⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-05-30 更新
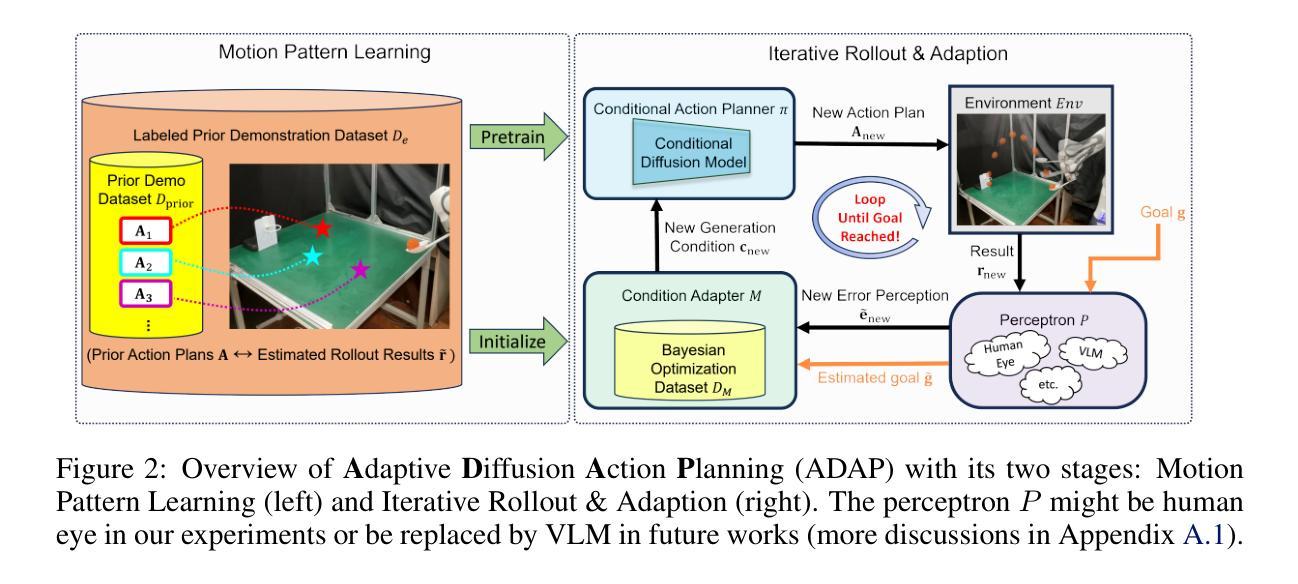
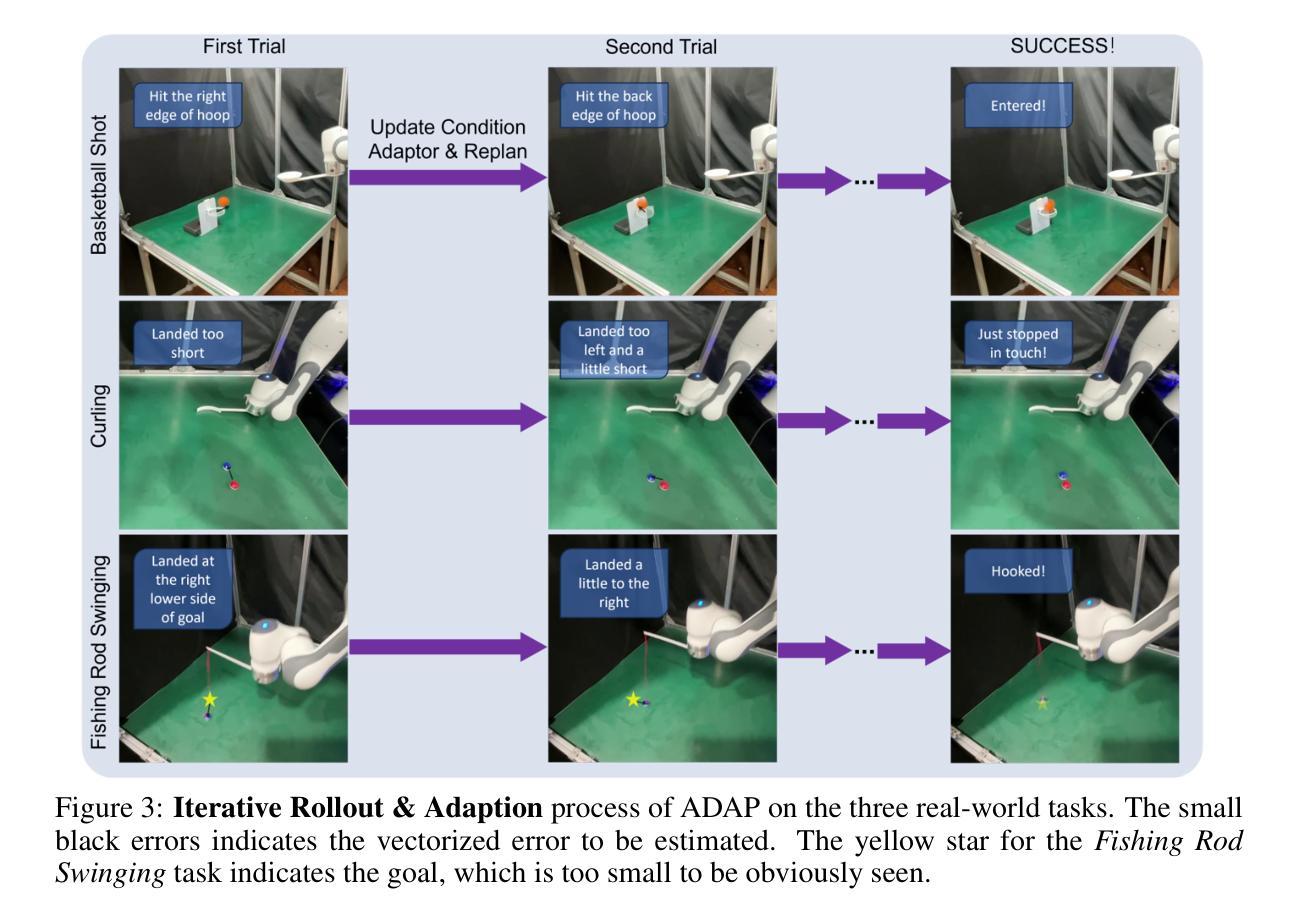
Mastering Agile Tasks with Limited Trials
Authors:Yihang Hu, Pingyue Sheng, Shengjie Wang, Yang Gao
Embodied robots nowadays can already handle many real-world manipulation tasks. However, certain other real-world tasks (e.g., shooting a basketball into a hoop) are highly agile and require high execution precision, presenting additional challenges for methods primarily designed for quasi-static manipulation tasks. This leads to increased efforts in costly data collection, laborious reward design, or complex motion planning. Such tasks, however, are far less challenging for humans. Say a novice basketball player typically needs only $\sim$10 attempts to make their first successful shot, by roughly imitating a motion prior and then iteratively adjusting their motion based on the past outcomes. Inspired by this human learning paradigm, we propose the Adaptive Diffusion Action Plannin (ADAP) algorithm, a simple & scalable approach which iteratively refines its action plan by few real-world trials within a learned prior motion pattern, until reaching a specific goal. Experiments demonstrated that ADAP can learn and accomplish a wide range of goal-conditioned agile dynamic tasks with human-level precision and efficiency directly in real-world, such as throwing a basketball into the hoop in fewer than 10 trials. Project website:https://adap-robotics.github.io/ .
现今,嵌入式机器人已经能够处理许多现实世界的操作任务。然而,某些其他现实世界的任务(例如,将篮球投进篮筐)高度敏捷且需要高精度的执行,对于主要为静态操纵任务设计的方法而言,这些任务带来了额外的挑战。这导致了成本高昂的数据收集、繁琐的奖励设计和复杂的运动规划工作量的增加。然而,对于人类来说,这样的任务并不那么具有挑战性。例如,新手篮球运动员通常需要大约十次尝试才能打出第一个成功的投篮,通过大致模仿之前的动作并不断根据过去的结果调整动作。受人类学习模式的启发,我们提出了自适应扩散动作规划(ADAP)算法,这是一种简单且可扩展的方法,通过在少数现实世界的试验中学习到的先前动作模式来迭代优化行动计划,直至达到特定目标。实验表明,ADAP能够在现实世界中直接学习和完成一系列目标导向的敏捷动态任务,达到人类水平的精度和效率,如在不到十次的尝试中将篮球投进篮筐。项目网站:[https://adap-robotics.github.io/] 。
论文及项目相关链接
Summary
本文介绍了自适应扩散动作规划(ADAP)算法,该算法通过模仿人类学习模式实现机器人的高效动态任务执行。在少量真实世界尝试中,机器人能迭代优化动作计划以达到特定目标,完成一系列目标导向的敏捷动态任务,如投篮等,并实现人类级别的精度和效率。
Key Takeaways
- 机器人处理现实世界的操作任务已具有相当能力,但对于需要高敏捷度和高精度的任务仍存在挑战。
- 人类学习新任务(如篮球投篮)通常通过模仿初步动作并基于过去的结果进行迭代调整,机器人可借鉴此模式。
- ADAP算法允许机器人在少量真实世界尝试中迭代优化动作计划,达成特定目标。
- ADAP算法可广泛应用于各种目标导向的敏捷动态任务。
- ADAP算法使得机器人能在真实世界中直接学习并执行任务,具有人类级别的精度和效率。
- 该算法通过简单且可扩展的方式实现机器人动作的精细化调整,提高了机器人的实用性。
点此查看论文截图



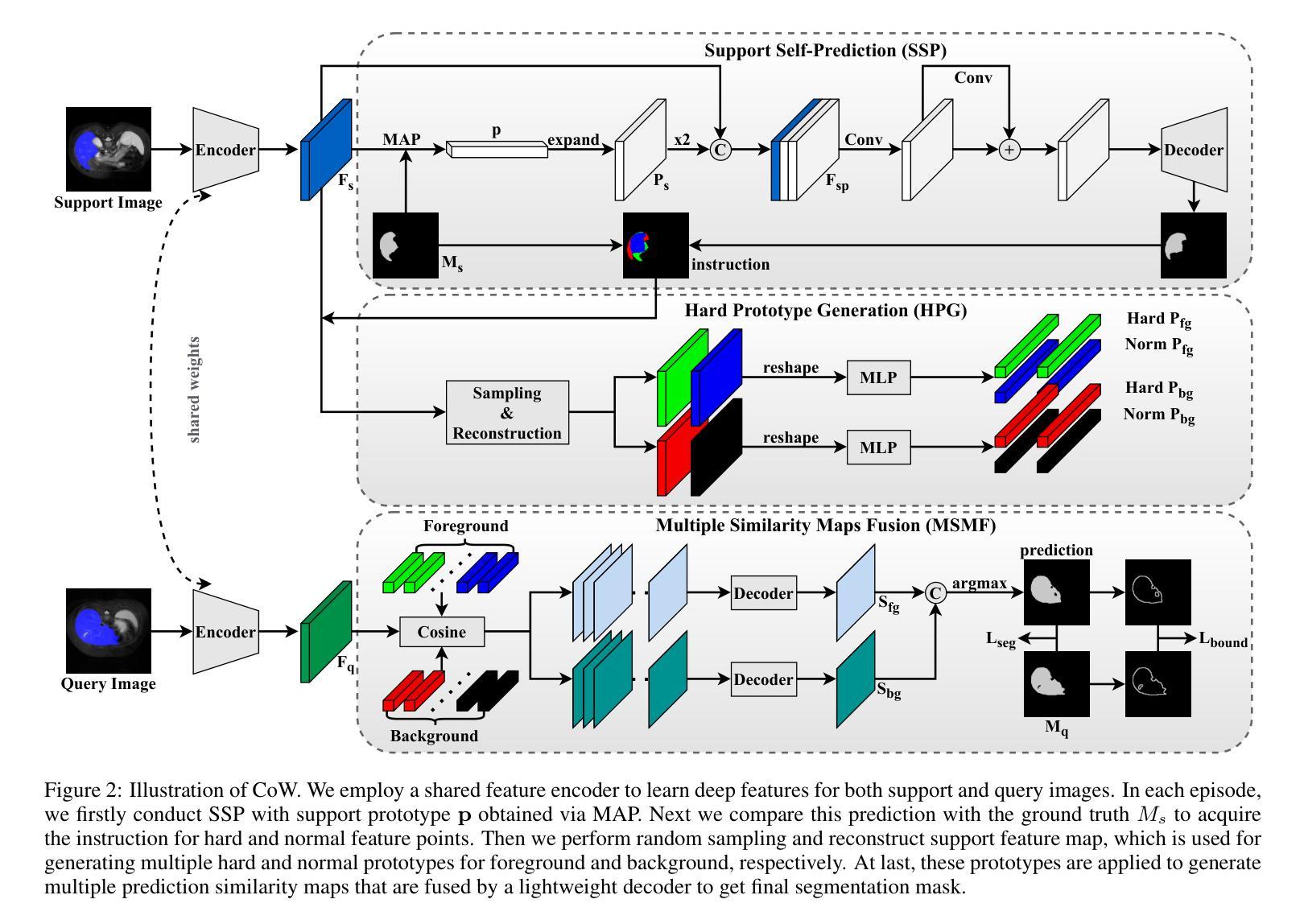
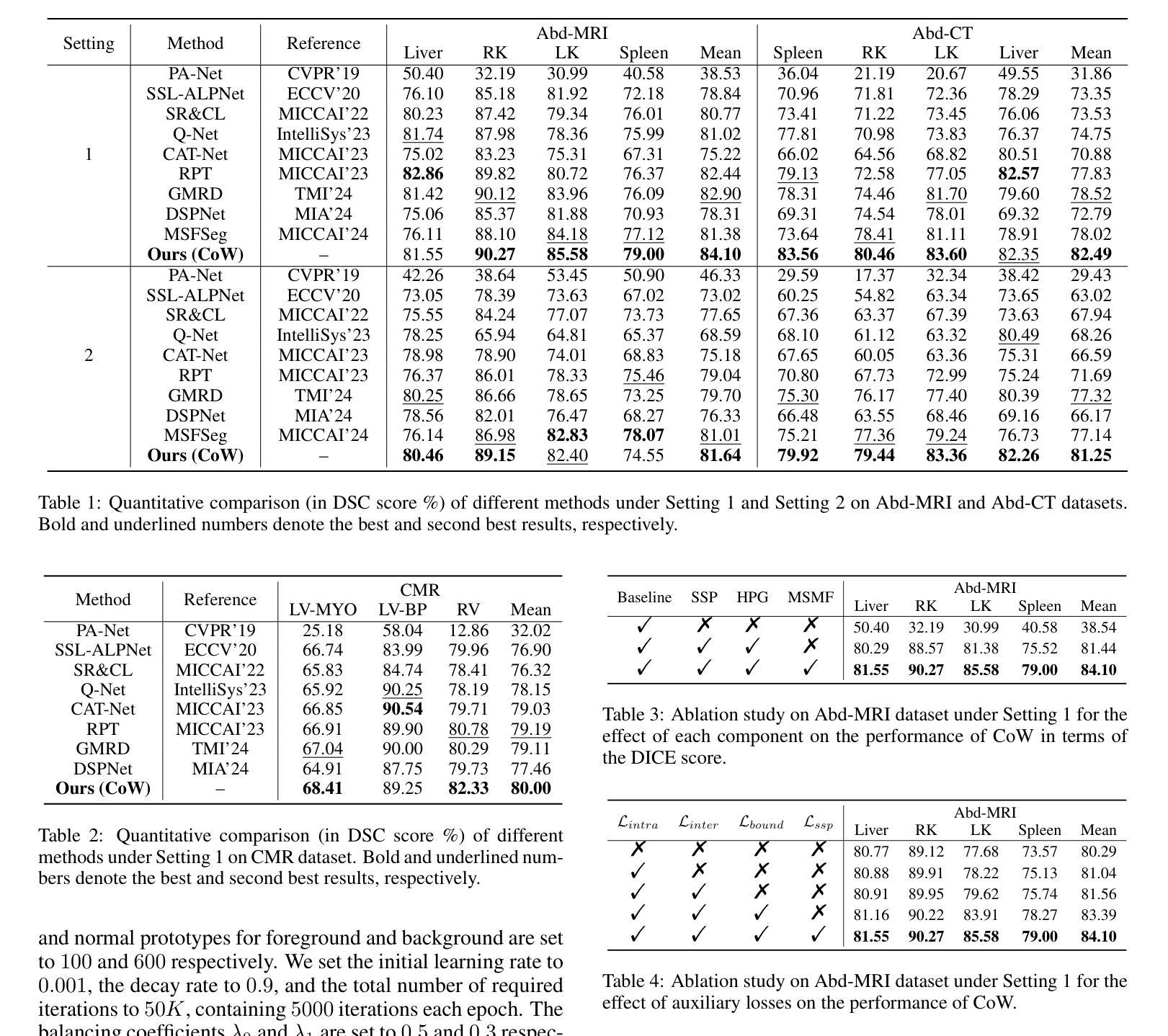
Concentrate on Weakness: Mining Hard Prototypes for Few-Shot Medical Image Segmentation
Authors:Jianchao Jiang, Haofeng Zhang
Few-Shot Medical Image Segmentation (FSMIS) has been widely used to train a model that can perform segmentation from only a few annotated images. However, most existing prototype-based FSMIS methods generate multiple prototypes from the support image solely by random sampling or local averaging, which can cause particularly severe boundary blurring due to the tendency for normal features accounting for the majority of features of a specific category. Consequently, we propose to focus more attention to those weaker features that are crucial for clear segmentation boundary. Specifically, we design a Support Self-Prediction (SSP) module to identify such weak features by comparing true support mask with one predicted by global support prototype. Then, a Hard Prototypes Generation (HPG) module is employed to generate multiple hard prototypes based on these weak features. Subsequently, a Multiple Similarity Maps Fusion (MSMF) module is devised to generate final segmenting mask in a dual-path fashion to mitigate the imbalance between foreground and background in medical images. Furthermore, we introduce a boundary loss to further constraint the edge of segmentation. Extensive experiments on three publicly available medical image datasets demonstrate that our method achieves state-of-the-art performance. Code is available at https://github.com/jcjiang99/CoW.
小样本医学图像分割(FSMIS)已被广泛应用于训练仅从少量标注图像中执行分割的模型。然而,大多数现有的基于原型的FSMIS方法仅通过随机抽样或局部平均从支持图像中生成多个原型,这可能导致边界模糊特别严重,因为正常特征往往构成某一特定类别的主要特征。因此,我们提议更多地关注那些对于清晰分割边界至关重要的较弱特征。具体来说,我们设计了一个支持自我预测(SSP)模块,通过比较真实的支持掩膜与全局支持原型预测的掩膜来识别这些弱特征。然后,采用硬原型生成(HPG)模块基于这些弱特征生成多个硬原型。随后,采用多相似度图融合(MSMF)模块以双路径方式生成最终的分割掩膜,以缓解医学图像中前景和背景之间的不平衡。此外,我们引入了一种边界损失来进一步约束分割的边缘。在三个公开的医学图像数据集上的大量实验表明,我们的方法达到了最先进的性能。代码可通过以下链接获取:https://github.com/jcjiang99/CoW。
论文及项目相关链接
PDF 12 pages, 9 figures, 9 tables, accepted by IJCAI 2025
Summary
少数样本医学图像分割(FSMIS)方法广泛应用于训练模型,仅从少量标注图像中执行分割任务。现有原型方法主要从支持图像中生成多个原型,但可能导致边界模糊。本文提出关注关键弱特征以明确分割边界,设计支持自我预测(SSP)模块识别弱特征,并采用硬原型生成(HPG)模块生成多个硬原型。此外,采用多重相似图融合(MSMF)模块生成最终分割掩膜,并引入边界损失以进一步约束分割边缘。在三个公开医学图像数据集上的实验表明,该方法达到领先水平。
Key Takeaways
- 少数样本医学图像分割(FSMIS)是训练模型进行分割的有效方法,仅需少量标注图像。
- 现有原型方法主要通过随机采样或局部平均从支持图像中生成多个原型,可能导致边界模糊。
- 本文强调关注关键弱特征以明确分割边界,设计SSP模块识别这些特征。
- 采用HPG模块生成多个硬原型,基于识别出的弱特征。
- 使用MSMF模块以双重路径方式生成最终分割掩膜,解决医学图像中前景与背景的不平衡问题。
- 引入边界损失以进一步约束分割边缘。
点此查看论文截图

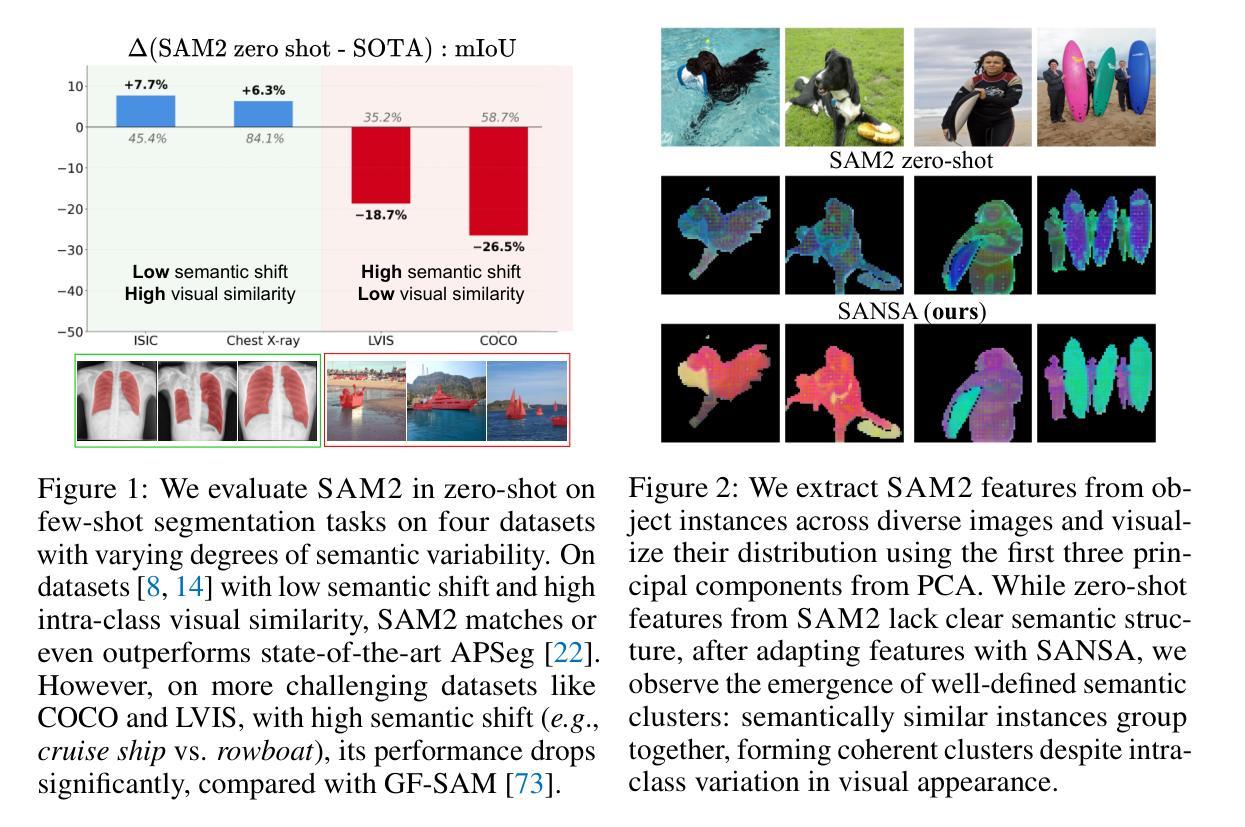
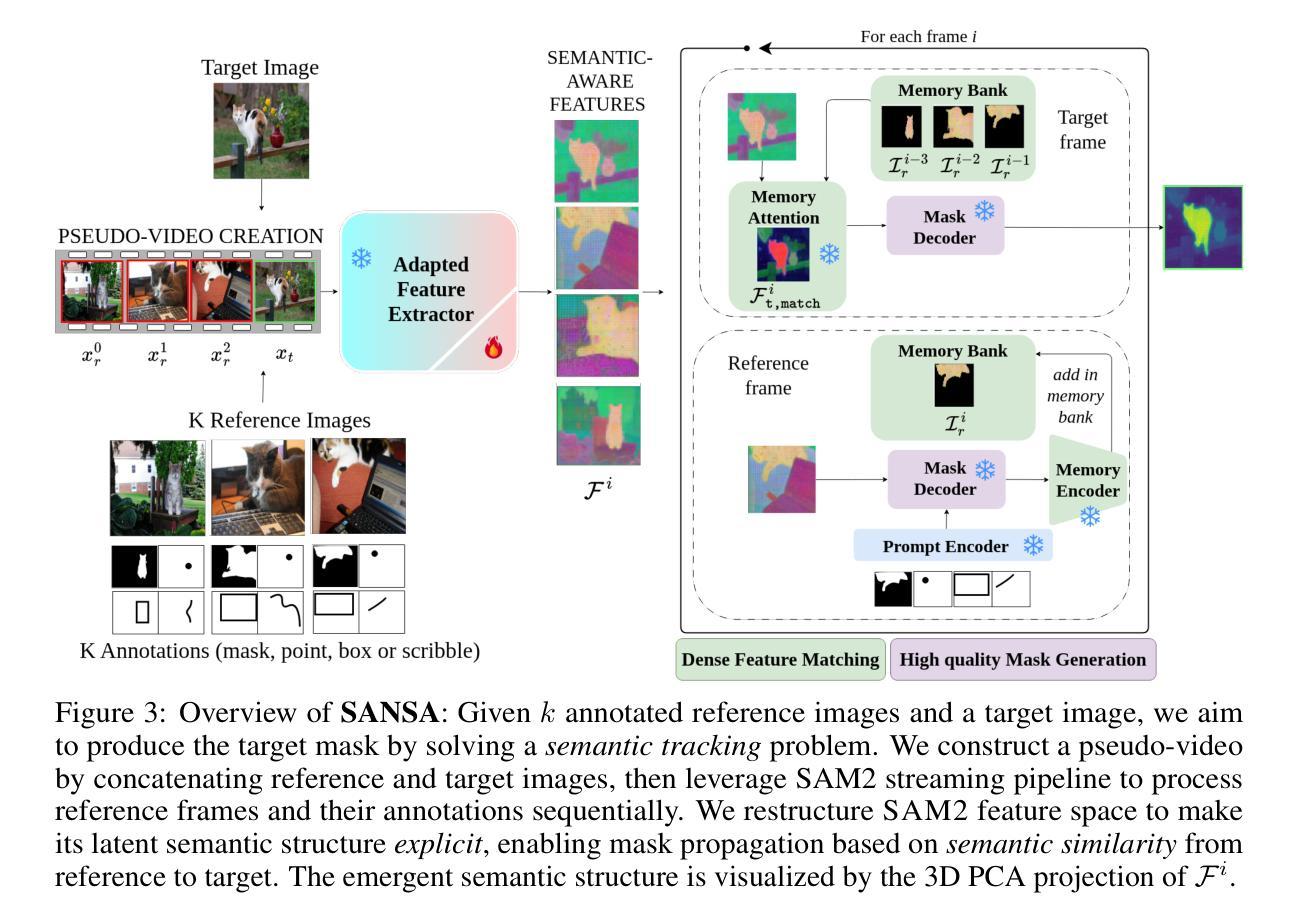
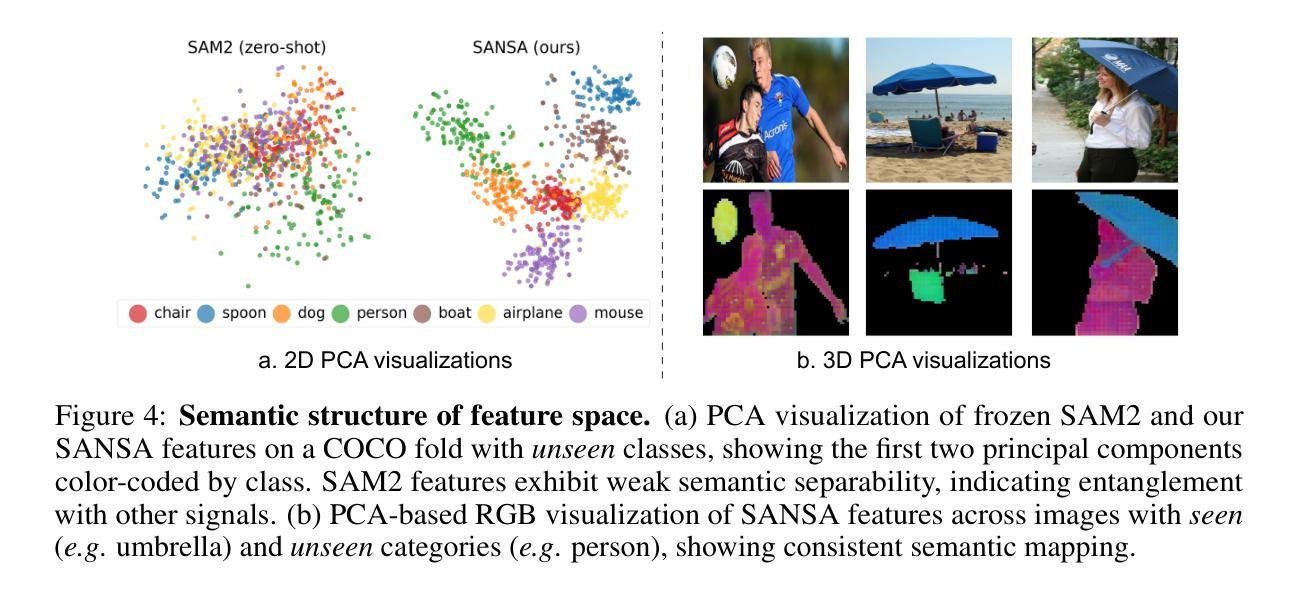
SANSA: Unleashing the Hidden Semantics in SAM2 for Few-Shot Segmentation
Authors:Claudia Cuttano, Gabriele Trivigno, Giuseppe Averta, Carlo Masone
Few-shot segmentation aims to segment unseen object categories from just a handful of annotated examples. This requires mechanisms that can both identify semantically related objects across images and accurately produce segmentation masks. We note that Segment Anything 2 (SAM2), with its prompt-and-propagate mechanism, offers both strong segmentation capabilities and a built-in feature matching process. However, we show that its representations are entangled with task-specific cues optimized for object tracking, which impairs its use for tasks requiring higher level semantic understanding. Our key insight is that, despite its class-agnostic pretraining, SAM2 already encodes rich semantic structure in its features. We propose SANSA (Semantically AligNed Segment Anything 2), a framework that makes this latent structure explicit, and repurposes SAM2 for few-shot segmentation through minimal task-specific modifications. SANSA achieves state-of-the-art performance on few-shot segmentation benchmarks specifically designed to assess generalization, outperforms generalist methods in the popular in-context setting, supports various prompts flexible interaction via points, boxes, or scribbles, and remains significantly faster and more compact than prior approaches. Code is available at https://github.com/ClaudiaCuttano/SANSA.
少数样本分割旨在从少量的标注样本中对未见过的目标类别进行分割。这要求机制能够在图像中识别语义相关的对象,并准确生成分割掩膜。我们注意到,借助提示和扩展机制,Segment Anything 2(SAM2)既具有强大的分割能力,又具备内置的特征匹配过程。然而,我们展示其在优化对象跟踪的特定任务线索时,其表示与这些线索纠缠在一起,这损害了其在需要更高层次语义理解的任务中的使用。我们的关键见解是,尽管SAM2具有类别无关的预训练,但它已经在其特性中编码了丰富的语义结构。我们提出了SANSA(语义对齐的Segment Anything 2),这是一个使这种潜在结构明确化的框架,并通过最少的特定任务修改使SAM2用于少数样本分割。SANSA在专门设计用于评估泛化的少数样本分割基准测试中实现了最先进的性能,在流行上下文设置中的通用方法表现优异,支持通过点、框或涂鸦进行各种提示灵活交互,并且相较于先前的方法,其速度更快、更紧凑。代码可在https://github.com/ClaudiaCuttano/SANSA找到。
论文及项目相关链接
PDF Code: https://github.com/ClaudiaCuttano/SANSA
Summary
本文介绍了Few-shot segmentation的目标和方法。文章指出Segment Anything 2(SAM2)虽然具有强大的分割能力和特征匹配功能,但其表示与任务特定线索纠缠在一起,影响其在需要高级语义理解的任务中的使用。文章提出SANSA框架,通过使SAM2的潜在结构显性化并对其进行最小任务特定的修改,用于少样本分割。SANSA实现了专为评估泛化能力而设计的少样本分割基准测试的最佳性能,在流行的上下文设置内优于通用方法,并支持通过各种提示进行灵活交互,同时速度更快、更紧凑。
Key Takeaways
- Few-shot segmentation旨在从少量标注的示例中对未见过的对象类别进行分割。
- Segment Anything 2(SAM2)具有强大的分割能力和特征匹配功能。
- SAM2的表示与任务特定线索纠缠在一起,影响其在高级语义理解任务中的应用。
- SANSA框架通过使SAM2的潜在结构显性化,并对其进行最小任务特定的修改,用于少样本分割。
- SANSA实现了专为评估泛化能力设计的少样本分割基准测试的最佳性能。
- SANSA在流行上下文设置内的性能优于通用方法。
- SANSA支持通过各种提示(如点、框或涂鸦)进行灵活交互,并且速度更快、更紧凑。
点此查看论文截图

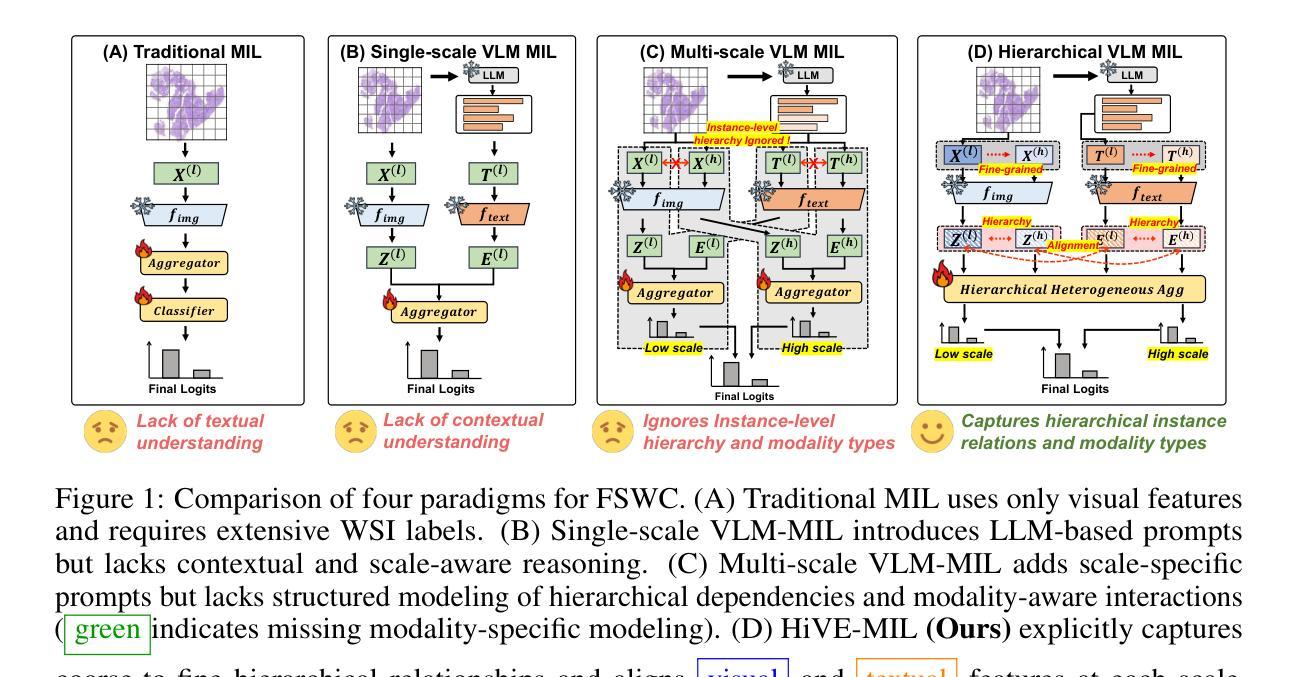
Few-Shot Learning from Gigapixel Images via Hierarchical Vision-Language Alignment and Modeling
Authors:Bryan Wong, Jong Woo Kim, Huazhu Fu, Mun Yong Yi
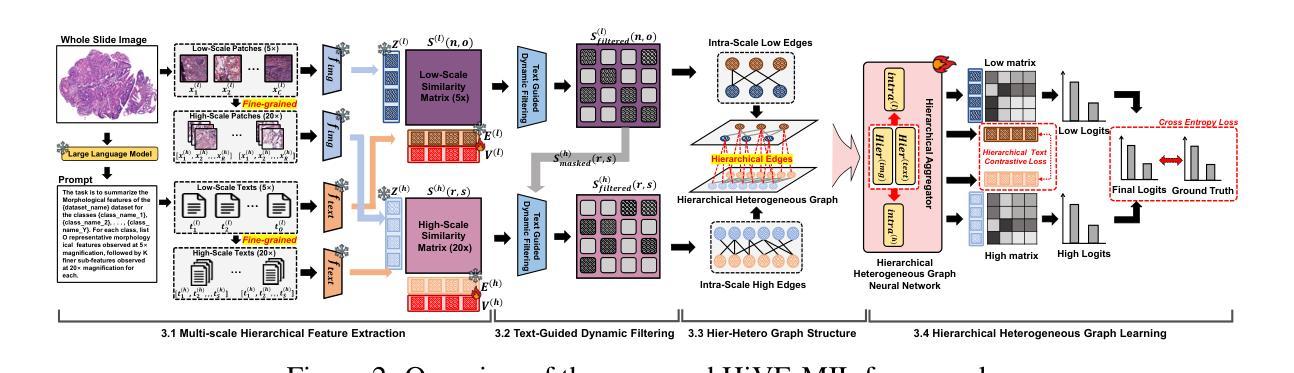
Vision-language models (VLMs) have recently been integrated into multiple instance learning (MIL) frameworks to address the challenge of few-shot, weakly supervised classification of whole slide images (WSIs). A key trend involves leveraging multi-scale information to better represent hierarchical tissue structures. However, existing methods often face two key limitations: (1) insufficient modeling of interactions within the same modalities across scales (e.g., 5x and 20x) and (2) inadequate alignment between visual and textual modalities on the same scale. To address these gaps, we propose HiVE-MIL, a hierarchical vision-language framework that constructs a unified graph consisting of (1) parent-child links between coarse (5x) and fine (20x) visual/textual nodes to capture hierarchical relationships, and (2) heterogeneous intra-scale edges linking visual and textual nodes on the same scale. To further enhance semantic consistency, HiVE-MIL incorporates a two-stage, text-guided dynamic filtering mechanism that removes weakly correlated patch-text pairs, and introduces a hierarchical contrastive loss to align textual semantics across scales. Extensive experiments on TCGA breast, lung, and kidney cancer datasets demonstrate that HiVE-MIL consistently outperforms both traditional MIL and recent VLM-based MIL approaches, achieving gains of up to 4.1% in macro F1 under 16-shot settings. Our results demonstrate the value of jointly modeling hierarchical structure and multimodal alignment for efficient and scalable learning from limited pathology data. The code is available at https://github.com/bryanwong17/HiVE-MIL
视觉语言模型(VLMs)最近已被纳入多实例学习(MIL)框架,以解决对全幻灯片图像(WSI)进行少量、弱监督分类的挑战。一种关键趋势是,利用多尺度信息来更好地表示层次化的组织结构。然而,现有方法通常面临两个主要局限性:(1)同一模态内不同尺度(例如,5倍和20倍)之间交互的建模不足;(2)同一尺度上视觉和文本模态之间的对齐不足。为了解决这些差距,我们提出了HiVE-MIL,这是一个层次化的视觉语言框架,它构建了一个统一图,包括(1)粗(5倍)和细(20倍)视觉/文本节点之间的父子链接,以捕获层次关系,以及(2)在同一尺度上连接视觉和文本节点的异构图内边。为了进一步增强语义一致性,HiVE-MIL采用了一个两阶段的文本引导动态过滤机制,该机制消除了弱相关的补丁文本对,并引入了一种层次对比损失,以对齐不同尺度的文本语义。在TCGA乳腺癌、肺癌和肾癌数据集上的大量实验表明,HiVE-MIL始终优于传统的MIL和最新的基于VLM的MIL方法,在16次拍摄的宏观F1得分提高了高达4.1%。我们的结果证明了联合建模层次结构和多模态对齐对于从有限的病理学数据中实现高效和可扩展学习的价值。代码可在https://github.com/bryanwong17/HiVE-MIL中找到。
论文及项目相关链接
Summary
本文介绍了如何将视觉语言模型(VLMs)融入多实例学习(MIL)框架,以解决少样本、弱监督分类全幻灯片图像(WSIs)的挑战。文章强调了利用多尺度信息的趋势,并指出了现有方法的两个主要局限性。为解决这些问题,本文提出了HiVE-MIL框架,通过构建统一图来捕捉层次关系,并增强语义一致性。实验表明,HiVE-MIL在TCGA乳腺癌、肺癌和肾癌数据集上表现出优异的性能。
Key Takeaways
- VLMs被集成到MIL框架中,用于解决少样本、弱监督分类的WSI挑战。
- 利用多尺度信息成为关键趋势,但现有方法存在局限性。
- HiVE-MIL框架通过构建统一图来捕捉层次关系,包括父子链接和异质内尺度边缘。
- HiVE-MIL采用两阶段文本引导的动态过滤机制,增强语义一致性。
- HiVE-MIL引入层次对比损失,对齐同一尺度的文本语义。
- 实验表明HiVE-MIL在多种数据集上表现优异,尤其是TCGA数据集。
- 代码已公开,可供进一步研究使用。
点此查看论文截图

C-LoRA: Contextual Low-Rank Adaptation for Uncertainty Estimation in Large Language Models
Authors:Amir Hossein Rahmati, Sanket Jantre, Weifeng Zhang, Yucheng Wang, Byung-Jun Yoon, Nathan M. Urban, Xiaoning Qian
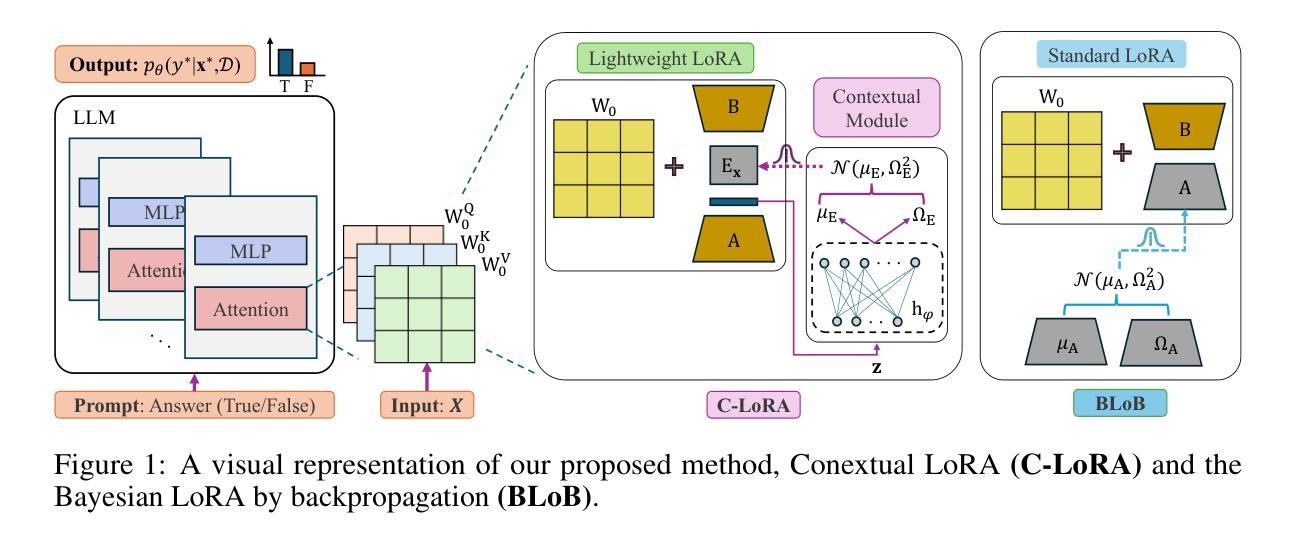
Low-Rank Adaptation (LoRA) offers a cost-effective solution for fine-tuning large language models (LLMs), but it often produces overconfident predictions in data-scarce few-shot settings. To address this issue, several classical statistical learning approaches have been repurposed for scalable uncertainty-aware LoRA fine-tuning. However, these approaches neglect how input characteristics affect the predictive uncertainty estimates. To address this limitation, we propose Contextual Low-Rank Adaptation (\textbf{C-LoRA}) as a novel uncertainty-aware and parameter efficient fine-tuning approach, by developing new lightweight LoRA modules contextualized to each input data sample to dynamically adapt uncertainty estimates. Incorporating data-driven contexts into the parameter posteriors, C-LoRA mitigates overfitting, achieves well-calibrated uncertainties, and yields robust predictions. Extensive experiments demonstrate that C-LoRA consistently outperforms the state-of-the-art uncertainty-aware LoRA methods in both uncertainty quantification and model generalization. Ablation studies further confirm the critical role of our contextual modules in capturing sample-specific uncertainties. C-LoRA sets a new standard for robust, uncertainty-aware LLM fine-tuning in few-shot regimes.
低秩适应(LoRA)为微调大型语言模型(LLM)提供了具有成本效益的解决方案,但在数据稀缺的少量样本环境中通常会产生过于自信的预测。为解决这一问题,几种经典的统计学习方法已被重新用于可扩展的具有不确定性的LoRA微调。然而,这些方法忽略了输入特征如何影响预测不确定性估计。为解决这一局限性,我们提出上下文低秩适应(C-LoRA)作为一种新型的具有不确定性的参数高效微调方法,通过开发针对每个输入数据样本的轻型LoRA模块来动态适应不确定性估计。通过将数据驱动上下文融入参数后验分布,C-LoRA缓解了过拟合问题,实现了校准良好的不确定性,并产生了稳健的预测。大量实验表明,在不确定度量模型和模型泛化方面,C-LoRA始终优于最新的具有不确定度的LoRA方法。消融研究进一步证实了我们的上下文模块在捕捉样本特定不确定性方面的关键作用。C-LoRA为少量样本环境下的稳健、具有不确定性的LLM微调设定了新的标准。
论文及项目相关链接
Summary
基于低秩适应(LoRA)的少量数据场景下的大型语言模型(LLM)微调方法虽然经济高效,但常常产生过于自信的预测结果。为解决这一问题,研究者提出一种新型的不确定性感知和参数高效的微调方法——上下文低秩适应(C-LoRA)。它通过开发针对每个输入数据样本的轻量化LoRA模块,动态适应不确定性估计,并将数据驱动上下文融入参数后验分布。C-LoRA能够缓解过拟合问题,实现良好校准的不确定性,产生稳健预测。实验表明,在不确定度量化与模型泛化方面,C-LoRA均优于现有不确定性感知的LoRA方法。
Key Takeaways
- 低秩适应(LoRA)是大型语言模型(LLM)微调的一种经济高效方法,但在少量数据场景下会产生过于自信的预测。
- 上下文低秩适应(C-LoRA)是一种新型的不确定性感知和参数高效的微调方法。
- C-LoRA通过开发针对每个输入数据样本的轻量化LoRA模块,实现动态适应不确定性估计。
- C-LoRA将数据驱动的上下文融入参数后验分布,以缓解过拟合问题并实现良好校准的不确定性。
- C-LoRA能够产生稳健预测,并在不确定度量化与模型泛化方面优于现有方法。
- 广泛实验证明C-LoRA的有效性,包括与现有不确定性感知的LoRA方法的对比。
点此查看论文截图

AI for Climate Finance: Agentic Retrieval and Multi-Step Reasoning for Early Warning System Investments
Authors:Saeid Ario Vaghefi, Aymane Hachcham, Veronica Grasso, Jiska Manicus, Nakiete Msemo, Chiara Colesanti Senni, Markus Leippold
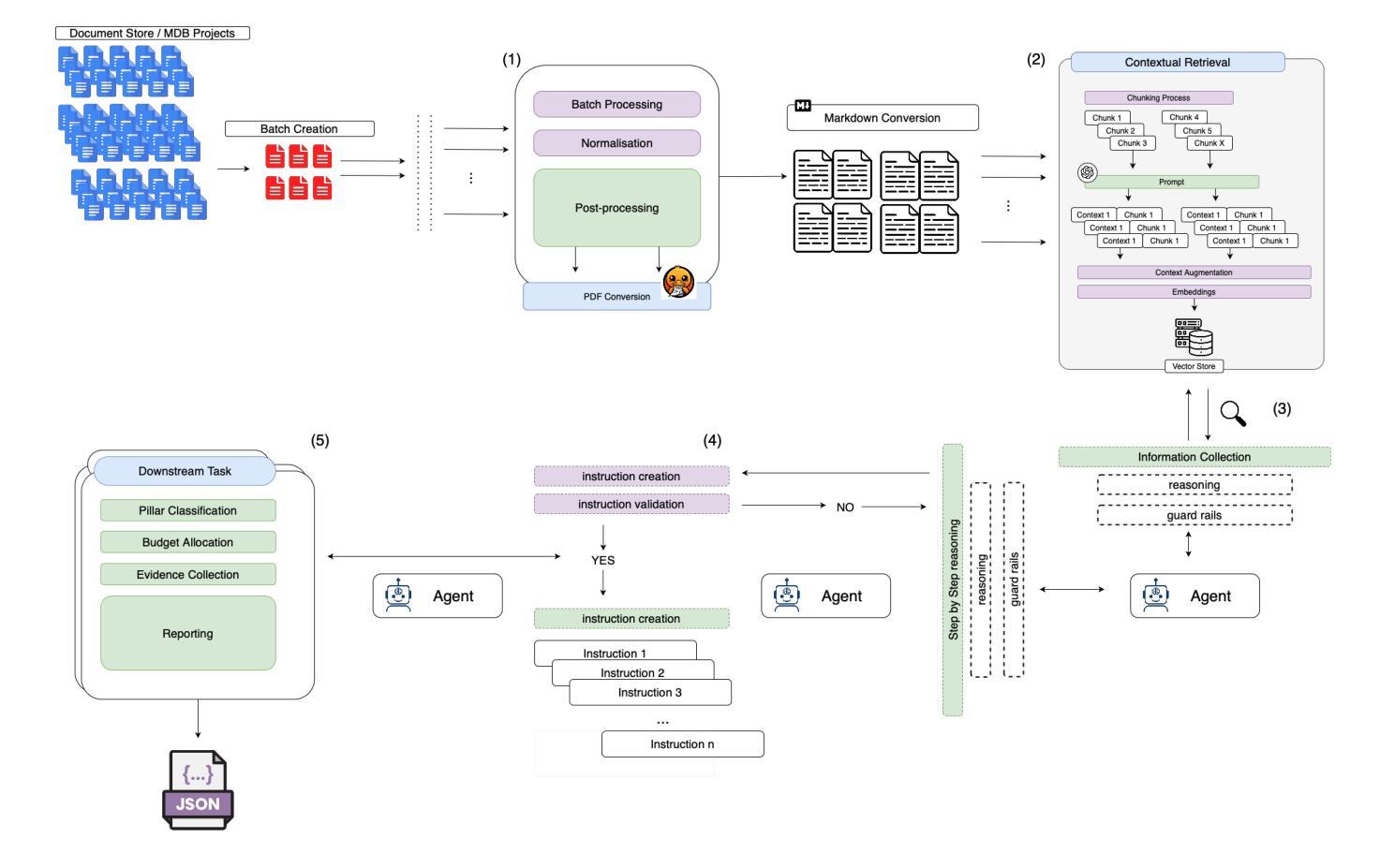
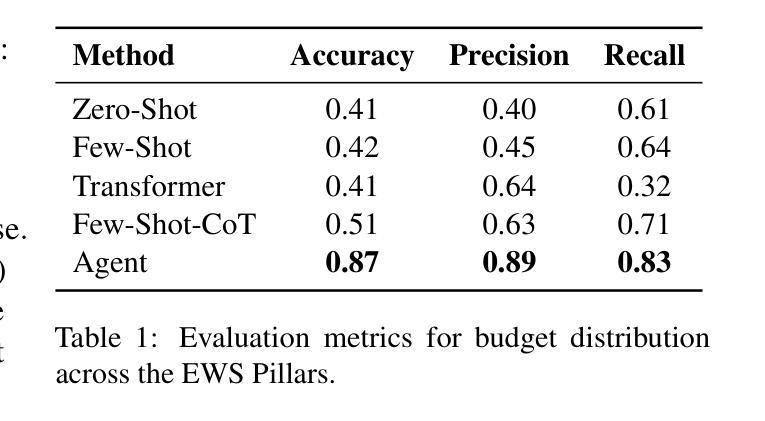
Tracking financial investments in climate adaptation is a complex and expertise-intensive task, particularly for Early Warning Systems (EWS), which lack standardized financial reporting across multilateral development banks (MDBs) and funds. To address this challenge, we introduce an LLM-based agentic AI system that integrates contextual retrieval, fine-tuning, and multi-step reasoning to extract relevant financial data, classify investments, and ensure compliance with funding guidelines. Our study focuses on a real-world application: tracking EWS investments in the Climate Risk and Early Warning Systems (CREWS) Fund. We analyze 25 MDB project documents and evaluate multiple AI-driven classification methods, including zero-shot and few-shot learning, fine-tuned transformer-based classifiers, chain-of-thought (CoT) prompting, and an agent-based retrieval-augmented generation (RAG) approach. Our results show that the agent-based RAG approach significantly outperforms other methods, achieving 87% accuracy, 89% precision, and 83% recall. Additionally, we contribute a benchmark dataset and expert-annotated corpus, providing a valuable resource for future research in AI-driven financial tracking and climate finance transparency.
追踪气候适应领域的金融投资是一项复杂且需要专业技能的任务,特别是对于缺乏多边发展银行和基金标准化财务报告的早期预警系统(EWS)而言。为了应对这一挑战,我们引入了一个基于大型语言模型的智能AI系统,该系统结合了上下文检索、微调以及多步骤推理,以提取相关财务数据、分类投资并确保符合资金指导方针。我们的研究关注现实应用:追踪气候风险与早期预警系统(CREWS)基金中的EWS投资。我们分析了25份MDB项目文件,并评估了多种AI驱动的分类方法,包括零样本和少样本学习、微调基于转换器的分类器、链式思维(CoT)提示以及基于代理的检索增强生成(RAG)方法等。我们的结果表明,基于代理的RAG方法显著优于其他方法,达到了87%的准确率、89%的精确率和8 3%的召回率。此外,我们还贡献了一个基准数据集和专家注释语料库,为AI驱动的金融追踪和气候金融透明度的未来研究提供了有价值的资源。
论文及项目相关链接
Summary
本文介绍了一个基于大型语言模型(LLM)的智能化AI系统,用于追踪气候适应的金融投资。该系统结合了语境检索、微调技术和多步骤推理,能够从多边发展银行的项目文件中提取相关数据,对投资进行分类,并确保符合资助指南的要求。研究重点是在气候风险和预警系统基金(CREWS)中对早期预警系统(EWS)投资的跟踪。研究评估了多种AI分类方法,最终发现基于代理的检索增强生成(RAG)方法表现最佳,准确率、精确度和召回率分别达到了87%、89%和83%。同时,本文还贡献了一个基准数据集和专家注释语料库,为未来AI驱动的金融追踪和气候金融透明度的研究提供了宝贵资源。
Key Takeaways
- LLM-based AI系统被用于追踪气候适应的金融投资,解决了早期预警系统(EWS)缺乏标准化财务报告的挑战。
- 该系统通过结合语境检索、微调技术和多步骤推理,能够从多边发展银行的项目文档中提取相关金融数据。
- 研究焦点是气候风险和预警系统基金(CREWS)中的EWS投资跟踪。
- 多种AI分类方法被评估,包括零样本和少样本学习、微调过的基于变压器的分类器、思维链提示和基于代理的检索增强生成(RAG)方法。
- 基于代理的RAG方法表现最佳,准确率、精确度和召回率分别达到了87%、89%和83%。
- 研究贡献了一个基准数据集和专家注释语料库,为未来的AI金融追踪和气候金融透明度研究提供了资源。
点此查看论文截图

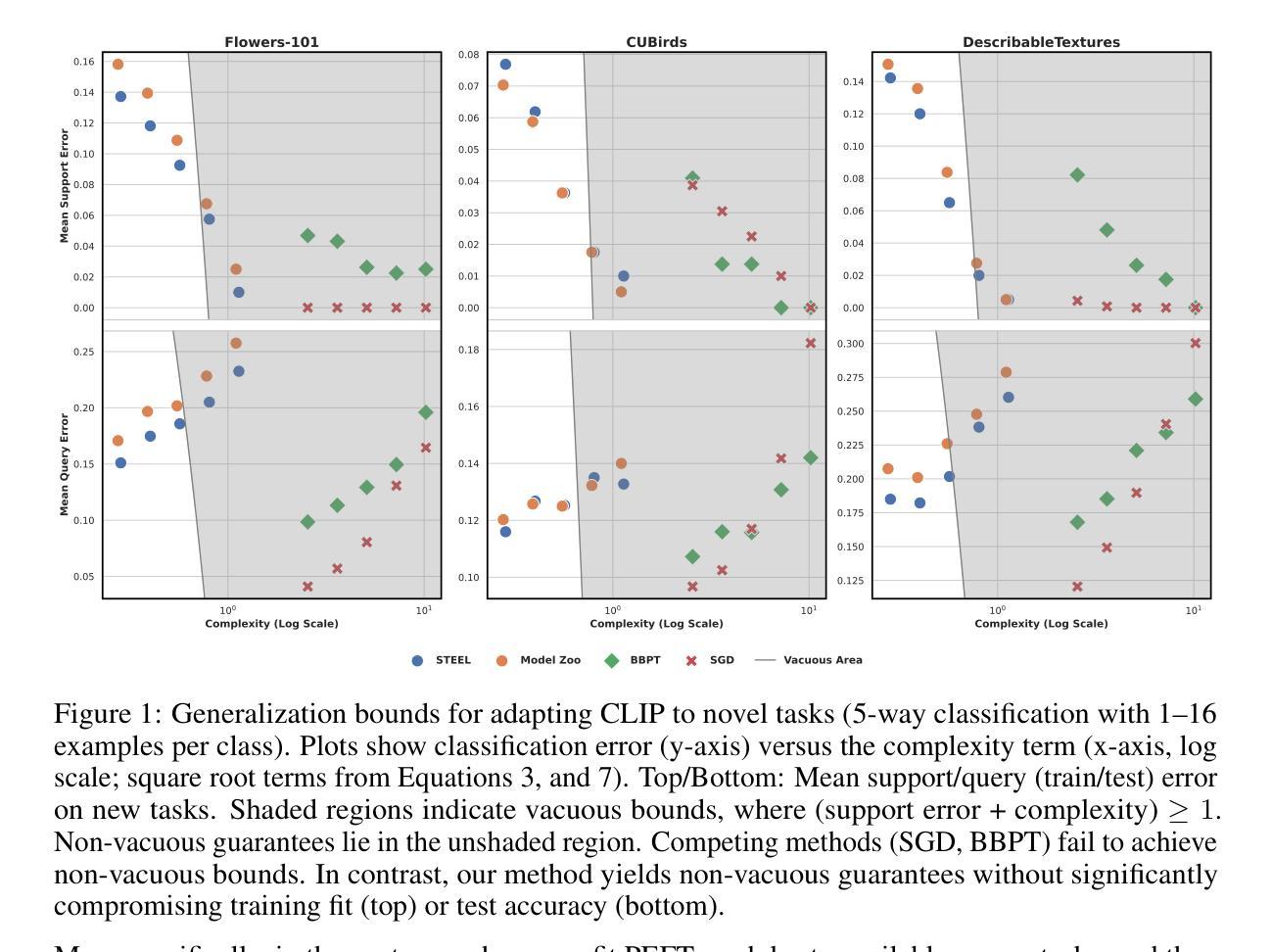
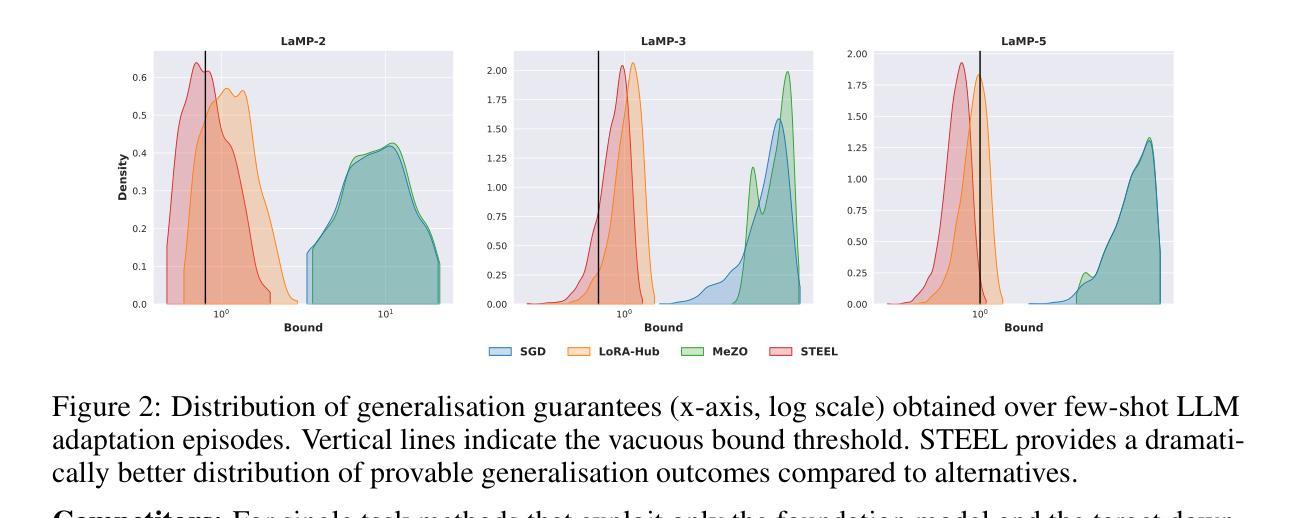
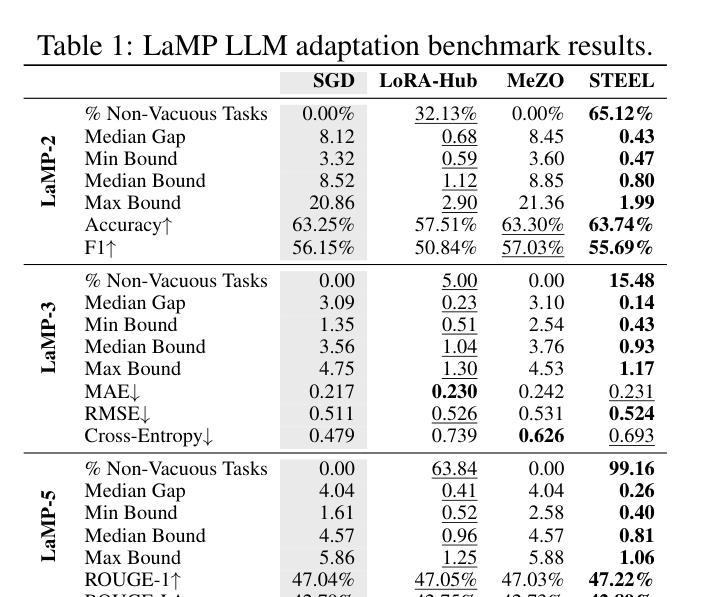
Model Diffusion for Certifiable Few-shot Transfer Learning
Authors:Fady Rezk, Royson Lee, Henry Gouk, Timothy Hospedales, Minyoung Kim
In contemporary deep learning, a prevalent and effective workflow for solving low-data problems is adapting powerful pre-trained foundation models (FMs) to new tasks via parameter-efficient fine-tuning (PEFT). However, while empirically effective, the resulting solutions lack generalisation guarantees to certify their accuracy - which may be required for ethical or legal reasons prior to deployment in high-importance applications. In this paper we develop a novel transfer learning approach that is designed to facilitate non-vacuous learning theoretic generalisation guarantees for downstream tasks, even in the low-shot regime. Specifically, we first use upstream tasks to train a distribution over PEFT parameters. We then learn the downstream task by a sample-and-evaluate procedure – sampling plausible PEFTs from the trained diffusion model and selecting the one with the highest likelihood on the downstream data. Crucially, this confines our model hypothesis to a finite set of PEFT samples. In contrast to the typical continuous hypothesis spaces of neural network weights, this facilitates tighter risk certificates. We instantiate our bound and show non-trivial generalization guarantees compared to existing learning approaches which lead to vacuous bounds in the low-shot regime.
在当前的深度学习中,解决低数据问题的一个流行且有效的工作流程是通过参数有效的微调(PEFT)将强大的预训练基础模型(FMs)适应到新任务。然而,尽管经验上有效,但所得解决方案缺乏泛化保证来证明其准确性,而在部署到高优先级应用之前,可能出于道德或法律原因需要这种保证。在本文中,我们开发了一种新型迁移学习方法,旨在促进下游任务的非空洞学习理论泛化保证,即使在低射击状态下也是如此。具体来说,我们首先使用上游任务来训练PEFT参数的分布。然后,我们通过采样和评估程序来学习下游任务——从训练的扩散模型中采样合理的PEFTs,并选择在下游数据上可能性最高的一个。关键的是,这将我们的模型假设限制在PEFT样本的有限集合中。与神经网络权重的典型连续假设空间相比,这有助于更紧密的风险证书。我们实现了我们的界限,并显示出与非空洞泛化保证的现有学习方法相比,在低射击状态下具有非平凡泛化保证的优势。
论文及项目相关链接
Summary
本文提出了一种新的迁移学习方法,旨在便于下游任务在非空泛化的学习理论泛化保证,即使在低数据量情况下也能实现。通过上游任务训练参数扩散模型,采用采样评估程序学习下游任务,从训练的扩散模型中采样可能的微调参数,选择在下游数据上可能性最高的一个。通过将模型假设限制在有限的微调参数样本集上,与传统的神经网络权重连续假设空间相比,能提供更严格的风险证书。
Key Takeaways
- 当代深度学习中,使用预训练基础模型进行参数有效微调是解决低数据问题的一种流行而有效的方法。
- 然而,现有方法缺乏泛化保证,无法在道德或法律原因要求在重要应用中部署时证明其准确性。
- 本文提出了一种新的迁移学习方法,通过上游任务训练参数扩散模型以提供非空泛化的学习理论泛化保证。
- 方法采用采样评估程序,从训练的扩散模型中采样可能的微调参数,选择适应下游数据的最佳参数。
- 通过将模型假设限制在有限的微调参数样本集上,该方法能提供更严格的风险证书。
- 与现有学习方法相比,本文方法在低数据量情况下提供了非泛化的泛化保证。
点此查看论文截图

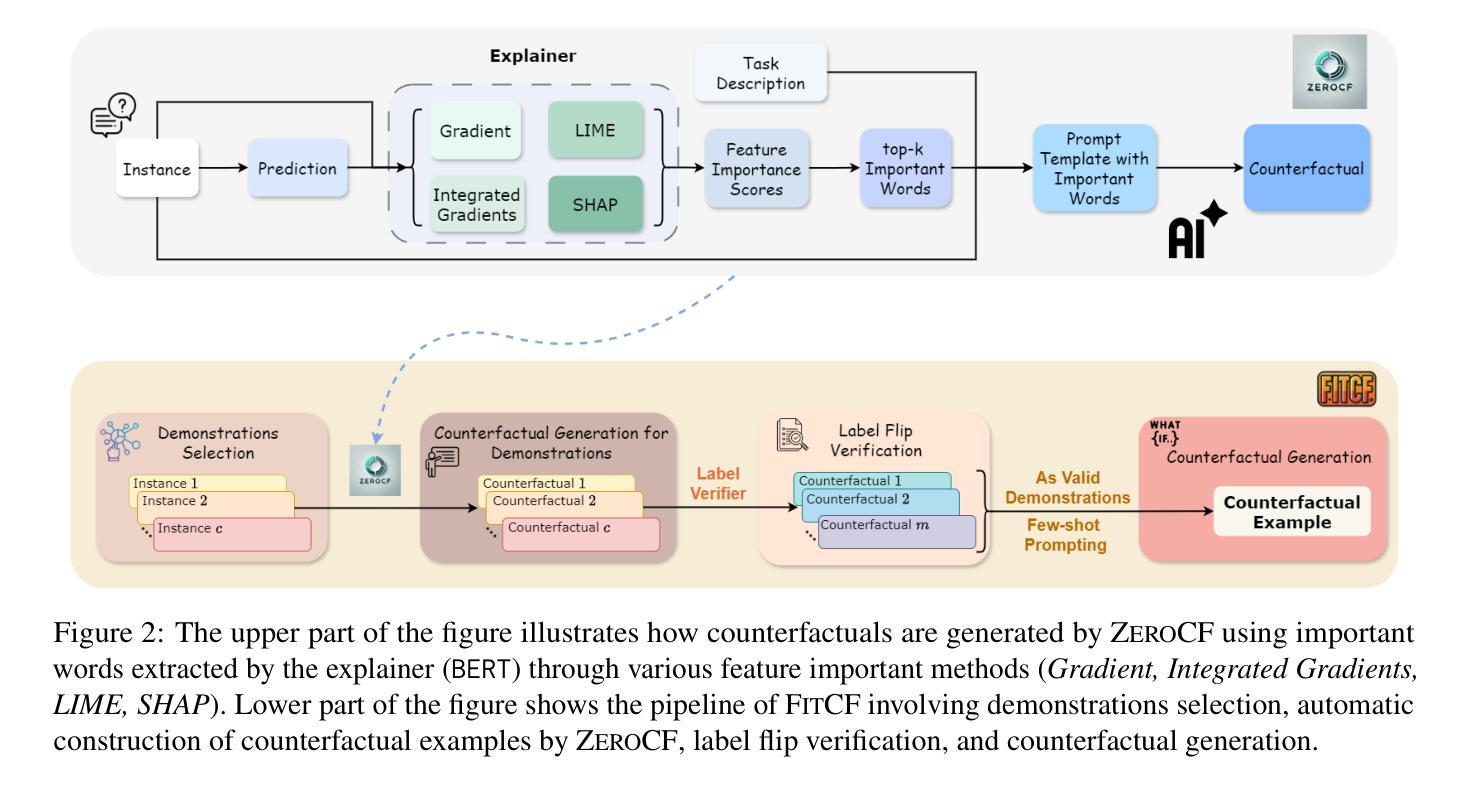
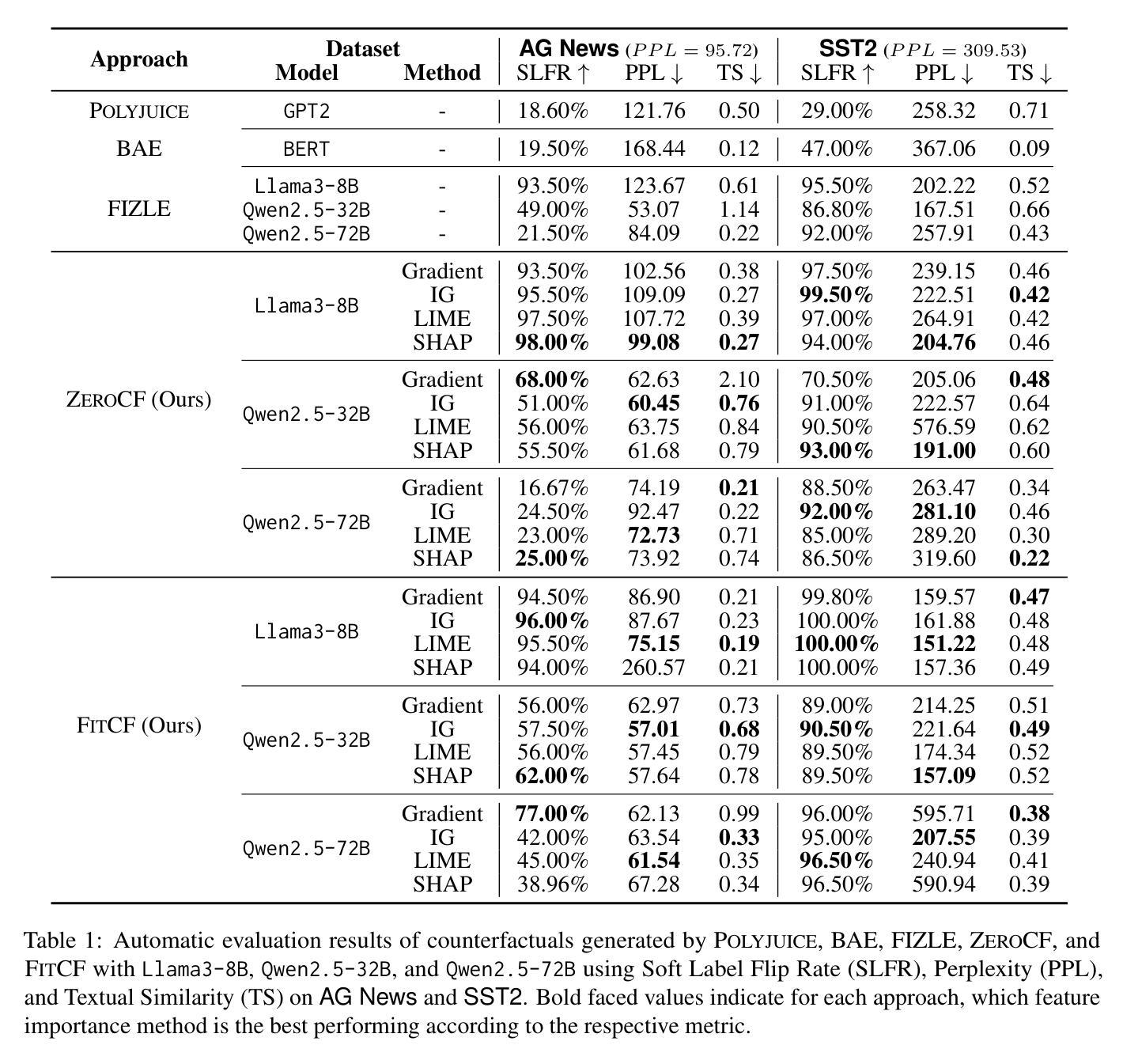
FitCF: A Framework for Automatic Feature Importance-guided Counterfactual Example Generation
Authors:Qianli Wang, Nils Feldhus, Simon Ostermann, Luis Felipe Villa-Arenas, Sebastian Möller, Vera Schmitt
Counterfactual examples are widely used in natural language processing (NLP) as valuable data to improve models, and in explainable artificial intelligence (XAI) to understand model behavior. The automated generation of counterfactual examples remains a challenging task even for large language models (LLMs), despite their impressive performance on many tasks. In this paper, we first introduce ZeroCF, a faithful approach for leveraging important words derived from feature attribution methods to generate counterfactual examples in a zero-shot setting. Second, we present a new framework, FitCF, which further verifies aforementioned counterfactuals by label flip verification and then inserts them as demonstrations for few-shot prompting, outperforming two state-of-the-art baselines. Through ablation studies, we identify the importance of each of FitCF’s core components in improving the quality of counterfactuals, as assessed through flip rate, perplexity, and similarity measures. Furthermore, we show the effectiveness of LIME and Integrated Gradients as backbone attribution methods for FitCF and find that the number of demonstrations has the largest effect on performance. Finally, we reveal a strong correlation between the faithfulness of feature attribution scores and the quality of generated counterfactuals, which we hope will serve as an important finding for future research in this direction.
在自然语言处理(NLP)中,反事实例子被广泛应用于改进模型的数据,同时也在可解释的人工智能(XAI)中被用来理解模型行为。尽管大型语言模型(LLM)在许多任务上表现出令人印象深刻的效果,但自动生成反事实例子仍然是一个具有挑战性的任务。在本文中,我们首先介绍了ZeroCF,这是一种忠实的方法,利用从特征归因方法派生出的重要单词,在无样本环境中生成反事实例子。其次,我们提出了一个新的框架FitCF,它通过标签翻转验证进一步验证了上述的反事实,然后将它们作为演示用于小样本提示,超越了两种最先进的基线方法。通过消融研究,我们确定了FitCF的每个核心组件在提高反事实质量方面的重要性,这通过翻转率、困惑度和相似性度量进行评估。此外,我们展示了LIME和集成梯度作为FitCF的骨干归因方法的有效性,并发现演示的数量对性能的影响最大。最后,我们揭示了特征归因分数忠实性与生成反事实质量之间的强烈相关性,我们希望这将成为未来研究的重要发现。
论文及项目相关链接
PDF ACL 2025 Findings; camera-ready version
Summary
本文介绍了在自然语言处理(NLP)和可解释人工智能(XAI)中广泛应用的反事实示例。文章提出了ZeroCF方法,利用特征归属方法得出的重要词汇在无样本环境下生成反事实示例。进一步,文章提出了FitCF框架,通过标签翻转验证前述反事实,并将其作为演示用于小样本提示,优于两个先进基线。文章还通过消融研究确定了FitCF核心组件在提高反事实质量方面的重要性,并展示了LIME和Integrated Gradients作为FitCF骨干归属方法的有效性。最后,文章揭示了特征归属分数忠实性与生成反事实质量之间的强相关性。
Key Takeaways
- Counterfactual examples are valuable in NLP and XAI.
- ZeroCF方法利用特征归属方法的重要词汇生成反事实示例。
- FitCF框架通过标签翻转验证反事实,并用于小样本提示。
- FitCF优于其他先进基线,其有效性通过消融研究得到证实。
- LIME和Integrated Gradients是有效的骨干归属方法。
- 演示的数量对性能影响最大。
- 特征归属分数的忠实性与生成的反事实质量之间存在强相关性。
点此查看论文截图

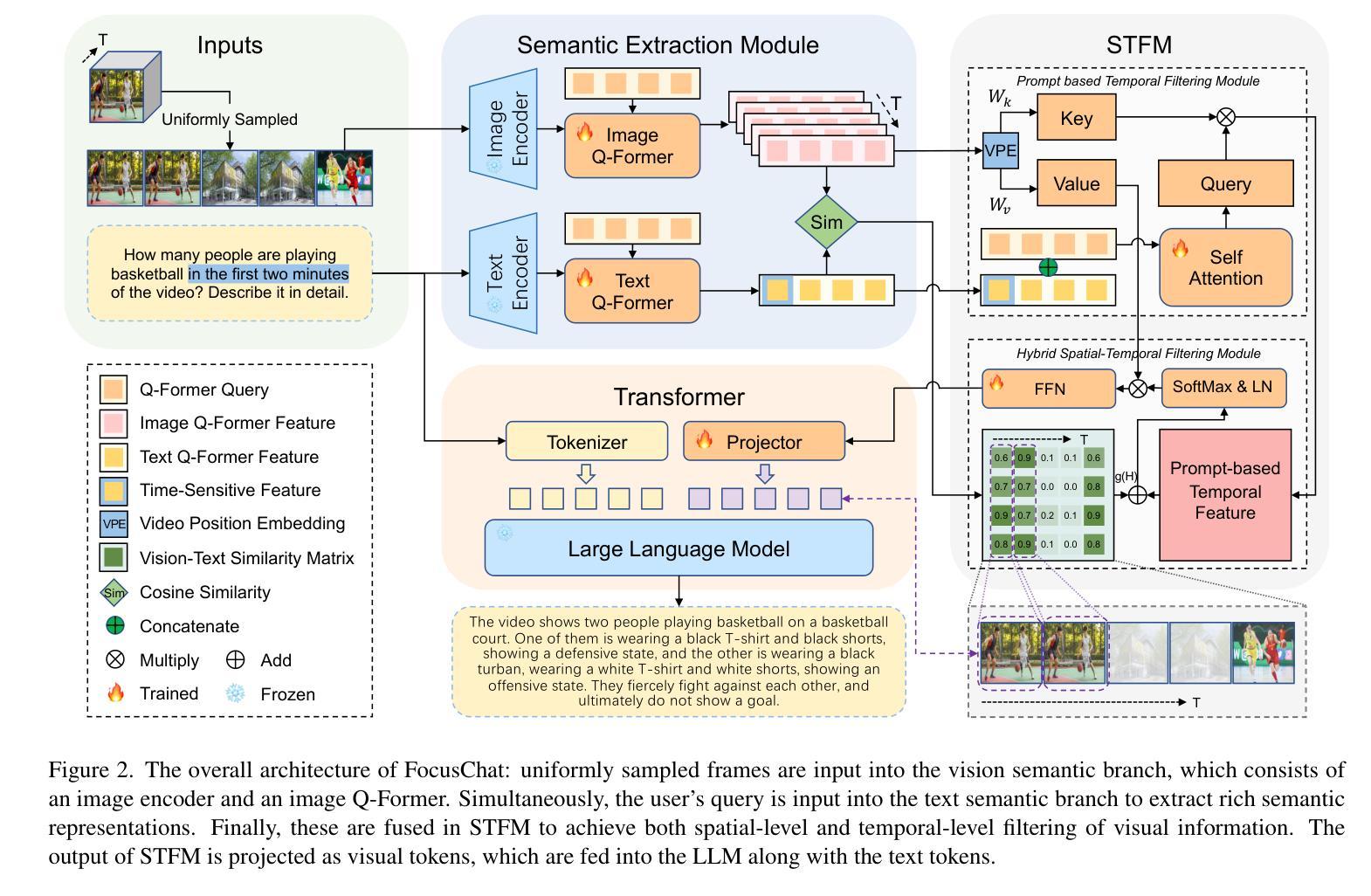
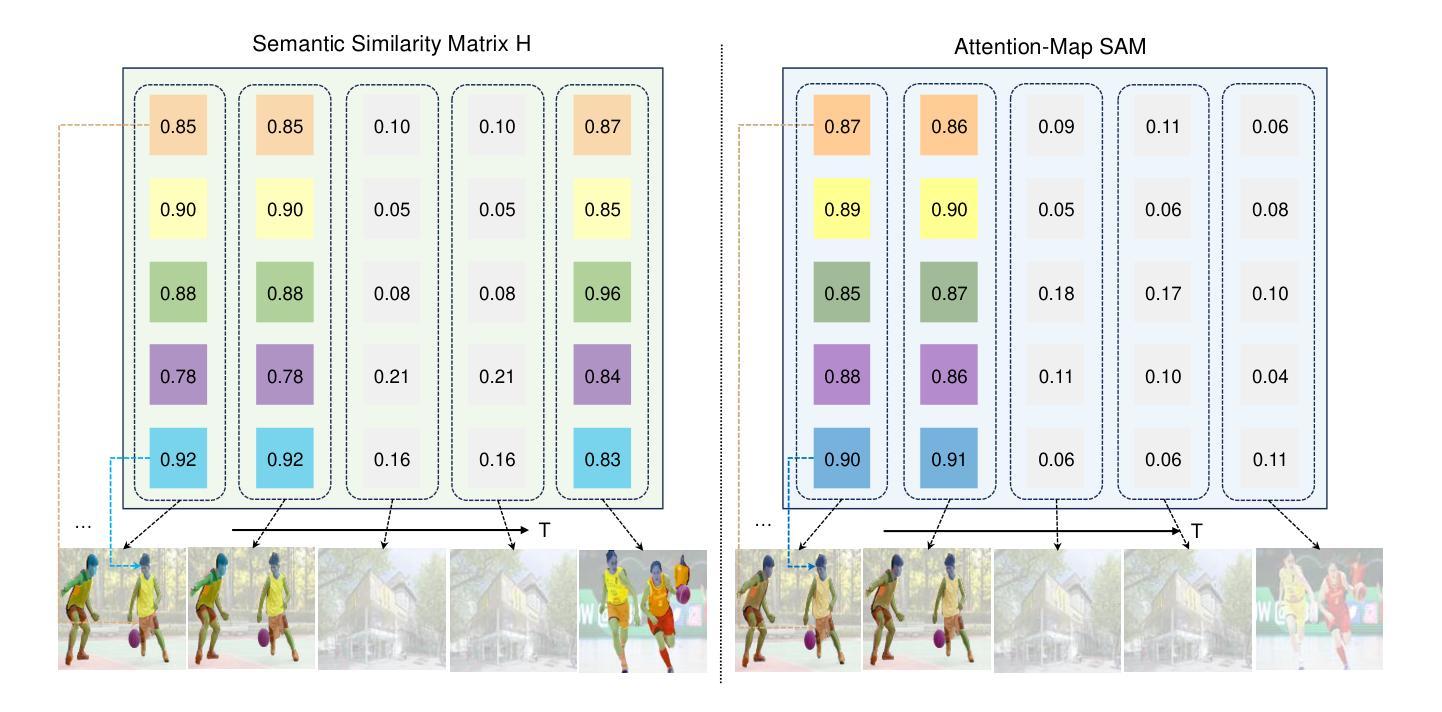
FocusChat: Text-guided Long Video Understanding via Spatiotemporal Information Filtering
Authors:Zheng Cheng, Rendong Wang, Zhicheng Wang
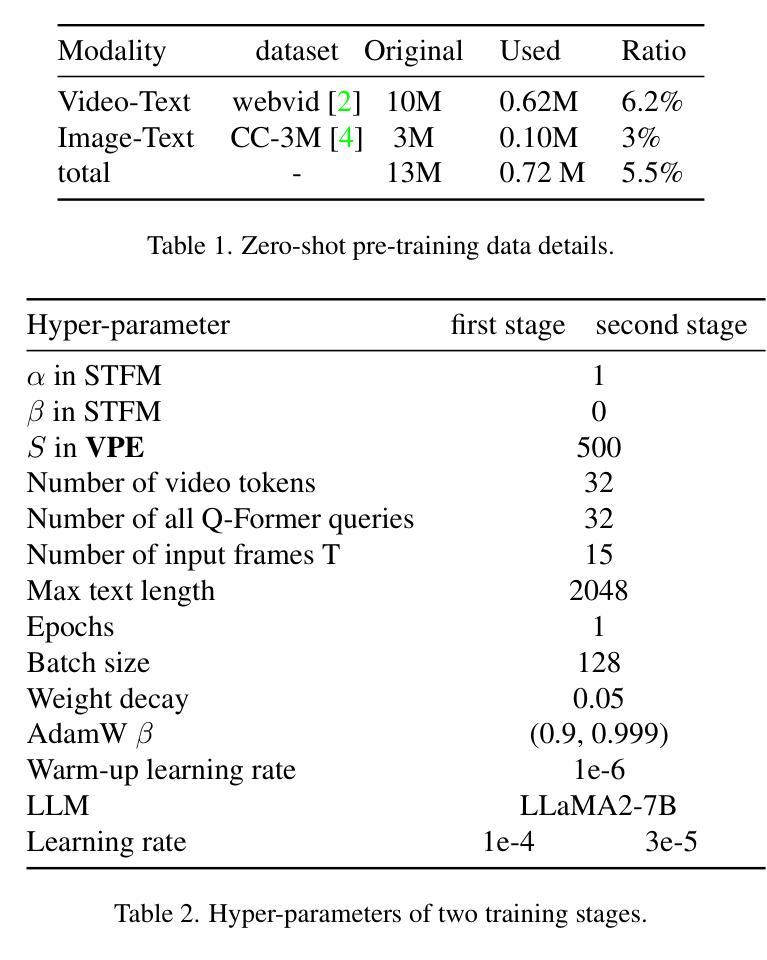
Recently, multi-modal large language models have made significant progress. However, visual information lacking of guidance from the user’s intention may lead to redundant computation and involve unnecessary visual noise, especially in long, untrimmed videos. To address this issue, we propose FocusChat, a text-guided multi-modal large language model (LLM) that emphasizes visual information correlated to the user’s prompt. In detail, Our model first undergoes the semantic extraction module, which comprises a visual semantic branch and a text semantic branch to extract image and text semantics, respectively. The two branches are combined using the Spatial-Temporal Filtering Module (STFM). STFM enables explicit spatial-level information filtering and implicit temporal-level feature filtering, ensuring that the visual tokens are closely aligned with the user’s query. It lowers the essential number of visual tokens inputted into the LLM. FocusChat significantly outperforms Video-LLaMA in zero-shot experiments, using an order of magnitude less training data with only 16 visual tokens occupied. It achieves results comparable to the state-of-the-art in few-shot experiments, with only 0.72M pre-training data.
近期,多模态大型语言模型取得了显著进展。然而,缺乏用户意图指导的视觉信息可能导致冗余计算并引入不必要的视觉噪音,特别是在长而无剪辑的视频中。为了解决这一问题,我们提出了FocusChat,这是一个受文本引导的多模态大型语言模型(LLM),它强调与用户提示相关的视觉信息。具体来说,我们的模型首先经过语义提取模块,该模块包括一个视觉语义分支和一个文本语义分支,分别提取图像和文本语义。这两个分支通过时空滤波模块(STFM)进行结合。STFM实现了显式的空间级信息滤波和隐式的特征级时间滤波,确保视觉令牌与用户查询紧密对齐。它降低了输入LLM的必要视觉令牌数量。FocusChat在零样本实验中显著优于Video-LLaMA,使用数量级的训练数据量更少,仅占用16个视觉令牌。在少量样本实验中,其达到的结果与最新技术相当,仅使用0.72M的预训练数据。
论文及项目相关链接
PDF 11 pages, 4 figures
Summary
文本描述了一种名为FocusChat的文本引导式多模态大型语言模型(LLM),该模型强调与用户提示相关的视觉信息。它通过语义提取模块和空间时间过滤模块,将图像和文本语义相结合,确保视觉令牌与用户查询紧密对齐,降低输入LLM的必需视觉令牌数量。FocusChat在零样本实验中显著优于Video-LLaMA,使用数量级较少的训练数据,仅有16个视觉令牌。在少量样本实验中,它达到了与最新技术相当的结果,只有0.72M的预训练数据。
Key Takeaways
- FocusChat是一个文本引导的多模态大型语言模型,旨在解决在视频处理中由于用户意图缺乏指导而导致的冗余计算和不必要的视觉噪音问题。
- FocusChat通过语义提取模块提取图像和文本语义,并通过空间时间过滤模块进行结合,确保视觉信息与用户查询对齐。
- 该模型降低了输入大型语言模型的必要视觉令牌数量。
- 在零样本实验中,FocusChat显著优于Video-LLaMA,使用了较少的训练数据。
- FocusChat在少量样本实验中表现出与最新技术相当的性能。
- FocusChat的预训练数据量较小,只有0.72M。
点此查看论文截图