⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-05-30 更新
Let Them Talk: Audio-Driven Multi-Person Conversational Video Generation
Authors:Zhe Kong, Feng Gao, Yong Zhang, Zhuoliang Kang, Xiaoming Wei, Xunliang Cai, Guanying Chen, Wenhan Luo
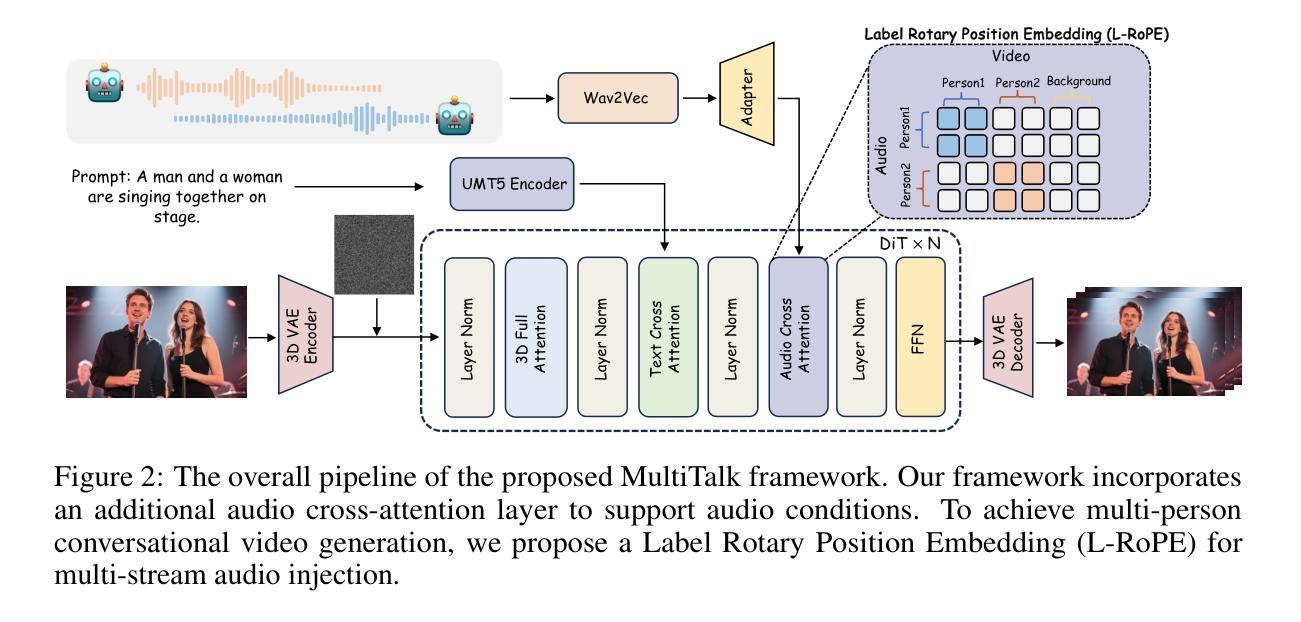
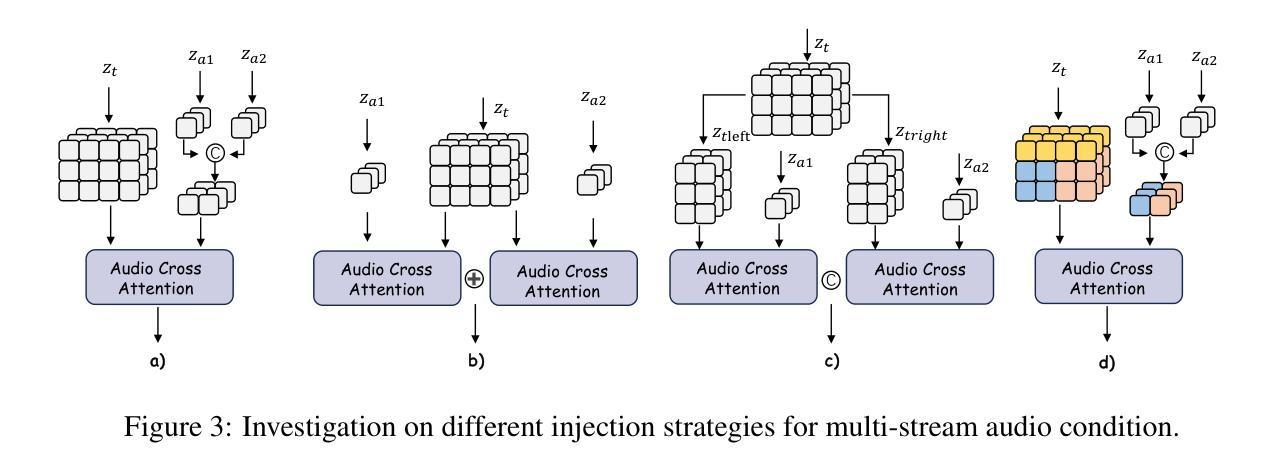
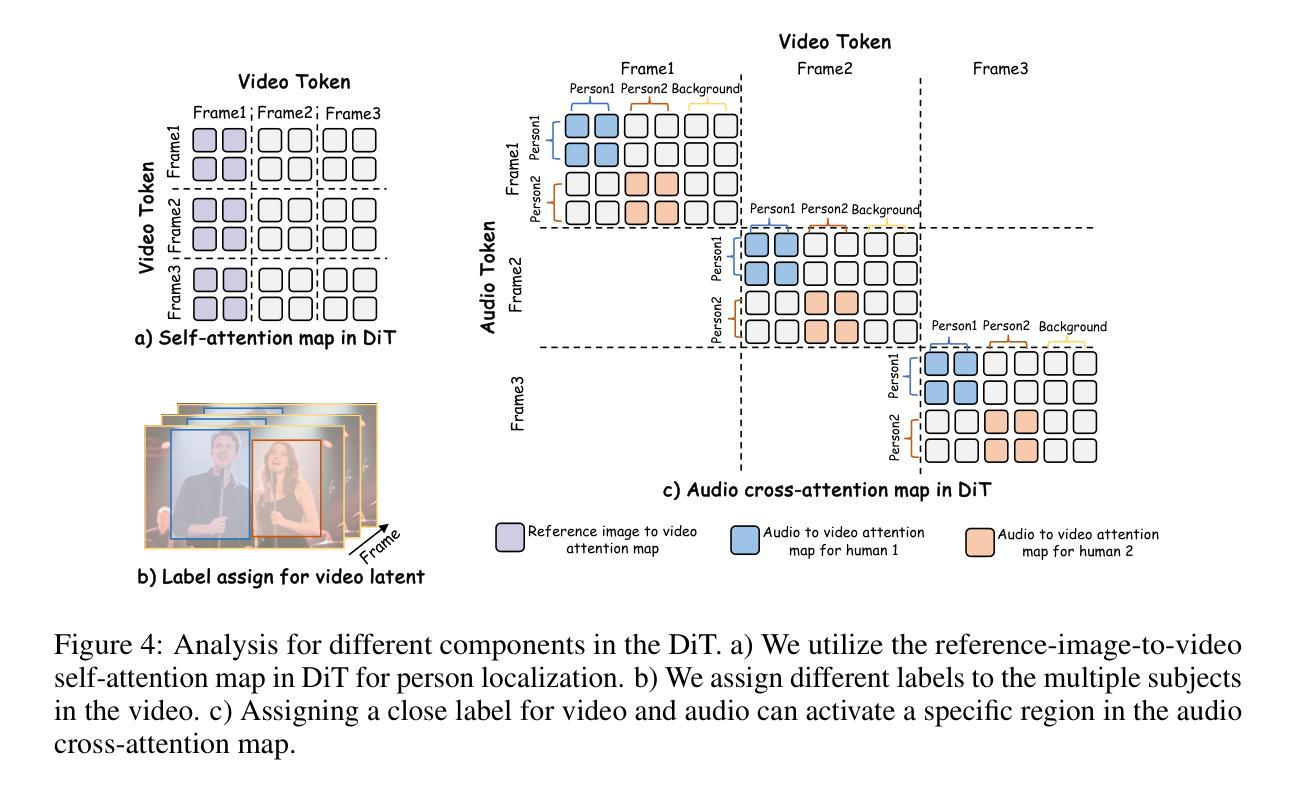
Audio-driven human animation methods, such as talking head and talking body generation, have made remarkable progress in generating synchronized facial movements and appealing visual quality videos. However, existing methods primarily focus on single human animation and struggle with multi-stream audio inputs, facing incorrect binding problems between audio and persons. Additionally, they exhibit limitations in instruction-following capabilities. To solve this problem, in this paper, we propose a novel task: Multi-Person Conversational Video Generation, and introduce a new framework, MultiTalk, to address the challenges during multi-person generation. Specifically, for audio injection, we investigate several schemes and propose the Label Rotary Position Embedding (L-RoPE) method to resolve the audio and person binding problem. Furthermore, during training, we observe that partial parameter training and multi-task training are crucial for preserving the instruction-following ability of the base model. MultiTalk achieves superior performance compared to other methods on several datasets, including talking head, talking body, and multi-person datasets, demonstrating the powerful generation capabilities of our approach.
音频驱动的人物动画方法,如说话头部和说话身体生成,在生成同步面部动作和吸引人的视频质量方面取得了显著的进步。然而,现有方法主要专注于单人动画,难以处理多流音频输入,面临音频和人物之间绑定不正确的问题。此外,它们在遵循指令的能力方面表现出局限性。为了解决这一问题,本文提出了一项新任务:多人对话视频生成,并介绍了一个新框架MultiTalk,以解决多人生成过程中的挑战。具体来说,对于音频注入,我们研究了多种方案,并提出标签旋转位置嵌入(L-RoPE)方法来解决音频和人物绑定问题。此外,在训练过程中,我们发现部分参数训练和多任务训练对于保持基础模型的指令遵循能力至关重要。MultiTalk在多个数据集上的表现优于其他方法,包括说话头部、说话身体和多人数据集,证明了我们方法的强大生成能力。
论文及项目相关链接
PDF Homepage: https://meigen-ai.github.io/multi-talk Github: https://github.com/MeiGen-AI/MultiTalk
Summary
本文介绍了音频驱动的人类动画方法,如生成说话的头和说话的身体,在生成同步面部动作和高质量视频方面取得了显著进展。然而,现有方法主要关注单人动画,面临多流音频输入的难题,存在音频与人物绑定不正确的问题,同时在指令跟随能力方面存在局限。为解决这些问题,本文提出了一个新的任务:多人对话视频生成,并引入了一个新框架MultiTalk。对于音频注入,我们研究了多种方案并提出了标签旋转位置嵌入(L-RoPE)方法来解决音频和人物绑定问题。此外,在训练过程中,我们发现部分参数训练和多任务训练对于保持基础模型的指令跟随能力至关重要。MultiTalk在多个数据集上的表现优于其他方法,包括说话的头、说话的身体和多人数据集,展示了我们的方法的强大生成能力。
Key Takeaways
- 音频驱动的人类动画方法在生成同步面部动作和高质量视频方面取得显著进展。
- 现有方法主要关注单人动画,面临多流音频输入时的难题。
- 提出了多人对话视频生成的新任务和MultiTalk新框架。
- 通过标签旋转位置嵌入(L-RoPE)方法解决音频和人物绑定问题。
- 部分参数训练和多任务训练对于保持模型的指令跟随能力至关重要。
- MultiTalk在多个数据集上的表现优于其他方法。
点此查看论文截图

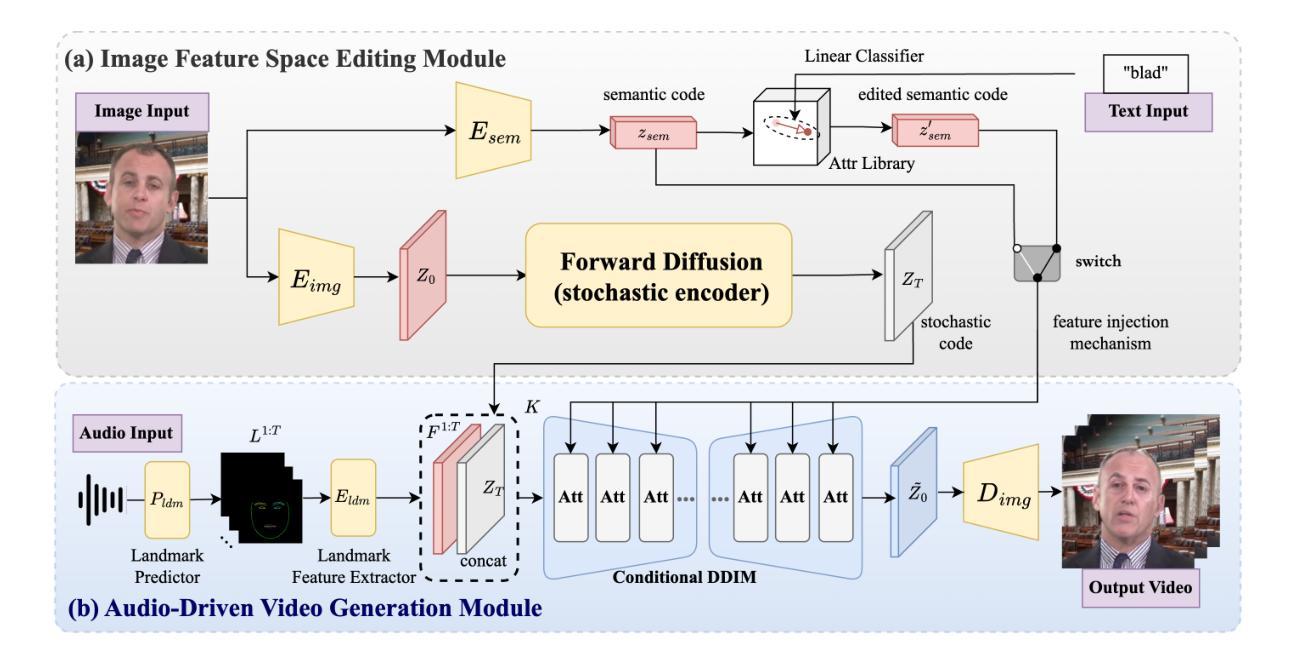
FaceEditTalker: Interactive Talking Head Generation with Facial Attribute Editing
Authors:Guanwen Feng, Zhiyuan Ma, Yunan Li, Junwei Jing, Jiahao Yang, Qiguang Miao
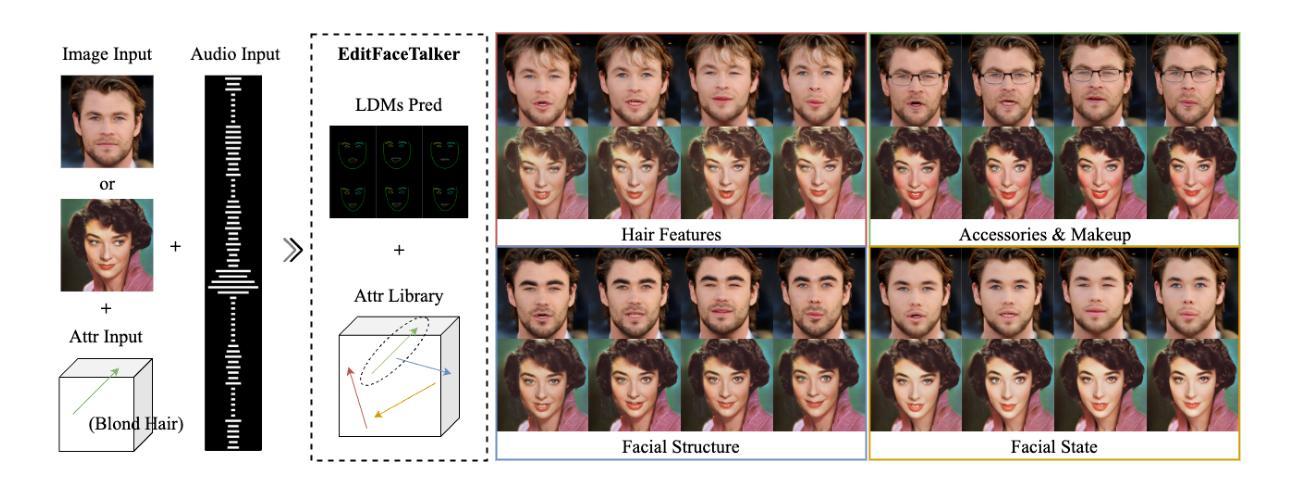
Recent advances in audio-driven talking head generation have achieved impressive results in lip synchronization and emotional expression. However, they largely overlook the crucial task of facial attribute editing. This capability is crucial for achieving deep personalization and expanding the range of practical applications, including user-tailored digital avatars, engaging online education content, and brand-specific digital customer service. In these key domains, the flexible adjustment of visual attributes-such as hairstyle, accessories, and subtle facial features is essential for aligning with user preferences, reflecting diverse brand identities, and adapting to varying contextual demands. In this paper, we present FaceEditTalker, a unified framework that enables controllable facial attribute manipulation while generating high-quality, audio-synchronized talking head videos. Our method consists of two key components: an image feature space editing module, which extracts semantic and detail features and allows flexible control over attributes like expression, hairstyle, and accessories; and an audio-driven video generation module, which fuses these edited features with audio-guided facial landmarks to drive a diffusion-based generator. This design ensures temporal coherence, visual fidelity, and identity preservation across frames. Extensive experiments on public datasets demonstrate that our method outperforms state-of-the-art approaches in lip-sync accuracy, video quality, and attribute controllability. Project page: https://peterfanfan.github.io/FaceEditTalker/
近期音频驱动说话人头部生成技术的进展在嘴唇同步和情感表达方面取得了令人印象深刻的结果。然而,它们大多忽略了面部属性编辑这一关键任务。这种能力对于实现深度个性化以及扩展实际应用范围至关重要,包括用户定制的数字化身、引人入胜的在线教育内容以及特定品牌的数字客户服务。在这些关键领域中,视觉属性的灵活调整,如发型、配饰和微妙的面部特征,对于符合用户偏好、反映多样化的品牌身份以及适应不同的上下文需求至关重要。在本文中,我们提出了FaceEditTalker,这是一个统一框架,能够在生成高质量、与音频同步的说话人头视频的同时,实现面部属性的可控操作。我们的方法由两个关键组件构成:图像特征空间编辑模块,该模块提取语义和细节特征,并允许对表情、发型和配饰等属性进行灵活控制;音频驱动视频生成模块,该模块将这些编辑后的特征与音频引导的面部关键点融合,以驱动基于扩散的生成器。这种设计确保了时间连贯性、视觉保真度和跨帧的身份保持。在公开数据集上的广泛实验表明,我们的方法在嘴唇同步准确性、视频质量和属性可控性方面优于最新技术方法。项目页面:https://peterfanfan.github.io/FaceEditTalker/(访问该页面可查看更多详细信息)
论文及项目相关链接
Summary:
近期音频驱动说话人头部生成技术取得显著进展,在嘴唇同步和情感表达方面表现出色。然而,面部属性编辑的关键任务却被忽视。本文提出FaceEditTalker框架,实现在生成高质量、与音频同步的说话人头视频时进行可控的面部属性操作。该框架包括图像特征空间编辑模块和音频驱动视频生成模块,分别负责提取语义和细节特征、控制属性,以及融合编辑特征与音频引导的面部地标,驱动扩散生成器。这确保了时间连贯性、视觉保真度和身份保留。在公共数据集上的实验表明,该方法在嘴唇同步准确性、视频质量和属性可控性方面优于现有技术。
Key Takeaways:
- 近期音频驱动说话人头部生成技术在嘴唇同步和情感表达方面取得显著进展,但面部属性编辑的重要性被忽视。
- FaceEditTalker框架实现了高质量、与音频同步的说话人头视频生成,同时支持可控的面部属性操作。
- 框架包含图像特征空间编辑模块,负责提取语义和细节特征,并允许灵活控制属性。
- 框架还包含音频驱动视频生成模块,融合编辑特征与音频引导的面部地标,以实现扩散生成器。
- 该设计确保了时间连贯性、视觉保真度和身份保留。
- 在公共数据集上的实验证明,FaceEditTalker在嘴唇同步、视频质量和属性可控性方面优于现有技术。
- FaceEditTalker具有广泛的应用前景,如用户定制数字化身、在线教育内容创作和品牌特定数字客户服务。
点此查看论文截图

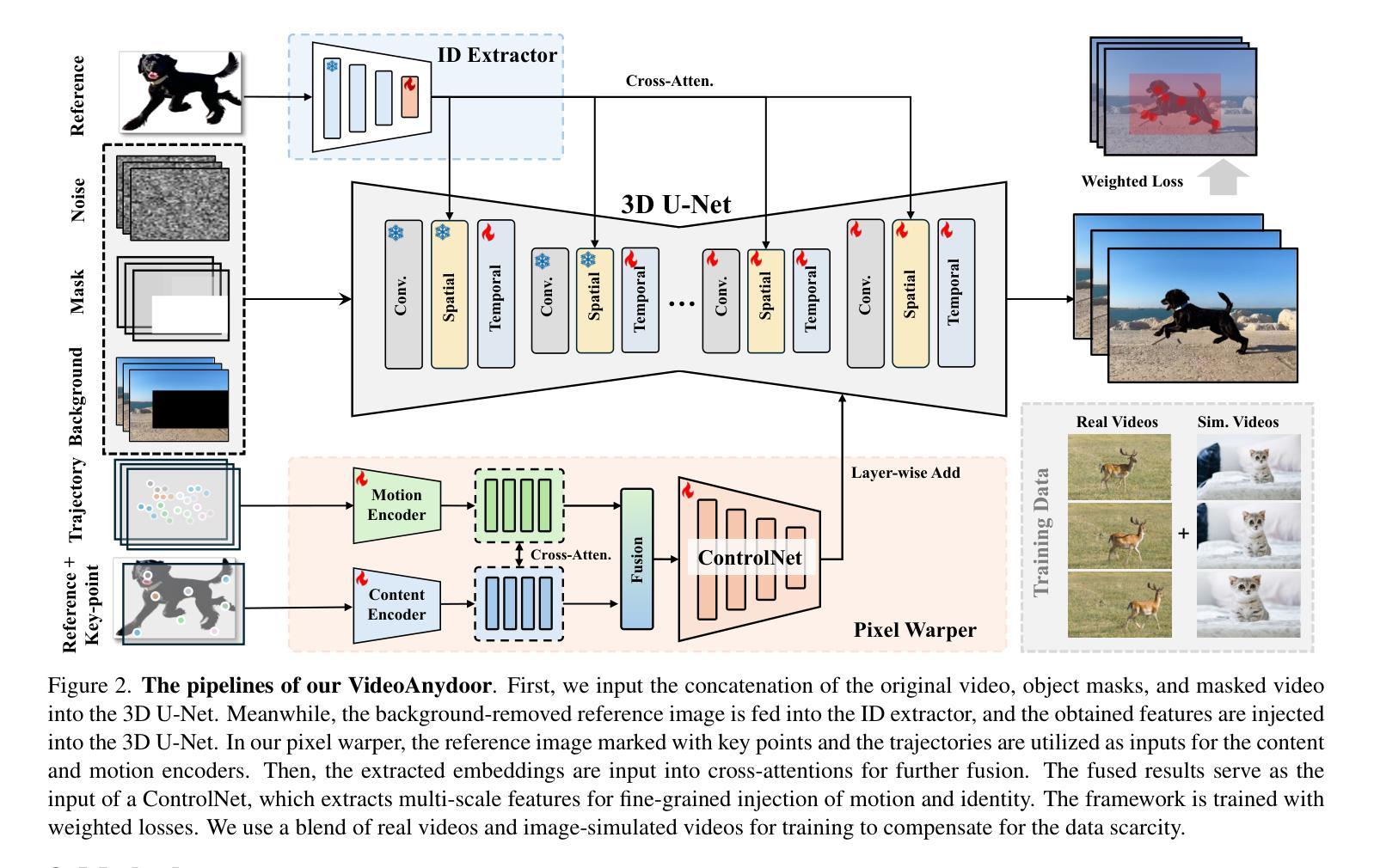
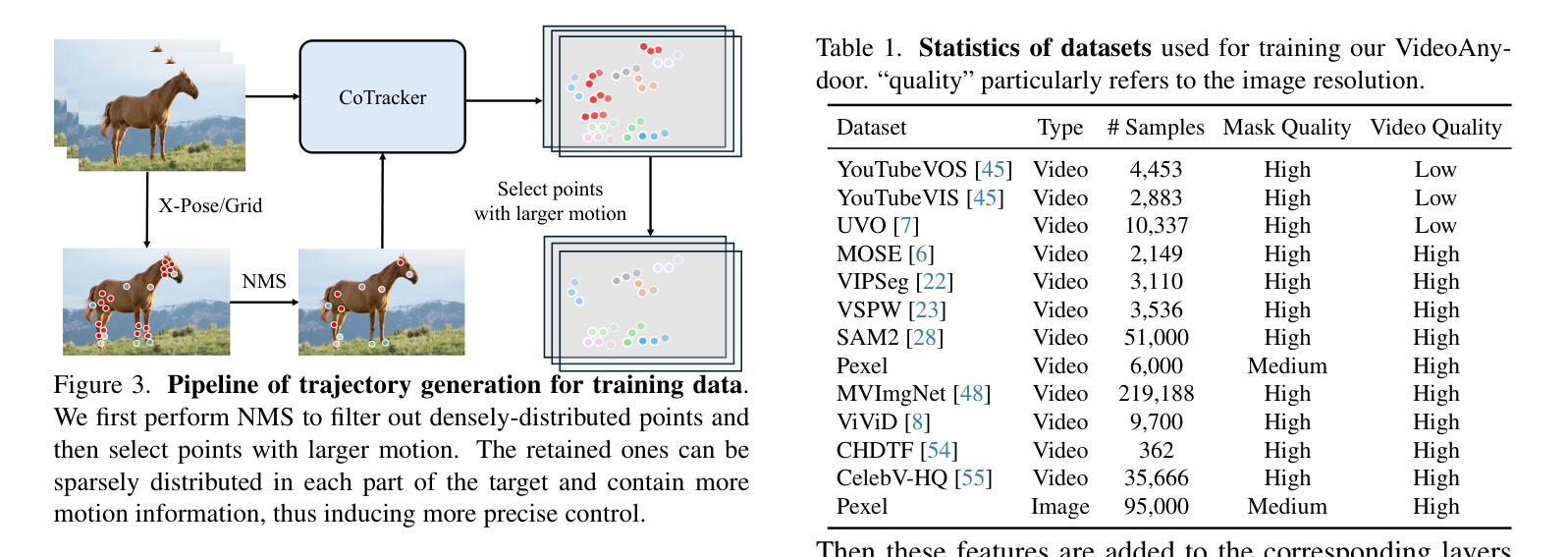
VideoAnydoor: High-fidelity Video Object Insertion with Precise Motion Control
Authors:Yuanpeng Tu, Hao Luo, Xi Chen, Sihui Ji, Xiang Bai, Hengshuang Zhao
Despite significant advancements in video generation, inserting a given object into videos remains a challenging task. The difficulty lies in preserving the appearance details of the reference object and accurately modeling coherent motions at the same time. In this paper, we propose VideoAnydoor, a zero-shot video object insertion framework with high-fidelity detail preservation and precise motion control. Starting from a text-to-video model, we utilize an ID extractor to inject the global identity and leverage a box sequence to control the overall motion. To preserve the detailed appearance and meanwhile support fine-grained motion control, we design a pixel warper. It takes the reference image with arbitrary key-points and the corresponding key-point trajectories as inputs. It warps the pixel details according to the trajectories and fuses the warped features with the diffusion U-Net, thus improving detail preservation and supporting users in manipulating the motion trajectories. In addition, we propose a training strategy involving both videos and static images with a weighted loss to enhance insertion quality. VideoAnydoor demonstrates significant superiority over existing methods and naturally supports various downstream applications (e.g., talking head generation, video virtual try-on, multi-region editing) without task-specific fine-tuning.
尽管视频生成领域已经取得了重大进展,但在视频中插入给定对象仍然是一项具有挑战性的任务。难点在于同时保留参考对象的外貌细节并准确模拟连贯的动作。在本文中,我们提出了VideoAnydoor,这是一个零样本视频对象插入框架,具有高保真细节保留和精确运动控制的特点。我们从文本到视频模型出发,利用ID提取器注入全局身份,并利用框序列控制整体运动。为了保留详细的外观同时支持精细的运动控制,我们设计了一个像素扭曲器。它接受带有任意关键点的参考图像和相应的关键点轨迹作为输入。它根据轨迹扭曲像素细节,并将扭曲的特征与扩散U-Net融合,从而提高了细节保留性,并支持用户操作运动轨迹。此外,我们提出了一种涉及视频和静态图像的训练策略,并使用加权损失来提高插入质量。VideoAnydoor显示出对现有方法的显著优势,并天然支持各种下游应用(例如,谈话头部生成、视频虚拟试穿、多区域编辑)而无需针对特定任务进行微调。
论文及项目相关链接
PDF Accepted by SIGGRAPH2025 Project page: https://videoanydoor.github.io/
摘要
该论文提出了一种名为VideoAnydoor的零样本视频物体插入框架,具备高保真细节保留和精确运动控制的特点。该框架从文本到视频模型出发,利用ID提取器注入全局身份,并通过序列框控制整体运动。为保留详细外观并支持精细运动控制,设计了像素扭曲器,其接收参考图像和相应的关键点轨迹作为输入,根据轨迹进行像素细节扭曲,并与扩散U-Net融合,从而提高细节保留能力并允许用户操作运动轨迹。此外,论文还提出了一种涉及视频和静态图像的训练策略,采用加权损失以增强插入质量。VideoAnydoor相较于现有方法具有显著优势,可自然应用于各种下游应用,如谈话头生成、视频虚拟试穿、多区域编辑等,无需针对特定任务进行微调。
要点解析
- VideoAnydoor是一个零样本视频物体插入框架,具备高保真细节保留和精确运动控制特性。
- 框架从文本到视频模型出发,利用ID提取器来注入全局身份识别信息。
- 通过序列框控制整体运动,同时设计像素扭曲器来保留详细外观并支持精细运动控制。
- 像素扭曲器接收参考图像和关键点轨迹作为输入,根据轨迹进行像素细节扭曲。
- 融合扭曲特征与扩散U-Net,提高了细节保留能力,并支持用户操作运动轨迹。
- 论文提出了涉及视频和静态图像的训练策略,采用加权损失以增强插入物体的质量。
点此查看论文截图