⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-05-30 更新
Deep Video Discovery: Agentic Search with Tool Use for Long-form Video Understanding
Authors:Xiaoyi Zhang, Zhaoyang Jia, Zongyu Guo, Jiahao Li, Bin Li, Houqiang Li, Yan Lu
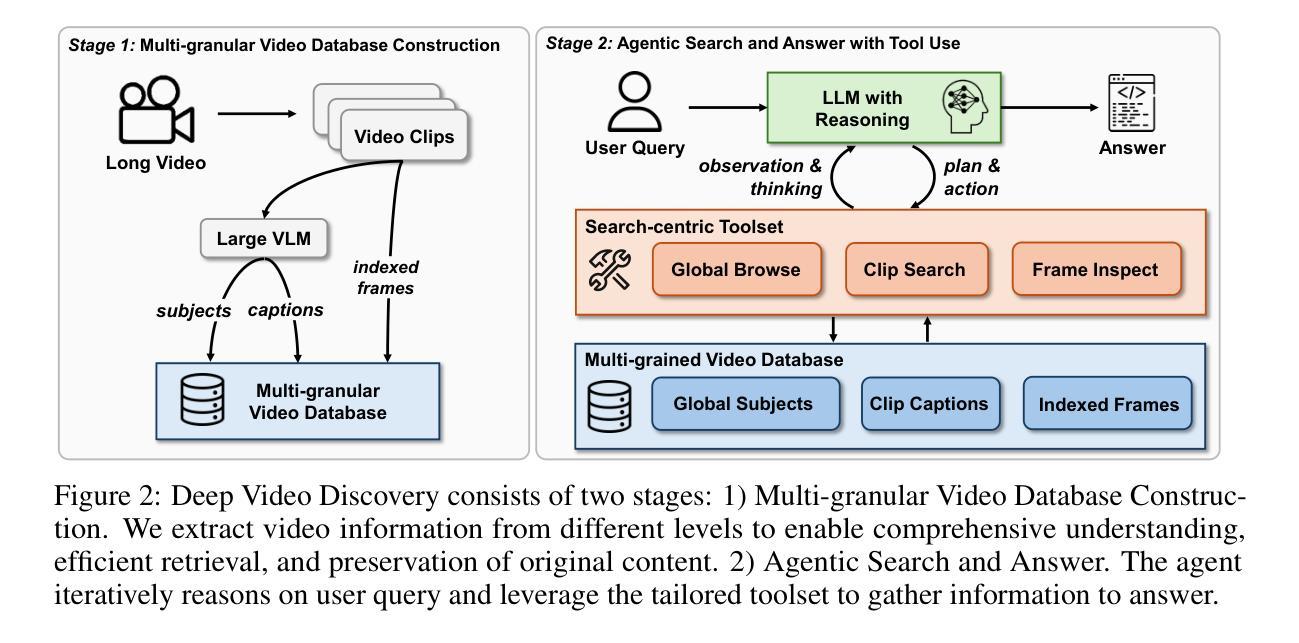
Long-form video understanding presents significant challenges due to extensive temporal-spatial complexity and the difficulty of question answering under such extended contexts. While Large Language Models (LLMs) have demonstrated considerable advancements in video analysis capabilities and long context handling, they continue to exhibit limitations when processing information-dense hour-long videos. To overcome such limitations, we propose the Deep Video Discovery agent to leverage an agentic search strategy over segmented video clips. Different from previous video agents manually designing a rigid workflow, our approach emphasizes the autonomous nature of agents. By providing a set of search-centric tools on multi-granular video database, our DVD agent leverages the advanced reasoning capability of LLM to plan on its current observation state, strategically selects tools, formulates appropriate parameters for actions, and iteratively refines its internal reasoning in light of the gathered information. We perform comprehensive evaluation on multiple long video understanding benchmarks that demonstrates the advantage of the entire system design. Our DVD agent achieves SOTA performance, significantly surpassing prior works by a large margin on the challenging LVBench dataset. Comprehensive ablation studies and in-depth tool analyses are also provided, yielding insights to further advance intelligent agents tailored for long-form video understanding tasks. The code will be released later.
长视频理解面临着巨大的挑战,这主要是因为存在大量的时空复杂性,以及在如此扩展的上下文中进行问答的困难。虽然大型语言模型(LLM)在视频分析能力和长文本处理能力方面取得了显著的进步,但在处理信息密集的一小时长的视频时,它们仍然表现出局限性。为了克服这些局限性,我们提出了深度视频发现代理(DVD agent),采用基于分割的视频片段的代理搜索策略。不同于之前手动设计刚性工作流程的视频代理,我们的方法强调代理的自主性。通过在多粒度视频数据库上提供一系列以搜索为中心的工具,DVD代理利用LLM的高级推理能力来规划其当前观察状态,策略性地选择工具,制定行动参数,并根据收集的信息迭代优化其内部推理。我们在多个长视频理解基准测试上对系统进行了全面评估,证明了整个系统设计的优势。我们的DVD代理达到了最先进的性能,在具有挑战性的LVBench数据集上大幅度超越了以前的工作。我们还提供了全面的消融研究和深入的工具分析,为针对长视频理解任务量身定制的智能代理的进一步发展提供了见解。代码将在稍后发布。
论文及项目相关链接
PDF V2 draft. Under review
Summary
长视频理解面临巨大的挑战,包括处理大量时空复杂性和在长时间背景下进行问答的困难。尽管大型语言模型(LLM)在视频分析能力和处理长文本方面取得了显著进展,但在处理信息密集的一小时长视频时仍存在局限性。为解决这些问题,我们提出了深度视频发现代理(DVD agent),采用代理搜索策略对分割的视频片段进行处理。我们的方法与以往手动设计刚性工作流程的视频代理不同,更加注重代理的自主性。在多个长视频理解基准测试上进行的全面评估表明,整个系统设计的优势。我们的DVD代理实现了卓越的性能,在具有挑战性的LVBench数据集上大大超越了以前的工作。此外,我们还提供了全面的消融研究和深入的工具分析,为针对长视频理解任务进一步改进智能代理提供了见解。代码将随后发布。
Key Takeaways
- 长视频理解面临时空复杂性和问答困难等挑战。
- 大型语言模型(LLM)在处理信息密集的一小时长视频时存在局限性。
- 深度视频发现代理(DVD agent)采用代理搜索策略处理分割的视频片段,强调自主性。
- DVD代理在多个长视频理解基准测试上表现优越,特别是在LVBench数据集上。
- DVD代理通过战略性选择工具、制定行动参数并依据获取的信息进行内部推理的迭代优化来克服LLM的局限性。
- 全面的消融研究和工具分析为进一步改进针对长视频理解任务的智能代理提供了有价值的见解。
点此查看论文截图


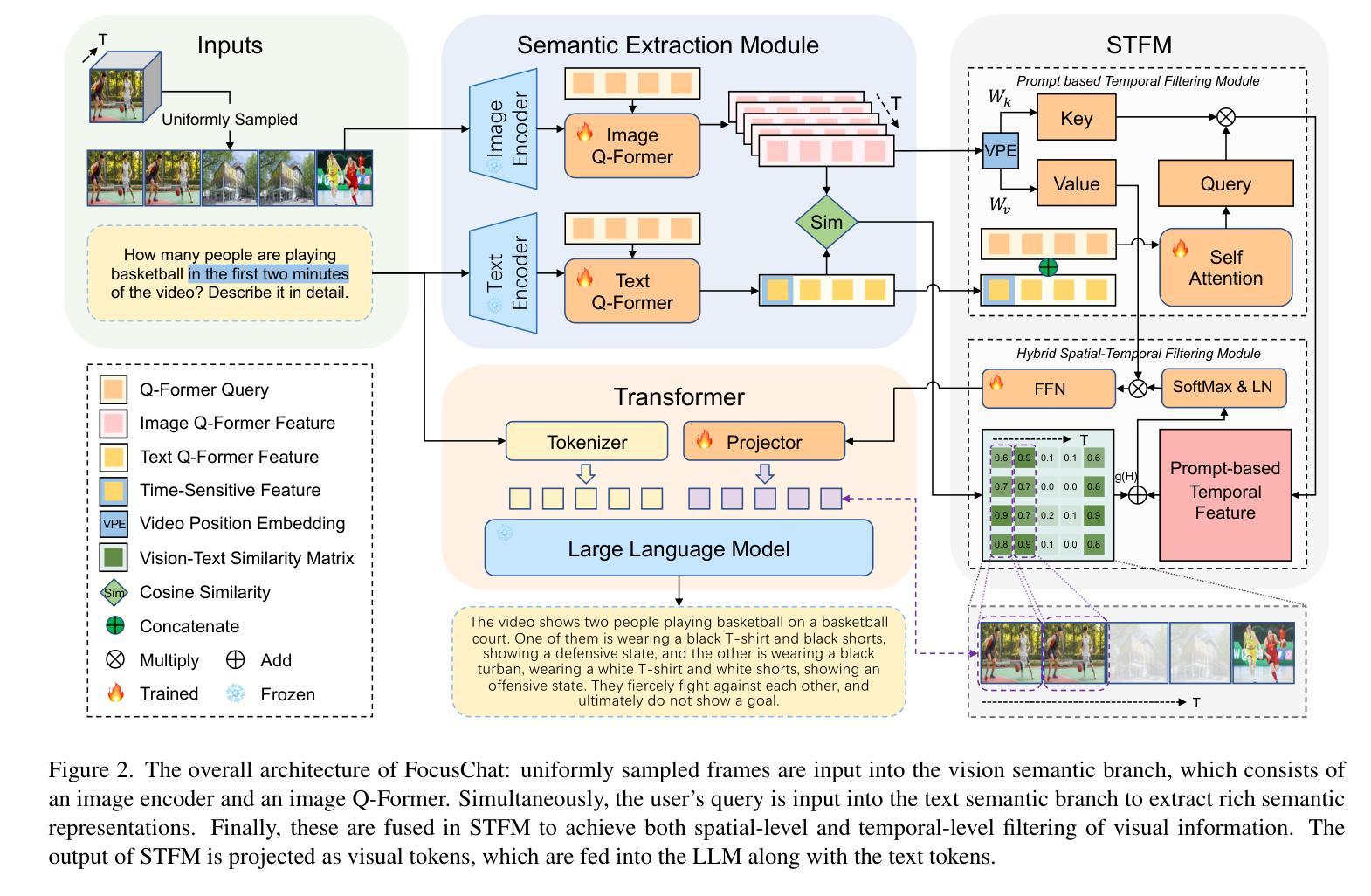
FocusChat: Text-guided Long Video Understanding via Spatiotemporal Information Filtering
Authors:Zheng Cheng, Rendong Wang, Zhicheng Wang
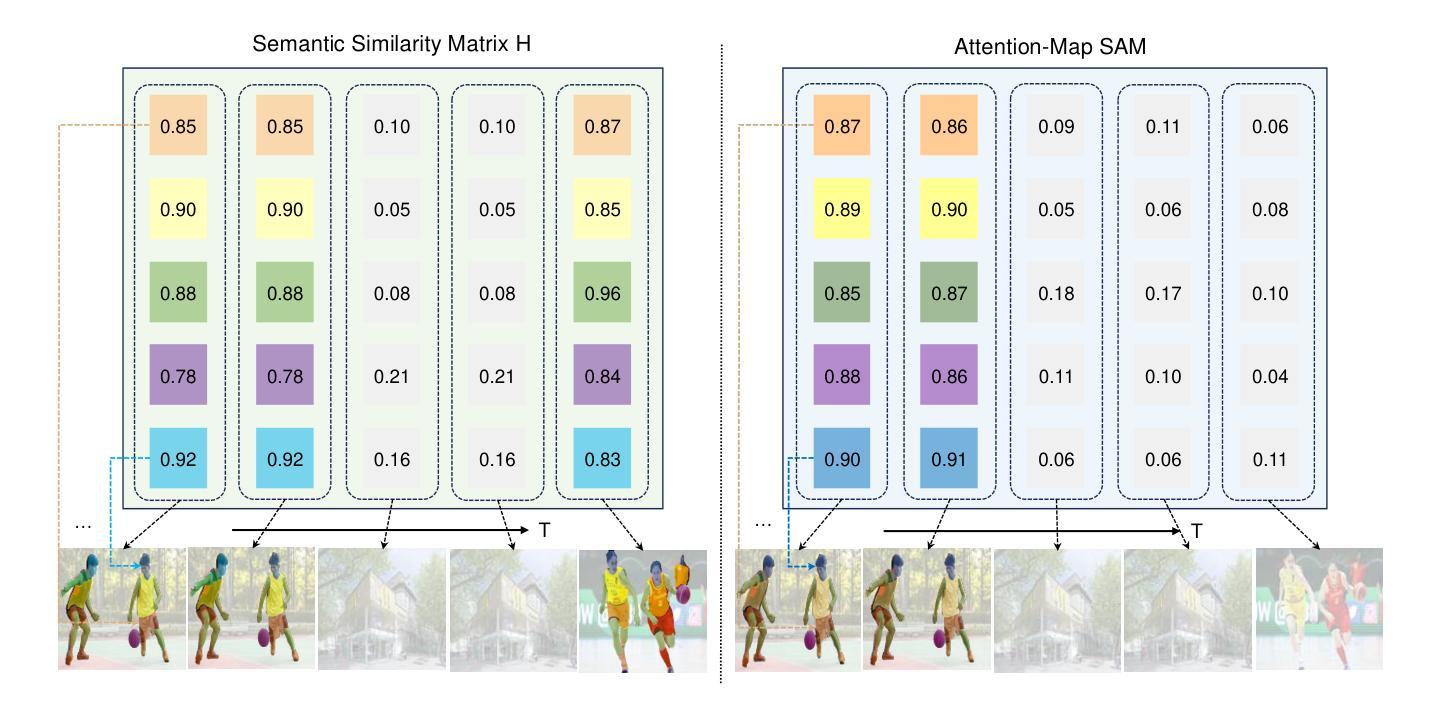
Recently, multi-modal large language models have made significant progress. However, visual information lacking of guidance from the user’s intention may lead to redundant computation and involve unnecessary visual noise, especially in long, untrimmed videos. To address this issue, we propose FocusChat, a text-guided multi-modal large language model (LLM) that emphasizes visual information correlated to the user’s prompt. In detail, Our model first undergoes the semantic extraction module, which comprises a visual semantic branch and a text semantic branch to extract image and text semantics, respectively. The two branches are combined using the Spatial-Temporal Filtering Module (STFM). STFM enables explicit spatial-level information filtering and implicit temporal-level feature filtering, ensuring that the visual tokens are closely aligned with the user’s query. It lowers the essential number of visual tokens inputted into the LLM. FocusChat significantly outperforms Video-LLaMA in zero-shot experiments, using an order of magnitude less training data with only 16 visual tokens occupied. It achieves results comparable to the state-of-the-art in few-shot experiments, with only 0.72M pre-training data.
近期,多模态大型语言模型取得了显著进展。然而,由于缺乏用户意图的指导,视觉信息可能导致冗余计算并引入不必要的视觉噪音,特别是在长而无剪辑的视频中。为了解决这一问题,我们提出了FocusChat,这是一种文本引导的多模态大型语言模型(LLM),它强调与用户提示相关的视觉信息。具体来说,我们的模型首先经过语义提取模块,该模块包括视觉语义分支和文本语义分支,分别提取图像和文本语义。这两个分支通过时空滤波模块(STFM)进行组合。STFM实现了明确的空间级信息滤波和隐式的时态级特征滤波,确保视觉令牌与用户查询紧密对齐。它降低了输入到LLM中的必要视觉令牌数量。FocusChat在零样本实验中显著优于Video-LLaMA,使用数量级较少的训练数据,仅占用16个视觉令牌。在少量样本实验中,它达到了与最新技术相当的结果,仅有0.72M预训练数据。
论文及项目相关链接
PDF 11 pages, 4 figures
Summary
多媒体大语言模型取得了重要进展,但在处理长视频时仍存在冗余计算和视觉噪声问题。为解决这一问题,本文提出了FocusChat模型,该模型通过文本指导的方式强调与用户提示相关的视觉信息。FocusChat模型通过语义提取模块和空间时间过滤模块实现视觉和文本信息的融合,确保视觉标记与用户查询紧密对齐,减少输入到语言模型的视觉标记数量。在零样本实验中,FocusChat显著优于Video-LLaMA模型,且使用较少的训练数据即可达到相近的效果。
Key Takeaways
- 多模态大语言模型在处理长视频时面临冗余计算和视觉噪声问题。
- FocusChat模型是一种文本指导的多模态大语言模型,强调与用户意图相关的视觉信息。
- FocusChat模型通过语义提取模块提取图像和文本语义,并结合空间时间过滤模块实现视觉和文本信息的融合。
- 该模型能够实现明确的空域级别信息过滤和隐性的时态级别特征过滤,确保视觉标记与用户查询对齐。
- FocusChat模型减少了输入到语言模型的视觉标记数量。
- 在零样本实验中,FocusChat模型显著优于Video-LLaMA模型。
点此查看论文截图