⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-05-31 更新
Improving Contrastive Learning for Referring Expression Counting
Authors:Kostas Triaridis, Panagiotis Kaliosis, E-Ro Nguyen, Jingyi Xu, Hieu Le, Dimitris Samaras
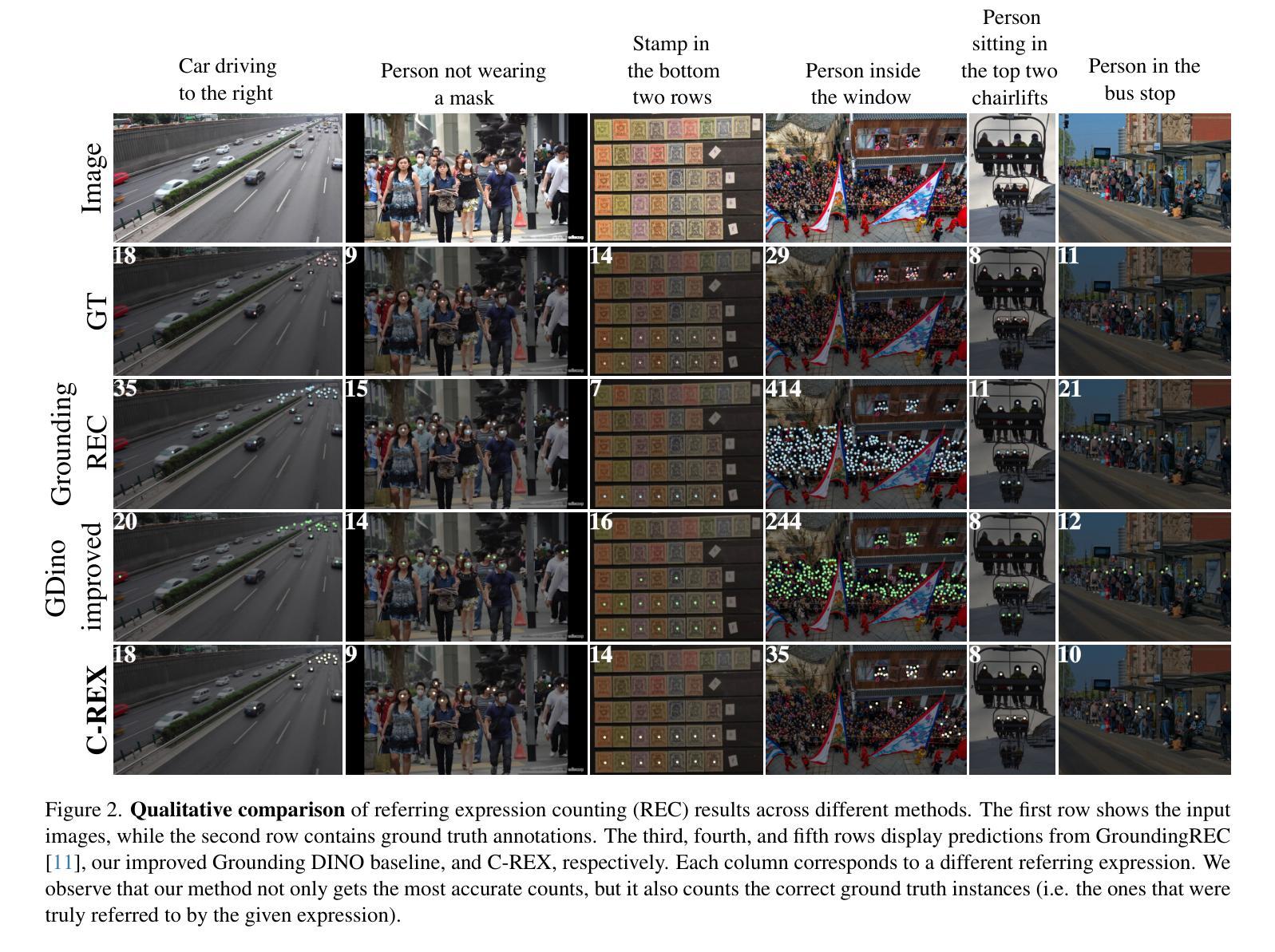
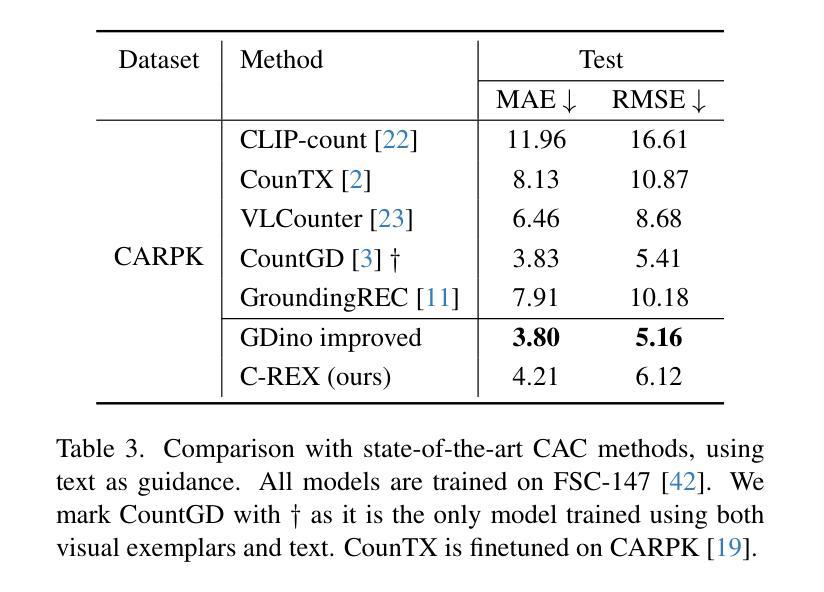
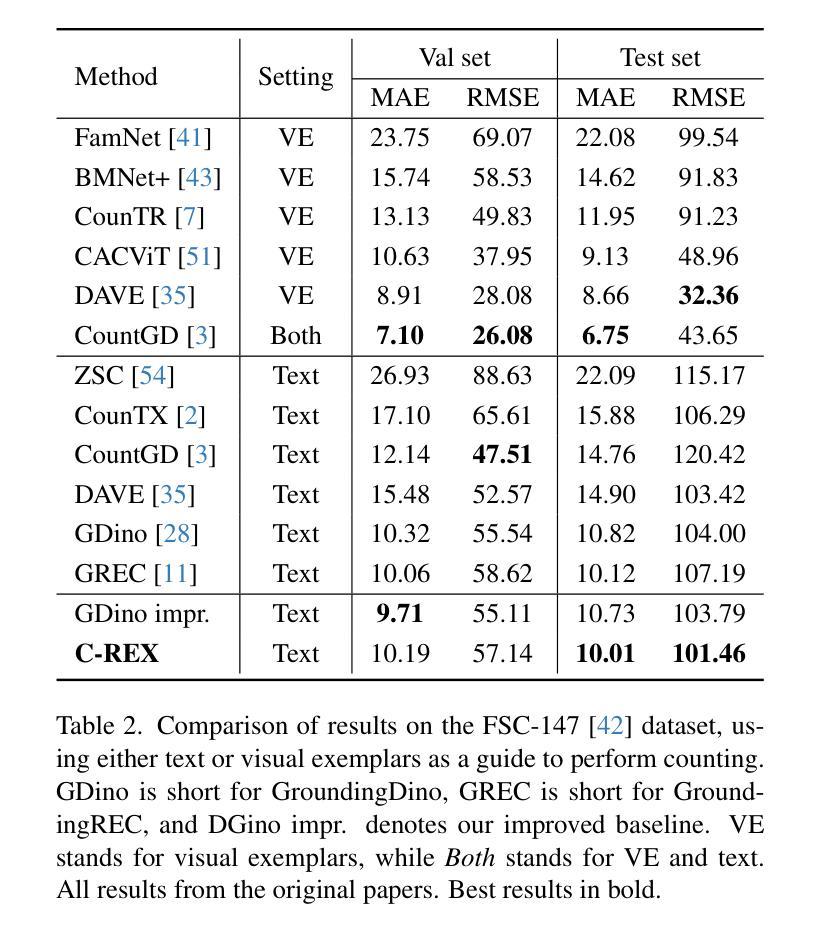
Object counting has progressed from class-specific models, which count only known categories, to class-agnostic models that generalize to unseen categories. The next challenge is Referring Expression Counting (REC), where the goal is to count objects based on fine-grained attributes and contextual differences. Existing methods struggle with distinguishing visually similar objects that belong to the same category but correspond to different referring expressions. To address this, we propose C-REX, a novel contrastive learning framework, based on supervised contrastive learning, designed to enhance discriminative representation learning. Unlike prior works, C-REX operates entirely within the image space, avoiding the misalignment issues of image-text contrastive learning, thus providing a more stable contrastive signal. It also guarantees a significantly larger pool of negative samples, leading to improved robustness in the learned representations. Moreover, we showcase that our framework is versatile and generic enough to be applied to other similar tasks like class-agnostic counting. To support our approach, we analyze the key components of sota detection-based models and identify that detecting object centroids instead of bounding boxes is the key common factor behind their success in counting tasks. We use this insight to design a simple yet effective detection-based baseline to build upon. Our experiments show that C-REX achieves state-of-the-art results in REC, outperforming previous methods by more than 22% in MAE and more than 10% in RMSE, while also demonstrating strong performance in class-agnostic counting. Code is available at https://github.com/cvlab-stonybrook/c-rex.
对象计数已经从特定类别的模型(仅计算已知类别)发展到了通用类别的模型(可推广到未见过的类别)。下一个挑战是引用表达式计数(REC),其目标是根据精细粒度的属性和上下文差异来计数对象。现有方法在区分视觉上相似但属于同一类别且对应于不同引用表达式的对象时遇到了困难。为了解决这一问题,我们提出了C-REX,这是一个基于有监督对比学习的新型对比学习框架,旨在增强判别表示学习。与以前的工作不同,C-REX完全在图像空间内运行,避免了图像文本对比学习中的不匹配问题,从而提供了更稳定的对比信号。它还保证了更大的负样本池,提高了学习到的表示的稳健性。此外,我们展示了我们的框架足够通用,可以应用于其他类似任务,如类别无关的计数。为了支持我们的方法,我们分析了最先进的检测模型的关键组件,并发现检测对象质心而不是边界框是它们在计数任务中取得成功的关键共同因素。我们利用这一见解设计了一个简单而有效的基于检测的基线来构建。我们的实验表明,C-REX在REC上实现了最新结果,与以前的方法相比,在MAE上提高了超过22%,在RMSE上提高了超过10%,同时在类别无关的计数方面也表现出强大的性能。代码可在https://github.com/cvlab-stonybrook/c-rex找到。
论文及项目相关链接
PDF 9 pages, 4 figures
Summary
该文本介绍了从特定类别的计数转向无类别限制的计数的新挑战——指代表达式计数(REC)。为解决现有方法在区分同一类别但指代表达式不同的相似对象上的困难,提出了基于监督对比学习的新型对比学习框架C-REX。C-REX在图像空间内操作,避免了图像文本对比学习的错位问题,提供了更稳定的对比信号。同时,C-REX确保了更大的负样本池,提高了学习到的表示的稳健性。此外,文中展示了该框架可以灵活应用于其他任务如非特定类别的计数。通过对当前先进检测模型的关键组件进行分析,发现检测对象质心而非边界框是在计数任务中取得成功的关键。基于这一见解,设计了一个简单而有效的基于检测的基线方法。实验表明,C-REX在REC上实现了最新结果,平均绝对误差(MAE)和均方根误差(RMSE)均超过了以前的方法的超过22%和超过的超过基于文本的更清晰简洁的摘要:
本文介绍了指代表达式计数(REC)的新挑战和解决方案。为解决区分同一类别但指代不同的对象的困难,提出了新型对比学习框架C-REX。C-REX在图像空间操作,具有稳定的对比信号和更大的负样本池。此外,它可以灵活应用于其他任务并改善了计数模型的性能。实验表明,C-REX在REC上表现卓越。
Key Takeaways
- 指代表达式计数(REC)成为新的挑战,需要模型根据精细粒度的属性和上下文差异进行对象计数。
- 现有方法在区分同一类别但指代表达式不同的对象上遇到困难。
- 提出了基于监督对比学习的新型对比学习框架C-REX。
- C-REX在图像空间内操作,避免图像文本对比学习的错位问题,提供稳定的对比信号。
- C-REX确保了更大的负样本池,提高了学习到的表示的稳健性。
- C-REX框架可以灵活应用于其他任务,如非特定类别的计数。
- 通过检测对象质心而非边界框来提高计数任务的性能。
点此查看论文截图


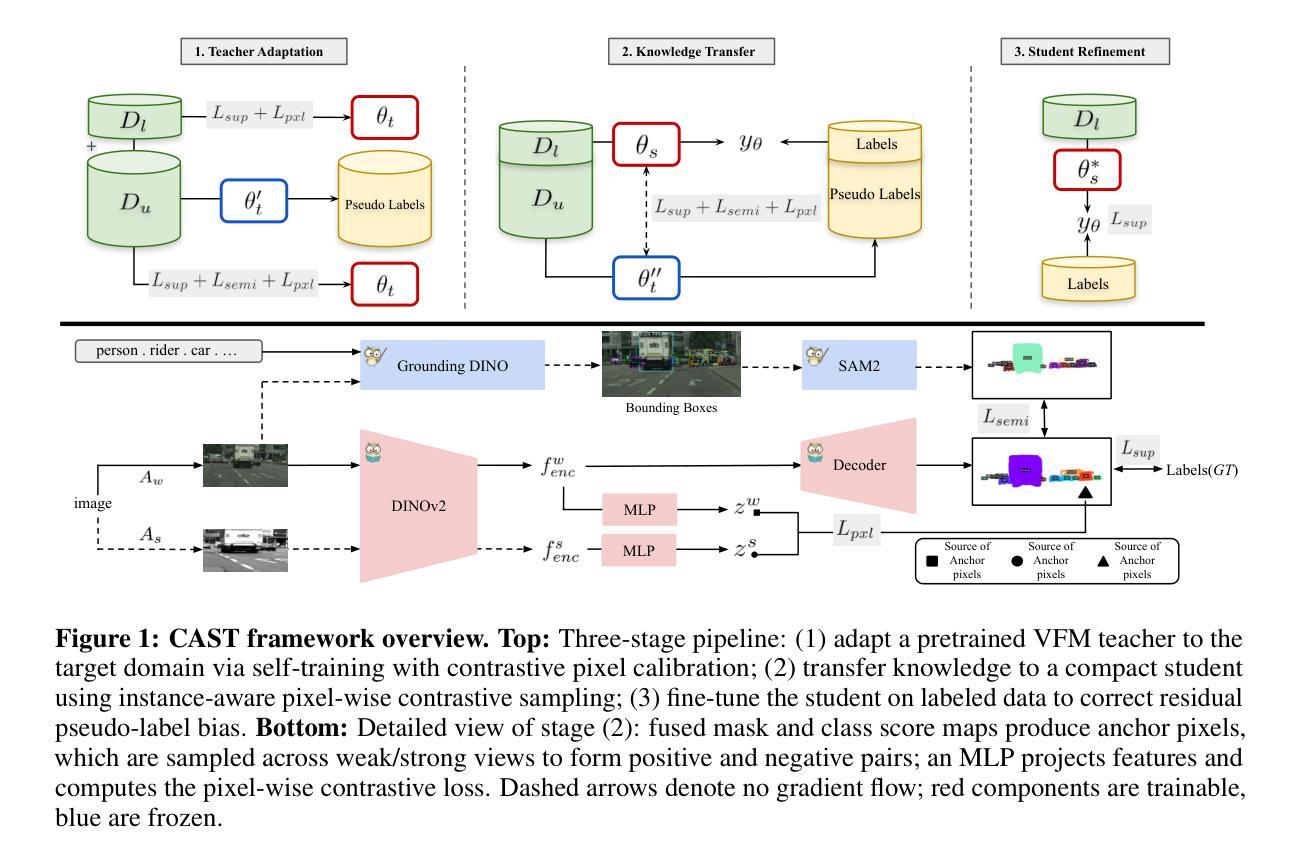
CAST: Contrastive Adaptation and Distillation for Semi-Supervised Instance Segmentation
Authors:Pardis Taghavi, Tian Liu, Renjie Li, Reza Langari, Zhengzhong Tu
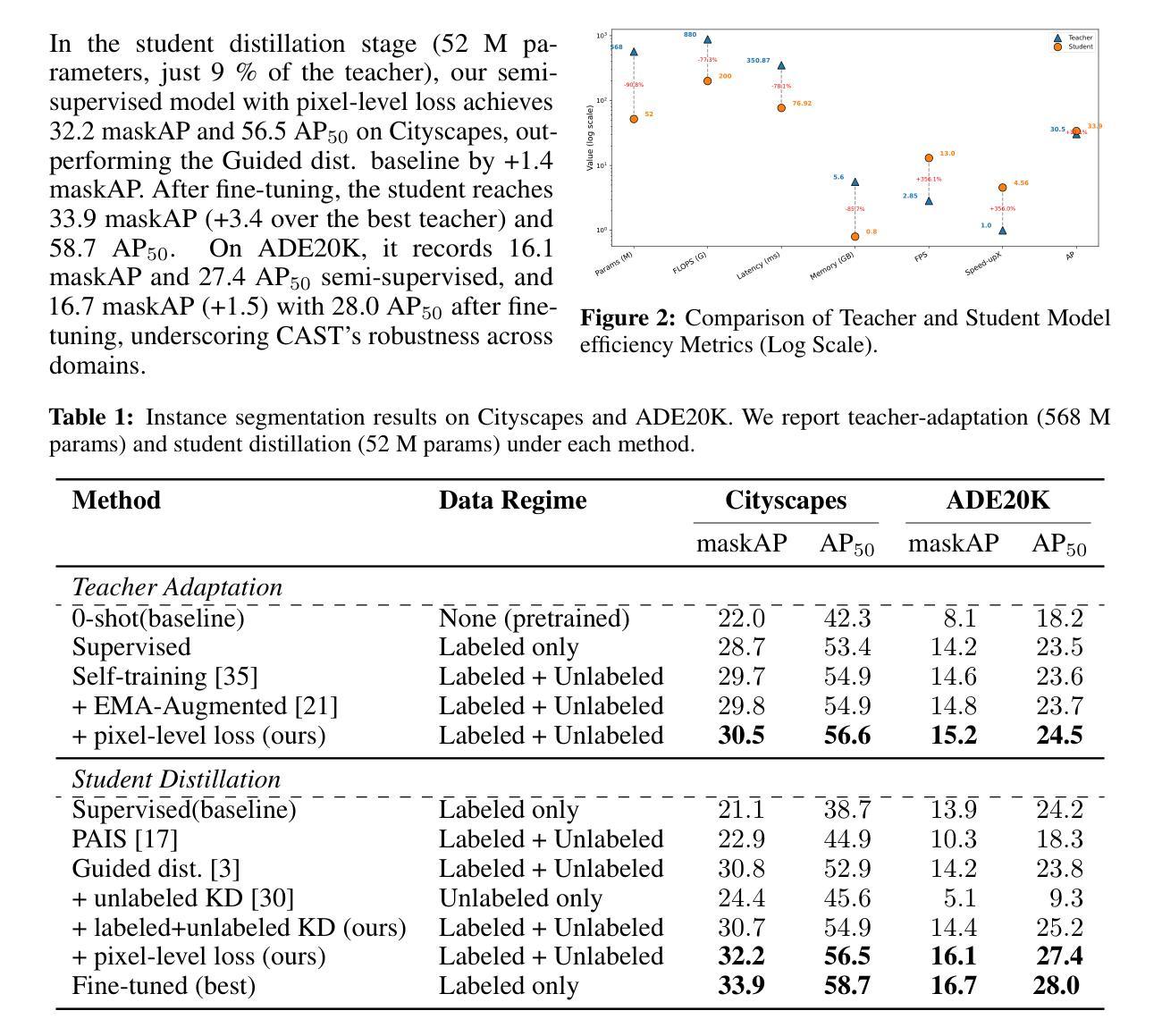
Instance segmentation demands costly per-pixel annotations and large models. We introduce CAST, a semi-supervised knowledge distillation (SSKD) framework that compresses pretrained vision foundation models (VFM) into compact experts using limited labeled and abundant unlabeled data. CAST unfolds in three stages: (1) domain adaptation of the VFM teacher(s) via self-training with contrastive pixel calibration, (2) distillation into a compact student via a unified multi-objective loss that couples standard supervision and pseudo-labels with our instance-aware pixel-wise contrastive term, and (3) fine-tuning on labeled data to remove residual pseudo-label bias. Central to CAST is an \emph{instance-aware pixel-wise contrastive loss} that fuses mask and class scores to mine informative negatives and enforce clear inter-instance margins. By maintaining this contrastive signal across both adaptation and distillation, we align teacher and student embeddings and fully leverage unlabeled images. On Cityscapes and ADE20K, our ~11X smaller student surpasses its adapted VFM teacher(s) by +3.4 AP (33.9 vs. 30.5) and +1.5 AP (16.7 vs. 15.2) and outperforms state-of-the-art semi-supervised approaches.
实例分割需要昂贵的逐像素标注和大型模型。我们引入了CAST,这是一种半监督知识蒸馏(SSKD)框架,它使用有限的标记数据和大量的无标记数据来压缩预训练的视觉基础模型(VFM)以形成紧凑的专家模型。CAST分为三个阶段:(1)通过对比像素校准进行自我训练,对VFM教师进行域适应;(2)通过统一的多目标损失来进行知识蒸馏,将知识蒸馏到紧凑的学生模型中,该损失结合了标准监督和伪标签,并与我们的实例感知像素级对比术语相结合;(3)在标记数据上进行微调,以消除剩余的伪标签偏见。CAST的核心是实例感知像素级对比损失,它融合了掩膜和类分数来挖掘信息否定的实例,并明确实例间的间隔。通过在整个适应和蒸馏过程中保持这种对比信号,我们对齐教师模型和学生模型的嵌入,并充分利用无标签图像。在Cityscapes和ADE20K上,我们较小的学生模型(~11倍)超越了其适应的VFM教师模型(+3.4 AP(33.9 vs. 30.5)和+1.5 AP(16.7 vs. 15.2)),并优于最新的半监督方法。
论文及项目相关链接
Summary
本文介绍了CAST,一种半监督知识蒸馏(SSKD)框架,用于利用有限标签和无标签数据将预训练的视觉基础模型(VFM)压缩成紧凑的专家模型,用于实例分割任务。CAST通过三个阶段实现:1)通过对比像素校准进行VFM教师的域自适应和自训练,2)通过统一的多目标损失函数蒸馏到紧凑的学生模型,该损失函数结合了标准监督和伪标签,以及实例感知的像素级对比术语,3)在标记数据上进行微调,以消除残留的伪标签偏见。CAST的核心是实例感知的像素级对比损失,它融合了掩膜和类分数来挖掘负面信息并执行明确的实例间边距。在Cityscapes和ADE20K上,我们的学生模型超越了适应的VFM教师,分别提高了3.4 AP和1.5 AP。
Key Takeaways
- CAST是一种半监督知识蒸馏框架,旨在利用有限的标签和无标签数据来压缩视觉基础模型。
- CAST包含三个阶段:域自适应、知识蒸馏和微调。
- CAST的核心是实例感知的像素级对比损失,用于融合掩膜和类分数。
- 通过对比像素校准进行自训练,以适应不同领域的数据。
- CAST通过统一的多目标损失函数结合标准监督和伪标签进行蒸馏。
- 在Cityscapes和ADE20K上,CAST的学生模型性能超越了VFM教师模型。
点此查看论文截图