⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-05-30 更新
SoPo: Text-to-Motion Generation Using Semi-Online Preference Optimization
Authors:Xiaofeng Tan, Hongsong Wang, Xin Geng, Pan Zhou
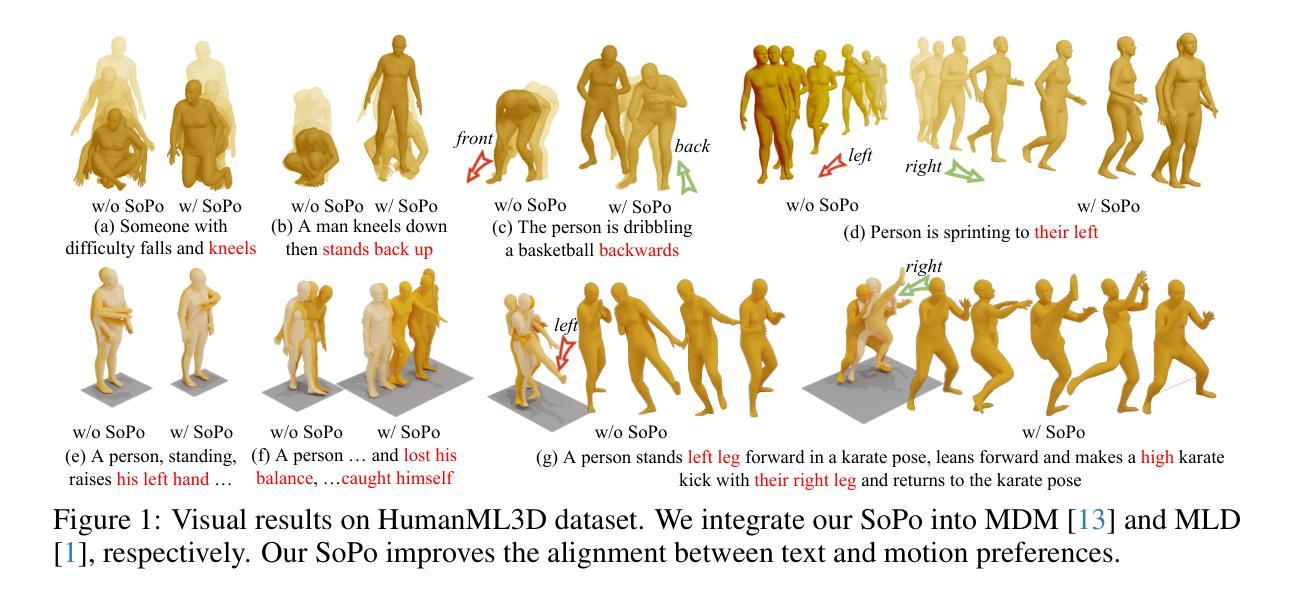
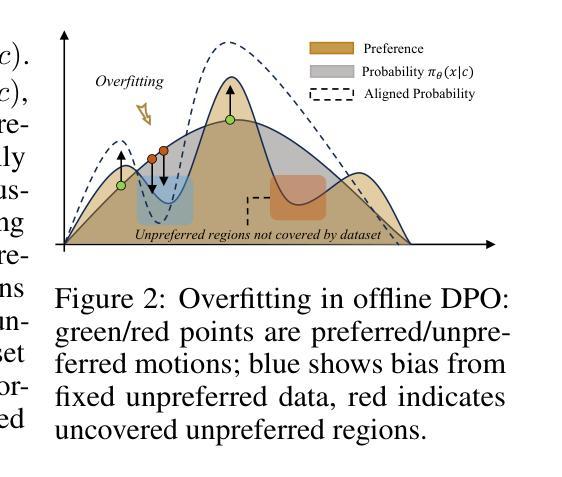
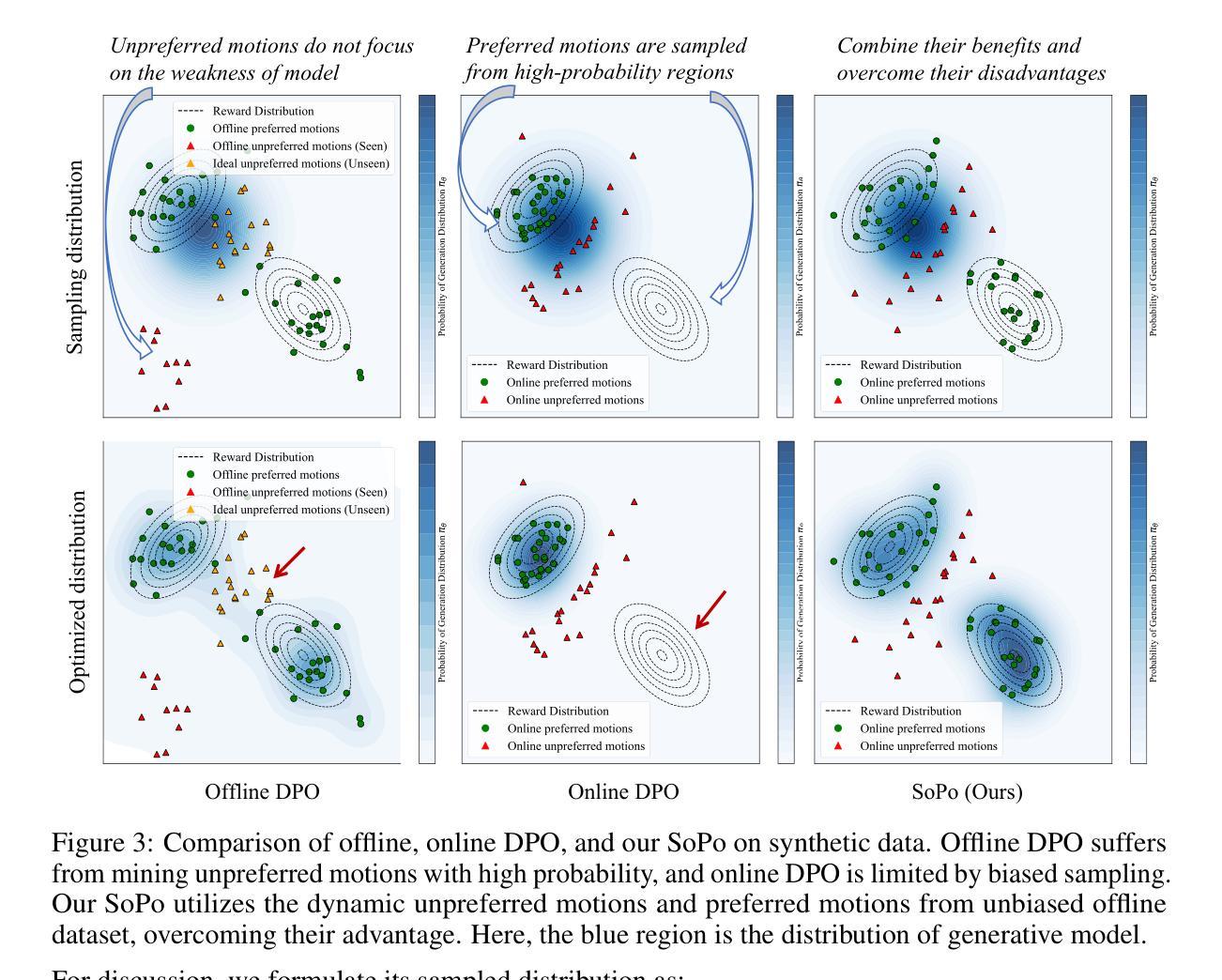
Text-to-motion generation is essential for advancing the creative industry but often presents challenges in producing consistent, realistic motions. To address this, we focus on fine-tuning text-to-motion models to consistently favor high-quality, human-preferred motions, a critical yet largely unexplored problem. In this work, we theoretically investigate the DPO under both online and offline settings, and reveal their respective limitation: overfitting in offline DPO, and biased sampling in online DPO. Building on our theoretical insights, we introduce Semi-online Preference Optimization (SoPo), a DPO-based method for training text-to-motion models using “semi-online” data pair, consisting of unpreferred motion from online distribution and preferred motion in offline datasets. This method leverages both online and offline DPO, allowing each to compensate for the other’s limitations. Extensive experiments demonstrate that SoPo outperforms other preference alignment methods, with an MM-Dist of 3.25% (vs e.g. 0.76% of MoDiPO) on the MLD model, 2.91% (vs e.g. 0.66% of MoDiPO) on MDM model, respectively. Additionally, the MLD model fine-tuned by our SoPo surpasses the SoTA model in terms of R-precision and MM Dist. Visualization results also show the efficacy of our SoPo in preference alignment. Project page: https://xiaofeng-tan.github.io/projects/SoPo/ .
文本到动作生成对于推动创意产业的发展至关重要,但在生产一致且逼真的动作时常常面临挑战。为了解决这个问题,我们专注于微调文本到动作模型,以一贯地偏向高质量、人类首选的动作,这是一个关键但尚未被充分研究的问题。在这项工作中,我们理论上探讨了在线和离线设置下的DPO(动态优先优化),并揭示了它们各自的局限性:离线DPO的过度拟合和在线DPO的偏采样问题。基于我们的理论见解,我们引入了Semi-online Preference Optimization(SoPo),这是一种基于DPO的方法,用于使用“半在线”数据对训练文本到动作模型进行微调。这些数据对由在线分布的不受欢迎的动作和离线数据集中的受欢迎动作组成。这种方法结合了在线和离线DPO的优势,使它们能够相互弥补彼此的不足。大量实验表明,SoPo优于其他偏好对齐方法,在MLD模型上的MM-Dist为3.25%(与其他偏好对齐方法的MM-Dist相比较)。此外,经过我们的SoPo精细调整的MLD模型在R-precision和MM Dist方面超过了当前最佳模型。可视化结果也显示了我们在偏好对齐方面的有效性。相关项目页面为:[https://xiaofeng-tan.github.io/projects/SoPo/] 。
论文及项目相关链接
Summary
本文关注文本到动作生成中的质量优化问题,提出一种半在线偏好优化(SoPo)方法,结合在线和离线数据对文本到动作模型进行训练。SoPo方法能够补偿离线数据过拟合和在线数据偏差采样的问题,提高模型的性能。实验结果显示,SoPo在MLD和MDM模型上的表现优于其他偏好对齐方法,并超越了当前最佳模型。
Key Takeaways
- 文本到动作生成面临挑战,需要提高动作的一致性和真实性。
- 研究重点是通过精细调整文本到动作模型,以产生高质量、符合人类偏好的动作。
- 提出了半在线偏好优化(SoPo)方法,结合在线和离线数据进行训练,解决了离线数据过拟合和在线数据偏差采样的问题。
- SoPo在MLD和MDM模型上的表现优于其他偏好对齐方法。
- SoPo能够提高模型性能,超越当前最佳模型。
- SoPo方法通过可视化结果展示了其偏好对齐的有效性。
点此查看论文截图