⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-05-30 更新
The Climb Carves Wisdom Deeper Than the Summit: On the Noisy Rewards in Learning to Reason
Authors:Ang Lv, Ruobing Xie, Xingwu Sun, Zhanhui Kang, Rui Yan
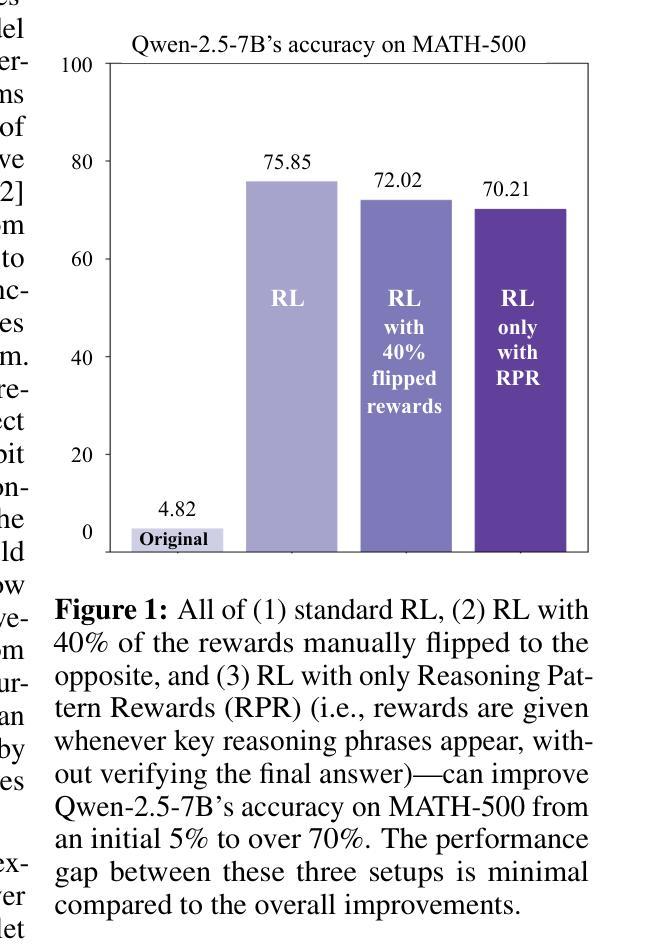
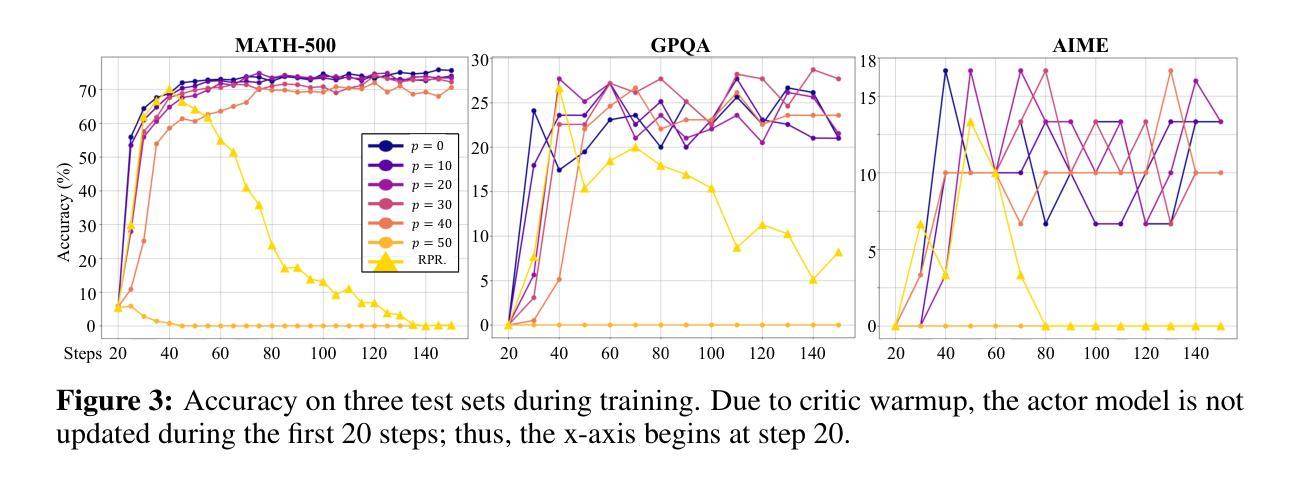
Recent studies on post-training large language models (LLMs) for reasoning through reinforcement learning (RL) typically focus on tasks that can be accurately verified and rewarded, such as solving math problems. In contrast, our research investigates the impact of reward noise, a more practical consideration for real-world scenarios involving the post-training of LLMs using reward models. We found that LLMs demonstrate strong robustness to substantial reward noise. For example, manually flipping 40% of the reward function’s outputs in math tasks still allows a Qwen-2.5-7B model to achieve rapid convergence, improving its performance on math tasks from 5% to 72%, compared to the 75% accuracy achieved by a model trained with noiseless rewards. Surprisingly, by only rewarding the appearance of key reasoning phrases (namely reasoning pattern reward, RPR), such as ``first, I need to’’-without verifying the correctness of answers, the model achieved peak downstream performance (over 70% accuracy for Qwen-2.5-7B) comparable to models trained with strict correctness verification and accurate rewards. Recognizing the importance of the reasoning process over the final results, we combined RPR with noisy reward models. RPR helped calibrate the noisy reward models, mitigating potential false negatives and enhancing the LLM’s performance on open-ended tasks. These findings suggest the importance of improving models’ foundational abilities during the pre-training phase while providing insights for advancing post-training techniques. Our code and scripts are available at https://github.com/trestad/Noisy-Rewards-in-Learning-to-Reason.
关于通过强化学习(RL)对大型语言模型(LLM)进行推理训练的近期研究通常侧重于可以准确验证和奖励的任务,例如解决数学问题。相比之下,我们的研究探讨了奖励噪声的影响,这是使用奖励模型对LLM进行后训练所涉及的更实际的考虑因素,这些考虑因素适用于真实世界场景。我们发现LLM对大量的奖励噪声表现出强大的稳健性。例如,在数学任务中,手动翻转奖励功能输出的40%,仍然允许Qwen-2.5-7B模型实现快速收敛,其在数学任务上的性能从5%提高到72%,而使用无噪声奖励训练的模型准确率为75%。令人惊讶的是,仅通过奖励关键推理短语的出现(即推理模式奖励,RPR),如“首先,我需要”,而不验证答案的正确性,该模型的下游性能达到峰值(Qwen-2.5-7B的准确率超过70%),可与经过严格正确性验证和准确奖励训练的模型相媲美。我们认识到推理过程比最终结果更重要,因此我们将RPR与嘈杂的奖励模型相结合。RPR有助于校准嘈杂的奖励模型,减少潜在的假阴性,并增强LLM在开放式任务上的性能。这些发现表明在预训练阶段提高模型的基本能力的重要性,同时为改进后训练技术提供了见解。我们的代码和脚本可在https://github.com/trestad/Noisy-Rewards-in-Learning-to-Reason获得。
论文及项目相关链接
PDF Preprint
Summary
本研究探讨了使用强化学习(RL)对大型语言模型(LLM)进行训练后的奖励噪声影响。研究发现在数学任务中,手动改变奖励函数的输出不会影响LLM模型的快速收敛和其性能的大幅提升。同时,通过仅奖励关键推理短语(如“首先,我需要”)而不验证答案的正确性,模型取得了与严格验证和准确奖励训练相当的下游性能。结合噪声奖励模型使用推理模式奖励(RPR)有助于校准噪声奖励模型,提高LLM在开放任务上的性能。此研究对于改善模型的预训练能力,并推进后训练技术提供了启示。
Key Takeaways
- 研究关注大型语言模型在强化学习训练后的奖励噪声影响。
- LLM对奖励噪声展现出强鲁棒性,如手动改变数学任务的奖励函数输出仍可实现性能提升。
- 仅通过奖励关键推理短语(如“首先,我需要”),即使不验证答案正确性,也能取得良好下游性能。
- 推理模式奖励(RPR)与噪声奖励模型结合使用有助于提高模型在开放任务上的性能表现。
- RPR有助于校准噪声奖励模型,减少潜在误判并提高LLM性能。
- 研究强调了预训练阶段对模型性能的重要性。
点此查看论文截图


Sherlock: Self-Correcting Reasoning in Vision-Language Models
Authors:Yi Ding, Ruqi Zhang
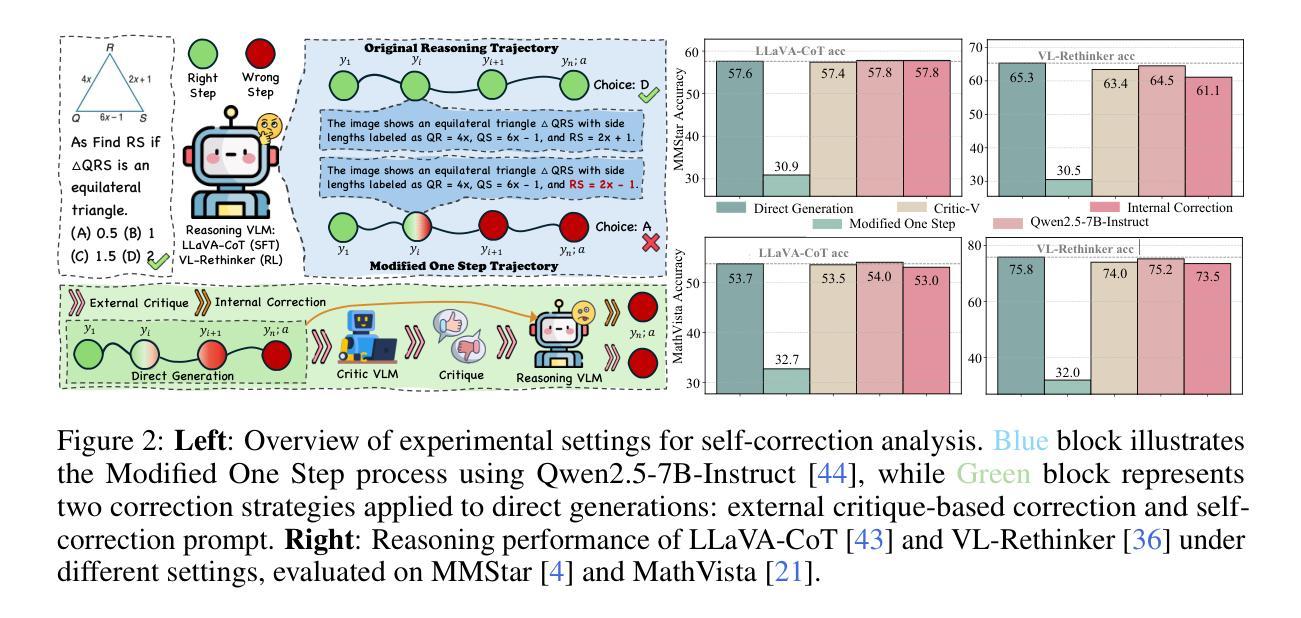
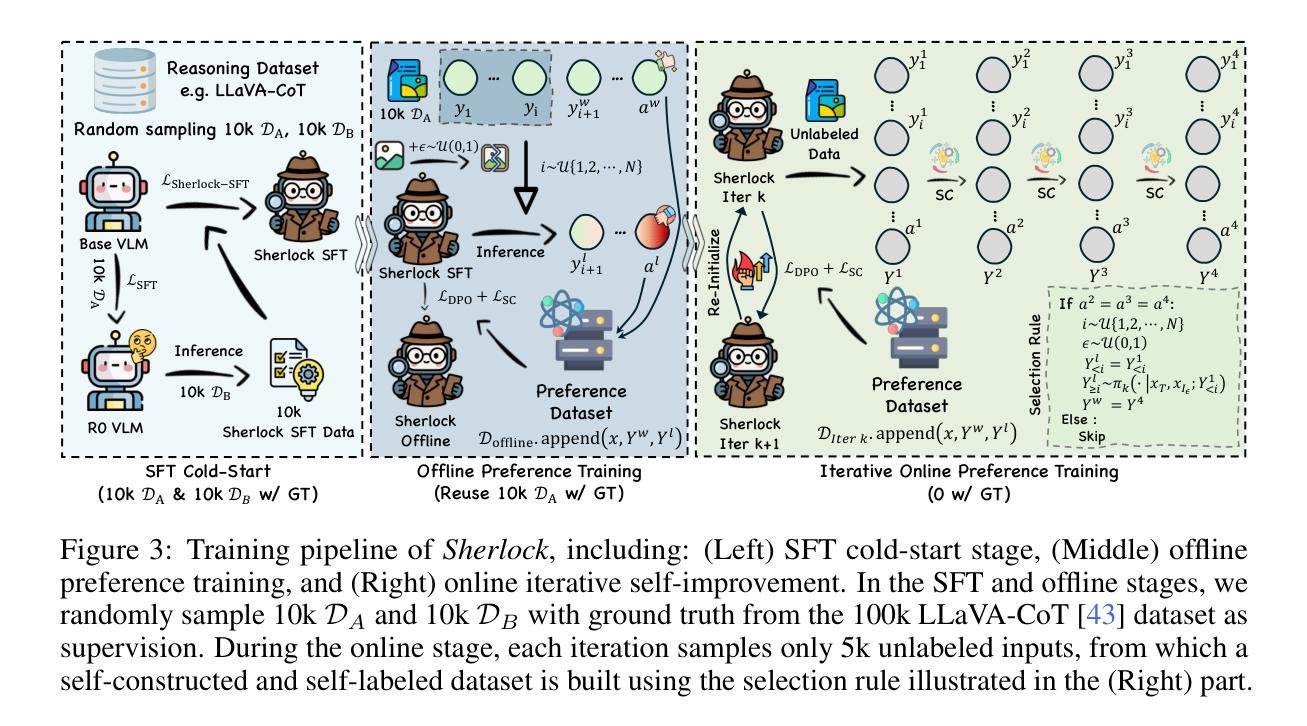
Reasoning Vision-Language Models (VLMs) have shown promising performance on complex multimodal tasks. However, they still face significant challenges: they are highly sensitive to reasoning errors, require large volumes of annotated data or accurate verifiers, and struggle to generalize beyond specific domains. To address these limitations, we explore self-correction as a strategy to enhance reasoning VLMs. We first conduct an in-depth analysis of reasoning VLMs’ self-correction abilities and identify key gaps. Based on our findings, we introduce Sherlock, a self-correction and self-improvement training framework. Sherlock introduces a trajectory-level self-correction objective, a preference data construction method based on visual perturbation, and a dynamic $\beta$ for preference tuning. Once the model acquires self-correction capabilities using only 20k randomly sampled annotated data, it continues to self-improve without external supervision. Built on the Llama3.2-Vision-11B model, Sherlock achieves remarkable results across eight benchmarks, reaching an average accuracy of 64.1 with direct generation and 65.4 after self-correction. It outperforms LLaVA-CoT (63.2), Mulberry (63.9), and LlamaV-o1 (63.4) while using less than 20% of the annotated data.
视觉语言模型(VLMs)在复杂的多媒体任务中表现出有前景的性能。然而,它们仍然面临重大挑战:高度敏感于推理错误,需要大量标注数据或精确验证器,并且在特定领域之外难以推广。为了解决这些局限性,我们探索了自我校正作为一种增强推理VLMs的策略。我们首先深入分析了推理VLMs的自我校正能力,并识别了关键差距。基于我们的发现,我们引入了Sherlock,一个自我校正和自我提升的训练框架。Sherlock引入了一个轨迹级的自我校正目标、一个基于视觉扰动的偏好数据构建方法以及一个用于偏好调整的动态β值。模型仅使用2万条随机采样标注数据获得自我校正能力后,即可继续进行自我提升而无需外部监督。基于Llama3.2-Vision-11B模型,Sherlock在八个基准测试上取得了显著成果,直接生成时的平均准确率为64.1,自我校正后提高到65.4。它的性能优于LLaVA-CoT(63.2)、Mulberry(63.9)和LlamaV-o1(63.4),而且使用的标注数据不到20%。
论文及项目相关链接
PDF 27 pages
Summary
在这个文本中,主要讨论了关于视觉语言模型(VLMs)面临的挑战及其改进方法。为提高模型的推理能力,研究者探索了自我校正策略,并引入了名为Sherlock的自我校正和自我提升训练框架。该框架通过引入轨迹级别的自我校正目标、基于视觉扰动的偏好数据构建方法和动态β偏好调整,使得模型在仅有2万随机采样标注数据的情况下获得自我校正能力,并能在没有外部监督的情况下持续自我提升。基于Llama3.2-Vision-11B模型构建的Sherlock在八个基准测试中取得了显著成果,使用自我校正后平均准确率达到了65.4%。
Key Takeaways
- 视觉语言模型(VLMs)在复杂多模态任务上表现良好,但仍面临推理误差敏感、需要大量标注数据和准确验证器以及难以跨域泛化等挑战。
- 研究者探索了自我校正策略,以提高VLMs的推理能力。
- 引入了名为Sherlock的自我校正和自我提升训练框架,包括轨迹级别的自我校正目标、基于视觉扰动的偏好数据构建方法和动态β偏好调整。
- Sherlock仅需2万随机采样标注数据就能获得自我校正能力,并能在没有外部监督的情况下持续自我提升。
- 基于Llama3.2-Vision-11B模型构建的Sherlock在多个基准测试中表现优秀,平均准确率达到了65.4%。
- Sherlock相较于其他模型(LLaVA-CoT、Mulberry、LlamaV-o1)使用了更少标注数据便取得了更高准确率。
- Sherlock的自我校正和自我提升策略对于解决视觉语言模型在推理任务中的挑战具有积极意义。
点此查看论文截图



WebDancer: Towards Autonomous Information Seeking Agency
Authors:Jialong Wu, Baixuan Li, Runnan Fang, Wenbiao Yin, Liwen Zhang, Zhengwei Tao, Dingchu Zhang, Zekun Xi, Yong Jiang, Pengjun Xie, Fei Huang, Jingren Zhou
Addressing intricate real-world problems necessitates in-depth information seeking and multi-step reasoning. Recent progress in agentic systems, exemplified by Deep Research, underscores the potential for autonomous multi-step research. In this work, we present a cohesive paradigm for building end-to-end agentic information seeking agents from a data-centric and training-stage perspective. Our approach consists of four key stages: (1) browsing data construction, (2) trajectories sampling, (3) supervised fine-tuning for effective cold start, and (4) reinforcement learning for enhanced generalisation. We instantiate this framework in a web agent based on the ReAct, WebDancer. Empirical evaluations on the challenging information seeking benchmarks, GAIA and WebWalkerQA, demonstrate the strong performance of WebDancer, achieving considerable results and highlighting the efficacy of our training paradigm. Further analysis of agent training provides valuable insights and actionable, systematic pathways for developing more capable agentic models. The codes and demo will be released in https://github.com/Alibaba-NLP/WebAgent.
解决复杂的现实世界问题需要进行深入的信息搜索和多步骤推理。以深度研究为例的代理系统(agentic systems)的最新进展突显了自主多步骤研究的潜力。在这项工作中,我们从数据为中心和训练阶段的角度,提出了构建端到端代理信息搜索代理的连贯范式。我们的方法包括四个关键阶段:(1)浏览数据构建,(2)轨迹采样,(3)有效冷启动的监督微调,以及(4)增强通用的强化学习。我们以基于ReAct的Web代理WebDancer实例化此框架。在具有挑战性的信息搜索基准测试GAIA和WebWalkerQA上的经验评估表明,WebDancer表现出强大的性能,取得了显著的结果,并突出了我们训练范式的有效性。对代理训练的进一步分析提供了宝贵的见解和可行的系统性途径,有助于开发更具能力的代理模型。代码和演示将在https://github.com/Alibaba-NLP/WebAgent发布。
论文及项目相关链接
Summary
该文本主要介绍了为解决现实世界中的复杂问题,需要深入的信息搜索和多步骤推理。通过介绍一种新型的端到端智能信息搜索代理的构建方法,展示了自主多步骤研究的潜力。该方法包括四个阶段:浏览数据构建、轨迹采样、监督微调实现冷启动以及强化学习提升泛化能力。通过在信息搜索基准测试上的实证评估,证明了该框架的有效性。
Key Takeaways
- 解决现实世界复杂问题需要深入信息搜索和多步骤推理。
- 新型端到端智能信息搜索代理的构建方法包括浏览数据构建、轨迹采样等四个阶段。
- 该方法通过监督微调实现冷启动,强化学习提升代理的泛化能力。
- 在信息搜索基准测试上的实证评估证明了该框架的有效性。
- 该代理框架在WebAgent上的实例应用取得了显著成果。
- 通过对代理训练的分析,提供了开发更强大代理模型的可行路径。
点此查看论文截图

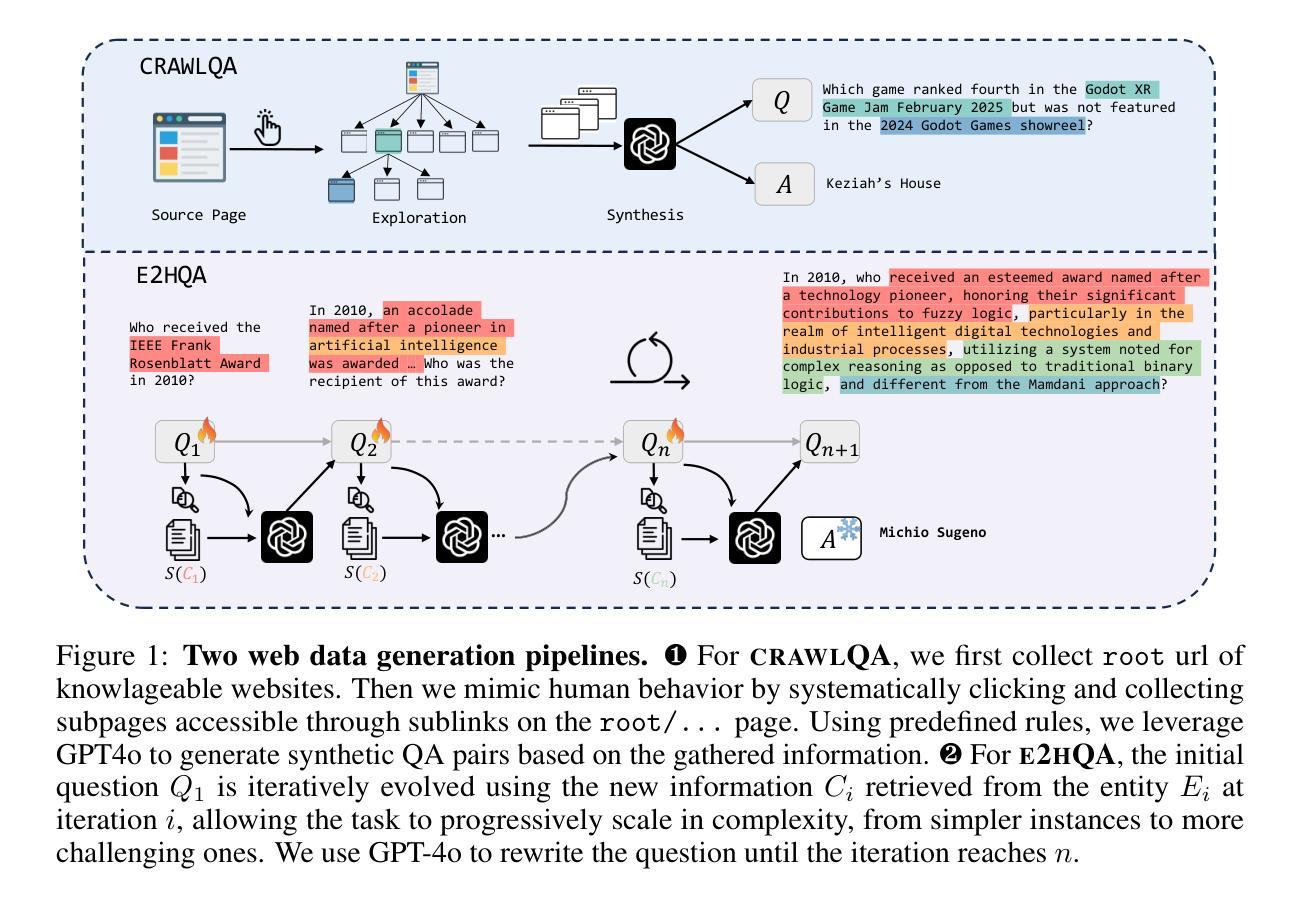
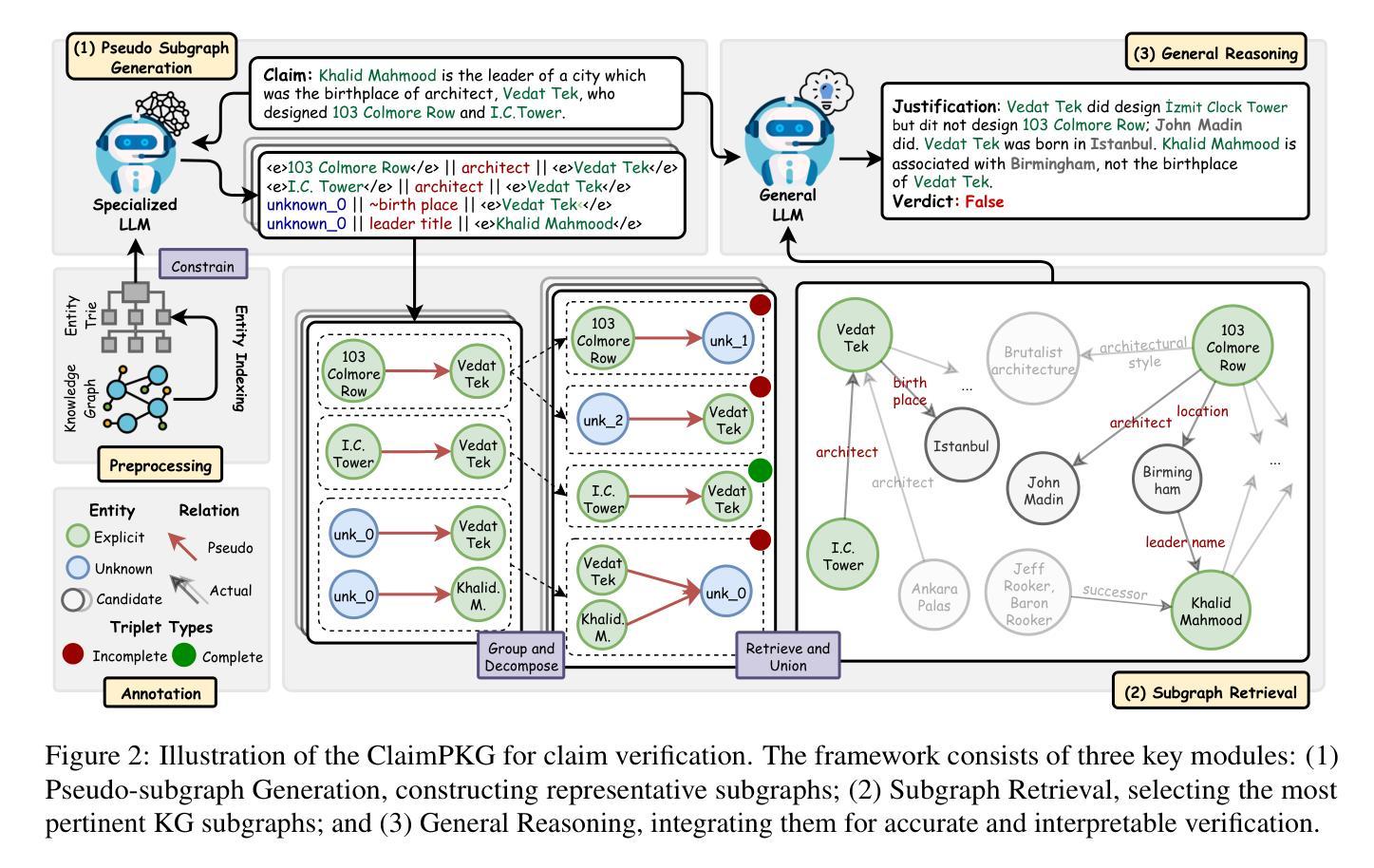
ClaimPKG: Enhancing Claim Verification via Pseudo-Subgraph Generation with Lightweight Specialized LLM
Authors:Hoang Pham, Thanh-Do Nguyen, Khac-Hoai Nam Bui
Integrating knowledge graphs (KGs) to enhance the reasoning capabilities of large language models (LLMs) is an emerging research challenge in claim verification. While KGs provide structured, semantically rich representations well-suited for reasoning, most existing verification methods rely on unstructured text corpora, limiting their ability to effectively leverage KGs. Additionally, despite possessing strong reasoning abilities, modern LLMs struggle with multi-step modular pipelines and reasoning over KGs without adaptation. To address these challenges, we propose ClaimPKG, an end-to-end framework that seamlessly integrates LLM reasoning with structured knowledge from KGs. Specifically, the main idea of ClaimPKG is to employ a lightweight, specialized LLM to represent the input claim as pseudo-subgraphs, guiding a dedicated subgraph retrieval module to identify relevant KG subgraphs. These retrieved subgraphs are then processed by a general-purpose LLM to produce the final verdict and justification. Extensive experiments on the FactKG dataset demonstrate that ClaimPKG achieves state-of-the-art performance, outperforming strong baselines in this research field by 9%-12% accuracy points across multiple categories. Furthermore, ClaimPKG exhibits zero-shot generalizability to unstructured datasets such as HoVer and FEVEROUS, effectively combining structured knowledge from KGs with LLM reasoning across various LLM backbones.
将知识图谱(KGs)整合到增强大型语言模型(LLMs)的推理能力中,是声明验证领域的新兴研究挑战。虽然知识图谱提供了结构化和语义丰富的表示形式,非常适合进行推理,但大多数现有的验证方法依赖于非结构化文本语料库,这限制了它们有效利用知识图谱的能力。此外,尽管具备强大的推理能力,但现代大型语言模型在处理多步骤模块化管道和基于知识图谱的推理时仍面临困难,除非进行适应。为了应对这些挑战,我们提出了ClaimPKG端到端框架,该框架无缝集成了大型语言模型的推理与知识图谱的结构化知识。具体来说,ClaimPKG的主要思想是利用一个轻量级的大型语言模型来将输入声明表示为伪子图,引导专用的子图检索模块识别相关的知识图谱子图。然后,这些检索到的子图被通用的大型语言模型处理,以得出最终裁决和解释。在FactKG数据集上的大量实验表明,ClaimPKG达到了最先进的性能水平,在该研究领域的多个类别中比强大的基线高出9%-12%的准确率。此外,ClaimPKG在无结构数据集(如HoVer和FEVEROUS)上表现出零样本泛化能力,有效地结合了知识图谱的结构化知识与大型语言模型的推理能力。
论文及项目相关链接
PDF Accepted by ACL 2025 findings
Summary:整合知识图谱以提升大型语言模型的推理能力,是声明验证领域的新兴研究挑战。知识图谱提供结构化和语义丰富的表示形式,适合进行推理。然而,大多数现有的验证方法依赖于非结构化文本语料库,无法有效利用知识图谱。为解决此问题,我们提出ClaimPKG框架,将LLM推理与知识图谱的结构化知识无缝集成。它通过轻量级LLM表示输入声明为伪子图,指导特定的子图检索模块识别相关的KG子图。这些检索到的子图再被通用LLM处理,产生最终裁决和依据。实验表明,ClaimPKG在FactKG数据集上取得了最先进的性能,比该领域强大的基线高出9%-12%的准确率点。此外,ClaimPKG在HoVer和FEVEROUS等非结构化数据集上表现出零样本泛化能力。
Key Takeaways:
- 知识图谱(KGs)对于增强大型语言模型(LLMs)的推理能力具有潜力。
- 现有验证方法主要依赖非结构化文本语料库,限制了知识图谱的有效利用。
- ClaimPKG框架通过集成LLM推理和知识图谱的结构化知识来解决这一挑战。
- ClaimPKG使用轻量级LLM将输入声明表示为伪子图,并引导子图检索。
- 检索到的子图由通用LLM处理,以产生最终裁决和依据。
- 在FactKG数据集上,ClaimPKG表现出卓越性能,准确率显著提高。
点此查看论文截图

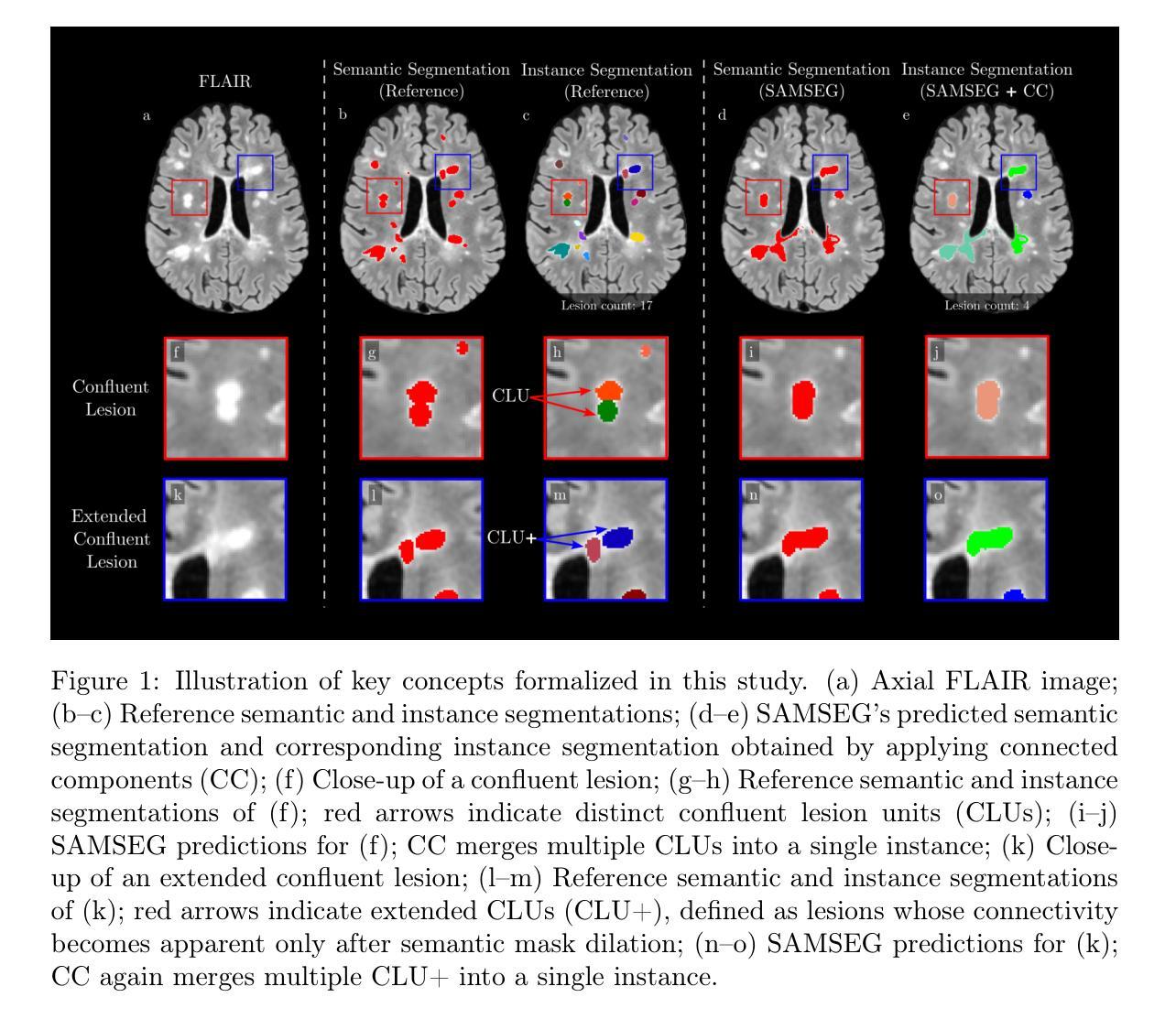
ConfLUNet: Multiple sclerosis lesion instance segmentation in presence of confluent lesions
Authors:Maxence Wynen, Pedro M. Gordaliza, Maxime Istasse, Anna Stölting, Pietro Maggi, Benoît Macq, Meritxell Bach Cuadra
Accurate lesion-level segmentation on MRI is critical for multiple sclerosis (MS) diagnosis, prognosis, and disease monitoring. However, current evaluation practices largely rely on semantic segmentation post-processed with connected components (CC), which cannot separate confluent lesions (aggregates of confluent lesion units, CLUs) due to reliance on spatial connectivity. To address this misalignment with clinical needs, we introduce formal definitions of CLUs and associated CLU-aware detection metrics, and include them in an exhaustive instance segmentation evaluation framework. Within this framework, we systematically evaluate CC and post-processing-based Automated Confluent Splitting (ACLS), the only existing methods for lesion instance segmentation in MS. Our analysis reveals that CC consistently underestimates CLU counts, while ACLS tends to oversplit lesions, leading to overestimated lesion counts and reduced precision. To overcome these limitations, we propose ConfLUNet, the first end-to-end instance segmentation framework for MS lesions. ConfLUNet jointly optimizes lesion detection and delineation from a single FLAIR image. Trained on 50 patients, ConfLUNet significantly outperforms CC and ACLS on the held-out test set (n=13) in instance segmentation (Panoptic Quality: 42.0% vs. 37.5%/36.8%; p = 0.017/0.005) and lesion detection (F1: 67.3% vs. 61.6%/59.9%; p = 0.028/0.013). For CLU detection, ConfLUNet achieves the highest F1[CLU] (81.5%), improving recall over CC (+12.5%, p = 0.015) and precision over ACLS (+31.2%, p = 0.003). By combining rigorous definitions, new CLU-aware metrics, a reproducible evaluation framework, and the first dedicated end-to-end model, this work lays the foundation for lesion instance segmentation in MS.
在磁共振成像(MRI)上进行精确的病变级别分割对于多发性硬化症(MS)的诊断、预后和疾病监测至关重要。然而,当前的评估实践主要依赖于通过连通组件(CC)进行后处理的语义分割,这无法分离融合性病变(融合性病变单位聚集的CLUs),因为它们依赖于空间连通性。为了解决这一临床需求的错配问题,我们引入了CLUs的正式定义和相关的CLU感知检测指标,并将其纳入详尽的实例分割评估框架中。在此框架内,我们系统地评估了基于连通组件(CC)和后处理的自动融合分割(ACLS),这是多发性硬化症病变实例分割中唯一存在的方法。我们的分析表明,CC始终低估了CLU计数,而ACLS倾向于过度分割病变,导致病变计数过高和精度降低。为了克服这些局限性,我们提出了ConfLUNet,这是多发性硬化症病变实例分割的第一个端到端框架。ConfLUNet联合优化从单个FLAIR图像中检测病变和轮廓描绘。在50名患者上进行训练后,ConfLUNet在保留的测试集(n=13)上的实例分割方面显著优于CC和ACLS(全景质量:42.0% vs. 37.5%/36.8%;p = 0.017/0.005),在病变检测方面也是如此(F1:67.3% vs. 61.6%/59.9%;p = 0.028/0.013)。对于CLU检测,ConfLUNet实现了最高的F1 [CLU](81.5%),在召回率上较CC提高了(+12.5%,p = 0.015),在精度上较ACLS提高了(+31.2%,p = 0.003)。通过结合严格的定义、新的CLU感知指标、可复制的评估框架和第一个专用的端到端模型,这项工作为多发性硬化症中的病变实例分割奠定了基础。
论文及项目相关链接
Summary
针对多发性硬化症(MS)的MRI图像进行精确的病灶级别分割对于诊断、预后和疾病监测至关重要。然而,当前的评价实践主要依赖于基于连通组件(CC)的语义分割,无法分离融合病灶(CLUs)。为解决这一问题,本文引入CLUs的正式定义和相关CLU感知检测指标,并将其纳入详尽的实例分割评估框架中。分析表明,CC低估了CLU计数,而现有的ACLS方法倾向于过度分割病灶。为解决这些局限性,本文提出ConfLUNet,这是首个针对MS病灶的端到端实例分割框架。ConfLUNet从单个FLAIR图像中联合优化病灶检测和轮廓描绘。在50名患者上的训练结果显示,ConfLUNet在实例分割和病灶检测方面显著优于CC和ACLS。此外,ConfLUNet实现了最高的CLU检测F1分数,在召回率上超过了CC,并在精确度上超越了ACLS。通过严格的定义、新的CLU感知指标、可复制的评价框架和首个端到端模型,这项工作为MS的病灶实例分割奠定了基础。
Key Takeaways
- 准确的多发性硬化症(MS)MRI病灶级别分割对诊断、预后和疾病监测至关重要。
- 当前使用的基于连通组件(CC)的语义分割无法有效分离融合病灶(CLUs)。
- 引入CLUs的正式定义和相关CLU感知检测指标,建立了一个全面的实例分割评估框架。
- 分析显示,CC低估了CLU计数,而现有的ACLS方法存在过度分割的问题。
- 提出ConfLUNet,一个针对MS的端到端实例分割框架,能联合优化病灶检测和轮廓描绘。
- ConfLUNet在实例分割和病灶检测方面显著优于CC和ACLS。
点此查看论文截图


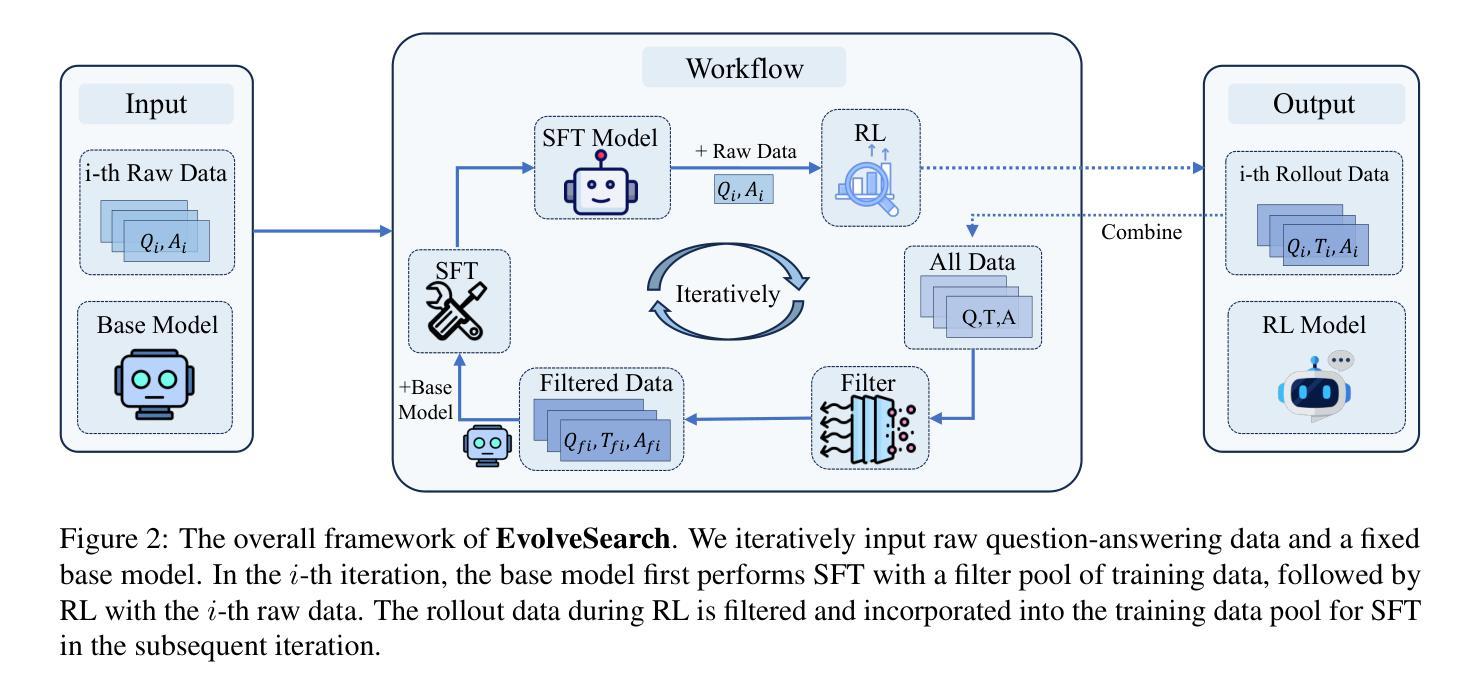
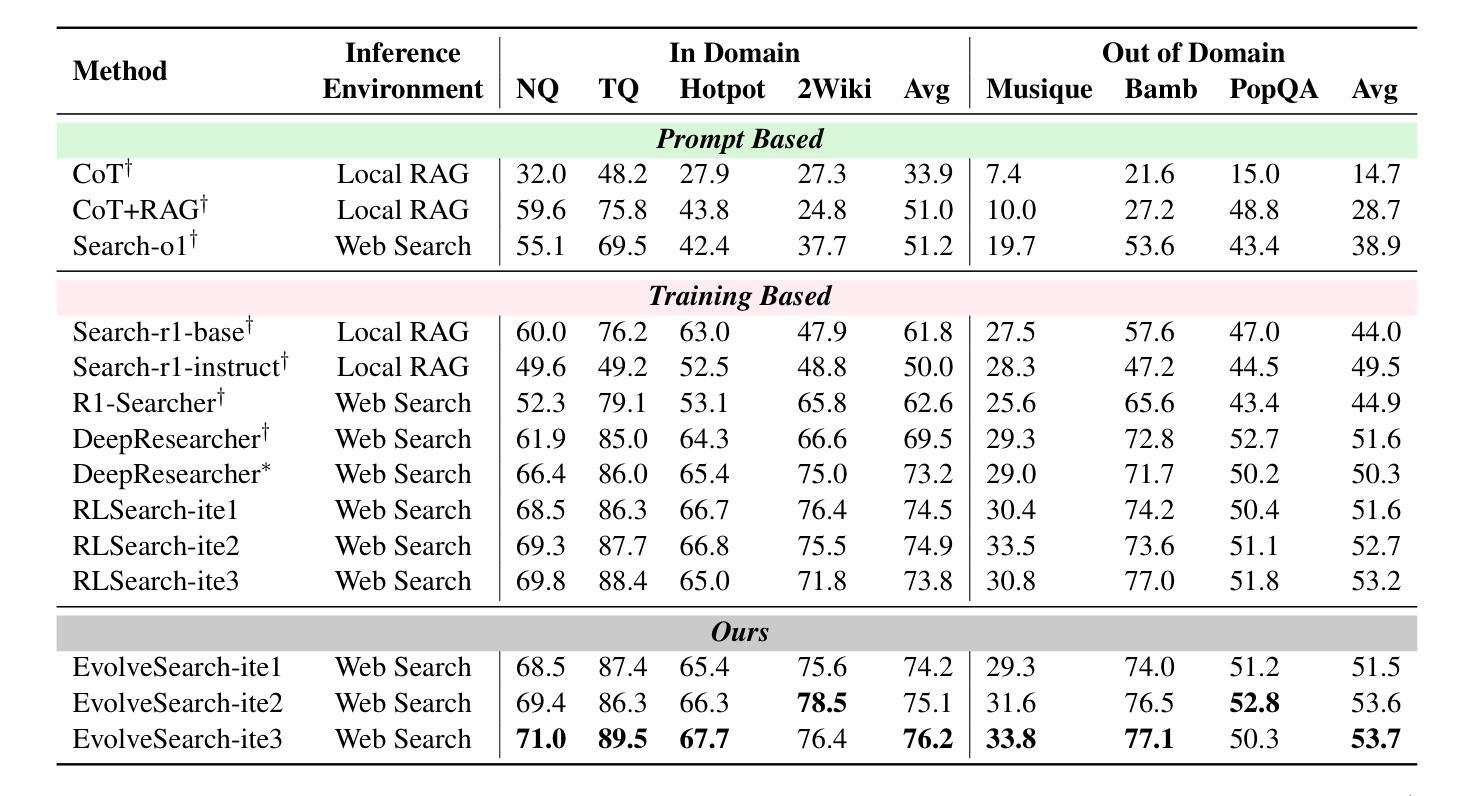
EvolveSearch: An Iterative Self-Evolving Search Agent
Authors:Dingchu Zhang, Yida Zhao, Jialong Wu, Baixuan Li, Wenbiao Yin, Liwen Zhang, Yong Jiang, Yufeng Li, Kewei Tu, Pengjun Xie, Fei Huang
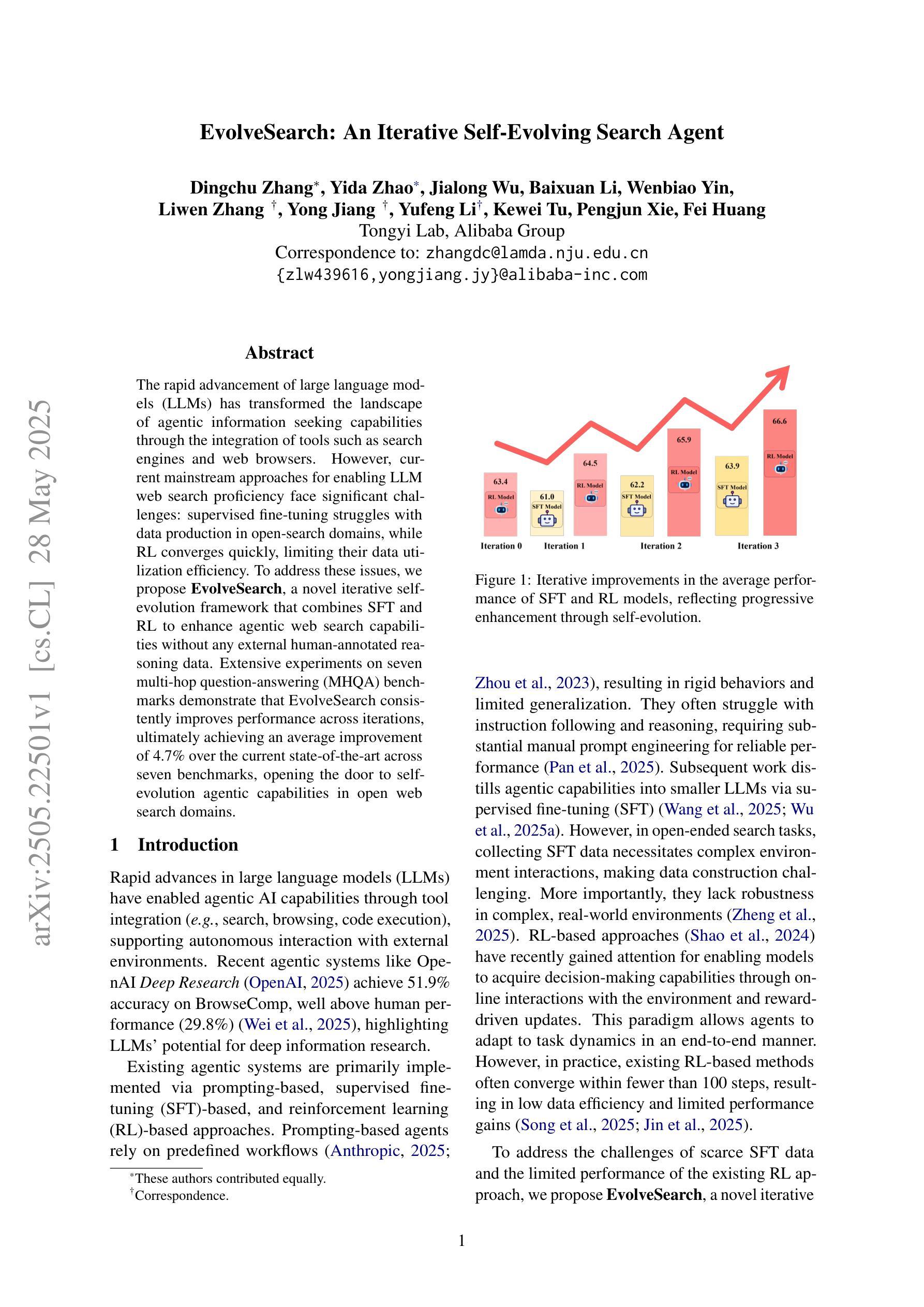
The rapid advancement of large language models (LLMs) has transformed the landscape of agentic information seeking capabilities through the integration of tools such as search engines and web browsers. However, current mainstream approaches for enabling LLM web search proficiency face significant challenges: supervised fine-tuning struggles with data production in open-search domains, while RL converges quickly, limiting their data utilization efficiency. To address these issues, we propose EvolveSearch, a novel iterative self-evolution framework that combines SFT and RL to enhance agentic web search capabilities without any external human-annotated reasoning data. Extensive experiments on seven multi-hop question-answering (MHQA) benchmarks demonstrate that EvolveSearch consistently improves performance across iterations, ultimately achieving an average improvement of 4.7% over the current state-of-the-art across seven benchmarks, opening the door to self-evolution agentic capabilities in open web search domains.
大型语言模型(LLM)的快速发展通过搜索引擎和浏览器等工具的集成,改变了智能信息检索能力的研究格局。然而,当前主流方法在实现LLM网络搜索能力方面面临重大挑战:监督微调在开放搜索领域的数据生产方面表现挣扎,而强化学习虽然收敛迅速,但数据利用效率有限。为了解决这些问题,我们提出了EvolveSearch,这是一个新型迭代自进化框架,结合了SFT和强化学习,无需任何外部人工注释推理数据即可增强智能网络搜索能力。在七个多跳问答基准测试上的实验表明,EvolveSearch在迭代过程中表现一致地改进性能,最终在七个基准测试上平均比当前最佳水平提高了4.7%,为开放网络搜索领域的智能自我进化能力的发展打开了大门。
论文及项目相关链接
Summary:大型语言模型(LLM)的快速发展通过集成搜索引擎和浏览器等技术,改变了信息检索能力的格局。然而,主流方法在实现LLM网络搜索能力方面面临挑战:监督微调面临开放搜索领域数据生成的问题,而强化学习收敛迅速,限制了数据利用效率。为解决这些问题,提出EvolveSearch框架,结合监督微调与强化学习,提高网络搜索能力,无需外部人类注释的推理数据。在七个多跳问答基准测试上的实验表明,EvolveSearch在迭代中性能持续提高,最终较现有技术平均提高了4.7%,为开放网络搜索领域的自主进化能力打开了大门。
Key Takeaways:
- 大型语言模型(LLM)在信息检索领域有重要应用,但面临监督微调与强化学习的挑战。
- EvolveSearch框架结合了监督微调(SFT)和强化学习(RL),旨在提高LLM的网络搜索能力。
- EvolveSearch无需外部人类注释的推理数据,提高了数据利用效率。
- 在七个多跳问答基准测试上,EvolveSearch较现有技术平均提高了4.7%的性能。
- EvolveSearch的迭代性质使其能够在不断进化中优化性能。
- 该框架的提出为开放网络搜索领域的自主进化能力研究带来了新的可能性。
点此查看论文截图


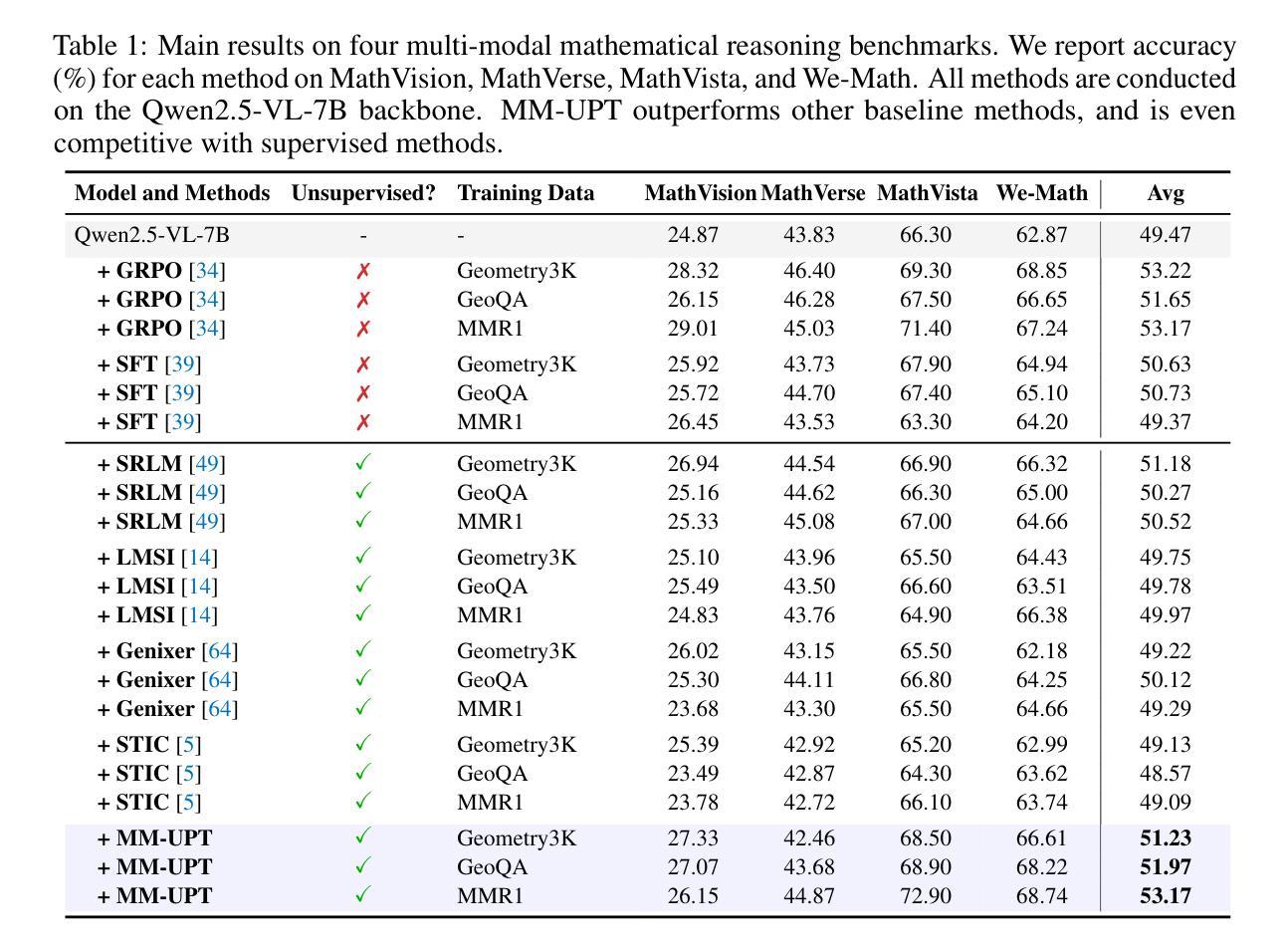
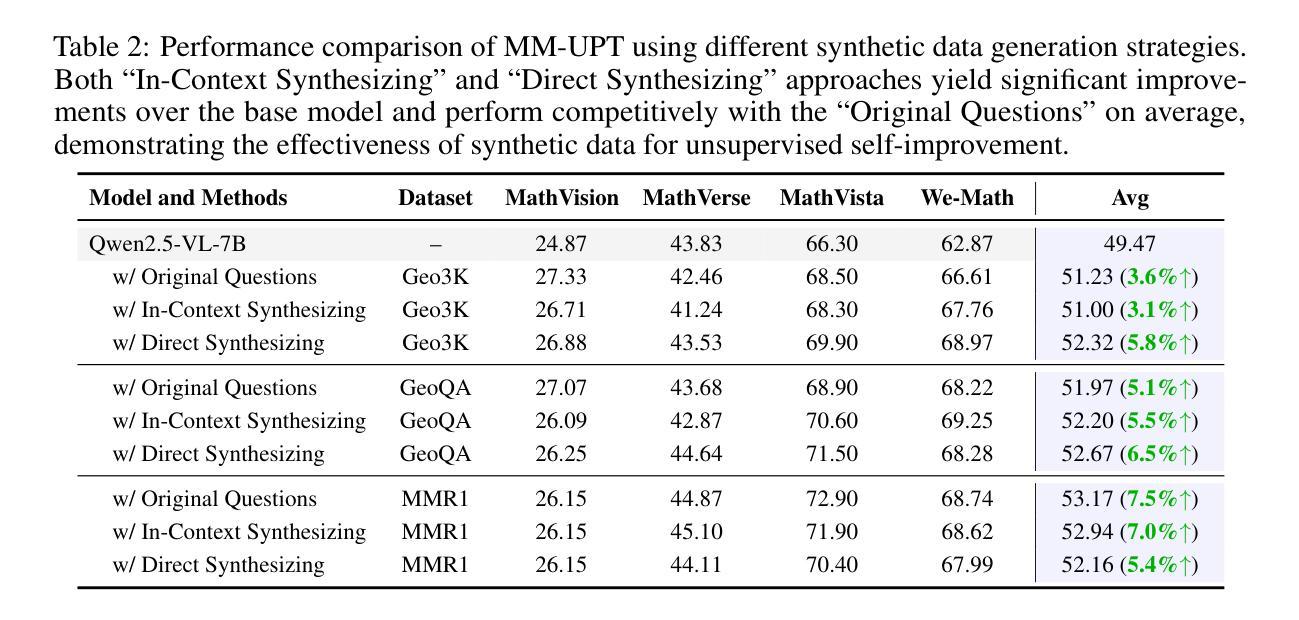
Unsupervised Post-Training for Multi-Modal LLM Reasoning via GRPO
Authors:Lai Wei, Yuting Li, Chen Wang, Yue Wang, Linghe Kong, Weiran Huang, Lichao Sun
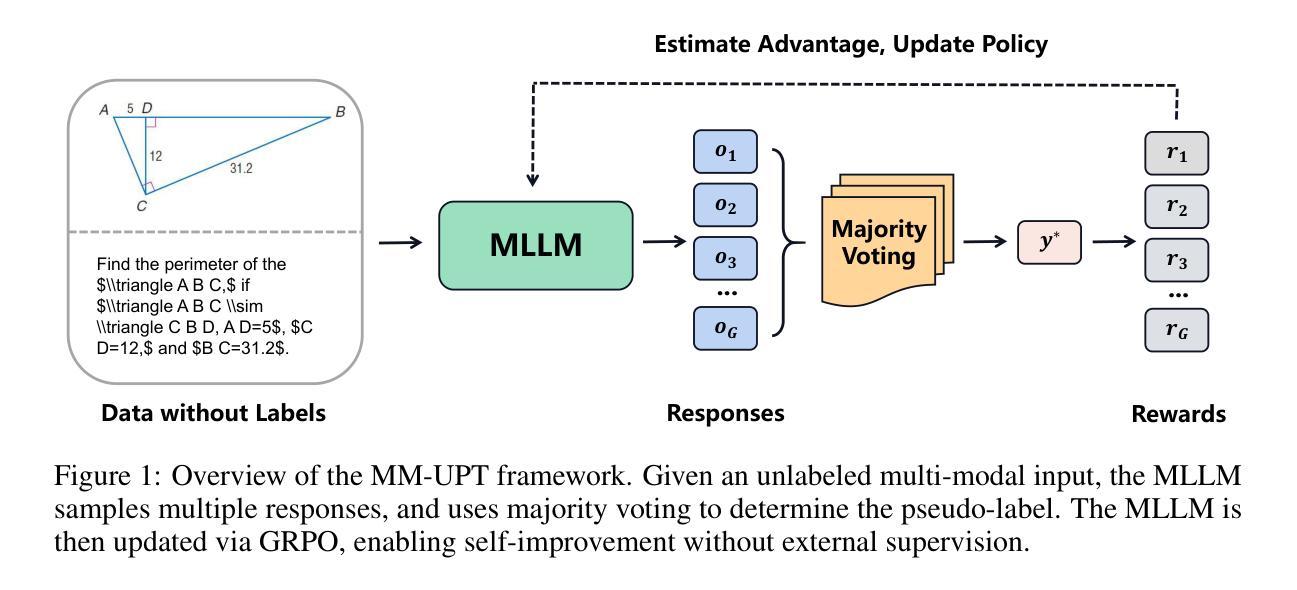
Improving Multi-modal Large Language Models (MLLMs) in the post-training stage typically relies on supervised fine-tuning (SFT) or reinforcement learning (RL). However, these supervised methods require expensive and manually annotated multi-modal data–an ultimately unsustainable resource. While recent efforts have explored unsupervised post-training, their methods are complex and difficult to iterate. In this work, we are the first to investigate the use of GRPO, a stable and scalable online RL algorithm, for enabling continual self-improvement without any external supervision. We propose MM-UPT, a simple yet effective framework for unsupervised post-training of MLLMs. MM-UPT builds upon GRPO, replacing traditional reward signals with a self-rewarding mechanism based on majority voting over multiple sampled responses. Our experiments demonstrate that MM-UPT significantly improves the reasoning ability of Qwen2.5-VL-7B (e.g., 66.3 %$\rightarrow$72.9 % on MathVista, 62.9 %$\rightarrow$68.7 % on We-Math), using standard dataset without ground truth labels. MM-UPT also outperforms prior unsupervised baselines and even approaches the results of supervised GRPO. Furthermore, we show that incorporating synthetic questions, generated solely by MLLM itself, can boost performance as well, highlighting a promising approach for scalable self-improvement. Overall, MM-UPT offers a new paradigm for continual, autonomous enhancement of MLLMs in the absence of external supervision. Our code is available at https://github.com/waltonfuture/MM-UPT.
在训练后阶段改进多模态大型语言模型(MLLMs)通常依赖于有监督的微调(SFT)或强化学习(RL)。然而,这些监督方法需要大量手动标注的多模态数据,这是一个最终无法持续的资源。虽然最近有尝试探索无监督的后训练,但他们的方法复杂且难以迭代。在这项工作中,我们首次调查了GRPO这一稳定且可扩展的在线RL算法的使用情况,以实现无需任何外部监督的持续自我改进。我们提出了MM-UPT,这是一个简单有效的多模态大型语言模型无监督后训练框架。MM-UPT建立在GRPO的基础上,用基于多数投票的多个采样响应的自我奖励机制取代了传统的奖励信号。我们的实验表明,在标准数据集上,无需真实标签,MM-UPT就能显著提高Qwen2.5-VL-7B的推理能力(例如,MathVista上的66.3%提升到72.9%,We-Math上的62.9%提升到68.7%)。MM-UPT也优于先前的无监督基准测试,甚至接近有监督GRPO的结果。此外,我们还证明了通过MLLM本身生成的合成问题也可以提高性能,这凸显了一种有前景的可扩展自我改进方法。总体而言,MM-UPT为在无外部监督的情况下对MLLM进行持续自主的改进提供了新的范式。我们的代码可通过以下网址获取:https://github.com/waltonfuture/MM-UPT。
论文及项目相关链接
摘要
MLLM的后训练阶段改进通常依赖于有监督的微调(SFT)或强化学习(RL)。然而,这些监督方法需要昂贵且手动注释的多模态数据,这是一种最终不可持续的资源。最近的研究虽然开始探索无监督的后训练,但其方法复杂且难以迭代。在这项工作中,我们首次调查了GRPO这一稳定且可扩展的在线RL算法在无需外部监督的情况下实现持续自我改进的能力。我们提出了MM-UPT,这是一个简单有效的MLLM无监督后训练框架。MM-UPT基于GRPO构建,用基于多数投票的自我奖励机制取代了传统的奖励信号。实验表明,MM-UPT显著提高了Qwen2.5-VL-7B的推理能力(例如,MathVista上的66.3%提高到72.9%,We-Math上的62.9%提高到68.7%),并且使用了没有真实标签的标准数据集。MM-UPT还优于先前的无监督基线,甚至接近有监督GRPO的结果。此外,我们证明了通过MLLM本身生成的合成问题也可以提高性能,这显示出了一种有前景的可扩展自我改进方法。总体而言,MM-UPT为在没有外部监督的情况下实现MLLM的持续自主增强提供了新的范式。我们的代码位于:https://github.com/waltonfuture/MM-UPT。
关键见解
- 介绍了MM-UPT作为一种新型的框架在无监督的后训练阶段用于改进多模态大型语言模型(MLLMs)。
- MM-UPT首次探索使用GRPO在线强化学习算法进行模型自主改进的可能。
- 通过多数投票的自我奖励机制,使得模型能在无外部监督的情况下自我改善性能。
- 实验结果证明了MM-UPT在提升模型推理能力上的有效性,特别是在数学领域的任务上。
- MM-UPT的性能超越了现有的无监督方法,并接近了受监督学习的结果。
- 集成由MLLM自身生成的合成问题能够进一步提升模型的性能表现。
点此查看论文截图

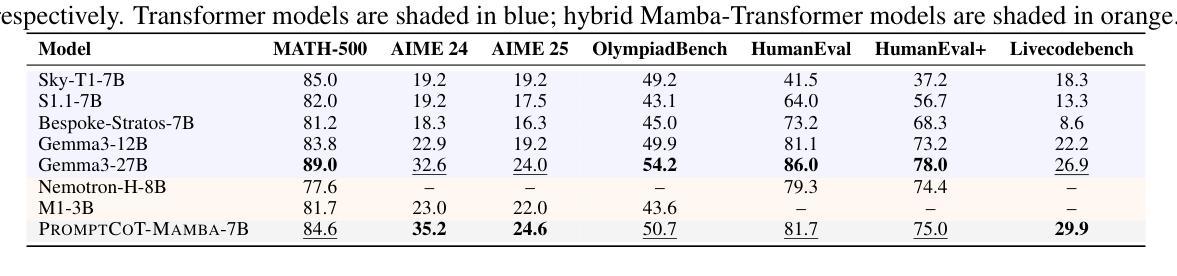
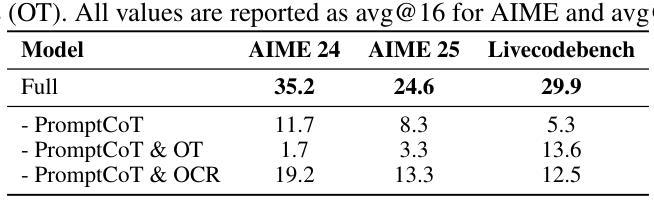
Scaling Reasoning without Attention
Authors:Xueliang Zhao, Wei Wu, Lingpeng Kong
Large language models (LLMs) have made significant advances in complex reasoning tasks, yet they remain bottlenecked by two core challenges: architectural inefficiency due to reliance on Transformers, and a lack of structured fine-tuning for high-difficulty domains. We introduce \ourmodel, an attention-free language model that addresses both issues through architectural and data-centric innovations. Built on the state space dual (SSD) layers of Mamba-2, our model eliminates the need for self-attention and key-value caching, enabling fixed-memory, constant-time inference. To train it for complex reasoning, we propose a two-phase curriculum fine-tuning strategy based on the \textsc{PromptCoT} synthesis paradigm, which generates pedagogically structured problems via abstract concept selection and rationale-guided generation. On benchmark evaluations, \ourmodel-7B outperforms strong Transformer and hybrid models of comparable scale, and even surpasses the much larger Gemma3-27B by 2.6% on AIME 24, 0.6% on AIME 25, and 3.0% on Livecodebench. These results highlight the potential of state space models as efficient and scalable alternatives to attention-based architectures for high-capacity reasoning.
大型语言模型(LLMs)在复杂推理任务方面取得了显著进展,但仍面临两大核心挑战:因依赖Transformer而导致的架构效率低下,以及缺乏针对高难度领域的结构化微调。我们推出了无注意力语言模型——ourmodel,它通过架构和数据中心的创新来解决这两个问题。我们的模型基于Mamba-2的状态空间双(SSD)层,消除了对自注意力和键值缓存的需求,实现了固定内存、恒定时间的推理。为了对其进行复杂推理训练,我们提出了基于PromptCoT合成范式的两阶段课程微调策略,通过抽象概念选择和理性引导生成,生成教育结构化问题。在基准评估中,ourmodel-7B表现优于同规模的优势Transformer和混合模型,甚至在AIME 24上超越了更大的Gemma3-27B 2.6%、AIME 25上提高了0.6%,以及在Livecodebench上提高了3.0%。这些结果突显了状态空间模型作为高效且可扩展的替代注意力基础架构进行高容量推理的潜力。
论文及项目相关链接
PDF preprint
Summary
大型语言模型(LLMs)在复杂推理任务中取得显著进展,但仍面临两大挑战:依赖Transformer的架构低效性和缺乏针对高难度域的结构化微调。本文提出的ourmodel是一种解决这两个问题的注意力自由的语言模型,通过架构和数据中心创新实现。该模型建立在Mamba-2的状态空间双重(SSD)层上,消除了对自注意力和键值缓存的需求,实现了固定内存、恒定时间的推理。为了对其进行复杂推理训练,本文提出了一种基于\text{PromptCoT}合成范式的两阶段课程微调策略,通过抽象概念选择和理性引导生成来生成教学结构化问题。在基准评估中,ourmodel-7B表现出优于同类规模的强大Transformer和混合模型的能力,甚至在AIME 24上比更大的Gemma3-27B高出2.6%,在AIME 25上高出0.6%,在Livecodebench上高出3.0%。这些结果突显了状态空间模型作为高效、可扩展的替代注意力基础架构进行高容量推理的潜力。
Key Takeaways
- 大型语言模型(LLMs)在复杂推理任务中面临两大挑战:架构低效性和缺乏结构化微调。
- ourmodel是一种注意力自由的语言模型,解决了这两个问题,通过架构和数据中心创新实现。
- ourmodel建立在Mamba-2的状态空间双重(SSD)层上,不需要自注意力和键值缓存,实现固定内存、恒定时间推理。
- 提出了基于\text{PromptCoT}合成范式的两阶段课程微调策略,用于复杂推理训练。
- ourmodel通过抽象概念选择和理性引导生成生成教学结构化问题。
- ourmodel-7B在基准评估中表现出卓越性能,优于同类规模的模型,甚至在某些评估上超过了更大的Gemma3-27B。
点此查看论文截图

Mitigating Overthinking in Large Reasoning Models via Manifold Steering
Authors:Yao Huang, Huanran Chen, Shouwei Ruan, Yichi Zhang, Xingxing Wei, Yinpeng Dong
Recent advances in Large Reasoning Models (LRMs) have demonstrated remarkable capabilities in solving complex tasks such as mathematics and coding. However, these models frequently exhibit a phenomenon known as overthinking during inference, characterized by excessive validation loops and redundant deliberation, leading to substantial computational overheads. In this paper, we aim to mitigate overthinking by investigating the underlying mechanisms from the perspective of mechanistic interpretability. We first showcase that the tendency of overthinking can be effectively captured by a single direction in the model’s activation space and the issue can be eased by intervening the activations along this direction. However, this efficacy soon reaches a plateau and even deteriorates as the intervention strength increases. We therefore systematically explore the activation space and find that the overthinking phenomenon is actually tied to a low-dimensional manifold, which indicates that the limited effect stems from the noises introduced by the high-dimensional steering direction. Based on this insight, we propose Manifold Steering, a novel approach that elegantly projects the steering direction onto the low-dimensional activation manifold given the theoretical approximation of the interference noise. Extensive experiments on DeepSeek-R1 distilled models validate that our method reduces output tokens by up to 71% while maintaining and even improving the accuracy on several mathematical benchmarks. Our method also exhibits robust cross-domain transferability, delivering consistent token reduction performance in code generation and knowledge-based QA tasks. Code is available at: https://github.com/Aries-iai/Manifold_Steering.
近年来,大型推理模型(LRMs)在解决数学和编程等复杂任务方面表现出了显著的能力。然而,这些模型在推理过程中经常表现出一种被称为“过度思考”的现象,其特征在于过多的验证循环和冗余的思索,导致计算开销大大增加。在本文中,我们从机械可解释性的角度探讨潜在机制,旨在减轻过度思考。我们首先展示,过度思考的倾向可以通过模型激活空间中的一个方向有效地捕获,通过沿此方向干预激活可以缓解该问题。然而,随着干预强度的增加,这种效果很快达到饱和,甚至恶化。因此,我们系统地探索了激活空间,并发现过度思考现象实际上与低维流形有关,这表明有限的效果源于高维引导方向引入的噪声。基于此见解,我们提出了流形转向(Manifold Steering)这一新方法,它将引导方向巧妙地投影到低维激活流形上,实现了干扰噪声的理论近似。在DeepSeek-R1蒸馏模型上的大量实验验证,我们的方法将输出令牌减少了高达71%,同时在多个数学基准测试上维持甚至提高了准确性。我们的方法还表现出强大的跨域可迁移性,在代码生成和知识问答任务中均表现出一致的令牌减少性能。代码可通过以下网址获取:https://github.com/Aries-iai/Manifold_Steering。
论文及项目相关链接
PDF 17 pages, 7 figures
Summary
大型推理模型(LRMs)在解决数学和编码等复杂任务方面展现出卓越的能力,但常常出现过度思考现象,导致计算开销增大。本文从机械解释性的角度探讨缓解过度思考的方法。通过干预模型的激活空间方向,可以有效捕捉过度思考倾向并缓解该问题,但随着干预强度的增加,效果会达到瓶颈甚至恶化。研究发现过度思考现象与低维流形有关,因此提出流形导航方法,将导航方向投影到低维激活流形上,以减少干扰噪声的理论近似。实验证明,该方法在保持甚至提高数学基准测试准确性的同时,减少了高达71%的输出标记。此方法还表现出跨域的可转移性,在代码生成和知识问答任务中实现了持续减少标记的性能。
Key Takeaways
- 大型推理模型(LRMs)在处理复杂任务时表现出优秀的性能,但存在过度思考现象,导致计算开销增大。
- 过度思考现象可以通过干预模型的激活空间方向来捕捉和缓解。
- 过度思考现象与低维流形有关,而现有的干预方法在高维导航方向上引入噪声,导致效果有限。
- 提出流形导航方法,将导航方向投影到低维激活流形上,减少干扰噪声,有效减少输出标记,提高模型效率。
- 流形导航方法在保持甚至提高数学基准测试准确性的同时,减少了高达71%的输出标记。
- 流形导航方法具有跨域的可转移性,适用于代码生成和知识问答等多种任务。
点此查看论文截图

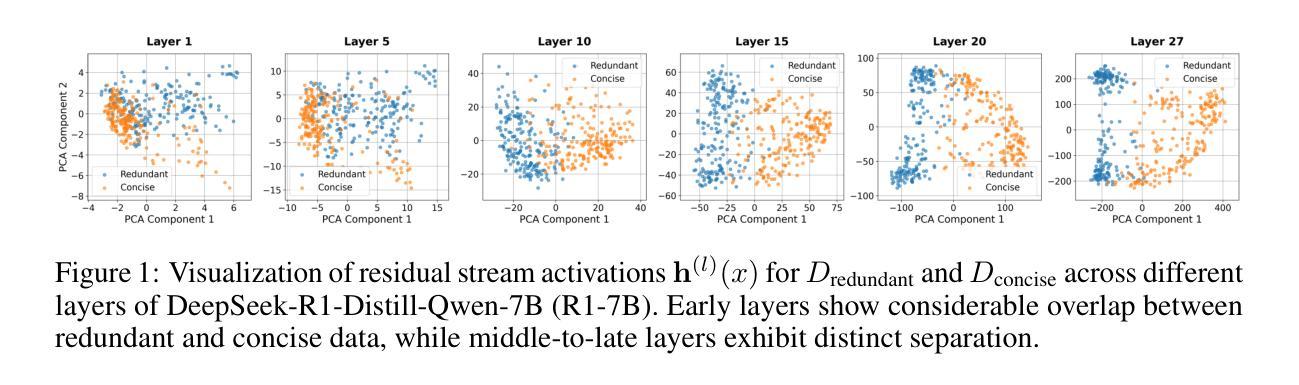
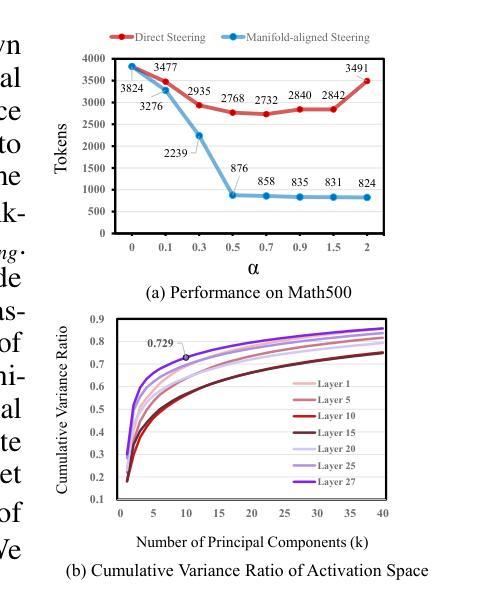
Self-Reflective Reinforcement Learning for Diffusion-based Image Reasoning Generation
Authors:Jiadong Pan, Zhiyuan Ma, Kaiyan Zhang, Ning Ding, Bowen Zhou
Diffusion models have recently demonstrated exceptional performance in image generation task. However, existing image generation methods still significantly suffer from the dilemma of image reasoning, especially in logic-centered image generation tasks. Inspired by the success of Chain of Thought (CoT) and Reinforcement Learning (RL) in LLMs, we propose SRRL, a self-reflective RL algorithm for diffusion models to achieve reasoning generation of logical images by performing reflection and iteration across generation trajectories. The intermediate samples in the denoising process carry noise, making accurate reward evaluation difficult. To address this challenge, SRRL treats the entire denoising trajectory as a CoT step with multi-round reflective denoising process and introduces condition guided forward process, which allows for reflective iteration between CoT steps. Through SRRL-based iterative diffusion training, we introduce image reasoning through CoT into generation tasks adhering to physical laws and unconventional physical phenomena for the first time. Notably, experimental results of case study exhibit that the superior performance of our SRRL algorithm even compared with GPT-4o. The project page is https://jadenpan0.github.io/srrl.github.io/.
扩散模型在图像生成任务中展现出了卓越的性能。然而,现有的图像生成方法仍然面临着图像推理的困境,特别是在以逻辑为中心的图像生成任务中。受到大型语言模型(LLM)中思维链(CoT)和强化学习(RL)成功的启发,我们提出了SRRL,这是一种用于扩散模型的自反思RL算法,通过在生成轨迹上进行反思和迭代,实现逻辑图像的推理生成。去噪过程中的中间样本带有噪声,使得准确的奖励评估变得困难。为解决这一挑战,SRRL将整个去噪轨迹视为多轮反思去噪过程的思维链步骤,并引入条件引导前向过程,允许在思维链步骤之间进行反思迭代。通过基于SRRL的迭代扩散训练,我们首次将遵循物理定律和非传统物理现象的图像推理引入生成任务中。值得注意的是,案例研究的实验结果表明,我们的SRRL算法甚至优于GPT- 4o。项目页面是https://jadenpan0.github.io/srrl.github.io/。
论文及项目相关链接
Summary
扩散模型在图像生成任务中表现出卓越性能,但在逻辑图像生成任务中仍面临图像推理的困境。受大型语言模型中思维链和强化学习成功的启发,我们提出SRRL,一种用于扩散模型的自反思强化学习算法,通过生成轨迹的反思和迭代实现逻辑图像的推理生成。为解决去噪过程中样本携带噪声导致的准确奖励评估困难的问题,SRRL将整个去噪轨迹视为多轮反思去噪过程的思维链步骤,并引入条件引导前向过程,实现思维链步骤之间的反思迭代。基于SRRL的迭代扩散训练,我们首次将遵循物理定律和非传统物理现象的图像推理引入生成任务。实验案例研究结果表明,SRRL算法性能优异,甚至优于GPT-4o。项目页面为链接。
Key Takeaways
- 扩散模型在图像生成任务中展现优秀性能,但在逻辑图像生成上仍面临挑战。
- 现有方法难以准确评估去噪过程中样本的奖励值。
- SRRL算法通过引入自反思机制解决此问题,将去噪轨迹视为多轮反思过程。
- 条件引导前向过程允许在思维链步骤之间进行反思迭代。
- SRRL首次将遵循物理定律和非传统物理现象的图像推理引入生成任务。
- 实验结果证明SRRL算法性能优于某些现有方法。
点此查看论文截图

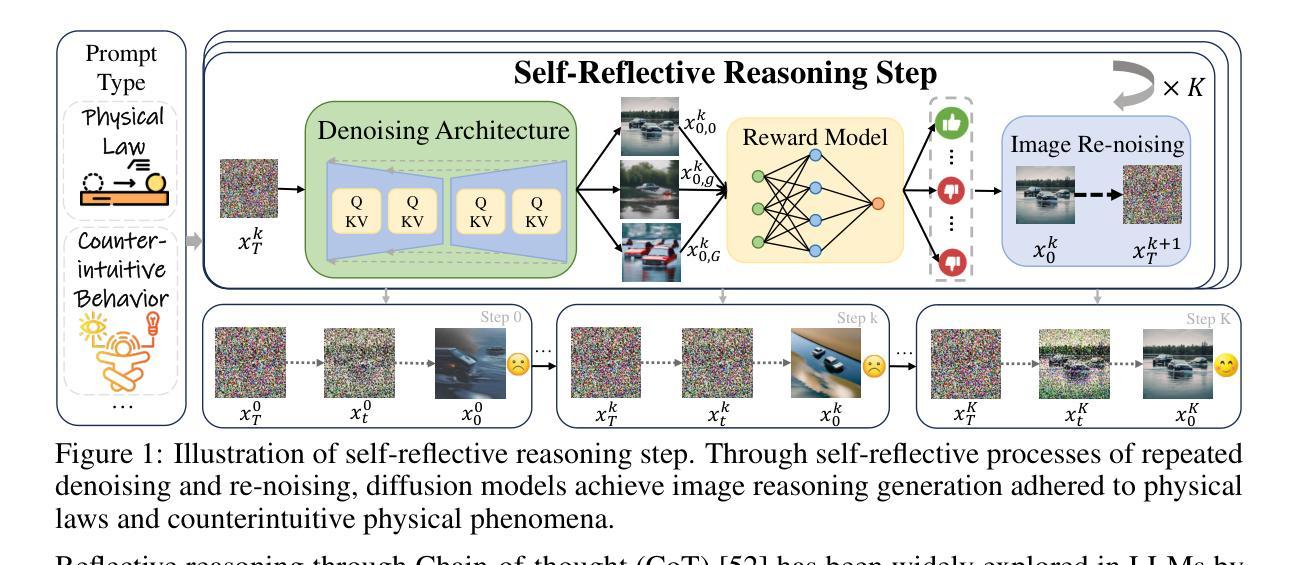
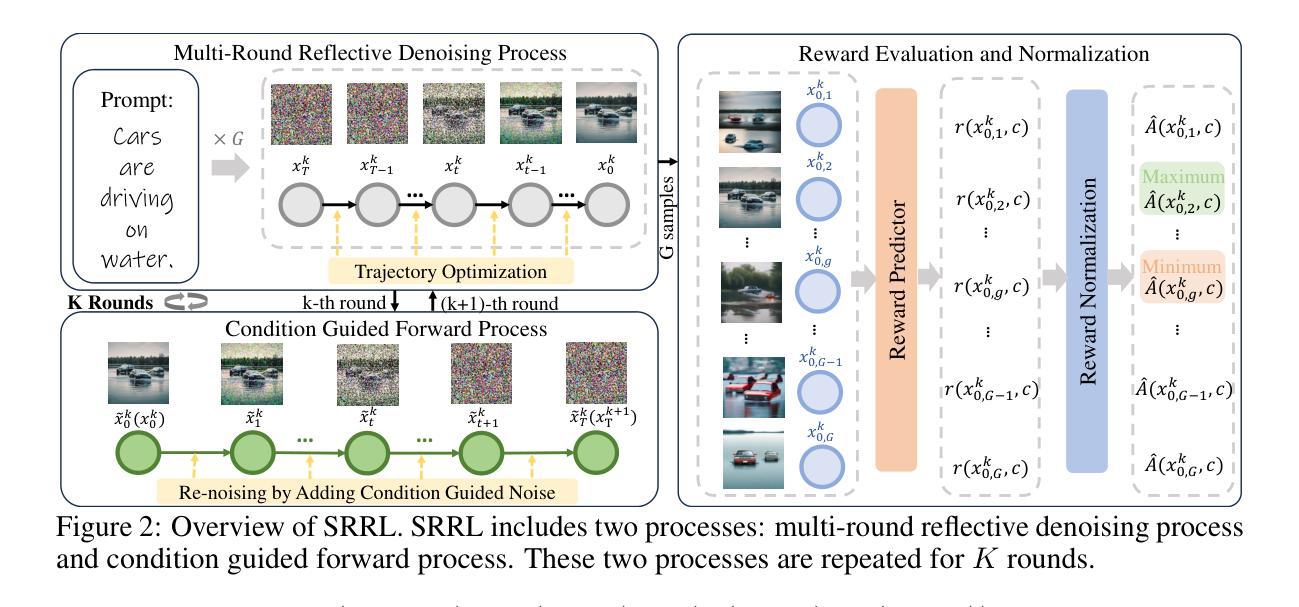

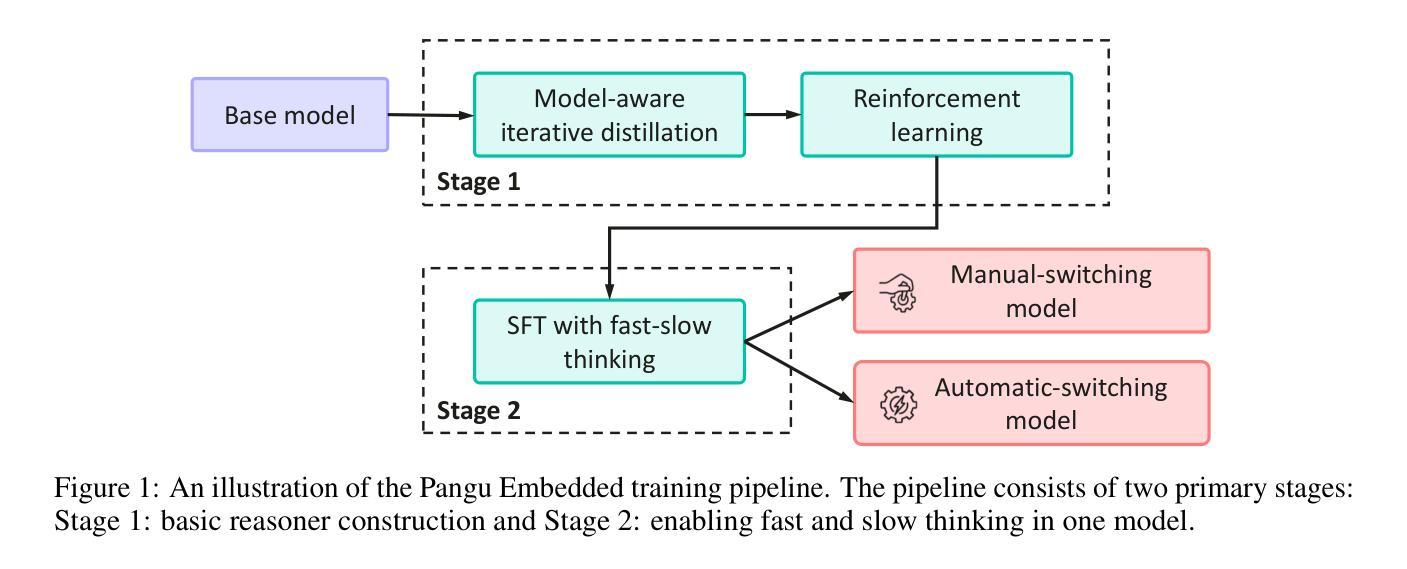
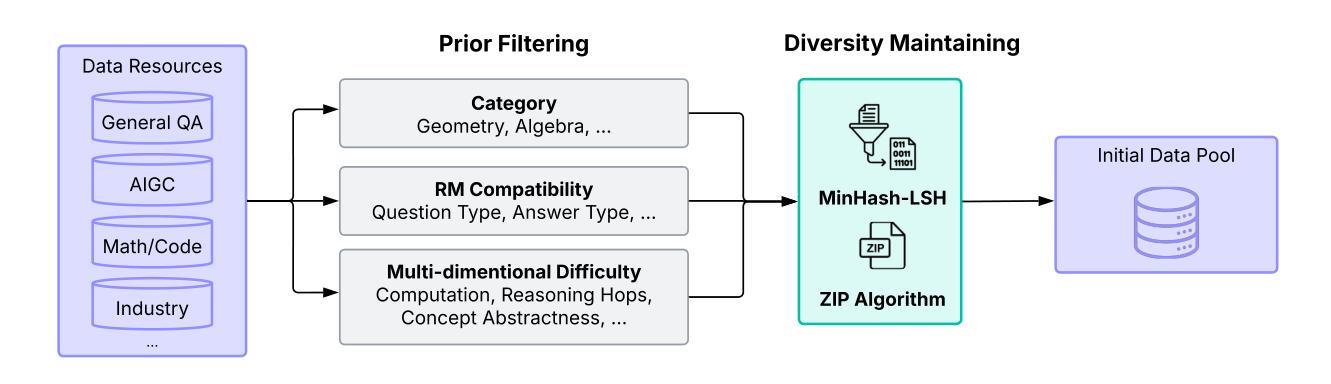
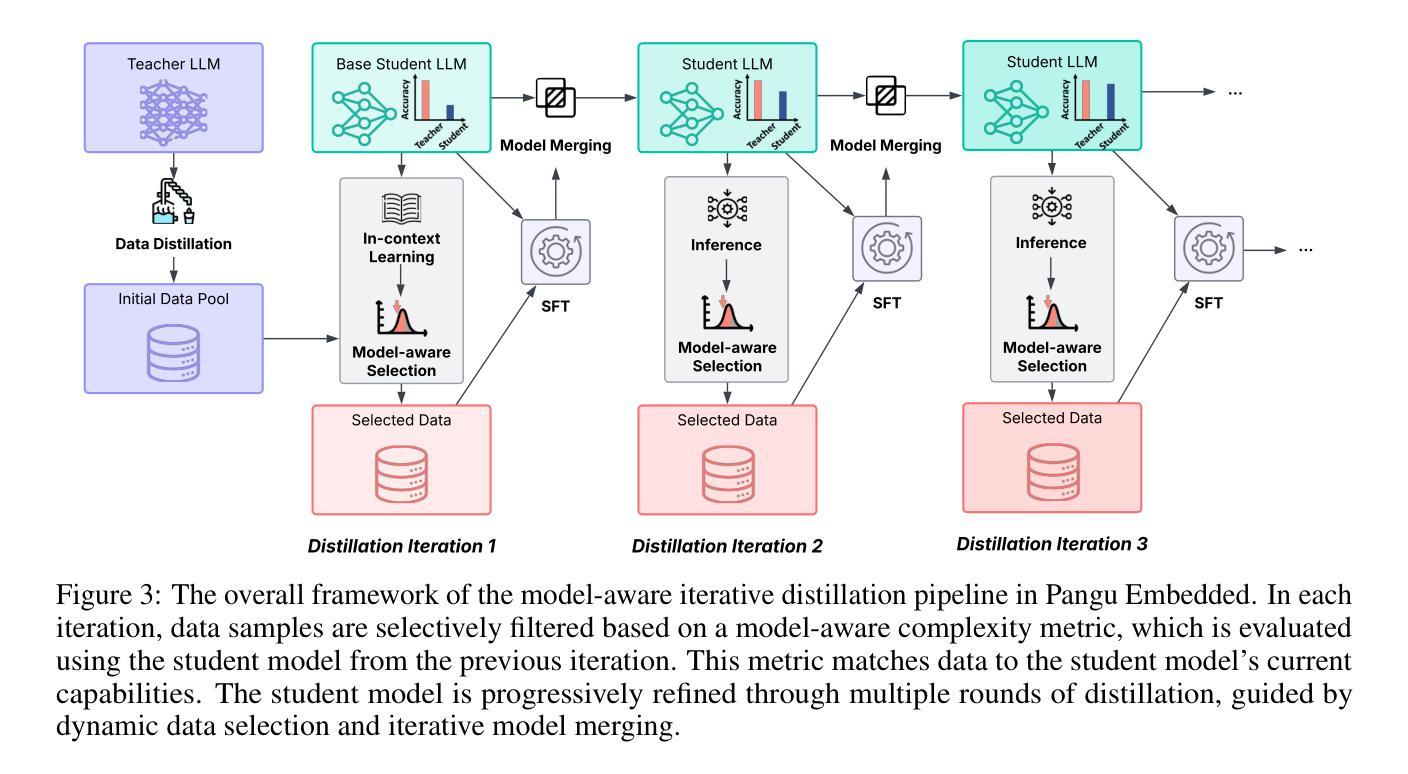
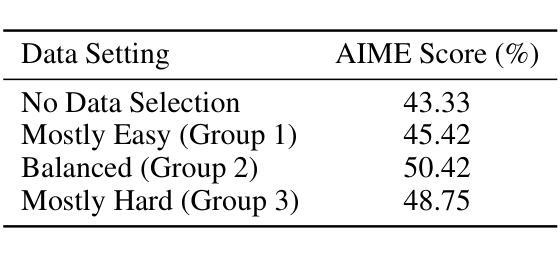
Pangu Embedded: An Efficient Dual-system LLM Reasoner with Metacognition
Authors:Hanting Chen, Yasheng Wang, Kai Han, Dong Li, Lin Li, Zhenni Bi, Jinpeng Li, Haoyu Wang, Fei Mi, Mingjian Zhu, Bin Wang, Kaikai Song, Yifei Fu, Xu He, Yu Luo, Chong Zhu, Quan He, Xueyu Wu, Wei He, Hailin Hu, Yehui Tang, Dacheng Tao, Xinghao Chen, Yunhe Wang, Other Contributors
This work presents Pangu Embedded, an efficient Large Language Model (LLM) reasoner developed on Ascend Neural Processing Units (NPUs), featuring flexible fast and slow thinking capabilities. Pangu Embedded addresses the significant computational costs and inference latency challenges prevalent in existing reasoning-optimized LLMs. We propose a two-stage training framework for its construction. In Stage 1, the model is finetuned via an iterative distillation process, incorporating inter-iteration model merging to effectively aggregate complementary knowledge. This is followed by reinforcement learning on Ascend clusters, optimized by a latency-tolerant scheduler that combines stale synchronous parallelism with prioritized data queues. The RL process is guided by a Multi-source Adaptive Reward System (MARS), which generates dynamic, task-specific reward signals using deterministic metrics and lightweight LLM evaluators for mathematics, coding, and general problem-solving tasks. Stage 2 introduces a dual-system framework, endowing Pangu Embedded with a “fast” mode for routine queries and a deeper “slow” mode for complex inference. This framework offers both manual mode switching for user control and an automatic, complexity-aware mode selection mechanism that dynamically allocates computational resources to balance latency and reasoning depth. Experimental results on benchmarks including AIME 2024, GPQA, and LiveCodeBench demonstrate that Pangu Embedded with 7B parameters, outperforms similar-size models like Qwen3-8B and GLM4-9B. It delivers rapid responses and state-of-the-art reasoning quality within a single, unified model architecture, highlighting a promising direction for developing powerful yet practically deployable LLM reasoners.
这篇论文介绍了Pangu Embedded,这是一个在Ascend神经网络处理单元(NPUs)上开发的高效大型语言模型(LLM)推理器,具备灵活的快思考和慢思考能力。Pangu Embedded解决了现有优化推理的LLM中普遍存在的计算成本高和推理延迟挑战。我们为其构建提出了一个两阶段训练框架。在第一阶段,模型通过迭代蒸馏过程进行微调,同时结合跨迭代模型合并,以有效地聚合互补知识。随后是在Ascend集群上进行强化学习,由延迟容忍调度器进行优化,该调度器结合了延迟同步并行性和优先级数据队列。强化学习过程由多源自适应奖励系统(MARS)引导,该系统利用确定性指标和轻量级LLM评估器为数学、编码和一般问题解决任务生成动态、特定任务的奖励信号。第二阶段引入了一个双系统框架,赋予Pangu Embedded一种用于常规查询的“快速”模式和一种用于复杂推理的更深层次“慢速”模式。该框架既提供手动模式切换供用户控制,又提供一种自动的、感知复杂性的模式选择机制,该机制能动态分配计算资源以平衡延迟和推理深度。在AIME 2024、GPQA和LiveCodeBench等基准测试上的实验结果表明,Pangu Embedded具有7B参数,优于类似规模的模型(如Qwen3-8B和GLM4-9B)。它在一个统一的模型架构内实现了快速响应和最新水平的推理质量,为开发强大且实际可部署的LLM推理器指明了有前途的方向。
论文及项目相关链接
Summary
基于Ascend神经处理单元(NPUs),开发出了一款高效的推理大语言模型——Pangu Embedded。它拥有灵活的快思考和慢思考能力,解决了现有推理优化型LLM中存在的计算成本高和推理延迟等挑战。通过两阶段训练框架构建,第一阶段通过迭代蒸馏过程微调模型,并结合模型合并来有效聚合互补知识。第二阶段采用强化学习,并结合延迟容忍调度器进行优化。Pangu Embedded具有快速模式和深度模式,可在基准测试上实现卓越性能,并优于类似规模的模型。
Key Takeaways
- Pangu Embedded是一个基于Ascend NPUs的高效LLM推理模型,具备快慢思考能力。
- 该模型通过两阶段训练框架构建,第一阶段通过迭代蒸馏和模型合并来优化知识整合。
- 第二阶段采用强化学习,结合延迟容忍调度器进行优化。
- Pangu Embedded具有快速响应和深度推理模式,可手动切换或自动根据复杂度选择模式。
- 该模型在AIME 2024、GPQA和LiveCodeBench等基准测试上表现出卓越性能。
- 与类似规模的模型相比,Pangu Embedded具有更高的推理质量和响应速度。
点此查看论文截图

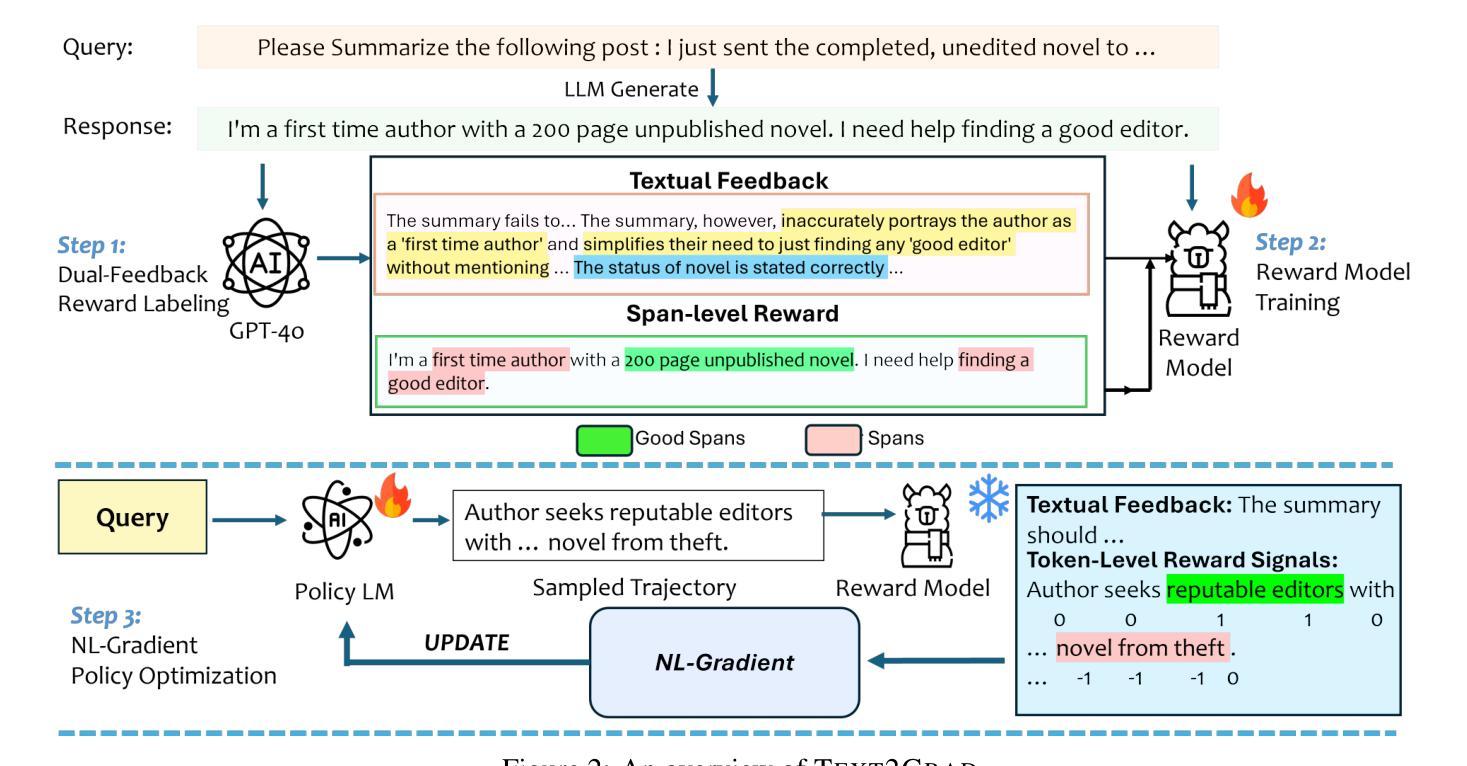
Text2Grad: Reinforcement Learning from Natural Language Feedback
Authors:Hanyang Wang, Lu Wang, Chaoyun Zhang, Tianjun Mao, Si Qin, Qingwei Lin, Saravan Rajmohan, Dongmei Zhang
Traditional RLHF optimizes language models with coarse, scalar rewards that mask the fine-grained reasons behind success or failure, leading to slow and opaque learning. Recent work augments RL with textual critiques through prompting or reflection, improving interpretability but leaving model parameters untouched. We introduce Text2Grad, a reinforcement-learning paradigm that turns free-form textual feedback into span-level gradients. Given human (or programmatic) critiques, Text2Grad aligns each feedback phrase with the relevant token spans, converts these alignments into differentiable reward signals, and performs gradient updates that directly refine the offending portions of the model’s policy. This yields precise, feedback-conditioned adjustments instead of global nudges. Text2Grad is realized through three components: (1) a high-quality feedback-annotation pipeline that pairs critiques with token spans; (2) a fine-grained reward model that predicts span-level reward on answer while generating explanatory critiques; and (3) a span-level policy optimizer that back-propagates natural-language gradients. Across summarization, code generation, and question answering, Text2Grad consistently surpasses scalar-reward RL and prompt-only baselines, providing both higher task metrics and richer interpretability. Our results demonstrate that natural-language feedback, when converted to gradients, is a powerful signal for fine-grained policy optimization. The code for our method is available at https://github.com/microsoft/Text2Grad
传统RLHF(强化学习人类反馈)通过粗略的标量奖励优化语言模型,这种奖励掩盖了成功或失败背后的精细原因,导致学习速度慢且透明度低。最近的工作通过提示或反思为RL增加了文本评价,提高了可解释性,但并未触及模型参数。我们引入了Text2Grad,一种将自由形式的文本反馈转化为跨度级梯度的强化学习范式。给定人类(或程序化的)评价,Text2Grad将每个反馈短语与相关的令牌跨度对齐,将这些对齐转换为可微分的奖励信号,并执行梯度更新,直接优化模型策略中的相关部分。这产生了精确的、基于反馈的调整,而不是全局的微调。Text2Grad通过三个组件实现:(1)高质量反馈注释管道,将评价与令牌跨度配对;(2)精细奖励模型,在生成答案的同时预测跨度级别的奖励并解释评价;(3)跨度级策略优化器,反向传播自然语言梯度。在摘要、代码生成和问答等任务中,Text2Grad始终超越了标量奖励RL和仅提示的基线,提供了更高的任务指标和更丰富的可解释性。我们的结果表明,当自然语言反馈被转化为梯度时,它是精细策略优化的强大信号。我们的方法的代码可在https://github.com/microsoft/Text2Grad中找到。
论文及项目相关链接
PDF The code for our method is available at https://github.com/microsoft/Text2Grad
Summary
文本介绍了传统强化学习在优化语言模型时存在的问题,如使用粗略的标量奖励导致学习速度慢且不够透明。为解决这一问题,最近的工作尝试将文本批评与强化学习相结合,以提高模型的可解释性,但并未触及模型参数。本文提出了一种名为Text2Grad的强化学习范式,它将自由形式的文本反馈转化为跨度的梯度。Text2Grad通过三个关键组件实现:高质量的反馈注释管道、精细奖励模型和跨度级政策优化器。该方法在总结、代码生成和问答任务上均超越了使用标量奖励的RL和仅使用提示的基线,既提高了任务指标又丰富了可解释性。
Key Takeaways
- 传统强化学习在优化语言模型时存在粗粒度奖励的问题,导致学习速度慢、不够透明。
- Text2Grad是一种新的强化学习范式,将自由形式的文本反馈转化为跨度级的梯度。
- Text2Grad包括三个关键组件:反馈注释管道、精细奖励模型和跨度级政策优化器。
- Text2Grad通过直接优化模型策略的相关部分,实现了精确、基于反馈的调整,而非全局微调。
- Text2Grad在多种任务上表现优越,包括总结、代码生成和问答,既提高了任务指标又增强了模型的可解释性。
- Text2Grad方法具有强大的实际应用潜力,可以将自然语言反馈转化为梯度,进行精细的政策优化。
点此查看论文截图

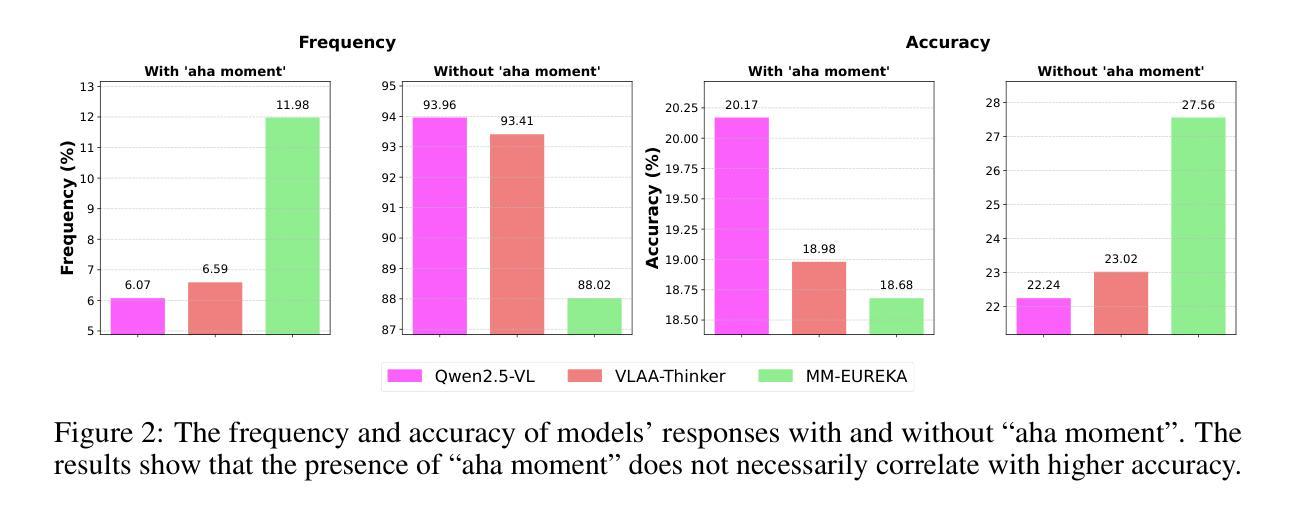
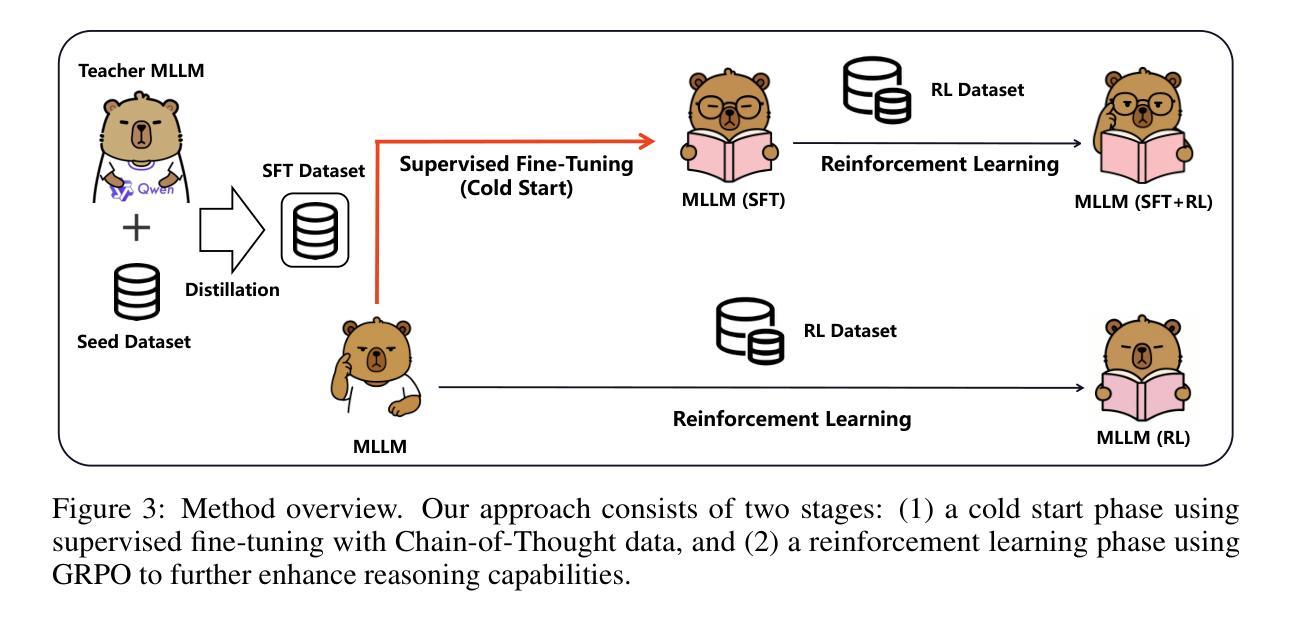
Advancing Multimodal Reasoning via Reinforcement Learning with Cold Start
Authors:Lai Wei, Yuting Li, Kaipeng Zheng, Chen Wang, Yue Wang, Linghe Kong, Lichao Sun, Weiran Huang
Recent advancements in large language models (LLMs) have demonstrated impressive chain-of-thought reasoning capabilities, with reinforcement learning (RL) playing a crucial role in this progress. While “aha moment” patterns–where models exhibit self-correction through reflection–are often attributed to emergent properties from RL, we first demonstrate that these patterns exist in multimodal LLMs (MLLMs) prior to RL training but may not necessarily correlate with improved reasoning performance. Building on these insights, we present a comprehensive study on enhancing multimodal reasoning through a two-stage approach: (1) supervised fine-tuning (SFT) as a cold start with structured chain-of-thought reasoning patterns, followed by (2) reinforcement learning via GRPO to further refine these capabilities. Our extensive experiments show that this combined approach consistently outperforms both SFT-only and RL-only methods across challenging multimodal reasoning benchmarks. The resulting models achieve state-of-the-art performance among open-source MLLMs at both 3B and 7B scales, with our 7B model showing substantial improvements over base models (e.g., 66.3 %$\rightarrow$73.4 % on MathVista, 62.9 %$\rightarrow$70.4 % on We-Math) and our 3B model achieving performance competitive with several 7B models. Overall, this work provides practical guidance for building advanced multimodal reasoning models. Our code is available at https://github.com/waltonfuture/RL-with-Cold-Start.
近期大型语言模型(LLM)的进步展示出了令人印象深刻的思维链推理能力,强化学习(RL)在这一过程中发挥了关键作用。虽然“啊哈时刻”模式——模型通过反思进行自我修正——通常被归因于RL的突发属性,但我们首先证明这些模式存在于多模态LLM(MLLM)的RL训练之前,但不一定与提高的推理性能相关联。基于这些见解,我们提出了一种通过两阶段方法增强多模态推理的综合研究:(1)使用结构化思维链推理模式的监督微调(SFT)作为冷启动;(2)通过GRPO进行强化学习,以进一步改进这些能力。我们的广泛实验表明,这种组合方法在各种具有挑战性的多模态推理基准测试中始终优于仅使用SFT或仅使用RL的方法。我们的模型在3B和7B规模上均达到了开源MLLM的最新性能水平,其中我们的7B模型在MathVista(从66.3%提高到73.4%)和We-Math(从62.9%提高到70.4%)上均实现了显著的性能提升。总的来说,这项工作为构建先进的多模态推理模型提供了实用指导。我们的代码位于https://github.com/waltonfuture/RL-with-Cold-Start。
论文及项目相关链接
Summary
大型语言模型(LLM)的最新进展展示了令人印象深刻的连续推理能力,强化学习(RL)在这一过程中发挥了关键作用。研究发现,“啊哈时刻”(模型通过反思进行自我纠正的时刻)的模式在RL训练之前就存在于多模态语言模型(MLLM)中,但并不一定与推理性能的提高有关。在此基础上,本研究通过两阶段的方法提升多模态推理能力:首先是监督微调(SFT)的冷启动阶段,形成结构化的连续推理模式,随后是进一步优化通过强化学习。实验表明,这种结合的方法在具有挑战性的多模态推理基准测试中表现优于仅使用SFT或仅使用RL的方法。所得到的模型在开源的MLLM中达到领先水平,例如在数学可视化领域提升了6%以上,且在更复杂的数学问题上表现优异。总的来说,本研究为构建先进的多模态推理模型提供了实际指导。代码已公开在GitHub上。
Key Takeaways
- 大型语言模型展现出强大的连续推理能力,强化学习在其中扮演重要角色。
- “啊哈时刻”模式在多模态语言模型中普遍存在,与推理性能的提升不必然相关。
- 两阶段方法用于增强多模态推理能力:监督微调冷启动后,通过强化学习进一步训练。
- 结合方法在多模态推理基准测试中表现优于单一方法。
- 模型在多个领域实现领先水平,包括数学可视化领域和复杂数学问题处理。
- 研究为构建先进多模态推理模型提供了实际指导。
点此查看论文截图

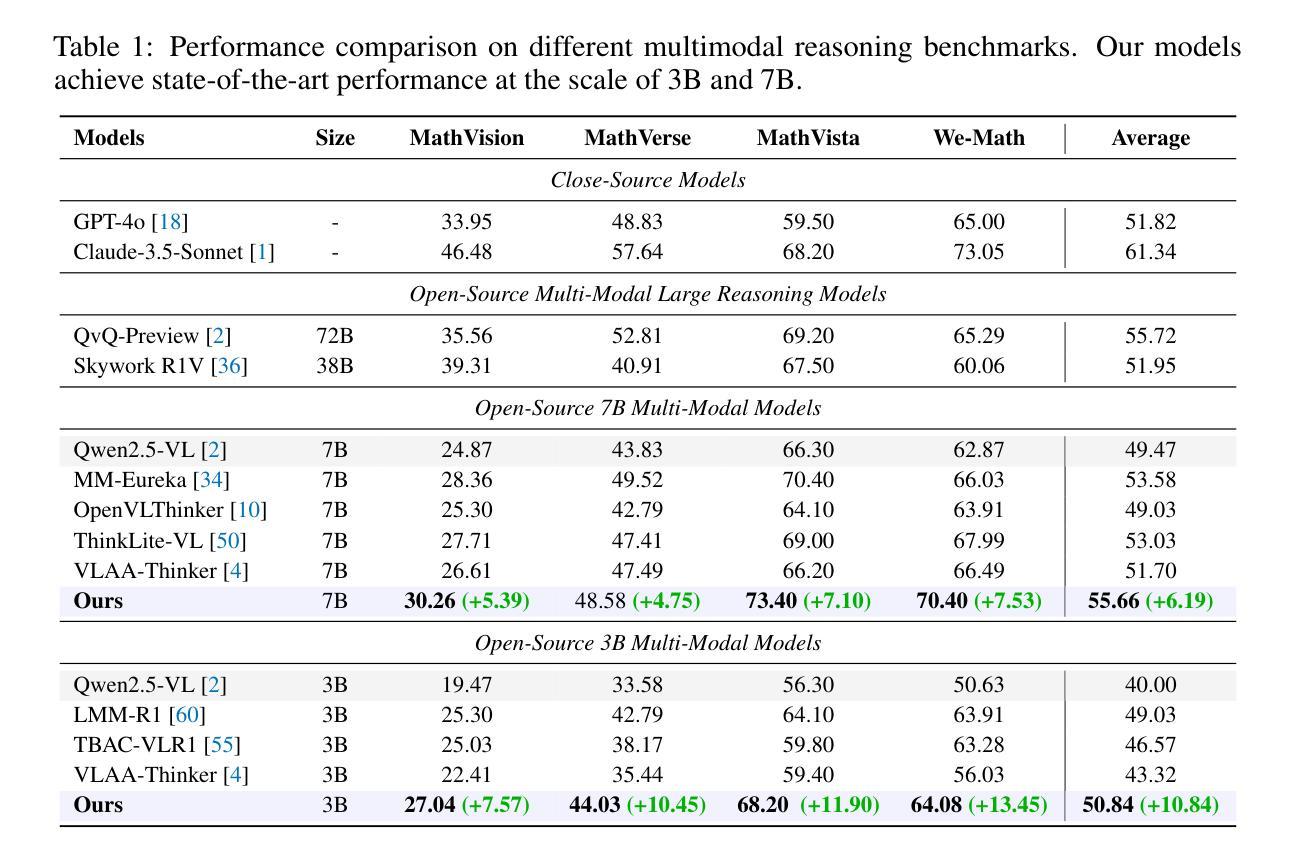
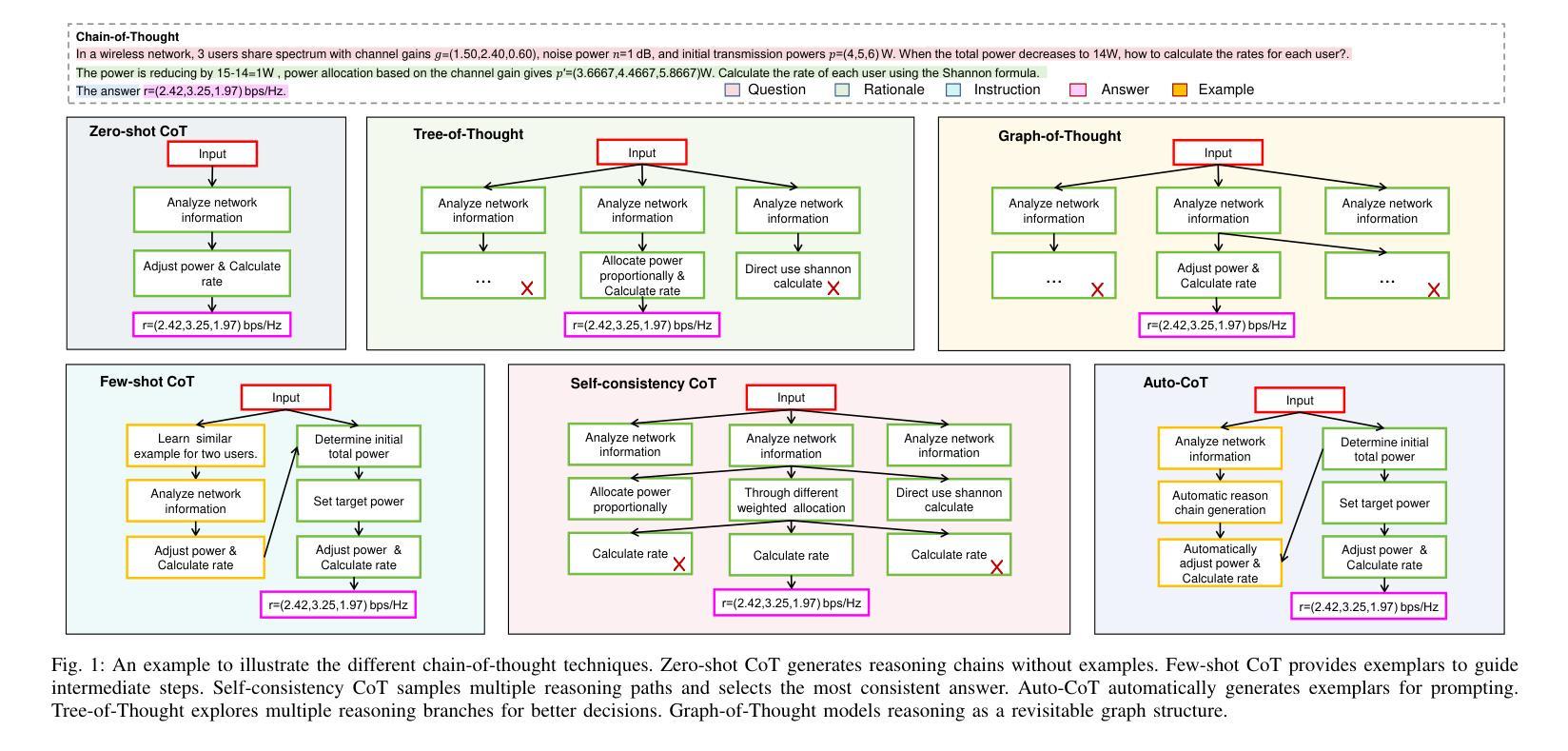
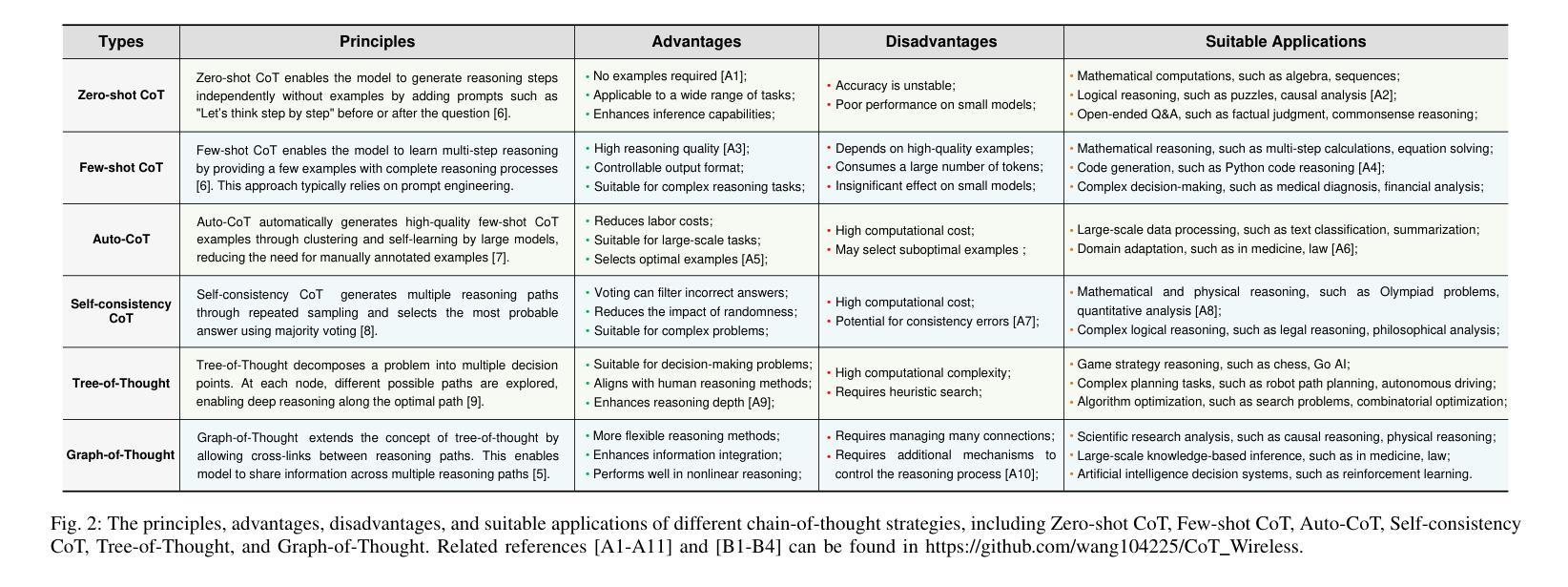
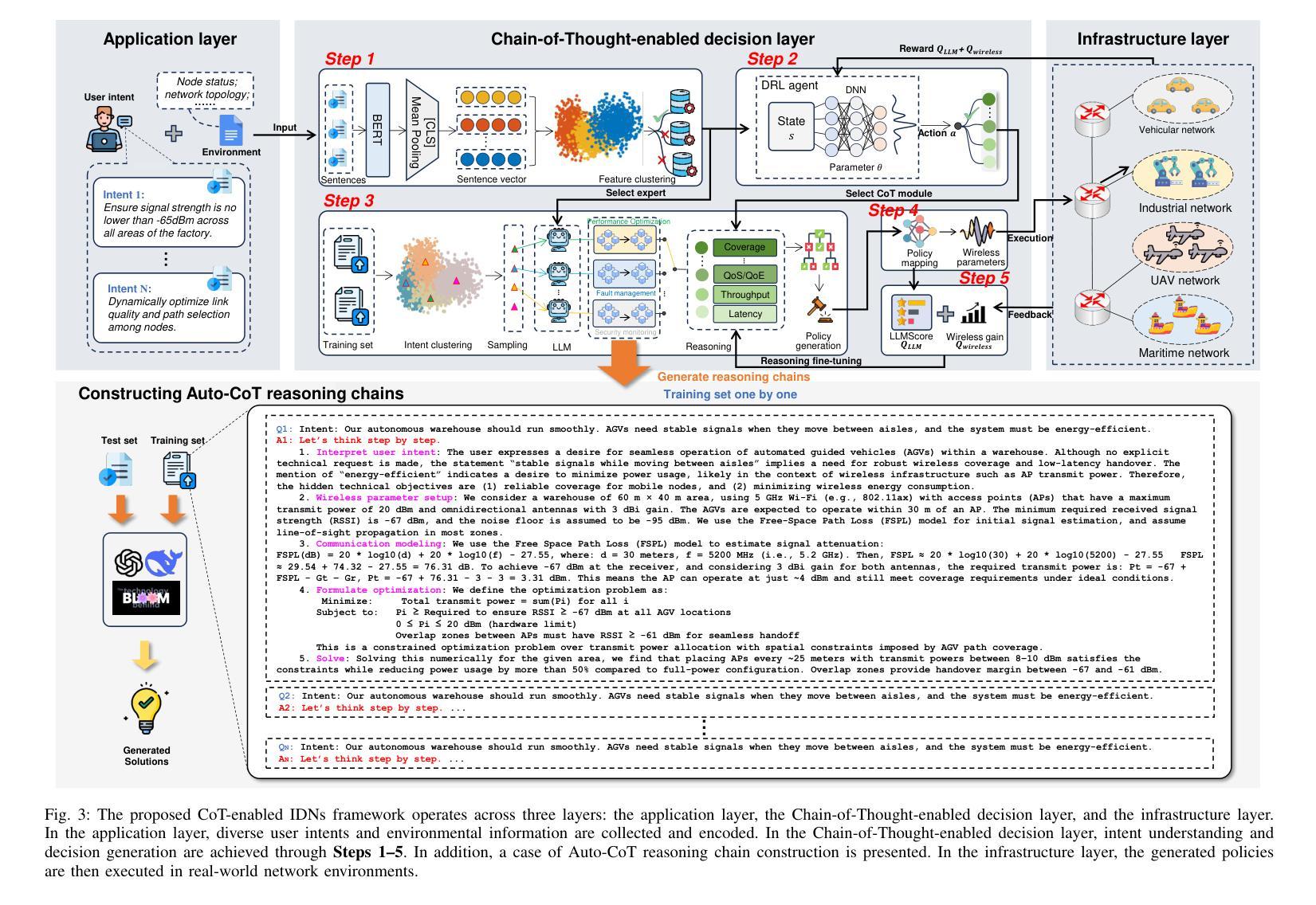
Chain-of-Thought for Large Language Model-empowered Wireless Communications
Authors:Xudong Wang, Jian Zhu, Ruichen Zhang, Lei Feng, Dusit Niyato, Jiacheng Wang, Hongyang Du, Shiwen Mao, Zhu Han
Recent advances in large language models (LLMs) have opened new possibilities for automated reasoning and decision-making in wireless networks. However, applying LLMs to wireless communications presents challenges such as limited capability in handling complex logic, generalization, and reasoning. Chain-of-Thought (CoT) prompting, which guides LLMs to generate explicit intermediate reasoning steps, has been shown to significantly improve LLM performance on complex tasks. Inspired by this, this paper explores the application potential of CoT-enhanced LLMs in wireless communications. Specifically, we first review the fundamental theory of CoT and summarize various types of CoT. We then survey key CoT and LLM techniques relevant to wireless communication and networking. Moreover, we introduce a multi-layer intent-driven CoT framework that bridges high-level user intent expressed in natural language with concrete wireless control actions. Our proposed framework sequentially parses and clusters intent, selects appropriate CoT reasoning modules via reinforcement learning, then generates interpretable control policies for system configuration. Using the unmanned aerial vehicle (UAV) network as a case study, we demonstrate that the proposed framework significantly outperforms a non-CoT baseline in both communication performance and quality of generated reasoning.
近期大型语言模型(LLM)的进步为无线网络的自动化推理和决策开启了新的可能性。然而,将LLM应用于无线通信也带来了挑战,如处理复杂逻辑、概括和推理的能力有限等。思维链(CoT)提示可以引导LLM生成明确的中间推理步骤,已被证明可以显著提高LLM在复杂任务上的性能。受此启发,本文探讨了增强型思维链LLM在无线通信中的应用潜力。具体来说,我们首先回顾了思维链的基本理论,并总结了各种思维链的类型。然后,我们调查了与无线通信和网络相关的关键思维链和LLM技术。此外,我们介绍了一个多层的意图驱动思维链框架,该框架将自然语言表达的高级用户意图与具体的无线控制动作联系起来。我们提出的框架按顺序解析和聚类意图,通过强化学习选择适当的思维链推理模块,然后为系统配置生成可解释的控制策略。以无人机(UAV)网络为案例研究,我们证明了所提出的框架在通信性能和生成的推理质量方面显著优于非思维链基准线。
论文及项目相关链接
PDF 7 pages, 5 figures
Summary
大型语言模型(LLM)在无线通讯领域的应用带来了新的自动化推理和决策可能性,但存在处理复杂逻辑、泛化和推理能力有限等挑战。链式思维(CoT)提示可以显著提高LLM在复杂任务上的性能。本文深入探讨了应用CoT增强LLM在无线通讯中的潜力,并介绍了多层次意图驱动CoT框架。该框架结合了自然语言表达的高层次用户意图与具体的无线控制动作,通过强化学习选择适当的CoT推理模块,生成可解释的控制策略进行系统配置。以无人机(UAV)网络为例,该框架在通信性能和推理质量上显著优于非CoT基准。
Key Takeaways
- 大型语言模型(LLM)在无线通讯领域的应用带来自动化推理和决策的新机会。
- 链式思维(CoT)提示可显著提高LLM在处理复杂任务时的性能。
- CoT增强LLM在无线通讯中的潜力得到探讨。
- 介绍了多层次意图驱动的CoT框架,结合高层次用户意图和具体无线控制动作。
- 该框架通过强化学习选择适当的CoT推理模块。
- 以无人机(UAV)网络为例,CoT框架在通信性能和推理质量上显著优于非CoT基准。
- LLM在无线通讯中的应用仍面临挑战,如复杂逻辑、泛化和推理能力的限制。
点此查看论文截图


Revisiting Group Relative Policy Optimization: Insights into On-Policy and Off-Policy Training
Authors:Youssef Mroueh, Nicolas Dupuis, Brian Belgodere, Apoorva Nitsure, Mattia Rigotti, Kristjan Greenewald, Jiri Navratil, Jerret Ross, Jesus Rios
We revisit Group Relative Policy Optimization (GRPO) in both on-policy and off-policy optimization regimes. Our motivation comes from recent work on off-policy Proximal Policy Optimization (PPO), which improves training stability, sampling efficiency, and memory usage. In addition, a recent analysis of GRPO suggests that estimating the advantage function with off-policy samples could be beneficial. Building on these observations, we adapt GRPO to the off-policy setting. We show that both on-policy and off-policy GRPO objectives yield an improvement in the reward. This result motivates the use of clipped surrogate objectives in the off-policy version of GRPO. We then compare the empirical performance of reinforcement learning with verifiable rewards in post-training using both GRPO variants. Our results show that off-policy GRPO either significantly outperforms or performs on par with its on-policy counterpart.
我们重新研究了Group Relative Policy Optimization(GRPO)在on-policy和off-policy优化机制下的应用。我们的灵感来自于近期关于off-policy近端策略优化(PPO)的研究,它提高了训练稳定性、采样效率和内存使用。此外,对GRPO的最新分析表明,利用off-policy样本估计优势函数可能是有益的。基于这些观察,我们将GRPO适应于off-policy设置。我们展示了on-policy和off-policy GRPO目标都提高了奖励。这一结果推动了在GRPO的off-policy版本中使用剪切替代目标。然后,我们在训练后使用这两种GRPO变体比较了可验证奖励的强化学习的经验性能。我们的结果表明,off-policy GRPO要么显著优于其on-policy对应版本,要么与之表现相当。
论文及项目相关链接
Summary
这篇文本主要探讨了Group Relative Policy Optimization (GRPO)在on-policy和off-policy优化环境下的应用。文章受到近期PPO算法的启发,该算法提高了训练稳定性、采样效率和内存使用。在此基础上,文章将GRPO适应到off-policy环境中,并发现无论是on-policy还是off-policy版本的GRPO都能提高奖励,这表明使用可剪辑的替代目标在off-policy版本的GRPO中是有效的。最后,文章通过实证研究比较了强化学习中可验证奖励在训练后的表现,结果表明off-policy GRPO在性能上显著优于或与on-policy GRPO不相上下。
Key Takeaways
- 文章探讨了Group Relative Policy Optimization (GRPO)在on-policy和off-policy两种优化环境下的应用。
- 受到近期PPO算法的启发,该算法提高了训练稳定性、采样效率和内存使用。
- 文章将GRPO适应到off-policy环境中,并发现无论是哪种版本的GRPO都能提高奖励。
- 使用可剪辑的替代目标在off-policy版本的GRPO中是有效的。
- 文章比较了强化学习中可验证奖励在训练后的表现。
- Off-policy GRPO在性能上显著优于或与on-policy GRPO不相上下。
点此查看论文截图

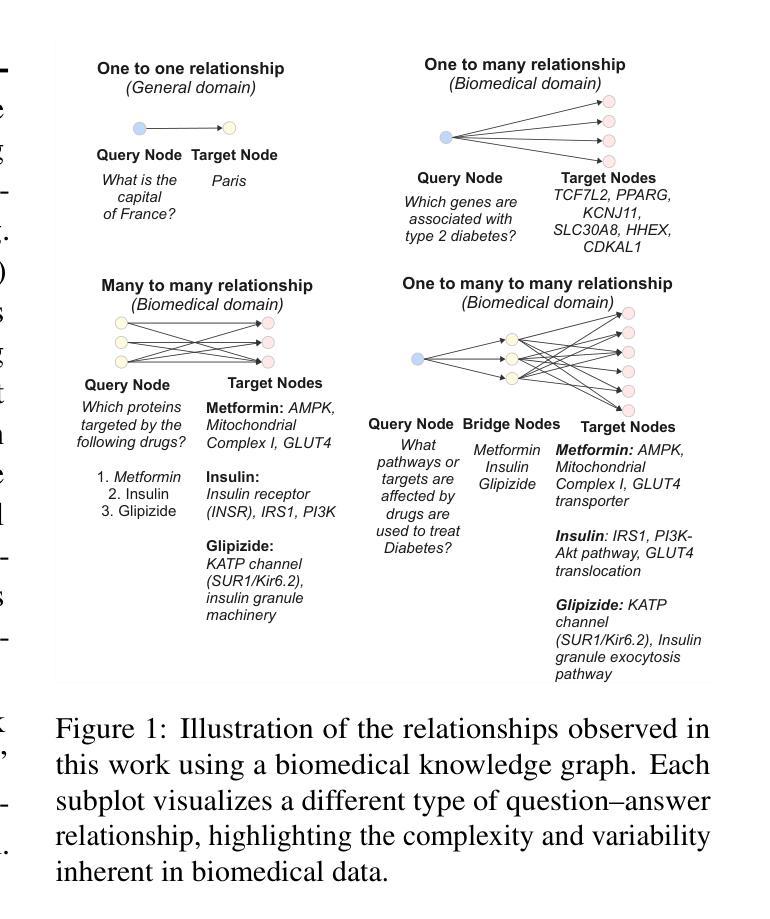
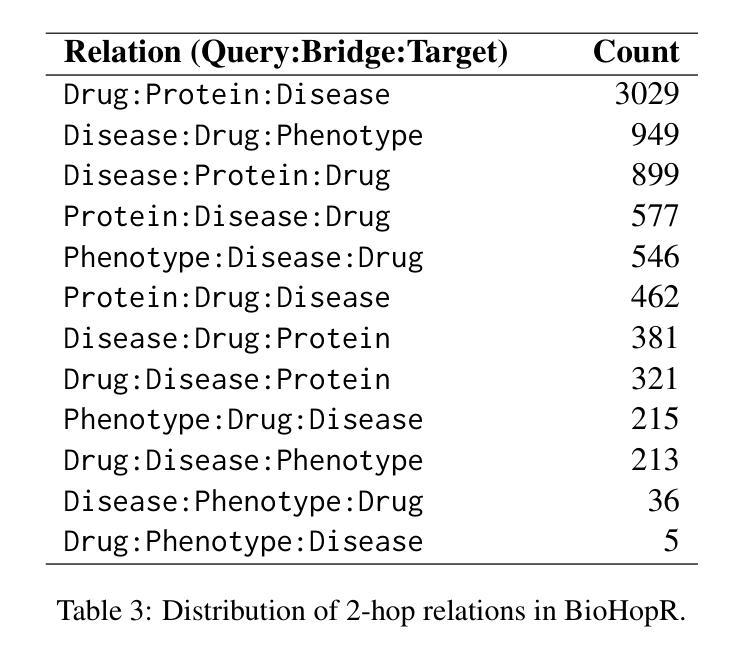
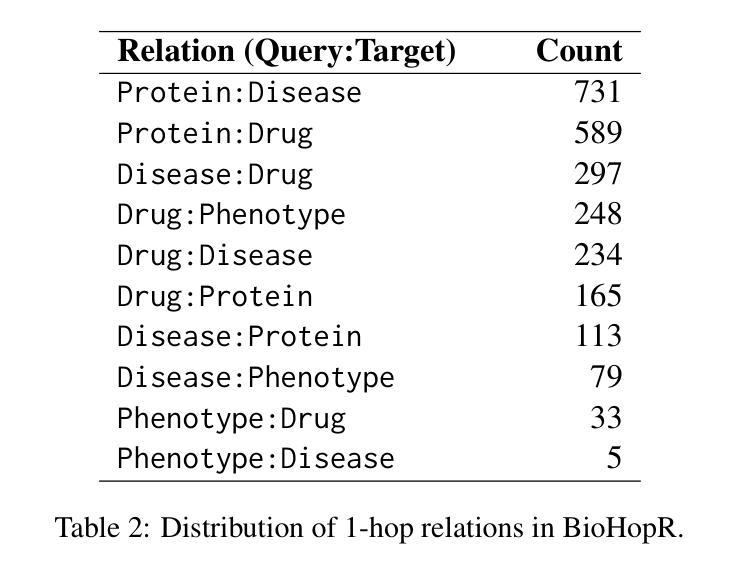
BioHopR: A Benchmark for Multi-Hop, Multi-Answer Reasoning in Biomedical Domain
Authors:Yunsoo Kim, Yusuf Abdulle, Honghan Wu
Biomedical reasoning often requires traversing interconnected relationships across entities such as drugs, diseases, and proteins. Despite the increasing prominence of large language models (LLMs), existing benchmarks lack the ability to evaluate multi-hop reasoning in the biomedical domain, particularly for queries involving one-to-many and many-to-many relationships. This gap leaves the critical challenges of biomedical multi-hop reasoning underexplored. To address this, we introduce BioHopR, a novel benchmark designed to evaluate multi-hop, multi-answer reasoning in structured biomedical knowledge graphs. Built from the comprehensive PrimeKG, BioHopR includes 1-hop and 2-hop reasoning tasks that reflect real-world biomedical complexities. Evaluations of state-of-the-art models reveal that O3-mini, a proprietary reasoning-focused model, achieves 37.93% precision on 1-hop tasks and 14.57% on 2-hop tasks, outperforming proprietary models such as GPT4O and open-source biomedical models including HuatuoGPT-o1-70B and Llama-3.3-70B. However, all models exhibit significant declines in multi-hop performance, underscoring the challenges of resolving implicit reasoning steps in the biomedical domain. By addressing the lack of benchmarks for multi-hop reasoning in biomedical domain, BioHopR sets a new standard for evaluating reasoning capabilities and highlights critical gaps between proprietary and open-source models while paving the way for future advancements in biomedical LLMs.
生物医学推理通常需要遍历药物、疾病和蛋白质等实体之间的互联关系。尽管大型语言模型(LLM)的突出性日益增强,但现有基准测试无法评估生物医学领域中的多跳推理,特别是对于涉及一对一和一对多关系的查询。这一差距使得生物医学多跳推理的关键挑战尚未得到充分探索。为了解决这一问题,我们引入了BioHopR,这是一个旨在评估结构化生物医学知识图谱中多跳多答案推理的新型基准测试。BioHopR建立在全面的PrimeKG之上,包含反映现实世界生物医学复杂性的1跳和2跳推理任务。对最新模型的评价显示,O3-mini,一个以推理为重点的专有模型,在1跳任务上达到37.93%的精度,在2跳任务上达到14.57%,超越了GPT4O等专有模型和包括HuatuoGPT-o1-70B和Llama-3.3-70B在内的开源生物医学模型。然而,所有模型在多跳性能上都有显著下降,这强调了解决生物医学领域隐式推理步骤的挑战。通过解决生物医学领域多跳推理基准测试的缺乏,BioHopR为评估推理能力设定了新标准,突出了专有模型和开源模型之间的关键差距,同时为生物医学LLM的未来发展铺平了道路。
论文及项目相关链接
摘要
本文介绍了生物医学推理中多跳推理的重要性及其挑战。针对现有基准测试无法评估生物医学领域多跳推理的问题,提出了一种新的基准测试BioHopR。该基准测试旨在评估结构化生物医学知识图中的多跳多答案推理能力。BioHopR包括反映现实生物医学复杂性的1跳和2跳推理任务。对现有模型的评估显示,自主开发的推理聚焦模型O3-mini在1跳任务上达到37.93%的准确率,在2跳任务上达到14.57%的准确率,优于GPT4O等自主模型以及开源生物医学模型,如HuatuoGPT-o1-70B和Llama-3.3-70B。然而,所有模型在多跳任务上的性能都有显著下降,凸显了解决生物医学领域隐含推理步骤的挑战。BioHopR填补了生物医学领域多跳推理基准测试的空白,为评估推理能力设定了新的标准,揭示了自主模型和开源模型之间的关键差距,并为生物医学大型语言模型的未来发展铺平了道路。
关键要点
- 生物医学推理需要跨实体之间的关联关系进行多跳推理,如药物、疾病和蛋白质。
- 尽管大型语言模型(LLMs)越来越受欢迎,但现有基准测试无法评估生物医学领域的多跳推理。
- 引入BioHopR基准测试,旨在评估结构化生物医学知识图中的多跳多答案推理能力。
- BioHopR包括反映现实生物医学复杂性的1跳和2跳推理任务。
- O3-mini模型在多跳任务性能评估中表现出最好的性能,但所有模型都面临解决生物医学领域隐含推理步骤的挑战。
- BioHopR填补了生物医学领域多跳推理基准测试的空白,为评估推理能力设定了新的标准。
点此查看论文截图


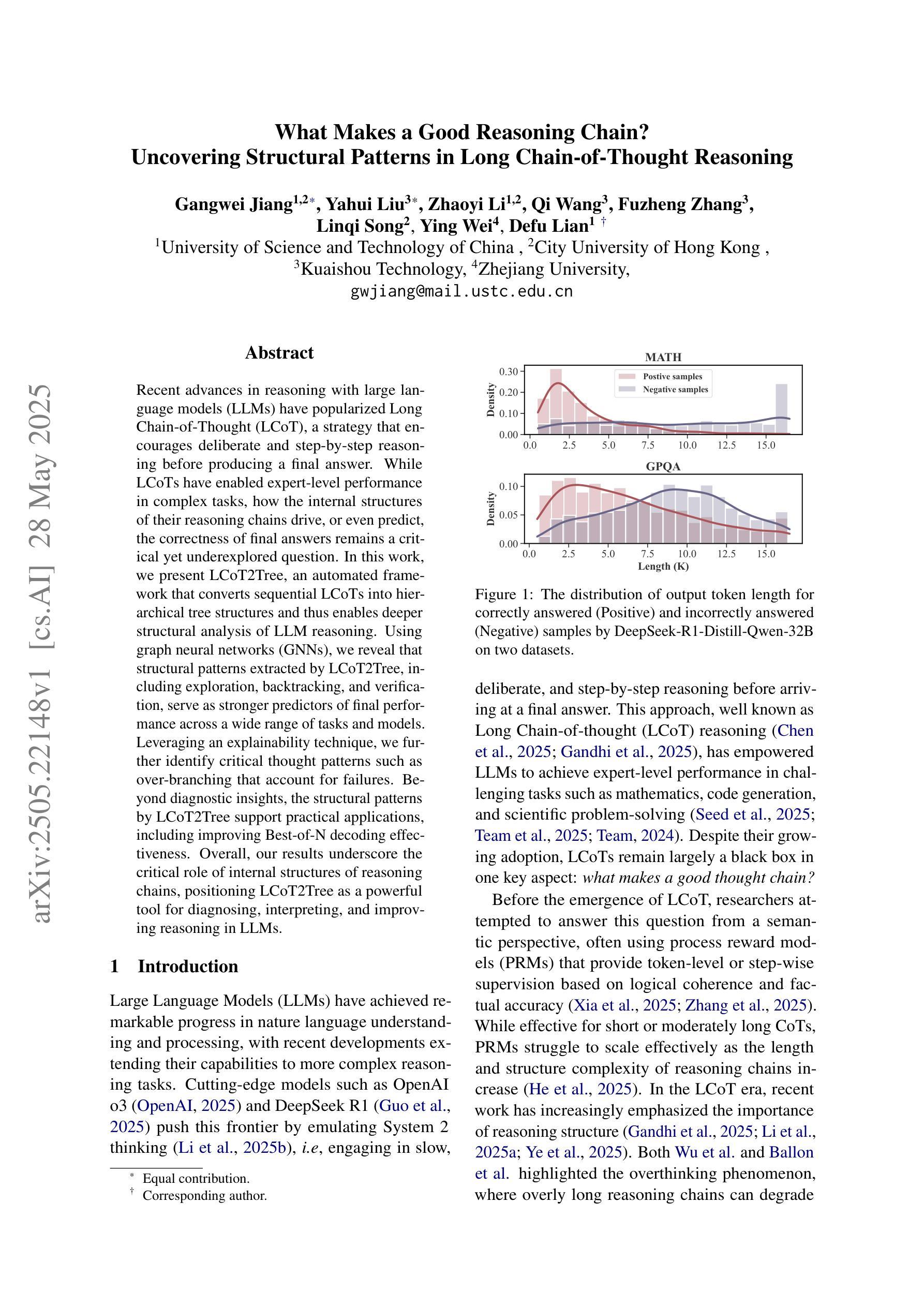
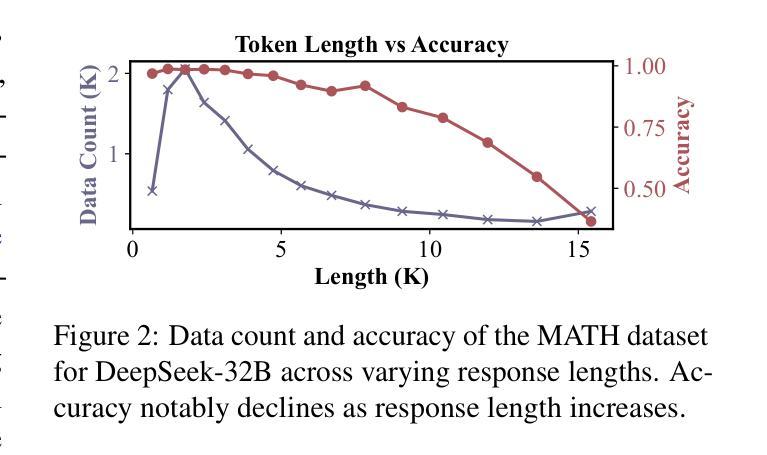
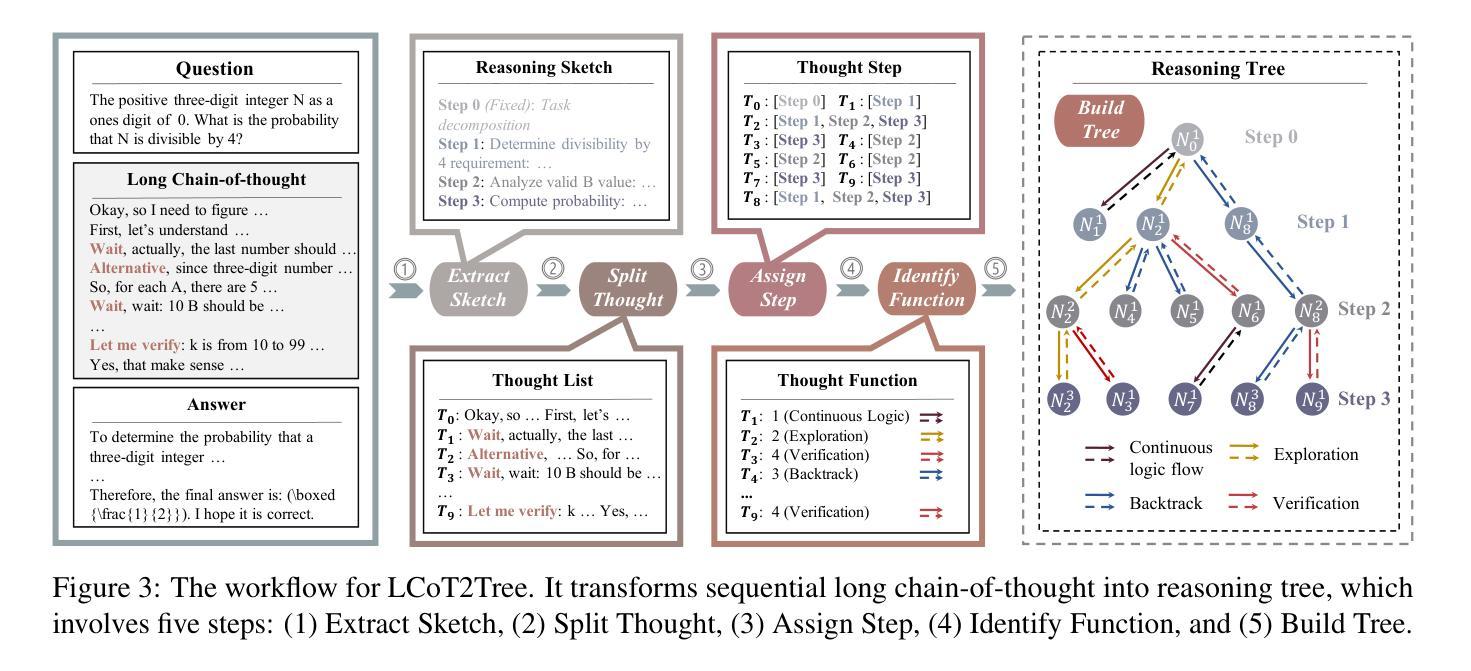
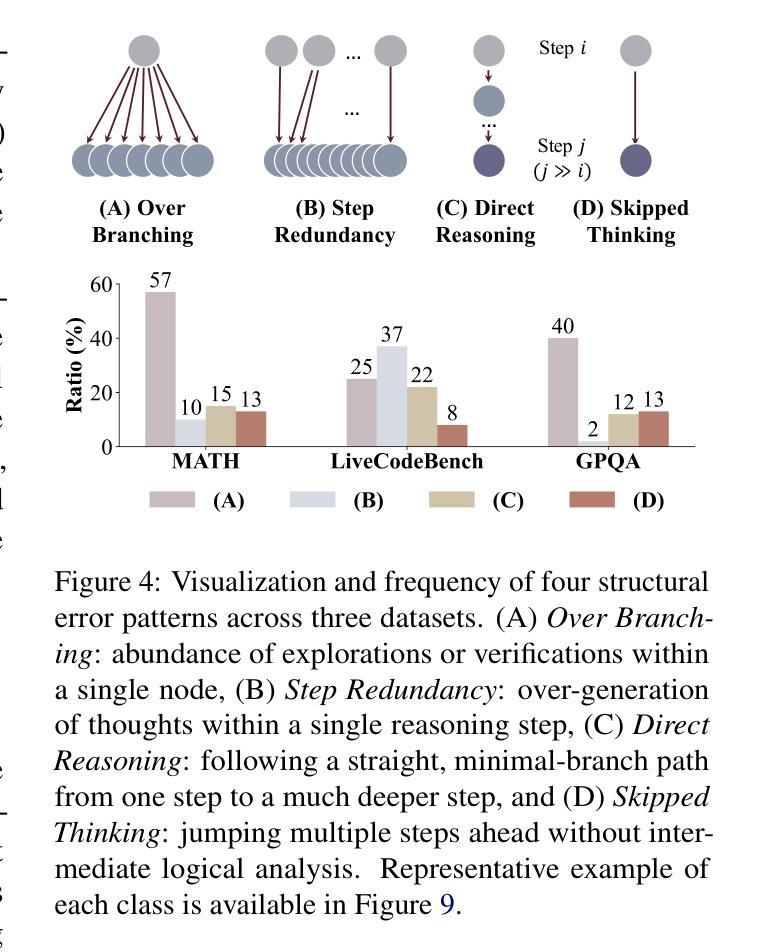
What Makes a Good Reasoning Chain? Uncovering Structural Patterns in Long Chain-of-Thought Reasoning
Authors:Gangwei Jiang, Yahui Liu, Zhaoyi Li, Qi Wang, Fuzheng Zhang, Linqi Song, Ying Wei, Defu Lian
Recent advances in reasoning with large language models (LLMs) have popularized Long Chain-of-Thought (LCoT), a strategy that encourages deliberate and step-by-step reasoning before producing a final answer. While LCoTs have enabled expert-level performance in complex tasks, how the internal structures of their reasoning chains drive, or even predict, the correctness of final answers remains a critical yet underexplored question. In this work, we present LCoT2Tree, an automated framework that converts sequential LCoTs into hierarchical tree structures and thus enables deeper structural analysis of LLM reasoning. Using graph neural networks (GNNs), we reveal that structural patterns extracted by LCoT2Tree, including exploration, backtracking, and verification, serve as stronger predictors of final performance across a wide range of tasks and models. Leveraging an explainability technique, we further identify critical thought patterns such as over-branching that account for failures. Beyond diagnostic insights, the structural patterns by LCoT2Tree support practical applications, including improving Best-of-N decoding effectiveness. Overall, our results underscore the critical role of internal structures of reasoning chains, positioning LCoT2Tree as a powerful tool for diagnosing, interpreting, and improving reasoning in LLMs.
近年来,随着大型语言模型(LLM)在推理方面的进展,长链思维(LCoT)策略逐渐普及。LCoT鼓励在产生最终答案之前进行深思熟虑、循序渐进的推理。虽然LCoT已经在复杂任务中实现了专家级性能,但其推理链的内部结构如何驱动甚至预测最终答案的正确性,仍然是一个关键但尚未深入探索的问题。
论文及项目相关链接
Summary
长链思维(LCoT)策略鼓励逐步推理,能在复杂任务中表现出专家级水平。然而,其内部推理链结构如何驱动甚至预测最终答案的正确性仍是关键且未被充分探索的问题。本研究提出LCoT2Tree框架,能将顺序的LCoTs转化为分层树结构,从而实现对LLM推理的更深层次结构分析。利用图神经网络(GNNs),我们发现LCoT2Tree提取的结构模式,如探索、回溯和验证等,在广泛的任务和模型中成为预测最终性能的更可靠指标。此外,借助解释技术,我们还发现了导致失败的关键思维模式,如过度分支。LCoT2Tree的结构模式不仅提供诊断洞察,还支持实际应用,如提高Best-of-N解码的有效性。总体而言,本研究强调推理链内部结构的重要性,并将LCoT2Tree定位为诊断、解释和改进LLM推理的强大工具。
Key Takeaways
- 长链思维(LCoT)策略能够促进逐步推理,在复杂任务中表现出专家级性能。
- LCoT2Tree框架能将LCoTs转化为分层树结构,便于对LLM推理进行深层次的结构分析。
- 图神经网络(GNNs)被用于分析LCoT2Tree的结构模式,发现探索、回溯和验证等模式对预测最终性能有重要作用。
- LCoT2Tree能识别导致失败的关键思维模式,如过度分支。
- LCoT2Tree的结构模式提供诊断洞察,并支持实际应用,如提高Best-of-N解码的有效性。
- 推理链内部结构的重要性被强调,对LLM推理的诊断、解释和改进有重要作用。
- LCoT2Tree定位为强大的工具,用于诊断、解释和改进LLM推理。
点此查看论文截图
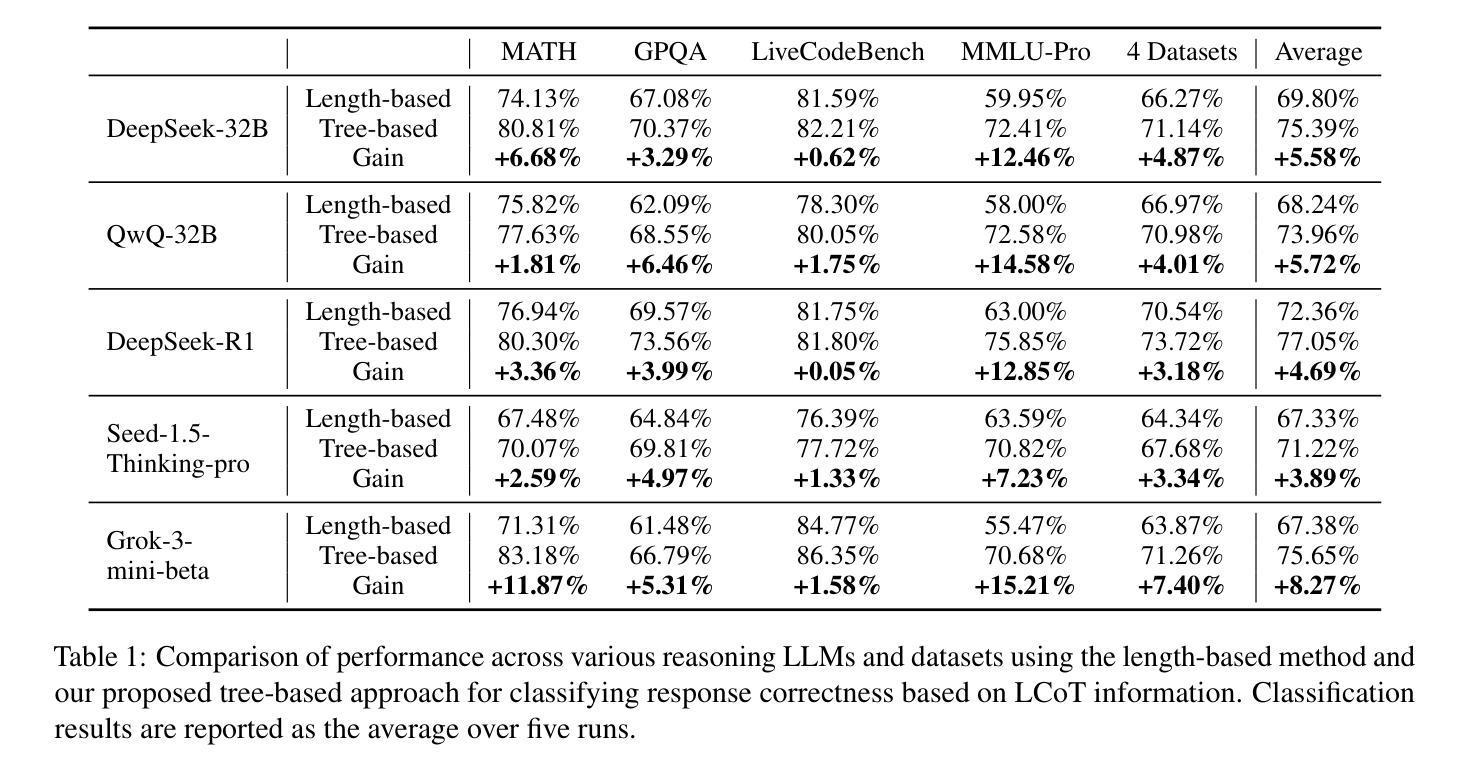
EULER: Enhancing the Reasoning Ability of Large Language Models through Error-Induced Learning
Authors:Zhuoyang Wu, Xinze Li, Zhenghao Liu, Yukun Yan, Zhiyuan Liu, Minghe Yu, Cheng Yang, Yu Gu, Ge Yu, Maosong Sun
Large Language Models (LLMs) have demonstrated strong reasoning capabilities and achieved promising results in mathematical problem-solving tasks. Learning from errors offers the potential to further enhance the performance of LLMs during Supervised Fine-Tuning (SFT). However, the errors in synthesized solutions are typically gathered from sampling trails, making it challenging to generate solution errors for each mathematical problem. This paper introduces the Error-IndUced LEaRning (EULER) model, which aims to develop an error exposure model that generates high-quality solution errors to enhance the mathematical reasoning capabilities of LLMs. Specifically, EULER optimizes the error exposure model to increase the generation probability of self-made solution errors while utilizing solutions produced by a superior LLM to regularize the generation quality. Our experiments across various mathematical problem datasets demonstrate the effectiveness of the EULER model, achieving an improvement of over 4% compared to all baseline models. Further analysis reveals that EULER is capable of synthesizing more challenging and educational solution errors, which facilitate both the training and inference processes of LLMs. All codes are available at https://github.com/NEUIR/EULER.
大规模语言模型(LLM)已经展现出强大的推理能力,并在数学问题解决任务中取得了有前景的结果。从错误中学习可以为监督微调(SFT)期间进一步改善LLM的性能提供潜力。然而,合成解决方案中的错误通常是从采样轨迹收集的,这使得为每个数学问题生成解决方案错误具有挑战性。本文介绍了误差诱导学习(EULER)模型,旨在开发一种误差暴露模型,以生成高质量的解决方案错误,以提高LLM的数学推理能力。具体来说,EULER优化误差暴露模型,以提高自制解决方案错误的生成概率,同时使用由高级LLM产生的解决方案来规范生成质量。我们在多个数学问题解决数据集上的实验证明了EULER模型的有效性,与所有基线模型相比,实现了超过4%的改进。进一步的分析表明,EULER能够合成更具挑战性和教育意义的解决方案错误,这有助于LLM的训练和推理过程。所有代码均可在https://github.com/NEUIR/EULER找到。
论文及项目相关链接
Summary
大型语言模型(LLM)在数学问题解决任务中展现出强大的推理能力,并获得了令人瞩目的成果。通过从错误中学习,可以提高LLM在监督微调(SFT)期间的性能。然而,从采样轨迹中收集的错误通常具有挑战性,难以生成每个数学问题的错误解决方案。本文介绍了Error-IndUced LEaRning(EULER)模型,旨在开发一种错误暴露模型,生成高质量的解决方案错误以增强LLM的数学推理能力。EULER优化了错误暴露模型,提高了自制解决方案错误的生成概率,并利用高级LLM产生的解决方案来规范生成质量。实验表明,EULER模型在各种数学问题数据集上表现出色,相较于所有基准模型提高了超过4%的性能。进一步分析表明,EULER能够合成更具挑战性和教育意义的解决方案错误,有助于LLM的训练和推理过程。
Key Takeaways
- 大型语言模型(LLMs)在数学问题解决任务中表现出强大的推理能力。
- 通过从错误中学习,可以提高LLM的性能。
- 挑战在于如何从采样轨迹中生成每个数学问题的错误解决方案。
- 引入Error-IndUced LEaRning(EULER)模型来解决此挑战。
- EULER模型旨在通过生成高质量的解决方案错误来增强LLM的数学推理能力。
- EULER优化了错误暴露模型,提高自制解决方案错误的生成概率,并利用高级LLM解决方案来规范生成质量。
点此查看论文截图


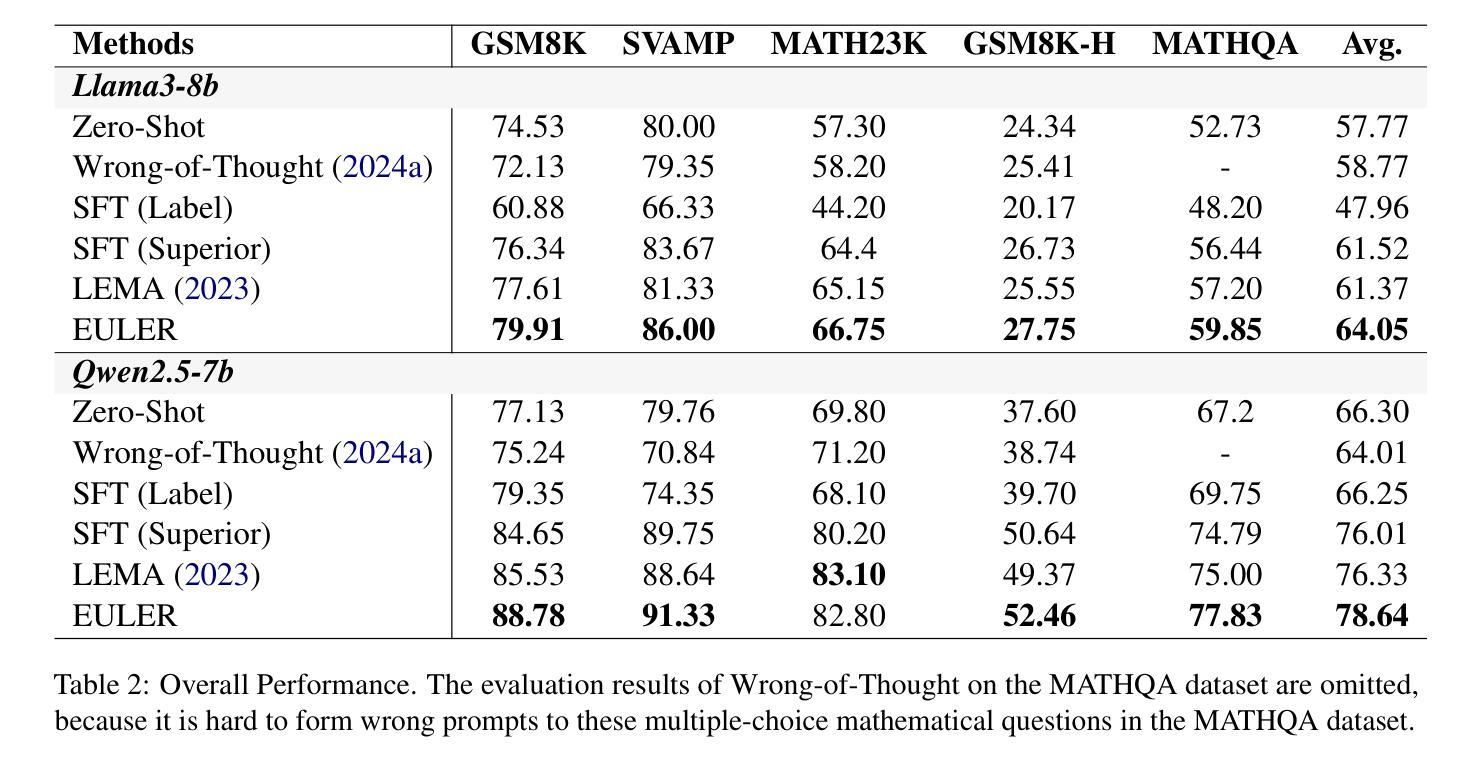
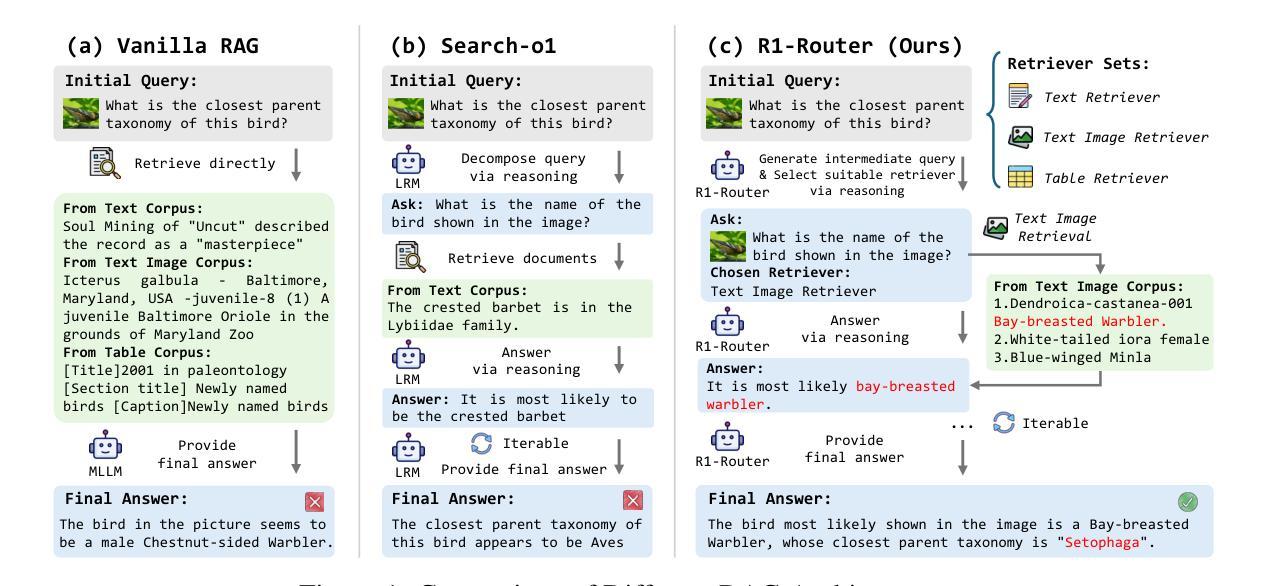
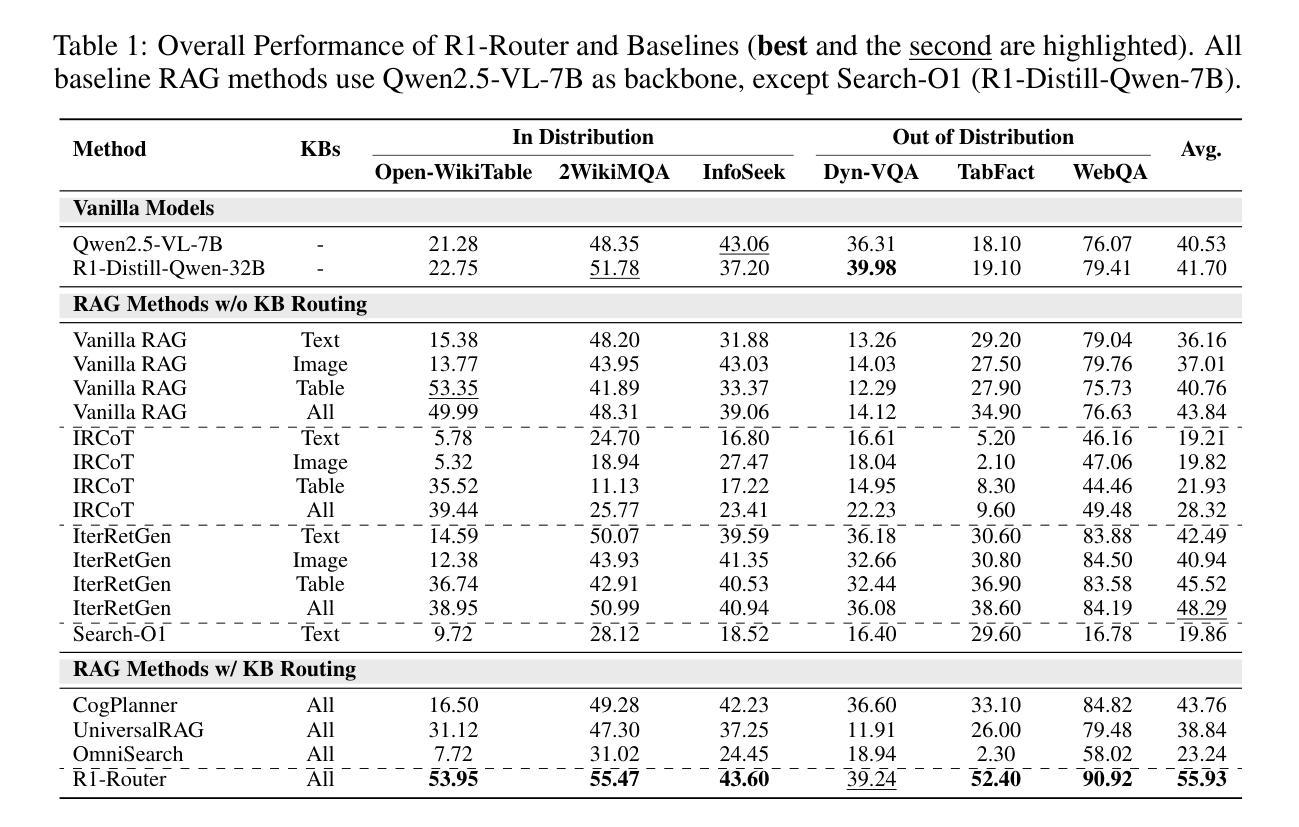
Learning to Route Queries Across Knowledge Bases for Step-wise Retrieval-Augmented Reasoning
Authors:Chunyi Peng, Zhipeng Xu, Zhenghao Liu, Yishan Li, Yukun Yan, Shuo Wang, Zhiyuan Liu, Yu Gu, Minghe Yu, Ge Yu, Maosong Sun
Multimodal Retrieval-Augmented Generation (MRAG) has shown promise in mitigating hallucinations in Multimodal Large Language Models (MLLMs) by incorporating external knowledge during generation. Existing MRAG methods typically adopt a static retrieval pipeline that fetches relevant information from multiple Knowledge Bases (KBs), followed by a refinement step. However, these approaches overlook the reasoning and planning capabilities of MLLMs to dynamically determine how to interact with different KBs during the reasoning process. To address this limitation, we propose R1-Router, a novel MRAG framework that learns to decide when and where to retrieve knowledge based on the evolving reasoning state. Specifically, R1-Router can generate follow-up queries according to the current reasoning step, routing these intermediate queries to the most suitable KB, and integrating external knowledge into a coherent reasoning trajectory to answer the original query. Furthermore, we introduce Step-wise Group Relative Policy Optimization (Step-GRPO), a tailored reinforcement learning algorithm that assigns step-specific rewards to optimize the reasoning behavior of MLLMs. Experimental results on various open-domain QA benchmarks across multiple modalities demonstrate that R1-Router outperforms baseline models by over 7%. Further analysis shows that R1-Router can adaptively and effectively leverage diverse KBs, reducing unnecessary retrievals and improving both efficiency and accuracy.
多模态检索增强生成(MRAG)通过生成过程中融入外部知识,在多模态大语言模型(MLLMs)中显示出缓解幻觉的潜力。现有的MRAG方法通常采用静态检索管道,从多个知识库(KBs)中获取相关信息,然后进行细化步骤。然而,这些方法忽视了MLLMs的推理和规划能力,无法动态确定在推理过程中如何与不同的KBs进行交互。为了解决这一局限性,我们提出了R1-Router,这是一种新型MRAG框架,能够学习根据不断变化的推理状态来决定何时何地检索知识。具体来说,R1-Router可以根据当前的推理步骤生成后续查询,将这些中间查询路由到最合适的知识库,并将外部知识整合到连贯的推理轨迹中以回答原始查询。此外,我们引入了逐步群组相对策略优化(Step-GRPO),这是一种定制的强化学习算法,用于分配步骤特定的奖励来优化MLLMs的推理行为。在不同模态的开放域问答基准测试上的实验结果表明,R1-Router比基线模型高出7%以上的表现。进一步的分析表明,R1-Router能够自适应和有效地利用各种KBs,减少不必要的检索,提高效率和准确性。
论文及项目相关链接
Summary
多媒体检索增强生成(MRAG)技术在缓解多媒体大型语言模型(MLLM)中的幻觉问题上显示出潜力。提出一种新型MRAG框架R1-Router,能够根据不断变化的推理状态决定何时何处检索知识。此外,还引入了分步骤组相对策略优化(Step-GRPO)算法,旨在优化MLLM的推理行为。实验结果表明,R1-Router在多个模态的开放域问答基准测试中优于基准模型。
Key Takeaways
- MRAG技术通过融入外部知识,在缓解MLLM模型幻觉方面取得进展。
- R1-Router是一个新颖的MRAG框架,能根据推理状态的演变来决定何时何地检索知识。
- R1-Router能生成后续查询,并将其路由到最合适的数据库,将外部知识整合到连贯的推理轨迹中。
- Step-GRPO是一种强化学习算法,用于优化MLLM的推理行为并赋予步骤特定的奖励。
- R1-Router在跨模态开放领域问答测试中表现优异,优于基准模型7%。
- R1-Router能自适应有效地利用不同的数据库,减少不必要的检索,提高效率和准确性。
点此查看论文截图

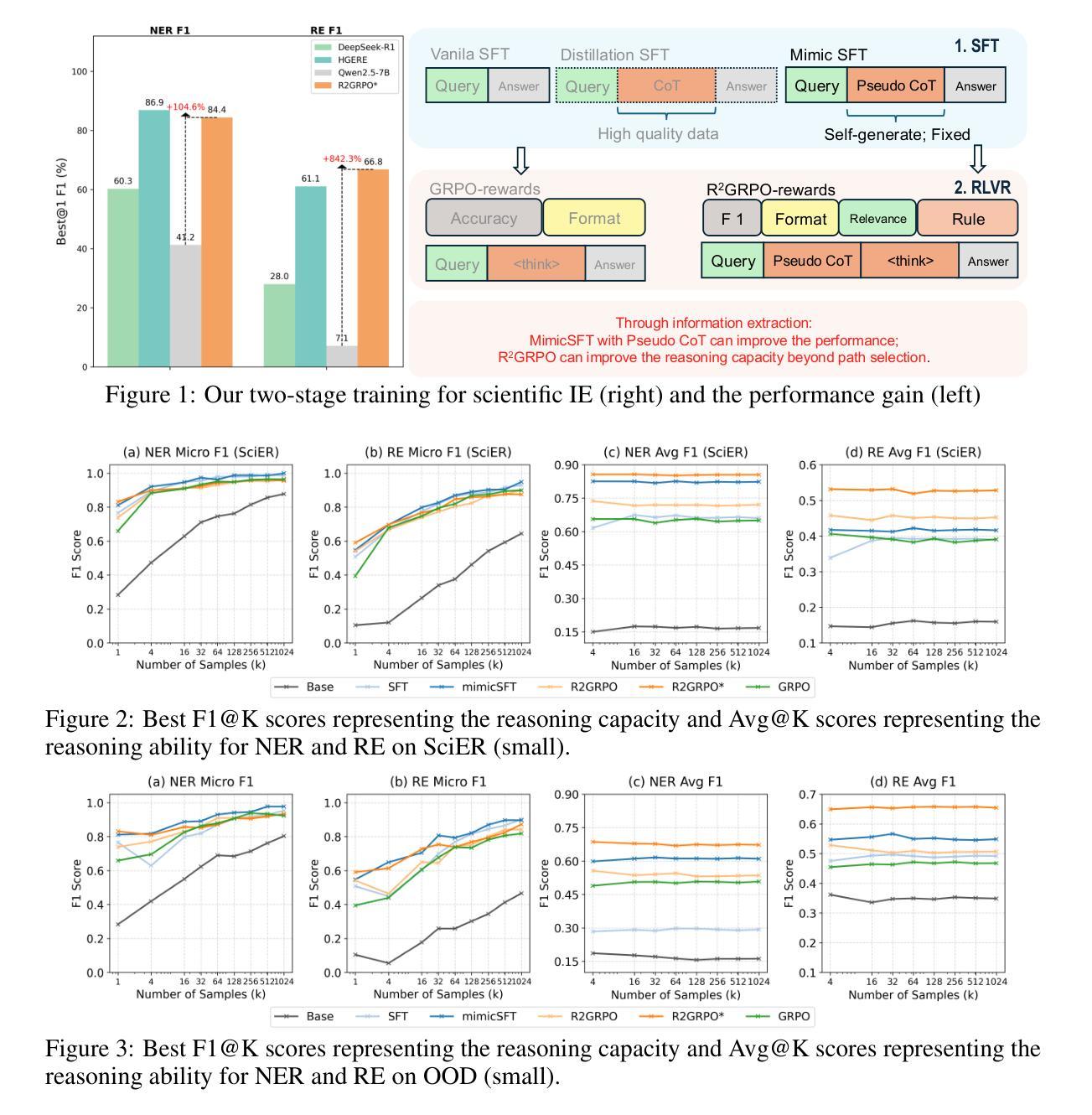
Beyond path selection: Better LLMs for Scientific Information Extraction with MimicSFT and Relevance and Rule-induced(R$^2$)GRPO
Authors:Ran Li, Shimin Di, Yuchen Liu, Chen Jing, Yu Qiu, Lei Chen
Previous study suggest that powerful Large Language Models (LLMs) trained with Reinforcement Learning with Verifiable Rewards (RLVR) only refines reasoning path without improving the reasoning capacity in math tasks while supervised-finetuning(SFT) with distillation can. We study this from the view of Scientific information extraction (SciIE) where LLMs and reasoning LLMs underperforms small Bert-based models. SciIE require both the reasoning and memorization. We argue that both SFT and RLVR can refine the reasoning path and improve reasoning capacity in a simple way based on SciIE. We propose two-stage training with 1. MimicSFT, using structured reasoning templates without needing high-quality chain-of-thought data, 2. R$^2$GRPO with relevance and rule-induced rewards. Experiments on scientific IE benchmarks show that both methods can improve the reasoning capacity. R$^2$GRPO with mimicSFT surpasses baseline LLMs and specialized supervised models in relation extraction. Our code is available at https://github.com/ranlislz/R2GRPO.
先前的研究表明,使用强化学习与可验证奖励(RLVR)训练的强大语言模型(LLM)只在数学任务中精炼推理路径,并不提高推理能力,而使用蒸馏技术进行监督微调(SFT)则可以。我们从科学信息提取(SciIE)的角度研究这个问题,发现大型语言模型和推理型语言模型的表现都不如基于小型BERT的模型。科学信息提取既需要推理能力也需要记忆能力。我们认为,基于SciIE,SFT和RLVR都能以简单的方式精炼推理路径并提高推理能力。我们提出了两阶段训练法:一是模仿SFT,使用结构化推理模板而无需高质量的思考链数据;二是R$^2$GRPO与相关性及规则诱导奖励相结合。在科学信息提取基准测试上的实验表明,这两种方法都能提高推理能力。结合了模仿SFT的R$^2$GRPO在关系提取上超越了基线LLM和专门的监督模型。我们的代码位于https://github.com/ranlislz/R2GRPO。
论文及项目相关链接
Summary
基于现有研究,大型语言模型(LLM)在强化学习验证奖励(RLVR)训练下,仅优化推理路径而不提高数学任务的推理能力。然而,通过蒸馏进行的有监督微调(SFT)可以改进这一点。从科学信息提取(SciIE)的角度研究,LLM和推理型LLM的表现不如基于小型BERT的模型。SciIE需要推理和记忆能力。我们认为SFT和RLVR都可以基于SciIE优化推理路径并提高推理能力。我们提出了两个阶段性的训练策略:1)MimicSFT,利用结构化推理模板无需高质量的思考链数据;2)R²GRPO与相关性及规则诱导奖励。在科学信息提取基准测试上的实验表明,这两种方法都能提高推理能力。结合了mimicSFT的R²GRPO在关系提取上超越了基线LLM和专门的监督模型。
Key Takeaways
- LLMs在RLVR训练下仅优化推理路径而不提高数学任务的推理能力。
- SFT结合蒸馏可以提高LLMs的推理能力。
- 从SciIE角度看,LLM和推理型LLM表现不如小型BERT模型。
- SciIE需要同时具备推理和记忆能力。
- SFT和RLVR都能基于SciIE优化推理路径。
- 提出了两阶段训练策略:MimicSFT和R²GRPO,前者利用结构化推理模板,后者结合相关性和规则诱导奖励。
点此查看论文截图