⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-05-30 更新
Tell me Habibi, is it Real or Fake?
Authors:Kartik Kuckreja, Parul Gupta, Injy Hamed, Thamar Solorio, Muhammad Haris Khan, Abhinav Dhall
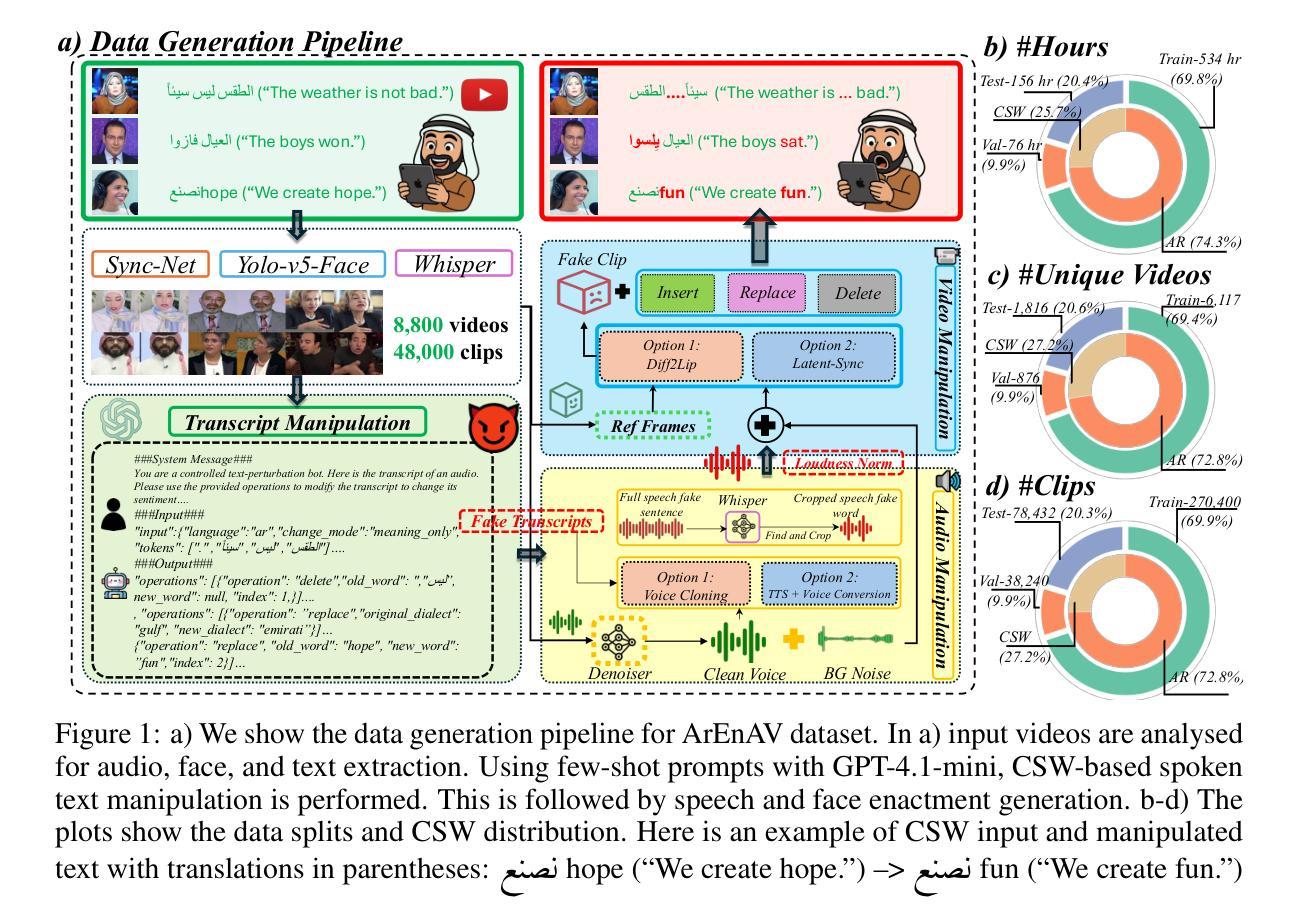
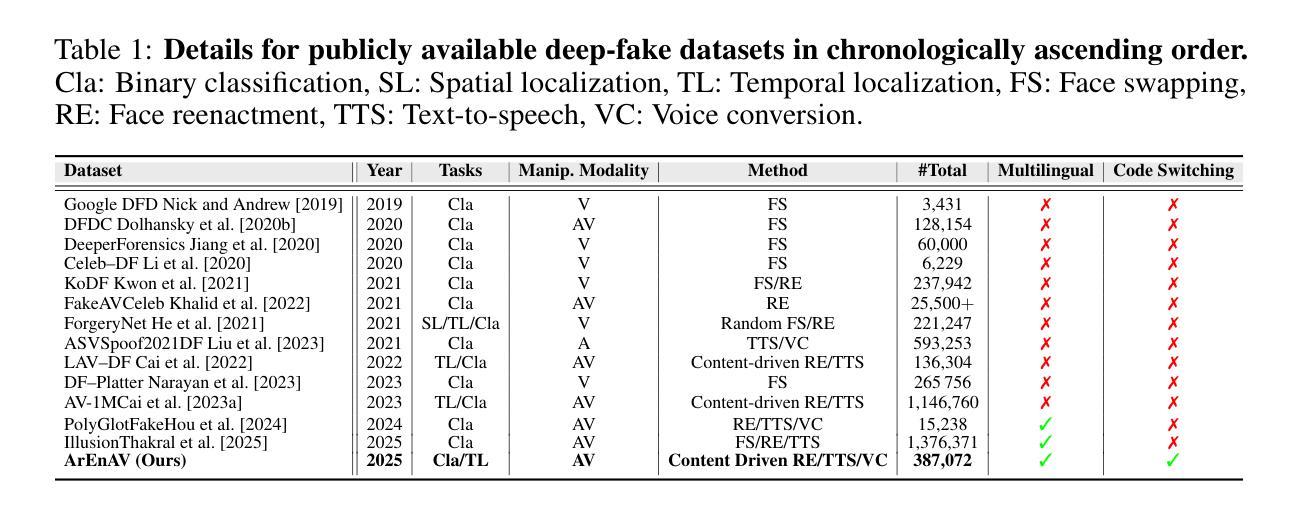
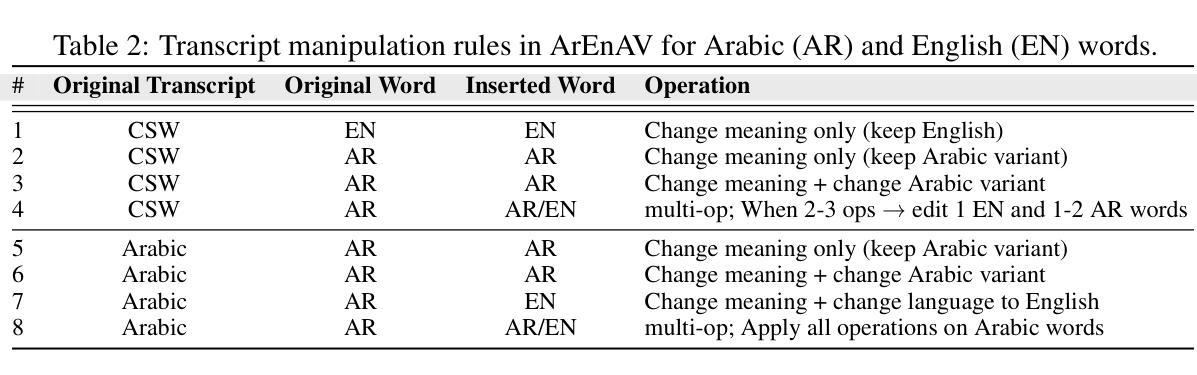
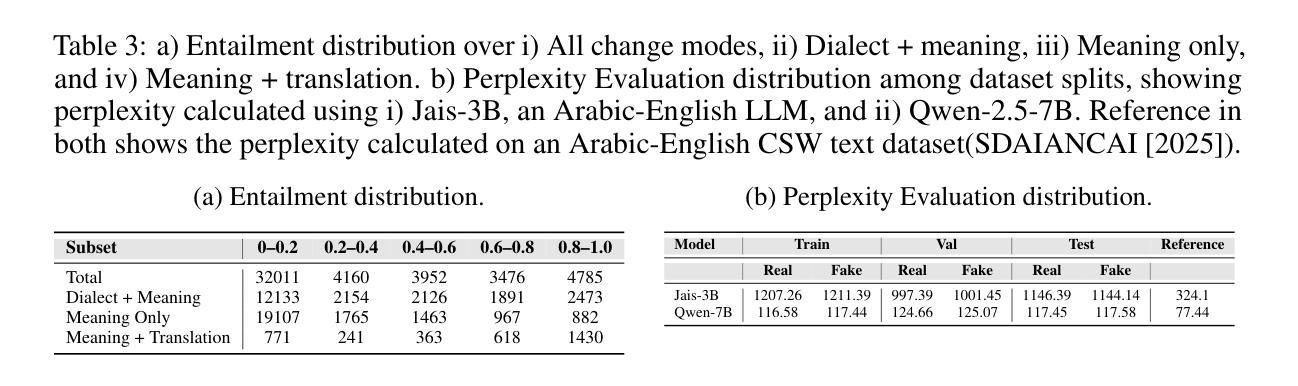
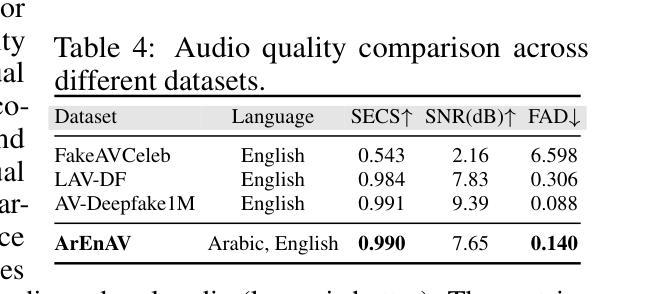
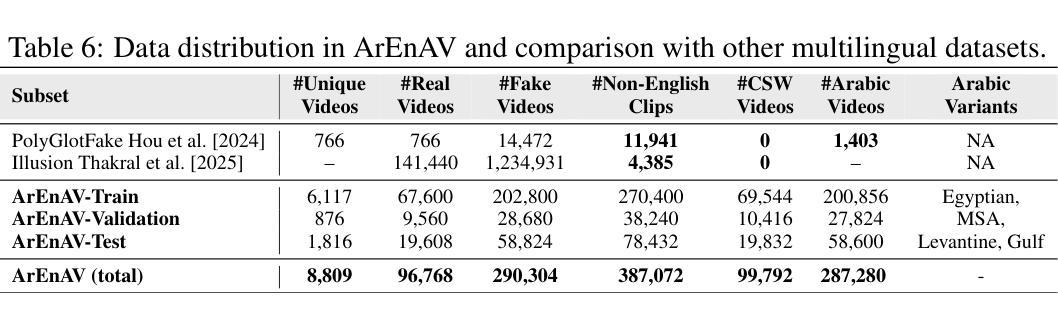
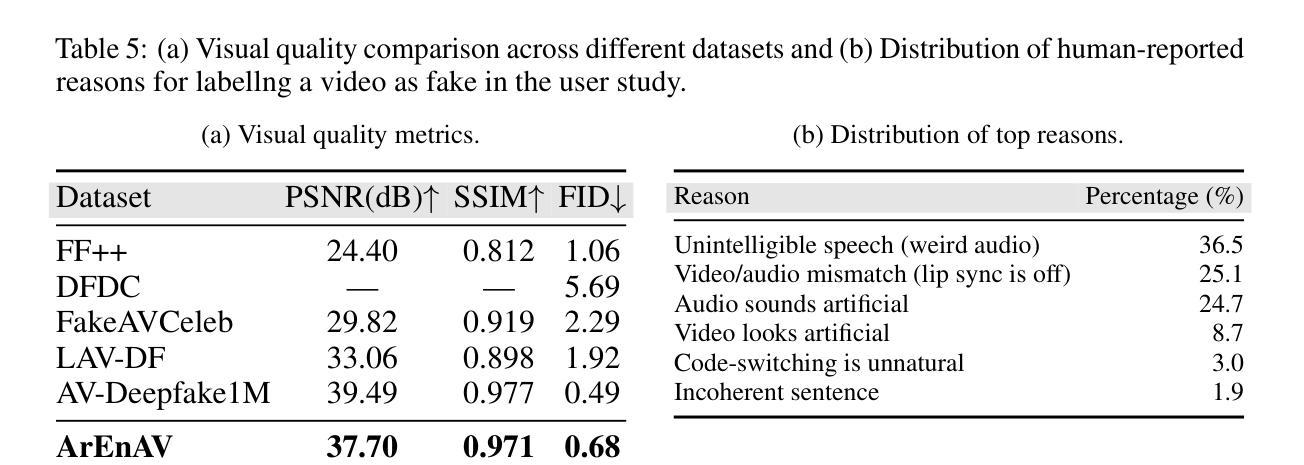
Deepfake generation methods are evolving fast, making fake media harder to detect and raising serious societal concerns. Most deepfake detection and dataset creation research focuses on monolingual content, often overlooking the challenges of multilingual and code-switched speech, where multiple languages are mixed within the same discourse. Code-switching, especially between Arabic and English, is common in the Arab world and is widely used in digital communication. This linguistic mixing poses extra challenges for deepfake detection, as it can confuse models trained mostly on monolingual data. To address this, we introduce \textbf{ArEnAV}, the first large-scale Arabic-English audio-visual deepfake dataset featuring intra-utterance code-switching, dialectal variation, and monolingual Arabic content. It \textbf{contains 387k videos and over 765 hours of real and fake videos}. Our dataset is generated using a novel pipeline integrating four Text-To-Speech and two lip-sync models, enabling comprehensive analysis of multilingual multimodal deepfake detection. We benchmark our dataset against existing monolingual and multilingual datasets, state-of-the-art deepfake detection models, and a human evaluation, highlighting its potential to advance deepfake research. The dataset can be accessed \href{https://huggingface.co/datasets/kartik060702/ArEnAV-Full}{here}.
深度伪造生成方法正在快速发展,使得虚假媒体更难检测,并引发了社会的严重关注。大多数深度伪造检测和数据集创建研究都集中在单语内容上,经常忽视多语种和代码切换语音的挑战,同一话语中混合了多种语言。在阿拉伯世界,代码切换,特别是阿拉伯语和英语之间的切换,是常见的,并广泛用于数字通信。这种语言混合给深度伪造检测带来了额外的挑战,因为它可能会混淆主要基于单语数据的模型。为解决这一问题,我们推出了ArEnAV,这是第一个大规模阿拉伯语-英语视听深度伪造数据集,具有跨语码转换、方言变化和单语阿拉伯语内容的特点。它包含了38.7万多个视频和超过765小时的真实和伪造的视频内容。我们的数据集是通过一个新型管道生成的,该管道集成了四种文本到语音和两种唇同步模型,能够全面分析多语种多媒体深度伪造检测。我们将数据集与现有的单语种和多语种数据集、最先进的深度伪造检测模型以及人类评估进行了比较,凸显了其在推动深度伪造研究方面的潜力。数据集可通过https://huggingface.co/datasets/kartik060702/ArEnAV-Full访问。
论文及项目相关链接
PDF 9 pages, 2 figures, 12 tables
Summary
深假技术生成方法发展迅速,使得假媒体更难检测并引发社会关注。当前大部分深度伪造检测和数据集创建研究都集中在单语内容上,忽略了多语种和混合语言带来的挑战。阿拉伯和英语的混合语言在阿拉伯世界普遍存在,给深度伪造检测带来了额外的挑战。为解决这一问题,我们推出了ArEnAV数据集,这是首个包含阿拉伯语和英语音视频深度伪造数据集,包含跨句混合语言、方言差异和单语阿拉伯语内容。数据集包含38.7万视频和超过765小时的真实和伪造视频。我们整合了四个文本转语音和两个唇同步模型来生成该数据集,以全面分析多语种模态深度伪造检测。我们对数据集进行了基准测试,与现有的单语种和多语种数据集以及最先进的深度伪造检测模型进行了比较,并进行了人类评估,突出了其对深度伪造研究的潜力。数据集可在此访问:[链接地址]。
Key Takeaways
- 深假技术快速发展带来社会担忧。
- 当前深度伪造检测和数据集研究主要关注单语内容。
- 多语言和混合语言挑战深度伪造检测。
- ArEnAV数据集是首个包含阿拉伯语和英语音视频深度伪造数据集。
- ArEnAV包含真实和伪造视频数据超过765小时。
- ArEnAV数据集的生成使用了创新的集成管道技术处理多种模型和语言分析需求。
点此查看论文截图


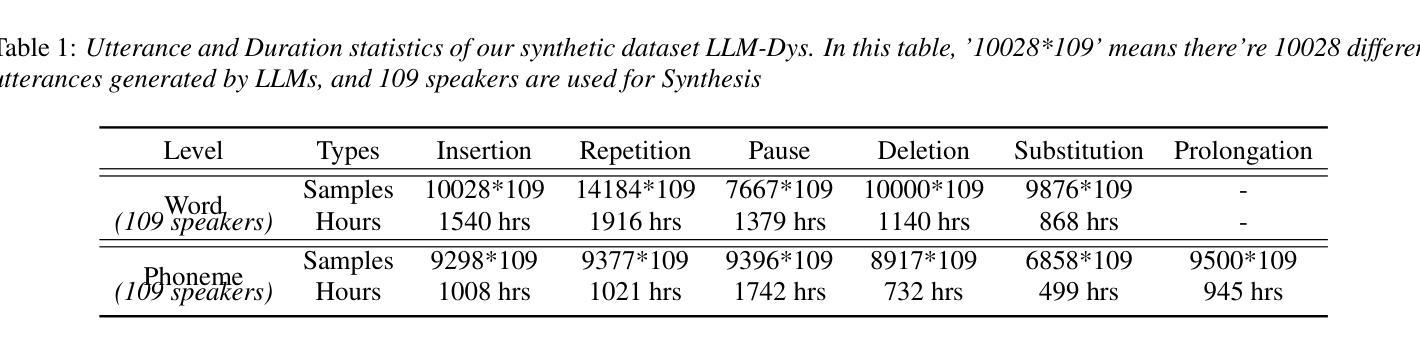
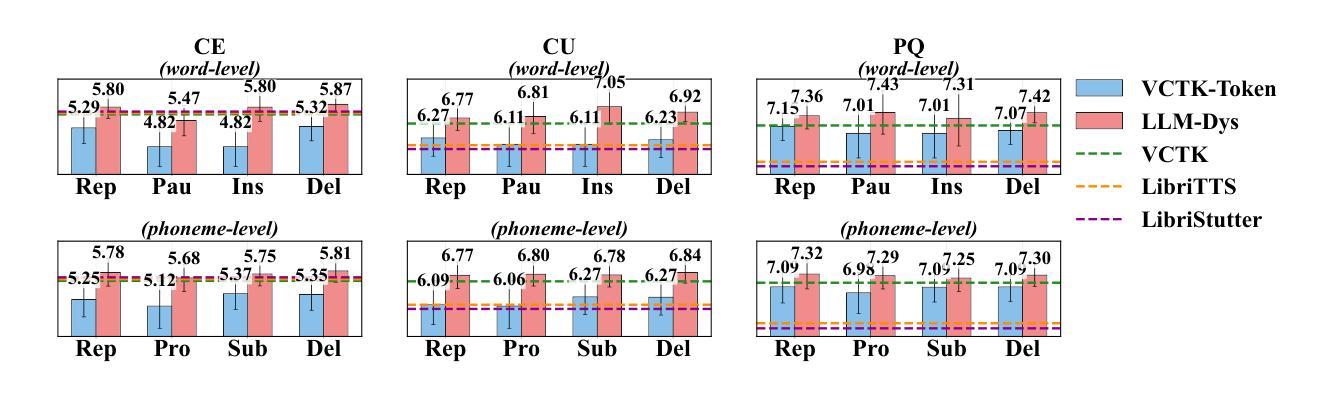
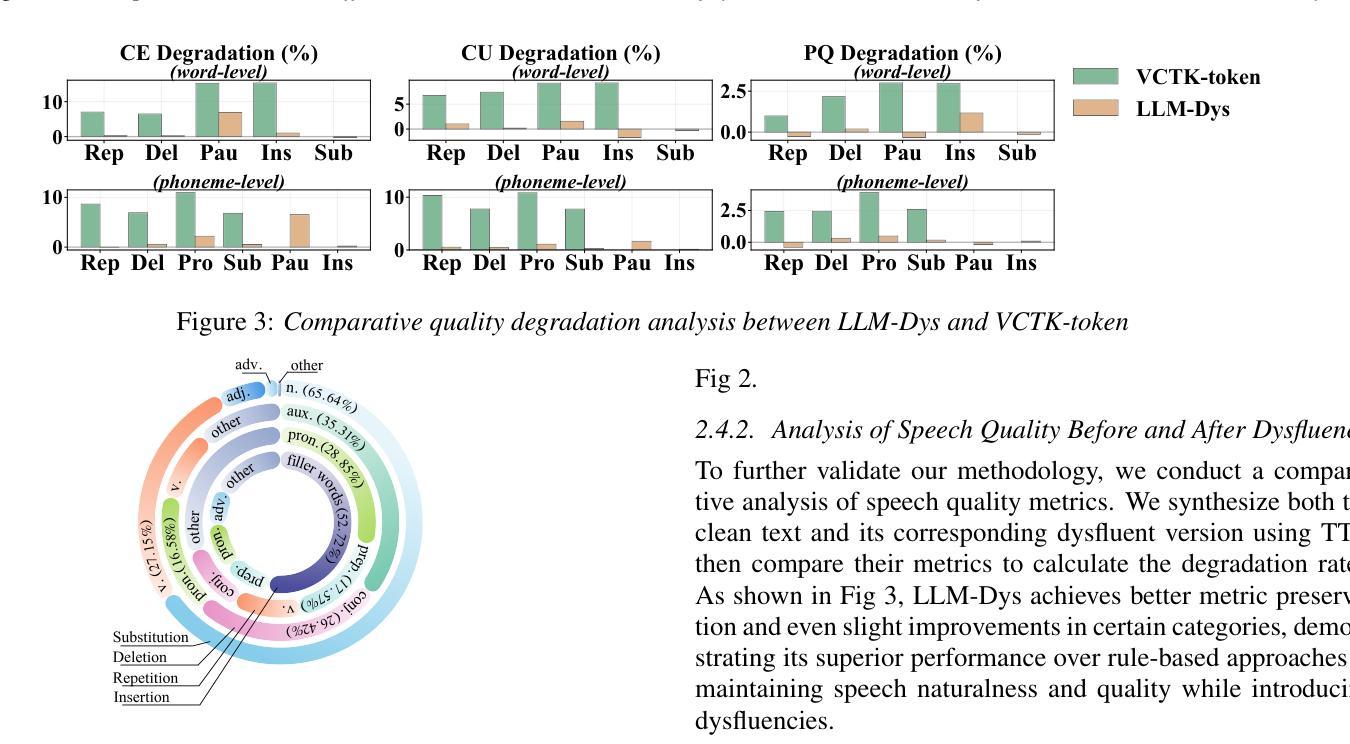
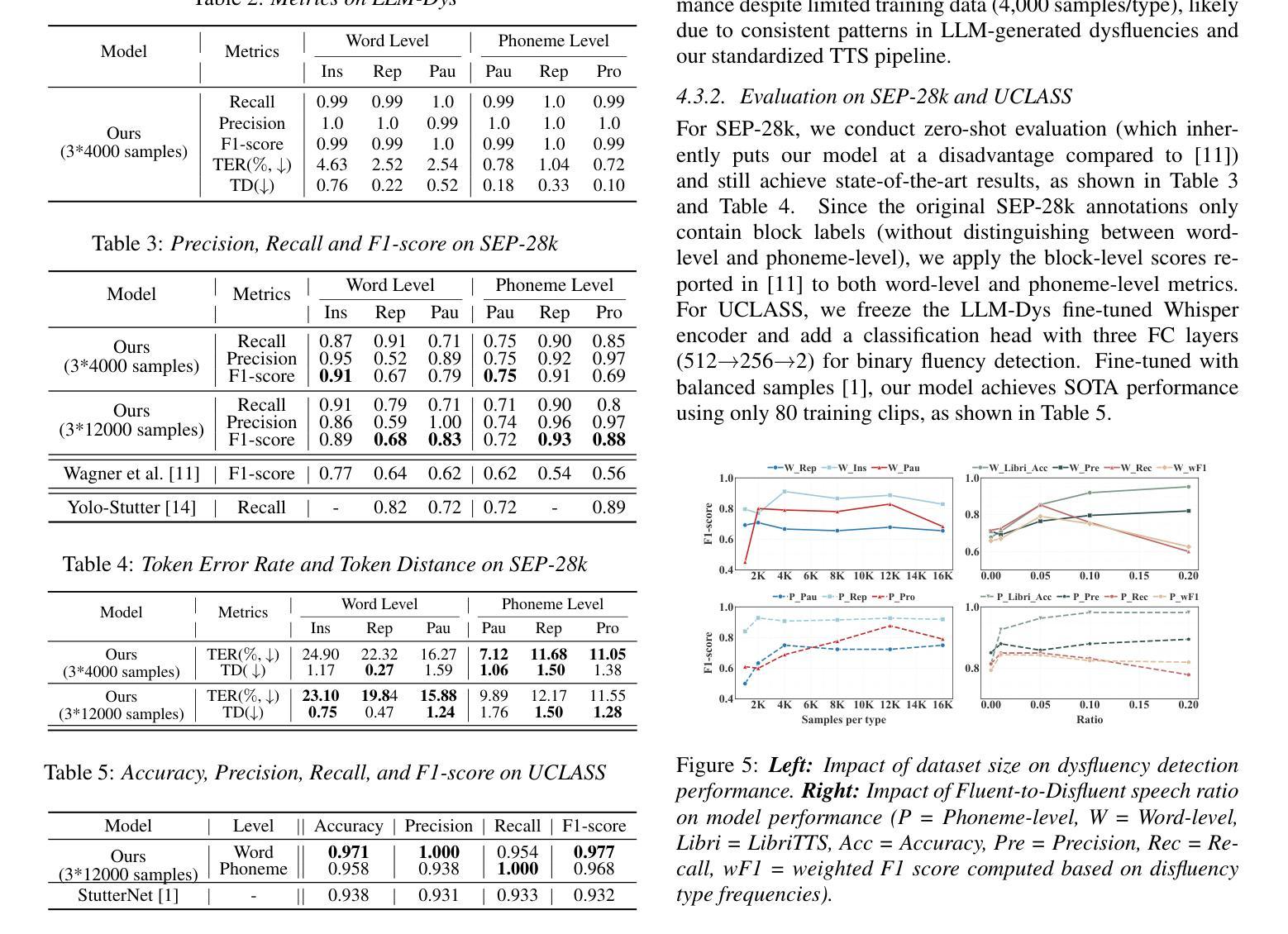
Analysis and Evaluation of Synthetic Data Generation in Speech Dysfluency Detection
Authors:Jinming Zhang, Xuanru Zhou, Jiachen Lian, Shuhe Li, William Li, Zoe Ezzes, Rian Bogley, Lisa Wauters, Zachary Miller, Jet Vonk, Brittany Morin, Maria Gorno-Tempini, Gopala Anumanchipalli
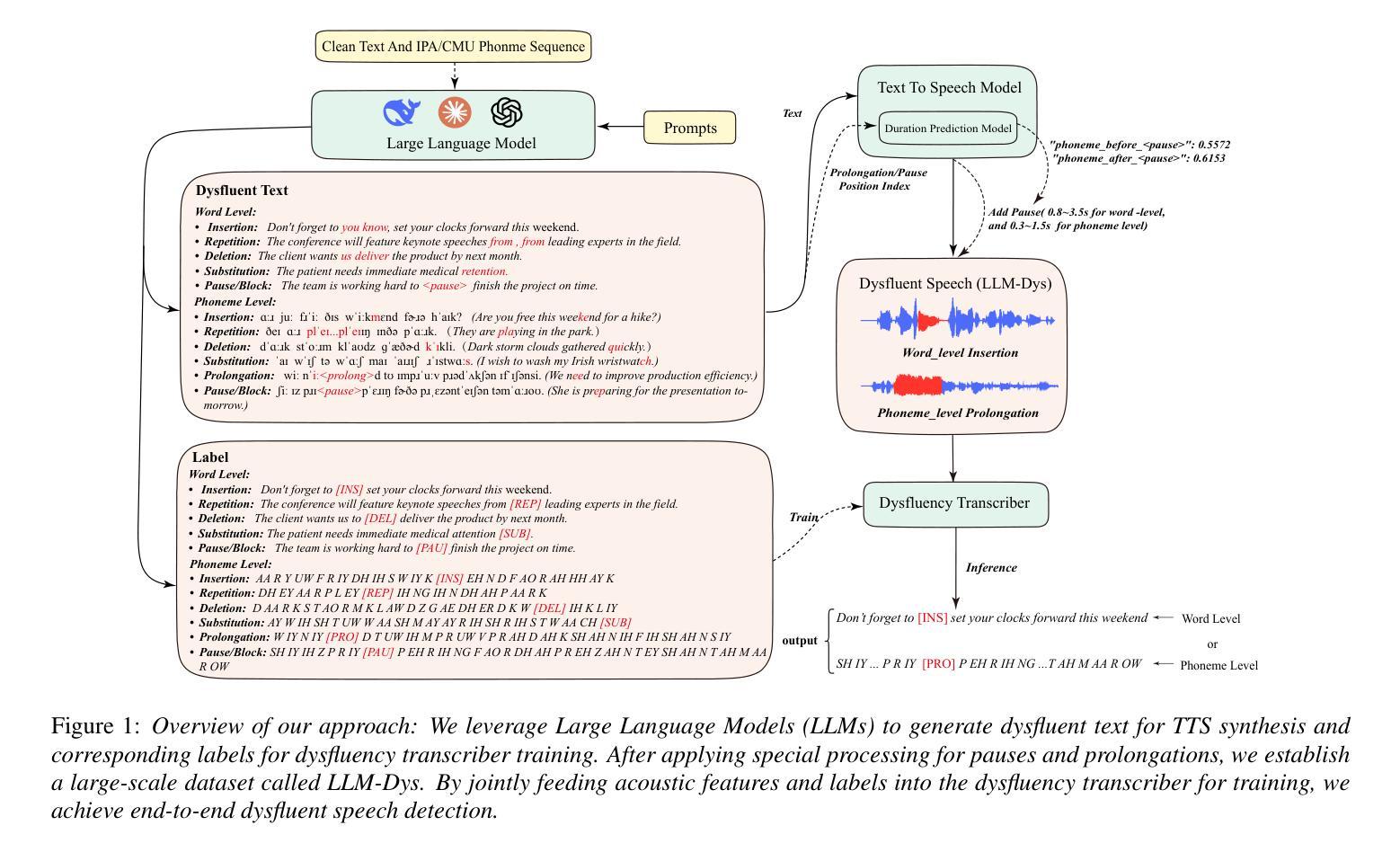
Speech dysfluency detection is crucial for clinical diagnosis and language assessment, but existing methods are limited by the scarcity of high-quality annotated data. Although recent advances in TTS model have enabled synthetic dysfluency generation, existing synthetic datasets suffer from unnatural prosody and limited contextual diversity. To address these limitations, we propose LLM-Dys – the most comprehensive dysfluent speech corpus with LLM-enhanced dysfluency simulation. This dataset captures 11 dysfluency categories spanning both word and phoneme levels. Building upon this resource, we improve an end-to-end dysfluency detection framework. Experimental validation demonstrates state-of-the-art performance. All data, models, and code are open-sourced at https://github.com/Berkeley-Speech-Group/LLM-Dys.
语音流畅性检测对于临床诊断和治疗语言评估至关重要,但现有方法受到高质量标注数据稀缺的限制。尽管最近文本转语音模型的进步已经能够实现合成流畅性生成,但现有的合成数据集存在韵律不自然和上下文多样性有限的缺点。为了解决这些局限性,我们提出了LLM-Dys——一个由大型语言模型增强流畅性模拟的最全面的流畅性语音语料库。该数据集涵盖了涵盖单词和音素级别的18个流畅性问题类别。基于此资源,我们改进了端到端的流畅性检测框架。实验验证显示其达到了最新技术水平。所有数据和模型都在https://github.com/Berkeley-Speech-Group/LLM-Dys上进行开源。
论文及项目相关链接
PDF Submitted to Interspeech 2025
Summary
本文介绍了语音流畅性检测在临床诊断和治疗语言评估中的重要性。然而,高质量标注数据的稀缺限制了现有方法的性能。尽管最近的TTS模型进步已经能够实现合成流畅性生成,但现有合成数据集存在语音韵律不自然和上下文多样性有限的问题。为解决这些问题,我们提出了LLM-Dys——一个由大型语言模型增强模拟流畅性的最全面的流畅性语音语料库。该数据集涵盖了词和音素两个级别的11种流畅性问题类别。基于这一资源,我们改进了一个端到端的流畅性检测框架,并通过实验验证取得了业界最佳性能。所有数据、模型和代码均已开源共享在https://github.com/Berkeley-Speech-Group/LLM-Dys。
Key Takeaways
- 语音流畅性检测在临床诊断和治疗语言评估中具有重要性。
- 现有方法受限于高质量标注数据的稀缺。
- TTS模型的最新进展能够实现合成流畅性的生成。
- 现有合成数据集存在语音韵律不自然和上下文多样性有限的问题。
- LLM-Dys是一个全面的流畅性语音语料库,由大型语言模型增强模拟流畅性。
- 该数据集涵盖了词和音素两个级别的11种流畅性问题类别。
点此查看论文截图

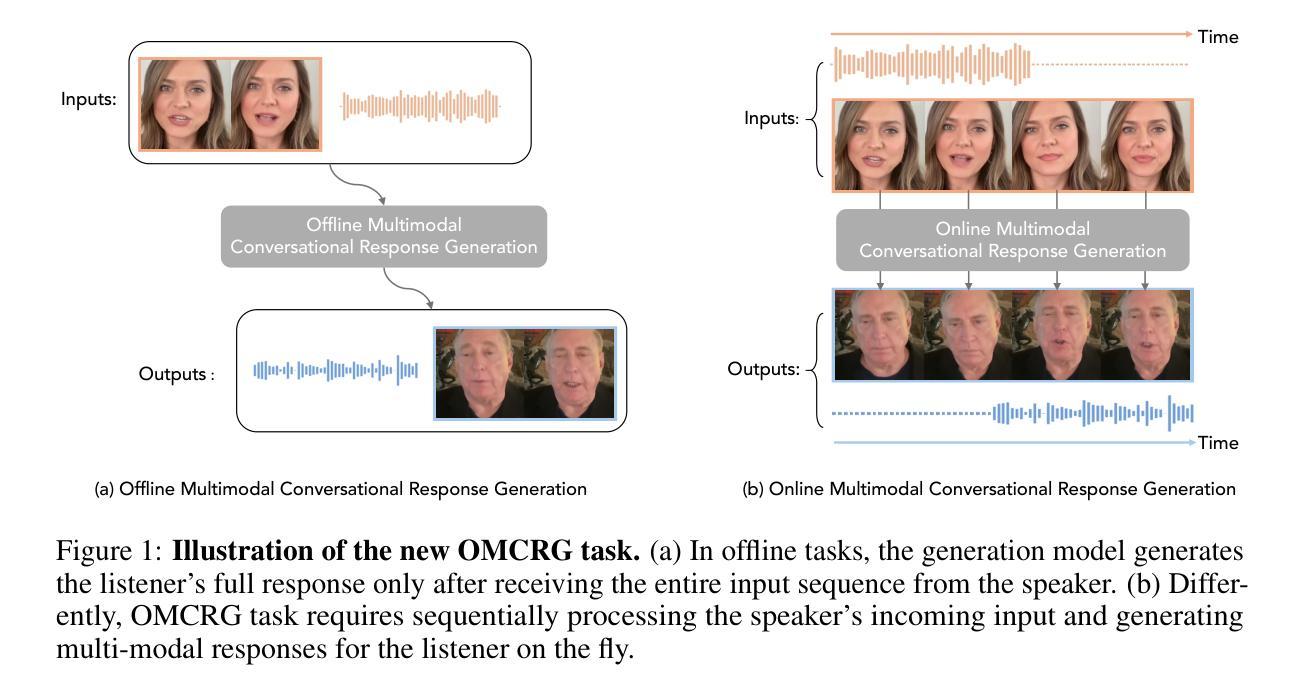
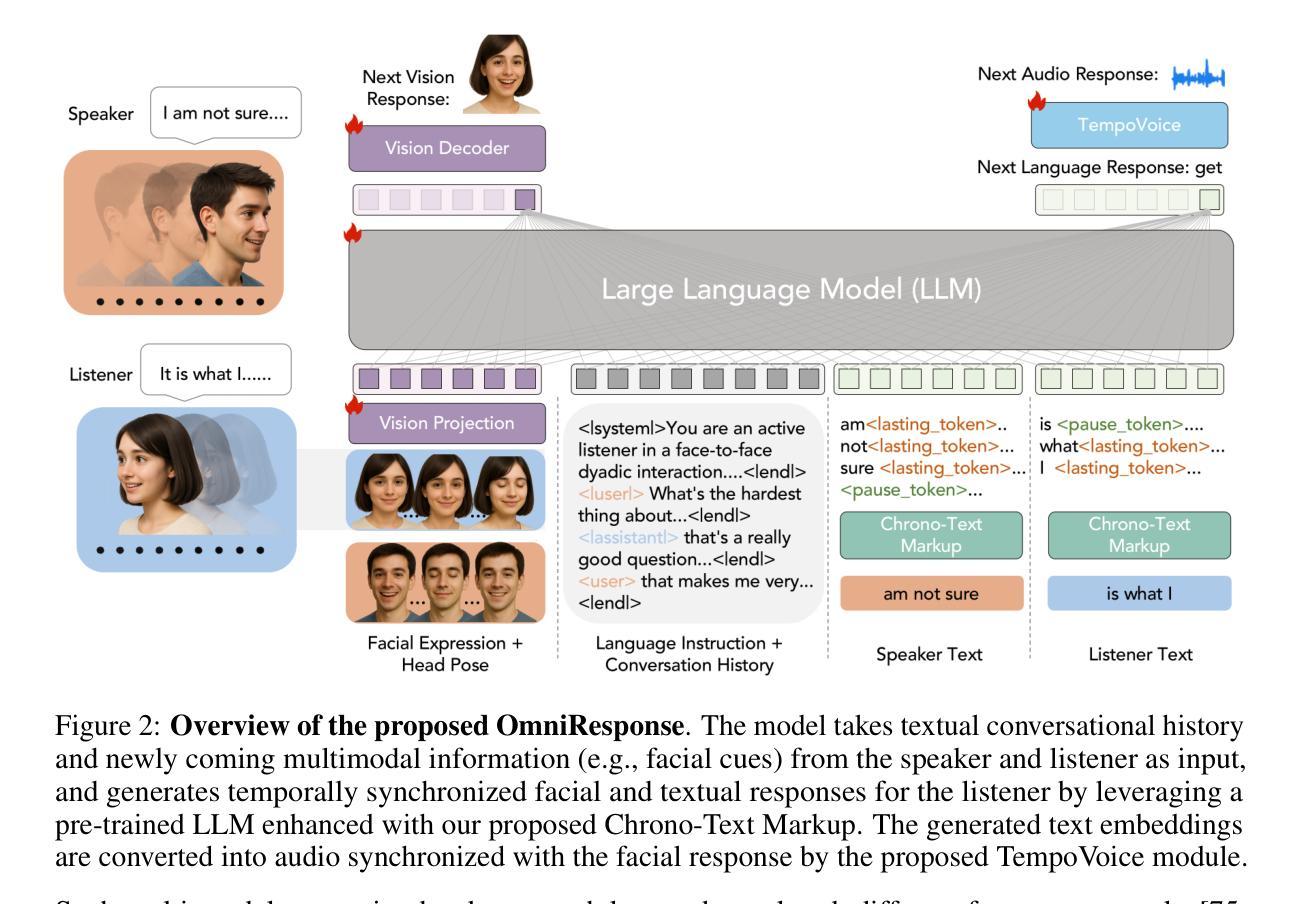
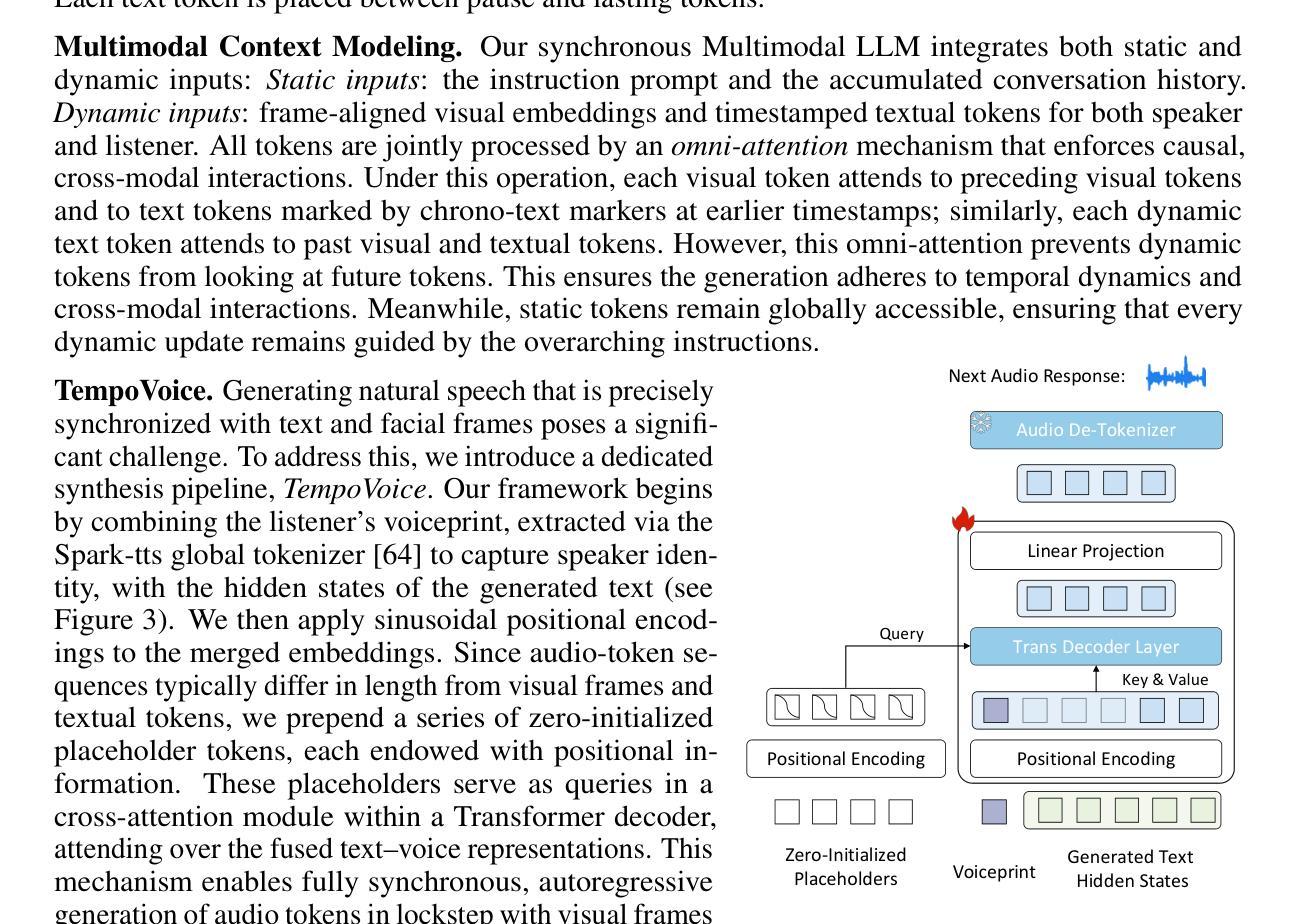
OmniResponse: Online Multimodal Conversational Response Generation in Dyadic Interactions
Authors:Cheng Luo, Jianghui Wang, Bing Li, Siyang Song, Bernard Ghanem
In this paper, we introduce Online Multimodal Conversational Response Generation (OMCRG), a novel task that aims to online generate synchronized verbal and non-verbal listener feedback, conditioned on the speaker’s multimodal input. OMCRG reflects natural dyadic interactions and poses new challenges in achieving synchronization between the generated audio and facial responses of the listener. To address these challenges, we innovatively introduce text as an intermediate modality to bridge the audio and facial responses. We hence propose OmniResponse, a Multimodal Large Language Model (MLLM) that autoregressively generates high-quality multi-modal listener responses. OmniResponse leverages a pretrained LLM enhanced with two novel components: Chrono-Text, which temporally anchors generated text tokens, and TempoVoice, a controllable online TTS module that produces speech synchronized with facial reactions. To support further OMCRG research, we present ResponseNet, a new dataset comprising 696 high-quality dyadic interactions featuring synchronized split-screen videos, multichannel audio, transcripts, and facial behavior annotations. Comprehensive evaluations conducted on ResponseNet demonstrate that OmniResponse significantly outperforms baseline models in terms of semantic speech content, audio-visual synchronization, and generation quality.
本文介绍了在线多模态对话响应生成(OMCRG)这一新任务,该任务旨在根据说话者的多模态输入,在线生成同步的言语和非言语听众反馈。OMCRG反映了自然的二元交互,并在实现生成音频和听众面部响应之间的同步方面提出了新的挑战。为了应对这些挑战,我们创新性地引入文本作为中间模态来桥接音频和面部响应。因此,我们提出了OmniResponse,这是一种多模态大型语言模型(MLLM),可以自回归地生成高质量的多模态听众响应。OmniResponse利用预训练的大型语言模型,并配备了两个新型组件:Chrono-Text,它暂时锚定生成的文本令牌;以及TempoVoice,这是一个可控的在线文本转语音(TTS)模块,能够产生与面部反应同步的语音。为了支持进一步的OMCRG研究,我们推出了ResponseNet数据集,包含696个高质量的二元交互视频,每个视频都包含同步的分割屏幕视频、多通道音频、字幕和面部行为注释。在ResponseNet上进行的综合评估表明,OmniResponse在语义语音内容、音视频同步和生成质量方面均显著优于基准模型。
论文及项目相关链接
PDF 23 pages, 9 figures
Summary
在线多模态对话响应生成(OMCRG)是一项旨在根据说话者的多模态输入在线生成同步的言语和非言语听众反馈的新任务。为应对挑战,引入了文本作为连接音频和面部响应的中间模态,并提出了OmniResponse多任务大型语言模型(MLLM)。该模型可自动生成高质量的多模态听众响应,并利用带有两个新组件的预训练LLM:用于临时锚定生成文本令牌的Chrono-Text和用于产生与面部反应同步语音的TempoVoice可控在线TTS模块。为了支持OMCRG研究,推出ResponseNet数据集,包含696个高质量双人互动同步分屏视频、多通道音频、字幕和面部行为注释。在ResponseNet上的综合评估表明,OmniResponse在语义语音内容、视听同步和生成质量方面显著优于基线模型。
Key Takeaways
- OMCRG任务旨在在线生成同步的言语和非言语听众反馈,基于说话者的多模态输入。
- 引入文本作为连接音频和面部响应的中间模态,以应对挑战。
- 提出OmniResponse多任务大型语言模型(MLLM),可自动生成高质量的多模态听众响应。
- OmniResponse利用带有Chrono-Text和TempoVoice两个新组件的预训练LLM。
- ResponseNet数据集包含同步分屏视频、多通道音频、字幕和面部行为注释,支持OMCRG研究。
- 综合评估显示,OmniResponse在语义语音内容、视听同步和生成质量方面优于基线模型。
点此查看论文截图

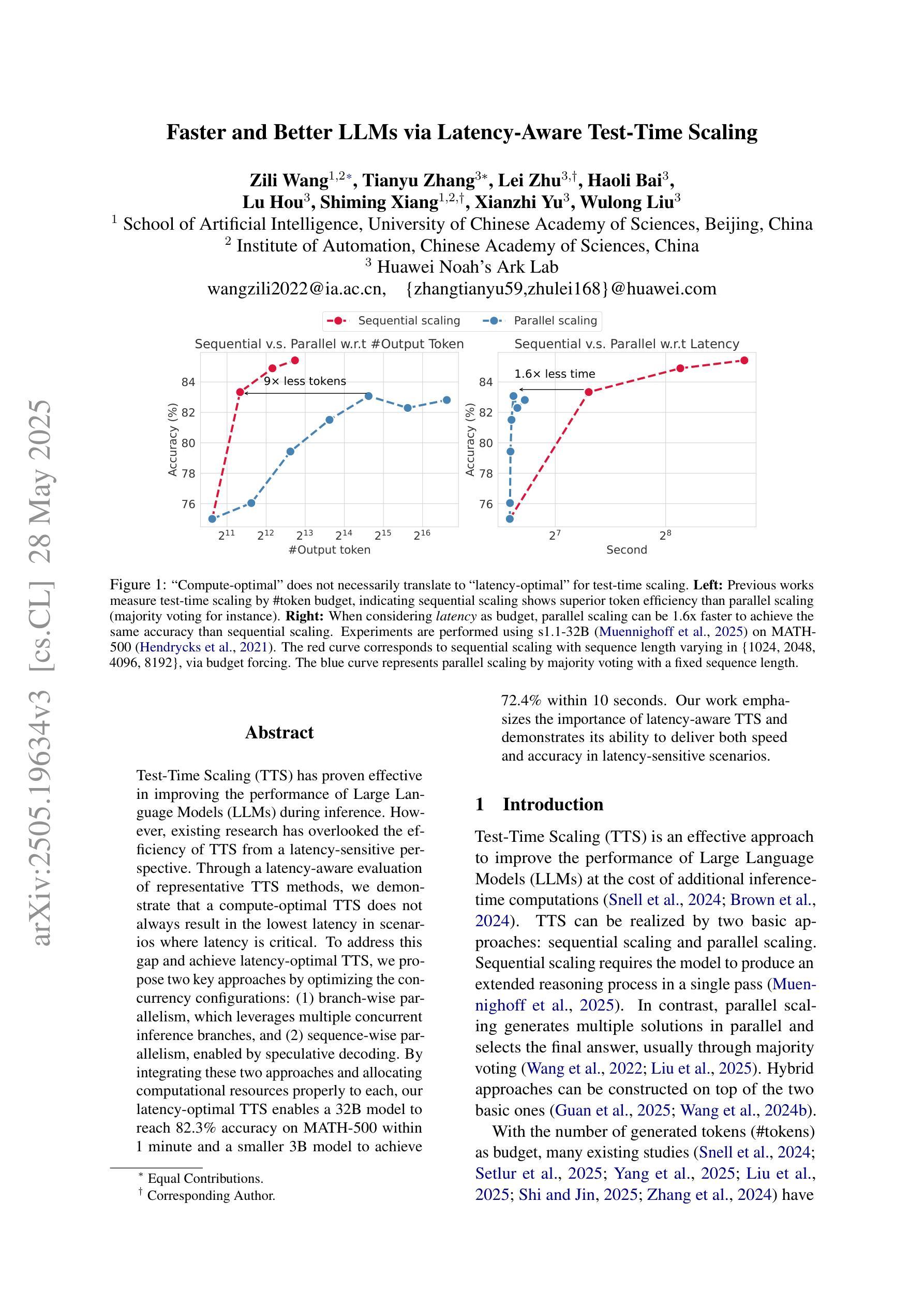
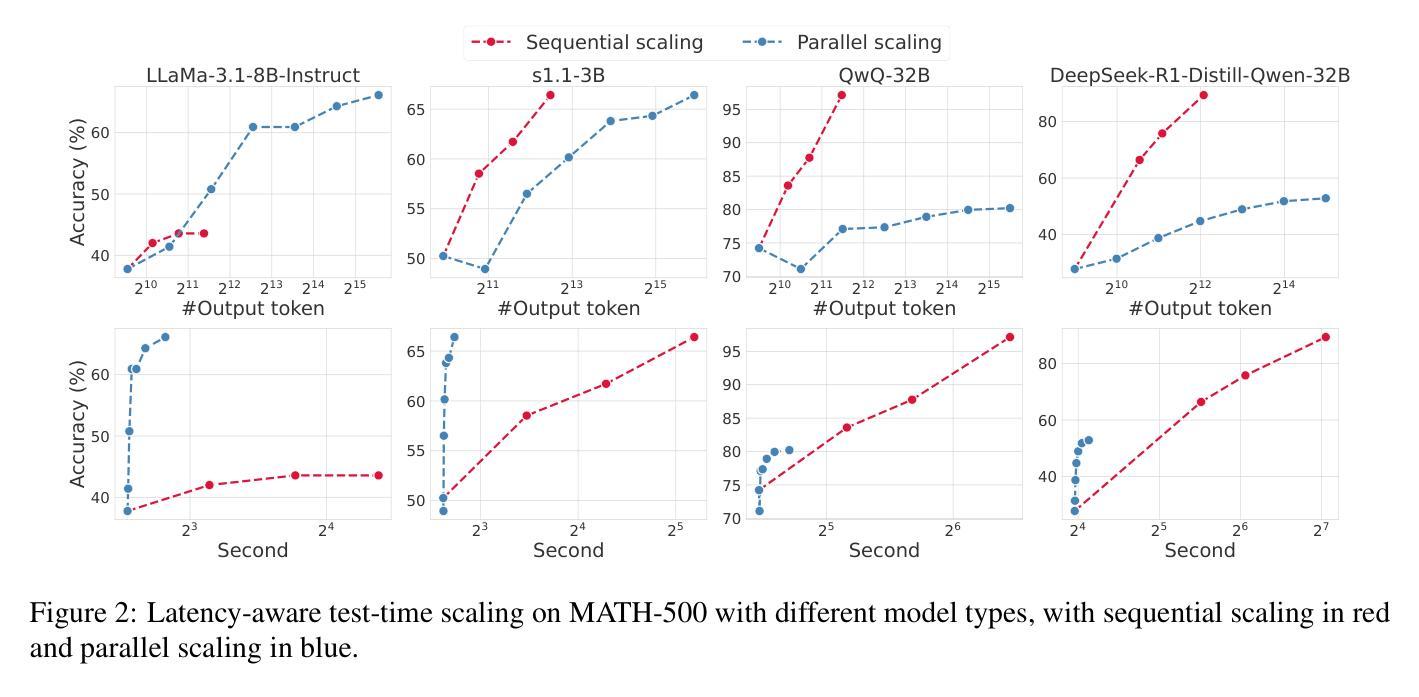
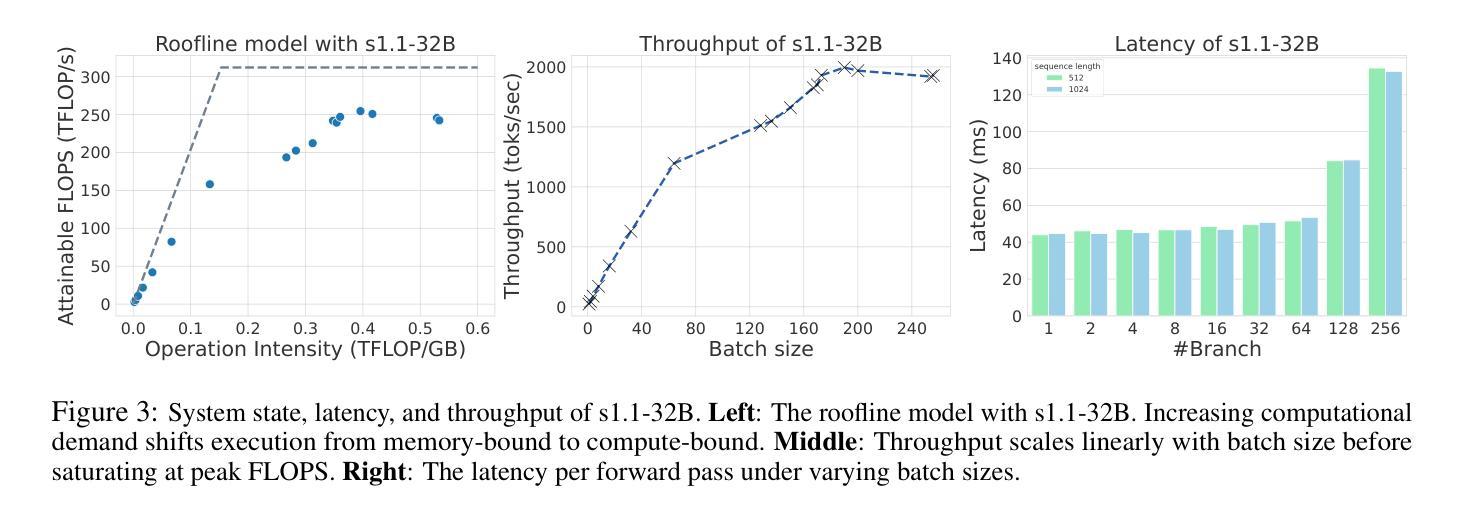
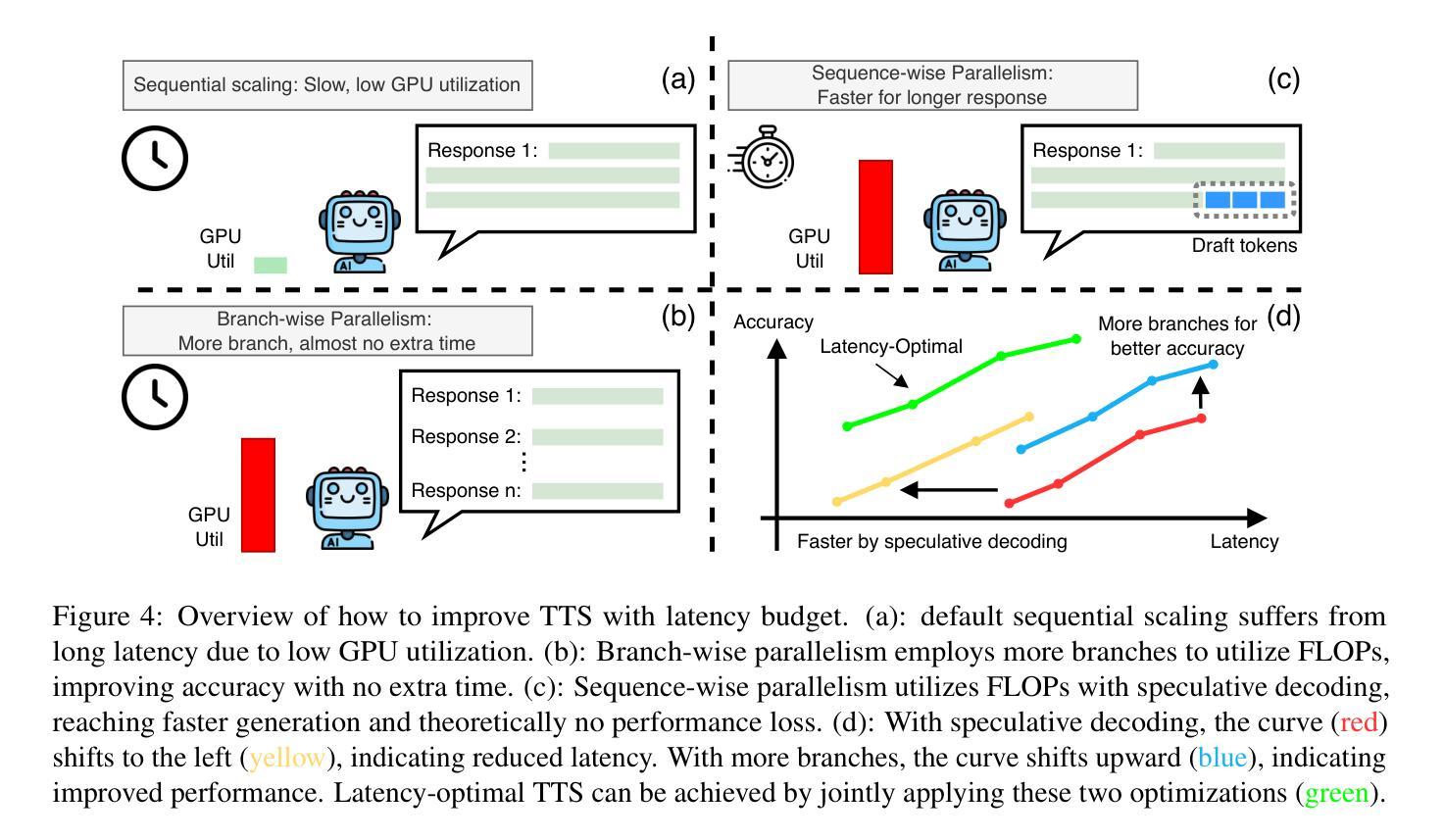
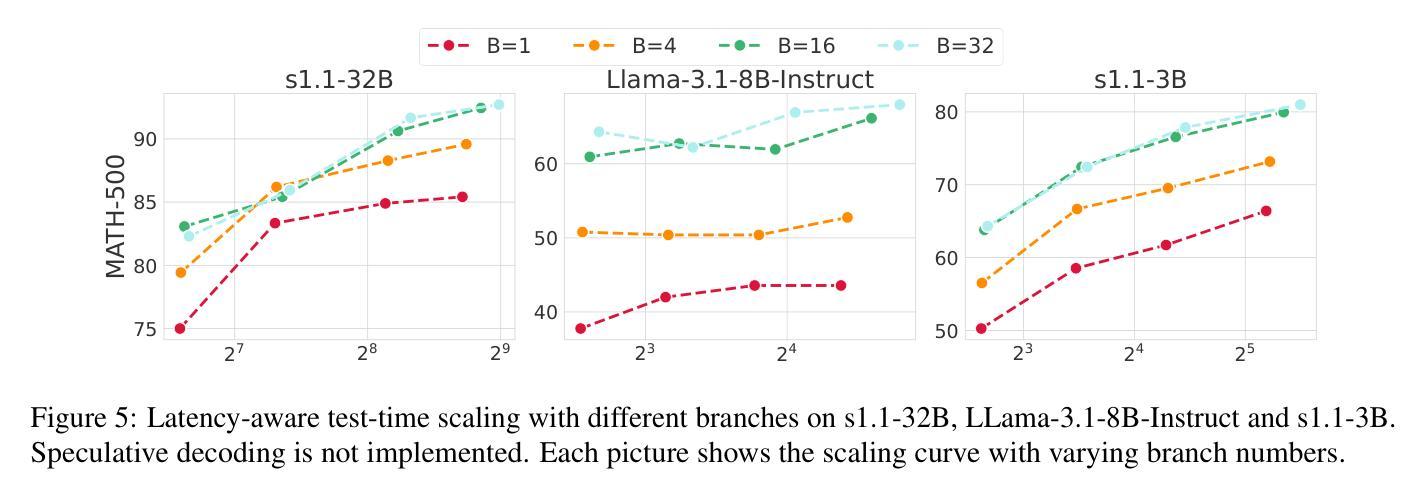
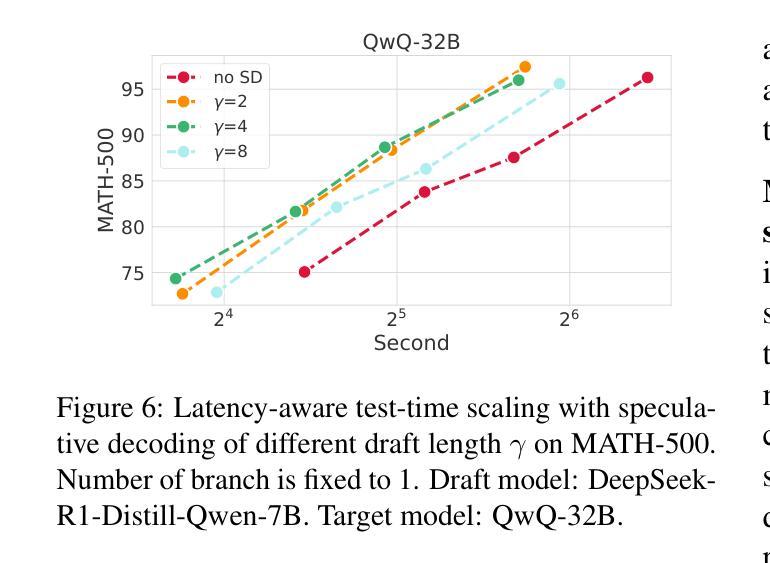
Faster and Better LLMs via Latency-Aware Test-Time Scaling
Authors:Zili Wang, Tianyu Zhang, Lei Zhu, Haoli Bai, Lu Hou, Shiming Xiang, Xianzhi Yu, Wulong Liu
Test-Time Scaling (TTS) has proven effective in improving the performance of Large Language Models (LLMs) during inference. However, existing research has overlooked the efficiency of TTS from a latency-sensitive perspective. Through a latency-aware evaluation of representative TTS methods, we demonstrate that a compute-optimal TTS does not always result in the lowest latency in scenarios where latency is critical. To address this gap and achieve latency-optimal TTS, we propose two key approaches by optimizing the concurrency configurations: (1) branch-wise parallelism, which leverages multiple concurrent inference branches, and (2) sequence-wise parallelism, enabled by speculative decoding. By integrating these two approaches and allocating computational resources properly to each, our latency-optimal TTS enables a 32B model to reach 82.3% accuracy on MATH-500 within 1 minute and a smaller 3B model to achieve 72.4% within 10 seconds. Our work emphasizes the importance of latency-aware TTS and demonstrates its ability to deliver both speed and accuracy in latency-sensitive scenarios.
测试时缩放(TTS)已证明在推理过程中能有效提高大语言模型(LLM)的性能。然而,现有研究从延迟敏感的角度忽视了TTS的效率。通过对代表性TTS方法的延迟感知评估,我们证明计算最优的TTS并不总是导致延迟最敏感场景中延迟最低。为了弥补这一差距并实现延迟优化的TTS,我们提出了两种通过优化并发配置的关键方法:(1)分支并行性,利用多个并发推理分支;(2)通过投机解码实现的序列并行性。通过整合这两种方法并为每种方法适当分配计算资源,我们的延迟优化TTS使32B模型在MATH-500上1分钟内达到82.3%的准确率,较小的3B模型在10秒内达到72.4%的准确率。我们的工作强调了延迟感知TTS的重要性,并展示了其在延迟敏感场景中实现速度和准确性的能力。
论文及项目相关链接
摘要
文本主要介绍了测试时间缩放(TTS)在提高大型语言模型(LLM)推理性能方面的有效性。然而,现有研究从延迟敏感的角度忽视了TTS的效率。通过延迟感知的代表性TTS方法的评估,我们证明了计算最优的TTS并不总是导致延迟最低的场景。为了弥补这一差距并实现延迟最优的TTS,我们提出了两种通过优化并发配置的关键方法:(1)分支并行性,利用多个并发推理分支;(2)序列并行性,通过投机解码实现。通过整合这两种方法并适当分配计算资源给每个部分,我们的延迟最优TTS使一个规模为32B的模型能在MATH-500测试中达到82.3%的准确率,并且只需一分钟;而一个更小的规模为3B的模型可以在10秒内达到72.4%的准确率。我们的工作强调了延迟感知TTS的重要性,并展示了其在需要即时反应的场景中能够同时实现速度和准确度的能力。
关键见解
- 测试时间缩放(TTS)能提高大型语言模型(LLM)的推理性能。
- 现有研究忽略了从延迟敏感的角度评估TTS的效率。
- 实现延迟最优的TTS需要优化并发配置,包括分支并行性和序列并行性。
- 通过整合这两种并行性方法,我们能有效地降低模型推理的延迟。
- 在延迟敏感的场景中,优化后的TTS能在保持高准确率的同时,显著提高推理速度。
- 规模为32B的模型能在MATH-500测试中达到82.3%的准确率,并且只需一分钟完成推理。
点此查看论文截图
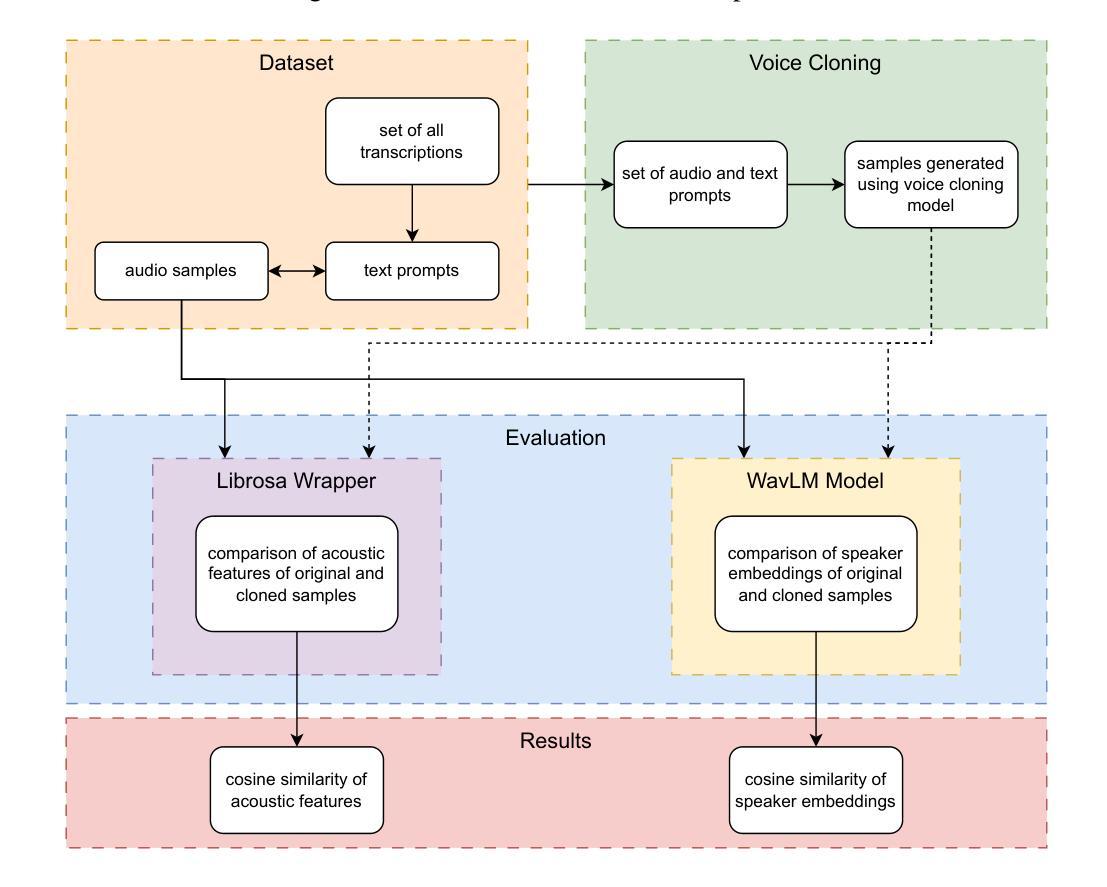
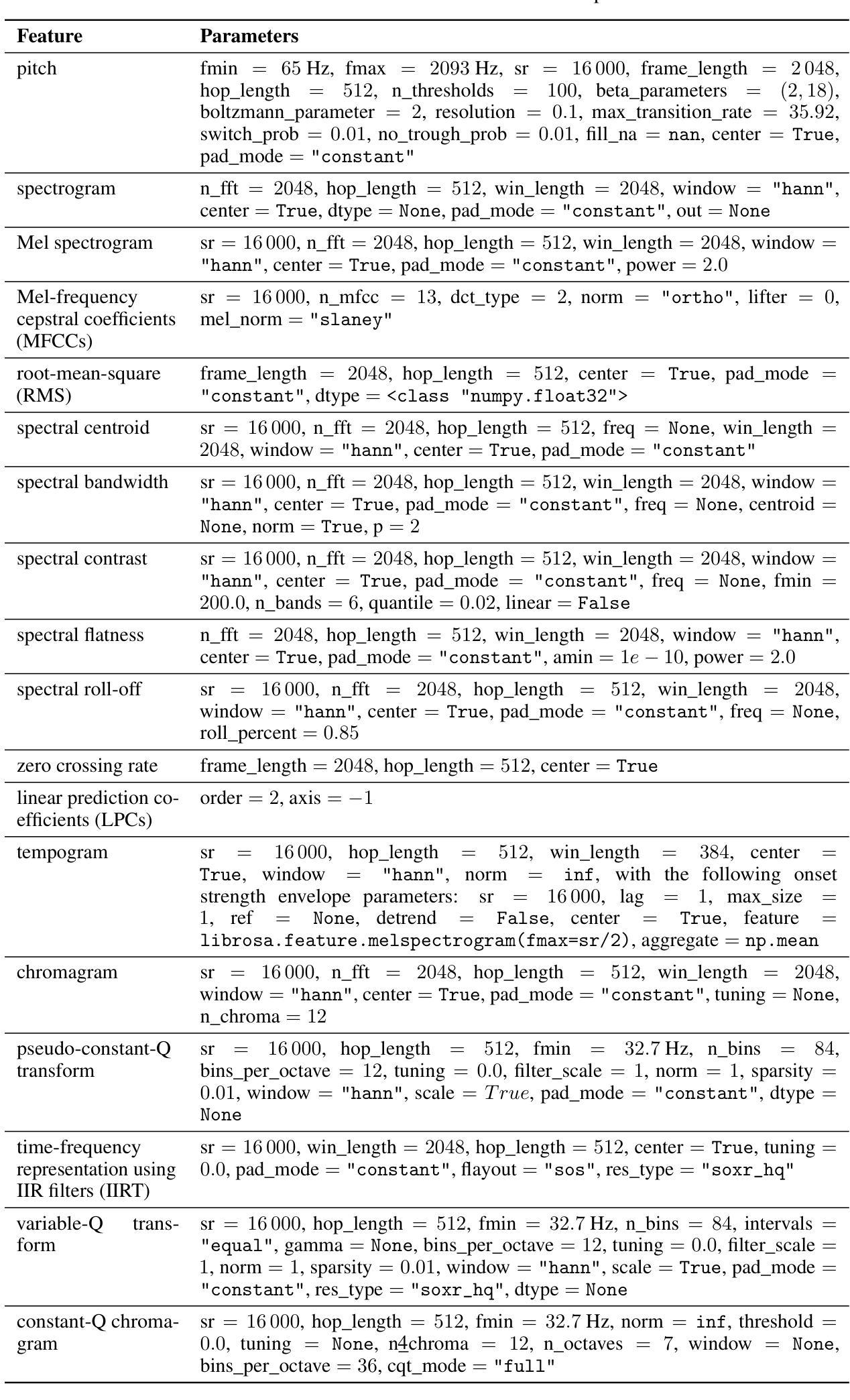
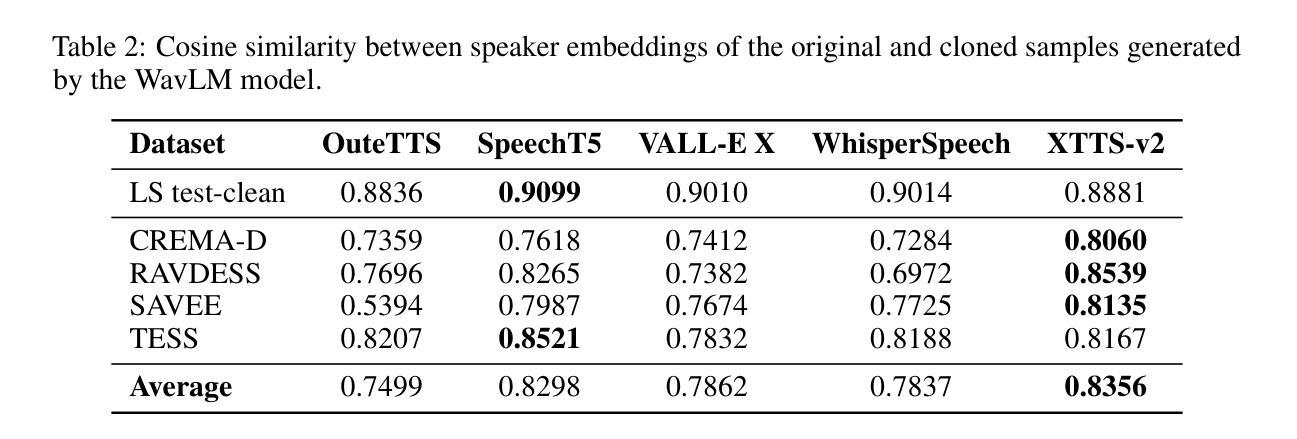
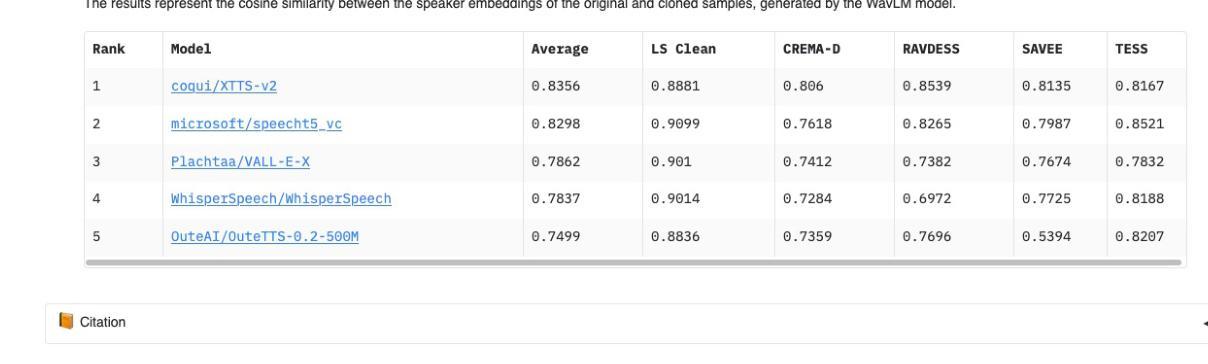
ClonEval: An Open Voice Cloning Benchmark
Authors:Iwona Christop, Tomasz Kuczyński, Marek Kubis
We present a novel benchmark for voice cloning text-to-speech models. The benchmark consists of an evaluation protocol, an open-source library for assessing the performance of voice cloning models, and an accompanying leaderboard. The paper discusses design considerations and presents a detailed description of the evaluation procedure. The usage of the software library is explained, along with the organization of results on the leaderboard.
我们为语音克隆文本到语音模型提出一个新的基准测试。该基准测试包括评估协议、评估语音克隆模型性能的开源库以及伴随的排行榜。论文讨论了设计考虑因素,并详细介绍了评估流程。同时解释了软件库的使用以及排行榜上结果的组织情况。
论文及项目相关链接
PDF Under review at NeurIPS
Summary
本文介绍了一个用于语音克隆文本到语音模型的新型基准测试。该基准测试包括评估协议、开源库以及排行榜,用以评估语音克隆模型的性能。文章讨论了设计考量,并详细介绍了评估流程、软件库的使用及结果展示方式。
Key Takeaways
- 介绍了新型的语音克隆文本到语音模型基准测试,包括评估协议和开源库。
- 该基准测试提供了评估语音克隆模型的性能的工具和排行榜。
- 文章讨论了设计该基准测试时的考量因素。
- 详细介绍了评估流程的具体步骤和方法。
- 说明了如何使用开源库进行模型性能的评估。
- 文章解释了结果展示的方式和组织形式。
- 此基准测试对于提升语音克隆模型的性能具有重要的作用。
点此查看论文截图

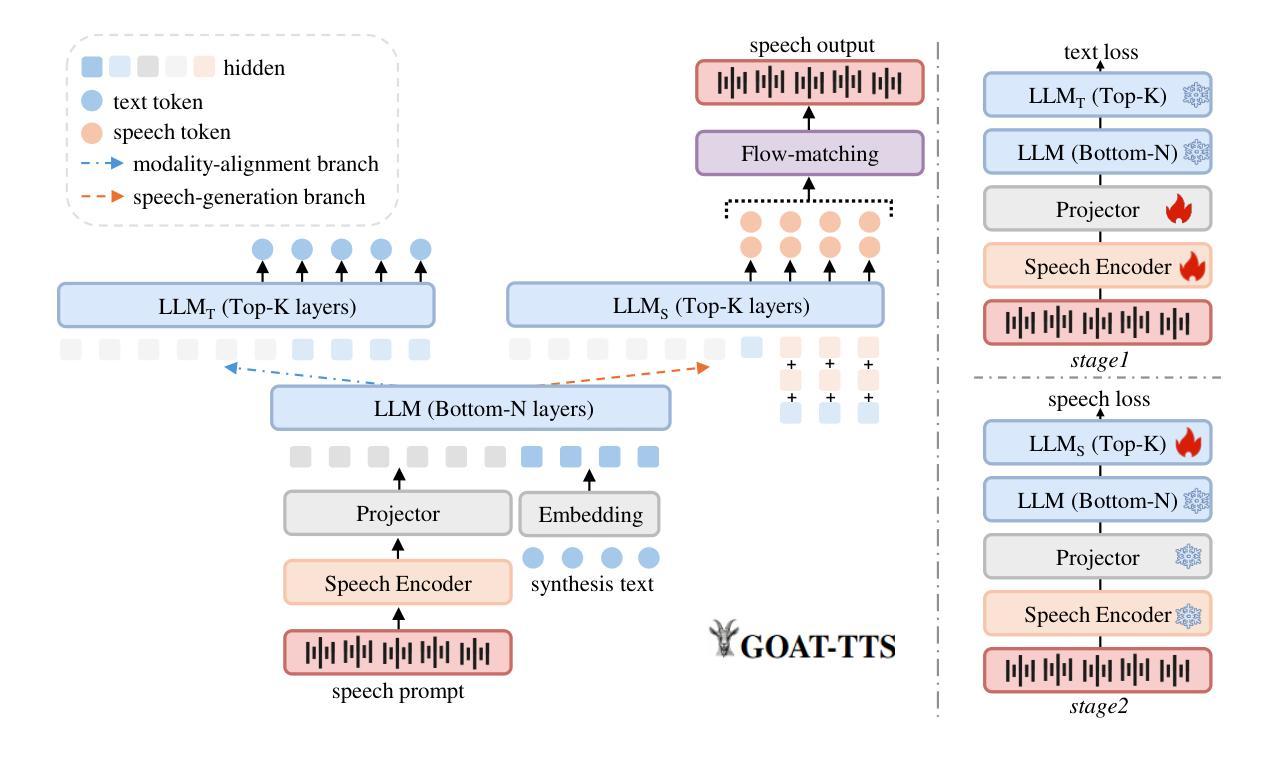
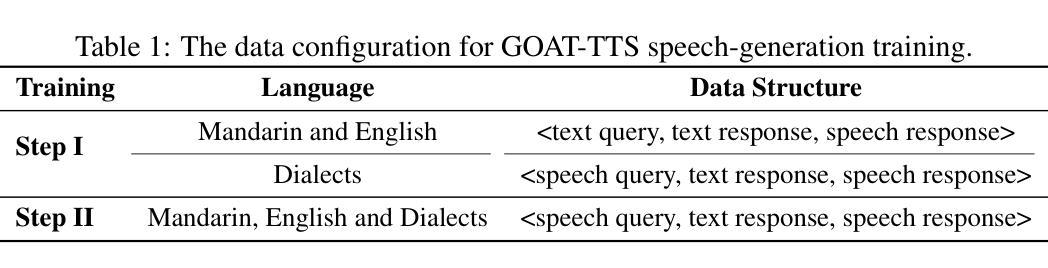
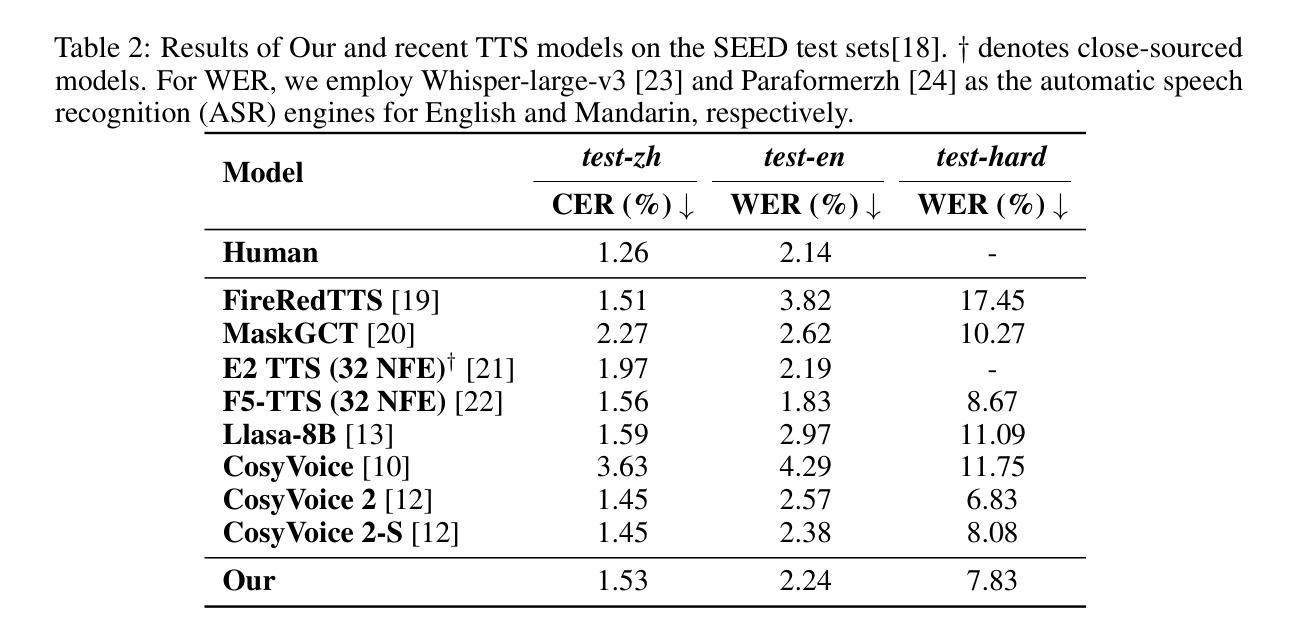
GOAT-TTS: Expressive and Realistic Speech Generation via A Dual-Branch LLM
Authors:Yaodong Song, Hongjie Chen, Jie Lian, Yuxin Zhang, Guangmin Xia, Zehan Li, Genliang Zhao, Jian Kang, Jie Li, Yongxiang Li, Xuelong Li
While large language models (LLMs) have revolutionized text-to-speech (TTS) synthesis through discrete tokenization paradigms, current architectures exhibit fundamental tensions between three critical dimensions: 1) irreversible loss of acoustic characteristics caused by quantization of speech prompts; 2) stringent dependence on precisely aligned prompt speech-text pairs that limit real-world deployment; and 3) catastrophic forgetting of the LLM’s native text comprehension during optimization for speech token generation. To address these challenges, we propose an LLM-based text-to-speech Generation approach Optimized via a novel dual-branch ArchiTecture (GOAT-TTS). Our framework introduces two key innovations: (1) The modality-alignment branch combines a speech encoder and projector to capture continuous acoustic embeddings, enabling bidirectional correlation between paralinguistic features (language, timbre, emotion) and semantic text representations without transcript dependency; (2) The speech-generation branch employs modular fine-tuning on top-k layers of an LLM for speech token prediction while freezing the bottom-n layers to preserve foundational linguistic knowledge. Moreover, multi-token prediction is introduced to support real-time streaming TTS synthesis. Experimental results demonstrate that our GOAT-TTS achieves performance comparable to state-of-the-art TTS models while validating the efficacy of synthesized dialect speech data.
虽然大型语言模型(LLM)通过离散标记化范式在文本到语音(TTS)合成领域带来了革命性的变革,但当前架构在三个关键维度之间表现出基本矛盾:1)由于语音提示的量化而导致的不可逆的声学特征损失;2)严格依赖于精确对齐的语音文本对,限制了其在现实世界的部署;3)在优化语音标记生成过程中,LLM对原生文本理解能力的灾难性遗忘。为了应对这些挑战,我们提出了一种基于LLM的文本到语音生成方法,通过一种新的双分支架构(GOAT-TTS)进行优化。我们的框架引入了两个关键创新点:(1)模态对齐分支结合了语音编码器和投影仪来捕获连续的声学嵌入,实现了副语言特征(语言、音色、情感)和语义文本表示之间的双向关联,无需转录依赖;(2)语音生成分支采用模块化微调,对LLM的前k层进行语音标记预测,同时冻结底部n层以保持基础语言知识。此外,还引入了多标记预测,以支持实时流式TTS合成。实验结果表明,我们的GOAT-TTS在达到最新TTS模型性能的同时,验证了合成方言语音数据的有效性。
论文及项目相关链接
Summary
基于大型语言模型(LLM)的文本到语音(TTS)合成方法已经取得了显著进展。然而,当前架构在三个关键方面存在基本矛盾。为了解决这些问题,我们提出了一个优化的双分支架构(GOAT-TTS)。该框架包括两个关键创新点:模态对齐分支和语音生成分支。通过模态对齐分支实现无字幕依赖的跨语言特征双向关联;通过语音生成分支对LLM进行模块化微调以实现语音令牌预测。实验结果表明,GOAT-TTS性能可与最新TTS模型相比,并验证了合成方言语音数据的有效性。
Key Takeaways
- 大型语言模型(LLM)在文本到语音(TTS)合成中已有显著进展,但仍存在三大挑战。
- 现有架构在量化语音提示时会导致不可逆的声学特征损失。
- 精确的语音-文本配对限制了现实世界的部署应用。
- 在优化语音令牌生成过程中,LLM会遗忘其原有的文本理解能力。
- GOAT-TTS框架通过模态对齐分支实现了跨语言特征的双向关联,无需字幕依赖。
- GOAT-TTS框架通过语音生成分支对LLM进行模块化微调,以支持实时流式传输TTS合成。
- 实验结果表明GOAT-TTS性能与最新TTS模型相当,并能有效合成方言语音数据。
点此查看论文截图

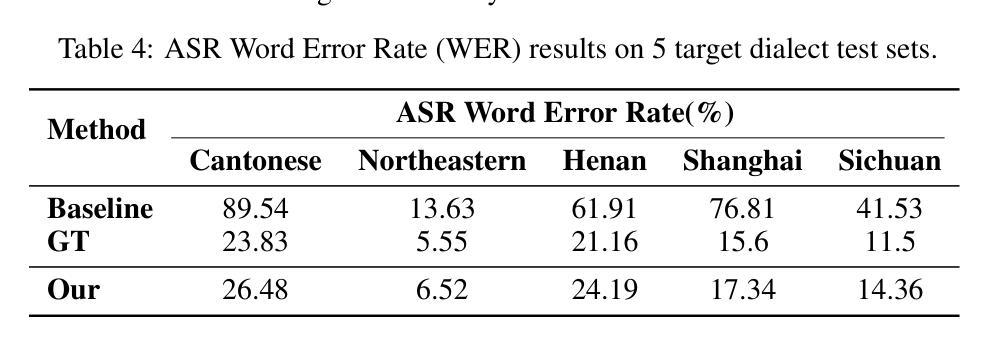
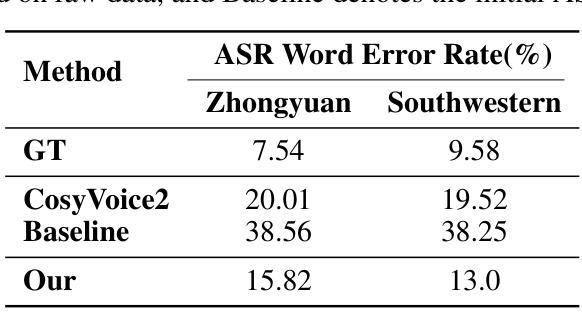
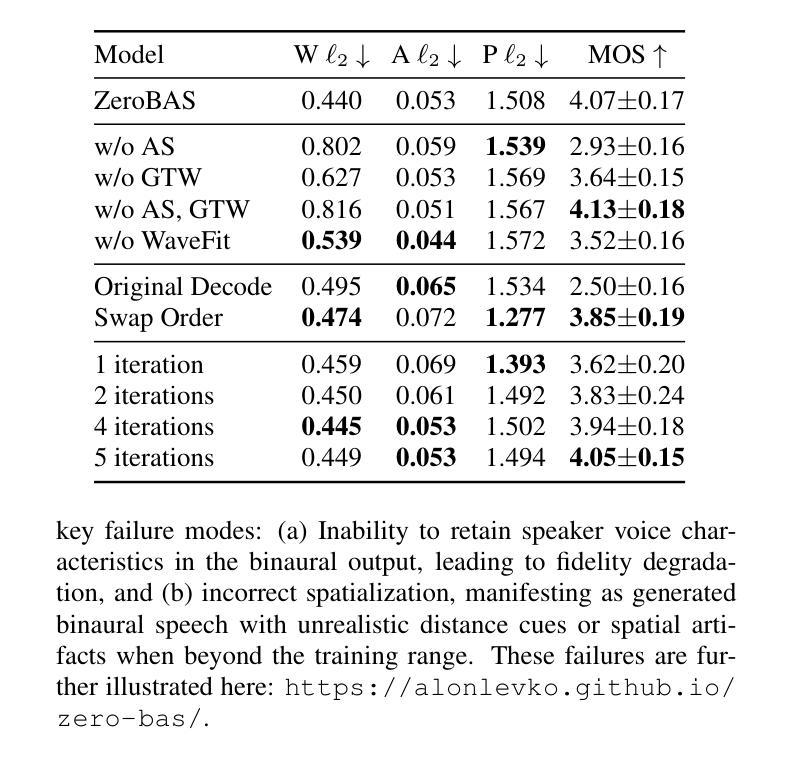
Zero-Shot Mono-to-Binaural Speech Synthesis
Authors:Alon Levkovitch, Julian Salazar, Soroosh Mariooryad, RJ Skerry-Ryan, Nadav Bar, Bastiaan Kleijn, Eliya Nachmani
We present ZeroBAS, a neural method to synthesize binaural audio from monaural audio recordings and positional information without training on any binaural data. To our knowledge, this is the first published zero-shot neural approach to mono-to-binaural audio synthesis. Specifically, we show that a parameter-free geometric time warping and amplitude scaling based on source location suffices to get an initial binaural synthesis that can be refined by iteratively applying a pretrained denoising vocoder. Furthermore, we find this leads to generalization across room conditions, which we measure by introducing a new dataset, TUT Mono-to-Binaural, to evaluate state-of-the-art monaural-to-binaural synthesis methods on unseen conditions. Our zero-shot method is perceptually on-par with the performance of supervised methods on the standard mono-to-binaural dataset, and even surpasses them on our out-of-distribution TUT Mono-to-Binaural dataset. Our results highlight the potential of pretrained generative audio models and zero-shot learning to unlock robust binaural audio synthesis.
我们提出了ZeroBAS方法,这是一种从单声道音频录制和位置信息合成双声道音频的神经方法,无需在任何双声道数据上进行训练。据我们所知,这是首次发布的从零开始学习单声道到双声道音频合成的神经方法。具体来说,我们展示了基于源位置的参数化几何时间扭曲和振幅缩放足以获得初步的双声道合成,可以通过迭代应用预训练的降噪编码器进行改进。此外,我们发现这导致了跨房间条件的泛化,我们通过引入一个新的数据集TUT Mono-to-Binaural来衡量这一点,以评估最先进的单声道到双声道合成方法在未见条件下的表现。我们的零样本方法与标准单声道到双声道数据集上的有监督方法在感知上表现相当,甚至在我们的离群TUT Mono-to-Binaural数据集上超过了它们。我们的结果突显了预训练的生成音频模型和零样本学习在解锁稳健的双声道音频合成方面的潜力。
论文及项目相关链接
Summary
无需训练即可合成双耳音频的新神经网络方法ZeroBAS。基于零数据学习和现有生成音频模型技术,将单声道音频转换为双耳音频,仅使用位置信息。通过几何时间扭曲和基于源位置的振幅缩放实现初步的双耳合成,再迭代应用预训练的降噪编解码器进行完善。在未见条件下的新数据集TUT Mono-to-Binaural上测试,零样本方法性能与标准单声道到双耳音频合成数据集上的监督方法相当,甚至超出其表现。突显了预训练生成音频模型和零样本学习的潜力。
Key Takeaways
- 无需训练即可合成双耳音频的新神经网络方法ZeroBAS被提出。
- 基于零数据学习和现有生成音频模型技术实现单声道到双耳音频的转换。
- 通过几何时间扭曲和基于源位置的振幅缩放实现初步的双耳合成。
- 使用预训练的降噪编解码器对初步合成结果进行完善。
- 在未见条件下的新数据集TUT Mono-to-Binaural上进行测试,验证了方法的泛化能力。
- 零样本方法在标准数据集上的性能与监督方法相当,甚至在未见条件下超出其表现。
点此查看论文截图

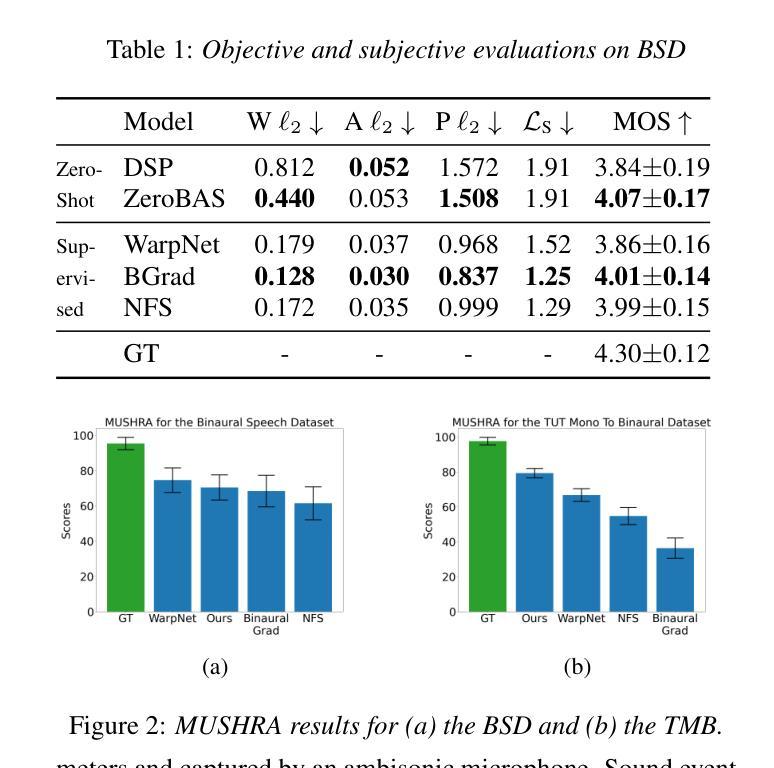
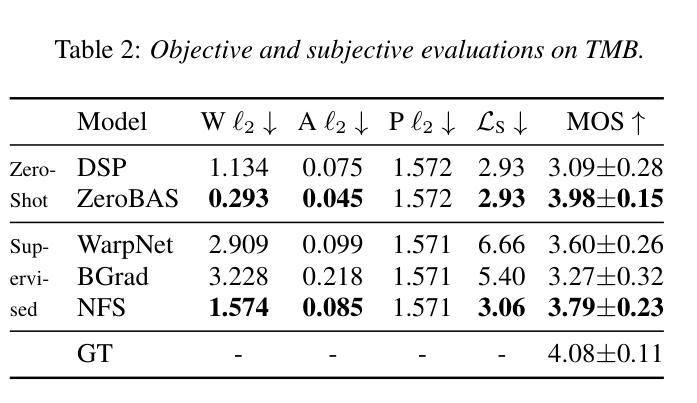
VQ-CTAP: Cross-Modal Fine-Grained Sequence Representation Learning for Speech Processing
Authors:Chunyu Qiang, Wang Geng, Yi Zhao, Ruibo Fu, Tao Wang, Cheng Gong, Tianrui Wang, Qiuyu Liu, Jiangyan Yi, Zhengqi Wen, Chen Zhang, Hao Che, Longbiao Wang, Jianwu Dang, Jianhua Tao
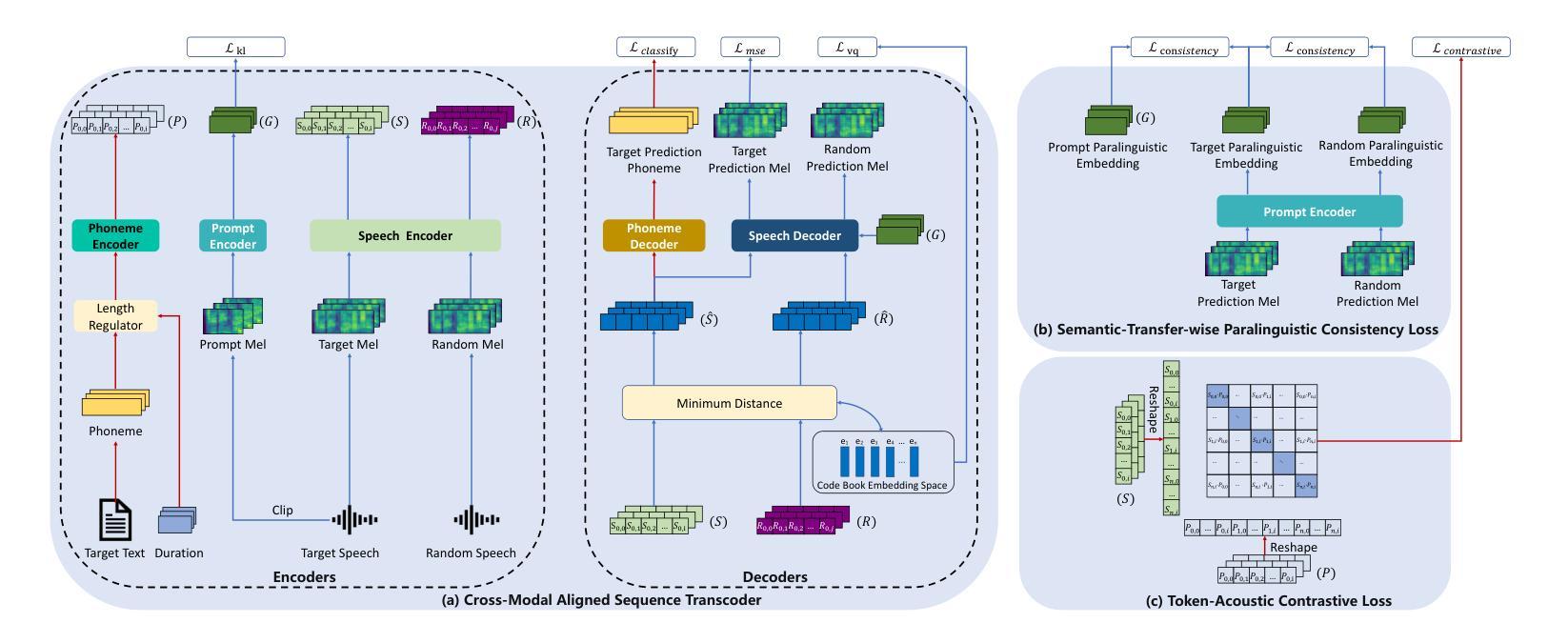
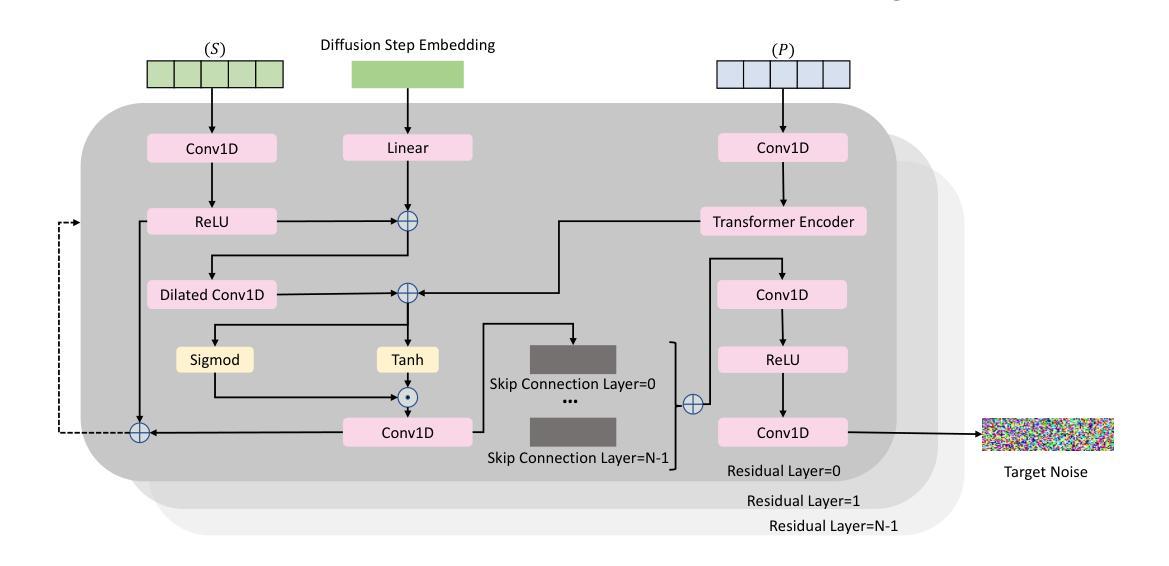
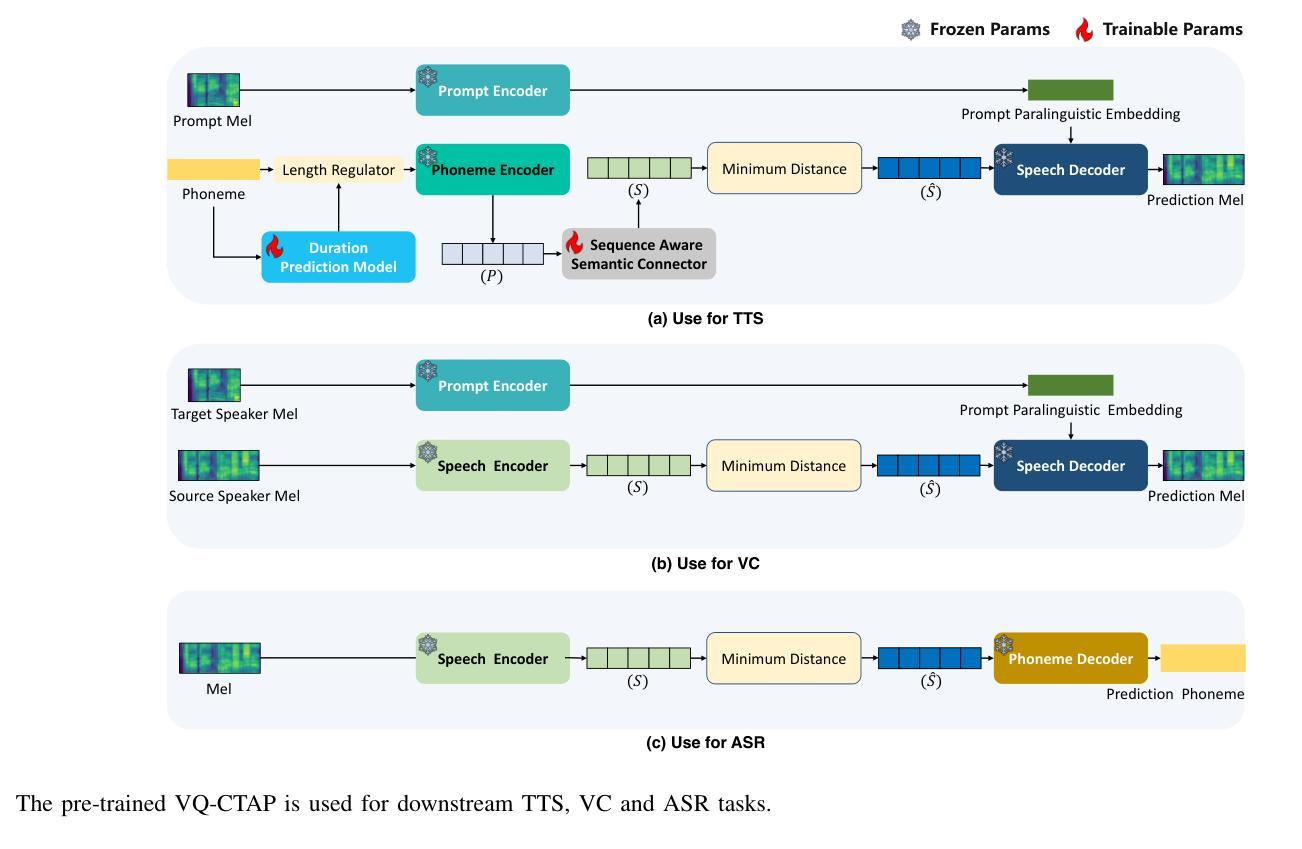
Deep learning has brought significant improvements to the field of cross-modal representation learning. For tasks such as text-to-speech (TTS), voice conversion (VC), and automatic speech recognition (ASR), a cross-modal fine-grained (frame-level) sequence representation is desired, emphasizing the semantic content of the text modality while de-emphasizing the paralinguistic information of the speech modality. We propose a method called “Vector Quantized Contrastive Token-Acoustic Pre-training (VQ-CTAP)”, which uses the cross-modal aligned sequence transcoder to bring text and speech into a joint multimodal space, learning how to connect text and speech at the frame level. The proposed VQ-CTAP is a paradigm for cross-modal sequence representation learning, offering a promising solution for fine-grained generation and recognition tasks in speech processing. The VQ-CTAP can be directly applied to VC and ASR tasks without fine-tuning or additional structures. We propose a sequence-aware semantic connector, which connects multiple frozen pre-trained modules for the TTS task, exhibiting a plug-and-play capability. We design a stepping optimization strategy to ensure effective model convergence by gradually injecting and adjusting the influence of various loss components. Furthermore, we propose a semantic-transfer-wise paralinguistic consistency loss to enhance representational capabilities, allowing the model to better generalize to unseen data and capture the nuances of paralinguistic information. In addition, VQ-CTAP achieves high-compression speech coding at a rate of 25Hz from 24kHz input waveforms, which is a 960-fold reduction in the sampling rate. The audio demo is available at https://qiangchunyu.github.io/VQCTAP/
深度学习为跨模态表示学习领域带来了重大改进。对于文本转语音(TTS)、语音转换(VC)和自动语音识别(ASR)等任务,我们期望得到一种跨模态精细(帧级)序列表示,强调文本模态的语义内容,同时淡化语音模态的副语言信息。我们提出了一种名为“向量量化对比令牌声学预训练(VQ-CTAP)”的方法,该方法使用跨模态对齐序列转码器将文本和语音带入联合多模态空间,学习如何在帧级别连接文本和语音。提出的VQ-CTAP是跨模态序列表示学习的一种范式,为语音处理中的精细粒度生成和识别任务提供了有前景的解决方案。VQ-CTAP可直接应用于VC和ASR任务,无需微调或额外结构。我们提出了一种序列感知语义连接器,它将多个冻结的预训练模块连接到TTS任务中,展现出即插即用的能力。我们设计了一种步进优化策略,通过逐步注入和调整各种损失分量的影响,以确保模型的有效收敛。此外,我们提出了一种语义转移副语言一致性损失,以增强表示能力,使模型能够更好地推广到未见数据并捕捉副语言信息的细微差别。另外,VQ-CTAP实现了高压缩语音编码,以25Hz的速率从24kHz输入波形进行编码,采样率降低了960倍。音频演示可在https://qiangchunyu.github.io/VQCTAP/进行查看。
论文及项目相关链接
摘要
深度学习极大提升了跨模态表征学习领域的能力,特别是在文本转语音(TTS)、语音转换(VC)和自动语音识别(ASR)等任务中。本文提出一种名为“向量量化对比令牌声学预训练(VQ-CTAP)”的方法,使用跨模态对齐序列转码器将文本和语音引入联合多模态空间,在帧级别连接文本和语音。此方法为跨模态序列表征学习提供了有力解决方案,适用于精细粒度的生成和识别任务。VQ-CTAP可直接应用于VC和ASR任务,无需微调或额外结构。设计序列感知语义连接器,为TTS任务连接多个冻结的预训练模块,展现即插即用能力。通过逐步优化策略确保模型有效收敛,同时提出语义转移旁语一致性损失以增强表征能力,使模型更好地泛化到未见数据和捕捉旁语信息的细微差别。此外,VQ-CTAP实现高压缩语音编码,以25Hz的采样率从24kHz输入波形,达到960倍的采样率降低。
关键见解
- 深度学习在跨模态表征学习领域取得显著进步,尤其在TTS、VC和ASR任务中。
- 提出VQ-CTAP方法,使用跨模态对齐序列转码器在帧级别连接文本和语音。
- VQ-CTAP是一种跨模态序列表征学习的范式,适用于精细粒度的生成和识别任务。
- VQ-CTAP可直接应用于VC和ASR任务,无需额外调整或结构。
- 设计序列感知语义连接器,展现对TTS任务的即插即用能力。
- 通过逐步优化策略和语义转移旁语一致性损失提高模型效能和泛化能力。
- VQ-CTAP实现高压缩语音编码,大幅降低采样率。
点此查看论文截图