⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-05-30 更新
Developing a Top-tier Framework in Naturalistic Conditions Challenge for Categorized Emotion Prediction: From Speech Foundation Models and Learning Objective to Data Augmentation and Engineering Choices
Authors:Tiantian Feng, Thanathai Lertpetchpun, Dani Byrd, Shrikanth Narayanan
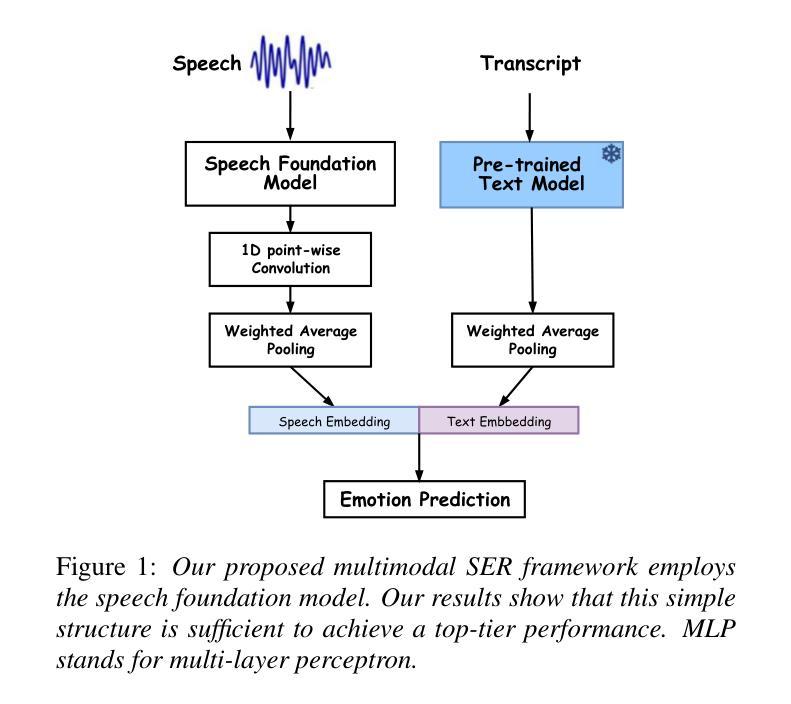
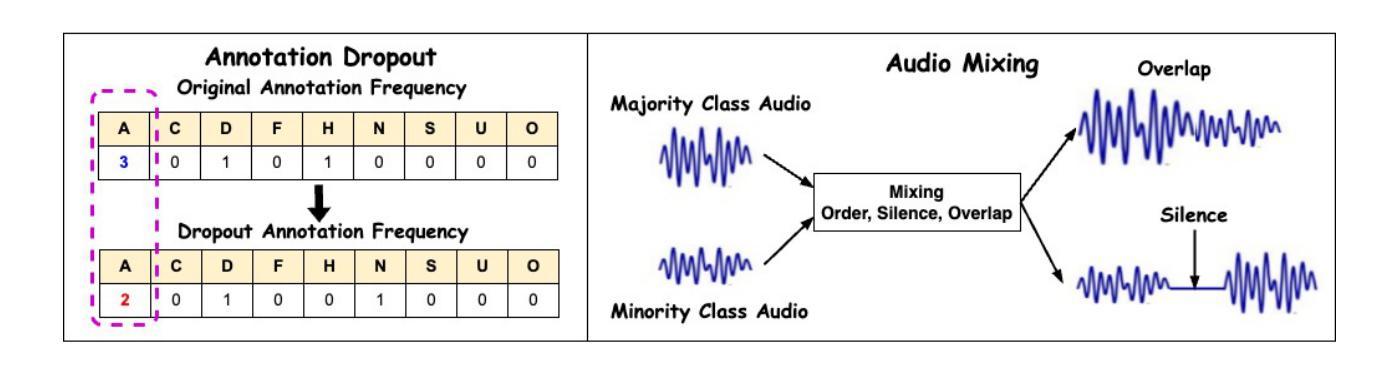
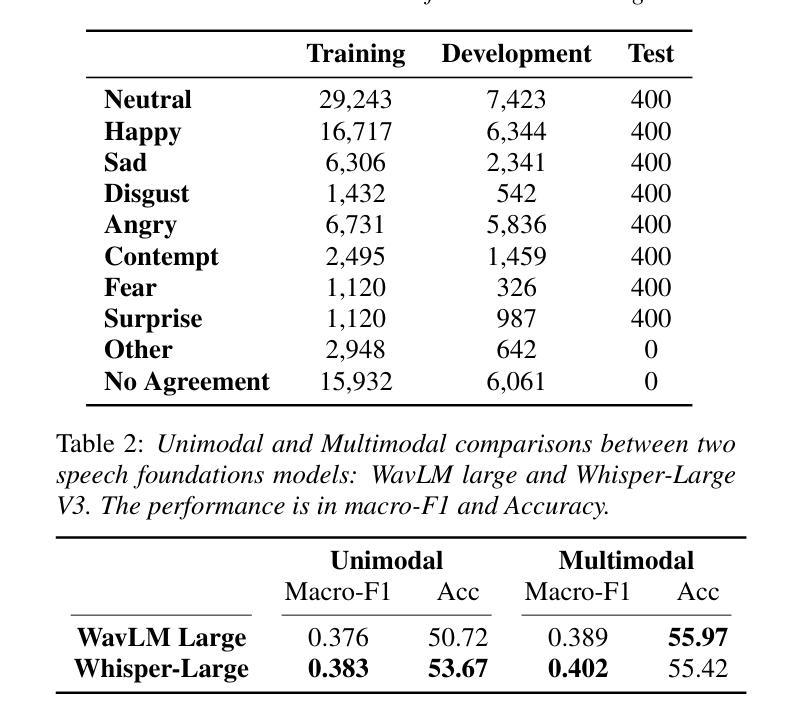
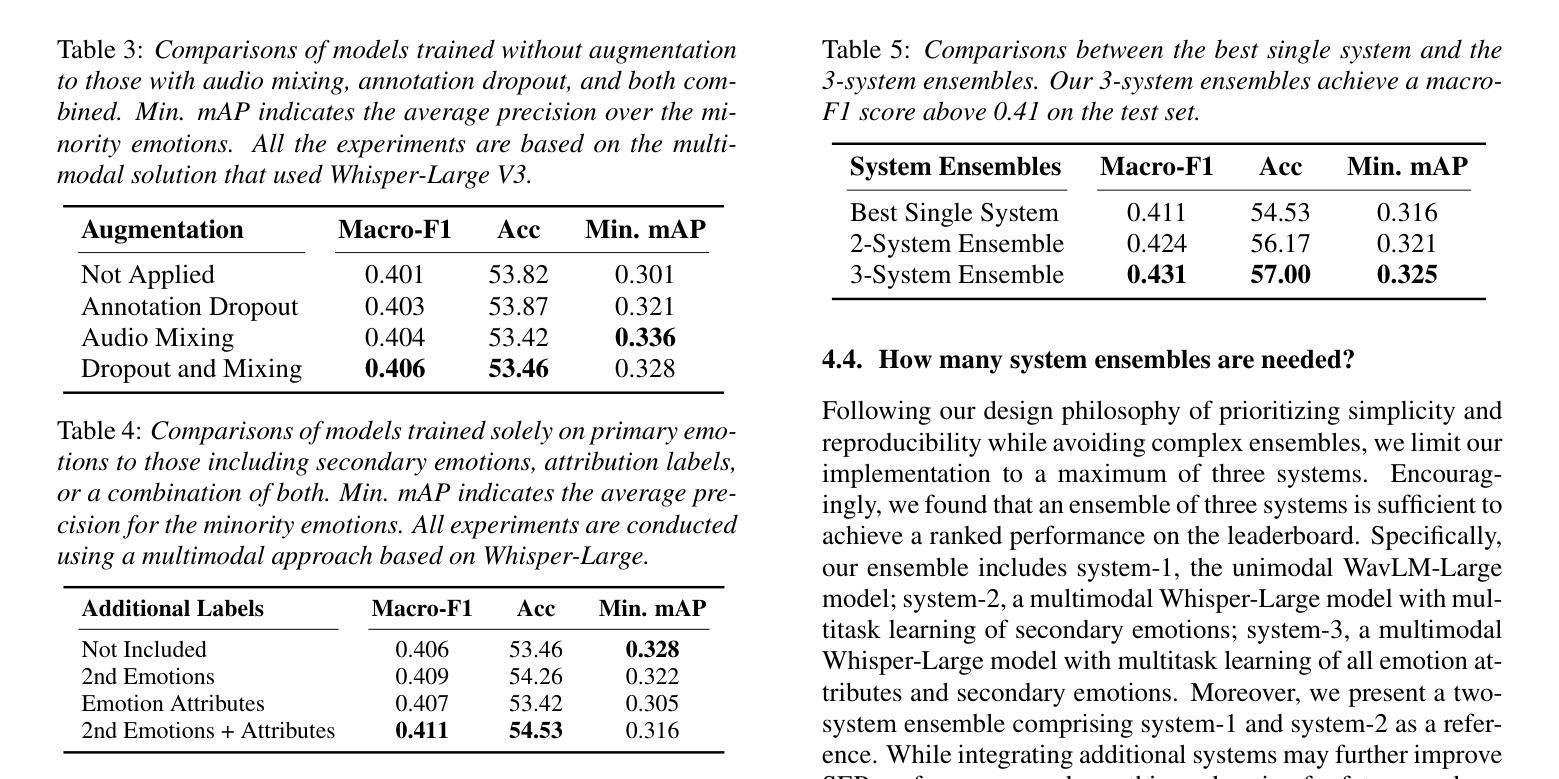
Speech emotion recognition (SER), particularly for naturally expressed emotions, remains a challenging computational task. Key challenges include the inherent subjectivity in emotion annotation and the imbalanced distribution of emotion labels in datasets. This paper introduces the \texttt{SAILER} system developed for participation in the INTERSPEECH 2025 Emotion Recognition Challenge (Task 1). The challenge dataset, which contains natural emotional speech from podcasts, serves as a valuable resource for studying imbalanced and subjective emotion annotations. Our system is designed to be simple, reproducible, and effective, highlighting critical choices in modeling, learning objectives, data augmentation, and engineering choices. Results show that even a single system (without ensembling) can outperform more than 95% of the submissions, with a Macro-F1 score exceeding 0.4. Moreover, an ensemble of three systems further improves performance, achieving a competitively ranked score (top-3 performing team). Our model is at: https://github.com/tiantiaf0627/vox-profile-release.
语音情感识别(SER),尤其是自然表达情感的识别,仍然是一项具有挑战性的计算任务。主要挑战包括情感注释中的固有主观性和数据集中情感标签的不平衡分布。本文介绍了为参与INTERSPEECH 2025情感识别挑战赛(任务1)而开发的`SAILER’系统。挑战赛数据集包含来自播客的自然情感语音,是研究不平衡和主观情感注释的宝贵资源。我们的系统设计简单、可复制、有效,强调建模、学习目标、数据增强和工程选择中的关键选择。结果表明,即使是一个单一的系统(不组合)也能表现出超过95%提交的性能,宏F1分数超过0.4。此外,三个系统的组合进一步提高了性能,实现了竞争排名(前三名队伍)。我们的模型位于:https://github.com/tiantiaf0627/vox-profile-release。
论文及项目相关链接
PDF Accepted to INTERSPEECH 2025
Summary
该论文针对语音情感识别(SER)面临的挑战,如情绪标注的主观性和数据集情感标签分布不均衡等问题,引入了为参与INTERSPEECH 2025情感识别挑战赛(任务1)而开发的SAILER系统。该系统旨在设计简单、可复制和高效,突出建模、学习目标、数据增强和工程选择的关键性。实验结果显示,即使是一个单一系统也能超越超过95%的提交结果,宏观F1分数超过0.4。通过集成三个系统,性能得到进一步提升,成为排名靠前的三支队伍之一。
Key Takeaways
- 语音情感识别(SER)依然是一项具有挑战性的计算任务,特别是在自然情感表达方面。
- 情绪标注的主观性和数据集情感标签分布不均衡是SER的主要挑战。
- 论文引入了
SAILER系统,专为INTERSPEECH 2025情感识别挑战赛设计。 SAILER系统的设计理念是简单、可复制和高效。- 该系统在建模、学习目标、数据增强和工程选择方面做出了关键性决策。
- 实验结果显示,单一系统的性能已超越大多数提交的结果,宏观F1分数超过0.4。
- 通过集成三个系统,取得了竞争力的排名,成为前三名队伍之一。
点此查看论文截图

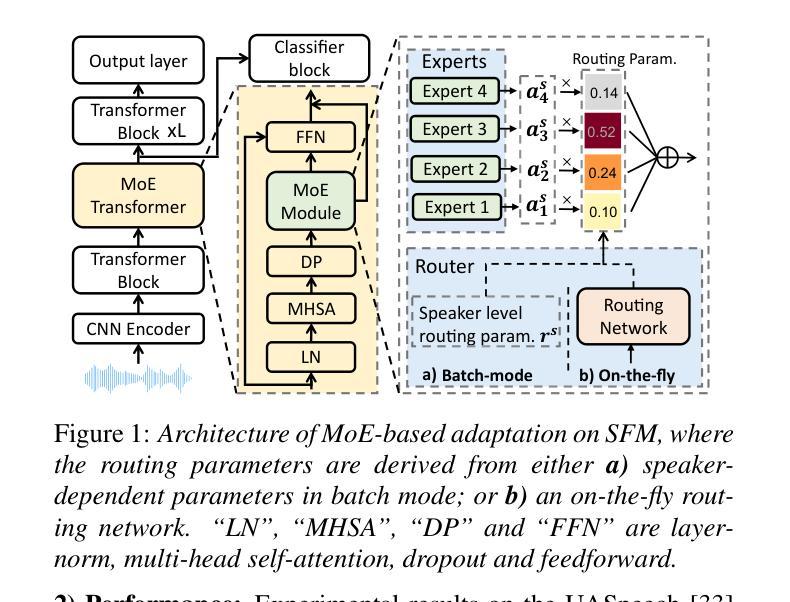
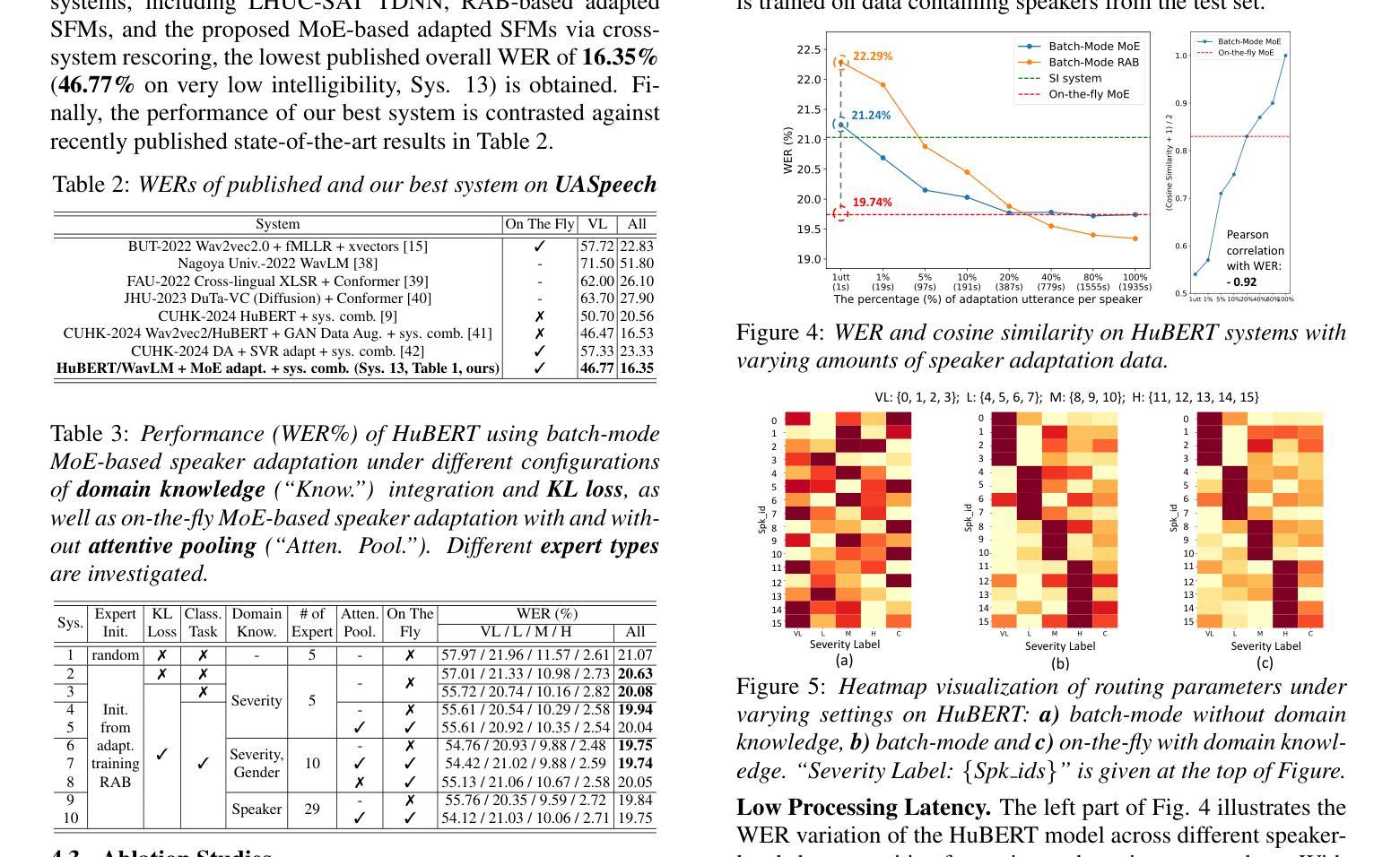
On-the-fly Routing for Zero-shot MoE Speaker Adaptation of Speech Foundation Models for Dysarthric Speech Recognition
Authors:Shujie HU, Xurong Xie, Mengzhe Geng, Jiajun Deng, Huimeng Wang, Guinan Li, Chengxi Deng, Tianzi Wang, Mingyu Cui, Helen Meng, Xunying Liu
This paper proposes a novel MoE-based speaker adaptation framework for foundation models based dysarthric speech recognition. This approach enables zero-shot adaptation and real-time processing while incorporating domain knowledge. Speech impairment severity and gender conditioned adapter experts are dynamically combined using on-the-fly predicted speaker-dependent routing parameters. KL-divergence is used to further enforce diversity among experts and their generalization to unseen speakers. Experimental results on the UASpeech corpus suggest that on-the-fly MoE-based adaptation produces statistically significant WER reductions of up to 1.34% absolute (6.36% relative) over the unadapted baseline HuBERT/WavLM models. Consistent WER reductions of up to 2.55% absolute (11.44% relative) and RTF speedups of up to 7 times are obtained over batch-mode adaptation across varying speaker-level data quantities. The lowest published WER of 16.35% (46.77% on very low intelligibility) is obtained.
本文提出了一种基于MoE的新型自适应框架,用于基于基础模型的发音障碍语音识别。这种方法实现了零样本自适应和实时处理,同时融入了领域知识。通过实时预测的说话人依赖路由参数,动态结合了语音障碍严重程度和性别条件适配器专家。KL散度被用来进一步强化专家之间的多样性以及它们对未见说话人的泛化能力。在UASpeech语料库上的实验结果表明,基于实时MoE的自适应相较于未适应的基线HuBERT/WavLM模型,产生了绝对达1.34%(相对减少6.36%)的显著词错误率(WER)降低。相较于批量模式的自适应,在不同说话人级别的数据量上,获得了最高达绝对2.55%(相对减少11.44%)的WER降低和最高达7倍的实时因子(RTF)加速。获得了最低的发布WER为16.35%(极低清晰度上为46.77%)。
论文及项目相关链接
PDF Accepted by Interspeech 2025
Summary
本文提出了一种基于MoE(Mixture of Experts)的说话人自适应框架,用于处理基于基础模型的发音障碍语音识别。该方法实现了零样本自适应和实时处理,同时融入了领域知识。通过动态结合语音障碍严重性和性别调节适配器专家,并使用即时预测的说话人依赖路由参数,实现了专家之间的多样性和对未见说话人的泛化。在UASpeech语料库上的实验结果表明,即时MoE自适应方法较未自适应的HuBERT/WavLM模型在词错误率(WER)上有显著下降,相对降低达6.36%,绝对降低达1.34%。在不同说话人级别的数据数量下,与批量模式自适应相比,获得了最多达2.55%的绝对WER降低和最多达7倍的实时处理速度提升。获得了迄今为止最低的WER为16.35%,在极低清晰度上的相对性能为46.77%。
Key Takeaways
- 论文提出了一种基于MoE的说话人自适应框架,专门用于处理发音障碍的语音识别。
- 该框架可以实现零样本自适应和实时处理,并融入领域知识。
- 通过动态结合语音障碍严重性和性别调节的适配器专家,提高了识别性能。
- 使用KL散度强化了专家间的多样性,并提高了对未见说话人的泛化能力。
- 在UASpeech语料库上的实验表明,该自适应框架在词错误率上有显著改进。
- 与未自适应的模型相比,该框架提供了相对降低的WER和绝对降低的WER具体数值。
点此查看论文截图



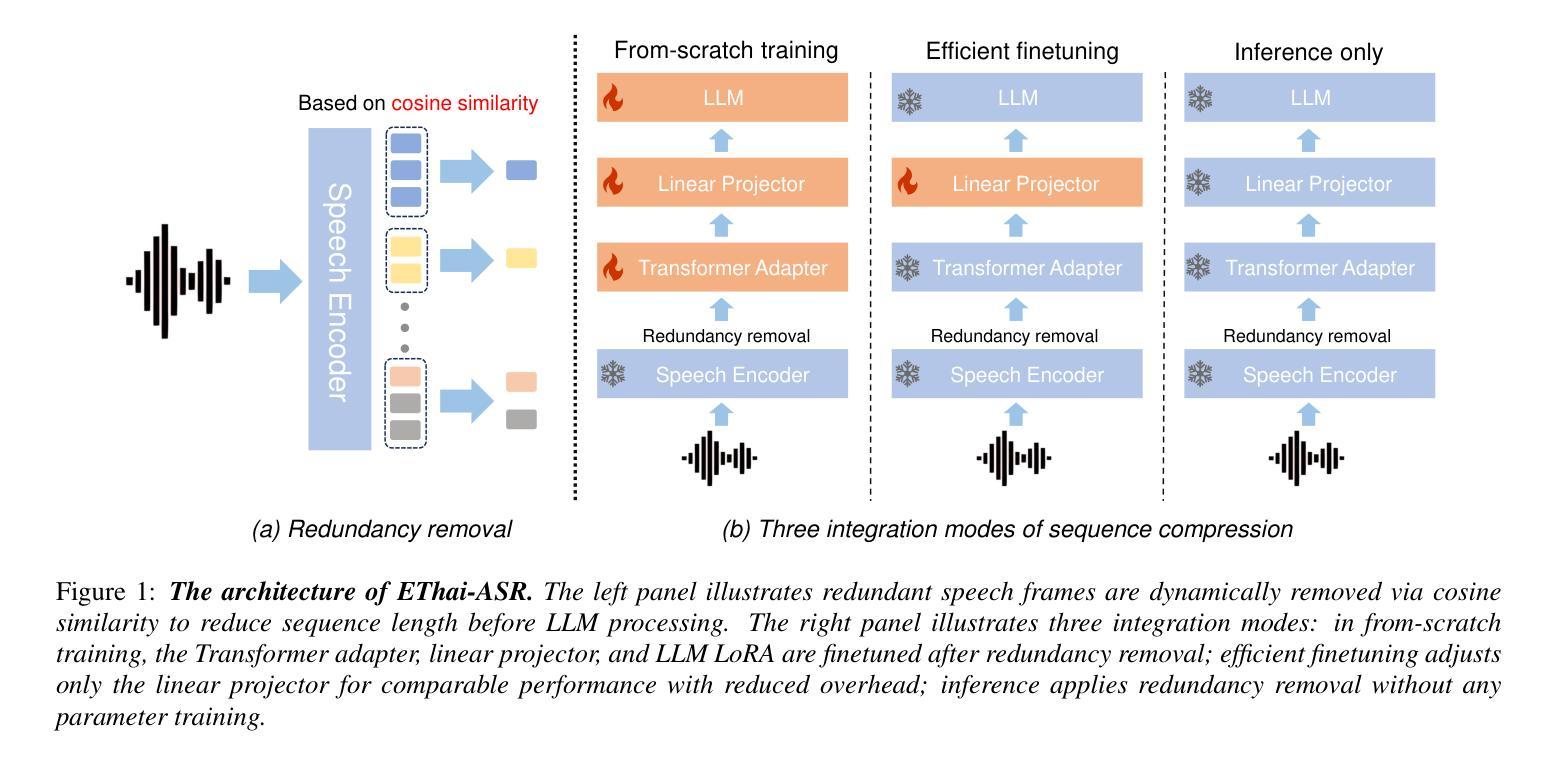
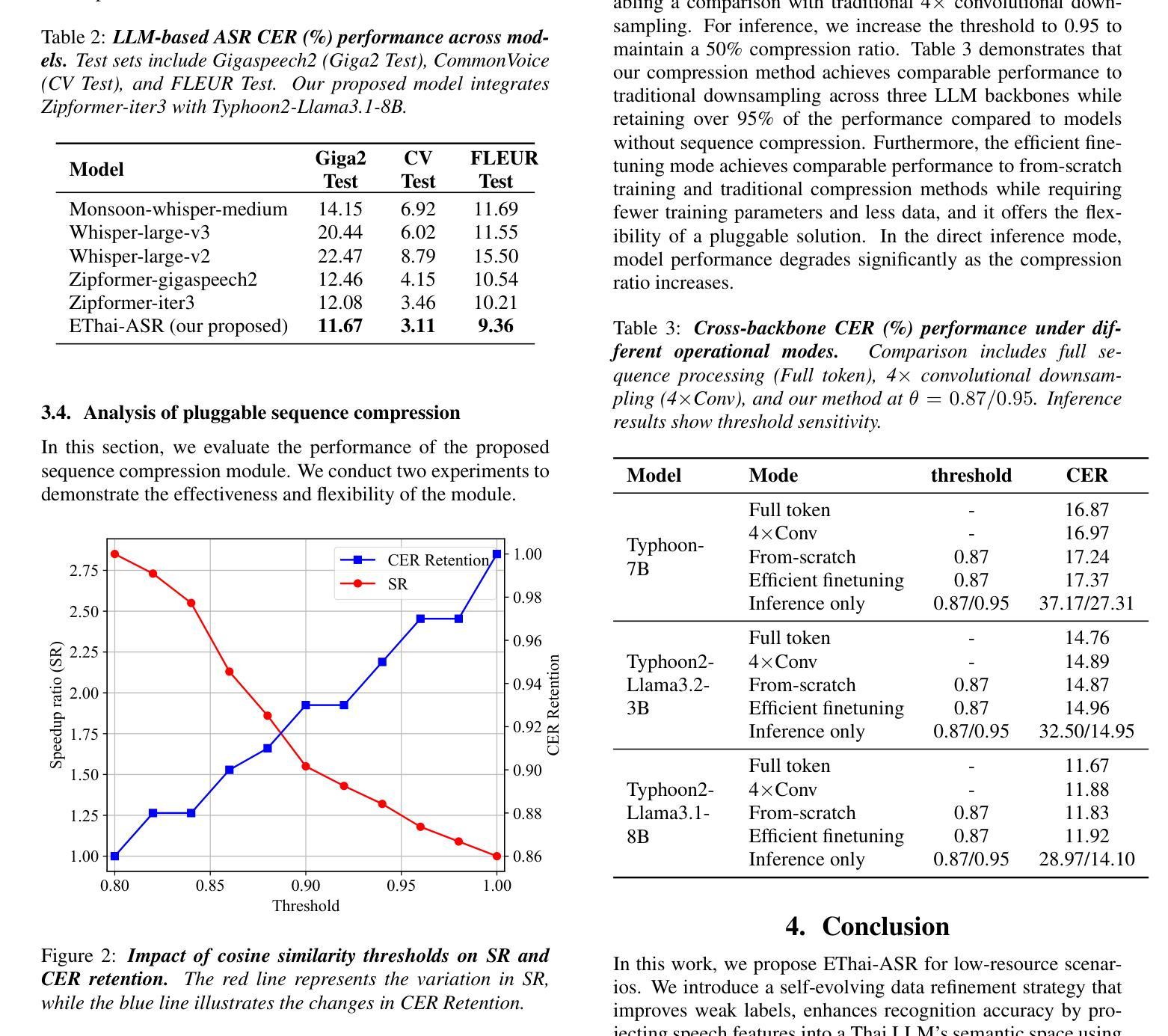
Weakly Supervised Data Refinement and Flexible Sequence Compression for Efficient Thai LLM-based ASR
Authors:Mingchen Shao, Xinfa Zhu, Chengyou Wang, Bingshen Mu, Hai Li, Ying Yan, Junhui Liu, Danming Xie, Lei Xie
Despite remarkable achievements, automatic speech recognition (ASR) in low-resource scenarios still faces two challenges: high-quality data scarcity and high computational demands. This paper proposes EThai-ASR, the first to apply large language models (LLMs) to Thai ASR and create an efficient LLM-based ASR system. EThai-ASR comprises a speech encoder, a connection module and a Thai LLM decoder. To address the data scarcity and obtain a powerful speech encoder, EThai-ASR introduces a self-evolving data refinement strategy to refine weak labels, yielding an enhanced speech encoder. Moreover, we propose a pluggable sequence compression module used in the connection module with three modes designed to reduce the sequence length, thus decreasing computational demands while maintaining decent performance. Extensive experiments demonstrate that EThai-ASR has achieved state-of-the-art accuracy in multiple datasets. We release our refined text transcripts to promote further research.
尽管取得了显著的成就,但在低资源场景下的自动语音识别(ASR)仍然面临两个挑战:高质量数据的稀缺和高计算需求。本文针对泰语ASR,首次应用大型语言模型(LLM)构建高效的LLM-based ASR系统,提出了EThai-ASR。EThai-ASR包括语音编码器、连接模块和泰语LLM解码器。为解决数据稀缺问题并获得强大的语音编码器,EThai-ASR引入了一种自我完善的数据精炼策略,以优化弱标签,从而产生增强的语音编码器。此外,我们提出了一种可插拔的序列压缩模块,用于连接模块中,设计了三种模式以减少序列长度,从而在保持性能的同时降低计算需求。大量实验表明,EThai-ASR在多个数据集上达到了最先进的准确性。我们发布了我们整理过的文本转录内容,以促进进一步的研究。
论文及项目相关链接
PDF Accepted by INTERSPEECH 2025
总结
这篇论文针对自动语音识别(ASR)在低资源场景下的两个挑战——高质量数据稀缺和计算需求高,提出了EThai-ASR系统。该系统首次将大型语言模型(LLMs)应用于泰语ASR,并创建了一个高效的LLM-based ASR系统。通过自我进化的数据精炼策略,EThai-ASR解决了数据稀缺问题,并增强了语音编码器的性能。此外,论文还提出了一个可插入的序列压缩模块,用于减少序列长度,从而降低计算需求同时保持不错的性能。实验表明,EThai-ASR在多个数据集上达到了最先进的准确度。
要点
- EThai-ASR系统解决了低资源环境下自动语音识别(ASR)的两个主要挑战:高质量数据稀缺和计算需求高。
- EThai-ASR首次将大型语言模型(LLMs)应用于泰语ASR。
- 通过自我进化的数据精炼策略,EThai-ASR增强了语音编码器的性能。
- 论文提出了一个可插入的序列压缩模块,用于减少计算需求同时保持性能。
- EThai-ASR在多个数据集上达到了最先进的准确度。
- 论文公开了精炼后的文本转录,以促进进一步研究。
点此查看论文截图

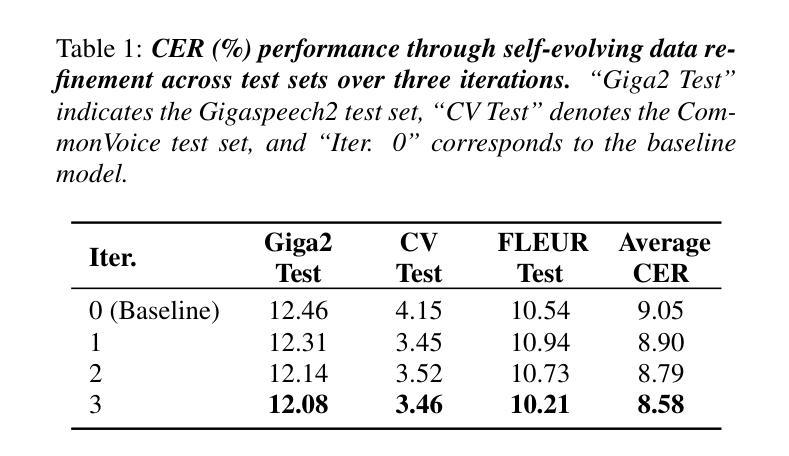
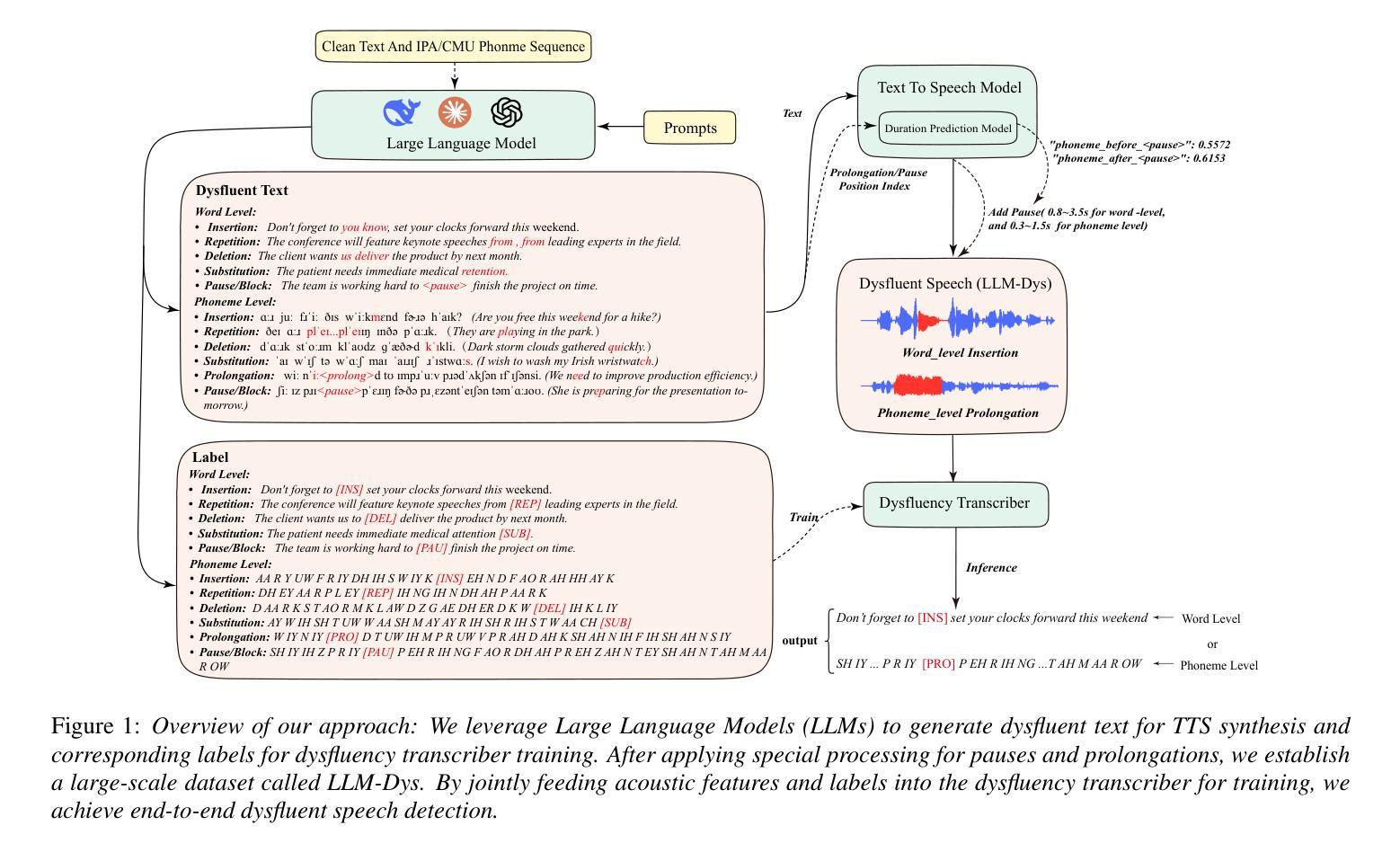
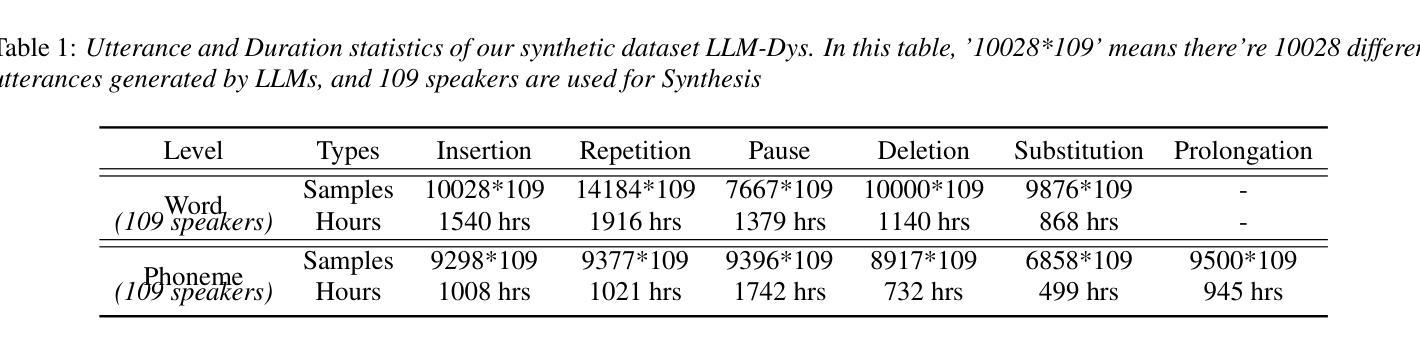
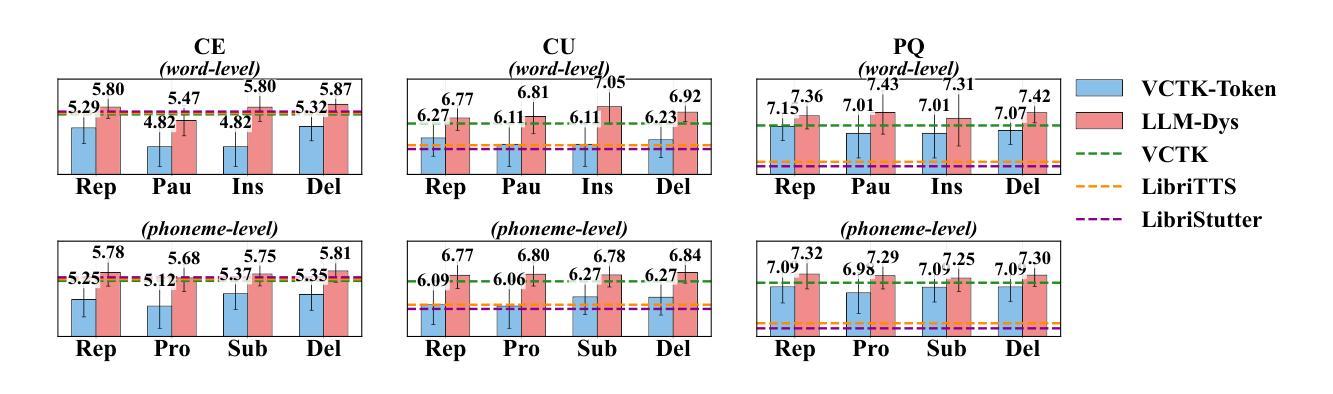
Analysis and Evaluation of Synthetic Data Generation in Speech Dysfluency Detection
Authors:Jinming Zhang, Xuanru Zhou, Jiachen Lian, Shuhe Li, William Li, Zoe Ezzes, Rian Bogley, Lisa Wauters, Zachary Miller, Jet Vonk, Brittany Morin, Maria Gorno-Tempini, Gopala Anumanchipalli
Speech dysfluency detection is crucial for clinical diagnosis and language assessment, but existing methods are limited by the scarcity of high-quality annotated data. Although recent advances in TTS model have enabled synthetic dysfluency generation, existing synthetic datasets suffer from unnatural prosody and limited contextual diversity. To address these limitations, we propose LLM-Dys – the most comprehensive dysfluent speech corpus with LLM-enhanced dysfluency simulation. This dataset captures 11 dysfluency categories spanning both word and phoneme levels. Building upon this resource, we improve an end-to-end dysfluency detection framework. Experimental validation demonstrates state-of-the-art performance. All data, models, and code are open-sourced at https://github.com/Berkeley-Speech-Group/LLM-Dys.
语音流畅性检测对于临床诊断和治疗语言评估至关重要,但现有方法受到高质量注释数据稀缺的限制。尽管最近文本到语音(TTS)模型的进步已经能够实现合成流畅性生成,但现有合成数据集存在语调不自然和上下文多样性有限的问题。为了解决这些局限性,我们提出了LLM-Dys——一个利用大型语言模型增强流畅性模拟的最全面的流畅性语音语料库。该数据集涵盖了跨越单词和音素级别的11个流畅性问题类别。基于这一资源,我们改进了一个端到端的流畅性检测框架。实验验证证明了其处于前沿的性能。所有数据和模型都在https://github.com/Berkeley-Speech-Group/LLM-Dys上开源。
论文及项目相关链接
PDF Submitted to Interspeech 2025
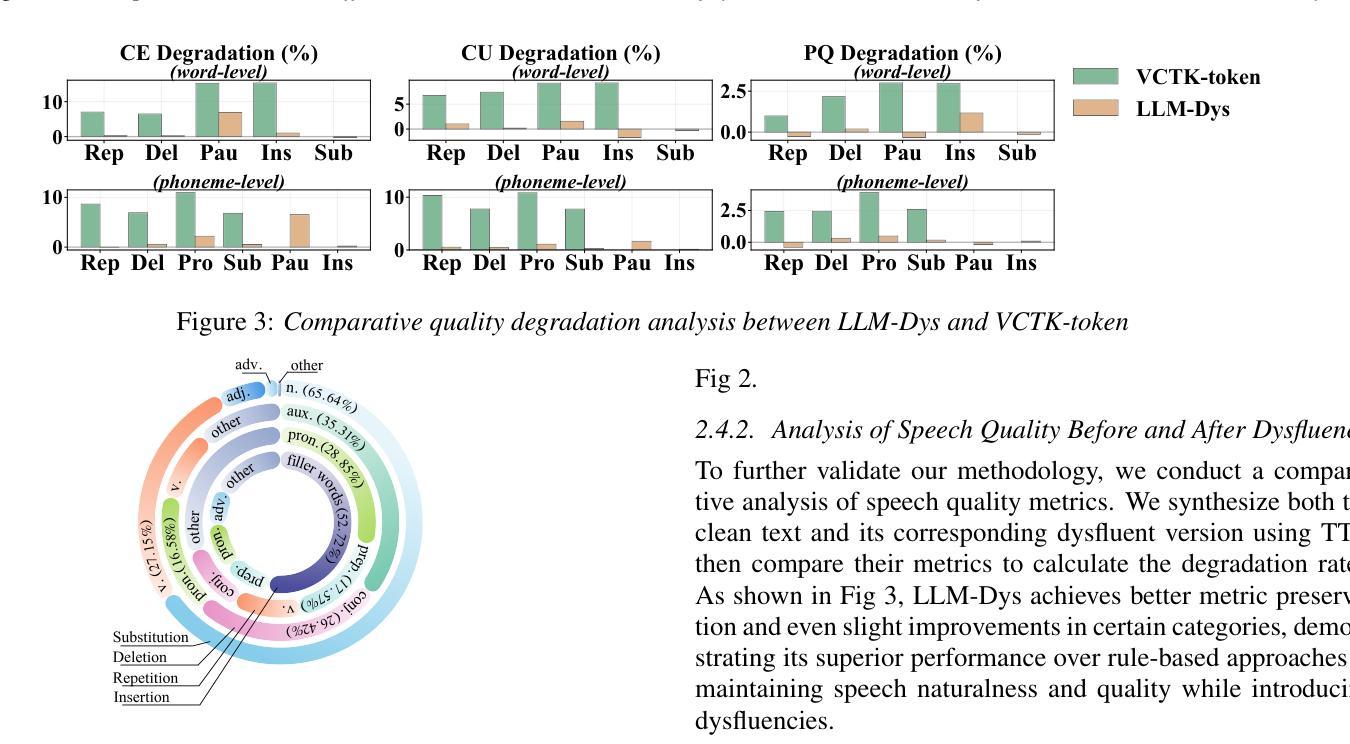
Summary
本文介绍了语音流畅性检测在临床诊断和治疗语言评估中的重要性。现有的方法受限于高质量标注数据的稀缺性。虽然最近的TTS模型进步能够实现合成流畅性生成,但现有合成数据集存在韵律不自然和上下文多样性有限的局限性。为此,我们提出了LLM-Dys——最全面的流畅性语音语料库,借助大型语言模型增强流畅性模拟。该数据集涵盖了词汇和音素两个层面上的11种流畅性问题类别。基于此资源,我们改进了端到端的流畅性检测框架。实验验证展示了其处于前沿的性能表现。所有相关数据、模型和代码已开源在:https://github.com/Berkeley-Speech-Group/LLM-Dys。
Key Takeaways
- 语音流畅性检测在临床诊断和治疗语言评估中具有重要性。
- 现有方法受限于高质量标注数据的稀缺性。
- TTS模型的进步能够实现合成流畅性生成,但存在韵律不自然和上下文多样性有限的局限性。
- 提出LLM-Dys——最全面的流畅性语音语料库,涵盖词汇和音素层面上的多种流畅性问题类别。
- 利用LLM-Dys改进了端到端的流畅性检测框架。
- 实验验证显示该框架具有前沿性能。
点此查看论文截图

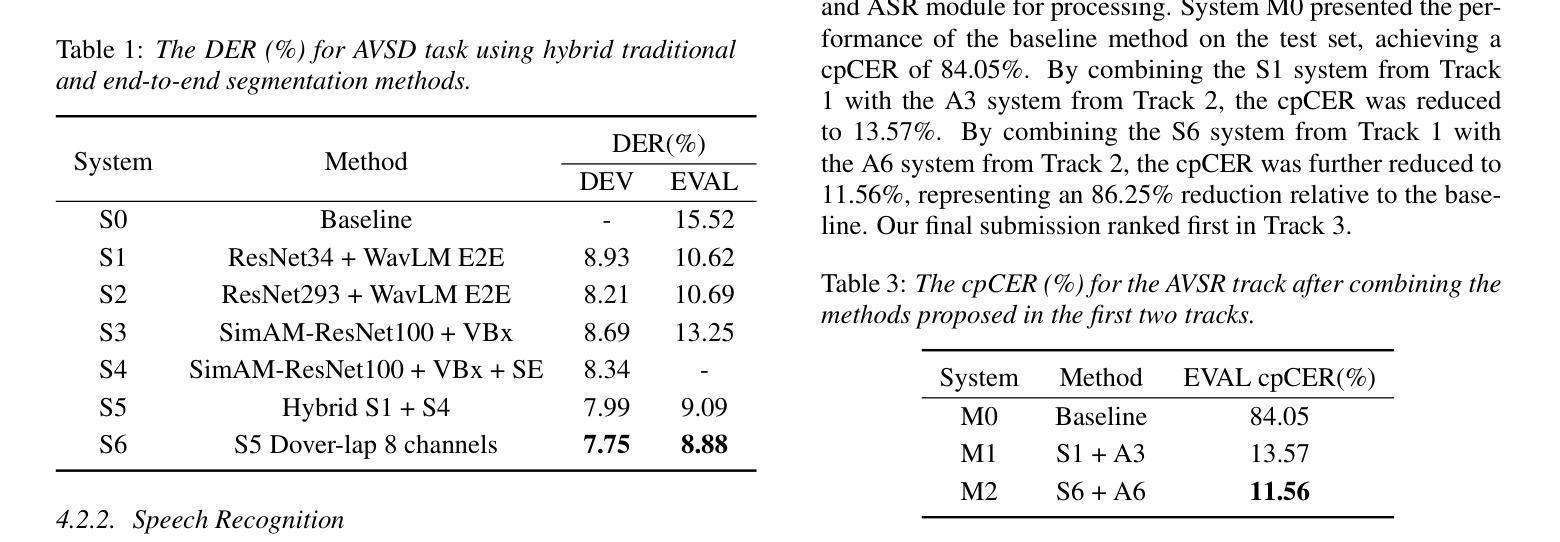
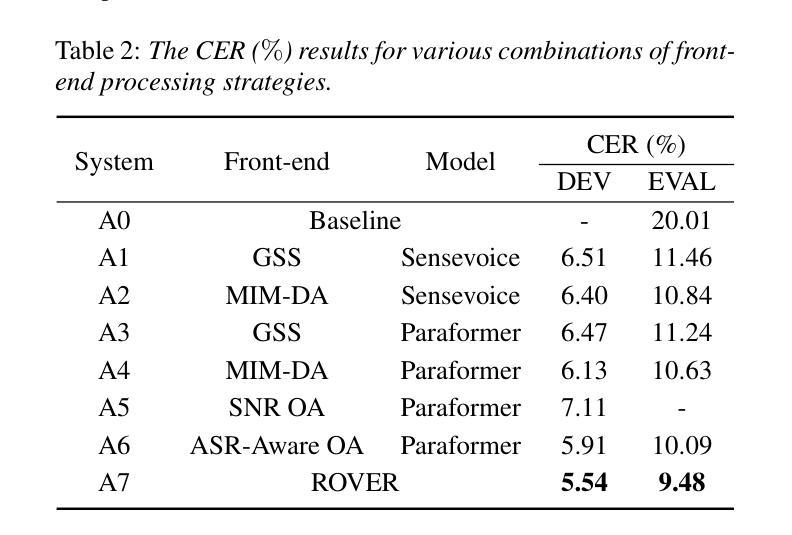
Overlap-Adaptive Hybrid Speaker Diarization and ASR-Aware Observation Addition for MISP 2025 Challenge
Authors:Shangkun Huang, Yuxuan Du, Jingwen Yang, Dejun Zhang, Xupeng Jia, Jing Deng, Jintao Kang, Rong Zheng
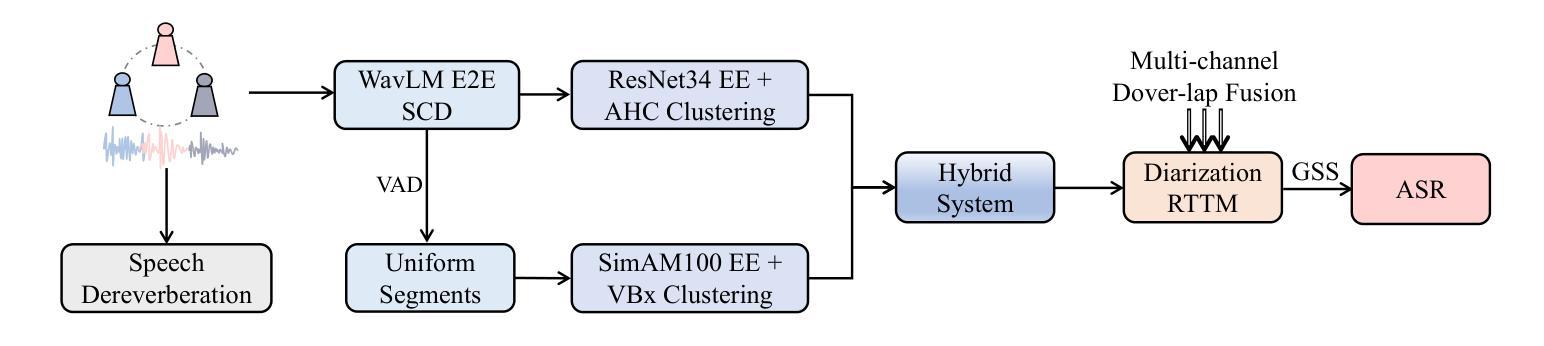
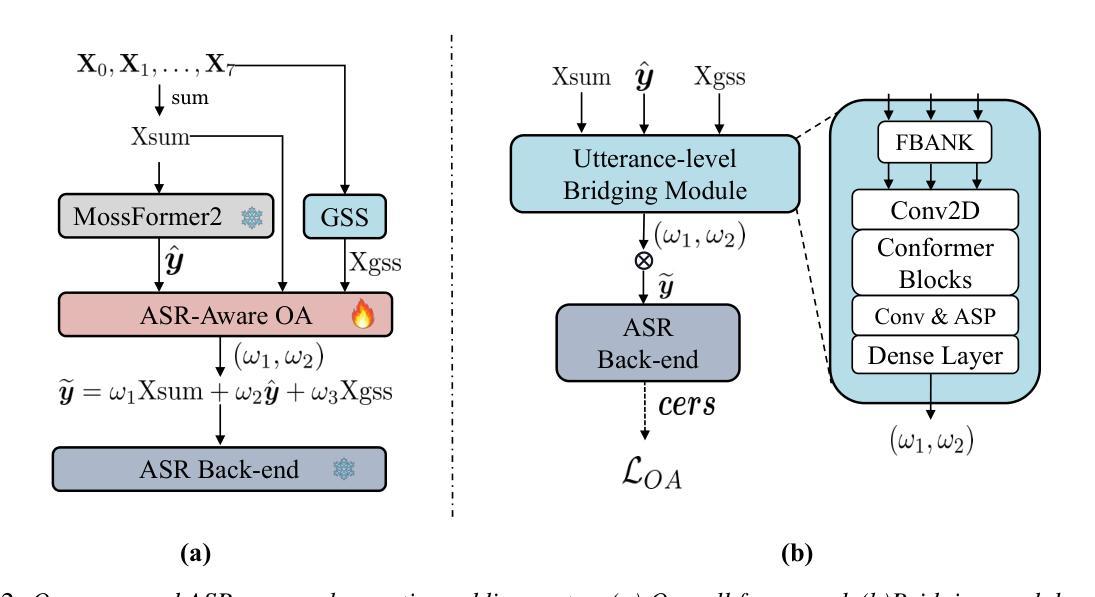
This paper presents the system developed to address the MISP 2025 Challenge. For the diarization system, we proposed a hybrid approach combining a WavLM end-to-end segmentation method with a traditional multi-module clustering technique to adaptively select the appropriate model for handling varying degrees of overlapping speech. For the automatic speech recognition (ASR) system, we proposed an ASR-aware observation addition method that compensates for the performance limitations of Guided Source Separation (GSS) under low signal-to-noise ratio conditions. Finally, we integrated the speaker diarization and ASR systems in a cascaded architecture to address Track 3. Our system achieved character error rates (CER) of 9.48% on Track 2 and concatenated minimum permutation character error rate (cpCER) of 11.56% on Track 3, ultimately securing first place in both tracks and thereby demonstrating the effectiveness of the proposed methods in real-world meeting scenarios.
本文介绍了为应对MISP 2025挑战而开发的系统。对于说话人分类系统,我们提出了一种混合方法,将WavLM端到端分割方法与传统的多模块聚类技术相结合,以自适应地选择处理不同程度重叠语音的合适模型。对于自动语音识别(ASR)系统,我们提出了一种ASR感知观测增加方法,以弥补在低声噪比条件下指导源分离(GSS)的性能限制。最后,我们将说话人分类和ASR系统以级联架构集成在一起,以解决第3赛道的问题。我们的系统在赛道2上取得了字符错误率(CER)为9.48%,赛道3上串联最小排列字符错误率(cpCER)为11.56%,最终在两道赛道上均获得第一名,从而证明了所提方法在真实会议场景中的有效性。
论文及项目相关链接
PDF Accepted to Interspeech 2025
Summary:
本文介绍了为应对MISP 2025挑战而开发的系统。文中提出了结合WavLM端到端分割方法和传统多模块聚类技术的混合方法来适应不同重叠语音程度的说话人识别。针对自动语音识别(ASR)系统,提出了ASR感知观测增加方法,以弥补在低信噪比条件下引导源分离(GSS)的性能限制。最后,将说话人识别和ASR系统以级联架构整合在一起应对第三轨道挑战。系统在第二轨道上实现了人物错误识别率为9.48%,在第三轨道上实现了最小排列人物错误识别率为11.56%,并获得了双轨道的第一名,证明了所提出方法在真实会议场景中的有效性。
Key Takeaways:
- 采用混合方法应对说话人识别挑战,结合WavLM端到端分割方法和传统多模块聚类技术以适应不同语音重叠程度。
- 针对ASR系统提出了ASR感知观测增加方法,以改善低信噪比环境下的性能。
- 通过级联架构整合说话人识别和ASR系统,应对第三轨道的挑战。
- 系统在第二和第三轨道的比赛中均取得了第一名的成绩。
- 提出了有效的应对策略,适用于真实会议场景。
- 系统的性能通过人物错误识别率来衡量,其中第二轨道的人物错误识别率为9.48%,第三轨道的最小排列人物错误识别率为11.56%。
点此查看论文截图

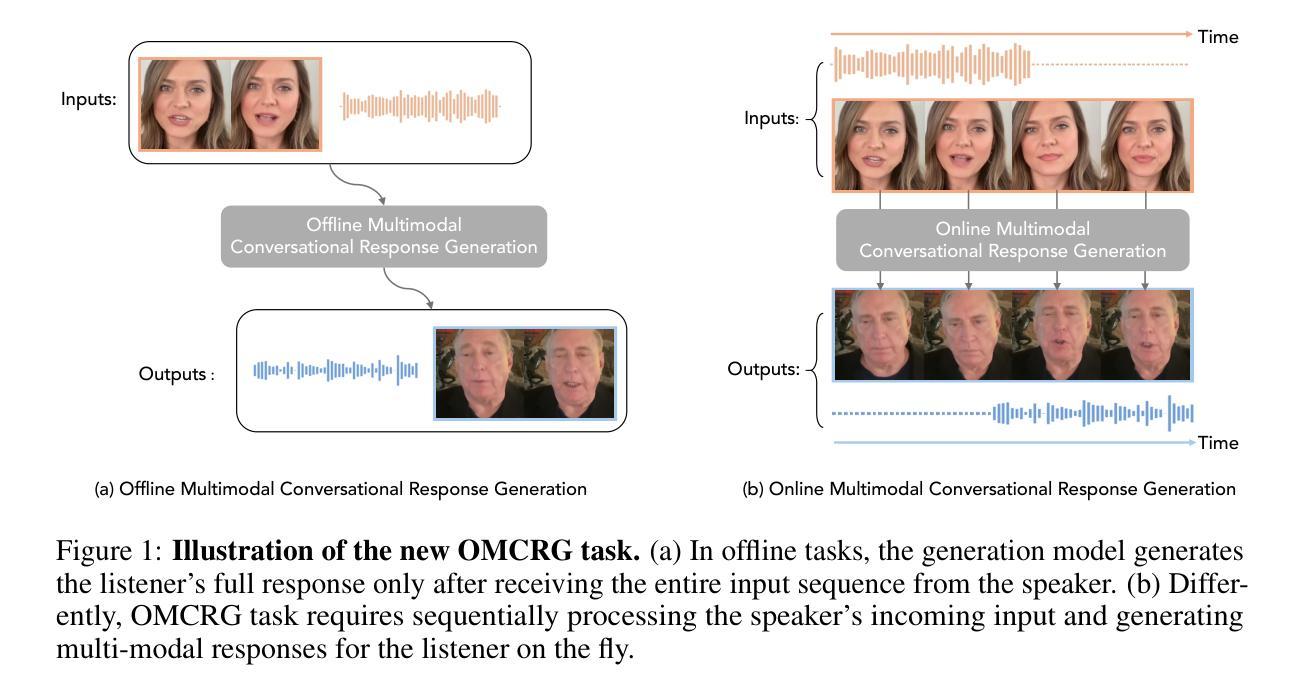
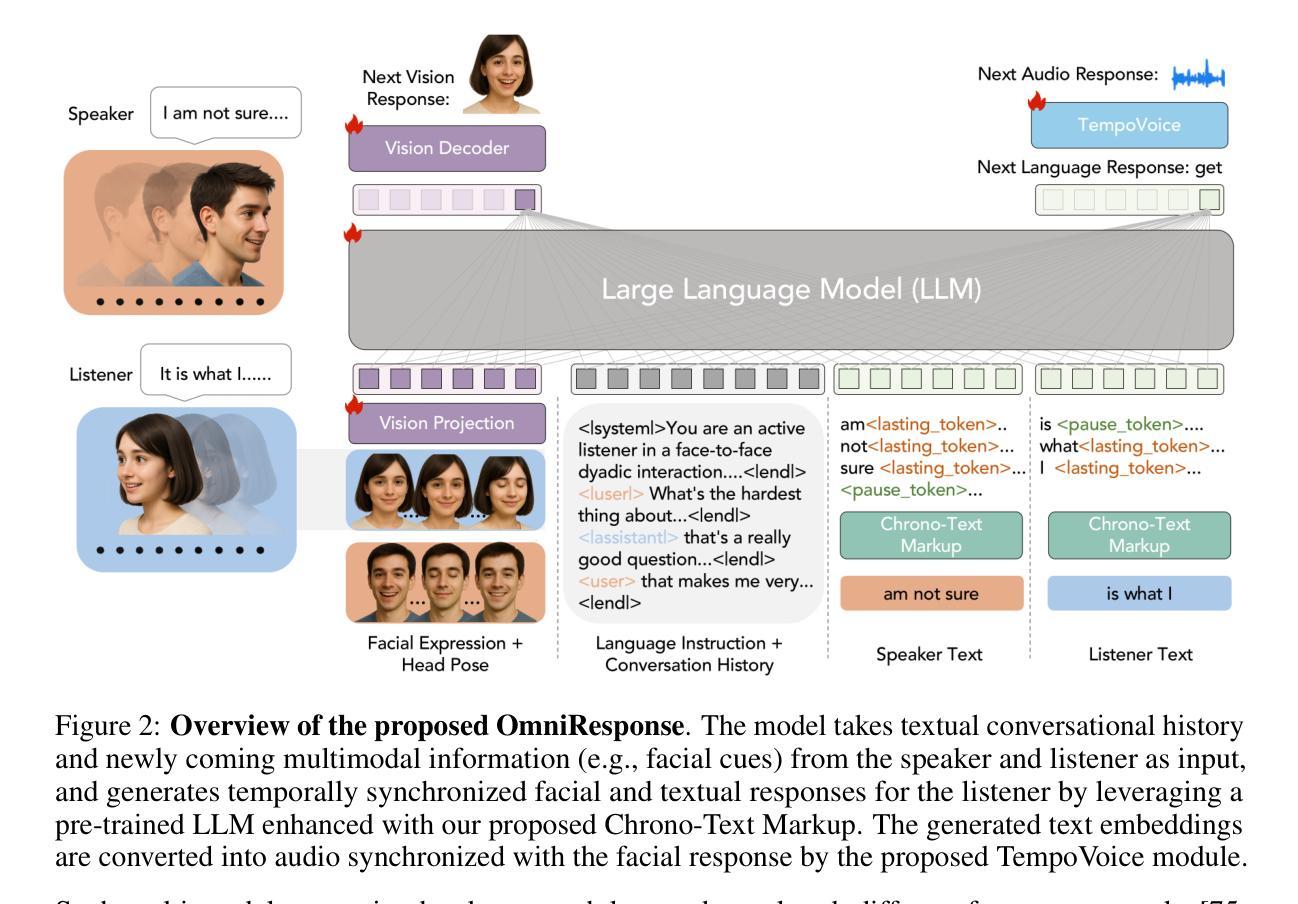
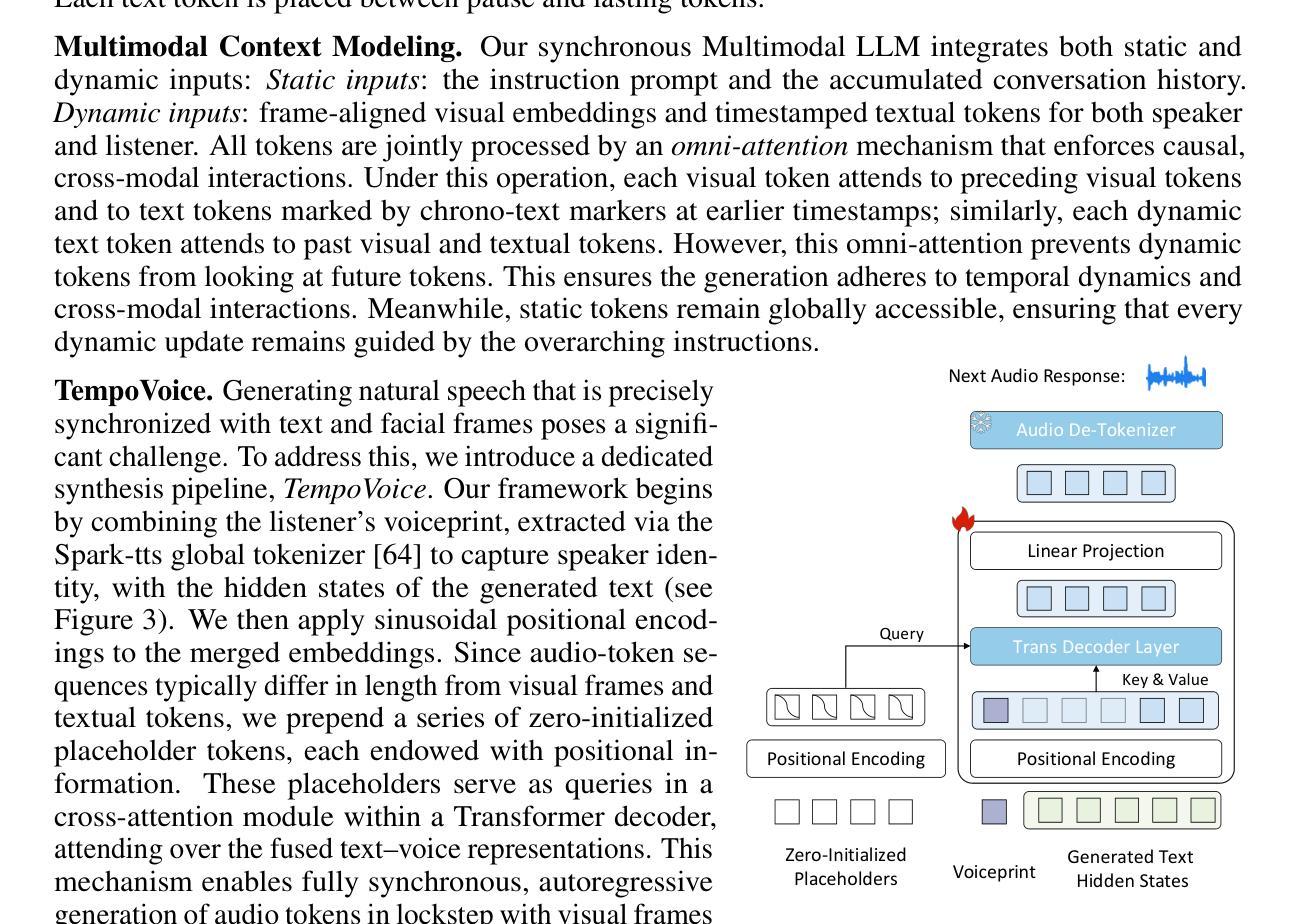
OmniResponse: Online Multimodal Conversational Response Generation in Dyadic Interactions
Authors:Cheng Luo, Jianghui Wang, Bing Li, Siyang Song, Bernard Ghanem
In this paper, we introduce Online Multimodal Conversational Response Generation (OMCRG), a novel task that aims to online generate synchronized verbal and non-verbal listener feedback, conditioned on the speaker’s multimodal input. OMCRG reflects natural dyadic interactions and poses new challenges in achieving synchronization between the generated audio and facial responses of the listener. To address these challenges, we innovatively introduce text as an intermediate modality to bridge the audio and facial responses. We hence propose OmniResponse, a Multimodal Large Language Model (MLLM) that autoregressively generates high-quality multi-modal listener responses. OmniResponse leverages a pretrained LLM enhanced with two novel components: Chrono-Text, which temporally anchors generated text tokens, and TempoVoice, a controllable online TTS module that produces speech synchronized with facial reactions. To support further OMCRG research, we present ResponseNet, a new dataset comprising 696 high-quality dyadic interactions featuring synchronized split-screen videos, multichannel audio, transcripts, and facial behavior annotations. Comprehensive evaluations conducted on ResponseNet demonstrate that OmniResponse significantly outperforms baseline models in terms of semantic speech content, audio-visual synchronization, and generation quality.
在这篇论文中,我们介绍了在线多模态对话响应生成(OMCRG)这一新任务,它的目标是根据说话者的多模态输入,在线生成同步的言语和非言语听众反馈。OMCRG反映了自然的二元交互,并实现在生成的音频和听众的面部响应之间的同步提出了新的挑战。为了应对这些挑战,我们创新地引入文本作为中间模态,以桥接音频和面部响应。因此,我们提出了OmniResponse,这是一种多模态大型语言模型(MLLM),可以自回归地生成高质量的多模态听众响应。OmniResponse利用了一个预训练的大型语言模型,并增强了两个新组件:Chrono-Text,它临时锚定生成的文本标记;以及TempoVoice,一个可控的在线文本到语音模块,能够产生与面部反应同步的语音。为了支持进一步的OMCRG研究,我们推出了ResponseNet,这是一个新的数据集,包含696个高质量的二元交互特征,具有同步分屏视频、多通道音频、文字记录和面部行为注释。在ResponseNet上进行的综合评估表明,OmniResponse在语义语音内容、视听同步和生成质量方面显著优于基准模型。
论文及项目相关链接
PDF 23 pages, 9 figures
Summary
本文介绍了在线多模态对话响应生成(OMCRG)任务,该任务旨在根据说话者的多模态输入,在线生成同步的言语和非言语听众反馈。为应对挑战,引入文本作为中间模态,提出OmniResponse多模态大型语言模型(MLLM),可自动生成高质量的多模态听众响应。OmniResponse利用预训练的大型语言模型,并增加两个新组件:Chrono-Text和TempoVoice,分别实现文本令牌的时间锚定和与面部反应同步的在线语音合成。为了支持OMCRG研究,推出ResponseNet数据集,包含高质量的双向互动同步分屏视频、多通道音频、文本记录和面部行为注释。评估表明,OmniResponse在语义语音内容、视听同步和生成质量方面显著优于基准模型。
Key Takeaways
- 引入了在线多模态对话响应生成(OMCRG)任务,旨在根据说话者的多模态输入生成同步的言语和非言语反馈。
- OMCRG反映了自然的双向互动,并带来了生成音频和面部响应同步的新挑战。
- 提出OmniResponse多模态大型语言模型(MLLM),通过引入文本作为中间模态来应对这些挑战,生成高质量的多模态听众响应。
- OmniResponse包含两个新组件:Chrono-Text和TempoVoice,分别实现文本的时间锚定和与面部反应同步的语音合成。
- 为了支持OMCRG研究,推出了ResponseNet数据集,包含同步的分屏视频、多通道音频、文本记录和面部行为注释。
- 评估显示,OmniResponse在语义语音内容、视听同步和生成质量方面超越基准模型。
点此查看论文截图

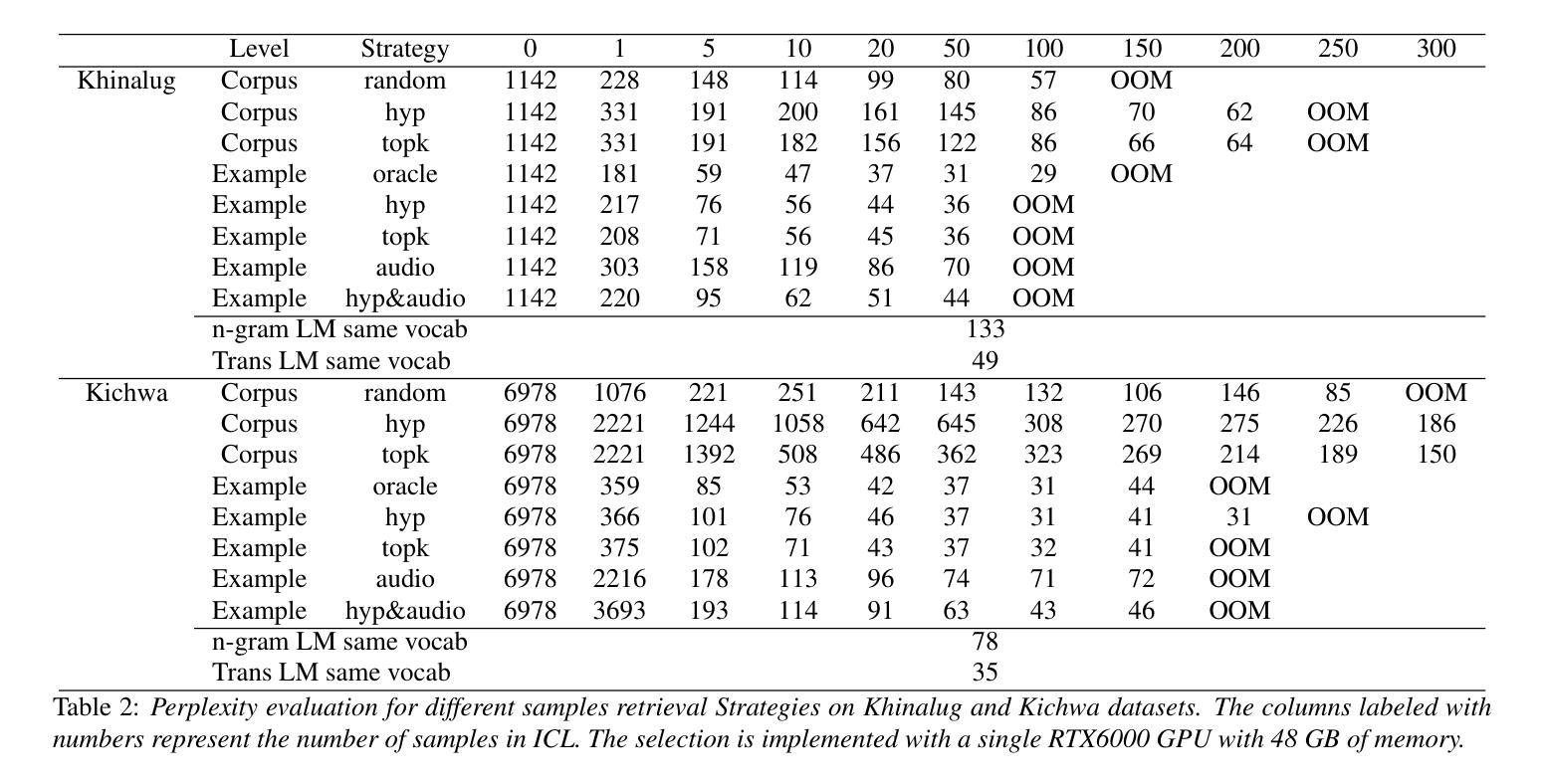
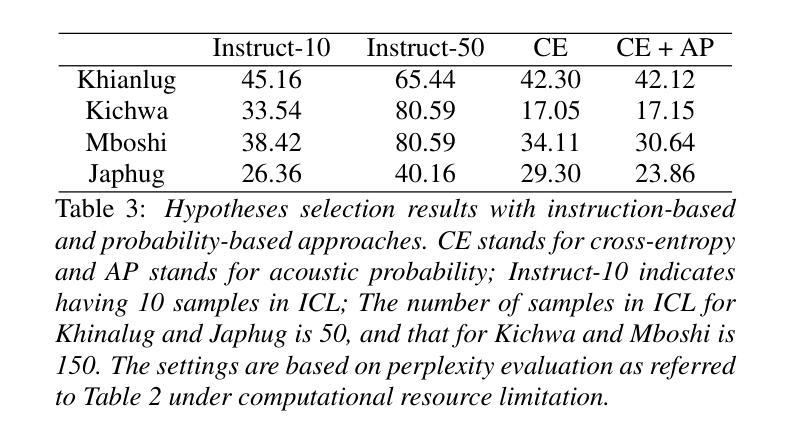
In-context Language Learning for Endangered Languages in Speech Recognition
Authors:Zhaolin Li, Jan Niehues
With approximately 7,000 languages spoken worldwide, current large language models (LLMs) support only a small subset. Prior research indicates LLMs can learn new languages for certain tasks without supervised data. We extend this investigation to speech recognition, investigating whether LLMs can learn unseen, low-resource languages through in-context learning (ICL). With experiments on four diverse endangered languages that LLMs have not been trained on, we find that providing more relevant text samples enhances performance in both language modelling and Automatic Speech Recognition (ASR) tasks. Furthermore, we show that the probability-based approach outperforms the traditional instruction-based approach in language learning. Lastly, we show ICL enables LLMs to achieve ASR performance that is comparable to or even surpasses dedicated language models trained specifically for these languages, while preserving the original capabilities of the LLMs.
全世界大约有7000种语言,而当前的大型语言模型(LLM)只支持一小部分。之前的研究表明,LLM可以在没有监督数据的情况下为某些任务学习新的语言。我们将其调查扩展到语音识别,研究LLM是否可以通过上下文学习(ICL)来学习未见过的低资源语言。我们在四种LLM未经训练的濒危语言上进行了实验,发现提供相关的文本样本有助于增强语言建模和自动语音识别(ASR)任务的表现。此外,我们还表明基于概率的方法优于传统的基于指令的学习方法在语言学习方面。最后,我们证明了ICL使LLM能够实现的ASR性能可与或甚至超越针对这些语言专门训练的专用语言模型,同时保留LLM的原始功能。
论文及项目相关链接
PDF Interspeech2025
Summary
大型语言模型(LLMs)能学习新语言以完成特定任务,无需监督数据。本研究扩展了这项探究,聚焦于语音识别的领域,探讨LLMs是否能通过上下文学习(ICL)学习未见过的低资源语言。在四种不同的濒危语言上的实验表明,提供相关的文本样本能提高语言建模和自动语音识别(ASR)任务的表现。此外,概率方法优于传统的指令方法用于语言学习。同时,上下文学习使LLMs的ASR性能与针对这些语言专门训练的模型相当甚至更优,同时保留了LLMs的原始能力。
Key Takeaways
- 大型语言模型能够在没有监督数据的情况下学习新语言以完成特定任务。
- 本研究首次将这一发现应用于语音识别的领域。
- 通过上下文学习(ICL),LLMs能够学习未见过的低资源语言。
- 提供相关文本样本能够提高语言建模和自动语音识别(ASR)的表现。
- 在概率方法的帮助下,LLMs的语言学习效果优于传统的指令方法。
- 上下文学习使LLMs的ASR性能与针对特定语言训练的模型相当甚至更优。
点此查看论文截图



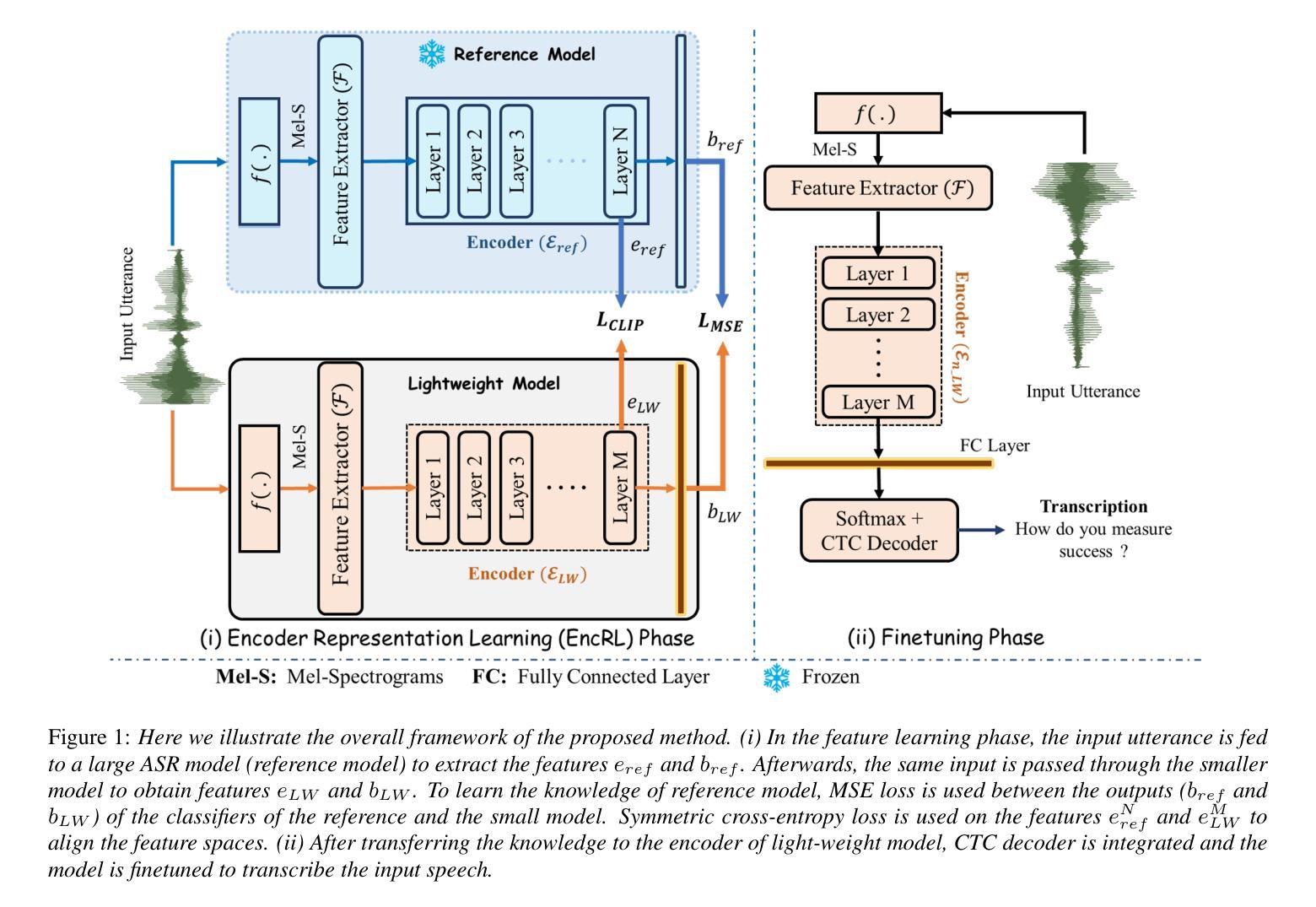
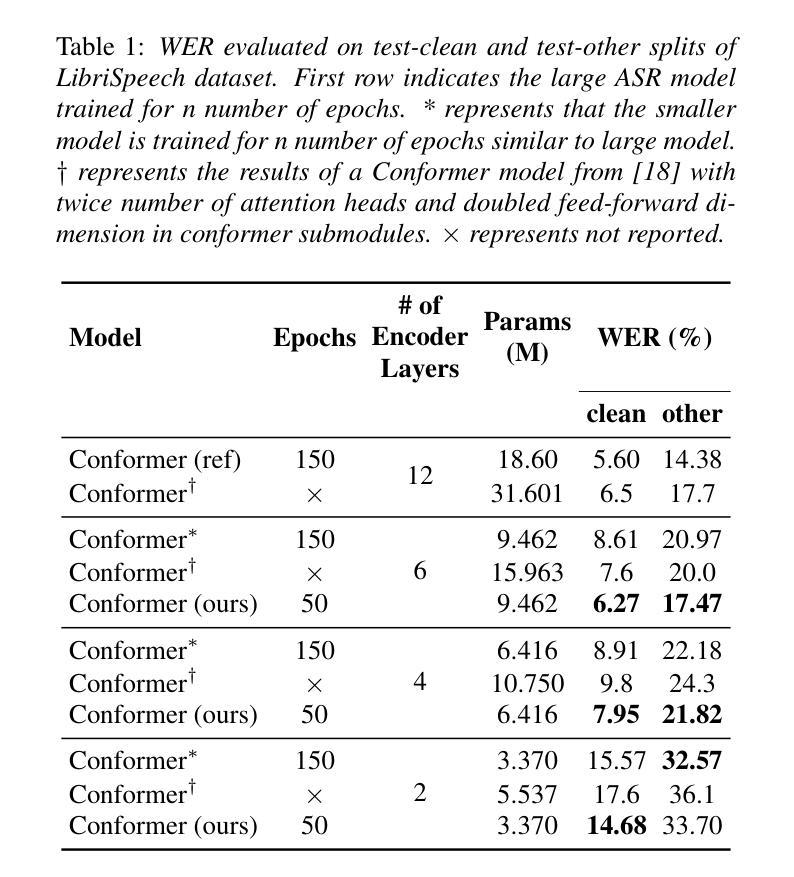
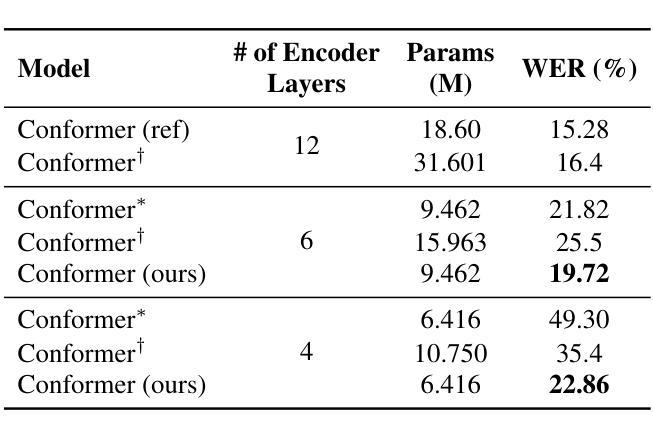
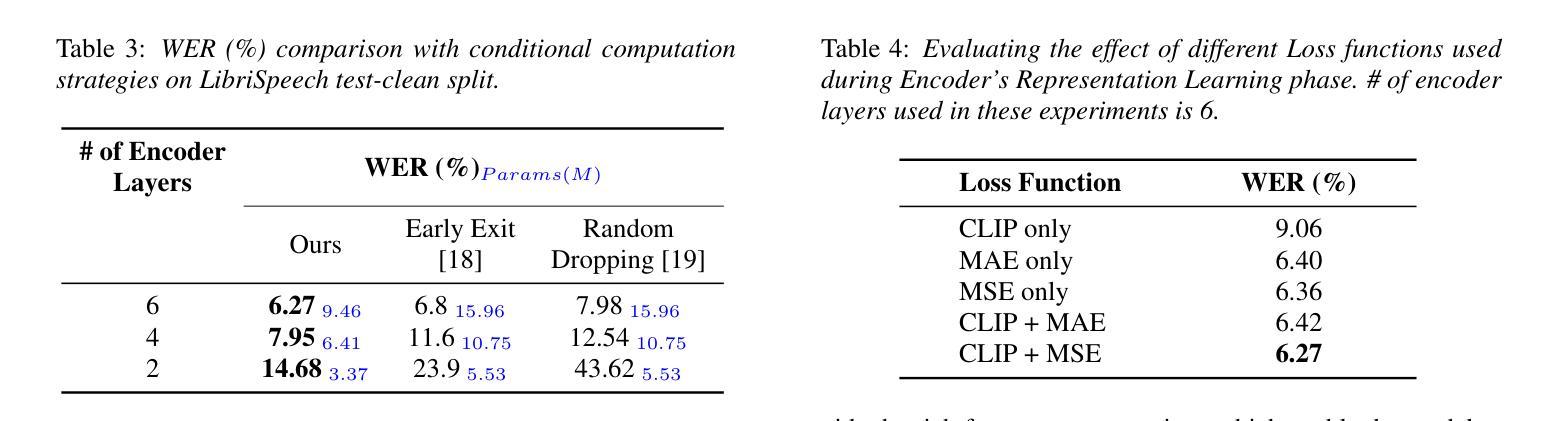
An Effective Training Framework for Light-Weight Automatic Speech Recognition Models
Authors:Abdul Hannan, Alessio Brutti, Shah Nawaz, Mubashir Noman
Recent advancement in deep learning encouraged developing large automatic speech recognition (ASR) models that achieve promising results while ignoring computational and memory constraints. However, deploying such models on low resource devices is impractical despite of their favorable performance. Existing approaches (pruning, distillation, layer skip etc.) transform the large models into smaller ones at the cost of significant performance degradation or require prolonged training of smaller models for better performance. To address these issues, we introduce an efficacious two-step representation learning based approach capable of producing several small sized models from a single large model ensuring considerably better performance in limited number of epochs. Comprehensive experimentation on ASR benchmarks reveals the efficacy of our approach, achieving three-fold training speed-up and up to 12.54% word error rate improvement.
最近深度学习的发展推动了大型自动语音识别(ASR)模型的开发,这些模型在忽略计算和内存限制的情况下取得了令人鼓舞的结果。然而,将这种模型部署在资源有限的设备上是不切实际的,尽管其性能表现良好。现有方法(如修剪、蒸馏、跳过层等)通过将大型模型转换为小型模型来降低成本,但这会导致性能显著下降,或者需要对小型模型进行更长时间的训练以获得更好的性能。为了解决这些问题,我们提出了一种有效的两步表示学习法,该方法能够从单一的大型模型中生成多个小型模型,并在有限的迭代次数内确保显著的性能提升。在ASR基准测试上的综合实验证明了我们方法的有效性,实现了三倍的训练速度提升和高达12.54%的词错误率改进。
论文及项目相关链接
PDF Accepted at InterSpeech 2025
Summary:
深度学习技术的最新进展推动了大型自动语音识别(ASR)模型的发展,这些模型在忽略计算和内存限制的情况下取得了令人鼓舞的结果。然而,将这些模型部署在资源有限的设备上并不实用。现有方法(如剪枝、蒸馏、层跳过等)将大型模型转换为小型模型,但付出了性能显著下降的代价,或者需要延长小型模型的训练时间以获得更好的性能。为解决这些问题,我们提出了一种有效的两步表示学习法,能从单一大型模型中生成多个小型模型,并在有限的训练周期中确保显著的性能提升。在ASR基准测试上的综合实验证明了该方法的有效性,实现了三倍的训练速度提升和最高达12.54%的词错误率改进。
Key Takeaways:
- 深度学习推动大型ASR模型发展,但资源有限设备的部署不实用。
- 现有方法转换大型模型为小型模型时,会牺牲性能或需要长时间训练。
- 提出一种有效的两步表示学习方法,从单一大型模型生成多个小型模型。
- 方法在ASR基准测试上经过综合实验验证,表现出显著性能提升。
- 方法实现了三倍的训练速度提升。
- 词错误率改进最高达12.54%。
- 此方法为解决大型ASR模型在资源有限设备上的部署问题提供了一种有效解决方案。
点此查看论文截图

VoxEval: Benchmarking the Knowledge Understanding Capabilities of End-to-End Spoken Language Models
Authors:Wenqian Cui, Xiaoqi Jiao, Ziqiao Meng, Irwin King
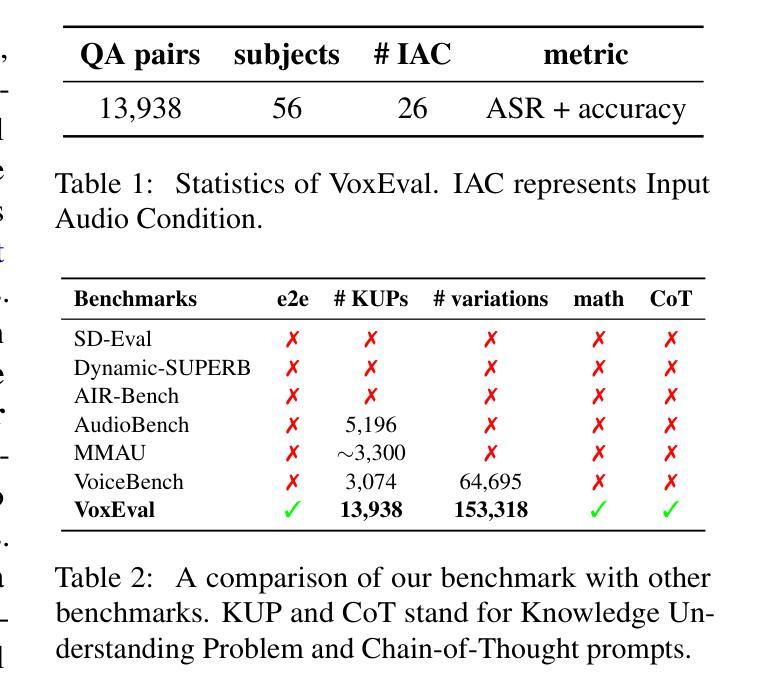
With the rising need for speech-based interaction models, end-to-end Spoken Language Models (SLMs) have emerged as a promising solution. While these models require comprehensive world knowledge for meaningful and reliable human interactions, existing question-answering (QA) benchmarks fall short in evaluating SLMs’ knowledge understanding due to their inability to support end-to-end speech evaluation and account for varied input audio conditions. To address these limitations, we present VoxEval, a novel SpeechQA benchmark that assesses SLMs’ knowledge understanding through pure speech interactions. Our benchmark 1) uniquely maintains speech format for both inputs and outputs, 2) evaluates model robustness across diverse input audio conditions, and 3) pioneers the assessment of complex tasks like mathematical reasoning in spoken format. Systematic evaluation demonstrates that VoxEval presents significant challenges to current SLMs, revealing their sensitivity to varying audio conditions and highlighting the need to enhance reasoning capabilities in future development. We hope this benchmark could guide the advancement of more sophisticated and reliable SLMs. VoxEval dataset is available at: https://github.com/dreamtheater123/VoxEval
随着基于语音的交互模型需求的增长,端到端的口语模型(SLM)作为一种有前景的解决方案而出现。虽然这些模型需要全面的世界知识来进行有意义和可靠的人类互动,但现有的问答(QA)基准测试在评估SLM的知识理解方面却表现不足,因为它们无法支持端到端的语音评估并考虑各种输入音频条件。为了解决这些局限性,我们推出了VoxEval,这是一个新的语音问答基准测试,它通过纯粹的语音互动来评估SLM的知识理解。我们的基准测试1)独特地保持语音格式的输入和输出,2)评估模型在不同输入音频条件下的稳健性,3)率先评估口语形式的复杂任务,如数学推理。系统评估表明,VoxEval给当前的SLM带来了巨大的挑战,显示出它们对各种音频条件的敏感性,并强调未来开发时需要增强推理能力。我们希望这个基准测试能引导更精细和更可靠的SLM的发展。VoxEval数据集可在:https://github.com/dreamtheater123/VoxEval获取。
论文及项目相关链接
PDF The Version of Record of this contribution is accepted to ACL 2025 main conference
总结
随着基于语音的交互模型的需求不断增加,端到端的口语模型(SLMs)已成为一种前景广阔的解决方案。现有问答(QA)基准测试在评估SLM的知识理解方面存在不足,无法支持端到端的语音评估并考虑各种输入音频条件。为解决这些问题,我们推出了VoxEval,一个全新的SpeechQA基准测试,通过纯语音交互评估SLM的知识理解。该基准测试独特之处在于1)保持语音输入输出格式,2)评估模型在不同输入音频条件下的稳健性,3)率先评估口语形式的复杂任务如数学推理。系统评估表明,VoxEval对当前SLM提出了重大挑战,突显了其对不同音频条件的敏感性,并强调未来发展中增强推理能力的必要性。我们期望此基准测试能推动更先进、更可靠的SLM的发展。
关键见解
- 端到端的口语模型(SLMs)在语音交互中展现出巨大潜力。
- 现有问答基准测试无法全面评估SLMs的知识理解。
- VoxEval是一个新的SpeechQA基准测试,以纯语音形式评估SLM的知识理解。
- VoxEval保持语音输入输出格式,评估模型在不同输入音频条件下的表现。
- VoxEval首次评估口语形式的复杂任务,如数学推理。
- 系统评估显示,VoxEval对当前SLM提出了重大挑战。
点此查看论文截图

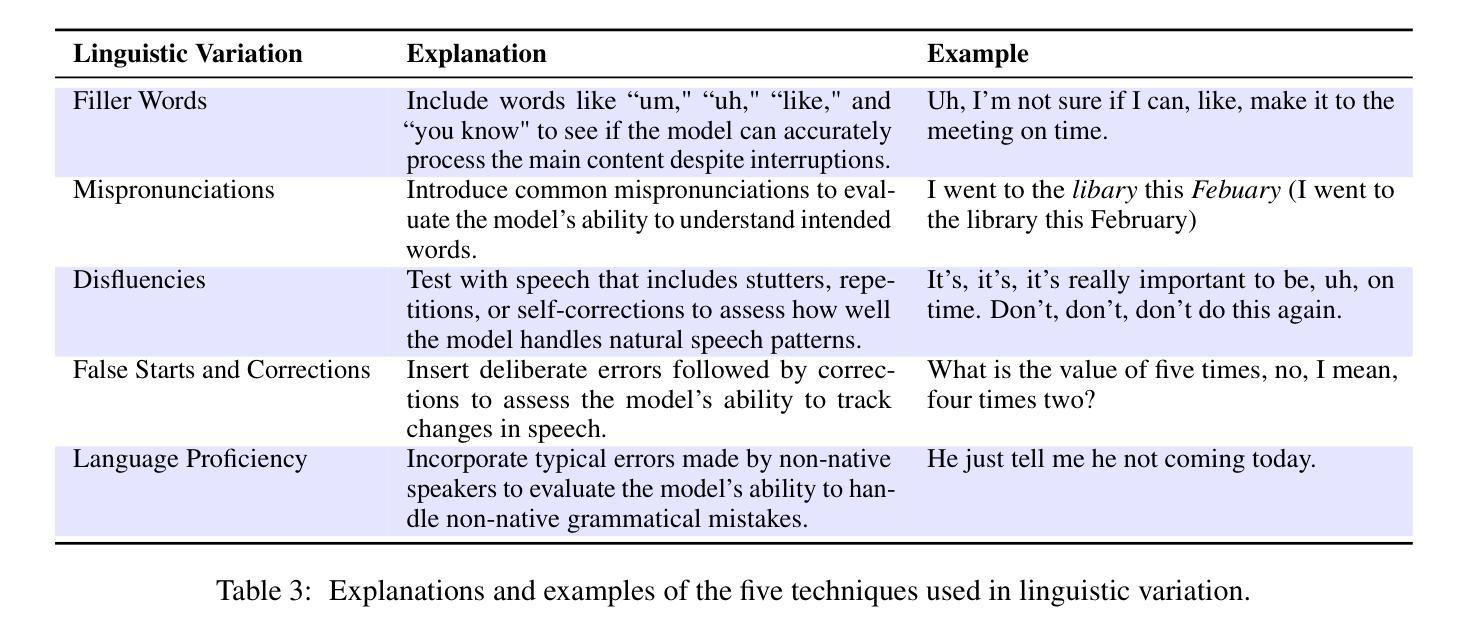

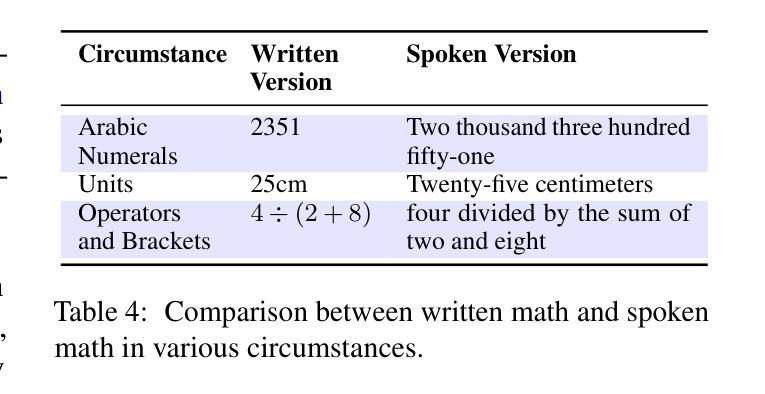
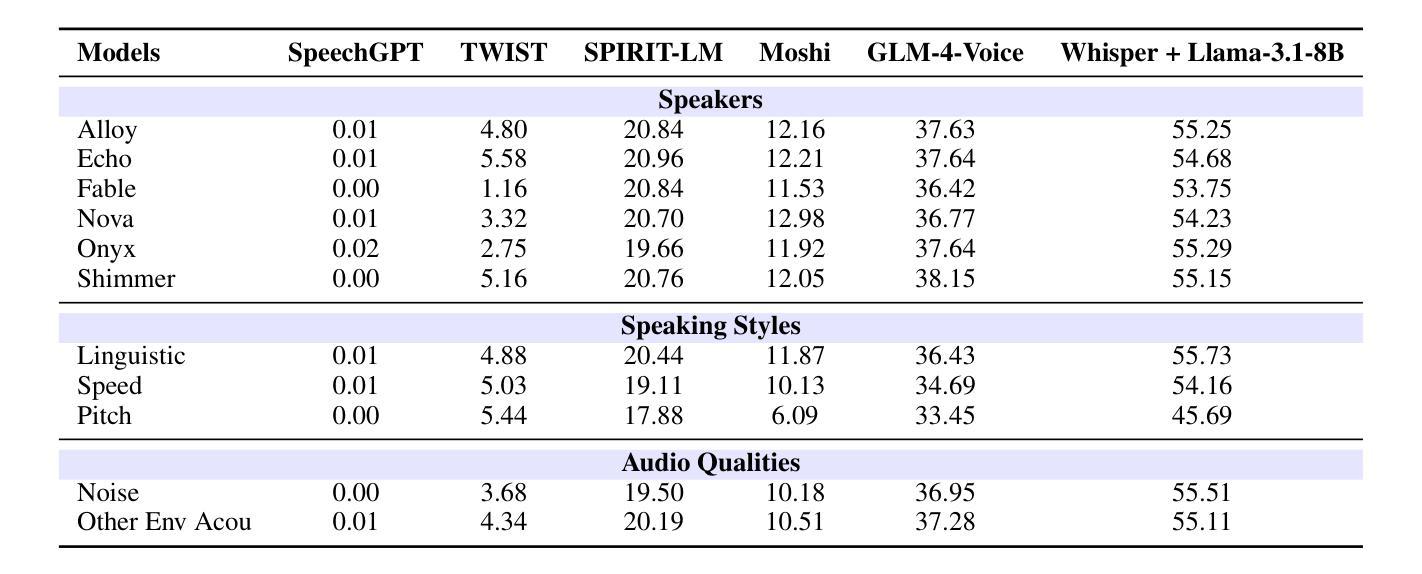

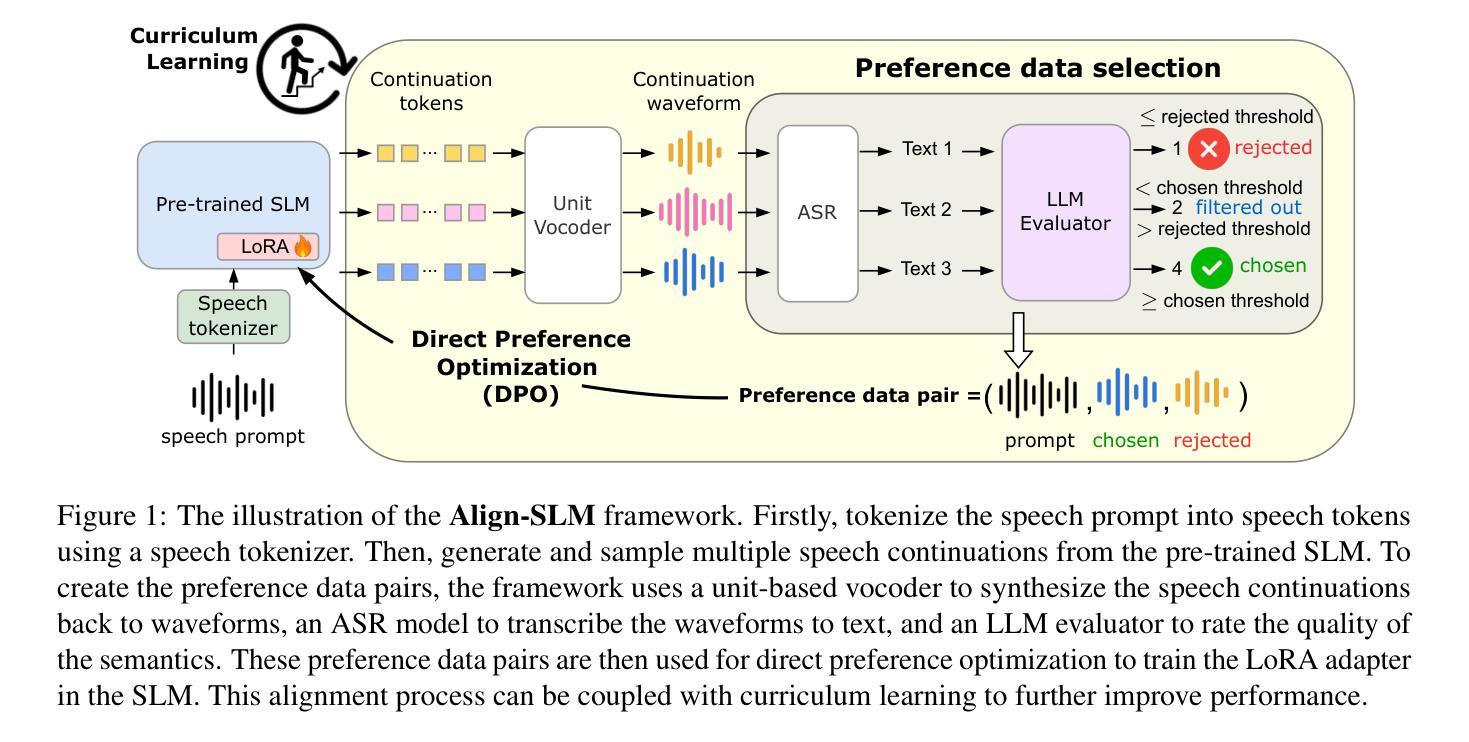
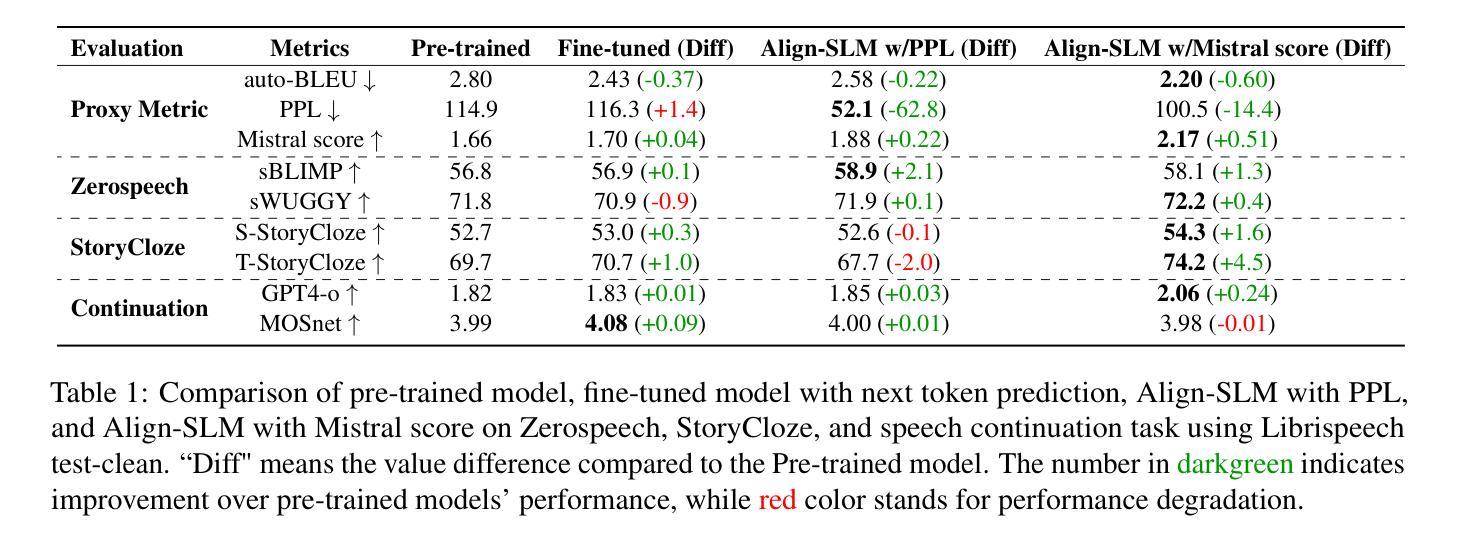
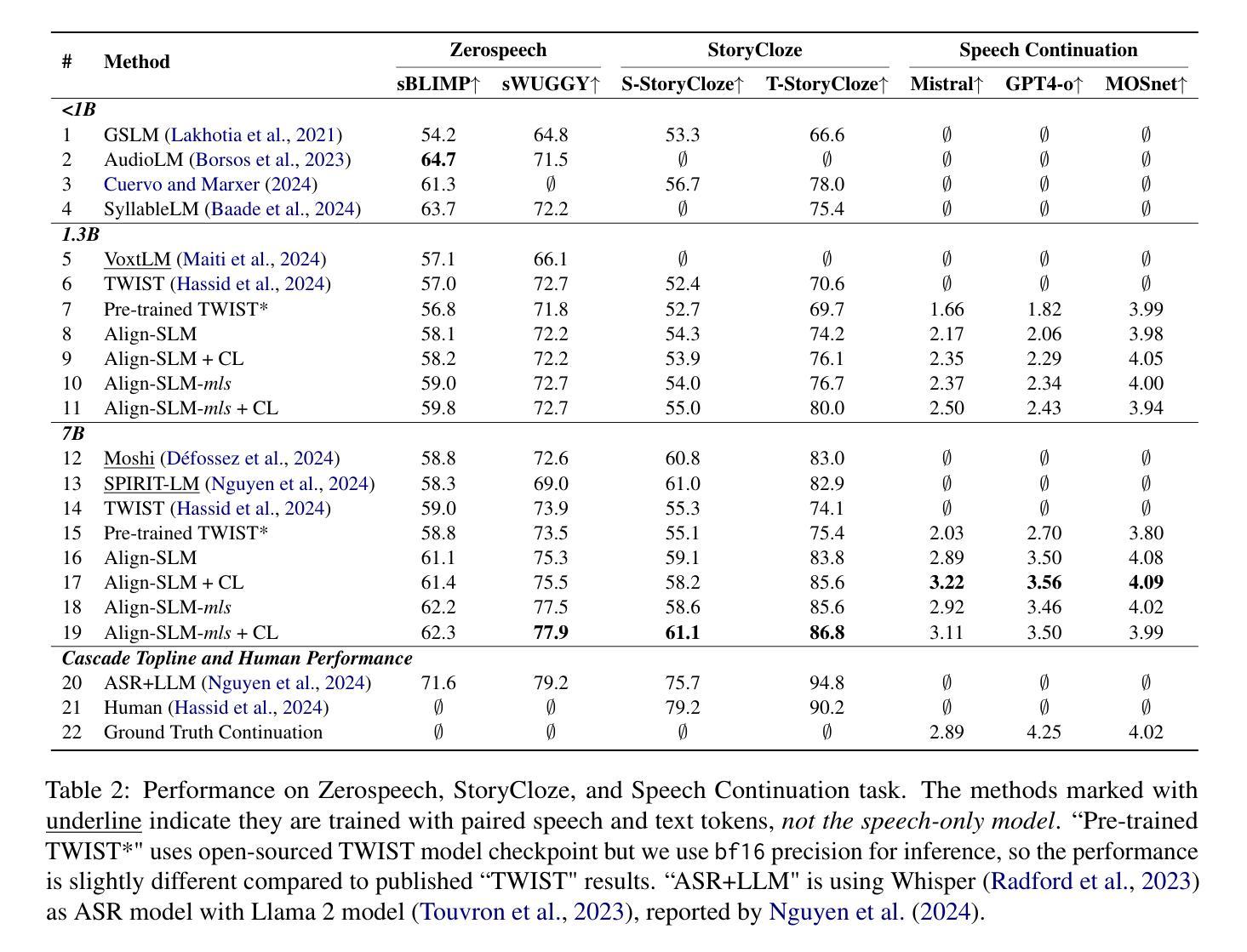
Align-SLM: Textless Spoken Language Models with Reinforcement Learning from AI Feedback
Authors:Guan-Ting Lin, Prashanth Gurunath Shivakumar, Aditya Gourav, Yile Gu, Ankur Gandhe, Hung-yi Lee, Ivan Bulyko
While textless Spoken Language Models (SLMs) have shown potential in end-to-end speech-to-speech modeling, they still lag behind text-based Large Language Models (LLMs) in terms of semantic coherence and relevance. This work introduces the Align-SLM framework, which leverages preference optimization inspired by Reinforcement Learning with AI Feedback (RLAIF) to enhance the semantic understanding of SLMs. Our approach generates multiple speech continuations from a given prompt and uses semantic metrics to create preference data for Direct Preference Optimization (DPO). We evaluate the framework using ZeroSpeech 2021 benchmarks for lexical and syntactic modeling, the spoken version of the StoryCloze dataset for semantic coherence, and other speech generation metrics, including the GPT4-o score and human evaluation. Experimental results show that our method achieves state-of-the-art performance for SLMs on most benchmarks, highlighting the importance of preference optimization to improve the semantics of SLMs.
无文本Spoken Language Models(SLM)在端到端语音到语音建模中显示出潜力,但在语义连贯性和相关性方面仍落后于基于文本的大型语言模型(LLM)。这项工作引入了Align-SLM框架,该框架利用受强化学习与人工智能反馈(RLAIF)启发的偏好优化,以增强SLM的语义理解。我们的方法从给定的提示生成多个语音连续片段,并使用语义度量来创建用于直接偏好优化(DPO)的偏好数据。我们使用ZeroSpeech 2021词汇和句法建模基准测试、StoryCloze数据集口语版对框架进行语义连贯性评估以及其他语音生成度量标准,包括GPT4-o得分和人类评估。实验结果表明,我们的方法在大多数基准测试上实现了SLM的最先进性能,突出了偏好优化对提高SLM语义的重要性。
论文及项目相关链接
PDF Accepted by ACL 2025
摘要
无文本Spoken Language Models(SLMs)在端到端的语音到语音建模中显示出潜力,但在语义连贯性和相关性方面仍落后于基于文本的大型语言模型(LLMs)。本研究引入了Align-SLM框架,该框架利用受强化学习与人工智能反馈(RLAIF)启发的偏好优化,以提高SLM的语义理解能力。该方法通过生成给定提示的多个语音连续片段并使用语义度量来创建用于直接偏好优化(DPO)的偏好数据。我们利用ZeroSpeech 2021词汇和句法建模基准测试、口语版StoryCloze数据集对框架进行了评估,包括GPT4评分和人类评估在内的其他语音生成指标。实验结果表明,我们的方法在大多数基准测试上实现了SLM的最先进性能,突显了偏好优化在提高SLM语义方面的重要性。
关键见解
- 无文本Spoken Language Models(SLMs)在端到端语音建模中有潜力,但语义连贯性和相关性方面仍有提升空间。
- 引入Align-SLM框架,通过偏好优化提高SLM的语义理解。
- 生成多个语音连续片段并使用语义度量创建偏好数据用于直接偏好优化(DPO)。
- 利用ZeroSpeech 2021基准测试和其他语音生成指标对框架进行评估。
- 方法在大多数基准测试上实现SLM的最先进性能。
- 偏好优化对提高SLM语义的重要性得到凸显。
- 该研究为改进SLM的语义性能提供了新的方向和策略。
点此查看论文截图

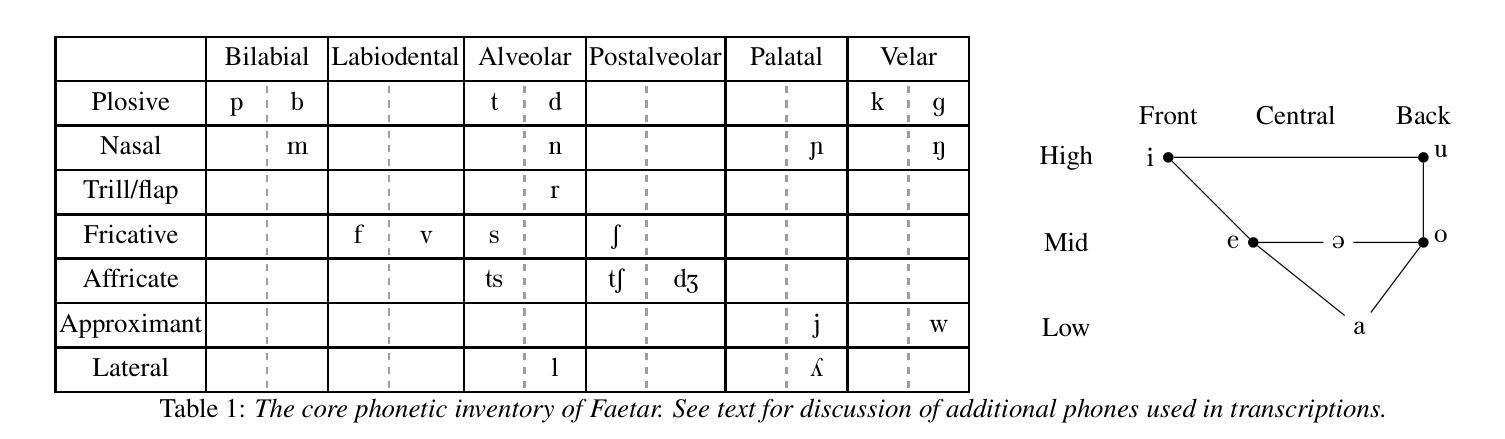
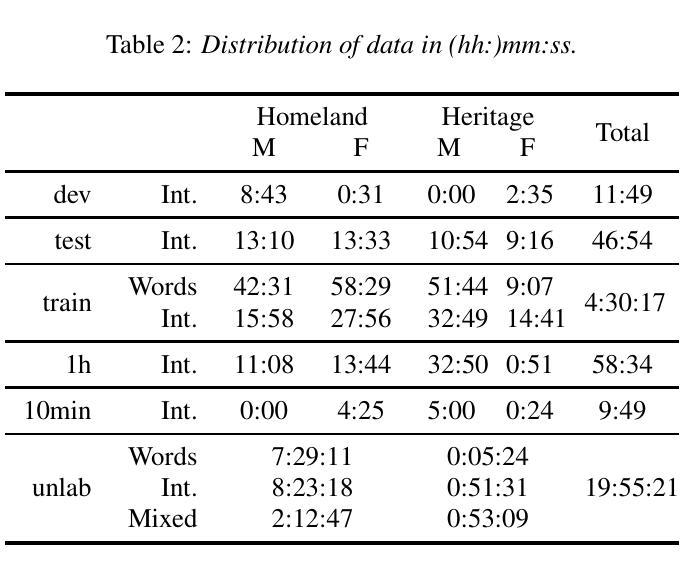
The Faetar Benchmark: Speech Recognition in a Very Under-Resourced Language
Authors:Michael Ong, Sean Robertson, Leo Peckham, Alba Jorquera Jimenez de Aberasturi, Paula Arkhangorodsky, Robin Huo, Aman Sakhardande, Mark Hallap, Naomi Nagy, Ewan Dunbar
We introduce the Faetar Automatic Speech Recognition Benchmark, a benchmark corpus designed to push the limits of current approaches to low-resource speech recognition. Faetar, a Franco-Proven\c{c}al variety spoken primarily in Italy, has no standard orthography, has virtually no existing textual or speech resources other than what is included in the benchmark, and is quite different from other forms of Franco-Proven\c{c}al. The corpus comes from field recordings, most of which are noisy, for which only 5 hrs have matching transcriptions, and for which forced alignment is of variable quality. The corpus contains an additional 20 hrs of unlabelled speech. We report baseline results from state-of-the-art multilingual speech foundation models with a best phone error rate of 30.4%, using a pipeline that continues pre-training on the foundation model using the unlabelled set.
我们介绍了Faetar自动语音识别基准测试,这是一个基准测试语料库,旨在推动当前方法在资源匮乏语音识别方面的极限。Faetar是一种主要在意大利使用的法罗-普罗旺斯方言,它没有标准的正字法,除了基准测试中包含的内容外,几乎没有现有的文本或语音资源,而且与其他形式的法罗-普罗旺斯方言有很大不同。该语料库来自现场录音,其中大部分噪音很大,只有5小时的匹配转录,并且强制对齐的质量参差不齐。语料库还包含额外的20小时未标注的语音。我们报告了使用最先进的跨语言语音基础模型的基线结果,最佳语音错误率为3.04%,使用在基础模型上继续使用未标注集进行预训练的管道。
论文及项目相关链接
PDF To appear in INTERSPEECH 2025
Summary
本文介绍了Faetar自动语音识别基准测试语料库,该语料库旨在推动当前低资源语音识别方法的前沿。该语料库主要关注的是一种在意大利使用的被称为Faetar的弗兰科-普罗旺斯方言,该方言没有标准的正字法,几乎没有现有的文本或语音资源,并且与其他形式的弗兰科-普罗旺斯方言有很大差异。语料库来自现场录音,其中大部分录音环境噪音较大,仅有五小时的录音有匹配的转录,并且强制对齐的质量不一。此外,语料库还包含额外的未标记的二十小时语音。利用多语言语音基准模型报道了最佳发音误差率为百分之三十的初步结果,并且通过使用未标记数据集继续对基准模型进行预训练的方式优化识别效果。
Key Takeaways
- Faetar自动语音识别基准测试语料库是为了推动低资源语音识别技术的极限而设计的。
- Faetar是一种几乎没有标准正字法的弗兰科-普罗旺斯方言,且与其他形式的弗兰科-普罗旺斯方言存在显著差异。
- 该语料库主要来自现场录音,包含大量的噪音,只有一小部分带有匹配的转录。
- 强制对齐的质量存在不确定性。
- 除了有转录的语音外,语料库还包含额外的未标记语音数据。
- 目前的多语言语音基准模型在Faetar自动语音识别上的最佳发音误差率为百分之三十。
点此查看论文截图

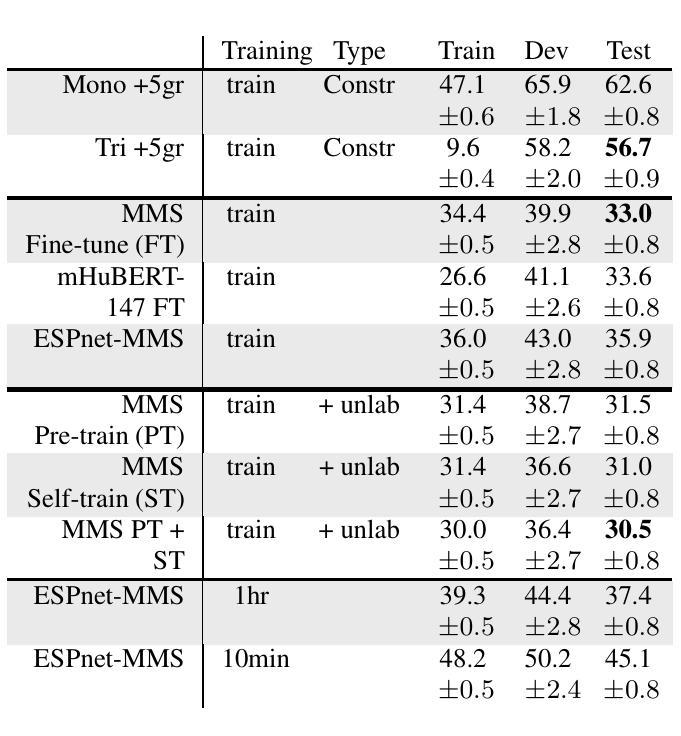
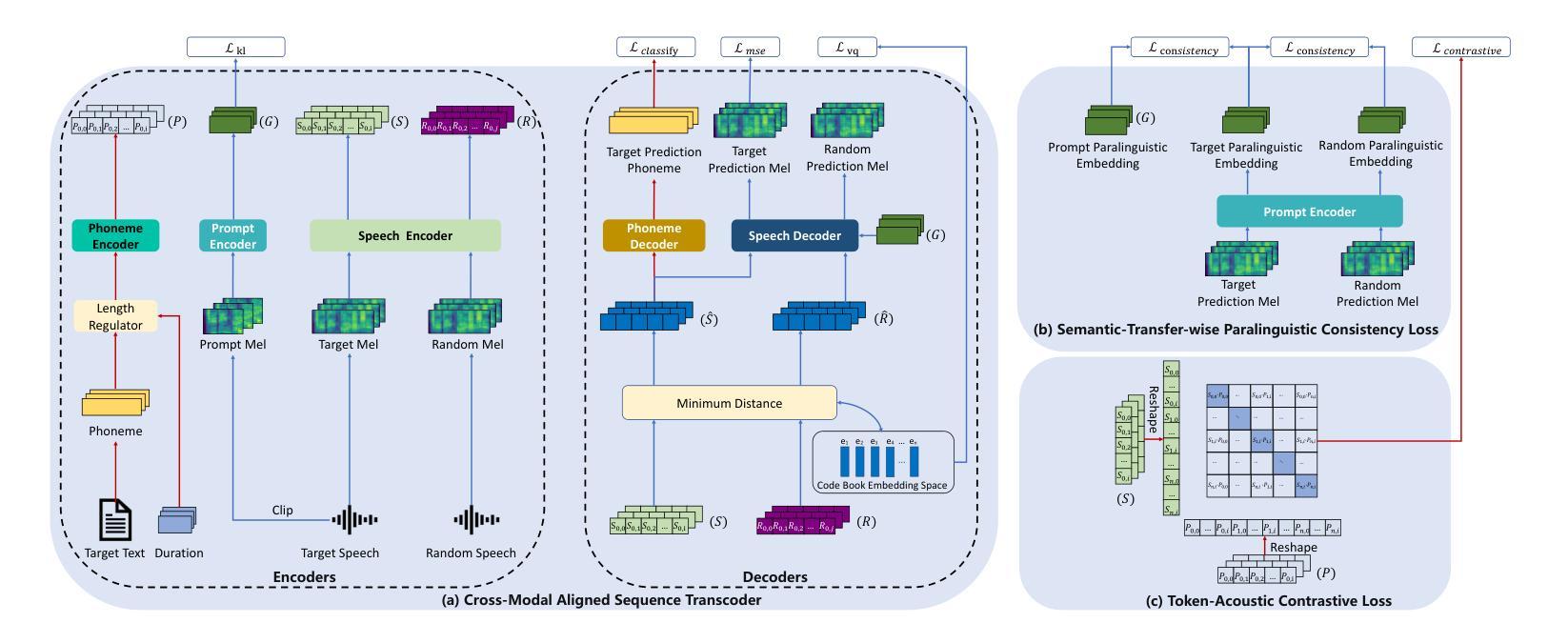
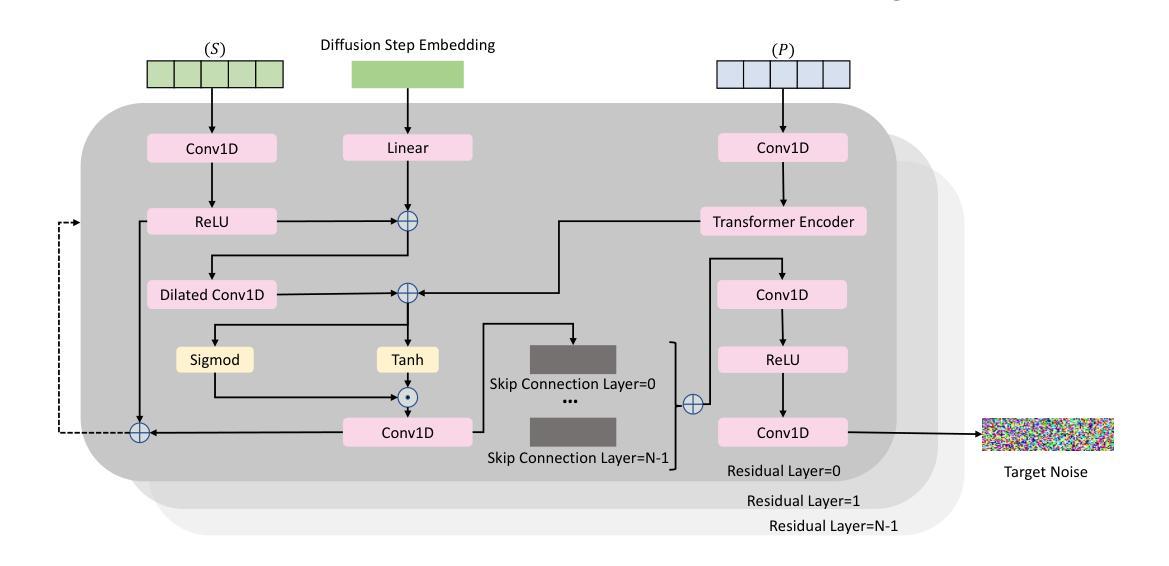
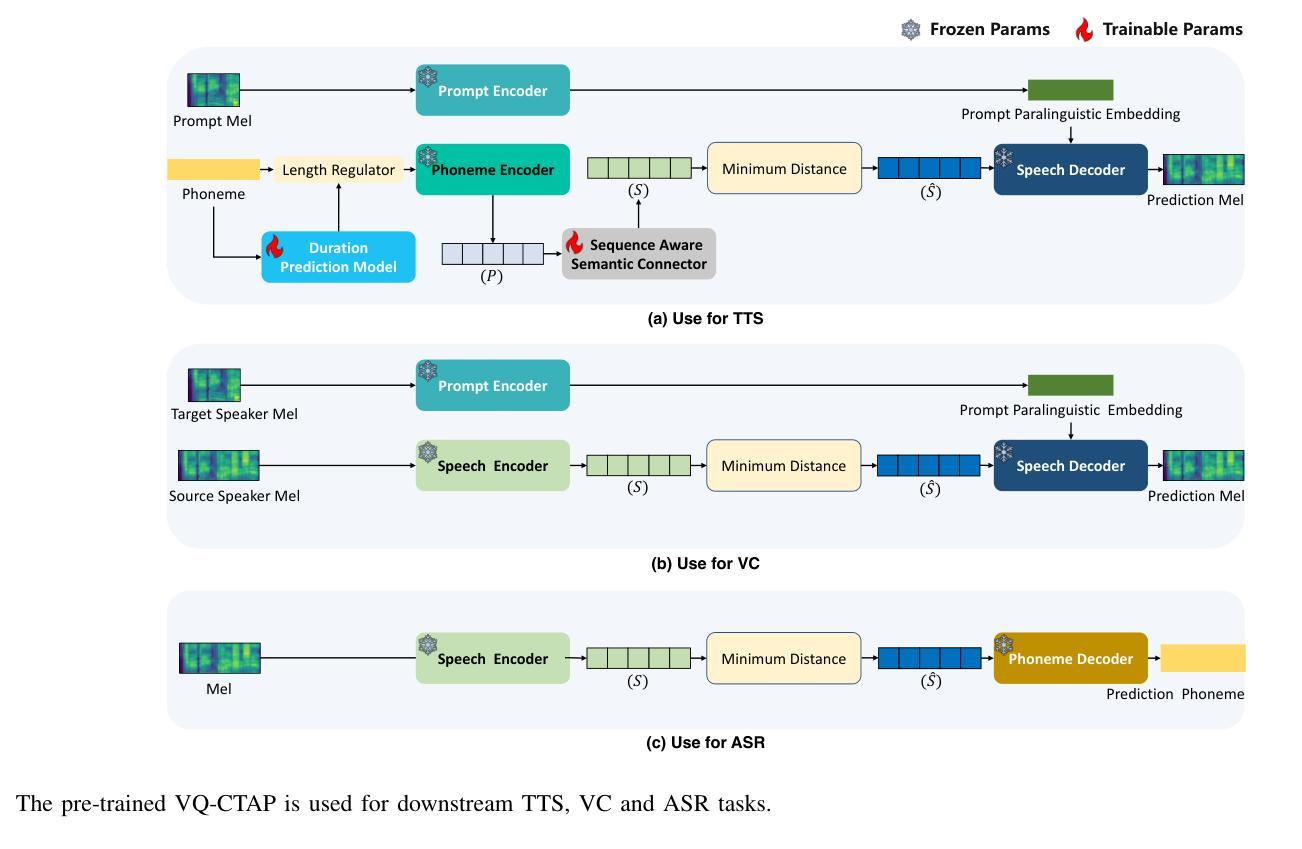
VQ-CTAP: Cross-Modal Fine-Grained Sequence Representation Learning for Speech Processing
Authors:Chunyu Qiang, Wang Geng, Yi Zhao, Ruibo Fu, Tao Wang, Cheng Gong, Tianrui Wang, Qiuyu Liu, Jiangyan Yi, Zhengqi Wen, Chen Zhang, Hao Che, Longbiao Wang, Jianwu Dang, Jianhua Tao
Deep learning has brought significant improvements to the field of cross-modal representation learning. For tasks such as text-to-speech (TTS), voice conversion (VC), and automatic speech recognition (ASR), a cross-modal fine-grained (frame-level) sequence representation is desired, emphasizing the semantic content of the text modality while de-emphasizing the paralinguistic information of the speech modality. We propose a method called “Vector Quantized Contrastive Token-Acoustic Pre-training (VQ-CTAP)”, which uses the cross-modal aligned sequence transcoder to bring text and speech into a joint multimodal space, learning how to connect text and speech at the frame level. The proposed VQ-CTAP is a paradigm for cross-modal sequence representation learning, offering a promising solution for fine-grained generation and recognition tasks in speech processing. The VQ-CTAP can be directly applied to VC and ASR tasks without fine-tuning or additional structures. We propose a sequence-aware semantic connector, which connects multiple frozen pre-trained modules for the TTS task, exhibiting a plug-and-play capability. We design a stepping optimization strategy to ensure effective model convergence by gradually injecting and adjusting the influence of various loss components. Furthermore, we propose a semantic-transfer-wise paralinguistic consistency loss to enhance representational capabilities, allowing the model to better generalize to unseen data and capture the nuances of paralinguistic information. In addition, VQ-CTAP achieves high-compression speech coding at a rate of 25Hz from 24kHz input waveforms, which is a 960-fold reduction in the sampling rate. The audio demo is available at https://qiangchunyu.github.io/VQCTAP/
深度学习为跨模态表示学习领域带来了重大改进。对于文本转语音(TTS)、语音转换(VC)和自动语音识别(ASR)等任务,我们期望得到一种跨模态精细(帧级)序列表示,它强调文本模态的语义内容,同时淡化语音模态的副语言信息。我们提出了一种名为“向量量化对比令牌声学预训练(VQ-CTAP)”的方法,该方法使用跨模态对齐序列转码器将文本和语音带入联合多模态空间,学习如何在帧级别连接文本和语音。所提的VQ-CTAP是跨模态序列表示学习的一种范式,为语音处理中的精细生成和识别任务提供了有前景的解决方案。VQ-CTAP可直接应用于VC和ASR任务,无需微调或额外结构。我们提出了一种序列感知语义连接器,它将多个冻结的预训练模块连接到TTS任务中,展现出即插即用的能力。我们设计了一种步进优化策略,通过逐步注入和调整各种损失成分的影响,以确保模型的有效收敛。此外,我们提出了一种语义转移副语言一致性损失,以增强表示能力,使模型能够更好地推广到未见数据并捕捉副语言信息的细微差别。另外,VQ-CTAP实现了高压缩语音编码,从24kHz输入波形以25Hz的速率进行编码,采样率降低了960倍。音频演示可在https://qiangchunyu.github.io/VQCTAP/找到。
论文及项目相关链接
摘要
深度学习在跨模态表征学习领域取得了显著进步。对于文本转语音(TTS)、语音转换(VC)和自动语音识别(ASR)等任务,需要跨模态精细(帧级)序列表征,强调文本模态的语义内容,同时淡化语音模态的副语言信息。本文提出一种名为“向量量化对比令牌声学预训练(VQ-CTAP)”的方法,使用跨模态对齐序列转码器将文本和语音带入联合多模态空间,在帧级别学习如何连接文本和语音。VQ-CTAP为跨模态序列表征学习提供了一种范式,为语音处理中的精细生成和识别任务提供了有前景的解决方案。该方法可直接应用于VC和ASR任务,无需微调或额外结构。针对TTS任务,本文提出一种序列感知语义连接器,可连接多个冻结的预训练模块,具有即插即用功能。此外,本文设计了一种步进优化策略,通过逐步注入和调整各种损失分量的影响,确保模型的有效收敛。还提出了一种语义转移副语言一致性损失,以提高表征能力,使模型能够更好地推广到未见数据并捕捉副语言信息的细微差别。此外,VQ-CTAP实现了高压缩语音编码,从24kHz输入波形以25Hz速率进行编码,采样率降低了960倍。音频演示可在[https://qiangchunyu.github.io/VQCTAP/]访问。
关键见解
- 深度学习在跨模态表征学习中取得显著进步,尤其在文本转语音、语音转换和自动语音识别等任务中。
- 提出一种名为VQ-CTAP的跨模态精细序列表征学习方法,将文本和语音带入联合多模态空间。
- VQ-CTAP可直接应用于语音转换和自动语音识别任务,无需额外调整。
- 针对文本转语音任务,引入序列感知语义连接器,实现模块即插即用。
- 采用步进优化策略,确保模型有效收敛,并提出语义转移副语言一致性损失以提高模型表征能力和泛化性能。
- VQ-CTAP实现高压缩语音编码,采样率大幅降低。
点此查看论文截图


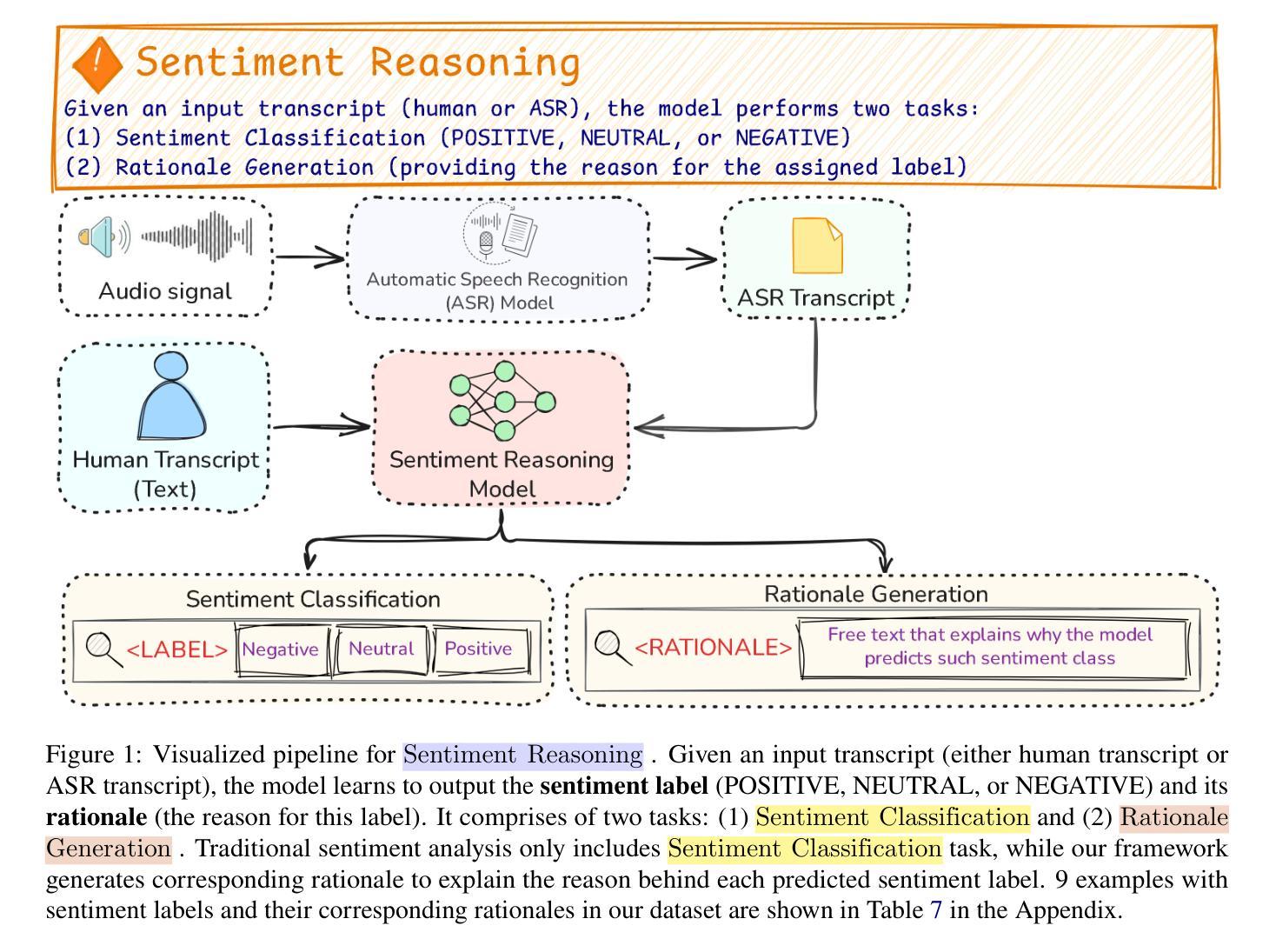
Sentiment Reasoning for Healthcare
Authors:Khai-Nguyen Nguyen, Khai Le-Duc, Bach Phan Tat, Duy Le, Long Vo-Dang, Truong-Son Hy
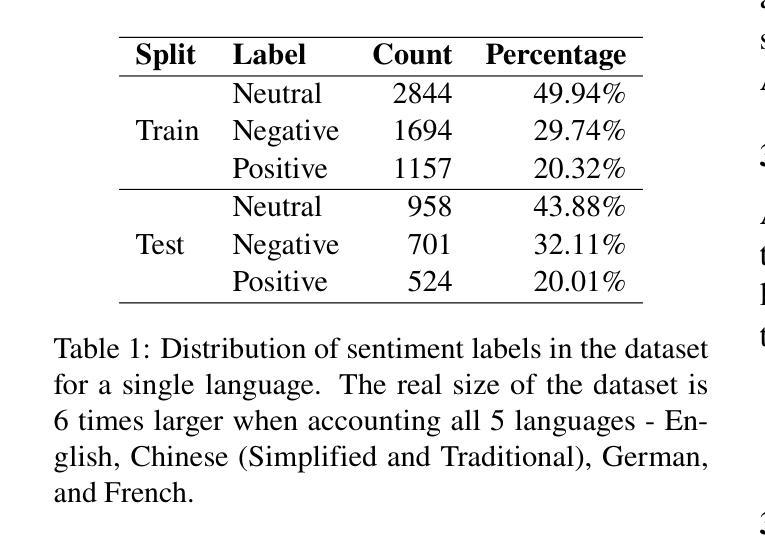
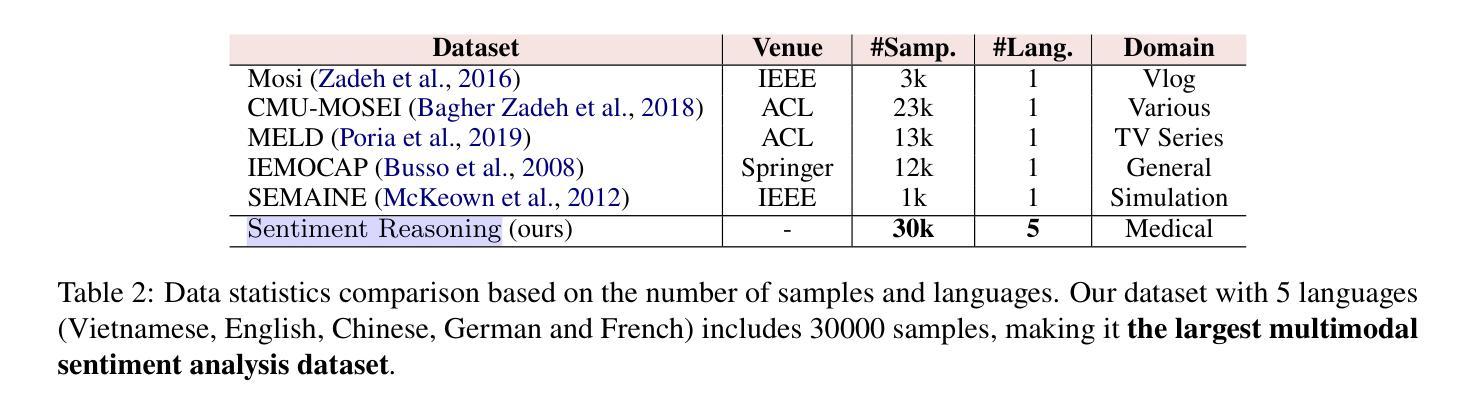
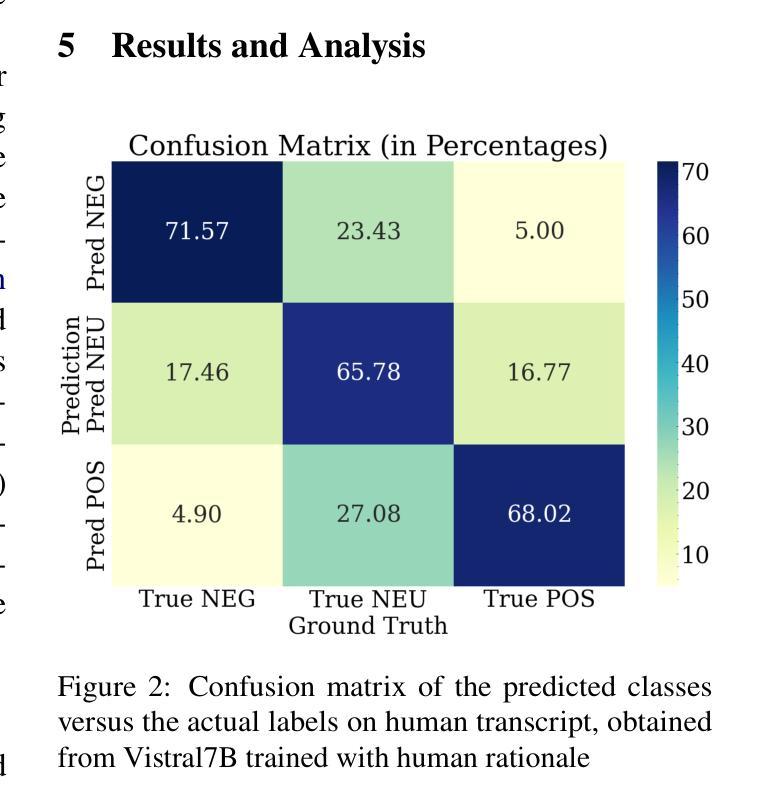
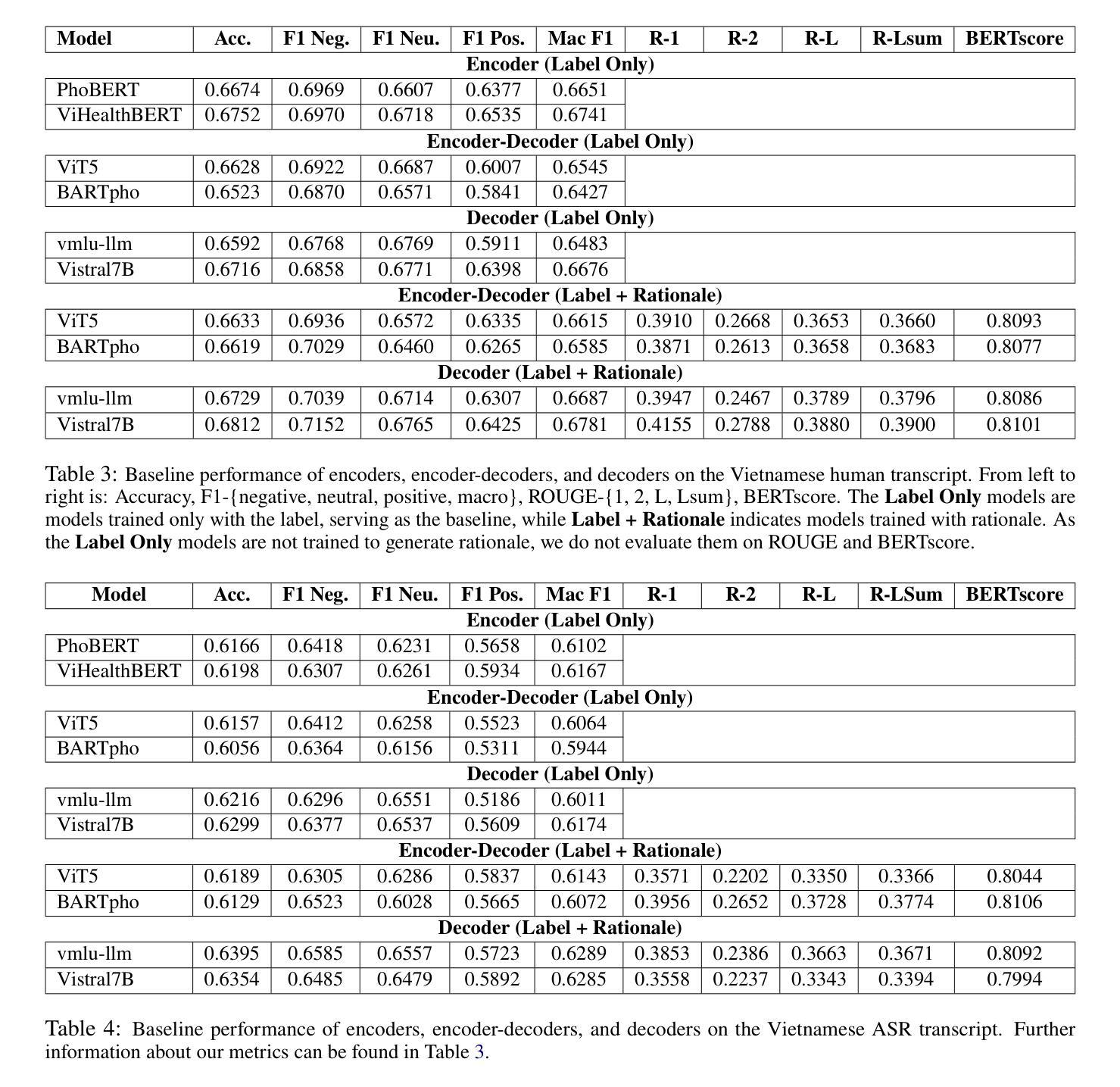
Transparency in AI healthcare decision-making is crucial. By incorporating rationales to explain reason for each predicted label, users could understand Large Language Models (LLMs)’s reasoning to make better decision. In this work, we introduce a new task - Sentiment Reasoning - for both speech and text modalities, and our proposed multimodal multitask framework and the world’s largest multimodal sentiment analysis dataset. Sentiment Reasoning is an auxiliary task in sentiment analysis where the model predicts both the sentiment label and generates the rationale behind it based on the input transcript. Our study conducted on both human transcripts and Automatic Speech Recognition (ASR) transcripts shows that Sentiment Reasoning helps improve model transparency by providing rationale for model prediction with quality semantically comparable to humans while also improving model’s classification performance (+2% increase in both accuracy and macro-F1) via rationale-augmented fine-tuning. Also, no significant difference in the semantic quality of generated rationales between human and ASR transcripts. All code, data (five languages - Vietnamese, English, Chinese, German, and French) and models are published online: https://github.com/leduckhai/Sentiment-Reasoning
人工智能医疗决策中的透明度至关重要。通过将每个预测标签的理由融入其中,用户可以理解大型语言模型(LLM)的推理,以做出更好的决策。在这项工作中,我们为语音和文本模态引入了一项新任务——情感推理,以及我们提出的多模态多任务框架和世界上最大的多模态情感分析数据集。情感推理是情感分析中的辅助任务,模型根据输入内容预测情感标签并生成其背后的理由。我们的研究在人工转录和自动语音识别(ASR)转录文本上进行,表明情感推理通过为模型预测提供理由,有助于提高模型的透明度,其语义质量与人类相当,同时还可通过理由增强微调提高模型的分类性能(+2%的准确率和宏观F1值提高)。此外,人工转录和ASR转录文本在生成理由的语义质量上没有显著差异。所有代码、数据(五种语言——越南语、英语、中文、德语和法语)和模型均在线发布:https://github.com/leduckhai/Sentiment-Reasoning
论文及项目相关链接
PDF ACL 2025 (Oral)
Summary
本文强调人工智能健康决策中的透明度至关重要。通过融入解释预测标签的理由,用户能更好地理解大型语言模型(LLMs)的推理过程以做出更好的决策。本文介绍了一项新的任务——情感推理,适用于语音和文字模态,并提出了一个多模态多任务框架和全球最大的多模态情感分析数据集。情感推理是情感分析中的一个辅助任务,模型基于输入内容预测情感标签并生成背后的理由。在人工转录和自动语音识别(ASR)转录的研究中,情感推理通过提供模型预测的理由提高了模型的透明度,同时生成的语义质量与人类相当,通过理由增强微调提高了模型的分类性能(准确率和宏F1分别提高2%)。此外,人工和ASR转录生成的解释理由在语义质量上没有显著差异。所有代码、数据和模型均已在线发布。
Key Takeaways
- 人工智能健康决策中的透明度至关重要,融入解释预测标签的理由有助于用户理解大型语言模型的推理过程。
- 介绍了新的任务——情感推理,适用于语音和文字模态。
- 提出了多模态多任务框架和全球最大的多模态情感分析数据集。
- 模型能基于输入内容预测情感标签并生成背后的理由。
- 情感推理提高了模型的透明度,并提高了模型的分类性能。
- 通过理由增强微调,模型的准确率和宏F1都有所提高。
点此查看论文截图

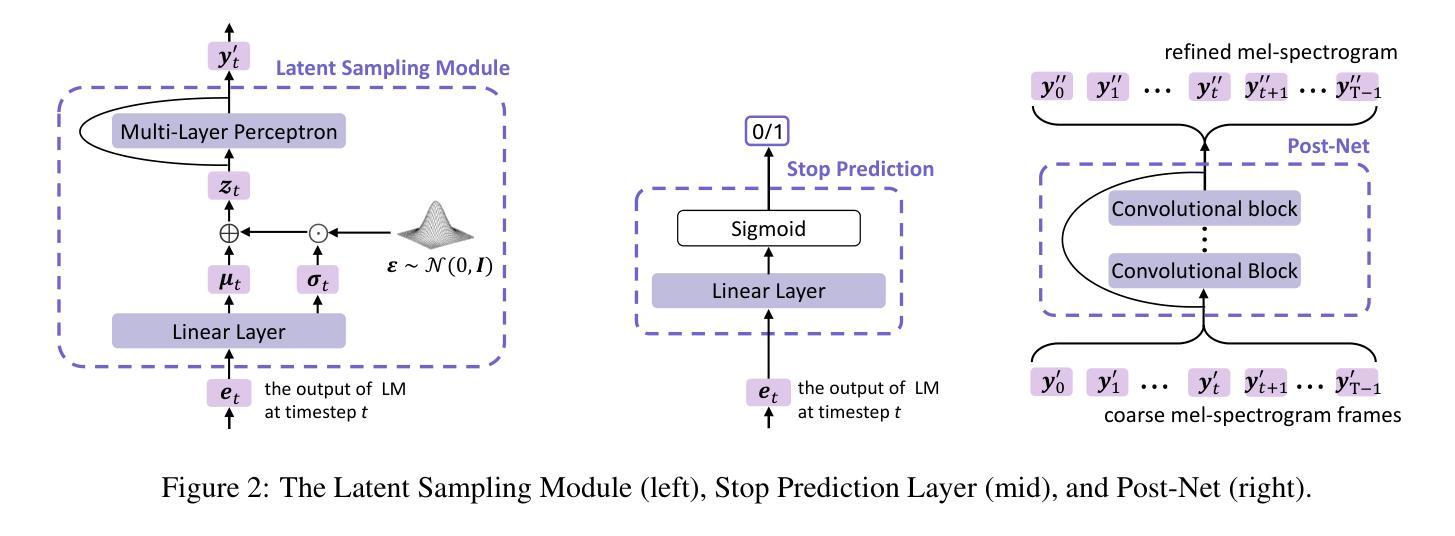
Autoregressive Speech Synthesis without Vector Quantization
Authors:Lingwei Meng, Long Zhou, Shujie Liu, Sanyuan Chen, Bing Han, Shujie Hu, Yanqing Liu, Jinyu Li, Sheng Zhao, Xixin Wu, Helen Meng, Furu Wei
We present MELLE, a novel continuous-valued token based language modeling approach for text-to-speech synthesis (TTS). MELLE autoregressively generates continuous mel-spectrogram frames directly from text condition, bypassing the need for vector quantization, which is typically designed for audio compression and sacrifices fidelity compared to continuous representations. Specifically, (i) instead of cross-entropy loss, we apply regression loss with a proposed spectrogram flux loss function to model the probability distribution of the continuous-valued tokens; (ii) we have incorporated variational inference into MELLE to facilitate sampling mechanisms, thereby enhancing the output diversity and model robustness. Experiments demonstrate that, compared to the two-stage codec language model VALL-E and its variants, the single-stage MELLE mitigates robustness issues by avoiding the inherent flaws of sampling vector-quantized codes, achieves superior performance across multiple metrics, and, most importantly, offers a more streamlined paradigm. The demos of our work are provided at https://aka.ms/melle.
我们提出了MELLE,这是一种基于连续值标记的新的文本转语音合成(TTS)语言建模方法。MELLE通过文本条件直接自回归生成连续的梅尔频谱帧,避免了向量量化的需求。向量量化通常用于音频压缩,与连续表示相比牺牲了保真度。具体来说,(i)我们没有使用交叉熵损失,而是应用了回归损失和提出的频谱流量损失函数来模拟连续值标记的概率分布;(ii)我们将变分推断融入MELLE,以促进采样机制,从而增强输出多样性和模型稳健性。实验表明,与两阶段编码器解码器语言模型VALL-E及其变体相比,单阶段的MELLE通过避免采样向量量化代码的固有缺陷,缓解了稳健性问题,在多个指标上实现了卓越性能,而且最重要的是,它提供了更简洁的范式。我们的工作演示见https://aka.ms/melle。
论文及项目相关链接
PDF Accepted to ACL 2025 Main
摘要
MELLE是一种针对文本到语音合成(TTS)的新型连续值令牌基础语言建模方法。MELLE能够直接从文本条件生成连续的梅尔频谱帧,从而绕过了通常需要向量量化的需求。该方法通过应用回归损失和一个提出的频谱流量损失函数来建模连续令牌的概率分布,并引入了变分推断来促进采样机制,从而提高输出多样性和模型鲁棒性。实验表明,与两阶段编码语言模型VALL-E及其变体相比,单阶段的MELLE避免了采样向量量化代码的固有缺陷,提高了多个指标的性能,并且提供了一个更简洁的范式。我们的工作演示地址为:[链接地址]。
要点掌握
- MELLE是一种新型的连续值令牌基础语言建模方法,用于文本到语音合成(TTS)。
- MELLE直接生成连续的梅尔频谱帧,绕过了向量量化的需求。
- MELLE应用回归损失和频谱流量损失函数来建模连续令牌的概率分布。
- MELLE引入了变分推断来促进采样机制,提高输出多样性和模型鲁棒性。
- 实验表明,MELLE相较于两阶段编码语言模型VALL-E及其变体,具有更高的性能和更简洁的范式。
- MELLE避免了采样向量量化代码的固有缺陷。
点此查看论文截图