⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-05-30 更新
MTVQA: Benchmarking Multilingual Text-Centric Visual Question Answering
Authors:Jingqun Tang, Qi Liu, Yongjie Ye, Jinghui Lu, Shu Wei, Chunhui Lin, Wanqing Li, Mohamad Fitri Faiz Bin Mahmood, Hao Feng, Zhen Zhao, Yanjie Wang, Yuliang Liu, Hao Liu, Xiang Bai, Can Huang
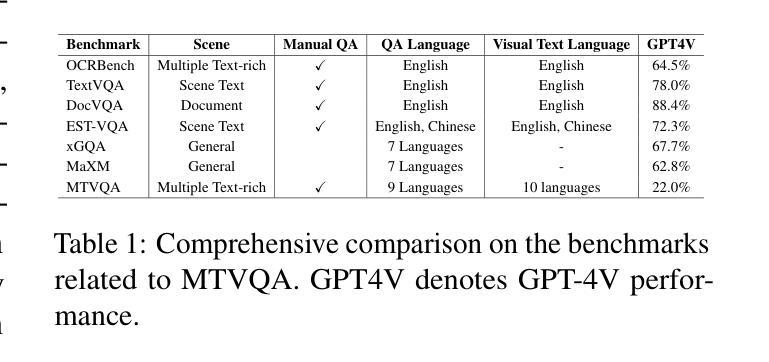
Text-Centric Visual Question Answering (TEC-VQA) in its proper format not only facilitates human-machine interaction in text-centric visual environments but also serves as a de facto gold proxy to evaluate AI models in the domain of text-centric scene understanding. Nonetheless, most existing TEC-VQA benchmarks have focused on high-resource languages like English and Chinese. Despite pioneering works to expand multilingual QA pairs in non-text-centric VQA datasets through translation engines, the translation-based protocol encounters a substantial “visual-textual misalignment” problem when applied to TEC-VQA. Specifically, it prioritizes the text in question-answer pairs while disregarding the visual text present in images. Moreover, it fails to address complexities related to nuanced meaning, contextual distortion, language bias, and question-type diversity. In this work, we tackle multilingual TEC-VQA by introducing MTVQA, the first benchmark featuring high-quality human expert annotations across 9 diverse languages, consisting of 6,778 question-answer pairs across 2,116 images. Further, by comprehensively evaluating numerous state-of-the-art Multimodal Large Language Models~(MLLMs), including Qwen2-VL, GPT-4o, GPT-4V, Claude3, and Gemini, on the MTVQA benchmark, it is evident that there is still a large room for performance improvement (Qwen2-VL scoring 30.9 versus 79.7 for human performance), underscoring the value of MTVQA. Additionally, we supply multilingual training data within the MTVQA dataset, demonstrating that straightforward fine-tuning with this data can substantially enhance multilingual TEC-VQA performance. We aspire that MTVQA will offer the research community fresh insights and stimulate further exploration in multilingual visual text comprehension. The project homepage is available at https://bytedance.github.io/MTVQA/.
文本中心化的视觉问答(TEC-VQA)在适当的形式下,不仅促进了文本中心化视觉环境中的人机交互,还作为评估文本中心化场景理解领域人工智能模型的实际黄金标准。然而,现有的TEC-VQA基准测试主要集中在英语和中文等资源丰富的语言上。尽管有开创性的工作通过翻译引擎在非文本中心化的VQA数据集中扩展了多语言问答对,但基于翻译的方法在应用于TEC-VQA时遇到了重大的“视觉文本不匹配”问题。具体来说,它优先考虑问答对中的文本,而忽视图像中呈现的视觉文本。此外,它无法解决与细微意义、上下文失真、语言偏见和问题类型多样性相关的复杂性。在这项工作中,我们通过引入MTVQA来解决多语言TEC-VQA问题,MTVQA是第一个在9种不同语言中具有高质量人类专家注释的基准测试,包含6778个问答对和2116张图像。此外,通过对众多最先进的多媒体大型语言模型(MLLMs)进行全面评估,包括Qwen2-VL、GPT-4o、GPT-4V、Claude3和Gemini在MTVQA基准上的表现,显然还有很大的性能提升空间(Qwen2-VL得分为30.9,而人类性能得分为79.7),这突显了MTVQA的价值。另外,我们在MTVQA数据集中提供了多语言训练数据,证明使用此数据进行直接微调可以大大提高多语言TEC-VQA的性能。我们期望MTVQA能为研究社区提供新的见解,并激发多语言视觉文本理解方面的进一步探索。项目主页可在[https://bytedance.github.io/MTVQA/]访问。
论文及项目相关链接
PDF Accepted by ACL 2025 findings
Summary
该文介绍了面向文本为中心视觉问答(TEC-VQA)的多语言基准测试MTVQA。MTVQA不仅支持多种语言,而且通过高质量的人类专家注释提供对图像中的文本的理解。文章指出当前多语言TEC-VQA面临的挑战,并评估了多种最新多模态大型语言模型在MTVQA基准测试上的性能。研究表明,仍存在很大的性能提升空间,并强调了MTVQA的价值。此外,该研究提供了多语言训练数据,证明通过微调这些数据可以显著提高多语言TEC-VQA的性能。
Key Takeaways
- MTVQA是面向文本为中心视觉问答(TEC-VQA)的首个多语言基准测试,支持9种不同语言。
- MTVQA包含高质量的人类专家注释,涵盖6778个问答对和2116张图像。
- 当前的多模态大型语言模型在MTVQA上的表现仍有待提升,与人类性能相比存在较大差距。
- MTVQA提供了一个多语言训练数据集,通过微调这些数据可以显著提高多语言TEC-VQA的性能。
- MTVQA有助于为学术界提供新的视角,并刺激对多语言视觉文本理解领域的进一步探索。
- 文章指出了当前多语言TEC-VQA面临的挑战,包括视觉文本不对齐、复杂语境、语言偏见和问句类型多样性等。
点此查看论文截图