平衡、协议变化和有限数据集多样性等挑战,文章关注单一域泛化设置,提出使用可学习的伪形态模块来生成形状感知、解剖有意义的类特定增强,结合监督对比学习模块,以提取稳健的类特定表示。实验表明,该方法在三个数据集上的性能有所提升,特别是在类不平衡和成像协议变化的情况下具有较好的泛化能力。
Key Takeaways
- 文章主要探讨当代深度学习模型在MRI检测阿尔茨海默病上的运用及其面临的挑战。
- 针对数据集中的类不平衡、协议变化和有限数据集多样性等问题,文章提出了单一域泛化设置的概念。
- 提出使用可学习的伪形态模块来生成形状感知、解剖有意义的类特定增强。
- 结合监督对比学习模块,以提取稳健的类特定表示,提高模型的泛化能力。
- 实验结果显示,该方法在三个数据集上的性能有所提升。
- 该方法尤其在处理类不平衡和成像协议变化的情况下展现出较好的泛化能力。
点此查看论文截图

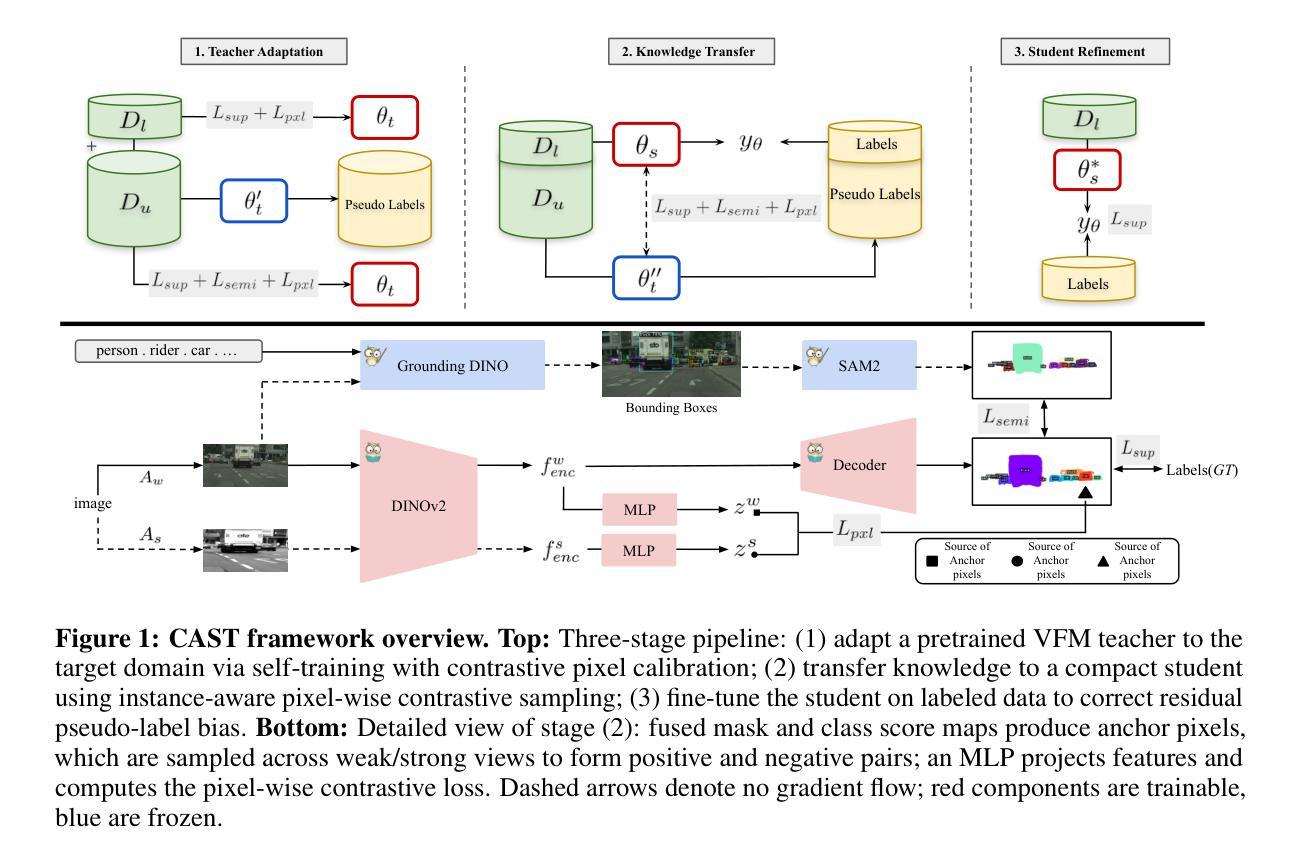
CAST: Contrastive Adaptation and Distillation for Semi-Supervised Instance Segmentation
Authors:Pardis Taghavi, Tian Liu, Renjie Li, Reza Langari, Zhengzhong Tu
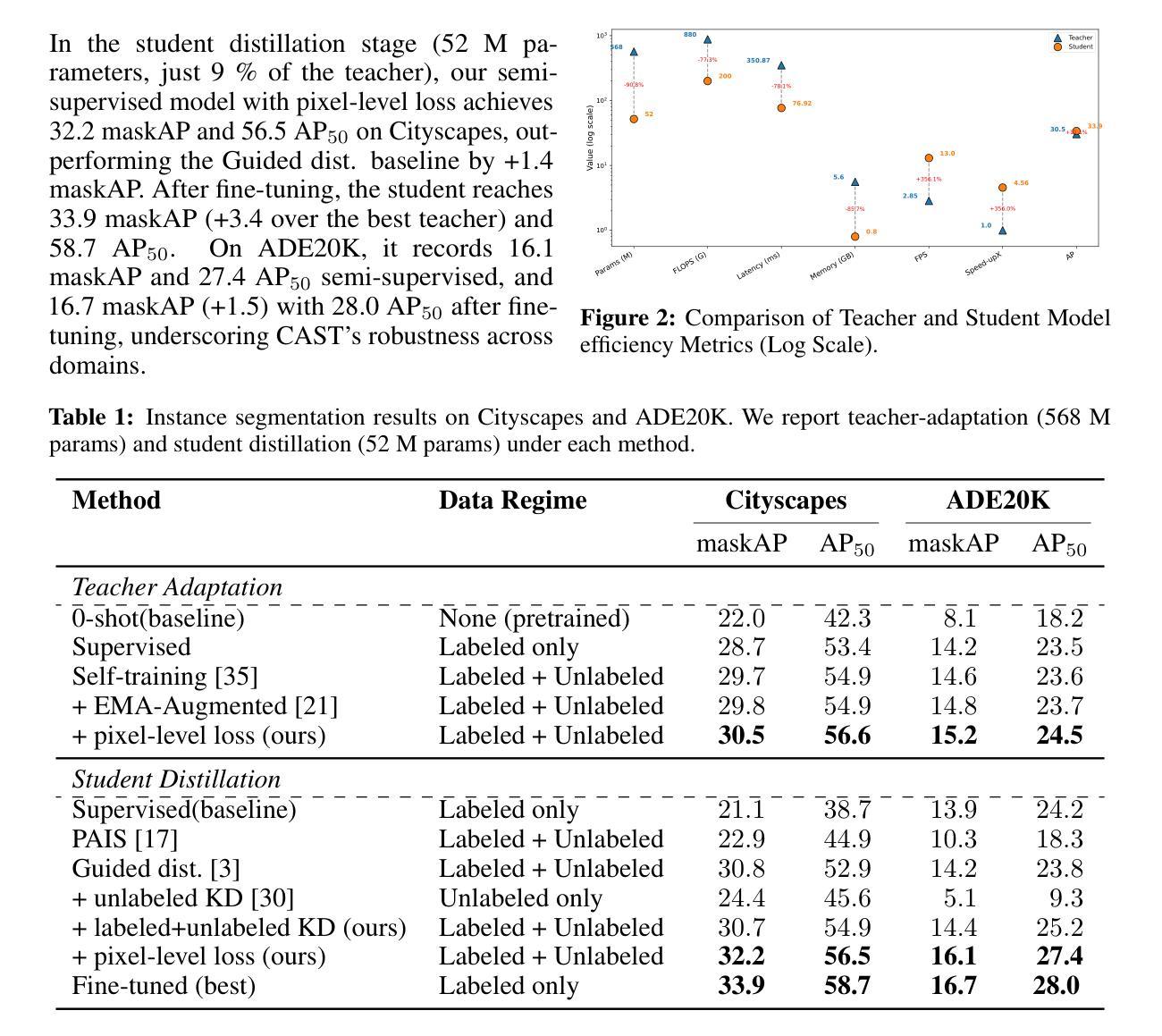
Instance segmentation demands costly per-pixel annotations and large models. We introduce CAST, a semi-supervised knowledge distillation (SSKD) framework that compresses pretrained vision foundation models (VFM) into compact experts using limited labeled and abundant unlabeled data. CAST unfolds in three stages: (1) domain adaptation of the VFM teacher(s) via self-training with contrastive pixel calibration, (2) distillation into a compact student via a unified multi-objective loss that couples standard supervision and pseudo-labels with our instance-aware pixel-wise contrastive term, and (3) fine-tuning on labeled data to remove residual pseudo-label bias. Central to CAST is an \emph{instance-aware pixel-wise contrastive loss} that fuses mask and class scores to mine informative negatives and enforce clear inter-instance margins. By maintaining this contrastive signal across both adaptation and distillation, we align teacher and student embeddings and fully leverage unlabeled images. On Cityscapes and ADE20K, our ~11X smaller student surpasses its adapted VFM teacher(s) by +3.4 AP (33.9 vs. 30.5) and +1.5 AP (16.7 vs. 15.2) and outperforms state-of-the-art semi-supervised approaches.
实例分割需要昂贵的逐像素标注和大型模型。我们引入了CAST,这是一种半监督知识蒸馏(SSKD)框架,它使用有限的标记数据和大量的无标记数据来压缩预训练的视觉基础模型(VFM)成为紧凑的专家模型。CAST分为三个阶段:(1)通过对比像素校准进行自我训练,对VFM教师进行域适应;(2)通过统一的多目标损失进行蒸馏,将标准监督和伪标签与我们的实例感知像素级对比项相结合,形成紧凑的学生模型;(3)在标记数据上进行微调,以消除剩余的伪标签偏见。CAST的核心是实例感知像素级对比损失,它融合掩膜和类分数来挖掘信息性负样本并强制明确的实例间边界。通过在整个适应和蒸馏过程中保持这种对比信号,我们对齐教师模型和学生模型的嵌入,并充分利用无标签图像。在Cityscapes和ADE20K上,我们较小的学生模型(约缩小了11倍)超过了其适应的VFM教师模型(+3.4 AP(33.9 vs. 30.5)和+1.5 AP(16.7 vs. 对比领先目前最先进的半监督方法。我们的方法显示出在半监督学习领域实现高性能实例分割的巨大潜力。
论文及项目相关链接
摘要
本研究引入了一种基于半监督知识蒸馏(SSKD)的压缩框架CAST,该框架利用有限的标签数据和大量的无标签数据将预训练的视觉基础模型(VFM)压缩成紧凑的专家模型,用于实例分割。CAST分为三个阶段:1)通过对比像素校准对VFM教师进行域自适应自训练,2)通过统一的多目标损失函数对紧凑学生进行蒸馏,该损失函数结合了标准监督和伪标签以及实例感知像素级的对比术语,3)在标记数据上进行微调以消除剩余的伪标签偏见。CAST的核心是实例感知像素级的对比损失,它通过融合掩膜和类分数来挖掘信息中的负面样本并强制实施清晰的实例间边界。通过在整个适应和蒸馏过程中保持对比信号,我们使教师和学生嵌入对齐并充分利用无标签图像。在Cityscapes和ADE20K上,我们较小的学生模型(约为教师的1/11大小)在适应性方面超过了其VFM教师,并超越了最新的半监督方法。
关键见解
- CAST是一种半监督知识蒸馏框架,旨在压缩预训练视觉基础模型(VFM)。
- CAST框架结合了标注和未标注的数据,以更小的模型实现了实例分割的优异性能。
- CAST通过三个主要阶段实现:教师模型的域自适应、学生模型的蒸馏以及微调以消除伪标签的偏见。
- CAST的核心是实例感知像素级的对比损失,它通过结合掩膜和类分数以增强模型的性能。
- 对比信号在整个适应和蒸馏过程中得到保持,以确保教师和学生嵌入的对齐。
点此查看论文截图