⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-05-30 更新
OmniResponse: Online Multimodal Conversational Response Generation in Dyadic Interactions
Authors:Cheng Luo, Jianghui Wang, Bing Li, Siyang Song, Bernard Ghanem
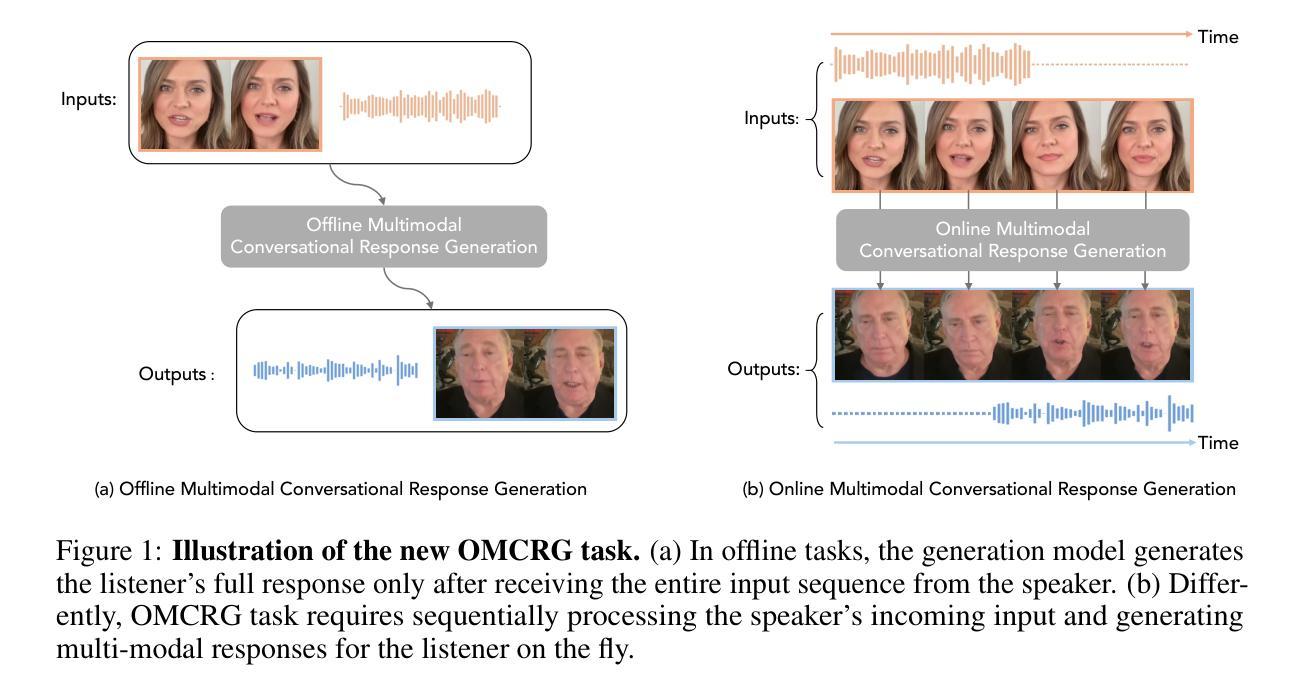
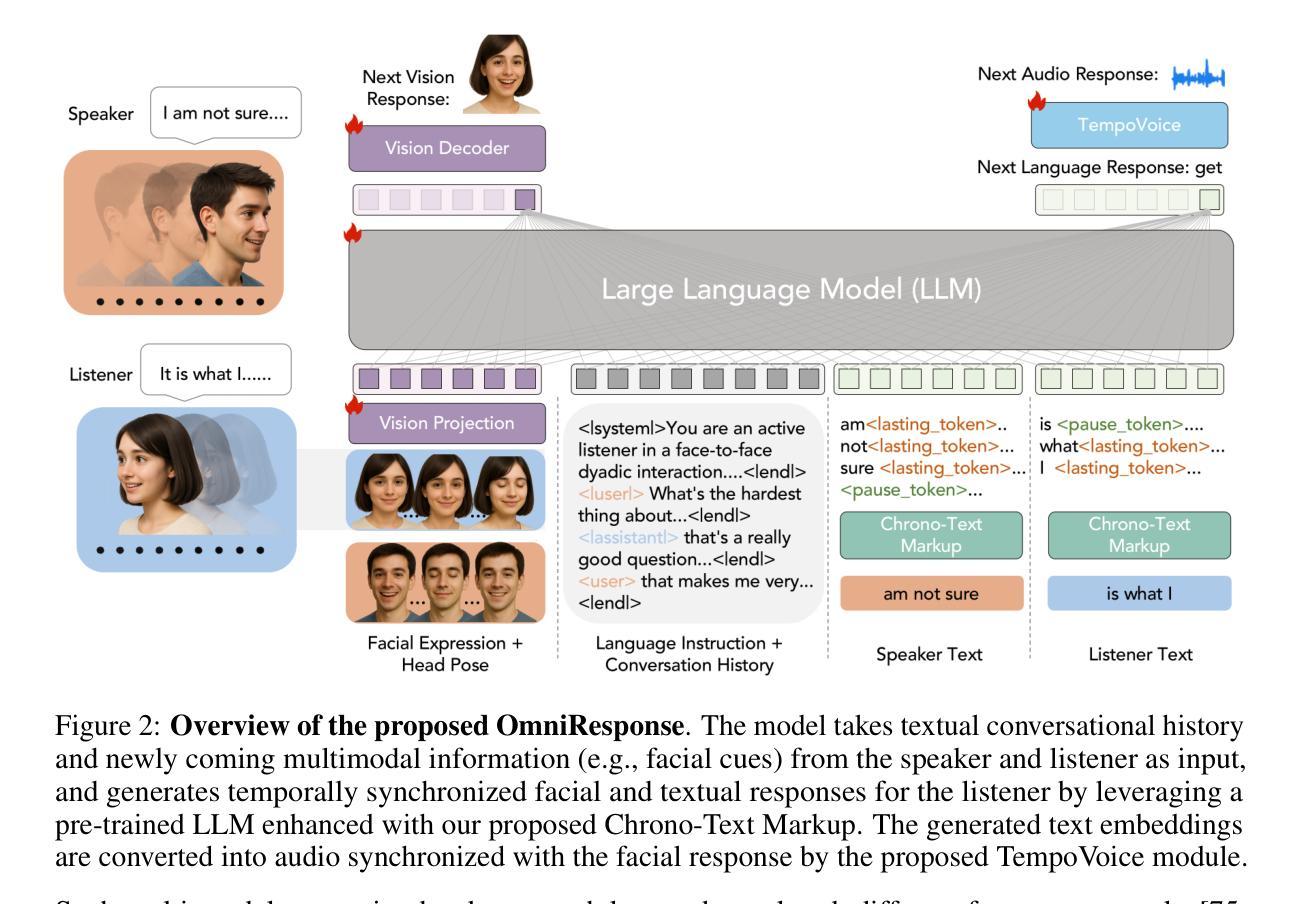
In this paper, we introduce Online Multimodal Conversational Response Generation (OMCRG), a novel task that aims to online generate synchronized verbal and non-verbal listener feedback, conditioned on the speaker’s multimodal input. OMCRG reflects natural dyadic interactions and poses new challenges in achieving synchronization between the generated audio and facial responses of the listener. To address these challenges, we innovatively introduce text as an intermediate modality to bridge the audio and facial responses. We hence propose OmniResponse, a Multimodal Large Language Model (MLLM) that autoregressively generates high-quality multi-modal listener responses. OmniResponse leverages a pretrained LLM enhanced with two novel components: Chrono-Text, which temporally anchors generated text tokens, and TempoVoice, a controllable online TTS module that produces speech synchronized with facial reactions. To support further OMCRG research, we present ResponseNet, a new dataset comprising 696 high-quality dyadic interactions featuring synchronized split-screen videos, multichannel audio, transcripts, and facial behavior annotations. Comprehensive evaluations conducted on ResponseNet demonstrate that OmniResponse significantly outperforms baseline models in terms of semantic speech content, audio-visual synchronization, and generation quality.
本文介绍了在线多模态对话响应生成(OMCRG)这一新任务,该任务旨在根据说话者的多模态输入,在线生成同步的言语和非言语听众反馈。OMCRG反映了自然的二元交互,并在实现生成音频和听众面部响应之间的同步方面提出了新的挑战。为了应对这些挑战,我们创新性地引入文本作为中间模态,以桥接音频和面部响应。因此,我们提出了OmniResponse,这是一种多模态大型语言模型(MLLM),可以自回归地生成高质量的多模态听众响应。OmniResponse利用预训练的大型语言模型,并增强两个新型组件:Chrono-Text,它临时锚定生成的文本标记;以及TempoVoice,一个可控的在线文本到语音模块,可产生与面部反应同步的语音。为了支持进一步的OMCRG研究,我们推出了ResponseNet数据集,包含696个高质量的二元交互视频,每个视频具有分屏同步视频、多通道音频、字幕和面部表情注释。在ResponseNet上进行的综合评估表明,OmniResponse在语义语音内容、视听同步和生成质量方面显著优于基准模型。
论文及项目相关链接
PDF 23 pages, 9 figures
Summary
本文介绍了在线多模态对话响应生成(OMCRG)任务,该任务旨在根据说话者的多模态输入,在线生成同步的言语和非言语听众反馈。为应对挑战,引入文本作为连接音频和面部响应的中间模态。提出OmniResponse多模态大型语言模型(MLLM),可自动生成高质量的多模态听众响应。OmniResponse利用预训练的大型语言模型,并加入两个新组件:Chrono-Text和TempoVoice。前者用于在生成文本时提供时间锚点,后者为可控的在线文本转语音模块,可与面部反应同步产生语音。为支持OMCRG研究,推出ResponseNet数据集,包含高质量的双向互动同步分屏视频、多通道音频、文字稿和面部行为标注。评估显示,OmniResponse在语义语音内容、音视频同步和生成质量方面显著优于基准模型。
Key Takeaways
- 介绍了在线多模态对话响应生成(OMCRG)任务,旨在生成与说话者多模态输入同步的听众反馈。
- 提出OmniResponse多模态大型语言模型(MLLM),能够自动生成高质量的多模态听众响应。
- 利用预训练的大型语言模型,并加入Chrono-Text和TempoVoice两个新组件,分别提供时间锚点和产生可控的在线文本转语音。
- 推出ResponseNet数据集,包含双向互动同步数据,用于支持OMCRG研究。
- OmniResponse在语义语音内容、音视频同步和生成质量方面显著优于基准模型。
- OMCRG反映了自然的双向互动,并带来了生成音频和面部响应之间的同步挑战。
点此查看论文截图